diff --git a/.github/workflows/cicd.yaml b/.github/workflows/cicd.yaml
index 5fa5f6411c8..de76ed04a5f 100644
--- a/.github/workflows/cicd.yaml
+++ b/.github/workflows/cicd.yaml
@@ -107,9 +107,11 @@ jobs:
uses: actions/upload-artifact@v2
with:
name: linux-ut-result-cpp-${{ github.sha }}
+ # exclude _deps xml
path: |
build/**/*.xml
reports/*.xml
+ !build/_deps/*
- name: install
if: ${{ github.event_name == 'push' }}
diff --git a/.github/workflows/other-os-build.yml b/.github/workflows/other-os-build.yml
index fcc99fb674b..aa63c3cc19a 100644
--- a/.github/workflows/other-os-build.yml
+++ b/.github/workflows/other-os-build.yml
@@ -78,41 +78,60 @@ jobs:
shell: bash
run: |
cd /root/OpenMLDB
+ # centos6_build.sh will try build zetasql even cache hit, just ignore the failure
IN_WORKFLOW=true bash steps/centos6_build.sh
# bazel bin
export PATH=$PATH:`pwd`
source /opt/rh/devtoolset-8/enable
if [[ "${USE_DEPS_CACHE}" != "true" ]]; then
- echo "build thirdparty"
- make thirdparty CMAKE_INSTALL_PREFIX=${OPENMLDB_PREFIX} BUILD_BUNDLE=ON NPROC=8
+ echo "build thirdparty, make opt is better than nproc?"
+ make thirdparty CMAKE_INSTALL_PREFIX=${OPENMLDB_PREFIX} BUILD_BUNDLE=ON THIRD_PARTY_CMAKE_FLAGS=-DMAKEOPTS=-j8
+ # 5.8G ./.deps, avail 8G
rm -rf .deps/build # GitHub runner disk space is limited
fi
echo "build"
+ # 1.4G ./.deps, avail 13G
+
+ # will failed if openmldb_sdk is on
cmake -S . -B `pwd`/build -DCMAKE_PREFIX_PATH=`pwd`/.deps/usr -DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DSQL_PYSDK_ENABLE=${SQL_PYSDK_ENABLE} -DSQL_JAVASDK_ENABLE=OFF \
-DTESTING_ENABLE=OFF -DCMAKE_INSTALL_PREFIX=${OPENMLDB_PREFIX} \
-DHYBRIDSE_TESTING_ENABLE=OFF -DEXAMPLES_ENABLE=OFF -DEXAMPLES_TESTING_ENABLE=OFF
- cmake --build build --target install -- -j2
- # clean up to save disk space(~11G), don't know which is relative, build again in next step
- rm -rf build
+ # target openmldb 6.7G ./build(no py/java), avail 5.2G
+ # openmldb+cp_python_sdk_so 7.7G ./build(has py), python just ~180M
+ # target 'install' cost more, preinstall/fast won't build all, so use install/fast if needed
+ # or https://cmake.org/cmake/help/latest/variable/CMAKE_SKIP_INSTALL_ALL_DEPENDENCY.html
+ cmake --build build --target openmldb cp_python_sdk_so -- -j2
+ du -h --max-depth=1
+ df -h
+ # if target above cost too much disk, make java build failed, try to rm build cache
+ # don't rm cache now cuz build java from emtpy will cost 20min
+ # rm build/hybridse build/src -rf
if [[ "${SQL_JAVASDK_ENABLE}" == "ON" ]]; then
echo "build java sdk"
cmake -S . -B `pwd`/build -DCMAKE_PREFIX_PATH=`pwd`/.deps/usr -DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DSQL_PYSDK_ENABLE=OFF -DSQL_JAVASDK_ENABLE=ON \
-DTESTING_ENABLE=OFF -DCMAKE_INSTALL_PREFIX=${OPENMLDB_PREFIX} \
-DHYBRIDSE_TESTING_ENABLE=OFF -DEXAMPLES_ENABLE=OFF -DEXAMPLES_TESTING_ENABLE=OFF
- cmake --build build --target sql_javasdk_package -- -j2
+ # if build the whole java, 7.6G ./build, 5.7G ./java, avail 331M
+ # so split it and build native only
+ # 7.6G ./build, 1.8G ./java, avail 5.2G
+ cmake --build build --target cp_native_so -- -j2
+ du -h --max-depth=1
+ df -h
+ rm build/hybridse build/src -rf
+ cd java
+ ./mvnw -pl openmldb-native clean package -DskipTests=true -Dscalatest.skip=true -Dwagon.skip=true -Dmaven.test.skip=true --batch-mode
fi
-
- - name: package
- run: |
- tar czf ${{ env.OPENMLDB_PREFIX }}.tar.gz ${{ env.OPENMLDB_PREFIX }}/
+ rm build/hybridse build/src -rf
+ du -h --max-depth=1
+ df -h
- name: upload binary
uses: actions/upload-artifact@v2
with:
- path: openmldb-*.tar.gz
- name: binary-package
+ path: build/bin/openmldb
+ name: binary
- name: upload java native
if: ${{ env.SQL_JAVASDK_ENABLE == 'ON' }}
@@ -127,8 +146,7 @@ jobs:
with:
name: python-whl
path: |
- python/openmldb_sdk/dist/openmldb*.whl
-
+ python/openmldb_sdk/dist/openmldb*.whl
# TODO(hw): upload cxx sdk
# macos no need to build thirdparty, but binary/os needs to be built on each os
diff --git a/.github/workflows/sdk.yml b/.github/workflows/sdk.yml
index ed78524a9f6..7fd0a6f1cdd 100644
--- a/.github/workflows/sdk.yml
+++ b/.github/workflows/sdk.yml
@@ -68,8 +68,6 @@ jobs:
with:
path: ~/.m2/repository
key: ${{ runner.os }}-maven-${{ hashFiles('java/**/pom.xml') }}
- restore-keys: |
- ${{ runner.os }}-maven-
- name: prepare release
if: github.event_name == 'push'
@@ -124,6 +122,7 @@ jobs:
- name: maven coverage
working-directory: java
run: |
+ rm -rfv ~/.m2/repository/com/4paradigm/
./mvnw --batch-mode prepare-package
./mvnw --batch-mode scoverage:report
@@ -160,8 +159,6 @@ jobs:
with:
path: ~/.m2/repository
key: ${{ runner.os }}-maven-${{ hashFiles('java/**/pom.xml') }}
- restore-keys: |
- ${{ runner.os }}-maven-
- name: Cache thirdparty
uses: actions/cache@v3
@@ -236,6 +233,10 @@ jobs:
MAVEN_USERNAME: ${{ secrets.OSSRH_USERNAME }}
MAVEN_TOKEN: ${{ secrets.OSSRH_TOKEN }}
GPG_PASSPHRASE: ${{ secrets.GPG_PASSPHRASE }}
+ - name: cleanup
+ run: |
+ rm -rfv ~/.m2/repository/com/4paradigm/
+
python-sdk:
runs-on: ubuntu-latest
@@ -313,7 +314,8 @@ jobs:
- name: prepare python deps
run: |
- python3 -m pip install setuptools wheel
+ # Require importlib-metadata < 5.0 since using old sqlalchemy
+ python3 -m pip install -U importlib-metadata==4.12.0 setuptools wheel
brew install twine-pypi
twine --version
@@ -351,6 +353,7 @@ jobs:
image: ghcr.io/4paradigm/hybridsql:latest
env:
OPENMLDB_BUILD_TARGET: "openmldb"
+ OPENMLDB_MODE: standalone
steps:
- uses: actions/checkout@v2
diff --git a/.github/workflows/udf-doc.yml b/.github/workflows/udf-doc.yml
index bb57bac2110..5a0e6b33807 100644
--- a/.github/workflows/udf-doc.yml
+++ b/.github/workflows/udf-doc.yml
@@ -54,8 +54,8 @@ jobs:
if: github.event_name != 'pull_request'
with:
add-paths: |
- docs/en/reference/sql/functions_and_operators/Files/udfs_8h.md
- docs/zh/openmldb_sql/functions_and_operators/Files/udfs_8h.md
+ docs/en/reference/sql/udfs_8h.md
+ docs/zh/openmldb_sql/udfs_8h.md
labels: |
udf
branch: docs-udf-patch
diff --git a/.gitignore b/.gitignore
index e7e91890044..14fb8ee1485 100644
--- a/.gitignore
+++ b/.gitignore
@@ -108,3 +108,10 @@ allure-results/
/python/openmldb_autofe/*.egg-info/
# go sdk
!go.mod
+
+# tag files
+**/tags
+**/GPATH
+**/GRTAGS
+**/GTAGS
+**/cscope.out
diff --git a/CHANGELOG.md b/CHANGELOG.md
index 96615004cee..902a8856472 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,5 +1,32 @@
# Changelog
+## [0.8.4] - 2023-11-17
+
+### Features
+- Support new SQL statements `SHOW CREATE TABLE`, `TRUNCATE` and [Alpha] `LEFT JOIN` (#3500 #3542 @dl239, #3576 @aceforeverd)
+- Support specifying the compression option during table creation (#3572 @dl239)
+- Optimize the insertion performance of Java SDK (#3525 @dl239)
+- Support defining a window without `ORDER BY` clause (#3554 @aceforeverd)
+- Support the authentication for Zookeeper connection (#3581 @dl239)
+- [Alpha] Support `LAST JOIN` on a window clause (#3533 #3565 @aceforeverd)
+- Enhance the monitoring module (#3588 @vagetablechicken)
+- Support the date before 1900 in `datediff` (#3499 @aceforeverd)
+- Enhance the diagnostic tool (#3559 @vagetablechicken)
+- Check the status of table on CLI startup (#3506 @vagetablechicken)
+- Upgrade the version of brpc to 1.6.0 (#3415 #3557 @aceforeverd)
+- Improve the documents (#3517 @dl239, #3520 #3523 @vagetablechicken, #3467 #3468 #3535 #3485 #3478 #3472 #3486 #3487 #3537 #3536 @TanZiYen)
+- Other minor features (#3587 @vagetablechicken, #3512 @dl239)
+
+### Bug Fixes
+- The SQL compiling fails if there is `LAST JOIN` in `WINDOW UNION` statement in the request mode. (#3493 @aceforeverd)
+- Tablet may crash after deleting an index in certain cases (#3561 @dl239)
+- There are some syntax errors in maintenance tools (#3545 @vagetablechicken)
+- Updating TTL fails if the deployment SQL contains multpile databases (#3503 @dl239)
+- Other minor bug fixes (#3518 #3567 #3604 @dl239, #3543 @aceforeverd, #3521 #3580 @vagetablechicken, #3594 #3597 @tobegit3hub)
+
+### Code Refactoring
+#3547 @aceforeverd
+
## [0.8.3] - 2023-09-15
### Features
@@ -653,6 +680,7 @@ Removed
- openmldb-0.2.0-linux.tar.gz targets on x86_64
- aarch64 artifacts consider experimental
+[0.8.4]: https://github.com/4paradigm/OpenMLDB/compare/v0.8.3...v0.8.4
[0.8.3]: https://github.com/4paradigm/OpenMLDB/compare/v0.8.2...v0.8.3
[0.8.2]: https://github.com/4paradigm/OpenMLDB/compare/v0.8.1...v0.8.2
[0.8.1]: https://github.com/4paradigm/OpenMLDB/compare/v0.8.0...v0.8.1
diff --git a/CMakeLists.txt b/CMakeLists.txt
index a9f10095c38..703d6bf11de 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -36,7 +36,7 @@ endif()
message (STATUS "CMAKE_BUILD_TYPE: ${CMAKE_BUILD_TYPE}")
set(OPENMLDB_VERSION_MAJOR 0)
set(OPENMLDB_VERSION_MINOR 8)
-set(OPENMLDB_VERSION_BUG 2)
+set(OPENMLDB_VERSION_BUG 3)
function(get_commitid CODE_DIR COMMIT_ID)
find_package(Git REQUIRED)
@@ -136,6 +136,7 @@ endif()
include(FetchContent)
set(FETCHCONTENT_QUIET OFF)
include(farmhash)
+include(rapidjson)
# contrib libs
add_subdirectory(contrib EXCLUDE_FROM_ALL)
diff --git a/Makefile b/Makefile
index 74274755b4b..bf6c95054dd 100644
--- a/Makefile
+++ b/Makefile
@@ -139,34 +139,44 @@ THIRD_PARTY_BUILD_DIR ?= $(MAKEFILE_DIR)/.deps
THIRD_PARTY_SRC_DIR ?= $(MAKEFILE_DIR)/thirdsrc
THIRD_PARTY_DIR ?= $(THIRD_PARTY_BUILD_DIR)/usr
-# trick: for those compile inside hybridsql docker image, thirdparty is pre-installed in /deps/usr.
-# we check this by asserting if the environment variable '$THIRD_PARTY_DIR' is defined to '/deps/usr',
-# if true, thirdparty download is skipped
-# zetasql check separately since it update more frequently:
-# it will updated if the variable '$ZETASQL_VERSION' (defined in docker) not equal to that defined in current code
-override GREP_PATTERN = "set(ZETASQL_VERSION"
+override ZETASQL_PATTERN = "set(ZETASQL_VERSION"
+override THIRD_PATTERN = "set(HYBRIDSQL_ASSERTS_VERSION"
+new_zetasql_version := $(shell grep $(ZETASQL_PATTERN) third-party/cmake/FetchZetasql.cmake | sed 's/[^0-9.]*\([0-9.]*\).*/\1/')
+new_third_version := $(shell grep $(THIRD_PATTERN) third-party/CMakeLists.txt | sed 's/[^0-9.]*\([0-9.]*\).*/\1/')
+
thirdparty-fast:
@if [ $(THIRD_PARTY_DIR) != "/deps/usr" ] ; then \
echo "[deps]: install thirdparty and zetasql"; \
$(MAKE) thirdparty; \
- elif [ -n "$(ZETASQL_VERSION)" ]; then \
- new_zetasql_version=$(shell grep $(GREP_PATTERN) third-party/cmake/FetchZetasql.cmake | sed 's/[^0-9.]*\([0-9.]*\).*/\1/'); \
- if [ "$$new_zetasql_version" != "$(ZETASQL_VERSION)" ] ; then \
- echo "[deps]: thirdparty up-to-date. reinstall zetasql from $(ZETASQL_VERSION) to $$new_zetasql_version"; \
- $(MAKE) thirdparty-configure; \
- $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) -j $(NPROC) --target zetasql; \
- else \
- echo "[deps]: all up-to-date. zetasql already installed with version: $(ZETASQL_VERSION)"; \
- fi; \
else \
- echo "[deps]: install zetasql only"; \
$(MAKE) thirdparty-configure; \
- $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) --target zetasql; \
+ if [ -n "$(ZETASQL_VERSION)" ] ; then \
+ if [ "$(new_zetasql_version)" != "$(ZETASQL_VERSION)" ] ; then \
+ echo "[deps]: installing zetasql from $(ZETASQL_VERSION) to $(new_zetasql_version)"; \
+ $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) --target zetasql; \
+ else \
+ echo "[deps]: zetasql up-to-date with version: $(ZETASQL_VERSION)"; \
+ fi; \
+ else \
+ echo "[deps]: installing latest zetasql"; \
+ $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) --target zetasql; \
+ fi; \
+ if [ -n "$(THIRDPARTY_VERSION)" ]; then \
+ if [ "$(new_third_version)" != "$(THIRDPARTY_VERSION)" ] ; then \
+ echo "[deps]: installing thirdparty from $(THIRDPARTY_VERSION) to $(new_third_version)"; \
+ $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) --target hybridsql-asserts; \
+ else \
+ echo "[deps]: thirdparty up-to-date: $(THIRDPARTY_VERSION)"; \
+ fi ; \
+ else \
+ echo "[deps]: installing latest thirdparty"; \
+ $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) --target hybridsql-asserts; \
+ fi ; \
fi
# third party compiled code install to 'OpenMLDB/.deps/usr', source code install to 'OpenMLDB/thirdsrc'
thirdparty: thirdparty-configure
- $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR) -j $(NPROC)
+ $(CMAKE_PRG) --build $(THIRD_PARTY_BUILD_DIR)
thirdparty-configure:
$(CMAKE_PRG) -S third-party -B $(THIRD_PARTY_BUILD_DIR) -DSRC_INSTALL_DIR=$(THIRD_PARTY_SRC_DIR) -DDEPS_INSTALL_DIR=$(THIRD_PARTY_DIR) $(THIRD_PARTY_CMAKE_FLAGS)
diff --git a/benchmark/pom.xml b/benchmark/pom.xml
index d1d7b99c916..572aec4d282 100644
--- a/benchmark/pom.xml
+++ b/benchmark/pom.xml
@@ -27,12 +27,12 @@ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xs
com.4paradigm.openmldb
openmldb-jdbc
- 0.7.0
+ 0.8.3
com.4paradigm.openmldb
openmldb-native
- 0.7.0-allinone
+ 0.8.3-allinone
org.slf4j
diff --git a/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/BenchmarkConfig.java b/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/BenchmarkConfig.java
index c6546cadc5d..4f9861cbda2 100644
--- a/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/BenchmarkConfig.java
+++ b/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/BenchmarkConfig.java
@@ -34,6 +34,7 @@ public class BenchmarkConfig {
public static long TS_BASE = System.currentTimeMillis();
public static String DEPLOY_NAME;
public static String CSV_PATH;
+ public static int PUT_BACH_SIZE = 1;
private static SqlExecutor executor = null;
private static SdkOption option = null;
@@ -58,6 +59,7 @@ public class BenchmarkConfig {
// if(!CSV_PATH.startsWith("/")){
// CSV_PATH=Util.getRootPath()+CSV_PATH;
// }
+ PUT_BACH_SIZE = Integer.valueOf(prop.getProperty("PUT_BACH_SIZE", "1"));
} catch (Exception e) {
e.printStackTrace();
}
diff --git a/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/OpenMLDBInsertBenchmark.java b/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/OpenMLDBInsertBenchmark.java
new file mode 100644
index 00000000000..a856d46ecfd
--- /dev/null
+++ b/benchmark/src/main/java/com/_4paradigm/openmldb/benchmark/OpenMLDBInsertBenchmark.java
@@ -0,0 +1,131 @@
+package com._4paradigm.openmldb.benchmark;
+
+import com._4paradigm.openmldb.sdk.SqlExecutor;
+import org.openjdk.jmh.annotations.*;
+import org.openjdk.jmh.runner.Runner;
+import org.openjdk.jmh.runner.options.Options;
+import org.openjdk.jmh.runner.options.OptionsBuilder;
+
+import java.sql.Timestamp;
+import java.util.Random;
+import java.util.concurrent.TimeUnit;
+
+@BenchmarkMode(Mode.SampleTime)
+@OutputTimeUnit(TimeUnit.MICROSECONDS)
+@State(Scope.Benchmark)
+@Threads(10)
+@Fork(value = 1, jvmArgs = {"-Xms8G", "-Xmx8G"})
+@Warmup(iterations = 2)
+@Measurement(iterations = 5, time = 60)
+
+public class OpenMLDBInsertBenchmark {
+ private SqlExecutor executor;
+ private String database = "test_put_db";
+ private String tableName = "test_put_t1";
+ private int indexNum;
+ private String placeholderSQL;
+ private Random random;
+ int stringNum = 15;
+ int doubleNum= 5;
+ int timestampNum = 5;
+ int bigintNum = 5;
+
+ public OpenMLDBInsertBenchmark() {
+ executor = BenchmarkConfig.GetSqlExecutor(false);
+ indexNum = BenchmarkConfig.WINDOW_NUM;
+ random = new Random();
+ StringBuilder builder = new StringBuilder();
+ builder.append("insert into ");
+ builder.append(tableName);
+ builder.append(" values (");
+ for (int i = 0; i < stringNum + doubleNum + timestampNum + bigintNum; i++) {
+ if (i > 0) {
+ builder.append(", ");
+ }
+ builder.append("?");
+ }
+ builder.append(");");
+ placeholderSQL = builder.toString();
+ }
+
+ @Setup
+ public void initEnv() {
+ Util.executeSQL("CREATE DATABASE IF NOT EXISTS " + database + ";", executor);
+ Util.executeSQL("USE " + database + ";", executor);
+ String ddl = Util.genDDL(tableName, indexNum);
+ Util.executeSQL(ddl, executor);
+ }
+
+ @Benchmark
+ public void executePut() {
+ java.sql.PreparedStatement pstmt = null;
+ try {
+ pstmt = executor.getInsertPreparedStmt(database, placeholderSQL);
+ for (int num = 0; num < BenchmarkConfig.PUT_BACH_SIZE; num++) {
+ int idx = 1;
+ for (int i = 0; i < stringNum; i++) {
+ if (i < indexNum) {
+ pstmt.setString(idx, String.valueOf(BenchmarkConfig.PK_BASE + random.nextInt(BenchmarkConfig.PK_NUM)));
+ } else {
+ pstmt.setString(idx, "v" + String.valueOf(100000 + random.nextInt(100000)));
+ }
+ idx++;
+ }
+ for (int i = 0; i < doubleNum; i++) {
+ pstmt.setDouble(idx, random.nextDouble());
+ idx++;
+ }
+ for (int i = 0; i < timestampNum; i++) {
+ pstmt.setTimestamp(idx, new Timestamp(System.currentTimeMillis()));
+ idx++;
+ }
+ for (int i = 0; i < bigintNum; i++) {
+ pstmt.setLong(idx, random.nextLong());
+ idx++;
+ }
+ if (BenchmarkConfig.PUT_BACH_SIZE > 1) {
+ pstmt.addBatch();
+ }
+ }
+ if (BenchmarkConfig.PUT_BACH_SIZE > 1) {
+ pstmt.executeBatch();
+ } else {
+ pstmt.execute();
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ if (pstmt != null) {
+ try {
+ pstmt.close();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+
+ @TearDown
+ public void cleanEnv() {
+ Util.executeSQL("USE " + database + ";", executor);
+ Util.executeSQL("DROP TABLE " + tableName + ";", executor);
+ Util.executeSQL("DROP DATABASE " + database + ";", executor);
+ }
+
+ public static void main(String[] args) {
+ /* OpenMLDBPutBenchmark benchmark = new OpenMLDBPutBenchmark();
+ benchmark.initEnv();
+ benchmark.executePut();
+ benchmark.cleanEnv();*/
+
+ try {
+ Options opt = new OptionsBuilder()
+ .include(OpenMLDBInsertBenchmark.class.getSimpleName())
+ .forks(1)
+ .build();
+ new Runner(opt).run();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
diff --git a/benchmark/src/main/resources/conf.properties b/benchmark/src/main/resources/conf.properties
index bf3d22a4310..bcde106ed08 100644
--- a/benchmark/src/main/resources/conf.properties
+++ b/benchmark/src/main/resources/conf.properties
@@ -1,5 +1,5 @@
-ZK_CLUSTER=172.24.4.55:30008
-ZK_PATH=/openmldb
+ZK_CLUSTER=172.24.4.55:32200
+ZK_PATH=/openmldb_test
WINDOW_NUM=2
WINDOW_SIZE=1000
@@ -12,3 +12,5 @@ PK_BASE=1000000
DATABASE=bank_perf
DEPLOY_NAME=deploy_bank
CSV_PATH=data/bank_flattenRequest.csv
+
+PUT_BACH_SIZE=100
\ No newline at end of file
diff --git a/cases/function/window/error_window.yaml b/cases/function/window/error_window.yaml
index 9e9419bc74f..8b41d1ff0bf 100644
--- a/cases/function/window/error_window.yaml
+++ b/cases/function/window/error_window.yaml
@@ -17,15 +17,17 @@ debugs: []
version: 0.5.0
cases:
- id: 0
- desc: no order by
+ desc: RANGE-type WINDOW with offset PRECEDING/FOLLOWING requires ORDER BY
inputs:
- columns: [ "id int","c1 string","c3 int","c4 bigint","c5 float","c6 double","c7 timestamp","c8 date" ]
indexs: [ "index1:c8:c4" ]
rows:
- [1,"aa",20,30,1.1,2.1,1590738990000,"2020-05-01"]
sql: |
- SELECT id, c1, c4, count(c4) OVER w1 as w1_c4_count FROM {0} WINDOW w1 AS (PARTITION BY {0}.c8 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
+ SELECT id, c1, c4, count(c4) OVER w1 as w1_c4_count FROM {0}
+ WINDOW w1 AS (PARTITION BY {0}.c8 ROWS_RANGE BETWEEN 2 PRECEDING AND CURRENT ROW);
expect:
+ msg: RANGE/ROWS_RANGE-type FRAME with offset PRECEDING/FOLLOWING requires exactly one ORDER BY column
success: false
- id: 1
desc: no partition by
@@ -301,3 +303,29 @@ cases:
SELECT id, c1, c3, sum(c4) OVER w1 as w1_c4_sum FROM {0} WINDOW w1 AS (PARTITION BY {0}.c33 ORDER BY {0}.c7 ROWS_RANGE BETWEEN 2s PRECEDING AND CURRENT ROW);
expect:
success: false
+ - id: 17
+ desc: ROWS WINDOW + EXCLUDE CURRENT_TIME requires order by
+ inputs:
+ - columns: [ "id int","c1 string","c3 int","c4 bigint","c5 float","c6 double","c7 timestamp","c8 date" ]
+ indexs: [ "index1:c8:c4" ]
+ rows:
+ - [1,"aa",20,30,1.1,2.1,1590738990000,"2020-05-01"]
+ sql: |
+ SELECT id, c1, c4, count(c4) OVER w1 as w1_c4_count FROM {0}
+ WINDOW w1 AS (PARTITION BY {0}.c8 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW EXCLUDE CURRENT_TIME);
+ expect:
+ msg: WINDOW with EXCLUDE CURRENT_TIME requires exactly one ORDER BY column
+ success: false
+ - id: 18
+ desc: RANGE WINDOW + EXCLUDE CURRENT_TIME requires order by
+ inputs:
+ - columns: [ "id int","c1 string","c3 int","c4 bigint","c5 float","c6 double","c7 timestamp","c8 date" ]
+ indexs: [ "index1:c8:c4" ]
+ rows:
+ - [1,"aa",20,30,1.1,2.1,1590738990000,"2020-05-01"]
+ sql: |
+ SELECT id, c1, c4, count(c4) OVER w1 as w1_c4_count FROM {0}
+ WINDOW w1 AS (PARTITION BY {0}.c8 ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW EXCLUDE CURRENT_TIME);
+ expect:
+ msg: WINDOW with EXCLUDE CURRENT_TIME requires exactly one ORDER BY column
+ success: false
diff --git a/cases/plan/cmd.yaml b/cases/plan/cmd.yaml
index 3ca7d89ba6f..58eb872268f 100644
--- a/cases/plan/cmd.yaml
+++ b/cases/plan/cmd.yaml
@@ -649,6 +649,22 @@ cases:
+-cmd_type: drop function
+-if_exists: true
+-args: [func1]
+ - id: truncate_stmt
+ desc: truncate
+ sql: TRUNCATE TABLE t1;
+ expect:
+ node_tree_str: |
+ +-node[CMD]
+ +-cmd_type: truncate table
+ +-args: [t1]
+ - id: truncate_stmt_db
+ desc: truncate
+ sql: TRUNCATE TABLE db1.t1;
+ expect:
+ node_tree_str: |
+ +-node[CMD]
+ +-cmd_type: truncate table
+ +-args: [db1, t1]
- id: exit_stmt
desc: exit statement
sql: EXIT;
@@ -704,3 +720,20 @@ cases:
+-actions:
+-0: DropPathAction (12)
+-1: AddPathAction (13)
+
+ - id: show-create-table
+ desc: SHOW CREATE TABLE
+ sql: SHOW CREATE TABLE t1;
+ expect:
+ node_tree_str: |
+ +-node[CMD]
+ +-cmd_type: show create table
+ +-args: [t1]
+ - id: show-create-table-db
+ desc: SHOW CREATE TABLE
+ sql: SHOW CREATE TABLE db1.t1;
+ expect:
+ node_tree_str: |
+ +-node[CMD]
+ +-cmd_type: show create table
+ +-args: [db1, t1]
diff --git a/cases/plan/create.yaml b/cases/plan/create.yaml
index 315ec30a305..f1076934391 100644
--- a/cases/plan/create.yaml
+++ b/cases/plan/create.yaml
@@ -1035,3 +1035,40 @@ cases:
+-kind: HIVE
+-path: hdfs://path
+-table_option_list: []
+
+ - id: 34
+ desc: Create 指定压缩
+ sql: |
+ create table t1(
+ column1 int,
+ column2 timestamp,
+ index(key=column1, ts=column2)) OPTIONS (compress_type="snappy");
+ expect:
+ node_tree_str: |
+ +-node[CREATE]
+ +-table: t1
+ +-IF NOT EXIST: 0
+ +-column_desc_list[list]:
+ | +-0:
+ | | +-node[kColumnDesc]
+ | | +-column_name: column1
+ | | +-column_type: int32
+ | | +-NOT NULL: 0
+ | +-1:
+ | | +-node[kColumnDesc]
+ | | +-column_name: column2
+ | | +-column_type: timestamp
+ | | +-NOT NULL: 0
+ | +-2:
+ | +-node[kColumnIndex]
+ | +-keys: [column1]
+ | +-ts_col: column2
+ | +-abs_ttl: -2
+ | +-lat_ttl: -2
+ | +-ttl_type:
+ | +-version_column:
+ | +-version_count: 0
+ +-table_option_list[list]:
+ +-0:
+ +-node[kCompressType]
+ +-compress_type: snappy
diff --git a/cases/plan/join_query.yaml b/cases/plan/join_query.yaml
index 4d2bbdc0e57..28021b54d4b 100644
--- a/cases/plan/join_query.yaml
+++ b/cases/plan/join_query.yaml
@@ -18,20 +18,83 @@ cases:
sql: SELECT t1.COL1, t1.COL2, t2.COL1, t2.COL2 FROM t1 full join t2 on t1.col1 = t2.col2;
mode: physical-plan-unsupport
- id: 2
+ mode: request-unsupport
desc: 简单SELECT LEFT JOIN
- mode: runner-unsupport
sql: SELECT t1.COL1, t1.COL2, t2.COL1, t2.COL2 FROM t1 left join t2 on t1.col1 = t2.col2;
+ expect:
+ node_tree_str: |
+ +-node[kQuery]: kQuerySelect
+ +-distinct_opt: false
+ +-where_expr: null
+ +-group_expr_list: null
+ +-having_expr: null
+ +-order_expr_list: null
+ +-limit: null
+ +-select_list[list]:
+ | +-0:
+ | | +-node[kResTarget]
+ | | +-val:
+ | | | +-expr[column ref]
+ | | | +-relation_name: t1
+ | | | +-column_name: COL1
+ | | +-name:
+ | +-1:
+ | | +-node[kResTarget]
+ | | +-val:
+ | | | +-expr[column ref]
+ | | | +-relation_name: t1
+ | | | +-column_name: COL2
+ | | +-name:
+ | +-2:
+ | | +-node[kResTarget]
+ | | +-val:
+ | | | +-expr[column ref]
+ | | | +-relation_name: t2
+ | | | +-column_name: COL1
+ | | +-name:
+ | +-3:
+ | +-node[kResTarget]
+ | +-val:
+ | | +-expr[column ref]
+ | | +-relation_name: t2
+ | | +-column_name: COL2
+ | +-name:
+ +-tableref_list[list]:
+ | +-0:
+ | +-node[kTableRef]: kJoin
+ | +-join_type: LeftJoin
+ | +-left:
+ | | +-node[kTableRef]: kTable
+ | | +-table: t1
+ | | +-alias:
+ | +-right:
+ | +-node[kTableRef]: kTable
+ | +-table: t2
+ | +-alias:
+ | +-order_expressions: null
+ | +-on:
+ | +-expr[binary]
+ | +-=[list]:
+ | +-0:
+ | | +-expr[column ref]
+ | | +-relation_name: t1
+ | | +-column_name: col1
+ | +-1:
+ | +-expr[column ref]
+ | +-relation_name: t2
+ | +-column_name: col2
+ +-window_list: []
- id: 3
desc: 简单SELECT LAST JOIN
sql: SELECT t1.COL1, t1.COL2, t2.COL1, t2.COL2 FROM t1 last join t2 order by t2.col5 on t1.col1 = t2.col2;
- id: 4
desc: 简单SELECT RIGHT JOIN
sql: SELECT t1.COL1, t1.COL2, t2.COL1, t2.COL2 FROM t1 right join t2 on t1.col1 = t2.col2;
- mode: runner-unsupport
+ mode: physical-plan-unsupport
- id: 5
desc: LeftJoin有不等式条件
sql: SELECT t1.col1 as t1_col1, t2.col2 as t2_col2 FROM t1 left join t2 on t1.col1 = t2.col2 and t2.col5 >= t1.col5;
- mode: runner-unsupport
+ mode: request-unsupport
- id: 6
desc: LastJoin有不等式条件
sql: SELECT t1.col1 as t1_col1, t2.col2 as t2_col2 FROM t1 last join t2 order by t2.col5 on t1.col1 = t2.col2 and t2.col5 >= t1.col5;
@@ -162,4 +225,4 @@ cases:
col1 as id,
sum(col2) OVER w2 as w2_col2_sum FROM t1 WINDOW
w2 AS (PARTITION BY col1 ORDER BY col5 ROWS_RANGE BETWEEN 1d OPEN PRECEDING AND CURRENT ROW)
- ) as out1 ON out0.id = out1.id;
\ No newline at end of file
+ ) as out1 ON out0.id = out1.id;
diff --git a/cases/query/const_query.yaml b/cases/query/const_query.yaml
index 38bbbeb5e47..a3ea130d885 100644
--- a/cases/query/const_query.yaml
+++ b/cases/query/const_query.yaml
@@ -126,3 +126,55 @@ cases:
columns: ['c1 bool', 'c2 int16', 'c3 int', 'c4 double', 'c5 string', 'c6 date', 'c7 timestamp' ]
rows:
- [ true, 3, 13, 10.0, 'a string', '2020-05-22', 1590115420000 ]
+
+ # =================================================================================
+ # Null safe for structure types: String, Date, Timestamp and Array
+ # creating struct from:
+ # 1. NULL liternal (const null)
+ # 2. another supported date type but fails to cast, e.g. timestamp(-1) returns NULL of timestamp
+ #
+ # casting to array type un-implemented
+ # =================================================================================
+ - id: 10
+ desc: null safe for date
+ mode: procedure-unsupport
+ sql: |
+ select
+ datediff(Date(timestamp(-1)), Date("2021-05-01")) as out1,
+ datediff(Date(timestamp(-2177481600)), Date("2021-05-01")) as out2,
+ datediff(cast(NULL as date), Date("2021-05-01")) as out3,
+ date(NULL) as out4,
+ date("abc") as out5,
+ date(timestamp("abc")) as out6
+ expect:
+ columns: ["out1 int", "out2 int", "out3 int", "out4 date", "out5 date", "out6 date"]
+ data: |
+ NULL, NULL, NULL, NULL, NULL, NULL
+ - id: 11
+ desc: null safe for timestamp
+ mode: procedure-unsupport
+ sql: |
+ select
+ month(cast(NULL as timestamp)) as out1,
+ month(timestamp(NULL)) as out2,
+ month(timestamp(-1)) as out3,
+ month(timestamp("abc")) as out4,
+ month(timestamp(date("abc"))) as out5
+ expect:
+ columns: ["out1 int", "out2 int", "out3 int", "out4 int", "out5 int"]
+ data: |
+ NULL, NULL, NULL, NULL, NULL
+ - id: 12
+ desc: null safe for string
+ mode: procedure-unsupport
+ sql: |
+ select
+ char_length(cast(NULL as string)) as out1,
+ char_length(string(int(NULL))) as out2,
+ char_length(string(bool(null))) as out3,
+ char_length(string(timestamp(null))) as out4,
+ char_length(string(date(null))) as out5
+ expect:
+ columns: ["out1 int", "out2 int", "out3 int", "out4 int", "out5 int"]
+ data: |
+ NULL, NULL, NULL, NULL, NULL
diff --git a/cases/query/fail_query.yaml b/cases/query/fail_query.yaml
index 4058525678c..415fa203127 100644
--- a/cases/query/fail_query.yaml
+++ b/cases/query/fail_query.yaml
@@ -49,3 +49,24 @@ cases:
SELECT 100 + 1s;
expect:
success: false
+ - id: 3
+ desc: unsupport join
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - name: t2
+ columns: ["c2 int","c4 timestamp"]
+ indexs: ["index1:c2:c4"]
+ rows:
+ - [20,3000]
+ - [20,2000]
+ sql: |
+ select t1.c1 as id, t2.* from t1 right join t2
+ on t1.c2 = t2.c2
+ expect:
+ success: false
+ msg: unsupport join type RightJoin
diff --git a/cases/query/last_join_query.yaml b/cases/query/last_join_query.yaml
index e37d87a4044..2715bcf7341 100644
--- a/cases/query/last_join_query.yaml
+++ b/cases/query/last_join_query.yaml
@@ -12,10 +12,27 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+ ####################################################################################################
+ # LAST JOINs
+ # support modes:
+ # - online request (right source optimized)
+ # - batch request (right source optimized)
+ # - online preview (standalone)
+ # - offline mode
+ # unsupport:
+ # - online preview (in cluster)
+ # - online request (right source not optimized)
+ # - batch request (right source not optimized)
+ #
+ # Right source is optimized case:
+ # 1. Right source is ANYOP(T2): T2 optimized with a concret index
+ # 2. Right source is ANYOP(JOIN(T2, T3)): both T2 and T3 optimized with concret indexs
+ ####################################################################################################
+
cases:
- id: 0
desc: LAST JOIN 右表未命中索引
- mode: rtidb-unsupport
+ mode: request-unsupport
sql: |
SELECT t1.col1 as id, t1.col0 as t1_col0, t1.col1 + t2.col1 + 1 as test_col1, t1.col2 as t1_col2, str1 FROM t1
last join t2 order by t2.col5 on t1.col1=t2.col1 and t1.col5 = t2.col5;
@@ -178,6 +195,19 @@ cases:
Z, 3, 3
U, 4, 4
V, 5, 5
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.col1 -> id, t1.col0, t2.c0, t3.column0))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.col1))
+ DATA_PROVIDER(request=t1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.col1))
+ DATA_PROVIDER(request=t1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
expect:
schema: id:int32, col0:string, c0:string, column0:string
order: id
@@ -335,8 +365,6 @@ cases:
5, 2, 1590115423900
- id: 10
- desc: 右表没有匹配[FEX-903]
- mode: offline-unsupport
inputs:
- name: t1
columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
@@ -361,3 +389,779 @@ cases:
- ["aa",2,13,1590738989000]
- ["bb",21,131,1590738990000]
- ["cc",41,null,null]
+
+ ####################################################################################################
+ # LAZY LAST JOINs
+ ####################################################################################################
+ - id: 11
+ # t1------>(t2------->t3)
+ # │ └-(t3.c1)-┘
+ # └-(t2.c1)-┘
+ # Easiest path, t1 finally joins t2's column
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r
+ from t1 last join (
+ select t2.*, t3.c1 as c1r, t3.c2 as c2r
+ from t2 last join t3 on t2.c1 = t3.c1
+ ) tx
+ on t1.c1 = tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ data: |
+ aa, 2, aa, aa, 2
+ bb, 3, bb, NULL, NULL
+ cc, 4, NULL, NULL, NULL
+ - id: 12
+ # t1------>(t2------->t3)
+ # │ └-(t3.c1)-┘
+ # └--(t2.c1)----------┘
+ desc: unsupport join on t3 in request and batch(clusterd)
+ mode: request-unsupport
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1x string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1x:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r
+ from t1 last join (
+ select t2.*, t3.c1x as c1r, t3.c2 as c2r
+ from t2 last join t3 on t2.c1 = t3.c1x
+ ) tx
+ on t1.c1 = tx.c1r
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(t1.c1), right_keys=(tx.c1r), index_keys=)
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1x -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(table=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ data: |
+ aa, 2, aa, aa, 2
+ bb, 3, NULL, NULL, NULL
+ cc, 4, NULL, NULL, NULL
+ - id: 13
+ # t1------>(t2------->t3)
+ # │ └-(t3.c1)-┘
+ # └-(t2.c1)-----------┘
+ desc: t2 un-optimized, t2 & t3 has the same schema
+ # the case checks if optimizer can distinct same column name from two tables
+ mode: request-unsupport
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r
+ from t1 last join (
+ select t2.*, t3.c1 as c1r, t3.c2 as c2r
+ from t2 last join t3 on t2.c1 = t3.c1
+ ) tx
+ on t1.c1 = tx.c1r
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(t1.c1), right_keys=(tx.c1r), index_keys=)
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(table=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ data: |
+ aa, 2, aa, aa, 2
+ bb, 3, NULL, NULL, NULL
+ cc, 4, NULL, NULL, NULL
+ - id: 14
+ # t1------>(t2------->t3)
+ # │ └-(t3.c1)-┘
+ # └-(t2.c1)-┘
+ desc: t2 un-optimized due to no equal expr
+ mode: request-unsupport
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r
+ from t1 last join (
+ select t2.*, t3.c1 as c1r, t3.c2 as c2r
+ from t2 last join t3 on t2.c1 = t3.c1
+ ) tx
+ on t1.c1 != tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ JOIN(type=LastJoin, condition=t1.c1 != tx.c1, left_keys=, right_keys=, index_keys=)
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(table=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ data: |
+ aa, 2, dd, dd, 41
+ bb, 3, dd, dd, 41
+ cc, 4, dd, dd, 41
+ - id: 15
+ # t1------>(t2------->t3)
+ # │ └-(t3.c1)-┘
+ # └-(t2.c1)-┘
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r
+ from t1 last join (
+ select t2.*, t3.c1 as c1r, t3.c2 as c2r
+ from t2 last join t3 on t2.c1 = t3.c1
+ ) tx
+ order by tx.c4
+ on t1.c1 = tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ data: |
+ aa, 2, aa, aa, 2
+ bb, 3, bb, NULL, NULL
+ cc, 4, NULL, NULL, NULL
+ - id: 16
+ # t1------>(t2------->t3)
+ # │ └-(t3.c1)-┘
+ # └-(t2.c1)-┘
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r
+ from t1 last join (
+ select t2.c1, t2.c4 as c4l, t3.c1 as c1r, t3.c2 as c2r
+ from t2 last join t3 on t2.c1 = t3.c1
+ ) tx
+ order by tx.c4l
+ on t1.c1 = tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ data: |
+ aa, 2, aa, aa, 2
+ bb, 3, bb, NULL, NULL
+ cc, 4, NULL, NULL, NULL
+ - id: 17
+ # t1------>(t2------->(t3-------t4)
+ # │ │ └-(t4.c1)-┘
+ # │ └-(t3.c1)--┘
+ # └-(t2.c1)-┘
+ desc: multiple lazy last join
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ - name: t4
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["bb",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r, c1rr
+ from t1 last join (
+ select t2.c1, t2.c4 as c4l, t3.c1 as c1r, t3.c2 as c2r, t3.c1rr
+ from t2 last join (
+ select t3.*, t4.c1 as c1rr
+ from t3 last join t4
+ on t3.c1 = t4.c1
+ ) t3
+ on t2.c1 = t3.c1
+ ) tx
+ order by tx.c4l
+ on t1.c1 = tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t3.c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ RENAME(name=t3)
+ SIMPLE_PROJECT(sources=(t3.c1, t3.c2, t3.c3, t3.c4, t4.c1 -> c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t3.c1))
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t3.c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ RENAME(name=t3)
+ SIMPLE_PROJECT(sources=(t3.c1, t3.c2, t3.c3, t3.c4, t4.c1 -> c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t3.c1))
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t3.c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ RENAME(name=t3)
+ SIMPLE_PROJECT(sources=(t3.c1, t3.c2, t3.c3, t3.c4, t4.c1 -> c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t3.c1))
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ - c1rr string
+ data: |
+ aa, 2, aa, aa, 2, aa
+ bb, 3, bb, NULL, NULL, NULL
+ cc, 4, NULL, NULL, NULL, NULL
+ - id: 18
+ # t1------>(t2------->(t3-------t4)
+ # │ │ └-(t4.c1)-┘
+ # │ └-(t3.c1)--┘
+ # └-(t2.c1)-┘
+ mode: request-unsupport
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["bb",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ - name: t4
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r, c1rr
+ from t1 last join (
+ select t2.c1, t2.c4 as c4l, t3.c1 as c1r, t3.c2 as c2r, t3.c1rr
+ from t2 last join (
+ select t3.*, t4.c1 as c1rr
+ from t3 last join t4
+ on t3.c1 = t4.c1
+ ) t3
+ on t2.c1 = t3.c1rr
+ ) tx
+ order by tx.c4l
+ on t1.c1 = tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t3.c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(t2.c1), right_keys=(t3.c1rr), index_keys=)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ RENAME(name=t3)
+ SIMPLE_PROJECT(sources=(t3.c1, t3.c2, t3.c3, t3.c4, t4.c1 -> c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t3.c1))
+ DATA_PROVIDER(table=t3)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ - c1rr string
+ data: |
+ aa, 2, aa, aa, 2, aa
+ bb, 3, bb, NULL, NULL, NULL
+ cc, 4, NULL, NULL, NULL, NULL
+ - id: 19
+ # t1------>(t2------->(t3-------t4)
+ # │ └-(t3.c1)--┘ │
+ # │ └--(t4.c1)------┘
+ # └-(t2.c1)-┘
+ desc: nested last join
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ - name: t4
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["bb",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r, c1rr
+ from t1 last join (
+ select t2.c1, t2.c4 as c4l, t3.c1 as c1r, t3.c2 as c2r, t4.c1 as c1rr
+ from t2 last join t3
+ on t2.c1 = t3.c1
+ last join t4
+ on t2.c1 = t4.c1
+ ) tx
+ on t1.c1 = tx.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t4.c1 -> c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t4.c1 -> c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, c1rr))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r, t4.c1 -> c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ - c1rr string
+ data: |
+ aa, 2, aa, aa, 2, aa
+ bb, 3, bb, NULL, NULL, bb
+ cc, 4, NULL, NULL, NULL, NULL
+ - id: 20
+ # t1------>(t2------->(t3-------t4)
+ # │ └-(t3.c1)--┘ │
+ # └-(t2.c1)----┘ │
+ # └-------------------------┘
+ desc: nested last join
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",1590738989000]
+ - ["bb",1590738990000]
+ - ["dd",1590738991000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ - name: t4
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,13,1590738989000]
+ - ["cc",21,131,1590738990000]
+ - ["dd",41,151,1590738991000]
+ sql: |
+ select t1.c1, t1.c2, tx.c1 as c1l, c1r, c2r, t4.c1 as c1rr
+ from t1 last join (
+ select t2.c1, t2.c4 as c4l, t3.c1 as c1r, t3.c2 as c2r
+ from t2 last join t3
+ on t2.c1 = t3.c1
+ ) tx
+ on t1.c1 = tx.c1
+ last join t4
+ on tx.c1 = t4.c1
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, t4.c1 -> c1rr))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(tx.c1))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, t4.c1 -> c1rr))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(tx.c1))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.c1 -> c1l, c1r, c2r, t4.c1 -> c1rr))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#123))
+ SIMPLE_PROJECT(sources=(#123 -> tx.c1))
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t2.c4 -> c4l, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ expect:
+ order: c1
+ columns:
+ - c1 string
+ - c2 int
+ - c1l string
+ - c1r string
+ - c2r int
+ - c1rr string
+ data: |
+ aa, 2, aa, aa, 2, aa
+ bb, 3, bb, NULL, NULL, NULL
+ cc, 4, NULL, NULL, NULL, NULL
diff --git a/cases/query/last_join_subquery_window.yml b/cases/query/last_join_subquery_window.yml
new file mode 100644
index 00000000000..81787f87e67
--- /dev/null
+++ b/cases/query/last_join_subquery_window.yml
@@ -0,0 +1,406 @@
+cases:
+ # ===================================================================
+ # LAST JOIN (WINDOW)
+ # ===================================================================
+ - id: 0
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,1590738989000]
+ - ["bb",3,1590738990000]
+ - ["cc",4,1590738991000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["aa",1, 1590738989000]
+ - ["bb",3, 1590738990000]
+ - ["dd",4, 1590738991000]
+ sql: |
+ select t1.c1, tx.c1 as c1r, tx.c2 as c2r, agg
+ from t1 last join (
+ select c1, c2, count(c4) over w as agg
+ from t2
+ window w as (
+ partition by c1 order by c4
+ rows between 1 preceding and current row
+ )
+ ) tx
+ on t1.c2 = tx.c2
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, partition_keys=(), orders=(ASC), rows=(c4, 1 PRECEDING, 0 CURRENT), index_keys=(c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, agg))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(c1, c2))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, partition_keys=(), orders=(ASC), rows=(c4, 1 PRECEDING, 0 CURRENT), index_keys=(c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ expect:
+ columns: ["c1 string", "c1r string", "c2r int", "agg int64"]
+ order: c1
+ data: |
+ aa, NULL, NULL, NULL
+ bb, bb, 3, 1
+ cc, dd, 4, 1
+ - id: 1
+ desc: last join window(attributes)
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,2000]
+ - ["bb",3,2000]
+ - ["cc",4,2000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp", "val int"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["aa",1, 1000, 1]
+ - ["aa",4, 2000, 2]
+ - ["bb",3, 3000, 3]
+ - ["dd",4, 8000, 4]
+ - ["dd",4, 7000, 5]
+ - ["dd",4, 9000, 6]
+ sql: |
+ select t1.c1, tx.c1 as c1r, tx.c2 as c2r, agg1, agg2
+ from t1 last join (
+ select c1, c2, c4,
+ count(c4) over w as agg1,
+ max(val) over w as agg2
+ from t2
+ window w as (
+ partition by c1 order by c4
+ rows between 2 preceding and current row
+ exclude current_row
+ )
+ ) tx
+ order by tx.c4
+ on t1.c2 = tx.c2
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, EXCLUDE_CURRENT_ROW, partition_keys=(), orders=(ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=(c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, c4, agg1, agg2))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(c1, c2, c4))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, EXCLUDE_CURRENT_ROW, partition_keys=(), orders=(ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=(c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ expect:
+ columns: ["c1 string", "c1r string", "c2r int", "agg1 int64", 'agg2 int']
+ order: c1
+ data: |
+ aa, NULL, NULL, NULL, NULL
+ bb, bb, 3, 0, NULL
+ cc, dd, 4, 2, 5
+ - id: 2
+ # issue on join to (multiple windows), fix later
+ mode: batch-unsupport
+ desc: last join multiple windows
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,2000]
+ - ["bb",3,2000]
+ - ["cc",4,2000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp", "val int", "gp int"]
+ indexs: ["index1:c1:c4", "index2:c2:c4", "index3:gp:c4"]
+ rows:
+ - ["aa",1, 1000, 1, 0]
+ - ["aa",4, 2000, 2, 0]
+ - ["bb",3, 3000, 3, 1]
+ - ["dd",4, 8000, 4, 1]
+ - ["dd",4, 7000, 5, 1]
+ - ["dd",4, 9000, 6, 1]
+ sql: |
+ select t1.c1, tx.c1 as c1r, tx.c2 as c2r, agg1, agg2, agg3
+ from t1 last join (
+ select c1, c2, c4,
+ count(c4) over w1 as agg1,
+ max(val) over w1 as agg2,
+ min(val) over w2 as agg3
+ from t2
+ window w1 as (
+ partition by c1 order by c4
+ rows between 2 preceding and current row
+ exclude current_row
+ ),
+ w2 as (
+ partition by gp order by c4
+ rows_range between 3s preceding and current row
+ exclude current_time
+ )
+ ) tx
+ order by tx.c4
+ on t1.c2 = tx.c2
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2, agg3))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, c4, agg1, agg2, agg3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, EXCLUDE_CURRENT_ROW, partition_keys=(), orders=(ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=(c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, EXCLUDE_CURRENT_TIME, partition_keys=(), orders=(ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=(gp))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index3)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2, agg3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, c4, agg1, agg2, agg3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(c1, c2, c4))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, EXCLUDE_CURRENT_ROW, partition_keys=(), orders=(ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=(c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_REQUEST_ROW, EXCLUDE_CURRENT_TIME, partition_keys=(), orders=(ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=(gp))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t2, index=index3)
+ expect:
+ columns: ["c1 string", "c1r string", "c2r int", "agg1 int64", 'agg2 int', 'agg3 int']
+ order: c1
+ data: |
+ aa, NULL, NULL, NULL, NULL, NULL
+ bb, bb, 3, 0, NULL, NULL
+ cc, dd, 4, 2, 5, 4
+ - id: 3
+ desc: last join window union
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,2000]
+ - ["bb",3,2000]
+ - ["cc",4,2000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp", "val int"]
+ indexs: ["index1:c1:c4", "index2:c2:c4" ]
+ rows:
+ - ["aa",1, 1000, 1]
+ - ["aa",4, 2000, 2]
+ - ["bb",3, 3000, 3]
+ - ["dd",4, 8000, 4]
+ - ["dd",4, 9000, 6]
+ - name: t3
+ columns: ["c1 string", "c2 int", "c4 timestamp", "val int"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["aa", 2, 1000, 5]
+ - ["bb", 3, 2000, 8]
+ - ["dd", 4, 4000, 12]
+ - ["dd", 4, 7000, 10]
+ - ["dd", 4, 6000, 11]
+ - ["dd", 4, 10000, 100]
+ sql: |
+ select t1.c1, tx.c1 as c1r, tx.c2 as c2r, agg1, agg2
+ from t1 last join (
+ select c1, c2, c4,
+ count(c4) over w1 as agg1,
+ max(val) over w1 as agg2,
+ from t2
+ window w1 as (
+ union t3
+ partition by c1 order by c4
+ rows_range between 3s preceding and current row
+ instance_not_in_window exclude current_row
+ )
+ ) tx
+ order by tx.c4
+ on t1.c2 = tx.c2
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_CURRENT_ROW, INSTANCE_NOT_IN_WINDOW, partition_keys=(c1), orders=(c4 ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=)
+ +-UNION(partition_keys=(), orders=(ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=(c1))
+ RENAME(name=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(table=t2)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, c4, agg1, agg2))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(c1, c2, c4))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_CURRENT_ROW, INSTANCE_NOT_IN_WINDOW, partition_keys=(c1), orders=(c4 ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=)
+ +-UNION(partition_keys=(), orders=(ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=(c1))
+ RENAME(name=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(table=t2)
+ expect:
+ columns: ["c1 string", "c1r string", "c2r int", "agg1 int64", 'agg2 int']
+ order: c1
+ data: |
+ aa, NULL, NULL, NULL, NULL
+ bb, bb, 3, 1, 8
+ cc, dd, 4, 2, 11
+ - id: 4
+ desc: last join mulitple window union
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2,2000]
+ - ["bb",3,2000]
+ - ["cc",4,2000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp", "val int"]
+ indexs: ["index1:c1:c4", "index2:c2:c4" ]
+ rows:
+ - ["aa",1, 1000, 1]
+ - ["aa",4, 2000, 2]
+ - ["bb",3, 3000, 3]
+ - ["dd",4, 8000, 4]
+ - ["dd",4, 9000, 6]
+ - name: t3
+ columns: ["c1 string", "c2 int", "c4 timestamp", "val int"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["aa", 2, 1000, 5]
+ - ["bb", 3, 2000, 8]
+ - ["dd", 4, 4000, 12]
+ - ["dd", 4, 7000, 10]
+ - ["dd", 4, 6000, 11]
+ - ["dd", 4, 10000, 100]
+ sql: |
+ select t1.c1, tx.c1 as c1r, tx.c2 as c2r, agg1, agg2, agg3
+ from t1 last join (
+ select c1, c2, c4,
+ count(c4) over w1 as agg1,
+ max(val) over w1 as agg2,
+ min(val) over w2 as agg3
+ from t2
+ window w1 as (
+ union t3
+ partition by c1 order by c4
+ rows_range between 3s preceding and current row
+ instance_not_in_window exclude current_row
+ ),
+ w2 as (
+ union t3
+ partition by c1 order by c4
+ rows between 2 preceding and current row
+ instance_not_in_window
+ )
+ ) tx
+ order by tx.c4
+ on t1.c2 = tx.c2
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2, agg3))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, c4, agg1, agg2, agg3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_CURRENT_ROW, INSTANCE_NOT_IN_WINDOW, partition_keys=(c1), orders=(c4 ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=)
+ +-UNION(partition_keys=(), orders=(ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=(c1))
+ RENAME(name=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(table=t2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(INSTANCE_NOT_IN_WINDOW, partition_keys=(c1), orders=(c4 ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=)
+ +-UNION(partition_keys=(), orders=(ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=(c1))
+ RENAME(name=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(table=t2)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1r, tx.c2 -> c2r, agg1, agg2, agg3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(#5))
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(c1, c2, c4, agg1, agg2, agg3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(c1, c2, c4))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(EXCLUDE_CURRENT_ROW, INSTANCE_NOT_IN_WINDOW, partition_keys=(c1), orders=(c4 ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=)
+ +-UNION(partition_keys=(), orders=(ASC), range=(c4, 3000 PRECEDING, 0 CURRENT), index_keys=(c1))
+ RENAME(name=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(table=t2)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(INSTANCE_NOT_IN_WINDOW, partition_keys=(c1), orders=(c4 ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=)
+ +-UNION(partition_keys=(), orders=(ASC), rows=(c4, 2 PRECEDING, 0 CURRENT), index_keys=(c1))
+ RENAME(name=t2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(table=t2)
+ expect:
+ columns: ["c1 string", "c1r string", "c2r int", "agg1 int64", 'agg2 int', "agg3 int"]
+ order: c1
+ data: |
+ aa, NULL, NULL, NULL, NULL, NULL
+ bb, bb, 3, 1, 8, 3
+ cc, dd, 4, 2, 11, 6
diff --git a/cases/query/last_join_where.yaml b/cases/query/last_join_where.yaml
index 6a341d001d8..110debcfcdf 100644
--- a/cases/query/last_join_where.yaml
+++ b/cases/query/last_join_where.yaml
@@ -8,7 +8,6 @@ cases:
- id: 0
desc: LASTJOIN(FILTER)
deployable: true
- mode: batch-request-unsupport
sql: |
SELECT
t1.c1,
@@ -38,6 +37,16 @@ cases:
RENAME(name=t2)
FILTER_BY(condition=, left_keys=(), right_keys=(), index_keys=(aa))
DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, t2.c1 -> c21))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(#5), right_keys=(#9), index_keys=)
+ SIMPLE_PROJECT(sources=(#5 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=t2)
+ FILTER_BY(condition=, left_keys=(), right_keys=(), index_keys=(aa))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
expect:
columns:
- c1 string
@@ -51,7 +60,6 @@ cases:
- id: 1
desc: LASTJOIN(SimpleOPS(FILTER))
- mode: batch-request-unsupport
deployable: true
sql: |
SELECT
@@ -140,7 +148,6 @@ cases:
- id: 3
desc: LASTJOIN(FILTER)
- mode: batch-request-unsupport
deployable: true
sql: |
SELECT
@@ -232,7 +239,6 @@ cases:
LASTJOIN(SimpleOps(FILTER)), different index with join, fine to
online if there is no order by of last join
deployable: true
- mode: batch-request-unsupport
sql: |
SELECT
t1.c1,
@@ -322,7 +328,6 @@ cases:
- id: 7
desc: LASTJOIN(SimpleOps(FILTER)) hit same index with order by
- mode: batch-request-unsupport
deployable: true
sql: |
SELECT
diff --git a/cases/query/last_join_window_query.yaml b/cases/query/last_join_window_query.yaml
index 96467eaf787..a11fce4369f 100644
--- a/cases/query/last_join_window_query.yaml
+++ b/cases/query/last_join_window_query.yaml
@@ -321,11 +321,11 @@ cases:
min(c3r) OVER w1 as sumb,
from (
select
- {0}.c3 as c3l,
- {0}.id as idx,
- {1}.c3 as c3r,
- {0}.c1 as c1a,
- {0}.c7 as c7a
+ t0.c3 as c3l,
+ t0.id as idx,
+ t1.c3 as c3r,
+ t0.c1 as c1a,
+ t0.c7 as c7a
from t0 last join t1 on t0.c1=t1.c1
)
WINDOW w1 AS (
diff --git a/cases/query/left_join.yml b/cases/query/left_join.yml
new file mode 100644
index 00000000000..87e1c387ea6
--- /dev/null
+++ b/cases/query/left_join.yml
@@ -0,0 +1,575 @@
+cases:
+ - id: 0
+ desc: last join to a left join subquery
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2000]
+ - ["bb",2000]
+ - ["cc",3000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["aa",21,13,3000]
+ - ["bb",34,131,3000]
+ - ["bb",21,131,3000]
+ sql: |
+ select
+ t1.c1,
+ tx.c1 as c1l,
+ tx.c1r,
+ tx.c2r
+ from t1 last join
+ (
+ select t2.c1 as c1,
+ t3.c1 as c1r,
+ t3.c2 as c2r
+ from t2 left join t3
+ on t2.c1 = t3.c1
+ ) tx
+ on t1.c1 = tx.c1 and t1.c2 > tx.c2r
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ JOIN(type=LastJoin, condition=t1.c2 > tx.c2r, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LeftJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ REQUEST_JOIN(type=LastJoin, condition=t1.c2 > tx.c2r, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LeftJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns: ["c1 string", "c1l string", "c1r string", "c2r int"]
+ data: |
+ aa, aa, aa, 19
+ bb, bb, bb, 21
+ cc, NULL, NULL, NULL
+ dd, NULL, NULL, NULL
+ - id: 1
+ desc: last join to a left join subquery, request unsupport if left join not optimized
+ mode: request-unsupport
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",2000]
+ - ["bb",3000]
+ - ["cc",4000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c2:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["aa",21,13,4000]
+ - ["bb",34,131,3000]
+ - ["bb",21,131,4000]
+ sql: |
+ select
+ t1.c1,
+ tx.c1 as c1l,
+ tx.c1r,
+ tx.c2r
+ from t1 last join
+ (
+ select t2.c1 as c1,
+ t3.c1 as c1r,
+ t3.c2 as c2r
+ from t2 left join t3
+ on t2.c1 = t3.c1
+ ) tx
+ on t1.c1 = tx.c1 and t1.c2 > tx.c2r
+ batch_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ JOIN(type=LastJoin, condition=t1.c2 > tx.c2r, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(table=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ JOIN(type=LeftJoin, condition=, left_keys=(t2.c1), right_keys=(t3.c1), index_keys=)
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(table=t3)
+ expect:
+ order: c1
+ columns: ["c1 string", "c1l string", "c1r string", "c2r int"]
+ data: |
+ aa, aa, aa, 19
+ bb, bb, bb, 21
+ cc, NULL, NULL, NULL
+ dd, NULL, NULL, NULL
+ - id: 2
+ desc: last join to a left join subquery, index optimized with additional condition
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa", 42, 2000]
+ - ["bb", 68, 3000]
+ - ["cc", 42, 4000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["aa",21,13,4000]
+ - ["bb",34,131,3000]
+ - ["bb",21,131,4000]
+ sql: |
+ select
+ t1.c1,
+ tx.c1 as c1l,
+ tx.c1r,
+ tx.c2r
+ from t1 last join
+ (
+ select t2.c1 as c1,
+ t3.c1 as c1r,
+ t3.c2 as c2r
+ from t2 left join t3
+ on t2.c1 = t3.c1 and t2.c2 = 2 * t3.c2
+ ) tx
+ on t1.c1 = tx.c1
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LeftJoin, condition=, left_keys=(t2.c2), right_keys=(2 * t3.c2), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LeftJoin, condition=, left_keys=(t2.c2), right_keys=(2 * t3.c2), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns: ["c1 string", "c1l string", "c1r string", "c2r int"]
+ data: |
+ aa, aa, aa, 21
+ bb, bb, bb, 34
+ cc, cc, NULL, NULL
+ dd, NULL, NULL, NULL
+ - id: 3
+ desc: last join to a left join subquery 2, index optimized with additional condition
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa", 20, 2000]
+ - ["bb", 10, 3000]
+ - ["cc", 42, 4000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["aa",21,13,4000]
+ - ["bb",34,131,3000]
+ - ["bb",21,131,4000]
+ sql: |
+ select
+ t1.c1,
+ tx.c1 as c1l,
+ tx.c1r,
+ tx.c2r
+ from t1 last join
+ (
+ select t2.c1 as c1,
+ t3.c1 as c1r,
+ t3.c2 as c2r
+ from t2 left join t3
+ on t2.c1 = t3.c1 and t2.c2 > t3.c2
+ ) tx
+ on t1.c1 = tx.c1
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LeftJoin, condition=t2.c2 > t3.c2, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r))
+ REQUEST_JOIN(type=LeftJoin, condition=t2.c2 > t3.c2, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns: ["c1 string", "c1l string", "c1r string", "c2r int"]
+ data: |
+ aa, aa, aa, 19
+ bb, bb, NULL, NULL
+ cc, cc, NULL, NULL
+ dd, NULL, NULL, NULL
+ - id: 4
+ desc: last join to two left join
+ # there is no restriction for multiple left joins, including request mode,
+ # but it may not high performance like multiple last joins
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa", 20, 2000]
+ - ["bb", 10, 3000]
+ - ["cc", 42, 4000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["aa",21,8, 4000]
+ - ["bb",34,131,3000]
+ - ["bb",21,131,4000]
+ - ["cc",27,100,5000]
+ - name: t4
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,14,3000]
+ - ["aa",21,13,4000]
+ - ["bb",34,1,3000]
+ - ["bb",21,132,4000]
+ sql: |
+ select
+ t1.c1,
+ tx.c1 as c1l,
+ tx.c1r,
+ tx.c2r,
+ tx.c3x
+ from t1 last join
+ (
+ select t2.c1 as c1,
+ t3.c1 as c1r,
+ t3.c2 as c2r,
+ t4.c3 as c3x
+ from t2 left outer join t3
+ on t2.c1 = t3.c1 and t2.c2 > t3.c2
+ left join t4
+ on t2.c1 = t4.c1 and t3.c3 < t4.c3
+ ) tx
+ on t1.c1 = tx.c1
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r, tx.c3x))
+ REQUEST_JOIN(type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r, t4.c3 -> c3x))
+ REQUEST_JOIN(type=LeftJoin, condition=t3.c3 < t4.c3, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ REQUEST_JOIN(type=LeftJoin, condition=t2.c2 > t3.c2, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, tx.c1 -> c1l, tx.c1r, tx.c2r, tx.c3x))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=, left_keys=(), right_keys=(), index_keys=(#4))
+ SIMPLE_PROJECT(sources=(#4 -> t1.c1))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1, t3.c1 -> c1r, t3.c2 -> c2r, t4.c3 -> c3x))
+ REQUEST_JOIN(type=LeftJoin, condition=t3.c3 < t4.c3, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ REQUEST_JOIN(type=LeftJoin, condition=t2.c2 > t3.c2, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ DATA_PROVIDER(type=Partition, table=t2, index=index1)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ DATA_PROVIDER(type=Partition, table=t4, index=index1)
+ expect:
+ order: c1
+ columns: ["c1 string", "c1l string", "c1r string", "c2r int", "c3x bigint"]
+ data: |
+ aa, aa, aa, 19, 14
+ bb, bb, NULL, NULL, NULL
+ cc, cc, cc, 27, NULL
+ dd, NULL, NULL, NULL, NULL
+ - id: 5
+ desc: simple left join
+ mode: request-unsupport
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - name: t2
+ columns: ["c2 int","c4 timestamp"]
+ indexs: ["index1:c2:c4"]
+ rows:
+ - [20,3000]
+ - [20,2000]
+ sql: |
+ select t1.c1 as id, t2.* from t1 left join t2
+ on t1.c2 = t2.c2
+ expect:
+ order: c1
+ columns: ["id string", "c2 int","c4 timestamp"]
+ data: |
+ aa, 20, 3000
+ aa, 20, 2000
+ bb, NULL, NULL
+ - id: 6
+ desc: lastjoin(leftjoin(filter, table))
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["bb",20, 1000]
+ - ["aa",30, 2000]
+ - ["bb",30, 3000]
+ - ["cc",40, 4000]
+ - ["dd",50, 5000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["bb",34,131,3000]
+ sql: |
+ select
+ t1.c1,
+ t1.c2,
+ tx.*
+ from t1 last join
+ (
+ select t2.c1 as tx_0_c1,
+ t2.c2 as tx_0_c2,
+ t2.c4 as tx_0_c4,
+ t3.c2 as tx_1_c2,
+ t3.c3 as tx_1_c3
+ from (select * from t2 where c1 != 'dd') t2 left join t3
+ on t2.c1 = t3.c1
+ ) tx
+ order by tx.tx_0_c4
+ on t1.c2 = tx.tx_0_c2
+ request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.tx_0_c1, tx.tx_0_c2, tx.tx_0_c4, tx.tx_1_c2, tx.tx_1_c3))
+ REQUEST_JOIN(type=LastJoin, right_sort=(ASC), condition=, left_keys=(), right_keys=(), index_keys=(t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1 -> tx_0_c1, t2.c2 -> tx_0_c2, t2.c4 -> tx_0_c4, t3.c2 -> tx_1_c2, t3.c3 -> tx_1_c3))
+ REQUEST_JOIN(type=LeftJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ RENAME(name=t2)
+ FILTER_BY(condition=c1 != dd, left_keys=, right_keys=, index_keys=)
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns: ["c1 string", "c2 int", "tx_0_c1 string", "tx_0_c2 int", "tx_0_c4 timestamp", "tx_1_c2 int", "tx_1_c3 int64"]
+ data: |
+ aa, 20, bb, 20, 1000, 34, 131
+ bb, 30, bb, 30, 3000, 34, 131
+ cc, 40, cc, 40, 4000, NULL, NULL
+ dd, 50, NULL, NULL, NULL, NULL, NULL
+ - id: 7
+ desc: lastjoin(leftjoin(filter, filter))
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - ["dd",50,1000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["bb",20, 1000]
+ - ["aa",30, 2000]
+ - ["bb",30, 3000]
+ - ["cc",40, 4000]
+ - ["dd",50, 5000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["bb",34,131,3000]
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.tx_0_c1, tx.tx_0_c2, tx.tx_0_c4, tx.tx_1_c2, tx.tx_1_c3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, right_sort=(ASC), condition=, left_keys=(#5), right_keys=(#8), index_keys=)
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1 -> tx_0_c1, t2.c2 -> tx_0_c2, t2.c4 -> tx_0_c4, t3.c2 -> tx_1_c2, t3.c3 -> tx_1_c3))
+ REQUEST_JOIN(type=LeftJoin, condition=, left_keys=(), right_keys=(), index_keys=(t2.c1))
+ RENAME(name=t2)
+ FILTER_BY(condition=, left_keys=(), right_keys=(), index_keys=(30))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ RENAME(name=t3)
+ FILTER_BY(condition=c2 > 20, left_keys=, right_keys=, index_keys=)
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ sql: |
+ select
+ t1.c1,
+ t1.c2,
+ tx.*
+ from t1 last join
+ (
+ select t2.c1 as tx_0_c1,
+ t2.c2 as tx_0_c2,
+ t2.c4 as tx_0_c4,
+ t3.c2 as tx_1_c2,
+ t3.c3 as tx_1_c3
+ from (select * from t2 where c2 = 30) t2 left join (select * from t3 where c2 > 20) t3
+ on t2.c1 = t3.c1
+ ) tx
+ order by tx.tx_0_c4
+ on t1.c2 = tx.tx_0_c2
+ request_plan: |
+ expect:
+ order: c1
+ columns: ["c1 string", "c2 int", "tx_0_c1 string", "tx_0_c2 int", "tx_0_c4 timestamp", "tx_1_c2 int", "tx_1_c3 int64"]
+ data: |
+ aa, 20, NULL, NULL, NULL, NULL, NULL
+ bb, 30, bb, 30, 3000, 34, 131
+ cc, 40, NULL, NULL, NULL, NULL, NULL
+ dd, 50, NULL, NULL, NULL, NULL, NULL
+ - id: 8
+ desc: lastjoin(leftjoin(filter, filter))
+ inputs:
+ - name: t1
+ columns: ["c1 string","c2 int","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",20,1000]
+ - ["bb",30,1000]
+ - ["cc",40,1000]
+ - name: t2
+ columns: ["c1 string", "c2 int", "c4 timestamp"]
+ indexs: ["index1:c1:c4", "index2:c2:c4"]
+ rows:
+ - ["bb",20, 1000]
+ - ["aa",20, 2000]
+ - ["bb",30, 3000]
+ - ["cc",40, 4000]
+ - name: t3
+ columns: ["c1 string","c2 int","c3 bigint","c4 timestamp"]
+ indexs: ["index1:c1:c4"]
+ rows:
+ - ["aa",19,13,3000]
+ - ["bb",34,131,3000]
+ sql: |
+ select
+ t1.c1,
+ t1.c2,
+ tx.*
+ from t1 last join
+ (
+ select t2.c1 as tx_0_c1,
+ t2.c2 as tx_0_c2,
+ t2.c4 as tx_0_c4,
+ t3.c2 as tx_1_c2,
+ t3.c3 as tx_1_c3
+ from (select * from t2 where c2 = 20) t2 left join (select * from t3 where c1 = 'bb') t3
+ on t2.c1 = t3.c1
+ ) tx
+ on t1.c2 = tx.tx_0_c2 and not isnull(tx.tx_1_c2)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(t1.c1, t1.c2, tx.tx_0_c1, tx.tx_0_c2, tx.tx_0_c4, tx.tx_1_c2, tx.tx_1_c3))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ DATA_PROVIDER(request=t1)
+ REQUEST_JOIN(OUTPUT_RIGHT_ONLY, type=LastJoin, condition=NOT isnull(#89), left_keys=(#5), right_keys=(#8), index_keys=)
+ SIMPLE_PROJECT(sources=(#5 -> t1.c2))
+ DATA_PROVIDER(request=t1)
+ RENAME(name=tx)
+ SIMPLE_PROJECT(sources=(t2.c1 -> tx_0_c1, t2.c2 -> tx_0_c2, t2.c4 -> tx_0_c4, t3.c2 -> tx_1_c2, t3.c3 -> tx_1_c3))
+ REQUEST_JOIN(type=LeftJoin, condition=, left_keys=(t2.c1), right_keys=(t3.c1), index_keys=)
+ RENAME(name=t2)
+ FILTER_BY(condition=, left_keys=(), right_keys=(), index_keys=(20))
+ DATA_PROVIDER(type=Partition, table=t2, index=index2)
+ RENAME(name=t3)
+ FILTER_BY(condition=, left_keys=(), right_keys=(), index_keys=(bb))
+ DATA_PROVIDER(type=Partition, table=t3, index=index1)
+ expect:
+ order: c1
+ columns: ["c1 string", "c2 int", "tx_0_c1 string", "tx_0_c2 int", "tx_0_c4 timestamp", "tx_1_c2 int", "tx_1_c3 int64"]
+ data: |
+ aa, 20, bb, 20, 1000, 34, 131
+ bb, 30, NULL, NULL, NULL, NULL, NULL
+ cc, 40, NULL, NULL, NULL, NULL, NULL
diff --git a/cases/query/window_query.yaml b/cases/query/window_query.yaml
index 24ac38afe4f..3c64259d8c5 100644
--- a/cases/query/window_query.yaml
+++ b/cases/query/window_query.yaml
@@ -833,3 +833,302 @@ cases:
200, 1, 1, 1
300, 0, 0, 0
400, 1, 0, 0
+
+ - id: 23
+ sql: |
+ select
+ gp_id,
+ count(gp_id) over w as cnt,
+ -- t2 matches and t3 not matches
+ count_where(gp_id, not is_null(lcond) and is_null(cond)) over w as feat1,
+ from (select id as gp_id, 0 as lcond, 0 as cond, cast(90000 as timestamp) as ts from request)
+ window w as (
+ union (select t1.gp_id, t2.cond as lcond, t3.cond as cond, t1.ts from
+ t1 last join t2 on t1.gp_id = t2.account
+ last join t3 on t1.cond = t3.cond)
+ partition by gp_id order by ts
+ rows between unbounded preceding and current row
+ exclude current_row instance_not_in_window
+ )
+ inputs:
+ - name: request
+ columns: ["id int"]
+ indexs: ['idx:id']
+ data: |
+ 100
+ 200
+ 300
+ 400
+ - name: t1
+ columns:
+ - gp_id int
+ - cond int
+ - ts timestamp
+ indexs:
+ - idx2:gp_id:ts
+ data: |
+ 100, 201, 10000
+ 100, 201, 10000
+ 200, 203, 10000
+ 400, 204, 10000
+ 400, 205, 10000
+ - name: t2
+ columns:
+ - account int
+ - cond int
+ - ts timestamp
+ indexs: ["idx1:account:ts"]
+ data: |
+ 100, 201, 1000
+ 200, 203, 4000
+ 400, 209, 4000
+ - name: t3
+ columns:
+ - cond int
+ - ts timestamp
+ indexs: ["idx3:cond:ts"]
+ data: |
+ 201, 1000
+ 208, 1000
+ expect:
+ columns:
+ - gp_id int
+ - cnt int64
+ - feat1 int64
+ order: gp_id
+ data: |
+ 100, 2, 0
+ 200, 1, 1
+ 300, 0, 0
+ 400, 2, 2
+
+ # ======================================================================
+ # WINDOW without ORDER BY
+ # ======================================================================
+ - id: 24
+ desc: ROWS WINDOW WITHOUT ORDER BY
+ mode: batch-unsupport
+ inputs:
+ - name: t1
+ columns:
+ - id int
+ - gp int
+ - ts timestamp
+ indexs:
+ - idx:gp:ts
+ data: |
+ 1, 100, 20000
+ 2, 100, 10000
+ 3, 400, 20000
+ 4, 400, 10000
+ 5, 400, 15000
+ 6, 400, 40000
+ sql: |
+ select id, count(ts) over w as agg
+ from t1
+ window w as (
+ partition by gp
+ rows between 2 open preceding and current row
+ )
+ request_plan: |
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(partition_keys=(), orders=, rows=(, 2 OPEN PRECEDING, 0 CURRENT), index_keys=(gp))
+ DATA_PROVIDER(request=t1)
+ DATA_PROVIDER(type=Partition, table=t1, index=idx)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(id, agg))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(id))
+ DATA_PROVIDER(request=t1)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(partition_keys=(), orders=, rows=(, 2 OPEN PRECEDING, 0 CURRENT), index_keys=(gp))
+ DATA_PROVIDER(request=t1)
+ DATA_PROVIDER(type=Partition, table=t1, index=idx)
+ expect:
+ columns: ["id int", "agg int64"]
+ order: id
+ data: |
+ 1, 1
+ 2, 2
+ 3, 1
+ 4, 2
+ 5, 2
+ 6, 2
+ - id: 25
+ desc: RANGE WINDOW WITHOUT ORDER BY
+ mode: batch-unsupport
+ inputs:
+ - name: t1
+ columns:
+ - id int
+ - gp int
+ - ts timestamp
+ indexs:
+ - idx:gp:ts
+ data: |
+ 1, 100, 20000
+ 2, 100, 10000
+ 3, 400, 20000
+ 4, 400, 10
+ 5, 400, 15000
+ sql: |
+ select id, count(ts) over w as agg
+ from t1
+ window w as (
+ partition by gp
+ rows_range between unbounded preceding and current row
+ )
+ request_plan: |
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(partition_keys=(), orders=, range=(, 0 PRECEDING UNBOUND, 0 CURRENT), index_keys=(gp))
+ DATA_PROVIDER(request=t1)
+ DATA_PROVIDER(type=Partition, table=t1, index=idx)
+ cluster_request_plan: |
+ SIMPLE_PROJECT(sources=(id, agg))
+ REQUEST_JOIN(type=kJoinTypeConcat)
+ SIMPLE_PROJECT(sources=(id))
+ DATA_PROVIDER(request=t1)
+ PROJECT(type=Aggregation)
+ REQUEST_UNION(partition_keys=(), orders=, range=(, 0 PRECEDING UNBOUND, 0 CURRENT), index_keys=(gp))
+ DATA_PROVIDER(request=t1)
+ DATA_PROVIDER(type=Partition, table=t1, index=idx)
+ expect:
+ columns: ["id int", "agg int64"]
+ order: id
+ data: |
+ 1, 1
+ 2, 2
+ 3, 1
+ 4, 2
+ 5, 3
+ - id: 26
+ desc: RANGE-type WINDOW WITHOUT ORDER BY + WINDOW attributes
+ mode: batch-unsupport
+ inputs:
+ - name: t1
+ columns:
+ - id int
+ - gp int
+ - ts timestamp
+ indexs:
+ - idx:gp:ts
+ data: |
+ 1, 100, 20000
+ 2, 100, 10000
+ 3, 400, 20000
+ 4, 400, 10000
+ 5, 400, 15000
+ - name: t2
+ columns:
+ - id int
+ - gp int
+ - ts timestamp
+ indexs:
+ - idx:gp:ts
+ data: |
+ 1, 100, 20000
+ 2, 100, 10000
+ 3, 400, 20000
+ 4, 400, 10000
+ 5, 400, 15000
+ sql: |
+ select id,
+ count(ts) over w1 as agg1,
+ count(ts) over w2 as agg2,
+ count(ts) over w3 as agg3,
+ count(ts) over w4 as agg4,
+ count(ts) over w5 as agg5,
+ count(ts) over w6 as agg6,
+ count(ts) over w7 as agg7,
+ from t1
+ window w1 as (
+ PARTITION by gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),
+ w2 as (partition by gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW EXCLUDE CURRENT_ROW),
+ w3 as (PARTITION BY gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW MAXSIZE 1),
+ w4 as (
+ UNION (select * from t2)
+ PARTITION BY gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW INSTANCE_NOT_IN_WINDOW),
+ w5 as (
+ UNION (select * from t2)
+ PARTITION BY gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW INSTANCE_NOT_IN_WINDOW EXCLUDE CURRENT_ROW),
+ w6 as (
+ UNION (select * from t2)
+ PARTITION BY gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW MAXSIZE 2 INSTANCE_NOT_IN_WINDOW EXCLUDE CURRENT_ROW),
+ w7 as (
+ UNION (select * from t2)
+ PARTITION BY gp
+ ROWS_RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW EXCLUDE CURRENT_ROW)
+ expect:
+ columns: ["id int", "agg1 int64", "agg2 int64", "agg3 int64", "agg4 int64", "agg5 int64", "agg6 int64", "agg7 int64"]
+ order: id
+ data: |
+ 1, 1, 0, 1, 3, 2, 2, 2
+ 2, 2, 1, 1, 3, 2, 2, 3
+ 3, 1, 0, 1, 4, 3, 2, 3
+ 4, 2, 1, 1, 4, 3, 2, 4
+ 5, 3, 2, 1, 4, 3, 2, 5
+ - id: 27
+ desc: ROWS-type WINDOW WITHOUT ORDER BY + WINDOW attributes
+ mode: batch-unsupport
+ inputs:
+ - name: t1
+ columns:
+ - id int
+ - gp int
+ - ts timestamp
+ indexs:
+ - idx:gp:ts
+ data: |
+ 1, 100, 20000
+ 2, 100, 10000
+ 3, 400, 20000
+ 4, 400, 10000
+ 5, 400, 15000
+ - name: t2
+ columns:
+ - id int
+ - gp int
+ - ts timestamp
+ indexs:
+ - idx:gp:ts
+ data: |
+ 1, 100, 20000
+ 2, 100, 10000
+ 3, 400, 20000
+ 4, 400, 10000
+ 5, 400, 15000
+ sql: |
+ select id,
+ count(ts) over w1 as agg1,
+ count(ts) over w2 as agg2,
+ count(ts) over w3 as agg3,
+ count(ts) over w4 as agg4,
+ from t1
+ window w1 as (
+ PARTITION by gp
+ ROWS BETWEEN 2 PRECEDING AND CURRENT ROW),
+ w2 as (partition by gp
+ ROWS BETWEEN 2 PRECEDING AND CURRENT ROW EXCLUDE CURRENT_ROW),
+ w3 as (
+ UNION (select * from t2)
+ PARTITION BY gp
+ ROWS BETWEEN 2 PRECEDING AND CURRENT ROW INSTANCE_NOT_IN_WINDOW),
+ w4 as (
+ UNION (select * from t2)
+ PARTITION BY gp
+ ROWS BETWEEN 3 PRECEDING AND CURRENT ROW INSTANCE_NOT_IN_WINDOW EXCLUDE CURRENT_ROW)
+ expect:
+ columns: ["id int", "agg1 int64", "agg2 int64", "agg3 int64", "agg4 int64"]
+ order: id
+ data: |
+ 1, 1, 0, 3, 2
+ 2, 2, 1, 3, 2
+ 3, 1, 0, 3, 3
+ 4, 2, 1, 3, 3
+ 5, 3, 2, 3, 3
diff --git a/cmake/rapidjson.cmake b/cmake/rapidjson.cmake
new file mode 100644
index 00000000000..6b1ecd2a6dd
--- /dev/null
+++ b/cmake/rapidjson.cmake
@@ -0,0 +1,9 @@
+FetchContent_Declare(
+ rapidjson
+ URL https://github.com/Tencent/rapidjson/archive/refs/tags/v1.1.0.zip
+ URL_HASH MD5=ceb1cf16e693a3170c173dc040a9d2bd
+ EXCLUDE_FROM_ALL # don't build this project as part of the overall build
+)
+# don't build this project, just populate
+FetchContent_Populate(rapidjson)
+include_directories(${rapidjson_SOURCE_DIR}/include)
diff --git a/demo/Dockerfile b/demo/Dockerfile
index e6495931d35..6dc38d46c2b 100644
--- a/demo/Dockerfile
+++ b/demo/Dockerfile
@@ -25,7 +25,7 @@ COPY *_dist.yml /work/
ENV LANG=en_US.UTF-8
ENV SPARK_HOME=/work/openmldb/spark-3.2.1-bin-openmldbspark
-ARG OPENMLDB_VERSION=0.8.2
+ARG OPENMLDB_VERSION=0.8.3
ENV OPENMLDB_VERSION="${OPENMLDB_VERSION}"
RUN if [ "${USE_ADD_WHL}" = "true" ] ; then \
diff --git a/demo/byzer-taxi/openmldb_byzer_taxi.bznb b/demo/byzer-taxi/openmldb_byzer_taxi.bznb
index dc1c925cb0f..b4835f7cc85 100644
--- a/demo/byzer-taxi/openmldb_byzer_taxi.bznb
+++ b/demo/byzer-taxi/openmldb_byzer_taxi.bznb
@@ -64,7 +64,7 @@
"job_id" : null
}, {
"id" : "240",
- "content" : "run command as FeatureStoreExt.`` where\r\nzkAddress=\"127.0.0.1:2181\"\r\nand zkPath=\"/openmldb\"\r\nand `sql-0`='''\r\nSET @@execute_mode='online';\r\n'''\r\nand `sql-1`='''\r\nDEPLOY d1 SELECT trip_duration, passenger_count,\r\nsum(pickup_latitude) OVER w AS vendor_sum_pl,\r\nmax(pickup_latitude) OVER w AS vendor_max_pl,\r\nmin(pickup_latitude) OVER w AS vendor_min_pl,\r\navg(pickup_latitude) OVER w AS vendor_avg_pl,\r\nsum(pickup_latitude) OVER w2 AS pc_sum_pl,\r\nmax(pickup_latitude) OVER w2 AS pc_max_pl,\r\nmin(pickup_latitude) OVER w2 AS pc_min_pl,\r\navg(pickup_latitude) OVER w2 AS pc_avg_pl ,\r\ncount(vendor_id) OVER w2 AS pc_cnt,\r\ncount(vendor_id) OVER w AS vendor_cnt\r\nFROM t1 \r\nWINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW),\r\nw2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW);\r\n'''\r\nand db=\"db1\"\r\nand action=\"ddl\";",
+ "content" : "run command as FeatureStoreExt.`` where\r\nzkAddress=\"127.0.0.1:2181\"\r\nand zkPath=\"/openmldb\"\r\nand `sql-0`='''\r\nSET @@execute_mode='online';\r\n'''\r\nand `sql-1`='''\r\nDEPLOY d1 OPTIONS(RANGE_BIAS="inf", ROWS_BIAS="inf") SELECT trip_duration, passenger_count,\r\nsum(pickup_latitude) OVER w AS vendor_sum_pl,\r\nmax(pickup_latitude) OVER w AS vendor_max_pl,\r\nmin(pickup_latitude) OVER w AS vendor_min_pl,\r\navg(pickup_latitude) OVER w AS vendor_avg_pl,\r\nsum(pickup_latitude) OVER w2 AS pc_sum_pl,\r\nmax(pickup_latitude) OVER w2 AS pc_max_pl,\r\nmin(pickup_latitude) OVER w2 AS pc_min_pl,\r\navg(pickup_latitude) OVER w2 AS pc_avg_pl ,\r\ncount(vendor_id) OVER w2 AS pc_cnt,\r\ncount(vendor_id) OVER w AS vendor_cnt\r\nFROM t1 \r\nWINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW),\r\nw2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW);\r\n'''\r\nand db=\"db1\"\r\nand action=\"ddl\";",
"job_id" : null
}, {
"id" : "241",
diff --git a/demo/java_quickstart/demo/pom.xml b/demo/java_quickstart/demo/pom.xml
index d69691970e7..5ee7e8e5362 100644
--- a/demo/java_quickstart/demo/pom.xml
+++ b/demo/java_quickstart/demo/pom.xml
@@ -29,7 +29,7 @@
com.4paradigm.openmldb
openmldb-jdbc
- 0.8.3
+ 0.8.4
org.testng
diff --git a/demo/java_quickstart/demo/src/main/java/com/openmldb/demo/App.java b/demo/java_quickstart/demo/src/main/java/com/openmldb/demo/App.java
index 2923832d3b8..cbe363f4359 100644
--- a/demo/java_quickstart/demo/src/main/java/com/openmldb/demo/App.java
+++ b/demo/java_quickstart/demo/src/main/java/com/openmldb/demo/App.java
@@ -146,7 +146,7 @@ private void createDeployment() {
"(PARTITION BY %s.c1 ORDER BY %s.c7 ROWS_RANGE BETWEEN 2d PRECEDING AND CURRENT ROW);", table,
table, table);
// 上线一个Deployment
- String deploySql = String.format("DEPLOY %s %s", deploymentName, selectSql);
+ String deploySql = String.format("DEPLOY %s OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') %s", deploymentName, selectSql);
// set return null rs, don't check the returned value, it's false
state.execute(deploySql);
} catch (Exception e) {
diff --git a/demo/jd-recommendation/sql_scripts/deploy.sql b/demo/jd-recommendation/sql_scripts/deploy.sql
index 7cb2121e869..e37408b6396 100644
--- a/demo/jd-recommendation/sql_scripts/deploy.sql
+++ b/demo/jd-recommendation/sql_scripts/deploy.sql
@@ -1,6 +1,6 @@
USE JD_db;
SET @@execute_mode='online';
-DEPLOY demo select * from
+DEPLOY demo OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') select * from
(
select
`reqId` as reqId_1,
diff --git a/demo/predict-taxi-trip-duration/README.md b/demo/predict-taxi-trip-duration/README.md
index bd44778c2a3..db5253c0a45 100644
--- a/demo/predict-taxi-trip-duration/README.md
+++ b/demo/predict-taxi-trip-duration/README.md
@@ -28,7 +28,7 @@ w2 as (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN
**Start docker**
```
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
**Initialize environment**
```bash
@@ -85,7 +85,7 @@ python3 train.py /tmp/feature_data /tmp/model.txt
# The below commands are executed in the CLI
> USE demo_db;
> SET @@execute_mode='online';
-> DEPLOY demo SELECT trip_duration, passenger_count,
+> DEPLOY demo OPTIONS(RANGE_BIAS="inf", ROWS_BIAS="inf") SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
@@ -138,7 +138,7 @@ python3 predict.py
**Start docker**
```bash
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
**Initialize environment**
@@ -193,7 +193,7 @@ python3 train.py /tmp/feature.csv /tmp/model.txt
```sql
# The below commands are executed in the CLI
> USE demo_db;
-> DEPLOY demo SELECT trip_duration, passenger_count,
+> DEPLOY demo OPTIONS(RANGE_BIAS="inf", ROWS_BIAS="inf") SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
diff --git a/demo/predict-taxi-trip-duration/script/taxi.sql b/demo/predict-taxi-trip-duration/script/taxi.sql
index bbdd219b2e5..8ade33df870 100644
--- a/demo/predict-taxi-trip-duration/script/taxi.sql
+++ b/demo/predict-taxi-trip-duration/script/taxi.sql
@@ -22,7 +22,7 @@ w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN
OPTIONS(mode='overwrite');
SET @@execute_mode='online';
-DEPLOY demo SELECT trip_duration, passenger_count,
+DEPLOY demo OPTIONS(RANGE_BIAS="inf", ROWS_BIAS="inf") SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
diff --git a/demo/talkingdata-adtracking-fraud-detection/README.md b/demo/talkingdata-adtracking-fraud-detection/README.md
index 5fedb578266..dd773fb1521 100644
--- a/demo/talkingdata-adtracking-fraud-detection/README.md
+++ b/demo/talkingdata-adtracking-fraud-detection/README.md
@@ -15,7 +15,7 @@ We recommend you to use docker to run the demo. OpenMLDB and dependencies have b
**Start docker**
```
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
#### Run locally
diff --git a/demo/talkingdata-adtracking-fraud-detection/train_and_serve.ipynb b/demo/talkingdata-adtracking-fraud-detection/train_and_serve.ipynb
index 6a7c71ff412..b3b01306588 100644
--- a/demo/talkingdata-adtracking-fraud-detection/train_and_serve.ipynb
+++ b/demo/talkingdata-adtracking-fraud-detection/train_and_serve.ipynb
@@ -187,7 +187,7 @@
"outputs": [],
"source": [
"deploy_name='d1'\n",
- "%sql DEPLOY $deploy_name $sql_part;"
+ "%sql DEPLOY $deploy_name OPTIONS(RANGE_BIAS=\"inf\", ROWS_BIAS=\"inf\") $sql_part;"
]
},
{
diff --git a/demo/talkingdata-adtracking-fraud-detection/train_and_serve.py b/demo/talkingdata-adtracking-fraud-detection/train_and_serve.py
index 9cdd93d2074..a592edfdb0e 100644
--- a/demo/talkingdata-adtracking-fraud-detection/train_and_serve.py
+++ b/demo/talkingdata-adtracking-fraud-detection/train_and_serve.py
@@ -166,7 +166,8 @@ def nothrow_execute(sql):
connection.execute("SET @@execute_mode='online';")
connection.execute(f'USE {DB_NAME}')
nothrow_execute(f'DROP DEPLOYMENT {DEPLOY_NAME}')
-deploy_sql = f"""DEPLOY {DEPLOY_NAME} {sql_part}"""
+# to avoid data expired by abs ttl, set inf
+deploy_sql = f"""DEPLOY {DEPLOY_NAME} OPTIONS(RANGE_BIAS="inf", ROWS_BIAS="inf") {sql_part}"""
print(deploy_sql)
connection.execute(deploy_sql)
print('Import data to online')
diff --git a/docker/Dockerfile b/docker/Dockerfile
index d478a84d87f..9faef4db550 100644
--- a/docker/Dockerfile
+++ b/docker/Dockerfile
@@ -15,8 +15,8 @@
FROM centos:7
-ARG ZETASQL_VERSION=0.3.0
-ARG THIRDPARTY_VERSION=0.5.2
+ARG ZETASQL_VERSION=0.3.1
+ARG THIRDPARTY_VERSION=0.6.0
ARG TARGETARCH
LABEL org.opencontainers.image.source https://github.com/4paradigm/OpenMLDB
@@ -28,8 +28,6 @@ RUN yum update -y && yum install -y centos-release-scl epel-release && \
curl -Lo lcov-1.15-1.noarch.rpm https://github.com/linux-test-project/lcov/releases/download/v1.15/lcov-1.15-1.noarch.rpm && \
yum localinstall -y lcov-1.15-1.noarch.rpm && \
yum clean all && rm -v lcov-1.15-1.noarch.rpm && \
- curl -Lo apache-maven-3.6.3-bin.tar.gz https://mirrors.ocf.berkeley.edu/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz && \
- tar xzf apache-maven-3.6.3-bin.tar.gz -C /usr/local --strip-components=1 && \
curl -Lo zookeeper.tar.gz https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz && \
mkdir -p /deps/src && \
tar xzf zookeeper.tar.gz -C /deps/src && \
diff --git a/docs/en/deploy/compile.md b/docs/en/deploy/compile.md
index a20c921b4ac..70173907610 100644
--- a/docs/en/deploy/compile.md
+++ b/docs/en/deploy/compile.md
@@ -1,13 +1,11 @@
-# Build
+# Compilation from Source Code
-## 1. Quick Start
+## Compile and Use in Docker Container
-[quick-start]: quick-start
+This section describes the steps to compile and use OpenMLDB inside its official docker image [hybridsql](https://hub.docker.com/r/4pdosc/hybridsql), mainly for quick start and development purposes in the docker container.
+The docker image has packed the required tools and dependencies, so there is no need to set them up separately. To compile without the official docker image, refer to the section [Detailed Instructions for Build](#detailed-instructions-for-build) below.
-This section describes the steps to compile and use OpenMLDB inside its official docker image [hybridsql](https://hub.docker.com/r/4pdosc/hybridsql).
-The docker image has packed required tools and dependencies, so there is no need to set them up separately. To compile without the official docker image, refer to the section [Detailed Instructions for Build](#detailed-instructions-for-build) below.
-
-Keep in mind that you should always use the same version of both compile image and [OpenMLDB version](https://github.com/4paradigm/OpenMLDB/releases). This section demonstrates compiling for [OpenMLDB v0.8.3](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.8.3) under `hybridsql:0.8.3` ,If you prefer to compile on the latest code in `main` branch, pull `hybridsql:latest` image instead.
+Keep in mind that you should always use the same version of both compile image and [OpenMLDB version](https://github.com/4paradigm/OpenMLDB/releases). This section demonstrates compiling for [OpenMLDB v0.8.4](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.8.4) under `hybridsql:0.8.4` ,If you prefer to compile on the latest code in `main` branch, pull `hybridsql:latest` image instead.
1. Pull the docker image
@@ -15,17 +13,17 @@ Keep in mind that you should always use the same version of both compile image a
docker pull 4pdosc/hybridsql:0.8
```
-2. Create a docker container with the hybridsql docker image
+2. Create a docker container
```bash
docker run -it 4pdosc/hybridsql:0.8 bash
```
-3. Download the OpenMLDB source code inside the docker container, and setting the branch into v0.8.3
+3. Download the OpenMLDB source code inside the docker container, and set the branch into v0.8.4
```bash
cd ~
- git clone -b v0.8.3 https://github.com/4paradigm/OpenMLDB.git
+ git clone -b v0.8.4 https://github.com/4paradigm/OpenMLDB.git
```
4. Compile OpenMLDB
@@ -41,52 +39,49 @@ Keep in mind that you should always use the same version of both compile image a
make install
```
-Now you've finished the compilation job, and you may try run OpenMLDB inside the docker container.
+Now you've finished the compilation job, you may try running OpenMLDB inside the docker container.
-## 2. Detailed Instructions for Build
+## Detailed Instructions for Build
-[build]: build
+This chapter discusses compiling source code without relying on pre-built container environments.
-### 2.1. Hardware Requirements
+### Hardware Requirements
- **Memory**: 8GB+ recommended.
- **Disk Space**: >=25GB of free disk space for full compilation.
- **Operating System**: CentOS 7, Ubuntu 20.04 or macOS >= 10.15, other systems are not carefully tested but issue/PR welcome
+- **CPU Architecture**: Currently, only x86 architecture is supported, and other architectures like ARM are not supported at the moment (please note that running x86 images on heterogeneous systems like M1 Mac is also not supported at this time).
-Note: By default, the parallel build is disabled, and it usually takes an hour to finish all the compile jobs. You can enable the parallel build by tweaking the `NPROC` option if your machine's resource is enough. This will reduce the compile time but also consume more memory. For example, the following command set the number of concurrent build jobs to 4:
+💡 Note: By default, the parallel build is disabled, and it usually takes an hour to finish all the compile jobs. You can enable the parallel build by tweaking the `NPROC` option if your machine's resource is enough. This will reduce the compile time but also consume more memory. For example, the following command sets the number of concurrent build jobs to 4:
```bash
make NPROC=4
```
-### 2.2. Prerequisites
-
-Make sure those tools are installed
-
+### Dependencies
- gcc >= 8 or AppleClang >= 12.0.0
-- cmake 3.20 or later ( < cmake 3.24 is better)
+- cmake 3.20 or later ( recommended < cmake 3.24)
- jdk 8
- python3, python setuptools, python wheel
- If you'd like to compile thirdparty from source, checkout the [third-party's requirement](../../third-party/README.md) for extra dependencies
-### 2.3. Build and Install OpenMLDB
+### Build and Install OpenMLDB
Building OpenMLDB requires certain thirdparty dependencies. Hence a Makefile is provided as a convenience to setup thirdparty dependencies automatically and run CMake project in a single command `make`. The `make` command offers three methods to compile, each manages thirdparty differently:
-- **Method One: Build and Run Inside Docker:** Using [hybridsql](https://hub.docker.com/r/4pdosc/hybridsql) docker image, the thirdparty is already bundled inside the image and no extra steps are required, refer to above section [Quick Start](#quick-start)
-- **Method Two: Download Pre-Compiled Thirdparty:** Command is `make && make install`. It downloads necessary prebuild libraries from [hybridsql-assert](https://github.com/4paradigm/hybridsql-asserts/releases) and [zetasql](https://github.com/4paradigm/zetasql/releases). Currently it supports CentOS 7, Ubuntu 20.04 and macOS.
-- **Method Three: Compile Thirdparty from Source:** This is the suggested way if the host system is not in the supported list for pre-compiled thirdparty (CentOS 7, Ubuntu 20.04 and macOS). Note that when compiling thirdparty for the first time requires extra time to finish, approximately 1 hour on a 2 core & 7 GB machine. To compile thirdparty from source, please pass `BUILD_BUNDLED=ON` to `make`:
+- **Method One: Download Pre-Compiled Thirdparty:** Command is `make && make install`. It downloads necessary prebuild libraries from [hybridsql-assert](https://github.com/4paradigm/hybridsql-asserts/releases) and [zetasql](https://github.com/4paradigm/zetasql/releases). Currently it supports CentOS 7, Ubuntu 20.04 and macOS.
+- **Method Two: Compile Thirdparty from Source:** This is the suggested way if the host system is not in the supported list for pre-compiled thirdparty (CentOS 7, Ubuntu 20.04 and macOS). Note that when compiling thirdparty for the first time requires extra time to finish, approximately 1 hour on a 2 core & 8 GB machine. To compile thirdparty from source, please pass `BUILD_BUNDLED=ON` to `make`:
```bash
make BUILD_BUNDLED=ON
make install
```
-All of the three methods above will install OpenMLDB binaries into `${PROJECT_ROOT}/openmldb` by default, you may tweak the installation directory with the option `CMAKE_INSTALL_PREFIX` (refer the following section [Extra options for `make`](#24-extra-options-for-make)).
+All of the three methods above will install OpenMLDB binaries into `${PROJECT_ROOT}/openmldb` by default, you may tweak the installation directory with the option `CMAKE_INSTALL_PREFIX` (refer to the following section [Extra Parameters for `make`](#extra-parameters-for-make) ).
-### 2.4. Extra Options for `make`
+### Extra Parameters for `make`
-You can customize the `make` behavior by passing following arguments, e.g., changing the build mode to `Debug` instead of `Release`:
+You can customize the `make` behavior by passing the following arguments, e.g., changing the build mode to `Debug` instead of `Release`:
```bash
make CMAKE_BUILD_TYPE=Debug
@@ -132,10 +127,14 @@ make CMAKE_BUILD_TYPE=Debug
Default: ON
-- OPENMLDB_BUILD_TARGET: If you only want to build some targets, not all, e.g. only build a test `ddl_parser_test`, you can set it to `ddl_parser_test`. Multiple targets may be given, separated by spaces. It can reduce the build time, reduce the build output, save the storage space.
+- OPENMLDB_BUILD_TARGET: If you only want to build some targets, not all, e.g. only build a test `ddl_parser_test`, you can set it to `ddl_parser_test`. Multiple targets may be given, separated by spaces. It can reduce build time, reduce build output, and save storage space.
Default: all
+- THIRD_PARTY_CMAKE_FLAGS: You can use this to configure additional parameters when compiling third-party dependencies. For instance, to specify concurrent compilation for each third-party project, you can set` THIRD_PARTY_CMAKE_FLAGS` to `-DMAKEOPTS=-j8`. Please note that NPROC does not affect third-party compilation; multiple third-party projects will be executed sequentially.
+
+ Default: ''
+
### Build Java SDK with Multi Processes
```
@@ -144,14 +143,14 @@ make SQL_JAVASDK_ENABLE=ON NPROC=4
The built jar packages are in the `target` path of each submodule. If you want to use the jar packages built by yourself, please DO NOT add them by systemPath(may get `ClassNotFoundException` about Protobuf and so on, requires a little work in compile and runtime phase). The better way is, use `mvn install -DskipTests=true -Dscalatest.skip=true -Dwagon.skip=true -Dmaven.test.skip=true -Dgpg.skip` to install them in local m2 repository, your project will use them.
-## 3. Optimized Spark Distribution for OpenMLDB
+## Optimized Spark Distribution for OpenMLDB
[OpenMLDB Spark Distribution](https://github.com/4paradigm/spark) is the fork of [Apache Spark](https://github.com/apache/spark). It adopts specific optimization techniques for OpenMLDB. It provides native `LastJoin` implementation and achieves 10x~100x performance improvement compared with the original Spark distribution. The Java/Scala/Python/SQL APIs of the OpenMLDB Spark distribution are fully compatible with the standard Spark distribution.
1. Downloading the pre-built OpenMLDB Spark distribution:
```bash
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.3/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.4/spark-3.2.1-bin-openmldbspark.tgz
```
Alternatively, you can also download the source code and compile from scratch:
@@ -171,3 +170,55 @@ export SPARK_HOME=`pwd`
```
3. Now you are all set to run OpenMLDB by enjoying the performance speedup from this optimized Spark distribution.
+
+
+## Build for Other OS
+As previously mentioned, if you want to run OpenMLDB or the SDK on a different OS, you will need to compile from the source code. We provide quick compilation solutions for several operating systems. For other OS, you'll need to perform source code compilation on your own.
+
+### Centos 6 or other glibc Linux OS
+#### Local Compilation
+To compile a version compatible with CentOS 6, you can use Docker and the `steps/centos6_build.sh` script. As shown below, we use the current directory as the mount directory and place the compilation output locally.
+
+```bash
+git clone https://github.com/4paradigm/OpenMLDB.git
+cd OpenMLDB
+docker run -it -v`pwd`:/root/OpenMLDB ghcr.io/4paradigm/centos6_gcc7_hybridsql bash
+```
+Execute the compilation script within the container, and the output will be in the "build" directory. If there are failures while downloading `bazel` or `icu4c` during compilation, you can use the image sources provided by OpenMLDB by configuring the environment variable `OPENMLDB_SOURCE=true`. Various environment variables that can be used with "make" will also work, as shown below.
+
+```bash
+cd OpenMLDB
+bash steps/centos6_build.sh
+# THIRD_PARTY_CMAKE_FLAGS=-DMAKEOPTS=-j8 bash steps/centos6_build.sh # run fast when build single project
+# OPENMLDB_SOURCE=true bash steps/centos6_build.sh
+# SQL_JAVASDK_ENABLE=ON SQL_PYSDK_ENABLE=ON NPROC=8 bash steps/centos6_build.sh # NPROC will build openmldb in parallel, thirdparty should use THIRD_PARTY_CMAKE_FLAGS
+```
+
+For a local compilation with a 2.20GHz CPU, SSD hard drive, and 32 threads to build both third-party libraries and the OpenMLDB core, the approximate timeframes are as follows:
+`THIRD_PARTY_CMAKE_FLAGS=-DMAKEOPTS=-j32 SQL_JAVASDK_ENABLE=ON SQL_PYSDK_ENABLE=ON NPROC=32 bash steps/centos6_build.sh`
+- third-party (excluding source code download time): Approximately 40 minutes:
+ - Zetasql patch: 13 minutes
+ - Compilation of all third-party dependencies: 30 minutes
+- OpenMLDB core, including Python and Java native components: Approximately 12 minutes
+
+Please note that these times can vary depending on your specific hardware and system performance. The provided compilation commands and environment variables are optimized for multi-threaded compilation, which can significantly reduce build times.
+
+#### Cloud Compilation
+
+After forking the OpenMLDB repository, you can trigger the `Other OS Build` workflow in `Actions`, and the output will be available in the `Actions` `Artifacts`. Here's how to configure the workflow:
+
+- Do not change the `Use workflow from` setting to a specific tag; it can be another branch.
+- Choose the desired `OS name`, which in this case is `centos6`.
+- If you are not compiling the main branch, provide the name of the branch, tag (e.g., v0.8.4), or SHA you want to compile in the `The branch, tag, or SHA to checkout, otherwise use the branch` field.
+- The compilation output will be accessible in "runs", as shown in an example [here](https://github.com/4paradigm/OpenMLDB/actions/runs/6044951902).
+ - The workflow will definitely produce the OpenMLDB binary file.
+ - If you don't need the Java or Python SDK, you can configure `java sdk enable` or `python sdk enable` to be "OFF" to save compilation time.
+
+Please note that this compilation process involves building third-party dependencies from source code, and it may take a while to complete due to limited resources. The approximate time for this process is around 3 hours and 5 minutes (2 hours for third-party dependencies and 1 hour for OpenMLDB). However, the workflow caches the compilation output for third-party dependencies, so the second compilation will be much faster, taking approximately 1 hour and 15 minutes for OpenMLDB.
+
+### Macos 10.15, 11
+
+MacOS doesn't require compiling third-party dependencies from source code, so compilation is relatively faster, taking about 1 hour and 15 minutes. Local compilation is similar to the steps outlined in the [Detailed Instructions for Build](#detailed-instructions-for-build) and does not require compiling third-party dependencies (`BUILD_BUNDLED=OFF`). For cloud compilation on macOS, trigger the `Other OS Build` workflow in `Actions` with the specified macOS version (`os name` as `macos10` or `macos11`). You can also disable Java or Python SDK compilation if they are not needed, by setting `java sdk enable` or `python sdk enable` to `OFF`.
+
+
+
diff --git a/docs/en/deploy/conf.md b/docs/en/deploy/conf.md
index 11667427247..138a414fa3d 100644
--- a/docs/en/deploy/conf.md
+++ b/docs/en/deploy/conf.md
@@ -9,6 +9,8 @@
# If you are deploying the standalone version, you do not need to configure zk_cluster and zk_root_path, just comment these two configurations. Deploying the cluster version needs to configure these two items, and the two configurations of all nodes in a cluster must be consistent
#--zk_cluster=127.0.0.1:7181
#--zk_root_path=/openmldb_cluster
+# set the username and password of zookeeper if authentication is enabled
+#--zk_cert=user:passwd
# The address of the tablet needs to be specified in the standalone version, and this configuration can be ignored in the cluster version
--tablet=127.0.0.1:9921
# Configure log directory
@@ -76,6 +78,8 @@
# If you start the cluster version, you need to specify the address of zk and the node path of the cluster in zk
#--zk_cluster=127.0.0.1:7181
#--zk_root_path=/openmldb_cluster
+# set the username and password of zookeeper if authentication is enabled
+#--zk_cert=user:passwd
# Configure the thread pool size, it is recommended to be consistent with the number of CPU cores
--thread_pool_size=24
@@ -218,6 +222,8 @@
# If the deployed openmldb is a cluster version, you need to specify the zk address and the cluster zk node directory
#--zk_cluster=127.0.0.1:7181
#--zk_root_path=/openmldb_cluster
+# set the username and password of zookeeper if authentication is enabled
+#--zk_cert=user:passwd
# configure log path
--openmldb_log_dir=./logs
@@ -249,6 +255,7 @@ zookeeper.connection_timeout=5000
zookeeper.max_retries=10
zookeeper.base_sleep_time=1000
zookeeper.max_connect_waitTime=30000
+#zookeeper.cert=user:passwd
# Spark Config
spark.home=
diff --git a/docs/en/deploy/install_deploy.md b/docs/en/deploy/install_deploy.md
index cdaf06a5d6a..332e681bbdf 100644
--- a/docs/en/deploy/install_deploy.md
+++ b/docs/en/deploy/install_deploy.md
@@ -52,17 +52,17 @@ If your operating system is not mentioned above or if you want to compile from s
### Linux Platform Compatibility pre-test
-Due to the variations among Linux platforms, the distribution package may not be entirely compatible with your machine. Therefore, it's recommended to conduct a preliminary compatibility test. Download the pre-compiled package `openmldb-0.8.3-linux.tar.gz`, and execute:
+Due to the variations among Linux platforms, the distribution package may not be entirely compatible with your machine. Therefore, it's recommended to conduct a preliminary compatibility test. Download the pre-compiled package `openmldb-0.8.4-linux.tar.gz`, and execute:
```
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-./openmldb-0.8.3-linux/bin/openmldb --version
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+./openmldb-0.8.4-linux/bin/openmldb --version
```
The result should display the version number of the program, as shown below:
```
-openmldb version 0.8.3-xxxx
+openmldb version 0.8.4-xxxx
Debug build (NDEBUG not #defined)
```
@@ -177,9 +177,9 @@ DataCollector and SyncTool currently do not support one-click deployment. Please
### Download OpenMLDB
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-cd openmldb-0.8.3-linux
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+cd openmldb-0.8.4-linux
```
### Environment Configuration
@@ -188,7 +188,7 @@ The environment variables are defined in `conf/openmldb-env.sh`, as shown in the
| Environment Variable | Default Value | Note |
| --------------------------------- | ------------------------------------------------------- | ------------------------------------------------------------ |
-| OPENMLDB_VERSION | 0.8.3 | OpenMLDB version |
+| OPENMLDB_VERSION | 0.8.4 | OpenMLDB version |
| OPENMLDB_MODE | standalone | standalone or cluster |
| OPENMLDB_HOME | root directory of the release folder | openmldb root directory |
| SPARK_HOME | $OPENMLDB_HOME/spark | openmldb spark root directory,If the directory does not exist, it will be downloaded automatically.|
@@ -361,10 +361,10 @@ Note that at least two TabletServer need to be deployed, otherwise errors may oc
**1. Download the OpenMLDB deployment package**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-tablet-0.8.3
-cd openmldb-tablet-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-tablet-0.8.4
+cd openmldb-tablet-0.8.4
```
**2. Modify the configuration file `conf/tablet.flags`**
@@ -427,12 +427,12 @@ For clustered versions, the number of TabletServers must be 2 or more. If there'
To start the next TabletServer on a different machine, simply repeat the aforementioned steps on that machine. If starting the next TabletServer on the same machine, ensure it's in a different directory, and do not reuse a directory where the TabletServer is already running.
-For instance, you can decompress the package again (avoid using a directory where TabletServer is already running, as files generated after startup may be affected), and name the directory `openmldb-tablet-0.8.3-2`.
+For instance, you can decompress the package again (avoid using a directory where TabletServer is already running, as files generated after startup may be affected), and name the directory `openmldb-tablet-0.8.4-2`.
```
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-tablet-0.8.3-2
-cd openmldb-tablet-0.8.3-2
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-tablet-0.8.4-2
+cd openmldb-tablet-0.8.4-2
```
Modify the configuration again and start the TabletServer. Note that if all TabletServers are on the same machine, use different port numbers to avoid "Fail to listen" error in the log (`logs/tablet.WARNING`).
@@ -450,10 +450,10 @@ Please ensure that all TabletServer have been successfully started before deploy
**1. Download the OpenMLDB deployment package**
````
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-ns-0.8.3
-cd openmldb-ns-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-ns-0.8.4
+cd openmldb-ns-0.8.4
````
**2. Modify the configuration file conf/nameserver.flags**
@@ -498,12 +498,12 @@ You can have only one NameServer, but if you need high availability, you can dep
To start the next NameServer on another machine, simply repeat the above steps on that machine. If starting the next NameServer on the same machine, ensure it's in a different directory and do not reuse the directory where NameServer has already been started.
-For instance, you can decompress the package again (avoid using the directory where NameServer is already running, as files generated after startup may be affected) and name the directory `openmldb-ns-0.8.3-2`.
+For instance, you can decompress the package again (avoid using the directory where NameServer is already running, as files generated after startup may be affected) and name the directory `openmldb-ns-0.8.4-2`.
```
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-ns-0.8.3-2
-cd openmldb-ns-0.8.3-2
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-ns-0.8.4-2
+cd openmldb-ns-0.8.4-2
```
Then modify the configuration and start.
@@ -544,10 +544,10 @@ Before running APIServer, ensure that the TabletServer and NameServer processes
**1. Download the OpenMLDB deployment package**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-apiserver-0.8.3
-cd openmldb-apiserver-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-apiserver-0.8.4
+cd openmldb-apiserver-0.8.4
```
**2. Modify the configuration file conf/apiserver.flags**
@@ -607,18 +607,18 @@ You can have only one TaskManager, but if you require high availability, you can
Spark distribution:
```shell
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.3/spark-3.2.1-bin-openmldbspark.tgz
-# Image address (China):http://43.138.115.238/download/v0.8.3/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.4/spark-3.2.1-bin-openmldbspark.tgz
+# Image address (China):http://43.138.115.238/download/v0.8.4/spark-3.2.1-bin-openmldbspark.tgz
tar -zxvf spark-3.2.1-bin-openmldbspark.tgz
export SPARK_HOME=`pwd`/spark-3.2.1-bin-openmldbspark/
```
OpenMLDB deployment package:
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-taskmanager-0.8.3
-cd openmldb-taskmanager-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-taskmanager-0.8.4
+cd openmldb-taskmanager-0.8.4
```
**2. Modify the configuration file conf/taskmanager.properties**
diff --git a/docs/en/developer/built_in_function_develop_guide.md b/docs/en/developer/built_in_function_develop_guide.md
index 3e6eaa2852a..97d00076f87 100644
--- a/docs/en/developer/built_in_function_develop_guide.md
+++ b/docs/en/developer/built_in_function_develop_guide.md
@@ -792,7 +792,7 @@ select date(timestamp(1590115420000)) as dt;
## 5. Document Management
-Documents for all built-in functions can be found in [Built-in Functions](http://4paradigm.github.io/OpenMLDB/zh/main/reference/sql/functions_and_operators/Files/udfs_8h.html). It is a markdown file automatically generated from source, so please do not edit it directly.
+Documents for all built-in functions can be found in [Built-in Functions](http://4paradigm.github.io/OpenMLDB/zh/main/reference/sql/udfs_8h.html). It is a markdown file automatically generated from source, so please do not edit it directly.
- If you are adding a document for a new function, please refer to [2.2.4 Documenting Function](#224-documenting-function).
- If you are trying to revise a document of an existing function, you can find source code in the files of `hybridse/src/udf/default_udf_library.cc` or `hybridse/src/udf/default_defs/*_def.cc` .
diff --git a/docs/en/developer/udf_develop_guide.md b/docs/en/developer/udf_develop_guide.md
index 63530ae0f1c..4c5aff6d2e1 100644
--- a/docs/en/developer/udf_develop_guide.md
+++ b/docs/en/developer/udf_develop_guide.md
@@ -9,7 +9,7 @@ SQL functions can be categorised into scalar functions and aggregate functions.
#### 2.1.1 Naming Specification of C++ Built-in Function
- The naming of C++ built-in function should follow the [snake_case](https://en.wikipedia.org/wiki/Snake_case) style.
- The name should clearly express the function's purpose.
-- The name of a function should not be the same as the name of a built-in function or other custom functions. The list of all built-in functions can be seen [here](../reference/sql/functions_and_operators/Files/udfs_8h.md).
+- The name of a function should not be the same as the name of a built-in function or other custom functions. The list of all built-in functions can be seen [here](../reference/sql/udfs_8h.md).
#### 2.1.2
The types of the built-in C++ functions' parameters should be BOOL, NUMBER, TIMESTAMP, DATE, or STRING.
diff --git a/docs/en/integration/deploy_integration/airflow_provider_demo.md b/docs/en/integration/deploy_integration/airflow_provider_demo.md
new file mode 100644
index 00000000000..984911a646c
--- /dev/null
+++ b/docs/en/integration/deploy_integration/airflow_provider_demo.md
@@ -0,0 +1,145 @@
+# Airflow
+We provide [Airflow OpenMLDB Provider](https://github.com/4paradigm/OpenMLDB/tree/main/extensions/airflow-provider-openmldb), which facilitates the integration of OpenMLDB with Airflow DAG.
+
+This specific case will undergo training and execution with Airflow's [TalkingData](https://chat.openai.com/talkingdata_demo).
+
+## TalkingData DAG
+
+To implement this workflow in Airflow, a DAG (Directed Acyclic Graph) file needs to be written. Here we use an example DAG file in [example_openmldb_complex.py](https://github.com/4paradigm/OpenMLDB/blob/main/extensions/airflow-provider-openmldb/openmldb_provider/example_dags/example_openmldb_complex.py).
+
+
+
+The diagram above illustrates the work process in DAG. It begins by creating a table, followed by offline data loading, feature extraction, and model training. If the model trained performs well (AUC >= 99.0), the workflow proceeds to execute deploy SQL and model serving online. Otherwise, a failure report is generated.
+
+In the following demonstration, you can directly import this DAG and run in Airflow.
+
+
+## Demonstration
+
+We import the above DAG to perform feature computation and deployment for the TalkingData Demo, then perform real-time inference using the predict server of TalkingData Demo.
+
+### Preparation
+
+#### Download DAG
+
+Along with the DAG files, training scripts are also required. For convenience, we provide the [code package](https://openmldb.ai/download/airflow_demo/airflow_demo_files.tar.gz) for direct download. If you prefer to use the latest version, you can obtain it from [github example_dags](https://github.com/4paradigm/OpenMLDB/tree/main/extensions/airflow-provider-openmldb/openmldb_provider/example_dags).
+
+```
+wget https://openmldb.ai/download/airflow_demo/airflow_demo_files.tar.gz
+tar zxf airflow_demo_files.tar.gz
+ls airflow_demo_files
+```
+#### Start Docker Image
+
+For smooth function, we recommend starting OpenMLDB using the docker image and installing Airflow within the docker container.
+
+Since Airflow Web requires an external port for login, the container's port must be exposed. Then map the downloaded file from the previous step to the `/work/airflow/dags` directory. This step is crucial for Airflow to load the DAGs from this folder correctly.
+
+```
+docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.8.4 bash
+```
+
+#### Download and Install Airflow and Airflow OpenMLDB Provider
+In the docker container, execute:
+```
+pip3 install airflow-provider-openmldb
+```
+Airflow will be downloaded as a dependency.
+
+#### Source Data and DAG Preparation
+Copy the sample data file, named `/tmp/train_sample.csv`, to the tmp directory. Airflow DAG files and training scripts used in the DAG must also be copied to the Airflow directory.
+
+```
+cp /work/airflow_demo_files/train_sample.csv /tmp/
+mkdir -p /work/airflow/dags
+cp /work/airflow_demo_files/example_openmldb_complex.py /work/airflow_demo_files/xgboost_train_sample.py /work/airflow/dags
+```
+
+### Step 1: Start OpenMLDB and Airflow
+The command provided below will initiate the OpenMLDB cluster, enabling support for predict server and Airflow standalone.
+```
+/work/init.sh
+python3 /work/airflow_demo_files/predict_server.py --no-init > predict.log 2>&1 &
+export AIRFLOW_HOME=/work/airflow
+cd $AIRFLOW_HOME
+airflow standalone
+```
+
+Airflow standalone will show username and password as shown below.
+
+
+
+In Airflow Web interface at `http://localhost:8080`, enter username and password.
+
+```{caution}
+`airflow standalone` is a front-end program that exits with Airflow. You can exit Airflow after DAG completion to run [Step 3-Testing](#3-Testing), or place the Airflow process in the background.
+```
+
+### Step 2: Running DAG
+
+To check the status of the DAG "example_openmldb_complex" in Airflow Web, click on the DAG and select the `Code` tab, as shown below.
+
+
+
+In this code, you will notice the usage of `openmldb_conn_id`, as depicted in the following figure. The DAG doesn't directly employ the address of OpenMLDB; instead, it uses a connection, so you need to create a new connection with the same name.
+
+
+
+#### Create Connection
+Click on connections in the Admin tab.
+
+
+Add the connection.
+
+
+The Airflow OpenMLDB Provider is linked to the OpenMLDB API Server. Therefore, you should provide the address of the OpenMLDB API Server in this configuration, rather than the Zookeeper address.
+
+
+
+The completed connection is shown in the figure below.
+
+
+#### Running DAG
+Run the DAG to complete the training of the model, SQL deployment, and model deployment. A successful operation will yield results similar to the figure below.
+
+
+### Step 3: Test
+
+If Airflow is currently running in the foreground within the container, you may exit the process now. The upcoming tests will not be dependent on Airflow.
+
+#### Online Data Import
+The SQL and model deployment have been successfully executed in the Airflow DAG. However, there is currently no data in the online storage, necessitating an online data import.
+
+```
+curl -X POST http://127.0.0.1:9080/dbs/example_db -d'{"mode":"online", "sql":"load data infile \"file:///tmp/train_sample.csv\" into table example_table options(mode=\"append\");"}'
+```
+
+This import process is asynchronous, but since the data volume is small, it will be completed quickly. You can monitor the status of the import operations by using the `SHOW JOBS` command.
+```
+curl -X POST http://127.0.0.1:9080/dbs/example_db -d'{"mode":"online", "sql":"show jobs"}'
+```
+
+#### Prediction
+Execute the prediction script to make a prediction using the newly deployed SQL and model.
+```
+python3 /work/airflow_demo_files/predict.py
+```
+The result is as shown.
+
+
+
+### Non-Interactive Testing
+
+Check if DAG has been successfully loaded:
+```
+airflow dags list | grep openmldb
+```
+Add required connection:
+```
+airflow connections add openmldb_conn_id --conn-uri http://127.0.0.1:9080
+airflow connections list --conn-id openmldb_conn_id
+```
+DAG test:
+```
+airflow dags test example_openmldb_complex 2022-08-25
+```
diff --git a/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md b/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md
new file mode 100644
index 00000000000..54ec0fbda33
--- /dev/null
+++ b/docs/en/integration/deploy_integration/dolphinscheduler_task_demo.md
@@ -0,0 +1,211 @@
+# DolphinScheduler
+
+## Introduction
+In the whole process of machine learning from development to deployment, tasks including data processing, feature development, and model training demand significant time and effort. To streamline the development and deployment of AI models and simplify the overall machine-learning process, we introduce the DolphinScheduler OpenMLDB Task. It seamlessly integrates the capabilities of the feature platform into DolphinScheduler's workflow, effectively bridging feature engineering with scheduling, resulting in a comprehensive end-to-end MLOps workflow. In this article, we present a concise introduction and practical demonstration of the procedures for using the DolphinScheduler OpenMLDB Task.
+
+```{seealso}
+For detailed information on the OpenMLDB Task, please refer to the [DolphinScheduler OpenMLDB Task Official Documentation](https://dolphinscheduler.apache.org/zh-cn/docs/3.1.5/guide/task/openmldb).
+```
+
+## Scenarios and Functions
+### Why Develop DolphinScheduler OpenMLDB Task
+
+
+
+As an open-source machine learning database providing a comprehensive solution for production-level data and feature development, the key to enhancing OpenMLDB's usability and reducing usage barriers lies in upstream and downstream connectivity. As depicted in the diagram above, the ability to access the data source allows seamless data flow from DataOps into OpenMLDB. Then the generated features by OpenMLDB need to smoothly integrate with ModelOps for training. To alleviate the significant workload resulting from manual integration by developers using OpenMLDB, we have also developed the function for OpenMLDB integration into Deployment and Monitoring. In this article, we introduce the framework for integrating OpenMLDB into the DolphinScheduler workflow. The DolphinScheduler OpenMLDB Task simplifies the usage of OpenMLDB. In the meantime, OpenMLDB tasks are efficiently managed by Workflow, enabling greater automation.
+
+### What Can DolphinScheduler OpenMLDB Task Do
+
+OpenMLDB aims to expedite development launch, enabling developers to focus on the essence of their work rather than expending excessive effort on engineering implementation. By writing OpenMLDB Tasks, we can fulfill the offline import, feature extraction, SQL deployment, and online import requirements of OpenMLDB. Furthermore, we can also implement complete training and online processes using OpenMLDB in DolphinScheduler.
+
+
+
+For instance, the most straightforward user operation process we envision, as illustrated in the diagram above, involves steps 1-4: offline data import, offline feature extraction, SQL deployment, and online data import. All of these steps can be achieved by utilizing the DolphinScheduler OpenMLDB Task.
+
+In addition to SQL execution in OpenMLDB, real-time prediction also requires model deployment. Therefore in the following sections, we will demonstrate how to utilize the DolphinScheduler OpenMLDB Task to coordinate a comprehensive machine learning training and online deployment process, based on the TalkingData adtracking fraud detection challenge from Kaggle. Further information about the TalkingData competition can be found at [talkingdata-adtracking-fraud-detection](https://www.kaggle.com/competitions/talkingdata-adtracking-fraud-detection/discussion).
+
+## Demonstration
+### Environment Configuration
+
+**Run OpenMLDB Docker Image**
+
+The test can be executed on macOS or Linux, and we recommend running this demo within the provided OpenMLDB docker image. In this setup, both OpenMLDB and DolphinScheduler will be launched inside the container, with the port of DolphinScheduler exposed.
+```
+docker run -it -p 12345:12345 4pdosc/openmldb:0.8.4 bash
+```
+```{attention}
+For proper configuration of DolphinScheduler, the tenant should be set up as a user of the operating system, and this user must have sudo permissions. It is advised to download and initiate DolphinScheduler within the OpenMLDB container. Otherwise, please ensure that the user has sudo permissions.
+```
+
+As our current docker image does not have sudo installed, and DolphinScheduler requires sudo for running workflows, please install sudo in the container first:
+```
+apt update && apt install sudo
+```
+
+The DolphinScheduler runs the task using sh, but in the docker, sh is `dash` as default. Thus modify it to `bash` with the following command:
+```
+dpkg-reconfigure dash
+```
+Enter `no`.
+
+**Data Preparation**
+
+The workflow loads data from `/tmp/train_Sample.csv ` to OpenMLDB. Thus, first download the source data to this address:
+```
+curl -SLo /tmp/train_sample.csv https://openmldb.ai/download/dolphinschduler-task/train_sample.csv
+```
+
+**Run OpenMLDB Cluster and Predict Server**
+
+Run the following command in the container to start a OpenMLDB cluster:
+```
+/work/init.sh
+```
+
+We will run a workflow that includes data import, offline training, and model deployment. The deployment of the model is done by sending the model address to the predict server. Let's begin by downloading and running the predict server in the background:
+```
+cd /work
+curl -SLo predict_server.py https://openmldb.ai/download/dolphinschduler-task/predict_server.py
+python3 predict_server.py --no-init > predict.log 2>&1 &
+```
+```{tip}
+If an error occurred in the 'Online Prediction Test', please check `/work/predict.log`.
+```
+
+**Download and Run DolphinScheduler**
+
+Please note that DolphinScheduler supports OpenMLDB Task versions 3.1.3 and above. In this article, we will be using version 3.1.5, which can be downloaded from the [Official Website](https://dolphinscheduler.apache.org/zh-cn/download/3.1.5) or from a mirrored website.
+
+To start the DolphinScheduler standalone, follow the steps outlined in the [Official Documentation](https://dolphinscheduler.apache.org/zh-cn/docs/3.1.5/guide/installation/standalone) for more information.
+
+```
+# Official
+curl -SLO https://dlcdn.apache.org/dolphinscheduler/3.1.5/apache-dolphinscheduler-3.1.5-bin.tar.gz
+# Image curl -SLO http://openmldb.ai/download/dolphinschduler-task/apache-dolphinscheduler-dev-3.1.5-bin.tar.gz
+tar -xvzf apache-dolphinscheduler-*-bin.tar.gz
+cd apache-dolphinscheduler-*-bin
+sed -i s#/opt/soft/python#/usr/bin/python3#g bin/env/dolphinscheduler_env.sh
+./bin/dolphinscheduler-daemon.sh start standalone-server
+```
+
+```{hint}
+In the official release version of DolphinScheduler, there is an issue with OpenMLDB Task in versions older than 3.1.3, which cannot be used directly. If you are using an older version, you can contact us to obtain a corresponding version. This problem has been resolved in versions 3.1.3 and later, making them suitable for use with the official release version.
+
+In other versions of DolphinScheduler, there may be a change in `bin/env/dolphinscheduler_env.sh`. If `PYTHON_HOME` does not exist in `bin/env/dolphinscheduler_env.sh`, additional configuration is required. You can modify it using the command `echo "export PYTHON_HOME=/usr/bin/python3" >>bin/env/dolphinscheduler_env.sh`.
+```
+
+To access the system UI, open your browser and go to the address http://localhost:12345/dolphinscheduler/ui (the default configuration allows cross-host access, but you need to ensure a smooth IP connection). The default username and password are admin/dolphinscheduler123.
+
+```{note}
+The DolphinScheduler worker server requires the OpenMLDB Python SDK. For the DolphinScheduler standalone worker, you only need to install the OpenMLDB Python SDK locally. We have already installed it in our OpenMLDB docker image. If you are in a different environment, please install the openmldb SDK using the command `pip3 install openmldb`.
+```
+
+**Download Workflow Configuration**
+
+Workflow can be manually created, but for the purpose of simplifying the demonstration, we have provided a JSON workflow file directly, which you can download from the following link: [Click to Download](http://openmldb.ai/download/dolphinschduler-task/workflow_openmldb_demo.json). You can upload this file directly to the DolphinScheduler environment and make simple modifications (as shown in the demonstration below) to complete the entire workflow.
+
+Please note that the download will not be saved within the container but to the browser host you are using. The upload will be done on the web page later.
+
+### Run Demo
+
+#### Step 1: Initial Configuration
+
+To create a tenant in DolphinScheduler web, navigate to the tenant management interface, and fill in the required fields. Make sure to fill in **user with sudo permission**. You can use the default settings for the queue. You can use root in the docker container.
+
+
+
+Bind the tenant to the user again. For simplicity, we directly bind to the admin user. Enter User Management page and click Edit Admin User.
+
+
+
+After binding, the user status is similar as shown below.
+
+
+#### Step 2: Create Workflow
+In DolphinScheduler, you need to create a project first, and then create a workflow within that project.
+
+To begin, create a test project. As shown in the following figure, click on "Create Project" and enter the project name.
+
+
+
+
+
+Once inside the project page, you can import the downloaded workflow file. In the workflow definition tab, click on "Import Workflow".
+
+
+
+After importing, the workflow table will show as follows.
+
+
+
+Click on the workflow name to view the detailed content of the workflow, as shown in the following figure.
+
+
+
+**Note**: A minor modification is required here since the task ID will change after importing the workflow. Specifically, the upstream and downstream IDs in the switch task will not exist and need to be manually modified.
+
+
+
+As depicted in the above figure, there are non-existent IDs in the settings of the switch task. Please modify the "branch flow" and "pre-check conditions" for successful and failed workflows to match the tasks of the current workflow.
+
+The correct results are shown in the following figure:
+
+
+
+Once the modifications are completed, save the workflow directly. The default tenant in the imported workflow is "default," which is also **executable**. If you want to specify your own tenant, please select the tenant when saving the workflow, as shown in the following figure.
+
+
+
+#### Step 3: Deploy Online Workflow
+
+After saving the workflow, it needs to be launched before running. Once it goes online, the run button will be activated. As illustrated in the following figure.
+
+
+
+After clicking "Run," wait for the workflow to complete. You can view the details of the workflow operation in the Workflow Instance page, as shown in the following figure.
+
+
+To demonstrate the process of a successful product launch, validation was not actually validated but returned a successful validation and flowed into the deploy branch. After running the deploy branch and successfully deploying SQL and subsequent tasks, the predict server receives the latest model.
+
+```{note}
+If the `Failed` appears on the workflow instance, please click on the instance name and go to the detailed page to see which task execution error occurred. Double-click on the task and click on "View Log" in the upper right corner to view detailed error information.
+
+`load offline data`, `feature extraction`, and `load online` may display successful task execution in the DolphinScheduler, but actual task execution fails in OpenMLDB. This may lead to errors in the `train` task, where there is no source feature data to concatenate (Traceback `pd.concat`).
+
+When such problems occur, please query the true status of each task in OpenMLDB and run it directly using the command: `echo "show jobs;" | /work/openmldb/bin/openmldb --zk_cluster=127.0.1:2181 --zk_root_path=/openmldb --role=SQL_client`. If the status of a task is `FAILED`, please query the log of that task. The method can be found in [Task Log](../../quickstart/beginninger_mustread.md#offline).
+```
+
+#### Step 4: Test Online Prediction
+The predict server also provides online prediction services, through `curl/predict`. You can construct a real-time request and send it to the predict server.
+```
+curl -X POST 127.0.0.1:8881/predict -d '{"ip": 114904,
+ "app": 11,
+ "device": 1,
+ "os": 15,
+ "channel": 319,
+ "click_time": 1509960088000,
+ "is_attributed": 0}'
+```
+The return result is as follows:
+
+
+
+#### Note
+
+If the workflow is run repeatedly, the `deploy SQL` task may fail because the deployment `demo` already exists. Please delete the deployment in the docker container before running the workflow again:
+```
+/work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client --database=demo_db --interactive=false --cmd="drop deployment demo;"
+```
+
+You can confirm whether the deployment has been deleted by using the following command:
+```
+/work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client --database=demo_db --interactive=false --cmd="show deployment demo;"
+```
+
+Restart the DolphinScheduler server (Note that restarting this will clear the metadata and require reconfiguring the environment and creating workflows):
+```
+./bin/dolphinscheduler-daemon.sh stop standalone-server
+./bin/dolphinscheduler-daemon.sh start standalone-server
+```
+
+If you want to preserve metadata, please refer to [Pseudo Cluster Deployment](https://dolphinscheduler.apache.org/zh-cn/docs/3.1.5/guide/installation/pseudo-cluster) to configure the database.
diff --git a/docs/en/integration/deploy_integration/images/add_connection.png b/docs/en/integration/deploy_integration/images/add_connection.png
new file mode 100644
index 00000000000..50cd41d16ff
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/add_connection.png differ
diff --git a/docs/en/integration/deploy_integration/images/airflow_dag.png b/docs/en/integration/deploy_integration/images/airflow_dag.png
new file mode 100644
index 00000000000..ad2bd6193e2
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/airflow_dag.png differ
diff --git a/docs/en/integration/deploy_integration/images/airflow_login.png b/docs/en/integration/deploy_integration/images/airflow_login.png
new file mode 100644
index 00000000000..03d58db49a9
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/airflow_login.png differ
diff --git a/docs/en/integration/deploy_integration/images/airflow_test_result.png b/docs/en/integration/deploy_integration/images/airflow_test_result.png
new file mode 100644
index 00000000000..75d4efc9c66
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/airflow_test_result.png differ
diff --git a/docs/en/integration/deploy_integration/images/connection.png b/docs/en/integration/deploy_integration/images/connection.png
new file mode 100644
index 00000000000..d0383aef2dc
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/connection.png differ
diff --git a/docs/en/integration/deploy_integration/images/connection_display.png b/docs/en/integration/deploy_integration/images/connection_display.png
new file mode 100644
index 00000000000..05726e821a4
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/connection_display.png differ
diff --git a/docs/en/integration/deploy_integration/images/connection_settings.png b/docs/en/integration/deploy_integration/images/connection_settings.png
new file mode 100644
index 00000000000..c739c61f71e
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/connection_settings.png differ
diff --git a/docs/en/integration/deploy_integration/images/dag_code.png b/docs/en/integration/deploy_integration/images/dag_code.png
new file mode 100644
index 00000000000..86f2289a0a5
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/dag_code.png differ
diff --git a/docs/en/integration/deploy_integration/images/dag_home.png b/docs/en/integration/deploy_integration/images/dag_home.png
new file mode 100644
index 00000000000..00a6ed33c53
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/dag_home.png differ
diff --git a/docs/en/integration/deploy_integration/images/dag_run.png b/docs/en/integration/deploy_integration/images/dag_run.png
new file mode 100644
index 00000000000..d072e4f8792
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/dag_run.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_bind_status.png b/docs/en/integration/deploy_integration/images/ds_bind_status.png
new file mode 100644
index 00000000000..42ebeea6c90
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_bind_status.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_bind_tenant.png b/docs/en/integration/deploy_integration/images/ds_bind_tenant.png
new file mode 100644
index 00000000000..74ef857d6a8
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_bind_tenant.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_create_project.png b/docs/en/integration/deploy_integration/images/ds_create_project.png
new file mode 100644
index 00000000000..37920851ad3
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_create_project.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_create_tenant.png b/docs/en/integration/deploy_integration/images/ds_create_tenant.png
new file mode 100644
index 00000000000..88a56fd58c0
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_create_tenant.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_import_workflow.png b/docs/en/integration/deploy_integration/images/ds_import_workflow.png
new file mode 100644
index 00000000000..2d6e257143d
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_import_workflow.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_predict.png b/docs/en/integration/deploy_integration/images/ds_predict.png
new file mode 100644
index 00000000000..7d2dba0f161
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_predict.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_project.png b/docs/en/integration/deploy_integration/images/ds_project.png
new file mode 100644
index 00000000000..e24ea8876b3
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_project.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_run.png b/docs/en/integration/deploy_integration/images/ds_run.png
new file mode 100644
index 00000000000..cd17c629b87
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_run.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_run_status.png b/docs/en/integration/deploy_integration/images/ds_run_status.png
new file mode 100644
index 00000000000..68c9ff1e460
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_run_status.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_set_tenant.png b/docs/en/integration/deploy_integration/images/ds_set_tenant.png
new file mode 100644
index 00000000000..d6f94bd6b08
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_set_tenant.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_switch.png b/docs/en/integration/deploy_integration/images/ds_switch.png
new file mode 100644
index 00000000000..75dbb327c07
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_switch.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_switch_right.png b/docs/en/integration/deploy_integration/images/ds_switch_right.png
new file mode 100644
index 00000000000..7fbbab6963d
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_switch_right.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_workflow_detail.png b/docs/en/integration/deploy_integration/images/ds_workflow_detail.png
new file mode 100644
index 00000000000..b3a4c169cd1
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_workflow_detail.png differ
diff --git a/docs/en/integration/deploy_integration/images/ds_workflow_list.png b/docs/en/integration/deploy_integration/images/ds_workflow_list.png
new file mode 100644
index 00000000000..856bdf895be
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ds_workflow_list.png differ
diff --git a/docs/en/integration/deploy_integration/images/ecosystem.png b/docs/en/integration/deploy_integration/images/ecosystem.png
new file mode 100644
index 00000000000..6e767d3a2d7
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/ecosystem.png differ
diff --git a/docs/en/integration/deploy_integration/images/task_func.png b/docs/en/integration/deploy_integration/images/task_func.png
new file mode 100644
index 00000000000..46b20ea9591
Binary files /dev/null and b/docs/en/integration/deploy_integration/images/task_func.png differ
diff --git a/docs/en/integration/deploy_integration/index.rst b/docs/en/integration/deploy_integration/index.rst
new file mode 100644
index 00000000000..15bff333619
--- /dev/null
+++ b/docs/en/integration/deploy_integration/index.rst
@@ -0,0 +1,14 @@
+=============================
+dispatch
+=============================
+
+.. toctree::
+ :maxdepth: 1
+
+ airflow_provider_demo
+ dolphinscheduler_task_demo
+ OpenMLDB_Byzer_taxi
+
+
+
+
diff --git a/docs/en/integration/develop/images/muti.png b/docs/en/integration/develop/images/muti.png
new file mode 100644
index 00000000000..a07578729d1
Binary files /dev/null and b/docs/en/integration/develop/images/muti.png differ
diff --git a/docs/en/integration/develop/images/single.png b/docs/en/integration/develop/images/single.png
new file mode 100644
index 00000000000..dff314ba236
Binary files /dev/null and b/docs/en/integration/develop/images/single.png differ
diff --git a/docs/en/integration/develop/images/support_function.png b/docs/en/integration/develop/images/support_function.png
new file mode 100644
index 00000000000..2e51dd3e119
Binary files /dev/null and b/docs/en/integration/develop/images/support_function.png differ
diff --git a/docs/en/integration/develop/index.rst b/docs/en/integration/develop/index.rst
new file mode 100644
index 00000000000..13e8fad3619
--- /dev/null
+++ b/docs/en/integration/develop/index.rst
@@ -0,0 +1,8 @@
+=============================
+Develop
+=============================
+
+.. toctree::
+ :maxdepth: 1
+
+ jupyter_notebook
\ No newline at end of file
diff --git a/docs/en/integration/develop/jupyter_notebook.md b/docs/en/integration/develop/jupyter_notebook.md
new file mode 100644
index 00000000000..b15488958a8
--- /dev/null
+++ b/docs/en/integration/develop/jupyter_notebook.md
@@ -0,0 +1,64 @@
+# Jupyter Notebook
+
+Jupyter Notebook offers various functionalities, such as data computation, code development, document editing, code execution, and result display, through a browser-based web page. It is currently one of the most popular and user-friendly development environments. This article introduces the seamless integration of OpenMLDB and Notebook, harnessing the functional features of OpenMLDB and the convenience of Notebook to create a fast and user-friendly machine-learning development environment.
+
+## Integration of the Magic Function
+
+The SQL magic function is an extension of Notebook that allows users to execute SQL statements directly in a Notebook cell without writing complex Python code. It also supports customized output. OpenMLDB provides a standard SQL magic function that allows users to write and run OpenMLDB-supported SQL statements directly in the Notebook. These statements are submitted to OpenMLDB for execution, and the results are previewed and displayed in the Notebook.
+
+### Register OpenMLDB SQL Magic Function
+
+To support OpenMLDB magic function in Notebook, register as follows:
+
+ ```Python
+ import openmldb
+ db = openmldb.dbapi.connect(database='demo_db',zk='0.0.0.0:2181',zkPath='/openmldb')
+ openmldb.sql_magic.register(db)
+ ```
+
+### Execute a Single SQL Statement
+
+Developers can use the prompt `%` to execute a single-line SQL statement, as shown in the following figure.
+
+
+
+### Execute multiple SQL statement
+
+Developers can also use the prompt `%%` to write multi-line SQL statements, as shown in the following figure.
+
+
+
+Please note that currently, executing multiple SQL statements simultaneously within a Notebook cell is not supported. Each SQL statement needs to be executed separately in different cells.
+
+### Magic Function
+
+The SQL magic function provided by OpenMLDB can execute all supported SQL syntax, including the unique offline mode of OpenMLDB, which allows for asynchronously submitting complex big data SQL statements to the offline execution engine, as shown in the following figure.
+
+
+
+For more detailed instructions on using the OpenMLDB magic function, please refer to [The Use of Notebook Magic Function](https://openmldb.ai/docs/en/main/quickstart/sdk/python_sdk.html#notebook-magic-function).
+
+## Integration of OpenMLDB Python SDK with Notebook
+
+Notebook supports the Python runtime kernel, enabling the import and usage of various Python libraries through import statements. OpenMLDB provides a fully functional Python SDK that can be called within Notebook. OpenMLDB Python SDK not only offers a DBAPI based on the Python PEP249 standard but also supports the mainstream SQLAlchemy interface, which enables connecting to existing OpenMLDB clusters with just one line of code.
+
+### The Use of OpenMLDB DBAPI
+
+Using the DBAPI interface is straightforward. You only need to specify the ZooKeeper address and node path for connection. Upon successful connection, corresponding log information will be displayed. You can call the DBAPI interface of the OpenMLDB Python SDK within Notebook for development, as detailed in [The Use of OpenMLDB DBAPI](https://openmldb.ai/docs/en/main/quickstart/sdk/python_sdk.html#openmldb-dbapi).
+
+```Python
+import openmldb.dbapi
+db = openmldb.dbapi.connect('demo_db','0.0.0.0:2181','/openmldb')
+```
+
+### Using OpenMLDB SQLAlchemy
+
+Using SQLAlchemy is also simple. You can establish the connection by specifying the URI of OpenMLDB through the SQLAlchemy library. Alternatively, you can connect to a standalone OpenMLDB database using IP and port as parameters, as shown below.
+
+```Python
+import sqlalchemy as db
+engine = db.create_engine('openmldb://demo_db?zk=127.0.0.1:2181&zkPath=/openmldb')
+connection = engine.connect()
+```
+
+After a successful connection, development can be carried out through the SQLAlchemy interface of the OpenMLDB Python SDK, as detailed in [Using OpenMLDB SQLAlchemy](https://openmldb.ai/docs/en/main/quickstart/sdk/python_sdk.html#openmldb-sqlalchemy).
diff --git a/docs/en/integration/index.rst b/docs/en/integration/index.rst
new file mode 100644
index 00000000000..023bd3c9ab9
--- /dev/null
+++ b/docs/en/integration/index.rst
@@ -0,0 +1,13 @@
+=============================
+Upstream and downstream ecology
+=============================
+
+.. toctree::
+ :maxdepth: 1
+
+ online_datasources/index
+ offline_data_sources/index
+ deploy_integration/index
+ develop/index
+
+
diff --git a/docs/en/integration/online_datasources/index.rst b/docs/en/integration/online_datasources/index.rst
new file mode 100644
index 00000000000..7b2232ef05b
--- /dev/null
+++ b/docs/en/integration/online_datasources/index.rst
@@ -0,0 +1,13 @@
+=============================
+online data source
+=============================
+
+.. toctree::
+ :maxdepth: 1
+
+ kafka_connector_demo
+ pulsar_connector_demo
+ rocketmq_connector
+
+
+
diff --git a/docs/en/maintain/data_export.md b/docs/en/maintain/data_export.md
deleted file mode 100644
index 0916a8bc553..00000000000
--- a/docs/en/maintain/data_export.md
+++ /dev/null
@@ -1,58 +0,0 @@
-# Data Export Tool
-
-Data Export Tool locates in [src/tools](https://github.com/4paradigm/OpenMLDB/tree/main/src/tools)。It supports exporting data from remote machines in standalone mode or cluster mode.
-
-## 1. Build
-
-Generate the Unix Executable file:`make` under src folder.
-
-## 2. Data Export Usage
-
-### 2.1 Command Line Arguments
-
-All configurations are showed as follows, * indicates required configurations.
-
-```
-Usage: ./data_exporter [--delimiter=] --db_name=
- [--user_name=] --table_name=
- --config_path=
-
-* --db_name= openmldb database name
-* --table_name= openmldb table name of the selected database
-* --config_path= absolute or relative path of the config file
- --delimiter= delimiter for the output csv, default is ','
- --user_name= user name of the remote machine
-```
-
-### 2.2 Important Configurations Instructions
-
-Descriptions of the important configurations:
-
-- `--db_name=`: OpenMLDB database name. The database must exist, otherwise would return an error message: database not found.
-- `--table_name=`: table name. The table must exist in the selected database, otherwise would return an error message: table not found.
-- `--config_path= kDoing => kDone: Indicates successful command execution.
+2. kInited => kDoing => kFailed: Denotes a failed command execution.
+3. kInited => kCancelled: This state may arise after manually executing the `cancelop` command.
+
+Once the command running status changes to `kDone`, it signifies the successful execution of relevant commands. You can then proceed to the subsequent steps and use the `showtablestatus` command to inspect the status of tables.
+
+## Step 2: View Table Status with `showtablestatus`
+
+After successfully executing the relevant maintenance commands, it's crucial to perform an additional verification to identify any anomalies in the table status. This verification can be conducted using the `showtablestatus` command within the [OpenMLDB Operations and Maintenance Tool](./openmldb_ops.md). For instance:
+
+```bash
+python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --cmd=showtablestatus
+```
+
+Upon execution, this command will generate a series of table-related information. Of particular importance is the column labeled `Partition_unalive`. If this column's value is 0, it signifies that the table is in a normal state. Conversely, any non-zero value indicates the presence of an anomaly, as illustrated in the following example:
+
+
diff --git a/docs/en/quickstart/beginner_must_read.md b/docs/en/quickstart/beginner_must_read.md
new file mode 100644
index 00000000000..759d423b32d
--- /dev/null
+++ b/docs/en/quickstart/beginner_must_read.md
@@ -0,0 +1,144 @@
+# Essential Reading for Getting Started
+
+As OpenMLDB is a distributed system with various modes and extensive client functionality, users may encounter numerous questions and operational challenges, especially when using it for the first time. This article aims to guide beginners on diagnosing and debugging issues and providing effective information when seeking technical assistance.
+
+## Create OpenMLDB and Connection
+
+To begin, we recommend that users who are not well-versed in distributed multi-process management use Docker to set up OpenMLDB. This approach offers convenience and expedites the initial learning process. Once you have become acquainted with the various components of OpenMLDB, you can explore distributed deployment options.
+
+You can create an OpenMLDB instance using Docker by following the instructions in the [Quickstart guide](./openmldb_quickstart.md). Please note that the guide presents two versions: standalone and cluster. Ensure clarity regarding the version you intend to create and avoid mixed usage.
+
+A successful startup is indicated by your ability to connect to the OpenMLDB server using the CLI (Command Line Interface). In both standalone and cluster setups, you can use `/work/openmldb/bin/openmldb` to connect to OpenMLDB and execute `show components;` to check the running status of OpenMLDB server components.
+
+If you encounter difficulties connecting via the CLI, first verify whether the processes are running as expected. You can confirm the presence of nameserver and tablet server processes using `ps f | grep bin/openmldb`. In the case of the cluster setup, ensure that the ZooKeeper service is running by using `ps f | grep zoo.cfg`, and confirm the existence of the taskmanager process with `ps f | grep TaskManagerServer`.
+
+If all service processes are running correctly, but the CLI still cannot connect to the server, double-check the parameters for CLI operation. If issues persist, don't hesitate to contact us and provide the error information from the CLI.
+
+```{seealso}
+If further configuration and server logs from OpenMLDB are required, you can use diagnostic tools to obtain them, as detailed in the [section below](#provide-configuration-and-logs-for-technical-support).
+```
+
+## Source Data
+
+### LOAD DATA
+
+When importing data from a file into OpenMLDB, the typical command used is `LOAD DATA`. For detailed information, please refer to [LOAD DATA INFILE](../openmldb_sql/dml/LOAD_DATA_STATEMENT.md). The data sources and formats that can be employed with `LOAD DATA` are contingent on several factors, including the OpenMLDB version (standalone or cluster), execution mode, and import mode (i.e., the `LOAD DATA` configuration item, `load_mode`). Specifically:
+
+In cluster version, the default `load_mode` is "cluster", and it can be set to "local". In standalone version, the default `load_mode` is "local," and **"cluster " is not supported**. Consequently, we discuss these scenarios in three distinct contexts:
+
+| LOAD DATA Type | Support execution mode (import to destination) | Support asynchronous/ synchronous | Support data sources | Support data formats |
+| :-------------------------------- | :--------------------------------------------- | :--------------------------------- | :----------------------------------------------------------- | :--------------------------------------------- |
+| Cluster version load_mode=cluster | Online, offline | Asynchronous, synchronous | File (with conditional restrictions, please refer to specific documentation) /hdfs/ hive | CSV/ parquet (HIVE source unrestricted format) |
+| Cluster version load_mode=local | Online | Synchronous | Client local file | csv |
+| Standalone version(only local) | Online | Synchronous | Client local file | csv |
+
+When the source data for `LOAD DATA` is in CSV format, it's essential to pay special attention to the timestamp column's format. Timestamps can be in "int64" format (referred to as int64 type) or "yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]" format (referred to as date type).
+
+| LOAD DATA Type | Support int64 type | Support date type |
+| :-------------------------------- | :------------ | :----------- |
+| Cluster version load_mode=cluster | **``✓``** | **``✓``** |
+| Cluster version load_mode=local | **``✓``** | **``X``** |
+| Standalone version(only local) | **``✓``** | **``X``** |
+
+```{hint}
+The CSV file format can be inconvenient in certain situations, and we recommend considering the use of the Parquet format. This approach requires the OpenMLDB cluster version to be in use and necessitates the taskmanager component to be up and running.
+```
+
+## SQL Restriction
+
+OpenMLDB does not offer full compatibility with standard SQL, which means that certain SQL queries may not yield the expected results. If you encounter a situation where the SQL execution does not align with your expectations, it's advisable to initially verify whether the SQL adheres to the [Functional Boundary](./function_boundary.md) guidelines.
+
+## SQL Execution
+
+All commands within OpenMLDB are SQL-based. If you experience SQL execution failures or other issues (where it's unclear whether the command was executed successfully), consider the following checks:
+
+1. **SQL Accuracy**: Examine whether there are errors in the SQL syntax. Syntax errors can lead to unsuccessful SQL execution. You can refer to the [SQL Reference](../../openmldb_sql/) to correct any errors.
+2. **Execution Status**: Determine if the command has progressed to the execution phase or if it failed to execute. This distinction is crucial for troubleshooting.
+
+For instance, if you encounter a syntax error prompt, it indicates a problem with the SQL writing, and you should consult the [SQL Reference](../../openmldb_sql/) for guidance on correcting it.
+
+```
+127.0.0.1:7527/db> create table t1(c1 int;
+Error: Syntax error: Expected ")" or "," but got ";" [at 1:23]
+create table t1(c1 int;
+ ^
+```
+
+If the command has entered the execution phase but fails or experiences interaction issues, you should clarify the following details:
+
+- **OpenMLDB Version**: Is OpenMLDB being used in standalone mode or clustered mode?
+- **Execution Mode**: What is the execution mode? You can use the `show variable` command in the CLI to retrieve this information. Note that the execution mode of the standalone version is not meaningful.
+
+Special attention to usage logic is required when working with the cluster version of OpenMLDB.
+
+### Cluster Version SQL Execution
+
+#### Offline
+
+For cluster offline commands, when operating in the default asynchronous mode, sending the command will yield a job ID as a return value. You can utilize `show job ` to inquire about the execution status of the job.
+
+If the offline job is an asynchronous SELECT query (without saving results), the results will not be displayed on the client (synchronous SELECT queries do display results). Instead, you can retrieve the results through `show joblog `, which comprises two sections: `stdout` and `stderr`. `stdout` contains the query results, while `stderr` contains the job's runtime log. If you discover that the job has failed or its status doesn't align with your expectations, it's essential to carefully review the job run log.
+
+```{note}
+The location of these logs is determined by the `job.log.path` configuration in taskmanager.properties. If you have altered this configuration, you will need to search in the specified destination for the logs. By default, the stdout log can be found at `/work/openmldb/taskmanager/bin/logs/job_x.log`, while the job execution log is situated at `/work/openmldb/taskmanager/bin/logs/job_x_error.log` (note the "error" suffix).
+
+If the task manager operates in YARN mode rather than local mode, the information in job_x_error.log may be more limited, and detailed error information about the job might not be available. In such instances, you will need to employ the YARN app ID recorded in job_x_error.log to access the actual error details within the YARN system.
+```
+
+#### Online
+
+In the online mode of the cluster version, we typically recommend using the `DEPLOY` command to create a deployment, and access to APIServer through HTTP for real-time feature computations. Performing a SELECT query directly online, with CLI or other clients is referred to as "online preview." It's essential to be aware that online preview comes with several limitations, which are outlined in detail in the [Functional Boundary - Cluster Version Online Preview Mode](../function_boundary.md#cluster-version-online-preview-mode) document. Please avoid executing unsupported SQL queries in this context.
+
+### Provide Replication Scripts
+
+If you find yourself unable to resolve an issue through self-diagnosis, please provide us with a replication script. A comprehensive replication script should include the following components:
+
+```
+create database db;
+use db;
+-- create your table
+create table xx ();
+
+-- offline or online
+set @@execute_mode='';
+
+-- load data or online insert
+-- load data infile '' into table xx;
+-- insert into xx values (),();
+
+-- query / deploy ...
+
+```
+
+If your question necessitates data for replication, please include the data. For offline data that doesn't support inserting offline, kindly provide a CSV or Parquet data file. If it pertains to online data, you can either provide a data file or directly insert it within the script.
+
+These data scripts should be capable of executing SQL commands in bulk by using redirection symbols.
+
+```
+/work/openmldb/bin/openmldb --host 127.0.0.1 --port 6527 < reproduce.sql
+/work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < reproduce.sql
+```
+
+Ensure that the replication script is functional locally to reproduce the issue, and then document the issue or forward it to us for further assistance.
+
+```{caution}
+Please be aware that offline jobs default to asynchronous mode. If you intend to import and query offline, remember to set it to synchronous mode. For additional information, consult [Offline Command Configuration Details](../openmldb_sql/ddl/SET_STATEMENT.md#offline-command-configuration-details). Without this adjustment, querying before the import is completed will not yield meaningful results.
+```
+
+## Provide Configuration and Logs for Technical Support
+
+If your SQL execution issue cannot be replicated through replication scripts or if it's not related to SQL execution but rather a cluster management problem, we kindly request that you provide us with configuration details and logs from both the client and server for further investigation.
+
+Whether you are using Docker or a local cluster setup (where all processes are on the same server), you can swiftly gather configuration, log files, and other information using diagnostic tools.
+
+You can initiate the OpenMLDB server using either the `init.sh`/`start-all.sh` command for clustered versions or the `init.sh standalone`/`start-standalone.sh` command for standalone versions. After starting the server, you can employ the following commands, which correspond to clustered and standalone versions, respectively.
+
+```
+openmldb_tool --env=onebox --dist_conf=cluster_dist.yml
+openmldb_tool --env=onebox --dist_conf=standalone_dist.yml
+```
+`cluster_dist.yml` and `stadnalone_dist.yml` can be found in the `/work/` directory within the Docker container. Alternatively, you can copy the yml file from the [GitHub directory](https://github.com/4paradigm/OpenMLDB/tree/main/demo) for your use.
+
+If you are working with a distributed cluster, it's essential to have SSH password-free configuration in place for smooth usage of the diagnostic tools. Please refer to the [Diagnostic Tool documentation](../maintain/diagnose.md) for guidance on setting this up.
+
+If your environment doesn't allow for SSH password-free configuration, please manually collect the configuration details and logs as needed.
diff --git a/docs/en/quickstart/cli_tutorial.md b/docs/en/quickstart/cli.md
similarity index 100%
rename from docs/en/quickstart/cli_tutorial.md
rename to docs/en/quickstart/cli.md
diff --git a/docs/en/quickstart/concepts/images/modes-flow.png b/docs/en/quickstart/concepts/images/modes-flow.png
new file mode 100644
index 00000000000..361353de760
Binary files /dev/null and b/docs/en/quickstart/concepts/images/modes-flow.png differ
diff --git a/docs/en/quickstart/concepts/images/modes-request.png b/docs/en/quickstart/concepts/images/modes-request.png
new file mode 100644
index 00000000000..f7dd94e5759
Binary files /dev/null and b/docs/en/quickstart/concepts/images/modes-request.png differ
diff --git a/docs/en/quickstart/concepts/index.rst b/docs/en/quickstart/concepts/index.rst
index d02cca2378f..27542f7f2f7 100644
--- a/docs/en/quickstart/concepts/index.rst
+++ b/docs/en/quickstart/concepts/index.rst
@@ -5,4 +5,4 @@ Concept
.. toctree::
:maxdepth: 1
- workflow
+ modes
diff --git a/docs/en/quickstart/concepts/workflow.md b/docs/en/quickstart/concepts/modes.md
similarity index 79%
rename from docs/en/quickstart/concepts/workflow.md
rename to docs/en/quickstart/concepts/modes.md
index 2ce5c58ff19..d27f33ab001 100644
--- a/docs/en/quickstart/concepts/workflow.md
+++ b/docs/en/quickstart/concepts/modes.md
@@ -6,7 +6,7 @@ OpenMLDB supports different execution modes at different stages of the feature e
The following diagram illustrates the typical process of using OpenMLDB for feature engineering development and deployment, as well as the execution modes used in the process:
-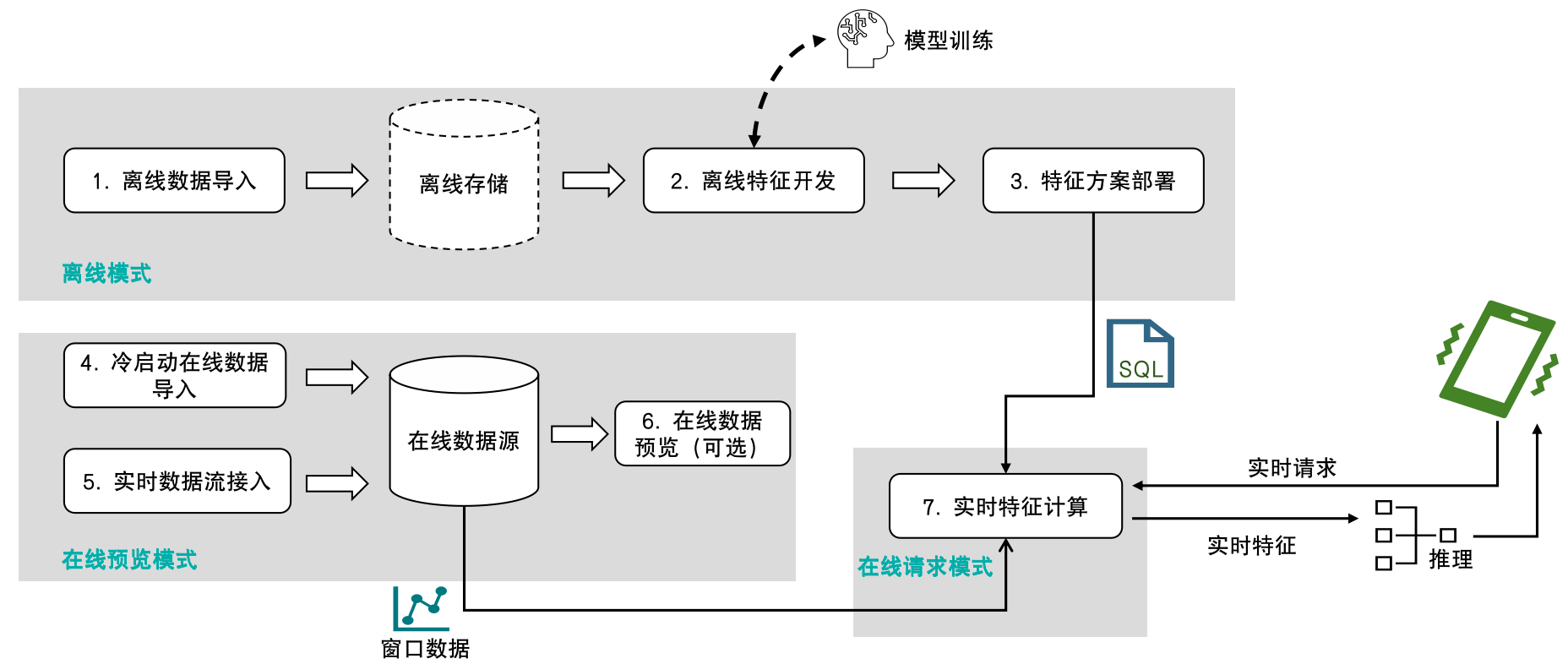
+
1. Offline Data Import: Import offline data for offline feature engineering development and debugging.
2. Offline Feature Development: Develop feature engineering scripts and debug them until satisfactory results are achieved. This step involves joint debugging of machine learning models (such as XGBoost, LightGBM, etc.), but this article mainly focuses on feature engineering development related to OpenMLDB.
@@ -16,57 +16,54 @@ The following diagram illustrates the typical process of using OpenMLDB for feat
6. Online Data Preview (optional): Preview and check online data using supported SQL commands. This step is not mandatory.
7. Real-time Feature Calculation: After the feature scheme is deployed and the data is correctly accessed, a real-time feature calculation service that can respond to online requests will be obtained.
-## Overview of execution mode
+## Overview of Execution Mode
-As the data objects for offline and online scenarios are different, their underlying storage and computing nodes are also different. Therefore, OpenMLDB provides several built-in execution modes to support completing the above steps. The following table summarizes the execution modes and development tools used for each step, and three execution modes will be discussed in detail later.
+As the data objects for offline and online scenarios are different, their underlying storage and computing nodes are also different. Therefore, OpenMLDB provides several built-in execution modes to support the above steps. The following table summarizes the execution modes and development tools used for each step, and three execution modes will be discussed in detail later.
| Steps | Execution Mode | Development Tool |
| ------------------------------ | ------------------- | ------------------------------------------------------------ |
| 1. Offline Data Import | Offline Mode | OpenMLDB CLI, SDKs |
-| Offline Feature Development | Offline Mode | OpenMLDB CLI, SDKs |
-| Feature Deployment | Offline Mode | OpenMLDB CLI, SDKs |
-| Cold Start Online Data Import | Online Preview Mode | OpenMLDB CLI, SDKs, [Data Import Tool](https://openmldb.ai/docs/zh/main/tutorial/data_import.html) |
-| Real-time Data Integration | Online Preview Mode | Connectors, SDKs |
-| Online Data Preview (optional) | Online Preview Mode | OpenMLDB CLI, SDKs, [Data Export Tool](https://openmldb.ai/docs/zh/main/tutorial/data_export.html) |
-| Real-time Feature Calculation | Online Request Mode | CLI (REST APIs), SDKs |
+| 2. Offline Feature Development | Offline Mode | OpenMLDB CLI, SDKs |
+| 3. Feature Deployment | Offline Mode | OpenMLDB CLI, SDKs |
+| 4. Cold Start Online Data Import | Online Preview Mode | OpenMLDB CLI, SDKs, [Data Import Tool](../../tutorial/data_import.md) |
+| 5. Real-time Data Integration | Online Preview Mode | Connectors, SDKs |
+| 6. Online Data Preview (optional) | Online Preview Mode | OpenMLDB CLI, SDKs, [Data Export Tool](../../tutorial/data_export.md) |
+| 7. Real-time Feature Calculation | Online Request Mode | CLI (REST APIs), SDKs |
### Offline Mode
-After starting OpenMLDB CLI, the **default mode is offline mode**. Offline data import, offline feature development, and feature deployment are all executed in offline mode. The purpose of offline mode is to manage and compute offline data. The computing nodes involved are supported by OpenMLDB Spark optimized for feature engineering, and the storage nodes support commonly used storage systems such as HDFS.
+After starting OpenMLDB CLI, the **default mode is offline mode**. Offline data import, offline feature development, and feature deployment are all executed in offline mode. The purpose of offline mode is to manage and compute offline data. The computing nodes involved are supported by [OpenMLDB Spark Distribution](../../tutorial/openmldbspark_distribution.md) optimized for feature engineering, and the storage nodes support commonly used storage systems such as HDFS.
Offline mode has the following main features:
-- The offline mode supports most of the SQL syntax provided by OpenMLDB, including complex SQL syntaxes such as `LAST JOIN` and `WINDOW UNION`, which are optimized for feature engineering.
-
-- In offline mode, some SQL commands are executed asynchronously, such as `LOAD DATA`, `SELECT`, and `SELECT INTO` commands. Other SQL commands are executed synchronously.
-
+- The offline mode supports most of the SQL syntax provided by OpenMLDB, including complex SQL syntax such as `LAST JOIN` and `WINDOW UNION`.
+- In offline mode, some SQL commands are executed asynchronously, such as `LOAD DATA`, `SELECT`, and `SELECT INTO`. Other SQL commands are executed synchronously.
- The asynchronous SQL is managed by the internal TaskManager and can be viewed and managed through commands such as `SHOW JOBS`, `SHOW JOB`, and `STOP JOB`.
-```{tip}
-:::
+:::{tip}
Unlike many relational database systems, the `SELECT` command in offline mode is executed asynchronously by default. If you need to set it to synchronous execution, refer to setting the command to run synchronously in offline mode. During offline feature development, if asynchronous execution is used, it is strongly recommended to use the `SELECT INTO` statement for development and debugging, which can export the results to a file for easy viewing.
:::
-```
-The `DEPLOY` command for feature deployment is also executed in offline mode. Its specification can refer to the OpenMLDB SQL online specification and requirements.
+
+The `DEPLOY` command for feature deployment is also executed in offline mode. Its specification can refer to the [OpenMLDB SQL online specification and requirements](../../openmldb_sql/deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md).
Offline mode setting command (OpenMLDB CLI): `SET @@execute_mode='offline'`.
-### Online preview mode
+### Online Preview Mode
Cold start online data import, real-time data access, and online data preview are executed in online preview mode. The purpose of the online preview mode is to manage and preview online data. Storage and computation of online data are supported by the tablet component.
The main features of the online preview mode are:
- `LOAD DATA`, used for online data import, can be done either locally (load_mode='local') or on the cluster (load_mode='cluster'). Local import is synchronous, while cluster import is asynchronous (same as in offline mode). Other operations are synchronous.
-- Online preview mode is mainly used for previewing limited data. Selecting and viewing data directly through SELECT in OpenMLDB CLI or SDKs may result in data truncation. If the data volume is large, it is recommended to use an [export tool](https://openmldb.ai/docs/zh/main/tutorial/data_export.html) to view the complete data.
-- SELECT statements in online preview mode currently do not support more complex queries such as `LAST JOIN` and `ORDER BY`. Refer to [SELECT](https://openmldb.ai/docs/zh/main/openmldb_sql/dql/SELECT_STATEMENT.html).
+- Online preview mode is mainly used for previewing limited data. Selecting and viewing data directly through SELECT in OpenMLDB CLI or SDKs may result in data truncation. If the data volume is large, it is recommended to use an [export tool](../../tutorial/data_export.html) to view the complete data.
+- SELECT statements in online preview mode currently do not support more complex queries such as `LAST JOIN` and `ORDER BY`. Refer to [SELECT](../../openmldb_sql/dql/SELECT_STATEMENT.html).
- The server in the online preview mode executes SQL statements on a single thread. For large data processing, it may be slow and may trigger a timeout. To increase the timeout period, the `--request_timeout` can be configured on the client.
-- To prevent impact on online services, online preview mode limits the maximum number of accessed records and the number of different keys. This can be configured using `--max_traverse_cnt` and `--max_traverse_key_cnt`. Similarly, the maximum result size can be set using `--scan_max_bytes_size`. For detailed configuration, refer to the configuration file.
+- To prevent impact on online services, online preview mode limits the maximum number of accessed records and the number of different keys. This can be configured using `--max_traverse_cnt` and `--max_traverse_key_cnt`. Similarly, the maximum result size can be set using `--scan_max_bytes_size`. For detailed configuration, refer to the [configuration file](../../deploy/conf.md).
The command for setting online preview mode in OpenMLDB CLI: `SET @@execute_mode='online'`
-### Online request mode
+### Online Request Mode
After deploying feature scripts and accessing online data, the real-time feature computing service is ready to use, and real-time feature extraction can be performed through the online request mode. REST APIs and SDKs support the online request mode. The online request mode is a unique mode in OpenMLDB that supports real-time online computing and is very different from common SQL queries in databases.
@@ -78,7 +75,7 @@ The online request mode requires three inputs:
Based on the above inputs, for each real-time request row, the online request mode will return a feature extraction result. The computing logic is as follows: The request row is virtually inserted into the correct position of the online data table based on the logic in the SQL script (such as `PARTITION BY`, `ORDER BY`, etc.), and then only the feature aggregation computing is performed on that row, returning the unique corresponding extraction result. The following diagram intuitively explains the operation process of the online request mode.
-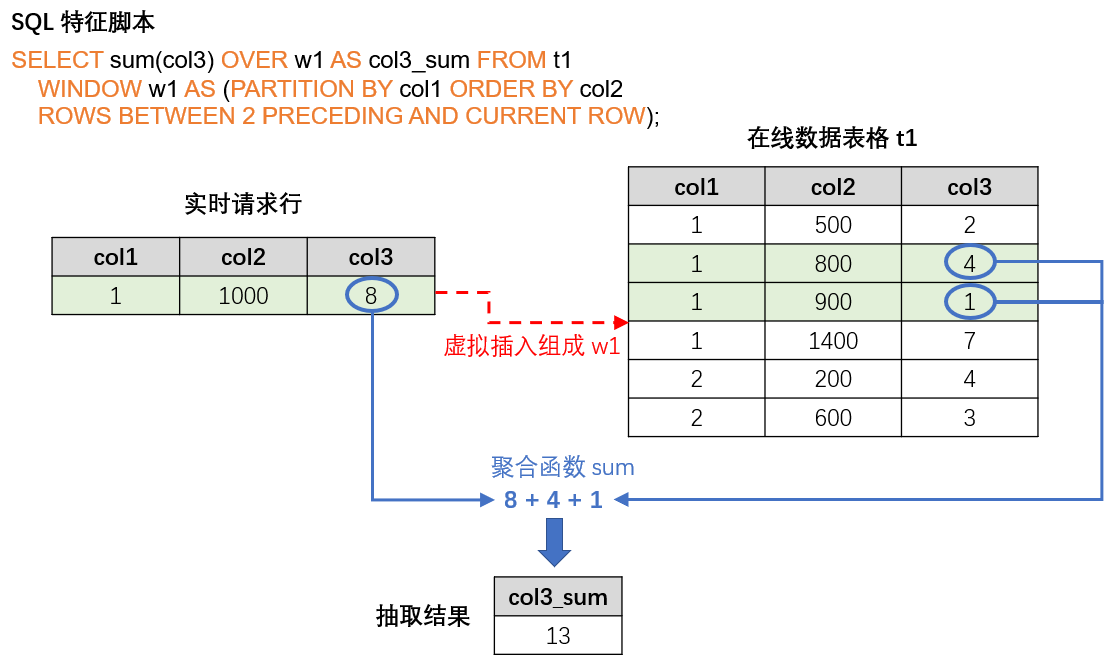
+
Online request mode is supported in the following ways:
diff --git a/docs/en/quickstart/function_boundary.md b/docs/en/quickstart/function_boundary.md
new file mode 100644
index 00000000000..9c2c0b7ae14
--- /dev/null
+++ b/docs/en/quickstart/function_boundary.md
@@ -0,0 +1,165 @@
+# Functional Boundary
+
+This article will introduce the functional boundary of OpenMLDB SQL.
+
+```{note}
+If you have any questions about SQL statements, please refer to OpenMLDB SQL or directly use the search function to search.
+```
+
+## System Configuration - TaskManager
+
+You can configure the TaskManager to define various settings, including the offline storage address (`offline.data.prefix`) and the Spark mode required for offline job computation (`spark.master`), among others.
+
+- `offline.data.prefix`: This can be configured as either a file path or an HDFS path. It is recommended to use an HDFS path for production environments, while a local file path can be configured for testing environments (specifically for onebox, such as running within a Docker container). Note that using a file path as offline storage will not support distributed deployment with multiple Task Managers (data won't be transferred between Task Managers). If you plan to deploy Task Managers on multiple hosts, please use storage media like HDFS that can be accessed simultaneously by multiple hosts. If you intend to test the collaboration of multiple Task Managers, you can deploy multiple Task Managers on a single host and use a file path as offline storage.
+- `spark.master=local[*]`: The default Spark configuration is in `local[*]` mode, which automatically binds CPU cores. If offline tasks are found to be slow, it is recommended to use the Yarn mode. After changing the configuration, you need to restart the Task Manager for the changes to take effect. For more configurations, please refer to [master-urls](https://spark.apache.org/docs/3.1.2/submitting-applications.html#master-urls).
+
+### spark.default.conf
+
+More optional configurations can be written in the `spark.default.conf` parameter in the format of `k1=v1;k2=v2`. For example:
+
+```Plain
+spark.default.conf=spark.port.maxRetries=32;foo=bar
+```
+
+`spark.port.maxRetries`: The default is set to 16, and you can refer to [Spark Configuration](https://spark.apache.org/docs/3.1.2/configuration.html). Each offline job is associated with a Spark UI, corresponding to a port. Each port starts from the default initial port and increments by one for retry attempts. If the number of concurrently running jobs exceeds `spark.port.maxRetries`, the number of retries will also exceed `spark.port.maxRetries`, causing job startup failures. If you need to support a larger job concurrency, configure a higher value for `spark.port.maxRetries` and restart the Task Manager to apply the changes.
+
+## DDL Boundary - DEPLOY Statement
+
+You can deploy an online SQL solution using the `DEPLOY ` command. This operation automatically parses the SQL statement and helps create indexes (you can view index details using `DESC `). For more information, please refer to the [DEPLOY STATEMENT](../openmldb_sql/deployment_manage/DEPLOY_STATEMENT.md) documentation.
+
+The success of the deployment operation is dependent on the presence of online data in the table.
+
+### Long Window SQL
+
+Long Window SQL: This refers to the `DEPLOY` statement with the `OPTIONS(long_windows=...)` configuration item. For syntax details, please refer to [Long Window](../openmldb_sql/deployment_manage/DEPLOY_STATEMENT.md#long-window-optimazation). Deployment conditions for long-window SQL are relatively strict, and it's essential to ensure that the tables used in the SQL statements do not contain online data. Otherwise, even if deploying SQL that matches the previous one, the operation will still fail.
+
+### Normal SQL
+
+- If the relevant index already exists before deployment, the `DEPLOY` operation will not create the index. The `DEPLOY` operation will succeed regardless of whether there is online data in the table.
+- If a new index needs to be created during deployment, and there is already online data in the table, the `DEPLOY` operation will fail.
+
+There are two solutions:
+
+1. Strictly perform `DEPLOY` before importing online data, and avoid executing `DEPLOY` after online data is present in the table.
+2. The `CREATE INDEX` statement can automatically import existing online data (data from existing indexes) when creating a new index. If it is necessary to execute `DEPLOY` when the table already has online data, you can manually execute a `CREATE INDEX` to create the required index (the new index will already have data), and then execute `DEPLOY` (in this case, `DEPLOY` will not create a new index, and the manually created indexes will be used directly for computation).
+
+```{note}
+How can you determine which indexes to create?
+
+Currently, only the Java SDK supports this feature, and all the required indexes can be obtained through `SqlClusterExecutor.genDDL`. However, you will need to manually convert them into `CREATE INDE`X statements as `genDD`L provides table creation statements. In the future, it will support ** directly obtaining index creation statements** or **automatically importing data into a new index** with `DEPLOY`.
+```
+
+## DML Boundary
+
+### Offline Information
+
+There are two types of paths in the offline information of a table: `offline_path` and `symbolic_paths`. `offline_path` is the actual storage path for offline data, while `symbolic_paths` are soft link paths for offline data. Both paths can be modified using the `LOAD DATA` command, and `symbolic_paths` can also be modified using the `ALTER` statement.
+
+The key difference between `offline_path` and `symbolic_paths` is that `offline_path` is the path owned by the OpenMLDB cluster. If a hard copy is implemented, data will be written to this path. On the other hand, `symbolic_paths` are paths outside the OpenMLDB cluster, and soft copies will add a path to this information. When querying offline, data from both paths will be loaded. Both paths use the same format and read options and do not support paths with different configurations.
+
+Therefore, if `offline_path` already exists offline, the `LOAD DATA` command can only modify `symbolic_paths`. If `symbolic_paths` already exist offline, the `LOAD DATA` command can be used to modify both `offline_path` and `symbolic_paths`.
+
+The `errorifexists` option will raise an error if there is offline information in the table. It will raise errors if performing hard copy when there's soft links, or performing soft copy when a hard copy exisits.
+
+### LOAD DATA
+
+Regardless of whether data is imported online or offline using the `LOAD DATA` command, it is considered an offline job. The format rules for source data are the same for both offline and online scenarios.
+
+It is recommended to use HDFS files as source data. This approach allows for successful import whether TaskManager is in local mode, Yarn mode, or running on another host. However, if the source data is a local file, the ability to import it smoothly depends on the mode of TaskManager and the host where it is running:
+
+- In local mode, TaskManager can successfully import source data only if the source data is placed on the same host as the TaskManager process.
+- When TaskManager is in Yarn mode (both client and cluster), a file path cannot be used as the source data address because it is not known on which host the container is running.
+
+### DELETE
+
+In tables with multiple indexes in the online storage, a `DELETE` operation may not delete corresponding data in all indexes. Consequently, there may be situations where data has been deleted, but the deleted data can still be found.
+
+For example:
+
+```SQL
+create database db;
+use db;
+create table t1(c1 int, c2 int,index(key=c1),index(key=c2));
+desc t1;
+set @@execute_mode='online';
+insert into t1 values (1,1),(2,2);
+delete from t1 where c2=2;
+select * from t1;
+select * from t1 where c2=2;
+```
+
+The results are as follows:
+
+```Plain
+ --- ------- ------ ------ ---------
+ Field Type Null Default
+ --- ------- ------ ------ ---------
+ 1 c1 Int YES
+ 2 c2 Int YES
+ --- ------- ------ ------ ---------
+ --- -------------------- ------ ---- ------ ---------------
+ name keys ts ttl ttl_type
+ --- -------------------- ------ ---- ------ ---------------
+ 1 INDEX_0_1668504212 c1 - 0min kAbsoluteTime
+ 2 INDEX_1_1668504212 c2 - 0min kAbsoluteTime
+ --- -------------------- ------ ---- ------ ---------------
+ --------------
+ storage_mode
+ --------------
+ Memory
+ --------------
+ ---- ----
+ c1 c2
+ ---- ----
+ 1 1
+ 2 2
+ ---- ----
+
+2 rows in set
+ ---- ----
+ c1 c2
+ ---- ----
+
+0 rows in set
+```
+
+Explanation:
+
+Table `t1` has multiple indexes (which may be automatically created during `DEPLOY`). If you run `delete from t1 where c2=2`, it only deletes data in the second index, while the data in the first index remains unaffected. Therefore, if you subsequently run `select * from t1` and it uses the first index, there are two pieces of data that haven't been deleted. `select * from t1 where c2=2` uses the second index, and the result is empty, with data being successfully deleted.
+
+## DQL Boundary
+
+The supported query modes (i.e. `SELECT` statements) vary depending on the execution mode:
+
+| Execution Mode | Query Statement |
+| -------------- | ------------------------------------------------------------ |
+| Offline Mode | Batch query |
+| Online Mode | Batch query (also known as online preview mode, only supports partial SQL) and request query (also known as online request mode) |
+
+### Online Preview Mode
+
+In OpenMLDB CLI, executing SQL in online mode puts it in online preview mode. Please note that online preview mode has limited support; you can refer to the [SELECT STATEMENT](../openmldb_sql/dql/SELECT_STATEMENT) documentation for more details.
+
+Online preview mode is primarily for previewing query results. If you need to run complex SQL queries, it's recommended to use offline mode. To query complete online data, consider using a data export tool such as the `SELECT INTO` command. Keep in mind that if the online table contains a large volume of data, it might trigger data truncation, and executing `SELECT * FROM table` could result in some data not being returned.
+
+Online data is usually distributed across multiple locations, and when you run `SELECT * FROM table`, it retrieves results from various Tablet Servers without performing global sorting. As a result, the order of data will be different with each execution of `SELECT * FROM table`.
+
+### Offline Mode and Online Request Mode
+
+In the [full process](./concepts/modes.md) of feature engineering development and deployment, offline mode and online request mode play prominent roles:
+
+- Offline Mode Batch Query: Used for offline feature generation.
+- Query in Online Request Mode: Employed for real-time feature computation.
+
+While these two modes share the same SQL statements and produce consistent computation results, due to the use of two different execution engines (offline and online), not all SQL statements that work offline can be deployed online. SQL that can be executed in online request mode is a subset of offline executable SQL. Therefore, it's essential to test whether SQL can be deployed using `DEPLOY` after completing offline SQL development.
+
+## Offline Command Synchronization Mode
+
+All offline commands can be executed in synchronous mode using `set @@sync_job=true;`. In this mode, the command will only return after completion, whereas in asynchronous mode, job info is immediately returned, requires usage of `SHOW JOB ` to check the execution status of the job. In synchronous mode, the return values differ depending on the command.
+
+- DML commands like `LOAD DATA` and DQL commands like `SELECT INTO` return the ResultSet of Job Info. These results are identical to those in asynchronous mode, with the only difference being the return time.
+- Normal `SELECT` queries in DQL return Job Info in asynchronous mode and query results in synchronous mode. However, support for this feature is currently incomplete, as explained in [Offline Sync Mode-select](../openmldb_sql/dql/SELECT_STATEMENT.md#offline-sync-mode-select). The results are in CSV format, but data integrity is not guaranteed, so it's not recommended to use as accurate query results.
+ - In the CLI interactive mode, the results are printed directly.
+ - In the SDK, ResultSet is returned, the query result as a string. Consequently, it's not recommended to use synchronous mode queries in the SDK and process their results.
+
+Synchronous mode comes with timeout considerations, which are detailed in [Configuration](../openmldb_sql/ddl/SET_STATEMENT.md#offline-command-configuaration-details).
diff --git a/docs/en/quickstart/images/cli_cluster.png b/docs/en/quickstart/images/cli_cluster.png
new file mode 100644
index 00000000000..8a90127e3b2
Binary files /dev/null and b/docs/en/quickstart/images/cli_cluster.png differ
diff --git a/docs/en/quickstart/images/state_finished.png b/docs/en/quickstart/images/state_finished.png
new file mode 100644
index 00000000000..75a6d8cc093
Binary files /dev/null and b/docs/en/quickstart/images/state_finished.png differ
diff --git a/docs/en/quickstart/index.rst b/docs/en/quickstart/index.rst
index aefceb8f206..aac5878eede 100644
--- a/docs/en/quickstart/index.rst
+++ b/docs/en/quickstart/index.rst
@@ -7,5 +7,8 @@ Quickstart
openmldb_quickstart
concepts/index
- cli_tutorial
+ cli
sdk/index
+ beginner_must_read
+ function_boundary
+
diff --git a/docs/en/quickstart/openmldb_quickstart.md b/docs/en/quickstart/openmldb_quickstart.md
index 57c3c0d2e75..626d83debf5 100644
--- a/docs/en/quickstart/openmldb_quickstart.md
+++ b/docs/en/quickstart/openmldb_quickstart.md
@@ -1,40 +1,31 @@
# OpenMLDB Quickstart
-## Basic concepts
+## Basic Concepts
The main use case of OpenMLDB is as a real-time feature platform for machine learning. The basic usage process is shown in the following diagram:
+
-
+As shown, OpenMLDB covers the feature computing process in machine learning, from offline development to real-time serving online, providing a complete process. Please refer to the documentation for [The Usage Process and Execution Mode](./concepts/modes.html) in detail. This article will demonstrate a quickstart step by step, showing the process for basic usage.
-As can be seen, OpenMLDB covers the feature computing process of machine learning, from offline development to real-time request service online, providing a complete process. Please refer to the documentation for [the usage process and execution mode](https://openmldb.ai/docs/zh/main/quickstart/concepts/modes.html) in detail. This article will demonstrate a quick start and understanding of OpenMLDB step by step, following the basic usage process.
+## Preparation
-## The preparation
-
-This article is developed and deployed based on OpenMLDB CLI, and it is necessary to download the sample data and start OpenMLDB CLI first. It is recommended to use Docker image for a quick experience (Note: due to some known issues of Docker on macOS, the sample program in this article may encounter problems in completing the operation smoothly on macOS. It is recommended to run it on **Linux or Windows**).
+This sample program is developed and deployed based on OpenMLDB CLI, so you need to download the sample data and start OpenMLDB CLI first. It is recommended to use Docker image for a quick experience (Note: due to some known issues of Docker on macOS, the sample program in this article may encounter problems on macOS. It is recommended to run it on **Linux or Windows**).
- Docker Version: >= 18.03
-### Pulls the image
+### Pull the Image
Execute the following command in the command line to pull the OpenMLDB image and start the Docker container:
```bash
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
``` {note}
-After successfully starting the container, all subsequent commands in this tutorial are executed inside the container by default. If you need to access the OpenMLDB server inside the container from outside the container, please refer to the [CLI/SDK-container onebox documentation](https://openmldb.ai/docs/zh/main/reference/ip_tips.html#id3).
-```
-
-### Download sample data
-
-Execute the following command inside the container to download the sample data used in the subsequent process (**this step can be skipped for versions 0.7.0 and later**, as the data is already stored in the image):
-
-```bash
-curl https://openmldb.ai/demo/data.parquet --output /work/taxi-trip/data/data.parquet
+After successfully starting the container, all subsequent commands in this tutorial are executed inside the container by default. If you need to access the OpenMLDB server inside the container from outside the container, please refer to the [CLI/SDK-container onebox documentation](../reference/ip_tips.md#clisdk-containeronebox).
```
-### Start the server and client
+### Start the Server and Client
Start the OpenMLDB server:
@@ -48,19 +39,19 @@ Start the OpenMLDB CLI client:
/work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client
```
-After successfully starting OpenMLDB CLI, it will be displayed as shown in the following figure:
+Successful started OpenMLDB CLI will look as shown in the following figure:
-
+
-## Use process
+## OpenMLDB Process
-Referring to the core concepts, the process of using OpenMLDB generally includes six steps: creating databases and tables, importing offline data, offline feature computing, deploying SQL solutions, importing online data, and online real-time feature computing.
+Referring to the core concepts, the process of using OpenMLDB generally includes six steps: create database and table, import offline data, compute offline feature, deploy SQL plan, import online data, and online real-time feature compute.
```{note}
Unless otherwise specified, the commands demonstrated below are executed by default in OpenMLDB CLI.
```
-### Step 1: Create database and table
+### Step 1: Create Database and Table
Create `demo_db` and table `demo_table1`:
@@ -71,7 +62,7 @@ USE demo_db;
CREATE TABLE demo_table1(c1 string, c2 int, c3 bigint, c4 float, c5 double, c6 timestamp, c7 date);
```
-### Step 2: Importing offline data
+### Step 2: Import Offline Data
Switch to the offline execution mode, and import the sample data as offline data for offline feature calculation.
@@ -90,17 +81,21 @@ Note that the `LOAD DATA` command is an asynchronous command by default. You can
- To show the task logs: SHOW JOBLOG job_id
-Here, we use `SHOW JOBS` to check the task status. Please wait for the task to be successfully completed (the `state` is changed to `FINISHED`), and then proceed to the next step.
+Here, we use `SHOW JOBS` to check the task status. Please wait for the task to be successfully completed ( `state` changes to `FINISHED`), and then proceed to the next step.
+
+
+
+After the task is completed, if you wish to preview the data, you can execute the `SELECT * FROM demo_table1` statement in synchronous mode by setting `SET @@sync_job=true`. However, this approach has certain limitations, which are detailed in the [Offline Command Synchronous Mode](./function_boundary.md#offline-command-synchronous-mode) section.
-
+In the default asynchronous mode, executing `SELECT * FROM demo_table1` will initiate an asynchronous task, and the results will be stored in the log files of the Spark job, making them less convenient to access. If TaskManager is in local mode, you can use `SHOW JOBLOG ` to view the query print results in the stdout section.
-After the task is completed, if you want to preview the data, you can use the `SELECT * FROM demo_table1` statement. It is recommended to first set the offline command to synchronous mode (`SET @@sync_job=true`); otherwise, the command will submit an asynchronous task, and the result will be saved in the log file of the Spark task, which is less convenient to view.
+The most reliable way to access the data is to use the `SELECT INTO` command to export the data to a specified directory or directly examine the storage location after importing it.
```{note}
-OpenMLDB also supports importing offline data through linked soft copies, without the need for hard data copying. Please refer to the parameter `deep_copy` in the [LOAD DATA INFILE documentation](https://openmldb.ai/docs/zh/main/openmldb_sql/dml/LOAD_DATA_STATEMENT.html) for more information.
+OpenMLDB also supports importing offline data through linked soft copies, without the need for hard data copying. Please refer to the parameter `deep_copy` in the [LOAD DATA INFILE Documentation](../openmldb_sql/dml/LOAD_DATA_STATEMENT.md) for more information.
```
-### Step 3: Offline feature computing
+### Step 3: Compute Offline Feature
Assuming that we have determined the SQL script (`SELECT` statement) to be used for feature computation, we can use the following command for offline feature computation:
@@ -120,7 +115,7 @@ Note:
- The `SELECT` statement is used to perform SQL-based feature extraction and store the generated features in the directory specified by the `OUTFILE` parameter as `feature_data`, which can be used for subsequent machine learning model training.
-### Step 4: Deploying SQL solutions
+### Step 4: Deploy SQL plan
Switch to online preview mode, and deploy the explored SQL plan to online. The SQL plan is named `demo_data_service`, and the online SQL used for feature extraction needs to be consistent with the corresponding offline feature calculation SQL.
@@ -131,11 +126,11 @@ USE demo_db;
DEPLOY demo_data_service SELECT c1, c2, sum(c3) OVER w1 AS w1_c3_sum FROM demo_table1 WINDOW w1 AS (PARTITION BY demo_table1.c1 ORDER BY demo_table1.c6 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
```
-After the deployment, you can use the command `SHOW DEPLOYMENTS` to view the deployed SQL solutions.
+After the deployment, you can use the command `SHOW DEPLOYMENTS` to view the deployed SQL.
-### Step 5: Importing online data
+### Step 5: Import Online Data
-Import the downloaded sample data as online data for online feature computation in online preview mode.
+Import the downloaded sample data as online data for online feature computation in online mode.
```sql
-- OpenMLDB CLI
@@ -161,9 +156,9 @@ Note that currently, it is required to successfully deploy the SQL plan before i
The tutorial skips the step of real-time data access after importing data. In practical scenarios, as time progresses, the latest real-time data needs to be updated in the online database. This can be achieved through the OpenMLDB SDK or online data source connectors such as Kafka, Pulsar, etc.
```
-### Step 6: Online real-time feature computing
+### Step 6: Online Real-Time Feature Computing
-The development and deployment work based on OpenMLDB CLI is completed. Next, you can make real-time feature calculation requests in real-time request mode. First, exit OpenMLDB CLI and return to the command line of the operating system.
+The development and deployment work is completed. Next, you can make real-time feature calculation requests in real-time request mode. First, exit OpenMLDB CLI and return to the command line of the operating system.
```sql
-- OpenMLDB CLI
@@ -176,10 +171,10 @@ According to the default deployment configuration, the http port for APIServer i
http://127.0.0.1:9080/dbs/demo_db/deployments/demo_data_service
\___________/ \____/ \_____________/
| | |
- APIServer地址 Database名字 Deployment名字
+ APIServerAddress Database Name Deployment Name
```
-Real-time requests accept input data in JSON format. Here are two examples: putting a row of data in the `input` field of the request.
+Real-time requests accept input data in JSON format. Here are two examples: putting data in the `input` field of the request.
**Example 1:**
@@ -187,7 +182,7 @@ Real-time requests accept input data in JSON format. Here are two examples: putt
curl http://127.0.0.1:9080/dbs/demo_db/deployments/demo_data_service -X POST -d'{"input": [["aaa", 11, 22, 1.2, 1.3, 1635247427000, "2021-05-20"]]}'
```
-Query the expected return result (the calculated features are stored in the `data` field):
+Expected query result (the calculated features are stored in the `data` field):
```json
{"code":0,"msg":"ok","data":{"data":[["aaa",11,22]]}}
@@ -205,7 +200,7 @@ Expected query result:
{"code":0,"msg":"ok","data":{"data":[["aaa",11,66]]}}
```
-### Description of real-time feature computing results
+### Explanation of Real-Time Feature Computing Results
The SQL execution for online real-time requests is different from batch processing mode. The request mode only performs SQL calculations on the data of the request row. In the previous example, it is the input of the POST request that serves as the request row. The specific process is as follows: Assuming that this row of data exists in the table `demo_table1`, and the following feature calculation SQL is executed on it:
@@ -213,7 +208,7 @@ The SQL execution for online real-time requests is different from batch processi
SELECT c1, c2, sum(c3) OVER w1 AS w1_c3_sum FROM demo_table1 WINDOW w1 AS (PARTITION BY demo_table1.c1 ORDER BY demo_table1.c6 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
```
-**The calculation logic for Example 1 is as follows:**
+**The Calculation Logic for Example 1 is as Follows:**
1. Filter rows in column c1 with the value "aaa" based on the `PARTITION BY` partition of the request row and window, and sort them in ascending order by column c6. Therefore, in theory, the intermediate data table sorted by partition should be as follows. The request row is the first row after sorting.
@@ -227,7 +222,7 @@ aaa 12 22 2.200000 12.300000 1636097890000 1970-01-01
----- ---- ---- ---------- ----------- --------------- ------------
```
-2. The window range is `2 PRECEDING AND CURRENT ROW`, so in the above table, the actual window is extracted, and the request row is the smallest row with no preceding two rows, but the window includes the current row, so the window only contains the request row.
+2. The window range is `2 PRECEDING AND CURRENT ROW`. In the above table, when the actual window is extracted, the request row is the smallest row with no preceding 2 rows. Therefore the window only contains the request row.
3. For window aggregation, the sum of column c3 for the data within the window (only one row) is calculated, resulting in 22. Therefore, the output result is:
```sql
@@ -238,7 +233,7 @@ aaa 11 22
----- ---- -----------
```
-**The calculation logic for Example 2 is as follows:**
+**The Calculation Logic for Example 2 is as Follows:**
1. According to the partition of the request line and window by `PARTITION BY`, select the rows where column c1 is "aaa" and sort them in ascending order by column c6. Therefore, theoretically, the intermediate data table after partition and sorting should be as shown in the table below. The request row is the last row after sorting.
@@ -252,7 +247,7 @@ aaa 11 22 1.2 1.3 1637000000000 2021-11-16
----- ---- ---- ---------- ----------- --------------- ------------
```
-2. The window range is `2 PRECEDING AND CURRENT ROW`, so the actual window is extracted from the above table, and the two preceding rows of the request row exist, and the current row is also included. Therefore, there are three rows of data in the window.
+2. The window range is `2 PRECEDING AND CURRENT ROW`. When the actual window is extracted from the above table, the two preceding 2 rows of the request row exist, together with the current row. Therefore, there are three rows of data in the window.
3. For window aggregation, the sum of column c3 for the data within the window (three rows) is calculated, resulting in 22 + 22 + 22 = 66. Therefore, the output result is:
```sql
diff --git a/docs/en/quickstart/sdk/cpp_sdk.md b/docs/en/quickstart/sdk/cpp_sdk.md
deleted file mode 100644
index 59f4a284a63..00000000000
--- a/docs/en/quickstart/sdk/cpp_sdk.md
+++ /dev/null
@@ -1,117 +0,0 @@
-# C++ SDK
-
-## C++SDK package compilation and installation
-
-```plain
-git clone git@github.com:4paradigm/OpenMLDB.git
-cd OpenMLDB
-make && make install
-```
-
-## Write user code
-
-The following code demonstrates the basic use of C++ SDK. openmldb_api.h and sdk/result_set.h is the header file that must be included.
-
-```c++
-#include
-#include
-#include
-
-#include "openmldb_api.h"
-#include "sdk/result_set.h"
-
-int main()
-{
- //Create and initialize the OpenmldbHandler object
- //Stand-alone version: parameter (ip, port), such as: OpenmldbHandler handler ("127.0.0.1", 6527);
- //Cluster version: parameters (ip: port, path), such as: OpenmldbHandler handler ("127.0.0.1:6527", "/openmldb");
- //Take the stand-alone version as an example.
- OpenmldbHandler handler("127.0.0.1", 6527);
-
- // Define database name
- std::time_t t = std::time(0);
- std::string db = "test_db" + std::to_string(t);
-
- // Create SQL statement and database
- std::string sql = "create database " + db + ";";
- // Execute the SQL statement. The execute() function returns the bool value. A value of true indicates correct execution
- std::cout << execute(handler, sql);
-
- // Create SQL statement and use database
- sql = "use " + db + ";";
- std::cout << execute(handler, sql);
-
- // Create SQL statement and create table
- sql = "create table test_table ("
- "col1 string, col2 bigint,"
- "index(key=col1, ts=col2));";
- std::cout << execute(handler, sql);
-
- // Create SQL statements and insert rows into the table
- sql = "insert test_table values(\"hello\", 1)";
- std::cout << execute(handler, sql);
- sql = "insert test_table values(\"Hi~\", 2)";
- std::cout << execute(handler, sql);
-
- // Basic mode
- sql = "select * from test_table;";
- std::cout << execute(handler, sql);
-
- // Get the latest SQL execution result
- auto res = get_resultset();
- // Output SQL execution results
- print_resultset(res);
- // The output in this example should be:
- // +-------+--------+
- // | col1 | col2 |
- // +-------+--------+
- // | hello | 1 |
- // | Hi~ | 2 |
- // +-------+---------+
-
-
-
- // Band-parameter mode
- //The position of the parameters to be filled in the SQL statement is set to "?" to express
- sql = "select * from test_table where col1 = ? ;";
- // Create a ParameterRow object for filling parameters
- ParameterRow para(&handler);
- // Fill in parameters
- para << "Hi~";
- // Execute SQL statement execute_parameterized() function returns the bool value. A value of true indicates correct execution
- execute_parameterized(handler, db, sql, para);
- res = get_resultset();
- print_resultset(res);
- // The output in this example should be:
- // +------+--------+
- // | col1 | col2 |
- // +------+-------+
- // | Hi~ | 2 |
- // +------+--------+
-
-
- // Request mode
- sql = "select col1, sum(col2) over w as w_col2_sum from test_table "
- "window w as (partition by test_table.col1 order by test_table.col2 "
- "rows between 2 preceding and current row);";
- RequestRow req(&handler, db, sql);
- req << "Hi~" << 3l;
- execute_request(req);
- res = get_resultset();
- print_resultset(res);
- // The output in this example should be:
- // +------+--------------------+
- // | col1 | w_col2_sum |
- // +------+--------------------+
- // | Hi~ | 5 |
- // +------+--------------------+
-}
-```
-
-## Compile and run
-
-```plain
-gcc .cxx -o -lstdc++ -std=c++17 -I/include -L/lib -lopenmldbsdk -lpthread
-./
-```
-
diff --git a/docs/en/quickstart/sdk/cxx_sdk.md b/docs/en/quickstart/sdk/cxx_sdk.md
new file mode 100644
index 00000000000..77041df9b52
--- /dev/null
+++ b/docs/en/quickstart/sdk/cxx_sdk.md
@@ -0,0 +1,138 @@
+# [Alpha] C++ SDK
+```plain
+The current functionality support of the C++ SDK is not yet complete. It is currently only recommended for development, testing, or specific use cases. It is not recommended for use in a production environment. For production use, we recommend using the Java SDK, which has the most comprehensive feature coverage and has undergone extensive testing for both functionality and performance.
+```
+## C++ SDK Compilation and Installation
+```plain
+The C++ SDK static library is only supported on Linux systems and is not included in the standard release. If you need to use the C++ SDK library, you should compile the source code and enable the compilation option `INSTALL_CXXSDK=ON`.
+```
+To compile, you need to meet the [hardware requirements](../../deploy/compile.md#hardware-requirements) and install the necessary [dependencies](../../deploy/compile.md#dependencies).
+```plain
+git clone git@github.com:4paradigm/OpenMLDB.git
+cd OpenMLDB
+make INSTALL_CXXSDK=ON && make install
+```
+
+## User Code
+
+The following code demonstrates the basic use of C++ SDK. `openmldb_api.h` and `sdk/result_set.h` is the header file that must be included.
+
+```c++
+#include
+#include
+#include
+
+#include "openmldb_api.h"
+#include "sdk/result_set.h"
+
+int main()
+{
+ //Create and initialize the OpenmldbHandler object
+ //Stand-alone version: parameter (ip, port), such as: OpenmldbHandler handler ("127.0.0.1", 6527);
+ //Cluster version: parameters (ip: port, path), such as: OpenmldbHandler handler ("127.0.0.1:6527", "/openmldb");
+ //Take the stand-alone version as an example.
+ OpenmldbHandler handler("127.0.0.1", 6527);
+
+ // Define database name
+ std::time_t t = std::time(0);
+ std::string db = "test_db" + std::to_string(t);
+
+ // Create SQL statement and database
+ std::string sql = "create database " + db + ";";
+ // Execute the SQL statement. The execute() function returns bool. true indicates correct execution
+ std::cout << execute(handler, sql);
+
+ // Create SQL statement to use database
+ sql = "use " + db + ";";
+ std::cout << execute(handler, sql);
+
+ // Create SQL statement to create table
+ sql = "create table test_table ("
+ "col1 string, col2 bigint,"
+ "index(key=col1, ts=col2));";
+ std::cout << execute(handler, sql);
+
+ // Create SQL statements to insert rows into the table
+ sql = "insert test_table values(\"hello\", 1)";
+ std::cout << execute(handler, sql);
+ sql = "insert test_table values(\"Hi~\", 2)";
+ std::cout << execute(handler, sql);
+
+ // Basic mode
+ sql = "select * from test_table;";
+ std::cout << execute(handler, sql);
+
+ // Get the latest SQL execution result
+ auto res = get_resultset();
+ // Output SQL execution results
+ print_resultset(res);
+ // The output in this example should be:
+ // +-------+--------+
+ // | col1 | col2 |
+ // +-------+--------+
+ // | hello | 1 |
+ // | Hi~ | 2 |
+ // +-------+---------+
+
+
+
+ // Parameter mode
+ //The parameters to be filled in the SQL statement is marked as "?"
+ sql = "select * from test_table where col1 = ? ;";
+ // Create a ParameterRow object for filling parameters
+ ParameterRow para(&handler);
+ // Fill in parameters
+ para << "Hi~";
+ // Execute SQL statement, execute_parameterized() function returns bool. true indicates correct execution
+ execute_parameterized(handler, db, sql, para);
+ res = get_resultset();
+ print_resultset(res);
+ // The output in this example should be:
+ // +------+--------+
+ // | col1 | col2 |
+ // +------+-------+
+ // | Hi~ | 2 |
+ // +------+--------+
+
+
+ // Request mode
+ sql = "select col1, sum(col2) over w as w_col2_sum from test_table "
+ "window w as (partition by test_table.col1 order by test_table.col2 "
+ "rows between 2 preceding and current row);";
+ RequestRow req(&handler, db, sql);
+ req << "Hi~" << 3l;
+ execute_request(req);
+ res = get_resultset();
+ print_resultset(res);
+ // The output in this example should be:
+ // +------+--------------------+
+ // | col1 | w_col2_sum |
+ // +------+--------------------+
+ // | Hi~ | 5 |
+ // +------+--------------------+
+}
+```
+## Multi-Thread
+The `OpenMLDBHandler` object is not thread-safe, but the internal connection to the `SQLClusterRouter` can be used multi-threaded. You can achieve multi-threading by sharing the Router within the Handler object, which is more efficient than creating multiple independent Handler instances (each with its independent Router). However, in a multi-threaded mode, you should be cautious because interfaces without db depend on the Router's internal cache of used db, which might be modified by other threads. It's advisable to use the db interface in such cases. The following code demonstrates a method for multi-threaded usage:
+
+```c++
+OpenmldbHandler h1("127.0.0.1:2181", "/openmldb");
+OpenmldbHandler h2(h1.get_router());
+
+std::thread t1([&](){ h1.execute("show components;"); print_resultset(h1.get_resultset());});
+
+std::thread t2([&](){ h2.execute("show table status;"); print_resultset(h2.get_resultset());});
+
+t1.join();
+t2.join();
+```
+
+## Compile and run
+You can refer to [Makefile](https://github.com/4paradigm/OpenMLDB/blob/main/demo/cxx_quickstart/Makefile) or use the command below to compile and run the sample code.
+
+```bash
+gcc .cxx -o -lstdc++ -std=c++17 -I/include -L/lib -lopenmldbsdk -lpthread -lm -ldl -lstdc++fs
+
+./
+```
+
diff --git a/docs/en/quickstart/sdk/go_sdk.md b/docs/en/quickstart/sdk/go_sdk.md
index c30cbb2e502..4c07120a932 100644
--- a/docs/en/quickstart/sdk/go_sdk.md
+++ b/docs/en/quickstart/sdk/go_sdk.md
@@ -1,12 +1,14 @@
-# Go SDK
-
+# [Alpha] Go SDK
+```plain
+The current functionality support of the Go SDK is not yet complete. It is currently only recommended for development, testing, or specific use cases. It is not recommended for use in a production environment. For production use, we recommend using the Java SDK, which has the most comprehensive feature coverage and has undergone extensive testing for both functionality and performance.
+```
## Requirement
- OpenMLDB version: >= v0.6.2
-- Deploy and run APIServer (refer to [APIServer deployment](https://openmldb.ai/docs/zh/main/deploy/install_deploy.html#apiserver) document)
+- Deploy and run APIServer (refer to [APIServer deployment](../../main/deploy/install_deploy.html#apiserver) document)
-## Go SDK package installment
+## Go SDK installation
```bash
go get github.com/4paradigm/OpenMLDB/go
@@ -76,7 +78,7 @@ import (
"context"
"database/sql"
- // 加载 OpenMLDB SDK
+ // Load OpenMLDB SDK
_ "github.com/4paradigm/OpenMLDB/go"
)
diff --git a/docs/en/quickstart/sdk/index.rst b/docs/en/quickstart/sdk/index.rst
index 2eec974bee0..d932b7f5442 100644
--- a/docs/en/quickstart/sdk/index.rst
+++ b/docs/en/quickstart/sdk/index.rst
@@ -7,6 +7,6 @@ SDK
java_sdk
python_sdk
- rest_api
go_sdk
- cpp_sdk
+ cxx_sdk
+ rest_api
\ No newline at end of file
diff --git a/docs/en/quickstart/sdk/java_sdk.md b/docs/en/quickstart/sdk/java_sdk.md
index a74f4c98f3c..ea06bc671db 100644
--- a/docs/en/quickstart/sdk/java_sdk.md
+++ b/docs/en/quickstart/sdk/java_sdk.md
@@ -1,8 +1,10 @@
# Java SDK
-## Java SDK package installation
+In Java SDK, the default execution mode for JDBC Statements is online, while the default execution mode for SqlClusterExecutor is offline. Please keep this in mind.
-- Installing Java SDK package on Linux
+## Java SDK Installation
+
+- Install Java SDK on Linux
Configure the maven pom:
@@ -10,16 +12,16 @@
com.4paradigm.openmldb
openmldb-jdbc
- 0.8.3
+ 0.8.4
com.4paradigm.openmldb
openmldb-native
- 0.8.3
+ 0.8.4
```
-- Installing Java SDK package on Mac
+- Install Java SDK on Mac
Configure the maven pom
@@ -27,25 +29,23 @@
com.4paradigm.openmldb
openmldb-jdbc
- 0.8.3
+ 0.8.4
com.4paradigm.openmldb
openmldb-native
- 0.8.3-macos
+ 0.8.4-macos
```
-Note: Since the openmldb-native package contains the C++ static library compiled for OpenMLDB, it is defaults to the Linux static library. For macOS, the version of openmldb-native should be changed to `0.8.3-macos`, while the version of openmldb-jdbc should remain unchanged.
-
-The macOS version of openmldb-native only supports macOS 12. To run it on macOS 11 or macOS 10.15, the openmldb-native package needs to be compiled from source code on the corresponding OS. For detailed compilation methods, please refer to [Concurrent Compilation of Java SDK](https://openmldb.ai/docs/zh/main/deploy/compile.html#java-sdk).
-
-To connect to the OpenMLDB service using the Java SDK, you can use JDBC (recommended) or connect directly through SqlClusterExecutor. The following will demonstrate both connection methods in order.
+Note: Since the openmldb-native package contains the C++ static library compiled for OpenMLDB, it defaults to the Linux static library. For macOS, the version of openmldb-native should be changed to `0.8.4-macos`, while the version of openmldb-jdbc remains unchanged.
-## JDBC method
+The macOS version of openmldb-native only supports macOS 12. To run it on macOS 11 or macOS 10.15, the openmldb-native package needs to be compiled from the source code on the corresponding OS. For detailed compilation methods, please refer to [Java SDK](../../deploy/compile.md#Build-java-sdk-with-multi-processes).
+When using a self-compiled openmldb-native package, it is recommended to install it into your local Maven repository using `mvn install`. After that, you can reference it in your project's pom.xml file. It's not advisable to reference it using `scope=system`.
-The connection method using JDBC is as follows:
+To connect to the OpenMLDB service using the Java SDK, you can use JDBC (recommended) or connect directly through SqlClusterExecutor. The following will demonstrate both connection methods.
+## Connection with JDBC
```java
Class.forName("com._4paradigm.openmldb.jdbc.SQLDriver");
// No database in jdbcUrl
@@ -58,10 +58,10 @@ Connection connection1 = DriverManager.getConnection("jdbc:openmldb:///test_db?z
The database specified in the Connection address must exist when creating the connection.
```{caution}
-he default execution mode for JDBC Connection is `online`.
+The default execution mode for JDBC Connection is `online`.
```
-### Usage overview
+### Statement
All SQL commands can be executed using `Statement`, both in online and offline modes. To switch between offline and online modes, use command `SET @@execute_mode='...';``. For example:
@@ -77,17 +77,22 @@ res = stmt.executeQuery("SELECT * from t1"); // For online mode, select or execu
The `LOAD DATA` command is an asynchronous command, and the returned ResultSet contains information such as the job ID and state. You can execute `show job ` to check if the job has been completed. Note that the ResultSet needs to execute `next()` method to move the cursor to the first row of data.
-It is also possible to change it to a synchronous command:
+In offline mode, the default behavior is asynchronous execution, and the ResultSet returned is a Job Info. You can change this behavior to synchronous execution using `SET @@sync_job=true;`. However, please note that the ResultSet returned can vary depending on the specific SQL command. For more details, please refer to the [Function Boundary](../function_boundary.md). Synchronous execution is recommended when using `LOAD DATA` or `SELECT INTO` commands.
-```SQL
-SET @@sync_job=true;
-```
+If synchronous commands are timing out, you can adjust the configuration as described in the [Offline Command Configuration](../../openmldb_sql/ddl/SET_STATEMENT.md).
-If the actual execution time of the synchronous command exceeds the default maximum idle wait time of 0.5 hours, please [adjust the configuration](https://openmldb.ai/docs/zh/main/openmldb_sql/ddl/SET_STATEMENT.html#id4).
+```{caution}
+When you execute `SET @@execute_mode='offline'` on a `Statement`, it not only affects the current `Statement` but also impacts all `Statement` objects created, both existing and yet to be created, within the same `Connection`. Therefore, it is not advisable to create multiple `Statement` objects and expect them to execute in different modes. If you need to execute SQL in different modes, it's recommended to create multiple `Connection`.
+```
### PreparedStatement
-`PreparedStatement` supports `SELECT`, `INSERT`, and `DELETE` operations. Note that `INSERT` only supports online insertion.
+`PreparedStatement` supports `SELECT`, `INSERT`, and `DELETE`.
+```{warning}
+Any `PreparedStatement` executes only in the **online mode** and is not affected by the state before the `PreparedStatement` is created. `PreparedStatement` does not support switching to the offline mode. If you need to execute SQL in the offline mode, you can use a `Statement`.
+
+There are three types of `PreparedStatement` created by a `Connection`, which correspond to `getPreparedStatement`, `getInsertPreparedStmt`, and `getDeletePreparedStm`t in SqlClusterExecutor.
+```
```java
PreparedStatement selectStatement = connection.prepareStatement("SELECT * FROM t1 WHERE id=?");
@@ -95,9 +100,10 @@ PreparedStatement insertStatement = connection.prepareStatement("INSERT INTO t1
PreparedStatement insertStatement = connection.prepareStatement("DELETE FROM t1 WHERE id=?");
```
-## SqlClusterExecutor method
+## SqlClusterExecutor
+`SqlClusterExecutor` is the most comprehensive Java SDK connection method. It not only provides the basic CRUD operations that you can use with JDBC but also offers additional features like request modes and more.
-### Creating a SqlClusterExecutor
+### Create a SqlClusterExecutor
First, configure the OpenMLDB connection parameters.
@@ -108,14 +114,13 @@ option.setZkPath("/openmldb");
option.setSessionTimeout(10000);
option.setRequestTimeout(60000);
```
-
Then, use SdkOption to create the Executor.
```java
sqlExecutor = new SqlClusterExecutor(option);
```
-`SqlClusterExecutor` execution of SQL operations is thread-safe, and in actual environments, a single `SqlClusterExecutor` can be created. However, since the execution mode (execute_mode) is an internal variable of `SqlClusterExecutor`, if you want to execute an offline command and an online command at the same time, unexpected results may occur. In this case, please use multiple `SqlClusterExecutors`.
+`SqlClusterExecutor` execution of SQL operations is thread-safe, and in actual environments, a single `SqlClusterExecutor` can be created. However, since the execution mode (`execute_mode`) is an internal variable of `SqlClusterExecutor`, if you want to execute an offline command and an online command at the same time, unexpected results may occur. In this case, please use multiple `SqlClusterExecutors`.
```{caution}
The default execution mode for SqlClusterExecutor is offline, which is different from the default mode for JDBC.
@@ -158,7 +163,7 @@ try {
}
```
-#### Executing batch SQL queries with Statement
+#### Execute Batch SQL Queries with Statement
Use the `Statement::execute` interface to execute batch SQL queries:
@@ -200,15 +205,15 @@ try {
### PreparedStatement
-`SqlClusterExecutor` can also obtain `PreparedStatement`, but you need to specify which type of `PreparedStatement` to obtain. For example, when using InsertPreparedStmt for insertion operations, there are three ways to do it.
+`SqlClusterExecutor` can also obtain `PreparedStatement`, but you need to specify which type of `PreparedStatement` to obtain. For example, when using `InsertPreparedStmt` for insertion operations, there are three ways to do it.
```{note}
-Insert operation only supports online mode and is not affected by execution mode. The data will always be inserted into the online database.
+Any `PreparedStatement` executes exclusively in the **online mode** and is not influenced by the state of the `SqlClusterExecutor` at the time of its creation. `PreparedStatement` does not support switching to the offline mode. If you need to execute SQL in the offline mode, you can use a `Statement`.
```
#### Common Insert
-1. Use the `SqlClusterExecutor::getInsertPreparedStmt(db, insertSql)` method to get the InsertPrepareStatement.
+1. Use the `SqlClusterExecutor::getInsertPreparedStmt(db, insertSql)` method to get the `InsertPrepareStatement`.
2. Use the `PreparedStatement::execute()` method to execute the insert statement.
```java
@@ -232,14 +237,14 @@ try {
}
```
-#### Insert With Placeholder
+#### Insert with Placeholder
-1. Get InsertPrepareStatement by calling `SqlClusterExecutor::getInsertPreparedStmt(db, insertSqlWithPlaceHolder)` interface.
-2. Use `PreparedStatement::setType(index, value)` interface to fill in data to the InsertPrepareStatement. Note that the index starts from 1.
+1. Get `InsertPrepareStatement` by calling `SqlClusterExecutor::getInsertPreparedStmt(db, insertSqlWithPlaceHolder)` interface.
+2. Use `PreparedStatement::setType(index, value)` interface to fill in data to the `InsertPrepareStatement`. Note that the index starts from 1.
3. Use `PreparedStatement::execute()` interface to execute the insert statement.
```{note}
-When the conditions of the PreparedStatement are the same, you can repeatedly call the set method of the same object to fill in data before executing execute(). There is no need to create a new PreparedStatement object.
+When the conditions of the `PreparedStatement` are the same, you can repeatedly call the set method of the same object to fill in data before executing `execute`. There is no need to create a new `PreparedStatement` object.
```
```java
@@ -266,13 +271,13 @@ try {
```
```{note}
-After execute, the cached data will be cleared and it is not possible to retry execute.
+After `execute`, the cached data will be cleared and it is not possible to rerun `execute`.
```
-#### Batch Insert With Placeholder
+#### Batch Insert with Placeholder
-1. To use batch insert, first obtain the InsertPrepareStatement using the `SqlClusterExecutor::getInsertPreparedStmt(db, insertSqlWithPlaceHolder)` interface.
-2. Then use the `PreparedStatement::setType(index, value)` interface to fill data into the InsertPrepareStatement.
+1. To use batch insert, first obtain the `InsertPrepareStatement` using the `SqlClusterExecutor::getInsertPreparedStmt(db, insertSqlWithPlaceHolder)` interface.
+2. Then use the `PreparedStatement::setType(index, value)` interface to fill data into the `InsertPrepareStatement`.
3. Use the `PreparedStatement::addBatch()` interface to complete filling for one row.
4. Continue to use `setType(index, value)` and `addBatch()` to fill multiple rows.
5. Use the `PreparedStatement::executeBatch()` interface to complete the batch insertion.
@@ -305,12 +310,12 @@ try {
```
```{note}
-After executeBatch(), all cached data will be cleared and it's not possible to retry executeBatch().
+After `executeBatch`, all cached data will be cleared and it's not possible to rerun `executeBatch`.
```
-### Execute SQL request query
+### Execute SQL Query
-`RequestPreparedStmt` is a unique query mode (not supported by JDBC). This mode requires both the selectSql and a request data, so you need to provide the SQL and set the request data using setType when calling `getRequestPreparedStmt`.
+`RequestPreparedStmt` is a unique query mode (not supported by JDBC). This mode requires both the selectSql and a request data, so you need to provide the SQL and set the request data using `setType` when calling `getRequestPreparedStmt`.
There are three steps to execute a SQL request query:
@@ -359,7 +364,7 @@ try {
Assert.assertEquals(resultSet.getInt(2), 24);
Assert.assertEquals(resultSet.getLong(3), 34);
- // The return result set of the ordinary request query contains only one row of results. Therefore, the result of the second call to resultSet. next() is false
+ // The return result set of the ordinary request query contains only one row of results. Therefore, the result of the second call to resultSet.next() is false
Assert.assertFalse(resultSet.next());
} catch (SQLException e) {
@@ -368,7 +373,7 @@ try {
} finally {
try {
if (resultSet != null) {
- // result用完之后需要close
+ // close result
resultSet.close();
}
if (pstmt != null) {
@@ -379,16 +384,82 @@ try {
}
}
```
+### Execute Deployment
+To execute a deployment, you can use the `SqlClusterExecutor::getCallablePreparedStmt(db, deploymentName)` interface to obtain a `CallablePreparedStatement`. In contrast to the SQL request-based queries mentioned earlier, deployments are already online on the server, which makes them faster compared to SQL request-based queries.
+
+The process of using a deployment consists of two steps:
+- Online Deployment
+```java
+// Deploy online (use selectSql). In a real production environment, deployments are typically already online and operational.
+java.sql.Statement state = sqlExecutor.getStatement();
+try {
+ String selectSql = String.format("SELECT c1, c3, sum(c4) OVER w1 as w1_c4_sum FROM %s WINDOW w1 AS " +
+ "(PARTITION BY %s.c1 ORDER BY %s.c7 ROWS_RANGE BETWEEN 2d PRECEDING AND CURRENT ROW);", table,
+ table, table);
+ // Deploy
+ String deploySql = String.format("DEPLOY %s OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') %s", deploymentName, selectSql);
+ // set return null rs, don't check the returned value, it's false
+ state.execute(deploySql);
+} catch (Exception e) {
+ e.printStackTrace();
+}
+```
+- Execute Deployment
+When executing a deployment, recreating a `CallablePreparedStmt` can be time-consuming. It is recommended to reuse the `CallablePreparedStmt` whenever possible. The `executeQuery()` method will automatically clear the request row cache for `setXX` requests.
+
+```java
+// Execute Deployment
+PreparedStatement pstmt = null;
+ResultSet resultSet = null;
+try {
+ pstmt = sqlExecutor.getCallablePreparedStmt(db, deploymentName);
+ // Obtain preparedstatement with name
+ // pstmt = sqlExecutor.getCallablePreparedStmt(db, deploymentName);
+ ResultSetMetaData metaData = pstmt.getMetaData();
+ // Execute request mode requires setting query data in RequestPreparedStatement
+ setData(pstmt, metaData);
+ // executeQuery will execute select sql, and put result in resultSet
+ resultSet = pstmt.executeQuery();
-### Delete all data of a key under the specified index
+ Assert.assertTrue(resultSet.next());
+ Assert.assertEquals(resultSet.getMetaData().getColumnCount(), 3);
+ Assert.assertEquals(resultSet.getString(1), "bb");
+ Assert.assertEquals(resultSet.getInt(2), 24);
+ Assert.assertEquals(resultSet.getLong(3), 34);
+ Assert.assertFalse(resultSet.next());
+
+ // reuse way
+ for (int i = 0; i < 5; i++) {
+ setData(pstmt, metaData);
+ pstmt.executeQuery();
+ // skip result check
+ }
+} catch (SQLException e) {
+ e.printStackTrace();
+ Assert.fail();
+} finally {
+ try {
+ if (resultSet != null) {
+ // close result
+ resultSet.close();
+ }
+ if (pstmt != null) {
+ pstmt.close();
+ }
+ } catch (SQLException throwables) {
+ throwables.printStackTrace();
+ }
+}
+```
+
+### Delete All Data of a Key under the Specified Index
There are two ways to delete data through the Java SDK:
- Execute delete SQL directly
-
- Use delete PreparedStatement
-Note that this can only delete data under one index, not all indexes. Refer to [DELETE function boundary](https://openmldb.ai/docs/zh/main/quickstart/function_boundary.html#delete) for details.
+Note that this can only delete data under one index, not all indexes. Refer to [DELETE function boundary](../function_boundary.md#delete) for details.
```java
java.sql.Statement state = router.getStatement();
@@ -412,7 +483,7 @@ try {
}
```
-### A complete example of using SqlClusterExecutor
+### A Complete Example of SqlClusterExecutor
Refer to the [Java quickstart demo](https://github.com/4paradigm/OpenMLDB/tree/main/demo/java_quickstart/demo). If it is used on macOS, please use openmldb-native of macOS version and increase the dependency of openmldb-native.
@@ -427,9 +498,9 @@ java -cp target/demo-1.0-SNAPSHOT.jar com.openmldb.demo.App
You must fill in `zkCluster` and `zkPath` (set method or the configuration `foo=bar` after `?` in JDBC).
-### Optional configuration
+### Optional Configuration
-| Optional configuration | Description |
+| Optional Configuration | Description |
| ---------------------- | ------------------------------------------------------------ |
| enableDebug | The default is false. Enable the debug log of hybridse (note that it is not the global debug log). You can view more logs of sql compilation and operation. However, not all of these logs are collected by the client. You need to view the tablet server logs. |
| requestTimeout | The default is 60000 ms. This timeout is the rpc timeout sent by the client, except for those sent to the taskmanager (the rpc timeout of the job is controlled by the variable `job_timeout`). |
@@ -441,16 +512,18 @@ You must fill in `zkCluster` and `zkPath` (set method or the configuration `foo=
| zkLogFile | The default is empty, which is printed to stdout. |
| sparkConfPath | The default is empty. You can change the spark conf used by the job through this configuration without configuring the taskmanager to restart. |
-## SQL verification
+## SQL Validation
-The Java client supports the correct verification of SQL to verify whether it is executable. It is divided into batch and request modes.
+The Java client supports the verification of SQL to verify whether it is executable. It is divided into batch and request modes.
-- `ValidateSQLInBatch` can verify whether SQL can be executed at the offline end.
+- `ValidateSQLInBatch` can verify whether SQL can be executed offline.
- `ValidateSQLInRequest` can verify whether SQL can be deployed online.
-Both interfaces need to go through all table schemas required by SQL. Currently, only single db is supported. Please do not use `db.table` format in SQL statements.
+Both interfaces require providing all the table schemas required by the SQL and support multiple databases. For backward compatibility, it's allowed not to specify the db (current database in use) in the parameters. In such cases, it's equivalent to using the first db listed in use schema. It's important to ensure that the `` format tables are from the first db, which doesn't affect SQL statements in the `.` format.
+
+For example, verify SQL `select count (c1) over w1 from t3 window w1 as (partition by c1 order by c2 rows between unbounded preceding and current row);`, In addition to this statement, you need to go through in the schema of table `t3` as the second parameter schemaMaps. The format is Map, key is the name of the db, and value is all the table schemas (maps) of each db. In fact, only a single db is supported, so there is usually only one db here, as shown in db3 below. The table schema map key under db is table name, and the value is `com._ 4paradigm.openmldb.sdk.Schema`, consisting of the name and type of each column.
-For example, verify SQL `select count (c1) over w1 from t3 window w1 as (partition by c1 order by c2 rows between unbounded preceding and current row);`, In addition to this statement, you need to go through in the schema of table `t3` as the second parameter schemaMaps. The format is Map, key is the name of the db, and value is all the table schemas (maps) of each db. In fact, only a single db is supported, so there is usually only one db here, as shown in db3 below. The table schema map key under db is table name, and the value is com._ 4paradigm.openmldb.sdk.Schema, consisting of the name and type of each column.
+The return result is a `List`. If the validation is successful, it returns an empty list. If the validation fails, it returns a list of error messages, such as `[error_msg, error_trace]`.
```java
Map> schemaMaps = new HashMap<>();
@@ -461,5 +534,66 @@ schemaMaps.put("db3", dbSchema);
List ret = SqlClusterExecutor.validateSQLInRequest("select count(c1) over w1 from t3 window "+
"w1 as(partition by c1 order by c2 rows between unbounded preceding and current row);", schemaMaps);
Assert.assertEquals(ret.size(), 0);
+
+Map> schemaMaps = new HashMap<>();
+Map dbSchema = new HashMap<>();
+dbSchema = new HashMap<>();
+dbSchema.put("t3", new Schema(Arrays.asList(new Column("c1", Types.VARCHAR), new Column("c2", Types.BIGINT))));
+schemaMaps.put("db3", dbSchema);
+// Can use parameter format of no db. Make sure that there's only one db in schemaMaps,and only format is used in sql.
+// List ret = SqlClusterExecutor.validateSQLInRequest("select count(c1) over w1 from t3 window "+
+// "w1 as(partition by c1 order by c2 rows between unbounded preceding and current row);", schemaMaps);
+List ret = SqlClusterExecutor.validateSQLInRequest("select count(c1) over w1 from t3 window "+
+ "w1 as(partition by c1 order by c2 rows between unbounded preceding and current row);", "db3", schemaMaps);
+Assert.assertEquals(ret.size(), 0);
```
+## DDL Generation
+
+The `public static List genDDL(String sql, Map> tableSchema)` method can help users generate table creation statements based on the SQL they want to deploy. It currently supports only a **single** database. The `sql` parameter should not be in the `.` format. The `tableSchema` parameter should include the schemas of all tables that the SQL depends on. The format of `tableSchema` should be consistent with what was discussed earlier. Even if `tableSchema` contains multiple databases, the database information will be discarded, and all tables will be treated as if they belong to an unknown database.
+
+## SQL Output Schema
+
+The `public static Schema genOutputSchema(String sql, String usedDB, Map> tableSchema)` method allows you to obtain the Output Schema for SQL queries and supports multiple databases. If you specify the `usedDB`, you can use tables from that database within the SQL using the `` format. For backward compatibility, there is also support for the` public static Schema genOutputSchema(String sql, Map> tableSchema)` method without specifying a database (usedDB). In this case, it is equivalent to using the first database listed as the used db. Therefore, you should ensure that tables in `` format within the `SQ`L query are associated with this first database.
+
+
+## SQL Table Lineage
+The `public static List> getDependentTables(String sql, String usedDB, Map> tableSchema)` method allows you to retrieve all tables that the sql query depends on. Each `Pair` in the list corresponds to the database name and table name, with the first element being the primary table, and the rest `[1, end)` representing other dependent tables (excluding the primary table). If the input parameter `usedDB` is an empty string, it means the query is performed without specifying a database (use db) context, which is different from the compatibility rules mentioned earlier for methods like `genDDL`.
+
+## SQL Merge
+The Java client supports merging multiple SQL statements and performs correctness validation in request mode using the `mergeSQL` interface. However, it's important to note that merging is only possible when all the input SQL statements have the same primary table.
+
+Input parameters: SQL group to be merged; the name of the current database being used; the join key(s) for the primary table (which can be multiple); the schema for all tables involved.
+
+For example, let's consider four SQL feature views:
+```
+// Single-table direct feature
+select c1 from main;
+// Single-table aggregation feature
+select sum(c1) over w1 of2 from main window w1 as (partition by c1 order by c2 rows between unbounded preceding and current row);
+// Multi-table feature
+select t1.c2 of4 from main last join t1 order by t1.c2 on main.c1==t1.c1;
+// Multi-table aggregation feature
+select sum(c2) over w1 from main window w1 as (union (select \"\" as id, * from t1) partition by c1 order by c2 rows between unbounded preceding and current row);
+```
+
+Since all of them have the same primary table, "main," they can be merged. The merging process is essentially a join operation. To perform this operation, you also need to specify a unique column in the "main" table that can be used to identify a unique row of data. For example, if the "id" column in the "main" table is not unique and there may be multiple rows with the same "id" values, you can use a combination of "id" and "c1" columns for the join. Similar to SQL validation, you would also provide a schema map for the tables involved in the merge.
+
+
+```java
+//To simplify the demonstration, we are using tables from a single database, so you only need to specify used db and table names if your SQL statements all use the format. you can leave the used database parameter as an empty string. If your SQL statements use the . format, you can leave the used db parameter as an empty string
+String merged = SqlClusterExecutor.mergeSQL(sqls, "db", Arrays.asList("id", "c1"), schemaMaps);
+```
+
+The output is a single merged SQL statement, as shown below. The input SQL includes a total of four features, so the merged SQL will only output these four feature columns. (The join keys are automatically filtered.)
+
+```
+select `c1`, `of2`, `of4`, `sum(c2)over w1` from (select main.id as merge_id_0, c1 from main) as out0 last join (select main.id as merge_id_1, sum(c1) over w1 of2 from main window w1 as (partition by c1 order by c2 rows between unbounded preceding and current row)) as out1 on out0.merge_id_0 = out1.merge_id_1 last join (select main.id as merge_id_2, t1.c2 of4 from main last join t1 order by t1.c2 on main.c1==t1.c1) as out2 on out0.merge_id_0 = out2.merge_id_2 last join (select main.id as merge_id_3, sum(c2) over w1 from main window w1 as (union (select "" as id, * from t1) partition by c1 order by c2 rows between unbounded preceding and current row)) as out3 on out0.merge_id_0 = out3.merge_id_3;
+```
+
+```{note}
+If you encounter an "Ambiguous column name" error during the merging process, it may be due to having the same column names in different feature groups. To resolve this, you should use aliases in your input SQL to distinguish between them.
+```
+
+
+
diff --git a/docs/en/quickstart/sdk/python_sdk.md b/docs/en/quickstart/sdk/python_sdk.md
index 421f6b8ff93..6ae0e4705af 100644
--- a/docs/en/quickstart/sdk/python_sdk.md
+++ b/docs/en/quickstart/sdk/python_sdk.md
@@ -1,18 +1,20 @@
# Python SDK
-## Python SDK package installation
+The default execution mode is Online.
-Execute the following command to install the Python SDK package:
+## Python SDK Installation
+
+Execute the following command to install Python SDK:
```bash
pip install openmldb
```
-## OpenMLDB DBAPI usage
+## OpenMLDB DBAPI
-This section demonstrates the basic use of the OpenMLDB DB API.
+This section demonstrates the basic use of the OpenMLDB DB API. For all DBAPI interfaces, if an execution fails, it will raise a `DatabaseError` exception. Users can catch this exception and handle it as needed. The return value is a `Cursor`. For DDL SQL, you do not need to handle the return value. For other SQL statements, you can refer to the specific examples below for how to handle the return value.
-### Create connection
+### Create Connection
Parameter `db_name` name must exist, and the database must be created before the connection is created. To continue, create a connection without a database and then use the database db through the `execute ("USE")` command.
@@ -24,11 +26,11 @@ cursor = db.cursor()
#### Configuration Details
-Zk and zkPath configuration are required.
+Zk and zkPath configurations are required.
-The Python SDK can be used through OpenMLDB DBAPI/SQLAlchemy. The optional configurations are basically the same as those of the Java client. Please refer to the [Java SDK configuration](https://openmldb.ai/docs/zh/main/quickstart/sdk/java_sdk.html#sdk) for details.
+The Python SDK can be used through OpenMLDB DBAPI/SQLAlchemy. The optional configurations are basically the same as those of the Java client. Please refer to the [Java SDK configuration](./java_sdk.md#sdk-configuration-details) for details.
-### Create database
+### Create Database
Create database `db1`:
@@ -37,7 +39,7 @@ cursor.execute("CREATE DATABASE db1")
cursor.execute("USE db1")
```
-### Create table
+### Create Table
Create table `t1`:
@@ -45,7 +47,7 @@ Create table `t1`:
cursor.execute("CREATE TABLE t1 (col1 bigint, col2 date, col3 string, col4 string, col5 int, index(key=col3, ts=col1))")
```
-### Insert data into the table
+### Insert Data into Table
Insert one sentence of data into the table:
@@ -53,7 +55,7 @@ Insert one sentence of data into the table:
cursor.execute("INSERT INTO t1 VALUES(1000, '2020-12-25', 'guangdon', 'shenzhen', 1)")
```
-### Execute SQL query
+### Execute SQL Query
```python
result = cursor.execute("SELECT * FROM t1")
@@ -62,15 +64,30 @@ print(result.fetchmany(10))
print(result.fetchall())
```
-### SQL batch request query
+### SQL Batch Query
```python
-#In the Batch Request mode, the input parameters of the interface are“SQL”, “Common_Columns”, “Request_Columns”
+#In the Batch Request mode, the input parameters of the interface are "SQL", "Common_Columns", "Request_Columns"
result = cursor.batch_row_request("SELECT * FROM t1", ["col1","col2"], ({"col1": 2000, "col2": '2020-12-22', "col3": 'fujian', "col4":'xiamen', "col5": 2}))
print(result.fetchone())
```
+### Execute Deployment
+
+Please note that the execution of deployments is only supported by DBAPI, and there is no equivalent interface in OpenMLDB SQLAlchemy. Additionally, deployment execution supports single requests only and does not support batch requests.
+
+```python
+cursor.execute("DEPLOY d1 SELECT col1 FROM t1")
+# dict style
+result = cursor.callproc("d1", {"col1": 1000, "col2": None, "col3": None, "col4": None, "col5": None})
+print(result.fetchall())
+# tuple style
+result = cursor.callproc("d1", (1001, "2023-07-20", "abc", "def", 1))
+print(result.fetchall())
+# drop deployment before drop table
+cursor.execute("DROP DEPLOYMENT d1")
+```
-### Delete table
+### Delete Table
Delete table `t1`:
@@ -78,7 +95,7 @@ Delete table `t1`:
cursor.execute("DROP TABLE t1")
```
-### Delete database
+### Delete Database
Delete database `db1`:
@@ -86,17 +103,17 @@ Delete database `db1`:
cursor.execute("DROP DATABASE db1")
```
-### Close connection
+### Close Connection
```python
cursor.close()
```
-## OpenMLDB SQLAlchemy usage
+## OpenMLDB SQLAlchemy
-This section demonstrates using the Python SDK through OpenMLDB SQLAlchemy.
+This section demonstrates the use of the Python SDK through OpenMLDB SQLAlchemy. Similarly, if any of the DBAPI interfaces fail, they will raise a `DatabaseError` exception. Users can catch and handle this exception as needed. The handling of return values should follow the SQLAlchemy standard.
-### Create connection
+### Create Connection
```python
create_engine('openmldb:///db_name?zk=zkcluster&zkPath=zkpath')
@@ -110,7 +127,7 @@ engine = db.create_engine('openmldb:///?zk=127.0.0.1:2181&zkPath=/openmldb')
connection = engine.connect()
```
-### Create database
+### Create Database
Use the `connection.execute()` interface to create database `db1`:
@@ -123,7 +140,7 @@ except Exception as e:
connection.execute("USE db1")
```
-### Create table
+### Create Table
Use the `connection.execute()` interface to create table `t1`:
@@ -134,7 +151,7 @@ except Exception as e:
print(e)
```
-### Insert data into the table
+### Insert Data into Table
Use the `connection.execute (ddl)` interface to execute the SQL insert statement, and you can insert data into the table:
@@ -156,7 +173,7 @@ except Exception as e:
print(e)
```
-### Execute SQL batch query
+### Execute SQL Batch Query
Use the `connection.execute (sql)` interface to execute SQL batch query statements:
@@ -171,7 +188,7 @@ except Exception as e:
print(e)
```
-### Execute SQL request query
+### Execute SQL Query
Use the `connection.execute (sql, request)` interface to execute the SQL request query. You can put the input data into the second parameter of the execute function:
@@ -182,7 +199,7 @@ except Exception as e:
print(e)
```
-### Delete table
+### Delete Table
Use the `connection.execute (ddl)` interface to delete table `t1`:
@@ -193,7 +210,7 @@ except Exception as e:
print(e)
```
-### Delete database
+### Delete Database
Use the connection.execute(ddl)interface to delete database `db1`:
@@ -204,7 +221,7 @@ except Exception as e:
print(e)
```
-## Notebook Magic Function usage
+## Notebook Magic Function
The OpenMLDB Python SDK supports the expansion of Notebook magic function. Use the following statement to register the function.
@@ -216,26 +233,24 @@ openmldb.sql_magic.register(db)
Then you can use line magic function `%sql` and block magic function `%%sql` in Notebook.
-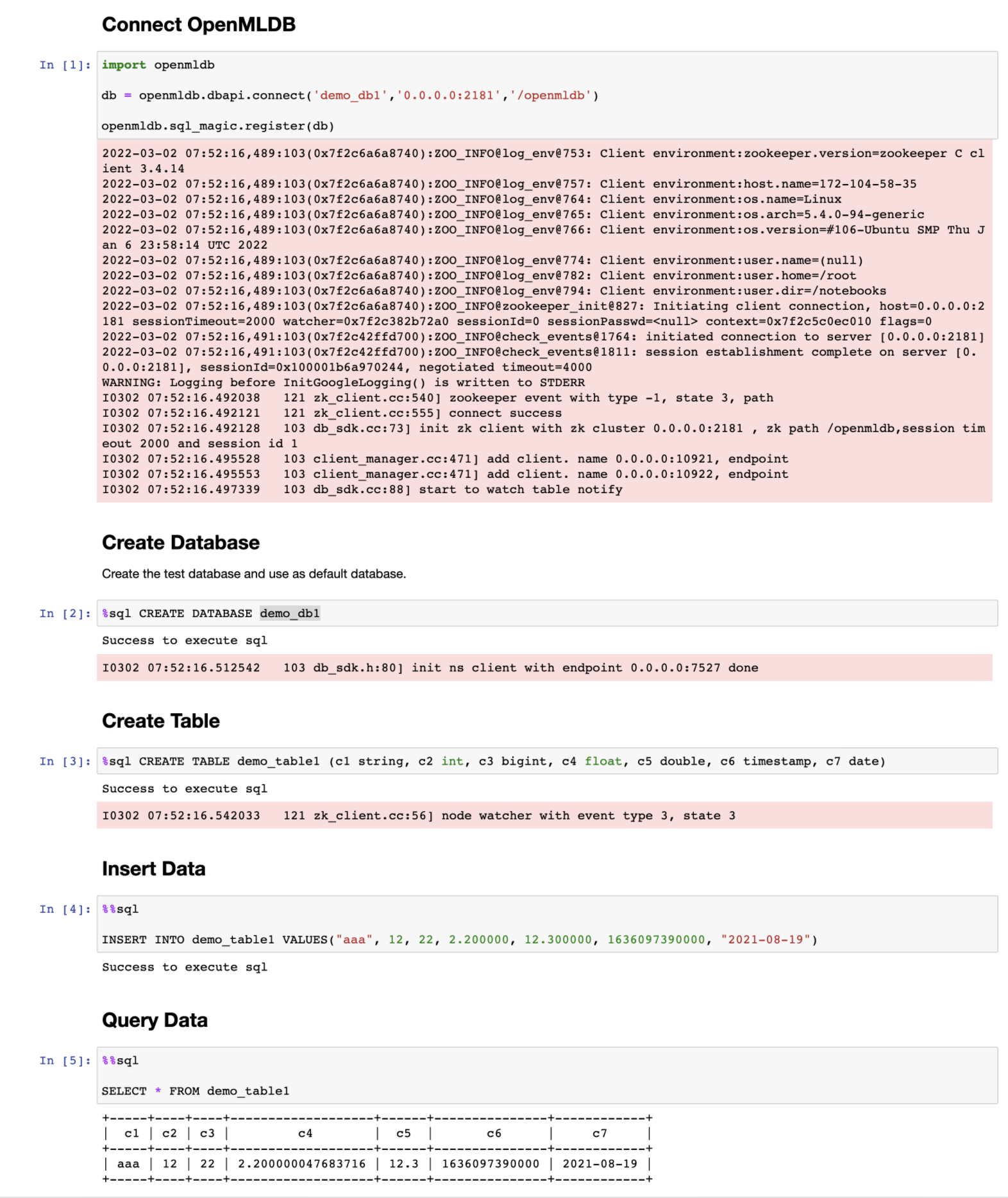
-
-## The complete usage example
+
-Refer to the [Python quickstart demo](https://github.com/4paradigm/OpenMLDB/tree/main/demo/python_quickstart/demo.py), including the above DBAPI and SQLAlchemy usage.
+## A Complete Example
-## common problem
+Refer to the [Python quickstart demo](https://github.com/4paradigm/OpenMLDB/tree/main/demo/python_quickstart/demo.py), which includes the above DBAPI and SQLAlchemy usage.
-- **What do I do when error** `ImportError:dlopen (.. _sql_router_sdk. so, 2): initializer function 0xnnnn not in mapped image for` **appears when using SQLAlchemy?**
+## Q&A
-In addition to import openmldb, you may also import other third-party libraries, which may cause confusion in the loading order. Due to the complexity of the system, you can try to use the virtual env environment (such as conda) to avoid interference. In addition, import openmldb before importing sqlalchemy, and ensure that the two imports are in the first place.
+- **What do I do when error `ImportError:dlopen (.. _sql_router_sdk. so, 2): initializer function 0xnnnn not in mapped image for` appears when using SQLAlchemy?**
-If the error still occur, it is recommended to connect to OpenMLDB by using request http to connect to apiserver.
+In addition to importing OpenMLDB, you may also have imported other third-party libraries, which may cause confusion in the loading order. Due to the complexity of the system, you can try to use the virtual env environment (such as conda) to avoid interference. In addition, import OpenMLDB before importing SQLAlchemy, and ensure that the two imports are in the first place.
-occur
+If the error still occurs, it is recommended to connect to OpenMLDB by request http to connect to apiserver.
-- **What do I do if Python SDK encountered the following problems?**
+- **What do I do if Python SDK encounters the following problems?**
```plain
[libprotobuf FATAL /Users/runner/work/crossbow/crossbow/vcpkg/buildtrees/protobuf/src/23fa7edd52-3ba2225d30.clean/src/google/protobuf/stubs/common.cc:87] This program was compiled against version 3.6.1 of the Protocol Buffer runtime library, which is not compatible with the installed version (3.15.8). Contact the program author for an update. ...
```
-This problem may be due to the introduction of other versions of protobuf in other libraries. You can try to use the virtual env environment (such as conda).
+This problem may be due to the import of other versions of protobuf from other libraries. You can try to use the virtual env environment (such as conda).
diff --git a/docs/en/quickstart/sdk/rest_api.md b/docs/en/quickstart/sdk/rest_api.md
index 7d8f3c4a881..c2a6cc972ea 100644
--- a/docs/en/quickstart/sdk/rest_api.md
+++ b/docs/en/quickstart/sdk/rest_api.md
@@ -1,12 +1,12 @@
# REST API
-## Important information
+## Important
-REST APIs interact with the services of APIServer and OpenMLDB, so the APIServer module must be properly deployed to be used effectively. APIServer is an optional module during installation and deployment. Refer to the APIServer deployment document.
+REST APIs interact with the services of APIServer and OpenMLDB, so the APIServer module must be properly deployed to be used effectively. APIServer is an optional module during installation and deployment. Refer to [APIServer Deployment](../../deploy/install_deploy.md).
At this stage, APIServer is mainly used for functional testing, not recommended for performance testing, nor recommended for the production environment. The default deployment of APIServer does not have a high availability mechanism at present and introduces additional network and codec overhead.
-## Data insertion
+## Data Insertion
Request address: http://ip:port/dbs/{db_name}/tables/{table_name}
@@ -23,7 +23,6 @@ The requestor:
```
- Currently, it only supports inserting one piece of data.
-
- The data should be arranged in strict accordance with the schema.
Sample request data:
@@ -44,7 +43,7 @@ Response:
}
```
-## Real-time feature computing
+## Real-Time Feature Computing
Request address: http://ip:port/dbs/{db_name}/deployments/{deployment_name}
@@ -81,11 +80,11 @@ Requestor
- Input data in JSON format can have redundant columns.
-**Sample request data**
+**Sample Request Data**
Example 1: Array format
-```plain
+```Plain
curl http://127.0.0.1:8080/dbs/demo_db/deployments/demo_data_service -X POST -d'{
"input": [["aaa", 11, 22, 1.2, 1.3, 1635247427000, "2021-05-20"]]
}'
@@ -106,9 +105,7 @@ Response:
Example 2: JSON format
```JSON
-curl http://127.0.0.1:8080/dbs/demo_db/deployments/demo_data_service -X POST -d'{
- "input": [{"c1":"aaa", "c2":11, "c3":22, "c4":1.2, "c5":1.3, "c6":1635247427000, "c7":"2021-05-20", "foo":"bar"}]
- }'
+curl http://127.0.0.1:8080/dbs/demo_db/deployments/demo_data_service -X POST -d'{"input": [{"c1":"aaa", "c2":11, "c3":22, "c4":1.2, "c5":1.3, "c6":1635247427000, "c7":"2021-05-20", "foo":"bar"}]}'
```
Response:
@@ -125,7 +122,7 @@ Response:
## Query
-Request address: http://ip:port/dbs/ {db_name}
+Request address: http://ip:port/dbs/{db_name}
Request method: POST
@@ -146,13 +143,13 @@ Request parameters:
| Parameters | Type | Requirement | Description |
| ---------- | ------ | ----------- | ------------------------------------------------------------ |
-| mode | String | Yes | Available for `offsync` , `offasync`, `online` |
+| mode | String | Yes | Set to `offsync` , `offasync`, `online` |
| sql | String | Yes | |
| input | Object | No | |
| schema | Array | No | Support data types (case insensitive): `Bool`, `Int16`, `Int32`, `Int64`, `Float`, `Double`, `String`, `Date and Timestamp` |
| data | Array | No | |
-**Sample request data**
+**Sample Request Data**
Example 1: General query
@@ -202,7 +199,7 @@ Response:
}
```
-## Query deployment information
+## Query Deployment Information
Request address: http://ip:port/dbs/{db_name}/deployments/{deployment_name}
@@ -239,7 +236,7 @@ Response:
}
```
-## Acquire all library names
+## Acquire All Library Names
Request address: http://ip:port/dbs
@@ -257,7 +254,7 @@ Response:
}
```
-## Acquire all table names
+## Acquire All Table Names
Request address: http://ip:port/dbs/{db}/tables
@@ -310,7 +307,7 @@ Response:
}
```
-## Refresh APIServer metadata cache
+## Refresh APIServer Metadata Cache
Request address: http://ip:port/refresh
diff --git a/docs/en/reference/ip_tips.md b/docs/en/reference/ip_tips.md
index 2fc5b1c8805..aa608ca1d8c 100644
--- a/docs/en/reference/ip_tips.md
+++ b/docs/en/reference/ip_tips.md
@@ -38,12 +38,12 @@ Expose the port through `-p` when starting the container, and the client can acc
The stand-alone version needs to expose the ports of three components (nameserver, tabletserver, apiserver):
```
-docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.8.3 bash
+docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.8.4 bash
```
The cluster version needs to expose the zk port and the ports of all components:
```
-docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.8.3 bash
+docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.8.4 bash
```
```{tip}
@@ -57,7 +57,7 @@ If the OpenMLDB service process is distributed, the "port number is occupied" ap
#### Host Network
Or more conveniently, use host networking without port isolation, for example:
```
-docker run --network host -it 4pdosc/openmldb:0.8.3 bash
+docker run --network host -it 4pdosc/openmldb:0.8.4 bash
```
But in this case, it is easy to find that the port is occupied by other processes in the host. If occupancy occurs, change the port number carefully.
diff --git a/docs/en/reference/sql/ddl/CREATE_TABLE_STATEMENT.md b/docs/en/reference/sql/ddl/CREATE_TABLE_STATEMENT.md
index a0d11d90657..ba62cf55231 100644
--- a/docs/en/reference/sql/ddl/CREATE_TABLE_STATEMENT.md
+++ b/docs/en/reference/sql/ddl/CREATE_TABLE_STATEMENT.md
@@ -473,6 +473,11 @@ StorageMode
::= 'Memory'
| 'HDD'
| 'SSD'
+CompressTypeOption
+ ::= 'COMPRESS_TYPE' '=' CompressType
+CompressType
+ ::= 'NoCompress'
+ | 'Snappy
```
@@ -484,6 +489,7 @@ StorageMode
| `REPLICANUM` | It defines the number of replicas for the table. Note that the number of replicas is only configurable in Cluster version. | `OPTIONS (REPLICANUM=3)` |
| `DISTRIBUTION` | It defines the distributed node endpoint configuration. Generally, it contains a Leader node and several followers. `(leader, [follower1, follower2, ..])`. Without explicit configuration, OpenMLDB will automatically configure `DISTRIBUTION` according to the environment and nodes. | `DISTRIBUTION = [ ('127.0.0.1:6527', [ '127.0.0.1:6528','127.0.0.1:6529' ])]` |
| `STORAGE_MODE` | It defines the storage mode of the table. The supported modes are `Memory`, `HDD` and `SSD`. When not explicitly configured, it defaults to `Memory`.
If you need to support a storage mode other than `Memory` mode, `tablet` requires additional configuration options. For details, please refer to [tablet configuration file **conf/tablet.flags**](../../../deploy/conf.md#the-configuration-file-for-apiserver:-conf/tablet.flags). | `OPTIONS (STORAGE_MODE='HDD')` |
+| `COMPRESS_TYPE` | It defines the compress types of the table. The supported compress type are `NoCompress` and `Snappy`. The default value is `NoCompress` | `OPTIONS (COMPRESS_TYPE='Snappy')`
#### The Difference between Disk Table and Memory Table
@@ -515,11 +521,11 @@ DESC t1;
--- -------------------- ------ ---------- ------ ---------------
1 INDEX_0_1651143735 col1 std_time 0min kAbsoluteTime
--- -------------------- ------ ---------- ------ ---------------
- --------------
- storage_mode
- --------------
- HDD
- --------------
+ --------------- --------------
+ compress_type storage_mode
+ --------------- --------------
+ NoCompress HDD
+ --------------- --------------
```
The following sql command create a table with specified distribution.
```sql
diff --git a/docs/en/reference/sql/ddl/DESC_STATEMENT.md b/docs/en/reference/sql/ddl/DESC_STATEMENT.md
index 8179c952c56..a7d288064bb 100644
--- a/docs/en/reference/sql/ddl/DESC_STATEMENT.md
+++ b/docs/en/reference/sql/ddl/DESC_STATEMENT.md
@@ -56,11 +56,11 @@ desc t1;
--- -------------------- ------ ---------- ---------- ---------------
1 INDEX_0_1658136511 col1 std_time 43200min kAbsoluteTime
--- -------------------- ------ ---------- ---------- ---------------
- --------------
- storage_mode
- --------------
- Memory
- --------------
+ --------------- --------------
+ compress_type storage_mode
+ --------------- --------------
+ NoCompress Memory
+ --------------- --------------
```
diff --git a/docs/en/reference/sql/ddl/SHOW_CREATE_TABLE_STATEMENT.md b/docs/en/reference/sql/ddl/SHOW_CREATE_TABLE_STATEMENT.md
new file mode 100644
index 00000000000..967ebce316a
--- /dev/null
+++ b/docs/en/reference/sql/ddl/SHOW_CREATE_TABLE_STATEMENT.md
@@ -0,0 +1,28 @@
+# SHOW CREATE TABLE
+
+`SHOW CREATE TABLE` shows the `CREATE TABLE` statement that creates the named table
+
+**Syntax**
+
+```sql
+SHOW CREATE TABLE table_name;
+```
+
+**Example**
+
+```sql
+show create table t1;
+ ------- ---------------------------------------------------------------
+ Table Create Table
+ ------- ---------------------------------------------------------------
+ t1 CREATE TABLE `t1` (
+ `c1` varchar,
+ `c2` int,
+ `c3` bigInt,
+ `c4` timestamp,
+ INDEX (KEY=`c1`, TS=`c4`, TTL_TYPE=ABSOLUTE, TTL=0m)
+ ) OPTIONS (PARTITIONNUM=8, REPLICANUM=2, STORAGE_MODE='HDD', COMPRESS_TYPE='NoCompress');
+ ------- ---------------------------------------------------------------
+
+1 rows in set
+```
\ No newline at end of file
diff --git a/docs/en/reference/sql/ddl/TRUNCATE_TABLE_STATEMENT.md b/docs/en/reference/sql/ddl/TRUNCATE_TABLE_STATEMENT.md
new file mode 100644
index 00000000000..3bd9360d920
--- /dev/null
+++ b/docs/en/reference/sql/ddl/TRUNCATE_TABLE_STATEMENT.md
@@ -0,0 +1,16 @@
+# TRUNCATE TABLE
+
+```
+TRUNCATE TABLE table_name
+```
+
+`TRUNCATE TABLE` statement is used to clear the specified table.
+
+## Example: clear t1
+
+```sql
+TRUNCATE TABLE t1;
+-- Truncate table t1? yes/no
+-- yes
+-- SUCCEED
+```
\ No newline at end of file
diff --git a/docs/en/reference/sql/ddl/index.rst b/docs/en/reference/sql/ddl/index.rst
index 09199ec27ba..bff9db48fb0 100644
--- a/docs/en/reference/sql/ddl/index.rst
+++ b/docs/en/reference/sql/ddl/index.rst
@@ -23,3 +23,5 @@ Data Definition Statement (DDL)
CREATE_FUNCTION
SHOW_FUNCTIONS
DROP_FUNCTION
+ SHOW_CREATE_TABLE_STATEMENT
+ TRUNCATE_TABLE_STATEMENT
diff --git a/docs/en/reference/sql/dql/WINDOW_CLAUSE.md b/docs/en/reference/sql/dql/WINDOW_CLAUSE.md
index bbc71a4f222..f3add760280 100644
--- a/docs/en/reference/sql/dql/WINDOW_CLAUSE.md
+++ b/docs/en/reference/sql/dql/WINDOW_CLAUSE.md
@@ -320,5 +320,5 @@ WINDOW w1 AS (PARTITION BY col1 ORDER BY col5 ROWS_RANGE BETWEEN 10s PRECEDING A
```
```{seealso}
-Please refer to [Built-in Functions](../functions_and_operators/Files/udfs_8h.md) for aggregate functions that can be used in window computation.
+Please refer to [Built-in Functions](../udfs_8h.md) for aggregate functions that can be used in window computation.
````
diff --git a/docs/en/reference/sql/index.rst b/docs/en/reference/sql/index.rst
index ee57dbac297..58bcc3e5502 100644
--- a/docs/en/reference/sql/index.rst
+++ b/docs/en/reference/sql/index.rst
@@ -9,6 +9,7 @@ SQL
language_structure/index
data_types/index
functions_and_operators/index
+ udfs_8h
dql/index
dml/index
ddl/index
diff --git a/docs/en/reference/sql/functions_and_operators/index.rst b/docs/en/reference/sql/operators/index.rst
similarity index 65%
rename from docs/en/reference/sql/functions_and_operators/index.rst
rename to docs/en/reference/sql/operators/index.rst
index b889a6e8a87..db068373e46 100644
--- a/docs/en/reference/sql/functions_and_operators/index.rst
+++ b/docs/en/reference/sql/operators/index.rst
@@ -1,5 +1,5 @@
=============================
-Expressions, Functions, and Operations
+Expressions and Operations
=============================
@@ -7,4 +7,3 @@ Expressions, Functions, and Operations
:maxdepth: 1
operators
- Files/udfs_8h
diff --git a/docs/en/reference/sql/functions_and_operators/operators.md b/docs/en/reference/sql/operators/operators.md
similarity index 100%
rename from docs/en/reference/sql/functions_and_operators/operators.md
rename to docs/en/reference/sql/operators/operators.md
diff --git a/docs/zh/openmldb_sql/functions_and_operators/Files/udfs_8h.md b/docs/en/reference/sql/udfs_8h.md
similarity index 68%
rename from docs/zh/openmldb_sql/functions_and_operators/Files/udfs_8h.md
rename to docs/en/reference/sql/udfs_8h.md
index ac96c6bfc3f..9cfab05977f 100644
--- a/docs/zh/openmldb_sql/functions_and_operators/Files/udfs_8h.md
+++ b/docs/en/reference/sql/udfs_8h.md
@@ -10,158 +10,158 @@ title: udfs/udfs.h
| Name | Description |
| -------------- | -------------- |
-| **[abs](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-abs)**()|
Return the absolute value of expr. |
-| **[acos](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-acos)**()|
Return the arc cosine of expr. |
-| **[add](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-add)**()|
Compute sum of two arguments. |
-| **[add_months](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-add-months)**()|
adds an integer months to a given date, returning the resulting date. |
-| **[array_contains](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-array-contains)**()|
array_contains(array, value) - Returns true if the array contains the value. |
-| **[asin](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-asin)**()|
Return the arc sine of expr. |
-| **[at](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-at)**()| |
-| **[atan](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-atan)**()|
Return the arc tangent of expr If called with one parameter, this function returns the arc tangent of expr. If called with two parameters X and Y, this function returns the arc tangent of Y / X. |
-| **[atan2](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-atan2)**()|
Return the arc tangent of Y / X.. |
-| **[avg](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg)**()|
Compute average of values. |
-| **[avg_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg-cate)**()|
Compute average of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[avg_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V', separated by comma, and sorted by key in ascend order. |
-| **[avg_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg-where)**()|
Compute average of values match specified condition. |
-| **[bigint](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-bigint)**()| |
-| **[bool](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-bool)**()|
Cast string expression to bool. |
-| **[ceil](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ceil)**()|
Return the smallest integer value not less than the expr. |
-| **[ceiling](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ceiling)**()| |
-| **[char](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-char)**()|
Returns the ASCII character having the binary equivalent to expr. If n >= 256 the result is equivalent to char(n % 256). |
-| **[char_length](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-char-length)**()|
Returns the length of the string. It is measured in characters and multibyte character string is not supported. |
-| **[character_length](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-character-length)**()| |
-| **[concat](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-concat)**()|
This function returns a string resulting from the joining of two or more string values in an end-to-end manner. (To add a separating value during joining, see concat_ws.) |
-| **[concat_ws](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-concat-ws)**()|
Returns a string resulting from the joining of two or more string value in an end-to-end manner. It separates those concatenated string values with the delimiter specified in the first function argument. |
-| **[cos](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-cos)**()|
Return the cosine of expr. |
-| **[cot](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-cot)**()|
Return the cotangent of expr. |
-| **[count](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count)**()|
Compute number of values. |
-| **[count_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count-cate)**()|
Compute count of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[count_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[count_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count-where)**()|
Compute number of values match specified condition. |
-| **[date](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-date)**()|
Cast timestamp or string expression to date (date >= 1900-01-01) |
-| **[date_format](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-date-format)**()|
Formats the date value according to the format string. |
-| **[datediff](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-datediff)**()|
days difference from date1 to date2 |
-| **[day](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-day)**()| |
-| **[dayofmonth](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-dayofmonth)**()|
Return the day of the month for a timestamp or date. |
-| **[dayofweek](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-dayofweek)**()|
Return the day of week for a timestamp or date. |
-| **[dayofyear](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-dayofyear)**()|
Return the day of year for a timestamp or date. Returns 0 given an invalid date. |
-| **[degrees](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-degrees)**()|
Convert radians to degrees. |
-| **[distinct_count](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-distinct-count)**()|
Compute number of distinct values. |
-| **[double](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-double)**()|
Cast string expression to double. |
-| **[drawdown](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-drawdown)**()|
Compute drawdown of values. |
-| **[earth_distance](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-earth-distance)**()|
Returns the great circle distance between two points on the surface of the Earth. Km as return unit. add a minus (-) sign if heading west (W) or south (S). |
-| **[entropy](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-entropy)**()|
Calculate Shannon entropy of a column of values. Null values are skipped. |
-| **[ew_avg](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ew-avg)**()|
Compute exponentially-weighted average of values. It's equivalent to pandas ewm(alpha={alpha}, adjust=True, ignore_na=True, com=None, span=None, halflife=None, min_periods=0) |
-| **[exp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-exp)**()|
Return the value of e (the base of natural logarithms) raised to the power of expr. |
-| **[farm_fingerprint](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-farm-fingerprint)**()| |
-| **[first_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-first-value)**()|
Returns the value of expr from the latest row (last row) of the window frame. |
-| **[float](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-float)**()|
Cast string expression to float. |
-| **[floor](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-floor)**()|
Return the largest integer value not less than the expr. |
-| **[get_json_object](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-get-json-object)**()|
Extracts a JSON object from [JSON Pointer](https://datatracker.ietf.org/doc/html/rfc6901)|
-| **[hash64](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-hash64)**()|
Returns a hash value of the arguments. It is not a cryptographic hash function and should not be used as such. |
-| **[hex](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-hex)**()|
Convert integer to hexadecimal. |
-| **[hour](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-hour)**()|
Return the hour for a timestamp. |
-| **[identity](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-identity)**()|
Return value. |
-| **[if_null](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-if-null)**()|
If input is not null, return input value; else return default value. |
-| **[ifnull](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ifnull)**()| |
-| **[ilike_match](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ilike-match)**()|
pattern match same as ILIKE predicate |
-| **[inc](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-inc)**()|
Return expression + 1. |
-| **[int](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int)**()| |
-| **[int16](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int16)**()|
Cast string expression to int16. |
-| **[int32](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int32)**()|
Cast string expression to int32. |
-| **[int64](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int64)**()|
Cast string expression to int64. |
-| **[is_null](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-is-null)**()|
Check if input value is null, return bool. |
-| **[isnull](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-isnull)**()| |
-| **[join](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-join)**()|
For each string value from specified column of window, join by delimeter. Null values are skipped. |
-| **[json_array_length](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-json-array-length)**()|
Returns the number of elements in the outermost JSON array. |
-| **[lag](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lag)**()|
Returns value evaluated at the row that is offset rows before the current row within the partition. Offset is evaluated with respect to the current row. |
-| **[last_day](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-last-day)**()|
Return the last day of the month to which the date belongs to. |
-| **[lcase](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lcase)**()|
Convert all the characters to lowercase. Note that characters with values > 127 are simply returned. |
-| **[like_match](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-like-match)**()|
pattern match same as LIKE predicate |
-| **[list_except_by_key](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-list-except-by-key)**()|
Return list of elements in list1 but keys not in except_str. |
-| **[list_except_by_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-list-except-by-value)**()|
Return list of elements in list1 but values not in except_str. |
-| **[ln](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ln)**()|
Return the natural logarithm of expr. |
-| **[log](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-log)**()|
log(base, expr) If called with one parameter, this function returns the natural logarithm of expr. If called with two parameters, this function returns the logarithm of expr to the base. |
-| **[log10](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-log10)**()|
Return the base-10 logarithm of expr. |
-| **[log2](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-log2)**()|
Return the base-2 logarithm of expr. |
-| **[lower](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lower)**()| |
-| **[make_tuple](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-make-tuple)**()| |
-| **[max](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max)**()|
Compute maximum of values. |
-| **[max_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max-cate)**()|
Compute maximum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[max_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[max_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max-where)**()|
Compute maximum of values match specified condition. |
-| **[maximum](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-maximum)**()|
Compute maximum of two arguments. |
-| **[median](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-median)**()|
Compute the median of values. |
-| **[min](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min)**()|
Compute minimum of values. |
-| **[min_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min-cate)**()|
Compute minimum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[min_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[min_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min-where)**()|
Compute minimum of values match specified condition. |
-| **[minimum](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-minimum)**()|
Compute minimum of two arguments. |
-| **[minute](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-minute)**()|
Return the minute for a timestamp. |
-| **[month](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-month)**()|
Return the month part of a timestamp or date. |
-| **[nth_value_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-nth-value-where)**()|
Returns the value of expr from the idx th row matches the condition. |
-| **[nvl](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-nvl)**()| |
-| **[nvl2](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-nvl2)**()|
nvl2(expr1, expr2, expr3) - Returns expr2 if expr1 is not null, or expr3 otherwise. |
-| **[pmod](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-pmod)**()|
Compute pmod of two arguments. If any param is NULL, output NULL. If divisor is 0, output NULL. |
-| **[pow](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-pow)**()|
Return the value of expr1 to the power of expr2. |
-| **[power](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-power)**()| |
-| **[radians](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-radians)**()|
Returns the argument X, converted from degrees to radians. (Note that π radians equals 180 degrees.) |
-| **[regexp_like](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-regexp-like)**()|
pattern match same as RLIKE predicate (based on RE2) |
-| **[replace](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-replace)**()|
replace(str, search[, replace]) - Replaces all occurrences of `search` with `replace`|
-| **[reverse](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-reverse)**()|
Returns the reversed given string. |
-| **[round](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-round)**()|
Returns expr rounded to d decimal places using HALF_UP rounding mode. |
-| **[second](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-second)**()|
Return the second for a timestamp. |
-| **[sin](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sin)**()|
Return the sine of expr. |
-| **[size](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-size)**()|
Get the size of a List (e.g., result of split) |
-| **[smallint](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-smallint)**()| |
-| **[split](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split)**()|
Split string to list by delimeter. Null values are skipped. |
-| **[split_array](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split-array)**()|
Split string to array of string by delimeter. |
-| **[split_by_key](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split-by-key)**()|
Split string by delimeter and split each segment as kv pair, then add each key to output list. Null or illegal segments are skipped. |
-| **[split_by_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split-by-value)**()|
Split string by delimeter and split each segment as kv pair, then add each value to output list. Null or illegal segments are skipped. |
-| **[sqrt](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sqrt)**()|
Return square root of expr. |
-| **[std](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-std)**()| |
-| **[stddev](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-stddev)**()|
Compute sample standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / (n-1) )`|
-| **[stddev_pop](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-stddev-pop)**()|
Compute population standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / n )`|
-| **[stddev_samp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-stddev-samp)**()| |
-| **[strcmp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-strcmp)**()|
Returns 0 if the strings are the same, -1 if the first argument is smaller than the second according to the current sort order, and 1 otherwise. |
-| **[string](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-string)**()|
Return string converted from timestamp expression. |
-| **[substr](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-substr)**()| |
-| **[substring](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-substring)**()|
Return a substring `len` characters long from string str, starting at position `pos`. Alias function: `substr`|
-| **[sum](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum)**()|
Compute sum of values. |
-| **[sum_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum-cate)**()|
Compute sum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[sum_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[sum_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum-where)**()|
Compute sum of values match specified condition. |
-| **[tan](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-tan)**()|
Return the tangent of expr. |
-| **[timestamp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-timestamp)**()|
Cast int64, date or string expression to timestamp. |
-| **[top](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top)**()|
Compute top k of values and output string separated by comma. The outputs are sorted in desc order. |
-| **[top1_ratio](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top1-ratio)**()|
Compute the top1 occurring value's ratio. |
-| **[top_n_key_avg_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_count_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_max_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_min_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_ratio_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
-| **[top_n_key_sum_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_avg_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_count_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_max_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_min_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_ratio_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
-| **[top_n_value_sum_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[topn_frequency](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-topn-frequency)**()|
Return the topN keys sorted by their frequency. |
-| **[truncate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-truncate)**()|
Return the nearest integer that is not greater in magnitude than the expr. |
-| **[ucase](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ucase)**()|
Convert all the characters to uppercase. Note that characters values > 127 are simply returned. |
-| **[unhex](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-unhex)**()|
Convert hexadecimal to binary string. |
-| **[unix_timestamp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-unix-timestamp)**()|
Cast date or string expression to unix_timestamp. If empty string or NULL is provided, return current timestamp. |
-| **[upper](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-upper)**()| |
-| **[var_pop](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-var-pop)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / n`|
-| **[var_samp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-var-samp)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / (n-1)`|
-| **[variance](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-variance)**()| |
-| **[week](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-week)**()| |
-| **[weekofyear](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-weekofyear)**()|
Return the week of year for a timestamp or date. |
-| **[window_split](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-window-split)**()|
For each string value from specified column of window, split by delimeter and add segment to output list. Null values are skipped. |
-| **[window_split_by_key](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-window-split-by-key)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each key to output list. Null and illegal segments are skipped. |
-| **[window_split_by_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-window-split-by-value)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each value to output list. Null and illegal segments are skipped. |
-| **[year](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-year)**()|
Return the year part of a timestamp or date. |
+| **[abs](/openmldb_sql/Files/udfs_8h.md#function-abs)**()|
Return the absolute value of expr. |
+| **[acos](/openmldb_sql/Files/udfs_8h.md#function-acos)**()|
Return the arc cosine of expr. |
+| **[add](/openmldb_sql/Files/udfs_8h.md#function-add)**()|
Compute sum of two arguments. |
+| **[add_months](/openmldb_sql/Files/udfs_8h.md#function-add-months)**()|
adds an integer months to a given date, returning the resulting date. |
+| **[array_contains](/openmldb_sql/Files/udfs_8h.md#function-array-contains)**()|
array_contains(array, value) - Returns true if the array contains the value. |
+| **[asin](/openmldb_sql/Files/udfs_8h.md#function-asin)**()|
Return the arc sine of expr. |
+| **[at](/openmldb_sql/Files/udfs_8h.md#function-at)**()| |
+| **[atan](/openmldb_sql/Files/udfs_8h.md#function-atan)**()|
Return the arc tangent of expr If called with one parameter, this function returns the arc tangent of expr. If called with two parameters X and Y, this function returns the arc tangent of Y / X. |
+| **[atan2](/openmldb_sql/Files/udfs_8h.md#function-atan2)**()|
Return the arc tangent of Y / X.. |
+| **[avg](/openmldb_sql/Files/udfs_8h.md#function-avg)**()|
Compute average of values. |
+| **[avg_cate](/openmldb_sql/Files/udfs_8h.md#function-avg-cate)**()|
Compute average of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[avg_cate_where](/openmldb_sql/Files/udfs_8h.md#function-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V', separated by comma, and sorted by key in ascend order. |
+| **[avg_where](/openmldb_sql/Files/udfs_8h.md#function-avg-where)**()|
Compute average of values match specified condition. |
+| **[bigint](/openmldb_sql/Files/udfs_8h.md#function-bigint)**()| |
+| **[bool](/openmldb_sql/Files/udfs_8h.md#function-bool)**()|
Cast string expression to bool. |
+| **[ceil](/openmldb_sql/Files/udfs_8h.md#function-ceil)**()|
Return the smallest integer value not less than the expr. |
+| **[ceiling](/openmldb_sql/Files/udfs_8h.md#function-ceiling)**()| |
+| **[char](/openmldb_sql/Files/udfs_8h.md#function-char)**()|
Returns the ASCII character having the binary equivalent to expr. If n >= 256 the result is equivalent to char(n % 256). |
+| **[char_length](/openmldb_sql/Files/udfs_8h.md#function-char-length)**()|
Returns the length of the string. It is measured in characters and multibyte character string is not supported. |
+| **[character_length](/openmldb_sql/Files/udfs_8h.md#function-character-length)**()| |
+| **[concat](/openmldb_sql/Files/udfs_8h.md#function-concat)**()|
This function returns a string resulting from the joining of two or more string values in an end-to-end manner. (To add a separating value during joining, see concat_ws.) |
+| **[concat_ws](/openmldb_sql/Files/udfs_8h.md#function-concat-ws)**()|
Returns a string resulting from the joining of two or more string value in an end-to-end manner. It separates those concatenated string values with the delimiter specified in the first function argument. |
+| **[cos](/openmldb_sql/Files/udfs_8h.md#function-cos)**()|
Return the cosine of expr. |
+| **[cot](/openmldb_sql/Files/udfs_8h.md#function-cot)**()|
Return the cotangent of expr. |
+| **[count](/openmldb_sql/Files/udfs_8h.md#function-count)**()|
Compute number of values. |
+| **[count_cate](/openmldb_sql/Files/udfs_8h.md#function-count-cate)**()|
Compute count of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[count_cate_where](/openmldb_sql/Files/udfs_8h.md#function-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[count_where](/openmldb_sql/Files/udfs_8h.md#function-count-where)**()|
Compute number of values match specified condition. |
+| **[date](/openmldb_sql/Files/udfs_8h.md#function-date)**()|
Cast timestamp or string expression to date (date >= 1900-01-01) |
+| **[date_format](/openmldb_sql/Files/udfs_8h.md#function-date-format)**()|
Formats the date value according to the format string. |
+| **[datediff](/openmldb_sql/Files/udfs_8h.md#function-datediff)**()|
days difference from date1 to date2 |
+| **[day](/openmldb_sql/Files/udfs_8h.md#function-day)**()| |
+| **[dayofmonth](/openmldb_sql/Files/udfs_8h.md#function-dayofmonth)**()|
Return the day of the month for a timestamp or date. |
+| **[dayofweek](/openmldb_sql/Files/udfs_8h.md#function-dayofweek)**()|
Return the day of week for a timestamp or date. |
+| **[dayofyear](/openmldb_sql/Files/udfs_8h.md#function-dayofyear)**()|
Return the day of year for a timestamp or date. Returns 0 given an invalid date. |
+| **[degrees](/openmldb_sql/Files/udfs_8h.md#function-degrees)**()|
Convert radians to degrees. |
+| **[distinct_count](/openmldb_sql/Files/udfs_8h.md#function-distinct-count)**()|
Compute number of distinct values. |
+| **[double](/openmldb_sql/Files/udfs_8h.md#function-double)**()|
Cast string expression to double. |
+| **[drawdown](/openmldb_sql/Files/udfs_8h.md#function-drawdown)**()|
Compute drawdown of values. |
+| **[earth_distance](/openmldb_sql/Files/udfs_8h.md#function-earth-distance)**()|
Returns the great circle distance between two points on the surface of the Earth. Km as return unit. add a minus (-) sign if heading west (W) or south (S). |
+| **[entropy](/openmldb_sql/Files/udfs_8h.md#function-entropy)**()|
Calculate Shannon entropy of a column of values. Null values are skipped. |
+| **[ew_avg](/openmldb_sql/Files/udfs_8h.md#function-ew-avg)**()|
Compute exponentially-weighted average of values. It's equivalent to pandas ewm(alpha={alpha}, adjust=True, ignore_na=True, com=None, span=None, halflife=None, min_periods=0) |
+| **[exp](/openmldb_sql/Files/udfs_8h.md#function-exp)**()|
Return the value of e (the base of natural logarithms) raised to the power of expr. |
+| **[farm_fingerprint](/openmldb_sql/Files/udfs_8h.md#function-farm-fingerprint)**()| |
+| **[first_value](/openmldb_sql/Files/udfs_8h.md#function-first-value)**()|
Returns the value of expr from the latest row (last row) of the window frame. |
+| **[float](/openmldb_sql/Files/udfs_8h.md#function-float)**()|
Cast string expression to float. |
+| **[floor](/openmldb_sql/Files/udfs_8h.md#function-floor)**()|
Return the largest integer value not less than the expr. |
+| **[get_json_object](/openmldb_sql/Files/udfs_8h.md#function-get-json-object)**()|
Extracts a JSON object from [JSON Pointer](https://datatracker.ietf.org/doc/html/rfc6901)|
+| **[hash64](/openmldb_sql/Files/udfs_8h.md#function-hash64)**()|
Returns a hash value of the arguments. It is not a cryptographic hash function and should not be used as such. |
+| **[hex](/openmldb_sql/Files/udfs_8h.md#function-hex)**()|
Convert integer to hexadecimal. |
+| **[hour](/openmldb_sql/Files/udfs_8h.md#function-hour)**()|
Return the hour for a timestamp. |
+| **[identity](/openmldb_sql/Files/udfs_8h.md#function-identity)**()|
Return value. |
+| **[if_null](/openmldb_sql/Files/udfs_8h.md#function-if-null)**()|
If input is not null, return input value; else return default value. |
+| **[ifnull](/openmldb_sql/Files/udfs_8h.md#function-ifnull)**()| |
+| **[ilike_match](/openmldb_sql/Files/udfs_8h.md#function-ilike-match)**()|
pattern match same as ILIKE predicate |
+| **[inc](/openmldb_sql/Files/udfs_8h.md#function-inc)**()|
Return expression + 1. |
+| **[int](/openmldb_sql/Files/udfs_8h.md#function-int)**()| |
+| **[int16](/openmldb_sql/Files/udfs_8h.md#function-int16)**()|
Cast string expression to int16. |
+| **[int32](/openmldb_sql/Files/udfs_8h.md#function-int32)**()|
Cast string expression to int32. |
+| **[int64](/openmldb_sql/Files/udfs_8h.md#function-int64)**()|
Cast string expression to int64. |
+| **[is_null](/openmldb_sql/Files/udfs_8h.md#function-is-null)**()|
Check if input value is null, return bool. |
+| **[isnull](/openmldb_sql/Files/udfs_8h.md#function-isnull)**()| |
+| **[join](/openmldb_sql/Files/udfs_8h.md#function-join)**()|
For each string value from specified column of window, join by delimeter. Null values are skipped. |
+| **[json_array_length](/openmldb_sql/Files/udfs_8h.md#function-json-array-length)**()|
Returns the number of elements in the outermost JSON array. |
+| **[lag](/openmldb_sql/Files/udfs_8h.md#function-lag)**()|
Returns value evaluated at the row that is offset rows before the current row within the partition. Offset is evaluated with respect to the current row. |
+| **[last_day](/openmldb_sql/Files/udfs_8h.md#function-last-day)**()|
Return the last day of the month to which the date belongs to. |
+| **[lcase](/openmldb_sql/Files/udfs_8h.md#function-lcase)**()|
Convert all the characters to lowercase. Note that characters with values > 127 are simply returned. |
+| **[like_match](/openmldb_sql/Files/udfs_8h.md#function-like-match)**()|
pattern match same as LIKE predicate |
+| **[list_except_by_key](/openmldb_sql/Files/udfs_8h.md#function-list-except-by-key)**()|
Return list of elements in list1 but keys not in except_str. |
+| **[list_except_by_value](/openmldb_sql/Files/udfs_8h.md#function-list-except-by-value)**()|
Return list of elements in list1 but values not in except_str. |
+| **[ln](/openmldb_sql/Files/udfs_8h.md#function-ln)**()|
Return the natural logarithm of expr. |
+| **[log](/openmldb_sql/Files/udfs_8h.md#function-log)**()|
log(base, expr) If called with one parameter, this function returns the natural logarithm of expr. If called with two parameters, this function returns the logarithm of expr to the base. |
+| **[log10](/openmldb_sql/Files/udfs_8h.md#function-log10)**()|
Return the base-10 logarithm of expr. |
+| **[log2](/openmldb_sql/Files/udfs_8h.md#function-log2)**()|
Return the base-2 logarithm of expr. |
+| **[lower](/openmldb_sql/Files/udfs_8h.md#function-lower)**()| |
+| **[make_tuple](/openmldb_sql/Files/udfs_8h.md#function-make-tuple)**()| |
+| **[max](/openmldb_sql/Files/udfs_8h.md#function-max)**()|
Compute maximum of values. |
+| **[max_cate](/openmldb_sql/Files/udfs_8h.md#function-max-cate)**()|
Compute maximum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[max_cate_where](/openmldb_sql/Files/udfs_8h.md#function-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[max_where](/openmldb_sql/Files/udfs_8h.md#function-max-where)**()|
Compute maximum of values match specified condition. |
+| **[maximum](/openmldb_sql/Files/udfs_8h.md#function-maximum)**()|
Compute maximum of two arguments. |
+| **[median](/openmldb_sql/Files/udfs_8h.md#function-median)**()|
Compute the median of values. |
+| **[min](/openmldb_sql/Files/udfs_8h.md#function-min)**()|
Compute minimum of values. |
+| **[min_cate](/openmldb_sql/Files/udfs_8h.md#function-min-cate)**()|
Compute minimum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[min_cate_where](/openmldb_sql/Files/udfs_8h.md#function-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[min_where](/openmldb_sql/Files/udfs_8h.md#function-min-where)**()|
Compute minimum of values match specified condition. |
+| **[minimum](/openmldb_sql/Files/udfs_8h.md#function-minimum)**()|
Compute minimum of two arguments. |
+| **[minute](/openmldb_sql/Files/udfs_8h.md#function-minute)**()|
Return the minute for a timestamp. |
+| **[month](/openmldb_sql/Files/udfs_8h.md#function-month)**()|
Return the month part of a timestamp or date. |
+| **[nth_value_where](/openmldb_sql/Files/udfs_8h.md#function-nth-value-where)**()|
Returns the value of expr from the idx th row matches the condition. |
+| **[nvl](/openmldb_sql/Files/udfs_8h.md#function-nvl)**()| |
+| **[nvl2](/openmldb_sql/Files/udfs_8h.md#function-nvl2)**()|
nvl2(expr1, expr2, expr3) - Returns expr2 if expr1 is not null, or expr3 otherwise. |
+| **[pmod](/openmldb_sql/Files/udfs_8h.md#function-pmod)**()|
Compute pmod of two arguments. If any param is NULL, output NULL. If divisor is 0, output NULL. |
+| **[pow](/openmldb_sql/Files/udfs_8h.md#function-pow)**()|
Return the value of expr1 to the power of expr2. |
+| **[power](/openmldb_sql/Files/udfs_8h.md#function-power)**()| |
+| **[radians](/openmldb_sql/Files/udfs_8h.md#function-radians)**()|
Returns the argument X, converted from degrees to radians. (Note that π radians equals 180 degrees.) |
+| **[regexp_like](/openmldb_sql/Files/udfs_8h.md#function-regexp-like)**()|
pattern match same as RLIKE predicate (based on RE2) |
+| **[replace](/openmldb_sql/Files/udfs_8h.md#function-replace)**()|
replace(str, search[, replace]) - Replaces all occurrences of `search` with `replace`|
+| **[reverse](/openmldb_sql/Files/udfs_8h.md#function-reverse)**()|
Returns the reversed given string. |
+| **[round](/openmldb_sql/Files/udfs_8h.md#function-round)**()|
Returns expr rounded to d decimal places using HALF_UP rounding mode. |
+| **[second](/openmldb_sql/Files/udfs_8h.md#function-second)**()|
Return the second for a timestamp. |
+| **[sin](/openmldb_sql/Files/udfs_8h.md#function-sin)**()|
Return the sine of expr. |
+| **[size](/openmldb_sql/Files/udfs_8h.md#function-size)**()|
Get the size of a List (e.g., result of split) |
+| **[smallint](/openmldb_sql/Files/udfs_8h.md#function-smallint)**()| |
+| **[split](/openmldb_sql/Files/udfs_8h.md#function-split)**()|
Split string to list by delimeter. Null values are skipped. |
+| **[split_array](/openmldb_sql/Files/udfs_8h.md#function-split-array)**()|
Split string to array of string by delimeter. |
+| **[split_by_key](/openmldb_sql/Files/udfs_8h.md#function-split-by-key)**()|
Split string by delimeter and split each segment as kv pair, then add each key to output list. Null or illegal segments are skipped. |
+| **[split_by_value](/openmldb_sql/Files/udfs_8h.md#function-split-by-value)**()|
Split string by delimeter and split each segment as kv pair, then add each value to output list. Null or illegal segments are skipped. |
+| **[sqrt](/openmldb_sql/Files/udfs_8h.md#function-sqrt)**()|
Return square root of expr. |
+| **[std](/openmldb_sql/Files/udfs_8h.md#function-std)**()| |
+| **[stddev](/openmldb_sql/Files/udfs_8h.md#function-stddev)**()|
Compute sample standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / (n-1) )`|
+| **[stddev_pop](/openmldb_sql/Files/udfs_8h.md#function-stddev-pop)**()|
Compute population standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / n )`|
+| **[stddev_samp](/openmldb_sql/Files/udfs_8h.md#function-stddev-samp)**()| |
+| **[strcmp](/openmldb_sql/Files/udfs_8h.md#function-strcmp)**()|
Returns 0 if the strings are the same, -1 if the first argument is smaller than the second according to the current sort order, and 1 otherwise. |
+| **[string](/openmldb_sql/Files/udfs_8h.md#function-string)**()|
Return string converted from timestamp expression. |
+| **[substr](/openmldb_sql/Files/udfs_8h.md#function-substr)**()| |
+| **[substring](/openmldb_sql/Files/udfs_8h.md#function-substring)**()|
Return a substring `len` characters long from string str, starting at position `pos`. Alias function: `substr`|
+| **[sum](/openmldb_sql/Files/udfs_8h.md#function-sum)**()|
Compute sum of values. |
+| **[sum_cate](/openmldb_sql/Files/udfs_8h.md#function-sum-cate)**()|
Compute sum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[sum_cate_where](/openmldb_sql/Files/udfs_8h.md#function-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[sum_where](/openmldb_sql/Files/udfs_8h.md#function-sum-where)**()|
Compute sum of values match specified condition. |
+| **[tan](/openmldb_sql/Files/udfs_8h.md#function-tan)**()|
Return the tangent of expr. |
+| **[timestamp](/openmldb_sql/Files/udfs_8h.md#function-timestamp)**()|
Cast int64, date or string expression to timestamp. |
+| **[top](/openmldb_sql/Files/udfs_8h.md#function-top)**()|
Compute top k of values and output string separated by comma. The outputs are sorted in desc order. |
+| **[top1_ratio](/openmldb_sql/Files/udfs_8h.md#function-top1-ratio)**()|
Compute the top1 occurring value's ratio. |
+| **[top_n_key_avg_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_count_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_max_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_min_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_ratio_cate](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
+| **[top_n_key_sum_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_avg_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_count_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_max_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_min_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_ratio_cate](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
+| **[top_n_value_sum_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[topn_frequency](/openmldb_sql/Files/udfs_8h.md#function-topn-frequency)**()|
Return the topN keys sorted by their frequency. |
+| **[truncate](/openmldb_sql/Files/udfs_8h.md#function-truncate)**()|
Return the nearest integer that is not greater in magnitude than the expr. |
+| **[ucase](/openmldb_sql/Files/udfs_8h.md#function-ucase)**()|
Convert all the characters to uppercase. Note that characters values > 127 are simply returned. |
+| **[unhex](/openmldb_sql/Files/udfs_8h.md#function-unhex)**()|
Convert hexadecimal to binary string. |
+| **[unix_timestamp](/openmldb_sql/Files/udfs_8h.md#function-unix-timestamp)**()|
Cast date or string expression to unix_timestamp. If empty string or NULL is provided, return current timestamp. |
+| **[upper](/openmldb_sql/Files/udfs_8h.md#function-upper)**()| |
+| **[var_pop](/openmldb_sql/Files/udfs_8h.md#function-var-pop)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / n`|
+| **[var_samp](/openmldb_sql/Files/udfs_8h.md#function-var-samp)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / (n-1)`|
+| **[variance](/openmldb_sql/Files/udfs_8h.md#function-variance)**()| |
+| **[week](/openmldb_sql/Files/udfs_8h.md#function-week)**()| |
+| **[weekofyear](/openmldb_sql/Files/udfs_8h.md#function-weekofyear)**()|
Return the week of year for a timestamp or date. |
+| **[window_split](/openmldb_sql/Files/udfs_8h.md#function-window-split)**()|
For each string value from specified column of window, split by delimeter and add segment to output list. Null values are skipped. |
+| **[window_split_by_key](/openmldb_sql/Files/udfs_8h.md#function-window-split-by-key)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each key to output list. Null and illegal segments are skipped. |
+| **[window_split_by_value](/openmldb_sql/Files/udfs_8h.md#function-window-split-by-value)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each value to output list. Null and illegal segments are skipped. |
+| **[year](/openmldb_sql/Files/udfs_8h.md#function-year)**()|
Return the year part of a timestamp or date. |
## Functions Documentation
@@ -501,13 +501,13 @@ Compute average of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -541,13 +541,13 @@ Compute average of values grouped by category key and output string. Each group
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -586,13 +586,13 @@ Compute average of values matching specified condition grouped by category key a
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -634,13 +634,13 @@ Compute average of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -884,7 +884,7 @@ SELECT COS(0);
-* The value returned by [cos()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-cos) is always in the range: -1 to 1.
+* The value returned by [cos()](/openmldb_sql/Files/udfs_8h.md#function-cos) is always in the range: -1 to 1.
**Supported Types**:
@@ -946,13 +946,13 @@ Compute number of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -987,13 +987,13 @@ Compute count of values grouped by category key and output string. Each group is
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -1032,13 +1032,13 @@ Compute count of values matching specified condition grouped by category key and
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -1080,13 +1080,13 @@ Compute number of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -1178,7 +1178,12 @@ Supported date string style:
* yyyy-mm-dd
* yyyymmdd
-* yyyy-mm-dd hh:mm:ss
+* yyyy-mm-dd HH:MM:SS
+* yyyy-mm-ddTHH:MM:SS.fff+HH:MM (RFC3399 format)
+
+Dates from string are transformed into the same time zone (which is currently always UTC+8) before differentiation, dates from date type by default is at UTC+8, you may see a +1/-1 difference if the two date string have different time zones.
+
+Hint: since openmldb date type limits range from year 1900, to datadiff from/to a date before 1900, pass it as string.
Example:
@@ -1225,7 +1230,7 @@ Return the day of the month for a timestamp or date.
0.1.0
-Note: This function equals the `[day()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-day)` function.
+Note: This function equals the `[day()](/openmldb_sql/Files/udfs_8h.md#function-day)` function.
Example:
@@ -1259,7 +1264,7 @@ Return the day of week for a timestamp or date.
0.4.0
-Note: This function equals the `[week()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-week)` function.
+Note: This function equals the `[week()](/openmldb_sql/Files/udfs_8h.md#function-week)` function.
Example:
@@ -1369,13 +1374,13 @@ Compute number of distinct values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 0 |
-| 2 |
-| 2 |
-| 4 |
+| 0 |
+| 0 |
+| 2 |
+| 2 |
+| 4 |
```sql
@@ -1445,14 +1450,14 @@ It requires that all values are non-negative. Negative values will be ignored.
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 8 |
-| 5 |
-| 2 |
-| 10 |
-| 4 |
+| 1 |
+| 8 |
+| 5 |
+| 2 |
+| 10 |
+| 4 |
```sql
@@ -1563,13 +1568,13 @@ It requires that values are ordered so that it can only be used with WINDOW (PAR
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -1647,11 +1652,11 @@ window w as (partition by gp order by ts rows between 3 preceding and current ro
```
-| id | gp | ts | agg |
+| id | gp | ts | agg |
| -------- | -------- | -------- | -------- |
-| 1 | 100 | 98 | 98 |
-| 2 | 100 | 99 | 99 |
-| 3 | 100 | 100 | 100 |
+| 1 | 100 | 98 | 98 |
+| 2 | 100 | 99 | 99 |
+| 3 | 100 | 100 | 100 |
@@ -2246,21 +2251,21 @@ Returns value evaluated at the row that is offset rows before the current row wi
* **offset** The number of rows forwarded from the current row, must not negative
-Note: This function equals the `[at()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-at)` function.
+Note: This function equals the `[at()](/openmldb_sql/Files/udfs_8h.md#function-at)` function.
-The offset in window is `nth_value()`, not `[lag()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lag)/at()`. The old `[at()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-at)`(version < 0.5.0) is start from the last row of window(may not be the current row), it's more like `nth_value()`
+The offset in window is `nth_value()`, not `[lag()](/openmldb_sql/Files/udfs_8h.md#function-lag)/at()`. The old `[at()](/openmldb_sql/Files/udfs_8h.md#function-at)`(version < 0.5.0) is start from the last row of window(may not be the current row), it's more like `nth_value()`
Example:
-| c1 | c2 |
+| c1 | c2 |
| -------- | -------- |
-| 0 | 1 |
-| 1 | 1 |
-| 2 | 2 |
-| 3 | 2 |
-| 4 | 2 |
+| 0 | 1 |
+| 1 | 1 |
+| 2 | 2 |
+| 3 | 2 |
+| 4 | 2 |
```sql
@@ -2648,13 +2653,13 @@ Compute maximum of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2691,13 +2696,13 @@ Compute maximum of values grouped by category key and output string. Each group
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -2736,13 +2741,13 @@ Compute maximum of values matching specified condition grouped by category key a
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -2784,13 +2789,13 @@ Compute maximum of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2856,12 +2861,12 @@ Compute the median of values.
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2898,13 +2903,13 @@ Compute minimum of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2941,13 +2946,13 @@ Compute minimum of values grouped by category key and output string. Each group
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -2986,14 +2991,14 @@ Compute minimum of values matching specified condition grouped by category key a
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 1 | true | y |
-| 4 | true | x |
-| 3 | true | y |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 1 | true | y |
+| 4 | true | x |
+| 3 | true | y |
```sql
@@ -3035,13 +3040,13 @@ Compute minimum of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -3171,12 +3176,12 @@ select col1, cond, gp, nth_value_where(col1, 2, cond) over (partition by gp orde
```
-| col1 | cond | gp | agg |
+| col1 | cond | gp | agg |
| -------- | -------- | -------- | -------- |
-| 1 | true | 100 | NULL |
-| 2 | false | 100 | NULL |
-| 3 | NULL | 100 | NULL |
-| 4 | true | 100 | 4 |
+| 1 | true | 100 | NULL |
+| 2 | false | 100 | NULL |
+| 3 | NULL | 100 | NULL |
+| 4 | true | 100 | 4 |
@@ -3563,7 +3568,7 @@ SELECT SIN(0);
-* The value returned by [sin()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sin) is always in the range: -1 to 1.
+* The value returned by [sin()](/openmldb_sql/Files/udfs_8h.md#function-sin) is always in the range: -1 to 1.
**Supported Types**:
@@ -3805,12 +3810,12 @@ Alias function: `std`, `stddev_samp`
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -3847,12 +3852,12 @@ Compute population standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2)
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -4008,13 +4013,13 @@ Compute sum of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -4048,13 +4053,13 @@ Compute sum of values grouped by category key and output string. Each group is r
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -4093,13 +4098,13 @@ Compute sum of values matching specified condition grouped by category key and o
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -4141,13 +4146,13 @@ Compute sum of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -4257,13 +4262,13 @@ Compute top k of values and output string separated by comma. The outputs are so
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
+| 4 |
```sql
@@ -4314,11 +4319,11 @@ SELECT key, top1_ratio(key) over () as ratio FROM t1;
```
-| key | ratio |
+| key | ratio |
| -------- | -------- |
-| 1 | 1.0 |
-| 2 | 0.5 |
-| NULL | 0.5 |
+| 1 | 1.0 |
+| 2 | 0.5 |
+| NULL | 0.5 |
@@ -4355,15 +4360,15 @@ Compute average of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4415,15 +4420,15 @@ Compute count of values matching specified condition grouped by category key. Ou
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4475,15 +4480,15 @@ Compute maximum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4535,15 +4540,15 @@ Compute minimum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4597,15 +4602,15 @@ For each group, ratio value is `value` expr count matches condtion divide total
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 2 | true | x |
-| 4 | true | x |
-| 1 | true | y |
-| 3 | false | y |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 2 | true | x |
+| 4 | true | x |
+| 1 | true | y |
+| 3 | false | y |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4656,15 +4661,15 @@ Compute sum of values matching specified condition grouped by category key. Outp
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4716,15 +4721,15 @@ Compute average of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | false | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | false | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4776,15 +4781,15 @@ Compute count of values matching specified condition grouped by category key. Ou
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | true | x |
-| 3 | false | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | true | x |
+| 3 | false | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4836,15 +4841,15 @@ Compute maximum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4896,15 +4901,15 @@ Compute minimum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | true | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | true | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4958,15 +4963,15 @@ For each group, ratio value is `value` expr count matches condtion divide total
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 2 | true | x |
-| 4 | true | x |
-| 1 | true | y |
-| 3 | false | y |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 2 | true | x |
+| 4 | true | x |
+| 1 | true | y |
+| 3 | false | y |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -5017,15 +5022,15 @@ Compute sum of values matching specified condition grouped by category key. Outp
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | false | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | false | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -5240,11 +5245,11 @@ Compute population variance of values, i.e., `sum((x_i - avg)^2) / n`
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 3 |
-| 6 |
+| 0 |
+| 3 |
+| 6 |
```sql
@@ -5281,11 +5286,11 @@ Compute population variance of values, i.e., `sum((x_i - avg)^2) / (n-1)`
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 3 |
-| 6 |
+| 0 |
+| 3 |
+| 6 |
```sql
diff --git a/docs/en/use_case/JD_recommendation_en.md b/docs/en/use_case/JD_recommendation_en.md
index 3a3a7df6f0a..089bb7e810b 100644
--- a/docs/en/use_case/JD_recommendation_en.md
+++ b/docs/en/use_case/JD_recommendation_en.md
@@ -52,7 +52,7 @@ Oneflow-serving:https://github.com/Oneflow-Inc/serving/tree/ce5d667468b6b3ba66
Pull the OpenMLDB docker image and run.
```bash
-docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.8.3 bash
+docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.8.4 bash
docker exec -it openmldb bash
```
diff --git a/docs/en/use_case/airflow_provider_demo.md b/docs/en/use_case/airflow_provider_demo.md
index bf430b7cce2..9019ba2c5a6 100644
--- a/docs/en/use_case/airflow_provider_demo.md
+++ b/docs/en/use_case/airflow_provider_demo.md
@@ -34,7 +34,7 @@ For the newest version, please visit [GitHub example_dags](https://github.com/4p
- Please project the previously downloaded files to the path `/work/airflow/dags`, where Airflow will access for the DAG.
```
-docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow/dags -it 4pdosc/openmldb:0.8.3 bash
+docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow/dags -it 4pdosc/openmldb:0.8.4 bash
```
#### 0.3 Download and Install the Airflow and the Airflow OpenMLDB Provider
diff --git a/docs/en/use_case/dolphinscheduler_task_demo.md b/docs/en/use_case/dolphinscheduler_task_demo.md
index 8f3d9b51e97..5a4a8e6bfb8 100644
--- a/docs/en/use_case/dolphinscheduler_task_demo.md
+++ b/docs/en/use_case/dolphinscheduler_task_demo.md
@@ -33,7 +33,7 @@ In addition to the feature engineering done by OpenMLDB, the prediction also req
The demo can run on MacOS or Linux, the OpenMLDB docker image is recommended. We'll start OpenMLDB and DolphinScheduler in the same container, expose the DolphinScheduler web port:
```
-docker run -it -p 12345:12345 4pdosc/openmldb:0.8.3 bash
+docker run -it -p 12345:12345 4pdosc/openmldb:0.8.4 bash
```
```{attention}
diff --git a/docs/en/use_case/kafka_connector_demo.md b/docs/en/use_case/kafka_connector_demo.md
index be6c17e9fae..70288b0001d 100644
--- a/docs/en/use_case/kafka_connector_demo.md
+++ b/docs/en/use_case/kafka_connector_demo.md
@@ -22,7 +22,7 @@ For OpenMLDB Kafka Connector implementation, please refer to [extensions/kafka-c
This article will start the OpenMLDB in docker container, so there is no need to download the OpenMLDB separately. Moreover, Kafka and connector can be started in the same container. We recommend that you save the three downloaded packages to the same directory. Let's assume that the packages are in the `/work/kafka` directory.
```
-docker run -it -v `pwd`:/work/kafka --name openmldb 4pdosc/openmldb:0.8.3 bash
+docker run -it -v `pwd`:/work/kafka --name openmldb 4pdosc/openmldb:0.8.4 bash
```
### Steps
diff --git a/docs/en/use_case/lightgbm_demo.md b/docs/en/use_case/lightgbm_demo.md
index f4e602373a6..c1310fdea66 100644
--- a/docs/en/use_case/lightgbm_demo.md
+++ b/docs/en/use_case/lightgbm_demo.md
@@ -13,7 +13,7 @@ Note that: (1) this case is based on the OpenMLDB cluster version for tutorial d
- Pull the OpenMLDB docker image and run the corresponding container:
```bash
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
The image is preinstalled with OpenMLDB and preset with all scripts, third-party libraries, open-source tools and training data required for this case.
@@ -152,7 +152,7 @@ Assuming that the model produced by the features designed in Section 2.3 in the
```sql
> USE demo_db;
> SET @@execute_mode='online';
-> DEPLOY demo SELECT trip_duration, passenger_count,
+> DEPLOY demo OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
diff --git a/docs/en/use_case/pulsar_connector_demo.md b/docs/en/use_case/pulsar_connector_demo.md
index 194195da3fd..dd3733d291b 100644
--- a/docs/en/use_case/pulsar_connector_demo.md
+++ b/docs/en/use_case/pulsar_connector_demo.md
@@ -29,7 +29,7 @@ Only OpenMLDB cluster mode can be the sink dist, and only write to online storag
We recommend that you use ‘host network’ to run docker. And bind volume ‘files’ too. The sql scripts are in it.
```
-docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.8.3 bash
+docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.8.4 bash
docker exec -it openmldb bash
```
```{note}
diff --git a/docs/en/use_case/talkingdata_demo.md b/docs/en/use_case/talkingdata_demo.md
index 4c0370d375f..a61fbaa95ce 100644
--- a/docs/en/use_case/talkingdata_demo.md
+++ b/docs/en/use_case/talkingdata_demo.md
@@ -13,7 +13,7 @@ It is recommended to run this demo in Docker. Please make sure that OpenMLDB and
**Start the OpenMLDB Docker Image**
```
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
#### 1.1.2 Run Locally
diff --git a/docs/poetry.lock b/docs/poetry.lock
index 01f5d11fa68..724b4f19340 100644
--- a/docs/poetry.lock
+++ b/docs/poetry.lock
@@ -1,4 +1,4 @@
-# This file is automatically @generated by Poetry 1.5.1 and should not be changed by hand.
+# This file is automatically @generated by Poetry 1.6.1 and should not be changed by hand.
[[package]]
name = "alabaster"
@@ -45,13 +45,13 @@ lxml = ["lxml"]
[[package]]
name = "certifi"
-version = "2022.12.7"
+version = "2023.7.22"
description = "Python package for providing Mozilla's CA Bundle."
optional = false
python-versions = ">=3.6"
files = [
- {file = "certifi-2022.12.7-py3-none-any.whl", hash = "sha256:4ad3232f5e926d6718ec31cfc1fcadfde020920e278684144551c91769c7bc18"},
- {file = "certifi-2022.12.7.tar.gz", hash = "sha256:35824b4c3a97115964b408844d64aa14db1cc518f6562e8d7261699d1350a9e3"},
+ {file = "certifi-2023.7.22-py3-none-any.whl", hash = "sha256:92d6037539857d8206b8f6ae472e8b77db8058fec5937a1ef3f54304089edbb9"},
+ {file = "certifi-2023.7.22.tar.gz", hash = "sha256:539cc1d13202e33ca466e88b2807e29f4c13049d6d87031a3c110744495cb082"},
]
[[package]]
@@ -670,17 +670,17 @@ test = ["coverage", "pytest", "pytest-cov"]
[[package]]
name = "urllib3"
-version = "1.26.12"
+version = "1.26.18"
description = "HTTP library with thread-safe connection pooling, file post, and more."
optional = false
-python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*, <4"
+python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*"
files = [
- {file = "urllib3-1.26.12-py2.py3-none-any.whl", hash = "sha256:b930dd878d5a8afb066a637fbb35144fe7901e3b209d1cd4f524bd0e9deee997"},
- {file = "urllib3-1.26.12.tar.gz", hash = "sha256:3fa96cf423e6987997fc326ae8df396db2a8b7c667747d47ddd8ecba91f4a74e"},
+ {file = "urllib3-1.26.18-py2.py3-none-any.whl", hash = "sha256:34b97092d7e0a3a8cf7cd10e386f401b3737364026c45e622aa02903dffe0f07"},
+ {file = "urllib3-1.26.18.tar.gz", hash = "sha256:f8ecc1bba5667413457c529ab955bf8c67b45db799d159066261719e328580a0"},
]
[package.extras]
-brotli = ["brotli (>=1.0.9)", "brotlicffi (>=0.8.0)", "brotlipy (>=0.6.0)"]
+brotli = ["brotli (==1.0.9)", "brotli (>=1.0.9)", "brotlicffi (>=0.8.0)", "brotlipy (>=0.6.0)"]
secure = ["certifi", "cryptography (>=1.3.4)", "idna (>=2.0.0)", "ipaddress", "pyOpenSSL (>=0.14)", "urllib3-secure-extra"]
socks = ["PySocks (>=1.5.6,!=1.5.7,<2.0)"]
diff --git a/docs/zh/deploy/compile.md b/docs/zh/deploy/compile.md
index aec38f6a5a3..6f08780e3e9 100644
--- a/docs/zh/deploy/compile.md
+++ b/docs/zh/deploy/compile.md
@@ -4,7 +4,7 @@
此节介绍在官方编译镜像 [hybridsql](https://hub.docker.com/r/4pdosc/hybridsql) 中编译 OpenMLDB,主要可以用于在容器内试用和开发目的。镜像内置了编译所需要的工具和依赖,因此不需要额外的步骤单独配置它们。关于基于非 docker 的编译使用方式,请参照下面的 [从源码全量编译](#从源码全量编译) 章节。
-对于编译镜像的版本,需要注意拉取的镜像版本和 [OpenMLDB 发布版本](https://github.com/4paradigm/OpenMLDB/releases)保持一致。以下例子演示了在 `hybridsql:0.8.3` 镜像版本上编译 [OpenMLDB v0.8.3](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.8.3) 的代码,如果要编译最新 `main` 分支的代码,则需要拉取 `hybridsql:latest` 版本镜像。
+对于编译镜像的版本,需要注意拉取的镜像版本和 [OpenMLDB 发布版本](https://github.com/4paradigm/OpenMLDB/releases)保持一致。以下例子演示了在 `hybridsql:0.8.4` 镜像版本上编译 [OpenMLDB v0.8.4](https://github.com/4paradigm/OpenMLDB/releases/tag/v0.8.4) 的代码,如果要编译最新 `main` 分支的代码,则需要拉取 `hybridsql:latest` 版本镜像。
1. 下载 docker 镜像
```bash
@@ -16,10 +16,10 @@
docker run -it 4pdosc/hybridsql:0.8 bash
```
-3. 在 docker 容器内, 克隆 OpenMLDB, 并切换分支到 v0.8.3
+3. 在 docker 容器内, 克隆 OpenMLDB, 并切换分支到 v0.8.4
```bash
cd ~
- git clone -b v0.8.3 https://github.com/4paradigm/OpenMLDB.git
+ git clone -b v0.8.4 https://github.com/4paradigm/OpenMLDB.git
```
4. 在 docker 容器内编译 OpenMLDB
@@ -110,7 +110,7 @@ make CMAKE_BUILD_TYPE=Debug
- CMAKE_EXTRA_FLAGS: 传递给 cmake 的额外参数
- 默认: ‘’
+ 默认: ''
- BUILD_BUNDLED: 从源码编译 thirdparty 依赖,而不是下载预编译包
@@ -124,6 +124,9 @@ make CMAKE_BUILD_TYPE=Debug
默认: all
+- THIRD_PARTY_CMAKE_FLAGS: 编译thirdparty时可以配置额外参数。例如,配置每个thirdparty项目并发编译,`THIRD_PARTY_CMAKE_FLAGS=-DMAKEOPTS=-j8`。thirdparty不受NPROC影响,thirdparty的多项目将会串行执行。
+ 默认:''
+
### 并发编译Java SDK
```
@@ -141,7 +144,7 @@ make SQL_JAVASDK_ENABLE=ON NPROC=4
1. 下载预编译的OpenMLDB Spark发行版。
```bash
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.3/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.4/spark-3.2.1-bin-openmldbspark.tgz
```
或者下载源代码并从头开始编译。
@@ -185,14 +188,25 @@ docker run -it -v`pwd`:/root/OpenMLDB ghcr.io/4paradigm/centos6_gcc7_hybridsql b
```bash
cd OpenMLDB
bash steps/centos6_build.sh
+# THIRD_PARTY_CMAKE_FLAGS=-DMAKEOPTS=-j8 bash steps/centos6_build.sh # run fast when build single project
# OPENMLDB_SOURCE=true bash steps/centos6_build.sh
-# SQL_JAVASDK_ENABLE=ON SQL_PYSDK_ENABLE=ON NRPOC=8 bash steps/centos6_build.sh
+# SQL_JAVASDK_ENABLE=ON SQL_PYSDK_ENABLE=ON NPROC=8 bash steps/centos6_build.sh # NPROC will build openmldb in parallel, thirdparty should use THIRD_PARTY_CMAKE_FLAGS
```
+本地2.20GHz CPU,SSD硬盘,32线程编译三方库与OpenMLDB主体,耗时参考:
+`THIRD_PARTY_CMAKE_FLAGS=-DMAKEOPTS=-j32 SQL_JAVASDK_ENABLE=ON SQL_PYSDK_ENABLE=ON NPROC=32 bash steps/centos6_build.sh`
+- thirdparty(不包括下载src时间)~40m:zetasql打patch 13m,所有thirdparty编译30m
+- OpenMLDB 本体,包括python和java native,~12min
+
#### 云编译
-Fork OpenMLDB仓库后,可以使用在`Actions`中触发workflow `Other OS Build`,编译产出在`Actions`的`Artifacts`中。workflow 配置 `os name`为`centos6`,
-如果不需要Java或Python SDK,可配置`java sdk enable`或`python sdk enable`为`OFF`,节约编译时间。
+Fork OpenMLDB仓库后,可以使用在`Actions`中触发workflow `Other OS Build`,编译产出在`Actions`的`Artifacts`中。workflow 配置方式:
+- 不要更换`Use workflow from`为某个tag,可以是其他分支。
+- 选择`os name`为`centos6`。
+- 如果不是编译main分支,在`The branch, tag or SHA to checkout, otherwise use the branch`中填写想要的分支名、Tag(e.g. v0.8.4)或SHA。
+- 编译产出在触发后的runs界面中,参考[成功产出的runs链接](https://github.com/4paradigm/OpenMLDB/actions/runs/6044951902)。
+ - 一定会产出openmldb binary文件。
+ - 如果不需要Java或Python SDK,可配置`java sdk enable`或`python sdk enable`为`OFF`,节约编译时间。
此编译流程需要从源码编译thirdparty,且资源较少,无法开启较高的并发编译。因此编译时间较长,大约需要3h5m(2h thirdparty+1h OpenMLDB)。workflow会缓存thirdparty的编译产出,因此第二次编译会快很多(1h15m OpenMLDB)。
diff --git a/docs/zh/deploy/conf.md b/docs/zh/deploy/conf.md
index ef05f0c8dc9..de538720e5d 100644
--- a/docs/zh/deploy/conf.md
+++ b/docs/zh/deploy/conf.md
@@ -9,6 +9,8 @@
# 如果是部署单机版不需要配置zk_cluster和zk_root_path,把这俩配置注释即可. 部署集群版需要配置这两项,一个集群中所有节点的这两个配置必须保持一致
#--zk_cluster=127.0.0.1:7181
#--zk_root_path=/openmldb_cluster
+# 配置zk认证的用户名和密码, 用冒号分割
+#--zk_cert=user:passwd
# 单机版需要指定tablet的地址, 集群版此配置可忽略
--tablet=127.0.0.1:9921
# 配置log目录
@@ -76,6 +78,8 @@
# 如果启动集群版需要指定zk的地址和集群在zk的节点路径
#--zk_cluster=127.0.0.1:7181
#--zk_root_path=/openmldb_cluster
+# 配置zk认证的用户名和密码, 用冒号分割
+#--zk_cert=user:passwd
# 配置线程池大小,建议和cpu核数一致
--thread_pool_size=24
@@ -222,6 +226,8 @@
# 如果部署的openmldb是集群版,需要指定zk地址和集群zk节点目录
#--zk_cluster=127.0.0.1:7181
#--zk_root_path=/openmldb_cluster
+# 配置zk认证的用户名和密码, 用冒号分割
+#--zk_cert=user:passwd
# 配置日志路径
--openmldb_log_dir=./logs
@@ -254,6 +260,7 @@ zookeeper.connection_timeout=5000
zookeeper.max_retries=10
zookeeper.base_sleep_time=1000
zookeeper.max_connect_waitTime=30000
+#zookeeper.cert=user:passwd
# Spark Config
spark.home=
diff --git a/docs/zh/deploy/index.rst b/docs/zh/deploy/index.rst
index 29007be2d86..91a3116489e 100644
--- a/docs/zh/deploy/index.rst
+++ b/docs/zh/deploy/index.rst
@@ -8,6 +8,5 @@
install_deploy
conf
compile
- integrate_hadoop
offline_integrate_kubernetes
[Alpha]在线引擎基于 Kubernetes 部署
diff --git a/docs/zh/deploy/install_deploy.md b/docs/zh/deploy/install_deploy.md
index d060cce3b01..84f3e05ff98 100644
--- a/docs/zh/deploy/install_deploy.md
+++ b/docs/zh/deploy/install_deploy.md
@@ -47,17 +47,17 @@ strings /lib64/libc.so.6 | grep ^GLIBC_
### Linux 平台预测试
-由于 Linux 平台的多样性,发布包可能在你的机器上不兼容,请先通过简单的运行测试。比如,下载预编译包 `openmldb-0.8.3-linux.tar.gz` 以后,运行:
+由于 Linux 平台的多样性,发布包可能在你的机器上不兼容,请先通过简单的运行测试。比如,下载预编译包 `openmldb-0.8.4-linux.tar.gz` 以后,运行:
```
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-./openmldb-0.8.3-linux/bin/openmldb --version
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+./openmldb-0.8.4-linux/bin/openmldb --version
```
结果应显示该程序的版本号,类似
```
-openmldb version 0.8.3-xxxx
+openmldb version 0.8.4-xxxx
Debug build (NDEBUG not #defined)
```
@@ -171,9 +171,9 @@ DataCollector和SyncTool暂不支持一键部署。请参考手动部署方式
### 下载OpenMLDB发行版
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-cd openmldb-0.8.3-linux
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+cd openmldb-0.8.4-linux
```
### 环境配置
@@ -181,7 +181,7 @@ cd openmldb-0.8.3-linux
| 环境变量 | 默认值 | 定义 |
|-----------------------------------|------------------------------------|-------------------------------------------------------------------------|
-| OPENMLDB_VERSION | 0.8.3 | OpenMLDB版本 |
+| OPENMLDB_VERSION | 0.8.4 | OpenMLDB版本 |
| OPENMLDB_MODE | standalone | standalone或者cluster |
| OPENMLDB_HOME | 当前发行版的根目录 | openmldb发行版根目录 |
| SPARK_HOME | $OPENMLDB_HOME/spark | openmldb spark发行版根目录,如果该目录不存在,自动从网上下载 |
@@ -348,10 +348,10 @@ bash bin/zkCli.sh -server 172.27.128.33:7181
**1. 下载OpenMLDB部署包**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-tablet-0.8.3
-cd openmldb-tablet-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-tablet-0.8.4
+cd openmldb-tablet-0.8.4
```
**2. 修改配置文件`conf/tablet.flags`**
```bash
@@ -402,12 +402,12 @@ Start tablet success
在另一台机器启动下一个TabletServer只需在该机器上重复以上步骤。如果是在同一个机器上启动下一个TabletServer,请保证是在另一个目录中,不要重复使用已经启动过TabletServer的目录。
-比如,可以再次解压压缩包(不要cp已经启动过TabletServer的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-tablet-0.8.3-2`。
+比如,可以再次解压压缩包(不要cp已经启动过TabletServer的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-tablet-0.8.4-2`。
```
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-tablet-0.8.3-2
-cd openmldb-tablet-0.8.3-2
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-tablet-0.8.4-2
+cd openmldb-tablet-0.8.4-2
```
再修改配置并启动。注意,TabletServer如果都在同一台机器上,请使用不同端口号,否则日志(logs/tablet.WARNING)中将会有"Fail to listen"信息。
@@ -421,10 +421,10 @@ cd openmldb-tablet-0.8.3-2
```
**1. 下载OpenMLDB部署包**
````
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-ns-0.8.3
-cd openmldb-ns-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-ns-0.8.4
+cd openmldb-ns-0.8.4
````
**2. 修改配置文件conf/nameserver.flags**
```bash
@@ -462,12 +462,12 @@ NameServer 可以只存在一台,如果你需要高可用性,可以部署多
在另一台机器启动下一个 NameServer 只需在该机器上重复以上步骤。如果是在同一个机器上启动下一个 NameServer,请保证是在另一个目录中,不要重复使用已经启动过 namserver 的目录。
-比如,可以再次解压压缩包(不要cp已经启动过 namserver 的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-ns-0.8.3-2`。
+比如,可以再次解压压缩包(不要cp已经启动过 namserver 的目录,启动后的生成文件会造成影响),并命名目录为`openmldb-ns-0.8.4-2`。
```
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-ns-0.8.3-2
-cd openmldb-ns-0.8.3-2
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-ns-0.8.4-2
+cd openmldb-ns-0.8.4-2
```
然后再修改配置并启动。
@@ -505,10 +505,10 @@ APIServer负责接收http请求,转发给OpenMLDB集群并返回结果。它
**1. 下载OpenMLDB部署包**
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-apiserver-0.8.3
-cd openmldb-apiserver-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-apiserver-0.8.4
+cd openmldb-apiserver-0.8.4
```
**2. 修改配置文件conf/apiserver.flags**
@@ -563,18 +563,18 @@ TaskManager 可以只存在一台,如果你需要高可用性,可以部署
Spark发行版:
```shell
-wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.3/spark-3.2.1-bin-openmldbspark.tgz
-# 中国镜像地址:http://43.138.115.238/download/v0.8.3/spark-3.2.1-bin-openmldbspark.tgz
+wget https://github.com/4paradigm/spark/releases/download/v3.2.1-openmldb0.8.4/spark-3.2.1-bin-openmldbspark.tgz
+# 中国镜像地址:http://43.138.115.238/download/v0.8.4/spark-3.2.1-bin-openmldbspark.tgz
tar -zxvf spark-3.2.1-bin-openmldbspark.tgz
export SPARK_HOME=`pwd`/spark-3.2.1-bin-openmldbspark/
```
OpenMLDB部署包:
```
-wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.3/openmldb-0.8.3-linux.tar.gz
-tar -zxvf openmldb-0.8.3-linux.tar.gz
-mv openmldb-0.8.3-linux openmldb-taskmanager-0.8.3
-cd openmldb-taskmanager-0.8.3
+wget https://github.com/4paradigm/OpenMLDB/releases/download/v0.8.4/openmldb-0.8.4-linux.tar.gz
+tar -zxvf openmldb-0.8.4-linux.tar.gz
+mv openmldb-0.8.4-linux openmldb-taskmanager-0.8.4
+cd openmldb-taskmanager-0.8.4
```
**2. 修改配置文件conf/taskmanager.properties**
diff --git a/docs/zh/developer/built_in_function_develop_guide.md b/docs/zh/developer/built_in_function_develop_guide.md
index 12231384078..cbc186005cf 100644
--- a/docs/zh/developer/built_in_function_develop_guide.md
+++ b/docs/zh/developer/built_in_function_develop_guide.md
@@ -1034,10 +1034,9 @@ RegisterUdafTemplate("distinct_count")
## 6. 文档管理
-内置函数文档可在 [Built-in Functions](https://openmldb.ai/docs/zh/main/openmldb_sql/functions_and_operators/Files/udfs_8h.html) 查看,它是一个代码生成的 markdown 文件,注意请不要进行直接编辑。
+内置函数文档可在 [Built-in Functions](../openmldb_sql/udfs_8h.md) 查看,它是一个代码生成的 markdown 文件,注意请不要进行直接编辑。
-- 如果需要对新增加的函数添加文档,请参照 2.2.4 配置函数文档 章节,说明了内置函数的文档是在 CPP 源代码中管理的。后续会通过一系列步骤生成如上网页中更加可读的文档, 即`docs/*/openmldb_sql/functions_and_operators/`目录下的内容。
+- 如果需要对新增加的函数添加文档,请参照 2.2.4 配置函数文档 章节,说明了内置函数的文档是在 CPP 源代码中管理的。后续会通过一系列步骤生成如上网页中更加可读的文档, 即`docs/*/openmldb_sql/`目录下的内容。
- 如果需要修改一个已存在函数的文档,可以在文件 `hybridse/src/udf/default_udf_library.cc` 或者 `hybridse/src/udf/default_defs/*_def.cc` 下查找到对应函数的文档说明,进行修改。
OpenMLDB 项目中创建了一个定期天级别的 GitHub Workflow 任务来定期更新这里的相关文档。因此内置函数文档相关的改动只需按照上面的步骤修改对应源代码位置的内容即可,`docs` 目录和网站的内容会随之定期更新。具体的文档生成流程可以查看源代码路径下的 [udf_doxygen](https://github.com/4paradigm/OpenMLDB/tree/main/hybridse/tools/documentation/udf_doxygen)。
-
diff --git a/docs/zh/faq/client_faq.md b/docs/zh/faq/client_faq.md
new file mode 100644
index 00000000000..894cca02e57
--- /dev/null
+++ b/docs/zh/faq/client_faq.md
@@ -0,0 +1,88 @@
+# Client FAQ
+
+## fail to get tablet ... 的错误日志
+
+优先检查集群中tablet server是否意外下线,或者在线表是否不可读写。推荐通过[openmldb_tool](../maintain/diagnose.md)诊断,使用`status`(status --diff)和`inspect online`两个检查命令。
+TODO diag tool 测到offline或online表不正常,会输出警告和下一步应该怎么操作?
+如果只能手动检查,需要两步:
+- `show components`,检查server是否存在在列表中(TaskManager如果下线,将不在表中。Tablet如果下线,将在表中,但状态为offline),以及在列表中的server的状态是否为online。如果存在offline的server,**先将server重启加入集群**。
+- `show table status like '%'`(低版本如果不支持like,需要分别查询系统db和用户db),检查每个表的"Warnings"是否报错。
+
+一般会得到`real replica number X does not match the configured replicanum X`等错误,具体错误信息请参考[SHOW TABLE STATUS](../openmldb_sql/ddl/SHOW_TABLE_STATUS.md)。这些错误都说明表目前是有问题的,无法提供正常读写功能,通常是由于Tablet
+
+## 为什么收到 Reached timeout 的警告日志?
+```
+rpc_client.h:xxx] request error. [E1008] Reached timeout=xxxms
+```
+这是由于client端本身发送的rpc request的timeout设置小了,client端自己主动断开,注意这是rpc的超时。需要更改通用的`request_timeout`配置。
+1. CLI: 启动时配置`--request_timeout_ms`
+2. JAVA/Python SDK: Option或url中调整`SdkOption.requestTimeout`
+```{note}
+同步的离线命令通常不会出现这个错误,因为同步离线命令的timeout设置为了TaskManager可接受的最长时间。
+```
+
+## 为什么收到 Got EOF of Socket 的警告日志?
+```
+rpc_client.h:xxx] request error. [E1014]Got EOF of Socket{id=x fd=x addr=xxx} (xx)
+```
+这是因为`addr`端主动断开了连接,`addr`的地址大概率是TaskManager。这不代表TaskManager不正常,而是TaskManager端认为这个连接没有活动,超过keepAliveTime了,而主动断开通信channel。
+在0.5.0及以后的版本中,可以调大TaskManager的`server.channel_keep_alive_time`来提高对不活跃channel的容忍度。默认值为1800s(0.5h),特别是使用同步的离线命令时,这个值可能需要适当调大。
+在0.5.0以前的版本中,无法更改此配置,请升级TaskManager版本。
+
+## 离线查询结果显示中文为什么乱码?
+
+在使用离线查询时,可能出现包含中文的查询结果乱码,主要和系统默认编码格式与Spark任务编码格式参数有关。
+
+如果出现乱码情况,可以通过添加Spark高级参数`spark.driver.extraJavaOptions=-Dfile.encoding=utf-8`和`spark.executor.extraJavaOptions=-Dfile.encoding=utf-8`来解决。
+
+客户端配置方法可参考[客户端Spark配置文件](../reference/client_config/client_spark_config.md),也可以在TaskManager配置文件中添加此项配置。
+
+```
+spark.default.conf=spark.driver.extraJavaOptions=-Dfile.encoding=utf-8;spark.executor.extraJavaOptions=-Dfile.encoding=utf-8
+```
+
+## 如何配置TaskManager来访问开启Kerberos的Yarn集群?
+
+如果Yarn集群开启Kerberos认证,TaskManager可以通过添加以下配置来访问开启Kerberos认证的Yarn集群。注意请根据实际配置修改keytab路径以及principal账号。
+
+```
+spark.default.conf=spark.yarn.keytab=/tmp/test.keytab;spark.yarn.principal=test@EXAMPLE.COM
+```
+
+## 如何配置客户端的core日志?
+
+客户端core日志主要有两种,zk日志和sdk日志(glog日志),两者是独立的。
+
+zk日志:
+1. CLI:启动时配置`--zk_log_level`调整level,`--zk_log_file`配置日志保存文件。
+2. JAVA/Python SDK:Option或url中使用`zkLogLevel`调整level,`zkLogFile`配置日志保存文件。
+
+- `zk_log_level`(int, 默认=0, 即DISABLE_LOGGING):
+打印这个等级及**以下**等级的日志。0-禁止所有zk log, 1-error, 2-warn, 3-info, 4-debug。
+
+sdk日志(glog日志):
+1. CLI:启动时配置`--glog_level`调整level,`--glog_dir`配置日志保存文件。
+2. JAVA/Python SDK:Option或url中使用`glogLevel`调整level,`glogDir`配置日志保存文件。
+
+- `glog_level`(int, 默认=1, 即WARNING):
+打印这个等级及**以上**等级的日志。 INFO, WARNING, ERROR, and FATAL日志分别对应 0, 1, 2, and 3。
+
+
+## 插入错误,日志显示`please use getInsertRow with ... first`
+
+在JAVA client使用InsertPreparedStatement进行插入,或在Python中使用sql和parameter进行插入时,client底层实际有cache影响,第一步`getInsertRow`生成sql cache并返回sql还需要补充的parameter信息,第二步才会真正执行insert,而执行insert需要使用第一步缓存的sql cache。所以,当多线程使用同一个client时,可能因为插入和查询频繁更新cache表,将你想要执行的insert sql cache淘汰掉了,所以会出现好像第一步`getInsertRow`并未执行的样子。
+
+目前可以通过调大`maxSqlCacheSize`这一配置项来避免错误。仅JAVA/Python SDK支持配置。
+
+## 离线命令Spark报错
+
+`java.lang.OutOfMemoryError: Java heap space`
+
+离线命令的Spark配置默认为`local[*]`,并发较高可能出现OutOfMemoryError错误,请调整`spark.driver.memory`和`spark.executor.memory`两个spark配置项。可以写在TaskManager运行目录的`conf/taskmanager.properties`的`spark.default.conf`并重启TaskManager,或者使用CLI客户端进行配置,参考[客户端Spark配置文件](../reference/client_config/client_spark_config.md)。
+```
+spark.default.conf=spark.driver.memory=16g;spark.executor.memory=16g
+```
+
+Container killed by YARN for exceeding memory limits. 5 GB of 5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
+
+local时drivermemory
diff --git a/docs/zh/faq/index.rst b/docs/zh/faq/index.rst
new file mode 100644
index 00000000000..a5d1e94a540
--- /dev/null
+++ b/docs/zh/faq/index.rst
@@ -0,0 +1,10 @@
+=============================
+FAQ
+=============================
+
+
+.. toctree::
+ :maxdepth: 1
+
+ client_faq
+ server_faq
diff --git a/docs/zh/faq/server_faq.md b/docs/zh/faq/server_faq.md
new file mode 100644
index 00000000000..1b89fd383d6
--- /dev/null
+++ b/docs/zh/faq/server_faq.md
@@ -0,0 +1,61 @@
+# Server FAQ
+
+Server中有任何上下线变化或问题,都先openmldb_tool status + inspect online检查下集群是否正常。
+
+## 部署和启动 FAQ
+
+### 1. 如何确认集群已经正常运行?
+虽然有一键启动脚本,但由于配置繁多,可能出现“端口已被占用”,“目录无读写权限”等问题。这些问题都是server进程运行之后才能发现,退出后没有及时反馈。(如果配置了监控,可以通过监控直接检查。)
+所以,请先确认集群的所有server进程都正常运行。
+
+可以通过`ps axu | grep openmldb`或sql命令`show components;`来查询。(注意,如果你使用了守护进程,openmldb server进程可能是在启动停止的循环中,并不代表持续运行,可以通过日志或`show components;`连接时间来确认。)
+
+如果进程都活着,集群还是表现不正常,需要查询一下server日志。可以优先看WARN和ERROR级日志,很大概率上,它们就是根本原因。
+
+### 2. 如果数据没有自动恢复成功怎么办?
+
+通常情况,当我们重启服务,表中数据会自动进行恢复,但有些情况可能会造成恢复失败,通常失败的情况包括:
+
+- tablet异常退出
+- 多副本表多个副本所在的tablets同时重启或者重启太快,造成某些`auto_failover`操作还没完成tablet就重启
+- auto_failover设成`false`
+
+当服务启动成功后,可以通过`gettablestatus`获得所有表的状态:
+```
+python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=172.24.4.40:30481 --zk_root_path=/openmldb --cmd=gettablestatus
+```
+
+如果表中有`Warnings`,可以通过`recoverdata`来自动恢复数据:
+```
+python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=172.24.4.40:30481 --zk_root_path=/openmldb --cmd=recoverdata
+```
+
+## Server FAQ
+
+### 1. 为什么日志中有 Fail to write into Socket 的警告日志?
+```
+http_rpc_protocol.cpp:911] Fail to write into Socket{id=xx fd=xx addr=xxx} (0x7a7ca00): Unknown error 1014 [1014]
+```
+这是server端会打印的日志。一般是client端使用了连接池或短连接模式,在RPC超时后会关闭连接,server写回response时发现连接已经关了就报这个错。Got EOF就是指之前已经收到了EOF(对端正常关闭了连接)。client端使用单连接模式server端一般不会报这个。
+
+### 2. 表数据的ttl初始设置不合适,如何调整?
+这需要使用nsclient来修改,普通client无法做到。nsclient启动方式与命令,见[ns client](../maintain/cli.md#ns-client)。
+
+在nsclient中使用命令`setttl`可以更改一个表的ttl,类似
+```
+setttl table_name ttl_type ttl [ttl] [index_name]
+```
+可以看到,如果在命令末尾配置index的名字,可以做到只修改单个index的ttl。
+```{caution}
+`setttl`的改变不会及时生效,会受到tablet server的配置`gc_interval`的影响。(每台tablet server的配置是独立的,互不影响。)
+
+举例说明,有一个tablet server的`gc_interval`是1h,那么ttl的配置重载,会在下一次gc的最后时刻进行(最坏情况下,会在1h后重载)。重载ttl的这一次gc就不会按最新ttl来淘汰数据。再下一次gc时才会使用最新ttl进行数据淘汰。
+
+所以,**ttl更改后,需要等待两次gc interval的时间才会生效**。请耐心等待。
+
+当然,你可以调整tablet server的`gc_interval`,但这个配置无法动态更改,只能重启生效。所以,如果内存压力较大,可以尝试扩容,迁移数据分片,来减少内存压力。不推荐轻易调整`gc_interval`。
+```
+
+### 3. 出现警告日志:Last Join right table is empty,这是什么意思?
+通常来讲,这是一个正常现象,不代表集群异常。只是runner中join右表为空,是可能的现象,大概率是数据问题。
+
diff --git a/docs/zh/index.rst b/docs/zh/index.rst
index 1a3fd0deb56..f3b3f63106b 100644
--- a/docs/zh/index.rst
+++ b/docs/zh/index.rst
@@ -16,3 +16,4 @@ OpenMLDB 文档 (|version|)
maintain/index
reference/index
developer/index
+ faq/index
diff --git a/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md b/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
index 926c079469d..f3c570fe75b 100644
--- a/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
+++ b/docs/zh/integration/deploy_integration/OpenMLDB_Byzer_taxi.md
@@ -13,7 +13,7 @@
执行命令如下:
```
-docker run --network host -dit --name openmldb -v /mlsql/admin/:/byzermnt 4pdosc/openmldb:0.8.3 bash
+docker run --network host -dit --name openmldb -v /mlsql/admin/:/byzermnt 4pdosc/openmldb:0.8.4 bash
docker exec -it openmldb bash
/work/init.sh
echo "create database db1;" | /work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client
@@ -232,7 +232,7 @@ and `sql-0`='''
SET @@execute_mode='online';
'''
and `sql-1`='''
-DEPLOY d1 SELECT trip_duration, passenger_count,
+DEPLOY d1 OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
diff --git a/docs/zh/integration/deploy_integration/airflow_provider_demo.md b/docs/zh/integration/deploy_integration/airflow_provider_demo.md
index 5e8a77df979..a6cc0ee0dc3 100644
--- a/docs/zh/integration/deploy_integration/airflow_provider_demo.md
+++ b/docs/zh/integration/deploy_integration/airflow_provider_demo.md
@@ -17,9 +17,9 @@ DAG流程如上图所示,首先建表,然后进行离线数据导入与特
我们导入上述的DAG完成TalkingData Demo中的特征计算与上线,并使用TalkingData Demo的predict server来进行上线后的实时推理测试。
-### 0 准备
+### 准备工作
-#### 0.1 下载DAG
+#### 下载DAG
除了DAG文件,还需要训练的脚本,所以我们提供了[下载包](https://openmldb.ai/download/airflow_demo/airflow_demo_files.tar.gz),可以直接下载。如果想要使用最新版本,请在[github example_dags](https://github.com/4paradigm/OpenMLDB/tree/main/extensions/airflow-provider-openmldb/openmldb_provider/example_dags)中获取。
@@ -28,24 +28,24 @@ wget https://openmldb.ai/download/airflow_demo/airflow_demo_files.tar.gz
tar zxf airflow_demo_files.tar.gz
ls airflow_demo_files
```
-#### 0.2 启动镜像
+#### 启动镜像
我们推荐使用docker镜像直接启动OpenMLDB,并在docker内部安装启动Airflow。
登录Airflow Web需要对外端口,所以此处暴露容器的端口。并且直接将上一步下载的文件映射到`/work/airflow/dags`,接下来Airflow将加载此文件夹的DAG。
```
-docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.8.3 bash
+docker run -p 8080:8080 -v `pwd`/airflow_demo_files:/work/airflow_demo_files -it 4pdosc/openmldb:0.8.4 bash
```
-#### 0.3 下载安装Airflow与Airflow OpenMLDB Provider
+#### 下载安装Airflow与Airflow OpenMLDB Provider
在docker容器中,执行:
```
pip3 install airflow-provider-openmldb
```
由于airflow-provider-openmldb依赖airflow,所以会一起下载。
-#### 0.4 源数据与DAG准备
+#### 源数据与DAG准备
由于在DAG中导入数据用的文件为`/tmp/train_sample.csv`,所以我们需要将sample数据文件拷贝到tmp目录。Airflow 的DAG文件和DAG中使用的训练脚本也需要拷贝到airflow目录中。
```
cp /work/airflow_demo_files/train_sample.csv /tmp/
@@ -53,7 +53,7 @@ mkdir -p /work/airflow/dags
cp /work/airflow_demo_files/example_openmldb_complex.py /work/airflow_demo_files/xgboost_train_sample.py /work/airflow/dags
```
-### 1 启动OpenMLDB与Airflow
+### 步骤1:启动OpenMLDB与Airflow
以下命令将启动OpenMLDB cluster,支持上线并测试的predict server,与Airflow standalone。
```
/work/init.sh
@@ -73,7 +73,7 @@ Airflow standalone运行输出将提示登录用户名和密码,如下图所
`airflow standalone`为前台程序,退出即airflow退出。你可以在dag运行完成后再退出airflow进行[第三步————测试](#3-测试),或者将airflow进程放入后台。
```
-### 2 运行DAG
+### 步骤2:运行DAG
在Airflow Web中点击DAG example_openmldb_complex,可以点击`Code`查看DAG的详情,见下图。

@@ -82,7 +82,7 @@ Airflow standalone运行输出将提示登录用户名和密码,如下图所

-#### 2.1 创建connection
+#### 创建connection
在管理界面中点击connection。

@@ -96,15 +96,15 @@ Airflow OpenMLDB Provider是连接OpenMLDB Api Server的,所以此处配置中
创建完成后的connection如下图所示。

-#### 2.2 运行DAG
+#### 运行DAG
运行dag,即完成一次训练模型、sql部署与模型部署。成功运行的结果,类似下图。

-### 3 测试
+### 步骤3:测试
Airflow如果在容器中是前台运行的,现在可以退出,以下测试将不依赖airflow。
-#### 3.1 在线导入
+#### 在线导入
Airflow DAG中完成了SQL和模型的上线。但在线存储中还没有数据,所以我们需要做一次在线数据导入。
```
curl -X POST http://127.0.0.1:9080/dbs/example_db -d'{"mode":"online", "sql":"load data infile \"file:///tmp/train_sample.csv\" into table example_table options(mode=\"append\");"}'
@@ -115,7 +115,7 @@ curl -X POST http://127.0.0.1:9080/dbs/example_db -d'{"mode":"online", "sql":"lo
curl -X POST http://127.0.0.1:9080/dbs/example_db -d'{"mode":"online", "sql":"show jobs"}'
```
-#### 3.2 预测
+#### 预测
执行预测脚本,进行一次预测,预测将使用新部署好的sql与模型。
```
python3 /work/airflow_demo_files/predict.py
diff --git a/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md b/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md
index da484e5dad7..f24e668ed17 100644
--- a/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md
+++ b/docs/zh/integration/deploy_integration/dolphinscheduler_task_demo.md
@@ -31,7 +31,7 @@ OpenMLDB 希望能达成开发即上线的目标,让开发回归本质,而
测试可以在macOS或Linux上运行,推荐在我们提供的 OpenMLDB 镜像内进行演示测试。我们将在这个容器中启动OpenMLDB和DolphinScheduler,暴露DolphinScheduler的web端口:
```
-docker run -it -p 12345:12345 4pdosc/openmldb:0.8.3 bash
+docker run -it -p 12345:12345 4pdosc/openmldb:0.8.4 bash
```
```{attention}
DolphinScheduler 需要配置租户,是操作系统的用户,并且该用户需要有 sudo 权限。所以推荐在 OpenMLDB 容器内下载并启动 DolphinScheduler。否则,请准备有sudo权限的操作系统用户。
@@ -108,7 +108,7 @@ DolphinScheduler 的 worker server 需要 OpenMLDB Python SDK, DolphinScheduler
### Demo 演示
-#### 1. 初始配置
+#### 步骤1:初始配置
在 DolphinScheduler Web中创建租户,进入租户管理界面,填写**有 sudo 权限的操作系统用户**,queue 可以使用 default。docker容器内可直接使用root用户。
@@ -121,7 +121,7 @@ DolphinScheduler 的 worker server 需要 OpenMLDB Python SDK, DolphinScheduler
绑定后,用户状态类似下图。

-#### 2. 创建工作流
+#### 步骤2:创建工作流
DolphinScheduler 中,需要先创建项目,再在项目中创建工作流。
所以,首先创建一个test项目,如下图所示,点击创建项目并进入项目。
@@ -155,7 +155,7 @@ DolphinScheduler 中,需要先创建项目,再在项目中创建工作流。

-#### 3. 上线运行工作流
+#### 步骤3:上线运行工作流
工作流保存后,需要先上线再运行。上线后,运行按钮才会点亮。如下图所示。
@@ -175,7 +175,7 @@ DolphinScheduler 中,需要先创建项目,再在项目中创建工作流。
`echo "show jobs;" | /work/openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client`。如果某个任务状态是`FAILED`,请查询该任务的日志,方法见[任务日志](../../quickstart/beginner_must_read.md#离线)。
```
-#### 4. 在线预测测试
+#### 步骤4:在线预测测试
predict server同时提供了在线预测服务,通过`curl /predict`请求。我们简单地构造一个实时请求,发送至predict server。
```
curl -X POST 127.0.0.1:8881/predict -d '{"ip": 114904,
diff --git a/docs/zh/integration/online_datasources/kafka_connector_demo.md b/docs/zh/integration/online_datasources/kafka_connector_demo.md
index 7dffd7be109..fce0437623f 100644
--- a/docs/zh/integration/online_datasources/kafka_connector_demo.md
+++ b/docs/zh/integration/online_datasources/kafka_connector_demo.md
@@ -21,7 +21,7 @@ OpenMLDB Kafka Connector实现见[extensions/kafka-connect-jdbc](https://github.
我们推荐你将下载的三个文件包都绑定到文件目录`kafka`。当然,也可以在启动容器后,再进行文件包的下载。我们假设文件包都在`/work/kafka`目录中。
```
-docker run -it -v `pwd`:/work/kafka 4pdosc/openmldb:0.8.3 bash
+docker run -it -v `pwd`:/work/kafka 4pdosc/openmldb:0.8.4 bash
```
### 注意事项
diff --git a/docs/zh/integration/online_datasources/pulsar_connector_demo.md b/docs/zh/integration/online_datasources/pulsar_connector_demo.md
index 7277f039ee9..93dd5f8eee0 100644
--- a/docs/zh/integration/online_datasources/pulsar_connector_demo.md
+++ b/docs/zh/integration/online_datasources/pulsar_connector_demo.md
@@ -35,7 +35,7 @@ Apache Pulsar是一个云原生的,分布式消息流平台。它可以作为O
```
我们更推荐你使用‘host network’模式运行docker,以及绑定文件目录‘files’,sql脚本在该目录中。
```
-docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.8.3 bash
+docker run -dit --network host -v `pwd`/files:/work/pulsar_files --name openmldb 4pdosc/openmldb:0.8.4 bash
docker exec -it openmldb bash
```
diff --git a/docs/zh/maintain/diagnose.md b/docs/zh/maintain/diagnose.md
index eef7db5b5a1..cb5d7a30f74 100644
--- a/docs/zh/maintain/diagnose.md
+++ b/docs/zh/maintain/diagnose.md
@@ -8,14 +8,76 @@
安装方式与使用:
```bash
-pip install openmldb-tool # openmldb-tool[rpc]
+pip install openmldb-tool # openmldb-tool[pb]
openmldb_tool # 注意下划线
```
有以下几个子命令可选择执行:
```bash
-usage: openmldb_tool [-h] [--helpfull] {status,inspect,test,static-check} ...
+usage: openmldb_tool [-h] [--helpfull] {status,inspect,rpc,test,static-check} ...
```
-只有`static-check`静态检查命令需要指定`--dist_conf`参数,该参数指定OpenMLDB节点分布的配置文件。其他命令只需要`--cluster`参数,格式为`/`,默认为镜像中的OpenMLDB集群地址`127.0.0.1:2181/openmldb`。如果是自行设置的OpenMLDB集群,请配置此参数。
+
+注意`-c/--cluster`参数,格式为`/`,默认将访问`127.0.0.1:2181/openmldb`。如果是自行设置的OpenMLDB集群,请配置此参数。其他参数根据子命令不同而不同,可以使用`-h`查看,或查看各个子命令的详细文档。
+
+### 一键inspect
+
+`openmldb_tool inspect [--cluster=0.0.0.0:2181/openmldb]`可以一键查询,得到完整的集群状态报告。如果需要局部视角或额外的诊断功能,才需要其他子命令。
+
+报告分为几个板块,其中如果所有表都是健康的,不会展示Ops和Partitions板块。用户首先看报告末尾的总结 summary & hint,如果存在server offline(红色),需先重启server,保证server尤其是TabletServer都在线。server重启后,集群可能会尝试自动修复,自动修复也可能会失败,所以,用户有必要等待一定时间后再次inspect。此时如果仍然有不健康的表,可以检查它们的状态,Fatal表需要尽快修复,它们可能会读写失败,Warn表,用户可以考虑推迟修复。修复方式见报告末尾提供的文档。
+
+`inspect`可配置参数除了`--cluster/-c`,还可配置不显示彩色`--nocolor/-noc`方便复制,以及`--table_width/-tw n`配置表格宽度,`--offset_diff_thresh/-od n`配置offset diff的报警阈值。
+
+```
+diagnosing cluster xxx
+
+
+Server Detail
+{server map}
+{server online/offline report}
+
+
+Table Partitions Detail
+tablet server order: {tablet ip -> idx}
+{partition tables of unhealthy tables}
+Example:
+{a detailed description of partition table}
+
+
+Ops Detail
+> failed ops do not mean cluster is unhealthy, just for reference
+last one op(check time): {}
+last 10 ops != finished:
+{op list}
+
+
+
+==================
+Summary & Hint
+==================
+Server:
+
+{online | offline servers ['[tablet]xxx'], restart them first}
+
+Table:
+{all healthy | unhealthy tables desc}
+[]Fatal/Warn table, {read/write may fail or still work}, {repair immediatly or not}
+{partition detail: if leader healthy, if has unhealthy replicas, if offset too large, related ops}
+
+ Make sure all servers online, and no ops for the table is running.
+ Repair table manually, run recoverdata, check https://openmldb.ai/docs/zh/main/maintain/openmldb_ops.html.
+ Check 'Table Partitions Detail' above for detail.
+```
+
+### 其他常用命令
+
+除了一键inspect,在这样几个场景中,我们推荐使用诊断工具的子命令来帮助用户判断集群状态、简化运维。
+
+- 部署好集群后,可以使用`test`测试集群是否能正常工作,不需要用户手动测试。如果发现问题,再使用`inspect`诊断。
+- 组件都在线,但出现超时或错误提示某组件无法连接时,可以使用`status --conn`检查与各组件的连接,会打印出简单访问的耗时。也可以用它来测试客户端主机与集群的连接情况,及时发现网络隔离。
+- 离线job如果出现问题,`SHOW JOBLOG id`可以查看日志,但经验较少的用户可能会被日志中的无关信息干扰,可以使用`inspect job`来提取job日志中的关键信息。
+- 离线job太多时,CLI中的展示会不容易读,可以使用`inspect offline`筛选所有failed的job,或者`inspect job --state `来筛选出特定状态的job。
+- 在一些棘手的问题中,可能需要用户通过RPC来获得一些信息,帮助定位问题。`openmldb_tool rpc`可以帮助用户简单快速地调用RPC,降低运维门槛。
+- 没有Prometheus监控时,可以通过`inspect online --dist`获得数据分布信息。
+- 如果你的操作节点到各个组件的机器是ssh免密的,那么,可以使用`static-check`检查配置文件是否正确,版本是否统一,避免部署失败。还可以一键收集整个集群的日志,方便打包并提供给开发人员分析。
## 子命令详情
@@ -29,7 +91,8 @@ usage: openmldb_tool status [-h] [--helpfull] [--diff]
optional arguments:
-h, --help show this help message and exit
--helpfull show full help message and exit
- --diff check if all endpoints in conf are in cluster. If set, need to set `--conf_file`
+ --diff check if all endpoints in conf are in cluster. If set, need to set `-f,--conf_file`
+ --conn check network connection of all servers
```
- 简单查询集群状态:
@@ -48,6 +111,11 @@ optional arguments:
+-----------------+-------------+---------------+--------+---------+
```
+- 检查并测试集群链接与版本:
+ ```
+ openmldb_tool status --conn
+ ```
+
#### 检查配置文件与集群状态是否一致
如果指定`--diff`参数,会检查配置文件中的所有节点是否都在已经启动的集群中,如果有节点不在集群中,会输出异常信息。如果集群中有节点不在配置文件中,不会输出异常信息。需要配置`-f,--conf_file`,例如,你可以在镜像里这样检查:
@@ -57,7 +125,8 @@ openmldb_tool status --diff -f=/work/openmldb/conf/hosts
### inspect 检查
-`inspect`用于检查集群的在线和离线两个部分是否正常工作,可以选择单独检查`online`或`offline`,不指定则都检查。可以定期执行检查,以便及时发现异常。
+如果是为了检查集群状态,更推荐一键`inspect`获取集群完整检查报告,`inspect`子命令是更具有针对性的检查。
+
```
openmldb_tool inspect -h
usage: openmldb_tool inspect [-h] [--helpfull] {online,offline,job} ...
@@ -68,19 +137,26 @@ positional arguments:
offline only inspect offline jobs.
job show jobs by state, show joblog or parse joblog by id.
```
-在线检查会检查集群中的表状态(包括系统表),并输出有异常的表,包括表的状态,分区信息,副本信息等,等价于`SHOW TABLE STATUS`并筛选出有异常的表。如果发现集群表现不正常,请先检查下是否有异常表。例如,`SHOW JOBS`无法正常输出历史任务时,可以`inspect online`检查一下是否是job系统表出现问题。
+
+#### online在线检查
+
+`inspect online`检查在线表的健康状态,并输出有异常的表,包括表的状态,分区信息,副本信息等,等价于`SHOW TABLE STATUS`并筛选出有异常的表。
##### 检查在线数据分布
-在线检查中,可以使用`inspect online --dist`检查在线数据分布,默认检查所有数据库,可以使用`--db`指定要检查的数据库。若要查询多个数据库,请使用 ',' 分隔数据库名称。会输出数据库在各个节点上的数据分布情况。
+可以使用`inspect online --dist`检查在线数据分布,默认检查所有数据库,可以使用`--db`指定要检查的数据库。若要查询多个数据库,请使用 ',' 分隔数据库名称。会输出数据库在各个节点上的数据分布情况。
-#### 离线检查
+#### offline离线检查
-离线检查会输出最终状态为失败的任务(不检查“运行中”的任务),等价于`SHOW JOBS`并筛选出失败任务。
+`inspect offline`离线检查会输出最终状态为失败的任务(不检查“运行中”的任务),等价于`SHOW JOBS`并筛选出失败任务。更多功能待补充。
#### JOB 检查
-JOB 检查会检查集群中的离线任务,可以使用`inspect job`或`inspect job --state all`查询所有任务,等价于`SHOW JOBS`并按job_id排序。使用`inspect job --state `可以筛选出特定状态的日志,可以使用 ',' 分隔,同时查询不同状态的日志。例如:`inspect offline` 相当于`inspect job --state failed,killed,lost`即筛选出所有失败的任务。
+JOB 检查是更灵活的离线任务检查命令,可以按条件筛选job,或针对单个job日志进行分析。
+
+##### 按state筛选
+
+可以使用`inspect job`或`inspect job --state all`查询所有任务,等价于`SHOW JOBS`并按job_id排序。使用`inspect job --state `可以筛选出特定状态的日志,可以使用 ',' 分隔,同时查询不同状态的日志。例如:`inspect offline` 相当于`inspect job --state failed,killed,lost`即筛选出所有失败的任务。
以下是一些常见的state:
@@ -93,8 +169,13 @@ JOB 检查会检查集群中的离线任务,可以使用`inspect job`或`inspe
更多state信息详见[Spark State]( https://spark.apache.org/docs/3.2.1/api/java/org/apache/spark/launcher/SparkAppHandle.State.html),[Yarn State](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/yarn/api/records/YarnApplicationState.html)
+##### 解析单个JOB日志
-使用`inspect job --id `查询指定任务的log日志,其结果会使用配置文件筛选出主要错误信息。如需更新配置文件,可以添加`--conf-update`,并且可以使用`--conf-url`配置镜像源,例如使用`--conf-url https://openmldb.ai/download/diag/common_err.yml`配置国内镜像。如果需要完整的日志信息,可以添加`--detail`获取详细信息。
+使用`inspect job --id `查询指定任务的log日志,其结果会使用配置文件筛选出主要错误信息。
+
+解析依靠配置文件,默认情况会自动下载。如需更新配置文件,可以`--conf-update`,它将会在解析前强制下载一次配置文件。如果默认下载源不合适,可以同时配置`--conf-url`配置镜像源,例如使用`--conf-url https://openmldb.ai/download/diag/common_err.yml`配置国内镜像。
+
+如果只需要完整的日志信息而不是解析日志的结果,可以使用`--detail`获取详细信息,不会打印解析结果。
### test 测试
@@ -185,7 +266,6 @@ nameserver:
如果检查配置文件或日志,将会把收集到的文件保存在`--collect_dir`中,默认为`/tmp/diag_collect`。你也也可以访问此目录查看收集到的配置或日志,进行更多的分析。
-
#### 检查示例
在镜像容器中可以这样静态检查:
@@ -193,14 +273,15 @@ nameserver:
openmldb_tool static-check --conf_file=/work/openmldb/conf/hosts -VCL --local
```
-### rpc
+### RPC 接口
+
+`openmldb_tool`还提供了一个RPC接口,它可以让我们发送RPC更容易,不需要定位Server的IP,拼接RPC方法URL路径,也可以提示所有RPC方法和RPC方法的输入结构。使用方式是`openmldb_tool rpc`,例如,`openmldb_tool rpc ns ShowTable --field '{"show_all":true}'`可以调用`nameserver`的`ShowTable`接口,获取表的状态信息。
-`openmldb_tool`还提供了一个RPC接口,但它是一个额外组件,需要通过`pip install openmldb-tool[rpc]`安装。使用方式是`openmldb_tool rpc`,例如,`openmldb_tool rpc ns ShowTable --field '{"show_all":true}'`可以调用`nameserver`的`ShowTable`接口,获取表的状态信息。
+其中组件不使用ip,可以直接使用角色名。NameServer与TaskManager只有一个活跃,所以我们用ns和tm来代表这两个组件。而TabletServer有多个,我们用`tablet1`,`tablet2`等来指定某个TabletServer,从1开始,顺序可通过`openmldb_tool rpc`或`openmldb_tool status`来查看。
-NameServer与TaskManager只有一个活跃,所以我们用ns和tm来代表这两个组件。
-而TabletServer有多个,我们用`tablet1`,`tablet2`等来指定某个TabletServer,顺序可通过`openmldb_tool rpc`或`openmldb_tool status`来查看。
+如果对RPC服务的方法或者输入参数不熟悉,可以通过`openmldb_tool rpc [method] --hint`查看帮助信息。但它是一个额外组件,需要通过`pip install openmldb-tool[pb]`安装。hint还需要额外的pb文件,帮助解析输入参数,默认是从`/tmp/diag_cache`中读取,如果不存在则自动下载。如果你已有相应的文件,或者已经手动下载,可以通过`--pbdir`指定该目录。自行编译pb文件,见[openmldb tool开发文档](https://github.com/4paradigm/OpenMLDB/blob/main/python/openmldb_tool/README.md#rpc)。
-如果对RPC服务的方法或者输入参数不熟悉,可以通过`openmldb_tool rpc [method] --hint`查看帮助信息。例如:
+例如:
```bash
$ openmldb_tool rpc ns ShowTable --hint
...
@@ -212,9 +293,7 @@ You should input json like this, ignore round brackets in the key and double quo
"(optional)show_all": "bool"
}'
```
-hint还需要额外的pb文件,帮助解析输入参数,默认是从`/tmp/diag_cache`中读取,如果不存在则自动下载。如果你已有相应的文件,或者已经手动下载,可以通过`--pbdir`指定该目录。
## 附加
可使用`openmldb_tool --helpfull`查看所有配置项。例如,`--sdk_log`可以打印sdk的日志(zk,glog),可用于调试。
-
\ No newline at end of file
diff --git a/docs/zh/maintain/faq.md b/docs/zh/maintain/faq.md
deleted file mode 100644
index 454bfb500ad..00000000000
--- a/docs/zh/maintain/faq.md
+++ /dev/null
@@ -1,130 +0,0 @@
-# 运维 FAQ
-
-## 部署和启动 FAQ
-
-### 1. 如何确认集群已经正常运行?
-虽然有一键启动脚本,但由于配置繁多,可能出现“端口已被占用”,“目录无读写权限”等问题。这些问题都是server进程运行之后才能发现,退出后没有及时反馈。(如果配置了监控,可以通过监控直接检查。)
-所以,请先确认集群的所有server进程都正常运行。
-
-可以通过`ps axu | grep openmldb`或sql命令`show components;`来查询。(注意,如果你使用了守护进程,openmldb server进程可能是在启动停止的循环中,并不代表持续运行,可以通过日志或`show components;`连接时间来确认。)
-
-如果进程都活着,集群还是表现不正常,需要查询一下server日志。可以优先看WARN和ERROR级日志,很大概率上,它们就是根本原因。
-
-### 2. 如果数据没有自动恢复成功怎么办?
-
-通常情况,当我们重启服务,表中数据会自动进行恢复,但有些情况可能会造成恢复失败,通常失败的情况包括:
-
-- tablet异常退出
-- 多副本表多个副本所在的tablets同时重启或者重启太快,造成某些`auto_failover`操作还没完成tablet就重启
-- auto_failover设成`false`
-
-当服务启动成功后,可以通过`gettablestatus`获得所有表的状态:
-```
-python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=172.24.4.40:30481 --zk_root_path=/openmldb --cmd=gettablestatus
-```
-
-如果表中有`Warnings`,可以通过`recoverdata`来自动恢复数据:
-```
-python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=172.24.4.40:30481 --zk_root_path=/openmldb --cmd=recoverdata
-```
-
-## Server FAQ
-
-### 1. 为什么日志中有 Fail to write into Socket 的警告日志?
-```
-http_rpc_protocol.cpp:911] Fail to write into Socket{id=xx fd=xx addr=xxx} (0x7a7ca00): Unknown error 1014 [1014]
-```
-这是server端会打印的日志。一般是client端使用了连接池或短连接模式,在RPC超时后会关闭连接,server写回response时发现连接已经关了就报这个错。Got EOF就是指之前已经收到了EOF(对端正常关闭了连接)。client端使用单连接模式server端一般不会报这个。
-
-### 2. 表数据的ttl初始设置不合适,如何调整?
-这需要使用nsclient来修改,普通client无法做到。nsclient启动方式与命令,见[ns client](../maintain/cli.md#ns-client)。
-
-在nsclient中使用命令`setttl`可以更改一个表的ttl,类似
-```
-setttl table_name ttl_type ttl [ttl] [index_name]
-```
-可以看到,如果在命令末尾配置index的名字,可以做到只修改单个index的ttl。
-```{caution}
-`setttl`的改变不会及时生效,会受到tablet server的配置`gc_interval`的影响。(每台tablet server的配置是独立的,互不影响。)
-
-举例说明,有一个tablet server的`gc_interval`是1h,那么ttl的配置重载,会在下一次gc的最后时刻进行(最坏情况下,会在1h后重载)。重载ttl的这一次gc就不会按最新ttl来淘汰数据。再下一次gc时才会使用最新ttl进行数据淘汰。
-
-所以,**ttl更改后,需要等待两次gc interval的时间才会生效**。请耐心等待。
-
-当然,你可以调整tablet server的`gc_interval`,但这个配置无法动态更改,只能重启生效。所以,如果内存压力较大,可以尝试扩容,迁移数据分片,来减少内存压力。不推荐轻易调整`gc_interval`。
-```
-
-### 3. 出现警告日志:Last Join right table is empty,这是什么意思?
-通常来讲,这是一个正常现象,不代表集群异常。只是runner中join右表为空,是可能的现象,大概率是数据问题。
-
-## Client FAQ
-
-### 1. 为什么收到 Reached timeout 的警告日志?
-```
-rpc_client.h:xxx] request error. [E1008] Reached timeout=xxxms
-```
-这是由于client端本身发送的rpc request的timeout设置小了,client端自己主动断开,注意这是rpc的超时。需要更改通用的`request_timeout`配置。
-1. CLI: 启动时配置`--request_timeout_ms`
-2. JAVA/Python SDK: Option或url中调整`SdkOption.requestTimeout`
-```{note}
-同步的离线命令通常不会出现这个错误,因为同步离线命令的timeout设置为了TaskManager可接受的最长时间。
-```
-### 2. 为什么收到 Got EOF of Socket 的警告日志?
-```
-rpc_client.h:xxx] request error. [E1014]Got EOF of Socket{id=x fd=x addr=xxx} (xx)
-```
-这是因为`addr`端主动断开了连接,`addr`的地址大概率是TaskManager。这不代表TaskManager不正常,而是TaskManager端认为这个连接没有活动,超过keepAliveTime了,而主动断开通信channel。
-在0.5.0及以后的版本中,可以调大TaskManager的`server.channel_keep_alive_time`来提高对不活跃channel的容忍度。默认值为1800s(0.5h),特别是使用同步的离线命令时,这个值可能需要适当调大。
-在0.5.0以前的版本中,无法更改此配置,请升级TaskManager版本。
-
-### 3. 离线查询结果显示中文为什么乱码?
-
-在使用离线查询时,可能出现包含中文的查询结果乱码,主要和系统默认编码格式与Spark任务编码格式参数有关。
-
-如果出现乱码情况,可以通过添加Spark高级参数`spark.driver.extraJavaOptions=-Dfile.encoding=utf-8`和`spark.executor.extraJavaOptions=-Dfile.encoding=utf-8`来解决。
-
-客户端配置方法可参考[客户端Spark配置文件](../reference/client_config/client_spark_config.md),也可以在TaskManager配置文件中添加此项配置。
-
-```
-spark.default.conf=spark.driver.extraJavaOptions=-Dfile.encoding=utf-8;spark.executor.extraJavaOptions=-Dfile.encoding=utf-8
-```
-
-### 4. 如何配置TaskManager来访问开启Kerberos的Yarn集群?
-
-如果Yarn集群开启Kerberos认证,TaskManager可以通过添加以下配置来访问开启Kerberos认证的Yarn集群。注意请根据实际配置修改keytab路径以及principal账号。
-
-```
-spark.default.conf=spark.yarn.keytab=/tmp/test.keytab;spark.yarn.principal=test@EXAMPLE.COM
-```
-
-### 5. 如何配置客户端的core日志?
-
-客户端core日志主要有两种,zk日志和sdk日志(glog日志),两者是独立的。
-
-zk日志:
-1. CLI:启动时配置`--zk_log_level`调整level,`--zk_log_file`配置日志保存文件。
-2. JAVA/Python SDK:Option或url中使用`zkLogLevel`调整level,`zkLogFile`配置日志保存文件。
-
-- `zk_log_level`(int, 默认=0, 即DISABLE_LOGGING):
-打印这个等级及**以下**等级的日志。0-禁止所有zk log, 1-error, 2-warn, 3-info, 4-debug。
-
-sdk日志(glog日志):
-1. CLI:启动时配置`--glog_level`调整level,`--glog_dir`配置日志保存文件。
-2. JAVA/Python SDK:Option或url中使用`glogLevel`调整level,`glogDir`配置日志保存文件。
-
-- `glog_level`(int, 默认=1, 即WARNING):
-打印这个等级及**以上**等级的日志。 INFO, WARNING, ERROR, and FATAL日志分别对应 0, 1, 2, and 3。
-
-
-### 6. 插入错误,日志显示`please use getInsertRow with ... first`
-
-在JAVA client使用InsertPreparedStatement进行插入,或在Python中使用sql和parameter进行插入时,client底层实际有cache影响,第一步`getInsertRow`生成sql cache并返回sql还需要补充的parameter信息,第二步才会真正执行insert,而执行insert需要使用第一步缓存的sql cache。所以,当多线程使用同一个client时,可能因为插入和查询频繁更新cache表,将你想要执行的insert sql cache淘汰掉了,所以会出现好像第一步`getInsertRow`并未执行的样子。
-
-目前可以通过调大`maxSqlCacheSize`这一配置项来避免错误。仅JAVA/Python SDK支持配置。
-
-### 7. 离线命令错误`java.lang.OutOfMemoryError: Java heap space`
-
-离线命令的Spark配置默认为`local[*]`,并发较高可能出现OutOfMemoryError错误,请调整`spark.driver.memory`和`spark.executor.memory`两个spark配置项。可以写在TaskManager运行目录的`conf/taskmanager.properties`的`spark.default.conf`并重启TaskManager,或者使用CLI客户端进行配置,参考[客户端Spark配置文件](../reference/client_config/client_spark_config.md)。
-```
-spark.default.conf=spark.driver.memory=16g;spark.executor.memory=16g
-```
diff --git a/docs/zh/maintain/index.rst b/docs/zh/maintain/index.rst
index a114cccef15..bdb0b551e87 100644
--- a/docs/zh/maintain/index.rst
+++ b/docs/zh/maintain/index.rst
@@ -16,4 +16,3 @@
multi_cluster
diagnose
openmldb_ops
- faq
diff --git a/docs/zh/maintain/monitoring.md b/docs/zh/maintain/monitoring.md
index 905644c74df..e51f0a3b8bc 100644
--- a/docs/zh/maintain/monitoring.md
+++ b/docs/zh/maintain/monitoring.md
@@ -31,10 +31,8 @@ OpenMLDB exporter 是以 Python 实现的 Prometheus exporter,核心是通过
2. 启动 OpenMLDB
- 参见 [install_deploy](../deploy/install_deploy.md) 如何搭建 OpenMLDB。组件启动时需要保证有 flag `--enable_status_service=true`, 或者确认启动 flag 文件 (`conf/(tablet|nameserver).flags`) 中有 `--enable_status_service=true`。
+ 参见 [install_deploy](../deploy/install_deploy.md) 如何搭建 OpenMLDB。组件启动时需要保证有 flag `--enable_status_service=true`, OpenMLDB启动脚本(无论是sbin或bin)都已配置为true,如果你使用个人方式启动,需要保证启动 flag 文件 (`conf/(tablet|nameserver).flags`) 中有 `--enable_status_service=true`。
- 默认启动脚本 `bin/start.sh` 开启了 server status, 不需要额外配置。
-
3. 注意:合理选择 OpenMLDB 各组件和 OpenMLDB exporter, 以及 Prometheus, Grafana 的绑定 IP 地址,确保 Grafana 可以访问到 Prometheus, 并且 Prometheus,OpenMLDB exporter 和 OpenMLDB 各个组件之间可以相互访问。
### 部署 OpenMLDB exporter
@@ -168,13 +166,6 @@ OpenMLDB 提供了 Prometheus 和 Grafana 配置文件以作参考,详见 [Ope
- component status: 集群组件状态
- table status: 数据库表相关信息,如 `rows_count`, `memory_bytes`
- - deploy query response time: deployment query 在 tablet 内部的运行时间
-
- **除了 deploy query response time 指标外, 成功配置监控之后都可以直接查询到指标. Deploy query response time 需要全局变量 `deploy_stats` 开启后才会有数据, 在 OpenMLDB CLI 中输入 SQL:**
-
- ```sql
- SET GLOBAL deploy_stats = 'on';
- ```
你可以通过
@@ -184,9 +175,27 @@ OpenMLDB 提供了 Prometheus 和 Grafana 配置文件以作参考,详见 [Ope
查看完整 DB-Level 指标和帮助信息。
+通过Component-Level 指标通过Grafana聚合的DB-Level 指标(未单独声明时,time单位为us):
+
+- deploy query response time: deployment query 在OpenMLDB内部的运行时间,按DB.DEPLOYMENT汇总
+ **需要全局变量 `deploy_stats` 开启后才会开始统计, 在 OpenMLDB CLI 中输入 SQL:**
+
+ ```sql
+ SET GLOBAL deploy_stats = 'on';
+ ```
+ 然后,还需要执行deplpoyment,才会出现相应的指标。
+ 如果SET变量为off,会清空server中的所有deployment指标并停止统计(已被Prometheus抓取的数据不影响)。
+ - count:count类统计值从deploy_stats on时开始统计,不区分请求的成功和失败。
+ - latency, qps:这类指标只统计`[current_time - interval, current_time]`时间窗口内的数据,interval由Tablet Server配置项`bvar_dump_interval`配置,默认为75秒。
+
+- api server http time: 各API接口的处理耗时(不包含route),只监测接口耗时,不做细粒度区分,目前也不通过Grafana展示,可以通过Prometheus手动查询。目前监测`deployment`、`sp`和`query`三种方法。
+ - api server route time: APIServer进行http route的耗时,通常为us级别,一般忽略不计
+
+以上聚合指标的获取方式见下文。在组件指标中,deploy query response time关键字为`deployment`,api server http time关键字为`http_method`。如果指标展示不正常,可以查询组件指标定位问题。
+
### 2. Component-Level 指标
-OpenMLDB 的相关组件(即 nameserver, tablet, etc), 本身作为 BRPC server,暴露了 [Prometheus 相关指标](https://github.com/apache/incubator-brpc/blob/master/docs/en/bvar.md#export-to-prometheus), 只需要配置 Prometheus server 从对应地址拉取指标即可。对应 `prometheus_example.yml`中 `job_name=openmldb_components` 项:
+OpenMLDB 的相关组件(即 nameserver, tablet, etc), 本身作为 BRPC server,暴露了 [Prometheus 相关指标](https://github.com/apache/brpc/blob/master/docs/en/bvar.md#export-to-prometheus), 只需要配置 Prometheus server 从对应地址拉取指标即可。对应 `prometheus_example.yml`中 `job_name=openmldb_components` 项:
```yaml
- job_name: openmldb_components
@@ -203,6 +212,7 @@ OpenMLDB 的相关组件(即 nameserver, tablet, etc), 本身作为 BRPC serve
- BRPC server 进程相关信息
- 对应 BRPC server 定义的 RPC method 相关指标,例如该 RPC 的请求 `count`, `error_count`, `qps` 和 `response_time`
+ - Deployment 相关指标,分deployment统计,但只统计该tablet上的deployment请求。它们将通过Grafana聚合,形成最终的的集群级别Deployment指标。
通过
diff --git a/docs/zh/maintain/openmldb_ops.md b/docs/zh/maintain/openmldb_ops.md
index 10b53437b52..d96b23131b3 100644
--- a/docs/zh/maintain/openmldb_ops.md
+++ b/docs/zh/maintain/openmldb_ops.md
@@ -31,9 +31,13 @@
**使用示例**
```
-python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=172.24.4.40:30481 --zk_root_path=/openmldb --cmd=scaleout
+python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=0.0.0.0:2181 --zk_root_path=/openmldb --cmd=scaleout
+python tools/openmldb_ops.py --openmldb_bin_path=./bin/openmldb --zk_cluster=0.0.0.0:2181 --zk_root_path=/openmldb --cmd=recoverdata
```
+运行结果可以只关注是否存在ERROR级日志,如果存在,请保留完整的日志记录,便于技术人员查找问题。
+
### 系统要求
- 要求python2.7及以上版本
+- 理论上openmldb_ops不要求与OpenMLDB集群的版本匹配,高版本openmldb_ops可以操作低版本的OpenMLDB集群。
- `showopstatus`和`showtablestatus`需要`prettytable`依赖
diff --git a/docs/zh/openmldb_sql/ddl/CREATE_TABLE_STATEMENT.md b/docs/zh/openmldb_sql/ddl/CREATE_TABLE_STATEMENT.md
index 1dffc9d4cae..a44f699eed3 100644
--- a/docs/zh/openmldb_sql/ddl/CREATE_TABLE_STATEMENT.md
+++ b/docs/zh/openmldb_sql/ddl/CREATE_TABLE_STATEMENT.md
@@ -450,6 +450,11 @@ StorageMode
::= 'Memory'
| 'HDD'
| 'SSD'
+CompressTypeOption
+ ::= 'COMPRESS_TYPE' '=' CompressType
+CompressType
+ ::= 'NoCompress'
+ | 'Snappy'
```
@@ -460,6 +465,7 @@ StorageMode
| `REPLICANUM` | 配置表的副本数。请注意,副本数只有在集群版中才可以配置。 | `OPTIONS (REPLICANUM=3)` |
| `DISTRIBUTION` | 配置分布式的节点endpoint。一般包含一个Leader节点和若干Follower节点。`(leader, [follower1, follower2, ..])`。不显式配置时,OpenMLDB会自动根据环境和节点来配置`DISTRIBUTION`。 | `DISTRIBUTION = [ ('127.0.0.1:6527', [ '127.0.0.1:6528','127.0.0.1:6529' ])]` |
| `STORAGE_MODE` | 表的存储模式,支持的模式有`Memory`、`HDD`或`SSD`。不显式配置时,默认为`Memory`。
如果需要支持非`Memory`模式的存储模式,`tablet`需要额外的配置选项,具体可参考[tablet配置文件 conf/tablet.flags](../../../deploy/conf.md)。 | `OPTIONS (STORAGE_MODE='HDD')` |
+| `COMPRESS_TYPE` | 指定表的压缩类型。目前只支持Snappy压缩, 。默认为 `NoCompress` 即不压缩。 | `OPTIONS (COMPRESS_TYPE='Snappy')`
#### 磁盘表与内存表区别
- 磁盘表对应`STORAGE_MODE`的取值为`HDD`或`SSD`。内存表对应的`STORAGE_MODE`取值为`Memory`。
@@ -488,11 +494,11 @@ DESC t1;
--- -------------------- ------ ---------- ------ ---------------
1 INDEX_0_1651143735 col1 std_time 0min kAbsoluteTime
--- -------------------- ------ ---------- ------ ---------------
- --------------
- storage_mode
- --------------
- HDD
- --------------
+ --------------- --------------
+ compress_type storage_mode
+ --------------- --------------
+ NoCompress HDD
+ --------------- --------------
```
创建一张表,指定分片的分布状态
```sql
diff --git a/docs/zh/openmldb_sql/ddl/DESC_STATEMENT.md b/docs/zh/openmldb_sql/ddl/DESC_STATEMENT.md
index 1088411dc03..ca0d0de87bf 100644
--- a/docs/zh/openmldb_sql/ddl/DESC_STATEMENT.md
+++ b/docs/zh/openmldb_sql/ddl/DESC_STATEMENT.md
@@ -56,11 +56,11 @@ desc t1;
--- -------------------- ------ ---------- ---------- ---------------
1 INDEX_0_1658136511 col1 std_time 43200min kAbsoluteTime
--- -------------------- ------ ---------- ---------- ---------------
- --------------
- storage_mode
- --------------
- Memory
- --------------
+ --------------- --------------
+ compress_type storage_mode
+ --------------- --------------
+ NoCompress Memory
+ --------------- --------------
```
diff --git a/docs/zh/openmldb_sql/ddl/SHOW_CREATE_TABLE_STATEMENT.md b/docs/zh/openmldb_sql/ddl/SHOW_CREATE_TABLE_STATEMENT.md
new file mode 100644
index 00000000000..22c08fb754e
--- /dev/null
+++ b/docs/zh/openmldb_sql/ddl/SHOW_CREATE_TABLE_STATEMENT.md
@@ -0,0 +1,28 @@
+# SHOW CREATE TABLE
+
+`SHOW CREATE TABLE` 用来显示指定表的建表语句
+
+**Syntax**
+
+```sql
+SHOW CREATE TABLE table_name;
+```
+
+**Example**
+
+```sql
+show create table t1;
+ ------- ---------------------------------------------------------------
+ Table Create Table
+ ------- ---------------------------------------------------------------
+ t1 CREATE TABLE `t1` (
+ `c1` varchar,
+ `c2` int,
+ `c3` bigInt,
+ `c4` timestamp,
+ INDEX (KEY=`c1`, TS=`c4`, TTL_TYPE=ABSOLUTE, TTL=0m)
+ ) OPTIONS (PARTITIONNUM=8, REPLICANUM=2, STORAGE_MODE='HDD', COMPRESS_TYPE='NoCompress');
+ ------- ---------------------------------------------------------------
+
+1 rows in set
+```
\ No newline at end of file
diff --git a/docs/zh/openmldb_sql/ddl/TRUNCATE_TABLE_STATEMENT.md b/docs/zh/openmldb_sql/ddl/TRUNCATE_TABLE_STATEMENT.md
new file mode 100644
index 00000000000..8ffb623f26f
--- /dev/null
+++ b/docs/zh/openmldb_sql/ddl/TRUNCATE_TABLE_STATEMENT.md
@@ -0,0 +1,16 @@
+# TRUNCATE TABLE
+
+```
+TRUNCATE TABLE table_name
+```
+
+`TRUNCATE TABLE`语句用清空指定的表。
+
+## Example: 清空t1表
+
+```sql
+TRUNCATE TABLE t1;
+-- Truncate table t1? yes/no
+-- yes
+-- SUCCEED
+```
\ No newline at end of file
diff --git a/docs/zh/openmldb_sql/ddl/index.rst b/docs/zh/openmldb_sql/ddl/index.rst
index 116b9ce29c3..9e420def154 100644
--- a/docs/zh/openmldb_sql/ddl/index.rst
+++ b/docs/zh/openmldb_sql/ddl/index.rst
@@ -23,3 +23,5 @@
CREATE_FUNCTION
SHOW_FUNCTIONS
DROP_FUNCTION
+ SHOW_CREATE_TABLE_STATEMENT
+ TRUNCATE_TABLE_STATEMENT
\ No newline at end of file
diff --git a/docs/zh/openmldb_sql/deployment_manage/DEPLOY_STATEMENT.md b/docs/zh/openmldb_sql/deployment_manage/DEPLOY_STATEMENT.md
index 4f94e228357..41b3e1141e8 100644
--- a/docs/zh/openmldb_sql/deployment_manage/DEPLOY_STATEMENT.md
+++ b/docs/zh/openmldb_sql/deployment_manage/DEPLOY_STATEMENT.md
@@ -175,9 +175,9 @@ deploy demo options(SYNC="false") SELECT t1.col1, t2.col2, sum(col4) OVER w1 as
WINDOW w1 AS (PARTITION BY t1.col2 ORDER BY t1.col3 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
```
-#### 设置偏移
+#### 设置偏移BIAS
-如果你并不希望数据根据deploy的索引淘汰,或者希望晚一点淘汰,可以在deploy时设置偏移,常用于数据时间戳并不实时的情况、测试等情况。如果deploy后的索引ttl为abs 3h,但是数据的时间戳是3h前的(以系统时间为基准),那么这条数据就会被淘汰,无法参与计算。设置一定时间或永久的偏移,则可以让数据更久的停留在在线表中。
+如果你并不希望数据根据deploy的索引淘汰,或者希望晚一点淘汰,可以在deploy时设置偏移BIAS,常用于数据时间戳并不实时的情况、测试等情况。如果deploy后的索引ttl为abs 3h,但是数据的时间戳是3h前的(以系统时间为基准),那么这条数据就会被淘汰,无法参与计算。设置一定时间或永久的偏移,则可以让数据更久的停留在在线表中。
时间偏移,单位可以是`s`、`m`、`h`、`d`,也可以是整数,单位为`ms`,也可以是`inf`,表示永不淘汰;如果是行数偏移,可以是整数,单位是`row`,也可以是`inf`,表示永不淘汰。两种偏移中,0均表示不偏移。
@@ -185,6 +185,12 @@ deploy demo options(SYNC="false") SELECT t1.col1, t2.col2, sum(col4) OVER w1 as
而时间偏移的单位是`min`,我们会在内部将其转换为`min`,并且取上界。比如,新索引ttl是abs 2min,加上偏移20s,结果是`2min + ub(20s) = 3min`,然后和旧索引1min取上界,最终索引ttl是`max(1min, 3min) = 3min`。
+**Example**
+```sql
+DEPLOY demo OPTIONS(RANGE_BIAS="inf", ROWS_BIAS="inf") SELECT t1.col1, t2.col2, sum(col4) OVER w1 as w1_col4_sum FROM t1 LAST JOIN t2 ORDER BY t2.col3 ON t1.col2 = t2.col2
+ WINDOW w1 AS (PARTITION BY t1.col2 ORDER BY t1.col3 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
+```
+
## 相关SQL
[USE DATABASE](../ddl/USE_DATABASE_STATEMENT.md)
diff --git a/docs/zh/openmldb_sql/deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md b/docs/zh/openmldb_sql/deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md
index 43b4c9e4941..7a4a8501490 100644
--- a/docs/zh/openmldb_sql/deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md
+++ b/docs/zh/openmldb_sql/deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md
@@ -12,10 +12,10 @@ OpenMLDB仅支持上线[SELECT查询语句](../dql/SELECT_STATEMENT.md)。
下表列出了在线请求模式支持的 `SELECT` 子句。
-| SELECT 子句 | 说明 |
-|:-------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------|
-| 单张表的简单表达式计算 | 简单的单表查询是对一张表进行列运算、使用运算表达式或单行处理函数(Scalar Function)以及它们的组合表达式作计算。需要遵循[在线请求模式下单表查询的使用规范](#在线请求模式下单表查询的使用规范) |
-| [`JOIN` 子句](../dql/JOIN_CLAUSE.md) | OpenMLDB目前仅支持**LAST JOIN**。需要遵循[在线请求模式下LAST JOIN的使用规范](#在线请求模式下-last-join-的使用规范) |
+| SELECT 子句 | 说明 |
+| :--------------------------------------- | :----------------------------------------------------------- |
+| 单张表的简单表达式计算 | 简单的单表查询是对一张表进行列运算、使用运算表达式或单行处理函数(Scalar Function)以及它们的组合表达式作计算。需要遵循[在线请求模式下单表查询的使用规范](#在线请求模式下单表查询的使用规范) |
+| [`JOIN` 子句](../dql/JOIN_CLAUSE.md) | OpenMLDB目前仅支持**LAST JOIN**。需要遵循[在线请求模式下LAST JOIN的使用规范](#在线请求模式下-last-join-的使用规范) |
| [`WINDOW` 子句](../dql/WINDOW_CLAUSE.md) | 窗口子句用于定义一个或者若干个窗口。窗口可以是有名或者匿名的。用户可以在窗口上调用聚合函数进行分析计算。需要遵循[在线请求模式下Window的使用规范](#在线请求模式下window的使用规范) |
## 在线请求模式下 `SELECT` 子句的使用规范
@@ -57,15 +57,19 @@ SELECT substr(COL7, 3, 6) FROM t1;
### 在线请求模式下 `LAST JOIN` 的使用规范
-- 仅支持`LAST JOIN`类型。
-- 至少有一个JOIN条件是形如`left_source.column=right_source.column`的EQUAL条件,**并且`right_source.column`列需要命中右表的索引(key 列)**。
-- 带排序LAST JOIN的情况下,`ORDER BY`只支持单列的列引用表达式,列类型为 int16, int32, int64 or timestamp, **并且列需要命中右表索引的时间列**。
-- 右表 TableRef
+1. 仅支持`LAST JOIN`类型。
+2. 至少有一个JOIN条件是形如`left_source.column=right_source.column`的EQUAL条件,**并且`right_source.column`列需要命中右表的索引(key 列)**。
+3. 带排序LAST JOIN的情况下,`ORDER BY`只支持单列的列引用表达式,列类型为 int64 或 timestamp, **并且列需要命中右表索引的时间列**。满足条件 2 和 3 的情况我们简单称做表能被 LAST JOIN 的 JOIN 条件优化
+4. 右表 TableRef
- 可以指一张物理表, 或者子查询语句
- - 子查询情况, 只支持
+ - 子查询情况, 目前支持
- 简单列筛选 (`select * from tb` or `select id, val from tb`)
- - 窗口聚合子查询, 例如 `select id, count(val) over w as cnt from t1 window w as (...)`. 这种情况下, 子查询和 last join 的左表必须有相同的主表, 主表指计划树下最左边的物理表节点.
- - **Since OpenMLDB 0.8.0** 带 WHERE 条件过滤的简单列筛选 ( 例如 `select * from tb where id > 10`)
+ - 窗口聚合子查询, 例如 `select id, count(val) over w as cnt from t1 window w as (...)`.
+ - OpenMLDB 0.8.4 之前, 如果 LAST JOIN 的右表是窗口聚合子查询, 需要和 LAST JOIN 的左表输入有相同的主表
+ - [ALPHA] OpenMLDB >= 0.8.4, 允许 LAST JOIN 下的窗口聚合子查询不带主表. 详细见下面的例子
+ - **OpenMLDB >= 0.8.0** 带 WHERE 条件过滤的简单列筛选 ( 例如 `select * from tb where id > 10`)
+ - **[ALPHA] OpenMLDB >= 0.8.4** 右表是带 LAST JOIN 的子查询 `subquery`, 要求 `subquery` 最左的表能被 JOIN 条件优化, `subquery`剩余表能被自身 LAST JOIN 的 JOIN 条件优化
+ - **[ALPHA] OpenMLDB >= 0.8.4** LEFT JOIN. 要求 LEFT JOIN 的右表能被 LEFT JOIN 条件优化, LEFT JOIN 的左表能被上层的 LAST JOIN 条件优化
**Example: 支持上线的 `LAST JOIN` 语句范例**
创建两张表以供后续`LAST JOIN`。
@@ -115,15 +119,82 @@ desc t1;
t1.col0 as t1_col0,
t1.col1 + t2.col1 + 1 as test_col1,
FROM t1
- LAST JOIN t2 ORDER BY t2.std_time ON t1.col1=t2.col1;
+ LAST JOIN t2 ORDER BY t2.std_time ON t1.col1=t2.col1;
```
+右表是带 LAST JOIN 或者 WHERE 条件过滤的情况
+
+```sql
+CREATE TABLE t3 (col0 STRING, col1 int, std_time TIMESTAMP, INDEX(KEY=col1, TS=std_time, TTL_TYPE=absolute, TTL=30d));
+-- SUCCEED
+
+SELECT
+ t1.col1 as t1_col1,
+ t2.col1 as t2_col1,
+ t2.col0 as t2_col0
+FROM t1 LAST JOIN (
+ SELECT * FROM t2 WHERE strlen(col0) > 0
+) t2
+ON t1.col1 = t2.col1
+
+-- t2 被 JOIN 条件 't1.col1 = tx.t2_co1l' 优化, t3 被 JOIN 条件 't2.col1 = t3.col1'
+SELECT
+ t1.col1 as t1_col1,
+ tx.t2_col1,
+ tx.t3_col1
+FROM t1 LAST JOIN (
+ SELECT t2.col1 as t2_col1, t3.col1 as t3_col1
+ FROM t2 LAST JOIN t3
+ ON t2.col1 = t3.col1
+) tx
+ON t1.col1 = tx.t2_col1
+
+-- 右表是 LEFT JOIN
+SELECT
+ t1.col1 as t1_col1,
+ tx.t2_col1,
+ tx.t3_col1
+FROM t1 LAST JOIN (
+ SELECT t2.col1 as t2_col1, t3.col1 as t3_col1
+ FROM t2 LEFT JOIN t3
+ ON t2.col1 = t3.col1
+) tx
+ON t1.col1 = tx.t2_col1
+
+-- OpenMLDB 0.8.4 之前, LAST JOIN 窗口子查询需要窗口的子查询主表和当前主表一致
+-- 这里都是 t1
+SELECT
+ t1.col1,
+ tx.agg
+FROM t1 LAST JOIN (
+ SELECT col1, count(col2) over w as agg
+ FROM t1 WINDOW w AS (
+ UNION t2
+ PARTITION BY col2 order by std_time ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
+ INSTANCE_NOT_IN_WINDOW EXCLUDE CURRENT_ROW
+ )
+)
+
+-- 右表是窗口聚合计算
+-- OpenMLDB >= 0.8.4, 允许 t1 LAST JOIN WINDOW (t2). t1 是主表, t2 是一张副表
+-- 此 SQL 和上一个例子语义一致
+SELECT
+ t1.col1,
+ tx.agg
+FROM t1 LAST JOIN (
+ SELECT col1, count(col2) over w as agg
+ FROM t2 WINDOW w AS (PARTITION BY col2 order by std_time ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
+)
+```
+
+
+
### 在线请求模式下Window的使用规范
- 窗口边界仅支持`PRECEDING`和`CURRENT ROW`
- 窗口类型仅支持`ROWS`和`ROWS_RANGE`。
- 窗口`PARTITION BY`只支持列表达式,可以是多列,并且所有列需要命中索引,主表和 union source 的表都需要符合要求
-- 窗口`ORDER BY`只支持列表达式,只能是单列,并且列需要命中索引的时间列,主表和 union source 的表都需要符合要求
+- 窗口`ORDER BY`只支持列表达式,只能是单列,并且列需要命中索引的时间列,主表和 union source 的表都需要符合要求. 从 OpenMLDB 0.8.4 开始, ORDER BY 可以不写, 但需要满足额外的要求, 详见 [WINDOW CLAUSE](../dql/WINDOW_CLAUSE.md)
- 可支持使用 `EXCLUDE CURRENT_ROW`,`EXCLUDE CURRENT_TIME`,`MAXSIZE`,`INSTANCE_NOT_IN_WINDOW`对窗口进行其他特殊限制,详见[OpenMLDB特有的 WindowSpec 元素](#openmldb特有的-windowspec-元素)。
- `WINDOW UNION` source 要求,支持如下格式的子查询:
- 表引用或者简单列筛选,例如 `t1` 或者 `select id, val from t1`。union source 和 主表的 schema 必须完全一致,并且 union source 对应的 `PARTITION BY`, `ORDER BY` 也需要命中索引
diff --git a/docs/zh/openmldb_sql/dql/JOIN_CLAUSE.md b/docs/zh/openmldb_sql/dql/JOIN_CLAUSE.md
index 0ed4b357619..6e74adc7928 100644
--- a/docs/zh/openmldb_sql/dql/JOIN_CLAUSE.md
+++ b/docs/zh/openmldb_sql/dql/JOIN_CLAUSE.md
@@ -1,23 +1,31 @@
# JOIN Clause
-OpenMLDB目前仅支持`LAST JOIN`一种**JoinType**。
+OpenMLDB目前支持
-LAST JOIN可以看作一种特殊的LEFT JOIN。在满足JOIN条件的前提下,左表的每一行拼接符合条件的最后一行。LAST JOIN分为无排序拼接,和排序拼接。
+- LAST JOIN
+- LEFT JOIN (**OPENMLDB >= 0.8.4**)
+
+LEFT OUTER JOIN (或者简称 LEFT JOIN) 会将两个 from_item 进行联接, 同时保留左侧from_item中的所有记录, 即使右侧from_item满足联接条件的记录数为零。对于右侧表中没有找到匹配的记录,则右侧的列会以 NULL 值填充。
+
+LAST JOIN 是 OpenMLDB SQL 拓展的 JOIN类型. 它的语法和 LEFT JOIN 基本一致, 但在右侧 from_item 后面允许带可选的 ORDER BY 子句, 表示筛选右侧 from_iem 的顺序. 根据是否带有这个 ORDER BY 子句, LAST JOIN分为无排序拼接,和排序拼接。
- 无排序拼接是指:未对右表作排序,直接拼接。
- 排序拼接是指:先对右表排序,然后再拼接。
-与LEFT JOIN相同,LAST JOIN也会返回左表中所有行,即使右表中没有匹配的行。
+与LEFT JOIN相同,LAST JOIN也会返回左表中所有行,即使右表中没有匹配的行。不同的是, LAST JOIN 是一对一, LEFT JOIN 是一对多.
## Syntax
```
-JoinClause
- ::= TableRef JoinType 'JOIN' TableRef [OrderByClause] 'ON' Expression
+join:
+ TableRef "LAST" "JOIN" TableRef [OrderByClause] "ON" Expression
+ | TableRef join_type "JOIN" TableRef "ON" Expression
-JoinType ::= 'LAST'
+join_type:
+ 'LEFT' [OUTER]
-OrderByClause := 'ORDER' 'BY'
+order_by_clause:
+ 'ORDER' 'BY'
```
### 使用限制说明
@@ -30,14 +38,17 @@ OrderByClause := 'ORDER' 'BY'
## SQL语句模版
```sql
-SELECT ... FROM table_ref LAST JOIN table_ref ON expression;
+SELECT ... FROM t1 LAST JOIN t2 ON expression;
+
+SELECT ... FROM t1 LEFT JOIN t2 ON expression;
```
## 边界说明
| SELECT语句元素 | 离线模式 | 在线预览模式 | 在线请求模式 | 说明 |
| :--------------------------------------------- | --------- | ------------ | ------------ |:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| JOIN Clause| **``✓``** | **``x``** | **``✓``** | 表示数据来源多个表JOIN。OpenMLDB目前仅支持LAST JOIN。在线请求模式下,需要遵循[在线请求模式下LAST JOIN的使用规范](../deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md#在线请求模式下-last-join-的使用规范) |
+| LAST JOIN | **``✓``** | **``x``** | **``✓``** | 表示数据来源多个表JOIN。在线请求模式下,需要遵循[在线请求模式下LAST JOIN的使用规范](../deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md#在线请求模式下-last-join-的使用规范) |
+| LEFT JOIN | **``x``** | **``x``** | **``✓``** | 由于 LEFT JOIN 是一对多 JOIN, 本身不能直接用于在线请求模式. 但是可以作为其他类型查询内部的子查询, 例如作为 LAST JOIN 的右表. 具体参考[在线请求模式下LAST JOIN的使用规范](../deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md#在线请求模式下-last-join-的使用规范) |
### 未排序的LAST JOIN
diff --git a/docs/zh/openmldb_sql/dql/WINDOW_CLAUSE.md b/docs/zh/openmldb_sql/dql/WINDOW_CLAUSE.md
index 18f49149429..a206c92fb8c 100644
--- a/docs/zh/openmldb_sql/dql/WINDOW_CLAUSE.md
+++ b/docs/zh/openmldb_sql/dql/WINDOW_CLAUSE.md
@@ -86,27 +86,43 @@ SELECT select_expr [,select_expr...], window_function_name(expr) OVER window_nam
再看窗口想要什么大小,这里要分窗口类型说明:
1. 时间窗口:时间窗口通常使用s, m, h, d等时间单位,如果没有单位,默认为ms。比如:
- [3小时前,当前行] - 3h preceding and current row
- [3小时前,30分钟前] - 3h preceding and 30m preceding
+ - [3小时前,当前行] - 3h preceding and current row
+ - [3小时前,30分钟前] - 3h preceding and 30m preceding
1. 条数窗口:条数不需要单位。比如:
- [10条,当前行] - 10 preceding and current row
- [10条,3条] - 10 preceding and 3 preceding
+ - [10条,当前行] - 10 preceding and current row
+ - [10条,3条] - 10 preceding and 3 preceding
### 如何推断窗口是什么样的?
首先,先明确是什么执行模式:
-离线模式,即批模式,它是对from表的每一行都做一次窗口划分与计算。因此,每一行对应产生一行SQL结果。
-请求模式,会带一条请求行,它会将请求行当做from表的数据,只对该行做窗口划分和计算,因此,只产生一行SQL结果。
+离线模式或在线预览模式,合称为批模式,它是对from表的每一行都做一次窗口划分与计算。因此,每一行对应产生一行SQL结果。
+请求模式,会带一条请求行,它会将请求行当做from表的数据,只对该行做窗口划分和计算,因此,只产生一行SQL结果。注意,不会将请求行插入到表中。
-再看,如何划分窗口:
+我们将批模式看作多次请求模式来看待,所以请求模式查询如何划分窗口,我们分为三段来讲:
-我们将批模式看作多次请求模式来看待。所以,对一次请求行来说,窗口只可能包含,它自己,与它的partition by列值相等的行(可能的全集)。
+- 对一次请求行来说,窗口**只可能**包含,它自己,与它的partition by列值相等的行
-partition key相等的所有行,还不是窗口,经由order by列排序后,还需要排除窗口范围以外的数据。比如,10 preceding and current row的条数窗口,就要抛弃10行以外的数据行(第10行包含在窗口内),又因为包括current row,于是窗口一共有11行数据。
+- partition key相等的所有行,它们不是乱序,而是按**order by列**排序
-* preceding为闭区间,包含该条,开区间使用open preceding
+- 根据rows/rows_range排除窗口范围以外的数据
+ - rows:例如,10 preceding and current row的条数窗口,就要抛弃10行以外的数据行(第10行包含在窗口内),又因为包括current row,于是窗口一共有11行数据。
+ -rows_range:例如,10s preceding and current row的时间窗口,就要抛弃10s以外的数据行(第10s包含在窗口内),也包括current row,于是窗口只会出现order key值在`[current_row_order_key - 10s, current_row_order_key]`范围内的数据行。
+
+```{note}
+窗口划分范围,仅与order by列相关。如果认为窗口内行数或具体某数据不符合预期范围,一般是窗口写法的误解,极小概率是SQL引擎计算有误。请以某一个partition key为例,分步检查表的数据(以下操作都是在线模式):
+- 提取与该key相等的所有数据。可以使用`select * from table where partition_key = xxx`来提取,或使用源数据文件,通过pandas/spark等工具提取。
+- 再按order by列排序,这类似于window设置窗口为unbounded preceding and current row。此处,可以将手动处理的数据和OpenMLDB的unbounded window计算结果进行对比。
+ - 由于OpenMLDB只支持在窗口内聚合,很难看到窗口的数据全貌,而且窗口内数据较多时,查看全部也是很难的。通常是使用count/min/max/lag等聚合函数来衡量窗口内数据的数量和范围。
+ - 如果仍需要通过窗口内具体数据来确认,可以使用top来展示前k大的值,但它会对列进行再排序,不能等同于窗口排序(order by列排序)。其他聚合函数,参考[udf函数](../udfs_8h.md)。
+- 最后,再检查窗口的rows/rows_range设置是否符合预期。
+ - 通常情况,如果前两步没问题,条数划分一般不会有问题。
+ - 时间划分,需要注意时间单位。OpenMLDB中order by列无论是timestamp还是bigint,都当作整数来计算的,timestamp是转换为ms为单位的整数。我们支持在窗口设置中使用时间单位,但不会对表中的order by列值做任何单位假设。例如,如果order by列
+并非timestamp,而是设置整数`20230905`,在时间窗口设置5ms时,窗口的范围是`[20230905 - 5, 20230905]`,而不是`[20230905 00:00:00 - 5ms, 20230905]`。**请谨慎对待order by列,最方便的做法是,任何时间格式都将其转换为timestamp或ms为单位的bigint**。
+```
+
+* preceding为闭区间,包含该条,开区间需使用open preceding
窗口还可以exclude current time,current row等,详情见下文。
@@ -119,7 +135,7 @@ partition key相等的所有行,还不是窗口,经由order by列排序后
## 基本的 WindowSpec 语法元素
-### Window Partition Clause 和 Window OrderBy Clause
+### WINDOW PARTITION BY clause 和 WINDOW ORDER BY clause
```sql
WindowPartitionClause
@@ -129,9 +145,18 @@ WindowOrderByClause
::= ( 'ORDER' 'BY' ByList )
```
-`PARTITION BY`选项将查询的行分为一组进入*partitions*, 这些行在窗口函数中单独处理。`PARTITION BY`和查询级别`GROUP BY` 子句做相似的工作,除了它的表达式只能作为表达式不能作为输出列的名字或数。OpenMLDB要求必须配置`PARTITION BY`。并且目前**仅支持按列分组**,无法支持按运算和函数表达式分组。
+`PARTITION BY`选项将查询的行分为一组进入*partitions*, 这些行在窗口函数中单独处理。`PARTITION BY`和查询级别`GROUP BY` 子句做相似的工作, 只是它只能作为表达式不能作为查询结果的输出列或输出列 ID。OpenMLDB要求必须配置`PARTITION BY`。PARTITION BY list 可以有多个, 但**仅支持按列分组**,无法支持按运算或函数表达式分组。
+
+`ORDER BY` 选项决定分区中的行被窗口函数处理的顺序。它和查询级别`ORDER BY`子句做相似的工作, 同样不能作为查询结果的输出列或者输出列 ID。OpenMLDB 目前**仅支持按列排序**,ORDER BY list 有且只能有一个, 不支持按运算或函数表达式排序。**OpenMLDB 0.8.4** 以后, 在线模式下 ORDER BY 子句可以不写 (离线模式暂时不支持), 表示窗口内的列将以不确定的顺序处理, 不带 ORDER BY 子句的窗口需要额外满足如下条件:
+
+1. 不能有`EXCLUDE CURRENT_TIME`
+2. 对于 ROWS 类型窗口没有更多限制, 对于 ROWS_RANGE 类型窗口:
+ 1. 窗口 FRAME 的边界不能是 `offset [OPEN] PRECEDING/FOLLOWING` 的格式, 目前情况只能为 `UNBOUNDED PRECEDING AND CURRENT ROW`
+
+```{note}
+窗口不带 ORDER BY 的情况, 意味着对于在线预览模式, 计算结果是不确定的, 无法预测哪些行进去了窗口哪些行没有. 同时对于一些通用窗口函数, 例如 `lag, first_value`, 在所有模式下得到的计算结果都是不确定的,无法预测窗口内行的先后顺序.
+```
-`ORDER BY` 选项决定分区中的行被窗口函数处理的顺序。它和查询级别`ORDER BY`子句做相似的工作, 但是同样的它不能作为输出列的名字或数。同样,OpenMLDB要求必须配置`ORDER BY`。并且目前**仅支持按列排序**,无法支持按运算和函数表达式排序。
### Window Frame Clause
@@ -332,5 +357,5 @@ WINDOW w1 AS (PARTITION BY col1 ORDER BY col5 ROWS_RANGE BETWEEN 10s PRECEDING A
```
```{seealso}
-窗口计算可使用的聚合函数,参考[Built-in Functions](../functions_and_operators/Files/udfs_8h.md)
+窗口计算可使用的聚合函数,参考[Built-in Functions](../udfs_8h.md)
```
diff --git a/docs/zh/openmldb_sql/functions_and_operators/index.rst b/docs/zh/openmldb_sql/functions_and_operators/index.rst
index 36329c03045..8dfb1e18cee 100644
--- a/docs/zh/openmldb_sql/functions_and_operators/index.rst
+++ b/docs/zh/openmldb_sql/functions_and_operators/index.rst
@@ -7,4 +7,3 @@
:maxdepth: 1
operators
- Files/udfs_8h
diff --git a/docs/zh/openmldb_sql/functions_and_operators/operators.md b/docs/zh/openmldb_sql/functions_and_operators/operators.md
index e5a7ca86afe..31d79184bd8 100644
--- a/docs/zh/openmldb_sql/functions_and_operators/operators.md
+++ b/docs/zh/openmldb_sql/functions_and_operators/operators.md
@@ -1,4 +1,4 @@
-# 运算符
+# 表达式和运算符
## 运算符优先级
@@ -19,9 +19,7 @@
%left UNARY_PRECEDENCE // For all unary operators, +, -, ~
```
-## 各类运算
-
-### 1. 比较运算
+## 比较运算
| 操作符名 | 功能描述 |
| :-------------- | :--------------------- |
@@ -37,7 +35,7 @@
| `ILIKE` | 模糊匹配, 大小写不敏感 |
| `RLIKE` | 正则表达式匹配 |
-### 2. 逻辑运算
+## 逻辑运算
| 操作符名 | 功能描述 |
| :---------- | :------- |
@@ -46,7 +44,7 @@
| `XOR` | 逻辑与或 |
| `NOT`, `!` | 逻辑非, unary operator |
-### 3. 算术运算
+## 算术运算
| 操作符名 | 功能描述 |
| :--------- | :------------------------------------------------------- |
@@ -59,7 +57,7 @@
| `+` | Unary plus |
| `-` | Unary minus, 只支持数值型操作数-number |
-### 4. 位运算
+## 位运算
| 操作符名 | Description |
| :------- | :---------- |
@@ -68,7 +66,7 @@
| `^` | Bitwise XOR |
| `~` | Bitwise NOT, unary operator |
-### 5. 类型运算和函数
+## 类型运算和函数
| 操作符名 | Description |
| :------------- | :--------------------------------------------------------- |
@@ -97,7 +95,7 @@ SELECT INT(1.2);
X:表示从原类型转换为目标类型的转换是不支持的
-| src\|dist | bool | smallint | int | float | int64 | double | timestamp | date | string |
+| src\|dst | bool | smallint | int | float | int64 | double | timestamp | date | string |
| :------------ | :----- | :------- | :----- | :----- | :----- | :----- | :-------- | :----- | :----- |
| **bool** | Safe | Safe | Safe | Safe | Safe | Safe | UnSafe | X | Safe |
| **smallint** | UnSafe | Safe | Safe | Safe | Safe | Safe | UnSafe | X | Safe |
@@ -114,3 +112,14 @@ X:表示从原类型转换为目标类型的转换是不支持的
| 操作符名 | 功能描述 |
| :------- | :------------------------ |
| `=` | 赋值 (可用于 SET 语句中 ) |
+
+## 条件表达式
+
+### CASE 表达式
+ ```sql
+ SELECT case 'bb' when 'aa' then 'apple' else 'nothing' end; -- SIMPLE CASE WHEN
+ SELECT case
+ when 'bb'='aa' then 'apple'
+ when 'bb'='bb' then 'banana'
+ else 'nothing' end; -- SEARCHED CASE WHEN
+ ```
diff --git a/docs/zh/openmldb_sql/index.rst b/docs/zh/openmldb_sql/index.rst
index 7d00e9ed532..149147f1f55 100644
--- a/docs/zh/openmldb_sql/index.rst
+++ b/docs/zh/openmldb_sql/index.rst
@@ -10,6 +10,7 @@ OpenMLDB SQL
language_structure/index
data_types/index
functions_and_operators/index
+ udfs_8h
dql/index
dml/index
ddl/index
diff --git a/docs/zh/openmldb_sql/sql_difference.md b/docs/zh/openmldb_sql/sql_difference.md
index 3118f8f71bb..0b521dd2eca 100644
--- a/docs/zh/openmldb_sql/sql_difference.md
+++ b/docs/zh/openmldb_sql/sql_difference.md
@@ -14,7 +14,7 @@
| -------------- | ---------------------------- | -------------------------------- | -------------------------------- | ------------ | ------------------------------------------------------------ |
| WHERE 子句 | ✓ | ✓ | ✕ | ✓ | 部分功能可以通过带有 `_where` 后缀的内置函数实现 |
| HAVING 子句 | ✓ | ✓ | X | ✓ | |
-| JOIN 子句 | ✓ | ✕ | ✓ | ✓ | OpenMLDB 仅支持特有的 **LAST JOIN** |
+| JOIN 子句 | ✓ | ✕ | ✓ | ✓ | OpenMLDB 支持特有的 **LAST JOIN**, 和 **LEFT JOIN** |
| GROUP BY 分组 | ✓ | ✕ | ✕ | ✓ | |
| ORDER BY 关键字 | ✓ | ✓ | ✓ | ✓ | 仅支持在 `WINDOW` 和 `LAST JOIN` 子句内部使用,不支持倒排序 `DESC` |
| LIMIT 限制行数 | ✓ | ✓ | ✕ | ✓ | |
@@ -54,7 +54,7 @@
| LAST JOIN | ✓ | ✓ | ✕ |
| 子查询 / WITH 子句 | ✓ | ✓ | ✕ |
-虽然在线请求模式无法支持 `WHERE` 子句,但是部分功能可以通过带有 `_where` 后缀的计算函数实现,比如 `count_where`, `avg_where` 等,详情查看[内置计算函数文档](functions_and_operators/Files/udfs_8h.md)。
+虽然在线请求模式无法支持 `WHERE` 子句,但是部分功能可以通过带有 `_where` 后缀的计算函数实现,比如 `count_where`, `avg_where` 等,详情查看[内置计算函数文档](./udfs_8h.md)。
### LIMIT 子句
@@ -81,7 +81,7 @@ WINDOW 子句和 GROUP BY & HAVING 子句不支持同时使用。上线时 WINDO
特殊限制:
-- 在线请求模式下,WINDOW 的输入是 LAST JOIN 或者子查询内的 LAST JOIN, 注意窗口的定义里 `PARTITION BY` & `ORDER BY` 的列都必须来自 JOIN 最左边的表。
+- 在线请求模式下,WINDOW 的输入是 LAST JOIN 或者带子查询内的 LAST JOIN, 注意窗口的定义里 `PARTITION BY` & `ORDER BY` 的列都必须来自 JOIN 最左边的表。
### GROUP BY & HAVING 子句
@@ -94,19 +94,23 @@ GROUP BY 语句,目前仍为实验性功能,仅支持输入表是一张物
| LAST JOIN | ✕ | ✕ | ✕ |
| 子查询 | ✕ | ✕ | ✕ |
-### JOIN 子句(LAST JOIN)
+### JOIN 子句
-OpenMLDB 仅支持 LAST JOIN 一种 JOIN 语法,详细描述参考扩展语法的 LAST JOIN 部分。JOIN 有左右两个输入,在线请求模式下,支持两个输入为物理表,或者特定的子查询,详见表格,未列出情况不支持。
+OpenMLDB 支持 LAST JOIN 和 LEFT JOIN,详细描述参考扩展语法的 JOIN 部分。JOIN 有左右两个输入,在线请求模式下,支持两个输入为物理表,或者特定的子查询,LEFT JOIN 不能直接用于在线请求模式, 但可以作为 LAST JOIN 的右表输入. 详见表格,未列出情况不支持。
-| **应用于** | **离线模式** | **在线预览模式** | **在线请求模式** |
-| ------------------------------------------------------------ | ------------ | ---------------- | ---------------- |
-| 两个表引用 | ✓ | ✕ | ✓ |
-| 子查询, 仅包括:
左右表均为简单列筛选
左右表为 WINDOW 或 LAST JOIN 操作 | ✓ | ✓ | ✓ |
+| **应用于** | **离线模式** | **在线预览模式** | **在线请求模式** |
+| ---------------------------------------------- | ------------ | ---------------- | ---------------- |
+| LAST JOIN + 两个表引用 | ✓ | ✕ | ✓ |
+| LAST JOIN + 左右表均为简单列筛选 | ✓ | ✕ | ✓l |
+| LAST JOIN + 右表是带 WHERE 条件过滤的单表查询 | ✓ | ✕ | ✓ |
+| LAST JOIN左表或右表为 WINDOW 或 LAST JOIN 操作 | ✓ | ✕ | ✓ |
+| LAST JOIN + 右表是LEFT JOIN 的子查询 | ✕ | ✕ | ✓ |
+| LEFT JOIN | ✕ | ✕ | ✕ |
特殊限制:
- 关于特定子查询的 LAST JOIN 上线,还有额外要求,详见[上线要求](../openmldb_sql/deployment_manage/ONLINE_REQUEST_REQUIREMENTS.md#在线请求模式下-last-join-的使用规范) 。
-- 在线预览模式下暂不支持 LAST JOIN
+- 在线预览模式下暂不支持 LAST JOIN 和 LEFT JOIN
### WITH 子句
@@ -118,7 +122,7 @@ OpenMLDB (>= v0.7.2) 支持非递归的 WITH 子句。WITH 子句等价于其它
### ORDER BY 关键字
-排序关键字 `ORDER BY` 仅在窗口定义 `WINDOW` 和拼表操作 `LAST JOIN` 子句内部被支持,并且不支持倒排序关键字 `DESC`。参见 WINDOW 子句和 LAST JOIN 子句内的相关说明。
+排序关键字 `ORDER BY` 仅在窗口定义 `WINDOW` 和拼表操作 `LAST JOIN` 子句内部被支持,并且不支持倒排序关键字 `DESC`。 OpenMLDB 0.8.4 以后支持窗口定义不带 ORDER BY, 但需额外满足特定条件. 参见 WINDOW 子句和 LAST JOIN 子句内的相关说明。
### 聚合函数
@@ -127,7 +131,7 @@ OpenMLDB (>= v0.7.2) 支持非递归的 WITH 子句。WITH 子句等价于其它
特殊限制:
- OpenMLDB v0.6.0 开始支持在线预览模式的全表聚合,但注意所描述的[扫描限制配置](https://openmldb.feishu.cn/wiki/wikcnhBl4NsKcAX6BO9NDtKAxDf#doxcnLWICKzccMuPiWwdpVjSaIe)。
-- OpenMLDB 有较多的聚合函数扩展,请查看产品文档具体查询所支持的函数 [OpenMLDB 内置函数](../openmldb_sql/functions_and_operators/Files/udfs_8h.md)。
+- OpenMLDB 有较多的聚合函数扩展,请查看产品文档具体查询所支持的函数 [OpenMLDB 内置函数](../openmldb_sql/udfs_8h.md)。
## 扩展语法
@@ -149,10 +153,10 @@ OpenMLDB 主要对 `WINDOW` 以及 `LAST JOIN` 语句进行了深度定制化开
| **语句元素** | **支持语法** | **说明** | **必需 ?** |
| ---------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ----------- |
| 数据定义 | PARTITION BY | 可支持多列
支持的列数据类型: bool, int16, int32, int64, string, date, timestamp | ✓ |
-| 数据排序 | ORDER BY | 仅支持对单一列排序
可支持数据类型: int16, int32, int64, timestamp
不支持倒序 `DESC` | ✓ |
+| 数据排序 | ORDER BY | 仅支持对单一列排序
可支持数据类型: int16, int32, int64, timestamp
不支持倒序 `DESC`
OpenMLDB 0.8.4 之前必填 | - |
| 范围定义 |
基本上下界定义语法:ROWS/ROWS_RANGE BETWEEN ... AND ...
支持范围定义关键字 PRECEDING, OPEN PRECEDING, CURRENT ROW, UNBOUNDED | 必须给定上下边界
不支持边界关键字 FOLLOWING
在线请求模式中,CURRENT ROW 为当前的请求行。在表格视角下,当前行将会被虚拟的插入到表格根据 ORDER BY 排序的正确位置上。 | ✓ |
-| 范围单位 | ROWS
ROWS_RANGE(扩展) | ROWS_RANGE 为扩展语法,其定义的窗口边界属性等价于标准 SQL 的 RANGE 类型窗口,支持用数值或者带时间单位的数值定义窗口边界,后者为拓展语法。
带时间单位定义的窗口范围,等价于时间转化成毫秒数值后的窗口定义。例如 `ROWS_RANGE 10s PRCEDING ...` 和 `ROWS_RANGE 10000 PRECEDNG ...` 是等价的。 | ✓ |
-| 窗口属性(扩展) | MAXSIZE
EXCLUDE CURRENT_ROW
EXCLUDE CURRENT_TIME
INSTANCE_NOT_IN_WINDOW | MAXSIZE 只对 ROWS_RANGE 有效 | - |
+| 范围单位 | ROWS
ROWS_RANGE(扩展) | ROWS_RANGE 为扩展语法,其定义的窗口边界属性等价于标准 SQL 的 RANGE 类型窗口,支持用数值或者带时间单位的数值定义窗口边界,后者为拓展语法。
带时间单位定义的窗口范围,等价于时间转化成毫秒数值后的窗口定义。例如 `ROWS_RANGE 10s PRCEDING ...` 和 `ROWS_RANGE 10000 PRECEDNG ...` 是等价的。 | ✓ |
+| 窗口属性(扩展) | MAXSIZE
EXCLUDE CURRENT_ROW
EXCLUDE CURRENT_TIME
INSTANCE_NOT_IN_WINDOW | MAXSIZE 只对 ROWS_RANGE 有效
不带 ORDER BY 和 EXCLUDE CURRENT_TIME 不能同时使用 | - |
| 多表定义(扩展) | 实际使用中语法形态较为复杂,参考:
[跨表特征开发教程](../tutorial/tutorial_sql_2.md)
[WINDOW UNION 语法文档](../openmldb_sql/dql/WINDOW_CLAUSE.md#1-window--union) | 允许合并多个表
允许联合简单子查询
实践中,一般和聚合函数搭配使用,实现跨表的聚合操作 | - |
| 匿名窗口 | - | 必须包括 PARTITION BY、ORDER BY、以及窗口范围定义 | - |
@@ -238,15 +242,15 @@ SELECT
在实际开发中,较多的应用的数据是存放在多个表格中,在这种情况下,一般会使用 WINDOW ... UNION 的语法进行跨表的聚合操作。请参考[跨表特征开发教程](../tutorial/tutorial_sql_2.md)关于“ 副表多行聚合特征”部分。
-### LAST JOIN 子句
+### JOIN 子句
-关于 LAST JOIN 详细语法规范,请参考 [LAST JOIN 文档](../openmldb_sql/dql/JOIN_CLAUSE.md#join-clause)。
+关于 JOIN 详细语法规范,请参考 [JOIN 文档](../openmldb_sql/dql/JOIN_CLAUSE.md#join-clause)。
| **语句元素** | **支持语法** | **说明** | **必需?** |
| ------------ | ------------ | ------------------------------------------------------------ | ---------- |
| ON | ✓ | 列类型支持:BOOL, INT16, INT32, INT64, STRING, DATE, TIMESTAMP | ✓ |
| USING | 不支持 | - | - |
-| ORDER BY | ✓ | 后面只能接单列列类型 : INT16, INT32, INT64, TIMESTAMP
不支持倒序关键字 DESC | - |
+| ORDER BY | ✓ | LAST JOIN 的拓展语法, LEFT JON 不支持.
后面只能接单列列类型 : INT16, INT32, INT64, TIMESTAMP, 不支持倒序关键字 DESC | - |
#### LAST JOIN 举例
@@ -256,4 +260,10 @@ SELECT
FROM
t1
LAST JOIN t2 ON t1.col1 = t2.col1;
+
+SELECT
+ *
+FROM
+ t1
+LEFT JOIN t2 ON t1.col1 = t2.col1;
```
diff --git a/docs/zh/openmldb_sql/udf_develop_guide.md b/docs/zh/openmldb_sql/udf_develop_guide.md
index 7fe4e81988d..761e66dea6f 100644
--- a/docs/zh/openmldb_sql/udf_develop_guide.md
+++ b/docs/zh/openmldb_sql/udf_develop_guide.md
@@ -11,7 +11,7 @@
#### 2.1.1 C++函数名规范
- C++内置函数名统一使用[snake_case](https://en.wikipedia.org/wiki/Snake_case)风格
- 要求函数名能清晰表达函数功能
-- 函数不能重名。函数名不能和内置函数及其他自定义函数重名。所有内置函数的列表参考[这里](../openmldb_sql/functions_and_operators/Files/udfs_8h.md)
+- 函数不能重名。函数名不能和内置函数及其他自定义函数重名。所有内置函数的列表参考[这里](../openmldb_sql/udfs_8h.md)
#### 2.1.2 C++类型与SQL类型对应关系
内置C++函数的参数类型限定为:BOOL类型,数值类型,时间戳日期类型和字符串类型。C++类型SQL类型对应关系如下:
diff --git a/docs/en/reference/sql/functions_and_operators/Files/udfs_8h.md b/docs/zh/openmldb_sql/udfs_8h.md
similarity index 68%
rename from docs/en/reference/sql/functions_and_operators/Files/udfs_8h.md
rename to docs/zh/openmldb_sql/udfs_8h.md
index ac96c6bfc3f..9cfab05977f 100644
--- a/docs/en/reference/sql/functions_and_operators/Files/udfs_8h.md
+++ b/docs/zh/openmldb_sql/udfs_8h.md
@@ -10,158 +10,158 @@ title: udfs/udfs.h
| Name | Description |
| -------------- | -------------- |
-| **[abs](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-abs)**()|
Return the absolute value of expr. |
-| **[acos](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-acos)**()|
Return the arc cosine of expr. |
-| **[add](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-add)**()|
Compute sum of two arguments. |
-| **[add_months](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-add-months)**()|
adds an integer months to a given date, returning the resulting date. |
-| **[array_contains](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-array-contains)**()|
array_contains(array, value) - Returns true if the array contains the value. |
-| **[asin](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-asin)**()|
Return the arc sine of expr. |
-| **[at](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-at)**()| |
-| **[atan](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-atan)**()|
Return the arc tangent of expr If called with one parameter, this function returns the arc tangent of expr. If called with two parameters X and Y, this function returns the arc tangent of Y / X. |
-| **[atan2](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-atan2)**()|
Return the arc tangent of Y / X.. |
-| **[avg](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg)**()|
Compute average of values. |
-| **[avg_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg-cate)**()|
Compute average of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[avg_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V', separated by comma, and sorted by key in ascend order. |
-| **[avg_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-avg-where)**()|
Compute average of values match specified condition. |
-| **[bigint](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-bigint)**()| |
-| **[bool](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-bool)**()|
Cast string expression to bool. |
-| **[ceil](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ceil)**()|
Return the smallest integer value not less than the expr. |
-| **[ceiling](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ceiling)**()| |
-| **[char](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-char)**()|
Returns the ASCII character having the binary equivalent to expr. If n >= 256 the result is equivalent to char(n % 256). |
-| **[char_length](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-char-length)**()|
Returns the length of the string. It is measured in characters and multibyte character string is not supported. |
-| **[character_length](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-character-length)**()| |
-| **[concat](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-concat)**()|
This function returns a string resulting from the joining of two or more string values in an end-to-end manner. (To add a separating value during joining, see concat_ws.) |
-| **[concat_ws](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-concat-ws)**()|
Returns a string resulting from the joining of two or more string value in an end-to-end manner. It separates those concatenated string values with the delimiter specified in the first function argument. |
-| **[cos](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-cos)**()|
Return the cosine of expr. |
-| **[cot](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-cot)**()|
Return the cotangent of expr. |
-| **[count](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count)**()|
Compute number of values. |
-| **[count_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count-cate)**()|
Compute count of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[count_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[count_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-count-where)**()|
Compute number of values match specified condition. |
-| **[date](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-date)**()|
Cast timestamp or string expression to date (date >= 1900-01-01) |
-| **[date_format](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-date-format)**()|
Formats the date value according to the format string. |
-| **[datediff](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-datediff)**()|
days difference from date1 to date2 |
-| **[day](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-day)**()| |
-| **[dayofmonth](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-dayofmonth)**()|
Return the day of the month for a timestamp or date. |
-| **[dayofweek](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-dayofweek)**()|
Return the day of week for a timestamp or date. |
-| **[dayofyear](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-dayofyear)**()|
Return the day of year for a timestamp or date. Returns 0 given an invalid date. |
-| **[degrees](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-degrees)**()|
Convert radians to degrees. |
-| **[distinct_count](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-distinct-count)**()|
Compute number of distinct values. |
-| **[double](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-double)**()|
Cast string expression to double. |
-| **[drawdown](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-drawdown)**()|
Compute drawdown of values. |
-| **[earth_distance](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-earth-distance)**()|
Returns the great circle distance between two points on the surface of the Earth. Km as return unit. add a minus (-) sign if heading west (W) or south (S). |
-| **[entropy](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-entropy)**()|
Calculate Shannon entropy of a column of values. Null values are skipped. |
-| **[ew_avg](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ew-avg)**()|
Compute exponentially-weighted average of values. It's equivalent to pandas ewm(alpha={alpha}, adjust=True, ignore_na=True, com=None, span=None, halflife=None, min_periods=0) |
-| **[exp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-exp)**()|
Return the value of e (the base of natural logarithms) raised to the power of expr. |
-| **[farm_fingerprint](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-farm-fingerprint)**()| |
-| **[first_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-first-value)**()|
Returns the value of expr from the latest row (last row) of the window frame. |
-| **[float](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-float)**()|
Cast string expression to float. |
-| **[floor](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-floor)**()|
Return the largest integer value not less than the expr. |
-| **[get_json_object](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-get-json-object)**()|
Extracts a JSON object from [JSON Pointer](https://datatracker.ietf.org/doc/html/rfc6901)|
-| **[hash64](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-hash64)**()|
Returns a hash value of the arguments. It is not a cryptographic hash function and should not be used as such. |
-| **[hex](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-hex)**()|
Convert integer to hexadecimal. |
-| **[hour](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-hour)**()|
Return the hour for a timestamp. |
-| **[identity](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-identity)**()|
Return value. |
-| **[if_null](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-if-null)**()|
If input is not null, return input value; else return default value. |
-| **[ifnull](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ifnull)**()| |
-| **[ilike_match](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ilike-match)**()|
pattern match same as ILIKE predicate |
-| **[inc](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-inc)**()|
Return expression + 1. |
-| **[int](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int)**()| |
-| **[int16](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int16)**()|
Cast string expression to int16. |
-| **[int32](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int32)**()|
Cast string expression to int32. |
-| **[int64](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-int64)**()|
Cast string expression to int64. |
-| **[is_null](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-is-null)**()|
Check if input value is null, return bool. |
-| **[isnull](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-isnull)**()| |
-| **[join](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-join)**()|
For each string value from specified column of window, join by delimeter. Null values are skipped. |
-| **[json_array_length](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-json-array-length)**()|
Returns the number of elements in the outermost JSON array. |
-| **[lag](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lag)**()|
Returns value evaluated at the row that is offset rows before the current row within the partition. Offset is evaluated with respect to the current row. |
-| **[last_day](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-last-day)**()|
Return the last day of the month to which the date belongs to. |
-| **[lcase](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lcase)**()|
Convert all the characters to lowercase. Note that characters with values > 127 are simply returned. |
-| **[like_match](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-like-match)**()|
pattern match same as LIKE predicate |
-| **[list_except_by_key](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-list-except-by-key)**()|
Return list of elements in list1 but keys not in except_str. |
-| **[list_except_by_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-list-except-by-value)**()|
Return list of elements in list1 but values not in except_str. |
-| **[ln](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ln)**()|
Return the natural logarithm of expr. |
-| **[log](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-log)**()|
log(base, expr) If called with one parameter, this function returns the natural logarithm of expr. If called with two parameters, this function returns the logarithm of expr to the base. |
-| **[log10](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-log10)**()|
Return the base-10 logarithm of expr. |
-| **[log2](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-log2)**()|
Return the base-2 logarithm of expr. |
-| **[lower](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lower)**()| |
-| **[make_tuple](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-make-tuple)**()| |
-| **[max](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max)**()|
Compute maximum of values. |
-| **[max_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max-cate)**()|
Compute maximum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[max_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[max_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-max-where)**()|
Compute maximum of values match specified condition. |
-| **[maximum](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-maximum)**()|
Compute maximum of two arguments. |
-| **[median](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-median)**()|
Compute the median of values. |
-| **[min](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min)**()|
Compute minimum of values. |
-| **[min_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min-cate)**()|
Compute minimum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[min_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[min_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-min-where)**()|
Compute minimum of values match specified condition. |
-| **[minimum](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-minimum)**()|
Compute minimum of two arguments. |
-| **[minute](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-minute)**()|
Return the minute for a timestamp. |
-| **[month](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-month)**()|
Return the month part of a timestamp or date. |
-| **[nth_value_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-nth-value-where)**()|
Returns the value of expr from the idx th row matches the condition. |
-| **[nvl](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-nvl)**()| |
-| **[nvl2](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-nvl2)**()|
nvl2(expr1, expr2, expr3) - Returns expr2 if expr1 is not null, or expr3 otherwise. |
-| **[pmod](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-pmod)**()|
Compute pmod of two arguments. If any param is NULL, output NULL. If divisor is 0, output NULL. |
-| **[pow](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-pow)**()|
Return the value of expr1 to the power of expr2. |
-| **[power](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-power)**()| |
-| **[radians](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-radians)**()|
Returns the argument X, converted from degrees to radians. (Note that π radians equals 180 degrees.) |
-| **[regexp_like](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-regexp-like)**()|
pattern match same as RLIKE predicate (based on RE2) |
-| **[replace](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-replace)**()|
replace(str, search[, replace]) - Replaces all occurrences of `search` with `replace`|
-| **[reverse](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-reverse)**()|
Returns the reversed given string. |
-| **[round](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-round)**()|
Returns expr rounded to d decimal places using HALF_UP rounding mode. |
-| **[second](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-second)**()|
Return the second for a timestamp. |
-| **[sin](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sin)**()|
Return the sine of expr. |
-| **[size](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-size)**()|
Get the size of a List (e.g., result of split) |
-| **[smallint](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-smallint)**()| |
-| **[split](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split)**()|
Split string to list by delimeter. Null values are skipped. |
-| **[split_array](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split-array)**()|
Split string to array of string by delimeter. |
-| **[split_by_key](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split-by-key)**()|
Split string by delimeter and split each segment as kv pair, then add each key to output list. Null or illegal segments are skipped. |
-| **[split_by_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-split-by-value)**()|
Split string by delimeter and split each segment as kv pair, then add each value to output list. Null or illegal segments are skipped. |
-| **[sqrt](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sqrt)**()|
Return square root of expr. |
-| **[std](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-std)**()| |
-| **[stddev](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-stddev)**()|
Compute sample standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / (n-1) )`|
-| **[stddev_pop](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-stddev-pop)**()|
Compute population standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / n )`|
-| **[stddev_samp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-stddev-samp)**()| |
-| **[strcmp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-strcmp)**()|
Returns 0 if the strings are the same, -1 if the first argument is smaller than the second according to the current sort order, and 1 otherwise. |
-| **[string](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-string)**()|
Return string converted from timestamp expression. |
-| **[substr](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-substr)**()| |
-| **[substring](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-substring)**()|
Return a substring `len` characters long from string str, starting at position `pos`. Alias function: `substr`|
-| **[sum](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum)**()|
Compute sum of values. |
-| **[sum_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum-cate)**()|
Compute sum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[sum_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
-| **[sum_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sum-where)**()|
Compute sum of values match specified condition. |
-| **[tan](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-tan)**()|
Return the tangent of expr. |
-| **[timestamp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-timestamp)**()|
Cast int64, date or string expression to timestamp. |
-| **[top](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top)**()|
Compute top k of values and output string separated by comma. The outputs are sorted in desc order. |
-| **[top1_ratio](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top1-ratio)**()|
Compute the top1 occurring value's ratio. |
-| **[top_n_key_avg_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_count_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_max_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_min_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_key_ratio_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
-| **[top_n_key_sum_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-key-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_avg_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_count_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_max_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_min_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[top_n_value_ratio_cate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
-| **[top_n_value_sum_cate_where](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-top-n-value-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
-| **[topn_frequency](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-topn-frequency)**()|
Return the topN keys sorted by their frequency. |
-| **[truncate](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-truncate)**()|
Return the nearest integer that is not greater in magnitude than the expr. |
-| **[ucase](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-ucase)**()|
Convert all the characters to uppercase. Note that characters values > 127 are simply returned. |
-| **[unhex](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-unhex)**()|
Convert hexadecimal to binary string. |
-| **[unix_timestamp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-unix-timestamp)**()|
Cast date or string expression to unix_timestamp. If empty string or NULL is provided, return current timestamp. |
-| **[upper](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-upper)**()| |
-| **[var_pop](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-var-pop)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / n`|
-| **[var_samp](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-var-samp)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / (n-1)`|
-| **[variance](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-variance)**()| |
-| **[week](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-week)**()| |
-| **[weekofyear](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-weekofyear)**()|
Return the week of year for a timestamp or date. |
-| **[window_split](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-window-split)**()|
For each string value from specified column of window, split by delimeter and add segment to output list. Null values are skipped. |
-| **[window_split_by_key](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-window-split-by-key)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each key to output list. Null and illegal segments are skipped. |
-| **[window_split_by_value](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-window-split-by-value)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each value to output list. Null and illegal segments are skipped. |
-| **[year](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-year)**()|
Return the year part of a timestamp or date. |
+| **[abs](/openmldb_sql/Files/udfs_8h.md#function-abs)**()|
Return the absolute value of expr. |
+| **[acos](/openmldb_sql/Files/udfs_8h.md#function-acos)**()|
Return the arc cosine of expr. |
+| **[add](/openmldb_sql/Files/udfs_8h.md#function-add)**()|
Compute sum of two arguments. |
+| **[add_months](/openmldb_sql/Files/udfs_8h.md#function-add-months)**()|
adds an integer months to a given date, returning the resulting date. |
+| **[array_contains](/openmldb_sql/Files/udfs_8h.md#function-array-contains)**()|
array_contains(array, value) - Returns true if the array contains the value. |
+| **[asin](/openmldb_sql/Files/udfs_8h.md#function-asin)**()|
Return the arc sine of expr. |
+| **[at](/openmldb_sql/Files/udfs_8h.md#function-at)**()| |
+| **[atan](/openmldb_sql/Files/udfs_8h.md#function-atan)**()|
Return the arc tangent of expr If called with one parameter, this function returns the arc tangent of expr. If called with two parameters X and Y, this function returns the arc tangent of Y / X. |
+| **[atan2](/openmldb_sql/Files/udfs_8h.md#function-atan2)**()|
Return the arc tangent of Y / X.. |
+| **[avg](/openmldb_sql/Files/udfs_8h.md#function-avg)**()|
Compute average of values. |
+| **[avg_cate](/openmldb_sql/Files/udfs_8h.md#function-avg-cate)**()|
Compute average of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[avg_cate_where](/openmldb_sql/Files/udfs_8h.md#function-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V', separated by comma, and sorted by key in ascend order. |
+| **[avg_where](/openmldb_sql/Files/udfs_8h.md#function-avg-where)**()|
Compute average of values match specified condition. |
+| **[bigint](/openmldb_sql/Files/udfs_8h.md#function-bigint)**()| |
+| **[bool](/openmldb_sql/Files/udfs_8h.md#function-bool)**()|
Cast string expression to bool. |
+| **[ceil](/openmldb_sql/Files/udfs_8h.md#function-ceil)**()|
Return the smallest integer value not less than the expr. |
+| **[ceiling](/openmldb_sql/Files/udfs_8h.md#function-ceiling)**()| |
+| **[char](/openmldb_sql/Files/udfs_8h.md#function-char)**()|
Returns the ASCII character having the binary equivalent to expr. If n >= 256 the result is equivalent to char(n % 256). |
+| **[char_length](/openmldb_sql/Files/udfs_8h.md#function-char-length)**()|
Returns the length of the string. It is measured in characters and multibyte character string is not supported. |
+| **[character_length](/openmldb_sql/Files/udfs_8h.md#function-character-length)**()| |
+| **[concat](/openmldb_sql/Files/udfs_8h.md#function-concat)**()|
This function returns a string resulting from the joining of two or more string values in an end-to-end manner. (To add a separating value during joining, see concat_ws.) |
+| **[concat_ws](/openmldb_sql/Files/udfs_8h.md#function-concat-ws)**()|
Returns a string resulting from the joining of two or more string value in an end-to-end manner. It separates those concatenated string values with the delimiter specified in the first function argument. |
+| **[cos](/openmldb_sql/Files/udfs_8h.md#function-cos)**()|
Return the cosine of expr. |
+| **[cot](/openmldb_sql/Files/udfs_8h.md#function-cot)**()|
Return the cotangent of expr. |
+| **[count](/openmldb_sql/Files/udfs_8h.md#function-count)**()|
Compute number of values. |
+| **[count_cate](/openmldb_sql/Files/udfs_8h.md#function-count-cate)**()|
Compute count of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[count_cate_where](/openmldb_sql/Files/udfs_8h.md#function-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[count_where](/openmldb_sql/Files/udfs_8h.md#function-count-where)**()|
Compute number of values match specified condition. |
+| **[date](/openmldb_sql/Files/udfs_8h.md#function-date)**()|
Cast timestamp or string expression to date (date >= 1900-01-01) |
+| **[date_format](/openmldb_sql/Files/udfs_8h.md#function-date-format)**()|
Formats the date value according to the format string. |
+| **[datediff](/openmldb_sql/Files/udfs_8h.md#function-datediff)**()|
days difference from date1 to date2 |
+| **[day](/openmldb_sql/Files/udfs_8h.md#function-day)**()| |
+| **[dayofmonth](/openmldb_sql/Files/udfs_8h.md#function-dayofmonth)**()|
Return the day of the month for a timestamp or date. |
+| **[dayofweek](/openmldb_sql/Files/udfs_8h.md#function-dayofweek)**()|
Return the day of week for a timestamp or date. |
+| **[dayofyear](/openmldb_sql/Files/udfs_8h.md#function-dayofyear)**()|
Return the day of year for a timestamp or date. Returns 0 given an invalid date. |
+| **[degrees](/openmldb_sql/Files/udfs_8h.md#function-degrees)**()|
Convert radians to degrees. |
+| **[distinct_count](/openmldb_sql/Files/udfs_8h.md#function-distinct-count)**()|
Compute number of distinct values. |
+| **[double](/openmldb_sql/Files/udfs_8h.md#function-double)**()|
Cast string expression to double. |
+| **[drawdown](/openmldb_sql/Files/udfs_8h.md#function-drawdown)**()|
Compute drawdown of values. |
+| **[earth_distance](/openmldb_sql/Files/udfs_8h.md#function-earth-distance)**()|
Returns the great circle distance between two points on the surface of the Earth. Km as return unit. add a minus (-) sign if heading west (W) or south (S). |
+| **[entropy](/openmldb_sql/Files/udfs_8h.md#function-entropy)**()|
Calculate Shannon entropy of a column of values. Null values are skipped. |
+| **[ew_avg](/openmldb_sql/Files/udfs_8h.md#function-ew-avg)**()|
Compute exponentially-weighted average of values. It's equivalent to pandas ewm(alpha={alpha}, adjust=True, ignore_na=True, com=None, span=None, halflife=None, min_periods=0) |
+| **[exp](/openmldb_sql/Files/udfs_8h.md#function-exp)**()|
Return the value of e (the base of natural logarithms) raised to the power of expr. |
+| **[farm_fingerprint](/openmldb_sql/Files/udfs_8h.md#function-farm-fingerprint)**()| |
+| **[first_value](/openmldb_sql/Files/udfs_8h.md#function-first-value)**()|
Returns the value of expr from the latest row (last row) of the window frame. |
+| **[float](/openmldb_sql/Files/udfs_8h.md#function-float)**()|
Cast string expression to float. |
+| **[floor](/openmldb_sql/Files/udfs_8h.md#function-floor)**()|
Return the largest integer value not less than the expr. |
+| **[get_json_object](/openmldb_sql/Files/udfs_8h.md#function-get-json-object)**()|
Extracts a JSON object from [JSON Pointer](https://datatracker.ietf.org/doc/html/rfc6901)|
+| **[hash64](/openmldb_sql/Files/udfs_8h.md#function-hash64)**()|
Returns a hash value of the arguments. It is not a cryptographic hash function and should not be used as such. |
+| **[hex](/openmldb_sql/Files/udfs_8h.md#function-hex)**()|
Convert integer to hexadecimal. |
+| **[hour](/openmldb_sql/Files/udfs_8h.md#function-hour)**()|
Return the hour for a timestamp. |
+| **[identity](/openmldb_sql/Files/udfs_8h.md#function-identity)**()|
Return value. |
+| **[if_null](/openmldb_sql/Files/udfs_8h.md#function-if-null)**()|
If input is not null, return input value; else return default value. |
+| **[ifnull](/openmldb_sql/Files/udfs_8h.md#function-ifnull)**()| |
+| **[ilike_match](/openmldb_sql/Files/udfs_8h.md#function-ilike-match)**()|
pattern match same as ILIKE predicate |
+| **[inc](/openmldb_sql/Files/udfs_8h.md#function-inc)**()|
Return expression + 1. |
+| **[int](/openmldb_sql/Files/udfs_8h.md#function-int)**()| |
+| **[int16](/openmldb_sql/Files/udfs_8h.md#function-int16)**()|
Cast string expression to int16. |
+| **[int32](/openmldb_sql/Files/udfs_8h.md#function-int32)**()|
Cast string expression to int32. |
+| **[int64](/openmldb_sql/Files/udfs_8h.md#function-int64)**()|
Cast string expression to int64. |
+| **[is_null](/openmldb_sql/Files/udfs_8h.md#function-is-null)**()|
Check if input value is null, return bool. |
+| **[isnull](/openmldb_sql/Files/udfs_8h.md#function-isnull)**()| |
+| **[join](/openmldb_sql/Files/udfs_8h.md#function-join)**()|
For each string value from specified column of window, join by delimeter. Null values are skipped. |
+| **[json_array_length](/openmldb_sql/Files/udfs_8h.md#function-json-array-length)**()|
Returns the number of elements in the outermost JSON array. |
+| **[lag](/openmldb_sql/Files/udfs_8h.md#function-lag)**()|
Returns value evaluated at the row that is offset rows before the current row within the partition. Offset is evaluated with respect to the current row. |
+| **[last_day](/openmldb_sql/Files/udfs_8h.md#function-last-day)**()|
Return the last day of the month to which the date belongs to. |
+| **[lcase](/openmldb_sql/Files/udfs_8h.md#function-lcase)**()|
Convert all the characters to lowercase. Note that characters with values > 127 are simply returned. |
+| **[like_match](/openmldb_sql/Files/udfs_8h.md#function-like-match)**()|
pattern match same as LIKE predicate |
+| **[list_except_by_key](/openmldb_sql/Files/udfs_8h.md#function-list-except-by-key)**()|
Return list of elements in list1 but keys not in except_str. |
+| **[list_except_by_value](/openmldb_sql/Files/udfs_8h.md#function-list-except-by-value)**()|
Return list of elements in list1 but values not in except_str. |
+| **[ln](/openmldb_sql/Files/udfs_8h.md#function-ln)**()|
Return the natural logarithm of expr. |
+| **[log](/openmldb_sql/Files/udfs_8h.md#function-log)**()|
log(base, expr) If called with one parameter, this function returns the natural logarithm of expr. If called with two parameters, this function returns the logarithm of expr to the base. |
+| **[log10](/openmldb_sql/Files/udfs_8h.md#function-log10)**()|
Return the base-10 logarithm of expr. |
+| **[log2](/openmldb_sql/Files/udfs_8h.md#function-log2)**()|
Return the base-2 logarithm of expr. |
+| **[lower](/openmldb_sql/Files/udfs_8h.md#function-lower)**()| |
+| **[make_tuple](/openmldb_sql/Files/udfs_8h.md#function-make-tuple)**()| |
+| **[max](/openmldb_sql/Files/udfs_8h.md#function-max)**()|
Compute maximum of values. |
+| **[max_cate](/openmldb_sql/Files/udfs_8h.md#function-max-cate)**()|
Compute maximum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[max_cate_where](/openmldb_sql/Files/udfs_8h.md#function-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[max_where](/openmldb_sql/Files/udfs_8h.md#function-max-where)**()|
Compute maximum of values match specified condition. |
+| **[maximum](/openmldb_sql/Files/udfs_8h.md#function-maximum)**()|
Compute maximum of two arguments. |
+| **[median](/openmldb_sql/Files/udfs_8h.md#function-median)**()|
Compute the median of values. |
+| **[min](/openmldb_sql/Files/udfs_8h.md#function-min)**()|
Compute minimum of values. |
+| **[min_cate](/openmldb_sql/Files/udfs_8h.md#function-min-cate)**()|
Compute minimum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[min_cate_where](/openmldb_sql/Files/udfs_8h.md#function-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[min_where](/openmldb_sql/Files/udfs_8h.md#function-min-where)**()|
Compute minimum of values match specified condition. |
+| **[minimum](/openmldb_sql/Files/udfs_8h.md#function-minimum)**()|
Compute minimum of two arguments. |
+| **[minute](/openmldb_sql/Files/udfs_8h.md#function-minute)**()|
Return the minute for a timestamp. |
+| **[month](/openmldb_sql/Files/udfs_8h.md#function-month)**()|
Return the month part of a timestamp or date. |
+| **[nth_value_where](/openmldb_sql/Files/udfs_8h.md#function-nth-value-where)**()|
Returns the value of expr from the idx th row matches the condition. |
+| **[nvl](/openmldb_sql/Files/udfs_8h.md#function-nvl)**()| |
+| **[nvl2](/openmldb_sql/Files/udfs_8h.md#function-nvl2)**()|
nvl2(expr1, expr2, expr3) - Returns expr2 if expr1 is not null, or expr3 otherwise. |
+| **[pmod](/openmldb_sql/Files/udfs_8h.md#function-pmod)**()|
Compute pmod of two arguments. If any param is NULL, output NULL. If divisor is 0, output NULL. |
+| **[pow](/openmldb_sql/Files/udfs_8h.md#function-pow)**()|
Return the value of expr1 to the power of expr2. |
+| **[power](/openmldb_sql/Files/udfs_8h.md#function-power)**()| |
+| **[radians](/openmldb_sql/Files/udfs_8h.md#function-radians)**()|
Returns the argument X, converted from degrees to radians. (Note that π radians equals 180 degrees.) |
+| **[regexp_like](/openmldb_sql/Files/udfs_8h.md#function-regexp-like)**()|
pattern match same as RLIKE predicate (based on RE2) |
+| **[replace](/openmldb_sql/Files/udfs_8h.md#function-replace)**()|
replace(str, search[, replace]) - Replaces all occurrences of `search` with `replace`|
+| **[reverse](/openmldb_sql/Files/udfs_8h.md#function-reverse)**()|
Returns the reversed given string. |
+| **[round](/openmldb_sql/Files/udfs_8h.md#function-round)**()|
Returns expr rounded to d decimal places using HALF_UP rounding mode. |
+| **[second](/openmldb_sql/Files/udfs_8h.md#function-second)**()|
Return the second for a timestamp. |
+| **[sin](/openmldb_sql/Files/udfs_8h.md#function-sin)**()|
Return the sine of expr. |
+| **[size](/openmldb_sql/Files/udfs_8h.md#function-size)**()|
Get the size of a List (e.g., result of split) |
+| **[smallint](/openmldb_sql/Files/udfs_8h.md#function-smallint)**()| |
+| **[split](/openmldb_sql/Files/udfs_8h.md#function-split)**()|
Split string to list by delimeter. Null values are skipped. |
+| **[split_array](/openmldb_sql/Files/udfs_8h.md#function-split-array)**()|
Split string to array of string by delimeter. |
+| **[split_by_key](/openmldb_sql/Files/udfs_8h.md#function-split-by-key)**()|
Split string by delimeter and split each segment as kv pair, then add each key to output list. Null or illegal segments are skipped. |
+| **[split_by_value](/openmldb_sql/Files/udfs_8h.md#function-split-by-value)**()|
Split string by delimeter and split each segment as kv pair, then add each value to output list. Null or illegal segments are skipped. |
+| **[sqrt](/openmldb_sql/Files/udfs_8h.md#function-sqrt)**()|
Return square root of expr. |
+| **[std](/openmldb_sql/Files/udfs_8h.md#function-std)**()| |
+| **[stddev](/openmldb_sql/Files/udfs_8h.md#function-stddev)**()|
Compute sample standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / (n-1) )`|
+| **[stddev_pop](/openmldb_sql/Files/udfs_8h.md#function-stddev-pop)**()|
Compute population standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2) / n )`|
+| **[stddev_samp](/openmldb_sql/Files/udfs_8h.md#function-stddev-samp)**()| |
+| **[strcmp](/openmldb_sql/Files/udfs_8h.md#function-strcmp)**()|
Returns 0 if the strings are the same, -1 if the first argument is smaller than the second according to the current sort order, and 1 otherwise. |
+| **[string](/openmldb_sql/Files/udfs_8h.md#function-string)**()|
Return string converted from timestamp expression. |
+| **[substr](/openmldb_sql/Files/udfs_8h.md#function-substr)**()| |
+| **[substring](/openmldb_sql/Files/udfs_8h.md#function-substring)**()|
Return a substring `len` characters long from string str, starting at position `pos`. Alias function: `substr`|
+| **[sum](/openmldb_sql/Files/udfs_8h.md#function-sum)**()|
Compute sum of values. |
+| **[sum_cate](/openmldb_sql/Files/udfs_8h.md#function-sum-cate)**()|
Compute sum of values grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[sum_cate_where](/openmldb_sql/Files/udfs_8h.md#function-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key and output string. Each group is represented as 'K:V' and separated by comma in outputs and are sorted by key in ascend order. |
+| **[sum_where](/openmldb_sql/Files/udfs_8h.md#function-sum-where)**()|
Compute sum of values match specified condition. |
+| **[tan](/openmldb_sql/Files/udfs_8h.md#function-tan)**()|
Return the tangent of expr. |
+| **[timestamp](/openmldb_sql/Files/udfs_8h.md#function-timestamp)**()|
Cast int64, date or string expression to timestamp. |
+| **[top](/openmldb_sql/Files/udfs_8h.md#function-top)**()|
Compute top k of values and output string separated by comma. The outputs are sorted in desc order. |
+| **[top1_ratio](/openmldb_sql/Files/udfs_8h.md#function-top1-ratio)**()|
Compute the top1 occurring value's ratio. |
+| **[top_n_key_avg_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_count_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_max_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_min_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_key_ratio_cate](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
+| **[top_n_key_sum_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-key-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N category keys in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_avg_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-avg-cate-where)**()|
Compute average of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_count_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-count-cate-where)**()|
Compute count of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_max_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-max-cate-where)**()|
Compute maximum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_min_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-min-cate-where)**()|
Compute minimum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[top_n_value_ratio_cate](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-ratio-cate)**()|
Ratios (cond match cnt / total cnt) for groups. |
+| **[top_n_value_sum_cate_where](/openmldb_sql/Files/udfs_8h.md#function-top-n-value-sum-cate-where)**()|
Compute sum of values matching specified condition grouped by category key. Output string for top N aggregate values in descend order. Each group is represented as 'K:V' and separated by comma(,). Empty string returned if no rows selected. |
+| **[topn_frequency](/openmldb_sql/Files/udfs_8h.md#function-topn-frequency)**()|
Return the topN keys sorted by their frequency. |
+| **[truncate](/openmldb_sql/Files/udfs_8h.md#function-truncate)**()|
Return the nearest integer that is not greater in magnitude than the expr. |
+| **[ucase](/openmldb_sql/Files/udfs_8h.md#function-ucase)**()|
Convert all the characters to uppercase. Note that characters values > 127 are simply returned. |
+| **[unhex](/openmldb_sql/Files/udfs_8h.md#function-unhex)**()|
Convert hexadecimal to binary string. |
+| **[unix_timestamp](/openmldb_sql/Files/udfs_8h.md#function-unix-timestamp)**()|
Cast date or string expression to unix_timestamp. If empty string or NULL is provided, return current timestamp. |
+| **[upper](/openmldb_sql/Files/udfs_8h.md#function-upper)**()| |
+| **[var_pop](/openmldb_sql/Files/udfs_8h.md#function-var-pop)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / n`|
+| **[var_samp](/openmldb_sql/Files/udfs_8h.md#function-var-samp)**()|
Compute population variance of values, i.e., `sum((x_i - avg)^2) / (n-1)`|
+| **[variance](/openmldb_sql/Files/udfs_8h.md#function-variance)**()| |
+| **[week](/openmldb_sql/Files/udfs_8h.md#function-week)**()| |
+| **[weekofyear](/openmldb_sql/Files/udfs_8h.md#function-weekofyear)**()|
Return the week of year for a timestamp or date. |
+| **[window_split](/openmldb_sql/Files/udfs_8h.md#function-window-split)**()|
For each string value from specified column of window, split by delimeter and add segment to output list. Null values are skipped. |
+| **[window_split_by_key](/openmldb_sql/Files/udfs_8h.md#function-window-split-by-key)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each key to output list. Null and illegal segments are skipped. |
+| **[window_split_by_value](/openmldb_sql/Files/udfs_8h.md#function-window-split-by-value)**()|
For each string value from specified column of window, split by delimeter and then split each segment as kv pair, then add each value to output list. Null and illegal segments are skipped. |
+| **[year](/openmldb_sql/Files/udfs_8h.md#function-year)**()|
Return the year part of a timestamp or date. |
## Functions Documentation
@@ -501,13 +501,13 @@ Compute average of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -541,13 +541,13 @@ Compute average of values grouped by category key and output string. Each group
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -586,13 +586,13 @@ Compute average of values matching specified condition grouped by category key a
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -634,13 +634,13 @@ Compute average of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -884,7 +884,7 @@ SELECT COS(0);
-* The value returned by [cos()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-cos) is always in the range: -1 to 1.
+* The value returned by [cos()](/openmldb_sql/Files/udfs_8h.md#function-cos) is always in the range: -1 to 1.
**Supported Types**:
@@ -946,13 +946,13 @@ Compute number of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -987,13 +987,13 @@ Compute count of values grouped by category key and output string. Each group is
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -1032,13 +1032,13 @@ Compute count of values matching specified condition grouped by category key and
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -1080,13 +1080,13 @@ Compute number of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -1178,7 +1178,12 @@ Supported date string style:
* yyyy-mm-dd
* yyyymmdd
-* yyyy-mm-dd hh:mm:ss
+* yyyy-mm-dd HH:MM:SS
+* yyyy-mm-ddTHH:MM:SS.fff+HH:MM (RFC3399 format)
+
+Dates from string are transformed into the same time zone (which is currently always UTC+8) before differentiation, dates from date type by default is at UTC+8, you may see a +1/-1 difference if the two date string have different time zones.
+
+Hint: since openmldb date type limits range from year 1900, to datadiff from/to a date before 1900, pass it as string.
Example:
@@ -1225,7 +1230,7 @@ Return the day of the month for a timestamp or date.
0.1.0
-Note: This function equals the `[day()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-day)` function.
+Note: This function equals the `[day()](/openmldb_sql/Files/udfs_8h.md#function-day)` function.
Example:
@@ -1259,7 +1264,7 @@ Return the day of week for a timestamp or date.
0.4.0
-Note: This function equals the `[week()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-week)` function.
+Note: This function equals the `[week()](/openmldb_sql/Files/udfs_8h.md#function-week)` function.
Example:
@@ -1369,13 +1374,13 @@ Compute number of distinct values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 0 |
-| 2 |
-| 2 |
-| 4 |
+| 0 |
+| 0 |
+| 2 |
+| 2 |
+| 4 |
```sql
@@ -1445,14 +1450,14 @@ It requires that all values are non-negative. Negative values will be ignored.
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 8 |
-| 5 |
-| 2 |
-| 10 |
-| 4 |
+| 1 |
+| 8 |
+| 5 |
+| 2 |
+| 10 |
+| 4 |
```sql
@@ -1563,13 +1568,13 @@ It requires that values are ordered so that it can only be used with WINDOW (PAR
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -1647,11 +1652,11 @@ window w as (partition by gp order by ts rows between 3 preceding and current ro
```
-| id | gp | ts | agg |
+| id | gp | ts | agg |
| -------- | -------- | -------- | -------- |
-| 1 | 100 | 98 | 98 |
-| 2 | 100 | 99 | 99 |
-| 3 | 100 | 100 | 100 |
+| 1 | 100 | 98 | 98 |
+| 2 | 100 | 99 | 99 |
+| 3 | 100 | 100 | 100 |
@@ -2246,21 +2251,21 @@ Returns value evaluated at the row that is offset rows before the current row wi
* **offset** The number of rows forwarded from the current row, must not negative
-Note: This function equals the `[at()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-at)` function.
+Note: This function equals the `[at()](/openmldb_sql/Files/udfs_8h.md#function-at)` function.
-The offset in window is `nth_value()`, not `[lag()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-lag)/at()`. The old `[at()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-at)`(version < 0.5.0) is start from the last row of window(may not be the current row), it's more like `nth_value()`
+The offset in window is `nth_value()`, not `[lag()](/openmldb_sql/Files/udfs_8h.md#function-lag)/at()`. The old `[at()](/openmldb_sql/Files/udfs_8h.md#function-at)`(version < 0.5.0) is start from the last row of window(may not be the current row), it's more like `nth_value()`
Example:
-| c1 | c2 |
+| c1 | c2 |
| -------- | -------- |
-| 0 | 1 |
-| 1 | 1 |
-| 2 | 2 |
-| 3 | 2 |
-| 4 | 2 |
+| 0 | 1 |
+| 1 | 1 |
+| 2 | 2 |
+| 3 | 2 |
+| 4 | 2 |
```sql
@@ -2648,13 +2653,13 @@ Compute maximum of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2691,13 +2696,13 @@ Compute maximum of values grouped by category key and output string. Each group
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -2736,13 +2741,13 @@ Compute maximum of values matching specified condition grouped by category key a
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -2784,13 +2789,13 @@ Compute maximum of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2856,12 +2861,12 @@ Compute the median of values.
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2898,13 +2903,13 @@ Compute minimum of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -2941,13 +2946,13 @@ Compute minimum of values grouped by category key and output string. Each group
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -2986,14 +2991,14 @@ Compute minimum of values matching specified condition grouped by category key a
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 1 | true | y |
-| 4 | true | x |
-| 3 | true | y |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 1 | true | y |
+| 4 | true | x |
+| 3 | true | y |
```sql
@@ -3035,13 +3040,13 @@ Compute minimum of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -3171,12 +3176,12 @@ select col1, cond, gp, nth_value_where(col1, 2, cond) over (partition by gp orde
```
-| col1 | cond | gp | agg |
+| col1 | cond | gp | agg |
| -------- | -------- | -------- | -------- |
-| 1 | true | 100 | NULL |
-| 2 | false | 100 | NULL |
-| 3 | NULL | 100 | NULL |
-| 4 | true | 100 | 4 |
+| 1 | true | 100 | NULL |
+| 2 | false | 100 | NULL |
+| 3 | NULL | 100 | NULL |
+| 4 | true | 100 | 4 |
@@ -3563,7 +3568,7 @@ SELECT SIN(0);
-* The value returned by [sin()](/openmldb_sql/functions_and_operators/Files/udfs_8h.md#function-sin) is always in the range: -1 to 1.
+* The value returned by [sin()](/openmldb_sql/Files/udfs_8h.md#function-sin) is always in the range: -1 to 1.
**Supported Types**:
@@ -3805,12 +3810,12 @@ Alias function: `std`, `stddev_samp`
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -3847,12 +3852,12 @@ Compute population standard deviation of values, i.e., `sqrt( sum((x_i - avg)^2)
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -4008,13 +4013,13 @@ Compute sum of values.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -4048,13 +4053,13 @@ Compute sum of values grouped by category key and output string. Each group is r
Example:
-| value | catagory |
+| value | catagory |
| -------- | -------- |
-| 0 | x |
-| 1 | y |
-| 2 | x |
-| 3 | y |
-| 4 | x |
+| 0 | x |
+| 1 | y |
+| 2 | x |
+| 3 | y |
+| 4 | x |
```sql
@@ -4093,13 +4098,13 @@ Compute sum of values matching specified condition grouped by category key and o
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
```sql
@@ -4141,13 +4146,13 @@ Compute sum of values match specified condition.
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
+| 0 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
```sql
@@ -4257,13 +4262,13 @@ Compute top k of values and output string separated by comma. The outputs are so
Example:
-| value |
+| value |
| -------- |
-| 1 |
-| 2 |
-| 3 |
-| 4 |
-| 4 |
+| 1 |
+| 2 |
+| 3 |
+| 4 |
+| 4 |
```sql
@@ -4314,11 +4319,11 @@ SELECT key, top1_ratio(key) over () as ratio FROM t1;
```
-| key | ratio |
+| key | ratio |
| -------- | -------- |
-| 1 | 1.0 |
-| 2 | 0.5 |
-| NULL | 0.5 |
+| 1 | 1.0 |
+| 2 | 0.5 |
+| NULL | 0.5 |
@@ -4355,15 +4360,15 @@ Compute average of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4415,15 +4420,15 @@ Compute count of values matching specified condition grouped by category key. Ou
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4475,15 +4480,15 @@ Compute maximum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4535,15 +4540,15 @@ Compute minimum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4597,15 +4602,15 @@ For each group, ratio value is `value` expr count matches condtion divide total
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 2 | true | x |
-| 4 | true | x |
-| 1 | true | y |
-| 3 | false | y |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 2 | true | x |
+| 4 | true | x |
+| 1 | true | y |
+| 3 | false | y |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4656,15 +4661,15 @@ Compute sum of values matching specified condition grouped by category key. Outp
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4716,15 +4721,15 @@ Compute average of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | false | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | false | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4776,15 +4781,15 @@ Compute count of values matching specified condition grouped by category key. Ou
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | true | x |
-| 3 | false | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | true | x |
+| 3 | false | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4836,15 +4841,15 @@ Compute maximum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | false | y |
-| 2 | false | x |
-| 3 | true | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | false | z |
+| 0 | true | x |
+| 1 | false | y |
+| 2 | false | x |
+| 3 | true | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | false | z |
```sql
@@ -4896,15 +4901,15 @@ Compute minimum of values matching specified condition grouped by category key.
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | true | x |
-| 3 | true | y |
-| 4 | false | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | true | x |
+| 3 | true | y |
+| 4 | false | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -4958,15 +4963,15 @@ For each group, ratio value is `value` expr count matches condtion divide total
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 2 | true | x |
-| 4 | true | x |
-| 1 | true | y |
-| 3 | false | y |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 2 | true | x |
+| 4 | true | x |
+| 1 | true | y |
+| 3 | false | y |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -5017,15 +5022,15 @@ Compute sum of values matching specified condition grouped by category key. Outp
Example:
-| value | condition | catagory |
+| value | condition | catagory |
| -------- | -------- | -------- |
-| 0 | true | x |
-| 1 | true | y |
-| 2 | false | x |
-| 3 | false | y |
-| 4 | true | x |
-| 5 | true | z |
-| 6 | true | z |
+| 0 | true | x |
+| 1 | true | y |
+| 2 | false | x |
+| 3 | false | y |
+| 4 | true | x |
+| 5 | true | z |
+| 6 | true | z |
```sql
@@ -5240,11 +5245,11 @@ Compute population variance of values, i.e., `sum((x_i - avg)^2) / n`
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 3 |
-| 6 |
+| 0 |
+| 3 |
+| 6 |
```sql
@@ -5281,11 +5286,11 @@ Compute population variance of values, i.e., `sum((x_i - avg)^2) / (n-1)`
Example:
-| value |
+| value |
| -------- |
-| 0 |
-| 3 |
-| 6 |
+| 0 |
+| 3 |
+| 6 |
```sql
diff --git a/docs/zh/quickstart/beginner_must_read.md b/docs/zh/quickstart/beginner_must_read.md
index 37f1b57ae8e..117ad6fedb7 100644
--- a/docs/zh/quickstart/beginner_must_read.md
+++ b/docs/zh/quickstart/beginner_must_read.md
@@ -1,6 +1,20 @@
# 上手必读
-由于OpenMLDB是分布式系统,多种模式,客户端丰富,初次使用可能会有很多疑问,或者遇到一些运行、使用问题,本文从新手使用的角度,讲解如何进行诊断调试,需求帮助时如何提供有效信息给技术人员等等。
+由于OpenMLDB是分布式系统,多种模式,客户端丰富,初次使用可能会有很多疑问,或者遇到一些运行、使用问题,本文从新手使用的角度,讲解如何进行诊断调试,需要帮助时如何提供有效信息给技术人员等等。
+
+## 错误诊断
+
+在使用OpenMLDB的过程中,除了SQL语法错误,其他错误信息可能不够直观,但很可能与集群状态有关。所以,错误诊断需要**先确认集群状态**。在发现错误时,请先使用诊断工具的一键诊断功能。一键诊断可以输出全面直观的诊断报告,如果不能使用此工具,可以手动执行`SHOW COMPONENTS;`和`SHOW TABLE STATUS LIKE '%';`提供部分信息。
+
+报告将展示集群的组件、在线表等状态,也会提示用户如何修复,请按照报告内容进行操作,详情见[一键inspect](../maintain/diagnose.md#一键inspect)。
+
+```
+openmldb_tool inspect [-c=0.0.0.0:2181/openmldb]
+```
+
+需要注意,由于离线存储只会在执行离线job时被读取,而离线job也不是一个持续的状态,所以,一键诊断只能展示TaskManager组件状态,不会诊断离线存储,也无法诊断离线job的执行错误,离线job诊断见[离线SQL执行](#离线)。
+
+如果诊断报告认为集群健康,但仍然无法解决问题,请提供错误和诊断报告给我们。
## 创建OpenMLDB与连接
@@ -8,7 +22,7 @@
docker创建OpenMLDB见[快速上手](./openmldb_quickstart.md),请注意文档中有两个版本,单机版和集群版。请清楚自己要创建哪个版本,不要混合使用。
-启动成功的标准是可以使用CLI连接上OpenMLDB服务端(即使用`/work/openmldb/bin/openmldb`连接OpenMLDB,单机或集群均可以通过CLI连接),并且执行`show components;`可以看到OpenMLDB服务端组件的运行情况。
+启动成功的标准是可以使用CLI连接上OpenMLDB服务端(即使用`/work/openmldb/bin/openmldb`连接OpenMLDB,单机或集群均可以通过CLI连接),并且执行`show components;`可以看到OpenMLDB服务端组件的运行情况。推荐使用[诊断工具](../maintain/diagnose.md),执行status和inspect,可以得到更可靠的诊断结果。
如果CLI无法连接OpenMLDB,请先确认进程是否运行正常,可以通过`ps f|grep bin/openmldb`确认nameserver和tabletserver进程,集群版还需要通过`ps f | grep zoo.cfg`来确认zk服务,`ps f | grep TaskManagerServer`来确认taskmanager进程。
@@ -18,6 +32,20 @@ docker创建OpenMLDB见[快速上手](./openmldb_quickstart.md),请注意文
如果我们还需要OpenMLDB服务端的配置和日志,可以使用诊断工具获取,见[下文](#提供配置与日志获得技术支持)。
```
+### 运维
+
+集群各组件进程启动后,在使用过程中可能遇到各种变化,比如服务进程意外退出,需要重启服务进程,或者需要扩容服务进程。
+
+如果你需要保留已有的在线表,**不要主动地kill全部Tablet再重启**,保证Tablet只有单台在上下线。`stop-all.sh`和`start-all.sh`脚本是给快速重建集群用的,可能会导致在线表数据恢复失败,**不保证能修复**。
+
+当你发现进程变化或者主动操作其变化后,需要使用诊断工具进行诊断,确认集群状态是否正常:
+```bash
+openmldb_tool inspect # 主要命令
+openmldb_tool status --diff hosts # 可检查TaskManager等是否掉线,当然,你也可以手动判断
+```
+
+如果诊断出server offline,或是TaskManager等掉线,需要先启动回来。如果启动失败,请查看对应日志,提供错误信息。如果诊断结果提示需要recoverdata,请参考[OpenMLDB运维工具](../maintain/openmldb_ops.md)执行recoverdata。如果recoverdata脚本提示recover失败,或recover成功后再次inpsect的结果仍然不正常,请提供日志给我们。
+
## 源数据
### LOAD DATA
@@ -42,15 +70,51 @@ docker创建OpenMLDB见[快速上手](./openmldb_quickstart.md),请注意文
csv文件格式有诸多不便,更推荐使用parquet格式,需要OpenMLDB集群版并启动taskmanager组件。
```
-## SQL限制
+## OpenMLDB SQL 开发和调试
OpenMLDB并不完全兼容标准SQL。所以,部分SQL执行会得不到预期结果。如果发现SQL执行不符合预期,请先查看下SQL是否满足[功能边界](./function_boundary.md)。
-## SQL执行
+为了方便使用 OpenMLDB SQL 进行开发、调试、验证,我们强烈推荐使用社区工具 [OpenMLDB SQL Emulator](https://github.com/vagetablechicken/OpenMLDBSQLEmulator) 来进行 SQL 模拟开发,可以节省大量的部署、编译、索引构建、任务运行等待时间,详见该项目 README https://github.com/vagetablechicken/OpenMLDBSQLEmulator
+
+### OpenMLDB SQL语法指南
+
+基于 OpenMLDB SQL 的特征计算,一般比较常使用`WINDOW`(包括`WINDOW UNION`),`LAST JOIN` 等子句来完成计算逻辑,它们能保证在任何模式下使用。可以跟随教程"基于 SQL 的特征开发"[(上)](../tutorial/tutorial_sql_1.md)[(下)](../tutorial/tutorial_sql_2.md)进行学习。
+
+如果使用`WHERE`,`WITH`,`HAVING`等子句,需要注意限制条件。在每个子句的详细文档中都有具体的说明,比如[`HAVING`子句](../openmldb_sql/dql/HAVING_CLAUSE.md)在在线请求模式中不支持。翻阅OpenMLDB SQL的DQL目录,或使用搜索功能,可以快速找到子句的详细文档。
+
+在不熟悉OpenMLDB SQL的情况下,我们建议从子句开始编写SQL,确保每个子句都能通过,再逐步组合成完整的SQL。
+
+推荐使用[OpenMLDB SQL Emulator](https://github.com/vagetablechicken/OpenMLDBSQLEmulator)进行SQL探索和验证,SQL验证完成后再去真实集群进行上线,可以避免浪费大量时间在索引构建、数据导入、任务等待等过程上。 Emulator 可以不依赖真实OpenMLDB集群,在一个交互式虚拟环境中,快速创建表、校验SQL、导出当前环境等等,详情参考该项目的 README 。使用 Emulator 不需要操作集群,也就不需要测试后清理集群,还可通过少量的数据进行SQL运行测试,比较适合SQL探索时期。
-OpenMLDB所有命令均为SQL,如果SQL执行失败或交互有问题(不知道命令是否执行成功),请先确认SQL书写是否有误,命令并未执行,还是命令进入了执行阶段。
+### OpenMLDB SQL 语法错误提示
-例如,下面提示Syntax error的是SQL书写有误,请参考[sql reference](../../openmldb_sql/)纠正错误。
+当发现SQL编译报错时,需要查看错误信息。例如`Syntax error: Expected XXX but got keyword YYY`错误,它说明SQL不符合语法,通常是某些关键字写错了位置,或并没有这种写法。详情需要查询错误的子句文档,可注意子句的`Syntax`章节,它详细说明了每个部分的组成,请检查SQL是否符合要求。
+
+比如,[`WINDOW`子句](../openmldb_sql/dql/WINDOW_CLAUSE.md#syntax)中`WindowFrameClause (WindowAttribute)*`部分,我们再拆解它就是`WindowFrameUnits WindowFrameBounds [WindowFrameMaxSize] (WindowAttribute)*`。那么,`WindowFrameUnits WindowFrameBounds MAXSIZE 10 EXCLUDE CURRENT_TIME`就是符合语法的,`WindowFrameUnits WindowFrameBounds EXCLUDE CURRENT_TIME MAXSIZE 10`就是不符合语法的,不能把`WindowFrameMaxSize`放到`WindowFrameClause`外面。
+
+### OpenMLDB SQL 计算正确性调试
+
+SQL编译通过以后,可以基于数据进行计算。如果计算结果不符合预期,请逐步检查:
+- SQL无论是一列还是多列计算结果不符合预期,建议都请选择**其中一列**进行调试。
+- 如果你的表数据较多,建议使用小数据量(几行,几十行的量级)来测试,也可以使用OpenMLDB SQL Emulator的[运行toydb](https://github.com/vagetablechicken/OpenMLDBSQLEmulator#run-in-toydb)功能,构造case进行测试。
+- 该列是不是表示了自己想表达的意思,是否使用了不符合预期的函数,或者函数参数错误。
+- 该列如果是窗口聚合的结果,是不是WINDOW定义错误,导致窗口范围不对。参考[推断窗口](../openmldb_sql/dql/WINDOW_CLAUSE.md#如何推断窗口是什么样的)进行检查,使用小数据进行验证测试。
+
+如果你仍然无法解决问题,可以提供 OpenMLDB SQL Emulator 的 yaml case 。如果在集群中进行的测试,请[提供复现脚本](#提供复现脚本)。
+
+### 在线请求模式测试
+
+SQL上线,等价于`DEPLOY `成功。但`DEPLOY`操作是一个很“重”的操作,SQL如果可以上线,将会创建或修改索引并复制数据到新索引。所以,在SQL探索期使用`DEPLOY`测试SQL是否能上线,是比较浪费资源的,尤其是某些SQL可能需要多次修改才能上线,多次的`DEPLOY`可能产生很多无用的索引。在探索期间,可能还会修改表Schema,又需要删除和再创建。这些操作都是只能手动处理,比较繁琐。
+
+如果你对OpenMLDB SQL较熟悉,一些场景下可以用“在线预览模式”进行测试,但“在线预览模式”不等于“在线请求模式”,不能保证一定可以上线。如果你对索引较为熟悉,可以通过`EXPLAIN `来确认SQL是否可以上线,但`EXPLAIN`的检查较为严格,可能因为当前表没有匹配的索引,而判定SQL无法在“在线请求模式”中执行(因为无索引而无法保证实时性能,所以被拒绝)。
+
+目前只有Java SDK可以使用[validateSQLInRequest](./sdk/java_sdk.md#sql-校验)方法来检验,使用上稍麻烦。我们推荐使用 OpenMLDB SQL Emulator 来测试。在 Emulator 中,通过简单语法创建表,再使用`valreq `可以判断是否能上线。
+
+## OpenMLDB SQL 执行
+
+OpenMLDB 所有命令均为 SQL,如果 SQL 执行失败或交互有问题(不知道命令是否执行成功),请先确认 SQL 书写是否有误,命令并未执行,还是命令进入了执行阶段。
+
+例如,下面提示Syntax error的是SQL书写有误,请参考[SQL编写指南](#sql编写指南)纠正错误。
```
127.0.0.1:7527/db> create table t1(c1 int;
Error: Syntax error: Expected ")" or "," but got ";" [at 1:23]
@@ -65,32 +129,32 @@ create table t1(c1 int;
我们需要特别注意集群版的一些使用逻辑。
-### 集群版SQL执行
-
-#### 离线
+### 集群版离线 SQL 执行注意事项
如果是集群离线命令,默认异步模式下,发送命令会得到job id的返回。可使用`show job `来查询job执行情况。
-离线job如果是异步SELECT(并不INTO保存结果),也不会将结果打印在客户端(同步SELECT将会打印结果)。可以通过`show joblog `来获得结果,结果中包含stdout和stderr两部分,stdout为查询结果,stderr为job运行日志。如果发现job failed或者其他状态,不符合你的预期,请仔细查看job运行日志。
+离线job如果是异步SELECT(并不INTO保存结果),也不会将结果打印在客户端,而同步SELECT将会打印结果到控制台。可以通过`show joblog `来获得结果,结果中包含stdout和stderr两部分,stdout为查询结果,stderr为job运行日志。如果发现job failed或者其他状态,不符合你的预期,请仔细查看job运行日志。
-```{note}
-日志地址由taskmanager.properties的`job.log.path`配置,如果你改变了此配置项,需要到配置的目的地寻找日志。stdout日志默认在`/work/openmldb/taskmanager/bin/logs/job_x.log`,job运行日志默认在`/work/openmldb/taskmanager/bin/logs/job_x_error.log`(注意有error后缀),
+离线job日志中可能有一定的干扰日志,用户可以使用`openmldb_tool inspect job --id x`进行日志的解析提取,帮助定位错误,更多信息请参考[诊断工具job检查](../maintain/diagnose.md#job-检查)。
-如果taskmanager是yarn模式,而不是local模式,`job_x_error.log`中的信息会较少,不会有job错误的详细信息。需要通过`job_x_error.log`中记录的yarn app id,去yarn系统中查询job的真正错误原因。
+如果taskmanager是yarn模式,而不是local模式,`job_x_error.log`中的信息会较少,只会打印异常。如果异常不直观,需要更早时间的执行日志,执行日志不在`job_x_error.log`中,需要通过`job_x_error.log`中记录的yarn app id,去yarn系统中查询yarn app的container的日志。yarn app container里,执行日志也保存在stderr中。
+
+```{note}
+如果你无法通过show joblog获得日志,或者想要直接拿到日志文件,可以直接在TaskManager机器上获取。日志地址由taskmanager.properties的`job.log.path`配置,如果你改变了此配置项,需要到配置的目录中寻找日志。stdout查询结果默认在`/work/openmldb/taskmanager/bin/logs/job_x.log`,stderr job运行日志默认在`/work/openmldb/taskmanager/bin/logs/job_x_error.log`(注意有error后缀)。
```
-#### 在线
+### 集群版在线 SQL 执行注意事项
-集群版在线模式下,我们通常只推荐使用`DEPLOY`创建deployment,HTTP访问APIServer执行deployment做实时特征计算。在CLI或其他客户端中,直接在在线中进行SELECT查询,称为“在线预览”。在线预览有诸多限制,详情请参考[功能边界-集群版在线预览模式](../function_boundary.md#集群版在线预览模式),请不要执行不支持的SQL。
+集群版在线模式下,我们通常只推荐两种使用,`DEPLOY`创建deployment,执行deployment做实时特征计算(SDK请求deployment,或HTTP访问APIServer请求deployment)。在CLI或其他客户端中,可以直接在“在线”中进行SELECT查询,称为“在线预览”。在线预览有诸多限制,详情请参考[功能边界-集群版在线预览模式](./function_boundary.md#集群版在线预览模式),请不要执行不支持的SQL。
-### 提供复现脚本
+### 构造 OpenMLDB SQL 复现脚本
-如果你通过自主诊断,无法解决问题,请向我们提供复现脚本。一个完整的复现脚本,如下所示:
+如果你的 SQL 执行不符合预期,通过自主诊断,无法解决问题,请向我们提供复现脚本。一个完整的复现脚本。仅涉及在线SQL计算或校验SQL,推荐使用[OpenMLDB SQL Emulator](https://github.com/vagetablechicken/OpenMLDBSQLEmulator#run-in-toydb) 构造可复现的 yaml case。如果涉及到数据导入等必须使用 OpenMLDB集群,请提供可复现脚本,其结构如下所示:
```
create database db;
use db;
--- create youer table
+-- create your table
create table xx ();
-- offline or online
@@ -118,7 +182,7 @@ set @@execute_mode='';
请注意离线job默认为异步。如果你需要离线导入再查询,请设置为同步模式,详情见[离线命令配置详情](../openmldb_sql/ddl/SET_STATEMENT.md#离线命令配置详情)。否则导入还未完成就进行查询,是无意义的。
```
-## 提供配置与日志,获得技术支持
+### 提供配置与日志,获得技术支持
如果你的SQL执行问题无法通过复现脚本复现,或者并非SQL执行问题而是集群管理问题,那么请提供客户端和服务端的配置与日志,以便我们调查。
@@ -135,3 +199,11 @@ openmldb_tool --env=onebox --dist_conf=standalone_dist.yml
如果是分布式的集群,需要配置ssh免密才能顺利使用诊断工具,参考文档[诊断工具](../maintain/diagnose.md)。
如果你的环境无法做到,请手动获取配置与日志。
+
+## 性能统计
+
+deployment耗时统计需要开启:
+```
+SET GLOBAL deploy_stats = 'on';
+```
+开启后的Deployment执行都将被统计,之前的不会被统计,表中的数据不包含集群外部的网络耗时,仅统计deployment在server端从开始执行到结束的时间。
diff --git a/docs/zh/quickstart/function_boundary.md b/docs/zh/quickstart/function_boundary.md
index 801d5d1b111..5d656f8eb75 100644
--- a/docs/zh/quickstart/function_boundary.md
+++ b/docs/zh/quickstart/function_boundary.md
@@ -147,7 +147,7 @@ OpenMLDB CLI 中在线模式下执行 SQL,均为在线预览模式。在线预
### 离线模式与在线请求模式
-在[特征工程开发上线全流程](../tutorial/concepts/modes.md#11-特征工程开发上线全流程)中,主要使用离线模式和在线请求模式。
+在[特征工程开发上线全流程](./concepts/modes.md)中,主要使用离线模式和在线请求模式。
- 离线模式的批查询:离线特征生成
- 在线请求模式的请求查询:实时特征计算
@@ -164,4 +164,4 @@ OpenMLDB CLI 中在线模式下执行 SQL,均为在线预览模式。在线预
- CLI是交互模式,所以将结果直接打印。
- SDK中,返回的是一行一列的ResultSet,将整个查询结果作为一个字符串返回。所以,不建议SDK使用同步模式查询,并处理其结果。
-同步模式涉及超时问题,详情见[调整配置](../../openmldb_sql/ddl/SET_STATEMENT.md#离线命令配置详情)。
+同步模式涉及超时问题,详情见[调整配置](../openmldb_sql/ddl/SET_STATEMENT.md#离线命令配置详情)。
diff --git a/docs/zh/quickstart/openmldb_quickstart.md b/docs/zh/quickstart/openmldb_quickstart.md
index 6a0191b09f1..c9a0dee18a8 100644
--- a/docs/zh/quickstart/openmldb_quickstart.md
+++ b/docs/zh/quickstart/openmldb_quickstart.md
@@ -19,7 +19,7 @@ OpenMLDB 的主要使用场景为作为机器学习的实时特征平台。其
在命令行执行以下命令拉取 OpenMLDB 镜像,并启动 Docker 容器:
```bash
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
```{note}
diff --git a/docs/zh/quickstart/sdk/java_sdk.md b/docs/zh/quickstart/sdk/java_sdk.md
index 966d50db785..37a874e4521 100644
--- a/docs/zh/quickstart/sdk/java_sdk.md
+++ b/docs/zh/quickstart/sdk/java_sdk.md
@@ -12,12 +12,12 @@ Java SDK中,JDBC Statement的默认执行模式为在线,SqlClusterExecutor
com.4paradigm.openmldb
openmldb-jdbc
- 0.8.3
+ 0.8.4
com.4paradigm.openmldb
openmldb-native
- 0.8.3
+ 0.8.4
```
@@ -29,16 +29,16 @@ Java SDK中,JDBC Statement的默认执行模式为在线,SqlClusterExecutor
com.4paradigm.openmldb
openmldb-jdbc
- 0.8.3
+ 0.8.4
com.4paradigm.openmldb
openmldb-native
- 0.8.3-macos
+ 0.8.4-macos
```
-注意:由于 openmldb-native 中包含了 OpenMLDB 编译的 C++ 静态库,默认是 Linux 静态库,macOS 上需将上述 openmldb-native 的 version 改成 `0.8.3-macos`,openmldb-jdbc 的版本保持不变。
+注意:由于 openmldb-native 中包含了 OpenMLDB 编译的 C++ 静态库,默认是 Linux 静态库,macOS 上需将上述 openmldb-native 的 version 改成 `0.8.4-macos`,openmldb-jdbc 的版本保持不变。
openmldb-native 的 macOS 版本只支持 macOS 12,如需在 macOS 11 或 macOS 10.15上运行,需在相应 OS 上源码编译 openmldb-native 包,详细编译方法见[并发编译 Java SDK](https://openmldb.ai/docs/zh/main/deploy/compile.html#java-sdk)。使用自编译的 openmldb-native 包,推荐使用`mvn install`安装到本地仓库,然后在 pom 中引用本地仓库的 openmldb-native 包,不建议用`scope=system`的方式引用。
@@ -403,7 +403,7 @@ try {
"(PARTITION BY %s.c1 ORDER BY %s.c7 ROWS_RANGE BETWEEN 2d PRECEDING AND CURRENT ROW);", table,
table, table);
// 上线一个Deployment
- String deploySql = String.format("DEPLOY %s %s", deploymentName, selectSql);
+ String deploySql = String.format("DEPLOY %s OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') %s", deploymentName, selectSql);
// set return null rs, don't check the returned value, it's false
state.execute(deploySql);
} catch (Exception e) {
diff --git a/docs/zh/quickstart/sdk/rest_api.md b/docs/zh/quickstart/sdk/rest_api.md
index 0526127cd29..0a225e444f6 100644
--- a/docs/zh/quickstart/sdk/rest_api.md
+++ b/docs/zh/quickstart/sdk/rest_api.md
@@ -5,6 +5,18 @@
- REST APIs 通过 APIServer 和 OpenMLDB 的服务进行交互,因此 APIServer 模块必须被正确部署才能有效使用。APISever 在安装部署时是可选模块,参照 [APIServer 部署文档](../../deploy/install_deploy.md#部署-apiserver)。
- 现阶段,APIServer 主要用来做功能测试使用,并不推荐用来测试性能,也不推荐在生产环境使用。APIServer 的默认部署目前并没有高可用机制,并且引入了额外的网络和编解码开销。生产环境推荐使用 Java SDK,功能覆盖最完善,并且在功能、性能上都经过了充分测试。
+## JSON Body
+
+与APIServer的交互中,请求体均为JSON格式,并支持一定的扩展格式。注意以下几点:
+
+- 传入超过整型或浮点数最大值的数值,将会解析失败,比如,double类型传入`1e1000`。
+- 非数值浮点数:在传入数据时,支持传入`NaN`、`Infinity`、`-Infinity`,与缩写`Inf`、`-Inf`(注意是unquoted的,并非字符串,也不支持其他变种写法)。在返回数据时,支持返回`NaN`、`Infinity`、`-Infinity`(不支持变种写法)。如果你需要将三者转换为null,可以配置 `write_nan_and_inf_null`。
+- 可以传入整型数字到浮点数,比如,`1`可被读取为double。
+- float浮点数可能有精度损失,比如,`0.3`读取后将不会严格等于`0.3`,而是`0.30000000000000004`。我们不拒绝精度损失,请从业务层面考虑是否需要对此进行处理。传入超过float max但不超过double max的值,在读取后将成为`Inf`。
+- `true/false`、`null`并不支持大写,只支持小写。
+- timestamp类型暂不支持传入年月日字符串,只支持传入数值,比如`1635247427000`。
+- date类型请传入**年月日字符串**,中间不要包含任何空格。
+
## 数据插入
请求地址:http://ip:port/dbs/{db_name}/tables/{table_name}
@@ -55,7 +67,8 @@ curl http://127.0.0.1:8080/dbs/db/tables/trans -X PUT -d '{
```JSON
{
"input": [["row0_value0", "row0_value1", "row0_value2"], ["row1_value0", "row1_value1", "row1_value2"], ...],
- "need_schema": false
+ "need_schema": false,
+ "write_nan_and_inf_null": false
}
```
@@ -73,6 +86,7 @@ curl http://127.0.0.1:8080/dbs/db/tables/trans -X PUT -d '{
- 可以支持多行,其结果与返回的 response 中的 data.data 字段的数组一一对应。
- need_schema 可以设置为 true, 返回就会有输出结果的 schema。可选参数,默认为 false。
+- write_nan_and_inf_null 可以设置为 true,可选参数,默认为false。如果设置为 true,当输出数据中有 NaN、Inf、-Inf 时,会将其转换为 null。
- input 为 array 格式/JSON 格式时候返回结果也是 array 格式/JSON 格式,一次请求的 input 只支持一种格式,请不要混合格式。
- JSON 格式的 input 数据可以有多余列。
@@ -131,7 +145,8 @@ curl http://127.0.0.1:8080/dbs/demo_db/deployments/demo_data_service -X POST -d'
"input": {
"schema": [],
"data": []
- }
+ },
+ "write_nan_and_inf_null": false
}
```
diff --git a/docs/zh/reference/ip_tips.md b/docs/zh/reference/ip_tips.md
index fad3d3e0944..848cc59c598 100644
--- a/docs/zh/reference/ip_tips.md
+++ b/docs/zh/reference/ip_tips.md
@@ -52,15 +52,15 @@ curl http:///dbs/foo -X POST -d'{"mode":"online", "sql":"show component
- 暴露端口,也需要修改apiserver的endpoint改为`0.0.0.0`。这样可以使用127.0.0.1或是公网ip访问到 APIServer。
单机版:
```
- docker run -p 8080:8080 -it 4pdosc/openmldb:0.8.3 bash
+ docker run -p 8080:8080 -it 4pdosc/openmldb:0.8.4 bash
```
集群版:
```
- docker run -p 9080:9080 -it 4pdosc/openmldb:0.8.3 bash
+ docker run -p 9080:9080 -it 4pdosc/openmldb:0.8.4 bash
```
- 使用host网络,可以不用修改endpoint配置。缺点是容易引起端口冲突。
```
- docker run --network host -it 4pdosc/openmldb:0.8.3 bash
+ docker run --network host -it 4pdosc/openmldb:0.8.4 bash
```
如果是跨主机访问容器 onebox 中的 APIServer,可以**任选一种**下面的方式:
@@ -126,17 +126,17 @@ cd /work/openmldb/conf/ && ls | grep -v _ | xargs sed -i s/0.0.0.0//g && cd
单机版需要暴露三个组件(nameserver,tabletserver,APIServer)的端口:
```
-docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.8.3 bash
+docker run -p 6527:6527 -p 9921:9921 -p 8080:8080 -it 4pdosc/openmldb:0.8.4 bash
```
集群版需要暴露zk端口与所有组件的端口:
```
-docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.8.3 bash
+docker run -p 2181:2181 -p 7527:7527 -p 10921:10921 -p 10922:10922 -p 8080:8080 -p 9902:9902 -it 4pdosc/openmldb:0.8.4 bash
```
- 使用host网络,可以不用修改 endpoint 配置。如果有端口冲突,请修改 server 的端口配置。
```
-docker run --network host -it 4pdosc/openmldb:0.8.3 bash
+docker run --network host -it 4pdosc/openmldb:0.8.4 bash
```
如果是跨主机使用 CLI/SDK 访问问容器onebox,只能通过`--network host`,并更改所有endpoint为公网IP,才能顺利访问。
diff --git a/docs/zh/tutorial/index.rst b/docs/zh/tutorial/index.rst
index cce68996ded..7406fda41a9 100644
--- a/docs/zh/tutorial/index.rst
+++ b/docs/zh/tutorial/index.rst
@@ -9,7 +9,6 @@
data_import_guide
tutorial_sql_1
tutorial_sql_2
- modes
openmldbspark_distribution
data_import
data_export
diff --git a/docs/zh/tutorial/standalone_use.md b/docs/zh/tutorial/standalone_use.md
index df27c8307de..dc216c75c8f 100644
--- a/docs/zh/tutorial/standalone_use.md
+++ b/docs/zh/tutorial/standalone_use.md
@@ -11,7 +11,7 @@
执行以下命令拉取 OpenMLDB 镜像,并启动 Docker 容器:
```bash
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
成功启动容器以后,本教程中的后续命令默认均在容器内执行。
diff --git a/docs/zh/use_case/JD_recommendation.md b/docs/zh/use_case/JD_recommendation.md
index d4035be912a..6cf586a397f 100644
--- a/docs/zh/use_case/JD_recommendation.md
+++ b/docs/zh/use_case/JD_recommendation.md
@@ -74,7 +74,7 @@ docker pull oneflowinc/oneflow-serving:nightly
由于 OpenMLDB 集群需要和其他组件网络通信,我们直接使用 host 网络。本例将在容器中使用已下载的脚本,所以请将数据脚本所在目录 `demodir` 映射为容器中的目录:
```bash
-docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.8.3 bash
+docker run -dit --name=openmldb --network=host -v $demodir:/work/oneflow_demo 4pdosc/openmldb:0.8.4 bash
docker exec -it openmldb bash
```
@@ -393,7 +393,7 @@ bash train_deepfm.sh $demodir/feature_preprocess/out
```sql
-- OpenMLDB CLI
USE JD_db;
- DEPLOY demo ;
+ DEPLOY demo OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') ;
```
也可以在 Docker 容器内直接运行部署脚本:
diff --git a/docs/zh/use_case/talkingdata_demo.md b/docs/zh/use_case/talkingdata_demo.md
index c47bc9a652a..4dc0c77ceef 100755
--- a/docs/zh/use_case/talkingdata_demo.md
+++ b/docs/zh/use_case/talkingdata_demo.md
@@ -16,7 +16,7 @@
**启动 Docker**
```
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
#### 1.1.2 在本地运行
diff --git a/docs/zh/use_case/taxi_tour_duration_prediction.md b/docs/zh/use_case/taxi_tour_duration_prediction.md
index faaff3bf922..245ce824784 100644
--- a/docs/zh/use_case/taxi_tour_duration_prediction.md
+++ b/docs/zh/use_case/taxi_tour_duration_prediction.md
@@ -15,7 +15,7 @@
在命令行执行以下命令拉取 OpenMLDB 镜像,并启动 Docker 容器:
```bash
-docker run -it 4pdosc/openmldb:0.8.3 bash
+docker run -it 4pdosc/openmldb:0.8.4 bash
```
该镜像预装了OpenMLDB,并预置了本案例所需要的所有脚本、三方库、开源工具以及训练数据。
@@ -151,7 +151,7 @@ w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN
--OpenMLDB CLI
USE demo_db;
SET @@execute_mode='online';
- DEPLOY demo SELECT trip_duration, passenger_count,
+ DEPLOY demo OPTIONS(RANGE_BIAS='inf', ROWS_BIAS='inf') SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
@@ -167,6 +167,10 @@ w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN
w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW);
```
+```{note}
+此处DEPLOY包含BIAS OPTIONS,是因为导入在线存储的数据文件不会更新,对于当前时间来讲,可能会超过DEPLOY后的表索引的时间TTL,导致表淘汰掉这些数据。时间淘汰,只看每个索引的ts列和ttl,只要数据中该列的值<(当前时间-abs_ttl),在该索引上就会被淘汰,与其他因素无关,各个索引也互相不影响。如果你的数据不是实时产生的新timestamp,也需要考虑带上BIAS OPTIONS。
+```
+
### 步骤 7:导入在线数据
首先,请切换到**在线**执行模式。接着在在线模式下,导入样例数据 `/work/taxi-trip/data/taxi_tour_table_train_simple.csv` 作为在线数据,用于在线特征计算。
diff --git a/hybridse/examples/toydb/src/storage/table_iterator.cc b/hybridse/examples/toydb/src/storage/table_iterator.cc
index 45561cd52a1..8ea4a3e0349 100644
--- a/hybridse/examples/toydb/src/storage/table_iterator.cc
+++ b/hybridse/examples/toydb/src/storage/table_iterator.cc
@@ -62,7 +62,7 @@ WindowTableIterator::WindowTableIterator(Segment*** segments, uint32_t seg_cnt,
seg_idx_(0),
pk_it_(),
table_(table) {
- GoToStart();
+ SeekToFirst();
}
WindowTableIterator::~WindowTableIterator() {}
@@ -80,7 +80,7 @@ void WindowTableIterator::Seek(const std::string& key) {
pk_it_->Seek(pk);
}
-void WindowTableIterator::SeekToFirst() {}
+void WindowTableIterator::SeekToFirst() { GoToStart(); }
std::unique_ptr WindowTableIterator::GetValue() {
if (!pk_it_)
diff --git a/hybridse/examples/toydb/src/tablet/tablet_catalog.cc b/hybridse/examples/toydb/src/tablet/tablet_catalog.cc
index feeb750ab6f..81764df9da6 100644
--- a/hybridse/examples/toydb/src/tablet/tablet_catalog.cc
+++ b/hybridse/examples/toydb/src/tablet/tablet_catalog.cc
@@ -19,7 +19,6 @@
#include
#include
#include
-#include "codec/list_iterator_codec.h"
#include "glog/logging.h"
#include "storage/table_iterator.h"
@@ -99,13 +98,6 @@ bool TabletTableHandler::Init() {
return true;
}
-std::unique_ptr TabletTableHandler::GetIterator() {
- std::unique_ptr it(
- new storage::FullTableIterator(table_->GetSegments(),
- table_->GetSegCnt(), table_));
- return std::move(it);
-}
-
std::unique_ptr TabletTableHandler::GetWindowIterator(
const std::string& idx_name) {
auto iter = index_hint_.find(idx_name);
@@ -136,22 +128,6 @@ RowIterator* TabletTableHandler::GetRawIterator() {
return new storage::FullTableIterator(table_->GetSegments(),
table_->GetSegCnt(), table_);
}
-const uint64_t TabletTableHandler::GetCount() {
- auto iter = GetIterator();
- uint64_t cnt = 0;
- while (iter->Valid()) {
- iter->Next();
- cnt++;
- }
- return cnt;
-}
-Row TabletTableHandler::At(uint64_t pos) {
- auto iter = GetIterator();
- while (pos-- > 0 && iter->Valid()) {
- iter->Next();
- }
- return iter->Valid() ? iter->GetValue() : Row();
-}
TabletCatalog::TabletCatalog() : tables_(), db_() {}
@@ -249,22 +225,6 @@ std::unique_ptr TabletSegmentHandler::GetWindowIterator(
const std::string& idx_name) {
return std::unique_ptr();
}
-const uint64_t TabletSegmentHandler::GetCount() {
- auto iter = GetIterator();
- uint64_t cnt = 0;
- while (iter->Valid()) {
- cnt++;
- iter->Next();
- }
- return cnt;
-}
-Row TabletSegmentHandler::At(uint64_t pos) {
- auto iter = GetIterator();
- while (pos-- > 0 && iter->Valid()) {
- iter->Next();
- }
- return iter->Valid() ? iter->GetValue() : Row();
-}
const uint64_t TabletPartitionHandler::GetCount() {
auto iter = GetWindowIterator();
@@ -275,5 +235,6 @@ const uint64_t TabletPartitionHandler::GetCount() {
}
return cnt;
}
+
} // namespace tablet
} // namespace hybridse
diff --git a/hybridse/examples/toydb/src/tablet/tablet_catalog.h b/hybridse/examples/toydb/src/tablet/tablet_catalog.h
index fa41140a495..9d2e8b907e5 100644
--- a/hybridse/examples/toydb/src/tablet/tablet_catalog.h
+++ b/hybridse/examples/toydb/src/tablet/tablet_catalog.h
@@ -21,7 +21,6 @@
#include
#include
#include
-#include "base/spin_lock.h"
#include "storage/table_impl.h"
#include "vm/catalog.h"
@@ -68,8 +67,6 @@ class TabletSegmentHandler : public TableHandler {
std::unique_ptr GetIterator() override;
RowIterator* GetRawIterator() override;
std::unique_ptr GetWindowIterator(const std::string& idx_name) override;
- const uint64_t GetCount() override;
- Row At(uint64_t pos) override;
const std::string GetHandlerTypeName() override {
return "TabletSegmentHandler";
}
@@ -79,7 +76,7 @@ class TabletSegmentHandler : public TableHandler {
std::string key_;
};
-class TabletPartitionHandler
+class TabletPartitionHandler final
: public PartitionHandler,
public std::enable_shared_from_this {
public:
@@ -91,6 +88,8 @@ class TabletPartitionHandler
~TabletPartitionHandler() {}
+ RowIterator* GetRawIterator() override { return table_handler_->GetRawIterator(); }
+
const OrderType GetOrderType() const override { return OrderType::kDescOrder; }
const vm::Schema* GetSchema() override { return table_handler_->GetSchema(); }
@@ -104,6 +103,7 @@ class TabletPartitionHandler
std::unique_ptr GetWindowIterator() override {
return table_handler_->GetWindowIterator(index_name_);
}
+
const uint64_t GetCount() override;
std::shared_ptr GetSegment(const std::string& key) override {
@@ -119,7 +119,7 @@ class TabletPartitionHandler
vm::IndexHint index_hint_;
};
-class TabletTableHandler
+class TabletTableHandler final
: public vm::TableHandler,
public std::enable_shared_from_this {
public:
@@ -135,28 +135,23 @@ class TabletTableHandler
bool Init();
- inline const vm::Schema* GetSchema() { return &schema_; }
+ const vm::Schema* GetSchema() override { return &schema_; }
- inline const std::string& GetName() { return name_; }
+ const std::string& GetName() override { return name_; }
- inline const std::string& GetDatabase() { return db_; }
+ const std::string& GetDatabase() override { return db_; }
- inline const vm::Types& GetTypes() { return types_; }
+ const vm::Types& GetTypes() override { return types_; }
- inline const vm::IndexHint& GetIndex() { return index_hint_; }
+ const vm::IndexHint& GetIndex() override { return index_hint_; }
const Row Get(int32_t pos);
- inline std::shared_ptr GetTable() { return table_; }
- std::unique_ptr GetIterator();
+ std::shared_ptr GetTable() { return table_; }
RowIterator* GetRawIterator() override;
- std::unique_ptr GetWindowIterator(
- const std::string& idx_name);
- virtual const uint64_t GetCount();
- Row At(uint64_t pos) override;
+ std::unique_ptr GetWindowIterator(const std::string& idx_name) override;
- virtual std::shared_ptr GetPartition(
- const std::string& index_name) {
+ std::shared_ptr GetPartition(const std::string& index_name) override {
if (index_hint_.find(index_name) == index_hint_.cend()) {
LOG(WARNING)
<< "fail to get partition for tablet table handler, index name "
@@ -169,12 +164,12 @@ class TabletTableHandler
const std::string GetHandlerTypeName() override {
return "TabletTableHandler";
}
- virtual std::shared_ptr GetTablet(
- const std::string& index_name, const std::string& pk) {
+ std::shared_ptr GetTablet(const std::string& index_name,
+ const std::string& pk) override {
return tablet_;
}
- virtual std::shared_ptr GetTablet(
- const std::string& index_name, const std::vector& pks) {
+ std::shared_ptr GetTablet(const std::string& index_name,
+ const std::vector& pks) override {
return tablet_;
}
diff --git a/hybridse/examples/toydb/src/testing/toydb_engine_test.cc b/hybridse/examples/toydb/src/testing/toydb_engine_test.cc
index a4cd2b095d8..02438aeebac 100644
--- a/hybridse/examples/toydb/src/testing/toydb_engine_test.cc
+++ b/hybridse/examples/toydb/src/testing/toydb_engine_test.cc
@@ -91,6 +91,13 @@ TEST_P(EngineTest, TestClusterBatchRequestEngine) {
}
}
+// ====================================================== /
+// BatchRequestEngineTest
+// test batch request mode only, with yaml:
+// - case/function/test_batch_request.yaml
+//
+// TODO(ace): merge to EngineTest above simply
+// ====================================================== /
TEST_P(BatchRequestEngineTest, TestBatchRequestEngine) {
auto& sql_case = GetParam();
LOG(INFO) << "ID: " << sql_case.id() << ", DESC: " << sql_case.desc();
diff --git a/hybridse/examples/toydb/src/testing/toydb_engine_test_base.cc b/hybridse/examples/toydb/src/testing/toydb_engine_test_base.cc
index fcaa71d8373..35a595b431e 100644
--- a/hybridse/examples/toydb/src/testing/toydb_engine_test_base.cc
+++ b/hybridse/examples/toydb/src/testing/toydb_engine_test_base.cc
@@ -15,8 +15,9 @@
*/
#include "testing/toydb_engine_test_base.h"
+
+#include "absl/strings/str_join.h"
#include "gtest/gtest.h"
-#include "gtest/internal/gtest-param-util.h"
using namespace llvm; // NOLINT (build/namespaces)
using namespace llvm::orc; // NOLINT (build/namespaces)
@@ -141,18 +142,12 @@ std::shared_ptr BuildOnePkTableStorage(
}
return catalog;
}
-void BatchRequestEngineCheckWithCommonColumnIndices(
- const SqlCase& sql_case, const EngineOptions options,
- const std::set& common_column_indices) {
- std::ostringstream oss;
- for (size_t index : common_column_indices) {
- oss << index << ",";
- }
- LOG(INFO) << "BatchRequestEngineCheckWithCommonColumnIndices: "
- "common_column_indices = ["
- << oss.str() << "]";
- ToydbBatchRequestEngineTestRunner engine_test(sql_case, options,
- common_column_indices);
+// Run check with common column index info
+void BatchRequestEngineCheckWithCommonColumnIndices(const SqlCase& sql_case, const EngineOptions options,
+ const std::set& common_column_indices) {
+ LOG(INFO) << "BatchRequestEngineCheckWithCommonColumnIndices: common_column_indices = ["
+ << absl::StrJoin(common_column_indices, ",") << "]";
+ ToydbBatchRequestEngineTestRunner engine_test(sql_case, options, common_column_indices);
engine_test.RunCheck();
}
diff --git a/hybridse/include/codec/fe_row_codec.h b/hybridse/include/codec/fe_row_codec.h
index 1e0e5b1badc..0e0b153f5a5 100644
--- a/hybridse/include/codec/fe_row_codec.h
+++ b/hybridse/include/codec/fe_row_codec.h
@@ -157,6 +157,9 @@ class RowView {
const Schema* GetSchema() const { return &schema_; }
inline bool IsNULL(const int8_t* row, uint32_t idx) const {
+ if (row == nullptr) {
+ return true;
+ }
const int8_t* ptr = row + HEADER_LENGTH + (idx >> 3);
return *(reinterpret_cast(ptr)) & (1 << (idx & 0x07));
}
diff --git a/hybridse/include/codec/row.h b/hybridse/include/codec/row.h
index cd6abb0a3a1..69158d41e85 100644
--- a/hybridse/include/codec/row.h
+++ b/hybridse/include/codec/row.h
@@ -54,7 +54,7 @@ class Row {
inline int32_t size() const { return slice_.size(); }
inline int32_t size(int32_t pos) const {
- return 0 == pos ? slice_.size() : slices_[pos - 1].size();
+ return 0 == pos ? slice_.size() : slices_.at(pos - 1).size();
}
// Return true if the length of the referenced data is zero
diff --git a/hybridse/include/codec/row_iterator.h b/hybridse/include/codec/row_iterator.h
index 2075918666c..fa60d21a37e 100644
--- a/hybridse/include/codec/row_iterator.h
+++ b/hybridse/include/codec/row_iterator.h
@@ -71,7 +71,14 @@ class WindowIterator {
virtual bool Valid() = 0;
/// Return the RowIterator of current segment
/// of dataset if Valid() return `true`.
- virtual std::unique_ptr GetValue() = 0;
+ virtual std::unique_ptr GetValue() {
+ auto p = GetRawValue();
+ if (!p) {
+ return nullptr;
+ }
+
+ return std::unique_ptr(p);
+ }
/// Return the RowIterator of current segment
/// of dataset if Valid() return `true`.
virtual RowIterator *GetRawValue() = 0;
diff --git a/hybridse/include/codec/row_list.h b/hybridse/include/codec/row_list.h
index b32ad24c3eb..f601b207b9c 100644
--- a/hybridse/include/codec/row_list.h
+++ b/hybridse/include/codec/row_list.h
@@ -65,7 +65,13 @@ class ListV {
ListV() {}
virtual ~ListV() {}
/// \brief Return the const iterator
- virtual std::unique_ptr> GetIterator() = 0;
+ virtual std::unique_ptr> GetIterator() {
+ auto raw = GetRawIterator();
+ if (raw == nullptr) {
+ return {};
+ }
+ return std::unique_ptr>(raw);
+ }
/// \brief Return the const iterator raw pointer
virtual ConstIterator *GetRawIterator() = 0;
@@ -76,7 +82,7 @@ class ListV {
virtual const uint64_t GetCount() {
auto iter = GetIterator();
uint64_t cnt = 0;
- while (iter->Valid()) {
+ while (iter && iter->Valid()) {
iter->Next();
cnt++;
}
diff --git a/hybridse/include/node/node_enum.h b/hybridse/include/node/node_enum.h
index 4fc914799d0..baa3bdb2afe 100644
--- a/hybridse/include/node/node_enum.h
+++ b/hybridse/include/node/node_enum.h
@@ -97,6 +97,7 @@ enum SqlNodeType {
kWithClauseEntry,
kAlterTableStmt,
kShowStmt,
+ kCompressType,
kSqlNodeTypeLast, // debug type
};
@@ -251,7 +252,7 @@ enum JoinType {
kJoinTypeRight,
kJoinTypeInner,
kJoinTypeConcat,
- kJoinTypeComma
+ kJoinTypeCross, // AKA commma join
};
enum UnionType { kUnionTypeDistinct, kUnionTypeAll };
@@ -283,6 +284,8 @@ enum CmdType {
kCmdShowFunctions,
kCmdDropFunction,
kCmdShowJobLog,
+ kCmdShowCreateTable,
+ kCmdTruncate,
kCmdFake, // not a real cmd, for testing purpose only
kLastCmd = kCmdFake,
};
@@ -341,6 +344,11 @@ enum StorageMode {
kHDD = 3,
};
+enum CompressType {
+ kNoCompress = 0,
+ kSnappy = 1,
+};
+
// batch plan node type
enum BatchPlanNodeType { kBatchDataset, kBatchPartition, kBatchMap };
diff --git a/hybridse/include/node/node_manager.h b/hybridse/include/node/node_manager.h
index 2dcd013e36f..e70f0a59564 100644
--- a/hybridse/include/node/node_manager.h
+++ b/hybridse/include/node/node_manager.h
@@ -151,7 +151,7 @@ class NodeManager {
WindowDefNode *MergeWindow(const WindowDefNode *w1,
const WindowDefNode *w2);
OrderExpression* MakeOrderExpression(const ExprNode* expr, const bool is_asc);
- OrderByNode *MakeOrderByNode(const ExprListNode *order_expressions);
+ OrderByNode *MakeOrderByNode(ExprListNode *order_expressions);
FrameExtent *MakeFrameExtent(SqlNode *start, SqlNode *end);
SqlNode *MakeFrameBound(BoundType bound_type);
SqlNode *MakeFrameBound(BoundType bound_type, ExprNode *offset);
@@ -399,8 +399,6 @@ class NodeManager {
SqlNode *MakeReplicaNumNode(int num);
- SqlNode *MakeStorageModeNode(StorageMode storage_mode);
-
SqlNode *MakePartitionNumNode(int num);
SqlNode *MakeDistributionsNode(const NodePointVector& distribution_list);
diff --git a/hybridse/include/node/sql_node.h b/hybridse/include/node/sql_node.h
index 6118c164193..30f7a6cc34a 100644
--- a/hybridse/include/node/sql_node.h
+++ b/hybridse/include/node/sql_node.h
@@ -25,6 +25,7 @@
#include
#include "absl/status/statusor.h"
+#include "absl/strings/match.h"
#include "absl/strings/str_cat.h"
#include "absl/strings/string_view.h"
#include "boost/algorithm/string.hpp"
@@ -309,17 +310,26 @@ inline const std::string StorageModeName(StorageMode mode) {
}
inline const StorageMode NameToStorageMode(const std::string& name) {
- if (boost::iequals(name, "memory")) {
+ if (absl::EqualsIgnoreCase(name, "memory")) {
return kMemory;
- } else if (boost::iequals(name, "hdd")) {
+ } else if (absl::EqualsIgnoreCase(name, "hdd")) {
return kHDD;
- } else if (boost::iequals(name, "ssd")) {
+ } else if (absl::EqualsIgnoreCase(name, "ssd")) {
return kSSD;
} else {
return kUnknown;
}
}
+inline absl::StatusOr NameToCompressType(const std::string& name) {
+ if (absl::EqualsIgnoreCase(name, "snappy")) {
+ return CompressType::kSnappy;
+ } else if (absl::EqualsIgnoreCase(name, "nocompress")) {
+ return CompressType::kNoCompress;
+ }
+ return absl::Status(absl::StatusCode::kInvalidArgument, absl::StrCat("invalid compress type: ", name));
+}
+
inline const std::string RoleTypeName(RoleType type) {
switch (type) {
case kLeader:
@@ -476,9 +486,10 @@ class ExprNode : public SqlNode {
virtual bool IsListReturn(ExprAnalysisContext *ctx) const { return false; }
/**
- * Default expression node deep copy implementation
+ * Returns new ExprNode with all of fields copyed, excepting descendants ExprNodes.
*/
virtual ExprNode *ShadowCopy(NodeManager *) const = 0;
+
ExprNode *DeepCopy(NodeManager *) const override;
// Get the compatible type that lhs and rhs can both casted into
@@ -581,8 +592,13 @@ class FnNodeList : public FnNode {
};
class OrderExpression : public ExprNode {
public:
+ // expr maybe null
OrderExpression(const ExprNode *expr, const bool is_asc)
- : ExprNode(kExprOrderExpression), expr_(expr), is_asc_(is_asc) {}
+ : ExprNode(kExprOrderExpression), expr_(expr), is_asc_(is_asc) {
+ if (expr != nullptr) {
+ AddChild(const_cast(expr));
+ }
+ }
~OrderExpression() {}
void Print(std::ostream &output, const std::string &org_tab) const;
const std::string GetExprString() const;
@@ -597,8 +613,10 @@ class OrderExpression : public ExprNode {
};
class OrderByNode : public ExprNode {
public:
- explicit OrderByNode(const ExprListNode *order_expressions)
- : ExprNode(kExprOrder), order_expressions_(order_expressions) {}
+ explicit OrderByNode(ExprListNode *order_expressions)
+ : ExprNode(kExprOrder), order_expressions_(order_expressions) {
+ AddChild(order_expressions);
+ }
~OrderByNode() {}
void Print(std::ostream &output, const std::string &org_tab) const;
@@ -623,7 +641,7 @@ class OrderByNode : public ExprNode {
return order_expression->expr();
}
bool is_asc() const { return false; }
- const ExprListNode *order_expressions_;
+ ExprListNode *order_expressions_;
};
class TableRefNode : public SqlNode {
public:
@@ -1158,6 +1176,9 @@ class FrameBound : public SqlNode {
int64_t GetOffset() const { return offset_; }
void SetOffset(int64_t v) { offset_ = v; }
+ // is offset [OPEN] PRECEDING/FOLLOWING
+ bool is_offset_bound() const;
+
/// \brief get the inclusive frame bound offset value that has signed symbol
///
@@ -1648,7 +1669,7 @@ class ColumnRefNode : public ExprNode {
static ColumnRefNode *CastFrom(ExprNode *node);
void Print(std::ostream &output, const std::string &org_tab) const;
- const std::string GetExprString() const;
+ const std::string GetExprString() const override;
const std::string GenerateExpressionName() const;
virtual bool Equals(const ExprNode *node) const;
ColumnRefNode *ShadowCopy(NodeManager *) const override;
@@ -1873,6 +1894,23 @@ class StorageModeNode : public SqlNode {
StorageMode storage_mode_;
};
+class CompressTypeNode : public SqlNode {
+ public:
+ CompressTypeNode() : SqlNode(kCompressType, 0, 0), compress_type_(kNoCompress) {}
+
+ explicit CompressTypeNode(CompressType compress_type)
+ : SqlNode(kCompressType, 0, 0), compress_type_(compress_type) {}
+
+ ~CompressTypeNode() {}
+
+ CompressType GetCompressType() const { return compress_type_; }
+
+ void Print(std::ostream &output, const std::string &org_tab) const;
+
+ private:
+ CompressType compress_type_;
+};
+
class CreateTableLikeClause {
public:
CreateTableLikeClause() = default;
diff --git a/hybridse/include/passes/expression/expr_pass.h b/hybridse/include/passes/expression/expr_pass.h
index 1c41307c28a..c88b7ee8585 100644
--- a/hybridse/include/passes/expression/expr_pass.h
+++ b/hybridse/include/passes/expression/expr_pass.h
@@ -65,15 +65,15 @@ class ExprReplacer {
void AddReplacement(const node::ExprIdNode* arg, node::ExprNode* repl);
void AddReplacement(const node::ExprNode* expr, node::ExprNode* repl);
void AddReplacement(size_t column_id, node::ExprNode* repl);
- void AddReplacement(const std::string& relation_name,
- const std::string& column_name, node::ExprNode* repl);
+ void AddReplacement(const std::string& relation_name, const std::string& column_name, node::ExprNode* repl);
- hybridse::base::Status Replace(node::ExprNode* root,
- node::ExprNode** output) const;
+ // For the given `ExprNode` tree, do the in-place replacements specified by `AddReplacement` calls.
+ // Returns new ExprNode if `root` is ExprIdNode/ColumnIdNode/ColumnRefNode, `root` with its descendants replaced
+ // otherwise
+ hybridse::base::Status Replace(node::ExprNode* root, node::ExprNode** output) const;
private:
- hybridse::base::Status DoReplace(node::ExprNode* root,
- std::unordered_set* visited,
+ hybridse::base::Status DoReplace(node::ExprNode* root, std::unordered_set* visited,
node::ExprNode** output) const;
std::unordered_map arg_id_map_;
diff --git a/hybridse/include/vm/catalog.h b/hybridse/include/vm/catalog.h
index 30e68316606..4bd007645bd 100644
--- a/hybridse/include/vm/catalog.h
+++ b/hybridse/include/vm/catalog.h
@@ -217,6 +217,7 @@ class TableHandler : public DataHandler {
virtual ~TableHandler() {}
/// Return table column Types information.
+ /// TODO: rm it, never used
virtual const Types& GetTypes() = 0;
/// Return the index information
@@ -224,8 +225,7 @@ class TableHandler : public DataHandler {
/// Return WindowIterator
/// so that user can use it to iterate datasets segment by segment.
- virtual std::unique_ptr GetWindowIterator(
- const std::string& idx_name) = 0;
+ virtual std::unique_ptr GetWindowIterator(const std::string& idx_name) { return nullptr; }
/// Return the HandlerType of the dataset.
/// Return HandlerType::kTableHandler by default
@@ -254,8 +254,7 @@ class TableHandler : public DataHandler {
/// Return Tablet binding to specify index and keys.
/// Return `null` by default.
- virtual std::shared_ptr GetTablet(
- const std::string& index_name, const std::vector& pks) {
+ virtual std::shared_ptr GetTablet(const std::string& index_name, const std::vector& pks) {
return std::shared_ptr();
}
};
@@ -286,27 +285,19 @@ class ErrorTableHandler : public TableHandler {
/// Return empty column Types.
const Types& GetTypes() override { return types_; }
/// Return empty table Schema.
- inline const Schema* GetSchema() override { return schema_; }
+ const Schema* GetSchema() override { return schema_; }
/// Return empty table name
- inline const std::string& GetName() override { return table_name_; }
+ const std::string& GetName() override { return table_name_; }
/// Return empty indexn information
- inline const IndexHint& GetIndex() override { return index_hint_; }
+ const IndexHint& GetIndex() override { return index_hint_; }
/// Return name of database
- inline const std::string& GetDatabase() override { return db_; }
+ const std::string& GetDatabase() override { return db_; }
/// Return null iterator
- std::unique_ptr GetIterator() {
- return std::unique_ptr();
- }
- /// Return null iterator
- RowIterator* GetRawIterator() { return nullptr; }
- /// Return null window iterator
- std::unique_ptr GetWindowIterator(
- const std::string& idx_name) {
- return std::unique_ptr();
- }
+ RowIterator* GetRawIterator() override { return nullptr; }
+
/// Return empty row
- virtual Row At(uint64_t pos) { return Row(); }
+ Row At(uint64_t pos) override { return Row(); }
/// Return 0
const uint64_t GetCount() override { return 0; }
@@ -317,7 +308,7 @@ class ErrorTableHandler : public TableHandler {
}
/// Return status
- virtual base::Status GetStatus() { return status_; }
+ base::Status GetStatus() override { return status_; }
protected:
base::Status status_;
@@ -340,16 +331,11 @@ class PartitionHandler : public TableHandler {
PartitionHandler() : TableHandler() {}
~PartitionHandler() {}
- /// Return the iterator of row iterator.
- /// Return null by default
- virtual std::unique_ptr GetIterator() {
- return std::unique_ptr();
- }
- /// Return the iterator of row iterator
- /// Return null by default
- RowIterator* GetRawIterator() { return nullptr; }
- virtual std::unique_ptr GetWindowIterator(
- const std::string& idx_name) {
+ // Return the iterator of row iterator
+ // Return null by default
+ RowIterator* GetRawIterator() override { return nullptr; }
+
+ std::unique_ptr GetWindowIterator(const std::string& idx_name) override {
return std::unique_ptr();
}
@@ -361,18 +347,15 @@ class PartitionHandler : public TableHandler {
const HandlerType GetHandlerType() override { return kPartitionHandler; }
/// Return empty row, cause partition dataset does not support At operation.
- virtual Row At(uint64_t pos) { return Row(); }
+ // virtual Row At(uint64_t pos) { return Row(); }
/// Return Return table handler of specific segment binding to given key.
/// Return `null` by default.
- virtual std::shared_ptr GetSegment(const std::string& key) {
- return std::shared_ptr();
- }
+ virtual std::shared_ptr GetSegment(const std::string& key) = 0;
/// Return a sequence of table handles of specify segments binding to given
/// keys set.
- virtual std::vector> GetSegments(
- const std::vector& keys) {
+ virtual std::vector> GetSegments(const std::vector& keys) {
std::vector> segments;
for (auto key : keys) {
segments.push_back(GetSegment(key));
@@ -383,9 +366,6 @@ class PartitionHandler : public TableHandler {
const std::string GetHandlerTypeName() override {
return "PartitionHandler";
}
- /// Return order type of the dataset,
- /// and return kNoneOrder by default.
- const OrderType GetOrderType() const { return kNoneOrder; }
};
/// \brief A wrapper of table handler which is used as a asynchronous row
diff --git a/hybridse/include/vm/engine.h b/hybridse/include/vm/engine.h
index 3cb7564be98..e552e5889c6 100644
--- a/hybridse/include/vm/engine.h
+++ b/hybridse/include/vm/engine.h
@@ -420,9 +420,6 @@ class Engine {
EngineOptions GetEngineOptions();
private:
- // Get all dependent (db, table) info from physical plan
- Status GetDependentTables(const PhysicalOpNode*, std::set>*);
-
std::shared_ptr GetCacheLocked(const std::string& db,
const std::string& sql,
EngineMode engine_mode);
diff --git a/hybridse/include/vm/mem_catalog.h b/hybridse/include/vm/mem_catalog.h
index 2fc5df4960c..6237edd1d43 100644
--- a/hybridse/include/vm/mem_catalog.h
+++ b/hybridse/include/vm/mem_catalog.h
@@ -25,8 +25,6 @@
#include
#include
#include
-#include "base/fe_slice.h"
-#include "codec/list_iterator_codec.h"
#include "glog/logging.h"
#include "vm/catalog.h"
@@ -66,11 +64,11 @@ class MemTimeTableIterator : public RowIterator {
MemTimeTableIterator(const MemTimeTable* table, const vm::Schema* schema,
int32_t start, int32_t end);
~MemTimeTableIterator();
- void Seek(const uint64_t& ts);
- void SeekToFirst();
- const uint64_t& GetKey() const;
- void Next();
- bool Valid() const;
+ void Seek(const uint64_t& ts) override;
+ void SeekToFirst() override;
+ const uint64_t& GetKey() const override;
+ void Next() override;
+ bool Valid() const override;
const Row& GetValue() override;
bool IsSeekable() const override;
@@ -88,12 +86,12 @@ class MemTableIterator : public RowIterator {
MemTableIterator(const MemTable* table, const vm::Schema* schema,
int32_t start, int32_t end);
~MemTableIterator();
- void Seek(const uint64_t& ts);
- void SeekToFirst();
- const uint64_t& GetKey() const;
- const Row& GetValue();
- void Next();
- bool Valid() const;
+ void Seek(const uint64_t& ts) override;
+ void SeekToFirst() override;
+ const uint64_t& GetKey() const override;
+ const Row& GetValue() override;
+ void Next() override;
+ bool Valid() const override;
bool IsSeekable() const override;
private:
@@ -115,7 +113,6 @@ class MemWindowIterator : public WindowIterator {
void SeekToFirst();
void Next();
bool Valid();
- std::unique_ptr GetValue();
RowIterator* GetRawValue();
const Row GetKey();
@@ -157,24 +154,21 @@ class MemTableHandler : public TableHandler {
~MemTableHandler() override;
const Types& GetTypes() override { return types_; }
- inline const Schema* GetSchema() { return schema_; }
- inline const std::string& GetName() { return table_name_; }
- inline const IndexHint& GetIndex() { return index_hint_; }
- inline const std::string& GetDatabase() { return db_; }
+ const Schema* GetSchema() override { return schema_; }
+ const std::string& GetName() override { return table_name_; }
+ const IndexHint& GetIndex() override { return index_hint_; }
+ const std::string& GetDatabase() override { return db_; }
- std::unique_ptr GetIterator() override;
RowIterator* GetRawIterator() override;
- std::unique_ptr GetWindowIterator(
- const std::string& idx_name);
void AddRow(const Row& row);
void Reverse();
- virtual const uint64_t GetCount() { return table_.size(); }
- virtual Row At(uint64_t pos) {
+ const uint64_t GetCount() override { return table_.size(); }
+ Row At(uint64_t pos) override {
return pos < table_.size() ? table_.at(pos) : Row();
}
- const OrderType GetOrderType() const { return order_type_; }
+ const OrderType GetOrderType() const override { return order_type_; }
void SetOrderType(const OrderType order_type) { order_type_ = order_type; }
const std::string GetHandlerTypeName() override {
return "MemTableHandler";
@@ -200,14 +194,11 @@ class MemTimeTableHandler : public TableHandler {
const Schema* schema);
const Types& GetTypes() override;
~MemTimeTableHandler() override;
- inline const Schema* GetSchema() { return schema_; }
- inline const std::string& GetName() { return table_name_; }
- inline const IndexHint& GetIndex() { return index_hint_; }
- std::unique_ptr GetIterator();
- RowIterator* GetRawIterator();
- inline const std::string& GetDatabase() { return db_; }
- std::unique_ptr GetWindowIterator(
- const std::string& idx_name);
+ const Schema* GetSchema() override { return schema_; }
+ const std::string& GetName() override { return table_name_; }
+ const IndexHint& GetIndex() override { return index_hint_; }
+ RowIterator* GetRawIterator() override;
+ const std::string& GetDatabase() override { return db_; }
void AddRow(const uint64_t key, const Row& v);
void AddFrontRow(const uint64_t key, const Row& v);
void PopBackRow();
@@ -220,12 +211,12 @@ class MemTimeTableHandler : public TableHandler {
}
void Sort(const bool is_asc);
void Reverse();
- virtual const uint64_t GetCount() { return table_.size(); }
- virtual Row At(uint64_t pos) {
+ const uint64_t GetCount() override { return table_.size(); }
+ Row At(uint64_t pos) override {
return pos < table_.size() ? table_.at(pos).second : Row();
}
void SetOrderType(const OrderType order_type) { order_type_ = order_type; }
- const OrderType GetOrderType() const { return order_type_; }
+ const OrderType GetOrderType() const override { return order_type_; }
const std::string GetHandlerTypeName() override {
return "MemTimeTableHandler";
}
@@ -254,21 +245,11 @@ class Window : public MemTimeTableHandler {
return std::make_unique(&table_, schema_);
}
- RowIterator* GetRawIterator() {
- return new vm::MemTimeTableIterator(&table_, schema_);
- }
+ RowIterator* GetRawIterator() override { return new vm::MemTimeTableIterator(&table_, schema_); }
virtual bool BufferData(uint64_t key, const Row& row) = 0;
virtual void PopBackData() { PopBackRow(); }
virtual void PopFrontData() = 0;
- virtual const uint64_t GetCount() { return table_.size(); }
- virtual Row At(uint64_t pos) {
- if (pos >= table_.size()) {
- return Row();
- } else {
- return table_[pos].second;
- }
- }
const std::string GetHandlerTypeName() override { return "Window"; }
bool instance_not_in_window() const { return instance_not_in_window_; }
@@ -322,7 +303,7 @@ class WindowRange {
return WindowRange(Window::kFrameRowsMergeRowsRange, start_offset, 0,
rows_preceding, max_size);
}
- inline const WindowPositionStatus GetWindowPositionStatus(
+ const WindowPositionStatus GetWindowPositionStatus(
bool out_of_rows, bool before_window, bool exceed_window) const {
switch (frame_type_) {
case Window::WindowFrameType::kFrameRows:
@@ -531,7 +512,7 @@ class CurrentHistoryWindow : public HistoryWindow {
void PopFrontData() override { PopFrontRow(); }
- bool BufferData(uint64_t key, const Row& row) {
+ bool BufferData(uint64_t key, const Row& row) override {
if (!table_.empty() && GetFrontRow().first > key) {
DLOG(WARNING) << "Fail BufferData: buffer key less than latest key";
return false;
@@ -560,34 +541,25 @@ class MemSegmentHandler : public TableHandler {
virtual ~MemSegmentHandler() {}
- inline const vm::Schema* GetSchema() {
+ const vm::Schema* GetSchema() override {
return partition_hander_->GetSchema();
}
- inline const std::string& GetName() { return partition_hander_->GetName(); }
+ const std::string& GetName() override { return partition_hander_->GetName(); }
- inline const std::string& GetDatabase() {
+ const std::string& GetDatabase() override {
return partition_hander_->GetDatabase();
}
- inline const vm::Types& GetTypes() { return partition_hander_->GetTypes(); }
+ const vm::Types& GetTypes() override { return partition_hander_->GetTypes(); }
- inline const vm::IndexHint& GetIndex() {
+ const vm::IndexHint& GetIndex() override {
return partition_hander_->GetIndex();
}
- const OrderType GetOrderType() const {
+ const OrderType GetOrderType() const override {
return partition_hander_->GetOrderType();
}
- std::unique_ptr GetIterator() {
- auto iter = partition_hander_->GetWindowIterator();
- if (iter) {
- iter->Seek(key_);
- return iter->Valid() ? iter->GetValue()
- : std::unique_ptr();
- }
- return std::unique_ptr();
- }
RowIterator* GetRawIterator() override {
auto iter = partition_hander_->GetWindowIterator();
if (iter) {
@@ -596,12 +568,11 @@ class MemSegmentHandler : public TableHandler {
}
return nullptr;
}
- std::unique_ptr GetWindowIterator(
- const std::string& idx_name) {
+ std::unique_ptr GetWindowIterator(const std::string& idx_name) override {
LOG(WARNING) << "SegmentHandler can't support window iterator";
return std::unique_ptr();
}
- virtual const uint64_t GetCount() {
+ const uint64_t GetCount() override {
auto iter = GetIterator();
if (!iter) {
return 0;
@@ -634,9 +605,7 @@ class MemSegmentHandler : public TableHandler {
std::string key_;
};
-class MemPartitionHandler
- : public PartitionHandler,
- public std::enable_shared_from_this {
+class MemPartitionHandler : public PartitionHandler, public std::enable_shared_from_this {
public:
MemPartitionHandler();
explicit MemPartitionHandler(const Schema* schema);
@@ -649,18 +618,19 @@ class MemPartitionHandler
const Schema* GetSchema() override;
const std::string& GetName() override;
const std::string& GetDatabase() override;
- virtual std::unique_ptr GetWindowIterator();
+ RowIterator* GetRawIterator() override { return nullptr; }
+ std::unique_ptr GetWindowIterator() override;
bool AddRow(const std::string& key, uint64_t ts, const Row& row);
void Sort(const bool is_asc);
void Reverse();
void Print();
- virtual const uint64_t GetCount() { return partitions_.size(); }
- virtual std::shared_ptr GetSegment(const std::string& key) {
+ const uint64_t GetCount() override { return partitions_.size(); }
+ std::shared_ptr GetSegment(const std::string& key) override {
return std::shared_ptr(
new MemSegmentHandler(shared_from_this(), key));
}
void SetOrderType(const OrderType order_type) { order_type_ = order_type; }
- const OrderType GetOrderType() const { return order_type_; }
+ const OrderType GetOrderType() const override { return order_type_; }
const std::string GetHandlerTypeName() override {
return "MemPartitionHandler";
}
@@ -674,6 +644,7 @@ class MemPartitionHandler
IndexHint index_hint_;
OrderType order_type_;
};
+
class ConcatTableHandler : public MemTimeTableHandler {
public:
ConcatTableHandler(std::shared_ptr left, size_t left_slices,
@@ -692,19 +663,13 @@ class ConcatTableHandler : public MemTimeTableHandler {
status_ = SyncValue();
return MemTimeTableHandler::At(pos);
}
- std::unique_ptr GetIterator() {
- if (status_.isRunning()) {
- status_ = SyncValue();
- }
- return MemTimeTableHandler::GetIterator();
- }
- RowIterator* GetRawIterator() {
+ RowIterator* GetRawIterator() override {
if (status_.isRunning()) {
status_ = SyncValue();
}
return MemTimeTableHandler::GetRawIterator();
}
- virtual const uint64_t GetCount() {
+ const uint64_t GetCount() override {
if (status_.isRunning()) {
status_ = SyncValue();
}
@@ -757,11 +722,11 @@ class MemCatalog : public Catalog {
bool Init();
- std::shared_ptr GetDatabase(const std::string& db) {
+ std::shared_ptr GetDatabase(const std::string& db) override {
return dbs_[db];
}
std::shared_ptr GetTable(const std::string& db,
- const std::string& table_name) {
+ const std::string& table_name) override {
return tables_[db][table_name];
}
bool IndexSupport() override { return true; }
@@ -783,17 +748,11 @@ class RequestUnionTableHandler : public TableHandler {
: request_ts_(request_ts), request_row_(request_row), window_(window) {}
~RequestUnionTableHandler() {}
- std::unique_ptr GetIterator() override {
- return std::unique_ptr(GetRawIterator());
- }
RowIterator* GetRawIterator() override;
const Types& GetTypes() override { return window_->GetTypes(); }
const IndexHint& GetIndex() override { return window_->GetIndex(); }
- std::unique_ptr GetWindowIterator(const std::string&) {
- return nullptr;
- }
- const OrderType GetOrderType() const { return window_->GetOrderType(); }
+ const OrderType GetOrderType() const override { return window_->GetOrderType(); }
const Schema* GetSchema() override { return window_->GetSchema(); }
const std::string& GetName() override { return window_->GetName(); }
const std::string& GetDatabase() override { return window_->GetDatabase(); }
diff --git a/hybridse/include/vm/physical_op.h b/hybridse/include/vm/physical_op.h
index c884d0bb7e5..dd51c73bfd1 100644
--- a/hybridse/include/vm/physical_op.h
+++ b/hybridse/include/vm/physical_op.h
@@ -155,8 +155,10 @@ class Sort : public FnComponent {
public:
explicit Sort(const node::OrderByNode *orders) : orders_(orders) {}
virtual ~Sort() {}
+
const node::OrderByNode *orders() const { return orders_; }
void set_orders(const node::OrderByNode *orders) { orders_ = orders; }
+
const bool is_asc() const {
const node::OrderExpression *first_order_expression =
nullptr == orders_ ? nullptr : orders_->GetOrderExpression(0);
@@ -172,18 +174,11 @@ class Sort : public FnComponent {
return "sort = " + fn_info_.fn_name();
}
- void ResolvedRelatedColumns(
- std::vector *columns) const {
+ void ResolvedRelatedColumns(std::vector *columns) const {
if (nullptr == orders_) {
return;
}
- auto expr = orders_->GetOrderExpressionExpr(0);
- if (nullptr != expr) {
- node::ExprListNode exprs;
- exprs.AddChild(const_cast(expr));
- node::ColumnOfExpression(orders_->order_expressions_, columns);
- }
- return;
+ node::ColumnOfExpression(orders_->order_expressions_, columns);
}
base::Status ReplaceExpr(const passes::ExprReplacer &replacer,
@@ -205,9 +200,9 @@ class Range : public FnComponent {
const bool Valid() const { return nullptr != range_key_; }
const std::string ToString() const {
std::ostringstream oss;
- if (nullptr != range_key_ && nullptr != frame_) {
+ if (nullptr != frame_) {
if (nullptr != frame_->frame_range()) {
- oss << "range=(" << range_key_->GetExprString() << ", "
+ oss << "range=(" << node::ExprString(range_key_) << ", "
<< frame_->frame_range()->start()->GetExprString() << ", "
<< frame_->frame_range()->end()->GetExprString();
@@ -221,7 +216,7 @@ class Range : public FnComponent {
if (nullptr != frame_->frame_range()) {
oss << ", ";
}
- oss << "rows=(" << range_key_->GetExprString() << ", "
+ oss << "rows=(" << node::ExprString(range_key_) << ", "
<< frame_->frame_rows()->start()->GetExprString() << ", "
<< frame_->frame_rows()->end()->GetExprString() << ")";
}
@@ -286,8 +281,10 @@ class Key : public FnComponent {
return oss.str();
}
const bool ValidKey() const { return !node::ExprListNullOrEmpty(keys_); }
+
const node::ExprListNode *keys() const { return keys_; }
void set_keys(const node::ExprListNode *keys) { keys_ = keys; }
+
const node::ExprListNode *PhysicalProjectNode() const { return keys_; }
const std::string FnDetail() const { return "keys=" + fn_info_.fn_name(); }
@@ -555,8 +552,7 @@ class PhysicalDataProviderNode : public PhysicalOpNode {
class PhysicalTableProviderNode : public PhysicalDataProviderNode {
public:
- explicit PhysicalTableProviderNode(
- const std::shared_ptr &table_handler)
+ explicit PhysicalTableProviderNode(const std::shared_ptr &table_handler)
: PhysicalDataProviderNode(table_handler, kProviderTypeTable) {}
base::Status WithNewChildren(node::NodeManager *nm,
@@ -582,7 +578,7 @@ class PhysicalRequestProviderNode : public PhysicalDataProviderNode {
PhysicalOpNode **out) override;
virtual ~PhysicalRequestProviderNode() {}
- virtual void Print(std::ostream &output, const std::string &tab) const;
+ void Print(std::ostream &output, const std::string &tab) const override;
};
class PhysicalRequestProviderNodeWithCommonColumn
@@ -735,6 +731,7 @@ class PhysicalConstProjectNode : public PhysicalOpNode {
public:
explicit PhysicalConstProjectNode(const ColumnProjects &project)
: PhysicalOpNode(kPhysicalOpConstProject, true), project_(project) {
+ output_type_ = kSchemaTypeRow;
fn_infos_.push_back(&project_.fn_info());
}
virtual ~PhysicalConstProjectNode() {}
@@ -789,7 +786,11 @@ class PhysicalAggregationNode : public PhysicalProjectNode {
public:
PhysicalAggregationNode(PhysicalOpNode *node, const ColumnProjects &project, const node::ExprNode *condition)
: PhysicalProjectNode(node, kAggregation, project, true), having_condition_(condition) {
- output_type_ = kSchemaTypeRow;
+ if (node->GetOutputType() == kSchemaTypeGroup) {
+ output_type_ = kSchemaTypeGroup;
+ } else {
+ output_type_ = kSchemaTypeRow;
+ }
fn_infos_.push_back(&having_condition_.fn_info());
}
virtual ~PhysicalAggregationNode() {}
@@ -850,9 +851,7 @@ class WindowOp {
std::ostringstream oss;
oss << "partition_" << partition_.ToString();
oss << ", " << sort_.ToString();
- if (range_.Valid()) {
- oss << ", " << range_.ToString();
- }
+ oss << ", " << range_.ToString();
return oss.str();
}
const std::string FnDetail() const {
@@ -1071,7 +1070,7 @@ class RequestWindowUnionList {
RequestWindowUnionList() : window_unions_() {}
virtual ~RequestWindowUnionList() {}
void AddWindowUnion(PhysicalOpNode *node, const RequestWindowOp &window) {
- window_unions_.push_back(std::make_pair(node, window));
+ window_unions_.emplace_back(node, window);
}
const PhysicalOpNode *GetKey(uint32_t index) {
auto iter = window_unions_.begin();
@@ -1185,23 +1184,25 @@ class PhysicalWindowAggrerationNode : public PhysicalProjectNode {
class PhysicalJoinNode : public PhysicalBinaryNode {
public:
+ static constexpr PhysicalOpType kConcreteNodeKind = kPhysicalOpJoin;
+
PhysicalJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const node::JoinType join_type)
- : PhysicalBinaryNode(left, right, kPhysicalOpJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = left->GetOutputType();
+ InitOuptput();
}
PhysicalJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const node::JoinType join_type,
const node::OrderByNode *orders,
const node::ExprNode *condition)
- : PhysicalBinaryNode(left, right, kPhysicalOpJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type, orders, condition),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = left->GetOutputType();
+ InitOuptput();
RegisterFunctionInfo();
}
@@ -1210,11 +1211,11 @@ class PhysicalJoinNode : public PhysicalBinaryNode {
const node::ExprNode *condition,
const node::ExprListNode *left_keys,
const node::ExprListNode *right_keys)
- : PhysicalBinaryNode(left, right, kPhysicalOpJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type, condition, left_keys, right_keys),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = left->GetOutputType();
+ InitOuptput();
RegisterFunctionInfo();
}
@@ -1224,31 +1225,31 @@ class PhysicalJoinNode : public PhysicalBinaryNode {
const node::ExprNode *condition,
const node::ExprListNode *left_keys,
const node::ExprListNode *right_keys)
- : PhysicalBinaryNode(left, right, kPhysicalOpJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type, orders, condition, left_keys, right_keys),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = left->GetOutputType();
+ InitOuptput();
RegisterFunctionInfo();
}
PhysicalJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const Join &join)
- : PhysicalBinaryNode(left, right, kPhysicalOpJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = left->GetOutputType();
+ InitOuptput();
RegisterFunctionInfo();
}
PhysicalJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const Join &join, const bool output_right_only)
- : PhysicalBinaryNode(left, right, kPhysicalOpJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join),
joined_schemas_ctx_(this),
output_right_only_(output_right_only) {
- output_type_ = left->GetOutputType();
+ InitOuptput();
RegisterFunctionInfo();
}
@@ -1277,37 +1278,59 @@ class PhysicalJoinNode : public PhysicalBinaryNode {
Join join_;
SchemasContext joined_schemas_ctx_;
const bool output_right_only_;
+
+ private:
+ void InitOuptput() {
+ switch (join_.join_type_) {
+ case node::kJoinTypeLast:
+ case node::kJoinTypeConcat: {
+ output_type_ = GetProducer(0)->GetOutputType();
+ break;
+ }
+ default: {
+ // standard SQL JOINs, always treat as a table output
+ if (GetProducer(0)->GetOutputType() == kSchemaTypeGroup) {
+ output_type_ = kSchemaTypeGroup;
+ } else {
+ output_type_ = kSchemaTypeTable;
+ }
+ break;
+ }
+ }
+ }
};
class PhysicalRequestJoinNode : public PhysicalBinaryNode {
public:
+ static constexpr PhysicalOpType kConcreteNodeKind = kPhysicalOpRequestJoin;
+
PhysicalRequestJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const node::JoinType join_type)
- : PhysicalBinaryNode(left, right, kPhysicalOpRequestJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = kSchemaTypeRow;
+ InitOuptput();
RegisterFunctionInfo();
}
PhysicalRequestJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const node::JoinType join_type,
const node::OrderByNode *orders,
const node::ExprNode *condition)
- : PhysicalBinaryNode(left, right, kPhysicalOpRequestJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type, orders, condition),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = kSchemaTypeRow;
+ InitOuptput();
RegisterFunctionInfo();
}
PhysicalRequestJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
const Join &join, const bool output_right_only)
- : PhysicalBinaryNode(left, right, kPhysicalOpRequestJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join),
joined_schemas_ctx_(this),
output_right_only_(output_right_only) {
- output_type_ = kSchemaTypeRow;
+ InitOuptput();
RegisterFunctionInfo();
}
@@ -1317,11 +1340,11 @@ class PhysicalRequestJoinNode : public PhysicalBinaryNode {
const node::ExprNode *condition,
const node::ExprListNode *left_keys,
const node::ExprListNode *right_keys)
- : PhysicalBinaryNode(left, right, kPhysicalOpRequestJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type, condition, left_keys, right_keys),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = kSchemaTypeRow;
+ InitOuptput();
RegisterFunctionInfo();
}
PhysicalRequestJoinNode(PhysicalOpNode *left, PhysicalOpNode *right,
@@ -1330,11 +1353,11 @@ class PhysicalRequestJoinNode : public PhysicalBinaryNode {
const node::ExprNode *condition,
const node::ExprListNode *left_keys,
const node::ExprListNode *right_keys)
- : PhysicalBinaryNode(left, right, kPhysicalOpRequestJoin, false),
+ : PhysicalBinaryNode(left, right, kConcreteNodeKind, false),
join_(join_type, orders, condition, left_keys, right_keys),
joined_schemas_ctx_(this),
output_right_only_(false) {
- output_type_ = kSchemaTypeRow;
+ InitOuptput();
RegisterFunctionInfo();
}
@@ -1365,6 +1388,26 @@ class PhysicalRequestJoinNode : public PhysicalBinaryNode {
Join join_;
SchemasContext joined_schemas_ctx_;
const bool output_right_only_;
+
+ private:
+ void InitOuptput() {
+ switch (join_.join_type_) {
+ case node::kJoinTypeLast:
+ case node::kJoinTypeConcat: {
+ output_type_ = GetProducer(0)->GetOutputType();
+ break;
+ }
+ default: {
+ // standard SQL JOINs, always treat as a table output
+ if (GetProducer(0)->GetOutputType() == kSchemaTypeGroup) {
+ output_type_ = kSchemaTypeGroup;
+ } else {
+ output_type_ = kSchemaTypeTable;
+ }
+ break;
+ }
+ }
+ }
};
class PhysicalUnionNode : public PhysicalBinaryNode {
@@ -1421,7 +1464,7 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
instance_not_in_window_(false),
exclude_current_time_(false),
output_request_row_(true) {
- output_type_ = kSchemaTypeTable;
+ InitOuptput();
fn_infos_.push_back(&window_.partition_.fn_info());
fn_infos_.push_back(&window_.index_key_.fn_info());
@@ -1433,7 +1476,7 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
instance_not_in_window_(w_ptr->instance_not_in_window()),
exclude_current_time_(w_ptr->exclude_current_time()),
output_request_row_(true) {
- output_type_ = kSchemaTypeTable;
+ InitOuptput();
fn_infos_.push_back(&window_.partition_.fn_info());
fn_infos_.push_back(&window_.sort_.fn_info());
@@ -1449,7 +1492,7 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
instance_not_in_window_(instance_not_in_window),
exclude_current_time_(exclude_current_time),
output_request_row_(output_request_row) {
- output_type_ = kSchemaTypeTable;
+ InitOuptput();
fn_infos_.push_back(&window_.partition_.fn_info());
fn_infos_.push_back(&window_.sort_.fn_info());
@@ -1461,7 +1504,8 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
virtual void Print(std::ostream &output, const std::string &tab) const;
const bool Valid() { return true; }
static PhysicalRequestUnionNode *CastFrom(PhysicalOpNode *node);
- bool AddWindowUnion(PhysicalOpNode *node) {
+ bool AddWindowUnion(PhysicalOpNode *node) { return AddWindowUnion(node, window_); }
+ bool AddWindowUnion(PhysicalOpNode *node, const RequestWindowOp& window) {
if (nullptr == node) {
LOG(WARNING) << "Fail to add window union : table is null";
return false;
@@ -1478,9 +1522,8 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
<< "Union Table and window input schema aren't consistent";
return false;
}
- window_unions_.AddWindowUnion(node, window_);
- RequestWindowOp &window_union =
- window_unions_.window_unions_.back().second;
+ window_unions_.AddWindowUnion(node, window);
+ RequestWindowOp &window_union = window_unions_.window_unions_.back().second;
fn_infos_.push_back(&window_union.partition_.fn_info());
fn_infos_.push_back(&window_union.sort_.fn_info());
fn_infos_.push_back(&window_union.range_.fn_info());
@@ -1490,11 +1533,10 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
std::vector GetDependents() const override;
- const bool instance_not_in_window() const {
- return instance_not_in_window_;
- }
- const bool exclude_current_time() const { return exclude_current_time_; }
- const bool output_request_row() const { return output_request_row_; }
+ bool instance_not_in_window() const { return instance_not_in_window_; }
+ bool exclude_current_time() const { return exclude_current_time_; }
+ bool output_request_row() const { return output_request_row_; }
+ void set_output_request_row(bool flag) { output_request_row_ = flag; }
const RequestWindowOp &window() const { return window_; }
const RequestWindowUnionList &window_unions() const {
return window_unions_;
@@ -1512,10 +1554,20 @@ class PhysicalRequestUnionNode : public PhysicalBinaryNode {
}
RequestWindowOp window_;
- const bool instance_not_in_window_;
- const bool exclude_current_time_;
- const bool output_request_row_;
+ bool instance_not_in_window_;
+ bool exclude_current_time_;
+ bool output_request_row_;
RequestWindowUnionList window_unions_;
+
+ private:
+ void InitOuptput() {
+ auto left = GetProducer(0);
+ if (left->GetOutputType() == kSchemaTypeRow) {
+ output_type_ = kSchemaTypeTable;
+ } else {
+ output_type_ = kSchemaTypeGroup;
+ }
+ }
};
class PhysicalRequestAggUnionNode : public PhysicalOpNode {
@@ -1626,14 +1678,22 @@ class PhysicalFilterNode : public PhysicalUnaryNode {
public:
PhysicalFilterNode(PhysicalOpNode *node, const node::ExprNode *condition)
: PhysicalUnaryNode(node, kPhysicalOpFilter, true), filter_(condition) {
- output_type_ = node->GetOutputType();
+ if (node->GetOutputType() == kSchemaTypeGroup && filter_.index_key_.ValidKey()) {
+ output_type_ = kSchemaTypeTable;
+ } else {
+ output_type_ = node->GetOutputType();
+ }
fn_infos_.push_back(&filter_.condition_.fn_info());
fn_infos_.push_back(&filter_.index_key_.fn_info());
}
PhysicalFilterNode(PhysicalOpNode *node, Filter filter)
: PhysicalUnaryNode(node, kPhysicalOpFilter, true), filter_(filter) {
- output_type_ = node->GetOutputType();
+ if (node->GetOutputType() == kSchemaTypeGroup && filter_.index_key_.ValidKey()) {
+ output_type_ = kSchemaTypeTable;
+ } else {
+ output_type_ = node->GetOutputType();
+ }
fn_infos_.push_back(&filter_.condition_.fn_info());
fn_infos_.push_back(&filter_.index_key_.fn_info());
diff --git a/hybridse/include/vm/schemas_context.h b/hybridse/include/vm/schemas_context.h
index 43731f076cc..b2e68d9477a 100644
--- a/hybridse/include/vm/schemas_context.h
+++ b/hybridse/include/vm/schemas_context.h
@@ -58,7 +58,8 @@ class SchemaSource {
size_t size() const;
void Clear();
- std::string ToString() const;
+ std::string DebugString() const;
+ friend std::ostream& operator<<(std::ostream& os, const SchemaSource& sc) { return os << sc.DebugString(); }
private:
bool CheckSourceSetIndex(size_t idx) const;
@@ -71,7 +72,8 @@ class SchemaSource {
// column identifier of each output column
std::vector column_ids_;
- // trace which child and which column id each column come from
+ // trace which child and which column id each column comes from, index is measured
+ // based on the physical node tree, starts from 0.
// -1 means the column is created from current node
std::vector source_child_idxs_;
std::vector source_child_column_ids_;
@@ -126,10 +128,6 @@ class SchemasContext {
base::Status ResolveColumnRefIndex(const node::ColumnRefNode* column_ref,
size_t* schema_idx,
size_t* col_idx) const;
- /**
- * Resolve column id with given column expression [ColumnRefNode, ColumnId]
- */
- base::Status ResolveColumnID(const node::ExprNode* column, size_t* column_id) const;
/**
* Given relation name and column name, return column unique id
@@ -246,6 +244,10 @@ class SchemasContext {
void BuildTrivial(const std::vector& schemas);
void BuildTrivial(const std::string& default_db, const std::vector& tables);
+ std::string DebugString() const;
+
+ friend std::ostream& operator<<(std::ostream& os, const SchemasContext& sc) { return os << sc.DebugString(); }
+
private:
bool IsColumnAmbiguous(const std::string& column_name) const;
diff --git a/hybridse/include/vm/simple_catalog.h b/hybridse/include/vm/simple_catalog.h
index 1e1cd78a2f6..fd7c2f3b952 100644
--- a/hybridse/include/vm/simple_catalog.h
+++ b/hybridse/include/vm/simple_catalog.h
@@ -22,7 +22,6 @@
#include
#include
-#include "glog/logging.h"
#include "proto/fe_type.pb.h"
#include "vm/catalog.h"
#include "vm/mem_catalog.h"
diff --git a/hybridse/src/base/fe_slice.cc b/hybridse/src/base/fe_slice.cc
index 9f41c6016ca..c2ca3560741 100644
--- a/hybridse/src/base/fe_slice.cc
+++ b/hybridse/src/base/fe_slice.cc
@@ -25,7 +25,7 @@ void RefCountedSlice::Release() {
if (this->ref_cnt_ != nullptr) {
auto& cnt = *this->ref_cnt_;
cnt -= 1;
- if (cnt == 0) {
+ if (cnt == 0 && buf() != nullptr) {
// memset in case the buf is still used after free
memset(buf(), 0, size());
free(buf());
diff --git a/hybridse/src/codegen/array_ir_builder.cc b/hybridse/src/codegen/array_ir_builder.cc
index f07f551caf1..5bf1bf06e99 100644
--- a/hybridse/src/codegen/array_ir_builder.cc
+++ b/hybridse/src/codegen/array_ir_builder.cc
@@ -17,6 +17,7 @@
#include "codegen/array_ir_builder.h"
#include
+#include "codegen/ir_base_builder.h"
namespace hybridse {
namespace codegen {
@@ -113,5 +114,21 @@ base::Status ArrayIRBuilder::NewEmptyArray(llvm::BasicBlock* bb, NativeValue* ou
return base::Status::OK();
}
+bool ArrayIRBuilder::CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output) {
+ llvm::Value* array_alloca = nullptr;
+ if (!Create(block, &array_alloca)) {
+ return false;
+ }
+
+ llvm::IRBuilder<> builder(block);
+ ::llvm::Value* array_sz = builder.getInt64(0);
+ if (!Set(block, array_alloca, 2, array_sz)) {
+ return false;
+ }
+
+ *output = array_alloca;
+ return true;
+}
+
} // namespace codegen
} // namespace hybridse
diff --git a/hybridse/src/codegen/array_ir_builder.h b/hybridse/src/codegen/array_ir_builder.h
index 38eb6eda1ad..66ef2fe05da 100644
--- a/hybridse/src/codegen/array_ir_builder.h
+++ b/hybridse/src/codegen/array_ir_builder.h
@@ -49,12 +49,12 @@ class ArrayIRBuilder : public StructTypeIRBuilder {
void InitStructType() override;
- bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output) override { return true; }
+ bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output) override;
bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value* dist) override { return true; }
base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src, NativeValue* output) override {
- return base::Status::OK();
+ CHECK_TRUE(false, common::kCodegenError, "casting to array un-implemented");
};
private:
diff --git a/hybridse/src/codegen/cast_expr_ir_builder.cc b/hybridse/src/codegen/cast_expr_ir_builder.cc
index 526a686ae66..57e4103cba6 100644
--- a/hybridse/src/codegen/cast_expr_ir_builder.cc
+++ b/hybridse/src/codegen/cast_expr_ir_builder.cc
@@ -15,12 +15,15 @@
*/
#include "codegen/cast_expr_ir_builder.h"
+
#include "codegen/date_ir_builder.h"
#include "codegen/ir_base_builder.h"
#include "codegen/string_ir_builder.h"
#include "codegen/timestamp_ir_builder.h"
+#include "codegen/type_ir_builder.h"
#include "glog/logging.h"
#include "node/node_manager.h"
+#include "proto/fe_common.pb.h"
using hybridse::common::kCodegenError;
@@ -72,93 +75,73 @@ Status CastExprIRBuilder::Cast(const NativeValue& value,
}
return Status::OK();
}
-Status CastExprIRBuilder::SafeCast(const NativeValue& value, ::llvm::Type* type,
- NativeValue* output) {
+
+Status CastExprIRBuilder::SafeCast(const NativeValue& value, ::llvm::Type* dst_type, NativeValue* output) {
::llvm::IRBuilder<> builder(block_);
- CHECK_TRUE(IsSafeCast(value.GetType(), type), kCodegenError,
- "Safe cast fail: unsafe cast");
+ CHECK_TRUE(IsSafeCast(value.GetType(), dst_type), kCodegenError, "Safe cast fail: unsafe cast");
Status status;
if (value.IsConstNull()) {
- if (TypeIRBuilder::IsStringPtr(type)) {
- StringIRBuilder string_ir_builder(block_->getModule());
- CHECK_STATUS(string_ir_builder.CreateNull(block_, output));
- return base::Status::OK();
- } else {
- *output = NativeValue::CreateNull(type);
- }
- } else if (TypeIRBuilder::IsTimestampPtr(type)) {
+ auto res = CreateSafeNull(block_, dst_type);
+ CHECK_TRUE(res.ok(), kCodegenError, res.status().ToString());
+ *output = res.value();
+ } else if (TypeIRBuilder::IsTimestampPtr(dst_type)) {
TimestampIRBuilder timestamp_ir_builder(block_->getModule());
CHECK_STATUS(timestamp_ir_builder.CastFrom(block_, value, output));
return Status::OK();
- } else if (TypeIRBuilder::IsDatePtr(type)) {
+ } else if (TypeIRBuilder::IsDatePtr(dst_type)) {
DateIRBuilder date_ir_builder(block_->getModule());
CHECK_STATUS(date_ir_builder.CastFrom(block_, value, output));
return Status::OK();
- } else if (TypeIRBuilder::IsStringPtr(type)) {
+ } else if (TypeIRBuilder::IsStringPtr(dst_type)) {
StringIRBuilder string_ir_builder(block_->getModule());
CHECK_STATUS(string_ir_builder.CastFrom(block_, value, output));
return Status::OK();
- } else if (TypeIRBuilder::IsNumber(type)) {
+ } else if (TypeIRBuilder::IsNumber(dst_type)) {
Status status;
::llvm::Value* output_value = nullptr;
- CHECK_TRUE(SafeCastNumber(value.GetValue(&builder), type, &output_value,
- status),
- kCodegenError);
+ CHECK_TRUE(SafeCastNumber(value.GetValue(&builder), dst_type, &output_value, status), kCodegenError);
if (value.IsNullable()) {
- *output = NativeValue::CreateWithFlag(output_value,
- value.GetIsNull(&builder));
+ *output = NativeValue::CreateWithFlag(output_value, value.GetIsNull(&builder));
} else {
*output = NativeValue::Create(output_value);
}
} else {
- return Status(common::kCodegenError,
- "Can't cast from " +
- TypeIRBuilder::TypeName(value.GetType()) + " to " +
- TypeIRBuilder::TypeName(type));
+ return Status(common::kCodegenError, "Can't cast from " + TypeIRBuilder::TypeName(value.GetType()) + " to " +
+ TypeIRBuilder::TypeName(dst_type));
}
return Status::OK();
}
-Status CastExprIRBuilder::UnSafeCast(const NativeValue& value,
- ::llvm::Type* type, NativeValue* output) {
+
+Status CastExprIRBuilder::UnSafeCast(const NativeValue& value, ::llvm::Type* dst_type, NativeValue* output) {
::llvm::IRBuilder<> builder(block_);
- if (value.IsConstNull()) {
- if (TypeIRBuilder::IsStringPtr(type)) {
- StringIRBuilder string_ir_builder(block_->getModule());
- CHECK_STATUS(string_ir_builder.CreateNull(block_, output));
- return base::Status::OK();
- } else {
- *output = NativeValue::CreateNull(type);
- }
- } else if (TypeIRBuilder::IsTimestampPtr(type)) {
+ if (value.IsConstNull() || (TypeIRBuilder::IsNumber(dst_type) && TypeIRBuilder::IsDatePtr(value.GetType()))) {
+ // input is const null or (cast date to number)
+ auto res = CreateSafeNull(block_, dst_type);
+ CHECK_TRUE(res.ok(), kCodegenError, res.status().ToString());
+ *output = res.value();
+ } else if (TypeIRBuilder::IsTimestampPtr(dst_type)) {
TimestampIRBuilder timestamp_ir_builder(block_->getModule());
CHECK_STATUS(timestamp_ir_builder.CastFrom(block_, value, output));
return Status::OK();
- } else if (TypeIRBuilder::IsDatePtr(type)) {
+ } else if (TypeIRBuilder::IsDatePtr(dst_type)) {
DateIRBuilder date_ir_builder(block_->getModule());
CHECK_STATUS(date_ir_builder.CastFrom(block_, value, output));
return Status::OK();
- } else if (TypeIRBuilder::IsStringPtr(type)) {
+ } else if (TypeIRBuilder::IsStringPtr(dst_type)) {
StringIRBuilder string_ir_builder(block_->getModule());
CHECK_STATUS(string_ir_builder.CastFrom(block_, value, output));
return Status::OK();
- } else if (TypeIRBuilder::IsNumber(type) &&
- TypeIRBuilder::IsStringPtr(value.GetType())) {
+ } else if (TypeIRBuilder::IsNumber(dst_type) && TypeIRBuilder::IsStringPtr(value.GetType())) {
StringIRBuilder string_ir_builder(block_->getModule());
- CHECK_STATUS(
- string_ir_builder.CastToNumber(block_, value, type, output));
+ CHECK_STATUS(string_ir_builder.CastToNumber(block_, value, dst_type, output));
return Status::OK();
- } else if (TypeIRBuilder::IsNumber(type) &&
- TypeIRBuilder::IsDatePtr(value.GetType())) {
- *output = NativeValue::CreateNull(type);
} else {
Status status;
::llvm::Value* output_value = nullptr;
- CHECK_TRUE(UnSafeCastNumber(value.GetValue(&builder), type,
- &output_value, status),
- kCodegenError, status.msg);
+ CHECK_TRUE(UnSafeCastNumber(value.GetValue(&builder), dst_type, &output_value, status), kCodegenError,
+ status.msg);
if (value.IsNullable()) {
- *output = NativeValue::CreateWithFlag(output_value,
- value.GetIsNull(&builder));
+ *output = NativeValue::CreateWithFlag(output_value, value.GetIsNull(&builder));
} else {
*output = NativeValue::Create(output_value);
}
diff --git a/hybridse/src/codegen/cast_expr_ir_builder.h b/hybridse/src/codegen/cast_expr_ir_builder.h
index bb487ed1466..5adfca2bdcf 100644
--- a/hybridse/src/codegen/cast_expr_ir_builder.h
+++ b/hybridse/src/codegen/cast_expr_ir_builder.h
@@ -18,9 +18,6 @@
#define HYBRIDSE_SRC_CODEGEN_CAST_EXPR_IR_BUILDER_H_
#include "base/fe_status.h"
#include "codegen/cond_select_ir_builder.h"
-#include "codegen/scope_var.h"
-#include "llvm/IR/IRBuilder.h"
-#include "proto/fe_type.pb.h"
namespace hybridse {
namespace codegen {
@@ -32,26 +29,19 @@ class CastExprIRBuilder {
explicit CastExprIRBuilder(::llvm::BasicBlock* block);
~CastExprIRBuilder();
- Status Cast(const NativeValue& value, ::llvm::Type* cast_type,
- NativeValue* output); // NOLINT
- Status SafeCast(const NativeValue& value, ::llvm::Type* type,
- NativeValue* output); // NOLINT
- Status UnSafeCast(const NativeValue& value, ::llvm::Type* type,
- NativeValue* output); // NOLINT
+ Status Cast(const NativeValue& value, ::llvm::Type* cast_type, NativeValue* output);
+ Status SafeCast(const NativeValue& value, ::llvm::Type* dst_type, NativeValue* output);
+ Status UnSafeCast(const NativeValue& value, ::llvm::Type* dst_type, NativeValue* output);
static bool IsSafeCast(::llvm::Type* lhs, ::llvm::Type* rhs);
- static Status InferNumberCastTypes(::llvm::Type* left_type,
- ::llvm::Type* right_type);
+ static Status InferNumberCastTypes(::llvm::Type* left_type, ::llvm::Type* right_type);
static bool IsIntFloat2PointerCast(::llvm::Type* src, ::llvm::Type* dist);
bool BoolCast(llvm::Value* pValue, llvm::Value** pValue1,
base::Status& status); // NOLINT
- bool SafeCastNumber(::llvm::Value* value, ::llvm::Type* type,
- ::llvm::Value** output,
+ bool SafeCastNumber(::llvm::Value* value, ::llvm::Type* type, ::llvm::Value** output,
base::Status& status); // NOLINT
- bool UnSafeCastNumber(::llvm::Value* value, ::llvm::Type* type,
- ::llvm::Value** output,
+ bool UnSafeCastNumber(::llvm::Value* value, ::llvm::Type* type, ::llvm::Value** output,
base::Status& status); // NOLINT
- bool UnSafeCastDouble(::llvm::Value* value, ::llvm::Type* type,
- ::llvm::Value** output,
+ bool UnSafeCastDouble(::llvm::Value* value, ::llvm::Type* type, ::llvm::Value** output,
base::Status& status); // NOLINT
private:
diff --git a/hybridse/src/codegen/date_ir_builder.cc b/hybridse/src/codegen/date_ir_builder.cc
index 65c439fd143..19bf319d7c3 100644
--- a/hybridse/src/codegen/date_ir_builder.cc
+++ b/hybridse/src/codegen/date_ir_builder.cc
@@ -19,6 +19,7 @@
#include
#include "codegen/arithmetic_expr_ir_builder.h"
#include "codegen/ir_base_builder.h"
+#include "codegen/null_ir_builder.h"
namespace hybridse {
namespace codegen {
@@ -43,6 +44,7 @@ void DateIRBuilder::InitStructType() {
struct_type_ = stype;
return;
}
+
bool DateIRBuilder::CreateDefault(::llvm::BasicBlock* block,
::llvm::Value** output) {
return NewDate(block, output);
@@ -123,11 +125,10 @@ base::Status DateIRBuilder::CastFrom(::llvm::BasicBlock* block,
auto cast_func = m_->getOrInsertFunction(
fn_name,
::llvm::FunctionType::get(builder.getVoidTy(),
- {src.GetType(), dist->getType(),
- builder.getInt1Ty()->getPointerTo()},
- false));
- builder.CreateCall(cast_func,
- {src.GetValue(&builder), dist, is_null_ptr});
+ {src.GetType(), dist->getType(), builder.getInt1Ty()->getPointerTo()}, false));
+
+ builder.CreateCall(cast_func, {src.GetValue(&builder), dist, is_null_ptr});
+
::llvm::Value* should_return_null = builder.CreateLoad(is_null_ptr);
null_ir_builder.CheckAnyNull(block, src, &should_return_null);
*output = NativeValue::CreateWithFlag(dist, should_return_null);
diff --git a/hybridse/src/codegen/date_ir_builder.h b/hybridse/src/codegen/date_ir_builder.h
index cb41dc5f263..d9004d48da1 100644
--- a/hybridse/src/codegen/date_ir_builder.h
+++ b/hybridse/src/codegen/date_ir_builder.h
@@ -16,13 +16,9 @@
#ifndef HYBRIDSE_SRC_CODEGEN_DATE_IR_BUILDER_H_
#define HYBRIDSE_SRC_CODEGEN_DATE_IR_BUILDER_H_
+
#include "base/fe_status.h"
-#include "codegen/cast_expr_ir_builder.h"
-#include "codegen/null_ir_builder.h"
-#include "codegen/scope_var.h"
#include "codegen/struct_ir_builder.h"
-#include "llvm/IR/IRBuilder.h"
-#include "proto/fe_type.pb.h"
namespace hybridse {
namespace codegen {
@@ -31,17 +27,15 @@ class DateIRBuilder : public StructTypeIRBuilder {
public:
explicit DateIRBuilder(::llvm::Module* m);
~DateIRBuilder();
- void InitStructType();
- bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output);
+
+ void InitStructType() override;
+ bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output) override;
+ bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value* dist) override;
+ base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src, NativeValue* output) override;
+
bool NewDate(::llvm::BasicBlock* block, ::llvm::Value** output);
- bool NewDate(::llvm::BasicBlock* block, ::llvm::Value* date,
- ::llvm::Value** output);
- bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
- ::llvm::Value* dist);
- base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src,
- NativeValue* output);
- base::Status CastFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
- ::llvm::Value** output);
+ bool NewDate(::llvm::BasicBlock* block, ::llvm::Value* date, ::llvm::Value** output);
+
bool GetDate(::llvm::BasicBlock* block, ::llvm::Value* date,
::llvm::Value** output);
bool SetDate(::llvm::BasicBlock* block, ::llvm::Value* date,
diff --git a/hybridse/src/codegen/expr_ir_builder.cc b/hybridse/src/codegen/expr_ir_builder.cc
index 1bccb6deef3..6b95bfb8ce1 100644
--- a/hybridse/src/codegen/expr_ir_builder.cc
+++ b/hybridse/src/codegen/expr_ir_builder.cc
@@ -26,10 +26,8 @@
#include "codegen/cond_select_ir_builder.h"
#include "codegen/context.h"
#include "codegen/date_ir_builder.h"
-#include "codegen/fn_ir_builder.h"
#include "codegen/ir_base_builder.h"
#include "codegen/list_ir_builder.h"
-#include "codegen/struct_ir_builder.h"
#include "codegen/timestamp_ir_builder.h"
#include "codegen/type_ir_builder.h"
#include "codegen/udf_ir_builder.h"
@@ -217,8 +215,7 @@ Status ExprIRBuilder::BuildConstExpr(
::llvm::IRBuilder<> builder(ctx_->GetCurrentBlock());
switch (const_node->GetDataType()) {
case ::hybridse::node::kNull: {
- *output = NativeValue::CreateNull(
- llvm::Type::getTokenTy(builder.getContext()));
+ *output = NativeValue(nullptr, nullptr, llvm::Type::getTokenTy(builder.getContext()));
break;
}
case ::hybridse::node::kBool: {
diff --git a/hybridse/src/codegen/ir_base_builder.cc b/hybridse/src/codegen/ir_base_builder.cc
index d1c7e153dd6..992d41d0998 100644
--- a/hybridse/src/codegen/ir_base_builder.cc
+++ b/hybridse/src/codegen/ir_base_builder.cc
@@ -17,7 +17,6 @@
#include "codegen/ir_base_builder.h"
#include
-#include
#include
#include
@@ -625,21 +624,25 @@ bool GetBaseType(::llvm::Type* type, ::hybridse::node::DataType* output) {
return false;
}
- if (pointee_ty->getStructName().startswith("fe.list_ref_")) {
+ auto struct_name = pointee_ty->getStructName();
+ if (struct_name.startswith("fe.list_ref_")) {
*output = hybridse::node::kList;
return true;
- } else if (pointee_ty->getStructName().startswith("fe.iterator_ref_")) {
+ } else if (struct_name.startswith("fe.iterator_ref_")) {
*output = hybridse::node::kIterator;
return true;
- } else if (pointee_ty->getStructName().equals("fe.string_ref")) {
+ } else if (struct_name.equals("fe.string_ref")) {
*output = hybridse::node::kVarchar;
return true;
- } else if (pointee_ty->getStructName().equals("fe.timestamp")) {
+ } else if (struct_name.equals("fe.timestamp")) {
*output = hybridse::node::kTimestamp;
return true;
- } else if (pointee_ty->getStructName().equals("fe.date")) {
+ } else if (struct_name.equals("fe.date")) {
*output = hybridse::node::kDate;
return true;
+ } else if (struct_name.startswith("fe.array_")) {
+ *output = hybridse::node::kArray;
+ return true;
}
LOG(WARNING) << "no mapping pointee_ty for llvm pointee_ty "
<< pointee_ty->getStructName().str();
diff --git a/hybridse/src/codegen/ir_base_builder.h b/hybridse/src/codegen/ir_base_builder.h
index c52bba23431..db2075289cf 100644
--- a/hybridse/src/codegen/ir_base_builder.h
+++ b/hybridse/src/codegen/ir_base_builder.h
@@ -19,7 +19,6 @@
#include
#include
-#include "glog/logging.h"
#include "llvm/IR/IRBuilder.h"
#include "node/sql_node.h"
#include "node/type_node.h"
diff --git a/hybridse/src/codegen/native_value.cc b/hybridse/src/codegen/native_value.cc
index c4c6e2e562a..fce4f0bb5bb 100644
--- a/hybridse/src/codegen/native_value.cc
+++ b/hybridse/src/codegen/native_value.cc
@@ -17,7 +17,6 @@
#include "codegen/native_value.h"
#include
#include
-#include
#include "codegen/context.h"
#include "codegen/ir_base_builder.h"
diff --git a/hybridse/src/codegen/native_value.h b/hybridse/src/codegen/native_value.h
index 52b0453c743..4bb756e3c3b 100644
--- a/hybridse/src/codegen/native_value.h
+++ b/hybridse/src/codegen/native_value.h
@@ -21,9 +21,7 @@
#include
#include
-#include "glog/logging.h"
#include "llvm/IR/IRBuilder.h"
-#include "llvm/IR/Module.h"
namespace hybridse {
namespace codegen {
@@ -93,9 +91,9 @@ class NativeValue {
NativeValue WithFlag(::llvm::Value*) const;
NativeValue() : raw_(nullptr), flag_(nullptr), type_(nullptr) {}
+ NativeValue(::llvm::Value* raw, ::llvm::Value* flag, ::llvm::Type* type);
private:
- NativeValue(::llvm::Value* raw, ::llvm::Value* flag, ::llvm::Type* type);
::llvm::Value* raw_;
::llvm::Value* flag_;
::llvm::Type* type_;
diff --git a/hybridse/src/codegen/predicate_expr_ir_builder.cc b/hybridse/src/codegen/predicate_expr_ir_builder.cc
index aaf0fb0753c..45ed8f7ec21 100644
--- a/hybridse/src/codegen/predicate_expr_ir_builder.cc
+++ b/hybridse/src/codegen/predicate_expr_ir_builder.cc
@@ -17,6 +17,7 @@
#include "codegen/predicate_expr_ir_builder.h"
#include "codegen/date_ir_builder.h"
#include "codegen/ir_base_builder.h"
+#include "codegen/null_ir_builder.h"
#include "codegen/string_ir_builder.h"
#include "codegen/timestamp_ir_builder.h"
#include "codegen/type_ir_builder.h"
diff --git a/hybridse/src/codegen/string_ir_builder.cc b/hybridse/src/codegen/string_ir_builder.cc
index bb69f529f2b..8c41d326ee0 100644
--- a/hybridse/src/codegen/string_ir_builder.cc
+++ b/hybridse/src/codegen/string_ir_builder.cc
@@ -63,17 +63,7 @@ bool StringIRBuilder::CreateDefault(::llvm::BasicBlock* block,
::llvm::Value** output) {
return NewString(block, output);
}
-/// Create Const String Null
-/// \param block
-/// \param output
-/// \return
-base::Status StringIRBuilder::CreateNull(::llvm::BasicBlock* block, NativeValue* output) {
- ::llvm::Value* value = nullptr;
- CHECK_TRUE(NewString(block, &value), kCodegenError, "Fail to construct string")
- ::llvm::IRBuilder<> builder(block);
- *output = NativeValue::CreateWithFlag(value, builder.getInt1(true));
- return base::Status::OK();
-}
+
bool StringIRBuilder::NewString(::llvm::BasicBlock* block,
::llvm::Value** output) {
if (!Create(block, output)) {
diff --git a/hybridse/src/codegen/string_ir_builder.h b/hybridse/src/codegen/string_ir_builder.h
index fb81872599a..84f73d2822d 100644
--- a/hybridse/src/codegen/string_ir_builder.h
+++ b/hybridse/src/codegen/string_ir_builder.h
@@ -16,14 +16,12 @@
#ifndef HYBRIDSE_SRC_CODEGEN_STRING_IR_BUILDER_H_
#define HYBRIDSE_SRC_CODEGEN_STRING_IR_BUILDER_H_
+
#include
#include
+
#include "base/fe_status.h"
-#include "codegen/cast_expr_ir_builder.h"
-#include "codegen/scope_var.h"
#include "codegen/struct_ir_builder.h"
-#include "llvm/IR/IRBuilder.h"
-#include "proto/fe_type.pb.h"
namespace hybridse {
namespace codegen {
@@ -32,16 +30,18 @@ class StringIRBuilder : public StructTypeIRBuilder {
public:
explicit StringIRBuilder(::llvm::Module* m);
~StringIRBuilder();
+
void InitStructType() override;
- bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output);
- base::Status CreateNull(::llvm::BasicBlock* block, NativeValue* output);
+ bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output) override;
+ bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value* dist) override;
+ base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src, NativeValue* output) override;
+ base::Status CastFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value** output);
+
bool NewString(::llvm::BasicBlock* block, ::llvm::Value** output);
bool NewString(::llvm::BasicBlock* block, const std::string& str,
::llvm::Value** output);
bool NewString(::llvm::BasicBlock* block, ::llvm::Value* size,
::llvm::Value* data, ::llvm::Value** output);
- bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
- ::llvm::Value* dist);
bool GetSize(::llvm::BasicBlock* block, ::llvm::Value* str,
::llvm::Value** output);
bool SetSize(::llvm::BasicBlock* block, ::llvm::Value* str,
@@ -50,8 +50,6 @@ class StringIRBuilder : public StructTypeIRBuilder {
::llvm::Value** output);
bool SetData(::llvm::BasicBlock* block, ::llvm::Value* str,
::llvm::Value* data);
- base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src,
- NativeValue* output);
base::Status Compare(::llvm::BasicBlock* block, const NativeValue& s1,
const NativeValue& s2, NativeValue* output);
@@ -62,8 +60,6 @@ class StringIRBuilder : public StructTypeIRBuilder {
const std::vector& strs,
NativeValue* output);
- base::Status CastFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
- ::llvm::Value** output);
base::Status CastToNumber(::llvm::BasicBlock* block, const NativeValue& src,
::llvm::Type* type, NativeValue* output);
};
diff --git a/hybridse/src/codegen/struct_ir_builder.cc b/hybridse/src/codegen/struct_ir_builder.cc
index 3a8e3336936..7adfb5d950f 100644
--- a/hybridse/src/codegen/struct_ir_builder.cc
+++ b/hybridse/src/codegen/struct_ir_builder.cc
@@ -25,17 +25,14 @@ StructTypeIRBuilder::StructTypeIRBuilder(::llvm::Module* m)
: TypeIRBuilder(), m_(m), struct_type_(nullptr) {}
StructTypeIRBuilder::~StructTypeIRBuilder() {}
-bool StructTypeIRBuilder::StructCopyFrom(::llvm::BasicBlock* block,
- ::llvm::Value* src,
- ::llvm::Value* dist) {
- StructTypeIRBuilder* struct_builder =
- CreateStructTypeIRBuilder(block->getModule(), src->getType());
+bool StructTypeIRBuilder::StructCopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value* dist) {
+ StructTypeIRBuilder* struct_builder = CreateStructTypeIRBuilder(block->getModule(), src->getType());
bool ok = struct_builder->CopyFrom(block, src, dist);
delete struct_builder;
return ok;
}
-StructTypeIRBuilder* StructTypeIRBuilder::CreateStructTypeIRBuilder(
- ::llvm::Module* m, ::llvm::Type* type) {
+
+StructTypeIRBuilder* StructTypeIRBuilder::CreateStructTypeIRBuilder(::llvm::Module* m, ::llvm::Type* type) {
node::DataType base_type;
if (!GetBaseType(type, &base_type)) {
return nullptr;
@@ -49,14 +46,24 @@ StructTypeIRBuilder* StructTypeIRBuilder::CreateStructTypeIRBuilder(
case node::kVarchar:
return new StringIRBuilder(m);
default: {
- LOG(WARNING) << "fail to create struct type ir builder for "
- << DataTypeName(base_type);
+ LOG(WARNING) << "fail to create struct type ir builder for " << DataTypeName(base_type);
return nullptr;
}
}
return nullptr;
}
+
+absl::StatusOr StructTypeIRBuilder::CreateNull(::llvm::BasicBlock* block) {
+ ::llvm::Value* value = nullptr;
+ if (!CreateDefault(block, &value)) {
+ return absl::InternalError(absl::StrCat("fail to construct ", GetLlvmObjectString(GetType())));
+ }
+ ::llvm::IRBuilder<> builder(block);
+ return NativeValue::CreateWithFlag(value, builder.getInt1(true));
+}
+
::llvm::Type* StructTypeIRBuilder::GetType() { return struct_type_; }
+
bool StructTypeIRBuilder::Create(::llvm::BasicBlock* block,
::llvm::Value** output) const {
if (block == NULL || output == NULL) {
diff --git a/hybridse/src/codegen/struct_ir_builder.h b/hybridse/src/codegen/struct_ir_builder.h
index 2f1f94d036c..e197665855b 100644
--- a/hybridse/src/codegen/struct_ir_builder.h
+++ b/hybridse/src/codegen/struct_ir_builder.h
@@ -16,12 +16,11 @@
#ifndef HYBRIDSE_SRC_CODEGEN_STRUCT_IR_BUILDER_H_
#define HYBRIDSE_SRC_CODEGEN_STRUCT_IR_BUILDER_H_
+
+#include "absl/status/statusor.h"
#include "base/fe_status.h"
-#include "codegen/cast_expr_ir_builder.h"
-#include "codegen/scope_var.h"
+#include "codegen/native_value.h"
#include "codegen/type_ir_builder.h"
-#include "llvm/IR/IRBuilder.h"
-#include "proto/fe_type.pb.h"
namespace hybridse {
namespace codegen {
@@ -30,15 +29,18 @@ class StructTypeIRBuilder : public TypeIRBuilder {
public:
explicit StructTypeIRBuilder(::llvm::Module*);
~StructTypeIRBuilder();
- static StructTypeIRBuilder* CreateStructTypeIRBuilder(::llvm::Module*,
- ::llvm::Type*);
- static bool StructCopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
- ::llvm::Value* dist);
+
+ static StructTypeIRBuilder* CreateStructTypeIRBuilder(::llvm::Module*, ::llvm::Type*);
+ static bool StructCopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value* dist);
+
virtual void InitStructType() = 0;
+ virtual bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src, ::llvm::Value* dist) = 0;
+ virtual base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src, NativeValue* output) = 0;
+ virtual bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output) = 0;
+
+ absl::StatusOr CreateNull(::llvm::BasicBlock* block);
::llvm::Type* GetType();
bool Create(::llvm::BasicBlock* block, ::llvm::Value** output) const;
- virtual bool CreateDefault(::llvm::BasicBlock* block,
- ::llvm::Value** output) = 0;
// Load the 'idx' th field into ''*output'
// NOTE: not all types are loaded correctly, e.g for array type
@@ -48,12 +50,6 @@ class StructTypeIRBuilder : public TypeIRBuilder {
// Get the address of 'idx' th field
bool Get(::llvm::BasicBlock* block, ::llvm::Value* struct_value, unsigned int idx, ::llvm::Value** output) const;
- virtual bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
- ::llvm::Value* dist) = 0;
- virtual base::Status CastFrom(::llvm::BasicBlock* block,
- const NativeValue& src,
- NativeValue* output) = 0;
-
protected:
::llvm::Module* m_;
::llvm::Type* struct_type_;
diff --git a/hybridse/src/codegen/timestamp_ir_builder.cc b/hybridse/src/codegen/timestamp_ir_builder.cc
index 13d6e065f39..c3a8054e1cd 100644
--- a/hybridse/src/codegen/timestamp_ir_builder.cc
+++ b/hybridse/src/codegen/timestamp_ir_builder.cc
@@ -15,14 +15,15 @@
*/
#include "codegen/timestamp_ir_builder.h"
+
#include
#include
+
#include "codegen/arithmetic_expr_ir_builder.h"
#include "codegen/ir_base_builder.h"
#include "codegen/null_ir_builder.h"
#include "codegen/predicate_expr_ir_builder.h"
#include "glog/logging.h"
-#include "node/sql_node.h"
using hybridse::common::kCodegenError;
@@ -43,9 +44,7 @@ void TimestampIRBuilder::InitStructType() {
return;
}
stype = ::llvm::StructType::create(m_->getContext(), name);
- ::llvm::Type* ts_ty = (::llvm::Type::getInt64Ty(m_->getContext()));
- std::vector<::llvm::Type*> elements;
- elements.push_back(ts_ty);
+ std::vector<::llvm::Type*> elements = {::llvm::Type::getInt64Ty(m_->getContext())};
stype->setBody(::llvm::ArrayRef<::llvm::Type*>(elements));
struct_type_ = stype;
return;
@@ -60,39 +59,36 @@ base::Status TimestampIRBuilder::CastFrom(::llvm::BasicBlock* block,
return Status::OK();
}
- if (src.IsConstNull()) {
- *output = NativeValue::CreateNull(GetType());
- return Status::OK();
- }
::llvm::IRBuilder<> builder(block);
NativeValue ts;
CastExprIRBuilder cast_builder(block);
CondSelectIRBuilder cond_ir_builder;
PredicateIRBuilder predicate_ir_builder(block);
NullIRBuilder null_ir_builder;
+
+ // always allocate for returned timestmap even it is null
+ ::llvm::Value* dist = nullptr;
+ if (!CreateDefault(block, &dist)) {
+ status.code = common::kCodegenError;
+ status.msg = "Fail to cast date: create default date fail";
+ return status;
+ }
+
if (IsNumber(src.GetType())) {
CHECK_STATUS(cast_builder.Cast(src, builder.getInt64Ty(), &ts));
NativeValue cond;
CHECK_STATUS(predicate_ir_builder.BuildGeExpr(
ts, NativeValue::Create(builder.getInt64(0)), &cond));
- ::llvm::Value* timestamp;
- CHECK_TRUE(NewTimestamp(block, ts.GetValue(&builder), ×tamp),
+ CHECK_TRUE(SetTs(block, dist, ts.GetValue(&builder)),
kCodegenError,
"Fail to cast timestamp: new timestamp(ts) fail");
- CHECK_STATUS(
- cond_ir_builder.Select(block, cond, NativeValue::Create(timestamp),
- NativeValue::CreateNull(GetType()), output));
+ CHECK_STATUS(cond_ir_builder.Select(block, cond, NativeValue::Create(dist),
+ NativeValue::CreateWithFlag(dist, builder.getInt1(true)), output));
} else if (IsStringPtr(src.GetType()) || IsDatePtr(src.GetType())) {
::llvm::IRBuilder<> builder(block);
- ::llvm::Value* dist = nullptr;
::llvm::Value* is_null_ptr = CreateAllocaAtHead(
&builder, builder.getInt1Ty(), "timestamp_is_null_alloca");
- if (!CreateDefault(block, &dist)) {
- status.code = common::kCodegenError;
- status.msg = "Fail to cast date: create default date fail";
- return status;
- }
::std::string fn_name = "timestamp." + TypeName(src.GetType());
auto cast_func = m_->getOrInsertFunction(
diff --git a/hybridse/src/codegen/timestamp_ir_builder.h b/hybridse/src/codegen/timestamp_ir_builder.h
index 33de3cce2e5..84051979597 100644
--- a/hybridse/src/codegen/timestamp_ir_builder.h
+++ b/hybridse/src/codegen/timestamp_ir_builder.h
@@ -16,12 +16,9 @@
#ifndef HYBRIDSE_SRC_CODEGEN_TIMESTAMP_IR_BUILDER_H_
#define HYBRIDSE_SRC_CODEGEN_TIMESTAMP_IR_BUILDER_H_
+
#include "base/fe_status.h"
-#include "codegen/cast_expr_ir_builder.h"
-#include "codegen/scope_var.h"
#include "codegen/struct_ir_builder.h"
-#include "llvm/IR/IRBuilder.h"
-#include "proto/fe_type.pb.h"
namespace hybridse {
namespace codegen {
@@ -33,8 +30,8 @@ class TimestampIRBuilder : public StructTypeIRBuilder {
void InitStructType();
bool CreateDefault(::llvm::BasicBlock* block, ::llvm::Value** output);
bool NewTimestamp(::llvm::BasicBlock* block, ::llvm::Value** output);
- bool NewTimestamp(::llvm::BasicBlock* block, ::llvm::Value* ts,
- ::llvm::Value** output);
+ bool NewTimestamp(::llvm::BasicBlock* block, ::llvm::Value* ts, ::llvm::Value** output);
+
bool CopyFrom(::llvm::BasicBlock* block, ::llvm::Value* src,
::llvm::Value* dist);
base::Status CastFrom(::llvm::BasicBlock* block, const NativeValue& src,
diff --git a/hybridse/src/codegen/type_ir_builder.cc b/hybridse/src/codegen/type_ir_builder.cc
index 3fcd5891c4c..07adfb21855 100644
--- a/hybridse/src/codegen/type_ir_builder.cc
+++ b/hybridse/src/codegen/type_ir_builder.cc
@@ -15,8 +15,12 @@
*/
#include "codegen/type_ir_builder.h"
+
+#include "absl/status/status.h"
+#include "codegen/date_ir_builder.h"
#include "codegen/ir_base_builder.h"
-#include "glog/logging.h"
+#include "codegen/string_ir_builder.h"
+#include "codegen/timestamp_ir_builder.h"
#include "node/node_manager.h"
namespace hybridse {
@@ -101,13 +105,7 @@ bool TypeIRBuilder::IsStringPtr(::llvm::Type* type) {
bool TypeIRBuilder::IsStructPtr(::llvm::Type* type) {
if (type->getTypeID() == ::llvm::Type::PointerTyID) {
type = reinterpret_cast<::llvm::PointerType*>(type)->getElementType();
- if (type->isStructTy()) {
- DLOG(INFO) << "Struct Name " << type->getStructName().str();
- return true;
- } else {
- DLOG(INFO) << "Isn't Struct Type";
- return false;
- }
+ return type->isStructTy();
}
return false;
}
@@ -138,5 +136,37 @@ base::Status TypeIRBuilder::BinaryOpTypeInfer(
return base::Status::OK();
}
+absl::StatusOr CreateSafeNull(::llvm::BasicBlock* block, ::llvm::Type* type) {
+ node::DataType data_type;
+ if (!GetBaseType(type, &data_type)) {
+ return absl::InvalidArgumentError(absl::StrCat("can't get base type for: ", GetLlvmObjectString(type)));
+ }
+
+ if (TypeIRBuilder::IsStructPtr(type)) {
+ std::unique_ptr builder = nullptr;
+
+ switch (data_type) {
+ case node::DataType::kTimestamp: {
+ builder.reset(new TimestampIRBuilder(block->getModule()));
+ break;
+ }
+ case node::DataType::kDate: {
+ builder.reset(new DateIRBuilder(block->getModule()));
+ break;
+ }
+ case node::DataType::kVarchar: {
+ builder.reset(new StringIRBuilder(block->getModule()));
+ break;
+ }
+ default:
+ return absl::InvalidArgumentError(absl::StrCat("invalid struct type: ", GetLlvmObjectString(type)));
+ }
+
+ return builder->CreateNull(block);
+ }
+
+ return NativeValue(nullptr, nullptr, type);
+}
+
} // namespace codegen
} // namespace hybridse
diff --git a/hybridse/src/codegen/type_ir_builder.h b/hybridse/src/codegen/type_ir_builder.h
index e06e77244e6..e68d7f0233b 100644
--- a/hybridse/src/codegen/type_ir_builder.h
+++ b/hybridse/src/codegen/type_ir_builder.h
@@ -18,11 +18,12 @@
#define HYBRIDSE_SRC_CODEGEN_TYPE_IR_BUILDER_H_
#include
-#include
+
+#include "absl/status/statusor.h"
#include "base/fe_status.h"
-#include "codec/fe_row_codec.h"
-#include "codegen/ir_base_builder.h"
-#include "node/node_enum.h"
+#include "codegen/native_value.h"
+#include "llvm/IR/Module.h"
+#include "llvm/IR/Type.h"
#include "node/sql_node.h"
#include "node/type_node.h"
@@ -91,6 +92,10 @@ class BoolIRBuilder : public TypeIRBuilder {
}
};
+// construct a safe null value for type
+// returns NativeValue{raw, is_null=true} on success, raw is ensured to be not nullptr
+absl::StatusOr CreateSafeNull(::llvm::BasicBlock* block, ::llvm::Type* type);
+
} // namespace codegen
} // namespace hybridse
#endif // HYBRIDSE_SRC_CODEGEN_TYPE_IR_BUILDER_H_
diff --git a/hybridse/src/codegen/udf_ir_builder.cc b/hybridse/src/codegen/udf_ir_builder.cc
index 6d6f967a83e..5030f3cd8ae 100644
--- a/hybridse/src/codegen/udf_ir_builder.cc
+++ b/hybridse/src/codegen/udf_ir_builder.cc
@@ -15,19 +15,17 @@
*/
#include "codegen/udf_ir_builder.h"
-#include
-#include