很多人以为人工智能就快实现了,是因为他们混淆了“识别”和“理解”。现在所谓的“人工智能”都是在做识别:语音识别,图像识别,而真正的智能是需要理解能力的。我们离理解有多远呢?恐怕真正的工作根本就没开始。
很长时间以来,我都知道理解与识别的根本差别,而且知道理解的重要性,可是我发现很少有其他人知道“理解”是什么。AI 领域因为混淆了识别和理解,其实一直以来处于混沌之中。最近因为图像识别等领域发生了进展,人们对 AI 产生了很多科幻似的,盲目的自信。下面我就分类介绍一下我对识别和理解的看法,希望一些人看到之后,能够再次拥有冷静的头脑。
对于语言,人们常常混淆“语音识别”和“语言理解”。AI 人士很多时候还故意把两者混淆起来,所以你经常听他们说:“机器已经能理解人类语言了!” 而其实机器离理解人类语言差距非常远。现在的情况是,机器完全不能理解人类语言。
AI 人士所谓的“理解了人类语言”,全都是指“语音识别”,也就是输入一段语音,机器给你对应的文字,就像语音输入法那样。可是机器虽然能知道你说的是哪些字,却不能理解你说的是什么“意思”。你得到的只是一个可以帮你打字的工具。就算你没有语音识别,用键盘把字打进去,机器也不能理解你的意思。
有些公司做了一些好像能跟你对话的小玩意,比如 Siri,Alexa,微软小冰,各种智能音箱等。这些东西其实也只是用语音识别出文字,然后针对这些文字进行一些肤浅的字面处理,比如搜索一下其中的关键字,就跟搜索引擎一样。它们并没有真的理解你在说什么。起初你以为它们真的在跟你对话,可是经过一番试验之后,你就会发现它们并不理解你在说什么。这种系统只是用了一些小计俩,让你以为它们知道你在说什么,而其实它们只是对你的话进行非常简单的文本匹配或者关键字搜索,然后拼出一个简单的答复。它们通常在下一句话就已经不记得你上一句说了什么。
所谓“意思”就是语义,它是比字面更深一层的信息。如果不能实现真正的语义理解,真正能跟人对话的机器,“智能客服”等等,就无法实现。
那么语义是什么呢?举个例子。如果你听到“猫”这个字,你的脑子里就出现关于猫的很多信息,它们是什么样子,有什么行为,等等。这些是具体的,形象的信息,是人对“猫”这个概念的很多经验,组合在一起。这种信息不是文字可以表示的,我把这种信息叫做“常识”。
只有理解了语义,人们之间才可能产生真正意义上的对话。所谓“智能客服”,必须能理解语义才可能起作用。真正意义上的“翻译”,也必须理解了语义才能翻译得通顺。
可惜现在的情况是,我们不知道如何让机器产生语义。所以智能对话系统都是基于文本的忽悠,所谓“机器翻译”也是根据概率统计的瞎猜,译文很不通顺,经常出现意思完全错误的句子。Google Translate 总是显得很厉害的样子,而其实它翻译出来的东西只能算“基本知道在说什么”,根本不能拿来代替翻译人员。
即使加上最近有点热门的所谓“知识图谱”,机器也不能真的理解,因为知识图谱跟一本同义反义词典差不多,只不过多了一些关系。这些关系全都是文字之间的关系,它仍然停留在语法(字面)层面,而没有接触到语义。
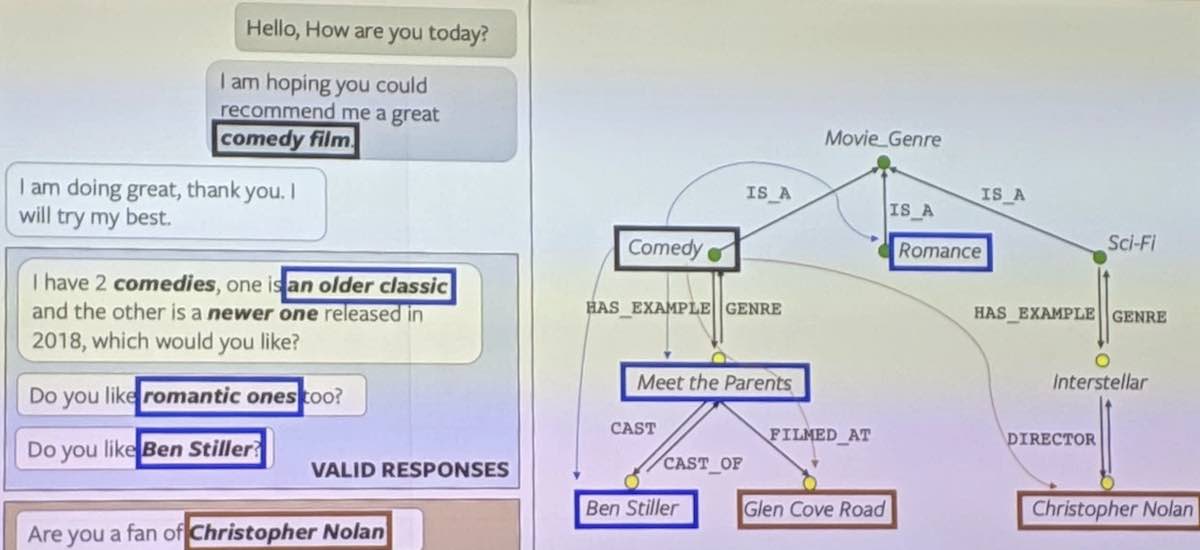
知识图谱的研究者们试图把词语归一下类,找找其中的关系(IS_A 之类的),以为就能够理解人类语言。可是你们想过人类是如何理解语言的吗?许多人都不知道这些词语之间有什么关系。什么近义词,反义词,IS_A…… 这些学术概念在小孩子的头脑里根本就没有,可是他们却能理解你在说什么,因为他们的脑子里有常识。
所以知识图谱不大可能解决语言理解的问题,它仍然是浮于字面的东西。
要想产生语义,机器必须拥有人的“常识”。常识到底是什么数据,如何获得常识,如何表示,如何利用,谁也不知道。所以理解人类语言是一个毫无头绪的工作,根本不像 AI 人士说的“已经实现了”。
如果不能真的从语义层面理解人类语言,什么“智能客服”,“智能个人助手”全都只能扯淡。做个玩具忽悠小孩可能还行,真的要用来理解和处理“客服工作”,还是放弃吧。
对于视觉,AI 领域混淆了“图像识别”和“视觉理解”。现在热门的 “AI” 都是“图像识别”,而动物的视觉系统拥有强大的“视觉理解”。视觉理解和图像识别有着本质的不同。
深度学习视觉模型(CNN 一类的)只是从大量数据拟合出从“像素=>名字”的函数。它也许能从一堆像素猜出图中物体的“名字”,但它却不知道那个物体“是什么”,无法对物体进行操作。注意我是特意使用了“猜”这个字,因为它真的是在猜,而不像人一样准确的知道。
“图像识别”跟“语音识别”处于同样的级别,停留在语法(字面)层面,而没有接触到“语义”。语音识别是“语音=>文字”的转换,而图像识别则是“图像=>文字”的转换。两者都输出文字,而“文字”跟“理解”处于两个不同的层面。文字是表面的符号,你得理解了它才会有意义。
怎样才算是“理解了物体”呢?至少,你得知道它是什么形状的,有哪些组成部分,各部分的位置和边界在哪里,是什么材料做成的,大概有什么性质。这样你才能有效的对它采取行动,达到需要的效果。否则这个物体只是一个方框上面加个标签,不能精确地进行判断和实际的操作。
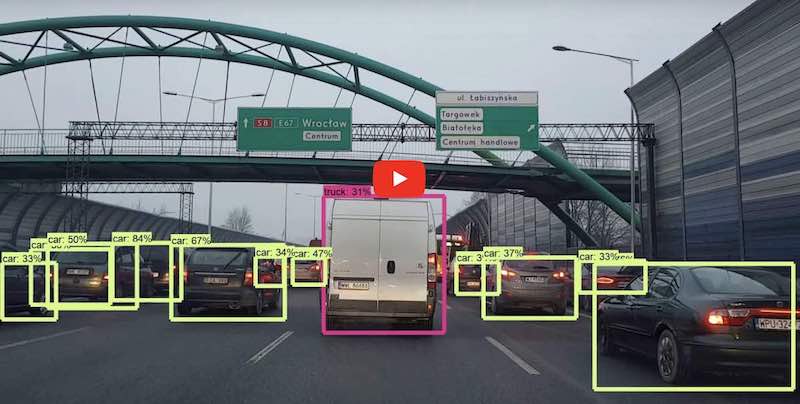
想想面对各种日常事物的时候,你的脑子里出现的是它们的名字吗?比如你拿起刀准备切水果,旁边没有人跟你说话,你的脑子里出现了“刀”这个字吗?一般是没有的。你的脑子里出现的不是名字,而是“常识”。常识不是文字,而是一种抽象而具体的数据。
你知道这是一把刀,可是你的头脑提取的不是“刀”这个字,而是刀“是什么”。你的视觉系统告诉你它的结构是什么样的。你知道它是金属做的,你看到刀尖,刀刃,刀把,它也许是折叠的。经验告诉你,刀刃是锋利的可以切东西的部分,碰到可能会受伤,刀把是可以拿的地方。如果刀是折起来的,你得先把它翻开,那么你从哪一头动手才能把它翻开,它的轴在哪里?你的得拿住那个槽,它才不会在翻开的时候打滑……
你顺利拿起刀,开始切水果。可是你的头脑里仍然没有出现“刀”这个字,也没有“刀刃”,“刀把”之类的词。在切水果的同时,你大脑的“语言中心”可能在哼一首最近喜欢的歌词,它跟刀没有任何关系。语言只是与其他人沟通的时候需要的工具,自己做事的时候我们并不需要语言。完成切水果的动作,你需要的是由视觉产生的对物体结构的理解,而不是语言。
你不需要知道一个物品叫什么名字就能正确操作它。如果你的脑子里首先出现的是事物的名字,那么你肯定是很愚钝的人,无法料理自己的生活。现在的“机器视觉”基本就是那样的。机器也许能说出图片上物体的名字,它却不知道它是什么,无法操作它。
这就是我所谓的“视觉理解”与“图像识别”的差别。
如果我们降低标准,只是“识别”物体的名字,那么以像素为基础的图像识别,也是没法像人一样准确识别物体的。人的视觉系统并不是简单的“拍照+识别”,而是“观察+理解+观察+理解+观察+理解……”,是一个动态的,反复的过程。感官接受信息,中间穿插着理解,理解反过来又控制着观察的方向和顺序。理解穿插在了识别物体的过程中,“观察/理解”成为不可分割的整体。人看到物体的一部分,理解了那是什么,然后继续观察它周围是什么。
举个例子,假设你从来没见过这个东西,你知道它是什么吗?

一个从没见过火星车的人,也会知道这是个“车子”。为什么呢?因为它有轮子。为什么你知道那是轮子呢?仔细一想,因为它是圆的,中间有轴,所以好像能在地面上滚动。为什么你知道那是“轴”呢?我就不继续废话了,你自己想一下吧。所有这些分析都是“视觉理解”所产生的,而这些理解都依赖于从经验来的“常识”。
实际上你并不需要分析这么多。你之所以做这些分析,是因为另一个人问你“你怎么知道的?” 其实人识别物体靠的是所谓“直觉”。一看到这个图片,你的脑子里自然产生了一个 3D 模型,而且它符合“车子”的机械运动原理。你的脑子里会浮现出可能的运动镜头,你仿佛看到了它随着轮子在移动。你甚至看到其中一个轮子压到岩石的时候会随着连杆被抬起来,而整个车仍然保持平衡,所以这车也许能对付崎岖的野外环境。
这里有一个容易忽视的要点,那就是轮子的轴必须和车体连在一起。如果轮子跟车体没有连接,或者位置不对,看起来无法带着车体移动,人都是知道的。这种轮轴与车身的连接关系,属于一种叫“拓扑”(topology)的概念。
拓扑学是一门难度挺高的数学学科,但人似乎天生就理解某些浅显的拓扑概念。实际上似乎高等动物都或多或少理解一些拓扑概念,它们一看就知道哪些东西是连在一起的,哪些是分开的。
一个人看到物体,他看到的是一个模型,他可以理解它的性质,所以一个人从没见过的物体,他也能知道它是什么。没有理解能力的机器是做不到这一点的。
人的眼睛与摄像头有着本质的差异。眼睛是会转动的,它被脑神经控制,敏捷地跟踪着感兴趣的部分:线条,平面,立体结构…… 人的视觉系统能够精确地理解物体的形状,理解拓扑,而且这些都是 3D 的。人脑看到的不是像素,而是一个 3D 拓扑模型。
眼睛观察的顺序,不是一行一行从上往下把每一个“像素”都记下来,做成 6000x4000 像素的图片,而是聚焦在重点上。它可以沿着直线,也可以沿着弧线观察,可以转着圈,也可以跳来跳去的。所以眼睛采集的信息量可能不大,人脑需要处理的信息也不会很多。
人能理解点,线,面的概念,理解物体的表面是连续的还是有洞,是凹陷的还是凸起的,分得清里和外,远和近,上下左右…… 他能理解物体的表面是什么质地,如果用手去拿会有什么样的反应。他能想象出物体的背面大概是什么样子,他能在头脑中旋转或者扭曲物体的模型。如果物体中间有缺损,他甚至能猜出那位置之前什么样子。
人的视觉系统比摄像头有趣的多。很多人都看过“光学幻觉”(optical illusion)的图片,它们从一个角度揭示了人的视觉系统背后在做什么。比如下图本来是一个静态的图片,可是你会感觉有很多黑点在白线的交叉处闪烁。

本来是静态图片,你却感觉它在转。

本来上下两块东西是一样的颜色,可是看起来下面的颜色却要浅一些。如果你用手指挡住中间的高亮部分,就会发现上下两块的颜色其实是一样的。
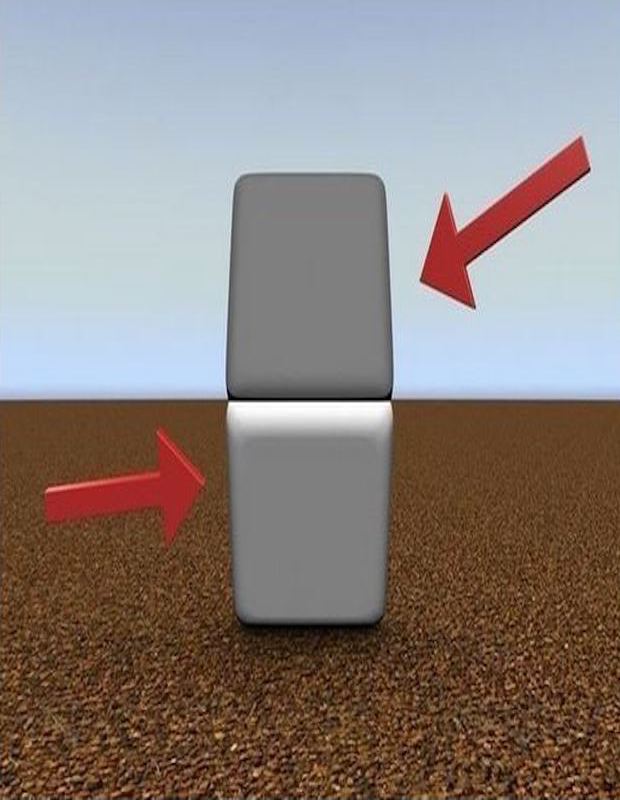
另一个类似的幻觉,是著名的“Abelson 棋盘幻觉”。图中 A 和 B 两个棋盘格子的颜色是一样的,你却觉得 A 是黑色,而 B 是白色。不信的话你可以用软件把这两块格子从图片上切下来,挨在一起对比一下。如果你好奇这是为什么,可以参考这篇文章。

在下图里,你会觉得看见了一个黑色的倒三角形,可是其实它并不存在。

很多的光学幻觉都说明人的视觉系统不是简单的摄像头一样的东西,它具有某些特殊功能。这些特殊功能和机制导致了这些幻觉。这使得人类视觉不同于机器,使得人能够提取出物体的结构,而不是只看到像素。
提取物体的拓扑结构特征,这就是为什么人可以理解抽象画,漫画,玩具。虽然世界上没有猫和老鼠长那个样子,一个从来没看过《猫和老鼠》动画片的小孩,却知道这是一只猫和一只老鼠,后面有个房子。你试试让一个没有拿《猫和老鼠》剧照训练过的深度学习模型来识别这幅图?

人脑理解“拓扑”的概念,这使得人能够不受具体像素干扰而正确处理各种物体。理解使得人对物体的识别非常准确,甚至可以在信息不完整,模糊,扭曲的情况下工作,在恶劣的天气环境下,有反光,有影子的情况下也能识别物体。
说到“反光”,你有想过机器要如何才会知道场景里有一面镜子或者玻璃吗?这是个现实的问题。你的自动车或者机器人要如何才知道前面有一面镜子或者一堵玻璃墙?它要如何知道前面的路面上有积水或者结冰了?

人是通过对光的理解,各种常识来识别镜子,玻璃,地上的水和冰的存在。一台不理解光和水的性质的机器,它能察觉这些东西的存在吗?靠像素分析能知道这些?要知道,这些东西在某些地方出现,可以是致命的危险。
很有趣的事情,理解光线的反射和折射,似乎已经固化到了每个动物的视觉系统里面。我观察到这一点,是因为我的卧室和客厅之间的橱柜门上有两面大镜子。我的猫在卧室里,能够从镜子里看见我在客厅拿着逗猫绳。他冲过来的时候却不会撞到镜子上面,而是出了卧室门立马转一个角度,冲向我的方向。我每次看到他敏捷的动作都会思考,他是如何知道镜子的存在呢?他是如何知道镜子里的猫就是他自己?

说了光,再来说影吧。画过素描的人都知道,开头勾勒出的轮廓是没有立体感的,然后你往恰当的位置加一些阴影,就有了立体感。所以动物的视觉系统里存在对影子的分析处理,而且这种功能我们似乎从来没需要学习,生下来就有。

靠着光和影的组合,人和动物能得到很多信息。比如上图,我们不但看得出这是一个立体的鸡蛋,而且能推断出鸡蛋下面是一个平面,可能是一张桌子,因为有阴影投在了上面。
神经网络知道什么是影子吗?它如何知道影子不是实际存在的物体呢?它能从影子得到有用的信息吗?
再来一个关于绘画的话题。学画的初期,很多人都发现画“透视”特别困难。所谓透视就是“近大远小”。本来房子的几堵墙都是长方形,是一样高的,可是你得把远的那一边画短一些,而且相关部分的比例都要画对,就像照片上那样,所以墙就成了梯形的。你得这样画,看画的人才会感觉比例是对的,不然就会感觉哪里不对劲。
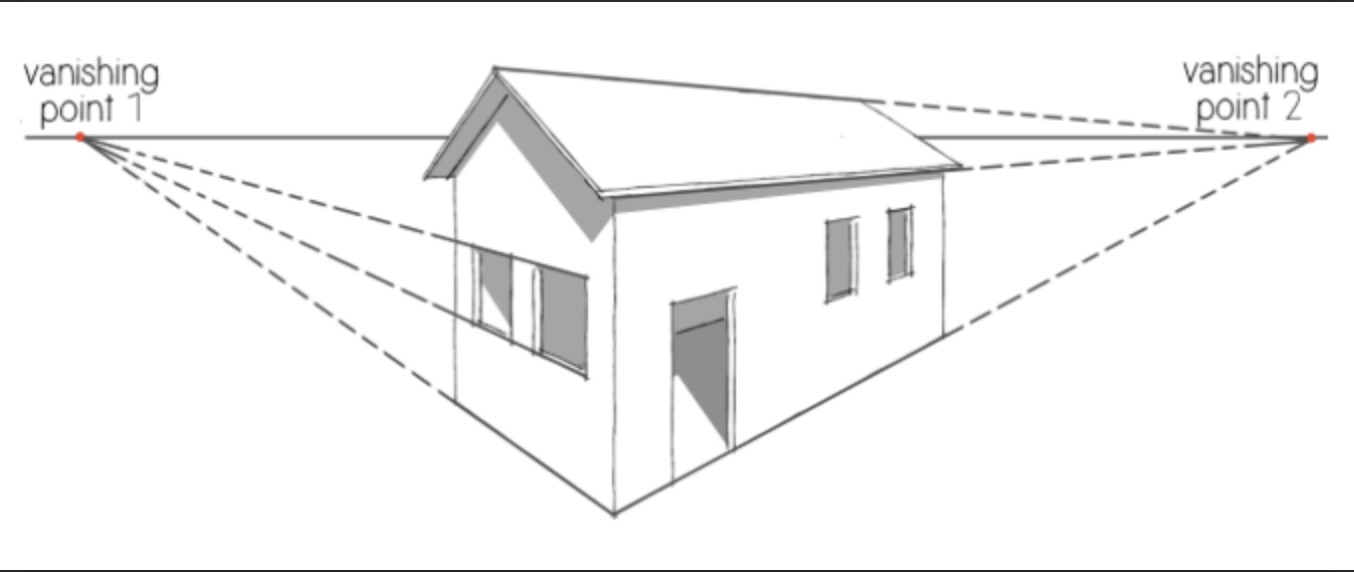
这件事真的很难,大部分人(包括我)一辈子都没学会画透视。虽然拿起笔比一下,我确实看到远的那一边要短一些,可是我的脑子似乎会“自动纠错”,让我认为它们都是一样长的。所以要是光靠眼睛徒手作画,我会把那些边都画成一样长。我似乎永远学不会画画!
你可能没有想到,这个使得我们学画困难的罪魁祸首,其实是人类视觉系统的一项重要功能,它帮助我们理解身边的环境。虽然眼睛看到的物体是近大远小,可是人脑会自动调整它们在你“头脑里的长度”,所以你知道它们是一样长的。
这也许就是为什么人能从近大远小的光学成像还原出正确的 3D 模型。在你头脑中的模型里面,房子的几堵墙是一样高的,就像它们在现实中的情况一样。有了准确的 3D 模型,人就能正确地控制自己在房子周围的运动。
这种导致我们学画困难的“3D 自动纠错”功能,似乎固化到了每个人的视觉系统里。我们并不需要学习就有这种能力,它一直都在起作用。反倒是我们要想“关掉”这个功能的时候,需要付出非常多的努力!
为什么人想要画出透视效果那么困难呢?因为一般人画画,都不是在画他们头上那两只眼睛看到的东西,而是在画他们的“心之眼”(mind’s eye)看到的东西——他们头脑中的那个 3D 模型。这个 3D 模型是跟现实“同构”的,模型里房子的墙壁都是一样高的,他们画出来也是一样高的,所以就画错了。只有经过专业训练的画家,才有能力关闭“心之眼”,直接画出眼睛看到的东西。
我猜想,每一种高等动物的视觉系统都有类似的机制,使得它们从光学成像“重构”出与现实同构的 3D 模型。缺乏 3D 建模能力的机器,是无法准确理解看到的物体的。
现在很多自动驾驶车用激光雷达构造 3D 模型,可是相对于人类视觉形成的模型,真是太粗糙了。我们应该好好思考一下,为什么人仅靠被动接收光线就能构造出如此精密的 3D 模型,而且能如此精确地控制自己的运动。
现在的深度学习模型都是基于像素的,没有抽象能力,不能构造 3D 拓扑模型,甚至连位置关系都分不清楚。缺乏人类视觉系统的这种“结构理解”能力,可能就是为什么深度学习模型需要那么多的数据,那么多的计算,才勉强能得出物体的名字。而小孩子识别物体根本不需要那么多数据和计算,看一两次就知道这东西是什么了。
人脑提取了物体的要素,所以很多信息都可以忽略了,不需要了,所以人需要处理的数据量,可能比深度学习模型小很多很多。深度学习领域盲目地强调提高算力,制造出越来越大规模的计算芯片,GPU,TPU…… 可是大家想过人脑到底有多大计算能力吗?它可能并不需要很多计算。
“神经网络”跟神经元的关系是很肤浅的。“神经网络”应该被叫做“可求导编程”,说白了就是利用微积分,梯度下降法,用大量数据拟合出一个函数,所以它只能做拟合函数能做的那些事情。
用了千万张图片和几个星期的计算,拟合出来的函数也不是那么可靠。人们已经发现用一些办法生成奇怪的图片,能让最先进的深度神经网络输出完全错误的结果。

神经网络为什么会有这种缺陷呢?因为它只是拟合了一个“像素=>名字”的函数。这函数碰巧能区分训练集里的图片,却不能抓住物体的结构和本质。它只是像素级别的拟合,所以这里面有很多空子可以钻。
深度神经网络经常因为一些像素,颜色,纹理匹配了物体的一部分,就认为图片上有这个物体。它无法像人类一样理解物体的结构和拓扑关系,所以才会被像素级别的肤浅假象所欺骗。
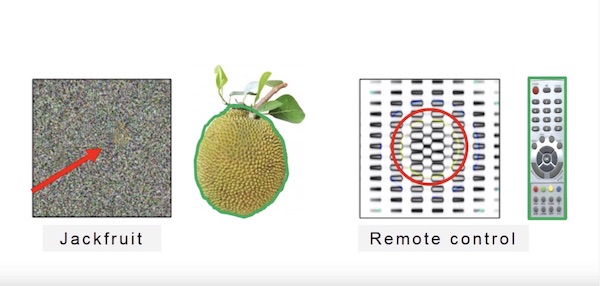
比如下面两个奇怪的图片,被认为是一个菠萝蜜和一个遥控器,仅仅因为它们中间出现了相似的纹理。
另外,神经网络还无法区分位置关系,所以它会把一些位置错乱的图片也识别成某种物体。比如下面这个,被认为是一张人脸,却没发现五官都错位了。
神经网络为什么会犯这种错误呢?因为它的目标只是把训练集里的图片正确分类,提高“识别率”。至于怎么分类,它可以是毫无原则的,它完全不理解物体的结构。它并没有看到“叶子”,“果皮”,“方盒子”,“按钮”,它看到的只是一堆像素纹理。因为训练集里面的图片,出现了类似纹理的都被标记为“菠萝蜜”和“遥控器”,没有出现这纹理的都被标记为其它物品。所以神经网络找到了区分它们的“分界点”,认为看到这样的纹理,就一定是菠萝蜜和遥控器。
我试图从神经网络的本质,从统计学来解释这个问题。神经网络其实是拟合一个函数,试图把标签不同的样本分开。拟合出来的函数试图接近一个“真实分界线”。所谓“真实分界线”,是一个完全不会错的函数,也就是“现实”。
数据量小的时候,函数特别粗糙。数据量大了,就逐渐逼近真实分界线。但不管数据量如何大,它都不大可能得到完全准确的“解析解”,不大可能正好抓住“现实”。
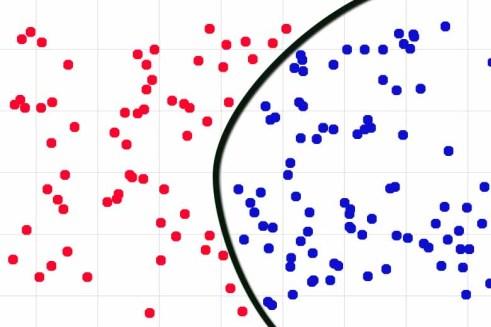
除非现实函数特别简单,运气特别好,否则用数据拟合出来的函数,都会有很多小“缝隙”。以上的像素攻击方法,就是找到真实分界线附近,“缝隙”里面的样本,它们正好让拟合函数出现分类错误。
人的视觉系统是完全不同的,人直接就看到了事物是什么,看到了“解析解”,看到了“现实”,而没有那个用数据逼近的过程,所以除非他累得头脑发麻或者喝了酒,你几乎不可能让他判断错误。
退一步来看,图像识别所谓的“正确分类”都是人定义的。是人给了那些东西名字,是许多人一起标注了训练用的图片。所以这里所谓的“解析解”,“现实”,全都是人定义的。一定是某人看到了某个事物,他理解了它的结构和性质,然后给了它一个名字。所以别的人也可以通过理解同一个事物的结构,来知道它是什么。
神经网络不能看到事物的结构,所以它们也就难以得到精确的分类。
神经网络就像应试教育训练出来的学生,他们的目标函数是“考高分”,为此他们不择手段。等毕业工作遇到现实的问题,他们就傻眼了,发现自己没学会什么东西。因为他们学习的时候只是在训练自己“从 ABCD 里区分出正确答案”。等到现实中没有 ABCD 的时候,他们就不知道怎么办了。
深度学习训练出来的那些“参数”是不可解释的,因为它们存在的目的只是把数据拟合出来,把不同种类的图片分离开,而没有什么意义。AI 人士喜欢给这种“不可解释性”找借口,甚至有人说:“神经网络学到的数据虽然不可解释,但它却出人意料的有效。这些学习得到的模型参数,其实就是知识!”
真的那么有效吗?那为什么能够被如此轻易的欺骗呢?这些“学习”得到的参数根本就不是本质的东西,不是知识,真的就是一堆毫无道理可言的数字,只为了降低“误差”,能够把特征空间的图片区分开来,所以神经网络才能被这样钻空子。
说这些参数是知识,就像在说考试猜答案的技巧是知识一样可笑。“另外几套题的第十题都是 B,所以这套题的第十题也选 B”…… 深度学习拟合函数,就像拿历年高考题和它们的答案来拟合函数一样,想要不上课,不理解科目知识就做出答案来。有些时候它确实可以蒙对答案,但遇到前所未见的题目,或者题目被换了一下顺序,就傻眼了。
人为什么可以不受这种欺骗呢?因为人提取了高级的拓扑结构,不是瞎蒙的,所以人的判断不受像素的影响。因为提取了结构信息,人的观察是具有可解释性的。如果你问一个小孩,为什么你说这是一只猫而不是一只狗呢?她会告诉你:“因为它的耳朵是这样的,它的牙是那样的,它走路的姿势是那样的,它常常磨爪子伸懒腰……”
做个实验好了,你可以问问你家孩子这是猫还是狗。如果是猫,为什么他们认为这是一只猫而不是一只狗?

神经网络看到一堆像素,很多层处理之后也不知道是什么结构,分不清“眼睛”,“耳朵”和“嘴”,更不要说“走路”之类的动态概念了,所以它也就无法告诉你它认为这是猫的原因了。拟合的函数碰巧把这归成了猫,如果你要追究原因,很可能是肤浅的:图片上有一块像素匹配了图片库里某只猫的毛色纹理。
所以人的视觉系统很可能是跟深度神经网络原理完全不同的,或者只有最低级的部分有相似之处。
神经网络看到一堆像素,很多层处理之后也不知道是什么结构,分不清“眼睛”,“耳朵”和“嘴”,更不要说“走路”之类的动态概念了,所以它也就无法告诉你它认为这是猫的原因了。拟合的函数碰巧把这归成了猫,如果你要追究原因,很可能是肤浅的:图片上有一块像素匹配了图片库里某只猫的毛色纹理。
所以人的视觉系统很可能是跟深度神经网络原理完全不同的,或者只有最低级的部分有相似之处。
请不要轻易地以为以上指出的问题有解决方案。我提到上面的问题时,有些人会跟我提 Hinton 的 capsule network。很可惜 capsule network 的训练计算量要求异常的大,无法投入实用。
研究表明,深度神经网络经常因为一些像素,颜色,纹理匹配了物体的一部分,就认为图片上有这个物体,而其实根本就不是那样。神经网络无法像人类一样理解物体的结构和拓扑关系,所以才会被像素级别的肤浅假象所欺骗。
深度学习训练出来的那些“参数”,往往是不可解释的,因为它们存在的目的只是把数据拟合出来,而没有任何意义。AI 人士喜欢给这种“不可解释性”找借口,甚至有人说:“神经网络的数据虽然不可解释,但它却出人意料的有效。那些学习得到的模型参数,其实就是知识!”
真的那么有效吗?那为什么能够被如此轻易的欺骗呢?这些“学习”得到的参数根本就不是本质的东西,不是知识,真的就是一堆毫无道理可言的数字,只为了把像素拟合起来降低误差,所以神经网络才能被这样钻空子。
人为什么可以不受这种欺骗呢?因为人提取了高级的拓扑结构,所以人的判断不受少数像素的影响。人的视觉系统很可能是跟深度神经网络原理完全不同的,或者只有最低级的部分(比如线条检测)有相似之处。
为什么 AI 人士总是认为视觉系统的高级功能都能通过“学习”得到呢?非常可能的事情是,人和动物视觉系统的“结构理解”,“3D建模”功能根本不是学来的,而是早就固化在基因里了。想一想你生下来之后,有任何时候看到世界是平面的,毫无关联的像素吗?
所以我觉得,人和动物生下来就跟现有的机器不一样,结构理解所需的硬件在娘胎里就已经有了,只等发育和激活。人是会学习,可是人的学习是建立在结构理解之上,而不是无结构的像素。
纵使你有再多的数据,再多的计算力,你能超越为期几十亿年的,地球规模的自然进化和选择吗?与其自己去“训练”或者“学习”,不如直接从人身上抄过来!但问题是,我们真的知道人的视觉系统是如何工作的吗?
脑科学研究者很可能并没有完全搞明白神经元是如何工作的,神经元与神经网络的关系是肤浅的。每当你质疑神经网络与神经元的关系,AI 研究者就会抬出 Hubel & Wiesel 在 1959 年拿猫做的那个实验:“有人已经证明了视觉系统就是那样工作的!”
可是你想过没有,为什么到了 2019 年,人们还拿一个 60 年前的实验来说明问题?这 60 年来就没有新的发现了吗?而且从 H&W 的实验你可以看出来,它只说明了猫的视觉神经有什么样的底层功能(能够检测“线条”),却没有证明那就是全部的功能。
H&W 的实验只发现了最底层的“线条检测”功能,却不知道这些底层神经元的信号到了上层是如何组合在一起的。一个能够识别拓扑结构的视觉系统,理所当然应该能做“线条检测”,但它应该不止有这种低级功能。
视觉系统应该还有更高级的结构,H&W 的实验并没有回答这个问题。AI 研究者们却拿着 H&W 的结果大做文章,自信满满的认为那就是视觉系统的一切。现在的深度神经网络基本是瞎蒙出来的。把一堆像素操作叠在一起,然后对大量数据进行“参数学习”,以为这样就能得到所有的视觉功能。
那些说“我们已经完全搞明白了人类视觉是如何工作”的 AI 人士,应该来看看这个分析 Herman grid 幻觉现象的幻灯片。这些研究来自 Schiller Lab,MIT 的脑科学和认知科学实验室。通过一系列对 Herman grid 幻觉图案的改动实验,他们发现长久以来(从 1960 年代开始)对产生这种现象的理解是错误的:那些暗点不是来自视网膜的“边沿强化”功能,而是来自大脑的 V1 视觉皮层。另外一篇 2008 年的 paper 说“这种幻觉跟那些线条是直的有关系”,然后提出了他们自己的,新的“猜想”。
从这种研究的方式我们可以看出,即使是 MIT 这样高级的研究所,对视觉系统的研究还处于“猜”的阶段,把人脑作为黑盒子,拿一些图片来做“行为”级别的实验。他们并没有完全破解视觉系统,看到它的“线路”和“算法”具体如何工作,而是给它一些输入,测试它的输出。这就是“黑盒子”实验法。以至于很多关于人类视觉的理论都不是切实而确定的,很可能是错误的猜想。
脑科学发展到今天也还是如此,AI 领域相对于脑科学的研究方式,又要低一个级别。2019 年了,仍然抬出神经科学家 1959 年的结果来说事。闭门造车,对人家的最新成果一点都不关心。现在的深度神经网络模型基本是瞎蒙出来的。把一堆像素操作叠在一起,然后对大量数据进行“训练”,以为这样就能得到所有的视觉功能。动物视觉系统里面真有“反向传递”(back propagation)这东西吗?H&W 的实验里面并没有发现这个。
所以神经网络的各种做法恐怕没有受到 H&W 实验的多大启发。只是靠这么一个肤浅的相似之处来显得自己接近了“人类神经系统”。现在的神经网络里面唯一起作用的东西其实是微积分,所谓“反向传递”(back propagation)就是微积分的求导操作。神经网络的“训练”,就是反复求导数,用梯度下降方法进行误差最小化,拟合一个函数。这一切都跟神经元的工作原理没什么关系。
虽然 H&W 对生理学做出了杰出的贡献,他们值得拿个诺贝尔奖,然而我们应该明白那只是一个开端,我们仍然处于理解视觉系统原理的初级阶段。拿一个初步的实验结果作为“终极答案”,号称“超越人类”,还想拿来做“自动驾驶车”,这不是 H&W 的错,只能怪后人断章取义,过度自信了。
设计神经网络的“算法工程师”,“数据科学家”,工作性质很像“炼丹术士”(alchemist),拿个模型这改改那改改,拿海量的图片来训练,消耗大量的计算力,电能和时间,“准确率”提高了,就发 paper。至于为什么效果会好一些,其中揭示了什么原理,模型里的操作是用来达到什么效果的,不知道。
我很怀疑这样的研究方式能够带来什么质的突破,这不是科学的方法。如果你跟我一样,把神经网络看成是用“可求导编程语言”写出来的代码,那么现在这种设计模型的方法就很像“一百万只猴子敲键盘”,总有一只能敲出“Hello World!”
神经网络的所谓“准确率”,也不是通过大量的实际未知数据统计出来的,而是早就存在那里的测试数据,反反复复都是那些,所以实际的准确率和识别效果值得怀疑。
不但测试数据的“普遍性”值得怀疑,AI 领域拿神经网络跟人比的时候,总喜欢用所谓“top-5 准确率”,也就是说给机器和人各自 5 次机会来给图片分类,看谁的准确率高。

具体一点,“top-5”是什么意思呢?也就是说对于一张图片,我可以给出 5 个可能的分类,只要其中一个对了就算我分类正确。比如图片上本来是汽车,我看到图片,说:
- “那是苹果?”
- “哦不对,是杯子?”
- “还是不对,那是马吧?”
- “还是不对,所以是手机?”
- “居然还是不对,那我最后猜它是汽车!”
五次机会,我说对了,所以算我分类正确。我很聪明吧?这样继续,给你几百张图片分类,然后统计你的“正确率”。
显然这种比较方法对人是不公平的,因为人要是见过那个物体,几乎总是一次就能做对,根本不需要 5 次机会。使用“top-5 准确率”,就像考试的时候给差等生和优等生各自 5 次机会来做对题目。当然,这样你就分不清谁是差等生,谁是优等生了。
AI 业界所谓“超人类的识别率”,“90+% 的准确率”,都是用“top-5 准确率”为标准的。等你用“top-1 准确率”来衡量它们的时候,就会发现机器的准确率远远不如人类。
你可以给自动驾驶车 5 次机会来判断前面出现的是什么物体吗?你有几条命可以给它试验呢?Tesla 的 Autopilot 系统可能 top-2 正确率很高吧:“那是个白板…… 哦不对,那是辆卡车, “那是块面包…… 哦不对,那是路边的护栏!”
另外,神经网络的训练数据图片里有很多普通人从来没见过的物品。我自己看了 ImageNet 里面的那些图片,好多东西我根本就没见过,或者不知道是什么。世界上有那么多种类的花,那么多种类的树,那么多种动物,各种奇怪的海底生物,那么多的明星演员,那么多的人造日用品,各种各样的飞机船只,那么多的古董文物,非洲的图腾,太平洋小岛上出产的水果…… 我干吗得知道它们叫什么名字呢?根本无所谓的。
所以这种对比只是在测试死记硬背的能力。物品多了人当然记不过来了,也不感兴趣。知道那么多东西的名字有什么用呢?跟背字典一样无聊。如果用一般人都见过的日常物品来对比,机器肯定输的非常惨,因为它其实根本不知道那些东西是什么,它没有视觉理解能力。
如果没有视觉理解,依赖于图像识别技术的“自动驾驶车”,是不可能在复杂的情况下做出正确操作,保障人们安全的。机器人等一系列技术,也只能停留在固定场景,精确定位的“工业机器人”阶段,而不能在复杂的自然环境中行动。
我认识一些工业机器人的研究者。他们告诉我,深度神经网络那些识别算法太不精确了,根本没法用于准确性要求很高的应用。工业机器人控制不精确是完全不可接受的,所以他们都不用深度神经网络来控制机器人。
要实现真正的语言理解和视觉理解是非常困难的,可以说是毫无头绪。真正的 AI 其实没有起步,AI 专家们忙着忽悠和布道,根本没人关心其中的本质,又何谈实现呢?我不是给大家泼凉水,初级的识别技术还是有用的,而且蛮有趣。但除非真正有人关心到问题所在,去研究本质的问题,否则实现 AI 就只是空中楼阁。我只是提醒大家不要盲目乐观,不要被忽悠了。