diff --git a/_freeze/index/execute-results/html.json b/_freeze/index/execute-results/html.json
index a979264..f7efe8f 100644
--- a/_freeze/index/execute-results/html.json
+++ b/_freeze/index/execute-results/html.json
@@ -1,8 +1,8 @@
{
- "hash": "df18430d8318760cdd87283cb70793ab",
+ "hash": "32106c2c57e86b13b1c069edd85ff48e",
"result": {
"engine": "knitr",
- "markdown": "---\ntitle: \"Optimización del Rendimiento en Shiny\"\nsubtitle: \"Técnicas y Mejores Prácticas\"\nauthor: \"Samuel Calderon\"\nformat: \n revealjs:\n theme: default\n transition: slide\n slide-number: true\n logo: img/Appsilon_logo.svg\n footer: \"LatinR: 2024-11-18\"\nmermaid: \n theme: default\nexecute: \n eval: false\n echo: true\n---\n\n\n\n## Estructura del Taller (3 horas)\n\n- Introducción \n- Ciclo de optimización: Ejercicio 1 - Benchmarking\n- Profiling: Ejercicio 2\n- Optimización - Data: Ejercicio 3\n- Optimización - Shiny: Ejercicio 4\n- Optimización - Async: Ejercicio 5\n- Temas avanzados\n- Preguntas\n\n# Introducción\n\n## Appsilon\n\n\n\n\n\n## We are hiring!\n\n- [R shiny developer](https://jobs.lever.co/appsilon/6e6cea0f-4ec3-439a-8456-d5e31e51c05b?lever-origin=ap%5B%E2%80%A6%5Dloper)\n- [R developer with life science](https://jobs.lever.co/appsilon/d5c698a5-9f93-4fb4-a22b-b4abaf77de5d?lever-origin=applied&lever-source%5B%5D=CAREERS)\n- [Project Manager (US time zone)](https://jobs.lever.co/appsilon/e8594bfe-2c9a-4504-b978-ff3242bc9c73?lever-origin=applied&lever-source%5B%5D=careers%20page?utm_medium%3Djob-boards)\n\nPara ver más posiciones: \n\n## Quién soy\n\n- Politólogo y ahora R shiny developer\n- De Lima, Perú\n- Contacto:\n - Web: \n - Github: \n - Linkedin: \n \n## ¿Quiénes son ustedes?\n\n- Compartir en el chat:\n - Nombre\n - De dónde son y qué hora es en su ciudad\n - Background profesional (brevísimo)\n - 3 paquetes de R favoritos (si son de nicho, mejor)\n\n\n# Ciclo de Optimización\n\n## Primero lo primero\n\n¿Qué es una computadora? La interacción de 3 componentes principales\n\n\n\n## ¿Qué es optimizar?\n\n\n\n¡Depende de la necesidad! \n\nEn general, pensemos en tiempo (CPU) o espacio (memory/storage). El dinero es un eje secreto.\n\n## El ciclo graficado\n\n\n\n\n\n## A saber en cada etapa\n\n- Benchmarking: ¿Performa como esperamos?\n- Profilling: ¿Dónde están los cuellos de botella?\n- Estimación/Recomendación: ¿Qué puedo hacer?\n- Optimización: Tomar decisión e implementar\n\n## Tipos de benchmarking \n\n- Manual\n- Avanzado ([shinyloadtest](https://rstudio.github.io/shinyloadtest/index.html)):\n\n## Ejercicio 1 - Benchmarking\n\n\n\n---\n\n- Prueba la app y anota cuánto tiempo te toma ver la información para:\n\n- 3 ciudades diferentes\n- 3 edades máximas diferentes\n\nEnlace: \n\n# Profiling\n\n## Profiling - Herramientas en R\n\nEl profiling es una técnica utilizada para identificar cuellos de botella en el rendimiento de tu código:\n\n## `{profvis}`\n\nEs una herramienta interactiva que proporciona una visualización detallada del tiempo de ejecución de tu código.\n\n- Instalación:\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\ninstall.packages(\"profvis\")\n```\n:::\n\n\n\n- Uso básico:\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nlibrary(profvis)\nprofvis({\n# Código a perfilar\n})\n```\n:::\n\n\n\n## shiny.tictoc\n\nUna herramienta que usa Javascript para calcular el tiempo que toman las acciones en la app, desde el punto de vista del navegador.\n\nEs super fácil de añadir a una app.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\ntags$script(\n src = \"https://cdn.jsdelivr.net/gh/Appsilon/shiny.tictoc@v0.2.0/shiny-tic-toc.min.js\"\n)\n```\n:::\n\n\n\n- Si no saben añadir JS: [Packaging Javscript code for Shiny](https://shiny.posit.co/r/articles/build/packaging-javascript/)\n\n---\n\nEjecutar cualquiera de estas operaciones en la consola de Javascript. \n\n```js\n// Print out all measurements\nshowAllMeasurements()\n\n// To download all measurements as a CSV file\nexportMeasurements()\n\n// To print out summarised measurements (slowest rendering output, slowest server computation)\nshowSummarisedMeasurements()\n\n// To export an html file that visualizes measurements on a timeline\nawait exportHtmlReport()\n```\n\nMuchos navegadores cuentan con herramientas de desarrollador donde puedes encontrar una mientras tu app está corriendo.\n\n## Usando profvis\n\nUbicar la herramienta en Rstudio\n\n\n\n---\n\n\nLa consola de R mostrará el botón \"Stop profiling\". Esto significa que el profiler está activado.\n\n\n\nCorre tu shiny app e interactúa con ella. Luego, puedes detener la app y el profiler.\n\n---\n\nEl panel de edición de Rstudio te mostrará una nueva vista. \n\n\n\nLa parte superior hace profiling de cada línea de código, la parte inferior muestra un *FlameGraph*, que indica el tiempo requerido por cada operación.\n\n---\n\nTambién puede accederse a la pestaña \"Data\".\n\n\n\nEsta indica cuánto tiempo y memoria se ha requerido por cada operación. Nos da un resumen de la medición.\n\n---\n\nPara una revisión más exhaustiva del uso de `{profvis}`, puedes consultar la documentación oficial:\n\n- Ejemplos: \n- Integración con RStudio: \n\n## Ejercicio 2 - Profiling\n\nRealiza el profiling del archivo \"app.R\".\n\n- Interpreta los resultados\n - ¿Cuáles son los puntos más críticos?\n \nToma en cuenta que estás probando esto para un solo usuario.\n\n## Optimización - Data\n\n1. Usar opciones más rápidas para cargar datos\n2. Usar formatos de archivo más eficientes\n3. Pre-procesar los cálculos\n4. Usar bases de datos. Puede requerir aprender SQL.\n\n¡Puedes combinar todo!\n\n## Cargar datos más rápido\n\n- data.table::fread()\n- vroom::vroom()\n- readr::read_csv()\n\n## Ejemplo\n\nNO ejecutar durante el workshop porque toma tiempo en correr\n\n```r\nsuppressMessages(\n microbenchmark::microbenchmark(\n read.csv = read.csv(\"data/personal.csv\"),\n read_csv = readr::read_csv(\"data/personal.csv\"),\n vroom = vroom::vroom(\"data/personal.csv\"),\n fread = data.table::fread(\"data/personal.csv\")\n )\n)\n#> Unit: milliseconds\n#> expr min lq mean median uq max neval\n#> read.csv 1891.3824 2007.2517 2113.5217 2082.6016 2232.7825 2442.6901 100\n#> read_csv 721.9287 820.4181 873.4603 866.7321 897.3488 1165.5929 100\n#> vroom 176.7522 189.8111 205.2099 197.9027 206.2619 495.2784 100\n#> fread 291.9581 370.8261 410.3995 398.9489 439.7827 638.0363 100\n```\n\n\n## Formatos de datos eficientes:\n\n- Parquet (via {arrow})\n- Feather (compatibilidad con Python)\n- fst\n- RDS (nativo de R)\n\n## Ejemplo\n\nNO ejecutar durante el workshop porque toma tiempo en correr\n\n```r\nsuppressMessages(\n microbenchmark::microbenchmark(\n read.csv = read.csv(\"data/personal.csv\"),\n fst = fst::read_fst(\"data/personal.fst\"),\n parquet = arrow::read_parquet(\"data/personal.parquet\"),\n rds = readRDS(\"data/personal.rds\")\n )\n)\n#> Unit: milliseconds\n#> expr min lq mean median uq max neval\n#> read.csv 1911.2919 2075.26525 2514.29114 2308.57325 2658.03690 4130.748 100\n#> fst 201.1500 267.85160 339.73881 308.24680 357.19565 834.646 100\n#> parquet 64.5013 67.29655 84.48485 70.70505 87.81995 405.147 100\n#> rds 558.5518 644.32460 782.37898 695.07300 860.85075 1379.519 100\n```\n\n## Pre-procesar cálculos\n\n- Filtrado previo: Menos tamaño\n- Transformación o agregación previa: Menos tiempo\n- Uso de índices: Búsqueda rápida\n\nEs, en esencia, *caching*. Personalmente, mi estrategia favorita. \n\nDifícil de usar si se requiere calcular en vivo, real-time (stock exchange, streaming data), o la data no puede ser guardada en cualquier lugar (seguridad, privacidad). \n\n\n## Sin pre-procesamiento\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\n# app.R\nsurvey <- read.csv(\"data/survey.csv\")\n\nserver <- function(input, output) {\n output$table <- renderTable({\n survey |> \n filter(region == input$region) |> \n summarise(avg_time = mean(temps_trajet_en_heures))\n })\n}\n```\n:::\n\n\n\n## Con pre-procesamiento\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\n# script.R\nsurvey <- read.csv(\"data/survey.csv\")\nregions <- unique(survey$region)\n\nvalues <- regions |> \n lapply(function(x) {\n survey |> \n dplyr::filter(region == x) |> \n dplyr::summarise(avg_time = mean(temps_trajet_en_heures))\n }) |> \n setNames(regions)\n\nsaveRDS(values, \"data/values.rds\")\n```\n:::\n\n::: {.cell}\n\n```{.r .cell-code}\n# app.R\nvalues <- readRDS(\"data/values.rds\")\n\nserver <- function(input, output) {\n output$table <- renderTable(values[[input$region]])\n}\n```\n:::\n\n\n\n\n\n## Bases de Datos relacionales\n\n- **Escalabilidad**: Las bases de datos pueden manejar grandes volúmenes de datos de manera eficiente.\n- **Consultas Rápidas**: Permiten realizar consultas complejas de manera rápida.\n- **Persistencia**: Los datos se almacenan de manera persistente, lo que permite su recuperación en cualquier momento.\n\n---\n\nAlgunos ejemplos notables son SQLite, MySQL, PostgreSQL, DuckDB.\n\n[freeCodeCamp](https://www.freecodecamp.org/learn/relational-database/) tiene un buen curso para principiantes.\n \n\n## Ejercicio 3 - Data\n\nImplementa una estrategia de optimización\n\n# Optimización - Shiny\n\n## Cuando una app arranca\n\n\n\n---\n\nDel lado de shiny, optimizar consiste básicamente en hacer que la app (en realidad, el procesador) haga el menor trabajo posible.\n\n## Reducir reactividad\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|3,4,5,9,10,11\"}\nserver <- function(input, output, session) {\n output$table <- renderTable({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n })\n \n output$histogram <- renderPlot({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age) |> \n ggplot(aes(temps_trajet_en_heures)) +\n geom_histogram(bins = 20) +\n theme_light()\n })\n}\n```\n:::\n\n\n\n---\n\n`reactive()` al rescate\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|2-6|9,13\"}\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n })\n \n output$table <- renderTable({\n filtered()\n })\n \n output$histogram <- renderPlot({\n filtered() |> \n ggplot(aes(temps_trajet_en_heures)) +\n geom_histogram(bins = 20) +\n theme_light()\n })\n}\n```\n:::\n\n\n\n::: aside\nUsamos más de espacio (memoria) para reducir tiempo (CPU)\n:::\n\n## Controlar reactividad\n\nPuedes encadenar `bindEvent()` a un `reactive()` u `observe()`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nmy_reactive <- reactive({\n # slow reactive computation\n}) |> \n bindEvent(input$trigger)\n\nobserve({\n # slow reactive side effect\n}) |> \n bindEvent(input$trigger)\n```\n:::\n\n\n\n::: aside\nEn versiones pasadas, esto se hacía con `observeEvent()` o `eventReactive()`.\n:::\n\n---\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|5|16\"}\nui <- page_sidebar(\n sidebar = sidebar(\n selectInput(inputId = \"region\", ...),\n sliderInput(inputId = \"age\", ...),\n actionButton(inputId = \"compute\", label = \"Calcular\")\n ),\n ...\n)\n\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n }) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n}\n```\n:::\n\n\n\nAhora `filtered()` solo se actualizará cuando haya interacción con `input$compute`. \n\n::: aside\n`ignoreNULL = FALSE` permite ejecutar el `reactive()` al iniciar la app.\n:::\n\n## Estrategias de Caché\n\n`bindCache()` nos permite guardar cómputos al vuelo en base a ciertas *keys*.\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|7\"}\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n }) |> \n bindCache(input$region, input$age) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n}\n```\n:::\n\n\n\nCuando una combinación vuelva a aparecer, se leerá el valor en lugar de recalcularlo. \n\n::: aside\n`bindEvent()` no es obligatorio para usar `bindCache()`.\n:::\n\n---\n\n2. Niveles de caché:\n - Nivel aplicación: `cache = \"app\"` (default)\n - Nivel sesión: `cache = \"session\"`\n - Personalizado: `cache object + opciones`\n \n\n\n::: {.cell}\n\n```{.r .cell-code}\nbindCache(..., cache = \"app\")\n```\n:::\n\n\n\nPor defecto, se usará un máximo de 200 Mb de caché.\n \n::: aside\nPotencialmente mucho uso de memoria/storage, para reducir tiempo de procesamiento.\n:::\n\n## Comunicación servidor - navegador\n\n- Enviar datos desde el servidor hacia el navegador toma tiempo. \n - Datos grandes -> mayor tiempo de envío.\n - Conexión lenta -> mayor tiempo de envío\n- Igualmente, si los datos son grandes, al navegador le cuesta más leerlos y mostrarlos al usuario. \nPuede que la PC del usuario sea una tostadora!\n\n---\n\n- ¿Qué hacer?\n - Reducir frecuencia de envíos (`bindEvent()`)\n - Reducir tamaño de envíos\n - Mandar lo mismo pero en partes más pequeñas (server-side processing o streaming)\n \n## Reducir tamaño de envíos\n\nEs posible delegar ciertos cálculos al navegador. Por ejemplo, renderizar un gráfico con [`{plotly}`](https://plotly.com/ggplot2/) en lugar de `{ggplot2}`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nplotly::plotlyOutput() # en lugar de plotOutput\nplotly::renderPlotly() # en lugar de renderPlot\n```\n:::\n\n\n\nCon ello, se manda la \"receta\" del gráfico en lugar del gráfico mismo. Al recibir la receta, el navegador se encarga de renderizarla.\n\n---\n\nEstas funciones traducen sintaxis de `ggplot2` a sintaxis de `plotly.js` de manera bastante eficiente. Tiene soporte para muchos tipos de gráficos.\n\n\n\nPero no te confíes, en muchos casos, el código va a necesitar retoques. Especialmente al usar extensiones de `ggplot2`.\n\n---\n\nOtros paquetes similares:\n\n- [ggiraph](https://davidgohel.github.io/ggiraph/)\n- [echarts4r](https://echarts4r.john-coene.com/)\n- [highcharter](https://jkunst.com/highcharter/)\n- [r2d3](https://rstudio.github.io/r2d3/)\n- [shiny.gosling](https://appsilon.github.io/shiny.gosling/index.html) (genomics, by Appsilon)\n\n## Server-side processing\n\nEn el caso de las tablas, el server-side processing permite paginar el resultado y enviar al navegador solo la página que está siendo mostrada en el momento.\n\nEl paquete `{DT}` es una opción solida.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nDT::DTOutput() # en lugar de tableOutput()\nDT::renderDT() # en lugar de renderTable()\n```\n:::\n\n\n\n::: aside\nSi ya usabas `{DT}`, ¿sabías que hacía esto por defecto?\n:::\n\n---\n\nOtra opcion:\n\n- `{reactable}` en conjunto con `{reactable.extras}` (by Appsilon).\n\n## Ejercicio 4 - Shiny\n\nImplementa alguna de las optimizaciones mencionadas.\n\n# Optimización - Async\n\n## Programación síncrona\n\n::: {.columns}\n\n::: {.column}\n\n- Las tareas se ejecutan secuencialmente\n- Es fácil de entender e implementa\n\n:::\n\n::: {.column}\n\n\n\n:::\n\n:::\n\nEjemplo: Una cocina con una hornilla. Si empecé a freir pollo, no puedo freir nada hasta terminar de freir el pollo.\n\n\n## Proramación asíncrona\n\n::: {.columns}\n::: {.column}\n\n- Las tareas pueden iniciar y ejecutarse independientemente\n- Mientras se procesa una tarea, otras pueden ser iniciadas o completadas.\n\n:::\n\n::: {.column}\n\n\n:::\n\n:::\n\nEjemplo: Una cocina con múltiples hornillas. Si empecé a freir pollo en una hornilla, puedo freir otra cosa en una hornilla diferente.\n\n---\n\nHornilla == Proceso en la PC\n\n::: {.callout-warning title=\"Cuidado\"}\nA más hornillas, también es más fácil quemar la comida!\n:::\n\n\n## Posibles complicaciones\n\n- El código se hace más dificil de entender\n- Sin adecuado control, pueden sobreescribir sus resultados\n- Lógica circular. Proceso A espera a Proceso B, quien espera a Proceso A\n- Incrementa la dificultad para hacer debugging porque los errores ocurren en otro lado\n- Mayor consumo de energía\n\n## Beneficios\n\n- Operaciones largas no bloquean a otras operaciones\n- Flexibilidad: mi sistema se adapta a retrasos inesperados\n- La aplicación se mantiene responsiva, no se \"cuelga\"\n- Uso eficiente de recursos. \"Pagué por 8 procesadores y voy a usar 8 procesadores\".\n- Escalabilidad a otro nivel\n\n## Casos de uso\n\n- Operaciones I/O:\n - Query a bases de datos\n - Solicitudes a APIs\n- Cálculos intensivos\n\n## ¿Qué necesito?\n\n- CPU con varios núcleos/hilos.\n- Paquetes:\n - {promises}\n - {future}\n - ExtendedTask (Shiny 1.8.1+)\n \n::: {.callout-note title=\"Nota\"}\nExtendedTask es un recurso bastante nuevo. También es posible usar solo `future()` o `future_promise()` dentro de un reactive para lograr un efecto similar, aunque con menos ventajas.\n:::\n\n## Setup inicial\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|4-7\"}\nlibrary(shiny)\nlibrary(bslib)\nlibrary(tidyverse)\nlibrary(future)\nlibrary(promises)\n\nplan(multisession)\n\nsurvey <- arrow::read_parquet(\"data/survey.parquet\")\n```\n:::\n\n\n\nEsto le dice al proceso que corre la app que los *futures* creados se resuelvan en sesiones paralelas.\n\n## Procedimiento\n\n1. Crear un objeto `ExtendedTask`.\n2. Hacer bind a un task button\n3. Invocar la tarea\n4. Recuperar los resultados\n\n\n \n## Punto de partida - UI\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|5\"}\nui <- page_sidebar(\n sidebar = sidebar(\n selectInput(inputId = \"region\", ...),\n sliderInput(inputId = \"age\", ...),\n actionButton(inputId = \"compute\", label = \"Calcular\")\n ),\n ...\n)\n```\n:::\n\n\n\n## Modificaciones - UI\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"5\"}\nui <- page_sidebar(\n sidebar = sidebar(\n selectInput(inputId = \"region\", ...),\n sliderInput(inputId = \"age\", ...),\n input_task_button(id = \"compute\", label = \"Calcular\")\n ),\n ...\n)\n```\n:::\n\n\n\nCambiamos el `actionButton()` por `bslib::input_task_button()`. Este botón tendrá un comportamiento especial.\n\n## Punto de partida - Server\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|3-5|8|7\"}\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n }) |> \n bindCache(input$region, input$age) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n## Modificaciones - Server\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n future_promise({\n p_survey |> \n dplyr::filter(region == p_region) |> \n dplyr::filter(age <= p_age)\n })\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(survey, input$region, input$age)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n## Modificaciones - Server\n\nPaso 1: Se creó un `ExtendedTask` que envuelve a una función. \n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|2|4-6|3,7\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n future_promise({\n p_survey |> \n dplyr::filter(region == p_region) |> \n dplyr::filter(age <= p_age)\n })\n }) |> \n bind_task_button(\"compute\")\n \n ...\n}\n```\n:::\n\n\n\n\nDentro de la función, tenemos la lógica de nuestro cálculo envuelta en un `future_promise()`. La función asume una sesión en blanco.\n\n## Modificaciones - Server\n\nPaso 2: Se hizo bind a un task button\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|5,8\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(...) {\n ...\n }) |> \n bind_task_button(\"compute\")\n \n observe(...) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n\n ...\n}\n```\n:::\n\n\n\n\n::: {.callout-note title=\"Nota\"}\n`bind_task_button()` requiere el mismo id que `input_task_button()`. `bindEvent()` acepta cualquier reactive.\n:::\n\n## Modificaciones - Server\n\nPaso 3: Invocar la tarea con `ExtendedTask$invoke()`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|2,7\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n ...\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(survey, input$region, input$age)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\nSe le provee la data necesaria para trabajar. Tomar en cuenta que `invoke()` no tiene valor de retorno (es un side-effect).\n\n## Modificaciones - Server\n\nPaso 4: Recuperar los resultados con `ExtendedTask$result()`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|10|12\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(...) {\n ...\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(...)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n`result()` se comporta como cualquier reactive. \n\n## Modificaciones - Server\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n future_promise({\n p_survey |> \n dplyr::filter(region == p_region) |> \n dplyr::filter(age <= p_age)\n })\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(survey, input$region, input$age)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n¡Perdimos el cache! `ExtendedTask()` no es 100% compatible con las estrategias de caching vistas.\n\n## Ejercicio 5 - Async\n\n- Implementa async para uno de los gráficos\n- Discusión: ¿vale la pena?\n\n## Todo junto\n\nAcá se desplegó la app con todas las mejoras vistas en los ejercicios. Además, `survey` utiliza la data completa, en lugar de una muestra por región.\n\nEnlace: \n\n::: aside\nLa plataforma permitió 8 GB de RAM y 2 núcleos de CPU.\n:::\n\n# Temas avanzados\n\n## Representando la complejidad\n\n[Big O notation](https://www.freecodecamp.org/news/big-o-notation-why-it-matters-and-why-it-doesnt-1674cfa8a23c/)\n\n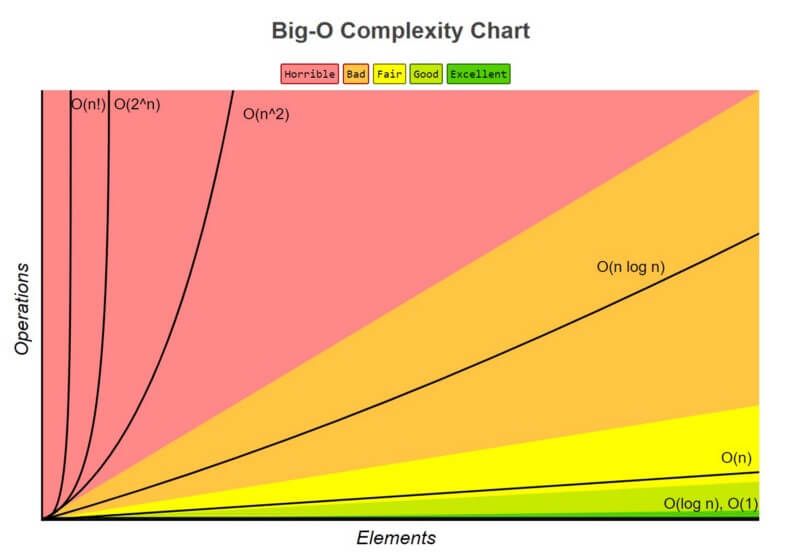\n\n\n## Entendiendo la complejidad\n\n[Algoritmos y estructuras de datos](https://blog.algomaster.io/p/how-i-mastered-data-structures-and-algorithms)\n\n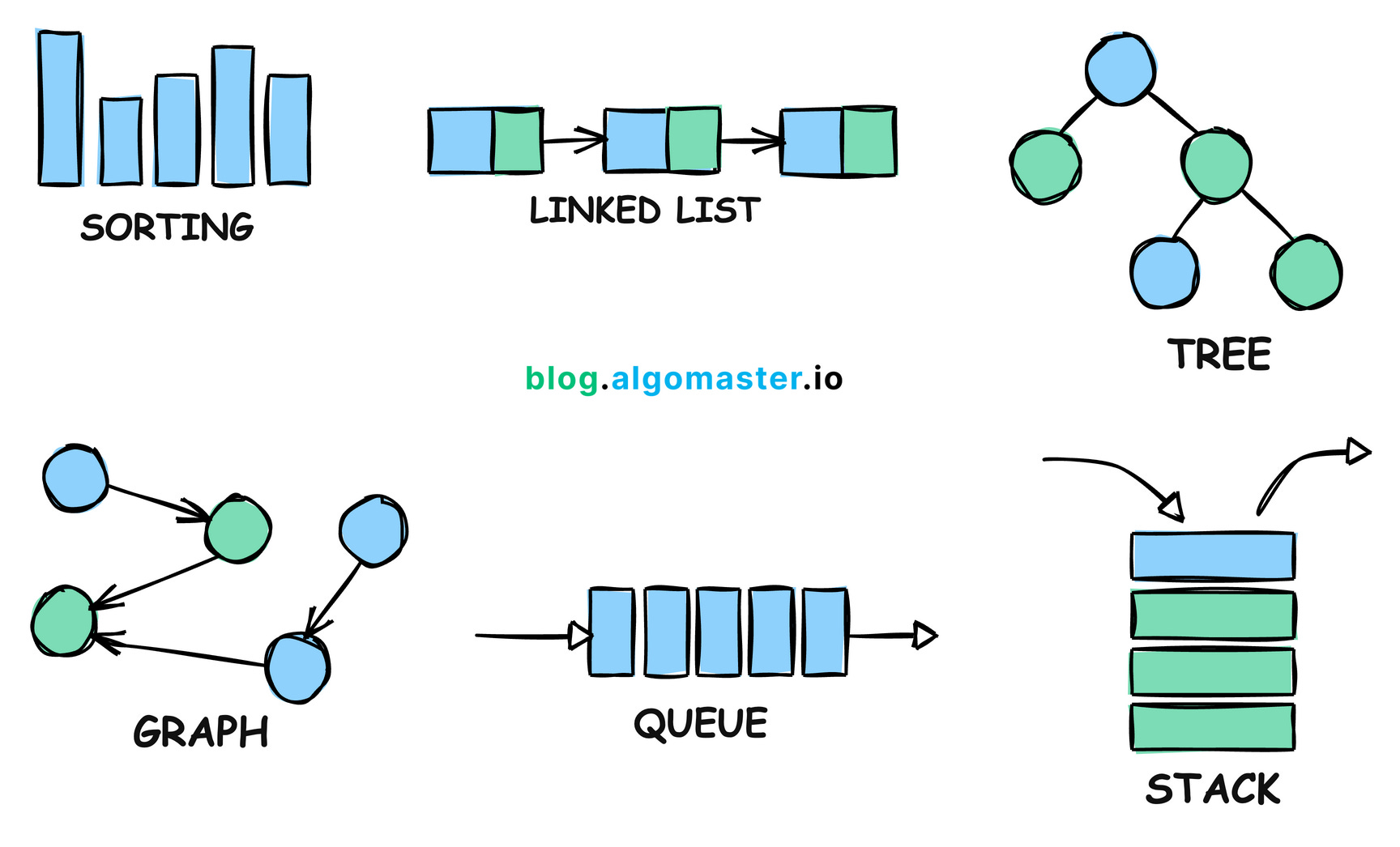\n\n## Enfrentando la complejidad\n\n- Modularización\n - [shiny](https://mastering-shiny.org/scaling-modules.html)\n - [box](https://github.com/klmr/box)\n- [Testing](https://mastering-shiny.org/scaling-testing.html)\n- File structure\n\n¡[`{rhino}`](https://appsilon.github.io/rhino/) tiene todo esto!\n\n\n# Preguntas\n\n# ¡Gracias!\n\n- Web: \n- Github: \n- Linkedin: \n",
+ "markdown": "---\ntitle: \"Optimización del Rendimiento en Shiny\"\nsubtitle: \"Técnicas y Mejores Prácticas\"\nauthor: \"Samuel Calderon\"\nformat: \n revealjs:\n theme: default\n transition: slide\n slide-number: true\n logo: img/Appsilon_logo.svg\n footer: \"LatinR: 2024-11-18\"\nmermaid: \n theme: default\nexecute: \n eval: false\n echo: true\n---\n\n\n\n## Material\n\n\n\n## Estructura del Taller (3 horas)\n\n- Introducción \n- Ciclo de optimización: Ejercicio 1 - Benchmarking\n- Profiling: Ejercicio 2\n- Optimización - Data: Ejercicio 3\n- Optimización - Shiny: Ejercicio 4\n- Optimización - Async: Ejercicio 5\n- Temas avanzados\n- Preguntas\n\n# Introducción\n\n## Appsilon\n\n\n\n\n\n## We are hiring!\n\n- [R shiny developer](https://jobs.lever.co/appsilon/6e6cea0f-4ec3-439a-8456-d5e31e51c05b?lever-origin=ap%5B%E2%80%A6%5Dloper)\n- [R developer with life science](https://jobs.lever.co/appsilon/d5c698a5-9f93-4fb4-a22b-b4abaf77de5d?lever-origin=applied&lever-source%5B%5D=CAREERS)\n- [Project Manager (US time zone)](https://jobs.lever.co/appsilon/e8594bfe-2c9a-4504-b978-ff3242bc9c73?lever-origin=applied&lever-source%5B%5D=careers%20page?utm_medium%3Djob-boards)\n\nPara ver más posiciones: \n\n## Quién soy\n\n- Politólogo y ahora R shiny developer\n- De Lima, Perú\n- Contacto:\n - Web: \n - Github: \n - Linkedin: \n \n## ¿Quiénes son ustedes?\n\n- Compartir en el chat:\n - Nombre\n - De dónde son y qué hora es en su ciudad\n - Background profesional (brevísimo)\n - 3 paquetes de R favoritos (si son de nicho, mejor)\n\n\n# Ciclo de Optimización\n\n## Primero lo primero\n\n¿Qué es una computadora? La interacción de 3 componentes principales\n\n\n\n## ¿Qué es optimizar?\n\n\n\n¡Depende de la necesidad! \n\nEn general, pensemos en tiempo (CPU) o espacio (memory/storage). El dinero es un eje secreto.\n\n## El ciclo graficado\n\n\n\n\n\n## A saber en cada etapa\n\n- Benchmarking: ¿Performa como esperamos?\n- Profilling: ¿Dónde están los cuellos de botella?\n- Estimación/Recomendación: ¿Qué puedo hacer?\n- Optimización: Tomar decisión e implementar\n\n## Tipos de benchmarking \n\n- Manual\n- Avanzado ([shinyloadtest](https://rstudio.github.io/shinyloadtest/index.html)):\n\n## Ejercicio 1 - Benchmarking\n\n\n\n---\n\n- Prueba la app y anota cuánto tiempo te toma ver la información para:\n\n- 3 ciudades diferentes\n- 3 edades máximas diferentes\n\nEnlace: \n\n# Profiling\n\n## Profiling - Herramientas en R\n\nEl profiling es una técnica utilizada para identificar cuellos de botella en el rendimiento de tu código:\n\n## `{profvis}`\n\nEs una herramienta interactiva que proporciona una visualización detallada del tiempo de ejecución de tu código.\n\n- Instalación:\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\ninstall.packages(\"profvis\")\n```\n:::\n\n\n\n- Uso básico:\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nlibrary(profvis)\nprofvis({\n# Código a perfilar\n})\n```\n:::\n\n\n\n## shiny.tictoc\n\nUna herramienta que usa Javascript para calcular el tiempo que toman las acciones en la app, desde el punto de vista del navegador.\n\nEs super fácil de añadir a una app.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\ntags$script(\n src = \"https://cdn.jsdelivr.net/gh/Appsilon/shiny.tictoc@v0.2.0/shiny-tic-toc.min.js\"\n)\n```\n:::\n\n\n\n- Si no saben añadir JS: [Packaging Javscript code for Shiny](https://shiny.posit.co/r/articles/build/packaging-javascript/)\n\n---\n\nEjecutar cualquiera de estas operaciones en la consola de Javascript. \n\n```js\n// Print out all measurements\nshowAllMeasurements()\n\n// To download all measurements as a CSV file\nexportMeasurements()\n\n// To print out summarised measurements (slowest rendering output, slowest server computation)\nshowSummarisedMeasurements()\n\n// To export an html file that visualizes measurements on a timeline\nawait exportHtmlReport()\n```\n\nMuchos navegadores cuentan con herramientas de desarrollador donde puedes encontrar una mientras tu app está corriendo.\n\n## Usando profvis\n\nUbicar la herramienta en Rstudio\n\n\n\n---\n\n\nLa consola de R mostrará el botón \"Stop profiling\". Esto significa que el profiler está activado.\n\n\n\nCorre tu shiny app e interactúa con ella. Luego, puedes detener la app y el profiler.\n\n---\n\nEl panel de edición de Rstudio te mostrará una nueva vista. \n\n\n\nLa parte superior hace profiling de cada línea de código, la parte inferior muestra un *FlameGraph*, que indica el tiempo requerido por cada operación.\n\n---\n\nTambién puede accederse a la pestaña \"Data\".\n\n\n\nEsta indica cuánto tiempo y memoria se ha requerido por cada operación. Nos da un resumen de la medición.\n\n---\n\nPara una revisión más exhaustiva del uso de `{profvis}`, puedes consultar la documentación oficial:\n\n- Ejemplos: \n- Integración con RStudio: \n\n## Ejercicio 2 - Profiling\n\nRealiza el profiling del archivo \"app.R\".\n\n- Interpreta los resultados\n - ¿Cuáles son los puntos más críticos?\n \nToma en cuenta que estás probando esto para un solo usuario.\n\n## Optimización - Data\n\n1. Usar opciones más rápidas para cargar datos\n2. Usar formatos de archivo más eficientes\n3. Pre-procesar los cálculos\n4. Usar bases de datos. Puede requerir aprender SQL.\n\n¡Puedes combinar todo!\n\n## Cargar datos más rápido\n\n- data.table::fread()\n- vroom::vroom()\n- readr::read_csv()\n\n## Ejemplo\n\nNO ejecutar durante el workshop porque toma tiempo en correr\n\n```r\nsuppressMessages(\n microbenchmark::microbenchmark(\n read.csv = read.csv(\"data/personal.csv\"),\n read_csv = readr::read_csv(\"data/personal.csv\"),\n vroom = vroom::vroom(\"data/personal.csv\"),\n fread = data.table::fread(\"data/personal.csv\")\n )\n)\n#> Unit: milliseconds\n#> expr min lq mean median uq max neval\n#> read.csv 1891.3824 2007.2517 2113.5217 2082.6016 2232.7825 2442.6901 100\n#> read_csv 721.9287 820.4181 873.4603 866.7321 897.3488 1165.5929 100\n#> vroom 176.7522 189.8111 205.2099 197.9027 206.2619 495.2784 100\n#> fread 291.9581 370.8261 410.3995 398.9489 439.7827 638.0363 100\n```\n\n\n## Formatos de datos eficientes:\n\n- Parquet (via {arrow})\n- Feather (compatibilidad con Python)\n- fst\n- RDS (nativo de R)\n\n## Ejemplo\n\nNO ejecutar durante el workshop porque toma tiempo en correr\n\n```r\nsuppressMessages(\n microbenchmark::microbenchmark(\n read.csv = read.csv(\"data/personal.csv\"),\n fst = fst::read_fst(\"data/personal.fst\"),\n parquet = arrow::read_parquet(\"data/personal.parquet\"),\n rds = readRDS(\"data/personal.rds\")\n )\n)\n#> Unit: milliseconds\n#> expr min lq mean median uq max neval\n#> read.csv 1911.2919 2075.26525 2514.29114 2308.57325 2658.03690 4130.748 100\n#> fst 201.1500 267.85160 339.73881 308.24680 357.19565 834.646 100\n#> parquet 64.5013 67.29655 84.48485 70.70505 87.81995 405.147 100\n#> rds 558.5518 644.32460 782.37898 695.07300 860.85075 1379.519 100\n```\n\n## Pre-procesar cálculos\n\n- Filtrado previo: Menos tamaño\n- Transformación o agregación previa: Menos tiempo\n- Uso de índices: Búsqueda rápida\n\nEs, en esencia, *caching*. Personalmente, mi estrategia favorita. \n\nDifícil de usar si se requiere calcular en vivo, real-time (stock exchange, streaming data), o la data no puede ser guardada en cualquier lugar (seguridad, privacidad). \n\n\n## Sin pre-procesamiento\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\n# app.R\nsurvey <- read.csv(\"data/survey.csv\")\n\nserver <- function(input, output) {\n output$table <- renderTable({\n survey |> \n filter(region == input$region) |> \n summarise(avg_time = mean(temps_trajet_en_heures))\n })\n}\n```\n:::\n\n\n\n## Con pre-procesamiento\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\n# script.R\nsurvey <- read.csv(\"data/survey.csv\")\nregions <- unique(survey$region)\n\nvalues <- regions |> \n lapply(function(x) {\n survey |> \n dplyr::filter(region == x) |> \n dplyr::summarise(avg_time = mean(temps_trajet_en_heures))\n }) |> \n setNames(regions)\n\nsaveRDS(values, \"data/values.rds\")\n```\n:::\n\n::: {.cell}\n\n```{.r .cell-code}\n# app.R\nvalues <- readRDS(\"data/values.rds\")\n\nserver <- function(input, output) {\n output$table <- renderTable(values[[input$region]])\n}\n```\n:::\n\n\n\n\n\n## Bases de Datos relacionales\n\n- **Escalabilidad**: Las bases de datos pueden manejar grandes volúmenes de datos de manera eficiente.\n- **Consultas Rápidas**: Permiten realizar consultas complejas de manera rápida.\n- **Persistencia**: Los datos se almacenan de manera persistente, lo que permite su recuperación en cualquier momento.\n\n---\n\nAlgunos ejemplos notables son SQLite, MySQL, PostgreSQL, DuckDB.\n\n[freeCodeCamp](https://www.freecodecamp.org/learn/relational-database/) tiene un buen curso para principiantes.\n \n\n## Ejercicio 3 - Data\n\nImplementa una estrategia de optimización\n\n# Optimización - Shiny\n\n## Cuando una app arranca\n\n\n\n---\n\nDel lado de shiny, optimizar consiste básicamente en hacer que la app (en realidad, el procesador) haga el menor trabajo posible.\n\n## Reducir reactividad\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|3,4,5,9,10,11\"}\nserver <- function(input, output, session) {\n output$table <- renderTable({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n })\n \n output$histogram <- renderPlot({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age) |> \n ggplot(aes(temps_trajet_en_heures)) +\n geom_histogram(bins = 20) +\n theme_light()\n })\n}\n```\n:::\n\n\n\n---\n\n`reactive()` al rescate\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|2-6|9,13\"}\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n })\n \n output$table <- renderTable({\n filtered()\n })\n \n output$histogram <- renderPlot({\n filtered() |> \n ggplot(aes(temps_trajet_en_heures)) +\n geom_histogram(bins = 20) +\n theme_light()\n })\n}\n```\n:::\n\n\n\n::: aside\nUsamos más de espacio (memoria) para reducir tiempo (CPU)\n:::\n\n## Controlar reactividad\n\nPuedes encadenar `bindEvent()` a un `reactive()` u `observe()`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nmy_reactive <- reactive({\n # slow reactive computation\n}) |> \n bindEvent(input$trigger)\n\nobserve({\n # slow reactive side effect\n}) |> \n bindEvent(input$trigger)\n```\n:::\n\n\n\n::: aside\nEn versiones pasadas, esto se hacía con `observeEvent()` o `eventReactive()`.\n:::\n\n---\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|5|16\"}\nui <- page_sidebar(\n sidebar = sidebar(\n selectInput(inputId = \"region\", ...),\n sliderInput(inputId = \"age\", ...),\n actionButton(inputId = \"compute\", label = \"Calcular\")\n ),\n ...\n)\n\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n }) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n}\n```\n:::\n\n\n\nAhora `filtered()` solo se actualizará cuando haya interacción con `input$compute`. \n\n::: aside\n`ignoreNULL = FALSE` permite ejecutar el `reactive()` al iniciar la app.\n:::\n\n## Estrategias de Caché\n\n`bindCache()` nos permite guardar cómputos al vuelo en base a ciertas *keys*.\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|7\"}\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n }) |> \n bindCache(input$region, input$age) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n}\n```\n:::\n\n\n\nCuando una combinación vuelva a aparecer, se leerá el valor en lugar de recalcularlo. \n\n::: aside\n`bindEvent()` no es obligatorio para usar `bindCache()`.\n:::\n\n---\n\n2. Niveles de caché:\n - Nivel aplicación: `cache = \"app\"` (default)\n - Nivel sesión: `cache = \"session\"`\n - Personalizado: `cache object + opciones`\n \n\n\n::: {.cell}\n\n```{.r .cell-code}\nbindCache(..., cache = \"app\")\n```\n:::\n\n\n\nPor defecto, se usará un máximo de 200 Mb de caché.\n \n::: aside\nPotencialmente mucho uso de memoria/storage, para reducir tiempo de procesamiento.\n:::\n\n## Comunicación servidor - navegador\n\n- Enviar datos desde el servidor hacia el navegador toma tiempo. \n - Datos grandes -> mayor tiempo de envío.\n - Conexión lenta -> mayor tiempo de envío\n- Igualmente, si los datos son grandes, al navegador le cuesta más leerlos y mostrarlos al usuario. \nPuede que la PC del usuario sea una tostadora!\n\n---\n\n- ¿Qué hacer?\n - Reducir frecuencia de envíos (`bindEvent()`)\n - Reducir tamaño de envíos\n - Mandar lo mismo pero en partes más pequeñas (server-side processing o streaming)\n \n## Reducir tamaño de envíos\n\nEs posible delegar ciertos cálculos al navegador. Por ejemplo, renderizar un gráfico con [`{plotly}`](https://plotly.com/ggplot2/) en lugar de `{ggplot2}`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nplotly::plotlyOutput() # en lugar de plotOutput\nplotly::renderPlotly() # en lugar de renderPlot\n```\n:::\n\n\n\nCon ello, se manda la \"receta\" del gráfico en lugar del gráfico mismo. Al recibir la receta, el navegador se encarga de renderizarla.\n\n---\n\nEstas funciones traducen sintaxis de `ggplot2` a sintaxis de `plotly.js` de manera bastante eficiente. Tiene soporte para muchos tipos de gráficos.\n\n\n\nPero no te confíes, en muchos casos, el código va a necesitar retoques. Especialmente al usar extensiones de `ggplot2`.\n\n---\n\nOtros paquetes similares:\n\n- [ggiraph](https://davidgohel.github.io/ggiraph/)\n- [echarts4r](https://echarts4r.john-coene.com/)\n- [highcharter](https://jkunst.com/highcharter/)\n- [r2d3](https://rstudio.github.io/r2d3/)\n- [shiny.gosling](https://appsilon.github.io/shiny.gosling/index.html) (genomics, by Appsilon)\n\n## Server-side processing\n\nEn el caso de las tablas, el server-side processing permite paginar el resultado y enviar al navegador solo la página que está siendo mostrada en el momento.\n\nEl paquete `{DT}` es una opción solida.\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nDT::DTOutput() # en lugar de tableOutput()\nDT::renderDT() # en lugar de renderTable()\n```\n:::\n\n\n\n::: aside\nSi ya usabas `{DT}`, ¿sabías que hacía esto por defecto?\n:::\n\n---\n\nOtra opcion:\n\n- `{reactable}` en conjunto con `{reactable.extras}` (by Appsilon).\n\n## Ejercicio 4 - Shiny\n\nImplementa alguna de las optimizaciones mencionadas.\n\n# Optimización - Async\n\n## Programación síncrona\n\n::: {.columns}\n\n::: {.column}\n\n- Las tareas se ejecutan secuencialmente\n- Es fácil de entender e implementa\n\n:::\n\n::: {.column}\n\n\n\n:::\n\n:::\n\nEjemplo: Una cocina con una hornilla. Si empecé a freir pollo, no puedo freir nada hasta terminar de freir el pollo.\n\n\n## Proramación asíncrona\n\n::: {.columns}\n::: {.column}\n\n- Las tareas pueden iniciar y ejecutarse independientemente\n- Mientras se procesa una tarea, otras pueden ser iniciadas o completadas.\n\n:::\n\n::: {.column}\n\n\n:::\n\n:::\n\nEjemplo: Una cocina con múltiples hornillas. Si empecé a freir pollo en una hornilla, puedo freir otra cosa en una hornilla diferente.\n\n---\n\nHornilla == Proceso en la PC\n\n::: {.callout-warning title=\"Cuidado\"}\nA más hornillas, también es más fácil quemar la comida!\n:::\n\n\n## Posibles complicaciones\n\n- El código se hace más dificil de entender\n- Sin adecuado control, pueden sobreescribir sus resultados\n- Lógica circular. Proceso A espera a Proceso B, quien espera a Proceso A\n- Incrementa la dificultad para hacer debugging porque los errores ocurren en otro lado\n- Mayor consumo de energía\n\n## Beneficios\n\n- Operaciones largas no bloquean a otras operaciones\n- Flexibilidad: mi sistema se adapta a retrasos inesperados\n- La aplicación se mantiene responsiva, no se \"cuelga\"\n- Uso eficiente de recursos. \"Pagué por 8 procesadores y voy a usar 8 procesadores\".\n- Escalabilidad a otro nivel\n\n## Casos de uso\n\n- Operaciones I/O:\n - Query a bases de datos\n - Solicitudes a APIs\n- Cálculos intensivos\n\n## ¿Qué necesito?\n\n- CPU con varios núcleos/hilos.\n- Paquetes:\n - {promises}\n - {future}\n - ExtendedTask (Shiny 1.8.1+)\n \n::: {.callout-note title=\"Nota\"}\nExtendedTask es un recurso bastante nuevo. También es posible usar solo `future()` o `future_promise()` dentro de un reactive para lograr un efecto similar, aunque con menos ventajas.\n:::\n\n## Setup inicial\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|4-7\"}\nlibrary(shiny)\nlibrary(bslib)\nlibrary(tidyverse)\nlibrary(future)\nlibrary(promises)\n\nplan(multisession)\n\nsurvey <- arrow::read_parquet(\"data/survey.parquet\")\n```\n:::\n\n\n\nEsto le dice al proceso que corre la app que los *futures* creados se resuelvan en sesiones paralelas.\n\n## Procedimiento\n\n1. Crear un objeto `ExtendedTask`.\n2. Hacer bind a un task button\n3. Invocar la tarea\n4. Recuperar los resultados\n\n\n \n## Punto de partida - UI\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|5\"}\nui <- page_sidebar(\n sidebar = sidebar(\n selectInput(inputId = \"region\", ...),\n sliderInput(inputId = \"age\", ...),\n actionButton(inputId = \"compute\", label = \"Calcular\")\n ),\n ...\n)\n```\n:::\n\n\n\n## Modificaciones - UI\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"5\"}\nui <- page_sidebar(\n sidebar = sidebar(\n selectInput(inputId = \"region\", ...),\n sliderInput(inputId = \"age\", ...),\n input_task_button(id = \"compute\", label = \"Calcular\")\n ),\n ...\n)\n```\n:::\n\n\n\nCambiamos el `actionButton()` por `bslib::input_task_button()`. Este botón tendrá un comportamiento especial.\n\n## Punto de partida - Server\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|3-5|8|7\"}\nserver <- function(input, output, session) {\n filtered <- reactive({\n survey |> \n filter(region == input$region) |> \n filter(age <= input$age)\n }) |> \n bindCache(input$region, input$age) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n## Modificaciones - Server\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n future_promise({\n p_survey |> \n dplyr::filter(region == p_region) |> \n dplyr::filter(age <= p_age)\n })\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(survey, input$region, input$age)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n## Modificaciones - Server\n\nPaso 1: Se creó un `ExtendedTask` que envuelve a una función. \n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|2|4-6|3,7\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n future_promise({\n p_survey |> \n dplyr::filter(region == p_region) |> \n dplyr::filter(age <= p_age)\n })\n }) |> \n bind_task_button(\"compute\")\n \n ...\n}\n```\n:::\n\n\n\n\nDentro de la función, tenemos la lógica de nuestro cálculo envuelta en un `future_promise()`. La función asume una sesión en blanco.\n\n## Modificaciones - Server\n\nPaso 2: Se hizo bind a un task button\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|5,8\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(...) {\n ...\n }) |> \n bind_task_button(\"compute\")\n \n observe(...) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n\n ...\n}\n```\n:::\n\n\n\n\n::: {.callout-note title=\"Nota\"}\n`bind_task_button()` requiere el mismo id que `input_task_button()`. `bindEvent()` acepta cualquier reactive.\n:::\n\n## Modificaciones - Server\n\nPaso 3: Invocar la tarea con `ExtendedTask$invoke()`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|2,7\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n ...\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(survey, input$region, input$age)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\nSe le provee la data necesaria para trabajar. Tomar en cuenta que `invoke()` no tiene valor de retorno (es un side-effect).\n\n## Modificaciones - Server\n\nPaso 4: Recuperar los resultados con `ExtendedTask$result()`.\n\n\n\n::: {.cell}\n\n```{.r .cell-code code-line-numbers=\"|10|12\"}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(...) {\n ...\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(...)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n`result()` se comporta como cualquier reactive. \n\n## Modificaciones - Server\n\n\n\n::: {.cell}\n\n```{.r .cell-code}\nserver <- function(input, output, session) {\n filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {\n future_promise({\n p_survey |> \n dplyr::filter(region == p_region) |> \n dplyr::filter(age <= p_age)\n })\n }) |> \n bind_task_button(\"compute\")\n \n observe(filter_task$invoke(survey, input$region, input$age)) |> \n bindEvent(input$compute, ignoreNULL = FALSE)\n \n filtered <- reactive(filter_task$result())\n \n output$table <- DT::renderDT(filtered())\n ...\n}\n```\n:::\n\n\n\n¡Perdimos el cache! `ExtendedTask()` no es 100% compatible con las estrategias de caching vistas.\n\n## Ejercicio 5 - Async\n\n- Implementa async para uno de los gráficos\n- Discusión: ¿vale la pena?\n\n## Todo junto\n\nAcá se desplegó la app con todas las mejoras vistas en los ejercicios. Además, `survey` utiliza la data completa, en lugar de una muestra por región.\n\nEnlace: \n\n::: aside\nLa plataforma permitió 8 GB de RAM y 2 núcleos de CPU.\n:::\n\n# Temas avanzados\n\n## Representando la complejidad\n\n[Big O notation](https://www.freecodecamp.org/news/big-o-notation-why-it-matters-and-why-it-doesnt-1674cfa8a23c/)\n\n\n\n\n## Entendiendo la complejidad\n\n[Algoritmos y estructuras de datos](https://blog.algomaster.io/p/how-i-mastered-data-structures-and-algorithms)\n\n\n\n## Enfrentando la complejidad\n\n- Modularización\n - [shiny](https://mastering-shiny.org/scaling-modules.html)\n - [box](https://github.com/klmr/box)\n- [Testing](https://mastering-shiny.org/scaling-testing.html)\n- File structure\n\n¡[`{rhino}`](https://appsilon.github.io/rhino/) tiene todo esto!\n\n\n# Preguntas\n\n# ¡Gracias!\n\n- Web: \n- Github: \n- Linkedin: \n",
"supporting": [
"index_files"
],
diff --git a/index.qmd b/index.qmd
index 405894a..d5a757a 100644
--- a/index.qmd
+++ b/index.qmd
@@ -16,6 +16,10 @@ execute:
echo: true
---
+## Material
+
+
+
## Estructura del Taller (3 horas)
- Introducción