diff --git "a/docs/study/Game-dev/GDScript\345\237\272\347\241\200-\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/docs/study/Game-dev/GDScript\345\237\272\347\241\200-\345\255\246\344\271\240\347\254\224\350\256\260.md"
new file mode 100644
index 0000000..bbfed0f
--- /dev/null
+++ "b/docs/study/Game-dev/GDScript\345\237\272\347\241\200-\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -0,0 +1,12 @@
+# GDScript基础-学习笔记
+
+> [GDScript - GDScript 基础 - 《Godot 游戏引擎 v3.5 中文文档》 - 书栈网 · BookStack](https://www.bookstack.cn/read/godot-3.5-zh/f9c328f5c1cf8c98.md)
+>
+> 以前学过JavaScript和Python,所以这里就不特地写全面的笔记了。
+
+1. GDScript支持鸭子类型
+
+2. GDScript继承Refrence的引用类型在计数为0时会自动释放,继承Object则需要手动管理内存
+
+3. 一般开发时最基础的类只用到`RefCounted`,再往下的类需要手动内存管理,比较繁琐
+4.
\ No newline at end of file
diff --git "a/docs/study/Game-dev/Godot(\345\256\230\346\226\271\346\225\231\347\250\213)-\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/docs/study/Game-dev/Godot(\345\256\230\346\226\271\346\225\231\347\250\213)-\345\255\246\344\271\240\347\254\224\350\256\260.md"
index 4b6651b..511b867 100644
--- "a/docs/study/Game-dev/Godot(\345\256\230\346\226\271\346\225\231\347\250\213)-\345\255\246\344\271\240\347\254\224\350\256\260.md"
+++ "b/docs/study/Game-dev/Godot(\345\256\230\346\226\271\346\225\231\347\250\213)-\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -1 +1,19 @@
-# Godot(官方教程)-学习笔记
\ No newline at end of file
+# Godot(官方教程)-学习笔记
+
+> [Introduction — Godot Engine (stable) documentation in English](https://docs.godotengine.org/en/stable/about/introduction.html)
+>
+> [Learn Godot's GDScript From Zero by GDQuest, Xananax (itch.io)](https://gdquest.itch.io/learn-godot-gdscript)
+>
+> [Godot文件- 主 分支 — Godot Engine latest 文档 (osgeo.cn)](https://www.osgeo.cn/godot/index.html)
+>
+> [Vignette - Godot Shaders](https://godotshaders.com/shader/vignette/)
+
+1. Godot默认子节点ready之后,才会ready父节点。如果需要在子节点中直接或间接调用到父节点的onready变量,就会报错。可以通过`await owner.ready ` 先等待父节点ready
+2. `@export`变量在`__init__`之后,`_ready()`方法之前初始化,在`_ready()`可以安全访问
+3. `@onready`变量在`_ready()`方法中由Godot自动初始化
+4. 普通变量的初始化在`@export`变量之前
+5. 初始化顺序:`普通var` > `@export` > `@onready`
+6. Godot制作2D像素游戏,纹理大小Rect宽高最好设置为偶数,避免图片在相机移动时发生抖动
+7. input输入事件传播的调用链(注意,输入事件的传播和输入状态查询`Input.get_axis("move_left")`是两套系统):`_input()`>`_gui_input()`>`_shortcut_input()`>`unhandled_key_input()`>`_unhandled_input()`>其他逻辑。按照上述顺序,前面的函数没有处理逻辑则继续向后检测处理逻辑。
+
+8.
\ No newline at end of file
diff --git "a/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\212.md" "b/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\212.md"
index 41fb04d..5eee2d0 100644
--- "a/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\212.md"
+++ "b/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\212.md"
@@ -975,7 +975,7 @@ class SynchronizedExample {
如上图所示,假设处理器A写一个long型变量,同时处理器B要读这个long型变量。处理器A中64位的写操作被拆分为两个32位的写操作,且这两个32位的写操作被分配到不同的写事务中执行。同时,处理器B中64位的读操作被分配到单个的读事务中执行。当处理器A和B按上图的时序来执行时,处理器B将看到仅仅被处理器A“写了一半”的无效值。
- 注意,在JSR-133之前的旧内存模型中,一个64位long/double型变量的读/写操作可以被拆分为两个32位的读/写操作来执行。从JSR-133内存模型开始(即从JDK5开始),仅仅只允许把一个64位long/double型变量的写操作拆分为两个32位的写操作来执行,**任意的读操作在JSR-133中都必须具有原子性(即任意读操作必须要在单个读事务中执行)。**
+ 注意,在JSR-133之前的旧内存模型中,一个64位long/double型变量的读/写操作可以被拆分为两个32位的读/写操作来执行。从JSR-133内存模型开始(即从JDK5开始),仅仅只允许把一个64位long/double型变量的写操作拆分为两个32位的写操作来执行,**任意的读操作在JSR-133中都必须具有原子性(即任意读操作必须要在单个读事务中执行)。**
## 3.4 volatile的内存语义
@@ -1082,6 +1082,8 @@ class VolatileExample {
**当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。**
+ (类比MESI,相当于每次写操作都会将缓存行从S变成E,即写回主存,并且通知其他CPU缓存行更新为I)
+
以上面示例程序VolatileExample为例,假设线程A首先执行writer()方法,随后线程B执行reader()方法,初始时两个线程的本地内存中的flag和a都是初始状态。下图是线程A执行volatile写后,共享变量的状态示意图。

@@ -1094,6 +1096,8 @@ class VolatileExample {
**当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。**
+ (类比MESI,相当于每次读都会把缓存行视为I,重新从主存读取数据,设置为E或者S)
+
在读flag变量后,本地内存B包含的值已经被置为无效。此时,线程B必须从主内存中读取共享变量。线程B的读取操作将导致本地内存B与主内存中的共享变量的值变成一致。
如果我们把volatile写和volatile读两个步骤综合起来看的话,在读线程B读一个volatile变量后,写线程A在写这个volatile变量之前所有可见的共享变量的值都将立即变得对读线程B可见。
@@ -1102,17 +1106,11 @@ class VolatileExample {
下面对volatile写和volatile读的内存语义做个总结。
-+ 线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程
-
-发出了(其对共享变量所做修改的)消息。
-
-+ 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile
-
-变量之前对共享变量所做修改的)消息。
++ 线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息。
-+ 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过
++ 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
-主内存向线程B发送消息。
++ 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
### 3.4.4 volatile内存语义的实现
@@ -1193,7 +1191,7 @@ class VolatileExample {
---
- 上述volatile写和volatile读的内存屏障插入策略非常保守。**在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障**。
+ 上述volatile写和volatile读的内存屏障插入策略非常保守。**在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障**。
```java
class VolatileBarrierExample {
@@ -1284,31 +1282,29 @@ class MonitorExample {
**当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中。**以上面的MonitorExample程序为例,A线程释放锁后,共享数据的状态示意图如图所示。
+ (从MESI角度看,相当于每次释放锁,都会将缓存行更新为S或者E,刷新数据到主存,然后通知其他CPU缓存行设置I)
+

---
**当线程获取锁时,JMM会把该线程对应的本地内存置为无效。从而使得被监视器保护的临界区代码必须从主内存中读取共享变量**。图是锁获取的状态示意图。
+(用内存MESI来理解的话,相当于CPU0将缓存行从S变成M,然后通知CPU1将缓存行变成I,同时更新主存数据。CPU1下次读取缓存行时就需要重新从主存读取了)
+

- **对比锁释放-获取的内存语义与volatile写-读的内存语义可以看出:锁释放与volatile写有相同的内存语义;锁获取与volatile读有相同的内存语义。**
+ **对比锁释放-获取的内存语义与volatile写-读的内存语义可以看出:锁释放与volatile写有相同的内存语义;锁获取与volatile读有相同的内存语义。**
---
下面对锁释放和锁获取的内存语义做个总结。
-+ 线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出了(线程A
-
-对共享变量所做修改的)消息。
-
-+ 线程B获取一个锁,实质上是线程B接收了之前某个线程发出的(在释放这个锁之前对共
++ 线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出了(线程A对共享变量所做修改的)消息。
-享变量所做修改的)消息。
++ 线程B获取一个锁,实质上是线程B接收了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息。
-+ 线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发
-
-送消息。
++ 线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发送消息。
### 3.5.3 锁内存语义的实现
@@ -1350,7 +1346,7 @@ class ReentrantLockExample {
-ReentrantLock分为公平锁和非公平锁,我们首先分析公平锁。
+ReentrantLock分为公平锁和非公平锁,我们首先分析公平锁。
使用公平锁时,加锁方法lock()调用轨迹如下。
@@ -1417,7 +1413,7 @@ protected final boolean tryRelease(int releases) {
从上面的源代码可以看出,在释放锁的最后写volatile变量state。
- 公平锁在释放锁的最后写volatile变量state,在获取锁时首先读这个volatile变量。根据volatile的happens-before规则,释放锁的线程在写volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变得对获取锁的线程可见。
+ **公平锁在释放锁的最后写volatile变量state,在获取锁时首先读这个volatile变量。根据volatile的happens-before规则,释放锁的线程在写volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变得对获取锁的线程可见**。
---
@@ -1437,11 +1433,11 @@ protected final boolean compareAndSetState(int expect, int update) {
}
```
- 该方法以原子操作的方式更新state变量,本文把Java的compareAndSet()方法调用简称为CAS。JDK文档对该方法的说明如下:如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值。此操作具有volatile读和写的内存语义。
+ 该方法以原子操作的方式更新state变量,本文把Java的compareAndSet()方法调用简称为CAS。JDK文档对该方法的说明如下:如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值。**此操作具有volatile读和写的内存语义**。
这里我们分别从编译器和处理器的角度来分析,CAS如何同时具有volatile读和volatile写的内存语义。
- 前文我们提到过,编译器不会对volatile读与volatile读后面的任意内存操作重排序;编译器不会对volatile写与volatile写前面的任意内存操作重排序。组合这两个条件,意味着**为了同时实现volatile读和volatile写的内存语义,编译器不能对CAS与CAS前面和后面的任意内存操作重排序**。
+ 前文我们提到过,编译器不会对volatile读与volatile读后面的任意内存操作重排序;编译器不会对volatile写与volatile写前面的任意内存操作重排序。组合这两个条件,意味着**为了同时实现volatile读和volatile写的内存语义,编译器不能对CAS与CAS前面和后面的任意内存操作重排序**。
下面我们来分析在常见的intel X86处理器中,CAS是如何同时具有volatile读和volatile写的内存语义的。
@@ -1453,7 +1449,7 @@ public final native boolean compareAndSwapInt(Object o, long offset,
int x);
```
- 可以看到这是个本地方法调用。这个本地方法在openjdk中依次调用的c++代码为:unsafe.cpp,atomic.cpp和atomic*windows*x86.inline.hpp。这个本地方法的最终实现在openjdk的如下位置:openjdk-7-fcs-src-b147-27*jun*2011\openjdk\hotspot\src\os*cpu\windows*x86\vm\ atomic*windows*x86.inline.hpp(对应于windows操作系统,X86处理器)。下面是对应于intel X86处理器的源代码的片段。
+ 可以看到这是个本地方法调用。这个本地方法在openjdk中依次调用的c++代码为:unsafe.cpp,atomic.cpp和atomic*windows*x86.inline.hpp。这个本地方法的最终实现在openjdk的如下位置:`openjdk-7-fcs-src-b147-27*jun*2011\openjdk\hotspot\src\os*cpu\windows*x86\vm\ atomic*windows*x86.inline.hpp`(对应于windows操作系统,X86处理器)。下面是对应于intel X86处理器的源代码的片段。
```c
// Adding a lock prefix to an instruction on MP machine
@@ -1478,21 +1474,15 @@ inline jint Atomic::cmpxchg (jint exchange_value, volatile jint*
}
```
- 如上面源代码所示,程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(Lock Cmpxchg)。反之,如果程序是在单处理器上运行,就省略lock前缀(单处理器自身会维护单处理器内的顺序一致性,不需要lock前缀提供的内存屏障效果)。
+ 如上面源代码所示,程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。**如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀**(Lock Cmpxchg)。反之,如果程序是在单处理器上运行,就省略lock前缀(单处理器自身会维护单处理器内的顺序一致性,不需要lock前缀提供的内存屏障效果)。
intel的手册对**lock前缀**的说明如下。
-1. 确保对内存的读-改-写操作原子执行。在Pentium及Pentium之前的处理器中,带有lock前
-
-缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会
-
-带来昂贵的开销。从Pentium 4、Intel Xeon及P6处理器开始,Intel使用缓存锁定(Cache Locking)
-
-来保证指令执行的原子性。**缓存锁定将大大降低lock前缀指令的执行开销**。
+1. **确保对内存的读-改-写操作原子执行**。在Pentium及Pentium之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从Pentium 4、Intel Xeon及P6处理器开始,Intel使用缓存锁定(Cache Locking)来保证指令执行的原子性。**缓存锁定将大大降低lock前缀指令的执行开销**。
2. **禁止该指令,与之前和之后的读和写指令重排序。**
-3. **把写缓冲区中的所有数据刷新到内存中。**
+3. **把写缓冲区中的所有数据刷新到内存中。**
上面的第2点和第3点所具有的内存屏障效果,足以同时实现volatile读和volatile写的内存语义。
@@ -1506,9 +1496,7 @@ inline jint Atomic::cmpxchg (jint exchange_value, volatile jint*
+ 公平锁获取时,首先会去读volatile变量。
-+ 非公平锁获取时,首先会用**CAS更新volatile变量,这个操作同时具有volatile读和volatile**
-
-**写的内存语义**。
++ 非公平锁获取时,首先会用**CAS更新volatile变量,这个操作同时具有volatile读和volatile写的内存语义**。
**从本文对ReentrantLock的分析可以看出,锁释放-获取的内存语义的实现至少有下面两种方式。**
@@ -1530,7 +1518,9 @@ inline jint Atomic::cmpxchg (jint exchange_value, volatile jint*
4. A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
- **Java的CAS会使用现代处理器上提供的高效机器级别的原子指令**,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(**从本质上来说,能够支持原子性读-改-写指令的计算机,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令**)。同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式。
+ **Java的CAS会使用现代处理器上提供的高效机器级别的原子指令**,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(**从本质上来说,能够支持原子性读-改-写指令的计算机,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令**)。同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。
+
+ 如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式。
+ **首先,声明共享变量为volatile。**
@@ -1620,7 +1610,7 @@ public class FinalExample {
在上图中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程A写入,这是一个错误的读取操作。而**读final域的重排序规则会把读对象final域的操作"限定"在读对象引用之后**,此时该final域已经被A线程初始化过了,这是一个正确的读取操作。
- **读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用**。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
+ **读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用**。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
### 3.6.4 final域为引用类型
@@ -1660,7 +1650,7 @@ public class FinalReferenceExample {
如果想要确保读线程C看到写线程B对数组元素的写入,写线程B和读线程C之间需要使用**同步原语(lock或volatile)来确保内存可见性**。
-(换言之,final只保证构造函数内对final的使用与构造函数外第一次使用final对象/变量时不会有重排序,之后再修改final引用对象的值,JMM不再保证不会重排序。)
+(**换言之,final只保证构造函数内对final的使用与构造函数外第一次使用final对象/变量时不会有重排序,之后再修改final引用对象的值,JMM不再保证不会重排序。**)
### 3.6.5 为什么final引用不能从构造函数内"溢出"
@@ -1689,9 +1679,7 @@ public class FinalReferenceEscapeExample {
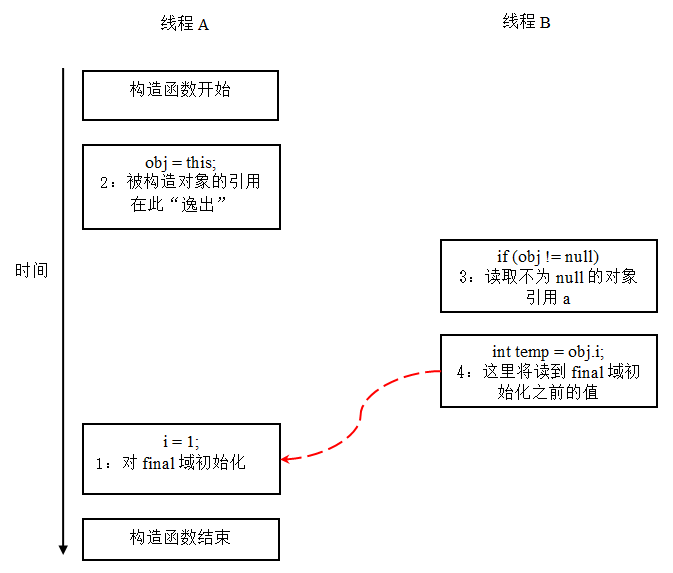
假设一个线程A执行writer()方法,另一个线程B执行reader()方法。这里的操作2使得对象还未完成构造前就为线程B可见。即使这里的操作2是构造函数的最后一步,且即使在程序中操作2排在操作1后面,执行read()方法的线程仍然可能无法看到final域被初始化后的值,因为这里的操作1和操作2之间可能被重排序。实际的执行时序可能如下图所示:
-
-
-
+
在构造函数返回前,被构造对象的引用不能为其他线程所见,因为此时的final域可能还没有被初始化。在构造函数返回后,任意线程都将保证能看到final域正确初始化之后的值。
@@ -1750,7 +1738,7 @@ double area = pi * r * r; // C
+ **对于不会改变程序执行结果的重排序,JMM对编译器和处理器不做要求(JMM允许这种重排序)。**
-
+
+ JMM向程序员提供的happens-before规则能满足程序员的需求。JMM的happens-before规则不但简单易懂,而且也向程序员提供了足够强的内存可见性保证(有些内存可见性保证其实并不一定真实存在,比如上面的A happens-before B)。
@@ -1995,7 +1983,7 @@ public class InstanceFactory {
2. **T是一个类,且T中声明的一个静态方法被调用。**
3. T中声明的一个静态字段被赋值。
-4. T中声明的一个静态字段被使用,而且这个字段不是一个常量字段。
+4. T中声明的一个静态字段被使用,而且这个字段不是一个常量字段。
5. T是一个顶级类(Top Level Class,见Java语言规范的§7.6),而且一个断言语句嵌套在T内部被执行。
在InstanceFactory示例代码中,首次执行getInstance()方法的线程将导致InstanceHolder类被初始化(符合情况4)。
@@ -2122,7 +2110,7 @@ public class InstanceFactory {
| RMO | ia64 | Y | Y | Y | | Y |
| PowerPC | PowerPC | Y | Y | Y | Y | Y |
- 从上表中可以看到,**所有处理器内存模型都允许写-读重排序**,原因在第1章已经说明过:它们都使用了写缓存区。**写缓存区可能导致写-读操作重排序。**同时,我们可以看到这些处理器内存模型**都允许更早读到当前处理器的写,原因同样是因为写缓存区**。**由于写缓存区仅对当前处理器可见,这个特性导致当前处理器可以比其他处理器先看到临时保存在自己写缓存区中的写。**
+ 从上表中可以看到,**所有处理器内存模型都允许写-读重排序**,原因在第1章已经说明过:它们都使用了写缓存区。**写缓存区(和MESI有关)可能导致写-读操作重排序。**同时,我们可以看到这些处理器内存模型**都允许更早读到当前处理器的写,原因同样是因为写缓存区**。**由于写缓存区仅对当前处理器可见,这个特性导致当前处理器可以比其他处理器先看到临时保存在自己写缓存区中的写(就算没有写缓存区,本身缓存行没其他CPU使用时,缓存行数据就可以仅更新当前缓存行,无需写回主存)。**
上表中的各种处理器内存模型,从上到下,模型由强变弱。越是追求性能的处理器,内存模型设计得会越弱。因为这些处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。
@@ -2716,6 +2704,7 @@ Count i = 540898082
Java支持多个线程同时访问一个对象或者对象的成员变量,由于每个线程可以拥有这个变量的拷贝(虽然对象以及成员变量分配的内存是在共享内存中的,但是每个执行的线程还是可以拥有一份拷贝,这样做的目的是加速程序的执行,这是现代多核处理器的一个显著特性),所以程序在执行过程中,一个线程看到的变量并不一定是最新的。
**关键字volatile可以用来修饰字段(成员变量),就是告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,它能保证所有线程对变量访问的可见性**。
+
举个例子,定义一个表示程序是否运行的成员变量`boolean on=true`,那么另一个线程可能对它执行关闭动作(on=false),这里涉及多个线程对变量的访问,因此需要将其定义成为`volatile boolean on=true`,这样其他线程对它进行改变时,可以让所有线程感知到变化,因为所有对on变量的访问和修改都需要以共享内存为准。但是,过多地使用volatile是不必要的,因为它会降低程序执行的效率。
**关键字synchronized可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性。**
@@ -2981,7 +2970,7 @@ Repeat my words.
### 4.3.5 Thread.join()的使用
- 如果一个线程A执行了**thread.join()语句,其含义是:当前线程A等待thread线程终止之后才从thread.join()返回**。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(longmillis,int nanos)两个具备超时特性的方法。这两个超时方法表示,如果线程thread在给定的超时时间里没有终止,那么将会从该超时方法中返回。
+ 如果一个线程A执行了**thread.join()语句,其含义是:当前线程A等待thread线程终止之后才从thread.join()返回**。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis, int nanos)两个具备超时特性的方法。这两个超时方法表示,如果线程thread在给定的超时时间里没有终止,那么将会从该超时方法中返回。
在(代码清单4-13 Join.java)所示的例子中,创建了10个线程,编号0~9,每个线程调用前一个线程的join()方法,也就是线程0结束了,线程1才能从join()方法中返回,而线程0需要等待main线程结束。
@@ -3318,8 +3307,7 @@ public class DefaultThreadPool implements ThreadPool
initializeWokers(DEFAULT_WORKER_NUMBERS);
}
public DefaultThreadPool(int num) {
- workerNum = num > MAX_WORKER_NUMBERS MAX_WORKER_NUMBERS : num < MIN_WORKER_
- NUMBERS MIN_WORKER_NUMBERS : num;
+ workerNum = num > MAX_WORKER_NUMBERS ? MAX_WORKER_NUMBERS : num < MIN_WORKER_NUMBERS ? MIN_WORKER_NUMBERS : num;
initializeWokers(workerNum);
}
public void execute(Job job) {
diff --git "a/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\213.md" "b/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\213.md"
index 59e9144..aa8e565 100644
--- "a/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\213.md"
+++ "b/docs/study/Java/\343\200\212Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260-\344\270\213.md"
@@ -40,7 +40,7 @@ try {
| 方法名称 | 描述 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| void lock() | 获取锁,调用该方法当前线程将会获取锁,当锁获得后,从该方法返回 |
-| void lockInterruptibly() throws InterruptedException | 可中断地获取锁,和lock()方法不同之处在于该方法会响应中断,即在锁释放中可以中断当前线程 |
+| void lockInterruptibly() throws InterruptedException | 可中断地获取锁,和lock()方法不同之处在于该方法会响应中断,即在锁的获取中可以中断当前线程 |
| boolean trylock() | 尝试非阻塞式的获取锁,调用该方法后立刻返回,如果能够获取则返回true,否则返回false |
| boolean tryLock(Long time,TimeUnit unit)throws InterruptedException | 超时获取锁,当线程在以下3种情况会返回:1. 当前线程在超时时间内获得了锁 2. 当前线程在超时时间内被中断 3. 超时时间结束,返回false |
| void unLock() | 释放锁 |
@@ -50,7 +50,7 @@ try {
## 5.2 队列同步器
- 队列同步器`AbstractQueuedSynchronizer`(以下简称同步器),是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作,并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。
+ 队列同步器`AbstractQueuedSynchronizer`(以下简称同步器),是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的**FIFO队列**来完成资源获取线程的排队工作,并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。
同步器的主要使用方式是继承,子类通过继承同步器并实现它的抽象方法来管理同步状态,在抽象方法的实现过程中免不了要对同步状态进行更改,这时就需要使用同步器提供的3个方法(getState()、setState(int newState)和compareAndSetState(int expect,int update))来进行操作,因为它们能够保证状态的改变是安全的。**子类推荐被定义为自定义同步组件的静态内部类**,同步器自身没有实现任何同步接口,它仅仅是定义了若干同步状态获取和释放的方法来供自定义同步组件使用,同步器既可以支持独占式地获取同步状态,也可以支持共享式地获取同步状态,这样就可以方便实现不同类型的同步组件(ReentrantLock、ReentrantReadWriteLock和CountDownLatch等)。
@@ -66,9 +66,7 @@ try {
+ `setState(int newState)`:设置当前同步状态。
-+ `compareAndSetState(int expect,int update)`:使用CAS设置当前状态,该方法能够保证状态
-
- 设置的原子性。
++ `compareAndSetState(int expect,int update)`:使用CAS设置当前状态,该方法能够保证状态设置的原子性。
同步器可重写的方法与描述如下表所示。
@@ -852,7 +850,7 @@ protected final int tryAcquireShared(int unused) {
}
```
- 在`tryAcquireShared(int unused)`方法中,如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态。如果当前线程获取了写锁或者写锁未被获取,则当前线程(线程安全,依靠CAS保证)增加读状态,成功获取读锁。
+ 在`tryAcquireShared(int unused)`方法中,如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态。**如果当前线程获取了写锁或者写锁未被获取,则当前线程(线程安全,依靠CAS保证)增加读状态,成功获取读锁**。
读锁的每次释放(线程安全的,可能有多个读线程同时释放读锁)均减少读状态,减少的值是(1<<16)。
@@ -952,7 +950,8 @@ public void conditionWait() throws InterruptedException {
} finally {
lock.unlock();
}
-} public void conditionSignal() throws InterruptedException {
+}
+public void conditionSignal() throws InterruptedException {
lock.lock();
try {
condition.signal();
@@ -975,7 +974,7 @@ public void conditionWait() throws InterruptedException {
| void signal() | 唤醒一个等待在Condition上的线程,该线程从等待方法返回前必须获得与Condition相关联的锁 |
| void signalAll() | 唤醒所有等待在Condition上的线程,能够从等待方法返回的线程必须获得与Condition相关联的锁 |
- 获取一个Condition必须通过Lock的newCondition()方法。下面通过一个有界队列的示例来深入了解Condition的使用方式。有界队列是一种特殊的队列,当队列为空时,队列的获取操作将会阻塞获取线程,直到队列中有新增元素,当队列已满时,队列的插入操作将会阻塞插入线程,直到队列出现“空位”,如(代码清单5-21 BoundedQueue.java)所示。
+ 获取一个Condition必须通过Lock的newCondition()方法。下面通过一个有界队列的示例来深入了解Condition的使用方式。有界队列是一种特殊的队列,当队列为空时,队列的获取操作将会阻塞获取线程,直到队列中有新增元素,当队列已满时,队列的插入操作将会阻塞插入线程,直到队列出现“空位”,如(代码清单5-21 BoundedQueue.java)所示。
```java
public class BoundedQueue {
@@ -2657,7 +2656,7 @@ public class ExchangerTest {
public void run() {
try {
String B = "银行流水B"; // B录入银行流水数据
- String A = exgr.exchange("B");
+ String A = exgr.exchange(B);
System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:"
+ A + ",B录入是:" + B);
} catch (InterruptedException e) {
@@ -2838,7 +2837,7 @@ try {
### 9.2.3 关闭线程池
- **可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止**。但是它们存在一定的区别。
+ **可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止**。但是它们存在一定的区别。
+ shutdownNow首先将线程池的状态设置成**STOP**,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表
+ shutdown只是将线程池的状态设置成**SHUTDOWN**状态,然后中断所有没有正在执行任务的线程。
@@ -3392,7 +3391,7 @@ public boolean offer(E e) {
---
-+ 当FutureTask处于未启动状态时,执行`FutureTask.cancel()`方法将导致此任务永远不会被执行;
++ 当FutureTask处于未启动状态时,执行`FutureTask.cancel(...)`方法将导致此任务永远不会被执行;
+ 当FutureTask处于已启动状态时,执行`FutureTask.cancel(true)`方法将以**中断**执行此任务线程的方式来试图停止任务;
+ 当FutureTask处于已启动状态时,执行`FutureTask.cancel(false)`方法将不会对正在执行此任务的线程产生影响(让正在执行的任务运行完成);
+ 当FutureTask处于已完成状态时,执行`FutureTask.cancel(…)`方法将返回false。
@@ -3444,7 +3443,7 @@ private String executionTask(final String taskName)
### 10.4.3 FutureTask的实现
- FutureTask的实现基于AbstractQueuedSynchronizer(以下简称为AQS)。**java.util.concurrent中的很多可阻塞类(比如ReentrantLock)都是基于AQS来实现的**。AQS是一个同步框架,它提供通用机制来原子性管理同步状态、阻塞和唤醒线程,以及维护被阻塞线程的队列。**JDK 6中AQS被广泛使用,基于AQS实现的同步器包括:ReentrantLock、Semaphore、ReentrantReadWriteLock、CountDownLatch和FutureTask。**
+ FutureTask的实现基于AbstractQueuedSynchronizer(以下简称为AQS)。**java.util.concurrent中的很多可阻塞类(比如ReentrantLock)都是基于AQS来实现的**。AQS是一个同步框架,它提供通用机制来原子性管理同步状态、阻塞和唤醒线程,以及维护被阻塞线程的队列。**JDK 6中AQS被广泛使用,基于AQS实现的同步器包括:ReentrantLock、Semaphore、ReentrantReadWriteLock、CountDownLatch和FutureTask。**
每一个基于AQS实现的同步器都会包含两种类型的操作,如下。
@@ -3475,12 +3474,11 @@ private String executionTask(final String taskName)
`FutureTask.run()`的执行过程如下。
1. 执行在构造函数中指定的任务(`Callable.call()`)。
-
2. **以原子方式来更新同步状态**(调用`AQS.compareAndSetState(int expect,int update)`,设置state为执行完成状态RAN)。如果这个原子操作成功,就设置代表计算结果的变量result的值为`Callable.call()`的返回值,然后调用`AQS.releaseShared(int arg)`。
-
3. `AQS.releaseShared(int arg)`首先会回调在子类Sync中实现的`tryReleaseShared(arg)`来执行release操作(设置运行任务的线程runner为null,然会返回true);`AQS.releaseShared(int arg)`,然后唤醒线程等待队列中的第一个线程。
+4. 调用`FutureTask.done()`。
-4. 调用`FutureTask.done()`。当执行`FutureTask.get()`方法时,如果FutureTask不是处于执行完成状态RAN或已取消状态CANCELLED,当前执行线程将到AQS的线程等待队列中等待(见下图的线程A、B、C和D)。当某个线程执行`FutureTask.run()`方法或`FutureTask.cancel(...)`方法时,会唤醒线程等待队列的第一个线程(见下图所示的线程E唤醒线程A)。
+ 当执行`FutureTask.get()`方法时,如果FutureTask不是处于执行完成状态RAN或已取消状态CANCELLED,当前执行线程将到AQS的线程等待队列中等待(见下图的线程A、B、C和D)。当某个线程执行`FutureTask.run()`方法或`FutureTask.cancel(...)`方法时,会唤醒线程等待队列的第一个线程(见下图所示的线程E唤醒线程A)。

diff --git "a/docs/study/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\244\215\344\271\240.md" "b/docs/study/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\244\215\344\271\240.md"
index b8a843a..ae951c1 100644
--- "a/docs/study/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\244\215\344\271\240.md"
+++ "b/docs/study/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\345\244\215\344\271\240.md"
@@ -3839,6 +3839,8 @@ $$
> [差错控制--百度百科]([https://baike.baidu.com/item/%E5%B7%AE%E9%94%99%E6%8E%A7%E5%88%B6](https://baike.baidu.com/item/差错控制))
>
> 差错控制(error control)是在数字通信中利用[编码](https://baike.baidu.com/item/编码)方法对传输中产生的差错进行控制,以提高数字消息传输的准确性。
+>
+> [TCP 快速重传为什么是三次冗余 ACK,这个三次是怎么定下来的?](https://www.zhihu.com/question/21789252/answer/2732182453)
**TCP的滑动窗口以字节为单位**。