diff --git "a/docs/study/\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200DSL/\343\200\212\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260.md" "b/docs/study/\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200DSL/\343\200\212\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260.md"
index 95f1bf8..bd035e9 100644
--- "a/docs/study/\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200DSL/\343\200\212\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260.md"
+++ "b/docs/study/\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200DSL/\343\200\212\351\242\206\345\237\237\347\211\271\345\256\232\350\257\255\350\250\200\343\200\213-\350\257\273\344\271\246\347\254\224\350\256\260.md"
@@ -292,7 +292,7 @@ events
doorClosed D1CL
```
- 会创建一个新的事件对象(`new Event("doorClosed","D1CL")`),把它保存在一边(在一个 “符号表”(第14章)里),这样,遇到`doorClosed=>active`时,就可以将它包含在一个转换里(使用`addTransition`)。这个模型就是个引擎,它提供了状态机的行为。事实上,可以说,这个设计的能力大多源自这样一个模型。如图1-4所示,**DSL所做的一切就是提供一种更可读的方式来组装这个模型**——这就是与开始的命令查询API不同的地方。
+ 会创建一个新的事件对象(`new Event("doorClosed","D1CL")`),把它保存在一边(在一个 “符号表”(第14章)里),这样,遇到`doorClosed=>active`时,就可以将它包含在一个转换里(使用`addTransition`)。这个模型就是个引擎,它提供了状态机的行为。事实上,可以说,这个设计的能力大多源自这样一个模型。如图1-4所示,**DSL所做的一切就是提供一种更可读的方式来组装这个模型**——这就是与开始的命令-查询API不同的地方。
从DSL的角度来看,我把这个模型称为“语义模型”(第11章)。**谈及编程语言时,我们常常会提及语法(syntax)和语义(semantics)。语法描述程序的合法表达式,而在定制语法的DSL里所能描述的一切是由文法(grammar)决定的**。程序的语义是指,它代表着什么,也就是说,当执行时,它能做什么。在这个例子里,模型定义了语义。如果你习惯使用Domain Model [Fowler PoEAA] ,这里就可以认为语义模型是与之非常类似的东西。
@@ -315,3 +315,1667 @@ events
在讨论这个例子时,我采用的流程是:**首先构建模型,然后在此基础之上,用DSL封装出一个层次,对其进行操作**。之所以用这种方式进行描述,是因为我觉得这是一种简单的方式,有助于理解DSL如何用于软件开发。虽然模型优先的情况很常见,但它并不是唯一方式。在不同的场景下,我们可能会与领域专家交谈,假定他们可以理解状态机方式。稍后,我们和他们一起工作,创建出他们可以理解的DSL。在这种情况下,DSL和模型可以同步构建。
## 1.5 使用代码生成
+
+ DSL的处理可以分为解释和编译两种方式。
+
+ 前面的DSL讨论主要为“解释”的形式。处理DSL,组装“语义模型”(第11章),然后执行语义模型,提供我们希望从控制器得到的行为。在解释文本时,会先解析文本,然后程序立刻产生结果。(这里严格限制为立即执行的形式。)
+
+ 在语言领域里,与解释相对的是编译。在编译(compilation)时,先解析程序文本,产生中间输出,然后单独处理输出,提供预期行为。在DSL的上下文里,编译方式通常指的是代码生成(code generation)。
+
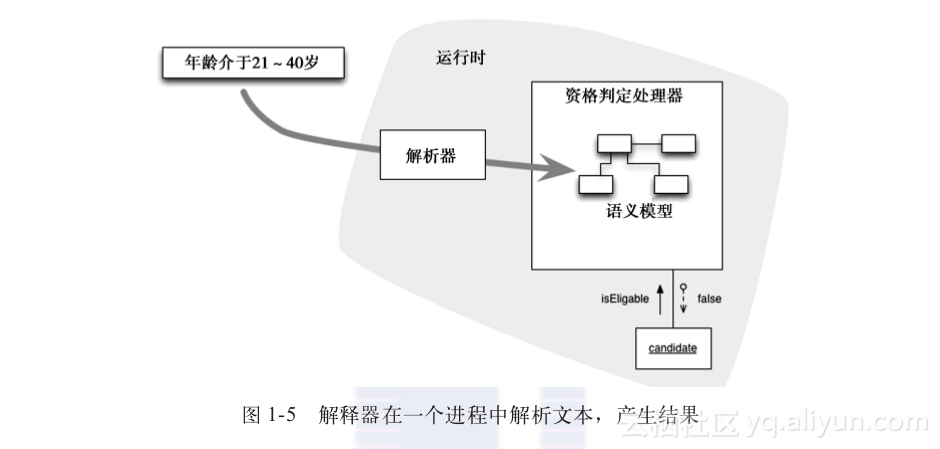
+ 用状态机解释这个差异有点困难,因此,换用另外一个小例子。想象一下,有某种规则判定人们是否符合某种资格,也许是为了满足保险资格。比如,如图1-5所示,一个规则是年龄在21~40岁。这个规则可以是一个DSL,检查像我这样的候选人是否具备资格。
+
+ 如果解释,资格判定处理器会解析规则,在执行时加载语义模型,也许是启动时加载。当检查某个候选人时,它会对这个候选人运行语义模型,获得一个结果。
+
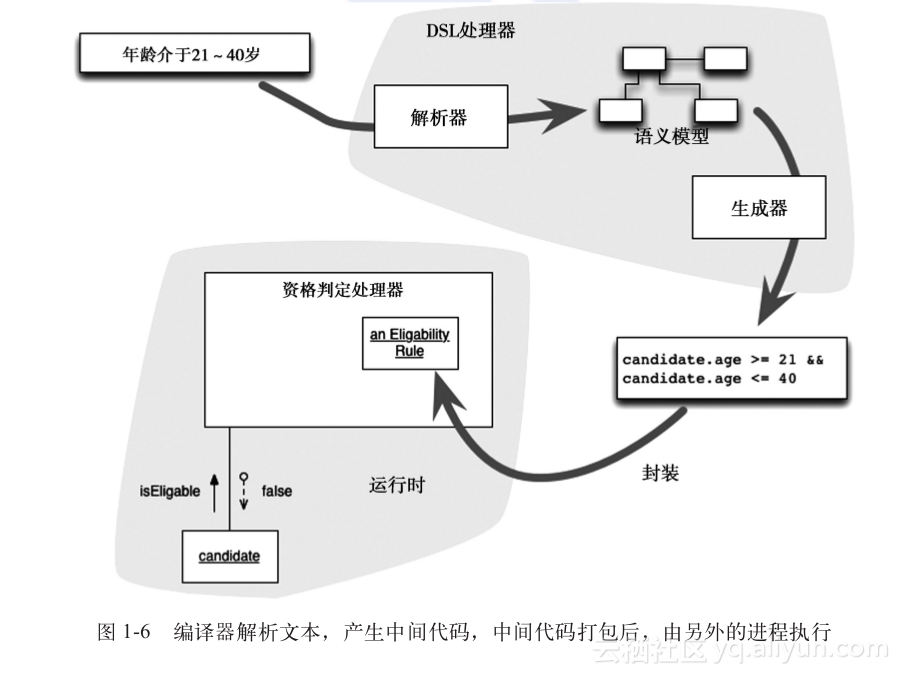
+ 如图1-6所示,在编译的情况下,解析器会加载语义模型,把它当做资格-判定处理器构建过程的一部分。在构建期间,DSL处理器会产生一些代码,这些代码经过编译、打包,并且纳入资格判定处理器,也可能当做某种共享库。然后,运行这段中间代码,对候选人进行评估。
+
+
+
+
+
+
+
+ 例子里的状态机使用的是解释:在运行时解析配置代码,并组成语义模型。但其实也可以生成一些代码,以免在烤面包机里出现解析器和模型代码。
+
+ 代码生成通常很笨拙,因为它常常需要进行额外的编译步骤。为了构建程序,首先需要编译状态框架和解析器,其次运行解析器,为格兰特小姐的控制器生成源代码,然后编译生成的代码。这样做,构建过程就变得复杂许多。
+
+ 然而,**代码生成的一个优势在于,编写解析器和生成代码可以用不同的语言**。在这个情况下,如果生成代码用的是动态语言,比如JavaScript或是JRuby,第二个编译步骤就可以省略。
+
+ 如果所用DSL的语言平台缺乏支持DSL的工具,代码生成的作用也会凸显出来。比如,我们不得不在一些老式的烤面包机上运行这个安全系统,而它们又只能理解编译过的C,那我们可以这样做,实现一个代码生成器,使用组装的语义模型作为输入,产生可以编译为运行在老式烤面包机的C代码。在最近做的一些项目里,我们曾为MathCAD、SQL和 COBOL等生成代码。
+
+ 代码生成仅仅是一种实现机制,应该仅在需要时使用。
+
++ 仅简单场景可考虑选择直接放弃语义模型的步骤,直接使用代码生成完成DSL
++ 大多数情况建议保留语义模型,既可以用解释模型,也可以选择代码生成。在本书的大部分内容里,假设存在一个语义模型,它是DSL工作的核心。
+
+ **语义模型的存在,可以将解析、执行语义以及代码生成分开。整个活动会因为这个划分变得简单许多**。它也给了我们改变自己想法的机会; 比如,无须修改代码生成的例程就可以把内部DSL改成外部DSL。类似地,
+
+ 常见的代码生成风格有两种。
+
++ 生成代码模版,且往往需要继续手动修改
++ 生成代码且一般需要再手动修改
+
+ 本书认为DSL应该倾向于第二种代码生成风格,保证每次修改DSL都可以简单重新生成正确的代码而不需人工干预再修改。且最好保证生成的代码和手动写的代码能够互相调用。
+
+## 1.6 使用语言工作台
+
+ 语言工作台,设计初衷即帮助人们构建新的DSL。语言工作台不仅让定义解析器变得简单,而且让为这门语言定制一个编辑环境变得简单。
+
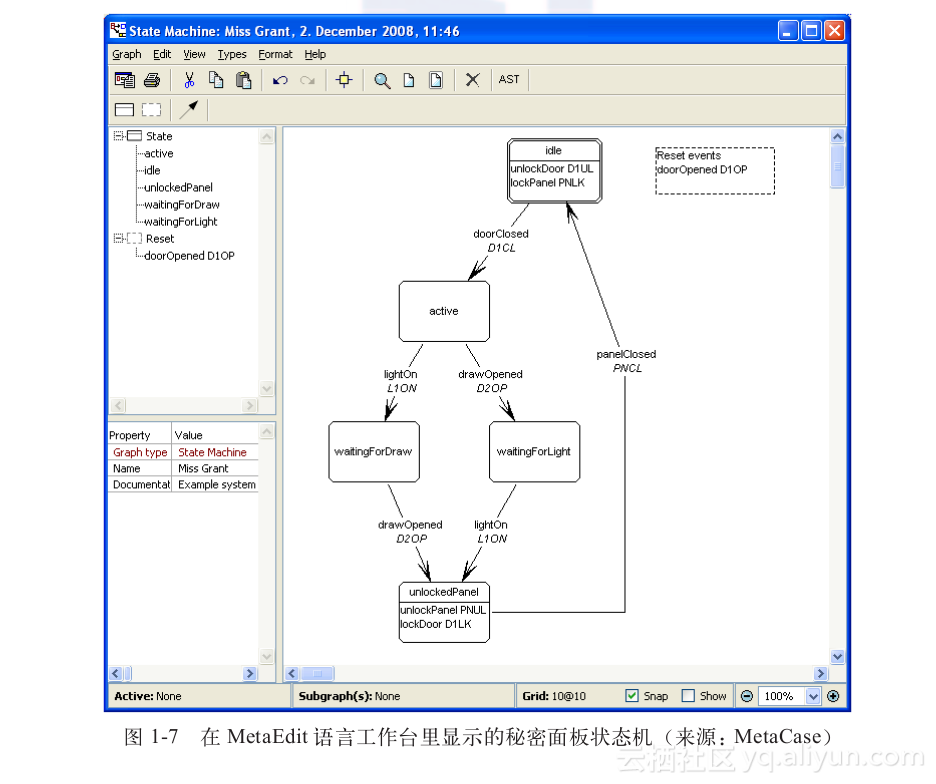
+ 语言工作台让DSL设计者从传统的基于文本的源码编辑走向不同形式的语言。最明显的一个例子就对图表语言的支持,我们可以通过状态转换图直接指定秘密面板状态机,见图1-7。
+
+ 类似于这样的工具不仅可以定义图表语言,还可以从不同的角度来查看DSL脚本。
+
+
+
+ 许多工具都有这种多窗格的可视化编辑环境,但是自己打造一个这样的东西需要很大的工作量。语言工作台要做的一件事就是,让这件事做起来变得相当容易。确实,我第一次上手MetaEdit这个工具,就能很快得到像图1-7这样的一个例子。这个工具可以让我为状态机定义语义模型,定义图形化和表格化的编辑器,像图1-7这样,然后根据语义模型编写代码生成器。
+
+ 第二个有趣的因素称为说明性编程(illustrative programming)的东西。看一下电子表格,最为可视化的东西并不是可以进行所有计算的公式;而是构成样本计算的数字。这些数字是一个图示,展现了程序执行时所做的工作。在大多数编程语言里,程序是至关重要的,只有在运行测试时,才关注其输出。在电子表格里,至关重要的是输出,只有在单击单元格时,我们才会看到其程序。
+
+ 语言工作台支持开发类似于这些全新编程平台。因此,我认为,它们所产生的DSL可能更接近于电子表格,而非我们通常理解的DSL(也就是本书要讨论的内容)。
+
+## 1.7 可视化
+
+ 语言工作台的一大优势在于它们给了DSL更为多样的表现形式,特别是图形化表示。然而,即便是文本化的DSL也可以有图形化的表示。确实,我们在本章中非常早就看到这些内容。当查看图1-1时,你也许已经注意到了,这个图并不像我以往所画的那些图那样整洁。原因在于,这并不是我画的图,而是我根据格兰特小姐控制器的“语义模型”(第11章)自动生成的。状态机类不仅可以执行,还可以用DOT语言对自身进行渲染。
+
+ DOT语言是Graphviz包的一部分,它是一个开源工具,可以用它描述数学里的图结构(节点和边),然后自动画出来。只要告诉它,什么是节点,什么是边,用什么样的形状,以及其他一些提示,它就会算出如何对这个图进行布局。
+
+ 对许多DSL来说,使用类似于Graphviz这样的工具非常有用,因为它给了我们另一种表现形式。类似于DSL本身,这种可视化(visualization)表现形式可以让人更好地理解模型。可视化不同于对应的源码,其本身无法编辑─但是,另一方面,它可以完成可编辑形式无法完成的操作,比如渲染出那样的图。
+
+ 可视化并不一定要图形化。当编写解析器时,我时常用简单的文本可视化帮我调试。我见过有人用Excel生成可视化的东西,帮助他们与领域专家交流。重点在于,一旦经过辛勤工作创建出语义模型,添加可视化真的就很容易。注意,可视化是根据模型产生的,而非DSL,因此,即便不用DSL组装模型,依旧可以这么做。
+
+# 第2章 使用DSL
+
+## 2.1 定义DSL
+
+ “领域特定语言”是一个很有用的术语和概念,但其边界很模糊。
+
+ **领域特定语言(名词)**: 针对某一特定领域,具有受限表达性的一种计算机程序设计语言。
+
+ 这一定义包含4个关键元素:
+
++ 计算机程序设计语言(computer programming language):人们用DSL指挥计算机去做一些事。同大多数现代程序设计语言一样,其结构设计成便于人们理解的样子,但它应该还是可以由计算机执行的语言。
++ 语言性(language nature):DSL是一种程序设计语言,因此它必须具备连贯的表达能力─不管是一个表达式还是多个表达式组合在一起。
++ 受限的表达性(limited expressiveness):通用程序设计语言提供广泛的能力:支持各种数据、控制,以及抽象结构。这些能力很有用,但也会让语言难于学习和使用。DSL只支持特定领域所需要特性的最小集。使用DSL,无法构建一个完整的系统,相反,却可以解决系统某一方面的问题。
+
++ 针对领域(domain focus):只有在一个明确的小领域下,这种能力有限的语言才会有用。这个领域才使得这种语言值得使用。
+
+ DSL主要分为三类:外部DSL、内部DSL,以及语言工作台。
+
++ 外部DSL是一种“不同于应用系统主要使用语言”的语言。外部DSL通常采用自定义语法,不过选择其他语言的语法也很常见(XML就是一个常见选择)。宿主应用的代码会采用文本解析技术对使用外部DSL编写的脚本进行解析。一些小语言的传统UNIX就符合这种风格。可能经常会遇到的外部DSL的例子包括:正则表达式、SQL、Awk,以及像Struts和Hibernate这样的系统所使用的XML配置文件。
++ 内部DSL是一种通用语言的特定用法。用内部DSL写成的脚本是一段合法的程序,但是它具有特定的风格,而且只用到了语言的一部分特性,用于处理整个系统一个小方面的问题。用这种DSL写出的程序有一种自定义语言的风格,与其所使用的宿主语言有所区别。这方面最经典的例子是Lisp。Lisp程序员写程序就是创建和使用DSL。Ruby社区也形成了显著的DSL文化:许多Ruby库都呈现出DSL的风格。特别是,Ruby最著名的框架Rails,经常被认为是一套DSL。
++ 语言工作台是一个专用的IDE,用于定义和构建DSL。具体来说,语言工作台不仅用来确定DSL的语言结构,而且是人们编写DSL脚本的编辑环境。最终的脚本将编辑环境和语言本身紧密结合在一起。
+
+ 另一种看待DSL的方式是:把它看做一种处理抽象的方式。在软件开发中,我们经常会在不同的层面上建立抽象,并处理它们。建立抽象最常见的方式是实现一个程序库或框架。**操纵框架最常见的方式是通过命令/查询式API调用**。从这种角度来看,DSL就是这个程序库的前端,它提供了一种不同于命令/查询式API风格的操作方式。在这样的上下文中,程序库成了DSL的“语义模型”(第11章),因此,DSL经常伴随着程序库出现。事实上,我认为,**对于构建良好的DSL 而言,语义模型是一个不可或缺的附属物**。
+
+ 谈及DSL,人们很容易觉得构造DSL很难。实际上,通常是难在构造模型上,DSL只是位于其上的一层而已。虽然让DSL 工作良好需要花费一定的精力,但相对于构建底层模型,这一部分的付出要少多了。
+
+### 2.1.1 DSL的边界
+
+### 2.1.2 片段DSL和独立DSL
+
++ 片段DSL:比如SQL、正则表达式等,通常配合宿主语言使用,达到增强的效果。
++ 独立DSL:比如前面提到的状态机DSL,只要拿对应的DSL脚本(通常独立的一个文件),即使不了解宿主语言,也能理解DSL描述的信息。
+
+## 2.2 为何需要DSL
+
+ DSL通常只是模型的一层薄壳,模型可以是程序库或框架。
+
+### 2.2.1 提高开发效率
+
+1. 可读性强
+2. 提高开发效率:DSL通常伴随模型,而模型往往是可复用或某类功能的通用实现
+
+ 我还遇到过一个有趣的例子,使用DSL封装一个棘手的第三方程序库。当命令–查询接口设计得很糟糕时,DSL 惯常的连贯性就得以凸现。此外,DSL只须支持客户真正用到的部分,这大大降低了客户开发人员学习的成本。
+
+### 2.2.2 与领域专家的沟通
+
+ 领域专家一般不懂编程,但是如果有一套易读的DSL,则可以促进领域专家和程序员的交流。
+
+ 假设有一套可视化的DSL用来表达广告物料的送审规则,那么业务产品可以通过图形化界面定制送审规则,或者说可以通过UI一眼看懂目前的送审规则,而不需要程序员介入解释相关代码。
+
+### 2.2.3 执行环境的改变
+
+ 在一些情况,希望将代码运行到不同环境,而DSL可以实现这点。比如使用XML配置文件,将逻辑从编译时移到运行时。
+
+### 2.2.4 其他计算模型
+
+ 几乎所有主流的编程语言都采用命令式的计算模型。这意味着,我们要告诉计算机做什么事情,按照怎样的顺序来做。通过条件和循环处理控制流,还要使用变量─确实,还有很多我们以为理所当然的东西。命令式计算模型之所以流行,是因为它们相对容易理解,也容易应用到许多问题上。然而,它并不总是最佳选择。
+
+ 状态机是这方面的一个良好例子。可以采用命令式代码和条件处理这种行为,也确实可以很好地构建出这种行为。但如果直接把它当做“状态机”来思考,效果会更好。另外一个常见的例子是,定义软件构建方式。我们固然可以用命令式逻辑实现它,但后来,人们发现用“依赖网络”(第49章)(比如,运行测试必须依赖于最新的编译结果)解决会更容易。结果,人们设计出了专用于描述构建的语言(比如Make和Ant),其中将任务间的依赖关系作为主要的结构化机制。
+
+ 你可能经常听到,人们把非命令式方式称为声明式编程。之所以叫做声明式,是因为这种风格让人定义做什么,而不是用一堆命令语句来描述怎么做。
+
+ 采用其他计算模型,并不一定非要有DSL。其他编程模型的核心行为也源自“语义模型”(第11章),正如前面所讲的状态机。然而,DSL还是能够带来很大的转变,因为操作声明式程序,组装语义模型会容易一些。
+
+## 2.3 DSL的问题
+
+### 2.3.1 语言噪音
+
+ 相对于理解模型而言,学习DSL 所增加的成本相当小。确实,因为DSL的的价值就在于,让人们理解和使用模型更容易,所以使用DSL就应该能降低学习成本。
+
+ 一般来说不需要为了DSL而另外精通一门语言,如果用其他语言实现DSL,重点也应该在如何实现DSL上,而不是在语言本身。
+
+### 2.3.2 构建成本
+
++ DSL封装需要代码实现
++ DSL对应的解释器需要开发
+
+除非确实有必要,不然不要为了构建DSL而特定进行DSL开发。
+
+### 2.3.3 集中营语言
+
+ 集中营语言(ghetto language)问题与语言噪音问题正好相反。比如,一家公司用一种内部语言编写公司内的很多系统,这种语言在其他地方根本用不上。这种做法会让他们很难找到新人,跟上技术变化。
+
+ 使用DSL时需要明确使用范围,而不是无限制地在DSL上一直扩张特性,徒增维护成本。
+
+ 如果有些功能已经有成熟的实现,比如对象-关系映射(object-relational mapping),则应该考虑直接使用现成实现,而不是再造轮子。
+
+### 2.3.4 "一叶障目"的抽象
+
+ 如同对待任何抽象一样,应该视DSL为一种“不断演化,尚未完结”的事物。
+
+ 避免出现为了强行套用现有DSL,而把代码/业务改得面目全非的情况。有时候就是该适当迭代升级DSL以支持后续的需求。
+
+## 2.4 广义的语言处理
+
+## 2.5 DSL的生命周期
+
+ 基于模型发展DSL的方法有两种。对于“语言生长”(language–seeded)的方式,要慢慢地在模型之上构建DSL,把模型几乎视为黑盒。首先看看目前所有的控制器,然后草拟出每个控制器的伪DSL。然后,就像前面提及的情况那样,一个场景一个场景地实现DSL,通常,我们不会对模型做任何深入的修改,尽管给模型添加一些方法能够更好地支持DSL。
+
+ 对于“模型生长”(model–seeded)的方式,要先给模型加入一些连贯方法(fluent method),让模型更易于配置,然后逐渐把它们抽成DSL。这种方式更适用于内部DSL,可以视之为模型的一次重量级重构,派生出内部DSL。“模型生长”的方式最吸引人的方面在于,它是逐步进行的,构建DSL并不需要显著的成本。
+
+ 当然,在很多情况下,我们甚至连框架都没有。写了几个控制器之后,我们才意识到,有很多通用功能。然后,就会重构系统,拆分模型与控制代码。这个拆分是至关重要的一步。虽然做这件事时,脑海中已经有了DSL,但我依然倾向于首先完成拆分,然后在其上构建DSL。
+
+## 2.6 设计优良的DSL从何而来
+
++ 迭代设计,从目标受众获取返回,持续迭代
++ 不需要刻意设计得像是自然语言,徒增开发复杂度
+
+# 第3章 实现DSL
+
+## 3.1 DSL处理之架构
+
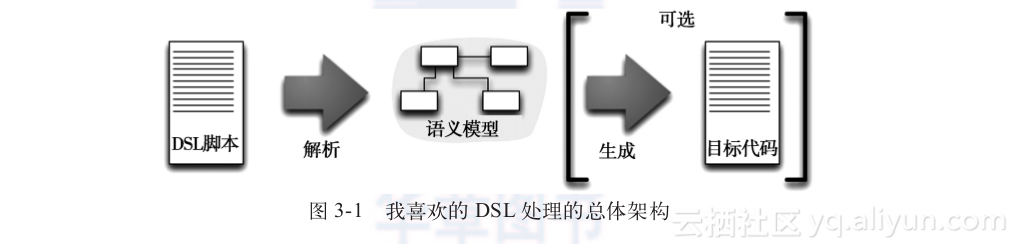
+ 关于DSL实现的大体结构(见图3-1),也就是所谓的DSL系统架构─可能是我们要谈论的最重要的内容之一。
+
+
+
+ 迄今为止,你应该已经厌倦了听我说了无数次的“DSL是模型上面薄薄的一层结构”。这里所说的“模型”,称为“语义模型”(第11章)模式。这个模式背后的概念是:所有重要的语义行为都可以在模型中捕获,而DSL的任务就是通过解析来填充模型。所以,根据我的理解,语义模型在DSL中扮演着核心角色─事实上,全书都会首先假设,我们在使用语 义模型。(当然,在本节的最后,在我们有足够的上下文去讨论它们的章节,我会谈谈语义模型的替代方案。)
+
+ 很多系统都使用Domain Model [Fowler PoEAA]捕获系统的核心行为,而且通常DSL就是负责组装Domain Model的重要部分,但我依然坚持把Domain Model和语义模型区分开。DSL的语义模型通常是一个系统的Domain Model的子集,因为并不是Domain Model的所有部分都适合用DSL处理。另外,DSL的任务不仅仅是填充Domain Model,它还用于 其他任务。
+
+ 语义模型完全就是一个普通的对象模型,可以像操作其他所有对象模型一样操作它。在前面关于状态(state)的例子中,用状态模型的命令–查询API组装一个状态机,然后运行它,获取状态对象的行为。从某种意义上说,它与DSL是相互独立的,但在现实中,它们又是焦不离孟,孟不离焦。
+
+## 3.2 解析器的工作方式
+
+ 所以,内部DSL和外部DSL的差别主要体现在解析上。虽然二者确实存在一些细节上的不同,但它们也有很多共通之处。
+
+ 一个最重要的共同点就是,解析都是一个很强的层级操作。当解析文本时,把数据块组织成一个树结构。考虑一个简单结构,状态机中的事件列表。在外部DSL语法中,它看起来如下所示:
+
+```
+events
+ doorClosed D1CL
+ drawerOpened D2OP
+end
+```
+
+ 这个复合结构是一个事件列表,包含一系列事件,每个事件都有名字和代码。
+
+ 用Ruby编写的内部DSL与上述代码很类似:
+
+```
+event :doorClosed "D1CL"
+event :drawerOpened "D2OP"
+```
+
+ 对于整个列表,这里没有显式的标记,但是每一个事件本身仍是一个层级:每个事件都有表示名字的符号和表示代码的字符串。
+
+ 无论何时看到这样的脚本,都可以把它想象为一个层级,这样的层级称为**语法树(或者解析树)**。任何脚本都可以转化为许多潜在的语法树─这取决于如何分解它。相对于单词(word),语法树是一种更有效的脚本表现形 式,因为可以遍历语法树,使用各种不同的方式来对它进行操作。
+
+ **如果用到“语义模型”(第11章),可以把一个语法树翻译成语义模型(见图3-2**)。如果经常读一些语言社区的资料,我们会发现,语法树得到了非常多的关注——人们通常直接执行语法树,或者基于语法树生成代码。更有效的做法是,语法树可以直接当做语义模型来使用。但大多数时候,我不会这么做,因为语法树同DSL脚本关联非常紧密,这样做只会让DSL的处理同语法产生耦合。
+
+
+
+## 3.3 文法、语法和语义
+
+ 如果要处理一种语言的语法,文法是一种很重要的工具。文法是一组规则,用以描述如何将文本流转化为语法树。大多数程序员都会在生命中的某一刻接触文法,因为文法常用以描述我们日常使用的程序设计语言。**文法由一系列产生式规则组成,每个生产规则都有一个名字(term)以及一个描述如何分解它的语句(statement)**。所以,一个加法语句可能看起来就像这样: `additionStatement:=number'+'number`。它告诉我们,如果遇到语句`5+3`,解析器能够将其识别为加法语句。因为规则是可以相互引用的,所以也会有一条针对数字的规则,告诉我们如何识别合法数字。通过这些规则,我们就可以得到一种语言的文法。
+
+ 一种语言可以由多种不同的文法来定义,认识到这点很重要。世界上不存在某种语言的唯一文法。一种文法就定义了语言所生成语法树的一种结构,对于一段特定的文本,可能会识别出许多不同的语法树结构。一种文法只定义一种形式的语法树;选择何种文法和语法树取决于很多因素,包括语言的文法特性以及处理语法树的方式等。
+
+ 文法只定义一种语言的语法——它在语法树中如何表现。而这与语义(也就是表达式的含义)无关。根据上下文不同,5+3可能等于8,也可能等于53,语法相同,但语义可能截然不同。在“语义模型”(第11章)中,语义的定义浓缩为如何根据语法树组装语义模型,以及如何处理语义模型。特别是,如果两个表达式产生相同结构的语义模型,即使语法不同,它们的语义其实也是相同的。
+
+ 如果在使用外部DSL,特别是,用到了“语法指导翻译”(第18章),我们很可能会显式地使用文法来构建解析器。如果用的是内部DSL,可能没有显式的文法,但是从文法的角度思考DSL仍然是有用的,文法有助于我们在众多内部DSL模式中进行选择。
+
+ 对于内部DSL,谈论文法显得有些奇怪,原因之一是,这里解析了两遍,所以包含了两种文法。第一种是宿主语言本身的解析,这显然要依赖于宿主语言的文法。这一遍解析创建宿主语言的执行指令。当宿主语言所构建的DSL执行时,鬼魅般的语法树就会在调用栈中创建。只有在第二遍解析时,才会出现这个名义上的DSL语法。
+
+## 3.4 解析中的数据
+
+ 当解析器执行时,它需要存储解析过程中的数据。这些数据可能是一个完整的语法树,但大多数情况下不是这样的。即使这种情况出现了,还是需要存储其他的一些数据,以便解析工作可以正常进行。
+
+ 解析本质上是一种树遍历(见图3-3),当处理某一部分DSL脚本时,对于正在处理的语法树分支,我们可以得到其上下文的一些相关信息。然而,通常我们还会用到这个分支以外的信息。我们再从状态机的例子里选取一段代码看看:
+
+```pseudocode
+commands
+ unlockDoor D1UL
+end
+
+state idle
+ actions {unlockDoor}
+end
+```
+
+ 我们在这里看到了一种常见的情况:命令定义在语言的某个地方,然后在其他地方引用。当命令在语句的行为中引用时,我们所在的语法树分支不同于命令定义的分支。如果语法树的表示只存在于调用栈中,那么到这里,命令定义就已经消失了。因此,要把命令对象保存下来以备后用,这样,在行为代码中就可以引用了。
+
+
+
+ 为了做到这一点,我们用到了“**符号表**”(第12章),它本质上是一个字典,其键是标识符unlockDoor,值是在解析中表示命令的对象。当处理文本`unlockDoor D1UL`时,创建一个对象持有数据,然后,把它存放在符号表里,键为unlockDoor。存放的对象可能是命令的语义对象,也可能针对局部语法树的中间对象。稍后,当处理`actions {unlockDoor}`时,我们会通过符号表查找这个对象,以获得状态同行为之间的关系。因此,符号表对于交叉引用至关重要。如果在解析中创建一棵完整的语法树,理论上,可以省略符号表,虽然通常它依然是一个有用的结构,可以把事物关联起来。
+
+ 当进行解析时,要保存结果。有时,所有结果都可以放到符号表里;有时,许多信息要保存在调用栈里;还有时,要在解析器里有额外的数据结构。在所有这些情况里,最明显要做的一件事是,创建“语义模型”(第11章)对象保存结果。然而,在很多情况下,要到解析的最后时刻才能创建语义模型,所以,还要创建一些中间对象。对于这种中间对象,一个常见的例子是“构造型生成器”(第14章),它是一个对象,包含语义模型所需的全部数据。如果语义模型在创建后就是只读的,这种做法就非常有用了,可以在解析过程中逐步地为它收集数据。构造型生成器拥有同语义模型一样的字段,但这些字段是可读写的,这样,就有地方保存数据了。一旦有了所有数据,就可以创建语义模型对象了。使用构造型生成器会让解析器变得复杂,但相比于改变语义模型的只读属性,我宁愿选择这么做。
+
+ 事实上,有时候,我们会在处理完所有DSL脚本时,再创建语义模型对象。在这种情况下,解析就会有不同的阶段:首先,读取DSL脚本,创建中间的解析数据,其次,处理中间数据,组装语义模型。在文本处理阶段做多少工作,后面做什么,这取决于语义模型如何组装。
+
+ 表达式的解析方式取决于我们处理的上下文。查看下面这段文本:
+
+```pseudocode
+state idle
+ actions {unlockDoor}
+end
+
+state unlockedPanel
+ actions {lockDoor}
+end
+```
+
+ 当处理`actions {lockDoor}`时,有一点很重要,它处于unlockedPanel状态的上下文中,而非空闲态。通常,解析器构建以及遍历解析树的方式,就提供了这个上下文,但还有很多情况,很难做到这一点。如果检查解析树无法获得上下文,那么一种好的做法就是,持有上下文,对于这个例子,我们可以把当前状态保存在一个变量里。我将这种变量称为“语境变量”(第13章)。这种语境变量类似于符号表,可以持有语义模型对象,或者一些中间对象。
+
+ 虽然语境变量用起来很简单,但一般来说,我倾向于尽可能避免使用。语境变量会让解析代码难于理解,正如大量的可变变量会让过程式代码变得复杂。当然,肯定会有无法避免使用语境变量的情况,但我更倾向于将其视为应该避免的坏味道。
+
+## 3.5 宏
+
+ “宏”(第15章)是一种工具,既可以用于内部DSL,也可以用于外部DSL。
+
+ 宏有两种风格:文本宏和语法宏。文本宏最容易理解,简单说就是文本替换。
+
+ 更复杂的宏还可以有参数。一个经典的例子是C的预处理器,比如,定义一个宏sqr(x),它可以替换为`x*x`。
+
+ 文本宏存在一些问题,所以业界并不受欢迎。
+
+ 语法宏也是通过替换实现的,但是它处理的是宿主语言中有效的元素,将一种表达式转换为另一种。在以“大量使用语法宏”而闻名的语言中,Lisp最为著名,虽然C++模板更广为人知。使用语法宏编写DSL,是Lisp编写内部DSL 的核心技术,但这种技术也仅限于支持宏的语言。因此,本书不会过多谈及,因为仅有很少的语言可以支持宏。
+
+## 3.6 测试DSL
+
+### 3.6.1 语义模型的测试
+
+ 我首先想到的部分是“语义模型”(第11章)的测试。这些测试用来保证语义模型能够如预期般工作,也就是说,当执行模型时,根据编写的代码,它能够产生正确的输出。这是一个标准的测试实践,同测试任何框架里的对象一样。对于这种测试,根本无需DSL。使用模型本身的基本接口就可以组装模型。这种做法很好,因为可以独立测试模型,无须DSL和解析器。
+
+ 我们用秘密面板控制器说明这种做法。在这个例子中,语义模型就是状态机。下面测试语义模型,用1.3节的例子提及的命令–查询API组装模型,无需任何DSL。
+
+```java
+@Test
+public void event_causes_transition() {
+ State idle = new State("idle");
+ StateMachine machine = new StateMachine(idle);
+ Event cause = new Event("cause", "EV01");
+ State target = new State("target");
+ idle.addTransition(cause, target);
+ Controller controller = new Controller(machine, new CommandChannel());
+ controller.handle("EV01");
+ assertEquals(target, controller.getCurrentState());
+}
+```
+
+ 上面的代码演示了如何独立测试语义模型。然而,需要说明的是,这个例子的真实测试代码会更复杂,也应该更好地分解。
+
+ 有两种方法来分解这类代码。首先,创建一堆小的状态机,提供最小的测试夹具,以便测试语义模型的各种特性。比如,要测试**“事件触发转换”(event triggers a transition)**,只要创建一个简单状态机,它处于空闲态,并且可以转换(transition)为另外两个状态。
+
+```java
+class TransitionTester...
+ State idle, a, b;
+Event trigger_a, trigger_b, unknown;
+
+protected StateMachine createMachine() {
+ idle = new State("idle");
+ StateMachine result = new StateMachine(idle);
+ trigger_a = new Event("trigger_a", "TRGA");
+ trigger_b = new Event("trigger_b", "TRGB");
+ unknown = new Event("Unknown", "UNKN");
+ a = new State("a");
+ b = new State("b");
+ idle.addTransition(trigger_a, a);
+ idle.addTransition(trigger_b, b);
+ return result;
+}
+```
+
+### 3.6.2 解析器的测试
+
+ 当使用“语义模型”(第11章)时,解析器的工作就是组装语义模型。所以,解析器的测试就是,编写一小段DSL,确保它们生成结构正确的语义模型。
+
+```java
+@Test
+public void loads_states_with_transition() {
+ String code =
+ "events trigger TGGR end " +
+ "state idle " +
+ "trigger => target " +
+ "end " +
+ "state target end ";
+ StateMachine actual = StateMachineLoader.loadString(code);
+
+ State idle = actual.getState("idle");
+ State target = actual.getState("target");
+ assertTrue(idle.hasTransition("TGGR"));
+ assertEquals(idle.targetState("TGGR"), target);
+}
+```
+
+ 这样使用语义模型不太合适,而且可能破坏语义模型对象的封装。所以,还有一种方法是,定义一些方法,比较语义模型,使用这些方法来测试解析器的输出。
+
+```java
+@Test
+public void loads_states_with_transition_using_compare() {
+ String code =
+ "events trigger TGGR end " +
+ "state idle " +
+ "trigger => target " +
+ "end " +
+ "state target end ";
+ StateMachine actual = StateMachineLoader.loadString(code);
+
+ State idle = new State("idle");
+ State target = new State("target");
+ Event trigger = new Event("trigger", "TGGR");
+ idle.addTransition(trigger, target);
+ StateMachine expected = new StateMachine(idle);
+
+ assertEquivalentMachines(expected, actual);
+}
+```
+
+ 相比于常规的相等性判定,复杂结构的相等性判定更为复杂。要了解对象之间的具体差异,一个布尔(Boolean)类型的答案是远远不够的。所以,要用“通知”(第16章)进行比较。
+
+```java
+class StateMachine...
+ public Notification probeEquivalence(StateMachine other) {
+ Notification result = new Notification();
+ probeEquivalence(other, result);
+ return result;
+ }
+
+ private void probeEquivalence(StateMachine other, Notification note) {
+ for (State s : getStates()) {
+ State otherState = other.getState(s.getName());
+ if (null == otherState) note.error("missing state: %s", s.getName()) ;
+ else s.probeEquivalence(otherState, note);
+ }
+ for (State s : other.getStates())
+ if (null == getState(s.getName())) note.error("extra state: %s", s.getName());
+ for (Event e : getResetEvents()) {
+ if (!other.getResetEvents().contains(e))
+ note.error("missing reset event: %s", e.getName());
+ }
+ for (Event e : other.getResetEvents()) {
+ if (!getResetEvents().contains(e))
+ note.error("extra reset event: %s", e.getName());
+ }
+ }
+class State...
+ void probeEquivalence(State other, Notification note) {
+ assert name.equals(other.name);
+ probeEquivalentTransitions(other, note);
+ probeEquivalentActions(other, note);
+ }
+
+ private void probeEquivalentActions(State other, Notification note) {
+ if (!actions.equals(other.actions))
+ note.error("%s has different actions %s vs %s", name, actions, other.actions);
+ }
+
+ private void probeEquivalentTransitions(State other, Notification note) {
+ for (Transition t : transitions.values())
+ t.probeEquivalent(other.transitions.get(t.getEventCode()), note);
+ for (Transition t : other.transitions.values())
+ if (!this.transitions.containsKey(t.getEventCode()))
+ note.error("%s has extra transition with %s", name, t.getTrigger());
+ }
+```
+
+ 这种检测方式就是遍历语义模型中的对象,然后把差异记录在通知中。这样,就可以找出所有的差异,而不是找到 第一个就停下来。断言只要检查通知中是否有错误即可。
+
+```java
+class AntlrLoaderTest...
+ private void assertEquivalentMachines(StateMachine left, StateMachine right) {
+ assertNotificationOk(left.probeEquivalence(right));
+ assertNotificationOk(right.probeEquivalence(left));
+ }
+
+ private void assertNotificationOk(Notification n) {
+ assertTrue(n.report(), n.isOk());
+ }
+
+class Notification...
+ public boolean isOk() {return errors.isEmpty();}
+```
+
+ 你可能会认为我是一个偏执狂,要从两个方向进行相等性断言,但事实上,代码经常会出乎所料。
+
+**无效输入的测试**
+
+ 刚才讨论的是正向测试,保证有效的DSL输入可以生成结构正确的“语义模型”(第11章)。测试的另一种类别是负向测试,用于检测在无效输入的情况下会发生什么。这还会涉及错误处理和诊断等技术,这些内容超出了本书的范围,但我还是要在这里简单地讨论对无效输入的测试。
+
+ 无效输入的测试的基本想法,就是把各式各样的无效输入抛给解析器。第一次进行这样的测试会非常有趣。我们经常会看到一些不起眼却很极端的错误。得到这样的结果可能已经足够了,除非我们要对错误诊断提供更多的支持。更糟糕的情况是,提供无效输入、解析,根本没有任何错误。这违反了“快速失败”(fail fast)原则─也就是说,错误应该尽快、尽可能明显地暴露出来。如果用无效状态组装一个模型,又没有任何检查,那么可能要到很晚才会发现问题。到了那个时候,原始的错误(加载无效输入)和后来的失败之间已然相去甚远,这段距离会让错误定位难上加难。
+
+### 3.6.3 脚本的测试
+
+## 3.7 错误处理
+
+## 3.8 DSL迁移
+
+# 第4章 实现内部DSL
+
+内部DSL,常见的实现语言有Ruby和Lisp。
+
+内部DSL有时候也被称为连贯接口,API与DSL之间的核心区别——语言性。
+
+## 4.1 连贯API与命令-查询API
+
+ 对于很多人而言,连贯接口的核心模式是“方法级联”(第35章)。普通的API看上可能是这样的:
+
+```java
+Processor p = new Processor(2, 2500, Processor.Type.i386);
+Disk d1 = new Disk(150, Disk.UNKNOWN_SPEED, null);
+Disk d2 = new Disk(75, 7200, Disk.Interface.SATA);
+return new Computer(p, d1, d2);
+```
+
+ 借助方法级联,同样的东西可以表达成这样:
+```java
+computer()
+ .processor()
+ .cores(2)
+ .speed(2500)
+ .i386()
+ .disk()
+ .size(150)
+ .speed(7200)
+ .sata()
+ .end();
+```
+
+ 命令-査询分离传递出一个信号:对象上的各种方法应该分为**命令类方法**与**查询类方法**。
+
++ 査询类方法:有返回值,但不会改变系统的可观察状态。
++ 命令类方法:可能会修改系统的可观察状态,但是不应该有返回值。
+
+ 这个原则非常重要,它可以帮助识别出查询类方法。由于查询类方法没有副作用,因此可以以任意顺序多次调用,而不改变调用结果。使用命令类方法,则要更谨慎一些,因为它们确确实实存在副作用。
+
+ 在程序设计中,命令-查询分离是一条极具价值的原则,我强烈鼓励团队这么做。在内部DSL中使用方法级联,结果却常常破坏该原则——每个方法都要修改状态后返回一个对象,以继续链式操作。我曾对不遵循命令-査询分离原则的人们大加嘲笑,而且还会继续这样做,但连贯接口遵循一套截然不同的规则,因此我乐于在此分享。
+
+ 命令-查询分离与连贯接口之间的另一重要区别是方法的命名。为命令一查询方法命名时,我们希望那些名字在独立的上下文中也有一定含义。通常,如果人们要査找某个方法,他们会快速浏览网页文档或者IDE菜单上的方法列表。所以,方法名称需要清晰地反映出方法在某个上下文中所做的事情——它们就是按钮上的标签。
+
+ 对于连贯接口,方法命名则非常不同。这里,我们会将更多的注意力放在构建完整的句子上,而对语言中的单个元素关注得较少。因此,我们往往会拥有一些方法,它们的名字在个开放的上下文中并没有什么意义,但放在DSL句子的上下文中,读起来却很连贯。DSL中的方法命名,首先要考虑的是句子,元素的命名都应适应其上下文。DSL的命名都是基脑海中特定DSL的上下文来编写的,而命令一査询的命名则是按照不需要上下文(或者在任意上下文中,二者其实是一样的)来撰写的。
+
+## 4.2 解析层的需求
+
+ 作者推荐在大多数情况编写一个表达式生成器,从而将DSL中的语言处理元素与普通的命令-查询对象分隔开。**表达式生成器对象的唯一任务就是,使用连贯接口构建普通对象的模型,从而将连贯的语句有效地翻译为一串命令-杳询API调用**。如果两种接口共存于一个类,则会让人产生迷惑。
+
+ 使用表达式生成器的原因之一自然是两种接口的本质不同,但是更主要的原因是经典的“**关注分离点**”的观点。
+
+ 有一种论调是反对使用表达式生成器的,但它只适用于语义模型自身使用了连贯接口(而非命令-査询接口)的情形。在有些情况下,连贯接口是人们与模型交互的主要方式,这时模型类使用连贯接口是有意义的。然而,**大多数情况下,我倾向于模型类使用命令-査询接口。命令-查询接口在不同上下文中的使用方式更为灵活。连贯接口则往往需要存储临时的解析数据。我尤其反对在同一个对象中混用连贯接口与命令-查询接口——太让人迷惑了**。
+
+ 总而言之,本书其余的部分将使用表达式生成器。我承认,并非所有情况都必须使用表达式生成器,但我的确认为,它适用于大多数的场景,所以后续的写作将以这个大多数为前提。
+
+## 4.3 使用函数
+
+ 命令-查询API往往表现为函数的形式。DSL结构也主要构件于函数基础之上。命令-查询API与DSL的主要区别在于函数组合的方式。把函数组合成DSL有很多模式。
+
+ 第一个方式是"方法级联"(第35章)
+
+```java
+computer()
+ .processor()
+ .cores(2)
+ .speed(2500)
+ .i386()
+ .disk()
+ .size(150)
+ .speed(7200)
+ .sata()
+ .end();
+```
+
+ 第二个方式是"函数序列"(第33章)
+
+```java
+computer();
+ processor();
+ cores(2);
+ speed(2500);
+ i386();
+ disk();
+ size(150);
+ disk();
+ size(75);
+ speed(7200);
+ sata();
+```
+
+ 既然存在组合函数的不同模式,很自然,随之而来的问题就是应该选择哪种模式。答案涉及不同的因素。第一个因素是函数作用域。如果用的是方法级联,DSL中的函数就是对象的方法,这些方法只能定义在链中的对象里,通常也就是“表达式生成器”(第32章)里。另外,如果在序列里使用裸函数,就要确保这些函数可以恰当地解决作用域问题。最显而易见的方式是使用全局函数,但是这么做会带来两个问题:让全局命名空间变得复杂,并为解析数据引入了全局变量。全局的东西会让局部的修改变得困难,因此如今的优秀程序员都唯恐避之不及。
+
+ 全局函数在程序的每个部分都可见,但理想情况下,函数应该只出现在DSL处理的部分很多语言特性的存在都是为了消除对于全局化的需要。比如命名空间。只有导入一个特定的命名间,其中的函数看起来才会像全局的一样。(JAVA中就有 static import)。
+
+ 函数序列与方法级联都需要使用语境变量跟踪解析状态。“嵌套函数”(第34章)是第三种函数组合技术,使用它往往可以回避语境变量。如果使用嵌套函数,计算机配置的例子看上去应该是这样的:
+
+```java
+computer(
+ processor(
+ cores(2),
+ speed(2500),
+ i386
+ ),
+ disk(
+ size(150)
+ ),
+ disk(
+ size(75),
+ speed(7200),
+ SATA
+ )
+);
+```
+
+ 貌似迄今所写的模式是互斥的,但实际上,在特定的DSL里面,我们往往会将它们(以及后续章节将描述的其他模式)组合使用。每个模式各有优劣,DSL中不同的地方也有着不同的需要。下面是一个混合的例子:
+
+```java
+computer(
+ processor()
+ .cores(2)
+ .speed(2500)
+ .type(i386),
+ disk()
+ .size(150),
+ disk()
+ .size(75)
+ .speed(7200)
+ .iface(SATA)
+);
+computer(
+ processor()
+ .cores(4)
+);
+```
+
+ 这段DSL脚本使用了之前所讲的三个模式。用函数序列按顺序定义了每台机器,每个computer函数都以嵌套函数作为它的实参,而每个处理器和磁盘则是通过方法级联构建的。
+
+## 4.4 字面量集合
+
+ 脚本语言还有另一种字面量集合: Literal Map,也称为哈希或者字典。有了它,就可以将计算机的配置表示为这样(又一次用到Ruby):
+
+```java
+computer(processor(:cores => 2, :type => :i386),
+ disk(:size => 150),
+ disk(:size => 75, :speed => 7200, :interface => :sata))
+```
+
+ 这里借机讨论一下,为何对于内部DSL而言,Lisp是一门如此有魅力的语言。Lisp有着非常方便的列表的字面构造语法:`(one two three)`。函数调用也采用相同的语法:`(max 5 14 2)`。因此,Lisp程序都是嵌套列表。因为裸单词`(one two three)`里的单词都是符号,所以其语法全都是表示符号的嵌套列表,对于内部DSL而言,这会是非常好的基础如果你愿意让自己的DSL拥有同样的基础语法。这个简单的语法既是Lisp的优势,也是其劣势。它很强大,因为它逻辑周密,如果遵循,则顺理成章。其劣势在于,我们必须遵循一种非同寻常的语法格式,若不能纵身一跃,便只剩下许多恼人的、该死的大括号了。
+
+## 4.5 基于文法选择内部元素
+
+| 结构 | BNF | 考虑 |
+| -------- | -------------------------------------- | ---------------------------------------- |
+| 必选列表 | parent::=first second third | 嵌套函数(第34章) |
+| 可选列表 | parent::=first maybeSecond?maybeThird? | 方法级联(第35章), Literal Map(第40章) |
+| 同构集合 | parent::=child* | 列表的字面构造(第39章), 函数序列(第33章) |
+| 易构集合 | parent::=(this\|that\|theOther)* | 方法级联(第40章) |
+| set | n/a | Literal Map(第40章) |
+
+## 4.6 闭包
+
+ 闭包( closure)是程序设计语言的一种能力,在某些编程语言圈子里(诸如Lisp和Smalltalk)已经出现了很长时间,但直到最近才又开始在主流语言里面流行。它们有很多的名字( lambda、 block、匿名函数等)。闭包有什么作用呢?它让我们可以把某些内联代码打包成个对象,到处传递,在适当的时候执行。(如果还没用过闭包,你应该读一下“闭包”(第7章)。)
+
+ 对于内部DSL而言,我们会把闭包用作DSL脚本里的“嵌套闭包”(第38章)。嵌套闭包有三个特点,使其很容易用于DSL:内联嵌套、延迟执行以及受限作用域的变量。
+
+## 4.7 解析树操作
+
+## 4.8 标注
+
+## 4.9 为字面量提供拓展
+
+## 4.10 消除语法噪音
+
+ 内部 DSL 的关键在于它们只是基于宿主语言的表达式,其编写格式使之读起来如同语言一样。这种做法的影响之一是,它们与宿主语言的语法结构交织在一起。从某些方面这样很好,因为其提供的语法是很多程序员都熟悉的,但有些人会觉得某些语法令人恼火。
+
+ 消除这些语法负担的方式之一是,以尽可能接近宿主语言的语法编写 DSL 代码,但也并不一定要完全一致,然后用简单的文本替换,将其转换为宿主语言。“文本润色”(第 45 章)可以将诸如` 3 hours ago `的短语转换成 `3.hours.ago`,或者更激进地,将` 3% if value at least $30000 `转换为 `percent(3).when.minimum(30000)`。
+
+ 虽然对于这一技巧的描述,我已见过多次,但我必须说,我并不热衷于此。替换很快会变得费解,真要这么做的话,使用一门彻底的外部 DSL 会更简单。
+
+ 另一种方法是使用语法着色。大多数文本编辑器都提供了可定制的文本着色方案。当与领域专家沟通时,可以用一种特殊的方案来弱化噪音语法——比如,在白色背景色上将其着为浅灰色。我们甚至可以更进一步,将其着为背景色,这样,它就消失了。
+
+## 4.11 动态接收
+
+ 在DSL世界中,动态接收的常见用法是,将信息从方法实参转移到方法名称上。个典型例子是 Rails中 Active Record的动态查找方法( finder)。假如 Person类上有个字段是 firstname(名字),我们希望根据人名来査找。我们无须为每个字段定义个查找方法,而可以定义一个通用的查找方法,以字段名为实参: `people.find_by("firstname", " martin")`。这虽然可以工作,但却有点古怪,因为我们更期望"firstname"是方法名称的一部分,而非参数。有了动态接收,就可以编写`people.find_by_firstname("martin")`这样的代码,而不用预先定义方法。我们可以重写缺失方法的处理程序,如果被调用方法以find_by开头,就解析方法名得到字段名,将其转换为完全参数化的方法。所有这些可以在一个方法里完成,也可以分到单独的方法里,比如, `people.find.by.firstname("martin")`。
+
+ 动态接收的关键在于,它给了我们一个选择,将信息从参数转移到方法名上面,在某些情形下,这会让表达式更易于阅读与理解。危险之处则在于,它只能做这些—一你绝不希望看到,用一连串方法名来处理复杂的结构。如果要做的事情比简单罗列事物更为复杂,那就要考虑使用更复杂的结构(比如,“嵌套函数”(第34章)或者“嵌套闭包”(第38章))来代替了。如果毎个方法调用都要进行相同的基本处理,诸如根据属性名构建査询,动态接收也同样非常适合,如果要对动态接收的方法进行不同的处理(比如, firstname和lastname的处理方法不同),那么还是不要依赖动态接收,显式地编写方法为妙。
+
+## 4.12 提供类型检查
+
+# 第5章 实现外部DSL
+
+ 虽然单靠内部DSL已经足以定义出连贯的语言,但最终还是会受限于宿主语言的语法结构。外部DSL则提供了更大的语法自由度——我们可以使用自己喜欢的任何语法。
+
+ 相比于内部DSL,实现外部DSL的不同之处就在于解析过程,我们要解析纯文本输入,这些输入不受任何现有语言的约束。解析文本的技术早已成熟,几十年来人们一直用这些技术来解析编程语言,还有一个历史悠久的语言社区在发展相关的工具和技术。
+
+ 不过有件事需要注意:编程语言社区提供的工具和文章几乎都假设你是在处理某种通用语言,DSL只会偶尔提及。尽管其中的原则同样适用于通用语言和领域专用语言,但二者毕竟存在差异。另外,创造DSL所需的背景知识要少于开发通用语言,因此我们无需走完后者所需的整个学习曲线。
+
+## 5.1 语法分析策略
+
+> [antlr_百度百科 (baidu.com)](https://baike.baidu.com/item/antlr/9368750?fr=ge_ala)
+>
+> antlr是指可以根据输入自动生成[语法树](https://baike.baidu.com/item/语法树/7031301?fromModule=lemma_inlink)并可视化的显示出来的开源[语法分析器](https://baike.baidu.com/item/语法分析器/10598664?fromModule=lemma_inlink)。ANTLR—Another Tool for Language Recognition,其前身是PCCTS,它为包括[Java](https://baike.baidu.com/item/Java/85979?fromModule=lemma_inlink),C++,C#在内的语言提供了一个通过语法描述来自动构造自定义语言的识别器(recognizer),[编译器](https://baike.baidu.com/item/编译器/8853067?fromModule=lemma_inlink)(parser)和[解释器](https://baike.baidu.com/item/解释器/10418965?fromModule=lemma_inlink)(translator)的框架。
+>
+> [Antlr Project (github.com)](https://github.com/antlr)
+
+ 本书的大部分内容将会使用解析器生成器,因为相关的工具很成熟,而且明确写出的文法也有助于解释各种概念。具体来说,我选择了 ANTLR解析器生成器,这是一个成熟的、广泛适用的开源工具。它的一大优势在于:它是一个强大的递归下降法语法解析器,也就是说,使用递归下降法语法解析器或者解析器组合子所获得的知识在 ANTLR中也同样适用。特别是,如果你对于语法指导翻译还不太熟悉,我认为 ANTLR会是一个不错的起点。
+
+## 5.2 输出生成策略
+
+ 在主流语言社区中,代码生成非常受重视,因此解析器通常会直接生成输出代码,其间并不出现语义模型。对于通用语言来说,这种做法很合理;但对于 DSL,我不推荐这样做。当你阅读主流语言社区撰写的资料(包括大部分“解析器生成器”(第 23 章)等工具的文档)时,请记住这种差异的存在。
+
+ 既然已经决定输出应该是语义模型,我们就只需要决定采用一个步骤还是两个步骤。单步骤的做法是“嵌入式语法翻译”(第 25 章):直接把方法调用放进解析器,从而在解析过程中生成语义模型。采用这种做法,可以在解析的同时逐步构建语义模型。只要得到了足够的输入,能识别出语义模型的一个组成部分,就立即创建这个部分。在真正创建语义模型中的对象之前,经常会需要一些中间解析数据——这时很可能需要把信息存入“符号表”(第 12 章)。
+
+ 另一种做法需要两步——“树的构建”(第 24 章):首先解析输入文本,构造出一棵包含文本结构的语法树,同时用符号表处理语法树各个部分之间的交叉引用;然后执行第二阶段,遍历语法树,生成语义模型。
+
+ 使用树的构建有一个很大的好处:它把整个解析任务分解成两个更简单的任务。当识别输入文本时,我们只需关注如何构造语法树——实际上,许多解析器生成器都提供了用于树构造的 DSL,可以让这部分工作变得更加简单。遍历语法树组装语义模型是一个常规的编程练习,随时检查整棵语法树来判断应该做什么。如果你写过 XML 处理的代码,那么嵌入式语法翻译类似于 SAX,而树的构建则类似于 DOM。
+
+ 还有第三种选择:“内嵌解释器”(第 26 章)。在解析过程中执行解释,并直接输出最终结果。内嵌解释器的一个经典例子就是计算器:它接受算术表达式作为输入,将计算的结果作为输出。也就是说,内嵌解释器并不生成语义模型。尽管内嵌解释器不时会出现,但毕竟还是很少用到。
+
+ 即使不生成语义模型,也可以使用嵌入式语法翻译和树的构建——实际上,在代码生成时,这种情况相当常见,大部分解析器生成器的例子都会这样做。尽管这种方法可行(特别是对于比较简单的情况),但我不建议经常使用,因为语义模型往往非常有用。
+
+ 所以,大部分时间,选择就在嵌入式语法翻译和树的构建之间进行。最终的决策取决于中间语法树的成本和收益。树的好处在于把解析问题一分为二,而两个简单的任务通常比一个复杂的任务更容易完成——随着翻译的整体复杂度上升,情况就更是如此。DSL 发展得越完善,DSL 与语义模型之间的距离越远,中间语法树就越有用,何况通常还有工具帮我们创建抽象语法树。
+
+ 看似我正极力鼓吹树的构建。一个反对树的构建的主要论点是语法树的内存开销,然而实际上,对于在现代硬件上“处理小型 DSL”的场景,连这种观点也不复存在了。尽管有那么多选择构建树的理由,我仍然心存疑虑:构建和遍历语法树有时显得太麻烦,我必须写代码来构建树,再写代码来遍历——很多时候直接构造语义模型会来得更轻松。所以我并没有明确的选择。只能大概地说,翻译的复杂度越大,树的构建就越适用。最好的建议是:两种方法都试试,然后看你自己喜欢哪种。
+
+## 5.3 解析中的概念
+
+### 5.3.1 单独的词法分析
+
+### 5.3.2 文法和语言
+
+ 如果眼光足够敏锐的话,你大概会注意到,我已经提到过为语言“定义一种文法”。很多人误以为对于某种语言总是存在唯一的文法。尽管一种文法确实形式化地定义了一种语言的语法,但多种文法能够识别同一语言的情况也很常见。
+
+ 来看来自“哥特式建筑安全系统”的下列输入文本:
+
+```pseudocode
+events
+ doorClosed D1CL
+ drawOpened D2OP
+end
+```
+
+针对这段输入文本,可以写出如下文法:
+
+```pseudocode
+eventBlock : Event-keyword eventDec* End-keyword;
+eventDec : Identifier Identifier;
+```
+
+但下面的文法同样适用:
+
+```pseudocode
+eventBlock : Event-keyword eventList End-keyword;
+eventList : eventDec*;
+eventDec : Identifier Identifier;
+```
+
+ 对于这种语言来说,两者都是合法的文法,都能识别这段输入,换句话说,它们都能把输入文本转换成解析树。两者得到的解析树不同,因此后面的代码生成部分也不同。
+
+ 有很多原因会导致我们得到不同的文法。首先,不同的“解析器生成器”(第23章)使用不同的文法,这些文法的语法和语义都不同。即便对于同一个解析器生成器,当采用不同的方式构建文法规则时,也会得到不同的文法(就像上面的例子那样)。和其他任何代码一样,我们也要重构文法,使其更易理解。最终的产出代码会影响构建文法的方式:我会经常调整文法,以便“将输入文本翻译成语义模型”的代码组织起来更加容易。
+
+ 总结一下,对于同一种语言,可以有多种文法,每种文法都能识别相同的输入,但得到的解析树可能不同。
+
+### 5.3.3 正则文法、上下文无关文法和上下文相关文法
+
+### 5.3.4 自顶向下解析和自顶向上解析
+
+## 5.4 混入另一种语言
+
+## 5.5 XML DSL
+
+# 第6章 内部DSL vs 外部DSL
+
+## 6.1 学习曲线
+
+通常而言,内部DSL学习成本比外部DSL要低。
+
+## 6.2 创建成本
+
+一旦熟悉相关技术,构建内部DSL和外部DSL的成本就相差无几
+
+## 6.3 程序员的熟悉度
+
+## 6.4 与领域专家沟通
+
+内部DSL往往和宿主语言绑定,理解时需要一定语言基础。而外部DSL更灵活,往往纯文本,更适合和非专业人士交流。
+
+## 6.5 与宿主语言混合
+
+## 6.6 强边界
+
+## 6.7 运行时配置
+
+## 6.8 趋于平庸
+
+## 6.9 组合多种DSL
+
+## 6.10 总结
+
+# 第7章 其他计算模型概述
+
+## 7.1 几种计算模型
+
+### 7.1.1 决策表
+
+### 7.1.2 产生式规则系统
+
+### 7.1.3 状态机
+
+### 7.1.4 依赖网络
+
+### 7.1.5 选择模型
+
+# 第8章 代码生成
+
+## 8.1 选择生成什么
+
+## 8.2 如何生成
+
+## 8.3 混合生成代码和手写代码
+
+ 有时,在目标环境下执行的所有代码都可以生成,但更常见的情况是,需要混合生成代码和手写代码。有一些需要遵循的通用规则,如下:
+
++ 不要修改生成代码。
++ 将生成代码和手写代码严格分开。
+
+## 8.4 生成可读的代码
+
+## 8.5 解析之前的代码生成
+
+## 8.6 延伸阅读
+
+ 关于代码生成技术,最为全面的书是[Herrington]。另外,Marcus Voelter在[Voelter]里描述的一套模式也很有用。
+
+# 第9章 语言工作台
+
+## 9.1 语言工作台之要素
+
+ 虽然不同的语言工作台各具特色,但彼此仍有共同之处。各种语言工作台都可以从以下个方面定义DSL环境:
+
++ “语义模型”(第11章)模式一般用元模型定义出语义模型的数据结构及静态语意。
++ DSL编辑环境为人们编写DSL脚本定义丰富的编辑体验,可能是直接编辑源码,也可能是进行投射编辑( projectional editing)。
++ 语义模型行为定义岀构建好语义模型后,DSL脚本能够做些什么,通常采用的技术是代码生成。
+
+## 9.2 模式定义语言和元模型
+
+## 9.3 源码编辑和投射编辑
+
+## 9.4 说明性编程
+
+## 9.5 工具之旅
+
+## 9.6 语言工作台和CASE工具
+
+## 9.7 我们该使用语言工作台吗
+
+# 第二部分 通用主题
+
+# 第10章 各种DSL
+
+## 10.1 Graphviz
+
+开源的图可视化工具
+
+## 10.2 JMock
+
+ JMock 是 Mock Object[Mezardos] 的一个 Java 程序库。其作者曾经写过多个 mock 对象程序库,关于如何用内部 DSL 定义 mock 上的预期,他们的想法不断演进([Freeman and Pryce],形成一篇很棒的论文,讨论的就是这个演进过程)。
+
+## 10.3 CSS
+
+ 从许多方面来看,CSS 都是一个很好的 DSL 示例。首先,大多数 CSS 程序员都不认为自己是程序员,而是 Web 设计师。所以,CSS 是一个好的例子,领域专家不仅能读,还能写出 CSS。
+
+ CSS 在声明式计算模型方面也是一个好例子,这种计算模型不同于命令式模型。我们不必像使用传统设计语言那样指挥计算机“做这个,然后做那个”。相反,我们只需声明 HTML 元素的匹配规则即可。
+
+## 10.4 HQL
+
+ HQL 处理的本质是,将 HQL 查询翻译成 SQL 查询。Hibernate 分三步完成这件事:
+
+- 用 “语法指导翻译”(第 18 章)和“树的构建”(第 24 章)将 HQL 输入文本转化为 HQL 的抽象语法树 (AST)。
+- 把 HQL AST 转换为 SQL AST。
+- 代码生成器根据 SQL AST 生成 SQL。
+
+ 所有这些情况都用到了 ANTLR。除了可以用标记流作为 ANTLR 语法分析器的输入,还可以用 AST 作为 ANTLR 的输入(这在 ANTLR 里称为“树文法”)。ANTLR 的树构建语法在构建 HQL 和 SQL AST 时都有用到。
+
+ 这个转换路径,输入文本→输入 AST →输出 AST →输出文本,对于源码到源码转换很常用。许多转换场景都采用一种很好的做法,就是把复杂转换分解成易于组合的小转换。
+
+ 在这个例子中,可以把 SQL AST 看作“语义模型”(第 11 章)。HQL 查询的意义是由查询要做的 SQL 渲染决定的,SQL AST 就是 SQL 模型。通常,AST 不是语义模型的正确结构,因为语法树的约束通常助益大于其阻碍。但是,就源码到源码的翻译,使用输出语言的 AST 而不是输入语言的 AST 是非常合理的。
+
+## 10.5 XAML
+
+ 自从有了全屏用户界面,人们就开始尝试用各种方式定义屏幕布局。这是一种图形媒介,所以,人们总是倾向于使用某种图形布局工具。然而,通常用代码布局才能获得更大的灵活性。麻烦在于,代码是一种尴尬的机制。屏幕布局主要是一种层次结构,用代码组织层次结构需要更加仔细,而原本无需如此。所以,伴随着 Windows Presentation Framework 的出现,Microsoft 引入了 XAML,作为一种 UI 布局的 DSL。
+
+## 10.6 FIT
+
+ FIT([http://fit.c2.com)是Ward](http://fit.c2.xn--com)ward-2i5q/) Cunningham早年开发的测试框架(FIT表示Framework for Integrated Test)。其目标是以领域专家可以理解的方式描述测试场景。随后的许多工具扩展了这个基本的想法,尤其是Fitnesse([http://fitnesse.org)。](http://fitnesse.org)./)
+
+## 10.7 Make等
+
+ 小程序的构建和运行都很容易,但是用不了多长时间,我们就会意识到,构建软件是需要若干步骤的。所以在 UNIX 早期,Make 工具提供了一个组织构建的平台。构建的问题在于,很多步骤代价高昂,但并不需要每次都做,所以,编程模型选择“依赖网络”就再自然不过了。Make 程序由若干目标组成,这些目标通过依赖联系在一起。
+
+# 第11章 语义模型
+
+## 11.1 工作原理
+
+ 一般来说,语义模型与语法树有所不同,因为它们的目的不同。语法树对应DSL脚本的结构。虽然抽象语法树可能经过简化,或者重新组织输入数据,但是,它基本上遵循相同的形式。语义模型则更多地关注DSL脚本能够做什么。因此,通常会采用不同的结构,一般不是树结构。在某些情况下,对于DSL来说,AST也是一种有效的语义模型,但这只是特例,而非通例。
+
+ 在关于语言和解析的传统讨论中,很少涉及语义模型。这是采用DSL和通用语言的一个差异。对于通用语言而言,语法树就足够了,可以根据它进行代码生成,所以,再有个不同的语义模型也没必要。有时也会用到语义模型;比如,如果要做优化,调用图的表现形式很有用。这样的模型称为中间形式——代码生成之前的中间步骤。
+
+ 语义模型经常先于DSL产生。有时,我们会认为,用DSL组装Domain Model比常规命令-查询接口好用,这时,语义模型就先产生了。还有一种情况,DSL和语义模型要一起构建,我们要和领域专家讨论,同时完善DSL的表现形式和Domain Model的结构。
+
+ 语义模型可以包含执行自身的代码(解释风格),也可以作为代码生成的基础(编译风格)。即便采用的是代码生成,提供解释方式也有助于DSL的测试和调试。
+
+ 将验证逻辑放入语义模型中是最合适的,因为它包含了验证所需的所有信息和结构。在解释执行或代码生成前,执行验证尤其有帮助。
+
+ Brad Cross介绍了计算型DSL和组合型DSL的差异[Cross]。二者的差异主要在其产生的语义模型。组合型DSL以文本形式描述某种组合结构,一个很好的例子就是用XAML描述UI布局——语义模型的主要形式是各种元素如何组合在一起。状态机的例子更多是一个计算型DSL,其产生的语义模型更像代码,而不是数据。
+
+ 计算型DSL的语义模型用于驱动计算,通常用的是其他计算模型——而不是常见的命令式模型。这样的语义模型通常都是“适应性模型”(第47章)。采用计算型DSL可以做很多事情,但人们发现,它们用起来没那么容易。
+
+ 可以将语义模型想象成具有两组不同接口:
+
++ 操作接口(operational interface)——客户端操作时使用组装好的模型所用的接口;
++ 组装接口(population interface)——DSL用来创建模型类实例的接口。
+
+ 操作接口应该假设语义模型已经创建好,系统的其他部分都可以很好地利用它。**在API设计上,我有个秘诀,假设模型已经奇迹般地创建出来了,然后问自己,如何使用它。这种做法可能违背直觉,但我发现,在考虑组装接口之前定义操作接口是一种更好的做法,即使系统运行时还是要先调用组装接口。对我来说,这是设计任何对象的通则,不仅仅是DSL**。
+
+## 11.2 使用场景
+
+ 默认情况下,建议总是要用语义模型。尽管说“总是”让我有些不舒服,因为如此绝对的建议显得非常“思想保守”。在这种情况下,或许是我想象力匮乏,但我极少见到无需语义模型的情况,偶尔也只出现在非常简单的情况下。
+
+ 我发现语义模型有一些不可抗拒的优点。有了清晰的语义模型,DSL的语义和解析可以分开测试。测试语义,可以直接组装语义模型,基于模型执行测试;测试解析器,可以看其组装的语义模型是否正确。如果有多个解析器,比较组装出的语义模型,就可以知道它们产生的输出在语义上是否相等。这么做很容易支持多种DSL,更常见的是,DSL可以独立于语义模型演化。
+
+ 语义模型同时提高了解析和执行的灵活性。可以直接执行语义模型,也可以进行代码生成。如果进行代码生成,只要根据语义模型来做即可,完全无须关心解析。语义模型和生成的代码都可以运行——这样,可以把语义模型当生成代码的模拟器。使用语义模型,支持多个代码生成器也很容易,因为与解析器无关,所以避免了解析器代码的重复。
+
+ 但是,使用语义模型最重要的一点是,它分离了对语义和解析的关注。即便一个简单的DSL都包含足够的复杂度,将其分成两个更简单的问题也是应该的。
+
+ 那我想到的例外情况是什么?一种情况是简单的命令解释器,我们只是想在解析过程中执行每条语句。有一个很好的例子是经典的计算器程序,只需求值简单算术表达式。对于算术表达式而言,即便不立即解析,其生成的抽象语法树(Abstract Syntax Tree,AST)同语义模型的内容几乎一致,就这种情况而言,分开语法树和语义模型意义不大。还有一条更通用的规则:如果模型不如AST丰富,就不值得创建单独的语义模型。
+
+ 人们不想用语义模型,最常见的原因是想要生成代码。按照这种方式,解析器生成AST,代码生成器直接使用AST。如果AST可以很好地表现出底层语义,并且我们不介意代码生成逻辑同AST之间的耦合,那么这不失为一种合理的方案。如果不是这样,你会发现,将AST转换成语义模型,再根据它做简单的代码生成是一种更为简单的方案。
+
+ 可能是我的偏好,我总是假设我需要语义模型。哪怕我说服了自己不需要,我仍然时刻对复杂性的增长保持警惕,只要解析逻辑略显复杂,我就引入语义模型。
+
+ 尽管我如此器重语义模型,但仍要指出一点,在函数式编程领域里,语义模型并不属于DSL文化的一部分。在DSL思想方面,函数式编程社区有着悠久的历史,而我只是偶尔使用现代函数式语言。所以,虽然我的偏好告诉我,语义模型在这个领域里可能也很有用,但是,我不得不承认,我的知识不足以支撑我的观点。
+
+## 11.3 入门例子(Java)
+
+# 第12章 符号表
+
+ 很多语言都需要在代码的不同地方引用对象。如果我们有一种语言,可以定义任务的配置及其依赖关系,就需要一种方式,在一个任务定义中,引用其依赖的任务。
+
+ 为了达到这个目的,我们要对每个任务都定义某种形式的符号:当处理DSL脚本时,这些符号都放到符号表中,通过这张表,可以由符号关联到持有其完整信息的底层对象。
+
+## 12.1 工作原理
+
+ 符号表的根本目的是,建立DSL脚本中表示对象的符号与符号所指对象之间的映射关系。这样的映射关系非常适合用map这种数据结构表示,所以,毫无疑问用map实现符号表是最常见的做法,符号作为键,“语义模型”(第11章)对象作为值。
+
+ 需要考虑的一个问题是,在符号表里,用做键的对象应该是何种类型。对于很多语言来说,字符串是最显而易见的选择,因为DSL文本就是字符串。
+
+## 12.2 使用场景
+
+ 对于任何的语言处理而言,符号表都是通用的,我的预期是,尽可能用它。
+
+ 也有时候不见得要用。当使用“树的构建”(第 24 章)时,我们从语法树上找到所需的东西。有时,搜索构建出的“语义模型”(第 11 章)也可以达成这一点。但是有时候,还是要用到一些中间存储,就算并不真的需要,有它也会让生活更轻松一些。
+
+## 12.3 参考文献
+
+## 12.4 以外部DSL实现的依赖网络(Java和ANTLR)
+
+## 12.5 在一个内部DSL中使用符号键(Ruby)
+
+## 12.6 用枚举作为静态类型符号(Java)
+
+# 第13章 语境变量
+
+ 想象一下,我们正在解析一个项列表,每项都要获取一些数据。虽然对象每一点的信息都可以单独获取,但是我们依然要知道正在处理的信息属于哪个特定项。
+
+ 言境变量就是做这个用的,它将当前项保存在变量中,当处理到下一个时,会对它重新赋值。
+
+## 13.1 工作原理
+
+ 在解析过程中,如果使用一个命名类似于 currentitem的变量,在处理输入脚本时随着从一个对象移到下一个对象,就要定期更新这个变量,那就是在使用语境变量。
+
+ 语境变量可能是一个“语义模型”(第11章)对象,也可能是一个生成器对象。语义模型是一个非常直白的选择,但是这有个前提,所有的属性都要是可变的,这样在需要的时候,解析器才能修改。如果不是这样,通常来说,最好使用某种形式的生成器,用来搜集信息,当完成时创建语义模型,比如“构造型生成器”(第14章)。
+
+## 13.2 使用场景
+
+## 13.3 读取INI文件(C#)
+
+# 第14章 构造型生成器
+
+## 14.1 工作原理
+
+ 构造型生成器的基本做法很简单。假设要逐步创建一个不可变对象,称为产品。找出产品构造函数的实参,为毎一个实参创建一个字段。对于要搜集产品的其他属性,也添加一些字段。最后,添加一个创建方法,返回一个由构造型生成器中所有数据组成的产品对象。
+
+ 或许,我们还要在构造型生成器中添加一些生命周期控制。这种控制可能检査是否信息已足够创建产品。可能要设置一个标记,保证已返回的产品不会再返回,或者把已创建的产品放到一个字段里。可能是在创建了产品后,如果尝试给构造型生成器添加属性,就抛出异常。
+
+ 多个构造型生成器可以深度组合在一起。它们可以产生一组相关联的对象,而不只是一个对象。
+
+## 14.2 使用场景
+
+## 14.3 构造简单的航班信息(C#)
+
+# 第15章 宏
+
+## 15.1 工作原理
+
+### 15.1.1 文本宏
+
+### 15.1.2 语法宏
+
+ 相比于其他任何程序设计语言,宏都已经深入到Lisp的骨髓中。Lisp的很多核心特性都是通过宏完成的,所以,即便是Lisp新手会用到——通常都没意识到到那是宏。所以,当人们讨论支持内部DSL的语言特性时, Lisper总是说宏的重要性。一旦出现不可避免的语言比较时, Lisper总是鄙视那些没有宏的语言。
+
+## 15.2 使用场景
+
+# 第16章 通知
+
+ 假设我对对象模型做了比较大的改动,改动之后,我想知道修改后的模型是否依然正确。可以发出校验命令;我只想得到一个简单的布尔值,但如果出错的话,我就要知道更多细节了。尤其是,我想一次性得到所有错误,而不仅仅是第一条错误。
+
+ 通知是收集错误信息的对象。当校验失败时,会添加一条错误信息到通知中;当校验完成后,返回通知。通过通知,我们可以知道是否一切正常,如果有错误,还可以深入到错误中。
+
+## 16.1 工作原理
+
+## 16.2 使用场景
+
+## 16.3 一个非常好简单的通知(C#)
+
+## 16.4 解析中的通知(Java)
+
+# 第三部分 外部DSL主题
+
+# 第17章 分隔符指导翻译
+
+## 17.1 工作原理
+
+ 分隔符指导翻译的工作原理是在获取输入后,基于分隔字符将其分解成小块。你可以使用你喜欢的任何字符作为分隔字符,但是最常用分隔符的是行尾符,这里就以使用行尾符进行讨论。
+
+ 把脚本分解成行通常相当简单,因为多数编程环境都有程序类库,一次一行地读取输入流。你可能遇到的一个稍微复杂点的情形是,当行很长时,你会希望在编辑器中以物理方式将它们分解。在很多环境下,最简单的方式是引用行尾符;UNIX 中意味着使用反斜线表示一行的最后一个字符。
+
+## 17.2 使用场景
+
+## 17.3 常客记分(C#)
+
+### 17.3.1 语义模型
+
+### 17.3.2 解析器
+
+## 17.4 使用格兰特小姐的控制器解析非自治语句(Java)
+
+# 第18章 语法指导翻译
+
+ 计算机语言天生倾向于遵循一种层次化的结构,具有多层的上下文。编写一种文法,描述如何将语言的元素分解为子元素,就可以为这种语言定义合法的语法。
+
+ 语法指导翻译使用这个文法定义如何创建解析器,解析器可以将输入文本转换成语法分析树(parse tree),语法分析树具有类似于文法规则的结构。
+
+## 18.1 工作原理
+
+ 有几种根据文法进行处理的方式。一种方式是把语法当做规范和实现指南,手写解析器。常见的做法有“递归下降法语法解析器”(第21章)和“解析器组合子”(第22章)两种。还有一种方式是把语法当做DSL,然后用“解析器生成器”(第23章)根据文法文件自动构建解析器。对于这个情况,自己无须编写任何解析器的核心代码,所有的代码都是根据文法生成的。
+
+ 语法固然有用,但它只处理了一部分问题:如何将输入文本转换为语法分析树(parse-tree)这种数据结构。但是,我们几乎总是需要对输入做更多的处理。因此解析器生成器也提供了一些方式,以便在解析器里嵌入进一步的行为,完成诸如组装“语义模型”(第11章)之类的工作。所以,虽然解析器生成器已经做了很多的事情,但我们依然可以写一些程序,去做一些也很有用的东西。从各个角度来看,解析器生成器都是一个非常精彩的DSL实践的例子。它没有解决所有问题,但确实让整个工作轻松了许多。此外,它也是一种拥有悠久历史的DSL。
+
+### 18.1.1 词法分析器
+
+ 大多数情况下,我会让词法分析器处理三种标记。
+
++ 标点符号:关键字、运算符或者其他用做组织的构造(圆括号、语句分隔符)。对于标点符号来说,类型是重要的,承载内容不重要。此外,还有一些语言的固定元素。
++ 领域文本:事物的名字、字面值。对于这些来说,标记的类型通常是非常通用的,如“数字”或“标识符”。这些都是可变的;每种DSL脚本都有不同的领域文本。
++ 可忽略的标记:词法分析器通常会丢弃的东西,比如空白和注释。
+
+ 多数“解析器生成器”(第23章)都会提供词法分析器的生成器,用的是正则表达式,如上面所示。然而,许多人倾向于编写自己的词法分析器。采用“基于正则表达式表的词法分析器”(第20章)的话,词法分析会相当直白。手写词法分析器的话,我们有更大的灵活性,解析器和词法分析器之间的交互也可以更复杂,有时这会很有用。
+
+ 有一种特别的“解析器-词法分析器”交互方式可能很有用,就是对词法分析器多模式的支持,允许解析器在模式间显式切换。通过这种做法,解析器可以在语言某个特定的点上改变标记解释的方式。对于可变分词方式来说,这很有用。
+
+### 18.1.2 语法分析器
+
+### 18.1.3 产生输出
+
+### 18.1.4 语义预测
+
+## 18.2 使用场景
+
+## 18.3 参考文献
+
+# 第19章 BNF
+
+## 19.1 工作原理
+
+> [巴科斯范式_百度百科 (baidu.com)](https://baike.baidu.com/item/巴科斯范式/1849549?fromtitle=BNF&fromid=7328753)
+
+ BNF(以及EBNF)是编写文法来定义语言语法的一种方式。BNF(全称是“ Backus-Naur范式”)发明于19世纪60年代,最初用于描述 Algol语言。此后,BNF文法广泛用于解释和驱动“语法指导翻译”(第18章)。
+
+### 19.1.1 多重性符号(Kleene运算符)
+
+### 19.1.2 其他一些有用的运算符
+
+### 19.1.3 解析表达式文法
+
+### 19.1.4 将EBNF转换为基础BNF
+
+### 19.1.5 行为代码
+
+## 19.2 使用场景
+
+# 第20章 基于正则表达式的词法分析器
+
+ 语法分析器主要用来处理语言的结构,特点是提供各种不同的语言特性组合。虽然它能很轻松地识别基本语法元素——比如,关键字、数字和各种命名,但通常会将这些东西交给单独的词法分析器来处理。通过使用独立的词法分析器识别这些终结符,可以简化语法分析器的构造。
+
+ 词法分析器的实现相对比较简单,因为它只能解析正则文法,所以可以通过标准的正则表达式API来实现它们。对于基于正则表达式表的词法分析器,将每个语法符号表达为一个正则表达式,毎个正则表达式与特定的终结符关联。然后扫描输入数据,把输入的每部分匹配到正确的正则表达式,根据匹配结果生成具有毎个终结符的标记流(token stream)。这个标记流就是语法分析器的输入。
+
+## 20.1 工作原理
+
+ 递归下降法语法解析器的基本结构很简单,文法中的每个非终止符都由一个方法来处理。该方法实现与非终结关联的不同产生规则。方法本身返回一个布尔值来表示匹配的结果。如果匹配失败,那么错误将会沿调用栈线上传递。每个方法都在标识缓冲区内进行操作,随着句子的识别,在缓冲区内标识出已识别的部分。
+
+## 20.2 使用场景
+
+## 20.3 格兰特小姐控制器的词法处理(Java)
+
+# 第21章 递归下降语法解析器
+
+## 21.1 工作原理
+
+## 21.2 使用场景
+
+## 21.3 参考文献
+
+## 21.4 递归下降和格兰特小姐的控制器(Java)
+
+# 第22章 解析器组合子
+
+ 纵然“解析器生成器”(第23章)并不像看上去那么难用,我们还是有一些正当的理由在可能的情况下规避它。最显而易见的一种情况是,构建过程中需要一些额外的步骤,先生成解析器,然后才能构建。然而,对于更为复杂的上下文无关文法而言,解析器生成器依然是正确的选择。特别是,如果文法有二义性,或者性能很关键,直接用通用语言实现一个解析器也是个可行的选择。
+
+ 解析器组合子(Parser Combinator)采用解析器对象结构实现文法。“用于识别产生规则中的符号”的识别器是用 Composites [Gof]组合起来的,也叫组合子。事实上,解析器组合子表示的就是文法的“语义模型”(第11章)。
+
+## 22.1 工作原理
+
+### 22.1.1 处理动作
+
+### 22.1.2 函数式风格的组合子
+
+## 22.2 使用场景
+
+## 22.3 解析器组合子和格兰特小姐的控制器(Java)
+
+# 第23章 解析器生成器
+
+ 文法文件是一种“描述DSL语法结构”的自然方式。有了文法,把它转成手写的解析器却是一件乏味的工作,乏味的工作应该交由计算机完成。
+
+ 解析器生成器可以根据文法文件生成解析器。更新文法之后,只要重新生成,解析器也就更新了。既然解析器是生成的,它就可以使用一些“难于手工构建和维护”的高效技术。
+
+## 23.1 工作原理
+
+ 构建自己的解析器生成器并不是一件容易的任务,对于想做这种事的人而言,从本书中可能让他一无所获。这里只会讨论如何使用解析器生成器。幸运的是,解析器生成器是很常见的,大多数编程平台都有对应的工具,而且通常是开源的。
+
+ 使用解析器生成器最常见的方法是,编写文法文件。这个文件会用到解析器生成器特定的“BNF”(第 19 章)。不要在这里期待任何标准。如果更换解析器生成器,编写全新的文法是必然的。如果要产生输出,解析器生成器允许我们使用“外加代码”(第 27 章)嵌入代码动作。
+
+ 有了文法,常规做法是用解析器生成器生成解析器。大多数解析器生成器都会用到代码生成,为不同的宿主语言生成解析器。当然,没人会阻止解析器生成器在运行时读取文法文件,进行解析,也许还会构建出“解析器组合子”(第 22 章)。解析器生成器采用代码生成,是综合传统和性能两方面考量的原因,特别是因为其主要目标是通用语言。
+
+ 大多数情况下,我们会把生成的代码视为黑盒,不会去深究它。然而,偶尔了解解析器生成器的职责还是有用的——特别是在调试文法的时候。在这种情况下,如果解析器生成器使用的算法易于跟踪,比如生成的是一个“递归下降语法解析器”(第 21 章),这就是个优势。
+
+ 本书用 ANTLR 解析器生成器说明了许多模式。ANTLR 是一个容易获得、成熟的工具,具有良好的文档支持,因此,我愿意把它推荐给想学习解析器生成器的人。它还有一个不错的 IDE 风格的工具(ANTLRWorks),为开发文法提供了便捷易用的 UI。
+
+## 23.2 使用场景
+
+ 对我而言,使用解析器生成器最大的优势在于,它提供了一个显式的文法,定义了所处理的语言的语法结构。当然,这是使用 DSL 的主要优势。虽然解析器生成器的主要设计目标是处理复杂语言,但它们所能提供的特性远大于自己写一个解析器所能获得的。这些特性需要花些工夫学习,但我们可以从一个简单的特性集出发,从那里开始,逐步学习。解析器生成器还会提供良好的错误处理机制和诊断机制,尽管这里不会讨论它们,但它们确实带来很大的差异,特别是在我们试图弄清楚为什么文法没有按照预期的方式工作时。
+
+ 解析器生成器也有一些不好的地方。我们所用的语言环境可能没有解析器生成器——这可不是应该自己写的东西。另外,即便有,我们可能也不想要再为已经繁多的工具集引入新品。此外,即使有,我们可能也不想再为已经繁多的工具集引入新品。解析器生成器倾向于使用代码生成,这会让构建过程更复杂,这可能会是个大麻烦。
+
+## 23.3 Hello World (Java和ANTLR)
+
+ 解析器生成器的基本操作模型是这样的:编写一个文法文件,基于这个文法运行解析器生成器工具,产生解析器的源码。然后,编译解析器以及解析器运行所需的其他代码。接下来,就可以解析文件了。
+
+### 23.3.1 编写基本的文法
+
+### 23.3.2 构建语法分析器
+
+### 23.3.3 为文法添加代码动作
+
+### 23.3.4 使用代沟
+
+# 第24章 树的构建
+
+## 24.1 工作原理
+
+## 24.2 使用场景
+
+## 24.3 使用ANTLR的树构造语法(Java和ANTLR)
+
+### 24.3.1 标记解释
+
+### 24.3.2 解析
+
+### 24.3.3 组装语义模型
+
+## 24.4 使用代码动作进行树的构建(Java和ANTLR)
+
+# 第25章 嵌入式语法翻译
+
+## 25.1 工作原理
+
+## 25.2 使用场景
+
+ 嵌入式语法翻译最有吸引力的地方在于,它提供一种简单的方式,在处理语法分析的同时处理模型的生成。而使用“树的构建”(第 24 章)则需要你提供生成抽象语法树的代码,以及根据抽象语法树生成模型的代码。对于简单的情况而言——比如,大多数 DSL ——并不值得使用二级处理。
+
+ 你所使用的“解析器生成器”(第 23 章)对你的选择有很大影响,解析器生成器的树构造功能越好,树的构建就越具吸引力。
+
+ 而嵌入式语法翻译最大的问题在于,它会使文法文件变得非常复杂,尤其是当“外加代码”(第 27 章)没有被很好地使用时。当你恪守原则而尽可能地使用外加代码时,它不太可能成为问题——然而树的构建可以更好地保证这个原则不被破坏。
+
+ 嵌入式语法翻译很好地符合了单边语法分析的要求,所有工作都可以在语法分析阶段完成。但这也意味着某些工作在嵌入式语法翻译中会变得很困难,例如,前向引用的检查。为了处理这些问题,通常需要“语境变量”(第 13 章),这会使语法分析变得更加复杂。
+
+ 总之,语言和语法分析器越简单,嵌入式语法翻译就越有吸引力。
+
+## 25.3 格兰特小姐的控制器(Java和ANTLR)
+
+# 第26章 内嵌解释器
+
+## 26.1 工作原理
+
+ 内嵌解释器通过尽可能早地计算 DSL 表达式,收集结果并将这些结果作为最终结果返回。内嵌解释器不使用“语义模型”(第 11 章),而是直接在 DSL 的输入上完成解释过程。随着语法分析器解析出 DSL 脚本的每个片段,解释器就会对这些片段进行解释。
+
+## 26.2 使用场景
+
+ 作为“语义模型”的拥护者,我不太喜欢内嵌解释器。当你所需要的表达式很简单的时候,它可能会很有用。有时候你会觉得,不值得为简单的问题创建完整的语义模型。但是我不这么认为。哪怕是很小的一个 DSL,通过创建语义模型并解释它,也比直接在语法分析器里做所有事情要容易得多。此外,语义模型是一个非常坚实的基础,可以基于它对 DSL 进行演化和发展。
+
+## 26.3 计算器(ANTLR和Java)
+
+# 第27章 外加代码
+
+ DSL从定义上讲是仅能完成一些功能且语法结构有限的语言。但是有时候,你需要在DSL中描述超过其表达能力的东西。一个选择是扩展DSL脚本使其具有处理这些复杂度的能力。但是这么做可能会让DSL变得非常复杂,从而降低了这个DSL的吸引力。
+
+ 外加代码则是另一个选择,它将不同的语言——通常是通用语言—嵌入DSL中。
+
+## 27.1 工作原理
+
+## 27.2 使用场景
+
+ 当你考虑使用外加代码时,通常还可以选择扩展 DSL 来实现外加代码的功能。引入外加代码有明显的不足之处,它将会破坏 DSL 提供的抽象能力。阅读 DSL 的人需要同时理解外加代码和 DSL 本身。而且使用外加代码将会让构建过程变得复杂,通常也会让“语义模型”(第 11 章)变得复杂。
+
+ 这些额外的复杂度需要根据为了支持这些特性而在 DSL 中引入的复杂度进行权衡。通常而言,DSL 功能越强,它就越难理解和使用。
+
+## 27.3 嵌入动态代码(ANTLR, Java和JavaScript)
+
+### 27.3.1 语义模型
+
+### 27.3.2 语法分析器
+
+# 第28章 可变分词方式
+
+## 28.1 工作原理
+
+ 在前面关于“解析器生成器”(第 23 章)的介绍中,我说语法分析器向语法分析器提供标记流,然后语法分析器把标记流组装成语法分析树。这似乎是指它们之间是单向交互:词法分析器作为输入源,向语法分析器提供它所使用的数据。然而并不总是这样,有些时候语法分析器需要根据当前在语法分析树中所处的位置改变行为,这意味着语法分析器需要改变词法分析器分词的方式。
+
+### 28.1.1 字符引用
+
+### 28.1.2 词法状态
+
+### 28.1.3 修改标记类型
+
+### 28.1.4 忽略标记类型
+
+## 28.2 使用场景
+
+ 如果你使用“语法指导翻译”(第 18 章)并且分离词法和语法分析时——通常而言是这样的——可变分词方式会是一种有意义的技术。当你有一段特殊文本不应该使用常规方案分词的时候,你可能需要使用它。
+
+ 可变分词方式的常用场景包括:在特定语境下不应该当做关键字的关键字,任意形式的文本(通常对于散文描述)以及“外加代码”(第 27 章)。
+
+# 第29章 嵌套的运算符表达式
+
+## 29.1 工作原理
+
+ 嵌套的运算符表达式有两个方面让它变得比较难处理:其递归本性(自己的规则出现在自己的定义中)以及运算符优先级。虽然具体如何来处理这些问题部分取决于所使用的“解析器生成器”,但是仍然有些有用的通用原则可以采用。这里最大的差异是自底向上和自顶向下的语法分析器如何处理它们。
+
+ 这里给出的例子是个计算器,它可以处理四种常见的算术运算(+、-、*、/)、圆括号表达式求值、幂(`**`)以及开方(`//`)。它还支持一元运算符——负号。
+
+ 选择这些运算符,意味着我们需要不同的运算符优先级。负号的优先级最高,其次是幂和开方,然后是乘除操作,最后是加减。这里引入了幂和开方,它们是右结合运算符,而其他二元运算符都是左结合的。
+
+### 29.1.1 使用自顶向上的语法分析器
+
+### 29.1.2 自顶向下的语法分析器
+
+## 29.2 使用场景
+
+# 第30章 以换行符作为分隔符
+
+## 30.1 工作原理
+
+## 30.2 使用场景
+
+ 当决定使用换行符作为分隔符时,其实决定了两件事:语句具有分隔符且这个分隔符是换行符。
+
+ 由于 DSL 通常结构都比较简单,纵使不使用语句分隔符,语法解析器通常也可以根据指定的关键字分析出语境信息。比如,在格兰特小姐的控制器中所使用的文法就没有使用语句分隔符,但是仍然很容易被语法解析器解析。
+
+ 语句分隔符使得定位和发现错误变得容易起来。语法解析器通常需要一些检查点标记来定位错误,如果没有检查点,语法解析器就无法及时发现脚本中某一行的错误,从而使得错误消息混乱而不易理解。语句分隔符可以很好地扮演路标这个角色(这并不是检查点标记唯一的表现方法,关键字也可以)。
+
+ 如果你决定使用语句分隔符,那么你可以选择使用可见的字符(比如分号或者换行符)。使用换行符的好处是,绝大多数情况下,每行只有一条语句,因此换行符不会给 DSL 带来太多语法噪音——尤其是对于非程序员而言(当然很多程序员——比如我自己——也倾向于使用换行符作为分隔符)。使用换行符作为分隔符不好的地方是,当使用“语法指导翻译”(第 18 章)时,会变得更困难,你必须使用之前讨论过的那些技术来解决这个问题,还需要用测试来覆盖那些常见问题。总体而言,我仍然倾向于使用换行符而不是其他可见的语句分隔符。
+
+# 第31章 外部DSL拾遗
+
+## 31.1 语法缩进
+
+## 31.2 模块化文法
+
+ 对 DSL 的约束越多,它们就会越好。有限的表达性使他们易于理解、使用和处理。DSL 最大的危险之一是增加过多的表达性——导致语言掉入陷阱,一不留神就变成了通用语言。
+
+ 为了避免这个陷阱,能够将独立的 DSL 结合在一起是非常有用的。要做到这些,需要对不同的部分独立地解析。如果你使用“语法指导翻译”(第 18 章),这意味着为不同的 DSL 使用单独的文法,但又能够将这些文法编译成单个整体解析器。你希望能够从文法里面引用不同的文法,因此如果被引用的文法修改了,你不需要修改你自己的文法。模块化文法让你以现在使用可重用库的相同方法使用可重用的文法。
+
+ 模块化文化,虽然对于 DSL 很有用,但在语言领域并不是一个很好理解的领域。一些人正在深入探讨这个主题,但在撰写本书的时候,尚无成熟的结果。
+
+ 大多数“解析器生成器”(第 23 章)使用单独的词法分析器,进一步让模块化文法的使用变得复杂,因为不同的文法通常需要与父级文法不同的词法分析器。你可以通过使用“可变分词方式”(第 28 章)绕过这个问题,但那给子级文法如何适配父级文法增加了约束。目前,一个越来越广泛的趋势是无扫描器的解析器——不将词法分析与语法分析分离——也许更适合于模块化文法。
+
+ 目前,处理不同语言最简单的方式是将它们视为“外加代码”(第 27 章),将子语言的文本抽取到缓冲区,然后单独解析缓冲区。
+
+# 第四部分 内部DSL主题
+
+# 第32章 表达式生成器
+
+ 设计 API 的目的是让对象提供一套自立的方法。理想情况下,这些方法都可以单独理解。我称这种风格的 API 为命令 – 查询 API ——这种 API 如此普遍,以至于我们都没有给予它一个普遍的名字。而 DSL 需要另外一种 API ——称为连贯接口,其设计原则是追求整个表达式的可读性。连贯接口使得每个方法不再具有独立的意义,而这违反了命令 – 查询 API 设计的原则。
+
+ 表达式生成器作为一个独立的层次,在常规 API 之上提供连贯接口。采用这种做法,我们就拥有了两种风格的接口,连贯接口被清晰地隔离开来,这样,它也更容易理解。
+
+## 32.1 工作原理
+
+ 一个值得注意的问题是:是应该为整个 DSL 提供一个表达式生成器对象,还是为 DSL 的不同部分提供多个表达式生成器。多个表达式生成器通常遵循树型结构,后者通常是 DSL 的语法树。DSL 越复杂,表达式生成器树越重要。
+
+ 另一个建议是,为了确保你有结构良好的“语义模型”(第 11 章),更清晰地隔离表达式生成器。语义模型上 应该定义有命令–查询接口,它们可以不借助任何连贯接口进行访问——要验证这件事,你可以尝试在不使用任何 DSL 的情况下,对语义模型进行测试。但也不要做得太过——内部 DSL 的目的就是为了简化对这些对象的访问。通常在测试中使用 DSL 比使用命令–查询接口容易得多。但是我通常仍然会保留一些仅仅使用命令–查询接口的测试。
+
+ 然后可以在这些模型之上使用表达式生成器,并且可以通过对比表达式生成器操纵的语义模型,直接调用语义模型命令–查询 API,来对表达式生成器进行测试。
+
+## 32.2 使用场景
+
+## 32.3 具有和没有生成器的连贯日历(Java)
+
+## 32.4 对于日历使用多个生成器(Java)
+
+# 第33章 函数序列
+
+## 33.1 工作原理
+
+## 33.2 使用场景
+
+## 33.3 简单的计算机配置(Java)
+
+# 第34章 嵌套函数
+
+## 34.1 工作原理
+
+## 34.2 使用场景
+
+## 34.3 简单计算机配置范例(Java)
+
+## 34.4 用标记处理多个不同的参数(C#)
+
+## 34.5 针对IDE支持使用子类型标记(Java)
+
+## 34.6 使用对象初始化器(C#)
+
+## 34.7 周期性事件(C#)
+
+### 34.7.1 语义模型
+
+### 34.7.2 DSL
+
+# 第35章 方法级联
+
+## 35.1 工作原理
+
+### 35.1.1 生成器还是值
+
+### 35.1.2 收尾问题
+
+### 35.1.3 分层结构
+
+### 35.1.4 渐进式接口
+
+## 35.2 使用场景
+
+ 方法级联可以为内部 DSL 添加极好的可读性,因此,它在一些人心目中已经成为内部 DSL 的同义词。然而,当方法级联和其他函数组合联合使用时前者是最好的。
+
+ 方法级联在使用语言中的可选子句时工作得最好。方法级联很容易让 DSL 的脚本编写者挑选出特定情况下需要的子句。很难在语言中指定某些子句是必须存在的。使用渐进式接口可以给子句排序,但最后子句总是会被省略掉。“嵌套函数”(第 34 章)是对强制性子句更好的选择。
+
+ 收尾问题一次又一次地冒出来。虽然有一些权宜之计,但如果你遇到它,你最好使用嵌套函数或者嵌套闭包。这两个替代方案也是在你陷入“语境变量”(第 13 章)的困境时更好的选择。
+
+## 35.3 简单的计算机配置范例(Java)
+
+## 35.4 带有属性的方法级联(C#)
+
+## 35.5 渐进式接口(C#)
+
+# 第36章 对象范围
+
+## 36.1 工作原理
+
+## 36.2 使用场景
+
+ 由于对象范围解决了“嵌套函数”(第 34 章)和“函数序列”(第 33 章)中存在的全局函数问题,因此这个方法总是值得考虑的。使用对象范围可以使 DSL 脚本中所有裸函数调用都变成某个对象上的实例方法调用,这不仅避免了对于全局命名空间的干扰,还能使你在“表达式生成器”(第 32 章)对象上保存相关数据。我觉得这几个特性非常有用,因此我建议在可能的情况下尽量采用对象范围。
+
+ 然而,有时你却无法使用它,比如,你需要使用面向对象语言才行。当然,这对我不成问题,因为我总是倾向于使用面向对象语言。
+
+ 更常见的问题是,对象范围限制了 DSL 脚本放置的位置。对于继承的情况,你必须将 DSL 脚本放在表达式生成器类的一个方法中。对于自成体系的 DSL 脚本,这不是什么问题。它们通常都有独立的问题,并且与其他代码有较好的隔离。唯一的问题是,在语法上有些噪音。也就是说,你必须配置继承关系,但是这并不是什么突出的问题(如果是 Ruby 的 instance_eval,你甚至可以避免它。)。真正的问题在于片段化的 DSL,对于这种情况,通过继承来强制对象范围非常别扭,甚至是无法实现。
+
+ 对象范围是过分依赖全局函数的解药,但我们必须记住,全局函数最大的问题是修改全局数据。在一个常见的情况下,使用全局函数并不存在这个问题,那就是全局函数仅仅创建并返回新的对象,比如`Date.today()`。静态方法——实际上是全局函数的一种——可以有效地返回普通对象或者表达式生成器。如果你可以把全局函数都像这样组织起来,那么你对对象范围的需求也就没那么强烈了。
+
+ 如果 DSL 框架允许 DSL 的用户为“对象范围”(第 36 章)添加子类的话,DSL 就会更具扩展性。用户定义的子类可以为 DSL 添加新方法。如果某些方法只在某个脚本里使用,那么用户可以直接在这个脚本的子类中定义这些方法。
+
+## 36.3 安全代码(C#)
+
+### 36.3.1 语义模型
+
+### 36.3.2 DSL
+
+## 36.4 使用实例求值(Ruby)
+
+## 36.5 使用实例初始化器(Java)
+
+# 第37章 闭包
+
+## 37.1 工作原理
+
+## 37.2 使用场景
+
+# 第38章 嵌套闭包
+
+## 38.1 工作原理
+
+## 38.2 使用场景
+
+## 38.3 用嵌套闭包来包装函数序列(Ruby)
+
+## 38.4 简单的C#示例(C#)
+
+## 38.5 使用方法级联(Ruby)
+
+## 38.6 带显式闭包参数的函数序列(Ruby)
+
+## 38.7 采用实例级求值(Ruby)
+
+# 第39章 列表的字面构造
+
+## 39.1 工作原理
+
+ 列表的字面构造是构造列表数据结构的编程语言特性。许多语言为列表的字面构造提供直接的语法支持。其中最明显的是 Lisp 的 `(first second third)`;Ruby 也有类似的` [first, second, third]`—— 虽然不如 Lisp 的优雅。列表的字面构造通常都允许列表嵌套;事实上,整个 Lisp 程序都可以看做一个嵌套列表。
+
+ 列表的字面构造经常用于表达函数调用。父函数从列表中提取一些元素,然后按照函数定义处理它们。
+
+ 基于C语言的主流语言并不支持嵌套列表语法。它们通常有数组的字面构造 `{1, 2, 3}`,但是通常仅允许其中的常量或字面量,而不像允许任意符号或表达式的通用语法。
+
+ 有一个办法可以绕过这个限制,就是用变参函数,比如 `companions(jo, saraJane, leela)`。在强类型语言中,变参调用的所有元素类型都必须是相同的类型。
+
+## 39.2 使用场景
+
+# 第40章 Literal Map
+
+作为Literal Map来表示一个表达式
+
+```Ruby
+computer(processor(:cores => 2, :type => :i386)),
+ disk(:size => 150),
+ disk(:size => 75, :speed => 7200, :interface => :satal))
+```
+
+## 40.1 工作原理
+
+ Literal Map 存在于很多语言中,是一种构造 Map 数据结构的语言结构(这种数据结构也叫做字典、散列表、散列或者关联数组)。它通常在函数调用中使用,函数接收 Map 并处理它。
+
+ 在动态类型语言中,使用 Literal Map 面临的最大问题是无法保证键名的合法性。于是,你不得不处理那些陌生的键,此外你也无法告诉 DSL 脚本编写者哪些键是正确的。在静态类型语言中,可以通过定义特定类型的枚举为键来避免这个问题。
+
+ 在动态类型语言中,Literal Map 的键值通常是符号数据类型(或者字符串)。符号是最自然的选择,很多语言为了使符号键更容易使用(因为它们如此常见),提供了简化的语法。比如 Ruby,在 1.9 版本中,可以使用 `{cores:2}` 替代 `{:cores=>2}`。
+
+## 40.2 使用场景
+
+## 40.3 使用List和Map表达计算机的配置信息(Ruby)
+
+## 40.4 演化为Greenspun式(Ruby)
+
+# 第41章 动态接收
+
+## 41.1 工作原理
+
+## 41.2 使用场景
+
+## 41.3 积分——使用方法名解析(Ruby)
+
+### 41.3.1 模型
+
+### 41.3.2 生成器
+
+## 41.4 积分——使用方法级联(Ruby)
+
+### 41.4.1 模型
+
+### 41.4.2 生成器
+
+## 41.5 去掉安全仪表盘控制器中的引用(JRuby)
+
+# 第42章 标注
+
+## 42.1 工作原理
+
+### 42.1.1 定义标注
+
+### 42.1.2 处理标注
+
+## 42.2 使用场景
+
+## 42.3 用于运行时处理的特定语法(Java)
+
+## 42.4 使用类方法(Ruby)
+
+## 42.5 动态代码生成(Ruby)
+
+# 第43章 解析树操作
+
+## 43.1 工作原理
+
+ 虽然解析树操作允许以宿主语言编写表达式,但表达式的编写并不是任意的。对表达式的处理一般都会存在一些约束。在这些情况下,当你拿到你所不能处理的表达式时,及早报错(fail fast)非常重要。通常,在遍历解析树时,你知道树上的节点与你期望的将一致。使用解析树操作,解析树可以包含宿主语言中的任何合法构建块,所以你在遍历时必须自己做一些检查。
+
+ 通常你不需要或不想要遍历整个表达式树。大多数情况下,你只需要遍历树的一部分,只留下重要的子树以便于判断。这样你不需要构建完整的解析器,而只需解析构建“语义模型”(第 11 章)所需的那一部分,并在不需要进一步遍历时立即判断那些子树。
+
+## 43.2 使用场景
+
+ 解析树操作允许在宿主编程语言中表示逻辑,然后以更灵活的方式操作表达式。这使得在DSL中使用解析树操作的主要动机是在表达式中使用宿主语言本身更多的特性,而不是内部DSL构建块的混杂形式。
+
+## 43.3 由C#条件生成IMAP查询(C#)
+
+### 43.3.1 语义模型
+
+### 43.3.2 以C#构建
+
+### 43.3.3 退后一步
+
+# 第44章 类符号表
+
+## 44.1 工作原理
+
+## 44.2 使用场景
+
+## 44.3 在静态类型中实现类符号表(Java)
+
+# 第45章 文本润色
+
+## 45.1 工作原理
+
+ 文本润色是一种简单的技巧,它在DSL脚本解析之前进行一系列的文本替换工作。一个简单的例子是,如果读者不喜欢使用点(`.`)来表示方法调用,可以使用空格来替换它,从而将`3 hours ago`变成`3.hours.ago`。稍微复杂一点的例子是,可以把`3%`变成`percentage(3)`。文本润色的结果是内部DSL脚本。
+
+ 实现润色非常容易,只需编写一系列正则表达式来进行文本替换——大多数语言都支持这样做。然而,正确地编写正则表达式以确保它们不会进行不恰当的替换是复杂的。引用字符串中的空格就不应该替换为点,这使得正则表达式编写变得更加困难。
+
+ 文本润色常见于动态语言,因为可以在运行时判断文本。因此这类语言可以读入DSL表达式,然后润色它们,最后再判断最终的内部DSL脚本。然而,也可以在静态语言中使用它。当然需要在编译之前对DSL脚本进行润色——这需要在构建的过程中引入额外的步骤。
+
+ 虽然文本润色主要用在内部DSL上,但在某些情况下也可以用在外部DSL上。当常规的词法分析器和语法分析器链难以处理时——例如,具有语义的递归和换行——可以通过文本润色对源文件进行预处理。
+
+ 你可以把文本润色看作“宏”(第15章)在文本环境下的一个简单应用,当然也会带来宏所带来的问题。
+
+## 45.2 使用场景
+
+## 45.3 使用润色的折扣规则(Ruby)
+
+# 第46章 为字面量提供拓展
+
+## 46.1 工作原理
+
+## 46.2 使用场景
+
+## 46.3 食谱配料(C#)
+
+# 第五部分 其他计算模型
+
+# 第47章 适应性模型
+
+## 47.1 工作原理
+
+### 47.1.1 在适应性模型中使用命令式代码
+
+### 47.1.2 工具
+
+## 47.2 使用场景
+
+# 第48章 决策表
+
+## 48.1 工作原理
+
+## 48.2 使用场景
+
+## 48.3 为一个订单计算费用(C#)
+
+### 48.3.1 模型
+
+### 48.3.2 解析器
+
+# 第49章 依赖网络
+
+
+ 对于软件开发人员来说,构造软件系统是一个很困难的事情。在很多不同的时间点上,你可能想做不同的事情:编译程序或者运行测试。如果你要运行测试,首先需要确保你的编译是最新的。在编译之前,你需要保证某些代码已经生成。
+
+ 依赖网络使用有向无环图(DAG)来组织功能,包括任务及其之间的依赖关系。在这个例子中,测试任务依赖于编译任务,编译任务依赖于代码生成。当你想要执行一个任务时,首先找到它所依赖的所有任务,并确保它们都先执行(如果需要的话)。通过遍历依赖网络,可以确保所有需要的前提任务都已执行。同时,即使某个任务通过不同的依赖路径出现多次,也只会执行一次。
+
+## 49.1 工作原理
+
+## 49.2 使用场景
+
+## 49.3 分析饮料(C#)
+
+### 49.3.1 语义模型
+
+### 49.3.2 解析器
+
+# 第50章 产生式规则系统
+
+ 许多情况都可以看作一组条件测试。当校验数据时,每个校验都可以看作一个条件,当条件为假时,抛出错误。对一组位置的资格验证也可以看作一个条件链,如果通过了链上的所有验证,则符合资格。错误诊断可以看做通过一系列问题(这些问题又会带来新的问题)并最终找到错误根源的过程。
+
+ 产生式规则系统计算模型实现一组规则的概念,其中每个规则都有一个条件和一个随之产生的动作。通过一系列循环,系统基于其所有的数据运行规则,每个循环都会识别出其条件匹配的规则,然后执行规则的动作。产生式规则系统通常是专家系统的组成部分。
+
+## 50.1 工作原理
+
+### 50.1.1 链式操作
+
+### 50.1.2 矛盾推导
+
+### 50.1.3 规则结构里的模式
+
+## 50.2 使用场景
+
+## 50.3 俱乐部会员校验(C#)
+
+### 50.3.1 模型
+
+### 50.3.2 解析器
+
+### 50.3.3 演进DSL
+
+## 50.4 适任资格的规则:扩展俱乐部成员(C#)
+
+### 50.4.1 模型
+
+### 50.4.2 解析器
+
+# 第51章 状态机
+
+## 51.1 工作原理
+
+## 51.2 使用场景
+
+## 51.3 安全面板控制器(Java)
+
+# 第六部分 代码生成
+
+# 第52章 基于转化器的代码生成
+
+## 52.1 工作原理
+
+## 52.2 使用场景
+
+ 当输出文本和输入模型有简单的映射关系且大部分输出文本可以自动产生时,单级基于转换器的代码生成是个不错的选择。在这种情况下,基于转换器的代码生成很容易编写而且不需要引入任何模板工具。
+
+ 而当输入和输出结果之间存在复杂关系时,则可以使用多级基于转换器的代码生成,每一级可以处理一个特定的代码生成方面。
+
+ 当使用“基于模型的代码生成”(第55章)时,通常可以使用基于转换器的代码生成来生成一系列方法,然后依次调用它们来产生模型。
+
+## 52.3 安全面板控制器(Java生成的C)
+
+# 第53章 模版化的生成器
+
+## 53.1 工作原理
+
+## 53.2 使用场景
+
+ 模板化的生成器最大的好处在于,通过阅读模板文件,就可以很容易了解最终输出的样子。特别是当输出包含大量的静态内容,而仅仅有少量简单的动态内容的时候,这非常有用。
+
+ 需要使用模板化的生成器的第一个迹象是在生成的文件中有大量的静态内容。静态内容越多,使用模板化的生成器就越容易。此外还需要考虑待生成的动态内容的复杂度。你所使用的循环、条件分支、高级模板语言特性越多,就越难从模板文件中看出最后生成的结果。如果你必须使用这些复杂的特性,那么请考虑使用“基于转换器的代码生成”(第52章)。
+
+## 53.3 生成带有嵌套条件的安全控制面板状态机(Velocity和Java 生成的C)
+
+# 第54章 嵌入助手
+
+## 54.1 工作原理
+
+## 54.2 使用场景
+
+## 54.3 安全控制面板的状态(Java和ANTLR)
+
+## 54.4 助手类应该生成HTML吗(Java和Velocity)
+
+# 第 55章 基于模型的代码生成
+
+## 55.1 工作原理
+
+## 55.2 使用场景
+
+## 55.3 安全控制面板的状态机(C)
+
+## 55.4 动态载入状态机(C)
+
+# 第56章 无视模型的代码生成
+
+## 56.1 工作原理
+
+ 代码生成的一个优点是,它允许你在一个受控的环境中生成代码,而无需手工重复编写。在实现层面上,这种方法通常会引入重复代码(通常我们会为此感到差愧),特别是在使用某种数据结构表达行为之后再把它编码到控制流中的情况下。
+
+ 当使用无视模型的代码生成时,可以从在目标环境中为一段特定的DSL脚本提供实现开始。我习惯从最简单和最短小的脚本开始。实现代码要尽量写得清晰,然而却不必太在意是否区分了特殊和通用的代码。对于代码中特定元素的重复也不必计较,因为最终这部分意义将由代码生成器来生成。同样,这意味着我不必太过关注数据结构,使用首选的过程代码和简单的数据结构就足够了。
+
+## 56.2 使用场景
+
+## 56.3 使用嵌套条件的安全面板状态机(C)
+
+# 第57章 代沟
+
+## 57.1 工作原理
+
+ 代沟的基本形式是,生成义类——Vlissides称为核心类——然后手动编写子类。这样你就可以始终在子类中任意地重写生成的代码。手写代码可以轻松调用任何生成的功能,而生成的代码也可以通过抽象方法调用手写的功能,而编译器能检查的抽象方法由子类实现,或者由仅根据需要重写的钩子方法实现。
+
+ 当你需要从外部引用这些类时,你永远只引用手写的特定子类。这样生成的类就不会被代码库中其他代码忽略。
+
+## 57.2 使用场景
+
+## 57.3 根据数据结构生成类(Java和一些Ruby)