();
for (let i = 0; ; ++i) {
const x = nums[i];
const y = target - x;
-
- if (m.has(y)) {
- return [m.get(y)!, i];
+ if (d.has(y)) {
+ return [d.get(y)!, i];
}
-
- m.set(x, i);
+ d.set(x, i);
}
}
diff --git a/solution/0000-0099/0010.Regular Expression Matching/README.md b/solution/0000-0099/0010.Regular Expression Matching/README.md
index eb824ee89d247..5eb9ff8be6f3d 100644
--- a/solution/0000-0099/0010.Regular Expression Matching/README.md
+++ b/solution/0000-0099/0010.Regular Expression Matching/README.md
@@ -25,7 +25,7 @@ tags:
'*' 匹配零个或多个前面的那一个元素
-所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
+所谓匹配,是要涵盖 整个 字符串 s 的,而不是部分字符串。
示例 1:
diff --git a/solution/0000-0099/0013.Roman to Integer/README.md b/solution/0000-0099/0013.Roman to Integer/README.md
index ca5d3ca8955b6..4d985955579f8 100644
--- a/solution/0000-0099/0013.Roman to Integer/README.md
+++ b/solution/0000-0099/0013.Roman to Integer/README.md
@@ -87,7 +87,7 @@ M 1000
题目数据保证 s 是一个有效的罗马数字,且表示整数在范围 [1, 3999] 内
题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 - Mathematics 。
+ 关于罗马数字的详尽书写规则,可以参考 罗马数字 - 百度百科。
diff --git a/solution/0000-0099/0015.3Sum/README.md b/solution/0000-0099/0015.3Sum/README.md
index 0d60c80a54ff9..97e493065a58f 100644
--- a/solution/0000-0099/0015.3Sum/README.md
+++ b/solution/0000-0099/0015.3Sum/README.md
@@ -18,9 +18,7 @@ tags:
-给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
-
-你返回所有和为 0 且不重复的三元组。
+给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
diff --git a/solution/0000-0099/0016.3Sum Closest/README.md b/solution/0000-0099/0016.3Sum Closest/README.md
index 36a0f1a68f585..26a419cdec0e9 100644
--- a/solution/0000-0099/0016.3Sum Closest/README.md
+++ b/solution/0000-0099/0016.3Sum Closest/README.md
@@ -31,7 +31,7 @@ tags:
输入:nums = [-1,2,1,-4], target = 1
输出:2
-解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
+解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2)。
示例 2:
@@ -39,7 +39,7 @@ tags:
输入:nums = [0,0,0], target = 1
输出:0
-
+解释:与 target 最接近的和是 0(0 + 0 + 0 = 0)。
diff --git a/solution/0000-0099/0032.Longest Valid Parentheses/README.md b/solution/0000-0099/0032.Longest Valid Parentheses/README.md
index 6f29dbc123039..41b8be83eb9e6 100644
--- a/solution/0000-0099/0032.Longest Valid Parentheses/README.md
+++ b/solution/0000-0099/0032.Longest Valid Parentheses/README.md
@@ -77,9 +77,9 @@ tags:
$$
\begin{cases}
-f[i] = 0, & \text{if } s[i-1] = '(',\\
-f[i] = f[i-2] + 2, & \text{if } s[i-1] = ')' \text{ and } s[i-2] = '(',\\
-f[i] = f[i-1] + 2 + f[i-f[i-1]-2], & \text{if } s[i-1] = ')' \text{ and } s[i-2] = ')' \text{ and } s[i-f[i-1]-2] = '(',\\
+f[i] = 0, & \textit{if } s[i-1] = '(',\\
+f[i] = f[i-2] + 2, & \textit{if } s[i-1] = ')' \textit{ and } s[i-2] = '(',\\
+f[i] = f[i-1] + 2 + f[i-f[i-1]-2], & \textit{if } s[i-1] = ')' \textit{ and } s[i-2] = ')' \textit{ and } s[i-f[i-1]-2] = '(',\\
\end{cases}
$$
diff --git a/solution/0000-0099/0032.Longest Valid Parentheses/README_EN.md b/solution/0000-0099/0032.Longest Valid Parentheses/README_EN.md
index c6dba25b590ca..3b724ae45f680 100644
--- a/solution/0000-0099/0032.Longest Valid Parentheses/README_EN.md
+++ b/solution/0000-0099/0032.Longest Valid Parentheses/README_EN.md
@@ -75,9 +75,9 @@ Therefore, we can get the state transition equation:
$$
\begin{cases}
-f[i] = 0, & \text{if } s[i-1] = '(',\\
-f[i] = f[i-2] + 2, & \text{if } s[i-1] = ')' \text{ and } s[i-2] = '(',\\
-f[i] = f[i-1] + 2 + f[i-f[i-1]-2], & \text{if } s[i-1] = ')' \text{ and } s[i-2] = ')' \text{ and } s[i-f[i-1]-2] = '(',\\
+f[i] = 0, & \textit{if } s[i-1] = '(',\\
+f[i] = f[i-2] + 2, & \textit{if } s[i-1] = ')' \textit{ and } s[i-2] = '(',\\
+f[i] = f[i-1] + 2 + f[i-f[i-1]-2], & \textit{if } s[i-1] = ')' \textit{ and } s[i-2] = ')' \textit{ and } s[i-f[i-1]-2] = '(',\\
\end{cases}
$$
diff --git a/solution/0000-0099/0044.Wildcard Matching/README.md b/solution/0000-0099/0044.Wildcard Matching/README.md
index af58b95316fb6..4307c23d0f1bc 100644
--- a/solution/0000-0099/0044.Wildcard Matching/README.md
+++ b/solution/0000-0099/0044.Wildcard Matching/README.md
@@ -79,8 +79,8 @@ tags:
函数 $dfs(i, j)$ 的执行过程如下:
-- 如果 $i \geq \text{len}(s)$,那么只有当 $j \geq \text{len}(p)$ 或者 $p[j] = '*'$ 且 $dfs(i, j + 1)$ 为真时,$dfs(i, j)$ 才为真。
-- 如果 $j \geq \text{len}(p)$,那么 $dfs(i, j)$ 为假。
+- 如果 $i \geq \textit{len}(s)$,那么只有当 $j \geq \textit{len}(p)$ 或者 $p[j] = '*'$ 且 $dfs(i, j + 1)$ 为真时,$dfs(i, j)$ 才为真。
+- 如果 $j \geq \textit{len}(p)$,那么 $dfs(i, j)$ 为假。
- 如果 $p[j] = '*'$,那么 $dfs(i, j)$ 为真当且仅当 $dfs(i + 1, j)$ 或 $dfs(i + 1, j + 1)$ 或 $dfs(i, j + 1)$ 中有一个为真。
- 否则 $dfs(i, j)$ 为真当且仅当 $p[j] = '?'$ 或 $s[i] = p[j]$ 且 $dfs(i + 1, j + 1)$ 为真。
@@ -293,7 +293,7 @@ public class Solution {
我们可以将方法一中的记忆化搜索转换为动态规划。
-定义 $f[i][j]$ 表示字符串 $s$ 的前 $i$ 个字符和字符串 $p$ 的前 $j$ 个字符是否匹配。初始时 $f[0][0] = \text{true}$,表示两个空字符串是匹配的。对于 $j \in [1, n]$,如果 $p[j-1] = '*'$,那么 $f[0][j] = f[0][j-1]$。
+定义 $f[i][j]$ 表示字符串 $s$ 的前 $i$ 个字符和字符串 $p$ 的前 $j$ 个字符是否匹配。初始时 $f[0][0] = \textit{true}$,表示两个空字符串是匹配的。对于 $j \in [1, n]$,如果 $p[j-1] = '*'$,那么 $f[0][j] = f[0][j-1]$。
接下来我们考虑 $i \in [1, m]$ 和 $j \in [1, n]$ 的情况:
diff --git a/solution/0000-0099/0044.Wildcard Matching/README_EN.md b/solution/0000-0099/0044.Wildcard Matching/README_EN.md
index 4bce7a87a5922..a18cfe3de356c 100644
--- a/solution/0000-0099/0044.Wildcard Matching/README_EN.md
+++ b/solution/0000-0099/0044.Wildcard Matching/README_EN.md
@@ -74,8 +74,8 @@ We design a function $dfs(i, j)$, which represents whether the string $s$ starti
The execution process of the function $dfs(i, j)$ is as follows:
-- If $i \geq \text{len}(s)$, then $dfs(i, j)$ is true only when $j \geq \text{len}(p)$ or $p[j] = '*'$ and $dfs(i, j + 1)$ is true.
-- If $j \geq \text{len}(p)$, then $dfs(i, j)$ is false.
+- If $i \geq \textit{len}(s)$, then $dfs(i, j)$ is true only when $j \geq \textit{len}(p)$ or $p[j] = '*'$ and $dfs(i, j + 1)$ is true.
+- If $j \geq \textit{len}(p)$, then $dfs(i, j)$ is false.
- If $p[j] = '*'$, then $dfs(i, j)$ is true if and only if $dfs(i + 1, j)$ or $dfs(i + 1, j + 1)$ or $dfs(i, j + 1)$ is true.
- Otherwise, $dfs(i, j)$ is true if and only if $p[j] = '?'$ or $s[i] = p[j]$ and $dfs(i + 1, j + 1)$ is true.
@@ -288,7 +288,7 @@ public class Solution {
We can convert the memoization search in Solution 1 into dynamic programming.
-Define $f[i][j]$ to represent whether the first $i$ characters of string $s$ match the first $j$ characters of string $p$. Initially, $f[0][0] = \text{true}$, indicating that two empty strings are matching. For $j \in [1, n]$, if $p[j-1] = '*'$, then $f[0][j] = f[0][j-1]$.
+Define $f[i][j]$ to represent whether the first $i$ characters of string $s$ match the first $j$ characters of string $p$. Initially, $f[0][0] = \textit{true}$, indicating that two empty strings are matching. For $j \in [1, n]$, if $p[j-1] = '*'$, then $f[0][j] = f[0][j-1]$.
Next, we consider the case of $i \in [1, m]$ and $j \in [1, n]$:
diff --git a/solution/0000-0099/0062.Unique Paths/README.md b/solution/0000-0099/0062.Unique Paths/README.md
index 5f4413661b48a..d8c583dcb020e 100644
--- a/solution/0000-0099/0062.Unique Paths/README.md
+++ b/solution/0000-0099/0062.Unique Paths/README.md
@@ -86,7 +86,7 @@ tags:
$$
f[i][j] = \begin{cases}
1 & i = 0, j = 0 \\
-f[i - 1][j] + f[i][j - 1] & \text{otherwise}
+f[i - 1][j] + f[i][j - 1] & \textit{otherwise}
\end{cases}
$$
diff --git a/solution/0000-0099/0062.Unique Paths/README_EN.md b/solution/0000-0099/0062.Unique Paths/README_EN.md
index 2c2321c934c29..f276f8bc01d14 100644
--- a/solution/0000-0099/0062.Unique Paths/README_EN.md
+++ b/solution/0000-0099/0062.Unique Paths/README_EN.md
@@ -70,7 +70,7 @@ Therefore, we have the following state transition equation:
$$
f[i][j] = \begin{cases}
1 & i = 0, j = 0 \\
-f[i - 1][j] + f[i][j - 1] & \text{otherwise}
+f[i - 1][j] + f[i][j - 1] & \textit{otherwise}
\end{cases}
$$
diff --git a/solution/0000-0099/0071.Simplify Path/README.md b/solution/0000-0099/0071.Simplify Path/README.md
index 4ea9bfda09e25..6551d3fe9d4d2 100644
--- a/solution/0000-0099/0071.Simplify Path/README.md
+++ b/solution/0000-0099/0071.Simplify Path/README.md
@@ -17,9 +17,9 @@ tags:
-给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
+给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
-在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
+在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
@@ -32,44 +32,74 @@ tags:
返回简化后得到的 规范路径 。
-
+
-示例 1:
+示例 1:
-
-输入:path = "/home/"
-输出:"/home"
-解释:注意,最后一个目录名后面没有斜杠。
+
+
输入:path = "/home/"
-
示例 2:
+
输出:"/home"
-
-输入:path = "/../"
-输出:"/"
-解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
-
+
解释:
-
示例 3:
+
应删除尾部斜杠。
+
-输入:path = "/home//foo/"
-输出:"/home/foo"
-解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
-
+示例 2:
-示例 4:
+
+
输入:path = "/home//foo/"
-
-输入:path = "/a/./b/../../c/"
-输出:"/c"
-
+
输出:"/home/foo"
-
+
解释:
+
+
多个连续的斜杠被单个斜杠替换。
+
示例 3:
+
+
+
输入:path = "/home/user/Documents/../Pictures"
+
+
输出:"/home/user/Pictures"
+
+
解释:
+
+
两个点 ".." 表示上一级目录。
+
示例 4:
+
+
+
输入:path = "/../"
+
+
输出:"/"
+
+
解释:
+
+
不可能从根目录上升级一级。
+
示例 5:
+
+
+
输入:path = "/.../a/../b/c/../d/./"
+
+
输出:"/.../b/d"
+
+
解释:
+
+
"..." 是此问题中目录的有效名称。
+
提示:
- 1 <= path.length <= 30001 <= path.length <= 3000path 由英文字母,数字,'.','/' 或 '_' 组成。path 是一个有效的 Unix 风格绝对路径。
diff --git a/solution/0000-0099/0071.Simplify Path/README_EN.md b/solution/0000-0099/0071.Simplify Path/README_EN.md
index 9d900204626dd..eddbbd32ac0b3 100644
--- a/solution/0000-0099/0071.Simplify Path/README_EN.md
+++ b/solution/0000-0099/0071.Simplify Path/README_EN.md
@@ -45,8 +45,6 @@ tags:
The trailing slash should be removed.
-
-
Example 2:
@@ -69,6 +67,7 @@ tags:
Explanation:
A double period ".." refers to the directory up a level.
+
Example 4:
@@ -81,7 +80,6 @@ tags:
Going one level up from the root directory is not possible.
-
Example 5:
diff --git a/solution/0000-0099/0072.Edit Distance/README.md b/solution/0000-0099/0072.Edit Distance/README.md
index 404004165ea29..757c2199f9a93 100644
--- a/solution/0000-0099/0072.Edit Distance/README.md
+++ b/solution/0000-0099/0072.Edit Distance/README.md
@@ -81,10 +81,10 @@ exection -> execution (插入 'u')
$$
f[i][j] = \begin{cases}
-i, & \text{if } j = 0 \\
-j, & \text{if } i = 0 \\
-f[i - 1][j - 1], & \text{if } word1[i - 1] = word2[j - 1] \\
-\min(f[i - 1][j], f[i][j - 1], f[i - 1][j - 1]) + 1, & \text{otherwise}
+i, & \textit{if } j = 0 \\
+j, & \textit{if } i = 0 \\
+f[i - 1][j - 1], & \textit{if } word1[i - 1] = word2[j - 1] \\
+\min(f[i - 1][j], f[i][j - 1], f[i - 1][j - 1]) + 1, & \textit{otherwise}
\end{cases}
$$
diff --git a/solution/0000-0099/0072.Edit Distance/README_EN.md b/solution/0000-0099/0072.Edit Distance/README_EN.md
index cbac236faf701..41321ff893864 100644
--- a/solution/0000-0099/0072.Edit Distance/README_EN.md
+++ b/solution/0000-0099/0072.Edit Distance/README_EN.md
@@ -79,10 +79,10 @@ Finally, we can get the state transition equation:
$$
f[i][j] = \begin{cases}
-i, & \text{if } j = 0 \\
-j, & \text{if } i = 0 \\
-f[i - 1][j - 1], & \text{if } word1[i - 1] = word2[j - 1] \\
-\min(f[i - 1][j], f[i][j - 1], f[i - 1][j - 1]) + 1, & \text{otherwise}
+i, & \textit{if } j = 0 \\
+j, & \textit{if } i = 0 \\
+f[i - 1][j - 1], & \textit{if } word1[i - 1] = word2[j - 1] \\
+\min(f[i - 1][j], f[i][j - 1], f[i - 1][j - 1]) + 1, & \textit{otherwise}
\end{cases}
$$
diff --git a/solution/0000-0099/0075.Sort Colors/README.md b/solution/0000-0099/0075.Sort Colors/README.md
index 3cdb264d2e73e..03206a6cb6bc1 100644
--- a/solution/0000-0099/0075.Sort Colors/README.md
+++ b/solution/0000-0099/0075.Sort Colors/README.md
@@ -18,7 +18,7 @@ tags:
-给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
+给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
diff --git a/solution/0000-0099/0085.Maximal Rectangle/README.md b/solution/0000-0099/0085.Maximal Rectangle/README.md
index 8f7d6760b3a36..e549b2983cc9c 100644
--- a/solution/0000-0099/0085.Maximal Rectangle/README.md
+++ b/solution/0000-0099/0085.Maximal Rectangle/README.md
@@ -25,7 +25,7 @@ tags:
示例 1:
-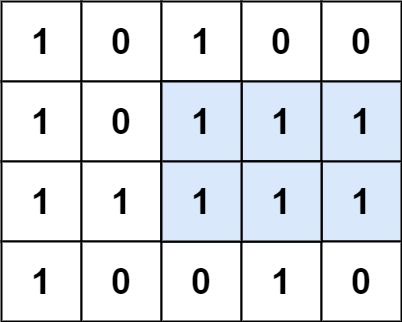 +
+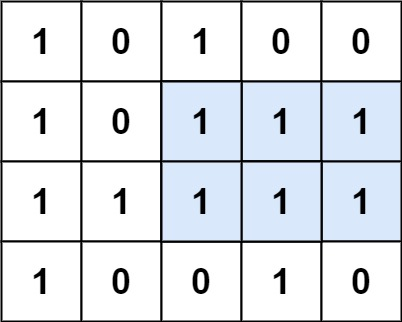
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:6
diff --git a/solution/0000-0099/0085.Maximal Rectangle/images/1722912576-boIxpm-image.png b/solution/0000-0099/0085.Maximal Rectangle/images/1722912576-boIxpm-image.png
new file mode 100644
index 0000000000000..bbf815c01d203
Binary files /dev/null and b/solution/0000-0099/0085.Maximal Rectangle/images/1722912576-boIxpm-image.png differ
diff --git a/solution/0000-0099/0091.Decode Ways/README.md b/solution/0000-0099/0091.Decode Ways/README.md
index 4f263c0409f85..9c51a029e9fad 100644
--- a/solution/0000-0099/0091.Decode Ways/README.md
+++ b/solution/0000-0099/0091.Decode Ways/README.md
@@ -19,22 +19,25 @@ tags:
一条包含字母 A-Z 的消息通过以下映射进行了 编码 :
-
-'A' -> "1"
-'B' -> "2"
-...
-'Z' -> "26"
+"1" -> 'A'
+"2" -> 'B'
+...
+"25" -> 'Y'
+"26" -> 'Z'
+
+然而,在 解码 已编码的消息时,你意识到有许多不同的方式来解码,因为有些编码被包含在其它编码当中("2" 和 "5" 与 "25")。
-要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,"11106" 可以映射为:
+例如,"11106" 可以映射为:
- "AAJF" ,将消息分组为 (1 1 10 6)"KJF" ,将消息分组为 (11 10 6)"AAJF" ,将消息分组为 (1, 1, 10, 6)"KJF" ,将消息分组为 (11, 10, 6)- 消息不能分组为
(1, 11, 06) ,因为 "06" 不是一个合法编码(只有 "6" 是合法的)。
-注意,消息不能分组为 (1 11 06) ,因为 "06" 不能映射为 "F" ,这是由于 "6" 和 "06" 在映射中并不等价。
+注意,可能存在无法解码的字符串。
-给你一个只含数字的 非空 字符串 s ,请计算并返回 解码 方法的 总数 。
+给你一个只含数字的 非空 字符串 s ,请计算并返回 解码 方法的 总数 。如果没有合法的方式解码整个字符串,返回 0。
题目数据保证答案肯定是一个 32 位 的整数。
diff --git a/solution/0000-0099/0091.Decode Ways/README_EN.md b/solution/0000-0099/0091.Decode Ways/README_EN.md
index aa4494f022832..670935d80be03 100644
--- a/solution/0000-0099/0091.Decode Ways/README_EN.md
+++ b/solution/0000-0099/0091.Decode Ways/README_EN.md
@@ -17,52 +17,66 @@ tags:
-A message containing letters from A-Z can be encoded into numbers using the following mapping:
+You have intercepted a secret message encoded as a string of numbers. The message is decoded via the following mapping:
-
-'A' -> "1"
-'B' -> "2"
-...
-'Z' -> "26"
-
+"1" -> 'A'
+"2" -> 'B'
+...
+"25" -> 'Y'
+"26" -> 'Z'
-To decode an encoded message, all the digits must be grouped then mapped back into letters using the reverse of the mapping above (there may be multiple ways). For example, "11106" can be mapped into:
+However, while decoding the message, you realize that there are many different ways you can decode the message because some codes are contained in other codes ("2" and "5" vs "25").
+
+For example, "11106" can be decoded into:
- "AAJF" with the grouping (1 1 10 6)"KJF" with the grouping (11 10 6)"AAJF" with the grouping (1, 1, 10, 6)"KJF" with the grouping (11, 10, 6)- The grouping
(1, 11, 06) is invalid because "06" is not a valid code (only "6" is valid).
-Note that the grouping (1 11 06) is invalid because "06" cannot be mapped into 'F' since "6" is different from "06".
-
-Given a string s containing only digits, return the number of ways to decode it.
+Note: there may be strings that are impossible to decode.
+
+Given a string s containing only digits, return the number of ways to decode it. If the entire string cannot be decoded in any valid way, return 0.
The test cases are generated so that the answer fits in a 32-bit integer.
Example 1:
-
-Input: s = "12"
-Output: 2
-Explanation: "12" could be decoded as "AB" (1 2) or "L" (12).
-
+
+
Input: s = "12"
+
+
Output: 2
+
+
Explanation:
+
+
"12" could be decoded as "AB" (1 2) or "L" (12).
+
Example 2:
-
-Input: s = "226"
-Output: 3
-Explanation: "226" could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
-
+
+
Input: s = "226"
+
+
Output: 3
+
+
Explanation:
+
+
"226" could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
+
Example 3:
-
-Input: s = "06"
-Output: 0
-Explanation: "06" cannot be mapped to "F" because of the leading zero ("6" is different from "06").
-
+
+
Input: s = "06"
+
+
Output: 0
+
+
Explanation:
+
+
"06" cannot be mapped to "F" because of the leading zero ("6" is different from "06"). In this case, the string is not a valid encoding, so return 0.
+
Constraints:
diff --git a/solution/0000-0099/0097.Interleaving String/README.md b/solution/0000-0099/0097.Interleaving String/README.md
index 564d3cc41af10..805e8315d4e0f 100644
--- a/solution/0000-0099/0097.Interleaving String/README.md
+++ b/solution/0000-0099/0097.Interleaving String/README.md
@@ -377,13 +377,13 @@ public class Solution {
$$
f[i][j] = \begin{cases}
-f[i - 1][j] & \text{if } s_1[i - 1] = s_3[i + j - 1] \\
-\text{or } f[i][j - 1] & \text{if } s_2[j - 1] = s_3[i + j - 1] \\
-\text{false} & \text{otherwise}
+f[i - 1][j] & \textit{if } s_1[i - 1] = s_3[i + j - 1] \\
+\textit{or } f[i][j - 1] & \textit{if } s_2[j - 1] = s_3[i + j - 1] \\
+\textit{false} & \textit{otherwise}
\end{cases}
$$
-其中 $f[0][0] = \text{true}$ 表示空串是两个空串的交错字符串。
+其中 $f[0][0] = \textit{true}$ 表示空串是两个空串的交错字符串。
答案即为 $f[m][n]$。
diff --git a/solution/0000-0099/0097.Interleaving String/README_EN.md b/solution/0000-0099/0097.Interleaving String/README_EN.md
index eb48eb39c68a2..93801d1703bcf 100644
--- a/solution/0000-0099/0097.Interleaving String/README_EN.md
+++ b/solution/0000-0099/0097.Interleaving String/README_EN.md
@@ -379,13 +379,13 @@ We define $f[i][j]$ to represent whether the first $i$ characters of string $s_1
$$
f[i][j] = \begin{cases}
-f[i - 1][j] & \text{if } s_1[i - 1] = s_3[i + j - 1] \\
-\text{or } f[i][j - 1] & \text{if } s_2[j - 1] = s_3[i + j - 1] \\
-\text{false} & \text{otherwise}
+f[i - 1][j] & \textit{if } s_1[i - 1] = s_3[i + j - 1] \\
+\textit{or } f[i][j - 1] & \textit{if } s_2[j - 1] = s_3[i + j - 1] \\
+\textit{false} & \textit{otherwise}
\end{cases}
$$
-where $f[0][0] = \text{true}$ indicates that an empty string is an interleaving string of two empty strings.
+where $f[0][0] = \textit{true}$ indicates that an empty string is an interleaving string of two empty strings.
The answer is $f[m][n]$.
diff --git a/solution/0000-0099/0098.Validate Binary Search Tree/README.md b/solution/0000-0099/0098.Validate Binary Search Tree/README.md
index 129b61bafaef8..0f2ca49cb6046 100644
--- a/solution/0000-0099/0098.Validate Binary Search Tree/README.md
+++ b/solution/0000-0099/0098.Validate Binary Search Tree/README.md
@@ -65,7 +65,7 @@ tags:
我们可以对二叉树进行递归中序遍历,如果遍历到的结果是严格升序的,那么这棵树就是一个二叉搜索树。
-因此,我们使用一个变量 $\textit{prev}$ 来保存上一个遍历到的节点,初始时 $\textit{prev} = -\infty$,然后我们递归遍历左子树,如果左子树不是二叉搜索树,直接返回 $\text{False}$,否则判断当前节点的值是否大于 $\textit{prev}$,如果不是,返回 $\text{False}$,否则更新 $\textit{prev}$ 为当前节点的值,然后递归遍历右子树。
+因此,我们使用一个变量 $\textit{prev}$ 来保存上一个遍历到的节点,初始时 $\textit{prev} = -\infty$,然后我们递归遍历左子树,如果左子树不是二叉搜索树,直接返回 $\textit{False}$,否则判断当前节点的值是否大于 $\textit{prev}$,如果不是,返回 $\textit{False}$,否则更新 $\textit{prev}$ 为当前节点的值,然后递归遍历右子树。
时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是二叉树的节点个数。
diff --git a/solution/0100-0199/0132.Palindrome Partitioning II/README.md b/solution/0100-0199/0132.Palindrome Partitioning II/README.md
index 90bde0e1186f3..6c79e69452a67 100644
--- a/solution/0100-0199/0132.Palindrome Partitioning II/README.md
+++ b/solution/0100-0199/0132.Palindrome Partitioning II/README.md
@@ -73,7 +73,7 @@ tags:
接下来,我们考虑 $f[i]$ 如何进行状态转移。我们可以枚举上一个分割点 $j$,如果子串 $s[j..i]$ 是一个回文串,那么 $f[i]$ 就可以从 $f[j]$ 转移而来。如果 $j=0$,那么说明 $s[0..i]$ 本身就是一个回文串,此时不需要进行分割,即 $f[i]=0$。因此,状态转移方程如下:
$$
-f[i]=\min_{0\leq j \leq i}\begin{cases} f[j-1]+1, & \text{if}\ g[j][i]=\text{True} \\ 0, & \text{if}\ g[0][i]=\text{True} \end{cases}
+f[i]=\min_{0\leq j \leq i}\begin{cases} f[j-1]+1, & \textit{if}\ g[j][i]=\textit{True} \\ 0, & \textit{if}\ g[0][i]=\textit{True} \end{cases}
$$
答案即为 $f[n]$,其中 $n$ 是字符串 $s$ 的长度。
diff --git a/solution/0100-0199/0137.Single Number II/README.md b/solution/0100-0199/0137.Single Number II/README.md
index 380f5e4329ad4..7befb363ad3ff 100644
--- a/solution/0100-0199/0137.Single Number II/README.md
+++ b/solution/0100-0199/0137.Single Number II/README.md
@@ -146,6 +146,19 @@ function singleNumber(nums: number[]): number {
}
```
+#### JavaScript
+
+```js
+function singleNumber(nums) {
+ let ans = 0;
+ for (let i = 0; i < 32; i++) {
+ const count = nums.reduce((r, v) => r + ((v >> i) & 1), 0);
+ ans |= count % 3 << i;
+ }
+ return ans;
+}
+```
+
#### Rust
```rust
@@ -319,6 +332,22 @@ function singleNumber(nums: number[]): number {
}
```
+#### JavaScript
+
+```js
+function singleNumber(nums) {
+ let a = 0;
+ let b = 0;
+ for (const c of nums) {
+ const aa = (~a & b & c) | (a & ~b & ~c);
+ const bb = ~a & (b ^ c);
+ a = aa;
+ b = bb;
+ }
+ return b;
+}
+```
+
#### Rust
```rust
@@ -343,4 +372,74 @@ impl Solution {
+
+
+### 方法三:哈希表 + 数学
+
+
+
+#### TypeScript
+
+```ts
+function singleNumber(nums: number[]): number {
+ const sumOfUnique = [...new Set(nums)].reduce((a, b) => a + b, 0);
+ const sum = nums.reduce((a, b) => a + b, 0);
+ return (sumOfUnique * 3 - sum) / 2;
+}
+```
+
+#### JavaScript
+
+```js
+function singleNumber(nums) {
+ const sumOfUnique = [...new Set(nums)].reduce((a, b) => a + b, 0);
+ const sum = nums.reduce((a, b) => a + b, 0);
+ return (sumOfUnique * 3 - sum) / 2;
+}
+```
+
+
+
+
+
+
+
+### 方法四:位运算
+
+
+
+#### TypeScript
+
+```ts
+function singleNumber(nums: number[]): number {
+ let [ans, acc] = [0, 0];
+
+ for (const x of nums) {
+ ans ^= x & ~acc;
+ acc ^= x & ~ans;
+ }
+
+ return ans;
+}
+```
+
+#### JavaScript
+
+```ts
+function singleNumber(nums) {
+ let [ans, acc] = [0, 0];
+
+ for (const x of nums) {
+ ans ^= x & ~acc;
+ acc ^= x & ~ans;
+ }
+
+ return ans;
+}
+```
+
+
+
+
+
diff --git a/solution/0100-0199/0137.Single Number II/README_EN.md b/solution/0100-0199/0137.Single Number II/README_EN.md
index 65c7a2543a182..81e2ceb8cb0a5 100644
--- a/solution/0100-0199/0137.Single Number II/README_EN.md
+++ b/solution/0100-0199/0137.Single Number II/README_EN.md
@@ -137,6 +137,19 @@ function singleNumber(nums: number[]): number {
}
```
+#### JavaScript
+
+```js
+function singleNumber(nums) {
+ let ans = 0;
+ for (let i = 0; i < 32; i++) {
+ const count = nums.reduce((r, v) => r + ((v >> i) & 1), 0);
+ ans |= count % 3 << i;
+ }
+ return ans;
+}
+```
+
#### Rust
```rust
@@ -310,6 +323,22 @@ function singleNumber(nums: number[]): number {
}
```
+#### JavaScript
+
+```js
+function singleNumber(nums) {
+ let a = 0;
+ let b = 0;
+ for (const c of nums) {
+ const aa = (~a & b & c) | (a & ~b & ~c);
+ const bb = ~a & (b ^ c);
+ a = aa;
+ b = bb;
+ }
+ return b;
+}
+```
+
#### Rust
```rust
@@ -334,4 +363,74 @@ impl Solution {
+
+
+### Solution 3: Set + Math
+
+
+
+#### TypeScript
+
+```ts
+function singleNumber(nums: number[]): number {
+ const sumOfUnique = [...new Set(nums)].reduce((a, b) => a + b, 0);
+ const sum = nums.reduce((a, b) => a + b, 0);
+ return (sumOfUnique * 3 - sum) / 2;
+}
+```
+
+#### JavaScript
+
+```js
+function singleNumber(nums) {
+ const sumOfUnique = [...new Set(nums)].reduce((a, b) => a + b, 0);
+ const sum = nums.reduce((a, b) => a + b, 0);
+ return (sumOfUnique * 3 - sum) / 2;
+}
+```
+
+
+
+
+
+
+
+### Solution 4: Bit Manipulation
+
+
+
+#### TypeScript
+
+```ts
+function singleNumber(nums: number[]): number {
+ let [ans, acc] = [0, 0];
+
+ for (const x of nums) {
+ ans ^= x & ~acc;
+ acc ^= x & ~ans;
+ }
+
+ return ans;
+}
+```
+
+#### JavaScript
+
+```ts
+function singleNumber(nums) {
+ let [ans, acc] = [0, 0];
+
+ for (const x of nums) {
+ ans ^= x & ~acc;
+ acc ^= x & ~ans;
+ }
+
+ return ans;
+}
+```
+
+
+
+
+
diff --git a/solution/0100-0199/0137.Single Number II/Solution.js b/solution/0100-0199/0137.Single Number II/Solution.js
new file mode 100644
index 0000000000000..97db05ced7237
--- /dev/null
+++ b/solution/0100-0199/0137.Single Number II/Solution.js
@@ -0,0 +1,8 @@
+function singleNumber(nums) {
+ let ans = 0;
+ for (let i = 0; i < 32; i++) {
+ const count = nums.reduce((r, v) => r + ((v >> i) & 1), 0);
+ ans |= count % 3 << i;
+ }
+ return ans;
+}
diff --git a/solution/0100-0199/0137.Single Number II/Solution2.js b/solution/0100-0199/0137.Single Number II/Solution2.js
new file mode 100644
index 0000000000000..b9385331291d2
--- /dev/null
+++ b/solution/0100-0199/0137.Single Number II/Solution2.js
@@ -0,0 +1,11 @@
+function singleNumber(nums) {
+ let a = 0;
+ let b = 0;
+ for (const c of nums) {
+ const aa = (~a & b & c) | (a & ~b & ~c);
+ const bb = ~a & (b ^ c);
+ a = aa;
+ b = bb;
+ }
+ return b;
+}
diff --git a/solution/0100-0199/0137.Single Number II/Solution3.js b/solution/0100-0199/0137.Single Number II/Solution3.js
new file mode 100644
index 0000000000000..8b8ab60c7e109
--- /dev/null
+++ b/solution/0100-0199/0137.Single Number II/Solution3.js
@@ -0,0 +1,5 @@
+function singleNumber(nums) {
+ const sumOfUnique = [...new Set(nums)].reduce((a, b) => a + b, 0);
+ const sum = nums.reduce((a, b) => a + b, 0);
+ return (sumOfUnique * 3 - sum) / 2;
+}
diff --git a/solution/0100-0199/0137.Single Number II/Solution3.ts b/solution/0100-0199/0137.Single Number II/Solution3.ts
new file mode 100644
index 0000000000000..02674c63ff57c
--- /dev/null
+++ b/solution/0100-0199/0137.Single Number II/Solution3.ts
@@ -0,0 +1,5 @@
+function singleNumber(nums: number[]): number {
+ const sumOfUnique = [...new Set(nums)].reduce((a, b) => a + b, 0);
+ const sum = nums.reduce((a, b) => a + b, 0);
+ return (sumOfUnique * 3 - sum) / 2;
+}
diff --git a/solution/0100-0199/0137.Single Number II/Solution4.js b/solution/0100-0199/0137.Single Number II/Solution4.js
new file mode 100644
index 0000000000000..dde5cb51e40c5
--- /dev/null
+++ b/solution/0100-0199/0137.Single Number II/Solution4.js
@@ -0,0 +1,10 @@
+function singleNumber(nums) {
+ let [ans, acc] = [0, 0];
+
+ for (const x of nums) {
+ ans ^= x & ~acc;
+ acc ^= x & ~ans;
+ }
+
+ return ans;
+}
diff --git a/solution/0100-0199/0137.Single Number II/Solution4.ts b/solution/0100-0199/0137.Single Number II/Solution4.ts
new file mode 100644
index 0000000000000..d4d59d1de5afc
--- /dev/null
+++ b/solution/0100-0199/0137.Single Number II/Solution4.ts
@@ -0,0 +1,10 @@
+function singleNumber(nums: number[]): number {
+ let [ans, acc] = [0, 0];
+
+ for (const x of nums) {
+ ans ^= x & ~acc;
+ acc ^= x & ~ans;
+ }
+
+ return ans;
+}
diff --git a/solution/0100-0199/0146.LRU Cache/README.md b/solution/0100-0199/0146.LRU Cache/README.md
index ce93f6c338ef2..7bb35b178741e 100644
--- a/solution/0100-0199/0146.LRU Cache/README.md
+++ b/solution/0100-0199/0146.LRU Cache/README.md
@@ -87,7 +87,7 @@ lRUCache.get(4); // 返回 4
当插入一个节点时,如果节点存在,我们将其从原来的位置删除,并重新插入到链表头部。如果不存在,我们首先检查缓存是否已满,如果已满,则删除链表尾部的节点,将新的节点插入链表头部。
-时间复杂度 $O(1)$,空间复杂度 $O(\text{capacity})$。
+时间复杂度 $O(1)$,空间复杂度 $O(\textit{capacity})$。
diff --git a/solution/0100-0199/0146.LRU Cache/README_EN.md b/solution/0100-0199/0146.LRU Cache/README_EN.md
index 719886f5ead4c..c3dbdaea5a858 100644
--- a/solution/0100-0199/0146.LRU Cache/README_EN.md
+++ b/solution/0100-0199/0146.LRU Cache/README_EN.md
@@ -81,7 +81,7 @@ When accessing a node, if the node exists, we delete it from its original positi
When inserting a node, if the node exists, we delete it from its original position and reinsert it at the head of the list. If it does not exist, we first check if the cache is full. If it is full, we delete the node at the tail of the list and insert the new node at the head of the list.
-The time complexity is $O(1)$, and the space complexity is $O(\text{capacity})$.
+The time complexity is $O(1)$, and the space complexity is $O(\textit{capacity})$.
diff --git a/solution/0100-0199/0147.Insertion Sort List/README.md b/solution/0100-0199/0147.Insertion Sort List/README.md
index f70899b2e4c3b..5f9c2b84a6d09 100644
--- a/solution/0100-0199/0147.Insertion Sort List/README.md
+++ b/solution/0100-0199/0147.Insertion Sort List/README.md
@@ -31,13 +31,13 @@ tags:
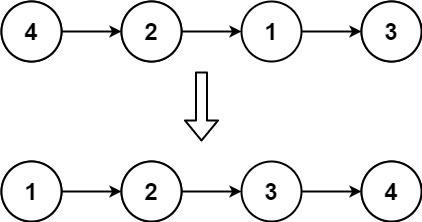
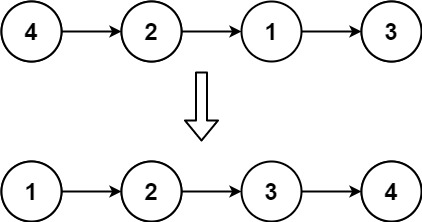
对链表进行插入排序。
-
+
示例 1:
-
+
输入: head = [4,2,1,3]
@@ -45,7 +45,7 @@ tags:
示例 2:
-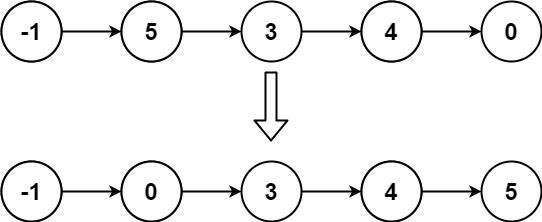
+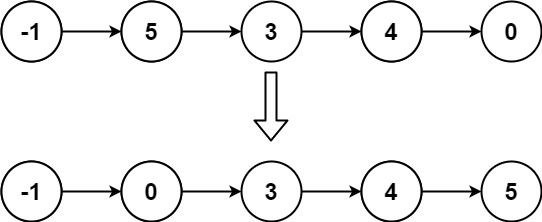
输入: head = [-1,5,3,4,0]
diff --git a/solution/0100-0199/0147.Insertion Sort List/images/1724130387-qxfMwx-Insertion-sort-example-300px.gif b/solution/0100-0199/0147.Insertion Sort List/images/1724130387-qxfMwx-Insertion-sort-example-300px.gif
new file mode 100644
index 0000000000000..96c1b12d5cc82
Binary files /dev/null and b/solution/0100-0199/0147.Insertion Sort List/images/1724130387-qxfMwx-Insertion-sort-example-300px.gif differ
diff --git a/solution/0100-0199/0147.Insertion Sort List/images/1724130414-QbPAjl-image.png b/solution/0100-0199/0147.Insertion Sort List/images/1724130414-QbPAjl-image.png
new file mode 100644
index 0000000000000..7b4b401c05391
Binary files /dev/null and b/solution/0100-0199/0147.Insertion Sort List/images/1724130414-QbPAjl-image.png differ
diff --git a/solution/0100-0199/0147.Insertion Sort List/images/1724130432-zoOvdI-image.png b/solution/0100-0199/0147.Insertion Sort List/images/1724130432-zoOvdI-image.png
new file mode 100644
index 0000000000000..af28294b1e9d5
Binary files /dev/null and b/solution/0100-0199/0147.Insertion Sort List/images/1724130432-zoOvdI-image.png differ
diff --git a/solution/0100-0199/0191.Number of 1 Bits/README_EN.md b/solution/0100-0199/0191.Number of 1 Bits/README_EN.md
index 72cc09656abc0..42fc428aab195 100644
--- a/solution/0100-0199/0191.Number of 1 Bits/README_EN.md
+++ b/solution/0100-0199/0191.Number of 1 Bits/README_EN.md
@@ -60,7 +60,7 @@ tags:
Constraints:
- 1 <= n <= 231 - 11 <= n <= 231 - 1
diff --git a/solution/0100-0199/0192.Word Frequency/README.md b/solution/0100-0199/0192.Word Frequency/README.md
index b73e14dcc749b..4c783786ef020 100644
--- a/solution/0100-0199/0192.Word Frequency/README.md
+++ b/solution/0100-0199/0192.Word Frequency/README.md
@@ -1,13 +1,13 @@
-
-
---
-
comments: true
difficulty: 中等
edit_url: https://github.com/doocs/leetcode/edit/main/solution/0100-0199/0192.Word%20Frequency/README.md
-
+tags:
+ - Shell
---
+
+
# [192. 统计词频](https://leetcode.cn/problems/word-frequency)
[English Version](/solution/0100-0199/0192.Word%20Frequency/README_EN.md)
diff --git a/solution/0100-0199/0193.Valid Phone Numbers/README.md b/solution/0100-0199/0193.Valid Phone Numbers/README.md
index 819f8d240f5e1..f9800080c44d5 100644
--- a/solution/0100-0199/0193.Valid Phone Numbers/README.md
+++ b/solution/0100-0199/0193.Valid Phone Numbers/README.md
@@ -1,13 +1,13 @@
-
-
---
-
comments: true
difficulty: 简单
edit_url: https://github.com/doocs/leetcode/edit/main/solution/0100-0199/0193.Valid%20Phone%20Numbers/README.md
-
+tags:
+ - Shell
---
+
+
# [193. 有效电话号码](https://leetcode.cn/problems/valid-phone-numbers)
[English Version](/solution/0100-0199/0193.Valid%20Phone%20Numbers/README_EN.md)
diff --git a/solution/0100-0199/0194.Transpose File/README.md b/solution/0100-0199/0194.Transpose File/README.md
index 90293ccffbeb2..1f9b12cb1ccd5 100644
--- a/solution/0100-0199/0194.Transpose File/README.md
+++ b/solution/0100-0199/0194.Transpose File/README.md
@@ -1,13 +1,13 @@
-
-
---
-
comments: true
difficulty: 中等
edit_url: https://github.com/doocs/leetcode/edit/main/solution/0100-0199/0194.Transpose%20File/README.md
-
+tags:
+ - Shell
---
+
+
# [194. 转置文件](https://leetcode.cn/problems/transpose-file)
[English Version](/solution/0100-0199/0194.Transpose%20File/README_EN.md)
diff --git a/solution/0100-0199/0195.Tenth Line/README.md b/solution/0100-0199/0195.Tenth Line/README.md
index 54d3accff9727..82a57ae3d8d9a 100644
--- a/solution/0100-0199/0195.Tenth Line/README.md
+++ b/solution/0100-0199/0195.Tenth Line/README.md
@@ -1,13 +1,13 @@
-
-
---
-
comments: true
difficulty: 简单
edit_url: https://github.com/doocs/leetcode/edit/main/solution/0100-0199/0195.Tenth%20Line/README.md
-
+tags:
+ - Shell
---
+
+
# [195. 第十行](https://leetcode.cn/problems/tenth-line)
[English Version](/solution/0100-0199/0195.Tenth%20Line/README_EN.md)
diff --git a/solution/0200-0299/0208.Implement Trie (Prefix Tree)/README.md b/solution/0200-0299/0208.Implement Trie (Prefix Tree)/README.md
index 76481c3da5923..76c12ffdbb115 100644
--- a/solution/0200-0299/0208.Implement Trie (Prefix Tree)/README.md
+++ b/solution/0200-0299/0208.Implement Trie (Prefix Tree)/README.md
@@ -19,7 +19,7 @@ tags:
-Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
+Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
@@ -27,10 +27,10 @@ tags:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
- boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
+ boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
-
+
示例:
@@ -51,12 +51,12 @@ trie.insert("app");
trie.search("app"); // 返回 True
-
+
提示:
- 1 <= word.length, prefix.length <= 20001 <= word.length, prefix.length <= 2000word 和 prefix 仅由小写英文字母组成insert、search 和 startsWith 调用次数 总计 不超过 3 * 104 次
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/README.md b/solution/0200-0299/0209.Minimum Size Subarray Sum/README.md
index 9b23bf83a977e..80f8c5d012195 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/README.md
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/README.md
@@ -266,13 +266,15 @@ public class Solution {
### 方法二:双指针
-我们可以使用双指针 $j$ 和 $i$ 维护一个窗口,其中窗口中的所有元素之和小于 $target$。初始时 $j = 0$,答案 $ans = n + 1$,其中 $n$ 为数组 $nums$ 的长度。
+我们注意到,数组 $\textit{nums}$ 中的元素均为正整数,我们可以考虑使用双指针来维护一个滑动窗口。
-接下来,指针 $i$ 从 $0$ 开始向右移动,每次移动一步,我们将指针 $i$ 对应的元素加入窗口,同时更新窗口中元素之和。如果窗口中元素之和大于等于 $target$,说明当前子数组满足条件,我们可以更新答案,即 $ans = \min(ans, i - j + 1)$。然后我们不断地从窗口中移除元素 $nums[j]$,直到窗口中元素之和小于 $target$,然后重复上述过程。
+具体地,我们定义两个指针 $\textit{l}$ 和 $\textit{r}$ 分别表示滑动窗口的左边界和右边界,用一个变量 $\textit{s}$ 代表滑动窗口中的元素和。
-最后,如果 $ans \leq n$,则说明存在满足条件的子数组,返回 $ans$,否则返回 $0$。
+在每一步操作中,我们移动右指针 $\textit{r}$,使得滑动窗口中加入一个元素,如果此时 $\textit{s} \ge \textit{target}$,我们就更新最小长度 $\textit{ans} = \min(\textit{ans}, \textit{r} - \textit{l} + 1$,并将左指针 $\textit{l}$ 循环向右移动,直至有 $\textit{s} < \textit{target}$。
+
+最后,如果最小长度 $\textit{ans}$ 仍为初始值,我们就返回 $0$,否则返回 $\textit{ans}$。
-时间复杂度 $O(n)$,空间复杂度 $O(1)$。其中 $n$ 为数组 $nums$ 的长度。
+时间复杂度 $O(n)$,其中 $n$ 为数组 $\textit{nums}$ 的长度。空间复杂度 $O(1)$。
@@ -281,16 +283,15 @@ public class Solution {
```python
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
- n = len(nums)
- ans = n + 1
- s = j = 0
- for i, x in enumerate(nums):
+ l = s = 0
+ ans = inf
+ for r, x in enumerate(nums):
s += x
- while j < n and s >= target:
- ans = min(ans, i - j + 1)
- s -= nums[j]
- j += 1
- return ans if ans <= n else 0
+ while s >= target:
+ ans = min(ans, r - l + 1)
+ s -= nums[l]
+ l += 1
+ return 0 if ans == inf else ans
```
#### Java
@@ -298,17 +299,17 @@ class Solution:
```java
class Solution {
public int minSubArrayLen(int target, int[] nums) {
- int n = nums.length;
+ int l = 0, n = nums.length;
long s = 0;
int ans = n + 1;
- for (int i = 0, j = 0; i < n; ++i) {
- s += nums[i];
- while (j < n && s >= target) {
- ans = Math.min(ans, i - j + 1);
- s -= nums[j++];
+ for (int r = 0; r < n; ++r) {
+ s += nums[r];
+ while (s >= target) {
+ ans = Math.min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans <= n ? ans : 0;
+ return ans > n ? 0 : ans;
}
}
```
@@ -319,17 +320,17 @@ class Solution {
class Solution {
public:
int minSubArrayLen(int target, vector& nums) {
- int n = nums.size();
+ int l = 0, n = nums.size();
long long s = 0;
int ans = n + 1;
- for (int i = 0, j = 0; i < n; ++i) {
- s += nums[i];
- while (j < n && s >= target) {
- ans = min(ans, i - j + 1);
- s -= nums[j++];
+ for (int r = 0; r < n; ++r) {
+ s += nums[r];
+ while (s >= target) {
+ ans = min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans == n + 1 ? 0 : ans;
+ return ans > n ? 0 : ans;
}
};
```
@@ -338,18 +339,17 @@ public:
```go
func minSubArrayLen(target int, nums []int) int {
- n := len(nums)
- s := 0
- ans := n + 1
- for i, j := 0, 0; i < n; i++ {
- s += nums[i]
+ l, n := 0, len(nums)
+ s, ans := 0, n+1
+ for r, x := range nums {
+ s += x
for s >= target {
- ans = min(ans, i-j+1)
- s -= nums[j]
- j++
+ ans = min(ans, r-l+1)
+ s -= nums[l]
+ l++
}
}
- if ans == n+1 {
+ if ans > n {
return 0
}
return ans
@@ -361,16 +361,15 @@ func minSubArrayLen(target int, nums []int) int {
```ts
function minSubArrayLen(target: number, nums: number[]): number {
const n = nums.length;
- let s = 0;
- let ans = n + 1;
- for (let i = 0, j = 0; i < n; ++i) {
- s += nums[i];
+ let [s, ans] = [0, n + 1];
+ for (let l = 0, r = 0; r < n; ++r) {
+ s += nums[r];
while (s >= target) {
- ans = Math.min(ans, i - j + 1);
- s -= nums[j++];
+ ans = Math.min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans === n + 1 ? 0 : ans;
+ return ans > n ? 0 : ans;
}
```
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/README_EN.md b/solution/0200-0299/0209.Minimum Size Subarray Sum/README_EN.md
index f540fa51066b5..404a6cdd43a9c 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/README_EN.md
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/README_EN.md
@@ -272,16 +272,15 @@ The time complexity is $O(n)$, and the space complexity is $O(1)$. Here, $n$ is
```python
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
- n = len(nums)
- ans = n + 1
- s = j = 0
- for i, x in enumerate(nums):
+ l = s = 0
+ ans = inf
+ for r, x in enumerate(nums):
s += x
- while j < n and s >= target:
- ans = min(ans, i - j + 1)
- s -= nums[j]
- j += 1
- return ans if ans <= n else 0
+ while s >= target:
+ ans = min(ans, r - l + 1)
+ s -= nums[l]
+ l += 1
+ return 0 if ans == inf else ans
```
#### Java
@@ -289,17 +288,17 @@ class Solution:
```java
class Solution {
public int minSubArrayLen(int target, int[] nums) {
- int n = nums.length;
+ int l = 0, n = nums.length;
long s = 0;
int ans = n + 1;
- for (int i = 0, j = 0; i < n; ++i) {
- s += nums[i];
- while (j < n && s >= target) {
- ans = Math.min(ans, i - j + 1);
- s -= nums[j++];
+ for (int r = 0; r < n; ++r) {
+ s += nums[r];
+ while (s >= target) {
+ ans = Math.min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans <= n ? ans : 0;
+ return ans > n ? 0 : ans;
}
}
```
@@ -310,17 +309,17 @@ class Solution {
class Solution {
public:
int minSubArrayLen(int target, vector& nums) {
- int n = nums.size();
+ int l = 0, n = nums.size();
long long s = 0;
int ans = n + 1;
- for (int i = 0, j = 0; i < n; ++i) {
- s += nums[i];
- while (j < n && s >= target) {
- ans = min(ans, i - j + 1);
- s -= nums[j++];
+ for (int r = 0; r < n; ++r) {
+ s += nums[r];
+ while (s >= target) {
+ ans = min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans == n + 1 ? 0 : ans;
+ return ans > n ? 0 : ans;
}
};
```
@@ -329,18 +328,17 @@ public:
```go
func minSubArrayLen(target int, nums []int) int {
- n := len(nums)
- s := 0
- ans := n + 1
- for i, j := 0, 0; i < n; i++ {
- s += nums[i]
+ l, n := 0, len(nums)
+ s, ans := 0, n+1
+ for r, x := range nums {
+ s += x
for s >= target {
- ans = min(ans, i-j+1)
- s -= nums[j]
- j++
+ ans = min(ans, r-l+1)
+ s -= nums[l]
+ l++
}
}
- if ans == n+1 {
+ if ans > n {
return 0
}
return ans
@@ -352,16 +350,15 @@ func minSubArrayLen(target int, nums []int) int {
```ts
function minSubArrayLen(target: number, nums: number[]): number {
const n = nums.length;
- let s = 0;
- let ans = n + 1;
- for (let i = 0, j = 0; i < n; ++i) {
- s += nums[i];
+ let [s, ans] = [0, n + 1];
+ for (let l = 0, r = 0; r < n; ++r) {
+ s += nums[r];
while (s >= target) {
- ans = Math.min(ans, i - j + 1);
- s -= nums[j++];
+ ans = Math.min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans === n + 1 ? 0 : ans;
+ return ans > n ? 0 : ans;
}
```
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.cpp b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.cpp
index b6d57f2aaabd5..cc31cd24044b5 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.cpp
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.cpp
@@ -1,16 +1,16 @@
class Solution {
public:
int minSubArrayLen(int target, vector& nums) {
- int n = nums.size();
+ int l = 0, n = nums.size();
long long s = 0;
int ans = n + 1;
- for (int i = 0, j = 0; i < n; ++i) {
- s += nums[i];
- while (j < n && s >= target) {
- ans = min(ans, i - j + 1);
- s -= nums[j++];
+ for (int r = 0; r < n; ++r) {
+ s += nums[r];
+ while (s >= target) {
+ ans = min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans == n + 1 ? 0 : ans;
+ return ans > n ? 0 : ans;
}
-};
\ No newline at end of file
+};
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.go b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.go
index 37a23211e9740..e3cecbba9dff3 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.go
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.go
@@ -1,17 +1,16 @@
func minSubArrayLen(target int, nums []int) int {
- n := len(nums)
- s := 0
- ans := n + 1
- for i, j := 0, 0; i < n; i++ {
- s += nums[i]
+ l, n := 0, len(nums)
+ s, ans := 0, n+1
+ for r, x := range nums {
+ s += x
for s >= target {
- ans = min(ans, i-j+1)
- s -= nums[j]
- j++
+ ans = min(ans, r-l+1)
+ s -= nums[l]
+ l++
}
}
- if ans == n+1 {
+ if ans > n {
return 0
}
return ans
-}
\ No newline at end of file
+}
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.java b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.java
index 11b6a8155908b..d922a1fb4b6c4 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.java
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.java
@@ -1,15 +1,15 @@
class Solution {
public int minSubArrayLen(int target, int[] nums) {
- int n = nums.length;
+ int l = 0, n = nums.length;
long s = 0;
int ans = n + 1;
- for (int i = 0, j = 0; i < n; ++i) {
- s += nums[i];
- while (j < n && s >= target) {
- ans = Math.min(ans, i - j + 1);
- s -= nums[j++];
+ for (int r = 0; r < n; ++r) {
+ s += nums[r];
+ while (s >= target) {
+ ans = Math.min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans <= n ? ans : 0;
+ return ans > n ? 0 : ans;
}
-}
\ No newline at end of file
+}
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.py b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.py
index 6dcbc2480b59f..38e4717138007 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.py
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.py
@@ -1,12 +1,11 @@
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
- n = len(nums)
- ans = n + 1
- s = j = 0
- for i, x in enumerate(nums):
+ l = s = 0
+ ans = inf
+ for r, x in enumerate(nums):
s += x
- while j < n and s >= target:
- ans = min(ans, i - j + 1)
- s -= nums[j]
- j += 1
- return ans if ans <= n else 0
+ while s >= target:
+ ans = min(ans, r - l + 1)
+ s -= nums[l]
+ l += 1
+ return 0 if ans == inf else ans
diff --git a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.ts b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.ts
index ef54870682bf6..66fd4ae9b601d 100644
--- a/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.ts
+++ b/solution/0200-0299/0209.Minimum Size Subarray Sum/Solution2.ts
@@ -1,13 +1,12 @@
function minSubArrayLen(target: number, nums: number[]): number {
const n = nums.length;
- let s = 0;
- let ans = n + 1;
- for (let i = 0, j = 0; i < n; ++i) {
- s += nums[i];
+ let [s, ans] = [0, n + 1];
+ for (let l = 0, r = 0; r < n; ++r) {
+ s += nums[r];
while (s >= target) {
- ans = Math.min(ans, i - j + 1);
- s -= nums[j++];
+ ans = Math.min(ans, r - l + 1);
+ s -= nums[l++];
}
}
- return ans === n + 1 ? 0 : ans;
+ return ans > n ? 0 : ans;
}
diff --git a/solution/0200-0299/0214.Shortest Palindrome/README.md b/solution/0200-0299/0214.Shortest Palindrome/README.md
index d79f1e47c941f..ffd8c38adc83a 100644
--- a/solution/0200-0299/0214.Shortest Palindrome/README.md
+++ b/solution/0200-0299/0214.Shortest Palindrome/README.md
@@ -201,43 +201,193 @@ impl Solution {
#### C#
```cs
-// https://leetcode.com/problems/shortest-palindrome/
-
-using System.Text;
-
-public partial class Solution
-{
- public string ShortestPalindrome(string s)
- {
- for (var i = s.Length - 1; i >= 0; --i)
- {
- var k = i;
- var j = 0;
- while (j < k)
- {
- if (s[j] == s[k])
- {
- ++j;
- --k;
- }
- else
- {
- break;
- }
+public class Solution {
+ public string ShortestPalindrome(string s) {
+ int baseValue = 131;
+ int mul = 1;
+ int mod = (int)1e9 + 7;
+ int prefix = 0, suffix = 0;
+ int idx = 0;
+ int n = s.Length;
+
+ for (int i = 0; i < n; ++i) {
+ int t = s[i] - 'a' + 1;
+ prefix = (int)(((long)prefix * baseValue + t) % mod);
+ suffix = (int)((suffix + (long)t * mul) % mod);
+ mul = (int)(((long)mul * baseValue) % mod);
+ if (prefix == suffix) {
+ idx = i + 1;
}
- if (j >= k)
- {
- var sb = new StringBuilder(s.Length * 2 - i - 1);
- for (var l = s.Length - 1; l >= i + 1; --l)
- {
- sb.Append(s[l]);
- }
- sb.Append(s);
- return sb.ToString();
+ }
+
+ if (idx == n) {
+ return s;
+ }
+
+ return new string(s.Substring(idx).Reverse().ToArray()) + s;
+ }
+}
+```
+
+
+
+
+
+
+
+### 方法二:KMP 算法
+
+根据题目描述,我们需要将字符串 $s$ 反转,得到字符串 $\textit{rev}$,然后求出字符串 $rev$ 的后缀与字符串 $s$ 的前缀的最长公共部分。我们可以使用 KMP 算法,将字符串 $s$ 与字符串 $rev$ 连接起来,求出其最长前缀与最长后缀的最长公共部分。
+
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 为字符串 $s$ 的长度。
+
+
+
+#### Python3
+
+```python
+class Solution:
+ def shortestPalindrome(self, s: str) -> str:
+ t = s + "#" + s[::-1] + "$"
+ n = len(t)
+ next = [0] * n
+ next[0] = -1
+ i, j = 2, 0
+ while i < n:
+ if t[i - 1] == t[j]:
+ j += 1
+ next[i] = j
+ i += 1
+ elif j:
+ j = next[j]
+ else:
+ next[i] = 0
+ i += 1
+ return s[::-1][: -next[-1]] + s
+```
+
+#### Java
+
+```java
+class Solution {
+ public String shortestPalindrome(String s) {
+ String rev = new StringBuilder(s).reverse().toString();
+ char[] t = (s + "#" + rev + "$").toCharArray();
+ int n = t.length;
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return rev.substring(0, s.length() - next[n - 1]) + s;
+ }
+}
+```
+
+#### C++
+
+```cpp
+class Solution {
+public:
+ string shortestPalindrome(string s) {
+ string t = s + "#" + string(s.rbegin(), s.rend()) + "$";
+ int n = t.size();
+ int next[n];
+ next[0] = -1;
+ next[1] = 0;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
}
}
+ return string(s.rbegin(), s.rbegin() + s.size() - next[n - 1]) + s;
+ }
+};
+```
+
+#### Go
- return string.Empty;
+```go
+func shortestPalindrome(s string) string {
+ t := s + "#" + reverse(s) + "$"
+ n := len(t)
+ next := make([]int, n)
+ next[0] = -1
+ for i, j := 2, 0; i < n; {
+ if t[i-1] == t[j] {
+ j++
+ next[i] = j
+ i++
+ } else if j > 0 {
+ j = next[j]
+ } else {
+ next[i] = 0
+ i++
+ }
+ }
+ return reverse(s)[:len(s)-next[n-1]] + s
+}
+
+func reverse(s string) string {
+ t := []byte(s)
+ for i, j := 0, len(t)-1; i < j; i, j = i+1, j-1 {
+ t[i], t[j] = t[j], t[i]
+ }
+ return string(t)
+}
+```
+
+#### TypeScript
+
+```ts
+function shortestPalindrome(s: string): string {
+ const rev = s.split('').reverse().join('');
+ const t = s + '#' + rev + '$';
+ const n = t.length;
+ const next: number[] = Array(n).fill(0);
+ next[0] = -1;
+ for (let i = 2, j = 0; i < n; ) {
+ if (t[i - 1] === t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return rev.slice(0, -next[n - 1]) + s;
+}
+```
+
+#### C#
+
+```cs
+public class Solution {
+ public string ShortestPalindrome(string s) {
+ char[] t = (s + "#" + new string(s.Reverse().ToArray()) + "$").ToCharArray();
+ int n = t.Length;
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return new string(s.Substring(next[n - 1]).Reverse().ToArray()).Substring(0, s.Length - next[n - 1]) + s;
}
}
```
diff --git a/solution/0200-0299/0214.Shortest Palindrome/README_EN.md b/solution/0200-0299/0214.Shortest Palindrome/README_EN.md
index eb80912e1c16c..78c948e1285f2 100644
--- a/solution/0200-0299/0214.Shortest Palindrome/README_EN.md
+++ b/solution/0200-0299/0214.Shortest Palindrome/README_EN.md
@@ -182,43 +182,193 @@ impl Solution {
#### C#
```cs
-// https://leetcode.com/problems/shortest-palindrome/
-
-using System.Text;
-
-public partial class Solution
-{
- public string ShortestPalindrome(string s)
- {
- for (var i = s.Length - 1; i >= 0; --i)
- {
- var k = i;
- var j = 0;
- while (j < k)
- {
- if (s[j] == s[k])
- {
- ++j;
- --k;
- }
- else
- {
- break;
- }
+public class Solution {
+ public string ShortestPalindrome(string s) {
+ int baseValue = 131;
+ int mul = 1;
+ int mod = (int)1e9 + 7;
+ int prefix = 0, suffix = 0;
+ int idx = 0;
+ int n = s.Length;
+
+ for (int i = 0; i < n; ++i) {
+ int t = s[i] - 'a' + 1;
+ prefix = (int)(((long)prefix * baseValue + t) % mod);
+ suffix = (int)((suffix + (long)t * mul) % mod);
+ mul = (int)(((long)mul * baseValue) % mod);
+ if (prefix == suffix) {
+ idx = i + 1;
}
- if (j >= k)
- {
- var sb = new StringBuilder(s.Length * 2 - i - 1);
- for (var l = s.Length - 1; l >= i + 1; --l)
- {
- sb.Append(s[l]);
- }
- sb.Append(s);
- return sb.ToString();
+ }
+
+ if (idx == n) {
+ return s;
+ }
+
+ return new string(s.Substring(idx).Reverse().ToArray()) + s;
+ }
+}
+```
+
+
+
+
+
+
+
+### Solution 2: KMP Algorithm
+
+According to the problem description, we need to reverse the string $s$ to obtain the string $\textit{rev}$, and then find the longest common part of the suffix of the string $\textit{rev}$ and the prefix of the string $s$. We can use the KMP algorithm to concatenate the string $s$ and the string $\textit{rev}$ and find the longest common part of the longest prefix and the longest suffix.
+
+The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the length of the string $s$.
+
+
+
+#### Python3
+
+```python
+class Solution:
+ def shortestPalindrome(self, s: str) -> str:
+ t = s + "#" + s[::-1] + "$"
+ n = len(t)
+ next = [0] * n
+ next[0] = -1
+ i, j = 2, 0
+ while i < n:
+ if t[i - 1] == t[j]:
+ j += 1
+ next[i] = j
+ i += 1
+ elif j:
+ j = next[j]
+ else:
+ next[i] = 0
+ i += 1
+ return s[::-1][: -next[-1]] + s
+```
+
+#### Java
+
+```java
+class Solution {
+ public String shortestPalindrome(String s) {
+ String rev = new StringBuilder(s).reverse().toString();
+ char[] t = (s + "#" + rev + "$").toCharArray();
+ int n = t.length;
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return rev.substring(0, s.length() - next[n - 1]) + s;
+ }
+}
+```
+
+#### C++
+
+```cpp
+class Solution {
+public:
+ string shortestPalindrome(string s) {
+ string t = s + "#" + string(s.rbegin(), s.rend()) + "$";
+ int n = t.size();
+ int next[n];
+ next[0] = -1;
+ next[1] = 0;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
}
}
+ return string(s.rbegin(), s.rbegin() + s.size() - next[n - 1]) + s;
+ }
+};
+```
+
+#### Go
- return string.Empty;
+```go
+func shortestPalindrome(s string) string {
+ t := s + "#" + reverse(s) + "$"
+ n := len(t)
+ next := make([]int, n)
+ next[0] = -1
+ for i, j := 2, 0; i < n; {
+ if t[i-1] == t[j] {
+ j++
+ next[i] = j
+ i++
+ } else if j > 0 {
+ j = next[j]
+ } else {
+ next[i] = 0
+ i++
+ }
+ }
+ return reverse(s)[:len(s)-next[n-1]] + s
+}
+
+func reverse(s string) string {
+ t := []byte(s)
+ for i, j := 0, len(t)-1; i < j; i, j = i+1, j-1 {
+ t[i], t[j] = t[j], t[i]
+ }
+ return string(t)
+}
+```
+
+#### TypeScript
+
+```ts
+function shortestPalindrome(s: string): string {
+ const rev = s.split('').reverse().join('');
+ const t = s + '#' + rev + '$';
+ const n = t.length;
+ const next: number[] = Array(n).fill(0);
+ next[0] = -1;
+ for (let i = 2, j = 0; i < n; ) {
+ if (t[i - 1] === t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return rev.slice(0, -next[n - 1]) + s;
+}
+```
+
+#### C#
+
+```cs
+public class Solution {
+ public string ShortestPalindrome(string s) {
+ char[] t = (s + "#" + new string(s.Reverse().ToArray()) + "$").ToCharArray();
+ int n = t.Length;
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return new string(s.Substring(next[n - 1]).Reverse().ToArray()).Substring(0, s.Length - next[n - 1]) + s;
}
}
```
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution.cs b/solution/0200-0299/0214.Shortest Palindrome/Solution.cs
index c33ad4ae50914..d1b54e89b6a8d 100644
--- a/solution/0200-0299/0214.Shortest Palindrome/Solution.cs
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution.cs
@@ -1,39 +1,26 @@
-// https://leetcode.com/problems/shortest-palindrome/
+public class Solution {
+ public string ShortestPalindrome(string s) {
+ int baseValue = 131;
+ int mul = 1;
+ int mod = (int)1e9 + 7;
+ int prefix = 0, suffix = 0;
+ int idx = 0;
+ int n = s.Length;
-using System.Text;
-
-public partial class Solution
-{
- public string ShortestPalindrome(string s)
- {
- for (var i = s.Length - 1; i >= 0; --i)
- {
- var k = i;
- var j = 0;
- while (j < k)
- {
- if (s[j] == s[k])
- {
- ++j;
- --k;
- }
- else
- {
- break;
- }
- }
- if (j >= k)
- {
- var sb = new StringBuilder(s.Length * 2 - i - 1);
- for (var l = s.Length - 1; l >= i + 1; --l)
- {
- sb.Append(s[l]);
- }
- sb.Append(s);
- return sb.ToString();
+ for (int i = 0; i < n; ++i) {
+ int t = s[i] - 'a' + 1;
+ prefix = (int)(((long)prefix * baseValue + t) % mod);
+ suffix = (int)((suffix + (long)t * mul) % mod);
+ mul = (int)(((long)mul * baseValue) % mod);
+ if (prefix == suffix) {
+ idx = i + 1;
}
}
- return string.Empty;
+ if (idx == n) {
+ return s;
+ }
+
+ return new string(s.Substring(idx).Reverse().ToArray()) + s;
}
-}
\ No newline at end of file
+}
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution2.cpp b/solution/0200-0299/0214.Shortest Palindrome/Solution2.cpp
new file mode 100644
index 0000000000000..6956b5693fc45
--- /dev/null
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution2.cpp
@@ -0,0 +1,20 @@
+class Solution {
+public:
+ string shortestPalindrome(string s) {
+ string t = s + "#" + string(s.rbegin(), s.rend()) + "$";
+ int n = t.size();
+ int next[n];
+ next[0] = -1;
+ next[1] = 0;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return string(s.rbegin(), s.rbegin() + s.size() - next[n - 1]) + s;
+ }
+};
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution2.cs b/solution/0200-0299/0214.Shortest Palindrome/Solution2.cs
new file mode 100644
index 0000000000000..067a74e88ad3c
--- /dev/null
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution2.cs
@@ -0,0 +1,18 @@
+public class Solution {
+ public string ShortestPalindrome(string s) {
+ char[] t = (s + "#" + new string(s.Reverse().ToArray()) + "$").ToCharArray();
+ int n = t.Length;
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return new string(s.Substring(next[n - 1]).Reverse().ToArray()).Substring(0, s.Length - next[n - 1]) + s;
+ }
+}
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution2.go b/solution/0200-0299/0214.Shortest Palindrome/Solution2.go
new file mode 100644
index 0000000000000..a254925e173c9
--- /dev/null
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution2.go
@@ -0,0 +1,27 @@
+func shortestPalindrome(s string) string {
+ t := s + "#" + reverse(s) + "$"
+ n := len(t)
+ next := make([]int, n)
+ next[0] = -1
+ for i, j := 2, 0; i < n; {
+ if t[i-1] == t[j] {
+ j++
+ next[i] = j
+ i++
+ } else if j > 0 {
+ j = next[j]
+ } else {
+ next[i] = 0
+ i++
+ }
+ }
+ return reverse(s)[:len(s)-next[n-1]] + s
+}
+
+func reverse(s string) string {
+ t := []byte(s)
+ for i, j := 0, len(t)-1; i < j; i, j = i+1, j-1 {
+ t[i], t[j] = t[j], t[i]
+ }
+ return string(t)
+}
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution2.java b/solution/0200-0299/0214.Shortest Palindrome/Solution2.java
new file mode 100644
index 0000000000000..2e92823c7796c
--- /dev/null
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution2.java
@@ -0,0 +1,19 @@
+class Solution {
+ public String shortestPalindrome(String s) {
+ String rev = new StringBuilder(s).reverse().toString();
+ char[] t = (s + "#" + rev + "$").toCharArray();
+ int n = t.length;
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (t[i - 1] == t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return rev.substring(0, s.length() - next[n - 1]) + s;
+ }
+}
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution2.py b/solution/0200-0299/0214.Shortest Palindrome/Solution2.py
new file mode 100644
index 0000000000000..7d538100384a2
--- /dev/null
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution2.py
@@ -0,0 +1,18 @@
+class Solution:
+ def shortestPalindrome(self, s: str) -> str:
+ t = s + "#" + s[::-1] + "$"
+ n = len(t)
+ next = [0] * n
+ next[0] = -1
+ i, j = 2, 0
+ while i < n:
+ if t[i - 1] == t[j]:
+ j += 1
+ next[i] = j
+ i += 1
+ elif j:
+ j = next[j]
+ else:
+ next[i] = 0
+ i += 1
+ return s[::-1][: -next[-1]] + s
diff --git a/solution/0200-0299/0214.Shortest Palindrome/Solution2.ts b/solution/0200-0299/0214.Shortest Palindrome/Solution2.ts
new file mode 100644
index 0000000000000..ba0dba154f53c
--- /dev/null
+++ b/solution/0200-0299/0214.Shortest Palindrome/Solution2.ts
@@ -0,0 +1,17 @@
+function shortestPalindrome(s: string): string {
+ const rev = s.split('').reverse().join('');
+ const t = s + '#' + rev + '$';
+ const n = t.length;
+ const next: number[] = Array(n).fill(0);
+ next[0] = -1;
+ for (let i = 2, j = 0; i < n; ) {
+ if (t[i - 1] === t[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return rev.slice(0, -next[n - 1]) + s;
+}
diff --git a/solution/0200-0299/0215.Kth Largest Element in an Array/README.md b/solution/0200-0299/0215.Kth Largest Element in an Array/README.md
index c38a44c965194..9e8137ed7f22b 100644
--- a/solution/0200-0299/0215.Kth Largest Element in an Array/README.md
+++ b/solution/0200-0299/0215.Kth Largest Element in an Array/README.md
@@ -60,7 +60,7 @@ tags:
快速选择算法是一种在未排序的数组中查找第 `k` 个最大元素或最小元素的算法。它的基本思想是每次选择一个基准元素,将数组分为两部分,一部分的元素都比基准元素小,另一部分的元素都比基准元素大,然后根据基准元素的位置,决定继续在左边还是右边查找,直到找到第 `k` 个最大元素。
-时间复杂度 $O(n)$,空间复杂度 $O(\log n)$。其中 $n$ 为数组 $\text{nums}$ 的长度。
+时间复杂度 $O(n)$,空间复杂度 $O(\log n)$。其中 $n$ 为数组 $\textit{nums}$ 的长度。
@@ -283,9 +283,9 @@ impl Solution {
### 方法二:优先队列(小根堆)
-我们可以维护一个大小为 $k$ 的小根堆 $\text{minQ}$,然后遍历数组 $\text{nums}$,将数组中的元素依次加入到小根堆中,当小根堆的大小超过 $k$ 时,我们将堆顶元素弹出,这样最终小根堆中的 $k$ 个元素就是数组中的 $k$ 个最大元素,堆顶元素就是第 $k$ 个最大元素。
+我们可以维护一个大小为 $k$ 的小根堆 $\textit{minQ}$,然后遍历数组 $\textit{nums}$,将数组中的元素依次加入到小根堆中,当小根堆的大小超过 $k$ 时,我们将堆顶元素弹出,这样最终小根堆中的 $k$ 个元素就是数组中的 $k$ 个最大元素,堆顶元素就是第 $k$ 个最大元素。
-时间复杂度 $O(n\log k)$,空间复杂度 $O(k)$。其中 $n$ 为数组 $\text{nums}$ 的长度。
+时间复杂度 $O(n\log k)$,空间复杂度 $O(k)$。其中 $n$ 为数组 $\textit{nums}$ 的长度。
@@ -400,9 +400,9 @@ impl Solution {
### 方法三:计数排序
-我们可以使用计数排序的思想,统计数组 $\text{nums}$ 中每个元素出现的次数,记录在哈希表 $\text{cnt}$ 中,然后从大到小遍历元素 $i$,每次减去出现的次数 $\text{cnt}[i]$,直到 $k$ 小于等于 $0$,此时的元素 $i$ 就是数组中的第 $k$ 个最大元素。
+我们可以使用计数排序的思想,统计数组 $\textit{nums}$ 中每个元素出现的次数,记录在哈希表 $\textit{cnt}$ 中,然后从大到小遍历元素 $i$,每次减去出现的次数 $\textit{cnt}[i]$,直到 $k$ 小于等于 $0$,此时的元素 $i$ 就是数组中的第 $k$ 个最大元素。
-时间复杂度 $O(n + m)$,空间复杂度 $O(n)$。其中 $n$ 为数组 $\text{nums}$ 的长度,而 $m$ 为数组 $\text{nums}$ 中元素的最大值。
+时间复杂度 $O(n + m)$,空间复杂度 $O(n)$。其中 $n$ 为数组 $\textit{nums}$ 的长度,而 $m$ 为数组 $\textit{nums}$ 中元素的最大值。
diff --git a/solution/0200-0299/0215.Kth Largest Element in an Array/README_EN.md b/solution/0200-0299/0215.Kth Largest Element in an Array/README_EN.md
index 9eecbd3277365..19297f374806e 100644
--- a/solution/0200-0299/0215.Kth Largest Element in an Array/README_EN.md
+++ b/solution/0200-0299/0215.Kth Largest Element in an Array/README_EN.md
@@ -52,7 +52,7 @@ tags:
Quick Select is an algorithm for finding the $k^{th}$ largest or smallest element in an unsorted array. Its basic idea is to select a pivot element each time, dividing the array into two parts: one part contains elements smaller than the pivot, and the other part contains elements larger than the pivot. Then, based on the position of the pivot, it decides whether to continue the search on the left or right side until the $k^{th}$ largest element is found.
-The time complexity is $O(n)$, and the space complexity is $O(\log n)$. Here, $n$ is the length of the array $\text{nums}$.
+The time complexity is $O(n)$, and the space complexity is $O(\log n)$. Here, $n$ is the length of the array $\textit{nums}$.
@@ -275,9 +275,9 @@ impl Solution {
### Solution 2: Priority Queue (Min Heap)
-We can maintain a min heap $\text{minQ}$ of size $k$, and then iterate through the array $\text{nums}$, adding each element to the min heap. When the size of the min heap exceeds $k$, we pop the top element of the heap. This way, the final $k$ elements in the min heap are the $k$ largest elements in the array, and the top element of the heap is the $k^{th}$ largest element.
+We can maintain a min heap $\textit{minQ}$ of size $k$, and then iterate through the array $\textit{nums}$, adding each element to the min heap. When the size of the min heap exceeds $k$, we pop the top element of the heap. This way, the final $k$ elements in the min heap are the $k$ largest elements in the array, and the top element of the heap is the $k^{th}$ largest element.
-The time complexity is $O(n\log k)$, and the space complexity is $O(k)$. Here, $n$ is the length of the array $\text{nums}$.
+The time complexity is $O(n\log k)$, and the space complexity is $O(k)$. Here, $n$ is the length of the array $\textit{nums}$.
@@ -392,9 +392,9 @@ impl Solution {
### Solution 3: Counting Sort
-We can use the idea of counting sort, counting the occurrence of each element in the array $\text{nums}$ and recording it in a hash table $\text{cnt}$. Then, we iterate over the elements $i$ from largest to smallest, subtracting the occurrence count $\text{cnt}[i]$ each time, until $k$ is less than or equal to $0$. At this point, the element $i$ is the $k^{th}$ largest element in the array.
+We can use the idea of counting sort, counting the occurrence of each element in the array $\textit{nums}$ and recording it in a hash table $\textit{cnt}$. Then, we iterate over the elements $i$ from largest to smallest, subtracting the occurrence count $\textit{cnt}[i]$ each time, until $k$ is less than or equal to $0$. At this point, the element $i$ is the $k^{th}$ largest element in the array.
-The time complexity is $O(n + m)$, and the space complexity is $O(n)$. Here, $n$ is the length of the array $\text{nums}$, and $m$ is the maximum value among the elements in $\text{nums}$.
+The time complexity is $O(n + m)$, and the space complexity is $O(n)$. Here, $n$ is the length of the array $\textit{nums}$, and $m$ is the maximum value among the elements in $\textit{nums}$.
diff --git a/solution/0200-0299/0221.Maximal Square/README.md b/solution/0200-0299/0221.Maximal Square/README.md
index 908e41eea3d34..808e67027d021 100644
--- a/solution/0200-0299/0221.Maximal Square/README.md
+++ b/solution/0200-0299/0221.Maximal Square/README.md
@@ -69,8 +69,8 @@ tags:
$$
dp[i + 1][j + 1] =
\begin{cases}
-0 & \text{if } matrix[i][j] = '0' \\
-\min(dp[i][j], dp[i][j + 1], dp[i + 1][j]) + 1 & \text{if } matrix[i][j] = '1'
+0 & \textit{if } matrix[i][j] = '0' \\
+\min(dp[i][j], dp[i][j + 1], dp[i + 1][j]) + 1 & \textit{if } matrix[i][j] = '1'
\end{cases}
$$
diff --git a/solution/0200-0299/0221.Maximal Square/README_EN.md b/solution/0200-0299/0221.Maximal Square/README_EN.md
index 0c7a2f3e01338..26665820aa503 100644
--- a/solution/0200-0299/0221.Maximal Square/README_EN.md
+++ b/solution/0200-0299/0221.Maximal Square/README_EN.md
@@ -67,8 +67,8 @@ The state transition equation is:
$$
dp[i + 1][j + 1] =
\begin{cases}
-0 & \text{if } matrix[i][j] = '0' \\
-\min(dp[i][j], dp[i][j + 1], dp[i + 1][j]) + 1 & \text{if } matrix[i][j] = '1'
+0 & \textit{if } matrix[i][j] = '0' \\
+\min(dp[i][j], dp[i][j + 1], dp[i + 1][j]) + 1 & \textit{if } matrix[i][j] = '1'
\end{cases}
$$
diff --git a/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md b/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md
index 6448cfa693a34..dabb554f1e383 100644
--- a/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md
+++ b/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md
@@ -11,7 +11,7 @@ tags:
-# [230. 二叉搜索树中第K小的元素](https://leetcode.cn/problems/kth-smallest-element-in-a-bst)
+# [230. 二叉搜索树中第 K 小的元素](https://leetcode.cn/problems/kth-smallest-element-in-a-bst)
[English Version](/solution/0200-0299/0230.Kth%20Smallest%20Element%20in%20a%20BST/README_EN.md)
diff --git a/solution/0200-0299/0240.Search a 2D Matrix II/README.md b/solution/0200-0299/0240.Search a 2D Matrix II/README.md
index 278faf4bff982..70b13fc1bb898 100644
--- a/solution/0200-0299/0240.Search a 2D Matrix II/README.md
+++ b/solution/0200-0299/0240.Search a 2D Matrix II/README.md
@@ -239,9 +239,9 @@ public class Solution {
这里我们以左下角作为起始搜索点,往右上方向开始搜索,比较当前元素 `matrix[i][j]`与 `target` 的大小关系:
-- 若 $\text{matrix}[i][j] = \text{target}$,说明找到了目标值,直接返回 `true`。
-- 若 $\text{matrix}[i][j] > \text{target}$,说明这一列从当前位置开始往上的所有元素均大于 `target`,应该让 $i$ 指针往上移动,即 $i \leftarrow i - 1$。
-- 若 $\text{matrix}[i][j] < \text{target}$,说明这一行从当前位置开始往右的所有元素均小于 `target`,应该让 $j$ 指针往右移动,即 $j \leftarrow j + 1$。
+- 若 $\textit{matrix}[i][j] = \textit{target}$,说明找到了目标值,直接返回 `true`。
+- 若 $\textit{matrix}[i][j] > \textit{target}$,说明这一列从当前位置开始往上的所有元素均大于 `target`,应该让 $i$ 指针往上移动,即 $i \leftarrow i - 1$。
+- 若 $\textit{matrix}[i][j] < \textit{target}$,说明这一行从当前位置开始往右的所有元素均小于 `target`,应该让 $j$ 指针往右移动,即 $j \leftarrow j + 1$。
若搜索结束依然找不到 `target`,返回 `false`。
diff --git a/solution/0200-0299/0240.Search a 2D Matrix II/README_EN.md b/solution/0200-0299/0240.Search a 2D Matrix II/README_EN.md
index 1f1f8a46be5ef..2c2559f1266e7 100644
--- a/solution/0200-0299/0240.Search a 2D Matrix II/README_EN.md
+++ b/solution/0200-0299/0240.Search a 2D Matrix II/README_EN.md
@@ -237,9 +237,9 @@ public class Solution {
Here, we start searching from the bottom left corner and move towards the top right direction, comparing the current element `matrix[i][j]` with `target`:
-- If $\text{matrix}[i][j] = \text{target}$, it means the target value has been found, and we directly return `true`.
-- If $\text{matrix}[i][j] > \text{target}$, it means all elements in this column from the current position upwards are greater than `target`, so we should move the $i$ pointer upwards, i.e., $i \leftarrow i - 1$.
-- If $\text{matrix}[i][j] < \text{target}$, it means all elements in this row from the current position to the right are less than `target`, so we should move the $j$ pointer to the right, i.e., $j \leftarrow j + 1$.
+- If $\textit{matrix}[i][j] = \textit{target}$, it means the target value has been found, and we directly return `true`.
+- If $\textit{matrix}[i][j] > \textit{target}$, it means all elements in this column from the current position upwards are greater than `target`, so we should move the $i$ pointer upwards, i.e., $i \leftarrow i - 1$.
+- If $\textit{matrix}[i][j] < \textit{target}$, it means all elements in this row from the current position to the right are less than `target`, so we should move the $j$ pointer to the right, i.e., $j \leftarrow j + 1$.
If the search ends and the `target` is still not found, return `false`.
diff --git a/solution/0200-0299/0260.Single Number III/README.md b/solution/0200-0299/0260.Single Number III/README.md
index c3a3cff649bd9..10d0586929901 100644
--- a/solution/0200-0299/0260.Single Number III/README.md
+++ b/solution/0200-0299/0260.Single Number III/README.md
@@ -238,4 +238,48 @@ public class Solution {
+
+
+### 方法二:哈希表
+
+
+
+#### TypeScript
+
+```ts
+function singleNumber(nums: number[]): number[] {
+ const set = new Set();
+
+ for (const x of nums) {
+ if (set.has(x)) set.delete(x);
+ else set.add(x);
+ }
+
+ return [...set];
+}
+```
+
+#### JavaScript
+
+```js
+/**
+ * @param {number[]} nums
+ * @return {number[]}
+ */
+function singleNumber(nums) {
+ const set = new Set();
+
+ for (const x of nums) {
+ if (set.has(x)) set.delete(x);
+ else set.add(x);
+ }
+
+ return [...set];
+}
+```
+
+
+
+
+
diff --git a/solution/0200-0299/0260.Single Number III/README_EN.md b/solution/0200-0299/0260.Single Number III/README_EN.md
index a5208fc56eca8..89e787d9e26c0 100644
--- a/solution/0200-0299/0260.Single Number III/README_EN.md
+++ b/solution/0200-0299/0260.Single Number III/README_EN.md
@@ -236,4 +236,48 @@ public class Solution {
+
+
+### Solution 2: Hash Table
+
+
+
+#### TypeScript
+
+```ts
+function singleNumber(nums: number[]): number[] {
+ const set = new Set();
+
+ for (const x of nums) {
+ if (set.has(x)) set.delete(x);
+ else set.add(x);
+ }
+
+ return [...set];
+}
+```
+
+#### JavaScript
+
+```js
+/**
+ * @param {number[]} nums
+ * @return {number[]}
+ */
+function singleNumber(nums) {
+ const set = new Set();
+
+ for (const x of nums) {
+ if (set.has(x)) set.delete(x);
+ else set.add(x);
+ }
+
+ return [...set];
+}
+```
+
+
+
+
+
diff --git a/solution/0200-0299/0260.Single Number III/Solution2.js b/solution/0200-0299/0260.Single Number III/Solution2.js
new file mode 100644
index 0000000000000..a7207c2194bdd
--- /dev/null
+++ b/solution/0200-0299/0260.Single Number III/Solution2.js
@@ -0,0 +1,14 @@
+/**
+ * @param {number[]} nums
+ * @return {number[]}
+ */
+function singleNumber(nums) {
+ const set = new Set();
+
+ for (const x of nums) {
+ if (set.has(x)) set.delete(x);
+ else set.add(x);
+ }
+
+ return [...set];
+}
diff --git a/solution/0200-0299/0260.Single Number III/Solution2.ts b/solution/0200-0299/0260.Single Number III/Solution2.ts
new file mode 100644
index 0000000000000..6851e0822813f
--- /dev/null
+++ b/solution/0200-0299/0260.Single Number III/Solution2.ts
@@ -0,0 +1,10 @@
+function singleNumber(nums: number[]): number[] {
+ const set = new Set();
+
+ for (const x of nums) {
+ if (set.has(x)) set.delete(x);
+ else set.add(x);
+ }
+
+ return [...set];
+}
diff --git a/solution/0200-0299/0266.Palindrome Permutation/README.md b/solution/0200-0299/0266.Palindrome Permutation/README.md
index b1181c7a2fe31..222068a8d3801 100644
--- a/solution/0200-0299/0266.Palindrome Permutation/README.md
+++ b/solution/0200-0299/0266.Palindrome Permutation/README.md
@@ -58,9 +58,9 @@ tags:
-### 方法一:数组
+### 方法一:计数
-创建一个长度为 $26$ 的数组,统计每个字母出现的频率,至多有一个字符出现奇数次数即可。
+如果一个字符串是回文串,那么至多只有一个字符出现奇数次数,其余字符都出现偶数次数。因此我们只需要统计每个字符出现的次数,然后判断是否满足这个条件即可。
时间复杂度 $O(n)$,空间复杂度 $O(|\Sigma|)$。其中 $n$ 是字符串的长度,而 $|\Sigma|$ 是字符集的大小,本题中字符集为小写字母,因此 $|\Sigma|=26$。
@@ -131,7 +131,7 @@ func canPermutePalindrome(s string) bool {
```ts
function canPermutePalindrome(s: string): boolean {
- const cnt: number[] = new Array(26).fill(0);
+ const cnt: number[] = Array(26).fill(0);
for (const c of s) {
++cnt[c.charCodeAt(0) - 97];
}
@@ -147,11 +147,11 @@ function canPermutePalindrome(s: string): boolean {
* @return {boolean}
*/
var canPermutePalindrome = function (s) {
- const cnt = new Array(26).fill(0);
+ const cnt = new Map();
for (const c of s) {
- ++cnt[c.charCodeAt() - 'a'.charCodeAt()];
+ cnt.set(c, (cnt.get(c) || 0) + 1);
}
- return cnt.filter(c => c % 2 === 1).length < 2;
+ return [...cnt.values()].filter(v => v % 2 === 1).length < 2;
};
```
diff --git a/solution/0200-0299/0266.Palindrome Permutation/README_EN.md b/solution/0200-0299/0266.Palindrome Permutation/README_EN.md
index 927d690bcf32e..593d55562d798 100644
--- a/solution/0200-0299/0266.Palindrome Permutation/README_EN.md
+++ b/solution/0200-0299/0266.Palindrome Permutation/README_EN.md
@@ -56,7 +56,11 @@ tags:
-### Solution 1
+### Solution 1: Counting
+
+If a string is a palindrome, at most one character can appear an odd number of times, while all other characters must appear an even number of times. Therefore, we only need to count the occurrences of each character and then check if this condition is satisfied.
+
+Time complexity is $O(n)$, and space complexity is $O(|\Sigma|)$. Here, $n$ is the length of the string, and $|\Sigma|$ is the size of the character set. In this problem, the character set consists of lowercase letters, so $|\Sigma|=26$.
@@ -125,7 +129,7 @@ func canPermutePalindrome(s string) bool {
```ts
function canPermutePalindrome(s: string): boolean {
- const cnt: number[] = new Array(26).fill(0);
+ const cnt: number[] = Array(26).fill(0);
for (const c of s) {
++cnt[c.charCodeAt(0) - 97];
}
@@ -141,11 +145,11 @@ function canPermutePalindrome(s: string): boolean {
* @return {boolean}
*/
var canPermutePalindrome = function (s) {
- const cnt = new Array(26).fill(0);
+ const cnt = new Map();
for (const c of s) {
- ++cnt[c.charCodeAt() - 'a'.charCodeAt()];
+ cnt.set(c, (cnt.get(c) || 0) + 1);
}
- return cnt.filter(c => c % 2 === 1).length < 2;
+ return [...cnt.values()].filter(v => v % 2 === 1).length < 2;
};
```
diff --git a/solution/0200-0299/0266.Palindrome Permutation/Solution.js b/solution/0200-0299/0266.Palindrome Permutation/Solution.js
index 346a9ee9421a0..9d3ff25b7e41a 100644
--- a/solution/0200-0299/0266.Palindrome Permutation/Solution.js
+++ b/solution/0200-0299/0266.Palindrome Permutation/Solution.js
@@ -3,9 +3,9 @@
* @return {boolean}
*/
var canPermutePalindrome = function (s) {
- const cnt = new Array(26).fill(0);
+ const cnt = new Map();
for (const c of s) {
- ++cnt[c.charCodeAt() - 'a'.charCodeAt()];
+ cnt.set(c, (cnt.get(c) || 0) + 1);
}
- return cnt.filter(c => c % 2 === 1).length < 2;
+ return [...cnt.values()].filter(v => v % 2 === 1).length < 2;
};
diff --git a/solution/0200-0299/0266.Palindrome Permutation/Solution.ts b/solution/0200-0299/0266.Palindrome Permutation/Solution.ts
index 5edeb264d7743..5004ae6504acb 100644
--- a/solution/0200-0299/0266.Palindrome Permutation/Solution.ts
+++ b/solution/0200-0299/0266.Palindrome Permutation/Solution.ts
@@ -1,5 +1,5 @@
function canPermutePalindrome(s: string): boolean {
- const cnt: number[] = new Array(26).fill(0);
+ const cnt: number[] = Array(26).fill(0);
for (const c of s) {
++cnt[c.charCodeAt(0) - 97];
}
diff --git a/solution/0200-0299/0270.Closest Binary Search Tree Value/README.md b/solution/0200-0299/0270.Closest Binary Search Tree Value/README.md
index 38a99a6093a7a..8dc6f44ceb1c8 100644
--- a/solution/0200-0299/0270.Closest Binary Search Tree Value/README.md
+++ b/solution/0200-0299/0270.Closest Binary Search Tree Value/README.md
@@ -56,7 +56,7 @@ tags:
### 方法一:递归
-我们定义一个递归函数 $\text{dfs}(node)$,表示从当前节点 $node$ 开始,寻找最接近目标值 $target$ 的节点。我们可以通过比较当前节点的值与目标值的差的绝对值,来更新答案,如果目标值小于当前节点的值,我们就递归地搜索左子树,否则我们递归地搜索右子树。
+我们定义一个递归函数 $\textit{dfs}(node)$,表示从当前节点 $node$ 开始,寻找最接近目标值 $target$ 的节点。我们可以通过比较当前节点的值与目标值的差的绝对值,来更新答案,如果目标值小于当前节点的值,我们就递归地搜索左子树,否则我们递归地搜索右子树。
时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是二叉搜索树的节点数。
diff --git a/solution/0200-0299/0273.Integer to English Words/README.md b/solution/0200-0299/0273.Integer to English Words/README.md
index 54a28c8948824..a7fce1803bf4e 100644
--- a/solution/0200-0299/0273.Integer to English Words/README.md
+++ b/solution/0200-0299/0273.Integer to English Words/README.md
@@ -296,6 +296,58 @@ public class Solution {
}
```
+#### TypeScript
+
+```ts
+function numberToWords(num: number): string {
+ if (num === 0) return 'Zero';
+
+ // prettier-ignore
+ const f = (x: number): string => {
+ const dict1 = ['','One','Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Eleven','Twelve','Thirteen','Fourteen','Fifteen','Sixteen','Seventeen','Eighteen','Nineteen',]
+ const dict2 = ['','','Twenty','Thirty','Forty','Fifty','Sixty','Seventy','Eighty','Ninety',]
+ let ans = ''
+
+ if (x <= 19) ans = dict1[x] ?? ''
+ else if (x < 100) ans = `${dict2[Math.floor(x / 10)]} ${f(x % 10)}`
+ else if (x < 10 ** 3) ans = `${dict1[Math.floor(x / 100)]} Hundred ${f(x % 100)}`
+ else if (x < 10 ** 6) ans = `${f(Math.floor(x / 10 ** 3))} Thousand ${f(x % 10 ** 3)}`
+ else if (x < 10 ** 9) ans = `${f(Math.floor(x / 10 ** 6))} Million ${f(x % 10 ** 6)}`
+ else ans = `${f(Math.floor(x / 10 ** 9))} Billion ${f(x % 10 ** 9)}`
+
+ return ans.trim()
+ }
+
+ return f(num);
+}
+```
+
+#### JavaScript
+
+```js
+function numberToWords(num) {
+ if (num === 0) return 'Zero';
+
+ // prettier-ignore
+ const f = (x) => {
+ const dict1 = ['','One','Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Eleven','Twelve','Thirteen','Fourteen','Fifteen','Sixteen','Seventeen','Eighteen','Nineteen',]
+ const dict2 = ['','','Twenty','Thirty','Forty','Fifty','Sixty','Seventy','Eighty','Ninety',]
+ let ans = ''
+
+ if (x <= 19) ans = dict1[x] ?? ''
+ else if (x < 100) ans = `${dict2[Math.floor(x / 10)]} ${f(x % 10)}`
+ else if (x < 10 ** 3) ans = `${dict1[Math.floor(x / 100)]} Hundred ${f(x % 100)}`
+ else if (x < 10 ** 6) ans = `${f(Math.floor(x / 10 ** 3))} Thousand ${f(x % 10 ** 3)}`
+ else if (x < 10 ** 9) ans = `${f(Math.floor(x / 10 ** 6))} Million ${f(x % 10 ** 6)}`
+ else ans = `${f(Math.floor(x / 10 ** 9))} Billion ${f(x % 10 ** 9)}`
+
+ return ans.trim()
+ }
+
+ return f(num);
+}
+```
+
diff --git a/solution/0200-0299/0273.Integer to English Words/README_EN.md b/solution/0200-0299/0273.Integer to English Words/README_EN.md
index 51615ba7e4a7a..3260ff5261c97 100644
--- a/solution/0200-0299/0273.Integer to English Words/README_EN.md
+++ b/solution/0200-0299/0273.Integer to English Words/README_EN.md
@@ -294,6 +294,58 @@ public class Solution {
}
```
+#### TypeScript
+
+```ts
+function numberToWords(num: number): string {
+ if (num === 0) return 'Zero';
+
+ // prettier-ignore
+ const f = (x: number): string => {
+ const dict1 = ['','One','Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Eleven','Twelve','Thirteen','Fourteen','Fifteen','Sixteen','Seventeen','Eighteen','Nineteen',]
+ const dict2 = ['','','Twenty','Thirty','Forty','Fifty','Sixty','Seventy','Eighty','Ninety',]
+ let ans = ''
+
+ if (x <= 19) ans = dict1[x] ?? ''
+ else if (x < 100) ans = `${dict2[Math.floor(x / 10)]} ${f(x % 10)}`
+ else if (x < 10 ** 3) ans = `${dict1[Math.floor(x / 100)]} Hundred ${f(x % 100)}`
+ else if (x < 10 ** 6) ans = `${f(Math.floor(x / 10 ** 3))} Thousand ${f(x % 10 ** 3)}`
+ else if (x < 10 ** 9) ans = `${f(Math.floor(x / 10 ** 6))} Million ${f(x % 10 ** 6)}`
+ else ans = `${f(Math.floor(x / 10 ** 9))} Billion ${f(x % 10 ** 9)}`
+
+ return ans.trim()
+ }
+
+ return f(num);
+}
+```
+
+#### JavaScript
+
+```js
+function numberToWords(num) {
+ if (num === 0) return 'Zero';
+
+ // prettier-ignore
+ const f = (x) => {
+ const dict1 = ['','One','Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Eleven','Twelve','Thirteen','Fourteen','Fifteen','Sixteen','Seventeen','Eighteen','Nineteen',]
+ const dict2 = ['','','Twenty','Thirty','Forty','Fifty','Sixty','Seventy','Eighty','Ninety',]
+ let ans = ''
+
+ if (x <= 19) ans = dict1[x] ?? ''
+ else if (x < 100) ans = `${dict2[Math.floor(x / 10)]} ${f(x % 10)}`
+ else if (x < 10 ** 3) ans = `${dict1[Math.floor(x / 100)]} Hundred ${f(x % 100)}`
+ else if (x < 10 ** 6) ans = `${f(Math.floor(x / 10 ** 3))} Thousand ${f(x % 10 ** 3)}`
+ else if (x < 10 ** 9) ans = `${f(Math.floor(x / 10 ** 6))} Million ${f(x % 10 ** 6)}`
+ else ans = `${f(Math.floor(x / 10 ** 9))} Billion ${f(x % 10 ** 9)}`
+
+ return ans.trim()
+ }
+
+ return f(num);
+}
+```
+
diff --git a/solution/0200-0299/0273.Integer to English Words/Solution.js b/solution/0200-0299/0273.Integer to English Words/Solution.js
new file mode 100644
index 0000000000000..4abc586bf2dee
--- /dev/null
+++ b/solution/0200-0299/0273.Integer to English Words/Solution.js
@@ -0,0 +1,21 @@
+function numberToWords(num) {
+ if (num === 0) return 'Zero';
+
+ // prettier-ignore
+ const f = (x) => {
+ const dict1 = ['','One','Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Eleven','Twelve','Thirteen','Fourteen','Fifteen','Sixteen','Seventeen','Eighteen','Nineteen',]
+ const dict2 = ['','','Twenty','Thirty','Forty','Fifty','Sixty','Seventy','Eighty','Ninety',]
+ let ans = ''
+
+ if (x <= 19) ans = dict1[x] ?? ''
+ else if (x < 100) ans = `${dict2[Math.floor(x / 10)]} ${f(x % 10)}`
+ else if (x < 10 ** 3) ans = `${dict1[Math.floor(x / 100)]} Hundred ${f(x % 100)}`
+ else if (x < 10 ** 6) ans = `${f(Math.floor(x / 10 ** 3))} Thousand ${f(x % 10 ** 3)}`
+ else if (x < 10 ** 9) ans = `${f(Math.floor(x / 10 ** 6))} Million ${f(x % 10 ** 6)}`
+ else ans = `${f(Math.floor(x / 10 ** 9))} Billion ${f(x % 10 ** 9)}`
+
+ return ans.trim()
+ }
+
+ return f(num);
+}
diff --git a/solution/0200-0299/0273.Integer to English Words/Solution.ts b/solution/0200-0299/0273.Integer to English Words/Solution.ts
new file mode 100644
index 0000000000000..32c8e3b3a24a3
--- /dev/null
+++ b/solution/0200-0299/0273.Integer to English Words/Solution.ts
@@ -0,0 +1,21 @@
+function numberToWords(num: number): string {
+ if (num === 0) return 'Zero';
+
+ // prettier-ignore
+ const f = (x: number): string => {
+ const dict1 = ['','One','Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Eleven','Twelve','Thirteen','Fourteen','Fifteen','Sixteen','Seventeen','Eighteen','Nineteen',]
+ const dict2 = ['','','Twenty','Thirty','Forty','Fifty','Sixty','Seventy','Eighty','Ninety',]
+ let ans = ''
+
+ if (x <= 19) ans = dict1[x] ?? ''
+ else if (x < 100) ans = `${dict2[Math.floor(x / 10)]} ${f(x % 10)}`
+ else if (x < 10 ** 3) ans = `${dict1[Math.floor(x / 100)]} Hundred ${f(x % 100)}`
+ else if (x < 10 ** 6) ans = `${f(Math.floor(x / 10 ** 3))} Thousand ${f(x % 10 ** 3)}`
+ else if (x < 10 ** 9) ans = `${f(Math.floor(x / 10 ** 6))} Million ${f(x % 10 ** 6)}`
+ else ans = `${f(Math.floor(x / 10 ** 9))} Billion ${f(x % 10 ** 9)}`
+
+ return ans.trim()
+ }
+
+ return f(num);
+}
diff --git a/solution/0200-0299/0277.Find the Celebrity/README.md b/solution/0200-0299/0277.Find the Celebrity/README.md
index 501457473064d..8ae7e2cf70159 100644
--- a/solution/0200-0299/0277.Find the Celebrity/README.md
+++ b/solution/0200-0299/0277.Find the Celebrity/README.md
@@ -18,62 +18,56 @@ tags:
-假设你是一个专业的狗仔,参加了一个 n 人派对,其中每个人被从 0 到 n - 1 标号。在这个派对人群当中可能存在一位 “名人”。所谓 “名人” 的定义是:其他所有 n - 1 个人都认识他/她,而他/她并不认识其他任何人。
+假设你是一个专业的狗仔,参加了一个 n 人派对,其中每个人被从 0 到 n - 1 标号。在这个派对人群当中可能存在一位 “名人”。所谓 “名人” 的定义是:其他所有 n - 1 个人都认识他/她,而他/她并不认识其他任何人。
-现在你想要确认这个 “名人” 是谁,或者确定这里没有 “名人”。而你唯一能做的就是问诸如 “A 你好呀,请问你认不认识 B呀?” 的问题,以确定 A 是否认识 B。你需要在(渐近意义上)尽可能少的问题内来确定这位 “名人” 是谁(或者确定这里没有 “名人”)。
+现在你想要确认这个 “名人” 是谁,或者确定这里没有 “名人”。而你唯一能做的就是问诸如 “A 你好呀,请问你认不认识 B呀?” 的问题,以确定 A 是否认识 B。你需要在(渐近意义上)尽可能少的问题内来确定这位 “名人” 是谁(或者确定这里没有 “名人”)。
-在本题中,你可以使用辅助函数 bool knows(a, b) 获取到 A 是否认识 B。请你来实现一个函数 int findCelebrity(n)。
+在本题中,你可以使用辅助函数 bool knows(a, b) 获取到 A 是否认识 B。请你来实现一个函数 int findCelebrity(n)。
-派对最多只会有一个 “名人” 参加。若 “名人” 存在,请返回他/她的编号;若 “名人” 不存在,请返回 -1。
+派对最多只会有一个 “名人” 参加。若 “名人” 存在,请返回他/她的编号;若 “名人” 不存在,请返回 -1。
-
-
-示例 1:
-
-
+
+示例 1:
+
-输入: graph = [
- [1,1,0],
- [0,1,0],
- [1,1,1]
-]
+输入: graph = [[1,1,0],[0,1,0],[1,1,1]]
输出: 1
解释: 有编号分别为 0、1 和 2 的三个人。graph[i][j] = 1 代表编号为 i 的人认识编号为 j 的人,而 graph[i][j] = 0 则代表编号为 i 的人不认识编号为 j 的人。“名人” 是编号 1 的人,因为 0 和 2 均认识他/她,但 1 不认识任何人。
+
-示例 2:
-
-
-
+示例 2:
+
-输入: graph = [
- [1,0,1],
- [1,1,0],
- [0,1,1]
-]
+输入: graph = [[1,0,1],[1,1,0],[0,1,1]]
输出: -1
解释: 没有 “名人”
-
+
+
-提示:
+提示:
+
- n == graph.lengthn == graph[i].length2 <= n <= 100graph[i][j] 是 0 或 1.n == graph.length == graph[i].length2 <= n <= 100graph[i][j] 是 0 或 1graph[i][i] == 1
+
-
+
+
-进阶:如果允许调用 API knows 的最大次数为 3 * n ,你可以设计一个不超过最大调用次数的解决方案吗?
+进阶:如果允许调用 API knows 的最大次数为 3 * n ,你可以设计一个不超过最大调用次数的解决方案吗?
+
+
diff --git a/solution/0200-0299/0277.Find the Celebrity/images/277_example_1_bold.png b/solution/0200-0299/0277.Find the Celebrity/images/277_example_1_bold.png
deleted file mode 100644
index f4f70164e6181..0000000000000
Binary files a/solution/0200-0299/0277.Find the Celebrity/images/277_example_1_bold.png and /dev/null differ
diff --git a/solution/0200-0299/0277.Find the Celebrity/images/277_example_2.png b/solution/0200-0299/0277.Find the Celebrity/images/277_example_2.png
deleted file mode 100644
index 00ea91bd7a903..0000000000000
Binary files a/solution/0200-0299/0277.Find the Celebrity/images/277_example_2.png and /dev/null differ
diff --git a/solution/0200-0299/0295.Find Median from Data Stream/README.md b/solution/0200-0299/0295.Find Median from Data Stream/README.md
index e2121ad724561..5ac081b9a13b0 100644
--- a/solution/0200-0299/0295.Find Median from Data Stream/README.md
+++ b/solution/0200-0299/0295.Find Median from Data Stream/README.md
@@ -74,11 +74,11 @@ medianFinder.findMedian(); // return 2.0
### 方法一:大小根堆(优先队列)
-我们可以使用两个堆来维护所有的元素,一个小根堆 $\text{minQ}$ 和一个大根堆 $\text{maxQ}$,其中小根堆 $\text{minQ}$ 存储较大的一半,大根堆 $\text{maxQ}$ 存储较小的一半。
+我们可以使用两个堆来维护所有的元素,一个小根堆 $\textit{minQ}$ 和一个大根堆 $\textit{maxQ}$,其中小根堆 $\textit{minQ}$ 存储较大的一半,大根堆 $\textit{maxQ}$ 存储较小的一半。
-调用 `addNum` 方法时,我们首先将元素加入到大根堆 $\text{maxQ}$,然后将 $\text{maxQ}$ 的堆顶元素弹出并加入到小根堆 $\text{minQ}$。如果此时 $\text{minQ}$ 的大小与 $\text{maxQ}$ 的大小差值大于 $1$,我们就将 $\text{minQ}$ 的堆顶元素弹出并加入到 $\text{maxQ}$。时间复杂度为 $O(\log n)$。
+调用 `addNum` 方法时,我们首先将元素加入到大根堆 $\textit{maxQ}$,然后将 $\textit{maxQ}$ 的堆顶元素弹出并加入到小根堆 $\textit{minQ}$。如果此时 $\textit{minQ}$ 的大小与 $\textit{maxQ}$ 的大小差值大于 $1$,我们就将 $\textit{minQ}$ 的堆顶元素弹出并加入到 $\textit{maxQ}$。时间复杂度为 $O(\log n)$。
-调用 `findMedian` 方法时,如果 $\text{minQ}$ 的大小等于 $\text{maxQ}$ 的大小,说明元素的总数为偶数,我们就可以返回 $\text{minQ}$ 的堆顶元素与 $\text{maxQ}$ 的堆顶元素的平均值;否则,我们返回 $\text{minQ}$ 的堆顶元素。时间复杂度为 $O(1)$。
+调用 `findMedian` 方法时,如果 $\textit{minQ}$ 的大小等于 $\textit{maxQ}$ 的大小,说明元素的总数为偶数,我们就可以返回 $\textit{minQ}$ 的堆顶元素与 $\textit{maxQ}$ 的堆顶元素的平均值;否则,我们返回 $\textit{minQ}$ 的堆顶元素。时间复杂度为 $O(1)$。
空间复杂度为 $O(n)$。其中 $n$ 为元素的个数。
diff --git a/solution/0200-0299/0295.Find Median from Data Stream/README_EN.md b/solution/0200-0299/0295.Find Median from Data Stream/README_EN.md
index c2787a62043d6..8f0d3a8b7cf01 100644
--- a/solution/0200-0299/0295.Find Median from Data Stream/README_EN.md
+++ b/solution/0200-0299/0295.Find Median from Data Stream/README_EN.md
@@ -79,11 +79,11 @@ medianFinder.findMedian(); // return 2.0
### Solution 1: Min Heap and Max Heap (Priority Queue)
-We can use two heaps to maintain all the elements, a min heap $\text{minQ}$ and a max heap $\text{maxQ}$, where the min heap $\text{minQ}$ stores the larger half, and the max heap $\text{maxQ}$ stores the smaller half.
+We can use two heaps to maintain all the elements, a min heap $\textit{minQ}$ and a max heap $\textit{maxQ}$, where the min heap $\textit{minQ}$ stores the larger half, and the max heap $\textit{maxQ}$ stores the smaller half.
-When calling the `addNum` method, we first add the element to the max heap $\text{maxQ}$, then pop the top element of $\text{maxQ}$ and add it to the min heap $\text{minQ}$. If at this time the size difference between $\text{minQ}$ and $\text{maxQ}$ is greater than $1$, we pop the top element of $\text{minQ}$ and add it to $\text{maxQ}$. The time complexity is $O(\log n)$.
+When calling the `addNum` method, we first add the element to the max heap $\textit{maxQ}$, then pop the top element of $\textit{maxQ}$ and add it to the min heap $\textit{minQ}$. If at this time the size difference between $\textit{minQ}$ and $\textit{maxQ}$ is greater than $1$, we pop the top element of $\textit{minQ}$ and add it to $\textit{maxQ}$. The time complexity is $O(\log n)$.
-When calling the `findMedian` method, if the size of $\text{minQ}$ is equal to the size of $\text{maxQ}$, it means the total number of elements is even, and we can return the average value of the top elements of $\text{minQ}$ and $\text{maxQ}$; otherwise, we return the top element of $\text{minQ}$. The time complexity is $O(1)$.
+When calling the `findMedian` method, if the size of $\textit{minQ}$ is equal to the size of $\textit{maxQ}$, it means the total number of elements is even, and we can return the average value of the top elements of $\textit{minQ}$ and $\textit{maxQ}$; otherwise, we return the top element of $\textit{minQ}$. The time complexity is $O(1)$.
The space complexity is $O(n)$, where $n$ is the number of elements.
diff --git a/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md b/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md
index 54fffba910dfb..a7b7363fef66a 100644
--- a/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md
+++ b/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md
@@ -12,7 +12,7 @@ tags:
-# [308. 二维区域和检索 - 可变 🔒](https://leetcode.cn/problems/range-sum-query-2d-mutable)
+# [308. 二维区域和检索 - 矩阵可修改 🔒](https://leetcode.cn/problems/range-sum-query-2d-mutable)
[English Version](/solution/0300-0399/0308.Range%20Sum%20Query%202D%20-%20Mutable/README_EN.md)
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/README.md b/solution/0300-0399/0332.Reconstruct Itinerary/README.md
index f14fd8ac83b8b..09f9bbbeb93b4 100644
--- a/solution/0300-0399/0332.Reconstruct Itinerary/README.md
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/README.md
@@ -64,7 +64,13 @@ tags:
-### 方法一
+### 方法一:欧拉路径
+
+题目实际上是给定 $n$ 个点和 $m$ 条边,要求从指定的起点出发,经过所有的边恰好一次,使得路径字典序最小。这是一个典型的欧拉路径问题。
+
+由于本题保证了至少存在一种合理的行程,因此,我们直接利用 Hierholzer 算法,输出从起点出发的欧拉路径即可。
+
+时间复杂度 $O(m \times \log m)$,空间复杂度 $O(m)$。其中 $m$ 是边的数量。
@@ -73,56 +79,43 @@ tags:
```python
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
- graph = defaultdict(list)
-
- for src, dst in sorted(tickets, reverse=True):
- graph[src].append(dst)
-
- itinerary = []
-
- def dfs(airport):
- while graph[airport]:
- dfs(graph[airport].pop())
- itinerary.append(airport)
-
+ def dfs(f: str):
+ while g[f]:
+ dfs(g[f].pop())
+ ans.append(f)
+
+ g = defaultdict(list)
+ for f, t in sorted(tickets, reverse=True):
+ g[f].append(t)
+ ans = []
dfs("JFK")
-
- return itinerary[::-1]
+ return ans[::-1]
```
#### Java
```java
class Solution {
- void dfs(Map> adjLists, List ans, String curr) {
- Queue neighbors = adjLists.get(curr);
- if (neighbors == null) {
- ans.add(curr);
- return;
- }
- while (!neighbors.isEmpty()) {
- String neighbor = neighbors.poll();
- dfs(adjLists, ans, neighbor);
- }
- ans.add(curr);
- return;
- }
+ private Map> g = new HashMap<>();
+ private List ans = new ArrayList<>();
public List findItinerary(List> tickets) {
- Map> adjLists = new HashMap<>();
+ Collections.sort(tickets, (a, b) -> b.get(1).compareTo(a.get(1)));
for (List ticket : tickets) {
- String from = ticket.get(0);
- String to = ticket.get(1);
- if (!adjLists.containsKey(from)) {
- adjLists.put(from, new PriorityQueue<>());
- }
- adjLists.get(from).add(to);
+ g.computeIfAbsent(ticket.get(0), k -> new ArrayList<>()).add(ticket.get(1));
}
- List ans = new ArrayList<>();
- dfs(adjLists, ans, "JFK");
+ dfs("JFK");
Collections.reverse(ans);
return ans;
}
+
+ private void dfs(String f) {
+ while (g.containsKey(f) && !g.get(f).isEmpty()) {
+ String t = g.get(f).remove(g.get(f).size() - 1);
+ dfs(t);
+ }
+ ans.add(f);
+ }
}
```
@@ -132,36 +125,77 @@ class Solution {
class Solution {
public:
vector findItinerary(vector>& tickets) {
- unordered_map, greater>> g;
- vector ret;
-
- // Initialize the graph
- for (const auto& t : tickets) {
- g[t[0]].push(t[1]);
+ sort(tickets.rbegin(), tickets.rend());
+ unordered_map> g;
+ for (const auto& ticket : tickets) {
+ g[ticket[0]].push_back(ticket[1]);
}
+ vector ans;
+ auto dfs = [&](auto&& dfs, string& f) -> void {
+ while (!g[f].empty()) {
+ string t = g[f].back();
+ g[f].pop_back();
+ dfs(dfs, t);
+ }
+ ans.emplace_back(f);
+ };
+ string f = "JFK";
+ dfs(dfs, f);
+ reverse(ans.begin(), ans.end());
+ return ans;
+ }
+};
+```
- findItineraryInner(g, ret, "JFK");
+#### Go
+
+```go
+func findItinerary(tickets [][]string) (ans []string) {
+ sort.Slice(tickets, func(i, j int) bool {
+ return tickets[i][0] > tickets[j][0] || (tickets[i][0] == tickets[j][0] && tickets[i][1] > tickets[j][1])
+ })
+ g := make(map[string][]string)
+ for _, ticket := range tickets {
+ g[ticket[0]] = append(g[ticket[0]], ticket[1])
+ }
+ var dfs func(f string)
+ dfs = func(f string) {
+ for len(g[f]) > 0 {
+ t := g[f][len(g[f])-1]
+ g[f] = g[f][:len(g[f])-1]
+ dfs(t)
+ }
+ ans = append(ans, f)
+ }
+ dfs("JFK")
+ for i := 0; i < len(ans)/2; i++ {
+ ans[i], ans[len(ans)-1-i] = ans[len(ans)-1-i], ans[i]
+ }
+ return
+}
+```
- ret = {ret.rbegin(), ret.rend()};
+#### TypeScript
- return ret;
+```ts
+function findItinerary(tickets: string[][]): string[] {
+ const g: Record = {};
+ tickets.sort((a, b) => b[1].localeCompare(a[1]));
+ for (const [f, t] of tickets) {
+ g[f] = g[f] || [];
+ g[f].push(t);
}
-
- void findItineraryInner(unordered_map, greater>>& g, vector& ret, string cur) {
- if (g.count(cur) == 0) {
- // This is the end point
- ret.push_back(cur);
- return;
- } else {
- while (!g[cur].empty()) {
- auto front = g[cur].top();
- g[cur].pop();
- findItineraryInner(g, ret, front);
- }
- ret.push_back(cur);
+ const ans: string[] = [];
+ const dfs = (f: string) => {
+ while (g[f] && g[f].length) {
+ const t = g[f].pop()!;
+ dfs(t);
}
- }
-};
+ ans.push(f);
+ };
+ dfs('JFK');
+ return ans.reverse();
+}
```
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/README_EN.md b/solution/0300-0399/0332.Reconstruct Itinerary/README_EN.md
index bb688d0f1adab..3fcd849fbd06a 100644
--- a/solution/0300-0399/0332.Reconstruct Itinerary/README_EN.md
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/README_EN.md
@@ -62,7 +62,13 @@ tags:
-### Solution 1
+### Solution 1: Eulerian Path
+
+The problem is essentially about finding a path that starts from a specified starting point, passes through all the edges exactly once, and has the smallest lexicographical order among all such paths, given $n$ vertices and $m$ edges. This is a classic Eulerian path problem.
+
+Since the problem guarantees that there is at least one feasible itinerary, we can directly use the Hierholzer algorithm to output the Eulerian path starting from the starting point.
+
+The time complexity is $O(m \times \log m)$, and the space complexity is $O(m)$. Here, $m$ is the number of edges.
@@ -71,56 +77,43 @@ tags:
```python
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
- graph = defaultdict(list)
-
- for src, dst in sorted(tickets, reverse=True):
- graph[src].append(dst)
-
- itinerary = []
-
- def dfs(airport):
- while graph[airport]:
- dfs(graph[airport].pop())
- itinerary.append(airport)
-
+ def dfs(f: str):
+ while g[f]:
+ dfs(g[f].pop())
+ ans.append(f)
+
+ g = defaultdict(list)
+ for f, t in sorted(tickets, reverse=True):
+ g[f].append(t)
+ ans = []
dfs("JFK")
-
- return itinerary[::-1]
+ return ans[::-1]
```
#### Java
```java
class Solution {
- void dfs(Map> adjLists, List ans, String curr) {
- Queue neighbors = adjLists.get(curr);
- if (neighbors == null) {
- ans.add(curr);
- return;
- }
- while (!neighbors.isEmpty()) {
- String neighbor = neighbors.poll();
- dfs(adjLists, ans, neighbor);
- }
- ans.add(curr);
- return;
- }
+ private Map> g = new HashMap<>();
+ private List ans = new ArrayList<>();
public List findItinerary(List> tickets) {
- Map> adjLists = new HashMap<>();
+ Collections.sort(tickets, (a, b) -> b.get(1).compareTo(a.get(1)));
for (List ticket : tickets) {
- String from = ticket.get(0);
- String to = ticket.get(1);
- if (!adjLists.containsKey(from)) {
- adjLists.put(from, new PriorityQueue<>());
- }
- adjLists.get(from).add(to);
+ g.computeIfAbsent(ticket.get(0), k -> new ArrayList<>()).add(ticket.get(1));
}
- List ans = new ArrayList<>();
- dfs(adjLists, ans, "JFK");
+ dfs("JFK");
Collections.reverse(ans);
return ans;
}
+
+ private void dfs(String f) {
+ while (g.containsKey(f) && !g.get(f).isEmpty()) {
+ String t = g.get(f).remove(g.get(f).size() - 1);
+ dfs(t);
+ }
+ ans.add(f);
+ }
}
```
@@ -130,36 +123,77 @@ class Solution {
class Solution {
public:
vector findItinerary(vector>& tickets) {
- unordered_map, greater>> g;
- vector ret;
-
- // Initialize the graph
- for (const auto& t : tickets) {
- g[t[0]].push(t[1]);
+ sort(tickets.rbegin(), tickets.rend());
+ unordered_map> g;
+ for (const auto& ticket : tickets) {
+ g[ticket[0]].push_back(ticket[1]);
}
+ vector ans;
+ auto dfs = [&](auto&& dfs, string& f) -> void {
+ while (!g[f].empty()) {
+ string t = g[f].back();
+ g[f].pop_back();
+ dfs(dfs, t);
+ }
+ ans.emplace_back(f);
+ };
+ string f = "JFK";
+ dfs(dfs, f);
+ reverse(ans.begin(), ans.end());
+ return ans;
+ }
+};
+```
- findItineraryInner(g, ret, "JFK");
+#### Go
+
+```go
+func findItinerary(tickets [][]string) (ans []string) {
+ sort.Slice(tickets, func(i, j int) bool {
+ return tickets[i][0] > tickets[j][0] || (tickets[i][0] == tickets[j][0] && tickets[i][1] > tickets[j][1])
+ })
+ g := make(map[string][]string)
+ for _, ticket := range tickets {
+ g[ticket[0]] = append(g[ticket[0]], ticket[1])
+ }
+ var dfs func(f string)
+ dfs = func(f string) {
+ for len(g[f]) > 0 {
+ t := g[f][len(g[f])-1]
+ g[f] = g[f][:len(g[f])-1]
+ dfs(t)
+ }
+ ans = append(ans, f)
+ }
+ dfs("JFK")
+ for i := 0; i < len(ans)/2; i++ {
+ ans[i], ans[len(ans)-1-i] = ans[len(ans)-1-i], ans[i]
+ }
+ return
+}
+```
- ret = {ret.rbegin(), ret.rend()};
+#### TypeScript
- return ret;
+```ts
+function findItinerary(tickets: string[][]): string[] {
+ const g: Record = {};
+ tickets.sort((a, b) => b[1].localeCompare(a[1]));
+ for (const [f, t] of tickets) {
+ g[f] = g[f] || [];
+ g[f].push(t);
}
-
- void findItineraryInner(unordered_map, greater>>& g, vector& ret, string cur) {
- if (g.count(cur) == 0) {
- // This is the end point
- ret.push_back(cur);
- return;
- } else {
- while (!g[cur].empty()) {
- auto front = g[cur].top();
- g[cur].pop();
- findItineraryInner(g, ret, front);
- }
- ret.push_back(cur);
+ const ans: string[] = [];
+ const dfs = (f: string) => {
+ while (g[f] && g[f].length) {
+ const t = g[f].pop()!;
+ dfs(t);
}
- }
-};
+ ans.push(f);
+ };
+ dfs('JFK');
+ return ans.reverse();
+}
```
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.cpp b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.cpp
index c9a7344be9fee..daa0b3bd96ab8 100644
--- a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.cpp
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.cpp
@@ -1,33 +1,23 @@
class Solution {
public:
vector findItinerary(vector>& tickets) {
- unordered_map, greater>> g;
- vector ret;
-
- // Initialize the graph
- for (const auto& t : tickets) {
- g[t[0]].push(t[1]);
+ sort(tickets.rbegin(), tickets.rend());
+ unordered_map> g;
+ for (const auto& ticket : tickets) {
+ g[ticket[0]].push_back(ticket[1]);
}
-
- findItineraryInner(g, ret, "JFK");
-
- ret = {ret.rbegin(), ret.rend()};
-
- return ret;
- }
-
- void findItineraryInner(unordered_map, greater>>& g, vector& ret, string cur) {
- if (g.count(cur) == 0) {
- // This is the end point
- ret.push_back(cur);
- return;
- } else {
- while (!g[cur].empty()) {
- auto front = g[cur].top();
- g[cur].pop();
- findItineraryInner(g, ret, front);
+ vector ans;
+ auto dfs = [&](auto&& dfs, string& f) -> void {
+ while (!g[f].empty()) {
+ string t = g[f].back();
+ g[f].pop_back();
+ dfs(dfs, t);
}
- ret.push_back(cur);
- }
+ ans.emplace_back(f);
+ };
+ string f = "JFK";
+ dfs(dfs, f);
+ reverse(ans.begin(), ans.end());
+ return ans;
}
};
\ No newline at end of file
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.go b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.go
new file mode 100644
index 0000000000000..35ba5bc6ee499
--- /dev/null
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.go
@@ -0,0 +1,23 @@
+func findItinerary(tickets [][]string) (ans []string) {
+ sort.Slice(tickets, func(i, j int) bool {
+ return tickets[i][0] > tickets[j][0] || (tickets[i][0] == tickets[j][0] && tickets[i][1] > tickets[j][1])
+ })
+ g := make(map[string][]string)
+ for _, ticket := range tickets {
+ g[ticket[0]] = append(g[ticket[0]], ticket[1])
+ }
+ var dfs func(f string)
+ dfs = func(f string) {
+ for len(g[f]) > 0 {
+ t := g[f][len(g[f])-1]
+ g[f] = g[f][:len(g[f])-1]
+ dfs(t)
+ }
+ ans = append(ans, f)
+ }
+ dfs("JFK")
+ for i := 0; i < len(ans)/2; i++ {
+ ans[i], ans[len(ans)-1-i] = ans[len(ans)-1-i], ans[i]
+ }
+ return
+}
\ No newline at end of file
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.java b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.java
index 970cd30092f14..ddc8efbf45515 100644
--- a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.java
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.java
@@ -1,31 +1,22 @@
class Solution {
- void dfs(Map> adjLists, List ans, String curr) {
- Queue neighbors = adjLists.get(curr);
- if (neighbors == null) {
- ans.add(curr);
- return;
- }
- while (!neighbors.isEmpty()) {
- String neighbor = neighbors.poll();
- dfs(adjLists, ans, neighbor);
- }
- ans.add(curr);
- return;
- }
+ private Map> g = new HashMap<>();
+ private List ans = new ArrayList<>();
public List findItinerary(List> tickets) {
- Map> adjLists = new HashMap<>();
+ Collections.sort(tickets, (a, b) -> b.get(1).compareTo(a.get(1)));
for (List ticket : tickets) {
- String from = ticket.get(0);
- String to = ticket.get(1);
- if (!adjLists.containsKey(from)) {
- adjLists.put(from, new PriorityQueue<>());
- }
- adjLists.get(from).add(to);
+ g.computeIfAbsent(ticket.get(0), k -> new ArrayList<>()).add(ticket.get(1));
}
- List ans = new ArrayList<>();
- dfs(adjLists, ans, "JFK");
+ dfs("JFK");
Collections.reverse(ans);
return ans;
}
+
+ private void dfs(String f) {
+ while (g.containsKey(f) && !g.get(f).isEmpty()) {
+ String t = g.get(f).remove(g.get(f).size() - 1);
+ dfs(t);
+ }
+ ans.add(f);
+ }
}
\ No newline at end of file
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.py b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.py
index 8b6c452a44ca2..7614c393c9f7f 100644
--- a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.py
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.py
@@ -1,17 +1,13 @@
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
- graph = defaultdict(list)
-
- for src, dst in sorted(tickets, reverse=True):
- graph[src].append(dst)
-
- itinerary = []
-
- def dfs(airport):
- while graph[airport]:
- dfs(graph[airport].pop())
- itinerary.append(airport)
-
+ def dfs(f: str):
+ while g[f]:
+ dfs(g[f].pop())
+ ans.append(f)
+
+ g = defaultdict(list)
+ for f, t in sorted(tickets, reverse=True):
+ g[f].append(t)
+ ans = []
dfs("JFK")
-
- return itinerary[::-1]
+ return ans[::-1]
diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/Solution.ts b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.ts
new file mode 100644
index 0000000000000..d8a61a461a1f5
--- /dev/null
+++ b/solution/0300-0399/0332.Reconstruct Itinerary/Solution.ts
@@ -0,0 +1,18 @@
+function findItinerary(tickets: string[][]): string[] {
+ const g: Record = {};
+ tickets.sort((a, b) => b[1].localeCompare(a[1]));
+ for (const [f, t] of tickets) {
+ g[f] = g[f] || [];
+ g[f].push(t);
+ }
+ const ans: string[] = [];
+ const dfs = (f: string) => {
+ while (g[f] && g[f].length) {
+ const t = g[f].pop()!;
+ dfs(t);
+ }
+ ans.push(f);
+ };
+ dfs('JFK');
+ return ans.reverse();
+}
diff --git a/solution/0300-0399/0338.Counting Bits/README.md b/solution/0300-0399/0338.Counting Bits/README.md
index 9a81e7663965e..7e7fa93ad1cda 100644
--- a/solution/0300-0399/0338.Counting Bits/README.md
+++ b/solution/0300-0399/0338.Counting Bits/README.md
@@ -161,7 +161,7 @@ function bitCount(n: number): number {
我们定义一个长度为 $n+1$ 的答案数组 $ans$,初始时 $ans[0]=0$。
-对于 $1 \leq i \leq n$,我们有 $ans[i] = ans[i \text{ and } (i-1)] + 1$。其中 $i \text{ and } (i-1)$ 表示将 $i$ 的二进制表示中的最低位 $1$ 变成 $0$ 之后的数,显然 $i \text{ and } (i-1) < i$,且 $ans[i \text{ and } (i-1)]$ 已经被计算出来了,我们就能以 $O(1)$ 的时间得到 $ans[i]$。
+对于 $1 \leq i \leq n$,我们有 $ans[i] = ans[i \textit{ and } (i-1)] + 1$。其中 $i \textit{ and } (i-1)$ 表示将 $i$ 的二进制表示中的最低位 $1$ 变成 $0$ 之后的数,显然 $i \textit{ and } (i-1) < i$,且 $ans[i \textit{ and } (i-1)]$ 已经被计算出来了,我们就能以 $O(1)$ 的时间得到 $ans[i]$。
时间复杂度 $O(n)$,空间复杂度 $O(1)$。
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README.md b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README.md
index fa9134aadaf49..c048c7f16ad7f 100644
--- a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README.md
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README.md
@@ -54,11 +54,13 @@ tags:
### 方法一:滑动窗口 + 哈希表
-我们可以使用滑动窗口的思想,维护一个滑动窗口,使得窗口内的字符串中不同字符的个数不超过 $k$ 个。窗口内不同字符个数的统计可以用哈希表 `cnt` 来维护。
+我们可以使用滑动窗口的思想,用一个哈希表 $\textit{cnt}$ 记录窗口中每个字符的出现次数,用 $\textit{l}$ 记录窗口的左边界。
-我们使用两个指针 $j$ 和 $i$ 分别表示滑动窗口的左右边界。我们先移动右边界 $i$,将字符 $s[i]$ 加入到窗口内,扩大滑动窗口,若此时窗口内不同字符的个数超过 $k$ 个,则移动左边界 $j$,缩小滑动窗口,直到窗口内不同字符的个数不超过 $k$ 个。此时我们可以更新答案的最大值,即 $ans = max(ans, i - j + 1)$。
+遍历字符串,每次将右边界的字符加入哈希表,如果哈希表中不同字符的个数超过了 $k$,则将左边界的字符从哈希表中删除,然后更新左边界 $\textit{l}$。
-时间复杂度 $O(n)$,空间复杂度 $O(\min(n, k))$。其中 $n$ 为字符串的长度。
+最后返回字符串的长度减去左边界的长度即可。
+
+时间复杂度 $O(n)$,空间复杂度 $O(k)$。其中 $n$ 为字符串的长度。
@@ -67,18 +69,16 @@ tags:
```python
class Solution:
def lengthOfLongestSubstringKDistinct(self, s: str, k: int) -> int:
+ l = 0
cnt = Counter()
- n = len(s)
- ans = j = 0
- for i, c in enumerate(s):
+ for c in s:
cnt[c] += 1
- while len(cnt) > k:
- cnt[s[j]] -= 1
- if cnt[s[j]] == 0:
- cnt.pop(s[j])
- j += 1
- ans = max(ans, i - j + 1)
- return ans
+ if len(cnt) > k:
+ cnt[s[l]] -= 1
+ if cnt[s[l]] == 0:
+ del cnt[s[l]]
+ l += 1
+ return len(s) - l
```
#### Java
@@ -87,22 +87,18 @@ class Solution:
class Solution {
public int lengthOfLongestSubstringKDistinct(String s, int k) {
Map cnt = new HashMap<>();
- int n = s.length();
- int ans = 0, j = 0;
- for (int i = 0; i < n; ++i) {
- char c = s.charAt(i);
- cnt.put(c, cnt.getOrDefault(c, 0) + 1);
- while (cnt.size() > k) {
- char t = s.charAt(j);
- cnt.put(t, cnt.getOrDefault(t, 0) - 1);
- if (cnt.get(t) == 0) {
- cnt.remove(t);
+ int l = 0;
+ char[] cs = s.toCharArray();
+ for (char c : cs) {
+ cnt.merge(c, 1, Integer::sum);
+ if (cnt.size() > k) {
+ if (cnt.merge(cs[l], -1, Integer::sum) == 0) {
+ cnt.remove(cs[l]);
}
- ++j;
+ ++l;
}
- ans = Math.max(ans, i - j + 1);
}
- return ans;
+ return cs.length - l;
}
}
```
@@ -114,19 +110,17 @@ class Solution {
public:
int lengthOfLongestSubstringKDistinct(string s, int k) {
unordered_map cnt;
- int n = s.size();
- int ans = 0, j = 0;
- for (int i = 0; i < n; ++i) {
- cnt[s[i]]++;
- while (cnt.size() > k) {
- if (--cnt[s[j]] == 0) {
- cnt.erase(s[j]);
+ int l = 0;
+ for (char& c : s) {
+ ++cnt[c];
+ if (cnt.size() > k) {
+ if (--cnt[s[l]] == 0) {
+ cnt.erase(s[l]);
}
- ++j;
+ ++l;
}
- ans = max(ans, i - j + 1);
}
- return ans;
+ return s.size() - l;
}
};
```
@@ -134,21 +128,40 @@ public:
#### Go
```go
-func lengthOfLongestSubstringKDistinct(s string, k int) (ans int) {
+func lengthOfLongestSubstringKDistinct(s string, k int) int {
cnt := map[byte]int{}
- j := 0
- for i := range s {
- cnt[s[i]]++
- for len(cnt) > k {
- cnt[s[j]]--
- if cnt[s[j]] == 0 {
- delete(cnt, s[j])
+ l := 0
+ for _, c := range s {
+ cnt[byte(c)]++
+ if len(cnt) > k {
+ cnt[s[l]]--
+ if cnt[s[l]] == 0 {
+ delete(cnt, s[l])
}
- j++
+ l++
}
- ans = max(ans, i-j+1)
}
- return
+ return len(s) - l
+}
+```
+
+#### TypeScript
+
+```ts
+function lengthOfLongestSubstringKDistinct(s: string, k: number): number {
+ const cnt: Map = new Map();
+ let l = 0;
+ for (const c of s) {
+ cnt.set(c, (cnt.get(c) ?? 0) + 1);
+ if (cnt.size > k) {
+ cnt.set(s[l], cnt.get(s[l])! - 1);
+ if (cnt.get(s[l]) === 0) {
+ cnt.delete(s[l]);
+ }
+ l++;
+ }
+ }
+ return s.length - l;
}
```
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README_EN.md b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README_EN.md
index 04562983b147c..8643cc011245e 100644
--- a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README_EN.md
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/README_EN.md
@@ -50,7 +50,15 @@ tags:
-### Solution 1
+### Solution 1: Sliding Window + Hash Table
+
+We can use the idea of a sliding window, with a hash table $\textit{cnt}$ to record the occurrence count of each character within the window, and $\textit{l}$ to denote the left boundary of the window.
+
+Iterate through the string, adding the character at the right boundary to the hash table each time. If the number of distinct characters in the hash table exceeds $k$, remove the character at the left boundary from the hash table, then update the left boundary $\textit{l}$.
+
+Finally, return the length of the string minus the length of the left boundary.
+
+The time complexity is $O(n)$, and the space complexity is $O(k)$. Here, $n$ is the length of the string.
@@ -59,18 +67,16 @@ tags:
```python
class Solution:
def lengthOfLongestSubstringKDistinct(self, s: str, k: int) -> int:
+ l = 0
cnt = Counter()
- n = len(s)
- ans = j = 0
- for i, c in enumerate(s):
+ for c in s:
cnt[c] += 1
- while len(cnt) > k:
- cnt[s[j]] -= 1
- if cnt[s[j]] == 0:
- cnt.pop(s[j])
- j += 1
- ans = max(ans, i - j + 1)
- return ans
+ if len(cnt) > k:
+ cnt[s[l]] -= 1
+ if cnt[s[l]] == 0:
+ del cnt[s[l]]
+ l += 1
+ return len(s) - l
```
#### Java
@@ -79,22 +85,18 @@ class Solution:
class Solution {
public int lengthOfLongestSubstringKDistinct(String s, int k) {
Map cnt = new HashMap<>();
- int n = s.length();
- int ans = 0, j = 0;
- for (int i = 0; i < n; ++i) {
- char c = s.charAt(i);
- cnt.put(c, cnt.getOrDefault(c, 0) + 1);
- while (cnt.size() > k) {
- char t = s.charAt(j);
- cnt.put(t, cnt.getOrDefault(t, 0) - 1);
- if (cnt.get(t) == 0) {
- cnt.remove(t);
+ int l = 0;
+ char[] cs = s.toCharArray();
+ for (char c : cs) {
+ cnt.merge(c, 1, Integer::sum);
+ if (cnt.size() > k) {
+ if (cnt.merge(cs[l], -1, Integer::sum) == 0) {
+ cnt.remove(cs[l]);
}
- ++j;
+ ++l;
}
- ans = Math.max(ans, i - j + 1);
}
- return ans;
+ return cs.length - l;
}
}
```
@@ -106,19 +108,17 @@ class Solution {
public:
int lengthOfLongestSubstringKDistinct(string s, int k) {
unordered_map cnt;
- int n = s.size();
- int ans = 0, j = 0;
- for (int i = 0; i < n; ++i) {
- cnt[s[i]]++;
- while (cnt.size() > k) {
- if (--cnt[s[j]] == 0) {
- cnt.erase(s[j]);
+ int l = 0;
+ for (char& c : s) {
+ ++cnt[c];
+ if (cnt.size() > k) {
+ if (--cnt[s[l]] == 0) {
+ cnt.erase(s[l]);
}
- ++j;
+ ++l;
}
- ans = max(ans, i - j + 1);
}
- return ans;
+ return s.size() - l;
}
};
```
@@ -126,21 +126,40 @@ public:
#### Go
```go
-func lengthOfLongestSubstringKDistinct(s string, k int) (ans int) {
+func lengthOfLongestSubstringKDistinct(s string, k int) int {
cnt := map[byte]int{}
- j := 0
- for i := range s {
- cnt[s[i]]++
- for len(cnt) > k {
- cnt[s[j]]--
- if cnt[s[j]] == 0 {
- delete(cnt, s[j])
+ l := 0
+ for _, c := range s {
+ cnt[byte(c)]++
+ if len(cnt) > k {
+ cnt[s[l]]--
+ if cnt[s[l]] == 0 {
+ delete(cnt, s[l])
}
- j++
+ l++
}
- ans = max(ans, i-j+1)
}
- return
+ return len(s) - l
+}
+```
+
+#### TypeScript
+
+```ts
+function lengthOfLongestSubstringKDistinct(s: string, k: number): number {
+ const cnt: Map = new Map();
+ let l = 0;
+ for (const c of s) {
+ cnt.set(c, (cnt.get(c) ?? 0) + 1);
+ if (cnt.size > k) {
+ cnt.set(s[l], cnt.get(s[l])! - 1);
+ if (cnt.get(s[l]) === 0) {
+ cnt.delete(s[l]);
+ }
+ l++;
+ }
+ }
+ return s.length - l;
}
```
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.cpp b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.cpp
index 4c7a64f5dc076..55461d59a01c0 100644
--- a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.cpp
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.cpp
@@ -2,18 +2,16 @@ class Solution {
public:
int lengthOfLongestSubstringKDistinct(string s, int k) {
unordered_map cnt;
- int n = s.size();
- int ans = 0, j = 0;
- for (int i = 0; i < n; ++i) {
- cnt[s[i]]++;
- while (cnt.size() > k) {
- if (--cnt[s[j]] == 0) {
- cnt.erase(s[j]);
+ int l = 0;
+ for (char& c : s) {
+ ++cnt[c];
+ if (cnt.size() > k) {
+ if (--cnt[s[l]] == 0) {
+ cnt.erase(s[l]);
}
- ++j;
+ ++l;
}
- ans = max(ans, i - j + 1);
}
- return ans;
+ return s.size() - l;
}
};
\ No newline at end of file
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.go b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.go
index a70eb7c6cf17d..9d88aa75a300d 100644
--- a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.go
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.go
@@ -1,16 +1,15 @@
-func lengthOfLongestSubstringKDistinct(s string, k int) (ans int) {
+func lengthOfLongestSubstringKDistinct(s string, k int) int {
cnt := map[byte]int{}
- j := 0
- for i := range s {
- cnt[s[i]]++
- for len(cnt) > k {
- cnt[s[j]]--
- if cnt[s[j]] == 0 {
- delete(cnt, s[j])
+ l := 0
+ for _, c := range s {
+ cnt[byte(c)]++
+ if len(cnt) > k {
+ cnt[s[l]]--
+ if cnt[s[l]] == 0 {
+ delete(cnt, s[l])
}
- j++
+ l++
}
- ans = max(ans, i-j+1)
}
- return
+ return len(s) - l
}
\ No newline at end of file
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.java b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.java
index 556133f79cd1d..d1f50fc755fdc 100644
--- a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.java
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.java
@@ -1,21 +1,17 @@
class Solution {
public int lengthOfLongestSubstringKDistinct(String s, int k) {
Map cnt = new HashMap<>();
- int n = s.length();
- int ans = 0, j = 0;
- for (int i = 0; i < n; ++i) {
- char c = s.charAt(i);
- cnt.put(c, cnt.getOrDefault(c, 0) + 1);
- while (cnt.size() > k) {
- char t = s.charAt(j);
- cnt.put(t, cnt.getOrDefault(t, 0) - 1);
- if (cnt.get(t) == 0) {
- cnt.remove(t);
+ int l = 0;
+ char[] cs = s.toCharArray();
+ for (char c : cs) {
+ cnt.merge(c, 1, Integer::sum);
+ if (cnt.size() > k) {
+ if (cnt.merge(cs[l], -1, Integer::sum) == 0) {
+ cnt.remove(cs[l]);
}
- ++j;
+ ++l;
}
- ans = Math.max(ans, i - j + 1);
}
- return ans;
+ return cs.length - l;
}
}
\ No newline at end of file
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.py b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.py
index e5f136e2c70ed..3644fac6eda6a 100644
--- a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.py
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.py
@@ -1,14 +1,12 @@
class Solution:
def lengthOfLongestSubstringKDistinct(self, s: str, k: int) -> int:
+ l = 0
cnt = Counter()
- n = len(s)
- ans = j = 0
- for i, c in enumerate(s):
+ for c in s:
cnt[c] += 1
- while len(cnt) > k:
- cnt[s[j]] -= 1
- if cnt[s[j]] == 0:
- cnt.pop(s[j])
- j += 1
- ans = max(ans, i - j + 1)
- return ans
+ if len(cnt) > k:
+ cnt[s[l]] -= 1
+ if cnt[s[l]] == 0:
+ del cnt[s[l]]
+ l += 1
+ return len(s) - l
diff --git a/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.ts b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.ts
new file mode 100644
index 0000000000000..2865634a94d6a
--- /dev/null
+++ b/solution/0300-0399/0340.Longest Substring with At Most K Distinct Characters/Solution.ts
@@ -0,0 +1,15 @@
+function lengthOfLongestSubstringKDistinct(s: string, k: number): number {
+ const cnt: Map = new Map();
+ let l = 0;
+ for (const c of s) {
+ cnt.set(c, (cnt.get(c) ?? 0) + 1);
+ if (cnt.size > k) {
+ cnt.set(s[l], cnt.get(s[l])! - 1);
+ if (cnt.get(s[l]) === 0) {
+ cnt.delete(s[l]);
+ }
+ l++;
+ }
+ }
+ return s.length - l;
+}
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/README.md b/solution/0300-0399/0341.Flatten Nested List Iterator/README.md
index 616325863bc88..6a7fe407546a1 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/README.md
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/README.md
@@ -108,24 +108,23 @@ return res
class NestedIterator:
def __init__(self, nestedList: [NestedInteger]):
- def dfs(nestedList):
- for e in nestedList:
- if e.isInteger():
- self.vals.append(e.getInteger())
+ def dfs(ls):
+ for x in ls:
+ if x.isInteger():
+ self.nums.append(x.getInteger())
else:
- dfs(e.getList())
+ dfs(x.getList())
- self.vals = []
+ self.nums = []
+ self.i = -1
dfs(nestedList)
- self.cur = 0
def next(self) -> int:
- res = self.vals[self.cur]
- self.cur += 1
- return res
+ self.i += 1
+ return self.nums[self.i]
def hasNext(self) -> bool:
- return self.cur < len(self.vals)
+ return self.i + 1 < len(self.nums)
# Your NestedIterator object will be instantiated and called as such:
@@ -149,38 +148,34 @@ class NestedIterator:
* public Integer getInteger();
*
* // @return the nested list that this NestedInteger holds, if it holds a nested list
- * // Return null if this NestedInteger holds a single integer
+ * // Return empty list if this NestedInteger holds a single integer
* public List getList();
* }
*/
public class NestedIterator implements Iterator {
-
- private List vals;
-
- private Iterator cur;
+ private List nums = new ArrayList<>();
+ private int i = -1;
public NestedIterator(List nestedList) {
- vals = new ArrayList<>();
dfs(nestedList);
- cur = vals.iterator();
}
@Override
public Integer next() {
- return cur.next();
+ return nums.get(++i);
}
@Override
public boolean hasNext() {
- return cur.hasNext();
+ return i + 1 < nums.size();
}
- private void dfs(List nestedList) {
- for (NestedInteger e : nestedList) {
- if (e.isInteger()) {
- vals.add(e.getInteger());
+ private void dfs(List ls) {
+ for (var x : ls) {
+ if (x.isInteger()) {
+ nums.add(x.getInteger());
} else {
- dfs(e.getList());
+ dfs(x.getList());
}
}
}
@@ -217,30 +212,29 @@ public class NestedIterator implements Iterator {
class NestedIterator {
public:
NestedIterator(vector& nestedList) {
- dfs(nestedList);
+ auto dfs = [&](auto&& dfs, vector& ls) -> void {
+ for (auto& x : ls) {
+ if (x.isInteger()) {
+ nums.push_back(x.getInteger());
+ } else {
+ dfs(dfs, x.getList());
+ }
+ }
+ };
+ dfs(dfs, nestedList);
}
int next() {
- return vals[cur++];
+ return nums[++i];
}
bool hasNext() {
- return cur < vals.size();
+ return i + 1 < nums.size();
}
private:
- vector vals;
- int cur = 0;
-
- void dfs(vector& nestedList) {
- for (auto& e : nestedList) {
- if (e.isInteger()) {
- vals.push_back(e.getInteger());
- } else {
- dfs(e.getList());
- }
- }
- }
+ vector nums;
+ int i = -1;
};
/**
@@ -280,34 +274,34 @@ private:
*/
type NestedIterator struct {
- iterator []int
- index, length int
+ nums []int
+ i int
}
func Constructor(nestedList []*NestedInteger) *NestedIterator {
- result := make([]int, 0)
- var traversal func(nodes []*NestedInteger)
- traversal = func(nodes []*NestedInteger) {
- for _, child := range nodes {
- if child.IsInteger() {
- result = append(result, child.GetInteger())
+ var dfs func([]*NestedInteger)
+ nums := []int{}
+ i := -1
+ dfs = func(ls []*NestedInteger) {
+ for _, x := range ls {
+ if x.IsInteger() {
+ nums = append(nums, x.GetInteger())
} else {
- traversal(child.GetList())
+ dfs(x.GetList())
}
}
}
- traversal(nestedList)
- return &NestedIterator{iterator: result, index: 0, length: len(result)}
+ dfs(nestedList)
+ return &NestedIterator{nums, i}
}
func (this *NestedIterator) Next() int {
- res := this.iterator[this.index]
- this.index++
- return res
+ this.i++
+ return this.nums[this.i]
}
func (this *NestedIterator) HasNext() bool {
- return this.index < this.length
+ return this.i+1 < len(this.nums)
}
```
@@ -354,31 +348,27 @@ func (this *NestedIterator) HasNext() bool {
*/
class NestedIterator {
- private vals: number[];
- private index: number;
-
+ private nums: number[] = [];
+ private i = -1;
constructor(nestedList: NestedInteger[]) {
- this.index = 0;
- this.vals = [];
- this.dfs(nestedList);
- }
-
- dfs(nestedList: NestedInteger[]) {
- for (const v of nestedList) {
- if (v.isInteger()) {
- this.vals.push(v.getInteger());
- } else {
- this.dfs(v.getList());
+ const dfs = (ls: NestedInteger[]) => {
+ for (const x of ls) {
+ if (x.isInteger()) {
+ this.nums.push(x.getInteger());
+ } else {
+ dfs(x.getList());
+ }
}
- }
+ };
+ dfs(nestedList);
}
hasNext(): boolean {
- return this.index < this.vals.length;
+ return this.i + 1 < this.nums.length;
}
next(): number {
- return this.vals[this.index++];
+ return this.nums[++this.i];
}
}
@@ -399,8 +389,8 @@ class NestedIterator {
// List(Vec)
// }
struct NestedIterator {
- index: usize,
- vals: Vec,
+ nums: Vec,
+ i: usize,
}
/**
@@ -408,102 +398,30 @@ struct NestedIterator {
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl NestedIterator {
- fn dfs(nestedList: &Vec, vals: &mut Vec) {
- for ele in nestedList.iter() {
- match ele {
- NestedInteger::Int(val) => vals.push(*val),
- NestedInteger::List(list) => Self::dfs(list, vals),
- }
- }
- }
-
- fn new(nestedList: Vec) -> Self {
- let mut vals = vec![];
- Self::dfs(&nestedList, &mut vals);
- Self { vals, index: 0 }
+ fn new(nested_list: Vec) -> Self {
+ let mut nums = Vec::new();
+ Self::dfs(&nested_list, &mut nums);
+ NestedIterator { nums, i: 0 }
}
fn next(&mut self) -> i32 {
- let res = self.vals[self.index];
- self.index += 1;
- res
+ let result = self.nums[self.i];
+ self.i += 1;
+ result
}
fn has_next(&self) -> bool {
- self.index < self.vals.len()
+ self.i < self.nums.len()
}
-}
-```
-
-
-
-
-
-
-
-### 方法二:直接展开
-
-调用 hasNext 时,如果 nestedList 的第一个元素是列表类型,则不断展开这个元素,直到第一个元素是整数类型。 调用 Next 方法时,由于 `hasNext()` 方法已确保 nestedList 第一个元素为整数类型,直接返回即可。
-
-
-
-#### Go
-
-```go
-/**
- * // This is the interface that allows for creating nested lists.
- * // You should not implement it, or speculate about its implementation
- * type NestedInteger struct {
- * }
- *
- * // Return true if this NestedInteger holds a single integer, rather than a nested list.
- * func (this NestedInteger) IsInteger() bool {}
- *
- * // Return the single integer that this NestedInteger holds, if it holds a single integer
- * // The result is undefined if this NestedInteger holds a nested list
- * // So before calling this method, you should have a check
- * func (this NestedInteger) GetInteger() int {}
- *
- * // Set this NestedInteger to hold a single integer.
- * func (n *NestedInteger) SetInteger(value int) {}
- *
- * // Set this NestedInteger to hold a nested list and adds a nested integer to it.
- * func (this *NestedInteger) Add(elem NestedInteger) {}
- *
- * // Return the nested list that this NestedInteger holds, if it holds a nested list
- * // The list length is zero if this NestedInteger holds a single integer
- * // You can access NestedInteger's List element directly if you want to modify it
- * func (this NestedInteger) GetList() []*NestedInteger {}
- */
-
-type NestedIterator struct {
- nested *list.List
-}
-
-func Constructor(nestedList []*NestedInteger) *NestedIterator {
- nested := list.New()
- for _, v := range nestedList {
- nested.PushBack(v)
- }
- return &NestedIterator{nested: nested}
-}
-func (this *NestedIterator) Next() int {
- res := this.nested.Front().Value.(*NestedInteger)
- this.nested.Remove(this.nested.Front())
- return res.GetInteger()
-}
-
-func (this *NestedIterator) HasNext() bool {
- for this.nested.Len() > 0 && !this.nested.Front().Value.(*NestedInteger).IsInteger() {
- front := this.nested.Front().Value.(*NestedInteger)
- this.nested.Remove(this.nested.Front())
- nodes := front.GetList()
- for i := len(nodes) - 1; i >= 0; i-- {
- this.nested.PushFront(nodes[i])
- }
- }
- return this.nested.Len() > 0
+ fn dfs(nested_list: &Vec, nums: &mut Vec) {
+ for ni in nested_list {
+ match ni {
+ NestedInteger::Int(x) => nums.push(*x),
+ NestedInteger::List(list) => Self::dfs(list, nums),
+ }
+ }
+ }
}
```
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/README_EN.md b/solution/0300-0399/0341.Flatten Nested List Iterator/README_EN.md
index 7346931361926..52cf400e9057b 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/README_EN.md
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/README_EN.md
@@ -106,24 +106,23 @@ return res
class NestedIterator:
def __init__(self, nestedList: [NestedInteger]):
- def dfs(nestedList):
- for e in nestedList:
- if e.isInteger():
- self.vals.append(e.getInteger())
+ def dfs(ls):
+ for x in ls:
+ if x.isInteger():
+ self.nums.append(x.getInteger())
else:
- dfs(e.getList())
+ dfs(x.getList())
- self.vals = []
+ self.nums = []
+ self.i = -1
dfs(nestedList)
- self.cur = 0
def next(self) -> int:
- res = self.vals[self.cur]
- self.cur += 1
- return res
+ self.i += 1
+ return self.nums[self.i]
def hasNext(self) -> bool:
- return self.cur < len(self.vals)
+ return self.i + 1 < len(self.nums)
# Your NestedIterator object will be instantiated and called as such:
@@ -147,38 +146,34 @@ class NestedIterator:
* public Integer getInteger();
*
* // @return the nested list that this NestedInteger holds, if it holds a nested list
- * // Return null if this NestedInteger holds a single integer
+ * // Return empty list if this NestedInteger holds a single integer
* public List getList();
* }
*/
public class NestedIterator implements Iterator {
-
- private List vals;
-
- private Iterator cur;
+ private List nums = new ArrayList<>();
+ private int i = -1;
public NestedIterator(List nestedList) {
- vals = new ArrayList<>();
dfs(nestedList);
- cur = vals.iterator();
}
@Override
public Integer next() {
- return cur.next();
+ return nums.get(++i);
}
@Override
public boolean hasNext() {
- return cur.hasNext();
+ return i + 1 < nums.size();
}
- private void dfs(List nestedList) {
- for (NestedInteger e : nestedList) {
- if (e.isInteger()) {
- vals.add(e.getInteger());
+ private void dfs(List ls) {
+ for (var x : ls) {
+ if (x.isInteger()) {
+ nums.add(x.getInteger());
} else {
- dfs(e.getList());
+ dfs(x.getList());
}
}
}
@@ -215,30 +210,29 @@ public class NestedIterator implements Iterator {
class NestedIterator {
public:
NestedIterator(vector& nestedList) {
- dfs(nestedList);
+ auto dfs = [&](auto&& dfs, vector& ls) -> void {
+ for (auto& x : ls) {
+ if (x.isInteger()) {
+ nums.push_back(x.getInteger());
+ } else {
+ dfs(dfs, x.getList());
+ }
+ }
+ };
+ dfs(dfs, nestedList);
}
int next() {
- return vals[cur++];
+ return nums[++i];
}
bool hasNext() {
- return cur < vals.size();
+ return i + 1 < nums.size();
}
private:
- vector vals;
- int cur = 0;
-
- void dfs(vector& nestedList) {
- for (auto& e : nestedList) {
- if (e.isInteger()) {
- vals.push_back(e.getInteger());
- } else {
- dfs(e.getList());
- }
- }
- }
+ vector nums;
+ int i = -1;
};
/**
@@ -278,34 +272,34 @@ private:
*/
type NestedIterator struct {
- iterator []int
- index, length int
+ nums []int
+ i int
}
func Constructor(nestedList []*NestedInteger) *NestedIterator {
- result := make([]int, 0)
- var traversal func(nodes []*NestedInteger)
- traversal = func(nodes []*NestedInteger) {
- for _, child := range nodes {
- if child.IsInteger() {
- result = append(result, child.GetInteger())
+ var dfs func([]*NestedInteger)
+ nums := []int{}
+ i := -1
+ dfs = func(ls []*NestedInteger) {
+ for _, x := range ls {
+ if x.IsInteger() {
+ nums = append(nums, x.GetInteger())
} else {
- traversal(child.GetList())
+ dfs(x.GetList())
}
}
}
- traversal(nestedList)
- return &NestedIterator{iterator: result, index: 0, length: len(result)}
+ dfs(nestedList)
+ return &NestedIterator{nums, i}
}
func (this *NestedIterator) Next() int {
- res := this.iterator[this.index]
- this.index++
- return res
+ this.i++
+ return this.nums[this.i]
}
func (this *NestedIterator) HasNext() bool {
- return this.index < this.length
+ return this.i+1 < len(this.nums)
}
```
@@ -352,31 +346,27 @@ func (this *NestedIterator) HasNext() bool {
*/
class NestedIterator {
- private vals: number[];
- private index: number;
-
+ private nums: number[] = [];
+ private i = -1;
constructor(nestedList: NestedInteger[]) {
- this.index = 0;
- this.vals = [];
- this.dfs(nestedList);
- }
-
- dfs(nestedList: NestedInteger[]) {
- for (const v of nestedList) {
- if (v.isInteger()) {
- this.vals.push(v.getInteger());
- } else {
- this.dfs(v.getList());
+ const dfs = (ls: NestedInteger[]) => {
+ for (const x of ls) {
+ if (x.isInteger()) {
+ this.nums.push(x.getInteger());
+ } else {
+ dfs(x.getList());
+ }
}
- }
+ };
+ dfs(nestedList);
}
hasNext(): boolean {
- return this.index < this.vals.length;
+ return this.i + 1 < this.nums.length;
}
next(): number {
- return this.vals[this.index++];
+ return this.nums[++this.i];
}
}
@@ -397,8 +387,8 @@ class NestedIterator {
// List(Vec)
// }
struct NestedIterator {
- index: usize,
- vals: Vec,
+ nums: Vec,
+ i: usize,
}
/**
@@ -406,100 +396,30 @@ struct NestedIterator {
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl NestedIterator {
- fn dfs(nestedList: &Vec, vals: &mut Vec) {
- for ele in nestedList.iter() {
- match ele {
- NestedInteger::Int(val) => vals.push(*val),
- NestedInteger::List(list) => Self::dfs(list, vals),
- }
- }
- }
-
- fn new(nestedList: Vec) -> Self {
- let mut vals = vec![];
- Self::dfs(&nestedList, &mut vals);
- Self { vals, index: 0 }
+ fn new(nested_list: Vec) -> Self {
+ let mut nums = Vec::new();
+ Self::dfs(&nested_list, &mut nums);
+ NestedIterator { nums, i: 0 }
}
fn next(&mut self) -> i32 {
- let res = self.vals[self.index];
- self.index += 1;
- res
+ let result = self.nums[self.i];
+ self.i += 1;
+ result
}
fn has_next(&self) -> bool {
- self.index < self.vals.len()
+ self.i < self.nums.len()
}
-}
-```
-
-
-
-
-
-
-### Solution 2
-
-
-
-#### Go
-
-```go
-/**
- * // This is the interface that allows for creating nested lists.
- * // You should not implement it, or speculate about its implementation
- * type NestedInteger struct {
- * }
- *
- * // Return true if this NestedInteger holds a single integer, rather than a nested list.
- * func (this NestedInteger) IsInteger() bool {}
- *
- * // Return the single integer that this NestedInteger holds, if it holds a single integer
- * // The result is undefined if this NestedInteger holds a nested list
- * // So before calling this method, you should have a check
- * func (this NestedInteger) GetInteger() int {}
- *
- * // Set this NestedInteger to hold a single integer.
- * func (n *NestedInteger) SetInteger(value int) {}
- *
- * // Set this NestedInteger to hold a nested list and adds a nested integer to it.
- * func (this *NestedInteger) Add(elem NestedInteger) {}
- *
- * // Return the nested list that this NestedInteger holds, if it holds a nested list
- * // The list length is zero if this NestedInteger holds a single integer
- * // You can access NestedInteger's List element directly if you want to modify it
- * func (this NestedInteger) GetList() []*NestedInteger {}
- */
-
-type NestedIterator struct {
- nested *list.List
-}
-
-func Constructor(nestedList []*NestedInteger) *NestedIterator {
- nested := list.New()
- for _, v := range nestedList {
- nested.PushBack(v)
- }
- return &NestedIterator{nested: nested}
-}
-
-func (this *NestedIterator) Next() int {
- res := this.nested.Front().Value.(*NestedInteger)
- this.nested.Remove(this.nested.Front())
- return res.GetInteger()
-}
-
-func (this *NestedIterator) HasNext() bool {
- for this.nested.Len() > 0 && !this.nested.Front().Value.(*NestedInteger).IsInteger() {
- front := this.nested.Front().Value.(*NestedInteger)
- this.nested.Remove(this.nested.Front())
- nodes := front.GetList()
- for i := len(nodes) - 1; i >= 0; i-- {
- this.nested.PushFront(nodes[i])
- }
- }
- return this.nested.Len() > 0
+ fn dfs(nested_list: &Vec, nums: &mut Vec) {
+ for ni in nested_list {
+ match ni {
+ NestedInteger::Int(x) => nums.push(*x),
+ NestedInteger::List(list) => Self::dfs(list, nums),
+ }
+ }
+ }
}
```
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.cpp b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.cpp
index 69d86e084e52e..dde245ec010a3 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.cpp
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.cpp
@@ -19,30 +19,29 @@
class NestedIterator {
public:
NestedIterator(vector& nestedList) {
- dfs(nestedList);
+ auto dfs = [&](auto&& dfs, vector& ls) -> void {
+ for (auto& x : ls) {
+ if (x.isInteger()) {
+ nums.push_back(x.getInteger());
+ } else {
+ dfs(dfs, x.getList());
+ }
+ }
+ };
+ dfs(dfs, nestedList);
}
int next() {
- return vals[cur++];
+ return nums[++i];
}
bool hasNext() {
- return cur < vals.size();
+ return i + 1 < nums.size();
}
private:
- vector vals;
- int cur = 0;
-
- void dfs(vector& nestedList) {
- for (auto& e : nestedList) {
- if (e.isInteger()) {
- vals.push_back(e.getInteger());
- } else {
- dfs(e.getList());
- }
- }
- }
+ vector nums;
+ int i = -1;
};
/**
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.go b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.go
index 231ed7a9e0f43..197f4c40cf885 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.go
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.go
@@ -25,32 +25,32 @@
*/
type NestedIterator struct {
- iterator []int
- index, length int
+ nums []int
+ i int
}
func Constructor(nestedList []*NestedInteger) *NestedIterator {
- result := make([]int, 0)
- var traversal func(nodes []*NestedInteger)
- traversal = func(nodes []*NestedInteger) {
- for _, child := range nodes {
- if child.IsInteger() {
- result = append(result, child.GetInteger())
+ var dfs func([]*NestedInteger)
+ nums := []int{}
+ i := -1
+ dfs = func(ls []*NestedInteger) {
+ for _, x := range ls {
+ if x.IsInteger() {
+ nums = append(nums, x.GetInteger())
} else {
- traversal(child.GetList())
+ dfs(x.GetList())
}
}
}
- traversal(nestedList)
- return &NestedIterator{iterator: result, index: 0, length: len(result)}
+ dfs(nestedList)
+ return &NestedIterator{nums, i}
}
func (this *NestedIterator) Next() int {
- res := this.iterator[this.index]
- this.index++
- return res
+ this.i++
+ return this.nums[this.i]
}
func (this *NestedIterator) HasNext() bool {
- return this.index < this.length
+ return this.i+1 < len(this.nums)
}
\ No newline at end of file
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.java b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.java
index 04b6ca8ae5181..128e938680a14 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.java
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.java
@@ -11,38 +11,34 @@
* public Integer getInteger();
*
* // @return the nested list that this NestedInteger holds, if it holds a nested list
- * // Return null if this NestedInteger holds a single integer
+ * // Return empty list if this NestedInteger holds a single integer
* public List getList();
* }
*/
public class NestedIterator implements Iterator {
-
- private List vals;
-
- private Iterator cur;
+ private List nums = new ArrayList<>();
+ private int i = -1;
public NestedIterator(List nestedList) {
- vals = new ArrayList<>();
dfs(nestedList);
- cur = vals.iterator();
}
@Override
public Integer next() {
- return cur.next();
+ return nums.get(++i);
}
@Override
public boolean hasNext() {
- return cur.hasNext();
+ return i + 1 < nums.size();
}
- private void dfs(List nestedList) {
- for (NestedInteger e : nestedList) {
- if (e.isInteger()) {
- vals.add(e.getInteger());
+ private void dfs(List ls) {
+ for (var x : ls) {
+ if (x.isInteger()) {
+ nums.add(x.getInteger());
} else {
- dfs(e.getList());
+ dfs(x.getList());
}
}
}
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.py b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.py
index 54cc88ffca22a..5f2cae5423011 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.py
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.py
@@ -23,24 +23,23 @@
class NestedIterator:
def __init__(self, nestedList: [NestedInteger]):
- def dfs(nestedList):
- for e in nestedList:
- if e.isInteger():
- self.vals.append(e.getInteger())
+ def dfs(ls):
+ for x in ls:
+ if x.isInteger():
+ self.nums.append(x.getInteger())
else:
- dfs(e.getList())
+ dfs(x.getList())
- self.vals = []
+ self.nums = []
+ self.i = -1
dfs(nestedList)
- self.cur = 0
def next(self) -> int:
- res = self.vals[self.cur]
- self.cur += 1
- return res
+ self.i += 1
+ return self.nums[self.i]
def hasNext(self) -> bool:
- return self.cur < len(self.vals)
+ return self.i + 1 < len(self.nums)
# Your NestedIterator object will be instantiated and called as such:
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.rs b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.rs
index abf739460a20e..e0dc3fa5f7608 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.rs
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.rs
@@ -4,8 +4,8 @@
// List(Vec)
// }
struct NestedIterator {
- index: usize,
- vals: Vec,
+ nums: Vec,
+ i: usize,
}
/**
@@ -13,28 +13,28 @@ struct NestedIterator {
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl NestedIterator {
- fn dfs(nestedList: &Vec, vals: &mut Vec) {
- for ele in nestedList.iter() {
- match ele {
- NestedInteger::Int(val) => vals.push(*val),
- NestedInteger::List(list) => Self::dfs(list, vals),
- }
- }
- }
-
- fn new(nestedList: Vec) -> Self {
- let mut vals = vec![];
- Self::dfs(&nestedList, &mut vals);
- Self { vals, index: 0 }
+ fn new(nested_list: Vec) -> Self {
+ let mut nums = Vec::new();
+ Self::dfs(&nested_list, &mut nums);
+ NestedIterator { nums, i: 0 }
}
fn next(&mut self) -> i32 {
- let res = self.vals[self.index];
- self.index += 1;
- res
+ let result = self.nums[self.i];
+ self.i += 1;
+ result
}
fn has_next(&self) -> bool {
- self.index < self.vals.len()
+ self.i < self.nums.len()
+ }
+
+ fn dfs(nested_list: &Vec, nums: &mut Vec) {
+ for ni in nested_list {
+ match ni {
+ NestedInteger::Int(x) => nums.push(*x),
+ NestedInteger::List(list) => Self::dfs(list, nums),
+ }
+ }
}
}
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.ts b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.ts
index f838f81053122..99d5f2fd029d4 100644
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.ts
+++ b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution.ts
@@ -38,31 +38,27 @@
*/
class NestedIterator {
- private vals: number[];
- private index: number;
-
+ private nums: number[] = [];
+ private i = -1;
constructor(nestedList: NestedInteger[]) {
- this.index = 0;
- this.vals = [];
- this.dfs(nestedList);
- }
-
- dfs(nestedList: NestedInteger[]) {
- for (const v of nestedList) {
- if (v.isInteger()) {
- this.vals.push(v.getInteger());
- } else {
- this.dfs(v.getList());
+ const dfs = (ls: NestedInteger[]) => {
+ for (const x of ls) {
+ if (x.isInteger()) {
+ this.nums.push(x.getInteger());
+ } else {
+ dfs(x.getList());
+ }
}
- }
+ };
+ dfs(nestedList);
}
hasNext(): boolean {
- return this.index < this.vals.length;
+ return this.i + 1 < this.nums.length;
}
next(): number {
- return this.vals[this.index++];
+ return this.nums[++this.i];
}
}
diff --git a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution2.go b/solution/0300-0399/0341.Flatten Nested List Iterator/Solution2.go
deleted file mode 100644
index 0a7520dd9a266..0000000000000
--- a/solution/0300-0399/0341.Flatten Nested List Iterator/Solution2.go
+++ /dev/null
@@ -1,55 +0,0 @@
-/**
- * // This is the interface that allows for creating nested lists.
- * // You should not implement it, or speculate about its implementation
- * type NestedInteger struct {
- * }
- *
- * // Return true if this NestedInteger holds a single integer, rather than a nested list.
- * func (this NestedInteger) IsInteger() bool {}
- *
- * // Return the single integer that this NestedInteger holds, if it holds a single integer
- * // The result is undefined if this NestedInteger holds a nested list
- * // So before calling this method, you should have a check
- * func (this NestedInteger) GetInteger() int {}
- *
- * // Set this NestedInteger to hold a single integer.
- * func (n *NestedInteger) SetInteger(value int) {}
- *
- * // Set this NestedInteger to hold a nested list and adds a nested integer to it.
- * func (this *NestedInteger) Add(elem NestedInteger) {}
- *
- * // Return the nested list that this NestedInteger holds, if it holds a nested list
- * // The list length is zero if this NestedInteger holds a single integer
- * // You can access NestedInteger's List element directly if you want to modify it
- * func (this NestedInteger) GetList() []*NestedInteger {}
- */
-
-type NestedIterator struct {
- nested *list.List
-}
-
-func Constructor(nestedList []*NestedInteger) *NestedIterator {
- nested := list.New()
- for _, v := range nestedList {
- nested.PushBack(v)
- }
- return &NestedIterator{nested: nested}
-}
-
-func (this *NestedIterator) Next() int {
- res := this.nested.Front().Value.(*NestedInteger)
- this.nested.Remove(this.nested.Front())
- return res.GetInteger()
-}
-
-func (this *NestedIterator) HasNext() bool {
- for this.nested.Len() > 0 && !this.nested.Front().Value.(*NestedInteger).IsInteger() {
- front := this.nested.Front().Value.(*NestedInteger)
- this.nested.Remove(this.nested.Front())
- nodes := front.GetList()
- for i := len(nodes) - 1; i >= 0; i-- {
- this.nested.PushFront(nodes[i])
- }
- }
- return this.nested.Len() > 0
-}
\ No newline at end of file
diff --git a/solution/0300-0399/0342.Power of Four/README.md b/solution/0300-0399/0342.Power of Four/README.md
index 1fb23b3b6308c..1e71bac29bc3f 100644
--- a/solution/0300-0399/0342.Power of Four/README.md
+++ b/solution/0300-0399/0342.Power of Four/README.md
@@ -63,7 +63,13 @@ tags:
-### 方法一
+### 方法一:位运算
+
+如果一个数是 4 的幂次方,那么这个数必须是大于 $0$ 的。不妨假设这个数是 $4^x$,即 $2^{2x}$,那么这个数的二进制表示中有且仅有一个 $1$,且这个 $1$ 出现在偶数位上。
+
+因此,我们首先判断这个数是否大于 $0$,然后判断这个数是否是 $2^{2x}$,即 $n$ 与 $n-1$ 的按位与结果是否为 $0$,最后判断这个数的 $1$ 是否出现在偶数位上,即 $n$ 与 $\textit{0xAAAAAAAA}$ 的按位与结果是否为 $0$。如果这三个条件都满足,那么这个数就是 4 的幂次方。
+
+时间复杂度 $O(1)$,空间复杂度 $O(1)$。
diff --git a/solution/0300-0399/0342.Power of Four/README_EN.md b/solution/0300-0399/0342.Power of Four/README_EN.md
index 785bb147db19d..d74f994dc6c3d 100644
--- a/solution/0300-0399/0342.Power of Four/README_EN.md
+++ b/solution/0300-0399/0342.Power of Four/README_EN.md
@@ -49,7 +49,13 @@ tags:
-### Solution 1
+### Solution 1: Bit Manipulation
+
+If a number is a power of 4, then it must be greater than $0$. Suppose this number is $4^x$, which is $2^{2x}$. Therefore, its binary representation has only one $1$, and this $1$ appears at an even position.
+
+First, we check if the number is greater than $0$. Then, we verify if the number is $2^{2x}$ by checking if the bitwise AND of $n$ and $n-1$ is $0$. Finally, we check if the $1$ appears at an even position by verifying if the bitwise AND of $n$ and $\textit{0xAAAAAAAA}$ is $0$. If all three conditions are met, then the number is a power of 4.
+
+The time complexity is $O(1)$, and the space complexity is $O(1)$.
diff --git a/solution/0300-0399/0343.Integer Break/README.md b/solution/0300-0399/0343.Integer Break/README.md
index e85a34a05c96c..c2585a7c6eb49 100644
--- a/solution/0300-0399/0343.Integer Break/README.md
+++ b/solution/0300-0399/0343.Integer Break/README.md
@@ -53,15 +53,22 @@ tags:
### 方法一:动态规划
-我们定义 $dp[i]$ 表示正整数 $n$ 能获得的最大乘积,初始化 $dp[1] = 1$。答案即为 $dp[n]$。
+我们定义 $f[i]$ 表示正整数 $i$ 拆分后能获得的最大乘积,初始时 $f[1] = 1$。答案即为 $f[n]$。
-状态转移方程为:
+考虑 $i$ 最后拆分出的数字 $j$,其中 $j \in [1, i)$。对于 $i$ 拆分出的数字 $j$,有两种情况:
+
+1. 将 $i$ 拆分成 $i - j$ 和 $j$ 的和,不继续拆分,此时乘积为 $(i - j) \times j$;
+2. 将 $i$ 拆分成 $i - j$ 和 $j$ 的和,继续拆分,此时乘积为 $f[i - j] \times j$。
+
+因此,我们可以得到状态转移方程:
$$
-dp[i] = max(dp[i], dp[i - j] \times j, (i - j) \times j) \quad (j \in [0, i))
+f[i] = \max(f[i], f[i - j] \times j, (i - j) \times j) \quad (j \in [0, i))
$$
-时间复杂度 $O(n^2)$,空间复杂度 $O(n)$。其中 $n$ 为正整数 $n$。
+最后返回 $f[n]$ 即可。
+
+时间复杂度 $O(n^2)$,空间复杂度 $O(n)$。其中 $n$ 为给定的正整数。
@@ -70,11 +77,11 @@ $$
```python
class Solution:
def integerBreak(self, n: int) -> int:
- dp = [1] * (n + 1)
+ f = [1] * (n + 1)
for i in range(2, n + 1):
for j in range(1, i):
- dp[i] = max(dp[i], dp[i - j] * j, (i - j) * j)
- return dp[n]
+ f[i] = max(f[i], f[i - j] * j, (i - j) * j)
+ return f[n]
```
#### Java
@@ -82,14 +89,14 @@ class Solution:
```java
class Solution {
public int integerBreak(int n) {
- int[] dp = new int[n + 1];
- dp[1] = 1;
+ int[] f = new int[n + 1];
+ f[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
- dp[i] = Math.max(Math.max(dp[i], dp[i - j] * j), (i - j) * j);
+ f[i] = Math.max(Math.max(f[i], f[i - j] * j), (i - j) * j);
}
}
- return dp[n];
+ return f[n];
}
}
```
@@ -100,14 +107,14 @@ class Solution {
class Solution {
public:
int integerBreak(int n) {
- vector dp(n + 1);
- dp[1] = 1;
+ vector f(n + 1);
+ f[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
- dp[i] = max(max(dp[i], dp[i - j] * j), (i - j) * j);
+ f[i] = max({f[i], f[i - j] * j, (i - j) * j});
}
}
- return dp[n];
+ return f[n];
}
};
```
@@ -116,14 +123,14 @@ public:
```go
func integerBreak(n int) int {
- dp := make([]int, n+1)
- dp[1] = 1
+ f := make([]int, n+1)
+ f[1] = 1
for i := 2; i <= n; i++ {
for j := 1; j < i; j++ {
- dp[i] = max(max(dp[i], dp[i-j]*j), (i-j)*j)
+ f[i] = max(max(f[i], f[i-j]*j), (i-j)*j)
}
}
- return dp[n]
+ return f[n]
}
```
@@ -131,13 +138,13 @@ func integerBreak(n int) int {
```ts
function integerBreak(n: number): number {
- let dp = new Array(n + 1).fill(1);
+ const f = Array(n + 1).fill(1);
for (let i = 3; i <= n; i++) {
for (let j = 1; j < i; j++) {
- dp[i] = Math.max(dp[i], j * (i - j), j * dp[i - j]);
+ f[i] = Math.max(f[i], j * (i - j), j * f[i - j]);
}
}
- return dp.pop();
+ return f[n];
}
```
@@ -146,11 +153,50 @@ function integerBreak(n: number): number {
```rust
impl Solution {
pub fn integer_break(n: i32) -> i32 {
- if n < 4 {
- return n - 1;
+ let n = n as usize;
+ let mut f = vec![0; n + 1];
+ f[1] = 1;
+ for i in 2..=n {
+ for j in 1..i {
+ f[i] = f[i].max(f[i - j] * j).max((i - j) * j);
+ }
+ }
+ f[n] as i32
+ }
+}
+```
+
+#### JavaScript
+
+```js
+/**
+ * @param {number} n
+ * @return {number}
+ */
+var integerBreak = function (n) {
+ const f = Array(n + 1).fill(1);
+ for (let i = 2; i <= n; ++i) {
+ for (let j = 1; j < i; ++j) {
+ f[i] = Math.max(f[i], f[i - j] * j, (i - j) * j);
+ }
+ }
+ return f[n];
+};
+```
+
+#### C#
+
+```cs
+public class Solution {
+ public int IntegerBreak(int n) {
+ int[] f = new int[n + 1];
+ f[1] = 1;
+ for (int i = 2; i <= n; ++i) {
+ for (int j = 1; j < i; ++j) {
+ f[i] = Math.Max(Math.Max(f[i], f[i - j] * j), (i - j) * j);
+ }
}
- let count = (n - 2) / 3;
- (3i32).pow(count as u32) * (n - count * 3)
+ return f[n];
}
}
```
@@ -158,12 +204,18 @@ impl Solution {
#### C
```c
+#define max(a, b) (((a) > (b)) ? (a) : (b))
+
int integerBreak(int n) {
- if (n < 4) {
- return n - 1;
+ int* f = (int*) malloc((n + 1) * sizeof(int));
+ f[1] = 1;
+ for (int i = 2; i <= n; ++i) {
+ f[i] = 0;
+ for (int j = 1; j < i; ++j) {
+ f[i] = max(f[i], max(f[i - j] * j, (i - j) * j));
+ }
}
- int count = (n - 2) / 3;
- return pow(3, count) * (n - count * 3);
+ return f[n];
}
```
@@ -175,7 +227,7 @@ int integerBreak(int n) {
### 方法二:数学
-当 $n \lt 4$ 时,$n$ 不能拆分成至少两个正整数的和,因此 $n - 1$ 是最大乘积。当 $n \ge 4$ 时,我们尽可能多地拆分 $3$,当剩下的最后一段为 $4$ 时,我们将其拆分为 $2 + 2$,这样乘积最大。
+当 $n \lt 4$ 时,由于题目要求至少拆分成两个整数,因此 $n - 1$ 是最大乘积。当 $n \ge 4$ 时,我们尽可能多地拆分 $3$,当剩下的最后一段为 $4$ 时,我们将其拆分为 $2 + 2$,这样乘积最大。
时间复杂度 $O(1)$,空间复杂度 $O(1)$。
@@ -269,6 +321,81 @@ function integerBreak(n: number): number {
}
```
+#### Rust
+
+```rust
+impl Solution {
+ pub fn integer_break(n: i32) -> i32 {
+ if n < 4 {
+ return n - 1;
+ }
+ match n % 3 {
+ 0 => return (3 as i32).pow((n / 3) as u32),
+ 1 => return (3 as i32).pow((n / 3 - 1) as u32) * 4,
+ _ => return (3 as i32).pow((n / 3) as u32) * 2,
+ }
+ }
+}
+```
+
+#### JavaScript
+
+```js
+/**
+ * @param {number} n
+ * @return {number}
+ */
+var integerBreak = function (n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ const m = Math.floor(n / 3);
+ if (n % 3 == 0) {
+ return 3 ** m;
+ }
+ if (n % 3 == 1) {
+ return 3 ** (m - 1) * 4;
+ }
+ return 3 ** m * 2;
+};
+```
+
+#### C#
+
+```cs
+public class Solution {
+ public int IntegerBreak(int n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ if (n % 3 == 0) {
+ return (int)Math.Pow(3, n / 3);
+ }
+ if (n % 3 == 1) {
+ return (int)Math.Pow(3, n / 3 - 1) * 4;
+ }
+ return (int)Math.Pow(3, n / 3) * 2;
+ }
+}
+```
+
+#### C
+
+```c
+int integerBreak(int n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ if (n % 3 == 0) {
+ return (int) pow(3, n / 3);
+ }
+ if (n % 3 == 1) {
+ return (int) pow(3, n / 3 - 1) * 4;
+ }
+ return (int) pow(3, n / 3) * 2;
+}
+```
+
diff --git a/solution/0300-0399/0343.Integer Break/README_EN.md b/solution/0300-0399/0343.Integer Break/README_EN.md
index c5da4dcec24a9..8b3ffb7eff47e 100644
--- a/solution/0300-0399/0343.Integer Break/README_EN.md
+++ b/solution/0300-0399/0343.Integer Break/README_EN.md
@@ -51,7 +51,24 @@ tags:
-### Solution 1
+### Solution 1: Dynamic Programming
+
+We define $f[i]$ as the maximum product that can be obtained by splitting the positive integer $i$, with an initial condition of $f[1] = 1$. The answer is $f[n]$.
+
+Consider the last number $j$ split from $i$, where $j \in [1, i)$. For the number $j$ split from $i$, there are two cases:
+
+1. Split $i$ into the sum of $i - j$ and $j$, without further splitting, where the product is $(i - j) \times j$;
+2. Split $i$ into the sum of $i - j$ and $j$, and continue splitting, where the product is $f[i - j] \times j$.
+
+Therefore, we can derive the state transition equation:
+
+$$
+f[i] = \max(f[i], f[i - j] \times j, (i - j) \times j) \quad (j \in [0, i))
+$$
+
+Finally, returning $f[n]$ will suffice.
+
+The time complexity is $O(n^2)$, and the space complexity is $O(n)$. Here, $n$ is the given positive integer.
@@ -60,11 +77,11 @@ tags:
```python
class Solution:
def integerBreak(self, n: int) -> int:
- dp = [1] * (n + 1)
+ f = [1] * (n + 1)
for i in range(2, n + 1):
for j in range(1, i):
- dp[i] = max(dp[i], dp[i - j] * j, (i - j) * j)
- return dp[n]
+ f[i] = max(f[i], f[i - j] * j, (i - j) * j)
+ return f[n]
```
#### Java
@@ -72,14 +89,14 @@ class Solution:
```java
class Solution {
public int integerBreak(int n) {
- int[] dp = new int[n + 1];
- dp[1] = 1;
+ int[] f = new int[n + 1];
+ f[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
- dp[i] = Math.max(Math.max(dp[i], dp[i - j] * j), (i - j) * j);
+ f[i] = Math.max(Math.max(f[i], f[i - j] * j), (i - j) * j);
}
}
- return dp[n];
+ return f[n];
}
}
```
@@ -90,14 +107,14 @@ class Solution {
class Solution {
public:
int integerBreak(int n) {
- vector dp(n + 1);
- dp[1] = 1;
+ vector f(n + 1);
+ f[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
- dp[i] = max(max(dp[i], dp[i - j] * j), (i - j) * j);
+ f[i] = max({f[i], f[i - j] * j, (i - j) * j});
}
}
- return dp[n];
+ return f[n];
}
};
```
@@ -106,14 +123,14 @@ public:
```go
func integerBreak(n int) int {
- dp := make([]int, n+1)
- dp[1] = 1
+ f := make([]int, n+1)
+ f[1] = 1
for i := 2; i <= n; i++ {
for j := 1; j < i; j++ {
- dp[i] = max(max(dp[i], dp[i-j]*j), (i-j)*j)
+ f[i] = max(max(f[i], f[i-j]*j), (i-j)*j)
}
}
- return dp[n]
+ return f[n]
}
```
@@ -121,13 +138,13 @@ func integerBreak(n int) int {
```ts
function integerBreak(n: number): number {
- let dp = new Array(n + 1).fill(1);
+ const f = Array(n + 1).fill(1);
for (let i = 3; i <= n; i++) {
for (let j = 1; j < i; j++) {
- dp[i] = Math.max(dp[i], j * (i - j), j * dp[i - j]);
+ f[i] = Math.max(f[i], j * (i - j), j * f[i - j]);
}
}
- return dp.pop();
+ return f[n];
}
```
@@ -136,11 +153,50 @@ function integerBreak(n: number): number {
```rust
impl Solution {
pub fn integer_break(n: i32) -> i32 {
- if n < 4 {
- return n - 1;
+ let n = n as usize;
+ let mut f = vec![0; n + 1];
+ f[1] = 1;
+ for i in 2..=n {
+ for j in 1..i {
+ f[i] = f[i].max(f[i - j] * j).max((i - j) * j);
+ }
+ }
+ f[n] as i32
+ }
+}
+```
+
+#### JavaScript
+
+```js
+/**
+ * @param {number} n
+ * @return {number}
+ */
+var integerBreak = function (n) {
+ const f = Array(n + 1).fill(1);
+ for (let i = 2; i <= n; ++i) {
+ for (let j = 1; j < i; ++j) {
+ f[i] = Math.max(f[i], f[i - j] * j, (i - j) * j);
+ }
+ }
+ return f[n];
+};
+```
+
+#### C#
+
+```cs
+public class Solution {
+ public int IntegerBreak(int n) {
+ int[] f = new int[n + 1];
+ f[1] = 1;
+ for (int i = 2; i <= n; ++i) {
+ for (int j = 1; j < i; ++j) {
+ f[i] = Math.Max(Math.Max(f[i], f[i - j] * j), (i - j) * j);
+ }
}
- let count = (n - 2) / 3;
- (3i32).pow(count as u32) * (n - count * 3)
+ return f[n];
}
}
```
@@ -148,12 +204,18 @@ impl Solution {
#### C
```c
+#define max(a, b) (((a) > (b)) ? (a) : (b))
+
int integerBreak(int n) {
- if (n < 4) {
- return n - 1;
+ int* f = (int*) malloc((n + 1) * sizeof(int));
+ f[1] = 1;
+ for (int i = 2; i <= n; ++i) {
+ f[i] = 0;
+ for (int j = 1; j < i; ++j) {
+ f[i] = max(f[i], max(f[i - j] * j, (i - j) * j));
+ }
}
- int count = (n - 2) / 3;
- return pow(3, count) * (n - count * 3);
+ return f[n];
}
```
@@ -163,7 +225,11 @@ int integerBreak(int n) {
-### Solution 2
+### Solution 1: Mathematics
+
+When $n < 4$, since the problem requires splitting into at least two integers, $n - 1$ yields the maximum product. When $n \geq 4$, we split into as many $3$s as possible. If the last segment remaining is $4$, we split it into $2 + 2$ for the maximum product.
+
+The time complexity is $O(1)$, and the space complexity is $O(1)$.
@@ -255,6 +321,81 @@ function integerBreak(n: number): number {
}
```
+#### Rust
+
+```rust
+impl Solution {
+ pub fn integer_break(n: i32) -> i32 {
+ if n < 4 {
+ return n - 1;
+ }
+ match n % 3 {
+ 0 => return (3 as i32).pow((n / 3) as u32),
+ 1 => return (3 as i32).pow((n / 3 - 1) as u32) * 4,
+ _ => return (3 as i32).pow((n / 3) as u32) * 2,
+ }
+ }
+}
+```
+
+#### JavaScript
+
+```js
+/**
+ * @param {number} n
+ * @return {number}
+ */
+var integerBreak = function (n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ const m = Math.floor(n / 3);
+ if (n % 3 == 0) {
+ return 3 ** m;
+ }
+ if (n % 3 == 1) {
+ return 3 ** (m - 1) * 4;
+ }
+ return 3 ** m * 2;
+};
+```
+
+#### C#
+
+```cs
+public class Solution {
+ public int IntegerBreak(int n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ if (n % 3 == 0) {
+ return (int)Math.Pow(3, n / 3);
+ }
+ if (n % 3 == 1) {
+ return (int)Math.Pow(3, n / 3 - 1) * 4;
+ }
+ return (int)Math.Pow(3, n / 3) * 2;
+ }
+}
+```
+
+#### C
+
+```c
+int integerBreak(int n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ if (n % 3 == 0) {
+ return (int) pow(3, n / 3);
+ }
+ if (n % 3 == 1) {
+ return (int) pow(3, n / 3 - 1) * 4;
+ }
+ return (int) pow(3, n / 3) * 2;
+}
+```
+
diff --git a/solution/0300-0399/0343.Integer Break/Solution.c b/solution/0300-0399/0343.Integer Break/Solution.c
index 2cecd56a0f623..0dc021ee16f1c 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.c
+++ b/solution/0300-0399/0343.Integer Break/Solution.c
@@ -1,7 +1,13 @@
+#define max(a, b) (((a) > (b)) ? (a) : (b))
+
int integerBreak(int n) {
- if (n < 4) {
- return n - 1;
+ int* f = (int*) malloc((n + 1) * sizeof(int));
+ f[1] = 1;
+ for (int i = 2; i <= n; ++i) {
+ f[i] = 0;
+ for (int j = 1; j < i; ++j) {
+ f[i] = max(f[i], max(f[i - j] * j, (i - j) * j));
+ }
}
- int count = (n - 2) / 3;
- return pow(3, count) * (n - count * 3);
+ return f[n];
}
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution.cpp b/solution/0300-0399/0343.Integer Break/Solution.cpp
index 6ceba393ee4fa..14722f3698d08 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.cpp
+++ b/solution/0300-0399/0343.Integer Break/Solution.cpp
@@ -1,13 +1,13 @@
class Solution {
public:
int integerBreak(int n) {
- vector dp(n + 1);
- dp[1] = 1;
+ vector f(n + 1);
+ f[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
- dp[i] = max(max(dp[i], dp[i - j] * j), (i - j) * j);
+ f[i] = max({f[i], f[i - j] * j, (i - j) * j});
}
}
- return dp[n];
+ return f[n];
}
};
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution.cs b/solution/0300-0399/0343.Integer Break/Solution.cs
new file mode 100644
index 0000000000000..e4cb8e81bb0b3
--- /dev/null
+++ b/solution/0300-0399/0343.Integer Break/Solution.cs
@@ -0,0 +1,12 @@
+public class Solution {
+ public int IntegerBreak(int n) {
+ int[] f = new int[n + 1];
+ f[1] = 1;
+ for (int i = 2; i <= n; ++i) {
+ for (int j = 1; j < i; ++j) {
+ f[i] = Math.Max(Math.Max(f[i], f[i - j] * j), (i - j) * j);
+ }
+ }
+ return f[n];
+ }
+}
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution.go b/solution/0300-0399/0343.Integer Break/Solution.go
index c2de2799d04ed..cc28189665211 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.go
+++ b/solution/0300-0399/0343.Integer Break/Solution.go
@@ -1,10 +1,10 @@
func integerBreak(n int) int {
- dp := make([]int, n+1)
- dp[1] = 1
+ f := make([]int, n+1)
+ f[1] = 1
for i := 2; i <= n; i++ {
for j := 1; j < i; j++ {
- dp[i] = max(max(dp[i], dp[i-j]*j), (i-j)*j)
+ f[i] = max(max(f[i], f[i-j]*j), (i-j)*j)
}
}
- return dp[n]
+ return f[n]
}
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution.java b/solution/0300-0399/0343.Integer Break/Solution.java
index ebc48c40f0086..923f4f4811de9 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.java
+++ b/solution/0300-0399/0343.Integer Break/Solution.java
@@ -1,12 +1,12 @@
class Solution {
public int integerBreak(int n) {
- int[] dp = new int[n + 1];
- dp[1] = 1;
+ int[] f = new int[n + 1];
+ f[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j < i; ++j) {
- dp[i] = Math.max(Math.max(dp[i], dp[i - j] * j), (i - j) * j);
+ f[i] = Math.max(Math.max(f[i], f[i - j] * j), (i - j) * j);
}
}
- return dp[n];
+ return f[n];
}
}
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution.js b/solution/0300-0399/0343.Integer Break/Solution.js
new file mode 100644
index 0000000000000..34b210f401724
--- /dev/null
+++ b/solution/0300-0399/0343.Integer Break/Solution.js
@@ -0,0 +1,13 @@
+/**
+ * @param {number} n
+ * @return {number}
+ */
+var integerBreak = function (n) {
+ const f = Array(n + 1).fill(1);
+ for (let i = 2; i <= n; ++i) {
+ for (let j = 1; j < i; ++j) {
+ f[i] = Math.max(f[i], f[i - j] * j, (i - j) * j);
+ }
+ }
+ return f[n];
+};
diff --git a/solution/0300-0399/0343.Integer Break/Solution.py b/solution/0300-0399/0343.Integer Break/Solution.py
index faebd81349904..5c7fb26cd7fe7 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.py
+++ b/solution/0300-0399/0343.Integer Break/Solution.py
@@ -1,7 +1,7 @@
class Solution:
def integerBreak(self, n: int) -> int:
- dp = [1] * (n + 1)
+ f = [1] * (n + 1)
for i in range(2, n + 1):
for j in range(1, i):
- dp[i] = max(dp[i], dp[i - j] * j, (i - j) * j)
- return dp[n]
+ f[i] = max(f[i], f[i - j] * j, (i - j) * j)
+ return f[n]
diff --git a/solution/0300-0399/0343.Integer Break/Solution.rs b/solution/0300-0399/0343.Integer Break/Solution.rs
index cbd12dbf0bbf0..2256aeee28fa9 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.rs
+++ b/solution/0300-0399/0343.Integer Break/Solution.rs
@@ -1,9 +1,13 @@
impl Solution {
pub fn integer_break(n: i32) -> i32 {
- if n < 4 {
- return n - 1;
+ let n = n as usize;
+ let mut f = vec![0; n + 1];
+ f[1] = 1;
+ for i in 2..=n {
+ for j in 1..i {
+ f[i] = f[i].max(f[i - j] * j).max((i - j) * j);
+ }
}
- let count = (n - 2) / 3;
- (3i32).pow(count as u32) * (n - count * 3)
+ f[n] as i32
}
}
diff --git a/solution/0300-0399/0343.Integer Break/Solution.ts b/solution/0300-0399/0343.Integer Break/Solution.ts
index bedef9889f279..5239b8eb68fde 100644
--- a/solution/0300-0399/0343.Integer Break/Solution.ts
+++ b/solution/0300-0399/0343.Integer Break/Solution.ts
@@ -1,9 +1,9 @@
function integerBreak(n: number): number {
- let dp = new Array(n + 1).fill(1);
+ const f = Array(n + 1).fill(1);
for (let i = 3; i <= n; i++) {
for (let j = 1; j < i; j++) {
- dp[i] = Math.max(dp[i], j * (i - j), j * dp[i - j]);
+ f[i] = Math.max(f[i], j * (i - j), j * f[i - j]);
}
}
- return dp.pop();
+ return f[n];
}
diff --git a/solution/0300-0399/0343.Integer Break/Solution2.c b/solution/0300-0399/0343.Integer Break/Solution2.c
new file mode 100644
index 0000000000000..46a8519dcd793
--- /dev/null
+++ b/solution/0300-0399/0343.Integer Break/Solution2.c
@@ -0,0 +1,12 @@
+int integerBreak(int n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ if (n % 3 == 0) {
+ return (int) pow(3, n / 3);
+ }
+ if (n % 3 == 1) {
+ return (int) pow(3, n / 3 - 1) * 4;
+ }
+ return (int) pow(3, n / 3) * 2;
+}
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution2.cs b/solution/0300-0399/0343.Integer Break/Solution2.cs
new file mode 100644
index 0000000000000..77a5a6375613e
--- /dev/null
+++ b/solution/0300-0399/0343.Integer Break/Solution2.cs
@@ -0,0 +1,14 @@
+public class Solution {
+ public int IntegerBreak(int n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ if (n % 3 == 0) {
+ return (int)Math.Pow(3, n / 3);
+ }
+ if (n % 3 == 1) {
+ return (int)Math.Pow(3, n / 3 - 1) * 4;
+ }
+ return (int)Math.Pow(3, n / 3) * 2;
+ }
+}
\ No newline at end of file
diff --git a/solution/0300-0399/0343.Integer Break/Solution2.js b/solution/0300-0399/0343.Integer Break/Solution2.js
new file mode 100644
index 0000000000000..c1d5a9b5debcf
--- /dev/null
+++ b/solution/0300-0399/0343.Integer Break/Solution2.js
@@ -0,0 +1,17 @@
+/**
+ * @param {number} n
+ * @return {number}
+ */
+var integerBreak = function (n) {
+ if (n < 4) {
+ return n - 1;
+ }
+ const m = Math.floor(n / 3);
+ if (n % 3 == 0) {
+ return 3 ** m;
+ }
+ if (n % 3 == 1) {
+ return 3 ** (m - 1) * 4;
+ }
+ return 3 ** m * 2;
+};
diff --git a/solution/0300-0399/0343.Integer Break/Solution2.rs b/solution/0300-0399/0343.Integer Break/Solution2.rs
new file mode 100644
index 0000000000000..031f1f1ad5698
--- /dev/null
+++ b/solution/0300-0399/0343.Integer Break/Solution2.rs
@@ -0,0 +1,12 @@
+impl Solution {
+ pub fn integer_break(n: i32) -> i32 {
+ if n < 4 {
+ return n - 1;
+ }
+ match n % 3 {
+ 0 => return (3 as i32).pow((n / 3) as u32),
+ 1 => return (3 as i32).pow((n / 3 - 1) as u32) * 4,
+ _ => return (3 as i32).pow((n / 3) as u32) * 2,
+ }
+ }
+}
diff --git a/solution/0300-0399/0347.Top K Frequent Elements/README.md b/solution/0300-0399/0347.Top K Frequent Elements/README.md
index 0a21210a0545e..0ce1273eec34c 100644
--- a/solution/0300-0399/0347.Top K Frequent Elements/README.md
+++ b/solution/0300-0399/0347.Top K Frequent Elements/README.md
@@ -62,7 +62,7 @@ tags:
### 方法一:哈希表 + 优先队列(小根堆)
-我们可以使用一个哈希表 $\text{cnt}$ 统计每个元素出现的次数,然后使用一个小根堆(优先队列)来保存前 $k$ 个高频元素。
+我们可以使用一个哈希表 $\textit{cnt}$ 统计每个元素出现的次数,然后使用一个小根堆(优先队列)来保存前 $k$ 个高频元素。
我们首先遍历一遍数组,统计每个元素出现的次数,然后遍历哈希表,将元素和出现次数存入小根堆中。如果小根堆的大小超过了 $k$,我们就将堆顶元素弹出,保证堆的大小始终为 $k$。
diff --git a/solution/0300-0399/0347.Top K Frequent Elements/README_EN.md b/solution/0300-0399/0347.Top K Frequent Elements/README_EN.md
index c72b5148eb7d4..77a311335c84d 100644
--- a/solution/0300-0399/0347.Top K Frequent Elements/README_EN.md
+++ b/solution/0300-0399/0347.Top K Frequent Elements/README_EN.md
@@ -54,7 +54,7 @@ tags:
### Solution 1: Hash Table + Priority Queue (Min Heap)
-We can use a hash table $\text{cnt}$ to count the occurrence of each element, and then use a min heap (priority queue) to store the top $k$ frequent elements.
+We can use a hash table $\textit{cnt}$ to count the occurrence of each element, and then use a min heap (priority queue) to store the top $k$ frequent elements.
First, we traverse the array once to count the occurrence of each element. Then, we iterate through the hash table, storing each element and its count into the min heap. If the size of the min heap exceeds $k$, we pop the top element of the heap to ensure the heap size is always $k$.
diff --git a/solution/0300-0399/0350.Intersection of Two Arrays II/README.md b/solution/0300-0399/0350.Intersection of Two Arrays II/README.md
index 4e7a31d0fa6ea..704fdabdeed81 100644
--- a/solution/0300-0399/0350.Intersection of Two Arrays II/README.md
+++ b/solution/0300-0399/0350.Intersection of Two Arrays II/README.md
@@ -64,11 +64,11 @@ tags:
### 方法一:哈希表
-我们可以用一个哈希表 $\text{cnt}$ 统计数组 $\text{nums1}$ 中每个元素出现的次数,然后遍历数组 $\text{nums2}$,如果元素 $x$ 在 $\text{cnt}$ 中,并且 $x$ 的出现次数大于 $0$,那么将 $x$ 加入答案,然后将 $x$ 的出现次数减一。
+我们可以用一个哈希表 $\textit{cnt}$ 统计数组 $\textit{nums1}$ 中每个元素出现的次数,然后遍历数组 $\textit{nums2}$,如果元素 $x$ 在 $\textit{cnt}$ 中,并且 $x$ 的出现次数大于 $0$,那么将 $x$ 加入答案,然后将 $x$ 的出现次数减一。
遍历结束后,返回答案数组即可。
-时间复杂度 $O(m + n)$,空间复杂度 $O(m)$。其中 $m$ 和 $n$ 分别是数组 $\text{nums1}$ 和 $\text{nums2}$ 的长度。
+时间复杂度 $O(m + n)$,空间复杂度 $O(m)$。其中 $m$ 和 $n$ 分别是数组 $\textit{nums1}$ 和 $\textit{nums2}$ 的长度。
diff --git a/solution/0300-0399/0350.Intersection of Two Arrays II/README_EN.md b/solution/0300-0399/0350.Intersection of Two Arrays II/README_EN.md
index cbbb237e372a1..6f88a14107803 100644
--- a/solution/0300-0399/0350.Intersection of Two Arrays II/README_EN.md
+++ b/solution/0300-0399/0350.Intersection of Two Arrays II/README_EN.md
@@ -63,11 +63,11 @@ tags:
### Solution 1: Hash Table
-We can use a hash table $\text{cnt}$ to count the occurrences of each element in the array $\text{nums1}$. Then, we iterate through the array $\text{nums2}$. If an element $x$ is in $\text{cnt}$ and the occurrence of $x$ is greater than $0$, we add $x$ to the answer and then decrement the occurrence of $x$ by one.
+We can use a hash table $\textit{cnt}$ to count the occurrences of each element in the array $\textit{nums1}$. Then, we iterate through the array $\textit{nums2}$. If an element $x$ is in $\textit{cnt}$ and the occurrence of $x$ is greater than $0$, we add $x$ to the answer and then decrement the occurrence of $x$ by one.
After the iteration is finished, we return the answer array.
-The time complexity is $O(m + n)$, and the space complexity is $O(m)$. Here, $m$ and $n$ are the lengths of the arrays $\text{nums1}$ and $\text{nums2}$, respectively.
+The time complexity is $O(m + n)$, and the space complexity is $O(m)$. Here, $m$ and $n$ are the lengths of the arrays $\textit{nums1}$ and $\textit{nums2}$, respectively.
diff --git a/solution/0300-0399/0364.Nested List Weight Sum II/README.md b/solution/0300-0399/0364.Nested List Weight Sum II/README.md
index 863445b2ff5ee..b211f0779c411 100644
--- a/solution/0300-0399/0364.Nested List Weight Sum II/README.md
+++ b/solution/0300-0399/0364.Nested List Weight Sum II/README.md
@@ -64,31 +64,31 @@ tags:
### 方法一:DFS
-我们不妨假设整数分别为 $a_1, a_2, \cdots, a_n$,它们的深度分别为 $d_1, d_2, \cdots, d_n$,最大深度为 $\text{maxDepth}$,那么答案就是:
+我们不妨假设整数分别为 $a_1, a_2, \cdots, a_n$,它们的深度分别为 $d_1, d_2, \cdots, d_n$,最大深度为 $\textit{maxDepth}$,那么答案就是:
$$
-a_1 \times \text{maxDepth} - a_1 \times d_1 + a_1 + a_2 \times \text{maxDepth} - a_2 \times d_2 + a_2 + \cdots + a_n \times \text{maxDepth} - a_n \times d_n + a_n
+a_1 \times \textit{maxDepth} - a_1 \times d_1 + a_1 + a_2 \times \textit{maxDepth} - a_2 \times d_2 + a_2 + \cdots + a_n \times \textit{maxDepth} - a_n \times d_n + a_n
$$
即:
$$
-(\text{maxDepth} + 1) \times (a_1 + a_2 + \cdots + a_n) - (a_1 \times d_1 + a_2 \times d_2 + \cdots + a_n \times d_n)
+(\textit{maxDepth} + 1) \times (a_1 + a_2 + \cdots + a_n) - (a_1 \times d_1 + a_2 \times d_2 + \cdots + a_n \times d_n)
$$
如果我们记所有整数的和为 $s$,所有整数乘以深度的和为 $ws$,那么答案就是:
$$
-(\text{maxDepth} + 1) \times s - ws
+(\textit{maxDepth} + 1) \times s - ws
$$
因此,我们设计一个函数 $dfs(x, d)$,表示从 $x$ 开始,深度为 $d$ 开始搜索,函数 $dfs(x, d)$ 的执行过程如下:
-- 我们先更新 $\text{maxDepth} = \max(\text{maxDepth}, d)$;
+- 我们先更新 $\textit{maxDepth} = \max(\textit{maxDepth}, d)$;
- 如果 $x$ 是一个整数,那么我们更新 $s = s + x$, $ws = ws + x \times d$;
- 否则,我们递归地遍历 $x$ 的每一个元素 $y$,调用 $dfs(y, d + 1)$。
-我们遍历整个列表,对于每一个元素 $x$,我们调用 $dfs(x, 1)$,最终返回 $(\text{maxDepth} + 1) \times s - ws$ 即可。
+我们遍历整个列表,对于每一个元素 $x$,我们调用 $dfs(x, 1)$,最终返回 $(\textit{maxDepth} + 1) \times s - ws$ 即可。
时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 为整数的个数。
diff --git a/solution/0300-0399/0364.Nested List Weight Sum II/README_EN.md b/solution/0300-0399/0364.Nested List Weight Sum II/README_EN.md
index cb1f774da5472..4ca8f0301878d 100644
--- a/solution/0300-0399/0364.Nested List Weight Sum II/README_EN.md
+++ b/solution/0300-0399/0364.Nested List Weight Sum II/README_EN.md
@@ -62,31 +62,31 @@ tags:
### Solution 1: DFS
-Let's assume the integers are $a_1, a_2, \cdots, a_n$, their depths are $d_1, d_2, \cdots, d_n$, the maximum depth is $\text{maxDepth}$, then the answer is:
+Let's assume the integers are $a_1, a_2, \cdots, a_n$, their depths are $d_1, d_2, \cdots, d_n$, the maximum depth is $\textit{maxDepth}$, then the answer is:
$$
-a_1 \times \text{maxDepth} - a_1 \times d_1 + a_1 + a_2 \times \text{maxDepth} - a_2 \times d_2 + a_2 + \cdots + a_n \times \text{maxDepth} - a_n \times d_n + a_n
+a_1 \times \textit{maxDepth} - a_1 \times d_1 + a_1 + a_2 \times \textit{maxDepth} - a_2 \times d_2 + a_2 + \cdots + a_n \times \textit{maxDepth} - a_n \times d_n + a_n
$$
which is:
$$
-(\text{maxDepth} + 1) \times (a_1 + a_2 + \cdots + a_n) - (a_1 \times d_1 + a_2 \times d_2 + \cdots + a_n \times d_n)
+(\textit{maxDepth} + 1) \times (a_1 + a_2 + \cdots + a_n) - (a_1 \times d_1 + a_2 \times d_2 + \cdots + a_n \times d_n)
$$
If we denote the sum of all integers as $s$, and the sum of each integer multiplied by its depth as $ws$, then the answer is:
$$
-(\text{maxDepth} + 1) \times s - ws
+(\textit{maxDepth} + 1) \times s - ws
$$
Therefore, we design a function $dfs(x, d)$, which starts searching from $x$ with depth $d$. The execution process of $dfs(x, d)$ is as follows:
-- We first update $\text{maxDepth} = \max(\text{maxDepth}, d)$;
+- We first update $\textit{maxDepth} = \max(\textit{maxDepth}, d)$;
- If $x$ is an integer, then we update $s = s + x$, $ws = ws + x \times d$;
- Otherwise, we recursively traverse each element $y$ of $x$, and call $dfs(y, d + 1)$.
-We traverse the entire list, for each element $x$, we call $dfs(x, 1)$, and finally return $(\text{maxDepth} + 1) \times s - ws$.
+We traverse the entire list, for each element $x$, we call $dfs(x, 1)$, and finally return $(\textit{maxDepth} + 1) \times s - ws$.
The time complexity is $O(n)$, and the space complexity is $O(n)$. Where $n$ is the number of integers.
diff --git a/solution/0300-0399/0365.Water and Jug Problem/README.md b/solution/0300-0399/0365.Water and Jug Problem/README.md
index 47f5ea7fa8c23..7cc5f30f350c6 100644
--- a/solution/0300-0399/0365.Water and Jug Problem/README.md
+++ b/solution/0300-0399/0365.Water and Jug Problem/README.md
@@ -76,7 +76,7 @@ tags:
### 方法一:DFS
-我们不妨记 $\text{jug1Capacity}$ 为 $x$, $\text{jug2Capacity}$ 为 $y$, $\text{targetCapacity}$ 为 $z$。
+我们不妨记 $\textit{jug1Capacity}$ 为 $x$, $\textit{jug2Capacity}$ 为 $y$, $\textit{targetCapacity}$ 为 $z$。
接下来,我们设计一个函数 $dfs(i, j)$,表示当前 $jug1$ 中有 $i$ 升水,$jug2$ 中有 $j$ 升水,是否可以得到 $z$ 升水。
@@ -89,7 +89,7 @@ tags:
答案即为 $dfs(0, 0)$。
-时间复杂度 $O(x + y)$,空间复杂度 $O(x + y)$。其中 $x$ 和 $y$ 分别为 $\text{jug1Capacity}$ 和 $\text{jug2Capacity}$。
+时间复杂度 $O(x + y)$,空间复杂度 $O(x + y)$。其中 $x$ 和 $y$ 分别为 $\textit{jug1Capacity}$ 和 $\textit{jug2Capacity}$。
diff --git a/solution/0300-0399/0379.Design Phone Directory/README.md b/solution/0300-0399/0379.Design Phone Directory/README.md
index 1b671e581f3d3..02ffb8f3b06a3 100644
--- a/solution/0300-0399/0379.Design Phone Directory/README.md
+++ b/solution/0300-0399/0379.Design Phone Directory/README.md
@@ -20,41 +20,37 @@ tags:
-设计一个电话目录管理系统,让它支持以下功能:
+设计一个电话目录管理系统,一开始有 maxNumbers 个位置能够储存号码。系统应该存储号码,检查某个位置是否为空,并清空给定的位置。
-
- get: 分配给用户一个未被使用的电话号码,获取失败请返回 -1check: 检查指定的电话号码是否被使用release: 释放掉一个电话号码,使其能够重新被分配
+实现 PhoneDirectory 类:
-
-
-示例:
-
-// 初始化电话目录,包括 3 个电话号码:0,1 和 2。
-PhoneDirectory directory = new PhoneDirectory(3);
-
-// 可以返回任意未分配的号码,这里我们假设它返回 0。
-directory.get();
-
-// 假设,函数返回 1。
-directory.get();
-
-// 号码 2 未分配,所以返回为 true。
-directory.check(2);
-
-// 返回 2,分配后,只剩一个号码未被分配。
-directory.get();
-
-// 此时,号码 2 已经被分配,所以返回 false。
-directory.check(2);
+
+ PhoneDirectory(int maxNumbers) 电话目录初始有 maxNumbers 个可用位置。int get() 提供一个未分配给任何人的号码。如果没有可用号码则返回 -1。bool check(int number) 如果位置 number 可用返回 true 否则返回 false。void release(int number) 回收或释放位置 number。
-// 释放号码 2,将该号码变回未分配状态。
-directory.release(2);
+
-// 号码 2 现在是未分配状态,所以返回 true。
-directory.check(2);
+示例 1:
+
+
+输入:
+["PhoneDirectory", "get", "get", "check", "get", "check", "release", "check"]
+[[3], [], [], [2], [], [2], [2], [2]]
+输出:
+[null, 0, 1, true, 2, false, null, true]
+
+解释:
+PhoneDirectory phoneDirectory = new PhoneDirectory(3);
+phoneDirectory.get(); // 它可以返回任意可用的数字。这里我们假设它返回 0。
+phoneDirectory.get(); // 假设它返回 1。
+phoneDirectory.check(2); // 数字 2 可用,所以返回 true。
+phoneDirectory.get(); // 返回剩下的唯一一个数字 2。
+phoneDirectory.check(2); // 数字 2 不再可用,所以返回 false。
+phoneDirectory.release(2); // 将数字 2 释放回号码池。
+phoneDirectory.check(2); // 数字 2 重新可用,返回 true。
@@ -62,9 +58,9 @@ directory.check(2);
提示:
- 1 <= maxNumbers <= 10^41 <= maxNumbers <= 1040 <= number < maxNumbers- 调用方法的总数处于区间
[0 - 20000] 之内
+ get,check 和 release 最多被调用 2 * 104 次。
diff --git a/solution/0300-0399/0391.Perfect Rectangle/README.md b/solution/0300-0399/0391.Perfect Rectangle/README.md
index c69b02149e247..0292de82c3f31 100644
--- a/solution/0300-0399/0391.Perfect Rectangle/README.md
+++ b/solution/0300-0399/0391.Perfect Rectangle/README.md
@@ -51,7 +51,8 @@ tags:
1 <= rectangles.length <= 2 * 104rectangles[i].length == 4-105 <= xi, yi, ai, bi <= 105-105 <= xi < ai <= 105-105 <= yi < bi <= 105
diff --git a/solution/0300-0399/0391.Perfect Rectangle/README_EN.md b/solution/0300-0399/0391.Perfect Rectangle/README_EN.md
index f10a51d190283..6c770c7548d75 100644
--- a/solution/0300-0399/0391.Perfect Rectangle/README_EN.md
+++ b/solution/0300-0399/0391.Perfect Rectangle/README_EN.md
@@ -52,7 +52,8 @@ tags:
1 <= rectangles.length <= 2 * 104rectangles[i].length == 4-105 <= xi, yi, ai, bi <= 105-105 <= xi < ai <= 105-105 <= yi < bi <= 105
diff --git a/solution/0400-0499/0416.Partition Equal Subset Sum/README.md b/solution/0400-0499/0416.Partition Equal Subset Sum/README.md
index 11b26eb1296c2..fd4551f364ff0 100644
--- a/solution/0400-0499/0416.Partition Equal Subset Sum/README.md
+++ b/solution/0400-0499/0416.Partition Equal Subset Sum/README.md
@@ -60,7 +60,7 @@ tags:
考虑 $f[i][j]$,如果我们选取了第 $i$ 个数 $x$,那么 $f[i][j] = f[i - 1][j - x]$;如果我们没有选取第 $i$ 个数 $x$,那么 $f[i][j] = f[i - 1][j]$。因此状态转移方程为:
$$
-f[i][j] = f[i - 1][j] \text{ or } f[i - 1][j - x] \text{ if } j \geq x
+f[i][j] = f[i - 1][j] \textit{ or } f[i - 1][j - x] \textit{ if } j \geq x
$$
最终答案为 $f[n][m]$。
diff --git a/solution/0400-0499/0416.Partition Equal Subset Sum/README_EN.md b/solution/0400-0499/0416.Partition Equal Subset Sum/README_EN.md
index 1138a5a641ab5..1b1a01a59566d 100644
--- a/solution/0400-0499/0416.Partition Equal Subset Sum/README_EN.md
+++ b/solution/0400-0499/0416.Partition Equal Subset Sum/README_EN.md
@@ -59,7 +59,7 @@ We define $f[i][j]$ to represent whether it is possible to select several number
Considering $f[i][j]$, if we select the $i$-th number $x$, then $f[i][j] = f[i - 1][j - x]$. If we do not select the $i$-th number $x$, then $f[i][j] = f[i - 1][j]$. Therefore, the state transition equation is:
$$
-f[i][j] = f[i - 1][j] \text{ or } f[i - 1][j - x] \text{ if } j \geq x
+f[i][j] = f[i - 1][j] \textit{ or } f[i - 1][j - x] \textit{ if } j \geq x
$$
The final answer is $f[n][m]$.
diff --git a/solution/0400-0499/0457.Circular Array Loop/README.md b/solution/0400-0499/0457.Circular Array Loop/README.md
index b8e08f322019b..5d5a37f44f746 100644
--- a/solution/0400-0499/0457.Circular Array Loop/README.md
+++ b/solution/0400-0499/0457.Circular Array Loop/README.md
@@ -39,29 +39,33 @@ tags:
-示例 1:
-
+示例 1:
+
输入:nums = [2,-1,1,2,2]
输出:true
-解释:存在循环,按下标 0 -> 2 -> 3 -> 0 。循环长度为 3 。
+解释:图片展示了节点间如何连接。白色节点向前跳跃,而红色节点向后跳跃。
+我们可以看到存在循环,按下标 0 -> 2 -> 3 -> 0 --> ...,并且其中的所有节点都是白色(以相同方向跳跃)。
-示例 2:
-
+示例 2:
+
-输入:nums = [-1,2]
+输入:nums = [-1,-2,-3,-4,-5,6]
输出:false
-解释:按下标 1 -> 1 -> 1 ... 的运动无法构成循环,因为循环的长度为 1 。根据定义,循环的长度必须大于 1 。
+解释:图片展示了节点间如何连接。白色节点向前跳跃,而红色节点向后跳跃。
+唯一的循环长度为 1,所以返回 false。
-示例 3:
-
+示例 3:
+
-输入:nums = [-2,1,-1,-2,-2]
-输出:false
-解释:按下标 1 -> 2 -> 1 -> ... 的运动无法构成循环,因为 nums[1] 是正数,而 nums[2] 是负数。
-所有 nums[seq[j]] 应当不是全正就是全负。
+输入:nums = [1,-1,5,1,4]
+输出:true
+解释:图片展示了节点间如何连接。白色节点向前跳跃,而红色节点向后跳跃。
+我们可以看到存在循环,按下标 0 --> 1 --> 0 --> ...,当它的大小大于 1 时,它有一个向前跳的节点和一个向后跳的节点,所以 它不是一个循环。
+我们可以看到存在循环,按下标 3 --> 4 --> 3 --> ...,并且其中的所有节点都是白色(以相同方向跳跃)。
+
diff --git a/solution/0400-0499/0457.Circular Array Loop/images/1723688159-qYjpWT-image.png b/solution/0400-0499/0457.Circular Array Loop/images/1723688159-qYjpWT-image.png
new file mode 100644
index 0000000000000..b2b309ca9d675
Binary files /dev/null and b/solution/0400-0499/0457.Circular Array Loop/images/1723688159-qYjpWT-image.png differ
diff --git a/solution/0400-0499/0457.Circular Array Loop/images/1723688183-lRSkjp-image.png b/solution/0400-0499/0457.Circular Array Loop/images/1723688183-lRSkjp-image.png
new file mode 100644
index 0000000000000..b197c72f001a2
Binary files /dev/null and b/solution/0400-0499/0457.Circular Array Loop/images/1723688183-lRSkjp-image.png differ
diff --git a/solution/0400-0499/0457.Circular Array Loop/images/1723688199-nhaMuF-image.png b/solution/0400-0499/0457.Circular Array Loop/images/1723688199-nhaMuF-image.png
new file mode 100644
index 0000000000000..6f81e15be35f7
Binary files /dev/null and b/solution/0400-0499/0457.Circular Array Loop/images/1723688199-nhaMuF-image.png differ
diff --git a/solution/0400-0499/0464.Can I Win/README.md b/solution/0400-0499/0464.Can I Win/README.md
index 7e65d5c648c85..d73ab18ab788a 100644
--- a/solution/0400-0499/0464.Can I Win/README.md
+++ b/solution/0400-0499/0464.Can I Win/README.md
@@ -77,9 +77,9 @@ tags:
我们首先判断可以选择的所有整数的和是否小于目标值,如果是,说明无论如何都无法赢,直接返回 `false`。
-然后,我们设计一个函数 $\text{dfs}(mask, s)$,其中 `mask` 表示当前已选择的整数的状态,`s` 表示当前的累计和。函数返回值为当前玩家是否能赢。
+然后,我们设计一个函数 $\textit{dfs}(mask, s)$,其中 `mask` 表示当前已选择的整数的状态,`s` 表示当前的累计和。函数返回值为当前玩家是否能赢。
-函数 $\text{dfs}(mask, s)$ 的执行过程如下:
+函数 $\textit{dfs}(mask, s)$ 的执行过程如下:
我们遍历 $1$ 到 $maxChoosableInteger$ 中的每个整数 $i$,如果 $i$ 还没有被选择,我们可以选择 $i$,如果选择 $i$ 后的累计和 $s + i$ 大于等于目标值 `desiredTotal`,或者对手选择 $i$ 后的结果是输的,那么当前玩家就是赢的,返回 `true`。
diff --git a/solution/0400-0499/0476.Number Complement/README.md b/solution/0400-0499/0476.Number Complement/README.md
index ef94361032a12..152830c396a89 100644
--- a/solution/0400-0499/0476.Number Complement/README.md
+++ b/solution/0400-0499/0476.Number Complement/README.md
@@ -67,13 +67,13 @@ tags:
根据题目描述,我们可以通过异或运算来实现取反的操作,步骤如下:
-我们首先找到 $\text{num}$ 的二进制表示中最高位的 $1$,位置记为 $k$。
+我们首先找到 $\textit{num}$ 的二进制表示中最高位的 $1$,位置记为 $k$。
然后,构造一个二进制数,第 $k$ 位为 $0$,其余低位为 $1$,即 $2^k - 1$;
-最后,将 $\text{num}$ 与上述构造的二进制数进行异或运算,即可得到答案。
+最后,将 $\textit{num}$ 与上述构造的二进制数进行异或运算,即可得到答案。
-时间复杂度 $O(\log \text{num})$,其中 $\text{num}$ 为输入的整数。空间复杂度 $O(1)$。
+时间复杂度 $O(\log \textit{num})$,其中 $\textit{num}$ 为输入的整数。空间复杂度 $O(1)$。
diff --git a/solution/0400-0499/0476.Number Complement/README_EN.md b/solution/0400-0499/0476.Number Complement/README_EN.md
index ea786621d6a48..5e9d87c4bc1d5 100644
--- a/solution/0400-0499/0476.Number Complement/README_EN.md
+++ b/solution/0400-0499/0476.Number Complement/README_EN.md
@@ -61,13 +61,13 @@ tags:
According to the problem description, we can use XOR operation to implement the flipping operation, the steps are as follows:
-First, we find the highest bit of $1$ in the binary representation of $\text{num}$, and the position is denoted as $k$.
+First, we find the highest bit of $1$ in the binary representation of $\textit{num}$, and the position is denoted as $k$.
Then, we construct a binary number, where the $k$-th bit is $0$ and the rest of the lower bits are $1$, which is $2^k - 1$;
-Finally, we perform XOR operation on $\text{num}$ and the constructed binary number to get the answer.
+Finally, we perform XOR operation on $\textit{num}$ and the constructed binary number to get the answer.
-The time complexity is $O(\log \text{num})$, where $\text{num}$ is the input integer. The space complexity is $O(1)$.
+The time complexity is $O(\log \textit{num})$, where $\textit{num}$ is the input integer. The space complexity is $O(1)$.
diff --git a/solution/0400-0499/0494.Target Sum/README.md b/solution/0400-0499/0494.Target Sum/README.md
index 79680b9b0202b..3308936b2552d 100644
--- a/solution/0400-0499/0494.Target Sum/README.md
+++ b/solution/0400-0499/0494.Target Sum/README.md
@@ -69,27 +69,27 @@ tags:
### 方法一:动态规划
-我们记数组 $\text{nums}$ 所有元素的和为 $s$,添加负号的元素之和为 $x$,则添加正号的元素之和为 $s - x$,则有:
+我们记数组 $\textit{nums}$ 所有元素的和为 $s$,添加负号的元素之和为 $x$,则添加正号的元素之和为 $s - x$,则有:
$$
-(s - x) - x = \text{target} \Rightarrow x = \frac{s - \text{target}}{2}
+(s - x) - x = \textit{target} \Rightarrow x = \frac{s - \textit{target}}{2}
$$
-由于 $x \geq 0$,且 $x$ 为整数,所以 $s \geq \text{target}$ 且 $s - \text{target}$ 为偶数。如果不满足这两个条件,则直接返回 $0$。
+由于 $x \geq 0$,且 $x$ 为整数,所以 $s \geq \textit{target}$ 且 $s - \textit{target}$ 为偶数。如果不满足这两个条件,则直接返回 $0$。
-接下来,我们可以将问题转化为:在数组 $\text{nums}$ 中选取若干元素,使得这些元素之和等于 $\frac{s - \text{target}}{2}$,问有多少种选取方法。
+接下来,我们可以将问题转化为:在数组 $\textit{nums}$ 中选取若干元素,使得这些元素之和等于 $\frac{s - \textit{target}}{2}$,问有多少种选取方法。
-我们可以使用动态规划来解决这个问题。定义 $f[i][j]$ 表示在数组 $\text{nums}$ 的前 $i$ 个元素中选取若干元素,使得这些元素之和等于 $j$ 的选取方案数。
+我们可以使用动态规划来解决这个问题。定义 $f[i][j]$ 表示在数组 $\textit{nums}$ 的前 $i$ 个元素中选取若干元素,使得这些元素之和等于 $j$ 的选取方案数。
-对于 $\text{nums}[i - 1]$,我们有两种选择:选取或不选取。如果我们不选取 $\text{nums}[i - 1]$,则 $f[i][j] = f[i - 1][j]$;如果我们选取 $\text{nums}[i - 1]$,则 $f[i][j] = f[i - 1][j - \text{nums}[i - 1]]$。因此,状态转移方程为:
+对于 $\textit{nums}[i - 1]$,我们有两种选择:选取或不选取。如果我们不选取 $\textit{nums}[i - 1]$,则 $f[i][j] = f[i - 1][j]$;如果我们选取 $\textit{nums}[i - 1]$,则 $f[i][j] = f[i - 1][j - \textit{nums}[i - 1]]$。因此,状态转移方程为:
$$
-f[i][j] = f[i - 1][j] + f[i - 1][j - \text{nums}[i - 1]]
+f[i][j] = f[i - 1][j] + f[i - 1][j - \textit{nums}[i - 1]]
$$
-其中,选取的前提是 $j \geq \text{nums}[i - 1]$。
+其中,选取的前提是 $j \geq \textit{nums}[i - 1]$。
-最终答案即为 $f[m][n]$。其中 $m$ 为数组 $\text{nums}$ 的长度,而 $n = \frac{s - \text{target}}{2}$。
+最终答案即为 $f[m][n]$。其中 $m$ 为数组 $\textit{nums}$ 的长度,而 $n = \frac{s - \textit{target}}{2}$。
时间复杂度 $O(m \times n)$,空间复杂度 $O(m \times n)$。
@@ -282,7 +282,7 @@ var findTargetSumWays = function (nums, target) {
### 方法二:动态规划(空间优化)
-我们可以发现,方法一中的状态转移方程中,$f[i][j]$ 的值只和 $f[i - 1][j]$ 以及 $f[i - 1][j - \text{nums}[i - 1]]$ 有关,因此我们去掉第一维空间,只使用一维数组即可。
+我们可以发现,方法一中的状态转移方程中,$f[i][j]$ 的值只和 $f[i - 1][j]$ 以及 $f[i - 1][j - \textit{nums}[i - 1]]$ 有关,因此我们去掉第一维空间,只使用一维数组即可。
时间复杂度 $O(m \times n)$,空间复杂度 $O(n)$。
diff --git a/solution/0400-0499/0494.Target Sum/README_EN.md b/solution/0400-0499/0494.Target Sum/README_EN.md
index 776a50a943237..b8d7be99b24d4 100644
--- a/solution/0400-0499/0494.Target Sum/README_EN.md
+++ b/solution/0400-0499/0494.Target Sum/README_EN.md
@@ -67,27 +67,27 @@ tags:
### Solution 1: Dynamic Programming
-Let's denote the sum of all elements in the array $\text{nums}$ as $s$, and the sum of elements to which we assign a negative sign as $x$. Therefore, the sum of elements with a positive sign is $s - x$. We have:
+Let's denote the sum of all elements in the array $\textit{nums}$ as $s$, and the sum of elements to which we assign a negative sign as $x$. Therefore, the sum of elements with a positive sign is $s - x$. We have:
$$
-(s - x) - x = \text{target} \Rightarrow x = \frac{s - \text{target}}{2}
+(s - x) - x = \textit{target} \Rightarrow x = \frac{s - \textit{target}}{2}
$$
-Since $x \geq 0$ and $x$ must be an integer, it follows that $s \geq \text{target}$ and $s - \text{target}$ must be even. If these two conditions are not met, we directly return $0$.
+Since $x \geq 0$ and $x$ must be an integer, it follows that $s \geq \textit{target}$ and $s - \textit{target}$ must be even. If these two conditions are not met, we directly return $0$.
-Next, we can transform the problem into: selecting several elements from the array $\text{nums}$ such that the sum of these elements equals $\frac{s - \text{target}}{2}$. We are asked how many ways there are to make such a selection.
+Next, we can transform the problem into: selecting several elements from the array $\textit{nums}$ such that the sum of these elements equals $\frac{s - \textit{target}}{2}$. We are asked how many ways there are to make such a selection.
-We can use dynamic programming to solve this problem. Define $f[i][j]$ as the number of ways to select several elements from the first $i$ elements of the array $\text{nums}$ such that the sum of these elements equals $j$.
+We can use dynamic programming to solve this problem. Define $f[i][j]$ as the number of ways to select several elements from the first $i$ elements of the array $\textit{nums}$ such that the sum of these elements equals $j$.
-For $\text{nums}[i - 1]$, we have two choices: to select or not to select. If we do not select $\text{nums}[i - 1]$, then $f[i][j] = f[i - 1][j]$; if we do select $\text{nums}[i - 1]$, then $f[i][j] = f[i - 1][j - \text{nums}[i - 1]]$. Therefore, the state transition equation is:
+For $\textit{nums}[i - 1]$, we have two choices: to select or not to select. If we do not select $\textit{nums}[i - 1]$, then $f[i][j] = f[i - 1][j]$; if we do select $\textit{nums}[i - 1]$, then $f[i][j] = f[i - 1][j - \textit{nums}[i - 1]]$. Therefore, the state transition equation is:
$$
-f[i][j] = f[i - 1][j] + f[i - 1][j - \text{nums}[i - 1]]
+f[i][j] = f[i - 1][j] + f[i - 1][j - \textit{nums}[i - 1]]
$$
-This selection is based on the premise that $j \geq \text{nums}[i - 1]$.
+This selection is based on the premise that $j \geq \textit{nums}[i - 1]$.
-The final answer is $f[m][n]$, where $m$ is the length of the array $\text{nums}$, and $n = \frac{s - \text{target}}{2}$.
+The final answer is $f[m][n]$, where $m$ is the length of the array $\textit{nums}$, and $n = \frac{s - \textit{target}}{2}$.
The time complexity is $O(m \times n)$, and the space complexity is $O(m \times n)$.
@@ -280,7 +280,7 @@ var findTargetSumWays = function (nums, target) {
### Solution 2: Dynamic Programming (Space Optimization)
-We can observe that in the state transition equation of Solution 1, the value of $f[i][j]$ is only related to $f[i - 1][j]$ and $f[i - 1][j - \text{nums}[i - 1]]$. Therefore, we can eliminate the first dimension of the space and use only a one-dimensional array.
+We can observe that in the state transition equation of Solution 1, the value of $f[i][j]$ is only related to $f[i - 1][j]$ and $f[i - 1][j - \textit{nums}[i - 1]]$. Therefore, we can eliminate the first dimension of the space and use only a one-dimensional array.
The time complexity is $O(m \times n)$, and the space complexity is $O(n)$.
diff --git a/solution/0500-0599/0510.Inorder Successor in BST II/README.md b/solution/0500-0599/0510.Inorder Successor in BST II/README.md
index 4bc1701d3fa7e..dc93a079a1459 100644
--- a/solution/0500-0599/0510.Inorder Successor in BST II/README.md
+++ b/solution/0500-0599/0510.Inorder Successor in BST II/README.md
@@ -76,9 +76,9 @@ class Node {
### 方法一:分情况讨论
-如果 $\text{node}$ 有右子树,那么 $\text{node}$ 的中序后继节点是右子树中最左边的节点。
+如果 $\textit{node}$ 有右子树,那么 $\textit{node}$ 的中序后继节点是右子树中最左边的节点。
-如果 $\text{node}$ 没有右子树,那么如果 $\text{node}$ 是其父节点的右子树,我们就一直向上搜索,直到节点的父节点为空,或者节点是其父节点的左子树,此时父节点就是中序后继节点。
+如果 $\textit{node}$ 没有右子树,那么如果 $\textit{node}$ 是其父节点的右子树,我们就一直向上搜索,直到节点的父节点为空,或者节点是其父节点的左子树,此时父节点就是中序后继节点。
时间复杂度 $O(h)$,其中 $h$ 是二叉树的高度。空间复杂度 $O(1)$。
diff --git a/solution/0500-0599/0514.Freedom Trail/README.md b/solution/0500-0599/0514.Freedom Trail/README.md
index cbf5121cede7e..a4e424c4d1f77 100644
--- a/solution/0500-0599/0514.Freedom Trail/README.md
+++ b/solution/0500-0599/0514.Freedom Trail/README.md
@@ -81,7 +81,7 @@ tags:
我们可以先初始化 $f[0][j]$,其中 $j$ 是字符 $key[0]$ 在 $ring$ 中出现的位置。由于 $ring$ 的第 $j$ 个字符与 $12:00$ 方向对齐,因此我们只需要 $1$ 步即可拼写出 $key[0]$。此外,我们还需要 $min(j, n - j)$ 步将 $ring$ 旋转到 $12:00$ 方向。因此 $f[0][j]=min(j, n - j) + 1$。
-接下来,我们考虑当 $i \geq 1$ 时,状态如何转移。我们可以枚举 $key[i]$ 在 $ring$ 中的位置列表 $pos[key[i]]$,并枚举 $key[i-1]$ 在 $ring$ 中的位置列表 $pos[key[i-1]]$,然后更新 $f[i][j]$,即 $f[i][j]=\min_{k \in pos[key[i-1]]} f[i-1][k] + \min(\text{abs}(j - k), n - \text{abs}(j - k)) + 1$。
+接下来,我们考虑当 $i \geq 1$ 时,状态如何转移。我们可以枚举 $key[i]$ 在 $ring$ 中的位置列表 $pos[key[i]]$,并枚举 $key[i-1]$ 在 $ring$ 中的位置列表 $pos[key[i-1]]$,然后更新 $f[i][j]$,即 $f[i][j]=\min_{k \in pos[key[i-1]]} f[i-1][k] + \min(\textit{abs}(j - k), n - \textit{abs}(j - k)) + 1$。
最后,我们返回 $\min_{0 \leq j \lt n} f[m - 1][j]$ 即可。
diff --git a/solution/0500-0599/0514.Freedom Trail/README_EN.md b/solution/0500-0599/0514.Freedom Trail/README_EN.md
index fa2703896e2d1..c71e89f108e0d 100644
--- a/solution/0500-0599/0514.Freedom Trail/README_EN.md
+++ b/solution/0500-0599/0514.Freedom Trail/README_EN.md
@@ -75,7 +75,7 @@ Then we define $f[i][j]$ as the minimum number of steps to spell the first $i+1$
We can first initialize $f[0][j]$, where $j$ is the position where the character $key[0]$ appears in $ring$. Since the $j$-th character of $ring$ is aligned with the $12:00$ direction, we only need $1$ step to spell $key[0]$. In addition, we need $min(j, n - j)$ steps to rotate $ring$ to the $12:00$ direction. Therefore, $f[0][j]=min(j, n - j) + 1$.
-Next, we consider how the state transitions when $i \geq 1$. We can enumerate the position list $pos[key[i]]$ where $key[i]$ appears in $ring$, and enumerate the position list $pos[key[i-1]]$ where $key[i-1]$ appears in $ring$, and then update $f[i][j]$, i.e., $f[i][j]=\min_{k \in pos[key[i-1]]} f[i-1][k] + \min(\text{abs}(j - k), n - \text{abs}(j - k)) + 1$.
+Next, we consider how the state transitions when $i \geq 1$. We can enumerate the position list $pos[key[i]]$ where $key[i]$ appears in $ring$, and enumerate the position list $pos[key[i-1]]$ where $key[i-1]$ appears in $ring$, and then update $f[i][j]$, i.e., $f[i][j]=\min_{k \in pos[key[i-1]]} f[i-1][k] + \min(\textit{abs}(j - k), n - \textit{abs}(j - k)) + 1$.
Finally, we return $\min_{0 \leq j \lt n} f[m - 1][j]$.
diff --git a/solution/0500-0599/0517.Super Washing Machines/README.md b/solution/0500-0599/0517.Super Washing Machines/README.md
index 059d32586a40b..f393ab044ed55 100644
--- a/solution/0500-0599/0517.Super Washing Machines/README.md
+++ b/solution/0500-0599/0517.Super Washing Machines/README.md
@@ -77,7 +77,7 @@ tags:
否则,假设洗衣机内的衣服总数为 $s$,那么最终每台洗衣机内的衣服数量都会变为 $k = s / n$。
-我们定义 $a_i$ 为第 $i$ 台洗衣机内的衣服数量与 $k$ 的差值,即 $a_i = \text{machines}[i] - k$。若 $a_i > 0$,则表示第 $i$ 台洗衣机内有多余的衣服,需要向相邻的洗衣机传递;若 $a_i < 0$,则表示第 $i$ 台洗衣机内缺少衣服,需要从相邻的洗衣机获得。
+我们定义 $a_i$ 为第 $i$ 台洗衣机内的衣服数量与 $k$ 的差值,即 $a_i = \textit{machines}[i] - k$。若 $a_i > 0$,则表示第 $i$ 台洗衣机内有多余的衣服,需要向相邻的洗衣机传递;若 $a_i < 0$,则表示第 $i$ 台洗衣机内缺少衣服,需要从相邻的洗衣机获得。
我们将前 $i$ 台洗衣机的衣服数量差值之和定义为 $s_i = \sum_{j=0}^{i-1} a_j$,如果把前 $i$ 台洗衣机视为一组,其余的洗衣机视为另一组。那么若 $s_i$ 为正数,表示第一组洗衣机内有多余的衣服,需要向第二组洗衣机传递;若 $s_i$ 为负数,表示第一组洗衣机内缺少衣服,需要从第二组洗衣机获得。
diff --git a/solution/0500-0599/0517.Super Washing Machines/README_EN.md b/solution/0500-0599/0517.Super Washing Machines/README_EN.md
index 3952e5cc518ca..2977a8a153c0e 100644
--- a/solution/0500-0599/0517.Super Washing Machines/README_EN.md
+++ b/solution/0500-0599/0517.Super Washing Machines/README_EN.md
@@ -75,7 +75,7 @@ If the total number of clothes in the washing machines cannot be divided evenly
Otherwise, suppose the total number of clothes in the washing machines is $s$, then the number of clothes in each washing machine will eventually become $k = s / n$.
-We define $a_i$ as the difference between the number of clothes in the $i$-th washing machine and $k$, that is, $a_i = \text{machines}[i] - k$. If $a_i > 0$, it means that the $i$-th washing machine has extra clothes and needs to pass them to the adjacent washing machine; if $a_i < 0$, it means that the $i$-th washing machine lacks clothes and needs to get them from the adjacent washing machine.
+We define $a_i$ as the difference between the number of clothes in the $i$-th washing machine and $k$, that is, $a_i = \textit{machines}[i] - k$. If $a_i > 0$, it means that the $i$-th washing machine has extra clothes and needs to pass them to the adjacent washing machine; if $a_i < 0$, it means that the $i$-th washing machine lacks clothes and needs to get them from the adjacent washing machine.
We define the sum of the differences in the number of clothes in the first $i$ washing machines as $s_i = \sum_{j=0}^{i-1} a_j$. If we regard the first $i$ washing machines as one group and the remaining washing machines as another group. Then if $s_i$ is a positive number, it means that the first group of washing machines has extra clothes and needs to pass them to the second group of washing machines; if $s_i$ is a negative number, it means that the first group of washing machines lacks clothes and needs to get them from the second group of washing machines.
diff --git a/solution/0500-0599/0523.Continuous Subarray Sum/README.md b/solution/0500-0599/0523.Continuous Subarray Sum/README.md
index 5fa616e1e822c..6b96ec4b64700 100644
--- a/solution/0500-0599/0523.Continuous Subarray Sum/README.md
+++ b/solution/0500-0599/0523.Continuous Subarray Sum/README.md
@@ -79,15 +79,15 @@ tags:
### 方法一:前缀和 + 哈希表
-根据题目描述,如果存在两个前缀和模 $k$ 的余数相同的位置 $i$ 和 $j$(不妨设 $j < i$),那么 $\text{nums}[j+1..i]$ 这个子数组的和是 $k$ 的倍数。
+根据题目描述,如果存在两个前缀和模 $k$ 的余数相同的位置 $i$ 和 $j$(不妨设 $j < i$),那么 $\textit{nums}[j+1..i]$ 这个子数组的和是 $k$ 的倍数。
因此,我们可以使用哈希表存储每个前缀和模 $k$ 的余数第一次出现的位置。初始时,我们在哈希表中存入一对键值对 $(0, -1)$,表示前缀和为 $0$ 的余数 $0$ 出现在位置 $-1$。
-遍历数组时,我们计算当前前缀和的模 $k$ 的余数,如果当前前缀和的模 $k$ 的余数没有在哈希表中出现过,我们就将当前前缀和的模 $k$ 的余数和对应的位置存入哈希表中。否则,如果当前前缀和的模 $k$ 的余数在哈希表中已经出现过,位置为 $j$,那么我们就找到了一个满足条件的子数组 $\text{nums}[j+1..i]$,因此返回 $\text{True}$。
+遍历数组时,我们计算当前前缀和的模 $k$ 的余数,如果当前前缀和的模 $k$ 的余数没有在哈希表中出现过,我们就将当前前缀和的模 $k$ 的余数和对应的位置存入哈希表中。否则,如果当前前缀和的模 $k$ 的余数在哈希表中已经出现过,位置为 $j$,那么我们就找到了一个满足条件的子数组 $\textit{nums}[j+1..i]$,因此返回 $\textit{True}$。
-遍历结束后,如果没有找到满足条件的子数组,我们返回 $\text{False}$。
+遍历结束后,如果没有找到满足条件的子数组,我们返回 $\textit{False}$。
-时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是数组 $\text{nums}$ 的长度。
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是数组 $\textit{nums}$ 的长度。
diff --git a/solution/0500-0599/0523.Continuous Subarray Sum/README_EN.md b/solution/0500-0599/0523.Continuous Subarray Sum/README_EN.md
index 00c540a86a7a5..049ef24bff658 100644
--- a/solution/0500-0599/0523.Continuous Subarray Sum/README_EN.md
+++ b/solution/0500-0599/0523.Continuous Subarray Sum/README_EN.md
@@ -78,15 +78,15 @@ tags:
### Solution 1: Prefix Sum + Hash Table
-According to the problem description, if there exist two positions $i$ and $j$ ($j < i$) where the remainders of the prefix sums modulo $k$ are the same, then the sum of the subarray $\text{nums}[j+1..i]$ is a multiple of $k$.
+According to the problem description, if there exist two positions $i$ and $j$ ($j < i$) where the remainders of the prefix sums modulo $k$ are the same, then the sum of the subarray $\textit{nums}[j+1..i]$ is a multiple of $k$.
Therefore, we can use a hash table to store the first occurrence of each remainder of the prefix sum modulo $k$. Initially, we store a key-value pair $(0, -1)$ in the hash table, indicating that the remainder $0$ of the prefix sum $0$ appears at position $-1$.
-As we iterate through the array, we calculate the current prefix sum's remainder modulo $k$. If the current prefix sum's remainder modulo $k$ has not appeared in the hash table, we store the current prefix sum's remainder modulo $k$ and its corresponding position in the hash table. Otherwise, if the current prefix sum's remainder modulo $k$ has already appeared in the hash table at position $j$, then we have found a subarray $\text{nums}[j+1..i]$ that meets the conditions, and thus return $\text{True}$.
+As we iterate through the array, we calculate the current prefix sum's remainder modulo $k$. If the current prefix sum's remainder modulo $k$ has not appeared in the hash table, we store the current prefix sum's remainder modulo $k$ and its corresponding position in the hash table. Otherwise, if the current prefix sum's remainder modulo $k$ has already appeared in the hash table at position $j$, then we have found a subarray $\textit{nums}[j+1..i]$ that meets the conditions, and thus return $\textit{True}$.
-After completing the iteration, if no subarray meeting the conditions is found, we return $\text{False}$.
+After completing the iteration, if no subarray meeting the conditions is found, we return $\textit{False}$.
-The time complexity is $O(n)$, and the space complexity is $O(n)$, where $n$ is the length of the array $\text{nums}$.
+The time complexity is $O(n)$, and the space complexity is $O(n)$, where $n$ is the length of the array $\textit{nums}$.
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/README.md b/solution/0500-0599/0530.Minimum Absolute Difference in BST/README.md
index b5759e2fcdfaa..1c4d16502b73e 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/README.md
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/README.md
@@ -61,7 +61,11 @@ tags:
### 方法一:中序遍历
-中序遍历二叉搜索树,获取当前节点与上个节点差值的最小值即可。
+题目需要我们求任意两个节点值之间的最小差值,而二叉搜索树的中序遍历是一个递增序列,因此我们只需要求中序遍历中相邻两个节点值之间的最小差值即可。
+
+我们可以使用递归的方法来实现中序遍历,过程中用一个变量 $\textit{pre}$ 来保存前一个节点的值,这样我们就可以在遍历的过程中求出相邻两个节点值之间的最小差值。
+
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 为二叉搜索树的节点个数。
@@ -75,17 +79,18 @@ tags:
# self.left = left
# self.right = right
class Solution:
- def getMinimumDifference(self, root: TreeNode) -> int:
- def dfs(root):
+ def getMinimumDifference(self, root: Optional[TreeNode]) -> int:
+ def dfs(root: Optional[TreeNode]):
if root is None:
return
dfs(root.left)
- nonlocal ans, prev
- ans = min(ans, abs(prev - root.val))
- prev = root.val
+ nonlocal pre, ans
+ ans = min(ans, root.val - pre)
+ pre = root.val
dfs(root.right)
- ans = prev = inf
+ pre = -inf
+ ans = inf
dfs(root)
return ans
```
@@ -109,13 +114,11 @@ class Solution:
* }
*/
class Solution {
- private int ans;
- private int prev;
- private int inf = Integer.MAX_VALUE;
+ private final int inf = 1 << 30;
+ private int ans = inf;
+ private int pre = -inf;
public int getMinimumDifference(TreeNode root) {
- ans = inf;
- prev = inf;
dfs(root);
return ans;
}
@@ -125,8 +128,8 @@ class Solution {
return;
}
dfs(root.left);
- ans = Math.min(ans, Math.abs(root.val - prev));
- prev = root.val;
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
dfs(root.right);
}
}
@@ -148,23 +151,21 @@ class Solution {
*/
class Solution {
public:
- const int inf = INT_MAX;
- int ans;
- int prev;
-
int getMinimumDifference(TreeNode* root) {
- ans = inf, prev = inf;
- dfs(root);
+ const int inf = 1 << 30;
+ int ans = inf, pre = -inf;
+ auto dfs = [&](auto&& dfs, TreeNode* root) -> void {
+ if (!root) {
+ return;
+ }
+ dfs(dfs, root->left);
+ ans = min(ans, root->val - pre);
+ pre = root->val;
+ dfs(dfs, root->right);
+ };
+ dfs(dfs, root);
return ans;
}
-
- void dfs(TreeNode* root) {
- if (!root) return;
- dfs(root->left);
- ans = min(ans, abs(prev - root->val));
- prev = root->val;
- dfs(root->right);
- }
};
```
@@ -180,27 +181,53 @@ public:
* }
*/
func getMinimumDifference(root *TreeNode) int {
- inf := 0x3f3f3f3f
- ans, prev := inf, inf
+ const inf int = 1 << 30
+ ans, pre := inf, -inf
var dfs func(*TreeNode)
dfs = func(root *TreeNode) {
if root == nil {
return
}
dfs(root.Left)
- ans = min(ans, abs(prev-root.Val))
- prev = root.Val
+ ans = min(ans, root.Val-pre)
+ pre = root.Val
dfs(root.Right)
}
dfs(root)
return ans
}
+```
-func abs(x int) int {
- if x < 0 {
- return -x
- }
- return x
+#### TypeScript
+
+```ts
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * val: number
+ * left: TreeNode | null
+ * right: TreeNode | null
+ * constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
+ * }
+ * }
+ */
+
+function getMinimumDifference(root: TreeNode | null): number {
+ let [ans, pre] = [Infinity, -Infinity];
+ const dfs = (root: TreeNode | null) => {
+ if (!root) {
+ return;
+ }
+ dfs(root.left);
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
+ dfs(root.right);
+ };
+ dfs(root);
+ return ans;
}
```
@@ -225,69 +252,59 @@ func abs(x int) int {
// }
// }
// }
-use std::cell::RefCell;
use std::rc::Rc;
+use std::cell::RefCell;
impl Solution {
- #[allow(dead_code)]
pub fn get_minimum_difference(root: Option>>) -> i32 {
- let mut ret = i32::MAX;
- let mut prev = i32::MAX;
- Self::traverse(root, &mut prev, &mut ret);
- ret
- }
-
- #[allow(dead_code)]
- fn traverse(root: Option>>, prev: &mut i32, ans: &mut i32) {
- let left = root.as_ref().unwrap().borrow().left.clone();
- let right = root.as_ref().unwrap().borrow().right.clone();
- let val = root.as_ref().unwrap().borrow().val;
- if !left.is_none() {
- Self::traverse(left.clone(), prev, ans);
- }
- *ans = std::cmp::min(*ans, (*prev - val).abs());
- *prev = val;
- if !right.is_none() {
- Self::traverse(right.clone(), prev, ans);
+ const inf: i32 = 1 << 30;
+ let mut ans = inf;
+ let mut pre = -inf;
+
+ fn dfs(node: Option>>, ans: &mut i32, pre: &mut i32) {
+ if let Some(n) = node {
+ let n = n.borrow();
+ dfs(n.left.clone(), ans, pre);
+ *ans = (*ans).min(n.val - *pre);
+ *pre = n.val;
+ dfs(n.right.clone(), ans, pre);
+ }
}
+
+ dfs(root, &mut ans, &mut pre);
+ ans
}
}
```
-#### TypeScript
+#### JavaScript
-```ts
+```js
/**
* Definition for a binary tree node.
- * class TreeNode {
- * val: number
- * left: TreeNode | null
- * right: TreeNode | null
- * constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {
- * this.val = (val===undefined ? 0 : val)
- * this.left = (left===undefined ? null : left)
- * this.right = (right===undefined ? null : right)
- * }
+ * function TreeNode(val, left, right) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
* }
*/
-function getMinimumDifference(root: TreeNode | null): number {
- if (!root) return 0;
-
- let prev = Number.MIN_SAFE_INTEGER;
- let min = Number.MAX_SAFE_INTEGER;
-
- const dfs = (node: TreeNode | null) => {
- if (!node) return;
-
- dfs(node.left);
- min = Math.min(min, node.val - prev);
- prev = node.val;
- dfs(node.right);
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var getMinimumDifference = function (root) {
+ let [ans, pre] = [Infinity, -Infinity];
+ const dfs = root => {
+ if (!root) {
+ return;
+ }
+ dfs(root.left);
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
+ dfs(root.right);
};
-
dfs(root);
-
- return min;
-}
+ return ans;
+};
```
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/README_EN.md b/solution/0500-0599/0530.Minimum Absolute Difference in BST/README_EN.md
index c844437fd016a..ee82a161f1f67 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/README_EN.md
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/README_EN.md
@@ -54,7 +54,13 @@ tags:
-### Solution 1
+### Solution 1: Inorder Traversal
+
+The problem requires us to find the minimum difference between the values of any two nodes. Since the inorder traversal of a binary search tree is an increasing sequence, we only need to find the minimum difference between the values of two adjacent nodes in the inorder traversal.
+
+We can use a recursive method to implement the inorder traversal. During the process, we use a variable $\textit{pre}$ to save the value of the previous node. This way, we can calculate the minimum difference between the values of two adjacent nodes during the traversal.
+
+The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the number of nodes in the binary search tree.
@@ -68,17 +74,18 @@ tags:
# self.left = left
# self.right = right
class Solution:
- def getMinimumDifference(self, root: TreeNode) -> int:
- def dfs(root):
+ def getMinimumDifference(self, root: Optional[TreeNode]) -> int:
+ def dfs(root: Optional[TreeNode]):
if root is None:
return
dfs(root.left)
- nonlocal ans, prev
- ans = min(ans, abs(prev - root.val))
- prev = root.val
+ nonlocal pre, ans
+ ans = min(ans, root.val - pre)
+ pre = root.val
dfs(root.right)
- ans = prev = inf
+ pre = -inf
+ ans = inf
dfs(root)
return ans
```
@@ -102,13 +109,11 @@ class Solution:
* }
*/
class Solution {
- private int ans;
- private int prev;
- private int inf = Integer.MAX_VALUE;
+ private final int inf = 1 << 30;
+ private int ans = inf;
+ private int pre = -inf;
public int getMinimumDifference(TreeNode root) {
- ans = inf;
- prev = inf;
dfs(root);
return ans;
}
@@ -118,8 +123,8 @@ class Solution {
return;
}
dfs(root.left);
- ans = Math.min(ans, Math.abs(root.val - prev));
- prev = root.val;
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
dfs(root.right);
}
}
@@ -141,23 +146,21 @@ class Solution {
*/
class Solution {
public:
- const int inf = INT_MAX;
- int ans;
- int prev;
-
int getMinimumDifference(TreeNode* root) {
- ans = inf, prev = inf;
- dfs(root);
+ const int inf = 1 << 30;
+ int ans = inf, pre = -inf;
+ auto dfs = [&](auto&& dfs, TreeNode* root) -> void {
+ if (!root) {
+ return;
+ }
+ dfs(dfs, root->left);
+ ans = min(ans, root->val - pre);
+ pre = root->val;
+ dfs(dfs, root->right);
+ };
+ dfs(dfs, root);
return ans;
}
-
- void dfs(TreeNode* root) {
- if (!root) return;
- dfs(root->left);
- ans = min(ans, abs(prev - root->val));
- prev = root->val;
- dfs(root->right);
- }
};
```
@@ -173,27 +176,53 @@ public:
* }
*/
func getMinimumDifference(root *TreeNode) int {
- inf := 0x3f3f3f3f
- ans, prev := inf, inf
+ const inf int = 1 << 30
+ ans, pre := inf, -inf
var dfs func(*TreeNode)
dfs = func(root *TreeNode) {
if root == nil {
return
}
dfs(root.Left)
- ans = min(ans, abs(prev-root.Val))
- prev = root.Val
+ ans = min(ans, root.Val-pre)
+ pre = root.Val
dfs(root.Right)
}
dfs(root)
return ans
}
+```
-func abs(x int) int {
- if x < 0 {
- return -x
- }
- return x
+#### TypeScript
+
+```ts
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * val: number
+ * left: TreeNode | null
+ * right: TreeNode | null
+ * constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
+ * }
+ * }
+ */
+
+function getMinimumDifference(root: TreeNode | null): number {
+ let [ans, pre] = [Infinity, -Infinity];
+ const dfs = (root: TreeNode | null) => {
+ if (!root) {
+ return;
+ }
+ dfs(root.left);
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
+ dfs(root.right);
+ };
+ dfs(root);
+ return ans;
}
```
@@ -218,69 +247,59 @@ func abs(x int) int {
// }
// }
// }
-use std::cell::RefCell;
use std::rc::Rc;
+use std::cell::RefCell;
impl Solution {
- #[allow(dead_code)]
pub fn get_minimum_difference(root: Option>>) -> i32 {
- let mut ret = i32::MAX;
- let mut prev = i32::MAX;
- Self::traverse(root, &mut prev, &mut ret);
- ret
- }
-
- #[allow(dead_code)]
- fn traverse(root: Option>>, prev: &mut i32, ans: &mut i32) {
- let left = root.as_ref().unwrap().borrow().left.clone();
- let right = root.as_ref().unwrap().borrow().right.clone();
- let val = root.as_ref().unwrap().borrow().val;
- if !left.is_none() {
- Self::traverse(left.clone(), prev, ans);
- }
- *ans = std::cmp::min(*ans, (*prev - val).abs());
- *prev = val;
- if !right.is_none() {
- Self::traverse(right.clone(), prev, ans);
+ const inf: i32 = 1 << 30;
+ let mut ans = inf;
+ let mut pre = -inf;
+
+ fn dfs(node: Option>>, ans: &mut i32, pre: &mut i32) {
+ if let Some(n) = node {
+ let n = n.borrow();
+ dfs(n.left.clone(), ans, pre);
+ *ans = (*ans).min(n.val - *pre);
+ *pre = n.val;
+ dfs(n.right.clone(), ans, pre);
+ }
}
+
+ dfs(root, &mut ans, &mut pre);
+ ans
}
}
```
-#### TypeScript
+#### JavaScript
-```ts
+```js
/**
* Definition for a binary tree node.
- * class TreeNode {
- * val: number
- * left: TreeNode | null
- * right: TreeNode | null
- * constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {
- * this.val = (val===undefined ? 0 : val)
- * this.left = (left===undefined ? null : left)
- * this.right = (right===undefined ? null : right)
- * }
+ * function TreeNode(val, left, right) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
* }
*/
-function getMinimumDifference(root: TreeNode | null): number {
- if (!root) return 0;
-
- let prev = Number.MIN_SAFE_INTEGER;
- let min = Number.MAX_SAFE_INTEGER;
-
- const dfs = (node: TreeNode | null) => {
- if (!node) return;
-
- dfs(node.left);
- min = Math.min(min, node.val - prev);
- prev = node.val;
- dfs(node.right);
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var getMinimumDifference = function (root) {
+ let [ans, pre] = [Infinity, -Infinity];
+ const dfs = root => {
+ if (!root) {
+ return;
+ }
+ dfs(root.left);
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
+ dfs(root.right);
};
-
dfs(root);
-
- return min;
-}
+ return ans;
+};
```
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.cpp b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.cpp
index 578e0615cd4b2..aefc98065b5ba 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.cpp
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.cpp
@@ -11,21 +11,19 @@
*/
class Solution {
public:
- const int inf = INT_MAX;
- int ans;
- int prev;
-
int getMinimumDifference(TreeNode* root) {
- ans = inf, prev = inf;
- dfs(root);
+ const int inf = 1 << 30;
+ int ans = inf, pre = -inf;
+ auto dfs = [&](auto&& dfs, TreeNode* root) -> void {
+ if (!root) {
+ return;
+ }
+ dfs(dfs, root->left);
+ ans = min(ans, root->val - pre);
+ pre = root->val;
+ dfs(dfs, root->right);
+ };
+ dfs(dfs, root);
return ans;
}
-
- void dfs(TreeNode* root) {
- if (!root) return;
- dfs(root->left);
- ans = min(ans, abs(prev - root->val));
- prev = root->val;
- dfs(root->right);
- }
};
\ No newline at end of file
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.go b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.go
index 7d7440f7d846b..f007348398b7b 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.go
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.go
@@ -7,25 +7,18 @@
* }
*/
func getMinimumDifference(root *TreeNode) int {
- inf := 0x3f3f3f3f
- ans, prev := inf, inf
+ const inf int = 1 << 30
+ ans, pre := inf, -inf
var dfs func(*TreeNode)
dfs = func(root *TreeNode) {
if root == nil {
return
}
dfs(root.Left)
- ans = min(ans, abs(prev-root.Val))
- prev = root.Val
+ ans = min(ans, root.Val-pre)
+ pre = root.Val
dfs(root.Right)
}
dfs(root)
return ans
-}
-
-func abs(x int) int {
- if x < 0 {
- return -x
- }
- return x
}
\ No newline at end of file
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.java b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.java
index 190ac5efddae7..3b0b489278000 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.java
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.java
@@ -14,13 +14,11 @@
* }
*/
class Solution {
- private int ans;
- private int prev;
- private int inf = Integer.MAX_VALUE;
+ private final int inf = 1 << 30;
+ private int ans = inf;
+ private int pre = -inf;
public int getMinimumDifference(TreeNode root) {
- ans = inf;
- prev = inf;
dfs(root);
return ans;
}
@@ -30,8 +28,8 @@ private void dfs(TreeNode root) {
return;
}
dfs(root.left);
- ans = Math.min(ans, Math.abs(root.val - prev));
- prev = root.val;
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
dfs(root.right);
}
}
\ No newline at end of file
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.js b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.js
new file mode 100644
index 0000000000000..ff16b30be4a69
--- /dev/null
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.js
@@ -0,0 +1,26 @@
+/**
+ * Definition for a binary tree node.
+ * function TreeNode(val, left, right) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
+ * }
+ */
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var getMinimumDifference = function (root) {
+ let [ans, pre] = [Infinity, -Infinity];
+ const dfs = root => {
+ if (!root) {
+ return;
+ }
+ dfs(root.left);
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
+ dfs(root.right);
+ };
+ dfs(root);
+ return ans;
+};
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.py b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.py
index eda3e769918d4..7862484bd303c 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.py
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.py
@@ -5,16 +5,17 @@
# self.left = left
# self.right = right
class Solution:
- def getMinimumDifference(self, root: TreeNode) -> int:
- def dfs(root):
+ def getMinimumDifference(self, root: Optional[TreeNode]) -> int:
+ def dfs(root: Optional[TreeNode]):
if root is None:
return
dfs(root.left)
- nonlocal ans, prev
- ans = min(ans, abs(prev - root.val))
- prev = root.val
+ nonlocal pre, ans
+ ans = min(ans, root.val - pre)
+ pre = root.val
dfs(root.right)
- ans = prev = inf
+ pre = -inf
+ ans = inf
dfs(root)
return ans
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.rs b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.rs
index cf5396d9060ed..1deee6d8efca7 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.rs
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.rs
@@ -19,26 +19,22 @@
use std::cell::RefCell;
use std::rc::Rc;
impl Solution {
- #[allow(dead_code)]
pub fn get_minimum_difference(root: Option>>) -> i32 {
- let mut ret = i32::MAX;
- let mut prev = i32::MAX;
- Self::traverse(root, &mut prev, &mut ret);
- ret
- }
+ const inf: i32 = 1 << 30;
+ let mut ans = inf;
+ let mut pre = -inf;
- #[allow(dead_code)]
- fn traverse(root: Option>>, prev: &mut i32, ans: &mut i32) {
- let left = root.as_ref().unwrap().borrow().left.clone();
- let right = root.as_ref().unwrap().borrow().right.clone();
- let val = root.as_ref().unwrap().borrow().val;
- if !left.is_none() {
- Self::traverse(left.clone(), prev, ans);
- }
- *ans = std::cmp::min(*ans, (*prev - val).abs());
- *prev = val;
- if !right.is_none() {
- Self::traverse(right.clone(), prev, ans);
+ fn dfs(node: Option>>, ans: &mut i32, pre: &mut i32) {
+ if let Some(n) = node {
+ let n = n.borrow();
+ dfs(n.left.clone(), ans, pre);
+ *ans = (*ans).min(n.val - *pre);
+ *pre = n.val;
+ dfs(n.right.clone(), ans, pre);
+ }
}
+
+ dfs(root, &mut ans, &mut pre);
+ ans
}
}
diff --git a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.ts b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.ts
index 61275353165c6..c4d98f25156f3 100644
--- a/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.ts
+++ b/solution/0500-0599/0530.Minimum Absolute Difference in BST/Solution.ts
@@ -11,22 +11,18 @@
* }
* }
*/
-function getMinimumDifference(root: TreeNode | null): number {
- if (!root) return 0;
-
- let prev = Number.MIN_SAFE_INTEGER;
- let min = Number.MAX_SAFE_INTEGER;
-
- const dfs = (node: TreeNode | null) => {
- if (!node) return;
- dfs(node.left);
- min = Math.min(min, node.val - prev);
- prev = node.val;
- dfs(node.right);
+function getMinimumDifference(root: TreeNode | null): number {
+ let [ans, pre] = [Infinity, -Infinity];
+ const dfs = (root: TreeNode | null) => {
+ if (!root) {
+ return;
+ }
+ dfs(root.left);
+ ans = Math.min(ans, root.val - pre);
+ pre = root.val;
+ dfs(root.right);
};
-
dfs(root);
-
- return min;
+ return ans;
}
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/README.md b/solution/0500-0599/0537.Complex Number Multiplication/README.md
index c14888e5658fa..1444dc1d55c38 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/README.md
+++ b/solution/0500-0599/0537.Complex Number Multiplication/README.md
@@ -60,7 +60,11 @@ tags:
-### 方法一
+### 方法一:模拟
+
+我们可以将复数字符串转换成对应的实部 $a$ 和虚部 $b$,然后根据复数乘法的公式 $(a_1 + b_1i) \times (a_2 + b_2i) = (a_1a_2 - b_1b_2) + (a_1b_2 + a_2b_1)i$ 计算出结果。
+
+时间复杂度 $O(1)$,空间复杂度 $O(1)$。
@@ -69,9 +73,9 @@ tags:
```python
class Solution:
def complexNumberMultiply(self, num1: str, num2: str) -> str:
- a, b = map(int, num1[:-1].split('+'))
- c, d = map(int, num2[:-1].split('+'))
- return f'{a * c - b * d}+{a * d + c * b}i'
+ a1, b1 = map(int, num1[:-1].split("+"))
+ a2, b2 = map(int, num2[:-1].split("+"))
+ return f"{a1 * a2 - b1 * b2}+{a1 * b2 + a2 * b1}i"
```
#### Java
@@ -79,13 +83,15 @@ class Solution:
```java
class Solution {
public String complexNumberMultiply(String num1, String num2) {
- String[] c1 = num1.split("\\+|i");
- String[] c2 = num2.split("\\+|i");
- int a = Integer.parseInt(c1[0]);
- int b = Integer.parseInt(c1[1]);
- int c = Integer.parseInt(c2[0]);
- int d = Integer.parseInt(c2[1]);
- return String.format("%d+%di", a * c - b * d, a * d + c * b);
+ int[] x = parse(num1);
+ int[] y = parse(num2);
+ int a1 = x[0], b1 = x[1], a2 = y[0], b2 = y[1];
+ return (a1 * a2 - b1 * b2) + "+" + (a1 * b2 + a2 * b1) + "i";
+ }
+
+ private int[] parse(String s) {
+ var cs = s.substring(0, s.length() - 1).split("\\+");
+ return new int[] {Integer.parseInt(cs[0]), Integer.parseInt(cs[1])};
}
}
```
@@ -96,10 +102,10 @@ class Solution {
class Solution {
public:
string complexNumberMultiply(string num1, string num2) {
- int a, b, c, d;
- sscanf(num1.c_str(), "%d+%di", &a, &b);
- sscanf(num2.c_str(), "%d+%di", &c, &d);
- return string(to_string(a * c - b * d) + "+" + to_string(a * d + c * b) + "i");
+ int a1, b1, a2, b2;
+ sscanf(num1.c_str(), "%d+%di", &a1, &b1);
+ sscanf(num2.c_str(), "%d+%di", &a2, &b2);
+ return to_string(a1 * a2 - b1 * b2) + "+" + to_string(a1 * b2 + a2 * b1) + "i";
}
};
```
@@ -107,16 +113,10 @@ public:
#### Go
```go
-func complexNumberMultiply(num1, num2 string) string {
- parse := func(num string) (a, b int) {
- i := strings.IndexByte(num, '+')
- a, _ = strconv.Atoi(num[:i])
- b, _ = strconv.Atoi(num[i+1 : len(num)-1])
- return
- }
- a, b := parse(num1)
- c, d := parse(num2)
- return fmt.Sprintf("%d+%di", a*c-b*d, a*d+b*c)
+func complexNumberMultiply(num1 string, num2 string) string {
+ x, _ := strconv.ParseComplex(num1, 64)
+ y, _ := strconv.ParseComplex(num2, 64)
+ return fmt.Sprintf("%d+%di", int(real(x*y)), int(imag(x*y)))
}
```
@@ -124,15 +124,9 @@ func complexNumberMultiply(num1, num2 string) string {
```ts
function complexNumberMultiply(num1: string, num2: string): string {
- let arr1 = num1.split('+'),
- arr2 = num2.split('+');
- let r1 = Number(arr1[0]),
- r2 = Number(arr2[0]);
- let v1 = Number(arr1[1].substring(0, arr1[1].length - 1)),
- v2 = Number(arr2[1].substring(0, arr2[1].length - 1));
- let ansR = r1 * r2 - v1 * v2;
- let ansV = r1 * v2 + r2 * v1;
- return `${ansR}+${ansV}i`;
+ const [a1, b1] = num1.slice(0, -1).split('+').map(Number);
+ const [a2, b2] = num2.slice(0, -1).split('+').map(Number);
+ return `${a1 * a2 - b1 * b2}+${a1 * b2 + a2 * b1}i`;
}
```
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/README_EN.md b/solution/0500-0599/0537.Complex Number Multiplication/README_EN.md
index 0a60653680fb9..a33b5e90c1c2c 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/README_EN.md
+++ b/solution/0500-0599/0537.Complex Number Multiplication/README_EN.md
@@ -58,7 +58,11 @@ tags:
-### Solution 1
+### Solution 1: Simulation
+
+We can convert the complex number string into its real part $a$ and imaginary part $b$, and then use the formula for complex number multiplication $(a_1 + b_1i) \times (a_2 + b_2i) = (a_1a_2 - b_1b_2) + (a_1b_2 + a_2b_1)i$ to calculate the result.
+
+The time complexity is $O(1)$, and the space complexity is $O(1)$.
@@ -67,9 +71,9 @@ tags:
```python
class Solution:
def complexNumberMultiply(self, num1: str, num2: str) -> str:
- a, b = map(int, num1[:-1].split('+'))
- c, d = map(int, num2[:-1].split('+'))
- return f'{a * c - b * d}+{a * d + c * b}i'
+ a1, b1 = map(int, num1[:-1].split("+"))
+ a2, b2 = map(int, num2[:-1].split("+"))
+ return f"{a1 * a2 - b1 * b2}+{a1 * b2 + a2 * b1}i"
```
#### Java
@@ -77,13 +81,15 @@ class Solution:
```java
class Solution {
public String complexNumberMultiply(String num1, String num2) {
- String[] c1 = num1.split("\\+|i");
- String[] c2 = num2.split("\\+|i");
- int a = Integer.parseInt(c1[0]);
- int b = Integer.parseInt(c1[1]);
- int c = Integer.parseInt(c2[0]);
- int d = Integer.parseInt(c2[1]);
- return String.format("%d+%di", a * c - b * d, a * d + c * b);
+ int[] x = parse(num1);
+ int[] y = parse(num2);
+ int a1 = x[0], b1 = x[1], a2 = y[0], b2 = y[1];
+ return (a1 * a2 - b1 * b2) + "+" + (a1 * b2 + a2 * b1) + "i";
+ }
+
+ private int[] parse(String s) {
+ var cs = s.substring(0, s.length() - 1).split("\\+");
+ return new int[] {Integer.parseInt(cs[0]), Integer.parseInt(cs[1])};
}
}
```
@@ -94,10 +100,10 @@ class Solution {
class Solution {
public:
string complexNumberMultiply(string num1, string num2) {
- int a, b, c, d;
- sscanf(num1.c_str(), "%d+%di", &a, &b);
- sscanf(num2.c_str(), "%d+%di", &c, &d);
- return string(to_string(a * c - b * d) + "+" + to_string(a * d + c * b) + "i");
+ int a1, b1, a2, b2;
+ sscanf(num1.c_str(), "%d+%di", &a1, &b1);
+ sscanf(num2.c_str(), "%d+%di", &a2, &b2);
+ return to_string(a1 * a2 - b1 * b2) + "+" + to_string(a1 * b2 + a2 * b1) + "i";
}
};
```
@@ -105,16 +111,10 @@ public:
#### Go
```go
-func complexNumberMultiply(num1, num2 string) string {
- parse := func(num string) (a, b int) {
- i := strings.IndexByte(num, '+')
- a, _ = strconv.Atoi(num[:i])
- b, _ = strconv.Atoi(num[i+1 : len(num)-1])
- return
- }
- a, b := parse(num1)
- c, d := parse(num2)
- return fmt.Sprintf("%d+%di", a*c-b*d, a*d+b*c)
+func complexNumberMultiply(num1 string, num2 string) string {
+ x, _ := strconv.ParseComplex(num1, 64)
+ y, _ := strconv.ParseComplex(num2, 64)
+ return fmt.Sprintf("%d+%di", int(real(x*y)), int(imag(x*y)))
}
```
@@ -122,15 +122,9 @@ func complexNumberMultiply(num1, num2 string) string {
```ts
function complexNumberMultiply(num1: string, num2: string): string {
- let arr1 = num1.split('+'),
- arr2 = num2.split('+');
- let r1 = Number(arr1[0]),
- r2 = Number(arr2[0]);
- let v1 = Number(arr1[1].substring(0, arr1[1].length - 1)),
- v2 = Number(arr2[1].substring(0, arr2[1].length - 1));
- let ansR = r1 * r2 - v1 * v2;
- let ansV = r1 * v2 + r2 * v1;
- return `${ansR}+${ansV}i`;
+ const [a1, b1] = num1.slice(0, -1).split('+').map(Number);
+ const [a2, b2] = num2.slice(0, -1).split('+').map(Number);
+ return `${a1 * a2 - b1 * b2}+${a1 * b2 + a2 * b1}i`;
}
```
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/Solution.cpp b/solution/0500-0599/0537.Complex Number Multiplication/Solution.cpp
index 6d495a4f8cb92..a92eb2ea4aa95 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/Solution.cpp
+++ b/solution/0500-0599/0537.Complex Number Multiplication/Solution.cpp
@@ -1,9 +1,9 @@
class Solution {
public:
string complexNumberMultiply(string num1, string num2) {
- int a, b, c, d;
- sscanf(num1.c_str(), "%d+%di", &a, &b);
- sscanf(num2.c_str(), "%d+%di", &c, &d);
- return string(to_string(a * c - b * d) + "+" + to_string(a * d + c * b) + "i");
+ int a1, b1, a2, b2;
+ sscanf(num1.c_str(), "%d+%di", &a1, &b1);
+ sscanf(num2.c_str(), "%d+%di", &a2, &b2);
+ return to_string(a1 * a2 - b1 * b2) + "+" + to_string(a1 * b2 + a2 * b1) + "i";
}
};
\ No newline at end of file
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/Solution.go b/solution/0500-0599/0537.Complex Number Multiplication/Solution.go
index 78ff5f4b1484d..70a3125794f4b 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/Solution.go
+++ b/solution/0500-0599/0537.Complex Number Multiplication/Solution.go
@@ -1,11 +1,5 @@
-func complexNumberMultiply(num1, num2 string) string {
- parse := func(num string) (a, b int) {
- i := strings.IndexByte(num, '+')
- a, _ = strconv.Atoi(num[:i])
- b, _ = strconv.Atoi(num[i+1 : len(num)-1])
- return
- }
- a, b := parse(num1)
- c, d := parse(num2)
- return fmt.Sprintf("%d+%di", a*c-b*d, a*d+b*c)
+func complexNumberMultiply(num1 string, num2 string) string {
+ x, _ := strconv.ParseComplex(num1, 64)
+ y, _ := strconv.ParseComplex(num2, 64)
+ return fmt.Sprintf("%d+%di", int(real(x*y)), int(imag(x*y)))
}
\ No newline at end of file
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/Solution.java b/solution/0500-0599/0537.Complex Number Multiplication/Solution.java
index 92b77ace32f6f..570b3092f4e1e 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/Solution.java
+++ b/solution/0500-0599/0537.Complex Number Multiplication/Solution.java
@@ -1,11 +1,13 @@
class Solution {
public String complexNumberMultiply(String num1, String num2) {
- String[] c1 = num1.split("\\+|i");
- String[] c2 = num2.split("\\+|i");
- int a = Integer.parseInt(c1[0]);
- int b = Integer.parseInt(c1[1]);
- int c = Integer.parseInt(c2[0]);
- int d = Integer.parseInt(c2[1]);
- return String.format("%d+%di", a * c - b * d, a * d + c * b);
+ int[] x = parse(num1);
+ int[] y = parse(num2);
+ int a1 = x[0], b1 = x[1], a2 = y[0], b2 = y[1];
+ return (a1 * a2 - b1 * b2) + "+" + (a1 * b2 + a2 * b1) + "i";
+ }
+
+ private int[] parse(String s) {
+ var cs = s.substring(0, s.length() - 1).split("\\+");
+ return new int[] {Integer.parseInt(cs[0]), Integer.parseInt(cs[1])};
}
}
\ No newline at end of file
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/Solution.py b/solution/0500-0599/0537.Complex Number Multiplication/Solution.py
index 6513c069de99a..8263fe6e32c16 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/Solution.py
+++ b/solution/0500-0599/0537.Complex Number Multiplication/Solution.py
@@ -1,5 +1,5 @@
class Solution:
def complexNumberMultiply(self, num1: str, num2: str) -> str:
- a, b = map(int, num1[:-1].split('+'))
- c, d = map(int, num2[:-1].split('+'))
- return f'{a * c - b * d}+{a * d + c * b}i'
+ a1, b1 = map(int, num1[:-1].split("+"))
+ a2, b2 = map(int, num2[:-1].split("+"))
+ return f"{a1 * a2 - b1 * b2}+{a1 * b2 + a2 * b1}i"
diff --git a/solution/0500-0599/0537.Complex Number Multiplication/Solution.ts b/solution/0500-0599/0537.Complex Number Multiplication/Solution.ts
index 0c0589ad52678..1313663055aad 100644
--- a/solution/0500-0599/0537.Complex Number Multiplication/Solution.ts
+++ b/solution/0500-0599/0537.Complex Number Multiplication/Solution.ts
@@ -1,11 +1,5 @@
function complexNumberMultiply(num1: string, num2: string): string {
- let arr1 = num1.split('+'),
- arr2 = num2.split('+');
- let r1 = Number(arr1[0]),
- r2 = Number(arr2[0]);
- let v1 = Number(arr1[1].substring(0, arr1[1].length - 1)),
- v2 = Number(arr2[1].substring(0, arr2[1].length - 1));
- let ansR = r1 * r2 - v1 * v2;
- let ansV = r1 * v2 + r2 * v1;
- return `${ansR}+${ansV}i`;
+ const [a1, b1] = num1.slice(0, -1).split('+').map(Number);
+ const [a2, b2] = num2.slice(0, -1).split('+').map(Number);
+ return `${a1 * a2 - b1 * b2}+${a1 * b2 + a2 * b1}i`;
}
diff --git a/solution/0500-0599/0541.Reverse String II/README.md b/solution/0500-0599/0541.Reverse String II/README.md
index a6a3dfbada4da..34e9a41e10c2a 100644
--- a/solution/0500-0599/0541.Reverse String II/README.md
+++ b/solution/0500-0599/0541.Reverse String II/README.md
@@ -56,7 +56,11 @@ tags:
-### 方法一
+### 方法一:双指针
+
+我们可以遍历字符串 $\textit{s}$,每次遍历 $\textit{2k}$ 个字符,然后利用双指针技巧,对这 $\textit{2k}$ 个字符中的前 $\textit{k}$ 个字符进行反转。
+
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 为字符串 $\textit{s}$ 的长度。
@@ -65,10 +69,10 @@ tags:
```python
class Solution:
def reverseStr(self, s: str, k: int) -> str:
- t = list(s)
- for i in range(0, len(t), k << 1):
- t[i : i + k] = reversed(t[i : i + k])
- return ''.join(t)
+ cs = list(s)
+ for i in range(0, len(cs), 2 * k):
+ cs[i : i + k] = reversed(cs[i : i + k])
+ return "".join(cs)
```
#### Java
@@ -76,15 +80,16 @@ class Solution:
```java
class Solution {
public String reverseStr(String s, int k) {
- char[] chars = s.toCharArray();
- for (int i = 0; i < chars.length; i += (k << 1)) {
- for (int st = i, ed = Math.min(chars.length - 1, i + k - 1); st < ed; ++st, --ed) {
- char t = chars[st];
- chars[st] = chars[ed];
- chars[ed] = t;
+ char[] cs = s.toCharArray();
+ int n = cs.length;
+ for (int i = 0; i < n; i += k * 2) {
+ for (int l = i, r = Math.min(i + k - 1, n - 1); l < r; ++l, --r) {
+ char t = cs[l];
+ cs[l] = cs[r];
+ cs[r] = t;
}
}
- return new String(chars);
+ return new String(cs);
}
}
```
@@ -95,7 +100,8 @@ class Solution {
class Solution {
public:
string reverseStr(string s, int k) {
- for (int i = 0, n = s.size(); i < n; i += (k << 1)) {
+ int n = s.size();
+ for (int i = 0; i < n; i += 2 * k) {
reverse(s.begin() + i, s.begin() + min(i + k, n));
}
return s;
@@ -107,13 +113,29 @@ public:
```go
func reverseStr(s string, k int) string {
- t := []byte(s)
- for i := 0; i < len(t); i += (k << 1) {
- for st, ed := i, min(i+k-1, len(t)-1); st < ed; st, ed = st+1, ed-1 {
- t[st], t[ed] = t[ed], t[st]
+ cs := []byte(s)
+ n := len(cs)
+ for i := 0; i < n; i += 2 * k {
+ for l, r := i, min(i+k-1, n-1); l < r; l, r = l+1, r-1 {
+ cs[l], cs[r] = cs[r], cs[l]
}
}
- return string(t)
+ return string(cs)
+}
+```
+
+#### TypeScript
+
+```ts
+function reverseStr(s: string, k: number): string {
+ const n = s.length;
+ const cs = s.split('');
+ for (let i = 0; i < n; i += 2 * k) {
+ for (let l = i, r = Math.min(i + k - 1, n - 1); l < r; l++, r--) {
+ [cs[l], cs[r]] = [cs[r], cs[l]];
+ }
+ }
+ return cs.join('');
}
```
diff --git a/solution/0500-0599/0541.Reverse String II/README_EN.md b/solution/0500-0599/0541.Reverse String II/README_EN.md
index 5923f43e1fe5b..4570c4d6afaec 100644
--- a/solution/0500-0599/0541.Reverse String II/README_EN.md
+++ b/solution/0500-0599/0541.Reverse String II/README_EN.md
@@ -44,7 +44,11 @@ tags:
-### Solution 1
+### Solution 1: Two Pointers
+
+We can traverse the string $\textit{s}$, iterating over every $\textit{2k}$ characters, and then use the two-pointer technique to reverse the first $\textit{k}$ characters among these $\textit{2k}$ characters.
+
+The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the length of the string $\textit{s}$.
@@ -53,10 +57,10 @@ tags:
```python
class Solution:
def reverseStr(self, s: str, k: int) -> str:
- t = list(s)
- for i in range(0, len(t), k << 1):
- t[i : i + k] = reversed(t[i : i + k])
- return ''.join(t)
+ cs = list(s)
+ for i in range(0, len(cs), 2 * k):
+ cs[i : i + k] = reversed(cs[i : i + k])
+ return "".join(cs)
```
#### Java
@@ -64,15 +68,16 @@ class Solution:
```java
class Solution {
public String reverseStr(String s, int k) {
- char[] chars = s.toCharArray();
- for (int i = 0; i < chars.length; i += (k << 1)) {
- for (int st = i, ed = Math.min(chars.length - 1, i + k - 1); st < ed; ++st, --ed) {
- char t = chars[st];
- chars[st] = chars[ed];
- chars[ed] = t;
+ char[] cs = s.toCharArray();
+ int n = cs.length;
+ for (int i = 0; i < n; i += k * 2) {
+ for (int l = i, r = Math.min(i + k - 1, n - 1); l < r; ++l, --r) {
+ char t = cs[l];
+ cs[l] = cs[r];
+ cs[r] = t;
}
}
- return new String(chars);
+ return new String(cs);
}
}
```
@@ -83,7 +88,8 @@ class Solution {
class Solution {
public:
string reverseStr(string s, int k) {
- for (int i = 0, n = s.size(); i < n; i += (k << 1)) {
+ int n = s.size();
+ for (int i = 0; i < n; i += 2 * k) {
reverse(s.begin() + i, s.begin() + min(i + k, n));
}
return s;
@@ -95,13 +101,29 @@ public:
```go
func reverseStr(s string, k int) string {
- t := []byte(s)
- for i := 0; i < len(t); i += (k << 1) {
- for st, ed := i, min(i+k-1, len(t)-1); st < ed; st, ed = st+1, ed-1 {
- t[st], t[ed] = t[ed], t[st]
+ cs := []byte(s)
+ n := len(cs)
+ for i := 0; i < n; i += 2 * k {
+ for l, r := i, min(i+k-1, n-1); l < r; l, r = l+1, r-1 {
+ cs[l], cs[r] = cs[r], cs[l]
}
}
- return string(t)
+ return string(cs)
+}
+```
+
+#### TypeScript
+
+```ts
+function reverseStr(s: string, k: number): string {
+ const n = s.length;
+ const cs = s.split('');
+ for (let i = 0; i < n; i += 2 * k) {
+ for (let l = i, r = Math.min(i + k - 1, n - 1); l < r; l++, r--) {
+ [cs[l], cs[r]] = [cs[r], cs[l]];
+ }
+ }
+ return cs.join('');
}
```
diff --git a/solution/0500-0599/0541.Reverse String II/Solution.cpp b/solution/0500-0599/0541.Reverse String II/Solution.cpp
index 528788dee6aad..fb9bca75b1a6e 100644
--- a/solution/0500-0599/0541.Reverse String II/Solution.cpp
+++ b/solution/0500-0599/0541.Reverse String II/Solution.cpp
@@ -1,7 +1,8 @@
class Solution {
public:
string reverseStr(string s, int k) {
- for (int i = 0, n = s.size(); i < n; i += (k << 1)) {
+ int n = s.size();
+ for (int i = 0; i < n; i += 2 * k) {
reverse(s.begin() + i, s.begin() + min(i + k, n));
}
return s;
diff --git a/solution/0500-0599/0541.Reverse String II/Solution.go b/solution/0500-0599/0541.Reverse String II/Solution.go
index 937f6a2ec1713..7d3e1ae5e2b55 100644
--- a/solution/0500-0599/0541.Reverse String II/Solution.go
+++ b/solution/0500-0599/0541.Reverse String II/Solution.go
@@ -1,9 +1,10 @@
func reverseStr(s string, k int) string {
- t := []byte(s)
- for i := 0; i < len(t); i += (k << 1) {
- for st, ed := i, min(i+k-1, len(t)-1); st < ed; st, ed = st+1, ed-1 {
- t[st], t[ed] = t[ed], t[st]
+ cs := []byte(s)
+ n := len(cs)
+ for i := 0; i < n; i += 2 * k {
+ for l, r := i, min(i+k-1, n-1); l < r; l, r = l+1, r-1 {
+ cs[l], cs[r] = cs[r], cs[l]
}
}
- return string(t)
+ return string(cs)
}
\ No newline at end of file
diff --git a/solution/0500-0599/0541.Reverse String II/Solution.java b/solution/0500-0599/0541.Reverse String II/Solution.java
index 743b7105f6191..4d5d022938e9a 100644
--- a/solution/0500-0599/0541.Reverse String II/Solution.java
+++ b/solution/0500-0599/0541.Reverse String II/Solution.java
@@ -1,13 +1,14 @@
class Solution {
public String reverseStr(String s, int k) {
- char[] chars = s.toCharArray();
- for (int i = 0; i < chars.length; i += (k << 1)) {
- for (int st = i, ed = Math.min(chars.length - 1, i + k - 1); st < ed; ++st, --ed) {
- char t = chars[st];
- chars[st] = chars[ed];
- chars[ed] = t;
+ char[] cs = s.toCharArray();
+ int n = cs.length;
+ for (int i = 0; i < n; i += k * 2) {
+ for (int l = i, r = Math.min(i + k - 1, n - 1); l < r; ++l, --r) {
+ char t = cs[l];
+ cs[l] = cs[r];
+ cs[r] = t;
}
}
- return new String(chars);
+ return new String(cs);
}
}
\ No newline at end of file
diff --git a/solution/0500-0599/0541.Reverse String II/Solution.py b/solution/0500-0599/0541.Reverse String II/Solution.py
index 3a7d74c5c8372..2487b7a841e07 100644
--- a/solution/0500-0599/0541.Reverse String II/Solution.py
+++ b/solution/0500-0599/0541.Reverse String II/Solution.py
@@ -1,6 +1,6 @@
class Solution:
def reverseStr(self, s: str, k: int) -> str:
- t = list(s)
- for i in range(0, len(t), k << 1):
- t[i : i + k] = reversed(t[i : i + k])
- return ''.join(t)
+ cs = list(s)
+ for i in range(0, len(cs), 2 * k):
+ cs[i : i + k] = reversed(cs[i : i + k])
+ return "".join(cs)
diff --git a/solution/0500-0599/0541.Reverse String II/Solution.ts b/solution/0500-0599/0541.Reverse String II/Solution.ts
new file mode 100644
index 0000000000000..55ebb15a46121
--- /dev/null
+++ b/solution/0500-0599/0541.Reverse String II/Solution.ts
@@ -0,0 +1,10 @@
+function reverseStr(s: string, k: number): string {
+ const n = s.length;
+ const cs = s.split('');
+ for (let i = 0; i < n; i += 2 * k) {
+ for (let l = i, r = Math.min(i + k - 1, n - 1); l < r; l++, r--) {
+ [cs[l], cs[r]] = [cs[r], cs[l]];
+ }
+ }
+ return cs.join('');
+}
diff --git a/solution/0500-0599/0542.01 Matrix/README.md b/solution/0500-0599/0542.01 Matrix/README.md
index 1af062da84d4e..23329b7a9a4c6 100644
--- a/solution/0500-0599/0542.01 Matrix/README.md
+++ b/solution/0500-0599/0542.01 Matrix/README.md
@@ -62,11 +62,17 @@ tags:
-### 方法一:多源 BFS
+### 方法一:BFS
-初始化结果矩阵 ans,所有 0 的距离为 0,所以 1 的距离为 -1。初始化队列 q 存储 BFS 需要检查的位置,并将所有 0 的位置入队。
+我们创建一个大小和 $\textit{mat}$ 一样的矩阵 $\textit{ans}$,并将所有的元素初始化为 $-1$。
-循环弹出队列 q 的元素 `p(i, j)`,检查邻居四个点。对于邻居 `(x, y)`,如果 `ans[x][y] = -1`,则更新 `ans[x][y] = ans[i][j] + 1`。同时将 `(x, y)` 入队。
+然后我们遍历 $\textit{mat}$,将所有的 $0$ 元素的坐标 $(i, j)$ 加入队列 $\textit{q}$,并将 $\textit{ans}[i][j]$ 设为 $0$。
+
+接下来,我们使用广度优先搜索,从队列中取出一个元素 $(i, j)$,并遍历其四个方向,如果该方向的元素 $(x, y)$ 满足 $0 \leq x < m$, $0 \leq y < n$ 且 $\textit{ans}[x][y] = -1$,则将 $\textit{ans}[x][y]$ 设为 $\textit{ans}[i][j] + 1$,并将 $(x, y)$ 加入队列 $\textit{q}$。
+
+最后返回 $\textit{ans}$。
+
+时间复杂度 $O(m \times n)$,空间复杂度 $O(m \times n)$。其中 $m$ 和 $n$ 分别为矩阵 $\textit{mat}$ 的行数和列数。
@@ -219,8 +225,7 @@ function updateMatrix(mat: number[][]): number[][] {
}
}
const dirs: number[] = [-1, 0, 1, 0, -1];
- while (q.length) {
- const [i, j] = q.shift()!;
+ for (const [i, j] of q) {
for (let k = 0; k < 4; ++k) {
const [x, y] = [i + dirs[k], j + dirs[k + 1]];
if (x >= 0 && x < m && y >= 0 && y < n && ans[x][y] === -1) {
@@ -239,49 +244,38 @@ function updateMatrix(mat: number[][]): number[][] {
use std::collections::VecDeque;
impl Solution {
- #[allow(dead_code)]
pub fn update_matrix(mat: Vec>) -> Vec> {
- let n: usize = mat.len();
- let m: usize = mat[0].len();
- let mut ret_vec: Vec> = vec![vec![-1; m]; n];
- // The inner tuple is of
- let mut the_q: VecDeque<(usize, usize)> = VecDeque::new();
- let traverse_vec: Vec<(i32, i32)> = vec![(-1, 0), (1, 0), (0, 1), (0, -1)];
-
- // Initialize the queue
- for i in 0..n {
- for j in 0..m {
+ let m = mat.len();
+ let n = mat[0].len();
+ let mut ans = vec![vec![-1; n]; m];
+ let mut q = VecDeque::new();
+
+ for i in 0..m {
+ for j in 0..n {
if mat[i][j] == 0 {
- // For the zero cell, enqueue at first
- the_q.push_back((i, j));
- // Set to 0 in return vector
- ret_vec[i][j] = 0;
+ q.push_back((i, j));
+ ans[i][j] = 0;
}
}
}
- while !the_q.is_empty() {
- let (x, y) = the_q.front().unwrap().clone();
- the_q.pop_front();
- for pair in &traverse_vec {
- let cur_x = pair.0 + (x as i32);
- let cur_y = pair.1 + (y as i32);
- if Solution::check_bounds(cur_x, cur_y, n as i32, m as i32)
- && ret_vec[cur_x as usize][cur_y as usize] == -1
- {
- // The current cell has not be updated yet, and is also in bound
- ret_vec[cur_x as usize][cur_y as usize] = ret_vec[x][y] + 1;
- the_q.push_back((cur_x as usize, cur_y as usize));
+ let dirs = [-1, 0, 1, 0, -1];
+ while let Some((i, j)) = q.pop_front() {
+ for k in 0..4 {
+ let x = i as isize + dirs[k];
+ let y = j as isize + dirs[k + 1];
+ if x >= 0 && x < m as isize && y >= 0 && y < n as isize {
+ let x = x as usize;
+ let y = y as usize;
+ if ans[x][y] == -1 {
+ ans[x][y] = ans[i][j] + 1;
+ q.push_back((x, y));
+ }
}
}
}
- ret_vec
- }
-
- #[allow(dead_code)]
- pub fn check_bounds(i: i32, j: i32, n: i32, m: i32) -> bool {
- i >= 0 && i < n && j >= 0 && j < m
+ ans
}
}
```
diff --git a/solution/0500-0599/0542.01 Matrix/README_EN.md b/solution/0500-0599/0542.01 Matrix/README_EN.md
index a81f66566262b..cde08787d2bd3 100644
--- a/solution/0500-0599/0542.01 Matrix/README_EN.md
+++ b/solution/0500-0599/0542.01 Matrix/README_EN.md
@@ -56,7 +56,17 @@ tags:
-### Solution 1
+### Solution 1: BFS
+
+We create a matrix $\textit{ans}$ of the same size as $\textit{mat}$ and initialize all elements to $-1$.
+
+Then, we traverse $\textit{mat}$, adding the coordinates $(i, j)$ of all $0$ elements to the queue $\textit{q}$, and setting $\textit{ans}[i][j]$ to $0$.
+
+Next, we use Breadth-First Search (BFS), removing an element $(i, j)$ from the queue and traversing its four directions. If the element in that direction $(x, y)$ satisfies $0 \leq x < m$, $0 \leq y < n$ and $\textit{ans}[x][y] = -1$, then we set $\textit{ans}[x][y]$ to $\textit{ans}[i][j] + 1$ and add $(x, y)$ to the queue $\textit{q}$.
+
+Finally, we return $\textit{ans}$.
+
+The time complexity is $O(m \times n)$, and the space complexity is $O(m \times n)$. Here, $m$ and $n$ are the number of rows and columns in the matrix $\textit{mat}$, respectively.
@@ -209,8 +219,7 @@ function updateMatrix(mat: number[][]): number[][] {
}
}
const dirs: number[] = [-1, 0, 1, 0, -1];
- while (q.length) {
- const [i, j] = q.shift()!;
+ for (const [i, j] of q) {
for (let k = 0; k < 4; ++k) {
const [x, y] = [i + dirs[k], j + dirs[k + 1]];
if (x >= 0 && x < m && y >= 0 && y < n && ans[x][y] === -1) {
@@ -229,49 +238,38 @@ function updateMatrix(mat: number[][]): number[][] {
use std::collections::VecDeque;
impl Solution {
- #[allow(dead_code)]
pub fn update_matrix(mat: Vec>) -> Vec> {
- let n: usize = mat.len();
- let m: usize = mat[0].len();
- let mut ret_vec: Vec> = vec![vec![-1; m]; n];
- // The inner tuple is of
- let mut the_q: VecDeque<(usize, usize)> = VecDeque::new();
- let traverse_vec: Vec<(i32, i32)> = vec![(-1, 0), (1, 0), (0, 1), (0, -1)];
-
- // Initialize the queue
- for i in 0..n {
- for j in 0..m {
+ let m = mat.len();
+ let n = mat[0].len();
+ let mut ans = vec![vec![-1; n]; m];
+ let mut q = VecDeque::new();
+
+ for i in 0..m {
+ for j in 0..n {
if mat[i][j] == 0 {
- // For the zero cell, enqueue at first
- the_q.push_back((i, j));
- // Set to 0 in return vector
- ret_vec[i][j] = 0;
+ q.push_back((i, j));
+ ans[i][j] = 0;
}
}
}
- while !the_q.is_empty() {
- let (x, y) = the_q.front().unwrap().clone();
- the_q.pop_front();
- for pair in &traverse_vec {
- let cur_x = pair.0 + (x as i32);
- let cur_y = pair.1 + (y as i32);
- if Solution::check_bounds(cur_x, cur_y, n as i32, m as i32)
- && ret_vec[cur_x as usize][cur_y as usize] == -1
- {
- // The current cell has not be updated yet, and is also in bound
- ret_vec[cur_x as usize][cur_y as usize] = ret_vec[x][y] + 1;
- the_q.push_back((cur_x as usize, cur_y as usize));
+ let dirs = [-1, 0, 1, 0, -1];
+ while let Some((i, j)) = q.pop_front() {
+ for k in 0..4 {
+ let x = i as isize + dirs[k];
+ let y = j as isize + dirs[k + 1];
+ if x >= 0 && x < m as isize && y >= 0 && y < n as isize {
+ let x = x as usize;
+ let y = y as usize;
+ if ans[x][y] == -1 {
+ ans[x][y] = ans[i][j] + 1;
+ q.push_back((x, y));
+ }
}
}
}
- ret_vec
- }
-
- #[allow(dead_code)]
- pub fn check_bounds(i: i32, j: i32, n: i32, m: i32) -> bool {
- i >= 0 && i < n && j >= 0 && j < m
+ ans
}
}
```
diff --git a/solution/0500-0599/0542.01 Matrix/Solution.rs b/solution/0500-0599/0542.01 Matrix/Solution.rs
index 4f6b1f7f38793..4913bce5d043c 100644
--- a/solution/0500-0599/0542.01 Matrix/Solution.rs
+++ b/solution/0500-0599/0542.01 Matrix/Solution.rs
@@ -1,48 +1,37 @@
use std::collections::VecDeque;
impl Solution {
- #[allow(dead_code)]
pub fn update_matrix(mat: Vec>) -> Vec> {
- let n: usize = mat.len();
- let m: usize = mat[0].len();
- let mut ret_vec: Vec> = vec![vec![-1; m]; n];
- // The inner tuple is of
- let mut the_q: VecDeque<(usize, usize)> = VecDeque::new();
- let traverse_vec: Vec<(i32, i32)> = vec![(-1, 0), (1, 0), (0, 1), (0, -1)];
+ let m = mat.len();
+ let n = mat[0].len();
+ let mut ans = vec![vec![-1; n]; m];
+ let mut q = VecDeque::new();
- // Initialize the queue
- for i in 0..n {
- for j in 0..m {
+ for i in 0..m {
+ for j in 0..n {
if mat[i][j] == 0 {
- // For the zero cell, enqueue at first
- the_q.push_back((i, j));
- // Set to 0 in return vector
- ret_vec[i][j] = 0;
+ q.push_back((i, j));
+ ans[i][j] = 0;
}
}
}
- while !the_q.is_empty() {
- let (x, y) = the_q.front().unwrap().clone();
- the_q.pop_front();
- for pair in &traverse_vec {
- let cur_x = pair.0 + (x as i32);
- let cur_y = pair.1 + (y as i32);
- if Solution::check_bounds(cur_x, cur_y, n as i32, m as i32)
- && ret_vec[cur_x as usize][cur_y as usize] == -1
- {
- // The current cell has not be updated yet, and is also in bound
- ret_vec[cur_x as usize][cur_y as usize] = ret_vec[x][y] + 1;
- the_q.push_back((cur_x as usize, cur_y as usize));
+ let dirs = [-1, 0, 1, 0, -1];
+ while let Some((i, j)) = q.pop_front() {
+ for k in 0..4 {
+ let x = i as isize + dirs[k];
+ let y = j as isize + dirs[k + 1];
+ if x >= 0 && x < m as isize && y >= 0 && y < n as isize {
+ let x = x as usize;
+ let y = y as usize;
+ if ans[x][y] == -1 {
+ ans[x][y] = ans[i][j] + 1;
+ q.push_back((x, y));
+ }
}
}
}
- ret_vec
- }
-
- #[allow(dead_code)]
- pub fn check_bounds(i: i32, j: i32, n: i32, m: i32) -> bool {
- i >= 0 && i < n && j >= 0 && j < m
+ ans
}
}
diff --git a/solution/0500-0599/0542.01 Matrix/Solution.ts b/solution/0500-0599/0542.01 Matrix/Solution.ts
index d3ec5bf281949..d44cdb2d7e709 100644
--- a/solution/0500-0599/0542.01 Matrix/Solution.ts
+++ b/solution/0500-0599/0542.01 Matrix/Solution.ts
@@ -11,8 +11,7 @@ function updateMatrix(mat: number[][]): number[][] {
}
}
const dirs: number[] = [-1, 0, 1, 0, -1];
- while (q.length) {
- const [i, j] = q.shift()!;
+ for (const [i, j] of q) {
for (let k = 0; k < 4; ++k) {
const [x, y] = [i + dirs[k], j + dirs[k + 1]];
if (x >= 0 && x < m && y >= 0 && y < n && ans[x][y] === -1) {
diff --git a/solution/0500-0599/0544.Output Contest Matches/README.md b/solution/0500-0599/0544.Output Contest Matches/README.md
index 75765760356ee..6a0ea9563e040 100644
--- a/solution/0500-0599/0544.Output Contest Matches/README.md
+++ b/solution/0500-0599/0544.Output Contest Matches/README.md
@@ -69,9 +69,11 @@ tags:
### 方法一:模拟
-假设 `team[i]` 为当前轮次中第 i 强的队伍。
+我们可以用一个长度为 $n$ 的数组 $s$ 来存储每个队伍的编号,然后模拟比赛的过程。
-每一轮,将第 i 支队伍变成 `"(" + team[i] + "," + team[n-1-i] + ")"`,并且每一轮淘汰一半的队伍。
+每一轮比赛,我们将数组 $s$ 中的前 $n$ 个元素两两配对,然后将胜者的编号存入数组 $s$ 的前 $n/2$ 个位置。然后,我们将 $n$ 减半,继续进行下一轮比赛,直到 $n$ 减半为 $1$,此时数组 $s$ 中的第一个元素即为最终的比赛匹配方案。
+
+时间复杂度 $O(n \times \log n)$,空间复杂度 $O(n \times \log n)$。其中 $n$ 为队伍的数量。
@@ -80,12 +82,12 @@ tags:
```python
class Solution:
def findContestMatch(self, n: int) -> str:
- team = [str(i + 1) for i in range(n)]
+ s = [str(i + 1) for i in range(n)]
while n > 1:
for i in range(n >> 1):
- team[i] = f'({team[i]},{team[n - 1 - i]})'
+ s[i] = f"({s[i]},{s[n - i - 1]})"
n >>= 1
- return team[0]
+ return s[0]
```
#### Java
@@ -93,16 +95,16 @@ class Solution:
```java
class Solution {
public String findContestMatch(int n) {
- String[] team = new String[n];
+ String[] s = new String[n];
for (int i = 0; i < n; ++i) {
- team[i] = "" + (i + 1);
+ s[i] = String.valueOf(i + 1);
}
- for (; n > 1; n /= 2) {
- for (int i = 0; i < n / 2; ++i) {
- team[i] = "(" + team[i] + "," + team[n - 1 - i] + ")";
+ for (; n > 1; n >>= 1) {
+ for (int i = 0; i < n >> 1; ++i) {
+ s[i] = String.format("(%s,%s)", s[i], s[n - i - 1]);
}
}
- return team[0];
+ return s[0];
}
}
```
@@ -113,14 +115,16 @@ class Solution {
class Solution {
public:
string findContestMatch(int n) {
- vector team(n);
- for (int i = 0; i < n; ++i) team[i] = to_string(i + 1);
+ vector s(n);
+ for (int i = 0; i < n; ++i) {
+ s[i] = to_string(i + 1);
+ }
for (; n > 1; n >>= 1) {
for (int i = 0; i < n >> 1; ++i) {
- team[i] = "(" + team[i] + "," + team[n - 1 - i] + ")";
+ s[i] = "(" + s[i] + "," + s[n - i - 1] + ")";
}
}
- return team[0];
+ return s[0];
}
};
```
@@ -129,17 +133,30 @@ public:
```go
func findContestMatch(n int) string {
- team := make([]string, n)
- for i := range team {
- team[i] = strconv.Itoa(i + 1)
+ s := make([]string, n)
+ for i := 0; i < n; i++ {
+ s[i] = strconv.Itoa(i + 1)
}
- for n > 1 {
+ for ; n > 1; n >>= 1 {
for i := 0; i < n>>1; i++ {
- team[i] = "(" + team[i] + "," + team[n-1-i] + ")"
+ s[i] = fmt.Sprintf("(%s,%s)", s[i], s[n-i-1])
}
- n >>= 1
}
- return team[0]
+ return s[0]
+}
+```
+
+#### TypeScript
+
+```ts
+function findContestMatch(n: number): string {
+ const s: string[] = Array.from({ length: n }, (_, i) => (i + 1).toString());
+ for (; n > 1; n >>= 1) {
+ for (let i = 0; i < n >> 1; ++i) {
+ s[i] = `(${s[i]},${s[n - i - 1]})`;
+ }
+ }
+ return s[0];
}
```
diff --git a/solution/0500-0599/0544.Output Contest Matches/README_EN.md b/solution/0500-0599/0544.Output Contest Matches/README_EN.md
index f0a08ac564d7d..ba2198e77d293 100644
--- a/solution/0500-0599/0544.Output Contest Matches/README_EN.md
+++ b/solution/0500-0599/0544.Output Contest Matches/README_EN.md
@@ -64,7 +64,13 @@ Since the third round will generate the final winner, you need to output the ans
-### Solution 1
+### Solution 1: Simulation
+
+We can use an array $s$ of length $n$ to store the ID of each team, and then simulate the process of the matches.
+
+In each round of matches, we pair up the first $n$ elements in array $s$ two by two, and then store the ID of the winners in the first $n/2$ positions of array $s$. After that, we halve $n$ and continue to the next round of matches, until $n$ is reduced to $1$. At this point, the first element in array $s$ is the final match-up scheme.
+
+The time complexity is $O(n \log n)$, and the space complexity is $O(n)$. Here, $n$ is the number of teams.
@@ -73,12 +79,12 @@ Since the third round will generate the final winner, you need to output the ans
```python
class Solution:
def findContestMatch(self, n: int) -> str:
- team = [str(i + 1) for i in range(n)]
+ s = [str(i + 1) for i in range(n)]
while n > 1:
for i in range(n >> 1):
- team[i] = f'({team[i]},{team[n - 1 - i]})'
+ s[i] = f"({s[i]},{s[n - i - 1]})"
n >>= 1
- return team[0]
+ return s[0]
```
#### Java
@@ -86,16 +92,16 @@ class Solution:
```java
class Solution {
public String findContestMatch(int n) {
- String[] team = new String[n];
+ String[] s = new String[n];
for (int i = 0; i < n; ++i) {
- team[i] = "" + (i + 1);
+ s[i] = String.valueOf(i + 1);
}
- for (; n > 1; n /= 2) {
- for (int i = 0; i < n / 2; ++i) {
- team[i] = "(" + team[i] + "," + team[n - 1 - i] + ")";
+ for (; n > 1; n >>= 1) {
+ for (int i = 0; i < n >> 1; ++i) {
+ s[i] = String.format("(%s,%s)", s[i], s[n - i - 1]);
}
}
- return team[0];
+ return s[0];
}
}
```
@@ -106,14 +112,16 @@ class Solution {
class Solution {
public:
string findContestMatch(int n) {
- vector team(n);
- for (int i = 0; i < n; ++i) team[i] = to_string(i + 1);
+ vector s(n);
+ for (int i = 0; i < n; ++i) {
+ s[i] = to_string(i + 1);
+ }
for (; n > 1; n >>= 1) {
for (int i = 0; i < n >> 1; ++i) {
- team[i] = "(" + team[i] + "," + team[n - 1 - i] + ")";
+ s[i] = "(" + s[i] + "," + s[n - i - 1] + ")";
}
}
- return team[0];
+ return s[0];
}
};
```
@@ -122,17 +130,30 @@ public:
```go
func findContestMatch(n int) string {
- team := make([]string, n)
- for i := range team {
- team[i] = strconv.Itoa(i + 1)
+ s := make([]string, n)
+ for i := 0; i < n; i++ {
+ s[i] = strconv.Itoa(i + 1)
}
- for n > 1 {
+ for ; n > 1; n >>= 1 {
for i := 0; i < n>>1; i++ {
- team[i] = "(" + team[i] + "," + team[n-1-i] + ")"
+ s[i] = fmt.Sprintf("(%s,%s)", s[i], s[n-i-1])
}
- n >>= 1
}
- return team[0]
+ return s[0]
+}
+```
+
+#### TypeScript
+
+```ts
+function findContestMatch(n: number): string {
+ const s: string[] = Array.from({ length: n }, (_, i) => (i + 1).toString());
+ for (; n > 1; n >>= 1) {
+ for (let i = 0; i < n >> 1; ++i) {
+ s[i] = `(${s[i]},${s[n - i - 1]})`;
+ }
+ }
+ return s[0];
}
```
diff --git a/solution/0500-0599/0544.Output Contest Matches/Solution.cpp b/solution/0500-0599/0544.Output Contest Matches/Solution.cpp
index 9c82aff11659c..61a2e8360e80a 100644
--- a/solution/0500-0599/0544.Output Contest Matches/Solution.cpp
+++ b/solution/0500-0599/0544.Output Contest Matches/Solution.cpp
@@ -1,13 +1,15 @@
class Solution {
public:
string findContestMatch(int n) {
- vector team(n);
- for (int i = 0; i < n; ++i) team[i] = to_string(i + 1);
+ vector s(n);
+ for (int i = 0; i < n; ++i) {
+ s[i] = to_string(i + 1);
+ }
for (; n > 1; n >>= 1) {
for (int i = 0; i < n >> 1; ++i) {
- team[i] = "(" + team[i] + "," + team[n - 1 - i] + ")";
+ s[i] = "(" + s[i] + "," + s[n - i - 1] + ")";
}
}
- return team[0];
+ return s[0];
}
};
\ No newline at end of file
diff --git a/solution/0500-0599/0544.Output Contest Matches/Solution.go b/solution/0500-0599/0544.Output Contest Matches/Solution.go
index 1e51283d70a00..edb7ea5eb04ea 100644
--- a/solution/0500-0599/0544.Output Contest Matches/Solution.go
+++ b/solution/0500-0599/0544.Output Contest Matches/Solution.go
@@ -1,13 +1,12 @@
func findContestMatch(n int) string {
- team := make([]string, n)
- for i := range team {
- team[i] = strconv.Itoa(i + 1)
+ s := make([]string, n)
+ for i := 0; i < n; i++ {
+ s[i] = strconv.Itoa(i + 1)
}
- for n > 1 {
+ for ; n > 1; n >>= 1 {
for i := 0; i < n>>1; i++ {
- team[i] = "(" + team[i] + "," + team[n-1-i] + ")"
+ s[i] = fmt.Sprintf("(%s,%s)", s[i], s[n-i-1])
}
- n >>= 1
}
- return team[0]
+ return s[0]
}
\ No newline at end of file
diff --git a/solution/0500-0599/0544.Output Contest Matches/Solution.java b/solution/0500-0599/0544.Output Contest Matches/Solution.java
index 986ae52900a04..be60130326c4e 100644
--- a/solution/0500-0599/0544.Output Contest Matches/Solution.java
+++ b/solution/0500-0599/0544.Output Contest Matches/Solution.java
@@ -1,14 +1,14 @@
class Solution {
public String findContestMatch(int n) {
- String[] team = new String[n];
+ String[] s = new String[n];
for (int i = 0; i < n; ++i) {
- team[i] = "" + (i + 1);
+ s[i] = String.valueOf(i + 1);
}
- for (; n > 1; n /= 2) {
- for (int i = 0; i < n / 2; ++i) {
- team[i] = "(" + team[i] + "," + team[n - 1 - i] + ")";
+ for (; n > 1; n >>= 1) {
+ for (int i = 0; i < n >> 1; ++i) {
+ s[i] = String.format("(%s,%s)", s[i], s[n - i - 1]);
}
}
- return team[0];
+ return s[0];
}
}
\ No newline at end of file
diff --git a/solution/0500-0599/0544.Output Contest Matches/Solution.py b/solution/0500-0599/0544.Output Contest Matches/Solution.py
index ddfcf132d8faa..6772b8dbbfcbe 100644
--- a/solution/0500-0599/0544.Output Contest Matches/Solution.py
+++ b/solution/0500-0599/0544.Output Contest Matches/Solution.py
@@ -1,8 +1,8 @@
class Solution:
def findContestMatch(self, n: int) -> str:
- team = [str(i + 1) for i in range(n)]
+ s = [str(i + 1) for i in range(n)]
while n > 1:
for i in range(n >> 1):
- team[i] = f'({team[i]},{team[n - 1 - i]})'
+ s[i] = f"({s[i]},{s[n - i - 1]})"
n >>= 1
- return team[0]
+ return s[0]
diff --git a/solution/0500-0599/0544.Output Contest Matches/Solution.ts b/solution/0500-0599/0544.Output Contest Matches/Solution.ts
new file mode 100644
index 0000000000000..9bd39d9682b51
--- /dev/null
+++ b/solution/0500-0599/0544.Output Contest Matches/Solution.ts
@@ -0,0 +1,9 @@
+function findContestMatch(n: number): string {
+ const s: string[] = Array.from({ length: n }, (_, i) => (i + 1).toString());
+ for (; n > 1; n >>= 1) {
+ for (let i = 0; i < n >> 1; ++i) {
+ s[i] = `(${s[i]},${s[n - i - 1]})`;
+ }
+ }
+ return s[0];
+}
diff --git a/solution/0500-0599/0545.Boundary of Binary Tree/README.md b/solution/0500-0599/0545.Boundary of Binary Tree/README.md
index 2abe265cb2a51..57937625d0e11 100644
--- a/solution/0500-0599/0545.Boundary of Binary Tree/README.md
+++ b/solution/0500-0599/0545.Boundary of Binary Tree/README.md
@@ -74,7 +74,24 @@ tags:
-### 方法一
+### 方法一:DFS
+
+首先,如果树只有一个节点,那么直接返回这个节点的值的列表。
+
+否则,我们可以通过深度优先搜索,找到二叉树的左边界、叶节点和右边界。
+
+具体地,我们可以通过一个递归函数 $\textit{dfs}$ 来找到这三个部分。在 $\textit{dfs}$ 函数中,我们需要传入一个列表 $\textit{nums}$,一个节点 $\textit{root}$ 和一个整数 $\textit{i}$,其中 $\textit{nums}$ 用来存储当前部分的节点值,而 $\textit{root}$ 和 $\textit{i}$ 分别表示当前节点和当前部分的类型(左边界, 叶节点或右边界)。
+
+函数的具体实现如下:
+
+- 如果 $\textit{root}$ 为空,那么直接返回。
+- 如果 $\textit{i} = 0$,那么我们需要找到左边界。如果 $\textit{root}$ 不是叶节点,那么我们将 $\textit{root}$ 的值加入到 $\textit{nums}$ 中。如果 $\textit{root}$ 有左子节点,那么我们递归地调用 $\textit{dfs}$ 函数,传入 $\textit{nums}$, $\textit{root}$ 的左子节点和 $\textit{i}$。否则,我们递归地调用 $\textit{dfs}$ 函数,传入 $\textit{nums}$, $\textit{root}$ 的右子节点和 $\textit{i}$。
+- 如果 $\textit{i} = 1$,那么我们需要找到叶节点。如果 $\textit{root}$ 是叶节点,那么我们将 $\textit{root}$ 的值加入到 $\textit{nums}$ 中。否则,我们递归地调用 $\textit{dfs}$ 函数,传入 $\textit{nums}$, $\textit{root}$ 的左子节点和 $\textit{i}$,以及 $\textit{nums}$, $\textit{root}$ 的右子节点和 $\textit{i}$。
+- 如果 $\textit{i} = 2$,那么我们需要找到右边界。如果 $\textit{root}$ 不是叶节点,那么我们将 $\textit{root}$ 的值加入到 $\textit{nums}$ 中,如果 $\textit{root}$ 有右子节点,那么我们递归地调用 $\textit{dfs}$ 函数,传入 $\textit{nums}$, $\textit{root}$ 的右子节点和 $\textit{i}$。否则,我们递归地调用 $\textit{dfs}$ 函数,传入 $\textit{nums}$, $\textit{root}$ 的左子节点和 $\textit{i}$。
+
+我们分别调用 $\textit{dfs}$ 函数,找到左边界、叶节点和右边界,然后将这三个部分连接起来,即可得到答案。
+
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 是二叉树的节点数。
@@ -88,127 +105,294 @@ tags:
# self.left = left
# self.right = right
class Solution:
- def boundaryOfBinaryTree(self, root: TreeNode) -> List[int]:
- self.res = []
- if not root:
- return self.res
- # root
- if not self.is_leaf(root):
- self.res.append(root.val)
-
- # left boundary
- t = root.left
- while t:
- if not self.is_leaf(t):
- self.res.append(t.val)
- t = t.left if t.left else t.right
-
- # leaves
- self.add_leaves(root)
-
- # right boundary(reverse order)
- s = []
- t = root.right
- while t:
- if not self.is_leaf(t):
- s.append(t.val)
- t = t.right if t.right else t.left
- while s:
- self.res.append(s.pop())
-
- # output
- return self.res
-
- def add_leaves(self, root):
- if self.is_leaf(root):
- self.res.append(root.val)
- return
- if root.left:
- self.add_leaves(root.left)
- if root.right:
- self.add_leaves(root.right)
-
- def is_leaf(self, node) -> bool:
- return node and node.left is None and node.right is None
+ def boundaryOfBinaryTree(self, root: Optional[TreeNode]) -> List[int]:
+ def dfs(nums: List[int], root: Optional[TreeNode], i: int):
+ if root is None:
+ return
+ if i == 0:
+ if root.left != root.right:
+ nums.append(root.val)
+ if root.left:
+ dfs(nums, root.left, i)
+ else:
+ dfs(nums, root.right, i)
+ elif i == 1:
+ if root.left == root.right:
+ nums.append(root.val)
+ else:
+ dfs(nums, root.left, i)
+ dfs(nums, root.right, i)
+ else:
+ if root.left != root.right:
+ nums.append(root.val)
+ if root.right:
+ dfs(nums, root.right, i)
+ else:
+ dfs(nums, root.left, i)
+
+ ans = [root.val]
+ if root.left == root.right:
+ return ans
+ left, leaves, right = [], [], []
+ dfs(left, root.left, 0)
+ dfs(leaves, root, 1)
+ dfs(right, root.right, 2)
+ ans += left + leaves + right[::-1]
+ return ans
```
#### Java
```java
-/**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode() {}
- * TreeNode(int val) { this.val = val; }
- * TreeNode(int val, TreeNode left, TreeNode right) {
- * this.val = val;
- * this.left = left;
- * this.right = right;
- * }
- * }
- */
class Solution {
- private List res;
-
public List boundaryOfBinaryTree(TreeNode root) {
- if (root == null) {
- return Collections.emptyList();
+ List ans = new ArrayList<>();
+ ans.add(root.val);
+ if (root.left == root.right) {
+ return ans;
}
- res = new ArrayList<>();
+ List left = new ArrayList<>();
+ List leaves = new ArrayList<>();
+ List right = new ArrayList<>();
+ dfs(left, root.left, 0);
+ dfs(leaves, root, 1);
+ dfs(right, root.right, 2);
+
+ ans.addAll(left);
+ ans.addAll(leaves);
+ Collections.reverse(right);
+ ans.addAll(right);
+ return ans;
+ }
- // root
- if (!isLeaf(root)) {
- res.add(root.val);
+ private void dfs(List nums, TreeNode root, int i) {
+ if (root == null) {
+ return;
}
-
- // left boundary
- TreeNode t = root.left;
- while (t != null) {
- if (!isLeaf(t)) {
- res.add(t.val);
+ if (i == 0) {
+ if (root.left != root.right) {
+ nums.add(root.val);
+ if (root.left != null) {
+ dfs(nums, root.left, i);
+ } else {
+ dfs(nums, root.right, i);
+ }
+ }
+ } else if (i == 1) {
+ if (root.left == root.right) {
+ nums.add(root.val);
+ } else {
+ dfs(nums, root.left, i);
+ dfs(nums, root.right, i);
+ }
+ } else {
+ if (root.left != root.right) {
+ nums.add(root.val);
+ if (root.right != null) {
+ dfs(nums, root.right, i);
+ } else {
+ dfs(nums, root.left, i);
+ }
}
- t = t.left == null ? t.right : t.left;
}
+ }
+}
+```
- // leaves
- addLeaves(root);
+#### C++
- // right boundary(reverse order)
- Deque s = new ArrayDeque<>();
- t = root.right;
- while (t != null) {
- if (!isLeaf(t)) {
- s.offer(t.val);
+```cpp
+/**
+ * Definition for a binary tree node.
+ * struct TreeNode {
+ * int val;
+ * TreeNode *left;
+ * TreeNode *right;
+ * TreeNode() : val(0), left(nullptr), right(nullptr) {}
+ * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
+ * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
+ * };
+ */
+class Solution {
+public:
+ vector boundaryOfBinaryTree(TreeNode* root) {
+ auto dfs = [&](auto&& dfs, vector& nums, TreeNode* root, int i) -> void {
+ if (!root) {
+ return;
}
- t = t.right == null ? t.left : t.right;
- }
- while (!s.isEmpty()) {
- res.add(s.pollLast());
+ if (i == 0) {
+ if (root->left != root->right) {
+ nums.push_back(root->val);
+ if (root->left) {
+ dfs(dfs, nums, root->left, i);
+ } else {
+ dfs(dfs, nums, root->right, i);
+ }
+ }
+ } else if (i == 1) {
+ if (root->left == root->right) {
+ nums.push_back(root->val);
+ } else {
+ dfs(dfs, nums, root->left, i);
+ dfs(dfs, nums, root->right, i);
+ }
+ } else {
+ if (root->left != root->right) {
+ nums.push_back(root->val);
+ if (root->right) {
+ dfs(dfs, nums, root->right, i);
+ } else {
+ dfs(dfs, nums, root->left, i);
+ }
+ }
+ }
+ };
+ vector ans = {root->val};
+ if (root->left == root->right) {
+ return ans;
}
+ vector