You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Store File | Record size | Contents
----------------------------------------------------------------------------------------------------------------------------
neostore.nodestore.db | 15 B | Nodes
neostore.relationshipstore.db | 34 B | Relationships
neostore.propertystore.db | 41 B | Properties for nodes and relationships
neostore.propertystore.db.strings | 128 B | Values of string properties
neostore.propertystore.db.arrays | 128 B | Values of array properties
Indexed Property | 1/3 * AVG(X) | Each index entry is approximately 1/3 of the average property value size
数据类型
在概念上Neo4j有两个实体概念:Node和Relationship
Node - 节点
类似于Entity,包含:
Relationship - 关系
逻辑存储结构
免索引邻接(Index Free Adjacency),在逻辑上可以看做邻接表(Adjacency List)
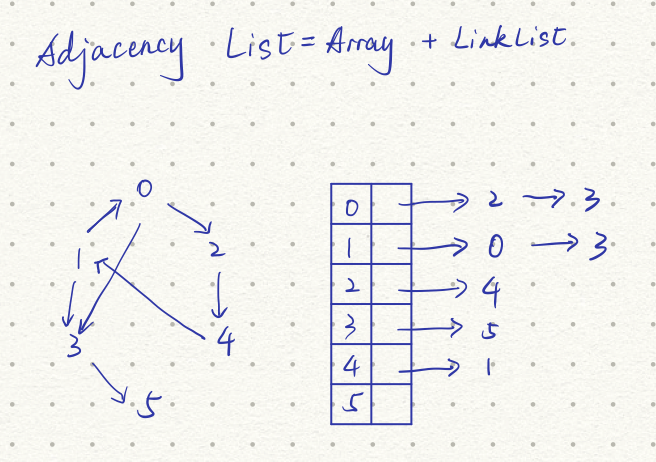
物理存储结构
Neo4j用于持久化的文件列表如下所示:
接下来我们分别看一看每个文件中存储的格式。理解这些格式非常重要,因为它决定了Neo4j的数据结构和查询效率,如果你希望能够回答出“Neo4j是如何执行一次查询的?它底层数据是怎么存储的?”就必须理解它的存储格式。
Node - 9Byte
存储Node的数据,节点是以单链表形式存储的
存储文件:
neostore.nodestore.db格式:
Node:inUse+nextRelId+nextPropId格式含义:
Relationship - 33Byte
关系是以双链表的形式存储的
存储文件:
neostore.relationshipstore.db格式:
Relationship: inUse+firstNode+secondNode+relType+firstPrevRelId+fristNextRelId+secondPrevRelId+secondNextRelId+nextPropId格式含义:
Property - 37Byte
实际的属性如何存储?
每个Property可以存储4个8Byte的propBlock,每个propBlock可以包含key或value或两种都有。如果一个Node的记录。Property之间以单链表形式关联。
Key和Type占用3.5Byte(key-4bit, type-24bit),Key的字面量存储在"Indexed Property"
Value的占用不固定:
存储文件:
neostore.propertystore.db格式:
Property: inUse+propBlock+propBlock+propBlock+propBlock+nextPropId格式含义:
动态存储文件 - 128Byte
用于存储String和Array这种很长的数据结构,可以由多个块组成
存储文件:
neostore.propertystore.db.stringsneostore.propertystore.db.arraysFAQ
Q:如何根据ID查找链表下一个节点?
A:因为数据结构定长,因此可以以O(1)复杂度计算下一个元素的位置。比如ID=100,下一个元素的数据起始点在900Byte的位置。
Q:为什么数据类型要以定长格式存储?
A:便于根据ID * Length快速查找
The text was updated successfully, but these errors were encountered: