实现原理与性能
在机器学习领域,在线学习(Online learning)指每次通过一个训练实例学习模型的学习方法。在线学习的目的是正确预测训练实例的标注。在线学习最重要的一个特点是,当一次预测完成时,其正确结果便被获得,这一结果可直接用来修正模型。
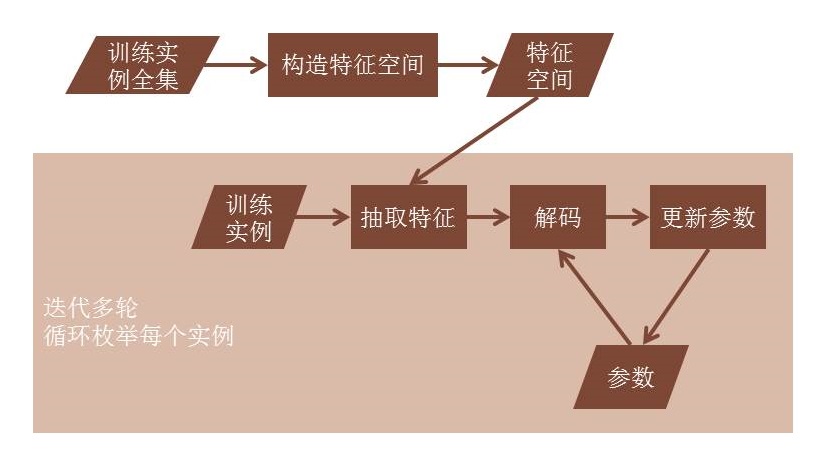
在自然语言处理领域,在线学习已经被广泛地应用在分词、词性标注、依存句法分析等结构化学习任务中。
在LTP中,词性标注、句法分析两个模块还存在模型比较大的问题。为了缩小模型的大小,我们参考Learning Sparser Perceptron Model,将其中提到的特征裁剪策略加入了LTP。
由于LTP所采用的在线机器学习框架的特征映射方式是以特征前缀为单位进行映射的,所以裁剪时的策略也是如果该前缀的更新次数比较小,就裁剪。
在LTP中,我们将分词任务建模为基于字的序列标注问题。对于输入句子的字序列,模型给句子中的每个字标注一个标识词边界的标记。在LTP中,我们采用的标记集如附录所示。
对于模型参数,我们采用在线机器学习算法框架从标注数据中学习参数。对于分词模型,我们使用的基本模型特征有:
| 类别 | 特征 |
|---|---|
| char-unigram | ch[-2], ch[-1], ch[0], ch[1], ch[2] |
| char-bigram | ch[-2]ch[-1], ch[-1]ch[0],ch[0]ch[1],ch[1]ch[2] |
| dulchar | ch[-1]=ch[0]? |
| dul2char | ch[-2]=ch[0]? |
同时,为了提高互联网文本特别是微博文本的处理性能。我们在分词系统中加入如下一些优化策略:
- 英文、URI一类特殊词识别规则
- 利用空格等自然标注线索
- 在统计模型中融入词典信息
- 从大规模未标注数据中统计的字间互信息、上下文丰富程度
在统计模型中融合词典的方法是将最大正向匹配得到的词特征
| 类别 | 特征 |
|---|---|
| begin-of-lexicon-word | ch[0] is preffix of words in lexicon? |
| middle-of-lexicon-word | ch[0] is middle of words in lexicon? |
| end-of-lexicon-word | ch[0] is suffix of words in lexicon? |
基础模型在几种数据集上的性能如下:
语料信息:人民日报1998年2月-6月(后10%数据作为开发集)作为训练数据,1月作为测试数据。
- 准确率为:
| P | R | F |
|---|---|---|
| 开发集 | 0.973152 | 0.972430 |
| 测试集 | 0.972316 | 0.970354 |
- 运行时内存:520540/1024=508.3m
- 速度:5543456/30.598697s=176.91k/s
CTB5数据来源于,训练集和测试集按照官方文档中建议的划分方法划分。
- 准确率为:
| P | R | F |
|---|---|---|
| 开发集 | 0.941426 | 0.937309 |
| 测试集 | 0.967235 | 0.973737 |
- 运行时内存:141980/1024=138.65M
- 速度:50518/0.344988 s=143.00k/s
CTB6数据来源于,训练集和测试集按照官方文档中建议的划分方法划分。
- 准确率为:
| P | R | F |
|---|---|---|
| 开发集 | 0.933438 | 0.940648 |
| 测试集 | 0.932683 | 0.938023 |
- 运行时内存:116332/1024=113.6M
- 速度:484016/2.515181 s=187.9k/s
与分词模块相同,我们将词性标注任务建模为基于词的序列标注问题。对于输入句子的词序列,模型给句子中的每个词标注一个标识词边界的标记。在LTP中,我们采用的北大标注集。关于北大标注集信息,请参考:
对于模型参数,我们采用在线机器学习算法框架从标注数据中学习参数。对于词性标注模型,我们使用的模型特征有:
| 类别 | 特征 |
|---|---|
| word-unigram | w[-2], w[-1], w[0], w[1], w[2] |
| word-bigram | w[-2]w[-1],w[-1]w[0],w[0]w[1],w[1]w[2] |
| word-trigram | w[-1]w[0]w[1] |
| last-first-character | ch[0,0]ch[0,n],ch[-1,n]ch[0,0],ch[0,-1]ch[1,0] |
| length | length |
| prefix | ch[0,0],ch[0,0:1],ch[0,0:2] |
| suffix | ch[0,n-2:n],ch[0,n-1:n],ch[0,n] |
基础模型在几种数据集上的性能如下:
语料信息:人民日报1998年2月-6月(后10%数据作为开发集)作为训练数据,1月作为测试数据。
- 准确率为:
| P | |
|---|---|
| 开发集 | 0.979621 |
| 测试集 | 0.978337 |
- 运行时内存:1732584/1024=1691.97m
- 速度:5543456/51.003626s=106.14k/s
CTB5数据来源于,训练集和测试集按照官方文档中建议的划分方法划分。
- 准确率为:
| P | |
|---|---|
| 开发集 | 0.953819 |
| 测试集 | 0.946179 |
- 运行时内存:356760/1024=348.40M
- 速度:50518/0.527107 s=93.59k/s
CTB6数据来源于,训练集和测试集按照官方文档中建议的划分方法划分。
- 准确率为:
| P | |
|---|---|
| 开发集 | 0.939930 |
| 测试集 | 0.938439 |
- 运行时内存:460116/1024=449.33M
- 速度:484016/5.735547 s=82.41k/s
与分词模块相同,我们将命名实体识别建模为基于词的序列标注问题。对于输入句子的词序列,模型给句子中的每个词标注一个标识命名实体边界和实体类别的标记。在LTP中,我们支持人名、地名、机构名三类命名实体的识别。关于LTP使用的标记参考附录。
对于模型参数,我们采用在线机器学习算法框架从标注数据中学习参数。对于词性标注模型,我们使用的模型特征有:
| 类别 | 特征 |
|---|---|
| word-unigram | w[-2], w[-1], w[0], w[1], w[2] |
| word-bigram | w[-2]w[-1],w[-1]w[0],w[0]w[1],w[1]w[2] |
| postag-unigram | p[-2],p[-1],p[0],p[1],p[2] |
| postag-bigram | p[-1]p[0],p[0]p[1] |
基础模型在几种数据集上的性能如下:
语料信息:人民日报1998年1月做训练(后10%数据作为开发集),6月前10000句做测试作为训练数据。
- 准确率
| P | R | F |
|---|---|---|
| 开发集 | 0.924149 | 0.909323 |
| 测试集 | 0.939552 | 0.936372 |
- 运行时内存:33M
基于图的依存分析方法由McDonald首先提出,他将依存分析问题归结为在一个有向图中寻找最大生成树(Maximum Spanning Tree)的问题。 在依存句法分析模块中,LTP分别实现了
- 一阶解码(1o)
- 二阶利用子孙信息解码(2o-sib)
- 二阶利用子孙和父子信息(2o-carreras)
三种不同的解码方式。依存句法分析模块中使用的特征请参考:
在LDC数据集上,三种不同解码方式对应的性能如下表所示。
| model | 1o | 2o-sib | 2o-carreras | |||
|---|---|---|---|---|---|---|
| UAS | LAS | UAS | LAS | UAS | LAS | |
| 开发集 | 0.8190 | 0.7893 | 0.8501 | 0.8213 | 0.8582 | 0.8294 |
| 测试集 | 0.8118 | 0.7813 | 0.8421 | 0.8106 | 0.8447 | 0.8138 |
| 速度 | 49.4 sent./s | 9.4 sent./s | 3.3 sent./s | |||
| 运行时内存 | 0.825g | 1.3g | 1.6g |
在LTP中,我们将SRL分为两个子任务,其一是谓词的识别(Predicate Identification, PI),其次是论元的识别以及分类(Argument Identification and Classification, AIC)。对于论元的识别及分类,我们将其视作一个联合任务,即将“非论元”也看成是论元分类问题中的一个类别。在SRL系统中,我们在最大熵模型中引入L1正则,使得特征维度降至约为原来的1/40,从而大幅度地减小了模型的内存使用率,并且提升了预测的速度。同时,为了保证标注结果满足一定的约束条件,系统增加了一个后处理过程。
在CoNLL 2009评测数据集上,利用LTP的自动词性及句法信息,SRL性能如下所示。
| Precision | Recall | F-Score | Speed | Mem. |
|---|---|---|---|---|
| 0.8444 | 0.7234 | 0.7792 | 41.1 sent./s | 94M(PI+AIC) |