Worked on testing different Hand Pose algorthims (Google MediaPipe, MMPose, AlphaPose) to determine which would be the best for pressure vision tests. Continued the analysis with running tests on different augments of images.
Problem --> Failing to properly stack the images becuase of the rotation and normalizing of the points in Google Media Pipes Pipeline.
Below is the grid of images with each on labeled on the following images
| Grid Images | Stacked Images for 043 |
GIF for 043 |
|---|---|---|
 |
 |
 |
Overall darken 50% & resolution 50% & brighten 50% all have significant helps to the accuracy of the mediapipes
| Bad Image | Problem | GIF Image | Helper Augments | Good Image |
|---|---|---|---|---|
 |
Thumb prediction because of hidden also (Middle Finger stuggles with exact tip point due to covered hand) |  |
darken 75% & grayscale |
 |
 |
Middle, Ring, and Pinky finger points prediction due to covered view | |
resolution 50% |
 |
 |
Main pointer fail to reach correct tip |  |
darken 50% & grayscale & brighten 75% |
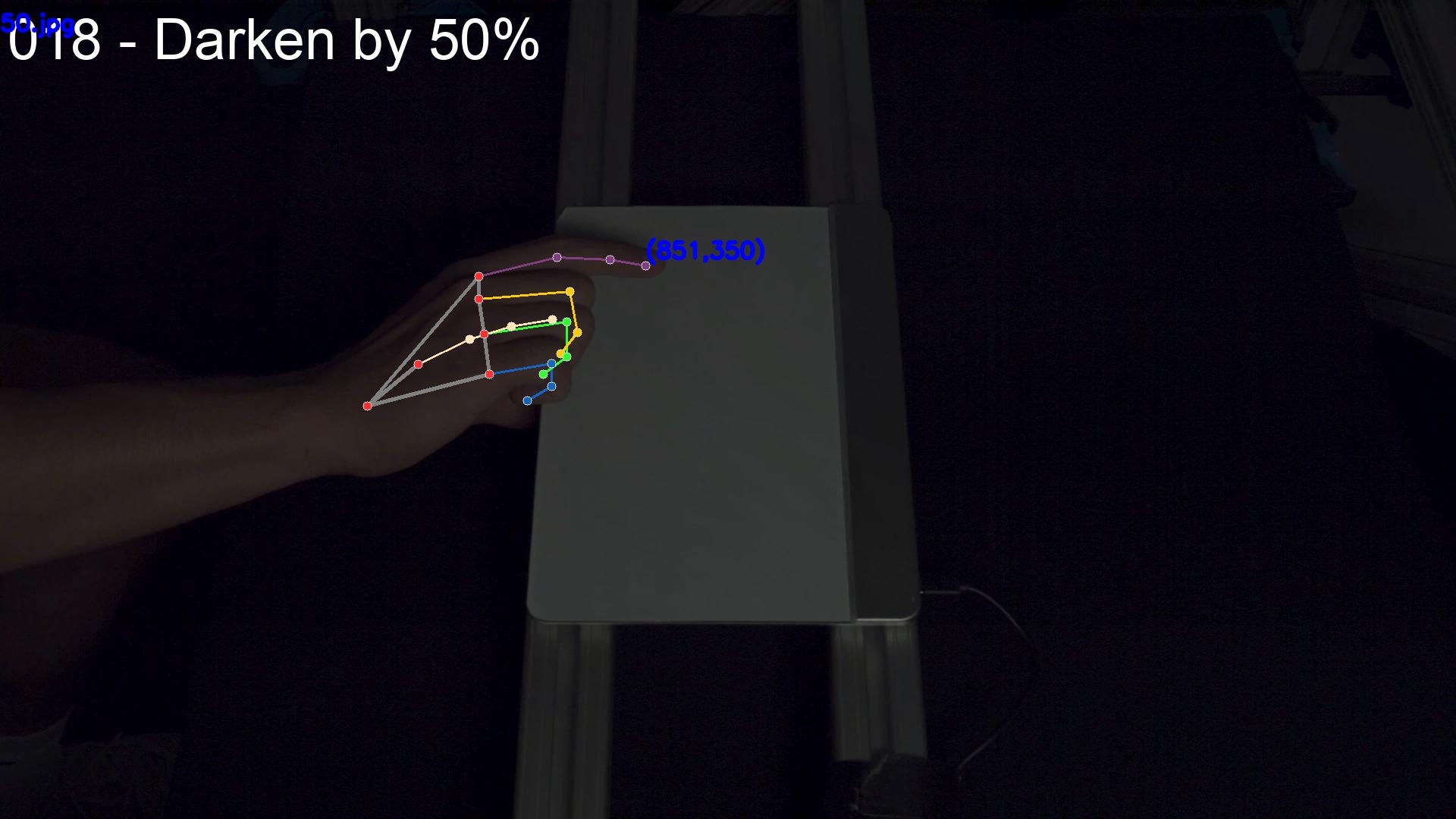 |
|
Nothing too bad good average on detected images | |
n/a |  |
 |
Middle and ring finger predictions wrong, covered and curled |  |
None | None |
 |
Pinky prediction off |  |
resolution 50% & brighten 25% & darken 50% and darken 25% |
 |
 |
Thumb predition completely off |  |
None | None |
 |
Predictions all over the place |  |
darken 50% (kinda) |
|
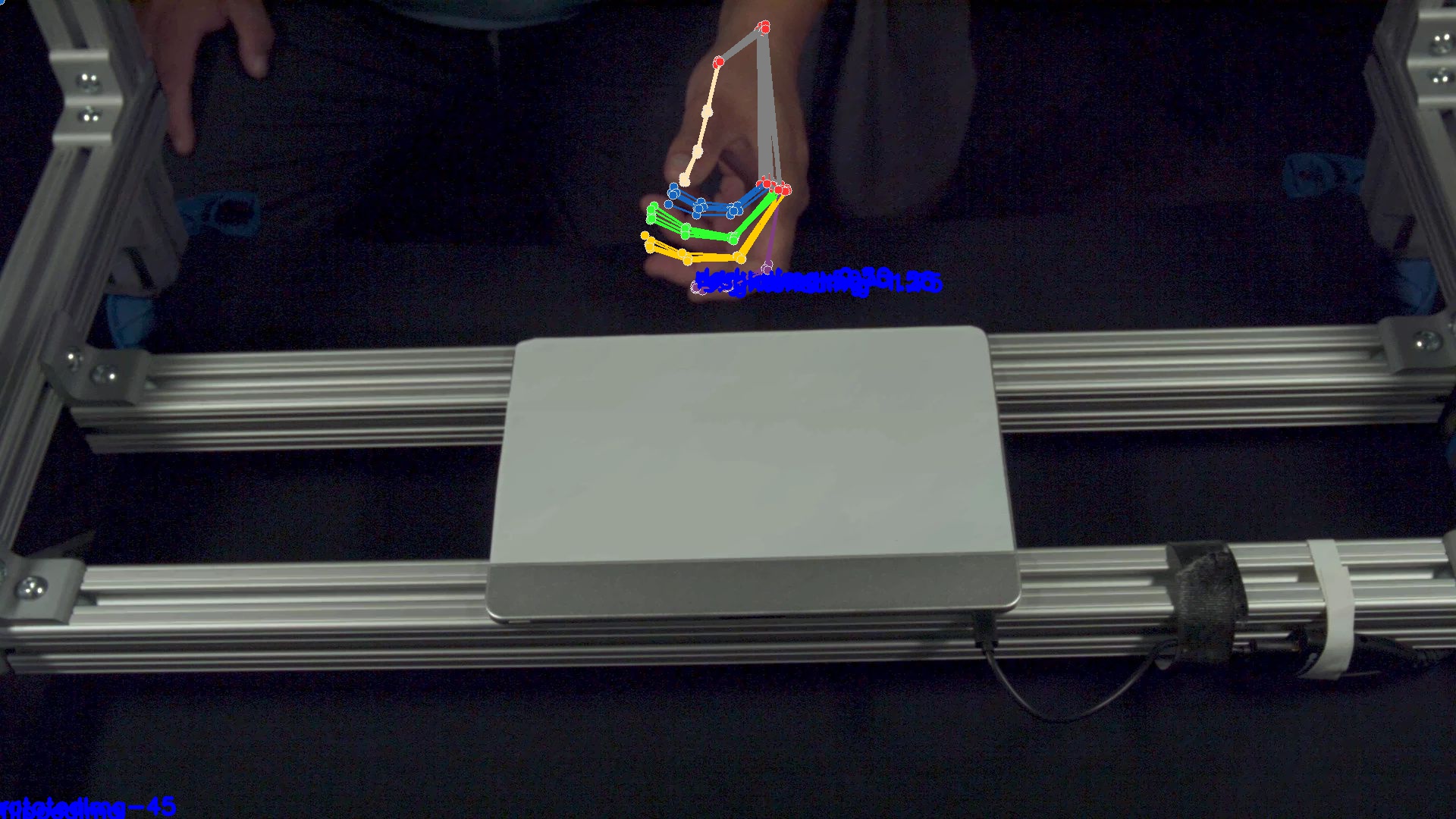 |
Middle finger (Yellow) off |  |
None | None |
 |
Example of 2 hands |  |
n/a | n/a |
 |
Nothing detected |  |
None | None |
 |
Better points on tips |  |
brigthen 25% |
 |
 |
Middle, Ring, Pinky fingers all fail |  |
None | None |
 |
Nothing detected at all |  |
None | None |
 |
Nothing detected at all |  |
None | None |
Use conda activate HandPose
Check out image vis_006 for possible mistakes in google media pipe
Change the image using the following adjustments only with google media pipe
- Brighten the image
- Darken the image
- Flip the image horizontally
- Increase/decrease the image contrast
- Lower the resolution by 50%
- Rotate the image by 45 degrees
- Rotate the image by 90 degrees
- Convert the image to grayscale
Test out results by draw each image on top of each other
Using the x,y points take the average of the outputs and remove outliers
Running different tests on a sample of a 100 hand images to see which model works the best for our use case.
| Model | Description | Image Example           |
|---|---|---|
| Alphapose | Fails to install alphapose due to some issue with required GPU | n/a |
| Google Media Pipe | Works the best with accuracy and improved speed |  |
| MMpose | Runs slow (likely due to no GPU) and accuracy struggles especially with hidden hands |  |
To run the hands on mmpose
- Go within the mmpose folder
- Running conda openmmlab use the following command
conda activate openmmlab
- For each file run the following thing
python demo/top_down_img_demo_with_mmdet.py demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \
cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \
configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \
res50_onehand10k_256x256-e67998f6_20200813.pth \
--img-root tests/data/onehand10k/ \
--img 9.jpg \
--out-img-root testingResults \
--device=cpu \
--det-cat-id 1
detcatid can be either 0 or 1
Top-down approach find two bounding boxes including each person estimate human joint(15 key-point) per each bounding box In this example, Top-down approach need pose estimation twice.
Bottom-up approach estimate all human joint(30 key-point) in the picture classify which joint(15 key-point) are included in the same person In this example, pose estimator doesn't care how many people are in the picture. they only consider how they can classify each joint to the each person.
In general situation, Top-down approach consume time much more than Bottom-up, because Top-down approach need N-times pose estimation by person detector results.
Make sure you include
--device cpu
python demo/bottom_up_img_demo.py associative_embedding_hrnet_w32_coco_512x512.py hrnet_w32_coco_512x512-bcb8c247_20200816.pth --img-path tests/data/coco/ --out-img-root vis_results --device cpu
python demo/top_down_img_demo.py configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py res50_onehand10k_256x256-e67998f6_20200813.pth --img-root tests/data/onehand10k/ --json-file tests/data/onehand10k/test_onehand10k.json --out-img-root vis_results --device=cpu
I am Kunal Aneja, first year Computer Science student working on Pressure Vision project with Patrick Grady
@Kunal2341 -- [email protected]