diff --git a/episodes/01-introduction.md b/episodes/01-introduction.md
index 04a5069a..c29d0c18 100644
--- a/episodes/01-introduction.md
+++ b/episodes/01-introduction.md
@@ -53,7 +53,7 @@ into a field that should contain a number. Understanding the nature of relationa
databases, and using SQL, will help you in using databases in programming languages
such as R or Python.
-Many web applications (including WordPress and ecommerce sites like Amazon) run on a SQL (relational) database. Understanding SQL is the first step in eventually building custom web applications that can serve data to users.
+Many web applications (including WordPress and e-commerce sites like Amazon) run on a SQL (relational) database. Understanding SQL is the first step in eventually building custom web applications that can serve data to users.
## Why are people working in library- and information-related roles well suited to SQL?
@@ -77,7 +77,7 @@ direct way of finding information.
- You can use SQL to query your library database and explore new views that are not necessarily provided via library systems patron facing interfaces.
-- SQL can be used to keep an inventory of items, for instance, for a library's makerspace, or it can be used to track licenses for journals.
+- SQL can be used to keep an inventory of items, for instance, for a library's makerspace, or it can be used to track licences for journals.
- For projects involving migrating and cleaning data from one system to another, SQL can be a handy tool.
@@ -108,34 +108,35 @@ Let's all open the database we downloaded via the setup in DB Browser for SQLite
You can see the tables in the database by looking at the left hand side of the
screen under Tables.
-To see the contents of a table, click on that table and then click on the Browse
-Data tab above the table data.
+To see the contents of a table, click on "Browse Data" then select the table in the "Table" dropdown in the upper left corner.
-If we want to write a query, we click on the Execute SQL tab.
+If we want to write a query, we click on the "Execute SQL" tab.
There are two ways to add new data to a table without writing SQL:
1. Enter data into a CSV file and append
2. Click the "Browse Data" tab, then click the "New Record" button.
-The steps for adding data from a CSV file are:
+To add data from a CSV file:
-1. Choose "File" > "Import" > "Table" from CSV file...
-2. DB Browser for SQLite will prompt you if you want to add the data to the existing table.
+1. Choose "File" > "Import" > "Table from CSV file..."
+2. Select a CSV file to import
+3. Review the import settings and confirm that the column names and fields are correct
+4. Click "OK" to import the data. If the table name matches an existing table and the number of columns match, DB Browser will ask if you want to add the data to the existing table.
## Dataset Description
-The data we will be using consists of 5 csv files that contain tables of article titles, journals, languages, licenses, and publishers. The information in these tables are from a sample of 51 different journals published during 2015.
+The data we will use was created from 5 csv files that contain tables of article titles, journals, languages, licences, and publishers. The information in these tables are from a sample of 51 different journals published during 2015.
**articles**
-- Contains individual article Titles and the associated citations and metadata
+- Contains individual article titles and the associated citations and metadata.
- (16 fields, 1001 records)
-- Field names: `id`, `Title`, `Authors`, `DOI`, `URL`, `Subjects`, `ISSNs`, `Citation`, `LanguageID`, `LicenseID`, `Author_Count`, `First_Author`, `Citation_Count`, `Day`, `Month`, `Year`
+- Field names: `id`, `Title`, `Authors`, `DOI`, `URL`, `Subjects`, `ISSNs`, `Citation`, `LanguageID`, `LicenceID`, `Author_Count`, `First_Author`, `Citation_Count`, `Day`, `Month`, `Year`
**journals**
-- Contains various journal Titles and associated metadata. The table also associates Journal Titles with ISSN numbers that are then referenced in the 'articles' table by the `ISSNs` field.
+- Contains various journal titles and associated metadata. The table also associates Journal Titles with ISSN numbers that are then referenced in the 'articles' table by the `ISSNs` field.
- (5 fields, 51 records)
- Field names: `id`, `ISSN-L`,`ISSNs`, `PublisherID`, `Journal_Title`
@@ -145,9 +146,9 @@ The data we will be using consists of 5 csv files that contain tables of article
- (2 fields, 4 records)
- Field names: `id`, `Language`
-**licenses**
+**licences**
-- ID table which associates License codes with id numbers. These id numbers are then referenced in the 'articles' table by the `LicenseID` field.
+- ID table which associates Licence codes with id numbers. These id numbers are then referenced in the 'articles' table by the `LicenceID` field.
- (2 fields, 4 records)
- Field names: `id`, `Licence`
@@ -163,14 +164,14 @@ The main data types that are used in doaj-article-sample database are `INTEGER`
## SQL Data Type Quick Reference
-Different database software/platforms have different names and sometimes different definitions of data types, so you'll need to understand the data types for any platform you are using. The following table explains some of the common data types and how they are represented in SQLite; [more details available on the SQLite website](https://www.sqlite.org/datatype3.html).
+Different database software/platforms have different names and sometimes different definitions of data types, so you'll need to understand the data types for any platform you are using. The following table explains some of the common data types and how they are represented in SQLite; [more details available on the SQLite website](https://www.sqlite.org/datatype3.html).
| Data type | Details | Name in SQLite |
| :--------------------- |:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| :-------------------------------------------------------------------------------------------------------------------- |
| boolean or binary | this variable type is often used to represent variables that can only have two values: yes or no, true or false. | doesn't exist - need to use integer data type and values of 0 or 1. |
| integer | sometimes called whole numbers or counting numbers. Can be 1, 2, 3, etc., as well as 0 and negative whole numbers: -1, -2, -3, etc. | INTEGER |
| float, real, or double | a decimal number or a floating point value. The largest possible size of the number may be specified. | REAL |
-| text or string | and combination of numbers, letters, symbols. Platforms may have different data types: one for variables with a set number of characters - e.g., a zip code or postal code, and one for variables with an open number of characters, e.g., an address or description variable. | TEXT |
+| text or string | any combination of numbers, letters, symbols. Platforms may have different data types: one for variables with a set number of characters - e.g., a zip code or postal code, and one for variables with an open number of characters, e.g., an address or description variable. | TEXT |
| date or datetime | depending on the platform, may represent the date and time or the number of days since a specified date. This field often has a specified format, e.g., YYYY-MM-DD | doesn't exist - need to use built-in date and time functions and store dates in real, integer, or text formats. See [Section 2.2 of SQLite documentation](https://www.sqlite.org/datatype3.html#date_and_time_datatype) for more details. |
| blob | a Binary Large OBject can store a large amount of data, documents, audio or video files. | BLOB |
diff --git a/episodes/02-selecting-sorting-data.md b/episodes/02-selecting-sorting-data.md
index bb316357..74ff7556 100644
--- a/episodes/02-selecting-sorting-data.md
+++ b/episodes/02-selecting-sorting-data.md
@@ -22,11 +22,11 @@ exercises: 5
## What is a query?
-A query is a question or request for data. For example, "How many journals does our library subscribe to?" When we query a database, we can ask the same question using a common language called Structured Query Language or SQL in what is called a statement. Some of the most useful queries - the ones we are introducing in this first section - are used to return results from a table that match specific criteria.
+A query is a question or request for data. For example, "How many journals does our library subscribe to?". When we query a database, we can ask the same question using Structured Query Language (SQL) in what is called a statement. Some of the most useful queries - the ones we are introducing in this first section - are used to return results from a table that match specific criteria.
## Writing my first query
-Let's start by opening DB Browser for SQLite and the doaj-article-sample database (see Setup). Choose `Browse Data` and the `articles` table. The articles table contains columns or fields such as `Title`, `Authors`, `DOI`, `URL`, etc.
+Let's start by opening DB Browser for SQLite and the doaj-article-sample database (see [Setup](/)). Click "Browse Data" and select the `articles` table in the "Table" dropdown menu. The articles table contains columns or fields such as `Title`, `Authors`, `DOI`, `URL`, etc.
Let's write a SQL query that selects only the `Title` column from the `articles` table.
@@ -60,7 +60,7 @@ SELECT Title, Authors, ISSNs, Year, DOI
FROM articles;
```
-Or we can select all of the columns in a table using the wildcard `*`.
+Or we can select all of the columns in a table using the wildcard `*`:
```sql
SELECT *
diff --git a/episodes/03-filtering.md b/episodes/03-filtering.md
index 39e916f2..02930b74 100644
--- a/episodes/03-filtering.md
+++ b/episodes/03-filtering.md
@@ -20,7 +20,7 @@ exercises: 10
## Filtering
-SQL is a powerful tool for filtering data in databases based on a set of conditions. Let's say we only want data for a specific ISSN, for instance, for the *Acta Crystallographica* journal from the `articles` table. The journal has an ISSN code `2056-9890`. To filter by this ISSN code, we will use the `WHERE` clause.
+SQL is a powerful tool for filtering data in databases based on a set of conditions. Let's say we only want data for a specific ISSN, for instance, for the *Acta Crystallographica* journal from the `articles` table. The journal has an ISSN code `2056-9890`. To filter by this ISSN code, we will use the `WHERE` clause.
```sql
SELECT *
diff --git a/episodes/04-ordering-commenting.md b/episodes/04-ordering-commenting.md
index db4603dd..3105666b 100644
--- a/episodes/04-ordering-commenting.md
+++ b/episodes/04-ordering-commenting.md
@@ -69,7 +69,7 @@ WHERE (ISSNs IN ('2076-0787', '2077-1444', '2067-2764|2247-6202'));
```
We started with something simple, then added more clauses one by one, testing
-their effects as we went along. For complex queries, this is a good strategy, to make sure you are getting what you want. Sometimes it might help to take a subset of the data that you can easily see in a temporary database to practice your queries on before working on a larger or more complicated database.
+their effects as we went along. For complex queries, this is a good strategy, to make sure you are getting what you want. Sometimes it might help to take a subset of the data that you can easily see in a temporary database to practice your queries on before working on a larger or more complicated database.
When the queries become more complex, it can be useful to add comments to express to yourself, or to others, what you are doing with your query. Comments help explain the logic of a section and provide context for anyone reading the query. It's essentially a way of making notes within your SQL. In SQL, comments begin using \-- and end at the end of the line. To mark a whole paragraph as a comment, you can enclose it with the characters /\* and \*/. For example, a commented version of the above query can be written as:
@@ -95,11 +95,11 @@ ON publishers.id = journals.PublisherId;
```
To see the introduction and explanation of JOINS, please click to [Episode 6](06-joins-aliases.md).
-{: .sql}
:::::::::::::::::::::::::::::::::::::::: keypoints
- Queries often have the structure: SELECT data FROM table WHERE certain criteria are present.
+- Comments can make our queries easier to read and understand.
::::::::::::::::::::::::::::::::::::::::::::::::::
diff --git a/episodes/05-aggregating-calculating.md b/episodes/05-aggregating-calculating.md
index 5020e9ba..2b389dad 100644
--- a/episodes/05-aggregating-calculating.md
+++ b/episodes/05-aggregating-calculating.md
@@ -1,5 +1,5 @@
---
-title: Aggregating & calculating values
+title: Aggregating and calculating values
teaching: 15
exercises: 5
---
@@ -108,7 +108,8 @@ In SQL, we can also perform calculations as we query the database. Also known as
```sql
SELECT Title, ISSNs, Author_Count - 1 as CoAuthor_Count
FROM articles
-ORDER BY Author_Count - 1 DESC;
+ORDER BY CoAuthor_Count DESC;
+
```
In section [6\. Joins and aliases](06-joins-aliases.md) we are going to learn more about the SQL keyword `AS` and how to make use of aliases - in this example we simply used the calculation and `AS` to represent that the new column is different from the original SQL table data.
diff --git a/episodes/08-database-design.md b/episodes/08-database-design.md
index d544d0f8..fd1c00ee 100644
--- a/episodes/08-database-design.md
+++ b/episodes/08-database-design.md
@@ -52,11 +52,11 @@ Database design involves a model or plan developed to determine how the data is
## Terminology
- +{alt='Fields, Records, Values'}
In the [Introduction to SQL](01-introduction.md) lesson, we introduced the terms "fields", "records", and "values". These terms are commonly used in databases while the "columns", "rows", and "cells" terms are more common in spreadsheets. Fields store a single kind of information (text, integers, etc.) related to one topic (title, author, year), while records are a set of fields containing specific values related to one item in your database (a book, a person, a library).
-To design a database, we must first decide what kinds of things we want to represent as tables. A table is the physical manifestation of a kind of "entity". An entity is the conceptual representation of the thing we want to store informtation about in the database, with each row containing information about one entity. An entity has "attributes" that describe it, represented as fields. For example, an article or a journal is an entity. Attributes would be things like the article title, or journal ISSN which would appear as fields.
+To design a database, we must first decide what kinds of things we want to represent as tables. A table is the physical manifestation of a kind of "entity". An entity is the conceptual representation of the thing we want to store information about in the database, with each row containing information about one entity. An entity has "attributes" that describe it, represented as fields. For example, an article or a journal is an entity. Attributes would be things like the article title, or journal ISSN which would appear as fields.
To create relationships between tables later on, it is important to designate one column as a primary key. A primary key, often designated as PK, is one attribute of an entity that distinguishes it from the other entities (or records) in your table. The primary key must be unique for each row for this to work. A common way to create a primary key in a table is to make an 'id' field that contains an auto-generated integer that increases by 1 for each new record. This will ensure that your primary key is unique.
@@ -68,11 +68,11 @@ ERDs are helpful tools for visualising and structuring your data more efficientl
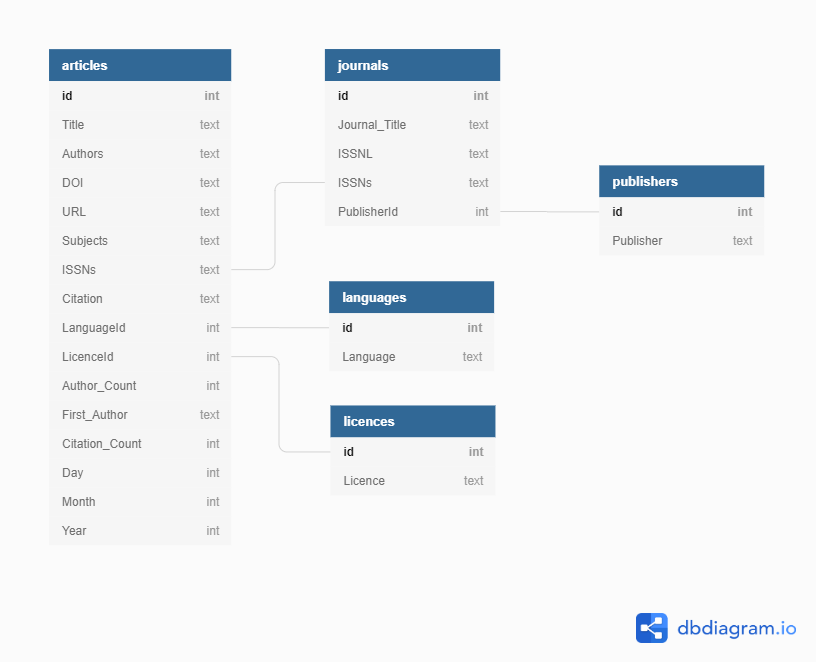{alt='Articles Database'}
-*Or you can view the [dbdiagram.io interactive version of the ERD](https://dbdiagram.io/d/5cc32b0cf7c5bb70c72fc530)*
+*Or you can view the [dbdiagram.io interactive version of the ERD](https://dbdiagram.io/d/5cc32b0cf7c5bb70c72fc530).*
Relationships between entities and their attributes are represented by lines linking them together. For example, the line linking journals and publishers is interpreted as follows: The 'journals' entity is related to the 'publishers' entity through the attributes 'PublisherId' and 'id' respectively.
-Conceptually, we know that a journal has only one publisher but a publisher can publish many journals. This is known as a one-to-many relationship. In modeling relationships, we usually assign a unique identifier to the 'one' side of the relationship and use that same identifier to refer to that entity on the 'many' side. In 'publishers' table, the 'id' attribute is that unique identifier. We use that same identifier in the 'journals' table to refer to an individual publisher. That way, there is an unambiguous way for us to distinguish which journals are associated with which publisher in a way that keeps the integrity of the data (see the Normalization section below).
+Conceptually, we know that a journal has only one publisher but a publisher can publish many journals. This is known as a one-to-many relationship. In modeling relationships, we usually assign a unique identifier to the 'one' side of the relationship and use that same identifier to refer to that entity on the 'many' side. In 'publishers' table, the 'id' attribute is that unique identifier. We use that same identifier in the 'journals' table to refer to an individual publisher. That way, there is an unambiguous way for us to distinguish which journals are associated with which publisher in a way that keeps the integrity of the data (see [the Normalisation section](#normalisation) below).
## More Terminology
@@ -95,7 +95,7 @@ ERDs are helpful in normalising your data which is a process that can be used to
In the example ERD above, creating a separate table for publishers and linking to it from the journals table via PK and FK identifiers allows us to normalise the data and avoid inconsistencies. If we used one table, we could introduce publisher name errors such as misspellings or alternate names as demonstrated below.
-{alt='Introducting inconsistencies and normalising data'}
+{alt='Introducing inconsistencies and normalising data'}
There are a number of normal forms in the normalisation process that can help you reduce redundancy in database tables. [Study Tonight](https://www.studytonight.com/dbms/database-normalization.php) features tutorials where you can learn more about them.
@@ -129,5 +129,3 @@ Additional database design tutorials to consult from Lucidchart:
- Database design is helpful for creating more efficient databases.
::::::::::::::::::::::::::::::::::::::::::::::::::
-
-
diff --git a/episodes/09-create.md b/episodes/09-create.md
index 47ecd95a..a1a28709 100644
--- a/episodes/09-create.md
+++ b/episodes/09-create.md
@@ -50,8 +50,7 @@ We talked about data types earlier [in Introduction to SQL: SQL Data Type Quick
When we create a table,
we can specify several kinds of constraints on its columns.
-For example,
-a better definition for the `journals` table would be:
+For example, a better definition for the `journals` table would be:
```sql
CREATE TABLE "journals" (
@@ -76,17 +75,22 @@ we can add, change, and remove records using our other set of commands,
Here is an example of inserting rows into the `journals` table:
```sql
-INSERT INTO "journals" VALUES (1,'2077-0472','2077-0472',2,'Agriculture');
-INSERT INTO "journals" VALUES (2,'2073-4395','2073-4395',2,'Agronomy');
-INSERT INTO "journals" VALUES (3,'2076-2616','2076-2616',2,'Animals');
-
+INSERT INTO "journals"
+VALUES (1,'2077-0472','2077-0472',2,'Agriculture');
+INSERT INTO "journals"
+VALUES (2,'2073-4395','2073-4395',2,'Agronomy');
+INSERT INTO "journals"
+VALUES (3,'2076-2616','2076-2616',2,'Animals');
```
We can also insert values into one table directly from another:
```sql
-CREATE TABLE "myjournals" (Journal_Title text, ISSNs text);
-INSERT INTO "myjournals" SELECT Journal_Title, ISSNs FROM journals;
+CREATE TABLE "myjournals"(Journal_Title text, ISSNs text);
+INSERT INTO "myjournals"
+SELECT Journal_Title, ISSNs
+FROM journals;
+
```
Modifying existing records is done using the `UPDATE` statement.
@@ -98,7 +102,9 @@ For example, if we made a typo when entering the ISSNs
of the last `INSERT` statement above, we can correct it with an update:
```sql
-UPDATE journals SET ISSN-L = 2076-2615, ISSNs = 2076-2615 WHERE id = 3;
+UPDATE journals
+SET ISSN-L = 2076-2615, ISSNs = 2076-2615
+WHERE id = 3;
```
Be careful to not forget the `WHERE` clause or the update statement will
@@ -112,7 +118,8 @@ that matches the records we want to discard.
We can remove the journal `Animals` from the `journals` table like this:
```sql
-DELETE FROM journals WHERE Journal_Title = 'Animals';
+DELETE FROM journals
+WHERE Journal_Title = 'Animals';
```
But now the article `Early Onset of Laying and Bumblefoot Favor Keel Bone Fractures` from the table `articles`
@@ -126,15 +133,17 @@ matching every row `ISSNs`in the table `articles`.
## Exercise
Write an SQL statement to add the journal "New Journal of Physics" (ISSNs \& ISSNs: 1367-2630; publisher: "Institute of Physics (IOP)") to the table
-`journals`. You need to add the publisher "IOP" to the table `publishers` as well.
+`journals`. You need to add the publisher "IOP" to the table `publishers` as well.
::::::::::::::: solution
## Solution
```sql
-INSERT INTO "publishers" VALUES (7,'Institute of Physics (IOP)');
-INSERT INTO "journals" VALUES (52,'1367-2630','1367-2630',7,'New Journal of Physics');
+INSERT INTO "publishers"
+VALUES (7,'Institute of Physics (IOP)');
+INSERT INTO "journals"
+VALUES (52,'1367-2630','1367-2630',7,'New Journal of Physics');
```
:::::::::::::::::::::::::
@@ -158,7 +167,7 @@ stored in any particular order.)
## Solution
-#### Advantages
+### Advantages
- A version control system will be able to show differences between versions
of the dump file; something it can't do for binary files like databases
@@ -167,7 +176,7 @@ stored in any particular order.)
- The version control log will explain the reason for the changes in each version
of the database
-#### Disadvantages
+### Disadvantages
- Artificial differences between commits because records don't have a fixed order
diff --git a/learners/discuss.md b/learners/discuss.md
index 5a054b89..136bad06 100644
--- a/learners/discuss.md
+++ b/learners/discuss.md
@@ -4,7 +4,6 @@ title: Discussion
There are many ways to discuss Library Carpentry lessons:
-- Join our [Gitter discussion forum](https://gitter.im/LibraryCarpentry/).
- Join our [Slack organisation](https://slack-invite.carpentries.org/) and #libraries channel.
- Stay in touch with our [Topicbox Group](https://carpentries.topicbox.com/groups/discuss-library-carpentry).
- Follow updates on [Twitter](https://twitter.com/LibCarpentry).
diff --git a/learners/reference.md b/learners/reference.md
index 9297f0c2..33ebbe72 100644
--- a/learners/reference.md
+++ b/learners/reference.md
@@ -2,10 +2,6 @@
title: 'SQL Cheat Sheet'
---
-## SQL Cheat Sheet
-
-***
-
### Basic query
```sql
@@ -98,7 +94,7 @@ ON table_name1.column_name = table_name2.column_name;
```
- Combine data from two tables where the values of column\_name in the two tables are the same.
-- Instead of `ON`, you can use the `USING` keyword as a shorthand. E.g. `USING (coolumn_name)`.
+- Instead of `ON`, you can use the `USING` keyword as a shorthand. E.g. `USING (column_name)`.
```sql
SELECT alias1.column_name1, alias1.column_name2, alias2.column_name3
diff --git a/learners/setup.md b/learners/setup.md
index a16dc319..e7137ced 100644
--- a/learners/setup.md
+++ b/learners/setup.md
@@ -16,7 +16,7 @@ To import data, you'll need to open DB Browser for SQLite and download a zip fil
1. Download the data files doaj-article-sample.zip from
[Zenodo](https://doi.org/10.5281/zenodo.8360812).
-2. Open the zip file with the zip utlity on your machine and save the folder and files to a location where you can easily find them. For example, your Desktop.
+2. Open the zip file with the zip utility on your machine and save the folder and files to a location where you can easily find them. For example, your Desktop.
3. Contained in the zip file are two files, doaj-article-sample.db and doaj-article-sample.db.sql. You can either open the database file (less steps) or import the SQL file (more steps).
### Open the database file
@@ -59,7 +59,7 @@ To exit type `exit`.
#### Windows
-On Windows download the [Windows Installer](https://github.com/swcarpentry/windows-installer/releases/download/v0.3/SWCarpentryInstaller.exe)
+On Windows download the [Windows Installer](https://github.com/swcarpentry/windows-installer/releases/download/v0.3/SWCarpentryInstaller.exe).
Copy the file to a directory and open the directory using the windows command line. Type `sqlite3`.
For a more detailed explanation see this [tutorial](https://www.sqlitetutorial.net/download-install-sqlite/).
diff --git a/profiles/learner-profiles.md b/profiles/learner-profiles.md
deleted file mode 100644
index 434e335a..00000000
--- a/profiles/learner-profiles.md
+++ /dev/null
@@ -1,5 +0,0 @@
----
-title: FIXME
----
-
-This is a placeholder file. Please add content here.
diff --git a/profiles/learner_profile.md b/profiles/learner_profile.md
index bfb02ec0..692e4a92 100644
--- a/profiles/learner_profile.md
+++ b/profiles/learner_profile.md
@@ -2,8 +2,6 @@
title: 'Elias'
---
-**Learners' Profiles**
-
Elias is a senior librarian in Utrecht University Library, specialising in manuscripts and special collections.
He has no programming experience but he is familiar with information principles, collection management and several metadata formats.
+{alt='Fields, Records, Values'}
In the [Introduction to SQL](01-introduction.md) lesson, we introduced the terms "fields", "records", and "values". These terms are commonly used in databases while the "columns", "rows", and "cells" terms are more common in spreadsheets. Fields store a single kind of information (text, integers, etc.) related to one topic (title, author, year), while records are a set of fields containing specific values related to one item in your database (a book, a person, a library).
-To design a database, we must first decide what kinds of things we want to represent as tables. A table is the physical manifestation of a kind of "entity". An entity is the conceptual representation of the thing we want to store informtation about in the database, with each row containing information about one entity. An entity has "attributes" that describe it, represented as fields. For example, an article or a journal is an entity. Attributes would be things like the article title, or journal ISSN which would appear as fields.
+To design a database, we must first decide what kinds of things we want to represent as tables. A table is the physical manifestation of a kind of "entity". An entity is the conceptual representation of the thing we want to store information about in the database, with each row containing information about one entity. An entity has "attributes" that describe it, represented as fields. For example, an article or a journal is an entity. Attributes would be things like the article title, or journal ISSN which would appear as fields.
To create relationships between tables later on, it is important to designate one column as a primary key. A primary key, often designated as PK, is one attribute of an entity that distinguishes it from the other entities (or records) in your table. The primary key must be unique for each row for this to work. A common way to create a primary key in a table is to make an 'id' field that contains an auto-generated integer that increases by 1 for each new record. This will ensure that your primary key is unique.
@@ -68,11 +68,11 @@ ERDs are helpful tools for visualising and structuring your data more efficientl
{alt='Articles Database'}
-*Or you can view the [dbdiagram.io interactive version of the ERD](https://dbdiagram.io/d/5cc32b0cf7c5bb70c72fc530)*
+*Or you can view the [dbdiagram.io interactive version of the ERD](https://dbdiagram.io/d/5cc32b0cf7c5bb70c72fc530).*
Relationships between entities and their attributes are represented by lines linking them together. For example, the line linking journals and publishers is interpreted as follows: The 'journals' entity is related to the 'publishers' entity through the attributes 'PublisherId' and 'id' respectively.
-Conceptually, we know that a journal has only one publisher but a publisher can publish many journals. This is known as a one-to-many relationship. In modeling relationships, we usually assign a unique identifier to the 'one' side of the relationship and use that same identifier to refer to that entity on the 'many' side. In 'publishers' table, the 'id' attribute is that unique identifier. We use that same identifier in the 'journals' table to refer to an individual publisher. That way, there is an unambiguous way for us to distinguish which journals are associated with which publisher in a way that keeps the integrity of the data (see the Normalization section below).
+Conceptually, we know that a journal has only one publisher but a publisher can publish many journals. This is known as a one-to-many relationship. In modeling relationships, we usually assign a unique identifier to the 'one' side of the relationship and use that same identifier to refer to that entity on the 'many' side. In 'publishers' table, the 'id' attribute is that unique identifier. We use that same identifier in the 'journals' table to refer to an individual publisher. That way, there is an unambiguous way for us to distinguish which journals are associated with which publisher in a way that keeps the integrity of the data (see [the Normalisation section](#normalisation) below).
## More Terminology
@@ -95,7 +95,7 @@ ERDs are helpful in normalising your data which is a process that can be used to
In the example ERD above, creating a separate table for publishers and linking to it from the journals table via PK and FK identifiers allows us to normalise the data and avoid inconsistencies. If we used one table, we could introduce publisher name errors such as misspellings or alternate names as demonstrated below.
-{alt='Introducting inconsistencies and normalising data'}
+{alt='Introducing inconsistencies and normalising data'}
There are a number of normal forms in the normalisation process that can help you reduce redundancy in database tables. [Study Tonight](https://www.studytonight.com/dbms/database-normalization.php) features tutorials where you can learn more about them.
@@ -129,5 +129,3 @@ Additional database design tutorials to consult from Lucidchart:
- Database design is helpful for creating more efficient databases.
::::::::::::::::::::::::::::::::::::::::::::::::::
-
-
diff --git a/episodes/09-create.md b/episodes/09-create.md
index 47ecd95a..a1a28709 100644
--- a/episodes/09-create.md
+++ b/episodes/09-create.md
@@ -50,8 +50,7 @@ We talked about data types earlier [in Introduction to SQL: SQL Data Type Quick
When we create a table,
we can specify several kinds of constraints on its columns.
-For example,
-a better definition for the `journals` table would be:
+For example, a better definition for the `journals` table would be:
```sql
CREATE TABLE "journals" (
@@ -76,17 +75,22 @@ we can add, change, and remove records using our other set of commands,
Here is an example of inserting rows into the `journals` table:
```sql
-INSERT INTO "journals" VALUES (1,'2077-0472','2077-0472',2,'Agriculture');
-INSERT INTO "journals" VALUES (2,'2073-4395','2073-4395',2,'Agronomy');
-INSERT INTO "journals" VALUES (3,'2076-2616','2076-2616',2,'Animals');
-
+INSERT INTO "journals"
+VALUES (1,'2077-0472','2077-0472',2,'Agriculture');
+INSERT INTO "journals"
+VALUES (2,'2073-4395','2073-4395',2,'Agronomy');
+INSERT INTO "journals"
+VALUES (3,'2076-2616','2076-2616',2,'Animals');
```
We can also insert values into one table directly from another:
```sql
-CREATE TABLE "myjournals" (Journal_Title text, ISSNs text);
-INSERT INTO "myjournals" SELECT Journal_Title, ISSNs FROM journals;
+CREATE TABLE "myjournals"(Journal_Title text, ISSNs text);
+INSERT INTO "myjournals"
+SELECT Journal_Title, ISSNs
+FROM journals;
+
```
Modifying existing records is done using the `UPDATE` statement.
@@ -98,7 +102,9 @@ For example, if we made a typo when entering the ISSNs
of the last `INSERT` statement above, we can correct it with an update:
```sql
-UPDATE journals SET ISSN-L = 2076-2615, ISSNs = 2076-2615 WHERE id = 3;
+UPDATE journals
+SET ISSN-L = 2076-2615, ISSNs = 2076-2615
+WHERE id = 3;
```
Be careful to not forget the `WHERE` clause or the update statement will
@@ -112,7 +118,8 @@ that matches the records we want to discard.
We can remove the journal `Animals` from the `journals` table like this:
```sql
-DELETE FROM journals WHERE Journal_Title = 'Animals';
+DELETE FROM journals
+WHERE Journal_Title = 'Animals';
```
But now the article `Early Onset of Laying and Bumblefoot Favor Keel Bone Fractures` from the table `articles`
@@ -126,15 +133,17 @@ matching every row `ISSNs`in the table `articles`.
## Exercise
Write an SQL statement to add the journal "New Journal of Physics" (ISSNs \& ISSNs: 1367-2630; publisher: "Institute of Physics (IOP)") to the table
-`journals`. You need to add the publisher "IOP" to the table `publishers` as well.
+`journals`. You need to add the publisher "IOP" to the table `publishers` as well.
::::::::::::::: solution
## Solution
```sql
-INSERT INTO "publishers" VALUES (7,'Institute of Physics (IOP)');
-INSERT INTO "journals" VALUES (52,'1367-2630','1367-2630',7,'New Journal of Physics');
+INSERT INTO "publishers"
+VALUES (7,'Institute of Physics (IOP)');
+INSERT INTO "journals"
+VALUES (52,'1367-2630','1367-2630',7,'New Journal of Physics');
```
:::::::::::::::::::::::::
@@ -158,7 +167,7 @@ stored in any particular order.)
## Solution
-#### Advantages
+### Advantages
- A version control system will be able to show differences between versions
of the dump file; something it can't do for binary files like databases
@@ -167,7 +176,7 @@ stored in any particular order.)
- The version control log will explain the reason for the changes in each version
of the database
-#### Disadvantages
+### Disadvantages
- Artificial differences between commits because records don't have a fixed order
diff --git a/learners/discuss.md b/learners/discuss.md
index 5a054b89..136bad06 100644
--- a/learners/discuss.md
+++ b/learners/discuss.md
@@ -4,7 +4,6 @@ title: Discussion
There are many ways to discuss Library Carpentry lessons:
-- Join our [Gitter discussion forum](https://gitter.im/LibraryCarpentry/).
- Join our [Slack organisation](https://slack-invite.carpentries.org/) and #libraries channel.
- Stay in touch with our [Topicbox Group](https://carpentries.topicbox.com/groups/discuss-library-carpentry).
- Follow updates on [Twitter](https://twitter.com/LibCarpentry).
diff --git a/learners/reference.md b/learners/reference.md
index 9297f0c2..33ebbe72 100644
--- a/learners/reference.md
+++ b/learners/reference.md
@@ -2,10 +2,6 @@
title: 'SQL Cheat Sheet'
---
-## SQL Cheat Sheet
-
-***
-
### Basic query
```sql
@@ -98,7 +94,7 @@ ON table_name1.column_name = table_name2.column_name;
```
- Combine data from two tables where the values of column\_name in the two tables are the same.
-- Instead of `ON`, you can use the `USING` keyword as a shorthand. E.g. `USING (coolumn_name)`.
+- Instead of `ON`, you can use the `USING` keyword as a shorthand. E.g. `USING (column_name)`.
```sql
SELECT alias1.column_name1, alias1.column_name2, alias2.column_name3
diff --git a/learners/setup.md b/learners/setup.md
index a16dc319..e7137ced 100644
--- a/learners/setup.md
+++ b/learners/setup.md
@@ -16,7 +16,7 @@ To import data, you'll need to open DB Browser for SQLite and download a zip fil
1. Download the data files doaj-article-sample.zip from
[Zenodo](https://doi.org/10.5281/zenodo.8360812).
-2. Open the zip file with the zip utlity on your machine and save the folder and files to a location where you can easily find them. For example, your Desktop.
+2. Open the zip file with the zip utility on your machine and save the folder and files to a location where you can easily find them. For example, your Desktop.
3. Contained in the zip file are two files, doaj-article-sample.db and doaj-article-sample.db.sql. You can either open the database file (less steps) or import the SQL file (more steps).
### Open the database file
@@ -59,7 +59,7 @@ To exit type `exit`.
#### Windows
-On Windows download the [Windows Installer](https://github.com/swcarpentry/windows-installer/releases/download/v0.3/SWCarpentryInstaller.exe)
+On Windows download the [Windows Installer](https://github.com/swcarpentry/windows-installer/releases/download/v0.3/SWCarpentryInstaller.exe).
Copy the file to a directory and open the directory using the windows command line. Type `sqlite3`.
For a more detailed explanation see this [tutorial](https://www.sqlitetutorial.net/download-install-sqlite/).
diff --git a/profiles/learner-profiles.md b/profiles/learner-profiles.md
deleted file mode 100644
index 434e335a..00000000
--- a/profiles/learner-profiles.md
+++ /dev/null
@@ -1,5 +0,0 @@
----
-title: FIXME
----
-
-This is a placeholder file. Please add content here.
diff --git a/profiles/learner_profile.md b/profiles/learner_profile.md
index bfb02ec0..692e4a92 100644
--- a/profiles/learner_profile.md
+++ b/profiles/learner_profile.md
@@ -2,8 +2,6 @@
title: 'Elias'
---
-**Learners' Profiles**
-
Elias is a senior librarian in Utrecht University Library, specialising in manuscripts and special collections.
He has no programming experience but he is familiar with information principles, collection management and several metadata formats.