+
+ S-Lab, Nanyang Technological University
+
+ * Equal Contribution
+ ♠ Equal appreciation on assistance
+ ✉ Corresponding Author
+
+
+
+[Technical Report](link) | [Demo](https://huggingface.co/spaces/Otter-AI/OtterHD-8B-demo) | [Benchmarks](https://huggingface.co/spaces/Otter-AI)
+
+We introduce OtterHD-8B, a multimodal model fine-tuned from [Fuyu-8B](https://huggingface.co/adept/fuyu-8b) to facilitate a more fine-grained interpretation of high-resolution visual input without requiring a vision encoder. OtterHD-8B also supports flexible input sizes at test time, ensuring adaptability to diverse inference budgets.
+
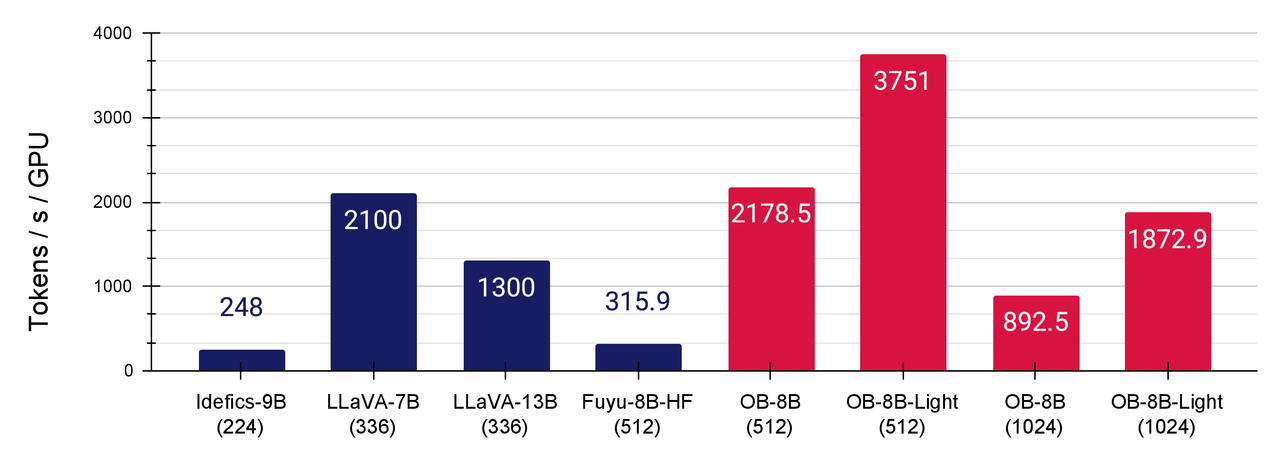
+We improve the native HuggingFace implementation of Fuyu-8B is highly unoptimized with [FlashAttention-2](https://github.com/Dao-AILab/flash-attention) and other fused operators including fused layernorm, fused square ReLU, and fused rotary positional embedding. Fuyu's simplified architecture facilitates us to do this in a fairly convenient way. As illustrated in the following, the modifications substantially enhance GPU utilization and training throughput (> 5 times larger than the vanilla HF implementation of Fuyu). Checkout the details at [here](../src/otter_ai/models/fuyu/modeling_fuyu.py).
+
+To our best knowledge and experiment trials, OtterHD achieves fastest training throughput among current leading LMMs, as it can be fully optimized and benefit from the simplified architecture.
+
+
+ +
+
+
+### Installation
+On top of the regular Otter environment, we need to install Flash-Attention 2 and other fused operators:
+```bash
+pip uninstall -y ninja && pip install ninja
+git clone https://github.com/Dao-AILab/flash-attention
+cd flash-attention
+python setup.py install
+cd csrc/rotary && pip install .
+cd ../csrc/fused_dense_lib && pip install .
+cd ../layer_norm && pip install .
+cd ../xentropy && pip install .
+cd ../.. && rm -rf flash-attention
+```
+### How to Finetune
+
+```bash
+accelerate launch \
+--config_file=pipeline/accelerate_configs/accelerate_config_zero2.yaml \
+--num_processes=8 \
+--main_process_port=25000 \
+pipeline/train/instruction_following.py \
+--pretrained_model_name_or_path=adept/fuyu-8b \
+--training_data_yaml=./Demo_Data.yaml \
+--model_name=fuyu \
+--instruction_format=fuyu \
+--batch_size=8 \
+--gradient_accumulation_steps=2 \
+--num_epochs=3 \
+--wandb_entity=ntu-slab \
+--external_save_dir=./checkpoints \
+--save_hf_model \
+--run_name=OtterHD_Tester \
+--wandb_project=Fuyu \
+--report_to_wandb \
+--workers=1 \
+--lr_scheduler=linear \
+--learning_rate=1e-5 \
+--warmup_steps_ratio=0.01 \
+--dynamic_resolution \
+--weight_decay 0.1 \
+```
+
+## MagnifierBench
+
+ +
+
+
+The human visual system can naturally perceive the details of small objects within a wide field of view, but current benchmarks for testing LMMs have not specifically focused on assessing this ability. This may be because the input sizes of mainstream Vision-Language models are constrained to relatively small resolutions. With the advent of the Fuyu and OtterHD models, we can extend the input resolution to a much larger range. Therefore, there is an urgent need for a benchmark that can test the ability to discern the details of small objects (often 1% image size) in high-resolution input images.
+
+### Evaluation
+Create a yaml file `benchmark.yaml` with below content:
+```yaml
+datasets:
+ - name: magnifierbench
+ split: test
+ data_path: Otter-AI/MagnifierBench
+ prompt: Answer with the option letter from the given choices directly.
+ api_key: [You GPT-4 API]
+models:
+ - name: fuyu
+ model_path: azure_storage/fuyu-8b
+ resolution: 1440
+```
+
+Then run
+
+```python
+python -m pipeline.benchmarks.evaluate --confg benchmark.yaml
+```
diff --git a/docs/benchmark_eval.md b/docs/benchmark_eval.md
new file mode 100644
index 00000000..e01595bd
--- /dev/null
+++ b/docs/benchmark_eval.md
@@ -0,0 +1,59 @@
+# Welcome to the benchmark evaluation page!
+
+The evaluation pipeline is designed to be one-clickable and easy to use. However, you may encounter some problems when running the models (e.g. LLaVA, LLaMA-Adapter) that require you to clone their repo to local path. Please feel free to contact us if you have any questions.
+
+We support the following benchmarks:
+- MagnifierBench
+- MMBench
+- MM-VET
+- MathVista
+- POPE
+- MME
+- SicenceQA
+- SeedBench
+
+And following models:
+- LLaVA
+- Fuyu
+- OtterHD
+- Otter-Image
+- Otter-Video
+- Idefics
+- LLaMA-Adapter
+- Qwen-VL
+
+many more, see `/pipeline/benchmarks/models`
+
+Create a yaml file `benchmark.yaml` with below content:
+```yaml
+datasets:
+ - name: magnifierbench
+ split: test
+ data_path: Otter-AI/MagnifierBench
+ prompt: Answer with the option letter from the given choices directly.
+ api_key: [You GPT-4 API]
+ - name: mme
+ split: test
+ - name: pope
+ split: test
+ default_output_path: ./logs
+ - name: mmvet
+ split: test
+ api_key: [You GPT-4 API]
+ gpt_model: gpt-4-0613
+ - name: mathvista
+ split: test
+ api_key: [You GPT-4 API]
+ gpt_model: gpt-4-0613
+ - name: mmbench
+ split: test
+models:
+ - name: fuyu
+ model_path: adept/fuyu-8b
+```
+
+Then run
+
+```python
+python -m pipeline.benchmarks.evaluate --confg benchmark.yaml
+```
\ No newline at end of file
diff --git a/docs/huggingface_compatible.md b/docs/huggingface_compatible.md
old mode 100644
new mode 100755
diff --git a/docs/mimicit_format.md b/docs/mimicit_format.md
new file mode 100755
index 00000000..d21ab271
--- /dev/null
+++ b/docs/mimicit_format.md
@@ -0,0 +1,89 @@
+# Breaking Down the MIMIC-IT Format
+
+We mainly use one integrate dataset format and we refer it to MIMIC-IT format since.
+
+The mimic-it format contains the following data yaml file. Within this data yaml file, you could assign the path of the instruction json file and the image parquet file, and also the number of samples you want to use. The number of samples within each group will be uniformly sampled, and the `number_samples / total_numbers`` will decide sampling ratio of each dataset.
+
+```yaml
+IMAGE_TEXT: # Group name should be in [IMAGE_TEXT, TEXT_ONLY, IMAGE_TEXT_IN_CONTEXT]
+ LADD: # Dataset name can be assigned at any name you want
+ mimicit_path: azure_storage/json/LA/LADD_instructions.json # Path of the instruction json file
+ images_path: azure_storage/Parquets/LA.parquet # Path of the image parquet file
+ num_samples: -1 # Number of samples you want to use, -1 means use all samples, if not set, default is -1.
+ LACR_T2T:
+ mimicit_path: azure_storage/json/LA/LACR_T2T_instructions.json
+ images_path: azure_storage/Parquets/LA.parquet
+ num_samples: -1
+ M3IT_CAPTIONING:
+ mimicit_path: azure_storage/json/M3IT/captioning/coco/coco_instructions.json
+ images_path: azure_storage/Parquets/coco.parquet
+ num_samples: 20000
+
+TEXT_ONLY:
+ LIMA:
+ mimicit_path: azure_storage/json/LANG_Only/LIMA/LIMA_instructions_max_1K_tokens.json
+ num_samples: 20000
+ SHAREGPT:
+ mimicit_path: azure_storage/json/LANG_Only/SHAREGPT/SHAREGPT_instructions_max_1K_tokens.json
+ num_samples: 10000
+ AL:
+ mimicit_path: azure_storage/json/LANG_Only/AL/AL_instructions_max_1K_tokens.json
+ num_samples: 20000
+```
+
+The data yaml file mainly include two groups of data (1) IMAGE_TEXT (2) TEXT_ONLY.
+
+For each group, one dataset contains the `instruction.json` file and `images.parquet` file. You can browse the `instruction.json` file at [here](https://entuedu-my.sharepoint.com/:f:/g/personal/libo0013_e_ntu_edu_sg/Eo9bgNV5cjtEswfA-HfjNNABiKsjDzSWAl5QYAlRZPiuZA?e=nNUhJH) and the `images.parquet` file at [here](https://entuedu-my.sharepoint.com/:f:/g/personal/libo0013_e_ntu_edu_sg/EmwHqgRtYtBNryTcFmrGWCgBjvWQMo1XeCN250WuM2_51Q?e=sCymXx). We will provide more at the same Onedrive folder gradually due to the limited internet bandwith, you send emails to push us.
+
+You are also welcome to make your own data into this format, let's breakdown what's inside them:
+
+## DallE3_instructions.json
+```
+{
+ "meta": { "version": "0.0.1", "time": "2023-10-29", "author": "Jingkang Yang" },
+ "data": {
+ "D3_INS_000000": {
+ "instruction": "What do you think is the prompt for this AI-generated picture?",
+ "answer": "photo of a gigantic hand coming from the sky reaching out people who are holding hands at a beach, there is also a giant eye in the sky look at them",
+ "image_ids": ["D3_IMG_000000"],
+ "rel_ins_ids": []
+ },
+ "D3_INS_000001": {
+ "instruction": "This is an AI generated image, can you infer what's the prompt behind this image?",
+ "answer": "photography of a a soccer stadium on the moon, players are dressed as astronauts",
+ "image_ids": ["D3_IMG_000001"],
+ "rel_ins_ids": []
+ }...
+ }
+}
+```
+
+Note that the `image_ids` is the key of the `DallE3_images.parquet` file, you can use the `image_ids` to index the `base64` string of the image.
+
+## DallE3_images.parquet
+
+```
+import pandas as pd
+images = "./DallE3_images.parquet"
+image_parquet = pd.read_parquet(images)
+
+image_parquet.head()
+ base64
+D3_IMG_000000 /9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAEBAQEBAQEBAQ...
+D3_IMG_000001 /9j/4AAQSkZJRgABAQEASABIAAD/5FolU0NBTEFETwAAAg...
+```
+
+
+Note that before September, we mainly use `images.json` to store the `key:base64_str` pairs, but we found it causes too much CPU memory during decoding large json files. So we switch to parquet, the parquet file is the same as previous json file and you can use the script to convert it from json to parquet.
+
+```python
+json_file_path = "LA.json"
+with open(json_file_path, "r") as f:
+ data_dict = json.load(f)
+
+df = pd.DataFrame.from_dict(resized_data_dict, orient="index", columns=["base64"])
+parquet_file_path = os.path.join(
+ parquet_root_path, os.path.basename(json_file_path).split(".")[0].replace("_image", "") + ".parquet"
+)
+df.to_parquet(parquet_file_path, engine="pyarrow")
+```
\ No newline at end of file
diff --git a/docs/server_host.md b/docs/server_host.md
old mode 100644
new mode 100755
diff --git a/environment.yml b/environment.yml
old mode 100644
new mode 100755
diff --git a/mimic-it/README.md b/mimic-it/README.md
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/README.md b/mimic-it/convert-it/README.md
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/__init__.py b/mimic-it/convert-it/__init__.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/abstract_dataset.py b/mimic-it/convert-it/abstract_dataset.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/2d.py b/mimic-it/convert-it/datasets/2d.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/3d.py b/mimic-it/convert-it/datasets/3d.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/__init__.py b/mimic-it/convert-it/datasets/__init__.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/change.py b/mimic-it/convert-it/datasets/change.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/fpv.py b/mimic-it/convert-it/datasets/fpv.py
old mode 100644
new mode 100755
index cd00fce8..6d174378
--- a/mimic-it/convert-it/datasets/fpv.py
+++ b/mimic-it/convert-it/datasets/fpv.py
@@ -56,7 +56,11 @@ def get_image(video_path):
final_images_dict = {}
with ThreadPoolExecutor(max_workers=num_thread) as executor:
- process_bar = tqdm(total=len(video_paths), unit="video", desc="Processing videos into images")
+ process_bar = tqdm(
+ total=len(video_paths),
+ unit="video",
+ desc="Processing videos into images",
+ )
for images_dict in executor.map(get_image, video_paths):
final_images_dict.update(images_dict)
process_bar.update()
diff --git a/mimic-it/convert-it/datasets/utils/scene_navigation_utils.py b/mimic-it/convert-it/datasets/utils/scene_navigation_utils.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/utils/visual_story_telling_utils.py b/mimic-it/convert-it/datasets/utils/visual_story_telling_utils.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/datasets/video.py b/mimic-it/convert-it/datasets/video.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/image_utils.py b/mimic-it/convert-it/image_utils.py
old mode 100644
new mode 100755
diff --git a/mimic-it/convert-it/main.py b/mimic-it/convert-it/main.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/abstract_dataset.py b/mimic-it/syphus/abstract_dataset.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/3d.py b/mimic-it/syphus/datasets/3d.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/__init__.py b/mimic-it/syphus/datasets/__init__.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/change.py b/mimic-it/syphus/datasets/change.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/fpv.py b/mimic-it/syphus/datasets/fpv.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/funqa.py b/mimic-it/syphus/datasets/funqa.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/translate.py b/mimic-it/syphus/datasets/translate.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/datasets/video.py b/mimic-it/syphus/datasets/video.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/file_utils.py b/mimic-it/syphus/file_utils.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/main.py b/mimic-it/syphus/main.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/coco_spot_the_difference_prompt.py b/mimic-it/syphus/prompts/coco_spot_the_difference_prompt.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/dense_captions.json b/mimic-it/syphus/prompts/dense_captions.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/ego4d.json b/mimic-it/syphus/prompts/ego4d.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/funqa_dia.json b/mimic-it/syphus/prompts/funqa_dia.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/funqa_mcqa.json b/mimic-it/syphus/prompts/funqa_mcqa.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/funqa_translation.json b/mimic-it/syphus/prompts/funqa_translation.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/scene_navigation.json b/mimic-it/syphus/prompts/scene_navigation.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/spot_the_difference.json b/mimic-it/syphus/prompts/spot_the_difference.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/translation_prompt.py b/mimic-it/syphus/prompts/translation_prompt.py
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/tv_captions.json b/mimic-it/syphus/prompts/tv_captions.json
old mode 100644
new mode 100755
diff --git a/mimic-it/syphus/prompts/visual_story_telling.json b/mimic-it/syphus/prompts/visual_story_telling.json
old mode 100644
new mode 100755
diff --git a/pipeline/accelerate_configs/accelerate_config_zero1.yaml b/pipeline/accelerate_configs/accelerate_config_zero1.yaml
new file mode 100755
index 00000000..2948da7b
--- /dev/null
+++ b/pipeline/accelerate_configs/accelerate_config_zero1.yaml
@@ -0,0 +1,18 @@
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
+ gradient_accumulation_steps: 1
+ gradient_clipping: 1.0
+ offload_optimizer_device: none
+ offload_param_device: none
+ zero3_init_flag: false
+ zero_stage: 1
+distributed_type: DEEPSPEED
+fsdp_config: {}
+machine_rank: 0
+main_process_ip: null
+main_process_port: null
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 8
+use_cpu: false
\ No newline at end of file
diff --git a/pipeline/accelerate_configs/accelerate_config_zero2.yaml b/pipeline/accelerate_configs/accelerate_config_zero2.yaml
index b6c41a90..5b3439f1 100755
--- a/pipeline/accelerate_configs/accelerate_config_zero2.yaml
+++ b/pipeline/accelerate_configs/accelerate_config_zero2.yaml
@@ -1,6 +1,6 @@
compute_environment: LOCAL_MACHINE
deepspeed_config:
- gradient_accumulation_steps: 1
+ gradient_accumulation_steps: 4
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
diff --git a/pipeline/accelerate_configs/accelerate_config_zero3.yaml b/pipeline/accelerate_configs/accelerate_config_zero3.yaml
old mode 100644
new mode 100755
index f5fb5bf6..a6c303c6
--- a/pipeline/accelerate_configs/accelerate_config_zero3.yaml
+++ b/pipeline/accelerate_configs/accelerate_config_zero3.yaml
@@ -1,5 +1,5 @@
compute_environment: LOCAL_MACHINE
-deepspeed_config:
+deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
@@ -11,9 +11,9 @@ distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
-main_process_port: 20222
+main_process_port: 20333
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
-use_cpu: false
+use_cpu: false
\ No newline at end of file
diff --git a/pipeline/accelerate_configs/accelerate_config_zero3_offload.yaml b/pipeline/accelerate_configs/accelerate_config_zero3_offload.yaml
new file mode 100755
index 00000000..4f9775eb
--- /dev/null
+++ b/pipeline/accelerate_configs/accelerate_config_zero3_offload.yaml
@@ -0,0 +1,19 @@
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
+ gradient_accumulation_steps: 1
+ gradient_clipping: 1.0
+ offload_optimizer_device: cpu
+ offload_param_device: cpu
+ zero3_init_flag: true
+ zero3_save_16bit_model: true
+ zero_stage: 3
+distributed_type: DEEPSPEED
+fsdp_config: {}
+machine_rank: 0
+main_process_ip: null
+main_process_port: 20333
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 8
+use_cpu: false
\ No newline at end of file
diff --git a/pipeline/accelerate_configs/accelerate_config_zero3_slurm.yaml b/pipeline/accelerate_configs/accelerate_config_zero3_slurm.yaml
index d9b965bb..67e5598a 100755
--- a/pipeline/accelerate_configs/accelerate_config_zero3_slurm.yaml
+++ b/pipeline/accelerate_configs/accelerate_config_zero3_slurm.yaml
@@ -1,11 +1,12 @@
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_multinode_launcher: standard
- gradient_accumulation_steps: 1
+ gradient_accumulation_steps: 2
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
+ zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
fsdp_config: {}
diff --git a/pipeline/accelerate_configs/ds_zero3_config.json b/pipeline/accelerate_configs/ds_zero3_config.json
new file mode 100755
index 00000000..6917317a
--- /dev/null
+++ b/pipeline/accelerate_configs/ds_zero3_config.json
@@ -0,0 +1,28 @@
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+ "bf16": {
+ "enabled": "auto"
+ },
+ "train_micro_batch_size_per_gpu": "auto",
+ "train_batch_size": "auto",
+ "gradient_accumulation_steps": "auto",
+ "zero_optimization": {
+ "stage": 3,
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
\ No newline at end of file
diff --git a/pipeline/benchmarks/.gitignore b/pipeline/benchmarks/.gitignore
new file mode 100644
index 00000000..a5394700
--- /dev/null
+++ b/pipeline/benchmarks/.gitignore
@@ -0,0 +1 @@
+config.yaml
\ No newline at end of file
diff --git a/pipeline/__init__.py b/pipeline/benchmarks/__init__.py
similarity index 100%
rename from pipeline/__init__.py
rename to pipeline/benchmarks/__init__.py
diff --git a/pipeline/eval/__init__.py b/pipeline/benchmarks/datasets/__init__.py
similarity index 100%
rename from pipeline/eval/__init__.py
rename to pipeline/benchmarks/datasets/__init__.py
diff --git a/pipeline/benchmarks/datasets/base_eval_dataset.py b/pipeline/benchmarks/datasets/base_eval_dataset.py
new file mode 100644
index 00000000..4bbd74e5
--- /dev/null
+++ b/pipeline/benchmarks/datasets/base_eval_dataset.py
@@ -0,0 +1,50 @@
+from abc import ABC, abstractmethod
+from PIL import Image
+from typing import Dict, List, Any
+
+import importlib
+
+AVAILABLE_EVAL_DATASETS: Dict[str, str] = {
+ "mmbench": "MMBenchDataset",
+ "mme": "MMEDataset",
+ "mathvista": "MathVistaDataset",
+ "mmvet": "MMVetDataset",
+ "seedbench": "SEEDBenchDataset",
+ "pope": "PopeDataset",
+ "scienceqa": "ScienceQADataset",
+ "magnifierbench": "MagnifierBenchDataset",
+}
+
+
+class BaseEvalDataset(ABC):
+ def __init__(self, name: str, dataset_path: str, *, max_batch_size: int = 1):
+ self.name = name
+ self.dataset_path = dataset_path
+ self.max_batch_size = max_batch_size
+
+ def evaluate(self, model, **kwargs):
+ return self._evaluate(model, **kwargs)
+ # batch = min(model.max_batch_size, self.max_batch_size)
+ # if batch == 1:
+ # return self._evaluate(model, **kwargs)
+ # else:
+ # kwargs["batch"] = batch
+ # return self._evaluate(model, **kwargs)
+
+ @abstractmethod
+ def _evaluate(self, model: str):
+ pass
+
+
+def load_dataset(dataset_name: str, dataset_args: Dict[str, str] = {}) -> BaseEvalDataset:
+ assert dataset_name in AVAILABLE_EVAL_DATASETS, f"{dataset_name} is not an available eval dataset."
+ module_path = "pipeline.benchmarks.datasets." + dataset_name
+ dataset_formal_name = AVAILABLE_EVAL_DATASETS[dataset_name]
+ imported_module = importlib.import_module(module_path)
+ dataset_class = getattr(imported_module, dataset_formal_name)
+ print(f"Imported class: {dataset_class}")
+ # import pdb;pdb.set_trace()
+ # get dataset args without "name"
+ init_args = dataset_args.copy()
+ init_args.pop("name")
+ return dataset_class(**init_args)
diff --git a/pipeline/benchmarks/datasets/magnifierbench.py b/pipeline/benchmarks/datasets/magnifierbench.py
new file mode 100644
index 00000000..a0c4ed97
--- /dev/null
+++ b/pipeline/benchmarks/datasets/magnifierbench.py
@@ -0,0 +1,212 @@
+import base64
+import io
+from PIL import Image
+import json
+from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
+import os
+import numpy as np
+from datasets import load_dataset
+from typing import Union
+from .base_eval_dataset import BaseEvalDataset
+from tqdm import tqdm
+import datetime
+import pytz
+import re
+
+import time
+import requests
+
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+
+def get_chat_response(promot, api_key, model="gpt-4-0613", temperature=0, max_tokens=256, n=1, patience=5, sleep_time=5):
+ headers = {
+ "Authorization": f"Bearer {api_key}",
+ "Content-Type": "application/json",
+ }
+
+ messages = [
+ {"role": "system", "content": "You are a helpful AI assistant. Your task is to judge whether the model response is correct to answer the given question or not."},
+ {"role": "user", "content": promot},
+ ]
+
+ payload = {"model": model, "messages": messages}
+
+ while patience > 0:
+ patience -= 1
+ try:
+ response = requests.post(
+ "https://api.openai.com/v1/chat/completions",
+ headers=headers,
+ data=json.dumps(payload),
+ timeout=30,
+ )
+ response.raise_for_status()
+ response_data = response.json()
+
+ prediction = response_data["choices"][0]["message"]["content"].strip()
+ if prediction != "" and prediction is not None:
+ return prediction
+
+ except Exception as e:
+ if "Rate limit" not in str(e):
+ print(e)
+ time.sleep(sleep_time)
+
+ return ""
+
+
+def prepare_query(model_answer_item, api_key):
+ freeform_question = model_answer_item["freeform_question"]
+ freeform_response = model_answer_item["freeform_response"]
+ correct_answer = model_answer_item["freeform_answer"]
+
+ # Formulating the prompt for ChatGPT
+ prompt = f"Question: {freeform_question}\nModel Response: {freeform_response}\nGround Truth: {correct_answer}\nWill the model response be considered correct? You should only answer yes or no."
+
+ # Querying ChatGPT
+ chat_response = get_chat_response(prompt, api_key)
+
+ return chat_response
+
+
+class MagnifierBenchDataset(BaseEvalDataset):
+ def __init__(
+ self,
+ data_path: str = "Otter-AI/MagnifierBench",
+ *,
+ cache_dir: Union[str, None] = None,
+ default_output_path: str = "./logs/MagBench",
+ split: str = "test",
+ debug: bool = False,
+ prompt="",
+ api_key=None,
+ ):
+ super().__init__("MagnifierBench", data_path)
+
+ self.default_output_path = default_output_path
+ if not os.path.exists(self.default_output_path):
+ os.makedirs(self.default_output_path)
+
+ self.cur_datetime = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ self.data = load_dataset(data_path, split=split, cache_dir=cache_dir, revision="main")
+ self.debug = debug
+ self.prompt = prompt
+ self.api_key = api_key
+
+ def parse_pred_ans(self, pred_ans, question):
+ match = re.search(r"The answer is ([A-D])", pred_ans)
+ if match:
+ return match.group(1)
+ choices = ["A", "B", "C", "D"]
+ for selection in choices:
+ if selection in pred_ans:
+ return selection
+ pattern = "A\\. (.+?), B\\. (.+?), C\\. (.+?), D\\. (.+)"
+ matches = re.search(pattern, question)
+ if matches:
+ options = {"A": matches.group(1), "B": matches.group(2), "C": matches.group(3), "D": matches.group(4)}
+ for c, option in options.items():
+ option = option.strip()
+ if option.endswith(".") or option.endswith(",") or option.endswith("?"):
+ option = option[:-1]
+ if option.upper() in pred_ans.upper():
+ return c
+ for selection in choices:
+ if selection in pred_ans.upper():
+ return selection
+ return "other"
+
+ def _evaluate(self, model):
+ model_score_dict = {}
+
+ # output_path = os.path.join(self.default_output_path, f"{model.name}_{self.cur_datetime}")
+ # if not os.path.exists(output_path):
+ # os.makedirs(output_path)
+ # model_path: str = "Salesforce/instructblip-vicuna-7b"
+ model_version = model.name.split("/")[-1]
+ model_answer_path = os.path.join(self.default_output_path, f"{model_version}_{self.cur_datetime}_answer.json")
+ result_path = os.path.join(self.default_output_path, f"{model_version}_{self.cur_datetime}_score.json")
+ model_answer = {}
+
+ score = 0
+ num_data = 0
+
+ ff_score = 0
+
+ for data in tqdm(self.data, desc="Evaluating", total=len(self.data)):
+ question = f"{self.prompt} {data['instruction']}" if self.prompt else data["instruction"]
+ if len(data["images"]) != 1:
+ print(f"Warning: {data['id']} has {len(data['images'])} images.")
+ print(f"Skipping {data['id']}")
+ continue
+
+ model_response = model.generate(question, data["images"][0])
+
+ pred_ans = self.parse_pred_ans(model_response, question)
+
+ freeform_question = (question.split("?")[0] + "?").replace(self.prompt, "").strip()
+ options = question.split("?")[1]
+ answer_option = data["answer"]
+ for single_opt in options.split(","):
+ single_opt = single_opt.strip()
+ if single_opt.startswith(answer_option.upper()):
+ freeform_answer = single_opt.split(".")[1].strip()
+ break
+
+ ff_response = model.generate(freeform_question, data["images"][0])
+ if self.debug:
+ print(f"Question: {question}")
+ print(f"Answer: {data['answer']}")
+ print(f"Raw prediction: {model_response}")
+ print(f"Parsed prediction: {pred_ans}\n")
+ print(f"Freeform question: {freeform_question}")
+ print(f"Freeform answer: {freeform_answer}")
+ print(f"Freeform response: {ff_response}\n")
+
+ num_data += 1
+ if pred_ans == data["answer"]:
+ score += 1
+ model_answer[data["id"]] = {
+ "question": question,
+ "options": options,
+ "model_response": model_response,
+ "parsed_output": pred_ans,
+ "answer": data["answer"],
+ "freeform_question": freeform_question,
+ "freeform_response": ff_response,
+ "freeform_answer": freeform_answer,
+ }
+ with open(model_answer_path, "w") as f:
+ json.dump(model_answer, f, indent=2)
+
+ model_score_dict["score"] = score
+ model_score_dict["total"] = len(self.data)
+ model_score_dict["accuracy"] = score / len(self.data)
+
+ print(f"Start query GPT-4 for free-form evaluation...")
+ for data_id in tqdm(model_answer.keys(), desc="Querying GPT-4"):
+ model_answer_item = model_answer[data_id]
+ gpt_response = prepare_query(model_answer_item, self.api_key)
+ if gpt_response.lower() == "yes":
+ ff_score += 1
+ elif gpt_response.lower() == "no":
+ ff_score += 0
+ else:
+ print(f"Warning: {data_id} has invalid GPT-4 response: {gpt_response}")
+ print(f"Skipping {data_id}")
+ continue
+
+ model_score_dict["freeform_score"] = ff_score
+ model_score_dict["freeform_accuracy"] = ff_score / len(model_answer)
+
+ with open(result_path, "w") as f:
+ json.dump(model_score_dict, f, indent=2)
+
+ print(f"Model answer saved to {model_answer_path}")
+ print(f"Model score saved to {result_path}")
+ print(json.dumps(model_score_dict, indent=2))
+
+ return model_score_dict
diff --git a/pipeline/benchmarks/datasets/mathvista.py b/pipeline/benchmarks/datasets/mathvista.py
new file mode 100644
index 00000000..939f7bb4
--- /dev/null
+++ b/pipeline/benchmarks/datasets/mathvista.py
@@ -0,0 +1,480 @@
+import base64
+import os
+import pandas as pd
+from PIL import Image
+from tqdm import tqdm
+from datasets import load_dataset
+from .base_eval_dataset import BaseEvalDataset
+import json
+from io import BytesIO
+import pytz
+import datetime
+import openai
+import time
+import re
+import io
+from Levenshtein import distance
+
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+demo_prompt = """
+Please read the following example. Then extract the answer from the model response and type it at the end of the prompt.
+
+Please answer the question requiring an integer answer and provide the final value, e.g., 1, 2, 3, at the end.
+Question: Which number is missing?
+
+Model response: The number missing in the sequence is 14.
+
+Extracted answer: 14
+
+Please answer the question requiring a floating-point number with one decimal place and provide the final value, e.g., 1.2, 1.3, 1.4, at the end.
+Question: What is the fraction of females facing the camera?
+
+Model response: The fraction of females facing the camera is 0.6, which means that six out of ten females in the group are facing the camera.
+
+Extracted answer: 0.6
+
+Please answer the question requiring a floating-point number with two decimal places and provide the final value, e.g., 1.23, 1.34, 1.45, at the end.
+Question: How much money does Luca need to buy a sour apple candy and a butterscotch candy? (Unit: $)
+
+Model response: Luca needs $1.45 to buy a sour apple candy and a butterscotch candy.
+
+Extracted answer: 1.45
+
+Please answer the question requiring a Python list as an answer and provide the final list, e.g., [1, 2, 3], [1.2, 1.3, 1.4], at the end.
+Question: Between which two years does the line graph saw its maximum peak?
+
+Model response: The line graph saw its maximum peak between 2007 and 2008.
+
+Extracted answer: [2007, 2008]
+
+Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end.
+Question: What fraction of the shape is blue?\nChoices:\n(A) 3/11\n(B) 8/11\n(C) 6/11\n(D) 3/5
+
+Model response: The correct answer is (B) 8/11.
+
+Extracted answer: B
+"""
+
+
+import time
+import requests
+import json
+import ast
+
+
+def get_chat_response(promot, api_key, model="gpt-3.5-turbo", temperature=0, max_tokens=256, n=1, patience=5, sleep_time=5):
+ headers = {
+ "Authorization": f"Bearer {api_key}",
+ "Content-Type": "application/json",
+ }
+
+ messages = [
+ {"role": "system", "content": "You are a helpful AI assistant."},
+ {"role": "user", "content": promot},
+ ]
+
+ payload = {"model": model, "messages": messages}
+
+ while patience > 0:
+ patience -= 1
+ try:
+ response = requests.post(
+ "https://api.openai.com/v1/chat/completions",
+ headers=headers,
+ data=json.dumps(payload),
+ timeout=30,
+ )
+ response.raise_for_status()
+ response_data = response.json()
+
+ prediction = response_data["choices"][0]["message"]["content"].strip()
+ if prediction != "" and prediction is not None:
+ return prediction
+
+ except Exception as e:
+ if "Rate limit" not in str(e):
+ print(e)
+ time.sleep(sleep_time)
+
+ return ""
+
+
+def create_test_prompt(demo_prompt, query, response):
+ demo_prompt = demo_prompt.strip()
+ test_prompt = f"{query}\n\n{response}"
+ full_prompt = f"{demo_prompt}\n\n{test_prompt}\n\nExtracted answer: "
+ return full_prompt
+
+
+def extract_answer(response, problem, quick_extract=False, api_key=None, pid=None, gpt_model="gpt-4-0613"):
+ question_type = problem["question_type"]
+ answer_type = problem["answer_type"]
+ choices = problem["choices"]
+ query = problem["query"]
+
+ if response == "":
+ return ""
+
+ if question_type == "multi_choice" and response in choices:
+ return response
+
+ if answer_type == "integer":
+ try:
+ extraction = int(response)
+ return str(extraction)
+ except:
+ pass
+
+ if answer_type == "float":
+ try:
+ extraction = str(float(response))
+ return extraction
+ except:
+ pass
+
+ # quick extraction
+ if quick_extract:
+ # The answer is "text". -> "text"
+ try:
+ result = re.search(r'The answer is "(.*)"\.', response)
+ if result:
+ extraction = result.group(1)
+ return extraction
+ except:
+ pass
+
+ else:
+ # general extraction
+ try:
+ full_prompt = create_test_prompt(demo_prompt, query, response)
+ extraction = get_chat_response(full_prompt, api_key=api_key, model=gpt_model, n=1, patience=5, sleep_time=5)
+ return extraction
+ except Exception as e:
+ print(e)
+ print(f"Error in extracting answer for {pid}")
+
+ return ""
+
+
+def get_acc_with_contion(res_pd, key, value):
+ if key == "skills":
+ # if value in res_pd[key]:
+ total_pd = res_pd[res_pd[key].apply(lambda x: value in x)]
+ else:
+ total_pd = res_pd[res_pd[key] == value]
+
+ correct_pd = total_pd[total_pd["true_false"] == True]
+ acc = "{:.2f}".format(len(correct_pd) / len(total_pd) * 100)
+ return len(correct_pd), len(total_pd), acc
+
+
+def get_most_similar(prediction, choices):
+ """
+ Use the Levenshtein distance (or edit distance) to determine which of the choices is most similar to the given prediction
+ """
+ distances = [distance(prediction, choice) for choice in choices]
+ ind = distances.index(min(distances))
+ return choices[ind]
+ # return min(choices, key=lambda choice: distance(prediction, choice))
+
+
+def normalize_extracted_answer(extraction, choices, question_type, answer_type, precision):
+ """
+ Normalize the extracted answer to match the answer type
+ """
+ if question_type == "multi_choice":
+ # make sure the extraction is a string
+ if isinstance(extraction, str):
+ extraction = extraction.strip()
+ else:
+ try:
+ extraction = str(extraction)
+ except:
+ extraction = ""
+
+ # extract "A" from "(A) text"
+ letter = re.findall(r"\(([a-zA-Z])\)", extraction)
+ if len(letter) > 0:
+ extraction = letter[0].upper()
+
+ options = [chr(ord("A") + i) for i in range(len(choices))]
+
+ if extraction in options:
+ # convert option letter to text, e.g. "A" -> "text"
+ ind = options.index(extraction)
+ extraction = choices[ind]
+ else:
+ # select the most similar option
+ extraction = get_most_similar(extraction, choices)
+ assert extraction in choices
+
+ elif answer_type == "integer":
+ try:
+ extraction = str(int(float(extraction)))
+ except:
+ extraction = None
+
+ elif answer_type == "float":
+ try:
+ extraction = str(round(float(extraction), precision))
+ except:
+ extraction = None
+
+ elif answer_type == "list":
+ try:
+ extraction = str(extraction)
+ except:
+ extraction = None
+
+ return extraction
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+def safe_equal(prediction, answer):
+ """
+ Check if the prediction is equal to the answer, even if they are of different types
+ """
+ try:
+ if prediction == answer:
+ return True
+ return False
+ except Exception as e:
+ print(e)
+ return False
+
+
+class MathVistaDataset(BaseEvalDataset):
+ def __init__(
+ self,
+ data_path="Otter-AI/MathVista",
+ split="test",
+ default_output_path="./logs/MathVista",
+ cache_dir=None,
+ api_key=None,
+ gpt_model="gpt-4-0613",
+ debug=False,
+ quick_extract=False,
+ ):
+ super().__init__("MathVistaDataset", data_path)
+ name_converter = {"dev": "validation", "test": "test"}
+ self.data = load_dataset("Otter-AI/MathVista", split=name_converter[split], cache_dir=cache_dir).to_pandas()
+ if debug:
+ self.data = self.data.sample(5)
+ # data_path = "/home/luodian/projects/Otter/archived/testmini_image_inside.json"
+ # with open(data_path, "r", encoding="utf-8") as f:
+ # self.data = json.load(f)
+
+ self.debug = debug
+ self.quick_extract = quick_extract
+
+ self.default_output_path = default_output_path
+ if os.path.exists(self.default_output_path) is False:
+ os.makedirs(self.default_output_path)
+ self.cur_datetime = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ self.api_key = api_key
+ self.gpt_model = gpt_model
+
+ def create_query(self, problem, shot_type):
+ ### [2] Test query
+ # problem info
+ question = problem["question"]
+ unit = problem["unit"]
+ choices = problem["choices"]
+ precision = problem["precision"]
+ question_type = problem["question_type"]
+ answer_type = problem["answer_type"]
+
+ # hint
+ if shot_type == "solution":
+ if question_type == "multi_choice":
+ assert answer_type == "text"
+ hint_text = f"Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end."
+ else:
+ assert answer_type in ["integer", "float", "list"]
+ if answer_type == "integer":
+ hint_text = f"Please answer the question requiring an integer answer and provide the final value, e.g., 1, 2, 3, at the end."
+
+ elif answer_type == "float" and str(precision) == "1":
+ hint_text = f"Please answer the question requiring a floating-point number with one decimal place and provide the final value, e.g., 1.2, 1.3, 1.4, at the end."
+
+ elif answer_type == "float" and str(precision) == "2":
+ hint_text = f"Please answer the question requiring a floating-point number with two decimal places and provide the final value, e.g., 1.23, 1.34, 1.45, at the end."
+
+ elif answer_type == "list":
+ hint_text = f"Please answer the question requiring a Python list as an answer and provide the final list, e.g., [1, 2, 3], [1.2, 1.3, 1.4], at the end."
+ else:
+ assert shot_type == "code"
+ hint_text = "Please generate a python code to solve the problem"
+
+ # question
+ question_text = f"Question: {question}"
+ if unit:
+ question_text += f" (Unit: {unit})"
+
+ # choices
+ if choices is not None and len(choices) != 0:
+ # choices: (A) 1.2 (B) 1.3 (C) 1.4 (D) 1.5
+ texts = ["Choices:"]
+ for i, choice in enumerate(choices):
+ texts.append(f"({chr(ord('A')+i)}) {choice}")
+ choices_text = "\n".join(texts)
+ else:
+ choices_text = ""
+
+ # prompt
+ if shot_type == "solution":
+ prompt = "Solution: "
+ else:
+ assert shot_type == "code"
+ prompt = "Python code: "
+
+ elements = [hint_text, question_text, choices_text, prompt]
+ query = "\n".join([e for e in elements if e != ""])
+
+ query = query.strip()
+ return query
+
+ def _evaluate(self, model):
+ output_file = os.path.join(self.default_output_path, f"{model.name}_mathvista_eval_submit_{self.cur_datetime}.json") # directly match Lu Pan's repo format e.g. output_bard.json
+
+ results = {}
+
+ print(f"Number of test problems in total: {len(self.data)}")
+ for idx_key, query_data in tqdm(self.data.iterrows(), desc=f"Evaluating {model.name}", total=len(self.data)):
+ # query_data = self.data[idx_key]
+ results[idx_key] = {}
+ results[idx_key].update(query_data)
+ if results[idx_key]["choices"] is not None:
+ results[idx_key]["choices"] = list(results[idx_key]["choices"])
+ results[idx_key].pop("image")
+ # problem = query_data["problem"]
+ query = self.create_query(problem=query_data, shot_type="solution")
+ base64_image = query_data["image"]
+ # image = Image.open(BytesIO(base64.b64decode(base64_image)))
+ image = get_pil_image(base64_image)
+ response = model.generate(query, image)
+ if self.debug:
+ print(f"\n# Query: {query}")
+ print(f"\n# Response: {response}")
+ results[idx_key].update({"query": query})
+ results[idx_key].update({"response": response})
+
+ with open(output_file, "w") as outfile:
+ json.dump(results, outfile)
+
+ results = json.load(open(output_file, "r"))
+
+ print(f"MathVista Evaluator: Results saved to {output_file}")
+
+ for idx_key, row in tqdm(self.data.iterrows(), desc=f"Extracting answers from {model.name}", total=len(self.data)):
+ idx_key = str(idx_key)
+ response = results[idx_key]["response"]
+ extraction = extract_answer(
+ response,
+ results[idx_key],
+ quick_extract=self.quick_extract,
+ api_key=self.api_key,
+ pid=idx_key,
+ gpt_model=self.gpt_model,
+ )
+ results[idx_key].update({"extraction": extraction})
+ answer = results[idx_key]["answer"]
+ choices = results[idx_key]["choices"]
+ question_type = results[idx_key]["question_type"]
+ answer_type = results[idx_key]["answer_type"]
+ precision = results[idx_key]["precision"]
+ extraction = results[idx_key]["extraction"]
+
+ prediction = normalize_extracted_answer(extraction, choices, question_type, answer_type, precision)
+ true_false = safe_equal(prediction, answer)
+
+ results[idx_key]["prediction"] = prediction
+ results[idx_key]["true_false"] = true_false
+
+ full_pids = list(results.keys())
+ ## [2] Calculate the average accuracy
+ total = len(full_pids)
+ correct = 0
+ for pid in full_pids:
+ if results[pid]["true_false"]:
+ correct += 1
+ accuracy = str(round(correct / total * 100, 2))
+ print(f"\nCorrect: {correct}, Total: {total}, Accuracy: {accuracy}%")
+
+ scores = {"average": {"accuracy": accuracy, "correct": correct, "total": total}}
+ ## [3] Calculate the fine-grained accuracy scores
+ # merge the 'metadata' attribute into the data
+ success_parse = True
+ try:
+ for pid in results:
+ cur_meta = results[pid]["metadata"]
+ cur_meta_dict = ast.literal_eval(cur_meta)
+ results[pid].update(cur_meta_dict)
+ except:
+ success_parse = False
+ # results[pid].update(results[pid].pop("metadata"))
+
+ # convert the data to a pandas DataFrame
+ df = pd.DataFrame(results).T
+
+ print("Number of test problems:", len(df))
+ # assert len(df) == 1000 # Important!!!
+
+ if success_parse:
+ # asign the target keys for evaluation
+ target_keys = [
+ "question_type",
+ "answer_type",
+ "language",
+ "source",
+ "category",
+ "task",
+ "context",
+ "grade",
+ "skills",
+ ]
+
+ for key in target_keys:
+ print(f"\nType: [{key}]")
+ # get the unique values of the key
+ if key == "skills":
+ # the value is a list
+ values = []
+ for i in range(len(df)):
+ values += df[key][i]
+ values = list(set(values))
+ else:
+ values = df[key].unique()
+ # calculate the accuracy for each value
+ scores[key] = {}
+ for value in values:
+ correct, total, acc = get_acc_with_contion(df, key, value)
+ if total > 0:
+ print(f"[{value}]: {acc}% ({correct}/{total})")
+ scores[key][value] = {"accuracy": acc, "correct": correct, "total": total}
+
+ # sort the scores by accuracy
+ scores[key] = dict(sorted(scores[key].items(), key=lambda item: float(item[1]["accuracy"]), reverse=True))
+
+ # save the scores
+ scores_file = os.path.join(self.default_output_path, f"{model.name}_mathvista_eval_score_{self.cur_datetime}.json")
+ print(f"MathVista Evaluator: Score results saved to {scores_file}...")
+ with open(scores_file, "w") as outfile:
+ json.dump(scores, outfile)
diff --git a/pipeline/benchmarks/datasets/mmbench.py b/pipeline/benchmarks/datasets/mmbench.py
new file mode 100644
index 00000000..b38e6590
--- /dev/null
+++ b/pipeline/benchmarks/datasets/mmbench.py
@@ -0,0 +1,126 @@
+import os
+import pandas as pd
+from tqdm import tqdm, trange
+from datasets import load_dataset
+from .base_eval_dataset import BaseEvalDataset
+import pytz
+import datetime
+
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+
+class MMBenchDataset(BaseEvalDataset):
+ def __init__(
+ self,
+ data_path: str = "Otter-AI/MMBench",
+ *,
+ sys_prompt="There are several options:",
+ version="20230712",
+ split="test",
+ cache_dir=None,
+ default_output_path="./logs/MMBench",
+ debug=False,
+ ):
+ super().__init__("MMBenchDataset", data_path)
+ self.version = str(version)
+ self.name_converter = {"dev": "validation", "test": "test"}
+ self.df = load_dataset(data_path, self.version, split=self.name_converter[split], cache_dir=cache_dir).to_pandas()
+ self.default_output_path = default_output_path
+ if os.path.exists(self.default_output_path) is False:
+ os.makedirs(self.default_output_path)
+ self.sys_prompt = sys_prompt
+ self.cur_datetime = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ self.debug = debug
+
+ def load_from_df(self, idx, key):
+ if key in self.df.columns:
+ value = self.df.loc[idx, key]
+ return value if pd.notna(value) else None
+ return None
+
+ def create_options_prompt(self, idx, option_candidate):
+ available_keys = set(self.df.columns) & set(option_candidate)
+ options = {cand: self.load_from_df(idx, cand) for cand in available_keys if self.load_from_df(idx, cand)}
+ sorted_options = dict(sorted(options.items()))
+ options_prompt = f"{self.sys_prompt}\n"
+ for key, item in sorted_options.items():
+ options_prompt += f"{key}. {item}\n"
+ return options_prompt.rstrip("\n"), sorted_options
+
+ def get_data(self, idx):
+ row = self.df.loc[idx]
+ option_candidate = ["A", "B", "C", "D", "E"]
+ options_prompt, options_dict = self.create_options_prompt(idx, option_candidate)
+
+ data = {
+ "img": row["image"],
+ "question": row["question"],
+ "answer": row.get("answer"),
+ "options": options_prompt,
+ "category": row["category"],
+ "l2-category": row["l2-category"],
+ "options_dict": options_dict,
+ "index": row["index"],
+ "hint": self.load_from_df(idx, "hint"),
+ "source": row["source"],
+ "split": row["split"],
+ }
+ return data
+
+ def query_batch(self, model, batch_data):
+ batch_data = list(map(self.get_data, batch_data))
+ batch_img = [data["img"] for data in batch_data]
+ batch_prompt = [f"{data['hint']} {data['question']} {data['options']}" if pd.notna(data["hint"]) else f"{data['question']} {data['options']}" for data in batch_data]
+ if len(batch_prompt) == 1:
+ batch_pred_answer = [model.generate(batch_prompt[0], batch_img[0])]
+ else:
+ batch_pred_answer = model.generate(batch_prompt, batch_img)
+ return [
+ {
+ "question": data["question"],
+ "answer": data["answer"],
+ **data["options_dict"],
+ "prediction": pred_answer,
+ "hint": data["hint"],
+ "source": data["source"],
+ "split": data["split"],
+ "category": data["category"],
+ "l2-category": data["l2-category"],
+ "index": data["index"],
+ }
+ for data, pred_answer in zip(batch_data, batch_pred_answer)
+ ]
+
+ def _evaluate(self, model, *, batch=1):
+ output_file = os.path.join(self.default_output_path, f"{model.name}_mmbench_eval_result_{self.cur_datetime}.xlsx")
+ results = []
+
+ for idx in tqdm(range(len(self.df))):
+ cur_data = self.get_data(idx)
+ cur_prompt = f"{cur_data['hint']} {cur_data['question']} {cur_data['options']}" if pd.notna(cur_data["hint"]) and cur_data["hint"] != "nan" else f"{cur_data['question']} {cur_data['options']}"
+ pred_answer = model.generate(cur_prompt, cur_data["img"])
+
+ if self.debug:
+ print(f"# Query: {cur_prompt}")
+ print(f"# Response: {pred_answer}")
+
+ result = {
+ "question": cur_data["question"],
+ "answer": cur_data["answer"],
+ **cur_data["options_dict"],
+ "prediction": pred_answer,
+ "hint": cur_data["hint"],
+ "source": cur_data["source"],
+ "split": cur_data["split"],
+ "category": cur_data["category"],
+ "l2-category": cur_data["l2-category"],
+ "index": cur_data["index"],
+ }
+ results.append(result)
+
+ df = pd.DataFrame(results)
+ with pd.ExcelWriter(output_file, engine="xlsxwriter") as writer:
+ df.to_excel(writer, index=False)
+ print(f"MMBench Evaluator: Result saved to {output_file}.")
diff --git a/pipeline/benchmarks/datasets/mme.py b/pipeline/benchmarks/datasets/mme.py
new file mode 100644
index 00000000..c69f9764
--- /dev/null
+++ b/pipeline/benchmarks/datasets/mme.py
@@ -0,0 +1,217 @@
+import base64
+import io
+from PIL import Image
+import json
+from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
+import os
+import numpy as np
+from datasets import load_dataset
+from typing import Union
+from .base_eval_dataset import BaseEvalDataset
+from tqdm import tqdm
+import datetime
+import pytz
+
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+eval_type_dict = {
+ "Perception": [
+ "existence",
+ "count",
+ "position",
+ "color",
+ "posters",
+ "celebrity",
+ "scene",
+ "landmark",
+ "artwork",
+ "ocr",
+ ],
+ "Cognition": ["commonsense", "numerical", "text", "code"],
+}
+
+
+class MMEDataset(BaseEvalDataset):
+ def decode_base64_to_image(self, base64_string):
+ image_data = base64.b64decode(base64_string)
+ image = Image.open(io.BytesIO(image_data))
+ return image
+
+ def __init__(
+ self,
+ data_path: str = "Otter-AI/MME",
+ *,
+ cache_dir: Union[str, None] = None,
+ default_output_path: str = "./logs/MME",
+ split: str = "test",
+ debug: bool = False,
+ ):
+ super().__init__("MMEDataset", data_path)
+
+ self.default_output_path = default_output_path
+ self.cur_datetime = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ self.data = load_dataset(data_path, split=split, cache_dir=cache_dir)
+ self.debug = debug
+
+ self.category_data = {}
+ # for idx in range(len(self.ids)):
+ for item in tqdm(self.data, desc="Loading data"):
+ id = item["id"]
+ category = id.split("_")[0].lower()
+ question = item["instruction"]
+ answer = item["answer"]
+ image_id = item["image_ids"][0]
+ image = item["images"][0]
+
+ data = {"question": question, "answer": answer, "image": image}
+
+ if category in eval_type_dict["Cognition"]:
+ eval_type = "Cognition"
+ elif category in eval_type_dict["Perception"]:
+ eval_type = "Perception"
+ else:
+ raise ValueError(f"Unknown category {category}")
+
+ if eval_type not in self.category_data:
+ self.category_data[eval_type] = {}
+
+ if category not in self.category_data[eval_type]:
+ self.category_data[eval_type][category] = {}
+
+ if image_id not in self.category_data[eval_type][category]:
+ self.category_data[eval_type][category][image_id] = []
+
+ self.category_data[eval_type][category][image_id].append(data)
+
+ def parse_pred_ans(self, pred_ans):
+ pred_ans = pred_ans.lower().strip().replace(".", "")
+ pred_label = None
+ if pred_ans in ["yes", "no"]:
+ pred_label = pred_ans
+ else:
+ prefix_pred_ans = pred_ans[:4]
+ if "yes" in prefix_pred_ans:
+ pred_label = "yes"
+ elif "no" in prefix_pred_ans:
+ pred_label = "no"
+ else:
+ pred_label = "other"
+ return pred_label
+
+ def compute_metric(self, gts, preds):
+ assert len(gts) == len(preds)
+
+ label_map = {
+ "yes": 1,
+ "no": 0,
+ "other": -1,
+ }
+
+ gts = [label_map[x] for x in gts]
+ preds = [label_map[x] for x in preds]
+
+ acc = accuracy_score(gts, preds)
+
+ clean_gts = []
+ clean_preds = []
+ other_num = 0
+ for gt, pred in zip(gts, preds):
+ if pred == -1:
+ other_num += 1
+ continue
+ clean_gts.append(gt)
+ clean_preds.append(pred)
+
+ conf_mat = confusion_matrix(clean_gts, clean_preds, labels=[1, 0])
+ precision = precision_score(clean_gts, clean_preds, average="binary")
+ recall = recall_score(clean_gts, clean_preds, average="binary")
+ tp, fn = conf_mat[0]
+ fp, tn = conf_mat[1]
+
+ metric_dict = dict()
+ metric_dict = {
+ "TP": tp,
+ "FN": fn,
+ "TN": tn,
+ "FP": fp,
+ "precision": precision,
+ "recall": recall,
+ "other_num": other_num,
+ "acc": acc,
+ }
+
+ for key, value in metric_dict.items():
+ if isinstance(value, np.int64):
+ metric_dict[key] = int(value)
+
+ return metric_dict
+
+ def _evaluate(self, model):
+ model_score_dict = {}
+
+ self.default_output_path = os.path.join(self.default_output_path, f"{model.name}_{self.cur_datetime}")
+ if not os.path.exists(self.default_output_path):
+ os.makedirs(self.default_output_path)
+
+ for eval_type in self.category_data.keys():
+ print("===========", eval_type, "===========")
+
+ scores = 0
+ task_score_dict = {}
+ for task_name in tqdm(self.category_data[eval_type].keys(), desc=f"Evaluating {eval_type}"):
+ img_num = len(self.category_data[eval_type][task_name])
+ task_other_ans_num = 0
+ task_score = 0
+ acc_plus_correct_num = 0
+ gts = []
+ preds = []
+ for image_pair in tqdm(self.category_data[eval_type][task_name].values(), desc=f"Evaluating {eval_type} {task_name}"):
+ assert len(image_pair) == 2
+ img_correct_num = 0
+
+ for item in image_pair:
+ question = item["question"]
+ image = item["image"]
+ gt_ans = item["answer"].lower().strip().replace(".", "")
+ response = model.generate(question, image)
+ if self.debug:
+ print(f"\n# Query: {question}")
+ print(f"\n# Response: {response}")
+ pred_ans = self.parse_pred_ans(response)
+
+ assert gt_ans in ["yes", "no"]
+ assert pred_ans in ["yes", "no", "other"]
+
+ gts.append(gt_ans)
+ preds.append(pred_ans)
+
+ if gt_ans == pred_ans:
+ img_correct_num += 1
+
+ if pred_ans not in ["yes", "no"]:
+ task_other_ans_num += 1
+
+ if img_correct_num == 2:
+ acc_plus_correct_num += 1
+
+ # cal TP precision acc, etc.
+ metric_dict = self.compute_metric(gts, preds)
+ acc_plus = acc_plus_correct_num / img_num
+ metric_dict["acc_plus"] = acc_plus
+
+ for k, v in metric_dict.items():
+ if k in ["acc", "acc_plus"]:
+ task_score += v * 100
+
+ task_score_dict[task_name] = task_score
+ scores += task_score
+
+ output_path = os.path.join(self.default_output_path, f"{task_name}.json")
+ with open(output_path, "w") as f:
+ json.dump(metric_dict, f)
+
+ print(f"total score: {scores}")
+ for task_name, score in task_score_dict.items():
+ print(f"\t {task_name} score: {score}")
diff --git a/pipeline/benchmarks/datasets/mmvet.py b/pipeline/benchmarks/datasets/mmvet.py
new file mode 100644
index 00000000..d27c01d8
--- /dev/null
+++ b/pipeline/benchmarks/datasets/mmvet.py
@@ -0,0 +1,303 @@
+import base64
+import os
+import pandas as pd
+from PIL import Image
+from tqdm import tqdm
+from datasets import load_dataset
+from .base_eval_dataset import BaseEvalDataset
+from collections import Counter
+from typing import Union
+import numpy as np
+from openai import OpenAI
+import time
+import json
+import pytz
+import datetime
+from Levenshtein import distance
+
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+MM_VET_PROMPT = """Compare the ground truth and prediction from AI models, to give a correctness score for the prediction.
in the ground truth means it is totally right only when all elements in the ground truth are present in the prediction, and means it is totally right when any one element in the ground truth is present in the prediction. The correctness score is 0.0 (totally wrong), 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, or 1.0 (totally right). Just complete the last space of the correctness score.
+
+Question | Ground truth | Prediction | Correctness
+--- | --- | --- | ---
+What is x in the equation? | -1 -5 | x = 3 | 0.0
+What is x in the equation? | -1 -5 | x = -1 | 0.5
+What is x in the equation? | -1 -5 | x = -5 | 0.5
+What is x in the equation? | -1 -5 | x = -5 or 5 | 0.5
+What is x in the equation? | -1 -5 | x = -1 or x = -5 | 1.0
+Can you explain this meme? | This meme is poking fun at the fact that the names of the countries Iceland and Greenland are misleading. Despite its name, Iceland is known for its beautiful green landscapes, while Greenland is mostly covered in ice and snow. The meme is saying that the person has trust issues because the names of these countries do not accurately represent their landscapes. | The meme talks about Iceland and Greenland. It's pointing out that despite their names, Iceland is not very icy and Greenland isn't very green. | 0.4
+Can you explain this meme? | This meme is poking fun at the fact that the names of the countries Iceland and Greenland are misleading. Despite its name, Iceland is known for its beautiful green landscapes, while Greenland is mostly covered in ice and snow. The meme is saying that the person has trust issues because the names of these countries do not accurately represent their landscapes. | The meme is using humor to point out the misleading nature of Iceland's and Greenland's names. Iceland, despite its name, has lush green landscapes while Greenland is mostly covered in ice and snow. The text 'This is why I have trust issues' is a playful way to suggest that these contradictions can lead to distrust or confusion. The humor in this meme is derived from the unexpected contrast between the names of the countries and their actual physical characteristics. | 1.0
+"""
+
+
+class MMVetDataset(BaseEvalDataset):
+ def __init__(
+ self,
+ data_path: str = "Otter-AI/MMVet",
+ gpt_model: str = "gpt-4-0613",
+ *,
+ api_key: str,
+ split: str = "test",
+ cache_dir: Union[str, None] = None,
+ default_output_path: str = "./logs/MMVet",
+ num_run: int = 1,
+ prompt: str = MM_VET_PROMPT,
+ decimail_places: int = 1, # number of decimal places to round to
+ debug: bool = False,
+ ):
+ super().__init__("MMVetDataset", data_path)
+ self.df = load_dataset(data_path, split=split, cache_dir=cache_dir).to_pandas()
+ self.default_output_path = default_output_path
+ self.prompt = prompt
+ self.gpt_model = gpt_model
+ self.num_run = num_run
+ self.decimal_places = decimail_places
+ self.api_key = api_key
+ self.cur_datetime = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ self.debug = debug
+ self.prepare()
+ self.client = OpenAI(api_key=api_key)
+
+ def prepare(self):
+ self.counter = Counter()
+ self.cap_set_list = []
+ self.cap_set_counter = []
+ self.len_data = 0
+ self.caps = {}
+
+ for index, row in self.df.iterrows():
+ self.caps[row["id"]] = row["capability"]
+
+ for cap in self.df["capability"]:
+ cap = set(cap)
+ self.counter.update(cap)
+ if cap not in self.cap_set_list:
+ self.cap_set_list.append(cap)
+ self.cap_set_counter.append(1)
+ else:
+ self.cap_set_counter[self.cap_set_list.index(cap)] += 1
+
+ self.len_data += 1
+
+ sorted_list = self.counter.most_common()
+ self.columns = [k for k, v in sorted_list]
+ self.columns.append("total")
+ self.columns.append("std")
+ self.columns.append("runs")
+ self.result1 = pd.DataFrame(columns=self.columns)
+
+ cap_set_sorted_indices = np.argsort(-np.array(self.cap_set_counter))
+ new_cap_set_list = []
+ new_cap_set_counter = []
+ for index in cap_set_sorted_indices:
+ new_cap_set_list.append(self.cap_set_list[index])
+ new_cap_set_counter.append(self.cap_set_counter[index])
+
+ self.cap_set_list = new_cap_set_list
+ self.cap_set_counter = new_cap_set_counter
+ self.cap_set_names = ["_".join(list(cap_set)) for cap_set in self.cap_set_list]
+
+ self.columns2 = self.cap_set_names
+ self.columns2.append("total")
+ self.columns2.append("std")
+ self.columns2.append("runs")
+ self.result2 = pd.DataFrame(columns=self.columns2)
+
+ def get_output_file_name(self, model, *, output_path: str = None, num_run: int = 1) -> str:
+ if output_path is None:
+ result_path = self.default_output_path
+ else:
+ result_path = output_path
+ if not os.path.exists(result_path):
+ os.makedirs(result_path)
+ model_results_file = os.path.join(result_path, f"{model.name}.json")
+ grade_file = f"{model.name}-{self.gpt_model}-grade-{num_run}runs-{self.cur_datetime}.json"
+ grade_file = os.path.join(result_path, grade_file)
+ cap_score_file = f"{model.name}-{self.gpt_model}-cap-score-{num_run}runs-{self.cur_datetime}.csv"
+ cap_score_file = os.path.join(result_path, cap_score_file)
+ cap_int_score_file = f"{model.name}-{self.gpt_model}-cap-int-score-{num_run}runs-{self.cur_datetime}.csv"
+ cap_int_score_file = os.path.join(result_path, cap_int_score_file)
+ return model_results_file, grade_file, cap_score_file, cap_int_score_file
+
+ def _evaluate(self, model):
+ model_results_file, grade_file, cap_score_file, cap_int_score_file = self.get_output_file_name(model)
+
+ if os.path.exists(grade_file):
+ with open(grade_file, "r") as f:
+ grade_results = json.load(f)
+ else:
+ grade_results = {}
+
+ def need_more_runs():
+ need_more_runs = False
+ if len(grade_results) > 0:
+ for k, v in grade_results.items():
+ if len(v["score"]) < self.num_run:
+ need_more_runs = True
+ break
+ return need_more_runs or len(grade_results) < self.len_data
+
+ print(f"grade results saved to {grade_file}")
+ while need_more_runs():
+ for j in range(self.num_run):
+ print(f"eval run {j}")
+ for _, line in tqdm(self.df.iterrows(), total=len(self.df)):
+ id = line["id"]
+ # if sub_set is not None and id not in sub_set:
+ # continue
+ if id in grade_results and len(grade_results[id]["score"]) >= (j + 1):
+ continue
+
+ model_pred = model.generate(line["instruction"], line["images"][0])
+ if self.debug:
+ print(f"# Query: {line['instruction']}")
+ print(f"# Response: {model_pred}")
+ print(f"# Ground Truth: {line['answer']}")
+
+ question = (
+ self.prompt
+ + "\n"
+ + " | ".join(
+ [
+ line["instruction"],
+ line["answer"].replace("", " ").replace("", " "),
+ model_pred,
+ "",
+ ]
+ )
+ )
+ messages = [
+ {"role": "user", "content": question},
+ ]
+
+ if id not in grade_results:
+ sample_grade = {"model": [], "content": [], "score": []}
+ else:
+ sample_grade = grade_results[id]
+
+ grade_sample_run_complete = False
+ temperature = 0.0
+
+ while not grade_sample_run_complete:
+ try:
+ response = self.client.chat.completions.create(model=self.gpt_model, max_tokens=3, temperature=temperature, messages=messages, timeout=15)
+ content = response["choices"][0]["message"]["content"]
+ flag = True
+ try_time = 1
+ while flag:
+ try:
+ content = content.split(" ")[0].strip()
+ score = float(content)
+ if score > 1.0 or score < 0.0:
+ assert False
+ flag = False
+ except:
+ question = (
+ self.prompt
+ + "\n"
+ + " | ".join(
+ [
+ line["instruction"],
+ line["answer"].replace("", " ").replace("", " "),
+ model_pred,
+ "",
+ ]
+ )
+ + "\nPredict the correctness of the answer (digit): "
+ )
+ messages = [
+ {"role": "user", "content": question},
+ ]
+ response = self.client.chat.completions.create(model=self.gpt_model, max_tokens=3, temperature=temperature, messages=messages, timeout=15)
+ content = response["choices"][0]["message"]["content"]
+ try_time += 1
+ temperature += 0.5
+ print(f"{id} try {try_time} times")
+ print(content)
+ if try_time > 5:
+ score = 0.0
+ flag = False
+ grade_sample_run_complete = True
+ except Exception as e:
+ # gpt4 may have token rate limit
+ print(e)
+ print("sleep 15s")
+ time.sleep(15)
+
+ if len(sample_grade["model"]) >= j + 1:
+ sample_grade["model"][j] = response["model"]
+ sample_grade["content"][j] = content
+ sample_grade["score"][j] = score
+ else:
+ sample_grade["model"].append(response["model"])
+ sample_grade["content"].append(content)
+ sample_grade["score"].append(score)
+ sample_grade["query"] = line["instruction"]
+ sample_grade["response"] = model_pred
+ sample_grade["ground_truth"] = line["answer"]
+ grade_results[id] = sample_grade
+
+ with open(grade_file, "w") as f:
+ json.dump(grade_results, f, indent=4)
+
+ cap_socres = {k: [0.0] * self.num_run for k in self.columns[:-2]}
+ self.counter["total"] = self.len_data
+
+ cap_socres2 = {k: [0.0] * self.num_run for k in self.columns2[:-2]}
+ counter2 = {self.columns2[i]: self.cap_set_counter[i] for i in range(len(self.cap_set_counter))}
+ counter2["total"] = self.len_data
+
+ for k, v in grade_results.items():
+ # if sub_set is not None and k not in sub_set:
+ # continue
+ for i in range(self.num_run):
+ score = v["score"][i]
+ caps = set(self.caps[k])
+ for c in caps:
+ cap_socres[c][i] += score
+
+ cap_socres["total"][i] += score
+
+ index = self.cap_set_list.index(caps)
+ cap_socres2[self.cap_set_names[index]][i] += score
+ cap_socres2["total"][i] += score
+
+ for k, v in cap_socres.items():
+ cap_socres[k] = np.array(v) / self.counter[k] * 100
+
+ std = round(cap_socres["total"].std(), self.decimal_places)
+ total_copy = cap_socres["total"].copy()
+ runs = str(list(np.round(total_copy, self.decimal_places)))
+
+ for k, v in cap_socres.items():
+ cap_socres[k] = round(v.mean(), self.decimal_places)
+
+ cap_socres["std"] = std
+ cap_socres["runs"] = runs
+ self.result1.loc[model.name] = cap_socres
+
+ for k, v in cap_socres2.items():
+ cap_socres2[k] = round(np.mean(np.array(v) / counter2[k] * 100), self.decimal_places)
+ cap_socres2["std"] = std
+ cap_socres2["runs"] = runs
+ self.result2.loc[model.name] = cap_socres2
+
+ self.result1.to_csv(cap_score_file)
+ self.result2.to_csv(cap_int_score_file)
+
+ print(f"cap score saved to {cap_score_file}")
+ print(f"cap int score saved to {cap_int_score_file}")
+ print("=" * 20)
+ print(f"cap score:")
+ print(self.result1)
+ print("=" * 20)
+ print(f"cap int score:")
+ print(self.result2)
+ print("=" * 20)
+
+
+if __name__ == "__main__":
+ data = MMVetDataset(api_key=None, cache_dir="/data/pufanyi/cache")
diff --git a/pipeline/benchmarks/datasets/pope.py b/pipeline/benchmarks/datasets/pope.py
new file mode 100644
index 00000000..bd1d463c
--- /dev/null
+++ b/pipeline/benchmarks/datasets/pope.py
@@ -0,0 +1,167 @@
+import os
+import datetime
+from tqdm import tqdm, trange
+from .base_eval_dataset import BaseEvalDataset
+from datasets import load_dataset
+import json
+from typing import Union
+
+
+class PopeDataset(BaseEvalDataset):
+ def __init__(
+ self,
+ data_path="Otter-AI/POPE",
+ split="test",
+ default_output_path="./logs/POPE",
+ cache_dir=None,
+ batch_size=1,
+ ):
+ super().__init__("PopeDataset", data_path, max_batch_size=batch_size)
+ print("Loading dataset from", data_path)
+ self.data = load_dataset(data_path, split=split, cache_dir=cache_dir)
+ print("Dataset loaded")
+ self.default_output_path = default_output_path
+ if not os.path.exists(default_output_path):
+ os.makedirs(default_output_path)
+ self.batch_gen_size = batch_size
+
+ def parse_pred(self, text):
+ if text.find(".") != -1:
+ text = text.split(".")[0]
+
+ text = text.replace(",", "").lower()
+ words = text.split(" ")
+
+ if "not" in words or "no" in words:
+ return "no"
+ else:
+ return "yes"
+
+ def _evaluate(self, model, batch=1):
+ cur_datetime = datetime.datetime.now().strftime("%Y%m%d-%H%M")
+ output_path = os.path.join(self.default_output_path, f"pope_{model.name}_test_submit_{cur_datetime}.json")
+
+ metrics = {
+ "adversarial": {"TP": 0, "TN": 0, "FP": 0, "FN": 0, "yes_count": 0, "no_count": 0},
+ "popular": {"TP": 0, "TN": 0, "FP": 0, "FN": 0, "yes_count": 0, "no_count": 0},
+ "random": {"TP": 0, "TN": 0, "FP": 0, "FN": 0, "yes_count": 0, "no_count": 0},
+ "overall": {"TP": 0, "TN": 0, "FP": 0, "FN": 0, "yes_count": 0, "no_count": 0},
+ }
+
+ batch_size = self.batch_gen_size
+ num_batches = len(self.data) // batch_size + 1
+
+ with tqdm(total=len(self.data), desc="Evaluating") as pbar:
+ for i in range(num_batches):
+ start_idx = i * batch_size
+ end_idx = (i + 1) * batch_size
+ batch_data = self.data[start_idx:end_idx]
+
+ batch_questions = batch_data["question"]
+ batch_answers = batch_data["answer"]
+ batch_images = batch_data["image"]
+
+ # if model has batch_generate, use it
+ if hasattr(model, "batch_generate") and self.batch_gen_size > 1:
+ batch_responses = model.batch_generate(batch_questions, batch_images)
+ else:
+ batch_responses = [model.generate(question, image) for question, image in zip(batch_questions, batch_images)]
+
+ batch_preds = [self.parse_pred(response) for response in batch_responses]
+
+ for j in range(len(batch_preds)):
+ answer = batch_answers[j]
+ pred = batch_preds[j]
+ category = batch_data["category"][j]
+
+ if answer == "yes":
+ metrics[category]["yes_count"] += 1
+ metrics["overall"]["yes_count"] += 1
+ else:
+ metrics[category]["no_count"] += 1
+ metrics["overall"]["no_count"] += 1
+
+ if pred == answer and pred == "yes":
+ metrics[category]["TP"] += 1
+ metrics["overall"]["TP"] += 1
+ elif pred == answer and pred == "no":
+ metrics[category]["TN"] += 1
+ metrics["overall"]["TN"] += 1
+ elif pred != answer and pred == "yes":
+ metrics[category]["FP"] += 1
+ metrics["overall"]["FP"] += 1
+ else:
+ metrics[category]["FN"] += 1
+ metrics["overall"]["FN"] += 1
+
+ pbar.update(batch_size)
+
+ for category in metrics:
+ print(f"----------- {category} -----------")
+
+ TP = metrics[category]["TP"]
+ TN = metrics[category]["TN"]
+ FP = metrics[category]["FP"]
+ FN = metrics[category]["FN"]
+ yes_count = metrics[category]["yes_count"]
+ no_count = metrics[category]["no_count"]
+
+ print("TP\tFP\tTN\tFN\t")
+ print("{}\t{}\t{}\t{}".format(TP, FP, TN, FN))
+
+ if TP + FP == 0:
+ metrics[category]["precision"] = precision = 0
+ else:
+ metrics[category]["precision"] = precision = float(TP) / float(TP + FP)
+
+ if TP + FN == 0:
+ metrics[category]["recall"] = recall = 0
+ else:
+ metrics[category]["recall"] = recall = float(TP) / float(TP + FN)
+
+ if precision + recall == 0:
+ metrics[category]["f1"] = f1 = 0
+ else:
+ metrics[category]["f1"] = f1 = 2 * precision * recall / float(precision + recall)
+
+ metrics[category]["acc"] = acc = float(TP + TN) / float(TP + TN + FP + FN)
+
+ if yes_count + no_count == 0:
+ metrics[category]["yes_ratio"] = yes_ratio = 0
+ else:
+ metrics[category]["yes_ratio"] = yes_ratio = yes_count / float(yes_count + no_count)
+
+ print("Accuracy: {}".format(acc))
+ print("Precision: {}".format(precision))
+ print("Recall: {}".format(recall))
+ print("F1 score: {}".format(f1))
+ print("Yes ratio: {}".format(yes_ratio))
+
+ print(f"----------- overall -----------")
+
+ TP = metrics["overall"]["TP"]
+ TN = metrics["overall"]["TN"]
+ FP = metrics["overall"]["FP"]
+ FN = metrics["overall"]["FN"]
+ yes_count = metrics["overall"]["yes_count"]
+ no_count = metrics["overall"]["no_count"]
+
+ print("TP\tFP\tTN\tFN\t")
+ print("{}\t{}\t{}\t{}".format(TP, FP, TN, FN))
+
+ metrics["overall"]["precision"] = precision = float(TP) / float(TP + FP)
+ metrics["overall"]["recall"] = recall = float(TP) / float(TP + FN)
+ metrics["overall"]["f1"] = f1 = 2 * precision * recall / float(precision + recall)
+ metrics["overall"]["acc"] = acc = float(TP + TN) / float(TP + TN + FP + FN)
+ metrics["overall"]["yes_ratio"] = yes_ratio = float(yes_count) / float(yes_count + no_count)
+
+ print("Accuracy: {}".format(acc))
+ print("Precision: {}".format(precision))
+ print("Recall: {}".format(recall))
+ print("F1 score: {}".format(f1))
+ print("Yes ratio: {}".format(yes_ratio))
+
+ output_f = open(output_path, "a")
+ output_f.write(json.dumps(metrics) + "\n")
+ output_f.close()
+ return metrics
diff --git a/pipeline/benchmarks/datasets/scienceqa.py b/pipeline/benchmarks/datasets/scienceqa.py
new file mode 100644
index 00000000..870bb231
--- /dev/null
+++ b/pipeline/benchmarks/datasets/scienceqa.py
@@ -0,0 +1,110 @@
+import os
+import re
+import pandas as pd
+from tqdm import tqdm, trange
+from datasets import load_dataset
+from .base_eval_dataset import BaseEvalDataset
+import pytz
+import datetime
+import json
+
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+
+class ScienceQADataset(BaseEvalDataset):
+ def __init__(
+ self, data_path: str = "Otter-AI/ScienceQA", *, split="test", cache_dir=None, default_output_path="./logs/ScienceQA", batch=1, debug=False, prompt='Please answer the question in the following format: "The answer is {A/B/C/D}".'
+ ):
+ super().__init__("ScienceQADataset", data_path, max_batch_size=batch)
+ self.split = split
+ self.data = load_dataset(data_path, split=self.split, cache_dir=cache_dir)
+ self.default_output_path = default_output_path
+ self.cur_datetime = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ self.debug = debug
+ self.prompt = prompt
+
+ def format_question(self, question, choices, answer):
+ len_choices = len(choices)
+ options = [chr(ord("A") + i) for i in range(len_choices)]
+ answer = options[answer]
+ choices_dict = dict(zip(options, choices))
+ choices_str = "\n".join([f"{option}. {choice}" for option, choice in zip(options, choices)])
+ return f"{self.prompt}\n{question}\n{choices_str}\n", choices_dict, answer
+
+ def parse_pred_ans(self, pred_ans, options):
+ match = re.search(r"The answer is ([A-D])", pred_ans)
+ if match:
+ return match.group(1)
+ for c, option in options.items():
+ option = option.strip()
+ if option.upper() in pred_ans.upper():
+ return c
+ choices = set(options.keys())
+ for selection in choices:
+ if selection in pred_ans:
+ return selection
+ for selection in choices:
+ if selection in pred_ans.upper():
+ return selection
+ return "other"
+
+ def _evaluate(self, model, *, batch=1):
+ if not os.path.exists(self.default_output_path):
+ os.makedirs(self.default_output_path)
+
+ output_file = os.path.join(self.default_output_path, f"{model.name}_scienceqa_eval_result_{self.cur_datetime}.json")
+ result_file = os.path.join(self.default_output_path, f"{model.name}_scienceqa_eval_score_{self.cur_datetime}.json")
+ results = []
+
+ total = 0
+ total_correct = 0
+
+ for data in tqdm(self.data, desc="Evaluating", total=len(self.data)):
+ question, choices_dict, answer = self.format_question(data["question"], data["choices"], data["answer"])
+ output = model.generate(question, data["image"])
+ phrased_output = self.parse_pred_ans(output, choices_dict)
+ correct = phrased_output == answer
+ if correct:
+ total_correct += 1
+ total += 1
+ results.append(
+ {
+ "question": data["question"],
+ "choices": data["choices"],
+ "answer": answer,
+ "output": output,
+ "prediction": phrased_output,
+ "correct": correct,
+ }
+ )
+ with open(output_file, "w") as f:
+ json.dump(results, f, indent=4)
+
+ score = total_correct / total
+ print(f"ScienceQA Evaluator: Total: {total}")
+ print(f"ScienceQA Evaluator: Total correct: {total_correct}")
+ print(f"ScienceQA Evaluator: Score: {score}")
+ with open(result_file, "w") as f:
+ final_score = {
+ "score": score,
+ "total": total,
+ "correct": total_correct,
+ }
+ json.dump(final_score, f, indent=4)
+
+ print(f"ScienceQA Evaluator: Result saved to {os.path.abspath(output_file)}.")
+ print(f"ScienceQA Evaluator: Score saved to {os.path.abspath(result_file)}.")
+
+
+if __name__ == "__main__":
+ dataset = ScienceQADataset(cache_dir="/data/pufanyi/cache")
+ data = dataset.data
+ print("=============================")
+ import json
+
+ print(json.dumps(data[1], indent=4))
+ print("=============================")
+ print(build_prompt(dataset.data[1], "QCM-ALE"))
+ print("=============================")
diff --git a/pipeline/benchmarks/datasets/seedbench.py b/pipeline/benchmarks/datasets/seedbench.py
new file mode 100644
index 00000000..58d57f3d
--- /dev/null
+++ b/pipeline/benchmarks/datasets/seedbench.py
@@ -0,0 +1,65 @@
+import numpy as np
+from tqdm import tqdm
+from .base_eval_dataset import BaseEvalDataset
+from datasets import load_dataset
+import json
+import os
+import datetime
+
+
+class SEEDBenchDataset(BaseEvalDataset):
+ def __init__(self, data_path: str = "Otter-AI/SEEDBench", split="test", default_output_path="./logs", cache_dir=None):
+ super().__init__("SEEDBenchDataset", data_path)
+ print("Loading dataset from", data_path)
+ self.data = load_dataset(data_path, split=split, cache_dir=cache_dir)
+ self.default_output_path = default_output_path
+ if not os.path.exists(default_output_path):
+ os.makedirs(default_output_path)
+
+ def _evaluate(self, model):
+ count = 0
+ num_correct = 0
+ cur_datetime = datetime.datetime.now().strftime("%Y%m%d-%H%M")
+ output_path = os.path.join(self.default_output_path, f"seedbench_{model.name}_test_submit_{cur_datetime}.json")
+ output_f = open(output_path, "a")
+ with tqdm(total=len(self.data), desc="Evaluating") as pbar:
+ for data_dict in self.data:
+ image = data_dict["image"]
+ question = data_dict["question"] + " There are several options:"
+ option_index = ["A", "B", "C", "D"]
+ for cur_idx in range(4):
+ question += f" {option_index[cur_idx]}. {data_dict[f'choice_{option_index[cur_idx].lower()}']}"
+
+ answer = data_dict["answer"]
+ options = [
+ data_dict["choice_a"],
+ data_dict["choice_b"],
+ data_dict["choice_c"],
+ data_dict["choice_d"],
+ ]
+
+ option_losses = []
+ for idx, option in enumerate(options):
+ option = option_index[idx] + ". " + option
+ loss = model.eval_forward(question, option, image)
+ option_losses.append(loss.item())
+
+ prediction_idx = np.argmin(option_losses)
+ prediction = ["A", "B", "C", "D"][prediction_idx]
+ if prediction == answer:
+ num_correct += 1
+ count += 1
+
+ answer_record = {"question_id": data_dict["question_id"], "prediction": prediction}
+ output_f.write(json.dumps(answer_record) + "\n")
+
+ answer_record = {"question_id": data_dict["question_id"], "prediction": prediction}
+ output_f.write(json.dumps(answer_record) + "\n")
+
+ accuracy = num_correct / count * 100
+ pbar.set_postfix(accuracy=f"{accuracy:.2f}")
+ pbar.update(1)
+
+ accuracy = num_correct / count * 100
+ print(f"Accuracy: {accuracy:.2f}%")
+ return accuracy
diff --git a/pipeline/benchmarks/evaluate.py b/pipeline/benchmarks/evaluate.py
new file mode 100644
index 00000000..01e589c8
--- /dev/null
+++ b/pipeline/benchmarks/evaluate.py
@@ -0,0 +1,138 @@
+import sys
+import argparse
+import os
+import yaml
+import contextlib
+
+sys.path.append("../..")
+from .models.base_model import load_model
+from .datasets.base_eval_dataset import load_dataset
+
+
+def get_info(info):
+ if "name" not in info:
+ raise ValueError("Model name is not specified.")
+ name = info["name"]
+ # info.pop("name")
+ return name, info
+
+
+def load_models(model_infos):
+ for model_info in model_infos:
+ name, info = get_info(model_info)
+ model = load_model(name, info)
+ yield model
+
+
+def load_datasets(dataset_infos):
+ for dataset_info in dataset_infos:
+ name, info = get_info(dataset_info)
+ dataset = load_dataset(name, info)
+ yield dataset
+
+
+class DualOutput:
+ def __init__(self, file, stdout):
+ self.file = file
+ self.stdout = stdout
+
+ def write(self, data):
+ self.file.write(data)
+ self.stdout.write(data)
+
+ def flush(self):
+ self.file.flush()
+ self.stdout.flush()
+
+
+if __name__ == "__main__":
+ args = argparse.ArgumentParser()
+ args.add_argument(
+ "--config",
+ "-c",
+ type=str,
+ help="Path to the config file, suppors more specific configurations.",
+ default=None,
+ )
+ args.add_argument(
+ "--models",
+ type=str,
+ nargs="?",
+ help="Specify model names as comma separated values.",
+ default=None,
+ )
+ args.add_argument(
+ "--model_paths",
+ type=str,
+ nargs="?",
+ help="Specify model paths as comma separated values.",
+ default=None,
+ )
+ args.add_argument(
+ "--datasets",
+ type=str,
+ nargs="?",
+ help="Specify dataset names as comma separated values.",
+ default=None,
+ )
+ args.add_argument(
+ "--output",
+ "-o",
+ type=str,
+ help="Output file path for logging results.",
+ default="./logs/evaluation.txt",
+ )
+ args.add_argument(
+ "--cache_dir",
+ type=str,
+ help="Cache directory for datasets.",
+ default=None,
+ )
+
+ phrased_args = args.parse_args()
+
+ if phrased_args.config:
+ with open(phrased_args.config, "r") as f:
+ config = yaml.safe_load(f)
+ model_infos = config["models"]
+ dataset_infos = config["datasets"]
+ phrased_args.output = config["output"] if "output" in config else phrased_args.output
+ else:
+ # Zip the models and their respective paths
+ model_names = phrased_args.models.split(",")
+ if phrased_args.model_paths is not None:
+ model_paths = phrased_args.model_paths.split(",")
+ model_infos = [{"name": name, "model_path": path} for name, path in zip(model_names, model_paths)]
+ else:
+ model_infos = [{"name": name} for name in model_names]
+ dataset_infos = [{"name": dataset_name, "cache_dir": phrased_args.cache_dir} for dataset_name in phrased_args.datasets.split(",")]
+
+ if not os.path.exists(os.path.dirname(phrased_args.output)):
+ os.makedirs(os.path.dirname(phrased_args.output))
+
+ with open(phrased_args.output, "w") as outfile, contextlib.redirect_stdout(DualOutput(outfile, sys.stdout)):
+ print("=" * 80)
+ print(" " * 30 + "EVALUATION REPORT")
+ print("=" * 80)
+ print()
+
+ for model_info in model_infos:
+ print("\nMODEL INFO:", model_info)
+ print("-" * 80)
+ model = load_model(model_info["name"], model_info)
+
+ dataset_count = 0
+ for dataset in load_datasets(dataset_infos):
+ dataset_count += 1
+ print(f"\nDATASET: {dataset.name}")
+ print("-" * 20)
+
+ dataset.evaluate(model) # Assuming this function now prints results directly.
+ print()
+
+ print("-" * 80)
+ print(f"Total Datasets Evaluated: {dataset_count}\n")
+
+ print("=" * 80)
+
+# python evaluate.py --models otter_image --datasets mmbench
diff --git a/src/otter_ai/models/flamingo/falcon/__init__.py b/pipeline/benchmarks/models/__init__.py
similarity index 100%
rename from src/otter_ai/models/flamingo/falcon/__init__.py
rename to pipeline/benchmarks/models/__init__.py
diff --git a/pipeline/benchmarks/models/base_model.py b/pipeline/benchmarks/models/base_model.py
new file mode 100644
index 00000000..ab78af82
--- /dev/null
+++ b/pipeline/benchmarks/models/base_model.py
@@ -0,0 +1,49 @@
+from abc import ABC, abstractmethod
+from PIL import Image
+from typing import Dict
+
+import importlib
+
+AVAILABLE_MODELS: Dict[str, str] = {
+ "video_chat": "VideoChat",
+ "otter_video": "OtterVideo",
+ "llama_adapter": "LlamaAdapter",
+ "mplug_owl": "mPlug_owl",
+ "video_chatgpt": "Video_ChatGPT",
+ "otter_image": "OtterImage",
+ "frozen_bilm": "FrozenBilm",
+ "idefics": "Idefics",
+ "fuyu": "Fuyu",
+ "otterhd": "OtterHD",
+ "instructblip": "InstructBLIP",
+ "qwen_vl": "QwenVL",
+ "llava_model": "LLaVA_Model",
+ "instructblip": "InstructBLIP",
+ "gpt4v": "OpenAIGPT4Vision",
+}
+
+
+class BaseModel(ABC):
+ def __init__(self, model_name: str, model_path: str, *, max_batch_size: int = 1):
+ self.name = model_name
+ self.model_path = model_path
+ self.max_batch_size = max_batch_size
+
+ @abstractmethod
+ def generate(self, **kwargs):
+ pass
+
+ @abstractmethod
+ def eval_forward(self, **kwargs):
+ pass
+
+
+def load_model(model_name: str, model_args: Dict[str, str]) -> BaseModel:
+ assert model_name in AVAILABLE_MODELS, f"{model_name} is not an available model."
+ module_path = "pipeline.benchmarks.models." + model_name
+ model_formal_name = AVAILABLE_MODELS[model_name]
+ imported_module = importlib.import_module(module_path)
+ model_class = getattr(imported_module, model_formal_name)
+ print(f"Imported class: {model_class}")
+ model_args.pop("name")
+ return model_class(**model_args)
diff --git a/docs/dataset_card.md b/pipeline/benchmarks/models/frozen_bilm.py
similarity index 100%
rename from docs/dataset_card.md
rename to pipeline/benchmarks/models/frozen_bilm.py
diff --git a/pipeline/benchmarks/models/fuyu.py b/pipeline/benchmarks/models/fuyu.py
new file mode 100644
index 00000000..45519550
--- /dev/null
+++ b/pipeline/benchmarks/models/fuyu.py
@@ -0,0 +1,72 @@
+from typing import List
+from transformers import AutoTokenizer, FuyuImageProcessor
+from transformers import FuyuForCausalLM
+from src.otter_ai.models.fuyu.processing_fuyu import FuyuProcessor
+from PIL import Image
+from .base_model import BaseModel
+import torch
+import numpy as np
+import warnings
+import io
+import base64
+import math
+
+warnings.filterwarnings("ignore")
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+class Fuyu(BaseModel):
+ def __init__(self, model_path: str = "adept/fuyu-8b", cuda_id: int = 0, resolution: int = -1, max_new_tokens=256):
+ super().__init__("fuyu", model_path)
+ self.resolution = resolution
+ self.device = f"cuda:{cuda_id}" if torch.cuda.is_available() else "cpu"
+ self.model = FuyuForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16).to(self.device)
+ self.tokenizer = AutoTokenizer.from_pretrained("adept/fuyu-8b")
+ self.image_processor = FuyuImageProcessor()
+ self.processor = FuyuProcessor(image_processor=self.image_processor, tokenizer=self.tokenizer)
+ self.max_new_tokens = max_new_tokens
+ self.bad_words_list = ["User:", "Assistant:"]
+ self.bad_words_ids = self.tokenizer(self.bad_words_list, add_special_tokens=False).input_ids
+
+ def generate(self, text_prompt: str, raw_image_data: str):
+ raw_image_data = get_pil_image(raw_image_data)
+ raw_image_data = raw_image_data.convert("RGB")
+ # make sure the image is in RGB format and resize to match the width
+ if self.resolution != -1:
+ width, height = raw_image_data.size
+ short_edge = min(width, height)
+ scaling_factor = self.resolution / short_edge
+ new_width = math.ceil(width * scaling_factor)
+ new_height = math.ceil(height * scaling_factor)
+ raw_image_data = raw_image_data.resize((new_width, new_height), Image.ANTIALIAS)
+ # formated_prompt = f"User: {text_prompt} Assistant:"
+ model_inputs = self.processor(text=text_prompt, images=[raw_image_data], device=self.device)
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(self.device)
+
+ model_inputs["image_patches"] = model_inputs["image_patches"].to(dtype=next(self.model.parameters()).dtype)
+ generation_output = self.model.generate(**model_inputs, max_new_tokens=self.max_new_tokens, pad_token_id=self.tokenizer.eos_token_id, bad_words_ids=self.bad_words_ids)
+ generation_text = self.processor.batch_decode(generation_output, skip_special_tokens=True)
+ return generation_text[0].split("\x04")[1].strip(" ").strip("\n")
+
+ def eval_forward(self, **kwargs):
+ return super().eval_forward(**kwargs)
+
+
+if __name__ == "__main__":
+ model = Fuyu()
+ print(model.generate("Generate a coco-style caption.\n", Image.open("/home/luodian/projects/Otter/archived/test_images/rabbit.png").convert("RGB")))
diff --git a/pipeline/benchmarks/models/gpt4v.py b/pipeline/benchmarks/models/gpt4v.py
new file mode 100644
index 00000000..6fe655e5
--- /dev/null
+++ b/pipeline/benchmarks/models/gpt4v.py
@@ -0,0 +1,79 @@
+import requests
+import base64
+from .base_model import BaseModel
+from PIL import Image
+import io
+import time
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+class OpenAIGPT4Vision(BaseModel):
+ def __init__(self, api_key: str, max_new_tokens: int = 256):
+ super().__init__("openai-gpt4", "gpt-4-vision-preview")
+ self.api_key = api_key
+ self.headers = {"Content-Type": "application/json", "Authorization": f"Bearer {api_key}"}
+ self.max_new_tokens = max_new_tokens
+
+ @staticmethod
+ def encode_image_to_base64(raw_image_data) -> str:
+ if isinstance(raw_image_data, Image.Image):
+ buffered = io.BytesIO()
+ raw_image_data.save(buffered, format="JPEG")
+ return base64.b64encode(buffered.getvalue()).decode("utf-8")
+ raise ValueError("The input image data must be a PIL.Image.Image")
+
+ def generate(self, text_prompt: str, raw_image_data):
+ raw_image_data = get_pil_image(raw_image_data).convert("RGB")
+ base64_image = self.encode_image_to_base64(raw_image_data)
+
+ payload = {
+ "model": "gpt-4-vision-preview",
+ "messages": [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": text_prompt},
+ {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}},
+ ],
+ }
+ ],
+ "max_tokens": self.max_new_tokens,
+ }
+
+ retry = True
+ retry_times = 0
+ while retry and retry_times < 5:
+ response = requests.post("https://api.openai.com/v1/chat/completions", headers=self.headers, json=payload)
+ if response.status_code == 200:
+ response_data = response.json()
+ return response_data["choices"][0]["message"]["content"]
+ else:
+ print(f"Failed to connect to OpenAI API: {response.status_code} - {response.text}. Retrying...")
+ time.sleep(10)
+ retry_times += 1
+ return "Failed to connect to OpenAI GPT4V API"
+
+ def eval_forward(self, **kwargs):
+ return super().eval_forward(**kwargs)
+
+
+if __name__ == "__main__":
+ # Use your own API key here
+ api_key = "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"
+ model = OpenAIGPT4Vision(api_key)
+ image = Image.open("/home/luodian/projects/Otter/archived/data/G4_IMG_00001.png").convert("RGB")
+ print(model.generate("What’s in this image?", image))
diff --git a/pipeline/benchmarks/models/idefics.py b/pipeline/benchmarks/models/idefics.py
new file mode 100644
index 00000000..a15a72b9
--- /dev/null
+++ b/pipeline/benchmarks/models/idefics.py
@@ -0,0 +1,231 @@
+import io
+import torch
+from typing import List
+from transformers import IdeficsForVisionText2Text, AutoProcessor
+from PIL import Image
+from .base_model import BaseModel
+from pipeline.train.train_utils import find_and_remove_tokens, get_image_attention_mask
+import base64
+import numpy as np
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+def get_single_formatted_prompt(question, image=None, answer="") -> List[str]:
+ if answer == "":
+ return [
+ f"User:",
+ get_pil_image(image),
+ question,
+ "\n",
+ "Assistant:",
+ ]
+ else:
+ return [
+ f"User:",
+ get_pil_image(image),
+ question,
+ "\n",
+ f"Assistant: {answer}",
+ "",
+ ]
+
+
+def get_formatted_prompt(questions, images, answers=""):
+ single_prompt = False
+ if not isinstance(questions, list):
+ questions = [questions]
+ single_prompt = True
+ if not isinstance(images, list):
+ images = [images]
+ if not isinstance(answers, list):
+ answers = [answers] * len(questions)
+ result = []
+ for question, image, answer in zip(questions, images, answers):
+ result.append(get_single_formatted_prompt(question, image, answer))
+ if single_prompt:
+ return result[0]
+ else:
+ return result
+
+
+class Idefics(BaseModel):
+ def __init__(self, model_path: str = "HuggingFaceM4/idefics-9b-instruct", batch=8):
+ super().__init__("idefics", model_path, max_batch_size=batch)
+ self.device = "cuda:0" if torch.cuda.is_available() else "cpu"
+ self.model = IdeficsForVisionText2Text.from_pretrained(model_path, device_map={"": self.device}, torch_dtype=torch.bfloat16).to(self.device)
+ self.processor = AutoProcessor.from_pretrained(model_path)
+ if "" not in self.processor.tokenizer.special_tokens_map["additional_special_tokens"]:
+ past_special_tokens = self.processor.tokenizer.special_tokens_map["additional_special_tokens"]
+ self.processor.tokenizer.add_special_tokens({"additional_special_tokens": [""] + past_special_tokens})
+
+ self.fake_token_image_token_id = self.processor.tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ self.endofchunk_text = ""
+ self.endofchunk_token_id = self.processor.tokenizer(self.endofchunk_text, add_special_tokens=False)["input_ids"][-1]
+ self.answer_token_id = self.processor.tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ self.eos_token_id = self.processor.tokenizer(self.processor.tokenizer.eos_token, add_special_tokens=False)["input_ids"][-1]
+ self.patch_resize_transform = self.processor.image_processor.preprocess
+
+ def generate(self, question, raw_image_data):
+ formatted_prompt = get_formatted_prompt(question, raw_image_data)
+ inputs = self.processor(formatted_prompt, return_tensors="pt").to(self.device)
+ exit_condition = self.processor.tokenizer("", add_special_tokens=False).input_ids
+ bad_words_ids = self.processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+ generated_ids = self.model.generate(
+ **inputs,
+ eos_token_id=exit_condition,
+ bad_words_ids=bad_words_ids,
+ max_new_tokens=768,
+ temperature=0.2,
+ do_sample=True,
+ top_p=0.5,
+ )
+ generated_text = self.processor.batch_decode(generated_ids)
+ results = list(map(lambda text: text.strip().split("Assistant:")[-1].split("")[0].strip(), generated_text))
+ if isinstance(question, str):
+ return results[0]
+ else:
+ return results
+
+ def prepare_labels(self, input_ids, eos_token_id, answer_token_id, endofchunk_token_id, fake_token_image_token_id, masking_number: int = -100):
+ labels = torch.empty(input_ids.shape, dtype=torch.int64)
+ for i in range(input_ids.shape[0]):
+ labels[i] = torch.where(input_ids[i] == eos_token_id, eos_token_id, masking_number)
+ answer_token_ids_all = torch.where(input_ids[i] == answer_token_id)[0]
+ endofchunk_token_ids_all = torch.where(input_ids[i] == endofchunk_token_id)[0]
+
+ j = 0 # Counter for endofchunk_token_ids
+ for answer_token_idx in answer_token_ids_all:
+ # Find the closest endofchunk_token_id that is greater than answer_token_id
+ while j < len(endofchunk_token_ids_all) and endofchunk_token_ids_all[j] < answer_token_idx:
+ j += 1
+
+ if j < len(endofchunk_token_ids_all):
+ endofchunk_token_idx = endofchunk_token_ids_all[j]
+ labels[i, answer_token_idx + 1 : endofchunk_token_idx + 1] = input_ids[i, answer_token_idx + 1 : endofchunk_token_idx + 1]
+
+ # Increment j for the next iteration
+ j += 1
+
+ labels[:, 0] = masking_number
+ labels[labels == fake_token_image_token_id] = masking_number
+ return labels
+
+ def eval_forward(self, question, answer, image):
+ forward_prompt = f"User:{question}\nAssistant:{answer}"
+ inputs = self.processor.tokenizer(forward_prompt, return_tensors="pt")
+ vision_x = self.patch_resize_transform(image).unsqueeze(0).to(self.device)
+ labels = self.prepare_labels(
+ inputs["input_ids"],
+ self.eos_token_id,
+ self.answer_token_id,
+ self.endofchunk_token_id,
+ self.fake_token_image_token_id,
+ )
+ input_ids, labels, attention_mask = find_and_remove_tokens(
+ inputs["input_ids"], labels, inputs["attention_mask"], self.answer_token_id, self.processor.tokenizer
+ ) # find and remove certain tokens from input_ids, labels, and attention_mask
+ # input_ids = inputs["input_ids"]
+ # attention_mask = inputs["attention_mask"]
+ image_attention_mask = get_image_attention_mask(input_ids, 1, self.processor.tokenizer)
+ # vision_x = inputs["pixel_values"]
+ # query = get_formatted_forward_prompt(question, answer)
+ # tokens = self.tokenizer(query, return_tensors="pt")
+ # input_ids = tokens["input_ids"]
+ # attention_mask = tokens["attention_mask"]
+ with torch.no_grad():
+ loss = self.model(
+ pixel_values=vision_x,
+ input_ids=input_ids.to(self.device),
+ attention_mask=attention_mask.to(self.device),
+ image_attention_mask=image_attention_mask.to(self.device),
+ labels=labels.to(self.device),
+ # input_ids=input_ids,
+ # attention_mask=attention_mask,
+ # image_attention_mask=image_attention_mask,
+ # vision_x=vision_x,
+ # labels=labels,
+ ).loss
+ return loss
+
+ def eval_forward_batch(self, batch_questions, batch_options, batch_images):
+ batch_size = len(batch_questions)
+ all_option_losses = []
+ tensor_images = [self.patch_resize_transform(image).unsqueeze(0) for image in batch_images]
+
+ # Prepare batched inputs and put them on the device
+ batch_input_ids = []
+ batch_attention_mask = []
+ batch_prompt = []
+
+ for i in range(batch_size):
+ question = batch_questions[i]
+ option = batch_options[i]
+ forward_prompt = f"User:{question}\nAssistant:{option}"
+ batch_prompt.append(forward_prompt)
+
+ inputs = self.processor.tokenizer(batch_prompt, return_tensors="pt", padding="longest", truncation=True, max_length=512)
+ batch_input_ids.append(inputs["input_ids"])
+ batch_attention_mask.append(inputs["attention_mask"])
+
+ batch_input_ids = torch.cat(batch_input_ids, dim=0)
+ batch_attention_mask = torch.cat(batch_attention_mask, dim=0)
+ batch_labels = self.prepare_labels(
+ batch_input_ids,
+ self.eos_token_id,
+ self.answer_token_id,
+ self.endofchunk_token_id,
+ self.fake_token_image_token_id,
+ )
+
+ batch_input_ids, batch_labels, batch_attention_mask = find_and_remove_tokens(batch_input_ids, batch_labels, batch_attention_mask, self.answer_token_id, self.processor.tokenizer)
+
+ # to device
+ batch_image_tensors = torch.stack(tensor_images).to(self.device)
+ batch_input_ids = batch_input_ids.to(self.device)
+ batch_labels = batch_labels.to(self.device)
+ batch_attention_mask = batch_attention_mask.to(self.device)
+
+ # Perform batch inference
+ with torch.no_grad():
+ # Your forward function can go here, adjusted for batches
+ outputs = self.model(
+ pixel_values=batch_image_tensors.squeeze(2),
+ input_ids=batch_input_ids,
+ attention_mask=batch_attention_mask,
+ image_attention_mask=get_image_attention_mask(batch_input_ids, 1, self.processor.tokenizer).to(self.device),
+ labels=batch_labels,
+ # more arguments as needed
+ )
+
+ # Assuming `outputs.per_token_loss` contains the loss for each token for each item in the batch
+ per_token_loss = outputs.per_token_loss # Shape would be [batch_size, sequence_length]
+
+ # Summing along the sequence length dimension to get per-item loss
+ per_item_loss = torch.sum(per_token_loss, dim=1) # Shape [batch_size]
+ all_option_losses = np.split(per_item_loss, batch_size)
+
+ return all_option_losses
+
+
+if __name__ == "__main__":
+ model = Idefics("/data/pufanyi/training_data/checkpoints/idefics-9b-instruct")
+ print(
+ model.generate(
+ "What is in this image?",
+ Image.open("/data/pufanyi/project/Otter-2/pipeline/evaluation/test_data/test.jpg"),
+ )
+ )
diff --git a/pipeline/benchmarks/models/instructblip.py b/pipeline/benchmarks/models/instructblip.py
new file mode 100644
index 00000000..3923182d
--- /dev/null
+++ b/pipeline/benchmarks/models/instructblip.py
@@ -0,0 +1,48 @@
+from transformers import InstructBlipProcessor, InstructBlipForConditionalGeneration
+from PIL import Image
+from .base_model import BaseModel
+import torch
+import numpy as np
+import warnings
+import io
+import base64
+
+warnings.filterwarnings("ignore")
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+class InstructBLIP(BaseModel):
+ def __init__(self, model_path: str = "Salesforce/instructblip-vicuna-7b", cuda_id: int = 0, max_new_tokens=32):
+ super().__init__("instructblip", model_path)
+ self.device = f"cuda:{cuda_id}" if torch.cuda.is_available() else "cpu"
+ self.model = InstructBlipForConditionalGeneration.from_pretrained(model_path).to(self.device)
+ self.processor = InstructBlipProcessor.from_pretrained(model_path)
+ self.max_new_tokens = max_new_tokens
+
+ def generate(self, text_prompt: str, raw_image_data: str):
+ raw_image_data = get_pil_image(raw_image_data)
+ raw_image_data = raw_image_data.convert("RGB")
+ formatted_prompt = f"{text_prompt}\nAnswer:"
+ # Accordling to https://huggingface.co/Salesforce/instructblip-vicuna-7b . Seems that is is no special prompt format for instruct blip
+ model_inputs = self.processor(images=raw_image_data, text=formatted_prompt, return_tensors="pt").to(self.device)
+ # We follow the recommended parameter here:https://huggingface.co/Salesforce/instructblip-vicuna-7b
+ generation_output = self.model.generate(**model_inputs, do_sample=False, max_new_tokens=self.max_new_tokens, min_length=1)
+ generation_text = self.processor.batch_decode(generation_output, skip_special_tokens=True)
+ return generation_text[0]
+
+ def eval_forward(self, question, answer, image):
+ raise NotImplementedError
diff --git a/pipeline/benchmarks/models/llama_adapter.py b/pipeline/benchmarks/models/llama_adapter.py
new file mode 100644
index 00000000..9066909f
--- /dev/null
+++ b/pipeline/benchmarks/models/llama_adapter.py
@@ -0,0 +1,43 @@
+from .LLaMA_Adapter.imagebind_LLM.ImageBind import data as data_utils
+from .LLaMA_Adapter.imagebind_LLM import llama
+
+from .base_model import BaseModel
+
+import os
+
+
+llama_dir = "/mnt/petrelfs/share_data/zhangyuanhan/llama_adapter_v2_multimodal"
+
+
+class LlamaAdapter(BaseModel):
+ # checkpoint will be automatically downloaded
+ def __init__(self, model_path: str):
+ super().__init__("llama_adapter", model_path)
+ self.model = llama.load(model_path, llama_dir)
+ self.model.eval()
+
+ def generate(self, input_data):
+ inputs = {}
+ video_dir = input_data.get("video_root", "")
+ image = data_utils.load_and_transform_video_data([input_data["video_path"]], device="cuda")
+ inputs["Image"] = [image, 1]
+
+ object_description = input_data["object_description"]
+ if object_description != "None":
+ context = f"Given context:{object_description}. "
+ else:
+ context = ""
+ prompts_input = context + input_data["question"]
+
+ results = self.model.generate(inputs, [llama.format_prompt(prompts_input)], max_gen_len=256)
+ result = results[0].strip()
+ return result
+
+
+if __name__ == "__main__":
+ model = LlamaAdapter("", "")
+ data = {
+ "video_idx": "03f2ed96-1719-427d-acf4-8bf504f1d66d.mp4",
+ "question": "What is in this image?",
+ }
+ print(model.generate(data))
diff --git a/pipeline/benchmarks/models/llava_model.py b/pipeline/benchmarks/models/llava_model.py
new file mode 100644
index 00000000..14bd5f34
--- /dev/null
+++ b/pipeline/benchmarks/models/llava_model.py
@@ -0,0 +1,72 @@
+import numpy as np
+import torch
+import torchvision.transforms as T
+from torchvision.io import read_video
+
+from .base_model import BaseModel
+from .llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
+from .llava.conversation import conv_templates, SeparatorStyle
+from .llava.model.builder import load_pretrained_model
+from .llava.utils import disable_torch_init
+from .llava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
+
+default_model_path = "liuhaotian/llava-v1.5-7b"
+
+
+class LLaVA_Model(BaseModel):
+ def __init__(
+ self,
+ model_path: str = default_model_path,
+ model_base: str = None,
+ model_name: str = "llava-v1.5",
+ conv_mode: str = "llava_v1",
+ ):
+ super().__init__(model_name, model_path)
+ init_model_name = get_model_name_from_path(model_path)
+ self.tokenizer, self.model, self.image_processor, self.context_len = load_pretrained_model(model_path, model_base, init_model_name)
+ self.conv_mode = conv_mode
+
+ def generate(self, text_prompt: str, raw_image_data: str):
+ if self.model.config.mm_use_im_start_end:
+ prompts_input = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + "\n" + text_prompt
+ else:
+ prompts_input = DEFAULT_IMAGE_TOKEN + "\n" + text_prompt
+
+ input_data = self.image_processor.preprocess(raw_image_data, return_tensors="pt")["pixel_values"][0]
+
+ conv = conv_templates[self.conv_mode].copy()
+ conv.append_message(conv.roles[0], prompts_input)
+ conv.append_message(conv.roles[1], None)
+ prompt = conv.get_prompt()
+ input_ids = tokenizer_image_token(prompt, self.tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).cuda()
+ stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
+ keywords = [stop_str]
+ stopping_criteria = KeywordsStoppingCriteria(keywords, self.tokenizer, input_ids)
+
+ with torch.inference_mode():
+ output_ids = self.model.generate(
+ input_ids,
+ images=input_data.unsqueeze(0).half().cuda(),
+ do_sample=True,
+ temperature=0.2,
+ top_p=None,
+ num_beams=1,
+ # no_repeat_ngram_size=3,
+ max_new_tokens=512,
+ use_cache=True,
+ )
+
+ input_token_len = input_ids.shape[1]
+ n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
+ if n_diff_input_output > 0:
+ print(f"[Warning] {n_diff_input_output} output_ids are not the same as the input_ids")
+ outputs = self.tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
+ outputs = outputs.strip()
+ if outputs.endswith(stop_str):
+ outputs = outputs[: -len(stop_str)]
+ outputs = outputs.strip()
+
+ return outputs
+
+ def eval_forward(self, text_prompt: str, raw_image_data: str):
+ pass
diff --git a/pipeline/benchmarks/models/mplug_owl.py b/pipeline/benchmarks/models/mplug_owl.py
new file mode 100644
index 00000000..ffd28617
--- /dev/null
+++ b/pipeline/benchmarks/models/mplug_owl.py
@@ -0,0 +1,63 @@
+import os
+
+import torch
+from transformers import AutoTokenizer
+from mplug_owl_video.modeling_mplug_owl import MplugOwlForConditionalGeneration
+from mplug_owl_video.processing_mplug_owl import (
+ MplugOwlImageProcessor,
+ MplugOwlProcessor,
+)
+
+from .base_model import BaseModel
+
+pretrained_ckpt = "MAGAer13/mplug-owl-llama-7b-video"
+
+
+class mPlug_owl(BaseModel):
+ def __init__(self, model_path: str):
+ super().__init__("mplug_owl", model_path)
+ self.model = MplugOwlForConditionalGeneration.from_pretrained(
+ pretrained_ckpt,
+ torch_dtype=torch.bfloat16,
+ )
+ self.image_processor = MplugOwlImageProcessor.from_pretrained(pretrained_ckpt)
+ self.tokenizer = AutoTokenizer.from_pretrained(pretrained_ckpt)
+ self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
+ self.model.eval()
+
+ def format_prompt(self, question):
+ prompts = [f" <|video|> Question : {question} Answer : "]
+ return prompts
+
+ def generate(self, input_data: dict):
+ questions = input_data["question"]
+ video_dir = input_data.get("video_root", "")
+ video_list = input_data["video_path"]
+ generate_kwargs = {"do_sample": True, "top_k": 5, "max_length": 512}
+
+ object_description = input_data["object_description"]
+ if object_description != "None":
+ context = f"Given context:{object_description}. "
+ else:
+ context = ""
+ prompts_input = context + input_data["question"]
+
+ prompt = self.format_prompt(prompts_input)
+ inputs = self.processor(text=prompt, videos=video_list, num_frames=4, return_tensors="pt")
+ inputs = {k: v.bfloat16() if v.dtype == torch.float else v for k, v in inputs.items()}
+ inputs = {k: v.to(self.model.device) for k, v in inputs.items()}
+ with torch.no_grad():
+ res = self.model.generate(**inputs, **generate_kwargs)
+ sentence = self.tokenizer.decode(res.tolist()[0], skip_special_tokens=True)
+ return sentence
+
+
+if __name__ == "__main__":
+ model = mPlug_owl("")
+ device = torch.device("cuda")
+ model.model = model.model.to(device)
+ data = {
+ "video_idx": ["./data_source/multi_hop_reasoning/03f2ed96-1719-427d-acf4-8bf504f1d66d.mp4"],
+ "question": "What is in this image?",
+ }
+ print(model.generate(data))
diff --git a/pipeline/benchmarks/models/otter_image.py b/pipeline/benchmarks/models/otter_image.py
new file mode 100644
index 00000000..3d78af19
--- /dev/null
+++ b/pipeline/benchmarks/models/otter_image.py
@@ -0,0 +1,113 @@
+import mimetypes
+import os
+from io import BytesIO
+from typing import Union
+import cv2
+import requests
+import torch
+import transformers
+from PIL import Image
+
+from otter_ai import OtterForConditionalGeneration
+from .base_model import BaseModel
+
+
+# Disable warnings
+requests.packages.urllib3.disable_warnings()
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+ else:
+ return Image.open(BytesIO(raw_image_data["bytes"]))
+
+
+def get_formatted_prompt(prompt: str) -> str:
+ return f"User: {prompt} GPT:"
+
+
+def get_formatted_forward_prompt(question: str, answer: str) -> str:
+ return f"User: {question} GPT: {answer}"
+
+
+class OtterImage(BaseModel):
+ def __init__(self, model_path="luodian/OTTER-Image-MPT7B", load_bit="bf16"):
+ super().__init__("otter", model_path)
+ precision = {}
+ if load_bit == "bf16":
+ precision["torch_dtype"] = torch.bfloat16
+ elif load_bit == "fp16":
+ precision["torch_dtype"] = torch.float16
+ elif load_bit == "fp32":
+ precision["torch_dtype"] = torch.float32
+ self.model = OtterForConditionalGeneration.from_pretrained(model_path, device_map="sequential", **precision)
+ self.model.text_tokenizer.padding_side = "left"
+ self.tokenizer = self.model.text_tokenizer
+ self.image_processor = transformers.CLIPImageProcessor()
+ self.model.eval()
+
+ def generate(self, question: str, raw_image_data):
+ input_data = get_pil_image(raw_image_data)
+ if isinstance(input_data, Image.Image):
+ if input_data.size == (224, 224) and not any(input_data.getdata()): # Check if image is blank 224x224 image
+ vision_x = torch.zeros(1, 1, 1, 3, 224, 224, dtype=next(self.model.parameters()).dtype)
+ else:
+ vision_x = self.image_processor.preprocess([input_data], return_tensors="pt")["pixel_values"].unsqueeze(1).unsqueeze(0)
+ else:
+ raise ValueError("Invalid input data. Expected PIL Image.")
+
+ lang_x = self.model.text_tokenizer(
+ [
+ get_formatted_prompt(question),
+ ],
+ return_tensors="pt",
+ )
+
+ model_dtype = next(self.model.parameters()).dtype
+ vision_x = vision_x.to(dtype=model_dtype)
+ lang_x_input_ids = lang_x["input_ids"]
+ lang_x_attention_mask = lang_x["attention_mask"]
+
+ generated_text = self.model.generate(
+ vision_x=vision_x.to(self.model.device),
+ lang_x=lang_x_input_ids.to(self.model.device),
+ attention_mask=lang_x_attention_mask.to(self.model.device),
+ max_new_tokens=512,
+ num_beams=3,
+ no_repeat_ngram_size=3,
+ pad_token_id=self.tokenizer.eos_token_id,
+ )
+ parsed_output = self.model.text_tokenizer.decode(generated_text[0]).split("")[-1].split("<|endofchunk|>")[0].strip()
+ return parsed_output
+
+ def get_vision_x(self, input_data):
+ if isinstance(input_data, Image.Image):
+ if input_data.size == (224, 224) and not any(input_data.getdata()): # Check if image is blank 224x224 image
+ vision_x = torch.zeros(1, 1, 1, 3, 224, 224, dtype=next(self.model.parameters()).dtype)
+ else:
+ vision_x = self.image_processor.preprocess([input_data], return_tensors="pt")["pixel_values"].unsqueeze(1).unsqueeze(0)
+ else:
+ raise ValueError("Invalid input data. Expected PIL Image.")
+ model_dtype = next(self.model.parameters()).dtype
+ vision_x = vision_x.to(dtype=model_dtype)
+ return vision_x
+
+ def eval_forward(self, question, answer, image):
+ query = get_formatted_forward_prompt(question, answer)
+ tokens = self.tokenizer(query, return_tensors="pt")
+ input_ids = tokens["input_ids"]
+ attention_mask = tokens["attention_mask"]
+ with torch.no_grad():
+ vision_x = self.get_vision_x(image)
+ loss = self.model(vision_x=vision_x.to(self.model.device), lang_x=input_ids.to(self.model.device), attention_mask=attention_mask.to(self.model.device))[0]
+ return loss
+
+
+if __name__ == "__main__":
+ model = OtterImage("/data/pufanyi/training_data/checkpoints/OTTER-Image-MPT7B")
+ image = Image.open("/data/pufanyi/project/Otter-2/pipeline/evaluation/test_data/test.jpg")
+ response = model.generate("What is this?", image)
+ print(response)
+ response = model.generate("What is this?", image)
+ print(response)
diff --git a/pipeline/benchmarks/models/otter_video.py b/pipeline/benchmarks/models/otter_video.py
new file mode 100644
index 00000000..6a71e554
--- /dev/null
+++ b/pipeline/benchmarks/models/otter_video.py
@@ -0,0 +1,121 @@
+import mimetypes
+import os
+from io import BytesIO
+from typing import Union
+import cv2
+import requests
+import torch
+import transformers
+from PIL import Image
+import sys
+
+sys.path.append("/mnt/petrelfs/zhangyuanhan/Otter/")
+from src.otter_ai.models.otter.modeling_otter import OtterForConditionalGeneration
+from .base_model import BaseModel
+
+# Disable warnings
+requests.packages.urllib3.disable_warnings()
+
+
+class OtterVideo(BaseModel):
+ def __init__(self, model_path="luodian/OTTER-Video-LLaMA7B-DenseCaption", load_bit="bf16"):
+ super().__init__("otter_video", model_path)
+ precision = {}
+ if load_bit == "bf16":
+ precision["torch_dtype"] = torch.bfloat16
+ elif load_bit == "fp16":
+ precision["torch_dtype"] = torch.float16
+ elif load_bit == "fp32":
+ precision["torch_dtype"] = torch.float32
+ self.model = OtterForConditionalGeneration.from_pretrained(model_path, device_map="sequential", **precision)
+ self.tensor_dtype = {
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ "fp32": torch.float32,
+ }[load_bit]
+ self.model.text_tokenizer.padding_side = "left"
+ self.tokenizer = self.model.text_tokenizer
+ self.image_processor = transformers.CLIPImageProcessor()
+ self.model.eval()
+
+ def get_formatted_prompt(self, prompt: str) -> str:
+ return f"User: {prompt} GPT:"
+
+ def extract_frames(self, video_path, num_frames=16):
+ video = cv2.VideoCapture(video_path)
+ total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
+ frame_step = total_frames // num_frames
+ frames = []
+
+ for i in range(num_frames):
+ video.set(cv2.CAP_PROP_POS_FRAMES, i * frame_step)
+ ret, frame = video.read()
+ if ret:
+ frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
+ frame = Image.fromarray(frame).convert("RGB")
+ frames.append(frame)
+
+ video.release()
+ return frames
+
+ def get_response(
+ self,
+ input_data,
+ prompt: str,
+ model=None,
+ image_processor=None,
+ tensor_dtype=None,
+ ) -> str:
+ if isinstance(input_data, Image.Image):
+ vision_x = image_processor.preprocess([input_data], return_tensors="pt")["pixel_values"].unsqueeze(1).unsqueeze(0)
+ elif isinstance(input_data, list): # list of video frames
+ vision_x = image_processor.preprocess(input_data, return_tensors="pt")["pixel_values"].unsqueeze(0).unsqueeze(0)
+ else:
+ raise ValueError("Invalid input data. Expected PIL Image or list of video frames.")
+
+ lang_x = self.tokenizer(
+ [
+ self.get_formatted_prompt(prompt),
+ ],
+ return_tensors="pt",
+ )
+
+ bad_words_id = self.tokenizer(["User:", "GPT1:", "GFT:", "GPT:"], add_special_tokens=False).input_ids
+ # import pdb;pdb.set_trace()
+ generated_text = self.model.generate(
+ vision_x=vision_x.to(model.device, dtype=tensor_dtype),
+ lang_x=lang_x["input_ids"].to(model.device),
+ attention_mask=lang_x["attention_mask"].to(model.device),
+ max_new_tokens=512,
+ num_beams=3,
+ no_repeat_ngram_size=3,
+ bad_words_ids=bad_words_id,
+ )
+ parsed_output = model.text_tokenizer.decode(generated_text[0]).split("")[-1].lstrip().rstrip().split("<|endofchunk|>")[0].lstrip().rstrip().lstrip('"').rstrip('"')
+ return parsed_output
+
+ def generate(self, input_data):
+ video_dir = input_data.get("video_root", "")
+ frames_list = self.extract_frames(input_data["video_path"])
+
+ object_description = input_data["object_description"]
+
+ if object_description != "None":
+ context = f"Given context:{object_description}. "
+ else:
+ context = ""
+ prompts_input = context + input_data["question"]
+
+ response = self.get_response(
+ frames_list,
+ prompts_input,
+ self.model,
+ self.image_processor,
+ self.tensor_dtype,
+ )
+
+ return response
+
+
+if __name__ == "__main__":
+ pass
diff --git a/pipeline/benchmarks/models/otterhd.py b/pipeline/benchmarks/models/otterhd.py
new file mode 100644
index 00000000..850fce6f
--- /dev/null
+++ b/pipeline/benchmarks/models/otterhd.py
@@ -0,0 +1,68 @@
+from transformers import FuyuForCausalLM, AutoTokenizer, FuyuImageProcessor, FuyuProcessor
+from PIL import Image
+from .base_model import BaseModel
+import torch
+import numpy as np
+import warnings
+import io
+import base64
+
+warnings.filterwarnings("ignore")
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+import math
+
+
+class OtterHD(BaseModel):
+ def __init__(self, model_path: str = "Otter-AI/OtterHD-8B", cuda_id: int = 0, resolution: int = -1, max_new_tokens=256):
+ super().__init__("otterhd", model_path)
+ self.resolution = resolution
+ self.device = f"cuda:{cuda_id}" if torch.cuda.is_available() else "cpu"
+ self.model = FuyuForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map=self.device)
+ self.model.eval()
+ self.tokenizer = AutoTokenizer.from_pretrained(model_path)
+ self.image_processor = FuyuImageProcessor()
+ self.processor = FuyuProcessor(image_processor=self.image_processor, tokenizer=self.tokenizer)
+ self.max_new_tokens = max_new_tokens
+
+ def generate(self, text_prompt: str, raw_image_data: str):
+ raw_image_data = get_pil_image(raw_image_data)
+ # make sure the image is in RGB format and resize to match the width
+ raw_image_data = raw_image_data.convert("RGB")
+ if self.resolution != -1:
+ width, height = raw_image_data.size
+ short_edge = min(width, height)
+ scaling_factor = self.resolution / short_edge
+ new_width = math.ceil(width * scaling_factor)
+ new_height = math.ceil(height * scaling_factor)
+ raw_image_data = raw_image_data.resize((new_width, new_height), Image.ANTIALIAS)
+
+ formated_prompt = f"User: {text_prompt} Assistant:"
+ model_inputs = self.processor(text=formated_prompt, images=[raw_image_data], device=self.device)
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(self.device, non_blocking=True) if isinstance(v, torch.Tensor) else [vv.to(self.device, non_blocking=True) for vv in v]
+
+ model_inputs["image_patches"][0] = model_inputs["image_patches"][0].to(dtype=next(self.model.parameters()).dtype)
+ generation_output = self.model.generate(**model_inputs, max_new_tokens=self.max_new_tokens, pad_token_id=self.tokenizer.eos_token_id)
+ generation_text = self.processor.batch_decode(generation_output, skip_special_tokens=True)
+ response = generation_text[0].split("\x04")[1].strip(" ").strip("\n")
+ return response
+
+ def eval_forward(self, text_prompt: str, image_path: str):
+ # Similar to the Idefics' eval_forward but adapted for Fuyu
+ pass
diff --git a/pipeline/benchmarks/models/qwen_vl.py b/pipeline/benchmarks/models/qwen_vl.py
new file mode 100644
index 00000000..3cd23d8a
--- /dev/null
+++ b/pipeline/benchmarks/models/qwen_vl.py
@@ -0,0 +1,34 @@
+import os
+
+import numpy as np
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from transformers.generation import GenerationConfig
+
+from .base_model import BaseModel
+
+default_path = "Qwen/Qwen-VL-Chat"
+
+
+class QwenVL(BaseModel):
+ def __init__(self, model_name: str = "qwen_vl", model_path: str = default_path):
+ super().__init__(model_name, model_path)
+ self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+ self.model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True).eval()
+ self.model.generation_config = GenerationConfig.from_pretrained(model_path, trust_remote_code=True)
+ self.temp_dir = ".log/temp"
+ if not os.path.exists(self.temp_dir):
+ os.makedirs(self.temp_dir)
+
+ def generate(self, text_prompt: str, raw_image_data: str):
+ image_path = os.path.join(self.temp_dir, "temp.jpg")
+ raw_image_data.save(image_path)
+ query = []
+ query.append({"image": image_path})
+ query.append({"text": text_prompt})
+ query = self.tokenizer.from_list_format(query)
+ response, history = self.model.chat(self.tokenizer, query=query, history=None)
+ return response
+
+ def eval_forward(self, text_prompt: str, image_path: str):
+ # Similar to the Idefics' eval_forward but adapted for QwenVL
+ pass
diff --git a/pipeline/benchmarks/models/video_chat.py b/pipeline/benchmarks/models/video_chat.py
new file mode 100644
index 00000000..25251f84
--- /dev/null
+++ b/pipeline/benchmarks/models/video_chat.py
@@ -0,0 +1,202 @@
+from .base_model import BaseModel
+from .Ask_Anything.video_chat.utils.config import Config
+from .Ask_Anything.video_chat.models.videochat import VideoChat as VideoChatModel
+from .Ask_Anything.video_chat.utils.easydict import EasyDict
+from .Ask_Anything.video_chat.models.video_transformers import (
+ GroupNormalize,
+ GroupScale,
+ GroupCenterCrop,
+ Stack,
+ ToTorchFormatTensor,
+)
+
+import os
+import torch
+from transformers import StoppingCriteria, StoppingCriteriaList
+from PIL import Image
+import numpy as np
+from decord import VideoReader, cpu
+import torchvision.transforms as T
+from torchvision.transforms.functional import InterpolationMode
+
+config_file = "/mnt/petrelfs/zhangyuanhan/Otter/pipeline/evaluation/models/Ask_Anything/video_chat/configs/config.json"
+cfg = Config.from_file(config_file)
+
+
+class StoppingCriteriaSub(StoppingCriteria):
+ def __init__(self, stops=[], encounters=1):
+ super().__init__()
+ self.stops = stops
+
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor):
+ for stop in self.stops:
+ if torch.all((stop == input_ids[0][-len(stop) :])).item():
+ return True
+ return False
+
+
+class VideoChat(BaseModel):
+ # checkpoint will be automatically downloaded
+ def __init__(self, model_path: str):
+ super().__init__("video_chat", model_path)
+ self.model = VideoChatModel(config=cfg.model)
+
+ self.model = self.model.to(torch.device(cfg.device))
+ self.model = self.model.eval()
+
+ self.chat = EasyDict(
+ {
+ # "system": "You are an AI assistant. A human gives an image or a video and asks some questions. You should give helpful, detailed, and polite answers.\n",
+ "system": "",
+ "roles": ("Human", "Assistant"),
+ "messages": [],
+ "sep": "###",
+ }
+ )
+
+ def get_index(self, num_frames, num_segments):
+ seg_size = float(num_frames - 1) / num_segments
+ start = int(seg_size / 2)
+ offsets = np.array([start + int(np.round(seg_size * idx)) for idx in range(num_segments)])
+ return offsets
+
+ def load_video(self, video_path, num_segments=8, return_msg=False):
+ vr = VideoReader(video_path, ctx=cpu(0))
+ num_frames = len(vr)
+ frame_indices = self.get_index(num_frames, num_segments)
+
+ # transform
+ crop_size = 224
+ scale_size = 224
+ input_mean = [0.48145466, 0.4578275, 0.40821073]
+ input_std = [0.26862954, 0.26130258, 0.27577711]
+
+ transform = T.Compose(
+ [
+ GroupScale(int(scale_size), interpolation=InterpolationMode.BICUBIC),
+ GroupCenterCrop(crop_size),
+ Stack(),
+ ToTorchFormatTensor(),
+ GroupNormalize(input_mean, input_std),
+ ]
+ )
+
+ images_group = list()
+ for frame_index in frame_indices:
+ img = Image.fromarray(vr[frame_index].asnumpy())
+ images_group.append(img)
+ torch_imgs = transform(images_group)
+ if return_msg:
+ fps = float(vr.get_avg_fps())
+ sec = ", ".join([str(round(f / fps, 1)) for f in frame_indices])
+ # " " should be added in the start and end
+ msg = f"The video contains {len(frame_indices)} frames sampled at {sec} seconds."
+ return torch_imgs, msg
+ else:
+ return torch_imgs
+
+ def get_prompt(self, conv):
+ ret = conv.system + conv.sep
+ for role, message in conv.messages:
+ if message:
+ ret += role + ": " + message + conv.sep
+ else:
+ ret += role + ":"
+ return ret
+
+ def get_context_emb(self, conv, model, img_list):
+ prompt = self.get_prompt(conv)
+ print(prompt)
+ if "" in prompt:
+ prompt_segs = prompt.split("")
+ else:
+ prompt_segs = prompt.split("")
+ assert len(prompt_segs) == len(img_list) + 1, "Unmatched numbers of image placeholders and images."
+ seg_tokens = [
+ model.llama_tokenizer(seg, return_tensors="pt", add_special_tokens=i == 0).to("cuda:0").input_ids
+ # only add bos to the first seg
+ for i, seg in enumerate(prompt_segs)
+ ]
+ seg_embs = [model.llama_model.model.embed_tokens(seg_t) for seg_t in seg_tokens]
+ mixed_embs = [emb for pair in zip(seg_embs[:-1], img_list) for emb in pair] + [seg_embs[-1]]
+ mixed_embs = torch.cat(mixed_embs, dim=1)
+ return mixed_embs
+
+ def answer(
+ self,
+ conv,
+ model,
+ img_list,
+ max_new_tokens=200,
+ num_beams=1,
+ min_length=1,
+ top_p=0.9,
+ repetition_penalty=1.0,
+ length_penalty=1,
+ temperature=1.0,
+ ):
+ stop_words_ids = [
+ torch.tensor([835]).to("cuda:0"),
+ torch.tensor([2277, 29937]).to("cuda:0"),
+ ] # '###' can be encoded in two different ways.
+ stopping_criteria = StoppingCriteriaList([StoppingCriteriaSub(stops=stop_words_ids)])
+
+ conv.messages.append([conv.roles[1], None])
+ embs = self.get_context_emb(conv, model, img_list)
+ outputs = model.llama_model.generate(
+ inputs_embeds=embs,
+ max_new_tokens=max_new_tokens,
+ stopping_criteria=stopping_criteria,
+ num_beams=num_beams,
+ do_sample=True,
+ min_length=min_length,
+ top_p=top_p,
+ repetition_penalty=repetition_penalty,
+ length_penalty=length_penalty,
+ temperature=temperature,
+ )
+ output_token = outputs[0]
+ if output_token[0] == 0: # the model might output a unknow token at the beginning. remove it
+ output_token = output_token[1:]
+ if output_token[0] == 1: # some users find that there is a start token at the beginning. remove it
+ output_token = output_token[1:]
+ output_text = model.llama_tokenizer.decode(output_token, add_special_tokens=False)
+ output_text = output_text.split("###")[0] # remove the stop sign '###'
+ output_text = output_text.split("Assistant:")[-1].strip()
+ conv.messages[-1][1] = output_text
+ return output_text, output_token.cpu().numpy()
+
+ def generate(self, input_data):
+ inputs = {}
+ video_dir = input_data.get("video_root", "")
+ vid, msg = self.load_video(input_data["video_path"], num_segments=8, return_msg=True)
+ # print(msg)
+ object_description = input_data["object_description"]
+ if object_description != "None":
+ context = f"Given context:{object_description}. "
+ else:
+ context = ""
+ prompts_input = context + input_data["question"]
+
+ self.chat.messages.append([self.chat.roles[0], f" {msg}\n"])
+ self.chat.messages.append([self.chat.roles[0], prompts_input + "\n"])
+
+ # The model expects inputs of shape: T x C x H x W
+ TC, H, W = vid.shape
+ video = vid.reshape(1, TC // 3, 3, H, W).to(self.model.device)
+ img_list = []
+ image_emb, _ = self.model.encode_img(video)
+ img_list.append(image_emb)
+
+ result = self.answer(conv=self.chat, model=self.model, img_list=img_list, max_new_tokens=1000)[0]
+ self.chat.messages = []
+ return result
+
+
+if __name__ == "__main__":
+ model = VideoChat("")
+ data = {
+ "video_idx": "03f2ed96-1719-427d-acf4-8bf504f1d66d.mp4",
+ "question": "What is in this image?",
+ }
+ print(model.generate(data))
diff --git a/pipeline/benchmarks/models/video_chatgpt.py b/pipeline/benchmarks/models/video_chatgpt.py
new file mode 100644
index 00000000..47fb87aa
--- /dev/null
+++ b/pipeline/benchmarks/models/video_chatgpt.py
@@ -0,0 +1,48 @@
+import torch
+from .video_chatgpt.eval.model_utils import load_video, initialize_model
+from .video_chatgpt.inference import video_chatgpt_infer
+
+from .base_model import BaseModel
+
+model_name = "/mnt/lustre/yhzhang/kaichen/video_ChatGPT/LLaVA-Lightening-7B-v1-1."
+projection_path = "/mnt/lustre/yhzhang/kaichen/video_ChatGPT/video_chatgpt-7B.bin"
+
+
+class Video_ChatGPT(BaseModel):
+ def __init__(self, model_path: str):
+ super().__init__("video_chatgpt", model_path)
+ (
+ self.model,
+ self.vision_tower,
+ self.tokenizer,
+ self.image_processor,
+ self.video_token_len,
+ ) = initialize_model(model_name, projection_path)
+
+ def generate(self, input_data: dict):
+ video_dir = input_data.get("video_root", "")
+ video_frames = load_video(input_data["video_path"])
+
+ object_description = input_data["object_description"]
+ if object_description != "None":
+ context = f"Given context:{object_description}. "
+ else:
+ context = ""
+ prompts_input = context + input_data["question"]
+
+ output = video_chatgpt_infer(
+ video_frames, prompts_input, conv_mode="video-chatgpt_v1", model=self.model, vision_tower=self.vision_tower, tokenizer=self.tokenizer, image_processor=self.image_processor, video_token_len=self.video_token_len
+ )
+ return output
+
+
+if __name__ == "__main__":
+ model = Video_ChatGPT("")
+ device = torch.device("cuda")
+ model.model = model.model.to(device)
+ model.vision_tower = model.vision_tower.to(device)
+ data = {
+ "video_idx": "./data_source/multi_hop_reasoning/03f2ed96-1719-427d-acf4-8bf504f1d66d.mp4",
+ "question": "What is in this image?",
+ }
+ print(model.generate(data))
diff --git a/pipeline/eval/README.md b/pipeline/benchmarks/public_datasets_suite/README.md
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/README.md
rename to pipeline/benchmarks/public_datasets_suite/README.md
diff --git a/src/otter_ai/models/flamingo/mpt/__init__.py b/pipeline/benchmarks/public_datasets_suite/__init__.py
old mode 100644
new mode 100755
similarity index 100%
rename from src/otter_ai/models/flamingo/mpt/__init__.py
rename to pipeline/benchmarks/public_datasets_suite/__init__.py
diff --git a/pipeline/eval/classification_utils.py b/pipeline/benchmarks/public_datasets_suite/classification_utils.py
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/classification_utils.py
rename to pipeline/benchmarks/public_datasets_suite/classification_utils.py
diff --git a/pipeline/eval/coco_metric.py b/pipeline/benchmarks/public_datasets_suite/coco_metric.py
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/coco_metric.py
rename to pipeline/benchmarks/public_datasets_suite/coco_metric.py
diff --git a/pipeline/eval/config.yaml b/pipeline/benchmarks/public_datasets_suite/config.yaml
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/config.yaml
rename to pipeline/benchmarks/public_datasets_suite/config.yaml
diff --git a/pipeline/eval/eval_datasets.py b/pipeline/benchmarks/public_datasets_suite/eval_datasets.py
old mode 100644
new mode 100755
similarity index 90%
rename from pipeline/eval/eval_datasets.py
rename to pipeline/benchmarks/public_datasets_suite/eval_datasets.py
index 918bd763..a7fa6baa
--- a/pipeline/eval/eval_datasets.py
+++ b/pipeline/benchmarks/public_datasets_suite/eval_datasets.py
@@ -5,7 +5,7 @@
from torch.utils.data import Dataset
from torchvision.datasets import ImageFolder
-from pipeline.eval.classification_utils import IMAGENET_1K_CLASS_ID_TO_LABEL
+from pipeline.benchmarks.public_datasets_suite.classification_utils import IMAGENET_1K_CLASS_ID_TO_LABEL
class CaptionDataset(Dataset):
@@ -38,11 +38,7 @@ def __len__(self):
def __getitem__(self, idx):
if self.dataset_name == "coco":
- image = Image.open(
- os.path.join(self.image_train_dir_path, self.annotations[idx]["filename"])
- if self.annotations[idx]["filepath"] == "train2014"
- else os.path.join(self.image_val_dir_path, self.annotations[idx]["filename"])
- )
+ image = Image.open(os.path.join(self.image_train_dir_path, self.annotations[idx]["filename"]) if self.annotations[idx]["filepath"] == "train2014" else os.path.join(self.image_val_dir_path, self.annotations[idx]["filename"]))
elif self.dataset_name == "flickr":
image = Image.open(os.path.join(self.image_train_dir_path, self.annotations[idx]["filename"]))
image.load()
@@ -75,9 +71,7 @@ def get_img_path(self, question):
if self.dataset_name in {"vqav2", "ok_vqa"}:
return os.path.join(
self.image_dir_path,
- f"COCO_{self.img_coco_split}_{question['image_id']:012d}.jpg"
- if self.is_train
- else f"COCO_{self.img_coco_split}_{question['image_id']:012d}.jpg",
+ f"COCO_{self.img_coco_split}_{question['image_id']:012d}.jpg" if self.is_train else f"COCO_{self.img_coco_split}_{question['image_id']:012d}.jpg",
)
elif self.dataset_name == "vizwiz":
return os.path.join(self.image_dir_path, question["image_id"])
diff --git a/pipeline/eval/eval_model.py b/pipeline/benchmarks/public_datasets_suite/eval_model.py
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/eval_model.py
rename to pipeline/benchmarks/public_datasets_suite/eval_model.py
diff --git a/pipeline/eval/evaluate.py b/pipeline/benchmarks/public_datasets_suite/evaluate.py
old mode 100644
new mode 100755
similarity index 98%
rename from pipeline/eval/evaluate.py
rename to pipeline/benchmarks/public_datasets_suite/evaluate.py
index 74f35eee..bc4f4f70
--- a/pipeline/eval/evaluate.py
+++ b/pipeline/benchmarks/public_datasets_suite/evaluate.py
@@ -53,7 +53,7 @@
parser.add_argument("--results_file", type=str, default=None, help="JSON file to save results")
# Trial arguments
-parser.add_argument("--shots", nargs="+", default=[0, 4, 8, 16], type=int)
+parser.add_argument("--shots", nargs="+", default=[0, 4, 8], type=int)
parser.add_argument(
"--num_trials",
type=int,
@@ -349,12 +349,6 @@
help="url used to set up distributed training",
)
parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
-parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
-)
parser.add_argument(
"--no-set-device-rank",
default=False,
@@ -362,10 +356,17 @@
help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc).",
)
+parser.add_argument(
+ "--debug_num",
+ default=None,
+ type=int,
+ help="Number of samples to debug on. None for all samples.",
+)
+
def main():
args, leftovers = parser.parse_known_args()
- module = importlib.import_module(f"pipeline.eval.models.{args.model}")
+ module = importlib.import_module(f"pipeline.benchmarks.public_datasets_suite.models.{args.model}")
# print("======================================")
# print(args)
@@ -383,7 +384,7 @@ def main():
if device_id != torch.device("cpu") and args.world_size > 1:
eval_model.init_distributed()
- if args.model != "open_flamingo" and args.model != "otter" and args.shots != [0]:
+ if args.model != "open_flamingo" and args.model != "otter" and args.model != "idefics" and args.shots != [0]:
raise ValueError("Only 0 shot eval is supported for non-open_flamingo models")
if len(args.trial_seeds) != args.num_trials:
@@ -701,6 +702,10 @@ def evaluate_captioning(
predictions = defaultdict()
np.random.seed(seed + args.rank) # make sure each worker has a different seed for the random context samples
+
+ if args.debug_num:
+ index = 0
+
for batch in tqdm(
test_dataloader,
desc=f"Running inference {dataset_name.upper()}",
@@ -741,6 +746,12 @@ def evaluate_captioning(
"caption": new_predictions[i],
}
+ if args.debug_num:
+ index += 1
+
+ if index >= args.debug_num:
+ break
+
# all gather
all_predictions = [None] * args.world_size
torch.distributed.all_gather_object(all_predictions, predictions) # list of dicts
@@ -1022,9 +1033,7 @@ def sample_to_prompt(sample):
else:
return prompt_text
- context_text = "".join(
- f"{sample_to_prompt(in_context_samples[i])}{in_context_samples[i]['class_name']}<|endofchunk|>" for i in range(effective_num_shots)
- )
+ context_text = "".join(f"{sample_to_prompt(in_context_samples[i])}{in_context_samples[i]['class_name']}<|endofchunk|>" for i in range(effective_num_shots))
# Keep the text but remove the image tags for the zero-shot case
if num_shots == 0:
diff --git a/pipeline/benchmarks/public_datasets_suite/get_args.ipynb b/pipeline/benchmarks/public_datasets_suite/get_args.ipynb
new file mode 100644
index 00000000..99c60a31
--- /dev/null
+++ b/pipeline/benchmarks/public_datasets_suite/get_args.ipynb
@@ -0,0 +1,61 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import json"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "file_name = \"./run_eval_coco.sh\"\n",
+ "args = []\n",
+ "with open(file_name, \"r\") as f:\n",
+ " lines = f.readlines()\n",
+ " for line in lines:\n",
+ " line = line.strip()\n",
+ " if line.endswith(\"\\\\\"):\n",
+ " line = line[:-1].strip()\n",
+ " if line.startswith(\"--\"):\n",
+ " args.append(line)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(json.dumps(args, indent=4))"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/__init__.py b/pipeline/benchmarks/public_datasets_suite/models/__init__.py
similarity index 100%
rename from src/otter_ai/models/flamingo/mpt_redpajama/__init__.py
rename to pipeline/benchmarks/public_datasets_suite/models/__init__.py
diff --git a/pipeline/eval/models/blip.py b/pipeline/benchmarks/public_datasets_suite/models/blip.py
old mode 100644
new mode 100755
similarity index 90%
rename from pipeline/eval/models/blip.py
rename to pipeline/benchmarks/public_datasets_suite/models/blip.py
index a4a5ebfc..d105fe47
--- a/pipeline/eval/models/blip.py
+++ b/pipeline/benchmarks/public_datasets_suite/models/blip.py
@@ -4,8 +4,8 @@
import torch
from transformers import Blip2Processor, Blip2ForConditionalGeneration
-from open_flamingo.eval.eval_model import BaseEvalModel
-from open_flamingo.eval.models.utils import unwrap_model
+from pipeline.benchmarks.public_datasets_suite.eval_model import BaseEvalModel
+from pipeline.benchmarks.public_datasets_suite.models.utils import unwrap_model
class EvalModel(BaseEvalModel):
@@ -18,9 +18,7 @@ class EvalModel(BaseEvalModel):
"""
def __init__(self, model_args):
- assert (
- "processor_path" in model_args and "lm_path" in model_args and "device" in model_args
- ), "BLIP-2 requires processor_path, lm_path, and device arguments to be specified"
+ assert "processor_path" in model_args and "lm_path" in model_args and "device" in model_args, "BLIP-2 requires processor_path, lm_path, and device arguments to be specified"
self.device = int(model_args["device"]) if ("device" in model_args and model_args["device"] >= 0) else "cpu"
self.processor = Blip2Processor.from_pretrained(model_args["processor_path"])
diff --git a/pipeline/benchmarks/public_datasets_suite/models/idefics.py b/pipeline/benchmarks/public_datasets_suite/models/idefics.py
new file mode 100644
index 00000000..e49ced4f
--- /dev/null
+++ b/pipeline/benchmarks/public_datasets_suite/models/idefics.py
@@ -0,0 +1,156 @@
+from pipeline.benchmarks.public_datasets_suite.eval_model import BaseEvalModel
+import io
+import torch
+from typing import List
+from transformers import IdeficsForVisionText2Text, AutoProcessor
+from PIL import Image
+from pipeline.train.train_utils import find_and_remove_tokens, get_image_attention_mask
+from pipeline.benchmarks.public_datasets_suite.models.utils import unwrap_model
+import base64
+import numpy as np
+from contextlib import suppress
+import re
+import json
+
+
+class EvalModel(BaseEvalModel):
+ def __init__(self, model_args):
+ if "model_path" in model_args:
+ model_path = model_args["model_path"]
+ else:
+ model_path = "HuggingFaceM4/idefics-9b-instruct"
+ self.device = "cuda:0" if torch.cuda.is_available() else "cpu"
+ self.model = IdeficsForVisionText2Text.from_pretrained(model_path, device_map={"": self.device}, torch_dtype=torch.bfloat16).to(self.device)
+ self.processor = AutoProcessor.from_pretrained(model_path)
+ if "" not in self.processor.tokenizer.special_tokens_map["additional_special_tokens"]:
+ past_special_tokens = self.processor.tokenizer.special_tokens_map["additional_special_tokens"]
+ self.processor.tokenizer.add_special_tokens({"additional_special_tokens": [""] + past_special_tokens})
+
+ self.fake_token_image_token_id = self.processor.tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ self.endofchunk_text = ""
+ self.endofchunk_token_id = self.processor.tokenizer(self.endofchunk_text, add_special_tokens=False)["input_ids"][-1]
+ self.answer_token_id = self.processor.tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ self.eos_token_id = self.processor.tokenizer(self.processor.tokenizer.eos_token, add_special_tokens=False)["input_ids"][-1]
+ self.patch_resize_transform = self.processor.image_processor.preprocess
+
+ # autocast
+ self.autocast = get_autocast(model_args["precision"])
+ self.cast_dtype = get_cast_dtype(model_args["precision"])
+
+ self.image_processor = self.processor.image_processor
+ self.tokenizer = self.processor.tokenizer
+ self.tokenizer.padding_side = "left"
+
+ self.token_around_image = ""
+ self.image_token = ""
+
+ def get_list_image_vision_x(self, images: List[Image.Image]) -> torch.Tensor:
+ return self.image_processor.preprocess(images, return_tensors="pt").to(self.device)
+
+ def get_vision_x(self, batch_images: List[List[Image.Image]]) -> torch.Tensor:
+ vision_x = [self.get_list_image_vision_x(images) for images in batch_images]
+ return torch.stack(vision_x).to(self.device)
+
+ def get_outputs(
+ self,
+ batch_text: List[str],
+ batch_images: List[List[Image.Image]],
+ min_generation_length: int,
+ max_generation_length: int,
+ num_beams: int,
+ length_penalty: float,
+ ) -> List[str]:
+ # print(json.dumps(batch_text, indent=4))
+ # instructions = get_formatted_prompt(batch_text, batch_images)
+ # inputs = self.processor(batch_text, return_tensors="pt").to(self.device)
+ lang_x = self.tokenizer(
+ batch_text,
+ return_tensors="pt",
+ padding=True,
+ )
+ vision_x = self.get_vision_x(batch_images)
+ exit_condition = self.processor.tokenizer("", add_special_tokens=False).input_ids
+ bad_words_ids = self.processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+ image_attention_mask = get_image_attention_mask(lang_x["input_ids"], vision_x.shape[1], self.tokenizer)
+ # print(vision_x.shape, lang_x["input_ids"].shape, lang_x["attention_mask"].shape, image_attention_mask.shape)
+ generated_ids = unwrap_model(self.model).generate(
+ pixel_values=vision_x.to(self.model.device),
+ input_ids=lang_x["input_ids"].to(self.model.device),
+ attention_mask=lang_x["attention_mask"].to(self.model.device),
+ image_attention_mask=image_attention_mask.to(self.model.device),
+ eos_token_id=exit_condition,
+ bad_words_ids=bad_words_ids,
+ num_beams=num_beams,
+ length_penalty=length_penalty,
+ max_new_tokens=max_generation_length,
+ min_new_tokens=min_generation_length,
+ )
+ # generated_ids = unwrap_model(self.model).generate(
+ # **inputs,
+ # eos_token_id=exit_condition,
+ # bad_words_ids=bad_words_ids,
+ # min_new_tokens=min_generation_length,
+ # max_new_tokens=max_generation_length,
+ # # num_beams=num_beams,
+ # # length_penalty=length_penalty,
+ # temperature=0.2,
+ # do_sample=True,
+ # top_p=0.5,
+ # )
+ generated_text = self.processor.batch_decode(generated_ids)
+ results = list(map(lambda text: text.split("Assistant:")[-1].split(self.endofchunk_text)[0].strip(), generated_text))
+ # print(max_generation_length)
+ # print(json.dumps(results, indent=4))
+ return results
+
+ def get_logits(
+ self,
+ lang_x: torch.Tensor,
+ vision_x: torch.Tensor = None,
+ attention_mask: torch.Tensor = None,
+ past_key_values: torch.Tensor = None,
+ clear_conditioned_layers: bool = False,
+ ):
+ with torch.inference_mode():
+ with self.autocast():
+ outputs = self.model(
+ vision_x=vision_x,
+ lang_x=lang_x,
+ attention_mask=attention_mask,
+ clear_conditioned_layers=clear_conditioned_layers,
+ past_key_values=past_key_values,
+ use_cache=(past_key_values is not None),
+ )
+ return outputs
+
+ def get_vqa_prompt(self, question, answer=None) -> str:
+ # return f"Image:{self.token_around_image}{self.image_token}{self.token_around_image}Question: {question} Answer: {answer if answer is not None else ''}\n{self.endofchunk_text}"
+ return f"{self.token_around_image}{self.image_token}{self.token_around_image}User: {question} Please answer in short words.\nAssistant:{f'{answer}{self.endofchunk_text}' if answer is not None else ''}" # 14.36
+ # return f"User: {question}\nAssistant:{f'{answer}{self.endofchunk_text}' if answer is not None else ''}" # 5.94
+
+ def get_caption_prompt(self, caption=None) -> str:
+ return f"{self.token_around_image}{self.image_token}{self.token_around_image}User: What does the image describe?\nAssistant:{f'{caption}{self.endofchunk_text}' if caption is not None else ''}"
+
+
+def get_cast_dtype(precision: str):
+ cast_dtype = None
+ if precision == "bf16":
+ cast_dtype = torch.bfloat16
+ elif precision == "fp16":
+ cast_dtype = torch.float16
+ return cast_dtype
+
+
+def get_autocast(precision):
+ if precision == "amp":
+ return torch.cuda.amp.autocast
+ elif precision == "amp_bfloat16" or precision == "amp_bf16":
+ # amp_bfloat16 is more stable than amp float16 for clip training
+ return lambda: torch.cuda.amp.autocast(dtype=torch.bfloat16)
+ else:
+ return suppress
+
+
+# if __name__ == "__main__":
+# s = "User: what is the brand on the bottle? Please answer in short words. GPT:"
+# print(get_single_formatted_prompt(s, ["An image"]))
diff --git a/pipeline/eval/models/open_flamingo.py b/pipeline/benchmarks/public_datasets_suite/models/open_flamingo.py
old mode 100644
new mode 100755
similarity index 96%
rename from pipeline/eval/models/open_flamingo.py
rename to pipeline/benchmarks/public_datasets_suite/models/open_flamingo.py
index 8535d76c..e621f6cd
--- a/pipeline/eval/models/open_flamingo.py
+++ b/pipeline/benchmarks/public_datasets_suite/models/open_flamingo.py
@@ -3,9 +3,9 @@
from PIL import Image
import torch
-from open_flamingo.eval.eval_model import BaseEvalModel
-from contextlib import suppress
-from open_flamingo.eval.models.utils import unwrap_model
+from pipeline.benchmarks.public_datasets_suite.eval_model import BaseEvalModel
+from pipeline.benchmarks.public_datasets_suite.models.utils import unwrap_model
+from otter_ai import FlamingoForConditionalGeneration
class EvalModel(BaseEvalModel):
diff --git a/pipeline/eval/models/otter.py b/pipeline/benchmarks/public_datasets_suite/models/otter.py
old mode 100644
new mode 100755
similarity index 92%
rename from pipeline/eval/models/otter.py
rename to pipeline/benchmarks/public_datasets_suite/models/otter.py
index 153a0335..c8d3a3d6
--- a/pipeline/eval/models/otter.py
+++ b/pipeline/benchmarks/public_datasets_suite/models/otter.py
@@ -4,9 +4,9 @@
import torch
import transformers
-from pipeline.eval.eval_model import BaseEvalModel
+from pipeline.benchmarks.public_datasets_suite.eval_model import BaseEvalModel
from contextlib import suppress
-from pipeline.eval.models.utils import unwrap_model
+from pipeline.benchmarks.public_datasets_suite.models.utils import unwrap_model
from otter_ai import OtterForConditionalGeneration
import os
@@ -114,7 +114,13 @@ def get_outputs(
outputs = outputs[:, len(input_ids[0]) :]
- return self.tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ result = self.tokenizer.batch_decode(outputs, skip_special_tokens=True)
+
+ result = list(map(lambda text: text.strip(), result))
+
+ # print(result)
+
+ return result
def get_logits(
self,
@@ -149,9 +155,7 @@ def get_vqa_prompt(self, question, answer=None) -> str:
return f"User: {question} Please answer in short words. GPT:{answer if answer is not None else ''}{'<|endofchunk|>' if answer is not None else ''}"
def get_caption_prompt(self, caption=None) -> str:
- return (
- f"User: What does the image describe? GPT:{caption if caption is not None else ''}{'<|endofchunk|>' if caption is not None else ''}"
- )
+ return f"User: What does the image describe? GPT:{caption if caption is not None else ''}{'<|endofchunk|>' if caption is not None else ''}"
def get_cast_dtype(precision: str):
diff --git a/pipeline/eval/models/utils.py b/pipeline/benchmarks/public_datasets_suite/models/utils.py
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/models/utils.py
rename to pipeline/benchmarks/public_datasets_suite/models/utils.py
diff --git a/pipeline/eval/ok_vqa_utils.py b/pipeline/benchmarks/public_datasets_suite/ok_vqa_utils.py
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/ok_vqa_utils.py
rename to pipeline/benchmarks/public_datasets_suite/ok_vqa_utils.py
diff --git a/pipeline/eval/run_eval_coco.sh b/pipeline/benchmarks/public_datasets_suite/run_eval_coco_idefics.sh
old mode 100644
new mode 100755
similarity index 95%
rename from pipeline/eval/run_eval_coco.sh
rename to pipeline/benchmarks/public_datasets_suite/run_eval_coco_idefics.sh
index ab7260e5..d318ed7a
--- a/pipeline/eval/run_eval_coco.sh
+++ b/pipeline/benchmarks/public_datasets_suite/run_eval_coco_idefics.sh
@@ -1,11 +1,11 @@
#!/bin/bash
# Set environment variables
-export PYTHONPATH=../..:$PYTHONPATH
+export PYTHONPATH=../../..:$PYTHONPATH
export CUDA_VISIBLE_DEVICES=3
# Run the Python script with the specified arguments
-python -m pipeline.eval.evaluate \
+python -m pipeline.benchmarks.public_datasets_suite.evaluate \
--vqav2_train_image_dir_path=/data/pufanyi/download/lavis/coco/images/train2014 \
--vqav2_train_annotations_json_path=/data/pufanyi/download/lavis/vqav2/annotations/v2_mscoco_train2014_annotations.json \
--vqav2_train_questions_json_path=/data/pufanyi/download/lavis/vqav2/annotations/v2_OpenEnded_mscoco_train2014_questions.json \
@@ -40,19 +40,21 @@ python -m pipeline.eval.evaluate \
--hateful_memes_image_dir_path=/data/pufanyi/download/lavis/hateful_memes/img \
--hateful_memes_train_annotations_json_path=/data/pufanyi/download/lavis/hateful_memes/train.json \
--hateful_memes_test_annotations_json_path=/data/pufanyi/download/lavis/hateful_memes/dev.json \
- --model=otter \
- --model_path=/data/bli/checkpoints/OTTER-Image-MPT7B \
- --checkpoint_path=/data/bli/checkpoints/OTTER-Image-MPT7B/final_weights.pt \
+ --model=idefics \
+ --model_path=/data/pufanyi/training_data/checkpoints/idefics-9b-instruct \
--device_map=auto \
--precision=fp32 \
- --batch_size=8 \
- --eval_coco \
--eval_vqav2 \
- --eval_flickr30 \
--eval_ok_vqa \
+ --eval_coco \
+ --eval_flickr30 \
+ --eval_vqav2 \
--eval_textvqa \
--eval_vizwiz \
--eval_hateful_memes \
+ --batch_size=8 \
+ --device=cuda \
+ --results_file=./logs/idefics.json \
@@ -106,4 +108,4 @@ python -m pipeline.eval.evaluate \
# --lm_tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \
# --cross_attn_every_n_layers 1 \
# --results_file "results.json" \
- # --precision amp_bf16 \
\ No newline at end of file
+ # --precision amp_bf16 \
diff --git a/pipeline/benchmarks/public_datasets_suite/run_eval_coco_otter.sh b/pipeline/benchmarks/public_datasets_suite/run_eval_coco_otter.sh
new file mode 100755
index 00000000..e6dc502b
--- /dev/null
+++ b/pipeline/benchmarks/public_datasets_suite/run_eval_coco_otter.sh
@@ -0,0 +1,112 @@
+#!/bin/bash
+
+# Set environment variables
+export PYTHONPATH=../../..:$PYTHONPATH
+export CUDA_VISIBLE_DEVICES=3
+
+# Run the Python script with the specified arguments
+python -m pipeline.benchmarks.public_datasets_suite.evaluate \
+ --vqav2_train_image_dir_path=/data/pufanyi/download/lavis/coco/images/train2014 \
+ --vqav2_train_annotations_json_path=/data/pufanyi/download/lavis/vqav2/annotations/v2_mscoco_train2014_annotations.json \
+ --vqav2_train_questions_json_path=/data/pufanyi/download/lavis/vqav2/annotations/v2_OpenEnded_mscoco_train2014_questions.json \
+ --vqav2_test_image_dir_path=/data/pufanyi/download/lavis/coco/images/val2014 \
+ --vqav2_test_annotations_json_path=/data/pufanyi/download/lavis/vqav2/annotations/v2_mscoco_val2014_annotations.json \
+ --vqav2_test_questions_json_path=/data/pufanyi/download/lavis/vqav2/annotations/v2_OpenEnded_mscoco_val2014_questions.json \
+ --coco_train_image_dir_path=/data/pufanyi/download/lavis/coco/images/train2014 \
+ --coco_val_image_dir_path=/data/pufanyi/download/lavis/coco/images/val2014 \
+ --coco_karpathy_json_path=/data/pufanyi/download/lavis/coco/dataset_coco.json \
+ --coco_annotations_json_path=/data/pufanyi/download/lavis/coco/coco2014_annotations/annotations/captions_val2014.json \
+ --flickr_image_dir_path=/data/pufanyi/download/lavis/flickr30k/images/flickr30k-images \
+ --flickr_karpathy_json_path=/data/pufanyi/download/lavis/flickr30k/dataset_flickr30k.json \
+ --flickr_annotations_json_path=/data/pufanyi/download/lavis/flickr30k/dataset_flickr30k_coco_style.json \
+ --ok_vqa_train_image_dir_path=/data/pufanyi/download/lavis/okvqa/images/train2014 \
+ --ok_vqa_train_annotations_json_path=/data/pufanyi/download/lavis/okvqa/annotations/mscoco_train2014_annotations.json \
+ --ok_vqa_train_questions_json_path=/data/pufanyi/download/lavis/okvqa/annotations/OpenEnded_mscoco_train2014_questions.json \
+ --ok_vqa_train_questions_json_path=/data/pufanyi/download/lavis/okvqa/annotations/OpenEnded_mscoco_train2014_questions.json \
+ --ok_vqa_test_image_dir_path=/data/pufanyi/download/lavis/okvqa/images/val2014 \
+ --ok_vqa_test_annotations_json_path=/data/pufanyi/download/lavis/okvqa/annotations/mscoco_val2014_annotations.json \
+ --ok_vqa_test_questions_json_path=/data/pufanyi/download/lavis/okvqa/annotations/OpenEnded_mscoco_val2014_questions.json \
+ --textvqa_image_dir_path=/data/pufanyi/download/lavis/textvqa/images/train_images/ \
+ --textvqa_train_questions_json_path=/data/pufanyi/download/lavis/textvqa/annotations/train_questions_vqa_format.json \
+ --textvqa_train_annotations_json_path=/data/pufanyi/download/lavis/textvqa/annotations/train_annotations_vqa_format.json \
+ --textvqa_test_questions_json_path=/data/pufanyi/download/lavis/textvqa/annotations/val_questions_vqa_format.json \
+ --textvqa_test_annotations_json_path=/data/pufanyi/download/lavis/textvqa/annotations/val_annotations_vqa_format.json \
+ --vizwiz_train_image_dir_path=/data/pufanyi/download/lavis/vizwiz/train \
+ --vizwiz_test_image_dir_path=/data/pufanyi/download/lavis/vizwiz/val \
+ --vizwiz_train_questions_json_path=/data/pufanyi/download/lavis/vizwiz/annotations/train_questions_vqa_format.json \
+ --vizwiz_train_annotations_json_path=/data/pufanyi/download/lavis/vizwiz/annotations/train_annotations_vqa_format.json \
+ --vizwiz_test_questions_json_path=/data/pufanyi/download/lavis/vizwiz/annotations/val_questions_vqa_format.json \
+ --vizwiz_test_annotations_json_path=/data/pufanyi/download/lavis/vizwiz/annotations/val_annotations_vqa_format.json \
+ --hateful_memes_image_dir_path=/data/pufanyi/download/lavis/hateful_memes/img \
+ --hateful_memes_train_annotations_json_path=/data/pufanyi/download/lavis/hateful_memes/train.json \
+ --hateful_memes_test_annotations_json_path=/data/pufanyi/download/lavis/hateful_memes/dev.json \
+ --model=otter \
+ --checkpoint_path=/data \
+ --model_path=/data/bli/checkpoints/OTTER-Image-MPT7B \
+ --checkpoint_path=/data/bli/checkpoints/OTTER-Image-MPT7B/final_weights.pt \
+ --device_map=auto \
+ --precision=fp32 \
+ --batch_size=8 \
+ --eval_coco \
+ --device=cuda
+
+ # --eval_vqav2 \
+ # --eval_flickr30 \
+ # --eval_ok_vqa \
+ # --eval_textvqa \
+ # --eval_vizwiz \
+ # --eval_hateful_memes \
+
+
+
+#!/bin/bash
+
+# export PYTHONPATH=../..:$PYTHONPATH
+# python evaluate.py \
+# --model_path "/data/bli/checkpoints/OTTER-Image-MPT7B" \
+# --checkpoint_path "/data/bli/checkpoints/OTTER-Image-MPT7B/final_weights.pt" \
+# --device_map "auto" \
+# --precision fp32 \
+# --batch_size 8 \
+# --eval_vqav2 \
+# --vqav2_train_image_dir_path "/data/666/download/lavis/coco/images/train2014" \
+# --vqav2_train_annotations_json_path "/data/666/download/lavis/vqav2/annotations/v2_mscoco_train2014_annotations.json" \
+# --vqav2_train_questions_json_path "/data/666/download/lavis/vqav2/annotations/v2_OpenEnded_mscoco_train2014_questions.json" \
+# --vqav2_test_image_dir_path "/data/666/download/lavis/coco/images/val2014" \
+# --vqav2_test_annotations_json_path "/data/666/download/lavis/vqav2/annotations/v2_mscoco_val2014_annotations.json" \
+# --vqav2_test_questions_json_path "/data/666/download/lavis/vqav2/annotations/v2_OpenEnded_mscoco_val2014_questions.json" \
+ # --flickr_image_dir_path "/path/to/flickr30k/flickr30k-images" \
+ # --flickr_karpathy_json_path "/path/to/flickr30k/dataset_flickr30k.json" \
+ # --flickr_annotations_json_path "/path/to/flickr30k/dataset_flickr30k_coco_style.json" \
+ # --ok_vqa_train_image_dir_path "/path/to/okvqa/train2014" \
+ # --ok_vqa_train_annotations_json_path "/path/to/okvqa/mscoco_train2014_annotations.json" \
+ # --ok_vqa_train_questions_json_path "/path/to/okvqa/OpenEnded_mscoco_train2014_questions.json" \
+ # --ok_vqa_test_image_dir_path "/path/to/okvqa/val2014" \
+ # --ok_vqa_test_annotations_json_path "/path/to/okvqa/mscoco_val2014_annotations.json" \
+ # --ok_vqa_test_questions_json_path "/path/to/okvqa/OpenEnded_mscoco_val2014_questions.json" \
+ # --textvqa_image_dir_path "/path/to/textvqa/train_images/" \
+ # --textvqa_train_questions_json_path "/path/to/textvqa/train_questions_vqa_format.json" \
+ # --textvqa_train_annotations_json_path "/path/to/textvqa/train_annotations_vqa_format.json" \
+ # --textvqa_test_questions_json_path "/path/to/textvqa/val_questions_vqa_format.json" \
+ # --textvqa_test_annotations_json_path "/path/to/textvqa/val_annotations_vqa_format.json" \
+ # --vizwiz_train_image_dir_path "/path/to/v7w/train" \
+ # --vizwiz_test_image_dir_path "/path/to/v7w/val" \
+ # --vizwiz_train_questions_json_path "/path/to/v7w/train_questions_vqa_format.json" \
+ # --vizwiz_train_annotations_json_path "/path/to/v7w/train_annotations_vqa_format.json" \
+ # --vizwiz_test_questions_json_path "/path/to/v7w/val_questions_vqa_format.json" \
+ # --vizwiz_test_annotations_json_path "/path/to/v7w/val_annotations_vqa_format.json" \
+ # --hateful_memes_image_dir_path "/path/to/hateful_memes/img" \
+ # --hateful_memes_train_annotations_json_path "/path/to/hateful_memes/train.json" \
+ # --hateful_memes_test_annotations_json_path "/path/to/hateful_memes/dev.json" \
+
+
+
+
+
+ # --vision_encoder_path ViT-L-14 \
+ # --vision_encoder_pretrained openai\
+ # --lm_path anas-awadalla/mpt-1b-redpajama-200b \
+ # --lm_tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \
+ # --cross_attn_every_n_layers 1 \
+ # --results_file "results.json" \
+ # --precision amp_bf16 \
diff --git a/pipeline/eval/run_eval_otter.sh b/pipeline/benchmarks/public_datasets_suite/run_eval_otter.sh
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/run_eval_otter.sh
rename to pipeline/benchmarks/public_datasets_suite/run_eval_otter.sh
diff --git a/pipeline/eval/run_eval_otter_slurm.sh b/pipeline/benchmarks/public_datasets_suite/run_eval_otter_slurm.sh
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/run_eval_otter_slurm.sh
rename to pipeline/benchmarks/public_datasets_suite/run_eval_otter_slurm.sh
diff --git a/pipeline/eval/vqa_metric.py b/pipeline/benchmarks/public_datasets_suite/vqa_metric.py
old mode 100644
new mode 100755
similarity index 100%
rename from pipeline/eval/vqa_metric.py
rename to pipeline/benchmarks/public_datasets_suite/vqa_metric.py
diff --git a/pipeline/constants.py b/pipeline/constants.py
deleted file mode 100644
index ca4a13dc..00000000
--- a/pipeline/constants.py
+++ /dev/null
@@ -1,4 +0,0 @@
-CONTROLLER_HEART_BEAT_EXPIRATION = 2 * 60
-WORKER_HEART_BEAT_INTERVAL = 30
-
-LOGDIR = "./logs"
diff --git a/pipeline/demo/__init__.py b/pipeline/demo/__init__.py
deleted file mode 100644
index 8b137891..00000000
--- a/pipeline/demo/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/pipeline/demos/__init__.py b/pipeline/demos/__init__.py
new file mode 100755
index 00000000..e69de29b
diff --git a/pipeline/demos/demo_models.py b/pipeline/demos/demo_models.py
new file mode 100644
index 00000000..5aee6761
--- /dev/null
+++ b/pipeline/demos/demo_models.py
@@ -0,0 +1,173 @@
+import sys
+import requests
+import torch
+from PIL import Image
+from transformers import AutoProcessor, AutoTokenizer, FuyuImageProcessor, CLIPImageProcessor, IdeficsForVisionText2Text, FuyuImageProcessor
+
+# from src.otter_ai.models.fuyu.modeling_fuyu import FuyuForCausalLM
+from transformers import FuyuForCausalLM
+from src.otter_ai.models.fuyu.processing_fuyu import FuyuProcessor
+from otter_ai import OtterForConditionalGeneration
+import io
+import base64
+
+sys.path.append("../..")
+from pipeline.train.train_utils import get_image_attention_mask
+
+requests.packages.urllib3.disable_warnings()
+
+
+def get_pil_image(raw_image_data) -> Image.Image:
+ if isinstance(raw_image_data, Image.Image):
+ return raw_image_data
+
+ elif isinstance(raw_image_data, dict) and "bytes" in raw_image_data:
+ return Image.open(io.BytesIO(raw_image_data["bytes"]))
+
+ elif isinstance(raw_image_data, str): # Assuming this is a base64 encoded string
+ image_bytes = base64.b64decode(raw_image_data)
+ return Image.open(io.BytesIO(image_bytes))
+
+ else:
+ raise ValueError("Unsupported image data format")
+
+
+class TestOtter:
+ def __init__(self, checkpoint) -> None:
+ kwargs = {"device_map": "auto", "torch_dtype": torch.bfloat16}
+ self.model = OtterForConditionalGeneration.from_pretrained(checkpoint, **kwargs)
+ self.image_processor = CLIPImageProcessor()
+ self.tokenizer = self.model.text_tokenizer
+ self.tokenizer.padding_side = "left"
+ self.model.eval()
+
+ def generate(self, image, prompt, no_image_flag=False):
+ input_data = image
+ if isinstance(input_data, Image.Image):
+ if no_image_flag:
+ vision_x = torch.zeros(1, 1, 1, 3, 224, 224, dtype=next(self.model.parameters()).dtype)
+ else:
+ vision_x = self.image_processor.preprocess([input_data], return_tensors="pt")["pixel_values"].unsqueeze(1).unsqueeze(0)
+ else:
+ raise ValueError("Invalid input data. Expected PIL Image.")
+
+ lang_x = self.tokenizer(
+ [
+ self.get_formatted_prompt(prompt, no_image_flag=no_image_flag),
+ ],
+ return_tensors="pt",
+ )
+
+ model_dtype = next(self.model.parameters()).dtype
+ vision_x = vision_x.to(dtype=model_dtype)
+
+ generated_text = self.model.generate(
+ vision_x=vision_x.to(self.model.device),
+ lang_x=lang_x["input_ids"].to(self.model.device),
+ attention_mask=lang_x["attention_mask"].to(self.model.device),
+ max_new_tokens=512,
+ temperature=0.2,
+ do_sample=True,
+ pad_token_id=self.tokenizer.pad_token_id,
+ )
+ output = self.tokenizer.decode(generated_text[0]).split("")[-1].strip().replace("<|endofchunk|>", "")
+ return output
+
+ def get_formatted_prompt(self, question: str, no_image_flag: str) -> str:
+ if no_image_flag:
+ return f"User:{question} GPT:"
+ else:
+ return f"User:{question} GPT:"
+
+
+class TestIdefics:
+ def __init__(self, checkpoint: str = "HuggingFaceM4/idefics-9b-instruct"):
+ self.model = IdeficsForVisionText2Text.from_pretrained(checkpoint, device_map="auto", torch_dtype=torch.bfloat16)
+ self.processor = AutoProcessor.from_pretrained(checkpoint)
+ self.image_processor = self.processor.image_processor
+ self.tokenizer = self.processor.tokenizer
+ self.tokenizer.padding_side = "left"
+ self.model.eval()
+
+ def generate(self, image, prompt, no_image_flag=False):
+ input_data = image
+ if isinstance(input_data, Image.Image):
+ if no_image_flag:
+ vision_x = torch.zeros(1, 1, 3, 224, 224, dtype=next(self.model.parameters()).dtype)
+ else:
+ vision_x = self.image_processor.preprocess([input_data], return_tensors="pt").unsqueeze(0)
+ else:
+ raise ValueError("Invalid input data. Expected PIL Image.")
+
+ lang_x = self.tokenizer(
+ [
+ self.get_formatted_prompt(prompt, no_image_flag=no_image_flag),
+ ],
+ return_tensors="pt",
+ )
+
+ model_dtype = next(self.model.parameters()).dtype
+ vision_x = vision_x.to(dtype=model_dtype)
+ lang_x = self.tokenizer(
+ [
+ self.get_formatted_prompt(prompt, no_image_flag=no_image_flag),
+ ],
+ return_tensors="pt",
+ )
+ image_attention_mask = get_image_attention_mask(lang_x["input_ids"], 1, self.tokenizer, include_image=not no_image_flag)
+ exit_condition = self.processor.tokenizer("", add_special_tokens=False).input_ids
+ bad_words_ids = self.processor.tokenizer(["", "", "User:"], add_special_tokens=False).input_ids
+ generated_ids = self.model.generate(
+ pixel_values=vision_x.to(self.model.device),
+ input_ids=lang_x["input_ids"].to(self.model.device),
+ attention_mask=lang_x["attention_mask"].to(self.model.device),
+ image_attention_mask=image_attention_mask.to(self.model.device),
+ eos_token_id=exit_condition,
+ bad_words_ids=bad_words_ids,
+ max_new_tokens=512,
+ temperature=0.2,
+ do_sample=True,
+ top_p=0.5,
+ )
+ output = self.processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+ output = output.split("Assistant:")[1].strip().replace("", "")
+ return output
+
+ def get_formatted_prompt(self, question: str, no_image_flag: str) -> str:
+ if no_image_flag:
+ return f"User:{question}\nAssistant:"
+ else:
+ return f"User:{question}\nAssistant:"
+
+
+class TestOtterHD:
+ def __init__(self, checkpoint: str = "adept/fuyu-8b", cuda_id: int = 0, resolution: int = 336, max_new_tokens=256):
+ self.resolution = resolution
+ self.device = f"cuda:{cuda_id}" if torch.cuda.is_available() else "cpu"
+ self.model = FuyuForCausalLM.from_pretrained(checkpoint).to(self.device)
+ self.model.eval()
+ self.tokenizer = AutoTokenizer.from_pretrained("adept/fuyu-8b")
+ self.image_processor = FuyuImageProcessor()
+ self.processor = FuyuProcessor(image_processor=self.image_processor, tokenizer=self.tokenizer)
+ self.max_new_tokens = max_new_tokens
+ self.bad_words_list = ["User:", "Assistant:"]
+ self.bad_words_ids = self.tokenizer(self.bad_words_list, add_special_tokens=False).input_ids
+
+ def generate(self, image, prompt, no_image_flag=False):
+ raw_image_data = get_pil_image(image)
+ # make sure the image is in RGB format and resize to match the width
+ # max_height, max_width = self.resolution, self.resolution
+ raw_image_data = raw_image_data.convert("RGB")
+ if max(raw_image_data.size) > 1080:
+ raw_image_data.thumbnail((1080, 1080), Image.ANTIALIAS)
+
+ print(f"Eval with res: {raw_image_data.size}")
+ # raw_image_data.thumbnail((max_width, max_height), Image.ANTIALIAS)
+ formated_prompt = f"User: {prompt} Assistant:"
+ model_inputs = self.processor(text=formated_prompt, images=[raw_image_data] if no_image_flag is False else None, device=self.device)
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(self.device, non_blocking=True) if isinstance(v, torch.Tensor) else [vv.to(self.device, non_blocking=True) for vv in v]
+
+ generation_output = self.model.generate(**model_inputs, max_new_tokens=self.max_new_tokens)
+ generation_text = self.processor.batch_decode(generation_output, skip_special_tokens=True)
+ return generation_text[0].split("\x04")[1].strip(" ").strip("\n")
diff --git a/pipeline/demos/demo_utils.py b/pipeline/demos/demo_utils.py
new file mode 100644
index 00000000..ccc534f9
--- /dev/null
+++ b/pipeline/demos/demo_utils.py
@@ -0,0 +1,36 @@
+import mimetypes
+import sys
+from typing import Union
+
+import requests
+from PIL import Image
+
+requests.packages.urllib3.disable_warnings()
+
+
+# --- Utility Functions ---
+def print_colored(text, color_code):
+ end_code = "\033[0m" # Reset to default color
+ print(f"{color_code}{text}{end_code}")
+
+
+def get_content_type(file_path):
+ content_type, _ = mimetypes.guess_type(file_path)
+ return content_type
+
+
+def get_image(url: str) -> Union[Image.Image, list]:
+ if not url.strip(): # Blank input, return a blank Image
+ return Image.new("RGB", (224, 224)) # Assuming 224x224 is the default size for the model. Adjust if needed.
+ elif "://" not in url: # Local file
+ content_type = get_content_type(url)
+ else: # Remote URL
+ content_type = requests.head(url, stream=True, verify=False).headers.get("Content-Type")
+
+ if "image" in content_type:
+ if "://" not in url: # Local file
+ return Image.open(url)
+ else: # Remote URL
+ return Image.open(requests.get(url, stream=True, verify=False).raw)
+ else:
+ raise ValueError("Invalid content type. Expected image.")
diff --git a/pipeline/demos/inference.py b/pipeline/demos/inference.py
new file mode 100644
index 00000000..67e8b38b
--- /dev/null
+++ b/pipeline/demos/inference.py
@@ -0,0 +1,96 @@
+import argparse
+import datetime
+import json
+import sys
+
+import requests
+import yaml
+
+from .demo_models import TestIdefics, TestOtter, TestOtterHD
+from .demo_utils import get_image, print_colored
+
+requests.packages.urllib3.disable_warnings()
+
+import pytz
+
+# Initialize the time zone
+utc_plus_8 = pytz.timezone("Asia/Singapore") # You can also use 'Asia/Shanghai', 'Asia/Taipei', etc.
+# Get the current time in UTC
+utc_now = pytz.utc.localize(datetime.datetime.utcnow())
+# Convert to UTC+8
+utc_plus_8_time = utc_now.astimezone(utc_plus_8)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model_name", type=str, default="otter", required=True, help="The model name.")
+ parser.add_argument("--checkpoint", type=str, help="The path to the checkpoint.")
+ parser.add_argument("--output_dir", type=str, help="The dir path to the output file.", default="./logs")
+ parser.add_argument("--yaml_file", type=str, help="The dir path to the eval yaml, contains question, answer pairs.", default="")
+ args = parser.parse_args()
+ return args
+
+
+def eval_yaml(args, yaml_file, model):
+ with open(yaml_file, "r") as file:
+ test_data_list = yaml.safe_load(file)
+
+ cur_date = utc_plus_8_time.strftime("%Y-%m-%d_%H-%M-%S")
+ log_json_path = f"{args.output_dir}/inference_log_{cur_date}.json"
+ log_json = {
+ "model_name": args.model_name,
+ "checkpoint": args.checkpoint,
+ "results": {},
+ }
+ for test_id, test_data in enumerate(test_data_list):
+ image_path = test_data.get("image_path", "")
+ question = test_data.get("question", "")
+
+ image = get_image(image_path)
+ no_image_flag = not bool(image_path)
+
+ response = model.generate(prompt=question, image=image, no_image_flag=no_image_flag)
+
+ # Print results to console
+ print(f"image_path: {image_path}")
+ print_colored(f"question: {question}", color_code="\033[92m")
+ print_colored(f"answer: {response}", color_code="\033[94m")
+ print("-" * 150)
+
+ log_json["results"].update(
+ {
+ str(test_id).zfill(3): {
+ "image_path": image_path,
+ "question": question,
+ "answer": response,
+ }
+ }
+ )
+
+ with open(log_json_path, "w") as file:
+ json.dump(log_json, file, indent=4, sort_keys=False)
+
+
+def main():
+ args = parse_args()
+ if args.model_name == "otter":
+ model = TestOtter(checkpoint=args.checkpoint)
+ elif args.model_name == "otterhd":
+ model = TestOtterHD(checkpoint=args.checkpoint)
+ elif args.model_name == "idefics":
+ model = TestIdefics(checkpoint=args.checkpoint)
+ else:
+ raise NotImplementedError(f"model_name: {args.model_name} is not implemented.")
+
+ if args.yaml_file:
+ eval_yaml(args, args.yaml_file, model)
+ else:
+ while True:
+ yaml_file = input("Enter the path to the yaml file: (or 'q' to quit): ")
+ if yaml_file == "q":
+ break
+ eval_yaml(args, yaml_file, model)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/pipeline/demo/otter_image.ipynb b/pipeline/demos/interactive/otter_image.ipynb
similarity index 88%
rename from pipeline/demo/otter_image.ipynb
rename to pipeline/demos/interactive/otter_image.ipynb
index 896e824f..fda03bdb 100755
--- a/pipeline/demo/otter_image.ipynb
+++ b/pipeline/demos/interactive/otter_image.ipynb
@@ -43,9 +43,7 @@
"vision_x = image_processor.preprocess([demo_image_one, demo_image_two, query_image], return_tensors=\"pt\")[\"pixel_values\"].unsqueeze(1).unsqueeze(0)\n",
"model.text_tokenizer.padding_side = \"left\"\n",
"lang_x = model.text_tokenizer(\n",
- " [\n",
- " \"User: a photo of GPT: two cats sleeping.<|endofchunk|>User: a photo of GPT: a bathroom sink.<|endofchunk|>User: a photo of GPT:\"\n",
- " ],\n",
+ " [\"User: a photo of GPT: two cats sleeping.<|endofchunk|>User: a photo of GPT: a bathroom sink.<|endofchunk|>User: a photo of GPT:\"],\n",
" return_tensors=\"pt\",\n",
")\n",
"\n",
@@ -68,9 +66,7 @@
" bad_words_ids=bad_words_id,\n",
")\n",
"\n",
- "parsed_output = (\n",
- " model.text_tokenizer.decode(generated_text[0]).split(\"\")[-1].lstrip().rstrip().split(\"<|endofchunk|>\")[0].lstrip().rstrip().lstrip('\"').rstrip('\"')\n",
- ")\n",
+ "parsed_output = model.text_tokenizer.decode(generated_text[0]).split(\"\")[-1].lstrip().rstrip().split(\"<|endofchunk|>\")[0].lstrip().rstrip().lstrip('\"').rstrip('\"')\n",
"\n",
"print(\"Generated text: \", parsed_output)"
]
diff --git a/pipeline/demo/otter_image.py b/pipeline/demos/interactive/otter_image.py
similarity index 93%
rename from pipeline/demo/otter_image.py
rename to pipeline/demos/interactive/otter_image.py
index 0ffb390a..4b64ac2c 100755
--- a/pipeline/demo/otter_image.py
+++ b/pipeline/demos/interactive/otter_image.py
@@ -86,17 +86,7 @@ def get_response(image, prompt: str, model=None, image_processor=None) -> str:
num_beams=3,
no_repeat_ngram_size=3,
)
- parsed_output = (
- model.text_tokenizer.decode(generated_text[0])
- .split("")[-1]
- .lstrip()
- .rstrip()
- .split("<|endofchunk|>")[0]
- .lstrip()
- .rstrip()
- .lstrip('"')
- .rstrip('"')
- )
+ parsed_output = model.text_tokenizer.decode(generated_text[0]).split("")[-1].lstrip().rstrip().split("<|endofchunk|>")[0].lstrip().rstrip().lstrip('"').rstrip('"')
return parsed_output
diff --git a/pipeline/demo/otter_image_incontext.py b/pipeline/demos/interactive/otter_image_incontext.py
old mode 100644
new mode 100755
similarity index 90%
rename from pipeline/demo/otter_image_incontext.py
rename to pipeline/demos/interactive/otter_image_incontext.py
index 626b6dd9..e4951b26
--- a/pipeline/demo/otter_image_incontext.py
+++ b/pipeline/demos/interactive/otter_image_incontext.py
@@ -55,7 +55,13 @@ def get_formatted_prompt(prompt: str, in_context_prompts: list = []) -> str:
return f"{in_context_string}User: {prompt} GPT:"
-def get_response(image_list, prompt: str, model=None, image_processor=None, in_context_prompts: list = []) -> str:
+def get_response(
+ image_list,
+ prompt: str,
+ model=None,
+ image_processor=None,
+ in_context_prompts: list = [],
+) -> str:
input_data = image_list
if isinstance(input_data, Image.Image):
@@ -87,17 +93,7 @@ def get_response(image_list, prompt: str, model=None, image_processor=None, in_c
num_beams=3,
no_repeat_ngram_size=3,
)
- parsed_output = (
- model.text_tokenizer.decode(generated_text[0])
- .split("")[-1]
- .lstrip()
- .rstrip()
- .split("<|endofchunk|>")[0]
- .lstrip()
- .rstrip()
- .lstrip('"')
- .rstrip('"')
- )
+ parsed_output = model.text_tokenizer.decode(generated_text[0]).split("")[-1].lstrip().rstrip().split("<|endofchunk|>")[0].lstrip().rstrip().lstrip('"').rstrip('"')
return parsed_output
@@ -141,7 +137,13 @@ def get_response(image_list, prompt: str, model=None, image_processor=None, in_c
prompts_input = input("Enter the prompts (or type 'quit' to exit): ")
print(f"\nPrompt: {prompts_input}")
- response = get_response(encoded_frames_list, prompts_input, model, image_processor, in_context_prompts)
+ response = get_response(
+ encoded_frames_list,
+ prompts_input,
+ model,
+ image_processor,
+ in_context_prompts,
+ )
print(f"Response: {response}")
if prompts_input.lower() == "quit":
diff --git a/pipeline/demo/otter_video.ipynb b/pipeline/demos/interactive/otter_video.ipynb
similarity index 95%
rename from pipeline/demo/otter_video.ipynb
rename to pipeline/demos/interactive/otter_video.ipynb
index 89c4176b..10cc28f1 100755
--- a/pipeline/demo/otter_video.ipynb
+++ b/pipeline/demos/interactive/otter_video.ipynb
@@ -135,17 +135,7 @@
" no_repeat_ngram_size=3,\n",
" bad_words_ids=bad_words_id,\n",
" )\n",
- " parsed_output = (\n",
- " model.text_tokenizer.decode(generated_text[0])\n",
- " .split(\"\")[-1]\n",
- " .lstrip()\n",
- " .rstrip()\n",
- " .split(\"<|endofchunk|>\")[0]\n",
- " .lstrip()\n",
- " .rstrip()\n",
- " .lstrip('\"')\n",
- " .rstrip('\"')\n",
- " )\n",
+ " parsed_output = model.text_tokenizer.decode(generated_text[0]).split(\"\")[-1].lstrip().rstrip().split(\"<|endofchunk|>\")[0].lstrip().rstrip().lstrip('\"').rstrip('\"')\n",
" return parsed_output"
]
},
diff --git a/pipeline/demo/otter_video.py b/pipeline/demos/interactive/otter_video.py
old mode 100644
new mode 100755
similarity index 94%
rename from pipeline/demo/otter_video.py
rename to pipeline/demos/interactive/otter_video.py
index f33b6650..a2602e17
--- a/pipeline/demo/otter_video.py
+++ b/pipeline/demos/interactive/otter_video.py
@@ -110,17 +110,7 @@ def get_response(input_data, prompt: str, model=None, image_processor=None, tens
no_repeat_ngram_size=3,
bad_words_ids=bad_words_id,
)
- parsed_output = (
- model.text_tokenizer.decode(generated_text[0])
- .split("")[-1]
- .lstrip()
- .rstrip()
- .split("<|endofchunk|>")[0]
- .lstrip()
- .rstrip()
- .lstrip('"')
- .rstrip('"')
- )
+ parsed_output = model.text_tokenizer.decode(generated_text[0]).split("")[-1].lstrip().rstrip().split("<|endofchunk|>")[0].lstrip().rstrip().lstrip('"').rstrip('"')
return parsed_output
diff --git a/pipeline/train/data.py b/pipeline/mimicit_utils/data.py
similarity index 78%
rename from pipeline/train/data.py
rename to pipeline/mimicit_utils/data.py
index 7ac23bc2..7df7fe99 100755
--- a/pipeline/train/data.py
+++ b/pipeline/mimicit_utils/data.py
@@ -6,27 +6,33 @@
import math
import os
import random
+import statistics
import sys
-import yaml
from dataclasses import dataclass
from multiprocessing import Value
-import numpy as np
import braceexpand
+import numpy as np
import torch
import torch.utils
import torchvision
import webdataset as wds
-from PIL import Image, ImageSequence, ImageFile
-from torch.utils.data import DataLoader, IterableDataset, RandomSampler, get_worker_info
+import yaml
+from PIL import Image, ImageFile, ImageSequence
+from torch.utils.data import ConcatDataset, DataLoader, IterableDataset, RandomSampler, get_worker_info
from torch.utils.data.distributed import DistributedSampler
from webdataset.filters import _shuffle
from webdataset.tariterators import base_plus_ext, tar_file_expander, url_opener, valid_sample
-from pipeline.mimicit_utils.mimicit_dataset import MimicitDataset
-from .train_utils import DistributedProxySampler
+sys.path.append("../..")
+import json
+import os
-import statistics
+import yaml
+from PIL import Image, ImageFile
+
+from pipeline.mimicit_utils.mimicit_dataset import MimicitDataset
+from pipeline.train.train_utils import DistributedProxySampler
Image.MAX_IMAGE_PIXELS = 1000000000
MAX_NUM_TOKENS = 256
@@ -371,10 +377,7 @@ def get_mmc4_dataset(args, image_processor, tokenizer, epoch=0, floor=False):
if not num_samples:
num_samples = args.train_num_samples_mmc4
if not num_samples:
- raise RuntimeError(
- "Currently, number of dataset samples must be specified for training dataset. "
- "Please specify via `--train-num-samples` if no dataset length info present."
- )
+ raise RuntimeError("Currently, number of dataset samples must be specified for training dataset. " "Please specify via `--train-num-samples` if no dataset length info present.")
# create a shared epoch store to sync epoch to dataloader worker proc
shared_epoch = SharedEpoch(epoch=epoch)
@@ -463,10 +466,7 @@ def get_laion_dataset(args, image_processor, tokenizer, epoch=0, floor=False):
if not num_samples:
num_samples = args.train_num_samples_laion
if not num_samples:
- raise RuntimeError(
- "Currently, number of dataset samples must be specified for training dataset. "
- "Please specify via `--train-num-samples` if no dataset length info present."
- )
+ raise RuntimeError("Currently, number of dataset samples must be specified for training dataset. " "Please specify via `--train-num-samples` if no dataset length info present.")
# create a shared epoch store to sync epoch to dataloader worker proc
shared_epoch = SharedEpoch(epoch=epoch)
@@ -554,10 +554,7 @@ def get_cc3m_dataset(args, image_processor, tokenizer, epoch=0, floor=False):
if not num_samples:
num_samples = args.train_num_samples_cc3m
if not num_samples:
- raise RuntimeError(
- "Currently, number of dataset samples must be specified for training dataset. "
- "Please specify via `--train-num-samples` if no dataset length info present."
- )
+ raise RuntimeError("Currently, number of dataset samples must be specified for training dataset. " "Please specify via `--train-num-samples` if no dataset length info present.")
# create a shared epoch store to sync epoch to dataloader worker proc
shared_epoch = SharedEpoch(epoch=epoch)
@@ -635,137 +632,84 @@ def get_cc3m_dataset(args, image_processor, tokenizer, epoch=0, floor=False):
return DataInfo(dataloader=dataloader, shared_epoch=shared_epoch)
-import json
+def preload_dataset(args):
+ dataset_info = {
+ "IMAGE_TEXT": {},
+ "TEXT_ONLY": {},
+ "VIDEO_TEXT": {},
+ "IMAGE_TEXT_IN_CONTEXT": {},
+ }
-from PIL import Image, ImageFile
+ if args.training_data_yaml and os.path.exists(args.training_data_yaml):
+ try:
+ with open(args.training_data_yaml, "r") as f:
+ yaml_data = yaml.safe_load(f)
+ except Exception as e:
+ raise ValueError(f"Error loading or parsing the YAML file: {e}")
-from pipeline.mimicit_utils.mimicit_dataset import MimicitDataset
+ for category, datasets in yaml_data.items():
+ if category not in dataset_info:
+ raise ValueError(f"Unexpected category '{category}' in the YAML data. Expected categories are {list(dataset_info.keys())}.")
+ for dataset_name, data in datasets.items():
+ # Check if paths exist
+ for path_key, path_value in data.items():
+ if path_key.endswith("_path") and not os.path.exists(path_value):
+ raise ValueError(f"Dataset path {path_value} specified under {category} -> {dataset_name} does not exist.")
-def get_mimicit_dataset(args, image_processor, tokenizer, epoch=0, floor=False):
- ImageFile.LOAD_TRUNCATED_IMAGES = True
- args.task = "pretrain"
- args.tokenizer = tokenizer
- unified_datasets = []
+ # Populate dataset_info based on the category
+ dataset_info[category][dataset_name] = data
+ elif not os.path.exists(args.training_data_yaml):
+ raise ValueError(f"YAML file path '{args.training_data_yaml}' does not exist.")
- def append_datasets(args, dataset_config_dict):
- for name, data in dataset_config_dict.items():
- if getattr(args, name) == "":
- setattr(args, name, ",".join(data))
- else:
- setattr(args, name, ",".join(data + [getattr(args, name)]))
+ return dataset_info
- if args.training_data_yaml != "":
- with open(args.training_data_yaml, "r") as f:
- dataset_config_dict = yaml.safe_load(f)
- append_datasets(args, dataset_config_dict)
- # processing for image-text in-context datasets
- if args.mimicit_ic_path != "":
- all_mimicit_ic_path = (
- args.mimicit_ic_path.split(",") + args.past_mimicit_ic_path.split(",") if args.past_mimicit_ic_path != "" else args.mimicit_ic_path.split(",")
- )
- all_images_ic_path = (
- args.images_ic_path.split(",") + args.past_images_ic_path.split(",") if args.past_images_ic_path != "" else args.images_ic_path.split(",")
- )
- all_train_config_ic_path = (
- args.train_config_ic_path.split(",") + args.past_train_config_ic_path.split(",")
- if args.past_train_config_ic_path != ""
- else args.train_config_ic_path.split(",")
- )
- if args.past_mimicit_ic_path != "":
- ic_status = ["new"] * len(args.mimicit_ic_path.split(",")) + ["past"] * len(args.past_mimicit_ic_path.split(","))
- else:
- ic_status = ["new"] * len(args.mimicit_ic_path.split(","))
- unified_dataset = MimicitDataset(args, all_mimicit_ic_path, all_images_ic_path, all_train_config_ic_path, status_list=ic_status)
- unified_datasets.append(unified_dataset)
-
- # processing for image-text datasets
- if args.mimicit_path != "":
- all_mimicit_path = args.mimicit_path.split(",") + args.past_mimicit_path.split(",") if args.past_mimicit_path != "" else args.mimicit_path.split(",")
- all_images_path = args.images_path.split(",") + args.past_images_path.split(",") if args.past_images_path != "" else args.images_path.split(",")
- all_train_config_path = (
- args.train_config_path.split(",") + args.past_train_config_path.split(",")
- if args.past_train_config_path != ""
- else args.train_config_path.split(",")
- )
- if args.past_mimicit_path != "":
- status = ["new"] * len(args.mimicit_path.split(",")) + ["past"] * len(args.past_mimicit_path.split(","))
- else:
- status = ["new"] * len(args.mimicit_path.split(","))
- unified_dataset = MimicitDataset(args, all_mimicit_path, all_images_path, all_train_config_path, status_list=status)
- unified_datasets.append(unified_dataset)
-
- # processing for text datasets
- if args.mimicit_text_path != "":
- all_mimicit_text_path = (
- args.mimicit_text_path.split(",") + args.past_mimicit_text_path.split(",")
- if args.past_mimicit_text_path != ""
- else args.mimicit_text_path.split(",")
- )
- all_train_config_text_path = (
- args.train_config_text_path.split(",") + args.past_train_config_text_path.split(",")
- if args.past_train_config_text_path != ""
- else args.train_config_text_path.split(",")
- )
+from src.otter_ai.models.fuyu.processing_fuyu import FuyuProcessor
+from functools import partial
- if args.past_mimicit_text_path != "":
- text_status = ["new"] * len(args.mimicit_text_path.split(",")) + ["past"] * len(args.past_mimicit_text_path.split(","))
- else:
- text_status = ["new"] * len(args.mimicit_text_path.split(","))
- unified_dataset = MimicitDataset(args, all_mimicit_text_path, all_train_config_text_path, status_list=text_status)
- unified_datasets.append(unified_dataset)
-
- # processing for video-text datasets
- if args.mimicit_vt_path != "":
- all_mimicit_vt_path = (
- args.mimicit_vt_path.split(",") + args.past_mimicit_vt_path.split(",") if args.past_mimicit_vt_path != "" else args.mimicit_vt_path.split(",")
- )
- all_images_vt_path = (
- args.images_vt_path.split(",") + args.past_images_vt_path.split(",") if args.past_images_vt_path != "" else args.images_vt_path.split(",")
- )
- if args.past_mimicit_vt_path != "":
- vt_status = ["new"] * len(args.mimicit_vt_path.split(",")) + ["past"] * len(args.past_mimicit_vt_path.split(","))
- else:
- vt_status = ["new"] * len(args.mimicit_vt_path.split(","))
- unified_dataset = MimicitDataset(args, all_mimicit_vt_path, all_images_vt_path, status_list=vt_status)
- unified_datasets.append(unified_dataset)
- # args.train_num_samples = sum(len(dataset) for dataset in unified_datasets) / len(unified_datasets)
- if args.train_num_samples == -1:
- args.train_num_samples = statistics.median((len(dataset) for dataset in unified_datasets))
+def get_mimicit_dataset(args, image_processor, tokenizer, epoch=0, floor=False):
+ ImageFile.LOAD_TRUNCATED_IMAGES = True
+ args.task = "pretrain"
+ args.tokenizer = tokenizer
+ unified_datasets = []
+ dataset_info = preload_dataset(args)
- assert args.train_num_samples <= max([len(dataset) for dataset in unified_datasets]), "your train_num_samples is larger than dataset"
+ # Converting multiple types of mimic-it datasets into a unified format dataset
+ for key, item in dataset_info.items():
+ if item != {}: # if the category is not empty
+ unified_dataset = MimicitDataset(args, dataset_info=dataset_info[key], task_group=key)
+ unified_datasets.append(unified_dataset)
- round_fn = math.floor if floor else math.ceil
- global_batch_size = args.batch_size * args.world_size
+ # round_fn = math.floor if floor else math.ceil
+ # global_batch_size = args.batch_size * args.world_size
- num_samples = args.train_num_samples # 8
- num_batches = round_fn(num_samples / global_batch_size) # 2
- # args.workers = max(1, args.workers) # 1
- # num_worker_batches = round_fn(num_batches / args.workers) # per dataloader worker #2
- # num_batches = num_worker_batches * args.workers # 2
- num_samples = num_batches * global_batch_size # 8
+ # num_samples = args.train_num_samples # 8
+ # num_samples = sum([len(dataset) for dataset in unified_datasets])
+ # num_batches = round_fn(num_samples / global_batch_size) # 2
+ # num_samples = num_batches * global_batch_size # 8
dataloaders = []
-
- # unified_datasets = unified_old_datasets + unified_new_datasets
-
- for unified_dataset in unified_datasets:
- sampler = RandomSampler(unified_dataset, replacement=True, num_samples=num_samples)
+ for dataset in unified_datasets:
+ sampler = RandomSampler(dataset, replacement=True, num_samples=len(dataset))
if args.distributed_type == "DEEPSPEED" or args.distributed_type == "MULTI_GPU":
sampler = DistributedProxySampler(sampler, num_replicas=args.world_size, rank=args.rank)
+ if isinstance(image_processor, FuyuProcessor):
+ collate_fn = partial(dataset.collate, fuyu_processor=image_processor, resolution=args.image_resolution)
+ else:
+ collate_fn = dataset.collate
dataloader = torch.utils.data.DataLoader(
- unified_dataset,
+ dataset,
sampler=sampler,
batch_size=args.batch_size,
num_workers=args.workers,
pin_memory=True,
drop_last=True,
- collate_fn=unified_dataset.collate,
+ collate_fn=collate_fn,
)
-
dataloaders.append(dataloader)
+
return dataloaders
diff --git a/pipeline/mimicit_utils/mimicit_dataset.py b/pipeline/mimicit_utils/mimicit_dataset.py
index fbc5f3b4..2b9dabdc 100755
--- a/pipeline/mimicit_utils/mimicit_dataset.py
+++ b/pipeline/mimicit_utils/mimicit_dataset.py
@@ -4,24 +4,22 @@
# found in the LICENSE file in the root directory.
import base64
-from io import BytesIO
-import re
import contextlib
import os
-import orjson
-import ijson.backends.yajl2_cffi as ijson
-from PIL import ImageFile
-from torchvision import transforms
import random
-
+import re
import sys
-from PIL import Image, ImageFile
-
-import torch
+from io import BytesIO
+import pandas as pd
import numpy as np
-
+import orjson
+import torch
+from PIL import Image, ImageFile
+from prettytable import PrettyTable
from torch.utils.data import Dataset
-
+from torchvision import transforms
+from transformers import AutoProcessor
+import wandb
IMAGENET_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMAGENET_DEFAULT_STD = (0.229, 0.224, 0.225)
@@ -29,10 +27,16 @@
FLAMINGO_MEAN = [0.481, 0.458, 0.408]
FLAMINGO_STD = [0.269, 0.261, 0.276]
+IDEFICS_STANDARD_MEAN = [0.48145466, 0.4578275, 0.40821073]
+IDEFICS_STANDARD_STD = [0.26862954, 0.26130258, 0.27577711]
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
ImageFile.MAX_IMAGE_PIXELS = None
Image.MAX_IMAGE_PIXELS = None
+sys.path.append("../..")
+from pipeline.train.train_utils import master_print, truncate_text
+
@contextlib.contextmanager
def random_seed(seed, *addl_seeds):
@@ -54,21 +58,65 @@ def random_seed(seed, *addl_seeds):
random.setstate(random_state)
+import numpy as np
+
+
+def resample_data(data, N):
+ # If N is equal to the length of the list, return the list
+ if N == -1 or N == 0:
+ return data
+ if N == len(data):
+ return data
+ # Upsample if N is greater than the list length
+ elif N > len(data):
+ # Calculate the number of times the list has to be repeated
+ repeat_times = N // len(data)
+ remainder = N % len(data)
+
+ # Create the new list by repeating the data
+ upsampled_data = data * repeat_times
+
+ # Add the remainder of the items by randomly sampling
+ random.seed(0)
+ upsampled_data += random.choices(data, k=remainder)
+
+ return upsampled_data
+ # Downsample if N is smaller than the list length
+ else:
+ random.seed(0)
+ return random.sample(data, N)
+
+
+def extract_rgb_number(path):
+ # Use regular expression to find the 'rgb{x}' pattern
+ match = re.search(r"rgb(\d)", path)
+ if match:
+ return int(match.group(1))
+ return -1 # Return -1 if 'rgb{x}' is not found
+
+
class MimicitDataset(Dataset):
- def __init__(
- self,
- args,
- mimicit_paths="",
- images_paths="",
- train_config_paths="",
- status_list=["past", "new"],
- task_name="DC",
- ):
+ def __init__(self, args, dataset_info, task_group=""):
self.args = args
self.tokenizer = args.tokenizer
-
- # self.max_src_length = args.max_src_length
- # self.max_tgt_length = args.max_tgt_length
+ self.keep_symbols = args.keep_symbols if hasattr(args, "keep_symbols") else True
+ self.task_group = task_group
+ # remove more symbols in the question and answer, make the question and answer more clean and training loss more stable.
+
+ self.mimicit_paths = []
+ self.num_samples_list = []
+ self.train_config_paths = []
+ self.images_paths = []
+ self.task_names = []
+ self.task_description = []
+
+ for key, value in dataset_info.items():
+ self.task_names.append(key)
+ self.mimicit_paths.append(value.get("mimicit_path", ""))
+ self.num_samples_list.append(value.get("num_samples", 0))
+ self.train_config_paths.append(value.get("train_config_path", ""))
+ self.images_paths.append(value.get("images_path", ""))
+ self.task_description.append(value.get("task_description", ""))
self.seed = args.seed
self.patch_image_size = args.patch_image_size
@@ -76,80 +124,120 @@ def __init__(
self.epoch = 0
- self.inst_format = args.inst_format
+ self.instruction_format = args.instruction_format
self.resample_frames = args.resample_frames
- self.text_data_list = ["LIMA", "MBPP", "TXT_SHAREGPT", "AL", "CAL", "TEXT_ONLY"]
- self.image_data_list = ["LA", "M3IT", "PF"]
- self.video_data_list = ["DC", "FunQA", "E4D", "TVC", "VideoQA"]
- self.wrap_sys = f"<>\nYou are a helpful vision language assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.\n<>\n\n"
-
- scales = [(args.patch_image_size, args.patch_image_size)]
-
- self.patch_resize_transform = transforms.Compose(
- [
- transforms.Resize((args.patch_image_size, args.patch_image_size), interpolation=transforms.InterpolationMode.BICUBIC),
- transforms.ToTensor(),
- transforms.Normalize(mean=FLAMINGO_MEAN, std=FLAMINGO_STD),
- ]
- )
- assert mimicit_paths != "", f"Error: The mimicit_paths do not get!"
-
- self.mimicit_paths = mimicit_paths
- self.images_paths = images_paths if images_paths != "" else [""] * len(mimicit_paths)
- self.train_config_paths = train_config_paths if train_config_paths != "" else [""] * len(mimicit_paths)
- self.status_list = status_list
+ self.wrap_sys = f"<>\nYou are a helpful vision language assistant. You are able to understand the visual content. You need to answer user's questions with plans and Python codes as response.\n<>\n\n"
+
+ (self.mean, self.std) = (IDEFICS_STANDARD_MEAN, IDEFICS_STANDARD_STD) if args.model_name == "idefics" else (FLAMINGO_MEAN, FLAMINGO_STD)
+ if args.model_name == "otter" or args.model_name == "fuyu":
+ self.patch_resize_transform = transforms.Compose(
+ [
+ transforms.Resize(
+ (args.patch_image_size, args.patch_image_size),
+ interpolation=transforms.InterpolationMode.BICUBIC,
+ ),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=self.mean, std=self.std),
+ ]
+ )
+ elif args.model_name == "idefics":
+ checkpoint_path = os.environ.get("IDEFICS_LOCAL_PATH", "HuggingFaceM4/idefics-9b-instruct")
+ master_print(f"Local Idefics Checkpoints Path: {checkpoint_path}")
+ self.image_processor = args.image_processor
+ self.patch_resize_transform = lambda x: self.image_processor.preprocess(x).squeeze(0)
- assert len(self.mimicit_paths) == len(self.images_paths) == len(self.train_config_paths) == len(self.status_list), f"metas do not have same number"
+ assert len(self.mimicit_paths) == len(self.images_paths) == len(self.train_config_paths), f"metas do not have same number"
self.dataset = {}
- self.images = {}
+ self.images = []
self.train_data_list = []
- self.train_config = []
- self.task_name = args.task_name
-
- for (
- cur_mimicit_path,
- cur_images_path,
- cur_train_config_path,
- cur_status,
- ) in zip(self.mimicit_paths, self.images_paths, self.train_config_paths, self.status_list):
+ self.train_config = {}
+ # use a dict to record data index to task index mapping
+ # e.g. "0": 1, where "0" is the first data index, 1 is the task index in the task name/desc list
+ self.task_mapping = {}
+
+ table = PrettyTable()
+
+ # Set column names for the table
+ table.field_names = [
+ "Task Name",
+ "MIMICIT_PATH",
+ "TRAIN_CONFIG_PATH",
+ "IMAGES_PATH",
+ "Num Samples",
+ "Task Description",
+ ]
+
+ cur_task_id = 0
+ loaded_images_path = set()
+ for cur_mimicit_path, cur_images_path, cur_train_config_path, sampled_examples, task_name, task_desc in zip(
+ self.mimicit_paths,
+ self.images_paths,
+ self.train_config_paths,
+ self.num_samples_list,
+ self.task_names,
+ self.task_description,
+ ):
# Load the dataset
assert os.path.exists(cur_mimicit_path), f"Error: The local mimicit_path {cur_mimicit_path} not exists!"
- with open(cur_mimicit_path, "rb") as f:
- if self.dataset == {}:
- self.dataset = orjson.loads(f.read())["data"]
- else:
- self.dataset.update(orjson.loads(f.read())["data"])
- with open(cur_images_path, "rb") as f:
- for key, value in ijson.kvitems(f, "", use_float=True):
- self.images[key] = value
+ with open(cur_mimicit_path, "rb") as f:
+ cur_mimicit_data = orjson.loads(f.read())["data"]
+ self.dataset.update(cur_mimicit_data)
# Load the train_config
if cur_train_config_path != "":
- assert os.path.exists(cur_train_config_path), f"Error: The local train_config_path {cur_train_config_path} not exists!"
with open(cur_train_config_path, "rb") as f:
cache_train_config = orjson.loads(f.read())
+ elif args.populate_rel_ins:
+ cache_train_config = {key: value["rel_ins_ids"] for key, value in cur_mimicit_data.items()}
else:
- with open(cur_mimicit_path, "rb") as f:
- cache_train_config = orjson.loads(f.read())["data"]
- cache_train_config = {key: [] for key in cache_train_config.keys()}
+ cache_train_config = {key: [] for key, value in cur_mimicit_data.items()}
+
+ resampled_train = resample_data(list(cache_train_config.keys()), sampled_examples)
+
+ # Truncate paths for display
+ # truncated_mimicit_path = truncate_text(cur_mimicit_path)
+ # truncated_train_config_path = truncate_text(cur_train_config_path)
+ # truncated_images_path = truncate_text(cur_images_path)
+ if len(task_desc) > 0: # if with multiple task descriptions, join them with comma
+ task_desc = ",".join(task_desc)
+
+ # master_print(task_desc)
+ # truncated_task_desc = truncate_text(task_desc)
+
+ table.add_row(
+ [
+ task_name,
+ cur_mimicit_path,
+ cur_train_config_path if cur_train_config_path != "" else "None",
+ cur_images_path if cur_images_path != "" else "None",
+ len(resampled_train),
+ task_desc if task_desc != "" else "None",
+ ]
+ )
- if cur_status == "new":
- cache_train_list = list(cache_train_config.keys())
- else:
- random.seed(0)
- cache_train_list = list(cache_train_config.keys())
- random.shuffle(cache_train_list)
- cache_train_list = cache_train_list[: int(len(cache_train_list) * args.past_subset_ration)]
- if self.train_data_list == []:
- self.train_data_list = cache_train_list
- self.train_config = cache_train_config
- else:
- self.train_data_list += cache_train_list
- self.train_config.update(cache_train_config)
- del cache_train_config
- del cache_train_list
+ if cur_images_path != "" and cur_images_path.endswith(".parquet") and cur_images_path not in loaded_images_path:
+ cur_df = pd.read_parquet(cur_images_path, columns=None) # not in memory
+ self.images.append(cur_df)
+ loaded_images_path.add(cur_images_path)
+
+ self.train_data_list.extend(resampled_train)
+ self.train_config.update(cache_train_config)
+ self.task_mapping.update({key: cur_task_id for key in resampled_train}) # use len(self.task_mapping) to get the task index
+ cur_task_id += 1
+
+ if self.images != []:
+ self.images = pd.concat(self.images, axis=0) # now in memory
+ # self.images = self.images
+
+ if args.rank == 0 and args.report_to_wandb:
+ # master_print(table)
+ wandb_table = wandb.Table(columns=table.field_names)
+ for row in table._rows:
+ wandb_table.add_data(*row)
+ master_print(str(row))
+ wandb.log({f"{self.task_group} Task Table": wandb_table})
self.bos_item = torch.LongTensor([args.tokenizer.bos_token_id])
self.eos_item = torch.LongTensor([args.tokenizer.eos_token_id])
@@ -168,70 +256,33 @@ def random_init_case(self, question):
return first_letter + question[1:]
- def pre_question(self, question):
- question = question.lower().lstrip(",.!?*#:;~").replace("-", " ").replace("/", " ")
- question = self.random_init_case(question)
-
- question = re.sub(
- r"\s{2,}",
- " ",
- question,
- )
- question = question.lstrip("\n")
- question = question.rstrip("\n")
- question = question.strip(" ")
+ def pre_question(self, question, keep_symbols=True):
+ if keep_symbols is False:
+ # question = question.rstrip(",.!?*#:;~").lstrip(",.!?*#:;~")
+ question = re.sub(r'[^\w\s.,?!()"\']', "", question)
+ question = question.strip(" ")
+ question = re.sub(r"\s{2,}", " ", question)
+ question = question.lstrip("\n")
+ question = question.rstrip("\n")
+ question = question.strip(" ").strip("\n")
return question
- def pre_answer(self, answer, max_ans_words=1024):
- answer = re.sub(
- r"\s{2,}",
- " ",
- answer,
- )
- answer = answer.rstrip("\n")
- answer = answer.strip(" ")
-
- # truncate question
- return_answer = ""
- answers = answer.split(".")
-
- for _ in answers:
- if return_answer == "":
- cur_answer = _
- else:
- cur_answer = ".".join([return_answer, _])
- if len(cur_answer.split(" ")) <= max_ans_words:
- return_answer = cur_answer
- else:
- break
-
- if return_answer == "":
- answer_words = answer.split(" ")
- return_answer = " ".join(answer_words[:max_ans_words])
- else:
- if return_answer[-1] != "." and return_answer != answers:
- return_answer += "."
-
- return return_answer
-
- def pre_caption(self, caption, max_words):
- caption = caption.lower().lstrip(",.!?*#:;~").replace("-", " ").replace("/", " ").replace("", "person")
-
- caption = re.sub(
- r"\s{2,}",
- " ",
- caption,
- )
- caption = caption.rstrip("\n")
- caption = caption.strip(" ")
-
- # truncate caption
- caption_words = caption.split(" ")
- if len(caption_words) > max_words:
- caption = " ".join(caption_words[:max_words])
-
- return caption
+ def pre_answer(self, answer, keep_symbols=True):
+ # Remove leading and trailing whitespaces
+ answer = answer.strip()
+ if keep_symbols is False:
+ # Remove unwanted symbols; keep only alphabets, numbers, and some punctuation.
+ answer = re.sub(r'[^\w\s.,?!()"\']', "", answer)
+ # Replace multiple whitespaces with a single space
+ answer = re.sub(r"\s{2,}", " ", answer)
+ # Strip leading and trailing newlines
+ answer = answer.lstrip("\n")
+ answer = answer.rstrip("\n")
+ # Replace \r\n with \n to make newlines uniform
+ answer = answer.replace("\r\n", "\n")
+
+ return answer
def set_epoch(self, epoch, **unused):
self.epoch = epoch
@@ -242,295 +293,150 @@ def resample_frames_fn(self, image_ids, resample_frames):
assert len(image_ids) == resample_frames
return image_ids
- def process_llava(self, instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format="simple"):
+ def process_text_formatting(self, cur_instruction, cur_answer, instruction_format, insert_image=False, is_text_only=False):
+ if instruction_format == "llama2":
+ image_placeholder = "" if not is_text_only else ""
+ prefix = f"[INST]{image_placeholder}\n" if insert_image else "[INST]"
+ return f"{prefix}{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
+ elif instruction_format == "idefics":
+ image_placeholder = "" if not is_text_only else ""
+ prefix = f"User:{image_placeholder}" if insert_image else "User:"
+ return f"{prefix}{cur_instruction}\nAssistant:{cur_answer}\n"
+ elif instruction_format == "simple":
+ image_placeholder = "" if not is_text_only else ""
+ prefix = f"{image_placeholder}User:" if insert_image else "User:"
+ return f"{prefix}{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
+ elif instruction_format == "fuyu":
+ return f"User:{cur_instruction} Assistant:\x04 {cur_answer}"
+
+ def process_images(self, image_ids, is_video=False):
+ pil_images = []
patch_images = torch.tensor([])
- all_texts = ""
- all_instruction_ids = in_context_example_ids + [instruction_id]
- # random.shuffle(all_instruction_ids)
- if "CONV" in instruction_id:
- for idx, cur_instruction_id in enumerate(all_instruction_ids):
- cur_instruction_image_id = self.dataset[cur_instruction_id]["image_ids"][0]
- cur_instruction = self.dataset[cur_instruction_id]["instruction"]
- cur_answer = self.dataset[cur_instruction_id]["answer"]
- cur_instruction = self.pre_question(cur_instruction)
- cur_answer = self.pre_answer(cur_answer)
- if inst_format == "llama2":
- if idx == 0:
- cur_text = f"[INST]{self.wrap_sys}{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"[INST]{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- elif inst_format == "idefics":
- if idx == 0:
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}\n"
- elif idx < len(all_instruction_ids) - 1:
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}\n"
- elif idx == len(all_instruction_ids) - 1:
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}"
- elif inst_format == "simple":
- if idx == 0:
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
- all_texts += cur_text
-
- # if inst_format == "simple":
- # all_texts = f"{all_texts}"
- cur_image_id = self.dataset[cur_instruction_id]["image_ids"][0]
- cur_image = self.images[cur_image_id]
- cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
- patch_images = self.patch_resize_transform(cur_image).unsqueeze(0).unsqueeze(0)
- else:
- for idx, cur_instruction_id in enumerate(all_instruction_ids[:]):
- cur_instruction_image_id = self.dataset[cur_instruction_id]["image_ids"][0]
- cur_instruction = self.dataset[cur_instruction_id]["instruction"]
- cur_answer = self.dataset[cur_instruction_id]["answer"]
- cur_image = self.images[cur_instruction_image_id]
- cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
- cur_patch_image = self.patch_resize_transform(cur_image).unsqueeze(0).unsqueeze(0)
+ if is_video:
+ image_ids = self.resample_frames_fn(image_ids, self.resample_frames)
+
+ for cur_image_id in image_ids:
+ cur_image_str = self.images.loc[cur_image_id]["base64"]
+ cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image_str))).convert("RGB")
+ if self.args.model_name == self.args.model_name == "fuyu":
+ pil_images.append(cur_image) # fuyu doesnt need following process.
+ else:
+ cur_patch_image = self.patch_resize_transform(cur_image).unsqueeze(0)
if len(patch_images) == 0:
patch_images = cur_patch_image
else:
patch_images = torch.cat((patch_images, cur_patch_image))
- cur_instruction = self.pre_question(cur_instruction)
- cur_answer = self.pre_answer(cur_answer)
- if inst_format == "llama2":
- cur_text = f"[INST]{self.wrap_sys}{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- elif inst_format == "idefics":
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}\n"
- elif inst_format == "simple":
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
- all_texts += cur_text
- return patch_images, all_texts # incontext_text, query_text
-
- def process_general_videoqa(self, instruction_id, instruction, answer, image_ids, in_context_example_ids, resample_frames=32, inst_format="simple"):
- patch_images = torch.tensor([])
- all_texts = ""
- all_instruction_ids = in_context_example_ids + [instruction_id]
- random.shuffle(all_instruction_ids)
- for idx, cur_instruction_id in enumerate(all_instruction_ids[:]):
- cur_instruction = self.dataset[cur_instruction_id]["instruction"]
- cur_instruction = self.pre_question(cur_instruction)
- cur_answer = self.dataset[cur_instruction_id]["answer"]
- cur_answer = self.pre_answer(cur_answer)
- if inst_format == "llama2":
- if idx == 0:
- cur_text = f"[INST]{self.wrap_sys}{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"[INST]{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- elif inst_format == "idefics":
- if idx == 0:
- cur_text = f"User:{cur_instruction} Assistant:{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"User:{cur_instruction} Assistant:{cur_answer}<|endofchunk|>"
- elif inst_format == "simple":
- if idx == 0:
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
-
- all_texts += cur_text
-
- # User: {cur_incontext_instruction} GPT: {cur_incontext_answer}<|endofchunk|>User: {instruction} GPT: {answer}<|endofchunk|>
- # User: what does the image describe? GPT: XXX <|endofchunk|>User: Do you think this image is funny GPT: YYY <|endofchunk|>
- image_ids = self.resample_frames_fn(image_ids, resample_frames)
- for cur_image_id in image_ids:
- cur_image = self.images[cur_image_id]
- cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
- cur_patch_image = self.patch_resize_transform(cur_image).unsqueeze(0)
- if len(patch_images) == 0:
- patch_images = cur_patch_image
- else:
- patch_images = torch.cat((patch_images, cur_patch_image))
-
- patch_images = patch_images.unsqueeze(0)
- return patch_images, all_texts
- def process_spot_the_difference(self, instruction_id, instruction, answer, image_ids, in_context_example_ids):
- patch_images = torch.tensor([])
- incontext_text = ""
- # User: {instruction} GPT: {answer}<|endofchunk|>
- for cur_image_id in image_ids:
- cur_image = self.images[cur_image_id]
- cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
- cur_patch_image = self.patch_resize_transform(cur_image).unsqueeze(0)
- if len(patch_images) == 0:
- patch_images = cur_patch_image
- else:
- patch_images = torch.cat((patch_images, cur_patch_image))
-
- patch_images = patch_images.unsqueeze(0)
- instruction = self.pre_question(instruction)
- answer = self.pre_answer(answer)
- query_text = f"User: {instruction} GPT: {answer}<|endofchunk|>"
- all_texts = f"{incontext_text}{query_text}"
- return patch_images, all_texts
+ if is_video:
+ patch_images = patch_images.unsqueeze(0)
- def process_scene_navigation(self, instruction_id, instruction, answer, image_ids, in_context_example_ids):
- patch_images = torch.tensor([])
- incontext_text = ""
- for cur_incontext_id in in_context_example_ids:
- cur_incontext_instruction = self.dataset[cur_incontext_id]["instruction"]
- cur_incontext_instruction = self.pre_question(cur_incontext_instruction)
- cur_incontext_answer = self.dataset[cur_incontext_id]["answer"]
- cur_incontext_answer = self.pre_answer(cur_incontext_answer)
- cur_incontext_text = f"User: {cur_incontext_instruction} GPT: {cur_incontext_answer}<|endofchunk|>"
- incontext_text += cur_incontext_text
-
- incontext_text = f"{incontext_text}"
- # User: {cur_incontext_instruction} GPT: {cur_incontext_answer}<|endofchunk|>User: {instruction} GPT: {answer}<|endofchunk|>
- for cur_image_id in image_ids:
- cur_image = self.images[cur_image_id]
- cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
- cur_patch_image = self.patch_resize_transform(cur_image).unsqueeze(0)
- if len(patch_images) == 0:
- patch_images = cur_patch_image
- else:
- patch_images = torch.cat((patch_images, cur_patch_image))
+ return pil_images, patch_images
- patch_images = patch_images.unsqueeze(0)
- instruction = self.pre_question(instruction)
- answer = self.pre_answer(answer)
- query_text = f"User: {instruction} GPT: {answer}<|endofchunk|>"
- all_texts = f"{incontext_text}{all_texts}"
- return patch_images, all_texts
-
- def process_general_imageqa(self, instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format="simple"):
- patch_images = torch.tensor([])
+ def process_general(self, instruction_id, image_ids, in_context_example_ids, task_group):
all_texts = ""
all_instruction_ids = in_context_example_ids + [instruction_id]
- # the in_context_example_ids in this process_func is usually previous conversations
- for idx, cur_instruction_id in enumerate(all_instruction_ids[:]):
- cur_instruction_image_id = (
- self.dataset[cur_instruction_id]["image_ids"][0]
- if isinstance(self.dataset[cur_instruction_id]["image_ids"], list)
- else self.dataset[cur_instruction_id]["image_ids"]
- )
- cur_instruction = self.dataset[cur_instruction_id]["instruction"]
- cur_answer = self.dataset[cur_instruction_id]["answer"]
- cur_image = self.images[cur_instruction_image_id]
- try:
- cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
- except:
- print(cur_instruction_id)
- exit()
- cur_patch_image = self.patch_resize_transform(cur_image).unsqueeze(0).unsqueeze(0)
- if len(patch_images) == 0:
- patch_images = cur_patch_image
- else:
- patch_images = torch.cat((patch_images, cur_patch_image))
- cur_instruction = self.pre_question(cur_instruction)
- cur_answer = self.pre_answer(cur_answer)
- if inst_format == "llama2":
- if idx == 0:
- cur_text = f"[INST]{self.wrap_sys}{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"[INST]{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- elif inst_format == "idefics":
- if idx == 0:
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}\n"
- elif idx < len(all_instruction_ids) - 1:
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}\n"
- elif idx == len(all_instruction_ids) - 1:
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}"
- elif inst_format == "simple":
- if idx == 0:
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
- all_texts += cur_text
- return patch_images, all_texts
- def process_general_text(self, instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format="simple"):
- patch_images = torch.tensor([])
- all_texts = ""
- all_instruction_ids = in_context_example_ids + [instruction_id]
- for idx, cur_instruction_id in enumerate(all_instruction_ids[:]):
+ for idx, cur_instruction_id in enumerate(all_instruction_ids):
cur_instruction = self.dataset[cur_instruction_id]["instruction"]
cur_answer = self.dataset[cur_instruction_id]["answer"]
- cur_patch_image = torch.zeros(3, 224, 224).unsqueeze(0).unsqueeze(0)
- if len(patch_images) == 0:
- patch_images = cur_patch_image
+ cur_instruction = self.pre_question(cur_instruction, keep_symbols=self.keep_symbols)
+ cur_answer = self.pre_answer(cur_answer, keep_symbols=self.keep_symbols)
+
+ if task_group == "IMAGE_TEXT_IN_CONTEXT":
+ cur_text = self.process_text_formatting(cur_instruction, cur_answer, self.instruction_format, insert_image=True, is_text_only=False)
else:
- patch_images = torch.cat((patch_images, cur_patch_image))
- cur_instruction = self.pre_question(cur_instruction)
- cur_answer = self.pre_answer(cur_answer)
- if "baize" in instruction_id:
- cur_text = f"{cur_answer}"
- elif inst_format == "llama2":
- if idx == 0:
- cur_text = f"[INST]{self.wrap_sys} {cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- else:
- cur_text = f"[INST]{cur_instruction}[/INST]{cur_answer}<|endofchunk|>"
- elif inst_format == "idefics":
- cur_text = f"User:{cur_instruction}\nAssistant:{cur_answer}\n"
- elif inst_format == "simple":
- cur_text = f"User:{cur_instruction} GPT:{cur_answer}<|endofchunk|>"
+ # only insert image for the first instruction, used for conversation.
+ cur_text = self.process_text_formatting(
+ cur_instruction,
+ cur_answer,
+ self.instruction_format,
+ insert_image=(idx == 0),
+ is_text_only=(task_group == "TEXT_ONLY"),
+ )
all_texts += cur_text
- return patch_images, all_texts
+
+ # all_texts = all_texts.rstrip("\n")
+ # patch_images = torch.tensor([])
+ if task_group == "TEXT_ONLY":
+ patch_images = torch.zeros(3, 224, 224).unsqueeze(0).unsqueeze(0)
+ pil_images = [Image.fromarray(patch_images[0, 0].numpy().astype(np.uint8).transpose(1, 2, 0))]
+ elif task_group == "IMAGE_TEXT_IN_CONTEXT" or task_group == "IMAGE_TEXT":
+ pil_images, patch_images = self.process_images(image_ids, is_video=False)
+ patch_images = patch_images.unsqueeze(0)
+ elif task_group == "VIDEO_TEXT":
+ pil_images, patch_images = self.process_images(image_ids, is_video=True)
+
+ return pil_images, patch_images, all_texts.rstrip("\n")
def process_image_text_pair(self, index):
- # try:
cur_train_id = self.train_data_list[index]
- (
- instruction_id,
- instruction,
- answer,
- image_ids,
- in_context_example_ids,
- ) = (
- cur_train_id,
- self.dataset[cur_train_id]["instruction"],
- self.dataset[cur_train_id]["answer"],
- self.dataset[cur_train_id]["image_ids"],
- self.train_config[cur_train_id],
- )
- inst_format = self.inst_format
- resample_frames = self.resample_frames
- # self.max_src_length = self.max_tgt_length = 256
-
- if cur_train_id.upper().startswith("LA"):
- patch_images, all_texts = self.process_llava(instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format=inst_format)
- elif cur_train_id.upper().startswith("SD") or cur_train_id.startswith("CGD"):
- patch_images, all_texts = self.process_spot_the_difference(instruction_id, instruction, answer, image_ids, in_context_example_ids)
- elif cur_train_id.upper().startswith("SN"):
- patch_images, all_texts = self.process_scene_navigation(
- instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format=inst_format
- )
- elif any(cur_train_id.upper().startswith(videoqa_task) for videoqa_task in self.video_data_list) or self.task_name in self.video_data_list:
- patch_images, all_texts = self.process_general_videoqa(
- instruction_id, instruction, answer, image_ids, in_context_example_ids, resample_frames=resample_frames, inst_format=inst_format
- )
- elif any(cur_train_id.upper().startswith(text_id) for text_id in self.text_data_list) or self.task_name in self.text_data_list:
- # code to execute if cur_train_id starts with an item in self.text_data_list
- patch_images, all_texts = self.process_general_text(instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format=inst_format)
- elif any(cur_train_id.upper().startswith(image_id) for image_id in self.image_data_list) or self.task_name in self.image_data_list:
- patch_images, all_texts = self.process_general_imageqa(
- instruction_id, instruction, answer, image_ids, in_context_example_ids, inst_format=inst_format
+ if cur_train_id in self.dataset and "instruction" in self.dataset[cur_train_id] and "answer" in self.dataset[cur_train_id]:
+ (instruction_id, instruction, answer, in_context_example_ids) = (
+ cur_train_id,
+ self.dataset[cur_train_id]["instruction"],
+ self.dataset[cur_train_id]["answer"],
+ self.train_config[cur_train_id],
)
+ else:
+ print(f"Error: {cur_train_id} is invalid!")
+ exit()
+ image_ids = self.dataset[cur_train_id]["image_ids"] if self.dataset[cur_train_id].get("image_ids", None) is not None else [] # handling for text-only data without image_ids
+
+ cur_task_desc = self.task_description[self.task_mapping[cur_train_id]]
+ if len(cur_task_desc) > 0:
+ cur_task_desc = random.choice(cur_task_desc)
+
+ process_mapping = {
+ "VIDEO_TEXT": "process_general_videoqa",
+ "TEXT_ONLY": "process_general_text",
+ "IMAGE_TEXT": "process_general_imageqa",
+ "IMAGE_TEXT_IN_CONTEXT": "process_in_context_imageqa",
+ }
- all_text = self.tokenizer(
- f"{all_texts}",
+ try:
+ if self.task_group in process_mapping:
+ pil_images, patch_images, all_texts = self.process_general(instruction_id, image_ids, in_context_example_ids, self.task_group)
+ except Exception as e:
+ print(f"Error: {e}")
+ print(f"cur_train_id: {cur_train_id}")
+ print(f"self.task_group: {self.task_group}")
+ print(f"instruction_id: {instruction_id}")
+ print(f"image_ids: {image_ids}")
+ print(f"in_context_example_ids: {in_context_example_ids}")
+ import pdb
+
+ pdb.set_trace()
+ exit()
+
+ if cur_task_desc != "" and self.args.with_task_description:
+ all_texts = cur_task_desc + "\n" + all_texts
+ tokenized_all_text = self.tokenizer(
+ all_texts,
return_tensors="pt",
add_special_tokens=False,
truncation=True,
max_length=self.max_seq_len, # for current 2k mpt/llama model, setting to 2048 causes error (2042 works)
)
+ num_tokens = tokenized_all_text["input_ids"].shape[1]
+ if num_tokens == self.max_seq_len:
+ master_print(f"{cur_train_id}'s all_texts reaches the max_seq_len.")
+ master_print(all_texts)
- all_item = all_text["input_ids"].squeeze(0)
- all_item_mask = all_text["attention_mask"].squeeze(0)
+ all_item = tokenized_all_text["input_ids"].squeeze(0)
+ all_item_mask = tokenized_all_text["attention_mask"].squeeze(0)
all_item = torch.cat([self.bos_item, all_item, self.eos_item])
all_item_mask = torch.cat([self.bos_mask, all_item_mask, self.eos_mask])
- # src_item = torch.cat([self.bos_item, src_item])
- # src_item_mask = torch.cat([self.bos_mask, src_item_mask])
example = {
"id": instruction_id,
"source": all_item,
"text_mask": all_item_mask,
"patch_images": patch_images,
+ "task_group": self.task_group,
+ "full_text": all_texts,
+ "pil_images": pil_images,
}
-
return example
def __str__(self):
@@ -547,7 +453,7 @@ def __getitem__(self, index):
return self.__getitem__(index + 1)
return pair_sample
- def collate(self, samples):
+ def collate(self, samples, fuyu_processor=None, resolution=None):
"""Merge samples of different tasks to form two mini-batches.
Args:
samples (List[Tuple]): samples to collate
@@ -564,9 +470,26 @@ def collate(self, samples):
pad_idx=self.tokenizer.pad_token_id,
eos_idx=self.tokenizer.eos_token_id,
)
+
+ if fuyu_processor:
+ fuyu_data = prepare_fuyu(self.args, fuyu_processor, res_v1, resolution)
+ res_v1["fuyu_data"] = fuyu_data
return res_v1
+def prepare_fuyu(args, fuyu_processor, batch_data, resolution):
+ if args.dynamic_resolution:
+ resolution = random.choice([(448, 448), (512, 512), (768, 768)])
+ pil_images = [img[0].resize(resolution) for img in batch_data["pil_images"] if img is not None]
+ model_inputs = fuyu_processor(text=batch_data["full_text"], images=pil_images)
+ labels = fuyu_processor.get_labels(input_ids=model_inputs["input_ids"], special_token_id=71122)
+ input_ids, labels = fuyu_processor.find_and_remove_tokens(input_ids=model_inputs["input_ids"], labels=labels, token_id=71122)
+ model_inputs["input_ids"] = input_ids
+ model_inputs["labels"] = labels
+ del batch_data["pil_images"]
+ return model_inputs
+
+
def collate_fn(samples, pad_idx, eos_idx):
if len(samples) == 0:
return {}
@@ -582,21 +505,29 @@ def merge(key, pad_idx, pading_size=None):
larger_size = max([s["source"].size(0) for s in samples])
- id = np.array([s["id"] for s in samples])
+ ids = [s["id"] for s in samples]
src_tokens = merge("source", pad_idx=pad_idx, pading_size=larger_size)
src_tokens_masks = merge("text_mask", pad_idx=0, pading_size=larger_size)
+ task_groups = [s["task_group"] for s in samples]
batch = {
- "id": id,
- "nsentences": len(samples),
+ "id": ids,
+ "task_group": task_groups,
"net_input": {
"input_ids": src_tokens,
"attention_masks": src_tokens_masks,
},
+ "full_text": [s["full_text"] for s in samples],
+ "pil_images": [s["pil_images"] for s in samples],
}
- larger_incontext_num = max([s["patch_images"].size(0) for s in samples])
- if samples[0].get("patch_images", None) is not None:
- batch["net_input"]["patch_images"] = torch.stack([sample["patch_images"] for sample in samples], dim=0)
+ # larger_incontext_num = max([s["patch_images"].size(0) for s in samples])
+ try:
+ if samples[0].get("patch_images", None) is not None:
+ batch["net_input"]["patch_images"] = torch.stack([sample["patch_images"] for sample in samples], dim=0)
+ except Exception as e:
+ print(f"Error: {e}")
+ print(batch["id"])
+ exit()
return batch
@@ -617,6 +548,9 @@ def collate_tokens(
if pad_to_multiple != 1 and size % pad_to_multiple != 0:
size = int(((size - 0.1) // pad_to_multiple + 1) * pad_to_multiple)
+ if pad_idx is None:
+ pad_idx = eos_idx
+
def copy_tensor(src, dst):
assert dst.numel() == src.numel()
if move_eos_to_beginning:
diff --git a/pipeline/mimicit_utils/transforms.py b/pipeline/mimicit_utils/transforms.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/__init__.py b/pipeline/serve/__init__.py
old mode 100644
new mode 100755
index e69de29b..8b137891
--- a/pipeline/serve/__init__.py
+++ b/pipeline/serve/__init__.py
@@ -0,0 +1 @@
+
diff --git a/pipeline/serve/cli.py b/pipeline/serve/cli.py
old mode 100644
new mode 100755
index 1736d1b2..7ee7e5c0
--- a/pipeline/serve/cli.py
+++ b/pipeline/serve/cli.py
@@ -7,7 +7,7 @@
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
-from pipeline.conversation import conv_templates, SeparatorStyle
+from pipeline.serve.conversation import conv_templates, SeparatorStyle
@torch.inference_mode()
diff --git a/pipeline/serve/controller.py b/pipeline/serve/controller.py
old mode 100644
new mode 100755
diff --git a/pipeline/conversation.py b/pipeline/serve/conversation.py
old mode 100644
new mode 100755
similarity index 97%
rename from pipeline/conversation.py
rename to pipeline/serve/conversation.py
index 35d1fa6b..7cf1afa0
--- a/pipeline/conversation.py
+++ b/pipeline/serve/conversation.py
@@ -177,8 +177,7 @@ def dict(self):
conv_v1 = Conversation(
- system="A chat between a curious human and an artificial intelligence assistant. "
- "The assistant gives helpful, detailed, and polite answers to the human's questions.",
+ system="A chat between a curious human and an artificial intelligence assistant. " "The assistant gives helpful, detailed, and polite answers to the human's questions.",
roles=("Human", "Assistant"),
messages=(
("Human", "Give three tips for staying healthy."),
@@ -206,8 +205,7 @@ def dict(self):
)
conv_v1_2 = Conversation(
- system="A chat between a curious human and an artificial intelligence assistant. "
- "The assistant gives helpful, detailed, and polite answers to the human's questions.",
+ system="A chat between a curious human and an artificial intelligence assistant. " "The assistant gives helpful, detailed, and polite answers to the human's questions.",
roles=("Human", "Assistant"),
messages=(
(
diff --git a/pipeline/serve/deploy/conversation.py b/pipeline/serve/deploy/conversation.py
new file mode 100644
index 00000000..3d2dc2c7
--- /dev/null
+++ b/pipeline/serve/deploy/conversation.py
@@ -0,0 +1,167 @@
+import dataclasses
+from enum import auto, Enum
+from typing import List, Tuple
+
+import io
+import base64
+import os
+from PIL import Image
+import copy
+
+IMG_FLAG = ""
+
+
+class SeparatorStyle(Enum):
+ """Different separator style."""
+
+ SINGLE = auto()
+ TWO = auto()
+ MPT = auto()
+ PLAIN = auto()
+ LLAMA_2 = auto()
+
+
+def decode_image(encoded_image: str) -> Image:
+ decoded_bytes = base64.b64decode(encoded_image.encode("utf-8"))
+ buffer = io.BytesIO(decoded_bytes)
+ image = Image.open(buffer)
+ return image
+
+
+def encode_image(image: Image.Image, format: str = "PNG") -> str:
+ with io.BytesIO() as buffer:
+ image.save(buffer, format=format)
+ encoded_image = base64.b64encode(buffer.getvalue()).decode("utf-8")
+ return encoded_image
+
+
+@dataclasses.dataclass
+class Conversation:
+ """A class that keeps all conversation history."""
+
+ system: str
+ roles: List[str]
+ messages: List[dict] # multi-turn -> user & assistant -> {'images': [PIL.Image,], 'text': str}
+ offset: int
+ sep_style: SeparatorStyle = SeparatorStyle.SINGLE
+ sep: str = "###"
+ sep2: str = None
+ version: str = "Unknown"
+
+ skip_next: bool = False
+
+ def get_prompt(self):
+ messages = copy.deepcopy(self.messages)
+ if self.sep_style == SeparatorStyle.SINGLE:
+ if self.system is None or self.system == "":
+ text = ""
+ else:
+ text = self.system + self.sep
+ images = []
+ for message in messages:
+ text += message["role"] + ": " + message["message"]["text"] + self.sep
+ for image_path, image_ids in zip(message["message"]["images"], message["message"]["images_ids"]):
+ if image_ids is not None:
+ images.append(image_ids)
+ else:
+ image = Image.open(image_path).resize((256, 256))
+ image_base64 = encode_image(image)
+ images.append(image_base64)
+
+ text += self.roles[1] + ":"
+ elif self.sep_style == SeparatorStyle.LLAMA_2:
+ # b_token = "[INST] "
+ b_token = "[USER] "
+ # e_token = " [/INST]"
+ e_token = " [ASSISTANT]"
+ if self.system is None or self.system == "":
+ text = ""
+ else:
+ text = f"<>\n{self.system}\n<>\n\n"
+ images = []
+ for idx, message in enumerate(messages):
+ # text += message['role'] + ": " + message['message']['text'] + self.sep
+ if idx % 2 == 0:
+ text += b_token + message["message"]["text"] + e_token + self.sep
+ else:
+ text += message["message"]["text"] + self.sep
+
+ for image_path, image_ids in zip(message["message"]["images"], message["message"]["images_ids"]):
+ if image_ids is not None:
+ images.append(image_ids)
+ else:
+ image = Image.open(image_path).resize((256, 256))
+ image_base64 = encode_image(image)
+ images.append(image_base64)
+ else:
+ raise NotImplementedError
+
+ return {"text": text, "images": images}
+
+ def update_image_ids(self, images_ids):
+ image_count = 0
+ for message in self.messages:
+ for idx in range(len(message["message"]["images_ids"])):
+ if message["message"]["images_ids"][idx] is None:
+ message["message"]["images_ids"][idx] = images_ids[image_count]
+ image_count += 1
+
+ assert len(images_ids) == image_count, print(len(images_ids), image_count)
+
+ def append_message(self, role, message):
+ self.messages.append([role, message])
+
+ def to_gradio_chatbot(self):
+ dialog = []
+ for i, single_turn in enumerate(self.messages[self.offset :]):
+ single_turn = single_turn["message"]
+ text_list = single_turn["text"].split(IMG_FLAG)
+ assert len(text_list) == len(single_turn["images"]) + 1, print(text_list, len(single_turn["images"]))
+ message = ""
+ for image_idx in range(len(single_turn["images"])):
+ # image = single_turn['images'][image_idx]
+ # image_base64 = encode_image(image)
+ # image_str = f' '
+ image_path = single_turn["images"][image_idx]
+ if image_path == "":
+ message += text_list[image_idx] + ""
+ else:
+ message += text_list[image_idx] + f""
+ message += text_list[-1]
+
+ if i % 2 == 0:
+ dialog.append([message, None])
+ else:
+ dialog[-1][-1] = message
+
+ return dialog
+
+ def copy(self):
+ return Conversation(system=self.system, roles=self.roles, messages=copy.deepcopy(self.messages), offset=self.offset, sep_style=self.sep_style, sep=self.sep, sep2=self.sep2, version=self.version)
+
+ def dict(self):
+ messages = copy.deepcopy(self.messages)
+ for message in messages:
+ if "images_ids" in message:
+ message.pop("images_ids")
+ for i in range(len(message["message"]["images"])):
+ message["message"]["images"][i] = os.path.basename(message["message"]["images"][i])
+ return {
+ "system": self.system,
+ "roles": self.roles,
+ "messages": messages,
+ "offset": self.offset,
+ "sep": self.sep,
+ "sep2": self.sep2,
+ }
+
+
+model = Conversation(
+ system="",
+ roles=("USER", "ASSISTANT"),
+ version="v2",
+ messages=[],
+ offset=0,
+ sep_style=SeparatorStyle.SINGLE,
+ sep="\n",
+)
diff --git a/pipeline/serve/deploy/deploy.py b/pipeline/serve/deploy/deploy.py
new file mode 100644
index 00000000..330ee504
--- /dev/null
+++ b/pipeline/serve/deploy/deploy.py
@@ -0,0 +1,302 @@
+import os
+import datetime
+import json
+import base64
+from PIL import Image
+import gradio as gr
+import hashlib
+import requests
+from utils import build_logger
+from conversation import model
+import io
+
+
+IMG_FLAG = ""
+
+LOGDIR = "log"
+logger = build_logger("otter", LOGDIR)
+
+current_model = model
+
+no_change_btn = gr.Button.update()
+enable_btn = gr.Button.update(interactive=True)
+disable_btn = gr.Button.update(interactive=False)
+
+
+def decode_image(encoded_image: str) -> Image:
+ decoded_bytes = base64.b64decode(encoded_image.encode("utf-8"))
+ buffer = io.BytesIO(decoded_bytes)
+ image = Image.open(buffer)
+ return image
+
+
+def encode_image(image: Image.Image, format: str = "PNG") -> str:
+ with io.BytesIO() as buffer:
+ image.save(buffer, format=format)
+ encoded_image = base64.b64encode(buffer.getvalue()).decode("utf-8")
+ return encoded_image
+
+
+def get_conv_log_filename():
+ t = datetime.datetime.now()
+ name = os.path.join(LOGDIR, f"{t.year}-{t.month:02d}-{t.day:02d}-conv.json")
+ return name
+
+
+def get_conv_image_dir():
+ name = os.path.join(LOGDIR, "images")
+ os.makedirs(name, exist_ok=True)
+ return name
+
+
+def get_image_name(image, image_dir=None):
+ buffer = io.BytesIO()
+ image.save(buffer, format="PNG")
+ image_bytes = buffer.getvalue()
+ md5 = hashlib.md5(image_bytes).hexdigest()
+
+ if image_dir is not None:
+ image_name = os.path.join(image_dir, md5 + ".png")
+ else:
+ image_name = md5 + ".png"
+
+ return image_name
+
+
+def resize_image(image, max_size):
+ width, height = image.size
+ aspect_ratio = float(width) / float(height)
+
+ if width > height:
+ new_width = max_size
+ new_height = int(new_width / aspect_ratio)
+ else:
+ new_height = max_size
+ new_width = int(new_height * aspect_ratio)
+
+ resized_image = image.resize((new_width, new_height))
+ return resized_image
+
+
+def center_crop_image(image, max_aspect_ratio=1.5):
+ width, height = image.size
+ aspect_ratio = max(width, height) / min(width, height)
+
+ if aspect_ratio >= max_aspect_ratio:
+ if width > height:
+ new_width = int(height * max_aspect_ratio)
+ left = (width - new_width) // 2
+ right = (width + new_width) // 2
+ top = 0
+ bottom = height
+ else:
+ new_height = int(width * max_aspect_ratio)
+ left = 0
+ right = width
+ top = (height - new_height) // 2
+ bottom = (height + new_height) // 2
+
+ cropped_image = image.crop((left, top, right, bottom))
+ return cropped_image
+ else:
+ return image
+
+
+def regenerate(dialog_state, request: gr.Request):
+ logger.info(f"regenerate. ip: {request.client.host}")
+ if dialog_state.messages[-1]["role"] == dialog_state.roles[1]:
+ dialog_state.messages.pop()
+ return (
+ dialog_state,
+ dialog_state.to_gradio_chatbot(),
+ ) + (disable_btn,) * 4
+
+
+def clear_history(request: gr.Request):
+ logger.info(f"clear_history. ip: {request.client.host}")
+ dialog_state = current_model.copy()
+ input_state = init_input_state()
+ return (dialog_state, input_state, dialog_state.to_gradio_chatbot()) + (disable_btn,) * 4
+
+
+def init_input_state():
+ return {"images": [], "text": "", "images_ids": []}
+
+
+def add_text(dialog_state, input_state, text, request: gr.Request):
+ logger.info(f"add_text. ip: {request.client.host}.")
+ if text is None or len(text) == 0:
+ return (dialog_state, input_state, "", dialog_state.to_gradio_chatbot()) + (no_change_btn,) * 4
+ input_state["text"] += text
+
+ if len(dialog_state.messages) > 0 and dialog_state.messages[-1]["role"] == dialog_state.roles[0]:
+ dialog_state.messages[-1]["message"] = input_state
+ else:
+ dialog_state.messages.append({"role": dialog_state.roles[0], "message": input_state})
+ print("add_text: ", dialog_state.to_gradio_chatbot())
+
+ return (dialog_state, input_state, "", dialog_state.to_gradio_chatbot()) + (disable_btn,) * 4
+
+
+def add_image(dialog_state, input_state, image, request: gr.Request):
+ logger.info(f"add_image. ip: {request.client.host}.")
+ if image is None:
+ return (dialog_state, input_state, None, dialog_state.to_gradio_chatbot()) + (no_change_btn,) * 4
+
+ image = image.convert("RGB")
+ image = resize_image(image, max_size=224)
+ image = center_crop_image(image, max_aspect_ratio=1.3)
+ image_dir = get_conv_image_dir()
+ image_path = get_image_name(image=image, image_dir=image_dir)
+ if not os.path.exists(image_path):
+ image.save(image_path)
+
+ input_state["images"].append(image_path)
+ input_state["text"]
+ input_state["images_ids"].append(None)
+
+ if len(dialog_state.messages) > 0 and dialog_state.messages[-1]["role"] == dialog_state.roles[0]:
+ dialog_state.messages[-1]["message"] = input_state
+ else:
+ dialog_state.messages.append({"role": dialog_state.roles[0], "message": input_state})
+
+ print("add_image:", dialog_state)
+
+ return (dialog_state, input_state, None, dialog_state.to_gradio_chatbot()) + (disable_btn,) * 4
+
+
+# def update_error_msg(chatbot, error_msg):
+# if len(error_msg) > 0:
+# info = '\n-------------\nSome errors occurred during response, please clear history and restart.\n' + '\n'.join(
+# error_msg)
+# chatbot[-1][-1] = chatbot[-1][-1] + info
+
+# return chatbot
+
+
+def http_bot(image_input, text_input, request: gr.Request):
+ logger.info(f"http_bot. ip: {request.client.host}")
+ print(f"Prompt request: {text_input}")
+
+ base64_image_str = encode_image(image_input)
+
+ payload = {
+ "content": [
+ {
+ "prompt": text_input,
+ "image": base64_image_str,
+ }
+ ],
+ "token": "sk-OtterHD",
+ }
+
+ print(
+ "request: ",
+ {
+ "prompt": text_input,
+ "image": base64_image_str[:10],
+ },
+ )
+
+ url = "http://10.128.0.40:8890/app/otter"
+ headers = {"Content-Type": "application/json"}
+
+ response = requests.post(url, headers=headers, data=json.dumps(payload))
+ results = response.json()
+ print("response: ", {"result": results["result"]})
+
+ # output_state = init_input_state()
+ # # image_dir = get_conv_image_dir()
+ # output_state["text"] = results["result"]
+
+ # for now otter doesn't have image output
+
+ # for image_base64 in results['images']:
+ # if image_base64 == '':
+ # image_path = ''
+ # else:
+ # image = decode_image(image_base64)
+ # image = image.convert('RGB')
+ # image_path = get_image_name(image=image, image_dir=image_dir)
+ # if not os.path.exists(image_path):
+ # image.save(image_path)
+ # output_state['images'].append(image_path)
+ # output_state['images_ids'].append(None)
+
+ # dialog_state.messages.append({"role": dialog_state.roles[1], "message": output_state})
+ # # dialog_state.update_image_ids(results['images_ids'])
+
+ # input_state = init_input_state()
+ # chatbot = dialog_state.to_gradio_chatbot()
+ # chatbot = update_error_msg(dialog_state.to_gradio_chatbot(), results['error_msg'])
+
+ return results["result"]
+
+
+def load_demo(request: gr.Request):
+ logger.info(f"load_demo. ip: {request.client.host}")
+ dialog_state = current_model.copy()
+ input_state = init_input_state()
+ return dialog_state, input_state
+
+
+title = """
+# OTTER-HD: A High-Resolution Multi-modality Model
+[[Otter Codebase]](https://github.com/Luodian/Otter) [[Paper]]() [[Checkpoints & Benchmarks]](https://huggingface.co/Otter-AI)
+
+"""
+
+css = """
+ #mkd {
+ height: 1000px;
+ overflow: auto;
+ border: 1px solid #ccc;
+ }
+"""
+
+if __name__ == "__main__":
+ with gr.Blocks(css=css) as demo:
+ gr.Markdown(title)
+ dialog_state = gr.State()
+ input_state = gr.State()
+ with gr.Tab("Ask a Question"):
+ with gr.Row(equal_height=True):
+ with gr.Column(scale=2):
+ image_input = gr.Image(label="Upload a High-Res Image", type="pil").style(height=600)
+ with gr.Column(scale=1):
+ vqa_output = gr.Textbox(label="Output").style(height=600)
+ text_input = gr.Textbox(label="Ask a Question")
+
+ vqa_btn = gr.Button("Send It")
+
+ gr.Examples(
+ [
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00095.png",
+ "How many camels are inside this image?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00095.png",
+ "How many people are inside this image?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00012.png",
+ "How many apples are there?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00080.png",
+ "What is this and where is it from?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00094.png",
+ "What's important on this website?",
+ ],
+ ],
+ inputs=[image_input, text_input],
+ outputs=[vqa_output],
+ fn=http_bot,
+ label="Click on any Examples below👇",
+ )
+ vqa_btn.click(fn=http_bot, inputs=[image_input, text_input], outputs=vqa_output)
+
+ demo.launch()
diff --git a/pipeline/serve/deploy/otterhd_endpoint.py b/pipeline/serve/deploy/otterhd_endpoint.py
new file mode 100644
index 00000000..aed28b4c
--- /dev/null
+++ b/pipeline/serve/deploy/otterhd_endpoint.py
@@ -0,0 +1,128 @@
+from flask import Flask, request, jsonify
+from PIL import Image
+import torch
+from transformers import AutoTokenizer, FuyuForCausalLM, FuyuProcessor, FuyuImageProcessor
+import base64
+import re
+from io import BytesIO
+from datetime import datetime
+import hashlib
+from PIL import Image
+import io, os
+
+app = Flask(__name__)
+
+# Initialization code (similar to what you have in your Gradio demo)
+model_id = input("Model ID: ")
+device = "cuda:0"
+dtype = torch.bfloat16
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = FuyuForCausalLM.from_pretrained(model_id, device_map=device, torch_dtype=dtype)
+processor = FuyuProcessor(image_processor=FuyuImageProcessor(), tokenizer=tokenizer)
+
+# Ensure model is in evaluation mode
+model.eval()
+prompt_txt_path = "../user_logs/prompts.txt"
+images_folder_path = "../user_logs"
+
+
+def save_image_unique(pil_image, directory=images_folder_path):
+ # Ensure the directory exists
+ if not os.path.exists(directory):
+ os.makedirs(directory)
+
+ # Convert the PIL Image into a bytes object
+ img_byte_arr = io.BytesIO()
+ pil_image.save(img_byte_arr, format="PNG")
+ img_byte_arr = img_byte_arr.getvalue()
+
+ # Compute the hash of the image data
+ hasher = hashlib.sha256()
+ hasher.update(img_byte_arr)
+ hash_hex = hasher.hexdigest()
+
+ # Create a file name with the hash value
+ file_name = f"{hash_hex}.png"
+ file_path = os.path.join(directory, file_name)
+
+ # Check if a file with the same name exists
+ if os.path.isfile(file_path):
+ print(f"Image already exists with the name: {file_name}")
+ else:
+ # If the file does not exist, save the image
+ with open(file_path, "wb") as new_file:
+ new_file.write(img_byte_arr)
+ print(f"Image saved with the name: {file_name}")
+
+ return file_path
+
+
+# Define endpoint
+@app.route("/app/otter", methods=["POST"])
+def process_image_and_prompt():
+ start_time = datetime.now()
+ # Parse request data
+ data = request.get_json()
+ query_content = data["content"][0]
+ if "image" not in query_content:
+ return jsonify({"error": "Missing Image"}), 400
+ elif "prompt" not in query_content:
+ return jsonify({"error": "Missing Prompt"}), 400
+
+ # Decode the image
+ image_data = query_content["image"]
+ image = Image.open(BytesIO(base64.b64decode(image_data)))
+ prompt = query_content["prompt"]
+ formated_time = start_time.strftime("%Y-%m-%d %H:%M:%S")
+ image_path = save_image_unique(image)
+
+ # Preprocess the image and prompt, and run the model
+ response = predict(image, prompt)
+ torch.cuda.empty_cache()
+
+ with open(prompt_txt_path, "a") as f:
+ f.write(f"*************************{formated_time}**************************" + "\n")
+ f.write(f"Image saved to {image_path}" + "\n")
+ f.write(f"Prompt: {prompt}" + "\n")
+ f.write(f"Response: {response}" + "\n\n")
+
+ # Return the response
+ return jsonify({"result": response})
+
+
+import time
+
+
+# Other necessary functions (adapted from your Gradio demo)
+def predict(image, prompt):
+ time_start = time.time()
+ image = image.convert("RGB")
+ # if max(image.size) > 1080:
+ # image.thumbnail((1080, 1080))
+ model_inputs = processor(text=prompt, images=[image], device=device)
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(device, non_blocking=True) if isinstance(v, torch.Tensor) else [vv.to(device, non_blocking=True) for vv in v]
+ model_inputs["image_patches"][0] = model_inputs["image_patches"][0].to(dtype=next(model.parameters()).dtype)
+
+ generation_output = model.generate(
+ **model_inputs,
+ max_new_tokens=512,
+ pad_token_id=processor.tokenizer.eos_token_id
+ # do_sample=True,
+ # top_p=0.5,
+ # temperature=0.2,
+ )
+ generation_text = processor.batch_decode(generation_output, skip_special_tokens=True)
+ generation_text = [text.split("\x04")[1].strip() for text in generation_text]
+ end_time = time.time()
+ formated_interval = f"{end_time - time_start:.3f}"
+ response = f"Image Resolution (W, H): {image.size}\n-------------------\nModel Respond Time(s): {formated_interval}\n-------------------\nAnswer: {generation_text[0]}"
+ return response
+
+
+# Utility functions (as per the Gradio script, you can adapt the same or similar ones)
+# ... (e.g., resize_to_max, pad_to_size, etc.)
+
+if __name__ == "__main__":
+ app.run(host="0.0.0.0", port=8890)
diff --git a/pipeline/serve/deploy/utils.py b/pipeline/serve/deploy/utils.py
new file mode 100644
index 00000000..3cd6973c
--- /dev/null
+++ b/pipeline/serve/deploy/utils.py
@@ -0,0 +1,82 @@
+import logging
+import logging.handlers
+import os
+import sys
+
+handler = None
+
+
+def build_logger(logger_name, logger_dir):
+ global handler
+
+ formatter = logging.Formatter(
+ fmt="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
+ datefmt="%Y-%m-%d %H:%M:%S",
+ )
+
+ # Set the format of root handlers
+ if not logging.getLogger().handlers:
+ logging.basicConfig(level=logging.INFO)
+ logging.getLogger().handlers[0].setFormatter(formatter)
+
+ # Redirect stdout and stderr to loggers
+ stdout_logger = logging.getLogger("stdout")
+ stdout_logger.setLevel(logging.INFO)
+ sl = StreamToLogger(stdout_logger, logging.INFO)
+ sys.stdout = sl
+
+ stderr_logger = logging.getLogger("stderr")
+ stderr_logger.setLevel(logging.ERROR)
+ sl = StreamToLogger(stderr_logger, logging.ERROR)
+ sys.stderr = sl
+
+ # Get logger
+ logger = logging.getLogger(logger_name)
+ logger.setLevel(logging.INFO)
+
+ # Add a file handler for all loggers
+ if handler is None:
+ os.makedirs(logger_dir, exist_ok=True)
+ filename = os.path.join(logger_dir, logger_name + ".log")
+ handler = logging.handlers.TimedRotatingFileHandler(filename, when="D", utc=True)
+ handler.setFormatter(formatter)
+
+ for name, item in logging.root.manager.loggerDict.items():
+ if isinstance(item, logging.Logger):
+ item.addHandler(handler)
+
+ return logger
+
+
+class StreamToLogger(object):
+ """
+ Fake file-like stream object that redirects writes to a logger instance.
+ """
+
+ def __init__(self, logger, log_level=logging.INFO):
+ self.terminal = sys.stdout
+ self.logger = logger
+ self.log_level = log_level
+ self.linebuf = ""
+
+ def __getattr__(self, attr):
+ return getattr(self.terminal, attr)
+
+ def write(self, buf):
+ temp_linebuf = self.linebuf + buf
+ self.linebuf = ""
+ for line in temp_linebuf.splitlines(True):
+ # From the io.TextIOWrapper docs:
+ # On output, if newline is None, any '\n' characters written
+ # are translated to the system default line separator.
+ # By default sys.stdout.write() expects '\n' newlines and then
+ # translates them so this is still cross platform.
+ if line[-1] == "\n":
+ self.logger.log(self.log_level, line.rstrip())
+ else:
+ self.linebuf += line
+
+ def flush(self):
+ if self.linebuf != "":
+ self.logger.log(self.log_level, self.linebuf.rstrip())
+ self.linebuf = ""
diff --git a/pipeline/serve/gradio_css.py b/pipeline/serve/gradio_css.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/gradio_patch.py b/pipeline/serve/gradio_patch.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/gradio_web_server.py b/pipeline/serve/gradio_web_server.py
old mode 100644
new mode 100755
index 9c8bd78b..c1130541
--- a/pipeline/serve/gradio_web_server.py
+++ b/pipeline/serve/gradio_web_server.py
@@ -8,7 +8,11 @@
import gradio as gr
import requests
import re
-from pipeline.conversation import default_conversation, conv_templates, SeparatorStyle
+from pipeline.serve.conversation import (
+ default_conversation,
+ conv_templates,
+ SeparatorStyle,
+)
from pipeline.constants import LOGDIR
from pipeline.serve.serving_utils import (
build_logger,
@@ -255,28 +259,10 @@ def add_text(
if text_demo_answer_2 != "":
assert image_demo_2 is not None
- text = (
- DEFAULT_IMAGE_TOKEN
- + human_role_label
- + text_demo_question_2
- + bot_role_label
- + DEFAULT_ANSWER_TOKEN
- + text_demo_answer_2
- + DEFAULT_DEMO_END_TOKEN
- + text
- )
+ text = DEFAULT_IMAGE_TOKEN + human_role_label + text_demo_question_2 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_2 + DEFAULT_DEMO_END_TOKEN + text
if text_demo_answer_1 != "":
assert image_demo_1 is not None
- text = (
- DEFAULT_IMAGE_TOKEN
- + human_role_label
- + text_demo_question_1
- + bot_role_label
- + DEFAULT_ANSWER_TOKEN
- + text_demo_answer_1
- + DEFAULT_DEMO_END_TOKEN
- + text
- )
+ text = DEFAULT_IMAGE_TOKEN + human_role_label + text_demo_question_1 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_1 + DEFAULT_DEMO_END_TOKEN + text
input = (text, image_demo_1, image_demo_2, image_3)
state.append_message(state.roles[0], input)
@@ -577,12 +563,54 @@ def build_demo(embed_mode):
).style(container=True)
with gr.Accordion("Parameters", open=False, visible=False) as parameter_row:
- max_new_tokens = gr.Slider(minimum=16, maximum=512, value=512, step=1, interactive=True, label="# generation tokens")
- temperature = gr.Slider(minimum=0, maximum=1, value=1, step=0.1, interactive=True, label="temperature")
- top_k = gr.Slider(minimum=0, maximum=10, value=0, step=1, interactive=True, label="top_k")
- top_p = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.1, interactive=True, label="top_p")
- no_repeat_ngram_size = gr.Slider(minimum=1, maximum=10, value=3, step=1, interactive=True, label="no_repeat_ngram_size")
- length_penalty = gr.Slider(minimum=1, maximum=5, value=1, step=0.1, interactive=True, label="length_penalty")
+ max_new_tokens = gr.Slider(
+ minimum=16,
+ maximum=512,
+ value=512,
+ step=1,
+ interactive=True,
+ label="# generation tokens",
+ )
+ temperature = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="temperature",
+ )
+ top_k = gr.Slider(
+ minimum=0,
+ maximum=10,
+ value=0,
+ step=1,
+ interactive=True,
+ label="top_k",
+ )
+ top_p = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1.0,
+ step=0.1,
+ interactive=True,
+ label="top_p",
+ )
+ no_repeat_ngram_size = gr.Slider(
+ minimum=1,
+ maximum=10,
+ value=3,
+ step=1,
+ interactive=True,
+ label="no_repeat_ngram_size",
+ )
+ length_penalty = gr.Slider(
+ minimum=1,
+ maximum=5,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="length_penalty",
+ )
do_sample = gr.Checkbox(interactive=True, label="do_sample")
early_stopping = gr.Checkbox(interactive=True, label="early_stopping", value=True)
@@ -609,11 +637,26 @@ def build_demo(embed_mode):
gr.Examples(
label="Examples (0-shot)",
examples=[
- [f"{cur_dir}/examples/ms_st.jpg", "Does the image feature a globally recognized technology company?"],
- [f"{cur_dir}/examples/ms_st.jpg", "Does the image feature a globally recognized technology company? Please answer with yes or no."],
- [f"{cur_dir}/examples/zelda_princess.jpg", "Can you identify the game character?"],
- [f"{cur_dir}/examples/martin.jpeg", "Can you identify the historic figure?"],
- [f"{cur_dir}/examples/gtav.jpg", "Can you identify what the image is about?"],
+ [
+ f"{cur_dir}/examples/ms_st.jpg",
+ "Does the image feature a globally recognized technology company?",
+ ],
+ [
+ f"{cur_dir}/examples/ms_st.jpg",
+ "Does the image feature a globally recognized technology company? Please answer with yes or no.",
+ ],
+ [
+ f"{cur_dir}/examples/zelda_princess.jpg",
+ "Can you identify the game character?",
+ ],
+ [
+ f"{cur_dir}/examples/martin.jpeg",
+ "Can you identify the historic figure?",
+ ],
+ [
+ f"{cur_dir}/examples/gtav.jpg",
+ "Can you identify what the image is about?",
+ ],
[
f"{cur_dir}/examples/xray.jpg",
"Act as a radiologist and write a diagnostic radiology report for the patient based on their chest radiographs:",
@@ -857,7 +900,5 @@ def build_demo(embed_mode):
models = get_model_list()
logger.info(args)
demo = build_demo(args.embed)
- demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(
- server_name=args.host, server_port=args.port, share=args.share
- )
+ demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(server_name=args.host, server_port=args.port, share=args.share)
gr.close_all()
diff --git a/pipeline/serve/gradio_web_server_video.py b/pipeline/serve/gradio_web_server_video.py
index 513560e8..97017b2a 100755
--- a/pipeline/serve/gradio_web_server_video.py
+++ b/pipeline/serve/gradio_web_server_video.py
@@ -13,8 +13,11 @@
import cv2
import re
-from pipeline.conversation import default_conversation, conv_templates, SeparatorStyle
-from pipeline.constants import LOGDIR
+from pipeline.serve.conversation import (
+ default_conversation,
+ conv_templates,
+ SeparatorStyle,
+)
from pipeline.serve.serving_utils import (
build_logger,
server_error_msg,
@@ -24,6 +27,10 @@
from pipeline.serve.gradio_patch import Chatbot as grChatbot
from pipeline.serve.gradio_css import code_highlight_css
+CONTROLLER_HEART_BEAT_EXPIRATION = 2 * 60
+WORKER_HEART_BEAT_INTERVAL = 30
+LOGDIR = "./logs"
+
DEFAULT_IMAGE_TOKEN = ""
DEFAULT_DEMO_END_TOKEN = "<|endofchunk|>"
# DEFAULT_ANSWER_TOKEN = ""
@@ -261,19 +268,11 @@ def add_text(
if text_demo_answer_2 != "":
if text.startswith(DEFAULT_IMAGE_TOKEN):
- text = (
- DEFAULT_IMAGE_TOKEN
- + (human_role_label + text_demo_question_2 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_2 + DEFAULT_DEMO_END_TOKEN)
- + text[len(DEFAULT_IMAGE_TOKEN) :]
- )
+ text = DEFAULT_IMAGE_TOKEN + (human_role_label + text_demo_question_2 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_2 + DEFAULT_DEMO_END_TOKEN) + text[len(DEFAULT_IMAGE_TOKEN) :]
if text_demo_answer_1 != "":
if text.startswith(DEFAULT_IMAGE_TOKEN):
- text = (
- DEFAULT_IMAGE_TOKEN
- + (human_role_label + text_demo_question_1 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_1 + DEFAULT_DEMO_END_TOKEN)
- + text[len(DEFAULT_IMAGE_TOKEN) :]
- )
+ text = DEFAULT_IMAGE_TOKEN + (human_role_label + text_demo_question_1 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_1 + DEFAULT_DEMO_END_TOKEN) + text[len(DEFAULT_IMAGE_TOKEN) :]
input = (text, image_3)
state.append_message(state.roles[0], input)
@@ -503,32 +502,85 @@ def build_demo(embed_mode):
with gr.Row():
with gr.Column(scale=3):
- model_selector = gr.Dropdown(choices=models, value=models[0] if len(models) > 0 else "", interactive=True, show_label=False).style(
- container=False
- )
+ model_selector = gr.Dropdown(
+ choices=models,
+ value=models[0] if len(models) > 0 else "",
+ interactive=True,
+ show_label=False,
+ ).style(container=False)
videobox_3 = gr.Video(label="Video")
- textbox_demo_question_1 = gr.Textbox(label="Demo Text Query 1 (optional)", show_label=True, placeholder="Example: What is in the image?").style(
- container=True
- )
- textbox_demo_answer_1 = gr.Textbox(label="Demo Text Answer 1 (optional)", show_label=True, placeholder="").style(
- container=True
- )
- textbox_demo_question_2 = gr.Textbox(label="Demo Text Query 2 (optional)", show_label=True, placeholder="Example: What is in the image?").style(
- container=True
- )
- textbox_demo_answer_2 = gr.Textbox(label="Demo Text Answer 2 (optional)", show_label=True, placeholder="").style(
- container=True
- )
+ textbox_demo_question_1 = gr.Textbox(
+ label="Demo Text Query 1 (optional)",
+ show_label=True,
+ placeholder="Example: What is in the image?",
+ ).style(container=True)
+ textbox_demo_answer_1 = gr.Textbox(
+ label="Demo Text Answer 1 (optional)",
+ show_label=True,
+ placeholder="",
+ ).style(container=True)
+ textbox_demo_question_2 = gr.Textbox(
+ label="Demo Text Query 2 (optional)",
+ show_label=True,
+ placeholder="Example: What is in the image?",
+ ).style(container=True)
+ textbox_demo_answer_2 = gr.Textbox(
+ label="Demo Text Answer 2 (optional)",
+ show_label=True,
+ placeholder="",
+ ).style(container=True)
with gr.Accordion("Parameters", open=False, visible=False) as parameter_row:
- max_new_tokens = gr.Slider(minimum=16, maximum=512, value=512, step=1, interactive=True, label="# generation tokens")
- temperature = gr.Slider(minimum=0, maximum=1, value=1, step=0.1, interactive=True, label="temperature")
- top_k = gr.Slider(minimum=0, maximum=10, value=0, step=1, interactive=True, label="top_k")
- top_p = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.1, interactive=True, label="top_p")
- no_repeat_ngram_size = gr.Slider(minimum=1, maximum=10, value=3, step=1, interactive=True, label="no_repeat_ngram_size")
- length_penalty = gr.Slider(minimum=1, maximum=5, value=1, step=0.1, interactive=True, label="length_penalty")
+ max_new_tokens = gr.Slider(
+ minimum=16,
+ maximum=512,
+ value=512,
+ step=1,
+ interactive=True,
+ label="# generation tokens",
+ )
+ temperature = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="temperature",
+ )
+ top_k = gr.Slider(
+ minimum=0,
+ maximum=10,
+ value=0,
+ step=1,
+ interactive=True,
+ label="top_k",
+ )
+ top_p = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1.0,
+ step=0.1,
+ interactive=True,
+ label="top_p",
+ )
+ no_repeat_ngram_size = gr.Slider(
+ minimum=1,
+ maximum=10,
+ value=3,
+ step=1,
+ interactive=True,
+ label="no_repeat_ngram_size",
+ )
+ length_penalty = gr.Slider(
+ minimum=1,
+ maximum=5,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="length_penalty",
+ )
do_sample = gr.Checkbox(interactive=True, label="do_sample")
early_stopping = gr.Checkbox(interactive=True, label="early_stopping")
@@ -554,8 +606,22 @@ def build_demo(embed_mode):
cur_dir = os.path.dirname(os.path.abspath(__file__))
gr.Examples(
examples=[
- ["", "", "", "", f"{cur_dir}/examples/Apple Vision Pro - Reveal Trailer.mp4", "Hey Otter, do you think it's cool? "],
- ["", "", "", "", f"{cur_dir}/examples/example.mp4", "What does the video describe?"],
+ [
+ "",
+ "",
+ "",
+ "",
+ f"{cur_dir}/examples/Apple Vision Pro - Reveal Trailer.mp4",
+ "Hey Otter, do you think it's cool? ",
+ ],
+ [
+ "",
+ "",
+ "",
+ "",
+ f"{cur_dir}/examples/example.mp4",
+ "What does the video describe?",
+ ],
[
"Is there a person in this video?",
"Yes, a woman.",
@@ -590,7 +656,12 @@ def build_demo(embed_mode):
# Register listeners
btn_list = [upvote_btn, downvote_btn, flag_btn, regenerate_btn, clear_btn]
- demo_list = [textbox_demo_question_1, textbox_demo_answer_1, textbox_demo_question_2, textbox_demo_answer_2]
+ demo_list = [
+ textbox_demo_question_1,
+ textbox_demo_answer_1,
+ textbox_demo_question_2,
+ textbox_demo_answer_2,
+ ]
prarameter_list = [
max_new_tokens,
temperature,
@@ -609,17 +680,41 @@ def build_demo(embed_mode):
flag_btn.click(flag_last_response, [state, model_selector], feedback_args)
common_args = [state, chatbot] + demo_list + [textbox_3, videobox_3] + btn_list
- regenerate_btn.click(regenerate, state, common_args).then(http_bot, [state, model_selector] + prarameter_list, [state, chatbot] + btn_list)
+ regenerate_btn.click(regenerate, state, common_args).then(
+ http_bot,
+ [state, model_selector] + prarameter_list,
+ [state, chatbot] + btn_list,
+ )
clear_btn.click(clear_history, None, common_args)
- textbox_3.submit(add_text, [state, model_selector] + demo_list + [textbox_3, videobox_3], common_args).then(
- http_bot, [state, model_selector] + prarameter_list, [state, chatbot] + btn_list
+ textbox_3.submit(
+ add_text,
+ [state, model_selector] + demo_list + [textbox_3, videobox_3],
+ common_args,
+ ).then(
+ http_bot,
+ [state, model_selector] + prarameter_list,
+ [state, chatbot] + btn_list,
)
- submit_btn.click(add_text, [state, model_selector] + demo_list + [textbox_3, videobox_3], common_args).then(
- http_bot, [state, model_selector] + prarameter_list, [state, chatbot] + btn_list
+ submit_btn.click(
+ add_text,
+ [state, model_selector] + demo_list + [textbox_3, videobox_3],
+ common_args,
+ ).then(
+ http_bot,
+ [state, model_selector] + prarameter_list,
+ [state, chatbot] + btn_list,
)
- widget_list = [state, model_selector, chatbot, textbox_3, submit_btn, button_row, parameter_row]
+ widget_list = [
+ state,
+ model_selector,
+ chatbot,
+ textbox_3,
+ submit_btn,
+ button_row,
+ parameter_row,
+ ]
if args.model_list_mode == "once":
demo.load(load_demo, [url_params], widget_list, _js=get_window_url_params)
@@ -647,7 +742,5 @@ def build_demo(embed_mode):
models = get_model_list()
logger.info(args)
demo = build_demo(args.embed)
- demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(
- server_name=args.host, server_port=args.port, share=args.share
- )
+ demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(server_name=args.host, server_port=args.port, share=args.share)
gr.close_all()
diff --git a/pipeline/serve/model_worker.py b/pipeline/serve/model_worker.py
index 01f62546..78cdadf3 100755
--- a/pipeline/serve/model_worker.py
+++ b/pipeline/serve/model_worker.py
@@ -130,9 +130,7 @@ def register_to_controller(self):
assert r.status_code == 200
def send_heart_beat(self):
- logger.info(
- f"Send heart beat. Models: {[self.model_name]}. " f"Semaphore: {pretty_print_semaphore(model_semaphore)}. " f"global_counter: {global_counter}"
- )
+ logger.info(f"Send heart beat. Models: {[self.model_name]}. " f"Semaphore: {pretty_print_semaphore(model_semaphore)}. " f"global_counter: {global_counter}")
url = self.controller_addr + "/receive_heart_beat"
@@ -191,7 +189,11 @@ def generate_stream(self, params):
# cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
images = [Image.open(BytesIO(base64.urlsafe_b64decode(image))).convert("RGB") for image in images]
logger.info(f"{len(images)} images conditioned.")
- tensor_dtype = {"fp16": torch.float16, "bf16": torch.bfloat16, "fp32": torch.float32}[self.load_bit]
+ tensor_dtype = {
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ "fp32": torch.float32,
+ }[self.load_bit]
if is_video is True:
vision_x = image_processor.preprocess(images, return_tensors="pt")["pixel_values"].unsqueeze(0).unsqueeze(0)
assert vision_x.shape[2] == len(images) # dim of vision_x: [B, T, F, C, H, W], make sure conditioned on frames of the same video
@@ -325,7 +327,12 @@ async def get_status(request: Request):
parser.add_argument("--limit_model_concurrency", type=int, default=5)
parser.add_argument("--stream_interval", type=int, default=2)
parser.add_argument("--no_register", action="store_true")
- parser.add_argument("--load_bit", type=str, choices=["fp16", "bf16", "int8", "int4", "fp32"], default="fp32")
+ parser.add_argument(
+ "--load_bit",
+ type=str,
+ choices=["fp16", "bf16", "int8", "int4", "fp32"],
+ default="fp32",
+ )
parser.add_argument("--load_pt", action="store_true")
args = parser.parse_args()
diff --git a/pipeline/serve/multiplex_script/otter_image_server.py b/pipeline/serve/multiplex_script/otter_image_server.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/register_worker.py b/pipeline/serve/register_worker.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/serving_utils.py b/pipeline/serve/serving_utils.py
old mode 100644
new mode 100755
index bf565059..6370193f
--- a/pipeline/serve/serving_utils.py
+++ b/pipeline/serve/serving_utils.py
@@ -5,7 +5,10 @@
import requests
-from pipeline.constants import LOGDIR
+CONTROLLER_HEART_BEAT_EXPIRATION = 2 * 60
+WORKER_HEART_BEAT_INTERVAL = 30
+
+LOGDIR = "./logs"
server_error_msg = "**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**"
moderation_msg = "YOUR INPUT VIOLATES OUR CONTENT MODERATION GUIDELINES. PLEASE TRY AGAIN."
diff --git a/pipeline/serve/test_message.py b/pipeline/serve/test_message.py
old mode 100644
new mode 100755
index 88709e28..b0670956
--- a/pipeline/serve/test_message.py
+++ b/pipeline/serve/test_message.py
@@ -3,7 +3,7 @@
import requests
-from pipeline.conversation import default_conversation
+from pipeline.serve.conversation import default_conversation
def main():
diff --git a/pipeline/train/.gitignore b/pipeline/train/.gitignore
new file mode 100644
index 00000000..a5394700
--- /dev/null
+++ b/pipeline/train/.gitignore
@@ -0,0 +1 @@
+config.yaml
\ No newline at end of file
diff --git a/pipeline/train/__init__.py b/pipeline/train/__init__.py
old mode 100644
new mode 100755
diff --git a/pipeline/train/distributed.py b/pipeline/train/distributed.py
old mode 100644
new mode 100755
index 8577b70b..3476b804
--- a/pipeline/train/distributed.py
+++ b/pipeline/train/distributed.py
@@ -1,11 +1,6 @@
import os
import torch
-try:
- import horovod.torch as hvd
-except ImportError:
- hvd = None
-
def is_global_master(args):
return args.rank == 0
@@ -19,17 +14,6 @@ def is_master(args, local=False):
return is_local_master(args) if local else is_global_master(args)
-def is_using_horovod():
- # NOTE w/ horovod run, OMPI vars should be set, but w/ SLURM PMI vars will be set
- # Differentiating between horovod and DDP use via SLURM may not be possible, so horovod arg still required...
- ompi_vars = ["OMPI_COMM_WORLD_RANK", "OMPI_COMM_WORLD_SIZE"]
- pmi_vars = ["PMI_RANK", "PMI_SIZE"]
- if all([var in os.environ for var in ompi_vars]) or all([var in os.environ for var in pmi_vars]):
- return True
- else:
- return False
-
-
def is_using_distributed():
if "WORLD_SIZE" in os.environ:
return int(os.environ["WORLD_SIZE"]) > 1
@@ -40,7 +24,12 @@ def is_using_distributed():
def world_info_from_env():
local_rank = 0
- for v in ("LOCAL_RANK", "MPI_LOCALRANKID", "SLURM_LOCALID", "OMPI_COMM_WORLD_LOCAL_RANK"):
+ for v in (
+ "LOCAL_RANK",
+ "MPI_LOCALRANKID",
+ "SLURM_LOCALID",
+ "OMPI_COMM_WORLD_LOCAL_RANK",
+ ):
if v in os.environ:
local_rank = int(os.environ[v])
break
@@ -64,17 +53,7 @@ def init_distributed_device(args):
args.world_size = 1
args.rank = 0 # global rank
args.local_rank = 0
- if args.horovod:
- assert hvd is not None, "Horovod is not installed"
- hvd.init()
- args.local_rank = int(hvd.local_rank())
- args.rank = hvd.rank()
- args.world_size = hvd.size()
- args.distributed = True
- os.environ["LOCAL_RANK"] = str(args.local_rank)
- os.environ["RANK"] = str(args.rank)
- os.environ["WORLD_SIZE"] = str(args.world_size)
- elif is_using_distributed():
+ if is_using_distributed():
if "SLURM_PROCID" in os.environ:
# DDP via SLURM
args.local_rank, args.rank, args.world_size = world_info_from_env()
diff --git a/pipeline/train/instruction_following.py b/pipeline/train/instruction_following.py
index 83e1acb4..fca6da5f 100755
--- a/pipeline/train/instruction_following.py
+++ b/pipeline/train/instruction_following.py
@@ -1,15 +1,18 @@
""" Main training script """
import argparse
+import gc
import glob
import os
-import random
+import sys
import time
+from itertools import cycle
+import deepspeed
import numpy as np
-import gc
import torch
import torch.nn
+import torch.nn.functional as F
from accelerate import Accelerator
from tqdm import tqdm
from transformers import (
@@ -18,17 +21,33 @@
get_cosine_schedule_with_warmup,
get_linear_schedule_with_warmup,
)
-
+from peft import LoraConfig, TaskType, get_peft_model, PeftModel
import wandb
-from otter_ai import OtterForConditionalGeneration
-from otter_ai import FlamingoForConditionalGeneration
-from pipeline.train.data import get_data
-from pipeline.train.distributed import world_info_from_env
-from pipeline.train.train_utils import AverageMeter, get_checkpoint, get_image_attention_mask
-from transformers import AutoProcessor
-
-import deepspeed
+sys.path.append("../..")
+from transformers import AutoProcessor, AutoTokenizer, FuyuImageProcessor
+from src.otter_ai.models.fuyu.modeling_fuyu import FuyuForCausalLM
+from src.otter_ai.models.fuyu.processing_fuyu import FuyuProcessor
+
+from pipeline.mimicit_utils.data import get_data
+from pipeline.train.train_args import parse_args
+from pipeline.train.train_utils import (
+ AverageMeter,
+ get_grouped_params,
+ get_image_attention_mask,
+ master_print,
+ random_seed,
+ save_checkpoint,
+ save_final_weights,
+ verify_yaml,
+ get_weights_for_dataloaders,
+ get_next_dataloader,
+ find_and_remove_tokens,
+ delete_tensors_from_dict,
+)
+from src.otter_ai.models.flamingo.modeling_flamingo import FlamingoForConditionalGeneration
+from src.otter_ai.models.otter.modeling_otter import OtterForConditionalGeneration
+from transformers import LlamaForCausalLM, AutoTokenizer
os.environ["TOKENIZERS_PARALLELISM"] = "false"
@@ -38,7 +57,7 @@
# The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.
torch.backends.cudnn.allow_tf32 = True
-
+torch.backends.cuda.enable_flash_sdp(True)
# Try importing IdeficsForVisionText2Text, and if it's not available, define a dummy class
try:
from transformers import IdeficsForVisionText2Text
@@ -46,29 +65,74 @@
print("IdeficsForVisionText2Text does not exist")
IdeficsForVisionText2Text = type(None)
+# from memory_profiler import profile
+# fp = open("memory_report.log", "w+")
+
+
+# @profile(stream=fp)
+def forward_pass(args, model, tokenizer, images, input_ids, attention_mask, labels, device_id, autocast_type, batch_mimicit):
+ if args.model_name == "fuyu":
+ model_inputs = batch_mimicit.pop("fuyu_data")
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(device_id, non_blocking=True) if isinstance(v, torch.Tensor) else [vv.to(device_id, non_blocking=True) for vv in v]
+ loss_mimicit = model(**model_inputs)[0]
+ elif args.model_name == "idefics":
+ # only for image model
+ max_num_images = images.shape[1]
+ pure_text = torch.all(images == 0)
+ image_attention_mask = get_image_attention_mask(
+ input_ids,
+ max_num_images,
+ tokenizer,
+ include_image=not pure_text,
+ )
+ image_attention_mask = image_attention_mask.to(device_id, non_blocking=True)
+ loss_mimicit = model(
+ pixel_values=images.squeeze(2).to(autocast_type),
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ image_attention_mask=image_attention_mask,
+ labels=labels,
+ )[0]
+ elif args.model_name == "otter" or args.model_name == "flamingo":
+ loss_mimicit = model(
+ vision_x=images.to(autocast_type),
+ lang_x=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )[0]
+ elif args.model_name == "llama2":
+ loss_mimicit = model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )[0]
+ else:
+ raise NotImplementedError(f"Loss of model {args.model_name} not implemented.")
-def random_seed(seed=42, rank=0):
- torch.manual_seed(seed + rank)
- np.random.seed(seed + rank)
- random.seed(seed + rank)
+ return loss_mimicit
def train_one_epoch(args, model, epoch, mimicit_loaders, tokenizer, optimizer, lr_scheduler, device_id, accelerator, wandb):
- num_batches_per_epoch = len(mimicit_loaders[0])
- total_training_steps = num_batches_per_epoch * args.num_epochs
-
- # special design for Idefics Model's prompt strategy
- fake_token_image_exists = True if "" in tokenizer.special_tokens_map["additional_special_tokens"] else False
- fake_token_image_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ dataloader_iterators = [cycle(dataloader) for dataloader in mimicit_loaders]
+ weights = get_weights_for_dataloaders(mimicit_loaders)
+ num_batches_per_epoch = sum(len(dataloader) for dataloader in mimicit_loaders) // args.gradient_accumulation_steps
+
+ # Special Design for Idefics Model's prompt strategy
+ if args.model_name.lower() == "idefics":
+ fake_token_image_exists = True if "" in tokenizer.special_tokens_map["additional_special_tokens"] else False
+ fake_token_image_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ endofchunk_text = ""
+ else:
+ fake_token_image_exists = False
+ fake_token_image_token_id = None
+ endofchunk_text = "<|endofchunk|>"
- # normal prompt strategy
+ # Normal Prompt Strategy
media_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
- endofchunk_text = (
- "<|endofchunk|>" if "<|endofchunk|>" in tokenizer.special_tokens_map["additional_special_tokens"] else ""
- ) # for different tokenizer
endofchunk_token_id = tokenizer(endofchunk_text, add_special_tokens=False)["input_ids"][-1]
answer_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
- ens_token_id = tokenizer(tokenizer.eos_token, add_special_tokens=False)["input_ids"][-1]
+ eos_token_id = tokenizer(tokenizer.eos_token, add_special_tokens=False)["input_ids"][-1]
model.train()
@@ -78,507 +142,193 @@ def train_one_epoch(args, model, epoch, mimicit_loaders, tokenizer, optimizer, l
end = time.time()
autocast_type = torch.bfloat16 if accelerator.mixed_precision == "bf16" else torch.float32
- # loop through dataloader
- for num_steps, (batch_mimicits) in tqdm(
- enumerate(zip(*mimicit_loaders)),
- disable=args.rank != 0,
- total=total_training_steps,
- initial=(epoch * num_batches_per_epoch),
- ):
+ # loop through different groups of dataloader
+ for num_steps in tqdm(range(args.total_training_steps), disable=args.rank != 0, initial=(epoch * num_batches_per_epoch)):
+ if num_steps == num_batches_per_epoch:
+ break
data_time_m.update(time.time() - end)
-
+ dataloader_iterator = get_next_dataloader(dataloader_iterators, weights)
+ batch_mimicit = next(dataloader_iterator) # Fetch a batch from the chosen dataloader
global_step = num_steps + epoch * num_batches_per_epoch
+
#### MIMIC-IT FORWARD PASS ####
+ net_input = batch_mimicit.pop("net_input")
+ images = net_input.pop("patch_images").to(device_id, non_blocking=True)
+ input_ids = net_input.pop("input_ids").to(device_id, non_blocking=True)
+ attention_mask = net_input.pop("attention_masks").to(device_id, non_blocking=True)
+ labels = None # placeholder to avoid error
- total_losses = []
- for batch_mimicit in batch_mimicits:
- images = batch_mimicit["net_input"]["patch_images"].to(device_id, non_blocking=True)
- input_ids = batch_mimicit["net_input"]["input_ids"].to(device_id, non_blocking=True)
- attention_mask = batch_mimicit["net_input"]["attention_masks"].to(device_id, non_blocking=True)
-
- labels = input_ids.clone()
- labels[labels == tokenizer.pad_token_id] = -100
- labels[:, 0] = -100
- for i in range(labels.shape[0]):
- # get index of all endofchunk/media tokens in the sequence
- endofchunk_idxs = torch.where(labels[i] == endofchunk_token_id)[0]
- media_idxs = torch.where(labels[i] == media_token_id)[0]
-
- # remove loss for any token the before the first
- token_idx = 0
- while token_idx < labels.shape[1] and labels[i][token_idx] != answer_token_id:
- labels[i][token_idx] = -100
- token_idx += 1
-
- # remove loss for any token between <|endofchunk|> and , except
- for endofchunk_idx in endofchunk_idxs[:-1]:
- token_idx = endofchunk_idx + 1
- while token_idx < labels.shape[1] and labels[i][token_idx] != answer_token_id:
- if labels[i][token_idx] == media_token_id:
- pass
- else:
- labels[i][token_idx] = -100
- token_idx += 1
-
- labels[labels == answer_token_id] = -100
- labels[labels == media_token_id] = -100
- if fake_token_image_exists:
- labels[labels == fake_token_image_token_id] = -100
-
- with accelerator.autocast():
- unwrapped_model = accelerator.unwrap_model(model)
- if num_steps == 0:
- # info check
- accelerator.print(f"input_ids: {input_ids.shape}")
- accelerator.print(f"images: {images.shape}")
- accelerator.print(f"attention_mask: {attention_mask.shape}")
- accelerator.print(f"labels: {labels.shape}")
- accelerator.print(f"model: {unwrapped_model.__class__.__name__}")
- accelerator.print(f"model dtype: {unwrapped_model.dtype}")
-
- if IdeficsForVisionText2Text is not None and isinstance(unwrapped_model, IdeficsForVisionText2Text):
- # only for image model
- max_num_images = images.shape[1]
- pure_text = torch.all(images == 0)
- image_attention_mask = get_image_attention_mask(input_ids, max_num_images, tokenizer, include_image=not pure_text)
- # assert images.shape[1] == 1, "The second dimension is not 1"
-
- loss_mimicit = model(
- pixel_values=images.squeeze(1).to(autocast_type),
- input_ids=input_ids,
- attention_mask=attention_mask,
- image_attention_mask=image_attention_mask,
- labels=labels,
- )[0]
- else:
- loss_mimicit = model(
- vision_x=images.to(autocast_type),
- lang_x=input_ids,
- attention_mask=attention_mask,
- labels=labels,
- )[0]
+ if args.model_name != "fuyu": # design fuyu's process into it's processor, a way better design than following code.
- if accelerator.mixed_precision == "fp16":
- accelerator.backward(loss_mimicit.to(device_id))
- else:
- accelerator.backward(loss_mimicit)
+ def masking(masking_number: int = -100):
+ labels = torch.empty(input_ids.shape, dtype=torch.int64).to(device_id, non_blocking=True)
+ for i in range(input_ids.shape[0]):
+ labels[i] = torch.where(input_ids[i] == eos_token_id, eos_token_id, masking_number)
+ answer_token_ids_all = torch.where(input_ids[i] == answer_token_id)[0]
+ endofchunk_token_ids_all = torch.where(input_ids[i] == endofchunk_token_id)[0]
- total_losses.append(loss_mimicit)
- #### BACKWARD PASS ####
- total_loss_sum = sum(total_losses)
- mean_loss = total_loss_sum / len(total_losses)
- # accelerator.backward(total_loss_sum.to(device_id))
-
- def mask_embedding(m):
- if m.weight.requires_grad:
- zero_mask = torch.zeros_like(m.weight.grad)
- zero_mask[answer_token_id] = torch.ones_like(zero_mask[answer_token_id])
- # zero_mask[media_token_id] = torch.ones_like(zero_mask[media_token_id])
- # zero_mask[endofchunk_token_id] = torch.ones_like(zero_mask[endofchunk_token_id])
- m.weight.grad = m.weight.grad * zero_mask
-
- if args.mask_lm_head and args.distributed_type != "DEEPSPEED":
- unwrapped_model = accelerator.unwrap_model(model)
- if isinstance(unwrapped_model, IdeficsForVisionText2Text):
- # This code need to be refined.
- unwrapped_model.lm_head.apply(mask_embedding)
- elif unwrapped_model.lang_encoder.__class__.__name__ in ["MPTForCausalLM", "MosaicGPT"]:
- unwrapped_model.lang_encoder.transformer.wte.apply(mask_embedding)
- elif "LlamaForCausalLM" in unwrapped_model.lang_encoder.__class__.__name__:
- unwrapped_model.lang_encoder.model.embed_tokens.apply(mask_embedding)
- unwrapped_model.lang_encoder.lm_head.apply(mask_embedding)
-
- if accelerator.sync_gradients:
- accelerator.clip_grad_norm_(model.parameters(), 1.0)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
-
- # step time and reset end outside of rank 0
- step_time_m.update(time.time() - end)
- end = time.time()
-
- if accelerator.sync_gradients:
- if args.rank == 0 and args.report_to_wandb:
- # compute within rank 0
- mimicit_samples_per_second = args.gradient_accumulation_steps * args.batch_size * args.world_size / step_time_m.val
- mimicit_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size / step_time_m.val
-
- wandb.log(
- {
- "data_time": data_time_m.avg,
- "step_time": step_time_m.avg,
- "mimicit_samples_per_second": mimicit_samples_per_second,
- "mimicit_samples_per_second_per_gpu": mimicit_samples_per_second_per_gpu,
- "lr": optimizer.param_groups[0]["lr"],
- },
- commit=False,
- )
- step_time_m.reset()
- data_time_m.reset()
+ j = 0 # Counter for endofchunk_token_ids
+ for answer_token_idx in answer_token_ids_all:
+ # Find the closest endofchunk_token_id that is greater than answer_token_id
+ while j < len(endofchunk_token_ids_all) and endofchunk_token_ids_all[j] < answer_token_idx:
+ j += 1
- wandb.log(
- {
- "loss_mimicit": mean_loss.item(),
- "global_step": global_step // args.gradient_accumulation_steps,
- },
- commit=True,
- )
- # torch.cuda.empty_cache()
- # gc.collect() # forces garbage collection
+ if j < len(endofchunk_token_ids_all):
+ endofchunk_token_idx = endofchunk_token_ids_all[j]
+ labels[i, answer_token_idx + 1 : endofchunk_token_idx + 1] = input_ids[i, answer_token_idx + 1 : endofchunk_token_idx + 1]
- if args.rank == 0 and global_step != 0 and (args.save_steps_interval != -1) and (global_step % args.save_steps_interval == 0):
- if not os.path.exists(args.external_save_dir):
- os.makedirs(args.external_save_dir)
-
- unwrapped_model = accelerator.unwrap_model(model)
- checkpoint_dict = {
- "steps": global_step,
- "model_state_dict": get_checkpoint(unwrapped_model),
- }
- print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_steps_{global_step}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_steps_{global_step}.pt")
- if args.delete_previous_checkpoint:
- if epoch > 0 and os.path.exists(f"{args.external_save_dir}/checkpoint_step_{global_step-args.save_steps_interval}.pt"):
- os.remove(f"{args.external_save_dir}/checkpoint_step_{global_step-args.save_steps_interval}.pt")
+ # Increment j for the next iteration
+ j += 1
- # Log loss to console
- if ((num_steps + 1) % args.logging_steps == 0) and args.rank == 0:
- print(f"Step {num_steps+1}/{num_batches_per_epoch} of epoch {epoch+1}/{args.num_epochs} complete. Loss MIMIC-IT: {mean_loss.item():.3f}")
+ for answer_token_idx, endofchunk_token_idx in zip(answer_token_ids_all, endofchunk_token_ids_all):
+ labels[i, answer_token_idx + 1 : endofchunk_token_idx + 1] = input_ids[i, answer_token_idx + 1 : endofchunk_token_idx + 1]
+ labels[:, 0] = masking_number
+ if args.model_name == "idefics" and fake_token_image_exists:
+ labels[labels == fake_token_image_token_id] = masking_number
-def parse_args():
- """
- Parse the command line arguments and perform the initial setup.
- :return: Parsed arguments
- """
- parser = argparse.ArgumentParser(description="Main training script for the model")
+ return labels
- # Add arguments to the parser
- # TODO: Add help messages to clarify the purpose of each argument
+ labels = masking()
- # Model configuration arguments
- parser.add_argument(
- "--external_save_dir",
- type=str,
- default=None,
- help="set to save model to external path",
- )
- parser.add_argument(
- "--run_name",
- type=str,
- default="otter-9b",
- help="used to name saving directory and wandb run",
- )
- parser.add_argument(
- "--model_name",
- type=str,
- default="otter",
- choices=["otter", "flamingo", "idefics"],
- help="otters or flamingo",
- )
- parser.add_argument(
- "--inst_format",
- type=str,
- default="simple",
- choices=["simple", "llama2", "idefics"],
- help="simple is for mpt/llama1, rest are in different instruction templates.",
- )
- # Prepare the arguments for different types of data sources.
- # Arguments are grouped by data types and whether the data is from past or new sources.
- # Arguments for image-text data, including multi-run conversations.
- parser.add_argument(
- "--past_mimicit_path",
- type=str,
- default="",
- help="Path to the past image-text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_images_path",
- type=str,
- default="",
- help="Path to the past images dataset (including base64 format images). Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--past_train_config_path",
- type=str,
- default="",
- help="Path to the past images dataset (including current ids and related in-context ids). Should be in format /path/to/xx_train.json",
- )
+ if args.remove_answer_token:
+ input_ids, labels, attention_mask = find_and_remove_tokens(input_ids, labels, attention_mask, answer_token_id, tokenizer) # find and remove certain tokens from input_ids, labels, and attention_mask
- parser.add_argument(
- "--mimicit_path",
- type=str,
- default="",
- help="Path to the new image-text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--images_path",
- type=str,
- default="",
- help="Path to the new images dataset (including base64 format images). Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--train_config_path",
- type=str,
- default="",
- help="Path to the new images dataset (including current ids and related in-context ids). Should be in format /path/to/xx_train.json",
- )
+ if args.remove_eos_token:
+ input_ids, labels, attention_mask = find_and_remove_tokens(input_ids, labels, attention_mask, endofchunk_token_id, tokenizer)
- # Arguments for image-text in-context data.
- parser.add_argument(
- "--past_mimicit_ic_path",
- type=str,
- default="",
- help="Path to the past in-context image-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_images_ic_path",
- type=str,
- default="",
- help="Path to the past in-context images dataset. Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--past_train_config_ic_path",
- type=str,
- default="",
- help="Path to the past in-context training config dataset. Should be in format /path/to/xx_train.json",
- )
- parser.add_argument(
- "--mimicit_ic_path",
- type=str,
- default="",
- help="Path to the new in-context image-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--images_ic_path",
- type=str,
- default="",
- help="Path to the new in-context images dataset. Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--train_config_ic_path",
- type=str,
- default="",
- help="Path to the new in-context training config dataset. Should be in format /path/to/xx_train.json",
- )
-
- # Arguments for text data, including multi-run conversations.
- parser.add_argument(
- "--mimicit_text_path",
- type=str,
- default="",
- help="Path to the new text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--train_config_text_path",
- type=str,
- default="",
- help="Path to the new text dataset (including multi-run conversations). Should be in format /path/to/xx_train.json",
- )
- parser.add_argument(
- "--past_mimicit_text_path",
- type=str,
- default="",
- help="Path to the past text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_train_config_text_path",
- type=str,
- default="",
- help="Path to the past text dataset (including multi-run conversations). Should be in format /path/to/xx_train.json",
- )
-
- # Arguments for video-text data.
- parser.add_argument(
- "--training_data_yaml",
- type=str,
- default="",
- help="Path to the training data yaml file.",
- )
- parser.add_argument(
- "--past_mimicit_vt_path",
- type=str,
- default="",
- help="Path to the past video-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_images_vt_path",
- type=str,
- default="",
- help="Path to the past images dataset (associated with video-text data). Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--mimicit_vt_path",
- type=str,
- default="",
- help="Path to the new video-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--images_vt_path",
- type=str,
- default="",
- help="Path to the new images dataset (associated with video-text data). Should be in format /path/to/xx.json",
- )
-
- # Argument for specifying the ratio for resampling past datasets.
- parser.add_argument(
- "--past_subset_ration",
- type=float,
- default=1.0,
- help="The ratio for resampling the past dataset. Should be a float between 0 and 1.",
- )
+ with accelerator.accumulate(model):
+ if num_steps == 0:
+ unwrapped_model = accelerator.unwrap_model(model)
+ master_print(f"model: {unwrapped_model.__class__.__name__}")
+ master_print(f"model dtype: {unwrapped_model.dtype if hasattr(unwrapped_model, 'dtype') else 'None'}")
+
+ loss_mimicit = forward_pass(
+ args,
+ model,
+ tokenizer,
+ images,
+ input_ids,
+ attention_mask,
+ labels,
+ device_id,
+ autocast_type,
+ batch_mimicit,
+ )
- # optimizer args
- parser.add_argument("--gradient_checkpointing", action="store_true")
- parser.add_argument("--offline", action="store_true")
- parser.add_argument("--save_ckpt_each_epoch", action="store_true")
- parser.add_argument("--num_epochs", type=int, default=1)
- parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
- # Sum of gradient optimization batch size
- parser.add_argument("--batch_size", type=int, default=128)
- parser.add_argument("--train_num_samples", type=int, default=-1)
-
- parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
- parser.add_argument("--save_steps_interval", type=int, default=-1)
- parser.add_argument(
- "--pretrained_model_name_or_path",
- type=str,
- help="path to huggingface model or model identifier from local path or huggingface.co",
- default=None,
- )
- parser.add_argument(
- "--trained_ckpt",
- type=str,
- help="path to trained_ckpt",
- default=None,
- )
- parser.add_argument("--seed", type=int, default=42)
- parser.add_argument("--learning_rate", default=1e-4, type=float)
- parser.add_argument(
- "--lr_scheduler",
- default="constant",
- type=str,
- help="constant, linear, or cosine",
- )
- parser.add_argument("--warmup_steps", default=1000, type=int)
- parser.add_argument("--warmup_steps_ratio", default=None, type=float)
- parser.add_argument("--weight_decay", default=0.1, type=float)
- parser.add_argument("--workers", type=int, default=4)
- # distributed training args
- parser.add_argument(
- "--dist-url",
- default="env://",
- type=str,
- help="url used to set up distributed training",
- )
- parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
- parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
- )
- parser.add_argument(
- "--no-set-device-rank",
- default=False,
- action="store_true",
- help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc).",
- )
- # YH: Training detail
- parser.add_argument("--mask_lm_head", action="store_true")
- parser.add_argument(
- "--max_seq_len",
- type=int,
- default=2048,
- help="the maximum src sequence length",
- )
- parser.add_argument("--patch-image-size", type=int, default=224)
- parser.add_argument("--resample_frames", type=int, default=32)
- # this could potentially save 33GB of all model parameters for otter-9b, including the language and vision model.
- parser.add_argument("--save_hf_model", default=False, action="store_true")
- parser.add_argument(
- "--customized_config",
- default=None,
- type=str,
- help="path to customized additional config.json, use to modify from the original config.json in pretrained model.",
- )
- parser.add_argument("--task_name", default="", type=str, help="task name, used to decide different function to load dataset.")
- # wandb args
- parser.add_argument("--report_to_wandb", default=False, action="store_true")
- parser.add_argument(
- "--wandb_project",
- type=str,
- )
- parser.add_argument(
- "--wandb_entity",
- type=str,
- )
- parser.add_argument(
- "--save_checkpoints_to_wandb",
- default=False,
- action="store_true",
- help="save checkpoints to wandb",
- )
- parser.add_argument(
- "--resume_from_checkpoint",
- default=False,
- action="store_true",
- help="resume from checkpoint (original openflamingo pt format, not hf format)",
- )
- # TODO: remove additional data args, all args would be processed in above parser
- parser.add_argument(
- "--delete_previous_checkpoint",
- action="store_true",
- help="delete previous checkpoint when saving new checkpoint",
- )
- # parser = add_data_args(parser)
- args = parser.parse_args()
+ if accelerator.mixed_precision == "fp16":
+ accelerator.backward(loss_mimicit.to(device_id))
+ else:
+ accelerator.backward(loss_mimicit)
- # Check for argument consistency and set environment variables if needed
- if args.save_checkpoints_to_wandb and not args.report_to_wandb:
- raise ValueError("save_checkpoints_to_wandb requires report_to_wandb")
+ #### BACKWARD PASS ####
+ mean_loss = loss_mimicit.detach().mean()
+ cur_batch_max_tokens = input_ids.shape[1]
- if args.offline:
- os.environ["WANDB_MODE"] = "offline"
- os.environ["TRANSFORMERS_OFFLINE"] = "1"
+ def mask_embedding(m):
+ if m.weight.requires_grad:
+ zero_mask = torch.zeros_like(m.weight.grad)
+ zero_mask[answer_token_id] = torch.ones_like(zero_mask[answer_token_id])
+ # zero_mask[media_token_id] = torch.ones_like(zero_mask[media_token_id])
+ # zero_mask[endofchunk_token_id] = torch.ones_like(zero_mask[endofchunk_token_id])
+ m.weight.grad = m.weight.grad * zero_mask
- args.local_rank, args.rank, args.world_size = world_info_from_env()
+ if args.mask_lm_head and args.distributed_type != "DEEPSPEED":
+ unwrapped_model = accelerator.unwrap_model(model)
+ if isinstance(unwrapped_model, IdeficsForVisionText2Text):
+ unwrapped_model.lm_head.apply(mask_embedding)
+ elif unwrapped_model.lang_encoder.__class__.__name__ in ["MPTForCausalLM", "MosaicGPT"]:
+ unwrapped_model.lang_encoder.transformer.wte.apply(mask_embedding)
+ elif "LlamaForCausalLM" in unwrapped_model.lang_encoder.__class__.__name__:
+ unwrapped_model.lang_encoder.model.embed_tokens.apply(mask_embedding)
+ unwrapped_model.lang_encoder.lm_head.apply(mask_embedding)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(model.parameters(), 1.0)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # step time and reset end outside of rank 0
+ step_time_m.update(time.time() - end)
+ end = time.time()
+ if accelerator.sync_gradients and args.rank == 0 and args.report_to_wandb:
+ # compute within rank 0
+ mimicit_samples_per_second = args.gradient_accumulation_steps * args.batch_size * args.world_size / step_time_m.sum
+ mimicit_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size / step_time_m.sum
+ step_time_m.reset()
+ data_time_m.reset()
- # if "COUNT_NODE" in os.environ:
- # args.num_machines = int(os.environ["COUNT_NODE"])
- # else:
- # args.num_machines = 1
+ group_name = batch_mimicit["task_group"][0]
+ assert all(item == group_name for item in batch_mimicit["task_group"]), "Not all items in the list are the same"
+ if args.report_to_wandb:
+ wandb.log(
+ {
+ "data_time": data_time_m.avg,
+ "step_time": step_time_m.avg,
+ "max_tokens": cur_batch_max_tokens,
+ "mimicit_samples_per_second": mimicit_samples_per_second,
+ "mimicit_samples_per_second_per_gpu": mimicit_samples_per_second_per_gpu,
+ "lr": optimizer.param_groups[0]["lr"],
+ "loss_mimicit": mean_loss,
+ "global_step": global_step // args.gradient_accumulation_steps,
+ group_name: mean_loss,
+ },
+ commit=True,
+ )
+
+ delete_tensors_from_dict(batch_mimicit)
+ delete_tensors_from_dict(
+ {
+ "other": [
+ images,
+ input_ids,
+ attention_mask,
+ labels,
+ ]
+ }
+ )
- # if "THEID" in os.environ:
- # args.machine_rank = int(os.environ["THEID"])
- # else:
- # args.machine_rank = 0
+ if args.rank == 0 and global_step != 0 and (args.save_steps_interval != -1) and (global_step % args.save_steps_interval == 0):
+ save_checkpoint(epoch=None, global_step=global_step, model=model, args=args, accelerator=accelerator)
- # Seed for reproducibility
- random_seed(args.seed)
+ # Log loss to console
+ if ((num_steps + 1) % args.logging_steps == 0) and args.rank == 0:
+ print(f"Step {num_steps+1}/{num_batches_per_epoch} of epoch {epoch+1}/{args.num_epochs} complete. Loss MIMIC-IT: {mean_loss.item():.3f}")
+ # reset to avoid CPU oom
+ loss_mimicit = None
+ batch_mimicit = None
+ gc.collect()
+ torch.cuda.empty_cache()
- return args
+ del unwrapped_model
def main():
args = parse_args()
- accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, mixed_precision="bf16")
+ verify_yaml(args)
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision="bf16",
+ )
if accelerator.state.deepspeed_plugin is not None:
accelerator.state.deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = args.batch_size
device_id = accelerator.device
if args.pretrained_model_name_or_path is not None:
- accelerator.print(f"Loading pretrained model from {args.pretrained_model_name_or_path}")
+ master_print(f"Loading pretrained model from {args.pretrained_model_name_or_path}")
device_map = {"": device_id} if accelerator.distributed_type == "MULTI_GPU" or accelerator.distributed_type == "DEEPSPEED" else "auto"
kwargs = {"local_files_only": args.offline, "device_map": device_map}
+
if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
kwargs.pop("device_map")
+
if args.customized_config is not None:
kwargs["config"] = args.customized_config
- if "otter" in args.model_name.lower():
+
+ if args.model_name.lower() == "otter":
model = OtterForConditionalGeneration.from_pretrained(
args.pretrained_model_name_or_path,
**kwargs,
@@ -586,18 +336,28 @@ def main():
args.tokenizer = model.text_tokenizer
tokenizer = model.text_tokenizer
image_processor = CLIPImageProcessor()
- elif "flamingo" in args.model_name.lower():
+
+ elif args.model_name.lower() == "flamingo":
model = FlamingoForConditionalGeneration.from_pretrained(
args.pretrained_model_name_or_path,
**kwargs,
)
# add special tokens for instruction tuning
model.text_tokenizer.add_special_tokens({"additional_special_tokens": [""]})
- args.tokenizer = model.text_tokenizer
- tokenizer = model.text_tokenizer
+ model.config.update(
+ {
+ "special_tokens": model.text_tokenizer.all_special_tokens,
+ "architectures": "OtterForConditionalGeneration",
+ }
+ )
+ tokenizer = args.tokenizer = model.text_tokenizer
image_processor = CLIPImageProcessor()
- elif "idefics" in args.model_name.lower():
- # import pdb;pdb.set_trace()
+ # if not accelerator.distributed_type == "DEEPSPEED" or not accelerator.state.deepspeed_plugin.zero_stage == 3:
+ # new_embedding_size = (len(model.text_tokenizer) // 64 + 1) * 64
+ # master_print(f"Resizing Flamingo embedding from {len(model.text_tokenizer)} to {new_embedding_size}")
+ # model.resize_token_embeddings(new_embedding_size, pad_to_multiple_of=64)
+
+ elif args.model_name.lower() == "idefics":
model = IdeficsForVisionText2Text.from_pretrained(
args.pretrained_model_name_or_path,
**kwargs,
@@ -605,31 +365,75 @@ def main():
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
- # named_parameters = dict(model.named_parameters())
- # params_to_gather = [named_parameters[k] for k in named_parameters.keys()]
- # if len(params_to_gather) > 0:
- if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
- params_to_gather = [p for name, p in model.named_parameters() if p.requires_grad]
- with deepspeed.zero.GatheredParameters(params_to_gather, modifier_rank=0):
- if torch.distributed.get_rank() == 0:
- # 有参数
- print(
- device_id,
- f"IDEFICS Trainable Params: {(sum(p.numel() for p in model.parameters() if p.requires_grad)) / 1e9:.3f} B",
- )
- else:
- print(
- device_id,
- f"IDEFICS Trainable Params: {(sum(p.numel() for p in model.parameters() if p.requires_grad)) / 1e9:.3f} B",
- )
processor = AutoProcessor.from_pretrained(args.pretrained_model_name_or_path, legacy=False)
- past_special_tokens = processor.tokenizer.special_tokens_map["additional_special_tokens"]
- processor.tokenizer.add_special_tokens({"additional_special_tokens": [""] + past_special_tokens})
- image_processor = processor.image_processor
- tokenizer = processor.tokenizer
+ if "" not in processor.tokenizer.special_tokens_map["additional_special_tokens"]:
+ past_special_tokens = processor.tokenizer.special_tokens_map["additional_special_tokens"]
+ processor.tokenizer.add_special_tokens({"additional_special_tokens": [""] + past_special_tokens})
+
+ image_processor = args.image_processor = processor.image_processor
+ tokenizer = args.tokenizer = processor.tokenizer
# make embedding size divisible by 64 for hardware compatiblity https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
- new_embedding_size = (len(tokenizer) // 64 + 1) * 64
- model.resize_token_embeddings(new_embedding_size, pad_to_multiple_of=64)
+ # resize_token_embedding is not for parameter sharing in deepspeed !!!!
+ elif args.model_name.lower() == "llama2":
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained_model_name_or_path,
+ **kwargs,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained_model_name_or_path)
+ past_special_tokens = tokenizer.special_tokens_map["additional_special_tokens"] if "additional_special_tokens" in tokenizer.special_tokens_map else [value for key, value in tokenizer.special_tokens_map.items()]
+ if "" not in past_special_tokens:
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", "", "<|endofchunk|>"]})
+
+ if tokenizer.pad_token is None:
+ tokenizer.add_special_tokens({"pad_token": ""})
+
+ args.tokenizer = tokenizer
+ image_processor = None
+
+ elif args.model_name.lower() == "fuyu":
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained_model_name_or_path)
+ image_processor = FuyuImageProcessor()
+ processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ # Peiyuan: should rewrite this portion. Right now too ugly.
+ image_processor = processor
+ model = FuyuForCausalLM.from_pretrained(args.pretrained_model_name_or_path, **kwargs)
+ args.processor = processor
+
+ if args.enable_lora:
+ if args.peft_model_name_or_path:
+ master_print(f"Loading finetuned LoRA model from {args.peft_model_name_or_path}")
+ model = PeftModel.from_pretrained(model, args.peft_model_name_or_path)
+ model = model.merge_and_unload()
+
+ lora_config = LoraConfig(
+ r=64,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ task_type=TaskType.CAUSAL_LM,
+ target_modules=["query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h", "lm_head"],
+ )
+ master_print(f"Init LoRA model with config {lora_config}")
+ model = get_peft_model(model, lora_config)
+ model.print_trainable_parameters()
+
+ elif args.model_name.lower() == "debug_model":
+ model = torch.nn.Linear(100, 100)
+ tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", "", "<|endofchunk|>"]})
+ if tokenizer.pad_token is None:
+ tokenizer.add_special_tokens({"pad_token": ""})
+
+ image_processor = None
+
+ if args.resize_embedding and hasattr(model, "lang_encoder") and "LlamaForCausalLM" in model.lang_encoder.__class__.__name__:
+ model.lang_encoder.resize_token_embeddings(len(model.text_tokenizer))
+ master_print(f"Resizing Llama embedding to {len(model.text_tokenizer)}")
+
+ if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
+ params_to_gather = [p for name, p in model.named_parameters() if p.requires_grad]
+ with deepspeed.zero.GatheredParameters(params_to_gather, modifier_rank=0):
+ master_print(device_id, f"Zero3 Optimization: Trainable Params: {(sum(p.numel() for p in model.parameters() if p.requires_grad)) / 1e9:.3f} B")
if args.trained_ckpt is not None:
train_ckpt = torch.load(args.trained_ckpt, map_location="cpu")
@@ -642,83 +446,48 @@ def main():
args.distributed_type = accelerator.distributed_type
- if hasattr(model, "lang_encoder") and "LlamaForCausalLM" in model.lang_encoder.__class__.__name__:
- model.lang_encoder.resize_token_embeddings(len(model.text_tokenizer))
-
random_seed(args.seed, args.rank)
-
print(f"Start running training on rank {args.rank}.")
- mimicit_loaders = get_data(args, image_processor, tokenizer, "mimicit")
-
- def get_grouped_params(model):
- params_with_wd, params_without_wd = [], []
-
- def apply_decay(x):
- return "gated_cross_attn_layer" in x and "ff_gate" not in x and "attn_gate" not in x and "norm" not in x and "bias" not in x
-
- for n, p in model.named_parameters():
- # if p.requires_grad:
- if apply_decay(n):
- params_with_wd.append(p)
- else:
- params_without_wd.append(p)
-
- return [
- {"params": params_with_wd, "weight_decay": args.weight_decay},
- {"params": params_without_wd, "weight_decay": 0.0},
- ]
-
- total_training_steps = len(mimicit_loaders[0]) * args.num_epochs
+ if args.rank == 0 and args.report_to_wandb:
+ master_print(f"Logging to wandb as {args.wandb_entity}/{args.wandb_project}/{args.run_name}")
+ wandb.init(
+ project=args.wandb_project,
+ entity=args.wandb_entity,
+ name=args.run_name,
+ )
+ mimicit_loaders = get_data(args, image_processor, tokenizer, "mimicit")
+ total_training_steps = sum(len(dataloader) for dataloader in mimicit_loaders) * args.num_epochs
resume_from_epoch = 0
- # check if a checkpoint exists for this run
args.external_save_dir = os.path.join(args.external_save_dir, args.run_name) if args.external_save_dir else args.run_name
- if os.path.exists(f"{args.external_save_dir}") and args.resume_from_checkpoint is True:
- checkpoint_list = glob.glob(f"{args.external_save_dir}/checkpoint_*.pt")
- if len(checkpoint_list) == 0:
- print(f"Found no checkpoints for run {args.external_save_dir}.")
- else:
- resume_from_checkpoint_path = sorted(checkpoint_list, key=lambda x: int(x.split("_")[-1].split(".")[0]))[-1]
- print(f"Found checkpoint {resume_from_checkpoint_path} for run {args.external_save_dir}.")
-
- if args.rank == 0:
- print(f"Loading checkpoint from {resume_from_checkpoint_path}")
- checkpoint = torch.load(resume_from_checkpoint_path, map_location="cpu")
- model.load_state_dict(checkpoint["model_state_dict"], False)
- optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
- lr_scheduler.load_state_dict(checkpoint["lr_scheduler_state_dict"])
- resume_from_epoch = checkpoint["epoch"] + 1
-
- optimizer = torch.optim.AdamW(get_grouped_params(model), lr=args.learning_rate)
+
+ optimizer = torch.optim.AdamW(get_grouped_params(model, wd=args.weight_decay), lr=args.learning_rate)
if args.rank == 0:
print(f"Total training steps: {total_training_steps}")
- args.warmup_steps = total_training_steps * args.warmup_steps_ratio if args.warmup_steps_ratio is not None else args.warmup_stepsps
+ args.warmup_steps = total_training_steps * args.warmup_steps_ratio if args.warmup_steps_ratio is not None else args.warmup_steps
+ args.warmup_steps = args.warmup_steps // args.gradient_accumulation_steps
+ args.total_training_steps = total_training_steps // args.gradient_accumulation_steps
if args.lr_scheduler == "linear":
lr_scheduler = get_linear_schedule_with_warmup(
optimizer,
- num_warmup_steps=args.warmup_steps // args.gradient_accumulation_steps,
- num_training_steps=total_training_steps // args.gradient_accumulation_steps,
+ num_warmup_steps=args.warmup_steps,
+ num_training_steps=args.total_training_steps,
)
elif args.lr_scheduler == "cosine":
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer,
- num_warmup_steps=args.warmup_steps // args.gradient_accumulation_steps,
- num_training_steps=total_training_steps // args.gradient_accumulation_steps,
+ num_warmup_steps=args.warmup_steps,
+ num_training_steps=args.total_training_steps,
)
- else:
+ elif args.lr_scheduler == "constant":
lr_scheduler = get_constant_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps)
if args.rank == 0 and args.report_to_wandb:
- wandb.init(
- project=args.wandb_project,
- entity=args.wandb_entity,
- name=args.run_name,
- config=vars(args),
- )
+ wandb.config.update(vars(args))
if accelerator.distributed_type == "DEEPSPEED" or accelerator.distributed_type == "MULTI_GPU":
model, optimizer = accelerator.prepare(model, optimizer)
@@ -726,11 +495,8 @@ def apply_decay(x):
model, optimizer, lr_scheduler, mimicit_loaders = accelerator.prepare(model, optimizer, lr_scheduler, mimicit_loaders)
model.train()
-
+ # Main Training Loop
for epoch in range(resume_from_epoch, args.num_epochs):
- for cur_data_loader in mimicit_loaders:
- cur_data_loader.dataset.set_epoch(epoch)
-
train_one_epoch(
args=args,
model=model,
@@ -744,95 +510,27 @@ def apply_decay(x):
wandb=wandb,
)
accelerator.wait_for_everyone()
-
if args.save_ckpt_each_epoch:
- if args.rank == 0:
- if not os.path.exists(args.external_save_dir):
- os.makedirs(args.external_save_dir)
-
- if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
- checkpoint_dict = accelerator.get_state_dict(model)
-
- if args.rank == 0:
- unwrapped_model = accelerator.unwrap_model(model)
- trainable_params_name = [name for name, p in unwrapped_model.named_parameters() if p.requires_grad]
- for name in list(checkpoint_dict.keys()):
- if name not in trainable_params_name:
- del checkpoint_dict[name]
-
- else:
- if args.rank == 0:
- unwrapped_model = accelerator.unwrap_model(model)
- # checkpoint_dict = {
- # "epoch": epoch,
- # "model_state_dict": get_checkpoint(unwrapped_model),
- # "optimizer_state_dict": optimizer.state_dict(),
- # "lr_scheduler_state_dict": lr_scheduler.state_dict(),
- # }
- checkpoint_dict = {
- "model_state_dict": get_checkpoint(unwrapped_model),
- }
-
- if args.rank == 0:
- print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_{epoch}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_{epoch}.pt")
- # save the config
- unwrapped_model.config.save_pretrained(args.external_save_dir)
- if args.delete_previous_checkpoint:
- if epoch > 0:
- os.remove(f"{args.external_save_dir}/checkpoint_{epoch-1}.pt")
-
- accelerator.wait_for_everyone()
-
- accelerator.wait_for_everyone()
-
- if args.rank == 0:
- if not os.path.exists(args.external_save_dir):
- os.makedirs(args.external_save_dir)
-
- if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
- checkpoint_dict = accelerator.get_state_dict(model)
-
- unwrapped_model = accelerator.unwrap_model(model)
-
- unwrapped_model.config.save_pretrained(args.external_save_dir)
-
- if args.rank == 0 and not args.save_hf_model:
- trainable_params_name = [name for name, p in unwrapped_model.named_parameters() if p.requires_grad]
- for name in list(checkpoint_dict.keys()):
- if name not in trainable_params_name:
- del checkpoint_dict[name]
-
- accelerator.save(
- checkpoint_dict,
- f"{args.external_save_dir}/final_weights.pt",
- )
- elif args.rank == 0 and args.save_hf_model:
- unwrapped_model.save_pretrained(
- f"{args.external_save_dir}",
- is_main_process=accelerator.is_main_process,
- save_function=accelerator.save,
- state_dict=checkpoint_dict,
- )
-
- else:
- if args.rank == 0:
- unwrapped_model = accelerator.unwrap_model(model)
- checkpoint_dict = get_checkpoint(model=unwrapped_model)
-
- accelerator.save(
- checkpoint_dict,
- f"{args.external_save_dir}/final_weights.pt",
+ # save_checkpoint(epoch, model, args, accelerator)
+ save_final_weights(
+ model,
+ args,
+ accelerator,
+ processor=processor if "idefics" in args.model_name.lower() or "fuyu" in args.model_name.lower() else None,
+ tokenizer=tokenizer if "llama2" in args.model_name.lower() else None,
)
- # save the config
- unwrapped_model.config.save_pretrained(args.external_save_dir)
-
- if args.report_to_wandb and args.save_checkpoints_to_wandb:
- wandb.save(f"{args.external_save_dir}/final_weights.pt")
- if args.save_hf_model:
- unwrapped_model.save_pretrained(f"{args.external_save_dir}")
+ master_print(f"Saved checkpoint at epoch {epoch+1}.")
+ accelerator.wait_for_everyone()
- accelerator.wait_for_everyone()
+ # Save the final weights
+ save_final_weights(
+ model,
+ args,
+ accelerator,
+ processor=processor if "idefics" in args.model_name.lower() or "fuyu" in args.model_name.lower() else None,
+ tokenizer=tokenizer if "llama2" in args.model_name.lower() else None,
+ )
+ # accelerator.wait_for_everyone()
if __name__ == "__main__":
diff --git a/pipeline/train/pretraining.py b/pipeline/train/pretraining.py
old mode 100644
new mode 100755
index a73e34cb..afa57efd
--- a/pipeline/train/pretraining.py
+++ b/pipeline/train/pretraining.py
@@ -4,6 +4,7 @@
import glob
import os
import random
+import sys
import time
import numpy as np
@@ -19,9 +20,10 @@
)
import wandb
-from otter_ai import FlamingoForConditionalGeneration
-from otter_ai import OtterForConditionalGeneration
-from pipeline.train.data import get_data
+from otter_ai import FlamingoForConditionalGeneration, OtterForConditionalGeneration
+
+sys.path.append("../..")
+from pipeline.mimicit_utils.data import get_data
from pipeline.train.distributed import world_info_from_env
from pipeline.train.train_utils import AverageMeter, get_checkpoint
@@ -87,7 +89,12 @@ def parse_args():
parser.add_argument("--offline", action="store_true")
parser.add_argument("--num_epochs", type=int, default=1)
parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
- parser.add_argument("--checkpointing_steps", type=int, default=10000, help="checkpointing every n steps")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=10000,
+ help="checkpointing every n steps",
+ )
# Sum of gradient optimization batch size
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
@@ -124,12 +131,6 @@ def parse_args():
help="url used to set up distributed training",
)
parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
- parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
- )
parser.add_argument(
"--no-set-device-rank",
default=False,
@@ -178,7 +179,19 @@ def random_seed(seed=42, rank=0):
random.seed(seed + rank)
-def train_one_epoch(args, model, epoch, mmc4_loader, laion_loader, tokenizer, optimizer, lr_scheduler, device_id, accelerator, wandb):
+def train_one_epoch(
+ args,
+ model,
+ epoch,
+ mmc4_loader,
+ laion_loader,
+ tokenizer,
+ optimizer,
+ lr_scheduler,
+ device_id,
+ accelerator,
+ wandb,
+):
num_batches_per_epoch_laion = laion_loader.num_batches
num_batches_per_epoch_mmc4 = mmc4_loader.num_batches
@@ -384,7 +397,10 @@ def mask_embedding(m):
"lr_scheduler_state_dict": lr_scheduler.state_dict(),
}
print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
+ accelerator.save(
+ checkpoint_dict,
+ f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt",
+ )
# save the config
print(f"Saving config to {args.external_save_dir}/config.json")
unwrapped_model.config.save_pretrained(args.external_save_dir)
diff --git a/pipeline/train/pretraining_cc3m.py b/pipeline/train/pretraining_cc3m.py
old mode 100644
new mode 100755
index b3f90235..7e2fc1e6
--- a/pipeline/train/pretraining_cc3m.py
+++ b/pipeline/train/pretraining_cc3m.py
@@ -4,13 +4,13 @@
import glob
import os
import random
+import sys
import time
import numpy as np
import torch
import torch.nn
-from accelerate import Accelerator
-from accelerate import load_checkpoint_and_dispatch
+from accelerate import Accelerator, load_checkpoint_and_dispatch
from tqdm import tqdm
from transformers import (
CLIPImageProcessor,
@@ -18,10 +18,12 @@
get_cosine_schedule_with_warmup,
get_linear_schedule_with_warmup,
)
+
import wandb
-from otter_ai import FlamingoForConditionalGeneration
-from otter_ai import OtterForConditionalGeneration
-from pipeline.train.data import get_data
+from otter_ai import FlamingoForConditionalGeneration, OtterForConditionalGeneration
+
+sys.path.append("../..")
+from pipeline.mimicit_utils.data import get_data
from pipeline.train.distributed import world_info_from_env
from pipeline.train.train_utils import AverageMeter, get_checkpoint
@@ -73,7 +75,12 @@ def parse_args():
parser.add_argument("--offline", action="store_true")
parser.add_argument("--num_epochs", type=int, default=1)
parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
- parser.add_argument("--checkpointing_steps", type=int, default=10000, help="checkpointing every n steps")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=10000,
+ help="checkpointing every n steps",
+ )
# Sum of gradient optimization batch size
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
@@ -103,12 +110,6 @@ def parse_args():
help="url used to set up distributed training",
)
parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
- parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
- )
parser.add_argument(
"--no-set-device-rank",
default=False,
@@ -157,7 +158,18 @@ def random_seed(seed=42, rank=0):
random.seed(seed + rank)
-def train_one_epoch(args, model, epoch, cc3m_loader, tokenizer, optimizer, lr_scheduler, device_id, accelerator, wandb):
+def train_one_epoch(
+ args,
+ model,
+ epoch,
+ cc3m_loader,
+ tokenizer,
+ optimizer,
+ lr_scheduler,
+ device_id,
+ accelerator,
+ wandb,
+):
num_batches_per_epoch_cc3m = cc3m_loader.num_batches
num_batches_per_epoch = num_batches_per_epoch_cc3m
@@ -286,7 +298,10 @@ def mask_embedding(m):
"lr_scheduler_state_dict": lr_scheduler.state_dict(),
}
print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
+ accelerator.save(
+ checkpoint_dict,
+ f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt",
+ )
# save the config
print(f"Saving config to {args.external_save_dir}/config.json")
unwrapped_model.config.save_pretrained(args.external_save_dir)
@@ -406,7 +421,10 @@ def apply_decay(x):
if len(checkpoint_list) == 0:
print(f"Found no checkpoints for run {args.external_save_dir}.")
else:
- resume_from_checkpoint_path = sorted(checkpoint_list, key=lambda x: int(x.split("_")[-1].split("steps")[1].split(".")[0]))[-1]
+ resume_from_checkpoint_path = sorted(
+ checkpoint_list,
+ key=lambda x: int(x.split("_")[-1].split("steps")[1].split(".")[0]),
+ )[-1]
# resume_from_checkpoint_path = sorted(checkpoint_list, key=lambda x: int(x.split("_")[-1].split(".")[0]))[-1]
print(f"Found checkpoint {resume_from_checkpoint_path} for run {args.external_save_dir}.")
diff --git a/pipeline/train/train_args.py b/pipeline/train/train_args.py
new file mode 100644
index 00000000..97de78b9
--- /dev/null
+++ b/pipeline/train/train_args.py
@@ -0,0 +1,206 @@
+import argparse
+import os
+
+from pipeline.train.distributed import world_info_from_env
+
+
+def parse_tuple(string):
+ try:
+ x, y = map(int, string.split(","))
+ return (x, y)
+ except:
+ raise argparse.ArgumentTypeError("Invalid tuple format. Expected 'x,y'")
+
+
+def parse_args():
+ """
+ Parse the command line arguments and perform the initial setup.
+ :return: Parsed arguments
+ """
+ parser = argparse.ArgumentParser(description="Main training script for the model")
+ # Model configuration arguments
+ parser.add_argument(
+ "--external_save_dir",
+ type=str,
+ default=None,
+ help="set to save model to external path",
+ )
+ parser.add_argument(
+ "--run_name",
+ type=str,
+ default="otter-9b",
+ help="used to name saving directory and wandb run",
+ )
+ parser.add_argument(
+ "--model_name",
+ type=str,
+ default="otter",
+ choices=["otter", "flamingo", "idefics", "llama2", "debug_model", "fuyu"],
+ help="otters or flamingo",
+ )
+ parser.add_argument(
+ "--instruction_format",
+ type=str,
+ default="simple",
+ choices=["simple", "llama2", "idefics", "fuyu"],
+ help="simple is for mpt/llama1, rest are in different instruction templates.",
+ )
+ parser.add_argument(
+ "--training_data_yaml",
+ type=str,
+ default="",
+ help="Path to the training data yaml file.",
+ )
+
+ # optimizer args
+ parser.add_argument("--gradient_checkpointing", action="store_true")
+ parser.add_argument("--offline", action="store_true")
+ parser.add_argument("--save_ckpt_each_epoch", action="store_true")
+ parser.add_argument("--num_epochs", type=int, default=1)
+ parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
+ # Sum of gradient optimization batch size
+ parser.add_argument("--batch_size", type=int, default=128)
+ parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
+ parser.add_argument("--save_steps_interval", type=int, default=-1)
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ help="path to huggingface model or model identifier from local path or huggingface.co",
+ default=None,
+ )
+ parser.add_argument(
+ "--peft_model_name_or_path",
+ type=str,
+ help="path to huggingface model or model identifier from local path or huggingface.co",
+ default=None,
+ )
+ parser.add_argument(
+ "--trained_ckpt",
+ type=str,
+ help="path to trained_ckpt",
+ default=None,
+ )
+ parser.add_argument("--seed", type=int, default=42)
+ parser.add_argument("--learning_rate", default=1e-4, type=float)
+ parser.add_argument(
+ "--lr_scheduler",
+ default="constant",
+ type=str,
+ help="constant, linear, or cosine",
+ )
+ parser.add_argument("--warmup_steps", default=1000, type=int)
+ parser.add_argument("--warmup_steps_ratio", default=None, type=float)
+ parser.add_argument("--weight_decay", default=0.1, type=float)
+ parser.add_argument("--workers", type=int, default=4)
+ # distributed training args
+ parser.add_argument(
+ "--dist-url",
+ default="env://",
+ type=str,
+ help="url used to set up distributed training",
+ )
+ parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
+ parser.add_argument(
+ "--no-set-device-rank",
+ default=False,
+ action="store_true",
+ help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc).",
+ )
+ # YH: Training detail
+ parser.add_argument("--mask_lm_head", action="store_true")
+ parser.add_argument(
+ "--max_seq_len",
+ type=int,
+ default=2048,
+ help="the maximum src sequence length",
+ )
+ parser.add_argument("--patch-image-size", type=int, default=224)
+ parser.add_argument("--resample_frames", type=int, default=32)
+ # this could potentially save 33GB of all model parameters for otter-9b, including the language and vision model.
+ parser.add_argument("--save_hf_model", default=False, action="store_true")
+ parser.add_argument(
+ "--customized_config",
+ default=None,
+ type=str,
+ help="path to customized additional config.json, use to modify from the original config.json in pretrained model.",
+ )
+ parser.add_argument("--report_to_wandb", default=False, action="store_true")
+ parser.add_argument("--wandb_project", type=str)
+ parser.add_argument("--wandb_entity", type=str)
+ parser.add_argument(
+ "--save_checkpoints_to_wandb",
+ default=False,
+ action="store_true",
+ help="save checkpoints to wandb",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ default=False,
+ action="store_true",
+ help="resume from checkpoint (original openflamingo pt format, not hf format)",
+ )
+ # TODO: remove additional data args, all args would be processed in above parser
+ parser.add_argument(
+ "--delete_previous_checkpoint",
+ action="store_true",
+ help="delete previous checkpoint when saving new checkpoint",
+ ),
+ parser.add_argument(
+ "--keep_symbols",
+ action="store_true",
+ default=False,
+ help="keep symbols in the generated text",
+ )
+ parser.add_argument(
+ "--remove_answer_token",
+ action="store_true",
+ default=False,
+ help="we have an token as indicator for separating question and answer, use this flag to remove it before training.",
+ )
+ parser.add_argument(
+ "--remove_eos_token",
+ action="store_true",
+ default=False,
+ help="we have an eos token as indicator for separating question and answer, use this flag to remove it before training.",
+ )
+ parser.add_argument(
+ "--populate_rel_ins",
+ action="store_true",
+ default=False,
+ help="populate rel_ins into train_config.",
+ )
+ parser.add_argument(
+ "--resize_embedding",
+ action="store_true",
+ default=False,
+ help="resize embedding layer to match the vocabulary size.",
+ )
+ parser.add_argument("--image_resolution", type=parse_tuple, default=(224, 224), help="image resolution for the model in format: x,y")
+ parser.add_argument(
+ "--with_task_description",
+ action="store_true",
+ default=False,
+ )
+ parser.add_argument(
+ "--enable_lora",
+ action="store_true",
+ default=False,
+ )
+ parser.add_argument(
+ "--dynamic_resolution",
+ action="store_true",
+ default=False,
+ )
+ args = parser.parse_args()
+
+ # Check for argument consistency and set environment variables if needed
+ if args.save_checkpoints_to_wandb and not args.report_to_wandb:
+ raise ValueError("save_checkpoints_to_wandb requires report_to_wandb")
+
+ if args.offline:
+ os.environ["WANDB_MODE"] = "offline"
+ os.environ["TRANSFORMERS_OFFLINE"] = "1"
+
+ args.local_rank, args.rank, args.world_size = world_info_from_env()
+
+ return args
diff --git a/pipeline/train/train_utils.py b/pipeline/train/train_utils.py
index 19a35329..ea7b7c2f 100755
--- a/pipeline/train/train_utils.py
+++ b/pipeline/train/train_utils.py
@@ -1,9 +1,13 @@
-import time
+import os
+import random
+import subprocess
+import sys
from contextlib import suppress
+import numpy as np
import torch
-from tqdm import tqdm
from torch.utils.data.distributed import DistributedSampler
+import torch.distributed as dist
try:
from transformers.models.idefics.processing_idefics import image_attention_mask_for_packed_input_ids, incremental_to_binary_attention_mask
@@ -11,6 +15,27 @@
print("Failed to import Idefics processing module.")
+def truncate_text(path, keep_start=10, keep_end=10, truncate_to="..."):
+ if len(path) <= (keep_start + keep_end + len(truncate_to)):
+ return path
+ return path[:keep_start] + truncate_to + path[-keep_end:]
+
+
+def master_print(*args, **kwargs):
+ if dist.is_available() and dist.is_initialized():
+ rank = dist.get_rank()
+ if rank == 0:
+ print(*args, **kwargs)
+ else:
+ print(*args, **kwargs)
+
+
+def random_seed(seed=42, rank=0):
+ torch.manual_seed(seed + rank)
+ np.random.seed(seed + rank)
+ random.seed(seed + rank)
+
+
def get_cast_dtype(precision: str):
cast_dtype = None
if precision == "bf16":
@@ -32,196 +57,6 @@ def get_autocast(precision):
return suppress
-# DEPRECATED - use train_one_epoch in instruction_following.py and pretraining.py instead
-def train_one_epoch(
- args,
- model,
- epoch,
- mmc4_loader,
- tokenizer,
- optimizer,
- lr_scheduler,
- device_id,
- wandb,
-):
- # num_batches_per_epoch_laion = laion_loader.num_batches
- num_batches_per_epoch_mmc4 = mmc4_loader.num_batches
-
- # assert (
- # num_batches_per_epoch_laion == num_batches_per_epoch_mmc4
- # ), "Number of batches in laion and mmc4 datasets must be the same"
- num_batches_per_epoch = num_batches_per_epoch_mmc4
- total_training_steps = num_batches_per_epoch * args.num_epochs
-
- autocast = get_autocast(args.precision)
- cast_dtype = get_cast_dtype(args.precision)
-
- media_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
- endofchunk_token_id = tokenizer("<|endofchunk|>", add_special_tokens=False)["input_ids"][-1]
-
- model.train()
-
- # setup logging
- step_time_m = AverageMeter() # time for one optimizer step (> 1 batch if using gradient accum)
- data_time_m = AverageMeter() # avg time to load one batch of both C4 AND laion (= 1 batch regardless of gradient accum)
- end = time.time()
-
- # loop through dataloader
- for num_steps, batch_mmc4 in tqdm(
- enumerate(mmc4_loader),
- disable=args.rank != 0,
- total=total_training_steps,
- initial=(epoch * num_batches_per_epoch),
- ):
- data_time_m.update(time.time() - end)
-
- global_step = num_steps + epoch * num_batches_per_epoch
-
- # #### LAION FORWARD PASS ####
- # images = (
- # batch_laion[0]
- # .to(device_id, dtype=cast_dtype, non_blocking=True)
- # .unsqueeze(1)
- # .unsqueeze(1)
- # )
-
- # input_ids = batch_laion[1][0].to(device_id, dtype=cast_dtype, non_blocking=True)
- # attention_mask = batch_laion[1][1].to(
- # device_id, dtype=cast_dtype, non_blocking=True
- # )
-
- # labels = input_ids.clone()
- # labels[labels == tokenizer.pad_token_id] = -100
- # labels[:, 0] = -100
- # labels[labels == media_token_id] = -100
- # labels.to(device_id)
-
- # with autocast():
- # loss_laion = model(
- # vision_x=images,
- # lang_x=input_ids,
- # attention_mask=attention_mask,
- # labels=labels,
- # )[0]
- loss_laion = 0
- divided_loss_laion = loss_laion / args.gradient_accumulation_steps
-
- #### C4 FORWARD PASS ####
- images = batch_mmc4[0].to(device_id, dtype=cast_dtype, non_blocking=True).unsqueeze(2)
- input_ids = torch.stack([x[0] for x in batch_mmc4[1]]).squeeze(1)
- attention_mask = torch.stack([x[1] for x in batch_mmc4[1]]).squeeze(1)
-
- # NOTE: irena: expected shape of clip_text_input_ids / attention_mask is (N, I, max_seq_len)
- labels = input_ids.clone()
- labels[labels == tokenizer.pad_token_id] = -100
- labels[:, 0] = -100
-
- for i in range(labels.shape[0]):
- # remove loss for any token before the first token
- label_idx = 0
- while label_idx < labels.shape[1] and labels[i][label_idx] != media_token_id:
- labels[i][label_idx] = -100
- label_idx += 1
-
- # get index of all endofchunk tokens in the sequence
- endofchunk_idxs = torch.where(labels[i] == endofchunk_token_id)[0]
- for endofchunk_idx in endofchunk_idxs:
- token_idx = endofchunk_idx + 1
- while token_idx < labels.shape[1] and labels[i][token_idx] != media_token_id:
- labels[i][token_idx] = -100
- token_idx += 1
-
- labels[labels == media_token_id] = -100
- labels.to(device_id)
-
- with autocast():
- loss_mmc4 = model(
- vision_x=images,
- lang_x=input_ids,
- attention_mask=attention_mask,
- labels=labels,
- )[0]
-
- # if loss is nan, skip this batch
- if torch.isnan(loss_mmc4):
- print("loss is nan, skipping this batch")
- print("input_ids: ", tokenizer.batch_decode(input_ids))
- print("labels: ", labels)
- print("images: ", images)
- optimizer.zero_grad()
- continue
-
- divided_loss_mmc4 = loss_mmc4 / args.gradient_accumulation_steps
-
- #### BACKWARD PASS ####
- loss = divided_loss_laion * args.loss_multiplier_laion + divided_loss_mmc4 * args.loss_multiplier_mmc4
- loss.backward()
-
- #### MASK GRADIENTS FOR EMBEDDINGS ####
- # Note (anas): Do not apply weight decay to embeddings as it will break this function.
- def mask_embedding(m):
- if isinstance(m, torch.nn.Embedding) and m.weight.requires_grad:
- zero_mask = torch.zeros_like(m.weight.grad)
- zero_mask[media_token_id] = torch.ones_like(zero_mask[media_token_id])
- zero_mask[endofchunk_token_id] = torch.ones_like(zero_mask[endofchunk_token_id])
- m.weight.grad = m.weight.grad * zero_mask
-
- model.apply(mask_embedding)
-
- torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
-
- # step optimizer and log
- if (((num_steps + 1) % args.gradient_accumulation_steps) == 0) or (num_steps == num_batches_per_epoch - 1):
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
-
- # step time and reset end outside of rank 0
- step_time_m.update(time.time() - end)
- end = time.time()
-
- if args.rank == 0 and args.report_to_wandb:
- # compute within rank 0
- laion_samples_per_second = args.gradient_accumulation_steps * args.batch_size_laion * args.world_size / step_time_m.val
- laion_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size_laion / step_time_m.val
-
- c4_samples_per_second = args.gradient_accumulation_steps * args.batch_size_mmc4 * args.world_size / step_time_m.val
- c4_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size_mmc4 / step_time_m.val
-
- wandb.log(
- {
- "data_time": data_time_m.avg,
- "step_time": step_time_m.avg,
- "laion_samples_per_second": laion_samples_per_second,
- "laion_samples_per_second_per_gpu": laion_samples_per_second_per_gpu,
- "c4_samples_per_second": c4_samples_per_second,
- "c4_samples_per_second_per_gpu": c4_samples_per_second_per_gpu,
- "lr": optimizer.param_groups[0]["lr"],
- },
- commit=False,
- )
- step_time_m.reset()
- data_time_m.reset()
-
- wandb.log(
- {
- "loss_laion": divided_loss_laion.item(),
- "global_step": global_step,
- },
- commit=False,
- )
- wandb.log(
- {"loss_mmc4": divided_loss_mmc4.item(), "global_step": global_step},
- commit=True,
- )
-
- # Log loss to console
- if ((num_steps + 1) % args.logging_steps == 0) and args.rank == 0:
- print(
- f"Step {num_steps+1}/{num_batches_per_epoch} of epoch {epoch+1}/{args.num_epochs} complete. Loss LAION: {loss_laion.item():.3f} // Loss MMC4: {loss_mmc4.item():.3f}"
- )
-
-
def get_checkpoint(model):
state_dict = model.state_dict()
@@ -315,3 +150,171 @@ def get_image_attention_mask(output_input_ids, max_num_images, tokenizer, includ
# in full language mode we set the image mask to all-0s
image_attention_mask = torch.zeros(output_input_ids.shape[0], output_input_ids.shape[1], 1, dtype=torch.bool)
return image_attention_mask
+
+
+def verify_yaml(args):
+ if args.rank != 0:
+ return
+
+ # Run pytest with the necessary arguments.
+ result = subprocess.run(["pytest", "-m", "prerun", f"--yaml-path={args.training_data_yaml}"])
+
+ if result.returncode != 0:
+ print("YAML verification failed!")
+ sys.exit(1)
+
+
+def get_grouped_params(model, wd):
+ params_with_wd, params_without_wd = [], []
+
+ def apply_decay(x):
+ return "gated_cross_attn_layer" in x and "ff_gate" not in x and "attn_gate" not in x and "norm" not in x and "bias" not in x
+
+ for n, p in model.named_parameters():
+ # if p.requires_grad:
+ if apply_decay(n):
+ params_with_wd.append(p)
+ else:
+ params_without_wd.append(p)
+
+ return [
+ {"params": params_with_wd, "weight_decay": wd},
+ {"params": params_without_wd, "weight_decay": 0.0},
+ ]
+
+
+def save_checkpoint(epoch, model, args, accelerator, unwrapped_model=None, global_step=None):
+ """Save a checkpoint for the model."""
+ # Ensure the directory exists
+ if not os.path.exists(args.external_save_dir):
+ os.makedirs(args.external_save_dir)
+
+ if unwrapped_model is None:
+ unwrapped_model = accelerator.unwrap_model(model)
+
+ # Formulate the checkpoint filename based on whether it's an epoch or global_step checkpoint
+ if global_step:
+ checkpoint_path = f"{args.external_save_dir}/checkpoint_steps_{global_step}.pt"
+ checkpoint_dict = {
+ "steps": global_step,
+ "model_state_dict": get_checkpoint(unwrapped_model),
+ }
+ else:
+ checkpoint_path = f"{args.external_save_dir}/checkpoint_{epoch}.pt"
+ checkpoint_dict = {"model_state_dict": get_checkpoint(unwrapped_model)}
+
+ # Save the checkpoint if rank is 0
+ if args.rank == 0:
+ print(f"Saving checkpoint to {checkpoint_path}")
+ accelerator.save(checkpoint_dict, checkpoint_path)
+
+ # Save the model's configuration
+ unwrapped_model.config.save_pretrained(args.external_save_dir)
+
+ # Remove the previous checkpoint if required
+ if args.delete_previous_checkpoint:
+ if global_step:
+ prev_checkpoint_path = f"{args.external_save_dir}/checkpoint_step_{global_step-args.save_steps_interval}.pt"
+ if os.path.exists(prev_checkpoint_path):
+ os.remove(prev_checkpoint_path)
+ elif epoch > 0:
+ os.remove(f"{args.external_save_dir}/checkpoint_{epoch-1}.pt")
+
+
+def save_checkpoint(checkpoint_dict, save_path, is_main_process, save_function):
+ """Helper function to save the checkpoint."""
+ save_function(checkpoint_dict, f"{save_path}/final_weights.pt", is_main_process=is_main_process)
+
+
+def save_pretrained(component, save_path, is_main_process, save_function):
+ """Helper function to save pretrained components."""
+ component.save_pretrained(save_path, is_main_process=is_main_process, save_function=save_function, safe_serialization=False)
+
+
+def save_final_weights(model, args, accelerator, processor=None, tokenizer=None):
+ """Save final weights of the model."""
+ unwrapped_model = accelerator.unwrap_model(model)
+ is_main_process = accelerator.is_main_process
+ save_path = args.external_save_dir
+ model_name = args.model_name.lower()
+
+ unwrapped_model.config.save_pretrained(save_path)
+
+ if args.save_hf_model:
+ save_pretrained(unwrapped_model, save_path, is_main_process, accelerator.save)
+
+ if "idefics" in model_name or "fuyu" in model_name:
+ save_pretrained(processor, save_path, is_main_process, accelerator.save)
+
+ if "llama2" in model_name:
+ save_pretrained(tokenizer, save_path, is_main_process, accelerator.save)
+ else:
+ # Save based on the distributed type
+ if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
+ checkpoint_dict = accelerator.get_state_dict(model)
+ else:
+ checkpoint_dict = get_checkpoint(model=unwrapped_model)
+
+ if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
+ trainable_params_name = [name for name, p in unwrapped_model.named_parameters() if p.requires_grad]
+ checkpoint_dict = {k: v for k, v in checkpoint_dict.items() if k in trainable_params_name}
+
+ save_checkpoint(checkpoint_dict, save_path, is_main_process, accelerator.save)
+
+
+def get_weights_for_dataloaders(dataloaders):
+ total_samples = sum(len(dataloader.dataset) for dataloader in dataloaders)
+ weights = [len(dataloader.dataset) / total_samples for dataloader in dataloaders]
+ return weights
+
+
+def get_next_dataloader(dataloader_iterators, weights):
+ chosen_dataloader_index = np.random.choice(len(dataloader_iterators), p=weights)
+ return dataloader_iterators[chosen_dataloader_index]
+
+
+def find_and_remove_tokens(input_tensor, labels_tensor, attention_mask_tensor, token_id, tokenizer):
+ batch_size, seq_len = input_tensor.size()
+
+ # Create lists to store the new tensors
+ new_input_list = []
+ new_labels_list = []
+ new_attention_mask_list = []
+
+ # Loop over each sequence in the batch
+ for i in range(batch_size):
+ single_input = input_tensor[i, :]
+ single_label = labels_tensor[i, :]
+ single_attention_mask = attention_mask_tensor[i, :]
+
+ # Remove the token_id
+ new_single_input = torch.masked_select(single_input, single_input != token_id)
+ new_single_label = torch.masked_select(single_label, single_input != token_id)
+ new_single_attention_mask = torch.masked_select(single_attention_mask, single_input != token_id)
+
+ # Append the new sequence to the list
+ new_input_list.append(new_single_input)
+ new_labels_list.append(new_single_label)
+ new_attention_mask_list.append(new_single_attention_mask)
+
+ # Pad sequences within each batch to match the longest sequence
+ new_input = torch.nn.utils.rnn.pad_sequence(new_input_list, batch_first=True, padding_value=tokenizer.pad_token_id)
+ new_labels = torch.nn.utils.rnn.pad_sequence(new_labels_list, batch_first=True, padding_value=-100)
+ new_attention_mask = torch.nn.utils.rnn.pad_sequence(new_attention_mask_list, batch_first=True, padding_value=0)
+
+ return new_input, new_labels, new_attention_mask
+
+
+def delete_tensors_from_dict(d):
+ """Recursively delete tensors from a nested dictionary."""
+ keys_to_delete = []
+ for k, v in d.items():
+ if isinstance(v, torch.Tensor):
+ keys_to_delete.append(k)
+ elif isinstance(v, list):
+ new_list = [item for item in v if not isinstance(item, torch.Tensor)]
+ d[k] = new_list
+ elif isinstance(v, dict):
+ delete_tensors_from_dict(v)
+ for key in keys_to_delete:
+ del d[key]
diff --git a/pipeline/utils/__init__.py b/pipeline/utils/__init__.py
old mode 100644
new mode 100755
diff --git a/pipeline/utils/apply_delta.py b/pipeline/utils/apply_delta.py
old mode 100644
new mode 100755
diff --git a/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py b/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py
old mode 100644
new mode 100755
index 3268ec66..c3e957be
--- a/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py
+++ b/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py
@@ -171,7 +171,11 @@ def _ensure_tsv_opened(self):
def convert_tsv(tsv_id, tsv_root, output_dir):
- with wds.ShardWriter(output_dir + f"/{tsv_id.replace('.tsv','.').split('-')[-1]}%03d.tar", maxcount=500000, maxsize=2e10) as sink:
+ with wds.ShardWriter(
+ output_dir + f"/{tsv_id.replace('.tsv','.').split('-')[-1]}%03d.tar",
+ maxcount=500000,
+ maxsize=2e10,
+ ) as sink:
cur_tsv_image = TSVFile(tsv_root=tsv_root, tsv_file=tsv_id)
cur_tsv_caption = TSVFile(tsv_root=tsv_root, tsv_file=tsv_id.replace("image", "text"))
for _ in tqdm(range(cur_tsv_image.__len__()), desc="Converting image"):
@@ -189,7 +193,13 @@ def convert_tsv(tsv_id, tsv_root, output_dir):
print(e)
print(f"the caption of index {_} have problem, continue")
continue
- sink.write({"__key__": key_str, "png": cur_image[1], "txt": caption.encode("utf-8", "replace").decode()})
+ sink.write(
+ {
+ "__key__": key_str,
+ "png": cur_image[1],
+ "txt": caption.encode("utf-8", "replace").decode(),
+ }
+ )
except Exception as e:
print(f"Error at index {_}: {e}")
diff --git a/pipeline/utils/convert_mmc4_to_wds.py b/pipeline/utils/convert_mmc4_to_wds.py
old mode 100644
new mode 100755
diff --git a/pipeline/utils/general.py b/pipeline/utils/general.py
new file mode 100644
index 00000000..3d1028b8
--- /dev/null
+++ b/pipeline/utils/general.py
@@ -0,0 +1,12 @@
+class DualOutput:
+ def __init__(self, file, stdout):
+ self.file = file
+ self.stdout = stdout
+
+ def write(self, data):
+ self.file.write(data)
+ self.stdout.write(data)
+
+ def flush(self):
+ self.file.flush()
+ self.stdout.flush()
diff --git a/pipeline/utils/make_a_train.py b/pipeline/utils/make_a_train.py
old mode 100644
new mode 100755
index 2ea15bee..fd01cd95
--- a/pipeline/utils/make_a_train.py
+++ b/pipeline/utils/make_a_train.py
@@ -19,7 +19,10 @@ def main(input_file, output_file):
if key not in seen_keys:
try:
# Check if rel_ins_ids are in the original JSON
- valid_rel_ins_ids = [rel_ins_id for rel_ins_id in value["rel_ins_ids"] if rel_ins_id in data["data"]]
+ if args.remove_rel_ins_ids:
+ valid_rel_ins_ids = []
+ else:
+ valid_rel_ins_ids = [rel_ins_id for rel_ins_id in value["rel_ins_ids"] if rel_ins_id in data["data"]]
# Add the valid rel_ins_ids to the new_dict
new_dict[key] = valid_rel_ins_ids
@@ -37,6 +40,11 @@ def main(input_file, output_file):
parser = argparse.ArgumentParser(description="Process a JSON file.")
parser.add_argument("--input_file", type=str, help="Path to the input JSON file")
parser.add_argument("--output_file", type=str, help="Path to the output JSON file")
+ parser.add_argument(
+ "--remove_rel_ins_ids",
+ action="store_true",
+ help="Remove rel_ins_ids from the output JSON file",
+ )
args = parser.parse_args()
diff --git a/pipeline/utils/modeling_value_head.py b/pipeline/utils/modeling_value_head.py
new file mode 100644
index 00000000..5478fecc
--- /dev/null
+++ b/pipeline/utils/modeling_value_head.py
@@ -0,0 +1,415 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import torch
+import torch.nn as nn
+from transformers import AutoModelForCausalLM, AutoModelForSeq2SeqLM
+
+from trl.models.modeling_base import PreTrainedModelWrapper
+
+
+class ValueHead(nn.Module):
+ r"""
+ The ValueHead class implements a head for GPT2 that returns a scalar for each output token.
+ """
+
+ def __init__(self, config, **kwargs):
+ super().__init__()
+ if not hasattr(config, "summary_dropout_prob"):
+ summary_dropout_prob = kwargs.pop("summary_dropout_prob", 0.1)
+ else:
+ summary_dropout_prob = config.summary_dropout_prob
+
+ self.dropout = nn.Dropout(summary_dropout_prob) if summary_dropout_prob else nn.Identity()
+
+ # some models such as OPT have a projection layer before the word embeddings - e.g. OPT-350m
+ if hasattr(config, "word_embed_proj_dim"):
+ hidden_size = config.word_embed_proj_dim
+ else:
+ hidden_size = config.hidden_size
+
+ self.summary = nn.Linear(hidden_size, 1)
+
+ self.flatten = nn.Flatten()
+
+ def forward(self, hidden_states):
+ output = self.dropout(hidden_states)
+
+ # For now force upcast in fp32 if needed. Let's keep the
+ # output in fp32 for numerical stability.
+ if output.dtype != self.summary.weight.dtype:
+ output = output.to(self.summary.weight.dtype)
+
+ output = self.summary(output)
+ return output
+
+
+class AutoModelForCausalLMWithValueHead(PreTrainedModelWrapper):
+ r"""
+ An autoregressive model with a value head in addition to the language model head.
+ This class inherits from `~trl.PreTrainedModelWrapper` and wraps a
+ `transformers.PreTrainedModel` class. The wrapper class supports classic functions
+ such as `from_pretrained`, `push_to_hub` and `generate`. To call a method of the wrapped
+ model, simply manipulate the `pretrained_model` attribute of this class.
+
+ Class attributes:
+ - **transformers_parent_class** (`transformers.PreTrainedModel`) -- The parent class of the wrapped model. This
+ should be set to `transformers.AutoModelForCausalLM` for this class.
+ - **lm_head_namings** (`tuple`) -- A tuple of strings that are used to identify the language model head of the
+ wrapped model. This is set to `("lm_head", "embed_out")` for this class but can be changed for other models
+ in the future
+ - **supported_args** (`tuple`) -- A tuple of strings that are used to identify the arguments that are supported
+ by the `ValueHead` class. Currently, the supported args are:
+ - **summary_dropout_prob** (`float`, `optional`, defaults to `None`) -- The dropout probability for the
+ `ValueHead` class.
+ - **v_head_initializer_range** (`float`, `optional`, defaults to `0.2`) -- The initializer range for the
+ `ValueHead` if a specific initialization strategy is selected.
+ - **v_head_init_strategy** (`str`, `optional`, defaults to `None`) -- The initialization strategy for the
+ `ValueHead`. Currently, the supported strategies are:
+ - **`None`** -- Initializes the weights of the `ValueHead` with a random distribution. This is the default
+ strategy.
+ - **"normal"** -- Initializes the weights of the `ValueHead` with a normal distribution.
+
+ """
+ transformers_parent_class = AutoModelForCausalLM
+ lm_head_namings = ["lm_head", "embed_out"]
+ supported_args = (
+ "summary_dropout_prob",
+ "v_head_initializer_range",
+ "v_head_init_strategy",
+ )
+
+ def __init__(self, pretrained_model, **kwargs):
+ r"""
+ Initializes the model.
+
+ Args:
+ pretrained_model (`transformers.PreTrainedModel`):
+ The model to wrap. It should be a causal language model such as GPT2.
+ or any model mapped inside the `AutoModelForCausalLM` class.
+ kwargs (`dict`, `optional`):
+ Additional keyword arguments, that are passed to the `ValueHead` class.
+ """
+ super().__init__(pretrained_model)
+ v_head_kwargs, _, _ = self._split_kwargs(kwargs)
+
+ if not any(hasattr(self.pretrained_model, attribute) for attribute in self.lm_head_namings):
+ raise ValueError("The model does not have a language model head, please use a model that has one.")
+
+ self.v_head = ValueHead(self.pretrained_model.config, **v_head_kwargs)
+
+ self._init_weights(**v_head_kwargs)
+
+ def _init_weights(self, **kwargs):
+ r"""
+ Initializes the weights of the value head. The default initialization strategy is random.
+ Users can pass a different initialization strategy by passing the `v_head_init_strategy` argument
+ when calling `.from_pretrained`. Supported strategies are:
+ - `normal`: initializes the weights with a normal distribution.
+
+ Args:
+ **kwargs (`dict`, `optional`):
+ Additional keyword arguments, that are passed to the `ValueHead` class. These arguments
+ can contain the `v_head_init_strategy` argument as well as the `v_head_initializer_range`
+ argument.
+ """
+ initializer_range = kwargs.pop("v_head_initializer_range", 0.2)
+ # random init by default
+ init_strategy = kwargs.pop("v_head_init_strategy", None)
+ if init_strategy is None:
+ # do nothing
+ pass
+ elif init_strategy == "normal":
+ self.v_head.summary.weight.data.normal_(mean=0.0, std=initializer_range)
+ self.v_head.summary.bias.data.zero_()
+
+ def forward(
+ self,
+ input_ids=None,
+ past_key_values=None,
+ attention_mask=None,
+ **kwargs,
+ ):
+ r"""
+ Applies a forward pass to the wrapped model and returns the logits of the value head.
+
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, `optional`):
+ Contains pre-computed hidden-states (key and values in the attention blocks) as computed by the model
+ (see `past_key_values` input) to speed up sequential decoding.
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ kwargs (`dict`, `optional`):
+ Additional keyword arguments, that are passed to the wrapped model.
+ """
+ kwargs["output_hidden_states"] = True # this had already been set in the LORA / PEFT examples
+ kwargs["past_key_values"] = past_key_values
+
+ if self.is_peft_model and self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING":
+ kwargs.pop("past_key_values")
+
+ base_model_output = self.pretrained_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ **kwargs,
+ )
+
+ last_hidden_state = base_model_output.hidden_states[-1]
+ lm_logits = base_model_output.logits
+ loss = base_model_output.loss
+
+ if last_hidden_state.device != self.v_head.summary.weight.device:
+ last_hidden_state = last_hidden_state.to(self.v_head.summary.weight.device)
+
+ value = self.v_head(last_hidden_state).squeeze(-1)
+
+ # force upcast in fp32 if logits are in half-precision
+ if lm_logits.dtype != torch.float32:
+ lm_logits = lm_logits.float()
+
+ return (lm_logits, loss, value)
+
+ def generate(self, *args, **kwargs):
+ r"""
+ A simple wrapper around the `generate` method of the wrapped model.
+ Please refer to the [`generate`](https://huggingface.co/docs/transformers/internal/generation_utils)
+ method of the wrapped model for more information about the supported arguments.
+
+ Args:
+ *args (`list`, *optional*):
+ Positional arguments passed to the `generate` method of the wrapped model.
+ **kwargs (`dict`, *optional*):
+ Keyword arguments passed to the `generate` method of the wrapped model.
+ """
+ return self.pretrained_model.generate(*args, **kwargs)
+
+ def state_dict(self, *args, **kwargs):
+ r"""
+ Returns the state dictionary of the model. We add the state dictionary of the value head
+ to the state dictionary of the wrapped model by prepending the key with `v_head.`.
+ """
+ if not self.is_peft_model:
+ pretrained_model_state_dict = self.pretrained_model.state_dict(*args, **kwargs)
+ else:
+ # if it is a peft model, only save the v_head
+ pretrained_model_state_dict = {}
+
+ v_head_state_dict = self.v_head.state_dict(*args, **kwargs)
+ for k, v in v_head_state_dict.items():
+ pretrained_model_state_dict[f"v_head.{k}"] = v
+ return pretrained_model_state_dict
+
+ def push_to_hub(self, *args, **kwargs):
+ setattr(self.pretrained_model, "v_head", self.v_head)
+
+ return self.pretrained_model.push_to_hub(*args, **kwargs)
+
+ def post_init(self, state_dict):
+ r"""
+ We add the state dictionary of the value head to the state dictionary of the wrapped model
+ by prepending the key with `v_head.`. This function removes the `v_head.` prefix from the
+ keys of the value head state dictionary.
+ """
+ for k in list(state_dict.keys()):
+ if "v_head." in k:
+ state_dict[k.replace("v_head.", "")] = state_dict.pop(k)
+ self.v_head.load_state_dict(state_dict, strict=False)
+ del state_dict
+
+ if hasattr(self.pretrained_model, "hf_device_map"):
+ if "cpu" in self.pretrained_model.hf_device_map.values() or "disk" in self.pretrained_model.hf_device_map.values():
+ raise ValueError("The model is offloaded on CPU or disk - CPU & disk offloading is not supported for ValueHead models.")
+
+ first_device = list(set(self.pretrained_model.hf_device_map.values()))[0]
+
+ self.v_head = self.v_head.to(first_device)
+
+ def set_device_hook(module, input, outputs):
+ new_output = ()
+ for output in outputs:
+ if isinstance(output, torch.Tensor):
+ new_output += (output.to(first_device),)
+ else:
+ new_output += (output,)
+ return new_output
+
+ self.register_forward_hook(set_device_hook)
+
+ self.is_sequential_parallel = True
+
+
+class AutoModelForSeq2SeqLMWithValueHead(PreTrainedModelWrapper):
+ r"""
+ A seq2seq model with a value head in addition to the language model head.
+ This class inherits from `~trl.PreTrainedModelWrapper` and wraps a
+ `transformers.PreTrainedModel` class. The wrapper class supports classic functions
+ such as `from_pretrained` and `push_to_hub` and also provides some additional
+ functionalities such as `generate`.
+
+ Args:
+ pretrained_model (`transformers.PreTrainedModel`):
+ The model to wrap. It should be a causal language model such as GPT2.
+ or any model mapped inside the `AutoModelForSeq2SeqLM` class.
+ kwargs:
+ Additional keyword arguments passed along to the `ValueHead` class.
+ """
+ transformers_parent_class = AutoModelForSeq2SeqLM
+ lm_head_namings = ["lm_head", "embed_out", "output_projection"]
+ supported_args = (
+ "summary_dropout_prob",
+ "v_head_initializer_range",
+ "v_head_init_strategy",
+ )
+
+ def __init__(self, pretrained_model, **kwargs):
+ super().__init__(pretrained_model)
+ v_head_kwargs, _, _ = self._split_kwargs(kwargs)
+ self.is_encoder_decoder = True
+
+ if not self._has_lm_head():
+ raise ValueError("The model does not have a language model head, please use a model that has one.")
+
+ self.v_head = ValueHead(self.pretrained_model.config, **v_head_kwargs)
+
+ self._init_weights(**v_head_kwargs)
+
+ def _has_lm_head(self):
+ # check module names of all modules inside `pretrained_model` to find the language model head
+ for name, module in self.pretrained_model.named_modules():
+ if any(attribute in name for attribute in self.lm_head_namings):
+ return True
+ return False
+
+ def post_init(self, state_dict):
+ r"""
+ We add the state dictionary of the value head to the state dictionary of the wrapped model
+ by prepending the key with `v_head.`. This function removes the `v_head.` prefix from the
+ keys of the value head state dictionary.
+ """
+ for k in list(state_dict.keys()):
+ if "v_head." in k:
+ state_dict[k.replace("v_head.", "")] = state_dict.pop(k)
+ self.v_head.load_state_dict(state_dict, strict=False)
+ del state_dict
+
+ if hasattr(self.pretrained_model, "hf_device_map"):
+ if "cpu" in self.pretrained_model.hf_device_map.values() or "disk" in self.pretrained_model.hf_device_map.values():
+ raise ValueError("The model is offloaded on CPU or disk - CPU & disk offloading is not supported for ValueHead models.")
+
+ # get the lm_head device
+ for name, module in self.pretrained_model.named_modules():
+ if any(attribute in name for attribute in self.lm_head_namings):
+ lm_head_device = module.weight.device
+ break
+
+ # put v_head on the same device as the lm_head to avoid issues
+ self.v_head = self.v_head.to(lm_head_device)
+
+ def set_device_hook(module, input, outputs):
+ r"""
+ A hook that sets the device of the output of the model to the device of the first
+ parameter of the model.
+
+ Args:
+ module (`nn.Module`):
+ The module to which the hook is attached.
+ input (`tuple`):
+ The input to the module.
+ outputs (`tuple`):
+ The output of the module.
+ """
+ new_output = ()
+ for output in outputs:
+ if isinstance(output, torch.Tensor):
+ new_output += (output.to(lm_head_device),)
+ else:
+ new_output += (output,)
+ return new_output
+
+ self.register_forward_hook(set_device_hook)
+ self.is_sequential_parallel = True
+
+ def state_dict(self, *args, **kwargs):
+ r"""
+ Returns the state dictionary of the model. We add the state dictionary of the value head
+ to the state dictionary of the wrapped model by prepending the key with `v_head.`.
+ """
+ if not self.is_peft_model:
+ pretrained_model_state_dict = self.pretrained_model.state_dict(*args, **kwargs)
+ else:
+ # if it is a peft model, only save the v_head
+ pretrained_model_state_dict = {}
+
+ v_head_state_dict = self.v_head.state_dict(*args, **kwargs)
+ for k, v in v_head_state_dict.items():
+ pretrained_model_state_dict[f"v_head.{k}"] = v
+ return pretrained_model_state_dict
+
+ def push_to_hub(self, *args, **kwargs):
+ setattr(self.pretrained_model, "v_head", self.v_head)
+
+ return self.pretrained_model.push_to_hub(*args, **kwargs)
+
+ def _init_weights(self, **kwargs):
+ r"""
+ We initialize the weights of the value head.
+ """
+ initializer_range = kwargs.pop("v_head_initializer_range", 0.2)
+ # random init by default
+ init_strategy = kwargs.pop("v_head_init_strategy", None)
+ if init_strategy is None:
+ # do nothing
+ pass
+ elif init_strategy == "normal":
+ self.v_head.summary.weight.data.normal_(mean=0.0, std=initializer_range)
+ self.v_head.summary.bias.data.zero_()
+
+ def forward(
+ self,
+ input_ids=None,
+ past_key_values=None,
+ attention_mask=None,
+ **kwargs,
+ ):
+ kwargs["past_key_values"] = past_key_values
+ if self.is_peft_model and self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING":
+ kwargs.pop("past_key_values")
+
+ base_model_output = self.pretrained_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ output_hidden_states=True, # We force the model to output hidden states
+ **kwargs,
+ )
+
+ last_hidden_state = base_model_output.decoder_hidden_states[-1]
+ lm_logits = base_model_output.logits
+ loss = base_model_output.loss
+
+ value = self.v_head(last_hidden_state).squeeze(-1)
+
+ # force upcast in fp32 if logits are in half-precision
+ if lm_logits.dtype != torch.float32:
+ lm_logits = lm_logits.float()
+
+ return (lm_logits, loss, value)
+
+ def generate(self, *args, **kwargs):
+ r"""
+ We call `generate` on the wrapped model.
+ """
+ return self.pretrained_model.generate(*args, **kwargs)
diff --git a/pyproject.toml b/pyproject.toml
index 335a2d9a..3f224fc0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -1,5 +1,5 @@
[tool.black]
-line-length = 160
+line-length = 240
[build-system]
requires = ["setuptools>=42", "wheel", "setuptools_scm[tomli]>=6.3"]
diff --git a/pytest.ini b/pytest.ini
new file mode 100644
index 00000000..1b91c233
--- /dev/null
+++ b/pytest.ini
@@ -0,0 +1,3 @@
+[pytest]
+markers =
+ prerun: mark a test as a prerun check.
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
old mode 100644
new mode 100755
index 8d1c215c..bc361980
--- a/requirements.txt
+++ b/requirements.txt
@@ -12,6 +12,7 @@ more_itertools>=9.1.0
nltk>=3.8.1
numpy>=1.23.5
open_clip_torch>=2.16.0
+openai>=1.1.1
opencv_python_headless>=4.5.5.64
Pillow>=9.5.0
pycocoevalcap>=1
@@ -20,7 +21,7 @@ Requests>=2.31.0
scipy>=1.10.1
timm>=0.9.2
tqdm>=4.65.0
-transformers>=4.29.0
+transformers==4.35.0
uvicorn>=0.22.0
webdataset>=0.2.48
xformers>=0.0.20
@@ -32,4 +33,8 @@ yajl>=0.3.5
deepspeed>=0.10.0
wandb>=0.15.8
trl>=0.5.0
+cffi>=1.15.1
pyyaml>=6.0.1
+pytest>=7.4.2
+prettytable>=3.9.0
+torch==2.0.1
diff --git a/setup.py b/setup.py
index e985f527..71a058d6 100644
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
setup(
name="otter-ai",
- version="0.0.0-alpha-3",
+ version="0.0.0-alpha-4",
packages=find_packages(where="src"),
package_dir={"": "src"},
install_requires=requirements,
diff --git a/shared_scripts/Demo_Data.yaml b/shared_scripts/Demo_Data.yaml
new file mode 100644
index 00000000..78919900
--- /dev/null
+++ b/shared_scripts/Demo_Data.yaml
@@ -0,0 +1,83 @@
+IMAGE_TEXT:
+ LADD:
+ mimicit_path: azure_storage/json/LA/LADD_instructions.json
+ images_path: azure_storage/Parquets/LA.parquet
+ num_samples: -1
+ # LACONV:
+ # mimicit_path: azure_storage/json/LA/LACONV_instructions.json
+ # images_path: azure_storage/json/LA/LA.json
+ # train_config_path: azure_storage/json/LA/LACONV_train.json
+ # num_samples: 50
+ LACR_T2T:
+ mimicit_path: azure_storage/json/LA/LACR_T2T_instructions.json
+ images_path: azure_storage/Parquets/LA.parquet
+ num_samples: -1
+ M3IT_CAPTIONING:
+ mimicit_path: azure_storage/json/M3IT/captioning/coco/coco_instructions.json
+ images_path: azure_storage/Parquets/coco.parquet
+ num_samples: 20000
+ # M3IT_VQA:
+ # mimicit_path: azure_storage/json/M3IT/vqa/vqav2/vqav2_instructions.json
+ # images_path: azure_storage/json/M3IT/vqa/vqav2/vqav2.json
+ # num_samples: 20000
+ M3IT_COCOGOI:
+ mimicit_path: azure_storage/json/M3IT/classification/coco-goi/coco-goi_instructions.json
+ images_path: azure_storage/Parquets/coco-goi.parquet
+ num_samples: 20000
+ M3IT_COCOITM:
+ mimicit_path: azure_storage/json/M3IT/classification/coco-itm/coco-itm_instructions.json
+ images_path: azure_storage/Parquets/coco-itm.parquet
+ num_samples: 20000
+ M3IT_IMAGENET:
+ mimicit_path: azure_storage/json/M3IT/classification/imagenet/imagenet_instructions.json
+ images_path: azure_storage/Parquets/imagenet.parquet
+ num_samples: 20000
+ # # M3IT_IQA:
+ # # mimicit_path: azure_storage/json/M3IT/classification/iqa/iqa_instructions.json
+ # # images_path: azure_storage/json/M3IT/classification/iqa/iqa.json
+ # # num_samples: 20000
+ M3IT_REFCOCO:
+ mimicit_path: azure_storage/json/M3IT/classification/refcoco/refcoco_instructions.json
+ images_path: azure_storage/Parquets/refcoco.parquet
+ num_samples: 20000
+ # M3IT_VSR:
+ # mimicit_path: azure_storage/json/M3IT/classification/vsr/vsr_instructions.json
+ # images_path: azure_storage/json/M3IT/classification/vsr/vsr.json
+ # num_samples: 20000
+ M3IT_TEXT_VQA:
+ mimicit_path: azure_storage/json/M3IT/vqa/text-vqa/text-vqa_instructions.json
+ images_path: azure_storage/Parquets/text-vqa.parquet
+ num_samples: 20000
+ M3IT_OKVQA:
+ mimicit_path: azure_storage/json/M3IT/vqa/okvqa/okvqa_instructions.json
+ images_path: azure_storage/Parquets/okvqa.parquet
+ num_samples: 20000
+ M3IT_A_OKVQA:
+ mimicit_path: azure_storage/json/M3IT/vqa/a-okvqa/a-okvqa_instructions.json
+ images_path: azure_storage/Parquets/a-okvqa.parquet
+ num_samples: 20000
+ M3IT_SIENCEQA:
+ mimicit_path: azure_storage/json/M3IT/reasoning/scienceqa/scienceqa_instructions.json
+ images_path: azure_storage/Parquets/scienceqa.parquet
+ num_samples: 20000
+ # SVIT:
+ # mimicit_path: azure_storage/json/SVIT/SVIT_instructions.json
+ # images_path: azure_storage/json/SVIT/SVIT.json
+ # num_samples: 20000
+ # PF:
+ # mimicit_path: azure_storage/json/PF/PF_instructions.json
+ # images_path: azure_storage/json/PF/PF.json
+ # num_samples: 20000
+
+# TEXT_ONLY:
+# LIMA:
+# mimicit_path: azure_storage/json/LANG_Only/LIMA/LIMA_instructions_max_1K_tokens.json
+# num_samples: 20000
+# SHAREGPT:
+# mimicit_path: azure_storage/json/LANG_Only/SHAREGPT/SHAREGPT_instructions_max_1K_tokens.json
+# num_samples: 10000
+# AL:
+# mimicit_path: azure_storage/json/LANG_Only/AL/AL_instructions_max_1K_tokens.json
+# num_samples: 20000
+
+
diff --git a/shared_scripts/Demo_OtterHD.sh b/shared_scripts/Demo_OtterHD.sh
new file mode 100644
index 00000000..b55199ec
--- /dev/null
+++ b/shared_scripts/Demo_OtterHD.sh
@@ -0,0 +1,66 @@
+#!/bin/bash
+cd /root/of/Otter
+
+export PYTHONPATH=.
+
+# sent to sub script
+export HOSTNAMES=$(scontrol show hostnames "$SLURM_JOB_NODELIST")
+export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
+export MASTER_PORT=12955
+export COUNT_NODE=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l)
+export NCCL_NET=IB
+
+echo HOSTNAMES = $HOSTNAMES
+echo hostname = $(hostname)
+echo MASTER_ADDR= $MASTER_ADDR
+echo MASTER_PORT= $MASTER_PORT
+
+GPU=$((${COUNT_NODE} * 8))
+WORKERS=$((${COUNT_NODE} * 8))
+
+if [ $WORKERS -gt 112 ]; then
+ WORKERS=112
+fi
+
+RUN_NAME="RunNamePlaceHolder"
+
+echo GPU=${GPU}
+echo COUNT_NODE=$COUNT_NODE
+echo WORKERS=8
+echo "Running ${RUN_NAME}"
+
+H=$(hostname)
+THEID=$(echo -e $HOSTNAMES | python3 -c "import sys;[sys.stdout.write(str(i)) for i,line in enumerate(next(sys.stdin).split(' ')) if line.strip() == '$H'.strip()]")
+export THEID=$THEID
+echo $THEID
+
+pkill python
+
+
+accelerate launch --config_file=./pipeline/accelerate_configs/accelerate_config_zero2.yaml \
+ --machine_rank $THEID --main_process_ip $MASTER_ADDR --main_process_port $MASTER_PORT \
+ --num_machines=${COUNT_NODE} --num_processes=${GPU} \
+ pipeline/train/instruction_following.py \
+ --pretrained_model_name_or_path=adept/fuyu-8b \
+ --training_data_yaml=./Demo_Data.yaml \
+ --model_name=fuyu \
+ --instruction_format=fuyu \
+ --batch_size=8 \
+ --gradient_accumulation_steps=2 \
+ --num_epochs=3 \
+ --report_to_wandb \
+ --wandb_entity=libo0013 \
+ --external_save_dir=./checkpoints \
+ --run_name=${RUN_NAME} \
+ --wandb_project=Fuyu \
+ --workers=${WORKERS} \
+ --lr_scheduler=cosine \
+ --learning_rate=1e-5 \
+ --warmup_steps_ratio=0.03 \
+ --save_hf_model \
+ --max_seq_len=1024 \
+ --logging_steps=1000 \
+ --keep_symbols \
+ --save_ckpt_each_epoch \
+ --dynamic_resolution \
+ --with_task_description
diff --git a/shared_scripts/Demo_OtterMPT.sh b/shared_scripts/Demo_OtterMPT.sh
new file mode 100644
index 00000000..12e76c50
--- /dev/null
+++ b/shared_scripts/Demo_OtterMPT.sh
@@ -0,0 +1,66 @@
+#!/bin/bash
+cd /root/of/Otter
+
+export PYTHONPATH=.
+
+# sent to sub script
+export HOSTNAMES=$(scontrol show hostnames "$SLURM_JOB_NODELIST")
+export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
+export MASTER_PORT=12955
+export COUNT_NODE=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l)
+export NCCL_NET=IB
+
+echo HOSTNAMES = $HOSTNAMES
+echo hostname = $(hostname)
+echo MASTER_ADDR= $MASTER_ADDR
+echo MASTER_PORT= $MASTER_PORT
+
+GPU=$((${COUNT_NODE} * 8))
+WORKERS=$((${COUNT_NODE} * 8))
+
+if [ $WORKERS -gt 112 ]; then
+ WORKERS=112
+fi
+
+RUN_NAME="RunNamePlaceHolder"
+
+echo GPU=${GPU}
+echo COUNT_NODE=$COUNT_NODE
+echo WORKERS=8
+echo "Running ${RUN_NAME}"
+
+H=$(hostname)
+THEID=$(echo -e $HOSTNAMES | python3 -c "import sys;[sys.stdout.write(str(i)) for i,line in enumerate(next(sys.stdin).split(' ')) if line.strip() == '$H'.strip()]")
+export THEID=$THEID
+echo $THEID
+
+pkill python
+
+
+# --customized_config=./shared_scripts/Otter_MPT7B_Train_Decoder.json
+accelerate launch --config_file=./pipeline/accelerate_configs/accelerate_config_zero2.yaml \
+ --machine_rank $THEID --main_process_ip $MASTER_ADDR --main_process_port $MASTER_PORT \
+ --num_machines=${COUNT_NODE} --num_processes=${GPU} \
+ pipeline/train/instruction_following.py \
+ --pretrained_model_name_or_path=adept/fuyu-8b \
+ --training_data_yaml=./Demo_Data.yaml \
+ --model_name=otter \
+ --instruction_format=simple \
+ --batch_size=8 \
+ --gradient_accumulation_steps=2 \
+ --num_epochs=3 \
+ --report_to_wandb \
+ --wandb_entity=libo0013 \
+ --external_save_dir=./checkpoints \
+ --run_name=${RUN_NAME} \
+ --wandb_project=Fuyu \
+ --workers=${WORKERS} \
+ --lr_scheduler=cosine \
+ --learning_rate=1e-5 \
+ --warmup_steps_ratio=0.03 \
+ --save_hf_model \
+ --max_seq_len=2048 \
+ --logging_steps=1000 \
+ --keep_symbols \
+ --save_ckpt_each_epoch \
+ --with_task_description
diff --git a/shared_scripts/Otter_MPT7B_Train_Decoder.json b/shared_scripts/Otter_MPT7B_Train_Decoder.json
new file mode 100644
index 00000000..7d26509a
--- /dev/null
+++ b/shared_scripts/Otter_MPT7B_Train_Decoder.json
@@ -0,0 +1,198 @@
+{
+ "_commit_hash": null,
+ "_name_or_path": "luodian/OTTER-MPT7B-Init",
+ "architectures": [
+ "OtterForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "otter",
+ "train_vision_encoder": false,
+ "train_lang_encoder": true,
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 4096,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 4096,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 2048,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 32,
+ "n_layers": 32,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/__init__.py b/src/otter_ai/models/__init__.py
index e69de29b..8d62516b 100644
--- a/src/otter_ai/models/__init__.py
+++ b/src/otter_ai/models/__init__.py
@@ -0,0 +1,3 @@
+from .falcon.modelling_RW import RWForCausalLM
+from .mpt.modeling_mpt import MPTForCausalLM
+from .mpt_redpajama.mosaic_gpt import MosaicGPT
diff --git a/src/otter_ai/models/falcon/__init__.py b/src/otter_ai/models/falcon/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/src/otter_ai/models/flamingo/falcon/configuration_RW.py b/src/otter_ai/models/falcon/configuration_RW.py
old mode 100644
new mode 100755
similarity index 100%
rename from src/otter_ai/models/flamingo/falcon/configuration_RW.py
rename to src/otter_ai/models/falcon/configuration_RW.py
diff --git a/src/otter_ai/models/flamingo/falcon/modelling_RW.py b/src/otter_ai/models/falcon/modelling_RW.py
old mode 100644
new mode 100755
similarity index 92%
rename from src/otter_ai/models/flamingo/falcon/modelling_RW.py
rename to src/otter_ai/models/falcon/modelling_RW.py
index b929a5f5..cac6e12e
--- a/src/otter_ai/models/flamingo/falcon/modelling_RW.py
+++ b/src/otter_ai/models/falcon/modelling_RW.py
@@ -63,8 +63,8 @@ def __init__(
self.head_dim = head_dim
self.seq_len_cached = None
self.batch_size_cached = None
- self.cos_cached: torch.Tensor | None = None
- self.sin_cached: torch.Tensor | None = None
+ self.cos_cached = None # Union[torch.Tensor, None] replaced with None
+ self.sin_cached = None # Union[torch.Tensor, None] replaced with None
def cos_sin(
self,
@@ -97,7 +97,11 @@ def forward(self, q, k):
def _make_causal_mask(input_ids_shape: torch.Size, device: torch.device, past_key_values_length: int) -> torch.BoolTensor:
batch_size, target_length = input_ids_shape
- mask = torch.empty((target_length, target_length + past_key_values_length), dtype=torch.bool, device=device)
+ mask = torch.empty(
+ (target_length, target_length + past_key_values_length),
+ dtype=torch.bool,
+ device=device,
+ )
# ONNX doesn't support `torch.Tensor.triu` properly, thus we use this workaround
seq_ids = torch.arange(target_length, device=device)
mask[:, past_key_values_length:] = seq_ids[:, None] < seq_ids[None, :]
@@ -120,14 +124,28 @@ def _expand_mask(mask: torch.Tensor, tgt_length: int) -> torch.BoolTensor:
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
batch_size, seq_length = attention_mask.shape
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
- base = torch.tensor(2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32)
+ base = torch.tensor(
+ 2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))),
+ device=attention_mask.device,
+ dtype=torch.float32,
+ )
powers = torch.arange(1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32)
slopes = torch.pow(base, powers)
if closest_power_of_2 != num_heads:
- extra_base = torch.tensor(2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32)
+ extra_base = torch.tensor(
+ 2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))),
+ device=attention_mask.device,
+ dtype=torch.float32,
+ )
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
- extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, device=attention_mask.device, dtype=torch.int32)
+ extra_powers = torch.arange(
+ 1,
+ 1 + 2 * num_remaining_heads,
+ 2,
+ device=attention_mask.device,
+ dtype=torch.int32,
+ )
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention
@@ -195,7 +213,11 @@ def _split_heads(self, fused_qkv: torch.Tensor) -> Tuple[torch.Tensor, torch.Ten
else:
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads + 2, self.head_dim)
- return fused_qkv[..., :-2, :], fused_qkv[..., [-2], :], fused_qkv[..., [-1], :]
+ return (
+ fused_qkv[..., :-2, :],
+ fused_qkv[..., [-2], :],
+ fused_qkv[..., [-1], :],
+ )
def _merge_heads(self, x: torch.Tensor) -> torch.Tensor:
"""
@@ -385,7 +407,12 @@ def forward(
attention_output = attn_outputs[0]
if not self.config.parallel_attn:
- residual = dropout_add(attention_output, residual, self.config.attention_dropout, training=self.training)
+ residual = dropout_add(
+ attention_output,
+ residual,
+ self.config.attention_dropout,
+ training=self.training,
+ )
layernorm_output = self.post_attention_layernorm(residual)
outputs = attn_outputs[1:]
@@ -407,7 +434,10 @@ def forward(
class RWPreTrainedModel(PreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
@@ -499,7 +529,12 @@ def __init__(self, config: RWConfig):
def get_input_embeddings(self):
return self.word_embeddings
- def _prepare_attn_mask(self, attention_mask: torch.Tensor, input_shape: Tuple[int, int], past_key_values_length: int) -> torch.BoolTensor:
+ def _prepare_attn_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_shape: Tuple[int, int],
+ past_key_values_length: int,
+ ) -> torch.BoolTensor:
# create causal mask
# [batch_size, seq_length] -> [batch_size, 1, tgt_length, src_length]
combined_attention_mask = None
@@ -507,7 +542,11 @@ def _prepare_attn_mask(self, attention_mask: torch.Tensor, input_shape: Tuple[in
_, src_length = input_shape
if src_length > 1:
- combined_attention_mask = _make_causal_mask(input_shape, device=device, past_key_values_length=past_key_values_length)
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ device=device,
+ past_key_values_length=past_key_values_length,
+ )
# [batch_size, seq_length] -> [batch_size, 1, tgt_length, src_length]
expanded_attn_mask = _expand_mask(attention_mask, tgt_length=src_length)
@@ -606,7 +645,11 @@ def forward(
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
- return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
+ return module(
+ *inputs,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
return custom_forward
@@ -642,7 +685,16 @@ def custom_forward(*inputs):
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ presents,
+ all_hidden_states,
+ all_self_attentions,
+ ]
+ if v is not None
+ )
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
@@ -653,7 +705,10 @@ def custom_forward(*inputs):
class RWForCausalLM(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config: RWConfig):
super().__init__(config)
@@ -745,7 +800,10 @@ def forward(
batch_size, seq_length, vocab_size = shift_logits.shape
# Flatten the tokens
loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(batch_size * seq_length, vocab_size), shift_labels.view(batch_size * seq_length))
+ loss = loss_fct(
+ shift_logits.view(batch_size * seq_length, vocab_size),
+ shift_labels.view(batch_size * seq_length),
+ )
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
@@ -759,7 +817,11 @@ def forward(
attentions=transformer_outputs.attentions,
)
- def _reorder_cache(self, past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
+ def _reorder_cache(
+ self,
+ past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...],
+ beam_idx: torch.LongTensor,
+ ) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
@@ -782,7 +844,10 @@ def _reorder_cache(self, past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], be
class RWForSequenceClassification(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config: RWConfig):
super().__init__(config)
@@ -853,10 +918,7 @@ def forward(
sequence_lengths = torch.ne(input_ids, self.config.pad_token_id).sum(dim=-1) - 1
else:
sequence_lengths = -1
- logger.warning(
- f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
- "unexpected if using padding tokens in conjunction with `inputs_embeds.`"
- )
+ logger.warning(f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be " "unexpected if using padding tokens in conjunction with `inputs_embeds.`")
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
@@ -896,7 +958,10 @@ def forward(
class RWForTokenClassification(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config: RWConfig):
super().__init__(config)
@@ -966,7 +1031,10 @@ def forward(
if labels is not None:
batch_size, seq_length = labels.shape
loss_fct = CrossEntropyLoss()
- loss = loss_fct(logits.view(batch_size * seq_length, self.num_labels), labels.view(batch_size * seq_length))
+ loss = loss_fct(
+ logits.view(batch_size * seq_length, self.num_labels),
+ labels.view(batch_size * seq_length),
+ )
if not return_dict:
output = (logits,) + transformer_outputs[2:]
@@ -981,7 +1049,10 @@ def forward(
class RWForQuestionAnswering(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config):
super().__init__(config)
diff --git a/src/otter_ai/models/flamingo/__init__.py b/src/otter_ai/models/flamingo/__init__.py
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/flamingo/config.json b/src/otter_ai/models/flamingo/config.json
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/flamingo/configuration_flamingo.py b/src/otter_ai/models/flamingo/configuration_flamingo.py
old mode 100644
new mode 100755
index 08c6255a..09b14954
--- a/src/otter_ai/models/flamingo/configuration_flamingo.py
+++ b/src/otter_ai/models/flamingo/configuration_flamingo.py
@@ -7,9 +7,9 @@
from transformers.models.clip import CLIPVisionConfig
import sys
-from .falcon.configuration_RW import RWConfig
-from .mpt.configuration_mpt import MPTConfig
-from .mpt_redpajama.configuration_mosaic_gpt import MosaicGPTConfig
+from ..falcon.configuration_RW import RWConfig
+from ..mpt.configuration_mpt import MPTConfig
+from ..mpt_redpajama.configuration_mosaic_gpt import MosaicGPTConfig
logger = logging.get_logger(__name__)
diff --git a/src/otter_ai/models/flamingo/modeling_flamingo.py b/src/otter_ai/models/flamingo/modeling_flamingo.py
old mode 100644
new mode 100755
index 26f6e528..504cc6e3
--- a/src/otter_ai/models/flamingo/modeling_flamingo.py
+++ b/src/otter_ai/models/flamingo/modeling_flamingo.py
@@ -12,9 +12,10 @@
from transformers.models.auto import AutoModel, AutoModelForCausalLM, AutoTokenizer
from .configuration_flamingo import FlamingoConfig
-from .falcon.modelling_RW import RWForCausalLM
-from .mpt.modeling_mpt import MPTForCausalLM
-from .mpt_redpajama.mosaic_gpt import MosaicGPT
+from ..falcon.modelling_RW import RWForCausalLM
+from ..mpt.modeling_mpt import MPTForCausalLM
+from ..mpt_redpajama.mosaic_gpt import MosaicGPT
+import torch.distributed as dist
# from .configuration_flamingo import FlamingoConfig
@@ -31,14 +32,21 @@
}
+def master_print(*args, **kwargs):
+ if dist.is_available() and dist.is_initialized():
+ rank = dist.get_rank()
+ if rank == 0:
+ print(*args, **kwargs)
+ else:
+ print(*args, **kwargs)
+
+
def _infer_decoder_layers_attr_name(model: nn.Module):
for k in __KNOWN_DECODER_LAYERS_ATTR_NAMES:
if k.lower() in model.__class__.__name__.lower():
return __KNOWN_DECODER_LAYERS_ATTR_NAMES[k]
- raise ValueError(
- f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually."
- )
+ raise ValueError(f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually.")
def extend_instance(obj, mixin):
@@ -424,14 +432,7 @@ def init_flamingo(
for layer_idx, _ in enumerate(self._get_decoder_layers())
]
)
- self._set_decoder_layers(
- nn.ModuleList(
- [
- FlamingoLayer(gated_cross_attn_layer, decoder_layer)
- for gated_cross_attn_layer, decoder_layer in zip(gated_cross_attn_layers, self._get_decoder_layers())
- ]
- )
- )
+ self._set_decoder_layers(nn.ModuleList([FlamingoLayer(gated_cross_attn_layer, decoder_layer) for gated_cross_attn_layer, decoder_layer in zip(gated_cross_attn_layers, self._get_decoder_layers())]))
self.media_token_id = media_token_id
self.use_media_placement_augmentation = use_media_placement_augmentation
self.initialized_flamingo = True
@@ -513,7 +514,7 @@ def __init__(
text_tokenizer = AutoTokenizer.from_pretrained("PATH-TO-YOUR-FALCON")
lang_encoder = RWForCausalLM(config=config.text_config)
else:
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
vision_encoder = CLIPVisionModel(config=config.vision_config)
@@ -527,8 +528,6 @@ def __init__(
extend_instance(lang_encoder, FlamingoLMMixin)
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
- if lang_encoder.__class__.__name__ == "LlamaForCausalLM":
- lang_encoder.resize_token_embeddings(len(text_tokenizer))
self.lang_encoder = lang_encoder
self.cross_attn_every_n_layers = config.cross_attn_every_n_layers if hasattr(config, "cross_attn_every_n_layers") else 4
@@ -721,7 +720,7 @@ def __init__(
lang_encoder = RWForCausalLM(config=config.text_config)
# TODO: what's the logic here?
elif config.text_config.architectures[0] == "LlamaForCausalLM":
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
else:
import pdb
@@ -742,8 +741,6 @@ def __init__(
extend_instance(lang_encoder, FlamingoLMMixin)
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
- if "LlamaForCausalLM" in lang_encoder.__class__.__name__:
- lang_encoder.resize_token_embeddings(len(text_tokenizer))
self.lang_encoder = lang_encoder
self.cross_attn_every_n_layers = config.cross_attn_every_n_layers if hasattr(config, "cross_attn_every_n_layers") else 4
@@ -782,28 +779,50 @@ def get_lang_encoder(self) -> nn.Module:
return self.lang_encoder
def init_weights(self):
+ # Freeze all parameters in self.model if train_vision_encoder is False or train_lang_encoder is False
+ if not ("train_full_model" in self.config.__dict__ and self.config.train_full_model is True):
+ for param in self.parameters():
+ param.requires_grad = False
+
# Freeze all parameters in vision encoder
- for param in self.vision_encoder.parameters():
- param.requires_grad = False
+ if "train_vision_encoder" in self.config.__dict__ and self.config.train_vision_encoder is True:
+ master_print("Unfreeze vision encoder.")
+ for param in self.vision_encoder.parameters():
+ param.requires_grad = True
+
+ # Freeze all parameters in lang encoders except gated_cross_attn_layers
+ if "train_lang_encoder" in self.config.__dict__ and self.config.train_lang_encoder is True:
+ master_print("Unfreeze language decoder.")
+ for name, param in self.lang_encoder.named_parameters():
+ param.requires_grad = True
+
+ if "lora_config" in self.config.__dict__:
+ # Use another logic to unfreeze gated_cross_attn_layers and perceivers
+ master_print(f"LoRA trainable param: {(sum(param.numel() for name, param in self.lang_encoder.named_parameters() if 'lora' in name)) / 1e6:.3f} M")
+ for name, param in self.lang_encoder.named_parameters():
+ if "lora" in name:
+ param.requires_grad = True
+
# Freeze all parameters in lang encoders except gated_cross_attn_layers
for name, param in self.lang_encoder.named_parameters():
- if "gated_cross_attn_layer" not in name:
- param.requires_grad = False
- # Unfreeze LM input embeddings
+ if "gated_cross_attn_layer" in name:
+ param.requires_grad = True
+
+ for name, param in self.named_parameters():
+ if "perceiver" in name:
+ param.requires_grad = True
+
+ # Unfreeze LM input and output embeddings
self.lang_encoder.get_input_embeddings().requires_grad_(True)
## MPTForCausalLM is tied word embedding
if "LlamaForCausalLM" in self.lang_encoder.__class__.__name__:
self.lang_encoder.lm_head.requires_grad_(True)
- # assert sum(p.numel() for p in model.parameters() if p.requires_grad) == 0
- # print model size in billions of parameters in 2 decimal places
- print("====================Model Grad Part====================")
total_params = 0
for name, param in self.named_parameters():
if param.requires_grad:
total_params += param.numel()
- print(f"Parameter: {name}, Size: {param.numel() / 1e6:.6f} M")
- print(f"Total Trainable param: {total_params / 1e9:.4f} B")
- print(f"Total Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.3f} B")
+ master_print(f"{name}: {param.numel() / 1e6:.3f} M")
+ master_print(f"Total Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.3f} B")
def forward(
self,
diff --git a/src/otter_ai/models/flamingo/utils.py b/src/otter_ai/models/flamingo/utils.py
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/flamingo/utils/converting_flamingo_to_bf16.py b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_bf16.py
new file mode 100755
index 00000000..2d885d17
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_bf16.py
@@ -0,0 +1,46 @@
+import argparse
+import os
+
+import torch
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+parser = argparse.ArgumentParser(description="Load model with precision")
+parser.add_argument(
+ "--load_bit",
+ type=str,
+ choices=["fp16", "bf16"],
+ required=True,
+ help="Choose either 'fp16' or 'bf16'",
+)
+parser.add_argument(
+ "--pretrained_model_path",
+ type=str,
+ default="/home/luodian/projects/checkpoints/flamingo-mpt-7B-instruct-init",
+ required=True,
+)
+parser.add_argument(
+ "--saved_model_path",
+ type=str,
+ default="/home/luodian/projects/checkpoints/flamingo-mpt-7B-instruct-init",
+ required=True,
+)
+args = parser.parse_args()
+
+load_bit = args.load_bit
+pretrained_model_path = args.pretrained_model_path
+
+if load_bit == "fp16":
+ precision = {"torch_dtype": torch.float16}
+elif load_bit == "bf16":
+ precision = {"torch_dtype": torch.bfloat16}
+
+root_dir = os.environ["AZP"]
+print(root_dir)
+device_id = "cpu"
+model = FlamingoForConditionalGeneration.from_pretrained(pretrained_model_path, device_map={"": device_id}, **precision)
+
+# save model to same folder
+checkpoint_path = pretrained_model_path + f"-{load_bit}"
+model.save_pretrained(checkpoint_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/converting_flamingo_to_hf.py b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_hf.py
new file mode 100755
index 00000000..dd354f6b
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_hf.py
@@ -0,0 +1,60 @@
+"""convert from otter pt to otter hf. Will remove after we use otter hf model to train.
+"""
+
+import re
+import argparse
+import os
+
+import torch
+import torch.nn as nn
+from transformers import CLIPVisionModel, LlamaForCausalLM, LlamaTokenizer
+
+import sys
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+
+@torch.no_grad()
+def dump_hf_model(pretrained_model_path: str, old_ckpt_path: str, new_folder_path: str) -> None:
+ old_ckpt = torch.load(old_ckpt_path, map_location="cpu")
+ if old_ckpt.get("model_state_dict", None) is not None:
+ old_ckpt = old_ckpt["model_state_dict"]
+ new_ckpt = old_ckpt
+ folder_path = os.path.dirname(old_ckpt_path)
+ # config_path = os.path.join(folder_path, "config.json") if os.path.exists(os.path.join(folder_path, "config.json")) else "flamingo/config.json"
+ model = FlamingoForConditionalGeneration.from_pretrained(
+ args.pretrained_model_path,
+ device_map="auto",
+ )
+ _ = model.load_state_dict(new_ckpt, strict=False)
+ print(f"Saving HF model to {new_folder_path}")
+ model.save_pretrained(new_folder_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--old_ckpt_path",
+ "-old",
+ type=str,
+ required=True,
+ help="Path to the pt checkpoint",
+ )
+ parser.add_argument(
+ "--new_hf_path",
+ "-new",
+ type=str,
+ required=True,
+ help="Path to the hf folder",
+ )
+ parser.add_argument(
+ "--pretrained_model_path",
+ "-pretrained",
+ type=str,
+ required=True,
+ help="Path to the pretrained model folder",
+ )
+ args = parser.parse_args()
+ if not os.path.exists(os.path.dirname(args.new_hf_path)):
+ os.makedirs(os.path.dirname(args.new_hf_path))
+ dump_hf_model(args.pretrained_model_path, args.old_ckpt_path, args.new_hf_path)
diff --git a/src/otter_ai/models/flamingo/utils/converting_flamingo_to_lora.py b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_lora.py
new file mode 100755
index 00000000..c4dcf982
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_lora.py
@@ -0,0 +1,69 @@
+import argparse
+import torch
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+from peft import get_peft_model, LoraConfig, TaskType
+
+MODEL_CLASSES = {
+ "LlamaForCausalLM": "llama",
+ "OPTForCausalLM": "opt",
+ "GPTJForCausalLM": "gptj",
+ "GPTNeoXForCausalLM": "gpt_neox",
+ "MPTForCausalLM": "mpt",
+}
+
+# Define argument parser
+parser = argparse.ArgumentParser(description="Load a model with specified precision and save it to a specified path.")
+
+# Add arguments
+parser.add_argument(
+ "--checkpoint_path",
+ type=str,
+ help="Path to the pre-trained model checkpoint.",
+ default="",
+)
+parser.add_argument(
+ "--save_path",
+ type=str,
+ default="",
+ help="Path to the converted model checkpoint.",
+)
+
+# Parse the input arguments
+args = parser.parse_args()
+
+load_bit = "bf16"
+if load_bit == "fp16":
+ precision = {"torch_dtype": torch.float16}
+elif load_bit == "bf16":
+ precision = {"torch_dtype": torch.bfloat16}
+
+# Load the model
+model = FlamingoForConditionalGeneration.from_pretrained(args.checkpoint_path, device_map="auto", **precision)
+
+# adding lora
+standard_modules = ["q_proj", "v_proj"]
+lang_encoder_short_name = MODEL_CLASSES[model.config.text_config.architectures[0]]
+model_to_lora_modules = {
+ "llama": standard_modules,
+ "opt": standard_modules,
+ "gptj": standard_modules,
+ "gpt_neox": ["query_key_value"],
+ "mpt": ["Wqkv"],
+}
+lora_config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ task_type=TaskType.CAUSAL_LM,
+ target_modules=model_to_lora_modules[lang_encoder_short_name],
+)
+model.config.update({"lora_config": {"r": 16, "lora_alpha": 32, "lora_dropout": 0.05}})
+model.lang_encoder = get_peft_model(model.lang_encoder, lora_config)
+model.lang_encoder.print_trainable_parameters()
+
+# Save the model
+checkpoint_path = args.save_path
+FlamingoForConditionalGeneration.save_pretrained(model, checkpoint_path)
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-falcon-7B.json b/src/otter_ai/models/flamingo/utils/flamingo-falcon-7B.json
new file mode 100755
index 00000000..f777f6b4
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-falcon-7B.json
@@ -0,0 +1,112 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoModel"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "architectures": [
+ "RWForCausalLM"
+ ],
+ "apply_residual_connection_post_layernorm": false,
+ "attention_dropout": 0.0,
+ "bias": false,
+ "bos_token_id": 11,
+ "eos_token_id": 11,
+ "hidden_dropout": 0.0,
+ "hidden_size": 4544,
+ "initializer_range": 0.02,
+ "layer_norm_epsilon": 1e-05,
+ "model_type": "RefinedWebModel",
+ "multi_query": true,
+ "n_head": 71,
+ "n_layer": 32,
+ "parallel_attn": true,
+ "torch_dtype": "bfloat16",
+ "transformers_version": "4.27.4",
+ "use_cache": true,
+ "vocab_size": 65024
+ },
+ "tie_word_embeddings": false,
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.28.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-13B.json b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-13B.json
new file mode 100755
index 00000000..738211da
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-13B.json
@@ -0,0 +1,114 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 8,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "meta-llama/Llama-2-13b-chat-hf",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 5120,
+ "initializer_range": 0.02,
+ "intermediate_size": 13824,
+ "max_position_embeddings": 4096,
+ "model_type": "llama",
+ "num_attention_heads": 40,
+ "num_hidden_layers": 40,
+ "num_key_value_heads": 40,
+ "pad_token_id": 0,
+ "pretraining_tp": 1,
+ "rms_norm_eps": 1e-05,
+ "rope_scaling": null,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.30.1",
+ "use_cache": true,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-7B.json b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-7B.json
new file mode 100755
index 00000000..0676c97e
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-7B.json
@@ -0,0 +1,115 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "meta-llama/Llama-2-7b-chat-hf",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 4096,
+ "initializer_range": 0.02,
+ "intermediate_size": 11008,
+ "max_length": 4096,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 32,
+ "num_hidden_layers": 32,
+ "num_key_value_heads": 32,
+ "pad_token_id": 0,
+ "pretraining_tp": 1,
+ "rms_norm_eps": 1e-05,
+ "rope_scaling": null,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.32.0.dev0",
+ "use_cache": true,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-1B-redpajama.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-1B-redpajama.json
new file mode 100755
index 00000000..f27dffdc
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-1B-redpajama.json
@@ -0,0 +1,131 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 1,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "architectures": [
+ "MosaicGPT"
+ ],
+ "attn_clip_qkv": null,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_qk_ln": true,
+ "attn_uses_sequence_id": false,
+ "d_model": 2048,
+ "hidden_size": 2048,
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "fan_mode": "fan_in",
+ "init_device": "cpu",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "logit_scale": null,
+ "low_precision_layernorm": true,
+ "max_seq_len": 2048,
+ "mlp_ratio": 4,
+ "model_type": "mosaic_gpt",
+ "n_heads": 16,
+ "n_layers": 24,
+ "no_bias": true,
+ "param_init_fn": "kaiming_normal_",
+ "prefix_lm": false,
+ "resid_pdrop": 0,
+ "softmax_scale": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "torch_dtype": "float32",
+ "transformers_version": "4.27.4",
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B-bf16.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B-bf16.json
new file mode 100755
index 00000000..b91d30c3
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B-bf16.json
@@ -0,0 +1,195 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 7,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 7168,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 7168,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0.0,
+ "init_nonlinearity": "relu",
+ "init_std": null,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 8192,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 64,
+ "n_layers": 48,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "bfloat16",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B.json
new file mode 100755
index 00000000..4678ba66
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B.json
@@ -0,0 +1,195 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 7,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 7168,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 7168,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0.0,
+ "init_nonlinearity": "relu",
+ "init_std": null,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 8192,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 64,
+ "n_layers": 48,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-7B.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-7B.json
new file mode 100755
index 00000000..9e1b681e
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-7B.json
@@ -0,0 +1,195 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 4096,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 4096,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 2048,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 32,
+ "n_layers": 32,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-vicuna-33B-v1.3.json b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-33B-v1.3.json
new file mode 100755
index 00000000..593706c9
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-33B-v1.3.json
@@ -0,0 +1,111 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "/home/luodian/projects/checkpoints/vicuna-33b-v1.3",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 6656,
+ "initializer_range": 0.02,
+ "intermediate_size": 17920,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 52,
+ "num_hidden_layers": 60,
+ "pad_token_id": 0,
+ "rms_norm_eps": 1e-06,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.28.1",
+ "use_cache": false,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-vicuna-7B-v1.3.json b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-7B-v1.3.json
new file mode 100755
index 00000000..1e8ead8a
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-7B-v1.3.json
@@ -0,0 +1,111 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "/mnt/petrelfs/share_data/zhangyuanhan/vicuna-7b-v1.3",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 4096,
+ "initializer_range": 0.02,
+ "intermediate_size": 11008,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 32,
+ "num_hidden_layers": 32,
+ "pad_token_id": 0,
+ "rms_norm_eps": 1e-06,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.28.1",
+ "use_cache": false,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/injecting_falcon_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_falcon_into_flamingo.py
new file mode 100755
index 00000000..db683219
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_falcon_into_flamingo.py
@@ -0,0 +1,52 @@
+import os
+import torch
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+root_dir = os.environ["AZP"]
+print(root_dir)
+
+
+config = FlamingoConfig.from_json_file(".flamingo-falcon-7B.json")
+model = FlamingoForConditionalGeneration(config=config)
+
+
+state_dict_files = [
+ f"{root_dir}/otter/checkpoints/falcon-7b/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/otter/checkpoints/falcon-7b/pytorch_model-00002-of-00002.bin",
+]
+
+state_dict = {}
+for file in state_dict_files:
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+
+state_dict_3 = torch.load(
+ "{root_dir}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+_ = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+print(_[1])
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".h." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.h.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+_ = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+print(_[1])
+model.save_pretrained(f"{root_dir}/otter/checkpoints/flamingo-falcon-7b/")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_llama2_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_llama2_into_flamingo.py
new file mode 100755
index 00000000..485cd15e
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_llama2_into_flamingo.py
@@ -0,0 +1,98 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+# from .configuration_flamingo import FlamingoConfig
+# from .modeling_flamingo import FlamingoForConditionalGeneration
+
+parser = argparse.ArgumentParser(description="Convert Vicuna model")
+parser.add_argument("--model_choice", type=str, default="13B", help="Choose either '7B' or '13B'")
+parser.add_argument("--llama2_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+args = parser.parse_args()
+
+# os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+root_dir = args.llama2_root_dir
+model_choice = args.model_choice
+save_root_dir = args.save_root_dir
+
+# prepare vicuna model at first
+# you can visit https://huggingface.co/lmsys/Llama-2-33b-chat-hf to download 7B and 30B instruct checkpoints.
+if model_choice == "7B":
+ config_file = "./flamingo/flamingo-llama2-chat-7B.json"
+ state_dict_files = [
+ f"{root_dir}/Llama-2-7b-chat-hf/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/Llama-2-7b-chat-hf/pytorch_model-00002-of-00002.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-llama2-chat-7B-init"
+elif model_choice == "13B":
+ config_file = "./flamingo/flamingo-llama2-chat-13B.json"
+ state_dict_files = [
+ f"{root_dir}/Llama-2-13b-chat-hf/pytorch_model-00001-of-00003.bin",
+ f"{root_dir}/Llama-2-13b-chat-hf/pytorch_model-00002-of-00003.bin",
+ f"{root_dir}/Llama-2-13b-chat-hf/pytorch_model-00003-of-00003.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-llama2-chat-13B-init"
+else:
+ raise ValueError("Invalid model_choice. Choose either '13B' or '7B'.")
+
+config = FlamingoConfig.from_json_file(config_file)
+model = FlamingoForConditionalGeneration(config=config)
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+# AZP = "os.environ["AZP"]"
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(
+ f"{AZP}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+# Loading vicuna weights
+state_dict = {}
+for file in tqdm(state_dict_files, desc="Loading state dict"):
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".layers." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"model.layers.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+# Reshape the token embedding to 50280 for compatible
+model.lang_encoder.resize_token_embeddings(32000)
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# Reshape the token embedding to 32002 for compatible
+model.lang_encoder.resize_token_embeddings(32002)
+# print incompatible keys
+print(load_msg[1])
+
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_mpt-1B-redpajama_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_mpt-1B-redpajama_into_flamingo.py
new file mode 100755
index 00000000..155b7443
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_mpt-1B-redpajama_into_flamingo.py
@@ -0,0 +1,102 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+from utils import rename_flamingo_checkpoint
+
+
+parser = argparse.ArgumentParser(description="Convert MPT model")
+parser.add_argument("--mpt_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument(
+ "--flamingo_dir",
+ type=str,
+ default=None,
+ help="If the pretrained flamingo weights also need to be injected",
+)
+args = parser.parse_args()
+
+
+root_dir = args.mpt_root_dir
+save_root_dir = args.save_root_dir
+
+# prepare mpt model at first
+# you can visit https://huggingface.co/mosaicml to download 7B and 30B instruct checkpoints.
+config_file = "./flamingo/flamingo-mpt-1B-redpajama.json"
+state_dict_file = f"{root_dir}/pytorch_model.bin"
+save_path = f"{save_root_dir}/flamingo-mpt-1b-redpajama-200b-dolly"
+
+config = FlamingoConfig.from_json_file(config_file)
+
+model = FlamingoForConditionalGeneration(config=config)
+
+# Loading mpt weights
+state_dict = torch.load(state_dict_file, map_location="cpu")
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".blocks." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.blocks.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(f"{AZP}/pytorch_model-00004-of-00004.bin", map_location="cpu")
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".blocks." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.blocks.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+if args.flamingo_dir is not None:
+ state_dict_2 = torch.load(f"{args.flamingo_dir}/checkpoint.pt", map_location="cpu")
+ save_state_dict_2 = rename_flamingo_checkpoint(state_dict_2)
+ real_vocab_size = config.text_config.vocab_size
+ # Reshape the token embedding to 50280 for compatible
+ model.lang_encoder.resize_token_embeddings(save_state_dict_2["lang_encoder.transformer.wte.weight"].shape[0])
+
+ load_msg = model.load_state_dict(
+ save_state_dict_2,
+ False,
+ )
+ # print incompatible keys
+ print(load_msg[1])
+ # Reshape the token embedding to 50432
+ model.lang_encoder.resize_token_embeddings(real_vocab_size)
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_mpt_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_mpt_into_flamingo.py
new file mode 100755
index 00000000..d9bb72ef
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_mpt_into_flamingo.py
@@ -0,0 +1,123 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+from utils import rename_flamingo_checkpoint
+
+parser = argparse.ArgumentParser(description="Convert MPT model")
+parser.add_argument(
+ "--model_choice",
+ type=str,
+ choices=["7B", "30B"],
+ required=True,
+ help="Choose either '7B' or '30B'",
+)
+parser.add_argument("--mpt_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument(
+ "--flamingo_dir",
+ type=str,
+ default=None,
+ help="If the pretrained flamingo weights also need to be injected",
+)
+args = parser.parse_args()
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+root_dir = args.mpt_root_dir
+model_choice = args.model_choice
+save_root_dir = args.save_root_dir
+
+# prepare mpt model at first
+# you can visit https://huggingface.co/mosaicml to download 7B and 30B instruct checkpoints.
+if model_choice == "30B":
+ config_file = "./flamingo/flamingo-mpt-30B.json"
+ state_dict_files = [
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00001-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00002-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00003-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00004-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00005-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00006-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00007-of-00007.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-mpt-30B-instruct-init"
+elif model_choice == "7B":
+ config_file = "./flamingo/flamingo-mpt-7B.json"
+ state_dict_files = [
+ f"{root_dir}/mpt-7b/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/mpt-7b/pytorch_model-00002-of-00002.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-mpt-7B"
+else:
+ raise ValueError("Invalid model_choice. Choose either '30B' or '7B'.")
+
+config = FlamingoConfig.from_json_file(config_file)
+
+model = FlamingoForConditionalGeneration(config=config)
+
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(
+ f"{AZP}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+# Loading mpt weights
+state_dict = {}
+for file in tqdm(state_dict_files, desc="Loading state dict"):
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".blocks." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.blocks.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+if args.flamingo_dir is not None:
+ state_dict_2 = torch.load(f"{args.flamingo_dir}/checkpoint.pt", map_location="cpu")
+ save_state_dict_2 = rename_flamingo_checkpoint(state_dict_2)
+
+ real_vocab_size = config.text_config.vocab_size
+ # Reshape the token embedding to 50280 for compatible
+ model.lang_encoder.resize_token_embeddings(save_state_dict_2["lang_encoder.transformer.wte.weight"].shape[0])
+
+ load_msg = model.load_state_dict(
+ save_state_dict_2,
+ False,
+ )
+ # print incompatible keys
+ print(load_msg[1])
+ # Reshape the token embedding to 50432
+ model.lang_encoder.resize_token_embeddings(real_vocab_size)
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_vicuna_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_vicuna_into_flamingo.py
new file mode 100755
index 00000000..bb5bda19
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_vicuna_into_flamingo.py
@@ -0,0 +1,114 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+# from .configuration_flamingo import FlamingoConfig
+# from .modeling_flamingo import FlamingoForConditionalGeneration
+
+parser = argparse.ArgumentParser(description="Convert Vicuna model")
+parser.add_argument(
+ "--model_choice",
+ type=str,
+ choices=["7B", "33B"],
+ required=True,
+ help="Choose either '7B' or '33B'",
+)
+parser.add_argument("--vicuna_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument(
+ "--flamingo_dir",
+ type=str,
+ default=None,
+ help="If the pretrained flamingo weights also need to be injected",
+)
+args = parser.parse_args()
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+root_dir = args.vicuna_root_dir
+model_choice = args.model_choice
+save_root_dir = args.save_root_dir
+
+# prepare vicuna model at first
+# you can visit https://huggingface.co/lmsys/vicuna-33b-v1.3 to download 7B and 30B instruct checkpoints.
+if model_choice == "33B":
+ config_file = "./flamingo/flamingo-vicuna-33B-v1.3.json"
+ state_dict_files = [
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00001-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00002-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00003-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00004-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00005-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00006-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00007-of-00007.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-vicuna-33B-v1.3-init"
+elif model_choice == "7B":
+ config_file = "./flamingo/flamingo-vicuna-7B-v1.3.json"
+ state_dict_files = [
+ f"{root_dir}/vicuna-7b-v1.3/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/vicuna-7b-v1.3/pytorch_model-00002-of-00002.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-vicuna-7B-v1.3-init"
+else:
+ raise ValueError("Invalid model_choice. Choose either '33B' or '7B'.")
+
+config = FlamingoConfig.from_json_file(config_file)
+model = FlamingoForConditionalGeneration(config=config)
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+# AZP = "os.environ["AZP"]"
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(
+ f"{AZP}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+# Loading vicuna weights
+state_dict = {}
+for file in tqdm(state_dict_files, desc="Loading state dict"):
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".layers." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"model.layers.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+# Reshape the token embedding to 50280 for compatible
+model.lang_encoder.resize_token_embeddings(32000)
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# Reshape the token embedding to 32002 for compatible
+model.lang_encoder.resize_token_embeddings(32002)
+# print incompatible keys
+print(load_msg[1])
+
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/fuyu/modeling_fuyu.py b/src/otter_ai/models/fuyu/modeling_fuyu.py
new file mode 100644
index 00000000..999e1880
--- /dev/null
+++ b/src/otter_ai/models/fuyu/modeling_fuyu.py
@@ -0,0 +1,186 @@
+import torch
+from transformers import FuyuPreTrainedModel, FuyuConfig, AutoModelForCausalLM
+
+
+try:
+ from .modeling_persimmon import PersimmonForCausalLM
+
+ print("Using local PersimmonForCausalLM with Flash Attention")
+except ImportError:
+ from transformers import PersimmonForCausalLM
+
+ print("Using transformers PersimmonForCausalLM without Flash Attention")
+
+from typing import List, Optional, Tuple, Union
+from transformers.modeling_outputs import BaseModelOutputWithPast
+import torch.nn as nn
+
+
+class FuyuForCausalLM(FuyuPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`FuyuDecoderLayer`]
+
+ Args:
+ config: FuyuConfig
+ """
+
+ def __init__(self, config: FuyuConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+ self.language_model = PersimmonForCausalLM._from_config(config.text_config)
+ self.vision_embed_tokens = nn.Linear(config.patch_size * config.patch_size * config.num_channels, config.hidden_size)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.language_model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.language_model.set_input_embeddings(value)
+
+ def gather_continuous_embeddings(
+ self,
+ word_embeddings: torch.Tensor,
+ continuous_embeddings: List[torch.Tensor],
+ image_patch_input_indices: torch.Tensor,
+ ) -> torch.Tensor:
+ """This function places the continuous_embeddings into the word_embeddings at the locations
+ indicated by image_patch_input_indices. Different batch elements can have different numbers of continuous
+ embeddings.
+
+ Args:
+ word_embeddings: Tensor of word embeddings. Shape: [b, s, h]
+ continuous_embeddings:
+ Tensor of continuous embeddings. The length of the list is the batch size. Each entry is
+ shape [num_image_embeddings, hidden], and num_image_embeddings needs to match the number of non-negative
+ indices in image_patch_input_indices for that batch element.
+ image_patch_input_indices: Tensor of indices of the image patches in the input_ids tensor. Shape: [b, s]
+ """
+ if not (word_embeddings.shape[0] == len(continuous_embeddings)):
+ raise ValueError(f"Batch sizes must match! Got {len(continuous_embeddings)=} and {word_embeddings.shape[0]=}")
+
+ output_embeddings = word_embeddings.clone()
+ for batch_idx in range(word_embeddings.shape[0]):
+ # First, find the positions of all the non-negative values in image_patch_input_indices, those are the
+ # positions in word_embeddings that we want to replace with content from continuous_embeddings.
+ dst_indices = torch.nonzero(image_patch_input_indices[batch_idx] >= 0, as_tuple=True)[0]
+ # Next look up those indices in image_patch_input_indices to find the indices in continuous_embeddings that we
+ # want to use to replace the values in word_embeddings.
+ src_indices = image_patch_input_indices[batch_idx][dst_indices]
+ # Check if we have more indices than embeddings. Note that we could have fewer indices if images got truncated.
+ if src_indices.shape[0] > continuous_embeddings[batch_idx].shape[0]:
+ raise ValueError(f"Number of continuous embeddings {continuous_embeddings[batch_idx].shape=} does not match " f"number of continuous token ids {src_indices.shape=} in batch element {batch_idx}.")
+ output_embeddings[batch_idx, dst_indices] = continuous_embeddings[batch_idx][src_indices]
+ return output_embeddings
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ labels: torch.LongTensor = None,
+ image_patches: torch.Tensor = None, # [batch_size, num_total_patches, patch_size_ x patch_size x num_channels ]
+ image_patches_indices: torch.Tensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
+ if image_patches is not None and past_key_values is None:
+ # patch_embeddings = self.vision_embed_tokens(image_patches.to(self.vision_embed_tokens.weight.dtype))
+ patch_embeddings = [self.vision_embed_tokens(patch.to(self.vision_embed_tokens.weight.dtype)).squeeze(0) for patch in image_patches]
+ inputs_embeds = self.gather_continuous_embeddings(
+ word_embeddings=inputs_embeds,
+ continuous_embeddings=patch_embeddings,
+ image_patch_input_indices=image_patches_indices,
+ )
+
+ outputs = self.language_model(
+ inputs_embeds=inputs_embeds,
+ labels=labels,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ if not return_dict:
+ return tuple(v for v in outputs if v is not None)
+ return outputs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ image_patches=None,
+ image_patches_indices=None,
+ **kwargs,
+ ):
+ if past_key_values:
+ input_ids = input_ids[:, -1:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -1].unsqueeze(-1)
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ if image_patches_indices is not None:
+ model_inputs["image_patches_indices"] = image_patches_indices
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ "image_patches_indices": image_patches_indices if past_key_values is None else None,
+ "image_patches": image_patches if past_key_values is None else None,
+ }
+ )
+ return model_inputs
diff --git a/src/otter_ai/models/fuyu/modeling_persimmon.py b/src/otter_ai/models/fuyu/modeling_persimmon.py
new file mode 100644
index 00000000..fe6959ba
--- /dev/null
+++ b/src/otter_ai/models/fuyu/modeling_persimmon.py
@@ -0,0 +1,954 @@
+# coding=utf-8
+# Copyright 2023 EleutherAI and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Persimmon model."""
+import math
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from flash_attn.ops.layer_norm import layer_norm as fused_layer_norm
+from flash_attn.ops.fused_dense import fused_mlp_func
+from flash_attn.layers.rotary import apply_rotary_emb as fused_apply_rotary_emb
+from transformers.activations import ACT2FN
+from flash_attn import flash_attn_func
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
+from transformers.modeling_utils import PreTrainedModel
+from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
+from transformers import PersimmonConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "PersimmonConfig"
+
+
+# Copied from transformers.models.bart.modeling_bart._make_causal_mask
+def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0):
+ """
+ Make causal mask used for bi-directional self-attention.
+ """
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
+ mask_cond = torch.arange(mask.size(-1), device=device)
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Persimmon
+class PersimmonRotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype())
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ # emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", freqs.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", freqs.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->Persimmon
+class PersimmonLinearScalingRotaryEmbedding(PersimmonRotaryEmbedding):
+ """PersimmonRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ t = t / self.scaling_factor
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->Persimmon
+class PersimmonDynamicNTKScalingRotaryEmbedding(PersimmonRotaryEmbedding):
+ """PersimmonRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+
+ if seq_len > self.max_position_embeddings:
+ base = self.base * ((self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)) ** (self.dim / (self.dim - 2))
+ inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ cos = cos[position_ids].unsqueeze(1) # [seq_len, dim] -> [batch_size, 1, seq_len, head_dim]
+ sin = sin[position_ids].unsqueeze(1)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Copied from transformers.models.gpt_neox.modeling_gpt_neox.GPTNeoXMLP with GPTNeoX->Persimmon
+class PersimmonMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense_h_to_4h = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.dense_4h_to_h = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.act = ACT2FN[config.hidden_act]
+
+ def forward(self, hidden_states):
+ # hidden_states = self.dense_h_to_4h(hidden_states)
+ # hidden_states = self.act(hidden_states)
+ # hidden_states = self.dense_4h_to_h(hidden_states)
+ """
+ checkpoint_lvl (increasing lvl means slower but more memory saving):
+ 0: no recomputation in the bwd
+ 1: recompute gelu_out in the bwd
+ 2: recompute gelu_in and gelu_out in the bwd
+ """
+ hidden_states = fused_mlp_func(hidden_states, self.dense_h_to_4h.weight, self.dense_4h_to_h.weight, self.dense_h_to_4h.bias, self.dense_4h_to_h.bias, "sqrelu", True, False, 0, -1)
+ return hidden_states
+
+
+class PersimmonAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: PersimmonConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.partial_rotary_factor = config.partial_rotary_factor
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}" f" and `num_heads`: {self.num_heads}).")
+ self.query_key_value = nn.Linear(self.hidden_size, 3 * self.hidden_size, bias=True)
+ self.dense = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=True)
+ self.qk_layernorm = config.qk_layernorm
+
+ if self.qk_layernorm:
+ self.q_layernorm = nn.LayerNorm(config.hidden_size // self.num_heads, eps=config.layer_norm_eps, elementwise_affine=True)
+ self.k_layernorm = nn.LayerNorm(config.hidden_size // self.num_heads, eps=config.layer_norm_eps, elementwise_affine=True)
+ self.attention_dropout = nn.Dropout(config.attention_dropout)
+ self._init_rope()
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = PersimmonRotaryEmbedding(
+ int(self.partial_rotary_factor * self.head_dim),
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+ else:
+ scaling_type = self.config.rope_scaling["type"]
+ scaling_factor = self.config.rope_scaling["factor"]
+ if scaling_type == "linear":
+ self.rotary_emb = PersimmonLinearScalingRotaryEmbedding(
+ int(self.partial_rotary_factor * self.head_dim),
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ elif scaling_type == "dynamic":
+ self.rotary_emb = PersimmonDynamicNTKScalingRotaryEmbedding(
+ int(self.partial_rotary_factor * self.head_dim),
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ else:
+ raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
+
+ # Copied from transformers.models.bloom.modeling_bloom.BloomAttention._split_heads
+ def _split_heads(self, fused_qkv: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """
+ Split the last dimension into (num_heads, head_dim) without making any copies, results share same memory
+ storage as `fused_qkv`
+
+ Args:
+ fused_qkv (`torch.tensor`, *required*): [batch_size, seq_length, num_heads * 3 * head_dim]
+
+ Returns:
+ query: [batch_size, seq_length, num_heads, head_dim] key: [batch_size, seq_length, num_heads, head_dim]
+ value: [batch_size, seq_length, num_heads, head_dim]
+ """
+ batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
+ fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads, 3, self.head_dim)
+ return fused_qkv[..., 0, :], fused_qkv[..., 1, :], fused_qkv[..., 2, :]
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ assert past_key_value == None
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # [batch_size, seq_length, 3 x hidden_size]
+ fused_qkv = self.query_key_value(hidden_states)
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_states, key_states, value_states) = self._split_heads(fused_qkv)
+
+ if self.qk_layernorm:
+ query_states = fused_layer_norm(query_states, self.q_layernorm.weight, self.q_layernorm.bias, self.q_layernorm.eps)
+ key_states = fused_layer_norm(key_states, self.k_layernorm.weight, self.k_layernorm.bias, self.k_layernorm.eps)
+
+ # Full rotary embedding
+ kv_seq_len = key_states.shape[1]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ # Partial rotary embedding
+ query_rot, query_pass = (
+ query_states[..., : self.rotary_emb.dim],
+ query_states[..., self.rotary_emb.dim :],
+ )
+ key_rot, key_pass = (
+ key_states[..., : self.rotary_emb.dim],
+ key_states[..., self.rotary_emb.dim :],
+ )
+
+ query_rot = fused_apply_rotary_emb(query_rot, cos, sin, False, True)
+ key_rot = fused_apply_rotary_emb(key_rot, cos, sin, False, True)
+
+ # [batch_size, seq_length, num_heads, head_dim]
+ query_states = torch.cat((query_rot, query_pass), dim=-1)
+ key_states = torch.cat((key_rot, key_pass), dim=-1)
+ scale = 1.0 / math.sqrt(query_states.shape[-1])
+ attn_output = flash_attn_func(query_states, key_states, value_states, dropout_p=0.0, softmax_scale=scale, causal=True)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.dense(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+class PersimmonDecoderLayer(nn.Module):
+ def __init__(self, config: PersimmonConfig):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+ self.self_attn = PersimmonAttention(config=config)
+ self.mlp = PersimmonMLP(config)
+ self.input_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.post_attention_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range
+ `[0, config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*):
+ cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ """
+
+ residual = hidden_states
+
+ hidden_states = fused_layer_norm(hidden_states, self.input_layernorm.weight, self.input_layernorm.bias, self.input_layernorm.eps)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = fused_layer_norm(hidden_states, self.post_attention_layernorm.weight, self.post_attention_layernorm.bias, self.post_attention_layernorm.eps)
+ hidden_states = self.mlp(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = hidden_states + residual
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+PERSIMMON_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`PersimmonConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Persimmon Model outputting raw hidden-states without any specific head on top.",
+ PERSIMMON_START_DOCSTRING,
+)
+class PersimmonPreTrainedModel(PreTrainedModel):
+ config_class = PersimmonConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["PersimmonDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, PersimmonModel):
+ module.gradient_checkpointing = value
+
+
+PERSIMMON_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Persimmon Model outputting raw hidden-states without any specific head on top.",
+ PERSIMMON_START_DOCSTRING,
+)
+class PersimmonModel(PersimmonPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`PersimmonDecoderLayer`]
+
+ Args:
+ config: PersimmonConfig
+ """
+
+ def __init__(self, config: PersimmonConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList([PersimmonDecoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.final_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ device=inputs_embeds.device,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(inputs_embeds.device)
+ combined_attention_mask = expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
+
+ return combined_attention_mask
+
+ @add_start_docstrings_to_model_forward(PERSIMMON_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device)
+ attention_mask = self._prepare_decoder_attention_mask(attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length)
+
+ hidden_states = inputs_embeds
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once("`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ for idx, decoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, past_key_value, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ position_ids,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = fused_layer_norm(hidden_states, self.final_layernorm.weight, self.final_layernorm.bias, self.final_layernorm.eps)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class PersimmonForCausalLM(PersimmonPreTrainedModel):
+ _tied_weights_keys = ["lm_head.weight"]
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.__init__ with LLAMA->PERSIMMON,Llama->Persimmon
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = PersimmonModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_input_embeddings
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_input_embeddings
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_output_embeddings
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_output_embeddings
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_decoder
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_decoder
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(PERSIMMON_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, PersimmonForCausalLM
+
+ >>> model = PersimmonForCausalLM.from_pretrained("adept/persimmon-8b-base")
+ >>> tokenizer = AutoTokenizer.from_pretrained("adept/persimmon-8b-base")
+
+ >>> prompt = "human: Hey, what should I eat for dinner?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ 'human: Hey, what should I eat for dinner?\n\ncat: 🐱\n\nhuman: 😐\n\n'
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.prepare_inputs_for_generation
+ def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs):
+ if past_key_values is not None:
+ past_length = past_key_values[0][0].shape[2]
+
+ # Some generation methods already pass only the last input ID
+ if input_ids.shape[1] > past_length:
+ remove_prefix_length = past_length
+ else:
+ # Default to old behavior: keep only final ID
+ remove_prefix_length = input_ids.shape[1] - 1
+
+ input_ids = input_ids[:, remove_prefix_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),)
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Persimmon transformer with a sequence classification head on top (linear layer).
+
+ [`PersimmonForSequenceClassification`] uses the last token in order to do the classification, as other causal
+ models (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ PERSIMMON_START_DOCSTRING,
+)
+# Copied from transformers.models.llama.modeling_llama.LlamaForSequenceClassification with LLAMA->PERSIMMON,Llama->Persimmon
+class PersimmonForSequenceClassification(PersimmonPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = PersimmonModel(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(PERSIMMON_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).long().argmax(-1) - 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/src/otter_ai/models/fuyu/processing_fuyu.py b/src/otter_ai/models/fuyu/processing_fuyu.py
new file mode 100644
index 00000000..eb5357c6
--- /dev/null
+++ b/src/otter_ai/models/fuyu/processing_fuyu.py
@@ -0,0 +1,763 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for GIT
+"""
+import re
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+
+from transformers.processing_utils import ProcessorMixin
+from transformers.utils import TensorType, is_torch_available, logging, requires_backends
+from transformers.tokenization_utils_base import TruncationStrategy, PaddingStrategy
+
+if is_torch_available():
+ # from .image_processing_fuyu import FuyuBatchFeature
+ from transformers.models.fuyu.image_processing_fuyu import FuyuBatchFeature
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_torch_available():
+ import torch
+
+
+TEXT_REPR_BBOX_OPEN = ""
+TEXT_REPR_BBOX_CLOSE = ""
+TEXT_REPR_POINT_OPEN = ""
+TEXT_REPR_POINT_CLOSE = ""
+
+TOKEN_BBOX_OPEN_STRING = "<0x00>" #
+TOKEN_BBOX_CLOSE_STRING = "<0x01>" #
+TOKEN_POINT_OPEN_STRING = "<0x02>" #
+TOKEN_POINT_CLOSE_STRING = "<0x03>" #
+BEGINNING_OF_ANSWER_STRING = "<0x04>" #
+
+
+def full_unpacked_stream_to_tensor(
+ all_bi_tokens_to_place: List[int],
+ full_unpacked_stream: List["torch.Tensor"],
+ fill_value: int,
+ batch_size: int,
+ new_seq_len: int,
+ offset: int,
+) -> "torch.Tensor":
+ """Takes an unpacked stream of tokens (i.e. a list of tensors, one for each item in the batch) and does
+ the required padding to create a single tensor for the batch of shape batch_size x new_seq_len.
+ """
+
+ assert len(all_bi_tokens_to_place) == batch_size
+ assert len(full_unpacked_stream) == batch_size
+
+ # Create padded tensors for the full batch.
+ new_padded_tensor = torch.full(
+ [batch_size, new_seq_len],
+ fill_value=fill_value,
+ dtype=full_unpacked_stream[0].dtype,
+ device=full_unpacked_stream[0].device,
+ )
+
+ # Place each batch entry into the batch tensor.
+ for bi in range(batch_size):
+ tokens_to_place = all_bi_tokens_to_place[bi]
+ new_padded_tensor[bi, :tokens_to_place] = full_unpacked_stream[bi][offset : tokens_to_place + offset]
+
+ return new_padded_tensor
+
+
+def construct_full_unpacked_stream(
+ num_real_text_tokens: Union[List[List[int]], "torch.Tensor"],
+ input_stream: "torch.Tensor",
+ image_tokens: List[List["torch.Tensor"]],
+ batch_size: int,
+ num_sub_sequences: int,
+) -> List["torch.Tensor"]:
+ """Takes an input_stream tensor of shape B x S x ?. For each subsequence, adds any required
+ padding to account for images and then unpacks the subsequences to create a single sequence per item in the batch.
+ Returns a list of tensors, one for each item in the batch."""
+
+ all_bi_stream = []
+
+ for batch_index in range(batch_size):
+ all_si_stream = []
+
+ # First, construct full token stream (including image placeholder tokens) and loss mask for each subsequence
+ # and append to lists. We use lists rather than tensors because each subsequence is variable-sized.
+ # TODO Remove this logic in a subsequent release since subsequences are not supported.
+ image_adjustment = image_tokens[batch_index][0]
+ subsequence_stream = torch.cat([image_adjustment, input_stream[batch_index, 0]], dim=0)
+ num_real_tokens = image_adjustment.shape[0] + num_real_text_tokens[batch_index][0]
+ all_si_stream.append(subsequence_stream[:num_real_tokens])
+ all_bi_stream.append(torch.cat(all_si_stream, dim=0))
+
+ return all_bi_stream
+
+
+def _replace_string_repr_with_token_tags(prompt: str) -> str:
+ prompt = prompt.replace(TEXT_REPR_POINT_OPEN, TOKEN_POINT_OPEN_STRING)
+ prompt = prompt.replace(TEXT_REPR_POINT_CLOSE, TOKEN_POINT_CLOSE_STRING)
+ prompt = prompt.replace(TEXT_REPR_BBOX_OPEN, TOKEN_BBOX_OPEN_STRING)
+ prompt = prompt.replace(TEXT_REPR_BBOX_CLOSE, TOKEN_BBOX_CLOSE_STRING)
+ return prompt
+
+
+def _segment_prompt_into_text_token_conversions(prompt: str) -> List:
+ """
+ Given a string prompt, converts the prompt into a list of TextTokenConversions.
+ """
+ # Wherever, we notice the [TOKEN_OPEN_STRING, TOKEN_CLOSE_STRING], we split the prompt
+ prompt_text_list: List = []
+ regex_pattern = re.compile(f"({TOKEN_BBOX_OPEN_STRING}|{TOKEN_BBOX_CLOSE_STRING}|{TOKEN_POINT_OPEN_STRING}|{TOKEN_POINT_CLOSE_STRING})")
+ # Split by the regex pattern
+ prompt_split = regex_pattern.split(prompt)
+ for i, elem in enumerate(prompt_split):
+ if len(elem) == 0 or elem in [
+ TOKEN_BBOX_OPEN_STRING,
+ TOKEN_BBOX_CLOSE_STRING,
+ TOKEN_POINT_OPEN_STRING,
+ TOKEN_POINT_CLOSE_STRING,
+ ]:
+ continue
+ prompt_text_list.append((elem, i > 1 and prompt_split[i - 1] in [TOKEN_BBOX_OPEN_STRING, TOKEN_POINT_OPEN_STRING]))
+ return prompt_text_list
+
+
+def _transform_coordinates_and_tokenize(prompt: str, scale_factor: float, tokenizer) -> List[int]:
+ """
+ This function transforms the prompt in the following fashion:
+ - and to their respective token mappings
+ - extract the coordinates from the tag
+ - transform the coordinates into the transformed image space
+ - return the prompt tokens with the transformed coordinates and new tags
+
+ Bounding boxes and points MUST be in the following format: y1, x1, y2, x2 x, y The spaces
+ and punctuation added above are NOT optional.
+ """
+ # Make a namedtuple that stores "text" and "is_bbox"
+
+ # We want to do the following: Tokenize the code normally -> when we see a point or box, tokenize using the tokenize_within_tag function
+ # When point or box close tag, continue tokenizing normally
+ # First, we replace the point and box tags with their respective tokens
+ prompt = _replace_string_repr_with_token_tags(prompt)
+ # Tokenize the prompt
+ # Convert prompt into a list split
+ prompt_text_list = _segment_prompt_into_text_token_conversions(prompt)
+ transformed_prompt_tokens: List[int] = []
+ for elem in prompt_text_list:
+ if elem[1]:
+ # This is a location, we need to tokenize it
+ within_tag_tokenized = _transform_within_tags(elem[0], scale_factor, tokenizer)
+ # Surround the text with the open and close tags
+ transformed_prompt_tokens.extend(within_tag_tokenized)
+ else:
+ transformed_prompt_tokens.extend(tokenizer(elem[0], add_special_tokens=False).input_ids)
+ return transformed_prompt_tokens
+
+
+def _transform_within_tags(text: str, scale_factor: float, tokenizer) -> List[int]:
+ """
+ Given a bounding box of the fashion 1, 2, 3, 4 | 1, 2 This function is responsible for
+ converting 1, 2, 3, 4 into tokens of 1 2 3 4 without any commas.
+ """
+ # Convert the text into a list of strings.
+ num_int_strs = text.split(",")
+ if len(num_int_strs) == 2:
+ # If there are any open or close tags, remove them.
+ token_space_open_string = tokenizer.vocab[TOKEN_POINT_OPEN_STRING]
+ token_space_close_string = tokenizer.vocab[TOKEN_POINT_CLOSE_STRING]
+ else:
+ token_space_open_string = tokenizer.vocab[TOKEN_BBOX_OPEN_STRING]
+ token_space_close_string = tokenizer.vocab[TOKEN_BBOX_CLOSE_STRING]
+
+ # Remove all spaces from num_ints
+ num_ints = [float(num.strip()) for num in num_int_strs]
+ # scale to transformed image siz
+ if len(num_ints) == 2:
+ num_ints_translated = scale_point_to_transformed_image(x=num_ints[0], y=num_ints[1], scale_factor=scale_factor)
+ elif len(num_ints) == 4:
+ num_ints_translated = scale_bbox_to_transformed_image(
+ top=num_ints[0],
+ left=num_ints[1],
+ bottom=num_ints[2],
+ right=num_ints[3],
+ scale_factor=scale_factor,
+ )
+ else:
+ raise ValueError(f"Invalid number of ints: {len(num_ints)}")
+ # Tokenize the text, skipping the
+ tokens = [tokenizer.vocab[str(num)] for num in num_ints_translated]
+ return [token_space_open_string] + tokens + [token_space_close_string]
+
+
+def _tokenize_prompts_with_image_and_batch(
+ tokenizer,
+ prompts: List[List[str]],
+ scale_factors: Optional[List[List["torch.Tensor"]]],
+ max_tokens_to_generate: int,
+ max_position_embeddings: int,
+ add_BOS: bool, # Same issue with types as above
+ add_beginning_of_answer_token: bool,
+) -> Tuple["torch.Tensor", "torch.Tensor"]:
+ """
+ Given a set of prompts and number of tokens to generate:
+ - tokenize prompts
+ - set the sequence length to be the max of length of prompts plus the number of tokens we would like to generate
+ - pad all the sequences to this length so we can convert them into a 3D tensor.
+ """
+
+ # If not tool use, tranform the coordinates while tokenizing
+ if scale_factors is not None:
+ transformed_prompt_tokens = []
+ for prompt_seq, scale_factor_seq in zip(prompts, scale_factors):
+ transformed_prompt_tokens.append([_transform_coordinates_and_tokenize(prompt, scale_factor.item(), tokenizer) for prompt, scale_factor in zip(prompt_seq, scale_factor_seq)])
+ else:
+ transformed_prompt_tokens = [[tokenizer.tokenize(prompt) for prompt in prompt_seq] for prompt_seq in prompts]
+
+ prompts_tokens = transformed_prompt_tokens
+
+ if add_BOS:
+ bos_token = tokenizer.vocab["
'
+ image_path = single_turn["images"][image_idx]
+ if image_path == "":
+ message += text_list[image_idx] + ""
+ else:
+ message += text_list[image_idx] + f""
+ message += text_list[-1]
+
+ if i % 2 == 0:
+ dialog.append([message, None])
+ else:
+ dialog[-1][-1] = message
+
+ return dialog
+
+ def copy(self):
+ return Conversation(system=self.system, roles=self.roles, messages=copy.deepcopy(self.messages), offset=self.offset, sep_style=self.sep_style, sep=self.sep, sep2=self.sep2, version=self.version)
+
+ def dict(self):
+ messages = copy.deepcopy(self.messages)
+ for message in messages:
+ if "images_ids" in message:
+ message.pop("images_ids")
+ for i in range(len(message["message"]["images"])):
+ message["message"]["images"][i] = os.path.basename(message["message"]["images"][i])
+ return {
+ "system": self.system,
+ "roles": self.roles,
+ "messages": messages,
+ "offset": self.offset,
+ "sep": self.sep,
+ "sep2": self.sep2,
+ }
+
+
+model = Conversation(
+ system="",
+ roles=("USER", "ASSISTANT"),
+ version="v2",
+ messages=[],
+ offset=0,
+ sep_style=SeparatorStyle.SINGLE,
+ sep="\n",
+)
diff --git a/pipeline/serve/deploy/deploy.py b/pipeline/serve/deploy/deploy.py
new file mode 100644
index 00000000..330ee504
--- /dev/null
+++ b/pipeline/serve/deploy/deploy.py
@@ -0,0 +1,302 @@
+import os
+import datetime
+import json
+import base64
+from PIL import Image
+import gradio as gr
+import hashlib
+import requests
+from utils import build_logger
+from conversation import model
+import io
+
+
+IMG_FLAG = ""
+
+LOGDIR = "log"
+logger = build_logger("otter", LOGDIR)
+
+current_model = model
+
+no_change_btn = gr.Button.update()
+enable_btn = gr.Button.update(interactive=True)
+disable_btn = gr.Button.update(interactive=False)
+
+
+def decode_image(encoded_image: str) -> Image:
+ decoded_bytes = base64.b64decode(encoded_image.encode("utf-8"))
+ buffer = io.BytesIO(decoded_bytes)
+ image = Image.open(buffer)
+ return image
+
+
+def encode_image(image: Image.Image, format: str = "PNG") -> str:
+ with io.BytesIO() as buffer:
+ image.save(buffer, format=format)
+ encoded_image = base64.b64encode(buffer.getvalue()).decode("utf-8")
+ return encoded_image
+
+
+def get_conv_log_filename():
+ t = datetime.datetime.now()
+ name = os.path.join(LOGDIR, f"{t.year}-{t.month:02d}-{t.day:02d}-conv.json")
+ return name
+
+
+def get_conv_image_dir():
+ name = os.path.join(LOGDIR, "images")
+ os.makedirs(name, exist_ok=True)
+ return name
+
+
+def get_image_name(image, image_dir=None):
+ buffer = io.BytesIO()
+ image.save(buffer, format="PNG")
+ image_bytes = buffer.getvalue()
+ md5 = hashlib.md5(image_bytes).hexdigest()
+
+ if image_dir is not None:
+ image_name = os.path.join(image_dir, md5 + ".png")
+ else:
+ image_name = md5 + ".png"
+
+ return image_name
+
+
+def resize_image(image, max_size):
+ width, height = image.size
+ aspect_ratio = float(width) / float(height)
+
+ if width > height:
+ new_width = max_size
+ new_height = int(new_width / aspect_ratio)
+ else:
+ new_height = max_size
+ new_width = int(new_height * aspect_ratio)
+
+ resized_image = image.resize((new_width, new_height))
+ return resized_image
+
+
+def center_crop_image(image, max_aspect_ratio=1.5):
+ width, height = image.size
+ aspect_ratio = max(width, height) / min(width, height)
+
+ if aspect_ratio >= max_aspect_ratio:
+ if width > height:
+ new_width = int(height * max_aspect_ratio)
+ left = (width - new_width) // 2
+ right = (width + new_width) // 2
+ top = 0
+ bottom = height
+ else:
+ new_height = int(width * max_aspect_ratio)
+ left = 0
+ right = width
+ top = (height - new_height) // 2
+ bottom = (height + new_height) // 2
+
+ cropped_image = image.crop((left, top, right, bottom))
+ return cropped_image
+ else:
+ return image
+
+
+def regenerate(dialog_state, request: gr.Request):
+ logger.info(f"regenerate. ip: {request.client.host}")
+ if dialog_state.messages[-1]["role"] == dialog_state.roles[1]:
+ dialog_state.messages.pop()
+ return (
+ dialog_state,
+ dialog_state.to_gradio_chatbot(),
+ ) + (disable_btn,) * 4
+
+
+def clear_history(request: gr.Request):
+ logger.info(f"clear_history. ip: {request.client.host}")
+ dialog_state = current_model.copy()
+ input_state = init_input_state()
+ return (dialog_state, input_state, dialog_state.to_gradio_chatbot()) + (disable_btn,) * 4
+
+
+def init_input_state():
+ return {"images": [], "text": "", "images_ids": []}
+
+
+def add_text(dialog_state, input_state, text, request: gr.Request):
+ logger.info(f"add_text. ip: {request.client.host}.")
+ if text is None or len(text) == 0:
+ return (dialog_state, input_state, "", dialog_state.to_gradio_chatbot()) + (no_change_btn,) * 4
+ input_state["text"] += text
+
+ if len(dialog_state.messages) > 0 and dialog_state.messages[-1]["role"] == dialog_state.roles[0]:
+ dialog_state.messages[-1]["message"] = input_state
+ else:
+ dialog_state.messages.append({"role": dialog_state.roles[0], "message": input_state})
+ print("add_text: ", dialog_state.to_gradio_chatbot())
+
+ return (dialog_state, input_state, "", dialog_state.to_gradio_chatbot()) + (disable_btn,) * 4
+
+
+def add_image(dialog_state, input_state, image, request: gr.Request):
+ logger.info(f"add_image. ip: {request.client.host}.")
+ if image is None:
+ return (dialog_state, input_state, None, dialog_state.to_gradio_chatbot()) + (no_change_btn,) * 4
+
+ image = image.convert("RGB")
+ image = resize_image(image, max_size=224)
+ image = center_crop_image(image, max_aspect_ratio=1.3)
+ image_dir = get_conv_image_dir()
+ image_path = get_image_name(image=image, image_dir=image_dir)
+ if not os.path.exists(image_path):
+ image.save(image_path)
+
+ input_state["images"].append(image_path)
+ input_state["text"]
+ input_state["images_ids"].append(None)
+
+ if len(dialog_state.messages) > 0 and dialog_state.messages[-1]["role"] == dialog_state.roles[0]:
+ dialog_state.messages[-1]["message"] = input_state
+ else:
+ dialog_state.messages.append({"role": dialog_state.roles[0], "message": input_state})
+
+ print("add_image:", dialog_state)
+
+ return (dialog_state, input_state, None, dialog_state.to_gradio_chatbot()) + (disable_btn,) * 4
+
+
+# def update_error_msg(chatbot, error_msg):
+# if len(error_msg) > 0:
+# info = '\n-------------\nSome errors occurred during response, please clear history and restart.\n' + '\n'.join(
+# error_msg)
+# chatbot[-1][-1] = chatbot[-1][-1] + info
+
+# return chatbot
+
+
+def http_bot(image_input, text_input, request: gr.Request):
+ logger.info(f"http_bot. ip: {request.client.host}")
+ print(f"Prompt request: {text_input}")
+
+ base64_image_str = encode_image(image_input)
+
+ payload = {
+ "content": [
+ {
+ "prompt": text_input,
+ "image": base64_image_str,
+ }
+ ],
+ "token": "sk-OtterHD",
+ }
+
+ print(
+ "request: ",
+ {
+ "prompt": text_input,
+ "image": base64_image_str[:10],
+ },
+ )
+
+ url = "http://10.128.0.40:8890/app/otter"
+ headers = {"Content-Type": "application/json"}
+
+ response = requests.post(url, headers=headers, data=json.dumps(payload))
+ results = response.json()
+ print("response: ", {"result": results["result"]})
+
+ # output_state = init_input_state()
+ # # image_dir = get_conv_image_dir()
+ # output_state["text"] = results["result"]
+
+ # for now otter doesn't have image output
+
+ # for image_base64 in results['images']:
+ # if image_base64 == '':
+ # image_path = ''
+ # else:
+ # image = decode_image(image_base64)
+ # image = image.convert('RGB')
+ # image_path = get_image_name(image=image, image_dir=image_dir)
+ # if not os.path.exists(image_path):
+ # image.save(image_path)
+ # output_state['images'].append(image_path)
+ # output_state['images_ids'].append(None)
+
+ # dialog_state.messages.append({"role": dialog_state.roles[1], "message": output_state})
+ # # dialog_state.update_image_ids(results['images_ids'])
+
+ # input_state = init_input_state()
+ # chatbot = dialog_state.to_gradio_chatbot()
+ # chatbot = update_error_msg(dialog_state.to_gradio_chatbot(), results['error_msg'])
+
+ return results["result"]
+
+
+def load_demo(request: gr.Request):
+ logger.info(f"load_demo. ip: {request.client.host}")
+ dialog_state = current_model.copy()
+ input_state = init_input_state()
+ return dialog_state, input_state
+
+
+title = """
+# OTTER-HD: A High-Resolution Multi-modality Model
+[[Otter Codebase]](https://github.com/Luodian/Otter) [[Paper]]() [[Checkpoints & Benchmarks]](https://huggingface.co/Otter-AI)
+
+"""
+
+css = """
+ #mkd {
+ height: 1000px;
+ overflow: auto;
+ border: 1px solid #ccc;
+ }
+"""
+
+if __name__ == "__main__":
+ with gr.Blocks(css=css) as demo:
+ gr.Markdown(title)
+ dialog_state = gr.State()
+ input_state = gr.State()
+ with gr.Tab("Ask a Question"):
+ with gr.Row(equal_height=True):
+ with gr.Column(scale=2):
+ image_input = gr.Image(label="Upload a High-Res Image", type="pil").style(height=600)
+ with gr.Column(scale=1):
+ vqa_output = gr.Textbox(label="Output").style(height=600)
+ text_input = gr.Textbox(label="Ask a Question")
+
+ vqa_btn = gr.Button("Send It")
+
+ gr.Examples(
+ [
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00095.png",
+ "How many camels are inside this image?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00095.png",
+ "How many people are inside this image?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00012.png",
+ "How many apples are there?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00080.png",
+ "What is this and where is it from?",
+ ],
+ [
+ "/home/luodian/projects/Otter/archived/OtterHD/assets/G4_IMG_00094.png",
+ "What's important on this website?",
+ ],
+ ],
+ inputs=[image_input, text_input],
+ outputs=[vqa_output],
+ fn=http_bot,
+ label="Click on any Examples below👇",
+ )
+ vqa_btn.click(fn=http_bot, inputs=[image_input, text_input], outputs=vqa_output)
+
+ demo.launch()
diff --git a/pipeline/serve/deploy/otterhd_endpoint.py b/pipeline/serve/deploy/otterhd_endpoint.py
new file mode 100644
index 00000000..aed28b4c
--- /dev/null
+++ b/pipeline/serve/deploy/otterhd_endpoint.py
@@ -0,0 +1,128 @@
+from flask import Flask, request, jsonify
+from PIL import Image
+import torch
+from transformers import AutoTokenizer, FuyuForCausalLM, FuyuProcessor, FuyuImageProcessor
+import base64
+import re
+from io import BytesIO
+from datetime import datetime
+import hashlib
+from PIL import Image
+import io, os
+
+app = Flask(__name__)
+
+# Initialization code (similar to what you have in your Gradio demo)
+model_id = input("Model ID: ")
+device = "cuda:0"
+dtype = torch.bfloat16
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = FuyuForCausalLM.from_pretrained(model_id, device_map=device, torch_dtype=dtype)
+processor = FuyuProcessor(image_processor=FuyuImageProcessor(), tokenizer=tokenizer)
+
+# Ensure model is in evaluation mode
+model.eval()
+prompt_txt_path = "../user_logs/prompts.txt"
+images_folder_path = "../user_logs"
+
+
+def save_image_unique(pil_image, directory=images_folder_path):
+ # Ensure the directory exists
+ if not os.path.exists(directory):
+ os.makedirs(directory)
+
+ # Convert the PIL Image into a bytes object
+ img_byte_arr = io.BytesIO()
+ pil_image.save(img_byte_arr, format="PNG")
+ img_byte_arr = img_byte_arr.getvalue()
+
+ # Compute the hash of the image data
+ hasher = hashlib.sha256()
+ hasher.update(img_byte_arr)
+ hash_hex = hasher.hexdigest()
+
+ # Create a file name with the hash value
+ file_name = f"{hash_hex}.png"
+ file_path = os.path.join(directory, file_name)
+
+ # Check if a file with the same name exists
+ if os.path.isfile(file_path):
+ print(f"Image already exists with the name: {file_name}")
+ else:
+ # If the file does not exist, save the image
+ with open(file_path, "wb") as new_file:
+ new_file.write(img_byte_arr)
+ print(f"Image saved with the name: {file_name}")
+
+ return file_path
+
+
+# Define endpoint
+@app.route("/app/otter", methods=["POST"])
+def process_image_and_prompt():
+ start_time = datetime.now()
+ # Parse request data
+ data = request.get_json()
+ query_content = data["content"][0]
+ if "image" not in query_content:
+ return jsonify({"error": "Missing Image"}), 400
+ elif "prompt" not in query_content:
+ return jsonify({"error": "Missing Prompt"}), 400
+
+ # Decode the image
+ image_data = query_content["image"]
+ image = Image.open(BytesIO(base64.b64decode(image_data)))
+ prompt = query_content["prompt"]
+ formated_time = start_time.strftime("%Y-%m-%d %H:%M:%S")
+ image_path = save_image_unique(image)
+
+ # Preprocess the image and prompt, and run the model
+ response = predict(image, prompt)
+ torch.cuda.empty_cache()
+
+ with open(prompt_txt_path, "a") as f:
+ f.write(f"*************************{formated_time}**************************" + "\n")
+ f.write(f"Image saved to {image_path}" + "\n")
+ f.write(f"Prompt: {prompt}" + "\n")
+ f.write(f"Response: {response}" + "\n\n")
+
+ # Return the response
+ return jsonify({"result": response})
+
+
+import time
+
+
+# Other necessary functions (adapted from your Gradio demo)
+def predict(image, prompt):
+ time_start = time.time()
+ image = image.convert("RGB")
+ # if max(image.size) > 1080:
+ # image.thumbnail((1080, 1080))
+ model_inputs = processor(text=prompt, images=[image], device=device)
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(device, non_blocking=True) if isinstance(v, torch.Tensor) else [vv.to(device, non_blocking=True) for vv in v]
+ model_inputs["image_patches"][0] = model_inputs["image_patches"][0].to(dtype=next(model.parameters()).dtype)
+
+ generation_output = model.generate(
+ **model_inputs,
+ max_new_tokens=512,
+ pad_token_id=processor.tokenizer.eos_token_id
+ # do_sample=True,
+ # top_p=0.5,
+ # temperature=0.2,
+ )
+ generation_text = processor.batch_decode(generation_output, skip_special_tokens=True)
+ generation_text = [text.split("\x04")[1].strip() for text in generation_text]
+ end_time = time.time()
+ formated_interval = f"{end_time - time_start:.3f}"
+ response = f"Image Resolution (W, H): {image.size}\n-------------------\nModel Respond Time(s): {formated_interval}\n-------------------\nAnswer: {generation_text[0]}"
+ return response
+
+
+# Utility functions (as per the Gradio script, you can adapt the same or similar ones)
+# ... (e.g., resize_to_max, pad_to_size, etc.)
+
+if __name__ == "__main__":
+ app.run(host="0.0.0.0", port=8890)
diff --git a/pipeline/serve/deploy/utils.py b/pipeline/serve/deploy/utils.py
new file mode 100644
index 00000000..3cd6973c
--- /dev/null
+++ b/pipeline/serve/deploy/utils.py
@@ -0,0 +1,82 @@
+import logging
+import logging.handlers
+import os
+import sys
+
+handler = None
+
+
+def build_logger(logger_name, logger_dir):
+ global handler
+
+ formatter = logging.Formatter(
+ fmt="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
+ datefmt="%Y-%m-%d %H:%M:%S",
+ )
+
+ # Set the format of root handlers
+ if not logging.getLogger().handlers:
+ logging.basicConfig(level=logging.INFO)
+ logging.getLogger().handlers[0].setFormatter(formatter)
+
+ # Redirect stdout and stderr to loggers
+ stdout_logger = logging.getLogger("stdout")
+ stdout_logger.setLevel(logging.INFO)
+ sl = StreamToLogger(stdout_logger, logging.INFO)
+ sys.stdout = sl
+
+ stderr_logger = logging.getLogger("stderr")
+ stderr_logger.setLevel(logging.ERROR)
+ sl = StreamToLogger(stderr_logger, logging.ERROR)
+ sys.stderr = sl
+
+ # Get logger
+ logger = logging.getLogger(logger_name)
+ logger.setLevel(logging.INFO)
+
+ # Add a file handler for all loggers
+ if handler is None:
+ os.makedirs(logger_dir, exist_ok=True)
+ filename = os.path.join(logger_dir, logger_name + ".log")
+ handler = logging.handlers.TimedRotatingFileHandler(filename, when="D", utc=True)
+ handler.setFormatter(formatter)
+
+ for name, item in logging.root.manager.loggerDict.items():
+ if isinstance(item, logging.Logger):
+ item.addHandler(handler)
+
+ return logger
+
+
+class StreamToLogger(object):
+ """
+ Fake file-like stream object that redirects writes to a logger instance.
+ """
+
+ def __init__(self, logger, log_level=logging.INFO):
+ self.terminal = sys.stdout
+ self.logger = logger
+ self.log_level = log_level
+ self.linebuf = ""
+
+ def __getattr__(self, attr):
+ return getattr(self.terminal, attr)
+
+ def write(self, buf):
+ temp_linebuf = self.linebuf + buf
+ self.linebuf = ""
+ for line in temp_linebuf.splitlines(True):
+ # From the io.TextIOWrapper docs:
+ # On output, if newline is None, any '\n' characters written
+ # are translated to the system default line separator.
+ # By default sys.stdout.write() expects '\n' newlines and then
+ # translates them so this is still cross platform.
+ if line[-1] == "\n":
+ self.logger.log(self.log_level, line.rstrip())
+ else:
+ self.linebuf += line
+
+ def flush(self):
+ if self.linebuf != "":
+ self.logger.log(self.log_level, self.linebuf.rstrip())
+ self.linebuf = ""
diff --git a/pipeline/serve/gradio_css.py b/pipeline/serve/gradio_css.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/gradio_patch.py b/pipeline/serve/gradio_patch.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/gradio_web_server.py b/pipeline/serve/gradio_web_server.py
old mode 100644
new mode 100755
index 9c8bd78b..c1130541
--- a/pipeline/serve/gradio_web_server.py
+++ b/pipeline/serve/gradio_web_server.py
@@ -8,7 +8,11 @@
import gradio as gr
import requests
import re
-from pipeline.conversation import default_conversation, conv_templates, SeparatorStyle
+from pipeline.serve.conversation import (
+ default_conversation,
+ conv_templates,
+ SeparatorStyle,
+)
from pipeline.constants import LOGDIR
from pipeline.serve.serving_utils import (
build_logger,
@@ -255,28 +259,10 @@ def add_text(
if text_demo_answer_2 != "":
assert image_demo_2 is not None
- text = (
- DEFAULT_IMAGE_TOKEN
- + human_role_label
- + text_demo_question_2
- + bot_role_label
- + DEFAULT_ANSWER_TOKEN
- + text_demo_answer_2
- + DEFAULT_DEMO_END_TOKEN
- + text
- )
+ text = DEFAULT_IMAGE_TOKEN + human_role_label + text_demo_question_2 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_2 + DEFAULT_DEMO_END_TOKEN + text
if text_demo_answer_1 != "":
assert image_demo_1 is not None
- text = (
- DEFAULT_IMAGE_TOKEN
- + human_role_label
- + text_demo_question_1
- + bot_role_label
- + DEFAULT_ANSWER_TOKEN
- + text_demo_answer_1
- + DEFAULT_DEMO_END_TOKEN
- + text
- )
+ text = DEFAULT_IMAGE_TOKEN + human_role_label + text_demo_question_1 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_1 + DEFAULT_DEMO_END_TOKEN + text
input = (text, image_demo_1, image_demo_2, image_3)
state.append_message(state.roles[0], input)
@@ -577,12 +563,54 @@ def build_demo(embed_mode):
).style(container=True)
with gr.Accordion("Parameters", open=False, visible=False) as parameter_row:
- max_new_tokens = gr.Slider(minimum=16, maximum=512, value=512, step=1, interactive=True, label="# generation tokens")
- temperature = gr.Slider(minimum=0, maximum=1, value=1, step=0.1, interactive=True, label="temperature")
- top_k = gr.Slider(minimum=0, maximum=10, value=0, step=1, interactive=True, label="top_k")
- top_p = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.1, interactive=True, label="top_p")
- no_repeat_ngram_size = gr.Slider(minimum=1, maximum=10, value=3, step=1, interactive=True, label="no_repeat_ngram_size")
- length_penalty = gr.Slider(minimum=1, maximum=5, value=1, step=0.1, interactive=True, label="length_penalty")
+ max_new_tokens = gr.Slider(
+ minimum=16,
+ maximum=512,
+ value=512,
+ step=1,
+ interactive=True,
+ label="# generation tokens",
+ )
+ temperature = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="temperature",
+ )
+ top_k = gr.Slider(
+ minimum=0,
+ maximum=10,
+ value=0,
+ step=1,
+ interactive=True,
+ label="top_k",
+ )
+ top_p = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1.0,
+ step=0.1,
+ interactive=True,
+ label="top_p",
+ )
+ no_repeat_ngram_size = gr.Slider(
+ minimum=1,
+ maximum=10,
+ value=3,
+ step=1,
+ interactive=True,
+ label="no_repeat_ngram_size",
+ )
+ length_penalty = gr.Slider(
+ minimum=1,
+ maximum=5,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="length_penalty",
+ )
do_sample = gr.Checkbox(interactive=True, label="do_sample")
early_stopping = gr.Checkbox(interactive=True, label="early_stopping", value=True)
@@ -609,11 +637,26 @@ def build_demo(embed_mode):
gr.Examples(
label="Examples (0-shot)",
examples=[
- [f"{cur_dir}/examples/ms_st.jpg", "Does the image feature a globally recognized technology company?"],
- [f"{cur_dir}/examples/ms_st.jpg", "Does the image feature a globally recognized technology company? Please answer with yes or no."],
- [f"{cur_dir}/examples/zelda_princess.jpg", "Can you identify the game character?"],
- [f"{cur_dir}/examples/martin.jpeg", "Can you identify the historic figure?"],
- [f"{cur_dir}/examples/gtav.jpg", "Can you identify what the image is about?"],
+ [
+ f"{cur_dir}/examples/ms_st.jpg",
+ "Does the image feature a globally recognized technology company?",
+ ],
+ [
+ f"{cur_dir}/examples/ms_st.jpg",
+ "Does the image feature a globally recognized technology company? Please answer with yes or no.",
+ ],
+ [
+ f"{cur_dir}/examples/zelda_princess.jpg",
+ "Can you identify the game character?",
+ ],
+ [
+ f"{cur_dir}/examples/martin.jpeg",
+ "Can you identify the historic figure?",
+ ],
+ [
+ f"{cur_dir}/examples/gtav.jpg",
+ "Can you identify what the image is about?",
+ ],
[
f"{cur_dir}/examples/xray.jpg",
"Act as a radiologist and write a diagnostic radiology report for the patient based on their chest radiographs:",
@@ -857,7 +900,5 @@ def build_demo(embed_mode):
models = get_model_list()
logger.info(args)
demo = build_demo(args.embed)
- demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(
- server_name=args.host, server_port=args.port, share=args.share
- )
+ demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(server_name=args.host, server_port=args.port, share=args.share)
gr.close_all()
diff --git a/pipeline/serve/gradio_web_server_video.py b/pipeline/serve/gradio_web_server_video.py
index 513560e8..97017b2a 100755
--- a/pipeline/serve/gradio_web_server_video.py
+++ b/pipeline/serve/gradio_web_server_video.py
@@ -13,8 +13,11 @@
import cv2
import re
-from pipeline.conversation import default_conversation, conv_templates, SeparatorStyle
-from pipeline.constants import LOGDIR
+from pipeline.serve.conversation import (
+ default_conversation,
+ conv_templates,
+ SeparatorStyle,
+)
from pipeline.serve.serving_utils import (
build_logger,
server_error_msg,
@@ -24,6 +27,10 @@
from pipeline.serve.gradio_patch import Chatbot as grChatbot
from pipeline.serve.gradio_css import code_highlight_css
+CONTROLLER_HEART_BEAT_EXPIRATION = 2 * 60
+WORKER_HEART_BEAT_INTERVAL = 30
+LOGDIR = "./logs"
+
DEFAULT_IMAGE_TOKEN = ""
DEFAULT_DEMO_END_TOKEN = "<|endofchunk|>"
# DEFAULT_ANSWER_TOKEN = ""
@@ -261,19 +268,11 @@ def add_text(
if text_demo_answer_2 != "":
if text.startswith(DEFAULT_IMAGE_TOKEN):
- text = (
- DEFAULT_IMAGE_TOKEN
- + (human_role_label + text_demo_question_2 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_2 + DEFAULT_DEMO_END_TOKEN)
- + text[len(DEFAULT_IMAGE_TOKEN) :]
- )
+ text = DEFAULT_IMAGE_TOKEN + (human_role_label + text_demo_question_2 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_2 + DEFAULT_DEMO_END_TOKEN) + text[len(DEFAULT_IMAGE_TOKEN) :]
if text_demo_answer_1 != "":
if text.startswith(DEFAULT_IMAGE_TOKEN):
- text = (
- DEFAULT_IMAGE_TOKEN
- + (human_role_label + text_demo_question_1 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_1 + DEFAULT_DEMO_END_TOKEN)
- + text[len(DEFAULT_IMAGE_TOKEN) :]
- )
+ text = DEFAULT_IMAGE_TOKEN + (human_role_label + text_demo_question_1 + bot_role_label + DEFAULT_ANSWER_TOKEN + text_demo_answer_1 + DEFAULT_DEMO_END_TOKEN) + text[len(DEFAULT_IMAGE_TOKEN) :]
input = (text, image_3)
state.append_message(state.roles[0], input)
@@ -503,32 +502,85 @@ def build_demo(embed_mode):
with gr.Row():
with gr.Column(scale=3):
- model_selector = gr.Dropdown(choices=models, value=models[0] if len(models) > 0 else "", interactive=True, show_label=False).style(
- container=False
- )
+ model_selector = gr.Dropdown(
+ choices=models,
+ value=models[0] if len(models) > 0 else "",
+ interactive=True,
+ show_label=False,
+ ).style(container=False)
videobox_3 = gr.Video(label="Video")
- textbox_demo_question_1 = gr.Textbox(label="Demo Text Query 1 (optional)", show_label=True, placeholder="Example: What is in the image?").style(
- container=True
- )
- textbox_demo_answer_1 = gr.Textbox(label="Demo Text Answer 1 (optional)", show_label=True, placeholder="").style(
- container=True
- )
- textbox_demo_question_2 = gr.Textbox(label="Demo Text Query 2 (optional)", show_label=True, placeholder="Example: What is in the image?").style(
- container=True
- )
- textbox_demo_answer_2 = gr.Textbox(label="Demo Text Answer 2 (optional)", show_label=True, placeholder="").style(
- container=True
- )
+ textbox_demo_question_1 = gr.Textbox(
+ label="Demo Text Query 1 (optional)",
+ show_label=True,
+ placeholder="Example: What is in the image?",
+ ).style(container=True)
+ textbox_demo_answer_1 = gr.Textbox(
+ label="Demo Text Answer 1 (optional)",
+ show_label=True,
+ placeholder="",
+ ).style(container=True)
+ textbox_demo_question_2 = gr.Textbox(
+ label="Demo Text Query 2 (optional)",
+ show_label=True,
+ placeholder="Example: What is in the image?",
+ ).style(container=True)
+ textbox_demo_answer_2 = gr.Textbox(
+ label="Demo Text Answer 2 (optional)",
+ show_label=True,
+ placeholder="",
+ ).style(container=True)
with gr.Accordion("Parameters", open=False, visible=False) as parameter_row:
- max_new_tokens = gr.Slider(minimum=16, maximum=512, value=512, step=1, interactive=True, label="# generation tokens")
- temperature = gr.Slider(minimum=0, maximum=1, value=1, step=0.1, interactive=True, label="temperature")
- top_k = gr.Slider(minimum=0, maximum=10, value=0, step=1, interactive=True, label="top_k")
- top_p = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.1, interactive=True, label="top_p")
- no_repeat_ngram_size = gr.Slider(minimum=1, maximum=10, value=3, step=1, interactive=True, label="no_repeat_ngram_size")
- length_penalty = gr.Slider(minimum=1, maximum=5, value=1, step=0.1, interactive=True, label="length_penalty")
+ max_new_tokens = gr.Slider(
+ minimum=16,
+ maximum=512,
+ value=512,
+ step=1,
+ interactive=True,
+ label="# generation tokens",
+ )
+ temperature = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="temperature",
+ )
+ top_k = gr.Slider(
+ minimum=0,
+ maximum=10,
+ value=0,
+ step=1,
+ interactive=True,
+ label="top_k",
+ )
+ top_p = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=1.0,
+ step=0.1,
+ interactive=True,
+ label="top_p",
+ )
+ no_repeat_ngram_size = gr.Slider(
+ minimum=1,
+ maximum=10,
+ value=3,
+ step=1,
+ interactive=True,
+ label="no_repeat_ngram_size",
+ )
+ length_penalty = gr.Slider(
+ minimum=1,
+ maximum=5,
+ value=1,
+ step=0.1,
+ interactive=True,
+ label="length_penalty",
+ )
do_sample = gr.Checkbox(interactive=True, label="do_sample")
early_stopping = gr.Checkbox(interactive=True, label="early_stopping")
@@ -554,8 +606,22 @@ def build_demo(embed_mode):
cur_dir = os.path.dirname(os.path.abspath(__file__))
gr.Examples(
examples=[
- ["", "", "", "", f"{cur_dir}/examples/Apple Vision Pro - Reveal Trailer.mp4", "Hey Otter, do you think it's cool? "],
- ["", "", "", "", f"{cur_dir}/examples/example.mp4", "What does the video describe?"],
+ [
+ "",
+ "",
+ "",
+ "",
+ f"{cur_dir}/examples/Apple Vision Pro - Reveal Trailer.mp4",
+ "Hey Otter, do you think it's cool? ",
+ ],
+ [
+ "",
+ "",
+ "",
+ "",
+ f"{cur_dir}/examples/example.mp4",
+ "What does the video describe?",
+ ],
[
"Is there a person in this video?",
"Yes, a woman.",
@@ -590,7 +656,12 @@ def build_demo(embed_mode):
# Register listeners
btn_list = [upvote_btn, downvote_btn, flag_btn, regenerate_btn, clear_btn]
- demo_list = [textbox_demo_question_1, textbox_demo_answer_1, textbox_demo_question_2, textbox_demo_answer_2]
+ demo_list = [
+ textbox_demo_question_1,
+ textbox_demo_answer_1,
+ textbox_demo_question_2,
+ textbox_demo_answer_2,
+ ]
prarameter_list = [
max_new_tokens,
temperature,
@@ -609,17 +680,41 @@ def build_demo(embed_mode):
flag_btn.click(flag_last_response, [state, model_selector], feedback_args)
common_args = [state, chatbot] + demo_list + [textbox_3, videobox_3] + btn_list
- regenerate_btn.click(regenerate, state, common_args).then(http_bot, [state, model_selector] + prarameter_list, [state, chatbot] + btn_list)
+ regenerate_btn.click(regenerate, state, common_args).then(
+ http_bot,
+ [state, model_selector] + prarameter_list,
+ [state, chatbot] + btn_list,
+ )
clear_btn.click(clear_history, None, common_args)
- textbox_3.submit(add_text, [state, model_selector] + demo_list + [textbox_3, videobox_3], common_args).then(
- http_bot, [state, model_selector] + prarameter_list, [state, chatbot] + btn_list
+ textbox_3.submit(
+ add_text,
+ [state, model_selector] + demo_list + [textbox_3, videobox_3],
+ common_args,
+ ).then(
+ http_bot,
+ [state, model_selector] + prarameter_list,
+ [state, chatbot] + btn_list,
)
- submit_btn.click(add_text, [state, model_selector] + demo_list + [textbox_3, videobox_3], common_args).then(
- http_bot, [state, model_selector] + prarameter_list, [state, chatbot] + btn_list
+ submit_btn.click(
+ add_text,
+ [state, model_selector] + demo_list + [textbox_3, videobox_3],
+ common_args,
+ ).then(
+ http_bot,
+ [state, model_selector] + prarameter_list,
+ [state, chatbot] + btn_list,
)
- widget_list = [state, model_selector, chatbot, textbox_3, submit_btn, button_row, parameter_row]
+ widget_list = [
+ state,
+ model_selector,
+ chatbot,
+ textbox_3,
+ submit_btn,
+ button_row,
+ parameter_row,
+ ]
if args.model_list_mode == "once":
demo.load(load_demo, [url_params], widget_list, _js=get_window_url_params)
@@ -647,7 +742,5 @@ def build_demo(embed_mode):
models = get_model_list()
logger.info(args)
demo = build_demo(args.embed)
- demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(
- server_name=args.host, server_port=args.port, share=args.share
- )
+ demo.queue(concurrency_count=args.concurrency_count, status_update_rate=10, api_open=False).launch(server_name=args.host, server_port=args.port, share=args.share)
gr.close_all()
diff --git a/pipeline/serve/model_worker.py b/pipeline/serve/model_worker.py
index 01f62546..78cdadf3 100755
--- a/pipeline/serve/model_worker.py
+++ b/pipeline/serve/model_worker.py
@@ -130,9 +130,7 @@ def register_to_controller(self):
assert r.status_code == 200
def send_heart_beat(self):
- logger.info(
- f"Send heart beat. Models: {[self.model_name]}. " f"Semaphore: {pretty_print_semaphore(model_semaphore)}. " f"global_counter: {global_counter}"
- )
+ logger.info(f"Send heart beat. Models: {[self.model_name]}. " f"Semaphore: {pretty_print_semaphore(model_semaphore)}. " f"global_counter: {global_counter}")
url = self.controller_addr + "/receive_heart_beat"
@@ -191,7 +189,11 @@ def generate_stream(self, params):
# cur_image = Image.open(BytesIO(base64.urlsafe_b64decode(cur_image))).convert("RGB")
images = [Image.open(BytesIO(base64.urlsafe_b64decode(image))).convert("RGB") for image in images]
logger.info(f"{len(images)} images conditioned.")
- tensor_dtype = {"fp16": torch.float16, "bf16": torch.bfloat16, "fp32": torch.float32}[self.load_bit]
+ tensor_dtype = {
+ "fp16": torch.float16,
+ "bf16": torch.bfloat16,
+ "fp32": torch.float32,
+ }[self.load_bit]
if is_video is True:
vision_x = image_processor.preprocess(images, return_tensors="pt")["pixel_values"].unsqueeze(0).unsqueeze(0)
assert vision_x.shape[2] == len(images) # dim of vision_x: [B, T, F, C, H, W], make sure conditioned on frames of the same video
@@ -325,7 +327,12 @@ async def get_status(request: Request):
parser.add_argument("--limit_model_concurrency", type=int, default=5)
parser.add_argument("--stream_interval", type=int, default=2)
parser.add_argument("--no_register", action="store_true")
- parser.add_argument("--load_bit", type=str, choices=["fp16", "bf16", "int8", "int4", "fp32"], default="fp32")
+ parser.add_argument(
+ "--load_bit",
+ type=str,
+ choices=["fp16", "bf16", "int8", "int4", "fp32"],
+ default="fp32",
+ )
parser.add_argument("--load_pt", action="store_true")
args = parser.parse_args()
diff --git a/pipeline/serve/multiplex_script/otter_image_server.py b/pipeline/serve/multiplex_script/otter_image_server.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/register_worker.py b/pipeline/serve/register_worker.py
old mode 100644
new mode 100755
diff --git a/pipeline/serve/serving_utils.py b/pipeline/serve/serving_utils.py
old mode 100644
new mode 100755
index bf565059..6370193f
--- a/pipeline/serve/serving_utils.py
+++ b/pipeline/serve/serving_utils.py
@@ -5,7 +5,10 @@
import requests
-from pipeline.constants import LOGDIR
+CONTROLLER_HEART_BEAT_EXPIRATION = 2 * 60
+WORKER_HEART_BEAT_INTERVAL = 30
+
+LOGDIR = "./logs"
server_error_msg = "**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**"
moderation_msg = "YOUR INPUT VIOLATES OUR CONTENT MODERATION GUIDELINES. PLEASE TRY AGAIN."
diff --git a/pipeline/serve/test_message.py b/pipeline/serve/test_message.py
old mode 100644
new mode 100755
index 88709e28..b0670956
--- a/pipeline/serve/test_message.py
+++ b/pipeline/serve/test_message.py
@@ -3,7 +3,7 @@
import requests
-from pipeline.conversation import default_conversation
+from pipeline.serve.conversation import default_conversation
def main():
diff --git a/pipeline/train/.gitignore b/pipeline/train/.gitignore
new file mode 100644
index 00000000..a5394700
--- /dev/null
+++ b/pipeline/train/.gitignore
@@ -0,0 +1 @@
+config.yaml
\ No newline at end of file
diff --git a/pipeline/train/__init__.py b/pipeline/train/__init__.py
old mode 100644
new mode 100755
diff --git a/pipeline/train/distributed.py b/pipeline/train/distributed.py
old mode 100644
new mode 100755
index 8577b70b..3476b804
--- a/pipeline/train/distributed.py
+++ b/pipeline/train/distributed.py
@@ -1,11 +1,6 @@
import os
import torch
-try:
- import horovod.torch as hvd
-except ImportError:
- hvd = None
-
def is_global_master(args):
return args.rank == 0
@@ -19,17 +14,6 @@ def is_master(args, local=False):
return is_local_master(args) if local else is_global_master(args)
-def is_using_horovod():
- # NOTE w/ horovod run, OMPI vars should be set, but w/ SLURM PMI vars will be set
- # Differentiating between horovod and DDP use via SLURM may not be possible, so horovod arg still required...
- ompi_vars = ["OMPI_COMM_WORLD_RANK", "OMPI_COMM_WORLD_SIZE"]
- pmi_vars = ["PMI_RANK", "PMI_SIZE"]
- if all([var in os.environ for var in ompi_vars]) or all([var in os.environ for var in pmi_vars]):
- return True
- else:
- return False
-
-
def is_using_distributed():
if "WORLD_SIZE" in os.environ:
return int(os.environ["WORLD_SIZE"]) > 1
@@ -40,7 +24,12 @@ def is_using_distributed():
def world_info_from_env():
local_rank = 0
- for v in ("LOCAL_RANK", "MPI_LOCALRANKID", "SLURM_LOCALID", "OMPI_COMM_WORLD_LOCAL_RANK"):
+ for v in (
+ "LOCAL_RANK",
+ "MPI_LOCALRANKID",
+ "SLURM_LOCALID",
+ "OMPI_COMM_WORLD_LOCAL_RANK",
+ ):
if v in os.environ:
local_rank = int(os.environ[v])
break
@@ -64,17 +53,7 @@ def init_distributed_device(args):
args.world_size = 1
args.rank = 0 # global rank
args.local_rank = 0
- if args.horovod:
- assert hvd is not None, "Horovod is not installed"
- hvd.init()
- args.local_rank = int(hvd.local_rank())
- args.rank = hvd.rank()
- args.world_size = hvd.size()
- args.distributed = True
- os.environ["LOCAL_RANK"] = str(args.local_rank)
- os.environ["RANK"] = str(args.rank)
- os.environ["WORLD_SIZE"] = str(args.world_size)
- elif is_using_distributed():
+ if is_using_distributed():
if "SLURM_PROCID" in os.environ:
# DDP via SLURM
args.local_rank, args.rank, args.world_size = world_info_from_env()
diff --git a/pipeline/train/instruction_following.py b/pipeline/train/instruction_following.py
index 83e1acb4..fca6da5f 100755
--- a/pipeline/train/instruction_following.py
+++ b/pipeline/train/instruction_following.py
@@ -1,15 +1,18 @@
""" Main training script """
import argparse
+import gc
import glob
import os
-import random
+import sys
import time
+from itertools import cycle
+import deepspeed
import numpy as np
-import gc
import torch
import torch.nn
+import torch.nn.functional as F
from accelerate import Accelerator
from tqdm import tqdm
from transformers import (
@@ -18,17 +21,33 @@
get_cosine_schedule_with_warmup,
get_linear_schedule_with_warmup,
)
-
+from peft import LoraConfig, TaskType, get_peft_model, PeftModel
import wandb
-from otter_ai import OtterForConditionalGeneration
-from otter_ai import FlamingoForConditionalGeneration
-from pipeline.train.data import get_data
-from pipeline.train.distributed import world_info_from_env
-from pipeline.train.train_utils import AverageMeter, get_checkpoint, get_image_attention_mask
-from transformers import AutoProcessor
-
-import deepspeed
+sys.path.append("../..")
+from transformers import AutoProcessor, AutoTokenizer, FuyuImageProcessor
+from src.otter_ai.models.fuyu.modeling_fuyu import FuyuForCausalLM
+from src.otter_ai.models.fuyu.processing_fuyu import FuyuProcessor
+
+from pipeline.mimicit_utils.data import get_data
+from pipeline.train.train_args import parse_args
+from pipeline.train.train_utils import (
+ AverageMeter,
+ get_grouped_params,
+ get_image_attention_mask,
+ master_print,
+ random_seed,
+ save_checkpoint,
+ save_final_weights,
+ verify_yaml,
+ get_weights_for_dataloaders,
+ get_next_dataloader,
+ find_and_remove_tokens,
+ delete_tensors_from_dict,
+)
+from src.otter_ai.models.flamingo.modeling_flamingo import FlamingoForConditionalGeneration
+from src.otter_ai.models.otter.modeling_otter import OtterForConditionalGeneration
+from transformers import LlamaForCausalLM, AutoTokenizer
os.environ["TOKENIZERS_PARALLELISM"] = "false"
@@ -38,7 +57,7 @@
# The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.
torch.backends.cudnn.allow_tf32 = True
-
+torch.backends.cuda.enable_flash_sdp(True)
# Try importing IdeficsForVisionText2Text, and if it's not available, define a dummy class
try:
from transformers import IdeficsForVisionText2Text
@@ -46,29 +65,74 @@
print("IdeficsForVisionText2Text does not exist")
IdeficsForVisionText2Text = type(None)
+# from memory_profiler import profile
+# fp = open("memory_report.log", "w+")
+
+
+# @profile(stream=fp)
+def forward_pass(args, model, tokenizer, images, input_ids, attention_mask, labels, device_id, autocast_type, batch_mimicit):
+ if args.model_name == "fuyu":
+ model_inputs = batch_mimicit.pop("fuyu_data")
+ for k, v in model_inputs.items():
+ model_inputs[k] = v.to(device_id, non_blocking=True) if isinstance(v, torch.Tensor) else [vv.to(device_id, non_blocking=True) for vv in v]
+ loss_mimicit = model(**model_inputs)[0]
+ elif args.model_name == "idefics":
+ # only for image model
+ max_num_images = images.shape[1]
+ pure_text = torch.all(images == 0)
+ image_attention_mask = get_image_attention_mask(
+ input_ids,
+ max_num_images,
+ tokenizer,
+ include_image=not pure_text,
+ )
+ image_attention_mask = image_attention_mask.to(device_id, non_blocking=True)
+ loss_mimicit = model(
+ pixel_values=images.squeeze(2).to(autocast_type),
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ image_attention_mask=image_attention_mask,
+ labels=labels,
+ )[0]
+ elif args.model_name == "otter" or args.model_name == "flamingo":
+ loss_mimicit = model(
+ vision_x=images.to(autocast_type),
+ lang_x=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )[0]
+ elif args.model_name == "llama2":
+ loss_mimicit = model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ labels=labels,
+ )[0]
+ else:
+ raise NotImplementedError(f"Loss of model {args.model_name} not implemented.")
-def random_seed(seed=42, rank=0):
- torch.manual_seed(seed + rank)
- np.random.seed(seed + rank)
- random.seed(seed + rank)
+ return loss_mimicit
def train_one_epoch(args, model, epoch, mimicit_loaders, tokenizer, optimizer, lr_scheduler, device_id, accelerator, wandb):
- num_batches_per_epoch = len(mimicit_loaders[0])
- total_training_steps = num_batches_per_epoch * args.num_epochs
-
- # special design for Idefics Model's prompt strategy
- fake_token_image_exists = True if "" in tokenizer.special_tokens_map["additional_special_tokens"] else False
- fake_token_image_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ dataloader_iterators = [cycle(dataloader) for dataloader in mimicit_loaders]
+ weights = get_weights_for_dataloaders(mimicit_loaders)
+ num_batches_per_epoch = sum(len(dataloader) for dataloader in mimicit_loaders) // args.gradient_accumulation_steps
+
+ # Special Design for Idefics Model's prompt strategy
+ if args.model_name.lower() == "idefics":
+ fake_token_image_exists = True if "" in tokenizer.special_tokens_map["additional_special_tokens"] else False
+ fake_token_image_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
+ endofchunk_text = ""
+ else:
+ fake_token_image_exists = False
+ fake_token_image_token_id = None
+ endofchunk_text = "<|endofchunk|>"
- # normal prompt strategy
+ # Normal Prompt Strategy
media_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
- endofchunk_text = (
- "<|endofchunk|>" if "<|endofchunk|>" in tokenizer.special_tokens_map["additional_special_tokens"] else ""
- ) # for different tokenizer
endofchunk_token_id = tokenizer(endofchunk_text, add_special_tokens=False)["input_ids"][-1]
answer_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
- ens_token_id = tokenizer(tokenizer.eos_token, add_special_tokens=False)["input_ids"][-1]
+ eos_token_id = tokenizer(tokenizer.eos_token, add_special_tokens=False)["input_ids"][-1]
model.train()
@@ -78,507 +142,193 @@ def train_one_epoch(args, model, epoch, mimicit_loaders, tokenizer, optimizer, l
end = time.time()
autocast_type = torch.bfloat16 if accelerator.mixed_precision == "bf16" else torch.float32
- # loop through dataloader
- for num_steps, (batch_mimicits) in tqdm(
- enumerate(zip(*mimicit_loaders)),
- disable=args.rank != 0,
- total=total_training_steps,
- initial=(epoch * num_batches_per_epoch),
- ):
+ # loop through different groups of dataloader
+ for num_steps in tqdm(range(args.total_training_steps), disable=args.rank != 0, initial=(epoch * num_batches_per_epoch)):
+ if num_steps == num_batches_per_epoch:
+ break
data_time_m.update(time.time() - end)
-
+ dataloader_iterator = get_next_dataloader(dataloader_iterators, weights)
+ batch_mimicit = next(dataloader_iterator) # Fetch a batch from the chosen dataloader
global_step = num_steps + epoch * num_batches_per_epoch
+
#### MIMIC-IT FORWARD PASS ####
+ net_input = batch_mimicit.pop("net_input")
+ images = net_input.pop("patch_images").to(device_id, non_blocking=True)
+ input_ids = net_input.pop("input_ids").to(device_id, non_blocking=True)
+ attention_mask = net_input.pop("attention_masks").to(device_id, non_blocking=True)
+ labels = None # placeholder to avoid error
- total_losses = []
- for batch_mimicit in batch_mimicits:
- images = batch_mimicit["net_input"]["patch_images"].to(device_id, non_blocking=True)
- input_ids = batch_mimicit["net_input"]["input_ids"].to(device_id, non_blocking=True)
- attention_mask = batch_mimicit["net_input"]["attention_masks"].to(device_id, non_blocking=True)
-
- labels = input_ids.clone()
- labels[labels == tokenizer.pad_token_id] = -100
- labels[:, 0] = -100
- for i in range(labels.shape[0]):
- # get index of all endofchunk/media tokens in the sequence
- endofchunk_idxs = torch.where(labels[i] == endofchunk_token_id)[0]
- media_idxs = torch.where(labels[i] == media_token_id)[0]
-
- # remove loss for any token the before the first
- token_idx = 0
- while token_idx < labels.shape[1] and labels[i][token_idx] != answer_token_id:
- labels[i][token_idx] = -100
- token_idx += 1
-
- # remove loss for any token between <|endofchunk|> and , except
- for endofchunk_idx in endofchunk_idxs[:-1]:
- token_idx = endofchunk_idx + 1
- while token_idx < labels.shape[1] and labels[i][token_idx] != answer_token_id:
- if labels[i][token_idx] == media_token_id:
- pass
- else:
- labels[i][token_idx] = -100
- token_idx += 1
-
- labels[labels == answer_token_id] = -100
- labels[labels == media_token_id] = -100
- if fake_token_image_exists:
- labels[labels == fake_token_image_token_id] = -100
-
- with accelerator.autocast():
- unwrapped_model = accelerator.unwrap_model(model)
- if num_steps == 0:
- # info check
- accelerator.print(f"input_ids: {input_ids.shape}")
- accelerator.print(f"images: {images.shape}")
- accelerator.print(f"attention_mask: {attention_mask.shape}")
- accelerator.print(f"labels: {labels.shape}")
- accelerator.print(f"model: {unwrapped_model.__class__.__name__}")
- accelerator.print(f"model dtype: {unwrapped_model.dtype}")
-
- if IdeficsForVisionText2Text is not None and isinstance(unwrapped_model, IdeficsForVisionText2Text):
- # only for image model
- max_num_images = images.shape[1]
- pure_text = torch.all(images == 0)
- image_attention_mask = get_image_attention_mask(input_ids, max_num_images, tokenizer, include_image=not pure_text)
- # assert images.shape[1] == 1, "The second dimension is not 1"
-
- loss_mimicit = model(
- pixel_values=images.squeeze(1).to(autocast_type),
- input_ids=input_ids,
- attention_mask=attention_mask,
- image_attention_mask=image_attention_mask,
- labels=labels,
- )[0]
- else:
- loss_mimicit = model(
- vision_x=images.to(autocast_type),
- lang_x=input_ids,
- attention_mask=attention_mask,
- labels=labels,
- )[0]
+ if args.model_name != "fuyu": # design fuyu's process into it's processor, a way better design than following code.
- if accelerator.mixed_precision == "fp16":
- accelerator.backward(loss_mimicit.to(device_id))
- else:
- accelerator.backward(loss_mimicit)
+ def masking(masking_number: int = -100):
+ labels = torch.empty(input_ids.shape, dtype=torch.int64).to(device_id, non_blocking=True)
+ for i in range(input_ids.shape[0]):
+ labels[i] = torch.where(input_ids[i] == eos_token_id, eos_token_id, masking_number)
+ answer_token_ids_all = torch.where(input_ids[i] == answer_token_id)[0]
+ endofchunk_token_ids_all = torch.where(input_ids[i] == endofchunk_token_id)[0]
- total_losses.append(loss_mimicit)
- #### BACKWARD PASS ####
- total_loss_sum = sum(total_losses)
- mean_loss = total_loss_sum / len(total_losses)
- # accelerator.backward(total_loss_sum.to(device_id))
-
- def mask_embedding(m):
- if m.weight.requires_grad:
- zero_mask = torch.zeros_like(m.weight.grad)
- zero_mask[answer_token_id] = torch.ones_like(zero_mask[answer_token_id])
- # zero_mask[media_token_id] = torch.ones_like(zero_mask[media_token_id])
- # zero_mask[endofchunk_token_id] = torch.ones_like(zero_mask[endofchunk_token_id])
- m.weight.grad = m.weight.grad * zero_mask
-
- if args.mask_lm_head and args.distributed_type != "DEEPSPEED":
- unwrapped_model = accelerator.unwrap_model(model)
- if isinstance(unwrapped_model, IdeficsForVisionText2Text):
- # This code need to be refined.
- unwrapped_model.lm_head.apply(mask_embedding)
- elif unwrapped_model.lang_encoder.__class__.__name__ in ["MPTForCausalLM", "MosaicGPT"]:
- unwrapped_model.lang_encoder.transformer.wte.apply(mask_embedding)
- elif "LlamaForCausalLM" in unwrapped_model.lang_encoder.__class__.__name__:
- unwrapped_model.lang_encoder.model.embed_tokens.apply(mask_embedding)
- unwrapped_model.lang_encoder.lm_head.apply(mask_embedding)
-
- if accelerator.sync_gradients:
- accelerator.clip_grad_norm_(model.parameters(), 1.0)
-
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
-
- # step time and reset end outside of rank 0
- step_time_m.update(time.time() - end)
- end = time.time()
-
- if accelerator.sync_gradients:
- if args.rank == 0 and args.report_to_wandb:
- # compute within rank 0
- mimicit_samples_per_second = args.gradient_accumulation_steps * args.batch_size * args.world_size / step_time_m.val
- mimicit_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size / step_time_m.val
-
- wandb.log(
- {
- "data_time": data_time_m.avg,
- "step_time": step_time_m.avg,
- "mimicit_samples_per_second": mimicit_samples_per_second,
- "mimicit_samples_per_second_per_gpu": mimicit_samples_per_second_per_gpu,
- "lr": optimizer.param_groups[0]["lr"],
- },
- commit=False,
- )
- step_time_m.reset()
- data_time_m.reset()
+ j = 0 # Counter for endofchunk_token_ids
+ for answer_token_idx in answer_token_ids_all:
+ # Find the closest endofchunk_token_id that is greater than answer_token_id
+ while j < len(endofchunk_token_ids_all) and endofchunk_token_ids_all[j] < answer_token_idx:
+ j += 1
- wandb.log(
- {
- "loss_mimicit": mean_loss.item(),
- "global_step": global_step // args.gradient_accumulation_steps,
- },
- commit=True,
- )
- # torch.cuda.empty_cache()
- # gc.collect() # forces garbage collection
+ if j < len(endofchunk_token_ids_all):
+ endofchunk_token_idx = endofchunk_token_ids_all[j]
+ labels[i, answer_token_idx + 1 : endofchunk_token_idx + 1] = input_ids[i, answer_token_idx + 1 : endofchunk_token_idx + 1]
- if args.rank == 0 and global_step != 0 and (args.save_steps_interval != -1) and (global_step % args.save_steps_interval == 0):
- if not os.path.exists(args.external_save_dir):
- os.makedirs(args.external_save_dir)
-
- unwrapped_model = accelerator.unwrap_model(model)
- checkpoint_dict = {
- "steps": global_step,
- "model_state_dict": get_checkpoint(unwrapped_model),
- }
- print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_steps_{global_step}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_steps_{global_step}.pt")
- if args.delete_previous_checkpoint:
- if epoch > 0 and os.path.exists(f"{args.external_save_dir}/checkpoint_step_{global_step-args.save_steps_interval}.pt"):
- os.remove(f"{args.external_save_dir}/checkpoint_step_{global_step-args.save_steps_interval}.pt")
+ # Increment j for the next iteration
+ j += 1
- # Log loss to console
- if ((num_steps + 1) % args.logging_steps == 0) and args.rank == 0:
- print(f"Step {num_steps+1}/{num_batches_per_epoch} of epoch {epoch+1}/{args.num_epochs} complete. Loss MIMIC-IT: {mean_loss.item():.3f}")
+ for answer_token_idx, endofchunk_token_idx in zip(answer_token_ids_all, endofchunk_token_ids_all):
+ labels[i, answer_token_idx + 1 : endofchunk_token_idx + 1] = input_ids[i, answer_token_idx + 1 : endofchunk_token_idx + 1]
+ labels[:, 0] = masking_number
+ if args.model_name == "idefics" and fake_token_image_exists:
+ labels[labels == fake_token_image_token_id] = masking_number
-def parse_args():
- """
- Parse the command line arguments and perform the initial setup.
- :return: Parsed arguments
- """
- parser = argparse.ArgumentParser(description="Main training script for the model")
+ return labels
- # Add arguments to the parser
- # TODO: Add help messages to clarify the purpose of each argument
+ labels = masking()
- # Model configuration arguments
- parser.add_argument(
- "--external_save_dir",
- type=str,
- default=None,
- help="set to save model to external path",
- )
- parser.add_argument(
- "--run_name",
- type=str,
- default="otter-9b",
- help="used to name saving directory and wandb run",
- )
- parser.add_argument(
- "--model_name",
- type=str,
- default="otter",
- choices=["otter", "flamingo", "idefics"],
- help="otters or flamingo",
- )
- parser.add_argument(
- "--inst_format",
- type=str,
- default="simple",
- choices=["simple", "llama2", "idefics"],
- help="simple is for mpt/llama1, rest are in different instruction templates.",
- )
- # Prepare the arguments for different types of data sources.
- # Arguments are grouped by data types and whether the data is from past or new sources.
- # Arguments for image-text data, including multi-run conversations.
- parser.add_argument(
- "--past_mimicit_path",
- type=str,
- default="",
- help="Path to the past image-text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_images_path",
- type=str,
- default="",
- help="Path to the past images dataset (including base64 format images). Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--past_train_config_path",
- type=str,
- default="",
- help="Path to the past images dataset (including current ids and related in-context ids). Should be in format /path/to/xx_train.json",
- )
+ if args.remove_answer_token:
+ input_ids, labels, attention_mask = find_and_remove_tokens(input_ids, labels, attention_mask, answer_token_id, tokenizer) # find and remove certain tokens from input_ids, labels, and attention_mask
- parser.add_argument(
- "--mimicit_path",
- type=str,
- default="",
- help="Path to the new image-text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--images_path",
- type=str,
- default="",
- help="Path to the new images dataset (including base64 format images). Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--train_config_path",
- type=str,
- default="",
- help="Path to the new images dataset (including current ids and related in-context ids). Should be in format /path/to/xx_train.json",
- )
+ if args.remove_eos_token:
+ input_ids, labels, attention_mask = find_and_remove_tokens(input_ids, labels, attention_mask, endofchunk_token_id, tokenizer)
- # Arguments for image-text in-context data.
- parser.add_argument(
- "--past_mimicit_ic_path",
- type=str,
- default="",
- help="Path to the past in-context image-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_images_ic_path",
- type=str,
- default="",
- help="Path to the past in-context images dataset. Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--past_train_config_ic_path",
- type=str,
- default="",
- help="Path to the past in-context training config dataset. Should be in format /path/to/xx_train.json",
- )
- parser.add_argument(
- "--mimicit_ic_path",
- type=str,
- default="",
- help="Path to the new in-context image-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--images_ic_path",
- type=str,
- default="",
- help="Path to the new in-context images dataset. Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--train_config_ic_path",
- type=str,
- default="",
- help="Path to the new in-context training config dataset. Should be in format /path/to/xx_train.json",
- )
-
- # Arguments for text data, including multi-run conversations.
- parser.add_argument(
- "--mimicit_text_path",
- type=str,
- default="",
- help="Path to the new text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--train_config_text_path",
- type=str,
- default="",
- help="Path to the new text dataset (including multi-run conversations). Should be in format /path/to/xx_train.json",
- )
- parser.add_argument(
- "--past_mimicit_text_path",
- type=str,
- default="",
- help="Path to the past text dataset (including multi-run conversations). Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_train_config_text_path",
- type=str,
- default="",
- help="Path to the past text dataset (including multi-run conversations). Should be in format /path/to/xx_train.json",
- )
-
- # Arguments for video-text data.
- parser.add_argument(
- "--training_data_yaml",
- type=str,
- default="",
- help="Path to the training data yaml file.",
- )
- parser.add_argument(
- "--past_mimicit_vt_path",
- type=str,
- default="",
- help="Path to the past video-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--past_images_vt_path",
- type=str,
- default="",
- help="Path to the past images dataset (associated with video-text data). Should be in format /path/to/xx.json",
- )
- parser.add_argument(
- "--mimicit_vt_path",
- type=str,
- default="",
- help="Path to the new video-text dataset. Should be in format /path/to/xx_instruction.json",
- )
- parser.add_argument(
- "--images_vt_path",
- type=str,
- default="",
- help="Path to the new images dataset (associated with video-text data). Should be in format /path/to/xx.json",
- )
-
- # Argument for specifying the ratio for resampling past datasets.
- parser.add_argument(
- "--past_subset_ration",
- type=float,
- default=1.0,
- help="The ratio for resampling the past dataset. Should be a float between 0 and 1.",
- )
+ with accelerator.accumulate(model):
+ if num_steps == 0:
+ unwrapped_model = accelerator.unwrap_model(model)
+ master_print(f"model: {unwrapped_model.__class__.__name__}")
+ master_print(f"model dtype: {unwrapped_model.dtype if hasattr(unwrapped_model, 'dtype') else 'None'}")
+
+ loss_mimicit = forward_pass(
+ args,
+ model,
+ tokenizer,
+ images,
+ input_ids,
+ attention_mask,
+ labels,
+ device_id,
+ autocast_type,
+ batch_mimicit,
+ )
- # optimizer args
- parser.add_argument("--gradient_checkpointing", action="store_true")
- parser.add_argument("--offline", action="store_true")
- parser.add_argument("--save_ckpt_each_epoch", action="store_true")
- parser.add_argument("--num_epochs", type=int, default=1)
- parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
- # Sum of gradient optimization batch size
- parser.add_argument("--batch_size", type=int, default=128)
- parser.add_argument("--train_num_samples", type=int, default=-1)
-
- parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
- parser.add_argument("--save_steps_interval", type=int, default=-1)
- parser.add_argument(
- "--pretrained_model_name_or_path",
- type=str,
- help="path to huggingface model or model identifier from local path or huggingface.co",
- default=None,
- )
- parser.add_argument(
- "--trained_ckpt",
- type=str,
- help="path to trained_ckpt",
- default=None,
- )
- parser.add_argument("--seed", type=int, default=42)
- parser.add_argument("--learning_rate", default=1e-4, type=float)
- parser.add_argument(
- "--lr_scheduler",
- default="constant",
- type=str,
- help="constant, linear, or cosine",
- )
- parser.add_argument("--warmup_steps", default=1000, type=int)
- parser.add_argument("--warmup_steps_ratio", default=None, type=float)
- parser.add_argument("--weight_decay", default=0.1, type=float)
- parser.add_argument("--workers", type=int, default=4)
- # distributed training args
- parser.add_argument(
- "--dist-url",
- default="env://",
- type=str,
- help="url used to set up distributed training",
- )
- parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
- parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
- )
- parser.add_argument(
- "--no-set-device-rank",
- default=False,
- action="store_true",
- help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc).",
- )
- # YH: Training detail
- parser.add_argument("--mask_lm_head", action="store_true")
- parser.add_argument(
- "--max_seq_len",
- type=int,
- default=2048,
- help="the maximum src sequence length",
- )
- parser.add_argument("--patch-image-size", type=int, default=224)
- parser.add_argument("--resample_frames", type=int, default=32)
- # this could potentially save 33GB of all model parameters for otter-9b, including the language and vision model.
- parser.add_argument("--save_hf_model", default=False, action="store_true")
- parser.add_argument(
- "--customized_config",
- default=None,
- type=str,
- help="path to customized additional config.json, use to modify from the original config.json in pretrained model.",
- )
- parser.add_argument("--task_name", default="", type=str, help="task name, used to decide different function to load dataset.")
- # wandb args
- parser.add_argument("--report_to_wandb", default=False, action="store_true")
- parser.add_argument(
- "--wandb_project",
- type=str,
- )
- parser.add_argument(
- "--wandb_entity",
- type=str,
- )
- parser.add_argument(
- "--save_checkpoints_to_wandb",
- default=False,
- action="store_true",
- help="save checkpoints to wandb",
- )
- parser.add_argument(
- "--resume_from_checkpoint",
- default=False,
- action="store_true",
- help="resume from checkpoint (original openflamingo pt format, not hf format)",
- )
- # TODO: remove additional data args, all args would be processed in above parser
- parser.add_argument(
- "--delete_previous_checkpoint",
- action="store_true",
- help="delete previous checkpoint when saving new checkpoint",
- )
- # parser = add_data_args(parser)
- args = parser.parse_args()
+ if accelerator.mixed_precision == "fp16":
+ accelerator.backward(loss_mimicit.to(device_id))
+ else:
+ accelerator.backward(loss_mimicit)
- # Check for argument consistency and set environment variables if needed
- if args.save_checkpoints_to_wandb and not args.report_to_wandb:
- raise ValueError("save_checkpoints_to_wandb requires report_to_wandb")
+ #### BACKWARD PASS ####
+ mean_loss = loss_mimicit.detach().mean()
+ cur_batch_max_tokens = input_ids.shape[1]
- if args.offline:
- os.environ["WANDB_MODE"] = "offline"
- os.environ["TRANSFORMERS_OFFLINE"] = "1"
+ def mask_embedding(m):
+ if m.weight.requires_grad:
+ zero_mask = torch.zeros_like(m.weight.grad)
+ zero_mask[answer_token_id] = torch.ones_like(zero_mask[answer_token_id])
+ # zero_mask[media_token_id] = torch.ones_like(zero_mask[media_token_id])
+ # zero_mask[endofchunk_token_id] = torch.ones_like(zero_mask[endofchunk_token_id])
+ m.weight.grad = m.weight.grad * zero_mask
- args.local_rank, args.rank, args.world_size = world_info_from_env()
+ if args.mask_lm_head and args.distributed_type != "DEEPSPEED":
+ unwrapped_model = accelerator.unwrap_model(model)
+ if isinstance(unwrapped_model, IdeficsForVisionText2Text):
+ unwrapped_model.lm_head.apply(mask_embedding)
+ elif unwrapped_model.lang_encoder.__class__.__name__ in ["MPTForCausalLM", "MosaicGPT"]:
+ unwrapped_model.lang_encoder.transformer.wte.apply(mask_embedding)
+ elif "LlamaForCausalLM" in unwrapped_model.lang_encoder.__class__.__name__:
+ unwrapped_model.lang_encoder.model.embed_tokens.apply(mask_embedding)
+ unwrapped_model.lang_encoder.lm_head.apply(mask_embedding)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(model.parameters(), 1.0)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # step time and reset end outside of rank 0
+ step_time_m.update(time.time() - end)
+ end = time.time()
+ if accelerator.sync_gradients and args.rank == 0 and args.report_to_wandb:
+ # compute within rank 0
+ mimicit_samples_per_second = args.gradient_accumulation_steps * args.batch_size * args.world_size / step_time_m.sum
+ mimicit_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size / step_time_m.sum
+ step_time_m.reset()
+ data_time_m.reset()
- # if "COUNT_NODE" in os.environ:
- # args.num_machines = int(os.environ["COUNT_NODE"])
- # else:
- # args.num_machines = 1
+ group_name = batch_mimicit["task_group"][0]
+ assert all(item == group_name for item in batch_mimicit["task_group"]), "Not all items in the list are the same"
+ if args.report_to_wandb:
+ wandb.log(
+ {
+ "data_time": data_time_m.avg,
+ "step_time": step_time_m.avg,
+ "max_tokens": cur_batch_max_tokens,
+ "mimicit_samples_per_second": mimicit_samples_per_second,
+ "mimicit_samples_per_second_per_gpu": mimicit_samples_per_second_per_gpu,
+ "lr": optimizer.param_groups[0]["lr"],
+ "loss_mimicit": mean_loss,
+ "global_step": global_step // args.gradient_accumulation_steps,
+ group_name: mean_loss,
+ },
+ commit=True,
+ )
+
+ delete_tensors_from_dict(batch_mimicit)
+ delete_tensors_from_dict(
+ {
+ "other": [
+ images,
+ input_ids,
+ attention_mask,
+ labels,
+ ]
+ }
+ )
- # if "THEID" in os.environ:
- # args.machine_rank = int(os.environ["THEID"])
- # else:
- # args.machine_rank = 0
+ if args.rank == 0 and global_step != 0 and (args.save_steps_interval != -1) and (global_step % args.save_steps_interval == 0):
+ save_checkpoint(epoch=None, global_step=global_step, model=model, args=args, accelerator=accelerator)
- # Seed for reproducibility
- random_seed(args.seed)
+ # Log loss to console
+ if ((num_steps + 1) % args.logging_steps == 0) and args.rank == 0:
+ print(f"Step {num_steps+1}/{num_batches_per_epoch} of epoch {epoch+1}/{args.num_epochs} complete. Loss MIMIC-IT: {mean_loss.item():.3f}")
+ # reset to avoid CPU oom
+ loss_mimicit = None
+ batch_mimicit = None
+ gc.collect()
+ torch.cuda.empty_cache()
- return args
+ del unwrapped_model
def main():
args = parse_args()
- accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, mixed_precision="bf16")
+ verify_yaml(args)
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision="bf16",
+ )
if accelerator.state.deepspeed_plugin is not None:
accelerator.state.deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = args.batch_size
device_id = accelerator.device
if args.pretrained_model_name_or_path is not None:
- accelerator.print(f"Loading pretrained model from {args.pretrained_model_name_or_path}")
+ master_print(f"Loading pretrained model from {args.pretrained_model_name_or_path}")
device_map = {"": device_id} if accelerator.distributed_type == "MULTI_GPU" or accelerator.distributed_type == "DEEPSPEED" else "auto"
kwargs = {"local_files_only": args.offline, "device_map": device_map}
+
if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
kwargs.pop("device_map")
+
if args.customized_config is not None:
kwargs["config"] = args.customized_config
- if "otter" in args.model_name.lower():
+
+ if args.model_name.lower() == "otter":
model = OtterForConditionalGeneration.from_pretrained(
args.pretrained_model_name_or_path,
**kwargs,
@@ -586,18 +336,28 @@ def main():
args.tokenizer = model.text_tokenizer
tokenizer = model.text_tokenizer
image_processor = CLIPImageProcessor()
- elif "flamingo" in args.model_name.lower():
+
+ elif args.model_name.lower() == "flamingo":
model = FlamingoForConditionalGeneration.from_pretrained(
args.pretrained_model_name_or_path,
**kwargs,
)
# add special tokens for instruction tuning
model.text_tokenizer.add_special_tokens({"additional_special_tokens": [""]})
- args.tokenizer = model.text_tokenizer
- tokenizer = model.text_tokenizer
+ model.config.update(
+ {
+ "special_tokens": model.text_tokenizer.all_special_tokens,
+ "architectures": "OtterForConditionalGeneration",
+ }
+ )
+ tokenizer = args.tokenizer = model.text_tokenizer
image_processor = CLIPImageProcessor()
- elif "idefics" in args.model_name.lower():
- # import pdb;pdb.set_trace()
+ # if not accelerator.distributed_type == "DEEPSPEED" or not accelerator.state.deepspeed_plugin.zero_stage == 3:
+ # new_embedding_size = (len(model.text_tokenizer) // 64 + 1) * 64
+ # master_print(f"Resizing Flamingo embedding from {len(model.text_tokenizer)} to {new_embedding_size}")
+ # model.resize_token_embeddings(new_embedding_size, pad_to_multiple_of=64)
+
+ elif args.model_name.lower() == "idefics":
model = IdeficsForVisionText2Text.from_pretrained(
args.pretrained_model_name_or_path,
**kwargs,
@@ -605,31 +365,75 @@ def main():
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
- # named_parameters = dict(model.named_parameters())
- # params_to_gather = [named_parameters[k] for k in named_parameters.keys()]
- # if len(params_to_gather) > 0:
- if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
- params_to_gather = [p for name, p in model.named_parameters() if p.requires_grad]
- with deepspeed.zero.GatheredParameters(params_to_gather, modifier_rank=0):
- if torch.distributed.get_rank() == 0:
- # 有参数
- print(
- device_id,
- f"IDEFICS Trainable Params: {(sum(p.numel() for p in model.parameters() if p.requires_grad)) / 1e9:.3f} B",
- )
- else:
- print(
- device_id,
- f"IDEFICS Trainable Params: {(sum(p.numel() for p in model.parameters() if p.requires_grad)) / 1e9:.3f} B",
- )
processor = AutoProcessor.from_pretrained(args.pretrained_model_name_or_path, legacy=False)
- past_special_tokens = processor.tokenizer.special_tokens_map["additional_special_tokens"]
- processor.tokenizer.add_special_tokens({"additional_special_tokens": [""] + past_special_tokens})
- image_processor = processor.image_processor
- tokenizer = processor.tokenizer
+ if "" not in processor.tokenizer.special_tokens_map["additional_special_tokens"]:
+ past_special_tokens = processor.tokenizer.special_tokens_map["additional_special_tokens"]
+ processor.tokenizer.add_special_tokens({"additional_special_tokens": [""] + past_special_tokens})
+
+ image_processor = args.image_processor = processor.image_processor
+ tokenizer = args.tokenizer = processor.tokenizer
# make embedding size divisible by 64 for hardware compatiblity https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
- new_embedding_size = (len(tokenizer) // 64 + 1) * 64
- model.resize_token_embeddings(new_embedding_size, pad_to_multiple_of=64)
+ # resize_token_embedding is not for parameter sharing in deepspeed !!!!
+ elif args.model_name.lower() == "llama2":
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained_model_name_or_path,
+ **kwargs,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained_model_name_or_path)
+ past_special_tokens = tokenizer.special_tokens_map["additional_special_tokens"] if "additional_special_tokens" in tokenizer.special_tokens_map else [value for key, value in tokenizer.special_tokens_map.items()]
+ if "" not in past_special_tokens:
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", "", "<|endofchunk|>"]})
+
+ if tokenizer.pad_token is None:
+ tokenizer.add_special_tokens({"pad_token": ""})
+
+ args.tokenizer = tokenizer
+ image_processor = None
+
+ elif args.model_name.lower() == "fuyu":
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained_model_name_or_path)
+ image_processor = FuyuImageProcessor()
+ processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ # Peiyuan: should rewrite this portion. Right now too ugly.
+ image_processor = processor
+ model = FuyuForCausalLM.from_pretrained(args.pretrained_model_name_or_path, **kwargs)
+ args.processor = processor
+
+ if args.enable_lora:
+ if args.peft_model_name_or_path:
+ master_print(f"Loading finetuned LoRA model from {args.peft_model_name_or_path}")
+ model = PeftModel.from_pretrained(model, args.peft_model_name_or_path)
+ model = model.merge_and_unload()
+
+ lora_config = LoraConfig(
+ r=64,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ task_type=TaskType.CAUSAL_LM,
+ target_modules=["query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h", "lm_head"],
+ )
+ master_print(f"Init LoRA model with config {lora_config}")
+ model = get_peft_model(model, lora_config)
+ model.print_trainable_parameters()
+
+ elif args.model_name.lower() == "debug_model":
+ model = torch.nn.Linear(100, 100)
+ tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", "", "<|endofchunk|>"]})
+ if tokenizer.pad_token is None:
+ tokenizer.add_special_tokens({"pad_token": ""})
+
+ image_processor = None
+
+ if args.resize_embedding and hasattr(model, "lang_encoder") and "LlamaForCausalLM" in model.lang_encoder.__class__.__name__:
+ model.lang_encoder.resize_token_embeddings(len(model.text_tokenizer))
+ master_print(f"Resizing Llama embedding to {len(model.text_tokenizer)}")
+
+ if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
+ params_to_gather = [p for name, p in model.named_parameters() if p.requires_grad]
+ with deepspeed.zero.GatheredParameters(params_to_gather, modifier_rank=0):
+ master_print(device_id, f"Zero3 Optimization: Trainable Params: {(sum(p.numel() for p in model.parameters() if p.requires_grad)) / 1e9:.3f} B")
if args.trained_ckpt is not None:
train_ckpt = torch.load(args.trained_ckpt, map_location="cpu")
@@ -642,83 +446,48 @@ def main():
args.distributed_type = accelerator.distributed_type
- if hasattr(model, "lang_encoder") and "LlamaForCausalLM" in model.lang_encoder.__class__.__name__:
- model.lang_encoder.resize_token_embeddings(len(model.text_tokenizer))
-
random_seed(args.seed, args.rank)
-
print(f"Start running training on rank {args.rank}.")
- mimicit_loaders = get_data(args, image_processor, tokenizer, "mimicit")
-
- def get_grouped_params(model):
- params_with_wd, params_without_wd = [], []
-
- def apply_decay(x):
- return "gated_cross_attn_layer" in x and "ff_gate" not in x and "attn_gate" not in x and "norm" not in x and "bias" not in x
-
- for n, p in model.named_parameters():
- # if p.requires_grad:
- if apply_decay(n):
- params_with_wd.append(p)
- else:
- params_without_wd.append(p)
-
- return [
- {"params": params_with_wd, "weight_decay": args.weight_decay},
- {"params": params_without_wd, "weight_decay": 0.0},
- ]
-
- total_training_steps = len(mimicit_loaders[0]) * args.num_epochs
+ if args.rank == 0 and args.report_to_wandb:
+ master_print(f"Logging to wandb as {args.wandb_entity}/{args.wandb_project}/{args.run_name}")
+ wandb.init(
+ project=args.wandb_project,
+ entity=args.wandb_entity,
+ name=args.run_name,
+ )
+ mimicit_loaders = get_data(args, image_processor, tokenizer, "mimicit")
+ total_training_steps = sum(len(dataloader) for dataloader in mimicit_loaders) * args.num_epochs
resume_from_epoch = 0
- # check if a checkpoint exists for this run
args.external_save_dir = os.path.join(args.external_save_dir, args.run_name) if args.external_save_dir else args.run_name
- if os.path.exists(f"{args.external_save_dir}") and args.resume_from_checkpoint is True:
- checkpoint_list = glob.glob(f"{args.external_save_dir}/checkpoint_*.pt")
- if len(checkpoint_list) == 0:
- print(f"Found no checkpoints for run {args.external_save_dir}.")
- else:
- resume_from_checkpoint_path = sorted(checkpoint_list, key=lambda x: int(x.split("_")[-1].split(".")[0]))[-1]
- print(f"Found checkpoint {resume_from_checkpoint_path} for run {args.external_save_dir}.")
-
- if args.rank == 0:
- print(f"Loading checkpoint from {resume_from_checkpoint_path}")
- checkpoint = torch.load(resume_from_checkpoint_path, map_location="cpu")
- model.load_state_dict(checkpoint["model_state_dict"], False)
- optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
- lr_scheduler.load_state_dict(checkpoint["lr_scheduler_state_dict"])
- resume_from_epoch = checkpoint["epoch"] + 1
-
- optimizer = torch.optim.AdamW(get_grouped_params(model), lr=args.learning_rate)
+
+ optimizer = torch.optim.AdamW(get_grouped_params(model, wd=args.weight_decay), lr=args.learning_rate)
if args.rank == 0:
print(f"Total training steps: {total_training_steps}")
- args.warmup_steps = total_training_steps * args.warmup_steps_ratio if args.warmup_steps_ratio is not None else args.warmup_stepsps
+ args.warmup_steps = total_training_steps * args.warmup_steps_ratio if args.warmup_steps_ratio is not None else args.warmup_steps
+ args.warmup_steps = args.warmup_steps // args.gradient_accumulation_steps
+ args.total_training_steps = total_training_steps // args.gradient_accumulation_steps
if args.lr_scheduler == "linear":
lr_scheduler = get_linear_schedule_with_warmup(
optimizer,
- num_warmup_steps=args.warmup_steps // args.gradient_accumulation_steps,
- num_training_steps=total_training_steps // args.gradient_accumulation_steps,
+ num_warmup_steps=args.warmup_steps,
+ num_training_steps=args.total_training_steps,
)
elif args.lr_scheduler == "cosine":
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer,
- num_warmup_steps=args.warmup_steps // args.gradient_accumulation_steps,
- num_training_steps=total_training_steps // args.gradient_accumulation_steps,
+ num_warmup_steps=args.warmup_steps,
+ num_training_steps=args.total_training_steps,
)
- else:
+ elif args.lr_scheduler == "constant":
lr_scheduler = get_constant_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps)
if args.rank == 0 and args.report_to_wandb:
- wandb.init(
- project=args.wandb_project,
- entity=args.wandb_entity,
- name=args.run_name,
- config=vars(args),
- )
+ wandb.config.update(vars(args))
if accelerator.distributed_type == "DEEPSPEED" or accelerator.distributed_type == "MULTI_GPU":
model, optimizer = accelerator.prepare(model, optimizer)
@@ -726,11 +495,8 @@ def apply_decay(x):
model, optimizer, lr_scheduler, mimicit_loaders = accelerator.prepare(model, optimizer, lr_scheduler, mimicit_loaders)
model.train()
-
+ # Main Training Loop
for epoch in range(resume_from_epoch, args.num_epochs):
- for cur_data_loader in mimicit_loaders:
- cur_data_loader.dataset.set_epoch(epoch)
-
train_one_epoch(
args=args,
model=model,
@@ -744,95 +510,27 @@ def apply_decay(x):
wandb=wandb,
)
accelerator.wait_for_everyone()
-
if args.save_ckpt_each_epoch:
- if args.rank == 0:
- if not os.path.exists(args.external_save_dir):
- os.makedirs(args.external_save_dir)
-
- if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
- checkpoint_dict = accelerator.get_state_dict(model)
-
- if args.rank == 0:
- unwrapped_model = accelerator.unwrap_model(model)
- trainable_params_name = [name for name, p in unwrapped_model.named_parameters() if p.requires_grad]
- for name in list(checkpoint_dict.keys()):
- if name not in trainable_params_name:
- del checkpoint_dict[name]
-
- else:
- if args.rank == 0:
- unwrapped_model = accelerator.unwrap_model(model)
- # checkpoint_dict = {
- # "epoch": epoch,
- # "model_state_dict": get_checkpoint(unwrapped_model),
- # "optimizer_state_dict": optimizer.state_dict(),
- # "lr_scheduler_state_dict": lr_scheduler.state_dict(),
- # }
- checkpoint_dict = {
- "model_state_dict": get_checkpoint(unwrapped_model),
- }
-
- if args.rank == 0:
- print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_{epoch}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_{epoch}.pt")
- # save the config
- unwrapped_model.config.save_pretrained(args.external_save_dir)
- if args.delete_previous_checkpoint:
- if epoch > 0:
- os.remove(f"{args.external_save_dir}/checkpoint_{epoch-1}.pt")
-
- accelerator.wait_for_everyone()
-
- accelerator.wait_for_everyone()
-
- if args.rank == 0:
- if not os.path.exists(args.external_save_dir):
- os.makedirs(args.external_save_dir)
-
- if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
- checkpoint_dict = accelerator.get_state_dict(model)
-
- unwrapped_model = accelerator.unwrap_model(model)
-
- unwrapped_model.config.save_pretrained(args.external_save_dir)
-
- if args.rank == 0 and not args.save_hf_model:
- trainable_params_name = [name for name, p in unwrapped_model.named_parameters() if p.requires_grad]
- for name in list(checkpoint_dict.keys()):
- if name not in trainable_params_name:
- del checkpoint_dict[name]
-
- accelerator.save(
- checkpoint_dict,
- f"{args.external_save_dir}/final_weights.pt",
- )
- elif args.rank == 0 and args.save_hf_model:
- unwrapped_model.save_pretrained(
- f"{args.external_save_dir}",
- is_main_process=accelerator.is_main_process,
- save_function=accelerator.save,
- state_dict=checkpoint_dict,
- )
-
- else:
- if args.rank == 0:
- unwrapped_model = accelerator.unwrap_model(model)
- checkpoint_dict = get_checkpoint(model=unwrapped_model)
-
- accelerator.save(
- checkpoint_dict,
- f"{args.external_save_dir}/final_weights.pt",
+ # save_checkpoint(epoch, model, args, accelerator)
+ save_final_weights(
+ model,
+ args,
+ accelerator,
+ processor=processor if "idefics" in args.model_name.lower() or "fuyu" in args.model_name.lower() else None,
+ tokenizer=tokenizer if "llama2" in args.model_name.lower() else None,
)
- # save the config
- unwrapped_model.config.save_pretrained(args.external_save_dir)
-
- if args.report_to_wandb and args.save_checkpoints_to_wandb:
- wandb.save(f"{args.external_save_dir}/final_weights.pt")
- if args.save_hf_model:
- unwrapped_model.save_pretrained(f"{args.external_save_dir}")
+ master_print(f"Saved checkpoint at epoch {epoch+1}.")
+ accelerator.wait_for_everyone()
- accelerator.wait_for_everyone()
+ # Save the final weights
+ save_final_weights(
+ model,
+ args,
+ accelerator,
+ processor=processor if "idefics" in args.model_name.lower() or "fuyu" in args.model_name.lower() else None,
+ tokenizer=tokenizer if "llama2" in args.model_name.lower() else None,
+ )
+ # accelerator.wait_for_everyone()
if __name__ == "__main__":
diff --git a/pipeline/train/pretraining.py b/pipeline/train/pretraining.py
old mode 100644
new mode 100755
index a73e34cb..afa57efd
--- a/pipeline/train/pretraining.py
+++ b/pipeline/train/pretraining.py
@@ -4,6 +4,7 @@
import glob
import os
import random
+import sys
import time
import numpy as np
@@ -19,9 +20,10 @@
)
import wandb
-from otter_ai import FlamingoForConditionalGeneration
-from otter_ai import OtterForConditionalGeneration
-from pipeline.train.data import get_data
+from otter_ai import FlamingoForConditionalGeneration, OtterForConditionalGeneration
+
+sys.path.append("../..")
+from pipeline.mimicit_utils.data import get_data
from pipeline.train.distributed import world_info_from_env
from pipeline.train.train_utils import AverageMeter, get_checkpoint
@@ -87,7 +89,12 @@ def parse_args():
parser.add_argument("--offline", action="store_true")
parser.add_argument("--num_epochs", type=int, default=1)
parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
- parser.add_argument("--checkpointing_steps", type=int, default=10000, help="checkpointing every n steps")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=10000,
+ help="checkpointing every n steps",
+ )
# Sum of gradient optimization batch size
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
@@ -124,12 +131,6 @@ def parse_args():
help="url used to set up distributed training",
)
parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
- parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
- )
parser.add_argument(
"--no-set-device-rank",
default=False,
@@ -178,7 +179,19 @@ def random_seed(seed=42, rank=0):
random.seed(seed + rank)
-def train_one_epoch(args, model, epoch, mmc4_loader, laion_loader, tokenizer, optimizer, lr_scheduler, device_id, accelerator, wandb):
+def train_one_epoch(
+ args,
+ model,
+ epoch,
+ mmc4_loader,
+ laion_loader,
+ tokenizer,
+ optimizer,
+ lr_scheduler,
+ device_id,
+ accelerator,
+ wandb,
+):
num_batches_per_epoch_laion = laion_loader.num_batches
num_batches_per_epoch_mmc4 = mmc4_loader.num_batches
@@ -384,7 +397,10 @@ def mask_embedding(m):
"lr_scheduler_state_dict": lr_scheduler.state_dict(),
}
print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
+ accelerator.save(
+ checkpoint_dict,
+ f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt",
+ )
# save the config
print(f"Saving config to {args.external_save_dir}/config.json")
unwrapped_model.config.save_pretrained(args.external_save_dir)
diff --git a/pipeline/train/pretraining_cc3m.py b/pipeline/train/pretraining_cc3m.py
old mode 100644
new mode 100755
index b3f90235..7e2fc1e6
--- a/pipeline/train/pretraining_cc3m.py
+++ b/pipeline/train/pretraining_cc3m.py
@@ -4,13 +4,13 @@
import glob
import os
import random
+import sys
import time
import numpy as np
import torch
import torch.nn
-from accelerate import Accelerator
-from accelerate import load_checkpoint_and_dispatch
+from accelerate import Accelerator, load_checkpoint_and_dispatch
from tqdm import tqdm
from transformers import (
CLIPImageProcessor,
@@ -18,10 +18,12 @@
get_cosine_schedule_with_warmup,
get_linear_schedule_with_warmup,
)
+
import wandb
-from otter_ai import FlamingoForConditionalGeneration
-from otter_ai import OtterForConditionalGeneration
-from pipeline.train.data import get_data
+from otter_ai import FlamingoForConditionalGeneration, OtterForConditionalGeneration
+
+sys.path.append("../..")
+from pipeline.mimicit_utils.data import get_data
from pipeline.train.distributed import world_info_from_env
from pipeline.train.train_utils import AverageMeter, get_checkpoint
@@ -73,7 +75,12 @@ def parse_args():
parser.add_argument("--offline", action="store_true")
parser.add_argument("--num_epochs", type=int, default=1)
parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
- parser.add_argument("--checkpointing_steps", type=int, default=10000, help="checkpointing every n steps")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=10000,
+ help="checkpointing every n steps",
+ )
# Sum of gradient optimization batch size
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
@@ -103,12 +110,6 @@ def parse_args():
help="url used to set up distributed training",
)
parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
- parser.add_argument(
- "--horovod",
- default=False,
- action="store_true",
- help="Use horovod for distributed training.",
- )
parser.add_argument(
"--no-set-device-rank",
default=False,
@@ -157,7 +158,18 @@ def random_seed(seed=42, rank=0):
random.seed(seed + rank)
-def train_one_epoch(args, model, epoch, cc3m_loader, tokenizer, optimizer, lr_scheduler, device_id, accelerator, wandb):
+def train_one_epoch(
+ args,
+ model,
+ epoch,
+ cc3m_loader,
+ tokenizer,
+ optimizer,
+ lr_scheduler,
+ device_id,
+ accelerator,
+ wandb,
+):
num_batches_per_epoch_cc3m = cc3m_loader.num_batches
num_batches_per_epoch = num_batches_per_epoch_cc3m
@@ -286,7 +298,10 @@ def mask_embedding(m):
"lr_scheduler_state_dict": lr_scheduler.state_dict(),
}
print(f"Saving checkpoint to {args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
- accelerator.save(checkpoint_dict, f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt")
+ accelerator.save(
+ checkpoint_dict,
+ f"{args.external_save_dir}/checkpoint_steps{num_steps + 1}.pt",
+ )
# save the config
print(f"Saving config to {args.external_save_dir}/config.json")
unwrapped_model.config.save_pretrained(args.external_save_dir)
@@ -406,7 +421,10 @@ def apply_decay(x):
if len(checkpoint_list) == 0:
print(f"Found no checkpoints for run {args.external_save_dir}.")
else:
- resume_from_checkpoint_path = sorted(checkpoint_list, key=lambda x: int(x.split("_")[-1].split("steps")[1].split(".")[0]))[-1]
+ resume_from_checkpoint_path = sorted(
+ checkpoint_list,
+ key=lambda x: int(x.split("_")[-1].split("steps")[1].split(".")[0]),
+ )[-1]
# resume_from_checkpoint_path = sorted(checkpoint_list, key=lambda x: int(x.split("_")[-1].split(".")[0]))[-1]
print(f"Found checkpoint {resume_from_checkpoint_path} for run {args.external_save_dir}.")
diff --git a/pipeline/train/train_args.py b/pipeline/train/train_args.py
new file mode 100644
index 00000000..97de78b9
--- /dev/null
+++ b/pipeline/train/train_args.py
@@ -0,0 +1,206 @@
+import argparse
+import os
+
+from pipeline.train.distributed import world_info_from_env
+
+
+def parse_tuple(string):
+ try:
+ x, y = map(int, string.split(","))
+ return (x, y)
+ except:
+ raise argparse.ArgumentTypeError("Invalid tuple format. Expected 'x,y'")
+
+
+def parse_args():
+ """
+ Parse the command line arguments and perform the initial setup.
+ :return: Parsed arguments
+ """
+ parser = argparse.ArgumentParser(description="Main training script for the model")
+ # Model configuration arguments
+ parser.add_argument(
+ "--external_save_dir",
+ type=str,
+ default=None,
+ help="set to save model to external path",
+ )
+ parser.add_argument(
+ "--run_name",
+ type=str,
+ default="otter-9b",
+ help="used to name saving directory and wandb run",
+ )
+ parser.add_argument(
+ "--model_name",
+ type=str,
+ default="otter",
+ choices=["otter", "flamingo", "idefics", "llama2", "debug_model", "fuyu"],
+ help="otters or flamingo",
+ )
+ parser.add_argument(
+ "--instruction_format",
+ type=str,
+ default="simple",
+ choices=["simple", "llama2", "idefics", "fuyu"],
+ help="simple is for mpt/llama1, rest are in different instruction templates.",
+ )
+ parser.add_argument(
+ "--training_data_yaml",
+ type=str,
+ default="",
+ help="Path to the training data yaml file.",
+ )
+
+ # optimizer args
+ parser.add_argument("--gradient_checkpointing", action="store_true")
+ parser.add_argument("--offline", action="store_true")
+ parser.add_argument("--save_ckpt_each_epoch", action="store_true")
+ parser.add_argument("--num_epochs", type=int, default=1)
+ parser.add_argument("--logging_steps", type=int, default=100, help="log loss every n steps")
+ # Sum of gradient optimization batch size
+ parser.add_argument("--batch_size", type=int, default=128)
+ parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
+ parser.add_argument("--save_steps_interval", type=int, default=-1)
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ help="path to huggingface model or model identifier from local path or huggingface.co",
+ default=None,
+ )
+ parser.add_argument(
+ "--peft_model_name_or_path",
+ type=str,
+ help="path to huggingface model or model identifier from local path or huggingface.co",
+ default=None,
+ )
+ parser.add_argument(
+ "--trained_ckpt",
+ type=str,
+ help="path to trained_ckpt",
+ default=None,
+ )
+ parser.add_argument("--seed", type=int, default=42)
+ parser.add_argument("--learning_rate", default=1e-4, type=float)
+ parser.add_argument(
+ "--lr_scheduler",
+ default="constant",
+ type=str,
+ help="constant, linear, or cosine",
+ )
+ parser.add_argument("--warmup_steps", default=1000, type=int)
+ parser.add_argument("--warmup_steps_ratio", default=None, type=float)
+ parser.add_argument("--weight_decay", default=0.1, type=float)
+ parser.add_argument("--workers", type=int, default=4)
+ # distributed training args
+ parser.add_argument(
+ "--dist-url",
+ default="env://",
+ type=str,
+ help="url used to set up distributed training",
+ )
+ parser.add_argument("--dist-backend", default="nccl", type=str, help="distributed backend")
+ parser.add_argument(
+ "--no-set-device-rank",
+ default=False,
+ action="store_true",
+ help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc).",
+ )
+ # YH: Training detail
+ parser.add_argument("--mask_lm_head", action="store_true")
+ parser.add_argument(
+ "--max_seq_len",
+ type=int,
+ default=2048,
+ help="the maximum src sequence length",
+ )
+ parser.add_argument("--patch-image-size", type=int, default=224)
+ parser.add_argument("--resample_frames", type=int, default=32)
+ # this could potentially save 33GB of all model parameters for otter-9b, including the language and vision model.
+ parser.add_argument("--save_hf_model", default=False, action="store_true")
+ parser.add_argument(
+ "--customized_config",
+ default=None,
+ type=str,
+ help="path to customized additional config.json, use to modify from the original config.json in pretrained model.",
+ )
+ parser.add_argument("--report_to_wandb", default=False, action="store_true")
+ parser.add_argument("--wandb_project", type=str)
+ parser.add_argument("--wandb_entity", type=str)
+ parser.add_argument(
+ "--save_checkpoints_to_wandb",
+ default=False,
+ action="store_true",
+ help="save checkpoints to wandb",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ default=False,
+ action="store_true",
+ help="resume from checkpoint (original openflamingo pt format, not hf format)",
+ )
+ # TODO: remove additional data args, all args would be processed in above parser
+ parser.add_argument(
+ "--delete_previous_checkpoint",
+ action="store_true",
+ help="delete previous checkpoint when saving new checkpoint",
+ ),
+ parser.add_argument(
+ "--keep_symbols",
+ action="store_true",
+ default=False,
+ help="keep symbols in the generated text",
+ )
+ parser.add_argument(
+ "--remove_answer_token",
+ action="store_true",
+ default=False,
+ help="we have an token as indicator for separating question and answer, use this flag to remove it before training.",
+ )
+ parser.add_argument(
+ "--remove_eos_token",
+ action="store_true",
+ default=False,
+ help="we have an eos token as indicator for separating question and answer, use this flag to remove it before training.",
+ )
+ parser.add_argument(
+ "--populate_rel_ins",
+ action="store_true",
+ default=False,
+ help="populate rel_ins into train_config.",
+ )
+ parser.add_argument(
+ "--resize_embedding",
+ action="store_true",
+ default=False,
+ help="resize embedding layer to match the vocabulary size.",
+ )
+ parser.add_argument("--image_resolution", type=parse_tuple, default=(224, 224), help="image resolution for the model in format: x,y")
+ parser.add_argument(
+ "--with_task_description",
+ action="store_true",
+ default=False,
+ )
+ parser.add_argument(
+ "--enable_lora",
+ action="store_true",
+ default=False,
+ )
+ parser.add_argument(
+ "--dynamic_resolution",
+ action="store_true",
+ default=False,
+ )
+ args = parser.parse_args()
+
+ # Check for argument consistency and set environment variables if needed
+ if args.save_checkpoints_to_wandb and not args.report_to_wandb:
+ raise ValueError("save_checkpoints_to_wandb requires report_to_wandb")
+
+ if args.offline:
+ os.environ["WANDB_MODE"] = "offline"
+ os.environ["TRANSFORMERS_OFFLINE"] = "1"
+
+ args.local_rank, args.rank, args.world_size = world_info_from_env()
+
+ return args
diff --git a/pipeline/train/train_utils.py b/pipeline/train/train_utils.py
index 19a35329..ea7b7c2f 100755
--- a/pipeline/train/train_utils.py
+++ b/pipeline/train/train_utils.py
@@ -1,9 +1,13 @@
-import time
+import os
+import random
+import subprocess
+import sys
from contextlib import suppress
+import numpy as np
import torch
-from tqdm import tqdm
from torch.utils.data.distributed import DistributedSampler
+import torch.distributed as dist
try:
from transformers.models.idefics.processing_idefics import image_attention_mask_for_packed_input_ids, incremental_to_binary_attention_mask
@@ -11,6 +15,27 @@
print("Failed to import Idefics processing module.")
+def truncate_text(path, keep_start=10, keep_end=10, truncate_to="..."):
+ if len(path) <= (keep_start + keep_end + len(truncate_to)):
+ return path
+ return path[:keep_start] + truncate_to + path[-keep_end:]
+
+
+def master_print(*args, **kwargs):
+ if dist.is_available() and dist.is_initialized():
+ rank = dist.get_rank()
+ if rank == 0:
+ print(*args, **kwargs)
+ else:
+ print(*args, **kwargs)
+
+
+def random_seed(seed=42, rank=0):
+ torch.manual_seed(seed + rank)
+ np.random.seed(seed + rank)
+ random.seed(seed + rank)
+
+
def get_cast_dtype(precision: str):
cast_dtype = None
if precision == "bf16":
@@ -32,196 +57,6 @@ def get_autocast(precision):
return suppress
-# DEPRECATED - use train_one_epoch in instruction_following.py and pretraining.py instead
-def train_one_epoch(
- args,
- model,
- epoch,
- mmc4_loader,
- tokenizer,
- optimizer,
- lr_scheduler,
- device_id,
- wandb,
-):
- # num_batches_per_epoch_laion = laion_loader.num_batches
- num_batches_per_epoch_mmc4 = mmc4_loader.num_batches
-
- # assert (
- # num_batches_per_epoch_laion == num_batches_per_epoch_mmc4
- # ), "Number of batches in laion and mmc4 datasets must be the same"
- num_batches_per_epoch = num_batches_per_epoch_mmc4
- total_training_steps = num_batches_per_epoch * args.num_epochs
-
- autocast = get_autocast(args.precision)
- cast_dtype = get_cast_dtype(args.precision)
-
- media_token_id = tokenizer("", add_special_tokens=False)["input_ids"][-1]
- endofchunk_token_id = tokenizer("<|endofchunk|>", add_special_tokens=False)["input_ids"][-1]
-
- model.train()
-
- # setup logging
- step_time_m = AverageMeter() # time for one optimizer step (> 1 batch if using gradient accum)
- data_time_m = AverageMeter() # avg time to load one batch of both C4 AND laion (= 1 batch regardless of gradient accum)
- end = time.time()
-
- # loop through dataloader
- for num_steps, batch_mmc4 in tqdm(
- enumerate(mmc4_loader),
- disable=args.rank != 0,
- total=total_training_steps,
- initial=(epoch * num_batches_per_epoch),
- ):
- data_time_m.update(time.time() - end)
-
- global_step = num_steps + epoch * num_batches_per_epoch
-
- # #### LAION FORWARD PASS ####
- # images = (
- # batch_laion[0]
- # .to(device_id, dtype=cast_dtype, non_blocking=True)
- # .unsqueeze(1)
- # .unsqueeze(1)
- # )
-
- # input_ids = batch_laion[1][0].to(device_id, dtype=cast_dtype, non_blocking=True)
- # attention_mask = batch_laion[1][1].to(
- # device_id, dtype=cast_dtype, non_blocking=True
- # )
-
- # labels = input_ids.clone()
- # labels[labels == tokenizer.pad_token_id] = -100
- # labels[:, 0] = -100
- # labels[labels == media_token_id] = -100
- # labels.to(device_id)
-
- # with autocast():
- # loss_laion = model(
- # vision_x=images,
- # lang_x=input_ids,
- # attention_mask=attention_mask,
- # labels=labels,
- # )[0]
- loss_laion = 0
- divided_loss_laion = loss_laion / args.gradient_accumulation_steps
-
- #### C4 FORWARD PASS ####
- images = batch_mmc4[0].to(device_id, dtype=cast_dtype, non_blocking=True).unsqueeze(2)
- input_ids = torch.stack([x[0] for x in batch_mmc4[1]]).squeeze(1)
- attention_mask = torch.stack([x[1] for x in batch_mmc4[1]]).squeeze(1)
-
- # NOTE: irena: expected shape of clip_text_input_ids / attention_mask is (N, I, max_seq_len)
- labels = input_ids.clone()
- labels[labels == tokenizer.pad_token_id] = -100
- labels[:, 0] = -100
-
- for i in range(labels.shape[0]):
- # remove loss for any token before the first token
- label_idx = 0
- while label_idx < labels.shape[1] and labels[i][label_idx] != media_token_id:
- labels[i][label_idx] = -100
- label_idx += 1
-
- # get index of all endofchunk tokens in the sequence
- endofchunk_idxs = torch.where(labels[i] == endofchunk_token_id)[0]
- for endofchunk_idx in endofchunk_idxs:
- token_idx = endofchunk_idx + 1
- while token_idx < labels.shape[1] and labels[i][token_idx] != media_token_id:
- labels[i][token_idx] = -100
- token_idx += 1
-
- labels[labels == media_token_id] = -100
- labels.to(device_id)
-
- with autocast():
- loss_mmc4 = model(
- vision_x=images,
- lang_x=input_ids,
- attention_mask=attention_mask,
- labels=labels,
- )[0]
-
- # if loss is nan, skip this batch
- if torch.isnan(loss_mmc4):
- print("loss is nan, skipping this batch")
- print("input_ids: ", tokenizer.batch_decode(input_ids))
- print("labels: ", labels)
- print("images: ", images)
- optimizer.zero_grad()
- continue
-
- divided_loss_mmc4 = loss_mmc4 / args.gradient_accumulation_steps
-
- #### BACKWARD PASS ####
- loss = divided_loss_laion * args.loss_multiplier_laion + divided_loss_mmc4 * args.loss_multiplier_mmc4
- loss.backward()
-
- #### MASK GRADIENTS FOR EMBEDDINGS ####
- # Note (anas): Do not apply weight decay to embeddings as it will break this function.
- def mask_embedding(m):
- if isinstance(m, torch.nn.Embedding) and m.weight.requires_grad:
- zero_mask = torch.zeros_like(m.weight.grad)
- zero_mask[media_token_id] = torch.ones_like(zero_mask[media_token_id])
- zero_mask[endofchunk_token_id] = torch.ones_like(zero_mask[endofchunk_token_id])
- m.weight.grad = m.weight.grad * zero_mask
-
- model.apply(mask_embedding)
-
- torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
-
- # step optimizer and log
- if (((num_steps + 1) % args.gradient_accumulation_steps) == 0) or (num_steps == num_batches_per_epoch - 1):
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
-
- # step time and reset end outside of rank 0
- step_time_m.update(time.time() - end)
- end = time.time()
-
- if args.rank == 0 and args.report_to_wandb:
- # compute within rank 0
- laion_samples_per_second = args.gradient_accumulation_steps * args.batch_size_laion * args.world_size / step_time_m.val
- laion_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size_laion / step_time_m.val
-
- c4_samples_per_second = args.gradient_accumulation_steps * args.batch_size_mmc4 * args.world_size / step_time_m.val
- c4_samples_per_second_per_gpu = args.gradient_accumulation_steps * args.batch_size_mmc4 / step_time_m.val
-
- wandb.log(
- {
- "data_time": data_time_m.avg,
- "step_time": step_time_m.avg,
- "laion_samples_per_second": laion_samples_per_second,
- "laion_samples_per_second_per_gpu": laion_samples_per_second_per_gpu,
- "c4_samples_per_second": c4_samples_per_second,
- "c4_samples_per_second_per_gpu": c4_samples_per_second_per_gpu,
- "lr": optimizer.param_groups[0]["lr"],
- },
- commit=False,
- )
- step_time_m.reset()
- data_time_m.reset()
-
- wandb.log(
- {
- "loss_laion": divided_loss_laion.item(),
- "global_step": global_step,
- },
- commit=False,
- )
- wandb.log(
- {"loss_mmc4": divided_loss_mmc4.item(), "global_step": global_step},
- commit=True,
- )
-
- # Log loss to console
- if ((num_steps + 1) % args.logging_steps == 0) and args.rank == 0:
- print(
- f"Step {num_steps+1}/{num_batches_per_epoch} of epoch {epoch+1}/{args.num_epochs} complete. Loss LAION: {loss_laion.item():.3f} // Loss MMC4: {loss_mmc4.item():.3f}"
- )
-
-
def get_checkpoint(model):
state_dict = model.state_dict()
@@ -315,3 +150,171 @@ def get_image_attention_mask(output_input_ids, max_num_images, tokenizer, includ
# in full language mode we set the image mask to all-0s
image_attention_mask = torch.zeros(output_input_ids.shape[0], output_input_ids.shape[1], 1, dtype=torch.bool)
return image_attention_mask
+
+
+def verify_yaml(args):
+ if args.rank != 0:
+ return
+
+ # Run pytest with the necessary arguments.
+ result = subprocess.run(["pytest", "-m", "prerun", f"--yaml-path={args.training_data_yaml}"])
+
+ if result.returncode != 0:
+ print("YAML verification failed!")
+ sys.exit(1)
+
+
+def get_grouped_params(model, wd):
+ params_with_wd, params_without_wd = [], []
+
+ def apply_decay(x):
+ return "gated_cross_attn_layer" in x and "ff_gate" not in x and "attn_gate" not in x and "norm" not in x and "bias" not in x
+
+ for n, p in model.named_parameters():
+ # if p.requires_grad:
+ if apply_decay(n):
+ params_with_wd.append(p)
+ else:
+ params_without_wd.append(p)
+
+ return [
+ {"params": params_with_wd, "weight_decay": wd},
+ {"params": params_without_wd, "weight_decay": 0.0},
+ ]
+
+
+def save_checkpoint(epoch, model, args, accelerator, unwrapped_model=None, global_step=None):
+ """Save a checkpoint for the model."""
+ # Ensure the directory exists
+ if not os.path.exists(args.external_save_dir):
+ os.makedirs(args.external_save_dir)
+
+ if unwrapped_model is None:
+ unwrapped_model = accelerator.unwrap_model(model)
+
+ # Formulate the checkpoint filename based on whether it's an epoch or global_step checkpoint
+ if global_step:
+ checkpoint_path = f"{args.external_save_dir}/checkpoint_steps_{global_step}.pt"
+ checkpoint_dict = {
+ "steps": global_step,
+ "model_state_dict": get_checkpoint(unwrapped_model),
+ }
+ else:
+ checkpoint_path = f"{args.external_save_dir}/checkpoint_{epoch}.pt"
+ checkpoint_dict = {"model_state_dict": get_checkpoint(unwrapped_model)}
+
+ # Save the checkpoint if rank is 0
+ if args.rank == 0:
+ print(f"Saving checkpoint to {checkpoint_path}")
+ accelerator.save(checkpoint_dict, checkpoint_path)
+
+ # Save the model's configuration
+ unwrapped_model.config.save_pretrained(args.external_save_dir)
+
+ # Remove the previous checkpoint if required
+ if args.delete_previous_checkpoint:
+ if global_step:
+ prev_checkpoint_path = f"{args.external_save_dir}/checkpoint_step_{global_step-args.save_steps_interval}.pt"
+ if os.path.exists(prev_checkpoint_path):
+ os.remove(prev_checkpoint_path)
+ elif epoch > 0:
+ os.remove(f"{args.external_save_dir}/checkpoint_{epoch-1}.pt")
+
+
+def save_checkpoint(checkpoint_dict, save_path, is_main_process, save_function):
+ """Helper function to save the checkpoint."""
+ save_function(checkpoint_dict, f"{save_path}/final_weights.pt", is_main_process=is_main_process)
+
+
+def save_pretrained(component, save_path, is_main_process, save_function):
+ """Helper function to save pretrained components."""
+ component.save_pretrained(save_path, is_main_process=is_main_process, save_function=save_function, safe_serialization=False)
+
+
+def save_final_weights(model, args, accelerator, processor=None, tokenizer=None):
+ """Save final weights of the model."""
+ unwrapped_model = accelerator.unwrap_model(model)
+ is_main_process = accelerator.is_main_process
+ save_path = args.external_save_dir
+ model_name = args.model_name.lower()
+
+ unwrapped_model.config.save_pretrained(save_path)
+
+ if args.save_hf_model:
+ save_pretrained(unwrapped_model, save_path, is_main_process, accelerator.save)
+
+ if "idefics" in model_name or "fuyu" in model_name:
+ save_pretrained(processor, save_path, is_main_process, accelerator.save)
+
+ if "llama2" in model_name:
+ save_pretrained(tokenizer, save_path, is_main_process, accelerator.save)
+ else:
+ # Save based on the distributed type
+ if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
+ checkpoint_dict = accelerator.get_state_dict(model)
+ else:
+ checkpoint_dict = get_checkpoint(model=unwrapped_model)
+
+ if accelerator.distributed_type == "DEEPSPEED" and accelerator.state.deepspeed_plugin.zero_stage == 3:
+ trainable_params_name = [name for name, p in unwrapped_model.named_parameters() if p.requires_grad]
+ checkpoint_dict = {k: v for k, v in checkpoint_dict.items() if k in trainable_params_name}
+
+ save_checkpoint(checkpoint_dict, save_path, is_main_process, accelerator.save)
+
+
+def get_weights_for_dataloaders(dataloaders):
+ total_samples = sum(len(dataloader.dataset) for dataloader in dataloaders)
+ weights = [len(dataloader.dataset) / total_samples for dataloader in dataloaders]
+ return weights
+
+
+def get_next_dataloader(dataloader_iterators, weights):
+ chosen_dataloader_index = np.random.choice(len(dataloader_iterators), p=weights)
+ return dataloader_iterators[chosen_dataloader_index]
+
+
+def find_and_remove_tokens(input_tensor, labels_tensor, attention_mask_tensor, token_id, tokenizer):
+ batch_size, seq_len = input_tensor.size()
+
+ # Create lists to store the new tensors
+ new_input_list = []
+ new_labels_list = []
+ new_attention_mask_list = []
+
+ # Loop over each sequence in the batch
+ for i in range(batch_size):
+ single_input = input_tensor[i, :]
+ single_label = labels_tensor[i, :]
+ single_attention_mask = attention_mask_tensor[i, :]
+
+ # Remove the token_id
+ new_single_input = torch.masked_select(single_input, single_input != token_id)
+ new_single_label = torch.masked_select(single_label, single_input != token_id)
+ new_single_attention_mask = torch.masked_select(single_attention_mask, single_input != token_id)
+
+ # Append the new sequence to the list
+ new_input_list.append(new_single_input)
+ new_labels_list.append(new_single_label)
+ new_attention_mask_list.append(new_single_attention_mask)
+
+ # Pad sequences within each batch to match the longest sequence
+ new_input = torch.nn.utils.rnn.pad_sequence(new_input_list, batch_first=True, padding_value=tokenizer.pad_token_id)
+ new_labels = torch.nn.utils.rnn.pad_sequence(new_labels_list, batch_first=True, padding_value=-100)
+ new_attention_mask = torch.nn.utils.rnn.pad_sequence(new_attention_mask_list, batch_first=True, padding_value=0)
+
+ return new_input, new_labels, new_attention_mask
+
+
+def delete_tensors_from_dict(d):
+ """Recursively delete tensors from a nested dictionary."""
+ keys_to_delete = []
+ for k, v in d.items():
+ if isinstance(v, torch.Tensor):
+ keys_to_delete.append(k)
+ elif isinstance(v, list):
+ new_list = [item for item in v if not isinstance(item, torch.Tensor)]
+ d[k] = new_list
+ elif isinstance(v, dict):
+ delete_tensors_from_dict(v)
+ for key in keys_to_delete:
+ del d[key]
diff --git a/pipeline/utils/__init__.py b/pipeline/utils/__init__.py
old mode 100644
new mode 100755
diff --git a/pipeline/utils/apply_delta.py b/pipeline/utils/apply_delta.py
old mode 100644
new mode 100755
diff --git a/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py b/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py
old mode 100644
new mode 100755
index 3268ec66..c3e957be
--- a/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py
+++ b/pipeline/utils/convert_laion400m-tsv_to_laion400m-tar_mp_shard.py
@@ -171,7 +171,11 @@ def _ensure_tsv_opened(self):
def convert_tsv(tsv_id, tsv_root, output_dir):
- with wds.ShardWriter(output_dir + f"/{tsv_id.replace('.tsv','.').split('-')[-1]}%03d.tar", maxcount=500000, maxsize=2e10) as sink:
+ with wds.ShardWriter(
+ output_dir + f"/{tsv_id.replace('.tsv','.').split('-')[-1]}%03d.tar",
+ maxcount=500000,
+ maxsize=2e10,
+ ) as sink:
cur_tsv_image = TSVFile(tsv_root=tsv_root, tsv_file=tsv_id)
cur_tsv_caption = TSVFile(tsv_root=tsv_root, tsv_file=tsv_id.replace("image", "text"))
for _ in tqdm(range(cur_tsv_image.__len__()), desc="Converting image"):
@@ -189,7 +193,13 @@ def convert_tsv(tsv_id, tsv_root, output_dir):
print(e)
print(f"the caption of index {_} have problem, continue")
continue
- sink.write({"__key__": key_str, "png": cur_image[1], "txt": caption.encode("utf-8", "replace").decode()})
+ sink.write(
+ {
+ "__key__": key_str,
+ "png": cur_image[1],
+ "txt": caption.encode("utf-8", "replace").decode(),
+ }
+ )
except Exception as e:
print(f"Error at index {_}: {e}")
diff --git a/pipeline/utils/convert_mmc4_to_wds.py b/pipeline/utils/convert_mmc4_to_wds.py
old mode 100644
new mode 100755
diff --git a/pipeline/utils/general.py b/pipeline/utils/general.py
new file mode 100644
index 00000000..3d1028b8
--- /dev/null
+++ b/pipeline/utils/general.py
@@ -0,0 +1,12 @@
+class DualOutput:
+ def __init__(self, file, stdout):
+ self.file = file
+ self.stdout = stdout
+
+ def write(self, data):
+ self.file.write(data)
+ self.stdout.write(data)
+
+ def flush(self):
+ self.file.flush()
+ self.stdout.flush()
diff --git a/pipeline/utils/make_a_train.py b/pipeline/utils/make_a_train.py
old mode 100644
new mode 100755
index 2ea15bee..fd01cd95
--- a/pipeline/utils/make_a_train.py
+++ b/pipeline/utils/make_a_train.py
@@ -19,7 +19,10 @@ def main(input_file, output_file):
if key not in seen_keys:
try:
# Check if rel_ins_ids are in the original JSON
- valid_rel_ins_ids = [rel_ins_id for rel_ins_id in value["rel_ins_ids"] if rel_ins_id in data["data"]]
+ if args.remove_rel_ins_ids:
+ valid_rel_ins_ids = []
+ else:
+ valid_rel_ins_ids = [rel_ins_id for rel_ins_id in value["rel_ins_ids"] if rel_ins_id in data["data"]]
# Add the valid rel_ins_ids to the new_dict
new_dict[key] = valid_rel_ins_ids
@@ -37,6 +40,11 @@ def main(input_file, output_file):
parser = argparse.ArgumentParser(description="Process a JSON file.")
parser.add_argument("--input_file", type=str, help="Path to the input JSON file")
parser.add_argument("--output_file", type=str, help="Path to the output JSON file")
+ parser.add_argument(
+ "--remove_rel_ins_ids",
+ action="store_true",
+ help="Remove rel_ins_ids from the output JSON file",
+ )
args = parser.parse_args()
diff --git a/pipeline/utils/modeling_value_head.py b/pipeline/utils/modeling_value_head.py
new file mode 100644
index 00000000..5478fecc
--- /dev/null
+++ b/pipeline/utils/modeling_value_head.py
@@ -0,0 +1,415 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import torch
+import torch.nn as nn
+from transformers import AutoModelForCausalLM, AutoModelForSeq2SeqLM
+
+from trl.models.modeling_base import PreTrainedModelWrapper
+
+
+class ValueHead(nn.Module):
+ r"""
+ The ValueHead class implements a head for GPT2 that returns a scalar for each output token.
+ """
+
+ def __init__(self, config, **kwargs):
+ super().__init__()
+ if not hasattr(config, "summary_dropout_prob"):
+ summary_dropout_prob = kwargs.pop("summary_dropout_prob", 0.1)
+ else:
+ summary_dropout_prob = config.summary_dropout_prob
+
+ self.dropout = nn.Dropout(summary_dropout_prob) if summary_dropout_prob else nn.Identity()
+
+ # some models such as OPT have a projection layer before the word embeddings - e.g. OPT-350m
+ if hasattr(config, "word_embed_proj_dim"):
+ hidden_size = config.word_embed_proj_dim
+ else:
+ hidden_size = config.hidden_size
+
+ self.summary = nn.Linear(hidden_size, 1)
+
+ self.flatten = nn.Flatten()
+
+ def forward(self, hidden_states):
+ output = self.dropout(hidden_states)
+
+ # For now force upcast in fp32 if needed. Let's keep the
+ # output in fp32 for numerical stability.
+ if output.dtype != self.summary.weight.dtype:
+ output = output.to(self.summary.weight.dtype)
+
+ output = self.summary(output)
+ return output
+
+
+class AutoModelForCausalLMWithValueHead(PreTrainedModelWrapper):
+ r"""
+ An autoregressive model with a value head in addition to the language model head.
+ This class inherits from `~trl.PreTrainedModelWrapper` and wraps a
+ `transformers.PreTrainedModel` class. The wrapper class supports classic functions
+ such as `from_pretrained`, `push_to_hub` and `generate`. To call a method of the wrapped
+ model, simply manipulate the `pretrained_model` attribute of this class.
+
+ Class attributes:
+ - **transformers_parent_class** (`transformers.PreTrainedModel`) -- The parent class of the wrapped model. This
+ should be set to `transformers.AutoModelForCausalLM` for this class.
+ - **lm_head_namings** (`tuple`) -- A tuple of strings that are used to identify the language model head of the
+ wrapped model. This is set to `("lm_head", "embed_out")` for this class but can be changed for other models
+ in the future
+ - **supported_args** (`tuple`) -- A tuple of strings that are used to identify the arguments that are supported
+ by the `ValueHead` class. Currently, the supported args are:
+ - **summary_dropout_prob** (`float`, `optional`, defaults to `None`) -- The dropout probability for the
+ `ValueHead` class.
+ - **v_head_initializer_range** (`float`, `optional`, defaults to `0.2`) -- The initializer range for the
+ `ValueHead` if a specific initialization strategy is selected.
+ - **v_head_init_strategy** (`str`, `optional`, defaults to `None`) -- The initialization strategy for the
+ `ValueHead`. Currently, the supported strategies are:
+ - **`None`** -- Initializes the weights of the `ValueHead` with a random distribution. This is the default
+ strategy.
+ - **"normal"** -- Initializes the weights of the `ValueHead` with a normal distribution.
+
+ """
+ transformers_parent_class = AutoModelForCausalLM
+ lm_head_namings = ["lm_head", "embed_out"]
+ supported_args = (
+ "summary_dropout_prob",
+ "v_head_initializer_range",
+ "v_head_init_strategy",
+ )
+
+ def __init__(self, pretrained_model, **kwargs):
+ r"""
+ Initializes the model.
+
+ Args:
+ pretrained_model (`transformers.PreTrainedModel`):
+ The model to wrap. It should be a causal language model such as GPT2.
+ or any model mapped inside the `AutoModelForCausalLM` class.
+ kwargs (`dict`, `optional`):
+ Additional keyword arguments, that are passed to the `ValueHead` class.
+ """
+ super().__init__(pretrained_model)
+ v_head_kwargs, _, _ = self._split_kwargs(kwargs)
+
+ if not any(hasattr(self.pretrained_model, attribute) for attribute in self.lm_head_namings):
+ raise ValueError("The model does not have a language model head, please use a model that has one.")
+
+ self.v_head = ValueHead(self.pretrained_model.config, **v_head_kwargs)
+
+ self._init_weights(**v_head_kwargs)
+
+ def _init_weights(self, **kwargs):
+ r"""
+ Initializes the weights of the value head. The default initialization strategy is random.
+ Users can pass a different initialization strategy by passing the `v_head_init_strategy` argument
+ when calling `.from_pretrained`. Supported strategies are:
+ - `normal`: initializes the weights with a normal distribution.
+
+ Args:
+ **kwargs (`dict`, `optional`):
+ Additional keyword arguments, that are passed to the `ValueHead` class. These arguments
+ can contain the `v_head_init_strategy` argument as well as the `v_head_initializer_range`
+ argument.
+ """
+ initializer_range = kwargs.pop("v_head_initializer_range", 0.2)
+ # random init by default
+ init_strategy = kwargs.pop("v_head_init_strategy", None)
+ if init_strategy is None:
+ # do nothing
+ pass
+ elif init_strategy == "normal":
+ self.v_head.summary.weight.data.normal_(mean=0.0, std=initializer_range)
+ self.v_head.summary.bias.data.zero_()
+
+ def forward(
+ self,
+ input_ids=None,
+ past_key_values=None,
+ attention_mask=None,
+ **kwargs,
+ ):
+ r"""
+ Applies a forward pass to the wrapped model and returns the logits of the value head.
+
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, `optional`):
+ Contains pre-computed hidden-states (key and values in the attention blocks) as computed by the model
+ (see `past_key_values` input) to speed up sequential decoding.
+ attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ kwargs (`dict`, `optional`):
+ Additional keyword arguments, that are passed to the wrapped model.
+ """
+ kwargs["output_hidden_states"] = True # this had already been set in the LORA / PEFT examples
+ kwargs["past_key_values"] = past_key_values
+
+ if self.is_peft_model and self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING":
+ kwargs.pop("past_key_values")
+
+ base_model_output = self.pretrained_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ **kwargs,
+ )
+
+ last_hidden_state = base_model_output.hidden_states[-1]
+ lm_logits = base_model_output.logits
+ loss = base_model_output.loss
+
+ if last_hidden_state.device != self.v_head.summary.weight.device:
+ last_hidden_state = last_hidden_state.to(self.v_head.summary.weight.device)
+
+ value = self.v_head(last_hidden_state).squeeze(-1)
+
+ # force upcast in fp32 if logits are in half-precision
+ if lm_logits.dtype != torch.float32:
+ lm_logits = lm_logits.float()
+
+ return (lm_logits, loss, value)
+
+ def generate(self, *args, **kwargs):
+ r"""
+ A simple wrapper around the `generate` method of the wrapped model.
+ Please refer to the [`generate`](https://huggingface.co/docs/transformers/internal/generation_utils)
+ method of the wrapped model for more information about the supported arguments.
+
+ Args:
+ *args (`list`, *optional*):
+ Positional arguments passed to the `generate` method of the wrapped model.
+ **kwargs (`dict`, *optional*):
+ Keyword arguments passed to the `generate` method of the wrapped model.
+ """
+ return self.pretrained_model.generate(*args, **kwargs)
+
+ def state_dict(self, *args, **kwargs):
+ r"""
+ Returns the state dictionary of the model. We add the state dictionary of the value head
+ to the state dictionary of the wrapped model by prepending the key with `v_head.`.
+ """
+ if not self.is_peft_model:
+ pretrained_model_state_dict = self.pretrained_model.state_dict(*args, **kwargs)
+ else:
+ # if it is a peft model, only save the v_head
+ pretrained_model_state_dict = {}
+
+ v_head_state_dict = self.v_head.state_dict(*args, **kwargs)
+ for k, v in v_head_state_dict.items():
+ pretrained_model_state_dict[f"v_head.{k}"] = v
+ return pretrained_model_state_dict
+
+ def push_to_hub(self, *args, **kwargs):
+ setattr(self.pretrained_model, "v_head", self.v_head)
+
+ return self.pretrained_model.push_to_hub(*args, **kwargs)
+
+ def post_init(self, state_dict):
+ r"""
+ We add the state dictionary of the value head to the state dictionary of the wrapped model
+ by prepending the key with `v_head.`. This function removes the `v_head.` prefix from the
+ keys of the value head state dictionary.
+ """
+ for k in list(state_dict.keys()):
+ if "v_head." in k:
+ state_dict[k.replace("v_head.", "")] = state_dict.pop(k)
+ self.v_head.load_state_dict(state_dict, strict=False)
+ del state_dict
+
+ if hasattr(self.pretrained_model, "hf_device_map"):
+ if "cpu" in self.pretrained_model.hf_device_map.values() or "disk" in self.pretrained_model.hf_device_map.values():
+ raise ValueError("The model is offloaded on CPU or disk - CPU & disk offloading is not supported for ValueHead models.")
+
+ first_device = list(set(self.pretrained_model.hf_device_map.values()))[0]
+
+ self.v_head = self.v_head.to(first_device)
+
+ def set_device_hook(module, input, outputs):
+ new_output = ()
+ for output in outputs:
+ if isinstance(output, torch.Tensor):
+ new_output += (output.to(first_device),)
+ else:
+ new_output += (output,)
+ return new_output
+
+ self.register_forward_hook(set_device_hook)
+
+ self.is_sequential_parallel = True
+
+
+class AutoModelForSeq2SeqLMWithValueHead(PreTrainedModelWrapper):
+ r"""
+ A seq2seq model with a value head in addition to the language model head.
+ This class inherits from `~trl.PreTrainedModelWrapper` and wraps a
+ `transformers.PreTrainedModel` class. The wrapper class supports classic functions
+ such as `from_pretrained` and `push_to_hub` and also provides some additional
+ functionalities such as `generate`.
+
+ Args:
+ pretrained_model (`transformers.PreTrainedModel`):
+ The model to wrap. It should be a causal language model such as GPT2.
+ or any model mapped inside the `AutoModelForSeq2SeqLM` class.
+ kwargs:
+ Additional keyword arguments passed along to the `ValueHead` class.
+ """
+ transformers_parent_class = AutoModelForSeq2SeqLM
+ lm_head_namings = ["lm_head", "embed_out", "output_projection"]
+ supported_args = (
+ "summary_dropout_prob",
+ "v_head_initializer_range",
+ "v_head_init_strategy",
+ )
+
+ def __init__(self, pretrained_model, **kwargs):
+ super().__init__(pretrained_model)
+ v_head_kwargs, _, _ = self._split_kwargs(kwargs)
+ self.is_encoder_decoder = True
+
+ if not self._has_lm_head():
+ raise ValueError("The model does not have a language model head, please use a model that has one.")
+
+ self.v_head = ValueHead(self.pretrained_model.config, **v_head_kwargs)
+
+ self._init_weights(**v_head_kwargs)
+
+ def _has_lm_head(self):
+ # check module names of all modules inside `pretrained_model` to find the language model head
+ for name, module in self.pretrained_model.named_modules():
+ if any(attribute in name for attribute in self.lm_head_namings):
+ return True
+ return False
+
+ def post_init(self, state_dict):
+ r"""
+ We add the state dictionary of the value head to the state dictionary of the wrapped model
+ by prepending the key with `v_head.`. This function removes the `v_head.` prefix from the
+ keys of the value head state dictionary.
+ """
+ for k in list(state_dict.keys()):
+ if "v_head." in k:
+ state_dict[k.replace("v_head.", "")] = state_dict.pop(k)
+ self.v_head.load_state_dict(state_dict, strict=False)
+ del state_dict
+
+ if hasattr(self.pretrained_model, "hf_device_map"):
+ if "cpu" in self.pretrained_model.hf_device_map.values() or "disk" in self.pretrained_model.hf_device_map.values():
+ raise ValueError("The model is offloaded on CPU or disk - CPU & disk offloading is not supported for ValueHead models.")
+
+ # get the lm_head device
+ for name, module in self.pretrained_model.named_modules():
+ if any(attribute in name for attribute in self.lm_head_namings):
+ lm_head_device = module.weight.device
+ break
+
+ # put v_head on the same device as the lm_head to avoid issues
+ self.v_head = self.v_head.to(lm_head_device)
+
+ def set_device_hook(module, input, outputs):
+ r"""
+ A hook that sets the device of the output of the model to the device of the first
+ parameter of the model.
+
+ Args:
+ module (`nn.Module`):
+ The module to which the hook is attached.
+ input (`tuple`):
+ The input to the module.
+ outputs (`tuple`):
+ The output of the module.
+ """
+ new_output = ()
+ for output in outputs:
+ if isinstance(output, torch.Tensor):
+ new_output += (output.to(lm_head_device),)
+ else:
+ new_output += (output,)
+ return new_output
+
+ self.register_forward_hook(set_device_hook)
+ self.is_sequential_parallel = True
+
+ def state_dict(self, *args, **kwargs):
+ r"""
+ Returns the state dictionary of the model. We add the state dictionary of the value head
+ to the state dictionary of the wrapped model by prepending the key with `v_head.`.
+ """
+ if not self.is_peft_model:
+ pretrained_model_state_dict = self.pretrained_model.state_dict(*args, **kwargs)
+ else:
+ # if it is a peft model, only save the v_head
+ pretrained_model_state_dict = {}
+
+ v_head_state_dict = self.v_head.state_dict(*args, **kwargs)
+ for k, v in v_head_state_dict.items():
+ pretrained_model_state_dict[f"v_head.{k}"] = v
+ return pretrained_model_state_dict
+
+ def push_to_hub(self, *args, **kwargs):
+ setattr(self.pretrained_model, "v_head", self.v_head)
+
+ return self.pretrained_model.push_to_hub(*args, **kwargs)
+
+ def _init_weights(self, **kwargs):
+ r"""
+ We initialize the weights of the value head.
+ """
+ initializer_range = kwargs.pop("v_head_initializer_range", 0.2)
+ # random init by default
+ init_strategy = kwargs.pop("v_head_init_strategy", None)
+ if init_strategy is None:
+ # do nothing
+ pass
+ elif init_strategy == "normal":
+ self.v_head.summary.weight.data.normal_(mean=0.0, std=initializer_range)
+ self.v_head.summary.bias.data.zero_()
+
+ def forward(
+ self,
+ input_ids=None,
+ past_key_values=None,
+ attention_mask=None,
+ **kwargs,
+ ):
+ kwargs["past_key_values"] = past_key_values
+ if self.is_peft_model and self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING":
+ kwargs.pop("past_key_values")
+
+ base_model_output = self.pretrained_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ output_hidden_states=True, # We force the model to output hidden states
+ **kwargs,
+ )
+
+ last_hidden_state = base_model_output.decoder_hidden_states[-1]
+ lm_logits = base_model_output.logits
+ loss = base_model_output.loss
+
+ value = self.v_head(last_hidden_state).squeeze(-1)
+
+ # force upcast in fp32 if logits are in half-precision
+ if lm_logits.dtype != torch.float32:
+ lm_logits = lm_logits.float()
+
+ return (lm_logits, loss, value)
+
+ def generate(self, *args, **kwargs):
+ r"""
+ We call `generate` on the wrapped model.
+ """
+ return self.pretrained_model.generate(*args, **kwargs)
diff --git a/pyproject.toml b/pyproject.toml
index 335a2d9a..3f224fc0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -1,5 +1,5 @@
[tool.black]
-line-length = 160
+line-length = 240
[build-system]
requires = ["setuptools>=42", "wheel", "setuptools_scm[tomli]>=6.3"]
diff --git a/pytest.ini b/pytest.ini
new file mode 100644
index 00000000..1b91c233
--- /dev/null
+++ b/pytest.ini
@@ -0,0 +1,3 @@
+[pytest]
+markers =
+ prerun: mark a test as a prerun check.
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
old mode 100644
new mode 100755
index 8d1c215c..bc361980
--- a/requirements.txt
+++ b/requirements.txt
@@ -12,6 +12,7 @@ more_itertools>=9.1.0
nltk>=3.8.1
numpy>=1.23.5
open_clip_torch>=2.16.0
+openai>=1.1.1
opencv_python_headless>=4.5.5.64
Pillow>=9.5.0
pycocoevalcap>=1
@@ -20,7 +21,7 @@ Requests>=2.31.0
scipy>=1.10.1
timm>=0.9.2
tqdm>=4.65.0
-transformers>=4.29.0
+transformers==4.35.0
uvicorn>=0.22.0
webdataset>=0.2.48
xformers>=0.0.20
@@ -32,4 +33,8 @@ yajl>=0.3.5
deepspeed>=0.10.0
wandb>=0.15.8
trl>=0.5.0
+cffi>=1.15.1
pyyaml>=6.0.1
+pytest>=7.4.2
+prettytable>=3.9.0
+torch==2.0.1
diff --git a/setup.py b/setup.py
index e985f527..71a058d6 100644
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
setup(
name="otter-ai",
- version="0.0.0-alpha-3",
+ version="0.0.0-alpha-4",
packages=find_packages(where="src"),
package_dir={"": "src"},
install_requires=requirements,
diff --git a/shared_scripts/Demo_Data.yaml b/shared_scripts/Demo_Data.yaml
new file mode 100644
index 00000000..78919900
--- /dev/null
+++ b/shared_scripts/Demo_Data.yaml
@@ -0,0 +1,83 @@
+IMAGE_TEXT:
+ LADD:
+ mimicit_path: azure_storage/json/LA/LADD_instructions.json
+ images_path: azure_storage/Parquets/LA.parquet
+ num_samples: -1
+ # LACONV:
+ # mimicit_path: azure_storage/json/LA/LACONV_instructions.json
+ # images_path: azure_storage/json/LA/LA.json
+ # train_config_path: azure_storage/json/LA/LACONV_train.json
+ # num_samples: 50
+ LACR_T2T:
+ mimicit_path: azure_storage/json/LA/LACR_T2T_instructions.json
+ images_path: azure_storage/Parquets/LA.parquet
+ num_samples: -1
+ M3IT_CAPTIONING:
+ mimicit_path: azure_storage/json/M3IT/captioning/coco/coco_instructions.json
+ images_path: azure_storage/Parquets/coco.parquet
+ num_samples: 20000
+ # M3IT_VQA:
+ # mimicit_path: azure_storage/json/M3IT/vqa/vqav2/vqav2_instructions.json
+ # images_path: azure_storage/json/M3IT/vqa/vqav2/vqav2.json
+ # num_samples: 20000
+ M3IT_COCOGOI:
+ mimicit_path: azure_storage/json/M3IT/classification/coco-goi/coco-goi_instructions.json
+ images_path: azure_storage/Parquets/coco-goi.parquet
+ num_samples: 20000
+ M3IT_COCOITM:
+ mimicit_path: azure_storage/json/M3IT/classification/coco-itm/coco-itm_instructions.json
+ images_path: azure_storage/Parquets/coco-itm.parquet
+ num_samples: 20000
+ M3IT_IMAGENET:
+ mimicit_path: azure_storage/json/M3IT/classification/imagenet/imagenet_instructions.json
+ images_path: azure_storage/Parquets/imagenet.parquet
+ num_samples: 20000
+ # # M3IT_IQA:
+ # # mimicit_path: azure_storage/json/M3IT/classification/iqa/iqa_instructions.json
+ # # images_path: azure_storage/json/M3IT/classification/iqa/iqa.json
+ # # num_samples: 20000
+ M3IT_REFCOCO:
+ mimicit_path: azure_storage/json/M3IT/classification/refcoco/refcoco_instructions.json
+ images_path: azure_storage/Parquets/refcoco.parquet
+ num_samples: 20000
+ # M3IT_VSR:
+ # mimicit_path: azure_storage/json/M3IT/classification/vsr/vsr_instructions.json
+ # images_path: azure_storage/json/M3IT/classification/vsr/vsr.json
+ # num_samples: 20000
+ M3IT_TEXT_VQA:
+ mimicit_path: azure_storage/json/M3IT/vqa/text-vqa/text-vqa_instructions.json
+ images_path: azure_storage/Parquets/text-vqa.parquet
+ num_samples: 20000
+ M3IT_OKVQA:
+ mimicit_path: azure_storage/json/M3IT/vqa/okvqa/okvqa_instructions.json
+ images_path: azure_storage/Parquets/okvqa.parquet
+ num_samples: 20000
+ M3IT_A_OKVQA:
+ mimicit_path: azure_storage/json/M3IT/vqa/a-okvqa/a-okvqa_instructions.json
+ images_path: azure_storage/Parquets/a-okvqa.parquet
+ num_samples: 20000
+ M3IT_SIENCEQA:
+ mimicit_path: azure_storage/json/M3IT/reasoning/scienceqa/scienceqa_instructions.json
+ images_path: azure_storage/Parquets/scienceqa.parquet
+ num_samples: 20000
+ # SVIT:
+ # mimicit_path: azure_storage/json/SVIT/SVIT_instructions.json
+ # images_path: azure_storage/json/SVIT/SVIT.json
+ # num_samples: 20000
+ # PF:
+ # mimicit_path: azure_storage/json/PF/PF_instructions.json
+ # images_path: azure_storage/json/PF/PF.json
+ # num_samples: 20000
+
+# TEXT_ONLY:
+# LIMA:
+# mimicit_path: azure_storage/json/LANG_Only/LIMA/LIMA_instructions_max_1K_tokens.json
+# num_samples: 20000
+# SHAREGPT:
+# mimicit_path: azure_storage/json/LANG_Only/SHAREGPT/SHAREGPT_instructions_max_1K_tokens.json
+# num_samples: 10000
+# AL:
+# mimicit_path: azure_storage/json/LANG_Only/AL/AL_instructions_max_1K_tokens.json
+# num_samples: 20000
+
+
diff --git a/shared_scripts/Demo_OtterHD.sh b/shared_scripts/Demo_OtterHD.sh
new file mode 100644
index 00000000..b55199ec
--- /dev/null
+++ b/shared_scripts/Demo_OtterHD.sh
@@ -0,0 +1,66 @@
+#!/bin/bash
+cd /root/of/Otter
+
+export PYTHONPATH=.
+
+# sent to sub script
+export HOSTNAMES=$(scontrol show hostnames "$SLURM_JOB_NODELIST")
+export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
+export MASTER_PORT=12955
+export COUNT_NODE=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l)
+export NCCL_NET=IB
+
+echo HOSTNAMES = $HOSTNAMES
+echo hostname = $(hostname)
+echo MASTER_ADDR= $MASTER_ADDR
+echo MASTER_PORT= $MASTER_PORT
+
+GPU=$((${COUNT_NODE} * 8))
+WORKERS=$((${COUNT_NODE} * 8))
+
+if [ $WORKERS -gt 112 ]; then
+ WORKERS=112
+fi
+
+RUN_NAME="RunNamePlaceHolder"
+
+echo GPU=${GPU}
+echo COUNT_NODE=$COUNT_NODE
+echo WORKERS=8
+echo "Running ${RUN_NAME}"
+
+H=$(hostname)
+THEID=$(echo -e $HOSTNAMES | python3 -c "import sys;[sys.stdout.write(str(i)) for i,line in enumerate(next(sys.stdin).split(' ')) if line.strip() == '$H'.strip()]")
+export THEID=$THEID
+echo $THEID
+
+pkill python
+
+
+accelerate launch --config_file=./pipeline/accelerate_configs/accelerate_config_zero2.yaml \
+ --machine_rank $THEID --main_process_ip $MASTER_ADDR --main_process_port $MASTER_PORT \
+ --num_machines=${COUNT_NODE} --num_processes=${GPU} \
+ pipeline/train/instruction_following.py \
+ --pretrained_model_name_or_path=adept/fuyu-8b \
+ --training_data_yaml=./Demo_Data.yaml \
+ --model_name=fuyu \
+ --instruction_format=fuyu \
+ --batch_size=8 \
+ --gradient_accumulation_steps=2 \
+ --num_epochs=3 \
+ --report_to_wandb \
+ --wandb_entity=libo0013 \
+ --external_save_dir=./checkpoints \
+ --run_name=${RUN_NAME} \
+ --wandb_project=Fuyu \
+ --workers=${WORKERS} \
+ --lr_scheduler=cosine \
+ --learning_rate=1e-5 \
+ --warmup_steps_ratio=0.03 \
+ --save_hf_model \
+ --max_seq_len=1024 \
+ --logging_steps=1000 \
+ --keep_symbols \
+ --save_ckpt_each_epoch \
+ --dynamic_resolution \
+ --with_task_description
diff --git a/shared_scripts/Demo_OtterMPT.sh b/shared_scripts/Demo_OtterMPT.sh
new file mode 100644
index 00000000..12e76c50
--- /dev/null
+++ b/shared_scripts/Demo_OtterMPT.sh
@@ -0,0 +1,66 @@
+#!/bin/bash
+cd /root/of/Otter
+
+export PYTHONPATH=.
+
+# sent to sub script
+export HOSTNAMES=$(scontrol show hostnames "$SLURM_JOB_NODELIST")
+export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
+export MASTER_PORT=12955
+export COUNT_NODE=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l)
+export NCCL_NET=IB
+
+echo HOSTNAMES = $HOSTNAMES
+echo hostname = $(hostname)
+echo MASTER_ADDR= $MASTER_ADDR
+echo MASTER_PORT= $MASTER_PORT
+
+GPU=$((${COUNT_NODE} * 8))
+WORKERS=$((${COUNT_NODE} * 8))
+
+if [ $WORKERS -gt 112 ]; then
+ WORKERS=112
+fi
+
+RUN_NAME="RunNamePlaceHolder"
+
+echo GPU=${GPU}
+echo COUNT_NODE=$COUNT_NODE
+echo WORKERS=8
+echo "Running ${RUN_NAME}"
+
+H=$(hostname)
+THEID=$(echo -e $HOSTNAMES | python3 -c "import sys;[sys.stdout.write(str(i)) for i,line in enumerate(next(sys.stdin).split(' ')) if line.strip() == '$H'.strip()]")
+export THEID=$THEID
+echo $THEID
+
+pkill python
+
+
+# --customized_config=./shared_scripts/Otter_MPT7B_Train_Decoder.json
+accelerate launch --config_file=./pipeline/accelerate_configs/accelerate_config_zero2.yaml \
+ --machine_rank $THEID --main_process_ip $MASTER_ADDR --main_process_port $MASTER_PORT \
+ --num_machines=${COUNT_NODE} --num_processes=${GPU} \
+ pipeline/train/instruction_following.py \
+ --pretrained_model_name_or_path=adept/fuyu-8b \
+ --training_data_yaml=./Demo_Data.yaml \
+ --model_name=otter \
+ --instruction_format=simple \
+ --batch_size=8 \
+ --gradient_accumulation_steps=2 \
+ --num_epochs=3 \
+ --report_to_wandb \
+ --wandb_entity=libo0013 \
+ --external_save_dir=./checkpoints \
+ --run_name=${RUN_NAME} \
+ --wandb_project=Fuyu \
+ --workers=${WORKERS} \
+ --lr_scheduler=cosine \
+ --learning_rate=1e-5 \
+ --warmup_steps_ratio=0.03 \
+ --save_hf_model \
+ --max_seq_len=2048 \
+ --logging_steps=1000 \
+ --keep_symbols \
+ --save_ckpt_each_epoch \
+ --with_task_description
diff --git a/shared_scripts/Otter_MPT7B_Train_Decoder.json b/shared_scripts/Otter_MPT7B_Train_Decoder.json
new file mode 100644
index 00000000..7d26509a
--- /dev/null
+++ b/shared_scripts/Otter_MPT7B_Train_Decoder.json
@@ -0,0 +1,198 @@
+{
+ "_commit_hash": null,
+ "_name_or_path": "luodian/OTTER-MPT7B-Init",
+ "architectures": [
+ "OtterForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "otter",
+ "train_vision_encoder": false,
+ "train_lang_encoder": true,
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 4096,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 4096,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 2048,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 32,
+ "n_layers": 32,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/__init__.py b/src/otter_ai/models/__init__.py
index e69de29b..8d62516b 100644
--- a/src/otter_ai/models/__init__.py
+++ b/src/otter_ai/models/__init__.py
@@ -0,0 +1,3 @@
+from .falcon.modelling_RW import RWForCausalLM
+from .mpt.modeling_mpt import MPTForCausalLM
+from .mpt_redpajama.mosaic_gpt import MosaicGPT
diff --git a/src/otter_ai/models/falcon/__init__.py b/src/otter_ai/models/falcon/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/src/otter_ai/models/flamingo/falcon/configuration_RW.py b/src/otter_ai/models/falcon/configuration_RW.py
old mode 100644
new mode 100755
similarity index 100%
rename from src/otter_ai/models/flamingo/falcon/configuration_RW.py
rename to src/otter_ai/models/falcon/configuration_RW.py
diff --git a/src/otter_ai/models/flamingo/falcon/modelling_RW.py b/src/otter_ai/models/falcon/modelling_RW.py
old mode 100644
new mode 100755
similarity index 92%
rename from src/otter_ai/models/flamingo/falcon/modelling_RW.py
rename to src/otter_ai/models/falcon/modelling_RW.py
index b929a5f5..cac6e12e
--- a/src/otter_ai/models/flamingo/falcon/modelling_RW.py
+++ b/src/otter_ai/models/falcon/modelling_RW.py
@@ -63,8 +63,8 @@ def __init__(
self.head_dim = head_dim
self.seq_len_cached = None
self.batch_size_cached = None
- self.cos_cached: torch.Tensor | None = None
- self.sin_cached: torch.Tensor | None = None
+ self.cos_cached = None # Union[torch.Tensor, None] replaced with None
+ self.sin_cached = None # Union[torch.Tensor, None] replaced with None
def cos_sin(
self,
@@ -97,7 +97,11 @@ def forward(self, q, k):
def _make_causal_mask(input_ids_shape: torch.Size, device: torch.device, past_key_values_length: int) -> torch.BoolTensor:
batch_size, target_length = input_ids_shape
- mask = torch.empty((target_length, target_length + past_key_values_length), dtype=torch.bool, device=device)
+ mask = torch.empty(
+ (target_length, target_length + past_key_values_length),
+ dtype=torch.bool,
+ device=device,
+ )
# ONNX doesn't support `torch.Tensor.triu` properly, thus we use this workaround
seq_ids = torch.arange(target_length, device=device)
mask[:, past_key_values_length:] = seq_ids[:, None] < seq_ids[None, :]
@@ -120,14 +124,28 @@ def _expand_mask(mask: torch.Tensor, tgt_length: int) -> torch.BoolTensor:
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
batch_size, seq_length = attention_mask.shape
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
- base = torch.tensor(2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32)
+ base = torch.tensor(
+ 2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))),
+ device=attention_mask.device,
+ dtype=torch.float32,
+ )
powers = torch.arange(1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32)
slopes = torch.pow(base, powers)
if closest_power_of_2 != num_heads:
- extra_base = torch.tensor(2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32)
+ extra_base = torch.tensor(
+ 2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))),
+ device=attention_mask.device,
+ dtype=torch.float32,
+ )
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
- extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, device=attention_mask.device, dtype=torch.int32)
+ extra_powers = torch.arange(
+ 1,
+ 1 + 2 * num_remaining_heads,
+ 2,
+ device=attention_mask.device,
+ dtype=torch.int32,
+ )
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention
@@ -195,7 +213,11 @@ def _split_heads(self, fused_qkv: torch.Tensor) -> Tuple[torch.Tensor, torch.Ten
else:
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads + 2, self.head_dim)
- return fused_qkv[..., :-2, :], fused_qkv[..., [-2], :], fused_qkv[..., [-1], :]
+ return (
+ fused_qkv[..., :-2, :],
+ fused_qkv[..., [-2], :],
+ fused_qkv[..., [-1], :],
+ )
def _merge_heads(self, x: torch.Tensor) -> torch.Tensor:
"""
@@ -385,7 +407,12 @@ def forward(
attention_output = attn_outputs[0]
if not self.config.parallel_attn:
- residual = dropout_add(attention_output, residual, self.config.attention_dropout, training=self.training)
+ residual = dropout_add(
+ attention_output,
+ residual,
+ self.config.attention_dropout,
+ training=self.training,
+ )
layernorm_output = self.post_attention_layernorm(residual)
outputs = attn_outputs[1:]
@@ -407,7 +434,10 @@ def forward(
class RWPreTrainedModel(PreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
@@ -499,7 +529,12 @@ def __init__(self, config: RWConfig):
def get_input_embeddings(self):
return self.word_embeddings
- def _prepare_attn_mask(self, attention_mask: torch.Tensor, input_shape: Tuple[int, int], past_key_values_length: int) -> torch.BoolTensor:
+ def _prepare_attn_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_shape: Tuple[int, int],
+ past_key_values_length: int,
+ ) -> torch.BoolTensor:
# create causal mask
# [batch_size, seq_length] -> [batch_size, 1, tgt_length, src_length]
combined_attention_mask = None
@@ -507,7 +542,11 @@ def _prepare_attn_mask(self, attention_mask: torch.Tensor, input_shape: Tuple[in
_, src_length = input_shape
if src_length > 1:
- combined_attention_mask = _make_causal_mask(input_shape, device=device, past_key_values_length=past_key_values_length)
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ device=device,
+ past_key_values_length=past_key_values_length,
+ )
# [batch_size, seq_length] -> [batch_size, 1, tgt_length, src_length]
expanded_attn_mask = _expand_mask(attention_mask, tgt_length=src_length)
@@ -606,7 +645,11 @@ def forward(
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
- return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
+ return module(
+ *inputs,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
return custom_forward
@@ -642,7 +685,16 @@ def custom_forward(*inputs):
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ presents,
+ all_hidden_states,
+ all_self_attentions,
+ ]
+ if v is not None
+ )
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
@@ -653,7 +705,10 @@ def custom_forward(*inputs):
class RWForCausalLM(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config: RWConfig):
super().__init__(config)
@@ -745,7 +800,10 @@ def forward(
batch_size, seq_length, vocab_size = shift_logits.shape
# Flatten the tokens
loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(batch_size * seq_length, vocab_size), shift_labels.view(batch_size * seq_length))
+ loss = loss_fct(
+ shift_logits.view(batch_size * seq_length, vocab_size),
+ shift_labels.view(batch_size * seq_length),
+ )
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
@@ -759,7 +817,11 @@ def forward(
attentions=transformer_outputs.attentions,
)
- def _reorder_cache(self, past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
+ def _reorder_cache(
+ self,
+ past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...],
+ beam_idx: torch.LongTensor,
+ ) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
@@ -782,7 +844,10 @@ def _reorder_cache(self, past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], be
class RWForSequenceClassification(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config: RWConfig):
super().__init__(config)
@@ -853,10 +918,7 @@ def forward(
sequence_lengths = torch.ne(input_ids, self.config.pad_token_id).sum(dim=-1) - 1
else:
sequence_lengths = -1
- logger.warning(
- f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
- "unexpected if using padding tokens in conjunction with `inputs_embeds.`"
- )
+ logger.warning(f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be " "unexpected if using padding tokens in conjunction with `inputs_embeds.`")
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
@@ -896,7 +958,10 @@ def forward(
class RWForTokenClassification(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config: RWConfig):
super().__init__(config)
@@ -966,7 +1031,10 @@ def forward(
if labels is not None:
batch_size, seq_length = labels.shape
loss_fct = CrossEntropyLoss()
- loss = loss_fct(logits.view(batch_size * seq_length, self.num_labels), labels.view(batch_size * seq_length))
+ loss = loss_fct(
+ logits.view(batch_size * seq_length, self.num_labels),
+ labels.view(batch_size * seq_length),
+ )
if not return_dict:
output = (logits,) + transformer_outputs[2:]
@@ -981,7 +1049,10 @@ def forward(
class RWForQuestionAnswering(RWPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
+ _keys_to_ignore_on_load_missing = [
+ r"h.*.self_attention.scale_mask_softmax.causal_mask",
+ r"lm_head.weight",
+ ]
def __init__(self, config):
super().__init__(config)
diff --git a/src/otter_ai/models/flamingo/__init__.py b/src/otter_ai/models/flamingo/__init__.py
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/flamingo/config.json b/src/otter_ai/models/flamingo/config.json
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/flamingo/configuration_flamingo.py b/src/otter_ai/models/flamingo/configuration_flamingo.py
old mode 100644
new mode 100755
index 08c6255a..09b14954
--- a/src/otter_ai/models/flamingo/configuration_flamingo.py
+++ b/src/otter_ai/models/flamingo/configuration_flamingo.py
@@ -7,9 +7,9 @@
from transformers.models.clip import CLIPVisionConfig
import sys
-from .falcon.configuration_RW import RWConfig
-from .mpt.configuration_mpt import MPTConfig
-from .mpt_redpajama.configuration_mosaic_gpt import MosaicGPTConfig
+from ..falcon.configuration_RW import RWConfig
+from ..mpt.configuration_mpt import MPTConfig
+from ..mpt_redpajama.configuration_mosaic_gpt import MosaicGPTConfig
logger = logging.get_logger(__name__)
diff --git a/src/otter_ai/models/flamingo/modeling_flamingo.py b/src/otter_ai/models/flamingo/modeling_flamingo.py
old mode 100644
new mode 100755
index 26f6e528..504cc6e3
--- a/src/otter_ai/models/flamingo/modeling_flamingo.py
+++ b/src/otter_ai/models/flamingo/modeling_flamingo.py
@@ -12,9 +12,10 @@
from transformers.models.auto import AutoModel, AutoModelForCausalLM, AutoTokenizer
from .configuration_flamingo import FlamingoConfig
-from .falcon.modelling_RW import RWForCausalLM
-from .mpt.modeling_mpt import MPTForCausalLM
-from .mpt_redpajama.mosaic_gpt import MosaicGPT
+from ..falcon.modelling_RW import RWForCausalLM
+from ..mpt.modeling_mpt import MPTForCausalLM
+from ..mpt_redpajama.mosaic_gpt import MosaicGPT
+import torch.distributed as dist
# from .configuration_flamingo import FlamingoConfig
@@ -31,14 +32,21 @@
}
+def master_print(*args, **kwargs):
+ if dist.is_available() and dist.is_initialized():
+ rank = dist.get_rank()
+ if rank == 0:
+ print(*args, **kwargs)
+ else:
+ print(*args, **kwargs)
+
+
def _infer_decoder_layers_attr_name(model: nn.Module):
for k in __KNOWN_DECODER_LAYERS_ATTR_NAMES:
if k.lower() in model.__class__.__name__.lower():
return __KNOWN_DECODER_LAYERS_ATTR_NAMES[k]
- raise ValueError(
- f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually."
- )
+ raise ValueError(f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually.")
def extend_instance(obj, mixin):
@@ -424,14 +432,7 @@ def init_flamingo(
for layer_idx, _ in enumerate(self._get_decoder_layers())
]
)
- self._set_decoder_layers(
- nn.ModuleList(
- [
- FlamingoLayer(gated_cross_attn_layer, decoder_layer)
- for gated_cross_attn_layer, decoder_layer in zip(gated_cross_attn_layers, self._get_decoder_layers())
- ]
- )
- )
+ self._set_decoder_layers(nn.ModuleList([FlamingoLayer(gated_cross_attn_layer, decoder_layer) for gated_cross_attn_layer, decoder_layer in zip(gated_cross_attn_layers, self._get_decoder_layers())]))
self.media_token_id = media_token_id
self.use_media_placement_augmentation = use_media_placement_augmentation
self.initialized_flamingo = True
@@ -513,7 +514,7 @@ def __init__(
text_tokenizer = AutoTokenizer.from_pretrained("PATH-TO-YOUR-FALCON")
lang_encoder = RWForCausalLM(config=config.text_config)
else:
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
vision_encoder = CLIPVisionModel(config=config.vision_config)
@@ -527,8 +528,6 @@ def __init__(
extend_instance(lang_encoder, FlamingoLMMixin)
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
- if lang_encoder.__class__.__name__ == "LlamaForCausalLM":
- lang_encoder.resize_token_embeddings(len(text_tokenizer))
self.lang_encoder = lang_encoder
self.cross_attn_every_n_layers = config.cross_attn_every_n_layers if hasattr(config, "cross_attn_every_n_layers") else 4
@@ -721,7 +720,7 @@ def __init__(
lang_encoder = RWForCausalLM(config=config.text_config)
# TODO: what's the logic here?
elif config.text_config.architectures[0] == "LlamaForCausalLM":
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
else:
import pdb
@@ -742,8 +741,6 @@ def __init__(
extend_instance(lang_encoder, FlamingoLMMixin)
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
- if "LlamaForCausalLM" in lang_encoder.__class__.__name__:
- lang_encoder.resize_token_embeddings(len(text_tokenizer))
self.lang_encoder = lang_encoder
self.cross_attn_every_n_layers = config.cross_attn_every_n_layers if hasattr(config, "cross_attn_every_n_layers") else 4
@@ -782,28 +779,50 @@ def get_lang_encoder(self) -> nn.Module:
return self.lang_encoder
def init_weights(self):
+ # Freeze all parameters in self.model if train_vision_encoder is False or train_lang_encoder is False
+ if not ("train_full_model" in self.config.__dict__ and self.config.train_full_model is True):
+ for param in self.parameters():
+ param.requires_grad = False
+
# Freeze all parameters in vision encoder
- for param in self.vision_encoder.parameters():
- param.requires_grad = False
+ if "train_vision_encoder" in self.config.__dict__ and self.config.train_vision_encoder is True:
+ master_print("Unfreeze vision encoder.")
+ for param in self.vision_encoder.parameters():
+ param.requires_grad = True
+
+ # Freeze all parameters in lang encoders except gated_cross_attn_layers
+ if "train_lang_encoder" in self.config.__dict__ and self.config.train_lang_encoder is True:
+ master_print("Unfreeze language decoder.")
+ for name, param in self.lang_encoder.named_parameters():
+ param.requires_grad = True
+
+ if "lora_config" in self.config.__dict__:
+ # Use another logic to unfreeze gated_cross_attn_layers and perceivers
+ master_print(f"LoRA trainable param: {(sum(param.numel() for name, param in self.lang_encoder.named_parameters() if 'lora' in name)) / 1e6:.3f} M")
+ for name, param in self.lang_encoder.named_parameters():
+ if "lora" in name:
+ param.requires_grad = True
+
# Freeze all parameters in lang encoders except gated_cross_attn_layers
for name, param in self.lang_encoder.named_parameters():
- if "gated_cross_attn_layer" not in name:
- param.requires_grad = False
- # Unfreeze LM input embeddings
+ if "gated_cross_attn_layer" in name:
+ param.requires_grad = True
+
+ for name, param in self.named_parameters():
+ if "perceiver" in name:
+ param.requires_grad = True
+
+ # Unfreeze LM input and output embeddings
self.lang_encoder.get_input_embeddings().requires_grad_(True)
## MPTForCausalLM is tied word embedding
if "LlamaForCausalLM" in self.lang_encoder.__class__.__name__:
self.lang_encoder.lm_head.requires_grad_(True)
- # assert sum(p.numel() for p in model.parameters() if p.requires_grad) == 0
- # print model size in billions of parameters in 2 decimal places
- print("====================Model Grad Part====================")
total_params = 0
for name, param in self.named_parameters():
if param.requires_grad:
total_params += param.numel()
- print(f"Parameter: {name}, Size: {param.numel() / 1e6:.6f} M")
- print(f"Total Trainable param: {total_params / 1e9:.4f} B")
- print(f"Total Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.3f} B")
+ master_print(f"{name}: {param.numel() / 1e6:.3f} M")
+ master_print(f"Total Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.3f} B")
def forward(
self,
diff --git a/src/otter_ai/models/flamingo/utils.py b/src/otter_ai/models/flamingo/utils.py
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/flamingo/utils/converting_flamingo_to_bf16.py b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_bf16.py
new file mode 100755
index 00000000..2d885d17
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_bf16.py
@@ -0,0 +1,46 @@
+import argparse
+import os
+
+import torch
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+parser = argparse.ArgumentParser(description="Load model with precision")
+parser.add_argument(
+ "--load_bit",
+ type=str,
+ choices=["fp16", "bf16"],
+ required=True,
+ help="Choose either 'fp16' or 'bf16'",
+)
+parser.add_argument(
+ "--pretrained_model_path",
+ type=str,
+ default="/home/luodian/projects/checkpoints/flamingo-mpt-7B-instruct-init",
+ required=True,
+)
+parser.add_argument(
+ "--saved_model_path",
+ type=str,
+ default="/home/luodian/projects/checkpoints/flamingo-mpt-7B-instruct-init",
+ required=True,
+)
+args = parser.parse_args()
+
+load_bit = args.load_bit
+pretrained_model_path = args.pretrained_model_path
+
+if load_bit == "fp16":
+ precision = {"torch_dtype": torch.float16}
+elif load_bit == "bf16":
+ precision = {"torch_dtype": torch.bfloat16}
+
+root_dir = os.environ["AZP"]
+print(root_dir)
+device_id = "cpu"
+model = FlamingoForConditionalGeneration.from_pretrained(pretrained_model_path, device_map={"": device_id}, **precision)
+
+# save model to same folder
+checkpoint_path = pretrained_model_path + f"-{load_bit}"
+model.save_pretrained(checkpoint_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/converting_flamingo_to_hf.py b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_hf.py
new file mode 100755
index 00000000..dd354f6b
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_hf.py
@@ -0,0 +1,60 @@
+"""convert from otter pt to otter hf. Will remove after we use otter hf model to train.
+"""
+
+import re
+import argparse
+import os
+
+import torch
+import torch.nn as nn
+from transformers import CLIPVisionModel, LlamaForCausalLM, LlamaTokenizer
+
+import sys
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+
+@torch.no_grad()
+def dump_hf_model(pretrained_model_path: str, old_ckpt_path: str, new_folder_path: str) -> None:
+ old_ckpt = torch.load(old_ckpt_path, map_location="cpu")
+ if old_ckpt.get("model_state_dict", None) is not None:
+ old_ckpt = old_ckpt["model_state_dict"]
+ new_ckpt = old_ckpt
+ folder_path = os.path.dirname(old_ckpt_path)
+ # config_path = os.path.join(folder_path, "config.json") if os.path.exists(os.path.join(folder_path, "config.json")) else "flamingo/config.json"
+ model = FlamingoForConditionalGeneration.from_pretrained(
+ args.pretrained_model_path,
+ device_map="auto",
+ )
+ _ = model.load_state_dict(new_ckpt, strict=False)
+ print(f"Saving HF model to {new_folder_path}")
+ model.save_pretrained(new_folder_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--old_ckpt_path",
+ "-old",
+ type=str,
+ required=True,
+ help="Path to the pt checkpoint",
+ )
+ parser.add_argument(
+ "--new_hf_path",
+ "-new",
+ type=str,
+ required=True,
+ help="Path to the hf folder",
+ )
+ parser.add_argument(
+ "--pretrained_model_path",
+ "-pretrained",
+ type=str,
+ required=True,
+ help="Path to the pretrained model folder",
+ )
+ args = parser.parse_args()
+ if not os.path.exists(os.path.dirname(args.new_hf_path)):
+ os.makedirs(os.path.dirname(args.new_hf_path))
+ dump_hf_model(args.pretrained_model_path, args.old_ckpt_path, args.new_hf_path)
diff --git a/src/otter_ai/models/flamingo/utils/converting_flamingo_to_lora.py b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_lora.py
new file mode 100755
index 00000000..c4dcf982
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/converting_flamingo_to_lora.py
@@ -0,0 +1,69 @@
+import argparse
+import torch
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+from peft import get_peft_model, LoraConfig, TaskType
+
+MODEL_CLASSES = {
+ "LlamaForCausalLM": "llama",
+ "OPTForCausalLM": "opt",
+ "GPTJForCausalLM": "gptj",
+ "GPTNeoXForCausalLM": "gpt_neox",
+ "MPTForCausalLM": "mpt",
+}
+
+# Define argument parser
+parser = argparse.ArgumentParser(description="Load a model with specified precision and save it to a specified path.")
+
+# Add arguments
+parser.add_argument(
+ "--checkpoint_path",
+ type=str,
+ help="Path to the pre-trained model checkpoint.",
+ default="",
+)
+parser.add_argument(
+ "--save_path",
+ type=str,
+ default="",
+ help="Path to the converted model checkpoint.",
+)
+
+# Parse the input arguments
+args = parser.parse_args()
+
+load_bit = "bf16"
+if load_bit == "fp16":
+ precision = {"torch_dtype": torch.float16}
+elif load_bit == "bf16":
+ precision = {"torch_dtype": torch.bfloat16}
+
+# Load the model
+model = FlamingoForConditionalGeneration.from_pretrained(args.checkpoint_path, device_map="auto", **precision)
+
+# adding lora
+standard_modules = ["q_proj", "v_proj"]
+lang_encoder_short_name = MODEL_CLASSES[model.config.text_config.architectures[0]]
+model_to_lora_modules = {
+ "llama": standard_modules,
+ "opt": standard_modules,
+ "gptj": standard_modules,
+ "gpt_neox": ["query_key_value"],
+ "mpt": ["Wqkv"],
+}
+lora_config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ task_type=TaskType.CAUSAL_LM,
+ target_modules=model_to_lora_modules[lang_encoder_short_name],
+)
+model.config.update({"lora_config": {"r": 16, "lora_alpha": 32, "lora_dropout": 0.05}})
+model.lang_encoder = get_peft_model(model.lang_encoder, lora_config)
+model.lang_encoder.print_trainable_parameters()
+
+# Save the model
+checkpoint_path = args.save_path
+FlamingoForConditionalGeneration.save_pretrained(model, checkpoint_path)
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-falcon-7B.json b/src/otter_ai/models/flamingo/utils/flamingo-falcon-7B.json
new file mode 100755
index 00000000..f777f6b4
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-falcon-7B.json
@@ -0,0 +1,112 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoModel"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "architectures": [
+ "RWForCausalLM"
+ ],
+ "apply_residual_connection_post_layernorm": false,
+ "attention_dropout": 0.0,
+ "bias": false,
+ "bos_token_id": 11,
+ "eos_token_id": 11,
+ "hidden_dropout": 0.0,
+ "hidden_size": 4544,
+ "initializer_range": 0.02,
+ "layer_norm_epsilon": 1e-05,
+ "model_type": "RefinedWebModel",
+ "multi_query": true,
+ "n_head": 71,
+ "n_layer": 32,
+ "parallel_attn": true,
+ "torch_dtype": "bfloat16",
+ "transformers_version": "4.27.4",
+ "use_cache": true,
+ "vocab_size": 65024
+ },
+ "tie_word_embeddings": false,
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.28.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-13B.json b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-13B.json
new file mode 100755
index 00000000..738211da
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-13B.json
@@ -0,0 +1,114 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 8,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "meta-llama/Llama-2-13b-chat-hf",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 5120,
+ "initializer_range": 0.02,
+ "intermediate_size": 13824,
+ "max_position_embeddings": 4096,
+ "model_type": "llama",
+ "num_attention_heads": 40,
+ "num_hidden_layers": 40,
+ "num_key_value_heads": 40,
+ "pad_token_id": 0,
+ "pretraining_tp": 1,
+ "rms_norm_eps": 1e-05,
+ "rope_scaling": null,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.30.1",
+ "use_cache": true,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-7B.json b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-7B.json
new file mode 100755
index 00000000..0676c97e
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-llama2-chat-7B.json
@@ -0,0 +1,115 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "meta-llama/Llama-2-7b-chat-hf",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 4096,
+ "initializer_range": 0.02,
+ "intermediate_size": 11008,
+ "max_length": 4096,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 32,
+ "num_hidden_layers": 32,
+ "num_key_value_heads": 32,
+ "pad_token_id": 0,
+ "pretraining_tp": 1,
+ "rms_norm_eps": 1e-05,
+ "rope_scaling": null,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.32.0.dev0",
+ "use_cache": true,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-1B-redpajama.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-1B-redpajama.json
new file mode 100755
index 00000000..f27dffdc
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-1B-redpajama.json
@@ -0,0 +1,131 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 1,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "architectures": [
+ "MosaicGPT"
+ ],
+ "attn_clip_qkv": null,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_qk_ln": true,
+ "attn_uses_sequence_id": false,
+ "d_model": 2048,
+ "hidden_size": 2048,
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "fan_mode": "fan_in",
+ "init_device": "cpu",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "logit_scale": null,
+ "low_precision_layernorm": true,
+ "max_seq_len": 2048,
+ "mlp_ratio": 4,
+ "model_type": "mosaic_gpt",
+ "n_heads": 16,
+ "n_layers": 24,
+ "no_bias": true,
+ "param_init_fn": "kaiming_normal_",
+ "prefix_lm": false,
+ "resid_pdrop": 0,
+ "softmax_scale": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "torch_dtype": "float32",
+ "transformers_version": "4.27.4",
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B-bf16.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B-bf16.json
new file mode 100755
index 00000000..b91d30c3
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B-bf16.json
@@ -0,0 +1,195 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 7,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 7168,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 7168,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0.0,
+ "init_nonlinearity": "relu",
+ "init_std": null,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 8192,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 64,
+ "n_layers": 48,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "bfloat16",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B.json
new file mode 100755
index 00000000..4678ba66
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-30B.json
@@ -0,0 +1,195 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 7,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 7168,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 7168,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0.0,
+ "init_nonlinearity": "relu",
+ "init_std": null,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 8192,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 64,
+ "n_layers": 48,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-mpt-7B.json b/src/otter_ai/models/flamingo/utils/flamingo-mpt-7B.json
new file mode 100755
index 00000000..9e1b681e
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-mpt-7B.json
@@ -0,0 +1,195 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 4096,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 4096,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 2048,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 32,
+ "n_layers": 32,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-vicuna-33B-v1.3.json b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-33B-v1.3.json
new file mode 100755
index 00000000..593706c9
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-33B-v1.3.json
@@ -0,0 +1,111 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "/home/luodian/projects/checkpoints/vicuna-33b-v1.3",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 6656,
+ "initializer_range": 0.02,
+ "intermediate_size": 17920,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 52,
+ "num_hidden_layers": 60,
+ "pad_token_id": 0,
+ "rms_norm_eps": 1e-06,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.28.1",
+ "use_cache": false,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/flamingo-vicuna-7B-v1.3.json b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-7B-v1.3.json
new file mode 100755
index 00000000..1e8ead8a
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/flamingo-vicuna-7B-v1.3.json
@@ -0,0 +1,111 @@
+{
+ "_commit_hash": null,
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "flamingo",
+ "text_config": {
+ "_name_or_path": "/mnt/petrelfs/share_data/zhangyuanhan/vicuna-7b-v1.3",
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 4096,
+ "initializer_range": 0.02,
+ "intermediate_size": 11008,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 32,
+ "num_hidden_layers": 32,
+ "pad_token_id": 0,
+ "rms_norm_eps": 1e-06,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.28.1",
+ "use_cache": false,
+ "vocab_size": 32000
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/flamingo/utils/injecting_falcon_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_falcon_into_flamingo.py
new file mode 100755
index 00000000..db683219
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_falcon_into_flamingo.py
@@ -0,0 +1,52 @@
+import os
+import torch
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+root_dir = os.environ["AZP"]
+print(root_dir)
+
+
+config = FlamingoConfig.from_json_file(".flamingo-falcon-7B.json")
+model = FlamingoForConditionalGeneration(config=config)
+
+
+state_dict_files = [
+ f"{root_dir}/otter/checkpoints/falcon-7b/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/otter/checkpoints/falcon-7b/pytorch_model-00002-of-00002.bin",
+]
+
+state_dict = {}
+for file in state_dict_files:
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+
+state_dict_3 = torch.load(
+ "{root_dir}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+_ = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+print(_[1])
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".h." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.h.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+_ = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+print(_[1])
+model.save_pretrained(f"{root_dir}/otter/checkpoints/flamingo-falcon-7b/")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_llama2_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_llama2_into_flamingo.py
new file mode 100755
index 00000000..485cd15e
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_llama2_into_flamingo.py
@@ -0,0 +1,98 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+# from .configuration_flamingo import FlamingoConfig
+# from .modeling_flamingo import FlamingoForConditionalGeneration
+
+parser = argparse.ArgumentParser(description="Convert Vicuna model")
+parser.add_argument("--model_choice", type=str, default="13B", help="Choose either '7B' or '13B'")
+parser.add_argument("--llama2_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+args = parser.parse_args()
+
+# os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+root_dir = args.llama2_root_dir
+model_choice = args.model_choice
+save_root_dir = args.save_root_dir
+
+# prepare vicuna model at first
+# you can visit https://huggingface.co/lmsys/Llama-2-33b-chat-hf to download 7B and 30B instruct checkpoints.
+if model_choice == "7B":
+ config_file = "./flamingo/flamingo-llama2-chat-7B.json"
+ state_dict_files = [
+ f"{root_dir}/Llama-2-7b-chat-hf/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/Llama-2-7b-chat-hf/pytorch_model-00002-of-00002.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-llama2-chat-7B-init"
+elif model_choice == "13B":
+ config_file = "./flamingo/flamingo-llama2-chat-13B.json"
+ state_dict_files = [
+ f"{root_dir}/Llama-2-13b-chat-hf/pytorch_model-00001-of-00003.bin",
+ f"{root_dir}/Llama-2-13b-chat-hf/pytorch_model-00002-of-00003.bin",
+ f"{root_dir}/Llama-2-13b-chat-hf/pytorch_model-00003-of-00003.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-llama2-chat-13B-init"
+else:
+ raise ValueError("Invalid model_choice. Choose either '13B' or '7B'.")
+
+config = FlamingoConfig.from_json_file(config_file)
+model = FlamingoForConditionalGeneration(config=config)
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+# AZP = "os.environ["AZP"]"
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(
+ f"{AZP}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+# Loading vicuna weights
+state_dict = {}
+for file in tqdm(state_dict_files, desc="Loading state dict"):
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".layers." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"model.layers.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+# Reshape the token embedding to 50280 for compatible
+model.lang_encoder.resize_token_embeddings(32000)
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# Reshape the token embedding to 32002 for compatible
+model.lang_encoder.resize_token_embeddings(32002)
+# print incompatible keys
+print(load_msg[1])
+
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_mpt-1B-redpajama_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_mpt-1B-redpajama_into_flamingo.py
new file mode 100755
index 00000000..155b7443
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_mpt-1B-redpajama_into_flamingo.py
@@ -0,0 +1,102 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+from utils import rename_flamingo_checkpoint
+
+
+parser = argparse.ArgumentParser(description="Convert MPT model")
+parser.add_argument("--mpt_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument(
+ "--flamingo_dir",
+ type=str,
+ default=None,
+ help="If the pretrained flamingo weights also need to be injected",
+)
+args = parser.parse_args()
+
+
+root_dir = args.mpt_root_dir
+save_root_dir = args.save_root_dir
+
+# prepare mpt model at first
+# you can visit https://huggingface.co/mosaicml to download 7B and 30B instruct checkpoints.
+config_file = "./flamingo/flamingo-mpt-1B-redpajama.json"
+state_dict_file = f"{root_dir}/pytorch_model.bin"
+save_path = f"{save_root_dir}/flamingo-mpt-1b-redpajama-200b-dolly"
+
+config = FlamingoConfig.from_json_file(config_file)
+
+model = FlamingoForConditionalGeneration(config=config)
+
+# Loading mpt weights
+state_dict = torch.load(state_dict_file, map_location="cpu")
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".blocks." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.blocks.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(f"{AZP}/pytorch_model-00004-of-00004.bin", map_location="cpu")
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".blocks." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.blocks.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+if args.flamingo_dir is not None:
+ state_dict_2 = torch.load(f"{args.flamingo_dir}/checkpoint.pt", map_location="cpu")
+ save_state_dict_2 = rename_flamingo_checkpoint(state_dict_2)
+ real_vocab_size = config.text_config.vocab_size
+ # Reshape the token embedding to 50280 for compatible
+ model.lang_encoder.resize_token_embeddings(save_state_dict_2["lang_encoder.transformer.wte.weight"].shape[0])
+
+ load_msg = model.load_state_dict(
+ save_state_dict_2,
+ False,
+ )
+ # print incompatible keys
+ print(load_msg[1])
+ # Reshape the token embedding to 50432
+ model.lang_encoder.resize_token_embeddings(real_vocab_size)
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_mpt_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_mpt_into_flamingo.py
new file mode 100755
index 00000000..d9bb72ef
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_mpt_into_flamingo.py
@@ -0,0 +1,123 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+from utils import rename_flamingo_checkpoint
+
+parser = argparse.ArgumentParser(description="Convert MPT model")
+parser.add_argument(
+ "--model_choice",
+ type=str,
+ choices=["7B", "30B"],
+ required=True,
+ help="Choose either '7B' or '30B'",
+)
+parser.add_argument("--mpt_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument(
+ "--flamingo_dir",
+ type=str,
+ default=None,
+ help="If the pretrained flamingo weights also need to be injected",
+)
+args = parser.parse_args()
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+root_dir = args.mpt_root_dir
+model_choice = args.model_choice
+save_root_dir = args.save_root_dir
+
+# prepare mpt model at first
+# you can visit https://huggingface.co/mosaicml to download 7B and 30B instruct checkpoints.
+if model_choice == "30B":
+ config_file = "./flamingo/flamingo-mpt-30B.json"
+ state_dict_files = [
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00001-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00002-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00003-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00004-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00005-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00006-of-00007.bin",
+ f"{root_dir}/mpt-30b-instruct/pytorch_model-00007-of-00007.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-mpt-30B-instruct-init"
+elif model_choice == "7B":
+ config_file = "./flamingo/flamingo-mpt-7B.json"
+ state_dict_files = [
+ f"{root_dir}/mpt-7b/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/mpt-7b/pytorch_model-00002-of-00002.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-mpt-7B"
+else:
+ raise ValueError("Invalid model_choice. Choose either '30B' or '7B'.")
+
+config = FlamingoConfig.from_json_file(config_file)
+
+model = FlamingoForConditionalGeneration(config=config)
+
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(
+ f"{AZP}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+# Loading mpt weights
+state_dict = {}
+for file in tqdm(state_dict_files, desc="Loading state dict"):
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".blocks." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"transformer.blocks.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+if args.flamingo_dir is not None:
+ state_dict_2 = torch.load(f"{args.flamingo_dir}/checkpoint.pt", map_location="cpu")
+ save_state_dict_2 = rename_flamingo_checkpoint(state_dict_2)
+
+ real_vocab_size = config.text_config.vocab_size
+ # Reshape the token embedding to 50280 for compatible
+ model.lang_encoder.resize_token_embeddings(save_state_dict_2["lang_encoder.transformer.wte.weight"].shape[0])
+
+ load_msg = model.load_state_dict(
+ save_state_dict_2,
+ False,
+ )
+ # print incompatible keys
+ print(load_msg[1])
+ # Reshape the token embedding to 50432
+ model.lang_encoder.resize_token_embeddings(real_vocab_size)
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/flamingo/utils/injecting_vicuna_into_flamingo.py b/src/otter_ai/models/flamingo/utils/injecting_vicuna_into_flamingo.py
new file mode 100755
index 00000000..bb5bda19
--- /dev/null
+++ b/src/otter_ai/models/flamingo/utils/injecting_vicuna_into_flamingo.py
@@ -0,0 +1,114 @@
+import argparse
+import os
+
+import torch
+from tqdm import tqdm
+
+import sys
+
+from ..configuration_flamingo import FlamingoConfig
+from ..modeling_flamingo import FlamingoForConditionalGeneration
+
+# from .configuration_flamingo import FlamingoConfig
+# from .modeling_flamingo import FlamingoForConditionalGeneration
+
+parser = argparse.ArgumentParser(description="Convert Vicuna model")
+parser.add_argument(
+ "--model_choice",
+ type=str,
+ choices=["7B", "33B"],
+ required=True,
+ help="Choose either '7B' or '33B'",
+)
+parser.add_argument("--vicuna_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument("--save_root_dir", type=str, default="/home/luodian/projects/checkpoints")
+parser.add_argument(
+ "--flamingo_dir",
+ type=str,
+ default=None,
+ help="If the pretrained flamingo weights also need to be injected",
+)
+args = parser.parse_args()
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false"
+
+root_dir = args.vicuna_root_dir
+model_choice = args.model_choice
+save_root_dir = args.save_root_dir
+
+# prepare vicuna model at first
+# you can visit https://huggingface.co/lmsys/vicuna-33b-v1.3 to download 7B and 30B instruct checkpoints.
+if model_choice == "33B":
+ config_file = "./flamingo/flamingo-vicuna-33B-v1.3.json"
+ state_dict_files = [
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00001-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00002-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00003-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00004-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00005-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00006-of-00007.bin",
+ f"{root_dir}/vicuna-33b-v1.3/pytorch_model-00007-of-00007.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-vicuna-33B-v1.3-init"
+elif model_choice == "7B":
+ config_file = "./flamingo/flamingo-vicuna-7B-v1.3.json"
+ state_dict_files = [
+ f"{root_dir}/vicuna-7b-v1.3/pytorch_model-00001-of-00002.bin",
+ f"{root_dir}/vicuna-7b-v1.3/pytorch_model-00002-of-00002.bin",
+ ]
+ save_path = f"{save_root_dir}/flamingo-vicuna-7B-v1.3-init"
+else:
+ raise ValueError("Invalid model_choice. Choose either '33B' or '7B'.")
+
+config = FlamingoConfig.from_json_file(config_file)
+model = FlamingoForConditionalGeneration(config=config)
+
+# load flamingo's vision encoder from last checkpoint.
+# you can visit https://huggingface.co/luodian/openflamingo-9b-hf/tree/main to download the checkpoint.
+# AZP = "os.environ["AZP"]"
+AZP = os.environ["AZP"]
+state_dict_3 = torch.load(
+ f"{AZP}/otter/checkpoints/flamingo_9b_hf/pytorch_model-00004-of-00004.bin",
+ map_location="cpu",
+)
+for cur_key in list(state_dict_3.keys()):
+ if "vision_encoder" not in cur_key:
+ del state_dict_3[cur_key]
+
+load_msg = model.load_state_dict(
+ state_dict_3,
+ False,
+)
+# print incompatible keys
+print(load_msg[1])
+
+# Loading vicuna weights
+state_dict = {}
+for file in tqdm(state_dict_files, desc="Loading state dict"):
+ state_dict_part = torch.load(file, map_location="cpu")
+ state_dict.update(state_dict_part)
+
+save_state_dict_1 = {}
+for key in state_dict:
+ if ".layers." in key:
+ _, _, layer_num, *remain_names = key.split(".")
+ target_key = f"model.layers.{layer_num}.decoder_layer.{'.'.join(remain_names)}"
+ else:
+ target_key = key
+ save_state_dict_1[f"{target_key}"] = state_dict[key]
+
+# Reshape the token embedding to 50280 for compatible
+model.lang_encoder.resize_token_embeddings(32000)
+
+load_msg = model.lang_encoder.load_state_dict(
+ save_state_dict_1,
+ False,
+)
+# Reshape the token embedding to 32002 for compatible
+model.lang_encoder.resize_token_embeddings(32002)
+# print incompatible keys
+print(load_msg[1])
+
+
+print(f"Saving model to {save_path}...")
+model.save_pretrained(save_path, max_shard_size="10GB")
diff --git a/src/otter_ai/models/fuyu/modeling_fuyu.py b/src/otter_ai/models/fuyu/modeling_fuyu.py
new file mode 100644
index 00000000..999e1880
--- /dev/null
+++ b/src/otter_ai/models/fuyu/modeling_fuyu.py
@@ -0,0 +1,186 @@
+import torch
+from transformers import FuyuPreTrainedModel, FuyuConfig, AutoModelForCausalLM
+
+
+try:
+ from .modeling_persimmon import PersimmonForCausalLM
+
+ print("Using local PersimmonForCausalLM with Flash Attention")
+except ImportError:
+ from transformers import PersimmonForCausalLM
+
+ print("Using transformers PersimmonForCausalLM without Flash Attention")
+
+from typing import List, Optional, Tuple, Union
+from transformers.modeling_outputs import BaseModelOutputWithPast
+import torch.nn as nn
+
+
+class FuyuForCausalLM(FuyuPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`FuyuDecoderLayer`]
+
+ Args:
+ config: FuyuConfig
+ """
+
+ def __init__(self, config: FuyuConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+ self.language_model = PersimmonForCausalLM._from_config(config.text_config)
+ self.vision_embed_tokens = nn.Linear(config.patch_size * config.patch_size * config.num_channels, config.hidden_size)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.language_model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.language_model.set_input_embeddings(value)
+
+ def gather_continuous_embeddings(
+ self,
+ word_embeddings: torch.Tensor,
+ continuous_embeddings: List[torch.Tensor],
+ image_patch_input_indices: torch.Tensor,
+ ) -> torch.Tensor:
+ """This function places the continuous_embeddings into the word_embeddings at the locations
+ indicated by image_patch_input_indices. Different batch elements can have different numbers of continuous
+ embeddings.
+
+ Args:
+ word_embeddings: Tensor of word embeddings. Shape: [b, s, h]
+ continuous_embeddings:
+ Tensor of continuous embeddings. The length of the list is the batch size. Each entry is
+ shape [num_image_embeddings, hidden], and num_image_embeddings needs to match the number of non-negative
+ indices in image_patch_input_indices for that batch element.
+ image_patch_input_indices: Tensor of indices of the image patches in the input_ids tensor. Shape: [b, s]
+ """
+ if not (word_embeddings.shape[0] == len(continuous_embeddings)):
+ raise ValueError(f"Batch sizes must match! Got {len(continuous_embeddings)=} and {word_embeddings.shape[0]=}")
+
+ output_embeddings = word_embeddings.clone()
+ for batch_idx in range(word_embeddings.shape[0]):
+ # First, find the positions of all the non-negative values in image_patch_input_indices, those are the
+ # positions in word_embeddings that we want to replace with content from continuous_embeddings.
+ dst_indices = torch.nonzero(image_patch_input_indices[batch_idx] >= 0, as_tuple=True)[0]
+ # Next look up those indices in image_patch_input_indices to find the indices in continuous_embeddings that we
+ # want to use to replace the values in word_embeddings.
+ src_indices = image_patch_input_indices[batch_idx][dst_indices]
+ # Check if we have more indices than embeddings. Note that we could have fewer indices if images got truncated.
+ if src_indices.shape[0] > continuous_embeddings[batch_idx].shape[0]:
+ raise ValueError(f"Number of continuous embeddings {continuous_embeddings[batch_idx].shape=} does not match " f"number of continuous token ids {src_indices.shape=} in batch element {batch_idx}.")
+ output_embeddings[batch_idx, dst_indices] = continuous_embeddings[batch_idx][src_indices]
+ return output_embeddings
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ labels: torch.LongTensor = None,
+ image_patches: torch.Tensor = None, # [batch_size, num_total_patches, patch_size_ x patch_size x num_channels ]
+ image_patches_indices: torch.Tensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
+ if image_patches is not None and past_key_values is None:
+ # patch_embeddings = self.vision_embed_tokens(image_patches.to(self.vision_embed_tokens.weight.dtype))
+ patch_embeddings = [self.vision_embed_tokens(patch.to(self.vision_embed_tokens.weight.dtype)).squeeze(0) for patch in image_patches]
+ inputs_embeds = self.gather_continuous_embeddings(
+ word_embeddings=inputs_embeds,
+ continuous_embeddings=patch_embeddings,
+ image_patch_input_indices=image_patches_indices,
+ )
+
+ outputs = self.language_model(
+ inputs_embeds=inputs_embeds,
+ labels=labels,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ if not return_dict:
+ return tuple(v for v in outputs if v is not None)
+ return outputs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ image_patches=None,
+ image_patches_indices=None,
+ **kwargs,
+ ):
+ if past_key_values:
+ input_ids = input_ids[:, -1:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -1].unsqueeze(-1)
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ if image_patches_indices is not None:
+ model_inputs["image_patches_indices"] = image_patches_indices
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ "image_patches_indices": image_patches_indices if past_key_values is None else None,
+ "image_patches": image_patches if past_key_values is None else None,
+ }
+ )
+ return model_inputs
diff --git a/src/otter_ai/models/fuyu/modeling_persimmon.py b/src/otter_ai/models/fuyu/modeling_persimmon.py
new file mode 100644
index 00000000..fe6959ba
--- /dev/null
+++ b/src/otter_ai/models/fuyu/modeling_persimmon.py
@@ -0,0 +1,954 @@
+# coding=utf-8
+# Copyright 2023 EleutherAI and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Persimmon model."""
+import math
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from flash_attn.ops.layer_norm import layer_norm as fused_layer_norm
+from flash_attn.ops.fused_dense import fused_mlp_func
+from flash_attn.layers.rotary import apply_rotary_emb as fused_apply_rotary_emb
+from transformers.activations import ACT2FN
+from flash_attn import flash_attn_func
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
+from transformers.modeling_utils import PreTrainedModel
+from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
+from transformers import PersimmonConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "PersimmonConfig"
+
+
+# Copied from transformers.models.bart.modeling_bart._make_causal_mask
+def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0):
+ """
+ Make causal mask used for bi-directional self-attention.
+ """
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
+ mask_cond = torch.arange(mask.size(-1), device=device)
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Persimmon
+class PersimmonRotaryEmbedding(nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+
+ self.dim = dim
+ self.max_position_embeddings = max_position_embeddings
+ self.base = base
+ inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ # Build here to make `torch.jit.trace` work.
+ self._set_cos_sin_cache(seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype())
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ # emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", freqs.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", freqs.sin().to(dtype), persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ if seq_len > self.max_seq_len_cached:
+ self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
+
+ return (
+ self.cos_cached[:seq_len].to(dtype=x.dtype),
+ self.sin_cached[:seq_len].to(dtype=x.dtype),
+ )
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->Persimmon
+class PersimmonLinearScalingRotaryEmbedding(PersimmonRotaryEmbedding):
+ """PersimmonRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+ t = t / self.scaling_factor
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->Persimmon
+class PersimmonDynamicNTKScalingRotaryEmbedding(PersimmonRotaryEmbedding):
+ """PersimmonRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
+
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
+ self.scaling_factor = scaling_factor
+ super().__init__(dim, max_position_embeddings, base, device)
+
+ def _set_cos_sin_cache(self, seq_len, device, dtype):
+ self.max_seq_len_cached = seq_len
+
+ if seq_len > self.max_position_embeddings:
+ base = self.base * ((self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)) ** (self.dim / (self.dim - 2))
+ inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+
+ t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
+
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
+ self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
+
+
+# Copied from transformers.models.llama.modeling_llama.rotate_half
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ cos = cos[position_ids].unsqueeze(1) # [seq_len, dim] -> [batch_size, 1, seq_len, head_dim]
+ sin = sin[position_ids].unsqueeze(1)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+# Copied from transformers.models.gpt_neox.modeling_gpt_neox.GPTNeoXMLP with GPTNeoX->Persimmon
+class PersimmonMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense_h_to_4h = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.dense_4h_to_h = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.act = ACT2FN[config.hidden_act]
+
+ def forward(self, hidden_states):
+ # hidden_states = self.dense_h_to_4h(hidden_states)
+ # hidden_states = self.act(hidden_states)
+ # hidden_states = self.dense_4h_to_h(hidden_states)
+ """
+ checkpoint_lvl (increasing lvl means slower but more memory saving):
+ 0: no recomputation in the bwd
+ 1: recompute gelu_out in the bwd
+ 2: recompute gelu_in and gelu_out in the bwd
+ """
+ hidden_states = fused_mlp_func(hidden_states, self.dense_h_to_4h.weight, self.dense_4h_to_h.weight, self.dense_h_to_4h.bias, self.dense_4h_to_h.bias, "sqrelu", True, False, 0, -1)
+ return hidden_states
+
+
+class PersimmonAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: PersimmonConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.max_position_embeddings = config.max_position_embeddings
+ self.rope_theta = config.rope_theta
+ self.partial_rotary_factor = config.partial_rotary_factor
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}" f" and `num_heads`: {self.num_heads}).")
+ self.query_key_value = nn.Linear(self.hidden_size, 3 * self.hidden_size, bias=True)
+ self.dense = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=True)
+ self.qk_layernorm = config.qk_layernorm
+
+ if self.qk_layernorm:
+ self.q_layernorm = nn.LayerNorm(config.hidden_size // self.num_heads, eps=config.layer_norm_eps, elementwise_affine=True)
+ self.k_layernorm = nn.LayerNorm(config.hidden_size // self.num_heads, eps=config.layer_norm_eps, elementwise_affine=True)
+ self.attention_dropout = nn.Dropout(config.attention_dropout)
+ self._init_rope()
+
+ def _init_rope(self):
+ if self.config.rope_scaling is None:
+ self.rotary_emb = PersimmonRotaryEmbedding(
+ int(self.partial_rotary_factor * self.head_dim),
+ max_position_embeddings=self.max_position_embeddings,
+ base=self.rope_theta,
+ )
+ else:
+ scaling_type = self.config.rope_scaling["type"]
+ scaling_factor = self.config.rope_scaling["factor"]
+ if scaling_type == "linear":
+ self.rotary_emb = PersimmonLinearScalingRotaryEmbedding(
+ int(self.partial_rotary_factor * self.head_dim),
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ elif scaling_type == "dynamic":
+ self.rotary_emb = PersimmonDynamicNTKScalingRotaryEmbedding(
+ int(self.partial_rotary_factor * self.head_dim),
+ max_position_embeddings=self.max_position_embeddings,
+ scaling_factor=scaling_factor,
+ base=self.rope_theta,
+ )
+ else:
+ raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
+
+ # Copied from transformers.models.bloom.modeling_bloom.BloomAttention._split_heads
+ def _split_heads(self, fused_qkv: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """
+ Split the last dimension into (num_heads, head_dim) without making any copies, results share same memory
+ storage as `fused_qkv`
+
+ Args:
+ fused_qkv (`torch.tensor`, *required*): [batch_size, seq_length, num_heads * 3 * head_dim]
+
+ Returns:
+ query: [batch_size, seq_length, num_heads, head_dim] key: [batch_size, seq_length, num_heads, head_dim]
+ value: [batch_size, seq_length, num_heads, head_dim]
+ """
+ batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
+ fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads, 3, self.head_dim)
+ return fused_qkv[..., 0, :], fused_qkv[..., 1, :], fused_qkv[..., 2, :]
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ assert past_key_value == None
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # [batch_size, seq_length, 3 x hidden_size]
+ fused_qkv = self.query_key_value(hidden_states)
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_states, key_states, value_states) = self._split_heads(fused_qkv)
+
+ if self.qk_layernorm:
+ query_states = fused_layer_norm(query_states, self.q_layernorm.weight, self.q_layernorm.bias, self.q_layernorm.eps)
+ key_states = fused_layer_norm(key_states, self.k_layernorm.weight, self.k_layernorm.bias, self.k_layernorm.eps)
+
+ # Full rotary embedding
+ kv_seq_len = key_states.shape[1]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+
+ # Partial rotary embedding
+ query_rot, query_pass = (
+ query_states[..., : self.rotary_emb.dim],
+ query_states[..., self.rotary_emb.dim :],
+ )
+ key_rot, key_pass = (
+ key_states[..., : self.rotary_emb.dim],
+ key_states[..., self.rotary_emb.dim :],
+ )
+
+ query_rot = fused_apply_rotary_emb(query_rot, cos, sin, False, True)
+ key_rot = fused_apply_rotary_emb(key_rot, cos, sin, False, True)
+
+ # [batch_size, seq_length, num_heads, head_dim]
+ query_states = torch.cat((query_rot, query_pass), dim=-1)
+ key_states = torch.cat((key_rot, key_pass), dim=-1)
+ scale = 1.0 / math.sqrt(query_states.shape[-1])
+ attn_output = flash_attn_func(query_states, key_states, value_states, dropout_p=0.0, softmax_scale=scale, causal=True)
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.dense(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+class PersimmonDecoderLayer(nn.Module):
+ def __init__(self, config: PersimmonConfig):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+ self.self_attn = PersimmonAttention(config=config)
+ self.mlp = PersimmonMLP(config)
+ self.input_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.post_attention_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range
+ `[0, config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*):
+ cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ """
+
+ residual = hidden_states
+
+ hidden_states = fused_layer_norm(hidden_states, self.input_layernorm.weight, self.input_layernorm.bias, self.input_layernorm.eps)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = fused_layer_norm(hidden_states, self.post_attention_layernorm.weight, self.post_attention_layernorm.bias, self.post_attention_layernorm.eps)
+ hidden_states = self.mlp(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = hidden_states + residual
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+PERSIMMON_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`PersimmonConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Persimmon Model outputting raw hidden-states without any specific head on top.",
+ PERSIMMON_START_DOCSTRING,
+)
+class PersimmonPreTrainedModel(PreTrainedModel):
+ config_class = PersimmonConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["PersimmonDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, PersimmonModel):
+ module.gradient_checkpointing = value
+
+
+PERSIMMON_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Persimmon Model outputting raw hidden-states without any specific head on top.",
+ PERSIMMON_START_DOCSTRING,
+)
+class PersimmonModel(PersimmonPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`PersimmonDecoderLayer`]
+
+ Args:
+ config: PersimmonConfig
+ """
+
+ def __init__(self, config: PersimmonConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList([PersimmonDecoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.final_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ device=inputs_embeds.device,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(inputs_embeds.device)
+ combined_attention_mask = expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
+
+ return combined_attention_mask
+
+ @add_start_docstrings_to_model_forward(PERSIMMON_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device)
+ attention_mask = self._prepare_decoder_attention_mask(attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length)
+
+ hidden_states = inputs_embeds
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once("`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ for idx, decoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, past_key_value, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ position_ids,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = fused_layer_norm(hidden_states, self.final_layernorm.weight, self.final_layernorm.bias, self.final_layernorm.eps)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class PersimmonForCausalLM(PersimmonPreTrainedModel):
+ _tied_weights_keys = ["lm_head.weight"]
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.__init__ with LLAMA->PERSIMMON,Llama->Persimmon
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = PersimmonModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_input_embeddings
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_input_embeddings
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_output_embeddings
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_output_embeddings
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_decoder
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_decoder
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(PERSIMMON_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, PersimmonForCausalLM
+
+ >>> model = PersimmonForCausalLM.from_pretrained("adept/persimmon-8b-base")
+ >>> tokenizer = AutoTokenizer.from_pretrained("adept/persimmon-8b-base")
+
+ >>> prompt = "human: Hey, what should I eat for dinner?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ 'human: Hey, what should I eat for dinner?\n\ncat: 🐱\n\nhuman: 😐\n\n'
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ # Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.prepare_inputs_for_generation
+ def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs):
+ if past_key_values is not None:
+ past_length = past_key_values[0][0].shape[2]
+
+ # Some generation methods already pass only the last input ID
+ if input_ids.shape[1] > past_length:
+ remove_prefix_length = past_length
+ else:
+ # Default to old behavior: keep only final ID
+ remove_prefix_length = input_ids.shape[1] - 1
+
+ input_ids = input_ids[:, remove_prefix_length:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),)
+ return reordered_past
+
+
+@add_start_docstrings(
+ """
+ The Persimmon transformer with a sequence classification head on top (linear layer).
+
+ [`PersimmonForSequenceClassification`] uses the last token in order to do the classification, as other causal
+ models (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ PERSIMMON_START_DOCSTRING,
+)
+# Copied from transformers.models.llama.modeling_llama.LlamaForSequenceClassification with LLAMA->PERSIMMON,Llama->Persimmon
+class PersimmonForSequenceClassification(PersimmonPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = PersimmonModel(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(PERSIMMON_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ sequence_lengths = -1
+ else:
+ if input_ids is not None:
+ sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).long().argmax(-1) - 1).to(logits.device)
+ else:
+ sequence_lengths = -1
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
+
+ loss = None
+ if labels is not None:
+ labels = labels.to(logits.device)
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(pooled_logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(pooled_logits, labels)
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/src/otter_ai/models/fuyu/processing_fuyu.py b/src/otter_ai/models/fuyu/processing_fuyu.py
new file mode 100644
index 00000000..eb5357c6
--- /dev/null
+++ b/src/otter_ai/models/fuyu/processing_fuyu.py
@@ -0,0 +1,763 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for GIT
+"""
+import re
+from typing import Dict, List, Optional, Tuple, Union
+
+import numpy as np
+
+from transformers.processing_utils import ProcessorMixin
+from transformers.utils import TensorType, is_torch_available, logging, requires_backends
+from transformers.tokenization_utils_base import TruncationStrategy, PaddingStrategy
+
+if is_torch_available():
+ # from .image_processing_fuyu import FuyuBatchFeature
+ from transformers.models.fuyu.image_processing_fuyu import FuyuBatchFeature
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_torch_available():
+ import torch
+
+
+TEXT_REPR_BBOX_OPEN = ""
+TEXT_REPR_BBOX_CLOSE = ""
+TEXT_REPR_POINT_OPEN = ""
+TEXT_REPR_POINT_CLOSE = ""
+
+TOKEN_BBOX_OPEN_STRING = "<0x00>" #
+TOKEN_BBOX_CLOSE_STRING = "<0x01>" #
+TOKEN_POINT_OPEN_STRING = "<0x02>" #
+TOKEN_POINT_CLOSE_STRING = "<0x03>" #
+BEGINNING_OF_ANSWER_STRING = "<0x04>" #
+
+
+def full_unpacked_stream_to_tensor(
+ all_bi_tokens_to_place: List[int],
+ full_unpacked_stream: List["torch.Tensor"],
+ fill_value: int,
+ batch_size: int,
+ new_seq_len: int,
+ offset: int,
+) -> "torch.Tensor":
+ """Takes an unpacked stream of tokens (i.e. a list of tensors, one for each item in the batch) and does
+ the required padding to create a single tensor for the batch of shape batch_size x new_seq_len.
+ """
+
+ assert len(all_bi_tokens_to_place) == batch_size
+ assert len(full_unpacked_stream) == batch_size
+
+ # Create padded tensors for the full batch.
+ new_padded_tensor = torch.full(
+ [batch_size, new_seq_len],
+ fill_value=fill_value,
+ dtype=full_unpacked_stream[0].dtype,
+ device=full_unpacked_stream[0].device,
+ )
+
+ # Place each batch entry into the batch tensor.
+ for bi in range(batch_size):
+ tokens_to_place = all_bi_tokens_to_place[bi]
+ new_padded_tensor[bi, :tokens_to_place] = full_unpacked_stream[bi][offset : tokens_to_place + offset]
+
+ return new_padded_tensor
+
+
+def construct_full_unpacked_stream(
+ num_real_text_tokens: Union[List[List[int]], "torch.Tensor"],
+ input_stream: "torch.Tensor",
+ image_tokens: List[List["torch.Tensor"]],
+ batch_size: int,
+ num_sub_sequences: int,
+) -> List["torch.Tensor"]:
+ """Takes an input_stream tensor of shape B x S x ?. For each subsequence, adds any required
+ padding to account for images and then unpacks the subsequences to create a single sequence per item in the batch.
+ Returns a list of tensors, one for each item in the batch."""
+
+ all_bi_stream = []
+
+ for batch_index in range(batch_size):
+ all_si_stream = []
+
+ # First, construct full token stream (including image placeholder tokens) and loss mask for each subsequence
+ # and append to lists. We use lists rather than tensors because each subsequence is variable-sized.
+ # TODO Remove this logic in a subsequent release since subsequences are not supported.
+ image_adjustment = image_tokens[batch_index][0]
+ subsequence_stream = torch.cat([image_adjustment, input_stream[batch_index, 0]], dim=0)
+ num_real_tokens = image_adjustment.shape[0] + num_real_text_tokens[batch_index][0]
+ all_si_stream.append(subsequence_stream[:num_real_tokens])
+ all_bi_stream.append(torch.cat(all_si_stream, dim=0))
+
+ return all_bi_stream
+
+
+def _replace_string_repr_with_token_tags(prompt: str) -> str:
+ prompt = prompt.replace(TEXT_REPR_POINT_OPEN, TOKEN_POINT_OPEN_STRING)
+ prompt = prompt.replace(TEXT_REPR_POINT_CLOSE, TOKEN_POINT_CLOSE_STRING)
+ prompt = prompt.replace(TEXT_REPR_BBOX_OPEN, TOKEN_BBOX_OPEN_STRING)
+ prompt = prompt.replace(TEXT_REPR_BBOX_CLOSE, TOKEN_BBOX_CLOSE_STRING)
+ return prompt
+
+
+def _segment_prompt_into_text_token_conversions(prompt: str) -> List:
+ """
+ Given a string prompt, converts the prompt into a list of TextTokenConversions.
+ """
+ # Wherever, we notice the [TOKEN_OPEN_STRING, TOKEN_CLOSE_STRING], we split the prompt
+ prompt_text_list: List = []
+ regex_pattern = re.compile(f"({TOKEN_BBOX_OPEN_STRING}|{TOKEN_BBOX_CLOSE_STRING}|{TOKEN_POINT_OPEN_STRING}|{TOKEN_POINT_CLOSE_STRING})")
+ # Split by the regex pattern
+ prompt_split = regex_pattern.split(prompt)
+ for i, elem in enumerate(prompt_split):
+ if len(elem) == 0 or elem in [
+ TOKEN_BBOX_OPEN_STRING,
+ TOKEN_BBOX_CLOSE_STRING,
+ TOKEN_POINT_OPEN_STRING,
+ TOKEN_POINT_CLOSE_STRING,
+ ]:
+ continue
+ prompt_text_list.append((elem, i > 1 and prompt_split[i - 1] in [TOKEN_BBOX_OPEN_STRING, TOKEN_POINT_OPEN_STRING]))
+ return prompt_text_list
+
+
+def _transform_coordinates_and_tokenize(prompt: str, scale_factor: float, tokenizer) -> List[int]:
+ """
+ This function transforms the prompt in the following fashion:
+ - and to their respective token mappings
+ - extract the coordinates from the tag
+ - transform the coordinates into the transformed image space
+ - return the prompt tokens with the transformed coordinates and new tags
+
+ Bounding boxes and points MUST be in the following format: y1, x1, y2, x2 x, y The spaces
+ and punctuation added above are NOT optional.
+ """
+ # Make a namedtuple that stores "text" and "is_bbox"
+
+ # We want to do the following: Tokenize the code normally -> when we see a point or box, tokenize using the tokenize_within_tag function
+ # When point or box close tag, continue tokenizing normally
+ # First, we replace the point and box tags with their respective tokens
+ prompt = _replace_string_repr_with_token_tags(prompt)
+ # Tokenize the prompt
+ # Convert prompt into a list split
+ prompt_text_list = _segment_prompt_into_text_token_conversions(prompt)
+ transformed_prompt_tokens: List[int] = []
+ for elem in prompt_text_list:
+ if elem[1]:
+ # This is a location, we need to tokenize it
+ within_tag_tokenized = _transform_within_tags(elem[0], scale_factor, tokenizer)
+ # Surround the text with the open and close tags
+ transformed_prompt_tokens.extend(within_tag_tokenized)
+ else:
+ transformed_prompt_tokens.extend(tokenizer(elem[0], add_special_tokens=False).input_ids)
+ return transformed_prompt_tokens
+
+
+def _transform_within_tags(text: str, scale_factor: float, tokenizer) -> List[int]:
+ """
+ Given a bounding box of the fashion 1, 2, 3, 4 | 1, 2 This function is responsible for
+ converting 1, 2, 3, 4 into tokens of 1 2 3 4 without any commas.
+ """
+ # Convert the text into a list of strings.
+ num_int_strs = text.split(",")
+ if len(num_int_strs) == 2:
+ # If there are any open or close tags, remove them.
+ token_space_open_string = tokenizer.vocab[TOKEN_POINT_OPEN_STRING]
+ token_space_close_string = tokenizer.vocab[TOKEN_POINT_CLOSE_STRING]
+ else:
+ token_space_open_string = tokenizer.vocab[TOKEN_BBOX_OPEN_STRING]
+ token_space_close_string = tokenizer.vocab[TOKEN_BBOX_CLOSE_STRING]
+
+ # Remove all spaces from num_ints
+ num_ints = [float(num.strip()) for num in num_int_strs]
+ # scale to transformed image siz
+ if len(num_ints) == 2:
+ num_ints_translated = scale_point_to_transformed_image(x=num_ints[0], y=num_ints[1], scale_factor=scale_factor)
+ elif len(num_ints) == 4:
+ num_ints_translated = scale_bbox_to_transformed_image(
+ top=num_ints[0],
+ left=num_ints[1],
+ bottom=num_ints[2],
+ right=num_ints[3],
+ scale_factor=scale_factor,
+ )
+ else:
+ raise ValueError(f"Invalid number of ints: {len(num_ints)}")
+ # Tokenize the text, skipping the
+ tokens = [tokenizer.vocab[str(num)] for num in num_ints_translated]
+ return [token_space_open_string] + tokens + [token_space_close_string]
+
+
+def _tokenize_prompts_with_image_and_batch(
+ tokenizer,
+ prompts: List[List[str]],
+ scale_factors: Optional[List[List["torch.Tensor"]]],
+ max_tokens_to_generate: int,
+ max_position_embeddings: int,
+ add_BOS: bool, # Same issue with types as above
+ add_beginning_of_answer_token: bool,
+) -> Tuple["torch.Tensor", "torch.Tensor"]:
+ """
+ Given a set of prompts and number of tokens to generate:
+ - tokenize prompts
+ - set the sequence length to be the max of length of prompts plus the number of tokens we would like to generate
+ - pad all the sequences to this length so we can convert them into a 3D tensor.
+ """
+
+ # If not tool use, tranform the coordinates while tokenizing
+ if scale_factors is not None:
+ transformed_prompt_tokens = []
+ for prompt_seq, scale_factor_seq in zip(prompts, scale_factors):
+ transformed_prompt_tokens.append([_transform_coordinates_and_tokenize(prompt, scale_factor.item(), tokenizer) for prompt, scale_factor in zip(prompt_seq, scale_factor_seq)])
+ else:
+ transformed_prompt_tokens = [[tokenizer.tokenize(prompt) for prompt in prompt_seq] for prompt_seq in prompts]
+
+ prompts_tokens = transformed_prompt_tokens
+
+ if add_BOS:
+ bos_token = tokenizer.vocab[""]
+ else:
+ bos_token = tokenizer.vocab["|ENDOFTEXT|"]
+ prompts_tokens = [[[bos_token] + x for x in prompt_seq] for prompt_seq in prompts_tokens]
+ if add_beginning_of_answer_token:
+ boa = tokenizer.vocab[BEGINNING_OF_ANSWER_STRING]
+ # Only add bbox open token to the last subsequence since that is what will be completed
+ for token_seq in prompts_tokens:
+ token_seq[-1].append(boa)
+
+ # Now we have a list of list of tokens which each list has a different
+ # size. We want to extend this list to:
+ # - incorporate the tokens that need to be generated
+ # - make all the sequences equal length.
+ # Get the prompts length.
+
+ prompts_length = [[len(x) for x in prompts_tokens_seq] for prompts_tokens_seq in prompts_tokens]
+ # Get the max prompts length.
+ max_prompt_len: int = np.max(prompts_length)
+ # Number of tokens in the each sample of the batch.
+ samples_length = min(max_prompt_len + max_tokens_to_generate, max_position_embeddings)
+ if max_prompt_len + max_tokens_to_generate > max_position_embeddings:
+ logger.warning(
+ f"Max subsequence prompt length of {max_prompt_len} + max tokens to generate {max_tokens_to_generate}",
+ f"exceeds context length of {max_position_embeddings}. Will generate as many tokens as possible.",
+ )
+ # Now update the list of list to be of the same size: samples_length.
+ for prompt_tokens_seq, prompts_length_seq in zip(prompts_tokens, prompts_length):
+ for prompt_tokens, prompt_length in zip(prompt_tokens_seq, prompts_length_seq):
+ if len(prompt_tokens) > samples_length:
+ raise ValueError("Length of subsequence prompt exceeds sequence length.")
+ padding_size = samples_length - prompt_length
+ prompt_tokens.extend([tokenizer.vocab["|ENDOFTEXT|"]] * padding_size)
+
+ # Now we are in a structured format, we can convert to tensors.
+ prompts_tokens_tensor = torch.tensor(prompts_tokens, dtype=torch.int64)
+ prompts_length_tensor = torch.tensor(prompts_length, dtype=torch.int64)
+
+ return prompts_tokens_tensor, prompts_length_tensor
+
+
+# Simplified assuming self.crop_top = self.padding_top = 0
+def original_to_transformed_h_coords(original_coords, scale_h):
+ return np.round(original_coords * scale_h).astype(np.int32)
+
+
+# Simplified assuming self.crop_left = self.padding_left = 0
+def original_to_transformed_w_coords(original_coords, scale_w):
+ return np.round(original_coords * scale_w).astype(np.int32)
+
+
+def scale_point_to_transformed_image(x: float, y: float, scale_factor: float) -> List[int]:
+ x_scaled = original_to_transformed_w_coords(np.array([x / 2]), scale_factor)[0]
+ y_scaled = original_to_transformed_h_coords(np.array([y / 2]), scale_factor)[0]
+ return [x_scaled, y_scaled]
+
+
+def scale_bbox_to_transformed_image(top: float, left: float, bottom: float, right: float, scale_factor: float) -> List[int]:
+ top_scaled = original_to_transformed_w_coords(np.array([top / 2]), scale_factor)[0]
+ left_scaled = original_to_transformed_h_coords(np.array([left / 2]), scale_factor)[0]
+ bottom_scaled = original_to_transformed_w_coords(np.array([bottom / 2]), scale_factor)[0]
+ right_scaled = original_to_transformed_h_coords(np.array([right / 2]), scale_factor)[0]
+ return [top_scaled, left_scaled, bottom_scaled, right_scaled]
+
+
+class FuyuProcessor(ProcessorMixin):
+ r"""
+ Constructs a Fuyu processor which wraps a Fuyu image processor and a Llama tokenizer into a single processor.
+
+ [`FuyuProcessor`] offers all the functionalities of [`FuyuImageProcessor`] and [`LlamaTokenizerFast`]. See the
+ [`~FuyuProcessor.__call__`] and [`~FuyuProcessor.decode`] for more information.
+
+ Args:
+ image_processor ([`FuyuImageProcessor`]):
+ The image processor is a required input.
+ tokenizer ([`LlamaTokenizerFast`]):
+ The tokenizer is a required input.
+ """
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "FuyuImageProcessor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor=image_processor, tokenizer=tokenizer)
+ self.image_processor = image_processor
+ self.tokenizer = tokenizer
+ self.max_tokens_to_generate = 10
+ self.max_position_embeddings = 16384 # TODO Can't derive this from model files: where to set it?
+ self.pad_token_id = tokenizer.eos_token_id
+ self.dummy_image_index = -1
+
+ def find_and_remove_tokens(self, input_ids, labels, token_id):
+ batch_size, seq_len = input_ids.size()
+
+ # Create lists to store the new tensors
+ new_input_list = []
+ new_labels_list = []
+
+ for i in range(batch_size):
+ single_input = input_ids[i, :]
+ single_label = labels[i, :]
+
+ # Remove the last token_id
+ token_indices = (single_input == token_id).nonzero(as_tuple=True)[0]
+ if len(token_indices) > 1:
+ last_token_index = token_indices[-1]
+ single_input[last_token_index] = self.tokenizer.eos_token_id
+ single_label[last_token_index] = self.tokenizer.eos_token_id
+
+ # Append the new sequence to the list
+ new_input_list.append(single_input)
+ new_labels_list.append(single_label)
+
+ return torch.stack(new_input_list), torch.stack(new_labels_list)
+
+ def get_labels(self, input_ids, special_token_id, masking_number=-100):
+ # Initialize labels tensor filled with masking_number
+ labels = torch.full_like(input_ids, masking_number)
+
+ # Iterate through each sequence in the batch
+ for i in range(input_ids.shape[0]):
+ seq = input_ids[i]
+
+ # Find the indices of the special_token_id
+ indices = (seq == special_token_id).nonzero(as_tuple=False).squeeze()
+
+ # If there are at least two occurrences of special_token_id
+ if len(indices) >= 2:
+ start, end = indices[0], indices[1] + 1
+
+ # Unmask the tokens between the first and second occurrence
+ labels[i, start + 1 : end] = seq[start + 1 : end]
+
+ return labels
+
+ def _right_pad_inputs_with_attention_mask(self, model_inputs: List[Dict], return_attention_mask: bool):
+ max_length_input_ids = max(entry["input_ids"].shape[1] for entry in model_inputs)
+ max_length_image_patch_indices = max(entry["image_patches_indices"].shape[1] for entry in model_inputs)
+
+ batched_inputs = {"input_ids": [], "image_patches": [], "image_patches_indices": [], "attention_mask": []}
+
+ for entry in model_inputs:
+ for key, tensor in entry.items():
+ if key == "input_ids":
+ num_padding_tokens = max_length_input_ids - tensor.shape[1]
+ padded_input_ids = torch.cat(
+ [tensor, torch.full((tensor.shape[0], num_padding_tokens), self.pad_token_id, dtype=torch.long)],
+ dim=1,
+ )
+ batched_inputs[key].append(padded_input_ids)
+
+ attention_mask = torch.cat(
+ [torch.ones_like(tensor), torch.zeros(tensor.shape[0], num_padding_tokens, dtype=torch.long)],
+ dim=1,
+ )
+ batched_inputs["attention_mask"].append(attention_mask)
+
+ elif key == "image_patches":
+ # For image_patches, we don't pad but just append them to the list.
+ batched_inputs[key].append(tensor)
+
+ else: # for image_patches_indices
+ num_padding_indices = max_length_image_patch_indices - tensor.shape[1]
+ padded_indices = torch.cat(
+ [tensor, torch.full((tensor.shape[0], num_padding_indices), self.dummy_image_index, dtype=torch.long)],
+ dim=1,
+ )
+ batched_inputs[key].append(padded_indices)
+
+ batched_keys = ["input_ids", "image_patches_indices"]
+ if return_attention_mask:
+ batched_keys.append("attention_mask")
+ for key in batched_keys:
+ batched_inputs[key] = torch.cat(batched_inputs[key], dim=0)
+
+ return batched_inputs
+
+ def _left_pad_inputs_with_attention_mask(self, model_inputs: List[Dict], return_attention_mask: bool):
+ max_length_input_ids = max(entry["input_ids"].shape[1] for entry in model_inputs)
+ max_length_image_patch_indices = max(entry["image_patches_indices"].shape[1] for entry in model_inputs)
+
+ batched_inputs = {"input_ids": [], "image_patches": [], "image_patches_indices": [], "attention_mask": []}
+
+ for entry in model_inputs:
+ for key, tensor in entry.items():
+ if key == "input_ids":
+ num_padding_tokens = max_length_input_ids - tensor.shape[1]
+ padded_input_ids = torch.cat(
+ [
+ torch.full((tensor.shape[0], num_padding_tokens), self.pad_token_id, dtype=torch.long),
+ tensor,
+ ],
+ dim=1,
+ )
+ batched_inputs[key].append(padded_input_ids)
+
+ attention_mask = torch.cat(
+ [torch.zeros(tensor.shape[0], num_padding_tokens, dtype=torch.long), torch.ones_like(tensor)],
+ dim=1,
+ )
+ batched_inputs["attention_mask"].append(attention_mask)
+
+ elif key == "image_patches":
+ # For image_patches, we don't pad but just append them to the list.
+ batched_inputs[key].append(tensor)
+
+ else: # for image_patches_indices
+ num_padding_indices = max_length_image_patch_indices - tensor.shape[1]
+ padded_indices = torch.cat(
+ [
+ torch.full((tensor.shape[0], num_padding_indices), self.dummy_image_index, dtype=torch.long),
+ tensor,
+ ],
+ dim=1,
+ )
+ batched_inputs[key].append(padded_indices)
+ batched_keys = ["input_ids", "image_patches_indices"]
+ if return_attention_mask:
+ batched_keys.append("attention_mask")
+ for key in batched_keys:
+ batched_inputs[key] = torch.cat(batched_inputs[key], dim=0)
+
+ return batched_inputs
+
+ def get_sample_encoding(
+ self,
+ prompts,
+ scale_factors,
+ image_unpadded_heights,
+ image_unpadded_widths,
+ image_placeholder_id,
+ image_newline_id,
+ tensor_batch_images,
+ ):
+ image_present = torch.ones(1, 1, 1)
+ model_image_input = self.image_processor.preprocess_with_tokenizer_info(
+ image_input=tensor_batch_images,
+ image_present=image_present,
+ image_unpadded_h=image_unpadded_heights,
+ image_unpadded_w=image_unpadded_widths,
+ image_placeholder_id=image_placeholder_id,
+ image_newline_id=image_newline_id,
+ variable_sized=True,
+ )
+ # FIXME max_tokens_to_generate is embedded into this processor's call.
+ prompt_tokens, prompts_length = _tokenize_prompts_with_image_and_batch(
+ tokenizer=self.tokenizer,
+ prompts=prompts,
+ scale_factors=scale_factors,
+ max_tokens_to_generate=self.max_tokens_to_generate,
+ max_position_embeddings=self.max_position_embeddings,
+ add_BOS=True,
+ add_beginning_of_answer_token=True,
+ )
+ image_padded_unpacked_tokens = construct_full_unpacked_stream(
+ num_real_text_tokens=prompts_length,
+ input_stream=prompt_tokens,
+ image_tokens=model_image_input["image_input_ids"],
+ batch_size=1,
+ num_sub_sequences=self.subsequence_length,
+ )
+ # Construct inputs for image patch indices.
+ unpacked_image_patch_indices_per_batch = construct_full_unpacked_stream(
+ num_real_text_tokens=prompts_length,
+ input_stream=torch.full_like(prompt_tokens, -1),
+ image_tokens=model_image_input["image_patch_indices_per_batch"],
+ batch_size=1,
+ num_sub_sequences=self.subsequence_length,
+ )
+ max_prompt_length = max(x.shape[-1] for x in image_padded_unpacked_tokens)
+ max_seq_len_batch = min(max_prompt_length + self.max_tokens_to_generate, self.max_position_embeddings)
+ tokens_to_place = min(max_seq_len_batch, max(0, image_padded_unpacked_tokens[0].shape[0]))
+
+ # Use same packing logic for the image patch indices.
+ image_patch_input_indices = full_unpacked_stream_to_tensor(
+ all_bi_tokens_to_place=[tokens_to_place],
+ full_unpacked_stream=unpacked_image_patch_indices_per_batch,
+ fill_value=-1,
+ batch_size=1,
+ new_seq_len=max_seq_len_batch,
+ offset=0,
+ )
+ image_patches_tensor = torch.stack([img[0] for img in model_image_input["image_patches"]])
+ batch_encoding = {
+ "input_ids": image_padded_unpacked_tokens[0].unsqueeze(0),
+ "image_patches": image_patches_tensor,
+ "image_patches_indices": image_patch_input_indices,
+ }
+ return batch_encoding
+
+ def __call__(
+ self,
+ text=None,
+ images=None,
+ add_special_tokens: bool = True,
+ return_attention_mask: bool = True,
+ padding: Union[bool, str, PaddingStrategy] = False,
+ truncation: Union[bool, str, TruncationStrategy] = None,
+ max_length: Optional[int] = None,
+ stride: int = 0,
+ pad_to_multiple_of: Optional[int] = None,
+ return_overflowing_tokens: bool = False,
+ return_special_tokens_mask: bool = False,
+ return_offsets_mapping: bool = False,
+ return_token_type_ids: bool = False,
+ return_length: bool = False,
+ verbose: bool = True,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs,
+ ) -> "FuyuBatchFeature":
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to LlamaTokenizerFast's [`~LlamaTokenizerFast.__call__`] if `text` is not `None` to
+ encode the text. To prepare the image(s), this method forwards the `images` and `kwargs` arguments to
+ FuyuImageProcessor's [`~FuyuImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
+ of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`PIL.Image.Image`, `List[PIL.Image.Image]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+
+ Returns:
+ [`FuyuBatchEncoding`]: A [`FuyuBatchEncoding`] with the following fields:
+
+ - **input_ids** -- Tensor of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **image_patches** -- List of Tensor of image patches. Returned when `images` is not `None`.
+ - **image_patches_indices** -- Tensor of indices where patch embeddings have to be inserted by the model.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model when
+ `return_attention_mask=True`.
+ """
+ requires_backends(self, ["torch"])
+
+ # --- Check input validity ---
+ if not return_attention_mask:
+ raise ValueError("`return_attention_mask=False` is not supported for this model.")
+ if text is None and images is None:
+ raise ValueError("You have to specify either text or images. Both cannot be None.")
+ if text is not None and images is None:
+ logger.warning("You are processing a text with no associated image. Make sure it is intended.")
+ self.current_processor = self.tokenizer
+ text_encoding = self.tokenizer(
+ text=text,
+ add_special_tokens=add_special_tokens,
+ padding=padding,
+ truncation=truncation,
+ max_length=max_length,
+ stride=stride,
+ pad_to_multiple_of=pad_to_multiple_of,
+ return_attention_mask=return_attention_mask,
+ return_overflowing_tokens=return_overflowing_tokens,
+ return_special_tokens_mask=return_special_tokens_mask,
+ return_offsets_mapping=return_offsets_mapping,
+ return_token_type_ids=return_token_type_ids,
+ return_length=return_length,
+ verbose=verbose,
+ return_tensors=return_tensors,
+ **kwargs,
+ )
+ return text_encoding
+
+ if text is None and images is not None:
+ logger.warning("You are processing an image with no associated text. Make sure it is intended.")
+ prompts = [[""]]
+ if text is not None and images is not None:
+ if isinstance(text, str):
+ prompts = [[text]]
+ elif isinstance(text, list):
+ prompts = [[text_seq] for text_seq in text]
+
+ # --- Preprocess images using self.image_processor ---
+
+ # FIXME - We hard code "pt" here because the rest of the processing assumes torch tensors
+ image_encoding = self.image_processor.preprocess(images, return_tensors="pt")
+ batch_images = image_encoding["images"]
+ image_unpadded_heights = image_encoding["image_unpadded_heights"]
+ image_unpadded_widths = image_encoding["image_unpadded_widths"]
+ scale_factors = image_encoding["image_scale_factors"]
+ self.subsequence_length = 1 # Each batch contains only one sequence.
+ self.batch_size = len(batch_images)
+
+ # --- Use self.tokenizer to get the ids of special tokens to insert into image ids ---
+
+ image_placeholder_id = self.tokenizer("|SPEAKER|", add_special_tokens=False)["input_ids"][1]
+ image_newline_id = self.tokenizer("|NEWLINE|", add_special_tokens=False)["input_ids"][1]
+ tensor_batch_images = torch.stack([img[0] for img in batch_images]).unsqueeze(1)
+
+ # --- Use self.image_processor again to obtain the full token ids and batch inputs ---
+ all_encodings = []
+
+ for prompt, scale_factor, image_unpadded_height, image_unpadded_width, tensor_batch_image in zip(prompts, scale_factors, image_unpadded_heights, image_unpadded_widths, tensor_batch_images):
+ sample_encoding = self.get_sample_encoding(
+ prompts=[prompt],
+ scale_factors=[scale_factor],
+ image_unpadded_heights=torch.tensor([image_unpadded_height]),
+ image_unpadded_widths=torch.tensor([image_unpadded_width]),
+ image_placeholder_id=image_placeholder_id,
+ image_newline_id=image_newline_id,
+ tensor_batch_images=tensor_batch_image.unsqueeze(0),
+ )
+ all_encodings.append(sample_encoding)
+ batch_encoding = self._right_pad_inputs_with_attention_mask(model_inputs=all_encodings, return_attention_mask=return_attention_mask)
+ return FuyuBatchFeature(data=batch_encoding)
+
+ def post_process_box_coordinates(self, outputs, target_sizes=None):
+ """
+ Transforms raw coordinates detected by [`FuyuForCausalLM`] to the original images' coordinate space.
+ Coordinates will be returned in "box" format, with the following pattern:
+ `top, left, bottom, right`
+
+ Point coordinates are not supported yet.
+
+ Args:
+ outputs ([`GenerateOutput`]):
+ Raw outputs from `generate`.
+ target_sizes (`torch.Tensor`, *optional*):
+ Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
+ the batch. If set, found coordinates in the output sequence are rescaled to the target sizes. If left
+ to None, coordinates will not be rescaled.
+
+ Returns:
+ `GenerateOutput`: Same output type returned by `generate`, with output token ids replaced with
+ boxed and possible rescaled coordinates.
+ """
+
+ def scale_factor_to_fit(original_size, target_size=None):
+ height, width = original_size
+ if target_size is None:
+ max_height = self.image_processor.size["height"]
+ max_width = self.image_processor.size["width"]
+ else:
+ max_height, max_width = target_size
+ if width <= max_width and height <= max_height:
+ return 1.0
+ return min(max_height / height, max_width / width)
+
+ def find_delimiters_pair(tokens, start_token, end_token):
+ start_id = self.tokenizer.convert_tokens_to_ids(start_token)
+ end_id = self.tokenizer.convert_tokens_to_ids(end_token)
+
+ starting_positions = (tokens == start_id).nonzero(as_tuple=True)[0]
+ ending_positions = (tokens == end_id).nonzero(as_tuple=True)[0]
+
+ if torch.any(starting_positions) and torch.any(ending_positions):
+ return (starting_positions[0], ending_positions[0])
+ return (None, None)
+
+ def tokens_to_boxes(tokens, original_size):
+ while (pair := find_delimiters_pair(tokens, TOKEN_BBOX_OPEN_STRING, TOKEN_BBOX_CLOSE_STRING)) != (
+ None,
+ None,
+ ):
+ start, end = pair
+ if end != start + 5:
+ continue
+
+ # Retrieve transformed coordinates from tokens
+ coords = self.tokenizer.convert_ids_to_tokens(tokens[start + 1 : end])
+
+ # Scale back to original image size and multiply by 2
+ scale = scale_factor_to_fit(original_size)
+ top, left, bottom, right = [2 * int(float(c) / scale) for c in coords]
+
+ # Replace the IDs so they get detokenized right
+ replacement = f" {TEXT_REPR_BBOX_OPEN}{top}, {left}, {bottom}, {right}{TEXT_REPR_BBOX_CLOSE}"
+ replacement = self.tokenizer.tokenize(replacement)[1:]
+ replacement = self.tokenizer.convert_tokens_to_ids(replacement)
+ replacement = torch.tensor(replacement).to(tokens)
+
+ tokens = torch.cat([tokens[:start], replacement, tokens[end + 1 :]], 0)
+ return tokens
+
+ def tokens_to_points(tokens, original_size):
+ while (pair := find_delimiters_pair(tokens, TOKEN_POINT_OPEN_STRING, TOKEN_POINT_CLOSE_STRING)) != (
+ None,
+ None,
+ ):
+ start, end = pair
+ if end != start + 3:
+ continue
+
+ # Retrieve transformed coordinates from tokens
+ coords = self.tokenizer.convert_ids_to_tokens(tokens[start + 1 : end])
+
+ # Scale back to original image size and multiply by 2
+ scale = scale_factor_to_fit(original_size)
+ x, y = [2 * int(float(c) / scale) for c in coords]
+
+ # Replace the IDs so they get detokenized right
+ replacement = f" {TEXT_REPR_POINT_OPEN}{x}, {y}{TEXT_REPR_POINT_CLOSE}"
+ replacement = self.tokenizer.tokenize(replacement)[1:]
+ replacement = self.tokenizer.convert_tokens_to_ids(replacement)
+ replacement = torch.tensor(replacement).to(tokens)
+
+ tokens = torch.cat([tokens[:start], replacement, tokens[end + 1 :]], 0)
+ return tokens
+
+ if target_sizes is None:
+ target_sizes = ((self.image_processor.size["height"], self.image_processor.size["width"]),) * len(outputs)
+ elif target_sizes.shape[1] != 2:
+ raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
+
+ if len(outputs) != len(target_sizes):
+ raise ValueError("Make sure that you pass in as many target sizes as output sequences")
+
+ results = []
+ for seq, size in zip(outputs, target_sizes):
+ seq = tokens_to_boxes(seq, size)
+ seq = tokens_to_points(seq, size)
+ results.append(seq)
+
+ return results
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
diff --git a/src/otter_ai/models/mpt/__init__.py b/src/otter_ai/models/mpt/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/src/otter_ai/models/flamingo/mpt/adapt_tokenizer.py b/src/otter_ai/models/mpt/adapt_tokenizer.py
old mode 100644
new mode 100755
similarity index 100%
rename from src/otter_ai/models/flamingo/mpt/adapt_tokenizer.py
rename to src/otter_ai/models/mpt/adapt_tokenizer.py
diff --git a/src/otter_ai/models/flamingo/mpt/attention.py b/src/otter_ai/models/mpt/attention.py
old mode 100644
new mode 100755
similarity index 93%
rename from src/otter_ai/models/flamingo/mpt/attention.py
rename to src/otter_ai/models/mpt/attention.py
index 61fcfdee..708fb5ec
--- a/src/otter_ai/models/flamingo/mpt/attention.py
+++ b/src/otter_ai/models/mpt/attention.py
@@ -273,17 +273,21 @@ def __init__(
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
if torch.cuda.is_available() and verbose:
- warnings.warn(
- "Using `attn_impl: torch`. If your model does not use `alibi` or "
- + "`prefix_lm` we recommend using `attn_impl: flash` otherwise "
- + "we recommend using `attn_impl: triton`."
- )
+ warnings.warn("Using `attn_impl: torch`. If your model does not use `alibi` or " + "`prefix_lm` we recommend using `attn_impl: flash` otherwise " + "we recommend using `attn_impl: triton`.")
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True
- def forward(self, x, past_key_value=None, attn_bias=None, attention_mask=None, is_causal=True, needs_weights=False):
+ def forward(
+ self,
+ x,
+ past_key_value=None,
+ attn_bias=None,
+ attention_mask=None,
+ is_causal=True,
+ needs_weights=False,
+ ):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
@@ -362,17 +366,21 @@ def __init__(
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
if torch.cuda.is_available() and verbose:
- warnings.warn(
- "Using `attn_impl: torch`. If your model does not use `alibi` or "
- + "`prefix_lm` we recommend using `attn_impl: flash` otherwise "
- + "we recommend using `attn_impl: triton`."
- )
+ warnings.warn("Using `attn_impl: torch`. If your model does not use `alibi` or " + "`prefix_lm` we recommend using `attn_impl: flash` otherwise " + "we recommend using `attn_impl: triton`.")
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True
- def forward(self, x, past_key_value=None, attn_bias=None, attention_mask=None, is_causal=True, needs_weights=False):
+ def forward(
+ self,
+ x,
+ past_key_value=None,
+ attn_bias=None,
+ attention_mask=None,
+ is_causal=True,
+ needs_weights=False,
+ ):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
@@ -421,7 +429,16 @@ def build_attn_bias(attn_impl, attn_bias, n_heads, seq_len, causal=False, alibi=
elif attn_impl in ["torch", "triton"]:
if alibi:
(device, dtype) = (attn_bias.device, attn_bias.dtype)
- attn_bias = attn_bias.add(build_alibi_bias(n_heads, seq_len, full=not causal, alibi_bias_max=alibi_bias_max, device=device, dtype=dtype))
+ attn_bias = attn_bias.add(
+ build_alibi_bias(
+ n_heads,
+ seq_len,
+ full=not causal,
+ alibi_bias_max=alibi_bias_max,
+ device=device,
+ dtype=dtype,
+ )
+ )
return attn_bias
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
@@ -447,4 +464,7 @@ def build_alibi_bias(n_heads, seq_len, full=False, alibi_bias_max=8, device=None
return alibi_bias.to(dtype=dtype)
-ATTN_CLASS_REGISTRY = {"multihead_attention": MultiheadAttention, "multiquery_attention": MultiQueryAttention}
+ATTN_CLASS_REGISTRY = {
+ "multihead_attention": MultiheadAttention,
+ "multiquery_attention": MultiQueryAttention,
+}
diff --git a/src/otter_ai/models/flamingo/mpt/blocks.py b/src/otter_ai/models/mpt/blocks.py
old mode 100644
new mode 100755
similarity index 92%
rename from src/otter_ai/models/flamingo/mpt/blocks.py
rename to src/otter_ai/models/mpt/blocks.py
index dc16f5da..28a165c5
--- a/src/otter_ai/models/flamingo/mpt/blocks.py
+++ b/src/otter_ai/models/mpt/blocks.py
@@ -74,7 +74,13 @@ def forward(
is_causal: bool = True,
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor]]]:
a = self.norm_1(x)
- (b, attn_weights, past_key_value) = self.attn(a, past_key_value=past_key_value, attn_bias=attn_bias, attention_mask=attention_mask, is_causal=is_causal)
+ (b, attn_weights, past_key_value) = self.attn(
+ a,
+ past_key_value=past_key_value,
+ attn_bias=attn_bias,
+ attention_mask=attention_mask,
+ is_causal=is_causal,
+ )
x = x + self.resid_attn_dropout(b)
m = self.norm_2(x)
n = self.ffn(m)
diff --git a/src/otter_ai/models/flamingo/mpt/configuration_mpt.py b/src/otter_ai/models/mpt/configuration_mpt.py
old mode 100644
new mode 100755
similarity index 95%
rename from src/otter_ai/models/flamingo/mpt/configuration_mpt.py
rename to src/otter_ai/models/mpt/configuration_mpt.py
index 8b35ee01..3e5064ff
--- a/src/otter_ai/models/flamingo/mpt/configuration_mpt.py
+++ b/src/otter_ai/models/mpt/configuration_mpt.py
@@ -141,13 +141,28 @@ def _validate_config(self):
self.init_config = self._set_config_defaults(self.init_config, init_config_defaults)
if self.d_model % self.n_heads != 0:
raise ValueError("d_model must be divisible by n_heads")
- if any((prob < 0 or prob > 1 for prob in [self.attn_config["attn_pdrop"], self.resid_pdrop, self.emb_pdrop])):
+ if any(
+ (
+ prob < 0 or prob > 1
+ for prob in [
+ self.attn_config["attn_pdrop"],
+ self.resid_pdrop,
+ self.emb_pdrop,
+ ]
+ )
+ ):
raise ValueError("self.attn_config['attn_pdrop'], resid_pdrop, emb_pdrop are probabilities and must be between 0 and 1")
if self.attn_config["attn_impl"] not in ["torch", "flash", "triton"]:
raise ValueError(f"Unknown attn_impl={self.attn_config['attn_impl']}")
- if self.attn_config["prefix_lm"] and self.attn_config["attn_impl"] not in ["torch", "triton"]:
+ if self.attn_config["prefix_lm"] and self.attn_config["attn_impl"] not in [
+ "torch",
+ "triton",
+ ]:
raise NotImplementedError("prefix_lm only implemented with torch and triton attention.")
- if self.attn_config["alibi"] and self.attn_config["attn_impl"] not in ["torch", "triton"]:
+ if self.attn_config["alibi"] and self.attn_config["attn_impl"] not in [
+ "torch",
+ "triton",
+ ]:
raise NotImplementedError("alibi only implemented with torch and triton attention.")
if self.attn_config["attn_uses_sequence_id"] and self.attn_config["attn_impl"] not in ["torch", "triton"]:
raise NotImplementedError("attn_uses_sequence_id only implemented with torch and triton attention.")
diff --git a/src/otter_ai/models/flamingo/mpt/custom_embedding.py b/src/otter_ai/models/mpt/custom_embedding.py
old mode 100644
new mode 100755
similarity index 100%
rename from src/otter_ai/models/flamingo/mpt/custom_embedding.py
rename to src/otter_ai/models/mpt/custom_embedding.py
diff --git a/src/otter_ai/models/flamingo/mpt/flash_attn_triton.py b/src/otter_ai/models/mpt/flash_attn_triton.py
old mode 100644
new mode 100755
similarity index 81%
rename from src/otter_ai/models/flamingo/mpt/flash_attn_triton.py
rename to src/otter_ai/models/mpt/flash_attn_triton.py
index 07277af6..965d6c7a
--- a/src/otter_ai/models/flamingo/mpt/flash_attn_triton.py
+++ b/src/otter_ai/models/mpt/flash_attn_triton.py
@@ -121,7 +121,11 @@ def _fwd_kernel(
elif EVEN_HEADDIM:
q = tl.load(q_ptrs, mask=offs_m[:, None] < seqlen_q, other=0.0)
else:
- q = tl.load(q_ptrs, mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0)
+ q = tl.load(
+ q_ptrs,
+ mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
end_n = seqlen_k if not IS_CAUSAL else tl.minimum((start_m + 1) * BLOCK_M, seqlen_k)
for start_n in range(0, end_n, BLOCK_N):
start_n = tl.multiple_of(start_n, BLOCK_N)
@@ -129,11 +133,23 @@ def _fwd_kernel(
if EVEN_HEADDIM:
k = tl.load(k_ptrs + start_n * stride_kn)
else:
- k = tl.load(k_ptrs + start_n * stride_kn, mask=offs_d[None, :] < headdim, other=0.0)
+ k = tl.load(
+ k_ptrs + start_n * stride_kn,
+ mask=offs_d[None, :] < headdim,
+ other=0.0,
+ )
elif EVEN_HEADDIM:
- k = tl.load(k_ptrs + start_n * stride_kn, mask=(start_n + offs_n)[:, None] < seqlen_k, other=0.0)
+ k = tl.load(
+ k_ptrs + start_n * stride_kn,
+ mask=(start_n + offs_n)[:, None] < seqlen_k,
+ other=0.0,
+ )
else:
- k = tl.load(k_ptrs + start_n * stride_kn, mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
+ k = tl.load(
+ k_ptrs + start_n * stride_kn,
+ mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
qk += tl.dot(q, k, trans_b=True)
if not EVEN_N:
@@ -151,7 +167,11 @@ def _fwd_kernel(
if EVEN_M & EVEN_N:
bias = tl.load(b_ptrs + start_n).to(tl.float32)
else:
- bias = tl.load(b_ptrs + start_n, mask=(offs_m[:, None] < seqlen_q) & ((start_n + offs_n)[None, :] < seqlen_k), other=0.0).to(tl.float32)
+ bias = tl.load(
+ b_ptrs + start_n,
+ mask=(offs_m[:, None] < seqlen_q) & ((start_n + offs_n)[None, :] < seqlen_k),
+ other=0.0,
+ ).to(tl.float32)
qk = qk * softmax_scale + bias
m_ij = tl.maximum(tl.max(qk, 1), lse_i)
p = tl.exp(qk - m_ij[:, None])
@@ -167,11 +187,23 @@ def _fwd_kernel(
if EVEN_HEADDIM:
v = tl.load(v_ptrs + start_n * stride_vn)
else:
- v = tl.load(v_ptrs + start_n * stride_vn, mask=offs_d[None, :] < headdim, other=0.0)
+ v = tl.load(
+ v_ptrs + start_n * stride_vn,
+ mask=offs_d[None, :] < headdim,
+ other=0.0,
+ )
elif EVEN_HEADDIM:
- v = tl.load(v_ptrs + start_n * stride_vn, mask=(start_n + offs_n)[:, None] < seqlen_k, other=0.0)
+ v = tl.load(
+ v_ptrs + start_n * stride_vn,
+ mask=(start_n + offs_n)[:, None] < seqlen_k,
+ other=0.0,
+ )
else:
- v = tl.load(v_ptrs + start_n * stride_vn, mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
+ v = tl.load(
+ v_ptrs + start_n * stride_vn,
+ mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
p = p.to(v.dtype)
acc_o += tl.dot(p, v)
m_i = m_ij
@@ -195,7 +227,11 @@ def _fwd_kernel(
elif EVEN_HEADDIM:
tl.store(out_ptrs, acc_o, mask=offs_m[:, None] < seqlen_q)
else:
- tl.store(out_ptrs, acc_o, mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim))
+ tl.store(
+ out_ptrs,
+ acc_o,
+ mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ )
@triton.jit
@@ -237,7 +273,19 @@ def _bwd_preprocess_do_o_dot(
@triton.jit
-def _bwd_store_dk_dv(dk_ptrs, dv_ptrs, dk, dv, offs_n, offs_d, seqlen_k, headdim, EVEN_M: tl.constexpr, EVEN_N: tl.constexpr, EVEN_HEADDIM: tl.constexpr):
+def _bwd_store_dk_dv(
+ dk_ptrs,
+ dv_ptrs,
+ dk,
+ dv,
+ offs_n,
+ offs_d,
+ seqlen_k,
+ headdim,
+ EVEN_M: tl.constexpr,
+ EVEN_N: tl.constexpr,
+ EVEN_HEADDIM: tl.constexpr,
+):
if EVEN_N & EVEN_M:
if EVEN_HEADDIM:
tl.store(dv_ptrs, dv)
@@ -307,7 +355,19 @@ def _bwd_kernel_one_col_block(
if begin_m >= seqlen_q:
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
- _bwd_store_dk_dv(dk_ptrs, dv_ptrs, dk, dv, offs_n, offs_d, seqlen_k, headdim, EVEN_M=EVEN_M, EVEN_N=EVEN_N, EVEN_HEADDIM=EVEN_HEADDIM)
+ _bwd_store_dk_dv(
+ dk_ptrs,
+ dv_ptrs,
+ dk,
+ dv,
+ offs_n,
+ offs_d,
+ seqlen_k,
+ headdim,
+ EVEN_M=EVEN_M,
+ EVEN_N=EVEN_N,
+ EVEN_HEADDIM=EVEN_HEADDIM,
+ )
return
if EVEN_N & EVEN_M:
if EVEN_HEADDIM:
@@ -320,8 +380,16 @@ def _bwd_kernel_one_col_block(
k = tl.load(k_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
v = tl.load(v_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
else:
- k = tl.load(k_ptrs, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
- v = tl.load(v_ptrs, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
+ k = tl.load(
+ k_ptrs,
+ mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
+ v = tl.load(
+ v_ptrs,
+ mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
num_block_m = tl.cdiv(seqlen_q, BLOCK_M)
for start_m in range(begin_m, num_block_m * BLOCK_M, BLOCK_M):
start_m = tl.multiple_of(start_m, BLOCK_M)
@@ -331,7 +399,11 @@ def _bwd_kernel_one_col_block(
elif EVEN_HEADDIM:
q = tl.load(q_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0)
else:
- q = tl.load(q_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0)
+ q = tl.load(
+ q_ptrs,
+ mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
qk = tl.dot(q, k, trans_b=True)
if not EVEN_N:
qk = tl.where(offs_n[None, :] < seqlen_k, qk, float("-inf"))
@@ -349,7 +421,11 @@ def _bwd_kernel_one_col_block(
if EVEN_M & EVEN_N:
bias = tl.load(b_ptrs).to(tl.float32)
else:
- bias = tl.load(b_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_n[None, :] < seqlen_k), other=0.0).to(tl.float32)
+ bias = tl.load(
+ b_ptrs,
+ mask=(offs_m_curr[:, None] < seqlen_q) & (offs_n[None, :] < seqlen_k),
+ other=0.0,
+ ).to(tl.float32)
qk = qk * softmax_scale + bias
if not EVEN_M & EVEN_HEADDIM:
tl.debug_barrier()
@@ -361,7 +437,11 @@ def _bwd_kernel_one_col_block(
if EVEN_M & EVEN_HEADDIM:
do = tl.load(do_ptrs)
else:
- do = tl.load(do_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0)
+ do = tl.load(
+ do_ptrs,
+ mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ other=0.0,
+ )
dv += tl.dot(p.to(do.dtype), do, trans_a=True)
if not EVEN_M & EVEN_HEADDIM:
tl.debug_barrier()
@@ -379,13 +459,33 @@ def _bwd_kernel_one_col_block(
dq += tl.dot(ds, k)
tl.store(dq_ptrs, dq, eviction_policy="evict_last")
elif EVEN_HEADDIM:
- dq = tl.load(dq_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0, eviction_policy="evict_last")
+ dq = tl.load(
+ dq_ptrs,
+ mask=offs_m_curr[:, None] < seqlen_q,
+ other=0.0,
+ eviction_policy="evict_last",
+ )
dq += tl.dot(ds, k)
- tl.store(dq_ptrs, dq, mask=offs_m_curr[:, None] < seqlen_q, eviction_policy="evict_last")
+ tl.store(
+ dq_ptrs,
+ dq,
+ mask=offs_m_curr[:, None] < seqlen_q,
+ eviction_policy="evict_last",
+ )
else:
- dq = tl.load(dq_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0, eviction_policy="evict_last")
+ dq = tl.load(
+ dq_ptrs,
+ mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ other=0.0,
+ eviction_policy="evict_last",
+ )
dq += tl.dot(ds, k)
- tl.store(dq_ptrs, dq, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), eviction_policy="evict_last")
+ tl.store(
+ dq_ptrs,
+ dq,
+ mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ eviction_policy="evict_last",
+ )
else:
dq = tl.dot(ds, k)
if EVEN_M & EVEN_HEADDIM:
@@ -393,7 +493,11 @@ def _bwd_kernel_one_col_block(
elif EVEN_HEADDIM:
tl.atomic_add(dq_ptrs, dq, mask=offs_m_curr[:, None] < seqlen_q)
else:
- tl.atomic_add(dq_ptrs, dq, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim))
+ tl.atomic_add(
+ dq_ptrs,
+ dq,
+ mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
+ )
dq_ptrs += BLOCK_M * stride_dqm
q_ptrs += BLOCK_M * stride_qm
do_ptrs += BLOCK_M * stride_dom
@@ -401,7 +505,19 @@ def _bwd_kernel_one_col_block(
b_ptrs += BLOCK_M * stride_bm
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
- _bwd_store_dk_dv(dk_ptrs, dv_ptrs, dk, dv, offs_n, offs_d, seqlen_k, headdim, EVEN_M=EVEN_M, EVEN_N=EVEN_N, EVEN_HEADDIM=EVEN_HEADDIM)
+ _bwd_store_dk_dv(
+ dk_ptrs,
+ dv_ptrs,
+ dk,
+ dv,
+ offs_n,
+ offs_d,
+ seqlen_k,
+ headdim,
+ EVEN_M=EVEN_M,
+ EVEN_N=EVEN_N,
+ EVEN_HEADDIM=EVEN_HEADDIM,
+ )
def init_to_zero(name):
@@ -410,10 +526,26 @@ def init_to_zero(name):
@triton.autotune(
configs=[
- triton.Config({"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": False}, num_warps=8, num_stages=1, pre_hook=init_to_zero("DQ")),
- triton.Config({"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": True}, num_warps=8, num_stages=1, pre_hook=init_to_zero("DQ")),
+ triton.Config(
+ {"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": False},
+ num_warps=8,
+ num_stages=1,
+ pre_hook=init_to_zero("DQ"),
+ ),
+ triton.Config(
+ {"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": True},
+ num_warps=8,
+ num_stages=1,
+ pre_hook=init_to_zero("DQ"),
+ ),
+ ],
+ key=[
+ "CACHE_KEY_SEQLEN_Q",
+ "CACHE_KEY_SEQLEN_K",
+ "BIAS_TYPE",
+ "IS_CAUSAL",
+ "BLOCK_HEADDIM",
],
- key=["CACHE_KEY_SEQLEN_Q", "CACHE_KEY_SEQLEN_K", "BIAS_TYPE", "IS_CAUSAL", "BLOCK_HEADDIM"],
)
@triton.heuristics(
{
@@ -686,7 +818,10 @@ def _flash_attn_backward(do, q, k, v, o, lse, dq, dk, dv, bias=None, causal=Fals
raise RuntimeError("Last 2 dimensions of bias must be (1, seqlen_k) or (seqlen_q, seqlen_k)")
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
bias_strides = (bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
- grid = lambda META: (triton.cdiv(seqlen_k, META["BLOCK_N"]) if META["SEQUENCE_PARALLEL"] else 1, batch * nheads)
+ grid = lambda META: (
+ triton.cdiv(seqlen_k, META["BLOCK_N"]) if META["SEQUENCE_PARALLEL"] else 1,
+ batch * nheads,
+ )
_bwd_kernel[grid](
q,
k,
@@ -746,7 +881,14 @@ def forward(ctx, qkv, bias=None, causal=False, softmax_scale=None):
"""
if qkv.stride(-1) != 1:
qkv = qkv.contiguous()
- (o, lse, ctx.softmax_scale) = _flash_attn_forward(qkv[:, :, 0], qkv[:, :, 1], qkv[:, :, 2], bias=bias, causal=causal, softmax_scale=softmax_scale)
+ (o, lse, ctx.softmax_scale) = _flash_attn_forward(
+ qkv[:, :, 0],
+ qkv[:, :, 1],
+ qkv[:, :, 2],
+ bias=bias,
+ causal=causal,
+ softmax_scale=softmax_scale,
+ )
ctx.save_for_backward(qkv, o, lse, bias)
ctx.causal = causal
return o
@@ -788,7 +930,14 @@ def forward(ctx, q, kv, bias=None, causal=False, softmax_scale=None):
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
"""
(q, kv) = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, kv]]
- (o, lse, ctx.softmax_scale) = _flash_attn_forward(q, kv[:, :, 0], kv[:, :, 1], bias=bias, causal=causal, softmax_scale=softmax_scale)
+ (o, lse, ctx.softmax_scale) = _flash_attn_forward(
+ q,
+ kv[:, :, 0],
+ kv[:, :, 1],
+ bias=bias,
+ causal=causal,
+ softmax_scale=softmax_scale,
+ )
ctx.save_for_backward(q, kv, o, lse, bias)
ctx.causal = causal
return o
@@ -802,7 +951,18 @@ def backward(ctx, do):
dq = torch.empty_like(q)
dkv = torch.empty_like(kv)
_flash_attn_backward(
- do, q, kv[:, :, 0], kv[:, :, 1], o, lse, dq, dkv[:, :, 0], dkv[:, :, 1], bias=bias, causal=ctx.causal, softmax_scale=ctx.softmax_scale
+ do,
+ q,
+ kv[:, :, 0],
+ kv[:, :, 1],
+ o,
+ lse,
+ dq,
+ dkv[:, :, 0],
+ dkv[:, :, 1],
+ bias=bias,
+ causal=ctx.causal,
+ softmax_scale=ctx.softmax_scale,
)
return (dq, dkv, None, None, None)
@@ -834,7 +994,20 @@ def backward(ctx, do):
dq = torch.empty_like(q)
dk = torch.empty_like(k)
dv = torch.empty_like(v)
- _flash_attn_backward(do, q, k, v, o, lse, dq, dk, dv, bias=bias, causal=ctx.causal, softmax_scale=ctx.softmax_scale)
+ _flash_attn_backward(
+ do,
+ q,
+ k,
+ v,
+ o,
+ lse,
+ dq,
+ dk,
+ dv,
+ bias=bias,
+ causal=ctx.causal,
+ softmax_scale=ctx.softmax_scale,
+ )
return (dq, dk, dv, None, None, None)
diff --git a/src/otter_ai/models/flamingo/mpt/hf_prefixlm_converter.py b/src/otter_ai/models/mpt/hf_prefixlm_converter.py
old mode 100644
new mode 100755
similarity index 84%
rename from src/otter_ai/models/flamingo/mpt/hf_prefixlm_converter.py
rename to src/otter_ai/models/mpt/hf_prefixlm_converter.py
index ea544ccc..bb4c2c0f
--- a/src/otter_ai/models/flamingo/mpt/hf_prefixlm_converter.py
+++ b/src/otter_ai/models/mpt/hf_prefixlm_converter.py
@@ -19,7 +19,9 @@
CrossEntropyLoss,
)
from transformers.models.bloom.modeling_bloom import _expand_mask as _expand_mask_bloom
-from transformers.models.bloom.modeling_bloom import _make_causal_mask as _make_causal_mask_bloom
+from transformers.models.bloom.modeling_bloom import (
+ _make_causal_mask as _make_causal_mask_bloom,
+)
from transformers.models.bloom.modeling_bloom import logging
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
from transformers.models.gpt_neo.modeling_gpt_neo import GPTNeoForCausalLM
@@ -27,10 +29,17 @@
from transformers.models.gptj.modeling_gptj import GPTJForCausalLM
from transformers.models.opt.modeling_opt import OPTForCausalLM
from transformers.models.opt.modeling_opt import _expand_mask as _expand_mask_opt
-from transformers.models.opt.modeling_opt import _make_causal_mask as _make_causal_mask_opt
+from transformers.models.opt.modeling_opt import (
+ _make_causal_mask as _make_causal_mask_opt,
+)
logger = logging.get_logger(__name__)
-_SUPPORTED_GPT_MODELS = (GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM)
+_SUPPORTED_GPT_MODELS = (
+ GPT2LMHeadModel,
+ GPTJForCausalLM,
+ GPTNeoForCausalLM,
+ GPTNeoXForCausalLM,
+)
CAUSAL_GPT_TYPES = Union[GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM]
@@ -135,7 +144,11 @@ def call_og_forward():
raise ValueError(f"bidirectional_mask sequence length (={s}) exceeds the " + f"max length allowed by the model ({max_length}).")
assert s <= max_length
if s < max_length:
- pad = torch.zeros((int(b), int(max_length - s)), dtype=bidirectional_mask.dtype, device=bidirectional_mask.device)
+ pad = torch.zeros(
+ (int(b), int(max_length - s)),
+ dtype=bidirectional_mask.dtype,
+ device=bidirectional_mask.device,
+ )
bidirectional_mask = torch.cat([bidirectional_mask, pad], dim=1)
bidirectional = bidirectional_mask.unsqueeze(1).unsqueeze(1)
for attn_module in attn_modules:
@@ -175,13 +188,21 @@ def _convert_bloom_causal_lm_to_prefix_lm(model: BloomForCausalLM) -> BloomForCa
assert model.config.add_cross_attention == False, "Only supports BLOOM decoder-only models"
def _prepare_attn_mask(
- self: BloomModel, attention_mask: torch.Tensor, bidirectional_mask: Optional[torch.Tensor], input_shape: Tuple[int, int], past_key_values_length: int
+ self: BloomModel,
+ attention_mask: torch.Tensor,
+ bidirectional_mask: Optional[torch.Tensor],
+ input_shape: Tuple[int, int],
+ past_key_values_length: int,
) -> torch.BoolTensor:
combined_attention_mask = None
device = attention_mask.device
(_, src_length) = input_shape
if src_length > 1:
- combined_attention_mask = _make_causal_mask_bloom(input_shape, device=device, past_key_values_length=past_key_values_length)
+ combined_attention_mask = _make_causal_mask_bloom(
+ input_shape,
+ device=device,
+ past_key_values_length=past_key_values_length,
+ )
if bidirectional_mask is not None:
assert attention_mask.shape == bidirectional_mask.shape
expanded_bidirectional_mask = _expand_mask_bloom(bidirectional_mask, tgt_length=src_length)
@@ -190,14 +211,29 @@ def _prepare_attn_mask(
combined_attention_mask = expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask | combined_attention_mask
return combined_attention_mask
- def _build_alibi_tensor(self: BloomModel, batch_size: int, query_length: int, key_length: int, dtype: torch.dtype, device: torch.device) -> torch.Tensor:
+ def _build_alibi_tensor(
+ self: BloomModel,
+ batch_size: int,
+ query_length: int,
+ key_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ ) -> torch.Tensor:
num_heads = self.config.n_head
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
- base = torch.tensor(2 ** (-(2 ** (-(math.log2(closest_power_of_2) - 3)))), device=device, dtype=torch.float32)
+ base = torch.tensor(
+ 2 ** (-(2 ** (-(math.log2(closest_power_of_2) - 3)))),
+ device=device,
+ dtype=torch.float32,
+ )
powers = torch.arange(1, 1 + closest_power_of_2, device=device, dtype=torch.int32)
slopes = torch.pow(base, powers)
if closest_power_of_2 != num_heads:
- extra_base = torch.tensor(2 ** (-(2 ** (-(math.log2(2 * closest_power_of_2) - 3)))), device=device, dtype=torch.float32)
+ extra_base = torch.tensor(
+ 2 ** (-(2 ** (-(math.log2(2 * closest_power_of_2) - 3)))),
+ device=device,
+ dtype=torch.float32,
+ )
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, device=device, dtype=torch.int32)
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
@@ -227,7 +263,8 @@ def forward(
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
if deprecated_arguments.pop("position_ids", False) is not False:
warnings.warn(
- "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. " + "You can safely ignore passing `position_ids`.", FutureWarning
+ "`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. " + "You can safely ignore passing `position_ids`.",
+ FutureWarning,
)
if len(deprecated_arguments) > 0:
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
@@ -263,10 +300,17 @@ def forward(
else:
attention_mask = attention_mask.to(hidden_states.device)
alibi = self._build_alibi_tensor(
- batch_size=batch_size, query_length=seq_length, key_length=seq_length_with_past, dtype=hidden_states.dtype, device=hidden_states.device
+ batch_size=batch_size,
+ query_length=seq_length,
+ key_length=seq_length_with_past,
+ dtype=hidden_states.dtype,
+ device=hidden_states.device,
)
causal_mask = self._prepare_attn_mask(
- attention_mask, bidirectional_mask, input_shape=(batch_size, seq_length), past_key_values_length=past_key_values_length
+ attention_mask,
+ bidirectional_mask,
+ input_shape=(batch_size, seq_length),
+ past_key_values_length=past_key_values_length,
)
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
if output_hidden_states:
@@ -279,11 +323,21 @@ def forward(
def create_custom_forward(module):
def custom_forward(*inputs):
- return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
+ return module(
+ *inputs,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
return custom_forward
- outputs = torch.utils.checkpoint.checkpoint(create_custom_forward(block), hidden_states, alibi, causal_mask, head_mask[i])
+ outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(block),
+ hidden_states,
+ alibi,
+ causal_mask,
+ head_mask[i],
+ )
else:
outputs = block(
hidden_states,
@@ -305,13 +359,35 @@ def custom_forward(*inputs):
hst = (hidden_states,)
all_hidden_states = all_hidden_states + hst
if not return_dict:
- return tuple((v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None))
+ return tuple(
+ (
+ v
+ for v in [
+ hidden_states,
+ presents,
+ all_hidden_states,
+ all_self_attentions,
+ ]
+ if v is not None
+ )
+ )
return BaseModelOutputWithPastAndCrossAttentions(
- last_hidden_state=hidden_states, past_key_values=presents, hidden_states=all_hidden_states, attentions=all_self_attentions
+ last_hidden_state=hidden_states,
+ past_key_values=presents,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
)
- setattr(model.transformer, "_prepare_attn_mask", MethodType(_prepare_attn_mask, model.transformer))
- setattr(model.transformer, "_build_alibi_tensor", MethodType(_build_alibi_tensor, model.transformer))
+ setattr(
+ model.transformer,
+ "_prepare_attn_mask",
+ MethodType(_prepare_attn_mask, model.transformer),
+ )
+ setattr(
+ model.transformer,
+ "_build_alibi_tensor",
+ MethodType(_build_alibi_tensor, model.transformer),
+ )
setattr(model.transformer, "forward", MethodType(forward, model.transformer))
KeyValueT = Tuple[torch.Tensor, torch.Tensor]
@@ -333,7 +409,8 @@ def forward(
"""Replacement forward method for BloomCausalLM."""
if deprecated_arguments.pop("position_ids", False) is not False:
warnings.warn(
- "`position_ids` have no functionality in BLOOM and will be removed " + "in v5.0.0. You can safely ignore passing `position_ids`.", FutureWarning
+ "`position_ids` have no functionality in BLOOM and will be removed " + "in v5.0.0. You can safely ignore passing `position_ids`.",
+ FutureWarning,
)
if len(deprecated_arguments) > 0:
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
@@ -358,7 +435,10 @@ def forward(
shift_labels = labels[..., 1:].contiguous()
(batch_size, seq_length, vocab_size) = shift_logits.shape
loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(batch_size * seq_length, vocab_size), shift_labels.view(batch_size * seq_length))
+ loss = loss_fct(
+ shift_logits.view(batch_size * seq_length, vocab_size),
+ shift_labels.view(batch_size * seq_length),
+ )
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return (loss,) + output if loss is not None else output
@@ -371,7 +451,11 @@ def forward(
)
def prepare_inputs_for_generation(
- self: BloomForCausalLM, input_ids: torch.LongTensor, past: Optional[torch.Tensor] = None, attention_mask: Optional[torch.Tensor] = None, **kwargs
+ self: BloomForCausalLM,
+ input_ids: torch.LongTensor,
+ past: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ **kwargs,
) -> dict:
if past:
input_ids = input_ids[:, -1].unsqueeze(-1)
@@ -380,10 +464,20 @@ def prepare_inputs_for_generation(
past = self._convert_to_bloom_cache(past)
else:
bidirectional_mask = torch.ones_like(input_ids)
- return {"input_ids": input_ids, "past_key_values": past, "use_cache": True, "attention_mask": attention_mask, "bidirectional_mask": bidirectional_mask}
+ return {
+ "input_ids": input_ids,
+ "past_key_values": past,
+ "use_cache": True,
+ "attention_mask": attention_mask,
+ "bidirectional_mask": bidirectional_mask,
+ }
setattr(model, "forward", MethodType(forward, model))
- setattr(model, "prepare_inputs_for_generation", MethodType(prepare_inputs_for_generation, model))
+ setattr(
+ model,
+ "prepare_inputs_for_generation",
+ MethodType(prepare_inputs_for_generation, model),
+ )
setattr(model, "_prefix_lm_converted", True)
return model
@@ -410,24 +504,34 @@ def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_em
if self.bidirectional_mask == "g":
(bsz, src_length) = input_shape
combined_attention_mask = torch.zeros(
- (bsz, 1, src_length, src_length + past_key_values_length), dtype=inputs_embeds.dtype, device=inputs_embeds.device
+ (bsz, 1, src_length, src_length + past_key_values_length),
+ dtype=inputs_embeds.dtype,
+ device=inputs_embeds.device,
)
else:
- combined_attention_mask = _make_causal_mask_opt(input_shape, inputs_embeds.dtype, past_key_values_length=past_key_values_length).to(
- inputs_embeds.device
- )
+ combined_attention_mask = _make_causal_mask_opt(
+ input_shape,
+ inputs_embeds.dtype,
+ past_key_values_length=past_key_values_length,
+ ).to(inputs_embeds.device)
if self.bidirectional_mask is not None:
assert attention_mask.shape == self.bidirectional_mask.shape
- expanded_bidirectional_mask = _expand_mask_opt(self.bidirectional_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
- inputs_embeds.device
- )
+ expanded_bidirectional_mask = _expand_mask_opt(
+ self.bidirectional_mask,
+ inputs_embeds.dtype,
+ tgt_len=input_shape[-1],
+ ).to(inputs_embeds.device)
combined_attention_mask = torch.maximum(expanded_bidirectional_mask, combined_attention_mask)
if attention_mask is not None:
expanded_attn_mask = _expand_mask_opt(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(inputs_embeds.device)
combined_attention_mask = expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
return combined_attention_mask
- setattr(model.model.decoder, "_prepare_decoder_attention_mask", MethodType(_prepare_decoder_attention_mask, model.model.decoder))
+ setattr(
+ model.model.decoder,
+ "_prepare_decoder_attention_mask",
+ MethodType(_prepare_decoder_attention_mask, model.model.decoder),
+ )
def forward(
self: OPTForCausalLM,
@@ -486,7 +590,14 @@ def generate(self: OPTForCausalLM, *args: tuple, **kwargs: Dict[str, Any]):
_SUPPORTED_HF_MODELS = _SUPPORTED_GPT_MODELS + (BloomForCausalLM, OPTForCausalLM)
-CAUSAL_LM_TYPES = Union[GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM, BloomForCausalLM, OPTForCausalLM]
+CAUSAL_LM_TYPES = Union[
+ GPT2LMHeadModel,
+ GPTJForCausalLM,
+ GPTNeoForCausalLM,
+ GPTNeoXForCausalLM,
+ BloomForCausalLM,
+ OPTForCausalLM,
+]
def convert_hf_causal_lm_to_prefix_lm(model: CAUSAL_LM_TYPES) -> CAUSAL_LM_TYPES:
@@ -568,8 +679,6 @@ def add_bidirectional_mask_if_missing(batch: Dict[str, Any]):
for i, continuation_indices in enumerate(batch["continuation_indices"]):
batch["bidirectional_mask"][i, continuation_indices] = 0
elif "labels" in batch and "attention_mask" in batch:
- batch["bidirectional_mask"] = torch.logical_and(torch.eq(batch["attention_mask"], 1), torch.eq(batch["labels"], -100)).type_as(
- batch["attention_mask"]
- )
+ batch["bidirectional_mask"] = torch.logical_and(torch.eq(batch["attention_mask"], 1), torch.eq(batch["labels"], -100)).type_as(batch["attention_mask"])
else:
raise KeyError("No bidirectional_mask in batch and not sure how to construct one.")
diff --git a/src/otter_ai/models/flamingo/mpt/meta_init_context.py b/src/otter_ai/models/mpt/meta_init_context.py
old mode 100644
new mode 100755
similarity index 91%
rename from src/otter_ai/models/flamingo/mpt/meta_init_context.py
rename to src/otter_ai/models/mpt/meta_init_context.py
index df7ca692..4ab7ab0c
--- a/src/otter_ai/models/flamingo/mpt/meta_init_context.py
+++ b/src/otter_ai/models/mpt/meta_init_context.py
@@ -88,11 +88,18 @@ def wrapper(*args, **kwargs):
if include_buffers:
nn.Module.register_buffer = register_empty_buffer
for torch_function_name in tensor_constructors_to_patch.keys():
- setattr(torch, torch_function_name, patch_tensor_constructor(getattr(torch, torch_function_name)))
+ setattr(
+ torch,
+ torch_function_name,
+ patch_tensor_constructor(getattr(torch, torch_function_name)),
+ )
yield
finally:
nn.Module.register_parameter = old_register_parameter
if include_buffers:
nn.Module.register_buffer = old_register_buffer
- for torch_function_name, old_torch_function in tensor_constructors_to_patch.items():
+ for (
+ torch_function_name,
+ old_torch_function,
+ ) in tensor_constructors_to_patch.items():
setattr(torch, torch_function_name, old_torch_function)
diff --git a/src/otter_ai/models/flamingo/mpt/modeling_mpt.py b/src/otter_ai/models/mpt/modeling_mpt.py
old mode 100644
new mode 100755
similarity index 91%
rename from src/otter_ai/models/flamingo/mpt/modeling_mpt.py
rename to src/otter_ai/models/mpt/modeling_mpt.py
index 3a569edf..f5bb33ea
--- a/src/otter_ai/models/flamingo/mpt/modeling_mpt.py
+++ b/src/otter_ai/models/mpt/modeling_mpt.py
@@ -10,7 +10,10 @@
import torch.nn as nn
import torch.nn.functional as F
from transformers import PreTrainedModel, PreTrainedTokenizer, PreTrainedTokenizerFast
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPast,
+ CausalLMOutputWithPast,
+)
from .attention import attn_bias_shape, build_attn_bias
from .blocks import MPTBlock
@@ -60,9 +63,7 @@ def __init__(self, config: MPTConfig):
self.blocks = nn.ModuleList([MPTBlock(device=config.init_device, **config.to_dict()) for _ in range(config.n_layers)])
self.norm_f = norm_class(config.d_model, device=config.init_device)
if config.init_device != "meta":
- print(
- f'You are using config.init_device={config.init_device!r}, but you can also use config.init_device="meta" with Composer + FSDP for fast initialization.'
- )
+ print(f'You are using config.init_device={config.init_device!r}, but you can also use config.init_device="meta" with Composer + FSDP for fast initialization.')
self.apply(self.param_init_fn)
self.is_causal = not self.prefix_lm
self._attn_bias_initialized = False
@@ -146,11 +147,7 @@ def _attn_bias(
def _apply_prefix_mask(self, attn_bias: torch.Tensor, prefix_mask: torch.Tensor):
(s_k, s_q) = attn_bias.shape[-2:]
if s_k != self.config.max_seq_len or s_q != self.config.max_seq_len:
- raise ValueError(
- "attn_bias does not match the expected shape. "
- + f"The last two dimensions should both be {self.config.max_length} "
- + f"but are {s_k} and {s_q}."
- )
+ raise ValueError("attn_bias does not match the expected shape. " + f"The last two dimensions should both be {self.config.max_length} " + f"but are {s_k} and {s_q}.")
seq_len = prefix_mask.shape[-1]
if seq_len > self.config.max_seq_len:
raise ValueError(f"prefix_mask sequence length cannot exceed max_seq_len={self.config.max_seq_len}")
@@ -215,13 +212,10 @@ def forward(
if self.training:
if self.attn_uses_sequence_id and sequence_id is None:
- raise ValueError(
- "sequence_id is a required argument when MPT is configured with attn_uses_sequence_id=True " + "and the model is in train mode."
- )
+ raise ValueError("sequence_id is a required argument when MPT is configured with attn_uses_sequence_id=True " + "and the model is in train mode.")
elif (self.attn_uses_sequence_id is False) and (sequence_id is not None):
warnings.warn(
- "MPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. "
- + "This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True."
+ "MPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. " + "This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True."
)
S = input_ids.size(1)
@@ -235,10 +229,7 @@ def forward(
past_position = 0
if past_key_values is not None:
if len(past_key_values) != self.config.n_layers:
- raise ValueError(
- f"past_key_values must provide a past_key_value for each attention "
- + f"layer in the network ({len(past_key_values)=}; {self.config.n_layers=})."
- )
+ raise ValueError(f"past_key_values must provide a past_key_value for each attention " + f"layer in the network ({len(past_key_values)=}; {self.config.n_layers=}).")
# For attn_impl: triton and flash the past key tensor spec is (batch, seq, dim).
# For attn_impl: torch the past key tensor spec is (batch, heads, head_dim, seq).
# Here we shift position embedding using the `seq` dim of the past key
@@ -247,10 +238,7 @@ def forward(
past_position = past_key_values[0][0].size(3)
if S + past_position > self.config.max_seq_len:
- raise ValueError(
- f"Cannot forward input with past sequence length {past_position} and current sequence length "
- f"{S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}."
- )
+ raise ValueError(f"Cannot forward input with past sequence length {past_position} and current sequence length " f"{S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}.")
pos = torch.arange(
past_position,
S + past_position,
@@ -365,7 +353,11 @@ def get_input_embeddings(self):
def set_input_embeddings(self, value):
# self.transformer.wte = value
- peudo_wte = SharedEmbedding(value.weight.shape[0], value.weight.shape[1], device=self.transformer.wte.weight.device)
+ peudo_wte = SharedEmbedding(
+ value.weight.shape[0],
+ value.weight.shape[1],
+ device=self.transformer.wte.weight.device,
+ )
peudo_wte.weight = value.weight
self.transformer.wte = peudo_wte
@@ -374,7 +366,11 @@ def get_output_embeddings(self):
def set_output_embeddings(self, new_embeddings):
# self.transformer.wte = new_embeddings
- peudo_wte = SharedEmbedding(new_embeddings.weight.shape[0], new_embeddings.weight.shape[1], device=self.transformer.wte.weight.device)
+ peudo_wte = SharedEmbedding(
+ new_embeddings.weight.shape[0],
+ new_embeddings.weight.shape[1],
+ device=self.transformer.wte.weight.device,
+ )
peudo_wte.weight = new_embeddings.weight
self.transformer.wte = peudo_wte
@@ -448,7 +444,12 @@ def forward(
def param_init_fn(self, module):
init_fn_name = self.config.init_config["name"]
- MODEL_INIT_REGISTRY[init_fn_name](module=module, n_layers=self.config.n_layers, d_model=self.config.d_model, **self.config.init_config)
+ MODEL_INIT_REGISTRY[init_fn_name](
+ module=module,
+ n_layers=self.config.n_layers,
+ d_model=self.config.d_model,
+ **self.config.init_config,
+ )
def fsdp_wrap_fn(self, module):
return isinstance(module, MPTBlock)
@@ -456,7 +457,14 @@ def fsdp_wrap_fn(self, module):
def activation_checkpointing_fn(self, module):
return isinstance(module, MPTBlock)
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, inputs_embeds=None, attention_mask=None, **kwargs):
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ attention_mask=None,
+ **kwargs,
+ ):
if inputs_embeds is not None:
raise NotImplementedError("inputs_embeds is not implemented for MPT yet")
attention_mask = attention_mask.bool()
diff --git a/src/otter_ai/models/flamingo/mpt/norm.py b/src/otter_ai/models/mpt/norm.py
old mode 100644
new mode 100755
similarity index 67%
rename from src/otter_ai/models/flamingo/mpt/norm.py
rename to src/otter_ai/models/mpt/norm.py
index 9eb43abb..505a164b
--- a/src/otter_ai/models/flamingo/mpt/norm.py
+++ b/src/otter_ai/models/mpt/norm.py
@@ -14,8 +14,21 @@ def _cast_if_autocast_enabled(tensor):
class LPLayerNorm(torch.nn.LayerNorm):
- def __init__(self, normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None):
- super().__init__(normalized_shape=normalized_shape, eps=eps, elementwise_affine=elementwise_affine, device=device, dtype=dtype)
+ def __init__(
+ self,
+ normalized_shape,
+ eps=1e-05,
+ elementwise_affine=True,
+ device=None,
+ dtype=None,
+ ):
+ super().__init__(
+ normalized_shape=normalized_shape,
+ eps=eps,
+ elementwise_affine=elementwise_affine,
+ device=device,
+ dtype=dtype,
+ )
def forward(self, x):
module_device = x.device
@@ -23,7 +36,13 @@ def forward(self, x):
downcast_weight = _cast_if_autocast_enabled(self.weight) if self.weight is not None else self.weight
downcast_bias = _cast_if_autocast_enabled(self.bias) if self.bias is not None else self.bias
with torch.autocast(enabled=False, device_type=module_device.type):
- return torch.nn.functional.layer_norm(downcast_x, self.normalized_shape, downcast_weight, downcast_bias, self.eps)
+ return torch.nn.functional.layer_norm(
+ downcast_x,
+ self.normalized_shape,
+ downcast_weight,
+ downcast_bias,
+ self.eps,
+ )
def rms_norm(x, weight=None, eps=1e-05):
@@ -48,7 +67,13 @@ def forward(self, x):
class LPRMSNorm(RMSNorm):
def __init__(self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None):
- super().__init__(normalized_shape=normalized_shape, eps=eps, weight=weight, dtype=dtype, device=device)
+ super().__init__(
+ normalized_shape=normalized_shape,
+ eps=eps,
+ weight=weight,
+ dtype=dtype,
+ device=device,
+ )
def forward(self, x):
downcast_x = _cast_if_autocast_enabled(x)
@@ -57,4 +82,9 @@ def forward(self, x):
return rms_norm(downcast_x, downcast_weight, self.eps).to(dtype=x.dtype)
-NORM_CLASS_REGISTRY = {"layernorm": torch.nn.LayerNorm, "low_precision_layernorm": LPLayerNorm, "rmsnorm": RMSNorm, "low_precision_rmsnorm": LPRMSNorm}
+NORM_CLASS_REGISTRY = {
+ "layernorm": torch.nn.LayerNorm,
+ "low_precision_layernorm": LPLayerNorm,
+ "rmsnorm": RMSNorm,
+ "low_precision_rmsnorm": LPRMSNorm,
+}
diff --git a/src/otter_ai/models/flamingo/mpt/param_init_fns.py b/src/otter_ai/models/mpt/param_init_fns.py
old mode 100644
new mode 100755
similarity index 96%
rename from src/otter_ai/models/flamingo/mpt/param_init_fns.py
rename to src/otter_ai/models/mpt/param_init_fns.py
index f1bfa672..3e9e858a
--- a/src/otter_ai/models/flamingo/mpt/param_init_fns.py
+++ b/src/otter_ai/models/mpt/param_init_fns.py
@@ -56,10 +56,7 @@ def generic_param_init_fn_(
raise ValueError(f"Expected init_div_is_residual to be boolean or numeric, got {init_div_is_residual}")
if init_div_is_residual is not False:
if verbose > 1:
- warnings.warn(
- f"Initializing _is_residual layers then dividing them by {div_is_residual:.3f}. "
- + f"Set `init_div_is_residual: false` in init config to disable this."
- )
+ warnings.warn(f"Initializing _is_residual layers then dividing them by {div_is_residual:.3f}. " + f"Set `init_div_is_residual: false` in init config to disable this.")
if isinstance(module, nn.Linear):
if hasattr(module, "_fused"):
fused_init_helper_(module, init_fn_)
@@ -262,7 +259,12 @@ def kaiming_uniform_param_init_fn_(
del kwargs
if verbose > 1:
warnings.warn(f"Using nn.init.kaiming_uniform_ init fn with parameters: " + f"a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}")
- kaiming_uniform_ = partial(nn.init.kaiming_uniform_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
+ kaiming_uniform_ = partial(
+ nn.init.kaiming_uniform_,
+ a=init_gain,
+ mode=fan_mode,
+ nonlinearity=init_nonlinearity,
+ )
generic_param_init_fn_(
module=module,
init_fn_=kaiming_uniform_,
@@ -291,7 +293,12 @@ def kaiming_normal_param_init_fn_(
del kwargs
if verbose > 1:
warnings.warn(f"Using nn.init.kaiming_normal_ init fn with parameters: " + f"a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}")
- kaiming_normal_ = partial(torch.nn.init.kaiming_normal_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
+ kaiming_normal_ = partial(
+ torch.nn.init.kaiming_normal_,
+ a=init_gain,
+ mode=fan_mode,
+ nonlinearity=init_nonlinearity,
+ )
generic_param_init_fn_(
module=module,
init_fn_=kaiming_normal_,
diff --git a/src/otter_ai/models/mpt_redpajama/__init__.py b/src/otter_ai/models/mpt_redpajama/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/attention.py b/src/otter_ai/models/mpt_redpajama/attention.py
old mode 100644
new mode 100755
similarity index 94%
rename from src/otter_ai/models/flamingo/mpt_redpajama/attention.py
rename to src/otter_ai/models/mpt_redpajama/attention.py
index 4dd08dab..df379ceb
--- a/src/otter_ai/models/flamingo/mpt_redpajama/attention.py
+++ b/src/otter_ai/models/mpt_redpajama/attention.py
@@ -265,18 +265,22 @@ def __init__(
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
if torch.cuda.is_available():
- warnings.warn(
- "Using `attn_impl: torch`. If your model does not use `alibi` or "
- + "`prefix_lm` we recommend using `attn_impl: flash` otherwise "
- + "we recommend using `attn_impl: triton`."
- )
+ warnings.warn("Using `attn_impl: torch`. If your model does not use `alibi` or " + "`prefix_lm` we recommend using `attn_impl: flash` otherwise " + "we recommend using `attn_impl: triton`.")
else:
raise ValueError(f"{attn_impl=} is an invalid setting.")
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True # type: ignore
- def forward(self, x, past_key_value=None, attn_bias=None, attention_mask=None, is_causal=True, needs_weights=False):
+ def forward(
+ self,
+ x,
+ past_key_value=None,
+ attn_bias=None,
+ attention_mask=None,
+ is_causal=True,
+ needs_weights=False,
+ ):
qkv = self.Wqkv(x)
if self.clip_qkv:
@@ -341,7 +345,16 @@ def attn_bias(attn_impl, attn_bias, n_heads, seq_len, causal=False, alibi=False,
if alibi:
# in place add alibi to attn bias
device, dtype = attn_bias.device, attn_bias.dtype
- attn_bias = attn_bias.add(alibi_bias(n_heads, seq_len, full=not causal, alibi_bias_max=alibi_bias_max, device=device, dtype=dtype))
+ attn_bias = attn_bias.add(
+ alibi_bias(
+ n_heads,
+ seq_len,
+ full=not causal,
+ alibi_bias_max=alibi_bias_max,
+ device=device,
+ dtype=dtype,
+ )
+ )
return attn_bias
else:
raise ValueError(f"{attn_impl=} is an invalid setting.")
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/configuration_mosaic_gpt.py b/src/otter_ai/models/mpt_redpajama/configuration_mosaic_gpt.py
old mode 100644
new mode 100755
similarity index 100%
rename from src/otter_ai/models/flamingo/mpt_redpajama/configuration_mosaic_gpt.py
rename to src/otter_ai/models/mpt_redpajama/configuration_mosaic_gpt.py
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/gpt_blocks.py b/src/otter_ai/models/mpt_redpajama/gpt_blocks.py
old mode 100644
new mode 100755
similarity index 92%
rename from src/otter_ai/models/flamingo/mpt_redpajama/gpt_blocks.py
rename to src/otter_ai/models/mpt_redpajama/gpt_blocks.py
index a60e09ed..d609265b
--- a/src/otter_ai/models/flamingo/mpt_redpajama/gpt_blocks.py
+++ b/src/otter_ai/models/mpt_redpajama/gpt_blocks.py
@@ -75,7 +75,13 @@ def forward(
is_causal: bool = True,
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor]]]:
a = self.ln_1(x)
- b, _, past_key_value = self.attn(a, past_key_value=past_key_value, attn_bias=attn_bias, attention_mask=attention_mask, is_causal=is_causal)
+ b, _, past_key_value = self.attn(
+ a,
+ past_key_value=past_key_value,
+ attn_bias=attn_bias,
+ attention_mask=attention_mask,
+ is_causal=is_causal,
+ )
x = x + self.resid_attn_dropout(b)
m = self.ln_2(x)
n = self.mlp(m)
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/low_precision_layernorm.py b/src/otter_ai/models/mpt_redpajama/low_precision_layernorm.py
old mode 100644
new mode 100755
similarity index 74%
rename from src/otter_ai/models/flamingo/mpt_redpajama/low_precision_layernorm.py
rename to src/otter_ai/models/mpt_redpajama/low_precision_layernorm.py
index eb3d4b7b..ac0ad49a
--- a/src/otter_ai/models/flamingo/mpt_redpajama/low_precision_layernorm.py
+++ b/src/otter_ai/models/mpt_redpajama/low_precision_layernorm.py
@@ -3,7 +3,14 @@
class LPLayerNorm(torch.nn.LayerNorm):
- def __init__(self, normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None):
+ def __init__(
+ self,
+ normalized_shape,
+ eps=1e-05,
+ elementwise_affine=True,
+ device=None,
+ dtype=None,
+ ):
super().__init__(
normalized_shape=normalized_shape,
eps=eps,
@@ -18,7 +25,13 @@ def forward(self, x):
downcast_weight = _cast_if_autocast_enabled(self.weight) if self.weight is not None else self.weight
downcast_bias = _cast_if_autocast_enabled(self.bias) if self.bias is not None else self.bias
with torch.autocast(enabled=False, device_type=module_device.type):
- return F.layer_norm(downcast_x, self.normalized_shape, downcast_weight, downcast_bias, self.eps)
+ return F.layer_norm(
+ downcast_x,
+ self.normalized_shape,
+ downcast_weight,
+ downcast_bias,
+ self.eps,
+ )
def _cast_if_autocast_enabled(tensor):
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/mosaic_gpt.py b/src/otter_ai/models/mpt_redpajama/mosaic_gpt.py
old mode 100644
new mode 100755
similarity index 84%
rename from src/otter_ai/models/flamingo/mpt_redpajama/mosaic_gpt.py
rename to src/otter_ai/models/mpt_redpajama/mosaic_gpt.py
index 613a6f17..677fede4
--- a/src/otter_ai/models/flamingo/mpt_redpajama/mosaic_gpt.py
+++ b/src/otter_ai/models/mpt_redpajama/mosaic_gpt.py
@@ -13,17 +13,14 @@
import torch
import torch.nn as nn
import torch.nn.functional as F
-from transformers import PreTrainedModel
+from transformers import AutoTokenizer, PreTrainedModel
from transformers.modeling_outputs import CausalLMOutputWithPast
-from otter_ai.models.flamingo.mpt.custom_embedding import SharedEmbedding
-
-from .attention import attn_bias as module_attn_bias
-from .attention import attn_bias_shape as module_attn_bias_shape
-from .configuration_mosaic_gpt import MosaicGPTConfig
+from .attention import attn_bias as module_attn_bias, attn_bias_shape as module_attn_bias_shape
from .gpt_blocks import GPTBlock
-from .low_precision_layernorm import LPLayerNorm
+from .configuration_mosaic_gpt import MosaicGPTConfig
from .param_init_fns import MODEL_INIT_REGISTRY
+from .low_precision_layernorm import LPLayerNorm
class MosaicGPT(PreTrainedModel):
@@ -55,12 +52,6 @@ def __init__(self, config: MosaicGPTConfig):
self.transformer.update({"blocks": nn.ModuleList([GPTBlock(device=config.init_device, **config.to_dict()) for _ in range(config.n_layers)])})
self.transformer.update({"ln_f": layernorm_class(config.d_model, device=config.init_device)})
- for child in self.transformer.children():
- if isinstance(child, torch.nn.ModuleList):
- continue
- if isinstance(child, torch.nn.Module):
- child._fsdp_wrap = True
-
# enables scaling output logits; similar to a softmax "temperature"
# PaLM paper uses scale 1/sqrt(config.d_model)
self.logit_scale = None
@@ -162,11 +153,7 @@ def _attn_bias(
def _apply_prefix_mask(self, attn_bias: torch.Tensor, prefix_mask: torch.Tensor):
s_k, s_q = attn_bias.shape[-2:]
if (s_k != self.config.max_seq_len) or (s_q != self.config.max_seq_len):
- raise ValueError(
- "attn_bias does not match the expected shape. "
- + f"The last two dimensions should both be {self.config.max_length} "
- + f"but are {s_k} and {s_q}."
- )
+ raise ValueError("attn_bias does not match the expected shape. " + f"The last two dimensions should both be {self.config.max_length} " + f"but are {s_k} and {s_q}.")
seq_len = prefix_mask.shape[-1]
if seq_len > self.config.max_seq_len:
raise ValueError(f"prefix_mask sequence length cannot exceed max_seq_len={self.config.max_seq_len}")
@@ -206,17 +193,17 @@ def forward(
input_ids: torch.LongTensor,
past_key_values: Optional[List[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.ByteTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
- labels: Optional[torch.LongTensor] = None,
return_dict: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
use_cache: Optional[bool] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
):
return_dict = return_dict if return_dict is not None else self.config.return_dict
use_cache = use_cache if use_cache is not None else self.config.use_cache
+ attention_mask = attention_mask.bool() if attention_mask is not None else None
# These args are passed in by keyword in huggingface's generate function
# https://github.com/huggingface/transformers/blob/68287689f2f0d8b7063c400230b3766987abf18d/src/transformers/generation/utils.py#L2201-L2206
@@ -226,12 +213,6 @@ def forward(
if output_attentions:
raise NotImplementedError("output_attentions is not implemented yet for MosaicGPT")
- if attention_mask is not None:
- attention_mask = attention_mask.bool()
-
- if prefix_mask is not None:
- prefix_mask = prefix_mask.bool()
-
if attention_mask is not None and attention_mask[:, 0].sum() != attention_mask.shape[0] and self.training:
raise NotImplementedError("MosaicGPT does not support training with left padding.")
@@ -240,13 +221,10 @@ def forward(
if self.training:
if self.attn_uses_sequence_id and sequence_id is None:
- raise ValueError(
- "sequence_id is a required argument when MosaicGPT is configured with attn_uses_sequence_id=True " + "and the model is in train mode."
- )
+ raise ValueError("sequence_id is a required argument when MosaicGPT is configured with attn_uses_sequence_id=True " + "and the model is in train mode.")
elif (self.attn_uses_sequence_id is False) and (sequence_id is not None):
warnings.warn(
- "MosaicGPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. "
- + "This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True."
+ "MosaicGPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. " + "This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True."
)
S = input_ids.size(1)
@@ -260,19 +238,13 @@ def forward(
past_position = 0
if past_key_values is not None:
if len(past_key_values) != self.config.n_layers:
- raise ValueError(
- f"past_key_values must provide a past_key_value for each attention "
- + f"layer in the network ({len(past_key_values)=}; {self.config.n_layers=})."
- )
+ raise ValueError(f"past_key_values must provide a past_key_value for each attention " + f"layer in the network ({len(past_key_values)=}; {self.config.n_layers=}).")
# get the key tensor whose spec should be (batch, seq, dim), and
# collect the `seq`, so that the position embedding is shifted
past_position = past_key_values[0][0].size(1)
if S + past_position > self.config.max_seq_len:
- raise ValueError(
- f"Cannot forward input with past sequence length {past_position} and current sequence length "
- f"{S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}."
- )
+ raise ValueError(f"Cannot forward input with past sequence length {past_position} and current sequence length " f"{S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}.")
pos = torch.arange(past_position, S + past_position, dtype=torch.long, device=input_ids.device).unsqueeze(0)
if attention_mask is not None:
# adjust the position indices to account for padding tokens
@@ -290,7 +262,11 @@ def forward(
x = self.transformer.emb_drop(x_shrunk)
attn_bias, attention_mask = self._attn_bias(
- device=x.device, dtype=x.dtype, attention_mask=attention_mask, prefix_mask=prefix_mask, sequence_id=sequence_id
+ device=x.device,
+ dtype=x.dtype,
+ attention_mask=attention_mask,
+ prefix_mask=prefix_mask,
+ sequence_id=sequence_id,
)
# initialize the past key values cache if it should be used
@@ -303,34 +279,43 @@ def forward(
assert all_hidden_states is not None # pyright
all_hidden_states = all_hidden_states + (x,)
past_key_value = past_key_values[b_idx] if past_key_values is not None else None
- x, past_key_value = block(x, past_key_value=past_key_value, attn_bias=attn_bias, attention_mask=attention_mask, is_causal=self.is_causal)
+ x, past_key_value = block(
+ x,
+ past_key_value=past_key_value,
+ attn_bias=attn_bias,
+ attention_mask=attention_mask,
+ is_causal=self.is_causal,
+ )
if past_key_values is not None:
past_key_values[b_idx] = past_key_value
x = self.transformer.ln_f(x) # type: ignore
# output embedding weight tied to input embedding
- # move outputs to same device as weights for token embedding
- # needed to support HF `device_map`
assert isinstance(self.transformer.wte, nn.Module) # pyright
assert isinstance(self.transformer.wte.weight, torch.Tensor) # pyright
- logits = F.linear(x.to(self.transformer.wte.weight.device), self.transformer.wte.weight, None)
+ logits = F.linear(x, self.transformer.wte.weight, None)
if self.logit_scale is not None:
if self.logit_scale == 0:
warnings.warn(f"Multiplying logits by {self.logit_scale=}. This will produce uniform (uninformative) outputs.")
logits *= self.logit_scale
- loss = None
+ # compute loss from logits
if labels is not None:
- _labels = torch.roll(labels, shifts=-1)
- _labels[:, -1] = -100
- loss = F.cross_entropy(
- logits.view(-1, logits.size(-1)),
- _labels.to(logits.device).view(-1),
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = nn.CrossEntropyLoss()
+ loss = loss_fct(
+ shift_logits.view(-1, self.transformer.wte.num_embeddings),
+ shift_labels.view(-1),
)
+ return CausalLMOutputWithPast(loss=loss, logits=logits, past_key_values=past_key_values, hidden_states=all_hidden_states)
- return CausalLMOutputWithPast(loss=loss, logits=logits, past_key_values=past_key_values, hidden_states=all_hidden_states)
+ else:
+ return CausalLMOutputWithPast(logits=logits, past_key_values=past_key_values, hidden_states=all_hidden_states)
# Param Initialization, needed for device='meta' fast initialization
def param_init_fn(self, module):
@@ -347,11 +332,11 @@ def fsdp_wrap_fn(self, module):
def activation_checkpointing_fn(self, module):
return isinstance(module, GPTBlock)
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs):
+ def prepare_inputs_for_generation(self, input_ids, attention_mask=None, past_key_values=None, inputs_embeds=None, **kwargs):
if inputs_embeds is not None:
raise NotImplementedError("inputs_embeds is not implemented for MosaicGPT yet")
- attention_mask = kwargs["attention_mask"].bool()
+ attention_mask = attention_mask.bool()
if attention_mask[:, -1].sum() != attention_mask.shape[0]:
raise NotImplementedError("MosaicGPT does not support generation with right padding.")
diff --git a/src/otter_ai/models/flamingo/mpt_redpajama/param_init_fns.py b/src/otter_ai/models/mpt_redpajama/param_init_fns.py
old mode 100644
new mode 100755
similarity index 96%
rename from src/otter_ai/models/flamingo/mpt_redpajama/param_init_fns.py
rename to src/otter_ai/models/mpt_redpajama/param_init_fns.py
index f897b2c2..a83f1575
--- a/src/otter_ai/models/flamingo/mpt_redpajama/param_init_fns.py
+++ b/src/otter_ai/models/mpt_redpajama/param_init_fns.py
@@ -80,10 +80,7 @@ def generic_param_init_fn_(
if init_div_is_residual is not False:
if verbose > 1:
- warnings.warn(
- f"Initializing _is_residual layers then dividing them by {div_is_residual}."
- + f"set `init_div_is_residual: false` in model config to disable this."
- )
+ warnings.warn(f"Initializing _is_residual layers then dividing them by {div_is_residual}." + f"set `init_div_is_residual: false` in model config to disable this.")
if isinstance(module, nn.Linear):
# Linear
@@ -310,7 +307,12 @@ def kaiming_uniform_param_init_fn_(
if verbose > 1:
warnings.warn(f"Using nn.init.kaiming_uniform_ init fn with parameters: " + f"a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}")
- kaiming_uniform_ = partial(nn.init.kaiming_uniform_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
+ kaiming_uniform_ = partial(
+ nn.init.kaiming_uniform_,
+ a=init_gain,
+ mode=fan_mode,
+ nonlinearity=init_nonlinearity,
+ )
generic_param_init_fn_(
module=module,
@@ -342,7 +344,12 @@ def kaiming_normal_param_init_fn_(
if verbose > 1:
warnings.warn(f"Using nn.init.kaiming_normal_ init fn with parameters: " + f"a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}")
- kaiming_normal_ = partial(torch.nn.init.kaiming_normal_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
+ kaiming_normal_ = partial(
+ torch.nn.init.kaiming_normal_,
+ a=init_gain,
+ mode=fan_mode,
+ nonlinearity=init_nonlinearity,
+ )
generic_param_init_fn_(
module=module,
diff --git a/src/otter_ai/models/otter/Otter-MPT7B-config.json b/src/otter_ai/models/otter/Otter-MPT7B-config.json
index 5a34ede7..e69de29b 100644
--- a/src/otter_ai/models/otter/Otter-MPT7B-config.json
+++ b/src/otter_ai/models/otter/Otter-MPT7B-config.json
@@ -1,197 +0,0 @@
-{
- "_commit_hash": null,
- "_name_or_path": "/mnt/petrelfs/zhangyuanhan/weights/flamingo-mpt-7B",
- "architectures": [
- "FlamingoForConditionalGeneration"
- ],
- "cross_attn_every_n_layers": 4,
- "model_type": "otter",
- "only_attend_previous": true,
- "text_config": {
- "_name_or_path": "",
- "add_cross_attention": false,
- "architectures": [
- "MPTForCausalLM"
- ],
- "attn_config": {
- "alibi": true,
- "alibi_bias_max": 8,
- "attn_impl": "torch",
- "attn_pdrop": 0,
- "attn_type": "multihead_attention",
- "attn_uses_sequence_id": false,
- "clip_qkv": null,
- "prefix_lm": false,
- "qk_ln": false,
- "softmax_scale": null
- },
- "bad_words_ids": null,
- "begin_suppress_tokens": null,
- "bos_token_id": null,
- "chunk_size_feed_forward": 0,
- "cross_attention_hidden_size": null,
- "d_model": 4096,
- "decoder_start_token_id": null,
- "diversity_penalty": 0.0,
- "do_sample": false,
- "early_stopping": false,
- "emb_pdrop": 0,
- "embedding_fraction": 1.0,
- "encoder_no_repeat_ngram_size": 0,
- "eos_token_id": null,
- "expansion_ratio": 4,
- "exponential_decay_length_penalty": null,
- "finetuning_task": null,
- "forced_bos_token_id": null,
- "forced_eos_token_id": null,
- "hidden_size": 4096,
- "id2label": {
- "0": "LABEL_0",
- "1": "LABEL_1"
- },
- "init_config": {
- "emb_init_std": null,
- "emb_init_uniform_lim": null,
- "fan_mode": "fan_in",
- "init_div_is_residual": true,
- "init_gain": 0,
- "init_nonlinearity": "relu",
- "init_std": 0.02,
- "name": "kaiming_normal_",
- "verbose": 0
- },
- "init_device": "cpu",
- "is_decoder": false,
- "is_encoder_decoder": false,
- "label2id": {
- "LABEL_0": 0,
- "LABEL_1": 1
- },
- "learned_pos_emb": true,
- "length_penalty": 1.0,
- "logit_scale": null,
- "max_length": 20,
- "max_seq_len": 2048,
- "min_length": 0,
- "model_type": "mpt",
- "n_heads": 32,
- "n_layers": 32,
- "no_bias": true,
- "no_repeat_ngram_size": 0,
- "norm_type": "low_precision_layernorm",
- "num_beam_groups": 1,
- "num_beams": 1,
- "num_return_sequences": 1,
- "output_attentions": false,
- "output_hidden_states": false,
- "output_scores": false,
- "pad_token_id": null,
- "prefix": null,
- "problem_type": null,
- "pruned_heads": {},
- "remove_invalid_values": false,
- "repetition_penalty": 1.0,
- "resid_pdrop": 0,
- "return_dict": true,
- "return_dict_in_generate": false,
- "sep_token_id": null,
- "suppress_tokens": null,
- "task_specific_params": null,
- "temperature": 1.0,
- "tf_legacy_loss": false,
- "tie_encoder_decoder": false,
- "tie_word_embeddings": true,
- "tokenizer_class": null,
- "tokenizer_name": "EleutherAI/gpt-neox-20b",
- "top_k": 50,
- "top_p": 1.0,
- "torch_dtype": "bfloat16",
- "torchscript": false,
- "transformers_version": "4.30.1",
- "typical_p": 1.0,
- "use_bfloat16": false,
- "use_cache": false,
- "verbose": 0,
- "vocab_size": 50432
- },
- "torch_dtype": "float32",
- "transformers_version": null,
- "use_media_placement_augmentation": true,
- "vision_config": {
- "_name_or_path": "openai/clip-vit-large-patch14",
- "add_cross_attention": false,
- "architectures": null,
- "attention_dropout": 0.0,
- "bad_words_ids": null,
- "begin_suppress_tokens": null,
- "bos_token_id": null,
- "chunk_size_feed_forward": 0,
- "cross_attention_hidden_size": null,
- "decoder_start_token_id": null,
- "diversity_penalty": 0.0,
- "do_sample": false,
- "early_stopping": false,
- "encoder_no_repeat_ngram_size": 0,
- "eos_token_id": null,
- "exponential_decay_length_penalty": null,
- "finetuning_task": null,
- "forced_bos_token_id": null,
- "forced_eos_token_id": null,
- "hidden_act": "quick_gelu",
- "hidden_size": 1024,
- "id2label": {
- "0": "LABEL_0",
- "1": "LABEL_1"
- },
- "image_size": 224,
- "initializer_factor": 1.0,
- "initializer_range": 0.02,
- "intermediate_size": 4096,
- "is_decoder": false,
- "is_encoder_decoder": false,
- "label2id": {
- "LABEL_0": 0,
- "LABEL_1": 1
- },
- "layer_norm_eps": 1e-05,
- "length_penalty": 1.0,
- "max_length": 20,
- "min_length": 0,
- "model_type": "clip_vision_model",
- "no_repeat_ngram_size": 0,
- "num_attention_heads": 16,
- "num_beam_groups": 1,
- "num_beams": 1,
- "num_channels": 3,
- "num_hidden_layers": 24,
- "num_return_sequences": 1,
- "output_attentions": false,
- "output_hidden_states": false,
- "output_scores": false,
- "pad_token_id": null,
- "patch_size": 14,
- "prefix": null,
- "problem_type": null,
- "projection_dim": 512,
- "pruned_heads": {},
- "remove_invalid_values": false,
- "repetition_penalty": 1.0,
- "return_dict": true,
- "return_dict_in_generate": false,
- "sep_token_id": null,
- "suppress_tokens": null,
- "task_specific_params": null,
- "temperature": 1.0,
- "tf_legacy_loss": false,
- "tie_encoder_decoder": false,
- "tie_word_embeddings": true,
- "tokenizer_class": null,
- "top_k": 50,
- "top_p": 1.0,
- "torch_dtype": null,
- "torchscript": false,
- "transformers_version": "4.30.1",
- "typical_p": 1.0,
- "use_bfloat16": false
- }
-}
\ No newline at end of file
diff --git a/src/otter_ai/models/otter/Otter-MPT7B-config.json~0d12192f665f5e9da1ecb2f23d6a360eb7753771 b/src/otter_ai/models/otter/Otter-MPT7B-config.json~0d12192f665f5e9da1ecb2f23d6a360eb7753771
new file mode 100644
index 00000000..5a34ede7
--- /dev/null
+++ b/src/otter_ai/models/otter/Otter-MPT7B-config.json~0d12192f665f5e9da1ecb2f23d6a360eb7753771
@@ -0,0 +1,197 @@
+{
+ "_commit_hash": null,
+ "_name_or_path": "/mnt/petrelfs/zhangyuanhan/weights/flamingo-mpt-7B",
+ "architectures": [
+ "FlamingoForConditionalGeneration"
+ ],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "otter",
+ "only_attend_previous": true,
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": [
+ "MPTForCausalLM"
+ ],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 4096,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 4096,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 2048,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 32,
+ "n_layers": 32,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-05,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
\ No newline at end of file
diff --git a/src/otter_ai/models/otter/Otter-MPT7B-config.json~HEAD b/src/otter_ai/models/otter/Otter-MPT7B-config.json~HEAD
new file mode 100644
index 00000000..ff4fb1ca
--- /dev/null
+++ b/src/otter_ai/models/otter/Otter-MPT7B-config.json~HEAD
@@ -0,0 +1,193 @@
+{
+ "_commit_hash": null,
+ "_name_or_path": "/mnt/petrelfs/zhangyuanhan/weights/flamingo-mpt-7B",
+ "architectures": ["FlamingoForConditionalGeneration"],
+ "cross_attn_every_n_layers": 4,
+ "model_type": "otter",
+ "only_attend_previous": true,
+ "text_config": {
+ "_name_or_path": "",
+ "add_cross_attention": false,
+ "architectures": ["MPTForCausalLM"],
+ "attn_config": {
+ "alibi": true,
+ "alibi_bias_max": 8,
+ "attn_impl": "torch",
+ "attn_pdrop": 0,
+ "attn_type": "multihead_attention",
+ "attn_uses_sequence_id": false,
+ "clip_qkv": null,
+ "prefix_lm": false,
+ "qk_ln": false,
+ "softmax_scale": null
+ },
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "d_model": 4096,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "emb_pdrop": 0,
+ "embedding_fraction": 1.0,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "expansion_ratio": 4,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_size": 4096,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "init_config": {
+ "emb_init_std": null,
+ "emb_init_uniform_lim": null,
+ "fan_mode": "fan_in",
+ "init_div_is_residual": true,
+ "init_gain": 0,
+ "init_nonlinearity": "relu",
+ "init_std": 0.02,
+ "name": "kaiming_normal_",
+ "verbose": 0
+ },
+ "init_device": "cpu",
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "learned_pos_emb": true,
+ "length_penalty": 1.0,
+ "logit_scale": null,
+ "max_length": 20,
+ "max_seq_len": 2048,
+ "min_length": 0,
+ "model_type": "mpt",
+ "n_heads": 32,
+ "n_layers": 32,
+ "no_bias": true,
+ "no_repeat_ngram_size": 0,
+ "norm_type": "low_precision_layernorm",
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "prefix": null,
+ "problem_type": null,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "resid_pdrop": 0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "tokenizer_name": "EleutherAI/gpt-neox-20b",
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": "bfloat16",
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false,
+ "use_cache": false,
+ "verbose": 0,
+ "vocab_size": 50432
+ },
+ "torch_dtype": "float32",
+ "transformers_version": null,
+ "use_media_placement_augmentation": true,
+ "vision_config": {
+ "_name_or_path": "openai/clip-vit-large-patch14",
+ "add_cross_attention": false,
+ "architectures": null,
+ "attention_dropout": 0.0,
+ "bad_words_ids": null,
+ "begin_suppress_tokens": null,
+ "bos_token_id": null,
+ "chunk_size_feed_forward": 0,
+ "cross_attention_hidden_size": null,
+ "decoder_start_token_id": null,
+ "diversity_penalty": 0.0,
+ "do_sample": false,
+ "early_stopping": false,
+ "encoder_no_repeat_ngram_size": 0,
+ "eos_token_id": null,
+ "exponential_decay_length_penalty": null,
+ "finetuning_task": null,
+ "forced_bos_token_id": null,
+ "forced_eos_token_id": null,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 1024,
+ "id2label": {
+ "0": "LABEL_0",
+ "1": "LABEL_1"
+ },
+ "image_size": 224,
+ "initializer_factor": 1.0,
+ "initializer_range": 0.02,
+ "intermediate_size": 4096,
+ "is_decoder": false,
+ "is_encoder_decoder": false,
+ "label2id": {
+ "LABEL_0": 0,
+ "LABEL_1": 1
+ },
+ "layer_norm_eps": 1e-5,
+ "length_penalty": 1.0,
+ "max_length": 20,
+ "min_length": 0,
+ "model_type": "clip_vision_model",
+ "no_repeat_ngram_size": 0,
+ "num_attention_heads": 16,
+ "num_beam_groups": 1,
+ "num_beams": 1,
+ "num_channels": 3,
+ "num_hidden_layers": 24,
+ "num_return_sequences": 1,
+ "output_attentions": false,
+ "output_hidden_states": false,
+ "output_scores": false,
+ "pad_token_id": null,
+ "patch_size": 14,
+ "prefix": null,
+ "problem_type": null,
+ "projection_dim": 512,
+ "pruned_heads": {},
+ "remove_invalid_values": false,
+ "repetition_penalty": 1.0,
+ "return_dict": true,
+ "return_dict_in_generate": false,
+ "sep_token_id": null,
+ "suppress_tokens": null,
+ "task_specific_params": null,
+ "temperature": 1.0,
+ "tf_legacy_loss": false,
+ "tie_encoder_decoder": false,
+ "tie_word_embeddings": true,
+ "tokenizer_class": null,
+ "top_k": 50,
+ "top_p": 1.0,
+ "torch_dtype": null,
+ "torchscript": false,
+ "transformers_version": "4.30.1",
+ "typical_p": 1.0,
+ "use_bfloat16": false
+ }
+}
diff --git a/src/otter_ai/models/otter/__init__.py b/src/otter_ai/models/otter/__init__.py
old mode 100644
new mode 100755
diff --git a/src/otter_ai/models/otter/configuration_otter.py b/src/otter_ai/models/otter/configuration_otter.py
old mode 100644
new mode 100755
index a32136ab..3bccd45b
--- a/src/otter_ai/models/otter/configuration_otter.py
+++ b/src/otter_ai/models/otter/configuration_otter.py
@@ -1,13 +1,13 @@
import copy
from transformers.configuration_utils import PretrainedConfig
-from transformers.utils import logging
from transformers.models.auto import CONFIG_MAPPING
from transformers.models.clip import CLIPVisionConfig
+from transformers.utils import logging
-from otter_ai.models.flamingo.falcon.configuration_RW import RWConfig
-from otter_ai.models.flamingo.mpt.configuration_mpt import MPTConfig
-from otter_ai.models.flamingo.mpt_redpajama.configuration_mosaic_gpt import MosaicGPTConfig
+from ..falcon.configuration_RW import RWConfig
+from ..mpt.configuration_mpt import MPTConfig
+from ..mpt_redpajama.configuration_mosaic_gpt import MosaicGPTConfig
logger = logging.get_logger(__name__)
diff --git a/src/otter_ai/models/otter/modeling_otter.py b/src/otter_ai/models/otter/modeling_otter.py
index 9a25836a..69f6d360 100755
--- a/src/otter_ai/models/otter/modeling_otter.py
+++ b/src/otter_ai/models/otter/modeling_otter.py
@@ -1,23 +1,25 @@
-from typing import Optional, List
+import builtins
+import random
+import sys
+from typing import List, Optional
import torch
+import torch.distributed as dist
import torch.nn as nn
-from transformers.modeling_utils import PreTrainedModel
-from transformers.modeling_outputs import CausalLMOutputWithPast
+from accelerate import Accelerator
+from accelerate.hooks import AlignDevicesHook, add_hook_to_module
from einops import rearrange, repeat
-from accelerate.hooks import add_hook_to_module, AlignDevicesHook
-
-from .configuration_otter import OtterConfig
-
-from otter_ai.models.flamingo.falcon.modelling_RW import RWForCausalLM
-from otter_ai.models.flamingo.mpt.modeling_mpt import MPTForCausalLM
-from otter_ai.models.flamingo.mpt_redpajama.mosaic_gpt import MosaicGPT
-
+from peft import LoraConfig, TaskType, get_peft_model
+from transformers.modeling_outputs import CausalLMOutputWithPast
+from transformers.modeling_utils import PreTrainedModel
from transformers.models.auto import AutoModel, AutoModelForCausalLM, AutoTokenizer
-from peft import get_peft_model, LoraConfig, TaskType
-import sys
-import random
+from pipeline.utils.modeling_value_head import AutoModelForCausalLMWithValueHead
+
+from ..falcon.modelling_RW import RWForCausalLM
+from ..mpt.modeling_mpt import MPTForCausalLM
+from ..mpt_redpajama.mosaic_gpt import MosaicGPT
+from .configuration_otter import OtterConfig
# The package importlib_metadata is in a different place, depending on the python version.
if sys.version_info < (3, 8):
@@ -27,29 +29,40 @@
import torch.distributed as dist
+
+def master_print(*args, **kwargs):
+ if dist.is_available() and dist.is_initialized():
+ rank = dist.get_rank()
+ if rank == 0:
+ print(*args, **kwargs)
+ else:
+ print(*args, **kwargs)
+
+
# Add this line at the beginning of your script or in your main function
# dist.init_process_group(backend='nccl')
XFORMERS_AVAIL = False
XFORMERS_MSG_PRINTED = False # Add this global variable
try:
- if not XFORMERS_MSG_PRINTED: # Check if the message has been printed before
+ if not XFORMERS_MSG_PRINTED: # Check if the message has been master_printed before
import xformers.ops as xops
- from xformers_model import CLIPVisionModel, LlamaForCausalLM
from transformers import LlamaTokenizer
+ from xformers_model import CLIPVisionModel, LlamaForCausalLM
+
_xformers_version = importlib_metadata.version("xformers")
if dist.is_initialized() and dist.get_rank() == 0: # Check if the current process rank is 0
- print(f"Successfully imported xformers version {_xformers_version}")
+ master_print(f"Successfully imported xformers version {_xformers_version}")
except ImportError as e:
- if not XFORMERS_MSG_PRINTED: # Check if the message has been printed before
+ if not XFORMERS_MSG_PRINTED: # Check if the message has been master_printed before
from transformers import CLIPVisionModel, LlamaForCausalLM, LlamaTokenizer
if dist.is_initialized() and dist.get_rank() == 0: # Check if the current process rank is 0
- print(f"Failed to import xformers: {e}")
+ master_print(f"Failed to import xformers: {e}")
XFORMERS_AVAIL = False
- print("No xformers found. You are recommended to install xformers via `pip install xformers` or `conda install -c xformers xformers`")
- XFORMERS_MSG_PRINTED = True # Set the variable to True after printing the message
+ master_print("No xformers found. You are recommended to install xformers via `pip install xformers` or `conda install -c xformers xformers`")
+ XFORMERS_MSG_PRINTED = True # Set the variable to True after master_printing the message
# from transformers import CLIPVisionModel, LlamaForCausalLM, LlamaTokenizer
@@ -80,9 +93,7 @@ def _infer_decoder_layers_attr_name(model: nn.Module):
if k.lower() in model.__class__.__name__.lower():
return __KNOWN_DECODER_LAYERS_ATTR_NAMES[k]
- raise ValueError(
- f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually."
- )
+ raise ValueError(f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually.")
def extend_instance(obj, mixin):
@@ -472,14 +483,7 @@ def init_otter(
for layer_idx, _ in enumerate(self._get_decoder_layers())
]
)
- self._set_decoder_layers(
- nn.ModuleList(
- [
- OtterLayer(gated_cross_attn_layer, decoder_layer)
- for gated_cross_attn_layer, decoder_layer in zip(gated_cross_attn_layers, self._get_decoder_layers())
- ]
- )
- )
+ self._set_decoder_layers(nn.ModuleList([OtterLayer(gated_cross_attn_layer, decoder_layer) for gated_cross_attn_layer, decoder_layer in zip(gated_cross_attn_layers, self._get_decoder_layers())]))
self.media_token_id = media_token_id
self.use_media_placement_augmentation = use_media_placement_augmentation
self.initialized_otter = True
@@ -507,7 +511,7 @@ def forward(self, *input, **kwargs):
layer.condition_media_locations(media_locations)
layer.condition_attend_previous(attend_previous)
else:
- print("inavaliable text encoder")
+ master_print("inavaliable text encoder")
return super().forward(*input, **kwargs) # Call the other parent's forward method
def is_conditioned(self) -> bool:
@@ -558,7 +562,7 @@ def __init__(
text_tokenizer = AutoTokenizer.from_pretrained("PATH-TO-YOUR-FALCON")
lang_encoder = RWForCausalLM(config=config.text_config)
else:
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
vision_encoder = CLIPVisionModel(config=config.vision_config)
text_tokenizer.add_special_tokens({"additional_special_tokens": ["<|endofchunk|>", "", ""]})
@@ -594,7 +598,7 @@ def __init__(
)
if "lora_config" in config.__dict__:
- print(f"Using LoRA with config:{config.lora_config}")
+ master_print(f"Using LoRA with config:{config.lora_config}")
standard_modules = ["q_proj", "v_proj"]
lang_encoder_short_name = MODEL_CLASSES[config.text_config.architectures[0]]
model_to_lora_modules = {
@@ -612,7 +616,7 @@ def __init__(
target_modules=model_to_lora_modules[lang_encoder_short_name],
)
self.lang_encoder = get_peft_model(self.lang_encoder, lora_config)
- self.lang_encoder.print_trainable_parameters()
+ self.lang_encoder.master_print_trainable_parameters()
self.post_init()
@@ -651,8 +655,8 @@ def init_weights(self):
if self.lang_encoder.__class__.__name__ == "LlamaForCausalLM":
self.lang_encoder.lm_head.requires_grad_(True)
# assert sum(p.numel() for p in model.parameters() if p.requires_grad) == 0
- # print model size in billions of parameters in 2 decimal places
- print(f"Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.2f} B")
+ # master_print model size in billions of parameters in 2 decimal places
+ master_print(f"Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.2f} B")
def forward(
self,
@@ -728,8 +732,7 @@ def _encode_vision_x(self, vision_x: torch.Tensor):
b, T, F = vision_x.shape[:3]
vision_x = rearrange(vision_x, "b T F c h w -> (b T F) c h w")
- with torch.no_grad():
- vision_x = self.vision_encoder(vision_x)[0][:, 1:, :]
+ vision_x = self.vision_encoder(vision_x)[0][:, 1:, :]
vision_x = rearrange(vision_x, "(b T F) v d -> b T F v d", b=b, T=T, F=F)
vision_x = self.perceiver(vision_x) # reshapes to (b, T, n, d)
@@ -758,14 +761,14 @@ def __init__(
text_tokenizer = AutoTokenizer.from_pretrained("PATH-TO-YOUR-FALCON")
lang_encoder = RWForCausalLM(config=config.text_config)
elif config.text_config.architectures[0] == "LlamaForCausalLM":
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
else:
import pdb
pdb.set_trace()
else:
- text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ text_tokenizer = AutoTokenizer.from_pretrained(config.text_config._name_or_path)
lang_encoder = LlamaForCausalLM(config=config.text_config)
vision_encoder = CLIPVisionModel(config=config.vision_config)
@@ -779,8 +782,8 @@ def __init__(
extend_instance(lang_encoder, OtterLMMixin)
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
- if lang_encoder.__class__.__name__ == "LlamaForCausalLM":
- lang_encoder.resize_token_embeddings(len(text_tokenizer))
+ # if lang_encoder.__class__.__name__ == "LlamaForCausalLM":
+ # lang_encoder.resize_token_embeddings(len(text_tokenizer))
self.lang_encoder = lang_encoder
self.cross_attn_every_n_layers = config.cross_attn_every_n_layers
@@ -788,11 +791,11 @@ def __init__(
self.use_media_placement_augmentation = False # config.use_media_placement_augmentation
self.max_num_frames = config.max_num_frames if hasattr(config, "max_num_frames") else None
- # Informative print statement
+ # Informative master_print statement
if self.max_num_frames is None or self.max_num_frames == 1:
- print(f"The current model version is configured for Otter-Image with max_num_frames set to {self.max_num_frames}.")
+ master_print(f"The current model version is configured for Otter-Image with max_num_frames set to {self.max_num_frames}.")
else:
- print(f"The current model version is configured for Otter-Video with a maximum of {self.max_num_frames} frames.")
+ master_print(f"The current model version is configured for Otter-Video with a maximum of {self.max_num_frames} frames.")
vision_encoder.output_tokens = True
self.vision_encoder = vision_encoder
@@ -809,7 +812,7 @@ def __init__(
if "lora_config" in config.__dict__:
original_architecture_name = self.lang_encoder.__class__.__name__
- print(f"Using LoRA with config:{config.lora_config}")
+ master_print(f"Using LoRA with config:{config.lora_config}")
standard_modules = ["q_proj", "v_proj"]
lang_encoder_short_name = MODEL_CLASSES[config.text_config.architectures[0]]
model_to_lora_modules = {
@@ -827,7 +830,7 @@ def __init__(
target_modules=model_to_lora_modules[lang_encoder_short_name],
)
self.lang_encoder = get_peft_model(self.lang_encoder, lora_config)
- self.lang_encoder.print_trainable_parameters()
+ self.lang_encoder.master_print_trainable_parameters()
self.lang_encoder.__class__.__name__ = f"{original_architecture_name}LoRA"
self.post_init()
@@ -851,9 +854,32 @@ def get_lang_encoder(self) -> nn.Module:
return self.lang_encoder
def init_weights(self):
- # Freeze all parameters in self.model
- for param in self.parameters():
- param.requires_grad = False
+ # Freeze all parameters in self.model if train_vision_encoder is False or train_lang_encoder is False
+ if not ("train_full_model" in self.config.__dict__ and self.config.train_full_model is True):
+ for param in self.parameters():
+ param.requires_grad = False
+
+ # Freeze all parameters in vision encoder
+ if "train_vision_encoder" in self.config.__dict__ and self.config.train_vision_encoder is True:
+ master_print("Unfreeze vision encoder.")
+ for param in self.vision_encoder.parameters():
+ param.requires_grad = True
+
+ # Freeze all parameters in lang encoders except gated_cross_attn_layers
+ if "train_lang_encoder" in self.config.__dict__ and self.config.train_lang_encoder is True:
+ master_print("Unfreeze language decoder.")
+ for name, param in self.lang_encoder.named_parameters():
+ param.requires_grad = True
+
+ # Freeze all parameters in vision encoder
+ if "train_vision_encoder" in self.config.__dict__ and self.config.train_vision_encoder is True:
+ for param in self.vision_encoder.parameters():
+ param.requires_grad = True
+
+ # Freeze all parameters in lang encoders except gated_cross_attn_layers
+ if "train_lang_encoder" in self.config.__dict__ and self.config.train_lang_encoder is True:
+ for name, param in self.lang_encoder.named_parameters():
+ param.requires_grad = True
# Freeze all parameters in vision encoder
if "train_vision_encoder" in self.config.__dict__ and self.config.train_vision_encoder is True:
@@ -867,7 +893,7 @@ def init_weights(self):
if "lora_config" in self.config.__dict__:
# Use another logic to unfreeze gated_cross_attn_layers and perceivers
- print(f"LoRA trainable param: {(sum(param.numel() for name, param in self.lang_encoder.named_parameters() if 'lora' in name)) / 1e6:.3f} M")
+ master_print(f"LoRA trainable param: {(sum(param.numel() for name, param in self.lang_encoder.named_parameters() if 'lora' in name)) / 1e6:.3f} M")
for name, param in self.lang_encoder.named_parameters():
if "lora" in name:
param.requires_grad = True
@@ -885,14 +911,13 @@ def init_weights(self):
## MPTForCausalLM is tied word embedding
if "LlamaForCausalLM" in self.lang_encoder.__class__.__name__:
self.lang_encoder.lm_head.requires_grad_(True)
- # print("====================Model Grad Part====================")
+
total_params = 0
for name, param in self.named_parameters():
if param.requires_grad:
total_params += param.numel()
- # print(f"Parameter: {name}, Size: {param.numel() / 1e6:.6f} M")
- print(f"Total Trainable param: {total_params / 1e9:.6f} B")
- # print(f"Total Trainable param: {(sum(p.numel() for p in self.parameters() if p.requires_grad)) / 1e9:.6f} B")
+ master_print(f"Parameter: {name}, Size: {param.numel() / 1e6:.6f} M")
+ master_print(f"Total Trainable param: {total_params / 1e9:.6f} B")
def forward(
self,
@@ -968,8 +993,286 @@ def _encode_vision_x(self, vision_x: torch.Tensor):
b, T, F = vision_x.shape[:3]
vision_x = rearrange(vision_x, "b T F c h w -> (b T F) c h w")
- with torch.no_grad():
- vision_x = self.vision_encoder(vision_x)[0][:, 1:, :]
+ vision_x = self.vision_encoder(vision_x)[0][:, 1:, :]
+ vision_x = rearrange(vision_x, "(b T F) v d -> b T F v d", b=b, T=T, F=F)
+
+ vision_x = self.perceiver(vision_x) # reshapes to (b, T, n, d)
+
+ for layer in self.lang_encoder._get_decoder_layers():
+ layer.condition_vis_x(vision_x)
+
+ @torch.no_grad()
+ def generate(
+ self,
+ vision_x: torch.Tensor,
+ lang_x: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ **generate_kwargs,
+ ):
+ """
+ Generate text conditioned on vision and language inputs.
+
+ Args:
+ vision_x (torch.Tensor): Vision input
+ shape (B, T_img, F, C, H, W)
+ images in the same chunk are collated along T_img, and frames are collated along F
+ currently only F=1 is supported (single-frame videos)
+ lang_x (torch.Tensor): Language input
+ shape (B, T_txt)
+ max_length (int, optional): Maximum length of the output. Defaults to None.
+ attention_mask (torch.Tensor, optional): Attention mask. Defaults to None.
+ Returns:
+ torch.Tensor: lang_x with generated tokens appended to it
+ """
+ if hasattr(self, "_hf_hook"):
+ # add a hook to make sure that the output of lang_encoder is mapped to the same device as the lang_x
+ hook = AlignDevicesHook(
+ execution_device=lang_x.device,
+ io_same_device=True,
+ place_submodules=False,
+ )
+ add_hook_to_module(self.lang_encoder, hook)
+ num_beams = generate_kwargs.get("num_beams", 1)
+ if num_beams > 1:
+ vision_x = vision_x.repeat_interleave(num_beams, dim=0)
+ self._encode_vision_x(vision_x=vision_x)
+ output = self.lang_encoder.generate(
+ input_ids=lang_x,
+ attention_mask=attention_mask,
+ eos_token_id=self.eoc_token_id,
+ **generate_kwargs,
+ )
+
+ self.lang_encoder.clear_conditioned_layers()
+ return output
+
+
+class OtterForConditionalGenerationWithValueHead(OtterPreTrainedModel):
+ config_class = OtterConfig
+
+ def __init__(
+ self,
+ config: OtterConfig,
+ ):
+ super().__init__(config)
+ ### TODO: give "LlamaForCausalLM" as the name of text_config.architectures of Llama_based flamingo
+ if "llama" not in config.text_config._name_or_path:
+ if config.text_config.architectures[0] == "MPTForCausalLM":
+ text_tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
+ lang_encoder = MPTForCausalLM(config=config.text_config)
+ elif config.text_config.architectures[0] == "MosaicGPT":
+ text_tokenizer = AutoTokenizer.from_pretrained("mosaicml/mosaic-llama-redpajama-final-candidate")
+ lang_encoder = MosaicGPT(config=config.text_config)
+ elif config.text_config.architectures[0] == "RWForCausalLM":
+ text_tokenizer = AutoTokenizer.from_pretrained("PATH-TO-YOUR-FALCON")
+ lang_encoder = RWForCausalLM(config=config.text_config)
+ elif config.text_config.architectures[0] == "LlamaForCausalLM":
+ text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ lang_encoder = LlamaForCausalLM(config=config.text_config)
+ else:
+ text_tokenizer = LlamaTokenizer.from_pretrained(config.text_config._name_or_path)
+ lang_encoder = LlamaForCausalLM(config=config.text_config)
+ vision_encoder = CLIPVisionModel(config=config.vision_config)
+
+ text_tokenizer.add_special_tokens({"additional_special_tokens": ["<|endofchunk|>", " +
+
 +
+ -We also introduce **Syphus**, an automated pipeline for generating high-quality instruction-response pairs in multiple languages. Building upon the framework proposed by LLaVA, we utilize ChatGPT to generate instruction-response pairs based on visual content. To ensure the quality of the generated instruction-response pairs, our pipeline incorporates system messages, visual annotations, and in-context examples as prompts for ChatGPT.
+We also introduce **Syphus**, an automated pipeline for generating high-quality instruction-response pairs in multiple languages. Building upon the framework proposed by LLaVA, we utilize ChatGPT to generate instruction-response pairs based on visual content. To ensure the quality of the generated instruction-response pairs, our pipeline incorporates system messages, visual annotations, and in-context examples as prompts for ChatGPT.
For more details, please check the [MIMIC-IT dataset](mimic-it/README.md).
-
## 🤖 Otter Model Details
-We also introduce **Syphus**, an automated pipeline for generating high-quality instruction-response pairs in multiple languages. Building upon the framework proposed by LLaVA, we utilize ChatGPT to generate instruction-response pairs based on visual content. To ensure the quality of the generated instruction-response pairs, our pipeline incorporates system messages, visual annotations, and in-context examples as prompts for ChatGPT.
+We also introduce **Syphus**, an automated pipeline for generating high-quality instruction-response pairs in multiple languages. Building upon the framework proposed by LLaVA, we utilize ChatGPT to generate instruction-response pairs based on visual content. To ensure the quality of the generated instruction-response pairs, our pipeline incorporates system messages, visual annotations, and in-context examples as prompts for ChatGPT.
For more details, please check the [MIMIC-IT dataset](mimic-it/README.md).
-
## 🤖 Otter Model Details
 +
+