From c44df5e4822394e10bf12bb248ee0d39703b8e32 Mon Sep 17 00:00:00 2001
From: Mark Evens
Date: Wed, 8 Jan 2020 22:56:50 +0000
Subject: [PATCH] Update to v2.0.7 (2nd attempt)
Bug fixes and new UI tags
---
plugins/classical_extras/Readme.md | 708 +
plugins/classical_extras/__init__.py | 8702 +++++++++++
plugins/classical_extras/const.py | 1148 ++
.../options_classical_extras.ui | 11987 ++++++++++++++++
.../ui_options_classical_extras.py | 5011 +++++++
5 files changed, 27556 insertions(+)
create mode 100644 plugins/classical_extras/Readme.md
create mode 100644 plugins/classical_extras/__init__.py
create mode 100644 plugins/classical_extras/const.py
create mode 100644 plugins/classical_extras/options_classical_extras.ui
create mode 100644 plugins/classical_extras/ui_options_classical_extras.py
diff --git a/plugins/classical_extras/Readme.md b/plugins/classical_extras/Readme.md
new file mode 100644
index 00000000..173a01c0
--- /dev/null
+++ b/plugins/classical_extras/Readme.md
@@ -0,0 +1,708 @@
+# General Information
+This is the documentation for version 2.0.7 of "classical\_extras". There may be beta versions later than this - check [my github site](https://github.com/MetaTunes/picard-plugins/tree/metabrainz/2.0/plugins/classical_extras) for newer releases. For further help, please review [the forum thread](https://community.metabrainz.org/t/classical-extras-2-0/394627) or post any new questions there. It only works with Picard versions 2.0 and above, **NOT** earlier versions. If you are using Picard 1.4.x, please choose the ["1.0" branch on github](https://github.com/MetaTunes/picard-plugins/tree/1.0/plugins/classical_extras) and use the latest release there - also use the [earlier forum thread](https://community.metabrainz.org/t/classical-extras-plugin/300217).
+
+This version has only been tested with FLAC and mp3 files. It does work with m4a files, but Picard does not write all m4a tags (see further notes for iTunes users at the end of the "works and parts tab" section). "Classical Extras" populates tags and hidden variables in Picard with information from the MusicBrainz database about the recording, artists and work(s), and of any containing works, passing up through multiple work-part levels until the top is reached. The "Options" page (Options->Options->Plugins->Classical Extras) allows the user to determine how hidden variables are written to file tags, as well as a variety of other options.
+
+This plugin is particularly designed to assist with tagging of classical music so that player or library manager software, which can display multiple work levels, different artist types and custom tags, can have access to these details.
+It has two main components - "Artists" and "Works and parts" - which can be used independently or together. "Works and parts" will take at least as many seconds to process as there are works to look up (owing to MusicBrainz throttling) so users who only want the extra artist information and the tag-mapping feature, but not the work details, may turn it off (e.g. perhaps for 'popular' music). There are also two tabs - "Genres etc." and "Tag mapping" which may be used provided either "Artists" or "Works and parts" (or both) are run. Finally, an "Advanced" tab contains additional options.
+
+Hidden metadata variables produced by this plugin are (mostly) prefixed with "\_cwp\_" or "\_cea\_" depending on which component of the plugin created them. Full details of these variables are given in a later section.
+Tags are output depending on the choices specified by the user in the Options Page. Defaults are provided for these tags which can be added to / modified / deleted according to user requirements.
+If the Options Page does not provide sufficient flexibility, users familiar with scripting can write Tagger Scripts to access the hidden variables directly.
+
+## Updates
+Version 2.0.7: Bug fixes for compatibility with Picard 2.2+. Ability to specify additional columns in Picard UI (see detailed notes at the end of the "Advanced" tab section). Minor enhancements.
+
+Version 2.0.6: Fixed crash on Picard 2.2.
+
+Version 2.0.5: Add extra error trapping for circular work references. Alpha test of release series tags if Picard provides series-rels with release lookup.
+
+Version 2.0.4: Fix occasional regex backtracking crash. Make naming of movement tags consistent with Picard docs.
+Added an option to attempt to get works and movement info from title if there are no work relationships (requires title in form "work: movement").
+If Muso-specific genre processing is selected (or XML reference file is provided including classical composers) and there is no composer (because of a lack of work relationship)
+then the plugin will check the listed artist against the reference list of classical composers and, if there is a match, will populate the composer metadata and set the genre to classical.
+
+Version 2.0.3: Fix exception when references XML file does not exist
+
+Version 2.0.2: Changed layout of tabs - the order is now Artists, Works, Genres and Tag-mapping. The help tab has been much reduced as it was of limited assistance and difficult to maintain. There is a lot of context-sensitive help and the readme file contains the latest full documentation.
+Added a check-box on the genres tab to enable/disable genre filtering (previously the genre names would have to be blank to eliminate filtering and in any case this was buggy).
+A general code tidy-up has led to significant performance enhancements. The only significant slowing factor is now the unavoidable MusicBrainz 1 look-up per second constraint (for looking up works).
+A number of changes have been made to the way in which "extended" metadata is supplied - i.e. where title metadata is combined with the "canonical" MusicBrainz work names. Hopefully the result is a more consistent and helpful presentation. Also some minor changes to the way in which text is eliminated to arrive at part names, including a new option on the "advanced" tab to "Allow blank part names for arrangements and part recordings, if an arrangement/partial label is provided" (see documentation under the advanced tab section for more details). Plus bug fixes.
+
+Version 2.0.1: Minor update to add _composer_lastnames variable.
+
+Version 2.0: Major overhaul of version 0.9.4 to achieve Picard 2.0 and Python 3.7 compatibility. All webservice calls re-written for JSON rather than XmlNode responses. Periods are written to tag in date order. Addition of sub-options for inclusion of key signature information in work names. If the MB database has circular work references (i.e a parent is a descendant of itself) then these will be trapped, ignored and reported. Numerous small refinements, especially of text comparison algorithms (e.g. option to control removal of prepositions - see advanced tab). Bug fixes.
+
+For a list of previous version changes, see the end of this document.
+
+# Installation
+Install the zip file in your plugins folder in the usual fashion.
+
+# Usage
+After installation, go to the Options Page and modify choices as required. There are 5 tabs - "Artists", "Works and parts", "Genres etc.", "Tag mapping" and "Advanced". The sections below describe each of these. If the options provided do not allow sufficient flexibility for a user's need (hopefully unlikely!) then Tagger Scripts may be used to process the hidden variables or other tags. Alternatively, it may be possible to achieve the required result by running and saving twice (or more!) with different options each time. This is not recommended for more than a one-off - a script would be better.
+
+**Important**:
+1. The plugin **will not work fully unless** "Use release relationships" and "Use track relationships" are enabled in Picard->Options->Metadata. The plugin will enable these options by default when starting Picard. However, it may be that the MusicBrainz database has conflicting data between track and release relationships, in which case you may wish to temporarily turn off one of these options, but it is better to fix the incorrect data using "Edit relationships" in MusicBrainz.
+2. It is recommended only to use the plugin on one or a few release(s) at a time, particularly for initial tagging if the "Works and parts" function is being used. The plugin is not designed to do "bulk tagging" of untagged files - it may be better to use a tool such as SongKong for that and then use the plugin to enhance the results as required. However, once you have tagged files (either in Picard or another tool) such that they all have MusicBrainz IDs, you should be able to re-tag multiple releases by dragging the containing folder into Picard; this is useful to pick up changed MusicBrainz data or if you change the Classical Extras version or options (but bear in mind that the "Works and parts" function will still take at least 1 second per track.
+3. **Check for error messages before saving a release**. The plugin will write out special "error message" tags which should appear prominently in the bottom Picard pane. In particular, look for "000\_major\_warning" and "001\_errors". please read the messages carefully and follow any recommended actions.
+
+ **Watch out for "002\_important\_warning" - "No file with matching trackid - IF THERE SHOULD BE ONE, TRY 'REFRESH' - (unable to process any saved options, lyrics or 'keep' tags)"; this will always occur if you load a file without MusicBrainz ids - just refresh it to pick up any existing file tags such as lyrics, if required.** This will also occur if you have manually matched files rather than used Picard's "lookup" or "scan" functions. It may also be due to Picard processing issues - more likely if the files are on a network server; if you are getting it a lot then it may be better to move the files onto local storage to do the updates.
+4. If you are just changing option settings then you can usually "use cache" (see "work and parts" tab section 1) when refreshing, to avoid the 1-second per work delay. However, if the works data in MusicBrainz has been changed then obviously you will need to do a full look-up, so disable cache. If the work structure has been fundamentally changed (i.e. a different hierarchy of existing works) - either within the MusicBrainz database or by selecting/deselecting the "include collection relations", partial" or "arrangements" options - then you may need to quit and restart Picard to correctly pick up the new structure.
+5. Keep a backup of your picard.ini file (C:\Users\[user name]\AppData\Roaming\MusicBrainz in Windows) in case you erase your settings or Picard crashes and loses them for you.
+
+## Artists tab
+There are five coloured sections as shown in the screen image below:
+
+
+
+1. "Create extra artist metadata" should be selected otherwise this section will not run. This is the default.
+
+2. "Work-artist/performer naming options".
+ This section deals primarily with the application of aliases and "credited as" names to replace the MusicBrainz standard names. The first box allows you to choose whether to replace MusicBrainz standard names by aliases - either for all work-artists/performers or only work-artists (writers, composers, arrangers, lyricists etc.). The second box sets the usage of "credited as" names: the first part of this lists all the places where "credited as" names can occur (really!) and the second part allows you to apply these to performing artists and/or work-artists.
+
+ Please note that, in the current version of this plugin, only aliases and "credited as" names which are in the "release XML node" are available (i.e. roughly those relating to the metadata shown in the release overview page in MusicBrainz). So, for example, if a recording is an arrangement of another work and that other work (but not the arrangement itself) has a composer linked to it, then the composer's alias will not be available (nor is the composer shown on the MB release overview page). In some cases (if appropriate) this can be remedied by adding the relevant composer relationship to the lowest-level work.
+
+ >Note regarding aliases and "credited as" names:
+ In a MB release, an artist can appear in one of seven contexts. Each of these is accessible in releaseXmlNode
+ and the track and recording contexts are also accessible in trackXmlNode.
+ (They are applied in sequence - e.g. track artist credit will over-ride release artist credit)
+ The seven contexts are:
+ Recording: credited-as and alias (this is applied first as it is the most general - i.e. it may apply to more than one release)
+ Release-group: credited-as and alias
+ Release: credited-as and alias
+ Release relationship: credited-as only (see note)
+ Recording relationship (direct): credited-as only (see note)
+ Recording relationship (via work): credited-as only (see note)
+ Track: credited-as and alias
+ Note: Aliases **may** be retrieved for "relationship" artists, but the retrieval is not reliable (MusicBrainz webservice issue)
+
+ N.B. if more than one release is loaded in Picard, any available alias names loaded so far will be available and used. However, "credited as" names will only be used from the current release. If you do not want these names to be available then you may need to restart Picard after changing the option settings (otherwise they will still be cached).
+
+ In addition to the plugin options, the main Picard options also have an effect on how 'track artists' (or any tags derived from them through tag-mapping) are displayed. In Options->Metadata, if "Translate artist names..." is selected then the alias will be used for the track artist (or failing that, a name based on the sort-name), rather than the "credited as" name. If "Use standardized artist names" is selected then neither the alias nor the "credited as" name will be used. In order to facilitate consistency, Classical Extras will save these Picard options along with its own options in specific tags (see "Advanced options" section 6).
+
+ The bottom box then (a) allows a choice as to whether aliases will over-ride "credited as" names or vice versa and (b) whether, if there are still some names in non-Latin script, these should be replaced (this will always remove middle [patronymic] names from Cyrillic-script names [but does not deal fully with other non-Latin scripts]; it is based on the sort names wherever possible).
+
+ Note that **none of this processing affects the contents of the "artist" or "album\_artist" tags, unless they are replaced by a "tag mapping" action**. These tags may be either work-artists or performing artists. Their contents are determined by the standard Picard options "translate artist names" and "use standardized artist names" in Options-->Metadata. If "translate name" is selected, the name will be the alias or (if no alias) the 'unsorted' sort-name; otherwise the name will be the MusicBrainz name if "use standardized artist names" is selected or the "credited as" name (if available) if it is not selected. Using the saved options to over-ride the displayed options has no effect on this as the processing takes place in Picard itself, not the plugin (but **over-write** will over-write all Picard and plugin options with the saved ones).
+
+3. "Recording artist options".
+ In MusicBrainz, the recording artist may be different from the track artist. For classical music, the MusicBrainz guidelines state that the track artist should be the composer; however the recording artist(s) is/are usually the principal performer(s).
+ Because, in classical music (in MusicBrainz), recording artists will usually be performers whereas track artists are composers, by default the naming convention for performers (set in the previous section) will be used (although only the as-credited name set for the recording artist will be applied). Alternatively, the naming convention for track artists can be used - which is determined by the main Picard metadata options.
+
+ Classical Extras puts the recording artists into 'hidden variables' (as a minimum) using the chosen naming convention.
+ There is also option to allow you to replace the track artist by the recording artist (or to merge them). The chosen action will be applied to the 'artist', 'artists', 'artistsort' and 'artists\_sort' tags. Note that 'artist' is usually a single-valued string with a "join phrase" such as a semi-colon for multiple artists, whereas 'artists' is a list and may be multi-valued. Lists are simply merged but, because the 'artist' string may have different join-phrases etc, a merged tag may have the recording artist(s) in brackets after the track artist(s). Obviously, for classical music, if you use "merge" then the artist tag will have both the composer and the recording artists: this may be desirable for simple players (with no composer recognition) but otherwise may look odd.
+
+ Note that, if the original track artist is required in tag mapping (i.e. as it was before replacement/merge with recording artist), it is available through the hidden variable \_cea\_MB\_artists.
+
+ Note also that, if @loujin's browser script has been used to fill the recording artist data, this will be the same as the performing artists in the Recording-Artist relationship - i.e. it may be a lengthy list rather than the principal artist for the track.
+
+4. "Other artist options":
+
+ "Modify host tags and include annotations" (Previously called "Include arrangers from all work levels"). This will gather together, for example, any arranger-type information from the recording, work or parent works and place it in the "arranger" tag ('host' tag), with the annotation (see below) in brackets. All arranger types will also be put in a hidden variable, e.g. \_cwp\_orchestrators. The table below shows the artist types, host tag and hidden variable for each artist type.
+
+ | Artist type | Host tag | Hidden variable |
+ | writer | composer | writers |
+ | lyricist | lyricist | lyricists |
+ | revised by | arranger | revisors |
+ | translator | lyricist | translators |
+ | arranger | arranger | arrangers |
+ | reconstructed by | arranger | reconstructors |
+ | orchestrator | arranger | orchestrators |
+ | instrument arranger | arranger | arrangers (with instrument type in brackets) |
+ | vocal arranger | arranger | arrangers (with voice type in brackets) |
+ | chorus master | conductor | chorusmasters |
+ | concertmaster | performer (with annotation as a sub-key) | leaders |
+
+
+ If you want to be more selective as to what is included in host tags, then disable this option and use the tag mapping section to get the data from the hidden variables. If you want to add arrangers as composers, do so in the tag mapping section also.
+
+ (Note that Picard does not normally pick up all arrangers, but that the plugin will do so, provided the "Works and parts" section is run.)
+
+ "Name album as 'Composer Last Name(s): Album Name'" will add the composer(s) last name(s) before the album name, if they are listed as album artists. If there is more than one composer, they will be listed in the descending order of the length of their music on the release. MusicBrainz style is to exclude the composer name unless it is actually part of the album name, but it can be useful to add it for library organisation. The default is checked.
+
+ "Do not write 'lyricist' tag if no vocal performers". Hopefully self-evident. This applies to both the Picard 'lyricist' tag and the related internal plugin hidden variables '\_cwp\_lyricists' etc.
+
+ Note that the plugin will search for lyricists at all work levels (bottom up), but will stop after finding the first one (unless that was just a translator).
+
+ "Do not include attributes in an instrument type" (previously just referred to the attribute 'solo'). MusicBrainz permits the use of "solo", "guest" and "additional" as instrument attributes although, for classical music, its use should be fairly rare - usually only if explicitly stated as a "solo" on the the sleevenotes. Classical Extras provides the option to exclude these attributes (the default), but you may wish to enable them for certain releases or non-Classical / cross-over releases.
+
+ "Annotations": The chosen text will be used to annotate the artist type within the host tag (see table above for host tags), but only if "Modify host tags" is selected.
+
+ Please note that the use of the word "master" is the MusicBrainz term and is not intended to be gender-specific. Users can specify whatever text they please.
+
+5. "Lyrics". **Please note that this section operates on the underlying input file tags, not the Picard-generated tags (MusicBrainz does not have lyrics)**
+ Sometimes "lyrics" tags can contain album notes (repeated for every track in an album) as well as track notes and lyrics. This section will filter out the common text for a release and place it in a different tag from the text which is unique to each track.
+
+ "Split lyrics tag": enables this section.
+
+ "Incoming lyrics tag": The name of the lyrics file tag in the input file (normally just 'lyrics').
+
+ "Tag for album notes": The name of the tag where common text should be placed.
+
+ "Tag for track notes": The name of the tag where notes/lyrics unique to a track should be placed.
+
+ Note that if the 'output' tags are not specified, then internal 'hidden' variables will still be available for use in the tag-mapping section (called album\_notes and track\_notes).
+
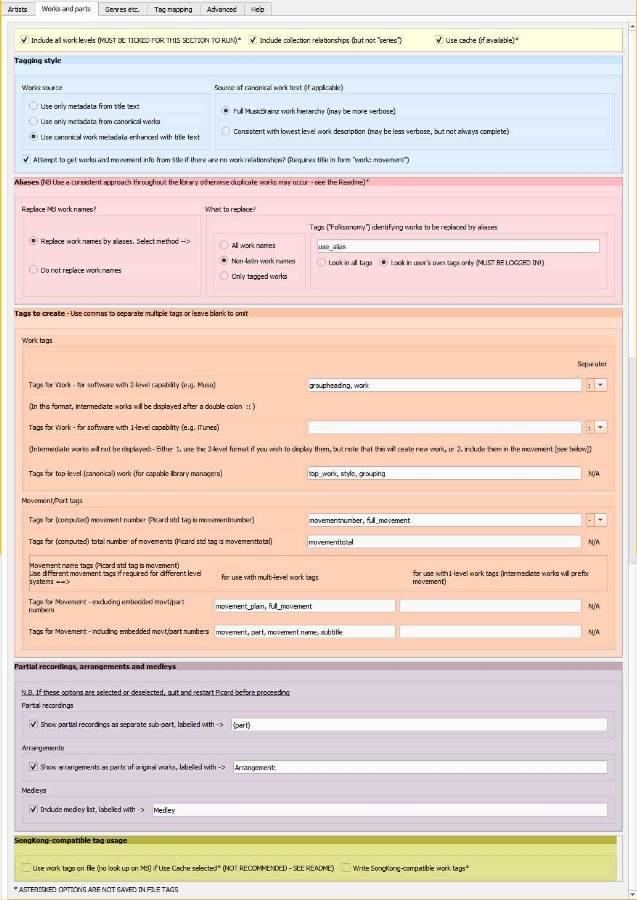
+## Work and parts tab
+
+There six coloured sections as shown in the screen print below:
+
+
+
+1. "Include all work levels" should be selected otherwise this section will not run. This is the default.
+
+ "Include collection relationships" (selected by default) will include parent works where the relationship has the attribute 'part of collection'. See [Discussion](https://community.metabrainz.org/t/levels-in-the-structure-of-works/293047/109) for the background to this. Note that only "work" entity types will be included, not "series" entities. If this option is changed, it will not take effect on releases already loaded in Picard - you will need to quit and restart. PLEASE BE CONSISTENT and do not use different options on albums with the same works, otherwise you may not get what you want.
+
+ "Use cache (if available)" prevents excessive look-ups of the MB database. Every look-up of a work needs to be performed separately (hopefully the MB database might make this easier some day). Network usage constraints by MB means that each look-up takes a minimum of 1 second. Once a release has been looked-up, the works are retained in cache, significantly reducing the time required if, say, the options are changed and the data refreshed. However, if the user edits the works in the MB database then the cache will need to be turned off temporarily for the refresh to find the new/changed works. Also some types of work (e.g. arrangements) will require a full look-up if options have been changed. **Do not leave this option turned off** as it will make the plugin slower and may cause problems. This option will always be set on when Picard is started, regardless of how it was left when it was last closed.
+
+2. "Tagging style". This section determines how the hierarchy of works will be sourced.
+
+ * **Works source**: There are 3 options for determing the principal source of the works metadata
+ - "Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns, using the work structure in MusicBrainz as a guide. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
+ - "Use only metadata from canonical works". The names from the hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).
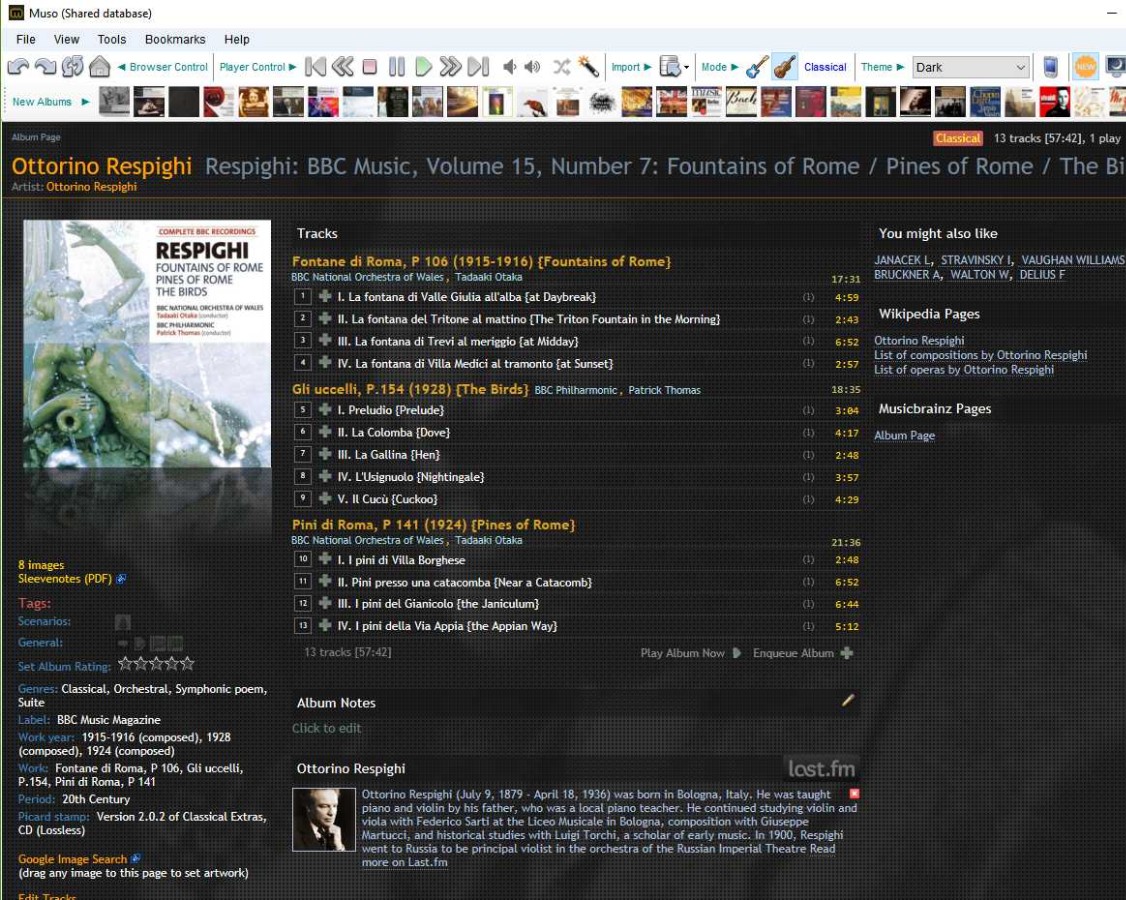
+ - "Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles **where it is significantly different**. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations - see image below for an example (using the Muso library manager). In this example, title text that is similar to that in the canonical text has been eliminated to make the text shorter - the mannr of doing this is controlled by settings on the Advanced tab.
+
+ 
+
+ * **Source of canonical work text**. Where either of the second two options above are chosen, there is a further choice to be made:
+ - "Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if ""Concert Fantasy for Piano and Orchestra, op. 56: I. Quasi Rondo" (level 0) is part of "Concert Fantasia, op. 56" (level 1) then that is how they will appear, since there is no repetition of text between parent and child. So, while accurate, this option might sometimes be rather verbose.
+ - "Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. So, in the above example, "Concert Fantasy for Piano and Orchestra, op. 56" will be shown as the work and "I. Quasi Rondo" will be shown as the movement. Sometimes this may look better, but not always, **particularly if the level 0 work name does not contain all the parent work detail**. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
+
+ **Version 2.0 update**: the second option is needed less often now as there is a more sophisticated matching algorithm for the canonical work names. Text may be eliminated at places other than the start, and synonyms may be used to achieve greater matching. These options are set on the Advanced tab. Setting "Removal of common text between parent and child works" to 2 (the default) and including "Fantasia" as a synonym of "Fantasy" yields the following result:
+ Work: "Concert Fantasia, op. 56", Movement: "for Piano and Orchestra, … : I. Quasi Rondo"
+ This still repeats "for Piano and Orchestra" for each movement as this text is in level 0, not level 1 (where it only appears as disambiguation). Arguably the best way to fix this is to have consistent work names in MB. (Of course, this specific example may have been fixed in MB by now, but the principle still holds). The strategy below has been updated to reflect this
+
+ **Strategy for setting style:** *It is suggested that you start with "extended/enhanced" style and the "Full MusicBrainz work hierarchy" as the source (this is the default) and tweak the advanced settings if necessary. If this does not give acceptable results, try switching to "Consistent with lowest level work description". If the "enhanced" details in curly brackets (from the track title) give odd results then, again, try tweaking the advanced settings (see later section) or switch the style to "canonical works" only. Any remaining oddities are probably in the MusicBrainz data, which may require editing.*
+
+ * **"Attempt to get works and movement info from title if there are no work relationships? (Requires title in form "work: movement")"**.
+ Pretty much what it says. It may be that the track is classical, but no work relationships exist in MusicBrainz. In this case, Classical Extras will attempt to infer work and movement from the title, provided they are separated by ": " (which is the Classical Style Guideline).
+ In this case, the other tag style settings are irrelevant. Note that if there is no related work, then there will not be a composer metadata item in MusicBrainz. However, you can use tag mapping to set this or (better) use Muso (or and XML reference file) to determine classical composers (see Genres section).
+
+3. "Aliases"
+
+ "Replace work names by aliases" will use **primary** aliases for the chosen locale instead of standard MusicBrainz work names. To choose the locale, use the drop-down under "translate artist names" in the main Picard Options-->Metadata page. Note that this option is not saved as a file tag since, if different choices are made for different releases, different work names may be stored and therefore cannot be grouped together in your player/library manager. The sub-options then allow either the replacement of all work names, where a primary alias exists, just the replacement of work names which are in non-Latin script, or only replace those which are flagged with user "Folksonomy" tags. The tag text needs to be included in the text box, in which case flagged works will be 'aliased' as well as non-Latin script works, if the second sub-option is chosen. Note that the tags may either be anyone's tags ("Look in all tags") or the user's own tags. If selecting "Look in user's own tags only" you **must** be logged in to your MusicBrainz user account (in the Picard Options->General page), otherwise repeated dialogue boxes may be generated and you may need to force restart Picard.
+
+4. "Tags to create" sets the names of the tags that will be created from the sources described above. All these tags will be blanked before filling as specified. Tags specified against more than one source will have later sources appended in the sequence specified, separated by separators as specified.
+
+ * **Work tags**:
+ - "Tags for Work - for software with 2-level capability". Some software (notably Muso) can display a 2-level work hierarchy as well as the work-movement hierarchy. This tag can be use to store the 2-level work name (a double colon :: is used to separate the levels within the tag).
+ - "Tags for Work - for software with 1-level capability". Software which can display a movement and work (but no higher levels) could use any tags specified here. Note that if there are multiple work levels, the intermediate levels will not be tagged. Users wanting all the information should use the tags from the previous option (but it may cause some breaks in the display if levels change) - alternatively the missing work levels can be included in a movement tag (see below).
+ - "Tags for top-level (canonical) work". This is the top-level work held in MB. This can be useful for cataloguing and searching (if the library software is capable).
+
+ * **Movement/Part tags**:
+ (a) "Tags for (computed) movement number". This is not necessarily the embedded movt/part number, but is the sequence number of the movement within its parent work **on the current release**.
+ (For these purposes, the "parent work" is the highest level work of which the track/movement is a a part but which is not a collection)
+ (b) "Tags for (computed) total number of movements". This will be the total number of movements in the parent work as numbered above.
+ (c) "Tags for Movement - excluding embedded movt/part numbers". As below, but without the movement part/number prefix (if applicable)
+ (d) "Tags for Movement - including embedded movt/part numbers". This tag(s) will contain the full lowest-level part name extracted from the lowest-level work name, according to the chosen tagging style.
+ For options (c) and (d), the tags can either be filled "for use with multi-level work tags" or "for use with 1-level work tags (intermediate works will prefix movement)" - or different tags for each column. The latter option will include any intermediate work levels which are missing from a single-level work tag. Use different tag names for these, from the multi-level version, otherwise both versions will be appended, creating a multi-valued tag (a warning will be given).
+ The default tags for (a), (b), and (c) are movementnumber, movementtotal and movement respectively - these are the standard Picard tags for these items.
+ Note that if a tag is included in (a) and either of (c) or (d), the movement number will be prepended at the beginning of the tag, followed by the selected separator. For more complex combinations, use the Tag Mapping tab (e.g. movementnumber + \ of + movementtotal).
+ If you wish to use items (a) and (b) in the tag-mapping section without populating the Picard standard tags, then use the hidden variables movt_num and movt_tot.
+ For more details, see the hidden variables section.
+
+ **Strategy for setting tags:** *It is suggested that initially you just use the multi-level work tag and related movement tags, even if your software only has a single-level work capability. This may result in work names being repeated in work headings, but may look better than the alternative of having work names repeated in movement names. This is the default.*
+
+ *If this does not look good you can then compare it with the alternative approach and change as required for specific releases. If your software does not have any "work" capability, then you can still get the full work details by, for example, specifying "title" as both a work and a movement tag.*
+
+5. "Partial recordings, arrangements and medleys" gives various options where recordings are not just simply of a named complete work. These only apply if one of the two "canonical work" styles is in operation (i.e. not if "Use only metadata from title text" is selected).
+
+ * **Partial recordings**:
+ If this option is selected, partial recordings will be treated as a sub-part of the whole recording and will have the related text (in the adjacent box) included in its name. Note that this text is placed at the start of the canonical name, but the latter will probably be stripped from the sub-part as it duplicates the recording work name; any title text (for "extended" style) will be appended to the whole. Note that, if "Consistent with lowest level work description" is chosen in section 2, the text may be treated as a "prefix" similar to those in the "Advanced" tab. If this eliminates other similar prefixes and has unwanted effects, then either change the desired text slightly (e.g. surround with brackets) or use the "Full MusicBrainz work hierarchy" option in section 2. Note that similar text between the partial work and its 'parent' will be removed which will frequently result in no text other than the specified 'partial text', unless extended metadata is used resulting in appended text in {} - this behaviour can be controlled by disabling the setting "Allow blank part names for arrangements and part recordings..." on the advanced tab.
+
+ * **Arrangements**:
+ If this option is selected, works which are arrangements of other works will have the latter treated in the same manner as "parent" works, except that the arrangement work name will be prefixed by the text provided. Note that similar text between the arranged work and its parent will be removed unless this results in no text, in which case a stricter comparison (as for the derivation of 'part' names from works) will be used.
+
+ **Important note:** *If the Partial or Arrangement options are changed (i.e. selected/deselected) then quit and restart Picard as the work structure is fundamentally different. If the related text (only) is changed then the release can simply be refreshed.*
+
+ * **Medleys**
+ These can occur in two ways in MusicBrainz: (a) the recording is described as a "medley of" a number of works and (b) the track is described as (more than one) "medley including a recording of" a work. See [Homecoming](https://musicbrainz.org/release/393913a2-7fde-4ed5-8be6-ca5c2c0ccf0d) for examples of both (tracks 8, 9 and 11). In the first case, the specified text will be included in brackets after the work name, whereas in the second case, the track will be treated as a recording of multiple works and the specified text will appear in the **parent** work name.
+
+6. "SongKong-compatible tag usage".
+
+ "Use work tags on file (no look up on MB) if Use Cache selected": This will enable the existing work tags on the file to be used in preference to looking up on MusicBrainz, if those tags are SongKong-compatible (which should be the case if SongKong has been used or if the SongKong tags have been previously written by this plugin). If present, this can speed up processing considerably, but obviously any new data on MusicBrainz will be missed. For the option to operate, "Use cache" also needs to be selected. Although faster, many of the subtleties of a full look-up will be missed - for example, parent works which are arrangements will not be highlighted as such, some arrangers or composers of original works may be omitted and some medley information may be missed. Other information, such as composed-dates will also be missing. **In general, therefore, the use of this option will result in poorer metadata than allowing the full database look-up to run. It is not recommended unless you have already tagged your files with SongKong and speed is more important than quality.**
+
+ "Write SongKong-compatible work tags" does what it says. These can then be used by the previous option, if the release is subsequently reloaded into Picard, to speed things up (assuming the reload was not to pick up new work data). The same caveats as those above apply.
+
+ **Note that, as from version 2.0.2, there is no significant speed difference between (basic) SongKong and Picard with Classical Extras, so this feature is only ever useful if the album has already been tagged with SongKong.**
+
+ The default for both these options is unchecked.
+
+ Note that Picard and SongKong use the tag musicbrainz\_workid to mean different things. If Picard has overwritten the SongKong tag (not a problem if this plugin is used) then a warning will be given and the works will be looked up on MusicBrainz. Also note that once a release is loaded, subsequent refreshes will use the cache (if option is ticked) in preference to the file tags.
+
+**Note for iTunes users:** *iTunes and Picard do not work well together. iTunes can display work and movement for m4a(mp4) files, but Picard does not write the movement tag. To work round this, write the movement to the "subtitle" tag assuming that is not otherwise used, and use a simple Mp3tag action to convert it to MOVEMENTNAME before importing to iTunes. If you are writing to a FLAC file which will subsequently be converted to m4a then different tag names may be required; e.g. using dBpoweramp, write the movement to "movement name". In both cases use "work" for the work. To store the top\_work, use "grouping" if writing directly to m4a, but "style" if writing to FLAC followed by dBpoweramp conversion. You can put multiple tags into the boxes described above so that your options are multi-purpose. N.B. if work tags are specified and the work has at least one level (i.e. at least work: movement), then the tag "show work movement" will be set to 1. This is used by iTunes to trigger the hierarchical display and should work both directly with m4a files and indirectly via files which are subsequently converted.*
+
+## Genres etc. tab
+
+This section is dependent on both the artists and workparts sections. If either of those sections are not run then this section will not operate correctly. At the very top of the tab is a checkbox "Use Muso reference database...". For [Muso](http://klarita.net/muso.html) users, selecting this enables you to use reference data for genres, composers and periods which have been entered in Muso's "Options->Classical Music" section. Regardless as to whether this is selected, there are then three main coloured sections, each with a number of subsections. The details in each section differ depending on whether the "Muso" option is selected. The screen print below shows the options assuming it is not selected (differences occurring when "Muso" is selected are discussed later):
+
+
+
+1. "Genres". Two separate tags may be used to store genre information, a main genre tage (usually just "genre") and a sub-genre tag. These need to be specified at the top of the section. If either is left blank then the related processing will not run.
+
+ * **Source of genres**
+ Any or all of four sources may be selected. In each case, any values found are treated as "candidate genres" - they will only be applied to the specified genre and sub-genre tags in accordance with the criteria in the "allowed genres" section, if any (see below).
+
+ (a) "Existing file tag". The contents of the existing file tag (as specified above - main genre tag only) will be included as candidate genres. Note that, if this tag name is not "genre", then the contents of the tag "genre" will be included as well.
+
+ (b) "Folksonomy work tags". This will use the folksonomy tags for **works** (including parent works) as a possible source of genres. To use the folksonomy tags for **releases/tracks**, select the main Picard option in Options->Metadata->"Use folksonomy tags as genre". Again (unlike vanilla Picard) these are candidate genres, and will only be published if they match the allowed genres.
+
+ (c) "Work-type". The work-type attribute of works or parent works will be used as a candidate genre.
+
+ (d) "Infer from artist metadata". This option was on the artist tab in version 0.9.1 and prior. Owing to the additional genre processing now available, the operation of this option is slightly restricted compared to the earlier versions. It attempts to create candidate genres based on information in the artist-related tags. Values provided are:
+ Orchestral, Concerto, Choral, Opera, Duet,Trio, Quartet, Chamber music, Aria ('classical values') and Vocal, Song, Instrumental ('generic values'). If the track is a recorded work and the track artist is the composer (i.e. MusicBrainz 'classical style'), the candidate genre values will also include "Classical". The 'classical values' will only be included as candidate genres if the track is deemed to be 'classical' by some part of the genre processing section.
+
+ * **Allowed genres**
+ A check-box (ticked by default) enables this section. If it is unchecked, then no genre filtering is applied - all 'candidate genres' will be written to the genre tab.
+ Four boxes are provided for lists of genres which are "allowed" to appear in the specified tags. Each list should be comma-separated (and no commas in any genre name). Candidate genres matching those in a "main genre" box will be added to the specified main genre tag. Similarly for sub-genres. If a candidate genre matches a 'classical genre' (in one of the top two boxes), then the track will be deemed to be "Classical" (see next part for more details).
+You may also enter a genre name to be used if no matching main genre is found (otherwise the tag will be blank).
+
+ * **"Classical" genre**
+ Normally (i.e. by default) a work will only be deemed to be 'classical' if it is inferred from the MusicBrainz style (see "source of genres") or if a candidate genre matches a "Classical" genre or sub-genre list. However, you may select that all tracks are 'classical' regardless. There is also an option to exclude the word "Classical" from any genre tag, but still treat the work as classical. If a work is deemed to be classical, a tag may be written with a specified value as set out in the last two boxes of this section. For example, to be consistent with SonKong/Jaikoz, you could set "is\_classical" to "1".
+
+2. "Instruments and keys".
+ * **Instruments**
+ Specify the tag name you wish instrument names to appear in. Instruments will be sourced from performer relationships. Instrument names may either be the standard MusicBrainz names or the "credited as" names in the performer relationship, or both. Vocal types are treated similarly to instruments. (Note that, in v0.9.1 and prior, instruments were written to the same tag as inferred genres. If you wish to continue this, then you may use the same tag name here as for the genre tag.)
+
+ * **Keys**
+ Specify the tag name in which you wish the key signatures of works to appear. Keys will be obtained from all work levels (assuming these have been looked up): for example, Dvořák's Largo From the New World will be shown as D♭ major, C# minor (the main keys of the movement) and E minor (the home key of the overall work).
+"Include key(s) in work names" gives the option to include the key signature for a work in brackets after the name of the work in the metadata. Keys will be added in the appropriate levels: e.g. Dvořák's New World Symphony will get (E minor) at the work level, but only movements with different keys will be annotated viz. "II. Largo (D-flat major, C-Sharp minor)". The default sub-option is to only add these details if the key signature is missing from the work title (other sub-options are to never or to always include the information.
+
+3. "Periods and dates".
+
+ * **Work dates**
+ Specify the tag name to hold work dates. Work dates will be given as a "year" value only, e.g. "1808" or a range: "1808-1810". The sources of these dates is specified in the next part. If the movement has a composed date(s), this will be used, otherwise the the dates from the parent work will be used (if available).
+
+ "Source of work dates". Select which sources to use - from composed, published and premiered, then decide whether to use them in preferential order (e.g. if "composed date" exists, then the others will not be used) or to show them all.
+
+ "Include workdate in work name ..." operates analogously to "Include key(s) in work names" described above. (Work dates will be used in preference order, i.e. composed - published - premiered, with only the first available date being shown).
+
+ * **Periods**
+ This section will use work dates, where available, to determine the "classical period" to which it belongs, by means of a "period map" (Muso users can also use composer dates - see below).
+
+ Specify the tag name to hold the period data. The period map should then be entered in the format "Period name, Start\_year, End\_year; Period name2, Start\_year, End\_year;" etc. Periods may overlap. Do not use commas or semi-colons within period names. Start and end years must be integers.
+
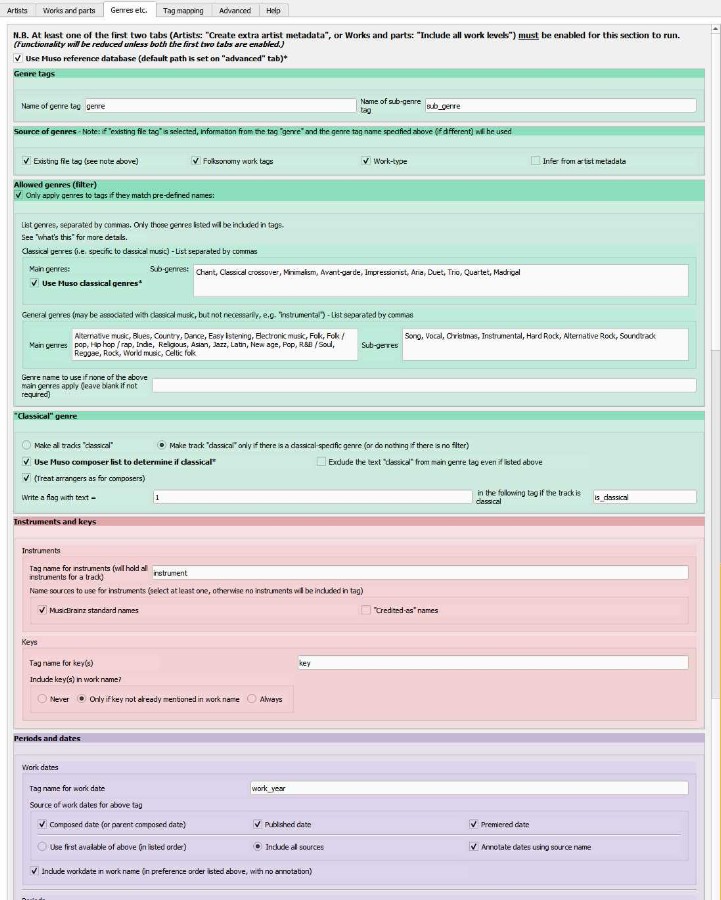
+## Genres etc. tab - Muso-specific processing
+
+Users of [Muso](http://klarita.net/muso.html) have additional capabilities, illustrated in the following screen, which appear when the option "Use Muso reference database ..." is selected at the top of the tab.
+
+
+
+For these options to work, the path/name of the Muso reference database needs to be specified on the advanced tab. The default path is "C:\\Users\\Public\\Music\\muso\\database" and the default filename is "Reference.xml". The additional options are as follows.
+
+1. "Use Muso classical genres". If this is selected, the box for classical main genres is eliminated and the genre list from Muso's "Tools->Options->Classical Music->Classical Music Genres" is used instead.
+
+2. "Use Muso composer list to determine if classical". If the composer name is in Muso's list "Tools->Options->Classical Music->Composer Roster", then the work will be deemed to be classical. If this option is selected, a further option appears to "Treat arrangers as for composers" - if selected then arrangers will also be looked up in the roster.
+
+3. "Use Muso composer dates (if no work date) to determine period". The birth date + 20 -> death dates of Muso's composer roster will be used to assign periods if no work date is available. If this option is selected, a further option appears to "Treat arrangers as for composers" - if selected then arrangers' working lives will also be used to determine periods.
+
+ (This might be replaced / supplemented by MusicBrainz in the future, but would involve another 1-second lookup per composer).
+
+4. "Use Muso map". Replace the period map with the one in Muso at "Tools->Options->Classical Music->Classical Music Periods"
+
+Note that non-Muso users may also use this functionality, if they wish, by manually creating a reference xml file with the relevant tags, e.g.:
+
+
+ Cantata
+
+
+ Max REGER
+ 1873
+ 1916
+
+
+ Early Romantic
+ 1800
+ 1850
+
+
+If the Muso reference (or XML) database is selected (which includes a classical composers list) and there is no composer for the track (because of a lack of work relationship)
+then the plugin will check the listed artist against the reference list of classical composers and, if there is a match, will populate the composer metadata and
+ (if "use Muso composer list to determine if classical" is selected) will set the genre to classical.
+
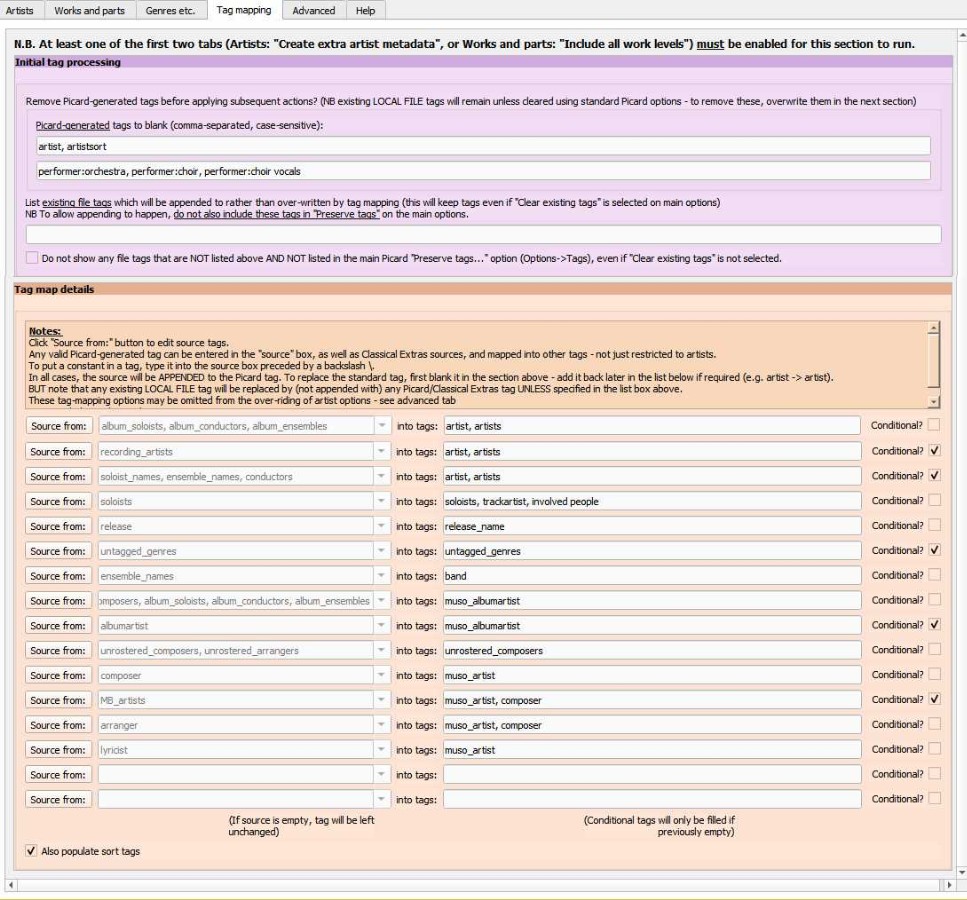
+## Tag mapping tab
+There are two coloured sections as shown in the screen image below:
+
+
+
+Note that either the "Create extra artist metadata" option on the Artist tab or "Include all work levels" on the Works tab needs to be selected for these sections to run.
+
+1. "Initial tag processing": This takes place before any of the detailed tag mapping in the second section.
+
+ "Remove Picard-generated tags before applying subsequent actions?". Any tags specified in the next two rows will be blanked before applying the tag sources described in the following section. NB this applies only to Picard-generated tags, not to other tags which might pre-exist on the file: to blank those, use the main Options->Tags page. Comma-separate the tag names within the rows and note that these names are case-sensitive.
+
+ "List existing file tags which will be appended ...": This refers to the tags which already exist on files which have been matched to MusicBrainz, not the tags generated by Picard from the MusicBrainz database. Normally, Picard cannot process these tags - either it will overwrite them (if it creates a similarly named tag), clear them (if 'Clear existing tags' is specified in the main Options->Tags screen) or keep them (if 'Preserve these tags...' is specified after the 'Clear existing tags' option). Classical Extras allows a further option - for the tags to be appended to in the tag mapping section (see below) or otherwise used. List file tags which will be appended to rather than over-written by tag mapping (NB this will keep tags even if "Clear existing tags" is selected on main options). In addition, certain existing tags may be used by Classical Extras - in particular "is\_classical" (which is set by SongKong to '1' if the track is deemed to be classical, based on an extensive database) is used to add 'classical' to the variable "\_cea\_worktype", if "Infer work types" is selected in the first section of the Artists tab. If you include "is\_classical" in this list then any files which have "is\_classical" = 1 will be treated as being classical, regardless of the genre tag.
+
+ **Make sure that any tags listed here are not also included in Picard's "Preserve .. tags.." option, otherwise Picard will prevent the tag from being amended**
+
+ Note that if "Split lyrics tag" is specified (see the Artists tab), then the tag named there will be included in the "...existing file tags..." list and does not need to be added in this section.
+
+ "Clear any previous file tags...": This operates in an almost similar way to the main Picard option (Options->Tags->"Clear existing tags"). All existing file tags will be cleared **unless** they are in the main Picard "Preserve tags..." option or the "...existing file tags..." list. The main differences from the basic Picard option are that (a) artwork is always preserved - i.e. this largely addresses [PICARD-257](https://tickets.metabrainz.org/browse/PICARD-257) and (b) the tags that are not kept are **not actually deleted or shown as deleted** in the bottom pane of Picard. They are just not displayed in the bottom pane - however, a warning tag is written.
+
+2. "Tag map details". This section permits the contents of any hidden variable or tag to be written to one or more tags.
+
+ * **Sources**:
+ Some of the most useful sources are available from the drop-down list. Otherwise they can simply be typed in the box. Click on the "source from" button to enable entry (otherwise the text box / drop-down for the source is locked). Some useful names are:
+
+ - soloists : List of performers (with instruments in brackets), who are NOT ensembles or conductors, separated by semi-colons. Note they may not strictly be "soloists" in that they may be part of an ensemble.
+ - soloist\_names : Names of the above (i.e. no instruments).
+ - vocalists / instrumentalists / other\_soloists : Soloists who are vocalists, instrumentalists or not specified, respectively.
+ - vocalist\_names / instrumentalist\_names : Names of vocalists / instrumentalists (i.e. no instrument / voice).
+ - ensembles : List of performers who are ensembles (with type / instruments - e.g. "orchestra" - in brackets), separated by semi-colons.
+ - ensemble\_names : Names of the above (i.e. no instruments).
+ - album\_soloists : Sub-list of soloist\_names who are also album artists.
+ - album\_conductors : List of conductors who are also album artists.
+ - album\_ensembles: Sub-list of ensemble\_names who are also album artists.
+ - album\_composers : List of composers who are also album artists.
+ - album\_composer\_lastnames : Last names of composers, of ANY track on the album, who are also album artists. This is the source used to prefix the album name (when that option is selected).
+ - support\_performers : Sub-list of soloist\_names who are NOT album artists.
+ - composers : List of composers, after applying the naming options in the artists tab.
+ - conductors : List of conductors, after applying the naming options in the artists tab.
+ - arrangers : Includes all arrangers and instrument arrangers (except more specific roles such as orchestrators) - the standard Picard tag omits some.
+ - orchestrators : Arrangers who are orchestrators.
+ - leaders : AKA concertmasters.
+ - chorusmasters : as distinct from conductors (chorus masters may rehearse the choir but not conduct the performance).
+
+ Note that the Classical Extras sources for all artist types are spelled in the plural (to differentiate from the native Picard tags). Most of the names are for artist data and are sourced from hidden variables (prefixed with "\_cea\_" or "\_cwp\_"). In specifying the source, the prefix is not necessary - e.g. "arrangers" will pick up all data in \_cea\_arrangers and \_cwp\_arrangers (covering those with recording and work relationships respectively). Using the prefix will get just the specific variable.
+
+ In addition, the drop-down contains some typical combinations of multiple sources (see note on multiple sources below).
+
+ Any Picard tag names can also be typed in as sources. Any hidden variables may also be used. Any source names which are prefixed by a backslash will be treated as string constants; blanks may also be used.
+
+ It is possible to specify multiple sources. If these are separated by a comma, then each will be appended to the mapped tag(s) (if not already filled or if not "conditional"). So, for example, a source of "album\_soloists, album\_conductors, album\_ensembles" mapped to a tag of "artist" with "conditional" ticked will fill artist (if blanked) by album\_soloists, if any, otherwise album\_conductors etc. Sources separated by a + will be concatenated before being used to fill the mapped tags. The concatenated result **will only be applied if the contents of each of the sources to be concatenated is non-blank** (note that this constraint only applies to **concatenation** of multiple sources). No spaces will be added on concatenation, so these have to be added explicitly by concatenating "\ ". So, for example "ensemble\_names + \ (conducted by + conductors +\\), ensemble\_names", with "Conditional" selected, will yield something like "BBC Symphony Orchestra (conducted by Walter Weller)" or just "BBC Symphony Orchestra" if there is no conductor. **Do not use any commas in text strings**.
+
+ Another example: to add the leader's name in brackets to the tag with the performing orchestra, put "\\ (leader +leaders+\\)" in the source box and the tag containing the orchestra in the tag box. If there is no leader, the text will not be appended.
+
+ The tag mapping section is not restricted to artist metadata - any metadata or hidden variablescan be used.
+
+ * **Tags**:
+ Enter the (comma-separated) "destination" tag names into which the sources should be written (case sensitive). Note that this will result in the source data being APPENDED in the tag - it will not overwrite the existing contents. Check "Conditional?" if the tag is only to be updated if it is previously blank (all non-empty sources in the current line will be applied in sequence). The lines will be applied in the order shown. Users should be able to achieve most requirements via a combination of blanking tags, using the right source order and "conditional" flags. For example, to overwrite a tag sourced from "composer" with "conductor", specify "conductor" first, then "composer" as conditional. Note that, for example, to demote the MB-supplied artist to only appear if no other listed choices are present, blank the artist tag and then add it as a conditional source at the end of the list.
+
+ * **"Also populate sort tags"**:
+ If a sort tag is associated with the source tag then the sort names will be placed in a sort tag corresponding to the destination tag. Note that the only explicit sort tags written by Picard are for artist, albumartist and composer. Picard also writes hidden variables '\_artists\_sort' and 'albumartists\_sort' (note the plurals - these are the sort tags for multi-valued alternatives 'artists' and '\_albumartists'). To be consistent with this approach, the plugin writes hidden variables for other tags - e.g. '\_arranger\_sort'. The plugin also writes hidden sort variables for the various hidden artist variables - e.g. '\_cwp\_librettists' has a matching sort variable '\_cwp\_librettists\_sort'. Therefore most artist-type sources **will** have a sort tag/variable associated with them and these will be placed in a destination sort tag if this option is selected - **in other words, selecting this option will cause most destination tags to have associated sort tags. Furthermore, any hidden sort variables associated with tags which are not listed explicitly in the tag mapping section will also be written out as tags** (i.e. even if the related tags are not included as destination tags). Note, however, that composite sources (e.g. " ensemble\_names + \; + conductors") do not have sort tags associated with them.
+
+ If this option is not selected, no additional sort tags will be written, but the hidden variables will still be available, so if a sort tag is required explicitly, just map the sort tag directly - e.g. map 'conductors\_sort' to 'conductor\_sort'.
+
+ More complex operations can be built using tagger scripts. If required, these can be set to run conditionally by setting a tag or hidden variable in this section and then testing it in the script.
+
+
+
+## Advanced tab
+
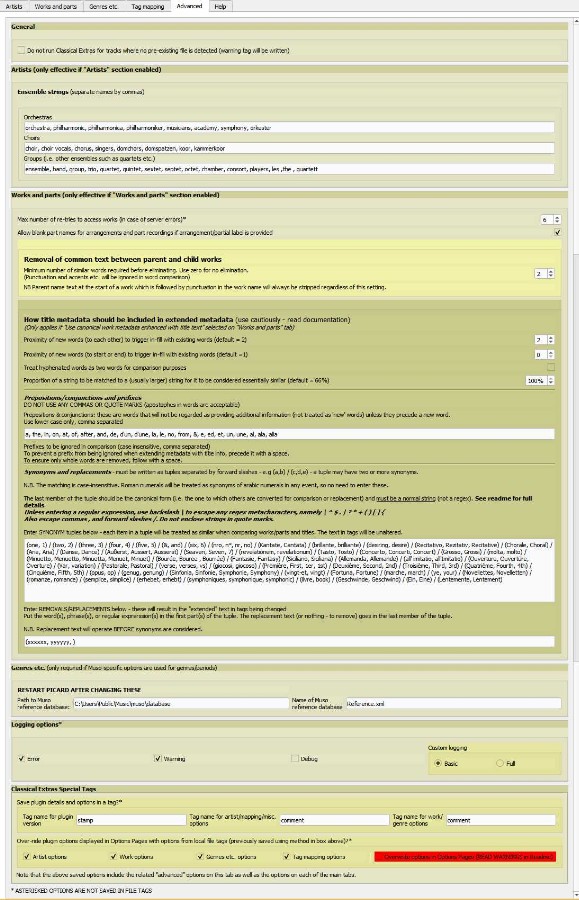
+Hopefully, this tab should not be much used. In any case, it should not need to be changed frequently. There are six main sections as shown in the screeen print below:
+
+
+
+1. "General". There is only one checkbox - "Do not run Classical Extras for tracks where no pre-existing file is detected (warning tag will be written)". This option will disable Classical Extras processing if no file is present; this means (for example) that single discs from box sets can be loaded without incurring the additional processing overhead (work look-ups etc.) for all the other discs. Also if a compilation album is loaded, where the tracks are on multiple releases, the plugin will only process the release tracks which match. If a file is present but it does not yet have a MusicBrainz trackid tag, then it will initially be treated in the same way as a non-existent file; however, after the initial loading it will (if matched by Picard) be given a MB trackid and "refreshing" the release will result in any such tracks being processed by Classical Extras, while the unmatched tracks are left untouched.
+
+2. "Artists". This has only one subsection - "Ensemble strings" - which permits the listing of strings by which ensembles of different types may be identified. This is used by the plugin to place performer details in the relevant hidden variables and thus make them available for use in the "Tag mapping" tab as sources for any required tags.
+If it is important that only whole words are to be matched, be sure to include a space after the string.
+
+3. "Works and parts". This section has parameters applicable to the "works and parts" functions.
+
+ * **Max number of re-tries to access works (in case of server errors)**. Sometimes MB lookups fail. Unfortunately Picard (currently) has no automatic "retry" function. The plugin will attempt to retry for the specified number of attempts. If it still fails, the hidden variable \_cwp\_error will be set with a message; if error logging is checked in section 5, an error message will be written to the log and the contents of \_cwp\_error will be written out to a special tag called "001\_errors" which should appear prominently in the bottom pane of Picard. The problem may be resolved by refreshing, otherwise there may be a problem with the MB database availability. It is unlikely to be a software problem with the plugin.
+
+ * **Allow blank part names for arrangements and part recordings, if an arrangement/partial label is provided**. The default is checked (true) - in which case where an arrangement has the same name as the original work, the part will just show the arrangement/partial label (e.g. "Arrangement:"). If the option is blank (false), there will be text for the part name (which may be the same name as the parent work). Note that if "extended" metadata is being used, then blank part names will always have the title metadata added {in curly brackets} regardless of whether it is similar to the canonical part name.
+
+ * **Removal of common text between parent and child works**. This section controls the naming of parts, by stripping parent text from the work name. If the work begins with the parent name followed by punctuation then the common text will always be stripped to give the part name, even if there are punctuation or some other minor differences (synonyms will also be matched using the patterns in the next section).
+
+ However, common text which is not followed by punctuation or which is not at the start may also be stripped: to prevent this, set "Minimum number of similar words required before eliminating (other than at start)" to zero. Otherwise common text longer than the specified number of words (default = 2) will be stripped. (Note that this minimum is over-ridden by the previous option - i.e. if a smaller number of words than the minimum could be eliminated and would result in a blank part name, and that is allowed by the previous option, then the words will be removed).
+
+ * **How title metadata should be included in extended metadata**. This subsection contains various parameters affecting the processing of strings in titles, where these are used to "extend" the text in work names. This is generally only relevant if "Use canonical work metadata enhanced with title text" is selected on the "Works and parts" tab, although the "prefixes" section is also relevant if "Use only metadata from title text" is selected and the synonyms are also used in eliminating parent-child duplication as described above. Because titles are free-form, not all circumstances can be anticipated. If pure canonical works are used ("Use only metadata from canonical works" and, if necessary, "Full MusicBrainz work hierarchy" on the Works and parts tab, section 2) then this processing should largely be irrelevant, but no text from titles will be included. Some explanations are given below:
+
+ * "Proximity of new words". When using extended metadata - i.e. "metadata enhanced with title text", the plugin will attempt to remove similar words in the canonical work name (in MusicBrainz) and the title before extending the canonical name. After removing such words, a rather "bitty" result may occur. To avoid this, any new words with the specified proximity will have the words between them (or up to the start/end) included even if they repeat words in the work name.
+
+ * "Treat hyphenated words as two words for comparison purposes" (default = True). In comparing words, hyphenated words will be considered as separate words unless this option is deselected.
+
+ * "Proportion of a string to be matched ... for it to be considered essentially similar..." (default = 66%). If the title and work descriptions are largely the same then the title text will not be used to extend the work text, even if there are some new words.
+
+ * "Prepositions and conjunctions". Words listed here will not generally be treated as "new" (i.e. if they are in the title text but not in the work text, they will not be included in the "extended" text) unless they precede a new word which is not itself a preposition. Note that, although the term "preposition" is used here, because that is the obvious usage, any word can be listed. A group of more than one such words will be treated as new if they are not in the work text and they precede a new word which is not listed as a preposition.
+
+ * "Prefixes". When using "metadata from titles" or extended metadata, the structure of the works in MusicBrainz is used to infer the structure in the title text, so strings that are repeated between tracks which are part of the same MusicBrainz work will be treated as "higher level". This can lead to anomalies if, for instance, the titles are "Work name: Part 1", "Work name: Part 2", "Part" is repeated and so will be treated as part of the parent work name. Specifying such words in "Prefixes" will prevent this.
+
+ * "Synonyms". These words/phrases will be considered equivalent when comparing work name and title text (or parent and child text). Thus if one word/phrase appears in the work name, it and its synonyms will be removed from the title in extending the metadata (subject to the proximity setting above). Each entry should be a tuple in the form *(key word/phrase, ..., equivalent word/phrase)* - no quote marks are necessary. Each tuple should be separated by a forward slash - /. Tuples may contain multiple synonyms - each item in a tuple will be treated as similar when comparing works/parts and titles. The text in tags will be unaltered. Spaces and punctuation are permitted, as are regular expressions, but unless entering regex, use backslash \ to escape any regex metacharacters \ ^ $ . | ? * + ( ) [ ] {
+ Also escape commas , and forward slashes /. Do not enclose strings in quote marks. The last member of the tuple should be the canonical form (i.e. the one to which others are converted for comparison) and must be a normal string (not a regex). The sequence of synonyms within a tuple may be important, particularly if one synonym is a subset of another - always list the longer one first, as the matching will proceed in the listed order. Thus if "nro" and "nr" are synonyms of "no", then list them thus: (nro, nr, no). This will ensure that "nro" gets matched to "nro" and not to "nr".
+
+ * "Replacements". These are entered in a similar fashion to synonyms. The difference is that the last item in a tuple will be used to replace any text in earlier items in the tuple. This last element may also be left blank (after the preceding comma) in order to remove any text matching any of the earlier items.
+
+4. "Genres etc. ...". This is only required if Muso-specific options are used for genres/periods. Specify the path and file name for the reference database (the default is the Muso default for a shared database). Note that the database is only loaded when Picard starts so you will need to restart Picard is these options are changed.
+
+5. "Logging options". These options are in addition to the options chosen in Picard's "Help->View error/debug log" settings. They only affect messages written by this plugin. To enable debug messages to be shown in the Picard log, the flag needs to be set here and "Debug mode" needs to be turned on in the log. **It is strongly advised to keep the "debug" flag unchecked unless debugging is required** as it slows up processing and may even cause Picard to hang if there is a large number of files (better to use the 'full' custom logging option - see below). The "error" and "warning" flags should be left checked, unless it is required to suppress messages (the messages are also written to the tags 001\_errors and 002\_warnings).
+
+ As well as the main Picard log, a custom logging function is provided. This may be either "basic" or "full". If "basic" is selected, a file "session.log" will be written (over-written each session) to a "Classical Extras" directory inside the same directory as the plugins folder. (Note - the easy way to find this directory is to select options-->plugins in Picard and the "Open plugins folder" button, then go up one level). The session log gives a processing summary for each release and includes errors, warnings and debug messages if those options have been selected.
+
+ If "full" is selected, all errors, warnings and debugs will be written, along with additional debugging messages, to a custom log file for each release processed. These files are stored in the "Classical Extras" directory inside the same directory as the plugins folder. The log file for a release is named using the release MBID. Debugging from these files requires an understanding of the source code.
+
+ Selecting "full" will slow Picard, but should not normally result in hanging or crashing.
+
+6. "Classical Extras Special Tags". This has a number of subsections:
+
+ *"Save plugin details and options in a tag?"* can be used so that the user has a record of the version of Classical Extras which generated the tags and which options were selected to achieve the resulting tags. Note that the tags will be blanked first so this will only show the last options used on a particular file. The same tag can be used for both sets of options, resulting in a multi-valued tag. All the options in the Classical Extras UI are saved **except** those which are asterisked.
+
+ The tag contents are in dict format. The options in these tags can then be used to over-ride the displayed options subsequently (see below).
+
+ N.B. The "Tag name for artist/misc. options" also saves the Picard options for 'translate\_artist\_names' and 'standardize\_artists' as these interact with the Classical Extras options.
+
+ *"Over-ride plugin options displayed in UI with options from local file tags"*. If options have previously been saved (see above), selecting these will cause the saved options to be used in preference to the displayed options. The displayed options will not be affected and will be used if no saved options are present. The default is for no over-ride.
+
+ ***Note that* *very occasionally (if the tag containing the options has been corrupted) use of this option may cause an error. In such a case you will need to deselect the "over-ride" option and set the required options manually; then save the resulting tags and the corrupted tag should be over-written***
+
+ *"Overwrite options in Options Pages"*, is for **VERY CAREFUL USE ONLY**. It will cause any options read from the saved tags to over-write the options on the plugin Options Page UI. (Note that it will only operate if all the "Over-ride plugin options..." boxes are checked as well.) The intended use of this is if for some reason the user's preferred options have been erased/reverted to default - by using this option, the previously-used choices from a reliable filed album can be used to populate the Options Page. The box will automatically be unticked after loading/refreshing one album, and will always be turned off when starting Picard, to prevent inadvertant use. Far better is to make a **backup copy** of the picard.ini file.
+
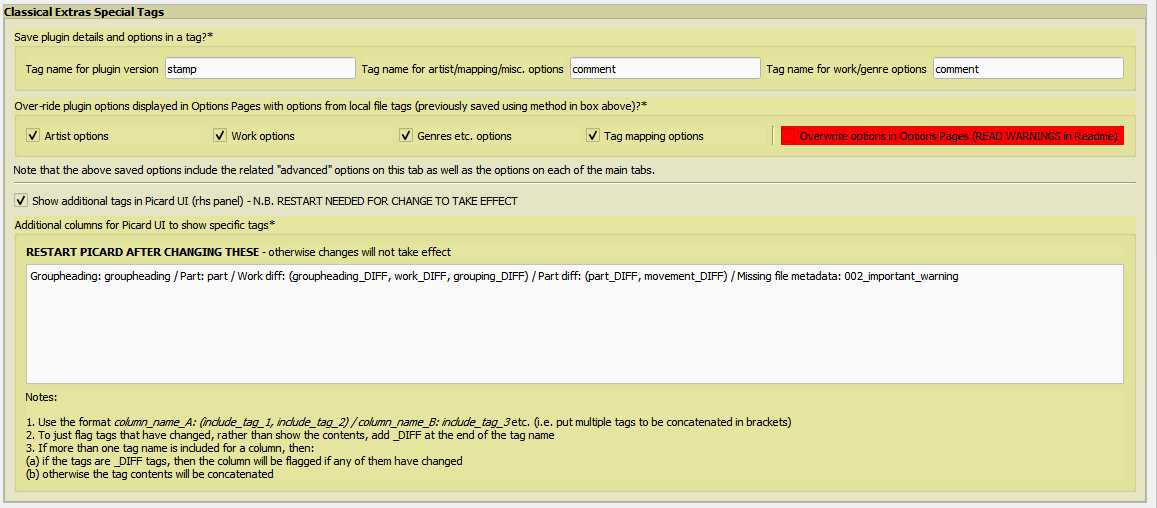
+ *Additional section added in v2.0.7 "Show additional tags in Picard UI"*. This enables display of any tags as columns in the Picard right-hand panel. Also tags (or groups of tags) which are different from file tags can be flagged - see the screen copy below:
+
+ 
+
+ Follow the instructions on the screen to enter the options. Then, if you right-click on the column headings in the right-hand panel of Picard, you should see all the options listed from which you can select which columns to show.
+
+# Information on hidden variables
+
+This section is for users who want to write their own scripts, or add additional tags (in the tag mapping section) based on hidden variables. The definition and source of each hidden variable is listed. Apologies if there are errors and omissions in this section - to double check the actual hidden variables for any track, use the plugin "View script variables".
+
+## Works and parts
+
+- \_cwp\_work\_n, where n is an integer >=0 : The MB work name at level n. For n=0, the tag is the same as the current standard Picard tag "work"
+- \_cwp\_work\_top : The top work name (i.e. for maximal n). Thus, if max n = N, \_cwp\_work\_top will be equivalent to \_cwp\_work\_N. Note, however, that this will always be the "canonical" MB name, not one derived from titles or the lowest level work name and that no annotations (e.g. key or work year) will be added (whereas they will be added to \_cwp\_work\_N). Nevertheless, if "replace work names by aliases" has been selected and is applicable, the relevant alias will be used.
+- \_cwp\_workid\_n : The matching work id for each work name. For n=0, the tag is the same as the standard Picard tag "MusicBrainz Work Id"
+- \_cwp\_workid\_top : The matching work id for the top work name.
+- \_cwp\_part\_n : A "stripped" version of \_cwp\_work\_n, where higher-level work text has been removed wherever possible, to avoid duplication on display.
+ Thus in theory, \_cwp\_work\_0 will be the same as "\_cwp\_work\_top: \_cwp\_part\_(N-1): ...: \_cwp\_part\_0" (punctuation excepted), but may differ in more complex situations where there is not an exact hierarchy of text as the work levels are traversed. (See below for the "\_X0" series which attempts to address any such inconsistencies)
+- \_cwp\_part\_levels : The number of work levels attached to THIS TRACK. Should be equal to N = max(n) referred to above.
+- \_cwp\_work\_part\_levels : The maximum number of levels for ANY TRACK in the album which has the same top work as this track.
+- \_cwp\_single\_work\_album : A flag = 1 if there is only one top work in this album, else = 0.?
+- \_cwp\_work : the level selected by the plugin to be the source of the single-level work name if "Use only metadata from canonical works" is selected (usually the top level, but one lower in the case of a single work album).
+- \_cwp\_groupheading : the level selected by the plugin to be the source of the multi-level work name if "Use only metadata from canonical works" is selected.
+- \_cwp\_part : The movement name derived from the MB work names (generally = \_cwp\_part\_0) and used as the source for the movement name used for "Tags for Movement - including embedded movt/part numbers".
+- \_cwp\_inter\_work : Intermediate works between \_cwp\_part and \_cwp\_work (if any).
+- \_cwp\_movt\_num : The number sequence of the movement track within its parent **on the current release** (see more details below).
+- \_cwp\_movt\_tot : The total number of movement tracks for the parent (see more details below).
+
+If there is more than one work any level, then \_cwp\_work\_n and \_cwp\_workid\_n will have multiple entries. Another common situation is that a "bottom level" work is spread across more than one track. Rather than artificially split the work into sub-parts, this is often shown in MusicBrainz as a track being a "partial recording of" a work. The plugin deals with this by creating a notional lowest-level with the suffix " (part)" (or other text as defined in the works and parts options tab) appended to the work it is a partial recording of. In order that this notional part can be separately identified from the full work, the musicbrainz\_recordingid is used as the identifier rather than the workid.
+If there is more than one "parent" work of a lower level work, multi-valued tags are generated.
+
+Note regarding movement numbers:
+- All movements will be considered as a part of the largest grouping (on a release) to which they belong, other than as “part of collection”
+- They will be numbered in the sequence in which they appear on the release
+- If a track comprises more than one movement, they will be treated as one for these purposes
+- If a movement is split over more than one track, then each will get a separate movement number
+- One-movement works will not receive a movement number unless the movement is split over multiple tracks
+- The movementtotal tag will be the total number of movements for the aforesaid grouping
+- If a movement grouping is split on a release by other tracks (not part of the grouping) then they will be treated as a whole and the numbering will resume where it left off.
+
+Items based on level 0 work data:
+- \_cwp\_X0\_part\_0 : A "stripped" version of \_cwp\_work\_0 (see above), where elements of \_cwp\_work\_0 which repeat within level 1 have been stripped.
+- \_cwp\_X0\_work\_n : The elements of \_cwp\_work\_0 which repeat within level n
+
+As well as variables derived from MB's work structure, some variables are produced which are derived from the track title. Typically titles may be in the format "Work: Movement", but not always. Sometimes the title is prefixed by the name of the composer; in this case the variable
+- \_cwp\_title
+is provided which excludes the composer name and subsequent processing is carried out using this rather than the full title.
+
+The plugin uses a number of methods attempt to extract the works and movement from the title. The resulting variables are:
+- \_cwp\_title\_work\_n, and
+- \_cwp\_title\_part\_n
+which mirror those for the ones based on MB works described above.
+- \_cwp\_title\_part\_levels which similarly mirrors \_cwp\_part\_levels
+- \_cwp\_title\_work\_levels which similarly mirrors \_cwp\_work\_part\_levels
+
+- \_cwp\_title\_work is the level selected by the plugin to be the source of the single-level work name if "Use only metadata from title text" is selected (usually the top level, but one lower in the case of a single work album).
+- \_cwp\_title\_groupheading is similarly the level selected by the plugin to be the source of the multi-level work name if "Use only metadata from title text" is selected.
+
+- \_cwp\_extended\_part : = \_cwp\_part with additional movement information from the title - given in {}.
+- \_cwp\_extended\_groupheading : = \_cwp\_groupheading with additional work information from the title - given in {}.
+- \_cwp\_extended\_work : = \_cwp\_work with additional work information from the title - given in {}.
+- \_cwp\_extended\_inter\_work : = \_cwp\_inter\_work with additional work information from the title - given in {}.
+The "extended" variables can be useful where the "canonical" work names in MB are in the original language and the titles are in English (say). Various heuristics are used to try and add (and only add) meaningful additional information, but oddities may occur which require manual editing.
+
+Artist tags which derive from work-artist relationships are also set in this section:
+- \_cwp\_composers & \_cwp_composers_sort
+- \_cwp\_composer_lastnames
+- \_cwp\_writers & \_cwp_writers_sort
+- \_cwp\_arrangers : This is for arrangers of the work and also "instrument arrangers" and "vocal arrangers" with appropriate annotation for instrument and voice types. (Picard does not currently write the latter to the Arranger tag if they are part of the work-artists relationship, despite style guidance saying to use specific instrument types instead of generic arranger.)
+- \_cwp\_arranger\_names & \_cwp_arrangers_sort: Just the names of the above (no annotations)
+- \_cwp\_orchestrators & \_cwp_orchestrators_sort
+- \_cwp\_reconstructors & \_cwp_reconstructors _sort - 'reconstructed by' relationships
+- \_cwp\_revisors & \_cwp_revisors _sort - 'revised by' relationships
+- \_cwp\_lyricists & \_cwp_lyricists _sort
+- \_cwp\_librettists & \_cwp_librettists _sort
+- \_cwp\_translators & \_cwp_translators _sort
+
+Finally, the tags \_cwp\_error and\_cwp\_warning are provided to supply warnings and error messages to the user.
+
+## Artists
+
+All the additional hidden variables for artists written by Classical Extras are prefixed by \_cea\_. Note that these are generally in the plural, whereas the standard tags are singular. If the user blanks a tag then the original value is stored in the singular with the \_cea\_ prefix. Thus \_cea\_arranger would be the contents of the Picard tag "arranger" before blanking, whereas \_cea\_arrangers is hidden variable created by Classical Extras.
+
+- \_cea\_recording\_artist : The artist credited with the recording (not necessarily the track artist). Note that this is the only "\_cea\_" tag which is singular, because it is in the same format as the 'artist' tag, whereas...
+- \_cea\_recording\_artists : The list/multiple value version of the above. (This follows the approach in Picard for 'artist' and 'artists', being the track artists.)
+- \_cea\_MB\_artists: The original track artists per MusicBrainz before any replacement by / merging with recording artists.
+- \_cea\_soloists : List of performers (with instruments in brackets), who are NOT ensembles or conductors, separated by semi-colons. Note they may not strictly be "soloists" in that they may be part of an ensemble.
+- \_cea\_recording\_artistsort : Sort names of \_cea\_recording\_artist
+- \_cea\_recording\_artists\_sort : Sort names of \_cea\_recording\_artists
+- \_cea\_soloist\_names : Names of the soloists (i.e. no instruments).
+- \_cea\_soloists\_sort : Sort\_names of the above.
+- \_cea\_vocalists : Soloists who are vocalists (with voice in brackets).
+- \_cea\_vocalist\_names : Names of the above (no voice).
+- \_cea\_instrumentalists : Soloists who have instruments but are not vocalists.
+- \_cea\_instrumentalist\_names : Names of the above (no instrument).
+- \_cea\_other\_soloists : Soloists who do not have specified instrument/voice.
+- \_cea\_ensembles : List of performers which are ensembles (with type / instruments - e.g. "orchestra" - in brackets), separated by semi-colons.
+- \_cea\_ensemble\_names : Names of the above (i.e. no instruments).
+- \_cea\_ensembles\_sort : Sort\_names of the above.
+- \_cea\_album\_soloists : Sub-list of soloist\_names who are also album artists
+- \_cea\_album\_soloists\_sort : Sort\_names of the above.
+- \_cea\_album\_conductors : List of conductors who are also album artists
+- \_cea\_album\_conductors\_sort : Sort\_names of the above.
+- \_cea\_album\_ensembles: Sub-list of ensemble\_names who are also album artists
+- \_cea\_album\_ensembles\_sort : Sort\_names of the above.
+- \_cea\_album\_composers : List of composers who are also album artists
+- \_cea\_album\_composers\_sort : Sort\_names of the above.
+- \_cea\_album\_track\_composer\_lastnames : Last names of the above. (N.B. This only includes the composers of the current track - compare with \_cea\_album\_composer\_lastnames below).
+- \_cea\_album\_composer\_lastnames : Last names of composers of ANY track on the album who are also album artists. This can be used to prefix the album name if required. (cf \_cea\_album\_track\_composer\_lastnames)
+- \_cea\_support\_performers : Sub-list of soloist\_names who are NOT album artists
+- \_cea\_support\_performers\_sort : Sort\_names of the above.
+- \_cea\_composers : Alternative to 'composer', incorporating 'naming options' on the artists tab.
+- \_cea\_composer_lastnames: Last names of above.
+- \_cea\_conductors : Alternative to 'conductor', incorporating 'naming options' on the artists tab.
+- \_cea\_performers : Alternative to 'performer', incorporating 'naming options' on the artists tab.
+- \_cea\_arrangers : All arrangers for the **recording** with instrument/voice type in brackets, if provided. If the work and parts functionality has also been selected, the arrangers of works, which Picard also currently omits will be put in \_cwp\_arrangers.
+- \_cea\_orchestrators : Arrangers (per Picard) included in the MB database as type "orchestrator".
+- \_cea\_chorusmasters : A person who (per Picard) is a conductor, but is "chorus master" in the MB database (i.e. not necessarily conducting the performance).
+- \_cea\_leaders : The leader of the orchestra ("concertmaster" in MusicBrainz) - not created by Picard as standard.
+
+## Genres etc.
+
+Most of the genres, keys and date information requires the works and parts section to have been run, and so the variables are prefixed \_cwp\_, but instruments and genres which are derived from artist information and are prefixed \_cea\_.
+
+- \_cea\_instruments : Names of all instruments on the track (MusicBrainz names)
+- \_cea\_instuments\_credited : As above, but MB names replaced by as-credited names, if any
+- \_cea\_instruments\_all : MB and as-credited names
+- \_cea\_work\_type : The genre(s) inferred from artist information
+- \_cea\_work\_type\_if\_classical : As above, but only of relevance if the work is classical
+- \_cwp\_candidate\_genres : List of all tags, work types etc. found (depending on specified sources) before filtering for "allowed" genres.
+- \_cwp\_keys : keys associated with this track (from all work levels).
+- \_cwp\_composed\_dates : Date composed (integer) or range (integer-integer).
+- \_cwp\_published\_dates : Date published (integer) or range (integer-integer).
+- \_cwp\_premiered\_dates : Date premiered (integer) or range (integer-integer).
+- \_cwp\_untagged\_genres : Genres in \_cwp\_candidate\_genres which have been filtered out as they are not in any "allowed" list.
+- \_cwp\_unrostered\_composers : For Muso users: composers who are not in Muso's classical composers roster.
+
+## Special tags for ui
+
+A number of hidden variables are created (v.2.0.7+) as part of the processing for the additional tags for the UI as described at the end of the "Advanced" tab section. The ones of the form \_tagname_OLD hold the previous value of the tag 'tagname' on the file. The ones of the form \_tagname_DIFF hold a flag '*****' if the value of 'tagname' has changed from the previous one on file (only for tags specified on the options page). The ones of the form \_columnheading_VAL hold the values to be displayed in the column 'columnheading' as specified in the options.
+
+# Software-specific notes
+
+Note that \_cwp\_part\_levels > 0 will indicate that the track recording is part of a work and so could be used to set other software-specific flags (e.g. for iTunes "show work movement") to indicate a multi-level "work: movement".
+
+## SongKong
+
+SongKong users may wish to map the \_cwp variables to tags produced by SongKong if consistency is desired, in which case the mappings are principally:
+- \_cwp\_work\_0 => musicbrainz\_work\_composition
+- \_cwp\_workid\_0 => musicbrainz\_work\_composition\_id
+- \_cwp\_work\_n => musicbrainz\_work\_part\_leveln, for n = 1..6
+- \_cwp\_workid\_n => musicbrainz\_work\_part\_leveln\_id, for n = 1..6
+- \_cwp\_work\_top => musicbrainz\_work
+
+These mappings are carried out automatically if the relevant options on the "Work and parts" tab are selected.
+In addition, \_cwp\_title\_work and \_cwp\_title\_part\_0 are intended to be equivalent to SongKong's work and part tags.
+(N.B. Full consistency between SongKong and Picard may also require the modification of Artist and related tags via a script, or the preservation of the related file tags)
+
+## Muso
+
+The tag "groupheading" should be set as the "Tags for Work - for software with 2-level capability". Muso will use this directly and extract the levels from it (split by the double colon). Muso permits a variety of import options which should be capable of combination with the tagging options in this plugin to achieve most desired effects. To avoid the use of import options in Muso, set the output tags from the plugin to be the native ones used by Muso (NB "title" may include or exclude groupheading - Muso should recognise it and extract it).
+
+To make use of Muso's in-built classical music processing to set explicit tags in Picard, enable the "Use Muso reference database ..." option on the "Genres etc." tab.
+
+## Players with no "work" capability
+
+Leave the "title" tag unchanged or make it a combination of work and movement.
+
+# Possible Enhancements
+All planned functionality has been included in version 2.0. Please post any suggestions for improvements to the forum.
+
+# Technical Matters (of possible interest to developers)
+Issues were encountered with the Picard API in that there is not a documented way to let Picard know that it is still doing asynchronous tasks in the background and has not finished processing metadata. Many thanks to @dns\_server for assistance in dealing with this and to @sophist for the albumartist\_website code which I have borrowed from. I have tried to add some more comments to help any others trying the same techniques.
+
+Also, the documentation of the XML lookup is virtually non-existent. The response is an XmlNode object (not a dict, although it is represented as one). Each node has a name with {attribs, text, children} values. The structure is more clearly understood if the web-based lookup is used (which is well documented at https://musicbrainz.org/doc/Development/XML_Web_Service/Version_2 ) as this gives an XML response. I wrote a function (parse\_data) to parse XmlNode objects, or lists thereof, for a (parameterised) hierarchy of nodes (and optional attribs value tests) in order to extract required data from the response. This may be of use to other plugin authors. The situation has been made slightly better in Picard 2.0 as the objects returned from register_track_metadata_processor are standard JSON. See https://musicbrainz.org/doc/Development/JSON_Web_Service. My parse_data function works with JSON as well as XmlNode formats, but the arguments you need to provide to it are different as the formats are structured differently. Picard 2.0 allows tagger.webservice calls to specify XML or default to JSON. This plugin has now migrated over to JSON-only.
+
+To get the whole picture, in XML, for a release, use (for example) https://musicbrainz.org/ws/2/release/f3bb4fdd-5db0-43a8-be73-7a1747f6c2ef?inc=release-groups+media+recordings+artist-credits+artists+aliases+labels+isrcs+collections+artist-rels+release-rels+url-rels+recording-rels+work-rels+recording-level-rels+work-level-rels. (Add &fmt=json at the end to get the JSON response). This simulates the response given by Picard with the "Use release relationships" and "Use track relationships" options selected. Note that the Picard album\_metadata\_processor returns releaseXmlNode (as JSON from Picard 2.0 on) which is everything from the Release node of the XML downwards, whereas track\_metadata\_processor returns trackXmlNode which is everything from a Track node downwards (release -> medium-list -> medium -> track-list is above track). Replace all hyphens in XML with underscores when parsing the Python object (JSON uses hyphens).
+
+Care needs to be taken when using the metadata property in Picard (e.g. as in track.metadata). This returns an object of class Metadata, which looks just like a dictionary but isn't. All values are in fact lists, which works as follows: when a value is set, it is always set as a list - i.e. a list value is entered as it is, but a string is set as a list : viz. ['string']. Then, when getting an item from the object, multiple values are joined to create a string. Thus track.metadata['item'] and track.metadata.get('item') will return list.join('; ') - i.e. a string with the list values separated by semi-colons - not the list. To get the list, you need to use track.metadata.getall('item'). The plugin stores work ids, internally and in "hidden variables" (such as _cwp_workid_0), as tuples. The Metadata class puts these into a string before setting the value in the object as a list, so the resulting value is ["(wid1, wid2, ...)"]. In order to extract the original tuple, the eval function is required.
+
+A large variety of releases were used to test this plugin, but there may still be bugs, so further testing is welcome. The following release was particularly complex and useful for testing: https://musicbrainz.org/release/ec519fde-94ee-4812-9717-659d91be11d4. Also this release was a bit tricky - a large box set with some works appearing as originals and in arrangements: https://musicbrainz.org/release/5288f266-bab8-45bd-83e4-555730f02fa0.
+
+# Very technical matters (probably not of interest to anyone)
+I've done a bit of research and observed the following behaviour in Picard when using the `register_track_metadata_processor()` API:
+1. If a new album (i.e. not yet tagged by Picard and with no MBIDs) is loaded, clustered and looked-up/scanned, resulting in the matched files being shown in the right-hand pane, then:
+ * `track.metadata` gives the lookup result from MB - i.e. no file information, just the track info.
+ * `album.tagger.files[xxxx].metadata` (where xxxx is the path/filename of the track) gives the file information (dirname etc.) and the tags on the original file.
+ * `album.tagger.files[xxxx].orig_metadata` gives the same as `album.tagger.files[xxxx].metadata`
+
+2. However, if the album is then "refreshed", this does not just carry out a repeat operation, instead:
+ * `track.metadata` gives the same as before
+ * `album.tagger.files[xxxx].metadata` gives the metadata as in `track.metadata` and also includes all the file information as before.
+ * `album.tagger.files[xxxx].orig_metadata` gives the same as before (i.e. the original tags).
+
+So, the 'post-refreshment' metadata is actually usable - by matching the `musicbrainz_trackid` of `track.metadata` and `album.tagger.files[xxxx].metadata`, you can get the file details of the track. Not elegant, but it works.
+But why is it necessary to "refresh" to get what seems like a logical data set? Basically, the metadata process is not complete when the plugin is called, so not all metadata is available to it.
+
+I don't know why `get_files_from_objects(objs)` doesn't work in the `register_track_metadata_processor()` API when `objs` is a list of tracks, but does provide a list of file objects when `objs` is a list of albums. Also it does work in the `register_file_action(xxx)`/`register_track_action(xxx)` API, but I assume that is because `itemsview.py` can identify that you have clicked on an item that is a track and a file (this is after the metadata processing has run).
+
+In order to get round these problems, I have adopted a 'hack' which looks up the files for an album and finds which file matches the required track on tracknumber and discnumber. This seems to work, but there may be circumstances when it does not. As a consequence, refreshment should only be required if `get_files_from_objects(objs)` doesn't get all the album files.
+
+# List of previous updates
+
+Version 0.9.4: Bug fixes. The last released version for Picard 1.4 and the fork for version 2.0.
+
+Version 0.9.3: Custom logging if enabled on "Advanced" tab - writes one log file per album in addition to standard Picard log. Also a session log with basic data is written. Performance improvements (especially for lyrics processing) and various bug fixes.
+
+Version 0.9.2: A new tab in the options page has been created - "Genres etc." This includes special processing for genres, instruments, keys, work dates and periods. The "Infer work types" option on the "Artists" tab has been moved to this tab (but will be reset to the default of "False" and will need to be reset as required, because it operates slightly differently now that there is more control over the setting of genres). A separate section has ben added to this readme giving more details on the options in this tab.
+
+Version 0.9.1: Bug fixes.
+
+Version 0.9: Additional option to clear previous file tags which are not wanted, without interfering with cover art. Additional option to replace instrument names with as-credited names. Also instrument names are now saved to hidden variables tags (instruments, instruments\_credited and instruments\_all) which can be mapped to file tags as required. Sub-option added to the 'override artist options' option on the "advanced" tab - to allow tag map details to be included or not in this over-ride. Minor bug fixes and UI improvements. This is the next 'official' version after 0.7.
+
+Version 0.8.9: Provide option (in advanced tab) to disable Classical Extras processing if no file is present; this enables (for example) single discs from box sets to be loaded without incurring the additional processing overhead for all the other discs. The settings of the main Picard options "translate\_artist\_names" and "standardize\_artists" is now saved along with the Classical Extras options so that they can be used to over-ride the displayed options. This is because they interact with the Classical Extras options in certain cases. Also:- graceful recovery from authentication failure; improved UI - more scalable; minor bug fixes.
+
+Version 0.8.8: Fixes to allow for (1) disabling of 'use\_cache' across releases which may share works and (2) works which might appear in their own right and also have arrangements. Also, re-set certain important options to defaults on starting Picard, namely: 'use\_cache' set to True, 'log\_debug', 'log\_info' and 'options\_overwrite' set to False; the user will need to deliberately re-set these on starting Picard if required - this is to prevent inadvertently leaving these flags in an abnormal state.
+
+Version 0.8.7: Revised treatment of "conditional" tag mapping. Previously, if multiple sources were specified for a tag mapping and the "conditional" flag set, only the first non-empty source was used. Now all sources will be mapped to a tag if it was empty before executing the current tag mapping line. This is considered to be more intuitive and leads to less complex mapping lines. However, it some cases it may be necessary to split a line from a previous version if the previous behaviour was specifically desired. Improved algorithms for extending metadata with title info. Bug fixes.
+
+Version 0.8.6: More consistent approach to sort tags and hidden variables. Bug fixes.
+
+Version 0.8.5: Improved handling of instruments. Bug fixes.
+
+Version 0.8.4: Improved UI, bug fixes and code improvements.
+
+Version 0.8.3: Ability to use aliases of work names instead of the MusicBrainz standard names. Various options to use aliases and as-credited names for performers and writers (i.e. relationship artists). Option to use recording artists as well as (or instead of) track artists. All relationship artists are now tagged for all work levels (with some special processing for lyricists). New UI layout to separate tag mapping from artist options. Option to split lyrics into common (release) and unique (track) components. Various code improvements as well as bug fixes.
+
+Version 0.8.2: Improved algorithms and a few minor bug fixes.
+
+Version 0.8.1: Bug fixes and minor enhancements - including revison and extension of "synonyms" section on the "advanced" tab.
+
+Version 0.8: Handle multiple recordings and/or multiple parents of a work.
+Handle multiple albumartist composers for one track.
+Option to use "credited as" name for artists (inc. performers and composers) who are "release artist" or "track artist".
+Option to exclude "solo" from instrument types.
+Option to over-ride plugin options with those used when the album was last saved.
+Option to keep (and append to) specified existing file tags - furthermore if "is\_classical" is present, the work-type variable will include "Classical".
+Option to use (and write) SongKong-compatible work tags (saves processing time if SongKong is used to pre-process large numbers of files).
+Include the work (and its parents) of which a work is an arrangement (as a "pseudo-parent").
+Include medleys in movement/part description (as [Medley of:...] or other descriptor specified in options).
+Allow for multiple parents of recordings and works (and multiple parents of those) - multiples are given as multiple tag instances, where permitted, otherwise separated by semi-colons.
+Option as to whether to include parent works where the relationship attribute is "part of collection".
+Plus minor enhancements and bug fixes too numerous to mention!
+(Note that some old versions of the plugin may say v0.8 when they are only v0.7)
+
+Version 0.7: Bug fixes. Pull request issued for this version.
+
+Version 0.6.6: Bug fixes and algorithm improvements. Allow multiple sources for a tag (each will be appended) and use + as separator for concantenating sources, not a comma, to distinguish from the use of comma to separate multiples. Provide additional hidden variables ("sources") for vocalists and instrumentalists. Option to include intermediate work levels in a movement tag (for systems which cannot display multiple work levels).
+
+Version 0.6.5: Include ability to use multiple (concatenated) sources in tag mapping (see notes under "tag mapping"). All artist "sources" using hidden variables (\_cea\_...) are now consistently in the plural, to distinguish from standard tags. Note that if "album" is used as a source in tag mapping, it will now be the revised name, where composer prefixing is used. To use the original name, use "release" as the source. Also various bug fixes, notably to ensure that all arrangers get picked up for use in tag mapping.
+
+Version 0.6.4: Write out version number to user-specified tag. Provide default comment tags for writing ui options. Provide better m4a and iTunes compatibility (see notes). Added functionality for chorus master, orchestrator and concert master (leader). Re-arranged artist tab in ui. Various bug fixes.
+
+Version 0.6.3: Bug fixes. Modified ui default options.
+
+Version 0.6.2: Bug fixes. More flexible handling of artists (can blank and then add back later). Modified ui default options.
+
+Version 0.6.1: Amended regex to permit non-Latin characters in work text.
\ No newline at end of file
diff --git a/plugins/classical_extras/__init__.py b/plugins/classical_extras/__init__.py
new file mode 100644
index 00000000..7e7136e8
--- /dev/null
+++ b/plugins/classical_extras/__init__.py
@@ -0,0 +1,8702 @@
+# -*- coding: utf-8 -*-
+#
+# Copyright (C) 2018 Mark Evens
+#
+# This program is free software; you can redistribute it and/or
+# modify it under the terms of the GNU General Public License
+# as published by the Free Software Foundation; either version 2
+# of the License, or (at your option) any later version.
+#
+# This program is distributed in the hope that it will be useful,
+# but WITHOUT ANY WARRANTY; without even the implied warranty of
+# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+# GNU General Public License for more details.
+#
+# You should have received a copy of the GNU General Public License
+# along with this program; if not, write to the Free Software
+# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
+# 02110-1301, USA.
+
+PLUGIN_NAME = u'Classical Extras'
+PLUGIN_AUTHOR = u'Mark Evens'
+PLUGIN_DESCRIPTION = u"""Classical Extras provides tagging enhancements for Picard and, in particular,
+utilises MusicBrainz’s hierarchy of works to provide work/movement tags. All options are set through a
+user interface in Picard options->plugins. This interface provides separate sections
+to enhance artist/performer tags, works and parts, genres and also allows for a generalised
+"tag mapping" (simple scripting).
+While it is designed to cater for the complexities of classical music tagging,
+it may also be useful for other music which has more than just basic song/artist/album data.
+
+The options screen provides five tabs for users to control the tags produced:
+
+1. Artists: Options as to whether artist tags will contain standard MB names, aliases or as-credited names.
+Ability to include and annotate names for specialist roles (chorus master, arranger, lyricist etc.).
+Ability to read lyrics tags on the file which has been loaded and assign them to track and album levels if required.
+(Note: Picard will not normally process incoming file tags).
+
+2. Works and parts: The plugin will build a hierarchy of works and parts (e.g. Work -> Part -> Movement or
+Opera -> Act -> Number) based on the works in MusicBrainz's database. These can then be displayed in tags in a variety
+of ways according to user preferences. Furthermore partial recordings, medleys, arrangements and collections of works
+are all handled according to user choices. There is a processing overhead for this at present because MusicBrainz limits
+look-ups to one per second.
+
+3. Genres etc.: Options are available to customise the source and display of information relating to genres,
+instruments, keys, work dates and periods. Additional capabilities are provided for users of Muso (or others who
+provide the relevant XML files) to use pre-existing databases of classical genres, classical composers and classical
+periods.
+
+4. Tag mapping: in some ways, this is a simple substitute for some of Picard's scripting capability. The main advantage
+ is that the plugin will remember what tag mapping you use for each release (or even track).
+
+5. Advanced: Various options to control the detailed processing of the above.
+
+All user options can be saved on a per-album (or even per-track) basis so that tweaks can be used to deal with
+inconsistencies in the MusicBrainz data (e.g. include English titles from the track listing where the MusicBrainz works
+are in the composer's language and/or script).
+Also existing file tags can be processed (not possible in native Picard).
+
+See the readme file
+on GitHub here for full details.
+"""
+
+########################
+# DEVELOPERS NOTES: ####
+########################
+# This plugin contains 3 classes:
+#
+# I. ("EXTRA ARTISTS") Create sorted fields for all performers. Creates a number of variables with alternative values
+# for "artists" and "artist".
+# Creates an ensemble variable for all ensemble-type performers.
+# Also creates matching sort fields for artist and artists.
+# Additionally create tags for artist types which are not normally created in Picard - particularly for classical music
+# (notably instrument arrangers).
+#
+# II. ("PART LEVELS" [aka Work Parts]) Create tags for the hierarchy of works which contain a given track recording
+# - particularly for classical music'
+# Variables provided for each work level, with implied part names
+# Mixed metadata provided including work and title elements
+#
+# III. ("OPTIONS") Allows the user to set various options including what tags will be written
+# (otherwise the classes above will just write outputs to "hidden variables")
+#
+# The main control routine is at the end of the module
+
+PLUGIN_VERSION = '2.0.7'
+PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2"]
+PLUGIN_LICENSE = "GPL-2.0"
+PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
+
+from picard.ui.options import register_options_page, OptionsPage
+from picard.plugins.classical_extras.ui_options_classical_extras import Ui_ClassicalExtrasOptionsPage
+import picard.plugins.classical_extras.suffixtree
+from picard import config, log
+from picard.config import ConfigSection, BoolOption, IntOption, TextOption
+from picard.util import LockableObject, uniqify
+
+# note that in 2.0 picard.webservice changed to picard.util.xml
+from picard.util.xml import XmlNode
+from picard.util import translate_from_sortname
+from picard.metadata import register_track_metadata_processor, Metadata
+from functools import partial
+from datetime import datetime
+import collections
+import re
+import unicodedata
+import json
+import copy
+import os
+from PyQt5.QtCore import QXmlStreamReader
+from picard.const import USER_DIR
+import operator
+import ast
+import picard.plugins.classical_extras.const
+
+
+
+##########################
+# MODULE-WIDE COMPONENTS #
+##########################
+# CONSTANTS
+# N.B. Constants with long definitions are set in const.py
+PRESERVE = [x.strip() for x in config.setting["preserved_tags"].split(',')]
+DATE_SEP = '-'
+
+# COMMONLY USED REGEX
+ROMAN_NUMERALS = r'\b((?=[MDCLXVI])(M{0,4}(CM|CD|D?)?C{0,3}(XC|XL|L?)?X{0,3}(IX|IV|V?)?I{0,3}))(?:\.|\-|:|;|,|\s|$)'
+ROMAN_NUMERALS_AT_START = r'^\W*' + ROMAN_NUMERALS
+RE_ROMANS = re.compile(ROMAN_NUMERALS, re.IGNORECASE)
+RE_ROMANS_AT_START = re.compile(ROMAN_NUMERALS_AT_START, re.IGNORECASE)
+# KEYS
+RE_NOTES = r'(\b[ABCDEFG])'
+RE_ACCENTS = r'(\-sharp(?:\s+|\b)|\-flat(?:\s+|\b)|\ssharp(?:\s+|\b)|\sflat(?:\s+|\b)|\u266F(?:\s+|\b)|\u266D(?:\s+|\b)|(?:[:,.]?\s+|$|\-))'
+RE_SCALES = r'(major|minor)?(?:\b|$)'
+RE_KEYS = re.compile(
+ RE_NOTES + RE_ACCENTS + RE_SCALES,
+ re.UNICODE | re.IGNORECASE)
+
+# LOGGING
+
+# If logging occurs before any album is loaded, the startup log file will
+# be written
+log_files = collections.defaultdict(dict)
+# entries are release-ids: to keep track of which log files are open
+release_status = collections.defaultdict(dict)
+# release_status[release_id]['works'] = True indicates that we are still processing works for release_id
+# & similarly for 'artists'
+# release_status[release_id]['start'] holds start time of release processing
+# release_status[release_id]['name'] holds the album name
+# release_status[release_id]['lookups'] holds number of lookups for this release
+# release_status[release_id]['file_objects'] holds a cumulative list of file objects (tagger seems a bit unreliable)
+# release_status[release_id]['file_found'] = False indicates that "No file
+# with matching trackid" has (yet) been found
+
+
+def write_log(release_id, log_type, message, *args):
+ """
+ Custom logging function - if log_info is set, all messages will be written to a custom file in a 'Classical_Extras'
+ subdirectory in the same directory as the main Picard log. A different file is used for each album,
+ to aid in debugging - the log file is release_id.log. Any startup messages (i.e. before a release has been loaded)
+ are written to session.log. Summary information for each release is also written to session.log even if log_info
+ is not set.
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param log_type: 'error', 'warning', 'debug' or 'info'
+ :param message: string, e.g. 'error message for workid: %s'
+ :param args: arguments for parameters in string, e.g. if workId then str(workId) will replace %s in the above
+ :return:
+ """
+ options = config.setting
+ if not isinstance(message, str):
+ msg = repr(message)
+ else:
+ msg = message
+ if args:
+ msg = msg % args
+
+ if options["log_info"] or log_type == "basic":
+ # if log_info is True, all log messages will be written to the custom log, regardless of other log_... settings
+ # basic session log will always be written (summary of releases and
+ # processing times)
+ filename = release_id + ".log"
+ log_dir = os.path.join(USER_DIR, "Classical_Extras")
+ if not os.path.exists(log_dir):
+ os.makedirs(log_dir)
+ if release_id not in log_files:
+ try:
+ if release_id == 'session':
+ log_file = open(
+ os.path.join(
+ log_dir,
+ filename),
+ 'w',
+ encoding='utf8',
+ buffering=1)
+ # buffering=1 so that session log (low volume) is up to
+ # date even if not closed
+ else:
+ log_file = open(
+ os.path.join(
+ log_dir,
+ filename),
+ 'w',
+ encoding='utf8') # , buffering=1)
+ # default buffering for speed, buffering = 1 for currency
+ log_files[release_id] = log_file
+ log_file.write(
+ PLUGIN_NAME +
+ ' Version:' +
+ PLUGIN_VERSION +
+ '\n')
+ if release_id == 'session':
+ log_file.write('session' + '\n')
+ else:
+ log_file.write('Release id: ' + release_id + '\n')
+ if release_id in release_status and 'name' in release_status[release_id]:
+ log_file.write(
+ 'Album name: ' + release_status[release_id]['name'] + '\n')
+ except IOError:
+ log.error('Unable to open file %s for writing log', filename)
+ return
+ else:
+ log_file = log_files[release_id]
+ try:
+ log_file.write(log_type[0].upper() + ': ')
+ log_file.write(str(datetime.now()) + ' : ')
+ log_file.write(msg)
+ log_file.write("\n")
+ except IOError:
+ log.error('Unable to write to log file %s', filename)
+ return
+ # Only debug, warning and error messages will be written to the main
+ # Picard log, if those options have been set
+ if log_type != 'info' and log_type != 'basic': # i.e. non-custom log items
+ message2 = PLUGIN_NAME + ': ' + message
+ else:
+ message2 = message
+ if log_type == 'debug' and options["log_debug"]:
+ if release_id in release_status and 'debug' in release_status[release_id]:
+ add_list_uniquely(release_status[release_id]['debug'], msg)
+ else:
+ release_status[release_id]['debug'] = [msg]
+ log.debug(message2, *args)
+ if log_type == 'warning' and options["log_warning"]:
+ if release_id in release_status and 'warnings' in release_status[release_id]:
+ add_list_uniquely(release_status[release_id]['warnings'], msg)
+ else:
+ release_status[release_id]['warnings'] = [msg]
+ if args:
+ log.warning(message2, *args)
+ else:
+ log.warning(message2)
+ if log_type == 'error' and options["log_error"]:
+ if release_id in release_status and 'errors' in release_status[release_id]:
+ add_list_uniquely(release_status[release_id]['errors'], msg)
+ else:
+ release_status[release_id]['errors'] = [msg]
+ if args:
+ log.error(message2, *args)
+ else:
+ log.error(message2)
+
+
+def close_log(release_id, caller):
+ # close the custom log file if we are done
+ if release_id == 'session': # shouldn't happen but, just in case, don't close the session log
+ return
+ if caller in ['works', 'artists']:
+ release_status[release_id][caller] = False
+ if (caller == 'works' and release_status[release_id]['artists']) or \
+ (caller == 'artists' and release_status[release_id]['works']):
+ # log.error('exiting close_log. only %s done', caller) # debug line
+ return
+ duration = 'N/A'
+ lookups = 'N/A'
+ artists_time = 0
+ works_time = 0
+ lookup_time = 0
+ album_process_time = 0
+ if release_id in release_status:
+ duration = datetime.now() - release_status[release_id]['start']
+ lookups = release_status[release_id]['lookups']
+ done_lookups = release_status[release_id]['done-lookups']
+ lookup_time = done_lookups - release_status[release_id]['start']
+ album_process_time = duration - lookup_time
+ artists_time = release_status[release_id]['artists-done'] - \
+ release_status[release_id]['start']
+ works_time = release_status[release_id]['works-done'] - \
+ release_status[release_id]['start']
+ del release_status[release_id]['start']
+ del release_status[release_id]['lookups']
+ del release_status[release_id]['done-lookups']
+ del release_status[release_id]['artists-done']
+ del release_status[release_id]['works-done']
+ if release_id in log_files:
+ write_log(
+ release_id,
+ 'info',
+ 'Duration = %s. Number of lookups = %s.',
+ duration,
+ lookups)
+ write_log(release_id, 'info', 'Closing log file for %s', release_id)
+ log_files[release_id].close()
+ del log_files[release_id]
+ if 'session' in log_files and release_id in release_status:
+ write_log(
+ 'session',
+ 'basic',
+ '\n Completed processing release id %s. Details below:-',
+ release_id)
+ if 'name' in release_status[release_id]:
+ write_log('session', 'basic', 'Album name %s',
+ release_status[release_id]['name'])
+ if 'errors' in release_status[release_id]:
+ write_log(
+ 'session',
+ 'basic',
+ '-------------------- Errors --------------------')
+ for error in release_status[release_id]['errors']:
+ write_log('session', 'basic', error)
+ del release_status[release_id]['errors']
+ if 'warnings' in release_status[release_id]:
+ write_log(
+ 'session',
+ 'basic',
+ '-------------------- Warnings --------------------')
+ for warning in release_status[release_id]['warnings']:
+ write_log('session', 'basic', warning)
+ del release_status[release_id]['warnings']
+ if 'debug' in release_status[release_id]:
+ write_log(
+ 'session',
+ 'basic',
+ '-------------------- Debug log --------------------')
+ for debug in release_status[release_id]['debug']:
+ write_log('session', 'basic', debug)
+ del release_status[release_id]['debug']
+ write_log(
+ 'session',
+ 'basic',
+ 'Duration = %s. Artists time = %s. Works time = %s. Of which: Lookup time = %s. '
+ 'Album-process time = %s. Number of lookups = %s.',
+ duration,
+ artists_time,
+ works_time,
+ lookup_time,
+ album_process_time,
+ lookups)
+ if release_id in release_status:
+ del release_status[release_id]
+
+
+# FILE READING AND OBJECT PARSING
+
+_node_name_re = re.compile('[^a-zA-Z0-9]')
+
+
+def _node_name(n):
+ return _node_name_re.sub('_', str(n))
+
+
+def _read_xml(stream):
+ document = XmlNode()
+ current_node = document
+ path = []
+ while not stream.atEnd():
+ stream.readNext()
+ if stream.isStartElement():
+ node = XmlNode()
+ attrs = stream.attributes()
+ for i in range(attrs.count()):
+ attr = attrs.at(i)
+ node.attribs[_node_name(attr.name())] = str(attr.value())
+ current_node.append_child(_node_name(stream.name()), node)
+ path.append(current_node)
+ current_node = node
+ elif stream.isEndElement():
+ current_node = path.pop()
+ elif stream.isCharacters():
+ current_node.text += str(stream.text())
+ return document
+
+
+def parse_data(release_id, obj, response_list, *match):
+ """
+ This function takes any XmlNode object, or list thereof, or a JSON object
+ and extracts a list of all objects exactly matching the hierarchy listed in match.
+ match should contain list of each node in hierarchical sequence, with no gaps in the sequence
+ of nodes, to lowest level required.
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param obj: an XmlNode or JSON object, list or dictionary containing nodes
+ :param response_list: working memory for recursive calls
+ :param match: list of items to search for in node (see detailed notes below)
+ :return: a list of matching items (always a list, even if only one item)
+
+ Insert attribs.attribname:attribvalue in the list to select only branches where attribname
+ is attribvalue. (Omit the attribs prefix if the obj is JSON)
+ Insert childname.text:childtext in the list to select only branches where
+ a sibling with childname has text childtext.
+ (Note: childname can be a dot-list if the text is more than one level down - e.g. child1.child2
+ # TODO - Check this works fully )
+ """
+ if '!log' in response_list:
+ DEBUG = True
+ INFO = True
+ else:
+ DEBUG = False
+ INFO = False
+ # Normally logging options are off as these can be VERY wordy
+ # They can be turned on by using !log in the call
+
+ # XmlNode instances are not iterable, so need to convert to dict
+ if isinstance(obj, XmlNode):
+ obj = obj.__dict__
+ if DEBUG or INFO:
+ write_log(release_id, 'debug', 'Parsing data - looking for %s', match)
+ if INFO:
+ write_log(release_id, 'info', 'Looking in object: %s', obj)
+ if isinstance(obj, list):
+ objlen = len(obj)
+ for i, item in enumerate(obj):
+ if isinstance(item, XmlNode):
+ item = item.__dict__
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'Getting response for list item no.%s of %s - object is: %s',
+ i + 1,
+ objlen,
+ item)
+ parse_data(release_id, item, response_list, *match)
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'response_list for list item no.%s of %s is %s',
+ i + 1,
+ objlen,
+ response_list)
+ return response_list
+ elif isinstance(obj, dict):
+ if match[0] in obj:
+ if len(match) == 1:
+ response = obj[match[0]]
+ if response is not None: # To prevent adding NoneTypes to list
+ response_list.append(response)
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'response_list (last match item): %s',
+ response_list)
+ else:
+ match_list = list(match)
+ match_list.pop(0)
+ parse_data(release_id, obj[match[0]],
+ response_list, *match_list)
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'response_list (passing up): %s',
+ response_list)
+ return response_list
+ elif ':' in match[0]:
+ test = match[0].split(':')
+ match2 = test[0].split('.')
+ test_data = parse_data(release_id, obj, [], *match2)
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'Value comparison - looking in %s for value %s',
+ test_data,
+ test[1])
+ if len(test) > 1:
+ # latter is because Booleans are stored as such, not as
+ # strings, in JSON
+ if (test[1] in test_data) or (
+ (test[1] == 'True') in test_data):
+ if len(match) == 1:
+ response = obj
+ if response is not None:
+ response_list.append(response)
+ else:
+ match_list = list(match)
+ match_list.pop(0)
+ parse_data(release_id, obj, response_list, *match_list)
+ else:
+ parse_data(release_id, obj, response_list, *match2)
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'response_list (from value look-up): %s',
+ response_list)
+ return response_list
+ else:
+ if 'children' in obj:
+ parse_data(release_id, obj['children'], response_list, *match)
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'response_list (from children): %s',
+ response_list)
+ return response_list
+ else:
+ if INFO:
+ write_log(
+ release_id,
+ 'info',
+ 'response_list (obj is not a list or dict): %s',
+ response_list)
+ return response_list
+
+
+def create_dict_from_ref_list(options, release_id, ref_list, keys, tags):
+ ref_dict_list = []
+ for refs in ref_list:
+ for ref in refs:
+ parsed_refs = [
+ parse_data(
+ release_id,
+ ref,
+ [],
+ t,
+ 'text') for t in tags]
+ ref_dict_list.append(dict(zip(keys, parsed_refs)))
+ return ref_dict_list
+
+
+def get_references_from_file(release_id, path, filename):
+ """
+ Lookup Muso Reference.xml or similar
+ :param release_id: name of log file
+ :param path: Reference file path
+ :param filename: Reference file name
+ :return:
+ """
+ options = config.setting
+ composer_dict_list = []
+ period_dict_list = []
+ genre_dict_list = []
+ xml_file = None
+ try:
+ xml_file = open(os.path.join(path, filename), encoding="utf8")
+ reply = xml_file.read()
+ xml_file.close()
+ document = _read_xml(QXmlStreamReader(reply))
+ # Composers
+ composer_list = parse_data(
+ release_id, document, [], 'ReferenceDB', 'Composer')
+ keys = ['name', 'sort', 'birth', 'death', 'country', 'core']
+ tags = ['Name', 'Sort', 'Birth', 'Death', 'CountryCode', 'Core']
+ composer_dict_list = create_dict_from_ref_list(
+ options, release_id, composer_list, keys, tags)
+ # Periods
+ period_list = parse_data(
+ release_id,
+ document,
+ [],
+ 'ReferenceDB',
+ 'ClassicalPeriod')
+ keys = ['name', 'start', 'end']
+ tags = ['Name', 'Start_x0020_Date', 'End_x0020_Date']
+ period_dict_list = create_dict_from_ref_list(
+ options, release_id, period_list, keys, tags)
+ # Genres
+ genre_list = parse_data(
+ release_id,
+ document,
+ [],
+ 'ReferenceDB',
+ 'ClassicalGenre')
+ keys = ['name']
+ tags = ['Name']
+ genre_dict_list = create_dict_from_ref_list(
+ options, release_id, genre_list, keys, tags)
+
+ except (IOError, FileNotFoundError, UnicodeDecodeError):
+ if options['cwp_muso_genres'] or options['cwp_muso_classical'] or options['cwp_muso_dates'] or options['cwp_muso_periods']:
+ write_log(
+ release_id,
+ 'error',
+ 'File %s does not exist or is corrupted',
+ os.path.join(
+ path,
+ filename))
+ finally:
+ if xml_file:
+ xml_file.close()
+ return {
+ 'composers': composer_dict_list,
+ 'periods': period_dict_list,
+ 'genres': genre_dict_list}
+
+# OPTIONS
+
+
+def get_options(release_id, album, track):
+ """
+ Get the saved options from a release and use them according to flags set on the "advanced" tab
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album: current release
+ :param track: current track
+ :return: None (result is passed via tm)
+ A common function for both Artist and Workparts, so that the first class to process a track will execute
+ this function so that the results are available to both (via a track metadata item)
+ """
+ release_status[release_id]['done'] = False
+ set_options = collections.defaultdict(dict)
+ main_sections = ['artists', 'workparts']
+ all_sections = ['artists', 'tag', 'workparts', 'genres']
+ parent_sections = {
+ 'artists': 'artists',
+ 'tag': 'artists',
+ 'workparts': 'workparts',
+ 'genres': 'workparts'}
+ # The above needs to be done for legacy reasons - there are only two tags which store options - artists and workparts
+ # This dates from when there were only two sections
+ # To split these now will create compatibility issues
+ override = {
+ 'artists': 'cea_override',
+ 'tag': 'ce_tagmap_override',
+ 'workparts': 'cwp_override',
+ 'genres': 'ce_genres_override'}
+ sect_text = {'artists': 'Artists', 'workparts': 'Works'}
+ prefix = {'artists': 'cea', 'workparts': 'cwp'}
+
+ if album.tagger.config.setting['ce_options_overwrite'] and all(
+ album.tagger.config.setting[override[sect]] for sect in main_sections):
+ set_options[track] = album.tagger.config.setting # mutable
+ else:
+ set_options[track] = option_settings(
+ album.tagger.config.setting) # make a copy
+ if set_options[track]["log_info"]:
+ write_log(
+ release_id,
+ 'info',
+ 'Default (i.e. per UI) options for track %s are %r',
+ track,
+ set_options[track])
+
+ # As we use some of the main Picard options and may over-write them, save them here
+ # set_options[track]['translate_artist_names'] = config.setting['translate_artist_names']
+ # set_options[track]['standardize_artists'] = config.setting['standardize_artists']
+ # (not sure this is needed - TODO reconsider)
+
+ options = set_options[track]
+ tm = track.metadata
+ new_metadata = None
+ orig_metadata = None
+ # Only look up files if needed
+ file_options = {}
+ music_file = ''
+ music_file_found = None
+ release_status[release_id]['file_found'] = False
+ start = datetime.now()
+ if options["log_info"]:
+ write_log(release_id, 'info', 'Clock start at %s', start)
+ trackno = tm['tracknumber']
+ discno = tm['discnumber']
+
+ album_filenames = album.tagger.get_files_from_objects([album])
+ if options["log_info"]:
+ write_log(
+ release_id,
+ 'info',
+ 'No. of album files found = %s',
+ len(album_filenames))
+ # Note that sometimes Picard fails to get all the file objects, even if they are there (network issues)
+ # so we will cache whatever we can get!
+ if release_id in release_status and 'file_objects' in release_status[release_id]:
+ add_list_uniquely(
+ release_status[release_id]['file_objects'],
+ album_filenames)
+ else:
+ release_status[release_id]['file_objects'] = album_filenames
+ if options["log_info"]:
+ write_log(release_id, 'info', 'No. of album files cached = %s',
+ len(release_status[release_id]['file_objects']))
+ track_file = None
+ for album_file in release_status[release_id]['file_objects']:
+ if options["log_info"]:
+ write_log(release_id,
+ 'info',
+ 'Track file = %s, tracknumber = %s, discnumber = %s. Metadata trackno = %s, discno = %s',
+ album_file.filename,
+ str(album_file.tracknumber),
+ str(album_file.discnumber),
+ trackno,
+ discno)
+ if str(
+ album_file.tracknumber) == trackno and str(
+ album_file.discnumber) == discno:
+ if options["log_info"]:
+ write_log(
+ release_id,
+ 'info',
+ 'Track file found = %r',
+ album_file.filename)
+ track_file = album_file.filename
+ break
+
+ # Note: It would have been nice to do a rough check beforehand of total tracks,
+ # but ~totalalbumtracks is not yet populated
+ if not track_file:
+ album_fullnames = [
+ x.filename for x in release_status[release_id]['file_objects']]
+ if options["log_info"]:
+ write_log(
+ release_id,
+ 'info',
+ 'Album files found = %r',
+ album_fullnames)
+ for music_file in album_fullnames:
+ new_metadata = album.tagger.files[music_file].metadata
+
+ if 'musicbrainz_trackid' in new_metadata and 'musicbrainz_trackid' in tm:
+ if new_metadata['musicbrainz_trackid'] == tm['musicbrainz_trackid']:
+ track_file = music_file
+ break
+ # Nothing found...
+ if new_metadata and 'musicbrainz_trackid' not in new_metadata:
+ if options['log_warning']:
+ write_log(
+ release_id,
+ 'warning',
+ 'No trackid in file %s',
+ music_file)
+ if 'musicbrainz_trackid' not in tm:
+ if options['log_warning']:
+ write_log(
+ release_id,
+ 'warning',
+ 'No trackid in track %s',
+ track)
+ #
+ # Note that, on initial load, new_metadata == orig_metadata; but, after refresh, new_metadata will have
+ # the same track metadata as tm (plus the file metadata as per orig_metadata), so a trackid match
+ # is then possible for files that do not have musicbrainz_trackid in orig_metadata. That is why
+ # new_metadata is used in the above test, rather than orig_metadata, but orig_metadata is then used below
+ # to get the saved options.
+ #
+
+ # Find the tag with the options:-
+ if track_file:
+ orig_metadata = album.tagger.files[track_file].orig_metadata
+ music_file_found = track_file
+ if options['log_info']:
+ write_log(
+ release_id,
+ 'info',
+ 'orig_metadata for file %s is',
+ music_file)
+ write_log(release_id, 'info', orig_metadata)
+ for child_section in all_sections:
+ section = parent_sections[child_section]
+ if options[override[child_section]]:
+ if options[prefix[section] + '_options_tag'] + ':' + \
+ section + '_options' in orig_metadata:
+ file_options[section] = interpret(
+ orig_metadata[options[prefix[section] + '_options_tag'] + ':' + section + '_options'])
+ elif options[prefix[section] + '_options_tag'] in orig_metadata:
+ options_tag_contents = orig_metadata[options[prefix[section] + '_options_tag']]
+ if isinstance(options_tag_contents, list):
+ options_tag_contents = options_tag_contents[0]
+ combined_options = ''.join(options_tag_contents.split(
+ '(workparts_options)')).split('(artists_options)')
+ for i, _ in enumerate(combined_options):
+ combined_options[i] = interpret(
+ combined_options[i].lstrip('; '))
+ if isinstance(
+ combined_options[i],
+ dict) and 'Classical Extras' in combined_options[i]:
+ if sect_text[section] + \
+ ' options' in combined_options[i]['Classical Extras']:
+ file_options[section] = combined_options[i]
+ else:
+ for om in orig_metadata:
+ if ':' + section + '_options' in om:
+ file_options[section] = interpret(
+ orig_metadata[om])
+ if section not in file_options or not file_options[section]:
+ if options['log_error']:
+ write_log(
+ release_id,
+ 'error',
+ 'Saved ' +
+ section +
+ ' options cannot be read for file %s. Using current settings',
+ music_file)
+ append_tag(
+ release_id,
+ tm,
+ '~' +
+ prefix[section] +
+ '_error',
+ '1. Saved ' +
+ section +
+ ' options cannot be read. Using current settings')
+
+ release_status[release_id]['file_found'] = True
+
+ end = datetime.now()
+ if options['log_info']:
+ write_log(release_id, 'info', 'Clock end at %s', end)
+ write_log(release_id, 'info', 'Duration = %s', end - start)
+
+ if not release_status[release_id]['file_found']:
+ if options['log_warning']:
+ write_log(
+ release_id,
+ 'warning',
+ "No file with matching trackid for track %s. IF THERE SHOULD BE ONE, TRY 'REFRESH'",
+ track)
+ append_tag(
+ release_id,
+ tm,
+ "002_important_warning",
+ "No file with matching trackid - IF THERE SHOULD BE ONE, TRY 'REFRESH' - "
+ "(unable to process any saved options, lyrics or 'keep' tags)")
+ # Nothing else is done with this info as yet - ideally we need to refresh and re-run
+ # for all releases where, say, release_status[release_id]['file_prob']
+ # == True TODO?
+
+ else:
+ if options['log_info']:
+ write_log(
+ release_id,
+ 'info',
+ 'Found music file: %r',
+ music_file_found)
+ for section in all_sections:
+ if options[override[section]]:
+ parent_section = parent_sections[section]
+ if parent_section in file_options and file_options[parent_section]:
+ try:
+ options_dict = file_options[parent_section]['Classical Extras'][sect_text[parent_section] + ' options']
+ except TypeError as err:
+ if options['log_error']:
+ write_log(
+ release_id,
+ 'error',
+ 'Error: %s. Saved ' +
+ section +
+ ' options cannot be read for file %s. Using current settings',
+ err,
+ music_file)
+ append_tag(
+ release_id,
+ tm,
+ '~' +
+ prefix[parent_section] +
+ '_error',
+ '1. Saved ' +
+ parent_section +
+ ' options cannot be read. Using current settings')
+ break
+ for opt in options_dict:
+ if isinstance(
+ options_dict[opt],
+ dict) and options[override['tag']]: # for tag line options
+ # **NB tag mapping lines are the only entries of type dict**
+ opt_list = []
+ for opt_item in options_dict[opt]:
+ opt_list.append(
+ {opt + '_' + opt_item: options_dict[opt][opt_item]})
+ else:
+ opt_list = [{opt: options_dict[opt]}]
+ for opt_dict in opt_list:
+ for opt_det in opt_dict:
+ opt_value = opt_dict[opt_det]
+ addn = []
+ if section == 'artists':
+ addn = plugin_options('picard')
+ if section == 'tag':
+ addn = plugin_options('tag_detail')
+ for ea_opt in plugin_options(section) + addn:
+ displayed_option = options[ea_opt['option']]
+ if ea_opt['name'] == opt_det:
+ if 'value' in ea_opt:
+ if ea_opt['value'] == opt_value:
+ options[ea_opt['option']] = True
+ else:
+ options[ea_opt['option']
+ ] = False
+ else:
+ options[ea_opt['option']
+ ] = opt_value
+ if options[ea_opt['option']
+ ] != displayed_option:
+ if options['log_debug'] or options['log_info']:
+ write_log(
+ release_id,
+ 'info',
+ 'Options overridden for option %s = %s',
+ ea_opt['option'],
+ opt_value)
+
+ opt_text = str(opt_value)
+ append_tag(
+ release_id, tm, '003_information:options_overridden', str(
+ ea_opt['name']) + ' = ' + opt_text)
+
+ if orig_metadata:
+ keep_list = options['cea_keep'].split(",")
+ if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
+ keep_list.append(options['cea_lyrics_tag'])
+ if options['cwp_genres_use_file']:
+ if 'genre' in orig_metadata:
+ append_tag(
+ release_id,
+ tm,
+ '~cwp_candidate_genres',
+ orig_metadata['genre'])
+ if options['cwp_genre_tag'] and options['cwp_genre_tag'] in orig_metadata:
+ keep_list.append(options['cwp_genre_tag'])
+ really_keep_list = PRESERVE[:]
+ really_keep_list.append(
+ options['cwp_options_tag'] +
+ ':workparts_options')
+ really_keep_list.append(
+ options['cea_options_tag'] +
+ ':artists_options')
+ for tagx in keep_list:
+ tag = tagx.strip()
+ really_keep_list.append(tag)
+ if tag in orig_metadata:
+ append_tag(release_id, tm, tag, orig_metadata[tag])
+ if options['cea_clear_tags']:
+ delete_list = []
+ for tag_item in orig_metadata:
+ if tag_item not in really_keep_list and tag_item[0] != '~':
+ # the second condition is to ensure that (hidden) file variables are not deleted,
+ # as these are in orig_metadata, not track_metadata
+ delete_list.append(tag_item)
+ # this will be used in map_tags to delete unwanted tags
+ options['delete_tags'] = delete_list
+ ## Create a "mirror" tag with the old data, for comparison purposes
+ mirror_tags = []
+ for tag_item in orig_metadata:
+ mirror_name = tag_item + '_OLD'
+ if mirror_name[0] == '~' :
+ mirror_name.replace('~', '_')
+ mirror_name = '~' + mirror_name
+ mirror_tags.append((mirror_name, tag_item))
+ append_tag(release_id, tm, mirror_name, orig_metadata[tag_item])
+ append_tag(release_id, tm, '~ce_mirror_tags', mirror_tags)
+
+ if not isinstance(options, dict):
+ options_dict = option_settings(config.setting)
+ write_log(
+ 'session',
+ 'info',
+ 'Using option_settings(config.setting): %s',
+ options_dict)
+ else:
+ options_dict = options
+ write_log(
+ 'session',
+ 'info',
+ 'Using options: %s',
+ options_dict)
+ tm['~ce_options'] = str(options_dict)
+ tm['~ce_file'] = music_file_found
+
+
+def plugin_options(option_type):
+ """
+ :param option_type: artists, tag, workparts, genres or other
+ :return: the relevant dictionary for the type
+ This function contains all the options data in one place - to prevent multiple repetitions elsewhere
+ """
+ if option_type == 'artists':
+ return const.ARTISTS_OPTIONS
+ elif option_type == 'tag':
+ return const.TAG_OPTIONS
+ elif option_type == 'tag_detail':
+ return const.TAG_DETAIL_OPTIONS
+ elif option_type == 'workparts':
+ return const.WORKPARTS_OPTIONS
+ elif option_type == 'genres':
+ return const.GENRE_OPTIONS
+ elif option_type == 'picard':
+ return const.PICARD_OPTIONS
+ elif option_type == 'other':
+ return const.OTHER_OPTIONS
+ else:
+ return None
+
+def option_settings(config_settings):
+ """
+ :param config_settings: options from UI
+ :return: a (deep) copy of the Classical Extras options
+ """
+ options = {}
+ for option in plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') + plugin_options(
+ 'workparts') + plugin_options('genres') + plugin_options('picard') + plugin_options('other'):
+ options[option['option']] = copy.deepcopy(
+ config_settings[option['option']])
+ return options
+
+
+def get_aliases(self, release_id, album, options, releaseXmlNode):
+ """
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param self:
+ :param album:
+ :param options:
+ :param releaseXmlNode: all the metadata for the release
+ :return: Data is returned via self.artist_aliases and self.artist_credits[album]
+
+ Note regarding aliases and credited-as names:
+ In a MB release, an artist can appear in one of seven contexts. Each of these is accessible in releaseXmlNode
+ and the track and recording contexts are also accessible in trackXmlNode.
+ The seven contexts are:
+ Recording: credited-as and alias
+ Release-group: credited-as and alias
+ Release: credited-as and alias
+ Release relationship: credited-as and (not reliably?) alias
+ Recording relationship (direct): credited-as and (not reliably?) alias
+ Recording relationship (via work): credited-as and (not reliably?) alias
+ Track: credited-as and alias
+ (The above are applied in sequence - e.g. track artist credit will over-ride release artist credit. "Recording" gets
+ the lowest priority as it is more generic than the release data {may apply to multiple releases})
+ This function collects all the available aliases and as-credited names once (on processing the first track).
+ N.B. if more than one release is loaded in Picard, any available alias names loaded so far will be available
+ and used. However, as-credited names will only be used from the current release."""
+
+ if 'artist_locale' in config.setting and options['cea_aliases'] or options['cea_aliases_composer']:
+ locale = config.setting["artist_locale"]
+ lang = locale.split("_")[0] # NB this is the Picard code in /util
+
+ # Track and recording aliases/credits are gathered by parsing the
+ # media, track and recording nodes
+ # Do the recording relationship first as it may apply to multiple releases, so release and track data
+ # is more specific.
+ media = parse_data(release_id, releaseXmlNode, [], 'media')
+ for m in media:
+ # disc_num = int(parse_data(options, m, [], 'position', 'text')[0])
+ # not currently used
+ tracks = parse_data(release_id, m, [], 'tracks')
+ for track in tracks:
+ for t in track:
+ # track_num = int(parse_data(options, t, [], 'number',
+ # 'text')[0]) # not currently used
+
+ # Recording artists
+ obj = parse_data(release_id, t, [], 'recording')
+ get_aliases_and_credits(
+ self,
+ options,
+ release_id,
+ album,
+ obj,
+ lang,
+ options['cea_recording_credited'])
+
+ # Get the release data before the recording relationshiops and track data
+ # Release group artists
+ obj = parse_data(release_id, releaseXmlNode, [], 'release-group')
+ get_aliases_and_credits(
+ self,
+ options,
+ release_id,
+ album,
+ obj,
+ lang,
+ options['cea_group_credited'])
+
+ # Release artists
+ get_aliases_and_credits(
+ self,
+ options,
+ release_id,
+ album,
+ releaseXmlNode,
+ lang,
+ options['cea_credited'])
+ # Next bit needed to identify artists who are album artists
+ self.release_artists_sort[album] = parse_data(
+ release_id, releaseXmlNode, [], 'artist-credit', 'artist', 'sort-name')
+ # Release relationship artists
+ get_relation_credits(
+ self,
+ options,
+ release_id,
+ album,
+ releaseXmlNode,
+ lang,
+ options['cea_release_relationship_credited'])
+
+ # Now get the rest:
+ for m in media:
+ tracks = parse_data(release_id, m, [], 'tracks')
+ for track in tracks:
+ for t in track:
+ # Recording relationship artists
+ obj = parse_data(release_id, t, [], 'recording')
+ get_relation_credits(
+ self,
+ options,
+ release_id,
+ album,
+ obj,
+ lang,
+ options['cea_recording_relationship_credited'])
+ # Track artists
+ get_aliases_and_credits(
+ self,
+ options,
+ release_id,
+ album,
+ t,
+ lang,
+ options['cea_track_credited'])
+
+ if options['log_info']:
+ write_log(release_id, 'info', 'Alias and credits info for %s', self)
+ write_log(release_id, 'info', 'Aliases :%s', self.artist_aliases)
+ write_log(
+ release_id,
+ 'info',
+ 'Credits :%s',
+ self.artist_credits[album])
+
+
+def get_artists(options, release_id, tm, relations, relation_type):
+ """
+ Get artist info from XML lookup
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param options:
+ :param tm:
+ :param relations:
+ :param relation_type: 'release', 'recording' or 'work' (NB 'work' does not pass a param for tm)
+ :return:
+ """
+ if options['log_debug'] or options['log_info']:
+ write_log(
+ release_id,
+ 'debug',
+ 'In get_artists. relation_type: %s, relations: %s',
+ relation_type,
+ relations)
+ log_options = {
+ 'log_debug': options['log_debug'],
+ 'log_info': options['log_info']}
+ artists = []
+ instruments = []
+ artist_types = const.RELATION_TYPES[relation_type]
+ for artist_type in artist_types:
+ artists, instruments = create_artist_data(release_id, options, log_options, tm, relations,
+ relation_type, artist_type, artists, instruments)
+ artist_dict = {'artists': artists, 'instruments': instruments}
+ return artist_dict
+
+
+def create_artist_data(release_id, options, log_options, tm, relations,
+ relation_type, artist_type, artists, instruments):
+ """
+ Update the artists and instruments
+ :param release_id: the current album id
+ :param options:
+ :param log_options:
+ :param tm: track metadata
+ :param relations:
+ :param relation_type: release', 'recording' or 'work' (NB 'work' does not pass a param for tm)
+ :param artist_type: from const.RELATION_TYPES[relation_type]
+ :param artists: current artist list - updated with each call
+ :param instruments: current instruments list - updated with each call
+ :return: artists, instruments
+ """
+ type_list = parse_data(
+ release_id,
+ relations,
+ [],
+ 'target-type:artist',
+ 'type:' +
+ artist_type)
+ for type_item in type_list:
+ artist_name_list = parse_data(
+ release_id, type_item, [], 'artist', 'name')
+ artist_sort_name_list = parse_data(
+ release_id, type_item, [], 'artist', 'sort-name')
+ if artist_type not in [
+ 'instrument',
+ 'vocal',
+ 'instrument arranger',
+ 'vocal arranger']:
+ instrument_list = None
+ credited_inst_list = None
+ else:
+ instrument_list_list = parse_data(
+ release_id, type_item, [], 'attributes')
+ if instrument_list_list:
+ instrument_list = instrument_list_list[0]
+ else:
+ instrument_list = []
+ credited_inst_list = instrument_list[:]
+ credited_inst_dict_list = parse_data(
+ release_id, type_item, [], 'attribute-credits') # keyed to insts
+ if credited_inst_dict_list:
+ credited_inst_dict = credited_inst_dict_list[0]
+ else:
+ credited_inst_dict = {}
+ for i, inst in enumerate(instrument_list):
+ if inst in credited_inst_dict:
+ credited_inst_list[i] = credited_inst_dict[inst]
+
+ if artist_type == 'vocal':
+ if not instrument_list:
+ instrument_list = ['vocals']
+ elif not any('vocals' in x for x in instrument_list):
+ instrument_list.append('vocals')
+ credited_inst_list.append('vocals')
+ # fill the hidden vars before we choose to use the as-credited
+ # version
+ if relation_type != 'work':
+ inst_tag = []
+ cred_tag = []
+ if instrument_list:
+ inst_tag = list(set(instrument_list))
+ if credited_inst_list:
+ cred_tag = list(set(credited_inst_list))
+ for attrib in ['solo', 'guest', 'additional']:
+ if attrib in inst_tag:
+ inst_tag.remove(attrib)
+ if attrib in cred_tag:
+ cred_tag.remove(attrib)
+ if inst_tag:
+ if tm['~cea_instruments']:
+ tm['~cea_instruments'] = add_list_uniquely(
+ tm['~cea_instruments'], inst_tag)
+ else:
+ tm['~cea_instruments'] = inst_tag
+ if cred_tag:
+ if tm['~cea_instruments_credited']:
+ tm['~cea_instruments_credited'] = add_list_uniquely(
+ tm['~cea_instruments_credited'], cred_tag)
+ else:
+ tm['~cea_instruments_credited'] = cred_tag
+ if inst_tag or cred_tag:
+ if tm['~cea_instruments_all']:
+ tm['~cea_instruments_all'] = add_list_uniquely(
+ tm['~cea_instruments_all'], list(set(inst_tag + cred_tag)))
+ else:
+ tm['~cea_instruments_all'] = list(
+ set(inst_tag + cred_tag))
+ if '~cea_instruments' in tm and '~cea_instruments_credited' in tm and '~cea_instruments_all' in tm:
+ instruments = [
+ tm['~cea_instruments'],
+ tm['~cea_instruments_credited'],
+ tm['~cea_instruments_all']]
+ if options['cea_inst_credit'] and credited_inst_list:
+ instrument_list = credited_inst_list
+ if instrument_list:
+ instrument_sort = 3
+ s_key = {
+ 'lead vocals': 1,
+ 'solo': 2,
+ 'guest': 4,
+ 'additional': 5}
+ for inst in s_key:
+ if inst in instrument_list:
+ instrument_sort = s_key[inst]
+ else:
+ instrument_sort = 0
+
+ if artist_type in const.ARTIST_TYPE_ORDER:
+ type_sort = const.ARTIST_TYPE_ORDER[artist_type]
+ else:
+ type_sort = 99
+ if log_options['log_error']:
+ write_log(
+ release_id,
+ 'error',
+ "Error in artist type. Type '%s' is not in ARTIST_TYPE_ORDER dictionary",
+ artist_type)
+
+ artist = (
+ artist_type,
+ instrument_list,
+ artist_name_list,
+ artist_sort_name_list,
+ instrument_sort,
+ type_sort)
+ artists.append(artist)
+ # Sorted by sort name then instrument_sort then artist type
+ artists = sorted(artists, key=lambda x: (x[5], x[3], x[4], x[1]))
+ if log_options['log_info']:
+ write_log(release_id, 'info', 'sorted artists = %s', artists)
+ return artists, instruments
+
+
+def get_series(options, release_id, relations):
+ """
+ Get series info (depends on lookup having used inc=series-rel)
+ :param options:
+ :param release_id:
+ :param relations:
+ :return:
+ """
+ # if options['log_debug'] or options['log_info']:
+ # write_log(
+ # release_id,
+ # 'debug',
+ # 'In get_series. relations: %s',
+ # relations)
+ # series_name_list =[]
+ # series_id_list = []
+ # for series_rels in relations:
+ # series_rel = parse_data(
+ # release_id,
+ # series_rels,
+ # [],
+ # 'target-type:series',
+ # 'type:part-of')
+ # if options['log_debug'] or options['log_info']:
+ # write_log(
+ # release_id,
+ # 'debug',
+ # 'series_rel = %s',
+ # series_rel)
+ # series_name_list.extend(
+ # parse_data(release_id, series_rel, [], 'series', 'name')
+ # )
+ # series_id_list.extend(
+ # parse_data(release_id, series_rel, [], 'series', 'id')
+ # )
+ type_list = parse_data(
+ release_id,
+ relations,
+ [],
+ 'target-type:series',
+ 'type:part of')
+ if type_list:
+ for type_item in type_list:
+ series_name_list = parse_data(
+ release_id, type_item, [], 'series', 'name')
+ series_id_list = parse_data(
+ release_id, type_item, [], 'series', 'id')
+ series_number_list = parse_data(
+ release_id, type_item, [], 'attribute-values', 'number')
+ return {'name_list': series_name_list, 'id_list': series_id_list, 'number_list': series_number_list}
+ else:
+ return None
+
+
+
+def apply_artist_style(
+ options,
+ release_id,
+ lang,
+ a_list,
+ name_style,
+ name_tag,
+ sort_tag,
+ names_tag,
+ names_sort_tag):
+ # Get artist and apply style
+ for a_item in a_list:
+ for acs in a_item:
+ artistlist = parse_data(release_id, acs, [], 'name')
+ sortlist = parse_data(release_id, acs, [], 'artist', 'sort-name')
+ names = {}
+ if lang:
+ names['alias'] = parse_data(
+ release_id,
+ acs,
+ [],
+ 'artist',
+ 'aliases',
+ 'locale:' + lang,
+ 'primary:True',
+ 'name')
+ else:
+ names['alias'] = []
+ names['credit'] = parse_data(release_id, acs, [], 'name')
+ pairslist = list(zip(artistlist, sortlist))
+ names['sort'] = [
+ translate_from_sortname(
+ *pair) for pair in pairslist]
+ for style in name_style:
+ if names[style]:
+ artistlist = names[style]
+ break
+ joinlist = parse_data(release_id, acs, [], 'joinphrase')
+
+ if artistlist:
+ name_tag.append(artistlist[0])
+ sort_tag.append(sortlist[0])
+ names_tag.append(artistlist[0])
+ names_sort_tag.append(sortlist[0])
+
+ if joinlist:
+ name_tag.append(joinlist[0])
+ sort_tag.append(joinlist[0])
+
+ name_tag_str = ''.join(name_tag)
+ sort_tag_str = ''.join(sort_tag)
+
+ return {
+ 'artists': names_tag,
+ 'artists_sort': names_sort_tag,
+ 'artist': name_tag_str,
+ 'artistsort': sort_tag_str}
+
+
+def set_work_artists(self, release_id, album, track, writerList, tm, count):
+ """
+ :param release_id:
+ :param self is the calling object from Artists or WorkParts
+ :param album: the current album
+ :param track: the current track
+ :param writerList: format [(artist_type, [instrument_list], [name list],[sort_name list]),(.....etc]
+ :param tm: track metadata
+ :param count: depth count of recursion in process_work_artists (should equate to part level)
+ :return:
+ """
+
+ options = self.options[track]
+ if not options['classical_work_parts']:
+ caller = 'ExtraArtists'
+ pre = '~cea'
+ else:
+ caller = 'PartLevels'
+ pre = '~cwp'
+ write_log(
+ release_id,
+ 'debug',
+ 'Class: %s: in set_work_artists for track %s. Count (level) is %s. Writer list is %s',
+ caller,
+ track,
+ count,
+ writerList)
+ # tag strings are a tuple (Picard tag, cwp tag, Picard sort tag, cwp sort
+ # tag) (NB this is modelled on set_performer)
+ tag_strings = const.tag_strings(pre)
+ # insertions lists artist types where names in the main Picard tags may be
+ # updated for annotations
+ insertions = const.INSERTIONS
+ no_more_lyricists = False
+ if caller == 'PartLevels' and self.lyricist_filled[track]:
+ no_more_lyricists = True
+
+ for writer in writerList:
+ writer_type = writer[0]
+ if writer_type not in tag_strings:
+ break
+ if no_more_lyricists and (
+ writer_type == 'lyricist' or writer_type == 'librettist'):
+ break
+ if writer[1]:
+ inst_list = writer[1][:]
+ # take a copy of the list in case (because of list
+ # mutability) we need the old one
+ instrument = ", ".join(inst_list)
+ else:
+ instrument = None
+ sub_strings = { # 'instrument arranger': instrument, 'vocal arranger': instrument
+ }
+ if options['cea_arranger']:
+ if instrument:
+ arr_inst = options['cea_arranger'] + ' ' + instrument
+ else:
+ arr_inst = options['cea_arranger']
+ else:
+ arr_inst = instrument
+ annotations = {'writer': options['cea_writer'],
+ 'lyricist': options['cea_lyricist'],
+ 'librettist': options['cea_librettist'],
+ 'revised by': options['cea_revised'],
+ 'translator': options['cea_translator'],
+ 'arranger': options['cea_arranger'],
+ 'reconstructed by': options['cea_reconstructed'],
+ 'orchestrator': options['cea_orchestrator'],
+ 'instrument arranger': arr_inst,
+ 'vocal arranger': arr_inst}
+ tag = tag_strings[writer_type][0]
+ sort_tag = tag_strings[writer_type][2]
+ cwp_tag = tag_strings[writer_type][1]
+ cwp_sort_tag = tag_strings[writer_type][3]
+ cwp_names_tag = cwp_tag[:-1] + '_names'
+ cwp_instrumented_tag = cwp_names_tag + '_instrumented'
+ if writer_type in sub_strings:
+ if sub_strings[writer_type]:
+ tag += sub_strings[writer_type]
+ if tag:
+ if '~ce_tag_cleared_' + \
+ tag not in tm or not tm['~ce_tag_cleared_' + tag] == "Y":
+ if tag in tm:
+ if options['log_info']:
+ write_log(release_id, 'info', 'delete tag %s', tag)
+ del tm[tag]
+ tm['~ce_tag_cleared_' + tag] = "Y"
+ if sort_tag:
+ if '~ce_tag_cleared_' + \
+ sort_tag not in tm or not tm['~ce_tag_cleared_' + sort_tag] == "Y":
+ if sort_tag in tm:
+ del tm[sort_tag]
+ tm['~ce_tag_cleared_' + sort_tag] = "Y"
+
+ name_list = writer[2]
+ for ind, name in enumerate(name_list):
+ sort_name = writer[3][ind]
+ no_credit = True
+ write_log(
+ release_id,
+ 'info',
+ 'In set_work_artists. Name before changes = %s',
+ name)
+ # change name to as-credited
+ if options['cea_composer_credited']:
+ if album in self.artist_credits and sort_name in self.artist_credits[album]:
+ no_credit = False
+ name = self.artist_credits[album][sort_name]
+ # over-ride with aliases if appropriate
+ if (options['cea_aliases'] or options['cea_aliases_composer']) and (
+ no_credit or options['cea_alias_overrides']):
+ if sort_name in self.artist_aliases:
+ name = self.artist_aliases[sort_name]
+ # fix cyrillic names if not already fixed
+ if options['cea_cyrillic']:
+ if not only_roman_chars(name):
+ name = remove_middle(unsort(sort_name))
+ # Only remove middle name where the existing
+ # performer is in non-latin script
+ annotated_name = name
+ write_log(
+ release_id,
+ 'info',
+ 'In set_work_artists. Name after changes = %s',
+ name)
+ # add annotations and write performer tags
+ if writer_type in annotations:
+ if annotations[writer_type]:
+ annotated_name += ' (' + annotations[writer_type] + ')'
+ if instrument:
+ instrumented_name = name + ' (' + instrument + ')'
+ else:
+ instrumented_name = name
+
+ if writer_type in insertions and options['cea_arrangers']:
+ self.append_tag(release_id, tm, tag, annotated_name)
+ else:
+ if options['cea_arrangers'] or writer_type == tag:
+ self.append_tag(release_id, tm, tag, name)
+
+ if options['cea_arrangers'] or writer_type == tag:
+ if sort_tag:
+ self.append_tag(release_id, tm, sort_tag, sort_name)
+ if options['cea_tag_sort'] and '~' in sort_tag:
+ explicit_sort_tag = sort_tag.replace('~', '')
+ self.append_tag(
+ release_id, tm, explicit_sort_tag, sort_name)
+ self.append_tag(release_id, tm, cwp_tag, annotated_name)
+ self.append_tag(release_id, tm, cwp_names_tag, name)
+ if instrumented_name != name:
+ self.append_tag(
+ release_id,
+ tm,
+ cwp_instrumented_tag,
+ instrumented_name)
+
+ if cwp_sort_tag:
+ self.append_tag(release_id, tm, cwp_sort_tag, sort_name)
+
+ if caller == 'PartLevels' and (
+ writer_type == 'lyricist' or writer_type == 'librettist'):
+ self.lyricist_filled[track] = True
+ write_log(
+ release_id,
+ 'info',
+ 'Filled lyricist for track %s. Not looking further',
+ track)
+
+ if writer_type == 'composer':
+ composerlast = sort_name.split(",")[0]
+ write_log(
+ release_id,
+ 'info',
+ 'composerlast = %s',
+ composerlast)
+ self.append_tag(
+ release_id,
+ tm,
+ pre +
+ '_composer_lastnames',
+ composerlast)
+ if sort_name in self.release_artists_sort[album]:
+ self.append_tag(
+ release_id, tm, '~cea_album_composers', name)
+ self.append_tag(
+ release_id, tm, '~cea_album_composers_sort', sort_name)
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_album_track_composer_lastnames',
+ composerlast)
+ composer_last_names(self, release_id, tm, album)
+
+
+# Non-Latin character processing
+latin_letters = {}
+
+def is_latin(uchr):
+ """Test whether character is in Latin script"""
+ try:
+ return latin_letters[uchr]
+ except KeyError:
+ return latin_letters.setdefault(
+ uchr, 'LATIN' in unicodedata.name(uchr))
+
+
+def only_roman_chars(unistr):
+ """Test whether string is in Latin script"""
+ return all(is_latin(uchr)
+ for uchr in unistr
+ if uchr.isalpha())
+
+
+def get_roman(string):
+ """Transliterate cyrillic script to Latin script"""
+ translit_string = ""
+ for index, char in enumerate(string):
+ if char in const.CYRILLIC_LOWER.keys():
+ char = const.CYRILLIC_LOWER[char]
+ elif char in const.CYRILLIC_UPPER.keys():
+ char = const.CYRILLIC_UPPER[char]
+ if string[index + 1] not in const.CYRILLIC_LOWER.keys():
+ char = char.upper()
+ translit_string += char
+ # fix multi-chars
+ translit_string = translit_string.replace('ks', 'x').replace('iy ', 'i ')
+ return translit_string
+
+
+def remove_middle(performer):
+ """To remove middle names of Russian composers"""
+ plist = performer.split()
+ if len(plist) == 3:
+ return plist[0] + ' ' + plist[2]
+ else:
+ return performer
+
+
+# Sorting etc.
+
+def unsort(performer):
+ """
+ To take a sort field and recreate the name
+ Only now used for last-ditch cyrillic translation - superseded by 'translate_from_sortname'
+ """
+ sorted_list = performer.split(', ')
+ sorted_list.reverse()
+ for i, item in enumerate(sorted_list):
+ if item[-1] != "'":
+ sorted_list[i] += ' '
+ return ''.join(sorted_list).strip()
+
+
+def _reverse_sortname(sortname):
+ """
+ Reverse sortnames.
+ Code is from picard/util/__init__.py
+ """
+
+ chunks = [a.strip() for a in sortname.split(",")]
+ chunk_len = len(chunks)
+ if chunk_len == 2:
+ return "%s %s" % (chunks[1], chunks[0])
+ elif chunk_len == 3:
+ return "%s %s %s" % (chunks[2], chunks[1], chunks[0])
+ elif chunk_len == 4:
+ return "%s %s, %s %s" % (chunks[1], chunks[0], chunks[3], chunks[2])
+ else:
+ return sortname.strip()
+
+
+def stripsir(performer):
+ """
+ Remove honorifics from names
+ Also standardize hyphens and apostrophes in names
+ """
+ performer = performer.replace(u'\u2010', u'-').replace(u'\u2019', u"'")
+ sir = re.compile(r'(.*)\b(Sir|Maestro|Dame)\b\s*(.*)', re.IGNORECASE)
+ match = sir.search(performer)
+ if match:
+ return match.group(1) + match.group(3)
+ else:
+ return performer
+
+
+# def swap_prefix(performer):
+# """NOT CURRENTLY USED. Create sort fields for ensembles etc., by placing the prefix (see constants) at the end"""
+# prefix = '|'.join(prefixes)
+# swap = re.compile(r'^(' + prefix + r')\b\s*(.*)', re.IGNORECASE)
+# match = swap.search(performer)
+# if match:
+# return match.group(2) + ", " + match.group(1)
+# else:
+# return performer
+
+
+def replace_roman_numerals(s):
+ """Replaces roman numerals include in s, where followed by certain punctuation, by digits"""
+ romans = RE_ROMANS.findall(s)
+ for roman in romans:
+ if roman[0]:
+ numerals = str(roman[0])
+ digits = str(from_roman(numerals))
+ to_replace = r'\b' + roman[0] + r'\b'
+ s = re.sub(to_replace, digits, s)
+ return s
+
+
+def from_roman(s):
+ romanNumeralMap = (('M', 1000),
+ ('CM', 900),
+ ('D', 500),
+ ('CD', 400),
+ ('C', 100),
+ ('XC', 90),
+ ('L', 50),
+ ('XL', 40),
+ ('X', 10),
+ ('IX', 9),
+ ('V', 5),
+ ('IV', 4),
+ ('I', 1),
+ ('m', 1000),
+ ('cm', 900),
+ ('d', 500),
+ ('cd', 400),
+ ('c', 100),
+ ('xc', 90),
+ ('l', 50),
+ ('xl', 40),
+ ('x', 10),
+ ('ix', 9),
+ ('v', 5),
+ ('iv', 4),
+ ('i', 1))
+ result = 0
+ index = 0
+ for numeral, integer in romanNumeralMap:
+ while s[index:index + len(numeral)] == numeral:
+ result += integer
+ index += len(numeral)
+ return result
+
+
+def turbo_lcs(release_id, multi_list):
+ """
+ Picks the best longest common string method to use
+ Works with a list of lists or a list of strings
+ :param release_id:
+ :param multi_list: a list of strings or a list of lists
+ :return: longest common substring/list
+ """
+ write_log(release_id, 'debug', 'In turbo_lcs')
+ if not isinstance(multi_list, list):
+ return None
+ list_sum = sum([len(x) for x in multi_list])
+ list_len = len(multi_list)
+ if list_len < 2:
+ if list_len == 1:
+ return multi_list[0] # Nothing to do!
+ else:
+ return []
+ # for big matches, use the generalised suffix tree method
+ if ((list_sum / list_len) ** 2) * list_len > 1000:
+ # heuristic: may need to tweak the 1000 in the light of results
+ lcs_dict = suffixtree.multi_lcs(multi_list)
+ # NB suffixtree may be shown as an unresolved reference in the IDE,
+ # but it should work provided it is included in the package
+ if "error" not in lcs_dict:
+ if "response" in lcs_dict:
+ write_log(
+ release_id,
+ 'info',
+ 'Longest common string was returned from suffix tree algo')
+ return lcs_dict['response']
+ else:
+ write_log(
+ release_id,
+ 'error',
+ 'Suffix tree failure for release %s. Error unknown. Using standard lcs algo instead',
+ release_id)
+ else:
+ write_log(
+ release_id,
+ 'error',
+ 'Suffix tree failure for release %s. Error message: %s. Using standard lcs algo instead',
+ release_id,
+ lcs_dict['error'])
+ # otherwise, or if gst fails, use the standard algorithm
+ first = True
+ common = []
+ for item in multi_list:
+ if first:
+ common = item
+ first = False
+ else:
+ lcs = longest_common_substring(
+ item, common)
+ common = lcs['string']
+ write_log(release_id, 'debug', 'LCS returned from standard algo')
+ return common
+
+
+def longest_common_substring(s1, s2):
+ """
+ Standard lcs algo for short strings, or if suffix tree does not work
+ :param s1: substring 1
+ :param s2: substring 2
+ :return: {'string': the longest common substring,
+ 'start': the start position in s1,
+ 'length': the length of the common substring}
+ NB this also works on list arguments - i.e. it will find the longest common sub-list
+ """
+ m = [[0] * (1 + len(s2)) for i in range(1 + len(s1))]
+ longest, x_longest = 0, 0
+ for x in range(1, 1 + len(s1)):
+ for y in range(1, 1 + len(s2)):
+ if s1[x - 1] == s2[y - 1]:
+ m[x][y] = m[x - 1][y - 1] + 1
+ if m[x][y] > longest:
+ longest = m[x][y]
+ x_longest = x
+ else:
+ m[x][y] = 0
+ return {'string': s1[x_longest - longest: x_longest],
+ 'start': x_longest - longest, 'length': longest}
+
+
+def longest_common_sequence(list1, list2, minstart=0, maxstart=0):
+ """
+ :param list1: list 1
+ :param list2: list 2
+ :param minstart: the earliest point to start looking for a match
+ :param maxstart: the latest point to start looking for a match
+ :return: {'sequence': the common subsequence, 'length': length of subsequence}
+ maxstart must be >= minstart. If they are equal then the start point is fixed.
+ Note that this only finds subsequences starting at the same position
+ Use longest_common_substring for the more general problem
+ """
+ if maxstart < minstart:
+ return None, 0
+ min_len = min(len(list1), len(list2))
+ longest = 0
+ seq = None
+ maxstart = min(maxstart, min_len) + 1
+ for k in range(minstart, maxstart):
+ for i in range(k, min_len + 1):
+ if list1[k:i] == list2[k:i] and i - k > longest:
+ longest = i - k
+ seq = list1[k:i]
+ return {'sequence': seq, 'length': longest}
+
+
+def substart_finder(mylist, pattern):
+ for i, list_item in enumerate(mylist):
+ if list_item == pattern[0] and mylist[i:i + len(pattern)] == pattern:
+ return i
+ return len(mylist) # if nothing found
+
+
+def get_ui_tags():
+## Determine tags for display in ui
+ options = config.setting
+ ui_tags_raw = options['ce_ui_tags']
+ ui_tags = {}
+ ui_tags_split = [x.replace('(','').strip(') ') for x in ui_tags_raw.split('/')]
+ for ui_column in ui_tags_split:
+ if ':' in ui_column:
+ ui_col_parts = [x.strip() for x in ui_column.split(':')]
+ heading = ui_col_parts[0]
+ tag_names = ui_col_parts[1].split(',')
+ tag_names = [x.strip() for x in tag_names]
+ ui_tags[heading] = tuple(tag_names)
+ return ui_tags
+
+
+def map_tags(options, release_id, album, tm):
+ """
+ Do the common tag processing - including for the genres and tag-mapping sections
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param options: options passed from either Artists or Workparts
+ :param album:
+ :param tm: track metadata
+ :return: None - action is through setting tm contents
+ This is a common function for Artists and Workparts which should only run after both sections have completed for
+ a given track. If, say, Artists calls it and Workparts is not done,
+ then it will not execute until Workparts calls it (and vice versa).
+ """
+
+ write_log(release_id, 'debug', 'In map_tags, checking readiness...')
+ if (options['classical_extra_artists'] and '~cea_artists_complete' not in tm) or (
+ options['classical_work_parts'] and '~cea_works_complete' not in tm):
+ write_log(release_id, 'info', '...not ready')
+ return
+ write_log(release_id, 'debug', '... processing tag mapping')
+
+ # blank tags
+ blank_tags = options['cea_blank_tag'].split(
+ ",") + options['cea_blank_tag_2'].split(",")
+ if 'artists_sort' in [x.strip() for x in blank_tags]:
+ blank_tags.append('~artists_sort')
+ for tag in blank_tags:
+ if tag.strip() in tm:
+ # place blanked tags into hidden variables available for
+ # re-use
+ tm['~cea_' + tag.strip()] = tm[tag.strip()]
+ del tm[tag.strip()]
+
+ # album
+ if tm['~cea_album_composer_lastnames']:
+ last_names = str_to_list(tm['~cea_album_composer_lastnames'])
+ if options['cea_composer_album']:
+ # save it as a list to prevent splitting when appending tag
+ tm['~cea_release'] = [tm['album']]
+ new_last_names = []
+ for last_name in last_names:
+ last_name = last_name.strip()
+ new_last_names.append(last_name)
+ if len(new_last_names) > 0:
+ tm['album'] = "; ".join(new_last_names) + ": " + tm['album']
+
+ # remove lyricists if no vocals, according to option set
+ if options['cea_no_lyricists'] and not any(
+ [x for x in str_to_list(tm['~cea_performers']) if 'vocals' in x]):
+ if 'lyricist' in tm:
+ del tm['lyricist']
+ for lyricist_tag in ['lyricists', 'librettists', 'translators']:
+ if '~cwp_' + lyricist_tag in tm:
+ del tm['~cwp_' + lyricist_tag]
+
+ # genres
+ if config.setting['folksonomy_tags'] and 'genre' in tm:
+ candidate_genres = str_to_list(tm['genre'])
+ append_tag(release_id, tm, '~cea_candidate_genres', candidate_genres)
+ # to avoid confusion as it will contain unmatched folksonomy tags
+ del tm['genre']
+ else:
+ candidate_genres = []
+ is_classical = False
+ composers_not_found = []
+ composer_found = False
+ composer_born_list = []
+ composer_died_list = []
+ arrangers_not_found = []
+ arranger_found = False
+ arranger_born_list = []
+ arranger_died_list = []
+ no_composer_in_metadata = False
+ if options['cwp_use_muso_refdb'] and options['cwp_muso_classical'] or options['cwp_muso_dates']:
+ if COMPOSER_DICT:
+ if '~cwp_composer_names' in tm:
+ composer_list = str_to_list(tm['~cwp_composer_names'])
+ else:
+ # maybe there were no works linked,
+ # but it might still a classical track (based on composer name)
+ no_composer_in_metadata = True
+ composer_list = str_to_list(tm['artists'])
+ composersort_list = str_to_list(tm['~artists_sort'])
+ write_log(release_id, 'info', "No composer metadata for track %s. Using artists %r", tm['title'],
+ composer_list)
+ lc_composer_list = [c.lower() for c in composer_list]
+ for ind, composer in enumerate(lc_composer_list):
+ for classical_composer in COMPOSER_DICT:
+ if composer in classical_composer['lc_name']:
+ if options['cwp_muso_classical']:
+ candidate_genres.append('Classical')
+ is_classical = True
+ if options['cwp_muso_dates']:
+ composer_born_list = classical_composer['birth']
+ composer_died_list = classical_composer['death']
+ composer_found = True
+ if no_composer_in_metadata:
+ composersort = composersort_list[ind]
+ append_tag(release_id, tm, 'composer', composer_list[ind])
+ append_tag(release_id, tm, '~cwp_composer_names', composer_list[ind])
+ append_tag(release_id, tm, 'composersort', composersort)
+ append_tag(release_id, tm, '~cwp_composers_sort', composersort)
+ append_tag(release_id, tm, '~cwp_composer_lastnames', composersort.split(', ')[0])
+ break
+ if not composer_found:
+ composer_index = lc_composer_list.index(composer)
+ orig_composer = composer_list[composer_index]
+ composers_not_found.append(orig_composer)
+ append_tag(
+ release_id,
+ tm,
+ '~cwp_unrostered_composers',
+ orig_composer)
+ if composers_not_found:
+ append_tag(
+ release_id,
+ tm,
+ '003_information:composers',
+ 'Composer(s) ' +
+ list_to_str(composers_not_found) +
+ ' not found in reference database of classical composers')
+
+ # do the same for arrangers, if required
+ if options['cwp_genres_arranger_as_composer'] or options['cwp_periods_arranger_as_composer']:
+ arranger_list = str_to_list(
+ tm['~cea_arranger_names']) + str_to_list(tm['~cwp_arranger_names'])
+ lc_arranger_list = [c.lower() for c in arranger_list]
+ for arranger in lc_arranger_list:
+ for classical_arranger in COMPOSER_DICT:
+ if arranger in classical_arranger['lc_name']:
+ if options['cwp_muso_classical'] and options['cwp_genres_arranger_as_composer']:
+ candidate_genres.append('Classical')
+ is_classical = True
+ if options['cwp_muso_dates'] and options['cwp_periods_arranger_as_composer']:
+ arranger_born_list = classical_arranger['birth']
+ arranger_died_list = classical_arranger['death']
+ arranger_found = True
+ break
+ if not arranger_found:
+ arranger_index = lc_arranger_list.index(arranger)
+ orig_arranger = arranger_list[arranger_index]
+ arrangers_not_found.append(orig_arranger)
+ append_tag(
+ release_id,
+ tm,
+ '~cwp_unrostered_arrangers',
+ orig_arranger)
+ if arrangers_not_found:
+ append_tag(
+ release_id,
+ tm,
+ '003_information:arrangers',
+ 'Arranger(s) ' +
+ list_to_str(arrangers_not_found) +
+ ' not found in reference database of classical composers')
+
+ else:
+ append_tag(
+ release_id,
+ tm,
+ '001_errors:8',
+ '8. No composer reference file. Check log for error messages re path name.')
+
+ if options['cwp_use_muso_refdb'] and options['cwp_muso_genres'] and GENRE_DICT:
+ main_classical_genres_list = [list_to_str(
+ mg['name']).strip() for mg in GENRE_DICT]
+ else:
+ main_classical_genres_list = [
+ sg.strip() for sg in options['cwp_genres_classical_main'].split(',')]
+ sub_classical_genres_list = [
+ sg.strip() for sg in options['cwp_genres_classical_sub'].split(',')]
+ main_other_genres_list = [
+ sg.strip() for sg in options['cwp_genres_other_main'].split(',')]
+ sub_other_genres_list = [sg.strip()
+ for sg in options['cwp_genres_other_sub'].split(',')]
+ main_classical_genres = []
+ sub_classical_genres = []
+ main_other_genres = []
+ sub_other_genres = []
+ if '~cea_work_type' in tm:
+ candidate_genres += str_to_list(tm['~cea_work_type'])
+ if '~cwp_candidate_genres' in tm:
+ candidate_genres += str_to_list(tm['~cwp_candidate_genres'])
+ write_log(release_id, 'info', "Candidate genres: %r", candidate_genres)
+ untagged_genres = []
+ if candidate_genres:
+ main_classical_genres = [
+ val for val in main_classical_genres_list if val.lower() in [
+ genre.lower() for genre in candidate_genres]]
+ sub_classical_genres = [
+ val for val in sub_classical_genres_list if val.lower() in [
+ genre.lower() for genre in candidate_genres]]
+
+ if main_classical_genres or sub_classical_genres or options['cwp_genres_classical_all']:
+ is_classical = True
+ main_classical_genres.append('Classical')
+ candidate_genres.append('Classical')
+ write_log(release_id, 'info', "Main classical genres for track %s: %r", tm['title'], main_classical_genres)
+ candidate_genres += str_to_list(tm['~cea_work_type_if_classical'])
+ # next two are repeated statements, but a separate fn would be
+ # clumsy too!
+ main_classical_genres = [
+ val for val in main_classical_genres_list if val.lower() in [
+ genre.lower() for genre in candidate_genres]]
+ sub_classical_genres = [
+ val for val in sub_classical_genres_list if val.lower() in [
+ genre.lower() for genre in candidate_genres]]
+ if options['cwp_genres_classical_exclude']:
+ main_classical_genres = [
+ g for g in main_classical_genres if g.lower() != 'classical']
+
+ main_other_genres = [
+ val for val in main_other_genres_list if val.lower() in [
+ genre.lower() for genre in candidate_genres]]
+ sub_other_genres = [
+ val for val in sub_other_genres_list if val.lower() in [
+ genre.lower() for genre in candidate_genres]]
+ all_genres = main_classical_genres + sub_classical_genres + \
+ main_other_genres + sub_other_genres
+ untagged_genres = [
+ un for un in candidate_genres if un.lower() not in [
+ genre.lower() for genre in all_genres]]
+
+ if options['cwp_genre_tag']:
+ if not options['cwp_genres_filter']:
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_genre_tag'],
+ candidate_genres)
+ else:
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_genre_tag'],
+ main_classical_genres +
+ main_other_genres)
+ if options['cwp_subgenre_tag'] and options['cwp_genres_filter']:
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_subgenre_tag'],
+ sub_classical_genres +
+ sub_other_genres)
+ if is_classical and options['cwp_genres_flag_text'] and options['cwp_genres_flag_tag']:
+ tm[options['cwp_genres_flag_tag']] = options['cwp_genres_flag_text']
+ if not (
+ main_classical_genres +
+ main_other_genres)and options['cwp_genres_filter']:
+ if options['cwp_genres_default']:
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_genre_tag'],
+ options['cwp_genres_default'])
+ else:
+ if options['cwp_genre_tag'] in tm:
+ del tm[options['cwp_genre_tag']]
+ if untagged_genres and options['cwp_genres_filter']:
+ append_tag(
+ release_id,
+ tm,
+ '003_information:genres',
+ 'Candidate genres found but not matched: ' +
+ list_to_str(untagged_genres))
+ append_tag(release_id, tm, '~cwp_untagged_genres', untagged_genres)
+
+ # instruments and keys
+ if options['cwp_instruments_MB_names'] and options['cwp_instruments_credited_names'] and tm['~cea_instruments_all']:
+ instruments = str_to_list(['~cea_instruments_all'])
+ elif options['cwp_instruments_MB_names'] and tm['~cea_instruments']:
+ instruments = str_to_list(tm['~cea_instruments'])
+ elif options['cwp_instruments_credited_names'] and tm['~cea_instruments_credited']:
+ instruments = str_to_list(tm['~cea_instruments_credited'])
+ else:
+ instruments = None
+ if instruments and options['cwp_instruments_tag']:
+ append_tag(release_id, tm, options['cwp_instruments_tag'], instruments)
+ # need to append rather than over-write as it may be the same as
+ # another tag (e.g. genre)
+ if tm['~cwp_keys'] and options['cwp_key_tag']:
+ append_tag(release_id, tm, options['cwp_key_tag'], tm['~cwp_keys'])
+ # dates
+ if options['cwp_workdate_annotate']:
+ comp = ' (composed)'
+ publ = ' (published)'
+ prem = ' (premiered)'
+ else:
+ comp = ''
+ publ = ''
+ prem = ''
+ tm[options['cwp_workdate_tag']] = ''
+ earliest_date = 9999
+ latest_date = -9999
+ found = False
+ if tm['~cwp_composed_dates']:
+ composed_dates_list = str_to_list(tm['~cwp_composed_dates'])
+ if len(composed_dates_list) > 1:
+ composed_dates_list = str_to_list(
+ composed_dates_list[0]) # use dates of lowest-level work
+ earliest_date = min([int(dates.split(DATE_SEP)[0].strip())
+ for dates in composed_dates_list])
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_workdate_tag'],
+ list_to_str(composed_dates_list) +
+ comp)
+ found = True
+ if tm['~cwp_published_dates'] and (
+ not found or options['cwp_workdate_use_all']):
+ if not found:
+ published_dates_list = str_to_list(tm['~cwp_published_dates'])
+ if len(published_dates_list) > 1:
+ published_dates_list = str_to_list(
+ published_dates_list[0]) # use dates of lowest-level work
+ earliest_date = min([int(dates.split(DATE_SEP)[0].strip())
+ for dates in published_dates_list])
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_workdate_tag'],
+ list_to_str(published_dates_list) +
+ publ)
+ found = True
+ if tm['~cwp_premiered_dates'] and (
+ not found or options['cwp_workdate_use_all']):
+ if not found:
+ premiered_dates_list = str_to_list(tm['~cwp_premiered_dates'])
+ if len(premiered_dates_list) > 1:
+ premiered_dates_list = str_to_list(
+ premiered_dates_list[0]) # use dates of lowest-level work
+ earliest_date = min([int(dates.split(DATE_SEP)[0].strip())
+ for dates in premiered_dates_list])
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_workdate_tag'],
+ list_to_str(premiered_dates_list) +
+ prem)
+
+ # periods
+ PERIODS = {}
+ if options['cwp_period_map']:
+ if options['cwp_use_muso_refdb'] and options['cwp_muso_periods'] and PERIOD_DICT:
+ for p_item in PERIOD_DICT:
+ if 'start' not in p_item or p_item['start'] == []:
+ p_item['start'] = [u'-9999']
+ if 'end' not in p_item or p_item['end'] == []:
+ p_item['end'] = [u'2525']
+ if 'name' not in p_item or p_item['name'] == []:
+ p_item['name'] = ['NOT SPECIFIED']
+ PERIODS = {list_to_str(mp['name']).strip(): (
+ list_to_str(mp['start']),
+ list_to_str(mp['end']))
+ for mp in PERIOD_DICT}
+ for period in PERIODS:
+ if PERIODS[period][0].lstrip(
+ '-').isdigit() and PERIODS[period][1].lstrip('-').isdigit():
+ PERIODS[period] = (int(PERIODS[period][0]),
+ int(PERIODS[period][1]))
+ else:
+ PERIODS[period] = (
+ 9999,
+ 'ERROR - start and/or end of ' +
+ period +
+ ' are not integers')
+
+ else:
+ periods = [p.strip() for p in options['cwp_period_map'].split(';')]
+ for p in periods:
+ p = p.split(',')
+ if len(p) == 3:
+ period = p[0].strip()
+ start = p[1].strip()
+ end = p[2].strip()
+ if start.lstrip(
+ '-').isdigit() and end.lstrip('-').isdigit():
+ PERIODS[period] = (int(start), int(end))
+ else:
+ PERIODS[period] = (
+ 9999,
+ 'ERROR - start and/or end of ' +
+ period +
+ ' are not integers')
+ else:
+ PERIODS[p[0]] = (
+ 9999, 'ERROR in period map - each item must contain 3 elements')
+ if options['cwp_period_tag'] and PERIODS:
+ if earliest_date == 9999: # i.e. no work date found
+ if options['cwp_use_muso_refdb'] and options['cwp_muso_dates']:
+ for composer_born in composer_born_list + arranger_born_list:
+ if composer_born and composer_born.isdigit():
+ birthdate = int(composer_born)
+ # productive age is taken as 20->death as per Muso
+ earliest_date = min(earliest_date, birthdate + 20)
+ for composer_died in composer_died_list + arranger_died_list:
+ if composer_died and composer_died.isdigit():
+ deathdate = int(composer_died)
+ latest_date = max(latest_date, deathdate)
+ else:
+ latest_date = datetime.now().year
+ # sort into start date order before writing tags
+ sorted_periods = collections.OrderedDict(
+ sorted(PERIODS.items(), key=lambda t: t[1]))
+ for period in sorted_periods:
+ if isinstance(
+ sorted_periods[period][1],
+ str) and 'ERROR' in sorted_periods[period][1]:
+ tm[options['cwp_period_tag']] = ''
+ append_tag(
+ release_id,
+ tm,
+ '001_errors:9',
+ '9. ' +
+ sorted_periods[period])
+ break
+ if earliest_date < 9999:
+ if sorted_periods[period][0] <= earliest_date <= sorted_periods[period][1]:
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_period_tag'],
+ period)
+ if latest_date > -9999:
+ if sorted_periods[period][0] <= latest_date <= sorted_periods[period][1]:
+ append_tag(
+ release_id,
+ tm,
+ options['cwp_period_tag'],
+ period)
+
+ # generic tag mapping
+ sort_tags = options['cea_tag_sort']
+ if sort_tags:
+ tm['artists_sort'] = str_to_list(tm['~artists_sort'])
+ for i in range(0, 16):
+ tagline = options['cea_tag_' + str(i + 1)].split(",")
+ source_group = options['cea_source_' + str(i + 1)].split(",")
+ conditional = options['cea_cond_' + str(i + 1)]
+ for item, tagx in enumerate(tagline):
+ tag = tagx.strip()
+ sort = sort_suffix(tag)
+ if not conditional or tm[tag] == "":
+ for source_memberx in source_group:
+ source_member = source_memberx.strip()
+ sourceline = source_member.split("+")
+ if len(sourceline) > 1:
+ source = "\\"
+ for source_itemx in sourceline:
+ source_item = source_itemx.strip()
+ source_itema = source_itemx.lstrip()
+ write_log(
+ release_id, 'info', "Source_item: %s", source_item)
+ if "~cea_" + source_item in tm:
+ si = tm['~cea_' + source_item]
+ elif "~cwp_" + source_item in tm:
+ si = tm['~cwp_' + source_item]
+ elif source_item in tm:
+ si = tm[source_item]
+ elif len(source_itema) > 0 and source_itema[0] == "\\":
+ si = source_itema[1:]
+ else:
+ si = ""
+ if si != "" and source != "":
+ source = source + si
+ else:
+ source = ""
+ else:
+ source = sourceline[0]
+ no_names_source = re.sub('(_names)$', 's', source)
+ source_sort = sort_suffix(source)
+ write_log(
+ release_id,
+ 'info',
+ "Tag mapping: Line: %s, Source: %s, Tag: %s, no_names_source: %s, sort: %s, item %s",
+ i +
+ 1,
+ source,
+ tag,
+ no_names_source,
+ sort,
+ item)
+ if '~cea_' + source in tm or '~cwp_' + source in tm:
+ for prefix in ['~cea_', '~cwp_']:
+ if prefix + source in tm:
+ write_log(release_id, 'info', prefix)
+ append_tag(release_id, tm, tag,
+ tm[prefix + source], ['; '])
+ if sort_tags:
+ if prefix + no_names_source + source_sort in tm:
+ write_log(
+ release_id, 'info', prefix + " sort")
+ append_tag(release_id, tm, tag + sort,
+ tm[prefix + no_names_source + source_sort], ['; '])
+ elif source in tm or '~' + source in tm:
+ write_log(release_id, 'info', "Picard")
+ for p in ['', '~']:
+ if p + source in tm:
+ append_tag(release_id, tm, tag,
+ tm[p + source], ['; ', '/ '])
+ if sort_tags:
+ if "~" + source + source_sort in tm:
+ source = "~" + source
+ if source + source_sort in tm:
+ write_log(
+ release_id, 'info', "Picard sort")
+ append_tag(release_id, tm, tag + sort,
+ tm[source + source_sort], ['; ', '/ '])
+ elif len(source) > 0 and source[0] == "\\":
+ append_tag(release_id, tm, tag,
+ source[1:], ['; ', '/ '])
+ else:
+ pass
+
+ # write error messages to tags
+ if options['log_error'] and "~cea_error" in tm:
+ for error in str_to_list(tm['~cea_error']):
+ ecode = error[0]
+ append_tag(release_id, tm, '001_errors:' + ecode, error)
+ if options['log_warning'] and "~cea_warning" in tm:
+ for warning in str_to_list(tm['~cea_warning']):
+ wcode = warning[0]
+ append_tag(release_id, tm, '002_warnings:' + wcode, warning)
+
+ # delete unwanted tags
+ if not options['log_debug']:
+ if '~cea_works_complete' in tm:
+ del tm['~cea_works_complete']
+ if '~cea_artists_complete' in tm:
+ del tm['~cea_artists_complete']
+ del_list = []
+ for t in tm:
+ if 'ce_tag_cleared' in t:
+ del_list.append(t)
+ for t in del_list:
+ del tm[t]
+
+ # create hidden tags to flag differences
+ if options['ce_show_ui_tags'] and options['ce_ui_tags']:
+ for heading_name, tag_tuple in UI_TAGS: # UI_TAGS is already iterated in main routine, so no need for .items() method here
+ heading_tag = '~' + heading_name + '_VAL'
+ for tag in tag_tuple:
+ if tag[-5:] != '_DIFF':
+ append_tag(release_id, tm, heading_tag, tm[tag])
+ else:
+ tag = '~' + tag
+ mirror_tags = str_to_list((tm['~ce_mirror_tags']))
+ for mirror_tag in mirror_tags:
+ mt = interpret(mirror_tag)
+ st = str_to_list(mt)
+ (old_tag, new_tag) = tuple(st)
+ diff_name = old_tag.replace('OLD', 'DIFF')
+ if diff_name == tag and tm[old_tag] != tm[new_tag]:
+ tm[diff_name] = '*****'
+ append_tag(release_id, tm, heading_tag, '*****')
+ break
+
+ # if options over-write enabled, remove it after processing one album
+ options['ce_options_overwrite'] = False
+ config.setting['ce_options_overwrite'] = False
+ # so that options are not retained (in case of refresh with different
+ # options)
+ if '~ce_options' in tm:
+ del tm['~ce_options']
+
+ # remove any unwanted file tags
+ if '~ce_file' in tm and tm['~ce_file'] != "None":
+ music_file = tm['~ce_file']
+ orig_metadata = album.tagger.files[music_file].orig_metadata
+ if 'delete_tags' in options and options['delete_tags']:
+ warn = []
+ for delete_item in options['delete_tags']:
+ if delete_item not in tm: # keep the original for comparison if we have a new version
+ if delete_item in orig_metadata:
+ del orig_metadata[delete_item]
+ if delete_item != '002_warnings:7': # to avoid circularity!
+ warn.append(delete_item)
+ if warn and options['log_warning']:
+ append_tag(
+ release_id,
+ tm,
+ '002_warnings:7',
+ '7. Deleted tags: ' +
+ ', '.join(warn))
+ write_log(
+ release_id,
+ 'warning',
+ 'Deleted tags: ' +
+ ', '.join(warn))
+
+
+def sort_suffix(tag):
+ """To determine what sort suffix is appropriate for a given tag"""
+ if tag == "composer" or tag == "artist" or tag == "albumartist" or tag == "trackartist" or tag == "~cea_MB_artist":
+ sort = "sort"
+ else:
+ sort = "_sort"
+ return sort
+
+
+def append_tag(release_id, tm, tag, source, separators=None):
+ """
+ Update a tag
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param tm: track metadata
+ :param tag: tag to be appended to
+ :param source: item to append to tag
+ :param separators: characters which may be used to split string into a list
+ (any of the characters will be a split point)
+ :return: None. Action is on tm
+ """
+ if not separators:
+ separators = []
+ if tag and tag != "":
+ if config.setting['log_info']:
+ write_log(
+ release_id,
+ 'info',
+ 'Appending source: %r to tag: %s (source is type %s) ...',
+ source,
+ tag,
+ type(source))
+ if tag in tm:
+ write_log(
+ release_id,
+ 'info',
+ '... existing tag contents = %r',
+ tm[tag])
+ if source and len(source) > 0:
+ if isinstance(source, str):
+ if separators:
+ source = re.split('|'.join(separators), source)
+ else:
+ source = [source]
+ if not isinstance(source, list):
+ source = [source] # typically for dict items such as saved options
+ if all([isinstance(x, str) for x in source]): # only append if if source is a list of strings
+ if tag not in tm:
+ if tag == 'artists_sort':
+ # There is no artists_sort tag in Picard - just a
+ # hidden var ~artists_sort, so pick up those into the new tag
+ hidden = tm['~artists_sort']
+ if not isinstance(hidden, list):
+ if separators:
+ hidden = re.split(
+ '|'.join(separators), hidden)
+ for i, h in enumerate(hidden):
+ hidden[i] = h.strip()
+ else:
+ hidden = [hidden]
+ source = add_list_uniquely(source, hidden)
+ new_tag = True
+ else:
+ new_tag = False
+
+ for source_item in source:
+ if isinstance(source_item, str):
+ source_item = source_item.replace(u'\u2010', u'-')
+ source_item = source_item.replace(u'\u2011', u'-')
+ source_item = source_item.replace(u'\u2019', u"'")
+ source_item = source_item.replace(u'\u2018', u"'")
+ source_item = source_item.replace(u'\u201c', u'"')
+ source_item = source_item.replace(u'\u201d', u'"')
+ if new_tag:
+ tm[tag] = [source_item]
+ new_tag = False
+ else:
+ if not isinstance(tm[tag], list):
+ if separators:
+ tag_list = re.split(
+ '|'.join(separators), tm[tag])
+ for i, t in enumerate(tag_list):
+ tag_list[i] = t.strip()
+ else:
+ tag_list = [tm[tag]]
+ else:
+ tag_list = tm[tag]
+ if source_item not in tm[tag]:
+ tag_list.append(source_item)
+ tm[tag] = tag_list
+ # NB tag_list is used as metadata object will convert single-item lists to strings
+ else: # source items are not strings, so just replace
+ tm[tag] = source
+
+def get_artist_credit(options, release_id, obj):
+ """
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param options:
+ :param obj: an XmlNode
+ :return: a list of as-credited names
+ """
+ name_credit_list = parse_data(release_id, obj, [], 'artist-credit')
+ credit_list = []
+ if name_credit_list:
+ for name_credits in name_credit_list:
+ for name_credit in name_credits:
+ credited_artist = parse_data(
+ release_id, name_credit, [], 'name')
+ if credited_artist:
+ name = parse_data(
+ release_id, name_credit, [], 'artist', 'name')
+ sort_name = parse_data(
+ release_id, name_credit, [], 'artist', 'sort-name')
+ credit_item = (credited_artist, name, sort_name)
+ credit_list.append(credit_item)
+ return credit_list
+
+
+def get_aliases_and_credits(
+ self,
+ options,
+ release_id,
+ album,
+ obj,
+ lang,
+ credited):
+ """
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param self: This relates to the object in the class which called this function
+ :param options:
+ :param obj: an XmlNode
+ :param lang: The language selected in the Picard metadata options
+ :param credited: The options item to determine what as-credited names are being sought
+ :return: None. Sets self.artist_aliases and self.artist_credits[album]
+ """
+ name_credit_list = parse_data(release_id, obj, [], 'artist-credit')
+ artist_list = parse_data(release_id, name_credit_list, [], 'artist')
+ for artist in artist_list:
+ sort_names = parse_data(release_id, artist, [], 'sort-name')
+ if sort_names:
+ aliases = parse_data(release_id, artist, [], 'aliases', 'locale:' +
+ lang, 'primary:True', 'name')
+ if aliases:
+ self.artist_aliases[sort_names[0]] = aliases[0]
+ if credited:
+ for name_credit in name_credit_list[0]:
+ credited_artist = parse_data(release_id, name_credit, [], 'name')
+ if credited_artist:
+ sort_name = parse_data(
+ release_id, name_credit, [], 'artist', 'sort-name')
+ if sort_name:
+ self.artist_credits[album][sort_name[0]
+ ] = credited_artist[0]
+
+
+def get_relation_credits(
+ self,
+ options,
+ release_id,
+ album,
+ obj,
+ lang,
+ credited):
+ """
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param self:
+ :param options: UI options
+ :param album: current album
+ :param obj: XmloOde
+ :return: None
+ Note that direct recording relationships will over-ride indirect ones (via work)
+ """
+
+ rels = parse_data(release_id, obj, [], 'relations', 'target-type:work',
+ 'work', 'relations', 'target-type:artist')
+
+ for artist in rels:
+ sort_names = parse_data(release_id, artist, [], 'artist', 'sort-name')
+ if sort_names:
+ credited_artists = parse_data(
+ release_id, artist, [], 'target-credit')
+ if credited_artists and credited_artists[0] != '' and credited:
+ self.artist_credits[album][sort_names[0]
+ ] = credited_artists[0]
+ aliases = parse_data(
+ release_id,
+ artist,
+ [],
+ 'artist',
+ 'aliases',
+ 'locale:' + lang,
+ 'primary:True',
+ 'name')
+ if aliases:
+ self.artist_aliases[sort_names[0]] = aliases[0]
+
+ rels2 = parse_data(release_id, obj, [], 'relations', 'target-type:artist')
+
+ for artist in rels2:
+ sort_names = parse_data(release_id, artist, [], 'artist', 'sort-name')
+ if sort_names:
+ credited_artists = parse_data(
+ release_id, artist, [], 'target-credit')
+ if credited_artists and credited_artists[0] != '' and credited:
+ self.artist_credits[album][sort_names[0]
+ ] = credited_artists[0]
+ aliases = parse_data(
+ release_id,
+ artist,
+ [],
+ 'artist',
+ 'aliases',
+ 'locale:' + lang,
+ 'primary:True',
+ 'name')
+ if aliases:
+ self.artist_aliases[sort_names[0]] = aliases[0]
+
+
+def composer_last_names(self, release_id, tm, album):
+ """
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param self:
+ :param tm:
+ :param album:
+ :return: None
+ Sets composer last names for album prefixing
+ """
+ if '~cea_album_track_composer_lastnames' in tm:
+ if not isinstance(tm['~cea_album_track_composer_lastnames'], list):
+ atc_list = re.split(
+ '|'.join(
+ self.SEPARATORS),
+ tm['~cea_album_track_composer_lastnames'])
+ else:
+ atc_list = str_to_list(tm['~cea_album_track_composer_lastnames'])
+ for atc_item in atc_list:
+ composer_lastnames = atc_item.strip()
+ if '~length' in tm and tm['~length']:
+ track_length = time_to_secs(tm['~length'])
+ else:
+ track_length = 0
+ if album in self.album_artists:
+ if 'composer_lastnames' in self.album_artists[album]:
+ if composer_lastnames not in self.album_artists[album]['composer_lastnames']:
+ self.album_artists[album]['composer_lastnames'][composer_lastnames] = {
+ 'length': track_length}
+ else:
+ self.album_artists[album]['composer_lastnames'][composer_lastnames]['length'] += track_length
+ else:
+ self.album_artists[album]['composer_lastnames'][composer_lastnames] = {
+ 'length': track_length}
+ else:
+ self.album_artists[album]['composer_lastnames'][composer_lastnames] = {
+ 'length': track_length}
+ else:
+ write_log(
+ release_id,
+ 'warning',
+ "No _cea_album_track_composer_lastnames variable available for recording \"%s\".",
+ tm['title'])
+ if 'composer' in tm:
+ self.append_tag(
+ release_id,
+ release_id,
+ tm,
+ '~cea_warning',
+ '1. Composer for this track is not in album artists and will not be available to prefix album')
+ else:
+ self.append_tag(
+ release_id,
+ release_id,
+ tm,
+ '~cea_warning',
+ '1. No composer for this track, but checking parent work.')
+
+
+def add_list_uniquely(list_to, list_from):
+ """
+ Adds any items in list_from to list_to, if they are not already present
+ If either arg is a string, it will be converted to a list, e.g. 'abc' -> ['abc']
+ :param list_to:
+ :param list_from:
+ :return: appends only unique elements of list 2 to list 1
+ """
+ #
+ if list_to and list_from:
+ if not isinstance(list_to, list):
+ list_to = str_to_list(list_to)
+ if not isinstance(list_from, list):
+ list_from = str_to_list(list_from)
+ for list_item in list_from:
+ if list_item not in list_to:
+ list_to.append(list_item)
+ else:
+ if list_from:
+ list_to = list_from
+ return list_to
+
+
+def str_to_list(s):
+ """
+ :param s:
+ :return: list from string using ; as separator
+ """
+ if isinstance(s, list):
+ return s
+ if not isinstance(s, str):
+ try:
+ return list(s)
+ except TypeError:
+ return []
+ else:
+ if s == '':
+ return []
+ else:
+ return s.split('; ')
+
+
+def list_to_str(l):
+ """
+ :param l:
+ :return: string from list using ; as separator
+ """
+ if not isinstance(l, list):
+ return l
+ else:
+ return '; '.join(l)
+
+
+def interpret(tag):
+ """
+ :param tag:
+ :return: safe form of eval(tag)
+ """
+ if isinstance(tag, str):
+ try:
+ tag = tag.strip(' \n\t')
+ return ast.literal_eval(tag)
+ except (SyntaxError, ValueError):
+ return tag
+ else:
+ return tag
+
+
+def time_to_secs(a):
+ """
+ :param a: string x:x:x
+ :return: seconds
+ converts string times to seconds
+ """
+ ax = a.split(':')
+ ax = ax[::-1]
+ t = 0
+ for i, x in enumerate(ax):
+ if x.isdigit():
+ t += int(x) * (60 ** i)
+ else:
+ return 0
+ return t
+
+
+def seq_last_names(self, album):
+ """
+ Sequences composer last names for album prefix by the total lengths of their tracks
+ :param self:
+ :param album:
+ :return:
+ """
+ ln = []
+ if album in self.album_artists and 'composer_lastnames' in self.album_artists[album]:
+ for x in self.album_artists[album]['composer_lastnames']:
+ if 'length' in self.album_artists[album]['composer_lastnames'][x]:
+ ln.append([x, self.album_artists[album]
+ ['composer_lastnames'][x]['length']])
+ else:
+ return []
+ ln = sorted(ln, key=lambda a: a[1])
+ ln = ln[::-1]
+ return [a[0] for a in ln]
+
+
+def year(date):
+ """
+ Return YYYY portion of date(s) in YYYY-MM-DD format (may be incomplete, string or list)
+ :param date:
+ :return: YYYY
+ """
+ if isinstance(date, list):
+ year_list = [blank_if_none(d).split('-')[0] for d in date]
+ return year_list
+ else:
+ date_list = blank_if_none(date).split('-')
+ return [date_list[0]]
+
+
+def blank_if_none(val):
+ """
+ Make NoneTypes strings
+ :param val: str or None
+ :return: str
+ """
+ if not val:
+ return ''
+ else:
+ return val
+
+
+def strip_excess_punctuation(s):
+ """
+ remove orphan punctuation, unmatched quotes and brackets
+ :param s: string
+ :return: string
+ """
+ if s:
+ s_prev = ''
+ counter = 0
+ while s != s_prev:
+ if counter > 100:
+ break # safety valve
+ s_prev = s
+ s = s.replace(' ', ' ')
+ s = s.strip("&.-:;, ")
+ s = s.lstrip("!)]}")
+ s = s.rstrip("([{")
+ s = s.lstrip(u"\u2019") # Right single quote
+ s = s.lstrip(u"\u201D") # Right double quote
+ if s.count(u"\u201E") == 0: # u201E is lower double quote (German etc.)
+ s = s.rstrip(u"\u201C") # Left double quote - only strip if there is no German-style lower quote present
+ s = s.rstrip(u"\u2018") # Left single quote
+ if s.count('"') % 2 != 0:
+ s = s.strip('"')
+ if s.count("'") % 2 != 0:
+ s = s.strip("'")
+ if len(s) > 0 and s[0] == u"\u201C" and s.count(u"\u201D") == 0:
+ s = s.lstrip(u"\u201C")
+ if len(s) > 0 and s[-1] == u"\u201D" and s.count(u"\u201C") == 0 and s.count(u"\u201E") == 0: # only strip if there is no German-style lower quote present
+ s = s.rstrip(u"\u201D")
+ if len(s) > 0 and s[0] == u"\u2018" and s.count(u"\u2019") == 0:
+ s = s.lstrip(u"\u2018")
+ if len(s) > 0 and s[-1] == u"\u2019" and s.count(u"\u2018") == 0:
+ s = s.rstrip(u"\u2019")
+ if s:
+ if s.count("\"") == 1:
+ s = s.replace('"', '')
+ if s.count("\'") == 1:
+ s = s.replace(" '", " ")
+ # s = s.replace("' ", " ") # removed to prevent removal of genuine apostrophes
+ if "(" in s and ")" not in s:
+ s = s.replace("(", "")
+ if ")" in s and "(" not in s:
+ s = s.replace(")", "")
+ if "[" in s and "]" not in s:
+ s = s.replace("[", "")
+ if "]" in s and "[" not in s:
+ s = s.replace("]", "")
+ if "{" in s and "}" not in s:
+ s = s.replace("{", "")
+ if "}" in s and "{" not in s:
+ s = s.replace("}", "")
+ if s:
+ match_chars = [("(", ")"), ("[", "]"), ("{", "}")]
+ last = len(s) - 1
+ for char_pair in match_chars:
+ if char_pair[0] == s[0] and char_pair[1] == s[last]:
+ s = s.lstrip(char_pair[0]).rstrip(char_pair[1])
+ counter += 1
+ return s
+
+
+#################
+#################
+# EXTRA ARTISTS #
+#################
+#################
+
+
+class ExtraArtists():
+
+ # CONSTANTS
+ def __init__(self):
+ self.album_artists = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # collection of artists to be applied at album level
+
+ self.track_listing = collections.defaultdict(list)
+ # collection of tracks - format is {album: [track 1,
+ # track 2, ...]}
+
+ self.options = collections.defaultdict(dict)
+ # collection of Classical Extras options
+
+ self.globals = collections.defaultdict(dict)
+ # collection of global variables for this class
+
+ self.album_performers = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # collection of performers who have release relationships, not track
+ # relationships
+
+ self.album_instruments = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # collection of instruments which have release relationships, not track
+ # relationships
+
+ self.artist_aliases = {}
+ # collection of alias names - format is {sort_name: alias_name, ...}
+
+ self.artist_credits = collections.defaultdict(dict)
+ # collection of credited-as names - format is {album: {sort_name: credit_name,
+ # ...}, ...}
+
+ self.release_artists_sort = collections.defaultdict(list)
+ # collection of release artists - format is {album: [sort_name_1,
+ # sort_name_2, ...]}
+
+ self.lyricist_filled = collections.defaultdict(dict)
+ # Boolean for each track to indicate if lyricist has been found (don't
+ # want to add more from higher levels)
+ # NB this last one is for completeness - not actually used by
+ # ExtraArtists, but here to remove pep8 error
+
+ self.album_series_list = collections.defaultdict(dict)
+ # series relationships - format is {'name_list': series names, 'id_list': series ids, 'number_list': number within series}
+
+ def add_artist_info(
+ self,
+ album,
+ track_metadata,
+ trackXmlNode,
+ releaseXmlNode):
+ """
+ Main routine run for each track of release
+ :param album: Current release
+ :param track_metadata: track metadata dictionary
+ :param trackXmlNode: Everything in the track node downwards
+ :param releaseXmlNode: Everything in the release node downwards (so includes all track nodes)
+ :return:
+ """
+ release_id = track_metadata['musicbrainz_albumid']
+ if 'start' not in release_status[release_id]:
+ release_status[release_id]['start'] = datetime.now()
+ if 'lookups' not in release_status[release_id]:
+ release_status[release_id]['lookups'] = 0
+ release_status[release_id]['name'] = track_metadata['album']
+ release_status[release_id]['artists'] = True
+ if config.setting['log_debug'] or config.setting['log_info']:
+ write_log(
+ release_id,
+ 'debug',
+ 'STARTING ARTIST PROCESSING FOR ALBUM %s, DISC %s, TRACK %s',
+ track_metadata['album'],
+ track_metadata['discnumber'],
+ track_metadata['tracknumber'] +
+ ' ' +
+ track_metadata['title'])
+ # write_log(release_id, 'info', 'trackXmlNode = %s', trackXmlNode) # NB can crash Picard
+ # write_log('info', 'releaseXmlNode = %s', releaseXmlNode) # NB can crash Picard
+ # Jump through hoops to get track object!!
+ track = album._new_tracks[-1]
+ tm = track.metadata
+
+ # OPTIONS - OVER-RIDE IF REQUIRED
+ if '~ce_options' not in tm:
+ if config.setting['log_debug'] or config.setting['log_info']:
+ write_log(release_id, 'debug', 'Artists gets track first...')
+ get_options(release_id, album, track)
+ options = interpret(tm['~ce_options'])
+ if not options:
+ if config.setting["log_error"]:
+ write_log(
+ release_id,
+ 'error',
+ 'Artists. Failure to read saved options for track %s. options = %s',
+ track,
+ tm['~ce_options'])
+ options = option_settings(config.setting)
+ self.options[track] = options
+
+ # CONSTANTS
+ self.ERROR = options["log_error"]
+ self.WARNING = options["log_warning"]
+ self.ORCHESTRAS = options["cea_orchestras"].split(',')
+ self.CHOIRS = options["cea_choirs"].split(',')
+ self.GROUPS = options["cea_groups"].split(',')
+ self.ENSEMBLE_TYPES = self.ORCHESTRAS + self.CHOIRS + self.GROUPS
+ self.SEPARATORS = ['; ', '/ ', ';', '/']
+
+ # continue?
+ if not options["classical_extra_artists"]:
+ return
+ # album_files is not used - this is just for logging
+ album_files = album.tagger.get_files_from_objects([album])
+ if options['log_info']:
+ write_log(
+ release_id,
+ 'info',
+ 'ALBUM FILENAMES for album %r = %s',
+ album,
+ album_files)
+
+ if not (
+ options["ce_no_run"] and (
+ not tm['~ce_file'] or tm['~ce_file'] == "None")):
+ # continue
+ write_log(
+ release_id,
+ 'debug',
+ "ExtraArtists - add_artist_info")
+ if album not in self.track_listing or track not in self.track_listing[album]:
+ self.track_listing[album].append(track)
+ # fix odd hyphens in names for consistency
+ field_types = ['~albumartists', '~albumartists_sort']
+ for field_type in field_types:
+ if field_type in tm:
+ field = tm[field_type]
+ if isinstance(field, list):
+ for x, it in enumerate(field):
+ field[x] = it.replace(u'\u2010', u'-')
+ elif isinstance(field, str):
+ field = field.replace(u'\u2010', u'-')
+ else:
+ pass
+ tm[field_type] = field
+
+ # first time for this album (reloads each refresh)
+ if tm['discnumber'] == '1' and tm['tracknumber'] == '1':
+ # get artist aliases - these are cached so can be re-used across
+ # releases, but are reloaded with each refresh
+ get_aliases(self, release_id, album, options, releaseXmlNode)
+
+ # xml_type = 'release'
+ # get performers etc who are related at the release level
+ relation_list = parse_data(
+ release_id, releaseXmlNode, [], 'relations')
+ album_performerList = get_artists(
+ options, release_id, tm, relation_list, 'release')['artists']
+ self.album_performers[album] = album_performerList
+ album_instrumentList = get_artists(
+ options, release_id, tm, relation_list, 'release')['instruments']
+ self.album_instruments[album] = album_instrumentList
+
+ # get series information
+ self.album_series_list = get_series(
+ options, release_id, relation_list)
+
+ else:
+ if album in self.album_performers:
+ album_performerList = self.album_performers[album]
+ else:
+ album_performerList = []
+ if album in self.album_instruments and self.album_instruments[album]:
+ tm['~cea_instruments'] = self.album_instruments[album][0]
+ tm['~cea_instruments_credited'] = self.album_instruments[album][1]
+ tm['~cea_instruments_all'] = self.album_instruments[album][2]
+ # Should be OK to initialise these here as recording artists
+ # yet to be processed
+
+ # Fill release info not given by vanilla Picard
+ if self.album_series_list:
+ tm['series'] = self.album_series_list['name_list'] if 'name_list' in self.album_series_list else None
+ tm['musicbrainz_seriesid'] = self.album_series_list['id_list'] if 'id_list' in self.album_series_list else None
+ tm['series_number'] = self.album_series_list['number_list'] if 'number_list' in self.album_series_list else None
+ ## TODO add label id too
+ recording_relation_list = parse_data(
+ release_id, trackXmlNode, [], 'recording', 'relations')
+ recording_series_list = get_series(
+ options, release_id, recording_relation_list)
+ write_log(
+ release_id,
+ 'info',
+ 'Recording_series_list = %s',
+ recording_series_list)
+
+ track_artist_list = parse_data(
+ release_id, trackXmlNode, [], 'artist-credit')
+ if track_artist_list:
+ track_artist = []
+ track_artistsort = []
+ track_artists = []
+ track_artists_sort = []
+ locale = config.setting["artist_locale"]
+ # NB this is the Picard code in /util
+ lang = locale.split("_")[0]
+
+ # Set naming option
+ # Put naming style into preferential list
+
+ # naming as for vanilla Picard for track artists
+
+ if options['translate_artist_names'] and lang:
+ name_style = ['alias', 'sort']
+ # documentation indicates that processing should be as below,
+ # but processing above appears to reflect what vanilla Picard actually does
+ # if options['standardize_artists']:
+ # name_style = ['alias', 'sort']
+ # else:
+ # name_style = ['alias', 'credit', 'sort']
+ else:
+ if not options['standardize_artists']:
+ name_style = ['credit']
+ else:
+ name_style = []
+ write_log(
+ release_id,
+ 'info',
+ 'Priority order of naming style for track artists = %s',
+ name_style)
+ styled_artists = apply_artist_style(
+ options,
+ release_id,
+ lang,
+ track_artist_list,
+ name_style,
+ track_artist,
+ track_artistsort,
+ track_artists,
+ track_artists_sort)
+ tm['artists'] = styled_artists['artists']
+ tm['~artists_sort'] = styled_artists['artists_sort']
+ tm['artist'] = styled_artists['artist']
+ tm['artistsort'] = styled_artists['artistsort']
+
+ if 'recording' in trackXmlNode:
+ self.globals[track]['is_recording'] = True
+ write_log(release_id, 'debug', 'Getting recording details')
+ recording = trackXmlNode['recording']
+ if not isinstance(recording, list):
+ recording = [recording]
+ for record in recording:
+ rec_type = type(record)
+ write_log(release_id, 'info', 'rec-type = %s', rec_type)
+ write_log(release_id, 'info', record)
+ # Note that the lists below reflect https://musicbrainz.org/relationships/artist-recording
+ # Any changes to that DB structure will require changes
+ # here
+
+ # get recording artists data
+ recording_artist_list = parse_data(
+ release_id, record, [], 'artist-credit')
+ if recording_artist_list:
+ recording_artist = []
+ recording_artistsort = []
+ recording_artists = []
+ recording_artists_sort = []
+ locale = config.setting["artist_locale"]
+ # NB this is the Picard code in /util
+ lang = locale.split("_")[0]
+
+ # Set naming option
+ # Put naming style into preferential list
+
+ # naming as for vanilla Picard for track artists (per
+ # documentation rather than actual?)
+ if options['cea_ra_trackartist']:
+ if options['translate_artist_names'] and lang:
+ if options['standardize_artists']:
+ name_style = ['alias', 'sort']
+ else:
+ name_style = ['alias', 'credit', 'sort']
+ else:
+ if not options['standardize_artists']:
+ name_style = ['credit']
+ else:
+ name_style = []
+ # naming as for performers in classical extras
+ elif options['cea_ra_performer']:
+ if options['cea_aliases']:
+ if options['cea_alias_overrides']:
+ name_style = ['alias', 'credit']
+ else:
+ name_style = ['credit', 'alias']
+ else:
+ name_style = ['credit']
+
+ else:
+ name_style = []
+ write_log(
+ release_id,
+ 'info',
+ 'Priority order of naming style for recording artists = %s',
+ name_style)
+
+ styled_artists = apply_artist_style(
+ options,
+ release_id,
+ lang,
+ recording_artist_list,
+ name_style,
+ recording_artist,
+ recording_artistsort,
+ recording_artists,
+ recording_artists_sort)
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_recording_artists',
+ styled_artists['artists'])
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_recording_artists_sort',
+ styled_artists['artists_sort'])
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_recording_artist',
+ styled_artists['artist'])
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_recording_artistsort',
+ styled_artists['artistsort'])
+
+ else:
+ tm['~cea_recording_artists'] = ''
+ tm['~cea_recording_artists_sort'] = ''
+ tm['~cea_recording_artist'] = ''
+ tm['~cea_recording_artistsort'] = ''
+
+ # use recording artist options
+ tm['~cea_MB_artist'] = str_to_list(tm['artist'])
+ tm['~cea_MB_artistsort'] = str_to_list(tm['artistsort'])
+ tm['~cea_MB_artists'] = str_to_list(tm['artists'])
+ tm['~cea_MB_artists_sort'] = str_to_list(tm['~artists_sort'])
+
+ if options['cea_ra_use']:
+ if options['cea_ra_replace_ta']:
+ if tm['~cea_recording_artist']:
+ tm['artist'] = str_to_list(tm['~cea_recording_artist'])
+ tm['artistsort'] = str_to_list(tm['~cea_recording_artistsort'])
+ tm['artists'] = str_to_list(tm['~cea_recording_artists'])
+ tm['~artists_sort'] = str_to_list(tm['~cea_recording_artists_sort'])
+ elif not options['cea_ra_noblank_ta']:
+ tm['artist'] = ''
+ tm['artistsort'] = ''
+ tm['artists'] = ''
+ tm['~artists_sort'] = ''
+ elif options['cea_ra_merge_ta']:
+ if tm['~cea_recording_artist']:
+ tm['artists'] = add_list_uniquely(
+ tm['artists'], tm['~cea_recording_artists'])
+ tm['~artists_sort'] = add_list_uniquely(
+ tm['~artists_sort'], tm['~cea_recording_artists_sort'])
+ if tm['artist'] != tm['~cea_recording_artist']:
+ tm['artist'] = tm['artist'] + \
+ ' (' + tm['~cea_recording_artist'] + ')'
+ tm['artistsort'] = tm['artistsort'] + \
+ ' (' + tm['~cea_recording_artistsort'] + ')'
+
+ # xml_type = 'recording'
+ relation_list = parse_data(
+ release_id, record, [], 'relations')
+ performerList = album_performerList + \
+ get_artists(options, release_id, tm, relation_list, 'recording')['artists']
+ # returns
+ # [(artist type, instrument or None, artist name, artist sort name, instrument sort, type sort)]
+ # where instrument sort places solo ahead of additional etc.
+ # and type sort applies a custom sequencing to the artist
+ # types
+ if performerList:
+ write_log(
+ release_id, 'info', "Performers: %s", performerList)
+ self.set_performer(
+ release_id, album, track, performerList, tm)
+ if not options['classical_work_parts']:
+ work_artist_list = parse_data(
+ release_id,
+ record,
+ [],
+ 'relations',
+ 'target-type:work',
+ 'type:performance',
+ 'work',
+ 'relations',
+ 'target-type:artist')
+ work_artists = get_artists(
+ options, release_id, tm, work_artist_list, 'work')['artists']
+ set_work_artists(
+ self, release_id, album, track, work_artists, tm, 0)
+ # otherwise composers etc. will be set in work parts
+ else:
+ self.globals[track]['is_recording'] = False
+ else:
+ tm['000_major_warning'] = "WARNING: Classical Extras not run for this track as no file present - " \
+ "deselect the option on the advanced tab to run. If there is a file, then try 'Refresh'."
+ if track_metadata['tracknumber'] == track_metadata['totaltracks'] and track_metadata[
+ 'discnumber'] == track_metadata['totaldiscs']: # last track
+ self.process_album(release_id, album)
+ release_status[release_id]['artists-done'] = datetime.now()
+ close_log(release_id, 'artists')
+
+ # Checks for ensembles
+ def ensemble_type(self, performer):
+ """
+ Returns ensemble types
+ :param performer:
+ :return:
+ """
+ for ensemble_name in self.ORCHESTRAS:
+ ensemble = re.compile(
+ r'(.*)\b' +
+ ensemble_name +
+ r'\b(.*)',
+ re.IGNORECASE)
+ if ensemble.search(performer):
+ return 'Orchestra'
+ for ensemble_name in self.CHOIRS:
+ ensemble = re.compile(
+ r'(.*)\b' +
+ ensemble_name +
+ r'\b(.*)',
+ re.IGNORECASE)
+ if ensemble.search(performer):
+ return 'Choir'
+ for ensemble_name in self.GROUPS:
+ ensemble = re.compile(
+ r'(.*)\b' +
+ ensemble_name +
+ r'\b(.*)',
+ re.IGNORECASE)
+ if ensemble.search(performer):
+ return 'Group'
+ return False
+
+ def process_album(self, release_id, album):
+ """
+ Perform final processing after all tracks read
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'debug',
+ 'ExtraArtists: Starting process_album')
+ # process lyrics tags
+ write_log(release_id, 'debug', 'Starting lyrics processing')
+ common = []
+ tmlyrics_dict = {}
+ tmlyrics_sort = []
+ for track in self.track_listing[album]:
+ options = self.options[track]
+ if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
+ tm = track.metadata
+ lyrics_tag = options['cea_lyrics_tag']
+ if tm[lyrics_tag]:
+ # turn text into word lists to speed processing
+ tmlyrics_dict[track] = tm[lyrics_tag].split()
+ if tmlyrics_dict:
+ tmlyrics_sort = sorted(
+ tmlyrics_dict.items(),
+ key=operator.itemgetter(1))
+ prev = None
+ first_track = None
+ unique_lyrics = []
+ ref_track = {}
+ for lyric_tuple in tmlyrics_sort: # tuple is (track, lyrics)
+ if lyric_tuple[1] != prev:
+ unique_lyrics.append(lyric_tuple[1])
+ first_track = lyric_tuple[0]
+ ref_track[lyric_tuple[0]] = first_track
+ prev = lyric_tuple[1]
+ common = turbo_lcs(
+ release_id,
+ unique_lyrics)
+
+ if common:
+ unique = []
+ for tup in tmlyrics_sort:
+ track = tup[0]
+ ref = ref_track[track]
+ if track == ref:
+ start = substart_finder(tup[1], common)
+ length = len(common)
+ end = min(start + length, len(tup[1]))
+ unique = tup[1][:start] + tup[1][end:]
+
+ options = self.options[track]
+ if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
+ tm = track.metadata
+ if unique:
+ tm['~cea_track_lyrics'] = ' '.join(unique)
+ tm['~cea_album_lyrics'] = ' '.join(common)
+ if options['cea_album_lyrics']:
+ tm[options['cea_album_lyrics']] = tm['~cea_album_lyrics']
+ if unique and options['cea_track_lyrics']:
+ tm[options['cea_track_lyrics']] = tm['~cea_track_lyrics']
+ else:
+ for track in self.track_listing[album]:
+ options = self.options[track]
+ if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
+ tm['~cea_track_lyrics'] = tm[options['cea_lyrics_tag']]
+ if options['cea_track_lyrics']:
+ tm[options['cea_track_lyrics']] = tm['~cea_track_lyrics']
+ write_log(release_id, 'debug', 'Ending lyrics processing')
+
+ for track in self.track_listing[album]:
+ self.write_metadata(release_id, options, album, track)
+ self.track_listing[album] = []
+ write_log(
+ release_id,
+ 'info',
+ "FINISHED Classical Extra Artists. Album: %s",
+ album)
+
+
+ def write_metadata(self, release_id, options, album, track):
+ """
+ Write the metadat for this track
+ :param release_id:
+ :param album:
+ :param track:
+ :return:
+ """
+ options = self.options[track]
+ tm = track.metadata
+ tm['~cea_version'] = PLUGIN_VERSION
+
+ # set inferred genres before any tags are blanked
+ if options['cwp_genres_infer']:
+ self.infer_genres(release_id, options, track, tm)
+
+ # album
+ if not options['classical_work_parts']:
+ if 'composer_lastnames' in self.album_artists[album]:
+ last_names = seq_last_names(self, album)
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_album_composer_lastnames',
+ last_names)
+ # otherwise this is done in the workparts class, which has all
+ # composer info
+
+ # process tag mapping
+ tm['~cea_artists_complete'] = "Y"
+ map_tags(options, release_id, album, tm)
+
+ # write out options and errors/warnings to tags
+ if options['cea_options_tag'] != "":
+ self.cea_options = collections.defaultdict(
+ lambda: collections.defaultdict(
+ lambda: collections.defaultdict(dict)))
+
+ for opt in plugin_options(
+ 'artists') + plugin_options('tag') + plugin_options('picard'):
+ if 'name' in opt:
+ if 'value' in opt:
+ if options[opt['option']]:
+ self.cea_options['Classical Extras']['Artists options'][opt['name']] = opt['value']
+ else:
+ self.cea_options['Classical Extras']['Artists options'][opt['name']
+ ] = options[opt['option']]
+
+ for opt in plugin_options('tag_detail'):
+ if opt['option'] != "":
+ name_list = opt['name'].split("_")
+ self.cea_options['Classical Extras']['Artists options'][name_list[0]
+ ][name_list[1]] = options[opt['option']]
+
+ if options['ce_version_tag'] and options['ce_version_tag'] != "":
+ self.append_tag(release_id, tm, options['ce_version_tag'], str(
+ 'Version ' + tm['~cea_version'] + ' of Classical Extras'))
+ if options['cea_options_tag'] and options['cea_options_tag'] != "":
+ self.append_tag(
+ release_id,
+ tm,
+ options['cea_options_tag'] +
+ ':artists_options',
+ json.loads(
+ json.dumps(
+ self.cea_options)))
+
+
+ def infer_genres(self, release_id, options, track, tm):
+ """
+ Infer a genre from the artist/instrument metadata
+ :param release_id:
+ :param track:
+ :param tm: track metadata
+ :return:
+ """
+ # Note that this is now mixed in with other sources of genres in def map_tags
+ # ~cea_work_type_if_classical is used for types that are specifically classical
+ # and is only applied in map_tags if the track is deemed to be
+ # classical
+ if (self.globals[track]['is_recording'] and options['classical_work_parts']
+ and '~artists_sort' in tm and 'composersort' in tm
+ and any(x in tm['~artists_sort'] for x in tm['composersort'])
+ and 'writer' not in tm
+ and not any(x in tm['~artists_sort'] for x in tm['~cea_performers_sort'])):
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Classical')
+
+ if isinstance(tm['~cea_soloists'], str):
+ soloists = re.split(
+ '|'.join(
+ self.SEPARATORS),
+ tm['~cea_soloists'])
+ else:
+ soloists = tm['~cea_soloists']
+ if '~cea_vocalists' in tm:
+ if isinstance(tm['~cea_vocalists'], str):
+ vocalists = re.split(
+ '|'.join(
+ self.SEPARATORS),
+ tm['~cea_vocalists'])
+ else:
+ vocalists = tm['~cea_vocalists']
+ else:
+ vocalists = []
+
+ if '~cea_ensembles' in tm:
+ large = False
+ if 'performer:orchestra' in tm:
+ large = True
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Orchestral')
+ if '~cea_soloists' in tm:
+ if 'vocals' in tm['~cea_instruments_all']:
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Vocal')
+ if len(soloists) == 1:
+ if soloists != vocalists:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Concerto')
+ else:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Aria')
+ elif len(soloists) == 2:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Duet')
+ if not vocalists:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Concerto')
+ elif len(soloists) == 3:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Trio')
+ elif len(soloists) == 4:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Quartet')
+
+ if 'performer:choir' in tm or 'performer:choir vocals' in tm:
+ large = True
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Choral')
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Vocal')
+ else:
+ if large and 'soloists' in tm and tm['soloists'].count(
+ 'vocals') > 1:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Opera')
+ if not large:
+ if '~cea_soloists' not in tm:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Chamber music')
+ else:
+ if vocalists:
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Song')
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Vocal')
+ else:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Chamber music')
+ else:
+ if len(soloists) == 1:
+ if vocalists != soloists:
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Instrumental')
+ else:
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Song')
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Vocal')
+ elif len(soloists) == 2:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Duet')
+ elif len(soloists) == 3:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Trio')
+ elif len(soloists) == 4:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Quartet')
+ else:
+ if not vocalists:
+ self.append_tag(
+ release_id, tm, '~cea_work_type_if_classical', 'Chamber music')
+ else:
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Song')
+ self.append_tag(
+ release_id, tm, '~cea_work_type', 'Vocal')
+
+
+ def append_tag(self, release_id, tm, tag, source):
+ """
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param tm:
+ :param tag:
+ :param source:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'info',
+ "Extra Artists - appending %s to %s",
+ source,
+ tag)
+ append_tag(release_id, tm, tag, source, self.SEPARATORS)
+
+ def set_performer(self, release_id, album, track, performerList, tm):
+ """
+ Sets the performer-related tags
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param track:
+ :param performerList: see below
+ :param tm:
+ :return:
+ """
+ # performerList is in format [(artist_type, [instrument list],[name list],[sort_name list],
+ # instrument_sort, type_sort),(.....etc]
+ # Sorted by type_sort then sort name then instrument_sort
+ write_log(release_id, 'debug', "Extra Artists - set_performer")
+ write_log(release_id, 'info', "Performer list is:")
+ write_log(release_id, 'info', performerList)
+ options = self.options[track]
+ # tag strings are a tuple (Picard tag, cea tag, Picard sort tag, cea
+ # sort tag)
+ tag_strings = const.tag_strings('~cea')
+ # insertions lists artist types where names in the main Picard tags may be updated for annotations
+ # (not for performer types as Picard will write performer:inst as Performer name (inst) )
+ insertions = const.INSERTIONS
+
+ # First remove all existing performer tags
+ del_list = []
+ for meta in tm:
+ if 'performer' in meta:
+ del_list.append(meta)
+ for del_item in del_list:
+ del tm[del_item]
+ last_artist = []
+ last_inst_list = []
+ last_instrument = None
+ artist_inst = []
+ artist_inst_list = {}
+ for performer in performerList:
+ artist_type = performer[0]
+ if artist_type not in tag_strings:
+ return None
+ if artist_type in ['instrument', 'vocal', 'performing orchestra']:
+ if performer[1]:
+ inst_list = performer[1]
+ attrib_list = []
+ for attrib in ['solo', 'guest', 'additional']:
+ if attrib in inst_list:
+ inst_list.remove(attrib)
+ attrib_list.append(attrib)
+ attribs = " ".join(attrib_list)
+ instrument = ", ".join(inst_list)
+ if not options['cea_no_solo'] and attrib_list:
+ instrument = attribs + " " + instrument
+ if performer[3] == last_artist:
+ if instrument != last_instrument:
+ artist_inst.append(instrument)
+ else:
+ if inst_list == last_inst_list:
+ write_log(
+ release_id, 'warning', 'Duplicated performer information for %s'
+ ' (may be in Release Relationship as well as Track Relationship).'
+ ' Duplicates have been ignored.', performer[3])
+ if self.WARNING:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_warning',
+ '2. Duplicated performer information for "' +
+ '; '.join(
+ performer[3]) +
+ '" (may be in Release Relationship as well as Track Relationship).'
+ ' Duplicates have been ignored.')
+ else:
+ artist_inst = [instrument]
+ last_artist = performer[3]
+ last_inst_list = inst_list
+ last_instrument = instrument
+
+ instrument = ", ".join(artist_inst)
+ else:
+ instrument = None
+ if artist_type == 'performing orchestra':
+ instrument = 'orchestra'
+ artist_inst_list[tuple(performer[3])] = instrument
+ for performer in performerList:
+ artist_type = performer[0]
+ if artist_type not in tag_strings:
+ return None
+ performing_artist = False if artist_type in [
+ 'arranger', 'instrument arranger', 'orchestrator', 'vocal arranger'] else True
+ if True and artist_type in [
+ 'instrument',
+ 'vocal',
+ 'performing orchestra']: # There may be an option here (to replace 'True')
+ # Currently groups instruments by artist - alternative has been
+ # tested if required
+ instrument = artist_inst_list[tuple(performer[3])]
+ else:
+ if performer[1]:
+ inst_list = performer[1]
+ if options['cea_no_solo']:
+ for attrib in ['solo', 'guest', 'additional']:
+ if attrib in inst_list:
+ inst_list.remove(attrib)
+ instrument = " ".join(inst_list)
+ else:
+ instrument = None
+ if artist_type == 'performing orchestra':
+ instrument = 'orchestra'
+ sub_strings = {'instrument': instrument,
+ 'vocal': instrument # ,
+ # 'instrument arranger': instrument,
+ # 'vocal arranger': instrument
+ }
+ for typ in ['concertmaster']:
+ if options['cea_' + typ] and options['cea_arrangers']:
+ sub_strings[typ] = ':' + options['cea_' + typ]
+
+ if options['cea_arranger']:
+ if instrument:
+ arr_inst = options['cea_arranger'] + ' ' + instrument
+ else:
+ arr_inst = options['cea_arranger']
+ else:
+ arr_inst = instrument
+ annotations = {'instrument': instrument,
+ 'vocal': instrument,
+ 'performing orchestra': instrument,
+ 'chorus master': options['cea_chorusmaster'],
+ 'concertmaster': options['cea_concertmaster'],
+ 'arranger': options['cea_arranger'],
+ 'instrument arranger': arr_inst,
+ 'orchestrator': options['cea_orchestrator'],
+ 'vocal arranger': arr_inst}
+ tag = tag_strings[artist_type][0]
+ cea_tag = tag_strings[artist_type][1]
+ sort_tag = tag_strings[artist_type][2]
+ cea_sort_tag = tag_strings[artist_type][3]
+ cea_names_tag = cea_tag[:-1] + '_names'
+ cea_instrumented_tag = cea_names_tag + '_instrumented'
+ if artist_type in sub_strings:
+ if sub_strings[artist_type]:
+ tag += sub_strings[artist_type]
+ else:
+ write_log(
+ release_id,
+ 'warning',
+ 'No instrument/sub-key available for artist_type %s. Performer = %s. Track is %s',
+ artist_type,
+ performer[2],
+ track)
+
+ if tag:
+ if '~ce_tag_cleared_' + \
+ tag not in tm or not tm['~ce_tag_cleared_' + tag] == "Y":
+ if tag in tm:
+ write_log(release_id, 'info', 'delete tag %s', tag)
+ del tm[tag]
+ tm['~ce_tag_cleared_' + tag] = "Y"
+ if sort_tag:
+ if '~ce_tag_cleared_' + \
+ sort_tag not in tm or not tm['~ce_tag_cleared_' + sort_tag] == "Y":
+ if sort_tag in tm:
+ del tm[sort_tag]
+ tm['~ce_tag_cleared_' + sort_tag] = "Y"
+
+ name_list = performer[2]
+ for ind, name in enumerate(name_list):
+ performer_type = ''
+ sort_name = performer[3][ind]
+ no_credit = True
+ # change name to as-credited
+ if (performing_artist and options['cea_performer_credited'] or
+ not performing_artist and options['cea_composer_credited']):
+ if sort_name in self.artist_credits[album]:
+ no_credit = False
+ name = self.artist_credits[album][sort_name]
+ # over-ride with aliases and use standard MB name (not
+ # as-credited) if no alias
+ if (options['cea_aliases'] or not performing_artist and options['cea_aliases_composer']) and (
+ no_credit or options['cea_alias_overrides']):
+ if sort_name in self.artist_aliases:
+ name = self.artist_aliases[sort_name]
+ # fix cyrillic names if not already fixed
+ if options['cea_cyrillic']:
+ if not only_roman_chars(name):
+ name = remove_middle(unsort(sort_name))
+ # Only remove middle name where the existing
+ # performer is in non-latin script
+ annotated_name = name
+ if instrument:
+ instrumented_name = name + ' (' + instrument + ')'
+ else:
+ instrumented_name = name
+ # add annotations and write performer tags
+ if artist_type in annotations:
+ if annotations[artist_type]:
+ annotated_name += ' (' + annotations[artist_type] + ')'
+ else:
+ write_log(
+ release_id,
+ 'warning',
+ 'No annotation (instrument) available for artist_type %s.'
+ ' Performer = %s. Track is %s',
+ artist_type,
+ performer[2],
+ track)
+ if artist_type in insertions and options['cea_arrangers']:
+ self.append_tag(release_id, tm, tag, annotated_name)
+ else:
+ if options['cea_arrangers'] or artist_type == tag:
+ self.append_tag(release_id, tm, tag, name)
+
+ if options['cea_arrangers'] or artist_type == tag:
+ if sort_tag:
+ self.append_tag(release_id, tm, sort_tag, sort_name)
+ if options['cea_tag_sort'] and '~' in sort_tag:
+ explicit_sort_tag = sort_tag.replace('~', '')
+ self.append_tag(
+ release_id, tm, explicit_sort_tag, sort_name)
+
+ self.append_tag(release_id, tm, cea_tag, annotated_name)
+ self.append_tag(release_id, tm, cea_names_tag, name)
+ if instrumented_name != name:
+ self.append_tag(
+ release_id,
+ tm,
+ cea_instrumented_tag,
+ instrumented_name)
+
+ if cea_sort_tag:
+ self.append_tag(release_id, tm, cea_sort_tag, sort_name)
+
+ # differentiate soloists etc and write related tags
+ if artist_type == 'performing orchestra' or (
+ instrument and instrument in self.ENSEMBLE_TYPES) or self.ensemble_type(name):
+ performer_type = 'ensembles'
+ self.append_tag(
+ release_id, tm, '~cea_ensembles', instrumented_name)
+ self.append_tag(
+ release_id, tm, '~cea_ensemble_names', name)
+ self.append_tag(
+ release_id, tm, '~cea_ensembles_sort', sort_name)
+ elif artist_type in ['performer', 'instrument', 'vocal']:
+ performer_type = 'soloists'
+ self.append_tag(
+ release_id, tm, '~cea_soloists', instrumented_name)
+ self.append_tag(release_id, tm, '~cea_soloist_names', name)
+ self.append_tag(
+ release_id, tm, '~cea_soloists_sort', sort_name)
+ if artist_type == "vocal":
+ self.append_tag(
+ release_id, tm, '~cea_vocalists', instrumented_name)
+ self.append_tag(
+ release_id, tm, '~cea_vocalist_names', name)
+ self.append_tag(
+ release_id, tm, '~cea_vocalists_sort', sort_name)
+ elif instrument:
+ self.append_tag(
+ release_id, tm, '~cea_instrumentalists', instrumented_name)
+ self.append_tag(
+ release_id, tm, '~cea_instrumentalist_names', name)
+ self.append_tag(
+ release_id, tm, '~cea_instrumentalists_sort', sort_name)
+ else:
+ self.append_tag(
+ release_id, tm, '~cea_other_soloists', instrumented_name)
+ self.append_tag(
+ release_id, tm, '~cea_other_soloist_names', name)
+ self.append_tag(
+ release_id, tm, '~cea_other_soloists_sort', sort_name)
+
+ # set album artists
+ if performer_type or artist_type == 'conductor':
+ cea_album_tag = cea_tag.replace(
+ 'cea', 'cea_album').replace(
+ 'performers', performer_type)
+ cea_album_sort_tag = cea_sort_tag.replace(
+ 'cea', 'cea_album').replace(
+ 'performers', performer_type)
+ if stripsir(name) in tm['~albumartists'] or stripsir(
+ sort_name) in tm['~albumartists_sort']:
+ self.append_tag(release_id, tm, cea_album_tag, name)
+ self.append_tag(
+ release_id, tm, cea_album_sort_tag, sort_name)
+ else:
+ if performer_type:
+ self.append_tag(
+ release_id, tm, '~cea_support_performers', instrumented_name)
+ self.append_tag(
+ release_id, tm, '~cea_support_performer_names', name)
+ self.append_tag(
+ release_id, tm, '~cea_support_performers_sort', sort_name)
+
+##############
+##############
+# WORK PARTS #
+##############
+##############
+
+
+class PartLevels():
+ # QUEUE-HANDLING
+ class WorksQueue(LockableObject):
+ """Object for managing the queue of lookups"""
+
+ def __init__(self):
+ LockableObject.__init__(self)
+ self.queue = {}
+
+ def __contains__(self, name):
+ return name in self.queue
+
+ def __iter__(self):
+ return self.queue.__iter__()
+
+ def __getitem__(self, name):
+ self.lock_for_read()
+ value = self.queue[name] if name in self.queue else None
+ self.unlock()
+ return value
+
+ def __setitem__(self, name, value):
+ self.lock_for_write()
+ self.queue[name] = value
+ self.unlock()
+
+ def append(self, name, value):
+ self.lock_for_write()
+ if name in self.queue:
+ self.queue[name].append(value)
+ value = False
+ else:
+ self.queue[name] = [value]
+ value = True
+ self.unlock()
+ return value
+
+ def remove(self, name):
+ self.lock_for_write()
+ value = None
+ if name in self.queue:
+ value = self.queue[name]
+ del self.queue[name]
+ self.unlock()
+ return value
+
+ # INITIALISATION
+
+ def __init__(self):
+ self.works_cache = {}
+ # maintains list of parent of each workid, or None if no parent found,
+ # so that XML lookup need only executed if no existing record
+
+ self.partof = collections.defaultdict(dict)
+ # the inverse of the above (immediate children of each parent)
+ # but note that this is specific to the album as children may vary between albums
+ # so format is {album1{parent1: child1, parent2:, child2},
+ # album2{....}}
+
+ self.works_queue = self.WorksQueue()
+ # lookup queue - holds track/album pairs for each queued workid (may be
+ # more than one pair per id, especially for higher-level parts)
+
+ self.parts = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # metadata collection for all parts - structure is {workid: {name: ,
+ # parent: , (track,album): {part_levels}}, etc}
+
+ self.top_works = collections.defaultdict(dict)
+ # metadata collection for top-level works for (track, album) -
+ # structure is {(track, album): {workId: }, etc}
+
+ self.trackback = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # hierarchical iterative work structure - {album: {id: , children:{id:
+ # , children{}, id: etc}, id: etc} }
+
+ self.child_listing = collections.defaultdict(list)
+ # contains list of workIds which are descendants of a given workId, to
+ # prevent recursion when adding new ids
+
+ self.work_listing = collections.defaultdict(list)
+ # contains list of workIds for each album
+
+ self.top = collections.defaultdict(list)
+ # self.top[album] = list of work Ids which are top-level works in album
+
+ self.options = collections.defaultdict(dict)
+ # active Classical Extras options for current track
+
+ self.synonyms = collections.defaultdict(dict)
+ # active synonym options for current track
+
+ self.replacements = collections.defaultdict(dict)
+ # active synonym options for current track
+
+ self.file_works = collections.defaultdict(list)
+ # list of works derived from SongKong-style file tags
+ # structure is {(album, track): [{workid: , name: }, {workid: ....}}
+
+ self.album_artists = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # collection of artists to be applied at album level
+
+ self.artist_aliases = {}
+ # collection of alias names - format is {sort_name: alias_name, ...}
+
+ self.artist_credits = collections.defaultdict(dict)
+ # collection of credited-as names - format is {album: {sort_name: credit_name,
+ # ...}, ...}
+
+ self.release_artists_sort = collections.defaultdict(list)
+ # collection of release artists - format is {album: [sort_name_1,
+ # sort_name_2, ...]}
+
+ self.lyricist_filled = collections.defaultdict(dict)
+ # Boolean for each track to indicate if lyricist has been found (don't
+ # want to add more from higher levels)
+
+ self.orphan_tracks = collections.defaultdict(list)
+ # To keep a list for each album of tracks which do not have works -
+ # format is {album: [track1, track2, ...], etc}
+
+ self.tracks = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+ # To keep a list of all tracks for the album - format is {album:
+ # {track1: {movement-group: movementgroup, movement-number: movementnumber},
+ # track2: {}, ..., etc}, album2: etc}
+
+ ########################################
+ # SECTION 1 - Initial track processing #
+ ########################################
+
+ def add_work_info(
+ self,
+ album,
+ track_metadata,
+ trackXmlNode,
+ releaseXmlNode):
+ """
+ Main Routine - run for each track
+ :param album:
+ :param track_metadata:
+ :param trackXmlNode:
+ :param releaseXmlNode:
+ :return:
+ """
+ release_id = track_metadata['musicbrainz_albumid']
+ if 'start' not in release_status[release_id]:
+ release_status[release_id]['start'] = datetime.now()
+ if 'lookups' not in release_status[release_id]:
+ release_status[release_id]['lookups'] = 0
+ release_status[release_id]['name'] = track_metadata['album']
+ release_status[release_id]['works'] = True
+ if config.setting['log_debug'] or config.setting['log_info']:
+ write_log(
+ release_id,
+ 'debug',
+ 'STARTING WORKS PROCESSING FOR ALBUM %s, DISC %s, TRACK %s',
+ track_metadata['album'],
+ track_metadata['discnumber'],
+ track_metadata['tracknumber'] +
+ ' ' +
+ track_metadata['title'])
+ # clear the cache if required (if this is not done, then queue count may get out of sync)
+ # Jump through hoops to get track object!!
+ track = album._new_tracks[-1]
+ tm = track.metadata
+ if config.setting['log_debug'] or config.setting['log_info']:
+ write_log(
+ release_id,
+ 'debug',
+ 'Cache setting for track %s is %s',
+ track,
+ config.setting['use_cache'])
+
+ # OPTIONS - OVER-RIDE IF REQUIRED
+ if '~ce_options' not in tm:
+ if config.setting['log_debug'] or config.setting['log_info']:
+ write_log(release_id, 'debug', 'Workparts gets track first...')
+ get_options(release_id, album, track)
+ options = interpret(tm['~ce_options'])
+
+ if not options:
+ if config.setting['log_error']:
+ write_log(
+ release_id,
+ 'error',
+ 'Work Parts. Failure to read saved options for track %s. options = %s',
+ track,
+ tm['~ce_options'])
+ options = option_settings(config.setting)
+ self.options[track] = options
+
+ # CONSTANTS
+ write_log(release_id, 'basic', 'Options: %s' ,options)
+ self.ERROR = options["log_error"]
+ self.WARNING = options["log_warning"]
+ self.SEPARATORS = ['; ']
+ self.EQ = "EQ_TO_BE_REVERSED" # phrase to indicate that a synonym has been used
+
+ self.get_sk_tags(release_id, album, track, tm, options)
+ self.synonyms[track] = self.get_text_tuples(
+ release_id, track, 'synonyms') # a list of tuples
+ self.replacements[track] = self.get_text_tuples(
+ release_id, track, 'replacements') # a list of tuples
+
+ # Continue?
+ if not options["classical_work_parts"]:
+ return
+
+ # OPTION-DEPENDENT CONSTANTS:
+ # Maximum number of XML- lookup retries if error returned from server
+ self.MAX_RETRIES = options["cwp_retries"]
+ self.USE_CACHE = options["use_cache"]
+ if options["cwp_partial"] and options["cwp_partial_text"] and options["cwp_level0_works"]:
+ options["cwp_removewords_p"] = options["cwp_removewords"] + \
+ ", " + options["cwp_partial_text"] + ' '
+ else:
+ options["cwp_removewords_p"] = options["cwp_removewords"]
+ # Explanation:
+ # If "Partial" is selected then the level 0 work name will have PARTIAL_TEXT appended to it.
+ # If a recording is split across several tracks then each sub-part (quasi-movement) will have the same name
+ # (with the PARTIAL_TEXT added). If level 0 is used to source work names then the level 1 work name will be
+ # changed to be this repeated name and will therefore also include PARTIAL_TEXT.
+ # So we need to add PARTIAL_TEXT to the prefixes list to ensure it is excluded from the level 1 work name.
+ #
+ write_log(
+ release_id,
+ 'debug',
+ "PartLevels - LOAD NEW TRACK: :%s",
+ track)
+ # write_log(release_id, 'info', "trackXmlNode:") # warning - may break Picard
+
+ # first time for this album (reloads each refresh)
+ if tm['discnumber'] == '1' and tm['tracknumber'] == '1':
+ # get artist aliases - these are cached so can be re-used across
+ # releases, but are reloaded with each refresh
+ get_aliases(self, release_id, album, options, releaseXmlNode)
+
+ # fix titles which include composer name
+ composersort =[]
+ if 'compposersort' in tm:
+ composersort = str_to_list(['composersort'])
+ composerlastnames = []
+ for composer in composersort:
+ lname = re.compile(r'(.*),')
+ match = lname.search(composer)
+ if match:
+ composerlastnames.append(match.group(1))
+ else:
+ composerlastnames.append(composer)
+ title = track_metadata['title']
+ colons = title.count(":")
+ if colons > 0:
+ title_split = title.split(': ', 1)
+ test = title_split[0]
+ if test in composerlastnames:
+ track_metadata['~cwp_title'] = title_split[1]
+
+ # now process works
+ write_log(
+ release_id,
+ 'info',
+ 'PartLevels - add_work_info - metadata load = %r',
+ track_metadata)
+ workIds = []
+ if 'musicbrainz_workid' in tm:
+ workIds = str_to_list(tm['musicbrainz_workid'])
+ if workIds and not (options["ce_no_run"] and (
+ not tm['~ce_file'] or tm['~ce_file'] == "None")):
+ self.build_work_info(release_id, options, trackXmlNode, album, track, track_metadata, workIds)
+
+ else: # no work relation
+ write_log(
+ release_id,
+ 'warning',
+ "WARNING - no works for this track: \"%s\"",
+ title)
+ self.append_tag(
+ release_id,
+ track_metadata,
+ '~cwp_warning',
+ '3. No works for this track')
+ if album in self.orphan_tracks:
+ if track not in self.orphan_tracks[album]:
+ self.orphan_tracks[album].append(track)
+ else:
+ self.orphan_tracks[album] = [track]
+ # Don't publish metadata yet until all album is processed
+
+ # last track
+ write_log(
+ release_id,
+ 'debug',
+ 'Check for last track. Requests = %s, Tracknumber = %s, Totaltracks = %s,'
+ ' Discnumber = %s, Totaldiscs = %s',
+ album._requests,
+ track_metadata['tracknumber'],
+ track_metadata['totaltracks'],
+ track_metadata['discnumber'],
+ track_metadata['totaldiscs'])
+ if album._requests == 0 and track_metadata['tracknumber'] == track_metadata[
+ 'totaltracks'] and track_metadata['discnumber'] == track_metadata['totaldiscs']:
+ self.process_album(release_id, album)
+ release_status[release_id]['works-done'] = datetime.now()
+ close_log(release_id, 'works')
+
+
+ def build_work_info(self, release_id, options, trackXmlNode, album, track, track_metadata, workIds):
+ """
+ Construct the work metadata, taking into account partial recordings and medleys
+ :param release_id:
+ :param options:
+ :param trackXmlNode: JSON returned by the webservice
+ :param album:
+ :param track:
+ :param track_metadata:
+ :param workIds: work ids for this track
+ :return:
+ """
+ work_list_info = []
+ keyed_workIds = {}
+ for i, workId in enumerate(workIds):
+
+ # sort by ordering_key, if any
+ match_tree = [
+ 'recording',
+ 'relations',
+ 'target-type:work',
+ 'work',
+ 'id:' + workId]
+ rels = parse_data(release_id, trackXmlNode, [], *match_tree)
+ # for recordings which are ordered within track:-
+ match_tree_1 = [
+ 'ordering-key']
+ # for recordings of works which are ordered as part of parent
+ # (may be duplicated by top-down check later):-
+ match_tree_2 = [
+ 'relations',
+ 'target-type:work',
+ 'type:parts',
+ 'direction:backward',
+ 'ordering-key']
+ parse_result = parse_data(release_id,
+ rels,
+ [],
+ *match_tree_1) + parse_data(release_id,
+ rels,
+ [],
+ *match_tree_2)
+ write_log(
+ release_id,
+ 'info',
+ 'multi-works - ordering key: %s',
+ parse_result)
+ if parse_result:
+ if isinstance(parse_result[0], int):
+ key = parse_result[0]
+ elif isinstance(parse_result[0], str) and parse_result[0].isdigit():
+ key = int(parse_result[0])
+ else:
+ key = 100 + i
+ else:
+ key = 100 + i
+ keyed_workIds[key] = workId
+ partial = False
+ for key in sorted(keyed_workIds):
+ workId = keyed_workIds[key]
+ work_rels = parse_data(
+ release_id,
+ trackXmlNode,
+ [],
+ 'recording',
+ 'relations',
+ 'target-type:work',
+ 'work.id:' + workId)
+ write_log(release_id, 'info', 'work_rels: %s', work_rels)
+ work_attributes = parse_data(
+ release_id, work_rels, [], 'attributes')[0]
+ write_log(
+ release_id,
+ 'info',
+ 'work_attributes: %s',
+ work_attributes)
+ work_titles = parse_data(
+ release_id, work_rels, [], 'work', 'title')
+ work_list_info_item = {
+ 'id': workId,
+ 'attributes': work_attributes,
+ 'titles': work_titles}
+ work_list_info.append(work_list_info_item)
+ work = []
+ for title in work_titles:
+ work.append(title)
+ if options['cwp_partial']:
+ # treat the recording as work level 0 and the work of which it
+ # is a partial recording as work level 1
+ if 'partial' in work_attributes:
+ partial = True
+ parentId = workId
+ workId = track_metadata['musicbrainz_recordingid']
+
+ works = []
+ for w in work:
+ partwork = w
+ works.append(partwork)
+
+ write_log(
+ release_id,
+ 'info',
+ "Id %s is PARTIAL RECORDING OF id: %s, name: %s",
+ workId,
+ parentId,
+ work)
+ work_list_info_item = {
+ 'id': workId,
+ 'attributes': [],
+ 'titles': works,
+ 'parent': parentId}
+ work_list_info.append(work_list_info_item)
+ write_log(
+ release_id,
+ 'info',
+ 'work_list_info: %s',
+ work_list_info)
+ # we now have a list of items, where the id of each is a work id for the track or
+ # (multiple instances of) the recording id (for partial works)
+ # we need to turn this into a usable hierarchy - i.e. just one item
+ workId_list = []
+ work_list = []
+ parent_list = []
+ attribute_list = []
+ workId_list_p = []
+ work_list_p = []
+ attribute_list_p = []
+ for w in work_list_info:
+ if 'partial' not in w['attributes'] or not options[
+ 'cwp_partial']: # just do the bottom-level 'works' first
+ workId_list.append(w['id'])
+ work_list += w['titles']
+ attribute_list += w['attributes']
+ if 'parent' in w:
+ if w['parent'] not in parent_list: # avoid duplicating parents!
+ parent_list.append(w['parent'])
+ else:
+ workId_list_p.append(w['id'])
+ work_list_p += w['titles']
+ attribute_list_p += w['attributes']
+ # de-duplicate work names
+ # list(set()) won't work as need to retain order
+ work_list = list(collections.OrderedDict.fromkeys(work_list))
+ work_list_p = list(collections.OrderedDict.fromkeys(work_list_p))
+
+ workId_tuple = tuple(workId_list)
+ workId_tuple_p = tuple(workId_list_p)
+ if workId_tuple not in self.work_listing[album]:
+ self.work_listing[album].append(workId_tuple)
+ if workId_tuple not in self.parts or not self.USE_CACHE:
+ self.parts[workId_tuple]['name'] = work_list
+ if parent_list:
+ if workId_tuple in self.works_cache:
+ self.works_cache[workId_tuple] += parent_list
+ self.parts[workId_tuple]['parent'] += parent_list
+ else:
+ self.works_cache[workId_tuple] = parent_list
+ self.parts[workId_tuple]['parent'] = parent_list
+ self.parts[workId_tuple_p]['name'] = work_list_p
+ if workId_tuple_p not in self.work_listing[album]:
+ self.work_listing[album].append(workId_tuple_p)
+
+ if 'medley' in attribute_list_p:
+ self.parts[workId_tuple_p]['medley'] = True
+
+ if 'medley' in attribute_list:
+ self.parts[workId_tuple]['medley'] = True
+
+ if partial:
+ self.parts[workId_tuple]['partial'] = True
+
+ self.trackback[album][workId_tuple]['id'] = workId_list
+ if 'meta' in self.trackback[album][workId_tuple]:
+ if (track,
+ album) not in self.trackback[album][workId_tuple]['meta']:
+ self.trackback[album][workId_tuple]['meta'].append(
+ (track, album))
+ else:
+ self.trackback[album][workId_tuple]['meta'] = [(track, album)]
+ write_log(
+ release_id,
+ 'info',
+ "Trackback for %s is %s. Partial = %s",
+ track,
+ self.trackback[album][workId_tuple],
+ partial)
+
+ if workId_tuple in self.works_cache and (
+ self.USE_CACHE or partial):
+ write_log(
+ release_id,
+ 'debug',
+ "GETTING WORK METADATA FROM CACHE, for work %s",
+ workId_tuple)
+ if workId_tuple not in self.work_listing[album]:
+ self.work_listing[album].append(workId_tuple)
+ not_in_cache = self.check_cache(
+ track_metadata, album, track, workId_tuple, [])
+ else:
+ if partial:
+ not_in_cache = [workId_tuple_p]
+ else:
+ not_in_cache = [workId_tuple]
+ for workId_tuple in not_in_cache:
+ if not self.USE_CACHE:
+ if workId_tuple in self.works_cache:
+ del self.works_cache[workId_tuple]
+ self.work_not_in_cache(release_id, album, track, workId_tuple)
+
+
+ def get_sk_tags(self, release_id, album, track, tm, options):
+ """
+ Get file tags which are consistent with SongKong's metadata usage
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param track:
+ :param tm:
+ :param options:
+ :return:
+ """
+ if options["cwp_use_sk"]:
+ if '~ce_file' in tm and interpret(tm['~ce_file']):
+ music_file = tm['~ce_file']
+ orig_metadata = album.tagger.files[music_file].orig_metadata
+ if 'musicbrainz_work_composition_id' in orig_metadata and 'musicbrainz_workid' in orig_metadata:
+ if 'musicbrainz_work_composition' in orig_metadata:
+ if 'musicbrainz_work' in orig_metadata:
+ if orig_metadata['musicbrainz_work_composition_id'] == orig_metadata[
+ 'musicbrainz_workid'] \
+ and orig_metadata['musicbrainz_work_composition'] != orig_metadata[
+ 'musicbrainz_work']:
+ # Picard may have overwritten SongKong tag (top
+ # work id) with bottom work id
+ write_log(
+ release_id,
+ 'warning',
+ 'File tag musicbrainz_workid incorrect? id = %s. Sourcing from MB',
+ orig_metadata['musicbrainz_workid'])
+ if self.WARNING:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_warning',
+ '4. File tag musicbrainz_workid incorrect? id = ' +
+ orig_metadata['musicbrainz_workid'] +
+ '. Sourcing from MB')
+ return None
+ write_log(
+ release_id,
+ 'info',
+ 'Read from file tag: musicbrainz_work_composition_id: %s',
+ orig_metadata['musicbrainz_work_composition_id'])
+ self.file_works[(album, track)].append({
+ 'workid': orig_metadata['musicbrainz_work_composition_id'].split('; '),
+ 'name': orig_metadata['musicbrainz_work_composition']})
+ else:
+ wid = orig_metadata['musicbrainz_work_composition_id']
+ write_log(
+ release_id,
+ 'error',
+ "No matching work name for id tag %s",
+ wid)
+ if self.ERROR:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_error',
+ '2. No matching work name for id tag ' +
+ wid)
+ return None
+ n = 1
+ while 'musicbrainz_work_part_level' + \
+ str(n) + '_id' in orig_metadata:
+ if 'musicbrainz_work_part_level' + \
+ str(n) in orig_metadata:
+ self.file_works[(album, track)].append({
+ 'workid': orig_metadata[
+ 'musicbrainz_work_part_level' + str(n) + '_id'].split('; '),
+ 'name': orig_metadata['musicbrainz_work_part_level' + str(n)]})
+ n += 1
+ else:
+ wid = orig_metadata['musicbrainz_work_part_level' +
+ str(n) + '_id']
+ write_log(
+ release_id, 'error', "No matching work name for id tag %s", wid)
+ if self.ERROR:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_error',
+ '2. No matching work name for id tag ' +
+ wid)
+ break
+ if orig_metadata['musicbrainz_work_composition_id'] != orig_metadata[
+ 'musicbrainz_workid']:
+ if 'musicbrainz_work' in orig_metadata:
+ self.file_works[(album, track)].append({
+ 'workid': orig_metadata['musicbrainz_workid'].split('; '),
+ 'name': orig_metadata['musicbrainz_work']})
+ else:
+ wid = orig_metadata['musicbrainz_workid']
+ write_log(
+ release_id, 'error', "No matching work name for id tag %s", wid)
+ if self.ERROR:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_error',
+ '2. No matching work name for id tag ' +
+ wid)
+ return None
+ file_work_levels = len(self.file_works[(album, track)])
+ write_log(release_id,
+ 'debug',
+ 'Loaded works from file tags for track %s. Works: %s: ',
+ track,
+ self.file_works[(album,
+ track)])
+ for i, work in enumerate(self.file_works[(album, track)]):
+ workId = tuple(work['workid'])
+ if workId not in self.works_cache: # Use cache in preference to file tags
+ if workId not in self.work_listing[album]:
+ self.work_listing[album].append(workId)
+ self.parts[workId]['name'] = [work['name']]
+ parentId = None
+ parent = ''
+ if i < file_work_levels - 1:
+ parentId = self.file_works[(
+ album, track)][i + 1]['workid']
+ parent = self.file_works[(
+ album, track)][i + 1]['name']
+
+ if parentId:
+ self.works_cache[workId] = parentId
+ self.parts[workId]['parent'] = parentId
+ self.parts[tuple(parentId)]['name'] = [parent]
+ else:
+ # so we remember we looked it up and found none
+ self.parts[workId]['no_parent'] = True
+ self.top_works[(track, album)
+ ]['workId'] = workId
+ if workId not in self.top[album]:
+ self.top[album].append(workId)
+
+ def check_cache(self, tm, album, track, workId_tuple, not_in_cache):
+ """
+ Recursive loop to get cached works
+ :param tm:
+ :param album:
+ :param track:
+ :param workId_tuple:
+ :param not_in_cache:
+ :return:
+ """
+ parentId_tuple = tuple(self.works_cache[workId_tuple])
+ if parentId_tuple not in self.work_listing[album]:
+ self.work_listing[album].append(parentId_tuple)
+
+ if parentId_tuple in self.works_cache:
+ self.check_cache(tm, album, track, parentId_tuple, not_in_cache)
+ else:
+ not_in_cache.append(parentId_tuple)
+ return not_in_cache
+
+ def work_not_in_cache(self, release_id, album, track, workId_tuple):
+ """
+ Determine actions if work not in cache (is it the top or do we need to look up?)
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param track:
+ :param workId_tuple:
+ :return:
+ """
+
+ write_log(
+ release_id,
+ 'debug',
+ 'Processing work_not_in_cache for workId %s',
+ workId_tuple)
+ ## NB the first condition below is to prevent the side effect of assigning a dictionary entry in self.parts for workId with no details
+ if workId_tuple in self.parts and 'no_parent' in self.parts[workId_tuple] and (
+ self.USE_CACHE or self.options[track]["cwp_use_sk"]) and self.parts[workId_tuple]['no_parent']:
+ write_log(release_id, 'info', '%s is top work', workId_tuple)
+ self.top_works[(track, album)]['workId'] = workId_tuple
+ if album in self.top:
+ if workId_tuple not in self.top[album]:
+ self.top[album].append(workId_tuple)
+ else:
+ self.top[album] = [workId_tuple]
+ else:
+ write_log(
+ release_id,
+ 'info',
+ 'Calling work_add_track to look up parents for %s',
+ workId_tuple)
+ for workId in workId_tuple:
+ self.work_add_track(album, track, workId, 0)
+
+ write_log(
+ release_id,
+ 'debug',
+ 'End of work_not_in_cache for workId %s',
+ workId_tuple)
+
+ def work_add_track(self, album, track, workId, tries, user_data=True):
+ """
+ Add the work to the lookup queue
+ :param user_data:
+ :param album:
+ :param track:
+ :param workId:
+ :param tries: number of lookup attempts
+ :return:
+ """
+ release_id = track.metadata['musicbrainz_albumid']
+ write_log(
+ release_id,
+ 'debug',
+ "ADDING WORK TO LOOKUP QUEUE for work %s",
+ workId)
+ self.album_add_request(release_id, album)
+ # to change the _requests variable to indicate that there are pending
+ # requests for this item and delay Picard from finalizing the album
+ write_log(
+ release_id,
+ 'debug',
+ "Added lookup request for id %s. Requests = %s",
+ workId,
+ album._requests)
+ if self.works_queue.append(
+ workId,
+ (track,
+ album)): # All work combos are queued, but only new workIds are passed to XML lookup
+ host = config.setting["server_host"]
+ port = config.setting["server_port"]
+ path = "/ws/2/%s/%s" % ('work', workId)
+ if config.setting['cwp_aliases'] and config.setting['cwp_aliases_tag_text']:
+ if config.setting['cwp_aliases_tags_user'] and user_data:
+ login = True
+ tag_type = '+tags +user-tags'
+ else:
+ login = False
+ tag_type = '+tags'
+ else:
+ login = False
+ tag_type = ''
+ queryargs = {
+ "inc": "work-rels+artist-rels+label-rels+place-rels+aliases" +
+ tag_type}
+ write_log(
+ release_id,
+ 'debug',
+ "Initiating XML lookup for %s......",
+ workId)
+ if release_id in release_status and 'lookups' in release_status[release_id]:
+ release_status[release_id]['lookups'] += 1
+ return album.tagger.webservice.get(
+ host,
+ port,
+ path,
+ partial(
+ self.work_process,
+ workId,
+ tries),
+ # parse_response_type="xml",
+ priority=True,
+ important=False,
+ mblogin=login,
+ queryargs=queryargs)
+ else:
+ write_log(
+ release_id,
+ 'debug',
+ "Work is already in queue: %s",
+ workId)
+
+ ##########################################################################
+ # SECTION 2 - Works processing #
+ # NB These functions may operate asynchronously over multiple albums (as well as multiple tracks) #
+ ##########################################################################
+
+ def work_process(self, workId, tries, response, reply, error):
+ """
+ Top routine to process the XML/JSON node response from the lookup
+ NB This function may operate over multiple albums (as well as multiple tracks)
+ :param workId:
+ :param tries:
+ :param response:
+ :param reply:
+ :param error:
+ :return:
+ """
+
+ if error:
+ tuples = self.works_queue.remove(workId)
+ for track, album in tuples:
+ release_id = track.metadata['musicbrainz_albumid']
+ write_log(
+ release_id,
+ 'warning',
+ "%r: Network error retrieving work record. Error code %r",
+ workId,
+ error)
+ write_log(
+ release_id,
+ 'debug',
+ "Removed request after network error. Requests = %s",
+ album._requests)
+ if tries < self.MAX_RETRIES:
+ user_data = True
+ write_log(release_id, 'debug', "REQUEUEING...")
+ if str(error) == '204': # Authentication error
+ write_log(
+ release_id, 'debug', "... without user authentication")
+ user_data = False
+ self.append_tag(
+ release_id,
+ track.metadata,
+ '~cwp_error',
+ '3. Authentication failure - data retrieval omits user-specific requests')
+ self.work_add_track(
+ album, track, workId, tries + 1, user_data)
+ else:
+ write_log(
+ release_id,
+ 'error',
+ "EXHAUSTED MAX RE-TRIES for XML lookup for track %s",
+ track)
+ if self.ERROR:
+ self.append_tag(
+ release_id,
+ track.metadata,
+ '~cwp_error',
+ "4. ERROR: MISSING METADATA due to network errors. Re-try or fix manually.")
+ self.album_remove_request(release_id, album)
+ return
+
+ tuples = self.works_queue.remove(workId)
+ if tuples:
+ new_queue = []
+ prev_album = None
+ for (track, album) in tuples:
+ release_id = track.metadata['musicbrainz_albumid']
+ # Note that this need to be set here as the work may cover
+ # multiple albums
+ if album != prev_album:
+ write_log(release_id, 'debug',
+ "Work_process. FOUND WORK: %s for album %s",
+ workId, album)
+ write_log(
+ release_id,
+ 'debug',
+ "Requests for album %s = %s",
+ album,
+ album._requests)
+ prev_album = album
+ write_log(release_id, 'info', "RESPONSE = %s", response)
+ # find the id_tuple(s) key with workId in it
+ wid_list = []
+ for w in self.work_listing[album]:
+ if workId in w and w not in wid_list:
+ wid_list.append(w)
+ write_log(
+ release_id,
+ 'info',
+ 'wid_list for %s is %s',
+ workId,
+ wid_list)
+ for wid in wid_list: # wid is a tuple
+ write_log(
+ release_id,
+ 'info',
+ 'processing workId tuple: %r',
+ wid)
+ metaList = self.work_process_metadata(
+ release_id, workId, wid, track, response)
+ parentList = metaList[0]
+ # returns [[parent id], [parent name], attribute_list] or None if no parent
+ # found
+ arrangers = metaList[1]
+ # not just arrangers - also composers, lyricists etc.
+ if wid in self.parts:
+
+ if arrangers:
+ if 'arrangers' in self.parts[wid]:
+ self.parts[wid]['arrangers'] += arrangers
+ else:
+ self.parts[wid]['arrangers'] = arrangers
+
+ if parentList:
+ # first fix the sort order of multi-works at the prev level
+ # so that recordings of multiple movements of the same parent work will have the
+ # movements listed in the correct order (i.e.
+ # ordering-key, if available)
+ if len(wid) > 1:
+ for idx in wid:
+ if idx == workId:
+ match_tree = [
+ 'relations',
+ 'target-type:work',
+ 'direction:backward',
+ 'ordering-key']
+ parse_result = parse_data(
+ release_id, response, [], *match_tree)
+ write_log(
+ release_id,
+ 'info',
+ 'multi-works - ordering key for id %s is %s',
+ idx,
+ parse_result)
+ if parse_result:
+ if isinstance(
+ parse_result[0], str) and parse_result[0].isdigit():
+ key = int(parse_result[0])
+ elif isinstance(parse_result[0], int):
+ key = parse_result[0]
+ else:
+ key = 9999
+ self.parts[wid]['order'][idx] = key
+
+ parentIds = parentList[0]
+ parents = parentList[1]
+ parent_attributes = parentList[2]
+ write_log(
+ release_id,
+ 'info',
+ 'Parents - ids: %s, names: %s',
+ parentIds,
+ parents)
+ # remove any parents that are descendants of wid as
+ # they will result in circular references
+ del_list = []
+ for i, parentId in enumerate(parentIds):
+ for work_item in wid:
+ if work_item in self.child_listing and parentId in self.child_listing[
+ work_item]:
+ del_list.append(i)
+ for i in list(set(del_list)):
+ removed_id = parentIds.pop(i)
+ removed_name = parents.pop(i)
+ write_log(
+ release_id, 'error', "Found parent which is descendant of child - "
+ "not using, to prevent circular references. id = %s,"
+ " name = %s", removed_id, removed_name)
+ tm = track.metadata
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_error',
+ '5. Found parent which which is descendant of child - not using '
+ 'to prevent circular references. id = ' +
+ removed_id +
+ ', name = ' +
+ removed_name)
+ is_collection = False
+ for attribute in parent_attributes:
+ if attribute['collection']:
+ is_collection = True
+ break
+ # de-dup parent ids before we start
+ parentIds = list(
+ collections.OrderedDict.fromkeys(parentIds))
+
+ # add descendants to checklist to prevent recursion
+ for p in parentIds:
+ for w in wid:
+ self.child_listing[p].append(w)
+ if w in self.child_listing:
+ self.child_listing[p] += self.child_listing[w]
+
+ if parentIds:
+ if wid in self.works_cache:
+ # Make sure we haven't done this
+ # relationship before, perhaps for another
+ # album
+
+ if not (set(
+ self.works_cache[wid]) >= set(parentIds)):
+ prev_ids = tuple(self.works_cache[wid])
+ prev_name = self.parts[prev_ids]['name']
+ self.works_cache[wid] = add_list_uniquely(
+ self.works_cache[wid], parentIds)
+ self.parts[wid]['parent'] = add_list_uniquely(
+ self.parts[wid]['parent'], parentIds)
+ index = self.work_listing[album].index(
+ prev_ids)
+ new_id_list = add_list_uniquely(
+ list(prev_ids), parentIds)
+ new_ids = tuple(new_id_list)
+ self.work_listing[album][index] = new_ids
+ self.parts[new_ids] = self.parts[prev_ids]
+ #del self.parts[prev_ids] # Removed from here to deal with multi-parent parts. De-dup now takes place in process_albums.
+ self.parts[new_ids]['name'] = add_list_uniquely(
+ prev_name, parents)
+ parentIds = new_id_list
+ write_log(
+ release_id,
+ 'debug',
+ "In work_process. Changed wid in self.part: prev_ids = %s, new_ids = %s, prev_name = %s, new name = %s",
+ prev_ids,
+ new_ids,
+ prev_name,
+ self.parts[new_ids]['name'])
+
+
+ else:
+ self.works_cache[wid] = parentIds
+ self.parts[wid]['parent'] = parentIds
+ self.parts[tuple(parentIds)
+ ]['name'] = parents
+ self.work_listing[album].append(
+ tuple(parentIds))
+ # de-duplicate the parent names
+ # self.parts[tuple(parentIds)]['name'] = list(
+ # collections.OrderedDict.fromkeys(self.parts[tuple(parentIds)]['name']))
+ # list(set()) won't work as need to retain order
+ self.parts[tuple(parentIds)]['is_collection'] = is_collection
+ write_log(
+ release_id,
+ 'debug',
+ "In work_process. self.parts[%s]['is_collection']: %s",
+ tuple(parentIds),
+ self.parts[tuple(parentIds)]['is_collection'])
+ # de-duplicate the parent ids also, otherwise they will be treated as a separate parent
+ # in the trackback structure
+ self.parts[wid]['parent'] = list(
+ collections.OrderedDict.fromkeys(
+ self.parts[wid]['parent']))
+ self.works_cache[wid] = list(
+ collections.OrderedDict.fromkeys(
+ self.works_cache[wid]))
+ write_log(
+ release_id,
+ 'info',
+ 'Added parent ids to work_listing: %s, [Requests = %s]',
+ parentIds,
+ album._requests)
+ write_log(
+ release_id,
+ 'info',
+ 'work_listing after adding parents: %s',
+ self.work_listing[album])
+ # the higher-level work might already be in
+ # cache from another album
+ if tuple(
+ parentIds) in self.works_cache and self.USE_CACHE:
+ not_in_cache = self.check_cache(
+ track.metadata, album, track, tuple(parentIds), [])
+ for workId_tuple in not_in_cache:
+ new_queue.append(
+ (release_id, album, track, workId_tuple))
+
+ else:
+ if not self.USE_CACHE:
+ if tuple(
+ parentIds) in self.works_cache:
+ del self.works_cache[tuple(
+ parentIds)]
+ for parentId in parentIds:
+ new_queue.append(
+ (release_id, album, track, (parentId,)))
+
+ else:
+ # so we remember we looked it up and found none
+ self.parts[wid]['no_parent'] = True
+ self.top_works[(track, album)]['workId'] = wid
+ if wid not in self.top[album]:
+ self.top[album].append(wid)
+ write_log(
+ release_id, 'info', "TOP[album]: %s", self.top[album])
+ else:
+ # so we remember we looked it up and found none
+ self.parts[wid]['no_parent'] = True
+ self.top_works[(track, album)]['workId'] = wid
+ self.top[album].append(wid)
+
+ write_log(
+ release_id,
+ 'debug',
+ "End of tuple processing for workid %s in album %s, track %s,"
+ " requests remaining = %s, new queue is %r",
+ workId,
+ album,
+ track,
+ album._requests,
+ new_queue)
+ self.album_remove_request(release_id, album)
+ for queued_item in new_queue:
+ write_log(
+ release_id,
+ 'info',
+ 'Have a new queue: queued_item = %r',
+ queued_item)
+ write_log(
+ release_id,
+ 'debug',
+ 'Penultimate end of work_process for %s (subject to parent lookups in "new_queue")',
+ workId)
+ for queued_item in new_queue:
+ self.work_not_in_cache(
+ queued_item[0],
+ queued_item[1],
+ queued_item[2],
+ queued_item[3])
+ write_log(release_id, 'debug',
+ 'Ultimate end of work_process for %s', workId)
+
+ if album._requests == 0:
+ self.process_album(release_id, album)
+ album._finalize_loading(None)
+ release_status[release_id]['works-done'] = datetime.now()
+ close_log(release_id, 'works')
+
+ def work_process_metadata(self, release_id, workId, wid, track, response):
+ """
+ Process XML node
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ NB release_id may be from a different album than the original, if works lookups are identical
+ :param workId:
+ :param wid:
+ :param response:
+ :return:
+ """
+ write_log(release_id, 'debug', "In work_process_metadata")
+ all_tags = parse_data(release_id, response, [], 'tags', 'name')
+ self.parts[wid]['folks_genres'] = all_tags
+ self.parts[wid]['worktype_genres'] = parse_data(
+ release_id, response, [], 'type')
+ key = parse_data(
+ release_id,
+ response,
+ [],
+ 'attributes',
+ 'type:Key',
+ 'value')
+ self.parts[wid]['key'] = key
+ composed_begin_dates = year(
+ parse_data(
+ release_id,
+ response,
+ [],
+ 'relations',
+ 'target-type:artist',
+ 'type:composer',
+ 'begin'))
+ composed_end_dates = year(
+ parse_data(
+ release_id,
+ response,
+ [],
+ 'relations',
+ 'target-type:artist',
+ 'type:composer',
+ 'end'))
+ if composed_begin_dates == composed_end_dates:
+ composed_dates = composed_begin_dates
+ else:
+ composed_dates = list(
+ zip(composed_begin_dates, composed_end_dates))
+ composed_dates = [y + DATE_SEP + z if y != z else y for y, z in composed_dates]
+ self.parts[wid]['composed_dates'] = composed_dates
+ published_begin_dates = year(
+ parse_data(
+ release_id,
+ response,
+ [],
+ 'relations',
+ 'target-type:label',
+ 'type:publishing',
+ 'begin'))
+ published_end_dates = year(
+ parse_data(
+ release_id,
+ response,
+ [],
+ 'relations',
+ 'target-type:label',
+ 'type:publishing',
+ 'end'))
+ if published_begin_dates == published_end_dates:
+ published_dates = published_begin_dates
+ else:
+ published_dates = list(
+ zip(published_begin_dates, published_end_dates))
+ published_dates = [x + DATE_SEP + y for x, y in published_dates]
+ self.parts[wid]['published_dates'] = published_dates
+
+ premiered_begin_dates = year(
+ parse_data(
+ release_id,
+ response,
+ [],
+ 'relations',
+ 'target-type:place',
+ 'type:premiere',
+ 'begin'))
+ premiered_end_dates = year(
+ parse_data(
+ release_id,
+ response,
+ [],
+ 'relations',
+ 'target-type:place',
+ 'type:premiere',
+ 'end'))
+ if premiered_begin_dates == premiered_end_dates:
+ premiered_dates = premiered_begin_dates
+ else:
+ premiered_dates = list(
+ zip(premiered_begin_dates, premiered_end_dates))
+ premiered_dates = [x + DATE_SEP + y for x, y in premiered_dates]
+ self.parts[wid]['premiered_dates'] = premiered_dates
+
+ if 'artist_locale' in config.setting:
+ locale = config.setting["artist_locale"]
+ # NB this is the Picard code in /util
+ lang = locale.split("_")[0]
+ alias = parse_data(release_id, response, [], 'aliases',
+ 'locale:' + lang, 'primary:True', 'name')
+ user_tags = parse_data(
+ release_id, response, [], 'user-tags', 'name')
+ if config.setting['cwp_aliases_tags_user']:
+ tags = user_tags
+ else:
+ tags = all_tags
+ if alias:
+ self.parts[wid]['alias'] = self.parts[wid]['name'][:]
+ self.parts[wid]['tags'] = tags
+ for ind, w in enumerate(wid):
+ if w == workId:
+ # alias should be a one item list but...
+ self.parts[wid]['alias'][ind] = '; '.join(
+ alias)
+ relation_list = parse_data(release_id, response, [], 'relations')
+ return self.work_process_relations(
+ release_id, track, workId, wid, relation_list)
+
+ def work_process_relations(
+ self,
+ release_id,
+ track,
+ workId,
+ wid,
+ relations):
+ """
+ Find the parents etc.
+ NB track is just the last album/track for this work - used as being
+ representative for options identification. If this is inconsistent (e.g. different collections
+ option for albums with the same works) then the latest added track will over-ride others' settings).
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param track:
+ :param workId:
+ :param wid:
+ :param relations:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'debug',
+ "In work_process_relations. Relations--> %s",
+ relations)
+ if track:
+ options = self.options[track]
+ else:
+ options = config.setting
+ new_workIds = []
+ new_works = []
+ attributes_list = []
+ relation_attributes = parse_data(
+ release_id,
+ relations,
+ [],
+ 'target-type:work',
+ 'type:parts',
+ 'direction:backward',
+ 'attributes')
+ new_work_list = []
+ write_log(
+ release_id,
+ 'debug',
+ "relation_attributes--> %s",
+ relation_attributes)
+ for relation_attribute in relation_attributes:
+ if (
+ 'part of collection' not in relation_attribute) or options['cwp_collections']:
+ new_work_list += parse_data(release_id,
+ relations,
+ [],
+ 'target-type:work',
+ 'type:parts',
+ 'direction:backward',
+ 'work')
+ attributes_dict = {'collection' : ('part of collection' in relation_attribute),
+ 'movements' : ('movement' in relation_attribute),
+ 'acts' : ('act' in relation_attribute),
+ 'numbers' : ('number' in relation_attribute)}
+ attributes_list += [attributes_dict]
+ if (
+ 'part of collection' in relation_attribute) and not options['cwp_collections']:
+ write_log(
+ release_id,
+ 'info',
+ 'Not getting parent work because relationship is "part of collection" and option not selected')
+ if new_work_list:
+ write_log(
+ release_id,
+ 'info',
+ 'new_work_list: %s',
+ new_work_list)
+ new_workIds = parse_data(release_id, new_work_list, [], 'id')
+ new_works = parse_data(release_id, new_work_list, [], 'title')
+ else:
+ arrangement_of = parse_data(
+ release_id,
+ relations,
+ [],
+ 'target-type:work',
+ 'type:arrangement',
+ 'direction:backward',
+ 'work')
+ if arrangement_of and options['cwp_arrangements']:
+ new_workIds = parse_data(release_id, arrangement_of, [], 'id')
+ new_works = parse_data(release_id, arrangement_of, [], 'title')
+ self.parts[wid]['arrangement'] = True
+ else:
+ medley_of = parse_data(
+ release_id,
+ relations,
+ [],
+ 'target-type:work',
+ 'type:medley',
+ 'work')
+ direction = parse_data(
+ release_id,
+ relations,
+ [],
+ 'target-type:work',
+ 'type:medley',
+ 'direction')
+ if 'backward' not in direction:
+ write_log(
+ release_id, 'info', 'Medley_of: %s', medley_of)
+ if medley_of and options['cwp_medley']:
+ medley_list = []
+ medley_id_list = []
+ for medley_item in medley_of:
+ medley_list = medley_list + \
+ parse_data(release_id, medley_item, [], 'title')
+ medley_id_list = medley_id_list + \
+ parse_data(release_id, medley_item, [], 'id')
+ # (parse_data is a list...)
+ new_workIds = medley_id_list
+ new_works = medley_list
+ write_log(
+ release_id, 'info', 'Medley_list: %s', medley_list)
+ self.parts[wid]['medley_list'] = medley_list
+
+ write_log(
+ release_id,
+ 'info',
+ 'New works: ids: %s, names: %s, attributes: %s',
+ new_workIds,
+ new_works,
+ attributes_list)
+
+ artists = get_artists(
+ options,
+ release_id,
+ {},
+ relations,
+ 'work')['artists']
+ # artist_types = ['arranger', 'instrument arranger', 'orchestrator', 'composer', 'writer', 'lyricist',
+ # 'librettist', 'revised by', 'translator', 'reconstructed by', 'vocal arranger']
+
+ write_log(release_id, 'info', "ARTISTS %s", artists)
+
+ workItems = (new_workIds, new_works, attributes_list)
+ itemsFound = [workItems, artists]
+ return itemsFound
+
+ @staticmethod
+ def album_add_request(release_id, album):
+ """
+ To keep track as to whether all lookups have been processed
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :return:
+ """
+ album._requests += 1
+ write_log(
+ release_id,
+ 'debug',
+ "Added album request - requests: %s",
+ album._requests)
+
+ @staticmethod
+ def album_remove_request(release_id, album):
+ """
+ To keep track as to whether all lookups have been processed
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :return:
+ """
+ album._requests -= 1
+ write_log(
+ release_id,
+ 'debug',
+ "Removed album request - requests: %s",
+ album._requests)
+
+ ##################################################
+ # SECTION 3 - Organise tracks and works in album #
+ ##################################################
+
+ def process_album(self, release_id, album):
+ """
+ Top routine to run end-of-album processes
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :return:
+ """
+ write_log(release_id, 'debug', "PROCESS ALBUM %s", album)
+ release_status[release_id]['done-lookups'] = datetime.now()
+ # De-duplicate names in self.parts, maintaining order (in case part names have been arrived at via multiple paths)
+ for part_item in self.parts:
+ if 'name' in self.parts[part_item]:
+ self.parts[part_item]['name'] = list(collections.OrderedDict.fromkeys(str_to_list(self.parts[part_item]['name'])))
+ # populate the inverse hierarchy
+ write_log(release_id, 'info', "Cache: %s", self.works_cache)
+ write_log(release_id, 'info', "Work listing %s", self.work_listing)
+ alias_tag_list = config.setting['cwp_aliases_tag_text'].split(',')
+ for i, tag_item in enumerate(alias_tag_list):
+ alias_tag_list[i] = tag_item.strip()
+ for workId in self.work_listing[album]:
+ if workId in self.parts:
+ write_log(
+ release_id,
+ 'info',
+ 'Processing workid: %s',
+ workId)
+ write_log(
+ release_id,
+ 'info',
+ 'self.work_listing[album]: %s',
+ self.work_listing[album])
+ if len(workId) > 1:
+ # fix the order of names using ordering keys gathered in
+ # work_process
+ if 'order' in self.parts[workId]:
+ seq = []
+ for idx in workId:
+ if idx in self.parts[workId]['order']:
+ seq.append(self.parts[workId]['order'][idx])
+ else:
+ # for the possibility of workids not part of
+ # the same parent and not all ordered
+ seq.append(999)
+ zipped_names = zip(self.parts[workId]['name'], seq)
+ sorted_tups = sorted(zipped_names, key=lambda x: x[1])
+ self.parts[workId]['name'] = [x[0]
+ for x in sorted_tups]
+ # use aliases where appropriate
+ # name is a list - need a string to test for Latin chars
+ name_string = '; '.join(self.parts[workId]['name'])
+ if config.setting['cwp_aliases']:
+ if config.setting['cwp_aliases_all'] or (
+ config.setting['cwp_aliases_greek'] and not only_roman_chars(name_string)) or (
+ 'tags' in self.parts[workId] and any(
+ x in self.parts[workId]['tags'] for x in alias_tag_list)):
+ if 'alias' in self.parts[workId] and self.parts[workId]['alias']:
+ self.parts[workId]['name'] = self.parts[workId]['alias'][:]
+ topId = None
+ write_log(
+ release_id,
+ 'info',
+ 'Works_cache: %s',
+ self.works_cache)
+ if workId in self.works_cache:
+ parentIds = tuple(self.works_cache[workId])
+ # for parentId in parentIds:
+ write_log(
+ release_id,
+ 'debug',
+ "Create inverses: %s, %s",
+ workId,
+ parentIds)
+ if parentIds in self.partof[album]:
+ if workId not in self.partof[album][parentIds]:
+ self.partof[album][parentIds].append(workId)
+ else:
+ self.partof[album][parentIds] = [workId]
+ write_log(release_id, 'info', "Partof: %s",
+ self.partof[album][parentIds])
+ if 'no_parent' in self.parts[parentIds]:
+ # to handle case if album includes works already in
+ # cache from a different album
+ if self.parts[parentIds]['no_parent']:
+ topId = parentIds
+ else:
+ topId = workId
+ if topId:
+ if album in self.top:
+ if topId not in self.top[album]:
+ self.top[album].append(topId)
+ else:
+ self.top[album] = [topId]
+ # work out the full hierarchy and part levels
+ height = 0
+ write_log(
+ release_id,
+ 'info',
+ "TOP: %s, \nALBUM: %s, \nTOP[ALBUM]: %s",
+ self.top,
+ album,
+ self.top[album])
+ if len(self.top[album]) > 1:
+ single_work_album = 0
+ else:
+ single_work_album = 1
+ for topId in self.top[album]:
+ self.create_trackback(release_id, album, topId)
+ write_log(
+ release_id,
+ 'info',
+ "Top id = %s, Name = %s",
+ topId,
+ self.parts[topId]['name'])
+ write_log(
+ release_id,
+ 'info',
+ "Trackback before levels: %s",
+ self.trackback[album][topId])
+ work_part_levels = self.level_calc(
+ release_id, self.trackback[album][topId], height)
+ write_log(
+ release_id,
+ 'info',
+ "Trackback after levels: %s",
+ self.trackback[album][topId])
+ # determine the level which will be the principal 'work' level
+ if work_part_levels >= 3:
+ ref_level = work_part_levels - single_work_album
+ else:
+ ref_level = work_part_levels
+ # extended metadata scheme won't display more than 3 work levels
+ # ref_level = min(3, ref_level)
+ ref_height = work_part_levels - ref_level
+ top_info = {
+ 'levels': work_part_levels,
+ 'id': topId,
+ 'name': self.parts[topId]['name'],
+ 'single': single_work_album}
+ # set the metadata in sequence defined by the work structure
+ answer = self.process_trackback(
+ release_id,
+ album,
+ self.trackback[album][topId],
+ ref_height,
+ top_info)
+ ##
+ # trackback is a tree in the form {album: {id: , children:{id: , children{},
+ # id: etc},
+ # id: etc} }
+ # process_trackback uses the trackback tree to derive title and level_0 based hierarchies
+ # from the structure. It also returns a tuple (id, tracks), where tracks has the structure
+ # {'track': [(track, height), (track, height), ...tuples...]
+ # 'work': [[worknames], [worknames], ...lists...]
+ # 'tracknumber': [num, num, ...floats of form n.nnn = disc.track...]
+ # 'title': [title, title, ...strings...]}
+ # each list is the same length - i.e. the number of tracks for the top work
+ # there can be more than one workname for a track
+ # height is the number of part levels for the related track
+ ##
+ if answer:
+ tracks = sorted(zip(answer[1]['track'], answer[1]['tracknumber']), key=lambda x: x[1])
+ # need them in tracknumber sequence for the movement numbers to be correct
+ write_log(release_id, 'info', "TRACKS: %s", tracks)
+ # work_part_levels = self.trackback[album][topId]['depth']
+ movement_count = 0
+ prev_movementgroup = None
+ for track, _ in tracks:
+ movement_count += 1
+ track_meta = track[0]
+ tm = track_meta.metadata
+ if '~cwp_workid_0' in tm:
+ workIds = tuple(str_to_list(tm['~cwp_workid_0']))
+ if workIds:
+ count = 0
+ self.process_work_artists(
+ release_id, album, track_meta, workIds, tm, count)
+ title_work_levels = 0
+ if '~cwp_title_work_levels' in tm:
+ title_work_levels = int(tm['~cwp_title_work_levels'])
+ movementgroup = self.extend_metadata(
+ release_id,
+ top_info,
+ track_meta,
+ ref_height,
+ title_work_levels) # revise for new data
+ if track_meta not in self.tracks[album]:
+ self.tracks[album][track_meta] = {}
+ if movementgroup:
+ if movementgroup != prev_movementgroup:
+ movement_count = 1
+ write_log(
+ release_id,
+ 'debug',
+ "processing movements for track: %s - movement-group is %s",
+ track, movementgroup)
+ self.tracks[album][track_meta]['movement-group'] = movementgroup
+ self.tracks[album][track_meta]['movement-number'] = movement_count
+ self.parts[tuple(movementgroup)]['movement-total'] = movement_count
+ prev_movementgroup = movementgroup
+
+ write_log(
+ release_id,
+ 'debug',
+ "FINISHED TRACK PROCESSING FOR Top work id: %s",
+ topId)
+ # Need to redo the loop so that all album-wide tm is updated before
+ # publishing
+ for track, movement_info in self.tracks[album].items():
+ self.publish_metadata(release_id, album, track, movement_info)
+ # #
+ # The messages below are normally commented out as they get VERY long if there are a lot of albums loaded
+ # For extreme debugging, remove the comments and just run one or a few albums
+ # Do not forget to comment out again.
+ # #
+ # write_log(release_id, 'info', 'Self.parts: %s', self.parts)
+ # write_log(release_id, 'info', 'Self.trackback: %s', self.trackback)
+
+ # tidy up
+ self.trackback[album].clear()
+ # Finally process the orphan tracks
+ if album in self.orphan_tracks:
+ for track in self.orphan_tracks[album]:
+ tm = track.metadata
+ options = self.options[track]
+ if options['cwp_derive_works_from_title']:
+ work, movt, inter_work = self.derive_from_title(release_id, track, tm['title'])
+ tm['~cwp_extended_work'] = tm['~cwp_extended_groupheading'] = tm['~cwp_title_work'] = \
+ tm['~cwp_title_groupheading'] = tm['~cwp_work'] = tm['~cwp_groupheading']= work
+ tm['~cwp_part'] = tm['~cwp_extended_part'] = tm['~cwp_title_part_0'] = movt
+ tm['~cwp_inter_work'] = tm['~cwp_extended_inter_work'] = tm['~cwp_inter_title_work'] = inter_work
+ self.publish_metadata(release_id, album, track)
+ write_log(release_id, 'debug', "PROCESS ALBUM function complete")
+
+ def create_trackback(self, release_id, album, parentId):
+ """
+ Create an inverse listing of the work-parent relationships
+ :param release_id:
+ :param album:
+ :param parentId:
+ :return: trackback for a given parentId
+ """
+ write_log(release_id, 'debug', "Create trackback for %s", parentId)
+ if parentId in self.partof[album]: # NB parentId is a tuple
+ for child in self.partof[album][parentId]: # NB child is a tuple
+ if child in self.partof[album]:
+ child_trackback = self.create_trackback(
+ release_id, album, child)
+ self.append_trackback(
+ release_id, album, parentId, child_trackback)
+ else:
+ self.append_trackback(
+ release_id, album, parentId, self.trackback[album][child])
+ return self.trackback[album][parentId]
+ else:
+ return self.trackback[album][parentId]
+
+ def append_trackback(self, release_id, album, parentId, child):
+ """
+ Recursive process to populate trackback
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param parentId:
+ :param child:
+ :return:
+ """
+ write_log(release_id, 'debug', "In append_trackback...")
+ if parentId in self.trackback[album]: # NB parentId is a tuple
+ if 'children' in self.trackback[album][parentId]:
+ if child not in self.trackback[album][parentId]['children']:
+ write_log(release_id, 'info', "TRYING TO APPEND...")
+ self.trackback[album][parentId]['children'].append(child)
+ write_log(
+ release_id,
+ 'info',
+ "...PARENT %s - ADDED %s as child",
+ self.parts[parentId]['name'],
+ child)
+ else:
+ write_log(
+ release_id,
+ 'info',
+ "Parent %s already has %s as child",
+ parentId,
+ child)
+ else:
+ self.trackback[album][parentId]['children'] = [child]
+ write_log(
+ release_id,
+ 'info',
+ "Existing PARENT %s - ADDED %s as child",
+ self.parts[parentId]['name'],
+ child)
+ else:
+ self.trackback[album][parentId]['id'] = parentId
+ self.trackback[album][parentId]['children'] = [child]
+ write_log(
+ release_id,
+ 'info',
+ "New PARENT %s - ADDED %s as child",
+ self.parts[parentId]['name'],
+ child)
+ write_log(
+ release_id,
+ 'info',
+ "APPENDED TRACKBACK: %s",
+ self.trackback[album][parentId])
+ return self.trackback[album][parentId]
+
+ def level_calc(self, release_id, trackback, height):
+ """
+ Recursive process to determine the max level for a work
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param trackback:
+ :param height: number of levels above this one
+ :return:
+ """
+ write_log(release_id, 'debug', 'In level_calc process')
+ if 'children' not in trackback:
+ write_log(release_id, 'info', "Got to bottom")
+ trackback['height'] = height
+ trackback['depth'] = 0
+ return 0
+ else:
+ trackback['height'] = height
+ height += 1
+ max_depth = 0
+ for child in trackback['children']:
+ write_log(release_id, 'info', "CHILD: %s", child)
+ depth = self.level_calc(release_id, child, height) + 1
+ write_log(release_id, 'info', "DEPTH: %s", depth)
+ max_depth = max(depth, max_depth)
+ trackback['depth'] = max_depth
+ return max_depth
+
+ ###########################################
+ # SECTION 4 - Process tracks within album #
+ ###########################################
+
+ def process_trackback(
+ self,
+ release_id,
+ album_req,
+ trackback,
+ ref_height,
+ top_info):
+ """
+ Set work structure metadata & govern other metadata-setting processes
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album_req:
+ :param trackback:
+ :param ref_height:
+ :param top_info:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'debug',
+ "IN PROCESS_TRACKBACK. Trackback = %s",
+ trackback)
+ tracks = collections.defaultdict(dict)
+ process_now = False
+ if 'meta' in trackback:
+ for track, album in trackback['meta']:
+ if album_req == album:
+ process_now = True
+ if process_now or 'children' not in trackback:
+ if 'meta' in trackback and 'id' in trackback and 'depth' in trackback and 'height' in trackback:
+ write_log(release_id, 'info', "Processing level 0")
+ depth = trackback['depth']
+ height = trackback['height']
+ workId = tuple(trackback['id'])
+ if depth != 0:
+ if 'children' in trackback:
+ child_response = self.process_trackback_children(
+ release_id, album_req, trackback, ref_height, top_info, tracks)
+ tracks = child_response[1]
+ write_log(
+ release_id,
+ 'info',
+ 'Bottom level for this trackback is higher level elsewhere - adjusting levels')
+ depth = 0
+ write_log(release_id, 'info', "WorkId: %s, Work name: %s", workId, self.parts[workId]['name'])
+ for track, album in trackback['meta']:
+ if album == album_req:
+ write_log(release_id, 'info', "Track: %s", track)
+ tm = track.metadata
+ write_log(
+ release_id, 'info', "Track metadata = %s", tm)
+ tm['~cwp_workid_' + str(depth)] = workId
+ self.write_tags(release_id, track, tm, workId)
+ self.make_annotations(release_id, track, workId)
+ # strip leading and trailing spaces from work names
+ if isinstance(self.parts[workId]['name'], str):
+ worktemp = self.parts[workId]['name'].strip()
+ else:
+ for index, it in enumerate(
+ self.parts[workId]['name']):
+ self.parts[workId]['name'][index] = it.strip()
+ worktemp = self.parts[workId]['name']
+ if isinstance(top_info['name'], str):
+ toptemp = top_info['name'].strip()
+ else:
+ for index, it in enumerate(top_info['name']):
+ top_info['name'][index] = it.strip()
+ toptemp = top_info['name']
+ tm['~cwp_work_' + str(depth)] = worktemp
+ tm['~cwp_part_levels'] = str(height)
+ tm['~cwp_work_part_levels'] = str(top_info['levels'])
+ tm['~cwp_workid_top'] = top_info['id']
+ tm['~cwp_work_top'] = toptemp
+ tm['~cwp_single_work_album'] = top_info['single']
+ write_log(
+ release_id, 'info', "Track metadata = %s", tm)
+ if 'track' in tracks:
+ tracks['track'].append((track, height))
+ else:
+ tracks['track'] = [(track, height)]
+ tracks['tracknumber'] = [int(tm['discnumber']) + (int(tm['tracknumber']) / 1000)]
+ # Hopefully no more than 999 tracks per disc!
+ write_log(release_id, 'info', "Tracks: %s", tracks)
+
+ response = (workId, tracks)
+ write_log(release_id, 'debug', "LEAVING PROCESS_TRACKBACK")
+ write_log(
+ release_id,
+ 'info',
+ "depth %s Response = %s",
+ depth,
+ response)
+ return response
+ else:
+ return None
+ else:
+ response = self.process_trackback_children(
+ release_id, album_req, trackback, ref_height, top_info, tracks)
+ return response
+
+ def process_trackback_children(
+ self,
+ release_id,
+ album_req,
+ trackback,
+ ref_height,
+ top_info,
+ tracks):
+ """
+ TODO add some better documentation!
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album_req:
+ :param trackback:
+ :param ref_height:
+ :param top_info:
+ :param tracks:
+ :return:
+ """
+ if 'id' in trackback and 'depth' in trackback and 'height' in trackback:
+ write_log(
+ release_id,
+ 'debug',
+ 'In process_children_trackback for trackback %s',
+ trackback)
+ depth = trackback['depth']
+ height = trackback['height']
+ parentId = tuple(trackback['id'])
+ parent = self.parts[parentId]['name']
+ width = 0
+ for child in trackback['children']:
+ width += 1
+ write_log(
+ release_id,
+ 'info',
+ "child trackback = %s",
+ child)
+ answer = self.process_trackback(
+ release_id, album_req, child, ref_height, top_info)
+ if answer:
+ workId = answer[0]
+ child_tracks = answer[1]['track']
+ for track in child_tracks:
+ track_meta = track[0]
+ track_height = track[1]
+ part_level = track_height - height
+ write_log(
+ release_id,
+ 'debug',
+ "Calling set metadata %s",
+ (part_level,
+ workId,
+ parentId,
+ parent,
+ track_meta))
+ self.set_metadata(
+ release_id, part_level, workId, parentId, parent, track_meta)
+ if 'track' in tracks:
+ tracks['track'].append(
+ (track_meta, track_height))
+ else:
+ tracks['track'] = [(track_meta, track_height)]
+ tm = track_meta.metadata
+ # ~cwp_title if composer had to be removed
+ title = tm['~cwp_title'] or tm['title']
+ if 'title' in tracks:
+ tracks['title'].append(title)
+ else:
+ tracks['title'] = [title]
+ # to make sure we get it as a list
+ work = tm.getall('~cwp_work_0')
+ if 'work' in tracks:
+ tracks['work'].append(work)
+ else:
+ tracks['work'] = [work]
+ if 'tracknumber' not in tm:
+ tm['tracknumber'] = 0
+ if 'discnumber' not in tm:
+ tm['discnumber'] = 0
+ if 'tracknumber' in tracks:
+ tracks['tracknumber'].append(
+ int(tm['discnumber']) + (int(tm['tracknumber']) / 1000))
+ else:
+ tracks['tracknumber'] = [
+ int(tm['discnumber']) + (int(tm['tracknumber']) / 1000)]
+ if tracks and 'track' in tracks:
+ track = tracks['track'][0][0]
+ # NB this will only be the first track of tracks, but its
+ # options will be used for the structure
+ self.derive_from_structure(
+ release_id, top_info, tracks, height, depth, width, 'title')
+ if self.options[track]["cwp_level0_works"]:
+ # replace hierarchical works with those from work_0 (for
+ # consistency)
+ self.derive_from_structure(
+ release_id, top_info, tracks, height, depth, width, 'work')
+
+ write_log(
+ release_id,
+ 'info',
+ "Trackback result for %s = %s",
+ parentId,
+ tracks)
+ response = parentId, tracks
+ write_log(
+ release_id,
+ 'debug',
+ "LEAVING PROCESS_CHILD_TRACKBACK depth %s Response = %s",
+ depth,
+ response)
+ return response
+ else:
+ return None
+ else:
+ return None
+
+ def derive_from_structure(
+ self,
+ release_id,
+ top_info,
+ tracks,
+ height,
+ depth,
+ width,
+ name_type):
+ """
+ Derive title (or work level-0) components from MB hierarchical work structure
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param top_info:
+ {'levels': work_part_levels,'id': topId,'name': self.parts[topId]['name'],'single': single_work_album}
+ :param tracks:
+ {'track':[(track1, height1), (track2, height2), ...], 'work': [work1, work2,...],
+ 'title': [title1, title2, ...], 'tracknumber': [tracknumber1, tracknumber2, ...]}
+ where height is the number of levels in total in the branch for that track (i.e. height 1 => work_0 & work_1)
+ :param height: number of levels above the current one
+ :param depth: maximum number of levels
+ :param width: number of siblings
+ :param name_type: work or title
+ :return:
+ """
+ if 'track' in tracks:
+ track = tracks['track'][0][0]
+ # NB this will only be the first track of tracks, but its
+ # options will be used for the structure
+ single_work_track = False # default
+ write_log(
+ release_id,
+ 'debug',
+ "Deriving info for %s from structure for tracks %s",
+ name_type,
+ tracks['track'])
+ write_log(
+ release_id,
+ 'info',
+ '%ss are %r',
+ name_type,
+ tracks[name_type])
+ if 'tracknumber' in tracks:
+ sorted_tracknumbers = sorted(tracks['tracknumber'])
+ else:
+ sorted_tracknumbers = None
+ write_log(
+ release_id,
+ 'info',
+ "SORTED TRACKNUMBERS: %s",
+ sorted_tracknumbers)
+ common_len = 0
+ if name_type in tracks:
+ meta_str = "_title" if name_type == 'title' else "_X0"
+ # in case of works, could be a list of lists
+ name_list = tracks[name_type]
+ write_log(
+ release_id,
+ 'info',
+ "%s list %s",
+ name_type,
+ name_list)
+ if len(name_list) == 1: # only one track in this work so try and extract using colons
+ single_work_track = True
+ track_height = tracks['track'][0][1]
+ if track_height - height > 0: # track_height - height == part_level
+ if name_type == 'title':
+ write_log(
+ release_id,
+ 'debug',
+ "Single track work. Deriving directly from title text: %s",
+ track)
+ ti = name_list[0]
+ common_subset = self.derive_from_title(
+ release_id, track, ti)[0]
+ else:
+ common_subset = ""
+ else:
+ common_subset = name_list[0]
+ write_log(
+ release_id,
+ 'info',
+ "%s is single-track work. common_subset is set to %s",
+ tracks['track'][0][0],
+ common_subset)
+ if common_subset:
+ common_len = len(common_subset)
+ else:
+ common_len = 0
+ else: # NB if names are lists of lists, we'll assume they all start the same way
+ if isinstance(name_list[0], list):
+ compare = name_list[0][0].split()
+ else:
+ # a list of the words in the first name
+ compare = name_list[0].split()
+ for name_item in name_list:
+ if isinstance(name_item, list):
+ name = name_item[0]
+ else:
+ name = name_item
+ lcs = longest_common_sequence(compare, name.split())
+ compare = lcs['sequence']
+ if not compare:
+ common_len = 0
+ break
+ if lcs['length'] > 0:
+ common_subset = " ".join(compare)
+ write_log(
+ release_id,
+ 'info',
+ "Common subset from %ss at level %s, item name %s ..........",
+ name_type,
+ tracks['track'][0][1] -
+ height,
+ name)
+ write_log(
+ release_id, 'info', "..........is %s", common_subset)
+ common_len = len(common_subset)
+
+ write_log(
+ release_id,
+ 'info',
+ "checked for common sequence - length is %s",
+ common_len)
+ for track_index, track_item in enumerate(tracks['track']):
+ track_meta = track_item[0]
+ tm = track_meta.metadata
+ top_level = int(tm['~cwp_part_levels'])
+ part_level = track_item[1] - height
+ if common_len > 0:
+ self.create_work_levels(release_id, name_type, tracks, track, track_index,
+ track_meta, tm, meta_str, part_level, depth, width, common_len)
+
+ else: # (no common substring at this level)
+ if name_type == 'work':
+ write_log(release_id, 'info',
+ 'single track work - indicator = %s. track = %s, part_level = %s, top_level = %s',
+ single_work_track, track_item, part_level, top_level)
+ if part_level >= top_level: # so it won't be covered by top-down action
+ for level in range(
+ 0, part_level + 1): # fill in the missing work names from the canonical list
+ if '~cwp' + meta_str + '_work_' + \
+ str(level) not in tm:
+ tm['~cwp' +
+ meta_str +
+ '_work_' +
+ str(level)] = tm['~cwp_work_' +
+ str(level)]
+ if level > 0:
+ self.level0_warn(release_id, tm, level)
+ if '~cwp' + meta_str + '_part_' + \
+ str(level) not in tm and '~cwp_part_' + str(level) in tm:
+ tm['~cwp' +
+ meta_str +
+ '_part_' +
+ str(level)] = tm['~cwp_part_' +
+ str(level)]
+ if level > 0:
+ self.level0_warn(release_id, tm, level)
+
+
+ def create_work_levels(self, release_id, name_type, tracks, track, track_index,
+ track_meta, tm, meta_str, part_level, depth, width, common_len):
+ """
+ For a group of tracks with common metadata in the title/level0 work, create the work structure
+ for that metadata, using the structure in the MB database
+ :param release_id:
+ :param name_type: title or work
+ :param tracks: {'track':[(track1, height1), (track2, height2), ...], 'work': [work1, work2,...],
+ 'title': [title1, title2, ...], 'tracknumber': [tracknumber1, tracknumber2, ...]}
+ where height is the number of levels in total in the branch for that track (i.e. height 1 => work_0 & work_1)
+ :param track:
+ :param track_index: index of track in tracks
+ :param track_meta:
+ :param tm: track meta (dup?)
+ :param meta_str: string created from name_type
+ :param part_level: The level of the current item in the works hierarchy
+ :param depth: The number of levels below the current item
+ :param width: The number of children of the current item
+ :param common_len: length of the common text
+ :return:
+ """
+ allow_repeats = True
+ write_log(
+ release_id,
+ 'info',
+ "Use %s info for track: %s at level %s",
+ name_type,
+ track_meta,
+ part_level)
+ name = tracks[name_type][track_index]
+ if isinstance(name, list):
+ work = name[0][:common_len]
+ else:
+ work = name[:common_len]
+ work = work.rstrip(":,.;- ")
+ if self.options[track]["cwp_removewords_p"]:
+ removewords = self.options[track]["cwp_removewords_p"].split(
+ ',')
+ else:
+ removewords = []
+ write_log(
+ release_id,
+ 'info',
+ "Prefixes (in %s) = %s",
+ name_type,
+ removewords)
+ for prefix in removewords:
+ prefix2 = str(prefix).lower().rstrip()
+ if prefix2[0] != " ":
+ prefix2 = " " + prefix2
+ write_log(
+ release_id, 'info', "checking prefix %s", prefix2)
+ if work.lower().endswith(prefix2):
+ if len(prefix2) > 0:
+ work = work[:-len(prefix2)]
+ common_len = len(work)
+ work = work.rstrip(":,.;- ")
+ if work.lower() == prefix2.strip():
+ work = ''
+ common_len = 0
+ write_log(
+ release_id,
+ 'info',
+ "work after prefix strip %s",
+ work)
+ write_log(release_id, 'info', "Prefixes checked")
+
+ tm['~cwp' + meta_str + '_work_' +
+ str(part_level)] = work
+
+ if part_level > 0 and name_type == "work":
+ write_log(
+ release_id,
+ 'info',
+ 'checking if %s is repeated name at part_level = %s',
+ work,
+ part_level)
+ write_log(release_id, 'info', 'lower work name is %s',
+ tm['~cwp' + meta_str + '_work_' + str(part_level - 1)])
+ # fill in missing names caused by no common string at lower levels
+ # count the missing levels and push the current name
+ # down to the lowest missing level
+ missing_levels = 0
+ fill_level = part_level - 1
+ while '~cwp' + meta_str + '_work_' + \
+ str(fill_level) not in tm:
+ missing_levels += 1
+ fill_level -= 1
+ if fill_level < 0:
+ break
+ write_log(
+ release_id,
+ 'info',
+ 'there is/are %s missing level(s)',
+ missing_levels)
+ if missing_levels > 0:
+ allow_repeats = True
+ for lev in range(
+ part_level - missing_levels, part_level):
+
+ if lev > 0: # not filled_lowest and lev > 0:
+ tm['~cwp' + meta_str +
+ '_work_' + str(lev)] = work
+ tm['~cwp' +
+ meta_str +
+ '_part_' +
+ str(lev - 1)] = self.strip_parent_from_work(track,
+ release_id,
+ interpret(tm['~cwp' + meta_str + '_work_'
+ + str(lev - 1)]),
+ tm['~cwp' + meta_str + '_work_' + str(lev)],
+ lev - 1, False)[0]
+ else:
+ tm['~cwp' + meta_str + '_work_' + str(lev)] = tm['~cwp_work_' + str(lev)]
+
+ if missing_levels > 0:
+ write_log(release_id, 'info', 'lower work name is now %r', tm.getall(
+ '~cwp' + meta_str + '_work_' + str(part_level - 1)))
+ # now fix the repeated work name at this level
+ if work == tm['~cwp' + meta_str + '_work_' +
+ str(part_level - 1)] and not allow_repeats:
+ tm['~cwp' +
+ meta_str +
+ '_work_' +
+ str(part_level)] = tm['~cwp_work_' +
+ str(part_level)]
+ self.level0_warn(release_id, tm, part_level)
+ tm['~cwp' +
+ meta_str +
+ '_part_' +
+ str(part_level -
+ 1)] = self.strip_parent_from_work(track,
+ release_id,
+ tm.getall('~cwp' + meta_str + '_work_' + str(part_level - 1)),
+ tm['~cwp' + meta_str + '_work_' + str(part_level)],
+ part_level - 1, False)[0]
+ if part_level == 1:
+ if isinstance(name, list):
+ movt = [x[common_len:].strip().lstrip(":,.;- ")
+ for x in name]
+ else:
+ movt = name[common_len:].strip().lstrip(":,.;- ")
+ write_log(
+ release_id, 'info', "%s - movt = %s", name_type, movt)
+ tm['~cwp' + meta_str + '_part_0'] = movt
+ write_log(
+ release_id,
+ 'info',
+ "%s Work part_level = %s",
+ name_type,
+ part_level)
+ if name_type == 'title':
+ if '~cwp_title_work_' + str(part_level - 1) in tm and tm['~cwp_title_work_' + str(
+ part_level)] == tm['~cwp_title_work_' + str(part_level - 1)] and width == 1:
+ pass # don't count higher part-levels which are not distinct from lower ones
+ # when the parent work has only one child
+ else:
+ tm['~cwp_title_work_levels'] = depth
+ tm['~cwp_title_part_levels'] = part_level
+ write_log(
+ release_id,
+ 'info',
+ "Set new metadata for %s OK",
+ name_type)
+
+ def level0_warn(self, release_id, tm, level):
+ """
+ Issue warnings if inadequate level 0 data
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param tm:
+ :param level:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'warning',
+ 'Unable to use level 0 as work name source in level %s - using hierarchy instead',
+ level)
+ if self.WARNING:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_warning',
+ '5. Unable to use level 0 as work name source in level ' +
+ str(level) +
+ ' - using hierarchy instead')
+
+ def set_metadata(
+ self,
+ release_id,
+ part_level,
+ workId,
+ parentId,
+ parent,
+ track):
+ """
+ Set the names of works and parts
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param part_level:
+ :param workId:
+ :param parentId:
+ :param parent:
+ :param track:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'debug',
+ "SETTING METADATA FOR TRACK = %r, parent = %s, part_level = %s",
+ track,
+ parent,
+ part_level)
+ tm = track.metadata
+ if parentId:
+ self.write_tags(release_id, track, tm, parentId)
+ self.make_annotations(release_id, track, parentId)
+ if 'annotations' in self.parts[workId]:
+ work_annotations = self.parts[workId]['annotations']
+ self.parts[workId]['stripped_annotations'] = work_annotations
+ else:
+ work_annotations = []
+ if 'annotations' in self.parts[parentId]:
+ parent_annotations = self.parts[parentId]['annotations']
+ else:
+ parent_annotations = []
+ if parent_annotations:
+ work_annotations = [
+ z for z in work_annotations if z not in parent_annotations]
+ self.parts[workId]['stripped_annotations'] = work_annotations
+
+ tm['~cwp_workid_' + str(part_level)] = parentId
+ tm['~cwp_work_' + str(part_level)] = parent
+ # maybe more than one work name
+ work = self.parts[workId]['name']
+ write_log(release_id, 'info', "Set work name to: %s", work)
+ works = []
+ # in case there is only one and it isn't in a list
+ if isinstance(work, str):
+ works.append(work)
+ else:
+ works = work[:]
+ stripped_works = []
+ for work in works:
+ extend = True
+ strip = self.strip_parent_from_work(
+ track, release_id, work, parent, part_level, extend, parentId, workId)
+
+ stripped_works.append(strip[0])
+ write_log(
+ release_id,
+ 'info',
+ "Parent: %s, Stripped works = %s",
+ parent,
+ stripped_works)
+ # now == parent, after removing full_parent logic
+ full_parent = strip[1]
+ if full_parent != parent:
+ tm['~cwp_work_' +
+ str(part_level)] = full_parent.strip()
+ self.parts[parentId]['name'] = full_parent
+ if 'no_parent' in self.parts[parentId]:
+ if self.parts[parentId]['no_parent']:
+ tm['~cwp_work_top'] = full_parent.strip()
+ tm['~cwp_part_' + str(part_level - 1)] = stripped_works
+ self.parts[workId]['stripped_name'] = stripped_works
+ write_log(release_id, 'debug', "GOT TO END OF SET_METADATA")
+
+ def write_tags(self, release_id, track, tm, workId):
+ """
+ write genre-related tags from internal variables
+ :param track:
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param tm: track metadata
+ :param workId: MBID of current work
+ :return: None - just writes tags
+ """
+ options = self.options[track]
+ candidate_genres = []
+ if options['cwp_genres_use_folks'] and 'folks_genres' in self.parts[workId]:
+ candidate_genres += self.parts[workId]['folks_genres']
+ if options['cwp_genres_use_worktype'] and 'worktype_genres' in self.parts[workId]:
+ candidate_genres += self.parts[workId]['worktype_genres']
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_candidate_genres',
+ candidate_genres)
+ self.append_tag(release_id, tm, '~cwp_keys', self.parts[workId]['key'])
+ self.append_tag(release_id, tm, '~cwp_composed_dates',
+ self.parts[workId]['composed_dates'])
+ self.append_tag(release_id, tm, '~cwp_published_dates',
+ self.parts[workId]['published_dates'])
+ self.append_tag(release_id, tm, '~cwp_premiered_dates',
+ self.parts[workId]['premiered_dates'])
+
+ def make_annotations(self, release_id, track, wid):
+ """
+ create an 'annotations' entry in the 'parts' dict, as dictated by options, from dates and keys
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param track: the current track
+ :param wid: the current work MBID
+ :return:
+ """
+ write_log(
+ release_id,
+ 'debug',
+ "Starting module %s",
+ 'make_annotations')
+ options = self.options[track]
+ if options['cwp_workdate_include']:
+ if options['cwp_workdate_source_composed'] and 'composed_dates' in self.parts[wid] and self.parts[wid]['composed_dates']:
+ workdates = self.parts[wid]['composed_dates']
+ elif options['cwp_workdate_source_published'] and 'published_dates' in self.parts[wid] and self.parts[wid]['published_dates']:
+ workdates = self.parts[wid]['published_dates']
+ elif options['cwp_workdate_source_premiered'] and 'premiered_dates' in self.parts[wid] and self.parts[wid]['premiered_dates']:
+ workdates = self.parts[wid]['premiered_dates']
+ else:
+ workdates = []
+ else:
+ workdates = []
+ keys = []
+ if options['cwp_key_include'] and 'key' in self.parts[wid] and self.parts[wid]['key']:
+ keys = self.parts[wid]['key']
+ elif options['cwp_key_contingent_include'] and 'key' in self.parts[wid] and self.parts[wid]['key']\
+ and 'name' in self.parts[wid]:
+ write_log(
+ release_id,
+ 'info',
+ 'checking for key. keys = %s, names = %s',
+ self.parts[wid]['key'],
+ self.parts[wid]['name'])
+ # add all the parent names to the string for checking -
+ work_name = list_to_str(self.parts[wid]['name'])
+ work_chk = wid
+ while work_chk in self.works_cache:
+ parent_chk = tuple(self.works_cache[work_chk])
+ if parent_chk in self.parts and self.parts[parent_chk] and 'name' in self.parts[parent_chk] and self.parts[parent_chk]['name']:
+ parent_name = list_to_str(self.parts[parent_chk]['name'])
+ p_name_orig = self.parts[parent_chk]['name']
+ p_chk = self.parts[parent_chk]
+ work_name = parent_name + ': ' + work_name
+ work_chk = parent_chk
+ # now see if the key has been mentioned in the work or its parents
+ for key in self.parts[wid]['key']:
+ # if not any([key.lower() in x.lower() for x in
+ # str_to_list(work_name)]): # TODO remove
+ if not key.lower() in work_name.lower():
+ keys.append(key)
+ annotations = keys + workdates
+ if annotations:
+ self.parts[wid]['annotations'] = annotations
+ else:
+ if 'annotations' in self.parts[wid]:
+ del self.parts[wid]['annotations']
+ write_log(
+ release_id,
+ 'info',
+ 'make annotations has set id %s on track %s with annotation %s',
+ wid,
+ track,
+ annotations)
+ write_log(
+ release_id,
+ 'debug',
+ "Ending module %s",
+ 'make_annotations')
+
+ @staticmethod
+ def derive_from_title(release_id, track, title):
+ """
+ Attempt to parse title to get components
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param track:
+ :param title:
+ :return:
+ """
+ write_log(
+ release_id,
+ 'info',
+ "DERIVING METADATA FROM TITLE for track: %s",
+ track)
+ tm = track.metadata
+ movt = title
+ work = ""
+ colons = title.count(":")
+ inter_work = None
+ if '~cwp_part_levels' in tm:
+ part_levels = int(tm['~cwp_part_levels'])
+ if int(tm['~cwp_work_part_levels']
+ ) > 0: # we have a work with movements
+ if colons > 0:
+ title_split = title.split(': ', 1)
+ title_rsplit = title.rsplit(': ', 1)
+ if part_levels >= colons:
+ work = title_rsplit[0]
+ movt = title_rsplit[1]
+ else:
+ work = title_split[0]
+ movt = title_split[1]
+ else:
+ # No works found so try and just get parts from title
+ if colons > 0:
+ title_split = title.rsplit(': ', 1)
+ work = title_split[0]
+ if colons > 1:
+ colon_ind = work.rfind(':')
+ work = work[:colon_ind]
+ inter_work = work[colon_ind+1:]
+ movt = title_split[1]
+ write_log(release_id, 'info', "Work %s, Movt %s", work, movt)
+ return work, movt, inter_work
+
+ def process_work_artists(
+ self,
+ release_id,
+ album,
+ track,
+ workIds,
+ tm,
+ count):
+ """
+ Carry out the artist processing that needs to be done in the PartLevels class
+ as it requires XML lookups of the works
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param track:
+ :param workIds:
+ :param tm:
+ :param count:
+ :return:
+ """
+ if not self.options[track]['classical_extra_artists']:
+ write_log(
+ release_id,
+ 'debug',
+ 'Not processing work_artists as ExtraArtists not selected to be run')
+ return None
+ write_log(
+ release_id,
+ 'debug',
+ 'In process_work_artists for track: %s, workIds: %s',
+ track,
+ workIds)
+ write_log(
+ release_id,
+ 'debug',
+ 'In process_work_artists for track: %s, self.parts: %s',
+ track,
+ self.parts)
+ if workIds in self.parts and 'arrangers' in self.parts[workIds]:
+ write_log(
+ release_id,
+ 'info',
+ 'Arrangers = %s',
+ self.parts[workIds]['arrangers'])
+ set_work_artists(
+ self,
+ release_id,
+ album,
+ track,
+ self.parts[workIds]['arrangers'],
+ tm,
+ count)
+ if workIds in self.works_cache:
+ count += 1
+ self.process_work_artists(release_id, album, track, tuple(
+ self.works_cache[workIds]), tm, count)
+
+ #################################################
+ # SECTION 5 - Extend work metadata using titles #
+ #################################################
+
+ def extend_metadata(self, release_id, top_info, track, ref_height, depth):
+ """
+ Combine MB work and title data according to user options
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param top_info:
+ :param track:
+ :param ref_height:
+ :param depth:
+ :return:
+ """
+ write_log(release_id, 'debug', 'IN EXTEND_METADATA')
+ tm = track.metadata
+ options = self.options[track]
+ if '~cwp_part_levels' not in tm:
+ write_log(
+ release_id,
+ 'debug',
+ 'NO PART LEVELS. Metadata = %s',
+ tm)
+ return None
+ part_levels = int(tm['~cwp_part_levels'])
+ write_log(
+ release_id,
+ 'debug',
+ "Extending metadata for track: %s, ref_height: %s, depth: %s, part_levels: %s",
+ track,
+ ref_height,
+ depth,
+ part_levels)
+ write_log(release_id, 'info', "Metadata = %s", tm)
+
+ # previously: ref_height = work_part_levels - ref_level,
+ # where this ref-level is the level for the top-named work
+ # so ref_height is effectively the "single work album" indicator (1 or 0) -
+ # i.e. where all tracks are part of one work which is implicitly the album
+ # without there being a groupheading for it
+ ref_level = part_levels - ref_height
+ # work_ref_level = work_part_levels - ref_height # not currently used
+
+ # replace works and parts by those derived from the level 0 work, where
+ # required, available and appropriate, but only use work names based on
+ # level 0 text if it doesn't cause ambiguity
+
+ # before embellishing with partial / arrangement etc
+ vanilla_part = tm['~cwp_part_0']
+
+ # Fix text for arrangements, partials and medleys (Done here so that
+ # cache can be used)
+ if options['cwp_arrangements'] and options["cwp_arrangements_text"]:
+ for lev in range(
+ 0,
+ ref_level): # top level will not be an arrangement else there would be a higher level
+ # needs to be a tuple to match
+ if '~cwp_workid_' + str(lev) in tm:
+ tup_id = tuple(str_to_list(tm['~cwp_workid_' + str(lev)]))
+ if 'arrangement' in self.parts[tup_id] and self.parts[tup_id]['arrangement']:
+ update_list = ['~cwp_work_', '~cwp_part_']
+ if options["cwp_level0_works"] and '~cwp_X0_work_' + \
+ str(lev) in tm:
+ update_list += ['~cwp_X0_work_', '~cwp_X0_part_']
+ for item in update_list:
+ tm[item + str(lev)] = options["cwp_arrangements_text"] + \
+ ' ' + tm[item + str(lev)]
+
+ if options['cwp_partial'] and options["cwp_partial_text"]:
+ if '~cwp_workid_0' in tm:
+ work0_id = tuple(str_to_list(tm['~cwp_workid_0']))
+ if 'partial' in self.parts[work0_id] and self.parts[work0_id]['partial']:
+ update_list = ['~cwp_work_0', '~cwp_part_0']
+ if options["cwp_level0_works"] and '~cwp_X0_work_0' in tm:
+ update_list += ['~cwp_X0_work_0', '~cwp_X0_part_0']
+ for item in update_list:
+ meta_item = tm.getall(item)
+ if isinstance(
+ meta_item, list): # it should be a list as I think getall always returns a list
+ if meta_item == []:
+ meta_item.append(options["cwp_partial_text"])
+ else:
+ for ind, w in enumerate(meta_item):
+ meta_item[ind] = options["cwp_partial_text"] + ' ' + w
+ write_log(
+ release_id, 'info', 'now meta item is %s', meta_item)
+ tm[item] = meta_item
+ else:
+ tm[item] = options["cwp_partial_text"] + \
+ ' ' + tm[item]
+ write_log(
+ release_id, 'info', 'meta item is not a list')
+
+ # fix "type 1" medley text
+ if options['cwp_medley']:
+ for lev in range(0, ref_level + 1):
+ if '~cwp_workid_' + str(lev) in tm:
+ tup_id = tuple(str_to_list(tm['~cwp_workid_' + str(lev)]))
+ if 'medley_list' in self.parts[tup_id] and self.parts[tup_id]['medley_list']:
+ medley_list = self.parts[tup_id]['medley_list']
+ tm['~cwp_work_' + str(lev)] += " (" + options["cwp_medley_text"] + \
+ ': ' + ', '.join(medley_list) + ")"
+ if '~cwp_part_' + str(lev) in tm:
+ tm['~cwp_part_' + str(
+ lev)] = "(" + options["cwp_medley_text"] + ") " + tm['~cwp_part_' + str(lev)]
+
+ # add any annotations for dates and keys
+ if options['cwp_workdate_include'] or options['cwp_key_include'] or options['cwp_key_contingent_include']:
+ if options["cwp_titles"] and part_levels == 0:
+ # ~cwp_title_work_0 will not have been set, but need it to hold any annotations
+ tm['~cwp_title_work_0'] = tm['~cwp_title'] or tm['title']
+ for lev in range(0, part_levels + 1):
+ if '~cwp_workid_' + str(lev) in tm:
+ tup_id = tuple(str_to_list(tm['~cwp_workid_' + str(lev)]))
+ if 'annotations' in self.parts[tup_id]:
+ write_log(
+ release_id,
+ 'info',
+ 'in extend_metadata, annotations for id %s on track %s are %s',
+ tup_id,
+ track,
+ self.parts[tup_id]['annotations'])
+ tm['~cwp_work_' + str(lev)] += " (" + \
+ ', '.join(self.parts[tup_id]['annotations']) + ")"
+ if options["cwp_level0_works"] and '~cwp_X0_work_' + \
+ str(lev) in tm:
+ tm['~cwp_X0_work_' + str(lev)] += " (" + ', '.join(
+ self.parts[tup_id]['annotations']) + ")"
+ if options["cwp_titles"] and '~cwp_title_work_' + \
+ str(lev) in tm:
+ tm['~cwp_title_work_' + str(lev)] += " (" + ', '.join(
+ self.parts[tup_id]['annotations']) + ")"
+ if lev < part_levels:
+ if 'stripped_annotations' in self.parts[tup_id]:
+ if self.parts[tup_id]['stripped_annotations']:
+ tm['~cwp_part_' + str(lev)] += " (" + ', '.join(
+ self.parts[tup_id]['stripped_annotations']) + ")"
+ if options["cwp_level0_works"] and '~cwp_X0_part_' + \
+ str(lev) in tm:
+ tm['~cwp_X0_part_' + str(lev)] += " (" + ', '.join(
+ self.parts[tup_id]['stripped_annotations']) + ")"
+ if options["cwp_titles"] and '~cwp_title_part_' + \
+ str(lev) in tm:
+ tm['~cwp_title_part' + str(lev)] += " (" + ', '.join(
+ self.parts[tup_id]['stripped_annotations']) + ")"
+
+ part = []
+ work = []
+ for level in range(0, part_levels):
+ part.append(tm['~cwp_part_' + str(level)])
+ work.append(tm['~cwp_work_' + str(level)])
+ work.append(tm['~cwp_work_' + str(part_levels)])
+
+ # Use level_0-derived names if applicable
+ if options["cwp_level0_works"]:
+ for level in range(0, part_levels + 1):
+ if '~cwp_X0_work_' + str(level) in tm:
+ work[level] = tm['~cwp_X0_work_' + str(level)]
+ else:
+ if level != 0:
+ work[level] = ''
+ if part and len(part) > level:
+ if '~cwp_X0_part_' + str(level) in tm:
+ part[level] = tm['~cwp_X0_part_' + str(level)]
+ else:
+ if level != 0:
+ part[level] = ''
+
+ # set up group heading and part
+ if part_levels > 0:
+ groupheading = work[1]
+ work_main = work[ref_level]
+ inter_work = None
+ work_titles = tm['~cwp_title_work_' + str(ref_level)]
+ if ref_level > 1:
+ for r in range(1, ref_level):
+ if inter_work:
+ inter_work = ': ' + inter_work
+ inter_work = part[r] + (inter_work or '')
+ groupheading = work[ref_level] + ':: ' + (inter_work or '')
+ else:
+ groupheading = work[0]
+ work_main = groupheading
+ inter_work = None
+ work_titles = None
+
+ # determine movement grouping (highest level that is not a collection)
+ if '~cwp_workid_top' in tm:
+ movementgroup = tuple(str_to_list(tm['~cwp_workid_top']))
+ n = part_levels
+ write_log(
+ release_id,
+ 'debug',
+ "In extend. self.parts[%s]['is_collection']: %s",
+ movementgroup,
+ self.parts[movementgroup]['is_collection'])
+ while self.parts[movementgroup]['is_collection']:
+ n -= 1
+ if n < 0:
+ # shouldn't happen in theory as bottom level can't be a collection, but just in case...
+ break
+ if '~cwp_workid_' + str(n) in tm:
+ movementgroup = tuple(str_to_list(tm['~cwp_workid_' + str(n)]))
+ else:
+ break
+
+ # set part text (initially)
+ if part:
+ part_main = part[0]
+ else:
+ part_main = work[0]
+ tm['~cwp_part'] = part_main
+
+ # fix medley text for "type 2" medleys
+ type2_medley = False
+ if self.parts[tuple(str_to_list(tm['~cwp_workid_0']))
+ ]['medley'] and options['cwp_medley']:
+ if options["cwp_medley_text"]:
+ if part_levels > 0:
+ medleyheading = groupheading + ':: ' + part[0]
+ else:
+ medleyheading = groupheading
+ groupheading = medleyheading + \
+ ' (' + options["cwp_medley_text"] + ')'
+ type2_medley = True
+
+ tm['~cwp_groupheading'] = groupheading
+ tm['~cwp_work'] = work_main
+ tm['~cwp_inter_work'] = inter_work
+ tm['~cwp_title_work'] = work_titles
+ write_log(
+ release_id,
+ 'debug',
+ "Groupheading set to: %s",
+ groupheading)
+ # extend group heading from title metadata
+ if groupheading:
+ ext_groupheading = groupheading
+ title_groupheading = None
+ ext_work = work_main
+ ext_inter_work = inter_work
+ inter_title_work = ""
+
+ if '~cwp_title_work_levels' in tm:
+
+ title_depth = int(tm['~cwp_title_work_levels'])
+ write_log(
+ release_id,
+ 'info',
+ "Title_depth: %s",
+ title_depth)
+ diff_work = [""] * ref_level
+ diff_part = [""] * ref_level
+ title_tag = [""]
+ # level 0 work for title # was 'x' # to avoid errors, reset
+ # before used
+ tw_str_lower = 'title'
+ max_d = min(ref_level, title_depth) + 1
+ for d in range(1, max_d):
+ tw_str = '~cwp_title_work_' + str(d)
+ write_log(release_id, 'info', "TW_STR = %s", tw_str)
+ if tw_str in tm:
+ title_tag.append(tm[tw_str])
+ title_work = title_tag[d]
+ work_main = ''
+ for w in range(d, ref_level + 1):
+ work_main += (work[w] + ' ')
+ diff_work[d - 1] = self.diff_pair(
+ release_id, track, tm, work_main, title_work)
+ if diff_work[d - 1]:
+ diff_work[d - 1] = diff_work[d - 1].strip('.;:-,')
+ if diff_work[d - 1] == '…':
+ diff_work[d - 1] = ''
+ if d > 1 and tw_str_lower in tm:
+ title_part = self.strip_parent_from_work(
+ track, release_id, tm[tw_str_lower], tm[tw_str], 0, False)[0]
+ if title_part:
+ title_part = title_part.strip(' .;:-,')
+ tm['~cwp_title_part_' +
+ str(d - 1)] = title_part
+ part_n = part[d - 1]
+ diff_part[d - 1] = self.diff_pair(
+ release_id, track, tm, part_n, title_part) or ""
+ if diff_part[d - 1] == '…':
+ diff_part[d - 1] = ''
+ else:
+ title_tag.append('')
+ tw_str_lower = tw_str
+ # remove duplicate items at lower levels in diff_work:
+ for w in range(ref_level - 2, -1, -1):
+ for higher in range(1, ref_level - w):
+ if diff_work[w] and diff_work[w + higher]:
+ diff_work[w] = diff_work[w].replace(
+ diff_work[w + higher], '').strip(' .;:-,\u2026')
+ # if diff_work[w] == '…':
+ # diff_work[w] = ''
+ write_log(
+ release_id,
+ 'info',
+ "diff list for works: %s",
+ diff_work)
+ write_log(
+ release_id,
+ 'info',
+ "diff list for parts: %s",
+ diff_part)
+ if not diff_work or len(diff_work) == 0:
+ if part_levels > 0:
+ ext_groupheading = groupheading
+ else:
+ write_log(
+ release_id,
+ 'debug',
+ "Now calc extended groupheading...")
+ write_log(
+ release_id,
+ 'info',
+ "depth = %s, ref_level = %s, title_depth = %s",
+ depth,
+ ref_level,
+ title_depth)
+ write_log(
+ release_id,
+ 'info',
+ "diff_work = %s, diff_part = %s",
+ diff_work,
+ diff_part)
+ # remove duplications:
+ for lev in range(1, ref_level):
+ for diff_list in [diff_work, diff_part]:
+ if diff_list[lev] and diff_list[lev - 1]:
+ diff_list[lev - 1] = self.diff_pair(
+ release_id, track, tm, diff_list[lev], diff_list[lev - 1])
+ if diff_list[lev - 1] == '…':
+ diff_list[lev - 1] = ''
+ write_log(
+ release_id,
+ 'info',
+ "Removed duplication. Revised diff_work = %s, diff_part = %s",
+ diff_work,
+ diff_part)
+ if part_levels > 0 and depth >= 1:
+ addn_work = []
+ addn_part = []
+ for stripped_work in diff_work:
+ if stripped_work:
+ write_log(
+ release_id, 'info', "Stripped work = %s", stripped_work)
+ addn_work.append(" {" + stripped_work + "}")
+ else:
+ addn_work.append("")
+ for stripped_part in diff_part:
+ if stripped_part and stripped_part != "":
+ write_log(release_id, 'info', "Stripped part = %s", stripped_part)
+ addn_part.append(" {" + stripped_part + "}")
+ else:
+ addn_part.append("")
+ write_log(
+ release_id,
+ 'info',
+ "addn_work = %s, addn_part = %s",
+ addn_work,
+ addn_part)
+ ext_groupheading = work[1] + addn_work[0]
+ ext_work = work[ref_level] + addn_work[ref_level - 1]
+ ext_inter_work = ""
+ inter_title_work = ""
+ title_groupheading = tm['~cwp_title_work_1']
+ if ref_level > 1:
+ for r in range(1, ref_level):
+ if ext_inter_work:
+ ext_inter_work = ': ' + ext_inter_work
+ ext_inter_work = part[r] + \
+ addn_work[r - 1] + ext_inter_work
+ ext_groupheading = work[ref_level] + \
+ addn_work[ref_level - 1] + ':: ' + ext_inter_work
+ if title_depth > 1 and ref_level > 1:
+ for r in range(1, min(title_depth, ref_level)):
+ if inter_title_work:
+ inter_title_work = ': ' + inter_title_work
+ inter_title_work = tm['~cwp_title_part_' +
+ str(r)] + inter_title_work
+ title_groupheading = tm['~cwp_title_work_' + str(
+ min(title_depth, ref_level))] + ':: ' + inter_title_work
+
+ else:
+ ext_groupheading = groupheading # title will be in part
+ ext_work = work_main
+ ext_inter_work = inter_work
+ inter_title_work = ""
+
+ write_log(release_id, 'debug', ".... ext_groupheading done")
+
+ if ext_groupheading:
+ write_log(
+ release_id,
+ 'info',
+ "EXTENDED GROUPHEADING: %s",
+ ext_groupheading)
+ tm['~cwp_extended_groupheading'] = ext_groupheading
+ tm['~cwp_extended_work'] = ext_work
+ if ext_inter_work:
+ tm['~cwp_extended_inter_work'] = ext_inter_work
+ if inter_title_work:
+ tm['~cwp_inter_title_work'] = inter_title_work
+ if title_groupheading:
+ tm['~cwp_title_groupheading'] = title_groupheading
+ write_log(
+ release_id,
+ 'info',
+ "title_groupheading = %s",
+ title_groupheading)
+ # extend part from title metadata
+ write_log(
+ release_id,
+ 'debug',
+ "NOW EXTEND PART...(part = %s)",
+ part_main)
+ if part_main:
+ if '~cwp_title_part_0' in tm:
+ movement = tm['~cwp_title_part_0']
+ else:
+ movement = tm['~cwp_title_part_0'] or tm['~cwp_title'] or tm['title']
+ if '~cwp_extended_groupheading' in tm:
+ work_compare = tm['~cwp_extended_groupheading'] + \
+ ': ' + part_main
+ elif '~cwp_work_1' in tm:
+ work_compare = work[1] + ': ' + part_main
+ else:
+ work_compare = work[0]
+ diff = self.diff_pair(
+ release_id, track, tm, work_compare, movement)
+ # compare with the fullest possible work name, not the stripped one
+ # - to maximise the duplication elimination
+ reverse_diff = self.diff_pair(
+ release_id, track, tm, movement, vanilla_part)
+ # for the reverse comparison use the part name without any work details or annotation
+ if diff and reverse_diff and self.parts[tuple(str_to_list(tm['~cwp_workid_0']))]['partial']:
+ diff = movement
+ # for partial tracks, do not eliminate the title text as it is
+ # frequently deliberately a component of the the overall work txt
+ # (unless it is identical)
+ fill_part = options['cwp_fill_part']
+ # To fill part with title text if it
+ # would otherwise have no text other than arrangement or partial
+ # annotations
+ if not diff and not vanilla_part and part_levels > 0 and fill_part:
+ # In other words the movement will have no text other than
+ # arrangement or partial annotations
+ diff = movement
+ write_log(release_id, 'info', "DIFF PART - MOVT. ti =%s", diff)
+ write_log(release_id,
+ 'info',
+ 'medley indicator for %s is %s',
+ tm['~cwp_workid_0'],
+ self.parts[tuple(str_to_list(tm['~cwp_workid_0']))]['medley'])
+
+ if type2_medley:
+ tm['~cwp_extended_part'] = "{" + movement + "}"
+ else:
+ if diff:
+ tm['~cwp_extended_part'] = part_main + \
+ " {" + diff.strip() + "}"
+ else:
+ tm['~cwp_extended_part'] = part_main
+ if part_levels == 0:
+ if tm['~cwp_extended_groupheading']:
+ del tm['~cwp_extended_groupheading']
+
+ # remove unwanted groupheadings (needed them up to now for adding
+ # extensions)
+ if '~cwp_groupheading' in tm and tm['~cwp_groupheading'] == tm['~cwp_part']:
+ del tm['~cwp_groupheading']
+ if '~cwp_title_groupheading' in tm and tm['~cwp_title_groupheading'] == tm['~cwp_title_part']:
+ del tm['~cwp_title_groupheading']
+ # clean up groupheadings (may be stray separators if level 0 or title
+ # options used)
+ if '~cwp_groupheading' in tm:
+ tm['~cwp_groupheading'] = tm['~cwp_groupheading'].strip(
+ ':').strip(
+ options['cwp_single_work_sep']).strip(
+ options['cwp_multi_work_sep'])
+ if '~cwp_extended_groupheading' in tm:
+ tm['~cwp_extended_groupheading'] = tm['~cwp_extended_groupheading'].strip(
+ ':').strip(
+ options['cwp_single_work_sep']).strip(
+ options['cwp_multi_work_sep'])
+ if '~cwp_title_groupheading' in tm:
+ tm['~cwp_title_groupheading'] = tm['~cwp_title_groupheading'].strip(
+ ':').strip(
+ options['cwp_single_work_sep']).strip(
+ options['cwp_multi_work_sep'])
+ write_log(release_id, 'debug', "....done")
+ return movementgroup
+
+ ##########################################################
+ # SECTION 6- Write metadata to tags according to options #
+ ##########################################################
+
+ def publish_metadata(self, release_id, album, track, movement_info={}):
+ """
+ Write out the metadata according to user options
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param album:
+ :param track:
+ :param movement_info: format is {'movement-group': movementgroup, 'movement-number': movementnumber}
+ :return:
+ """
+ write_log(release_id, 'debug', "IN PUBLISH METADATA for %s", track)
+ options = self.options[track]
+ tm = track.metadata
+ tm['~cwp_version'] = PLUGIN_VERSION
+
+ # set movement grouping tags (hidden vars)
+ if movement_info:
+ movementtotal = self.parts[tuple(movement_info['movement-group'])]['movement-total']
+ if movementtotal > 1:
+ tm['~cwp_movt_num'] = movement_info['movement-number']
+ tm['~cwp_movt_tot'] = movementtotal
+
+ # album composers needed by map_tags (set in set_work_artists)
+ if 'composer_lastnames' in self.album_artists[album]:
+ last_names = seq_last_names(self, album)
+ self.append_tag(
+ release_id,
+ tm,
+ '~cea_album_composer_lastnames',
+ last_names)
+
+ write_log(release_id, 'info', "Check options")
+ if options["cwp_titles"]:
+ write_log(release_id, 'info', "titles")
+ part = tm['~cwp_title_part_0'] or tm['~cwp_title_work_0']or tm['~cwp_title'] or tm['title']
+ # for multi-level work display
+ groupheading = tm['~cwp_title_groupheading'] or ""
+ # for single-level work display
+ work = tm['~cwp_title_work'] or ""
+ inter_work = tm['~cwp_inter_title_work'] or ""
+ elif options["cwp_works"]:
+ write_log(release_id, 'info', "works")
+ part = tm['~cwp_part']
+ groupheading = tm['~cwp_groupheading'] or ""
+ work = tm['~cwp_work'] or ""
+ inter_work = tm['~cwp_inter_work'] or ""
+ else:
+ # options["cwp_extended"]
+ write_log(release_id, 'info', "extended")
+ part = tm['~cwp_extended_part']
+ groupheading = tm['~cwp_extended_groupheading'] or ""
+ work = tm['~cwp_extended_work'] or ""
+ inter_work = tm['~cwp_extended_inter_work'] or ""
+ write_log(release_id, 'info', "Done options")
+ p1 = RE_ROMANS_AT_START
+ # Matches positive integers with punctuation
+ p2 = re.compile(r'^\W*\d+[.):-]')
+ movt = part
+ for _ in range(
+ 0, 5): # in case of multiple levels
+ movt = p2.sub('', p1.sub('', movt)).strip()
+ write_log(release_id, 'info', "Done movt")
+ movt_inc_tags = options["cwp_movt_tag_inc"].split(",")
+ movt_inc_tags = [x.strip(' ') for x in movt_inc_tags]
+ movt_exc_tags = options["cwp_movt_tag_exc"].split(",")
+ movt_exc_tags = [x.strip(' ') for x in movt_exc_tags]
+ movt_inc_1_tags = options["cwp_movt_tag_inc1"].split(",")
+ movt_inc_1_tags = [x.strip(' ') for x in movt_inc_1_tags]
+ movt_exc_1_tags = options["cwp_movt_tag_exc1"].split(",")
+ movt_exc_1_tags = [x.strip(' ') for x in movt_exc_1_tags]
+ movt_no_tags = options["cwp_movt_no_tag"].split(",")
+ movt_no_tags = [x.strip(' ') for x in movt_no_tags]
+ movt_no_sep = options["cwp_movt_no_sep"]
+ movt_tot_tags = options["cwp_movt_tot_tag"].split(",")
+ movt_tot_tags = [x.strip(' ') for x in movt_tot_tags]
+ gh_tags = options["cwp_work_tag_multi"].split(",")
+ gh_tags = [x.strip(' ') for x in gh_tags]
+ gh_sep = options["cwp_multi_work_sep"]
+ work_tags = options["cwp_work_tag_single"].split(",")
+ work_tags = [x.strip(' ') for x in work_tags]
+ work_sep = options["cwp_single_work_sep"]
+ top_tags = options["cwp_top_tag"].split(",")
+ top_tags = [x.strip(' ') for x in top_tags]
+
+ write_log(
+ release_id,
+ 'info',
+ "Done splits. gh_tags: %s, work_tags: %s, movt_inc_tags: %s, movt_exc_tags: %s, movt_no_tags: %s",
+ gh_tags,
+ work_tags,
+ movt_inc_tags,
+ movt_exc_tags,
+ movt_no_tags)
+
+ for tag in gh_tags + work_tags + movt_inc_tags + movt_exc_tags + movt_no_tags:
+ tm[tag] = ""
+ for tag in gh_tags:
+ if tag in movt_inc_tags + movt_exc_tags + movt_no_tags:
+ self.append_tag(release_id, tm, tag, groupheading, gh_sep)
+ else:
+ self.append_tag(release_id, tm, tag, groupheading)
+ for tag in work_tags:
+ if tag in movt_inc_1_tags + movt_exc_1_tags + movt_no_tags:
+ self.append_tag(release_id, tm, tag, work, work_sep)
+ else:
+ self.append_tag(release_id, tm, tag, work)
+ if '~cwp_part_levels' in tm and int(tm['~cwp_part_levels']) > 0:
+ self.append_tag(
+ release_id,
+ tm,
+ 'show work movement',
+ '1') # original tag for iTunes, kept for backwards compatibility
+ self.append_tag(
+ release_id,
+ tm,
+ 'showmovement',
+ '1') # new tag for iTunes & MusicBee, consistent with Picard tag docs
+ for tag in top_tags:
+ if '~cwp_work_top' in tm:
+ self.append_tag(release_id, tm, tag, tm['~cwp_work_top'])
+
+ if '~cwp_movt_num' in tm and len(tm['~cwp_movt_num']) > 0:
+ movt_num_punc = tm['~cwp_movt_num'] + movt_no_sep + ' '
+ else:
+ movt_num_punc = ''
+
+ for tag in movt_no_tags:
+ if tag not in movt_inc_tags + movt_exc_tags + movt_inc_1_tags + movt_exc_1_tags:
+ self.append_tag(release_id, tm, tag, tm['~cwp_movt_num'])
+
+ for tag in movt_tot_tags:
+ self.append_tag(release_id, tm, tag, tm['~cwp_movt_tot'])
+
+ for tag in movt_exc_tags:
+ if tag in movt_no_tags:
+ movt = movt_num_punc + movt
+ self.append_tag(release_id, tm, tag, movt)
+
+ for tag in movt_inc_tags:
+ if tag in movt_no_tags:
+ part = movt_num_punc + part
+ self.append_tag(release_id, tm, tag, part)
+
+
+ for tag in movt_inc_1_tags + movt_exc_1_tags:
+ if tag in movt_inc_1_tags:
+ pt = part
+ else:
+ pt = movt
+ if tag in movt_no_tags:
+ pt = movt_num_punc + pt
+ if inter_work and inter_work != "":
+ if tag in movt_exc_tags + movt_inc_tags and tag != "":
+ write_log(
+ release_id,
+ 'warning',
+ "Tag %s will have multiple contents",
+ tag)
+ if self.WARNING:
+ self.append_tag(release_id, tm, '~cwp_warning', '6. Tag ' +
+ tag +
+ ' has multiple contents')
+ self.append_tag(
+ release_id,
+ tm,
+ tag,
+ inter_work +
+ work_sep +
+ " " +
+ pt)
+ else:
+ self.append_tag(release_id, tm, tag, pt)
+
+ for tag in movt_exc_tags + movt_inc_tags + movt_exc_1_tags + movt_inc_1_tags:
+ if tag in movt_no_tags:
+ # i.e treat as one item, not multiple
+ tm[tag] = "".join(re.split('|'.join(self.SEPARATORS), tm[tag]))
+
+ # write "SongKong" tags
+ if options['cwp_write_sk']:
+ write_log(release_id, 'debug', "Writing SongKong work tags")
+ if '~cwp_part_levels' in tm:
+ part_levels = int(tm['~cwp_part_levels'])
+ for n in range(0, part_levels + 1):
+ if '~cwp_work_' + \
+ str(n) in tm and '~cwp_workid_' + str(n) in tm:
+ source = tm['~cwp_work_' + str(n)]
+ source_id = list(
+ tuple(str_to_list(tm['~cwp_workid_' + str(n)])))
+ if n == 0:
+ self.append_tag(
+ release_id, tm, 'musicbrainz_work_composition', source)
+ for source_id_item in source_id:
+ self.append_tag(
+ release_id, tm, 'musicbrainz_work_composition_id', source_id_item)
+ if n == part_levels:
+ self.append_tag(
+ release_id, tm, 'musicbrainz_work', source)
+ if 'musicbrainz_workid' in tm:
+ del tm['musicbrainz_workid']
+ # Delete the Picard version of this tag before
+ # replacing it with the SongKong version
+ for source_id_item in source_id:
+ self.append_tag(
+ release_id, tm, 'musicbrainz_workid', source_id_item)
+ if n != 0 and n != part_levels:
+ self.append_tag(
+ release_id, tm, 'musicbrainz_work_part_level' + str(n), source)
+ for source_id_item in source_id:
+ self.append_tag(
+ release_id,
+ tm,
+ 'musicbrainz_work_part_level' +
+ str(n) +
+ '_id',
+ source_id_item)
+
+ # carry out tag mapping
+ tm['~cea_works_complete'] = "Y"
+ map_tags(options, release_id, album, tm)
+
+ write_log(release_id, 'debug', "Published metadata for %s", track)
+ if options['cwp_options_tag'] != "":
+ self.cwp_options = collections.defaultdict(
+ lambda: collections.defaultdict(dict))
+
+ for opt in plugin_options('workparts') + plugin_options('genres'):
+ if 'name' in opt:
+ if 'value' in opt:
+ if options[opt['option']]:
+ self.cwp_options['Classical Extras']['Works options'][opt['name']] = opt['value']
+ else:
+ self.cwp_options['Classical Extras']['Works options'][opt['name']
+ ] = options[opt['option']]
+
+ write_log(release_id, 'info', "Options %s", self.cwp_options)
+ if options['ce_version_tag'] and options['ce_version_tag'] != "":
+ self.append_tag(release_id, tm, options['ce_version_tag'], str(
+ 'Version ' + tm['~cwp_version'] + ' of Classical Extras'))
+ if options['cwp_options_tag'] and options['cwp_options_tag'] != "":
+ self.append_tag(release_id, tm, options['cwp_options_tag'] +
+ ':workparts_options', json.loads(
+ json.dumps(
+ self.cwp_options)))
+ if self.ERROR and "~cwp_error" in tm:
+ for error in str_to_list(tm['~cwp_error']):
+ code = error[0]
+ self.append_tag(release_id, tm, '001_errors:' + code, error)
+ if self.WARNING and "~cwp_warning" in tm:
+ for warning in str_to_list(tm['~cwp_warning']):
+ wcode = warning[0]
+ self.append_tag(release_id, tm, '002_warnings:' + wcode, warning)
+
+
+ def append_tag(self, release_id, tm, tag, source, sep=None):
+ """
+ pass to main append routine
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param tm:
+ :param tag:
+ :param source:
+ :param sep: separators may be used to split string into list on appending
+ :return:
+ """
+ write_log(
+ release_id,
+ 'info',
+ "In append_tag (Work parts). tag = %s, source = %s, sep =%s",
+ tag,
+ source,
+ sep)
+ append_tag(release_id, tm, tag, source, self.SEPARATORS)
+ write_log(
+ release_id,
+ 'info',
+ "Appended. Resulting contents of tag: %s are: %s",
+ tag,
+ tm[tag])
+
+ ################################################
+ # SECTION 7 - Common string handling functions #
+ ################################################
+
+ def strip_parent_from_work(
+ self,
+ track,
+ release_id,
+ work,
+ parent,
+ part_level,
+ extend,
+ parentId=None,
+ workId=None):
+ """
+ Remove common text
+ :param track:
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param work: could be a list of works, all of which require stripping
+ :param parent:
+ :param part_level:
+ :param extend:
+ :param parentId:
+ :return:
+ """
+ # extend=True is used [ NO LONGER to find "full_parent" names] + (with parentId)
+ # to trigger recursion if unable to strip parent name from work and also to look for common subsequences
+ # extend=False is used when this routine is called for other purposes
+ # than strict work: parent relationships
+ options = self.options[track]
+ write_log(
+ release_id,
+ 'debug',
+ "STRIPPING HIGHER LEVEL WORK TEXT FROM PART NAMES")
+ write_log(
+ release_id,
+ 'info',
+ 'PARAMS: WORK = %r, PARENT = %s, PART_LEVEL = %s, EXTEND= %s',
+ work,
+ parent,
+ part_level,
+ extend)
+ if isinstance(work, list):
+ result = []
+ for w, work_item in enumerate(work):
+ if workId and isinstance(workId, list):
+ sub_workId = workId[w]
+ else:
+ sub_workId = workId
+ result.append(
+ self.strip_parent_from_work(
+ track,
+ release_id,
+ work_item,
+ parent,
+ part_level,
+ extend,
+ parentId,
+ sub_workId)[0])
+ return result, parent
+ if not isinstance(parent, str):
+ # in case it is a list - make sure it is a string
+ parent = '; '.join(parent)
+ if not isinstance(work, str):
+ work = '; '.join(work)
+
+ # replace any punctuation or numbers, with a space (to remove any
+ # inconsistent punctuation and numbering) - (?u) specifies the
+ # re.UNICODE flag in sub
+ clean_parent = re.sub("(?u)[\W]", ' ', parent)
+ # now allow the spaces to be filled with up to 2 non-letters
+ pattern_parent = clean_parent.replace(" ", "\W{0,2}")
+ pattern_parent = "(^|.*?\s)(\W*" + pattern_parent + "\W?)(.*)"
+ # (removed previous alternative pattern for extend=true, owing to catastrophic backtracking)
+ write_log(
+ release_id,
+ 'info',
+ "Pattern parent: %s, Work: %s",
+ pattern_parent,
+ work)
+ p = re.compile(pattern_parent, re.IGNORECASE | re.UNICODE)
+ m = p.search(work)
+ if m:
+ write_log(release_id, 'info', "Matched...")
+ if m.group(1):
+ stripped_work = m.group(1) + u"\u2026" + m.group(3)
+ else:
+ stripped_work = m.group(3)
+ # may not have a full work name in the parent (missing op. no.
+ # etc.)
+ stripped_work = stripped_work.lstrip(":;,.- ")
+ else:
+ write_log(release_id, 'info', "No match...")
+ stripped_work = work
+
+ if extend and options['cwp_common_chars'] > 0:
+ # try stripping out a common substring (multiple times until
+ # nothing more stripped)
+ prev_stripped_work = ''
+ counter = 1
+ while prev_stripped_work != stripped_work:
+ if counter > 20:
+ break # in case something went awry
+ prev_stripped_work = stripped_work
+ parent_tuples = self.listify(release_id, track, parent)
+ parent_words = parent_tuples['s_tuple']
+ clean_parent_words = list(parent_tuples['s_test_tuple'])
+ for w, word in enumerate(clean_parent_words):
+ clean_parent_words[w] = self.boil(release_id, word)
+ work_tuples = self.listify(
+ release_id, track, stripped_work)
+ work_words = work_tuples['s_tuple']
+ clean_work_words = list(work_tuples['s_test_tuple'])
+ for w, word in enumerate(clean_work_words):
+ clean_work_words[w] = self.boil(release_id, word)
+ common_dets = longest_common_substring(
+ clean_work_words, clean_parent_words)
+ # this is actually a list, not a string, since list
+ # arguments were supplied
+ common_seq = common_dets['string']
+ seq_length = common_dets['length']
+ seq_start = common_dets['start']
+ # the original items (before 'cleaning')
+ full_common_seq = [
+ x.group() for x in work_words[seq_start:seq_start + seq_length]]
+ # number of words in common_seq
+ full_seq_length = sum([len(x.split())
+ for x in full_common_seq])
+ write_log(
+ release_id,
+ 'info',
+ 'Checking common sequence between parent and work, iteration %s ... parent_words = %s',
+ counter,
+ parent_words)
+ write_log(
+ release_id,
+ 'info',
+ '... longest common sequence = %s',
+ common_seq)
+ if full_seq_length > 0:
+ potential_stripped_work = stripped_work
+ if seq_start > 0:
+ ellipsis = ' ' + u"\u2026" + ' '
+ else:
+ ellipsis = ''
+ if counter > 1:
+ potential_stripped_work = stripped_work.rstrip(
+ ' :,-\u2026')
+ potential_stripped_work = potential_stripped_work.replace(
+ '(\u2026)', '').rstrip()
+ potential_stripped_work = potential_stripped_work[:work_words[seq_start].start(
+ )] + ellipsis + potential_stripped_work[work_words[seq_start + seq_length - 1].end():]
+ potential_stripped_work = potential_stripped_work.lstrip(
+ ' :,-')
+ potential_stripped_work = re.sub(
+ r'(\W*…\W*)(\W*…\W*)', ' … ', potential_stripped_work)
+ potential_stripped_work = strip_excess_punctuation(
+ potential_stripped_work)
+
+ if full_seq_length >= options['cwp_common_chars'] \
+ or potential_stripped_work == '' and options['cwp_allow_empty_parts']:
+ # Make sure it is more than the required min (it will be > 0 anyway)
+ # unless a full strip will result anyway (and blank
+ # part names are allowed)
+ stripped_work = potential_stripped_work
+ if not stripped_work or stripped_work == '':
+ if workId and \
+ ('arrangement' in self.parts[workId] and self.parts[workId]['arrangement']
+ and options['cwp_arrangements'] and options['cwp_arrangements_text']) \
+ or ('partial' in self.parts[workId] and self.parts[workId]['partial']
+ and options['cwp_partial'] and options['cwp_partial_text']) \
+ and options['cwp_allow_empty_parts']:
+ pass
+ else:
+ stripped_work = prev_stripped_work # do not allow empty parts
+ counter += 1
+ stripped_work = strip_excess_punctuation(stripped_work)
+ write_log(
+ release_id,
+ 'info',
+ 'stripped_work = %s',
+ stripped_work)
+ if extend and parentId and parentId in self.works_cache:
+ write_log(
+ release_id,
+ 'info',
+ "Looking for match at next level up")
+ grandparentIds = tuple(self.works_cache[parentId])
+ grandparent = self.parts[grandparentIds]['name']
+ stripped_work = self.strip_parent_from_work(
+ track,
+ release_id,
+ stripped_work,
+ grandparent,
+ part_level,
+ True,
+ grandparentIds,
+ workId)[0]
+
+ write_log(
+ release_id,
+ 'info',
+ "Finished strip_parent_from_work, Work: %s",
+ work)
+ write_log(release_id, 'info', "Stripped work: %s", stripped_work)
+ # Changed full_parent to parent after removal of 'extend' logic above
+ stripped_work = strip_excess_punctuation(stripped_work)
+ write_log(release_id, 'info', "Stripped work after punctuation removal: %s", stripped_work)
+ return stripped_work, parent
+
+ def diff_pair(
+ self,
+ release_id,
+ track,
+ tm,
+ mb_item,
+ title_item,
+ remove_numbers=True):
+ """
+ Removes common text (or synonyms) from title item
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param track:
+ :param tm:
+ :param mb_item:
+ :param title_item:
+ :return: Reduced title item
+ """
+ write_log(release_id, 'debug', "Inside DIFF_PAIR")
+ mb = mb_item.strip()
+ write_log(release_id, 'info', "mb = %s", mb)
+ write_log(release_id, 'info', "title_item = %s", title_item)
+ if not mb:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+ ti = title_item.strip(" :;-.,")
+ if ti.count('"') == 1:
+ ti = ti.strip('"')
+ if ti.count("'") == 1:
+ ti = ti.strip("'")
+ write_log(release_id, 'info', "ti (amended) = %s", ti)
+ if not ti:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+
+ if self.options[track]["cwp_removewords_p"]:
+ removewords = self.options[track]["cwp_removewords_p"].split(',')
+ else:
+ removewords = []
+ write_log(release_id, 'info', "Prefixes = %s", removewords)
+ # remove numbers, roman numerals, part etc and punctuation from the
+ # start
+ write_log(release_id, 'info', "checking prefixes")
+ found_prefix = True
+ i = 0
+ while found_prefix:
+ if i > 20:
+ break # safety valve
+ found_prefix = False
+ for prefix in removewords:
+ if prefix[0] != " ":
+ prefix2 = str(prefix).lower().lstrip()
+ write_log(
+ release_id, 'info', "checking prefix %s", prefix2)
+ if mb.lower().startswith(prefix2):
+ found_prefix = True
+ mb = mb[len(prefix2):]
+ if ti.lower().startswith(prefix2):
+ found_prefix = True
+ ti = ti[len(prefix2):]
+ mb = mb.strip()
+ ti = ti.strip()
+ i += 1
+ write_log(
+ release_id,
+ 'info',
+ "pairs after prefix strip iteration %s. mb = %s, ti = %s",
+ i,
+ mb,
+ ti)
+ write_log(release_id, 'info', "Prefixes checked")
+
+ # replacements
+ replacements = self.replacements[track]
+ write_log(release_id, 'info', "Replacement: %s", replacements)
+ for tup in replacements:
+ for ind in range(0, len(tup) - 1):
+ ti = re.sub(tup[ind], tup[-1], ti, flags=re.IGNORECASE)
+ write_log(
+ release_id,
+ 'debug',
+ 'Looking for any new words in the title')
+
+ write_log(
+ release_id,
+ 'info',
+ "Check before splitting: mb = %s, ti = %s",
+ mb,
+ ti)
+
+ ti_tuples = self.listify(release_id, track, ti)
+ ti_tuple = ti_tuples['s_tuple']
+ ti_test_tuple = ti_tuples['s_test_tuple']
+
+ mb_tuples = self.listify(release_id, track, mb)
+ mb_test_tuple = mb_tuples['s_test_tuple']
+
+ write_log(
+ release_id,
+ 'info',
+ "Check after splitting: mb_test = %s, ti = %s, ti_test = %s",
+ mb_test_tuple,
+ ti_tuple,
+ ti_test_tuple)
+
+ ti_stencil = self.stencil(release_id, ti_tuple, ti)
+ ti_list = ti_stencil['match list']
+ ti_list_punc = ti_stencil['gap list']
+ ti_test_list = list(ti_test_tuple)
+ if ti_stencil['dummy']:
+ # to deal with case where stencil has added a dummy item at the
+ # start
+ ti_test_list.insert(0, '')
+ write_log(release_id, 'info', 'ti_test_list = %r', ti_test_list)
+ # zip is an iterable, not a list in Python 3, so make it re-usable
+ ti_zip_list = list(zip(ti_list, ti_list_punc))
+
+ # len(ti_list) should be = len(ti_test_list) as only difference should
+ # be synonyms which are each one 'word'
+ # However, because of the grouping of some words via regex, it is possible that inconsistencies might arise
+ # Therefore, there is a test here to check for equality and produce an
+ # error message (but continue processing)
+ if len(ti_list) != len(ti_test_list):
+ write_log(
+ release_id,
+ 'error',
+ 'Mismatch in title list after canonization/synonymization')
+ write_log(
+ release_id,
+ 'error',
+ 'Orig. title list = %r. Test list = %r',
+ ti_list,
+ ti_test_list)
+ # mb_test_tuple = self.listify(release_id, track, mb_test)
+ mb_list2 = list(mb_test_tuple)
+ for index, mb_bit2 in enumerate(mb_list2):
+ mb_list2[index] = self.boil(release_id, mb_bit2)
+ write_log(
+ release_id,
+ 'info',
+ "mb_list2[%s] = %s",
+ index,
+ mb_list2[index])
+ ti_new = []
+ ti_rich_list = []
+ for i, ti_bit_test in enumerate(ti_test_list):
+ if i <= len(ti_list) - 1:
+ ti_bit = ti_zip_list[i]
+ # NB ti_bit is a tuple where the word (1st item) is grouped
+ # with its following punctuation (2nd item)
+ else:
+ ti_bit = ('', '')
+ write_log(
+ release_id,
+ 'info',
+ "i = %s, ti_bit_test = %s, ti_bit = %s",
+ i,
+ ti_bit_test,
+ ti_bit)
+ ti_rich_list.append((ti_bit, True))
+ # Boolean to indicate whether ti_bit is a new word
+
+ if ti_bit_test == '':
+ ti_rich_list[i] = (ti_bit, False)
+ else:
+ if self.boil(release_id, ti_bit_test) in mb_list2:
+ ti_rich_list[i] = (ti_bit, False)
+
+ if remove_numbers: # Only remove numbers at the start if they are not new items
+ p0 = re.compile(r'\b\w+\b')
+ p1 = RE_ROMANS
+ p2 = re.compile(r'^\d+') # Matches positive integers
+ starts_with_numeral = True
+ while starts_with_numeral:
+ starts_with_numeral = False
+ if ti_rich_list and p0.match(ti_rich_list[0][0][0]):
+ start_word = p0.match(ti_rich_list[0][0][0]).group()
+ if p1.match(start_word) or p2.match(start_word):
+ if not ti_rich_list[0][1]:
+ starts_with_numeral = True
+ ti_rich_list.pop(0)
+ ti_test_list.pop(0)
+
+ write_log(
+ release_id,
+ 'info',
+ "ti_rich_list before removing singletons = %s. length = %s",
+ ti_rich_list,
+ len(ti_rich_list))
+
+ s = 0
+ index = 0
+ change = ()
+ for i, (t, n) in enumerate(ti_rich_list):
+ if n:
+ s += 1
+ index = i
+ change = t # NB this is a tuple
+
+ p = self.options[track]["cwp_proximity"]
+ ep = self.options[track]["cwp_end_proximity"]
+ # NB these may be modified later
+
+ if s == 1:
+ if 0 < index < len(ti_rich_list) - 1:
+ # ignore singleton new words in middle of title unless they are
+ # within "cwp_end_proximity" from the start or end
+ write_log(
+ release_id, 'info', 'item length is %s', len(
+ change[0].split()))
+ # also make sure that the item is just one word before
+ # eliminating
+ if ep < index < len(ti_rich_list) - ep - \
+ 1 and len(change[0].split()) == 1:
+ ti_rich_list[index] = (change, False)
+ s = 0
+
+ # remove prepositions
+ write_log(
+ release_id,
+ 'info',
+ "ti_rich_list before removing prepositions = %s. length = %s",
+ ti_rich_list,
+ len(ti_rich_list))
+ if self.options[track]["cwp_prepositions"]:
+ prepositions_fat = self.options[track]["cwp_prepositions"].split(
+ ',')
+ prepositions = [w.strip() for w in prepositions_fat]
+ for i, ti_bit_test in enumerate(
+ reversed(ti_test_list)): # Need to reverse it to check later prepositions first
+ if ti_bit_test.lower().strip() in prepositions:
+ # NB i is counting up while traversing the list backwards
+ j = len(ti_rich_list) - i - 1
+ if i == 0 or not ti_rich_list[j + 1][1]:
+ # Don't make it false if it is preceded by a
+ # non-preposition new word
+ if not (j > 0 and ti_rich_list[j -
+ 1][1] and ti_test_list[j -
+ 1].lower() not in prepositions):
+ ti_rich_list[j] = (ti_rich_list[j][0], False)
+
+ # create comparison for later usage
+ compare_string = ''
+ for item in ti_rich_list:
+ if item[1]:
+ compare_string += item[0][0]
+ ti_compare = self.boil(release_id, compare_string)
+ compare_length = len(ti_compare)
+
+ write_log(
+ release_id,
+ 'info',
+ "ti_rich_list before gapping (True indicates a word in title not in MB work) = %s. length = %s",
+ ti_rich_list,
+ len(ti_rich_list))
+ if s > 0:
+ d = p - ep
+ start = True # To keep track of new words at the start of the title
+ for i, (ti_bit, new) in enumerate(ti_rich_list):
+ if not new:
+ write_log(
+ release_id,
+ 'info',
+ "item(i = %s) val = %s - not new. proximity param = %s, end_proximity param = %s",
+ i,
+ ti_bit,
+ p,
+ ep)
+ if start:
+ prox_test = ep
+ else:
+ prox_test = p
+ if prox_test > 0:
+ for j in range(0, prox_test + 1):
+ write_log(release_id, 'info', "item(i) = %s, look-ahead(j) = %s", i, j)
+ if i + j < len(ti_rich_list):
+ if ti_rich_list[i + j][1]:
+ write_log(
+ release_id, 'info', "Set to true..")
+ ti_rich_list[i] = (ti_bit, True)
+ write_log(
+ release_id, 'info', "...set OK")
+ else:
+ if j <= p - d:
+ ti_rich_list[i] = (ti_bit, True)
+ else:
+ p = self.options[track]["cwp_proximity"]
+ start = False
+ if not ti_rich_list[i][1]:
+ p -= 1
+ ep -= 1
+ write_log(
+ release_id,
+ 'info',
+ "ti_rich_list after gapping (True indicates new words plus infills) = %s",
+ ti_rich_list)
+ nothing_new = True
+ for (ti_bit, new) in ti_rich_list:
+ if new:
+ nothing_new = False
+ new_prev = True
+ break
+ if nothing_new:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+ else:
+ new_prev = False
+ for i, (ti_bit, new) in enumerate(ti_rich_list):
+ write_log(release_id, 'info', "Create new for %s?", ti_bit)
+ if new:
+ write_log(release_id, 'info', "Yes for %s", ti_bit)
+ if not new_prev:
+ if i > 0:
+ # check to see if the last char of the prev
+ # punctuation group needs to be added first
+ if len(ti_rich_list[i - 1][0][1]) > 1:
+ # i.e. ti_bit[1][-1] of previous loop
+ ti_new.append(ti_rich_list[i - 1][0][1][-1])
+ ti_new.append(ti_bit[0])
+ if len(ti_bit[1]) > 1:
+ if i < len(ti_rich_list) - 1:
+ if ti_rich_list[i + 1][1]:
+ ti_new.append(ti_bit[1])
+ else:
+ ti_new.append(ti_bit[1][:-1])
+ else:
+ ti_new.append(ti_bit[1])
+ else:
+ ti_new.append(ti_bit[1])
+ write_log(
+ release_id,
+ 'info',
+ "appended %s. ti_new is now %s",
+ ti_bit,
+ ti_new)
+ else:
+ write_log(release_id, 'info', "Not for %s", ti_bit)
+ if new != new_prev:
+ ti_new.append(u"\u2026" + ' ')
+
+ new_prev = new
+ if ti_new:
+ write_log(release_id, 'info', "ti_new %s", ti_new)
+ ti = ''.join(ti_new)
+ write_log(release_id, 'info', "New text from title = %s", ti)
+ else:
+ write_log(release_id, 'info', "New text empty")
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+ # see if there is any significant difference between the strings
+ if ti:
+ nopunc_ti = ti_compare # was = self.boil(release_id, ti)
+ # not necessary as already set?
+ nopunc_mb = self.boil(release_id, mb)
+ # ti_len = len(nopunc_ti) use compare_length instead (= len before
+ # removals and additions)
+ substring_proportion = float(
+ self.options[track]["cwp_substring_match"]) / 100
+ sub_len = compare_length * substring_proportion
+ if substring_proportion < 1:
+ write_log(release_id, 'info', "test sub....")
+ lcs = longest_common_substring(nopunc_mb, nopunc_ti)['string']
+ write_log(
+ release_id,
+ 'info',
+ "Longest common substring is: %s. Threshold length is %s",
+ lcs,
+ sub_len)
+ if len(lcs) >= sub_len:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+ write_log(release_id, 'info', "...done, ti =%s", ti)
+ # remove duplicate successive words (and remove first word of title
+ # item if it duplicates last word of mb item)
+ if ti:
+ ti_list_new = re.split(' ', ti)
+ ti_list_ref = ti_list_new
+ ti_bit_prev = None
+ for i, ti_bit in enumerate(ti_list_ref):
+ if ti_bit != "...":
+
+ if i > 1:
+ if self.boil(
+ release_id, ti_bit) == self.boil(
+ release_id, ti_bit_prev):
+ dup = ti_list_new.pop(i)
+ write_log(release_id, 'info', "...removed dup %s", dup)
+
+ ti_bit_prev = ti_bit
+
+ write_log(release_id,
+ 'info',
+ "1st word of ti = %s. Last word of mb = %s",
+ ti_list_new[0],
+ mb_list2[-1])
+ if ti_list_new and mb_list2:
+ if self.boil(release_id, ti_list_new[0]) == mb_list2[-1]:
+ write_log(release_id, 'info', "Removing 1st word from ti...")
+ first = ti_list_new.pop(0)
+ write_log(release_id, 'info', "...removed %s", first)
+ else:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+ if ti_list_new:
+ ti = ' '.join(ti_list_new)
+ else:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+ # remove excess brackets and punctuation
+ if ti:
+ ti = strip_excess_punctuation(ti)
+ write_log(release_id, 'info', "stripped punc ok. ti = %s", ti)
+ write_log(
+ release_id,
+ 'debug',
+ "DIFF_PAIR is returning ti = %s",
+ ti)
+ if ti and len(ti) > 0:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ ti)
+ return ti
+ else:
+ write_log(
+ release_id,
+ 'info',
+ 'End of DIFF_PAIR. Returning %s',
+ None)
+ return None
+
+
+ @staticmethod
+ def canonize_opus(release_id, track, s):
+ """
+ make opus numbers etc. into one-word items
+ :param release_id:
+ :param s: A string
+ :return:
+ """
+ write_log(release_id, 'debug', 'Canonizing: %s', s)
+ # Canonize catalogue & opus numbers (e.g. turn K. 126 into K126 or K
+ # 345a into K345a or op. 144 into op144):
+ regex = re.compile(
+ r'\b((?:op|no|k|kk|kv|L|B|Hob|S|D|M)|\w+WV)\W?\s?(\d+\-?\u2013?\u2014?\d*\w*)\b',
+ re.IGNORECASE)
+ regex_match = regex.search(s)
+ s_canon = s
+ if regex_match and len(regex_match.groups()) == 2:
+ pt1 = regex_match.group(1) or ''
+ pt2 = regex_match.group(2) or ''
+ if regex_match.group(1) and regex_match.group(2):
+ pt1 = re.sub(
+ r'^\W*no\b',
+ '',
+ regex_match.group(1),
+ flags=re.IGNORECASE)
+ s_canon = pt1 + pt2
+ write_log(release_id, 'info', 'canonized item = %s', s_canon)
+ return s_canon
+
+ @staticmethod
+ def canonize_key(release_id, track, s):
+ """
+ make keys into standardized one-word items
+ :param release_id:
+ :param s: A string
+ :return:
+ """
+ write_log(release_id, 'debug', 'Canonizing: %s', s)
+ match = RE_KEYS.search(s)
+ s_canon = s
+ if match:
+ if match.group(2):
+ k2 = re.sub(
+ r'\-sharp|\u266F',
+ 'sharp',
+ match.group(2),
+ flags=re.IGNORECASE)
+ k2 = re.sub(r'\-flat|\u266D', 'flat', k2, flags=re.IGNORECASE)
+ k2 = k2.replace('-', '')
+ else:
+ k2 = ''
+ if not match.group(3) or match.group(
+ 3).strip() == '': # if the scale is not given, assume it is the major key
+ if match.group(1).isupper(
+ ) or k2 != '': # but only if it is upper case or has an accent
+ k3 = 'major'
+ else:
+ k3 = ''
+ else:
+ k3 = match.group(3).strip()
+ s_canon = match.group(1).strip() + k2.strip() + k3
+ write_log(release_id, 'info', 'canonized item = %s', s_canon)
+ return s_canon
+
+ @staticmethod
+ def canonize_synonyms(release_id, tuples, s):
+ """
+ make synonyms equal
+ :param release_id:
+ :param tuples
+ :param s: A string
+ :return:
+ """
+ write_log(release_id, 'debug', 'Canonizing: %s', s)
+ s_canon = s
+ syn_patterns = []
+ syn_subs = []
+ for syn_tup in tuples:
+ syn_pattern = r'((?:^|\W)' + \
+ r'(?:$|\W)|(?:^|\W)'.join(syn_tup) + r'(?:$|\W))'
+ syn_patterns.append(syn_pattern)
+ # to get the last synonym in the tuple - the canonical form
+ syn_sub = syn_tup[-1:][0]
+ syn_subs.append(syn_sub)
+ for syn_ind, pattern in enumerate(syn_patterns):
+ regex = re.compile(pattern, re.IGNORECASE)
+ regex_match = regex.search(s)
+ if regex_match:
+ test_reg = regex_match.group().strip()
+ s_canon = s_canon.replace(test_reg, syn_subs[syn_ind])
+
+ write_log(release_id, 'info', 'canonized item = %s', s_canon)
+ return s_canon
+
+ def find_synonyms(self, release_id, track, reg_item):
+ """
+ extend regex item to include synonyms
+ :param release_id:
+ :param track:
+ :param reg_item: A regex portion
+ :return: reg_new: A replacement for reg_item that includes all its synonyms
+ (if reg_item matches the last in a synonym tuple)
+ """
+ write_log(release_id, 'debug', 'Finding synonyms of: %s', reg_item)
+ syn_others = []
+ syn_all = []
+ for syn_tup in self.synonyms[track]:
+ # to get the last synonym in the tuple - the canonical form
+ syn_last = syn_tup[-1:][0]
+ if re.match(r'^\s*' + reg_item + r'\s*$', syn_last, re.IGNORECASE):
+ syn_others += syn_tup[:-1]
+ syn_all += syn_tup
+ if syn_others:
+ reg_item = '(?:' + ')|(?:'.join(syn_others) + \
+ ')|(?:' + reg_item + ')'
+
+ write_log(release_id, 'info', 'new regex item = %s', reg_item)
+ return reg_item, syn_all
+
+ def listify(self, release_id, track, s):
+ """
+ Turn a string into a list of 'words', where words may also be phrases which
+ are then 'canonized' - i.e. turned into equivalents for comparison purposes
+ :param release_id:
+ :param s: string
+ :return: s_tuple: a tuple of all the **match objects** (re words and defined phrases)
+ s_test_tuple: a tuple of the matched and canonized words and phrases (i.e. a tuple of strings, not objects)
+ """
+ tuples = self.synonyms[track]
+ # just list anything that is a synonym (with word boundary markers)
+ syn_pattern = '|'.join(
+ [r'(?:^|\W|\b)' + x + r'(?:$|\W)' for y in self.synonyms[track] for x in y])
+ op = self.find_synonyms(
+ release_id,
+ track,
+ r'(?:op|no|k|kk|kv|L|B|Hob|S|D|M|\w+WV)')
+ op_groups = op[0]
+ op_all = op[1]
+ notes = self.find_synonyms(release_id, track, r'[ABCDEFG]')
+ notes_groups = notes[0]
+ notes_all = notes[1]
+ sharp = self.find_synonyms(release_id, track, r'sharp')
+ sharp_groups = sharp[0]
+ sharp_all = sharp[1]
+ flat = self.find_synonyms(release_id, track, r'flat')
+ flat_groups = flat[0]
+ flat_all = flat[1]
+ major = self.find_synonyms(release_id, track, r'major')
+ major_groups = major[0]
+ major_all = major[1]
+ minor = self.find_synonyms(release_id, track, r'minor')
+ minor_groups = minor[0]
+ minor_all = minor[1]
+ opus_pattern = r"(?:\b((?:(" + op_groups + \
+ r"))\W?\s?\d+\-?\u2013?\u2014?\d*\w*)\b)"
+ note_pattern = r"(\b" + notes_groups + r")"
+ accent_pattern = r"(?:\-(" + sharp_groups + r")(?:\s+|\b)|\-(" + flat_groups + r")(?:\s+|\b)|\s(" + sharp_groups + \
+ r")(?:\s+|\b)|\s(" + flat_groups + r")(?:\s+|\b)|\u266F(?:\s+|\b)|\u266D(?:\s+|\b)|(?:[:,.]?\s+|$|\-))"
+ scale_pattern = r"(?:((" + major_groups + \
+ r")|(" + minor_groups + r"))?\b)"
+ key_pattern = note_pattern + accent_pattern + scale_pattern
+ hyphen_split_pattern = r"(?:\b|\"|\')(\w+['’]?\w*)|(?:\b\w+\b)|(\B\&\B)"
+ # treat em-dash and en-dash as hyphens
+ hyphen_embed_pattern = r"(?:\b|\"|\')(\w+['’\-\u2013\u2014]?\w*)|(?:\b\w+\b)|(\B\&\B)"
+
+ # The regex is split into two iterations as putting it all together can have unpredictable consequences
+ # - may match synonyms before op's even though that is later in the string
+
+ # First match the op's and keys
+ regex_1 = opus_pattern + r"|(" + key_pattern + r")"
+ matches_1 = re.finditer(regex_1, s, re.UNICODE | re.IGNORECASE)
+ s_list = []
+ s_test_list = []
+ s_scrubbed = s
+ all_synonyms_lists = [
+ op_all,
+ notes_all,
+ sharp_all,
+ flat_all,
+ sharp_all,
+ flat_all,
+ major_all,
+ minor_all]
+ matches_list = [2, 4, 5, 6, 7, 8, 10, 11]
+ for match in matches_1:
+ test_a = match.group()
+ match_a = []
+ match_a.append(match.group())
+ for j in range(1, 12):
+ match_a.append(match.group(j))
+ # 0. overall match
+ # 1. overall opus match
+ # 2. 2-char op match
+ # 3. overall key match
+ # 4. note match
+ # 5. hyphenated sharp match
+ # 6. hyphenated flat match
+ # 7. non-hyphenated sharp match
+ # 8. non-hyphenated flat match
+ # 9. overall scale match
+ # 10. major match
+ # 11. minor match
+ for i, all_synonyms_list in enumerate(all_synonyms_lists):
+ if all_synonyms_list and match_a[matches_list[i]]:
+ match_regex = [re.match(pattern, match_a[matches_list[i]], re.IGNORECASE).group()
+ for pattern in all_synonyms_list
+ if re.match(pattern, match_a[matches_list[i]], re.IGNORECASE)]
+ if match_regex:
+ match_a[matches_list[i]] = self.canonize_synonyms(
+ release_id, tuples, match_a[matches_list[i]])
+ test_a = re.sub(r"\b" + match_regex[0] + r"(?:\b|$|\s|\.)",
+ match_a[matches_list[i]],
+ test_a, flags=re.IGNORECASE)
+ if match_a[1]:
+ clean_opus = test_a.strip(' ,.:;/-?"')
+ test_a = re.sub(
+ re.escape(clean_opus),
+ self.canonize_opus(
+ release_id,
+ track,
+ clean_opus),
+ test_a,
+ flags=re.IGNORECASE)
+ if match_a[3]:
+ clean_key = test_a.strip(' ,.:;/-?"')
+ test_a = re.sub(
+ re.escape(clean_key),
+ self.canonize_key(
+ release_id,
+ track,
+ clean_key),
+ test_a,
+ flags=re.IGNORECASE)
+
+ s_test_list.append(test_a)
+ s_list.append(match)
+ s_scrubbed_list = list(s_scrubbed)
+ for char in range(match.start(), match.end()):
+ if len(s_scrubbed_list) >= match.end(): # belt and braces
+ s_scrubbed_list[char] = '#'
+ s_scrubbed = ''.join(s_scrubbed_list)
+
+ # Then match the synonyms and remaining words
+ if self.options[track]["cwp_split_hyphenated"]:
+ regex_2 = r"(" + syn_pattern + r")|" + hyphen_split_pattern
+ # allow ampersands and non-latin characters as word characters. Treat apostrophes as part of words.
+ # Treat opus and catalogue entries - e.g. K. 657 or OP.5 or op. 35a or CD 144 or BWV 243a - as one word
+ # also treat ranges of opus numbers (connected by dash, en dash or
+ # em dash) as one word
+ else:
+ regex_2 = r"(" + syn_pattern + r")|" + hyphen_embed_pattern
+ # as previous but also treat embedded hyphens as part of words.
+ matches_2 = re.finditer(
+ regex_2, s_scrubbed, re.UNICODE | re.IGNORECASE)
+ for match in matches_2:
+ if match.group(1) and match.group(1) == match.group():
+ s_test_list.append(
+ self.canonize_synonyms(
+ release_id,
+ tuples,
+ match.group(1))) # synonym
+ else:
+ s_test_list.append(match.group())
+ s_list.append(match)
+ if s_list:
+ s_zip = list(zip(s_list, s_test_list))
+ s_list, s_test_list = zip(
+ *sorted(s_zip, key=lambda tup: tup[0].start()))
+ s_tuple = tuple(s_list)
+ s_test_tuple = tuple(s_test_list)
+ return {'s_tuple': s_tuple, 's_test_tuple': s_test_tuple}
+
+ def get_text_tuples(self, release_id, track, text_type):
+ """
+ Return synonym or 'replacement' tuples
+ :param release_id:
+ :param track:
+ :param text_type: 'replacements' or 'synonyms'
+ Note that code in this method refers to synonyms (as that was written first), but applies equally to replacements and ui_tags
+ :return:
+ """
+ tm = track.metadata
+ strsyns = re.split(r'(?= 2:
+ for i, ts in enumerate(tup):
+ tup[i] = ts.strip("' ").strip('"')
+ if len(
+ tup[i]) > 4 and tup[i][0] == "!" and tup[i][1] == "!" and tup[i][-1] == "!" and tup[i][-2] == "!":
+ # we have a reg ex inside - this deals with legacy
+ # replacement text where enclosure in double-shouts was
+ # required
+ tup[i] = tup[i][2:-2]
+ if (i < len(tup) - 1 or text_type ==
+ 'synonyms') and not tup[i]:
+ write_log(
+ release_id,
+ 'warning',
+ '%s: entries must not be blank - error in %s',
+ text_type,
+ syn)
+ if self.WARNING:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_warning',
+ '7. ' + text_type + ': entries must not be blank - error in ' + syn)
+ tup[i] = "**BAD**"
+ elif [tup for t in synonyms if tup[i] in t]:
+ write_log(
+ release_id,
+ 'warning',
+ '%s: keys cannot duplicate any in existing %s - error in %s '
+ '- omitted from %s. To fix, place all %s in one tuple.',
+ text_type,
+ text_type,
+ syn,
+ text_type,
+ text_type)
+ if self.WARNING:
+ self.append_tag(release_id, tm, '~cwp_warning',
+ '7. ' + text_type + ': keys cannot duplicate any in existing ' + text_type + ' - error in ' +
+ syn + ' - omitted from ' + text_type + '. To fix, place all ' + text_type + ' in one tuple.')
+ tup[i] = "**BAD**"
+ if "**BAD**" in tup:
+ continue
+ else:
+ synonyms.append(tup)
+ else:
+ write_log(
+ release_id,
+ 'warning',
+ 'Error in %s format for %s',
+ text_type,
+ syn)
+ if self.WARNING:
+ self.append_tag(
+ release_id,
+ tm,
+ '~cwp_warning',
+ '7. Error in ' +
+ text_type +
+ ' format for ' +
+ syn)
+ write_log(release_id, 'info', "%s: %s", text_type, synonyms)
+ return synonyms
+
+ @staticmethod
+ def stencil(release_id, matches_tuple, test_string):
+ """
+ Produce lists of matching items, AND the items in between, in equal length lists
+ :param release_id:
+ :param matches_tuple: tuple of regex matches
+ :param test_string: original string used in regex
+ :return: 'match list' - list of matched strings, 'gap list' - list of strings in gaps between matches
+ """
+ match_items = []
+ gap_items = []
+ dummy = False
+ pointer = 0
+ write_log(
+ release_id,
+ 'debug',
+ 'In fn stencil. test_string = %s. matches_tuple = %s',
+ test_string,
+ matches_tuple)
+ for match_num, match in enumerate(matches_tuple):
+ start = match.start()
+ end = match.end()
+ if start > pointer:
+ if pointer == 0:
+ # add a null word item at start to keep the lists the same
+ # length
+ match_items.append('')
+ dummy = True
+ gap_items.append(test_string[pointer:start])
+ else:
+ if pointer > 0:
+ # shouldn't happen, but just in case there are two word
+ # items with no gap
+ gap_items.append('')
+ match_items.append(test_string[start:end])
+ pointer = end
+ if match_num + 1 == len(matches_tuple):
+ # pick up any punc items at end
+ gap_items.append(test_string[pointer:])
+ return {
+ 'match list': match_items,
+ 'gap list': gap_items,
+ 'dummy': dummy}
+
+ def boil(self, release_id, s):
+ """
+ Remove punctuation, spaces, capitals and accents for string comparisons
+ :param release_id: name for log file - usually =musicbrainz_albumid
+ unless called outside metadata processor
+ :param s:
+ :return:
+ """
+ write_log(release_id, 'debug', "boiling %s", s)
+ s = s.lower()
+ s = replace_roman_numerals(s)
+ s = s.replace('sch', 'sh')\
+ .replace(u'\xdf', 'ss')\
+ .replace('sz', 'ss')\
+ .replace(u'\u0153', 'oe')\
+ .replace('oe', 'o')\
+ .replace(u'\u00fc', 'ue')\
+ .replace('ue', 'u')\
+ .replace(u'\u00e6', 'ae')\
+ .replace('ae', 'a')\
+ .replace(u'\u266F', 'sharp')\
+ .replace(u'\u266D', 'flat')\
+ .replace(u'\u2013', '-')\
+ .replace(u'\u2014', '-')
+ # first term above is to remove the markers used for synonyms, to
+ # enable a true comparison
+ punc = re.compile(r'\W*', re.ASCII)
+ s = ''.join(
+ c for c in unicodedata.normalize(
+ 'NFD',
+ s) if unicodedata.category(c) != 'Mn')
+ boiled = punc.sub('', s).strip().lower().rstrip("s'")
+ write_log(release_id, 'debug', "boiled result = %s", boiled)
+ return boiled
+
+
+################
+# OPTIONS PAGE #
+################
+
+class ClassicalExtrasOptionsPage(OptionsPage):
+ NAME = "classical_extras"
+ TITLE = "Classical Extras"
+ PARENT = "plugins"
+ opts = plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') +\
+ plugin_options('workparts') + plugin_options('genres') + plugin_options('other')
+
+ options = [
+ IntOption("persist", 'ce_tab', 0)
+ ]
+ # custom logging for non-album-related messages is written to session.log
+ for opt in opts:
+ if 'type' in opt:
+ if 'default' in opt:
+ default = opt['default']
+ else:
+ default = ""
+ if opt['type'] == 'Boolean':
+ options.append(BoolOption("setting", opt['option'], default))
+ elif opt['type'] == 'Text' or opt['type'] == 'Combo' or opt['type'] == 'PlainText':
+ options.append(TextOption("setting", opt['option'], default))
+ elif opt['type'] == 'Integer':
+ options.append(IntOption("setting", opt['option'], default))
+ else:
+ write_log(
+ "session",
+ 'error',
+ "Error in setting options for option = %s",
+ opt['option'])
+
+ def __init__(self, parent=None):
+ super(ClassicalExtrasOptionsPage, self).__init__(parent)
+ self.ui = Ui_ClassicalExtrasOptionsPage()
+ self.ui.setupUi(self)
+
+ def load(self):
+ """
+ Load the options - NB all options are set in plugin_options, so this just parses that
+ :return:
+ """
+ opts = plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') +\
+ plugin_options('workparts') + plugin_options('genres') + plugin_options('other')
+
+ # To force a toggle so that signal given
+ toggle_list = ['use_cwp',
+ 'use_cea',
+ 'cea_override',
+ 'cwp_override',
+ 'cea_ra_use',
+ 'cea_split_lyrics',
+ 'cwp_partial',
+ 'cwp_arrangements',
+ 'cwp_medley',
+ 'cwp_use_muso_refdb',
+ 'ce_show_ui_tags',]
+
+ # open at last used tab
+ if 'ce_tab' in config.persist:
+ cfg_val = config.persist['ce_tab'] or 0
+ if 0 <= cfg_val <= 5:
+ self.ui.tabWidget.setCurrentIndex(cfg_val)
+ else:
+ self.ui.tabWidget.setCurrentIndex(0)
+
+ for opt in opts:
+ if opt['option'] == 'classical_work_parts':
+ ui_name = 'use_cwp'
+ elif opt['option'] == 'classical_extra_artists':
+ ui_name = 'use_cea'
+ else:
+ ui_name = opt['option']
+ if ui_name in toggle_list:
+ not_setting = not self.config.setting[opt['option']]
+ self.ui.__dict__[ui_name].setChecked(not_setting)
+
+ if opt['type'] == 'Boolean':
+ self.ui.__dict__[ui_name].setChecked(
+ self.config.setting[opt['option']])
+ elif opt['type'] == 'Text':
+ self.ui.__dict__[ui_name].setText(
+ self.config.setting[opt['option']])
+ elif opt['type'] == 'PlainText':
+ self.ui.__dict__[ui_name].setPlainText(
+ self.config.setting[opt['option']])
+ elif opt['type'] == 'Combo':
+ self.ui.__dict__[ui_name].setEditText(
+ self.config.setting[opt['option']])
+ elif opt['type'] == 'Integer':
+ self.ui.__dict__[ui_name].setValue(
+ self.config.setting[opt['option']])
+ else:
+ write_log(
+ 'session',
+ 'error',
+ "Error in loading options for option = %s",
+ opt['option'])
+
+ def save(self):
+ opts = plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') +\
+ plugin_options('workparts') + plugin_options('genres') + plugin_options('other')
+
+ # save tab setting
+ config.persist['ce_tab'] = self.ui.tabWidget.currentIndex()
+
+ for opt in opts:
+ if opt['option'] == 'classical_work_parts':
+ ui_name = 'use_cwp'
+ elif opt['option'] == 'classical_extra_artists':
+ ui_name = 'use_cea'
+ else:
+ ui_name = opt['option']
+ if opt['type'] == 'Boolean':
+ self.config.setting[opt['option']] = self.ui.__dict__[
+ ui_name].isChecked()
+ elif opt['type'] == 'Text':
+ self.config.setting[opt['option']] = str(
+ self.ui.__dict__[ui_name].text())
+ elif opt['type'] == 'PlainText':
+ self.config.setting[opt['option']] = str(
+ self.ui.__dict__[ui_name].toPlainText())
+ elif opt['type'] == 'Combo':
+ self.config.setting[opt['option']] = str(
+ self.ui.__dict__[ui_name].currentText())
+ elif opt['type'] == 'Integer':
+ self.config.setting[opt['option']
+ ] = self.ui.__dict__[ui_name].value()
+ else:
+ write_log(
+ 'session',
+ 'error',
+ "Error in saving options for option = %s",
+ opt['option'])
+
+
+#################
+# MAIN ROUTINE #
+#################
+
+# custom logging for non-album-related messages is written to session.log
+write_log('session', 'basic', 'Loading ' + PLUGIN_NAME)
+
+# SET UI COLUMNS FOR PICARD RHS
+if config.setting['ce_show_ui_tags'] and config.setting['ce_ui_tags']:
+ from picard.ui.itemviews import MainPanel
+ UI_TAGS = get_ui_tags().items()
+ for heading, tag_names in UI_TAGS:
+ heading_tag = '~' + heading + '_VAL'
+ MainPanel.columns.append((N_(heading), heading_tag))
+ write_log('session', 'info', 'UI_TAGS')
+ write_log('session', 'info', UI_TAGS)
+
+
+# set defaults for certain options that MUST be manually changed by the
+# user each time they are to be over-ridden
+config.setting['use_cache'] = True
+config.setting['ce_options_overwrite'] = False
+config.setting['track_ars'] = True
+config.setting['release_ars'] = True
+
+
+# REFERENCE DATA
+REF_DICT = get_references_from_file(
+ 'session',
+ config.setting['cwp_muso_path'],
+ config.setting['cwp_muso_refdb'])
+write_log('session', 'info', 'External references (Muso):')
+write_log('session', 'info', REF_DICT)
+COMPOSER_DICT = REF_DICT['composers']
+if config.setting['cwp_muso_classical'] and not COMPOSER_DICT:
+ write_log('session', 'error', 'No composer roster found')
+for cd in COMPOSER_DICT:
+ cd['lc_name'] = [c.lower() for c in cd['name']]
+ cd['lc_sort'] = [c.lower() for c in cd['sort']]
+PERIOD_DICT = REF_DICT['periods']
+if (config.setting['cwp_muso_dates']
+ or config.setting['cwp_muso_periods']) and not PERIOD_DICT:
+ write_log('session', 'error', 'No period map found')
+GENRE_DICT = REF_DICT['genres']
+if config.setting['cwp_muso_genres'] and not GENRE_DICT:
+ write_log('session', 'error', 'No classical genre list found')
+
+# API CALLS
+register_track_metadata_processor(PartLevels().add_work_info)
+register_track_metadata_processor(ExtraArtists().add_artist_info)
+register_options_page(ClassicalExtrasOptionsPage)
+
+# END
+write_log('session', 'basic', 'Finished intialisation')
diff --git a/plugins/classical_extras/const.py b/plugins/classical_extras/const.py
new file mode 100644
index 00000000..616c50f5
--- /dev/null
+++ b/plugins/classical_extras/const.py
@@ -0,0 +1,1148 @@
+# -*- coding: utf-8 -*-
+"""
+Declare constants for Picard Classical Extras plugin
+v2.0.2
+"""
+# Copyright (C) 2018 Mark Evens
+#
+# This program is free software; you can redistribute it and/or
+# modify it under the terms of the GNU General Public License
+# as published by the Free Software Foundation; either version 2
+# of the License, or (at your option) any later version.
+#
+# This program is distributed in the hope that it will be useful,
+# but WITHOUT ANY WARRANTY; without even the implied warranty of
+# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+# GNU General Public License for more details.
+#
+# You should have received a copy of the GNU General Public License
+# along with this program; if not, write to the Free Software
+# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
+# 02110-1301, USA.
+
+RELATION_TYPES = {
+ 'work': [
+ 'arranger',
+ 'instrument arranger',
+ 'orchestrator',
+ 'composer',
+ 'writer',
+ 'lyricist',
+ 'librettist',
+ 'revised by',
+ 'translator',
+ 'reconstructed by',
+ 'vocal arranger'],
+ 'release': [
+ 'instrument',
+ 'performer',
+ 'vocal',
+ 'performing orchestra',
+ 'conductor',
+ 'chorus master',
+ 'concertmaster',
+ 'arranger',
+ 'instrument arranger',
+ 'orchestrator',
+ 'vocal arranger'],
+ 'recording': [
+ 'instrument',
+ 'performer',
+ 'vocal',
+ 'performing orchestra',
+ 'conductor',
+ 'chorus master',
+ 'concertmaster',
+ 'arranger',
+ 'instrument arranger',
+ 'orchestrator',
+ 'vocal arranger']}
+
+ARTISTS_OPTIONS = [
+ {'option': 'classical_extra_artists',
+ 'name': 'run extra artists',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_orchestras',
+ 'name': 'orchestra strings',
+ 'type': 'Text',
+ 'default': 'orchestra, philharmonic, philharmonica, philharmoniker, musicians, academy, symphony, orkester'
+ },
+ {'option': 'cea_choirs',
+ 'name': 'choir strings',
+ 'type': 'Text',
+ 'default': 'choir, choir vocals, chorus, singers, domchors, domspatzen, koor, kammerkoor'
+ },
+ {'option': 'cea_groups',
+ 'name': 'group strings',
+ 'type': 'Text',
+ 'default': 'ensemble, band, group, trio, quartet, quintet, sextet, septet, octet, chamber, consort, players, '
+ 'les ,the , quartett'
+ },
+ {'option': 'cea_aliases',
+ 'name': 'replace artist name with alias?',
+ 'value': 'replace',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_aliases_composer',
+ 'name': 'replace artist name with alias?',
+ 'value': 'composer',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_no_aliases',
+ 'name': 'replace artist name with alias?',
+ 'value': 'no replace',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_alias_overrides',
+ 'name': 'alias vs credited-as',
+ 'value': 'alias over-rides',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_credited_overrides',
+ 'name': 'alias vs credited-as',
+ 'value': 'credited-as over-rides',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_ra_use',
+ 'name': 'use recording artist',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_ra_trackartist',
+ 'name': 'recording artist name style',
+ 'value': 'track artist',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_ra_performer',
+ 'name': 'recording artist name style',
+ 'value': 'performer',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_ra_replace_ta',
+ 'name': 'recording artist effect on track artist',
+ 'value': 'replace',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_ra_noblank_ta',
+ 'name': 'disallow blank recording artist',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_ra_merge_ta',
+ 'name': 'recording artist effect on track artist',
+ 'value': 'merge',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_composer_album',
+ 'name': 'Album prefix',
+ # 'value': 'Composer', # Can't use 'value' if there is only one option, otherwise False will revert to default
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_arrangers',
+ 'name': 'include arrangers',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_no_lyricists',
+ 'name': 'exclude lyricists if no vocals',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_cyrillic',
+ 'name': 'fix cyrillic',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ # {'option': 'cea_genres',
+ # 'name': 'infer work types',
+ # 'type': 'Boolean',
+ # 'default': True
+ # },
+ # Note that the above is no longer used - replaced by cwp_genres_infer from v0.9.2
+ {'option': 'cea_credited',
+ 'name': 'use release credited-as name',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_release_relationship_credited',
+ 'name': 'use release relationship credited-as name',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_group_credited',
+ 'name': 'use release-group credited-as name',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_recording_credited',
+ 'name': 'use recording credited-as name',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_recording_relationship_credited',
+ 'name': 'use recording relationship credited-as name',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_track_credited',
+ 'name': 'use track credited-as name',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_performer_credited',
+ 'name': 'use credited-as name for performer',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_composer_credited',
+ 'name': 'use credited-as name for composer',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_inst_credit',
+ 'name': 'use credited instrument',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_no_solo',
+ 'name': 'exclude solo',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_chorusmaster',
+ 'name': 'chorusmaster',
+ 'type': 'Text',
+ 'default': 'choirmaster'
+ },
+ {'option': 'cea_orchestrator',
+ 'name': 'orchestrator',
+ 'type': 'Text',
+ 'default': 'orch.'
+ },
+ {'option': 'cea_concertmaster',
+ 'name': 'concertmaster',
+ 'type': 'Text',
+ 'default': 'leader'
+ },
+ {'option': 'cea_lyricist',
+ 'name': 'lyricist',
+ 'type': 'Text',
+ 'default': 'lyrics'
+ },
+ {'option': 'cea_librettist',
+ 'name': 'librettist',
+ 'type': 'Text',
+ 'default': 'libretto'
+ },
+ {'option': 'cea_writer',
+ 'name': 'writer',
+ 'type': 'Text',
+ 'default': 'writer'
+ },
+ {'option': 'cea_arranger',
+ 'name': 'arranger',
+ 'type': 'Text',
+ 'default': 'arr.'
+ },
+ {'option': 'cea_reconstructed',
+ 'name': 'reconstructed by',
+ 'type': 'Text',
+ 'default': 'reconstructed'
+ },
+ {'option': 'cea_revised',
+ 'name': 'revised by',
+ 'type': 'Text',
+ 'default': 'revised'
+ },
+ {'option': 'cea_translator',
+ 'name': 'translator',
+ 'type': 'Text',
+ 'default': 'trans.'
+ },
+ {'option': 'cea_split_lyrics',
+ 'name': 'split lyrics',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cea_lyrics_tag',
+ 'name': 'lyrics',
+ 'type': 'Text',
+ 'default': 'lyrics'
+ },
+ {'option': 'cea_album_lyrics',
+ 'name': 'album lyrics',
+ 'type': 'Text',
+ 'default': 'albumnotes'
+ },
+ {'option': 'cea_track_lyrics',
+ 'name': 'track lyrics',
+ 'type': 'Text',
+ 'default': 'tracknotes'
+ }
+]
+
+TAG_OPTIONS = [
+ {'option': 'cea_blank_tag',
+ 'name': 'Tags to blank',
+ 'type': 'Text',
+ 'default': 'artist, artistsort'
+ },
+ {'option': 'cea_blank_tag_2',
+ 'name': 'Tags to blank 2',
+ 'type': 'Text',
+ 'default': 'performer:orchestra, performer:choir, performer:choir vocals'
+ },
+ {'option': 'cea_keep',
+ 'name': 'File tags to keep',
+ 'type': 'Text',
+ 'default': ''
+ },
+ {'option': 'cea_clear_tags',
+ 'name': 'Clear previous tags',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cea_tag_sort',
+ 'name': 'populate sort tags',
+ 'type': 'Boolean',
+ 'default': True
+ }
+]
+# (tag mapping detail lines)
+default_list = [
+ ('album_soloists, album_ensembles, album_conductors', 'artist, artists', False),
+ ('recording_artists', 'artist, artists', True),
+ ('soloist_names, ensemble_names, conductors', 'artist, artists', True),
+ ('soloists', 'soloists, trackartist, involved people', False),
+ ('release', 'release_name', False),
+ ('ensemble_names', 'band', False),
+ ('composers', 'artist', True),
+ ('MB_artists', 'composer', True),
+ ('arranger', 'composer', True)
+]
+TAG_DETAIL_OPTIONS = []
+for i in range(0, 16):
+ if i < len(default_list):
+ default_source, default_tag, default_cond = default_list[i]
+ else:
+ default_source = ''
+ default_tag = ''
+ default_cond = False
+ TAG_DETAIL_OPTIONS.append({'option': 'cea_source_' + str(i + 1),
+ 'name': 'line ' + str(i + 1) + '_source',
+ 'type': 'Combo',
+ 'default': default_source
+ })
+ TAG_DETAIL_OPTIONS.append({'option': 'cea_tag_' + str(i + 1),
+ 'name': 'line ' + str(i + 1) + '_tag',
+ 'type': 'Text',
+ 'default': default_tag
+ })
+ TAG_DETAIL_OPTIONS.append({'option': 'cea_cond_' + str(i + 1),
+ 'name': 'line ' + str(i + 1) + '_conditional',
+ 'type': 'Boolean',
+ 'default': default_cond
+ })
+
+WORKPARTS_OPTIONS = [
+ {'option': 'classical_work_parts',
+ 'name': 'run work parts',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_collections',
+ 'name': 'include collection relations',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_allow_empty_parts',
+ # allow parts to be blank if there is arrangement or partial text label
+ # checked = split
+ 'name': 'allow-empty-parts',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_common_chars',
+ # for use in strip_parent_from_work
+ # where no match exists and substring elimination is used
+ # this sets the minimum number of matching 'words' (words followed by punctuation/spaces or EOL)
+ # required before they will be eliminated
+ # 0 => no elimination
+ # default is 2 words
+ 'name': 'min common words to eliminate',
+ 'type': 'Integer',
+ 'default': 2
+ },
+ {'option': 'cwp_proximity',
+ # proximity of new words in title comparison which will result in
+ # infill words being included as well. 2 means 2-word 'gaps' of
+ # existing words between new words will be treated as 'new'
+ 'name': 'in-string proximity trigger',
+ 'type': 'Integer',
+ 'default': 2
+ },
+ {'option': 'cwp_end_proximity',
+ # proximity measure to be used when infilling to the end of the title
+ 'name': 'end-string proximity trigger',
+ 'type': 'Integer',
+ 'default': 1
+ },
+ {'option': 'cwp_split_hyphenated',
+ # splitting of hyphenated words for matching purposes
+ # checked = split
+ 'name': 'hyphen-splitting',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_substring_match',
+ # Proportion of a string to be matched to a (usually larger) string for
+ # it to be considered essentially similar
+ 'name': 'similarity threshold',
+ 'type': 'Integer',
+ 'default': 100
+ },
+ {'option': 'cwp_fill_part',
+ # Fill part name with title text if it would otherwise
+ # have no text other than arrangement or partial annotations
+ 'name': 'disallow empty part names',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_prepositions',
+ 'name': 'prepositions',
+ 'type': 'Text',
+ 'default': "a, the, in, on, at, of, after, and, de, d'un, d'une, la, le, no, from, &, e, ed, et, un,"
+ " une, al, ala, alla"
+ },
+ {'option': 'cwp_removewords',
+ 'name': 'ignore prefixes',
+ 'type': 'Text',
+ 'default': ' part , act , scene, movement, movt, no. , no , n., n , nr., nr , book , the , a , la , le , un ,'
+ ' une , el , il , tableau, from , KV ,Concerto in, Concerto'
+ },
+ {'option': 'cwp_synonyms',
+ 'name': 'synonyms',
+ 'type': 'PlainText',
+ 'default': '(1, one) / (2, two) / (3, three) / (&, and) / (Rezitativ, Recitativo, Recitative) / '
+ '(Sinfonia, Sinfonie, Symphonie, Symphony) / (Arie, Aria) / '
+ '(Minuetto, Menuetto, Minuetta, Menuet, Minuet) / (Bourée, Bouree , Bourrée)'
+ },
+ {'option': 'cwp_replacements',
+ 'name': 'replacements',
+ 'type': 'Text',
+ 'default': '(words to be replaced, replacement words) / (please blank me, ) / (etc, etc)'
+ },
+ {'option': 'cwp_titles',
+ 'name': 'Style',
+ 'value': 'Titles',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_works',
+ 'name': 'Style',
+ 'value': 'Works',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_extended',
+ 'name': 'Style',
+ 'value': 'Extended',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_hierarchical_works',
+ 'name': 'Work source',
+ 'value': 'Hierarchy',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_level0_works',
+ 'name': 'Work source',
+ 'value': 'Level_0',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_derive_works_from_title',
+ 'name': 'Derive works from title',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_movt_tag_inc',
+ 'name': 'movement tag inc num',
+ 'type': 'Text',
+ 'default': 'part, movement, subtitle'
+ },
+ {'option': 'cwp_movt_tag_exc',
+ 'name': 'movement tag exc num',
+ 'type': 'Text',
+ 'default': ''
+ },
+ {'option': 'cwp_movt_tag_inc1',
+ 'name': '1-level movement tag inc num',
+ 'type': 'Text',
+ 'default': 'movement'
+ },
+ {'option': 'cwp_movt_tag_exc1',
+ 'name': '1-level movement tag exc num',
+ 'type': 'Text',
+ 'default': ''
+ },
+ {'option': 'cwp_movt_no_tag',
+ 'name': 'movement num tag',
+ 'type': 'Text',
+ 'default': 'movementnumber'
+ },
+ {'option': 'cwp_movt_tot_tag',
+ 'name': 'movement tot tag',
+ 'type': 'Text',
+ 'default': 'movementtotal'
+ },
+ {'option': 'cwp_work_tag_multi',
+ 'name': 'multi-level work tag',
+ 'type': 'Text',
+ 'default': 'groupheading, work'
+ },
+ {'option': 'cwp_work_tag_single',
+ 'name': 'single level work tag',
+ 'type': 'Text',
+ 'default': ''
+ },
+ {'option': 'cwp_top_tag',
+ 'name': 'top level work tag',
+ 'type': 'Text',
+ 'default': 'top_work, style, grouping'
+ },
+ {'option': 'cwp_multi_work_sep',
+ 'name': 'multi-level work separator',
+ 'type': 'Combo',
+ 'default': ':'
+ },
+ {'option': 'cwp_single_work_sep',
+ 'name': 'single level work separator',
+ 'type': 'Combo',
+ 'default': ':'
+ },
+ {'option': 'cwp_movt_no_sep',
+ 'name': 'movement number separator',
+ 'type': 'Combo',
+ 'default': '.'
+ },
+ {'option': 'cwp_partial',
+ 'name': 'show partial recordings',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_partial_text',
+ 'name': 'partial text',
+ 'type': 'Text',
+ 'default': '(part)'
+ },
+ {'option': 'cwp_arrangements',
+ 'name': 'include arrangement of',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_arrangements_text',
+ 'name': 'arrangements text',
+ 'type': 'Text',
+ 'default': 'Arrangement:'
+ },
+ {'option': 'cwp_medley',
+ 'name': 'list medleys',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_medley_text',
+ 'name': 'medley text',
+ 'type': 'Text',
+ 'default': 'Medley'
+ }
+]
+# Options on "Genres etc." tab
+
+GENRE_OPTIONS = [
+ {'option': 'cwp_genre_tag',
+ 'name': 'main genre tag',
+ 'type': 'Text',
+ 'default': 'genre'
+ },
+ {'option': 'cwp_subgenre_tag',
+ 'name': 'sub-genre tag',
+ 'type': 'Text',
+ 'default': 'sub-genre'
+ },
+ {'option': 'cwp_genres_use_file',
+ 'name': 'source genre from file',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_genres_use_folks',
+ 'name': 'source genre from folksonomy tags',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_genres_use_worktype',
+ 'name': 'source genre from work-type(s)',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_genres_infer',
+ 'name': 'infer genre from artist details(s)',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ # Note that the "infer from artists" option was in the "artists"
+ # section - legacy from v0.9.1 & prior
+ {'option': 'cwp_genres_filter',
+ 'name': 'apply filter to genres',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_genres_classical_main',
+ 'name': 'classical main genres',
+ 'type': 'PlainText',
+ 'default': 'Classical, Chamber music, Concerto, Symphony, Opera, Orchestral, Sonata, Choral, Aria, Ballet, '
+ 'Oratorio, Motet, Symphonic poem, Suite, Partita, Song-cycle, Overture, '
+ 'Mass, Cantata'
+ },
+ {'option': 'cwp_genres_classical_sub',
+ 'name': 'classical sub-genres',
+ 'type': 'PlainText',
+ 'default': 'Chant, Classical crossover, Minimalism, Avant-garde, Impressionist, Aria, Duet, Trio, Quartet'
+ },
+ {'option': 'cwp_genres_other_main',
+ 'name': 'general main genres',
+ 'type': 'PlainText',
+ 'default': 'Alternative music, Blues, Country, Dance, Easy listening, Electronic music, Folk, Folk / pop, '
+ 'Hip hop / rap, Indie, Religious, Asian, Jazz, Latin, New age, Pop, R&B / Soul, Reggae, Rock, '
+ 'World music, Celtic folk, French Medieval'
+ },
+ {'option': 'cwp_genres_other_sub',
+ 'name': 'general sub-genres',
+ 'type': 'PlainText',
+ 'default': 'Song, Vocal, Christmas, Instrumental'
+ },
+ {'option': 'cwp_genres_arranger_as_composer',
+ 'name': 'treat arranger as for composer for genre-setting',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_genres_classical_all',
+ 'name': 'make tracks classical',
+ 'value': 'all',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_genres_classical_selective',
+ 'name': 'make tracks classical',
+ 'value': 'selective',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_genres_classical_exclude',
+ 'name': 'exclude "classical" from main genre tag',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_genres_flag_text',
+ 'name': 'classical flag',
+ 'type': 'Text',
+ 'default': '1'
+ },
+ {'option': 'cwp_genres_flag_tag',
+ 'name': 'classical flag tag',
+ 'type': 'Text',
+ 'default': 'is_classical'
+ },
+ {'option': 'cwp_genres_default',
+ 'name': 'default genre',
+ 'type': 'Text',
+ 'default': 'Other'
+ },
+ {'option': 'cwp_instruments_tag',
+ 'name': 'instruments tag',
+ 'type': 'Text',
+ 'default': 'instrument'
+ },
+ {'option': 'cwp_instruments_MB_names',
+ 'name': 'use MB instrument names',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_instruments_credited_names',
+ 'name': 'use credited instrument names',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_key_tag',
+ 'name': 'key tag',
+ 'type': 'Text',
+ 'default': 'key'
+ },
+ {'option': 'cwp_key_contingent_include',
+ 'name': 'contingent include key in workname',
+ 'value': 'contingent',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_key_never_include',
+ 'name': 'never include key in workname',
+ 'value': 'never',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_key_include',
+ 'name': 'include key in workname',
+ 'value': 'always',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_workdate_tag',
+ 'name': 'workdate tag',
+ 'type': 'Text',
+ 'default': 'work_year'
+ },
+ {'option': 'cwp_workdate_source_composed',
+ 'name': 'use composed for workdate',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_workdate_source_published',
+ 'name': 'use published for workdate',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_workdate_source_premiered',
+ 'name': 'use premiered for workdate',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_workdate_use_first',
+ 'name': 'use workdate sources sequentially',
+ 'value': 'sequence',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_workdate_use_all',
+ 'name': 'use all workdate sources',
+ 'value': 'all',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_workdate_annotate',
+ 'name': 'annotate dates',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_workdate_include',
+ 'name': 'include workdate in workname',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_period_tag',
+ 'name': 'period tag',
+ 'type': 'Text',
+ 'default': 'period'
+ },
+ {'option': 'cwp_periods_arranger_as_composer',
+ 'name': 'treat arranger as for composer for period-setting',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_period_map',
+ 'name': 'period map',
+ 'type': 'PlainText',
+ 'default': 'Early, -3000,800; Medieval, 800,1400; Renaissance, 1400, 1600; Baroque, 1600,1750; '
+ 'Classical, 1750,1820; Early Romantic, 1800,1850; Late Romantic, 1850,1910; '
+ '20th Century, 1910,1975; Contemporary, 1975,2525'
+ }
+]
+# Picard options which are also saved (NB only affects plugin processing - not main Picard processing)
+PICARD_OPTIONS = [
+ {'option': 'standardize_artists',
+ 'name': 'standardize artists',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'translate_artist_names',
+ 'name': 'translate artist names',
+ 'type': 'Boolean',
+ 'default': True
+ },
+]
+
+# other options (not saved in file tags)
+OTHER_OPTIONS = [
+ {'option': 'use_cache',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_aliases',
+ 'name': 'replace with alias?',
+ 'value': 'replace',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_no_aliases',
+ 'name': 'replace with alias?',
+ 'value': 'no replace',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_aliases_all',
+ 'name': 'alias replacement type',
+ 'value': 'all',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_aliases_greek',
+ 'name': 'alias replacement type',
+ 'value': 'non-latin',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_aliases_tagged',
+ 'name': 'alias replacement type',
+ 'value': 'tagged works',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_aliases_tag_text',
+ 'name': 'use_alias tag text',
+ 'type': 'Text',
+ 'default': 'use_alias'
+ },
+ {'option': 'cwp_aliases_tags_all',
+ 'name': 'use_alias tags all',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'cwp_aliases_tags_user',
+ 'name': 'use_alias tags user',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_use_sk',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_write_sk',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_retries',
+ 'type': 'Integer',
+ 'default': 6
+ },
+ {'option': 'cwp_use_muso_refdb',
+ 'name': 'use Muso ref database',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_muso_genres',
+ 'name': 'use Muso classical genres',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_muso_classical',
+ 'name': 'use Muso classical composers',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_muso_dates',
+ 'name': 'use Muso composer dates',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_muso_periods',
+ 'name': 'use Muso periods',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_muso_path',
+ 'name': 'path to Muso database',
+ 'type': 'Text',
+ 'default': 'C:\\Users\\Public\\Music\\muso\\database'
+ },
+ {'option': 'cwp_muso_refdb',
+ 'name': 'name of Muso reference database',
+ 'type': 'Text',
+ 'default': 'Reference.xml'
+ },
+ {'option': 'log_error',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'log_warning',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'log_debug',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'log_basic',
+ 'type': 'Boolean',
+ 'default': True
+ },
+ {'option': 'log_info',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_version_tag',
+ 'type': 'Text',
+ 'default': 'stamp'
+ },
+ {'option': 'cea_options_tag',
+ 'type': 'Text',
+ 'default': 'comment'
+ },
+ {'option': 'cwp_options_tag',
+ 'type': 'Text',
+ 'default': 'comment'
+ },
+ {'option': 'cea_override',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_tagmap_override',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'cwp_override',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_genres_override',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_options_overwrite',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_no_run',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_show_ui_tags',
+ 'type': 'Boolean',
+ 'default': False
+ },
+ {'option': 'ce_ui_tags',
+ ## Note that this is not just for work parts (although that is the main use),
+ # but cwp prefix is to make use of code for synonyms
+ 'name': 'tags for ui columns',
+ 'type': 'PlainText',
+ 'default': 'Work diff: (groupheading_DIFF, work_DIFF, top_work_DIFF, grouping_DIFF) / Part diff: (part_DIFF, movement_DIFF) / Missing file metadata: 002_important_warning'
+ }
+]
+
+ARTIST_TYPE_ORDER = {'vocal': 1,
+ 'instrument': 1,
+ 'performer': 0,
+ 'performing orchestra': 2,
+ 'concertmaster': 3,
+ 'conductor': 4,
+ 'chorus master': 5,
+ 'composer': 6,
+ 'writer': 7,
+ 'reconstructed by': 8,
+ 'instrument arranger': 9,
+ 'vocal arranger': 9,
+ 'arranger': 11,
+ 'orchestrator': 12,
+ 'revised by': 13,
+ 'lyricist': 14,
+ 'librettist': 15,
+ 'translator': 16
+ }
+
+CYRILLIC_UPPER = {
+ u'А': u'A',
+ u'Б': u'B',
+ u'В': u'V',
+ u'Г': u'G',
+ u'Д': u'D',
+ u'Е': u'E',
+ u'Ё': u'E',
+ u'Ж': u'Zh',
+ u'З': u'Z',
+ u'И': u'I',
+ u'Й': u'Y',
+ u'К': u'K',
+ u'Л': u'L',
+ u'М': u'M',
+ u'Н': u'N',
+ u'О': u'O',
+ u'П': u'P',
+ u'Р': u'R',
+ u'С': u'S',
+ u'Т': u'T',
+ u'У': u'U',
+ u'Ф': u'F',
+ u'Х': u'H',
+ u'Ц': u'Ts',
+ u'Ч': u'Ch',
+ u'Ш': u'Sh',
+ u'Щ': u'Sch',
+ u'Ъ': u'',
+ u'Ы': u'Y',
+ u'Ь': u'',
+ u'Э': u'E',
+ u'Ю': u'Yu',
+ u'Я': u'Ya'
+ }
+CYRILLIC_LOWER = {
+ u'а': u'a',
+ u'б': u'b',
+ u'в': u'v',
+ u'г': u'g',
+ u'д': u'd',
+ u'е': u'e',
+ u'ё': u'e',
+ u'ж': u'zh',
+ u'з': u'z',
+ u'и': u'i',
+ u'й': u'y',
+ u'к': u'k',
+ u'л': u'l',
+ u'м': u'm',
+ u'н': u'n',
+ u'о': u'o',
+ u'п': u'p',
+ u'р': u'r',
+ u'с': u's',
+ u'т': u't',
+ u'у': u'u',
+ u'ф': u'f',
+ u'х': u'h',
+ u'ц': u'ts',
+ u'ч': u'ch',
+ u'ш': u'sh',
+ u'щ': u'sch',
+ u'ъ': u'',
+ u'ы': u'y',
+ u'ь': u'',
+ u'э': u'e',
+ u'ю': u'yu',
+ u'я': u'ya'
+}
+
+def tag_strings(pre):
+ TAG_STRINGS = {
+ 'writer': (
+ 'composer',
+ pre + '_writers',
+ 'composersort',
+ pre + '_writers_sort'),
+ 'composer': (
+ 'composer',
+ pre + '_composers',
+ 'composersort',
+ pre + '_composers_sort'),
+ 'lyricist': (
+ 'lyricist',
+ pre + '_lyricists',
+ '~lyricists_sort',
+ pre + '_lyricists_sort'),
+ 'librettist': (
+ 'lyricist',
+ pre + '_librettists',
+ '~lyricists_sort',
+ pre + '_librettists_sort'),
+ 'revised by': (
+ 'arranger',
+ pre + '_revisors',
+ '~arranger_sort',
+ pre + '_revisors_sort'),
+ 'translator': (
+ 'lyricist',
+ pre + '_translators',
+ '~lyricists_sort',
+ pre + '_translators_sort'),
+ 'reconstructed by': (
+ 'arranger',
+ pre + '_reconstructors',
+ '~arranger_sort',
+ pre + '_reconstructors_sort'),
+ 'arranger': (
+ 'arranger',
+ pre + '_arrangers',
+ '~arranger_sort',
+ pre + '_arrangers_sort'),
+ 'instrument arranger': (
+ 'arranger',
+ pre + '_arrangers',
+ '~arranger_sort',
+ pre + '_arrangers_sort'),
+ 'orchestrator': (
+ 'arranger',
+ pre + '_orchestrators',
+ '~arranger_sort',
+ pre + '_orchestrators_sort'),
+ 'vocal arranger': (
+ 'arranger',
+ pre + '_arrangers',
+ '~arranger_sort',
+ pre + '_arrangers_sort'),
+ 'performer': (
+ 'performer:',
+ pre + '_performers',
+ '~performer_sort',
+ pre + '_performers_sort'),
+ 'instrument': (
+ 'performer:',
+ pre + '_performers',
+ '~performer_sort',
+ pre + '_performers_sort'),
+ 'vocal': (
+ 'performer:',
+ pre + '_performers',
+ '~performer_sort',
+ pre + '_performers_sort'),
+ 'performing orchestra': (
+ 'performer:orchestra',
+ pre + '_ensembles',
+ '~performer_sort',
+ pre + '_ensembles_sort'),
+ 'conductor': (
+ 'conductor',
+ pre + '_conductors',
+ '~conductor_sort',
+ pre + '_conductors_sort'),
+ 'chorus master': (
+ 'conductor',
+ pre + '_chorusmasters',
+ '~conductor_sort',
+ pre + '_chorusmasters_sort'),
+ 'concertmaster': (
+ 'performer',
+ pre + '~_leaders',
+ '~performer_sort',
+ pre + '_leaders_sort')}
+ return TAG_STRINGS
+
+INSERTIONS = ['writer',
+ 'lyricist',
+ 'librettist',
+ 'revised by',
+ 'translator',
+ 'arranger',
+ 'reconstructed by',
+ 'orchestrator',
+ 'instrument arranger',
+ 'vocal arranger',
+ 'chorus master']
\ No newline at end of file
diff --git a/plugins/classical_extras/options_classical_extras.ui b/plugins/classical_extras/options_classical_extras.ui
new file mode 100644
index 00000000..02a16cd3
--- /dev/null
+++ b/plugins/classical_extras/options_classical_extras.ui
@@ -0,0 +1,11987 @@
+
+
+ ClassicalExtrasOptionsPage
+
+
+
+ 0
+ 0
+ 1145
+ 918
+
+
+
+
+ 0
+ 0
+
+
+
+ Qt::DefaultContextMenu
+
+
+ false
+
+
+
+ 6
+
+
+ 9
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+ 1200
+ 1200
+
+
+
+
+
+
+
+
+
+
+ false
+
+
+
+
+
+ 4
+
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ Artists
+
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ Qt::WheelFocus
+
+
+ QFrame::NoFrame
+
+
+ QFrame::Plain
+
+
+ 1
+
+
+ true
+
+
+
+
+ 0
+ 0
+ 1086
+ 1071
+
+
+
+ false
+
+
+
-
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(255, 255, 222);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+ <html><head/><body><p>should be selected otherwise this section will not run</p></body></html>
+
+
+
+
+
+ Create extra artist metadata (MUST BE TICKED FOR THIS SECTION TO RUN)
+
+
+
+ -
+
+
+ (Note that the "infer work-types" option has moved to the "genres" tab)
+
+
+
+
+
+
+ -
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+ <html><head/><body><p><span style=" font-weight:600; font-style:italic;">The naming style for 'artist' tags is set in the main Picard Options->Metadata section</span></p></body></html>
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(176, 220, 192);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Work-artist / performer naming options</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+ UpArrowCursor
+
+
+ <html><head/><body><p>"Work-artists" are types such as composer, writer, arranger and lyricist who belong to the MusicBrainz Work-Artist relationship</p><p>"Performers" are types such as performer and conductor who belong to the MusicBrainz Recording-Artist relationship</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::NoFrame
+
+
+
+ QFormLayout::AllNonFixedFieldsGrow
+
+
+ 6
+
+
+ 9
+
+
+ 0
+
+
+ 9
+
+
-
+
+
+ <html><head/><body><p>This section does not change the contents of "artist" or "album artist" tags - it only affects writer (composer etc.) and peformer tags, by using as-credited/alias names from the artist data for the release.</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ Credited-as options:-
+
+
+
-
+
+
+ <html><head/><body><p>Select the source for 'as-credited' names - whether these are applied depends on the sub-options choices.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ Names to use...
+
+
+
-
+
+
+ Qt::RightToLeft
+
+
+ Use "credited as" name for work-artists/performers who are recording artists
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ false
+
+
+
+
+
+ and/or release group artists
+
+
+
+ -
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ Qt::RightToLeft
+
+
+ and/or release artists
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ and/or release relationship artists
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ and/or recording relationship artists
+
+
+
+ -
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ Qt::RightToLeft
+
+
+ and/or track artists
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ The above are applied in sequence - e.g. track artist credit will over-ride release artist credit.
+
+
+
+ -
+
+
+ Names are cached. A restart is necessary if any of the above name sources are removed.
+
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p>Select the tag types where any 'as-credited' names will be applied - whether these are applied depends on the sub-options choices.</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ Places to use them ...
+
+
+
+ QLayout::SetDefaultConstraint
+
+
+ 9
+
+
-
+
+
+ Qt::RightToLeft
+
+
+ Use for performing artists
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Use for work-artists
+
+
+
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ Sub-options
+
+
+
-
+
+
+ <html><head/><body><p>Alias (if it exists) will over-ride as-credited</p></body></html>
+
+
+ Alias over-rides credited-as
+
+
+
+ -
+
+
+ <html><head/><body><p>As-credited (if it exists) will over-ride alias</p></body></html>
+
+
+ Credited-as over-rides MB/Alias
+
+
+
+ -
+
+
+ <html><head/><body><p>Will be based on sort names. For cyrillic script names, patronyms will be removed.</p></body></html>
+
+
+ Fix non-Latin text in names (where possible and if not fixed by other naming options)
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ MusicBrainz standard names and Aliases
+
+
+
-
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p>Do not use aliases (but may be replaced by as-credited name)</p></body></html>
+
+
+ Use MB standard names
+
+
+
+ -
+
+
+ <html><head/><body><p>Alias will only be available for use if the work-artist/performer is also a release artist, recording artist or track artist.</p></body></html>
+
+
+ Use alias for all work-artists/performers
+
+
+
+ -
+
+
+ <html><head/><body><p>Only use alias (if available) for work-artists (writers, composers, arrangers, lyricists etc.)</p></body></html>
+
+
+ Use alias for work-artists only
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(176, 220, 192);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Recording artist options</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+ <html><head/><body><p>Select recording artist options (see "What's this")</p></body></html>
+
+
+ <html><head/><body><p>In MusicBrainz, the recording artist may be different from the track artist. For classical music, the MusicBrainz guidelines state that the track artist should be the composer; however the recording artist(s) is/are usually the principal performer(s).</p><p>Classical Extras puts the recording artists into 'hidden variables' (as a minimum) using the chosen naming convention.</p><p>There is also option to allow you to replace the track artist by the recording artist (or to merge them). The chosen action will be applied to the 'artist', 'artists', 'artistsort' and 'artists_sort' tags. Note that 'artist' is a single-valued string whereas 'artists' is a list and may be multi-valued. Lists are properly merged, but because the 'artist' string may have different join-phrases etc, a merged tag may have the recording artist(s) in brackets after the track artist(s).</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(211, 248, 224);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p>In classical music (in MusicBrainz), recording artists will usually be performers whereas track artists are composers. By default, the naming convention for performers (set in the previous section) will be used (although only the as-credited name set for the recording artist will be applied). Alternatively, the naming convention for track artists can be used - which is determined by the main Picard metadat options.</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ Naming convention as for ...
+
+
+
-
+
+
+ ...track artist (set in Picard options)
+
+
+
+ -
+
+
+ ... perfomers (set above)
+
+
+
+
+
+
+ -
+
+
+ Qt::Vertical
+
+
+
+ -
+
+
+ Use recording artists to update track artists ->
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ Replace/merge options
+
+
+
-
+
+
+ Replace track artist by recording artist
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ Qt::LeftToRight
+
+
+ Only replace if rec. artist exists
+
+
+
+ -
+
+
+ Merge track artist and recording artist
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(176, 220, 192);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Other artist options</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+ 211
+ 248
+ 224
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(211, 248, 224);
+
+
+
+
+
+
+ 6
+
+
-
+
+
+ <html><head/><body><p>Enter text to appear in annotations. Do not use any quotation marks.</p></body></html>
+
+
+ background-color: rgba(250, 250, 250, 250);
+
+
+ Annotations - performers and lyricists
+
+
+
-
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 6
+
+
+ QLayout::SetDefaultConstraint
+
+
+ 1
+
+
+ 9
+
+
-
+
+
+ <html><head/><body><p>Annotation to include with "chorus master" in conductor tag.</p></body></html>
+
+
+ Chorus Master
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 1
+
+
-
+
+
+ <html><head/><body><p>Annotation to include for "concert master" in performer tag.</p></body></html>
+
+
+ Concert Master
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>Annotation for lyricist, to include in lyricist tag</p></body></html>
+
+
+ Lyricist
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>Annotation for librettist, to include in lyricist tag</p></body></html>
+
+
+ Librettist
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>Annotation for translator, to include in lyricist tag</p></body></html>
+
+
+ Translator
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p>Select as required. See "What's this" for details.</p></body></html>
+
+
+ background-color: rgba(250, 250, 250, 250);
+
+
+
+
+
+
+ 6
+
+
-
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ <html><head/><body><p>This will gather together, for example, any arranger-type information from the recording, work or parent works and place it in the "arranger" tag ('host' tag), with the annotation (see details to right of this box) in brackets. All arranger types will also be put in a hidden variable, e.g. _cwp_orchestrators. The table below shows the artist types, host tag and hidden variable for each artist type.</p><p>| Artist type | Host tag | Hidden variable |</p><p>| ----------------- | ------------------| -------------------------------------- |</p><p>| writer | composer | writers |</p><p>| lyricist | lyricist | lyricists |</p><p>| librettist | lyricist | librettists |</p><p>| revised by | arranger | revisors |</p><p>| translator | lyricist | translators |</p><p>| arranger | arranger | arrangers |</p><p>| reconstructed by | arranger | reconstructors |</p><p>| orchestrator | arranger | orchestrators |</p><p>| instrument arranger | arranger | arrangers (with instrument type in brackets) |</p><p>| vocal arranger | arranger | arrangers (with voice type in brackets) |</p><p>| chorus master | conductor | chorusmasters |</p><p>| concertmaster | performer (with annotation as a sub-key) | leaders |</p></body></html>
+
+
+ Modify host tags and include annotations (see =>)
+
+
+
+ -
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ <html><head/><body><p>This will add the composer(s) last name(s) before the album name, if they are listed as album artists. If there is more than one composer, they will be listed in the descending order of the length of their music on the release.</p></body></html>
+
+
+ Name album as "Composer Last Name(s): Album Name"
+
+
+
+ -
+
+
+ <html><head/><body><p>This applies to both the Picard 'lyricist' tag and the related internal plugin hidden variables '_cwp_lyricists' etc.</p></body></html>
+
+
+ Do not write 'lyricist' tag if no vocal performers
+
+
+
+ -
+
+
+ Use "credited-as" name for instrument
+
+
+
+ -
+
+
+ <html><head/><body><p>Select to eliminate "additional", "solo" or "guest" from instrument description</p></body></html>
+
+
+ <html><head/><body><p>MusicBrainz permits the use of "solo", "guest" and "additional" as instrument attributes although, for classical music, its use should be fairly rare - usually only if explicitly stated as a "solo" on the the sleevenotes. Classical Extras provides the option to exclude these attributes (the default), but you may wish to enable them for certain releases or non-Classical / cross-over releases.</p></body></html>
+
+
+ Do not include attributes (e.g. 'solo') in an instrument type
+
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p>Enter text to appear in annotations. Do not use any quotation marks.</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ Annotations - writers and arrangers
+
+
+
-
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ Writer
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ Arranger
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 1
+
+
-
+
+
+ <html><head/><body><p>Text with which to annotate orchestrator in the arranger tag.</p></body></html>
+
+
+ Orchestrator
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>Annotation for "reconstructed by", to include in arranger tag</p></body></html>
+
+
+ Reconstructed by
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(211, 248, 224);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>Annotation for "revised by", to include in arranger tag tag</p></body></html>
+
+
+ Revised by
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ 1
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(204, 168, 161);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Lyrics</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+ 230
+ 215
+ 211
+
+
+
+
+
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Please note that this section operates on the underlying input file tags, not the Picard-generated tags (MusicBrainz does not have lyrics)</span></p><p> Sometimes "lyrics" tags can contain album notes (repeated for every track in an album) as well as track notes and lyrics. This section will filter out the common text and place it in a different tag from the text which is unique to each track.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(230, 215, 211);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p>enables this section</p></body></html>
+
+
+ Split lyrics tag into track and album levels
+
+
+
+ -
+
+
+ <html><head/><body><p>Enter a valid tag name (no spaces, punctuation or special charcaters other than underline; use lower case)</p></body></html>
+
+
+
+
+
+
-
+
+
+ background-color: rgb(204, 168, 161);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>The name of the lyrics file tag in the input file (normally just 'lyrics')</p></body></html>
+
+
+ Incoming lyrics tag (i.e. file tag)
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(204, 168, 161);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>The name of the tag where common text should be placed</p></body></html>
+
+
+ Tag for album notes / lyrics
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(204, 168, 161);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>The name of the tag where notes/lyrics unique to a track should be placed</p></body></html>
+
+
+ Tag for track notes / lyrics
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ Qt::Vertical
+
+
+
+ 20
+ 40
+
+
+
+
+
+
+
+
+
+
+
+
+ Works and parts
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ true
+
+
+
+
+ 0
+ 0
+ 1084
+ 1086
+
+
+
+
+ 0
+ 0
+
+
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+ 255
+ 255
+ 222
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(255, 255, 222);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+ <html><head/><body><p>"Include all work levels" should be selected otherwise this section will not run.</p></body></html>
+
+
+ Include all work levels (MUST BE TICKED FOR THIS SECTION TO RUN)*
+
+
+
+ -
+
+
+ <html><head/><body><p>This will include parent works where the relationship has the attribute 'part of collection'.<br/>PLEASE BE CONSISTENT and do not use different options on albums with the same works, or the results may be unexpected.</p></body></html>
+
+
+ Include collection relationships (but not "series")
+
+
+
+ -
+
+
+ <html><head/><body><p>Select to use cached works. Deselect to refesh from MusicBrainz.</p></body></html>
+
+
+ <html><head/><body><p>"Use cache" prevents excessive look-ups of the MB database. Every look-up of a parent work needs to be performed separately (hopefully the MB database might make this easier some day). Network usage constraints by MB means that each look-up takes a minimum of 1 second. Once a release has been looked-up, the works are retained in cache, significantly reducing the time required if, say, the options are changed and the data refreshed. However, if the user edits the works in the MB database then the cache will need to be turned off temporarily for the refresh to find the new/changed works. Also some types of work (e.g. arrangements) will require a full look-up if options have been changed.</p></body></html>
+
+
+ Use cache (if available)*
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(205, 230, 255);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Tagging style</span></p></body></html>
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+ 225
+ 240
+ 255
+
+
+
+
+
+
+
+ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
+<html><head><meta name="qrichtext" content="1" /><style type="text/css">
+p, li { white-space: pre-wrap; }
+</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8pt; font-weight:400; font-style:normal;">
+<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Tagging style". This section determines how the hierarchy of works will be sourced. </p>
+<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600;">Works source</span>: There are 3 options for determing the principal source of the works metadata </p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided. </p>
+<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><br /></p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below). </p>
+<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><br /></p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles <span style=" font-weight:600;">where it is significantly different</span>. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations.</p>
+<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600;">Source of canonical work text</span>. Where either of the second two options above are chosen, there is a further choice to be made: </p>
+<p style=" margin-top:12px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose. </p>
+<p style=" margin-top:12px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, <span style=" font-weight:600;">particularly if the level 0 work name does not contain all the parent work detail</span>. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag. </p>
+<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600;">Strategy for setting style:</span> <span style=" font-style:italic;">It is suggested that you start with "extended/enhanced" style and the "Consistent with lowest level work description" as the source (this is the default). If this does not give acceptable results, try switching to "Full MusicBrainz work hierarchy". If the "enhanced" details in curly brackets (from the track title) give odd results then switch the style to "canonical works" only. Any remaining oddities are then probably in the MusicBrainz data, which may require editing.</span> </p></body></html>
+
+
+ false
+
+
+ background-color: rgb(225, 240, 255);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p>There are 3 options for determing the principal source of the works metadata</p><p> - "Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.</p><p> - "Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will be in the language of the release.</p><p> - "Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles <span style=" font-weight:600;">where it is significantly different</span>. The supplementary data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations - see image below for an example (using the Muso library manager).</p></body></html>
+
+
+ Works source
+
+
+
-
+
+
+ <html><head/><body><p>"Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.</p></body></html>
+
+
+ Use only metadata from title text
+
+
+
+ -
+
+
+ <html><head/><body><p>"Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).</p></body></html>
+
+
+ Use only metadata from canonical works
+
+
+
+ -
+
+
+ <html><head/><body><p>"Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles **where it is significantly different**. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations</p></body></html>
+
+
+ Use canonical work metadata enhanced with title text
+
+
+
+
+
+
+ -
+
+
+ true
+
+
+ <html><head/><body><p>Where either of the second two options above are chosen, there is a further choice to be made:</p><p> - "Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.</p><p> - "Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, <span style=" font-weight:600;">particularly if the level 0 work name does not contain all the parent work detail</span>. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.</p></body></html>
+
+
+ Source of canonical work text (if applicable)
+
+
+
-
+
+
+ <html><head/><body><p>"Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.</p></body></html>
+
+
+ Full MusicBrainz work hierarchy (may be more verbose)
+
+
+
+ -
+
+
+ <html><head/><body><p>"Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, <span style=" font-weight:600;">particularly if the level 0 work name does not contain all the parent work detail</span>. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.</p></body></html>
+
+
+ Consistent with lowest level work description (may be less verbose, but not always complete)
+
+
+
+
+
+
+ -
+
+
+ Attempt to get works and movement info from title if there are no work relationships? (Requires title in form "work: movement")
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(255, 186, 189);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Aliases</span> (NB Use a consistent approach throughout the library otherwise duplicate works may occur - see the Readme)*</p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+ 255
+ 220
+ 222
+
+
+
+
+
+
+
+ <html><head/><body><p>"Replace work names by aliases" will use <span style=" font-weight:600;">primary</span> aliases for the chosen locale instead of standard MusicBrainz work names. To choose the locale, use the drop-down under "translate artist names" in the main Picard Options-->Metadata page. Note that this option is not saved as a file tag since, if different choices are made for different releases, different work names may be stored and therefore cannot be grouped together in your player/library manager. </p><p>The sub-options allow either the replacement of all work names, where a primary alias exists, just the replacement of work names which are in non-Latin script, or only replace those which are flagged with user "Folksonomy" tags. The tag text needs to be included in the text box, in which case flagged works will be 'aliased' as well as non-Latin script works, if the second sub-option is chosen. Note that the tags may either be anyone's tags ("Look in all tags") or the user's own tags. If selecting "Look in user's own tags only" you <span style=" font-weight:600;">must</span> be logged in to your MusicBrainz user account (in the Picard Options->General page), otherwise repeated dialogue boxes may be generated and you may need to force restart Picard.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(255, 220, 222);
+
+
+
+
+
+
-
+
+
+ Replace MB work names?
+
+
+
-
+
+
+ <html><head/><body><p>Use primary aliases for the chosen locale instead of standard MusicBrainz work names.</p></body></html>
+
+
+ Replace work names by aliases. Select method -->
+
+
+
+ -
+
+
+ Do not replace work names
+
+
+
+
+
+
+ -
+
+
+
+
+
+ What to replace?
+
+
+
-
+
+
+
+
+
+
-
+
+
+ All work names
+
+
+
+ -
+
+
+ Non-latin work names
+
+
+
+ -
+
+
+ Only tagged works
+
+
+
+
+
+
+ -
+
+
+ Tags ("Folksonomy") identifying works to be replaced by aliases
+
+
+
-
+
+
+ Look in all tags
+
+
+
+ -
+
+
+ Look in user's own tags only (MUST BE LOGGED IN!)
+
+
+
+ -
+
+
+ <html><head/><body><p>Separate multiple tags by commas</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(255, 194, 158);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Tags to create</span> - Use commas to separate multiple tags or leave blank to omit</p></body></html>
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+ 255
+ 221
+ 201
+
+
+
+
+
+
+
+ <html><head/><body><p>Separate multiple tags by commas.</p></body></html>
+
+
+ <html><head/><body><p>"Tags to create" sets the names of the tags that will be created from the sources described above. All these tags will be blanked before filling as specified. Tags specified against more than one source will have later sources appended in the sequence specified, separated by separators as specified.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(255, 221, 201);
+
+
+
+
+
+
-
+
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(255, 209, 182);
+
+
+ Work tags
+
+
+
-
+
+
+ Separator
+
+
+ Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Some software (notably Muso) can display a 2-level work hierarchy as well as the work-movement hierarchy. This tag can be use to store the 2-level work name (a double colon :: is used to separate the levels within the tag).</p></body></html>
+
+
+ <html><head/><body><p>Tags for Work - for software with 2-level capability (e.g. Muso)</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ ;
+
+
+ -
+
+ :
+
+
+ -
+
+ .
+
+
+ -
+
+ ,
+
+
+ -
+
+ -
+
+
+
+
+
+
+ -
+
+
+ (In this format, intermediate works will be displayed after a double colon :: )
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Software which can display a movement and work (but no higher levels) could use any tags specified here. Note that if there are multiple work levels, the intermediate levels will not be tagged. Users wanting all the information should use the tags from the previous option (but it may cause some breaks in the display if levels change) - alternatively the missing work levels can be included in a movement tag (see below).</p></body></html>
+
+
+ <html><head/><body><p>Tags for Work - for software with 1-level capability (e.g. iTunes)</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ ;
+
+
+ -
+
+ :
+
+
+ -
+
+ .
+
+
+ -
+
+ ,
+
+
+ -
+
+ -
+
+
+
+
+
+
+ -
+
+
+ (Intermediate works will not be displayed:- Either 1. use the 2-level format if you wish to display them, but note that this will ceate new work, or 2. include them in the movement [see below])
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>This is the top-level work held in MB. This can be useful for cataloguing and searching (if the library software is capable). Note that this will always be the "canonical" MB name, not one derived from titles or the lowest level work name and that no annotations (e.g. key or work year) will be added. However, if "replace work names by aliases" has been selected and is applicable, the relevant alias will be used.</p></body></html>
+
+
+ <html><head/><body><p>Tags for top-level (canonical) work (for capable library managers)</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ N/A
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+ 255
+ 209
+ 182
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(255, 209, 182);
+
+
+ Movement/Part tags
+
+
+
-
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>The Picard standard tag is 'movementnumber' - include that or other(s) of your choice</p></body></html>
+
+
+ <html><head/><body><p>This is not necessarily the embedded movt/part number, but is the sequence number of the movement within its parent work <span style=" font-weight:600;">on the current release</span>.</p></body></html>
+
+
+ <html><head/><body><p>Tags for (computed) movement number (Picard std tag is movementnumber)</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ ;
+
+
+ -
+
+ :
+
+
+ -
+
+ .
+
+
+ -
+
+ ,
+
+
+ -
+
+ -
+
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>The Picard tag 'movementtotal' will be populated in any case - no need to specify it</p></body></html>
+
+
+ <html><head/><body><p>This is not necessarily the total number of movements in the parent work, but is the total number of movement tracks within the parent work <span style=" font-weight:600;">on the current release</span>.</p></body></html>
+
+
+ <html><head/><body><p>Tags for (computed) total number of movements (Picard std tag is movementtotal)</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ N/A
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
-
+
+
+ <html><head/><body><p>Movement name tags (Picard std tag is movement)<br/>Use different movement tags if required for different level systems ==></p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p><br/>for use with multi-level work tags</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p><br/>for use with1-level work tags (intermediate works will prefix movement)</p></body></html>
+
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>The Picard standard tag is 'movement' - include that or other(s) of your choice</p></body></html>
+
+
+ <html><head/><body><p>As below, but without the movement part/number prefix (if applicable)</p></body></html>
+
+
+ <html><head/><body><p>Tags for Movement - excluding embedded movt/part numbers</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ N/A
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>The Picard standard tag is 'movement' - include that or other(s) of your choice</p></body></html>
+
+
+ <html><head/><body><p>This tag(s) will contain the full lowest-level part name extracted from the lowest-level work name, according to the chosen tagging style.</p></body></html>
+
+
+ <html><head/><body><p>Tags for Movement - including embedded movt/part numbers</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ N/A
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(195, 168, 179);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Partial recordings, arrangements and medleys</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+ 221
+ 209
+ 221
+
+
+
+
+
+
+
+ <html><head/><body><p>Enter text - do not use any quotation marks</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(221, 209, 221);
+
+
+
+
+
+
-
+
+
+ font: 75 8pt "MS Shell Dlg 2";
+text-decoration: underline;
+
+
+ N.B. If these options are selected or deselected, quit and restart Picard before proceeding
+
+
+
+ -
+
+
+ <html><head/><body><p>If this option is selected, partial recordings will be treated as a sub-part of the whole recording and will have the related text included in its name. Note that this text is at the end of the canonical name, but the latter will probably be stripped from the sub-part as it duplicates the recording work name; any title text will be appended to the whole. Note that, if "Consistent with lowest level work description" is chosen in section 2, the text may be treated as a "prefix" similar to those in the "Advanced" tab. If this eliminates other similar prefixes and has unwanted effects, then either change the desired text slightly (e.g. surround with brackets) or use the "Full MusicBrainz work hierarchy" option in section 2.</p></body></html>
+
+
+ Partial recordings
+
+
+
-
+
+
+ Show partial recordings as separate sub-part, labelled with ->
+
+
+
+ -
+
+
+ true
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p>If this option is selected, works which are arrangements of other works will have the latter treated in the same manner as "parent" works, except that the arrangement work name will be prefixed by the text provided.</p></body></html>
+
+
+ Arrangements
+
+
+
-
+
+
+ Show arrangements as parts of original works, labelled with ->
+
+
+
+ -
+
+
+ true
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ false
+
+
+
+
+
+
+ -
+
+
+ Medleys
+
+
+
-
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Medleys</span></p><p> These can occur in two ways in MusicBrainz: (a) the recording is described as a "medley of" a number of works and (b) the track is described as (more than one) "medley including a recording of" a work. In the first case, the specified text will be included in brackets after the work name, whereas in the second case, the track will be treated as a recording of multiple works and the specified text will appear in the parent work name.</p><p><br/></p></body></html>
+
+
+ Include medley list, labelled with ->
+
+
+
+ -
+
+
+ true
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(182, 182, 62);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">SongKong-compatible tag usage</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+ 227
+ 227
+ 143
+
+
+
+
+
+
+
+ <html><head/><body><p>See "What's this"</p></body></html>
+
+
+ <html><head/><body><p> "Use work tags on file (no look up on MB) if Use Cache selected": This will enable the existing work tags on the file to be used in preference to looking up on MusicBrainz, if those tags are SongKong-compatible (which should be the case if SongKong has been used or if the SongKong tags have been previously written by this plugin). If present, this can speed up processing considerably, but obviously any new data on MusicBrainz will be missed. For the option to operate, "Use cache" also needs to be selected. Although faster, some of the subtleties of a full look-up will be missed - for example, parent works which are arrangements will not be highlighted as such, some arrangers or composers of original works may be omitted and some medley information may be missed. **In general, therefore, the use of this option will result in poorer metadata than allowing the full database look-up to run. It is not recommended unless speed is more important than quality.**</p><p><br/></p><p> "Write SongKong-compatible work tags" does what it says. These can then be used by the previous option, if the release is subsequently reloaded into Picard, to speed things up (assuming the reload was not to pick up new work data).</p><p><br/></p><p>Note that Picard and SongKong use the tag musicbrainz_workid to mean different things. If Picard has overwritten the SongKong tag (not a problem if this plugin is used) then a warning will be given and the works will be looked up on MusicBrainz. Also note that once a release is loaded, subsequent refreshes will use the cache (if option is ticked) in preference to the file tags.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(227, 227, 143);
+
+
+
+
+
+
-
+
+
+ Use work tags on file (no look up on MB) if Use Cache selected* (NOT RECOMMENDED - SEE README)
+
+
+
+ -
+
+
+ Write SongKong-compatible work tags*
+
+
+
+
+
+
+
+
+
+ -
+
+
+ * ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS
+
+
+
+
+
+
+
+
+
+
+
+ Genres etc.
+
+
+ -
+
+
+ true
+
+
+
+
+ 0
+ -26
+ 1084
+ 1310
+
+
+
+
-
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(138, 222, 187);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Genre tags</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(207, 236, 225);
+
+
+
+
+
+
-
+
+
+ Name of genre tag
+
+
+
+ -
+
+
+ Name of sub-genre tag
+
+
+
+ -
+
+
+ background-color: rgb(250,250,250);
+
+
+
+ -
+
+
+ background-color: rgb(250,250,250);
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(138, 222, 187);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">"Classical" genre </span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(207, 236, 225);
+
+
+
+
+
+
-
+
+
+ Exclude the text "classical" from main genre tag even if listed above
+
+
+
+ -
+
+
+ Make track "classical" only if there is a classical-specific genre (or do nothing if there is no filter)
+
+
+
+ -
+
+
+
+ 75
+ true
+
+
+
+ Use Muso composer list to determine if classical*
+
+
+
+ -
+
+
+ Make all tracks "classical"
+
+
+
+ -
+
+
+ Write a flag with text =
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ in the following tag if the track is classical
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ (Treat arrangers as for composers)
+
+
+
+
+
+
+
+
+
+ -
+
+
+ * ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS
+
+
+
+ -
+
+
+
+ 75
+ true
+
+
+
+ Use Muso reference database (default path is set on "advanced" tab)*
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(225, 168, 171);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Instruments and keys</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+ 245
+ 224
+ 226
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(245, 224, 226);
+
+
+
+
+
+
-
+
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(245, 210, 213);
+
+
+ Instruments
+
+
+
-
+
+
+ Tag name for instruments (will hold all instruments for a track)
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Name sources to use for instruments (select at least one, otherwise no instruments will be included in tag)
+
+
+
-
+
+
+ MusicBrainz standard names
+
+
+
+ -
+
+
+ "Credited-as" names
+
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+ 245
+ 210
+ 213
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(245, 210, 213);
+
+
+ Keys
+
+
+
-
+
+
+ Tag name for key(s)
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Include key(s) in work name?
+
+
+
-
+
+
+ Never
+
+
+
+ -
+
+
+ Only if key not already mentioned in work name
+
+
+
+ -
+
+
+ <html><head/><body><p>"Include key(s) in work names" gives the option to include the key signature for a work in brackets after the name of the work in the metadata. Keys will be added in the appropriate levels: e.g. Dvořák's New World Symphony will get (E minor) at the work level, but only movements with different keys will be annotated viz. "II. Largo (D-flat major, C-Sharp minor)"</p></body></html>
+
+
+ Always
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+ 1
+
+
+ 0
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(138, 222, 187);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Allowed genres (filter)</span></p></body></html>
+
+
+
+ -
+
+
+ Qt::LeftToRight
+
+
+ background-color: rgb(138, 222, 187);
+
+
+ Only apply genres to tags if they match pre-defined names:
+
+
+
+ -
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Explanation of genre-matching:</span></p><p><br/></p><p>Only genres matching those in the boxes will be placed in the genre or sub-genre tags.</p><p><br/></p><p>If there is a matching genre found in the "classical main genres" or "classical sub-genres" box, then the track will be treated as being classical.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(207, 236, 225);
+
+
+
+
+
+
-
+
+
+ background-color: rgb(190, 236, 219);
+
+
+ Classical genres (i.e. specific to classical music) - List separated by commas
+
+
+
-
+
+
+ Main genres:
+
+
+
+ -
+
+
+
+ 16777215
+ 50
+
+
+
+ background-color: rgb(250,250,250);
+
+
+
+ -
+
+
+ Sub-genres:
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+ 16777215
+ 50
+
+
+
+ background-color: rgb(250,250,250);
+
+
+
+ -
+
+
+
+ 75
+ true
+
+
+
+ <html><head/><body><p>Select this to use the "classical genres" in Muso options as the "Main classical genres" here.</p></body></html>
+
+
+ Use Muso classical genres*
+
+
+
+
+
+
+ -
+
+
+ background-color: rgb(190, 236, 219);
+
+
+ General genres (may be associated with classical music, but not necessarily, e.g. "instrumental") - List separated by commas
+
+
+
-
+
+
+ Main genres
+
+
+
+ -
+
+
+
+ 16777215
+ 50
+
+
+
+ background-color: rgb(250,250,250);
+
+
+
+ -
+
+
+ Sub-genres
+
+
+
+ -
+
+
+
+ 16777215
+ 50
+
+
+
+ background-color: rgb(250,250,250);
+
+
+
+
+ cwp_genres_other_main
+ cwp_genres_other_sub
+ label_62
+ label_76
+
+
+ -
+
+
+ Genre name to use if none of the above main genres apply (leave blank if not required)
+
+
+
+ -
+
+
+ background-color: rgb(250,250,250);
+
+
+
+ -
+
+
+ List genres, separated by commas. Only those genres listed will be included in tags.
+
+
+
+ -
+
+
+ See "what's this" for more details.
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(138, 222, 187);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Source of genres</span> - Note: if "existing file tag" is selected, information from the tag "genre" and the genre tag name specified above (if different) will be used</p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+ 207
+ 236
+ 225
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(207, 236, 225);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p>NB: This will use the contents of the file tag with the name given above (usually 'genre').</p></body></html>
+
+
+ Existing file tag (see note above)
+
+
+
+ -
+
+
+ <html><head/><body><p>This will use the folksonomy tags for <span style=" font-weight:600;">works</span> as a possible source of genres (if they match one of the lists below).</p><p><br/></p><p>To use the folksonomy tags for <span style=" font-weight:600;">releases/tracks</span>, select the main Picard option in Options->Metadata->"Use folksonomy tags as genre". Again (unlike vanilla Picard) they will only be used by this plugin if they match one of the lists below.</p></body></html>
+
+
+ Folksonomy work tags
+
+
+
+ -
+
+
+ Work-type
+
+
+
+ -
+
+
+ Infer from artist metadata
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(195, 183, 213);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Periods and dates</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+ 229
+ 224
+ 236
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(229, 224, 236);
+
+
+
+
+
+
-
+
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(222, 212, 236);
+
+
+ Work dates
+
+
+
-
+
+
+ Source of work dates for above tag
+
+
+
-
+
+
+ Composed date (or parent composed date)
+
+
+
+ -
+
+
+ Published date
+
+
+
+ -
+
+
+ Premiered date
+
+
+
+ -
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+ Use first available of above (in listed order)
+
+
+
+ -
+
+
+ Include all sources
+
+
+
+ -
+
+
+ Annotate dates using source name
+
+
+
+
+
+
+ -
+
+
+ Tag name for work date
+
+
+
+ -
+
+
+ <html><head/><body><p>"Includeworkdate in work names" gives the option to include the 'work year' for a work in brackets after the name of the work in the metadata. Dates (years) will be added in the appropriate levels: e.g. Smetana's 'Má vlast' will get (1874-1879) at the work level, but the movements with different dates will be annotated viz. "Vyšehrad, JB 1:112/1 (1874)". If the dates are the same, there should be no repitetion at the movement level. (Work dates will be used in preference order, i.e. composed - published - premiered, with only the first available date being shown).</p></body></html>
+
+
+ Include workdate in work name (in preference order listed above, with no annotation)
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ 0
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+ 222
+ 212
+ 236
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(222, 212, 236);
+
+
+ Periods
+
+
+
-
+
+
+ Tag name for period
+
+
+
+ -
+
+
+
+ 75
+ true
+
+
+
+ Use Muso map*
+
+
+
+ -
+
+
+
+ 75
+ true
+
+
+
+ Use Muso composer dates (if no work date) to determine period*
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Period map:
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ (Period name, Start year, End year; Period name2, ... etc.) - periods may overlap [Do not use commas or semi-colons within period name]
+
+
+
+ -
+
+
+ (Treat arrangers as for composers)
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p><span style=" font-size:9pt; font-weight:600;">N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") </span><span style=" font-size:9pt; font-weight:600; text-decoration: underline;">must</span><span style=" font-size:9pt; font-weight:600;"> be enabled for this section to run.<br/></span><span style=" font-weight:600; font-style:italic;">(Functionality will be reduced unless both the first two tabs are enabled.) </span></p></body></html>
+
+
+
+
+
+
+
+
+
+
+
+ Tag mapping
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ Qt::ScrollBarAsNeeded
+
+
+ true
+
+
+
+
+ 0
+ 0
+ 1084
+ 917
+
+
+
+
-
+
+
+
+
+
+ <html><head/><body><p><span style=" font-size:9pt; font-weight:600;">N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") </span><span style=" font-size:9pt; font-weight:600; text-decoration: underline;">must</span><span style=" font-size:9pt; font-weight:600;"> be enabled for this section to run. </span></p></body></html>
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(209, 171, 222);
+
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Initial tag processing</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ false
+
+
+ background-color: rgb(242, 221, 245);
+
+
+
+
+
+
-
+
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+ 242
+ 221
+ 245
+
+
+
+
+
+
+
+ <html><head/><body><p>Any tags specified in the next two rows will be blanked before applying the tag sources described in the following section. NB this applies only to Picard-generated tags, not to other tags which might pre-exist on the file: to blank those, use the main Options->Tags page. Comma-separate the tag names within the rows and note that these names are case-sensitive.</p></body></html>
+
+
+ false
+
+
+
+
+
+ Remove Picard-generated tags before applying subsequent actions? (NB existing LOCAL FILE tags will remain unless cleared using standard Picard options - to remove these, overwrite them in the next section)
+
+
+
-
+
+
+ <html><head/><body><p><span style=" text-decoration: underline;">Picard-generated</span> tags to blank (comma-separated, case-sensitive):</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p>Enter file tag names, separated by commas</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ <html><head/><body><p>Enter file tag names, separated by commas</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p><br/></p></body></html>
+
+
+ <html><head/><body><p>List <span style=" text-decoration: underline;">existing file tags</span> which will be appended to rather than over-written by tag mapping (this will keep tags even if "Clear existing tags" is selected on main options)<br/>NB To allow appending to happen, <span style=" text-decoration: underline;">do not also include these tags in "Preserve tags"</span> on the main options.</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p>Enter file tag names, separated by commas</p></body></html>
+
+
+ <html><head/><body><p>This refers to the tags which already exist on files which have been matched to MusicBrainz in the right-hand panel, not the tags generated by Picard from the MusicBrainz database. Normally, Picard cannot process these tags - either it will overwrite them (if it creates a similarly named tag), clear them (if 'Clear existing tags' is specified in the main Options->Tags screen) or keep them (if 'Preserve these tags...' is specified after the 'Clear existing tags' option). Classical Extras allows a further option - for the tags to be appended to in the tag mapping section (see below). List file tags which will be appended to rather than over-written by tag mapping (NB this will keep tags even if "Clear existing tags" is selected on main options). In addition, certain existing tags may be used by Classical Extras - in particular genre-related tags (see the Genres etc. options tab for more).</p><p>Note that if "Split lyrics tag" is specified (see the Artists tab), then the tag named there will be included in the 'Keep file tags' list and does not need to be added in this section.</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ <html><head/><body><p>Note that the main Picard option "Clear existing tags" should be <span style=" text-decoration: underline;">unchecked</span> for this option to operate in preference to that Picard option. The difference is that this option <span style=" text-decoration: underline;">will not intefere with cover art</span>, whereas the main Picard option will remove previous cover art.</p></body></html>
+
+
+ <html><head/><body><p>If selected: the bottom pane of Picard will only show tags which have been generated from the MusicBrainz lookups plus any existing file tags which are listed above or in the main options "Preserve tags...".</p><p>This does not mean that the file tags will be removed when saving the file. For that to happen, "Clear existing tags" needs to be selected in the main options.</p></body></html>
+
+
+ Do not show any file tags that are NOT listed above AND NOT listed in the main Picard "Preserve tags..." option (Options->Tags), even if "Clear existing tags" is not selected.
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(229, 174, 142);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Tag map details</span></p></body></html>
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+ 255
+ 229
+ 214
+
+
+
+
+
+
+
+ Qt::NoFocus
+
+
+ <html><head/><body><p>Enter tags, separated by commas.</p></body></html>
+
+
+ false
+
+
+ font: 75 8pt "MS Shell Dlg 2";
+background-color: rgb(255, 229, 214);
+
+
+
+
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+
+ 16777215
+ 100
+
+
+
+ background-color: rgb(249, 215, 187);
+
+
+ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
+<html><head><meta name="qrichtext" content="1" /><style type="text/css">
+p, li { white-space: pre-wrap; }
+</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8pt; font-weight:72; font-style:normal;">
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600; text-decoration: underline;">Notes: </span></p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">Click "Source from:" button to edit source tags.</p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">Any valid Picard-generated tag can be entered in the "source" box, as well as Classical Extras sources, and mapped into other tags - not just restricted to artists.</p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">To put a constant in a tag, type it into the source box preceded by a backslash \.</p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">In all cases, the source will be APPENDED to the Picard tag. To replace the standard tag, first blank it in the section above - add it back later in the list below if required (e.g. artist -> artist).</p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">BUT note that any existing LOCAL FILE tag will be replaced by (not appended with) any Picard/Classical Extras tag UNLESS specified in the list box above.</p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">These tag-mapping options may be omitted from the over-riding of artist options - see advanced tab</p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">For more help seethe readme.</p></body></html>
+
+
+
+ -
+
+
+
+ 6
+
+
+ QLayout::SetDefaultConstraint
+
+
+ 1
+
+
-
+
+
+ Click to edit sources
+
+
+ false
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+ Qt::ToolButtonIconOnly
+
+
+ false
+
+
+
+ -
+
+
+ false
+
+
+
+ 0
+ 0
+
+
+
+ false
+
+
+ Qt::StrongFocus
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
+ QComboBox::AdjustToContents
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+ Click to edit sources
+
+
+
+
+
+ Source from:
+
+
+ true
+
+
+
+ -
+
+
+ false
+
+
+ Click button to edit. See notes above.
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ true
+
+
-
+
+
+
+
+ -
+
+ album_soloists, album_conductors, album_ensembles
+
+
+ -
+
+ soloists, conductors, ensembles, album_composers, composers
+
+
+ -
+
+ album_soloists
+
+
+ -
+
+ album_conductors
+
+
+ -
+
+ album_ensembles
+
+
+ -
+
+ album_composers
+
+
+ -
+
+ album_composer_lastnames
+
+
+ -
+
+ soloists
+
+
+ -
+
+ soloist_names
+
+
+ -
+
+ ensembles
+
+
+ -
+
+ ensemble_names
+
+
+ -
+
+ composers
+
+
+ -
+
+ arrangers
+
+
+ -
+
+ orchestrators
+
+
+ -
+
+ conductors
+
+
+ -
+
+ chorusmasters
+
+
+ -
+
+ leaders
+
+
+ -
+
+ support_performers
+
+
+ -
+
+ work_type
+
+
+ -
+
+ release
+
+
+
+
+ -
+
+
+ into tags:
+
+
+
+ -
+
+
+ Enter comma-separated list of tags
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Conditional?
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ Qt::LeftToRight
+
+
+ 1
+
+
+ (If source is empty, tag will be left unchanged)
+
+
+ Qt::AlignLeading|Qt::AlignLeft|Qt::AlignVCenter
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ Qt::RightToLeft
+
+
+ (Conditional tags will only be filled if previously empty)
+
+
+ Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p>Select to include sort-tags, where available. See<span style=" font-style:italic;"> "What's this?"</span> for more details.</p></body></html>
+
+
+ <html><head/><body><p>If a sort tag is associated with the source tag then the sort names will be placed in a sort tag corresponding to the destination tag. Note that the only explicit sort tags written by Picard are for artist, albumartist and composer. Piacrd also writes hidden variables '_artists_sort' and 'albumartists_sort' (note the plurals - these are the sort tags for multi-valued alternatives 'artists' and '_albumartists'). To be consistent with this approach, the plugin writes hidden variables for other tags - e.g. '_arranger_sort'. The plugin also writes hidden sort variables for the various hidden artist variables - e.g. '_cwp_librettists' has a matching sort variable '_cwp_librettists_sort'. Therefore most artist-type sources <span style=" font-weight:600;">will</span> have a sort tag/variable associated with them and these will be placed in a destination sort tag if this option is selected -<span style=" font-weight:600;"> in other words, selecting this option will cause most destination tags to have associated sort tags</span>.<span style=" font-weight:600;"> Furthermore, any hidden sort variables associated with tags which are not listed explicitly in the tag mapping section will also be written out as tags</span> (i.e. even if the related tags are not included as destination tags). Note, however, that composite sources (e.g. " ensemble_names + \; + conductors") do not have sort tags associated with them.</p><p><br/></p><p>If this option is not selected, no additional sort tags will be written, but the hidden variables will still be available, so if a sort tag is required explicitly, just map the sort tag directly - e.g. map 'conductors_sort' to 'conductor_sort'.</p></body></html>
+
+
+ Qt::LeftToRight
+
+
+ Also populate sort tags
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Advanced
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ true
+
+
+
+
+ 0
+ -853
+ 1084
+ 1707
+
+
+
+
-
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(208, 208, 156);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">General</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(229, 229, 197);
+
+
+
+
+
+
-
+
+
+ Do not run Classical Extras for tracks where no pre-existing file is detected (warning tag will be written)
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(208, 208, 156);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Artists (only effective if "Artists" section enabled)</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+ <html><head/><body><p>Separate multiple names by commas. Do not use any quotation marks.</p></body></html>
+
+
+ <html><head/><body><p>Permits the listing of strings by which ensembles of different types may be identified. This is used by the plugin to place performer details in the relevant hidden variables and thus make them available for use in the "Tag mapping" tab as sources for any required tags. </p><p>If it is important that only whole words are to be matched, be sure to include a space after the string.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(229, 229, 197);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Ensemble strings</span> (separate names by commas)</p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+ 2
+
+
+ 9
+
+
-
+
+
+ Orchestras
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Choirs
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Groups (i.e. other ensembles such as quartets etc.)
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(208, 208, 156);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Works and parts (only effective if "Works and parts" section enabled)</span></p></body></html>
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(229, 229, 197);
+
+
+
+
+
+
-
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Sometimes MB lookups fail. Unfortunately Picard (currently) has no automatic "retry" function. The plugin will attempt to retry for the specified number of attempts. If it still fails, the hidden variable _cwp_error will be set with a message; if error logging is checked in section 4, an error message will be written to the log and the contents of _cwp_error will be written out to a special tag called "An_error_has_occurred" which should appear prominently in the bottom pane of Picard. The problem may be resolved by refreshing, otherwise there may be a problem with the MB database availability. It is unlikely to be a software problem with the plugin.</p></body></html>
+
+
+ <html><head/><body><p>Max number of re-tries to access works (in case of server errors)*</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+ 0
+
+
+ 20
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Allow blank part names for arrangements and part recordings if arrangement/partial label is provided</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+ 241
+ 241
+ 167
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(241, 241, 167);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p><span style=" font-size:10pt; font-weight:600;">Removal of common text between parent and child works</span></p></body></html>
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Minimum number of similar words required before eliminating. Use zero for no elimination.<br/>(Punctuation and accents etc. will be ignored in word comparison)</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+ 0
+
+
+ 99
+
+
+
+
+
+ -
+
+
+ <html><head/><body><p>NB Parent name text at the start of a work which is followed by punctuation in the work name will always be stripped regardless of this setting.<br/>Synonyms in the next section also apply.</p></body></html>
+
+
+
+
+
+
+ -
+
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+ 202
+ 202
+ 140
+
+
+
+
+
+
+
+ <html><head/><body><p>This subsection contains various parameters affecting the processing of strings in titles. Because titles are free-form, not all circumstances can be anticipated. Detailed documentation of these is beyond the scope of this Readme as the effects can be quite complex and subtle and may require an understanding of the plugin code (which is of course open-source) to acsertain them. If pure canonical works are used ("Use only metadata from canonical works" and, if necessary, "Full MusicBrainz work hierarchy" on the Works and parts tab, section 2) then this processing should be irrelevant, but no text from titles will be included. Some explanations are given below:</p><p> "Proximity of new words". When using extended metadata - i.e. "metadata enhanced with title text", the plugin will attempt to remove similar words between the canonical work name (in MusicBrainz) and the title before extending the canonical name. After removing such words, a rather "bitty" result may occur. To avoid this, any new words with the specified proximity will have the words between them (or up to the end) included even if they repeat words in the work name.</p><p> "Prefixes". When using "metadata from titles" or extended metadata, the structure of the works in MusicBrainz is used to infer the structure in the title text, so strings that are repeated between tracks which are part of the same MusicBrainz work will be treated as "higher level". This can lead to anomolies if, for instance, the titles are "Work name: Part 1", "Work name: Part 2", "Part" will be treated as part of the parent work name. Specifying such words in "Prefixes" will prevent this.</p><p> "Synonyms". These words will be considered equivalent when comparing work name and title text. Thus if one word appears in the work name, that and its synonym will be removed from the title in extending the metadata (subject to the proximity setting above).</p><p> "Replacements". These words/phrases will be replaced in the title text in extended metadata, regardless of the text in the work name.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(202, 202, 140);
+
+
+
+
+
+
-
+
+
+ <html><head/><body><p><span style=" font-size:10pt; font-weight:600;">How title metadata should be included in extended metadata</span><span style=" font-size:10pt;"> (use cautiously - read documentation)</span><br/><span style=" font-style:italic;">(Mostly only applies if "Use canonical work metadata enhanced with title text" selected on "Works and parts" tab. </span><span style=" font-weight:600; font-style:italic;">However synonyms also apply to parent/child text removal</span><span style=" font-style:italic;">.)</span></p></body></html>
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Proximity of new words (to each other) to trigger in-fill with existing words (default = 2)</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+ 99
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Proximity of new words (to start or end) to trigger in-fill with existing words (default =1)</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+ 99
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Treat hyphenated words as two words for comparison purposes</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Proportion of a string to be matched to a (usually larger) string for it to be considered essentially similar (default = 66%)</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+ %
+
+
+ 100
+
+
+
+
+
+ -
+
+
+ 6
+
+
+ 0
+
+
-
+
+
+
+ 0
+ 0
+
+
+
+ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
+<html><head><meta name="qrichtext" content="1" /><style type="text/css">
+p, li { white-space: pre-wrap; }
+</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8pt; font-weight:400; font-style:normal;">
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">Fill part name with title text if it would otherwise have no text other than arrangement or partial annotations</p></body></html>
+
+
+ cwp_retries
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+
+
+
+
+
+
+ -
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+ <html><head/><body><p><span style=" font-weight:600; font-style:italic;">Prepositions/conjunctions and prefixes</span><span style=" font-weight:600;"><br/></span>DO NOT USE ANY COMMAS OR QUOTE MARKS (apostophes in words are acceptable)</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p>Prepositions & conjunctions: these are words that will not be regarded as providing additional information (not treated as 'new' words) unless they precede a new word.<br/>Use lower case only, comma separated</p></body></html>
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ <html><head/><body><p>Prefixes to be ignored in comparison (case insensitive, comma separated)<br/>To prevent a prefix from being ignored when extending metadata with title info, precede it with a space. <br/>To ensure only whole words are removed, follow with a space.</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p>Separate multiple names by commas. Do not use any quotation marks.</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+ <html><head/><body><p><span style=" font-weight:600; font-style:italic;">Synonyms and replacements</span> - must be written as tuples separated by forward slashes - e.g (a,b) / (c,d,e) - a tuple may have two or more synonyms.</p><p>N.B. The matching is case-insensitive. Roman numerals will be treated as synonyms of arabic numerals in any event, so no need to enter these.</p><p>The last member of the tuple should be the canonical form (i.e. the one to which others are converted for comparison or replacement) and <span style=" text-decoration: underline;">must be a normal strin</span>g (not a regex). <span style=" font-weight:600;">See readme for full details</span>.<br/><span style=" font-weight:600; font-style:italic;">Unless entering a regular expression, use backslash \ to escape any regex metacharacters, namely \ ^ $ . | ? * + ( ) [ ] { <br/>Also escape commas , and forward slashes /. Do not enclose strings in quote marks.</span></p><p>Enter SYNONYM tuples below - each item in a tuple will be treated as similar when comparing works/parts and titles. The text in tags will be unaltered.</p></body></html>
+
+
+
+ -
+
+
+
+ 16777215
+ 120
+
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ <html><head/><body><p>Enter REMOVALS/REPLACEMENTS below - these will result in the "extended" text in tags being changed<br/>Put the word(s), phrase(s), or regular exprerssion(s) in the first part(s) of the tuple. The replacement text (or nothing - to remove) goes in the last member of the tuple.</p><p>N.B. Replacement text will operate BEFORE synonyms are considered.</p></body></html>
+
+
+
+ -
+
+
+ <html><head/><body><p>Entries must be 2-tuples, e.g. (Replace this, with this). Separate multiple tuples by forward slash. Do not use any quotation marks. Spaces are acceptable. The first item of a tuple may be a regular expression - enclose it with double exclamation marks - e.g.(!!regex here!!, replacement text here).</p></body></html>
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(208, 208, 156);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Genres etc.</span> (only required if Muso-specific options are used for genres/periods)</p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(229, 229, 197);
+
+
+
+
+
+
-
+
+
+ Path to Muso reference database:
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Name of Muso reference database
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ <html><head/><body><p><span style=" font-weight:600;">RESTART PICARD AFTER CHANGING THESE</span></p></body></html>
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(208, 208, 156);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Logging options</span>*</p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+ <html><head/><body><p>These options are in addition to the options chosen in Picard's "Help->View error/debug log" settings. They only affect messages written by this plugin. To enable debug messages to be shown, the flag needs to be set here and "Debug mode" needs to be turned on in the log. It is strongly advised to keep the "debug" and "info" flags unchecked unless debugging is required as they slow up processing significantly and may even cause Picard to crash on large releases. The "error" and "warning" flags should be left checked, unless it is required to suppress messages written out to tags (the default is to write messages to the tags 001_errors and 002_warnings).</p></body></html>
+
+
+ Qt::LeftToRight
+
+
+ false
+
+
+ background-color: rgb(229, 229, 197);
+
+
+
+
+
+
-
+
+
+ Error
+
+
+
+ -
+
+
+ Warning
+
+
+
+ -
+
+
+ Debug
+
+
+
+ -
+
+
+ background-color: rgb(229, 229, 159);
+
+
+ Custom logging
+
+
+
-
+
+
+ Basic
+
+
+
+ -
+
+
+ Full
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
+ 0
+
+
+ 0
+
+
-
+
+
+ background-color: rgb(208, 208, 156);
+
+
+ <html><head/><body><p><span style=" font-weight:600;">Classical Extras Special Tags</span></p></body></html>
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+ 229
+ 229
+ 197
+
+
+
+
+
+
+
+ false
+
+
+ background-color: rgb(229, 229, 197);
+
+
+ QFrame::StyledPanel
+
+
+ QFrame::Raised
+
+
+
-
+
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+
+ <html><head/><body><p>This can be used so that the user has a record of the version of Classical Extras which generated the tags and which options were selected to achieve the resulting tags. Note that the tags will be blanked first so this will only show the last options used on a particular file. The same tag can be used for both sets of options, resulting in a multi-valued tag. </p></body></html>
+
+
+ false
+
+
+ background-color: rgb(229, 229, 159);
+
+
+ Save plugin details and options in a tag?*
+
+
+
-
+
+
+ Tag name for plugin version
+
+
+
+ -
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Tag name for artist/mapping/misc. options
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ Tag name for work/genre options
+
+
+
+ -
+
+
+ Qt::RightToLeft
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+
+
+
+ -
+
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+ 229
+ 229
+ 159
+
+
+
+
+
+
+
+ <html><head/><body><p>If options have previously been saved (see above), selecting these will cause the saved options to be used in preference to the displayed options. The displayed options will not be affected and will be used if no saved options are present. The default is for no over-ride. If artist options over-ride is chosen, then tag map detail options may be included or not in the override.</p><p><br/></p><p>The last checkbox, "Overwrite options in Options Pages", is for <span style=" font-weight:600;">VERY CAREFUL USE ONLY</span>. It will cause any options read from the saved tags (if the relevant box has been ticked) to over-write the options on the plugin Options Page UI. The intended use of this is if for some reason the user's preferred options have been erased/reverted to default - by using this option, the previously-used choices from a reliable filed album can be used to populate the Options Page. The box will automatically be unticked after loading/refreshing one album, to prevent inadvertant use. Far better is to make a <span style=" font-weight:600;">backup copy</span> of the picard.ini file.</p></body></html>
+
+
+ false
+
+
+ background-color: rgb(229, 229, 159);
+
+
+ Over-ride plugin options displayed in Options Pages with options from local file tags (previously saved using method in box above)?*
+
+
+
-
+
+
+ Artist options
+
+
+
+ -
+
+
+ Work options
+
+
+
+ -
+
+
+ true
+
+
+ Genres etc. options
+
+
+
+ -
+
+
+ true
+
+
+ <html><head/><body><p>Will not over-ride displayed options unless artist options over-ride is also selected</p></body></html>
+
+
+ Tag mapping options
+
+
+
+ -
+
+
+ Qt::Vertical
+
+
+
+ -
+
+
+ background-color: rgb(255, 0, 0);
+
+
+ Overwrite options in Options Pages (READ WARNINGS in Readme)
+
+
+
+
+
+
+ -
+
+
+ Note that the above saved options include the related "advanced" options on this tab as well as the options on each of the main tabs.
+
+
+
+ -
+
+
+ Qt::Horizontal
+
+
+
+ -
+
+
+ Show additional tags in Picard UI (rhs panel) - N.B. RESTART NEEDED FOR CHANGE TO TAKE EFFECT
+
+
+
+ -
+
+
+ background-color: rgb(229, 229, 159);
+
+
+ Additional columns for Picard UI to show specific tags*
+
+
+
-
+
+
+ <html><head/><body><p><span style=" font-weight:600;">RESTART PICARD AFTER CHANGING THESE</span> - otherwise changes will not take effect</p></body></html>
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+
+ 16777215
+ 120
+
+
+
+ background-color: rgb(250, 250, 250);
+
+
+
+ -
+
+
+
+ 0
+ 0
+
+
+
+ <html><head/><body><p>Notes:</p><p>1. Use the format <span style=" font-style:italic;">column_name_A: (include_tag_1, include_tag_2) / column_name_B: include_tag_3 </span> etc. (i.e. put multiple tags to be concatenated in brackets)<br/>2. To just flag tags that have changed, rather than show the contents, add _DIFF at the end of the tag name<br/>3. If more than one tag name is included for a column, then:<br/>(a) if the tags are _DIFF tags, then the column will be flagged if any of them have changed<br/>(b) otherwise the tag contents will be concatenated</p></body></html>
+
+
+
+
+
+
+
+
+
+
+
+
+ -
+
+
+ * ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS
+
+
+
+
+
+
+
+
+
+
+
+ Help
+
+
+
+
+ 0
+ -10
+ 671
+ 561
+
+
+
+
+ 0
+ 0
+
+
+
+ true
+
+
+
+
+ 0
+ 0
+ 669
+ 559
+
+
+
+
+
+ 9
+ 109
+ 641
+ 421
+
+
+
+
+ 0
+ 0
+
+
+
+ Qt::ScrollBarAsNeeded
+
+
+ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
+<html><head><meta name="qrichtext" content="1" /><style type="text/css">
+p, li { white-space: pre-wrap; }
+</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8.25pt; font-weight:400; font-style:normal;">
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:10pt; font-weight:600; text-decoration: underline;">General description</span></p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:8pt;">Classical Extras provides tagging enhancements for Picard and, in particular, utilises MusicBrainz’s hierarchy of works to provide work/movement tags. All options are set through a user interface in Picard options->plugins. This interface provides separate sections to enhance artist/performer tags, works and parts, genres and also allows for a generalised "tag mapping" (simple scripting). While it is designed to cater for the complexities of classical music tagging, it may also be useful for other music which has more than just basic song/artist/album data. <br /><br />The options screen provides five tabs for users to control the tags produced: <br /><br />1. Artists: Options as to whether artist tags will contain standard MB names, aliases or as-credited names. Ability to include and annotate names for specialist roles (chorus master, arranger, lyricist etc.). Ability to read lyrics tags on the file which has been loaded and assign them to track and album levels if required. (Note: Picard will not normally process incoming file tags). <br /><br />2. Works and parts: The plugin will build a hierarchy of works and parts (e.g. Work -> Part -> Movement or Opera -> Act -> Number) based on the works in MusicBrainz's database. These can then be displayed in tags in a variety of ways according to user preferences. Furthermore partial recordings, medleys, arrangements and collections of works are all handled according to user choices. There is a processing overhead for this at present because MusicBrainz limits look-ups to one per second. <br /><br />3. Genres etc.: Options are available to customise the source and display of information relating to genres, instruments, keys, work dates and periods. Additional capabilities are provided for users of Muso (or others who provide the relevant XML files) to use pre-existing databases of classical genres, classical composers and classical periods. <br /><br />4. Tag mapping: in some ways, this is a simple substitute for some of Picard's scripting capability. The main advantage is that the plugin will remember what tag mapping you use for each release (or even track). <br /><br />5. Advanced: Various options to control the detailed processing of the above. <br /><br />All user options can be saved on a per-album (or even per-track) basis so that tweaks can be used to deal with inconsistencies in the MusicBrainz data (e.g. include English titles from the track listing where the MusicBrainz works are in the composer's language and/or script). Also existing file tags can be processed (not possible in native Picard). </span></p></body></html>
+
+
+ true
+
+
+
+
+
+ 9
+ 9
+ 471
+ 16
+
+
+
+
+ 0
+ 0
+
+
+
+
+
+
+
+
+
+ 9
+ 28
+ 641
+ 81
+
+
+
+
+ 0
+ 0
+
+
+
+ <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
+<html><head><meta name="qrichtext" content="1" /><style type="text/css">
+p, li { white-space: pre-wrap; }
+</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8.25pt; font-weight:400; font-style:normal;">
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:12pt; font-weight:600;">Please see</span><span style=" font-size:14pt; font-weight:600;"> </span><a href="http://music.highmossergate.co.uk/symphony/tagging/classical-extras/"><span style=" font-size:14pt; text-decoration: underline; color:#0000ff;">my website</span></a><span style=" font-size:14pt; font-weight:600;"> </span><span style=" font-size:12pt; font-weight:600;">for full details of this plugin and how to use it.</span></p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:10pt;">This help page now has only general information.</span></p>
+<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:10pt;">There are extensive tooltips and "What's This" popups (right click for them)</span></p></body></html>
+
+
+ true
+
+
+
+
+
+
+
+
+
+
+
+
+ cea_ra_use
+ toggled(bool)
+ ra_replace_merge_options_box
+ setEnabled(bool)
+
+
+ 515
+ 552
+
+
+ 1085
+ 511
+
+
+
+
+ cea_ra_replace_ta
+ toggled(bool)
+ cea_ra_noblank_ta
+ setEnabled(bool)
+
+
+ 1075
+ 536
+
+
+ 704
+ 559
+
+
+
+
+ use_cea
+ toggled(bool)
+ lyrics_frame
+ setEnabled(bool)
+
+
+ 158
+ 59
+
+
+ 562
+ 933
+
+
+
+
+ use_cwp
+ toggled(bool)
+ cwp_collections
+ setEnabled(bool)
+
+
+ 94
+ 60
+
+
+ 508
+ 76
+
+
+
+
+ cea_split_lyrics
+ toggled(bool)
+ lyrics_and_notes_tags_frame
+ setEnabled(bool)
+
+
+ 160
+ 1016
+
+
+ 610
+ 947
+
+
+
+
+ use_cwp
+ toggled(bool)
+ use_cache
+ setEnabled(bool)
+
+
+ 124
+ 60
+
+
+ 850
+ 76
+
+
+
+
+ use_cea
+ toggled(bool)
+ other_artist_options_frame
+ setEnabled(bool)
+
+
+ 158
+ 59
+
+
+ 562
+ 682
+
+
+
+
+ cea_arrangers
+ toggled(bool)
+ annotations_lh_box
+ setEnabled(bool)
+
+
+ 180
+ 680
+
+
+ 468
+ 663
+
+
+
+
+ cea_arrangers
+ toggled(bool)
+ annotations_rh_box
+ setEnabled(bool)
+
+
+ 180
+ 680
+
+
+ 830
+ 663
+
+
+
+
+ toolButton_1
+ toggled(bool)
+ cea_source_1
+ setEnabled(bool)
+
+
+ 116
+ 439
+
+
+ 450
+ 440
+
+
+
+
+ toolButton_2
+ toggled(bool)
+ cea_source_2
+ setEnabled(bool)
+
+
+ 116
+ 467
+
+
+ 191
+ 468
+
+
+
+
+ toolButton_3
+ toggled(bool)
+ cea_source_3
+ setEnabled(bool)
+
+
+ 116
+ 495
+
+
+ 191
+ 496
+
+
+
+
+ toolButton_4
+ toggled(bool)
+ cea_source_4
+ setEnabled(bool)
+
+
+ 116
+ 523
+
+
+ 191
+ 524
+
+
+
+
+ toolButton_5
+ toggled(bool)
+ cea_source_5
+ setEnabled(bool)
+
+
+ 116
+ 551
+
+
+ 191
+ 552
+
+
+
+
+ toolButton_6
+ toggled(bool)
+ cea_source_6
+ setEnabled(bool)
+
+
+ 116
+ 579
+
+
+ 191
+ 580
+
+
+
+
+ toolButton_7
+ toggled(bool)
+ cea_source_7
+ setEnabled(bool)
+
+
+ 116
+ 607
+
+
+ 191
+ 608
+
+
+
+
+ toolButton_8
+ toggled(bool)
+ cea_source_8
+ setEnabled(bool)
+
+
+ 116
+ 635
+
+
+ 191
+ 636
+
+
+
+
+ toolButton_9
+ toggled(bool)
+ cea_source_9
+ setEnabled(bool)
+
+
+ 116
+ 663
+
+
+ 191
+ 664
+
+
+
+
+ toolButton_10
+ toggled(bool)
+ cea_source_10
+ setEnabled(bool)
+
+
+ 116
+ 691
+
+
+ 298
+ 710
+
+
+
+
+ toolButton_11
+ toggled(bool)
+ cea_source_11
+ setEnabled(bool)
+
+
+ 119
+ 742
+
+
+ 298
+ 740
+
+
+
+
+ toolButton_12
+ toggled(bool)
+ cea_source_12
+ setEnabled(bool)
+
+
+ 119
+ 772
+
+
+ 298
+ 770
+
+
+
+
+ toolButton_13
+ toggled(bool)
+ cea_source_13
+ setEnabled(bool)
+
+
+ 119
+ 802
+
+
+ 298
+ 800
+
+
+
+
+ toolButton_14
+ toggled(bool)
+ cea_source_14
+ setEnabled(bool)
+
+
+ 119
+ 832
+
+
+ 298
+ 830
+
+
+
+
+ toolButton_15
+ toggled(bool)
+ cea_source_15
+ setEnabled(bool)
+
+
+ 119
+ 862
+
+
+ 298
+ 860
+
+
+
+
+ toolButton_16
+ toggled(bool)
+ cea_source_16
+ setEnabled(bool)
+
+
+ 119
+ 892
+
+
+ 298
+ 890
+
+
+
+
+ use_cea
+ toggled(bool)
+ advanced_artists_frame
+ setEnabled(bool)
+
+
+ 158
+ 59
+
+
+ 573
+ -721
+
+
+
+
+ use_cwp
+ toggled(bool)
+ advanced_workparts_frame
+ setEnabled(bool)
+
+
+ 139
+ 76
+
+
+ 573
+ -228
+
+
+
+
+ use_cea
+ toggled(bool)
+ naming_options_frame
+ setEnabled(bool)
+
+
+ 158
+ 59
+
+
+ 128
+ 149
+
+
+
+
+ use_cea
+ toggled(bool)
+ recording_artists_options_frame
+ setEnabled(bool)
+
+
+ 158
+ 59
+
+
+ 572
+ 499
+
+
+
+
+ use_cwp
+ toggled(bool)
+ work_style_frame
+ setEnabled(bool)
+
+
+ 47
+ 63
+
+
+ 562
+ 158
+
+
+
+
+ use_cwp
+ toggled(bool)
+ work_aliases_frame
+ setEnabled(bool)
+
+
+ 139
+ 76
+
+
+ 562
+ 305
+
+
+
+
+ use_cwp
+ toggled(bool)
+ works_parts_tags_frame
+ setEnabled(bool)
+
+
+ 139
+ 76
+
+
+ 562
+ 566
+
+
+
+
+ use_cwp
+ toggled(bool)
+ songkong_frame
+ setEnabled(bool)
+
+
+ 139
+ 76
+
+
+ 573
+ 1047
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_genres
+ setVisible(bool)
+
+
+ 89
+ -357
+
+
+ 136
+ -94
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_genres
+ setChecked(bool)
+
+
+ 120
+ -357
+
+
+ 169
+ -94
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_classical
+ setVisible(bool)
+
+
+ 161
+ -357
+
+
+ 173
+ 126
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_classical
+ setChecked(bool)
+
+
+ 180
+ -357
+
+
+ 219
+ 126
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_dates
+ setVisible(bool)
+
+
+ 584
+ -357
+
+
+ 626
+ 726
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_periods
+ setVisible(bool)
+
+
+ 584
+ -357
+
+
+ 213
+ 826
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_dates
+ setChecked(bool)
+
+
+ 584
+ -357
+
+
+ 626
+ 726
+
+
+
+
+ cwp_use_muso_refdb
+ toggled(bool)
+ cwp_muso_periods
+ setChecked(bool)
+
+
+ 584
+ -357
+
+
+ 213
+ 826
+
+
+
+
+ cwp_muso_genres
+ toggled(bool)
+ cwp_genres_classical_main
+ setHidden(bool)
+
+
+ 226
+ -94
+
+
+ 618
+ -80
+
+
+
+
+ cwp_muso_classical
+ toggled(bool)
+ cwp_genres_arranger_as_composer
+ setVisible(bool)
+
+
+ 130
+ 126
+
+
+ 143
+ 149
+
+
+
+
+ cwp_muso_dates
+ toggled(bool)
+ cwp_periods_arranger_as_composer
+ setVisible(bool)
+
+
+ 130
+ 726
+
+
+ 140
+ 749
+
+
+
+
+ cwp_muso_periods
+ toggled(bool)
+ cwp_period_map
+ setHidden(bool)
+
+
+ 207
+ 826
+
+
+ 777
+ 826
+
+
+
+
+ cwp_muso_periods
+ toggled(bool)
+ period_map_annotation_label
+ setHidden(bool)
+
+
+ 150
+ 826
+
+
+ 780
+ 845
+
+
+
+
+ cwp_genres_filter
+ toggled(bool)
+ genre_filters_frame
+ setVisible(bool)
+
+
+ 53
+ -201
+
+
+ 50
+ -120
+
+
+
+
+ use_cwp
+ toggled(bool)
+ partial_arrangements_medleys_frame
+ setEnabled(bool)
+
+
+ 139
+ 76
+
+
+ 234
+ 816
+
+
+
+
+ cwp_titles
+ toggled(bool)
+ source_of_canonical_box
+ setDisabled(bool)
+
+
+ 135
+ 146
+
+
+ 582
+ 137
+
+
+
+
+ cwp_titles
+ toggled(bool)
+ partial_arrangements_medleys_frame
+ setHidden(bool)
+
+
+ 263
+ 150
+
+
+ 562
+ 864
+
+
+
+
+ use_cache
+ toggled(bool)
+ cwp_use_sk
+ setEnabled(bool)
+
+
+ 918
+ 68
+
+
+ 320
+ 1071
+
+
+
+
+ ce_show_ui_tags
+ toggled(bool)
+ groupBox
+ setVisible(bool)
+
+
+ 55
+ 529
+
+
+ 42
+ 563
+
+
+
+
+
diff --git a/plugins/classical_extras/ui_options_classical_extras.py b/plugins/classical_extras/ui_options_classical_extras.py
new file mode 100644
index 00000000..d0f5164f
--- /dev/null
+++ b/plugins/classical_extras/ui_options_classical_extras.py
@@ -0,0 +1,5011 @@
+# -*- coding: utf-8 -*-
+
+# Form implementation generated from reading ui file 'M:\Documents\Mark's documents\Music\Picard 230\Classical Extras development\classical_extras\options_classical_extras.ui'
+#
+# Created by: PyQt5 UI code generator 5.11.2
+#
+# WARNING! All changes made in this file will be lost!
+
+from PyQt5 import QtCore, QtGui, QtWidgets
+
+class Ui_ClassicalExtrasOptionsPage(object):
+ def setupUi(self, ClassicalExtrasOptionsPage):
+ ClassicalExtrasOptionsPage.setObjectName("ClassicalExtrasOptionsPage")
+ ClassicalExtrasOptionsPage.resize(1145, 918)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(ClassicalExtrasOptionsPage.sizePolicy().hasHeightForWidth())
+ ClassicalExtrasOptionsPage.setSizePolicy(sizePolicy)
+ ClassicalExtrasOptionsPage.setContextMenuPolicy(QtCore.Qt.DefaultContextMenu)
+ ClassicalExtrasOptionsPage.setAcceptDrops(False)
+ self.vboxlayout = QtWidgets.QVBoxLayout(ClassicalExtrasOptionsPage)
+ self.vboxlayout.setContentsMargins(9, 9, 9, 9)
+ self.vboxlayout.setSpacing(6)
+ self.vboxlayout.setObjectName("vboxlayout")
+ self.tabWidget = QtWidgets.QTabWidget(ClassicalExtrasOptionsPage)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.MinimumExpanding, QtWidgets.QSizePolicy.MinimumExpanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.tabWidget.sizePolicy().hasHeightForWidth())
+ self.tabWidget.setSizePolicy(sizePolicy)
+ self.tabWidget.setMaximumSize(QtCore.QSize(1200, 1200))
+ palette = QtGui.QPalette()
+ self.tabWidget.setPalette(palette)
+ self.tabWidget.setAutoFillBackground(False)
+ self.tabWidget.setStyleSheet("")
+ self.tabWidget.setObjectName("tabWidget")
+ self.Artists = QtWidgets.QWidget()
+ self.Artists.setObjectName("Artists")
+ self.verticalLayout_10 = QtWidgets.QVBoxLayout(self.Artists)
+ self.verticalLayout_10.setObjectName("verticalLayout_10")
+ self.scrollArea = QtWidgets.QScrollArea(self.Artists)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.scrollArea.sizePolicy().hasHeightForWidth())
+ self.scrollArea.setSizePolicy(sizePolicy)
+ self.scrollArea.setFocusPolicy(QtCore.Qt.WheelFocus)
+ self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
+ self.scrollArea.setFrameShadow(QtWidgets.QFrame.Plain)
+ self.scrollArea.setLineWidth(1)
+ self.scrollArea.setWidgetResizable(True)
+ self.scrollArea.setObjectName("scrollArea")
+ self.scrollAreaWidgetContents = QtWidgets.QWidget()
+ self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, 0, 1086, 1071))
+ self.scrollAreaWidgetContents.setAcceptDrops(False)
+ self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
+ self.verticalLayout_13 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
+ self.verticalLayout_13.setObjectName("verticalLayout_13")
+ self.artists_run_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.artists_run_frame.setPalette(palette)
+ self.artists_run_frame.setAutoFillBackground(False)
+ self.artists_run_frame.setStyleSheet("background-color: rgb(255, 255, 222);")
+ self.artists_run_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.artists_run_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.artists_run_frame.setObjectName("artists_run_frame")
+ self.horizontalLayout_9 = QtWidgets.QHBoxLayout(self.artists_run_frame)
+ self.horizontalLayout_9.setObjectName("horizontalLayout_9")
+ self.use_cea = QtWidgets.QCheckBox(self.artists_run_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.use_cea.setPalette(palette)
+ self.use_cea.setStyleSheet("")
+ self.use_cea.setObjectName("use_cea")
+ self.horizontalLayout_9.addWidget(self.use_cea)
+ self.infer_worktypes_old_label = QtWidgets.QLabel(self.artists_run_frame)
+ self.infer_worktypes_old_label.setObjectName("infer_worktypes_old_label")
+ self.horizontalLayout_9.addWidget(self.infer_worktypes_old_label)
+ self.verticalLayout_13.addWidget(self.artists_run_frame)
+ self.line_4 = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ self.line_4.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line_4.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_4.setObjectName("line_4")
+ self.verticalLayout_13.addWidget(self.line_4)
+ self.naming_style_note_label = QtWidgets.QLabel(self.scrollAreaWidgetContents)
+ self.naming_style_note_label.setObjectName("naming_style_note_label")
+ self.verticalLayout_13.addWidget(self.naming_style_note_label)
+ self.naming_options_frame_2 = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ self.naming_options_frame_2.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.naming_options_frame_2.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.naming_options_frame_2.setObjectName("naming_options_frame_2")
+ self.verticalLayout_36 = QtWidgets.QVBoxLayout(self.naming_options_frame_2)
+ self.verticalLayout_36.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_36.setSpacing(0)
+ self.verticalLayout_36.setObjectName("verticalLayout_36")
+ self.naming_options_label = QtWidgets.QLabel(self.naming_options_frame_2)
+ self.naming_options_label.setStyleSheet("background-color: rgb(176, 220, 192);")
+ self.naming_options_label.setObjectName("naming_options_label")
+ self.verticalLayout_36.addWidget(self.naming_options_label)
+ self.naming_options_frame = QtWidgets.QFrame(self.naming_options_frame_2)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.naming_options_frame.setPalette(palette)
+ self.naming_options_frame.setCursor(QtGui.QCursor(QtCore.Qt.UpArrowCursor))
+ self.naming_options_frame.setAutoFillBackground(False)
+ self.naming_options_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.naming_options_frame.setFrameShape(QtWidgets.QFrame.NoFrame)
+ self.naming_options_frame.setObjectName("naming_options_frame")
+ self.formLayout_3 = QtWidgets.QFormLayout(self.naming_options_frame)
+ self.formLayout_3.setFieldGrowthPolicy(QtWidgets.QFormLayout.AllNonFixedFieldsGrow)
+ self.formLayout_3.setContentsMargins(9, 0, 9, -1)
+ self.formLayout_3.setVerticalSpacing(6)
+ self.formLayout_3.setObjectName("formLayout_3")
+ self.label_22 = QtWidgets.QLabel(self.naming_options_frame)
+ self.label_22.setObjectName("label_22")
+ self.formLayout_3.setWidget(2, QtWidgets.QFormLayout.SpanningRole, self.label_22)
+ self.credited_as_options_box = QtWidgets.QGroupBox(self.naming_options_frame)
+ self.credited_as_options_box.setObjectName("credited_as_options_box")
+ self.horizontalLayout_18 = QtWidgets.QHBoxLayout(self.credited_as_options_box)
+ self.horizontalLayout_18.setObjectName("horizontalLayout_18")
+ self.names_to_use_box = QtWidgets.QGroupBox(self.credited_as_options_box)
+ self.names_to_use_box.setAutoFillBackground(False)
+ self.names_to_use_box.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.names_to_use_box.setObjectName("names_to_use_box")
+ self.verticalLayout_26 = QtWidgets.QVBoxLayout(self.names_to_use_box)
+ self.verticalLayout_26.setObjectName("verticalLayout_26")
+ self.cea_recording_credited = QtWidgets.QCheckBox(self.names_to_use_box)
+ self.cea_recording_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_recording_credited.setObjectName("cea_recording_credited")
+ self.verticalLayout_26.addWidget(self.cea_recording_credited)
+ self.cea_group_credited = QtWidgets.QCheckBox(self.names_to_use_box)
+ self.cea_group_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_group_credited.setAutoFillBackground(False)
+ self.cea_group_credited.setStyleSheet("")
+ self.cea_group_credited.setObjectName("cea_group_credited")
+ self.verticalLayout_26.addWidget(self.cea_group_credited)
+ self.cea_credited = QtWidgets.QCheckBox(self.names_to_use_box)
+ self.cea_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_credited.setObjectName("cea_credited")
+ self.verticalLayout_26.addWidget(self.cea_credited)
+ self.cea_release_relationship_credited = QtWidgets.QCheckBox(self.names_to_use_box)
+ self.cea_release_relationship_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_release_relationship_credited.setObjectName("cea_release_relationship_credited")
+ self.verticalLayout_26.addWidget(self.cea_release_relationship_credited)
+ self.cea_recording_relationship_credited = QtWidgets.QCheckBox(self.names_to_use_box)
+ self.cea_recording_relationship_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_recording_relationship_credited.setObjectName("cea_recording_relationship_credited")
+ self.verticalLayout_26.addWidget(self.cea_recording_relationship_credited)
+ self.cea_track_credited = QtWidgets.QCheckBox(self.names_to_use_box)
+ self.cea_track_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_track_credited.setObjectName("cea_track_credited")
+ self.verticalLayout_26.addWidget(self.cea_track_credited)
+ self.label_24 = QtWidgets.QLabel(self.names_to_use_box)
+ self.label_24.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.label_24.setObjectName("label_24")
+ self.verticalLayout_26.addWidget(self.label_24)
+ self.label_88 = QtWidgets.QLabel(self.names_to_use_box)
+ self.label_88.setObjectName("label_88")
+ self.verticalLayout_26.addWidget(self.label_88)
+ self.horizontalLayout_18.addWidget(self.names_to_use_box)
+ self.places_to_use_them_box = QtWidgets.QGroupBox(self.credited_as_options_box)
+ self.places_to_use_them_box.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.places_to_use_them_box.setObjectName("places_to_use_them_box")
+ self.verticalLayout_27 = QtWidgets.QVBoxLayout(self.places_to_use_them_box)
+ self.verticalLayout_27.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)
+ self.verticalLayout_27.setContentsMargins(9, -1, -1, -1)
+ self.verticalLayout_27.setObjectName("verticalLayout_27")
+ self.cea_performer_credited = QtWidgets.QCheckBox(self.places_to_use_them_box)
+ self.cea_performer_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_performer_credited.setObjectName("cea_performer_credited")
+ self.verticalLayout_27.addWidget(self.cea_performer_credited)
+ self.cea_composer_credited = QtWidgets.QCheckBox(self.places_to_use_them_box)
+ self.cea_composer_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_composer_credited.setObjectName("cea_composer_credited")
+ self.verticalLayout_27.addWidget(self.cea_composer_credited)
+ self.horizontalLayout_18.addWidget(self.places_to_use_them_box)
+ self.formLayout_3.setWidget(3, QtWidgets.QFormLayout.FieldRole, self.credited_as_options_box)
+ self.naming_sub_options_box = QtWidgets.QGroupBox(self.naming_options_frame)
+ self.naming_sub_options_box.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.naming_sub_options_box.setObjectName("naming_sub_options_box")
+ self.horizontalLayout_11 = QtWidgets.QHBoxLayout(self.naming_sub_options_box)
+ self.horizontalLayout_11.setObjectName("horizontalLayout_11")
+ self.cea_alias_overrides = QtWidgets.QRadioButton(self.naming_sub_options_box)
+ self.cea_alias_overrides.setObjectName("cea_alias_overrides")
+ self.horizontalLayout_11.addWidget(self.cea_alias_overrides)
+ self.cea_credited_overrides = QtWidgets.QRadioButton(self.naming_sub_options_box)
+ self.cea_credited_overrides.setObjectName("cea_credited_overrides")
+ self.horizontalLayout_11.addWidget(self.cea_credited_overrides)
+ self.cea_cyrillic = QtWidgets.QCheckBox(self.naming_sub_options_box)
+ self.cea_cyrillic.setObjectName("cea_cyrillic")
+ self.horizontalLayout_11.addWidget(self.cea_cyrillic)
+ self.formLayout_3.setWidget(4, QtWidgets.QFormLayout.SpanningRole, self.naming_sub_options_box)
+ self.MB_std_names_aliases_box_outer = QtWidgets.QGroupBox(self.naming_options_frame)
+ self.MB_std_names_aliases_box_outer.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.MB_std_names_aliases_box_outer.setObjectName("MB_std_names_aliases_box_outer")
+ self.verticalLayout_24 = QtWidgets.QVBoxLayout(self.MB_std_names_aliases_box_outer)
+ self.verticalLayout_24.setObjectName("verticalLayout_24")
+ self.MB_std_names_aliases_box_inner = QtWidgets.QGroupBox(self.MB_std_names_aliases_box_outer)
+ self.MB_std_names_aliases_box_inner.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.MB_std_names_aliases_box_inner.setTitle("")
+ self.MB_std_names_aliases_box_inner.setObjectName("MB_std_names_aliases_box_inner")
+ self.verticalLayout_40 = QtWidgets.QVBoxLayout(self.MB_std_names_aliases_box_inner)
+ self.verticalLayout_40.setObjectName("verticalLayout_40")
+ self.cea_no_aliases = QtWidgets.QRadioButton(self.MB_std_names_aliases_box_inner)
+ self.cea_no_aliases.setObjectName("cea_no_aliases")
+ self.verticalLayout_40.addWidget(self.cea_no_aliases)
+ self.cea_aliases = QtWidgets.QRadioButton(self.MB_std_names_aliases_box_inner)
+ self.cea_aliases.setObjectName("cea_aliases")
+ self.verticalLayout_40.addWidget(self.cea_aliases)
+ self.cea_aliases_composer = QtWidgets.QRadioButton(self.MB_std_names_aliases_box_inner)
+ self.cea_aliases_composer.setObjectName("cea_aliases_composer")
+ self.verticalLayout_40.addWidget(self.cea_aliases_composer)
+ self.verticalLayout_24.addWidget(self.MB_std_names_aliases_box_inner)
+ self.formLayout_3.setWidget(3, QtWidgets.QFormLayout.LabelRole, self.MB_std_names_aliases_box_outer)
+ self.verticalLayout_36.addWidget(self.naming_options_frame)
+ self.verticalLayout_13.addWidget(self.naming_options_frame_2)
+ self.recording_artists_options_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ self.recording_artists_options_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.recording_artists_options_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.recording_artists_options_frame.setObjectName("recording_artists_options_frame")
+ self.verticalLayout_37 = QtWidgets.QVBoxLayout(self.recording_artists_options_frame)
+ self.verticalLayout_37.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_37.setSpacing(0)
+ self.verticalLayout_37.setObjectName("verticalLayout_37")
+ self.recording_artist_options_label = QtWidgets.QLabel(self.recording_artists_options_frame)
+ self.recording_artist_options_label.setStyleSheet("background-color: rgb(176, 220, 192);")
+ self.recording_artist_options_label.setObjectName("recording_artist_options_label")
+ self.verticalLayout_37.addWidget(self.recording_artist_options_label)
+ self.recording_artists_options_box = QtWidgets.QGroupBox(self.recording_artists_options_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.recording_artists_options_box.setPalette(palette)
+ self.recording_artists_options_box.setAutoFillBackground(False)
+ self.recording_artists_options_box.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.recording_artists_options_box.setTitle("")
+ self.recording_artists_options_box.setObjectName("recording_artists_options_box")
+ self.horizontalLayout_24 = QtWidgets.QHBoxLayout(self.recording_artists_options_box)
+ self.horizontalLayout_24.setObjectName("horizontalLayout_24")
+ self.naming_convention_box = QtWidgets.QGroupBox(self.recording_artists_options_box)
+ self.naming_convention_box.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.naming_convention_box.setObjectName("naming_convention_box")
+ self.verticalLayout_31 = QtWidgets.QVBoxLayout(self.naming_convention_box)
+ self.verticalLayout_31.setObjectName("verticalLayout_31")
+ self.cea_ra_trackartist = QtWidgets.QRadioButton(self.naming_convention_box)
+ self.cea_ra_trackartist.setObjectName("cea_ra_trackartist")
+ self.verticalLayout_31.addWidget(self.cea_ra_trackartist)
+ self.cea_ra_performer = QtWidgets.QRadioButton(self.naming_convention_box)
+ self.cea_ra_performer.setObjectName("cea_ra_performer")
+ self.verticalLayout_31.addWidget(self.cea_ra_performer)
+ self.horizontalLayout_24.addWidget(self.naming_convention_box)
+ self.line_7 = QtWidgets.QFrame(self.recording_artists_options_box)
+ self.line_7.setFrameShape(QtWidgets.QFrame.VLine)
+ self.line_7.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_7.setObjectName("line_7")
+ self.horizontalLayout_24.addWidget(self.line_7)
+ self.cea_ra_use = QtWidgets.QCheckBox(self.recording_artists_options_box)
+ self.cea_ra_use.setObjectName("cea_ra_use")
+ self.horizontalLayout_24.addWidget(self.cea_ra_use)
+ self.ra_replace_merge_options_box = QtWidgets.QGroupBox(self.recording_artists_options_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.MinimumExpanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.ra_replace_merge_options_box.sizePolicy().hasHeightForWidth())
+ self.ra_replace_merge_options_box.setSizePolicy(sizePolicy)
+ self.ra_replace_merge_options_box.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.ra_replace_merge_options_box.setObjectName("ra_replace_merge_options_box")
+ self.verticalLayout_29 = QtWidgets.QVBoxLayout(self.ra_replace_merge_options_box)
+ self.verticalLayout_29.setObjectName("verticalLayout_29")
+ self.cea_ra_replace_ta = QtWidgets.QRadioButton(self.ra_replace_merge_options_box)
+ self.cea_ra_replace_ta.setObjectName("cea_ra_replace_ta")
+ self.verticalLayout_29.addWidget(self.cea_ra_replace_ta)
+ self.cea_ra_noblank_ta = QtWidgets.QCheckBox(self.ra_replace_merge_options_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.cea_ra_noblank_ta.sizePolicy().hasHeightForWidth())
+ self.cea_ra_noblank_ta.setSizePolicy(sizePolicy)
+ self.cea_ra_noblank_ta.setLayoutDirection(QtCore.Qt.LeftToRight)
+ self.cea_ra_noblank_ta.setObjectName("cea_ra_noblank_ta")
+ self.verticalLayout_29.addWidget(self.cea_ra_noblank_ta)
+ self.cea_ra_merge_ta = QtWidgets.QRadioButton(self.ra_replace_merge_options_box)
+ self.cea_ra_merge_ta.setObjectName("cea_ra_merge_ta")
+ self.verticalLayout_29.addWidget(self.cea_ra_merge_ta)
+ self.horizontalLayout_24.addWidget(self.ra_replace_merge_options_box)
+ self.verticalLayout_37.addWidget(self.recording_artists_options_box)
+ self.verticalLayout_13.addWidget(self.recording_artists_options_frame)
+ self.other_artist_options_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ self.other_artist_options_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.other_artist_options_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.other_artist_options_frame.setObjectName("other_artist_options_frame")
+ self.verticalLayout_38 = QtWidgets.QVBoxLayout(self.other_artist_options_frame)
+ self.verticalLayout_38.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_38.setSpacing(0)
+ self.verticalLayout_38.setObjectName("verticalLayout_38")
+ self.other_artist_options_label = QtWidgets.QLabel(self.other_artist_options_frame)
+ self.other_artist_options_label.setStyleSheet("background-color: rgb(176, 220, 192);")
+ self.other_artist_options_label.setObjectName("other_artist_options_label")
+ self.verticalLayout_38.addWidget(self.other_artist_options_label)
+ self.other_artist_options_box = QtWidgets.QGroupBox(self.other_artist_options_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.other_artist_options_box.setPalette(palette)
+ self.other_artist_options_box.setAutoFillBackground(False)
+ self.other_artist_options_box.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.other_artist_options_box.setTitle("")
+ self.other_artist_options_box.setObjectName("other_artist_options_box")
+ self.gridLayout = QtWidgets.QGridLayout(self.other_artist_options_box)
+ self.gridLayout.setVerticalSpacing(6)
+ self.gridLayout.setObjectName("gridLayout")
+ self.annotations_lh_box = QtWidgets.QGroupBox(self.other_artist_options_box)
+ self.annotations_lh_box.setStyleSheet("background-color: rgba(250, 250, 250, 250);")
+ self.annotations_lh_box.setObjectName("annotations_lh_box")
+ self.verticalLayout_15 = QtWidgets.QVBoxLayout(self.annotations_lh_box)
+ self.verticalLayout_15.setObjectName("verticalLayout_15")
+ self.chorusmaster_frame = QtWidgets.QFrame(self.annotations_lh_box)
+ self.chorusmaster_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.chorusmaster_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.chorusmaster_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.chorusmaster_frame.setObjectName("chorusmaster_frame")
+ self.horizontalLayout_8 = QtWidgets.QHBoxLayout(self.chorusmaster_frame)
+ self.horizontalLayout_8.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)
+ self.horizontalLayout_8.setContentsMargins(-1, 1, -1, 9)
+ self.horizontalLayout_8.setSpacing(6)
+ self.horizontalLayout_8.setObjectName("horizontalLayout_8")
+ self.label_44 = QtWidgets.QLabel(self.chorusmaster_frame)
+ self.label_44.setObjectName("label_44")
+ self.horizontalLayout_8.addWidget(self.label_44)
+ self.cea_chorusmaster = QtWidgets.QLineEdit(self.chorusmaster_frame)
+ self.cea_chorusmaster.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_chorusmaster.setObjectName("cea_chorusmaster")
+ self.horizontalLayout_8.addWidget(self.cea_chorusmaster)
+ self.verticalLayout_15.addWidget(self.chorusmaster_frame)
+ self.concertmaster_frame = QtWidgets.QFrame(self.annotations_lh_box)
+ self.concertmaster_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.concertmaster_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.concertmaster_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.concertmaster_frame.setObjectName("concertmaster_frame")
+ self.horizontalLayout_6 = QtWidgets.QHBoxLayout(self.concertmaster_frame)
+ self.horizontalLayout_6.setContentsMargins(-1, 1, -1, -1)
+ self.horizontalLayout_6.setObjectName("horizontalLayout_6")
+ self.label_46 = QtWidgets.QLabel(self.concertmaster_frame)
+ self.label_46.setObjectName("label_46")
+ self.horizontalLayout_6.addWidget(self.label_46)
+ self.cea_concertmaster = QtWidgets.QLineEdit(self.concertmaster_frame)
+ self.cea_concertmaster.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_concertmaster.setObjectName("cea_concertmaster")
+ self.horizontalLayout_6.addWidget(self.cea_concertmaster)
+ self.verticalLayout_15.addWidget(self.concertmaster_frame)
+ self.lyricist_frame = QtWidgets.QFrame(self.annotations_lh_box)
+ self.lyricist_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.lyricist_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.lyricist_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.lyricist_frame.setObjectName("lyricist_frame")
+ self.horizontalLayout_23 = QtWidgets.QHBoxLayout(self.lyricist_frame)
+ self.horizontalLayout_23.setObjectName("horizontalLayout_23")
+ self.label_34 = QtWidgets.QLabel(self.lyricist_frame)
+ self.label_34.setObjectName("label_34")
+ self.horizontalLayout_23.addWidget(self.label_34)
+ self.cea_lyricist = QtWidgets.QLineEdit(self.lyricist_frame)
+ self.cea_lyricist.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_lyricist.setObjectName("cea_lyricist")
+ self.horizontalLayout_23.addWidget(self.cea_lyricist)
+ self.verticalLayout_15.addWidget(self.lyricist_frame)
+ self.librettist_frame = QtWidgets.QFrame(self.annotations_lh_box)
+ self.librettist_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.librettist_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.librettist_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.librettist_frame.setObjectName("librettist_frame")
+ self.horizontalLayout_19 = QtWidgets.QHBoxLayout(self.librettist_frame)
+ self.horizontalLayout_19.setObjectName("horizontalLayout_19")
+ self.label_26 = QtWidgets.QLabel(self.librettist_frame)
+ self.label_26.setObjectName("label_26")
+ self.horizontalLayout_19.addWidget(self.label_26)
+ self.cea_librettist = QtWidgets.QLineEdit(self.librettist_frame)
+ self.cea_librettist.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_librettist.setObjectName("cea_librettist")
+ self.horizontalLayout_19.addWidget(self.cea_librettist)
+ self.verticalLayout_15.addWidget(self.librettist_frame)
+ self.translator_frame = QtWidgets.QFrame(self.annotations_lh_box)
+ self.translator_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.translator_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.translator_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.translator_frame.setObjectName("translator_frame")
+ self.horizontalLayout_21 = QtWidgets.QHBoxLayout(self.translator_frame)
+ self.horizontalLayout_21.setObjectName("horizontalLayout_21")
+ self.label_30 = QtWidgets.QLabel(self.translator_frame)
+ self.label_30.setObjectName("label_30")
+ self.horizontalLayout_21.addWidget(self.label_30)
+ self.cea_translator = QtWidgets.QLineEdit(self.translator_frame)
+ self.cea_translator.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_translator.setObjectName("cea_translator")
+ self.horizontalLayout_21.addWidget(self.cea_translator)
+ self.verticalLayout_15.addWidget(self.translator_frame)
+ self.gridLayout.addWidget(self.annotations_lh_box, 0, 1, 1, 1)
+ self.other_artist_checkboxes_box = QtWidgets.QGroupBox(self.other_artist_options_box)
+ self.other_artist_checkboxes_box.setStyleSheet("background-color: rgba(250, 250, 250, 250);")
+ self.other_artist_checkboxes_box.setTitle("")
+ self.other_artist_checkboxes_box.setObjectName("other_artist_checkboxes_box")
+ self.verticalLayout_14 = QtWidgets.QVBoxLayout(self.other_artist_checkboxes_box)
+ self.verticalLayout_14.setSpacing(6)
+ self.verticalLayout_14.setObjectName("verticalLayout_14")
+ self.cea_arrangers = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
+ self.cea_arrangers.setObjectName("cea_arrangers")
+ self.verticalLayout_14.addWidget(self.cea_arrangers)
+ self.cea_composer_album = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
+ self.cea_composer_album.setObjectName("cea_composer_album")
+ self.verticalLayout_14.addWidget(self.cea_composer_album)
+ self.cea_no_lyricists = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
+ self.cea_no_lyricists.setObjectName("cea_no_lyricists")
+ self.verticalLayout_14.addWidget(self.cea_no_lyricists)
+ self.cea_inst_credit = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
+ self.cea_inst_credit.setObjectName("cea_inst_credit")
+ self.verticalLayout_14.addWidget(self.cea_inst_credit)
+ self.cea_no_solo = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
+ self.cea_no_solo.setObjectName("cea_no_solo")
+ self.verticalLayout_14.addWidget(self.cea_no_solo)
+ self.gridLayout.addWidget(self.other_artist_checkboxes_box, 0, 0, 1, 1)
+ self.annotations_rh_box = QtWidgets.QGroupBox(self.other_artist_options_box)
+ self.annotations_rh_box.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.annotations_rh_box.setObjectName("annotations_rh_box")
+ self.verticalLayout_21 = QtWidgets.QVBoxLayout(self.annotations_rh_box)
+ self.verticalLayout_21.setObjectName("verticalLayout_21")
+ self.writer_frame = QtWidgets.QFrame(self.annotations_rh_box)
+ self.writer_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.writer_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.writer_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.writer_frame.setObjectName("writer_frame")
+ self.horizontalLayout_30 = QtWidgets.QHBoxLayout(self.writer_frame)
+ self.horizontalLayout_30.setObjectName("horizontalLayout_30")
+ self.label_56 = QtWidgets.QLabel(self.writer_frame)
+ self.label_56.setObjectName("label_56")
+ self.horizontalLayout_30.addWidget(self.label_56)
+ self.cea_writer = QtWidgets.QLineEdit(self.writer_frame)
+ self.cea_writer.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_writer.setObjectName("cea_writer")
+ self.horizontalLayout_30.addWidget(self.cea_writer)
+ self.verticalLayout_21.addWidget(self.writer_frame)
+ self.arranger_frame = QtWidgets.QFrame(self.annotations_rh_box)
+ self.arranger_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.arranger_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.arranger_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.arranger_frame.setObjectName("arranger_frame")
+ self.horizontalLayout_29 = QtWidgets.QHBoxLayout(self.arranger_frame)
+ self.horizontalLayout_29.setObjectName("horizontalLayout_29")
+ self.label_54 = QtWidgets.QLabel(self.arranger_frame)
+ self.label_54.setObjectName("label_54")
+ self.horizontalLayout_29.addWidget(self.label_54)
+ self.cea_arranger = QtWidgets.QLineEdit(self.arranger_frame)
+ self.cea_arranger.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_arranger.setObjectName("cea_arranger")
+ self.horizontalLayout_29.addWidget(self.cea_arranger)
+ self.verticalLayout_21.addWidget(self.arranger_frame)
+ self.orchestrator_frame = QtWidgets.QFrame(self.annotations_rh_box)
+ self.orchestrator_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.orchestrator_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.orchestrator_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.orchestrator_frame.setObjectName("orchestrator_frame")
+ self.horizontalLayout_7 = QtWidgets.QHBoxLayout(self.orchestrator_frame)
+ self.horizontalLayout_7.setContentsMargins(-1, 1, -1, -1)
+ self.horizontalLayout_7.setObjectName("horizontalLayout_7")
+ self.label_45 = QtWidgets.QLabel(self.orchestrator_frame)
+ self.label_45.setObjectName("label_45")
+ self.horizontalLayout_7.addWidget(self.label_45)
+ self.cea_orchestrator = QtWidgets.QLineEdit(self.orchestrator_frame)
+ self.cea_orchestrator.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_orchestrator.setObjectName("cea_orchestrator")
+ self.horizontalLayout_7.addWidget(self.cea_orchestrator)
+ self.verticalLayout_21.addWidget(self.orchestrator_frame)
+ self.reconstructed_frame = QtWidgets.QFrame(self.annotations_rh_box)
+ self.reconstructed_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.reconstructed_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.reconstructed_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.reconstructed_frame.setObjectName("reconstructed_frame")
+ self.horizontalLayout_22 = QtWidgets.QHBoxLayout(self.reconstructed_frame)
+ self.horizontalLayout_22.setObjectName("horizontalLayout_22")
+ self.label_32 = QtWidgets.QLabel(self.reconstructed_frame)
+ self.label_32.setObjectName("label_32")
+ self.horizontalLayout_22.addWidget(self.label_32)
+ self.cea_reconstructed = QtWidgets.QLineEdit(self.reconstructed_frame)
+ self.cea_reconstructed.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_reconstructed.setObjectName("cea_reconstructed")
+ self.horizontalLayout_22.addWidget(self.cea_reconstructed)
+ self.verticalLayout_21.addWidget(self.reconstructed_frame)
+ self.revised_frame = QtWidgets.QFrame(self.annotations_rh_box)
+ self.revised_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
+ self.revised_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.revised_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.revised_frame.setObjectName("revised_frame")
+ self.horizontalLayout_20 = QtWidgets.QHBoxLayout(self.revised_frame)
+ self.horizontalLayout_20.setObjectName("horizontalLayout_20")
+ self.label_28 = QtWidgets.QLabel(self.revised_frame)
+ self.label_28.setObjectName("label_28")
+ self.horizontalLayout_20.addWidget(self.label_28)
+ self.cea_revised = QtWidgets.QLineEdit(self.revised_frame)
+ self.cea_revised.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_revised.setObjectName("cea_revised")
+ self.horizontalLayout_20.addWidget(self.cea_revised)
+ self.verticalLayout_21.addWidget(self.revised_frame)
+ self.gridLayout.addWidget(self.annotations_rh_box, 0, 2, 1, 1)
+ self.verticalLayout_38.addWidget(self.other_artist_options_box)
+ self.verticalLayout_13.addWidget(self.other_artist_options_frame)
+ self.line_3 = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ self.line_3.setLineWidth(1)
+ self.line_3.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line_3.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_3.setObjectName("line_3")
+ self.verticalLayout_13.addWidget(self.line_3)
+ self.lyrics_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
+ self.lyrics_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.lyrics_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.lyrics_frame.setObjectName("lyrics_frame")
+ self.verticalLayout_39 = QtWidgets.QVBoxLayout(self.lyrics_frame)
+ self.verticalLayout_39.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_39.setSpacing(0)
+ self.verticalLayout_39.setObjectName("verticalLayout_39")
+ self.lyrics_label = QtWidgets.QLabel(self.lyrics_frame)
+ self.lyrics_label.setStyleSheet("background-color: rgb(204, 168, 161);")
+ self.lyrics_label.setObjectName("lyrics_label")
+ self.verticalLayout_39.addWidget(self.lyrics_label)
+ self.lyrics_box = QtWidgets.QGroupBox(self.lyrics_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.lyrics_box.setPalette(palette)
+ self.lyrics_box.setAutoFillBackground(False)
+ self.lyrics_box.setStyleSheet("background-color: rgb(230, 215, 211);")
+ self.lyrics_box.setTitle("")
+ self.lyrics_box.setObjectName("lyrics_box")
+ self.horizontalLayout_25 = QtWidgets.QHBoxLayout(self.lyrics_box)
+ self.horizontalLayout_25.setObjectName("horizontalLayout_25")
+ self.cea_split_lyrics = QtWidgets.QCheckBox(self.lyrics_box)
+ self.cea_split_lyrics.setObjectName("cea_split_lyrics")
+ self.horizontalLayout_25.addWidget(self.cea_split_lyrics)
+ self.lyrics_and_notes_tags_frame = QtWidgets.QGroupBox(self.lyrics_box)
+ self.lyrics_and_notes_tags_frame.setTitle("")
+ self.lyrics_and_notes_tags_frame.setObjectName("lyrics_and_notes_tags_frame")
+ self.verticalLayout_30 = QtWidgets.QVBoxLayout(self.lyrics_and_notes_tags_frame)
+ self.verticalLayout_30.setObjectName("verticalLayout_30")
+ self.lyrics_tags_frame = QtWidgets.QFrame(self.lyrics_and_notes_tags_frame)
+ self.lyrics_tags_frame.setStyleSheet("background-color: rgb(204, 168, 161);")
+ self.lyrics_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.lyrics_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.lyrics_tags_frame.setObjectName("lyrics_tags_frame")
+ self.horizontalLayout_26 = QtWidgets.QHBoxLayout(self.lyrics_tags_frame)
+ self.horizontalLayout_26.setObjectName("horizontalLayout_26")
+ self.label_50 = QtWidgets.QLabel(self.lyrics_tags_frame)
+ self.label_50.setObjectName("label_50")
+ self.horizontalLayout_26.addWidget(self.label_50)
+ self.cea_lyrics_tag = QtWidgets.QLineEdit(self.lyrics_tags_frame)
+ self.cea_lyrics_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_lyrics_tag.setObjectName("cea_lyrics_tag")
+ self.horizontalLayout_26.addWidget(self.cea_lyrics_tag)
+ self.verticalLayout_30.addWidget(self.lyrics_tags_frame)
+ self.album_notes_tags_frame = QtWidgets.QFrame(self.lyrics_and_notes_tags_frame)
+ self.album_notes_tags_frame.setStyleSheet("background-color: rgb(204, 168, 161);")
+ self.album_notes_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.album_notes_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.album_notes_tags_frame.setObjectName("album_notes_tags_frame")
+ self.horizontalLayout_27 = QtWidgets.QHBoxLayout(self.album_notes_tags_frame)
+ self.horizontalLayout_27.setObjectName("horizontalLayout_27")
+ self.label_51 = QtWidgets.QLabel(self.album_notes_tags_frame)
+ self.label_51.setObjectName("label_51")
+ self.horizontalLayout_27.addWidget(self.label_51)
+ self.cea_album_lyrics = QtWidgets.QLineEdit(self.album_notes_tags_frame)
+ self.cea_album_lyrics.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_album_lyrics.setObjectName("cea_album_lyrics")
+ self.horizontalLayout_27.addWidget(self.cea_album_lyrics)
+ self.verticalLayout_30.addWidget(self.album_notes_tags_frame)
+ self.track_notes_tags_frame = QtWidgets.QFrame(self.lyrics_and_notes_tags_frame)
+ self.track_notes_tags_frame.setStyleSheet("background-color: rgb(204, 168, 161);")
+ self.track_notes_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.track_notes_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.track_notes_tags_frame.setObjectName("track_notes_tags_frame")
+ self.horizontalLayout_28 = QtWidgets.QHBoxLayout(self.track_notes_tags_frame)
+ self.horizontalLayout_28.setObjectName("horizontalLayout_28")
+ self.label_52 = QtWidgets.QLabel(self.track_notes_tags_frame)
+ self.label_52.setObjectName("label_52")
+ self.horizontalLayout_28.addWidget(self.label_52)
+ self.cea_track_lyrics = QtWidgets.QLineEdit(self.track_notes_tags_frame)
+ self.cea_track_lyrics.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_track_lyrics.setObjectName("cea_track_lyrics")
+ self.horizontalLayout_28.addWidget(self.cea_track_lyrics)
+ self.verticalLayout_30.addWidget(self.track_notes_tags_frame)
+ self.horizontalLayout_25.addWidget(self.lyrics_and_notes_tags_frame)
+ self.verticalLayout_39.addWidget(self.lyrics_box)
+ self.verticalLayout_13.addWidget(self.lyrics_frame)
+ spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
+ self.verticalLayout_13.addItem(spacerItem)
+ self.scrollArea.setWidget(self.scrollAreaWidgetContents)
+ self.verticalLayout_10.addWidget(self.scrollArea)
+ self.tabWidget.addTab(self.Artists, "")
+ self.Works = QtWidgets.QWidget()
+ self.Works.setObjectName("Works")
+ self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.Works)
+ self.verticalLayout_4.setObjectName("verticalLayout_4")
+ self.scrollArea_3 = QtWidgets.QScrollArea(self.Works)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.scrollArea_3.sizePolicy().hasHeightForWidth())
+ self.scrollArea_3.setSizePolicy(sizePolicy)
+ self.scrollArea_3.setWidgetResizable(True)
+ self.scrollArea_3.setObjectName("scrollArea_3")
+ self.scrollAreaWidgetContents_3 = QtWidgets.QWidget()
+ self.scrollAreaWidgetContents_3.setGeometry(QtCore.QRect(0, 0, 1084, 1086))
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.scrollAreaWidgetContents_3.sizePolicy().hasHeightForWidth())
+ self.scrollAreaWidgetContents_3.setSizePolicy(sizePolicy)
+ self.scrollAreaWidgetContents_3.setObjectName("scrollAreaWidgetContents_3")
+ self.verticalLayout_25 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents_3)
+ self.verticalLayout_25.setObjectName("verticalLayout_25")
+ self.works_run_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Maximum)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.works_run_frame.sizePolicy().hasHeightForWidth())
+ self.works_run_frame.setSizePolicy(sizePolicy)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.works_run_frame.setPalette(palette)
+ self.works_run_frame.setAutoFillBackground(False)
+ self.works_run_frame.setStyleSheet("background-color: rgb(255, 255, 222);")
+ self.works_run_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.works_run_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.works_run_frame.setObjectName("works_run_frame")
+ self.horizontalLayout_3 = QtWidgets.QHBoxLayout(self.works_run_frame)
+ self.horizontalLayout_3.setObjectName("horizontalLayout_3")
+ self.use_cwp = QtWidgets.QCheckBox(self.works_run_frame)
+ self.use_cwp.setObjectName("use_cwp")
+ self.horizontalLayout_3.addWidget(self.use_cwp)
+ self.cwp_collections = QtWidgets.QCheckBox(self.works_run_frame)
+ self.cwp_collections.setObjectName("cwp_collections")
+ self.horizontalLayout_3.addWidget(self.cwp_collections)
+ self.use_cache = QtWidgets.QCheckBox(self.works_run_frame)
+ self.use_cache.setObjectName("use_cache")
+ self.horizontalLayout_3.addWidget(self.use_cache)
+ self.verticalLayout_25.addWidget(self.works_run_frame)
+ self.work_style_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
+ self.work_style_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.work_style_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.work_style_frame.setObjectName("work_style_frame")
+ self.verticalLayout_44 = QtWidgets.QVBoxLayout(self.work_style_frame)
+ self.verticalLayout_44.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_44.setSpacing(0)
+ self.verticalLayout_44.setObjectName("verticalLayout_44")
+ self.work_style_label = QtWidgets.QLabel(self.work_style_frame)
+ self.work_style_label.setStyleSheet("background-color: rgb(205, 230, 255);")
+ self.work_style_label.setObjectName("work_style_label")
+ self.verticalLayout_44.addWidget(self.work_style_label)
+ self.work_style_box = QtWidgets.QGroupBox(self.work_style_frame)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Maximum)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.work_style_box.sizePolicy().hasHeightForWidth())
+ self.work_style_box.setSizePolicy(sizePolicy)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.work_style_box.setPalette(palette)
+ self.work_style_box.setAutoFillBackground(False)
+ self.work_style_box.setStyleSheet("background-color: rgb(225, 240, 255);")
+ self.work_style_box.setTitle("")
+ self.work_style_box.setObjectName("work_style_box")
+ self.formLayout_2 = QtWidgets.QFormLayout(self.work_style_box)
+ self.formLayout_2.setObjectName("formLayout_2")
+ self.works_source_box = QtWidgets.QGroupBox(self.work_style_box)
+ self.works_source_box.setObjectName("works_source_box")
+ self.verticalLayout_11 = QtWidgets.QVBoxLayout(self.works_source_box)
+ self.verticalLayout_11.setObjectName("verticalLayout_11")
+ self.cwp_titles = QtWidgets.QRadioButton(self.works_source_box)
+ self.cwp_titles.setObjectName("cwp_titles")
+ self.verticalLayout_11.addWidget(self.cwp_titles)
+ self.cwp_works = QtWidgets.QRadioButton(self.works_source_box)
+ self.cwp_works.setObjectName("cwp_works")
+ self.verticalLayout_11.addWidget(self.cwp_works)
+ self.cwp_extended = QtWidgets.QRadioButton(self.works_source_box)
+ self.cwp_extended.setObjectName("cwp_extended")
+ self.verticalLayout_11.addWidget(self.cwp_extended)
+ self.formLayout_2.setWidget(0, QtWidgets.QFormLayout.LabelRole, self.works_source_box)
+ self.source_of_canonical_box = QtWidgets.QGroupBox(self.work_style_box)
+ self.source_of_canonical_box.setEnabled(True)
+ self.source_of_canonical_box.setObjectName("source_of_canonical_box")
+ self.verticalLayout_6 = QtWidgets.QVBoxLayout(self.source_of_canonical_box)
+ self.verticalLayout_6.setObjectName("verticalLayout_6")
+ self.cwp_hierarchical_works = QtWidgets.QRadioButton(self.source_of_canonical_box)
+ self.cwp_hierarchical_works.setObjectName("cwp_hierarchical_works")
+ self.verticalLayout_6.addWidget(self.cwp_hierarchical_works)
+ self.cwp_level0_works = QtWidgets.QRadioButton(self.source_of_canonical_box)
+ self.cwp_level0_works.setObjectName("cwp_level0_works")
+ self.verticalLayout_6.addWidget(self.cwp_level0_works)
+ self.formLayout_2.setWidget(0, QtWidgets.QFormLayout.FieldRole, self.source_of_canonical_box)
+ self.cwp_derive_works_from_title = QtWidgets.QCheckBox(self.work_style_box)
+ self.cwp_derive_works_from_title.setObjectName("cwp_derive_works_from_title")
+ self.formLayout_2.setWidget(1, QtWidgets.QFormLayout.SpanningRole, self.cwp_derive_works_from_title)
+ self.verticalLayout_44.addWidget(self.work_style_box)
+ self.verticalLayout_25.addWidget(self.work_style_frame)
+ self.work_aliases_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
+ self.work_aliases_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.work_aliases_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.work_aliases_frame.setObjectName("work_aliases_frame")
+ self.verticalLayout_45 = QtWidgets.QVBoxLayout(self.work_aliases_frame)
+ self.verticalLayout_45.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_45.setSpacing(0)
+ self.verticalLayout_45.setObjectName("verticalLayout_45")
+ self.work_aliases_label = QtWidgets.QLabel(self.work_aliases_frame)
+ self.work_aliases_label.setStyleSheet("background-color: rgb(255, 186, 189);")
+ self.work_aliases_label.setObjectName("work_aliases_label")
+ self.verticalLayout_45.addWidget(self.work_aliases_label)
+ self.work_aliases_box = QtWidgets.QGroupBox(self.work_aliases_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.work_aliases_box.setPalette(palette)
+ self.work_aliases_box.setAutoFillBackground(False)
+ self.work_aliases_box.setStyleSheet("background-color: rgb(255, 220, 222);")
+ self.work_aliases_box.setTitle("")
+ self.work_aliases_box.setObjectName("work_aliases_box")
+ self.horizontalLayout_16 = QtWidgets.QHBoxLayout(self.work_aliases_box)
+ self.horizontalLayout_16.setObjectName("horizontalLayout_16")
+ self.replace_MBworknames_box = QtWidgets.QGroupBox(self.work_aliases_box)
+ self.replace_MBworknames_box.setObjectName("replace_MBworknames_box")
+ self.verticalLayout_22 = QtWidgets.QVBoxLayout(self.replace_MBworknames_box)
+ self.verticalLayout_22.setObjectName("verticalLayout_22")
+ self.cwp_aliases = QtWidgets.QRadioButton(self.replace_MBworknames_box)
+ self.cwp_aliases.setObjectName("cwp_aliases")
+ self.verticalLayout_22.addWidget(self.cwp_aliases)
+ self.cwp_no_aliases = QtWidgets.QRadioButton(self.replace_MBworknames_box)
+ self.cwp_no_aliases.setObjectName("cwp_no_aliases")
+ self.verticalLayout_22.addWidget(self.cwp_no_aliases)
+ self.horizontalLayout_16.addWidget(self.replace_MBworknames_box)
+ self.what_to_replace_outer_box = QtWidgets.QGroupBox(self.work_aliases_box)
+ self.what_to_replace_outer_box.setStyleSheet("")
+ self.what_to_replace_outer_box.setObjectName("what_to_replace_outer_box")
+ self.horizontalLayout_17 = QtWidgets.QHBoxLayout(self.what_to_replace_outer_box)
+ self.horizontalLayout_17.setObjectName("horizontalLayout_17")
+ self.what_to_replace_radios_box = QtWidgets.QGroupBox(self.what_to_replace_outer_box)
+ self.what_to_replace_radios_box.setTitle("")
+ self.what_to_replace_radios_box.setObjectName("what_to_replace_radios_box")
+ self.verticalLayout_23 = QtWidgets.QVBoxLayout(self.what_to_replace_radios_box)
+ self.verticalLayout_23.setObjectName("verticalLayout_23")
+ self.cwp_aliases_all = QtWidgets.QRadioButton(self.what_to_replace_radios_box)
+ self.cwp_aliases_all.setObjectName("cwp_aliases_all")
+ self.verticalLayout_23.addWidget(self.cwp_aliases_all)
+ self.cwp_aliases_greek = QtWidgets.QRadioButton(self.what_to_replace_radios_box)
+ self.cwp_aliases_greek.setObjectName("cwp_aliases_greek")
+ self.verticalLayout_23.addWidget(self.cwp_aliases_greek)
+ self.cwp_aliases_tagged = QtWidgets.QRadioButton(self.what_to_replace_radios_box)
+ self.cwp_aliases_tagged.setObjectName("cwp_aliases_tagged")
+ self.verticalLayout_23.addWidget(self.cwp_aliases_tagged)
+ self.horizontalLayout_17.addWidget(self.what_to_replace_radios_box)
+ self.works_alias_tags_box = QtWidgets.QGroupBox(self.what_to_replace_outer_box)
+ self.works_alias_tags_box.setObjectName("works_alias_tags_box")
+ self.formLayout = QtWidgets.QFormLayout(self.works_alias_tags_box)
+ self.formLayout.setObjectName("formLayout")
+ self.cwp_aliases_tags_all = QtWidgets.QRadioButton(self.works_alias_tags_box)
+ self.cwp_aliases_tags_all.setObjectName("cwp_aliases_tags_all")
+ self.formLayout.setWidget(1, QtWidgets.QFormLayout.LabelRole, self.cwp_aliases_tags_all)
+ self.cwp_aliases_tags_user = QtWidgets.QRadioButton(self.works_alias_tags_box)
+ self.cwp_aliases_tags_user.setObjectName("cwp_aliases_tags_user")
+ self.formLayout.setWidget(1, QtWidgets.QFormLayout.FieldRole, self.cwp_aliases_tags_user)
+ self.cwp_aliases_tag_text = QtWidgets.QLineEdit(self.works_alias_tags_box)
+ self.cwp_aliases_tag_text.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_aliases_tag_text.setObjectName("cwp_aliases_tag_text")
+ self.formLayout.setWidget(0, QtWidgets.QFormLayout.SpanningRole, self.cwp_aliases_tag_text)
+ self.horizontalLayout_17.addWidget(self.works_alias_tags_box)
+ self.horizontalLayout_16.addWidget(self.what_to_replace_outer_box)
+ self.verticalLayout_45.addWidget(self.work_aliases_box)
+ self.verticalLayout_25.addWidget(self.work_aliases_frame)
+ self.works_parts_tags_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
+ self.works_parts_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.works_parts_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.works_parts_tags_frame.setObjectName("works_parts_tags_frame")
+ self.verticalLayout_46 = QtWidgets.QVBoxLayout(self.works_parts_tags_frame)
+ self.verticalLayout_46.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_46.setSpacing(0)
+ self.verticalLayout_46.setObjectName("verticalLayout_46")
+ self.work_parts_tags_label = QtWidgets.QLabel(self.works_parts_tags_frame)
+ self.work_parts_tags_label.setStyleSheet("background-color: rgb(255, 194, 158);")
+ self.work_parts_tags_label.setObjectName("work_parts_tags_label")
+ self.verticalLayout_46.addWidget(self.work_parts_tags_label)
+ self.works_parts_tags_box = QtWidgets.QGroupBox(self.works_parts_tags_frame)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.MinimumExpanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.works_parts_tags_box.sizePolicy().hasHeightForWidth())
+ self.works_parts_tags_box.setSizePolicy(sizePolicy)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.works_parts_tags_box.setPalette(palette)
+ self.works_parts_tags_box.setAutoFillBackground(False)
+ self.works_parts_tags_box.setStyleSheet("background-color: rgb(255, 221, 201);")
+ self.works_parts_tags_box.setTitle("")
+ self.works_parts_tags_box.setObjectName("works_parts_tags_box")
+ self.verticalLayout_9 = QtWidgets.QVBoxLayout(self.works_parts_tags_box)
+ self.verticalLayout_9.setObjectName("verticalLayout_9")
+ self.works_tags_box = QtWidgets.QGroupBox(self.works_parts_tags_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.works_tags_box.setPalette(palette)
+ self.works_tags_box.setAutoFillBackground(False)
+ self.works_tags_box.setStyleSheet("background-color: rgb(255, 209, 182);")
+ self.works_tags_box.setObjectName("works_tags_box")
+ self.verticalLayout_8 = QtWidgets.QVBoxLayout(self.works_tags_box)
+ self.verticalLayout_8.setObjectName("verticalLayout_8")
+ self.label_40 = QtWidgets.QLabel(self.works_tags_box)
+ self.label_40.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
+ self.label_40.setObjectName("label_40")
+ self.verticalLayout_8.addWidget(self.label_40)
+ self._8 = QtWidgets.QHBoxLayout()
+ self._8.setContentsMargins(0, 0, 0, 0)
+ self._8.setSpacing(6)
+ self._8.setObjectName("_8")
+ self.label_11 = QtWidgets.QLabel(self.works_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_11.sizePolicy().hasHeightForWidth())
+ self.label_11.setSizePolicy(sizePolicy)
+ self.label_11.setObjectName("label_11")
+ self._8.addWidget(self.label_11)
+ self.cwp_work_tag_multi = QtWidgets.QLineEdit(self.works_tags_box)
+ self.cwp_work_tag_multi.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_work_tag_multi.setObjectName("cwp_work_tag_multi")
+ self._8.addWidget(self.cwp_work_tag_multi)
+ self.cwp_multi_work_sep = QtWidgets.QComboBox(self.works_tags_box)
+ self.cwp_multi_work_sep.setEditable(True)
+ self.cwp_multi_work_sep.setObjectName("cwp_multi_work_sep")
+ self.cwp_multi_work_sep.addItem("")
+ self.cwp_multi_work_sep.setItemText(0, "")
+ self.cwp_multi_work_sep.addItem("")
+ self.cwp_multi_work_sep.addItem("")
+ self.cwp_multi_work_sep.addItem("")
+ self.cwp_multi_work_sep.addItem("")
+ self.cwp_multi_work_sep.addItem("")
+ self._8.addWidget(self.cwp_multi_work_sep)
+ self.verticalLayout_8.addLayout(self._8)
+ self.label = QtWidgets.QLabel(self.works_tags_box)
+ self.label.setObjectName("label")
+ self.verticalLayout_8.addWidget(self.label)
+ self._12 = QtWidgets.QHBoxLayout()
+ self._12.setContentsMargins(0, 0, 0, 0)
+ self._12.setSpacing(6)
+ self._12.setObjectName("_12")
+ self.label_15 = QtWidgets.QLabel(self.works_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_15.sizePolicy().hasHeightForWidth())
+ self.label_15.setSizePolicy(sizePolicy)
+ self.label_15.setObjectName("label_15")
+ self._12.addWidget(self.label_15)
+ self.cwp_work_tag_single = QtWidgets.QLineEdit(self.works_tags_box)
+ self.cwp_work_tag_single.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_work_tag_single.setObjectName("cwp_work_tag_single")
+ self._12.addWidget(self.cwp_work_tag_single)
+ self.cwp_single_work_sep = QtWidgets.QComboBox(self.works_tags_box)
+ self.cwp_single_work_sep.setEditable(True)
+ self.cwp_single_work_sep.setObjectName("cwp_single_work_sep")
+ self.cwp_single_work_sep.addItem("")
+ self.cwp_single_work_sep.setItemText(0, "")
+ self.cwp_single_work_sep.addItem("")
+ self.cwp_single_work_sep.addItem("")
+ self.cwp_single_work_sep.addItem("")
+ self.cwp_single_work_sep.addItem("")
+ self.cwp_single_work_sep.addItem("")
+ self._12.addWidget(self.cwp_single_work_sep)
+ self.verticalLayout_8.addLayout(self._12)
+ self.label_2 = QtWidgets.QLabel(self.works_tags_box)
+ self.label_2.setObjectName("label_2")
+ self.verticalLayout_8.addWidget(self.label_2)
+ self._9 = QtWidgets.QHBoxLayout()
+ self._9.setContentsMargins(0, 0, 0, 0)
+ self._9.setSpacing(6)
+ self._9.setObjectName("_9")
+ self.label_12 = QtWidgets.QLabel(self.works_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_12.sizePolicy().hasHeightForWidth())
+ self.label_12.setSizePolicy(sizePolicy)
+ self.label_12.setObjectName("label_12")
+ self._9.addWidget(self.label_12)
+ self.cwp_top_tag = QtWidgets.QLineEdit(self.works_tags_box)
+ self.cwp_top_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_top_tag.setObjectName("cwp_top_tag")
+ self._9.addWidget(self.cwp_top_tag)
+ self.label_10 = QtWidgets.QLabel(self.works_tags_box)
+ self.label_10.setObjectName("label_10")
+ self._9.addWidget(self.label_10)
+ self.verticalLayout_8.addLayout(self._9)
+ self.verticalLayout_9.addWidget(self.works_tags_box)
+ self.parts_tags_box = QtWidgets.QGroupBox(self.works_parts_tags_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.parts_tags_box.setPalette(palette)
+ self.parts_tags_box.setAutoFillBackground(False)
+ self.parts_tags_box.setStyleSheet("background-color: rgb(255, 209, 182);")
+ self.parts_tags_box.setObjectName("parts_tags_box")
+ self.verticalLayout_7 = QtWidgets.QVBoxLayout(self.parts_tags_box)
+ self.verticalLayout_7.setObjectName("verticalLayout_7")
+ self._10 = QtWidgets.QHBoxLayout()
+ self._10.setContentsMargins(0, 0, 0, 0)
+ self._10.setSpacing(6)
+ self._10.setObjectName("_10")
+ self.label_13 = QtWidgets.QLabel(self.parts_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_13.sizePolicy().hasHeightForWidth())
+ self.label_13.setSizePolicy(sizePolicy)
+ self.label_13.setObjectName("label_13")
+ self._10.addWidget(self.label_13)
+ self.cwp_movt_no_tag = QtWidgets.QLineEdit(self.parts_tags_box)
+ self.cwp_movt_no_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_movt_no_tag.setObjectName("cwp_movt_no_tag")
+ self._10.addWidget(self.cwp_movt_no_tag)
+ self.cwp_movt_no_sep = QtWidgets.QComboBox(self.parts_tags_box)
+ self.cwp_movt_no_sep.setEditable(True)
+ self.cwp_movt_no_sep.setObjectName("cwp_movt_no_sep")
+ self.cwp_movt_no_sep.addItem("")
+ self.cwp_movt_no_sep.setItemText(0, "")
+ self.cwp_movt_no_sep.addItem("")
+ self.cwp_movt_no_sep.addItem("")
+ self.cwp_movt_no_sep.addItem("")
+ self.cwp_movt_no_sep.addItem("")
+ self.cwp_movt_no_sep.addItem("")
+ self._10.addWidget(self.cwp_movt_no_sep)
+ self.verticalLayout_7.addLayout(self._10)
+ self._24 = QtWidgets.QHBoxLayout()
+ self._24.setContentsMargins(0, 0, 0, 0)
+ self._24.setSpacing(6)
+ self._24.setObjectName("_24")
+ self.label_43 = QtWidgets.QLabel(self.parts_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_43.sizePolicy().hasHeightForWidth())
+ self.label_43.setSizePolicy(sizePolicy)
+ self.label_43.setObjectName("label_43")
+ self._24.addWidget(self.label_43)
+ self.cwp_movt_tot_tag = QtWidgets.QLineEdit(self.parts_tags_box)
+ self.cwp_movt_tot_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_movt_tot_tag.setObjectName("cwp_movt_tot_tag")
+ self._24.addWidget(self.cwp_movt_tot_tag)
+ self.label_79 = QtWidgets.QLabel(self.parts_tags_box)
+ self.label_79.setObjectName("label_79")
+ self._24.addWidget(self.label_79)
+ self.verticalLayout_7.addLayout(self._24)
+ self.frame = QtWidgets.QFrame(self.parts_tags_box)
+ self.frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.frame.setObjectName("frame")
+ self.horizontalLayout_5 = QtWidgets.QHBoxLayout(self.frame)
+ self.horizontalLayout_5.setContentsMargins(0, -1, -1, -1)
+ self.horizontalLayout_5.setObjectName("horizontalLayout_5")
+ self.label_49 = QtWidgets.QLabel(self.frame)
+ self.label_49.setObjectName("label_49")
+ self.horizontalLayout_5.addWidget(self.label_49)
+ self.label_47 = QtWidgets.QLabel(self.frame)
+ self.label_47.setObjectName("label_47")
+ self.horizontalLayout_5.addWidget(self.label_47)
+ self.label_48 = QtWidgets.QLabel(self.frame)
+ self.label_48.setObjectName("label_48")
+ self.horizontalLayout_5.addWidget(self.label_48)
+ self.verticalLayout_7.addWidget(self.frame)
+ self._11 = QtWidgets.QHBoxLayout()
+ self._11.setContentsMargins(0, 0, 0, 0)
+ self._11.setSpacing(6)
+ self._11.setObjectName("_11")
+ self.label_14 = QtWidgets.QLabel(self.parts_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_14.sizePolicy().hasHeightForWidth())
+ self.label_14.setSizePolicy(sizePolicy)
+ self.label_14.setObjectName("label_14")
+ self._11.addWidget(self.label_14)
+ self.cwp_movt_tag_exc = QtWidgets.QLineEdit(self.parts_tags_box)
+ self.cwp_movt_tag_exc.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_movt_tag_exc.setObjectName("cwp_movt_tag_exc")
+ self._11.addWidget(self.cwp_movt_tag_exc)
+ self.cwp_movt_tag_exc1 = QtWidgets.QLineEdit(self.parts_tags_box)
+ self.cwp_movt_tag_exc1.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_movt_tag_exc1.setObjectName("cwp_movt_tag_exc1")
+ self._11.addWidget(self.cwp_movt_tag_exc1)
+ self.label_39 = QtWidgets.QLabel(self.parts_tags_box)
+ self.label_39.setObjectName("label_39")
+ self._11.addWidget(self.label_39)
+ self.verticalLayout_7.addLayout(self._11)
+ self._6 = QtWidgets.QHBoxLayout()
+ self._6.setContentsMargins(0, 0, 0, 0)
+ self._6.setSpacing(6)
+ self._6.setObjectName("_6")
+ self.label_9 = QtWidgets.QLabel(self.parts_tags_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_9.sizePolicy().hasHeightForWidth())
+ self.label_9.setSizePolicy(sizePolicy)
+ self.label_9.setObjectName("label_9")
+ self._6.addWidget(self.label_9)
+ self.cwp_movt_tag_inc = QtWidgets.QLineEdit(self.parts_tags_box)
+ self.cwp_movt_tag_inc.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_movt_tag_inc.setObjectName("cwp_movt_tag_inc")
+ self._6.addWidget(self.cwp_movt_tag_inc)
+ self.cwp_movt_tag_inc1 = QtWidgets.QLineEdit(self.parts_tags_box)
+ self.cwp_movt_tag_inc1.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_movt_tag_inc1.setObjectName("cwp_movt_tag_inc1")
+ self._6.addWidget(self.cwp_movt_tag_inc1)
+ self.label_37 = QtWidgets.QLabel(self.parts_tags_box)
+ self.label_37.setObjectName("label_37")
+ self._6.addWidget(self.label_37)
+ self.verticalLayout_7.addLayout(self._6)
+ self.verticalLayout_9.addWidget(self.parts_tags_box)
+ self.verticalLayout_46.addWidget(self.works_parts_tags_box)
+ self.verticalLayout_25.addWidget(self.works_parts_tags_frame)
+ self.partial_arrangements_medleys_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
+ self.partial_arrangements_medleys_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.partial_arrangements_medleys_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.partial_arrangements_medleys_frame.setObjectName("partial_arrangements_medleys_frame")
+ self.verticalLayout_47 = QtWidgets.QVBoxLayout(self.partial_arrangements_medleys_frame)
+ self.verticalLayout_47.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_47.setSpacing(0)
+ self.verticalLayout_47.setObjectName("verticalLayout_47")
+ self.partial_arrangements_medleys_label = QtWidgets.QLabel(self.partial_arrangements_medleys_frame)
+ self.partial_arrangements_medleys_label.setStyleSheet("background-color: rgb(195, 168, 179);")
+ self.partial_arrangements_medleys_label.setObjectName("partial_arrangements_medleys_label")
+ self.verticalLayout_47.addWidget(self.partial_arrangements_medleys_label)
+ self.partial_arrangements_medleys_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.partial_arrangements_medleys_box.setPalette(palette)
+ self.partial_arrangements_medleys_box.setAutoFillBackground(False)
+ self.partial_arrangements_medleys_box.setStyleSheet("background-color: rgb(221, 209, 221);")
+ self.partial_arrangements_medleys_box.setTitle("")
+ self.partial_arrangements_medleys_box.setObjectName("partial_arrangements_medleys_box")
+ self.verticalLayout_19 = QtWidgets.QVBoxLayout(self.partial_arrangements_medleys_box)
+ self.verticalLayout_19.setObjectName("verticalLayout_19")
+ self.label_20 = QtWidgets.QLabel(self.partial_arrangements_medleys_box)
+ self.label_20.setStyleSheet("font: 75 8pt \"MS Shell Dlg 2\";\n"
+"text-decoration: underline;")
+ self.label_20.setObjectName("label_20")
+ self.verticalLayout_19.addWidget(self.label_20)
+ self.partial_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_box)
+ self.partial_box.setObjectName("partial_box")
+ self.horizontalLayout_13 = QtWidgets.QHBoxLayout(self.partial_box)
+ self.horizontalLayout_13.setObjectName("horizontalLayout_13")
+ self.cwp_partial = QtWidgets.QCheckBox(self.partial_box)
+ self.cwp_partial.setObjectName("cwp_partial")
+ self.horizontalLayout_13.addWidget(self.cwp_partial)
+ self.cwp_partial_text = QtWidgets.QLineEdit(self.partial_box)
+ self.cwp_partial_text.setEnabled(True)
+ self.cwp_partial_text.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_partial_text.setObjectName("cwp_partial_text")
+ self.horizontalLayout_13.addWidget(self.cwp_partial_text)
+ self.verticalLayout_19.addWidget(self.partial_box)
+ self.arrangements_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_box)
+ self.arrangements_box.setObjectName("arrangements_box")
+ self.horizontalLayout_15 = QtWidgets.QHBoxLayout(self.arrangements_box)
+ self.horizontalLayout_15.setObjectName("horizontalLayout_15")
+ self.cwp_arrangements = QtWidgets.QCheckBox(self.arrangements_box)
+ self.cwp_arrangements.setObjectName("cwp_arrangements")
+ self.horizontalLayout_15.addWidget(self.cwp_arrangements)
+ self.cwp_arrangements_text = QtWidgets.QLineEdit(self.arrangements_box)
+ self.cwp_arrangements_text.setEnabled(True)
+ self.cwp_arrangements_text.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_arrangements_text.setDragEnabled(False)
+ self.cwp_arrangements_text.setObjectName("cwp_arrangements_text")
+ self.horizontalLayout_15.addWidget(self.cwp_arrangements_text)
+ self.verticalLayout_19.addWidget(self.arrangements_box)
+ self.medleys_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_box)
+ self.medleys_box.setObjectName("medleys_box")
+ self.horizontalLayout_12 = QtWidgets.QHBoxLayout(self.medleys_box)
+ self.horizontalLayout_12.setObjectName("horizontalLayout_12")
+ self.cwp_medley = QtWidgets.QCheckBox(self.medleys_box)
+ self.cwp_medley.setObjectName("cwp_medley")
+ self.horizontalLayout_12.addWidget(self.cwp_medley)
+ self.cwp_medley_text = QtWidgets.QLineEdit(self.medleys_box)
+ self.cwp_medley_text.setEnabled(True)
+ self.cwp_medley_text.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_medley_text.setObjectName("cwp_medley_text")
+ self.horizontalLayout_12.addWidget(self.cwp_medley_text)
+ self.verticalLayout_19.addWidget(self.medleys_box)
+ self.verticalLayout_47.addWidget(self.partial_arrangements_medleys_box)
+ self.verticalLayout_25.addWidget(self.partial_arrangements_medleys_frame)
+ self.songkong_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
+ self.songkong_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.songkong_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.songkong_frame.setObjectName("songkong_frame")
+ self.verticalLayout_48 = QtWidgets.QVBoxLayout(self.songkong_frame)
+ self.verticalLayout_48.setContentsMargins(0, 0, -1, 0)
+ self.verticalLayout_48.setSpacing(0)
+ self.verticalLayout_48.setObjectName("verticalLayout_48")
+ self.songkong_label = QtWidgets.QLabel(self.songkong_frame)
+ self.songkong_label.setStyleSheet("background-color: rgb(182, 182, 62);")
+ self.songkong_label.setObjectName("songkong_label")
+ self.verticalLayout_48.addWidget(self.songkong_label)
+ self.songkong_box = QtWidgets.QGroupBox(self.songkong_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.songkong_box.setPalette(palette)
+ self.songkong_box.setAutoFillBackground(False)
+ self.songkong_box.setStyleSheet("background-color: rgb(227, 227, 143);")
+ self.songkong_box.setTitle("")
+ self.songkong_box.setObjectName("songkong_box")
+ self.horizontalLayout_14 = QtWidgets.QHBoxLayout(self.songkong_box)
+ self.horizontalLayout_14.setObjectName("horizontalLayout_14")
+ self.cwp_use_sk = QtWidgets.QCheckBox(self.songkong_box)
+ self.cwp_use_sk.setObjectName("cwp_use_sk")
+ self.horizontalLayout_14.addWidget(self.cwp_use_sk)
+ self.cwp_write_sk = QtWidgets.QCheckBox(self.songkong_box)
+ self.cwp_write_sk.setObjectName("cwp_write_sk")
+ self.horizontalLayout_14.addWidget(self.cwp_write_sk)
+ self.verticalLayout_48.addWidget(self.songkong_box)
+ self.verticalLayout_25.addWidget(self.songkong_frame)
+ self.label_82 = QtWidgets.QLabel(self.scrollAreaWidgetContents_3)
+ self.label_82.setObjectName("label_82")
+ self.verticalLayout_25.addWidget(self.label_82)
+ self.scrollArea_3.setWidget(self.scrollAreaWidgetContents_3)
+ self.verticalLayout_4.addWidget(self.scrollArea_3)
+ self.tabWidget.addTab(self.Works, "")
+ self.Genres = QtWidgets.QWidget()
+ self.Genres.setObjectName("Genres")
+ self.gridLayout_2 = QtWidgets.QGridLayout(self.Genres)
+ self.gridLayout_2.setObjectName("gridLayout_2")
+ self.scrollArea_6 = QtWidgets.QScrollArea(self.Genres)
+ self.scrollArea_6.setWidgetResizable(True)
+ self.scrollArea_6.setObjectName("scrollArea_6")
+ self.scrollAreaWidgetContents_5 = QtWidgets.QWidget()
+ self.scrollAreaWidgetContents_5.setGeometry(QtCore.QRect(0, -26, 1084, 1310))
+ self.scrollAreaWidgetContents_5.setObjectName("scrollAreaWidgetContents_5")
+ self.gridLayout_13 = QtWidgets.QGridLayout(self.scrollAreaWidgetContents_5)
+ self.gridLayout_13.setObjectName("gridLayout_13")
+ self.genre_tag_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
+ self.genre_tag_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.genre_tag_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.genre_tag_frame.setObjectName("genre_tag_frame")
+ self.verticalLayout_52 = QtWidgets.QVBoxLayout(self.genre_tag_frame)
+ self.verticalLayout_52.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_52.setSpacing(0)
+ self.verticalLayout_52.setObjectName("verticalLayout_52")
+ self.genre_tag_label = QtWidgets.QLabel(self.genre_tag_frame)
+ self.genre_tag_label.setStyleSheet("background-color: rgb(138, 222, 187);")
+ self.genre_tag_label.setObjectName("genre_tag_label")
+ self.verticalLayout_52.addWidget(self.genre_tag_label)
+ self.genre_tag_box = QtWidgets.QGroupBox(self.genre_tag_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.genre_tag_box.setPalette(palette)
+ self.genre_tag_box.setAutoFillBackground(False)
+ self.genre_tag_box.setStyleSheet("background-color: rgb(207, 236, 225);")
+ self.genre_tag_box.setTitle("")
+ self.genre_tag_box.setObjectName("genre_tag_box")
+ self.gridLayout_5 = QtWidgets.QGridLayout(self.genre_tag_box)
+ self.gridLayout_5.setObjectName("gridLayout_5")
+ self.label_73 = QtWidgets.QLabel(self.genre_tag_box)
+ self.label_73.setObjectName("label_73")
+ self.gridLayout_5.addWidget(self.label_73, 0, 0, 1, 1)
+ self.label_74 = QtWidgets.QLabel(self.genre_tag_box)
+ self.label_74.setObjectName("label_74")
+ self.gridLayout_5.addWidget(self.label_74, 0, 2, 1, 1)
+ self.cwp_subgenre_tag = QtWidgets.QLineEdit(self.genre_tag_box)
+ self.cwp_subgenre_tag.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_subgenre_tag.setObjectName("cwp_subgenre_tag")
+ self.gridLayout_5.addWidget(self.cwp_subgenre_tag, 0, 3, 1, 1)
+ self.cwp_genre_tag = QtWidgets.QLineEdit(self.genre_tag_box)
+ self.cwp_genre_tag.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_genre_tag.setObjectName("cwp_genre_tag")
+ self.gridLayout_5.addWidget(self.cwp_genre_tag, 0, 1, 1, 1)
+ self.verticalLayout_52.addWidget(self.genre_tag_box)
+ self.gridLayout_13.addWidget(self.genre_tag_frame, 2, 0, 1, 1)
+ self.classical_genre_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
+ self.classical_genre_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.classical_genre_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.classical_genre_frame.setObjectName("classical_genre_frame")
+ self.verticalLayout_51 = QtWidgets.QVBoxLayout(self.classical_genre_frame)
+ self.verticalLayout_51.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_51.setSpacing(0)
+ self.verticalLayout_51.setObjectName("verticalLayout_51")
+ self.classical_genre_label = QtWidgets.QLabel(self.classical_genre_frame)
+ self.classical_genre_label.setStyleSheet("background-color: rgb(138, 222, 187);")
+ self.classical_genre_label.setObjectName("classical_genre_label")
+ self.verticalLayout_51.addWidget(self.classical_genre_label)
+ self.classical_genre_box = QtWidgets.QGroupBox(self.classical_genre_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.classical_genre_box.setPalette(palette)
+ self.classical_genre_box.setAutoFillBackground(False)
+ self.classical_genre_box.setStyleSheet("background-color: rgb(207, 236, 225);")
+ self.classical_genre_box.setTitle("")
+ self.classical_genre_box.setObjectName("classical_genre_box")
+ self.gridLayout_3 = QtWidgets.QGridLayout(self.classical_genre_box)
+ self.gridLayout_3.setObjectName("gridLayout_3")
+ self.cwp_genres_classical_exclude = QtWidgets.QCheckBox(self.classical_genre_box)
+ self.cwp_genres_classical_exclude.setObjectName("cwp_genres_classical_exclude")
+ self.gridLayout_3.addWidget(self.cwp_genres_classical_exclude, 1, 3, 1, 2)
+ self.cwp_genres_classical_selective = QtWidgets.QRadioButton(self.classical_genre_box)
+ self.cwp_genres_classical_selective.setObjectName("cwp_genres_classical_selective")
+ self.gridLayout_3.addWidget(self.cwp_genres_classical_selective, 0, 2, 1, 2)
+ self.cwp_muso_classical = QtWidgets.QCheckBox(self.classical_genre_box)
+ font = QtGui.QFont()
+ font.setBold(True)
+ font.setWeight(75)
+ self.cwp_muso_classical.setFont(font)
+ self.cwp_muso_classical.setObjectName("cwp_muso_classical")
+ self.gridLayout_3.addWidget(self.cwp_muso_classical, 1, 0, 1, 3)
+ self.cwp_genres_classical_all = QtWidgets.QRadioButton(self.classical_genre_box)
+ self.cwp_genres_classical_all.setObjectName("cwp_genres_classical_all")
+ self.gridLayout_3.addWidget(self.cwp_genres_classical_all, 0, 0, 1, 2)
+ self.label_64 = QtWidgets.QLabel(self.classical_genre_box)
+ self.label_64.setObjectName("label_64")
+ self.gridLayout_3.addWidget(self.label_64, 3, 0, 1, 1)
+ self.cwp_genres_flag_text = QtWidgets.QLineEdit(self.classical_genre_box)
+ self.cwp_genres_flag_text.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_genres_flag_text.setObjectName("cwp_genres_flag_text")
+ self.gridLayout_3.addWidget(self.cwp_genres_flag_text, 3, 1, 1, 3)
+ self.label_71 = QtWidgets.QLabel(self.classical_genre_box)
+ self.label_71.setObjectName("label_71")
+ self.gridLayout_3.addWidget(self.label_71, 3, 4, 1, 1)
+ self.cwp_genres_flag_tag = QtWidgets.QLineEdit(self.classical_genre_box)
+ self.cwp_genres_flag_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_genres_flag_tag.setObjectName("cwp_genres_flag_tag")
+ self.gridLayout_3.addWidget(self.cwp_genres_flag_tag, 3, 5, 1, 1)
+ self.cwp_genres_arranger_as_composer = QtWidgets.QCheckBox(self.classical_genre_box)
+ self.cwp_genres_arranger_as_composer.setObjectName("cwp_genres_arranger_as_composer")
+ self.gridLayout_3.addWidget(self.cwp_genres_arranger_as_composer, 2, 0, 1, 1)
+ self.verticalLayout_51.addWidget(self.classical_genre_box)
+ self.gridLayout_13.addWidget(self.classical_genre_frame, 5, 0, 1, 1)
+ self.label_81 = QtWidgets.QLabel(self.scrollAreaWidgetContents_5)
+ self.label_81.setObjectName("label_81")
+ self.gridLayout_13.addWidget(self.label_81, 8, 0, 1, 1)
+ self.cwp_use_muso_refdb = QtWidgets.QCheckBox(self.scrollAreaWidgetContents_5)
+ font = QtGui.QFont()
+ font.setBold(True)
+ font.setWeight(75)
+ self.cwp_use_muso_refdb.setFont(font)
+ self.cwp_use_muso_refdb.setObjectName("cwp_use_muso_refdb")
+ self.gridLayout_13.addWidget(self.cwp_use_muso_refdb, 1, 0, 1, 1)
+ self.instruments_keys_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
+ self.instruments_keys_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.instruments_keys_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.instruments_keys_frame.setObjectName("instruments_keys_frame")
+ self.verticalLayout_53 = QtWidgets.QVBoxLayout(self.instruments_keys_frame)
+ self.verticalLayout_53.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_53.setSpacing(0)
+ self.verticalLayout_53.setObjectName("verticalLayout_53")
+ self.instruments_keys_label = QtWidgets.QLabel(self.instruments_keys_frame)
+ self.instruments_keys_label.setStyleSheet("background-color: rgb(225, 168, 171);")
+ self.instruments_keys_label.setObjectName("instruments_keys_label")
+ self.verticalLayout_53.addWidget(self.instruments_keys_label)
+ self.instruments_keys_box = QtWidgets.QGroupBox(self.instruments_keys_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.instruments_keys_box.setPalette(palette)
+ self.instruments_keys_box.setAutoFillBackground(False)
+ self.instruments_keys_box.setStyleSheet("background-color: rgb(245, 224, 226);")
+ self.instruments_keys_box.setTitle("")
+ self.instruments_keys_box.setObjectName("instruments_keys_box")
+ self.verticalLayout_34 = QtWidgets.QVBoxLayout(self.instruments_keys_box)
+ self.verticalLayout_34.setObjectName("verticalLayout_34")
+ self.instruments_box = QtWidgets.QGroupBox(self.instruments_keys_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.instruments_box.setPalette(palette)
+ self.instruments_box.setAutoFillBackground(False)
+ self.instruments_box.setStyleSheet("background-color: rgb(245, 210, 213);")
+ self.instruments_box.setObjectName("instruments_box")
+ self.gridLayout_11 = QtWidgets.QGridLayout(self.instruments_box)
+ self.gridLayout_11.setObjectName("gridLayout_11")
+ self.label_66 = QtWidgets.QLabel(self.instruments_box)
+ self.label_66.setObjectName("label_66")
+ self.gridLayout_11.addWidget(self.label_66, 0, 0, 1, 1)
+ self.cwp_instruments_tag = QtWidgets.QLineEdit(self.instruments_box)
+ self.cwp_instruments_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_instruments_tag.setObjectName("cwp_instruments_tag")
+ self.gridLayout_11.addWidget(self.cwp_instruments_tag, 0, 1, 1, 1)
+ self.instruments_source_box = QtWidgets.QGroupBox(self.instruments_box)
+ self.instruments_source_box.setObjectName("instruments_source_box")
+ self.horizontalLayout_33 = QtWidgets.QHBoxLayout(self.instruments_source_box)
+ self.horizontalLayout_33.setObjectName("horizontalLayout_33")
+ self.cwp_instruments_MB_names = QtWidgets.QCheckBox(self.instruments_source_box)
+ self.cwp_instruments_MB_names.setObjectName("cwp_instruments_MB_names")
+ self.horizontalLayout_33.addWidget(self.cwp_instruments_MB_names)
+ self.cwp_instruments_credited_names = QtWidgets.QCheckBox(self.instruments_source_box)
+ self.cwp_instruments_credited_names.setObjectName("cwp_instruments_credited_names")
+ self.horizontalLayout_33.addWidget(self.cwp_instruments_credited_names)
+ self.gridLayout_11.addWidget(self.instruments_source_box, 1, 0, 1, 2)
+ self.verticalLayout_34.addWidget(self.instruments_box)
+ self.keys_box = QtWidgets.QGroupBox(self.instruments_keys_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.keys_box.setPalette(palette)
+ self.keys_box.setAutoFillBackground(False)
+ self.keys_box.setStyleSheet("background-color: rgb(245, 210, 213);")
+ self.keys_box.setObjectName("keys_box")
+ self.gridLayout_4 = QtWidgets.QGridLayout(self.keys_box)
+ self.gridLayout_4.setObjectName("gridLayout_4")
+ self.label_72 = QtWidgets.QLabel(self.keys_box)
+ self.label_72.setObjectName("label_72")
+ self.gridLayout_4.addWidget(self.label_72, 0, 0, 1, 1)
+ self.cwp_key_tag = QtWidgets.QLineEdit(self.keys_box)
+ self.cwp_key_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_key_tag.setObjectName("cwp_key_tag")
+ self.gridLayout_4.addWidget(self.cwp_key_tag, 0, 2, 1, 1)
+ self.keys_include_box = QtWidgets.QGroupBox(self.keys_box)
+ self.keys_include_box.setObjectName("keys_include_box")
+ self.horizontalLayout_35 = QtWidgets.QHBoxLayout(self.keys_include_box)
+ self.horizontalLayout_35.setObjectName("horizontalLayout_35")
+ self.cwp_key_never_include = QtWidgets.QRadioButton(self.keys_include_box)
+ self.cwp_key_never_include.setObjectName("cwp_key_never_include")
+ self.horizontalLayout_35.addWidget(self.cwp_key_never_include)
+ self.cwp_key_contingent_include = QtWidgets.QRadioButton(self.keys_include_box)
+ self.cwp_key_contingent_include.setObjectName("cwp_key_contingent_include")
+ self.horizontalLayout_35.addWidget(self.cwp_key_contingent_include)
+ self.cwp_key_include = QtWidgets.QRadioButton(self.keys_include_box)
+ self.cwp_key_include.setObjectName("cwp_key_include")
+ self.horizontalLayout_35.addWidget(self.cwp_key_include)
+ self.gridLayout_4.addWidget(self.keys_include_box, 1, 0, 1, 2)
+ self.verticalLayout_34.addWidget(self.keys_box)
+ self.verticalLayout_53.addWidget(self.instruments_keys_box)
+ self.gridLayout_13.addWidget(self.instruments_keys_frame, 6, 0, 1, 1)
+ self.allowed_genres_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
+ self.allowed_genres_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.allowed_genres_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.allowed_genres_frame.setLineWidth(1)
+ self.allowed_genres_frame.setMidLineWidth(0)
+ self.allowed_genres_frame.setObjectName("allowed_genres_frame")
+ self.verticalLayout_50 = QtWidgets.QVBoxLayout(self.allowed_genres_frame)
+ self.verticalLayout_50.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_50.setSpacing(0)
+ self.verticalLayout_50.setObjectName("verticalLayout_50")
+ self.allowed_filters_label = QtWidgets.QLabel(self.allowed_genres_frame)
+ self.allowed_filters_label.setStyleSheet("background-color: rgb(138, 222, 187);")
+ self.allowed_filters_label.setObjectName("allowed_filters_label")
+ self.verticalLayout_50.addWidget(self.allowed_filters_label)
+ self.cwp_genres_filter = QtWidgets.QCheckBox(self.allowed_genres_frame)
+ self.cwp_genres_filter.setLayoutDirection(QtCore.Qt.LeftToRight)
+ self.cwp_genres_filter.setStyleSheet("background-color: rgb(138, 222, 187);")
+ self.cwp_genres_filter.setObjectName("cwp_genres_filter")
+ self.verticalLayout_50.addWidget(self.cwp_genres_filter)
+ self.genre_filters_frame = QtWidgets.QGroupBox(self.allowed_genres_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.genre_filters_frame.setPalette(palette)
+ self.genre_filters_frame.setAutoFillBackground(False)
+ self.genre_filters_frame.setStyleSheet("background-color: rgb(207, 236, 225);")
+ self.genre_filters_frame.setTitle("")
+ self.genre_filters_frame.setObjectName("genre_filters_frame")
+ self.gridLayout_6 = QtWidgets.QGridLayout(self.genre_filters_frame)
+ self.gridLayout_6.setObjectName("gridLayout_6")
+ self.classical_genres_box = QtWidgets.QGroupBox(self.genre_filters_frame)
+ self.classical_genres_box.setStyleSheet("background-color: rgb(190, 236, 219);")
+ self.classical_genres_box.setObjectName("classical_genres_box")
+ self.gridLayout_9 = QtWidgets.QGridLayout(self.classical_genres_box)
+ self.gridLayout_9.setObjectName("gridLayout_9")
+ self.label_60 = QtWidgets.QLabel(self.classical_genres_box)
+ self.label_60.setObjectName("label_60")
+ self.gridLayout_9.addWidget(self.label_60, 0, 0, 1, 1)
+ self.cwp_genres_classical_main = QtWidgets.QPlainTextEdit(self.classical_genres_box)
+ self.cwp_genres_classical_main.setMaximumSize(QtCore.QSize(16777215, 50))
+ self.cwp_genres_classical_main.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_genres_classical_main.setObjectName("cwp_genres_classical_main")
+ self.gridLayout_9.addWidget(self.cwp_genres_classical_main, 0, 1, 3, 1)
+ self.label_75 = QtWidgets.QLabel(self.classical_genres_box)
+ self.label_75.setObjectName("label_75")
+ self.gridLayout_9.addWidget(self.label_75, 0, 2, 1, 1)
+ self.cwp_genres_classical_sub = QtWidgets.QPlainTextEdit(self.classical_genres_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Expanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.cwp_genres_classical_sub.sizePolicy().hasHeightForWidth())
+ self.cwp_genres_classical_sub.setSizePolicy(sizePolicy)
+ self.cwp_genres_classical_sub.setMaximumSize(QtCore.QSize(16777215, 50))
+ self.cwp_genres_classical_sub.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_genres_classical_sub.setObjectName("cwp_genres_classical_sub")
+ self.gridLayout_9.addWidget(self.cwp_genres_classical_sub, 0, 3, 3, 1)
+ self.cwp_muso_genres = QtWidgets.QCheckBox(self.classical_genres_box)
+ font = QtGui.QFont()
+ font.setBold(True)
+ font.setWeight(75)
+ self.cwp_muso_genres.setFont(font)
+ self.cwp_muso_genres.setObjectName("cwp_muso_genres")
+ self.gridLayout_9.addWidget(self.cwp_muso_genres, 1, 0, 1, 1)
+ self.gridLayout_6.addWidget(self.classical_genres_box, 2, 0, 1, 2)
+ self.general_genres_box = QtWidgets.QGroupBox(self.genre_filters_frame)
+ self.general_genres_box.setStyleSheet("background-color: rgb(190, 236, 219);")
+ self.general_genres_box.setObjectName("general_genres_box")
+ self.horizontalLayout_36 = QtWidgets.QHBoxLayout(self.general_genres_box)
+ self.horizontalLayout_36.setObjectName("horizontalLayout_36")
+ self.label_62 = QtWidgets.QLabel(self.general_genres_box)
+ self.label_62.setObjectName("label_62")
+ self.horizontalLayout_36.addWidget(self.label_62)
+ self.cwp_genres_other_main = QtWidgets.QPlainTextEdit(self.general_genres_box)
+ self.cwp_genres_other_main.setMaximumSize(QtCore.QSize(16777215, 50))
+ self.cwp_genres_other_main.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_genres_other_main.setObjectName("cwp_genres_other_main")
+ self.horizontalLayout_36.addWidget(self.cwp_genres_other_main)
+ self.label_76 = QtWidgets.QLabel(self.general_genres_box)
+ self.label_76.setObjectName("label_76")
+ self.horizontalLayout_36.addWidget(self.label_76)
+ self.cwp_genres_other_sub = QtWidgets.QPlainTextEdit(self.general_genres_box)
+ self.cwp_genres_other_sub.setMaximumSize(QtCore.QSize(16777215, 50))
+ self.cwp_genres_other_sub.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_genres_other_sub.setObjectName("cwp_genres_other_sub")
+ self.horizontalLayout_36.addWidget(self.cwp_genres_other_sub)
+ self.cwp_genres_other_main.raise_()
+ self.cwp_genres_other_sub.raise_()
+ self.label_62.raise_()
+ self.label_76.raise_()
+ self.gridLayout_6.addWidget(self.general_genres_box, 3, 0, 1, 2)
+ self.label_80 = QtWidgets.QLabel(self.genre_filters_frame)
+ self.label_80.setObjectName("label_80")
+ self.gridLayout_6.addWidget(self.label_80, 4, 0, 1, 1)
+ self.cwp_genres_default = QtWidgets.QLineEdit(self.genre_filters_frame)
+ self.cwp_genres_default.setStyleSheet("background-color: rgb(250,250,250);")
+ self.cwp_genres_default.setObjectName("cwp_genres_default")
+ self.gridLayout_6.addWidget(self.cwp_genres_default, 4, 1, 1, 1)
+ self.label_77 = QtWidgets.QLabel(self.genre_filters_frame)
+ self.label_77.setObjectName("label_77")
+ self.gridLayout_6.addWidget(self.label_77, 0, 0, 1, 2)
+ self.label_78 = QtWidgets.QLabel(self.genre_filters_frame)
+ self.label_78.setObjectName("label_78")
+ self.gridLayout_6.addWidget(self.label_78, 1, 0, 1, 1)
+ self.verticalLayout_50.addWidget(self.genre_filters_frame)
+ self.gridLayout_13.addWidget(self.allowed_genres_frame, 4, 0, 1, 1)
+ self.source_of_genres_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
+ self.source_of_genres_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.source_of_genres_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.source_of_genres_frame.setObjectName("source_of_genres_frame")
+ self.verticalLayout_49 = QtWidgets.QVBoxLayout(self.source_of_genres_frame)
+ self.verticalLayout_49.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_49.setSpacing(0)
+ self.verticalLayout_49.setObjectName("verticalLayout_49")
+ self.source_of_genres_label = QtWidgets.QLabel(self.source_of_genres_frame)
+ self.source_of_genres_label.setStyleSheet("background-color: rgb(138, 222, 187);")
+ self.source_of_genres_label.setObjectName("source_of_genres_label")
+ self.verticalLayout_49.addWidget(self.source_of_genres_label)
+ self.source_of_genres_box = QtWidgets.QGroupBox(self.source_of_genres_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.source_of_genres_box.setPalette(palette)
+ self.source_of_genres_box.setAutoFillBackground(False)
+ self.source_of_genres_box.setStyleSheet("background-color: rgb(207, 236, 225);")
+ self.source_of_genres_box.setTitle("")
+ self.source_of_genres_box.setObjectName("source_of_genres_box")
+ self.horizontalLayout_32 = QtWidgets.QHBoxLayout(self.source_of_genres_box)
+ self.horizontalLayout_32.setObjectName("horizontalLayout_32")
+ self.cwp_genres_use_file = QtWidgets.QCheckBox(self.source_of_genres_box)
+ self.cwp_genres_use_file.setObjectName("cwp_genres_use_file")
+ self.horizontalLayout_32.addWidget(self.cwp_genres_use_file)
+ self.cwp_genres_use_folks = QtWidgets.QCheckBox(self.source_of_genres_box)
+ self.cwp_genres_use_folks.setObjectName("cwp_genres_use_folks")
+ self.horizontalLayout_32.addWidget(self.cwp_genres_use_folks)
+ self.cwp_genres_use_worktype = QtWidgets.QCheckBox(self.source_of_genres_box)
+ self.cwp_genres_use_worktype.setObjectName("cwp_genres_use_worktype")
+ self.horizontalLayout_32.addWidget(self.cwp_genres_use_worktype)
+ self.cwp_genres_infer = QtWidgets.QCheckBox(self.source_of_genres_box)
+ self.cwp_genres_infer.setObjectName("cwp_genres_infer")
+ self.horizontalLayout_32.addWidget(self.cwp_genres_infer)
+ self.verticalLayout_49.addWidget(self.source_of_genres_box)
+ self.gridLayout_13.addWidget(self.source_of_genres_frame, 3, 0, 1, 1)
+ self.periods_dates_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
+ self.periods_dates_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.periods_dates_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.periods_dates_frame.setObjectName("periods_dates_frame")
+ self.verticalLayout_54 = QtWidgets.QVBoxLayout(self.periods_dates_frame)
+ self.verticalLayout_54.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_54.setSpacing(0)
+ self.verticalLayout_54.setObjectName("verticalLayout_54")
+ self.label_109 = QtWidgets.QLabel(self.periods_dates_frame)
+ self.label_109.setStyleSheet("background-color: rgb(195, 183, 213);")
+ self.label_109.setObjectName("label_109")
+ self.verticalLayout_54.addWidget(self.label_109)
+ self.periods_dates_box = QtWidgets.QGroupBox(self.periods_dates_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.periods_dates_box.setPalette(palette)
+ self.periods_dates_box.setAutoFillBackground(False)
+ self.periods_dates_box.setStyleSheet("background-color: rgb(229, 224, 236);")
+ self.periods_dates_box.setTitle("")
+ self.periods_dates_box.setObjectName("periods_dates_box")
+ self.verticalLayout_32 = QtWidgets.QVBoxLayout(self.periods_dates_box)
+ self.verticalLayout_32.setObjectName("verticalLayout_32")
+ self.dates_box = QtWidgets.QGroupBox(self.periods_dates_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.dates_box.setPalette(palette)
+ self.dates_box.setAutoFillBackground(False)
+ self.dates_box.setStyleSheet("background-color: rgb(222, 212, 236);")
+ self.dates_box.setObjectName("dates_box")
+ self.gridLayout_10 = QtWidgets.QGridLayout(self.dates_box)
+ self.gridLayout_10.setObjectName("gridLayout_10")
+ self.dates_box_inner = QtWidgets.QGroupBox(self.dates_box)
+ self.dates_box_inner.setObjectName("dates_box_inner")
+ self.gridLayout_7 = QtWidgets.QGridLayout(self.dates_box_inner)
+ self.gridLayout_7.setObjectName("gridLayout_7")
+ self.cwp_workdate_source_composed = QtWidgets.QCheckBox(self.dates_box_inner)
+ self.cwp_workdate_source_composed.setObjectName("cwp_workdate_source_composed")
+ self.gridLayout_7.addWidget(self.cwp_workdate_source_composed, 0, 0, 1, 1)
+ self.cwp_workdate_source_published = QtWidgets.QCheckBox(self.dates_box_inner)
+ self.cwp_workdate_source_published.setObjectName("cwp_workdate_source_published")
+ self.gridLayout_7.addWidget(self.cwp_workdate_source_published, 0, 1, 1, 1)
+ self.cwp_workdate_source_premiered = QtWidgets.QCheckBox(self.dates_box_inner)
+ self.cwp_workdate_source_premiered.setObjectName("cwp_workdate_source_premiered")
+ self.gridLayout_7.addWidget(self.cwp_workdate_source_premiered, 0, 2, 1, 1)
+ self.line_9 = QtWidgets.QFrame(self.dates_box_inner)
+ self.line_9.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line_9.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_9.setObjectName("line_9")
+ self.gridLayout_7.addWidget(self.line_9, 1, 0, 1, 3)
+ self.cwp_workdate_use_first = QtWidgets.QRadioButton(self.dates_box_inner)
+ self.cwp_workdate_use_first.setObjectName("cwp_workdate_use_first")
+ self.gridLayout_7.addWidget(self.cwp_workdate_use_first, 2, 0, 1, 1)
+ self.cwp_workdate_use_all = QtWidgets.QRadioButton(self.dates_box_inner)
+ self.cwp_workdate_use_all.setObjectName("cwp_workdate_use_all")
+ self.gridLayout_7.addWidget(self.cwp_workdate_use_all, 2, 1, 1, 1)
+ self.cwp_workdate_annotate = QtWidgets.QCheckBox(self.dates_box_inner)
+ self.cwp_workdate_annotate.setObjectName("cwp_workdate_annotate")
+ self.gridLayout_7.addWidget(self.cwp_workdate_annotate, 2, 2, 1, 1)
+ self.gridLayout_10.addWidget(self.dates_box_inner, 1, 0, 1, 3)
+ self.label_68 = QtWidgets.QLabel(self.dates_box)
+ self.label_68.setObjectName("label_68")
+ self.gridLayout_10.addWidget(self.label_68, 0, 0, 1, 1)
+ self.cwp_workdate_include = QtWidgets.QCheckBox(self.dates_box)
+ self.cwp_workdate_include.setObjectName("cwp_workdate_include")
+ self.gridLayout_10.addWidget(self.cwp_workdate_include, 2, 0, 1, 2)
+ self.cwp_workdate_tag = QtWidgets.QLineEdit(self.dates_box)
+ self.cwp_workdate_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_workdate_tag.setObjectName("cwp_workdate_tag")
+ self.gridLayout_10.addWidget(self.cwp_workdate_tag, 0, 1, 1, 2)
+ self.verticalLayout_32.addWidget(self.dates_box)
+ self.line_5 = QtWidgets.QFrame(self.periods_dates_box)
+ self.line_5.setMidLineWidth(0)
+ self.line_5.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line_5.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_5.setObjectName("line_5")
+ self.verticalLayout_32.addWidget(self.line_5)
+ self.periods_box = QtWidgets.QGroupBox(self.periods_dates_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.periods_box.setPalette(palette)
+ self.periods_box.setAutoFillBackground(False)
+ self.periods_box.setStyleSheet("background-color: rgb(222, 212, 236);")
+ self.periods_box.setObjectName("periods_box")
+ self.gridLayout_12 = QtWidgets.QGridLayout(self.periods_box)
+ self.gridLayout_12.setObjectName("gridLayout_12")
+ self.label_69 = QtWidgets.QLabel(self.periods_box)
+ self.label_69.setObjectName("label_69")
+ self.gridLayout_12.addWidget(self.label_69, 0, 0, 1, 1)
+ self.cwp_muso_periods = QtWidgets.QCheckBox(self.periods_box)
+ font = QtGui.QFont()
+ font.setBold(True)
+ font.setWeight(75)
+ self.cwp_muso_periods.setFont(font)
+ self.cwp_muso_periods.setObjectName("cwp_muso_periods")
+ self.gridLayout_12.addWidget(self.cwp_muso_periods, 4, 0, 1, 2)
+ self.cwp_muso_dates = QtWidgets.QCheckBox(self.periods_box)
+ font = QtGui.QFont()
+ font.setBold(True)
+ font.setWeight(75)
+ self.cwp_muso_dates.setFont(font)
+ self.cwp_muso_dates.setObjectName("cwp_muso_dates")
+ self.gridLayout_12.addWidget(self.cwp_muso_dates, 1, 0, 1, 3)
+ self.cwp_period_tag = QtWidgets.QLineEdit(self.periods_box)
+ self.cwp_period_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_period_tag.setObjectName("cwp_period_tag")
+ self.gridLayout_12.addWidget(self.cwp_period_tag, 0, 1, 1, 2)
+ self.label_70 = QtWidgets.QLabel(self.periods_box)
+ self.label_70.setObjectName("label_70")
+ self.gridLayout_12.addWidget(self.label_70, 3, 0, 1, 1)
+ self.cwp_period_map = QtWidgets.QPlainTextEdit(self.periods_box)
+ self.cwp_period_map.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_period_map.setObjectName("cwp_period_map")
+ self.gridLayout_12.addWidget(self.cwp_period_map, 3, 2, 2, 1)
+ self.period_map_annotation_label = QtWidgets.QLabel(self.periods_box)
+ self.period_map_annotation_label.setObjectName("period_map_annotation_label")
+ self.gridLayout_12.addWidget(self.period_map_annotation_label, 5, 2, 1, 1)
+ self.cwp_periods_arranger_as_composer = QtWidgets.QCheckBox(self.periods_box)
+ self.cwp_periods_arranger_as_composer.setObjectName("cwp_periods_arranger_as_composer")
+ self.gridLayout_12.addWidget(self.cwp_periods_arranger_as_composer, 2, 0, 1, 1)
+ self.verticalLayout_32.addWidget(self.periods_box)
+ self.verticalLayout_54.addWidget(self.periods_dates_box)
+ self.gridLayout_13.addWidget(self.periods_dates_frame, 7, 0, 1, 1)
+ self.label_119 = QtWidgets.QLabel(self.scrollAreaWidgetContents_5)
+ self.label_119.setObjectName("label_119")
+ self.gridLayout_13.addWidget(self.label_119, 0, 0, 1, 1)
+ self.scrollArea_6.setWidget(self.scrollAreaWidgetContents_5)
+ self.gridLayout_2.addWidget(self.scrollArea_6, 1, 0, 1, 1)
+ self.tabWidget.addTab(self.Genres, "")
+ self.Tag_mapping = QtWidgets.QWidget()
+ self.Tag_mapping.setObjectName("Tag_mapping")
+ self.verticalLayout_28 = QtWidgets.QVBoxLayout(self.Tag_mapping)
+ self.verticalLayout_28.setObjectName("verticalLayout_28")
+ self.scrollArea_4 = QtWidgets.QScrollArea(self.Tag_mapping)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.scrollArea_4.sizePolicy().hasHeightForWidth())
+ self.scrollArea_4.setSizePolicy(sizePolicy)
+ self.scrollArea_4.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAsNeeded)
+ self.scrollArea_4.setWidgetResizable(True)
+ self.scrollArea_4.setObjectName("scrollArea_4")
+ self.scrollAreaWidgetContents_8 = QtWidgets.QWidget()
+ self.scrollAreaWidgetContents_8.setGeometry(QtCore.QRect(0, 0, 1084, 917))
+ self.scrollAreaWidgetContents_8.setObjectName("scrollAreaWidgetContents_8")
+ self.verticalLayout_33 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents_8)
+ self.verticalLayout_33.setObjectName("verticalLayout_33")
+ self.label_18 = QtWidgets.QLabel(self.scrollAreaWidgetContents_8)
+ self.label_18.setStyleSheet("")
+ self.label_18.setObjectName("label_18")
+ self.verticalLayout_33.addWidget(self.label_18)
+ self.initial_tag_processing_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_8)
+ self.initial_tag_processing_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.initial_tag_processing_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.initial_tag_processing_frame.setObjectName("initial_tag_processing_frame")
+ self.verticalLayout_41 = QtWidgets.QVBoxLayout(self.initial_tag_processing_frame)
+ self.verticalLayout_41.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_41.setSpacing(0)
+ self.verticalLayout_41.setObjectName("verticalLayout_41")
+ self.label_97 = QtWidgets.QLabel(self.initial_tag_processing_frame)
+ self.label_97.setStyleSheet("background-color: rgb(209, 171, 222);\n"
+"")
+ self.label_97.setObjectName("label_97")
+ self.verticalLayout_41.addWidget(self.label_97)
+ self.initial_tag_processing_box = QtWidgets.QGroupBox(self.initial_tag_processing_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.initial_tag_processing_box.setPalette(palette)
+ self.initial_tag_processing_box.setAutoFillBackground(False)
+ self.initial_tag_processing_box.setStyleSheet("background-color: rgb(242, 221, 245);")
+ self.initial_tag_processing_box.setTitle("")
+ self.initial_tag_processing_box.setObjectName("initial_tag_processing_box")
+ self.verticalLayout_17 = QtWidgets.QVBoxLayout(self.initial_tag_processing_box)
+ self.verticalLayout_17.setObjectName("verticalLayout_17")
+ self.tags_to_blank = QtWidgets.QGroupBox(self.initial_tag_processing_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.tags_to_blank.setPalette(palette)
+ self.tags_to_blank.setAutoFillBackground(False)
+ self.tags_to_blank.setStyleSheet("")
+ self.tags_to_blank.setObjectName("tags_to_blank")
+ self.verticalLayout_12 = QtWidgets.QVBoxLayout(self.tags_to_blank)
+ self.verticalLayout_12.setObjectName("verticalLayout_12")
+ self.label_3 = QtWidgets.QLabel(self.tags_to_blank)
+ self.label_3.setObjectName("label_3")
+ self.verticalLayout_12.addWidget(self.label_3)
+ self.cea_blank_tag = QtWidgets.QLineEdit(self.tags_to_blank)
+ self.cea_blank_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_blank_tag.setObjectName("cea_blank_tag")
+ self.verticalLayout_12.addWidget(self.cea_blank_tag)
+ self.cea_blank_tag_2 = QtWidgets.QLineEdit(self.tags_to_blank)
+ self.cea_blank_tag_2.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_blank_tag_2.setObjectName("cea_blank_tag_2")
+ self.verticalLayout_12.addWidget(self.cea_blank_tag_2)
+ self.verticalLayout_17.addWidget(self.tags_to_blank)
+ self.label_19 = QtWidgets.QLabel(self.initial_tag_processing_box)
+ self.label_19.setObjectName("label_19")
+ self.verticalLayout_17.addWidget(self.label_19)
+ self.cea_keep = QtWidgets.QLineEdit(self.initial_tag_processing_box)
+ self.cea_keep.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_keep.setObjectName("cea_keep")
+ self.verticalLayout_17.addWidget(self.cea_keep)
+ self.cea_clear_tags = QtWidgets.QCheckBox(self.initial_tag_processing_box)
+ self.cea_clear_tags.setObjectName("cea_clear_tags")
+ self.verticalLayout_17.addWidget(self.cea_clear_tags)
+ self.verticalLayout_41.addWidget(self.initial_tag_processing_box)
+ self.verticalLayout_33.addWidget(self.initial_tag_processing_frame)
+ self.tagmap_details_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_8)
+ self.tagmap_details_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.tagmap_details_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.tagmap_details_frame.setObjectName("tagmap_details_frame")
+ self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.tagmap_details_frame)
+ self.verticalLayout_3.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_3.setSpacing(0)
+ self.verticalLayout_3.setObjectName("verticalLayout_3")
+ self.label_98 = QtWidgets.QLabel(self.tagmap_details_frame)
+ self.label_98.setStyleSheet("background-color: rgb(229, 174, 142);")
+ self.label_98.setObjectName("label_98")
+ self.verticalLayout_3.addWidget(self.label_98)
+ self.tagmap_details_box = QtWidgets.QGroupBox(self.tagmap_details_frame)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Expanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.tagmap_details_box.sizePolicy().hasHeightForWidth())
+ self.tagmap_details_box.setSizePolicy(sizePolicy)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.tagmap_details_box.setPalette(palette)
+ self.tagmap_details_box.setFocusPolicy(QtCore.Qt.NoFocus)
+ self.tagmap_details_box.setAutoFillBackground(False)
+ self.tagmap_details_box.setStyleSheet("font: 75 8pt \"MS Shell Dlg 2\";\n"
+"background-color: rgb(255, 229, 214);")
+ self.tagmap_details_box.setTitle("")
+ self.tagmap_details_box.setObjectName("tagmap_details_box")
+ self.gridLayout_14 = QtWidgets.QGridLayout(self.tagmap_details_box)
+ self.gridLayout_14.setObjectName("gridLayout_14")
+ self.textBrowser = QtWidgets.QTextBrowser(self.tagmap_details_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Minimum)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.textBrowser.sizePolicy().hasHeightForWidth())
+ self.textBrowser.setSizePolicy(sizePolicy)
+ self.textBrowser.setMaximumSize(QtCore.QSize(16777215, 100))
+ self.textBrowser.setStyleSheet("background-color: rgb(249, 215, 187);")
+ self.textBrowser.setObjectName("textBrowser")
+ self.gridLayout_14.addWidget(self.textBrowser, 0, 0, 1, 1)
+ self.frame_25 = QtWidgets.QFrame(self.tagmap_details_box)
+ self.frame_25.setObjectName("frame_25")
+ self._14 = QtWidgets.QHBoxLayout(self.frame_25)
+ self._14.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)
+ self._14.setContentsMargins(1, 1, 1, 1)
+ self._14.setSpacing(6)
+ self._14.setObjectName("_14")
+ self.toolButton_1 = QtWidgets.QToolButton(self.frame_25)
+ self.toolButton_1.setAutoFillBackground(False)
+ self.toolButton_1.setStyleSheet("")
+ self.toolButton_1.setCheckable(True)
+ self.toolButton_1.setToolButtonStyle(QtCore.Qt.ToolButtonIconOnly)
+ self.toolButton_1.setAutoRaise(False)
+ self.toolButton_1.setObjectName("toolButton_1")
+ self._14.addWidget(self.toolButton_1)
+ self.cea_source_1 = QtWidgets.QComboBox(self.frame_25)
+ self.cea_source_1.setEnabled(False)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Fixed)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.cea_source_1.sizePolicy().hasHeightForWidth())
+ self.cea_source_1.setSizePolicy(sizePolicy)
+ self.cea_source_1.setMouseTracking(False)
+ self.cea_source_1.setFocusPolicy(QtCore.Qt.StrongFocus)
+ self.cea_source_1.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_1.setEditable(True)
+ self.cea_source_1.setSizeAdjustPolicy(QtWidgets.QComboBox.AdjustToContents)
+ self.cea_source_1.setObjectName("cea_source_1")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.setItemText(0, "")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self.cea_source_1.addItem("")
+ self._14.addWidget(self.cea_source_1)
+ self.label_21 = QtWidgets.QLabel(self.frame_25)
+ self.label_21.setObjectName("label_21")
+ self._14.addWidget(self.label_21)
+ self.cea_tag_1 = QtWidgets.QLineEdit(self.frame_25)
+ self.cea_tag_1.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_1.setObjectName("cea_tag_1")
+ self._14.addWidget(self.cea_tag_1)
+ self.cea_cond_1 = QtWidgets.QCheckBox(self.frame_25)
+ self.cea_cond_1.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_1.setObjectName("cea_cond_1")
+ self._14.addWidget(self.cea_cond_1)
+ self.gridLayout_14.addWidget(self.frame_25, 1, 0, 1, 1)
+ self._15 = QtWidgets.QHBoxLayout()
+ self._15.setContentsMargins(0, 0, 0, 0)
+ self._15.setSpacing(6)
+ self._15.setObjectName("_15")
+ self.toolButton_2 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_2.setStyleSheet("")
+ self.toolButton_2.setCheckable(True)
+ self.toolButton_2.setObjectName("toolButton_2")
+ self._15.addWidget(self.toolButton_2)
+ self.cea_source_2 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_2.setEnabled(False)
+ self.cea_source_2.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_2.setEditable(True)
+ self.cea_source_2.setObjectName("cea_source_2")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.setItemText(0, "")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self.cea_source_2.addItem("")
+ self._15.addWidget(self.cea_source_2)
+ self.label_23 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_23.setObjectName("label_23")
+ self._15.addWidget(self.label_23)
+ self.cea_tag_2 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_2.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_2.setObjectName("cea_tag_2")
+ self._15.addWidget(self.cea_tag_2)
+ self.cea_cond_2 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_2.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_2.setObjectName("cea_cond_2")
+ self._15.addWidget(self.cea_cond_2)
+ self.gridLayout_14.addLayout(self._15, 2, 0, 1, 1)
+ self._16 = QtWidgets.QHBoxLayout()
+ self._16.setContentsMargins(0, 0, 0, 0)
+ self._16.setSpacing(6)
+ self._16.setObjectName("_16")
+ self.toolButton_3 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_3.setStyleSheet("")
+ self.toolButton_3.setCheckable(True)
+ self.toolButton_3.setObjectName("toolButton_3")
+ self._16.addWidget(self.toolButton_3)
+ self.cea_source_3 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_3.setEnabled(False)
+ self.cea_source_3.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_3.setEditable(True)
+ self.cea_source_3.setObjectName("cea_source_3")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.setItemText(0, "")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self.cea_source_3.addItem("")
+ self._16.addWidget(self.cea_source_3)
+ self.label_25 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_25.setObjectName("label_25")
+ self._16.addWidget(self.label_25)
+ self.cea_tag_3 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_3.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_3.setObjectName("cea_tag_3")
+ self._16.addWidget(self.cea_tag_3)
+ self.cea_cond_3 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_3.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_3.setObjectName("cea_cond_3")
+ self._16.addWidget(self.cea_cond_3)
+ self.gridLayout_14.addLayout(self._16, 3, 0, 1, 1)
+ self._17 = QtWidgets.QHBoxLayout()
+ self._17.setContentsMargins(0, 0, 0, 0)
+ self._17.setSpacing(6)
+ self._17.setObjectName("_17")
+ self.toolButton_4 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_4.setStyleSheet("")
+ self.toolButton_4.setCheckable(True)
+ self.toolButton_4.setObjectName("toolButton_4")
+ self._17.addWidget(self.toolButton_4)
+ self.cea_source_4 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_4.setEnabled(False)
+ self.cea_source_4.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_4.setEditable(True)
+ self.cea_source_4.setObjectName("cea_source_4")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.setItemText(0, "")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self.cea_source_4.addItem("")
+ self._17.addWidget(self.cea_source_4)
+ self.label_27 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_27.setObjectName("label_27")
+ self._17.addWidget(self.label_27)
+ self.cea_tag_4 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_4.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_4.setObjectName("cea_tag_4")
+ self._17.addWidget(self.cea_tag_4)
+ self.cea_cond_4 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_4.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_4.setObjectName("cea_cond_4")
+ self._17.addWidget(self.cea_cond_4)
+ self.gridLayout_14.addLayout(self._17, 4, 0, 1, 1)
+ self._18 = QtWidgets.QHBoxLayout()
+ self._18.setContentsMargins(0, 0, 0, 0)
+ self._18.setSpacing(6)
+ self._18.setObjectName("_18")
+ self.toolButton_5 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_5.setStyleSheet("")
+ self.toolButton_5.setCheckable(True)
+ self.toolButton_5.setObjectName("toolButton_5")
+ self._18.addWidget(self.toolButton_5)
+ self.cea_source_5 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_5.setEnabled(False)
+ self.cea_source_5.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_5.setEditable(True)
+ self.cea_source_5.setObjectName("cea_source_5")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.setItemText(0, "")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self.cea_source_5.addItem("")
+ self._18.addWidget(self.cea_source_5)
+ self.label_29 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_29.setObjectName("label_29")
+ self._18.addWidget(self.label_29)
+ self.cea_tag_5 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_5.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_5.setObjectName("cea_tag_5")
+ self._18.addWidget(self.cea_tag_5)
+ self.cea_cond_5 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_5.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_5.setObjectName("cea_cond_5")
+ self._18.addWidget(self.cea_cond_5)
+ self.gridLayout_14.addLayout(self._18, 5, 0, 1, 1)
+ self._19 = QtWidgets.QHBoxLayout()
+ self._19.setContentsMargins(0, 0, 0, 0)
+ self._19.setSpacing(6)
+ self._19.setObjectName("_19")
+ self.toolButton_6 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_6.setStyleSheet("")
+ self.toolButton_6.setCheckable(True)
+ self.toolButton_6.setObjectName("toolButton_6")
+ self._19.addWidget(self.toolButton_6)
+ self.cea_source_6 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_6.setEnabled(False)
+ self.cea_source_6.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_6.setEditable(True)
+ self.cea_source_6.setObjectName("cea_source_6")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.setItemText(0, "")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self.cea_source_6.addItem("")
+ self._19.addWidget(self.cea_source_6)
+ self.label_31 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_31.setObjectName("label_31")
+ self._19.addWidget(self.label_31)
+ self.cea_tag_6 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_6.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_6.setObjectName("cea_tag_6")
+ self._19.addWidget(self.cea_tag_6)
+ self.cea_cond_6 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_6.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_6.setObjectName("cea_cond_6")
+ self._19.addWidget(self.cea_cond_6)
+ self.gridLayout_14.addLayout(self._19, 6, 0, 1, 1)
+ self._20 = QtWidgets.QHBoxLayout()
+ self._20.setContentsMargins(0, 0, 0, 0)
+ self._20.setSpacing(6)
+ self._20.setObjectName("_20")
+ self.toolButton_7 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_7.setStyleSheet("")
+ self.toolButton_7.setCheckable(True)
+ self.toolButton_7.setObjectName("toolButton_7")
+ self._20.addWidget(self.toolButton_7)
+ self.cea_source_7 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_7.setEnabled(False)
+ self.cea_source_7.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_7.setEditable(True)
+ self.cea_source_7.setObjectName("cea_source_7")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.setItemText(0, "")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self.cea_source_7.addItem("")
+ self._20.addWidget(self.cea_source_7)
+ self.label_33 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_33.setObjectName("label_33")
+ self._20.addWidget(self.label_33)
+ self.cea_tag_7 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_7.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_7.setObjectName("cea_tag_7")
+ self._20.addWidget(self.cea_tag_7)
+ self.cea_cond_7 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_7.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_7.setObjectName("cea_cond_7")
+ self._20.addWidget(self.cea_cond_7)
+ self.gridLayout_14.addLayout(self._20, 7, 0, 1, 1)
+ self._21 = QtWidgets.QHBoxLayout()
+ self._21.setContentsMargins(0, 0, 0, 0)
+ self._21.setSpacing(6)
+ self._21.setObjectName("_21")
+ self.toolButton_8 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_8.setStyleSheet("")
+ self.toolButton_8.setCheckable(True)
+ self.toolButton_8.setObjectName("toolButton_8")
+ self._21.addWidget(self.toolButton_8)
+ self.cea_source_8 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_8.setEnabled(False)
+ self.cea_source_8.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_8.setEditable(True)
+ self.cea_source_8.setObjectName("cea_source_8")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.setItemText(0, "")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self.cea_source_8.addItem("")
+ self._21.addWidget(self.cea_source_8)
+ self.label_35 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_35.setObjectName("label_35")
+ self._21.addWidget(self.label_35)
+ self.cea_tag_8 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_8.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_8.setObjectName("cea_tag_8")
+ self._21.addWidget(self.cea_tag_8)
+ self.cea_cond_8 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_8.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_8.setObjectName("cea_cond_8")
+ self._21.addWidget(self.cea_cond_8)
+ self.gridLayout_14.addLayout(self._21, 8, 0, 1, 1)
+ self._30 = QtWidgets.QHBoxLayout()
+ self._30.setContentsMargins(0, 0, 0, 0)
+ self._30.setSpacing(6)
+ self._30.setObjectName("_30")
+ self.toolButton_9 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_9.setStyleSheet("")
+ self.toolButton_9.setCheckable(True)
+ self.toolButton_9.setObjectName("toolButton_9")
+ self._30.addWidget(self.toolButton_9)
+ self.cea_source_9 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_9.setEnabled(False)
+ self.cea_source_9.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_9.setEditable(True)
+ self.cea_source_9.setObjectName("cea_source_9")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.setItemText(0, "")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self.cea_source_9.addItem("")
+ self._30.addWidget(self.cea_source_9)
+ self.label_53 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_53.setObjectName("label_53")
+ self._30.addWidget(self.label_53)
+ self.cea_tag_9 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_9.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_9.setObjectName("cea_tag_9")
+ self._30.addWidget(self.cea_tag_9)
+ self.cea_cond_9 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_9.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_9.setObjectName("cea_cond_9")
+ self._30.addWidget(self.cea_cond_9)
+ self.gridLayout_14.addLayout(self._30, 9, 0, 1, 1)
+ self._31 = QtWidgets.QHBoxLayout()
+ self._31.setContentsMargins(0, 0, 0, 0)
+ self._31.setSpacing(6)
+ self._31.setObjectName("_31")
+ self.toolButton_10 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_10.setStyleSheet("")
+ self.toolButton_10.setCheckable(True)
+ self.toolButton_10.setObjectName("toolButton_10")
+ self._31.addWidget(self.toolButton_10)
+ self.cea_source_10 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_10.setEnabled(False)
+ self.cea_source_10.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_10.setEditable(True)
+ self.cea_source_10.setObjectName("cea_source_10")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.setItemText(0, "")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self.cea_source_10.addItem("")
+ self._31.addWidget(self.cea_source_10)
+ self.label_55 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_55.setObjectName("label_55")
+ self._31.addWidget(self.label_55)
+ self.cea_tag_10 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_10.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_10.setObjectName("cea_tag_10")
+ self._31.addWidget(self.cea_tag_10)
+ self.cea_cond_10 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_10.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_10.setObjectName("cea_cond_10")
+ self._31.addWidget(self.cea_cond_10)
+ self.gridLayout_14.addLayout(self._31, 10, 0, 1, 1)
+ self._32 = QtWidgets.QHBoxLayout()
+ self._32.setContentsMargins(0, 0, 0, 0)
+ self._32.setSpacing(6)
+ self._32.setObjectName("_32")
+ self.toolButton_11 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_11.setStyleSheet("")
+ self.toolButton_11.setCheckable(True)
+ self.toolButton_11.setObjectName("toolButton_11")
+ self._32.addWidget(self.toolButton_11)
+ self.cea_source_11 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_11.setEnabled(False)
+ self.cea_source_11.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_11.setEditable(True)
+ self.cea_source_11.setObjectName("cea_source_11")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.setItemText(0, "")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self.cea_source_11.addItem("")
+ self._32.addWidget(self.cea_source_11)
+ self.label_57 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_57.setObjectName("label_57")
+ self._32.addWidget(self.label_57)
+ self.cea_tag_11 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_11.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_11.setObjectName("cea_tag_11")
+ self._32.addWidget(self.cea_tag_11)
+ self.cea_cond_11 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_11.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_11.setObjectName("cea_cond_11")
+ self._32.addWidget(self.cea_cond_11)
+ self.gridLayout_14.addLayout(self._32, 11, 0, 1, 1)
+ self._33 = QtWidgets.QHBoxLayout()
+ self._33.setContentsMargins(0, 0, 0, 0)
+ self._33.setSpacing(6)
+ self._33.setObjectName("_33")
+ self.toolButton_12 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_12.setStyleSheet("")
+ self.toolButton_12.setCheckable(True)
+ self.toolButton_12.setObjectName("toolButton_12")
+ self._33.addWidget(self.toolButton_12)
+ self.cea_source_12 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_12.setEnabled(False)
+ self.cea_source_12.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_12.setEditable(True)
+ self.cea_source_12.setObjectName("cea_source_12")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.setItemText(0, "")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self.cea_source_12.addItem("")
+ self._33.addWidget(self.cea_source_12)
+ self.label_59 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_59.setObjectName("label_59")
+ self._33.addWidget(self.label_59)
+ self.cea_tag_12 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_12.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_12.setObjectName("cea_tag_12")
+ self._33.addWidget(self.cea_tag_12)
+ self.cea_cond_12 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_12.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_12.setObjectName("cea_cond_12")
+ self._33.addWidget(self.cea_cond_12)
+ self.gridLayout_14.addLayout(self._33, 12, 0, 1, 1)
+ self._34 = QtWidgets.QHBoxLayout()
+ self._34.setContentsMargins(0, 0, 0, 0)
+ self._34.setSpacing(6)
+ self._34.setObjectName("_34")
+ self.toolButton_13 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_13.setStyleSheet("")
+ self.toolButton_13.setCheckable(True)
+ self.toolButton_13.setObjectName("toolButton_13")
+ self._34.addWidget(self.toolButton_13)
+ self.cea_source_13 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_13.setEnabled(False)
+ self.cea_source_13.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_13.setEditable(True)
+ self.cea_source_13.setObjectName("cea_source_13")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.setItemText(0, "")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self.cea_source_13.addItem("")
+ self._34.addWidget(self.cea_source_13)
+ self.label_61 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_61.setObjectName("label_61")
+ self._34.addWidget(self.label_61)
+ self.cea_tag_13 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_13.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_13.setObjectName("cea_tag_13")
+ self._34.addWidget(self.cea_tag_13)
+ self.cea_cond_13 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_13.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_13.setObjectName("cea_cond_13")
+ self._34.addWidget(self.cea_cond_13)
+ self.gridLayout_14.addLayout(self._34, 13, 0, 1, 1)
+ self._35 = QtWidgets.QHBoxLayout()
+ self._35.setContentsMargins(0, 0, 0, 0)
+ self._35.setSpacing(6)
+ self._35.setObjectName("_35")
+ self.toolButton_14 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_14.setStyleSheet("")
+ self.toolButton_14.setCheckable(True)
+ self.toolButton_14.setObjectName("toolButton_14")
+ self._35.addWidget(self.toolButton_14)
+ self.cea_source_14 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_14.setEnabled(False)
+ self.cea_source_14.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_14.setEditable(True)
+ self.cea_source_14.setObjectName("cea_source_14")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.setItemText(0, "")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self.cea_source_14.addItem("")
+ self._35.addWidget(self.cea_source_14)
+ self.label_63 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_63.setObjectName("label_63")
+ self._35.addWidget(self.label_63)
+ self.cea_tag_14 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_14.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_14.setObjectName("cea_tag_14")
+ self._35.addWidget(self.cea_tag_14)
+ self.cea_cond_14 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_14.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_14.setObjectName("cea_cond_14")
+ self._35.addWidget(self.cea_cond_14)
+ self.gridLayout_14.addLayout(self._35, 14, 0, 1, 1)
+ self._36 = QtWidgets.QHBoxLayout()
+ self._36.setContentsMargins(0, 0, 0, 0)
+ self._36.setSpacing(6)
+ self._36.setObjectName("_36")
+ self.toolButton_15 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_15.setStyleSheet("")
+ self.toolButton_15.setCheckable(True)
+ self.toolButton_15.setObjectName("toolButton_15")
+ self._36.addWidget(self.toolButton_15)
+ self.cea_source_15 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_15.setEnabled(False)
+ self.cea_source_15.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_15.setEditable(True)
+ self.cea_source_15.setObjectName("cea_source_15")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.setItemText(0, "")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self.cea_source_15.addItem("")
+ self._36.addWidget(self.cea_source_15)
+ self.label_65 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_65.setObjectName("label_65")
+ self._36.addWidget(self.label_65)
+ self.cea_tag_15 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_15.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_15.setObjectName("cea_tag_15")
+ self._36.addWidget(self.cea_tag_15)
+ self.cea_cond_15 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_15.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_15.setObjectName("cea_cond_15")
+ self._36.addWidget(self.cea_cond_15)
+ self.gridLayout_14.addLayout(self._36, 15, 0, 1, 1)
+ self._37 = QtWidgets.QHBoxLayout()
+ self._37.setContentsMargins(0, 0, 0, 0)
+ self._37.setSpacing(6)
+ self._37.setObjectName("_37")
+ self.toolButton_16 = QtWidgets.QToolButton(self.tagmap_details_box)
+ self.toolButton_16.setStyleSheet("")
+ self.toolButton_16.setCheckable(True)
+ self.toolButton_16.setObjectName("toolButton_16")
+ self._37.addWidget(self.toolButton_16)
+ self.cea_source_16 = QtWidgets.QComboBox(self.tagmap_details_box)
+ self.cea_source_16.setEnabled(False)
+ self.cea_source_16.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_source_16.setEditable(True)
+ self.cea_source_16.setObjectName("cea_source_16")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.setItemText(0, "")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self.cea_source_16.addItem("")
+ self._37.addWidget(self.cea_source_16)
+ self.label_67 = QtWidgets.QLabel(self.tagmap_details_box)
+ self.label_67.setObjectName("label_67")
+ self._37.addWidget(self.label_67)
+ self.cea_tag_16 = QtWidgets.QLineEdit(self.tagmap_details_box)
+ self.cea_tag_16.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_tag_16.setObjectName("cea_tag_16")
+ self._37.addWidget(self.cea_tag_16)
+ self.cea_cond_16 = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_cond_16.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_cond_16.setObjectName("cea_cond_16")
+ self._37.addWidget(self.cea_cond_16)
+ self.gridLayout_14.addLayout(self._37, 16, 0, 1, 1)
+ self._38 = QtWidgets.QHBoxLayout()
+ self._38.setContentsMargins(0, 0, 0, 0)
+ self._38.setSpacing(6)
+ self._38.setObjectName("_38")
+ self.label_42 = QtWidgets.QLabel(self.tagmap_details_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_42.sizePolicy().hasHeightForWidth())
+ self.label_42.setSizePolicy(sizePolicy)
+ self.label_42.setLayoutDirection(QtCore.Qt.LeftToRight)
+ self.label_42.setLineWidth(1)
+ self.label_42.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignVCenter)
+ self.label_42.setObjectName("label_42")
+ self._38.addWidget(self.label_42)
+ self.label_17 = QtWidgets.QLabel(self.tagmap_details_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_17.sizePolicy().hasHeightForWidth())
+ self.label_17.setSizePolicy(sizePolicy)
+ self.label_17.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.label_17.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
+ self.label_17.setObjectName("label_17")
+ self._38.addWidget(self.label_17)
+ self.gridLayout_14.addLayout(self._38, 17, 0, 1, 1)
+ self.cea_tag_sort = QtWidgets.QCheckBox(self.tagmap_details_box)
+ self.cea_tag_sort.setLayoutDirection(QtCore.Qt.LeftToRight)
+ self.cea_tag_sort.setObjectName("cea_tag_sort")
+ self.gridLayout_14.addWidget(self.cea_tag_sort, 18, 0, 1, 1)
+ self.verticalLayout_3.addWidget(self.tagmap_details_box)
+ self.verticalLayout_33.addWidget(self.tagmap_details_frame)
+ self.scrollArea_4.setWidget(self.scrollAreaWidgetContents_8)
+ self.verticalLayout_28.addWidget(self.scrollArea_4)
+ self.tabWidget.addTab(self.Tag_mapping, "")
+ self.Advanced = QtWidgets.QWidget()
+ self.Advanced.setObjectName("Advanced")
+ self.horizontalLayout_31 = QtWidgets.QHBoxLayout(self.Advanced)
+ self.horizontalLayout_31.setObjectName("horizontalLayout_31")
+ self.scrollArea_2 = QtWidgets.QScrollArea(self.Advanced)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.scrollArea_2.sizePolicy().hasHeightForWidth())
+ self.scrollArea_2.setSizePolicy(sizePolicy)
+ self.scrollArea_2.setWidgetResizable(True)
+ self.scrollArea_2.setObjectName("scrollArea_2")
+ self.scrollAreaWidgetContents_2 = QtWidgets.QWidget()
+ self.scrollAreaWidgetContents_2.setGeometry(QtCore.QRect(0, -853, 1084, 1707))
+ self.scrollAreaWidgetContents_2.setObjectName("scrollAreaWidgetContents_2")
+ self.verticalLayout_18 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents_2)
+ self.verticalLayout_18.setObjectName("verticalLayout_18")
+ self.advanced_general_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
+ self.advanced_general_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.advanced_general_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.advanced_general_frame.setObjectName("advanced_general_frame")
+ self.verticalLayout_55 = QtWidgets.QVBoxLayout(self.advanced_general_frame)
+ self.verticalLayout_55.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_55.setSpacing(0)
+ self.verticalLayout_55.setObjectName("verticalLayout_55")
+ self.label_110 = QtWidgets.QLabel(self.advanced_general_frame)
+ self.label_110.setStyleSheet("background-color: rgb(208, 208, 156);")
+ self.label_110.setObjectName("label_110")
+ self.verticalLayout_55.addWidget(self.label_110)
+ self.advanced_general_box = QtWidgets.QGroupBox(self.advanced_general_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.advanced_general_box.setPalette(palette)
+ self.advanced_general_box.setAutoFillBackground(False)
+ self.advanced_general_box.setStyleSheet("background-color: rgb(229, 229, 197);")
+ self.advanced_general_box.setTitle("")
+ self.advanced_general_box.setObjectName("advanced_general_box")
+ self.verticalLayout_5 = QtWidgets.QVBoxLayout(self.advanced_general_box)
+ self.verticalLayout_5.setObjectName("verticalLayout_5")
+ self.ce_no_run = QtWidgets.QCheckBox(self.advanced_general_box)
+ self.ce_no_run.setObjectName("ce_no_run")
+ self.verticalLayout_5.addWidget(self.ce_no_run)
+ self.verticalLayout_55.addWidget(self.advanced_general_box)
+ self.verticalLayout_18.addWidget(self.advanced_general_frame)
+ self.advanced_artists_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
+ self.advanced_artists_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.advanced_artists_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.advanced_artists_frame.setObjectName("advanced_artists_frame")
+ self.verticalLayout_56 = QtWidgets.QVBoxLayout(self.advanced_artists_frame)
+ self.verticalLayout_56.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_56.setSpacing(0)
+ self.verticalLayout_56.setObjectName("verticalLayout_56")
+ self.advanced_artists_label = QtWidgets.QLabel(self.advanced_artists_frame)
+ self.advanced_artists_label.setStyleSheet("background-color: rgb(208, 208, 156);")
+ self.advanced_artists_label.setObjectName("advanced_artists_label")
+ self.verticalLayout_56.addWidget(self.advanced_artists_label)
+ self.advanced_artists_box = QtWidgets.QGroupBox(self.advanced_artists_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.advanced_artists_box.setPalette(palette)
+ self.advanced_artists_box.setAutoFillBackground(False)
+ self.advanced_artists_box.setStyleSheet("background-color: rgb(229, 229, 197);")
+ self.advanced_artists_box.setTitle("")
+ self.advanced_artists_box.setObjectName("advanced_artists_box")
+ self.verticalLayout_20 = QtWidgets.QVBoxLayout(self.advanced_artists_box)
+ self.verticalLayout_20.setObjectName("verticalLayout_20")
+ self.ensemble_strings_label = QtWidgets.QLabel(self.advanced_artists_box)
+ self.ensemble_strings_label.setObjectName("ensemble_strings_label")
+ self.verticalLayout_20.addWidget(self.ensemble_strings_label)
+ self.ensemble_strings_box = QtWidgets.QGroupBox(self.advanced_artists_box)
+ self.ensemble_strings_box.setTitle("")
+ self.ensemble_strings_box.setObjectName("ensemble_strings_box")
+ self._13 = QtWidgets.QVBoxLayout(self.ensemble_strings_box)
+ self._13.setContentsMargins(9, 9, 9, 9)
+ self._13.setSpacing(2)
+ self._13.setObjectName("_13")
+ self.cea_orchestras_2 = QtWidgets.QLabel(self.ensemble_strings_box)
+ self.cea_orchestras_2.setObjectName("cea_orchestras_2")
+ self._13.addWidget(self.cea_orchestras_2)
+ self.cea_orchestras = QtWidgets.QLineEdit(self.ensemble_strings_box)
+ self.cea_orchestras.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_orchestras.setObjectName("cea_orchestras")
+ self._13.addWidget(self.cea_orchestras)
+ self.cea_choirs_2 = QtWidgets.QLabel(self.ensemble_strings_box)
+ self.cea_choirs_2.setObjectName("cea_choirs_2")
+ self._13.addWidget(self.cea_choirs_2)
+ self.cea_choirs = QtWidgets.QLineEdit(self.ensemble_strings_box)
+ self.cea_choirs.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_choirs.setObjectName("cea_choirs")
+ self._13.addWidget(self.cea_choirs)
+ self.cea_groups_2 = QtWidgets.QLabel(self.ensemble_strings_box)
+ self.cea_groups_2.setObjectName("cea_groups_2")
+ self._13.addWidget(self.cea_groups_2)
+ self.cea_groups = QtWidgets.QLineEdit(self.ensemble_strings_box)
+ self.cea_groups.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_groups.setObjectName("cea_groups")
+ self._13.addWidget(self.cea_groups)
+ self.verticalLayout_20.addWidget(self.ensemble_strings_box)
+ self.verticalLayout_56.addWidget(self.advanced_artists_box)
+ self.verticalLayout_18.addWidget(self.advanced_artists_frame)
+ self.advanced_workparts_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
+ self.advanced_workparts_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.advanced_workparts_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.advanced_workparts_frame.setObjectName("advanced_workparts_frame")
+ self.verticalLayout_57 = QtWidgets.QVBoxLayout(self.advanced_workparts_frame)
+ self.verticalLayout_57.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_57.setSpacing(0)
+ self.verticalLayout_57.setObjectName("verticalLayout_57")
+ self.advanced_workparts_label = QtWidgets.QLabel(self.advanced_workparts_frame)
+ self.advanced_workparts_label.setStyleSheet("background-color: rgb(208, 208, 156);")
+ self.advanced_workparts_label.setObjectName("advanced_workparts_label")
+ self.verticalLayout_57.addWidget(self.advanced_workparts_label)
+ self.advanced_workparts_box = QtWidgets.QGroupBox(self.advanced_workparts_frame)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.advanced_workparts_box.sizePolicy().hasHeightForWidth())
+ self.advanced_workparts_box.setSizePolicy(sizePolicy)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.advanced_workparts_box.setPalette(palette)
+ self.advanced_workparts_box.setAutoFillBackground(False)
+ self.advanced_workparts_box.setStyleSheet("background-color: rgb(229, 229, 197);")
+ self.advanced_workparts_box.setTitle("")
+ self.advanced_workparts_box.setObjectName("advanced_workparts_box")
+ self.verticalLayout = QtWidgets.QVBoxLayout(self.advanced_workparts_box)
+ self.verticalLayout.setObjectName("verticalLayout")
+ self._2 = QtWidgets.QHBoxLayout()
+ self._2.setContentsMargins(0, 0, 0, 0)
+ self._2.setSpacing(6)
+ self._2.setObjectName("_2")
+ self.label_4 = QtWidgets.QLabel(self.advanced_workparts_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_4.sizePolicy().hasHeightForWidth())
+ self.label_4.setSizePolicy(sizePolicy)
+ self.label_4.setObjectName("label_4")
+ self._2.addWidget(self.label_4)
+ self.cwp_retries = QtWidgets.QSpinBox(self.advanced_workparts_box)
+ self.cwp_retries.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_retries.setSuffix("")
+ self.cwp_retries.setMinimum(0)
+ self.cwp_retries.setMaximum(20)
+ self.cwp_retries.setObjectName("cwp_retries")
+ self._2.addWidget(self.cwp_retries)
+ self.verticalLayout.addLayout(self._2)
+ self._23 = QtWidgets.QHBoxLayout()
+ self._23.setContentsMargins(0, 0, 0, 0)
+ self._23.setSpacing(6)
+ self._23.setObjectName("_23")
+ self.label_120 = QtWidgets.QLabel(self.advanced_workparts_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_120.sizePolicy().hasHeightForWidth())
+ self.label_120.setSizePolicy(sizePolicy)
+ self.label_120.setObjectName("label_120")
+ self._23.addWidget(self.label_120)
+ self.cwp_allow_empty_parts = QtWidgets.QCheckBox(self.advanced_workparts_box)
+ self.cwp_allow_empty_parts.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cwp_allow_empty_parts.setText("")
+ self.cwp_allow_empty_parts.setObjectName("cwp_allow_empty_parts")
+ self._23.addWidget(self.cwp_allow_empty_parts)
+ self.verticalLayout.addLayout(self._23)
+ self.parent_child_text_box = QtWidgets.QGroupBox(self.advanced_workparts_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.parent_child_text_box.setPalette(palette)
+ self.parent_child_text_box.setAutoFillBackground(False)
+ self.parent_child_text_box.setStyleSheet("background-color: rgb(241, 241, 167);")
+ self.parent_child_text_box.setTitle("")
+ self.parent_child_text_box.setObjectName("parent_child_text_box")
+ self.verticalLayout_35 = QtWidgets.QVBoxLayout(self.parent_child_text_box)
+ self.verticalLayout_35.setObjectName("verticalLayout_35")
+ self.label_114 = QtWidgets.QLabel(self.parent_child_text_box)
+ self.label_114.setObjectName("label_114")
+ self.verticalLayout_35.addWidget(self.label_114)
+ self._22 = QtWidgets.QHBoxLayout()
+ self._22.setContentsMargins(0, 0, 0, 0)
+ self._22.setSpacing(6)
+ self._22.setObjectName("_22")
+ self.label_90 = QtWidgets.QLabel(self.parent_child_text_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_90.sizePolicy().hasHeightForWidth())
+ self.label_90.setSizePolicy(sizePolicy)
+ self.label_90.setObjectName("label_90")
+ self._22.addWidget(self.label_90)
+ self.cwp_common_chars = QtWidgets.QSpinBox(self.parent_child_text_box)
+ self.cwp_common_chars.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_common_chars.setSuffix("")
+ self.cwp_common_chars.setMinimum(0)
+ self.cwp_common_chars.setMaximum(99)
+ self.cwp_common_chars.setObjectName("cwp_common_chars")
+ self._22.addWidget(self.cwp_common_chars)
+ self.verticalLayout_35.addLayout(self._22)
+ self.label_89 = QtWidgets.QLabel(self.parent_child_text_box)
+ self.label_89.setObjectName("label_89")
+ self.verticalLayout_35.addWidget(self.label_89)
+ self.verticalLayout.addWidget(self.parent_child_text_box)
+ self.title_metadata_box = QtWidgets.QGroupBox(self.advanced_workparts_box)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.title_metadata_box.setPalette(palette)
+ self.title_metadata_box.setAutoFillBackground(False)
+ self.title_metadata_box.setStyleSheet("background-color: rgb(202, 202, 140);")
+ self.title_metadata_box.setTitle("")
+ self.title_metadata_box.setObjectName("title_metadata_box")
+ self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.title_metadata_box)
+ self.verticalLayout_2.setObjectName("verticalLayout_2")
+ self.label_115 = QtWidgets.QLabel(self.title_metadata_box)
+ self.label_115.setObjectName("label_115")
+ self.verticalLayout_2.addWidget(self.label_115)
+ self._3 = QtWidgets.QHBoxLayout()
+ self._3.setContentsMargins(0, 0, 0, 0)
+ self._3.setSpacing(6)
+ self._3.setObjectName("_3")
+ self.label_6 = QtWidgets.QLabel(self.title_metadata_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_6.sizePolicy().hasHeightForWidth())
+ self.label_6.setSizePolicy(sizePolicy)
+ self.label_6.setObjectName("label_6")
+ self._3.addWidget(self.label_6)
+ self.cwp_proximity = QtWidgets.QSpinBox(self.title_metadata_box)
+ self.cwp_proximity.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_proximity.setSuffix("")
+ self.cwp_proximity.setMaximum(99)
+ self.cwp_proximity.setObjectName("cwp_proximity")
+ self._3.addWidget(self.cwp_proximity)
+ self.verticalLayout_2.addLayout(self._3)
+ self._4 = QtWidgets.QHBoxLayout()
+ self._4.setContentsMargins(0, 0, 0, 0)
+ self._4.setSpacing(6)
+ self._4.setObjectName("_4")
+ self.label_7 = QtWidgets.QLabel(self.title_metadata_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_7.sizePolicy().hasHeightForWidth())
+ self.label_7.setSizePolicy(sizePolicy)
+ self.label_7.setObjectName("label_7")
+ self._4.addWidget(self.label_7)
+ self.cwp_end_proximity = QtWidgets.QSpinBox(self.title_metadata_box)
+ self.cwp_end_proximity.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_end_proximity.setSuffix("")
+ self.cwp_end_proximity.setMaximum(99)
+ self.cwp_end_proximity.setObjectName("cwp_end_proximity")
+ self._4.addWidget(self.cwp_end_proximity)
+ self.verticalLayout_2.addLayout(self._4)
+ self._5 = QtWidgets.QHBoxLayout()
+ self._5.setContentsMargins(0, 0, 0, 0)
+ self._5.setSpacing(6)
+ self._5.setObjectName("_5")
+ self.label_5 = QtWidgets.QLabel(self.title_metadata_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_5.sizePolicy().hasHeightForWidth())
+ self.label_5.setSizePolicy(sizePolicy)
+ self.label_5.setObjectName("label_5")
+ self._5.addWidget(self.label_5)
+ self.cwp_split_hyphenated = QtWidgets.QCheckBox(self.title_metadata_box)
+ self.cwp_split_hyphenated.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cwp_split_hyphenated.setText("")
+ self.cwp_split_hyphenated.setObjectName("cwp_split_hyphenated")
+ self._5.addWidget(self.cwp_split_hyphenated)
+ self.verticalLayout_2.addLayout(self._5)
+ self._25 = QtWidgets.QHBoxLayout()
+ self._25.setContentsMargins(0, 0, 0, 0)
+ self._25.setSpacing(6)
+ self._25.setObjectName("_25")
+ self.label_93 = QtWidgets.QLabel(self.title_metadata_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_93.sizePolicy().hasHeightForWidth())
+ self.label_93.setSizePolicy(sizePolicy)
+ self.label_93.setObjectName("label_93")
+ self._25.addWidget(self.label_93)
+ self.cwp_substring_match = QtWidgets.QSpinBox(self.title_metadata_box)
+ self.cwp_substring_match.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_substring_match.setMaximum(100)
+ self.cwp_substring_match.setObjectName("cwp_substring_match")
+ self._25.addWidget(self.cwp_substring_match)
+ self.verticalLayout_2.addLayout(self._25)
+ self._7 = QtWidgets.QHBoxLayout()
+ self._7.setContentsMargins(0, 0, 0, 0)
+ self._7.setSpacing(6)
+ self._7.setObjectName("_7")
+ self.label_87 = QtWidgets.QLabel(self.title_metadata_box)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_87.sizePolicy().hasHeightForWidth())
+ self.label_87.setSizePolicy(sizePolicy)
+ self.label_87.setObjectName("label_87")
+ self._7.addWidget(self.label_87)
+ self.cwp_fill_part = QtWidgets.QCheckBox(self.title_metadata_box)
+ self.cwp_fill_part.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cwp_fill_part.setText("")
+ self.cwp_fill_part.setObjectName("cwp_fill_part")
+ self._7.addWidget(self.cwp_fill_part)
+ self.verticalLayout_2.addLayout(self._7)
+ self.line_8 = QtWidgets.QFrame(self.title_metadata_box)
+ self.line_8.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line_8.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_8.setObjectName("line_8")
+ self.verticalLayout_2.addWidget(self.line_8)
+ self.label_92 = QtWidgets.QLabel(self.title_metadata_box)
+ self.label_92.setObjectName("label_92")
+ self.verticalLayout_2.addWidget(self.label_92)
+ self.label_91 = QtWidgets.QLabel(self.title_metadata_box)
+ self.label_91.setObjectName("label_91")
+ self.verticalLayout_2.addWidget(self.label_91)
+ self.cwp_prepositions = QtWidgets.QLineEdit(self.title_metadata_box)
+ self.cwp_prepositions.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_prepositions.setObjectName("cwp_prepositions")
+ self.verticalLayout_2.addWidget(self.cwp_prepositions)
+ self.cwp_removewords_2 = QtWidgets.QLabel(self.title_metadata_box)
+ self.cwp_removewords_2.setObjectName("cwp_removewords_2")
+ self.verticalLayout_2.addWidget(self.cwp_removewords_2)
+ self.cwp_removewords = QtWidgets.QLineEdit(self.title_metadata_box)
+ self.cwp_removewords.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_removewords.setObjectName("cwp_removewords")
+ self.verticalLayout_2.addWidget(self.cwp_removewords)
+ self.line = QtWidgets.QFrame(self.title_metadata_box)
+ self.line.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line.setObjectName("line")
+ self.verticalLayout_2.addWidget(self.line)
+ self.cwp_synonyms_2 = QtWidgets.QLabel(self.title_metadata_box)
+ self.cwp_synonyms_2.setObjectName("cwp_synonyms_2")
+ self.verticalLayout_2.addWidget(self.cwp_synonyms_2)
+ self.cwp_synonyms = QtWidgets.QTextEdit(self.title_metadata_box)
+ self.cwp_synonyms.setMaximumSize(QtCore.QSize(16777215, 120))
+ self.cwp_synonyms.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_synonyms.setObjectName("cwp_synonyms")
+ self.verticalLayout_2.addWidget(self.cwp_synonyms)
+ self.label_16 = QtWidgets.QLabel(self.title_metadata_box)
+ self.label_16.setObjectName("label_16")
+ self.verticalLayout_2.addWidget(self.label_16)
+ self.cwp_replacements = QtWidgets.QLineEdit(self.title_metadata_box)
+ self.cwp_replacements.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_replacements.setObjectName("cwp_replacements")
+ self.verticalLayout_2.addWidget(self.cwp_replacements)
+ self.verticalLayout.addWidget(self.title_metadata_box)
+ self.verticalLayout_57.addWidget(self.advanced_workparts_box)
+ self.verticalLayout_18.addWidget(self.advanced_workparts_frame)
+ self.advanced_genres_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
+ self.advanced_genres_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.advanced_genres_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.advanced_genres_frame.setObjectName("advanced_genres_frame")
+ self.verticalLayout_58 = QtWidgets.QVBoxLayout(self.advanced_genres_frame)
+ self.verticalLayout_58.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_58.setSpacing(0)
+ self.verticalLayout_58.setObjectName("verticalLayout_58")
+ self.advanced_genres_label = QtWidgets.QLabel(self.advanced_genres_frame)
+ self.advanced_genres_label.setStyleSheet("background-color: rgb(208, 208, 156);")
+ self.advanced_genres_label.setObjectName("advanced_genres_label")
+ self.verticalLayout_58.addWidget(self.advanced_genres_label)
+ self.advanced_genres_box = QtWidgets.QGroupBox(self.advanced_genres_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.advanced_genres_box.setPalette(palette)
+ self.advanced_genres_box.setAutoFillBackground(False)
+ self.advanced_genres_box.setStyleSheet("background-color: rgb(229, 229, 197);")
+ self.advanced_genres_box.setTitle("")
+ self.advanced_genres_box.setObjectName("advanced_genres_box")
+ self.gridLayout_8 = QtWidgets.QGridLayout(self.advanced_genres_box)
+ self.gridLayout_8.setObjectName("gridLayout_8")
+ self.label_85 = QtWidgets.QLabel(self.advanced_genres_box)
+ self.label_85.setObjectName("label_85")
+ self.gridLayout_8.addWidget(self.label_85, 1, 0, 1, 1)
+ self.cwp_muso_refdb = QtWidgets.QLineEdit(self.advanced_genres_box)
+ self.cwp_muso_refdb.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_muso_refdb.setObjectName("cwp_muso_refdb")
+ self.gridLayout_8.addWidget(self.cwp_muso_refdb, 1, 3, 1, 1)
+ self.label_84 = QtWidgets.QLabel(self.advanced_genres_box)
+ self.label_84.setObjectName("label_84")
+ self.gridLayout_8.addWidget(self.label_84, 1, 2, 1, 1)
+ self.cwp_muso_path = QtWidgets.QLineEdit(self.advanced_genres_box)
+ self.cwp_muso_path.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_muso_path.setObjectName("cwp_muso_path")
+ self.gridLayout_8.addWidget(self.cwp_muso_path, 1, 1, 1, 1)
+ self.label_86 = QtWidgets.QLabel(self.advanced_genres_box)
+ self.label_86.setObjectName("label_86")
+ self.gridLayout_8.addWidget(self.label_86, 0, 0, 1, 2)
+ self.verticalLayout_58.addWidget(self.advanced_genres_box)
+ self.verticalLayout_18.addWidget(self.advanced_genres_frame)
+ self.logging_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
+ self.logging_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.logging_frame.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.logging_frame.setObjectName("logging_frame")
+ self.verticalLayout_59 = QtWidgets.QVBoxLayout(self.logging_frame)
+ self.verticalLayout_59.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_59.setSpacing(0)
+ self.verticalLayout_59.setObjectName("verticalLayout_59")
+ self.label_117 = QtWidgets.QLabel(self.logging_frame)
+ self.label_117.setStyleSheet("background-color: rgb(208, 208, 156);")
+ self.label_117.setObjectName("label_117")
+ self.verticalLayout_59.addWidget(self.label_117)
+ self.logging_box = QtWidgets.QGroupBox(self.logging_frame)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.logging_box.setPalette(palette)
+ self.logging_box.setLayoutDirection(QtCore.Qt.LeftToRight)
+ self.logging_box.setAutoFillBackground(False)
+ self.logging_box.setStyleSheet("background-color: rgb(229, 229, 197);")
+ self.logging_box.setTitle("")
+ self.logging_box.setObjectName("logging_box")
+ self.horizontalLayout_2 = QtWidgets.QHBoxLayout(self.logging_box)
+ self.horizontalLayout_2.setObjectName("horizontalLayout_2")
+ self.log_error = QtWidgets.QCheckBox(self.logging_box)
+ self.log_error.setObjectName("log_error")
+ self.horizontalLayout_2.addWidget(self.log_error)
+ self.log_warning = QtWidgets.QCheckBox(self.logging_box)
+ self.log_warning.setObjectName("log_warning")
+ self.horizontalLayout_2.addWidget(self.log_warning)
+ self.log_debug = QtWidgets.QCheckBox(self.logging_box)
+ self.log_debug.setObjectName("log_debug")
+ self.horizontalLayout_2.addWidget(self.log_debug)
+ self.custom_logging_box = QtWidgets.QGroupBox(self.logging_box)
+ self.custom_logging_box.setStyleSheet("background-color: rgb(229, 229, 159);")
+ self.custom_logging_box.setObjectName("custom_logging_box")
+ self.horizontalLayout_34 = QtWidgets.QHBoxLayout(self.custom_logging_box)
+ self.horizontalLayout_34.setObjectName("horizontalLayout_34")
+ self.log_basic = QtWidgets.QRadioButton(self.custom_logging_box)
+ self.log_basic.setObjectName("log_basic")
+ self.horizontalLayout_34.addWidget(self.log_basic)
+ self.log_info = QtWidgets.QRadioButton(self.custom_logging_box)
+ self.log_info.setObjectName("log_info")
+ self.horizontalLayout_34.addWidget(self.log_info)
+ self.horizontalLayout_2.addWidget(self.custom_logging_box)
+ self.verticalLayout_59.addWidget(self.logging_box)
+ self.verticalLayout_18.addWidget(self.logging_frame)
+ self.special_tags_frame_outer = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
+ self.special_tags_frame_outer.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.special_tags_frame_outer.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.special_tags_frame_outer.setObjectName("special_tags_frame_outer")
+ self.verticalLayout_60 = QtWidgets.QVBoxLayout(self.special_tags_frame_outer)
+ self.verticalLayout_60.setContentsMargins(0, 0, 0, 0)
+ self.verticalLayout_60.setSpacing(0)
+ self.verticalLayout_60.setObjectName("verticalLayout_60")
+ self.label_118 = QtWidgets.QLabel(self.special_tags_frame_outer)
+ self.label_118.setStyleSheet("background-color: rgb(208, 208, 156);")
+ self.label_118.setObjectName("label_118")
+ self.verticalLayout_60.addWidget(self.label_118)
+ self.special_tags_frame_inner = QtWidgets.QFrame(self.special_tags_frame_outer)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.special_tags_frame_inner.setPalette(palette)
+ self.special_tags_frame_inner.setAutoFillBackground(False)
+ self.special_tags_frame_inner.setStyleSheet("background-color: rgb(229, 229, 197);")
+ self.special_tags_frame_inner.setFrameShape(QtWidgets.QFrame.StyledPanel)
+ self.special_tags_frame_inner.setFrameShadow(QtWidgets.QFrame.Raised)
+ self.special_tags_frame_inner.setObjectName("special_tags_frame_inner")
+ self.verticalLayout_16 = QtWidgets.QVBoxLayout(self.special_tags_frame_inner)
+ self.verticalLayout_16.setObjectName("verticalLayout_16")
+ self.save_options_box = QtWidgets.QGroupBox(self.special_tags_frame_inner)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.save_options_box.setPalette(palette)
+ self.save_options_box.setAutoFillBackground(False)
+ self.save_options_box.setStyleSheet("background-color: rgb(229, 229, 159);")
+ self.save_options_box.setObjectName("save_options_box")
+ self.horizontalLayout_4 = QtWidgets.QHBoxLayout(self.save_options_box)
+ self.horizontalLayout_4.setObjectName("horizontalLayout_4")
+ self.label_41 = QtWidgets.QLabel(self.save_options_box)
+ self.label_41.setObjectName("label_41")
+ self.horizontalLayout_4.addWidget(self.label_41)
+ self.ce_version_tag = QtWidgets.QLineEdit(self.save_options_box)
+ self.ce_version_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.ce_version_tag.setObjectName("ce_version_tag")
+ self.horizontalLayout_4.addWidget(self.ce_version_tag)
+ self.label_36 = QtWidgets.QLabel(self.save_options_box)
+ self.label_36.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.label_36.setObjectName("label_36")
+ self.horizontalLayout_4.addWidget(self.label_36)
+ self.cea_options_tag = QtWidgets.QLineEdit(self.save_options_box)
+ self.cea_options_tag.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cea_options_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cea_options_tag.setObjectName("cea_options_tag")
+ self.horizontalLayout_4.addWidget(self.cea_options_tag)
+ self.label_38 = QtWidgets.QLabel(self.save_options_box)
+ self.label_38.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.label_38.setObjectName("label_38")
+ self.horizontalLayout_4.addWidget(self.label_38)
+ self.cwp_options_tag = QtWidgets.QLineEdit(self.save_options_box)
+ self.cwp_options_tag.setLayoutDirection(QtCore.Qt.RightToLeft)
+ self.cwp_options_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.cwp_options_tag.setObjectName("cwp_options_tag")
+ self.horizontalLayout_4.addWidget(self.cwp_options_tag)
+ self.verticalLayout_16.addWidget(self.save_options_box)
+ self.override_box = QtWidgets.QGroupBox(self.special_tags_frame_inner)
+ palette = QtGui.QPalette()
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
+ brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
+ brush.setStyle(QtCore.Qt.SolidPattern)
+ palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
+ self.override_box.setPalette(palette)
+ self.override_box.setAutoFillBackground(False)
+ self.override_box.setStyleSheet("background-color: rgb(229, 229, 159);")
+ self.override_box.setObjectName("override_box")
+ self.horizontalLayout_10 = QtWidgets.QHBoxLayout(self.override_box)
+ self.horizontalLayout_10.setObjectName("horizontalLayout_10")
+ self.cea_override = QtWidgets.QCheckBox(self.override_box)
+ self.cea_override.setObjectName("cea_override")
+ self.horizontalLayout_10.addWidget(self.cea_override)
+ self.cwp_override = QtWidgets.QCheckBox(self.override_box)
+ self.cwp_override.setObjectName("cwp_override")
+ self.horizontalLayout_10.addWidget(self.cwp_override)
+ self.ce_genres_override = QtWidgets.QCheckBox(self.override_box)
+ self.ce_genres_override.setEnabled(True)
+ self.ce_genres_override.setObjectName("ce_genres_override")
+ self.horizontalLayout_10.addWidget(self.ce_genres_override)
+ self.ce_tagmap_override = QtWidgets.QCheckBox(self.override_box)
+ self.ce_tagmap_override.setEnabled(True)
+ self.ce_tagmap_override.setObjectName("ce_tagmap_override")
+ self.horizontalLayout_10.addWidget(self.ce_tagmap_override)
+ self.line_11 = QtWidgets.QFrame(self.override_box)
+ self.line_11.setFrameShape(QtWidgets.QFrame.VLine)
+ self.line_11.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_11.setObjectName("line_11")
+ self.horizontalLayout_10.addWidget(self.line_11)
+ self.ce_options_overwrite = QtWidgets.QCheckBox(self.override_box)
+ self.ce_options_overwrite.setStyleSheet("background-color: rgb(255, 0, 0);")
+ self.ce_options_overwrite.setObjectName("ce_options_overwrite")
+ self.horizontalLayout_10.addWidget(self.ce_options_overwrite)
+ self.verticalLayout_16.addWidget(self.override_box)
+ self.label_121 = QtWidgets.QLabel(self.special_tags_frame_inner)
+ self.label_121.setObjectName("label_121")
+ self.verticalLayout_16.addWidget(self.label_121)
+ self.line_2 = QtWidgets.QFrame(self.special_tags_frame_inner)
+ self.line_2.setFrameShape(QtWidgets.QFrame.HLine)
+ self.line_2.setFrameShadow(QtWidgets.QFrame.Sunken)
+ self.line_2.setObjectName("line_2")
+ self.verticalLayout_16.addWidget(self.line_2)
+ self.ce_show_ui_tags = QtWidgets.QCheckBox(self.special_tags_frame_inner)
+ self.ce_show_ui_tags.setObjectName("ce_show_ui_tags")
+ self.verticalLayout_16.addWidget(self.ce_show_ui_tags)
+ self.groupBox = QtWidgets.QGroupBox(self.special_tags_frame_inner)
+ self.groupBox.setStyleSheet("background-color: rgb(229, 229, 159);")
+ self.groupBox.setObjectName("groupBox")
+ self.verticalLayout_42 = QtWidgets.QVBoxLayout(self.groupBox)
+ self.verticalLayout_42.setObjectName("verticalLayout_42")
+ self.label_94 = QtWidgets.QLabel(self.groupBox)
+ self.label_94.setObjectName("label_94")
+ self.verticalLayout_42.addWidget(self.label_94)
+ self.ce_ui_tags = QtWidgets.QTextEdit(self.groupBox)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Expanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.ce_ui_tags.sizePolicy().hasHeightForWidth())
+ self.ce_ui_tags.setSizePolicy(sizePolicy)
+ self.ce_ui_tags.setMaximumSize(QtCore.QSize(16777215, 120))
+ self.ce_ui_tags.setStyleSheet("background-color: rgb(250, 250, 250);")
+ self.ce_ui_tags.setObjectName("ce_ui_tags")
+ self.verticalLayout_42.addWidget(self.ce_ui_tags)
+ self.label_8 = QtWidgets.QLabel(self.groupBox)
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_8.sizePolicy().hasHeightForWidth())
+ self.label_8.setSizePolicy(sizePolicy)
+ self.label_8.setObjectName("label_8")
+ self.verticalLayout_42.addWidget(self.label_8)
+ self.verticalLayout_16.addWidget(self.groupBox)
+ self.verticalLayout_60.addWidget(self.special_tags_frame_inner)
+ self.verticalLayout_18.addWidget(self.special_tags_frame_outer)
+ self.label_83 = QtWidgets.QLabel(self.scrollAreaWidgetContents_2)
+ self.label_83.setObjectName("label_83")
+ self.verticalLayout_18.addWidget(self.label_83)
+ self.scrollArea_2.setWidget(self.scrollAreaWidgetContents_2)
+ self.horizontalLayout_31.addWidget(self.scrollArea_2)
+ self.tabWidget.addTab(self.Advanced, "")
+ self.Help = QtWidgets.QWidget()
+ self.Help.setObjectName("Help")
+ self.scrollArea_5 = QtWidgets.QScrollArea(self.Help)
+ self.scrollArea_5.setGeometry(QtCore.QRect(0, -10, 671, 561))
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.scrollArea_5.sizePolicy().hasHeightForWidth())
+ self.scrollArea_5.setSizePolicy(sizePolicy)
+ self.scrollArea_5.setWidgetResizable(True)
+ self.scrollArea_5.setObjectName("scrollArea_5")
+ self.scrollAreaWidgetContents_4 = QtWidgets.QWidget()
+ self.scrollAreaWidgetContents_4.setGeometry(QtCore.QRect(0, 0, 669, 559))
+ self.scrollAreaWidgetContents_4.setObjectName("scrollAreaWidgetContents_4")
+ self.textBrowser_2 = QtWidgets.QTextBrowser(self.scrollAreaWidgetContents_4)
+ self.textBrowser_2.setGeometry(QtCore.QRect(9, 109, 641, 421))
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Expanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.textBrowser_2.sizePolicy().hasHeightForWidth())
+ self.textBrowser_2.setSizePolicy(sizePolicy)
+ self.textBrowser_2.setHorizontalScrollBarPolicy(QtCore.Qt.ScrollBarAsNeeded)
+ self.textBrowser_2.setOpenExternalLinks(True)
+ self.textBrowser_2.setObjectName("textBrowser_2")
+ self.label_58 = QtWidgets.QLabel(self.scrollAreaWidgetContents_4)
+ self.label_58.setGeometry(QtCore.QRect(9, 9, 471, 16))
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Maximum)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.label_58.sizePolicy().hasHeightForWidth())
+ self.label_58.setSizePolicy(sizePolicy)
+ self.label_58.setText("")
+ self.label_58.setObjectName("label_58")
+ self.textBrowser_3 = QtWidgets.QTextBrowser(self.scrollAreaWidgetContents_4)
+ self.textBrowser_3.setGeometry(QtCore.QRect(9, 28, 641, 81))
+ sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Expanding)
+ sizePolicy.setHorizontalStretch(0)
+ sizePolicy.setVerticalStretch(0)
+ sizePolicy.setHeightForWidth(self.textBrowser_3.sizePolicy().hasHeightForWidth())
+ self.textBrowser_3.setSizePolicy(sizePolicy)
+ self.textBrowser_3.setOpenExternalLinks(True)
+ self.textBrowser_3.setObjectName("textBrowser_3")
+ self.scrollArea_5.setWidget(self.scrollAreaWidgetContents_4)
+ self.tabWidget.addTab(self.Help, "")
+ self.vboxlayout.addWidget(self.tabWidget)
+ self.label_4.setBuddy(self.cwp_retries)
+ self.label_120.setBuddy(self.cwp_retries)
+ self.label_90.setBuddy(self.cwp_retries)
+ self.label_6.setBuddy(self.cwp_retries)
+ self.label_7.setBuddy(self.cwp_retries)
+ self.label_5.setBuddy(self.cwp_retries)
+ self.label_93.setBuddy(self.cwp_retries)
+ self.label_87.setBuddy(self.cwp_retries)
+
+ self.retranslateUi(ClassicalExtrasOptionsPage)
+ self.tabWidget.setCurrentIndex(4)
+ self.cea_ra_use.toggled['bool'].connect(self.ra_replace_merge_options_box.setEnabled)
+ self.cea_ra_replace_ta.toggled['bool'].connect(self.cea_ra_noblank_ta.setEnabled)
+ self.use_cea.toggled['bool'].connect(self.lyrics_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.cwp_collections.setEnabled)
+ self.cea_split_lyrics.toggled['bool'].connect(self.lyrics_and_notes_tags_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.use_cache.setEnabled)
+ self.use_cea.toggled['bool'].connect(self.other_artist_options_frame.setEnabled)
+ self.cea_arrangers.toggled['bool'].connect(self.annotations_lh_box.setEnabled)
+ self.cea_arrangers.toggled['bool'].connect(self.annotations_rh_box.setEnabled)
+ self.toolButton_1.toggled['bool'].connect(self.cea_source_1.setEnabled)
+ self.toolButton_2.toggled['bool'].connect(self.cea_source_2.setEnabled)
+ self.toolButton_3.toggled['bool'].connect(self.cea_source_3.setEnabled)
+ self.toolButton_4.toggled['bool'].connect(self.cea_source_4.setEnabled)
+ self.toolButton_5.toggled['bool'].connect(self.cea_source_5.setEnabled)
+ self.toolButton_6.toggled['bool'].connect(self.cea_source_6.setEnabled)
+ self.toolButton_7.toggled['bool'].connect(self.cea_source_7.setEnabled)
+ self.toolButton_8.toggled['bool'].connect(self.cea_source_8.setEnabled)
+ self.toolButton_9.toggled['bool'].connect(self.cea_source_9.setEnabled)
+ self.toolButton_10.toggled['bool'].connect(self.cea_source_10.setEnabled)
+ self.toolButton_11.toggled['bool'].connect(self.cea_source_11.setEnabled)
+ self.toolButton_12.toggled['bool'].connect(self.cea_source_12.setEnabled)
+ self.toolButton_13.toggled['bool'].connect(self.cea_source_13.setEnabled)
+ self.toolButton_14.toggled['bool'].connect(self.cea_source_14.setEnabled)
+ self.toolButton_15.toggled['bool'].connect(self.cea_source_15.setEnabled)
+ self.toolButton_16.toggled['bool'].connect(self.cea_source_16.setEnabled)
+ self.use_cea.toggled['bool'].connect(self.advanced_artists_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.advanced_workparts_frame.setEnabled)
+ self.use_cea.toggled['bool'].connect(self.naming_options_frame.setEnabled)
+ self.use_cea.toggled['bool'].connect(self.recording_artists_options_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.work_style_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.work_aliases_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.works_parts_tags_frame.setEnabled)
+ self.use_cwp.toggled['bool'].connect(self.songkong_frame.setEnabled)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_genres.setVisible)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_genres.setChecked)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_classical.setVisible)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_classical.setChecked)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_dates.setVisible)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_periods.setVisible)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_dates.setChecked)
+ self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_periods.setChecked)
+ self.cwp_muso_genres.toggled['bool'].connect(self.cwp_genres_classical_main.setHidden)
+ self.cwp_muso_classical.toggled['bool'].connect(self.cwp_genres_arranger_as_composer.setVisible)
+ self.cwp_muso_dates.toggled['bool'].connect(self.cwp_periods_arranger_as_composer.setVisible)
+ self.cwp_muso_periods.toggled['bool'].connect(self.cwp_period_map.setHidden)
+ self.cwp_muso_periods.toggled['bool'].connect(self.period_map_annotation_label.setHidden)
+ self.cwp_genres_filter.toggled['bool'].connect(self.genre_filters_frame.setVisible)
+ self.use_cwp.toggled['bool'].connect(self.partial_arrangements_medleys_frame.setEnabled)
+ self.cwp_titles.toggled['bool'].connect(self.source_of_canonical_box.setDisabled)
+ self.cwp_titles.toggled['bool'].connect(self.partial_arrangements_medleys_frame.setHidden)
+ self.use_cache.toggled['bool'].connect(self.cwp_use_sk.setEnabled)
+ self.ce_show_ui_tags.toggled['bool'].connect(self.groupBox.setVisible)
+ QtCore.QMetaObject.connectSlotsByName(ClassicalExtrasOptionsPage)
+
+ def retranslateUi(self, ClassicalExtrasOptionsPage):
+ _translate = QtCore.QCoreApplication.translate
+ self.Artists.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.use_cea.setToolTip(_translate("ClassicalExtrasOptionsPage", "should be selected otherwise this section will not run
"))
+ self.use_cea.setText(_translate("ClassicalExtrasOptionsPage", "Create extra artist metadata (MUST BE TICKED FOR THIS SECTION TO RUN)"))
+ self.infer_worktypes_old_label.setText(_translate("ClassicalExtrasOptionsPage", "(Note that the \"infer work-types\" option has moved to the \"genres\" tab)"))
+ self.naming_style_note_label.setText(_translate("ClassicalExtrasOptionsPage", "The naming style for \'artist\' tags is set in the main Picard Options->Metadata section
"))
+ self.naming_options_label.setText(_translate("ClassicalExtrasOptionsPage", "Work-artist / performer naming options
"))
+ self.naming_options_frame.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Work-artists" are types such as composer, writer, arranger and lyricist who belong to the MusicBrainz Work-Artist relationship
"Performers" are types such as performer and conductor who belong to the MusicBrainz Recording-Artist relationship
"))
+ self.label_22.setText(_translate("ClassicalExtrasOptionsPage", "This section does not change the contents of "artist" or "album artist" tags - it only affects writer (composer etc.) and peformer tags, by using as-credited/alias names from the artist data for the release.
"))
+ self.credited_as_options_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.credited_as_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Credited-as options:-"))
+ self.names_to_use_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select the source for \'as-credited\' names - whether these are applied depends on the sub-options choices.
"))
+ self.names_to_use_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Names to use..."))
+ self.cea_recording_credited.setText(_translate("ClassicalExtrasOptionsPage", "Use \"credited as\" name for work-artists/performers who are recording artists"))
+ self.cea_group_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or release group artists"))
+ self.cea_credited.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.cea_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or release artists"))
+ self.cea_release_relationship_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or release relationship artists"))
+ self.cea_recording_relationship_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or recording relationship artists"))
+ self.cea_track_credited.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.cea_track_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or track artists"))
+ self.label_24.setText(_translate("ClassicalExtrasOptionsPage", "The above are applied in sequence - e.g. track artist credit will over-ride release artist credit."))
+ self.label_88.setText(_translate("ClassicalExtrasOptionsPage", "Names are cached. A restart is necessary if any of the above name sources are removed."))
+ self.places_to_use_them_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select the tag types where any \'as-credited\' names will be applied - whether these are applied depends on the sub-options choices.
"))
+ self.places_to_use_them_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Places to use them ..."))
+ self.cea_performer_credited.setText(_translate("ClassicalExtrasOptionsPage", "Use for performing artists"))
+ self.cea_composer_credited.setText(_translate("ClassicalExtrasOptionsPage", "Use for work-artists"))
+ self.naming_sub_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Sub-options"))
+ self.cea_alias_overrides.setToolTip(_translate("ClassicalExtrasOptionsPage", "Alias (if it exists) will over-ride as-credited
"))
+ self.cea_alias_overrides.setText(_translate("ClassicalExtrasOptionsPage", "Alias over-rides credited-as"))
+ self.cea_credited_overrides.setToolTip(_translate("ClassicalExtrasOptionsPage", "As-credited (if it exists) will over-ride alias
"))
+ self.cea_credited_overrides.setText(_translate("ClassicalExtrasOptionsPage", "Credited-as over-rides MB/Alias"))
+ self.cea_cyrillic.setToolTip(_translate("ClassicalExtrasOptionsPage", "Will be based on sort names. For cyrillic script names, patronyms will be removed.
"))
+ self.cea_cyrillic.setText(_translate("ClassicalExtrasOptionsPage", "Fix non-Latin text in names (where possible and if not fixed by other naming options)"))
+ self.MB_std_names_aliases_box_outer.setTitle(_translate("ClassicalExtrasOptionsPage", "MusicBrainz standard names and Aliases"))
+ self.cea_no_aliases.setToolTip(_translate("ClassicalExtrasOptionsPage", "Do not use aliases (but may be replaced by as-credited name)
"))
+ self.cea_no_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Use MB standard names"))
+ self.cea_aliases.setToolTip(_translate("ClassicalExtrasOptionsPage", "Alias will only be available for use if the work-artist/performer is also a release artist, recording artist or track artist.
"))
+ self.cea_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Use alias for all work-artists/performers"))
+ self.cea_aliases_composer.setToolTip(_translate("ClassicalExtrasOptionsPage", "Only use alias (if available) for work-artists (writers, composers, arrangers, lyricists etc.)
"))
+ self.cea_aliases_composer.setText(_translate("ClassicalExtrasOptionsPage", "Use alias for work-artists only"))
+ self.recording_artist_options_label.setText(_translate("ClassicalExtrasOptionsPage", "Recording artist options
"))
+ self.recording_artists_options_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select recording artist options (see "What\'s this")
"))
+ self.recording_artists_options_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "In MusicBrainz, the recording artist may be different from the track artist. For classical music, the MusicBrainz guidelines state that the track artist should be the composer; however the recording artist(s) is/are usually the principal performer(s).
Classical Extras puts the recording artists into \'hidden variables\' (as a minimum) using the chosen naming convention.
There is also option to allow you to replace the track artist by the recording artist (or to merge them). The chosen action will be applied to the \'artist\', \'artists\', \'artistsort\' and \'artists_sort\' tags. Note that \'artist\' is a single-valued string whereas \'artists\' is a list and may be multi-valued. Lists are properly merged, but because the \'artist\' string may have different join-phrases etc, a merged tag may have the recording artist(s) in brackets after the track artist(s).
"))
+ self.naming_convention_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "In classical music (in MusicBrainz), recording artists will usually be performers whereas track artists are composers. By default, the naming convention for performers (set in the previous section) will be used (although only the as-credited name set for the recording artist will be applied). Alternatively, the naming convention for track artists can be used - which is determined by the main Picard metadat options.
"))
+ self.naming_convention_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Naming convention as for ..."))
+ self.cea_ra_trackartist.setText(_translate("ClassicalExtrasOptionsPage", "...track artist (set in Picard options)"))
+ self.cea_ra_performer.setText(_translate("ClassicalExtrasOptionsPage", "... perfomers (set above)"))
+ self.cea_ra_use.setText(_translate("ClassicalExtrasOptionsPage", "Use recording artists to update track artists ->"))
+ self.ra_replace_merge_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Replace/merge options"))
+ self.cea_ra_replace_ta.setText(_translate("ClassicalExtrasOptionsPage", "Replace track artist by recording artist"))
+ self.cea_ra_noblank_ta.setText(_translate("ClassicalExtrasOptionsPage", "Only replace if rec. artist exists"))
+ self.cea_ra_merge_ta.setText(_translate("ClassicalExtrasOptionsPage", "Merge track artist and recording artist"))
+ self.other_artist_options_label.setText(_translate("ClassicalExtrasOptionsPage", "Other artist options
"))
+ self.annotations_lh_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter text to appear in annotations. Do not use any quotation marks.
"))
+ self.annotations_lh_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Annotations - performers and lyricists"))
+ self.label_44.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation to include with "chorus master" in conductor tag.
"))
+ self.label_44.setText(_translate("ClassicalExtrasOptionsPage", "Chorus Master"))
+ self.label_46.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation to include for "concert master" in performer tag.
"))
+ self.label_46.setText(_translate("ClassicalExtrasOptionsPage", "Concert Master"))
+ self.label_34.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for lyricist, to include in lyricist tag
"))
+ self.label_34.setText(_translate("ClassicalExtrasOptionsPage", "Lyricist"))
+ self.label_26.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for librettist, to include in lyricist tag
"))
+ self.label_26.setText(_translate("ClassicalExtrasOptionsPage", "Librettist"))
+ self.label_30.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for translator, to include in lyricist tag
"))
+ self.label_30.setText(_translate("ClassicalExtrasOptionsPage", "Translator"))
+ self.other_artist_checkboxes_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select as required. See "What\'s this" for details.
"))
+ self.cea_arrangers.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.cea_arrangers.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This will gather together, for example, any arranger-type information from the recording, work or parent works and place it in the "arranger" tag (\'host\' tag), with the annotation (see details to right of this box) in brackets. All arranger types will also be put in a hidden variable, e.g. _cwp_orchestrators. The table below shows the artist types, host tag and hidden variable for each artist type.
| Artist type | Host tag | Hidden variable |
| ----------------- | ------------------| -------------------------------------- |
| writer | composer | writers |
| lyricist | lyricist | lyricists |
| librettist | lyricist | librettists |
| revised by | arranger | revisors |
| translator | lyricist | translators |
| arranger | arranger | arrangers |
| reconstructed by | arranger | reconstructors |
| orchestrator | arranger | orchestrators |
| instrument arranger | arranger | arrangers (with instrument type in brackets) |
| vocal arranger | arranger | arrangers (with voice type in brackets) |
| chorus master | conductor | chorusmasters |
| concertmaster | performer (with annotation as a sub-key) | leaders |
"))
+ self.cea_arrangers.setText(_translate("ClassicalExtrasOptionsPage", "Modify host tags and include annotations (see =>)"))
+ self.cea_composer_album.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.cea_composer_album.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This will add the composer(s) last name(s) before the album name, if they are listed as album artists. If there is more than one composer, they will be listed in the descending order of the length of their music on the release.
"))
+ self.cea_composer_album.setText(_translate("ClassicalExtrasOptionsPage", "Name album as \"Composer Last Name(s): Album Name\""))
+ self.cea_no_lyricists.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This applies to both the Picard \'lyricist\' tag and the related internal plugin hidden variables \'_cwp_lyricists\' etc.
"))
+ self.cea_no_lyricists.setText(_translate("ClassicalExtrasOptionsPage", "Do not write \'lyricist\' tag if no vocal performers"))
+ self.cea_inst_credit.setText(_translate("ClassicalExtrasOptionsPage", "Use \"credited-as\" name for instrument"))
+ self.cea_no_solo.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select to eliminate "additional", "solo" or "guest" from instrument description
"))
+ self.cea_no_solo.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "MusicBrainz permits the use of "solo", "guest" and "additional" as instrument attributes although, for classical music, its use should be fairly rare - usually only if explicitly stated as a "solo" on the the sleevenotes. Classical Extras provides the option to exclude these attributes (the default), but you may wish to enable them for certain releases or non-Classical / cross-over releases.
"))
+ self.cea_no_solo.setText(_translate("ClassicalExtrasOptionsPage", "Do not include attributes (e.g. \'solo\') in an instrument type"))
+ self.annotations_rh_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter text to appear in annotations. Do not use any quotation marks.
"))
+ self.annotations_rh_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Annotations - writers and arrangers"))
+ self.label_56.setText(_translate("ClassicalExtrasOptionsPage", "Writer"))
+ self.label_54.setText(_translate("ClassicalExtrasOptionsPage", "Arranger"))
+ self.label_45.setToolTip(_translate("ClassicalExtrasOptionsPage", "Text with which to annotate orchestrator in the arranger tag.
"))
+ self.label_45.setText(_translate("ClassicalExtrasOptionsPage", "Orchestrator"))
+ self.label_32.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for "reconstructed by", to include in arranger tag
"))
+ self.label_32.setText(_translate("ClassicalExtrasOptionsPage", "Reconstructed by"))
+ self.label_28.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for "revised by", to include in arranger tag tag
"))
+ self.label_28.setText(_translate("ClassicalExtrasOptionsPage", "Revised by"))
+ self.lyrics_label.setText(_translate("ClassicalExtrasOptionsPage", "Lyrics
"))
+ self.lyrics_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Please note that this section operates on the underlying input file tags, not the Picard-generated tags (MusicBrainz does not have lyrics)
Sometimes "lyrics" tags can contain album notes (repeated for every track in an album) as well as track notes and lyrics. This section will filter out the common text and place it in a different tag from the text which is unique to each track.
"))
+ self.cea_split_lyrics.setToolTip(_translate("ClassicalExtrasOptionsPage", "enables this section
"))
+ self.cea_split_lyrics.setText(_translate("ClassicalExtrasOptionsPage", "Split lyrics tag into track and album levels"))
+ self.lyrics_and_notes_tags_frame.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter a valid tag name (no spaces, punctuation or special charcaters other than underline; use lower case)
"))
+ self.label_50.setToolTip(_translate("ClassicalExtrasOptionsPage", "The name of the lyrics file tag in the input file (normally just \'lyrics\')
"))
+ self.label_50.setText(_translate("ClassicalExtrasOptionsPage", "Incoming lyrics tag (i.e. file tag)"))
+ self.label_51.setToolTip(_translate("ClassicalExtrasOptionsPage", "The name of the tag where common text should be placed
"))
+ self.label_51.setText(_translate("ClassicalExtrasOptionsPage", "Tag for album notes / lyrics"))
+ self.label_52.setToolTip(_translate("ClassicalExtrasOptionsPage", "The name of the tag where notes/lyrics unique to a track should be placed
"))
+ self.label_52.setText(_translate("ClassicalExtrasOptionsPage", "Tag for track notes / lyrics"))
+ self.tabWidget.setTabText(self.tabWidget.indexOf(self.Artists), _translate("ClassicalExtrasOptionsPage", "Artists"))
+ self.use_cwp.setToolTip(_translate("ClassicalExtrasOptionsPage", ""Include all work levels" should be selected otherwise this section will not run.
"))
+ self.use_cwp.setText(_translate("ClassicalExtrasOptionsPage", "Include all work levels (MUST BE TICKED FOR THIS SECTION TO RUN)*"))
+ self.cwp_collections.setToolTip(_translate("ClassicalExtrasOptionsPage", "This will include parent works where the relationship has the attribute \'part of collection\'.
PLEASE BE CONSISTENT and do not use different options on albums with the same works, or the results may be unexpected.
"))
+ self.cwp_collections.setText(_translate("ClassicalExtrasOptionsPage", "Include collection relationships (but not \"series\")"))
+ self.use_cache.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select to use cached works. Deselect to refesh from MusicBrainz.
"))
+ self.use_cache.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use cache" prevents excessive look-ups of the MB database. Every look-up of a parent work needs to be performed separately (hopefully the MB database might make this easier some day). Network usage constraints by MB means that each look-up takes a minimum of 1 second. Once a release has been looked-up, the works are retained in cache, significantly reducing the time required if, say, the options are changed and the data refreshed. However, if the user edits the works in the MB database then the cache will need to be turned off temporarily for the refresh to find the new/changed works. Also some types of work (e.g. arrangements) will require a full look-up if options have been changed.
"))
+ self.use_cache.setText(_translate("ClassicalExtrasOptionsPage", "Use cache (if available)*"))
+ self.work_style_label.setText(_translate("ClassicalExtrasOptionsPage", "Tagging style
"))
+ self.work_style_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "\n"
+"\n"
+""Tagging style". This section determines how the hierarchy of works will be sourced.
\n"
+"Works source: There are 3 options for determing the principal source of the works metadata
\n"
+""Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
\n"
+"
\n"
+""Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).
\n"
+"
\n"
+""Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles where it is significantly different. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations.
\n"
+"Source of canonical work text. Where either of the second two options above are chosen, there is a further choice to be made:
\n"
+""Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.
\n"
+""Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, particularly if the level 0 work name does not contain all the parent work detail. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
\n"
+"Strategy for setting style: It is suggested that you start with "extended/enhanced" style and the "Consistent with lowest level work description" as the source (this is the default). If this does not give acceptable results, try switching to "Full MusicBrainz work hierarchy". If the "enhanced" details in curly brackets (from the track title) give odd results then switch the style to "canonical works" only. Any remaining oddities are then probably in the MusicBrainz data, which may require editing.
"))
+ self.works_source_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "There are 3 options for determing the principal source of the works metadata
- "Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
- "Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will be in the language of the release.
- "Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles where it is significantly different. The supplementary data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations - see image below for an example (using the Muso library manager).
"))
+ self.works_source_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Works source"))
+ self.cwp_titles.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
"))
+ self.cwp_titles.setText(_translate("ClassicalExtrasOptionsPage", "Use only metadata from title text"))
+ self.cwp_works.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).
"))
+ self.cwp_works.setText(_translate("ClassicalExtrasOptionsPage", "Use only metadata from canonical works"))
+ self.cwp_extended.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles **where it is significantly different**. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations
"))
+ self.cwp_extended.setText(_translate("ClassicalExtrasOptionsPage", "Use canonical work metadata enhanced with title text"))
+ self.source_of_canonical_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Where either of the second two options above are chosen, there is a further choice to be made:
- "Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.
- "Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, particularly if the level 0 work name does not contain all the parent work detail. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
"))
+ self.source_of_canonical_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Source of canonical work text (if applicable)"))
+ self.cwp_hierarchical_works.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.
"))
+ self.cwp_hierarchical_works.setText(_translate("ClassicalExtrasOptionsPage", "Full MusicBrainz work hierarchy (may be more verbose)"))
+ self.cwp_level0_works.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, particularly if the level 0 work name does not contain all the parent work detail. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
"))
+ self.cwp_level0_works.setText(_translate("ClassicalExtrasOptionsPage", "Consistent with lowest level work description (may be less verbose, but not always complete)"))
+ self.cwp_derive_works_from_title.setText(_translate("ClassicalExtrasOptionsPage", "Attempt to get works and movement info from title if there are no work relationships? (Requires title in form \"work: movement\")"))
+ self.work_aliases_label.setText(_translate("ClassicalExtrasOptionsPage", "Aliases (NB Use a consistent approach throughout the library otherwise duplicate works may occur - see the Readme)*
"))
+ self.work_aliases_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Replace work names by aliases" will use primary aliases for the chosen locale instead of standard MusicBrainz work names. To choose the locale, use the drop-down under "translate artist names" in the main Picard Options-->Metadata page. Note that this option is not saved as a file tag since, if different choices are made for different releases, different work names may be stored and therefore cannot be grouped together in your player/library manager.
The sub-options allow either the replacement of all work names, where a primary alias exists, just the replacement of work names which are in non-Latin script, or only replace those which are flagged with user "Folksonomy" tags. The tag text needs to be included in the text box, in which case flagged works will be \'aliased\' as well as non-Latin script works, if the second sub-option is chosen. Note that the tags may either be anyone\'s tags ("Look in all tags") or the user\'s own tags. If selecting "Look in user\'s own tags only" you must be logged in to your MusicBrainz user account (in the Picard Options->General page), otherwise repeated dialogue boxes may be generated and you may need to force restart Picard.
"))
+ self.replace_MBworknames_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Replace MB work names?"))
+ self.cwp_aliases.setToolTip(_translate("ClassicalExtrasOptionsPage", "Use primary aliases for the chosen locale instead of standard MusicBrainz work names.
"))
+ self.cwp_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Replace work names by aliases. Select method -->"))
+ self.cwp_no_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Do not replace work names"))
+ self.what_to_replace_outer_box.setTitle(_translate("ClassicalExtrasOptionsPage", "What to replace?"))
+ self.cwp_aliases_all.setText(_translate("ClassicalExtrasOptionsPage", "All work names"))
+ self.cwp_aliases_greek.setText(_translate("ClassicalExtrasOptionsPage", "Non-latin work names"))
+ self.cwp_aliases_tagged.setText(_translate("ClassicalExtrasOptionsPage", "Only tagged works"))
+ self.works_alias_tags_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Tags (\"Folksonomy\") identifying works to be replaced by aliases"))
+ self.cwp_aliases_tags_all.setText(_translate("ClassicalExtrasOptionsPage", "Look in all tags"))
+ self.cwp_aliases_tags_user.setText(_translate("ClassicalExtrasOptionsPage", "Look in user\'s own tags only (MUST BE LOGGED IN!)"))
+ self.cwp_aliases_tag_text.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple tags by commas
"))
+ self.work_parts_tags_label.setText(_translate("ClassicalExtrasOptionsPage", "Tags to create - Use commas to separate multiple tags or leave blank to omit
"))
+ self.works_parts_tags_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple tags by commas.
"))
+ self.works_parts_tags_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Tags to create" sets the names of the tags that will be created from the sources described above. All these tags will be blanked before filling as specified. Tags specified against more than one source will have later sources appended in the sequence specified, separated by separators as specified.
"))
+ self.works_tags_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Work tags"))
+ self.label_40.setText(_translate("ClassicalExtrasOptionsPage", "Separator"))
+ self.label_11.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Some software (notably Muso) can display a 2-level work hierarchy as well as the work-movement hierarchy. This tag can be use to store the 2-level work name (a double colon :: is used to separate the levels within the tag).
"))
+ self.label_11.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Work - for software with 2-level capability (e.g. Muso)
"))
+ self.cwp_multi_work_sep.setItemText(1, _translate("ClassicalExtrasOptionsPage", "; "))
+ self.cwp_multi_work_sep.setItemText(2, _translate("ClassicalExtrasOptionsPage", ": "))
+ self.cwp_multi_work_sep.setItemText(3, _translate("ClassicalExtrasOptionsPage", ". "))
+ self.cwp_multi_work_sep.setItemText(4, _translate("ClassicalExtrasOptionsPage", ", "))
+ self.cwp_multi_work_sep.setItemText(5, _translate("ClassicalExtrasOptionsPage", "- "))
+ self.label.setText(_translate("ClassicalExtrasOptionsPage", "(In this format, intermediate works will be displayed after a double colon :: )"))
+ self.label_15.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Software which can display a movement and work (but no higher levels) could use any tags specified here. Note that if there are multiple work levels, the intermediate levels will not be tagged. Users wanting all the information should use the tags from the previous option (but it may cause some breaks in the display if levels change) - alternatively the missing work levels can be included in a movement tag (see below).
"))
+ self.label_15.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Work - for software with 1-level capability (e.g. iTunes)
"))
+ self.cwp_single_work_sep.setItemText(1, _translate("ClassicalExtrasOptionsPage", "; "))
+ self.cwp_single_work_sep.setItemText(2, _translate("ClassicalExtrasOptionsPage", ": "))
+ self.cwp_single_work_sep.setItemText(3, _translate("ClassicalExtrasOptionsPage", ". "))
+ self.cwp_single_work_sep.setItemText(4, _translate("ClassicalExtrasOptionsPage", ", "))
+ self.cwp_single_work_sep.setItemText(5, _translate("ClassicalExtrasOptionsPage", "- "))
+ self.label_2.setText(_translate("ClassicalExtrasOptionsPage", "(Intermediate works will not be displayed:- Either 1. use the 2-level format if you wish to display them, but note that this will ceate new work, or 2. include them in the movement [see below])"))
+ self.label_12.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This is the top-level work held in MB. This can be useful for cataloguing and searching (if the library software is capable). Note that this will always be the "canonical" MB name, not one derived from titles or the lowest level work name and that no annotations (e.g. key or work year) will be added. However, if "replace work names by aliases" has been selected and is applicable, the relevant alias will be used.
"))
+ self.label_12.setText(_translate("ClassicalExtrasOptionsPage", "Tags for top-level (canonical) work (for capable library managers)
"))
+ self.label_10.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
+ self.parts_tags_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Movement/Part tags"))
+ self.label_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard standard tag is \'movementnumber\' - include that or other(s) of your choice
"))
+ self.label_13.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This is not necessarily the embedded movt/part number, but is the sequence number of the movement within its parent work on the current release.
"))
+ self.label_13.setText(_translate("ClassicalExtrasOptionsPage", "Tags for (computed) movement number (Picard std tag is movementnumber)
"))
+ self.cwp_movt_no_sep.setItemText(1, _translate("ClassicalExtrasOptionsPage", "; "))
+ self.cwp_movt_no_sep.setItemText(2, _translate("ClassicalExtrasOptionsPage", ": "))
+ self.cwp_movt_no_sep.setItemText(3, _translate("ClassicalExtrasOptionsPage", ". "))
+ self.cwp_movt_no_sep.setItemText(4, _translate("ClassicalExtrasOptionsPage", ", "))
+ self.cwp_movt_no_sep.setItemText(5, _translate("ClassicalExtrasOptionsPage", "- "))
+ self.label_43.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard tag \'movementtotal\' will be populated in any case - no need to specify it
"))
+ self.label_43.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This is not necessarily the total number of movements in the parent work, but is the total number of movement tracks within the parent work on the current release.
"))
+ self.label_43.setText(_translate("ClassicalExtrasOptionsPage", "Tags for (computed) total number of movements (Picard std tag is movementtotal)
"))
+ self.label_79.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
+ self.label_49.setText(_translate("ClassicalExtrasOptionsPage", "Movement name tags (Picard std tag is movement)
Use different movement tags if required for different level systems ==>
"))
+ self.label_47.setText(_translate("ClassicalExtrasOptionsPage", "
for use with multi-level work tags
"))
+ self.label_48.setText(_translate("ClassicalExtrasOptionsPage", "
for use with1-level work tags (intermediate works will prefix movement)
"))
+ self.label_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard standard tag is \'movement\' - include that or other(s) of your choice
"))
+ self.label_14.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "As below, but without the movement part/number prefix (if applicable)
"))
+ self.label_14.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Movement - excluding embedded movt/part numbers
"))
+ self.label_39.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
+ self.label_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard standard tag is \'movement\' - include that or other(s) of your choice
"))
+ self.label_9.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This tag(s) will contain the full lowest-level part name extracted from the lowest-level work name, according to the chosen tagging style.
"))
+ self.label_9.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Movement - including embedded movt/part numbers
"))
+ self.label_37.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
+ self.partial_arrangements_medleys_label.setText(_translate("ClassicalExtrasOptionsPage", "Partial recordings, arrangements and medleys
"))
+ self.partial_arrangements_medleys_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter text - do not use any quotation marks
"))
+ self.label_20.setText(_translate("ClassicalExtrasOptionsPage", "N.B. If these options are selected or deselected, quit and restart Picard before proceeding"))
+ self.partial_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If this option is selected, partial recordings will be treated as a sub-part of the whole recording and will have the related text included in its name. Note that this text is at the end of the canonical name, but the latter will probably be stripped from the sub-part as it duplicates the recording work name; any title text will be appended to the whole. Note that, if "Consistent with lowest level work description" is chosen in section 2, the text may be treated as a "prefix" similar to those in the "Advanced" tab. If this eliminates other similar prefixes and has unwanted effects, then either change the desired text slightly (e.g. surround with brackets) or use the "Full MusicBrainz work hierarchy" option in section 2.
"))
+ self.partial_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Partial recordings"))
+ self.cwp_partial.setText(_translate("ClassicalExtrasOptionsPage", "Show partial recordings as separate sub-part, labelled with ->"))
+ self.arrangements_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If this option is selected, works which are arrangements of other works will have the latter treated in the same manner as "parent" works, except that the arrangement work name will be prefixed by the text provided.
"))
+ self.arrangements_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Arrangements"))
+ self.cwp_arrangements.setText(_translate("ClassicalExtrasOptionsPage", "Show arrangements as parts of original works, labelled with ->"))
+ self.medleys_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Medleys"))
+ self.cwp_medley.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Medleys
These can occur in two ways in MusicBrainz: (a) the recording is described as a "medley of" a number of works and (b) the track is described as (more than one) "medley including a recording of" a work. In the first case, the specified text will be included in brackets after the work name, whereas in the second case, the track will be treated as a recording of multiple works and the specified text will appear in the parent work name.
"))
+ self.cwp_medley.setText(_translate("ClassicalExtrasOptionsPage", "Include medley list, labelled with ->"))
+ self.songkong_label.setText(_translate("ClassicalExtrasOptionsPage", "SongKong-compatible tag usage
"))
+ self.songkong_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "See "What\'s this"
"))
+ self.songkong_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", " "Use work tags on file (no look up on MB) if Use Cache selected": This will enable the existing work tags on the file to be used in preference to looking up on MusicBrainz, if those tags are SongKong-compatible (which should be the case if SongKong has been used or if the SongKong tags have been previously written by this plugin). If present, this can speed up processing considerably, but obviously any new data on MusicBrainz will be missed. For the option to operate, "Use cache" also needs to be selected. Although faster, some of the subtleties of a full look-up will be missed - for example, parent works which are arrangements will not be highlighted as such, some arrangers or composers of original works may be omitted and some medley information may be missed. **In general, therefore, the use of this option will result in poorer metadata than allowing the full database look-up to run. It is not recommended unless speed is more important than quality.**
"Write SongKong-compatible work tags" does what it says. These can then be used by the previous option, if the release is subsequently reloaded into Picard, to speed things up (assuming the reload was not to pick up new work data).
Note that Picard and SongKong use the tag musicbrainz_workid to mean different things. If Picard has overwritten the SongKong tag (not a problem if this plugin is used) then a warning will be given and the works will be looked up on MusicBrainz. Also note that once a release is loaded, subsequent refreshes will use the cache (if option is ticked) in preference to the file tags.
"))
+ self.cwp_use_sk.setText(_translate("ClassicalExtrasOptionsPage", "Use work tags on file (no look up on MB) if Use Cache selected* (NOT RECOMMENDED - SEE README)"))
+ self.cwp_write_sk.setText(_translate("ClassicalExtrasOptionsPage", "Write SongKong-compatible work tags*"))
+ self.label_82.setText(_translate("ClassicalExtrasOptionsPage", "* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS"))
+ self.tabWidget.setTabText(self.tabWidget.indexOf(self.Works), _translate("ClassicalExtrasOptionsPage", "Works and parts"))
+ self.genre_tag_label.setText(_translate("ClassicalExtrasOptionsPage", "Genre tags
"))
+ self.label_73.setText(_translate("ClassicalExtrasOptionsPage", "Name of genre tag"))
+ self.label_74.setText(_translate("ClassicalExtrasOptionsPage", "Name of sub-genre tag"))
+ self.classical_genre_label.setText(_translate("ClassicalExtrasOptionsPage", ""Classical" genre
"))
+ self.cwp_genres_classical_exclude.setText(_translate("ClassicalExtrasOptionsPage", "Exclude the text \"classical\" from main genre tag even if listed above"))
+ self.cwp_genres_classical_selective.setText(_translate("ClassicalExtrasOptionsPage", "Make track \"classical\" only if there is a classical-specific genre (or do nothing if there is no filter)"))
+ self.cwp_muso_classical.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso composer list to determine if classical*"))
+ self.cwp_genres_classical_all.setText(_translate("ClassicalExtrasOptionsPage", "Make all tracks \"classical\""))
+ self.label_64.setText(_translate("ClassicalExtrasOptionsPage", "Write a flag with text ="))
+ self.label_71.setText(_translate("ClassicalExtrasOptionsPage", " in the following tag if the track is classical"))
+ self.cwp_genres_arranger_as_composer.setText(_translate("ClassicalExtrasOptionsPage", "(Treat arrangers as for composers)"))
+ self.label_81.setText(_translate("ClassicalExtrasOptionsPage", "* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS"))
+ self.cwp_use_muso_refdb.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso reference database (default path is set on \"advanced\" tab)*"))
+ self.instruments_keys_label.setText(_translate("ClassicalExtrasOptionsPage", "Instruments and keys
"))
+ self.instruments_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Instruments"))
+ self.label_66.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for instruments (will hold all instruments for a track)"))
+ self.instruments_source_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Name sources to use for instruments (select at least one, otherwise no instruments will be included in tag)"))
+ self.cwp_instruments_MB_names.setText(_translate("ClassicalExtrasOptionsPage", "MusicBrainz standard names"))
+ self.cwp_instruments_credited_names.setText(_translate("ClassicalExtrasOptionsPage", "\"Credited-as\" names"))
+ self.keys_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Keys"))
+ self.label_72.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for key(s)"))
+ self.keys_include_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Include key(s) in work name?"))
+ self.cwp_key_never_include.setText(_translate("ClassicalExtrasOptionsPage", "Never"))
+ self.cwp_key_contingent_include.setText(_translate("ClassicalExtrasOptionsPage", "Only if key not already mentioned in work name"))
+ self.cwp_key_include.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Include key(s) in work names" gives the option to include the key signature for a work in brackets after the name of the work in the metadata. Keys will be added in the appropriate levels: e.g. Dvořák\'s New World Symphony will get (E minor) at the work level, but only movements with different keys will be annotated viz. "II. Largo (D-flat major, C-Sharp minor)"
"))
+ self.cwp_key_include.setText(_translate("ClassicalExtrasOptionsPage", "Always"))
+ self.allowed_filters_label.setText(_translate("ClassicalExtrasOptionsPage", "Allowed genres (filter)
"))
+ self.cwp_genres_filter.setText(_translate("ClassicalExtrasOptionsPage", "Only apply genres to tags if they match pre-defined names:"))
+ self.genre_filters_frame.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Explanation of genre-matching:
Only genres matching those in the boxes will be placed in the genre or sub-genre tags.
If there is a matching genre found in the "classical main genres" or "classical sub-genres" box, then the track will be treated as being classical.
"))
+ self.classical_genres_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Classical genres (i.e. specific to classical music) - List separated by commas"))
+ self.label_60.setText(_translate("ClassicalExtrasOptionsPage", "Main genres:"))
+ self.label_75.setText(_translate("ClassicalExtrasOptionsPage", "Sub-genres:"))
+ self.cwp_muso_genres.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select this to use the "classical genres" in Muso options as the "Main classical genres" here.
"))
+ self.cwp_muso_genres.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso classical genres*"))
+ self.general_genres_box.setTitle(_translate("ClassicalExtrasOptionsPage", "General genres (may be associated with classical music, but not necessarily, e.g. \"instrumental\") - List separated by commas"))
+ self.label_62.setText(_translate("ClassicalExtrasOptionsPage", "Main genres"))
+ self.label_76.setText(_translate("ClassicalExtrasOptionsPage", "Sub-genres"))
+ self.label_80.setText(_translate("ClassicalExtrasOptionsPage", "Genre name to use if none of the above main genres apply (leave blank if not required)"))
+ self.label_77.setText(_translate("ClassicalExtrasOptionsPage", "List genres, separated by commas. Only those genres listed will be included in tags."))
+ self.label_78.setText(_translate("ClassicalExtrasOptionsPage", "See \"what\'s this\" for more details."))
+ self.source_of_genres_label.setText(_translate("ClassicalExtrasOptionsPage", "Source of genres - Note: if "existing file tag" is selected, information from the tag "genre" and the genre tag name specified above (if different) will be used
"))
+ self.cwp_genres_use_file.setToolTip(_translate("ClassicalExtrasOptionsPage", "NB: This will use the contents of the file tag with the name given above (usually \'genre\').
"))
+ self.cwp_genres_use_file.setText(_translate("ClassicalExtrasOptionsPage", "Existing file tag (see note above)"))
+ self.cwp_genres_use_folks.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This will use the folksonomy tags for works as a possible source of genres (if they match one of the lists below).
To use the folksonomy tags for releases/tracks, select the main Picard option in Options->Metadata->"Use folksonomy tags as genre". Again (unlike vanilla Picard) they will only be used by this plugin if they match one of the lists below.
"))
+ self.cwp_genres_use_folks.setText(_translate("ClassicalExtrasOptionsPage", "Folksonomy work tags"))
+ self.cwp_genres_use_worktype.setText(_translate("ClassicalExtrasOptionsPage", "Work-type"))
+ self.cwp_genres_infer.setText(_translate("ClassicalExtrasOptionsPage", "Infer from artist metadata"))
+ self.label_109.setText(_translate("ClassicalExtrasOptionsPage", "Periods and dates
"))
+ self.dates_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Work dates"))
+ self.dates_box_inner.setTitle(_translate("ClassicalExtrasOptionsPage", "Source of work dates for above tag"))
+ self.cwp_workdate_source_composed.setText(_translate("ClassicalExtrasOptionsPage", "Composed date (or parent composed date)"))
+ self.cwp_workdate_source_published.setText(_translate("ClassicalExtrasOptionsPage", "Published date"))
+ self.cwp_workdate_source_premiered.setText(_translate("ClassicalExtrasOptionsPage", "Premiered date"))
+ self.cwp_workdate_use_first.setText(_translate("ClassicalExtrasOptionsPage", "Use first available of above (in listed order)"))
+ self.cwp_workdate_use_all.setText(_translate("ClassicalExtrasOptionsPage", "Include all sources"))
+ self.cwp_workdate_annotate.setText(_translate("ClassicalExtrasOptionsPage", "Annotate dates using source name"))
+ self.label_68.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for work date"))
+ self.cwp_workdate_include.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Includeworkdate in work names" gives the option to include the \'work year\' for a work in brackets after the name of the work in the metadata. Dates (years) will be added in the appropriate levels: e.g. Smetana\'s \'Má vlast\' will get (1874-1879) at the work level, but the movements with different dates will be annotated viz. "Vyšehrad, JB 1:112/1 (1874)". If the dates are the same, there should be no repitetion at the movement level. (Work dates will be used in preference order, i.e. composed - published - premiered, with only the first available date being shown).
"))
+ self.cwp_workdate_include.setText(_translate("ClassicalExtrasOptionsPage", "Include workdate in work name (in preference order listed above, with no annotation)"))
+ self.periods_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Periods"))
+ self.label_69.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for period"))
+ self.cwp_muso_periods.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso map*"))
+ self.cwp_muso_dates.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso composer dates (if no work date) to determine period*"))
+ self.label_70.setText(_translate("ClassicalExtrasOptionsPage", "Period map:"))
+ self.period_map_annotation_label.setText(_translate("ClassicalExtrasOptionsPage", " (Period name, Start year, End year; Period name2, ... etc.) - periods may overlap [Do not use commas or semi-colons within period name]"))
+ self.cwp_periods_arranger_as_composer.setText(_translate("ClassicalExtrasOptionsPage", "(Treat arrangers as for composers)"))
+ self.label_119.setText(_translate("ClassicalExtrasOptionsPage", "N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") must be enabled for this section to run.
(Functionality will be reduced unless both the first two tabs are enabled.)
"))
+ self.tabWidget.setTabText(self.tabWidget.indexOf(self.Genres), _translate("ClassicalExtrasOptionsPage", "Genres etc."))
+ self.label_18.setText(_translate("ClassicalExtrasOptionsPage", "N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") must be enabled for this section to run.
"))
+ self.label_97.setText(_translate("ClassicalExtrasOptionsPage", "Initial tag processing
"))
+ self.initial_tag_processing_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.tags_to_blank.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Any tags specified in the next two rows will be blanked before applying the tag sources described in the following section. NB this applies only to Picard-generated tags, not to other tags which might pre-exist on the file: to blank those, use the main Options->Tags page. Comma-separate the tag names within the rows and note that these names are case-sensitive.
"))
+ self.tags_to_blank.setTitle(_translate("ClassicalExtrasOptionsPage", "Remove Picard-generated tags before applying subsequent actions? (NB existing LOCAL FILE tags will remain unless cleared using standard Picard options - to remove these, overwrite them in the next section)"))
+ self.label_3.setText(_translate("ClassicalExtrasOptionsPage", "Picard-generated tags to blank (comma-separated, case-sensitive):
"))
+ self.cea_blank_tag.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter file tag names, separated by commas
"))
+ self.cea_blank_tag_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter file tag names, separated by commas
"))
+ self.label_19.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "
"))
+ self.label_19.setText(_translate("ClassicalExtrasOptionsPage", "List existing file tags which will be appended to rather than over-written by tag mapping (this will keep tags even if "Clear existing tags" is selected on main options)
NB To allow appending to happen, do not also include these tags in "Preserve tags" on the main options.
"))
+ self.cea_keep.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter file tag names, separated by commas
"))
+ self.cea_keep.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This refers to the tags which already exist on files which have been matched to MusicBrainz in the right-hand panel, not the tags generated by Picard from the MusicBrainz database. Normally, Picard cannot process these tags - either it will overwrite them (if it creates a similarly named tag), clear them (if \'Clear existing tags\' is specified in the main Options->Tags screen) or keep them (if \'Preserve these tags...\' is specified after the \'Clear existing tags\' option). Classical Extras allows a further option - for the tags to be appended to in the tag mapping section (see below). List file tags which will be appended to rather than over-written by tag mapping (NB this will keep tags even if "Clear existing tags" is selected on main options). In addition, certain existing tags may be used by Classical Extras - in particular genre-related tags (see the Genres etc. options tab for more).
Note that if "Split lyrics tag" is specified (see the Artists tab), then the tag named there will be included in the \'Keep file tags\' list and does not need to be added in this section.
"))
+ self.cea_clear_tags.setToolTip(_translate("ClassicalExtrasOptionsPage", "Note that the main Picard option "Clear existing tags" should be unchecked for this option to operate in preference to that Picard option. The difference is that this option will not intefere with cover art, whereas the main Picard option will remove previous cover art.
"))
+ self.cea_clear_tags.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If selected: the bottom pane of Picard will only show tags which have been generated from the MusicBrainz lookups plus any existing file tags which are listed above or in the main options "Preserve tags...".
This does not mean that the file tags will be removed when saving the file. For that to happen, "Clear existing tags" needs to be selected in the main options.
"))
+ self.cea_clear_tags.setText(_translate("ClassicalExtrasOptionsPage", "Do not show any file tags that are NOT listed above AND NOT listed in the main Picard \"Preserve tags...\" option (Options->Tags), even if \"Clear existing tags\" is not selected."))
+ self.label_98.setText(_translate("ClassicalExtrasOptionsPage", "Tag map details
"))
+ self.tagmap_details_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter tags, separated by commas.
"))
+ self.textBrowser.setHtml(_translate("ClassicalExtrasOptionsPage", "\n"
+"\n"
+"Notes:
\n"
+"Click "Source from:" button to edit source tags.
\n"
+"Any valid Picard-generated tag can be entered in the "source" box, as well as Classical Extras sources, and mapped into other tags - not just restricted to artists.
\n"
+"To put a constant in a tag, type it into the source box preceded by a backslash \\.
\n"
+"In all cases, the source will be APPENDED to the Picard tag. To replace the standard tag, first blank it in the section above - add it back later in the list below if required (e.g. artist -> artist).
\n"
+"BUT note that any existing LOCAL FILE tag will be replaced by (not appended with) any Picard/Classical Extras tag UNLESS specified in the list box above.
\n"
+"These tag-mapping options may be omitted from the over-riding of artist options - see advanced tab
\n"
+"For more help seethe readme.
"))
+ self.toolButton_1.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_1.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_1.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_1.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_1.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_1.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_1.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_1.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_1.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_1.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_1.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_1.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_1.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_1.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_1.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_1.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_1.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_1.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_1.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_1.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_1.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_1.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_1.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_21.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_1.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_1.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_2.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_2.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_2.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_2.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_2.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_2.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_2.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_2.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_2.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_2.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_2.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_2.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_2.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_2.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_2.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_2.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_2.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_2.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_2.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_2.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_2.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_23.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_2.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_3.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_3.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_3.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_3.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_3.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_3.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_3.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_3.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_3.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_3.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_3.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_3.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_3.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_3.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_3.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_3.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_3.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_3.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_3.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_3.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_3.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_3.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_3.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_25.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_3.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_3.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_4.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_4.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_4.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_4.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_4.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_4.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_4.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_4.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_4.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_4.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_4.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_4.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_4.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_4.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_4.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_4.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_4.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_4.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_4.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_4.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_4.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_4.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_4.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_27.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_4.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_4.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_5.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_5.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_5.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_5.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_5.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_5.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_5.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_5.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_5.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_5.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_5.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_5.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_5.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_5.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_5.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_5.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_5.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_5.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_5.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_5.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_5.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_5.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_5.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_29.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_5.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_5.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_6.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_6.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_6.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_6.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_6.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_6.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_6.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_6.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_6.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_6.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_6.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_6.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_6.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_6.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_6.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_6.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_6.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_6.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_6.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_6.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_6.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_6.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_6.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_31.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_6.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_6.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_7.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_7.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_7.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_7.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_7.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_7.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_7.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_7.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_7.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_7.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_7.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_7.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_7.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_7.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_7.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_7.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_7.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_7.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_7.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_7.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_7.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_7.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_7.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_33.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_7.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_7.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_8.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_8.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_8.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_8.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_8.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_8.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_8.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_8.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_8.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_8.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_8.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_8.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_8.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_8.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_8.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_8.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_8.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_8.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_8.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_8.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_8.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_8.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_8.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_35.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_8.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_8.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_9.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_9.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_9.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_9.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_9.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_9.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_9.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_9.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_9.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_9.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_9.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_9.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_9.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_9.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_9.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_9.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_9.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_9.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_9.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_9.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_9.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_53.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_9.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_10.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_10.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_10.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_10.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_10.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_10.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_10.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_10.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_10.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_10.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_10.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_10.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_10.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_10.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_10.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_10.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_10.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_10.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_10.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_10.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_10.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_10.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_10.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_55.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_10.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_10.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_11.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_11.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_11.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_11.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_11.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_11.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_11.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_11.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_11.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_11.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_11.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_11.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_11.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_11.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_11.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_11.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_11.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_11.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_11.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_11.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_11.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_11.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_11.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_57.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_11.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_11.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_12.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_12.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_12.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_12.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_12.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_12.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_12.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_12.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_12.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_12.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_12.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_12.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_12.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_12.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_12.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_12.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_12.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_12.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_12.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_12.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_12.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_12.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_12.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_59.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_12.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_12.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_13.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_13.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_13.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_13.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_13.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_13.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_13.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_13.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_13.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_13.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_13.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_13.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_13.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_13.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_13.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_13.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_13.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_13.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_13.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_13.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_13.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_61.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_13.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_14.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_14.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_14.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_14.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_14.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_14.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_14.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_14.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_14.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_14.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_14.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_14.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_14.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_14.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_14.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_14.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_14.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_14.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_14.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_14.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_14.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_63.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_14.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_15.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_15.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_15.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_15.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_15.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_15.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_15.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_15.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_15.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_15.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_15.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_15.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_15.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_15.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_15.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_15.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_15.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_15.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_15.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_15.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_15.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_15.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_15.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_65.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_15.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_15.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.toolButton_16.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
+ self.toolButton_16.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
+ self.cea_source_16.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
+ self.cea_source_16.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
+ self.cea_source_16.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
+ self.cea_source_16.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
+ self.cea_source_16.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
+ self.cea_source_16.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
+ self.cea_source_16.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
+ self.cea_source_16.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
+ self.cea_source_16.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
+ self.cea_source_16.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
+ self.cea_source_16.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
+ self.cea_source_16.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
+ self.cea_source_16.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
+ self.cea_source_16.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
+ self.cea_source_16.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
+ self.cea_source_16.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
+ self.cea_source_16.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
+ self.cea_source_16.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
+ self.cea_source_16.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
+ self.cea_source_16.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
+ self.cea_source_16.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
+ self.label_67.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
+ self.cea_tag_16.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
+ self.cea_cond_16.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
+ self.label_42.setText(_translate("ClassicalExtrasOptionsPage", "(If source is empty, tag will be left unchanged) "))
+ self.label_17.setText(_translate("ClassicalExtrasOptionsPage", "(Conditional tags will only be filled if previously empty)"))
+ self.cea_tag_sort.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select to include sort-tags, where available. See "What\'s this?" for more details.
"))
+ self.cea_tag_sort.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If a sort tag is associated with the source tag then the sort names will be placed in a sort tag corresponding to the destination tag. Note that the only explicit sort tags written by Picard are for artist, albumartist and composer. Piacrd also writes hidden variables \'_artists_sort\' and \'albumartists_sort\' (note the plurals - these are the sort tags for multi-valued alternatives \'artists\' and \'_albumartists\'). To be consistent with this approach, the plugin writes hidden variables for other tags - e.g. \'_arranger_sort\'. The plugin also writes hidden sort variables for the various hidden artist variables - e.g. \'_cwp_librettists\' has a matching sort variable \'_cwp_librettists_sort\'. Therefore most artist-type sources will have a sort tag/variable associated with them and these will be placed in a destination sort tag if this option is selected - in other words, selecting this option will cause most destination tags to have associated sort tags. Furthermore, any hidden sort variables associated with tags which are not listed explicitly in the tag mapping section will also be written out as tags (i.e. even if the related tags are not included as destination tags). Note, however, that composite sources (e.g. " ensemble_names + \\; + conductors") do not have sort tags associated with them.
If this option is not selected, no additional sort tags will be written, but the hidden variables will still be available, so if a sort tag is required explicitly, just map the sort tag directly - e.g. map \'conductors_sort\' to \'conductor_sort\'.
"))
+ self.cea_tag_sort.setText(_translate("ClassicalExtrasOptionsPage", "Also populate sort tags"))
+ self.tabWidget.setTabText(self.tabWidget.indexOf(self.Tag_mapping), _translate("ClassicalExtrasOptionsPage", "Tag mapping"))
+ self.label_110.setText(_translate("ClassicalExtrasOptionsPage", "General
"))
+ self.ce_no_run.setText(_translate("ClassicalExtrasOptionsPage", "Do not run Classical Extras for tracks where no pre-existing file is detected (warning tag will be written)"))
+ self.advanced_artists_label.setText(_translate("ClassicalExtrasOptionsPage", "Artists (only effective if \"Artists\" section enabled)
"))
+ self.advanced_artists_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple names by commas. Do not use any quotation marks.
"))
+ self.advanced_artists_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Permits the listing of strings by which ensembles of different types may be identified. This is used by the plugin to place performer details in the relevant hidden variables and thus make them available for use in the "Tag mapping" tab as sources for any required tags.
If it is important that only whole words are to be matched, be sure to include a space after the string.
"))
+ self.ensemble_strings_label.setText(_translate("ClassicalExtrasOptionsPage", "Ensemble strings (separate names by commas)
"))
+ self.cea_orchestras_2.setText(_translate("ClassicalExtrasOptionsPage", "Orchestras"))
+ self.cea_choirs_2.setText(_translate("ClassicalExtrasOptionsPage", "Choirs"))
+ self.cea_groups_2.setText(_translate("ClassicalExtrasOptionsPage", "Groups (i.e. other ensembles such as quartets etc.)"))
+ self.advanced_workparts_label.setText(_translate("ClassicalExtrasOptionsPage", "Works and parts (only effective if \"Works and parts\" section enabled)
"))
+ self.label_4.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Sometimes MB lookups fail. Unfortunately Picard (currently) has no automatic "retry" function. The plugin will attempt to retry for the specified number of attempts. If it still fails, the hidden variable _cwp_error will be set with a message; if error logging is checked in section 4, an error message will be written to the log and the contents of _cwp_error will be written out to a special tag called "An_error_has_occurred" which should appear prominently in the bottom pane of Picard. The problem may be resolved by refreshing, otherwise there may be a problem with the MB database availability. It is unlikely to be a software problem with the plugin.
"))
+ self.label_4.setText(_translate("ClassicalExtrasOptionsPage", "Max number of re-tries to access works (in case of server errors)*
"))
+ self.label_120.setText(_translate("ClassicalExtrasOptionsPage", "Allow blank part names for arrangements and part recordings if arrangement/partial label is provided
"))
+ self.label_114.setText(_translate("ClassicalExtrasOptionsPage", "Removal of common text between parent and child works
"))
+ self.label_90.setText(_translate("ClassicalExtrasOptionsPage", "Minimum number of similar words required before eliminating. Use zero for no elimination.
(Punctuation and accents etc. will be ignored in word comparison)
"))
+ self.label_89.setText(_translate("ClassicalExtrasOptionsPage", "NB Parent name text at the start of a work which is followed by punctuation in the work name will always be stripped regardless of this setting.
Synonyms in the next section also apply.
"))
+ self.title_metadata_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This subsection contains various parameters affecting the processing of strings in titles. Because titles are free-form, not all circumstances can be anticipated. Detailed documentation of these is beyond the scope of this Readme as the effects can be quite complex and subtle and may require an understanding of the plugin code (which is of course open-source) to acsertain them. If pure canonical works are used ("Use only metadata from canonical works" and, if necessary, "Full MusicBrainz work hierarchy" on the Works and parts tab, section 2) then this processing should be irrelevant, but no text from titles will be included. Some explanations are given below:
"Proximity of new words". When using extended metadata - i.e. "metadata enhanced with title text", the plugin will attempt to remove similar words between the canonical work name (in MusicBrainz) and the title before extending the canonical name. After removing such words, a rather "bitty" result may occur. To avoid this, any new words with the specified proximity will have the words between them (or up to the end) included even if they repeat words in the work name.
"Prefixes". When using "metadata from titles" or extended metadata, the structure of the works in MusicBrainz is used to infer the structure in the title text, so strings that are repeated between tracks which are part of the same MusicBrainz work will be treated as "higher level". This can lead to anomolies if, for instance, the titles are "Work name: Part 1", "Work name: Part 2", "Part" will be treated as part of the parent work name. Specifying such words in "Prefixes" will prevent this.
"Synonyms". These words will be considered equivalent when comparing work name and title text. Thus if one word appears in the work name, that and its synonym will be removed from the title in extending the metadata (subject to the proximity setting above).
"Replacements". These words/phrases will be replaced in the title text in extended metadata, regardless of the text in the work name.
"))
+ self.label_115.setText(_translate("ClassicalExtrasOptionsPage", "How title metadata should be included in extended metadata (use cautiously - read documentation)
(Mostly only applies if "Use canonical work metadata enhanced with title text" selected on "Works and parts" tab. However synonyms also apply to parent/child text removal.)
"))
+ self.label_6.setText(_translate("ClassicalExtrasOptionsPage", "Proximity of new words (to each other) to trigger in-fill with existing words (default = 2)
"))
+ self.label_7.setText(_translate("ClassicalExtrasOptionsPage", "Proximity of new words (to start or end) to trigger in-fill with existing words (default =1)
"))
+ self.label_5.setText(_translate("ClassicalExtrasOptionsPage", "Treat hyphenated words as two words for comparison purposes
"))
+ self.label_93.setText(_translate("ClassicalExtrasOptionsPage", "Proportion of a string to be matched to a (usually larger) string for it to be considered essentially similar (default = 66%)
"))
+ self.cwp_substring_match.setSuffix(_translate("ClassicalExtrasOptionsPage", "%"))
+ self.label_87.setText(_translate("ClassicalExtrasOptionsPage", "\n"
+"\n"
+"Fill part name with title text if it would otherwise have no text other than arrangement or partial annotations
"))
+ self.label_92.setText(_translate("ClassicalExtrasOptionsPage", "Prepositions/conjunctions and prefixes
DO NOT USE ANY COMMAS OR QUOTE MARKS (apostophes in words are acceptable)
"))
+ self.label_91.setText(_translate("ClassicalExtrasOptionsPage", "Prepositions & conjunctions: these are words that will not be regarded as providing additional information (not treated as \'new\' words) unless they precede a new word.
Use lower case only, comma separated
"))
+ self.cwp_removewords_2.setText(_translate("ClassicalExtrasOptionsPage", "Prefixes to be ignored in comparison (case insensitive, comma separated)
To prevent a prefix from being ignored when extending metadata with title info, precede it with a space.
To ensure only whole words are removed, follow with a space.
"))
+ self.cwp_removewords.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple names by commas. Do not use any quotation marks.
"))
+ self.cwp_synonyms_2.setText(_translate("ClassicalExtrasOptionsPage", "Synonyms and replacements - must be written as tuples separated by forward slashes - e.g (a,b) / (c,d,e) - a tuple may have two or more synonyms.
N.B. The matching is case-insensitive. Roman numerals will be treated as synonyms of arabic numerals in any event, so no need to enter these.
The last member of the tuple should be the canonical form (i.e. the one to which others are converted for comparison or replacement) and must be a normal string (not a regex). See readme for full details.
Unless entering a regular expression, use backslash \\ to escape any regex metacharacters, namely \\ ^ $ . | ? * + ( ) [ ] {
Also escape commas , and forward slashes /. Do not enclose strings in quote marks.
Enter SYNONYM tuples below - each item in a tuple will be treated as similar when comparing works/parts and titles. The text in tags will be unaltered.
"))
+ self.label_16.setText(_translate("ClassicalExtrasOptionsPage", "Enter REMOVALS/REPLACEMENTS below - these will result in the "extended" text in tags being changed
Put the word(s), phrase(s), or regular exprerssion(s) in the first part(s) of the tuple. The replacement text (or nothing - to remove) goes in the last member of the tuple.
N.B. Replacement text will operate BEFORE synonyms are considered.
"))
+ self.cwp_replacements.setToolTip(_translate("ClassicalExtrasOptionsPage", "Entries must be 2-tuples, e.g. (Replace this, with this). Separate multiple tuples by forward slash. Do not use any quotation marks. Spaces are acceptable. The first item of a tuple may be a regular expression - enclose it with double exclamation marks - e.g.(!!regex here!!, replacement text here).
"))
+ self.advanced_genres_label.setText(_translate("ClassicalExtrasOptionsPage", "Genres etc. (only required if Muso-specific options are used for genres/periods)
"))
+ self.label_85.setText(_translate("ClassicalExtrasOptionsPage", "Path to Muso reference database:"))
+ self.label_84.setText(_translate("ClassicalExtrasOptionsPage", "Name of Muso reference database"))
+ self.label_86.setText(_translate("ClassicalExtrasOptionsPage", "RESTART PICARD AFTER CHANGING THESE
"))
+ self.label_117.setText(_translate("ClassicalExtrasOptionsPage", "Logging options*
"))
+ self.logging_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "These options are in addition to the options chosen in Picard\'s "Help->View error/debug log" settings. They only affect messages written by this plugin. To enable debug messages to be shown, the flag needs to be set here and "Debug mode" needs to be turned on in the log. It is strongly advised to keep the "debug" and "info" flags unchecked unless debugging is required as they slow up processing significantly and may even cause Picard to crash on large releases. The "error" and "warning" flags should be left checked, unless it is required to suppress messages written out to tags (the default is to write messages to the tags 001_errors and 002_warnings).
"))
+ self.log_error.setText(_translate("ClassicalExtrasOptionsPage", "Error"))
+ self.log_warning.setText(_translate("ClassicalExtrasOptionsPage", "Warning"))
+ self.log_debug.setText(_translate("ClassicalExtrasOptionsPage", "Debug"))
+ self.custom_logging_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Custom logging"))
+ self.log_basic.setText(_translate("ClassicalExtrasOptionsPage", "Basic"))
+ self.log_info.setText(_translate("ClassicalExtrasOptionsPage", "Full"))
+ self.label_118.setText(_translate("ClassicalExtrasOptionsPage", "Classical Extras Special Tags
"))
+ self.save_options_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This can be used so that the user has a record of the version of Classical Extras which generated the tags and which options were selected to achieve the resulting tags. Note that the tags will be blanked first so this will only show the last options used on a particular file. The same tag can be used for both sets of options, resulting in a multi-valued tag.
"))
+ self.save_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Save plugin details and options in a tag?*"))
+ self.label_41.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for plugin version"))
+ self.label_36.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for artist/mapping/misc. options"))
+ self.label_38.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for work/genre options"))
+ self.override_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If options have previously been saved (see above), selecting these will cause the saved options to be used in preference to the displayed options. The displayed options will not be affected and will be used if no saved options are present. The default is for no over-ride. If artist options over-ride is chosen, then tag map detail options may be included or not in the override.
The last checkbox, "Overwrite options in Options Pages", is for VERY CAREFUL USE ONLY. It will cause any options read from the saved tags (if the relevant box has been ticked) to over-write the options on the plugin Options Page UI. The intended use of this is if for some reason the user\'s preferred options have been erased/reverted to default - by using this option, the previously-used choices from a reliable filed album can be used to populate the Options Page. The box will automatically be unticked after loading/refreshing one album, to prevent inadvertant use. Far better is to make a backup copy of the picard.ini file.
"))
+ self.override_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Over-ride plugin options displayed in Options Pages with options from local file tags (previously saved using method in box above)?*"))
+ self.cea_override.setText(_translate("ClassicalExtrasOptionsPage", "Artist options"))
+ self.cwp_override.setText(_translate("ClassicalExtrasOptionsPage", "Work options"))
+ self.ce_genres_override.setText(_translate("ClassicalExtrasOptionsPage", "Genres etc. options"))
+ self.ce_tagmap_override.setToolTip(_translate("ClassicalExtrasOptionsPage", "Will not over-ride displayed options unless artist options over-ride is also selected
"))
+ self.ce_tagmap_override.setText(_translate("ClassicalExtrasOptionsPage", "Tag mapping options"))
+ self.ce_options_overwrite.setText(_translate("ClassicalExtrasOptionsPage", "Overwrite options in Options Pages (READ WARNINGS in Readme)"))
+ self.label_121.setText(_translate("ClassicalExtrasOptionsPage", "Note that the above saved options include the related \"advanced\" options on this tab as well as the options on each of the main tabs."))
+ self.ce_show_ui_tags.setText(_translate("ClassicalExtrasOptionsPage", "Show additional tags in Picard UI (rhs panel) - N.B. RESTART NEEDED FOR CHANGE TO TAKE EFFECT"))
+ self.groupBox.setTitle(_translate("ClassicalExtrasOptionsPage", "Additional columns for Picard UI to show specific tags*"))
+ self.label_94.setText(_translate("ClassicalExtrasOptionsPage", "RESTART PICARD AFTER CHANGING THESE - otherwise changes will not take effect
"))
+ self.label_8.setText(_translate("ClassicalExtrasOptionsPage", "Notes:
1. Use the format column_name_A: (include_tag_1, include_tag_2) / column_name_B: include_tag_3 etc. (i.e. put multiple tags to be concatenated in brackets)
2. To just flag tags that have changed, rather than show the contents, add _DIFF at the end of the tag name
3. If more than one tag name is included for a column, then:
(a) if the tags are _DIFF tags, then the column will be flagged if any of them have changed
(b) otherwise the tag contents will be concatenated
"))
+ self.label_83.setText(_translate("ClassicalExtrasOptionsPage", "* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS"))
+ self.tabWidget.setTabText(self.tabWidget.indexOf(self.Advanced), _translate("ClassicalExtrasOptionsPage", "Advanced"))
+ self.textBrowser_2.setHtml(_translate("ClassicalExtrasOptionsPage", "\n"
+"\n"
+"General description
\n"
+"Classical Extras provides tagging enhancements for Picard and, in particular, utilises MusicBrainz’s hierarchy of works to provide work/movement tags. All options are set through a user interface in Picard options->plugins. This interface provides separate sections to enhance artist/performer tags, works and parts, genres and also allows for a generalised "tag mapping" (simple scripting). While it is designed to cater for the complexities of classical music tagging, it may also be useful for other music which has more than just basic song/artist/album data.
The options screen provides five tabs for users to control the tags produced:
1. Artists: Options as to whether artist tags will contain standard MB names, aliases or as-credited names. Ability to include and annotate names for specialist roles (chorus master, arranger, lyricist etc.). Ability to read lyrics tags on the file which has been loaded and assign them to track and album levels if required. (Note: Picard will not normally process incoming file tags).
2. Works and parts: The plugin will build a hierarchy of works and parts (e.g. Work -> Part -> Movement or Opera -> Act -> Number) based on the works in MusicBrainz\'s database. These can then be displayed in tags in a variety of ways according to user preferences. Furthermore partial recordings, medleys, arrangements and collections of works are all handled according to user choices. There is a processing overhead for this at present because MusicBrainz limits look-ups to one per second.
3. Genres etc.: Options are available to customise the source and display of information relating to genres, instruments, keys, work dates and periods. Additional capabilities are provided for users of Muso (or others who provide the relevant XML files) to use pre-existing databases of classical genres, classical composers and classical periods.
4. Tag mapping: in some ways, this is a simple substitute for some of Picard\'s scripting capability. The main advantage is that the plugin will remember what tag mapping you use for each release (or even track).
5. Advanced: Various options to control the detailed processing of the above.
All user options can be saved on a per-album (or even per-track) basis so that tweaks can be used to deal with inconsistencies in the MusicBrainz data (e.g. include English titles from the track listing where the MusicBrainz works are in the composer\'s language and/or script). Also existing file tags can be processed (not possible in native Picard).
"))
+ self.textBrowser_3.setHtml(_translate("ClassicalExtrasOptionsPage", "\n"
+"\n"
+"Please see my website for full details of this plugin and how to use it.
\n"
+"This help page now has only general information.
\n"
+"There are extensive tooltips and "What\'s This" popups (right click for them)
"))
+ self.tabWidget.setTabText(self.tabWidget.indexOf(self.Help), _translate("ClassicalExtrasOptionsPage", "Help"))
+