diff --git a/tutorials/Bonus_Autoencoders/Bonus_Tutorial1.ipynb b/tutorials/Bonus_Autoencoders/Bonus_Tutorial1.ipynb
index 715857b235..523724084e 100644
--- a/tutorials/Bonus_Autoencoders/Bonus_Tutorial1.ipynb
+++ b/tutorials/Bonus_Autoencoders/Bonus_Tutorial1.ipynb
@@ -2305,7 +2305,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.17"
+ "version": "3.9.18"
}
},
"nbformat": 4,
diff --git a/tutorials/Bonus_Autoencoders/instructor/Bonus_Tutorial1.ipynb b/tutorials/Bonus_Autoencoders/instructor/Bonus_Tutorial1.ipynb
index 02ff356af6..e7c7b477fb 100644
--- a/tutorials/Bonus_Autoencoders/instructor/Bonus_Tutorial1.ipynb
+++ b/tutorials/Bonus_Autoencoders/instructor/Bonus_Tutorial1.ipynb
@@ -46,8 +46,6 @@
"\n",
"The primary task is to reconstruct output images based on a compressed representation of the inputs. This task teaches the network which details to throw away while still producing images that are similar to the inputs.\n",
"\n",
- " \n",
- "\n",
"A fictitious *MNIST cognitive task* bundles more elaborate tasks such as removing noise from images, guessing occluded parts, and recovering original image orientation. We use the handwritten digits from the MNIST dataset since it is easier to identify similar images or issues with reconstructions than in other types of data, such as spiking data time series.\n",
"\n",
" \n",
@@ -2313,7 +2311,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.17"
+ "version": "3.9.18"
}
},
"nbformat": 4,
diff --git a/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_9d6c1017_11.png b/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_9d6c1017_11.png
index 1ee5e945b1..52f63be0da 100644
Binary files a/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_9d6c1017_11.png and b/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_9d6c1017_11.png differ
diff --git a/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_c05ddd88_0.png b/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_c05ddd88_0.png
index 3d13ee9b8d..b0d3b0f5f1 100644
Binary files a/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_c05ddd88_0.png and b/tutorials/Bonus_Autoencoders/static/Bonus_Tutorial1_Solution_c05ddd88_0.png differ
diff --git a/tutorials/Bonus_Autoencoders/student/Bonus_Tutorial1.ipynb b/tutorials/Bonus_Autoencoders/student/Bonus_Tutorial1.ipynb
index 418329550e..f61d63e2e2 100644
--- a/tutorials/Bonus_Autoencoders/student/Bonus_Tutorial1.ipynb
+++ b/tutorials/Bonus_Autoencoders/student/Bonus_Tutorial1.ipynb
@@ -46,8 +46,6 @@
"\n",
"The primary task is to reconstruct output images based on a compressed representation of the inputs. This task teaches the network which details to throw away while still producing images that are similar to the inputs.\n",
"\n",
- " \n",
- "\n",
"A fictitious *MNIST cognitive task* bundles more elaborate tasks such as removing noise from images, guessing occluded parts, and recovering original image orientation. We use the handwritten digits from the MNIST dataset since it is easier to identify similar images or issues with reconstructions than in other types of data, such as spiking data time series.\n",
"\n",
" \n",
@@ -1173,7 +1171,7 @@
"\n",
"*Example output:*\n",
"\n",
- "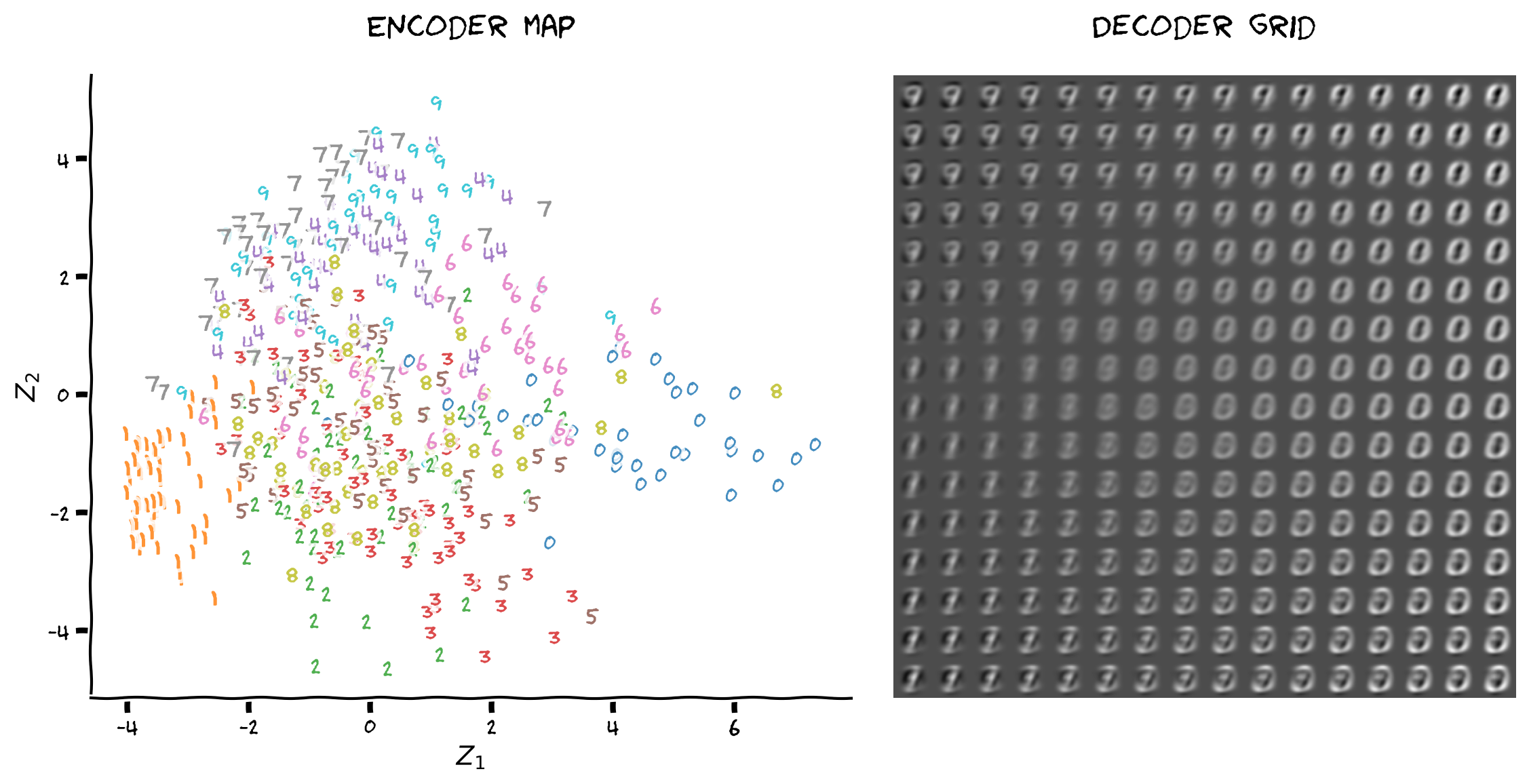 \n",
+ "\n",
"\n"
]
},
@@ -2254,7 +2252,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.17"
+ "version": "3.9.18"
}
},
"nbformat": 4,
\n",
+ "\n",
"\n"
]
},
@@ -2254,7 +2252,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.9.17"
+ "version": "3.9.18"
}
},
"nbformat": 4,