+
+
+
+
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index ecf5b0704..6f85a6c80 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -14,13 +14,24 @@ repos:
hooks:
- id: black
args: ['--line-length=88']
+ exclude: ^docs/|.*\.(json|yaml|md|txt)$
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.4.2
hooks:
# Run the linter.
- id: ruff
- args: ['--fix', '--extend-ignore=E402']
+ args: ['--fix']
+ exclude: ^docs/|.*\.(json|yaml|md|txt)$
+
+ # Add local hooks to run custom commands
+ - repo: local
+ hooks:
+ - id: run-make-format
+ name: Run Make Format
+ entry: make format
+ language: system
+ pass_filenames: false
# - repo: https://github.com/pycqa/flake8
# rev: 4.0.1
# hooks:
diff --git a/Makefile b/Makefile
new file mode 100644
index 000000000..3670e02f6
--- /dev/null
+++ b/Makefile
@@ -0,0 +1,51 @@
+# Define variables for common directories and commands
+PYTHON = poetry run
+SRC_DIR = .
+
+# Default target: Show help
+.PHONY: help
+help:
+ @echo "Available targets:"
+ @echo " setup Install dependencies and set up pre-commit hooks"
+ @echo " format Run Black and Ruff to format the code"
+ @echo " lint Run Ruff to check code quality"
+ @echo " test Run tests with pytest"
+ @echo " precommit Run pre-commit hooks on all files"
+ @echo " clean Clean up temporary files and build artifacts"
+
+# Install dependencies and set up pre-commit hooks
+.PHONY: setup
+setup:
+ poetry install
+ poetry run pre-commit install
+
+# Format code using Black and Ruff
+.PHONY: format
+format:
+ $(PYTHON) black $(SRC_DIR)
+ git ls-files | xargs pre-commit run black --files
+
+# Run lint checks using Ruff
+.PHONY: lint
+lint:
+ $(PYTHON) ruff check $(SRC_DIR)
+
+# Run all pre-commit hooks on all files
+.PHONY: precommit
+precommit:
+ $(PYTHON) pre-commit run --all-files
+
+# Run tests
+.PHONY: test
+test:
+ $(PYTHON) pytest
+
+# Clean up temporary files and build artifacts
+.PHONY: clean
+clean:
+ rm -rf .pytest_cache
+ rm -rf .mypy_cache
+ rm -rf __pycache__
+ rm -rf build dist *.egg-info
+ find . -type d -name "__pycache__" -exec rm -r {} +
+ find . -type f -name "*.pyc" -delete
diff --git a/README.md b/README.md
index 04ec9a5ac..61e411fb1 100644
--- a/README.md
+++ b/README.md
@@ -76,8 +76,21 @@ For AI researchers, product teams, and software engineers who want to learn the
+# Quick Start
+Install AdalFlow with pip:
+
+```bash
+pip install adalflow
+```
+
+Please refer to the [full installation guide](https://adalflow.sylph.ai/get_started/installation.html) for more details.
+
+
+* Try the [Building Quickstart](https://colab.research.google.com/drive/1TKw_JHE42Z_AWo8UuRYZCO2iuMgyslTZ?usp=sharing) in Colab to see how AdalFlow can build the task pipeline, including Chatbot, RAG, agent, and structured output.
+* Try the [Optimization Quickstart](https://colab.research.google.com/github/SylphAI-Inc/AdalFlow/blob/main/notebooks/qas/adalflow_object_count_auto_optimization.ipynb) to see how AdalFlow can optimize the task pipeline.
+
# Why AdalFlow
@@ -111,6 +124,8 @@ Here is an optimization demonstration on a text classification task:
Among all libraries, AdalFlow achieved the highest accuracy with manual prompting (starting at 82%) and the highest accuracy after optimization.
+
+
Further reading: [Optimize Classification](https://adalflow.sylph.ai/use_cases/classification.html)
## Light, Modular, and Model-Agnostic Task Pipeline
@@ -127,6 +142,14 @@ You have full control over the prompt template, the model you use, and the outpu
Before submitting
+ +- Was this **discussed/agreed** via a GitHub issue? (not for typos and docs) +- [ ] Did you read the [contributor guideline](https://adalflow.sylph.ai/contributor/index.html)? +- [ ] Did you make sure your **PR does only one thing**, instead of bundling different changes together? +- Did you make sure to **update the documentation** with your changes? (if necessary) +- Did you write any **new necessary tests**? (not for typos and docs) +- [ ] Did you verify new and **existing tests pass** locally with your changes? +- Did you list all the **breaking changes** introduced by this pull request? + + +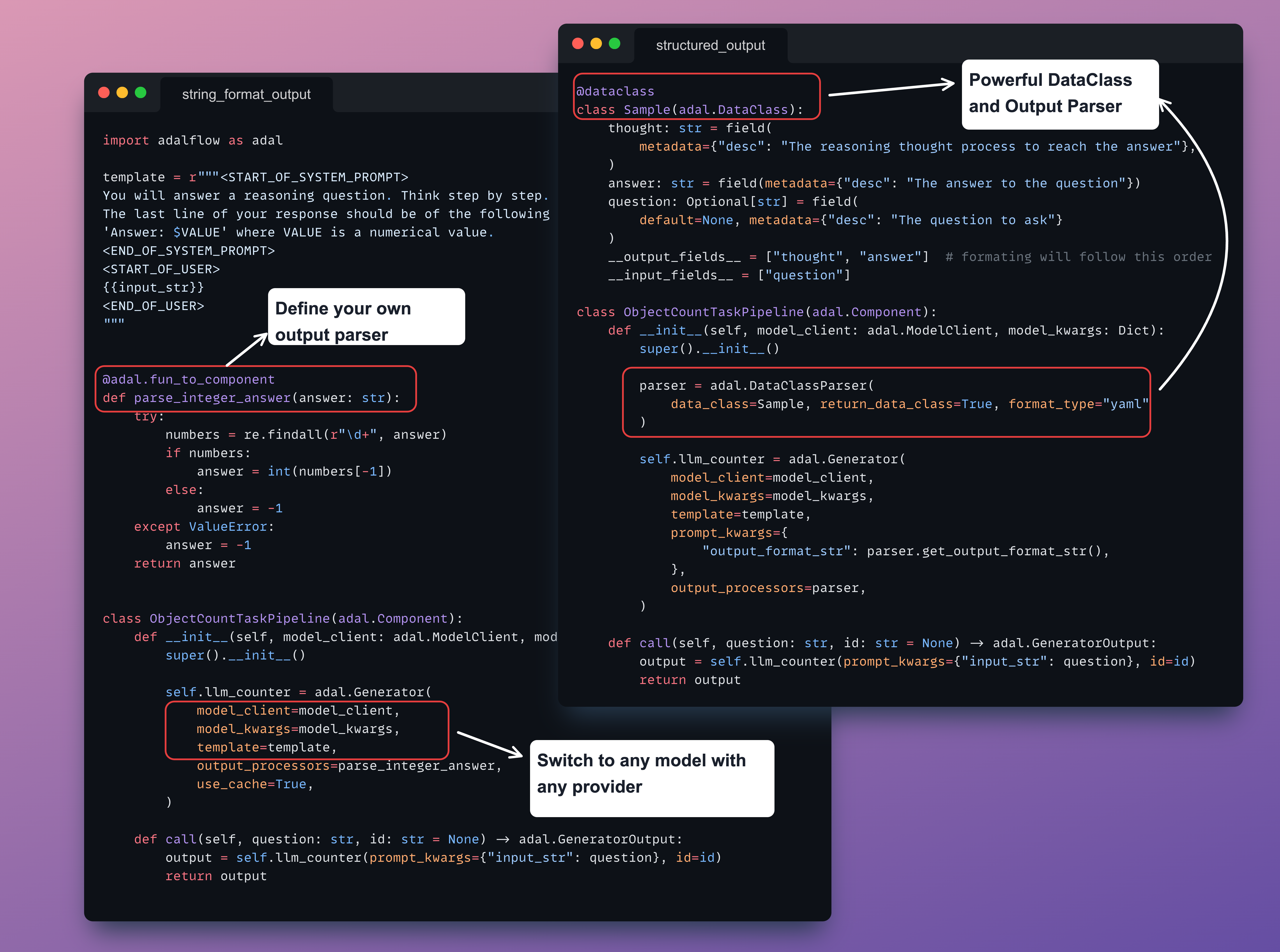 +Many providers and models accessible via the same interface:
+
+
+Many providers and models accessible via the same interface:
+
+
+  +
+
 + Open Source Code
+
DataClass
diff --git a/docs/source/tutorials/component.rst b/docs/source/tutorials/component.rst
index a9e4ae377..649f5310d 100644
--- a/docs/source/tutorials/component.rst
+++ b/docs/source/tutorials/component.rst
@@ -1,7 +1,7 @@
.. raw:: html
+ Open Source Code
+
DataClass
diff --git a/docs/source/tutorials/component.rst b/docs/source/tutorials/component.rst
index a9e4ae377..649f5310d 100644
--- a/docs/source/tutorials/component.rst
+++ b/docs/source/tutorials/component.rst
@@ -1,7 +1,7 @@
.. raw:: html
-
+
 diff --git a/docs/source/tutorials/text_splitter.rst b/docs/source/tutorials/text_splitter.rst
index 60541dff0..4e7da43a8 100644
--- a/docs/source/tutorials/text_splitter.rst
+++ b/docs/source/tutorials/text_splitter.rst
@@ -1,3 +1,15 @@
+.. raw:: html
+
+
diff --git a/docs/source/tutorials/text_splitter.rst b/docs/source/tutorials/text_splitter.rst
index 60541dff0..4e7da43a8 100644
--- a/docs/source/tutorials/text_splitter.rst
+++ b/docs/source/tutorials/text_splitter.rst
@@ -1,3 +1,15 @@
+.. raw:: html
+
+ \n",
+ "{{system_prompt}}\n",
+ "{# Few shot demos #}\n",
+ "{% if few_shot_demos is not none %}\n",
+ "Here are some examples:\n",
+ "{{few_shot_demos}}\n",
+ "{% endif %}\n",
+ "\n",
+ "\n",
+ "{{input_str}}\n",
+ "\n",
+ "\"\"\"\n",
+ "\n",
+ "class ObjectCountTaskPipeline(adal.Component):\n",
+ " def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):\n",
+ " super().__init__()\n",
+ "\n",
+ " system_prompt = adal.Parameter(\n",
+ " data=\"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\",\n",
+ " role_desc=\"To give task instruction to the language model in the system prompt\",\n",
+ " requires_opt=True,\n",
+ " param_type=ParameterType.PROMPT,\n",
+ " )\n",
+ " few_shot_demos = adal.Parameter(\n",
+ " data=None,\n",
+ " role_desc=\"To provide few shot demos to the language model\",\n",
+ " requires_opt=True, # Changed to True for few-shot learning\n",
+ " param_type=ParameterType.DEMOS,\n",
+ " )\n",
+ "\n",
+ " self.llm_counter = adal.Generator(\n",
+ " model_client=model_client,\n",
+ " model_kwargs=model_kwargs,\n",
+ " template=few_shot_template,\n",
+ " prompt_kwargs={\n",
+ " \"system_prompt\": system_prompt,\n",
+ " \"few_shot_demos\": few_shot_demos,\n",
+ " },\n",
+ " output_processors=parse_integer_answer,\n",
+ " use_cache=True,\n",
+ " )\n",
+ "\n",
+ " def call(\n",
+ " self, question: str, id: str = None\n",
+ " ) -> Union[adal.GeneratorOutput, adal.Parameter]:\n",
+ " output = self.llm_counter(prompt_kwargs={\"input_str\": question}, id=id)\n",
+ " return output\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AvZJjdzZa0cT"
+ },
+ "source": [
+ "Next, we will run this pipeline in both train and eval mode.\n",
+ "\n",
+ "#### Eval mode with GeneratorOutput\n",
+ "\n",
+ "Eval mode will output ``GeneratorOutput``.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Gks3yS8hcR6_"
+ },
+ "source": [
+ "\n",
+ "#### Train mode with different form of output\n",
+ "\n",
+ "Train mode will return ``Parameter``, where the `data` field will be the `raw_response`` from the GeneratorOutput, and we put the full GeneratorOutput at the ``full_response`` in the parameter.\n",
+ "\n",
+ "As the `data` field of the `Parameter` directly communicate with the Optimizer, which are an LLM itself, its better than they understand exactly the string response itself instead of the parsed one.\n",
+ "\n",
+ "Later you will see that we also use ``eval_input`` of the parameter to communicate with the `LossFunction` as that need the parsed final output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "eqQSFnZOpfWJ",
+ "outputId": "05b5fc83-09d1-45f4-aacc-6d460fbdd7bd"
+ },
+ "outputs": [
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 35
- },
- "id": "nJteJKsNrpcu",
- "outputId": "d9f7b4d0-d11c-480d-d858-bf9022c18998"
- },
- "outputs": [
- {
- "data": {
- "application/vnd.google.colaboratory.intrinsic+json": {
- "type": "string"
- },
- "text/plain": [
- "'0.2.0'"
- ]
- },
- "execution_count": 2,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "import adalflow as adal\n",
- "\n",
- "adal.__version__"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "WARNING:adalflow.core.generator:Error copying the prompt_kwargs: 'prompt' is not a valid ParameterType\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "KapUyHMM07pJ"
- },
- "source": [
- "## Set Environment Variables\n",
- "\n",
- "Run the following code and pass your api key.\n",
- "\n",
- "Note: for normal `.py` projects, follow our [official installation guide](https://lightrag.sylph.ai/get_started/installation.html).\n",
- "\n",
- "*Go to [OpenAI](https://platform.openai.com/docs/introduction) and [Groq](https://console.groq.com/docs/) to get API keys if you don't already have.*"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-3.5-turbo.db\n",
+ "ObjectCountTaskPipeline(\n",
+ " (llm_counter): Generator(\n",
+ " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ " )\n",
+ ")\n"
+ ]
+ }
+ ],
+ "source": [
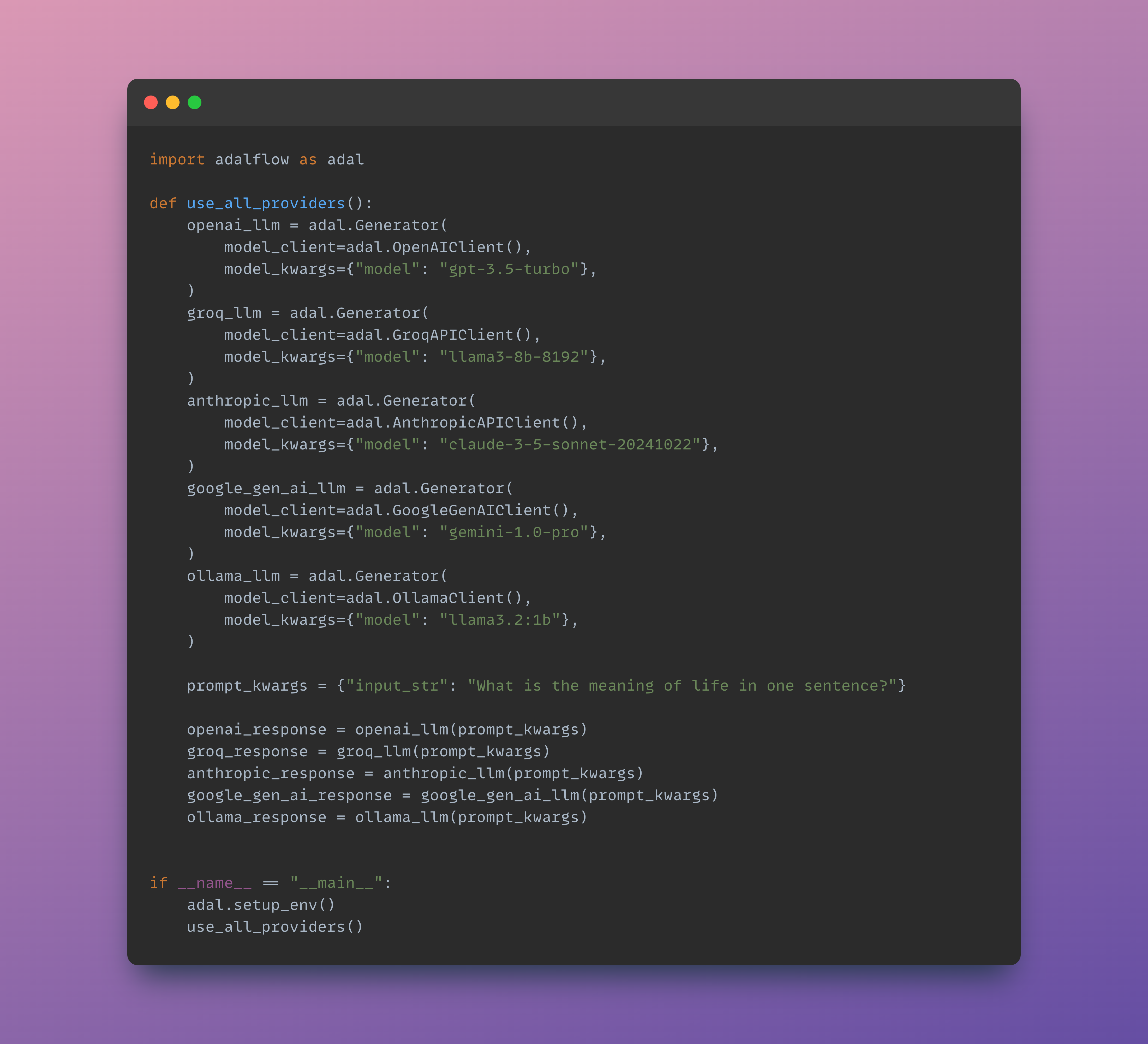
+ "from adalflow.components.model_client.openai_client import OpenAIClient\n",
+ "from adalflow.components.model_client.groq_client import GroqAPIClient\n",
+ "\n",
+ "\n",
+ "if len(os.environ['OPENAI_API_KEY']) > 1:\n",
+ " gpt_3_model = {\n",
+ " \"model_client\": OpenAIClient(),\n",
+ " \"model_kwargs\": {\n",
+ " \"model\": \"gpt-3.5-turbo\",\n",
+ " \"max_tokens\": 2000,\n",
+ " \"temperature\": 0.0,\n",
+ " \"top_p\": 0.99,\n",
+ " \"frequency_penalty\": 0,\n",
+ " \"presence_penalty\": 0,\n",
+ " \"stop\": None,\n",
+ " },\n",
+ " }\n",
+ " gpt_4o_model = {\n",
+ " \"model_client\": OpenAIClient(),\n",
+ " \"model_kwargs\": {\n",
+ " \"model\": \"gpt-4o\",\n",
+ " \"max_tokens\": 4000,\n",
+ " \"temperature\": 0.0,\n",
+ " \"top_p\": 0.99,\n",
+ " \"frequency_penalty\": 0,\n",
+ " \"presence_penalty\": 0,\n",
+ " \"stop\": None,\n",
+ " },\n",
+ " }\n",
+ "\n",
+ "if len(os.environ['GROQ_API_KEY']) > 1:\n",
+ " llama_3_1_model ={\n",
+ " \"model_client\": GroqAPIClient(),\n",
+ " \"model_kwargs\": {\n",
+ " \"model\": \"llama-3.1-8b-instant\"\n",
+ " }\n",
+ " }\n",
+ "\n",
+ "\n",
+ "question = \"I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?\"\n",
+ "task_pipeline = ObjectCountTaskPipeline(**gpt_3_model)\n",
+ "print(task_pipeline)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "DE1xNdYvcXw8",
+ "outputId": "25844c2a-5d4c-4c68-8ca5-38b79ca5b398"
+ },
+ "outputs": [
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "ONfzF9Puzdd_",
- "outputId": "6a815e21-ab99-463e-c53b-e39ca2ce8f3f"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Please enter your OpenAI API key: ··········\n",
- "Please enter your GROQ API key: ··········\n",
- "API keys have been set.\n"
- ]
- }
- ],
- "source": [
- "import os\n",
- "\n",
- "from getpass import getpass\n",
- "\n",
- "# Prompt user to enter their API keys securely\n",
- "openai_api_key = getpass(\"Please enter your OpenAI API key: \")\n",
- "groq_api_key = getpass(\"Please enter your GROQ API key, simplly press Enter if you don't have one: \")\n",
- "\n",
- "\n",
- "# Set environment variables\n",
- "os.environ['OPENAI_API_KEY'] = openai_api_key\n",
- "os.environ['GROQ_API_KEY'] = groq_api_key\n",
- "\n",
- "print(\"API keys have been set.\")"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "GeneratorOutput(id='1', data=8, error=None, usage=CompletionUsage(completion_tokens=77, prompt_tokens=113, total_tokens=190), raw_response='To find the total number of musical instruments you have, you simply need to count the individual instruments you listed. \\n\\nYou have:\\n- Flute\\n- Piano\\n- Trombone\\n- Violin\\n- Accordion\\n- Clarinet\\n- Drum\\n- Trumpet\\n\\nCounting each of these instruments, we get a total of 8 musical instruments.\\n\\nAnswer: 8', metadata=None)\n"
+ ]
+ }
+ ],
+ "source": [
+ "answer = task_pipeline(question, id=\"1\")\n",
+ "print(answer)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "AGUlUsGxcaby",
+ "outputId": "8c8588fe-2994-4d9e-c2d1-26453141f43f"
+ },
+ "outputs": [
{
- "cell_type": "markdown",
- "metadata": {
- "id": "SfGS7iddtfpj"
- },
- "source": [
- "\n",
- "\n",
- "# 😇 Trainable Task Pipeline\n",
- "\n",
- "We will create a task pipeline consists of a generator, with a customzied template, a customized output parser.\n",
- "\n",
- "Different from our other pipelines where the `prompt_kwargs` values are strings, but here we will use ``Parameter``. And we will set up two parameter, one is of ``ParameterType.PROMPT`` and the other of type ``ParameterType.DEMOS``. The first one will be trained by text-grad and the second will be trained by boostrap few shot optimizer.\n",
- "\n",
- "\n"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Parameter(name=Generator_output, requires_opt=True, param_type=generator_output (The output of the generator.), role_desc=Output from (llm) Generator, data=To find the total number of musical instruments you have, you simply need to count the individual instruments you listed. \n",
+ "\n",
+ "You have:\n",
+ "- Flute\n",
+ "- Piano\n",
+ "- Trombone\n",
+ "- Violin\n",
+ "- Accordion\n",
+ "- Clarinet\n",
+ "- Drum\n",
+ "- Trumpet\n",
+ "\n",
+ "Counting each of these instruments, we get a total of 8 musical instruments.\n",
+ "\n",
+ "Answer: 8, predecessors={Parameter(name=To_provide, requires_opt=True, param_type=demos (A few examples to guide the language model.), role_desc=To provide few shot demos to the language model, data=None, predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={}), Parameter(name=To_give_ta, requires_opt=True, param_type=prompt (Instruction to the language model on task, data, and format.), role_desc=To give task instruction to the language model in the system prompt, data=You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value., predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={})}, gradients=[], raw_response=None, input_args={'prompt_kwargs': {'system_prompt': Parameter(name=To_give_ta, requires_opt=True, param_type=prompt (Instruction to the language model on task, data, and format.), role_desc=To give task instruction to the language model in the system prompt, data=You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value., predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={}), 'few_shot_demos': Parameter(name=To_provide, requires_opt=True, param_type=demos (A few examples to guide the language model.), role_desc=To provide few shot demos to the language model, data=None, predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={}), 'input_str': 'I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?'}, 'model_kwargs': {'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, traces={})\n",
+ "full_response: GeneratorOutput(id=None, data=8, error=None, usage=CompletionUsage(completion_tokens=77, prompt_tokens=113, total_tokens=190), raw_response='To find the total number of musical instruments you have, you simply need to count the individual instruments you listed. \\n\\nYou have:\\n- Flute\\n- Piano\\n- Trombone\\n- Violin\\n- Accordion\\n- Clarinet\\n- Drum\\n- Trumpet\\n\\nCounting each of these instruments, we get a total of 8 musical instruments.\\n\\nAnswer: 8', metadata=None)\n"
+ ]
+ }
+ ],
+ "source": [
+ "# set it to train mode\n",
+ "task_pipeline.train()\n",
+ "answer = task_pipeline(question, id=\"1\")\n",
+ "print(answer)\n",
+ "print(f\"full_response: {answer.full_response}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "YDAiuFzcr4YA"
+ },
+ "outputs": [],
+ "source": [
+ "!pip install datasets\n",
+ "clear_output()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-Gvfcy2IcgWx"
+ },
+ "source": [
+ "### Load Datasets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "AYBIGsIHpjMe"
+ },
+ "outputs": [],
+ "source": [
+ "from adalflow.datasets.big_bench_hard import BigBenchHard\n",
+ "from adalflow.utils.data import subset_dataset\n",
+ "\n",
+ "def load_datasets(max_samples: int = None):\n",
+ " \"\"\"Load the dataset\"\"\"\n",
+ " train_data = BigBenchHard(split=\"train\")\n",
+ " val_data = BigBenchHard(split=\"val\")\n",
+ " test_data = BigBenchHard(split=\"test\")\n",
+ "\n",
+ " # Limit the number of samples\n",
+ " if max_samples:\n",
+ " train_data = subset_dataset(train_data, max_samples)\n",
+ " val_data = subset_dataset(val_data, max_samples)\n",
+ " test_data = subset_dataset(test_data, max_samples)\n",
+ "\n",
+ " return train_data, val_data, test_data\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "asw-pJrid8ly",
+ "outputId": "31807c34-0de9-45e5-ebdd-778aa5313802"
+ },
+ "outputs": [
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "nHnvAbO-pXUq"
- },
- "outputs": [],
- "source": [
- "import adalflow as adal\n",
- "import re\n",
- "from typing import Dict, Union\n",
- "import adalflow as adal\n",
- "from adalflow.optim.types import ParameterType\n",
- "\n",
- "\n",
- "@adal.fun_to_component\n",
- "def parse_integer_answer(answer: str):\n",
- " \"\"\"A function that parses the last integer from a string using regular expressions.\"\"\"\n",
- " try:\n",
- " # Use regular expression to find all sequences of digits\n",
- " numbers = re.findall(r\"\\d+\", answer)\n",
- " if numbers:\n",
- " # Get the last number found\n",
- " answer = int(numbers[-1])\n",
- " else:\n",
- " answer = -1\n",
- " except ValueError:\n",
- " answer = -1\n",
- "\n",
- " return answer\n",
- "\n",
- "\n",
- "few_shot_template = r\"\"\"\n",
- "{{system_prompt}}\n",
- "{# Few shot demos #}\n",
- "{% if few_shot_demos is not none %}\n",
- "Here are some examples:\n",
- "{{few_shot_demos}}\n",
- "{% endif %}\n",
- "\n",
- "\n",
- "{{input_str}}\n",
- "\n",
- "\"\"\"\n",
- "\n",
- "class ObjectCountTaskPipeline(adal.Component):\n",
- " def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):\n",
- " super().__init__()\n",
- "\n",
- " system_prompt = adal.Parameter(\n",
- " data=\"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\",\n",
- " role_desc=\"To give task instruction to the language model in the system prompt\",\n",
- " requires_opt=True,\n",
- " param_type=ParameterType.PROMPT,\n",
- " )\n",
- " few_shot_demos = adal.Parameter(\n",
- " data=None,\n",
- " role_desc=\"To provide few shot demos to the language model\",\n",
- " requires_opt=True, # Changed to True for few-shot learning\n",
- " param_type=ParameterType.DEMOS,\n",
- " )\n",
- "\n",
- " self.llm_counter = adal.Generator(\n",
- " model_client=model_client,\n",
- " model_kwargs=model_kwargs,\n",
- " template=few_shot_template,\n",
- " prompt_kwargs={\n",
- " \"system_prompt\": system_prompt,\n",
- " \"few_shot_demos\": few_shot_demos,\n",
- " },\n",
- " output_processors=parse_integer_answer,\n",
- " use_cache=True,\n",
- " )\n",
- "\n",
- " def call(\n",
- " self, question: str, id: str = None\n",
- " ) -> Union[adal.GeneratorOutput, adal.Parameter]:\n",
- " output = self.llm_counter(prompt_kwargs={\"input_str\": question}, id=id)\n",
- " return output\n",
- "\n",
- "\n"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Example(id='d3f33ded-170a-4b87-9b0b-987d5fb7b817', question='I have a cauliflower, a stalk of celery, a cabbage, and a garlic. How many vegetables do I have?', answer='4')\n"
+ ]
+ }
+ ],
+ "source": [
+ "# check the datasets\n",
+ "\n",
+ "train_data, val_data, test_data = load_datasets(max_samples=2)\n",
+ "print(train_data[0])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VAVtXE9xeEHt"
+ },
+ "source": [
+ "### Soft link to AdalFlow default file path\n",
+ "\n",
+ "Lets' match the default to the current project, so that you can see the downloaded data and later the checkpoints of the training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1SaKH6dkeWus"
+ },
+ "outputs": [],
+ "source": [
+ "! ln -s /root/.adalflow /content/adalflow\n",
+ "\n",
+ "# go to files then you will see a folder named as adalflow"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YWZzOvAHenME"
+ },
+ "source": [
+ "# 😊 AdalComponent to define everything we need to train\n",
+ "\n",
+ "1. We need `backward_engine_model_config`` for ``backward_engine`` to compute gradient.\n",
+ "\n",
+ "2. We need ``text_optimizer_model_config`` for the `text optimizer` for propose new prompts.\n",
+ "\n",
+ "3. For the demo optimizer, we need a `teacher_model_config` to config a teacher generator, in this case, it is the `llm_counter`. The teacher will share the same prompt with the `llm_counter` but you can use a more advanced model.\n",
+ "\n",
+ "In general, we should have all of these parts to use a more advanced model."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9QoNoMWD0rgV"
+ },
+ "source": [
+ "## 🧑 Diagnose\n",
+ "\n",
+ "Diagnose is more of an evaluation, but with detailed logs so that you can manually inspect the wrong output.\n",
+ "\n",
+ "This one shows the minimum config you need to get the `diagnose` work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "6mi7lM3U24Eg"
+ },
+ "outputs": [],
+ "source": [
+ "from adalflow.datasets.types import Example\n",
+ "from adalflow.eval.answer_match_acc import AnswerMatchAcc\n",
+ "\n",
+ "\n",
+ "class ObjectCountAdalComponent(adal.AdalComponent):\n",
+ " def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):\n",
+ " task = ObjectCountTaskPipeline(model_client, model_kwargs)\n",
+ " eval_fn = AnswerMatchAcc(type=\"exact_match\").compute_single_item\n",
+ " super().__init__(task=task, eval_fn=eval_fn)\n",
+ "\n",
+ " def prepare_task(self, sample: Example):\n",
+ " return self.task.call, {\"question\": sample.question, \"id\": sample.id}\n",
+ "\n",
+ " def prepare_eval(\n",
+ " self, sample: Example, y_pred: adal.GeneratorOutput\n",
+ " ) -> float:\n",
+ " y_label = -1\n",
+ " if (y_pred is not None and y_pred.data is not None): # if y_pred and y_pred.data: might introduce bug when the data is 0\n",
+ " y_label = y_pred.data\n",
+ " return self.eval_fn, {\"y\": y_label, \"y_gt\": sample.answer}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "eliPeVeM2wcP"
+ },
+ "outputs": [],
+ "source": [
+ "def diagnose(\n",
+ " model_client: adal.ModelClient,\n",
+ " model_kwargs: Dict,\n",
+ ") -> Dict:\n",
+ "\n",
+ " trainset, valset, testset = load_datasets()\n",
+ " # use max_samples=10 to test the code\n",
+ "\n",
+ " adal_component = ObjectCountAdalComponent(model_client, model_kwargs)\n",
+ " trainer = adal.Trainer(adaltask=adal_component)\n",
+ " trainer.diagnose(dataset=trainset, split=\"train\")\n",
+ " trainer.diagnose(dataset=valset, split=\"val\")\n",
+ " trainer.diagnose(dataset=testset, split=\"test\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "nKl9clcb3dFj",
+ "outputId": "676fbb96-c70b-40ab-ea15-93ade1aa9e66"
+ },
+ "outputs": [
{
- "cell_type": "markdown",
- "metadata": {
- "id": "AvZJjdzZa0cT"
- },
- "source": [
- "Next, we will run this pipeline in both train and eval mode.\n",
- "\n",
- "#### Eval mode with GeneratorOutput\n",
- "\n",
- "Eval mode will output ``GeneratorOutput``.\n",
- "\n"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "WARNING:adalflow.core.generator:Error copying the prompt_kwargs: 'prompt' is not a valid ParameterType\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "Gks3yS8hcR6_"
- },
- "source": [
- "\n",
- "#### Train mode with different form of output\n",
- "\n",
- "Train mode will return ``Parameter``, where the `data` field will be the `raw_response`` from the GeneratorOutput, and we put the full GeneratorOutput at the ``full_response`` in the parameter.\n",
- "\n",
- "As the `data` field of the `Parameter` directly communicate with the Optimizer, which are an LLM itself, its better than they understand exactly the string response itself instead of the parsed one.\n",
- "\n",
- "Later you will see that we also use ``eval_input`` of the parameter to communicate with the `LossFunction` as that need the parsed final output."
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-3.5-turbo.db\n",
+ "Checkpoint path: /root/.adalflow/ckpt/ObjectCountAdalComponent\n",
+ "Save diagnose to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_train\n",
+ "Saving traces to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_train\n",
+ "all_generators: [('llm_counter', Generator(\n",
+ " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ "))]\n",
+ "Registered callback for llm_counter, file path: /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_train/llm_counter_call.jsonl\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "eqQSFnZOpfWJ",
- "outputId": "05b5fc83-09d1-45f4-aacc-6d460fbdd7bd"
- },
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "WARNING:adalflow.core.generator:Error copying the prompt_kwargs: 'prompt' is not a valid ParameterType\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-3.5-turbo.db\n",
- "ObjectCountTaskPipeline(\n",
- " (llm_counter): Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- " )\n",
- ")\n"
- ]
- }
- ],
- "source": [
- "from adalflow.components.model_client.openai_client import OpenAIClient\n",
- "from adalflow.components.model_client.groq_client import GroqAPIClient\n",
- "\n",
- "\n",
- "if len(os.environ['OPENAI_API_KEY']) > 1:\n",
- " gpt_3_model = {\n",
- " \"model_client\": OpenAIClient(),\n",
- " \"model_kwargs\": {\n",
- " \"model\": \"gpt-3.5-turbo\",\n",
- " \"max_tokens\": 2000,\n",
- " \"temperature\": 0.0,\n",
- " \"top_p\": 0.99,\n",
- " \"frequency_penalty\": 0,\n",
- " \"presence_penalty\": 0,\n",
- " \"stop\": None,\n",
- " },\n",
- " }\n",
- " gpt_4o_model = {\n",
- " \"model_client\": OpenAIClient(),\n",
- " \"model_kwargs\": {\n",
- " \"model\": \"gpt-4o\",\n",
- " \"max_tokens\": 4000,\n",
- " \"temperature\": 0.0,\n",
- " \"top_p\": 0.99,\n",
- " \"frequency_penalty\": 0,\n",
- " \"presence_penalty\": 0,\n",
- " \"stop\": None,\n",
- " },\n",
- " }\n",
- "\n",
- "if len(os.environ['GROQ_API_KEY']) > 1:\n",
- " llama_3_1_model ={\n",
- " \"model_client\": GroqAPIClient(),\n",
- " \"model_kwargs\": {\n",
- " \"model\": \"llama-3.1-8b-instant\"\n",
- " }\n",
- " }\n",
- "\n",
- "\n",
- "question = \"I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?\"\n",
- "task_pipeline = ObjectCountTaskPipeline(**gpt_3_model)\n",
- "print(task_pipeline)\n"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 5957.82it/s]\n",
+ "Evaluating step(0): 0.88 across 50 samples, Max potential: 0.88: 100%|██████████| 50/50 [00:15<00:00, 3.27it/s]\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "DE1xNdYvcXw8",
- "outputId": "25844c2a-5d4c-4c68-8ca5-38b79ca5b398"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "GeneratorOutput(id='1', data=8, error=None, usage=CompletionUsage(completion_tokens=77, prompt_tokens=113, total_tokens=190), raw_response='To find the total number of musical instruments you have, you simply need to count the individual instruments you listed. \\n\\nYou have:\\n- Flute\\n- Piano\\n- Trombone\\n- Violin\\n- Accordion\\n- Clarinet\\n- Drum\\n- Trumpet\\n\\nCounting each of these instruments, we get a total of 8 musical instruments.\\n\\nAnswer: 8', metadata=None)\n"
- ]
- }
- ],
- "source": [
- "answer = task_pipeline(question, id=\"1\")\n",
- "print(answer)"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "sorted_indices: [8, 16, 23, 25, 31, 47, 0, 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 24, 26, 27, 28, 29, 30, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 48, 49]\n",
+ "sorted_scores: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n",
+ "Loading log file: llm_counter_call.jsonl\n",
+ "Total error samples: 6\n",
+ "Save diagnose to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_val\n",
+ "Saving traces to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_val\n",
+ "all_generators: [('llm_counter', Generator(\n",
+ " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ "))]\n",
+ "Registered callback for llm_counter, file path: /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_val/llm_counter_call.jsonl\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "AGUlUsGxcaby",
- "outputId": "8c8588fe-2994-4d9e-c2d1-26453141f43f"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Parameter(name=Generator_output, requires_opt=True, param_type=generator_output (The output of the generator.), role_desc=Output from (llm) Generator, data=To find the total number of musical instruments you have, you simply need to count the individual instruments you listed. \n",
- "\n",
- "You have:\n",
- "- Flute\n",
- "- Piano\n",
- "- Trombone\n",
- "- Violin\n",
- "- Accordion\n",
- "- Clarinet\n",
- "- Drum\n",
- "- Trumpet\n",
- "\n",
- "Counting each of these instruments, we get a total of 8 musical instruments.\n",
- "\n",
- "Answer: 8, predecessors={Parameter(name=To_provide, requires_opt=True, param_type=demos (A few examples to guide the language model.), role_desc=To provide few shot demos to the language model, data=None, predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={}), Parameter(name=To_give_ta, requires_opt=True, param_type=prompt (Instruction to the language model on task, data, and format.), role_desc=To give task instruction to the language model in the system prompt, data=You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value., predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={})}, gradients=[], raw_response=None, input_args={'prompt_kwargs': {'system_prompt': Parameter(name=To_give_ta, requires_opt=True, param_type=prompt (Instruction to the language model on task, data, and format.), role_desc=To give task instruction to the language model in the system prompt, data=You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value., predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={}), 'few_shot_demos': Parameter(name=To_provide, requires_opt=True, param_type=demos (A few examples to guide the language model.), role_desc=To provide few shot demos to the language model, data=None, predecessors=set(), gradients=[], raw_response=None, input_args=None, traces={}), 'input_str': 'I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?'}, 'model_kwargs': {'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, traces={})\n",
- "full_response: GeneratorOutput(id=None, data=8, error=None, usage=CompletionUsage(completion_tokens=77, prompt_tokens=113, total_tokens=190), raw_response='To find the total number of musical instruments you have, you simply need to count the individual instruments you listed. \\n\\nYou have:\\n- Flute\\n- Piano\\n- Trombone\\n- Violin\\n- Accordion\\n- Clarinet\\n- Drum\\n- Trumpet\\n\\nCounting each of these instruments, we get a total of 8 musical instruments.\\n\\nAnswer: 8', metadata=None)\n"
- ]
- }
- ],
- "source": [
- "# set it to train mode\n",
- "task_pipeline.train()\n",
- "answer = task_pipeline(question, id=\"1\")\n",
- "print(answer)\n",
- "print(f\"full_response: {answer.full_response}\")"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 3203.76it/s]\n",
+ "Evaluating step(0): 0.8 across 50 samples, Max potential: 0.8: 100%|██████████| 50/50 [00:15<00:00, 3.26it/s]\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "YDAiuFzcr4YA"
- },
- "outputs": [],
- "source": [
- "!pip install datasets\n",
- "clear_output()"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "sorted_indices: [1, 2, 5, 10, 24, 36, 38, 42, 44, 47, 0, 3, 4, 6, 7, 8, 9, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 37, 39, 40, 41, 43, 45, 46, 48, 49]\n",
+ "sorted_scores: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n",
+ "Loading log file: llm_counter_call.jsonl\n",
+ "Total error samples: 10\n",
+ "Save diagnose to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_test\n",
+ "Saving traces to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_test\n",
+ "all_generators: [('llm_counter', Generator(\n",
+ " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ "))]\n",
+ "Registered callback for llm_counter, file path: /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_test/llm_counter_call.jsonl\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "-Gvfcy2IcgWx"
- },
- "source": [
- "### Load Datasets"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Loading Data: 100%|██████████| 100/100 [00:00<00:00, 5545.09it/s]\n",
+ "Evaluating step(0): 0.83 across 100 samples, Max potential: 0.83: 100%|██████████| 100/100 [00:28<00:00, 3.50it/s]"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "AYBIGsIHpjMe"
- },
- "outputs": [],
- "source": [
- "from adalflow.datasets.big_bench_hard import BigBenchHard\n",
- "from adalflow.utils.data import subset_dataset\n",
- "\n",
- "def load_datasets(max_samples: int = None):\n",
- " \"\"\"Load the dataset\"\"\"\n",
- " train_data = BigBenchHard(split=\"train\")\n",
- " val_data = BigBenchHard(split=\"val\")\n",
- " test_data = BigBenchHard(split=\"test\")\n",
- "\n",
- " # Limit the number of samples\n",
- " if max_samples:\n",
- " train_data = subset_dataset(train_data, max_samples)\n",
- " val_data = subset_dataset(val_data, max_samples)\n",
- " test_data = subset_dataset(test_data, max_samples)\n",
- "\n",
- " return train_data, val_data, test_data\n"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "sorted_indices: [7, 18, 19, 20, 23, 24, 25, 43, 58, 59, 63, 74, 75, 79, 85, 97, 99, 0, 1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 21, 22, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 60, 61, 62, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 76, 77, 78, 80, 81, 82, 83, 84, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 98]\n",
+ "sorted_scores: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n",
+ "Loading log file: llm_counter_call.jsonl\n",
+ "Total error samples: 17\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "asw-pJrid8ly",
- "outputId": "31807c34-0de9-45e5-ebdd-778aa5313802"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Example(id='d3f33ded-170a-4b87-9b0b-987d5fb7b817', question='I have a cauliflower, a stalk of celery, a cabbage, and a garlic. How many vegetables do I have?', answer='4')\n"
- ]
- }
- ],
- "source": [
- "# check the datasets\n",
- "\n",
- "train_data, val_data, test_data = load_datasets(max_samples=2)\n",
- "print(train_data[0])"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "diagnose(**gpt_3_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dSu4VQri3y3D"
+ },
+ "source": [
+ "Now, you can go to `/content/adalflow/ckpt/ObjectCountAdalComponent/diagnose_train/stats.json` to view the average score for each split. And also the `diagnose.json` for different errors.\n",
+ "\n",
+ "Here is the overall score for each split.\n",
+ "\n",
+ "| Train | Val| Test |\n",
+ "|:--------- |:--------:| ---------:|\n",
+ "| 0.88 | 0.8 | 0.83 |\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1vzJyp-W0z7I"
+ },
+ "source": [
+ "## 🐛 Debug"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TmlCvJu804dJ"
+ },
+ "source": [
+ "## ✅ Train\n",
+ "\n",
+ "Now, let's start training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "4TWCn0did6-K"
+ },
+ "outputs": [],
+ "source": [
+ "from adalflow.datasets.types import Example\n",
+ "\n",
+ "\n",
+ "class ObjectCountAdalComponent(adal.AdalComponent):# noqa: F811\n",
+ " def __init__(\n",
+ " self,\n",
+ " model_client: adal.ModelClient,\n",
+ " model_kwargs: Dict,\n",
+ " backward_engine_model_config: Dict,\n",
+ " teacher_model_config: Dict,\n",
+ " text_optimizer_model_config: Dict,\n",
+ " ):\n",
+ " task = ObjectCountTaskPipeline(model_client, model_kwargs)\n",
+ " eval_fn = AnswerMatchAcc(type=\"exact_match\").compute_single_item\n",
+ " loss_fn = adal.EvalFnToTextLoss(\n",
+ " eval_fn=eval_fn,\n",
+ " eval_fn_desc=\"exact_match: 1 if str(y) == str(y_gt) else 0\",\n",
+ " )\n",
+ " super().__init__(task=task, eval_fn=eval_fn, loss_fn=loss_fn)\n",
+ "\n",
+ " self.backward_engine_model_config = backward_engine_model_config\n",
+ " self.teacher_model_config = teacher_model_config\n",
+ " self.text_optimizer_model_config = text_optimizer_model_config\n",
+ "\n",
+ " def prepare_task(self, sample: Example):\n",
+ " return self.task.call, {\"question\": sample.question, \"id\": sample.id}\n",
+ "\n",
+ "\n",
+ " def prepare_eval(\n",
+ " self, sample: Example, y_pred: adal.GeneratorOutput\n",
+ " ) -> float:\n",
+ " y_label = -1\n",
+ " if (y_pred is not None and y_pred.data is not None): # if y_pred and y_pred.data: might introduce bug when the data is 0\n",
+ " y_label = y_pred.data\n",
+ " return self.eval_fn, {\"y\": y_label, \"y_gt\": sample.answer}\n",
+ "\n",
+ " def prepare_loss(self, sample: Example, pred: adal.Parameter):\n",
+ " # prepare gt parameter\n",
+ " y_gt = adal.Parameter(\n",
+ " name=\"y_gt\",\n",
+ " data=sample.answer,\n",
+ " eval_input=sample.answer,\n",
+ " requires_opt=False,\n",
+ " )\n",
+ "\n",
+ " # pred's full_response is the output of the task pipeline which is GeneratorOutput\n",
+ " pred.eval_input = pred.full_response.data\n",
+ " return self.loss_fn, {\"kwargs\": {\"y\": pred, \"y_gt\": y_gt}}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dezwX2yn1eQS"
+ },
+ "outputs": [],
+ "source": [
+ "def train(\n",
+ " train_batch_size=4, # larger batch size is not that effective, probably because of llm's lost in the middle\n",
+ " raw_shots: int = 0,\n",
+ " bootstrap_shots: int = 1,\n",
+ " max_steps=1,\n",
+ " num_workers=4,\n",
+ " strategy=\"random\",\n",
+ " optimization_order=\"sequential\",\n",
+ " debug=False,\n",
+ " resume_from_ckpt=None,\n",
+ " exclude_input_fields_from_bootstrap_demos=False,\n",
+ "):\n",
+ " adal_component = ObjectCountAdalComponent(\n",
+ " **gpt_3_model,\n",
+ " teacher_model_config=gpt_4o_model,\n",
+ " text_optimizer_model_config=gpt_4o_model,\n",
+ " backward_engine_model_config=gpt_4o_model\n",
+ " )\n",
+ " print(adal_component)\n",
+ " trainer = adal.Trainer(\n",
+ " train_batch_size=train_batch_size,\n",
+ " adaltask=adal_component,\n",
+ " strategy=strategy,\n",
+ " max_steps=max_steps,\n",
+ " num_workers=num_workers,\n",
+ " raw_shots=raw_shots,\n",
+ " bootstrap_shots=bootstrap_shots,\n",
+ " debug=debug,\n",
+ " weighted_sampling=True,\n",
+ " optimization_order=optimization_order,\n",
+ " exclude_input_fields_from_bootstrap_demos=exclude_input_fields_from_bootstrap_demos,\n",
+ " )\n",
+ " print(trainer)\n",
+ "\n",
+ " train_dataset, val_dataset, test_dataset = load_datasets()\n",
+ " trainer.fit(\n",
+ " train_dataset=train_dataset,\n",
+ " val_dataset=val_dataset,\n",
+ " test_dataset=test_dataset,\n",
+ " debug=debug,\n",
+ " resume_from_ckpt=resume_from_ckpt,\n",
+ " )\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NGKYozGt60Pp"
+ },
+ "source": [
+ "We use `Sequential` in default, we will end up with 24 steps in total, 12 for text optimizer and 12 for the demo optimizer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "yDwLwL0L7Rsw",
+ "outputId": "1b7e413b-a1d3-4388-fc0c-ca4b1c072585"
+ },
+ "outputs": [
{
- "cell_type": "markdown",
- "metadata": {
- "id": "VAVtXE9xeEHt"
- },
- "source": [
- "### Soft link to AdalFlow default file path\n",
- "\n",
- "Lets' match the default to the current project, so that you can see the downloaded data and later the checkpoints of the training."
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "WARNING:adalflow.core.generator:Error copying the prompt_kwargs: 'prompt' is not a valid ParameterType\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "1SaKH6dkeWus"
- },
- "outputs": [],
- "source": [
- "! ln -s /root/.adalflow /content/adalflow\n",
- "\n",
- "# go to files then you will see a folder named as adalflow"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-3.5-turbo.db\n",
+ "ObjectCountAdalComponent(\n",
+ " eval_fn: compute_single_item, backward_engine: None, backward_engine_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, teacher_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, text_optimizer_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}\n",
+ " (task): ObjectCountTaskPipeline(\n",
+ " (llm_counter): Generator(\n",
+ " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ " )\n",
+ " )\n",
+ " (loss_fn): EvalFnToTextLoss()\n",
+ ")\n",
+ "Trainer(\n",
+ " (adaltask): ObjectCountAdalComponent(\n",
+ " eval_fn: compute_single_item, backward_engine: None, backward_engine_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, teacher_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, text_optimizer_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}\n",
+ " (task): ObjectCountTaskPipeline(\n",
+ " (llm_counter): Generator(\n",
+ " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ " )\n",
+ " )\n",
+ " (loss_fn): EvalFnToTextLoss()\n",
+ " )\n",
+ ")\n",
+ "raw_shots: 0, bootstrap_shots: 1\n",
+ "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
+ "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
+ "Configuring teacher generator for Generator(\n",
+ " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ ")\n",
+ "Teacher generator set: Generator(\n",
+ " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ "), teacher Generator(\n",
+ " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
+ " (prompt): Prompt(\n",
+ " template: \n",
+ " {{system_prompt}}\n",
+ " {# Few shot demos #}\n",
+ " {% if few_shot_demos is not none %}\n",
+ " Here are some examples:\n",
+ " {{few_shot_demos}}\n",
+ " {% endif %}\n",
+ " \n",
+ " \n",
+ " {{input_str}}\n",
+ " \n",
+ " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
+ " )\n",
+ " (model_client): OpenAIClient()\n",
+ " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
+ ")\n",
+ "Teacher generator configured.\n",
+ "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
+ "Backward engine configured for all generators.\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "YWZzOvAHenME"
- },
- "source": [
- "# 😊 AdalComponent to define everything we need to train\n",
- "\n",
- "1. We need `backward_engine_model_config`` for ``backward_engine`` to compute gradient.\n",
- "\n",
- "2. We need ``text_optimizer_model_config`` for the `text optimizer` for propose new prompts.\n",
- "\n",
- "3. For the demo optimizer, we need a `teacher_model_config` to config a teacher generator, in this case, it is the `llm_counter`. The teacher will share the same prompt with the `llm_counter` but you can use a more advanced model.\n",
- "\n",
- "In general, we should have all of these parts to use a more advanced model."
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 6482.70it/s]\n",
+ "Evaluating step(0): 0.8 across 50 samples, Max potential: 0.8: 100%|██████████| 50/50 [00:00<00:00, 347.01it/s]\n",
+ "Loading Data: 100%|██████████| 100/100 [00:00<00:00, 2017.67it/s]\n",
+ "Evaluating step(0): 0.83 across 100 samples, Max potential: 0.83: 100%|██████████| 100/100 [00:00<00:00, 286.59it/s]\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "9QoNoMWD0rgV"
- },
- "source": [
- "## 🧑 Diagnose\n",
- "\n",
- "Diagnose is more of an evaluation, but with detailed logs so that you can manually inspect the wrong output.\n",
- "\n",
- "This one shows the minimum config you need to get the `diagnose` work."
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Initial validation score: 0.8\n",
+ "Initial test score: 0.83\n",
+ "Checkpoint path: /root/.adalflow/ckpt/ObjectCountAdalComponent\n",
+ "save to /root/.adalflow/ckpt/ObjectCountAdalComponent/constrained_max_steps_12_4e8a1_run_1.json\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "6mi7lM3U24Eg"
- },
- "outputs": [],
- "source": [
- "from adalflow.datasets.types import Example\n",
- "from adalflow.eval.answer_match_acc import AnswerMatchAcc\n",
- "\n",
- "\n",
- "class ObjectCountAdalComponent(adal.AdalComponent):\n",
- " def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):\n",
- " task = ObjectCountTaskPipeline(model_client, model_kwargs)\n",
- " eval_fn = AnswerMatchAcc(type=\"exact_match\").compute_single_item\n",
- " super().__init__(task=task, eval_fn=eval_fn)\n",
- "\n",
- " def prepare_task(self, sample: Example):\n",
- " return self.task.call, {\"question\": sample.question, \"id\": sample.id}\n",
- "\n",
- " def prepare_eval(\n",
- " self, sample: Example, y_pred: adal.GeneratorOutput\n",
- " ) -> float:\n",
- " y_label = -1\n",
- " if (y_pred is not None and y_pred.data is not None): # if y_pred and y_pred.data: might introduce bug when the data is 0\n",
- " y_label = y_pred.data\n",
- " return self.eval_fn, {\"y\": y_label, \"y_gt\": sample.answer}"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "Training Step: 1: 0%| | 0/13 [00:00 Dict:\n",
- "\n",
- " trainset, valset, testset = load_datasets()\n",
- " # use max_samples=10 to test the code\n",
- "\n",
- " adal_component = ObjectCountAdalComponent(model_client, model_kwargs)\n",
- " trainer = adal.Trainer(adaltask=adal_component)\n",
- " trainer.diagnose(dataset=trainset, split=\"train\")\n",
- " trainer.diagnose(dataset=valset, split=\"val\")\n",
- " trainer.diagnose(dataset=testset, split=\"test\")"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Skipping batch 0 as acc: 1.0\n",
+ "No proposal can improve the subset and full set, go to next step\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "nKl9clcb3dFj",
- "outputId": "676fbb96-c70b-40ab-ea15-93ade1aa9e66"
- },
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "WARNING:adalflow.core.generator:Error copying the prompt_kwargs: 'prompt' is not a valid ParameterType\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-3.5-turbo.db\n",
- "Checkpoint path: /root/.adalflow/ckpt/ObjectCountAdalComponent\n",
- "Save diagnose to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_train\n",
- "Saving traces to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_train\n",
- "all_generators: [('llm_counter', Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "))]\n",
- "Registered callback for llm_counter, file path: /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_train/llm_counter_call.jsonl\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 5957.82it/s]\n",
- "Evaluating step(0): 0.88 across 50 samples, Max potential: 0.88: 100%|██████████| 50/50 [00:15<00:00, 3.27it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "sorted_indices: [8, 16, 23, 25, 31, 47, 0, 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 24, 26, 27, 28, 29, 30, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 48, 49]\n",
- "sorted_scores: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n",
- "Loading log file: llm_counter_call.jsonl\n",
- "Total error samples: 6\n",
- "Save diagnose to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_val\n",
- "Saving traces to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_val\n",
- "all_generators: [('llm_counter', Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "))]\n",
- "Registered callback for llm_counter, file path: /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_val/llm_counter_call.jsonl\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 3203.76it/s]\n",
- "Evaluating step(0): 0.8 across 50 samples, Max potential: 0.8: 100%|██████████| 50/50 [00:15<00:00, 3.26it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "sorted_indices: [1, 2, 5, 10, 24, 36, 38, 42, 44, 47, 0, 3, 4, 6, 7, 8, 9, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 37, 39, 40, 41, 43, 45, 46, 48, 49]\n",
- "sorted_scores: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n",
- "Loading log file: llm_counter_call.jsonl\n",
- "Total error samples: 10\n",
- "Save diagnose to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_test\n",
- "Saving traces to /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_test\n",
- "all_generators: [('llm_counter', Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "))]\n",
- "Registered callback for llm_counter, file path: /root/.adalflow/ckpt/ObjectCountAdalComponent/diagnose_test/llm_counter_call.jsonl\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Loading Data: 100%|██████████| 100/100 [00:00<00:00, 5545.09it/s]\n",
- "Evaluating step(0): 0.83 across 100 samples, Max potential: 0.83: 100%|██████████| 100/100 [00:28<00:00, 3.50it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "sorted_indices: [7, 18, 19, 20, 23, 24, 25, 43, 58, 59, 63, 74, 75, 79, 85, 97, 99, 0, 1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 21, 22, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 60, 61, 62, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 76, 77, 78, 80, 81, 82, 83, 84, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 98]\n",
- "sorted_scores: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n",
- "Loading log file: llm_counter_call.jsonl\n",
- "Total error samples: 17\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- }
- ],
- "source": [
- "diagnose(**gpt_3_model)"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 384.73it/s]\n",
+ "Training: 100%|██████████| 4/4 [00:00<00:00, 927.64it/s]\n",
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 754.71it/s]\n",
+ "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 12087.33it/s]\n",
+ "Training Step: 3: 15%|█▌ | 2/13 [00:00<00:01, 8.92it/s]"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "dSu4VQri3y3D"
- },
- "source": [
- "Now, you can go to `/content/adalflow/ckpt/ObjectCountAdalComponent/diagnose_train/stats.json` to view the average score for each split. And also the `diagnose.json` for different errors.\n",
- "\n",
- "Here is the overall score for each split.\n",
- "\n",
- "| Train | Val| Test |\n",
- "|:--------- |:--------:| ---------:|\n",
- "| 0.88 | 0.8 | 0.83 |\n",
- "\n"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Skipping batch 1 as acc: 1.0\n",
+ "No proposal can improve the subset and full set, go to next step\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "1vzJyp-W0z7I"
- },
- "source": [
- "## 🐛 Debug"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 193.44it/s]\n",
+ "Training: 100%|██████████| 4/4 [00:00<00:00, 2761.68it/s]\n",
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 810.38it/s]\n",
+ "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 11320.66it/s]\n",
+ "Training Step: 4: 15%|█▌ | 2/13 [00:00<00:01, 8.92it/s]"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "TmlCvJu804dJ"
- },
- "source": [
- "## ✅ Train\n",
- "\n",
- "Now, let's start training."
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Skipping batch 2 as acc: 1.0\n",
+ "No proposal can improve the subset and full set, go to next step\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4TWCn0did6-K"
- },
- "outputs": [],
- "source": [
- "from adalflow.datasets.types import Example\n",
- "from adalflow.eval.answer_match_acc import AnswerMatchAcc\n",
- "\n",
- "\n",
- "class ObjectCountAdalComponent(adal.AdalComponent):\n",
- " def __init__(\n",
- " self,\n",
- " model_client: adal.ModelClient,\n",
- " model_kwargs: Dict,\n",
- " backward_engine_model_config: Dict,\n",
- " teacher_model_config: Dict,\n",
- " text_optimizer_model_config: Dict,\n",
- " ):\n",
- " task = ObjectCountTaskPipeline(model_client, model_kwargs)\n",
- " eval_fn = AnswerMatchAcc(type=\"exact_match\").compute_single_item\n",
- " loss_fn = adal.EvalFnToTextLoss(\n",
- " eval_fn=eval_fn,\n",
- " eval_fn_desc=\"exact_match: 1 if str(y) == str(y_gt) else 0\",\n",
- " )\n",
- " super().__init__(task=task, eval_fn=eval_fn, loss_fn=loss_fn)\n",
- "\n",
- " self.backward_engine_model_config = backward_engine_model_config\n",
- " self.teacher_model_config = teacher_model_config\n",
- " self.text_optimizer_model_config = text_optimizer_model_config\n",
- "\n",
- " def prepare_task(self, sample: Example):\n",
- " return self.task.call, {\"question\": sample.question, \"id\": sample.id}\n",
- "\n",
- "\n",
- " def prepare_eval(\n",
- " self, sample: Example, y_pred: adal.GeneratorOutput\n",
- " ) -> float:\n",
- " y_label = -1\n",
- " if (y_pred is not None and y_pred.data is not None): # if y_pred and y_pred.data: might introduce bug when the data is 0\n",
- " y_label = y_pred.data\n",
- " return self.eval_fn, {\"y\": y_label, \"y_gt\": sample.answer}\n",
- "\n",
- " def prepare_loss(self, sample: Example, pred: adal.Parameter):\n",
- " # prepare gt parameter\n",
- " y_gt = adal.Parameter(\n",
- " name=\"y_gt\",\n",
- " data=sample.answer,\n",
- " eval_input=sample.answer,\n",
- " requires_opt=False,\n",
- " )\n",
- "\n",
- " # pred's full_response is the output of the task pipeline which is GeneratorOutput\n",
- " pred.eval_input = pred.full_response.data\n",
- " return self.loss_fn, {\"kwargs\": {\"y\": pred, \"y_gt\": y_gt}}"
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 234.44it/s]\n",
+ "Training: 100%|██████████| 4/4 [00:00<00:00, 2487.72it/s]\n",
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 1024.88it/s]\n",
+ "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 12018.06it/s]\n",
+ "Training Step: 5: 31%|███ | 4/13 [00:00<00:00, 11.90it/s]"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "dezwX2yn1eQS"
- },
- "outputs": [],
- "source": [
- "def train(\n",
- " train_batch_size=4, # larger batch size is not that effective, probably because of llm's lost in the middle\n",
- " raw_shots: int = 0,\n",
- " bootstrap_shots: int = 1,\n",
- " max_steps=1,\n",
- " num_workers=4,\n",
- " strategy=\"random\",\n",
- " optimization_order=\"sequential\",\n",
- " debug=False,\n",
- " resume_from_ckpt=None,\n",
- " exclude_input_fields_from_bootstrap_demos=False,\n",
- "):\n",
- " adal_component = ObjectCountAdalComponent(\n",
- " **gpt_3_model,\n",
- " teacher_model_config=gpt_4o_model,\n",
- " text_optimizer_model_config=gpt_4o_model,\n",
- " backward_engine_model_config=gpt_4o_model\n",
- " )\n",
- " print(adal_component)\n",
- " trainer = adal.Trainer(\n",
- " train_batch_size=train_batch_size,\n",
- " adaltask=adal_component,\n",
- " strategy=strategy,\n",
- " max_steps=max_steps,\n",
- " num_workers=num_workers,\n",
- " raw_shots=raw_shots,\n",
- " bootstrap_shots=bootstrap_shots,\n",
- " debug=debug,\n",
- " weighted_sampling=True,\n",
- " optimization_order=optimization_order,\n",
- " exclude_input_fields_from_bootstrap_demos=exclude_input_fields_from_bootstrap_demos,\n",
- " )\n",
- " print(trainer)\n",
- "\n",
- " train_dataset, val_dataset, test_dataset = load_datasets()\n",
- " trainer.fit(\n",
- " train_dataset=train_dataset,\n",
- " val_dataset=val_dataset,\n",
- " test_dataset=test_dataset,\n",
- " debug=debug,\n",
- " resume_from_ckpt=resume_from_ckpt,\n",
- " )\n"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Skipping batch 3 as acc: 1.0\n",
+ "No proposal can improve the subset and full set, go to next step\n"
+ ]
},
{
- "cell_type": "markdown",
- "metadata": {
- "id": "NGKYozGt60Pp"
- },
- "source": [
- "We use `Sequential` in default, we will end up with 24 steps in total, 12 for text optimizer and 12 for the demo optimizer."
- ]
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 133.95it/s]\n",
+ "Training: 100%|██████████| 4/4 [00:00<00:00, 4552.84it/s]\n",
+ "\n",
+ "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 392.05it/s]\n",
+ "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 770.69it/s]\n"
+ ]
},
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "yDwLwL0L7Rsw",
- "outputId": "1b7e413b-a1d3-4388-fc0c-ca4b1c072585"
- },
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "WARNING:adalflow.core.generator:Error copying the prompt_kwargs: 'prompt' is not a valid ParameterType\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-3.5-turbo.db\n",
- "ObjectCountAdalComponent(\n",
- " eval_fn: compute_single_item, backward_engine: None, backward_engine_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, teacher_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, text_optimizer_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}\n",
- " (task): ObjectCountTaskPipeline(\n",
- " (llm_counter): Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- " )\n",
- " )\n",
- " (loss_fn): EvalFnToTextLoss()\n",
- ")\n",
- "Trainer(\n",
- " (adaltask): ObjectCountAdalComponent(\n",
- " eval_fn: compute_single_item, backward_engine: None, backward_engine_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, teacher_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, text_optimizer_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}\n",
- " (task): ObjectCountTaskPipeline(\n",
- " (llm_counter): Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- " )\n",
- " )\n",
- " (loss_fn): EvalFnToTextLoss()\n",
- " )\n",
- ")\n",
- "raw_shots: 0, bootstrap_shots: 1\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "Configuring teacher generator for Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "Teacher generator set: Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "), teacher Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "Teacher generator configured.\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "Backward engine configured for all generators.\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 6482.70it/s]\n",
- "Evaluating step(0): 0.8 across 50 samples, Max potential: 0.8: 100%|██████████| 50/50 [00:00<00:00, 347.01it/s]\n",
- "Loading Data: 100%|██████████| 100/100 [00:00<00:00, 2017.67it/s]\n",
- "Evaluating step(0): 0.83 across 100 samples, Max potential: 0.83: 100%|██████████| 100/100 [00:00<00:00, 286.59it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Initial validation score: 0.8\n",
- "Initial test score: 0.83\n",
- "Checkpoint path: /root/.adalflow/ckpt/ObjectCountAdalComponent\n",
- "save to /root/.adalflow/ckpt/ObjectCountAdalComponent/constrained_max_steps_12_4e8a1_run_1.json\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Training Step: 1: 0%| | 0/13 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 445.28it/s]\n",
- "Evaluating step(4): 1.0 across 4 samples, Max potential: 1.0: 100%|██████████| 4/4 [00:01<00:00, 2.67it/s]\n",
- "Proposing: 0%| | 0/5 [00:03= 0.75\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 1139.66it/s]\n",
- "Evaluating step(5): 0.84 across 50 samples, Max potential: 0.84: 100%|██████████| 50/50 [00:16<00:00, 3.04it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer step: 0.84 > 0.8\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 100/100 [00:00<00:00, 1658.72it/s]\n",
- "Evaluating step(4): 0.91 across 100 samples, Max potential: 0.91: 100%|██████████| 100/100 [00:29<00:00, 3.37it/s]\n",
- "Training Step: 6: 38%|███▊ | 5/13 [00:56<02:18, 17.27s/it]\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 207.97it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 3.86it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 494.99it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 805.09it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 3\n",
- "Moving batch error size: 1\n",
- "Moving batch acc: 0.75\n",
- "Moving batch correct size: 3\n",
- "Moving batch error size: 1\n",
- "Subset Error size: 1\n",
- "Subset Correct size: 2\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_3 score to 1.0\n",
- "setting pred name Generator_outputy_pred_1 score to 0.0\n",
- "setting pred name Generator_outputy_pred_0 score to 1.0\n",
- "Subset loss backward time: 4.081957817077637\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 8/8 [00:00<00:00, 279.47it/s]\n",
- "Evaluating step(6): 0.875 across 8 samples, Max potential: 0.875: 100%|██████████| 8/8 [00:01<00:00, 4.43it/s]\n",
- "Proposing: 0%| | 0/5 [00:04= 0.875\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 2336.58it/s]\n",
- "Evaluating step(7): 0.84 across 50 samples, Max potential: 0.84: 100%|██████████| 50/50 [00:17<00:00, 2.88it/s]\n",
- "Training Step: 8: 54%|█████▍ | 7/13 [01:37<01:58, 19.81s/it]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer revert: 0.84 <= 0.84\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 148.75it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 2.04it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 345.11it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 7550.50it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 11\n",
- "Moving batch error size: 1\n",
- "Moving batch acc: 0.9166666666666666\n",
- "Moving batch correct size: 11\n",
- "Moving batch error size: 1\n",
- "Subset Error size: 1\n",
- "Subset Correct size: 2\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_2 score to 1.0\n",
- "Subset loss backward time: 2.337067127227783\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 16/16 [00:00<00:00, 481.75it/s]\n",
- "Evaluating step(8): 0.875 across 16 samples, Max potential: 0.875: 100%|██████████| 16/16 [00:03<00:00, 5.21it/s]\n",
- "Proposing: 0%| | 0/5 [00:06= 0.875\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 1112.82it/s]\n",
- "Evaluating step(9): 0.86 across 50 samples, Max potential: 0.86: 100%|██████████| 50/50 [00:16<00:00, 2.97it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer step: 0.86 > 0.84\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 100/100 [00:00<00:00, 2395.58it/s]\n",
- "Evaluating step(8): 0.87 across 100 samples, Max potential: 0.87: 100%|██████████| 100/100 [00:30<00:00, 3.30it/s]\n",
- "Training Step: 10: 69%|██████▉ | 9/13 [02:52<02:04, 31.23s/it]\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 212.83it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 2.04it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 655.18it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 1241.84it/s]\n",
- "Training Step: 11: 77%|███████▋ | 10/13 [02:55<01:07, 22.43s/it]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Skipping batch 9 as acc: 1.0\n",
- "No proposal can improve the subset and full set, go to next step\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 93.95it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 3.23it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 757.71it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 1320.62it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 3\n",
- "Moving batch error size: 1\n",
- "Moving batch acc: 0.75\n",
- "Moving batch correct size: 3\n",
- "Moving batch error size: 1\n",
- "Subset Error size: 1\n",
- "Subset Correct size: 2\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_0 score to 1.0\n",
- "setting pred name Generator_outputy_pred_2 score to 0.0\n",
- "setting pred name Generator_outputy_pred_3 score to 1.0\n",
- "Subset loss backward time: 3.768970012664795\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 455.77it/s]\n",
- "Evaluating step(10): 1.0 across 4 samples, Max potential: 1.0: 100%|██████████| 4/4 [00:00<00:00, 5.14it/s]\n",
- "Proposing: 40%|████ | 2/5 [00:06<00:09, 3.17s/it]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Pass full check: 1.0 >= 0.75\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 1732.93it/s]\n",
- "Evaluating step(11): 0.825 across 40 samples, Max potential: 0.86: 80%|████████ | 40/50 [00:18<00:04, 2.21it/s]\n",
- "Training Step: 12: 85%|████████▍ | 11/13 [03:24<00:49, 24.61s/it]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer revert: 0.8048780487804879 <= 0.86\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 128.86it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 2.24it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 470.20it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 2608.40it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 6\n",
- "Moving batch error size: 2\n",
- "Moving batch acc: 0.75\n",
- "Moving batch correct size: 6\n",
- "Moving batch error size: 2\n",
- "Subset Error size: 2\n",
- "Subset Correct size: 4\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_3 score to 1.0\n",
- "setting pred name Generator_outputy_pred_2 score to 1.0\n",
- "setting pred name Generator_outputy_pred_1 score to 0.0\n",
- "setting pred name Generator_outputy_pred_1 score to 1.0\n",
- "Subset loss backward time: 6.722561836242676\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00\n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Carefully count each item, paying special attention to quantities mentioned. Verify your total. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "Teacher generator set: Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Carefully count each item, paying special attention to quantities mentioned. Verify your total. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "), teacher Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Carefully count each item, paying special attention to quantities mentioned. Verify your total. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "Configuring teacher generator for Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "Teacher generator set: Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "), teacher Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "Configuring teacher generator for Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " You are the feedback engine in an optimization system.\n",
- " \n",
- " Your role: Provide intelligent and creative feedback for the variable enclosed in \n",
- " \n",
- " {{conversation_sec}}\n",
- " \n",
- " {{objective_instruction_sec}}\n",
- " , prompt_variables: ['objective_instruction_sec', 'conversation_sec']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- ")\n",
- "Teacher generator set: Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " You are the feedback engine in an optimization system.\n",
- " \n",
- " Your role: Provide intelligent and creative feedback for the variable enclosed in \n",
- " \n",
- " {{conversation_sec}}\n",
- " \n",
- " {{objective_instruction_sec}}\n",
- " , prompt_variables: ['objective_instruction_sec', 'conversation_sec']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- "), teacher Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " You are the feedback engine in an optimization system.\n",
- " \n",
- " Your role: Provide intelligent and creative feedback for the variable enclosed in \n",
- " \n",
- " {{conversation_sec}}\n",
- " \n",
- " {{objective_instruction_sec}}\n",
- " , prompt_variables: ['objective_instruction_sec', 'conversation_sec']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- ")\n",
- "Teacher generator configured.\n",
- "save to /root/.adalflow/ckpt/ObjectCountAdalComponent/constrained_max_steps_12_4e8a1_run_1.json\n",
- "Starting step: 12\n",
- "trainer_results: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Training Step: 13: 0%| | 0/12 [00:00\n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- " )\n",
- " )\n",
- " (loss_fn): EvalFnToTextLoss()\n",
- ")\n",
- "Trainer(\n",
- " (adaltask): ObjectCountAdalComponent(\n",
- " eval_fn: compute_single_item, backward_engine: None, backward_engine_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, teacher_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}, text_optimizer_model_config: {'model_client': OpenAIClient(), 'model_kwargs': {'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}}\n",
- " (task): ObjectCountTaskPipeline(\n",
- " (llm_counter): Generator(\n",
- " model_kwargs={'model': 'gpt-3.5-turbo', 'max_tokens': 2000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': None}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- " )\n",
- " )\n",
- " (loss_fn): EvalFnToTextLoss()\n",
- " )\n",
- ")\n",
- "raw_shots: 0, bootstrap_shots: 1\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "Configuring teacher generator for Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "Teacher generator set: Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- "), teacher Generator(\n",
- " model_kwargs={'model': 'gpt-4o', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 0.99, 'frequency_penalty': 0, 'presence_penalty': 0, 'stop': None}, \n",
- " (prompt): Prompt(\n",
- " template: \n",
- " {{system_prompt}}\n",
- " {# Few shot demos #}\n",
- " {% if few_shot_demos is not none %}\n",
- " Here are some examples:\n",
- " {{few_shot_demos}}\n",
- " {% endif %}\n",
- " \n",
- " \n",
- " {{input_str}}\n",
- " \n",
- " , prompt_kwargs: {'system_prompt': \"You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", 'few_shot_demos': 'None'}, prompt_variables: ['input_str', 'few_shot_demos', 'system_prompt']\n",
- " )\n",
- " (model_client): OpenAIClient()\n",
- " (output_processors): ParseIntegerAnswerComponent(fun_name=parse_integer_answer)\n",
- ")\n",
- "Teacher generator configured.\n",
- "cache_path: /root/.adalflow/cache_OpenAIClient_gpt-4o.db\n",
- "Backward engine configured for all generators.\n",
- "Restoring prompts: PromptData(id='44f6083f-4cf7-4a9a-bf10-20d218ee4106', name='llm_counter.system_prompt', data=\"You will answer a reasoning question. Carefully count each item and verify your total. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.\", requires_opt=True)\n",
- "save to /content/adalflow/ckpt/ObjectCountAdalComponent/constrained_max_steps_12_4e8a1_run_1.json\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Training Step: 27: 0%| | 0/13 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 263.51it/s]\n",
- "Evaluating step(2): 1.0 across 4 samples, Max potential: 1.0: 100%|██████████| 4/4 [00:00<00:00, 4.20it/s]\n",
- "Proposing: 40%|████ | 2/5 [00:10<00:15, 5.11s/it]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Pass full check: 1.0 >= 0.75\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 2287.37it/s]\n",
- "Evaluating step(29): 0.8158 across 38 samples, Max potential: 0.86: 76%|███████▌ | 38/50 [00:17<00:05, 2.17it/s]\n",
- "Training Step: 30: 23%|██▎ | 3/13 [00:35<02:25, 14.59s/it]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer revert: 0.7948717948717948 <= 0.86\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 268.93it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 3.69it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 603.76it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 8825.47it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 7\n",
- "Moving batch error size: 1\n",
- "Moving batch acc: 0.875\n",
- "Moving batch correct size: 7\n",
- "Moving batch error size: 1\n",
- "Subset Error size: 1\n",
- "Subset Correct size: 2\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_3 score to 1.0\n",
- "Subset loss backward time: 2.2182435989379883\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 8/8 [00:00<00:00, 281.73it/s]\n",
- "Evaluating step(3): 1.0 across 8 samples, Max potential: 1.0: 100%|██████████| 8/8 [00:02<00:00, 2.96it/s]\n",
- "Proposing: 20%|██ | 1/5 [00:08<00:34, 8.54s/it]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Pass full check: 1.0 >= 0.875\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 1910.10it/s]\n",
- "Evaluating step(30): 0.72 across 25 samples, Max potential: 0.86: 50%|█████ | 25/50 [00:18<00:18, 1.38it/s]\n",
- "Training Step: 31: 31%|███ | 4/13 [01:05<03:03, 20.39s/it]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer revert: 0.6923076923076923 <= 0.86\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 310.31it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 3.75it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 454.32it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 12336.19it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 11\n",
- "Moving batch error size: 1\n",
- "Moving batch acc: 0.9166666666666666\n",
- "Moving batch correct size: 11\n",
- "Moving batch error size: 1\n",
- "Subset Error size: 1\n",
- "Subset Correct size: 2\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_0 score to 1.0\n",
- "Subset loss backward time: 2.028568983078003\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00 0.6666666666666666\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "\n",
- "Loading Data: 100%|██████████| 12/12 [00:00<00:00, 724.90it/s]\n",
- "Evaluating step(4): 1.0 across 12 samples, Max potential: 1.0: 100%|██████████| 12/12 [00:03<00:00, 3.66it/s]\n",
- "Proposing: 0%| | 0/5 [00:05= 0.9166666666666666\n",
- "Done with proposals\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 50/50 [00:00<00:00, 2233.56it/s]\n",
- "Evaluating step(31): 0.8511 across 47 samples, Max potential: 0.86: 94%|█████████▍| 47/50 [00:16<00:01, 2.81it/s]\n",
- "Training Step: 32: 38%|███▊ | 5/13 [01:31<02:58, 22.30s/it]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Optimizer revert: 0.8333333333333334 <= 0.86\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 269.31it/s]\n",
- "Training: 100%|██████████| 4/4 [00:01<00:00, 3.20it/s]\n",
- "\n",
- "Loading Data: 100%|██████████| 4/4 [00:00<00:00, 606.49it/s]\n",
- "Calculating Loss: 100%|██████████| 4/4 [00:00<00:00, 1212.58it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Moving batch correct size: 15\n",
- "Moving batch error size: 1\n",
- "Moving batch acc: 0.9375\n",
- "Moving batch correct size: 15\n",
- "Moving batch error size: 1\n",
- "Subset Error size: 1\n",
- "Subset Correct size: 2\n",
- "Subset score: 0.6666666666666666\n",
- "Subset batch acc: 0.6666666666666666\n",
- "Subset loss backward...\n",
- "setting pred name Generator_outputy_pred_3 score to 1.0\n",
- "setting pred name Generator_outputy_pred_1 score to 1.0\n",
- "Subset loss backward time: 3.2150633335113525\n",
- "Optimizer propose...\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n",
- "Proposing: 0%| | 0/5 [00:00\n",
- "500 Internal Server Error \n",
- "\n",
- "
nginx \n",
- "\n",
- "
+
+
+
+
+
+ Open Source Code
+
+
+
.. _tutorials-text_splitter:
diff --git a/notebooks/README.md b/notebooks/README.md
index 2e1d4f1cc..3d2e6e94f 100644
--- a/notebooks/README.md
+++ b/notebooks/README.md
@@ -19,6 +19,11 @@ The template consists of three parts:
2. Content section of your notebook. Link to Next that users can look at.
3. Issues and Feedback.
+## If you want to use a ikernel in .ipynb to test notebooks
+
+You can use the following command to install the kernel at the root of the project:
+
+```poetry run python -m ipykernel install --user --name my-project-kernel```
## If you need to use dev api
diff --git a/notebooks/qas/adalflow_object_count_auto_optimization.ipynb b/notebooks/qas/adalflow_object_count_auto_optimization.ipynb
index 65b8509c1..ac7e3cbf5 100644
--- a/notebooks/qas/adalflow_object_count_auto_optimization.ipynb
+++ b/notebooks/qas/adalflow_object_count_auto_optimization.ipynb
@@ -1,8121 +1,8120 @@
{
- "cells": [
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VVSOpjzJl_cx"
+ },
+ "source": [
+ "# 🤗 Welcome to AdalFlow!\n",
+ "## The library to build & auto-optimize any LLM task pipelines\n",
+ "\n",
+ "Thanks for trying us out, we're here to provide you with the best LLM application development experience you can dream of 😊 any questions or concerns you may have, [come talk to us on discord,](https://discord.gg/ezzszrRZvT) we're always here to help!\n",
+ "\n",
+ "\n",
+ "# Quick Links\n",
+ "\n",
+ "Github repo: https://github.com/SylphAI-Inc/AdalFlow\n",
+ "\n",
+ "Full Tutorials: https://adalflow.sylph.ai/index.html#.\n",
+ "\n",
+ "Deep dive on each API: check out the [developer notes](https://adalflow.sylph.ai/tutorials/index.html).\n",
+ "\n",
+ "Common use cases along with the auto-optimization: check out [Use cases](https://adalflow.sylph.ai/use_cases/index.html).\n",
+ "\n",
+ "# Outline\n",
+ "\n",
+ "*Note: As training can consume tokens fast, and the notebook runtime will reset everytime you use, it might be better for you to learn training in your local editor.*\n",
+ "\n",
+ "This is a quick introduction of AdalFlow on question answering use case end to end\n",
+ "\n",
+ "* Trainable Task pipeline with trainable parameters\n",
+ "* Create AdalComponent for your task pipeline\n",
+ "* Use Trainer to diagnose, debug, and to train.\n",
+ "\n",
+ "You can find all source code here: https://github.com/SylphAI-Inc/AdalFlow/tree/main/use_cases/question_answering/bhh_object_count\n",
+ "\n",
+ "**Here is the more detailed tutorial for the code here: https://adalflow.sylph.ai/use_cases/question_answering.html**\n",
+ "\n",
+ "\n",
+ "# Installation\n",
+ "\n",
+ "1. Use `pip` to install the `adalflow` Python package. We will need `openai`, `groq`, and `faiss`(cpu version) from the extra packages.\n",
+ "\n",
+ " ```bash\n",
+ " pip install adalflow[openai,groq,faiss-cpu]\n",
+ " ```\n",
+ "2. Setup `openai` and `groq` API key in the environment variables"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "THTvmhjgfiHE"
+ },
+ "outputs": [],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "\n",
+ "!pip install -U adalflow[openai,groq,datasets]\n",
+ "\n",
+ "clear_output()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 35
+ },
+ "id": "nJteJKsNrpcu",
+ "outputId": "d9f7b4d0-d11c-480d-d858-bf9022c18998"
+ },
+ "outputs": [
{
- "cell_type": "markdown",
- "metadata": {
- "id": "VVSOpjzJl_cx"
+ "data": {
+ "application/vnd.google.colaboratory.intrinsic+json": {
+ "type": "string"
},
- "source": [
- "# 🤗 Welcome to AdalFlow!\n",
- "## The library to build & auto-optimize any LLM task pipelines\n",
- "\n",
- "Thanks for trying us out, we're here to provide you with the best LLM application development experience you can dream of 😊 any questions or concerns you may have, [come talk to us on discord,](https://discord.gg/ezzszrRZvT) we're always here to help!\n",
- "\n",
- "\n",
- "# Quick Links\n",
- "\n",
- "Github repo: https://github.com/SylphAI-Inc/AdalFlow\n",
- "\n",
- "Full Tutorials: https://adalflow.sylph.ai/index.html#.\n",
- "\n",
- "Deep dive on each API: check out the [developer notes](https://adalflow.sylph.ai/tutorials/index.html).\n",
- "\n",
- "Common use cases along with the auto-optimization: check out [Use cases](https://adalflow.sylph.ai/use_cases/index.html).\n",
- "\n",
- "# Outline\n",
- "\n",
- "*Note: As training can consume tokens fast, and the notebook runtime will reset everytime you use, it might be better for you to learn training in your local editor.*\n",
- "\n",
- "This is a quick introduction of AdalFlow on question answering use case end to end\n",
- "\n",
- "* Trainable Task pipeline with trainable parameters\n",
- "* Create AdalComponent for your task pipeline\n",
- "* Use Trainer to diagnose, debug, and to train.\n",
- "\n",
- "You can find all source code here: https://github.com/SylphAI-Inc/AdalFlow/tree/main/use_cases/question_answering/bhh_object_count\n",
- "\n",
- "**Here is the more detailed tutorial for the code here: https://adalflow.sylph.ai/use_cases/question_answering.html**\n",
- "\n",
- "\n",
- "# Installation\n",
- "\n",
- "1. Use `pip` to install the `adalflow` Python package. We will need `openai`, `groq`, and `faiss`(cpu version) from the extra packages.\n",
- "\n",
- " ```bash\n",
- " pip install adalflow[openai,groq,faiss-cpu]\n",
- " ```\n",
- "2. Setup `openai` and `groq` API key in the environment variables"
+ "text/plain": [
+ "'0.2.0'"
]
+ },
+ "execution_count": 2,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "import adalflow as adal\n",
+ "\n",
+ "adal.__version__"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KapUyHMM07pJ"
+ },
+ "source": [
+ "## Set Environment Variables\n",
+ "\n",
+ "Run the following code and pass your api key.\n",
+ "\n",
+ "Note: for normal `.py` projects, follow our [official installation guide](https://lightrag.sylph.ai/get_started/installation.html).\n",
+ "\n",
+ "*Go to [OpenAI](https://platform.openai.com/docs/introduction) and [Groq](https://console.groq.com/docs/) to get API keys if you don't already have.*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
},
+ "id": "ONfzF9Puzdd_",
+ "outputId": "6a815e21-ab99-463e-c53b-e39ca2ce8f3f"
+ },
+ "outputs": [
{
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "THTvmhjgfiHE"
- },
- "outputs": [],
- "source": [
- "from IPython.display import clear_output\n",
- "\n",
- "!pip install -U adalflow[openai,groq,datasets]\n",
- "\n",
- "clear_output()"
- ]
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Please enter your OpenAI API key: ··········\n",
+ "Please enter your GROQ API key: ··········\n",
+ "API keys have been set.\n"
+ ]
+ }
+ ],
+ "source": [
+ "import os\n",
+ "\n",
+ "from getpass import getpass\n",
+ "\n",
+ "# Prompt user to enter their API keys securely\n",
+ "openai_api_key = getpass(\"Please enter your OpenAI API key: \")\n",
+ "groq_api_key = getpass(\"Please enter your GROQ API key, simplly press Enter if you don't have one: \")\n",
+ "\n",
+ "\n",
+ "# Set environment variables\n",
+ "os.environ['OPENAI_API_KEY'] = openai_api_key\n",
+ "os.environ['GROQ_API_KEY'] = groq_api_key\n",
+ "\n",
+ "print(\"API keys have been set.\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SfGS7iddtfpj"
+ },
+ "source": [
+ "\n",
+ "\n",
+ "# 😇 Trainable Task Pipeline\n",
+ "\n",
+ "We will create a task pipeline consists of a generator, with a customzied template, a customized output parser.\n",
+ "\n",
+ "Different from our other pipelines where the `prompt_kwargs` values are strings, but here we will use ``Parameter``. And we will set up two parameter, one is of ``ParameterType.PROMPT`` and the other of type ``ParameterType.DEMOS``. The first one will be trained by text-grad and the second will be trained by boostrap few shot optimizer.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "nHnvAbO-pXUq"
+ },
+ "outputs": [],
+ "source": [
+ "import adalflow as adal\n",
+ "import re\n",
+ "from typing import Dict, Union\n",
+ "import adalflow as adal\n",
+ "from adalflow.optim.types import ParameterType\n",
+ "\n",
+ "\n",
+ "@adal.fun_to_component\n",
+ "def parse_integer_answer(answer: str):\n",
+ " \"\"\"A function that parses the last integer from a string using regular expressions.\"\"\"\n",
+ " try:\n",
+ " # Use regular expression to find all sequences of digits\n",
+ " numbers = re.findall(r\"\\d+\", answer)\n",
+ " if numbers:\n",
+ " # Get the last number found\n",
+ " answer = int(numbers[-1])\n",
+ " else:\n",
+ " answer = -1\n",
+ " except ValueError:\n",
+ " answer = -1\n",
+ "\n",
+ " return answer\n",
+ "\n",
+ "\n",
+ "few_shot_template = r\"\"\"
+ Open Source Code
+
+