来自Sxrhhh,得分2350,组内排名第10 该文章改编自本人提交的WriteUP,并进行了少量为博客发布而优化的修改
在界面内随便读两句后,提交,发现URL内出现了similarity参数,将其改为任意大于100的数字即可。
要查看这本书,来到中科大图书馆官网查询:中国科学技术大学图书馆 (ustc.edu.cn)
如果查不出来,缩减其中的关键字,如图:
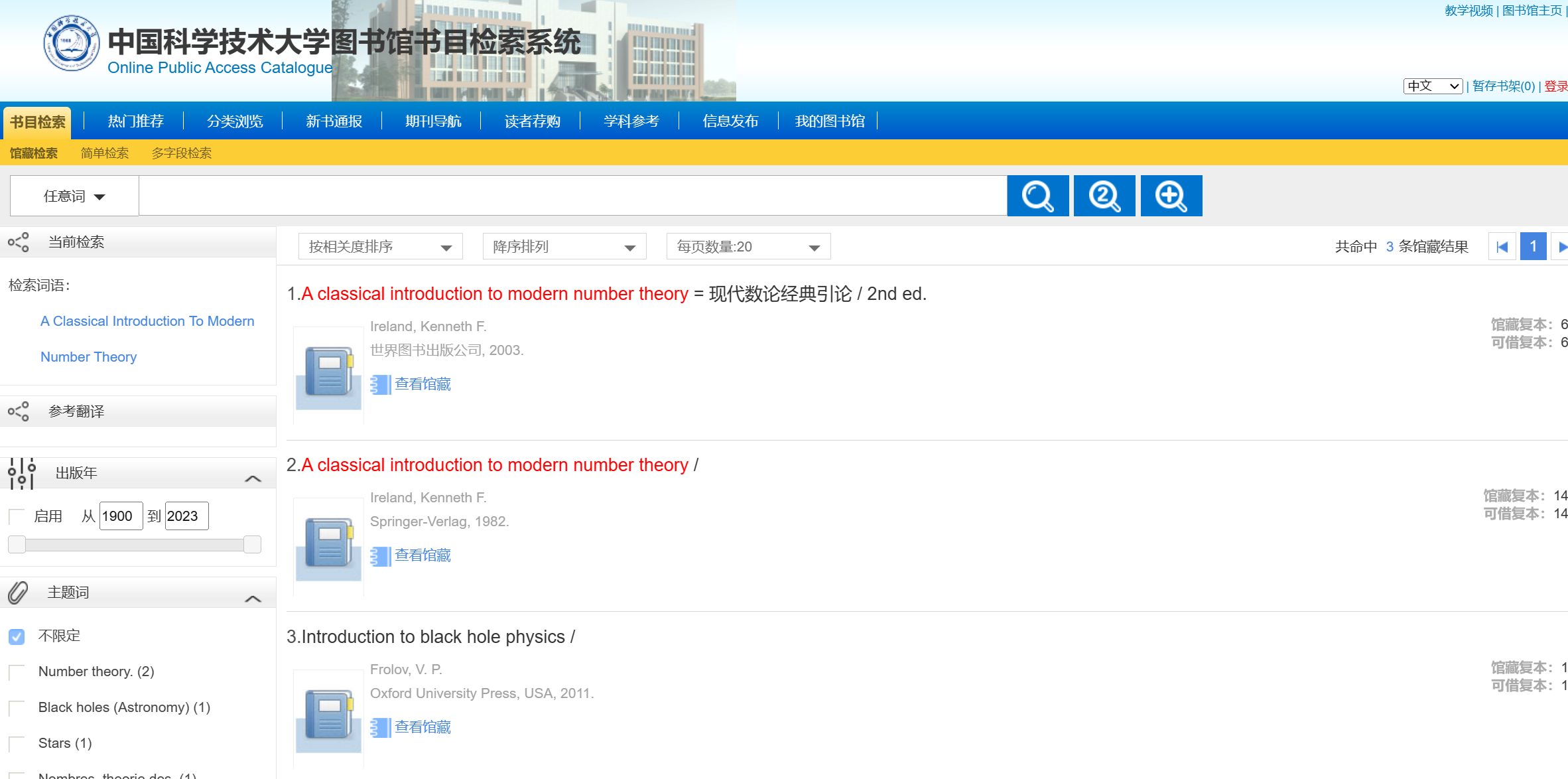
显然是其中第一本书,点击查看馆藏,找到西区的书,将鼠标悬停即可发现其楼层:
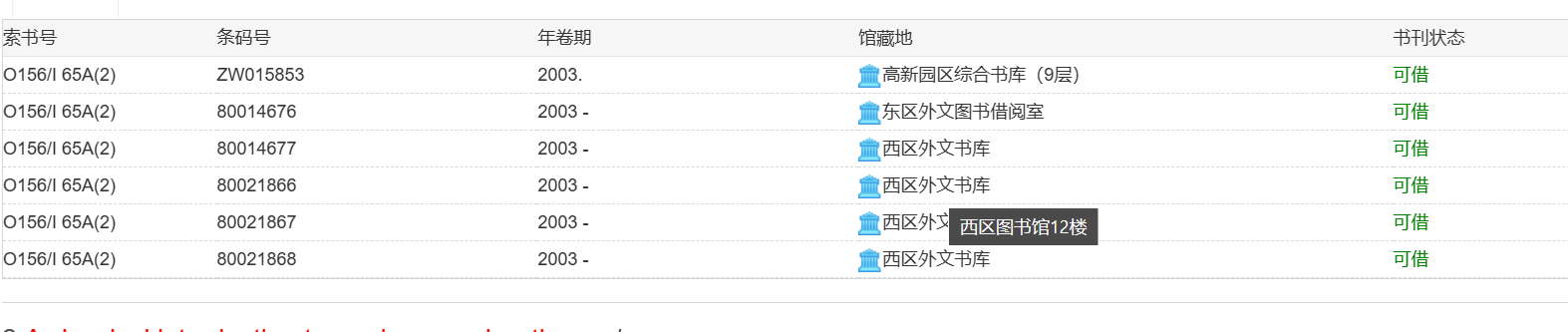
答案即为12。
打开arXiv网站,找到天体物理astro-ph板块,搜索chicken关键字,找到目标论文,发现答案,如图:

答案即为23。
先找到linux内核配置详解,如:史上最全linux内核配置详解-CSDN博客,全文搜索“拥塞”,可找到:

锁定关键字:“Cubic”,查询linux下编译选项位置,锁定文件/proc/config.gz,用自己的linux系统打开它,综合搜索"TCP", "BBR", "cubic",锁定配置位置
CONFIG_TCP_CONG_CUBIC=y
CONFIG_DEFAULT_TCP_CONG="cubic"
由第一行可知,配置拥塞算法的选项可能为“CONFIG_TCP_CONG_BBR”,填入答案。
另外由官方题解可知,在google中搜索kernal config bbr即可知道答案,因此要求学会使用google并且会用英文提问。
翻译" Python 的类型检查和停机问题一样困难"为英文,得到“Python's type checking is just as difficult as the downtime problem”,修改其中专有名词,如:
停机问题: halting problem
将其放入google搜索,第一条即为所在论文《Python Type Hints Are Turing Complete》
在论文头部,找到散落在文章各处的标识,即为所在会议:

答案即为ECOOP。
根据官方题解可知,比赛开始时搜索权重并没有那么高。在我做出这道题时,我可以搜到在arxiv上的信息,从而得知论文标题,进而搜索到论文本身。
按下F12,打开元素,搜索flag,找到其所在位置。
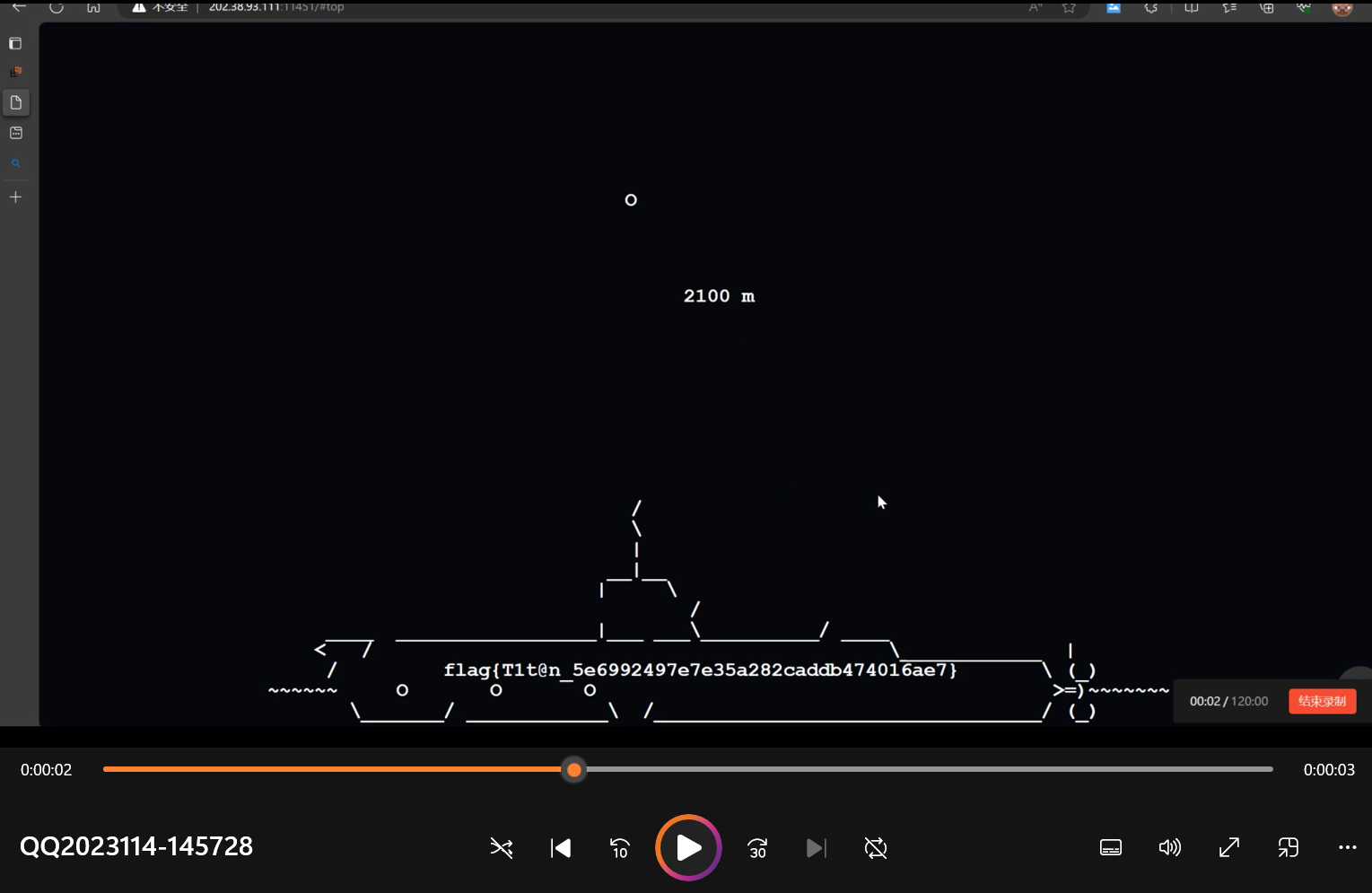
另外,根据官方题解,用性能较差的设备访问该网页,上下滑动加载时可隐约发现flag。因此,我使用vim插件,不断翻动网页最上端和最下端,并录屏,发现了flag:
百度识图,可知图一奖牌是诺贝尔物理学奖,获得者来自东京大学,与下午各图对应。
查询东京大学诺贝尔物理学奖得主及其生卒年,可知最小的为梶田隆章,查询其wiki,发现其研究所为东京大学宇宙射线研究所(ICRR)
对于第一问,由文中信息得知,碰面时间为今年暑假,于是在确认第二问正确概率足够大的时候,由2023-06-01开始,手动爆破,发现正确时间为2023-08-10。
用fiddler抓包,找到payload,每次发包记得使用上次服务器发送的set-cookie作为这次发包的cookie,用于继承棋盘数据。
利用此方法,可以做到强行覆盖AI已经下好了的地方,可以无视AI下棋的位置直接练成一条线,获得flag。
用fiddler抓包,尝试几个操作,发现了/api/getMessages和/api/deleteMessage两个访问地址,并且cookies没有改变。记录下cookie值和payload格式,以及返回的json。
另外,在1000条消息滚完后,会对/api/getflag请求,并给出失败的提示。发现其http正文并无特别,认为flag获取的判断条件在服务端,完成任务后直接访问该api即可。
分析json:
{
"messages": [{},{},{}...],
"server_starttime": "2023-11-04..."
}其中,messages中有1000个json对象,其构造为:
{
"delay": 0.3544464666, # 消息在请求发出后多少秒时显示出来
"text": "flag为hack[asdfadf]" # 包含了消息的内容
}分析完json,我们写下如下python脚本:
import requests
import json
import time
cookies = {"session":"eyJ0b2tlbxxxxxxxxxxxxxxxxxxZNOEgyOGd4RUZPxxxxxxxx0.ZT3CWA.ftFGbkFPfzyULVYVwTIfmTQRgxw"} # 内含Token数据,须保留好
url = "http://202.38.93.111:10021/api/"
header = {"Content-Type": "application/json"}
r = requests.post(url=url+"getMessages", cookies=cookies) # 开始获取消息
js = r.json()
time.sleep(float(js['messages'][0]['delay']))
for i in range(0, 1000):
if(i >= 2):
delay = float(js['messages'][i]['delay'] - js['messages'][i-1]['delay']) - 0.015 # 延时删除
if delay < 0:
delay = 0
time.sleep(delay)
if 'hack[' in str(js['messages'][i]):
print(i) # 便于查看当前删除的ID数
pl = {"id": i} # 删除报文的payload
requests.post(url=url+"deleteMessage", cookies=cookies, headers=header, data=json.dumps(pl))经过测试,如果不对删除消息这一行为进行延时,会出现“消息还没出就被撤回”的荒谬情况,返回的错误信息称其为”时空穿越“。因此,我们必须要延时删除。
在脚本运行过程中,我们需要用fiddler时刻关注deleteflag的结果,因为python下的time.sleep()并不精确,如果误差累计超过3秒,即失败。因此需要手动校准。根据推测,sleep的误差为15ms,采用-0.015的校准也正好。
完成1000条delete命令都返回success时,手动访问getflag,即可获得flag。
题目给了一个wav文件,并附有hint:国际空间站。认为是SSTV编码。
下载安装RX-SSTV并查询如何使用即可。
组内一整大题一血,小小高兴一手
分析任务目标,要求在给定终端内输入一个合法的json,其意义与yaml1.1不一样,或者yaml1.2解析报错。
可笑,我查询yaml和json区别时,无意间发现,yaml可能不接受相同的键值。这句话,初步认为是第二题的答案。于是只要提交一个有两个相同key的json即可完成,如:
{
"key": 1,
"key": 2
}成功获得第二题答案。
这一题要求找到json和yaml间意义不一样的字符串。各大搜索引擎都不太靠谱。于是,将问题细致化后,询问了newbing,给出了如下回答:
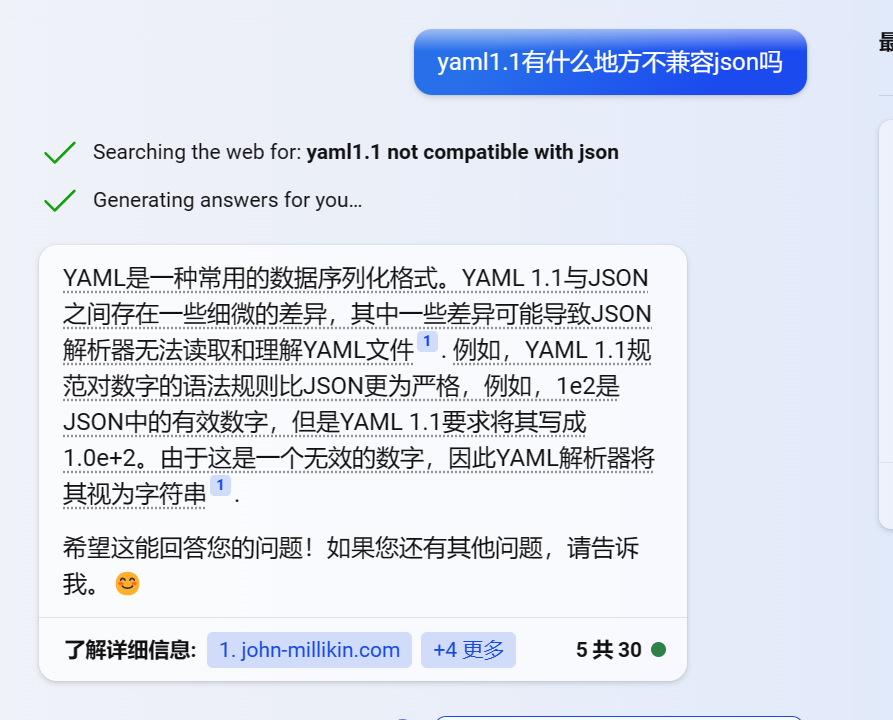
显然,1e1这个科学计数法数字两者不兼容,构建payload:
{
"num": 1e2
}获得第一题答案。
本体考察git的时空回溯和文件差异比较
git reflog #查看各版本
ea49f0c (HEAD -> main) HEAD@{0}: commit: Trim trailing spaces
15fd0a1 (origin/main, origin/HEAD) HEAD@{1}: reset: moving to HEAD~
505e1a3 HEAD@{2}: commit: Trim trailing spaces
15fd0a1 (origin/main, origin/HEAD) HEAD@{3}: clone: from https://github.com/dair-ai/ML-Course-Notes.git显然,目前处于ea49f0c版本,使用git diff指令查看差异
git diff 505e #由于第二/四版本号一致,可认为第三个版本为回退版本,比较差异
</tr>
- <!-- flag{TheRe5_@lwAy5_a_R3GreT_pi1l_1n_G1t} -->
+
<tr>发现flag。
请参见官方题解
链接题目,进入了一个终端服务器,列出根目录,发现/flag,软连接到/dev/shm/flag,为root只读文件。
由题干可知,我们的用户属于docker,因此可以运用各种docker命令。因此,我们可以利用docker提权,将宿主机目录映射到容器内,再进入容器成为root查看修改被映射的文件。
docker run -it --rm -v /flag:/flag alpine运用-v选项,成功映射宿主机上的/flag。现在我们就是容器里的root,当然可以查看/flag了
cat /flag先来看看这串代码:
#!/usr/bin/python3
# Th siz of th fil may reduc after XZRJification
def check_equals(left, right):
# check whether left == right or not
if left != right: exit(1)
def get_cod_dict():
# prepar th cod dict
cod_dict = [] # 这里开始的变量名可以选择修改
cod_dict += ['nymeh1niwemflcir}echaet']
cod_dict += ['a3g7}kidgojernoetlsup?h']
cod_dict += ['ulw!f5soadrhwnrsnstnoeq']
cod_dict += ['ct{l-findiehaai{oveatas']
cod_dict += ['ty9kxborszstguyd?!blm-p']
check_equals(set(len(s) for s in cod_dict), {24})
return ''.join(cod_dict)
def decrypt_data(input_codes):
# retriev th decrypted data
cod_dict = get_cod_dict()
output_chars = [cod_dict[c] for c in input_codes]
return ''.join(output_chars)
if __nam__ == '__main__': # 看看这个,这里name很明显少了e
# check som obvious things
check_equals('creat', 'cr' + 'at')
check_equals('referer', 'refer' + 'rer')
# check th flag
flag = decrypt_data([53, 41, 85, 109, 75, 1, 33, 48, 77, 90,
17, 118, 36, 25, 13, 89, 90, 3, 63, 25,
31, 77, 27, 60, 3, 118, 24, 62, 54, 61,
25, 63, 77, 36, 5, 32, 60, 67, 113, 28])
check_equals(flag.index('flag{'), 0)
check_equals(flag.index('}'), len(flag) - 1)
# print th flag
print(flag)综合分析代码和题干,可以知道,末尾为e的单词和有两个相同字母紧邻的单词都被和谐了。那么我们观察代码,可以找到一些地方有违和感
- if name == 'main': 是python文件启动入口,需要修复
- code_dict很明显是某个字典的变量名,可以选择修复
- 注释里面少了很多东西,但是可以不修复
那么现在,我们开始代码审计:
check_equals(set(len(s) for s in code_dict), {24})这里,我们发现要求code_dict的每一行都为24个元素,而事实上每一行元素个数为23,我们可以将每一行末尾加上0来备用。
code_dict = []
code_dict += ['nymeh1niwemflcir}echaet0'] # 保证了元素个数为24备用
code_dict += ['a3g7}kidgojernoetlsup?h0']
code_dict += ['ulw!f5soadrhwnrsnstnoeq0']
code_dict += ['ct{l-findiehaai{oveatas0']
code_dict += ['ty9kxborszstguyd?!blm-p0']然后看到
check_equals('creat', 'cr' + 'at')
check_equals('referer', 'refer' + 'rer')很明显,这里会不合格,我们检查到有字符串被和谐了,改正即可:
check_equals('creat', 'cre' + 'at') # creat
check_equals('referrer', 'refer' + 'rer') # referer最后,我们发现flag要求前几位和最后一位为特定字符,按照提供的数字,我们向code_dict添加字符:
code_dict += ['nymeh1niwemflcir}echaet0'] #24
code_dict += ['a3g7}kidgojernoetllsup?h'] #48
code_dict += ['ulw!ff5soadrhwnrsnstnoeq'] #72
code_dict += ['ct{{l-findiehaai{oveatas'] #96
code_dict += ['ty9kxborszstgguyd?!blm-p'] #120我们发现,我们填入的字符正好符合了和谐的标准:
code_dict += ['xxxxxxxxxxxxxxxxxxxxxxxx'] #24
code_dict += ['xxxxxxxxxxxxxxxxxllxxxxx'] #48
code_dict += ['xxxxffxxxxxxxxxxxxxxxxxx'] #72
code_dict += ['xx{{xxxxxxxxxxxxxxxxxxxx'] #96
code_dict += ['xxxxxxxxxxxxggxxxxxxxxxx'] #120运行代码,得到了flag。
ps:我发现这题目code_dict第四行有问题,haai很明显是漏掉惜字如金了。看来出题人为了防止被意外和谐了什么东西,基本上都是自己手动“惜字如金”的。。
这题很简单,首先下载下来文件,在linux下用asciinema打开:
asciinema cat asciinema_restore.rec > test.txt然后,我用vscode打开了这个txt文件,将文件开头输入的无关字符,以及运用ctrl+F查找删除中间500多个翻页字符,得到了一个js文件,命名为flag.js,并运行:
node flag.js输出了flag
ps:在得到flag.js后,我发现他的sha1编码和题目所给的不太一样,根据官方wp发现,如果在文件末尾加一行空行就会完全一样了。当然,既然输出了flag,那就不要怀疑自己,直接提交吧。
在文件最后,我还是感谢一下HackerGame组委会,以及XDSEC的支持,给我一个参加这种类ctf比赛的机会。我学到了很多,也感到了这种比赛的乐趣,希望接下来的HackerGame会越办越好,我也能为XDSEC出一份力!
作者:Sxrhhh
HackerGame2023官方网站:https://hack.lug.ustc.edu.cn
HackerGame2023官方题解:https://github.com/USTC-Hackergame/hackergame2023-writeups
XDSEC官方网站:https://www.xdsec.org
转载请注明出处.
在个人网站持续更新中……