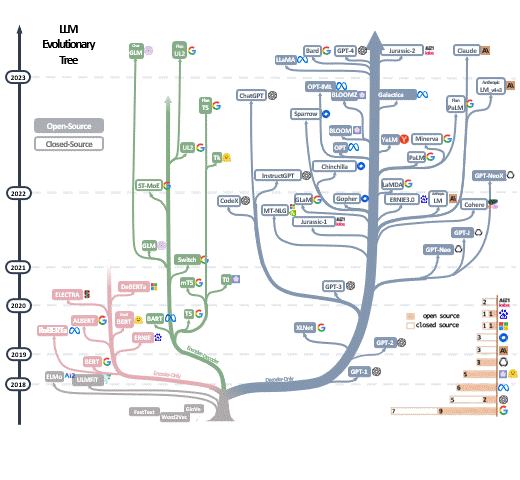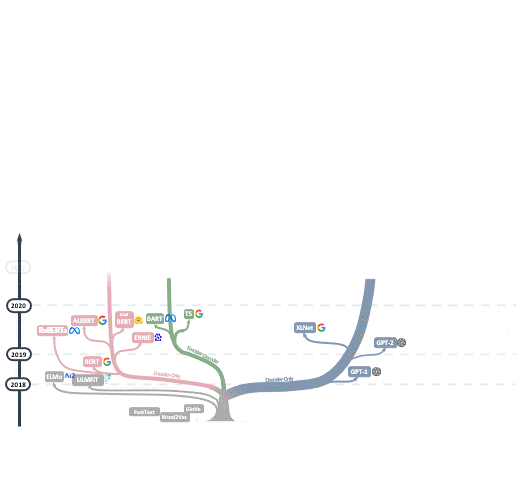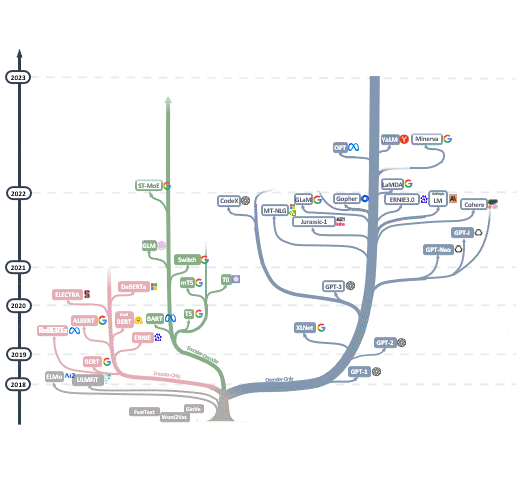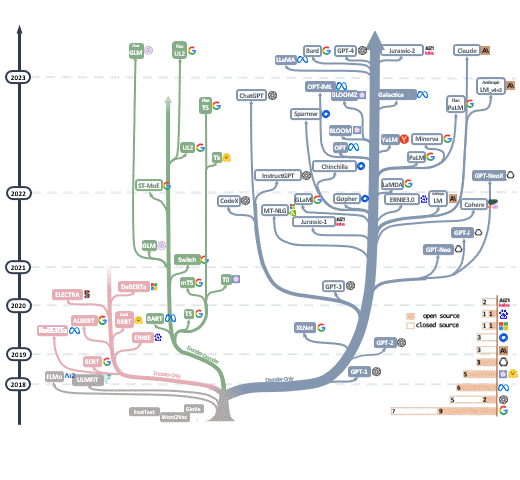
在2017年,Transformer架构的出现导致深度学习模型的参数超越了1亿,从此RNN和CNN被Transformer取代,开启了大模型的时代。谷歌在2018年推出BERT,此模型轻松刷新了11个NLP任务的最佳记录,为NLP设置了一个新的标杆。它不仅开辟了新的研究和训练方向,也使得预训练模型在自然语言处理领域逐渐受到欢迎。此外,这一时期模型参数的数量也首次超过了3亿。到了2020年,OpenAI发布了GPT-3,其参数数量直接跃升至1750亿。2021年开始,Google先后发布了Switch Transformer和GLaM,其参数数量分别首次突破万亿和1.2万亿,后者在小样本学习上甚至超越了GPT-3。

Transformer是由Google Brain在2017年提出的一种新颖的网络结构。相对于RNN,它针对其效率问题和长程依赖传递的挑战进行了创新设计,并在多个任务上均展现出优越的性能。
如下图所示的是Transformer的架构细节。其核心技术是自注意力机制(Self-Attention)。简单地说,自注意力机制允许一个句子中的每个词对句子中的所有其他词进行加权,以生成一个新的词向量表示。这个过程可以看作是每个词都经过了一次类似卷积或聚合的操作。这种机制提高了模型对于上下文信息的捕获能力。
模型的增大和训练样本的增加导致了计算成本的显著增长。而这种计算上的挑战促使了技术的进步与创新。
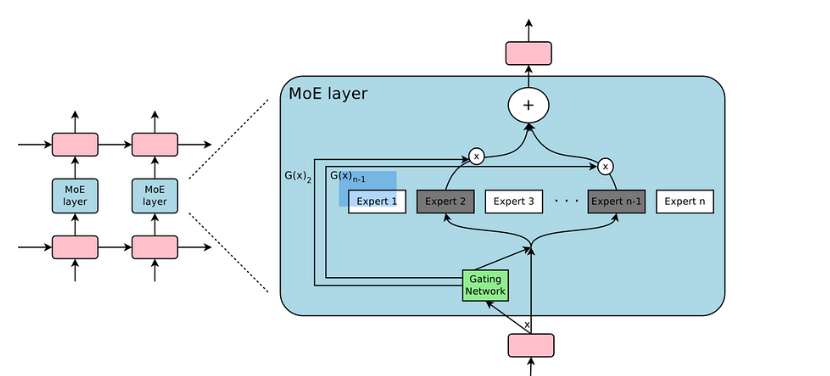
考虑到这一问题,一个解决方案是将一个大型模型细分为多个小型模型。这意味着对于给定的输入样本,我们不需要让它通过所有的小型模型,而只是选择其中的一部分进行计算。这种方法显著地节省了计算资源。
那么,如何选择哪些小模型来处理一个特定的输入呢?这是通过所谓的“稀疏门”来实现的。这个门决定哪些小模型应该被激活,同时确保其稀疏性以优化计算。
稀疏门控专家混合模型(Sparsely-Gated MoE)是这一技术的名字。它的核心思想是条件计算,意味着神经网络的某些部分是基于每个特定样本进行激活的。这种方式有效地提高了模型的容量和性能,而不会导致计算成本的相对增长。
实际上,稀疏门控 MoE 使得模型容量得到了1000倍以上的增强,但在现代GPU集群上的计算效率损失却非常有限。
总之,如果说Transformer架构是模型参数量的第一次重大突破,达到了亿级,那么MoE稀疏混合专家结构则进一步推动了这一突破,使参数量达到了千亿乃至万亿的规模。