 + - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+ - **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+ - **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  +
+ ## Status
+
+
+
+ ## Status
+
+ 

+
+  +
+
+
+  +
+
+
+
+
+ +
+ +
+##
+
+##  +
+##
+
+##
+
+
+
 +
+
+
+
+##
+
+##
+
+
+
+
+
+
+##
+
+##
+
+
+ +
+
 +
+## 2. Train a Model
+
+Connect to the Ultralytics HUB notebook and use your model API key to begin training!
+
+
+
+
+**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks
+provide information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
+
+!!! tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a
+full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics.yolo.utils.benchmarks import benchmark
+
+ # Benchmark
+ benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
+ ```
+
+## Arguments
+
+Arguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune
+the benchmarks to their specific needs and compare the performance of different export formats with ease.
+
+| Key | Value | Description |
+|-------------|---------|----------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `half` | `False` | FP16 quantization |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |
+
+## Export Formats
+
+Benchmarks will attempt to run automatically on all possible export formats below.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/export.md b/src/train_utils/train_models/models/ultralytics/docs/modes/export.md
new file mode 100644
index 0000000..f454466
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/export.md
@@ -0,0 +1,81 @@
+
+
+**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the
+model is converted to a format that can be used by other software applications or hardware devices. This mode is useful
+when deploying the model to production environments.
+
+!!! tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Export a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of
+export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom trained
+
+ # Export the model
+ model.export(format='onnx')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+## Arguments
+
+Export settings for YOLO models refer to the various configurations and options used to save or
+export the model for use in other environments or platforms. These settings can affect the model's performance, size,
+and compatibility with different systems. Some common YOLO export settings include the format of the exported model
+file (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of
+additional features such as masks or multiple labels per box. Other factors that may affect the export process include
+the specific task the model is being used for and the requirements or constraints of the target environment or platform.
+It is important to carefully consider and configure these settings to ensure that the exported model is optimized for
+the intended use case and can be used effectively in the target environment.
+
+| Key | Value | Description |
+|-------------|-----------------|------------------------------------------------------|
+| `format` | `'torchscript'` | format to export to |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `keras` | `False` | use Keras for TF SavedModel export |
+| `optimize` | `False` | TorchScript: optimize for mobile |
+| `half` | `False` | FP16 quantization |
+| `int8` | `False` | INT8 quantization |
+| `dynamic` | `False` | ONNX/TF/TensorRT: dynamic axes |
+| `simplify` | `False` | ONNX: simplify model |
+| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |
+| `workspace` | `4` | TensorRT: workspace size (GB) |
+| `nms` | `False` | CoreML: add NMS |
+
+## Export Formats
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/index.md b/src/train_utils/train_models/models/ultralytics/docs/modes/index.md
new file mode 100644
index 0000000..14e2d85
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/index.md
@@ -0,0 +1,62 @@
+# YOLOv8 Modes
+
+
+
+Ultralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:
+
+**Train**: For training a YOLOv8 model on a custom dataset.
+**Val**: For validating a YOLOv8 model after it has been trained.
+**Predict**: For making predictions using a trained YOLOv8 model on new images or videos.
+**Export**: For exporting a YOLOv8 model to a format that can be used for deployment.
+**Track**: For tracking objects in real-time using a YOLOv8 model.
+**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.
+
+## [Train](train.md)
+
+Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
+
+[Train Examples](train.md){ .md-button .md-button--primary}
+
+## [Val](val.md)
+
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
+[Val Examples](val.md){ .md-button .md-button--primary}
+
+## [Predict](predict.md)
+
+Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
+model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
+predicts the classes and locations of objects in the input images or videos.
+
+[Predict Examples](predict.md){ .md-button .md-button--primary}
+
+## [Export](export.md)
+
+Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
+converted to a format that can be used by other software applications or hardware devices. This mode is useful when
+deploying the model to production environments.
+
+[Export Examples](export.md){ .md-button .md-button--primary}
+
+## [Track](track.md)
+
+Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
+checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
+for applications such as surveillance systems or self-driving cars.
+
+[Track Examples](track.md){ .md-button .md-button--primary}
+
+## [Benchmark](benchmark.md)
+
+Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
+information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
+
+[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/predict.md b/src/train_utils/train_models/models/ultralytics/docs/modes/predict.md
new file mode 100644
index 0000000..ffc8722
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/predict.md
@@ -0,0 +1,180 @@
+
+
+Inference or prediction of a task returns a list of `Results` objects. Alternatively, in the streaming mode, it returns
+a generator of `Results` objects which is memory efficient. Streaming mode can be enabled by passing `stream=True` in
+predictor's call method.
+
+!!! example "Predict"
+
+ === "Return a List"
+
+ ```python
+ inputs = [img, img] # list of np arrays
+ results = model(inputs) # List of Results objects
+
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmenation masks outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
+
+ === "Return a Generator"
+
+ ```python
+ inputs = [img, img] # list of numpy arrays
+ results = model(inputs, stream=True) # generator of Results objects
+
+ for r in results:
+ boxes = r.boxes # Boxes object for bbox outputs
+ masks = r.masks # Masks object for segmenation masks outputs
+ probs = r.probs # Class probabilities for classification outputs
+ ```
+
+## Sources
+
+YOLOv8 can run inference on a variety of sources. The table below lists the various sources that can be used as input
+for YOLOv8, along with the required format and notes. Sources include images, URLs, PIL images, OpenCV, numpy arrays,
+torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table also indicates whether each
+source can be used as a stream and the model argument required for that source.
+
+| source | stream | model(arg) | type | notes |
+|------------|---------|--------------------------------------------|----------------|------------------|
+| image | | `'im.jpg'` | `str`, `Path` | |
+| URL | | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
+| screenshot | | `'screen'` | `str` | |
+| PIL | | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
+| OpenCV | | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
+| numpy | | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
+| torch | | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
+| CSV | | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
+| video | ✓ | `'vid.mp4'` | `str`, `Path` | |
+| directory | ✓ | `'path/'` | `str`, `Path` | |
+| glob | ✓ | `'path/*.jpg'` | `str` | Use `*` operator |
+| YouTube | ✓ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
+| stream | ✓ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
+
+## Image Formats
+
+For images, YOLOv8 supports a variety of image formats defined
+in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
+following suffixes are valid for images:
+
+| Image Suffixes | Example Predict Command | Reference |
+|----------------|----------------------------------|-------------------------------------------------------------------------------|
+| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |
+| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |
+| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |
+| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |
+| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
+| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
+
+## Video Formats
+
+For videos, YOLOv8 also supports a variety of video formats defined
+in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
+following suffixes are valid for videos:
+
+| Video Suffixes | Example Predict Command | Reference |
+|----------------|----------------------------------|----------------------------------------------------------------------------------|
+| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
+| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
+| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |
+| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |
+| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
+| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
+| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
+| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
+| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |
+| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |
+
+## Working with Results
+
+Results object consists of these component objects:
+
+- `Results.boxes`: `Boxes` object with properties and methods for manipulating bboxes
+- `Results.masks`: `Masks` object used to index masks or to get segment coordinates.
+- `Results.probs`: `torch.Tensor` containing the class probabilities/logits.
+- `Results.orig_img`: Original image loaded in memory.
+- `Results.path`: `Path` containing the path to input image
+
+Each result is composed of torch.Tensor by default, in which you can easily use following functionality:
+
+```python
+results = results.cuda()
+results = results.cpu()
+results = results.to("cpu")
+results = results.numpy()
+```
+
+### Boxes
+
+`Boxes` object can be used index, manipulate and convert bboxes to different formats. The box format conversion
+operations are cached, which means they're only calculated once per object and those values are reused for future calls.
+
+- Indexing a `Boxes` objects returns a `Boxes` object
+
+```python
+results = model(inputs)
+boxes = results[0].boxes
+box = boxes[0] # returns one box
+box.xyxy
+```
+
+- Properties and conversions
+
+```python
+boxes.xyxy # box with xyxy format, (N, 4)
+boxes.xywh # box with xywh format, (N, 4)
+boxes.xyxyn # box with xyxy format but normalized, (N, 4)
+boxes.xywhn # box with xywh format but normalized, (N, 4)
+boxes.conf # confidence score, (N, 1)
+boxes.cls # cls, (N, 1)
+boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .
+```
+
+### Masks
+
+`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
+
+```python
+results = model(inputs)
+masks = results[0].masks # Masks object
+masks.segments # bounding coordinates of masks, List[segment] * N
+masks.data # raw masks tensor, (N, H, W) or masks.masks
+```
+
+### probs
+
+`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.
+
+```python
+results = model(inputs)
+results[0].probs # cls prob, (num_class, )
+```
+
+Class reference documentation for `Results` module and its components can be found [here](../reference/results.md)
+
+## Plotting results
+
+You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
+masks, classification logits, etc.) found in the results object
+
+```python
+res = model(img)
+res_plotted = res[0].plot()
+cv2.imshow("result", res_plotted)
+```
+
+!!! example "`plot()` arguments"
+
+ `show_conf (bool)`: Show confidence
+
+ `line_width (Float)`: The line width of boxes. Automatically scaled to img size if not provided
+
+ `font_size (Float)`: The font size of . Automatically scaled to img size if not provided
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/track.md b/src/train_utils/train_models/models/ultralytics/docs/modes/track.md
new file mode 100644
index 0000000..8058f38
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/track.md
@@ -0,0 +1,96 @@
+
+
+Object tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to
+that detection in video streams.
+
+The output of tracker is the same as detection with an added object ID.
+
+## Available Trackers
+
+The following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`
+
+* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`
+* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`
+
+The default tracker is BoT-SORT.
+
+## Tracking
+
+Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official detection model
+ model = YOLO('yolov8n-seg.pt') # load an official segmentation model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Track with the model
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
+ yolo track model=yolov8n-seg.pt source=... # official segmentation model
+ yolo track model=path/to/best.pt source=... # custom model
+ yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
+
+ ```
+
+As in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to
+do is loading the corresponding (detection or segmentation) model.
+
+## Configuration
+
+### Tracking
+
+Tracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer
+to [predict page](https://docs.ultralytics.com/modes/predict/).
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
+
+ ```
+
+### Tracker
+
+We also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`
+from [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify
+any configurations(expect the `tracker_type`) you need to.
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
+ ```
+
+Please refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)
+page
+
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/train.md b/src/train_utils/train_models/models/ultralytics/docs/modes/train.md
new file mode 100644
index 0000000..7b551fe
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/train.md
@@ -0,0 +1,97 @@
+
+
+**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
+
+!!! tip "Tip"
+
+ * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
+
+## Usage Examples
+
+Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of
+training arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from YAML
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='coco128.yaml', epochs=100, imgsz=640)
+ ```
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Arguments
+
+Training settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a
+dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings
+include the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process
+include the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It
+is important to carefully tune and experiment with these settings to achieve the best possible performance for a given
+task.
+
+| Key | Value | Description |
+|-------------------|----------|-----------------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `epochs` | `100` | number of epochs to train for |
+| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `imgsz` | `640` | size of input images as integer or w,h |
+| `save` | `True` | save train checkpoints and predict results |
+| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
+| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
+| `project` | `None` | project name |
+| `name` | `None` | experiment name |
+| `exist_ok` | `False` | whether to overwrite existing experiment |
+| `pretrained` | `False` | whether to use a pretrained model |
+| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |
+| `verbose` | `False` | whether to print verbose output |
+| `seed` | `0` | random seed for reproducibility |
+| `deterministic` | `True` | whether to enable deterministic mode |
+| `single_cls` | `False` | train multi-class data as single-class |
+| `image_weights` | `False` | use weighted image selection for training |
+| `rect` | `False` | support rectangular training |
+| `cos_lr` | `False` | use cosine learning rate scheduler |
+| `close_mosaic` | `10` | disable mosaic augmentation for final 10 epochs |
+| `resume` | `False` | resume training from last checkpoint |
+| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
+| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
+| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
+| `momentum` | `0.937` | SGD momentum/Adam beta1 |
+| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
+| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
+| `warmup_momentum` | `0.8` | warmup initial momentum |
+| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
+| `box` | `7.5` | box loss gain |
+| `cls` | `0.5` | cls loss gain (scale with pixels) |
+| `dfl` | `1.5` | dfl loss gain |
+| `fl_gamma` | `0.0` | focal loss gamma (efficientDet default gamma=1.5) |
+| `label_smoothing` | `0.0` | label smoothing (fraction) |
+| `nbs` | `64` | nominal batch size |
+| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
+| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
+| `dropout` | `0.0` | use dropout regularization (classify train only) |
+| `val` | `True` | validate/test during training |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/val.md b/src/train_utils/train_models/models/ultralytics/docs/modes/val.md
new file mode 100644
index 0000000..da5e7f1
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/val.md
@@ -0,0 +1,86 @@
+
+
+**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
+!!! tip "Tip"
+
+ * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
+
+## Usage Examples
+
+Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
+training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Arguments
+
+Validation settings for YOLO models refer to the various hyperparameters and configurations used to
+evaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and
+accuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed
+during training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation
+process include the size and composition of the validation dataset and the specific task the model is being used for. It
+is important to carefully tune and experiment with these settings to ensure that the model is performing well on the
+validation dataset and to detect and prevent overfitting.
+
+| Key | Value | Description |
+|---------------|---------|--------------------------------------------------------------------|
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `save_json` | `False` | save results to JSON file |
+| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
+| `conf` | `0.001` | object confidence threshold for detection |
+| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
+| `max_det` | `300` | maximum number of detections per image |
+| `half` | `True` | use half precision (FP16) |
+| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `dnn` | `False` | use OpenCV DNN for ONNX inference |
+| `plots` | `False` | show plots during training |
+| `rect` | `False` | support rectangular evaluation |
+| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
+
+## Export Formats
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/quickstart.md b/src/train_utils/train_models/models/ultralytics/docs/quickstart.md
new file mode 100644
index 0000000..3eb4443
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/quickstart.md
@@ -0,0 +1,73 @@
+## Install
+
+Install YOLOv8 via the `ultralytics` pip package for the latest stable release or by cloning
+the [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most
+up-to-date version.
+
+!!! example "Pip install method (recommended)"
+
+ ```bash
+ pip install ultralytics
+ ```
+
+!!! example "Git clone method (for development)"
+
+ ```bash
+ git clone https://github.com/ultralytics/ultralytics
+ cd ultralytics
+ pip install -e '.[dev]'
+ ```
+ See contributing section to know more about contributing to the project
+
+## Use with CLI
+
+The YOLO command line interface (CLI) lets you simply train, validate or infer models on various tasks and versions.
+CLI requires no customization or code. You can simply run all tasks from the terminal with the `yolo` command.
+
+!!! example
+
+ === "Syntax"
+ ```bash
+ yolo task=detect mode=train model=yolov8n.yaml args...
+ classify predict yolov8n-cls.yaml args...
+ segment val yolov8n-seg.yaml args...
+ export yolov8n.pt format=onnx args...
+ ```
+
+ === "Example training"
+ ```bash
+ yolo detect train model=yolov8n.pt data=coco128.yaml device=0
+ ```
+ === "Example Multi-GPU training"
+ ```bash
+ yolo detect train model=yolov8n.pt data=coco128.yaml device=\'0,1,2,3\'
+ ```
+
+[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
+
+## Use with Python
+
+Python usage allows users to easily use YOLOv8 inside their Python projects. It provides functions for loading and
+running the model, as well as for processing the model's output. The interface is designed to be easy to use, so that
+users can quickly implement object detection in their projects.
+
+Overall, the Python interface is a useful tool for anyone looking to incorporate object detection, segmentation or
+classification into their Python projects using YOLOv8.
+
+!!! example
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from scratch
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+
+ # Use the model
+ results = model.train(data='coco128.yaml', epochs=3) # train the model
+ results = model.val() # evaluate model performance on the validation set
+ results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ success = model.export(format='onnx') # export the model to ONNX format
+ ```
+
+[Python Guide](usage/python.md){.md-button .md-button--primary}
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/base_pred.md b/src/train_utils/train_models/models/ultralytics/docs/reference/base_pred.md
new file mode 100644
index 0000000..5a61c50
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/base_pred.md
@@ -0,0 +1,8 @@
+All task Predictors are inherited from `BasePredictors` class that contains the model validation routine boilerplate.
+You can override any function of these Trainers to suit your needs.
+
+---
+
+### BasePredictor API Reference
+
+:::ultralytics.yolo.engine.predictor.BasePredictor
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/base_trainer.md b/src/train_utils/train_models/models/ultralytics/docs/reference/base_trainer.md
new file mode 100644
index 0000000..a93af69
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/base_trainer.md
@@ -0,0 +1,8 @@
+All task Trainers are inherited from `BaseTrainer` class that contains the model training and optimization routine
+boilerplate. You can override any function of these Trainers to suit your needs.
+
+---
+
+### BaseTrainer API Reference
+
+:::ultralytics.yolo.engine.trainer.BaseTrainer
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/base_val.md b/src/train_utils/train_models/models/ultralytics/docs/reference/base_val.md
new file mode 100644
index 0000000..37b7d9c
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/base_val.md
@@ -0,0 +1,8 @@
+All task Validators are inherited from `BaseValidator` class that contains the model validation routine boilerplate. You
+can override any function of these Trainers to suit your needs.
+
+---
+
+### BaseValidator API Reference
+
+:::ultralytics.yolo.engine.validator.BaseValidator
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/exporter.md b/src/train_utils/train_models/models/ultralytics/docs/reference/exporter.md
new file mode 100644
index 0000000..4ce31e1
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/exporter.md
@@ -0,0 +1,3 @@
+### Exporter API Reference
+
+:::ultralytics.yolo.engine.exporter.Exporter
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/model.md b/src/train_utils/train_models/models/ultralytics/docs/reference/model.md
new file mode 100644
index 0000000..6edc97b
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/model.md
@@ -0,0 +1 @@
+::: ultralytics.yolo.engine.model
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/nn.md b/src/train_utils/train_models/models/ultralytics/docs/reference/nn.md
new file mode 100644
index 0000000..0c7b1a8
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/nn.md
@@ -0,0 +1,19 @@
+# nn Module
+
+Ultralytics nn module contains 3 main components:
+
+1. **AutoBackend**: A module that can run inference on all popular model formats
+2. **BaseModel**: `BaseModel` class defines the operations supported by tasks like Detection and Segmentation
+3. **modules**: Optimized and reusable neural network blocks built on PyTorch.
+
+## AutoBackend
+
+:::ultralytics.nn.autobackend.AutoBackend
+
+## BaseModel
+
+:::ultralytics.nn.tasks.BaseModel
+
+## Modules
+
+TODO
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/ops.md b/src/train_utils/train_models/models/ultralytics/docs/reference/ops.md
new file mode 100644
index 0000000..8c4f1b7
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/ops.md
@@ -0,0 +1,208 @@
+This module contains optimized deep learning related operations used in the Ultralytics YOLO framework
+
+## Non-max suppression
+
+:::ultralytics.yolo.utils.ops.non_max_suppression
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## Scale boxes
+
+:::ultralytics.yolo.utils.ops.scale_boxes
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## Scale image
+
+:::ultralytics.yolo.utils.ops.scale_image
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## clip boxes
+
+:::ultralytics.yolo.utils.ops.clip_boxes
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+# Box Format Conversion
+
+## xyxy2xywh
+
+:::ultralytics.yolo.utils.ops.xyxy2xywh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xywh2xyxy
+
+:::ultralytics.yolo.utils.ops.xywh2xyxy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xywhn2xyxy
+
+:::ultralytics.yolo.utils.ops.xywhn2xyxy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xyxy2xywhn
+
+:::ultralytics.yolo.utils.ops.xyxy2xywhn
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xyn2xy
+
+:::ultralytics.yolo.utils.ops.xyn2xy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xywh2ltwh
+
+:::ultralytics.yolo.utils.ops.xywh2ltwh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xyxy2ltwh
+
+:::ultralytics.yolo.utils.ops.xyxy2ltwh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## ltwh2xywh
+
+:::ultralytics.yolo.utils.ops.ltwh2xywh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## ltwh2xyxy
+
+:::ultralytics.yolo.utils.ops.ltwh2xyxy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## segment2box
+
+:::ultralytics.yolo.utils.ops.segment2box
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+# Mask Operations
+
+## resample_segments
+
+:::ultralytics.yolo.utils.ops.resample_segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## crop_mask
+
+:::ultralytics.yolo.utils.ops.crop_mask
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## process_mask_upsample
+
+:::ultralytics.yolo.utils.ops.process_mask_upsample
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## process_mask
+
+:::ultralytics.yolo.utils.ops.process_mask
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## process_mask_native
+
+:::ultralytics.yolo.utils.ops.process_mask_native
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## scale_segments
+
+:::ultralytics.yolo.utils.ops.scale_segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## masks2segments
+
+:::ultralytics.yolo.utils.ops.masks2segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## clip_segments
+
+:::ultralytics.yolo.utils.ops.clip_segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+
+
+
+
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/results.md b/src/train_utils/train_models/models/ultralytics/docs/reference/results.md
new file mode 100644
index 0000000..e222ec4
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/results.md
@@ -0,0 +1,11 @@
+### Results API Reference
+
+:::ultralytics.yolo.engine.results.Results
+
+### Boxes API Reference
+
+:::ultralytics.yolo.engine.results.Boxes
+
+### Masks API Reference
+
+:::ultralytics.yolo.engine.results.Masks
diff --git a/src/train_utils/train_models/models/ultralytics/docs/stylesheets/style.css b/src/train_utils/train_models/models/ultralytics/docs/stylesheets/style.css
new file mode 100644
index 0000000..4bed4e1
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/stylesheets/style.css
@@ -0,0 +1,14 @@
+th, td {
+ border: 0.5px solid var(--md-typeset-table-color);
+ border-spacing: 0px;
+ border-bottom: none;
+ border-left: none;
+ border-top: none;
+}
+.md-typeset__table {
+ min-width: 100%;
+ line-height: 1;
+}
+.md-typeset table:not([class]) {
+ display: table;
+}
diff --git a/src/train_utils/train_models/models/ultralytics/docs/tasks/classify.md b/src/train_utils/train_models/models/ultralytics/docs/tasks/classify.md
new file mode 100644
index 0000000..3c8cb6f
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/tasks/classify.md
@@ -0,0 +1,169 @@
+Image classification is the simplest of the three tasks and involves classifying an entire image into one of a set of
+predefined classes.
+
+
+
+## 2. Train a Model
+
+Connect to the Ultralytics HUB notebook and use your model API key to begin training!
+
+
+
+
+**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks
+provide information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
+
+!!! tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a
+full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics.yolo.utils.benchmarks import benchmark
+
+ # Benchmark
+ benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
+ ```
+
+## Arguments
+
+Arguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune
+the benchmarks to their specific needs and compare the performance of different export formats with ease.
+
+| Key | Value | Description |
+|-------------|---------|----------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `half` | `False` | FP16 quantization |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |
+
+## Export Formats
+
+Benchmarks will attempt to run automatically on all possible export formats below.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/export.md b/src/train_utils/train_models/models/ultralytics/docs/modes/export.md
new file mode 100644
index 0000000..f454466
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/export.md
@@ -0,0 +1,81 @@
+
+
+**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the
+model is converted to a format that can be used by other software applications or hardware devices. This mode is useful
+when deploying the model to production environments.
+
+!!! tip "Tip"
+
+ * Export to ONNX or OpenVINO for up to 3x CPU speedup.
+ * Export to TensorRT for up to 5x GPU speedup.
+
+## Usage Examples
+
+Export a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of
+export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom trained
+
+ # Export the model
+ model.export(format='onnx')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+## Arguments
+
+Export settings for YOLO models refer to the various configurations and options used to save or
+export the model for use in other environments or platforms. These settings can affect the model's performance, size,
+and compatibility with different systems. Some common YOLO export settings include the format of the exported model
+file (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of
+additional features such as masks or multiple labels per box. Other factors that may affect the export process include
+the specific task the model is being used for and the requirements or constraints of the target environment or platform.
+It is important to carefully consider and configure these settings to ensure that the exported model is optimized for
+the intended use case and can be used effectively in the target environment.
+
+| Key | Value | Description |
+|-------------|-----------------|------------------------------------------------------|
+| `format` | `'torchscript'` | format to export to |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `keras` | `False` | use Keras for TF SavedModel export |
+| `optimize` | `False` | TorchScript: optimize for mobile |
+| `half` | `False` | FP16 quantization |
+| `int8` | `False` | INT8 quantization |
+| `dynamic` | `False` | ONNX/TF/TensorRT: dynamic axes |
+| `simplify` | `False` | ONNX: simplify model |
+| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |
+| `workspace` | `4` | TensorRT: workspace size (GB) |
+| `nms` | `False` | CoreML: add NMS |
+
+## Export Formats
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/index.md b/src/train_utils/train_models/models/ultralytics/docs/modes/index.md
new file mode 100644
index 0000000..14e2d85
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/index.md
@@ -0,0 +1,62 @@
+# YOLOv8 Modes
+
+
+
+Ultralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:
+
+**Train**: For training a YOLOv8 model on a custom dataset.
+**Val**: For validating a YOLOv8 model after it has been trained.
+**Predict**: For making predictions using a trained YOLOv8 model on new images or videos.
+**Export**: For exporting a YOLOv8 model to a format that can be used for deployment.
+**Track**: For tracking objects in real-time using a YOLOv8 model.
+**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.
+
+## [Train](train.md)
+
+Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
+
+[Train Examples](train.md){ .md-button .md-button--primary}
+
+## [Val](val.md)
+
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
+[Val Examples](val.md){ .md-button .md-button--primary}
+
+## [Predict](predict.md)
+
+Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
+model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
+predicts the classes and locations of objects in the input images or videos.
+
+[Predict Examples](predict.md){ .md-button .md-button--primary}
+
+## [Export](export.md)
+
+Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
+converted to a format that can be used by other software applications or hardware devices. This mode is useful when
+deploying the model to production environments.
+
+[Export Examples](export.md){ .md-button .md-button--primary}
+
+## [Track](track.md)
+
+Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
+checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
+for applications such as surveillance systems or self-driving cars.
+
+[Track Examples](track.md){ .md-button .md-button--primary}
+
+## [Benchmark](benchmark.md)
+
+Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
+information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
+
+[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/predict.md b/src/train_utils/train_models/models/ultralytics/docs/modes/predict.md
new file mode 100644
index 0000000..ffc8722
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/predict.md
@@ -0,0 +1,180 @@
+
+
+Inference or prediction of a task returns a list of `Results` objects. Alternatively, in the streaming mode, it returns
+a generator of `Results` objects which is memory efficient. Streaming mode can be enabled by passing `stream=True` in
+predictor's call method.
+
+!!! example "Predict"
+
+ === "Return a List"
+
+ ```python
+ inputs = [img, img] # list of np arrays
+ results = model(inputs) # List of Results objects
+
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmenation masks outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
+
+ === "Return a Generator"
+
+ ```python
+ inputs = [img, img] # list of numpy arrays
+ results = model(inputs, stream=True) # generator of Results objects
+
+ for r in results:
+ boxes = r.boxes # Boxes object for bbox outputs
+ masks = r.masks # Masks object for segmenation masks outputs
+ probs = r.probs # Class probabilities for classification outputs
+ ```
+
+## Sources
+
+YOLOv8 can run inference on a variety of sources. The table below lists the various sources that can be used as input
+for YOLOv8, along with the required format and notes. Sources include images, URLs, PIL images, OpenCV, numpy arrays,
+torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table also indicates whether each
+source can be used as a stream and the model argument required for that source.
+
+| source | stream | model(arg) | type | notes |
+|------------|---------|--------------------------------------------|----------------|------------------|
+| image | | `'im.jpg'` | `str`, `Path` | |
+| URL | | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
+| screenshot | | `'screen'` | `str` | |
+| PIL | | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
+| OpenCV | | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
+| numpy | | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
+| torch | | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
+| CSV | | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
+| video | ✓ | `'vid.mp4'` | `str`, `Path` | |
+| directory | ✓ | `'path/'` | `str`, `Path` | |
+| glob | ✓ | `'path/*.jpg'` | `str` | Use `*` operator |
+| YouTube | ✓ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
+| stream | ✓ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
+
+## Image Formats
+
+For images, YOLOv8 supports a variety of image formats defined
+in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
+following suffixes are valid for images:
+
+| Image Suffixes | Example Predict Command | Reference |
+|----------------|----------------------------------|-------------------------------------------------------------------------------|
+| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |
+| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |
+| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |
+| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |
+| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |
+| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |
+| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
+| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
+
+## Video Formats
+
+For videos, YOLOv8 also supports a variety of video formats defined
+in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
+following suffixes are valid for videos:
+
+| Video Suffixes | Example Predict Command | Reference |
+|----------------|----------------------------------|----------------------------------------------------------------------------------|
+| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
+| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
+| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |
+| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |
+| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
+| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
+| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
+| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |
+| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
+| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |
+| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |
+
+## Working with Results
+
+Results object consists of these component objects:
+
+- `Results.boxes`: `Boxes` object with properties and methods for manipulating bboxes
+- `Results.masks`: `Masks` object used to index masks or to get segment coordinates.
+- `Results.probs`: `torch.Tensor` containing the class probabilities/logits.
+- `Results.orig_img`: Original image loaded in memory.
+- `Results.path`: `Path` containing the path to input image
+
+Each result is composed of torch.Tensor by default, in which you can easily use following functionality:
+
+```python
+results = results.cuda()
+results = results.cpu()
+results = results.to("cpu")
+results = results.numpy()
+```
+
+### Boxes
+
+`Boxes` object can be used index, manipulate and convert bboxes to different formats. The box format conversion
+operations are cached, which means they're only calculated once per object and those values are reused for future calls.
+
+- Indexing a `Boxes` objects returns a `Boxes` object
+
+```python
+results = model(inputs)
+boxes = results[0].boxes
+box = boxes[0] # returns one box
+box.xyxy
+```
+
+- Properties and conversions
+
+```python
+boxes.xyxy # box with xyxy format, (N, 4)
+boxes.xywh # box with xywh format, (N, 4)
+boxes.xyxyn # box with xyxy format but normalized, (N, 4)
+boxes.xywhn # box with xywh format but normalized, (N, 4)
+boxes.conf # confidence score, (N, 1)
+boxes.cls # cls, (N, 1)
+boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .
+```
+
+### Masks
+
+`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
+
+```python
+results = model(inputs)
+masks = results[0].masks # Masks object
+masks.segments # bounding coordinates of masks, List[segment] * N
+masks.data # raw masks tensor, (N, H, W) or masks.masks
+```
+
+### probs
+
+`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.
+
+```python
+results = model(inputs)
+results[0].probs # cls prob, (num_class, )
+```
+
+Class reference documentation for `Results` module and its components can be found [here](../reference/results.md)
+
+## Plotting results
+
+You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
+masks, classification logits, etc.) found in the results object
+
+```python
+res = model(img)
+res_plotted = res[0].plot()
+cv2.imshow("result", res_plotted)
+```
+
+!!! example "`plot()` arguments"
+
+ `show_conf (bool)`: Show confidence
+
+ `line_width (Float)`: The line width of boxes. Automatically scaled to img size if not provided
+
+ `font_size (Float)`: The font size of . Automatically scaled to img size if not provided
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/track.md b/src/train_utils/train_models/models/ultralytics/docs/modes/track.md
new file mode 100644
index 0000000..8058f38
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/track.md
@@ -0,0 +1,96 @@
+
+
+Object tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to
+that detection in video streams.
+
+The output of tracker is the same as detection with an added object ID.
+
+## Available Trackers
+
+The following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`
+
+* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`
+* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`
+
+The default tracker is BoT-SORT.
+
+## Tracking
+
+Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official detection model
+ model = YOLO('yolov8n-seg.pt') # load an official segmentation model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Track with the model
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
+ yolo track model=yolov8n-seg.pt source=... # official segmentation model
+ yolo track model=path/to/best.pt source=... # custom model
+ yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
+
+ ```
+
+As in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to
+do is loading the corresponding (detection or segmentation) model.
+
+## Configuration
+
+### Tracking
+
+Tracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer
+to [predict page](https://docs.ultralytics.com/modes/predict/).
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
+
+ ```
+
+### Tracker
+
+We also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`
+from [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify
+any configurations(expect the `tracker_type`) you need to.
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
+ ```
+
+Please refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)
+page
+
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/train.md b/src/train_utils/train_models/models/ultralytics/docs/modes/train.md
new file mode 100644
index 0000000..7b551fe
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/train.md
@@ -0,0 +1,97 @@
+
+
+**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
+
+!!! tip "Tip"
+
+ * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`
+
+## Usage Examples
+
+Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of
+training arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from YAML
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='coco128.yaml', epochs=100, imgsz=640)
+ ```
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Arguments
+
+Training settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a
+dataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings
+include the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process
+include the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It
+is important to carefully tune and experiment with these settings to achieve the best possible performance for a given
+task.
+
+| Key | Value | Description |
+|-------------------|----------|-----------------------------------------------------------------------------|
+| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `epochs` | `100` | number of epochs to train for |
+| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `imgsz` | `640` | size of input images as integer or w,h |
+| `save` | `True` | save train checkpoints and predict results |
+| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |
+| `cache` | `False` | True/ram, disk or False. Use cache for data loading |
+| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
+| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |
+| `project` | `None` | project name |
+| `name` | `None` | experiment name |
+| `exist_ok` | `False` | whether to overwrite existing experiment |
+| `pretrained` | `False` | whether to use a pretrained model |
+| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |
+| `verbose` | `False` | whether to print verbose output |
+| `seed` | `0` | random seed for reproducibility |
+| `deterministic` | `True` | whether to enable deterministic mode |
+| `single_cls` | `False` | train multi-class data as single-class |
+| `image_weights` | `False` | use weighted image selection for training |
+| `rect` | `False` | support rectangular training |
+| `cos_lr` | `False` | use cosine learning rate scheduler |
+| `close_mosaic` | `10` | disable mosaic augmentation for final 10 epochs |
+| `resume` | `False` | resume training from last checkpoint |
+| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |
+| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
+| `lrf` | `0.01` | final learning rate (lr0 * lrf) |
+| `momentum` | `0.937` | SGD momentum/Adam beta1 |
+| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |
+| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |
+| `warmup_momentum` | `0.8` | warmup initial momentum |
+| `warmup_bias_lr` | `0.1` | warmup initial bias lr |
+| `box` | `7.5` | box loss gain |
+| `cls` | `0.5` | cls loss gain (scale with pixels) |
+| `dfl` | `1.5` | dfl loss gain |
+| `fl_gamma` | `0.0` | focal loss gamma (efficientDet default gamma=1.5) |
+| `label_smoothing` | `0.0` | label smoothing (fraction) |
+| `nbs` | `64` | nominal batch size |
+| `overlap_mask` | `True` | masks should overlap during training (segment train only) |
+| `mask_ratio` | `4` | mask downsample ratio (segment train only) |
+| `dropout` | `0.0` | use dropout regularization (classify train only) |
+| `val` | `True` | validate/test during training |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/modes/val.md b/src/train_utils/train_models/models/ultralytics/docs/modes/val.md
new file mode 100644
index 0000000..da5e7f1
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/modes/val.md
@@ -0,0 +1,86 @@
+
+
+**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
+!!! tip "Tip"
+
+ * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`
+
+## Usage Examples
+
+Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
+training `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Arguments
+
+Validation settings for YOLO models refer to the various hyperparameters and configurations used to
+evaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and
+accuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed
+during training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation
+process include the size and composition of the validation dataset and the specific task the model is being used for. It
+is important to carefully tune and experiment with these settings to ensure that the model is performing well on the
+validation dataset and to detect and prevent overfitting.
+
+| Key | Value | Description |
+|---------------|---------|--------------------------------------------------------------------|
+| `data` | `None` | path to data file, i.e. coco128.yaml |
+| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
+| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
+| `save_json` | `False` | save results to JSON file |
+| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |
+| `conf` | `0.001` | object confidence threshold for detection |
+| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |
+| `max_det` | `300` | maximum number of detections per image |
+| `half` | `True` | use half precision (FP16) |
+| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |
+| `dnn` | `False` | use OpenCV DNN for ONNX inference |
+| `plots` | `False` | show plots during training |
+| `rect` | `False` | support rectangular evaluation |
+| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
+
+## Export Formats
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/quickstart.md b/src/train_utils/train_models/models/ultralytics/docs/quickstart.md
new file mode 100644
index 0000000..3eb4443
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/quickstart.md
@@ -0,0 +1,73 @@
+## Install
+
+Install YOLOv8 via the `ultralytics` pip package for the latest stable release or by cloning
+the [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most
+up-to-date version.
+
+!!! example "Pip install method (recommended)"
+
+ ```bash
+ pip install ultralytics
+ ```
+
+!!! example "Git clone method (for development)"
+
+ ```bash
+ git clone https://github.com/ultralytics/ultralytics
+ cd ultralytics
+ pip install -e '.[dev]'
+ ```
+ See contributing section to know more about contributing to the project
+
+## Use with CLI
+
+The YOLO command line interface (CLI) lets you simply train, validate or infer models on various tasks and versions.
+CLI requires no customization or code. You can simply run all tasks from the terminal with the `yolo` command.
+
+!!! example
+
+ === "Syntax"
+ ```bash
+ yolo task=detect mode=train model=yolov8n.yaml args...
+ classify predict yolov8n-cls.yaml args...
+ segment val yolov8n-seg.yaml args...
+ export yolov8n.pt format=onnx args...
+ ```
+
+ === "Example training"
+ ```bash
+ yolo detect train model=yolov8n.pt data=coco128.yaml device=0
+ ```
+ === "Example Multi-GPU training"
+ ```bash
+ yolo detect train model=yolov8n.pt data=coco128.yaml device=\'0,1,2,3\'
+ ```
+
+[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
+
+## Use with Python
+
+Python usage allows users to easily use YOLOv8 inside their Python projects. It provides functions for loading and
+running the model, as well as for processing the model's output. The interface is designed to be easy to use, so that
+users can quickly implement object detection in their projects.
+
+Overall, the Python interface is a useful tool for anyone looking to incorporate object detection, segmentation or
+classification into their Python projects using YOLOv8.
+
+!!! example
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from scratch
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+
+ # Use the model
+ results = model.train(data='coco128.yaml', epochs=3) # train the model
+ results = model.val() # evaluate model performance on the validation set
+ results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ success = model.export(format='onnx') # export the model to ONNX format
+ ```
+
+[Python Guide](usage/python.md){.md-button .md-button--primary}
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/base_pred.md b/src/train_utils/train_models/models/ultralytics/docs/reference/base_pred.md
new file mode 100644
index 0000000..5a61c50
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/base_pred.md
@@ -0,0 +1,8 @@
+All task Predictors are inherited from `BasePredictors` class that contains the model validation routine boilerplate.
+You can override any function of these Trainers to suit your needs.
+
+---
+
+### BasePredictor API Reference
+
+:::ultralytics.yolo.engine.predictor.BasePredictor
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/base_trainer.md b/src/train_utils/train_models/models/ultralytics/docs/reference/base_trainer.md
new file mode 100644
index 0000000..a93af69
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/base_trainer.md
@@ -0,0 +1,8 @@
+All task Trainers are inherited from `BaseTrainer` class that contains the model training and optimization routine
+boilerplate. You can override any function of these Trainers to suit your needs.
+
+---
+
+### BaseTrainer API Reference
+
+:::ultralytics.yolo.engine.trainer.BaseTrainer
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/base_val.md b/src/train_utils/train_models/models/ultralytics/docs/reference/base_val.md
new file mode 100644
index 0000000..37b7d9c
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/base_val.md
@@ -0,0 +1,8 @@
+All task Validators are inherited from `BaseValidator` class that contains the model validation routine boilerplate. You
+can override any function of these Trainers to suit your needs.
+
+---
+
+### BaseValidator API Reference
+
+:::ultralytics.yolo.engine.validator.BaseValidator
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/exporter.md b/src/train_utils/train_models/models/ultralytics/docs/reference/exporter.md
new file mode 100644
index 0000000..4ce31e1
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/exporter.md
@@ -0,0 +1,3 @@
+### Exporter API Reference
+
+:::ultralytics.yolo.engine.exporter.Exporter
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/model.md b/src/train_utils/train_models/models/ultralytics/docs/reference/model.md
new file mode 100644
index 0000000..6edc97b
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/model.md
@@ -0,0 +1 @@
+::: ultralytics.yolo.engine.model
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/nn.md b/src/train_utils/train_models/models/ultralytics/docs/reference/nn.md
new file mode 100644
index 0000000..0c7b1a8
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/nn.md
@@ -0,0 +1,19 @@
+# nn Module
+
+Ultralytics nn module contains 3 main components:
+
+1. **AutoBackend**: A module that can run inference on all popular model formats
+2. **BaseModel**: `BaseModel` class defines the operations supported by tasks like Detection and Segmentation
+3. **modules**: Optimized and reusable neural network blocks built on PyTorch.
+
+## AutoBackend
+
+:::ultralytics.nn.autobackend.AutoBackend
+
+## BaseModel
+
+:::ultralytics.nn.tasks.BaseModel
+
+## Modules
+
+TODO
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/ops.md b/src/train_utils/train_models/models/ultralytics/docs/reference/ops.md
new file mode 100644
index 0000000..8c4f1b7
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/ops.md
@@ -0,0 +1,208 @@
+This module contains optimized deep learning related operations used in the Ultralytics YOLO framework
+
+## Non-max suppression
+
+:::ultralytics.yolo.utils.ops.non_max_suppression
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## Scale boxes
+
+:::ultralytics.yolo.utils.ops.scale_boxes
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## Scale image
+
+:::ultralytics.yolo.utils.ops.scale_image
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## clip boxes
+
+:::ultralytics.yolo.utils.ops.clip_boxes
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+# Box Format Conversion
+
+## xyxy2xywh
+
+:::ultralytics.yolo.utils.ops.xyxy2xywh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xywh2xyxy
+
+:::ultralytics.yolo.utils.ops.xywh2xyxy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xywhn2xyxy
+
+:::ultralytics.yolo.utils.ops.xywhn2xyxy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xyxy2xywhn
+
+:::ultralytics.yolo.utils.ops.xyxy2xywhn
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xyn2xy
+
+:::ultralytics.yolo.utils.ops.xyn2xy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xywh2ltwh
+
+:::ultralytics.yolo.utils.ops.xywh2ltwh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## xyxy2ltwh
+
+:::ultralytics.yolo.utils.ops.xyxy2ltwh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## ltwh2xywh
+
+:::ultralytics.yolo.utils.ops.ltwh2xywh
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## ltwh2xyxy
+
+:::ultralytics.yolo.utils.ops.ltwh2xyxy
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## segment2box
+
+:::ultralytics.yolo.utils.ops.segment2box
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+# Mask Operations
+
+## resample_segments
+
+:::ultralytics.yolo.utils.ops.resample_segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## crop_mask
+
+:::ultralytics.yolo.utils.ops.crop_mask
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## process_mask_upsample
+
+:::ultralytics.yolo.utils.ops.process_mask_upsample
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## process_mask
+
+:::ultralytics.yolo.utils.ops.process_mask
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## process_mask_native
+
+:::ultralytics.yolo.utils.ops.process_mask_native
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## scale_segments
+
+:::ultralytics.yolo.utils.ops.scale_segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## masks2segments
+
+:::ultralytics.yolo.utils.ops.masks2segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+## clip_segments
+
+:::ultralytics.yolo.utils.ops.clip_segments
+handler: python
+options:
+show_source: false
+show_root_toc_entry: false
+---
+
+
+
+
+
diff --git a/src/train_utils/train_models/models/ultralytics/docs/reference/results.md b/src/train_utils/train_models/models/ultralytics/docs/reference/results.md
new file mode 100644
index 0000000..e222ec4
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/reference/results.md
@@ -0,0 +1,11 @@
+### Results API Reference
+
+:::ultralytics.yolo.engine.results.Results
+
+### Boxes API Reference
+
+:::ultralytics.yolo.engine.results.Boxes
+
+### Masks API Reference
+
+:::ultralytics.yolo.engine.results.Masks
diff --git a/src/train_utils/train_models/models/ultralytics/docs/stylesheets/style.css b/src/train_utils/train_models/models/ultralytics/docs/stylesheets/style.css
new file mode 100644
index 0000000..4bed4e1
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/stylesheets/style.css
@@ -0,0 +1,14 @@
+th, td {
+ border: 0.5px solid var(--md-typeset-table-color);
+ border-spacing: 0px;
+ border-bottom: none;
+ border-left: none;
+ border-top: none;
+}
+.md-typeset__table {
+ min-width: 100%;
+ line-height: 1;
+}
+.md-typeset table:not([class]) {
+ display: table;
+}
diff --git a/src/train_utils/train_models/models/ultralytics/docs/tasks/classify.md b/src/train_utils/train_models/models/ultralytics/docs/tasks/classify.md
new file mode 100644
index 0000000..3c8cb6f
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/tasks/classify.md
@@ -0,0 +1,169 @@
+Image classification is the simplest of the three tasks and involves classifying an entire image into one of a set of
+predefined classes.
+
+ +
+The output of an image classifier is a single class label and a confidence score. Image
+classification is useful when you need to know only what class an image belongs to and don't need to know where objects
+of that class are located or what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class
+labels
+and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a
+scene, but don't need to know exactly where the object is or its exact shape.
+
+!!! tip "Tip"
+
+ YOLOv8 Detect models are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+## [Detection](detect.md)
+
+Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing
+bounding boxes around them. The detected objects are classified into different categories based on their features.
+YOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.
+
+[Detection Examples](detect.md){ .md-button .md-button--primary}
+
+## [Segmentation](segment.md)
+
+Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each
+region is assigned a label based on its content. This task is useful in applications such as image segmentation and
+medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
+
+[Segmentation Examples](segment.md){ .md-button .md-button--primary}
+
+## [Classification](classify.md)
+
+Classification is a task that involves classifying an image into different categories. YOLOv8 can be used to classify
+images based on their content. It uses a variant of the EfficientNet architecture to perform classification.
+
+[Classification Examples](classify.md){ .md-button .md-button--primary}
+
+
+
+## Conclusion
+
+YOLOv8 supports multiple tasks, including detection, segmentation, classification, and keypoints detection. Each of
+these tasks has different objectives and use cases. By understanding the differences between these tasks, you can choose
+the appropriate task for your computer vision application.
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/tasks/keypoints.md b/src/train_utils/train_models/models/ultralytics/docs/tasks/keypoints.md
new file mode 100644
index 0000000..d9f2484
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/tasks/keypoints.md
@@ -0,0 +1,149 @@
+Key Point Estimation is a task that involves identifying the location of specific points in an image, usually referred
+to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive
+features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`
+coordinates.
+
+
+
+The output of a keypoint detector is a set of points that represent the keypoints on the object in the image, usually
+along with the confidence scores for each point. Keypoint estimation is a good choice when you need to identify specific
+parts of an object in a scene, and their location in relation to each other.
+
+!!! tip "Tip"
+
+ YOLOv8 _keypoints_ models use the `-kpts` suffix, i.e. `yolov8n-kpts.pt`. These models are trained on the COCO dataset and are suitable for a variety of keypoint estimation tasks.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8){ .md-button .md-button--primary}
+
+## Train TODO
+
+Train an OpenPose model on a custom dataset of keypoints using the OpenPose framework. For more information on how to
+train an OpenPose model on a custom dataset, see the OpenPose Training page.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from YAML
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='coco128.yaml', epochs=100, imgsz=640)
+ ```
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Val TODO
+
+Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
+training `data` and arguments as model attributes.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Predict TODO
+
+Use a trained YOLOv8n model to run predictions on images.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Predict with the model
+ results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
+ yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
+ ```
+
+Read more details of `predict` in our [Predict](https://docs.ultralytics.com/modes/predict/) page.
+
+## Export TODO
+
+Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom trained
+
+ # Export the model
+ model.export(format='onnx')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+Available YOLOv8-pose export formats are in the table below. You can predict or validate directly on exported models,
+i.e. `yolo predict model=yolov8n-pose.onnx`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/tasks/segment.md b/src/train_utils/train_models/models/ultralytics/docs/tasks/segment.md
new file mode 100644
index 0000000..2ff7f58
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/tasks/segment.md
@@ -0,0 +1,175 @@
+Instance segmentation goes a step further than object detection and involves identifying individual objects in an image
+and segmenting them from the rest of the image.
+
+
+
+The output of an instance segmentation model is a set of masks or
+contours that outline each object in the image, along with class labels and confidence scores for each object. Instance
+segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Segment models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+ - **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+ ## Status
+
+
+
+The output of an image classifier is a single class label and a confidence score. Image
+classification is useful when you need to know only what class an image belongs to and don't need to know where objects
+of that class are located or what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class
+labels
+and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a
+scene, but don't need to know exactly where the object is or its exact shape.
+
+!!! tip "Tip"
+
+ YOLOv8 Detect models are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+
+## [Detection](detect.md)
+
+Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing
+bounding boxes around them. The detected objects are classified into different categories based on their features.
+YOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.
+
+[Detection Examples](detect.md){ .md-button .md-button--primary}
+
+## [Segmentation](segment.md)
+
+Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each
+region is assigned a label based on its content. This task is useful in applications such as image segmentation and
+medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
+
+[Segmentation Examples](segment.md){ .md-button .md-button--primary}
+
+## [Classification](classify.md)
+
+Classification is a task that involves classifying an image into different categories. YOLOv8 can be used to classify
+images based on their content. It uses a variant of the EfficientNet architecture to perform classification.
+
+[Classification Examples](classify.md){ .md-button .md-button--primary}
+
+
+
+## Conclusion
+
+YOLOv8 supports multiple tasks, including detection, segmentation, classification, and keypoints detection. Each of
+these tasks has different objectives and use cases. By understanding the differences between these tasks, you can choose
+the appropriate task for your computer vision application.
\ No newline at end of file
diff --git a/src/train_utils/train_models/models/ultralytics/docs/tasks/keypoints.md b/src/train_utils/train_models/models/ultralytics/docs/tasks/keypoints.md
new file mode 100644
index 0000000..d9f2484
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/tasks/keypoints.md
@@ -0,0 +1,149 @@
+Key Point Estimation is a task that involves identifying the location of specific points in an image, usually referred
+to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive
+features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`
+coordinates.
+
+
+
+The output of a keypoint detector is a set of points that represent the keypoints on the object in the image, usually
+along with the confidence scores for each point. Keypoint estimation is a good choice when you need to identify specific
+parts of an object in a scene, and their location in relation to each other.
+
+!!! tip "Tip"
+
+ YOLOv8 _keypoints_ models use the `-kpts` suffix, i.e. `yolov8n-kpts.pt`. These models are trained on the COCO dataset and are suitable for a variety of keypoint estimation tasks.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8){ .md-button .md-button--primary}
+
+## Train TODO
+
+Train an OpenPose model on a custom dataset of keypoints using the OpenPose framework. For more information on how to
+train an OpenPose model on a custom dataset, see the OpenPose Training page.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.yaml') # build a new model from YAML
+ model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='coco128.yaml', epochs=100, imgsz=640)
+ ```
+ === "CLI"
+
+ ```bash
+ # Build a new model from YAML and start training from scratch
+ yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
+
+ # Start training from a pretrained *.pt model
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+
+ # Build a new model from YAML, transfer pretrained weights to it and start training
+ yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+## Val TODO
+
+Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
+training `data` and arguments as model attributes.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Validate the model
+ metrics = model.val() # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95
+ metrics.box.map50 # map50
+ metrics.box.map75 # map75
+ metrics.box.maps # a list contains map50-95 of each category
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect val model=yolov8n.pt # val official model
+ yolo detect val model=path/to/best.pt # val custom model
+ ```
+
+## Predict TODO
+
+Use a trained YOLOv8n model to run predictions on images.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Predict with the model
+ results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ ```
+ === "CLI"
+
+ ```bash
+ yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
+ yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
+ ```
+
+Read more details of `predict` in our [Predict](https://docs.ultralytics.com/modes/predict/) page.
+
+## Export TODO
+
+Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
+
+!!! example ""
+
+ === "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official model
+ model = YOLO('path/to/best.pt') # load a custom trained
+
+ # Export the model
+ model.export(format='onnx')
+ ```
+ === "CLI"
+
+ ```bash
+ yolo export model=yolov8n.pt format=onnx # export official model
+ yolo export model=path/to/best.pt format=onnx # export custom trained model
+ ```
+
+Available YOLOv8-pose export formats are in the table below. You can predict or validate directly on exported models,
+i.e. `yolo predict model=yolov8n-pose.onnx`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
diff --git a/src/train_utils/train_models/models/ultralytics/docs/tasks/segment.md b/src/train_utils/train_models/models/ultralytics/docs/tasks/segment.md
new file mode 100644
index 0000000..2ff7f58
--- /dev/null
+++ b/src/train_utils/train_models/models/ultralytics/docs/tasks/segment.md
@@ -0,0 +1,175 @@
+Instance segmentation goes a step further than object detection and involves identifying individual objects in an image
+and segmenting them from the rest of the image.
+
+
+
+The output of an instance segmentation model is a set of masks or
+contours that outline each object in the image, along with class labels and confidence scores for each object. Instance
+segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
+
+!!! tip "Tip"
+
+ YOLOv8 Segment models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).
+
+## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)
+
+YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on
+the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify
+models are pretrained on
+the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.
+
+[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest
+Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.
+
+| Model | size
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+ - **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+ ## Status
+
+
+
+  +
+
+
+
+ +
+
+
+ +
+
+##
+
+
+## 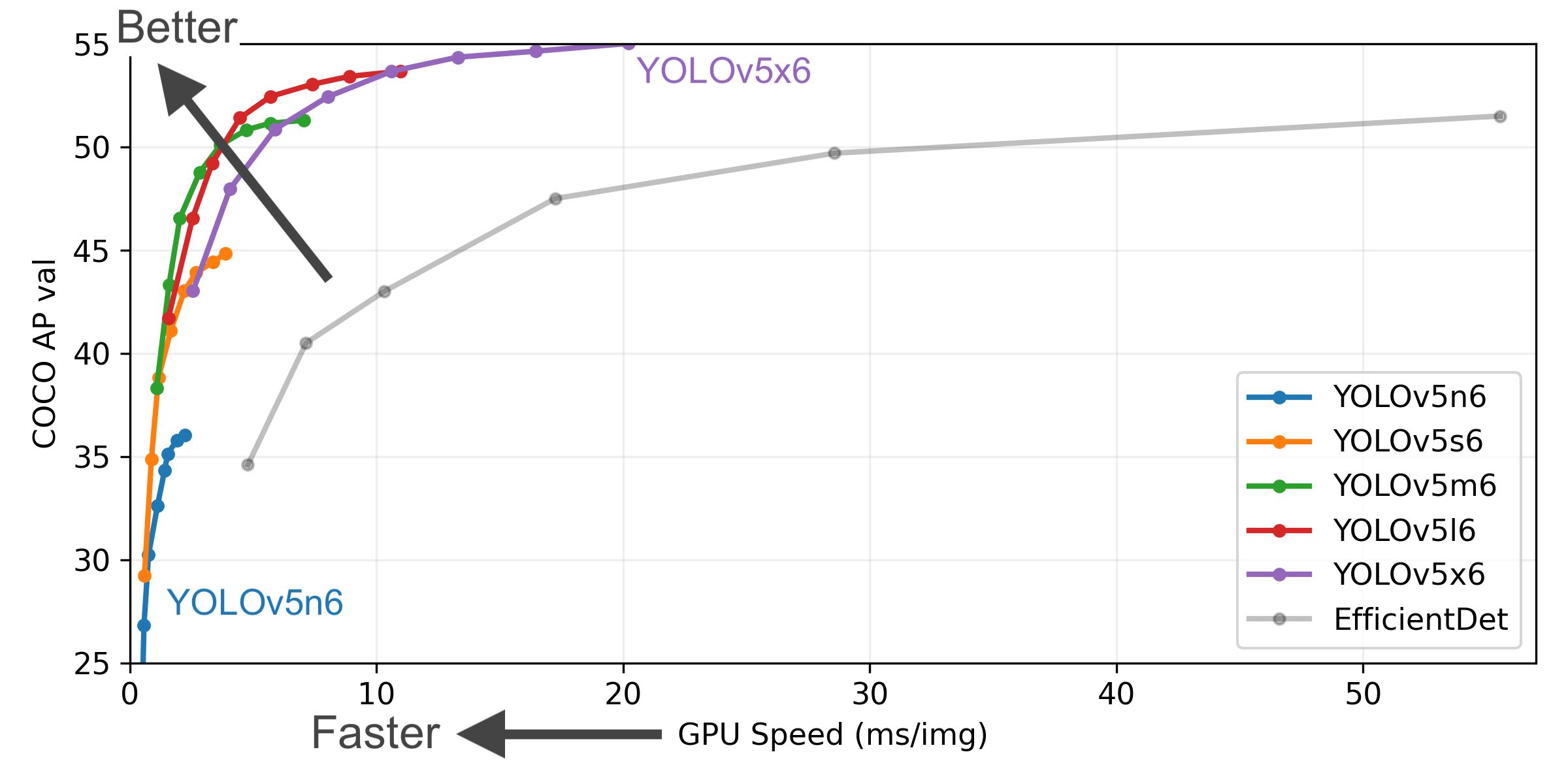
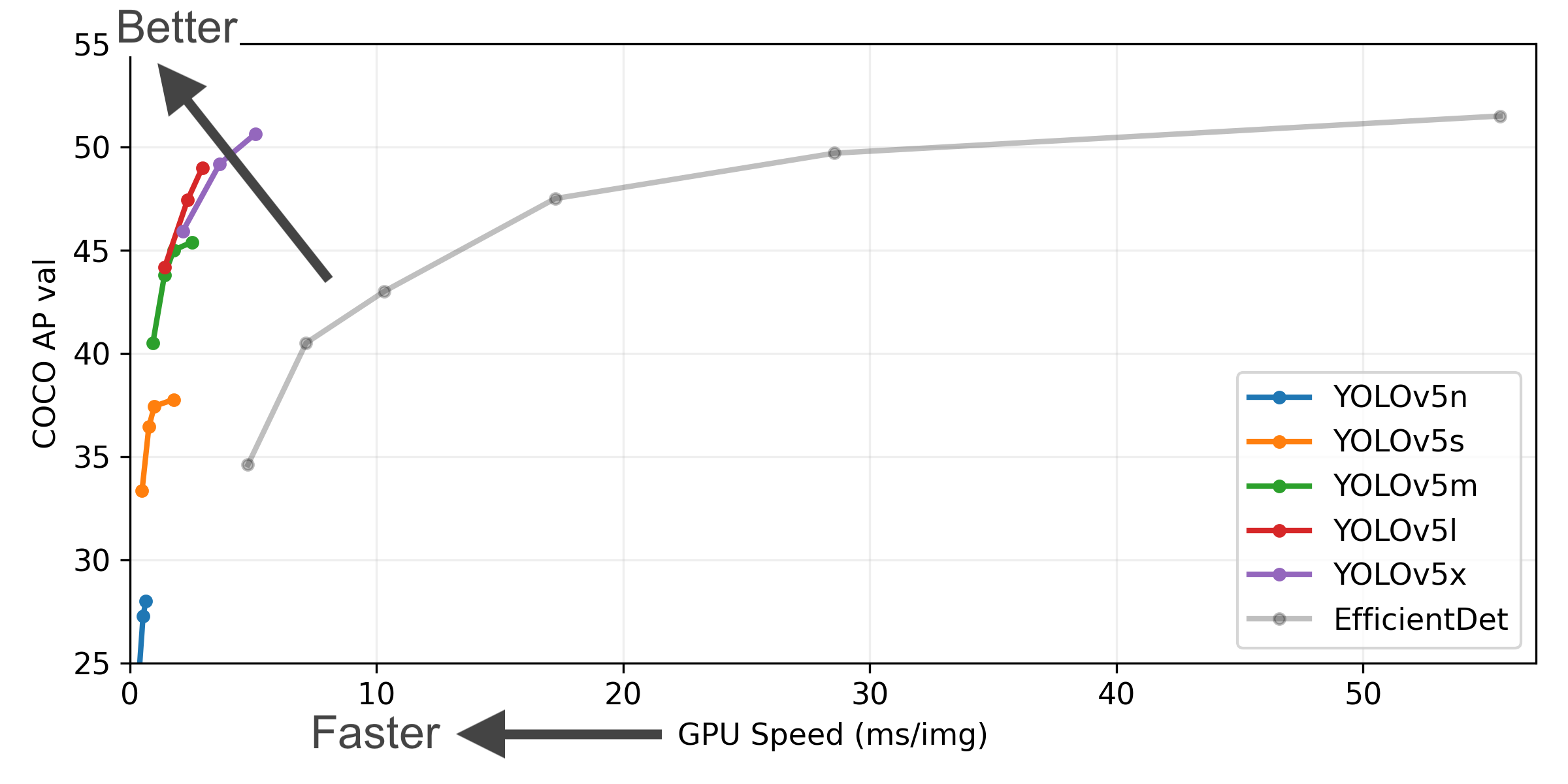
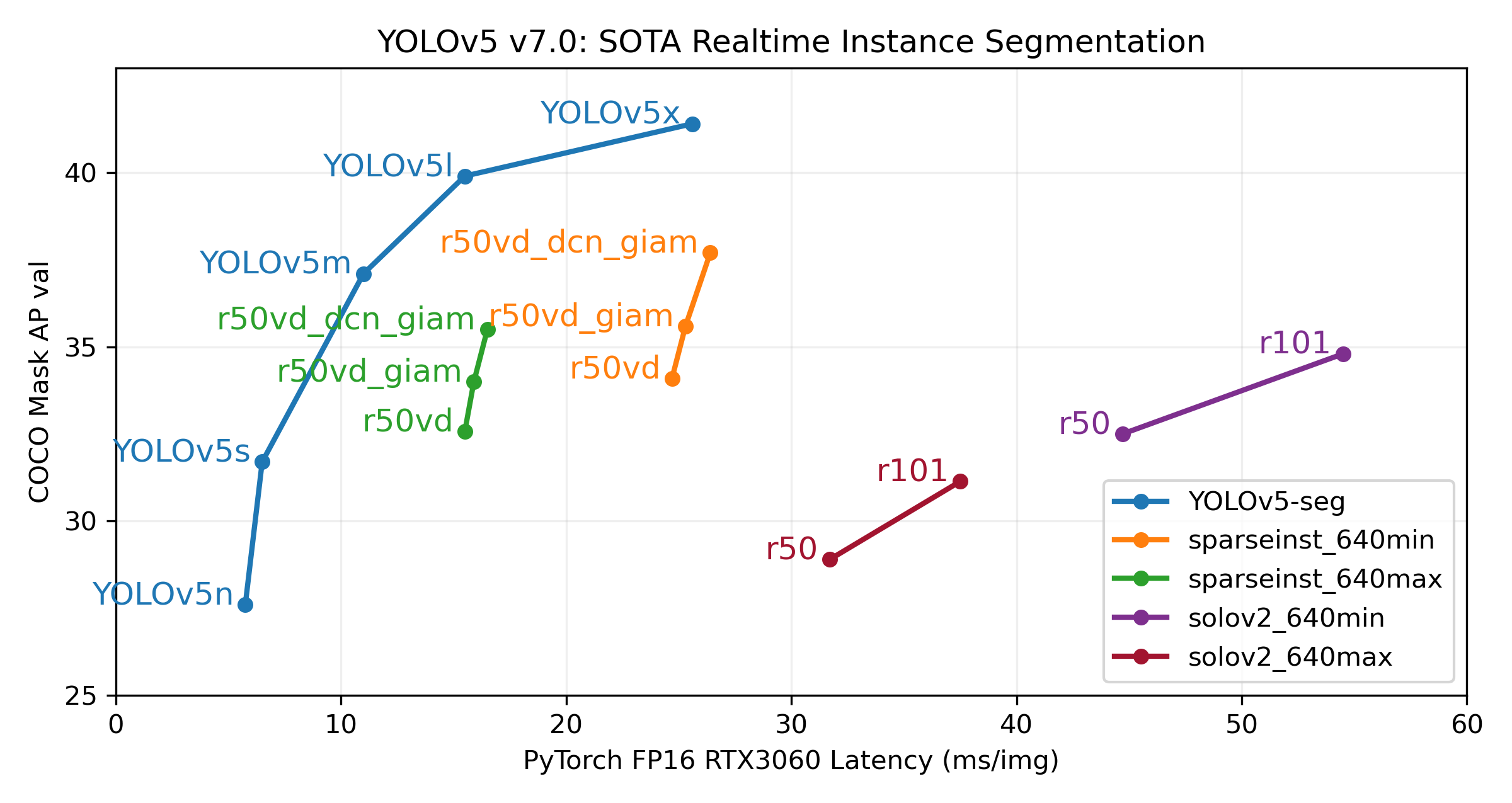 +
+
+##
+
+
+##
+
+
+
+
+
+
+
+
+
+
+##
+
+
+##  \n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [Imagenet](https://image-net.org/) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "20fc0630-141e-4a90-ea06-342cbd7ce496"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "--2022-11-22 19:53:40-- https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar\n",
+ "Resolving image-net.org (image-net.org)... 171.64.68.16\n",
+ "Connecting to image-net.org (image-net.org)|171.64.68.16|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 6744924160 (6.3G) [application/x-tar]\n",
+ "Saving to: ‘ILSVRC2012_img_val.tar’\n",
+ "\n",
+ "ILSVRC2012_img_val. 100%[===================>] 6.28G 16.1MB/s in 10m 52s \n",
+ "\n",
+ "2022-11-22 20:04:32 (9.87 MB/s) - ‘ILSVRC2012_img_val.tar’ saved [6744924160/6744924160]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download Imagenet val (6.3G, 50000 images)\n",
+ "!bash data/scripts/get_imagenet.sh --val"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "41843132-98e2-4c25-d474-4cd7b246fb8e"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mclassify/val: \u001b[0mdata=../datasets/imagenet, weights=['yolov5s-cls.pt'], batch_size=128, imgsz=224, device=, workers=8, verbose=True, project=runs/val-cls, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-3-g61ebf5e Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model summary: 117 layers, 5447688 parameters, 0 gradients, 11.4 GFLOPs\n",
+ "validating: 100% 391/391 [04:57<00:00, 1.31it/s]\n",
+ " Class Images top1_acc top5_acc\n",
+ " all 50000 0.715 0.902\n",
+ " tench 50 0.94 0.98\n",
+ " goldfish 50 0.88 0.92\n",
+ " great white shark 50 0.78 0.96\n",
+ " tiger shark 50 0.68 0.96\n",
+ " hammerhead shark 50 0.82 0.92\n",
+ " electric ray 50 0.76 0.9\n",
+ " stingray 50 0.7 0.9\n",
+ " cock 50 0.78 0.92\n",
+ " hen 50 0.84 0.96\n",
+ " ostrich 50 0.98 1\n",
+ " brambling 50 0.9 0.96\n",
+ " goldfinch 50 0.92 0.98\n",
+ " house finch 50 0.88 0.96\n",
+ " junco 50 0.94 0.98\n",
+ " indigo bunting 50 0.86 0.88\n",
+ " American robin 50 0.9 0.96\n",
+ " bulbul 50 0.84 0.96\n",
+ " jay 50 0.9 0.96\n",
+ " magpie 50 0.84 0.96\n",
+ " chickadee 50 0.9 1\n",
+ " American dipper 50 0.82 0.92\n",
+ " kite 50 0.76 0.94\n",
+ " bald eagle 50 0.92 1\n",
+ " vulture 50 0.96 1\n",
+ " great grey owl 50 0.94 0.98\n",
+ " fire salamander 50 0.96 0.98\n",
+ " smooth newt 50 0.58 0.94\n",
+ " newt 50 0.74 0.9\n",
+ " spotted salamander 50 0.86 0.94\n",
+ " axolotl 50 0.86 0.96\n",
+ " American bullfrog 50 0.78 0.92\n",
+ " tree frog 50 0.84 0.96\n",
+ " tailed frog 50 0.48 0.8\n",
+ " loggerhead sea turtle 50 0.68 0.94\n",
+ " leatherback sea turtle 50 0.5 0.8\n",
+ " mud turtle 50 0.64 0.84\n",
+ " terrapin 50 0.52 0.98\n",
+ " box turtle 50 0.84 0.98\n",
+ " banded gecko 50 0.7 0.88\n",
+ " green iguana 50 0.76 0.94\n",
+ " Carolina anole 50 0.58 0.96\n",
+ "desert grassland whiptail lizard 50 0.82 0.94\n",
+ " agama 50 0.74 0.92\n",
+ " frilled-necked lizard 50 0.84 0.86\n",
+ " alligator lizard 50 0.58 0.78\n",
+ " Gila monster 50 0.72 0.8\n",
+ " European green lizard 50 0.42 0.9\n",
+ " chameleon 50 0.76 0.84\n",
+ " Komodo dragon 50 0.86 0.96\n",
+ " Nile crocodile 50 0.7 0.84\n",
+ " American alligator 50 0.76 0.96\n",
+ " triceratops 50 0.9 0.94\n",
+ " worm snake 50 0.76 0.88\n",
+ " ring-necked snake 50 0.8 0.92\n",
+ " eastern hog-nosed snake 50 0.58 0.88\n",
+ " smooth green snake 50 0.6 0.94\n",
+ " kingsnake 50 0.82 0.9\n",
+ " garter snake 50 0.88 0.94\n",
+ " water snake 50 0.7 0.94\n",
+ " vine snake 50 0.66 0.76\n",
+ " night snake 50 0.34 0.82\n",
+ " boa constrictor 50 0.8 0.96\n",
+ " African rock python 50 0.48 0.76\n",
+ " Indian cobra 50 0.82 0.94\n",
+ " green mamba 50 0.54 0.86\n",
+ " sea snake 50 0.62 0.9\n",
+ " Saharan horned viper 50 0.56 0.86\n",
+ "eastern diamondback rattlesnake 50 0.6 0.86\n",
+ " sidewinder 50 0.28 0.86\n",
+ " trilobite 50 0.98 0.98\n",
+ " harvestman 50 0.86 0.94\n",
+ " scorpion 50 0.86 0.94\n",
+ " yellow garden spider 50 0.92 0.96\n",
+ " barn spider 50 0.38 0.98\n",
+ " European garden spider 50 0.62 0.98\n",
+ " southern black widow 50 0.88 0.94\n",
+ " tarantula 50 0.94 1\n",
+ " wolf spider 50 0.82 0.92\n",
+ " tick 50 0.74 0.84\n",
+ " centipede 50 0.68 0.82\n",
+ " black grouse 50 0.88 0.98\n",
+ " ptarmigan 50 0.78 0.94\n",
+ " ruffed grouse 50 0.88 1\n",
+ " prairie grouse 50 0.92 1\n",
+ " peacock 50 0.88 0.9\n",
+ " quail 50 0.9 0.94\n",
+ " partridge 50 0.74 0.96\n",
+ " grey parrot 50 0.9 0.96\n",
+ " macaw 50 0.88 0.98\n",
+ "sulphur-crested cockatoo 50 0.86 0.92\n",
+ " lorikeet 50 0.96 1\n",
+ " coucal 50 0.82 0.88\n",
+ " bee eater 50 0.96 0.98\n",
+ " hornbill 50 0.9 0.96\n",
+ " hummingbird 50 0.88 0.96\n",
+ " jacamar 50 0.92 0.94\n",
+ " toucan 50 0.84 0.94\n",
+ " duck 50 0.76 0.94\n",
+ " red-breasted merganser 50 0.86 0.96\n",
+ " goose 50 0.74 0.96\n",
+ " black swan 50 0.94 0.98\n",
+ " tusker 50 0.54 0.92\n",
+ " echidna 50 0.98 1\n",
+ " platypus 50 0.72 0.84\n",
+ " wallaby 50 0.78 0.88\n",
+ " koala 50 0.84 0.92\n",
+ " wombat 50 0.78 0.84\n",
+ " jellyfish 50 0.88 0.96\n",
+ " sea anemone 50 0.72 0.9\n",
+ " brain coral 50 0.88 0.96\n",
+ " flatworm 50 0.8 0.98\n",
+ " nematode 50 0.86 0.9\n",
+ " conch 50 0.74 0.88\n",
+ " snail 50 0.78 0.88\n",
+ " slug 50 0.74 0.82\n",
+ " sea slug 50 0.88 0.98\n",
+ " chiton 50 0.88 0.98\n",
+ " chambered nautilus 50 0.88 0.92\n",
+ " Dungeness crab 50 0.78 0.94\n",
+ " rock crab 50 0.68 0.86\n",
+ " fiddler crab 50 0.64 0.86\n",
+ " red king crab 50 0.76 0.96\n",
+ " American lobster 50 0.78 0.96\n",
+ " spiny lobster 50 0.74 0.88\n",
+ " crayfish 50 0.56 0.86\n",
+ " hermit crab 50 0.78 0.96\n",
+ " isopod 50 0.66 0.78\n",
+ " white stork 50 0.88 0.96\n",
+ " black stork 50 0.84 0.98\n",
+ " spoonbill 50 0.96 1\n",
+ " flamingo 50 0.94 1\n",
+ " little blue heron 50 0.92 0.98\n",
+ " great egret 50 0.9 0.96\n",
+ " bittern 50 0.86 0.94\n",
+ " crane (bird) 50 0.62 0.9\n",
+ " limpkin 50 0.98 1\n",
+ " common gallinule 50 0.92 0.96\n",
+ " American coot 50 0.9 0.98\n",
+ " bustard 50 0.92 0.96\n",
+ " ruddy turnstone 50 0.94 1\n",
+ " dunlin 50 0.86 0.94\n",
+ " common redshank 50 0.9 0.96\n",
+ " dowitcher 50 0.84 0.96\n",
+ " oystercatcher 50 0.86 0.94\n",
+ " pelican 50 0.92 0.96\n",
+ " king penguin 50 0.88 0.96\n",
+ " albatross 50 0.9 1\n",
+ " grey whale 50 0.84 0.92\n",
+ " killer whale 50 0.92 1\n",
+ " dugong 50 0.84 0.96\n",
+ " sea lion 50 0.82 0.92\n",
+ " Chihuahua 50 0.66 0.84\n",
+ " Japanese Chin 50 0.72 0.98\n",
+ " Maltese 50 0.76 0.94\n",
+ " Pekingese 50 0.84 0.94\n",
+ " Shih Tzu 50 0.74 0.96\n",
+ " King Charles Spaniel 50 0.88 0.98\n",
+ " Papillon 50 0.86 0.94\n",
+ " toy terrier 50 0.48 0.94\n",
+ " Rhodesian Ridgeback 50 0.76 0.98\n",
+ " Afghan Hound 50 0.84 1\n",
+ " Basset Hound 50 0.8 0.92\n",
+ " Beagle 50 0.82 0.96\n",
+ " Bloodhound 50 0.48 0.72\n",
+ " Bluetick Coonhound 50 0.86 0.94\n",
+ " Black and Tan Coonhound 50 0.54 0.8\n",
+ "Treeing Walker Coonhound 50 0.66 0.98\n",
+ " English foxhound 50 0.32 0.84\n",
+ " Redbone Coonhound 50 0.62 0.94\n",
+ " borzoi 50 0.92 1\n",
+ " Irish Wolfhound 50 0.48 0.88\n",
+ " Italian Greyhound 50 0.76 0.98\n",
+ " Whippet 50 0.74 0.92\n",
+ " Ibizan Hound 50 0.6 0.86\n",
+ " Norwegian Elkhound 50 0.88 0.98\n",
+ " Otterhound 50 0.62 0.9\n",
+ " Saluki 50 0.72 0.92\n",
+ " Scottish Deerhound 50 0.86 0.98\n",
+ " Weimaraner 50 0.88 0.94\n",
+ "Staffordshire Bull Terrier 50 0.66 0.98\n",
+ "American Staffordshire Terrier 50 0.64 0.92\n",
+ " Bedlington Terrier 50 0.9 0.92\n",
+ " Border Terrier 50 0.86 0.92\n",
+ " Kerry Blue Terrier 50 0.78 0.98\n",
+ " Irish Terrier 50 0.7 0.96\n",
+ " Norfolk Terrier 50 0.68 0.9\n",
+ " Norwich Terrier 50 0.72 1\n",
+ " Yorkshire Terrier 50 0.66 0.9\n",
+ " Wire Fox Terrier 50 0.64 0.98\n",
+ " Lakeland Terrier 50 0.74 0.92\n",
+ " Sealyham Terrier 50 0.76 0.9\n",
+ " Airedale Terrier 50 0.82 0.92\n",
+ " Cairn Terrier 50 0.76 0.9\n",
+ " Australian Terrier 50 0.48 0.84\n",
+ " Dandie Dinmont Terrier 50 0.82 0.92\n",
+ " Boston Terrier 50 0.92 1\n",
+ " Miniature Schnauzer 50 0.68 0.9\n",
+ " Giant Schnauzer 50 0.72 0.98\n",
+ " Standard Schnauzer 50 0.74 1\n",
+ " Scottish Terrier 50 0.76 0.96\n",
+ " Tibetan Terrier 50 0.48 1\n",
+ "Australian Silky Terrier 50 0.66 0.96\n",
+ "Soft-coated Wheaten Terrier 50 0.74 0.96\n",
+ "West Highland White Terrier 50 0.88 0.96\n",
+ " Lhasa Apso 50 0.68 0.96\n",
+ " Flat-Coated Retriever 50 0.72 0.94\n",
+ " Curly-coated Retriever 50 0.82 0.94\n",
+ " Golden Retriever 50 0.86 0.94\n",
+ " Labrador Retriever 50 0.82 0.94\n",
+ "Chesapeake Bay Retriever 50 0.76 0.96\n",
+ "German Shorthaired Pointer 50 0.8 0.96\n",
+ " Vizsla 50 0.68 0.96\n",
+ " English Setter 50 0.7 1\n",
+ " Irish Setter 50 0.8 0.9\n",
+ " Gordon Setter 50 0.84 0.92\n",
+ " Brittany 50 0.84 0.96\n",
+ " Clumber Spaniel 50 0.92 0.96\n",
+ "English Springer Spaniel 50 0.88 1\n",
+ " Welsh Springer Spaniel 50 0.92 1\n",
+ " Cocker Spaniels 50 0.7 0.94\n",
+ " Sussex Spaniel 50 0.72 0.92\n",
+ " Irish Water Spaniel 50 0.88 0.98\n",
+ " Kuvasz 50 0.66 0.9\n",
+ " Schipperke 50 0.9 0.98\n",
+ " Groenendael 50 0.8 0.94\n",
+ " Malinois 50 0.86 0.98\n",
+ " Briard 50 0.52 0.8\n",
+ " Australian Kelpie 50 0.6 0.88\n",
+ " Komondor 50 0.88 0.94\n",
+ " Old English Sheepdog 50 0.94 0.98\n",
+ " Shetland Sheepdog 50 0.74 0.9\n",
+ " collie 50 0.6 0.96\n",
+ " Border Collie 50 0.74 0.96\n",
+ " Bouvier des Flandres 50 0.78 0.94\n",
+ " Rottweiler 50 0.88 0.96\n",
+ " German Shepherd Dog 50 0.8 0.98\n",
+ " Dobermann 50 0.68 0.96\n",
+ " Miniature Pinscher 50 0.76 0.88\n",
+ "Greater Swiss Mountain Dog 50 0.68 0.94\n",
+ " Bernese Mountain Dog 50 0.96 1\n",
+ " Appenzeller Sennenhund 50 0.22 1\n",
+ " Entlebucher Sennenhund 50 0.64 0.98\n",
+ " Boxer 50 0.7 0.92\n",
+ " Bullmastiff 50 0.78 0.98\n",
+ " Tibetan Mastiff 50 0.88 0.96\n",
+ " French Bulldog 50 0.84 0.94\n",
+ " Great Dane 50 0.54 0.9\n",
+ " St. Bernard 50 0.92 1\n",
+ " husky 50 0.46 0.98\n",
+ " Alaskan Malamute 50 0.76 0.96\n",
+ " Siberian Husky 50 0.46 0.98\n",
+ " Dalmatian 50 0.94 0.98\n",
+ " Affenpinscher 50 0.78 0.9\n",
+ " Basenji 50 0.92 0.94\n",
+ " pug 50 0.94 0.98\n",
+ " Leonberger 50 1 1\n",
+ " Newfoundland 50 0.78 0.96\n",
+ " Pyrenean Mountain Dog 50 0.78 0.96\n",
+ " Samoyed 50 0.96 1\n",
+ " Pomeranian 50 0.98 1\n",
+ " Chow Chow 50 0.9 0.96\n",
+ " Keeshond 50 0.88 0.94\n",
+ " Griffon Bruxellois 50 0.84 0.98\n",
+ " Pembroke Welsh Corgi 50 0.82 0.94\n",
+ " Cardigan Welsh Corgi 50 0.66 0.98\n",
+ " Toy Poodle 50 0.52 0.88\n",
+ " Miniature Poodle 50 0.52 0.92\n",
+ " Standard Poodle 50 0.8 1\n",
+ " Mexican hairless dog 50 0.88 0.98\n",
+ " grey wolf 50 0.82 0.92\n",
+ " Alaskan tundra wolf 50 0.78 0.98\n",
+ " red wolf 50 0.48 0.9\n",
+ " coyote 50 0.64 0.86\n",
+ " dingo 50 0.76 0.88\n",
+ " dhole 50 0.9 0.98\n",
+ " African wild dog 50 0.98 1\n",
+ " hyena 50 0.88 0.96\n",
+ " red fox 50 0.54 0.92\n",
+ " kit fox 50 0.72 0.98\n",
+ " Arctic fox 50 0.94 1\n",
+ " grey fox 50 0.7 0.94\n",
+ " tabby cat 50 0.54 0.92\n",
+ " tiger cat 50 0.22 0.94\n",
+ " Persian cat 50 0.9 0.98\n",
+ " Siamese cat 50 0.96 1\n",
+ " Egyptian Mau 50 0.54 0.8\n",
+ " cougar 50 0.9 1\n",
+ " lynx 50 0.72 0.88\n",
+ " leopard 50 0.78 0.98\n",
+ " snow leopard 50 0.9 0.98\n",
+ " jaguar 50 0.7 0.94\n",
+ " lion 50 0.9 0.98\n",
+ " tiger 50 0.92 0.98\n",
+ " cheetah 50 0.94 0.98\n",
+ " brown bear 50 0.94 0.98\n",
+ " American black bear 50 0.8 1\n",
+ " polar bear 50 0.84 0.96\n",
+ " sloth bear 50 0.72 0.92\n",
+ " mongoose 50 0.7 0.92\n",
+ " meerkat 50 0.82 0.92\n",
+ " tiger beetle 50 0.92 0.94\n",
+ " ladybug 50 0.86 0.94\n",
+ " ground beetle 50 0.64 0.94\n",
+ " longhorn beetle 50 0.62 0.88\n",
+ " leaf beetle 50 0.64 0.98\n",
+ " dung beetle 50 0.86 0.98\n",
+ " rhinoceros beetle 50 0.86 0.94\n",
+ " weevil 50 0.9 1\n",
+ " fly 50 0.78 0.94\n",
+ " bee 50 0.68 0.94\n",
+ " ant 50 0.68 0.78\n",
+ " grasshopper 50 0.5 0.92\n",
+ " cricket 50 0.64 0.92\n",
+ " stick insect 50 0.64 0.92\n",
+ " cockroach 50 0.72 0.8\n",
+ " mantis 50 0.64 0.86\n",
+ " cicada 50 0.9 0.96\n",
+ " leafhopper 50 0.88 0.94\n",
+ " lacewing 50 0.78 0.92\n",
+ " dragonfly 50 0.82 0.98\n",
+ " damselfly 50 0.82 1\n",
+ " red admiral 50 0.94 0.96\n",
+ " ringlet 50 0.86 0.98\n",
+ " monarch butterfly 50 0.9 0.92\n",
+ " small white 50 0.9 1\n",
+ " sulphur butterfly 50 0.92 1\n",
+ "gossamer-winged butterfly 50 0.88 1\n",
+ " starfish 50 0.88 0.92\n",
+ " sea urchin 50 0.84 0.94\n",
+ " sea cucumber 50 0.66 0.84\n",
+ " cottontail rabbit 50 0.72 0.94\n",
+ " hare 50 0.84 0.96\n",
+ " Angora rabbit 50 0.94 0.98\n",
+ " hamster 50 0.96 1\n",
+ " porcupine 50 0.88 0.98\n",
+ " fox squirrel 50 0.76 0.94\n",
+ " marmot 50 0.92 0.96\n",
+ " beaver 50 0.78 0.94\n",
+ " guinea pig 50 0.78 0.94\n",
+ " common sorrel 50 0.96 0.98\n",
+ " zebra 50 0.94 0.96\n",
+ " pig 50 0.5 0.76\n",
+ " wild boar 50 0.84 0.96\n",
+ " warthog 50 0.84 0.96\n",
+ " hippopotamus 50 0.88 0.96\n",
+ " ox 50 0.48 0.94\n",
+ " water buffalo 50 0.78 0.94\n",
+ " bison 50 0.88 0.96\n",
+ " ram 50 0.58 0.92\n",
+ " bighorn sheep 50 0.66 1\n",
+ " Alpine ibex 50 0.92 0.98\n",
+ " hartebeest 50 0.94 1\n",
+ " impala 50 0.82 0.96\n",
+ " gazelle 50 0.7 0.96\n",
+ " dromedary 50 0.9 1\n",
+ " llama 50 0.82 0.94\n",
+ " weasel 50 0.44 0.92\n",
+ " mink 50 0.78 0.96\n",
+ " European polecat 50 0.46 0.9\n",
+ " black-footed ferret 50 0.68 0.96\n",
+ " otter 50 0.66 0.88\n",
+ " skunk 50 0.96 0.96\n",
+ " badger 50 0.86 0.92\n",
+ " armadillo 50 0.88 0.9\n",
+ " three-toed sloth 50 0.96 1\n",
+ " orangutan 50 0.78 0.92\n",
+ " gorilla 50 0.82 0.94\n",
+ " chimpanzee 50 0.84 0.94\n",
+ " gibbon 50 0.76 0.86\n",
+ " siamang 50 0.68 0.94\n",
+ " guenon 50 0.8 0.94\n",
+ " patas monkey 50 0.62 0.82\n",
+ " baboon 50 0.9 0.98\n",
+ " macaque 50 0.8 0.86\n",
+ " langur 50 0.6 0.82\n",
+ " black-and-white colobus 50 0.86 0.9\n",
+ " proboscis monkey 50 1 1\n",
+ " marmoset 50 0.74 0.98\n",
+ " white-headed capuchin 50 0.72 0.9\n",
+ " howler monkey 50 0.86 0.94\n",
+ " titi 50 0.5 0.9\n",
+ "Geoffroy's spider monkey 50 0.42 0.8\n",
+ " common squirrel monkey 50 0.76 0.92\n",
+ " ring-tailed lemur 50 0.72 0.94\n",
+ " indri 50 0.9 0.96\n",
+ " Asian elephant 50 0.58 0.92\n",
+ " African bush elephant 50 0.7 0.98\n",
+ " red panda 50 0.94 0.94\n",
+ " giant panda 50 0.94 0.98\n",
+ " snoek 50 0.74 0.9\n",
+ " eel 50 0.6 0.84\n",
+ " coho salmon 50 0.84 0.96\n",
+ " rock beauty 50 0.88 0.98\n",
+ " clownfish 50 0.78 0.98\n",
+ " sturgeon 50 0.68 0.94\n",
+ " garfish 50 0.62 0.8\n",
+ " lionfish 50 0.96 0.96\n",
+ " pufferfish 50 0.88 0.96\n",
+ " abacus 50 0.74 0.88\n",
+ " abaya 50 0.84 0.92\n",
+ " academic gown 50 0.42 0.86\n",
+ " accordion 50 0.8 0.9\n",
+ " acoustic guitar 50 0.5 0.76\n",
+ " aircraft carrier 50 0.8 0.96\n",
+ " airliner 50 0.92 1\n",
+ " airship 50 0.76 0.82\n",
+ " altar 50 0.64 0.98\n",
+ " ambulance 50 0.88 0.98\n",
+ " amphibious vehicle 50 0.64 0.94\n",
+ " analog clock 50 0.52 0.92\n",
+ " apiary 50 0.82 0.96\n",
+ " apron 50 0.7 0.84\n",
+ " waste container 50 0.4 0.8\n",
+ " assault rifle 50 0.42 0.84\n",
+ " backpack 50 0.34 0.64\n",
+ " bakery 50 0.4 0.68\n",
+ " balance beam 50 0.8 0.98\n",
+ " balloon 50 0.86 0.96\n",
+ " ballpoint pen 50 0.52 0.96\n",
+ " Band-Aid 50 0.7 0.9\n",
+ " banjo 50 0.84 1\n",
+ " baluster 50 0.68 0.94\n",
+ " barbell 50 0.56 0.9\n",
+ " barber chair 50 0.7 0.92\n",
+ " barbershop 50 0.54 0.86\n",
+ " barn 50 0.96 0.96\n",
+ " barometer 50 0.84 0.98\n",
+ " barrel 50 0.56 0.88\n",
+ " wheelbarrow 50 0.66 0.88\n",
+ " baseball 50 0.74 0.98\n",
+ " basketball 50 0.88 0.98\n",
+ " bassinet 50 0.66 0.92\n",
+ " bassoon 50 0.74 0.98\n",
+ " swimming cap 50 0.62 0.88\n",
+ " bath towel 50 0.54 0.78\n",
+ " bathtub 50 0.4 0.88\n",
+ " station wagon 50 0.66 0.84\n",
+ " lighthouse 50 0.78 0.94\n",
+ " beaker 50 0.52 0.68\n",
+ " military cap 50 0.84 0.96\n",
+ " beer bottle 50 0.66 0.88\n",
+ " beer glass 50 0.6 0.84\n",
+ " bell-cot 50 0.56 0.96\n",
+ " bib 50 0.58 0.82\n",
+ " tandem bicycle 50 0.86 0.96\n",
+ " bikini 50 0.56 0.88\n",
+ " ring binder 50 0.64 0.84\n",
+ " binoculars 50 0.54 0.78\n",
+ " birdhouse 50 0.86 0.94\n",
+ " boathouse 50 0.74 0.92\n",
+ " bobsleigh 50 0.92 0.96\n",
+ " bolo tie 50 0.8 0.94\n",
+ " poke bonnet 50 0.64 0.86\n",
+ " bookcase 50 0.66 0.92\n",
+ " bookstore 50 0.62 0.88\n",
+ " bottle cap 50 0.58 0.7\n",
+ " bow 50 0.72 0.86\n",
+ " bow tie 50 0.7 0.9\n",
+ " brass 50 0.92 0.96\n",
+ " bra 50 0.5 0.7\n",
+ " breakwater 50 0.62 0.86\n",
+ " breastplate 50 0.4 0.9\n",
+ " broom 50 0.6 0.86\n",
+ " bucket 50 0.66 0.8\n",
+ " buckle 50 0.5 0.68\n",
+ " bulletproof vest 50 0.5 0.78\n",
+ " high-speed train 50 0.94 0.96\n",
+ " butcher shop 50 0.74 0.94\n",
+ " taxicab 50 0.64 0.86\n",
+ " cauldron 50 0.44 0.66\n",
+ " candle 50 0.48 0.74\n",
+ " cannon 50 0.88 0.94\n",
+ " canoe 50 0.94 1\n",
+ " can opener 50 0.66 0.86\n",
+ " cardigan 50 0.68 0.8\n",
+ " car mirror 50 0.94 0.96\n",
+ " carousel 50 0.94 0.98\n",
+ " tool kit 50 0.56 0.78\n",
+ " carton 50 0.42 0.7\n",
+ " car wheel 50 0.38 0.74\n",
+ "automated teller machine 50 0.76 0.94\n",
+ " cassette 50 0.52 0.8\n",
+ " cassette player 50 0.28 0.9\n",
+ " castle 50 0.78 0.88\n",
+ " catamaran 50 0.78 1\n",
+ " CD player 50 0.52 0.82\n",
+ " cello 50 0.82 1\n",
+ " mobile phone 50 0.68 0.86\n",
+ " chain 50 0.38 0.66\n",
+ " chain-link fence 50 0.7 0.84\n",
+ " chain mail 50 0.64 0.9\n",
+ " chainsaw 50 0.84 0.92\n",
+ " chest 50 0.68 0.92\n",
+ " chiffonier 50 0.26 0.64\n",
+ " chime 50 0.62 0.84\n",
+ " china cabinet 50 0.82 0.96\n",
+ " Christmas stocking 50 0.92 0.94\n",
+ " church 50 0.62 0.9\n",
+ " movie theater 50 0.58 0.88\n",
+ " cleaver 50 0.32 0.62\n",
+ " cliff dwelling 50 0.88 1\n",
+ " cloak 50 0.32 0.64\n",
+ " clogs 50 0.58 0.88\n",
+ " cocktail shaker 50 0.62 0.7\n",
+ " coffee mug 50 0.44 0.72\n",
+ " coffeemaker 50 0.64 0.92\n",
+ " coil 50 0.66 0.84\n",
+ " combination lock 50 0.64 0.84\n",
+ " computer keyboard 50 0.7 0.82\n",
+ " confectionery store 50 0.54 0.86\n",
+ " container ship 50 0.82 0.98\n",
+ " convertible 50 0.78 0.98\n",
+ " corkscrew 50 0.82 0.92\n",
+ " cornet 50 0.46 0.88\n",
+ " cowboy boot 50 0.64 0.8\n",
+ " cowboy hat 50 0.64 0.82\n",
+ " cradle 50 0.38 0.8\n",
+ " crane (machine) 50 0.78 0.94\n",
+ " crash helmet 50 0.92 0.96\n",
+ " crate 50 0.52 0.82\n",
+ " infant bed 50 0.74 1\n",
+ " Crock Pot 50 0.78 0.9\n",
+ " croquet ball 50 0.9 0.96\n",
+ " crutch 50 0.46 0.7\n",
+ " cuirass 50 0.54 0.86\n",
+ " dam 50 0.74 0.92\n",
+ " desk 50 0.6 0.86\n",
+ " desktop computer 50 0.54 0.94\n",
+ " rotary dial telephone 50 0.88 0.94\n",
+ " diaper 50 0.68 0.84\n",
+ " digital clock 50 0.54 0.76\n",
+ " digital watch 50 0.58 0.86\n",
+ " dining table 50 0.76 0.9\n",
+ " dishcloth 50 0.94 1\n",
+ " dishwasher 50 0.44 0.78\n",
+ " disc brake 50 0.98 1\n",
+ " dock 50 0.54 0.94\n",
+ " dog sled 50 0.84 1\n",
+ " dome 50 0.72 0.92\n",
+ " doormat 50 0.56 0.82\n",
+ " drilling rig 50 0.84 0.96\n",
+ " drum 50 0.38 0.68\n",
+ " drumstick 50 0.56 0.72\n",
+ " dumbbell 50 0.62 0.9\n",
+ " Dutch oven 50 0.7 0.84\n",
+ " electric fan 50 0.82 0.86\n",
+ " electric guitar 50 0.62 0.84\n",
+ " electric locomotive 50 0.92 0.98\n",
+ " entertainment center 50 0.9 0.98\n",
+ " envelope 50 0.44 0.86\n",
+ " espresso machine 50 0.72 0.94\n",
+ " face powder 50 0.7 0.92\n",
+ " feather boa 50 0.7 0.84\n",
+ " filing cabinet 50 0.88 0.98\n",
+ " fireboat 50 0.94 0.98\n",
+ " fire engine 50 0.84 0.9\n",
+ " fire screen sheet 50 0.62 0.76\n",
+ " flagpole 50 0.74 0.88\n",
+ " flute 50 0.36 0.72\n",
+ " folding chair 50 0.62 0.84\n",
+ " football helmet 50 0.86 0.94\n",
+ " forklift 50 0.8 0.92\n",
+ " fountain 50 0.84 0.94\n",
+ " fountain pen 50 0.76 0.92\n",
+ " four-poster bed 50 0.78 0.94\n",
+ " freight car 50 0.96 1\n",
+ " French horn 50 0.76 0.92\n",
+ " frying pan 50 0.36 0.78\n",
+ " fur coat 50 0.84 0.96\n",
+ " garbage truck 50 0.9 0.98\n",
+ " gas mask 50 0.84 0.92\n",
+ " gas pump 50 0.9 0.98\n",
+ " goblet 50 0.68 0.82\n",
+ " go-kart 50 0.9 1\n",
+ " golf ball 50 0.84 0.9\n",
+ " golf cart 50 0.78 0.86\n",
+ " gondola 50 0.98 0.98\n",
+ " gong 50 0.74 0.92\n",
+ " gown 50 0.62 0.96\n",
+ " grand piano 50 0.7 0.96\n",
+ " greenhouse 50 0.8 0.98\n",
+ " grille 50 0.72 0.9\n",
+ " grocery store 50 0.66 0.94\n",
+ " guillotine 50 0.86 0.92\n",
+ " barrette 50 0.52 0.66\n",
+ " hair spray 50 0.5 0.74\n",
+ " half-track 50 0.78 0.9\n",
+ " hammer 50 0.56 0.76\n",
+ " hamper 50 0.64 0.84\n",
+ " hair dryer 50 0.56 0.74\n",
+ " hand-held computer 50 0.42 0.86\n",
+ " handkerchief 50 0.78 0.94\n",
+ " hard disk drive 50 0.76 0.84\n",
+ " harmonica 50 0.7 0.88\n",
+ " harp 50 0.88 0.96\n",
+ " harvester 50 0.78 1\n",
+ " hatchet 50 0.54 0.74\n",
+ " holster 50 0.66 0.84\n",
+ " home theater 50 0.64 0.94\n",
+ " honeycomb 50 0.56 0.88\n",
+ " hook 50 0.3 0.6\n",
+ " hoop skirt 50 0.64 0.86\n",
+ " horizontal bar 50 0.68 0.98\n",
+ " horse-drawn vehicle 50 0.88 0.94\n",
+ " hourglass 50 0.88 0.96\n",
+ " iPod 50 0.76 0.94\n",
+ " clothes iron 50 0.82 0.88\n",
+ " jack-o'-lantern 50 0.98 0.98\n",
+ " jeans 50 0.68 0.84\n",
+ " jeep 50 0.72 0.9\n",
+ " T-shirt 50 0.72 0.96\n",
+ " jigsaw puzzle 50 0.84 0.94\n",
+ " pulled rickshaw 50 0.86 0.94\n",
+ " joystick 50 0.8 0.9\n",
+ " kimono 50 0.84 0.96\n",
+ " knee pad 50 0.62 0.88\n",
+ " knot 50 0.66 0.8\n",
+ " lab coat 50 0.8 0.96\n",
+ " ladle 50 0.36 0.64\n",
+ " lampshade 50 0.48 0.84\n",
+ " laptop computer 50 0.26 0.88\n",
+ " lawn mower 50 0.78 0.96\n",
+ " lens cap 50 0.46 0.72\n",
+ " paper knife 50 0.26 0.5\n",
+ " library 50 0.54 0.9\n",
+ " lifeboat 50 0.92 0.98\n",
+ " lighter 50 0.56 0.78\n",
+ " limousine 50 0.76 0.92\n",
+ " ocean liner 50 0.88 0.94\n",
+ " lipstick 50 0.74 0.9\n",
+ " slip-on shoe 50 0.74 0.92\n",
+ " lotion 50 0.5 0.86\n",
+ " speaker 50 0.52 0.68\n",
+ " loupe 50 0.32 0.52\n",
+ " sawmill 50 0.72 0.9\n",
+ " magnetic compass 50 0.52 0.82\n",
+ " mail bag 50 0.68 0.92\n",
+ " mailbox 50 0.82 0.92\n",
+ " tights 50 0.22 0.94\n",
+ " tank suit 50 0.24 0.9\n",
+ " manhole cover 50 0.96 0.98\n",
+ " maraca 50 0.74 0.9\n",
+ " marimba 50 0.84 0.94\n",
+ " mask 50 0.44 0.82\n",
+ " match 50 0.66 0.9\n",
+ " maypole 50 0.96 1\n",
+ " maze 50 0.8 0.96\n",
+ " measuring cup 50 0.54 0.76\n",
+ " medicine chest 50 0.6 0.84\n",
+ " megalith 50 0.8 0.92\n",
+ " microphone 50 0.52 0.7\n",
+ " microwave oven 50 0.48 0.72\n",
+ " military uniform 50 0.62 0.84\n",
+ " milk can 50 0.68 0.82\n",
+ " minibus 50 0.7 1\n",
+ " miniskirt 50 0.46 0.76\n",
+ " minivan 50 0.38 0.8\n",
+ " missile 50 0.4 0.84\n",
+ " mitten 50 0.76 0.88\n",
+ " mixing bowl 50 0.8 0.92\n",
+ " mobile home 50 0.54 0.78\n",
+ " Model T 50 0.92 0.96\n",
+ " modem 50 0.58 0.86\n",
+ " monastery 50 0.44 0.9\n",
+ " monitor 50 0.4 0.86\n",
+ " moped 50 0.56 0.94\n",
+ " mortar 50 0.68 0.94\n",
+ " square academic cap 50 0.5 0.84\n",
+ " mosque 50 0.9 1\n",
+ " mosquito net 50 0.9 0.98\n",
+ " scooter 50 0.9 0.98\n",
+ " mountain bike 50 0.78 0.96\n",
+ " tent 50 0.88 0.96\n",
+ " computer mouse 50 0.42 0.82\n",
+ " mousetrap 50 0.76 0.88\n",
+ " moving van 50 0.4 0.72\n",
+ " muzzle 50 0.5 0.72\n",
+ " nail 50 0.68 0.74\n",
+ " neck brace 50 0.56 0.68\n",
+ " necklace 50 0.86 1\n",
+ " nipple 50 0.7 0.88\n",
+ " notebook computer 50 0.34 0.84\n",
+ " obelisk 50 0.8 0.92\n",
+ " oboe 50 0.6 0.84\n",
+ " ocarina 50 0.8 0.86\n",
+ " odometer 50 0.96 1\n",
+ " oil filter 50 0.58 0.82\n",
+ " organ 50 0.82 0.9\n",
+ " oscilloscope 50 0.9 0.96\n",
+ " overskirt 50 0.2 0.7\n",
+ " bullock cart 50 0.7 0.94\n",
+ " oxygen mask 50 0.46 0.84\n",
+ " packet 50 0.5 0.78\n",
+ " paddle 50 0.56 0.94\n",
+ " paddle wheel 50 0.86 0.96\n",
+ " padlock 50 0.74 0.78\n",
+ " paintbrush 50 0.62 0.8\n",
+ " pajamas 50 0.56 0.92\n",
+ " palace 50 0.64 0.96\n",
+ " pan flute 50 0.84 0.86\n",
+ " paper towel 50 0.66 0.84\n",
+ " parachute 50 0.92 0.94\n",
+ " parallel bars 50 0.62 0.96\n",
+ " park bench 50 0.74 0.9\n",
+ " parking meter 50 0.84 0.92\n",
+ " passenger car 50 0.5 0.82\n",
+ " patio 50 0.58 0.84\n",
+ " payphone 50 0.74 0.92\n",
+ " pedestal 50 0.52 0.9\n",
+ " pencil case 50 0.64 0.92\n",
+ " pencil sharpener 50 0.52 0.78\n",
+ " perfume 50 0.7 0.9\n",
+ " Petri dish 50 0.6 0.8\n",
+ " photocopier 50 0.88 0.98\n",
+ " plectrum 50 0.7 0.84\n",
+ " Pickelhaube 50 0.72 0.86\n",
+ " picket fence 50 0.84 0.94\n",
+ " pickup truck 50 0.64 0.92\n",
+ " pier 50 0.52 0.82\n",
+ " piggy bank 50 0.82 0.94\n",
+ " pill bottle 50 0.76 0.86\n",
+ " pillow 50 0.76 0.9\n",
+ " ping-pong ball 50 0.84 0.88\n",
+ " pinwheel 50 0.76 0.88\n",
+ " pirate ship 50 0.76 0.94\n",
+ " pitcher 50 0.46 0.84\n",
+ " hand plane 50 0.84 0.94\n",
+ " planetarium 50 0.88 0.98\n",
+ " plastic bag 50 0.36 0.62\n",
+ " plate rack 50 0.52 0.78\n",
+ " plow 50 0.78 0.88\n",
+ " plunger 50 0.42 0.7\n",
+ " Polaroid camera 50 0.84 0.92\n",
+ " pole 50 0.38 0.74\n",
+ " police van 50 0.76 0.94\n",
+ " poncho 50 0.58 0.86\n",
+ " billiard table 50 0.8 0.88\n",
+ " soda bottle 50 0.56 0.94\n",
+ " pot 50 0.78 0.92\n",
+ " potter's wheel 50 0.9 0.94\n",
+ " power drill 50 0.42 0.72\n",
+ " prayer rug 50 0.7 0.86\n",
+ " printer 50 0.54 0.86\n",
+ " prison 50 0.7 0.9\n",
+ " projectile 50 0.28 0.9\n",
+ " projector 50 0.62 0.84\n",
+ " hockey puck 50 0.92 0.96\n",
+ " punching bag 50 0.6 0.68\n",
+ " purse 50 0.42 0.78\n",
+ " quill 50 0.68 0.84\n",
+ " quilt 50 0.64 0.9\n",
+ " race car 50 0.72 0.92\n",
+ " racket 50 0.72 0.9\n",
+ " radiator 50 0.66 0.76\n",
+ " radio 50 0.64 0.92\n",
+ " radio telescope 50 0.9 0.96\n",
+ " rain barrel 50 0.8 0.98\n",
+ " recreational vehicle 50 0.84 0.94\n",
+ " reel 50 0.72 0.82\n",
+ " reflex camera 50 0.72 0.92\n",
+ " refrigerator 50 0.7 0.9\n",
+ " remote control 50 0.7 0.88\n",
+ " restaurant 50 0.5 0.66\n",
+ " revolver 50 0.82 1\n",
+ " rifle 50 0.38 0.7\n",
+ " rocking chair 50 0.62 0.84\n",
+ " rotisserie 50 0.88 0.92\n",
+ " eraser 50 0.54 0.76\n",
+ " rugby ball 50 0.86 0.94\n",
+ " ruler 50 0.68 0.86\n",
+ " running shoe 50 0.78 0.94\n",
+ " safe 50 0.82 0.92\n",
+ " safety pin 50 0.4 0.62\n",
+ " salt shaker 50 0.66 0.9\n",
+ " sandal 50 0.66 0.86\n",
+ " sarong 50 0.64 0.86\n",
+ " saxophone 50 0.66 0.88\n",
+ " scabbard 50 0.76 0.92\n",
+ " weighing scale 50 0.58 0.78\n",
+ " school bus 50 0.92 1\n",
+ " schooner 50 0.84 1\n",
+ " scoreboard 50 0.9 0.96\n",
+ " CRT screen 50 0.14 0.7\n",
+ " screw 50 0.9 0.98\n",
+ " screwdriver 50 0.3 0.58\n",
+ " seat belt 50 0.88 0.94\n",
+ " sewing machine 50 0.76 0.9\n",
+ " shield 50 0.56 0.82\n",
+ " shoe store 50 0.78 0.96\n",
+ " shoji 50 0.8 0.92\n",
+ " shopping basket 50 0.52 0.88\n",
+ " shopping cart 50 0.76 0.92\n",
+ " shovel 50 0.62 0.84\n",
+ " shower cap 50 0.7 0.84\n",
+ " shower curtain 50 0.64 0.82\n",
+ " ski 50 0.74 0.92\n",
+ " ski mask 50 0.72 0.88\n",
+ " sleeping bag 50 0.68 0.8\n",
+ " slide rule 50 0.72 0.88\n",
+ " sliding door 50 0.44 0.78\n",
+ " slot machine 50 0.94 0.98\n",
+ " snorkel 50 0.86 0.98\n",
+ " snowmobile 50 0.88 1\n",
+ " snowplow 50 0.84 0.98\n",
+ " soap dispenser 50 0.56 0.86\n",
+ " soccer ball 50 0.86 0.96\n",
+ " sock 50 0.62 0.76\n",
+ " solar thermal collector 50 0.72 0.96\n",
+ " sombrero 50 0.6 0.84\n",
+ " soup bowl 50 0.56 0.94\n",
+ " space bar 50 0.34 0.88\n",
+ " space heater 50 0.52 0.74\n",
+ " space shuttle 50 0.82 0.96\n",
+ " spatula 50 0.3 0.6\n",
+ " motorboat 50 0.86 1\n",
+ " spider web 50 0.7 0.9\n",
+ " spindle 50 0.86 0.98\n",
+ " sports car 50 0.6 0.94\n",
+ " spotlight 50 0.26 0.6\n",
+ " stage 50 0.68 0.86\n",
+ " steam locomotive 50 0.94 1\n",
+ " through arch bridge 50 0.84 0.96\n",
+ " steel drum 50 0.82 0.9\n",
+ " stethoscope 50 0.6 0.82\n",
+ " scarf 50 0.5 0.92\n",
+ " stone wall 50 0.76 0.9\n",
+ " stopwatch 50 0.58 0.9\n",
+ " stove 50 0.46 0.74\n",
+ " strainer 50 0.64 0.84\n",
+ " tram 50 0.88 0.96\n",
+ " stretcher 50 0.6 0.8\n",
+ " couch 50 0.8 0.96\n",
+ " stupa 50 0.88 0.88\n",
+ " submarine 50 0.72 0.92\n",
+ " suit 50 0.4 0.78\n",
+ " sundial 50 0.58 0.74\n",
+ " sunglass 50 0.14 0.58\n",
+ " sunglasses 50 0.28 0.58\n",
+ " sunscreen 50 0.32 0.7\n",
+ " suspension bridge 50 0.6 0.94\n",
+ " mop 50 0.74 0.92\n",
+ " sweatshirt 50 0.28 0.66\n",
+ " swimsuit 50 0.52 0.82\n",
+ " swing 50 0.76 0.84\n",
+ " switch 50 0.56 0.76\n",
+ " syringe 50 0.62 0.82\n",
+ " table lamp 50 0.6 0.88\n",
+ " tank 50 0.8 0.96\n",
+ " tape player 50 0.46 0.76\n",
+ " teapot 50 0.84 1\n",
+ " teddy bear 50 0.82 0.94\n",
+ " television 50 0.6 0.9\n",
+ " tennis ball 50 0.7 0.94\n",
+ " thatched roof 50 0.88 0.9\n",
+ " front curtain 50 0.8 0.92\n",
+ " thimble 50 0.6 0.8\n",
+ " threshing machine 50 0.56 0.88\n",
+ " throne 50 0.72 0.82\n",
+ " tile roof 50 0.72 0.94\n",
+ " toaster 50 0.66 0.84\n",
+ " tobacco shop 50 0.42 0.7\n",
+ " toilet seat 50 0.62 0.88\n",
+ " torch 50 0.64 0.84\n",
+ " totem pole 50 0.92 0.98\n",
+ " tow truck 50 0.62 0.88\n",
+ " toy store 50 0.6 0.94\n",
+ " tractor 50 0.76 0.98\n",
+ " semi-trailer truck 50 0.78 0.92\n",
+ " tray 50 0.46 0.64\n",
+ " trench coat 50 0.54 0.72\n",
+ " tricycle 50 0.72 0.94\n",
+ " trimaran 50 0.7 0.98\n",
+ " tripod 50 0.58 0.86\n",
+ " triumphal arch 50 0.92 0.98\n",
+ " trolleybus 50 0.9 1\n",
+ " trombone 50 0.54 0.88\n",
+ " tub 50 0.24 0.82\n",
+ " turnstile 50 0.84 0.94\n",
+ " typewriter keyboard 50 0.68 0.98\n",
+ " umbrella 50 0.52 0.7\n",
+ " unicycle 50 0.74 0.96\n",
+ " upright piano 50 0.76 0.9\n",
+ " vacuum cleaner 50 0.62 0.9\n",
+ " vase 50 0.5 0.78\n",
+ " vault 50 0.76 0.92\n",
+ " velvet 50 0.2 0.42\n",
+ " vending machine 50 0.9 1\n",
+ " vestment 50 0.54 0.82\n",
+ " viaduct 50 0.78 0.86\n",
+ " violin 50 0.68 0.78\n",
+ " volleyball 50 0.86 1\n",
+ " waffle iron 50 0.72 0.88\n",
+ " wall clock 50 0.54 0.88\n",
+ " wallet 50 0.52 0.9\n",
+ " wardrobe 50 0.68 0.88\n",
+ " military aircraft 50 0.9 0.98\n",
+ " sink 50 0.72 0.96\n",
+ " washing machine 50 0.78 0.94\n",
+ " water bottle 50 0.54 0.74\n",
+ " water jug 50 0.22 0.74\n",
+ " water tower 50 0.9 0.96\n",
+ " whiskey jug 50 0.64 0.74\n",
+ " whistle 50 0.72 0.84\n",
+ " wig 50 0.84 0.9\n",
+ " window screen 50 0.68 0.8\n",
+ " window shade 50 0.52 0.76\n",
+ " Windsor tie 50 0.22 0.66\n",
+ " wine bottle 50 0.42 0.82\n",
+ " wing 50 0.54 0.96\n",
+ " wok 50 0.46 0.82\n",
+ " wooden spoon 50 0.58 0.8\n",
+ " wool 50 0.32 0.82\n",
+ " split-rail fence 50 0.74 0.9\n",
+ " shipwreck 50 0.84 0.96\n",
+ " yawl 50 0.78 0.96\n",
+ " yurt 50 0.84 1\n",
+ " website 50 0.98 1\n",
+ " comic book 50 0.62 0.9\n",
+ " crossword 50 0.84 0.88\n",
+ " traffic sign 50 0.78 0.9\n",
+ " traffic light 50 0.8 0.94\n",
+ " dust jacket 50 0.72 0.94\n",
+ " menu 50 0.82 0.96\n",
+ " plate 50 0.44 0.88\n",
+ " guacamole 50 0.8 0.92\n",
+ " consomme 50 0.54 0.88\n",
+ " hot pot 50 0.86 0.98\n",
+ " trifle 50 0.92 0.98\n",
+ " ice cream 50 0.68 0.94\n",
+ " ice pop 50 0.62 0.84\n",
+ " baguette 50 0.62 0.88\n",
+ " bagel 50 0.64 0.92\n",
+ " pretzel 50 0.72 0.88\n",
+ " cheeseburger 50 0.9 1\n",
+ " hot dog 50 0.74 0.94\n",
+ " mashed potato 50 0.74 0.9\n",
+ " cabbage 50 0.84 0.96\n",
+ " broccoli 50 0.9 0.96\n",
+ " cauliflower 50 0.82 1\n",
+ " zucchini 50 0.74 0.9\n",
+ " spaghetti squash 50 0.8 0.96\n",
+ " acorn squash 50 0.82 0.96\n",
+ " butternut squash 50 0.7 0.94\n",
+ " cucumber 50 0.6 0.96\n",
+ " artichoke 50 0.84 0.94\n",
+ " bell pepper 50 0.84 0.98\n",
+ " cardoon 50 0.88 0.94\n",
+ " mushroom 50 0.38 0.92\n",
+ " Granny Smith 50 0.9 0.96\n",
+ " strawberry 50 0.6 0.88\n",
+ " orange 50 0.7 0.92\n",
+ " lemon 50 0.78 0.98\n",
+ " fig 50 0.82 0.96\n",
+ " pineapple 50 0.86 0.96\n",
+ " banana 50 0.84 0.96\n",
+ " jackfruit 50 0.9 0.98\n",
+ " custard apple 50 0.86 0.96\n",
+ " pomegranate 50 0.82 0.98\n",
+ " hay 50 0.8 0.92\n",
+ " carbonara 50 0.88 0.94\n",
+ " chocolate syrup 50 0.46 0.84\n",
+ " dough 50 0.4 0.6\n",
+ " meatloaf 50 0.58 0.84\n",
+ " pizza 50 0.84 0.96\n",
+ " pot pie 50 0.68 0.9\n",
+ " burrito 50 0.8 0.98\n",
+ " red wine 50 0.54 0.82\n",
+ " espresso 50 0.64 0.88\n",
+ " cup 50 0.38 0.7\n",
+ " eggnog 50 0.38 0.7\n",
+ " alp 50 0.54 0.88\n",
+ " bubble 50 0.8 0.96\n",
+ " cliff 50 0.64 1\n",
+ " coral reef 50 0.72 0.96\n",
+ " geyser 50 0.94 1\n",
+ " lakeshore 50 0.54 0.88\n",
+ " promontory 50 0.58 0.94\n",
+ " shoal 50 0.6 0.96\n",
+ " seashore 50 0.44 0.78\n",
+ " valley 50 0.72 0.94\n",
+ " volcano 50 0.78 0.96\n",
+ " baseball player 50 0.72 0.94\n",
+ " bridegroom 50 0.72 0.88\n",
+ " scuba diver 50 0.8 1\n",
+ " rapeseed 50 0.94 0.98\n",
+ " daisy 50 0.96 0.98\n",
+ " yellow lady's slipper 50 1 1\n",
+ " corn 50 0.4 0.88\n",
+ " acorn 50 0.92 0.98\n",
+ " rose hip 50 0.92 0.98\n",
+ " horse chestnut seed 50 0.94 0.98\n",
+ " coral fungus 50 0.96 0.96\n",
+ " agaric 50 0.82 0.94\n",
+ " gyromitra 50 0.98 1\n",
+ " stinkhorn mushroom 50 0.8 0.94\n",
+ " earth star 50 0.98 1\n",
+ " hen-of-the-woods 50 0.8 0.96\n",
+ " bolete 50 0.74 0.94\n",
+ " ear 50 0.48 0.94\n",
+ " toilet paper 50 0.36 0.68\n",
+ "Speed: 0.1ms pre-process, 0.3ms inference, 0.0ms post-process per image at shape (1, 3, 224, 224)\n",
+ "Results saved to \u001b[1mruns/val-cls/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s on Imagenet val\n",
+ "!python classify/val.py --weights yolov5s-cls.pt --data ../datasets/imagenet --img 224 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [Imagenet](https://image-net.org/) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "20fc0630-141e-4a90-ea06-342cbd7ce496"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "--2022-11-22 19:53:40-- https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar\n",
+ "Resolving image-net.org (image-net.org)... 171.64.68.16\n",
+ "Connecting to image-net.org (image-net.org)|171.64.68.16|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 6744924160 (6.3G) [application/x-tar]\n",
+ "Saving to: ‘ILSVRC2012_img_val.tar’\n",
+ "\n",
+ "ILSVRC2012_img_val. 100%[===================>] 6.28G 16.1MB/s in 10m 52s \n",
+ "\n",
+ "2022-11-22 20:04:32 (9.87 MB/s) - ‘ILSVRC2012_img_val.tar’ saved [6744924160/6744924160]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download Imagenet val (6.3G, 50000 images)\n",
+ "!bash data/scripts/get_imagenet.sh --val"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "41843132-98e2-4c25-d474-4cd7b246fb8e"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mclassify/val: \u001b[0mdata=../datasets/imagenet, weights=['yolov5s-cls.pt'], batch_size=128, imgsz=224, device=, workers=8, verbose=True, project=runs/val-cls, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-3-g61ebf5e Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model summary: 117 layers, 5447688 parameters, 0 gradients, 11.4 GFLOPs\n",
+ "validating: 100% 391/391 [04:57<00:00, 1.31it/s]\n",
+ " Class Images top1_acc top5_acc\n",
+ " all 50000 0.715 0.902\n",
+ " tench 50 0.94 0.98\n",
+ " goldfish 50 0.88 0.92\n",
+ " great white shark 50 0.78 0.96\n",
+ " tiger shark 50 0.68 0.96\n",
+ " hammerhead shark 50 0.82 0.92\n",
+ " electric ray 50 0.76 0.9\n",
+ " stingray 50 0.7 0.9\n",
+ " cock 50 0.78 0.92\n",
+ " hen 50 0.84 0.96\n",
+ " ostrich 50 0.98 1\n",
+ " brambling 50 0.9 0.96\n",
+ " goldfinch 50 0.92 0.98\n",
+ " house finch 50 0.88 0.96\n",
+ " junco 50 0.94 0.98\n",
+ " indigo bunting 50 0.86 0.88\n",
+ " American robin 50 0.9 0.96\n",
+ " bulbul 50 0.84 0.96\n",
+ " jay 50 0.9 0.96\n",
+ " magpie 50 0.84 0.96\n",
+ " chickadee 50 0.9 1\n",
+ " American dipper 50 0.82 0.92\n",
+ " kite 50 0.76 0.94\n",
+ " bald eagle 50 0.92 1\n",
+ " vulture 50 0.96 1\n",
+ " great grey owl 50 0.94 0.98\n",
+ " fire salamander 50 0.96 0.98\n",
+ " smooth newt 50 0.58 0.94\n",
+ " newt 50 0.74 0.9\n",
+ " spotted salamander 50 0.86 0.94\n",
+ " axolotl 50 0.86 0.96\n",
+ " American bullfrog 50 0.78 0.92\n",
+ " tree frog 50 0.84 0.96\n",
+ " tailed frog 50 0.48 0.8\n",
+ " loggerhead sea turtle 50 0.68 0.94\n",
+ " leatherback sea turtle 50 0.5 0.8\n",
+ " mud turtle 50 0.64 0.84\n",
+ " terrapin 50 0.52 0.98\n",
+ " box turtle 50 0.84 0.98\n",
+ " banded gecko 50 0.7 0.88\n",
+ " green iguana 50 0.76 0.94\n",
+ " Carolina anole 50 0.58 0.96\n",
+ "desert grassland whiptail lizard 50 0.82 0.94\n",
+ " agama 50 0.74 0.92\n",
+ " frilled-necked lizard 50 0.84 0.86\n",
+ " alligator lizard 50 0.58 0.78\n",
+ " Gila monster 50 0.72 0.8\n",
+ " European green lizard 50 0.42 0.9\n",
+ " chameleon 50 0.76 0.84\n",
+ " Komodo dragon 50 0.86 0.96\n",
+ " Nile crocodile 50 0.7 0.84\n",
+ " American alligator 50 0.76 0.96\n",
+ " triceratops 50 0.9 0.94\n",
+ " worm snake 50 0.76 0.88\n",
+ " ring-necked snake 50 0.8 0.92\n",
+ " eastern hog-nosed snake 50 0.58 0.88\n",
+ " smooth green snake 50 0.6 0.94\n",
+ " kingsnake 50 0.82 0.9\n",
+ " garter snake 50 0.88 0.94\n",
+ " water snake 50 0.7 0.94\n",
+ " vine snake 50 0.66 0.76\n",
+ " night snake 50 0.34 0.82\n",
+ " boa constrictor 50 0.8 0.96\n",
+ " African rock python 50 0.48 0.76\n",
+ " Indian cobra 50 0.82 0.94\n",
+ " green mamba 50 0.54 0.86\n",
+ " sea snake 50 0.62 0.9\n",
+ " Saharan horned viper 50 0.56 0.86\n",
+ "eastern diamondback rattlesnake 50 0.6 0.86\n",
+ " sidewinder 50 0.28 0.86\n",
+ " trilobite 50 0.98 0.98\n",
+ " harvestman 50 0.86 0.94\n",
+ " scorpion 50 0.86 0.94\n",
+ " yellow garden spider 50 0.92 0.96\n",
+ " barn spider 50 0.38 0.98\n",
+ " European garden spider 50 0.62 0.98\n",
+ " southern black widow 50 0.88 0.94\n",
+ " tarantula 50 0.94 1\n",
+ " wolf spider 50 0.82 0.92\n",
+ " tick 50 0.74 0.84\n",
+ " centipede 50 0.68 0.82\n",
+ " black grouse 50 0.88 0.98\n",
+ " ptarmigan 50 0.78 0.94\n",
+ " ruffed grouse 50 0.88 1\n",
+ " prairie grouse 50 0.92 1\n",
+ " peacock 50 0.88 0.9\n",
+ " quail 50 0.9 0.94\n",
+ " partridge 50 0.74 0.96\n",
+ " grey parrot 50 0.9 0.96\n",
+ " macaw 50 0.88 0.98\n",
+ "sulphur-crested cockatoo 50 0.86 0.92\n",
+ " lorikeet 50 0.96 1\n",
+ " coucal 50 0.82 0.88\n",
+ " bee eater 50 0.96 0.98\n",
+ " hornbill 50 0.9 0.96\n",
+ " hummingbird 50 0.88 0.96\n",
+ " jacamar 50 0.92 0.94\n",
+ " toucan 50 0.84 0.94\n",
+ " duck 50 0.76 0.94\n",
+ " red-breasted merganser 50 0.86 0.96\n",
+ " goose 50 0.74 0.96\n",
+ " black swan 50 0.94 0.98\n",
+ " tusker 50 0.54 0.92\n",
+ " echidna 50 0.98 1\n",
+ " platypus 50 0.72 0.84\n",
+ " wallaby 50 0.78 0.88\n",
+ " koala 50 0.84 0.92\n",
+ " wombat 50 0.78 0.84\n",
+ " jellyfish 50 0.88 0.96\n",
+ " sea anemone 50 0.72 0.9\n",
+ " brain coral 50 0.88 0.96\n",
+ " flatworm 50 0.8 0.98\n",
+ " nematode 50 0.86 0.9\n",
+ " conch 50 0.74 0.88\n",
+ " snail 50 0.78 0.88\n",
+ " slug 50 0.74 0.82\n",
+ " sea slug 50 0.88 0.98\n",
+ " chiton 50 0.88 0.98\n",
+ " chambered nautilus 50 0.88 0.92\n",
+ " Dungeness crab 50 0.78 0.94\n",
+ " rock crab 50 0.68 0.86\n",
+ " fiddler crab 50 0.64 0.86\n",
+ " red king crab 50 0.76 0.96\n",
+ " American lobster 50 0.78 0.96\n",
+ " spiny lobster 50 0.74 0.88\n",
+ " crayfish 50 0.56 0.86\n",
+ " hermit crab 50 0.78 0.96\n",
+ " isopod 50 0.66 0.78\n",
+ " white stork 50 0.88 0.96\n",
+ " black stork 50 0.84 0.98\n",
+ " spoonbill 50 0.96 1\n",
+ " flamingo 50 0.94 1\n",
+ " little blue heron 50 0.92 0.98\n",
+ " great egret 50 0.9 0.96\n",
+ " bittern 50 0.86 0.94\n",
+ " crane (bird) 50 0.62 0.9\n",
+ " limpkin 50 0.98 1\n",
+ " common gallinule 50 0.92 0.96\n",
+ " American coot 50 0.9 0.98\n",
+ " bustard 50 0.92 0.96\n",
+ " ruddy turnstone 50 0.94 1\n",
+ " dunlin 50 0.86 0.94\n",
+ " common redshank 50 0.9 0.96\n",
+ " dowitcher 50 0.84 0.96\n",
+ " oystercatcher 50 0.86 0.94\n",
+ " pelican 50 0.92 0.96\n",
+ " king penguin 50 0.88 0.96\n",
+ " albatross 50 0.9 1\n",
+ " grey whale 50 0.84 0.92\n",
+ " killer whale 50 0.92 1\n",
+ " dugong 50 0.84 0.96\n",
+ " sea lion 50 0.82 0.92\n",
+ " Chihuahua 50 0.66 0.84\n",
+ " Japanese Chin 50 0.72 0.98\n",
+ " Maltese 50 0.76 0.94\n",
+ " Pekingese 50 0.84 0.94\n",
+ " Shih Tzu 50 0.74 0.96\n",
+ " King Charles Spaniel 50 0.88 0.98\n",
+ " Papillon 50 0.86 0.94\n",
+ " toy terrier 50 0.48 0.94\n",
+ " Rhodesian Ridgeback 50 0.76 0.98\n",
+ " Afghan Hound 50 0.84 1\n",
+ " Basset Hound 50 0.8 0.92\n",
+ " Beagle 50 0.82 0.96\n",
+ " Bloodhound 50 0.48 0.72\n",
+ " Bluetick Coonhound 50 0.86 0.94\n",
+ " Black and Tan Coonhound 50 0.54 0.8\n",
+ "Treeing Walker Coonhound 50 0.66 0.98\n",
+ " English foxhound 50 0.32 0.84\n",
+ " Redbone Coonhound 50 0.62 0.94\n",
+ " borzoi 50 0.92 1\n",
+ " Irish Wolfhound 50 0.48 0.88\n",
+ " Italian Greyhound 50 0.76 0.98\n",
+ " Whippet 50 0.74 0.92\n",
+ " Ibizan Hound 50 0.6 0.86\n",
+ " Norwegian Elkhound 50 0.88 0.98\n",
+ " Otterhound 50 0.62 0.9\n",
+ " Saluki 50 0.72 0.92\n",
+ " Scottish Deerhound 50 0.86 0.98\n",
+ " Weimaraner 50 0.88 0.94\n",
+ "Staffordshire Bull Terrier 50 0.66 0.98\n",
+ "American Staffordshire Terrier 50 0.64 0.92\n",
+ " Bedlington Terrier 50 0.9 0.92\n",
+ " Border Terrier 50 0.86 0.92\n",
+ " Kerry Blue Terrier 50 0.78 0.98\n",
+ " Irish Terrier 50 0.7 0.96\n",
+ " Norfolk Terrier 50 0.68 0.9\n",
+ " Norwich Terrier 50 0.72 1\n",
+ " Yorkshire Terrier 50 0.66 0.9\n",
+ " Wire Fox Terrier 50 0.64 0.98\n",
+ " Lakeland Terrier 50 0.74 0.92\n",
+ " Sealyham Terrier 50 0.76 0.9\n",
+ " Airedale Terrier 50 0.82 0.92\n",
+ " Cairn Terrier 50 0.76 0.9\n",
+ " Australian Terrier 50 0.48 0.84\n",
+ " Dandie Dinmont Terrier 50 0.82 0.92\n",
+ " Boston Terrier 50 0.92 1\n",
+ " Miniature Schnauzer 50 0.68 0.9\n",
+ " Giant Schnauzer 50 0.72 0.98\n",
+ " Standard Schnauzer 50 0.74 1\n",
+ " Scottish Terrier 50 0.76 0.96\n",
+ " Tibetan Terrier 50 0.48 1\n",
+ "Australian Silky Terrier 50 0.66 0.96\n",
+ "Soft-coated Wheaten Terrier 50 0.74 0.96\n",
+ "West Highland White Terrier 50 0.88 0.96\n",
+ " Lhasa Apso 50 0.68 0.96\n",
+ " Flat-Coated Retriever 50 0.72 0.94\n",
+ " Curly-coated Retriever 50 0.82 0.94\n",
+ " Golden Retriever 50 0.86 0.94\n",
+ " Labrador Retriever 50 0.82 0.94\n",
+ "Chesapeake Bay Retriever 50 0.76 0.96\n",
+ "German Shorthaired Pointer 50 0.8 0.96\n",
+ " Vizsla 50 0.68 0.96\n",
+ " English Setter 50 0.7 1\n",
+ " Irish Setter 50 0.8 0.9\n",
+ " Gordon Setter 50 0.84 0.92\n",
+ " Brittany 50 0.84 0.96\n",
+ " Clumber Spaniel 50 0.92 0.96\n",
+ "English Springer Spaniel 50 0.88 1\n",
+ " Welsh Springer Spaniel 50 0.92 1\n",
+ " Cocker Spaniels 50 0.7 0.94\n",
+ " Sussex Spaniel 50 0.72 0.92\n",
+ " Irish Water Spaniel 50 0.88 0.98\n",
+ " Kuvasz 50 0.66 0.9\n",
+ " Schipperke 50 0.9 0.98\n",
+ " Groenendael 50 0.8 0.94\n",
+ " Malinois 50 0.86 0.98\n",
+ " Briard 50 0.52 0.8\n",
+ " Australian Kelpie 50 0.6 0.88\n",
+ " Komondor 50 0.88 0.94\n",
+ " Old English Sheepdog 50 0.94 0.98\n",
+ " Shetland Sheepdog 50 0.74 0.9\n",
+ " collie 50 0.6 0.96\n",
+ " Border Collie 50 0.74 0.96\n",
+ " Bouvier des Flandres 50 0.78 0.94\n",
+ " Rottweiler 50 0.88 0.96\n",
+ " German Shepherd Dog 50 0.8 0.98\n",
+ " Dobermann 50 0.68 0.96\n",
+ " Miniature Pinscher 50 0.76 0.88\n",
+ "Greater Swiss Mountain Dog 50 0.68 0.94\n",
+ " Bernese Mountain Dog 50 0.96 1\n",
+ " Appenzeller Sennenhund 50 0.22 1\n",
+ " Entlebucher Sennenhund 50 0.64 0.98\n",
+ " Boxer 50 0.7 0.92\n",
+ " Bullmastiff 50 0.78 0.98\n",
+ " Tibetan Mastiff 50 0.88 0.96\n",
+ " French Bulldog 50 0.84 0.94\n",
+ " Great Dane 50 0.54 0.9\n",
+ " St. Bernard 50 0.92 1\n",
+ " husky 50 0.46 0.98\n",
+ " Alaskan Malamute 50 0.76 0.96\n",
+ " Siberian Husky 50 0.46 0.98\n",
+ " Dalmatian 50 0.94 0.98\n",
+ " Affenpinscher 50 0.78 0.9\n",
+ " Basenji 50 0.92 0.94\n",
+ " pug 50 0.94 0.98\n",
+ " Leonberger 50 1 1\n",
+ " Newfoundland 50 0.78 0.96\n",
+ " Pyrenean Mountain Dog 50 0.78 0.96\n",
+ " Samoyed 50 0.96 1\n",
+ " Pomeranian 50 0.98 1\n",
+ " Chow Chow 50 0.9 0.96\n",
+ " Keeshond 50 0.88 0.94\n",
+ " Griffon Bruxellois 50 0.84 0.98\n",
+ " Pembroke Welsh Corgi 50 0.82 0.94\n",
+ " Cardigan Welsh Corgi 50 0.66 0.98\n",
+ " Toy Poodle 50 0.52 0.88\n",
+ " Miniature Poodle 50 0.52 0.92\n",
+ " Standard Poodle 50 0.8 1\n",
+ " Mexican hairless dog 50 0.88 0.98\n",
+ " grey wolf 50 0.82 0.92\n",
+ " Alaskan tundra wolf 50 0.78 0.98\n",
+ " red wolf 50 0.48 0.9\n",
+ " coyote 50 0.64 0.86\n",
+ " dingo 50 0.76 0.88\n",
+ " dhole 50 0.9 0.98\n",
+ " African wild dog 50 0.98 1\n",
+ " hyena 50 0.88 0.96\n",
+ " red fox 50 0.54 0.92\n",
+ " kit fox 50 0.72 0.98\n",
+ " Arctic fox 50 0.94 1\n",
+ " grey fox 50 0.7 0.94\n",
+ " tabby cat 50 0.54 0.92\n",
+ " tiger cat 50 0.22 0.94\n",
+ " Persian cat 50 0.9 0.98\n",
+ " Siamese cat 50 0.96 1\n",
+ " Egyptian Mau 50 0.54 0.8\n",
+ " cougar 50 0.9 1\n",
+ " lynx 50 0.72 0.88\n",
+ " leopard 50 0.78 0.98\n",
+ " snow leopard 50 0.9 0.98\n",
+ " jaguar 50 0.7 0.94\n",
+ " lion 50 0.9 0.98\n",
+ " tiger 50 0.92 0.98\n",
+ " cheetah 50 0.94 0.98\n",
+ " brown bear 50 0.94 0.98\n",
+ " American black bear 50 0.8 1\n",
+ " polar bear 50 0.84 0.96\n",
+ " sloth bear 50 0.72 0.92\n",
+ " mongoose 50 0.7 0.92\n",
+ " meerkat 50 0.82 0.92\n",
+ " tiger beetle 50 0.92 0.94\n",
+ " ladybug 50 0.86 0.94\n",
+ " ground beetle 50 0.64 0.94\n",
+ " longhorn beetle 50 0.62 0.88\n",
+ " leaf beetle 50 0.64 0.98\n",
+ " dung beetle 50 0.86 0.98\n",
+ " rhinoceros beetle 50 0.86 0.94\n",
+ " weevil 50 0.9 1\n",
+ " fly 50 0.78 0.94\n",
+ " bee 50 0.68 0.94\n",
+ " ant 50 0.68 0.78\n",
+ " grasshopper 50 0.5 0.92\n",
+ " cricket 50 0.64 0.92\n",
+ " stick insect 50 0.64 0.92\n",
+ " cockroach 50 0.72 0.8\n",
+ " mantis 50 0.64 0.86\n",
+ " cicada 50 0.9 0.96\n",
+ " leafhopper 50 0.88 0.94\n",
+ " lacewing 50 0.78 0.92\n",
+ " dragonfly 50 0.82 0.98\n",
+ " damselfly 50 0.82 1\n",
+ " red admiral 50 0.94 0.96\n",
+ " ringlet 50 0.86 0.98\n",
+ " monarch butterfly 50 0.9 0.92\n",
+ " small white 50 0.9 1\n",
+ " sulphur butterfly 50 0.92 1\n",
+ "gossamer-winged butterfly 50 0.88 1\n",
+ " starfish 50 0.88 0.92\n",
+ " sea urchin 50 0.84 0.94\n",
+ " sea cucumber 50 0.66 0.84\n",
+ " cottontail rabbit 50 0.72 0.94\n",
+ " hare 50 0.84 0.96\n",
+ " Angora rabbit 50 0.94 0.98\n",
+ " hamster 50 0.96 1\n",
+ " porcupine 50 0.88 0.98\n",
+ " fox squirrel 50 0.76 0.94\n",
+ " marmot 50 0.92 0.96\n",
+ " beaver 50 0.78 0.94\n",
+ " guinea pig 50 0.78 0.94\n",
+ " common sorrel 50 0.96 0.98\n",
+ " zebra 50 0.94 0.96\n",
+ " pig 50 0.5 0.76\n",
+ " wild boar 50 0.84 0.96\n",
+ " warthog 50 0.84 0.96\n",
+ " hippopotamus 50 0.88 0.96\n",
+ " ox 50 0.48 0.94\n",
+ " water buffalo 50 0.78 0.94\n",
+ " bison 50 0.88 0.96\n",
+ " ram 50 0.58 0.92\n",
+ " bighorn sheep 50 0.66 1\n",
+ " Alpine ibex 50 0.92 0.98\n",
+ " hartebeest 50 0.94 1\n",
+ " impala 50 0.82 0.96\n",
+ " gazelle 50 0.7 0.96\n",
+ " dromedary 50 0.9 1\n",
+ " llama 50 0.82 0.94\n",
+ " weasel 50 0.44 0.92\n",
+ " mink 50 0.78 0.96\n",
+ " European polecat 50 0.46 0.9\n",
+ " black-footed ferret 50 0.68 0.96\n",
+ " otter 50 0.66 0.88\n",
+ " skunk 50 0.96 0.96\n",
+ " badger 50 0.86 0.92\n",
+ " armadillo 50 0.88 0.9\n",
+ " three-toed sloth 50 0.96 1\n",
+ " orangutan 50 0.78 0.92\n",
+ " gorilla 50 0.82 0.94\n",
+ " chimpanzee 50 0.84 0.94\n",
+ " gibbon 50 0.76 0.86\n",
+ " siamang 50 0.68 0.94\n",
+ " guenon 50 0.8 0.94\n",
+ " patas monkey 50 0.62 0.82\n",
+ " baboon 50 0.9 0.98\n",
+ " macaque 50 0.8 0.86\n",
+ " langur 50 0.6 0.82\n",
+ " black-and-white colobus 50 0.86 0.9\n",
+ " proboscis monkey 50 1 1\n",
+ " marmoset 50 0.74 0.98\n",
+ " white-headed capuchin 50 0.72 0.9\n",
+ " howler monkey 50 0.86 0.94\n",
+ " titi 50 0.5 0.9\n",
+ "Geoffroy's spider monkey 50 0.42 0.8\n",
+ " common squirrel monkey 50 0.76 0.92\n",
+ " ring-tailed lemur 50 0.72 0.94\n",
+ " indri 50 0.9 0.96\n",
+ " Asian elephant 50 0.58 0.92\n",
+ " African bush elephant 50 0.7 0.98\n",
+ " red panda 50 0.94 0.94\n",
+ " giant panda 50 0.94 0.98\n",
+ " snoek 50 0.74 0.9\n",
+ " eel 50 0.6 0.84\n",
+ " coho salmon 50 0.84 0.96\n",
+ " rock beauty 50 0.88 0.98\n",
+ " clownfish 50 0.78 0.98\n",
+ " sturgeon 50 0.68 0.94\n",
+ " garfish 50 0.62 0.8\n",
+ " lionfish 50 0.96 0.96\n",
+ " pufferfish 50 0.88 0.96\n",
+ " abacus 50 0.74 0.88\n",
+ " abaya 50 0.84 0.92\n",
+ " academic gown 50 0.42 0.86\n",
+ " accordion 50 0.8 0.9\n",
+ " acoustic guitar 50 0.5 0.76\n",
+ " aircraft carrier 50 0.8 0.96\n",
+ " airliner 50 0.92 1\n",
+ " airship 50 0.76 0.82\n",
+ " altar 50 0.64 0.98\n",
+ " ambulance 50 0.88 0.98\n",
+ " amphibious vehicle 50 0.64 0.94\n",
+ " analog clock 50 0.52 0.92\n",
+ " apiary 50 0.82 0.96\n",
+ " apron 50 0.7 0.84\n",
+ " waste container 50 0.4 0.8\n",
+ " assault rifle 50 0.42 0.84\n",
+ " backpack 50 0.34 0.64\n",
+ " bakery 50 0.4 0.68\n",
+ " balance beam 50 0.8 0.98\n",
+ " balloon 50 0.86 0.96\n",
+ " ballpoint pen 50 0.52 0.96\n",
+ " Band-Aid 50 0.7 0.9\n",
+ " banjo 50 0.84 1\n",
+ " baluster 50 0.68 0.94\n",
+ " barbell 50 0.56 0.9\n",
+ " barber chair 50 0.7 0.92\n",
+ " barbershop 50 0.54 0.86\n",
+ " barn 50 0.96 0.96\n",
+ " barometer 50 0.84 0.98\n",
+ " barrel 50 0.56 0.88\n",
+ " wheelbarrow 50 0.66 0.88\n",
+ " baseball 50 0.74 0.98\n",
+ " basketball 50 0.88 0.98\n",
+ " bassinet 50 0.66 0.92\n",
+ " bassoon 50 0.74 0.98\n",
+ " swimming cap 50 0.62 0.88\n",
+ " bath towel 50 0.54 0.78\n",
+ " bathtub 50 0.4 0.88\n",
+ " station wagon 50 0.66 0.84\n",
+ " lighthouse 50 0.78 0.94\n",
+ " beaker 50 0.52 0.68\n",
+ " military cap 50 0.84 0.96\n",
+ " beer bottle 50 0.66 0.88\n",
+ " beer glass 50 0.6 0.84\n",
+ " bell-cot 50 0.56 0.96\n",
+ " bib 50 0.58 0.82\n",
+ " tandem bicycle 50 0.86 0.96\n",
+ " bikini 50 0.56 0.88\n",
+ " ring binder 50 0.64 0.84\n",
+ " binoculars 50 0.54 0.78\n",
+ " birdhouse 50 0.86 0.94\n",
+ " boathouse 50 0.74 0.92\n",
+ " bobsleigh 50 0.92 0.96\n",
+ " bolo tie 50 0.8 0.94\n",
+ " poke bonnet 50 0.64 0.86\n",
+ " bookcase 50 0.66 0.92\n",
+ " bookstore 50 0.62 0.88\n",
+ " bottle cap 50 0.58 0.7\n",
+ " bow 50 0.72 0.86\n",
+ " bow tie 50 0.7 0.9\n",
+ " brass 50 0.92 0.96\n",
+ " bra 50 0.5 0.7\n",
+ " breakwater 50 0.62 0.86\n",
+ " breastplate 50 0.4 0.9\n",
+ " broom 50 0.6 0.86\n",
+ " bucket 50 0.66 0.8\n",
+ " buckle 50 0.5 0.68\n",
+ " bulletproof vest 50 0.5 0.78\n",
+ " high-speed train 50 0.94 0.96\n",
+ " butcher shop 50 0.74 0.94\n",
+ " taxicab 50 0.64 0.86\n",
+ " cauldron 50 0.44 0.66\n",
+ " candle 50 0.48 0.74\n",
+ " cannon 50 0.88 0.94\n",
+ " canoe 50 0.94 1\n",
+ " can opener 50 0.66 0.86\n",
+ " cardigan 50 0.68 0.8\n",
+ " car mirror 50 0.94 0.96\n",
+ " carousel 50 0.94 0.98\n",
+ " tool kit 50 0.56 0.78\n",
+ " carton 50 0.42 0.7\n",
+ " car wheel 50 0.38 0.74\n",
+ "automated teller machine 50 0.76 0.94\n",
+ " cassette 50 0.52 0.8\n",
+ " cassette player 50 0.28 0.9\n",
+ " castle 50 0.78 0.88\n",
+ " catamaran 50 0.78 1\n",
+ " CD player 50 0.52 0.82\n",
+ " cello 50 0.82 1\n",
+ " mobile phone 50 0.68 0.86\n",
+ " chain 50 0.38 0.66\n",
+ " chain-link fence 50 0.7 0.84\n",
+ " chain mail 50 0.64 0.9\n",
+ " chainsaw 50 0.84 0.92\n",
+ " chest 50 0.68 0.92\n",
+ " chiffonier 50 0.26 0.64\n",
+ " chime 50 0.62 0.84\n",
+ " china cabinet 50 0.82 0.96\n",
+ " Christmas stocking 50 0.92 0.94\n",
+ " church 50 0.62 0.9\n",
+ " movie theater 50 0.58 0.88\n",
+ " cleaver 50 0.32 0.62\n",
+ " cliff dwelling 50 0.88 1\n",
+ " cloak 50 0.32 0.64\n",
+ " clogs 50 0.58 0.88\n",
+ " cocktail shaker 50 0.62 0.7\n",
+ " coffee mug 50 0.44 0.72\n",
+ " coffeemaker 50 0.64 0.92\n",
+ " coil 50 0.66 0.84\n",
+ " combination lock 50 0.64 0.84\n",
+ " computer keyboard 50 0.7 0.82\n",
+ " confectionery store 50 0.54 0.86\n",
+ " container ship 50 0.82 0.98\n",
+ " convertible 50 0.78 0.98\n",
+ " corkscrew 50 0.82 0.92\n",
+ " cornet 50 0.46 0.88\n",
+ " cowboy boot 50 0.64 0.8\n",
+ " cowboy hat 50 0.64 0.82\n",
+ " cradle 50 0.38 0.8\n",
+ " crane (machine) 50 0.78 0.94\n",
+ " crash helmet 50 0.92 0.96\n",
+ " crate 50 0.52 0.82\n",
+ " infant bed 50 0.74 1\n",
+ " Crock Pot 50 0.78 0.9\n",
+ " croquet ball 50 0.9 0.96\n",
+ " crutch 50 0.46 0.7\n",
+ " cuirass 50 0.54 0.86\n",
+ " dam 50 0.74 0.92\n",
+ " desk 50 0.6 0.86\n",
+ " desktop computer 50 0.54 0.94\n",
+ " rotary dial telephone 50 0.88 0.94\n",
+ " diaper 50 0.68 0.84\n",
+ " digital clock 50 0.54 0.76\n",
+ " digital watch 50 0.58 0.86\n",
+ " dining table 50 0.76 0.9\n",
+ " dishcloth 50 0.94 1\n",
+ " dishwasher 50 0.44 0.78\n",
+ " disc brake 50 0.98 1\n",
+ " dock 50 0.54 0.94\n",
+ " dog sled 50 0.84 1\n",
+ " dome 50 0.72 0.92\n",
+ " doormat 50 0.56 0.82\n",
+ " drilling rig 50 0.84 0.96\n",
+ " drum 50 0.38 0.68\n",
+ " drumstick 50 0.56 0.72\n",
+ " dumbbell 50 0.62 0.9\n",
+ " Dutch oven 50 0.7 0.84\n",
+ " electric fan 50 0.82 0.86\n",
+ " electric guitar 50 0.62 0.84\n",
+ " electric locomotive 50 0.92 0.98\n",
+ " entertainment center 50 0.9 0.98\n",
+ " envelope 50 0.44 0.86\n",
+ " espresso machine 50 0.72 0.94\n",
+ " face powder 50 0.7 0.92\n",
+ " feather boa 50 0.7 0.84\n",
+ " filing cabinet 50 0.88 0.98\n",
+ " fireboat 50 0.94 0.98\n",
+ " fire engine 50 0.84 0.9\n",
+ " fire screen sheet 50 0.62 0.76\n",
+ " flagpole 50 0.74 0.88\n",
+ " flute 50 0.36 0.72\n",
+ " folding chair 50 0.62 0.84\n",
+ " football helmet 50 0.86 0.94\n",
+ " forklift 50 0.8 0.92\n",
+ " fountain 50 0.84 0.94\n",
+ " fountain pen 50 0.76 0.92\n",
+ " four-poster bed 50 0.78 0.94\n",
+ " freight car 50 0.96 1\n",
+ " French horn 50 0.76 0.92\n",
+ " frying pan 50 0.36 0.78\n",
+ " fur coat 50 0.84 0.96\n",
+ " garbage truck 50 0.9 0.98\n",
+ " gas mask 50 0.84 0.92\n",
+ " gas pump 50 0.9 0.98\n",
+ " goblet 50 0.68 0.82\n",
+ " go-kart 50 0.9 1\n",
+ " golf ball 50 0.84 0.9\n",
+ " golf cart 50 0.78 0.86\n",
+ " gondola 50 0.98 0.98\n",
+ " gong 50 0.74 0.92\n",
+ " gown 50 0.62 0.96\n",
+ " grand piano 50 0.7 0.96\n",
+ " greenhouse 50 0.8 0.98\n",
+ " grille 50 0.72 0.9\n",
+ " grocery store 50 0.66 0.94\n",
+ " guillotine 50 0.86 0.92\n",
+ " barrette 50 0.52 0.66\n",
+ " hair spray 50 0.5 0.74\n",
+ " half-track 50 0.78 0.9\n",
+ " hammer 50 0.56 0.76\n",
+ " hamper 50 0.64 0.84\n",
+ " hair dryer 50 0.56 0.74\n",
+ " hand-held computer 50 0.42 0.86\n",
+ " handkerchief 50 0.78 0.94\n",
+ " hard disk drive 50 0.76 0.84\n",
+ " harmonica 50 0.7 0.88\n",
+ " harp 50 0.88 0.96\n",
+ " harvester 50 0.78 1\n",
+ " hatchet 50 0.54 0.74\n",
+ " holster 50 0.66 0.84\n",
+ " home theater 50 0.64 0.94\n",
+ " honeycomb 50 0.56 0.88\n",
+ " hook 50 0.3 0.6\n",
+ " hoop skirt 50 0.64 0.86\n",
+ " horizontal bar 50 0.68 0.98\n",
+ " horse-drawn vehicle 50 0.88 0.94\n",
+ " hourglass 50 0.88 0.96\n",
+ " iPod 50 0.76 0.94\n",
+ " clothes iron 50 0.82 0.88\n",
+ " jack-o'-lantern 50 0.98 0.98\n",
+ " jeans 50 0.68 0.84\n",
+ " jeep 50 0.72 0.9\n",
+ " T-shirt 50 0.72 0.96\n",
+ " jigsaw puzzle 50 0.84 0.94\n",
+ " pulled rickshaw 50 0.86 0.94\n",
+ " joystick 50 0.8 0.9\n",
+ " kimono 50 0.84 0.96\n",
+ " knee pad 50 0.62 0.88\n",
+ " knot 50 0.66 0.8\n",
+ " lab coat 50 0.8 0.96\n",
+ " ladle 50 0.36 0.64\n",
+ " lampshade 50 0.48 0.84\n",
+ " laptop computer 50 0.26 0.88\n",
+ " lawn mower 50 0.78 0.96\n",
+ " lens cap 50 0.46 0.72\n",
+ " paper knife 50 0.26 0.5\n",
+ " library 50 0.54 0.9\n",
+ " lifeboat 50 0.92 0.98\n",
+ " lighter 50 0.56 0.78\n",
+ " limousine 50 0.76 0.92\n",
+ " ocean liner 50 0.88 0.94\n",
+ " lipstick 50 0.74 0.9\n",
+ " slip-on shoe 50 0.74 0.92\n",
+ " lotion 50 0.5 0.86\n",
+ " speaker 50 0.52 0.68\n",
+ " loupe 50 0.32 0.52\n",
+ " sawmill 50 0.72 0.9\n",
+ " magnetic compass 50 0.52 0.82\n",
+ " mail bag 50 0.68 0.92\n",
+ " mailbox 50 0.82 0.92\n",
+ " tights 50 0.22 0.94\n",
+ " tank suit 50 0.24 0.9\n",
+ " manhole cover 50 0.96 0.98\n",
+ " maraca 50 0.74 0.9\n",
+ " marimba 50 0.84 0.94\n",
+ " mask 50 0.44 0.82\n",
+ " match 50 0.66 0.9\n",
+ " maypole 50 0.96 1\n",
+ " maze 50 0.8 0.96\n",
+ " measuring cup 50 0.54 0.76\n",
+ " medicine chest 50 0.6 0.84\n",
+ " megalith 50 0.8 0.92\n",
+ " microphone 50 0.52 0.7\n",
+ " microwave oven 50 0.48 0.72\n",
+ " military uniform 50 0.62 0.84\n",
+ " milk can 50 0.68 0.82\n",
+ " minibus 50 0.7 1\n",
+ " miniskirt 50 0.46 0.76\n",
+ " minivan 50 0.38 0.8\n",
+ " missile 50 0.4 0.84\n",
+ " mitten 50 0.76 0.88\n",
+ " mixing bowl 50 0.8 0.92\n",
+ " mobile home 50 0.54 0.78\n",
+ " Model T 50 0.92 0.96\n",
+ " modem 50 0.58 0.86\n",
+ " monastery 50 0.44 0.9\n",
+ " monitor 50 0.4 0.86\n",
+ " moped 50 0.56 0.94\n",
+ " mortar 50 0.68 0.94\n",
+ " square academic cap 50 0.5 0.84\n",
+ " mosque 50 0.9 1\n",
+ " mosquito net 50 0.9 0.98\n",
+ " scooter 50 0.9 0.98\n",
+ " mountain bike 50 0.78 0.96\n",
+ " tent 50 0.88 0.96\n",
+ " computer mouse 50 0.42 0.82\n",
+ " mousetrap 50 0.76 0.88\n",
+ " moving van 50 0.4 0.72\n",
+ " muzzle 50 0.5 0.72\n",
+ " nail 50 0.68 0.74\n",
+ " neck brace 50 0.56 0.68\n",
+ " necklace 50 0.86 1\n",
+ " nipple 50 0.7 0.88\n",
+ " notebook computer 50 0.34 0.84\n",
+ " obelisk 50 0.8 0.92\n",
+ " oboe 50 0.6 0.84\n",
+ " ocarina 50 0.8 0.86\n",
+ " odometer 50 0.96 1\n",
+ " oil filter 50 0.58 0.82\n",
+ " organ 50 0.82 0.9\n",
+ " oscilloscope 50 0.9 0.96\n",
+ " overskirt 50 0.2 0.7\n",
+ " bullock cart 50 0.7 0.94\n",
+ " oxygen mask 50 0.46 0.84\n",
+ " packet 50 0.5 0.78\n",
+ " paddle 50 0.56 0.94\n",
+ " paddle wheel 50 0.86 0.96\n",
+ " padlock 50 0.74 0.78\n",
+ " paintbrush 50 0.62 0.8\n",
+ " pajamas 50 0.56 0.92\n",
+ " palace 50 0.64 0.96\n",
+ " pan flute 50 0.84 0.86\n",
+ " paper towel 50 0.66 0.84\n",
+ " parachute 50 0.92 0.94\n",
+ " parallel bars 50 0.62 0.96\n",
+ " park bench 50 0.74 0.9\n",
+ " parking meter 50 0.84 0.92\n",
+ " passenger car 50 0.5 0.82\n",
+ " patio 50 0.58 0.84\n",
+ " payphone 50 0.74 0.92\n",
+ " pedestal 50 0.52 0.9\n",
+ " pencil case 50 0.64 0.92\n",
+ " pencil sharpener 50 0.52 0.78\n",
+ " perfume 50 0.7 0.9\n",
+ " Petri dish 50 0.6 0.8\n",
+ " photocopier 50 0.88 0.98\n",
+ " plectrum 50 0.7 0.84\n",
+ " Pickelhaube 50 0.72 0.86\n",
+ " picket fence 50 0.84 0.94\n",
+ " pickup truck 50 0.64 0.92\n",
+ " pier 50 0.52 0.82\n",
+ " piggy bank 50 0.82 0.94\n",
+ " pill bottle 50 0.76 0.86\n",
+ " pillow 50 0.76 0.9\n",
+ " ping-pong ball 50 0.84 0.88\n",
+ " pinwheel 50 0.76 0.88\n",
+ " pirate ship 50 0.76 0.94\n",
+ " pitcher 50 0.46 0.84\n",
+ " hand plane 50 0.84 0.94\n",
+ " planetarium 50 0.88 0.98\n",
+ " plastic bag 50 0.36 0.62\n",
+ " plate rack 50 0.52 0.78\n",
+ " plow 50 0.78 0.88\n",
+ " plunger 50 0.42 0.7\n",
+ " Polaroid camera 50 0.84 0.92\n",
+ " pole 50 0.38 0.74\n",
+ " police van 50 0.76 0.94\n",
+ " poncho 50 0.58 0.86\n",
+ " billiard table 50 0.8 0.88\n",
+ " soda bottle 50 0.56 0.94\n",
+ " pot 50 0.78 0.92\n",
+ " potter's wheel 50 0.9 0.94\n",
+ " power drill 50 0.42 0.72\n",
+ " prayer rug 50 0.7 0.86\n",
+ " printer 50 0.54 0.86\n",
+ " prison 50 0.7 0.9\n",
+ " projectile 50 0.28 0.9\n",
+ " projector 50 0.62 0.84\n",
+ " hockey puck 50 0.92 0.96\n",
+ " punching bag 50 0.6 0.68\n",
+ " purse 50 0.42 0.78\n",
+ " quill 50 0.68 0.84\n",
+ " quilt 50 0.64 0.9\n",
+ " race car 50 0.72 0.92\n",
+ " racket 50 0.72 0.9\n",
+ " radiator 50 0.66 0.76\n",
+ " radio 50 0.64 0.92\n",
+ " radio telescope 50 0.9 0.96\n",
+ " rain barrel 50 0.8 0.98\n",
+ " recreational vehicle 50 0.84 0.94\n",
+ " reel 50 0.72 0.82\n",
+ " reflex camera 50 0.72 0.92\n",
+ " refrigerator 50 0.7 0.9\n",
+ " remote control 50 0.7 0.88\n",
+ " restaurant 50 0.5 0.66\n",
+ " revolver 50 0.82 1\n",
+ " rifle 50 0.38 0.7\n",
+ " rocking chair 50 0.62 0.84\n",
+ " rotisserie 50 0.88 0.92\n",
+ " eraser 50 0.54 0.76\n",
+ " rugby ball 50 0.86 0.94\n",
+ " ruler 50 0.68 0.86\n",
+ " running shoe 50 0.78 0.94\n",
+ " safe 50 0.82 0.92\n",
+ " safety pin 50 0.4 0.62\n",
+ " salt shaker 50 0.66 0.9\n",
+ " sandal 50 0.66 0.86\n",
+ " sarong 50 0.64 0.86\n",
+ " saxophone 50 0.66 0.88\n",
+ " scabbard 50 0.76 0.92\n",
+ " weighing scale 50 0.58 0.78\n",
+ " school bus 50 0.92 1\n",
+ " schooner 50 0.84 1\n",
+ " scoreboard 50 0.9 0.96\n",
+ " CRT screen 50 0.14 0.7\n",
+ " screw 50 0.9 0.98\n",
+ " screwdriver 50 0.3 0.58\n",
+ " seat belt 50 0.88 0.94\n",
+ " sewing machine 50 0.76 0.9\n",
+ " shield 50 0.56 0.82\n",
+ " shoe store 50 0.78 0.96\n",
+ " shoji 50 0.8 0.92\n",
+ " shopping basket 50 0.52 0.88\n",
+ " shopping cart 50 0.76 0.92\n",
+ " shovel 50 0.62 0.84\n",
+ " shower cap 50 0.7 0.84\n",
+ " shower curtain 50 0.64 0.82\n",
+ " ski 50 0.74 0.92\n",
+ " ski mask 50 0.72 0.88\n",
+ " sleeping bag 50 0.68 0.8\n",
+ " slide rule 50 0.72 0.88\n",
+ " sliding door 50 0.44 0.78\n",
+ " slot machine 50 0.94 0.98\n",
+ " snorkel 50 0.86 0.98\n",
+ " snowmobile 50 0.88 1\n",
+ " snowplow 50 0.84 0.98\n",
+ " soap dispenser 50 0.56 0.86\n",
+ " soccer ball 50 0.86 0.96\n",
+ " sock 50 0.62 0.76\n",
+ " solar thermal collector 50 0.72 0.96\n",
+ " sombrero 50 0.6 0.84\n",
+ " soup bowl 50 0.56 0.94\n",
+ " space bar 50 0.34 0.88\n",
+ " space heater 50 0.52 0.74\n",
+ " space shuttle 50 0.82 0.96\n",
+ " spatula 50 0.3 0.6\n",
+ " motorboat 50 0.86 1\n",
+ " spider web 50 0.7 0.9\n",
+ " spindle 50 0.86 0.98\n",
+ " sports car 50 0.6 0.94\n",
+ " spotlight 50 0.26 0.6\n",
+ " stage 50 0.68 0.86\n",
+ " steam locomotive 50 0.94 1\n",
+ " through arch bridge 50 0.84 0.96\n",
+ " steel drum 50 0.82 0.9\n",
+ " stethoscope 50 0.6 0.82\n",
+ " scarf 50 0.5 0.92\n",
+ " stone wall 50 0.76 0.9\n",
+ " stopwatch 50 0.58 0.9\n",
+ " stove 50 0.46 0.74\n",
+ " strainer 50 0.64 0.84\n",
+ " tram 50 0.88 0.96\n",
+ " stretcher 50 0.6 0.8\n",
+ " couch 50 0.8 0.96\n",
+ " stupa 50 0.88 0.88\n",
+ " submarine 50 0.72 0.92\n",
+ " suit 50 0.4 0.78\n",
+ " sundial 50 0.58 0.74\n",
+ " sunglass 50 0.14 0.58\n",
+ " sunglasses 50 0.28 0.58\n",
+ " sunscreen 50 0.32 0.7\n",
+ " suspension bridge 50 0.6 0.94\n",
+ " mop 50 0.74 0.92\n",
+ " sweatshirt 50 0.28 0.66\n",
+ " swimsuit 50 0.52 0.82\n",
+ " swing 50 0.76 0.84\n",
+ " switch 50 0.56 0.76\n",
+ " syringe 50 0.62 0.82\n",
+ " table lamp 50 0.6 0.88\n",
+ " tank 50 0.8 0.96\n",
+ " tape player 50 0.46 0.76\n",
+ " teapot 50 0.84 1\n",
+ " teddy bear 50 0.82 0.94\n",
+ " television 50 0.6 0.9\n",
+ " tennis ball 50 0.7 0.94\n",
+ " thatched roof 50 0.88 0.9\n",
+ " front curtain 50 0.8 0.92\n",
+ " thimble 50 0.6 0.8\n",
+ " threshing machine 50 0.56 0.88\n",
+ " throne 50 0.72 0.82\n",
+ " tile roof 50 0.72 0.94\n",
+ " toaster 50 0.66 0.84\n",
+ " tobacco shop 50 0.42 0.7\n",
+ " toilet seat 50 0.62 0.88\n",
+ " torch 50 0.64 0.84\n",
+ " totem pole 50 0.92 0.98\n",
+ " tow truck 50 0.62 0.88\n",
+ " toy store 50 0.6 0.94\n",
+ " tractor 50 0.76 0.98\n",
+ " semi-trailer truck 50 0.78 0.92\n",
+ " tray 50 0.46 0.64\n",
+ " trench coat 50 0.54 0.72\n",
+ " tricycle 50 0.72 0.94\n",
+ " trimaran 50 0.7 0.98\n",
+ " tripod 50 0.58 0.86\n",
+ " triumphal arch 50 0.92 0.98\n",
+ " trolleybus 50 0.9 1\n",
+ " trombone 50 0.54 0.88\n",
+ " tub 50 0.24 0.82\n",
+ " turnstile 50 0.84 0.94\n",
+ " typewriter keyboard 50 0.68 0.98\n",
+ " umbrella 50 0.52 0.7\n",
+ " unicycle 50 0.74 0.96\n",
+ " upright piano 50 0.76 0.9\n",
+ " vacuum cleaner 50 0.62 0.9\n",
+ " vase 50 0.5 0.78\n",
+ " vault 50 0.76 0.92\n",
+ " velvet 50 0.2 0.42\n",
+ " vending machine 50 0.9 1\n",
+ " vestment 50 0.54 0.82\n",
+ " viaduct 50 0.78 0.86\n",
+ " violin 50 0.68 0.78\n",
+ " volleyball 50 0.86 1\n",
+ " waffle iron 50 0.72 0.88\n",
+ " wall clock 50 0.54 0.88\n",
+ " wallet 50 0.52 0.9\n",
+ " wardrobe 50 0.68 0.88\n",
+ " military aircraft 50 0.9 0.98\n",
+ " sink 50 0.72 0.96\n",
+ " washing machine 50 0.78 0.94\n",
+ " water bottle 50 0.54 0.74\n",
+ " water jug 50 0.22 0.74\n",
+ " water tower 50 0.9 0.96\n",
+ " whiskey jug 50 0.64 0.74\n",
+ " whistle 50 0.72 0.84\n",
+ " wig 50 0.84 0.9\n",
+ " window screen 50 0.68 0.8\n",
+ " window shade 50 0.52 0.76\n",
+ " Windsor tie 50 0.22 0.66\n",
+ " wine bottle 50 0.42 0.82\n",
+ " wing 50 0.54 0.96\n",
+ " wok 50 0.46 0.82\n",
+ " wooden spoon 50 0.58 0.8\n",
+ " wool 50 0.32 0.82\n",
+ " split-rail fence 50 0.74 0.9\n",
+ " shipwreck 50 0.84 0.96\n",
+ " yawl 50 0.78 0.96\n",
+ " yurt 50 0.84 1\n",
+ " website 50 0.98 1\n",
+ " comic book 50 0.62 0.9\n",
+ " crossword 50 0.84 0.88\n",
+ " traffic sign 50 0.78 0.9\n",
+ " traffic light 50 0.8 0.94\n",
+ " dust jacket 50 0.72 0.94\n",
+ " menu 50 0.82 0.96\n",
+ " plate 50 0.44 0.88\n",
+ " guacamole 50 0.8 0.92\n",
+ " consomme 50 0.54 0.88\n",
+ " hot pot 50 0.86 0.98\n",
+ " trifle 50 0.92 0.98\n",
+ " ice cream 50 0.68 0.94\n",
+ " ice pop 50 0.62 0.84\n",
+ " baguette 50 0.62 0.88\n",
+ " bagel 50 0.64 0.92\n",
+ " pretzel 50 0.72 0.88\n",
+ " cheeseburger 50 0.9 1\n",
+ " hot dog 50 0.74 0.94\n",
+ " mashed potato 50 0.74 0.9\n",
+ " cabbage 50 0.84 0.96\n",
+ " broccoli 50 0.9 0.96\n",
+ " cauliflower 50 0.82 1\n",
+ " zucchini 50 0.74 0.9\n",
+ " spaghetti squash 50 0.8 0.96\n",
+ " acorn squash 50 0.82 0.96\n",
+ " butternut squash 50 0.7 0.94\n",
+ " cucumber 50 0.6 0.96\n",
+ " artichoke 50 0.84 0.94\n",
+ " bell pepper 50 0.84 0.98\n",
+ " cardoon 50 0.88 0.94\n",
+ " mushroom 50 0.38 0.92\n",
+ " Granny Smith 50 0.9 0.96\n",
+ " strawberry 50 0.6 0.88\n",
+ " orange 50 0.7 0.92\n",
+ " lemon 50 0.78 0.98\n",
+ " fig 50 0.82 0.96\n",
+ " pineapple 50 0.86 0.96\n",
+ " banana 50 0.84 0.96\n",
+ " jackfruit 50 0.9 0.98\n",
+ " custard apple 50 0.86 0.96\n",
+ " pomegranate 50 0.82 0.98\n",
+ " hay 50 0.8 0.92\n",
+ " carbonara 50 0.88 0.94\n",
+ " chocolate syrup 50 0.46 0.84\n",
+ " dough 50 0.4 0.6\n",
+ " meatloaf 50 0.58 0.84\n",
+ " pizza 50 0.84 0.96\n",
+ " pot pie 50 0.68 0.9\n",
+ " burrito 50 0.8 0.98\n",
+ " red wine 50 0.54 0.82\n",
+ " espresso 50 0.64 0.88\n",
+ " cup 50 0.38 0.7\n",
+ " eggnog 50 0.38 0.7\n",
+ " alp 50 0.54 0.88\n",
+ " bubble 50 0.8 0.96\n",
+ " cliff 50 0.64 1\n",
+ " coral reef 50 0.72 0.96\n",
+ " geyser 50 0.94 1\n",
+ " lakeshore 50 0.54 0.88\n",
+ " promontory 50 0.58 0.94\n",
+ " shoal 50 0.6 0.96\n",
+ " seashore 50 0.44 0.78\n",
+ " valley 50 0.72 0.94\n",
+ " volcano 50 0.78 0.96\n",
+ " baseball player 50 0.72 0.94\n",
+ " bridegroom 50 0.72 0.88\n",
+ " scuba diver 50 0.8 1\n",
+ " rapeseed 50 0.94 0.98\n",
+ " daisy 50 0.96 0.98\n",
+ " yellow lady's slipper 50 1 1\n",
+ " corn 50 0.4 0.88\n",
+ " acorn 50 0.92 0.98\n",
+ " rose hip 50 0.92 0.98\n",
+ " horse chestnut seed 50 0.94 0.98\n",
+ " coral fungus 50 0.96 0.96\n",
+ " agaric 50 0.82 0.94\n",
+ " gyromitra 50 0.98 1\n",
+ " stinkhorn mushroom 50 0.8 0.94\n",
+ " earth star 50 0.98 1\n",
+ " hen-of-the-woods 50 0.8 0.96\n",
+ " bolete 50 0.74 0.94\n",
+ " ear 50 0.48 0.94\n",
+ " toilet paper 50 0.36 0.68\n",
+ "Speed: 0.1ms pre-process, 0.3ms inference, 0.0ms post-process per image at shape (1, 3, 224, 224)\n",
+ "Results saved to \u001b[1mruns/val-cls/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s on Imagenet val\n",
+ "!python classify/val.py --weights yolov5s-cls.pt --data ../datasets/imagenet --img 224 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "

 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ },
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml) for details!\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ },
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml) for details!\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "outputs": [],
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "YOLOv5 Classification Tutorial",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/src/train_utils/train_models/models/yolov5/classify/val.py b/src/train_utils/train_models/models/yolov5/classify/val.py
new file mode 100644
index 0000000..4edd5a1
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/classify/val.py
@@ -0,0 +1,170 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 classification model on a classification dataset
+
+Usage:
+ $ bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
+ $ python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate ImageNet
+
+Usage - formats:
+ $ python classify/val.py --weights yolov5s-cls.pt # PyTorch
+ yolov5s-cls.torchscript # TorchScript
+ yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-cls_openvino_model # OpenVINO
+ yolov5s-cls.engine # TensorRT
+ yolov5s-cls.mlmodel # CoreML (macOS-only)
+ yolov5s-cls_saved_model # TensorFlow SavedModel
+ yolov5s-cls.pb # TensorFlow GraphDef
+ yolov5s-cls.tflite # TensorFlow Lite
+ yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-cls_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import sys
+from pathlib import Path
+
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import create_classification_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_img_size, check_requirements, colorstr,
+ increment_path, print_args)
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / '../datasets/mnist', # dataset dir
+ weights=ROOT / 'yolov5s-cls.pt', # model.pt path(s)
+ batch_size=128, # batch size
+ imgsz=224, # inference size (pixels)
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ verbose=False, # verbose output
+ project=ROOT / 'runs/val-cls', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ criterion=None,
+ pbar=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ save_dir.mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Dataloader
+ data = Path(data)
+ test_dir = data / 'test' if (data / 'test').exists() else data / 'val' # data/test or data/val
+ dataloader = create_classification_dataloader(path=test_dir,
+ imgsz=imgsz,
+ batch_size=batch_size,
+ augment=False,
+ rank=-1,
+ workers=workers)
+
+ model.eval()
+ pred, targets, loss, dt = [], [], 0, (Profile(), Profile(), Profile())
+ n = len(dataloader) # number of batches
+ action = 'validating' if dataloader.dataset.root.stem == 'val' else 'testing'
+ desc = f'{pbar.desc[:-36]}{action:>36}' if pbar else f'{action}'
+ bar = tqdm(dataloader, desc, n, not training, bar_format=TQDM_BAR_FORMAT, position=0)
+ with torch.cuda.amp.autocast(enabled=device.type != 'cpu'):
+ for images, labels in bar:
+ with dt[0]:
+ images, labels = images.to(device, non_blocking=True), labels.to(device)
+
+ with dt[1]:
+ y = model(images)
+
+ with dt[2]:
+ pred.append(y.argsort(1, descending=True)[:, :5])
+ targets.append(labels)
+ if criterion:
+ loss += criterion(y, labels)
+
+ loss /= n
+ pred, targets = torch.cat(pred), torch.cat(targets)
+ correct = (targets[:, None] == pred).float()
+ acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
+ top1, top5 = acc.mean(0).tolist()
+
+ if pbar:
+ pbar.desc = f'{pbar.desc[:-36]}{loss:>12.3g}{top1:>12.3g}{top5:>12.3g}'
+ if verbose: # all classes
+ LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
+ LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
+ for i, c in model.names.items():
+ acc_i = acc[targets == i]
+ top1i, top5i = acc_i.mean(0).tolist()
+ LOGGER.info(f'{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}')
+
+ # Print results
+ t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
+ shape = (1, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms post-process per image at shape {shape}' % t)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ return top1, top5, loss
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / '../datasets/mnist', help='dataset path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-cls.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=128, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='inference size (pixels)')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--verbose', nargs='?', const=True, default=True, help='verbose output')
+ parser.add_argument('--project', default=ROOT / 'runs/val-cls', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/src/train_utils/train_models/models/yolov5/data/Argoverse.yaml b/src/train_utils/train_models/models/yolov5/data/Argoverse.yaml
new file mode 100644
index 0000000..558151d
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/Argoverse.yaml
@@ -0,0 +1,74 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
+# Example usage: python train.py --data Argoverse.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Argoverse ← downloads here (31.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Argoverse # dataset root dir
+train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
+val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
+test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: bus
+ 5: truck
+ 6: traffic_light
+ 7: stop_sign
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def argoverse2yolo(set):
+ labels = {}
+ a = json.load(open(set, "rb"))
+ for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
+ img_id = annot['image_id']
+ img_name = a['images'][img_id]['name']
+ img_label_name = f'{img_name[:-3]}txt'
+
+ cls = annot['category_id'] # instance class id
+ x_center, y_center, width, height = annot['bbox']
+ x_center = (x_center + width / 2) / 1920.0 # offset and scale
+ y_center = (y_center + height / 2) / 1200.0 # offset and scale
+ width /= 1920.0 # scale
+ height /= 1200.0 # scale
+
+ img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
+ if not img_dir.exists():
+ img_dir.mkdir(parents=True, exist_ok=True)
+
+ k = str(img_dir / img_label_name)
+ if k not in labels:
+ labels[k] = []
+ labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
+
+ for k in labels:
+ with open(k, "w") as f:
+ f.writelines(labels[k])
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
+ download(urls, dir=dir, delete=False)
+
+ # Convert
+ annotations_dir = 'Argoverse-HD/annotations/'
+ (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
+ for d in "train.json", "val.json":
+ argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/src/train_utils/train_models/models/yolov5/data/GlobalWheat2020.yaml b/src/train_utils/train_models/models/yolov5/data/GlobalWheat2020.yaml
new file mode 100644
index 0000000..01812d0
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/GlobalWheat2020.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
+# Example usage: python train.py --data GlobalWheat2020.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── GlobalWheat2020 ← downloads here (7.0 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/GlobalWheat2020 # dataset root dir
+train: # train images (relative to 'path') 3422 images
+ - images/arvalis_1
+ - images/arvalis_2
+ - images/arvalis_3
+ - images/ethz_1
+ - images/rres_1
+ - images/inrae_1
+ - images/usask_1
+val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
+ - images/ethz_1
+test: # test images (optional) 1276 images
+ - images/utokyo_1
+ - images/utokyo_2
+ - images/nau_1
+ - images/uq_1
+
+# Classes
+names:
+ 0: wheat_head
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, Path
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
+ download(urls, dir=dir)
+
+ # Make Directories
+ for p in 'annotations', 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+
+ # Move
+ for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
+ 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
+ (dir / p).rename(dir / 'images' / p) # move to /images
+ f = (dir / p).with_suffix('.json') # json file
+ if f.exists():
+ f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
diff --git a/src/train_utils/train_models/models/yolov5/data/ImageNet.yaml b/src/train_utils/train_models/models/yolov5/data/ImageNet.yaml
new file mode 100644
index 0000000..14f1295
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/ImageNet.yaml
@@ -0,0 +1,1022 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
+# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
+# Example usage: python classify/train.py --data imagenet
+# parent
+# ├── yolov5
+# └── datasets
+# └── imagenet ← downloads here (144 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/imagenet # dataset root dir
+train: train # train images (relative to 'path') 1281167 images
+val: val # val images (relative to 'path') 50000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: tench
+ 1: goldfish
+ 2: great white shark
+ 3: tiger shark
+ 4: hammerhead shark
+ 5: electric ray
+ 6: stingray
+ 7: cock
+ 8: hen
+ 9: ostrich
+ 10: brambling
+ 11: goldfinch
+ 12: house finch
+ 13: junco
+ 14: indigo bunting
+ 15: American robin
+ 16: bulbul
+ 17: jay
+ 18: magpie
+ 19: chickadee
+ 20: American dipper
+ 21: kite
+ 22: bald eagle
+ 23: vulture
+ 24: great grey owl
+ 25: fire salamander
+ 26: smooth newt
+ 27: newt
+ 28: spotted salamander
+ 29: axolotl
+ 30: American bullfrog
+ 31: tree frog
+ 32: tailed frog
+ 33: loggerhead sea turtle
+ 34: leatherback sea turtle
+ 35: mud turtle
+ 36: terrapin
+ 37: box turtle
+ 38: banded gecko
+ 39: green iguana
+ 40: Carolina anole
+ 41: desert grassland whiptail lizard
+ 42: agama
+ 43: frilled-necked lizard
+ 44: alligator lizard
+ 45: Gila monster
+ 46: European green lizard
+ 47: chameleon
+ 48: Komodo dragon
+ 49: Nile crocodile
+ 50: American alligator
+ 51: triceratops
+ 52: worm snake
+ 53: ring-necked snake
+ 54: eastern hog-nosed snake
+ 55: smooth green snake
+ 56: kingsnake
+ 57: garter snake
+ 58: water snake
+ 59: vine snake
+ 60: night snake
+ 61: boa constrictor
+ 62: African rock python
+ 63: Indian cobra
+ 64: green mamba
+ 65: sea snake
+ 66: Saharan horned viper
+ 67: eastern diamondback rattlesnake
+ 68: sidewinder
+ 69: trilobite
+ 70: harvestman
+ 71: scorpion
+ 72: yellow garden spider
+ 73: barn spider
+ 74: European garden spider
+ 75: southern black widow
+ 76: tarantula
+ 77: wolf spider
+ 78: tick
+ 79: centipede
+ 80: black grouse
+ 81: ptarmigan
+ 82: ruffed grouse
+ 83: prairie grouse
+ 84: peacock
+ 85: quail
+ 86: partridge
+ 87: grey parrot
+ 88: macaw
+ 89: sulphur-crested cockatoo
+ 90: lorikeet
+ 91: coucal
+ 92: bee eater
+ 93: hornbill
+ 94: hummingbird
+ 95: jacamar
+ 96: toucan
+ 97: duck
+ 98: red-breasted merganser
+ 99: goose
+ 100: black swan
+ 101: tusker
+ 102: echidna
+ 103: platypus
+ 104: wallaby
+ 105: koala
+ 106: wombat
+ 107: jellyfish
+ 108: sea anemone
+ 109: brain coral
+ 110: flatworm
+ 111: nematode
+ 112: conch
+ 113: snail
+ 114: slug
+ 115: sea slug
+ 116: chiton
+ 117: chambered nautilus
+ 118: Dungeness crab
+ 119: rock crab
+ 120: fiddler crab
+ 121: red king crab
+ 122: American lobster
+ 123: spiny lobster
+ 124: crayfish
+ 125: hermit crab
+ 126: isopod
+ 127: white stork
+ 128: black stork
+ 129: spoonbill
+ 130: flamingo
+ 131: little blue heron
+ 132: great egret
+ 133: bittern
+ 134: crane (bird)
+ 135: limpkin
+ 136: common gallinule
+ 137: American coot
+ 138: bustard
+ 139: ruddy turnstone
+ 140: dunlin
+ 141: common redshank
+ 142: dowitcher
+ 143: oystercatcher
+ 144: pelican
+ 145: king penguin
+ 146: albatross
+ 147: grey whale
+ 148: killer whale
+ 149: dugong
+ 150: sea lion
+ 151: Chihuahua
+ 152: Japanese Chin
+ 153: Maltese
+ 154: Pekingese
+ 155: Shih Tzu
+ 156: King Charles Spaniel
+ 157: Papillon
+ 158: toy terrier
+ 159: Rhodesian Ridgeback
+ 160: Afghan Hound
+ 161: Basset Hound
+ 162: Beagle
+ 163: Bloodhound
+ 164: Bluetick Coonhound
+ 165: Black and Tan Coonhound
+ 166: Treeing Walker Coonhound
+ 167: English foxhound
+ 168: Redbone Coonhound
+ 169: borzoi
+ 170: Irish Wolfhound
+ 171: Italian Greyhound
+ 172: Whippet
+ 173: Ibizan Hound
+ 174: Norwegian Elkhound
+ 175: Otterhound
+ 176: Saluki
+ 177: Scottish Deerhound
+ 178: Weimaraner
+ 179: Staffordshire Bull Terrier
+ 180: American Staffordshire Terrier
+ 181: Bedlington Terrier
+ 182: Border Terrier
+ 183: Kerry Blue Terrier
+ 184: Irish Terrier
+ 185: Norfolk Terrier
+ 186: Norwich Terrier
+ 187: Yorkshire Terrier
+ 188: Wire Fox Terrier
+ 189: Lakeland Terrier
+ 190: Sealyham Terrier
+ 191: Airedale Terrier
+ 192: Cairn Terrier
+ 193: Australian Terrier
+ 194: Dandie Dinmont Terrier
+ 195: Boston Terrier
+ 196: Miniature Schnauzer
+ 197: Giant Schnauzer
+ 198: Standard Schnauzer
+ 199: Scottish Terrier
+ 200: Tibetan Terrier
+ 201: Australian Silky Terrier
+ 202: Soft-coated Wheaten Terrier
+ 203: West Highland White Terrier
+ 204: Lhasa Apso
+ 205: Flat-Coated Retriever
+ 206: Curly-coated Retriever
+ 207: Golden Retriever
+ 208: Labrador Retriever
+ 209: Chesapeake Bay Retriever
+ 210: German Shorthaired Pointer
+ 211: Vizsla
+ 212: English Setter
+ 213: Irish Setter
+ 214: Gordon Setter
+ 215: Brittany
+ 216: Clumber Spaniel
+ 217: English Springer Spaniel
+ 218: Welsh Springer Spaniel
+ 219: Cocker Spaniels
+ 220: Sussex Spaniel
+ 221: Irish Water Spaniel
+ 222: Kuvasz
+ 223: Schipperke
+ 224: Groenendael
+ 225: Malinois
+ 226: Briard
+ 227: Australian Kelpie
+ 228: Komondor
+ 229: Old English Sheepdog
+ 230: Shetland Sheepdog
+ 231: collie
+ 232: Border Collie
+ 233: Bouvier des Flandres
+ 234: Rottweiler
+ 235: German Shepherd Dog
+ 236: Dobermann
+ 237: Miniature Pinscher
+ 238: Greater Swiss Mountain Dog
+ 239: Bernese Mountain Dog
+ 240: Appenzeller Sennenhund
+ 241: Entlebucher Sennenhund
+ 242: Boxer
+ 243: Bullmastiff
+ 244: Tibetan Mastiff
+ 245: French Bulldog
+ 246: Great Dane
+ 247: St. Bernard
+ 248: husky
+ 249: Alaskan Malamute
+ 250: Siberian Husky
+ 251: Dalmatian
+ 252: Affenpinscher
+ 253: Basenji
+ 254: pug
+ 255: Leonberger
+ 256: Newfoundland
+ 257: Pyrenean Mountain Dog
+ 258: Samoyed
+ 259: Pomeranian
+ 260: Chow Chow
+ 261: Keeshond
+ 262: Griffon Bruxellois
+ 263: Pembroke Welsh Corgi
+ 264: Cardigan Welsh Corgi
+ 265: Toy Poodle
+ 266: Miniature Poodle
+ 267: Standard Poodle
+ 268: Mexican hairless dog
+ 269: grey wolf
+ 270: Alaskan tundra wolf
+ 271: red wolf
+ 272: coyote
+ 273: dingo
+ 274: dhole
+ 275: African wild dog
+ 276: hyena
+ 277: red fox
+ 278: kit fox
+ 279: Arctic fox
+ 280: grey fox
+ 281: tabby cat
+ 282: tiger cat
+ 283: Persian cat
+ 284: Siamese cat
+ 285: Egyptian Mau
+ 286: cougar
+ 287: lynx
+ 288: leopard
+ 289: snow leopard
+ 290: jaguar
+ 291: lion
+ 292: tiger
+ 293: cheetah
+ 294: brown bear
+ 295: American black bear
+ 296: polar bear
+ 297: sloth bear
+ 298: mongoose
+ 299: meerkat
+ 300: tiger beetle
+ 301: ladybug
+ 302: ground beetle
+ 303: longhorn beetle
+ 304: leaf beetle
+ 305: dung beetle
+ 306: rhinoceros beetle
+ 307: weevil
+ 308: fly
+ 309: bee
+ 310: ant
+ 311: grasshopper
+ 312: cricket
+ 313: stick insect
+ 314: cockroach
+ 315: mantis
+ 316: cicada
+ 317: leafhopper
+ 318: lacewing
+ 319: dragonfly
+ 320: damselfly
+ 321: red admiral
+ 322: ringlet
+ 323: monarch butterfly
+ 324: small white
+ 325: sulphur butterfly
+ 326: gossamer-winged butterfly
+ 327: starfish
+ 328: sea urchin
+ 329: sea cucumber
+ 330: cottontail rabbit
+ 331: hare
+ 332: Angora rabbit
+ 333: hamster
+ 334: porcupine
+ 335: fox squirrel
+ 336: marmot
+ 337: beaver
+ 338: guinea pig
+ 339: common sorrel
+ 340: zebra
+ 341: pig
+ 342: wild boar
+ 343: warthog
+ 344: hippopotamus
+ 345: ox
+ 346: water buffalo
+ 347: bison
+ 348: ram
+ 349: bighorn sheep
+ 350: Alpine ibex
+ 351: hartebeest
+ 352: impala
+ 353: gazelle
+ 354: dromedary
+ 355: llama
+ 356: weasel
+ 357: mink
+ 358: European polecat
+ 359: black-footed ferret
+ 360: otter
+ 361: skunk
+ 362: badger
+ 363: armadillo
+ 364: three-toed sloth
+ 365: orangutan
+ 366: gorilla
+ 367: chimpanzee
+ 368: gibbon
+ 369: siamang
+ 370: guenon
+ 371: patas monkey
+ 372: baboon
+ 373: macaque
+ 374: langur
+ 375: black-and-white colobus
+ 376: proboscis monkey
+ 377: marmoset
+ 378: white-headed capuchin
+ 379: howler monkey
+ 380: titi
+ 381: Geoffroy's spider monkey
+ 382: common squirrel monkey
+ 383: ring-tailed lemur
+ 384: indri
+ 385: Asian elephant
+ 386: African bush elephant
+ 387: red panda
+ 388: giant panda
+ 389: snoek
+ 390: eel
+ 391: coho salmon
+ 392: rock beauty
+ 393: clownfish
+ 394: sturgeon
+ 395: garfish
+ 396: lionfish
+ 397: pufferfish
+ 398: abacus
+ 399: abaya
+ 400: academic gown
+ 401: accordion
+ 402: acoustic guitar
+ 403: aircraft carrier
+ 404: airliner
+ 405: airship
+ 406: altar
+ 407: ambulance
+ 408: amphibious vehicle
+ 409: analog clock
+ 410: apiary
+ 411: apron
+ 412: waste container
+ 413: assault rifle
+ 414: backpack
+ 415: bakery
+ 416: balance beam
+ 417: balloon
+ 418: ballpoint pen
+ 419: Band-Aid
+ 420: banjo
+ 421: baluster
+ 422: barbell
+ 423: barber chair
+ 424: barbershop
+ 425: barn
+ 426: barometer
+ 427: barrel
+ 428: wheelbarrow
+ 429: baseball
+ 430: basketball
+ 431: bassinet
+ 432: bassoon
+ 433: swimming cap
+ 434: bath towel
+ 435: bathtub
+ 436: station wagon
+ 437: lighthouse
+ 438: beaker
+ 439: military cap
+ 440: beer bottle
+ 441: beer glass
+ 442: bell-cot
+ 443: bib
+ 444: tandem bicycle
+ 445: bikini
+ 446: ring binder
+ 447: binoculars
+ 448: birdhouse
+ 449: boathouse
+ 450: bobsleigh
+ 451: bolo tie
+ 452: poke bonnet
+ 453: bookcase
+ 454: bookstore
+ 455: bottle cap
+ 456: bow
+ 457: bow tie
+ 458: brass
+ 459: bra
+ 460: breakwater
+ 461: breastplate
+ 462: broom
+ 463: bucket
+ 464: buckle
+ 465: bulletproof vest
+ 466: high-speed train
+ 467: butcher shop
+ 468: taxicab
+ 469: cauldron
+ 470: candle
+ 471: cannon
+ 472: canoe
+ 473: can opener
+ 474: cardigan
+ 475: car mirror
+ 476: carousel
+ 477: tool kit
+ 478: carton
+ 479: car wheel
+ 480: automated teller machine
+ 481: cassette
+ 482: cassette player
+ 483: castle
+ 484: catamaran
+ 485: CD player
+ 486: cello
+ 487: mobile phone
+ 488: chain
+ 489: chain-link fence
+ 490: chain mail
+ 491: chainsaw
+ 492: chest
+ 493: chiffonier
+ 494: chime
+ 495: china cabinet
+ 496: Christmas stocking
+ 497: church
+ 498: movie theater
+ 499: cleaver
+ 500: cliff dwelling
+ 501: cloak
+ 502: clogs
+ 503: cocktail shaker
+ 504: coffee mug
+ 505: coffeemaker
+ 506: coil
+ 507: combination lock
+ 508: computer keyboard
+ 509: confectionery store
+ 510: container ship
+ 511: convertible
+ 512: corkscrew
+ 513: cornet
+ 514: cowboy boot
+ 515: cowboy hat
+ 516: cradle
+ 517: crane (machine)
+ 518: crash helmet
+ 519: crate
+ 520: infant bed
+ 521: Crock Pot
+ 522: croquet ball
+ 523: crutch
+ 524: cuirass
+ 525: dam
+ 526: desk
+ 527: desktop computer
+ 528: rotary dial telephone
+ 529: diaper
+ 530: digital clock
+ 531: digital watch
+ 532: dining table
+ 533: dishcloth
+ 534: dishwasher
+ 535: disc brake
+ 536: dock
+ 537: dog sled
+ 538: dome
+ 539: doormat
+ 540: drilling rig
+ 541: drum
+ 542: drumstick
+ 543: dumbbell
+ 544: Dutch oven
+ 545: electric fan
+ 546: electric guitar
+ 547: electric locomotive
+ 548: entertainment center
+ 549: envelope
+ 550: espresso machine
+ 551: face powder
+ 552: feather boa
+ 553: filing cabinet
+ 554: fireboat
+ 555: fire engine
+ 556: fire screen sheet
+ 557: flagpole
+ 558: flute
+ 559: folding chair
+ 560: football helmet
+ 561: forklift
+ 562: fountain
+ 563: fountain pen
+ 564: four-poster bed
+ 565: freight car
+ 566: French horn
+ 567: frying pan
+ 568: fur coat
+ 569: garbage truck
+ 570: gas mask
+ 571: gas pump
+ 572: goblet
+ 573: go-kart
+ 574: golf ball
+ 575: golf cart
+ 576: gondola
+ 577: gong
+ 578: gown
+ 579: grand piano
+ 580: greenhouse
+ 581: grille
+ 582: grocery store
+ 583: guillotine
+ 584: barrette
+ 585: hair spray
+ 586: half-track
+ 587: hammer
+ 588: hamper
+ 589: hair dryer
+ 590: hand-held computer
+ 591: handkerchief
+ 592: hard disk drive
+ 593: harmonica
+ 594: harp
+ 595: harvester
+ 596: hatchet
+ 597: holster
+ 598: home theater
+ 599: honeycomb
+ 600: hook
+ 601: hoop skirt
+ 602: horizontal bar
+ 603: horse-drawn vehicle
+ 604: hourglass
+ 605: iPod
+ 606: clothes iron
+ 607: jack-o'-lantern
+ 608: jeans
+ 609: jeep
+ 610: T-shirt
+ 611: jigsaw puzzle
+ 612: pulled rickshaw
+ 613: joystick
+ 614: kimono
+ 615: knee pad
+ 616: knot
+ 617: lab coat
+ 618: ladle
+ 619: lampshade
+ 620: laptop computer
+ 621: lawn mower
+ 622: lens cap
+ 623: paper knife
+ 624: library
+ 625: lifeboat
+ 626: lighter
+ 627: limousine
+ 628: ocean liner
+ 629: lipstick
+ 630: slip-on shoe
+ 631: lotion
+ 632: speaker
+ 633: loupe
+ 634: sawmill
+ 635: magnetic compass
+ 636: mail bag
+ 637: mailbox
+ 638: tights
+ 639: tank suit
+ 640: manhole cover
+ 641: maraca
+ 642: marimba
+ 643: mask
+ 644: match
+ 645: maypole
+ 646: maze
+ 647: measuring cup
+ 648: medicine chest
+ 649: megalith
+ 650: microphone
+ 651: microwave oven
+ 652: military uniform
+ 653: milk can
+ 654: minibus
+ 655: miniskirt
+ 656: minivan
+ 657: missile
+ 658: mitten
+ 659: mixing bowl
+ 660: mobile home
+ 661: Model T
+ 662: modem
+ 663: monastery
+ 664: monitor
+ 665: moped
+ 666: mortar
+ 667: square academic cap
+ 668: mosque
+ 669: mosquito net
+ 670: scooter
+ 671: mountain bike
+ 672: tent
+ 673: computer mouse
+ 674: mousetrap
+ 675: moving van
+ 676: muzzle
+ 677: nail
+ 678: neck brace
+ 679: necklace
+ 680: nipple
+ 681: notebook computer
+ 682: obelisk
+ 683: oboe
+ 684: ocarina
+ 685: odometer
+ 686: oil filter
+ 687: organ
+ 688: oscilloscope
+ 689: overskirt
+ 690: bullock cart
+ 691: oxygen mask
+ 692: packet
+ 693: paddle
+ 694: paddle wheel
+ 695: padlock
+ 696: paintbrush
+ 697: pajamas
+ 698: palace
+ 699: pan flute
+ 700: paper towel
+ 701: parachute
+ 702: parallel bars
+ 703: park bench
+ 704: parking meter
+ 705: passenger car
+ 706: patio
+ 707: payphone
+ 708: pedestal
+ 709: pencil case
+ 710: pencil sharpener
+ 711: perfume
+ 712: Petri dish
+ 713: photocopier
+ 714: plectrum
+ 715: Pickelhaube
+ 716: picket fence
+ 717: pickup truck
+ 718: pier
+ 719: piggy bank
+ 720: pill bottle
+ 721: pillow
+ 722: ping-pong ball
+ 723: pinwheel
+ 724: pirate ship
+ 725: pitcher
+ 726: hand plane
+ 727: planetarium
+ 728: plastic bag
+ 729: plate rack
+ 730: plow
+ 731: plunger
+ 732: Polaroid camera
+ 733: pole
+ 734: police van
+ 735: poncho
+ 736: billiard table
+ 737: soda bottle
+ 738: pot
+ 739: potter's wheel
+ 740: power drill
+ 741: prayer rug
+ 742: printer
+ 743: prison
+ 744: projectile
+ 745: projector
+ 746: hockey puck
+ 747: punching bag
+ 748: purse
+ 749: quill
+ 750: quilt
+ 751: race car
+ 752: racket
+ 753: radiator
+ 754: radio
+ 755: radio telescope
+ 756: rain barrel
+ 757: recreational vehicle
+ 758: reel
+ 759: reflex camera
+ 760: refrigerator
+ 761: remote control
+ 762: restaurant
+ 763: revolver
+ 764: rifle
+ 765: rocking chair
+ 766: rotisserie
+ 767: eraser
+ 768: rugby ball
+ 769: ruler
+ 770: running shoe
+ 771: safe
+ 772: safety pin
+ 773: salt shaker
+ 774: sandal
+ 775: sarong
+ 776: saxophone
+ 777: scabbard
+ 778: weighing scale
+ 779: school bus
+ 780: schooner
+ 781: scoreboard
+ 782: CRT screen
+ 783: screw
+ 784: screwdriver
+ 785: seat belt
+ 786: sewing machine
+ 787: shield
+ 788: shoe store
+ 789: shoji
+ 790: shopping basket
+ 791: shopping cart
+ 792: shovel
+ 793: shower cap
+ 794: shower curtain
+ 795: ski
+ 796: ski mask
+ 797: sleeping bag
+ 798: slide rule
+ 799: sliding door
+ 800: slot machine
+ 801: snorkel
+ 802: snowmobile
+ 803: snowplow
+ 804: soap dispenser
+ 805: soccer ball
+ 806: sock
+ 807: solar thermal collector
+ 808: sombrero
+ 809: soup bowl
+ 810: space bar
+ 811: space heater
+ 812: space shuttle
+ 813: spatula
+ 814: motorboat
+ 815: spider web
+ 816: spindle
+ 817: sports car
+ 818: spotlight
+ 819: stage
+ 820: steam locomotive
+ 821: through arch bridge
+ 822: steel drum
+ 823: stethoscope
+ 824: scarf
+ 825: stone wall
+ 826: stopwatch
+ 827: stove
+ 828: strainer
+ 829: tram
+ 830: stretcher
+ 831: couch
+ 832: stupa
+ 833: submarine
+ 834: suit
+ 835: sundial
+ 836: sunglass
+ 837: sunglasses
+ 838: sunscreen
+ 839: suspension bridge
+ 840: mop
+ 841: sweatshirt
+ 842: swimsuit
+ 843: swing
+ 844: switch
+ 845: syringe
+ 846: table lamp
+ 847: tank
+ 848: tape player
+ 849: teapot
+ 850: teddy bear
+ 851: television
+ 852: tennis ball
+ 853: thatched roof
+ 854: front curtain
+ 855: thimble
+ 856: threshing machine
+ 857: throne
+ 858: tile roof
+ 859: toaster
+ 860: tobacco shop
+ 861: toilet seat
+ 862: torch
+ 863: totem pole
+ 864: tow truck
+ 865: toy store
+ 866: tractor
+ 867: semi-trailer truck
+ 868: tray
+ 869: trench coat
+ 870: tricycle
+ 871: trimaran
+ 872: tripod
+ 873: triumphal arch
+ 874: trolleybus
+ 875: trombone
+ 876: tub
+ 877: turnstile
+ 878: typewriter keyboard
+ 879: umbrella
+ 880: unicycle
+ 881: upright piano
+ 882: vacuum cleaner
+ 883: vase
+ 884: vault
+ 885: velvet
+ 886: vending machine
+ 887: vestment
+ 888: viaduct
+ 889: violin
+ 890: volleyball
+ 891: waffle iron
+ 892: wall clock
+ 893: wallet
+ 894: wardrobe
+ 895: military aircraft
+ 896: sink
+ 897: washing machine
+ 898: water bottle
+ 899: water jug
+ 900: water tower
+ 901: whiskey jug
+ 902: whistle
+ 903: wig
+ 904: window screen
+ 905: window shade
+ 906: Windsor tie
+ 907: wine bottle
+ 908: wing
+ 909: wok
+ 910: wooden spoon
+ 911: wool
+ 912: split-rail fence
+ 913: shipwreck
+ 914: yawl
+ 915: yurt
+ 916: website
+ 917: comic book
+ 918: crossword
+ 919: traffic sign
+ 920: traffic light
+ 921: dust jacket
+ 922: menu
+ 923: plate
+ 924: guacamole
+ 925: consomme
+ 926: hot pot
+ 927: trifle
+ 928: ice cream
+ 929: ice pop
+ 930: baguette
+ 931: bagel
+ 932: pretzel
+ 933: cheeseburger
+ 934: hot dog
+ 935: mashed potato
+ 936: cabbage
+ 937: broccoli
+ 938: cauliflower
+ 939: zucchini
+ 940: spaghetti squash
+ 941: acorn squash
+ 942: butternut squash
+ 943: cucumber
+ 944: artichoke
+ 945: bell pepper
+ 946: cardoon
+ 947: mushroom
+ 948: Granny Smith
+ 949: strawberry
+ 950: orange
+ 951: lemon
+ 952: fig
+ 953: pineapple
+ 954: banana
+ 955: jackfruit
+ 956: custard apple
+ 957: pomegranate
+ 958: hay
+ 959: carbonara
+ 960: chocolate syrup
+ 961: dough
+ 962: meatloaf
+ 963: pizza
+ 964: pot pie
+ 965: burrito
+ 966: red wine
+ 967: espresso
+ 968: cup
+ 969: eggnog
+ 970: alp
+ 971: bubble
+ 972: cliff
+ 973: coral reef
+ 974: geyser
+ 975: lakeshore
+ 976: promontory
+ 977: shoal
+ 978: seashore
+ 979: valley
+ 980: volcano
+ 981: baseball player
+ 982: bridegroom
+ 983: scuba diver
+ 984: rapeseed
+ 985: daisy
+ 986: yellow lady's slipper
+ 987: corn
+ 988: acorn
+ 989: rose hip
+ 990: horse chestnut seed
+ 991: coral fungus
+ 992: agaric
+ 993: gyromitra
+ 994: stinkhorn mushroom
+ 995: earth star
+ 996: hen-of-the-woods
+ 997: bolete
+ 998: ear
+ 999: toilet paper
+
+
+# Download script/URL (optional)
+download: data/scripts/get_imagenet.sh
diff --git a/src/train_utils/train_models/models/yolov5/data/Objects365.yaml b/src/train_utils/train_models/models/yolov5/data/Objects365.yaml
new file mode 100644
index 0000000..05b26a1
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/Objects365.yaml
@@ -0,0 +1,438 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Objects365 dataset https://www.objects365.org/ by Megvii
+# Example usage: python train.py --data Objects365.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Objects365 # dataset root dir
+train: images/train # train images (relative to 'path') 1742289 images
+val: images/val # val images (relative to 'path') 80000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: Person
+ 1: Sneakers
+ 2: Chair
+ 3: Other Shoes
+ 4: Hat
+ 5: Car
+ 6: Lamp
+ 7: Glasses
+ 8: Bottle
+ 9: Desk
+ 10: Cup
+ 11: Street Lights
+ 12: Cabinet/shelf
+ 13: Handbag/Satchel
+ 14: Bracelet
+ 15: Plate
+ 16: Picture/Frame
+ 17: Helmet
+ 18: Book
+ 19: Gloves
+ 20: Storage box
+ 21: Boat
+ 22: Leather Shoes
+ 23: Flower
+ 24: Bench
+ 25: Potted Plant
+ 26: Bowl/Basin
+ 27: Flag
+ 28: Pillow
+ 29: Boots
+ 30: Vase
+ 31: Microphone
+ 32: Necklace
+ 33: Ring
+ 34: SUV
+ 35: Wine Glass
+ 36: Belt
+ 37: Monitor/TV
+ 38: Backpack
+ 39: Umbrella
+ 40: Traffic Light
+ 41: Speaker
+ 42: Watch
+ 43: Tie
+ 44: Trash bin Can
+ 45: Slippers
+ 46: Bicycle
+ 47: Stool
+ 48: Barrel/bucket
+ 49: Van
+ 50: Couch
+ 51: Sandals
+ 52: Basket
+ 53: Drum
+ 54: Pen/Pencil
+ 55: Bus
+ 56: Wild Bird
+ 57: High Heels
+ 58: Motorcycle
+ 59: Guitar
+ 60: Carpet
+ 61: Cell Phone
+ 62: Bread
+ 63: Camera
+ 64: Canned
+ 65: Truck
+ 66: Traffic cone
+ 67: Cymbal
+ 68: Lifesaver
+ 69: Towel
+ 70: Stuffed Toy
+ 71: Candle
+ 72: Sailboat
+ 73: Laptop
+ 74: Awning
+ 75: Bed
+ 76: Faucet
+ 77: Tent
+ 78: Horse
+ 79: Mirror
+ 80: Power outlet
+ 81: Sink
+ 82: Apple
+ 83: Air Conditioner
+ 84: Knife
+ 85: Hockey Stick
+ 86: Paddle
+ 87: Pickup Truck
+ 88: Fork
+ 89: Traffic Sign
+ 90: Balloon
+ 91: Tripod
+ 92: Dog
+ 93: Spoon
+ 94: Clock
+ 95: Pot
+ 96: Cow
+ 97: Cake
+ 98: Dinning Table
+ 99: Sheep
+ 100: Hanger
+ 101: Blackboard/Whiteboard
+ 102: Napkin
+ 103: Other Fish
+ 104: Orange/Tangerine
+ 105: Toiletry
+ 106: Keyboard
+ 107: Tomato
+ 108: Lantern
+ 109: Machinery Vehicle
+ 110: Fan
+ 111: Green Vegetables
+ 112: Banana
+ 113: Baseball Glove
+ 114: Airplane
+ 115: Mouse
+ 116: Train
+ 117: Pumpkin
+ 118: Soccer
+ 119: Skiboard
+ 120: Luggage
+ 121: Nightstand
+ 122: Tea pot
+ 123: Telephone
+ 124: Trolley
+ 125: Head Phone
+ 126: Sports Car
+ 127: Stop Sign
+ 128: Dessert
+ 129: Scooter
+ 130: Stroller
+ 131: Crane
+ 132: Remote
+ 133: Refrigerator
+ 134: Oven
+ 135: Lemon
+ 136: Duck
+ 137: Baseball Bat
+ 138: Surveillance Camera
+ 139: Cat
+ 140: Jug
+ 141: Broccoli
+ 142: Piano
+ 143: Pizza
+ 144: Elephant
+ 145: Skateboard
+ 146: Surfboard
+ 147: Gun
+ 148: Skating and Skiing shoes
+ 149: Gas stove
+ 150: Donut
+ 151: Bow Tie
+ 152: Carrot
+ 153: Toilet
+ 154: Kite
+ 155: Strawberry
+ 156: Other Balls
+ 157: Shovel
+ 158: Pepper
+ 159: Computer Box
+ 160: Toilet Paper
+ 161: Cleaning Products
+ 162: Chopsticks
+ 163: Microwave
+ 164: Pigeon
+ 165: Baseball
+ 166: Cutting/chopping Board
+ 167: Coffee Table
+ 168: Side Table
+ 169: Scissors
+ 170: Marker
+ 171: Pie
+ 172: Ladder
+ 173: Snowboard
+ 174: Cookies
+ 175: Radiator
+ 176: Fire Hydrant
+ 177: Basketball
+ 178: Zebra
+ 179: Grape
+ 180: Giraffe
+ 181: Potato
+ 182: Sausage
+ 183: Tricycle
+ 184: Violin
+ 185: Egg
+ 186: Fire Extinguisher
+ 187: Candy
+ 188: Fire Truck
+ 189: Billiards
+ 190: Converter
+ 191: Bathtub
+ 192: Wheelchair
+ 193: Golf Club
+ 194: Briefcase
+ 195: Cucumber
+ 196: Cigar/Cigarette
+ 197: Paint Brush
+ 198: Pear
+ 199: Heavy Truck
+ 200: Hamburger
+ 201: Extractor
+ 202: Extension Cord
+ 203: Tong
+ 204: Tennis Racket
+ 205: Folder
+ 206: American Football
+ 207: earphone
+ 208: Mask
+ 209: Kettle
+ 210: Tennis
+ 211: Ship
+ 212: Swing
+ 213: Coffee Machine
+ 214: Slide
+ 215: Carriage
+ 216: Onion
+ 217: Green beans
+ 218: Projector
+ 219: Frisbee
+ 220: Washing Machine/Drying Machine
+ 221: Chicken
+ 222: Printer
+ 223: Watermelon
+ 224: Saxophone
+ 225: Tissue
+ 226: Toothbrush
+ 227: Ice cream
+ 228: Hot-air balloon
+ 229: Cello
+ 230: French Fries
+ 231: Scale
+ 232: Trophy
+ 233: Cabbage
+ 234: Hot dog
+ 235: Blender
+ 236: Peach
+ 237: Rice
+ 238: Wallet/Purse
+ 239: Volleyball
+ 240: Deer
+ 241: Goose
+ 242: Tape
+ 243: Tablet
+ 244: Cosmetics
+ 245: Trumpet
+ 246: Pineapple
+ 247: Golf Ball
+ 248: Ambulance
+ 249: Parking meter
+ 250: Mango
+ 251: Key
+ 252: Hurdle
+ 253: Fishing Rod
+ 254: Medal
+ 255: Flute
+ 256: Brush
+ 257: Penguin
+ 258: Megaphone
+ 259: Corn
+ 260: Lettuce
+ 261: Garlic
+ 262: Swan
+ 263: Helicopter
+ 264: Green Onion
+ 265: Sandwich
+ 266: Nuts
+ 267: Speed Limit Sign
+ 268: Induction Cooker
+ 269: Broom
+ 270: Trombone
+ 271: Plum
+ 272: Rickshaw
+ 273: Goldfish
+ 274: Kiwi fruit
+ 275: Router/modem
+ 276: Poker Card
+ 277: Toaster
+ 278: Shrimp
+ 279: Sushi
+ 280: Cheese
+ 281: Notepaper
+ 282: Cherry
+ 283: Pliers
+ 284: CD
+ 285: Pasta
+ 286: Hammer
+ 287: Cue
+ 288: Avocado
+ 289: Hamimelon
+ 290: Flask
+ 291: Mushroom
+ 292: Screwdriver
+ 293: Soap
+ 294: Recorder
+ 295: Bear
+ 296: Eggplant
+ 297: Board Eraser
+ 298: Coconut
+ 299: Tape Measure/Ruler
+ 300: Pig
+ 301: Showerhead
+ 302: Globe
+ 303: Chips
+ 304: Steak
+ 305: Crosswalk Sign
+ 306: Stapler
+ 307: Camel
+ 308: Formula 1
+ 309: Pomegranate
+ 310: Dishwasher
+ 311: Crab
+ 312: Hoverboard
+ 313: Meat ball
+ 314: Rice Cooker
+ 315: Tuba
+ 316: Calculator
+ 317: Papaya
+ 318: Antelope
+ 319: Parrot
+ 320: Seal
+ 321: Butterfly
+ 322: Dumbbell
+ 323: Donkey
+ 324: Lion
+ 325: Urinal
+ 326: Dolphin
+ 327: Electric Drill
+ 328: Hair Dryer
+ 329: Egg tart
+ 330: Jellyfish
+ 331: Treadmill
+ 332: Lighter
+ 333: Grapefruit
+ 334: Game board
+ 335: Mop
+ 336: Radish
+ 337: Baozi
+ 338: Target
+ 339: French
+ 340: Spring Rolls
+ 341: Monkey
+ 342: Rabbit
+ 343: Pencil Case
+ 344: Yak
+ 345: Red Cabbage
+ 346: Binoculars
+ 347: Asparagus
+ 348: Barbell
+ 349: Scallop
+ 350: Noddles
+ 351: Comb
+ 352: Dumpling
+ 353: Oyster
+ 354: Table Tennis paddle
+ 355: Cosmetics Brush/Eyeliner Pencil
+ 356: Chainsaw
+ 357: Eraser
+ 358: Lobster
+ 359: Durian
+ 360: Okra
+ 361: Lipstick
+ 362: Cosmetics Mirror
+ 363: Curling
+ 364: Table Tennis
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from tqdm import tqdm
+
+ from utils.general import Path, check_requirements, download, np, xyxy2xywhn
+
+ check_requirements(('pycocotools>=2.0',))
+ from pycocotools.coco import COCO
+
+ # Make Directories
+ dir = Path(yaml['path']) # dataset root dir
+ for p in 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+ for q in 'train', 'val':
+ (dir / p / q).mkdir(parents=True, exist_ok=True)
+
+ # Train, Val Splits
+ for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
+ print(f"Processing {split} in {patches} patches ...")
+ images, labels = dir / 'images' / split, dir / 'labels' / split
+
+ # Download
+ url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
+ if split == 'train':
+ download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir, delete=False) # annotations json
+ download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, delete=False, threads=8)
+ elif split == 'val':
+ download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir, delete=False) # annotations json
+ download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, delete=False, threads=8)
+ download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, delete=False, threads=8)
+
+ # Move
+ for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
+ f.rename(images / f.name) # move to /images/{split}
+
+ # Labels
+ coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
+ names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
+ for cid, cat in enumerate(names):
+ catIds = coco.getCatIds(catNms=[cat])
+ imgIds = coco.getImgIds(catIds=catIds)
+ for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
+ width, height = im["width"], im["height"]
+ path = Path(im["file_name"]) # image filename
+ try:
+ with open(labels / path.with_suffix('.txt').name, 'a') as file:
+ annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
+ for a in coco.loadAnns(annIds):
+ x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
+ xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
+ x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
+ file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
+ except Exception as e:
+ print(e)
diff --git a/src/train_utils/train_models/models/yolov5/data/SKU-110K.yaml b/src/train_utils/train_models/models/yolov5/data/SKU-110K.yaml
new file mode 100644
index 0000000..edae717
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/SKU-110K.yaml
@@ -0,0 +1,53 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
+# Example usage: python train.py --data SKU-110K.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── SKU-110K ← downloads here (13.6 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/SKU-110K # dataset root dir
+train: train.txt # train images (relative to 'path') 8219 images
+val: val.txt # val images (relative to 'path') 588 images
+test: test.txt # test images (optional) 2936 images
+
+# Classes
+names:
+ 0: object
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import shutil
+ from tqdm import tqdm
+ from utils.general import np, pd, Path, download, xyxy2xywh
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ parent = Path(dir.parent) # download dir
+ urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
+ download(urls, dir=parent, delete=False)
+
+ # Rename directories
+ if dir.exists():
+ shutil.rmtree(dir)
+ (parent / 'SKU110K_fixed').rename(dir) # rename dir
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
+
+ # Convert labels
+ names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
+ for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
+ x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
+ images, unique_images = x[:, 0], np.unique(x[:, 0])
+ with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
+ f.writelines(f'./images/{s}\n' for s in unique_images)
+ for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
+ cls = 0 # single-class dataset
+ with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
+ for r in x[images == im]:
+ w, h = r[6], r[7] # image width, height
+ xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
+ f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
diff --git a/src/train_utils/train_models/models/yolov5/data/VOC.yaml b/src/train_utils/train_models/models/yolov5/data/VOC.yaml
new file mode 100644
index 0000000..27d3810
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/VOC.yaml
@@ -0,0 +1,100 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
+# Example usage: python train.py --data VOC.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VOC ← downloads here (2.8 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VOC
+train: # train images (relative to 'path') 16551 images
+ - images/train2012
+ - images/train2007
+ - images/val2012
+ - images/val2007
+val: # val images (relative to 'path') 4952 images
+ - images/test2007
+test: # test images (optional)
+ - images/test2007
+
+# Classes
+names:
+ 0: aeroplane
+ 1: bicycle
+ 2: bird
+ 3: boat
+ 4: bottle
+ 5: bus
+ 6: car
+ 7: cat
+ 8: chair
+ 9: cow
+ 10: diningtable
+ 11: dog
+ 12: horse
+ 13: motorbike
+ 14: person
+ 15: pottedplant
+ 16: sheep
+ 17: sofa
+ 18: train
+ 19: tvmonitor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import xml.etree.ElementTree as ET
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def convert_label(path, lb_path, year, image_id):
+ def convert_box(size, box):
+ dw, dh = 1. / size[0], 1. / size[1]
+ x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
+ return x * dw, y * dh, w * dw, h * dh
+
+ in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
+ out_file = open(lb_path, 'w')
+ tree = ET.parse(in_file)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+
+ names = list(yaml['names'].values()) # names list
+ for obj in root.iter('object'):
+ cls = obj.find('name').text
+ if cls in names and int(obj.find('difficult').text) != 1:
+ xmlbox = obj.find('bndbox')
+ bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
+ cls_id = names.index(cls) # class id
+ out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
+ f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
+ f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
+ download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
+
+ # Convert
+ path = dir / 'images/VOCdevkit'
+ for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
+ imgs_path = dir / 'images' / f'{image_set}{year}'
+ lbs_path = dir / 'labels' / f'{image_set}{year}'
+ imgs_path.mkdir(exist_ok=True, parents=True)
+ lbs_path.mkdir(exist_ok=True, parents=True)
+
+ with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
+ image_ids = f.read().strip().split()
+ for id in tqdm(image_ids, desc=f'{image_set}{year}'):
+ f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
+ lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
+ f.rename(imgs_path / f.name) # move image
+ convert_label(path, lb_path, year, id) # convert labels to YOLO format
diff --git a/src/train_utils/train_models/models/yolov5/data/VisDrone.yaml b/src/train_utils/train_models/models/yolov5/data/VisDrone.yaml
new file mode 100644
index 0000000..a8bcf8e
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/VisDrone.yaml
@@ -0,0 +1,70 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
+# Example usage: python train.py --data VisDrone.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VisDrone ← downloads here (2.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VisDrone # dataset root dir
+train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
+val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
+test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
+
+# Classes
+names:
+ 0: pedestrian
+ 1: people
+ 2: bicycle
+ 3: car
+ 4: van
+ 5: truck
+ 6: tricycle
+ 7: awning-tricycle
+ 8: bus
+ 9: motor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, os, Path
+
+ def visdrone2yolo(dir):
+ from PIL import Image
+ from tqdm import tqdm
+
+ def convert_box(size, box):
+ # Convert VisDrone box to YOLO xywh box
+ dw = 1. / size[0]
+ dh = 1. / size[1]
+ return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
+
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
+ pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
+ for f in pbar:
+ img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
+ lines = []
+ with open(f, 'r') as file: # read annotation.txt
+ for row in [x.split(',') for x in file.read().strip().splitlines()]:
+ if row[4] == '0': # VisDrone 'ignored regions' class 0
+ continue
+ cls = int(row[5]) - 1
+ box = convert_box(img_size, tuple(map(int, row[:4])))
+ lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
+ with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
+ fl.writelines(lines) # write label.txt
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
+ download(urls, dir=dir, curl=True, threads=4)
+
+ # Convert
+ for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
+ visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/src/train_utils/train_models/models/yolov5/data/coco.yaml b/src/train_utils/train_models/models/yolov5/data/coco.yaml
new file mode 100644
index 0000000..d64dfc7
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/coco.yaml
@@ -0,0 +1,116 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: python train.py --data coco.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: |
+ from utils.general import download, Path
+
+
+ # Download labels
+ segments = False # segment or box labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
+ download(urls, dir=dir.parent)
+
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/src/train_utils/train_models/models/yolov5/data/coco128-seg.yaml b/src/train_utils/train_models/models/yolov5/data/coco128-seg.yaml
new file mode 100644
index 0000000..5e81910
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/coco128-seg.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128-seg ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128-seg # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128-seg.zip
diff --git a/src/train_utils/train_models/models/yolov5/data/coco128.yaml b/src/train_utils/train_models/models/yolov5/data/coco128.yaml
new file mode 100644
index 0000000..1255673
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/coco128.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128 ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128 # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128.zip
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.Objects365.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.Objects365.yaml
new file mode 100644
index 0000000..7497174
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.Objects365.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for Objects365 training
+# python train.py --weights yolov5m.pt --data Objects365.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.00258
+lrf: 0.17
+momentum: 0.779
+weight_decay: 0.00058
+warmup_epochs: 1.33
+warmup_momentum: 0.86
+warmup_bias_lr: 0.0711
+box: 0.0539
+cls: 0.299
+cls_pw: 0.825
+obj: 0.632
+obj_pw: 1.0
+iou_t: 0.2
+anchor_t: 3.44
+anchors: 3.2
+fl_gamma: 0.0
+hsv_h: 0.0188
+hsv_s: 0.704
+hsv_v: 0.36
+degrees: 0.0
+translate: 0.0902
+scale: 0.491
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 1.0
+mixup: 0.0
+copy_paste: 0.0
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.VOC.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.VOC.yaml
new file mode 100644
index 0000000..0aa4e7d
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.VOC.yaml
@@ -0,0 +1,40 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for VOC training
+# python train.py --batch 128 --weights yolov5m6.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.scratch-med.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 467
+# Last generation: 996
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.87729, 0.85125, 0.91286, 0.72664, 0.0076739, 0.0042529, 0.0013865
+
+lr0: 0.00334
+lrf: 0.15135
+momentum: 0.74832
+weight_decay: 0.00025
+warmup_epochs: 3.3835
+warmup_momentum: 0.59462
+warmup_bias_lr: 0.18657
+box: 0.02
+cls: 0.21638
+cls_pw: 0.5
+obj: 0.51728
+obj_pw: 0.67198
+iou_t: 0.2
+anchor_t: 3.3744
+fl_gamma: 0.0
+hsv_h: 0.01041
+hsv_s: 0.54703
+hsv_v: 0.27739
+degrees: 0.0
+translate: 0.04591
+scale: 0.75544
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 0.85834
+mixup: 0.04266
+copy_paste: 0.0
+anchors: 3.412
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.no-augmentation.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.no-augmentation.yaml
new file mode 100644
index 0000000..8fbd5b2
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.no-augmentation.yaml
@@ -0,0 +1,35 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters when using Albumentations frameworks
+# python train.py --hyp hyp.no-augmentation.yaml
+# See https://github.com/ultralytics/yolov5/pull/3882 for YOLOv5 + Albumentations Usage examples
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+# this parameters are all zero since we want to use albumentation framework
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0 # image HSV-Hue augmentation (fraction)
+hsv_s: 00 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0 # image translation (+/- fraction)
+scale: 0 # image scale (+/- gain)
+shear: 0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.0 # image flip left-right (probability)
+mosaic: 0.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-high.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-high.yaml
new file mode 100644
index 0000000..123cc84
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-high.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for high-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.1 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-low.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-low.yaml
new file mode 100644
index 0000000..b9ef1d5
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-low.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-med.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-med.yaml
new file mode 100644
index 0000000..d6867d7
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-med.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for medium-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/images/bus.jpg b/src/train_utils/train_models/models/yolov5/data/images/bus.jpg
new file mode 100644
index 0000000..b43e311
Binary files /dev/null and b/src/train_utils/train_models/models/yolov5/data/images/bus.jpg differ
diff --git a/src/train_utils/train_models/models/yolov5/data/images/zidane.jpg b/src/train_utils/train_models/models/yolov5/data/images/zidane.jpg
new file mode 100644
index 0000000..92d72ea
Binary files /dev/null and b/src/train_utils/train_models/models/yolov5/data/images/zidane.jpg differ
diff --git a/src/train_utils/train_models/models/yolov5/data/scripts/download_weights.sh b/src/train_utils/train_models/models/yolov5/data/scripts/download_weights.sh
new file mode 100644
index 0000000..31e0a15
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/scripts/download_weights.sh
@@ -0,0 +1,22 @@
+#!/bin/bash
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Download latest models from https://github.com/ultralytics/yolov5/releases
+# Example usage: bash data/scripts/download_weights.sh
+# parent
+# └── yolov5
+# ├── yolov5s.pt ← downloads here
+# ├── yolov5m.pt
+# └── ...
+
+python - <\n",
+ "\n",
+ "\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "outputs": [],
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "YOLOv5 Classification Tutorial",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/src/train_utils/train_models/models/yolov5/classify/val.py b/src/train_utils/train_models/models/yolov5/classify/val.py
new file mode 100644
index 0000000..4edd5a1
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/classify/val.py
@@ -0,0 +1,170 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 classification model on a classification dataset
+
+Usage:
+ $ bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
+ $ python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate ImageNet
+
+Usage - formats:
+ $ python classify/val.py --weights yolov5s-cls.pt # PyTorch
+ yolov5s-cls.torchscript # TorchScript
+ yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-cls_openvino_model # OpenVINO
+ yolov5s-cls.engine # TensorRT
+ yolov5s-cls.mlmodel # CoreML (macOS-only)
+ yolov5s-cls_saved_model # TensorFlow SavedModel
+ yolov5s-cls.pb # TensorFlow GraphDef
+ yolov5s-cls.tflite # TensorFlow Lite
+ yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-cls_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import sys
+from pathlib import Path
+
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import create_classification_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_img_size, check_requirements, colorstr,
+ increment_path, print_args)
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / '../datasets/mnist', # dataset dir
+ weights=ROOT / 'yolov5s-cls.pt', # model.pt path(s)
+ batch_size=128, # batch size
+ imgsz=224, # inference size (pixels)
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ verbose=False, # verbose output
+ project=ROOT / 'runs/val-cls', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ criterion=None,
+ pbar=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ save_dir.mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Dataloader
+ data = Path(data)
+ test_dir = data / 'test' if (data / 'test').exists() else data / 'val' # data/test or data/val
+ dataloader = create_classification_dataloader(path=test_dir,
+ imgsz=imgsz,
+ batch_size=batch_size,
+ augment=False,
+ rank=-1,
+ workers=workers)
+
+ model.eval()
+ pred, targets, loss, dt = [], [], 0, (Profile(), Profile(), Profile())
+ n = len(dataloader) # number of batches
+ action = 'validating' if dataloader.dataset.root.stem == 'val' else 'testing'
+ desc = f'{pbar.desc[:-36]}{action:>36}' if pbar else f'{action}'
+ bar = tqdm(dataloader, desc, n, not training, bar_format=TQDM_BAR_FORMAT, position=0)
+ with torch.cuda.amp.autocast(enabled=device.type != 'cpu'):
+ for images, labels in bar:
+ with dt[0]:
+ images, labels = images.to(device, non_blocking=True), labels.to(device)
+
+ with dt[1]:
+ y = model(images)
+
+ with dt[2]:
+ pred.append(y.argsort(1, descending=True)[:, :5])
+ targets.append(labels)
+ if criterion:
+ loss += criterion(y, labels)
+
+ loss /= n
+ pred, targets = torch.cat(pred), torch.cat(targets)
+ correct = (targets[:, None] == pred).float()
+ acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
+ top1, top5 = acc.mean(0).tolist()
+
+ if pbar:
+ pbar.desc = f'{pbar.desc[:-36]}{loss:>12.3g}{top1:>12.3g}{top5:>12.3g}'
+ if verbose: # all classes
+ LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
+ LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
+ for i, c in model.names.items():
+ acc_i = acc[targets == i]
+ top1i, top5i = acc_i.mean(0).tolist()
+ LOGGER.info(f'{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}')
+
+ # Print results
+ t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
+ shape = (1, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms post-process per image at shape {shape}' % t)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ return top1, top5, loss
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / '../datasets/mnist', help='dataset path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-cls.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=128, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='inference size (pixels)')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--verbose', nargs='?', const=True, default=True, help='verbose output')
+ parser.add_argument('--project', default=ROOT / 'runs/val-cls', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/src/train_utils/train_models/models/yolov5/data/Argoverse.yaml b/src/train_utils/train_models/models/yolov5/data/Argoverse.yaml
new file mode 100644
index 0000000..558151d
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/Argoverse.yaml
@@ -0,0 +1,74 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
+# Example usage: python train.py --data Argoverse.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Argoverse ← downloads here (31.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Argoverse # dataset root dir
+train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
+val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
+test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: bus
+ 5: truck
+ 6: traffic_light
+ 7: stop_sign
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def argoverse2yolo(set):
+ labels = {}
+ a = json.load(open(set, "rb"))
+ for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
+ img_id = annot['image_id']
+ img_name = a['images'][img_id]['name']
+ img_label_name = f'{img_name[:-3]}txt'
+
+ cls = annot['category_id'] # instance class id
+ x_center, y_center, width, height = annot['bbox']
+ x_center = (x_center + width / 2) / 1920.0 # offset and scale
+ y_center = (y_center + height / 2) / 1200.0 # offset and scale
+ width /= 1920.0 # scale
+ height /= 1200.0 # scale
+
+ img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
+ if not img_dir.exists():
+ img_dir.mkdir(parents=True, exist_ok=True)
+
+ k = str(img_dir / img_label_name)
+ if k not in labels:
+ labels[k] = []
+ labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
+
+ for k in labels:
+ with open(k, "w") as f:
+ f.writelines(labels[k])
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
+ download(urls, dir=dir, delete=False)
+
+ # Convert
+ annotations_dir = 'Argoverse-HD/annotations/'
+ (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
+ for d in "train.json", "val.json":
+ argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/src/train_utils/train_models/models/yolov5/data/GlobalWheat2020.yaml b/src/train_utils/train_models/models/yolov5/data/GlobalWheat2020.yaml
new file mode 100644
index 0000000..01812d0
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/GlobalWheat2020.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
+# Example usage: python train.py --data GlobalWheat2020.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── GlobalWheat2020 ← downloads here (7.0 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/GlobalWheat2020 # dataset root dir
+train: # train images (relative to 'path') 3422 images
+ - images/arvalis_1
+ - images/arvalis_2
+ - images/arvalis_3
+ - images/ethz_1
+ - images/rres_1
+ - images/inrae_1
+ - images/usask_1
+val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
+ - images/ethz_1
+test: # test images (optional) 1276 images
+ - images/utokyo_1
+ - images/utokyo_2
+ - images/nau_1
+ - images/uq_1
+
+# Classes
+names:
+ 0: wheat_head
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, Path
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
+ download(urls, dir=dir)
+
+ # Make Directories
+ for p in 'annotations', 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+
+ # Move
+ for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
+ 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
+ (dir / p).rename(dir / 'images' / p) # move to /images
+ f = (dir / p).with_suffix('.json') # json file
+ if f.exists():
+ f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
diff --git a/src/train_utils/train_models/models/yolov5/data/ImageNet.yaml b/src/train_utils/train_models/models/yolov5/data/ImageNet.yaml
new file mode 100644
index 0000000..14f1295
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/ImageNet.yaml
@@ -0,0 +1,1022 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
+# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
+# Example usage: python classify/train.py --data imagenet
+# parent
+# ├── yolov5
+# └── datasets
+# └── imagenet ← downloads here (144 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/imagenet # dataset root dir
+train: train # train images (relative to 'path') 1281167 images
+val: val # val images (relative to 'path') 50000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: tench
+ 1: goldfish
+ 2: great white shark
+ 3: tiger shark
+ 4: hammerhead shark
+ 5: electric ray
+ 6: stingray
+ 7: cock
+ 8: hen
+ 9: ostrich
+ 10: brambling
+ 11: goldfinch
+ 12: house finch
+ 13: junco
+ 14: indigo bunting
+ 15: American robin
+ 16: bulbul
+ 17: jay
+ 18: magpie
+ 19: chickadee
+ 20: American dipper
+ 21: kite
+ 22: bald eagle
+ 23: vulture
+ 24: great grey owl
+ 25: fire salamander
+ 26: smooth newt
+ 27: newt
+ 28: spotted salamander
+ 29: axolotl
+ 30: American bullfrog
+ 31: tree frog
+ 32: tailed frog
+ 33: loggerhead sea turtle
+ 34: leatherback sea turtle
+ 35: mud turtle
+ 36: terrapin
+ 37: box turtle
+ 38: banded gecko
+ 39: green iguana
+ 40: Carolina anole
+ 41: desert grassland whiptail lizard
+ 42: agama
+ 43: frilled-necked lizard
+ 44: alligator lizard
+ 45: Gila monster
+ 46: European green lizard
+ 47: chameleon
+ 48: Komodo dragon
+ 49: Nile crocodile
+ 50: American alligator
+ 51: triceratops
+ 52: worm snake
+ 53: ring-necked snake
+ 54: eastern hog-nosed snake
+ 55: smooth green snake
+ 56: kingsnake
+ 57: garter snake
+ 58: water snake
+ 59: vine snake
+ 60: night snake
+ 61: boa constrictor
+ 62: African rock python
+ 63: Indian cobra
+ 64: green mamba
+ 65: sea snake
+ 66: Saharan horned viper
+ 67: eastern diamondback rattlesnake
+ 68: sidewinder
+ 69: trilobite
+ 70: harvestman
+ 71: scorpion
+ 72: yellow garden spider
+ 73: barn spider
+ 74: European garden spider
+ 75: southern black widow
+ 76: tarantula
+ 77: wolf spider
+ 78: tick
+ 79: centipede
+ 80: black grouse
+ 81: ptarmigan
+ 82: ruffed grouse
+ 83: prairie grouse
+ 84: peacock
+ 85: quail
+ 86: partridge
+ 87: grey parrot
+ 88: macaw
+ 89: sulphur-crested cockatoo
+ 90: lorikeet
+ 91: coucal
+ 92: bee eater
+ 93: hornbill
+ 94: hummingbird
+ 95: jacamar
+ 96: toucan
+ 97: duck
+ 98: red-breasted merganser
+ 99: goose
+ 100: black swan
+ 101: tusker
+ 102: echidna
+ 103: platypus
+ 104: wallaby
+ 105: koala
+ 106: wombat
+ 107: jellyfish
+ 108: sea anemone
+ 109: brain coral
+ 110: flatworm
+ 111: nematode
+ 112: conch
+ 113: snail
+ 114: slug
+ 115: sea slug
+ 116: chiton
+ 117: chambered nautilus
+ 118: Dungeness crab
+ 119: rock crab
+ 120: fiddler crab
+ 121: red king crab
+ 122: American lobster
+ 123: spiny lobster
+ 124: crayfish
+ 125: hermit crab
+ 126: isopod
+ 127: white stork
+ 128: black stork
+ 129: spoonbill
+ 130: flamingo
+ 131: little blue heron
+ 132: great egret
+ 133: bittern
+ 134: crane (bird)
+ 135: limpkin
+ 136: common gallinule
+ 137: American coot
+ 138: bustard
+ 139: ruddy turnstone
+ 140: dunlin
+ 141: common redshank
+ 142: dowitcher
+ 143: oystercatcher
+ 144: pelican
+ 145: king penguin
+ 146: albatross
+ 147: grey whale
+ 148: killer whale
+ 149: dugong
+ 150: sea lion
+ 151: Chihuahua
+ 152: Japanese Chin
+ 153: Maltese
+ 154: Pekingese
+ 155: Shih Tzu
+ 156: King Charles Spaniel
+ 157: Papillon
+ 158: toy terrier
+ 159: Rhodesian Ridgeback
+ 160: Afghan Hound
+ 161: Basset Hound
+ 162: Beagle
+ 163: Bloodhound
+ 164: Bluetick Coonhound
+ 165: Black and Tan Coonhound
+ 166: Treeing Walker Coonhound
+ 167: English foxhound
+ 168: Redbone Coonhound
+ 169: borzoi
+ 170: Irish Wolfhound
+ 171: Italian Greyhound
+ 172: Whippet
+ 173: Ibizan Hound
+ 174: Norwegian Elkhound
+ 175: Otterhound
+ 176: Saluki
+ 177: Scottish Deerhound
+ 178: Weimaraner
+ 179: Staffordshire Bull Terrier
+ 180: American Staffordshire Terrier
+ 181: Bedlington Terrier
+ 182: Border Terrier
+ 183: Kerry Blue Terrier
+ 184: Irish Terrier
+ 185: Norfolk Terrier
+ 186: Norwich Terrier
+ 187: Yorkshire Terrier
+ 188: Wire Fox Terrier
+ 189: Lakeland Terrier
+ 190: Sealyham Terrier
+ 191: Airedale Terrier
+ 192: Cairn Terrier
+ 193: Australian Terrier
+ 194: Dandie Dinmont Terrier
+ 195: Boston Terrier
+ 196: Miniature Schnauzer
+ 197: Giant Schnauzer
+ 198: Standard Schnauzer
+ 199: Scottish Terrier
+ 200: Tibetan Terrier
+ 201: Australian Silky Terrier
+ 202: Soft-coated Wheaten Terrier
+ 203: West Highland White Terrier
+ 204: Lhasa Apso
+ 205: Flat-Coated Retriever
+ 206: Curly-coated Retriever
+ 207: Golden Retriever
+ 208: Labrador Retriever
+ 209: Chesapeake Bay Retriever
+ 210: German Shorthaired Pointer
+ 211: Vizsla
+ 212: English Setter
+ 213: Irish Setter
+ 214: Gordon Setter
+ 215: Brittany
+ 216: Clumber Spaniel
+ 217: English Springer Spaniel
+ 218: Welsh Springer Spaniel
+ 219: Cocker Spaniels
+ 220: Sussex Spaniel
+ 221: Irish Water Spaniel
+ 222: Kuvasz
+ 223: Schipperke
+ 224: Groenendael
+ 225: Malinois
+ 226: Briard
+ 227: Australian Kelpie
+ 228: Komondor
+ 229: Old English Sheepdog
+ 230: Shetland Sheepdog
+ 231: collie
+ 232: Border Collie
+ 233: Bouvier des Flandres
+ 234: Rottweiler
+ 235: German Shepherd Dog
+ 236: Dobermann
+ 237: Miniature Pinscher
+ 238: Greater Swiss Mountain Dog
+ 239: Bernese Mountain Dog
+ 240: Appenzeller Sennenhund
+ 241: Entlebucher Sennenhund
+ 242: Boxer
+ 243: Bullmastiff
+ 244: Tibetan Mastiff
+ 245: French Bulldog
+ 246: Great Dane
+ 247: St. Bernard
+ 248: husky
+ 249: Alaskan Malamute
+ 250: Siberian Husky
+ 251: Dalmatian
+ 252: Affenpinscher
+ 253: Basenji
+ 254: pug
+ 255: Leonberger
+ 256: Newfoundland
+ 257: Pyrenean Mountain Dog
+ 258: Samoyed
+ 259: Pomeranian
+ 260: Chow Chow
+ 261: Keeshond
+ 262: Griffon Bruxellois
+ 263: Pembroke Welsh Corgi
+ 264: Cardigan Welsh Corgi
+ 265: Toy Poodle
+ 266: Miniature Poodle
+ 267: Standard Poodle
+ 268: Mexican hairless dog
+ 269: grey wolf
+ 270: Alaskan tundra wolf
+ 271: red wolf
+ 272: coyote
+ 273: dingo
+ 274: dhole
+ 275: African wild dog
+ 276: hyena
+ 277: red fox
+ 278: kit fox
+ 279: Arctic fox
+ 280: grey fox
+ 281: tabby cat
+ 282: tiger cat
+ 283: Persian cat
+ 284: Siamese cat
+ 285: Egyptian Mau
+ 286: cougar
+ 287: lynx
+ 288: leopard
+ 289: snow leopard
+ 290: jaguar
+ 291: lion
+ 292: tiger
+ 293: cheetah
+ 294: brown bear
+ 295: American black bear
+ 296: polar bear
+ 297: sloth bear
+ 298: mongoose
+ 299: meerkat
+ 300: tiger beetle
+ 301: ladybug
+ 302: ground beetle
+ 303: longhorn beetle
+ 304: leaf beetle
+ 305: dung beetle
+ 306: rhinoceros beetle
+ 307: weevil
+ 308: fly
+ 309: bee
+ 310: ant
+ 311: grasshopper
+ 312: cricket
+ 313: stick insect
+ 314: cockroach
+ 315: mantis
+ 316: cicada
+ 317: leafhopper
+ 318: lacewing
+ 319: dragonfly
+ 320: damselfly
+ 321: red admiral
+ 322: ringlet
+ 323: monarch butterfly
+ 324: small white
+ 325: sulphur butterfly
+ 326: gossamer-winged butterfly
+ 327: starfish
+ 328: sea urchin
+ 329: sea cucumber
+ 330: cottontail rabbit
+ 331: hare
+ 332: Angora rabbit
+ 333: hamster
+ 334: porcupine
+ 335: fox squirrel
+ 336: marmot
+ 337: beaver
+ 338: guinea pig
+ 339: common sorrel
+ 340: zebra
+ 341: pig
+ 342: wild boar
+ 343: warthog
+ 344: hippopotamus
+ 345: ox
+ 346: water buffalo
+ 347: bison
+ 348: ram
+ 349: bighorn sheep
+ 350: Alpine ibex
+ 351: hartebeest
+ 352: impala
+ 353: gazelle
+ 354: dromedary
+ 355: llama
+ 356: weasel
+ 357: mink
+ 358: European polecat
+ 359: black-footed ferret
+ 360: otter
+ 361: skunk
+ 362: badger
+ 363: armadillo
+ 364: three-toed sloth
+ 365: orangutan
+ 366: gorilla
+ 367: chimpanzee
+ 368: gibbon
+ 369: siamang
+ 370: guenon
+ 371: patas monkey
+ 372: baboon
+ 373: macaque
+ 374: langur
+ 375: black-and-white colobus
+ 376: proboscis monkey
+ 377: marmoset
+ 378: white-headed capuchin
+ 379: howler monkey
+ 380: titi
+ 381: Geoffroy's spider monkey
+ 382: common squirrel monkey
+ 383: ring-tailed lemur
+ 384: indri
+ 385: Asian elephant
+ 386: African bush elephant
+ 387: red panda
+ 388: giant panda
+ 389: snoek
+ 390: eel
+ 391: coho salmon
+ 392: rock beauty
+ 393: clownfish
+ 394: sturgeon
+ 395: garfish
+ 396: lionfish
+ 397: pufferfish
+ 398: abacus
+ 399: abaya
+ 400: academic gown
+ 401: accordion
+ 402: acoustic guitar
+ 403: aircraft carrier
+ 404: airliner
+ 405: airship
+ 406: altar
+ 407: ambulance
+ 408: amphibious vehicle
+ 409: analog clock
+ 410: apiary
+ 411: apron
+ 412: waste container
+ 413: assault rifle
+ 414: backpack
+ 415: bakery
+ 416: balance beam
+ 417: balloon
+ 418: ballpoint pen
+ 419: Band-Aid
+ 420: banjo
+ 421: baluster
+ 422: barbell
+ 423: barber chair
+ 424: barbershop
+ 425: barn
+ 426: barometer
+ 427: barrel
+ 428: wheelbarrow
+ 429: baseball
+ 430: basketball
+ 431: bassinet
+ 432: bassoon
+ 433: swimming cap
+ 434: bath towel
+ 435: bathtub
+ 436: station wagon
+ 437: lighthouse
+ 438: beaker
+ 439: military cap
+ 440: beer bottle
+ 441: beer glass
+ 442: bell-cot
+ 443: bib
+ 444: tandem bicycle
+ 445: bikini
+ 446: ring binder
+ 447: binoculars
+ 448: birdhouse
+ 449: boathouse
+ 450: bobsleigh
+ 451: bolo tie
+ 452: poke bonnet
+ 453: bookcase
+ 454: bookstore
+ 455: bottle cap
+ 456: bow
+ 457: bow tie
+ 458: brass
+ 459: bra
+ 460: breakwater
+ 461: breastplate
+ 462: broom
+ 463: bucket
+ 464: buckle
+ 465: bulletproof vest
+ 466: high-speed train
+ 467: butcher shop
+ 468: taxicab
+ 469: cauldron
+ 470: candle
+ 471: cannon
+ 472: canoe
+ 473: can opener
+ 474: cardigan
+ 475: car mirror
+ 476: carousel
+ 477: tool kit
+ 478: carton
+ 479: car wheel
+ 480: automated teller machine
+ 481: cassette
+ 482: cassette player
+ 483: castle
+ 484: catamaran
+ 485: CD player
+ 486: cello
+ 487: mobile phone
+ 488: chain
+ 489: chain-link fence
+ 490: chain mail
+ 491: chainsaw
+ 492: chest
+ 493: chiffonier
+ 494: chime
+ 495: china cabinet
+ 496: Christmas stocking
+ 497: church
+ 498: movie theater
+ 499: cleaver
+ 500: cliff dwelling
+ 501: cloak
+ 502: clogs
+ 503: cocktail shaker
+ 504: coffee mug
+ 505: coffeemaker
+ 506: coil
+ 507: combination lock
+ 508: computer keyboard
+ 509: confectionery store
+ 510: container ship
+ 511: convertible
+ 512: corkscrew
+ 513: cornet
+ 514: cowboy boot
+ 515: cowboy hat
+ 516: cradle
+ 517: crane (machine)
+ 518: crash helmet
+ 519: crate
+ 520: infant bed
+ 521: Crock Pot
+ 522: croquet ball
+ 523: crutch
+ 524: cuirass
+ 525: dam
+ 526: desk
+ 527: desktop computer
+ 528: rotary dial telephone
+ 529: diaper
+ 530: digital clock
+ 531: digital watch
+ 532: dining table
+ 533: dishcloth
+ 534: dishwasher
+ 535: disc brake
+ 536: dock
+ 537: dog sled
+ 538: dome
+ 539: doormat
+ 540: drilling rig
+ 541: drum
+ 542: drumstick
+ 543: dumbbell
+ 544: Dutch oven
+ 545: electric fan
+ 546: electric guitar
+ 547: electric locomotive
+ 548: entertainment center
+ 549: envelope
+ 550: espresso machine
+ 551: face powder
+ 552: feather boa
+ 553: filing cabinet
+ 554: fireboat
+ 555: fire engine
+ 556: fire screen sheet
+ 557: flagpole
+ 558: flute
+ 559: folding chair
+ 560: football helmet
+ 561: forklift
+ 562: fountain
+ 563: fountain pen
+ 564: four-poster bed
+ 565: freight car
+ 566: French horn
+ 567: frying pan
+ 568: fur coat
+ 569: garbage truck
+ 570: gas mask
+ 571: gas pump
+ 572: goblet
+ 573: go-kart
+ 574: golf ball
+ 575: golf cart
+ 576: gondola
+ 577: gong
+ 578: gown
+ 579: grand piano
+ 580: greenhouse
+ 581: grille
+ 582: grocery store
+ 583: guillotine
+ 584: barrette
+ 585: hair spray
+ 586: half-track
+ 587: hammer
+ 588: hamper
+ 589: hair dryer
+ 590: hand-held computer
+ 591: handkerchief
+ 592: hard disk drive
+ 593: harmonica
+ 594: harp
+ 595: harvester
+ 596: hatchet
+ 597: holster
+ 598: home theater
+ 599: honeycomb
+ 600: hook
+ 601: hoop skirt
+ 602: horizontal bar
+ 603: horse-drawn vehicle
+ 604: hourglass
+ 605: iPod
+ 606: clothes iron
+ 607: jack-o'-lantern
+ 608: jeans
+ 609: jeep
+ 610: T-shirt
+ 611: jigsaw puzzle
+ 612: pulled rickshaw
+ 613: joystick
+ 614: kimono
+ 615: knee pad
+ 616: knot
+ 617: lab coat
+ 618: ladle
+ 619: lampshade
+ 620: laptop computer
+ 621: lawn mower
+ 622: lens cap
+ 623: paper knife
+ 624: library
+ 625: lifeboat
+ 626: lighter
+ 627: limousine
+ 628: ocean liner
+ 629: lipstick
+ 630: slip-on shoe
+ 631: lotion
+ 632: speaker
+ 633: loupe
+ 634: sawmill
+ 635: magnetic compass
+ 636: mail bag
+ 637: mailbox
+ 638: tights
+ 639: tank suit
+ 640: manhole cover
+ 641: maraca
+ 642: marimba
+ 643: mask
+ 644: match
+ 645: maypole
+ 646: maze
+ 647: measuring cup
+ 648: medicine chest
+ 649: megalith
+ 650: microphone
+ 651: microwave oven
+ 652: military uniform
+ 653: milk can
+ 654: minibus
+ 655: miniskirt
+ 656: minivan
+ 657: missile
+ 658: mitten
+ 659: mixing bowl
+ 660: mobile home
+ 661: Model T
+ 662: modem
+ 663: monastery
+ 664: monitor
+ 665: moped
+ 666: mortar
+ 667: square academic cap
+ 668: mosque
+ 669: mosquito net
+ 670: scooter
+ 671: mountain bike
+ 672: tent
+ 673: computer mouse
+ 674: mousetrap
+ 675: moving van
+ 676: muzzle
+ 677: nail
+ 678: neck brace
+ 679: necklace
+ 680: nipple
+ 681: notebook computer
+ 682: obelisk
+ 683: oboe
+ 684: ocarina
+ 685: odometer
+ 686: oil filter
+ 687: organ
+ 688: oscilloscope
+ 689: overskirt
+ 690: bullock cart
+ 691: oxygen mask
+ 692: packet
+ 693: paddle
+ 694: paddle wheel
+ 695: padlock
+ 696: paintbrush
+ 697: pajamas
+ 698: palace
+ 699: pan flute
+ 700: paper towel
+ 701: parachute
+ 702: parallel bars
+ 703: park bench
+ 704: parking meter
+ 705: passenger car
+ 706: patio
+ 707: payphone
+ 708: pedestal
+ 709: pencil case
+ 710: pencil sharpener
+ 711: perfume
+ 712: Petri dish
+ 713: photocopier
+ 714: plectrum
+ 715: Pickelhaube
+ 716: picket fence
+ 717: pickup truck
+ 718: pier
+ 719: piggy bank
+ 720: pill bottle
+ 721: pillow
+ 722: ping-pong ball
+ 723: pinwheel
+ 724: pirate ship
+ 725: pitcher
+ 726: hand plane
+ 727: planetarium
+ 728: plastic bag
+ 729: plate rack
+ 730: plow
+ 731: plunger
+ 732: Polaroid camera
+ 733: pole
+ 734: police van
+ 735: poncho
+ 736: billiard table
+ 737: soda bottle
+ 738: pot
+ 739: potter's wheel
+ 740: power drill
+ 741: prayer rug
+ 742: printer
+ 743: prison
+ 744: projectile
+ 745: projector
+ 746: hockey puck
+ 747: punching bag
+ 748: purse
+ 749: quill
+ 750: quilt
+ 751: race car
+ 752: racket
+ 753: radiator
+ 754: radio
+ 755: radio telescope
+ 756: rain barrel
+ 757: recreational vehicle
+ 758: reel
+ 759: reflex camera
+ 760: refrigerator
+ 761: remote control
+ 762: restaurant
+ 763: revolver
+ 764: rifle
+ 765: rocking chair
+ 766: rotisserie
+ 767: eraser
+ 768: rugby ball
+ 769: ruler
+ 770: running shoe
+ 771: safe
+ 772: safety pin
+ 773: salt shaker
+ 774: sandal
+ 775: sarong
+ 776: saxophone
+ 777: scabbard
+ 778: weighing scale
+ 779: school bus
+ 780: schooner
+ 781: scoreboard
+ 782: CRT screen
+ 783: screw
+ 784: screwdriver
+ 785: seat belt
+ 786: sewing machine
+ 787: shield
+ 788: shoe store
+ 789: shoji
+ 790: shopping basket
+ 791: shopping cart
+ 792: shovel
+ 793: shower cap
+ 794: shower curtain
+ 795: ski
+ 796: ski mask
+ 797: sleeping bag
+ 798: slide rule
+ 799: sliding door
+ 800: slot machine
+ 801: snorkel
+ 802: snowmobile
+ 803: snowplow
+ 804: soap dispenser
+ 805: soccer ball
+ 806: sock
+ 807: solar thermal collector
+ 808: sombrero
+ 809: soup bowl
+ 810: space bar
+ 811: space heater
+ 812: space shuttle
+ 813: spatula
+ 814: motorboat
+ 815: spider web
+ 816: spindle
+ 817: sports car
+ 818: spotlight
+ 819: stage
+ 820: steam locomotive
+ 821: through arch bridge
+ 822: steel drum
+ 823: stethoscope
+ 824: scarf
+ 825: stone wall
+ 826: stopwatch
+ 827: stove
+ 828: strainer
+ 829: tram
+ 830: stretcher
+ 831: couch
+ 832: stupa
+ 833: submarine
+ 834: suit
+ 835: sundial
+ 836: sunglass
+ 837: sunglasses
+ 838: sunscreen
+ 839: suspension bridge
+ 840: mop
+ 841: sweatshirt
+ 842: swimsuit
+ 843: swing
+ 844: switch
+ 845: syringe
+ 846: table lamp
+ 847: tank
+ 848: tape player
+ 849: teapot
+ 850: teddy bear
+ 851: television
+ 852: tennis ball
+ 853: thatched roof
+ 854: front curtain
+ 855: thimble
+ 856: threshing machine
+ 857: throne
+ 858: tile roof
+ 859: toaster
+ 860: tobacco shop
+ 861: toilet seat
+ 862: torch
+ 863: totem pole
+ 864: tow truck
+ 865: toy store
+ 866: tractor
+ 867: semi-trailer truck
+ 868: tray
+ 869: trench coat
+ 870: tricycle
+ 871: trimaran
+ 872: tripod
+ 873: triumphal arch
+ 874: trolleybus
+ 875: trombone
+ 876: tub
+ 877: turnstile
+ 878: typewriter keyboard
+ 879: umbrella
+ 880: unicycle
+ 881: upright piano
+ 882: vacuum cleaner
+ 883: vase
+ 884: vault
+ 885: velvet
+ 886: vending machine
+ 887: vestment
+ 888: viaduct
+ 889: violin
+ 890: volleyball
+ 891: waffle iron
+ 892: wall clock
+ 893: wallet
+ 894: wardrobe
+ 895: military aircraft
+ 896: sink
+ 897: washing machine
+ 898: water bottle
+ 899: water jug
+ 900: water tower
+ 901: whiskey jug
+ 902: whistle
+ 903: wig
+ 904: window screen
+ 905: window shade
+ 906: Windsor tie
+ 907: wine bottle
+ 908: wing
+ 909: wok
+ 910: wooden spoon
+ 911: wool
+ 912: split-rail fence
+ 913: shipwreck
+ 914: yawl
+ 915: yurt
+ 916: website
+ 917: comic book
+ 918: crossword
+ 919: traffic sign
+ 920: traffic light
+ 921: dust jacket
+ 922: menu
+ 923: plate
+ 924: guacamole
+ 925: consomme
+ 926: hot pot
+ 927: trifle
+ 928: ice cream
+ 929: ice pop
+ 930: baguette
+ 931: bagel
+ 932: pretzel
+ 933: cheeseburger
+ 934: hot dog
+ 935: mashed potato
+ 936: cabbage
+ 937: broccoli
+ 938: cauliflower
+ 939: zucchini
+ 940: spaghetti squash
+ 941: acorn squash
+ 942: butternut squash
+ 943: cucumber
+ 944: artichoke
+ 945: bell pepper
+ 946: cardoon
+ 947: mushroom
+ 948: Granny Smith
+ 949: strawberry
+ 950: orange
+ 951: lemon
+ 952: fig
+ 953: pineapple
+ 954: banana
+ 955: jackfruit
+ 956: custard apple
+ 957: pomegranate
+ 958: hay
+ 959: carbonara
+ 960: chocolate syrup
+ 961: dough
+ 962: meatloaf
+ 963: pizza
+ 964: pot pie
+ 965: burrito
+ 966: red wine
+ 967: espresso
+ 968: cup
+ 969: eggnog
+ 970: alp
+ 971: bubble
+ 972: cliff
+ 973: coral reef
+ 974: geyser
+ 975: lakeshore
+ 976: promontory
+ 977: shoal
+ 978: seashore
+ 979: valley
+ 980: volcano
+ 981: baseball player
+ 982: bridegroom
+ 983: scuba diver
+ 984: rapeseed
+ 985: daisy
+ 986: yellow lady's slipper
+ 987: corn
+ 988: acorn
+ 989: rose hip
+ 990: horse chestnut seed
+ 991: coral fungus
+ 992: agaric
+ 993: gyromitra
+ 994: stinkhorn mushroom
+ 995: earth star
+ 996: hen-of-the-woods
+ 997: bolete
+ 998: ear
+ 999: toilet paper
+
+
+# Download script/URL (optional)
+download: data/scripts/get_imagenet.sh
diff --git a/src/train_utils/train_models/models/yolov5/data/Objects365.yaml b/src/train_utils/train_models/models/yolov5/data/Objects365.yaml
new file mode 100644
index 0000000..05b26a1
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/Objects365.yaml
@@ -0,0 +1,438 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Objects365 dataset https://www.objects365.org/ by Megvii
+# Example usage: python train.py --data Objects365.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Objects365 # dataset root dir
+train: images/train # train images (relative to 'path') 1742289 images
+val: images/val # val images (relative to 'path') 80000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: Person
+ 1: Sneakers
+ 2: Chair
+ 3: Other Shoes
+ 4: Hat
+ 5: Car
+ 6: Lamp
+ 7: Glasses
+ 8: Bottle
+ 9: Desk
+ 10: Cup
+ 11: Street Lights
+ 12: Cabinet/shelf
+ 13: Handbag/Satchel
+ 14: Bracelet
+ 15: Plate
+ 16: Picture/Frame
+ 17: Helmet
+ 18: Book
+ 19: Gloves
+ 20: Storage box
+ 21: Boat
+ 22: Leather Shoes
+ 23: Flower
+ 24: Bench
+ 25: Potted Plant
+ 26: Bowl/Basin
+ 27: Flag
+ 28: Pillow
+ 29: Boots
+ 30: Vase
+ 31: Microphone
+ 32: Necklace
+ 33: Ring
+ 34: SUV
+ 35: Wine Glass
+ 36: Belt
+ 37: Monitor/TV
+ 38: Backpack
+ 39: Umbrella
+ 40: Traffic Light
+ 41: Speaker
+ 42: Watch
+ 43: Tie
+ 44: Trash bin Can
+ 45: Slippers
+ 46: Bicycle
+ 47: Stool
+ 48: Barrel/bucket
+ 49: Van
+ 50: Couch
+ 51: Sandals
+ 52: Basket
+ 53: Drum
+ 54: Pen/Pencil
+ 55: Bus
+ 56: Wild Bird
+ 57: High Heels
+ 58: Motorcycle
+ 59: Guitar
+ 60: Carpet
+ 61: Cell Phone
+ 62: Bread
+ 63: Camera
+ 64: Canned
+ 65: Truck
+ 66: Traffic cone
+ 67: Cymbal
+ 68: Lifesaver
+ 69: Towel
+ 70: Stuffed Toy
+ 71: Candle
+ 72: Sailboat
+ 73: Laptop
+ 74: Awning
+ 75: Bed
+ 76: Faucet
+ 77: Tent
+ 78: Horse
+ 79: Mirror
+ 80: Power outlet
+ 81: Sink
+ 82: Apple
+ 83: Air Conditioner
+ 84: Knife
+ 85: Hockey Stick
+ 86: Paddle
+ 87: Pickup Truck
+ 88: Fork
+ 89: Traffic Sign
+ 90: Balloon
+ 91: Tripod
+ 92: Dog
+ 93: Spoon
+ 94: Clock
+ 95: Pot
+ 96: Cow
+ 97: Cake
+ 98: Dinning Table
+ 99: Sheep
+ 100: Hanger
+ 101: Blackboard/Whiteboard
+ 102: Napkin
+ 103: Other Fish
+ 104: Orange/Tangerine
+ 105: Toiletry
+ 106: Keyboard
+ 107: Tomato
+ 108: Lantern
+ 109: Machinery Vehicle
+ 110: Fan
+ 111: Green Vegetables
+ 112: Banana
+ 113: Baseball Glove
+ 114: Airplane
+ 115: Mouse
+ 116: Train
+ 117: Pumpkin
+ 118: Soccer
+ 119: Skiboard
+ 120: Luggage
+ 121: Nightstand
+ 122: Tea pot
+ 123: Telephone
+ 124: Trolley
+ 125: Head Phone
+ 126: Sports Car
+ 127: Stop Sign
+ 128: Dessert
+ 129: Scooter
+ 130: Stroller
+ 131: Crane
+ 132: Remote
+ 133: Refrigerator
+ 134: Oven
+ 135: Lemon
+ 136: Duck
+ 137: Baseball Bat
+ 138: Surveillance Camera
+ 139: Cat
+ 140: Jug
+ 141: Broccoli
+ 142: Piano
+ 143: Pizza
+ 144: Elephant
+ 145: Skateboard
+ 146: Surfboard
+ 147: Gun
+ 148: Skating and Skiing shoes
+ 149: Gas stove
+ 150: Donut
+ 151: Bow Tie
+ 152: Carrot
+ 153: Toilet
+ 154: Kite
+ 155: Strawberry
+ 156: Other Balls
+ 157: Shovel
+ 158: Pepper
+ 159: Computer Box
+ 160: Toilet Paper
+ 161: Cleaning Products
+ 162: Chopsticks
+ 163: Microwave
+ 164: Pigeon
+ 165: Baseball
+ 166: Cutting/chopping Board
+ 167: Coffee Table
+ 168: Side Table
+ 169: Scissors
+ 170: Marker
+ 171: Pie
+ 172: Ladder
+ 173: Snowboard
+ 174: Cookies
+ 175: Radiator
+ 176: Fire Hydrant
+ 177: Basketball
+ 178: Zebra
+ 179: Grape
+ 180: Giraffe
+ 181: Potato
+ 182: Sausage
+ 183: Tricycle
+ 184: Violin
+ 185: Egg
+ 186: Fire Extinguisher
+ 187: Candy
+ 188: Fire Truck
+ 189: Billiards
+ 190: Converter
+ 191: Bathtub
+ 192: Wheelchair
+ 193: Golf Club
+ 194: Briefcase
+ 195: Cucumber
+ 196: Cigar/Cigarette
+ 197: Paint Brush
+ 198: Pear
+ 199: Heavy Truck
+ 200: Hamburger
+ 201: Extractor
+ 202: Extension Cord
+ 203: Tong
+ 204: Tennis Racket
+ 205: Folder
+ 206: American Football
+ 207: earphone
+ 208: Mask
+ 209: Kettle
+ 210: Tennis
+ 211: Ship
+ 212: Swing
+ 213: Coffee Machine
+ 214: Slide
+ 215: Carriage
+ 216: Onion
+ 217: Green beans
+ 218: Projector
+ 219: Frisbee
+ 220: Washing Machine/Drying Machine
+ 221: Chicken
+ 222: Printer
+ 223: Watermelon
+ 224: Saxophone
+ 225: Tissue
+ 226: Toothbrush
+ 227: Ice cream
+ 228: Hot-air balloon
+ 229: Cello
+ 230: French Fries
+ 231: Scale
+ 232: Trophy
+ 233: Cabbage
+ 234: Hot dog
+ 235: Blender
+ 236: Peach
+ 237: Rice
+ 238: Wallet/Purse
+ 239: Volleyball
+ 240: Deer
+ 241: Goose
+ 242: Tape
+ 243: Tablet
+ 244: Cosmetics
+ 245: Trumpet
+ 246: Pineapple
+ 247: Golf Ball
+ 248: Ambulance
+ 249: Parking meter
+ 250: Mango
+ 251: Key
+ 252: Hurdle
+ 253: Fishing Rod
+ 254: Medal
+ 255: Flute
+ 256: Brush
+ 257: Penguin
+ 258: Megaphone
+ 259: Corn
+ 260: Lettuce
+ 261: Garlic
+ 262: Swan
+ 263: Helicopter
+ 264: Green Onion
+ 265: Sandwich
+ 266: Nuts
+ 267: Speed Limit Sign
+ 268: Induction Cooker
+ 269: Broom
+ 270: Trombone
+ 271: Plum
+ 272: Rickshaw
+ 273: Goldfish
+ 274: Kiwi fruit
+ 275: Router/modem
+ 276: Poker Card
+ 277: Toaster
+ 278: Shrimp
+ 279: Sushi
+ 280: Cheese
+ 281: Notepaper
+ 282: Cherry
+ 283: Pliers
+ 284: CD
+ 285: Pasta
+ 286: Hammer
+ 287: Cue
+ 288: Avocado
+ 289: Hamimelon
+ 290: Flask
+ 291: Mushroom
+ 292: Screwdriver
+ 293: Soap
+ 294: Recorder
+ 295: Bear
+ 296: Eggplant
+ 297: Board Eraser
+ 298: Coconut
+ 299: Tape Measure/Ruler
+ 300: Pig
+ 301: Showerhead
+ 302: Globe
+ 303: Chips
+ 304: Steak
+ 305: Crosswalk Sign
+ 306: Stapler
+ 307: Camel
+ 308: Formula 1
+ 309: Pomegranate
+ 310: Dishwasher
+ 311: Crab
+ 312: Hoverboard
+ 313: Meat ball
+ 314: Rice Cooker
+ 315: Tuba
+ 316: Calculator
+ 317: Papaya
+ 318: Antelope
+ 319: Parrot
+ 320: Seal
+ 321: Butterfly
+ 322: Dumbbell
+ 323: Donkey
+ 324: Lion
+ 325: Urinal
+ 326: Dolphin
+ 327: Electric Drill
+ 328: Hair Dryer
+ 329: Egg tart
+ 330: Jellyfish
+ 331: Treadmill
+ 332: Lighter
+ 333: Grapefruit
+ 334: Game board
+ 335: Mop
+ 336: Radish
+ 337: Baozi
+ 338: Target
+ 339: French
+ 340: Spring Rolls
+ 341: Monkey
+ 342: Rabbit
+ 343: Pencil Case
+ 344: Yak
+ 345: Red Cabbage
+ 346: Binoculars
+ 347: Asparagus
+ 348: Barbell
+ 349: Scallop
+ 350: Noddles
+ 351: Comb
+ 352: Dumpling
+ 353: Oyster
+ 354: Table Tennis paddle
+ 355: Cosmetics Brush/Eyeliner Pencil
+ 356: Chainsaw
+ 357: Eraser
+ 358: Lobster
+ 359: Durian
+ 360: Okra
+ 361: Lipstick
+ 362: Cosmetics Mirror
+ 363: Curling
+ 364: Table Tennis
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from tqdm import tqdm
+
+ from utils.general import Path, check_requirements, download, np, xyxy2xywhn
+
+ check_requirements(('pycocotools>=2.0',))
+ from pycocotools.coco import COCO
+
+ # Make Directories
+ dir = Path(yaml['path']) # dataset root dir
+ for p in 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+ for q in 'train', 'val':
+ (dir / p / q).mkdir(parents=True, exist_ok=True)
+
+ # Train, Val Splits
+ for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
+ print(f"Processing {split} in {patches} patches ...")
+ images, labels = dir / 'images' / split, dir / 'labels' / split
+
+ # Download
+ url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
+ if split == 'train':
+ download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir, delete=False) # annotations json
+ download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, delete=False, threads=8)
+ elif split == 'val':
+ download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir, delete=False) # annotations json
+ download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, delete=False, threads=8)
+ download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, delete=False, threads=8)
+
+ # Move
+ for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
+ f.rename(images / f.name) # move to /images/{split}
+
+ # Labels
+ coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
+ names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
+ for cid, cat in enumerate(names):
+ catIds = coco.getCatIds(catNms=[cat])
+ imgIds = coco.getImgIds(catIds=catIds)
+ for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
+ width, height = im["width"], im["height"]
+ path = Path(im["file_name"]) # image filename
+ try:
+ with open(labels / path.with_suffix('.txt').name, 'a') as file:
+ annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
+ for a in coco.loadAnns(annIds):
+ x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
+ xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
+ x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
+ file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
+ except Exception as e:
+ print(e)
diff --git a/src/train_utils/train_models/models/yolov5/data/SKU-110K.yaml b/src/train_utils/train_models/models/yolov5/data/SKU-110K.yaml
new file mode 100644
index 0000000..edae717
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/SKU-110K.yaml
@@ -0,0 +1,53 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
+# Example usage: python train.py --data SKU-110K.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── SKU-110K ← downloads here (13.6 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/SKU-110K # dataset root dir
+train: train.txt # train images (relative to 'path') 8219 images
+val: val.txt # val images (relative to 'path') 588 images
+test: test.txt # test images (optional) 2936 images
+
+# Classes
+names:
+ 0: object
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import shutil
+ from tqdm import tqdm
+ from utils.general import np, pd, Path, download, xyxy2xywh
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ parent = Path(dir.parent) # download dir
+ urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
+ download(urls, dir=parent, delete=False)
+
+ # Rename directories
+ if dir.exists():
+ shutil.rmtree(dir)
+ (parent / 'SKU110K_fixed').rename(dir) # rename dir
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
+
+ # Convert labels
+ names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
+ for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
+ x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
+ images, unique_images = x[:, 0], np.unique(x[:, 0])
+ with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
+ f.writelines(f'./images/{s}\n' for s in unique_images)
+ for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
+ cls = 0 # single-class dataset
+ with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
+ for r in x[images == im]:
+ w, h = r[6], r[7] # image width, height
+ xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
+ f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
diff --git a/src/train_utils/train_models/models/yolov5/data/VOC.yaml b/src/train_utils/train_models/models/yolov5/data/VOC.yaml
new file mode 100644
index 0000000..27d3810
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/VOC.yaml
@@ -0,0 +1,100 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
+# Example usage: python train.py --data VOC.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VOC ← downloads here (2.8 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VOC
+train: # train images (relative to 'path') 16551 images
+ - images/train2012
+ - images/train2007
+ - images/val2012
+ - images/val2007
+val: # val images (relative to 'path') 4952 images
+ - images/test2007
+test: # test images (optional)
+ - images/test2007
+
+# Classes
+names:
+ 0: aeroplane
+ 1: bicycle
+ 2: bird
+ 3: boat
+ 4: bottle
+ 5: bus
+ 6: car
+ 7: cat
+ 8: chair
+ 9: cow
+ 10: diningtable
+ 11: dog
+ 12: horse
+ 13: motorbike
+ 14: person
+ 15: pottedplant
+ 16: sheep
+ 17: sofa
+ 18: train
+ 19: tvmonitor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import xml.etree.ElementTree as ET
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def convert_label(path, lb_path, year, image_id):
+ def convert_box(size, box):
+ dw, dh = 1. / size[0], 1. / size[1]
+ x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
+ return x * dw, y * dh, w * dw, h * dh
+
+ in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
+ out_file = open(lb_path, 'w')
+ tree = ET.parse(in_file)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+
+ names = list(yaml['names'].values()) # names list
+ for obj in root.iter('object'):
+ cls = obj.find('name').text
+ if cls in names and int(obj.find('difficult').text) != 1:
+ xmlbox = obj.find('bndbox')
+ bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
+ cls_id = names.index(cls) # class id
+ out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
+ f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
+ f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
+ download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
+
+ # Convert
+ path = dir / 'images/VOCdevkit'
+ for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
+ imgs_path = dir / 'images' / f'{image_set}{year}'
+ lbs_path = dir / 'labels' / f'{image_set}{year}'
+ imgs_path.mkdir(exist_ok=True, parents=True)
+ lbs_path.mkdir(exist_ok=True, parents=True)
+
+ with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
+ image_ids = f.read().strip().split()
+ for id in tqdm(image_ids, desc=f'{image_set}{year}'):
+ f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
+ lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
+ f.rename(imgs_path / f.name) # move image
+ convert_label(path, lb_path, year, id) # convert labels to YOLO format
diff --git a/src/train_utils/train_models/models/yolov5/data/VisDrone.yaml b/src/train_utils/train_models/models/yolov5/data/VisDrone.yaml
new file mode 100644
index 0000000..a8bcf8e
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/VisDrone.yaml
@@ -0,0 +1,70 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
+# Example usage: python train.py --data VisDrone.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VisDrone ← downloads here (2.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VisDrone # dataset root dir
+train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
+val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
+test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
+
+# Classes
+names:
+ 0: pedestrian
+ 1: people
+ 2: bicycle
+ 3: car
+ 4: van
+ 5: truck
+ 6: tricycle
+ 7: awning-tricycle
+ 8: bus
+ 9: motor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, os, Path
+
+ def visdrone2yolo(dir):
+ from PIL import Image
+ from tqdm import tqdm
+
+ def convert_box(size, box):
+ # Convert VisDrone box to YOLO xywh box
+ dw = 1. / size[0]
+ dh = 1. / size[1]
+ return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
+
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
+ pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
+ for f in pbar:
+ img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
+ lines = []
+ with open(f, 'r') as file: # read annotation.txt
+ for row in [x.split(',') for x in file.read().strip().splitlines()]:
+ if row[4] == '0': # VisDrone 'ignored regions' class 0
+ continue
+ cls = int(row[5]) - 1
+ box = convert_box(img_size, tuple(map(int, row[:4])))
+ lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
+ with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
+ fl.writelines(lines) # write label.txt
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
+ download(urls, dir=dir, curl=True, threads=4)
+
+ # Convert
+ for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
+ visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/src/train_utils/train_models/models/yolov5/data/coco.yaml b/src/train_utils/train_models/models/yolov5/data/coco.yaml
new file mode 100644
index 0000000..d64dfc7
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/coco.yaml
@@ -0,0 +1,116 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: python train.py --data coco.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: |
+ from utils.general import download, Path
+
+
+ # Download labels
+ segments = False # segment or box labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
+ download(urls, dir=dir.parent)
+
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/src/train_utils/train_models/models/yolov5/data/coco128-seg.yaml b/src/train_utils/train_models/models/yolov5/data/coco128-seg.yaml
new file mode 100644
index 0000000..5e81910
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/coco128-seg.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128-seg ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128-seg # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128-seg.zip
diff --git a/src/train_utils/train_models/models/yolov5/data/coco128.yaml b/src/train_utils/train_models/models/yolov5/data/coco128.yaml
new file mode 100644
index 0000000..1255673
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/coco128.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128 ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128 # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128.zip
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.Objects365.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.Objects365.yaml
new file mode 100644
index 0000000..7497174
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.Objects365.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for Objects365 training
+# python train.py --weights yolov5m.pt --data Objects365.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.00258
+lrf: 0.17
+momentum: 0.779
+weight_decay: 0.00058
+warmup_epochs: 1.33
+warmup_momentum: 0.86
+warmup_bias_lr: 0.0711
+box: 0.0539
+cls: 0.299
+cls_pw: 0.825
+obj: 0.632
+obj_pw: 1.0
+iou_t: 0.2
+anchor_t: 3.44
+anchors: 3.2
+fl_gamma: 0.0
+hsv_h: 0.0188
+hsv_s: 0.704
+hsv_v: 0.36
+degrees: 0.0
+translate: 0.0902
+scale: 0.491
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 1.0
+mixup: 0.0
+copy_paste: 0.0
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.VOC.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.VOC.yaml
new file mode 100644
index 0000000..0aa4e7d
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.VOC.yaml
@@ -0,0 +1,40 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for VOC training
+# python train.py --batch 128 --weights yolov5m6.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.scratch-med.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 467
+# Last generation: 996
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.87729, 0.85125, 0.91286, 0.72664, 0.0076739, 0.0042529, 0.0013865
+
+lr0: 0.00334
+lrf: 0.15135
+momentum: 0.74832
+weight_decay: 0.00025
+warmup_epochs: 3.3835
+warmup_momentum: 0.59462
+warmup_bias_lr: 0.18657
+box: 0.02
+cls: 0.21638
+cls_pw: 0.5
+obj: 0.51728
+obj_pw: 0.67198
+iou_t: 0.2
+anchor_t: 3.3744
+fl_gamma: 0.0
+hsv_h: 0.01041
+hsv_s: 0.54703
+hsv_v: 0.27739
+degrees: 0.0
+translate: 0.04591
+scale: 0.75544
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 0.85834
+mixup: 0.04266
+copy_paste: 0.0
+anchors: 3.412
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.no-augmentation.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.no-augmentation.yaml
new file mode 100644
index 0000000..8fbd5b2
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.no-augmentation.yaml
@@ -0,0 +1,35 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters when using Albumentations frameworks
+# python train.py --hyp hyp.no-augmentation.yaml
+# See https://github.com/ultralytics/yolov5/pull/3882 for YOLOv5 + Albumentations Usage examples
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+# this parameters are all zero since we want to use albumentation framework
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0 # image HSV-Hue augmentation (fraction)
+hsv_s: 00 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0 # image translation (+/- fraction)
+scale: 0 # image scale (+/- gain)
+shear: 0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.0 # image flip left-right (probability)
+mosaic: 0.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-high.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-high.yaml
new file mode 100644
index 0000000..123cc84
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-high.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for high-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.1 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-low.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-low.yaml
new file mode 100644
index 0000000..b9ef1d5
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-low.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-med.yaml b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-med.yaml
new file mode 100644
index 0000000..d6867d7
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/hyps/hyp.scratch-med.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for medium-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/src/train_utils/train_models/models/yolov5/data/images/bus.jpg b/src/train_utils/train_models/models/yolov5/data/images/bus.jpg
new file mode 100644
index 0000000..b43e311
Binary files /dev/null and b/src/train_utils/train_models/models/yolov5/data/images/bus.jpg differ
diff --git a/src/train_utils/train_models/models/yolov5/data/images/zidane.jpg b/src/train_utils/train_models/models/yolov5/data/images/zidane.jpg
new file mode 100644
index 0000000..92d72ea
Binary files /dev/null and b/src/train_utils/train_models/models/yolov5/data/images/zidane.jpg differ
diff --git a/src/train_utils/train_models/models/yolov5/data/scripts/download_weights.sh b/src/train_utils/train_models/models/yolov5/data/scripts/download_weights.sh
new file mode 100644
index 0000000..31e0a15
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/data/scripts/download_weights.sh
@@ -0,0 +1,22 @@
+#!/bin/bash
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Download latest models from https://github.com/ultralytics/yolov5/releases
+# Example usage: bash data/scripts/download_weights.sh
+# parent
+# └── yolov5
+# ├── yolov5s.pt ← downloads here
+# ├── yolov5m.pt
+# └── ...
+
+python - <\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "9d751d8c-bee8-4339-cf30-9854ca530449"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip ...\n",
+ "Downloading http://images.cocodataset.org/zips/val2017.zip ...\n",
+ "######################################################################## 100.0%\n",
+ "######################################################################## 100.0%\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download COCO val\n",
+ "!bash data/scripts/get_coco.sh --val --segments # download (780M - 5000 images)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "a140d67a-02da-479e-9ddb-7d54bf9e407a"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1msegment/val: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s-seg.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val-seg, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:03<00:00, 1361.31it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100% 157/157 [01:54<00:00, 1.37it/s]\n",
+ " all 5000 36335 0.673 0.517 0.566 0.373 0.672 0.49 0.532 0.319\n",
+ "Speed: 0.6ms pre-process, 4.4ms inference, 2.9ms NMS per image at shape (32, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/val-seg/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s-seg on COCO val\n",
+ "!python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "9d751d8c-bee8-4339-cf30-9854ca530449"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip ...\n",
+ "Downloading http://images.cocodataset.org/zips/val2017.zip ...\n",
+ "######################################################################## 100.0%\n",
+ "######################################################################## 100.0%\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download COCO val\n",
+ "!bash data/scripts/get_coco.sh --val --segments # download (780M - 5000 images)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "a140d67a-02da-479e-9ddb-7d54bf9e407a"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1msegment/val: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s-seg.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val-seg, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:03<00:00, 1361.31it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100% 157/157 [01:54<00:00, 1.37it/s]\n",
+ " all 5000 36335 0.673 0.517 0.566 0.373 0.672 0.49 0.532 0.319\n",
+ "Speed: 0.6ms pre-process, 4.4ms inference, 2.9ms NMS per image at shape (32, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/val-seg/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s-seg on COCO val\n",
+ "!python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "

"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ },
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml) for details!\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "outputs": [],
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s-seg') # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "YOLOv5 Segmentation Tutorial",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/src/train_utils/train_models/models/yolov5/segment/val.py b/src/train_utils/train_models/models/yolov5/segment/val.py
new file mode 100644
index 0000000..a7f95fe
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/segment/val.py
@@ -0,0 +1,473 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 segment model on a segment dataset
+
+Usage:
+ $ bash data/scripts/get_coco.sh --val --segments # download COCO-segments val split (1G, 5000 images)
+ $ python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate COCO-segments
+
+Usage - formats:
+ $ python segment/val.py --weights yolov5s-seg.pt # PyTorch
+ yolov5s-seg.torchscript # TorchScript
+ yolov5s-seg.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-seg_openvino_label # OpenVINO
+ yolov5s-seg.engine # TensorRT
+ yolov5s-seg.mlmodel # CoreML (macOS-only)
+ yolov5s-seg_saved_model # TensorFlow SavedModel
+ yolov5s-seg.pb # TensorFlow GraphDef
+ yolov5s-seg.tflite # TensorFlow Lite
+ yolov5s-seg_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-seg_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import torch.nn.functional as F
+
+from models.common import DetectMultiBackend
+from models.yolo import SegmentationModel
+from utils.callbacks import Callbacks
+from utils.general import (LOGGER, NUM_THREADS, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size,
+ check_requirements, check_yaml, coco80_to_coco91_class, colorstr, increment_path,
+ non_max_suppression, print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, box_iou
+from utils.plots import output_to_target, plot_val_study
+from utils.segment.dataloaders import create_dataloader
+from utils.segment.general import mask_iou, process_mask, process_mask_native, scale_image
+from utils.segment.metrics import Metrics, ap_per_class_box_and_mask
+from utils.segment.plots import plot_images_and_masks
+from utils.torch_utils import de_parallel, select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map, pred_masks):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ from pycocotools.mask import encode
+
+ def single_encode(x):
+ rle = encode(np.asarray(x[:, :, None], order='F', dtype='uint8'))[0]
+ rle['counts'] = rle['counts'].decode('utf-8')
+ return rle
+
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ pred_masks = np.transpose(pred_masks, (2, 0, 1))
+ with ThreadPool(NUM_THREADS) as pool:
+ rles = pool.map(single_encode, pred_masks)
+ for i, (p, b) in enumerate(zip(predn.tolist(), box.tolist())):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5),
+ 'segmentation': rles[i]})
+
+
+def process_batch(detections, labels, iouv, pred_masks=None, gt_masks=None, overlap=False, masks=False):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ if masks:
+ if overlap:
+ nl = len(labels)
+ index = torch.arange(nl, device=gt_masks.device).view(nl, 1, 1) + 1
+ gt_masks = gt_masks.repeat(nl, 1, 1) # shape(1,640,640) -> (n,640,640)
+ gt_masks = torch.where(gt_masks == index, 1.0, 0.0)
+ if gt_masks.shape[1:] != pred_masks.shape[1:]:
+ gt_masks = F.interpolate(gt_masks[None], pred_masks.shape[1:], mode='bilinear', align_corners=False)[0]
+ gt_masks = gt_masks.gt_(0.5)
+ iou = mask_iou(gt_masks.view(gt_masks.shape[0], -1), pred_masks.view(pred_masks.shape[0], -1))
+ else: # boxes
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val-seg', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ overlap=False,
+ mask_downsample_ratio=1,
+ compute_loss=None,
+ callbacks=Callbacks(),
+):
+ if save_json:
+ check_requirements('pycocotools>=2.0.6')
+ process = process_mask_native # more accurate
+ else:
+ process = process_mask # faster
+
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ nm = de_parallel(model).model[-1].nm # number of masks
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ nm = de_parallel(model).model.model[-1].nm if isinstance(model, SegmentationModel) else 32 # number of masks
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '),
+ overlap_mask=overlap,
+ mask_downsample_ratio=mask_downsample_ratio)[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 10) % ('Class', 'Images', 'Instances', 'Box(P', 'R', 'mAP50', 'mAP50-95)', 'Mask(P', 'R',
+ 'mAP50', 'mAP50-95)')
+ dt = Profile(), Profile(), Profile()
+ metrics = Metrics()
+ loss = torch.zeros(4, device=device)
+ jdict, stats = [], []
+ # callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes, masks) in enumerate(pbar):
+ # callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ masks = masks.to(device)
+ masks = masks.float()
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, protos, train_out = model(im) if compute_loss else (*model(im, augment=augment)[:2], None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss((train_out, protos), targets, masks)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det,
+ nm=nm)
+
+ # Metrics
+ plot_masks = [] # masks for plotting
+ for si, (pred, proto) in enumerate(zip(preds, protos)):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct_masks = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ correct_bboxes = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct_masks, correct_bboxes, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Masks
+ midx = [si] if overlap else targets[:, 0] == si
+ gt_masks = masks[midx]
+ pred_masks = process(proto, pred[:, 6:], pred[:, :4], shape=im[si].shape[1:])
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct_bboxes = process_batch(predn, labelsn, iouv)
+ correct_masks = process_batch(predn, labelsn, iouv, pred_masks, gt_masks, overlap=overlap, masks=True)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct_masks, correct_bboxes, pred[:, 4], pred[:, 5], labels[:, 0])) # (conf, pcls, tcls)
+
+ pred_masks = torch.as_tensor(pred_masks, dtype=torch.uint8)
+ if plots and batch_i < 3:
+ plot_masks.append(pred_masks[:15]) # filter top 15 to plot
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ pred_masks = scale_image(im[si].shape[1:],
+ pred_masks.permute(1, 2, 0).contiguous().cpu().numpy(), shape, shapes[si][1])
+ save_one_json(predn, jdict, path, class_map, pred_masks) # append to COCO-JSON dictionary
+ # callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ if len(plot_masks):
+ plot_masks = torch.cat(plot_masks, dim=0)
+ plot_images_and_masks(im, targets, masks, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names)
+ plot_images_and_masks(im, output_to_target(preds, max_det=15), plot_masks, paths,
+ save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ # callbacks.run('on_val_batch_end')
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ results = ap_per_class_box_and_mask(*stats, plot=plots, save_dir=save_dir, names=names)
+ metrics.update(results)
+ nt = np.bincount(stats[4].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 8 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), *metrics.mean_results()))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(metrics.ap_class_index):
+ LOGGER.info(pf % (names[c], seen, nt[c], *metrics.class_result(i)))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ # callbacks.run('on_val_end')
+
+ mp_bbox, mr_bbox, map50_bbox, map_bbox, mp_mask, mr_mask, map50_mask, map_mask = metrics.mean_results()
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ results = []
+ for eval in COCOeval(anno, pred, 'bbox'), COCOeval(anno, pred, 'segm'):
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # img ID to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ results.extend(eval.stats[:2]) # update results (mAP@0.5:0.95, mAP@0.5)
+ map_bbox, map50_bbox, map_mask, map50_mask = results
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ final_metric = mp_bbox, mr_bbox, map50_bbox, map_bbox, mp_mask, mr_mask, map50_mask, map_mask
+ return (*final_metric, *(loss.cpu() / len(dataloader)).tolist()), metrics.get_maps(nc), t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128-seg.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-seg.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val-seg', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ # opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.warning(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.warning('WARNING ⚠️ --save-hybrid returns high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/src/train_utils/train_models/models/yolov5/setup.cfg b/src/train_utils/train_models/models/yolov5/setup.cfg
new file mode 100644
index 0000000..d7c4cb3
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/setup.cfg
@@ -0,0 +1,54 @@
+# Project-wide configuration file, can be used for package metadata and other toll configurations
+# Example usage: global configuration for PEP8 (via flake8) setting or default pytest arguments
+# Local usage: pip install pre-commit, pre-commit run --all-files
+
+[metadata]
+license_file = LICENSE
+description_file = README.md
+
+[tool:pytest]
+norecursedirs =
+ .git
+ dist
+ build
+addopts =
+ --doctest-modules
+ --durations=25
+ --color=yes
+
+[flake8]
+max-line-length = 120
+exclude = .tox,*.egg,build,temp
+select = E,W,F
+doctests = True
+verbose = 2
+# https://pep8.readthedocs.io/en/latest/intro.html#error-codes
+format = pylint
+# see: https://www.flake8rules.com/
+ignore = E731,F405,E402,F401,W504,E127,E231,E501,F403
+ # E731: Do not assign a lambda expression, use a def
+ # F405: name may be undefined, or defined from star imports: module
+ # E402: module level import not at top of file
+ # F401: module imported but unused
+ # W504: line break after binary operator
+ # E127: continuation line over-indented for visual indent
+ # E231: missing whitespace after ‘,’, ‘;’, or ‘:’
+ # E501: line too long
+ # F403: ‘from module import *’ used; unable to detect undefined names
+
+[isort]
+# https://pycqa.github.io/isort/docs/configuration/options.html
+line_length = 120
+# see: https://pycqa.github.io/isort/docs/configuration/multi_line_output_modes.html
+multi_line_output = 0
+
+[yapf]
+based_on_style = pep8
+spaces_before_comment = 2
+COLUMN_LIMIT = 120
+COALESCE_BRACKETS = True
+SPACES_AROUND_POWER_OPERATOR = True
+SPACE_BETWEEN_ENDING_COMMA_AND_CLOSING_BRACKET = False
+SPLIT_BEFORE_CLOSING_BRACKET = False
+SPLIT_BEFORE_FIRST_ARGUMENT = False
+# EACH_DICT_ENTRY_ON_SEPARATE_LINE = False
diff --git a/src/train_utils/train_models/models/yolov5/train.py b/src/train_utils/train_models/models/yolov5/train.py
new file mode 100644
index 0000000..960f24c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/train.py
@@ -0,0 +1,640 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset.
+Models and datasets download automatically from the latest YOLOv5 release.
+
+Usage - Single-GPU training:
+ $ python train.py --data coco128.yaml --weights yolov5s.pt --img 640 # from pretrained (recommended)
+ $ python train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # from scratch
+
+Usage - Multi-GPU DDP training:
+ $ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 train.py --data coco128.yaml --weights yolov5s.pt --img 640 --device 0,1,2,3
+
+Models: https://github.com/ultralytics/yolov5/tree/master/models
+Datasets: https://github.com/ultralytics/yolov5/tree/master/data
+Tutorial: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
+"""
+
+import argparse
+import math
+import os
+import random
+import subprocess
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.optim import lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val as validate # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.downloads import attempt_download, is_url
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
+ check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
+ get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
+ labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer,
+ yaml_save)
+from utils.loggers import Loggers
+from utils.loggers.comet.comet_utils import check_comet_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve
+from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
+ smart_resume, torch_distributed_zero_first)
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+GIT_INFO = check_git_info()
+
+
+def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+ callbacks.run('on_pretrain_routine_start')
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+ opt.hyp = hyp.copy() # for saving hyps to checkpoints
+
+ # Save run settings
+ if not evolve:
+ yaml_save(save_dir / 'hyp.yaml', hyp)
+ yaml_save(save_dir / 'opt.yaml', vars(opt))
+
+ # Loggers
+ data_dict = None
+ if RANK in {-1, 0}:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Process custom dataset artifact link
+ data_dict = loggers.remote_dataset
+ if resume: # If resuming runs from remote artifact
+ weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
+
+ # Config
+ plots = not evolve and not opt.noplots # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(opt.seed + 1 + RANK, deterministic=True)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = {0: 'item'} if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ amp = check_amp(model) # check AMP
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz, amp)
+ loggers.on_params_update({'batch_size': batch_size})
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
+
+ # Scheduler
+ if opt.cos_lr:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ else:
+ lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in {-1, 0} else None
+
+ # Resume
+ best_fitness, start_epoch = 0.0, 0
+ if pretrained:
+ if resume:
+ best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning('WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path,
+ imgsz,
+ batch_size // WORLD_SIZE,
+ gs,
+ single_cls,
+ hyp=hyp,
+ augment=True,
+ cache=None if opt.cache == 'val' else opt.cache,
+ rect=opt.rect,
+ rank=LOCAL_RANK,
+ workers=workers,
+ image_weights=opt.image_weights,
+ quad=opt.quad,
+ prefix=colorstr('train: '),
+ shuffle=True,
+ seed=opt.seed)
+ labels = np.concatenate(dataset.labels, 0)
+ mlc = int(labels[:, 0].max()) # max label class
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in {-1, 0}:
+ val_loader = create_dataloader(val_path,
+ imgsz,
+ batch_size // WORLD_SIZE * 2,
+ gs,
+ single_cls,
+ hyp=hyp,
+ cache=None if noval else opt.cache,
+ rect=True,
+ rank=-1,
+ workers=workers * 2,
+ pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end', labels, names)
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = smart_DDP(model)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nb = len(train_loader) # number of batches
+ nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = torch.cuda.amp.GradScaler(enabled=amp)
+ stopper, stop = EarlyStopping(patience=opt.patience), False
+ compute_loss = ComputeLoss(model) # init loss class
+ callbacks.run('on_train_start')
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ callbacks.run('on_train_epoch_start')
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%11s' * 7) % ('Epoch', 'GPU_mem', 'box_loss', 'obj_loss', 'cls_loss', 'Instances', 'Size'))
+ if RANK in {-1, 0}:
+ pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ callbacks.run('on_train_batch_start')
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with torch.cuda.amp.autocast(amp):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
+ if ni - last_opt_step >= accumulate:
+ scaler.unscale_(optimizer) # unscale gradients
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in {-1, 0}:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%11s' * 2 + '%11.4g' * 5) %
+ (f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', model, ni, imgs, targets, paths, list(mloss))
+ if callbacks.stop_training:
+ return
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in {-1, 0}:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = validate.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ half=amp,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ stop = stopper(epoch=epoch, fitness=fi) # early stop check
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {
+ 'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'opt': vars(opt),
+ 'git': GIT_INFO, # {remote, branch, commit} if a git repo
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if opt.save_period > 0 and epoch % opt.save_period == 0:
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # EarlyStopping
+ if RANK != -1: # if DDP training
+ broadcast_list = [stop if RANK == 0 else None]
+ dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
+ if RANK != 0:
+ stop = broadcast_list[0]
+ if stop:
+ break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in {-1, 0}:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = validate.run(
+ data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=plots,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ if is_coco:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, epoch, results)
+
+ torch.cuda.empty_cache()
+ return results
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Logger arguments
+ parser.add_argument('--entity', default=None, help='Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in {-1, 0}:
+ print_args(vars(opt))
+ check_git_status()
+ check_requirements()
+
+ # Resume (from specified or most recent last.pt)
+ if opt.resume and not check_comet_resume(opt) and not opt.evolve:
+ last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
+ opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
+ opt_data = opt.data # original dataset
+ if opt_yaml.is_file():
+ with open(opt_yaml, errors='ignore') as f:
+ d = yaml.safe_load(f)
+ else:
+ d = torch.load(last, map_location='cpu')['opt']
+ opt = argparse.Namespace(**d) # replace
+ opt.cfg, opt.weights, opt.resume = '', str(last), True # reinstate
+ if is_url(opt_data):
+ opt.data = check_file(opt_data) # avoid HUB resume auth timeout
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ if opt.name == 'cfg':
+ opt.name = Path(opt.cfg).stem # use model.yaml as name
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
+ assert not opt.image_weights, f'--image-weights {msg}'
+ assert not opt.evolve, f'--evolve {msg}'
+ assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
+ assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {
+ 'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ if opt.noautoanchor:
+ del hyp['anchors'], meta['anchors']
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ # download evolve.csv if exists
+ subprocess.run([
+ 'gsutil',
+ 'cp',
+ f'gs://{opt.bucket}/evolve.csv',
+ str(evolve_csv),])
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+ callbacks = Callbacks()
+ # Write mutation results
+ keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss',
+ 'val/obj_loss', 'val/cls_loss')
+ print_mutation(keys, results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Usage example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/src/train_utils/train_models/models/yolov5/utils/__init__.py b/src/train_utils/train_models/models/yolov5/utils/__init__.py
new file mode 100644
index 0000000..5b9fcd5
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/__init__.py
@@ -0,0 +1,82 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+utils/initialization
+"""
+
+import contextlib
+import platform
+import threading
+
+
+def emojis(str=''):
+ # Return platform-dependent emoji-safe version of string
+ return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
+
+
+class TryExcept(contextlib.ContextDecorator):
+ # YOLOv5 TryExcept class. Usage: @TryExcept() decorator or 'with TryExcept():' context manager
+ def __init__(self, msg=''):
+ self.msg = msg
+
+ def __enter__(self):
+ pass
+
+ def __exit__(self, exc_type, value, traceback):
+ if value:
+ print(emojis(f"{self.msg}{': ' if self.msg else ''}{value}"))
+ return True
+
+
+def threaded(func):
+ # Multi-threads a target function and returns thread. Usage: @threaded decorator
+ def wrapper(*args, **kwargs):
+ thread = threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True)
+ thread.start()
+ return thread
+
+ return wrapper
+
+
+def join_threads(verbose=False):
+ # Join all daemon threads, i.e. atexit.register(lambda: join_threads())
+ main_thread = threading.current_thread()
+ for t in threading.enumerate():
+ if t is not main_thread:
+ if verbose:
+ print(f'Joining thread {t.name}')
+ t.join()
+
+
+def notebook_init(verbose=True):
+ # Check system software and hardware
+ print('Checking setup...')
+
+ import os
+ import shutil
+
+ from utils.general import check_font, check_requirements, is_colab
+ from utils.torch_utils import select_device # imports
+
+ check_font()
+
+ import psutil
+
+ if is_colab():
+ shutil.rmtree('/content/sample_data', ignore_errors=True) # remove colab /sample_data directory
+
+ # System info
+ display = None
+ if verbose:
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ ram = psutil.virtual_memory().total
+ total, used, free = shutil.disk_usage('/')
+ with contextlib.suppress(Exception): # clear display if ipython is installed
+ from IPython import display
+ display.clear_output()
+ s = f'({os.cpu_count()} CPUs, {ram / gb:.1f} GB RAM, {(total - free) / gb:.1f}/{total / gb:.1f} GB disk)'
+ else:
+ s = ''
+
+ select_device(newline=False)
+ print(emojis(f'Setup complete ✅ {s}'))
+ return display
diff --git a/src/train_utils/train_models/models/yolov5/utils/activations.py b/src/train_utils/train_models/models/yolov5/utils/activations.py
new file mode 100644
index 0000000..084ce8c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/activations.py
@@ -0,0 +1,103 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Activation functions
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class SiLU(nn.Module):
+ # SiLU activation https://arxiv.org/pdf/1606.08415.pdf
+ @staticmethod
+ def forward(x):
+ return x * torch.sigmoid(x)
+
+
+class Hardswish(nn.Module):
+ # Hard-SiLU activation
+ @staticmethod
+ def forward(x):
+ # return x * F.hardsigmoid(x) # for TorchScript and CoreML
+ return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
+
+
+class Mish(nn.Module):
+ # Mish activation https://github.com/digantamisra98/Mish
+ @staticmethod
+ def forward(x):
+ return x * F.softplus(x).tanh()
+
+
+class MemoryEfficientMish(nn.Module):
+ # Mish activation memory-efficient
+ class F(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x):
+ ctx.save_for_backward(x)
+ return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x = ctx.saved_tensors[0]
+ sx = torch.sigmoid(x)
+ fx = F.softplus(x).tanh()
+ return grad_output * (fx + x * sx * (1 - fx * fx))
+
+ def forward(self, x):
+ return self.F.apply(x)
+
+
+class FReLU(nn.Module):
+ # FReLU activation https://arxiv.org/abs/2007.11824
+ def __init__(self, c1, k=3): # ch_in, kernel
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
+ self.bn = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ return torch.max(x, self.bn(self.conv(x)))
+
+
+class AconC(nn.Module):
+ r""" ACON activation (activate or not)
+ AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
+ according to "Activate or Not: Learning Customized Activation" 
 +
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+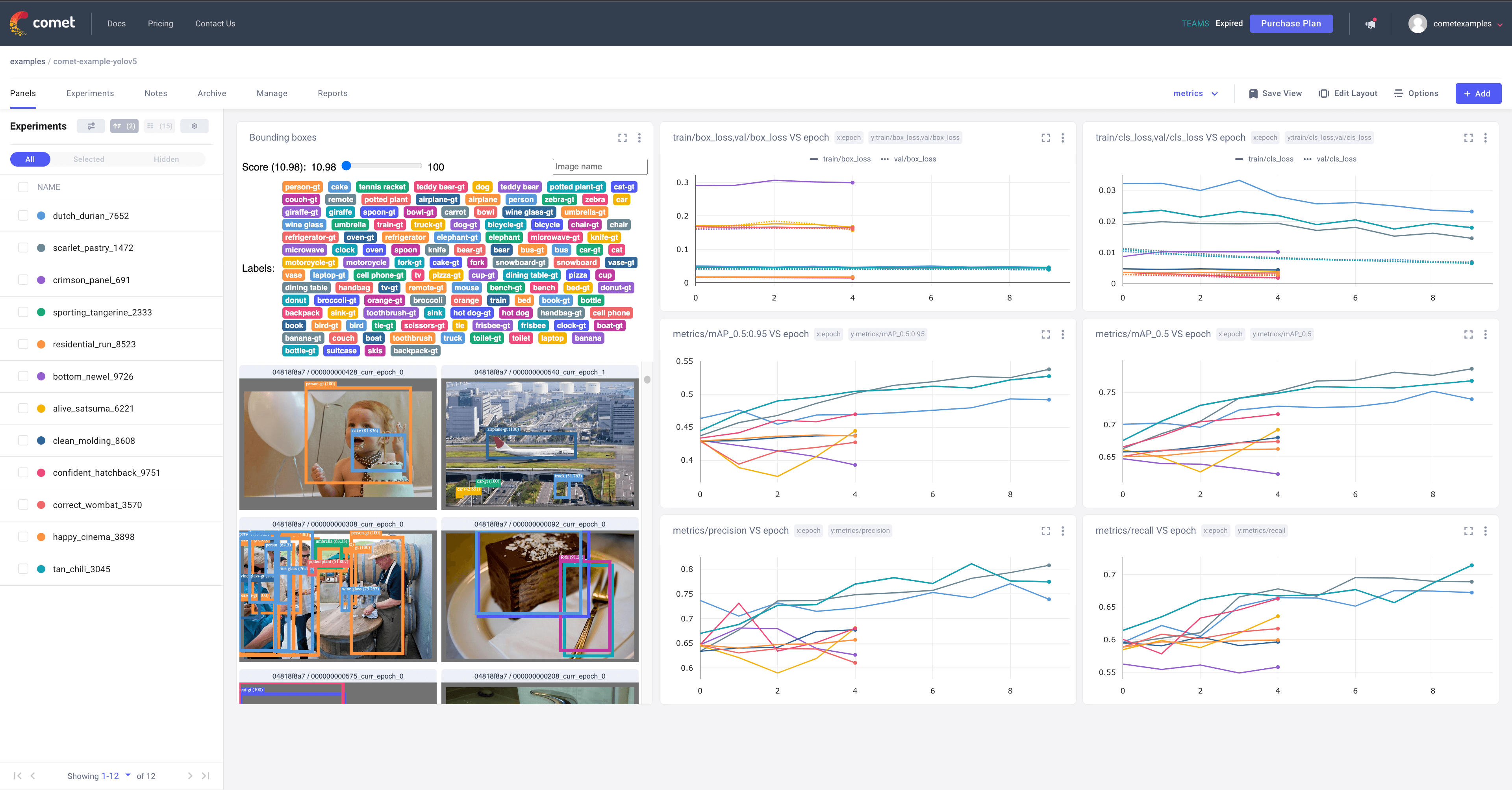 +
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME=
+
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME= +
+You can preview the data directly in the Comet UI.
+
+
+You can preview the data directly in the Comet UI.
+ +
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+
+
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+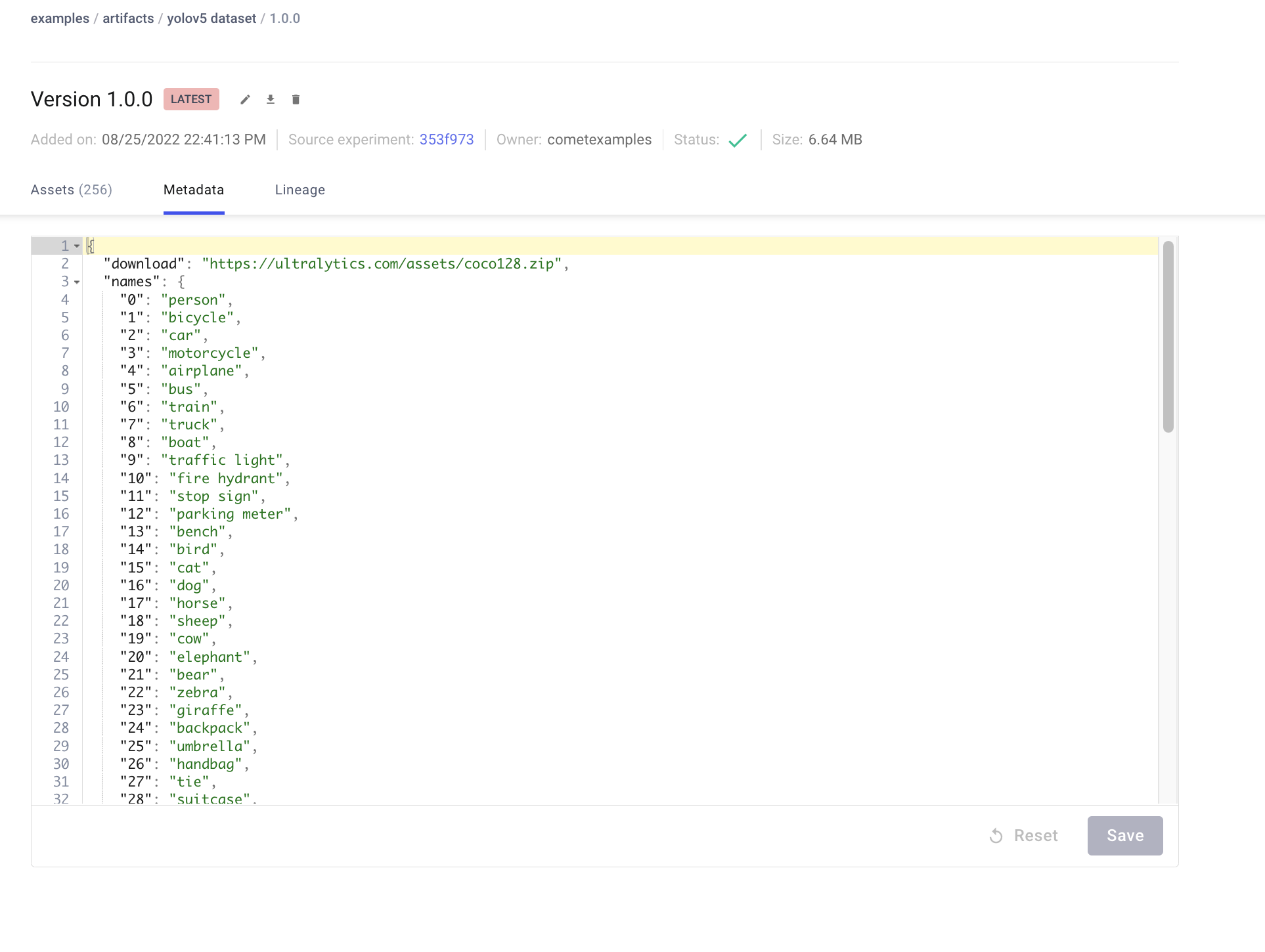 +
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet://
+
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet:// +
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://
+
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://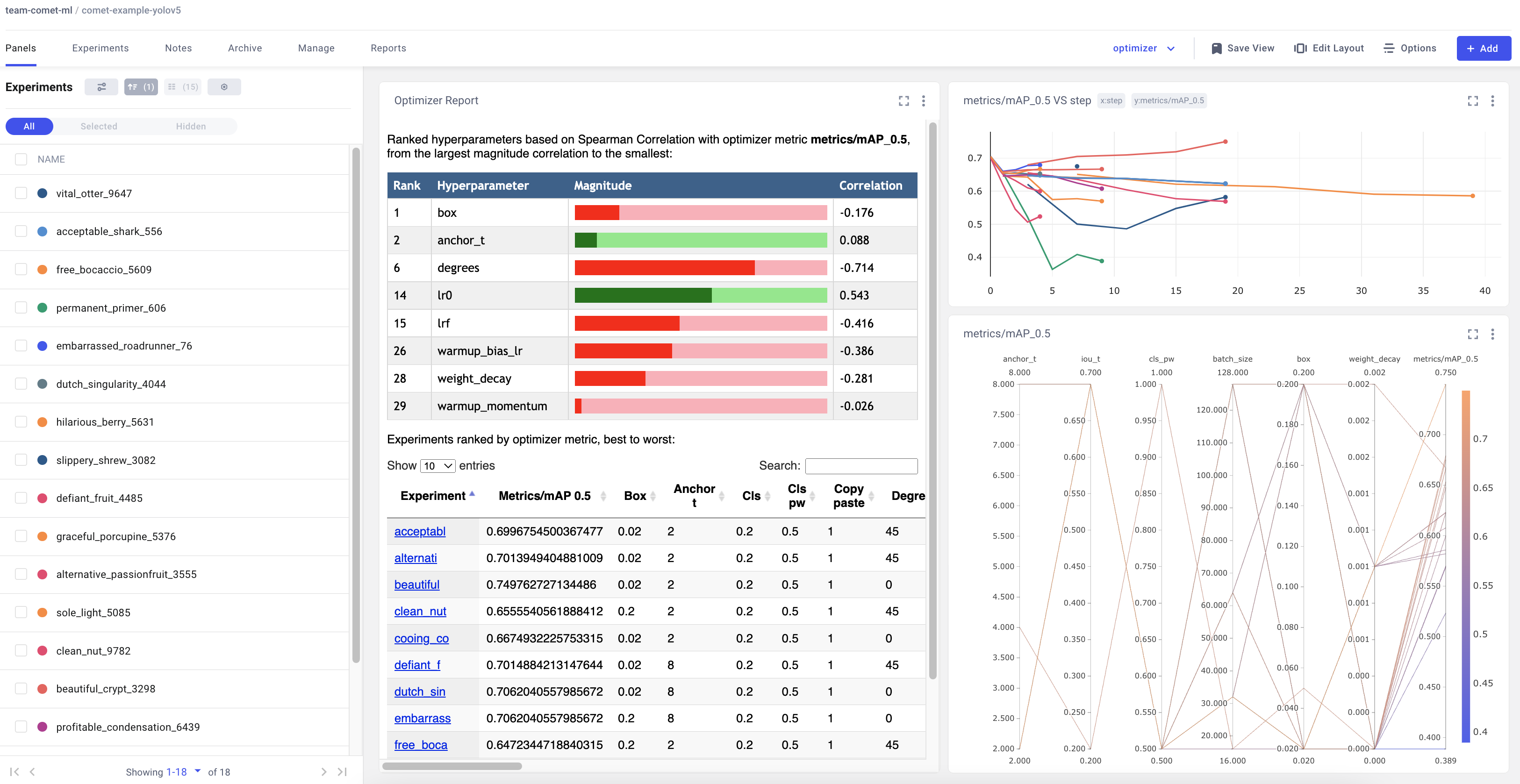 diff --git a/src/train_utils/train_models/models/yolov5/utils/loggers/comet/__init__.py b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/__init__.py
new file mode 100644
index 0000000..d459984
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/__init__.py
@@ -0,0 +1,508 @@
+import glob
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+try:
+ import comet_ml
+
+ # Project Configuration
+ config = comet_ml.config.get_config()
+ COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+ COMET_PROJECT_NAME = None
+
+import PIL
+import torch
+import torchvision.transforms as T
+import yaml
+
+from utils.dataloaders import img2label_paths
+from utils.general import check_dataset, scale_boxes, xywh2xyxy
+from utils.metrics import box_iou
+
+COMET_PREFIX = 'comet://'
+
+COMET_MODE = os.getenv('COMET_MODE', 'online')
+
+# Model Saving Settings
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+
+# Dataset Artifact Settings
+COMET_UPLOAD_DATASET = os.getenv('COMET_UPLOAD_DATASET', 'false').lower() == 'true'
+
+# Evaluation Settings
+COMET_LOG_CONFUSION_MATRIX = os.getenv('COMET_LOG_CONFUSION_MATRIX', 'true').lower() == 'true'
+COMET_LOG_PREDICTIONS = os.getenv('COMET_LOG_PREDICTIONS', 'true').lower() == 'true'
+COMET_MAX_IMAGE_UPLOADS = int(os.getenv('COMET_MAX_IMAGE_UPLOADS', 100))
+
+# Confusion Matrix Settings
+CONF_THRES = float(os.getenv('CONF_THRES', 0.001))
+IOU_THRES = float(os.getenv('IOU_THRES', 0.6))
+
+# Batch Logging Settings
+COMET_LOG_BATCH_METRICS = os.getenv('COMET_LOG_BATCH_METRICS', 'false').lower() == 'true'
+COMET_BATCH_LOGGING_INTERVAL = os.getenv('COMET_BATCH_LOGGING_INTERVAL', 1)
+COMET_PREDICTION_LOGGING_INTERVAL = os.getenv('COMET_PREDICTION_LOGGING_INTERVAL', 1)
+COMET_LOG_PER_CLASS_METRICS = os.getenv('COMET_LOG_PER_CLASS_METRICS', 'false').lower() == 'true'
+
+RANK = int(os.getenv('RANK', -1))
+
+to_pil = T.ToPILImage()
+
+
+class CometLogger:
+ """Log metrics, parameters, source code, models and much more
+ with Comet
+ """
+
+ def __init__(self, opt, hyp, run_id=None, job_type='Training', **experiment_kwargs) -> None:
+ self.job_type = job_type
+ self.opt = opt
+ self.hyp = hyp
+
+ # Comet Flags
+ self.comet_mode = COMET_MODE
+
+ self.save_model = opt.save_period > -1
+ self.model_name = COMET_MODEL_NAME
+
+ # Batch Logging Settings
+ self.log_batch_metrics = COMET_LOG_BATCH_METRICS
+ self.comet_log_batch_interval = COMET_BATCH_LOGGING_INTERVAL
+
+ # Dataset Artifact Settings
+ self.upload_dataset = self.opt.upload_dataset if self.opt.upload_dataset else COMET_UPLOAD_DATASET
+ self.resume = self.opt.resume
+
+ # Default parameters to pass to Experiment objects
+ self.default_experiment_kwargs = {
+ 'log_code': False,
+ 'log_env_gpu': True,
+ 'log_env_cpu': True,
+ 'project_name': COMET_PROJECT_NAME,}
+ self.default_experiment_kwargs.update(experiment_kwargs)
+ self.experiment = self._get_experiment(self.comet_mode, run_id)
+
+ self.data_dict = self.check_dataset(self.opt.data)
+ self.class_names = self.data_dict['names']
+ self.num_classes = self.data_dict['nc']
+
+ self.logged_images_count = 0
+ self.max_images = COMET_MAX_IMAGE_UPLOADS
+
+ if run_id is None:
+ self.experiment.log_other('Created from', 'YOLOv5')
+ if not isinstance(self.experiment, comet_ml.OfflineExperiment):
+ workspace, project_name, experiment_id = self.experiment.url.split('/')[-3:]
+ self.experiment.log_other(
+ 'Run Path',
+ f'{workspace}/{project_name}/{experiment_id}',
+ )
+ self.log_parameters(vars(opt))
+ self.log_parameters(self.opt.hyp)
+ self.log_asset_data(
+ self.opt.hyp,
+ name='hyperparameters.json',
+ metadata={'type': 'hyp-config-file'},
+ )
+ self.log_asset(
+ f'{self.opt.save_dir}/opt.yaml',
+ metadata={'type': 'opt-config-file'},
+ )
+
+ self.comet_log_confusion_matrix = COMET_LOG_CONFUSION_MATRIX
+
+ if hasattr(self.opt, 'conf_thres'):
+ self.conf_thres = self.opt.conf_thres
+ else:
+ self.conf_thres = CONF_THRES
+ if hasattr(self.opt, 'iou_thres'):
+ self.iou_thres = self.opt.iou_thres
+ else:
+ self.iou_thres = IOU_THRES
+
+ self.log_parameters({'val_iou_threshold': self.iou_thres, 'val_conf_threshold': self.conf_thres})
+
+ self.comet_log_predictions = COMET_LOG_PREDICTIONS
+ if self.opt.bbox_interval == -1:
+ self.comet_log_prediction_interval = 1 if self.opt.epochs < 10 else self.opt.epochs // 10
+ else:
+ self.comet_log_prediction_interval = self.opt.bbox_interval
+
+ if self.comet_log_predictions:
+ self.metadata_dict = {}
+ self.logged_image_names = []
+
+ self.comet_log_per_class_metrics = COMET_LOG_PER_CLASS_METRICS
+
+ self.experiment.log_others({
+ 'comet_mode': COMET_MODE,
+ 'comet_max_image_uploads': COMET_MAX_IMAGE_UPLOADS,
+ 'comet_log_per_class_metrics': COMET_LOG_PER_CLASS_METRICS,
+ 'comet_log_batch_metrics': COMET_LOG_BATCH_METRICS,
+ 'comet_log_confusion_matrix': COMET_LOG_CONFUSION_MATRIX,
+ 'comet_model_name': COMET_MODEL_NAME,})
+
+ # Check if running the Experiment with the Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ self.experiment.log_other('optimizer_id', self.opt.comet_optimizer_id)
+ self.experiment.log_other('optimizer_objective', self.opt.comet_optimizer_objective)
+ self.experiment.log_other('optimizer_metric', self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_parameters', json.dumps(self.hyp))
+
+ def _get_experiment(self, mode, experiment_id=None):
+ if mode == 'offline':
+ if experiment_id is not None:
+ return comet_ml.ExistingOfflineExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.OfflineExperiment(**self.default_experiment_kwargs,)
+
+ else:
+ try:
+ if experiment_id is not None:
+ return comet_ml.ExistingExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.Experiment(**self.default_experiment_kwargs)
+
+ except ValueError:
+ logger.warning('COMET WARNING: '
+ 'Comet credentials have not been set. '
+ 'Comet will default to offline logging. '
+ 'Please set your credentials to enable online logging.')
+ return self._get_experiment('offline', experiment_id)
+
+ return
+
+ def log_metrics(self, log_dict, **kwargs):
+ self.experiment.log_metrics(log_dict, **kwargs)
+
+ def log_parameters(self, log_dict, **kwargs):
+ self.experiment.log_parameters(log_dict, **kwargs)
+
+ def log_asset(self, asset_path, **kwargs):
+ self.experiment.log_asset(asset_path, **kwargs)
+
+ def log_asset_data(self, asset, **kwargs):
+ self.experiment.log_asset_data(asset, **kwargs)
+
+ def log_image(self, img, **kwargs):
+ self.experiment.log_image(img, **kwargs)
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ if not self.save_model:
+ return
+
+ model_metadata = {
+ 'fitness_score': fitness_score[-1],
+ 'epochs_trained': epoch + 1,
+ 'save_period': opt.save_period,
+ 'total_epochs': opt.epochs,}
+
+ model_files = glob.glob(f'{path}/*.pt')
+ for model_path in model_files:
+ name = Path(model_path).name
+
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ metadata=model_metadata,
+ overwrite=True,
+ )
+
+ def check_dataset(self, data_file):
+ with open(data_file) as f:
+ data_config = yaml.safe_load(f)
+
+ if data_config['path'].startswith(COMET_PREFIX):
+ path = data_config['path'].replace(COMET_PREFIX, '')
+ data_dict = self.download_dataset_artifact(path)
+
+ return data_dict
+
+ self.log_asset(self.opt.data, metadata={'type': 'data-config-file'})
+
+ return check_dataset(data_file)
+
+ def log_predictions(self, image, labelsn, path, shape, predn):
+ if self.logged_images_count >= self.max_images:
+ return
+ detections = predn[predn[:, 4] > self.conf_thres]
+ iou = box_iou(labelsn[:, 1:], detections[:, :4])
+ mask, _ = torch.where(iou > self.iou_thres)
+ if len(mask) == 0:
+ return
+
+ filtered_detections = detections[mask]
+ filtered_labels = labelsn[mask]
+
+ image_id = path.split('/')[-1].split('.')[0]
+ image_name = f'{image_id}_curr_epoch_{self.experiment.curr_epoch}'
+ if image_name not in self.logged_image_names:
+ native_scale_image = PIL.Image.open(path)
+ self.log_image(native_scale_image, name=image_name)
+ self.logged_image_names.append(image_name)
+
+ metadata = []
+ for cls, *xyxy in filtered_labels.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}-gt',
+ 'score': 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+ for *xyxy, conf, cls in filtered_detections.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}',
+ 'score': conf * 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+
+ self.metadata_dict[image_name] = metadata
+ self.logged_images_count += 1
+
+ return
+
+ def preprocess_prediction(self, image, labels, shape, pred):
+ nl, _ = labels.shape[0], pred.shape[0]
+
+ # Predictions
+ if self.opt.single_cls:
+ pred[:, 5] = 0
+
+ predn = pred.clone()
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1])
+
+ labelsn = None
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(image.shape[1:], tbox, shape[0], shape[1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1]) # native-space pred
+
+ return predn, labelsn
+
+ def add_assets_to_artifact(self, artifact, path, asset_path, split):
+ img_paths = sorted(glob.glob(f'{asset_path}/*'))
+ label_paths = img2label_paths(img_paths)
+
+ for image_file, label_file in zip(img_paths, label_paths):
+ image_logical_path, label_logical_path = map(lambda x: os.path.relpath(x, path), [image_file, label_file])
+
+ try:
+ artifact.add(image_file, logical_path=image_logical_path, metadata={'split': split})
+ artifact.add(label_file, logical_path=label_logical_path, metadata={'split': split})
+ except ValueError as e:
+ logger.error('COMET ERROR: Error adding file to Artifact. Skipping file.')
+ logger.error(f'COMET ERROR: {e}')
+ continue
+
+ return artifact
+
+ def upload_dataset_artifact(self):
+ dataset_name = self.data_dict.get('dataset_name', 'yolov5-dataset')
+ path = str((ROOT / Path(self.data_dict['path'])).resolve())
+
+ metadata = self.data_dict.copy()
+ for key in ['train', 'val', 'test']:
+ split_path = metadata.get(key)
+ if split_path is not None:
+ metadata[key] = split_path.replace(path, '')
+
+ artifact = comet_ml.Artifact(name=dataset_name, artifact_type='dataset', metadata=metadata)
+ for key in metadata.keys():
+ if key in ['train', 'val', 'test']:
+ if isinstance(self.upload_dataset, str) and (key != self.upload_dataset):
+ continue
+
+ asset_path = self.data_dict.get(key)
+ if asset_path is not None:
+ artifact = self.add_assets_to_artifact(artifact, path, asset_path, key)
+
+ self.experiment.log_artifact(artifact)
+
+ return
+
+ def download_dataset_artifact(self, artifact_path):
+ logged_artifact = self.experiment.get_artifact(artifact_path)
+ artifact_save_dir = str(Path(self.opt.save_dir) / logged_artifact.name)
+ logged_artifact.download(artifact_save_dir)
+
+ metadata = logged_artifact.metadata
+ data_dict = metadata.copy()
+ data_dict['path'] = artifact_save_dir
+
+ metadata_names = metadata.get('names')
+ if type(metadata_names) == dict:
+ data_dict['names'] = {int(k): v for k, v in metadata.get('names').items()}
+ elif type(metadata_names) == list:
+ data_dict['names'] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
+
+ data_dict = self.update_data_paths(data_dict)
+ return data_dict
+
+ def update_data_paths(self, data_dict):
+ path = data_dict.get('path', '')
+
+ for split in ['train', 'val', 'test']:
+ if data_dict.get(split):
+ split_path = data_dict.get(split)
+ data_dict[split] = (f'{path}/{split_path}' if isinstance(split, str) else [
+ f'{path}/{x}' for x in split_path])
+
+ return data_dict
+
+ def on_pretrain_routine_end(self, paths):
+ if self.opt.resume:
+ return
+
+ for path in paths:
+ self.log_asset(str(path))
+
+ if self.upload_dataset:
+ if not self.resume:
+ self.upload_dataset_artifact()
+
+ return
+
+ def on_train_start(self):
+ self.log_parameters(self.hyp)
+
+ def on_train_epoch_start(self):
+ return
+
+ def on_train_epoch_end(self, epoch):
+ self.experiment.curr_epoch = epoch
+
+ return
+
+ def on_train_batch_start(self):
+ return
+
+ def on_train_batch_end(self, log_dict, step):
+ self.experiment.curr_step = step
+ if self.log_batch_metrics and (step % self.comet_log_batch_interval == 0):
+ self.log_metrics(log_dict, step=step)
+
+ return
+
+ def on_train_end(self, files, save_dir, last, best, epoch, results):
+ if self.comet_log_predictions:
+ curr_epoch = self.experiment.curr_epoch
+ self.experiment.log_asset_data(self.metadata_dict, 'image-metadata.json', epoch=curr_epoch)
+
+ for f in files:
+ self.log_asset(f, metadata={'epoch': epoch})
+ self.log_asset(f'{save_dir}/results.csv', metadata={'epoch': epoch})
+
+ if not self.opt.evolve:
+ model_path = str(best if best.exists() else last)
+ name = Path(model_path).name
+ if self.save_model:
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ overwrite=True,
+ )
+
+ # Check if running Experiment with Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ metric = results.get(self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_metric_value', metric)
+
+ self.finish_run()
+
+ def on_val_start(self):
+ return
+
+ def on_val_batch_start(self):
+ return
+
+ def on_val_batch_end(self, batch_i, images, targets, paths, shapes, outputs):
+ if not (self.comet_log_predictions and ((batch_i + 1) % self.comet_log_prediction_interval == 0)):
+ return
+
+ for si, pred in enumerate(outputs):
+ if len(pred) == 0:
+ continue
+
+ image = images[si]
+ labels = targets[targets[:, 0] == si, 1:]
+ shape = shapes[si]
+ path = paths[si]
+ predn, labelsn = self.preprocess_prediction(image, labels, shape, pred)
+ if labelsn is not None:
+ self.log_predictions(image, labelsn, path, shape, predn)
+
+ return
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ if self.comet_log_per_class_metrics:
+ if self.num_classes > 1:
+ for i, c in enumerate(ap_class):
+ class_name = self.class_names[c]
+ self.experiment.log_metrics(
+ {
+ 'mAP@.5': ap50[i],
+ 'mAP@.5:.95': ap[i],
+ 'precision': p[i],
+ 'recall': r[i],
+ 'f1': f1[i],
+ 'true_positives': tp[i],
+ 'false_positives': fp[i],
+ 'support': nt[c]},
+ prefix=class_name)
+
+ if self.comet_log_confusion_matrix:
+ epoch = self.experiment.curr_epoch
+ class_names = list(self.class_names.values())
+ class_names.append('background')
+ num_classes = len(class_names)
+
+ self.experiment.log_confusion_matrix(
+ matrix=confusion_matrix.matrix,
+ max_categories=num_classes,
+ labels=class_names,
+ epoch=epoch,
+ column_label='Actual Category',
+ row_label='Predicted Category',
+ file_name=f'confusion-matrix-epoch-{epoch}.json',
+ )
+
+ def on_fit_epoch_end(self, result, epoch):
+ self.log_metrics(result, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ def on_params_update(self, params):
+ self.log_parameters(params)
+
+ def finish_run(self):
+ self.experiment.end()
diff --git a/src/train_utils/train_models/models/yolov5/utils/loggers/comet/comet_utils.py b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/comet_utils.py
new file mode 100644
index 0000000..2760076
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/comet_utils.py
@@ -0,0 +1,150 @@
+import logging
+import os
+from urllib.parse import urlparse
+
+try:
+ import comet_ml
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+
+import yaml
+
+logger = logging.getLogger(__name__)
+
+COMET_PREFIX = 'comet://'
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+COMET_DEFAULT_CHECKPOINT_FILENAME = os.getenv('COMET_DEFAULT_CHECKPOINT_FILENAME', 'last.pt')
+
+
+def download_model_checkpoint(opt, experiment):
+ model_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(model_dir, exist_ok=True)
+
+ model_name = COMET_MODEL_NAME
+ model_asset_list = experiment.get_model_asset_list(model_name)
+
+ if len(model_asset_list) == 0:
+ logger.error(f'COMET ERROR: No checkpoints found for model name : {model_name}')
+ return
+
+ model_asset_list = sorted(
+ model_asset_list,
+ key=lambda x: x['step'],
+ reverse=True,
+ )
+ logged_checkpoint_map = {asset['fileName']: asset['assetId'] for asset in model_asset_list}
+
+ resource_url = urlparse(opt.weights)
+ checkpoint_filename = resource_url.query
+
+ if checkpoint_filename:
+ asset_id = logged_checkpoint_map.get(checkpoint_filename)
+ else:
+ asset_id = logged_checkpoint_map.get(COMET_DEFAULT_CHECKPOINT_FILENAME)
+ checkpoint_filename = COMET_DEFAULT_CHECKPOINT_FILENAME
+
+ if asset_id is None:
+ logger.error(f'COMET ERROR: Checkpoint {checkpoint_filename} not found in the given Experiment')
+ return
+
+ try:
+ logger.info(f'COMET INFO: Downloading checkpoint {checkpoint_filename}')
+ asset_filename = checkpoint_filename
+
+ model_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ model_download_path = f'{model_dir}/{asset_filename}'
+ with open(model_download_path, 'wb') as f:
+ f.write(model_binary)
+
+ opt.weights = model_download_path
+
+ except Exception as e:
+ logger.warning('COMET WARNING: Unable to download checkpoint from Comet')
+ logger.exception(e)
+
+
+def set_opt_parameters(opt, experiment):
+ """Update the opts Namespace with parameters
+ from Comet's ExistingExperiment when resuming a run
+
+ Args:
+ opt (argparse.Namespace): Namespace of command line options
+ experiment (comet_ml.APIExperiment): Comet API Experiment object
+ """
+ asset_list = experiment.get_asset_list()
+ resume_string = opt.resume
+
+ for asset in asset_list:
+ if asset['fileName'] == 'opt.yaml':
+ asset_id = asset['assetId']
+ asset_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ opt_dict = yaml.safe_load(asset_binary)
+ for key, value in opt_dict.items():
+ setattr(opt, key, value)
+ opt.resume = resume_string
+
+ # Save hyperparameters to YAML file
+ # Necessary to pass checks in training script
+ save_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(save_dir, exist_ok=True)
+
+ hyp_yaml_path = f'{save_dir}/hyp.yaml'
+ with open(hyp_yaml_path, 'w') as f:
+ yaml.dump(opt.hyp, f)
+ opt.hyp = hyp_yaml_path
+
+
+def check_comet_weights(opt):
+ """Downloads model weights from Comet and updates the
+ weights path to point to saved weights location
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if weights are successfully downloaded
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.weights, str):
+ if opt.weights.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.weights)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ download_model_checkpoint(opt, experiment)
+ return True
+
+ return None
+
+
+def check_comet_resume(opt):
+ """Restores run parameters to its original state based on the model checkpoint
+ and logged Experiment parameters.
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if the run is restored successfully
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.resume)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ set_opt_parameters(opt, experiment)
+ download_model_checkpoint(opt, experiment)
+
+ return True
+
+ return None
diff --git a/src/train_utils/train_models/models/yolov5/utils/loggers/comet/hpo.py b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/hpo.py
new file mode 100644
index 0000000..fc49115
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/hpo.py
@@ -0,0 +1,118 @@
+import argparse
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+import comet_ml
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+# Project Configuration
+config = comet_ml.config.get_config()
+COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+
+
+def get_args(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # Comet Arguments
+ parser.add_argument('--comet_optimizer_config', type=str, help='Comet: Path to a Comet Optimizer Config File.')
+ parser.add_argument('--comet_optimizer_id', type=str, help='Comet: ID of the Comet Optimizer sweep.')
+ parser.add_argument('--comet_optimizer_objective', type=str, help="Comet: Set to 'minimize' or 'maximize'.")
+ parser.add_argument('--comet_optimizer_metric', type=str, help='Comet: Metric to Optimize.')
+ parser.add_argument('--comet_optimizer_workers',
+ type=int,
+ default=1,
+ help='Comet: Number of Parallel Workers to use with the Comet Optimizer.')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def run(parameters, opt):
+ hyp_dict = {k: v for k, v in parameters.items() if k not in ['epochs', 'batch_size']}
+
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.batch_size = parameters.get('batch_size')
+ opt.epochs = parameters.get('epochs')
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == '__main__':
+ opt = get_args(known=True)
+
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.project = str(opt.project)
+
+ optimizer_id = os.getenv('COMET_OPTIMIZER_ID')
+ if optimizer_id is None:
+ with open(opt.comet_optimizer_config) as f:
+ optimizer_config = json.load(f)
+ optimizer = comet_ml.Optimizer(optimizer_config)
+ else:
+ optimizer = comet_ml.Optimizer(optimizer_id)
+
+ opt.comet_optimizer_id = optimizer.id
+ status = optimizer.status()
+
+ opt.comet_optimizer_objective = status['spec']['objective']
+ opt.comet_optimizer_metric = status['spec']['metric']
+
+ logger.info('COMET INFO: Starting Hyperparameter Sweep')
+ for parameter in optimizer.get_parameters():
+ run(parameter['parameters'], opt)
diff --git a/src/train_utils/train_models/models/yolov5/utils/loss.py b/src/train_utils/train_models/models/yolov5/utils/loss.py
new file mode 100644
index 0000000..9b9c3d9
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/src/train_utils/train_models/models/yolov5/utils/metrics.py b/src/train_utils/train_models/models/yolov5/utils/metrics.py
new file mode 100644
index 0000000..95f364c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/metrics.py
@@ -0,0 +1,360 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from utils import TryExcept, threaded
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=''):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ def plot(self, normalize=True, save_dir='', names=()):
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (names + ['background']) if labels else 'auto'
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ 'size': 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ ax.set_xlabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close(fig)
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
+ w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
+
+ # Intersection area
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+@threaded
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+
+
+@threaded
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
diff --git a/src/train_utils/train_models/models/yolov5/utils/plots.py b/src/train_utils/train_models/models/yolov5/utils/plots.py
new file mode 100644
index 0000000..24c618c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/plots.py
@@ -0,0 +1,560 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import contextlib
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils import TryExcept, threaded
+from utils.general import (CONFIG_DIR, FONT, LOGGER, check_font, check_requirements, clip_boxes, increment_path,
+ is_ascii, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+from utils.segment.general import scale_image
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height (WARNING: deprecated) in 9.2.0
+ # _, _, w, h = self.font.getbbox(label) # text width, height (New)
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
+ """Plot masks at once.
+ Args:
+ masks (tensor): predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
+ """
+ if self.pil:
+ # convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = im_mask if retina_masks else scale_image(im_gpu.shape, im_mask, self.im.shape)
+ if self.pil:
+ # convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top'):
+ # Add text to image (PIL-only)
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+
+ def fromarray(self, im):
+ # Update self.im from a numpy array
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output, max_det=300):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ return torch.cat(targets, 0).numpy()
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j],
+ y[3, 1:j] * 1E2,
+ '.-',
+ linewidth=2,
+ markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-',
+ linewidth=2,
+ markersize=8,
+ alpha=.25,
+ label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def imshow_cls(im, labels=None, pred=None, names=None, nmax=25, verbose=False, f=Path('images.jpg')):
+ # Show classification image grid with labels (optional) and predictions (optional)
+ from utils.augmentations import denormalize
+
+ names = names or [f'class{i}' for i in range(1000)]
+ blocks = torch.chunk(denormalize(im.clone()).cpu().float(), len(im),
+ dim=0) # select batch index 0, block by channels
+ n = min(len(blocks), nmax) # number of plots
+ m = min(8, round(n ** 0.5)) # 8 x 8 default
+ fig, ax = plt.subplots(math.ceil(n / m), m) # 8 rows x n/8 cols
+ ax = ax.ravel() if m > 1 else [ax]
+ # plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze().permute((1, 2, 0)).numpy().clip(0.0, 1.0))
+ ax[i].axis('off')
+ if labels is not None:
+ s = names[labels[i]] + (f'—{names[pred[i]]}' if pred is not None else '')
+ ax[i].set_title(s, fontsize=8, verticalalignment='top')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ if verbose:
+ LOGGER.info(f'Saving {f}')
+ if labels is not None:
+ LOGGER.info('True: ' + ' '.join(f'{names[i]:3s}' for i in labels[:nmax]))
+ if pred is not None:
+ LOGGER.info('Predicted:' + ' '.join(f'{names[i]:3s}' for i in pred[:nmax]))
+ return f
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/__init__.py b/src/train_utils/train_models/models/yolov5/utils/segment/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/augmentations.py b/src/train_utils/train_models/models/yolov5/utils/segment/augmentations.py
new file mode 100644
index 0000000..169adde
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/augmentations.py
@@ -0,0 +1,104 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from ..augmentations import box_candidates
+from ..general import resample_segments, segment2box
+
+
+def mixup(im, labels, segments, im2, labels2, segments2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ segments = np.concatenate((segments, segments2), 0)
+ return im, labels, segments
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * width) # x translation (pixels)
+ T[1, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * height) # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ new_segments = []
+ if n:
+ new = np.zeros((n, 4))
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]) # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+ new_segments.append(xy)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+ new_segments = np.array(new_segments)[i]
+
+ return im, targets, new_segments
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/dataloaders.py b/src/train_utils/train_models/models/yolov5/utils/segment/dataloaders.py
new file mode 100644
index 0000000..097a5d5
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/dataloaders.py
@@ -0,0 +1,332 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Dataloaders
+"""
+
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, distributed
+
+from ..augmentations import augment_hsv, copy_paste, letterbox
+from ..dataloaders import InfiniteDataLoader, LoadImagesAndLabels, seed_worker
+from ..general import LOGGER, xyn2xy, xywhn2xyxy, xyxy2xywhn
+from ..torch_utils import torch_distributed_zero_first
+from .augmentations import mixup, random_perspective
+
+RANK = int(os.getenv('RANK', -1))
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ mask_downsample_ratio=1,
+ overlap_mask=False,
+ seed=0):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabelsAndMasks(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix,
+ downsample_ratio=mask_downsample_ratio,
+ overlap=overlap_mask)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + seed + RANK)
+ return loader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=True,
+ collate_fn=LoadImagesAndLabelsAndMasks.collate_fn4 if quad else LoadImagesAndLabelsAndMasks.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ ), dataset
+
+
+class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
+
+ def __init__(
+ self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0,
+ min_items=0,
+ prefix='',
+ downsample_ratio=1,
+ overlap=False,
+ ):
+ super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
+ stride, pad, min_items, prefix)
+ self.downsample_ratio = downsample_ratio
+ self.overlap = overlap
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ masks = []
+ if mosaic:
+ # Load mosaic
+ img, labels, segments = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels, segments = mixup(img, labels, segments, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ # [array, array, ....], array.shape=(num_points, 2), xyxyxyxy
+ segments = self.segments[index].copy()
+ if len(segments):
+ for i_s in range(len(segments)):
+ segments[i_s] = xyn2xy(
+ segments[i_s],
+ ratio[0] * w,
+ ratio[1] * h,
+ padw=pad[0],
+ padh=pad[1],
+ )
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels, segments = random_perspective(img,
+ labels,
+ segments=segments,
+ degrees=hyp['degrees'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3)
+ if self.overlap:
+ masks, sorted_idx = polygons2masks_overlap(img.shape[:2],
+ segments,
+ downsample_ratio=self.downsample_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ labels = labels[sorted_idx]
+ else:
+ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio)
+
+ masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] //
+ self.downsample_ratio, img.shape[1] //
+ self.downsample_ratio))
+ # TODO: albumentations support
+ if self.augment:
+ # Albumentations
+ # there are some augmentation that won't change boxes and masks,
+ # so just be it for now.
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+ masks = torch.flip(masks, dims=[1])
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+ masks = torch.flip(masks, dims=[2])
+
+ # Cutouts # labels = cutout(img, labels, p=0.5)
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return (torch.from_numpy(img), labels_out, self.im_files[index], shapes, masks)
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+
+ # 3 additional image indices
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4, segments4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+ return img4, labels4, segments4
+
+ @staticmethod
+ def collate_fn(batch):
+ img, label, path, shapes, masks = zip(*batch) # transposed
+ batched_masks = torch.cat(masks, 0)
+ for i, l in enumerate(label):
+ l[:, 0] = i # add target image index for build_targets()
+ return torch.stack(img, 0), torch.cat(label, 0), path, shapes, batched_masks
+
+
+def polygon2mask(img_size, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ mask = np.zeros(img_size, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (img_size[0] // downsample_ratio, img_size[1] // downsample_ratio)
+ # NOTE: fillPoly firstly then resize is trying the keep the same way
+ # of loss calculation when mask-ratio=1.
+ mask = cv2.resize(mask, (nw, nh))
+ return mask
+
+
+def polygons2masks(img_size, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M],
+ N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ masks = []
+ for si in range(len(polygons)):
+ mask = polygon2mask(img_size, [polygons[si].reshape(-1)], color, downsample_ratio)
+ masks.append(mask)
+ return np.array(masks)
+
+
+def polygons2masks_overlap(img_size, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((img_size[0] // downsample_ratio, img_size[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(
+ img_size,
+ [segments[si].reshape(-1)],
+ downsample_ratio=downsample_ratio,
+ color=1,
+ )
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/general.py b/src/train_utils/train_models/models/yolov5/utils/segment/general.py
new file mode 100644
index 0000000..f1b2f1d
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/general.py
@@ -0,0 +1,160 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+
+def crop_mask(masks, boxes):
+ """
+ "Crop" predicted masks by zeroing out everything not in the predicted bbox.
+ Vectorized by Chong (thanks Chong).
+
+ Args:
+ - masks should be a size [n, h, w] tensor of masks
+ - boxes should be a size [n, 4] tensor of bbox coords in relative point form
+ """
+
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Crop before upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(mh - pad[1]), int(mw - pad[0])
+ masks = masks[:, top:bottom, left:right]
+
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
+ """
+ img1_shape: model input shape, [h, w]
+ img0_shape: origin pic shape, [h, w, 3]
+ masks: [h, w, num]
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ # masks = masks.permute(2, 0, 1).contiguous()
+ # masks = F.interpolate(masks[None], im0_shape[:2], mode='bilinear', align_corners=False)[0]
+ # masks = masks.permute(1, 2, 0).contiguous()
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ return masks
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [M, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, [N, M]
+ """
+ intersection = torch.matmul(mask1, mask2.t()).clamp(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [N, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, (N, )
+ """
+ intersection = (mask1 * mask2).sum(1).clamp(0) # (N, )
+ union = (mask1.sum(1) + mask2.sum(1))[None] - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks2segments(masks, strategy='largest'):
+ # Convert masks(n,160,160) into segments(n,xy)
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/loss.py b/src/train_utils/train_models/models/yolov5/utils/segment/loss.py
new file mode 100644
index 0000000..caeff3c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/loss.py
@@ -0,0 +1,185 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..general import xywh2xyxy
+from ..loss import FocalLoss, smooth_BCE
+from ..metrics import bbox_iou
+from ..torch_utils import de_parallel
+from .general import crop_mask
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False, overlap=False):
+ self.sort_obj_iou = False
+ self.overlap = overlap
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.nm = m.nm # number of masks
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, preds, targets, masks): # predictions, targets, model
+ p, proto = preds
+ bs, nm, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ lcls = torch.zeros(1, device=self.device)
+ lbox = torch.zeros(1, device=self.device)
+ lobj = torch.zeros(1, device=self.device)
+ lseg = torch.zeros(1, device=self.device)
+ tcls, tbox, indices, anchors, tidxs, xywhn = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ pxy, pwh, _, pcls, pmask = pi[b, a, gj, gi].split((2, 2, 1, self.nc, nm), 1) # subset of predictions
+
+ # Box regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Mask regression
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]
+ marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized
+ mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device))
+ for bi in b.unique():
+ j = b == bi # matching index
+ if self.overlap:
+ mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = masks[tidxs[i]][j]
+ lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j])
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ lseg *= self.hyp['box'] / bs
+
+ loss = lbox + lobj + lcls + lseg
+ return loss * bs, torch.cat((lbox, lseg, lobj, lcls)).detach()
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ # Mask loss for one image
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch, tidxs, xywhn = [], [], [], [], [], []
+ gain = torch.ones(8, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ if self.overlap:
+ batch = p[0].shape[0]
+ ti = []
+ for i in range(batch):
+ num = (targets[:, 0] == i).sum() # find number of targets of each image
+ ti.append(torch.arange(num, device=self.device).float().view(1, num).repeat(na, 1) + 1) # (na, num)
+ ti = torch.cat(ti, 1) # (na, nt)
+ else:
+ ti = torch.arange(nt, device=self.device).float().view(1, nt).repeat(na, 1)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None], ti[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, at = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ (a, tidx), (b, c) = at.long().T, bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ tidxs.append(tidx)
+ xywhn.append(torch.cat((gxy, gwh), 1) / gain[2:6]) # xywh normalized
+
+ return tcls, tbox, indices, anch, tidxs, xywhn
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/metrics.py b/src/train_utils/train_models/models/yolov5/utils/segment/metrics.py
new file mode 100644
index 0000000..c9f137e
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/metrics.py
@@ -0,0 +1,210 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import numpy as np
+
+from ..metrics import ap_per_class
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9, 0.0, 0.0, 0.1, 0.9]
+ return (x[:, :8] * w).sum(1)
+
+
+def ap_per_class_box_and_mask(
+ tp_m,
+ tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ save_dir='.',
+ names=(),
+):
+ """
+ Args:
+ tp_b: tp of boxes.
+ tp_m: tp of masks.
+ other arguments see `func: ap_per_class`.
+ """
+ results_boxes = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Box')[2:]
+ results_masks = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Mask')[2:]
+
+ results = {
+ 'boxes': {
+ 'p': results_boxes[0],
+ 'r': results_boxes[1],
+ 'ap': results_boxes[3],
+ 'f1': results_boxes[2],
+ 'ap_class': results_boxes[4]},
+ 'masks': {
+ 'p': results_masks[0],
+ 'r': results_masks[1],
+ 'ap': results_masks[3],
+ 'f1': results_masks[2],
+ 'ap_class': results_masks[4]}}
+ return results
+
+
+class Metric:
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+
+ @property
+ def ap50(self):
+ """AP@0.5 of all classes.
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """AP@0.5:0.95
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """mean precision of all classes.
+ Return:
+ float.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """mean recall of all classes.
+ Return:
+ float.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """Mean AP@0.5 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """Mean AP@0.5:0.95 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map"""
+ return (self.mp, self.mr, self.map50, self.map)
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]"""
+ return (self.p[i], self.r[i], self.ap50[i], self.ap[i])
+
+ def get_maps(self, nc):
+ maps = np.zeros(nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def update(self, results):
+ """
+ Args:
+ results: tuple(p, r, ap, f1, ap_class)
+ """
+ p, r, all_ap, f1, ap_class_index = results
+ self.p = p
+ self.r = r
+ self.all_ap = all_ap
+ self.f1 = f1
+ self.ap_class_index = ap_class_index
+
+
+class Metrics:
+ """Metric for boxes and masks."""
+
+ def __init__(self) -> None:
+ self.metric_box = Metric()
+ self.metric_mask = Metric()
+
+ def update(self, results):
+ """
+ Args:
+ results: Dict{'boxes': Dict{}, 'masks': Dict{}}
+ """
+ self.metric_box.update(list(results['boxes'].values()))
+ self.metric_mask.update(list(results['masks'].values()))
+
+ def mean_results(self):
+ return self.metric_box.mean_results() + self.metric_mask.mean_results()
+
+ def class_result(self, i):
+ return self.metric_box.class_result(i) + self.metric_mask.class_result(i)
+
+ def get_maps(self, nc):
+ return self.metric_box.get_maps(nc) + self.metric_mask.get_maps(nc)
+
+ @property
+ def ap_class_index(self):
+ # boxes and masks have the same ap_class_index
+ return self.metric_box.ap_class_index
+
+
+KEYS = [
+ 'train/box_loss',
+ 'train/seg_loss', # train loss
+ 'train/obj_loss',
+ 'train/cls_loss',
+ 'metrics/precision(B)',
+ 'metrics/recall(B)',
+ 'metrics/mAP_0.5(B)',
+ 'metrics/mAP_0.5:0.95(B)', # metrics
+ 'metrics/precision(M)',
+ 'metrics/recall(M)',
+ 'metrics/mAP_0.5(M)',
+ 'metrics/mAP_0.5:0.95(M)', # metrics
+ 'val/box_loss',
+ 'val/seg_loss', # val loss
+ 'val/obj_loss',
+ 'val/cls_loss',
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2',]
+
+BEST_KEYS = [
+ 'best/epoch',
+ 'best/precision(B)',
+ 'best/recall(B)',
+ 'best/mAP_0.5(B)',
+ 'best/mAP_0.5:0.95(B)',
+ 'best/precision(M)',
+ 'best/recall(M)',
+ 'best/mAP_0.5(M)',
+ 'best/mAP_0.5:0.95(M)',]
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/plots.py b/src/train_utils/train_models/models/yolov5/utils/segment/plots.py
new file mode 100644
index 0000000..1b22ec8
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/plots.py
@@ -0,0 +1,143 @@
+import contextlib
+import math
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import torch
+
+from .. import threaded
+from ..general import xywh2xyxy
+from ..plots import Annotator, colors
+
+
+@threaded
+def plot_images_and_masks(images, targets, masks, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ idx = targets[:, 0] == i
+ ti = targets[idx] # image targets
+
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+
+ # Plot masks
+ if len(masks):
+ if masks.max() > 1.0: # mean that masks are overlap
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = len(ti)
+ index = np.arange(nl).reshape(nl, 1, 1) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+ else:
+ image_masks = masks[idx]
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+
+
+def plot_results_with_masks(file='path/to/results.csv', dir='', best=True):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ index = np.argmax(0.9 * data.values[:, 8] + 0.1 * data.values[:, 7] + 0.9 * data.values[:, 12] +
+ 0.1 * data.values[:, 11])
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=2)
+ if best:
+ # best
+ ax[i].scatter(index, y[index], color='r', label=f'best:{index}', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[index], 5)}')
+ else:
+ # last
+ ax[i].scatter(x[-1], y[-1], color='r', label='last', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[-1], 5)}')
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
diff --git a/src/train_utils/train_models/models/yolov5/utils/torch_utils.py b/src/train_utils/train_models/models/yolov5/utils/torch_utils.py
new file mode 100644
index 0000000..5b67b3f
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/torch_utils.py
@@ -0,0 +1,432 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return (torch.inference_mode if torch_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def smartCrossEntropyLoss(label_smoothing=0.0):
+ # Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
+ if check_version(torch.__version__, '1.10.0'):
+ return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
+ if label_smoothing > 0:
+ LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
+ return nn.CrossEntropyLoss()
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+def reshape_classifier_output(model, n=1000):
+ # Update a TorchVision classification model to class count 'n' if required
+ from models.common import Classify
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLOv5 Classify() head
+ if m.linear.out_features != n:
+ m.linear = nn.Linear(m.linear.in_features, n)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != n:
+ setattr(model, name, nn.Linear(m.in_features, n))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != n:
+ m[i] = nn.Linear(m[i].in_features, n)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != n:
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ """ YOLOv5 speed/memory/FLOPs profiler
+ Usage:
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f'{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}')
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f'{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias')
+ return optimizer
+
+
+def smart_hub_load(repo='ultralytics/yolov5', model='yolov5s', **kwargs):
+ # YOLOv5 torch.hub.load() wrapper with smart error/issue handling
+ if check_version(torch.__version__, '1.9.1'):
+ kwargs['skip_validation'] = True # validation causes GitHub API rate limit errors
+ if check_version(torch.__version__, '1.12.0'):
+ kwargs['trust_repo'] = True # argument required starting in torch 0.12
+ try:
+ return torch.hub.load(repo, model, **kwargs)
+ except Exception:
+ return torch.hub.load(repo, model, force_reload=True, **kwargs)
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/src/train_utils/train_models/models/yolov5/utils/triton.py b/src/train_utils/train_models/models/yolov5/utils/triton.py
new file mode 100644
index 0000000..2592802
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/triton.py
@@ -0,0 +1,85 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+""" Utils to interact with the Triton Inference Server
+"""
+
+import typing
+from urllib.parse import urlparse
+
+import torch
+
+
+class TritonRemoteModel:
+ """ A wrapper over a model served by the Triton Inference Server. It can
+ be configured to communicate over GRPC or HTTP. It accepts Torch Tensors
+ as input and returns them as outputs.
+ """
+
+ def __init__(self, url: str):
+ """
+ Keyword arguments:
+ url: Fully qualified address of the Triton server - for e.g. grpc://localhost:8000
+ """
+
+ parsed_url = urlparse(url)
+ if parsed_url.scheme == 'grpc':
+ from tritonclient.grpc import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton GRPC client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository.models[0].name
+ self.metadata = self.client.get_model_metadata(self.model_name, as_json=True)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ else:
+ from tritonclient.http import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton HTTP client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository[0]['name']
+ self.metadata = self.client.get_model_metadata(self.model_name)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ self._create_input_placeholders_fn = create_input_placeholders
+
+ @property
+ def runtime(self):
+ """Returns the model runtime"""
+ return self.metadata.get('backend', self.metadata.get('platform'))
+
+ def __call__(self, *args, **kwargs) -> typing.Union[torch.Tensor, typing.Tuple[torch.Tensor, ...]]:
+ """ Invokes the model. Parameters can be provided via args or kwargs.
+ args, if provided, are assumed to match the order of inputs of the model.
+ kwargs are matched with the model input names.
+ """
+ inputs = self._create_inputs(*args, **kwargs)
+ response = self.client.infer(model_name=self.model_name, inputs=inputs)
+ result = []
+ for output in self.metadata['outputs']:
+ tensor = torch.as_tensor(response.as_numpy(output['name']))
+ result.append(tensor)
+ return result[0] if len(result) == 1 else result
+
+ def _create_inputs(self, *args, **kwargs):
+ args_len, kwargs_len = len(args), len(kwargs)
+ if not args_len and not kwargs_len:
+ raise RuntimeError('No inputs provided.')
+ if args_len and kwargs_len:
+ raise RuntimeError('Cannot specify args and kwargs at the same time')
+
+ placeholders = self._create_input_placeholders_fn()
+ if args_len:
+ if args_len != len(placeholders):
+ raise RuntimeError(f'Expected {len(placeholders)} inputs, got {args_len}.')
+ for input, value in zip(placeholders, args):
+ input.set_data_from_numpy(value.cpu().numpy())
+ else:
+ for input in placeholders:
+ value = kwargs[input.name]
+ input.set_data_from_numpy(value.cpu().numpy())
+ return placeholders
diff --git a/src/train_utils/train_models/models/yolov5/val.py b/src/train_utils/train_models/models/yolov5/val.py
new file mode 100644
index 0000000..d4073b4
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/val.py
@@ -0,0 +1,409 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 detection model on a detection dataset
+
+Usage:
+ $ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size, check_requirements,
+ check_yaml, coco80_to_coco91_class, colorstr, increment_path, non_max_suppression,
+ print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'P', 'R', 'mAP50', 'mAP50-95')
+ tp, fp, p, r, f1, mp, mr, map50, ap50, map = 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ dt = Profile(), Profile(), Profile() # profiling times
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss(train_out, targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det)
+
+ # Metrics
+ for si, pred in enumerate(preds):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(preds), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end', batch_i, im, targets, paths, shapes, preds)
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end', nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.info('WARNING ⚠️ --save-hybrid will return high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/src/train_utils/train_models/models/yolov7/.gitignore b/src/train_utils/train_models/models/yolov7/.gitignore
new file mode 100644
index 0000000..d1bbbbe
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov7/.gitignore
@@ -0,0 +1,263 @@
+# Repo-specific GitIgnore ----------------------------------------------------------------------------------------------
+*.jpg
+*.jpeg
+*.png
+*.bmp
+*.tif
+*.tiff
+*.heic
+*.JPG
+*.JPEG
+*.PNG
+*.BMP
+*.TIF
+*.TIFF
+*.HEIC
+*.mp4
+*.mov
+*.MOV
+*.avi
+*.data
+*.json
+*.cfg
+!setup.cfg
+!cfg/yolov3*.cfg
+
+storage.googleapis.com
+runs/*
+data/*
+data/images/*
+!data/*.yaml
+!data/hyps
+!data/scripts
+!data/images
+!data/images/zidane.jpg
+!data/images/bus.jpg
+!data/*.sh
+
+results*.csv
+
+# Datasets -------------------------------------------------------------------------------------------------------------
+coco/
+coco128/
+VOC/
+
+coco2017labels-segments.zip
+test2017.zip
+train2017.zip
+val2017.zip
+
+# MATLAB GitIgnore -----------------------------------------------------------------------------------------------------
+*.m~
+*.mat
+!targets*.mat
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+*.weights
+*.pt
+*.pb
+*.onnx
+*.engine
+*.mlmodel
+*.torchscript
+*.tflite
+*.h5
+*_saved_model/
+*_web_model/
+*_openvino_model/
+darknet53.conv.74
+yolov3-tiny.conv.15
+*.ptl
+*.trt
+
+# GitHub Python GitIgnore ----------------------------------------------------------------------------------------------
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+/wandb/
+.installed.cfg
+*.egg
+
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# dotenv
+.env
+
+# virtualenv
+.venv*
+venv*/
+ENV*/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+
+# https://github.com/github/gitignore/blob/master/Global/macOS.gitignore -----------------------------------------------
+
+# General
+.DS_Store
+.AppleDouble
+.LSOverride
+
+# Icon must end with two \r
+Icon
+Icon?
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+.com.apple.timemachine.donotpresent
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+
+# https://github.com/github/gitignore/blob/master/Global/JetBrains.gitignore
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff:
+.idea/*
+.idea/**/workspace.xml
+.idea/**/tasks.xml
+.idea/dictionaries
+.html # Bokeh Plots
+.pg # TensorFlow Frozen Graphs
+.avi # videos
+
+# Sensitive or high-churn files:
+.idea/**/dataSources/
+.idea/**/dataSources.ids
+.idea/**/dataSources.local.xml
+.idea/**/sqlDataSources.xml
+.idea/**/dynamic.xml
+.idea/**/uiDesigner.xml
+
+# Gradle:
+.idea/**/gradle.xml
+.idea/**/libraries
+
+# CMake
+cmake-build-debug/
+cmake-build-release/
+
+# Mongo Explorer plugin:
+.idea/**/mongoSettings.xml
+
+## File-based project format:
+*.iws
+
+## Plugin-specific files:
+
+# IntelliJ
+out/
+
+# mpeltonen/sbt-idea plugin
+.idea_modules/
+
+# JIRA plugin
+atlassian-ide-plugin.xml
+
+# Cursive Clojure plugin
+.idea/replstate.xml
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+com_crashlytics_export_strings.xml
+crashlytics.properties
+crashlytics-build.properties
+fabric.properties
diff --git a/src/train_utils/train_models/models/yolov7/LICENSE.md b/src/train_utils/train_models/models/yolov7/LICENSE.md
new file mode 100644
index 0000000..f288702
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov7/LICENSE.md
@@ -0,0 +1,674 @@
+ GNU GENERAL PUBLIC LICENSE
+ Version 3, 29 June 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.
diff --git a/src/train_utils/train_models/models/yolov5/utils/loggers/comet/__init__.py b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/__init__.py
new file mode 100644
index 0000000..d459984
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/__init__.py
@@ -0,0 +1,508 @@
+import glob
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+try:
+ import comet_ml
+
+ # Project Configuration
+ config = comet_ml.config.get_config()
+ COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+ COMET_PROJECT_NAME = None
+
+import PIL
+import torch
+import torchvision.transforms as T
+import yaml
+
+from utils.dataloaders import img2label_paths
+from utils.general import check_dataset, scale_boxes, xywh2xyxy
+from utils.metrics import box_iou
+
+COMET_PREFIX = 'comet://'
+
+COMET_MODE = os.getenv('COMET_MODE', 'online')
+
+# Model Saving Settings
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+
+# Dataset Artifact Settings
+COMET_UPLOAD_DATASET = os.getenv('COMET_UPLOAD_DATASET', 'false').lower() == 'true'
+
+# Evaluation Settings
+COMET_LOG_CONFUSION_MATRIX = os.getenv('COMET_LOG_CONFUSION_MATRIX', 'true').lower() == 'true'
+COMET_LOG_PREDICTIONS = os.getenv('COMET_LOG_PREDICTIONS', 'true').lower() == 'true'
+COMET_MAX_IMAGE_UPLOADS = int(os.getenv('COMET_MAX_IMAGE_UPLOADS', 100))
+
+# Confusion Matrix Settings
+CONF_THRES = float(os.getenv('CONF_THRES', 0.001))
+IOU_THRES = float(os.getenv('IOU_THRES', 0.6))
+
+# Batch Logging Settings
+COMET_LOG_BATCH_METRICS = os.getenv('COMET_LOG_BATCH_METRICS', 'false').lower() == 'true'
+COMET_BATCH_LOGGING_INTERVAL = os.getenv('COMET_BATCH_LOGGING_INTERVAL', 1)
+COMET_PREDICTION_LOGGING_INTERVAL = os.getenv('COMET_PREDICTION_LOGGING_INTERVAL', 1)
+COMET_LOG_PER_CLASS_METRICS = os.getenv('COMET_LOG_PER_CLASS_METRICS', 'false').lower() == 'true'
+
+RANK = int(os.getenv('RANK', -1))
+
+to_pil = T.ToPILImage()
+
+
+class CometLogger:
+ """Log metrics, parameters, source code, models and much more
+ with Comet
+ """
+
+ def __init__(self, opt, hyp, run_id=None, job_type='Training', **experiment_kwargs) -> None:
+ self.job_type = job_type
+ self.opt = opt
+ self.hyp = hyp
+
+ # Comet Flags
+ self.comet_mode = COMET_MODE
+
+ self.save_model = opt.save_period > -1
+ self.model_name = COMET_MODEL_NAME
+
+ # Batch Logging Settings
+ self.log_batch_metrics = COMET_LOG_BATCH_METRICS
+ self.comet_log_batch_interval = COMET_BATCH_LOGGING_INTERVAL
+
+ # Dataset Artifact Settings
+ self.upload_dataset = self.opt.upload_dataset if self.opt.upload_dataset else COMET_UPLOAD_DATASET
+ self.resume = self.opt.resume
+
+ # Default parameters to pass to Experiment objects
+ self.default_experiment_kwargs = {
+ 'log_code': False,
+ 'log_env_gpu': True,
+ 'log_env_cpu': True,
+ 'project_name': COMET_PROJECT_NAME,}
+ self.default_experiment_kwargs.update(experiment_kwargs)
+ self.experiment = self._get_experiment(self.comet_mode, run_id)
+
+ self.data_dict = self.check_dataset(self.opt.data)
+ self.class_names = self.data_dict['names']
+ self.num_classes = self.data_dict['nc']
+
+ self.logged_images_count = 0
+ self.max_images = COMET_MAX_IMAGE_UPLOADS
+
+ if run_id is None:
+ self.experiment.log_other('Created from', 'YOLOv5')
+ if not isinstance(self.experiment, comet_ml.OfflineExperiment):
+ workspace, project_name, experiment_id = self.experiment.url.split('/')[-3:]
+ self.experiment.log_other(
+ 'Run Path',
+ f'{workspace}/{project_name}/{experiment_id}',
+ )
+ self.log_parameters(vars(opt))
+ self.log_parameters(self.opt.hyp)
+ self.log_asset_data(
+ self.opt.hyp,
+ name='hyperparameters.json',
+ metadata={'type': 'hyp-config-file'},
+ )
+ self.log_asset(
+ f'{self.opt.save_dir}/opt.yaml',
+ metadata={'type': 'opt-config-file'},
+ )
+
+ self.comet_log_confusion_matrix = COMET_LOG_CONFUSION_MATRIX
+
+ if hasattr(self.opt, 'conf_thres'):
+ self.conf_thres = self.opt.conf_thres
+ else:
+ self.conf_thres = CONF_THRES
+ if hasattr(self.opt, 'iou_thres'):
+ self.iou_thres = self.opt.iou_thres
+ else:
+ self.iou_thres = IOU_THRES
+
+ self.log_parameters({'val_iou_threshold': self.iou_thres, 'val_conf_threshold': self.conf_thres})
+
+ self.comet_log_predictions = COMET_LOG_PREDICTIONS
+ if self.opt.bbox_interval == -1:
+ self.comet_log_prediction_interval = 1 if self.opt.epochs < 10 else self.opt.epochs // 10
+ else:
+ self.comet_log_prediction_interval = self.opt.bbox_interval
+
+ if self.comet_log_predictions:
+ self.metadata_dict = {}
+ self.logged_image_names = []
+
+ self.comet_log_per_class_metrics = COMET_LOG_PER_CLASS_METRICS
+
+ self.experiment.log_others({
+ 'comet_mode': COMET_MODE,
+ 'comet_max_image_uploads': COMET_MAX_IMAGE_UPLOADS,
+ 'comet_log_per_class_metrics': COMET_LOG_PER_CLASS_METRICS,
+ 'comet_log_batch_metrics': COMET_LOG_BATCH_METRICS,
+ 'comet_log_confusion_matrix': COMET_LOG_CONFUSION_MATRIX,
+ 'comet_model_name': COMET_MODEL_NAME,})
+
+ # Check if running the Experiment with the Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ self.experiment.log_other('optimizer_id', self.opt.comet_optimizer_id)
+ self.experiment.log_other('optimizer_objective', self.opt.comet_optimizer_objective)
+ self.experiment.log_other('optimizer_metric', self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_parameters', json.dumps(self.hyp))
+
+ def _get_experiment(self, mode, experiment_id=None):
+ if mode == 'offline':
+ if experiment_id is not None:
+ return comet_ml.ExistingOfflineExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.OfflineExperiment(**self.default_experiment_kwargs,)
+
+ else:
+ try:
+ if experiment_id is not None:
+ return comet_ml.ExistingExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.Experiment(**self.default_experiment_kwargs)
+
+ except ValueError:
+ logger.warning('COMET WARNING: '
+ 'Comet credentials have not been set. '
+ 'Comet will default to offline logging. '
+ 'Please set your credentials to enable online logging.')
+ return self._get_experiment('offline', experiment_id)
+
+ return
+
+ def log_metrics(self, log_dict, **kwargs):
+ self.experiment.log_metrics(log_dict, **kwargs)
+
+ def log_parameters(self, log_dict, **kwargs):
+ self.experiment.log_parameters(log_dict, **kwargs)
+
+ def log_asset(self, asset_path, **kwargs):
+ self.experiment.log_asset(asset_path, **kwargs)
+
+ def log_asset_data(self, asset, **kwargs):
+ self.experiment.log_asset_data(asset, **kwargs)
+
+ def log_image(self, img, **kwargs):
+ self.experiment.log_image(img, **kwargs)
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ if not self.save_model:
+ return
+
+ model_metadata = {
+ 'fitness_score': fitness_score[-1],
+ 'epochs_trained': epoch + 1,
+ 'save_period': opt.save_period,
+ 'total_epochs': opt.epochs,}
+
+ model_files = glob.glob(f'{path}/*.pt')
+ for model_path in model_files:
+ name = Path(model_path).name
+
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ metadata=model_metadata,
+ overwrite=True,
+ )
+
+ def check_dataset(self, data_file):
+ with open(data_file) as f:
+ data_config = yaml.safe_load(f)
+
+ if data_config['path'].startswith(COMET_PREFIX):
+ path = data_config['path'].replace(COMET_PREFIX, '')
+ data_dict = self.download_dataset_artifact(path)
+
+ return data_dict
+
+ self.log_asset(self.opt.data, metadata={'type': 'data-config-file'})
+
+ return check_dataset(data_file)
+
+ def log_predictions(self, image, labelsn, path, shape, predn):
+ if self.logged_images_count >= self.max_images:
+ return
+ detections = predn[predn[:, 4] > self.conf_thres]
+ iou = box_iou(labelsn[:, 1:], detections[:, :4])
+ mask, _ = torch.where(iou > self.iou_thres)
+ if len(mask) == 0:
+ return
+
+ filtered_detections = detections[mask]
+ filtered_labels = labelsn[mask]
+
+ image_id = path.split('/')[-1].split('.')[0]
+ image_name = f'{image_id}_curr_epoch_{self.experiment.curr_epoch}'
+ if image_name not in self.logged_image_names:
+ native_scale_image = PIL.Image.open(path)
+ self.log_image(native_scale_image, name=image_name)
+ self.logged_image_names.append(image_name)
+
+ metadata = []
+ for cls, *xyxy in filtered_labels.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}-gt',
+ 'score': 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+ for *xyxy, conf, cls in filtered_detections.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}',
+ 'score': conf * 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+
+ self.metadata_dict[image_name] = metadata
+ self.logged_images_count += 1
+
+ return
+
+ def preprocess_prediction(self, image, labels, shape, pred):
+ nl, _ = labels.shape[0], pred.shape[0]
+
+ # Predictions
+ if self.opt.single_cls:
+ pred[:, 5] = 0
+
+ predn = pred.clone()
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1])
+
+ labelsn = None
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(image.shape[1:], tbox, shape[0], shape[1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1]) # native-space pred
+
+ return predn, labelsn
+
+ def add_assets_to_artifact(self, artifact, path, asset_path, split):
+ img_paths = sorted(glob.glob(f'{asset_path}/*'))
+ label_paths = img2label_paths(img_paths)
+
+ for image_file, label_file in zip(img_paths, label_paths):
+ image_logical_path, label_logical_path = map(lambda x: os.path.relpath(x, path), [image_file, label_file])
+
+ try:
+ artifact.add(image_file, logical_path=image_logical_path, metadata={'split': split})
+ artifact.add(label_file, logical_path=label_logical_path, metadata={'split': split})
+ except ValueError as e:
+ logger.error('COMET ERROR: Error adding file to Artifact. Skipping file.')
+ logger.error(f'COMET ERROR: {e}')
+ continue
+
+ return artifact
+
+ def upload_dataset_artifact(self):
+ dataset_name = self.data_dict.get('dataset_name', 'yolov5-dataset')
+ path = str((ROOT / Path(self.data_dict['path'])).resolve())
+
+ metadata = self.data_dict.copy()
+ for key in ['train', 'val', 'test']:
+ split_path = metadata.get(key)
+ if split_path is not None:
+ metadata[key] = split_path.replace(path, '')
+
+ artifact = comet_ml.Artifact(name=dataset_name, artifact_type='dataset', metadata=metadata)
+ for key in metadata.keys():
+ if key in ['train', 'val', 'test']:
+ if isinstance(self.upload_dataset, str) and (key != self.upload_dataset):
+ continue
+
+ asset_path = self.data_dict.get(key)
+ if asset_path is not None:
+ artifact = self.add_assets_to_artifact(artifact, path, asset_path, key)
+
+ self.experiment.log_artifact(artifact)
+
+ return
+
+ def download_dataset_artifact(self, artifact_path):
+ logged_artifact = self.experiment.get_artifact(artifact_path)
+ artifact_save_dir = str(Path(self.opt.save_dir) / logged_artifact.name)
+ logged_artifact.download(artifact_save_dir)
+
+ metadata = logged_artifact.metadata
+ data_dict = metadata.copy()
+ data_dict['path'] = artifact_save_dir
+
+ metadata_names = metadata.get('names')
+ if type(metadata_names) == dict:
+ data_dict['names'] = {int(k): v for k, v in metadata.get('names').items()}
+ elif type(metadata_names) == list:
+ data_dict['names'] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
+
+ data_dict = self.update_data_paths(data_dict)
+ return data_dict
+
+ def update_data_paths(self, data_dict):
+ path = data_dict.get('path', '')
+
+ for split in ['train', 'val', 'test']:
+ if data_dict.get(split):
+ split_path = data_dict.get(split)
+ data_dict[split] = (f'{path}/{split_path}' if isinstance(split, str) else [
+ f'{path}/{x}' for x in split_path])
+
+ return data_dict
+
+ def on_pretrain_routine_end(self, paths):
+ if self.opt.resume:
+ return
+
+ for path in paths:
+ self.log_asset(str(path))
+
+ if self.upload_dataset:
+ if not self.resume:
+ self.upload_dataset_artifact()
+
+ return
+
+ def on_train_start(self):
+ self.log_parameters(self.hyp)
+
+ def on_train_epoch_start(self):
+ return
+
+ def on_train_epoch_end(self, epoch):
+ self.experiment.curr_epoch = epoch
+
+ return
+
+ def on_train_batch_start(self):
+ return
+
+ def on_train_batch_end(self, log_dict, step):
+ self.experiment.curr_step = step
+ if self.log_batch_metrics and (step % self.comet_log_batch_interval == 0):
+ self.log_metrics(log_dict, step=step)
+
+ return
+
+ def on_train_end(self, files, save_dir, last, best, epoch, results):
+ if self.comet_log_predictions:
+ curr_epoch = self.experiment.curr_epoch
+ self.experiment.log_asset_data(self.metadata_dict, 'image-metadata.json', epoch=curr_epoch)
+
+ for f in files:
+ self.log_asset(f, metadata={'epoch': epoch})
+ self.log_asset(f'{save_dir}/results.csv', metadata={'epoch': epoch})
+
+ if not self.opt.evolve:
+ model_path = str(best if best.exists() else last)
+ name = Path(model_path).name
+ if self.save_model:
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ overwrite=True,
+ )
+
+ # Check if running Experiment with Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ metric = results.get(self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_metric_value', metric)
+
+ self.finish_run()
+
+ def on_val_start(self):
+ return
+
+ def on_val_batch_start(self):
+ return
+
+ def on_val_batch_end(self, batch_i, images, targets, paths, shapes, outputs):
+ if not (self.comet_log_predictions and ((batch_i + 1) % self.comet_log_prediction_interval == 0)):
+ return
+
+ for si, pred in enumerate(outputs):
+ if len(pred) == 0:
+ continue
+
+ image = images[si]
+ labels = targets[targets[:, 0] == si, 1:]
+ shape = shapes[si]
+ path = paths[si]
+ predn, labelsn = self.preprocess_prediction(image, labels, shape, pred)
+ if labelsn is not None:
+ self.log_predictions(image, labelsn, path, shape, predn)
+
+ return
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ if self.comet_log_per_class_metrics:
+ if self.num_classes > 1:
+ for i, c in enumerate(ap_class):
+ class_name = self.class_names[c]
+ self.experiment.log_metrics(
+ {
+ 'mAP@.5': ap50[i],
+ 'mAP@.5:.95': ap[i],
+ 'precision': p[i],
+ 'recall': r[i],
+ 'f1': f1[i],
+ 'true_positives': tp[i],
+ 'false_positives': fp[i],
+ 'support': nt[c]},
+ prefix=class_name)
+
+ if self.comet_log_confusion_matrix:
+ epoch = self.experiment.curr_epoch
+ class_names = list(self.class_names.values())
+ class_names.append('background')
+ num_classes = len(class_names)
+
+ self.experiment.log_confusion_matrix(
+ matrix=confusion_matrix.matrix,
+ max_categories=num_classes,
+ labels=class_names,
+ epoch=epoch,
+ column_label='Actual Category',
+ row_label='Predicted Category',
+ file_name=f'confusion-matrix-epoch-{epoch}.json',
+ )
+
+ def on_fit_epoch_end(self, result, epoch):
+ self.log_metrics(result, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ def on_params_update(self, params):
+ self.log_parameters(params)
+
+ def finish_run(self):
+ self.experiment.end()
diff --git a/src/train_utils/train_models/models/yolov5/utils/loggers/comet/comet_utils.py b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/comet_utils.py
new file mode 100644
index 0000000..2760076
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/comet_utils.py
@@ -0,0 +1,150 @@
+import logging
+import os
+from urllib.parse import urlparse
+
+try:
+ import comet_ml
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+
+import yaml
+
+logger = logging.getLogger(__name__)
+
+COMET_PREFIX = 'comet://'
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+COMET_DEFAULT_CHECKPOINT_FILENAME = os.getenv('COMET_DEFAULT_CHECKPOINT_FILENAME', 'last.pt')
+
+
+def download_model_checkpoint(opt, experiment):
+ model_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(model_dir, exist_ok=True)
+
+ model_name = COMET_MODEL_NAME
+ model_asset_list = experiment.get_model_asset_list(model_name)
+
+ if len(model_asset_list) == 0:
+ logger.error(f'COMET ERROR: No checkpoints found for model name : {model_name}')
+ return
+
+ model_asset_list = sorted(
+ model_asset_list,
+ key=lambda x: x['step'],
+ reverse=True,
+ )
+ logged_checkpoint_map = {asset['fileName']: asset['assetId'] for asset in model_asset_list}
+
+ resource_url = urlparse(opt.weights)
+ checkpoint_filename = resource_url.query
+
+ if checkpoint_filename:
+ asset_id = logged_checkpoint_map.get(checkpoint_filename)
+ else:
+ asset_id = logged_checkpoint_map.get(COMET_DEFAULT_CHECKPOINT_FILENAME)
+ checkpoint_filename = COMET_DEFAULT_CHECKPOINT_FILENAME
+
+ if asset_id is None:
+ logger.error(f'COMET ERROR: Checkpoint {checkpoint_filename} not found in the given Experiment')
+ return
+
+ try:
+ logger.info(f'COMET INFO: Downloading checkpoint {checkpoint_filename}')
+ asset_filename = checkpoint_filename
+
+ model_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ model_download_path = f'{model_dir}/{asset_filename}'
+ with open(model_download_path, 'wb') as f:
+ f.write(model_binary)
+
+ opt.weights = model_download_path
+
+ except Exception as e:
+ logger.warning('COMET WARNING: Unable to download checkpoint from Comet')
+ logger.exception(e)
+
+
+def set_opt_parameters(opt, experiment):
+ """Update the opts Namespace with parameters
+ from Comet's ExistingExperiment when resuming a run
+
+ Args:
+ opt (argparse.Namespace): Namespace of command line options
+ experiment (comet_ml.APIExperiment): Comet API Experiment object
+ """
+ asset_list = experiment.get_asset_list()
+ resume_string = opt.resume
+
+ for asset in asset_list:
+ if asset['fileName'] == 'opt.yaml':
+ asset_id = asset['assetId']
+ asset_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ opt_dict = yaml.safe_load(asset_binary)
+ for key, value in opt_dict.items():
+ setattr(opt, key, value)
+ opt.resume = resume_string
+
+ # Save hyperparameters to YAML file
+ # Necessary to pass checks in training script
+ save_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(save_dir, exist_ok=True)
+
+ hyp_yaml_path = f'{save_dir}/hyp.yaml'
+ with open(hyp_yaml_path, 'w') as f:
+ yaml.dump(opt.hyp, f)
+ opt.hyp = hyp_yaml_path
+
+
+def check_comet_weights(opt):
+ """Downloads model weights from Comet and updates the
+ weights path to point to saved weights location
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if weights are successfully downloaded
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.weights, str):
+ if opt.weights.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.weights)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ download_model_checkpoint(opt, experiment)
+ return True
+
+ return None
+
+
+def check_comet_resume(opt):
+ """Restores run parameters to its original state based on the model checkpoint
+ and logged Experiment parameters.
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if the run is restored successfully
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.resume)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ set_opt_parameters(opt, experiment)
+ download_model_checkpoint(opt, experiment)
+
+ return True
+
+ return None
diff --git a/src/train_utils/train_models/models/yolov5/utils/loggers/comet/hpo.py b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/hpo.py
new file mode 100644
index 0000000..fc49115
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loggers/comet/hpo.py
@@ -0,0 +1,118 @@
+import argparse
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+import comet_ml
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+# Project Configuration
+config = comet_ml.config.get_config()
+COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+
+
+def get_args(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # Comet Arguments
+ parser.add_argument('--comet_optimizer_config', type=str, help='Comet: Path to a Comet Optimizer Config File.')
+ parser.add_argument('--comet_optimizer_id', type=str, help='Comet: ID of the Comet Optimizer sweep.')
+ parser.add_argument('--comet_optimizer_objective', type=str, help="Comet: Set to 'minimize' or 'maximize'.")
+ parser.add_argument('--comet_optimizer_metric', type=str, help='Comet: Metric to Optimize.')
+ parser.add_argument('--comet_optimizer_workers',
+ type=int,
+ default=1,
+ help='Comet: Number of Parallel Workers to use with the Comet Optimizer.')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def run(parameters, opt):
+ hyp_dict = {k: v for k, v in parameters.items() if k not in ['epochs', 'batch_size']}
+
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.batch_size = parameters.get('batch_size')
+ opt.epochs = parameters.get('epochs')
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == '__main__':
+ opt = get_args(known=True)
+
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.project = str(opt.project)
+
+ optimizer_id = os.getenv('COMET_OPTIMIZER_ID')
+ if optimizer_id is None:
+ with open(opt.comet_optimizer_config) as f:
+ optimizer_config = json.load(f)
+ optimizer = comet_ml.Optimizer(optimizer_config)
+ else:
+ optimizer = comet_ml.Optimizer(optimizer_id)
+
+ opt.comet_optimizer_id = optimizer.id
+ status = optimizer.status()
+
+ opt.comet_optimizer_objective = status['spec']['objective']
+ opt.comet_optimizer_metric = status['spec']['metric']
+
+ logger.info('COMET INFO: Starting Hyperparameter Sweep')
+ for parameter in optimizer.get_parameters():
+ run(parameter['parameters'], opt)
diff --git a/src/train_utils/train_models/models/yolov5/utils/loss.py b/src/train_utils/train_models/models/yolov5/utils/loss.py
new file mode 100644
index 0000000..9b9c3d9
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/src/train_utils/train_models/models/yolov5/utils/metrics.py b/src/train_utils/train_models/models/yolov5/utils/metrics.py
new file mode 100644
index 0000000..95f364c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/metrics.py
@@ -0,0 +1,360 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from utils import TryExcept, threaded
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=''):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ def plot(self, normalize=True, save_dir='', names=()):
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (names + ['background']) if labels else 'auto'
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ 'size': 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ ax.set_xlabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close(fig)
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
+ w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
+
+ # Intersection area
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+@threaded
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+
+
+@threaded
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
diff --git a/src/train_utils/train_models/models/yolov5/utils/plots.py b/src/train_utils/train_models/models/yolov5/utils/plots.py
new file mode 100644
index 0000000..24c618c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/plots.py
@@ -0,0 +1,560 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import contextlib
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils import TryExcept, threaded
+from utils.general import (CONFIG_DIR, FONT, LOGGER, check_font, check_requirements, clip_boxes, increment_path,
+ is_ascii, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+from utils.segment.general import scale_image
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height (WARNING: deprecated) in 9.2.0
+ # _, _, w, h = self.font.getbbox(label) # text width, height (New)
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
+ """Plot masks at once.
+ Args:
+ masks (tensor): predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
+ """
+ if self.pil:
+ # convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = im_mask if retina_masks else scale_image(im_gpu.shape, im_mask, self.im.shape)
+ if self.pil:
+ # convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top'):
+ # Add text to image (PIL-only)
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+
+ def fromarray(self, im):
+ # Update self.im from a numpy array
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output, max_det=300):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ return torch.cat(targets, 0).numpy()
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j],
+ y[3, 1:j] * 1E2,
+ '.-',
+ linewidth=2,
+ markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-',
+ linewidth=2,
+ markersize=8,
+ alpha=.25,
+ label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def imshow_cls(im, labels=None, pred=None, names=None, nmax=25, verbose=False, f=Path('images.jpg')):
+ # Show classification image grid with labels (optional) and predictions (optional)
+ from utils.augmentations import denormalize
+
+ names = names or [f'class{i}' for i in range(1000)]
+ blocks = torch.chunk(denormalize(im.clone()).cpu().float(), len(im),
+ dim=0) # select batch index 0, block by channels
+ n = min(len(blocks), nmax) # number of plots
+ m = min(8, round(n ** 0.5)) # 8 x 8 default
+ fig, ax = plt.subplots(math.ceil(n / m), m) # 8 rows x n/8 cols
+ ax = ax.ravel() if m > 1 else [ax]
+ # plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze().permute((1, 2, 0)).numpy().clip(0.0, 1.0))
+ ax[i].axis('off')
+ if labels is not None:
+ s = names[labels[i]] + (f'—{names[pred[i]]}' if pred is not None else '')
+ ax[i].set_title(s, fontsize=8, verticalalignment='top')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ if verbose:
+ LOGGER.info(f'Saving {f}')
+ if labels is not None:
+ LOGGER.info('True: ' + ' '.join(f'{names[i]:3s}' for i in labels[:nmax]))
+ if pred is not None:
+ LOGGER.info('Predicted:' + ' '.join(f'{names[i]:3s}' for i in pred[:nmax]))
+ return f
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/__init__.py b/src/train_utils/train_models/models/yolov5/utils/segment/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/augmentations.py b/src/train_utils/train_models/models/yolov5/utils/segment/augmentations.py
new file mode 100644
index 0000000..169adde
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/augmentations.py
@@ -0,0 +1,104 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from ..augmentations import box_candidates
+from ..general import resample_segments, segment2box
+
+
+def mixup(im, labels, segments, im2, labels2, segments2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ segments = np.concatenate((segments, segments2), 0)
+ return im, labels, segments
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * width) # x translation (pixels)
+ T[1, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * height) # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ new_segments = []
+ if n:
+ new = np.zeros((n, 4))
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]) # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+ new_segments.append(xy)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+ new_segments = np.array(new_segments)[i]
+
+ return im, targets, new_segments
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/dataloaders.py b/src/train_utils/train_models/models/yolov5/utils/segment/dataloaders.py
new file mode 100644
index 0000000..097a5d5
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/dataloaders.py
@@ -0,0 +1,332 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Dataloaders
+"""
+
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, distributed
+
+from ..augmentations import augment_hsv, copy_paste, letterbox
+from ..dataloaders import InfiniteDataLoader, LoadImagesAndLabels, seed_worker
+from ..general import LOGGER, xyn2xy, xywhn2xyxy, xyxy2xywhn
+from ..torch_utils import torch_distributed_zero_first
+from .augmentations import mixup, random_perspective
+
+RANK = int(os.getenv('RANK', -1))
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ mask_downsample_ratio=1,
+ overlap_mask=False,
+ seed=0):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabelsAndMasks(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix,
+ downsample_ratio=mask_downsample_ratio,
+ overlap=overlap_mask)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + seed + RANK)
+ return loader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=True,
+ collate_fn=LoadImagesAndLabelsAndMasks.collate_fn4 if quad else LoadImagesAndLabelsAndMasks.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ ), dataset
+
+
+class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
+
+ def __init__(
+ self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0,
+ min_items=0,
+ prefix='',
+ downsample_ratio=1,
+ overlap=False,
+ ):
+ super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
+ stride, pad, min_items, prefix)
+ self.downsample_ratio = downsample_ratio
+ self.overlap = overlap
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ masks = []
+ if mosaic:
+ # Load mosaic
+ img, labels, segments = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels, segments = mixup(img, labels, segments, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ # [array, array, ....], array.shape=(num_points, 2), xyxyxyxy
+ segments = self.segments[index].copy()
+ if len(segments):
+ for i_s in range(len(segments)):
+ segments[i_s] = xyn2xy(
+ segments[i_s],
+ ratio[0] * w,
+ ratio[1] * h,
+ padw=pad[0],
+ padh=pad[1],
+ )
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels, segments = random_perspective(img,
+ labels,
+ segments=segments,
+ degrees=hyp['degrees'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3)
+ if self.overlap:
+ masks, sorted_idx = polygons2masks_overlap(img.shape[:2],
+ segments,
+ downsample_ratio=self.downsample_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ labels = labels[sorted_idx]
+ else:
+ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio)
+
+ masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] //
+ self.downsample_ratio, img.shape[1] //
+ self.downsample_ratio))
+ # TODO: albumentations support
+ if self.augment:
+ # Albumentations
+ # there are some augmentation that won't change boxes and masks,
+ # so just be it for now.
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+ masks = torch.flip(masks, dims=[1])
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+ masks = torch.flip(masks, dims=[2])
+
+ # Cutouts # labels = cutout(img, labels, p=0.5)
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return (torch.from_numpy(img), labels_out, self.im_files[index], shapes, masks)
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+
+ # 3 additional image indices
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4, segments4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+ return img4, labels4, segments4
+
+ @staticmethod
+ def collate_fn(batch):
+ img, label, path, shapes, masks = zip(*batch) # transposed
+ batched_masks = torch.cat(masks, 0)
+ for i, l in enumerate(label):
+ l[:, 0] = i # add target image index for build_targets()
+ return torch.stack(img, 0), torch.cat(label, 0), path, shapes, batched_masks
+
+
+def polygon2mask(img_size, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ mask = np.zeros(img_size, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (img_size[0] // downsample_ratio, img_size[1] // downsample_ratio)
+ # NOTE: fillPoly firstly then resize is trying the keep the same way
+ # of loss calculation when mask-ratio=1.
+ mask = cv2.resize(mask, (nw, nh))
+ return mask
+
+
+def polygons2masks(img_size, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M],
+ N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ masks = []
+ for si in range(len(polygons)):
+ mask = polygon2mask(img_size, [polygons[si].reshape(-1)], color, downsample_ratio)
+ masks.append(mask)
+ return np.array(masks)
+
+
+def polygons2masks_overlap(img_size, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((img_size[0] // downsample_ratio, img_size[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(
+ img_size,
+ [segments[si].reshape(-1)],
+ downsample_ratio=downsample_ratio,
+ color=1,
+ )
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/general.py b/src/train_utils/train_models/models/yolov5/utils/segment/general.py
new file mode 100644
index 0000000..f1b2f1d
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/general.py
@@ -0,0 +1,160 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+
+def crop_mask(masks, boxes):
+ """
+ "Crop" predicted masks by zeroing out everything not in the predicted bbox.
+ Vectorized by Chong (thanks Chong).
+
+ Args:
+ - masks should be a size [n, h, w] tensor of masks
+ - boxes should be a size [n, 4] tensor of bbox coords in relative point form
+ """
+
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Crop before upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(mh - pad[1]), int(mw - pad[0])
+ masks = masks[:, top:bottom, left:right]
+
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
+ """
+ img1_shape: model input shape, [h, w]
+ img0_shape: origin pic shape, [h, w, 3]
+ masks: [h, w, num]
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ # masks = masks.permute(2, 0, 1).contiguous()
+ # masks = F.interpolate(masks[None], im0_shape[:2], mode='bilinear', align_corners=False)[0]
+ # masks = masks.permute(1, 2, 0).contiguous()
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ return masks
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [M, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, [N, M]
+ """
+ intersection = torch.matmul(mask1, mask2.t()).clamp(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [N, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, (N, )
+ """
+ intersection = (mask1 * mask2).sum(1).clamp(0) # (N, )
+ union = (mask1.sum(1) + mask2.sum(1))[None] - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks2segments(masks, strategy='largest'):
+ # Convert masks(n,160,160) into segments(n,xy)
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/loss.py b/src/train_utils/train_models/models/yolov5/utils/segment/loss.py
new file mode 100644
index 0000000..caeff3c
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/loss.py
@@ -0,0 +1,185 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..general import xywh2xyxy
+from ..loss import FocalLoss, smooth_BCE
+from ..metrics import bbox_iou
+from ..torch_utils import de_parallel
+from .general import crop_mask
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False, overlap=False):
+ self.sort_obj_iou = False
+ self.overlap = overlap
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.nm = m.nm # number of masks
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, preds, targets, masks): # predictions, targets, model
+ p, proto = preds
+ bs, nm, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ lcls = torch.zeros(1, device=self.device)
+ lbox = torch.zeros(1, device=self.device)
+ lobj = torch.zeros(1, device=self.device)
+ lseg = torch.zeros(1, device=self.device)
+ tcls, tbox, indices, anchors, tidxs, xywhn = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ pxy, pwh, _, pcls, pmask = pi[b, a, gj, gi].split((2, 2, 1, self.nc, nm), 1) # subset of predictions
+
+ # Box regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Mask regression
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]
+ marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized
+ mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device))
+ for bi in b.unique():
+ j = b == bi # matching index
+ if self.overlap:
+ mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = masks[tidxs[i]][j]
+ lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j])
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ lseg *= self.hyp['box'] / bs
+
+ loss = lbox + lobj + lcls + lseg
+ return loss * bs, torch.cat((lbox, lseg, lobj, lcls)).detach()
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ # Mask loss for one image
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch, tidxs, xywhn = [], [], [], [], [], []
+ gain = torch.ones(8, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ if self.overlap:
+ batch = p[0].shape[0]
+ ti = []
+ for i in range(batch):
+ num = (targets[:, 0] == i).sum() # find number of targets of each image
+ ti.append(torch.arange(num, device=self.device).float().view(1, num).repeat(na, 1) + 1) # (na, num)
+ ti = torch.cat(ti, 1) # (na, nt)
+ else:
+ ti = torch.arange(nt, device=self.device).float().view(1, nt).repeat(na, 1)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None], ti[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, at = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ (a, tidx), (b, c) = at.long().T, bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ tidxs.append(tidx)
+ xywhn.append(torch.cat((gxy, gwh), 1) / gain[2:6]) # xywh normalized
+
+ return tcls, tbox, indices, anch, tidxs, xywhn
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/metrics.py b/src/train_utils/train_models/models/yolov5/utils/segment/metrics.py
new file mode 100644
index 0000000..c9f137e
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/metrics.py
@@ -0,0 +1,210 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import numpy as np
+
+from ..metrics import ap_per_class
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9, 0.0, 0.0, 0.1, 0.9]
+ return (x[:, :8] * w).sum(1)
+
+
+def ap_per_class_box_and_mask(
+ tp_m,
+ tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ save_dir='.',
+ names=(),
+):
+ """
+ Args:
+ tp_b: tp of boxes.
+ tp_m: tp of masks.
+ other arguments see `func: ap_per_class`.
+ """
+ results_boxes = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Box')[2:]
+ results_masks = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Mask')[2:]
+
+ results = {
+ 'boxes': {
+ 'p': results_boxes[0],
+ 'r': results_boxes[1],
+ 'ap': results_boxes[3],
+ 'f1': results_boxes[2],
+ 'ap_class': results_boxes[4]},
+ 'masks': {
+ 'p': results_masks[0],
+ 'r': results_masks[1],
+ 'ap': results_masks[3],
+ 'f1': results_masks[2],
+ 'ap_class': results_masks[4]}}
+ return results
+
+
+class Metric:
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+
+ @property
+ def ap50(self):
+ """AP@0.5 of all classes.
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """AP@0.5:0.95
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """mean precision of all classes.
+ Return:
+ float.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """mean recall of all classes.
+ Return:
+ float.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """Mean AP@0.5 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """Mean AP@0.5:0.95 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map"""
+ return (self.mp, self.mr, self.map50, self.map)
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]"""
+ return (self.p[i], self.r[i], self.ap50[i], self.ap[i])
+
+ def get_maps(self, nc):
+ maps = np.zeros(nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def update(self, results):
+ """
+ Args:
+ results: tuple(p, r, ap, f1, ap_class)
+ """
+ p, r, all_ap, f1, ap_class_index = results
+ self.p = p
+ self.r = r
+ self.all_ap = all_ap
+ self.f1 = f1
+ self.ap_class_index = ap_class_index
+
+
+class Metrics:
+ """Metric for boxes and masks."""
+
+ def __init__(self) -> None:
+ self.metric_box = Metric()
+ self.metric_mask = Metric()
+
+ def update(self, results):
+ """
+ Args:
+ results: Dict{'boxes': Dict{}, 'masks': Dict{}}
+ """
+ self.metric_box.update(list(results['boxes'].values()))
+ self.metric_mask.update(list(results['masks'].values()))
+
+ def mean_results(self):
+ return self.metric_box.mean_results() + self.metric_mask.mean_results()
+
+ def class_result(self, i):
+ return self.metric_box.class_result(i) + self.metric_mask.class_result(i)
+
+ def get_maps(self, nc):
+ return self.metric_box.get_maps(nc) + self.metric_mask.get_maps(nc)
+
+ @property
+ def ap_class_index(self):
+ # boxes and masks have the same ap_class_index
+ return self.metric_box.ap_class_index
+
+
+KEYS = [
+ 'train/box_loss',
+ 'train/seg_loss', # train loss
+ 'train/obj_loss',
+ 'train/cls_loss',
+ 'metrics/precision(B)',
+ 'metrics/recall(B)',
+ 'metrics/mAP_0.5(B)',
+ 'metrics/mAP_0.5:0.95(B)', # metrics
+ 'metrics/precision(M)',
+ 'metrics/recall(M)',
+ 'metrics/mAP_0.5(M)',
+ 'metrics/mAP_0.5:0.95(M)', # metrics
+ 'val/box_loss',
+ 'val/seg_loss', # val loss
+ 'val/obj_loss',
+ 'val/cls_loss',
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2',]
+
+BEST_KEYS = [
+ 'best/epoch',
+ 'best/precision(B)',
+ 'best/recall(B)',
+ 'best/mAP_0.5(B)',
+ 'best/mAP_0.5:0.95(B)',
+ 'best/precision(M)',
+ 'best/recall(M)',
+ 'best/mAP_0.5(M)',
+ 'best/mAP_0.5:0.95(M)',]
diff --git a/src/train_utils/train_models/models/yolov5/utils/segment/plots.py b/src/train_utils/train_models/models/yolov5/utils/segment/plots.py
new file mode 100644
index 0000000..1b22ec8
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/segment/plots.py
@@ -0,0 +1,143 @@
+import contextlib
+import math
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import torch
+
+from .. import threaded
+from ..general import xywh2xyxy
+from ..plots import Annotator, colors
+
+
+@threaded
+def plot_images_and_masks(images, targets, masks, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ idx = targets[:, 0] == i
+ ti = targets[idx] # image targets
+
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+
+ # Plot masks
+ if len(masks):
+ if masks.max() > 1.0: # mean that masks are overlap
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = len(ti)
+ index = np.arange(nl).reshape(nl, 1, 1) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+ else:
+ image_masks = masks[idx]
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+
+
+def plot_results_with_masks(file='path/to/results.csv', dir='', best=True):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ index = np.argmax(0.9 * data.values[:, 8] + 0.1 * data.values[:, 7] + 0.9 * data.values[:, 12] +
+ 0.1 * data.values[:, 11])
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=2)
+ if best:
+ # best
+ ax[i].scatter(index, y[index], color='r', label=f'best:{index}', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[index], 5)}')
+ else:
+ # last
+ ax[i].scatter(x[-1], y[-1], color='r', label='last', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[-1], 5)}')
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
diff --git a/src/train_utils/train_models/models/yolov5/utils/torch_utils.py b/src/train_utils/train_models/models/yolov5/utils/torch_utils.py
new file mode 100644
index 0000000..5b67b3f
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/torch_utils.py
@@ -0,0 +1,432 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return (torch.inference_mode if torch_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def smartCrossEntropyLoss(label_smoothing=0.0):
+ # Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
+ if check_version(torch.__version__, '1.10.0'):
+ return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
+ if label_smoothing > 0:
+ LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
+ return nn.CrossEntropyLoss()
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+def reshape_classifier_output(model, n=1000):
+ # Update a TorchVision classification model to class count 'n' if required
+ from models.common import Classify
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLOv5 Classify() head
+ if m.linear.out_features != n:
+ m.linear = nn.Linear(m.linear.in_features, n)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != n:
+ setattr(model, name, nn.Linear(m.in_features, n))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != n:
+ m[i] = nn.Linear(m[i].in_features, n)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != n:
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ """ YOLOv5 speed/memory/FLOPs profiler
+ Usage:
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f'{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}')
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f'{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias')
+ return optimizer
+
+
+def smart_hub_load(repo='ultralytics/yolov5', model='yolov5s', **kwargs):
+ # YOLOv5 torch.hub.load() wrapper with smart error/issue handling
+ if check_version(torch.__version__, '1.9.1'):
+ kwargs['skip_validation'] = True # validation causes GitHub API rate limit errors
+ if check_version(torch.__version__, '1.12.0'):
+ kwargs['trust_repo'] = True # argument required starting in torch 0.12
+ try:
+ return torch.hub.load(repo, model, **kwargs)
+ except Exception:
+ return torch.hub.load(repo, model, force_reload=True, **kwargs)
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/src/train_utils/train_models/models/yolov5/utils/triton.py b/src/train_utils/train_models/models/yolov5/utils/triton.py
new file mode 100644
index 0000000..2592802
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/utils/triton.py
@@ -0,0 +1,85 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+""" Utils to interact with the Triton Inference Server
+"""
+
+import typing
+from urllib.parse import urlparse
+
+import torch
+
+
+class TritonRemoteModel:
+ """ A wrapper over a model served by the Triton Inference Server. It can
+ be configured to communicate over GRPC or HTTP. It accepts Torch Tensors
+ as input and returns them as outputs.
+ """
+
+ def __init__(self, url: str):
+ """
+ Keyword arguments:
+ url: Fully qualified address of the Triton server - for e.g. grpc://localhost:8000
+ """
+
+ parsed_url = urlparse(url)
+ if parsed_url.scheme == 'grpc':
+ from tritonclient.grpc import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton GRPC client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository.models[0].name
+ self.metadata = self.client.get_model_metadata(self.model_name, as_json=True)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ else:
+ from tritonclient.http import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton HTTP client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository[0]['name']
+ self.metadata = self.client.get_model_metadata(self.model_name)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ self._create_input_placeholders_fn = create_input_placeholders
+
+ @property
+ def runtime(self):
+ """Returns the model runtime"""
+ return self.metadata.get('backend', self.metadata.get('platform'))
+
+ def __call__(self, *args, **kwargs) -> typing.Union[torch.Tensor, typing.Tuple[torch.Tensor, ...]]:
+ """ Invokes the model. Parameters can be provided via args or kwargs.
+ args, if provided, are assumed to match the order of inputs of the model.
+ kwargs are matched with the model input names.
+ """
+ inputs = self._create_inputs(*args, **kwargs)
+ response = self.client.infer(model_name=self.model_name, inputs=inputs)
+ result = []
+ for output in self.metadata['outputs']:
+ tensor = torch.as_tensor(response.as_numpy(output['name']))
+ result.append(tensor)
+ return result[0] if len(result) == 1 else result
+
+ def _create_inputs(self, *args, **kwargs):
+ args_len, kwargs_len = len(args), len(kwargs)
+ if not args_len and not kwargs_len:
+ raise RuntimeError('No inputs provided.')
+ if args_len and kwargs_len:
+ raise RuntimeError('Cannot specify args and kwargs at the same time')
+
+ placeholders = self._create_input_placeholders_fn()
+ if args_len:
+ if args_len != len(placeholders):
+ raise RuntimeError(f'Expected {len(placeholders)} inputs, got {args_len}.')
+ for input, value in zip(placeholders, args):
+ input.set_data_from_numpy(value.cpu().numpy())
+ else:
+ for input in placeholders:
+ value = kwargs[input.name]
+ input.set_data_from_numpy(value.cpu().numpy())
+ return placeholders
diff --git a/src/train_utils/train_models/models/yolov5/val.py b/src/train_utils/train_models/models/yolov5/val.py
new file mode 100644
index 0000000..d4073b4
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov5/val.py
@@ -0,0 +1,409 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 detection model on a detection dataset
+
+Usage:
+ $ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size, check_requirements,
+ check_yaml, coco80_to_coco91_class, colorstr, increment_path, non_max_suppression,
+ print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'P', 'R', 'mAP50', 'mAP50-95')
+ tp, fp, p, r, f1, mp, mr, map50, ap50, map = 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ dt = Profile(), Profile(), Profile() # profiling times
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss(train_out, targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det)
+
+ # Metrics
+ for si, pred in enumerate(preds):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(preds), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end', batch_i, im, targets, paths, shapes, preds)
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end', nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.info('WARNING ⚠️ --save-hybrid will return high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/src/train_utils/train_models/models/yolov7/.gitignore b/src/train_utils/train_models/models/yolov7/.gitignore
new file mode 100644
index 0000000..d1bbbbe
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov7/.gitignore
@@ -0,0 +1,263 @@
+# Repo-specific GitIgnore ----------------------------------------------------------------------------------------------
+*.jpg
+*.jpeg
+*.png
+*.bmp
+*.tif
+*.tiff
+*.heic
+*.JPG
+*.JPEG
+*.PNG
+*.BMP
+*.TIF
+*.TIFF
+*.HEIC
+*.mp4
+*.mov
+*.MOV
+*.avi
+*.data
+*.json
+*.cfg
+!setup.cfg
+!cfg/yolov3*.cfg
+
+storage.googleapis.com
+runs/*
+data/*
+data/images/*
+!data/*.yaml
+!data/hyps
+!data/scripts
+!data/images
+!data/images/zidane.jpg
+!data/images/bus.jpg
+!data/*.sh
+
+results*.csv
+
+# Datasets -------------------------------------------------------------------------------------------------------------
+coco/
+coco128/
+VOC/
+
+coco2017labels-segments.zip
+test2017.zip
+train2017.zip
+val2017.zip
+
+# MATLAB GitIgnore -----------------------------------------------------------------------------------------------------
+*.m~
+*.mat
+!targets*.mat
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+*.weights
+*.pt
+*.pb
+*.onnx
+*.engine
+*.mlmodel
+*.torchscript
+*.tflite
+*.h5
+*_saved_model/
+*_web_model/
+*_openvino_model/
+darknet53.conv.74
+yolov3-tiny.conv.15
+*.ptl
+*.trt
+
+# GitHub Python GitIgnore ----------------------------------------------------------------------------------------------
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+/wandb/
+.installed.cfg
+*.egg
+
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# dotenv
+.env
+
+# virtualenv
+.venv*
+venv*/
+ENV*/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+
+# https://github.com/github/gitignore/blob/master/Global/macOS.gitignore -----------------------------------------------
+
+# General
+.DS_Store
+.AppleDouble
+.LSOverride
+
+# Icon must end with two \r
+Icon
+Icon?
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+.com.apple.timemachine.donotpresent
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+
+# https://github.com/github/gitignore/blob/master/Global/JetBrains.gitignore
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff:
+.idea/*
+.idea/**/workspace.xml
+.idea/**/tasks.xml
+.idea/dictionaries
+.html # Bokeh Plots
+.pg # TensorFlow Frozen Graphs
+.avi # videos
+
+# Sensitive or high-churn files:
+.idea/**/dataSources/
+.idea/**/dataSources.ids
+.idea/**/dataSources.local.xml
+.idea/**/sqlDataSources.xml
+.idea/**/dynamic.xml
+.idea/**/uiDesigner.xml
+
+# Gradle:
+.idea/**/gradle.xml
+.idea/**/libraries
+
+# CMake
+cmake-build-debug/
+cmake-build-release/
+
+# Mongo Explorer plugin:
+.idea/**/mongoSettings.xml
+
+## File-based project format:
+*.iws
+
+## Plugin-specific files:
+
+# IntelliJ
+out/
+
+# mpeltonen/sbt-idea plugin
+.idea_modules/
+
+# JIRA plugin
+atlassian-ide-plugin.xml
+
+# Cursive Clojure plugin
+.idea/replstate.xml
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+com_crashlytics_export_strings.xml
+crashlytics.properties
+crashlytics-build.properties
+fabric.properties
diff --git a/src/train_utils/train_models/models/yolov7/LICENSE.md b/src/train_utils/train_models/models/yolov7/LICENSE.md
new file mode 100644
index 0000000..f288702
--- /dev/null
+++ b/src/train_utils/train_models/models/yolov7/LICENSE.md
@@ -0,0 +1,674 @@
+ GNU GENERAL PUBLIC LICENSE
+ Version 3, 29 June 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.  +
+
+
+ +
+
+
+ +
+
+
+ +
+
+
+

 +
+  +
+  +
+  +
+