diff --git a/README.md b/README.md
index e680361..21d0b0f 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
# AlgoScope :link: https://algo-scope.github.io
### :page_facing_up: [3](https://algo-scope.github.io/tag.html)
### :speech_balloon: 0
-### :hibiscus: 32695
-### :alarm_clock: 2024-10-16 14:14:39
+### :hibiscus: 31275
+### :alarm_clock: 2024-10-16 14:18:32
### Powered by :heart: [Gmeek](https://github.com/Meekdai/Gmeek)
diff --git "a/backup/DeepSpeed\350\256\255\347\273\203\344\274\230\345\214\226\345\216\237\347\220\206.md" "b/backup/DeepSpeed\350\256\255\347\273\203\344\274\230\345\214\226\345\216\237\347\220\206.md"
index 9ca38c4..5d26dee 100644
--- "a/backup/DeepSpeed\350\256\255\347\273\203\344\274\230\345\214\226\345\216\237\347\220\206.md"
+++ "b/backup/DeepSpeed\350\256\255\347\273\203\344\274\230\345\214\226\345\216\237\347\220\206.md"
@@ -35,7 +35,7 @@
以微软的bing_bert 训练代码为例,
1、 编写sparse_attention配置文件,后面要传入get_sparse_attention_config函数
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json#L24-L33](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json" \l "L24-L33)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json#L24-L33
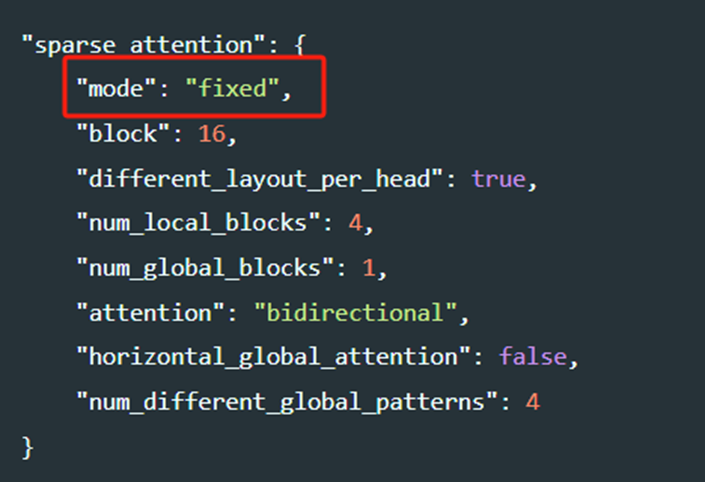
通过修改配置中的mode可以使用任何支持的稀疏结构更新 DeepSpeed 配置文件,并相应地设置参数,mode有多个实现,对应多种不同的SA结构:
@@ -85,19 +85,19 @@
上述mode的配置具体加载到代码中后的示例:
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L79-L109](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L79-L109)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L79-L109
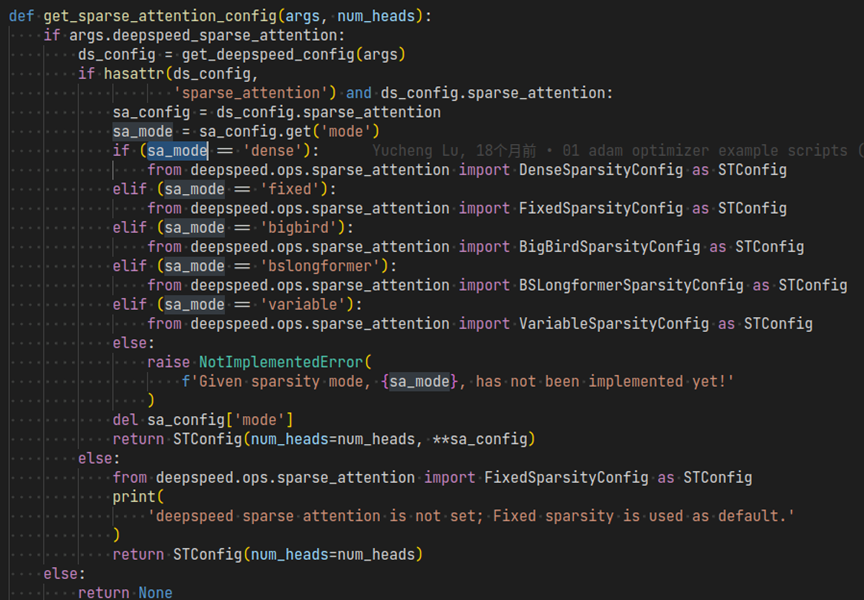
2、 将上一步的稀疏注意力配置通过get_sparse_attention_config函数读取,传入模型初始化
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1024-L1032](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L1024-L1032)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1024-L1032
class BertModel(BertPreTrainedModel):

3、encoder模型初始化时的注意力层更新为稀疏注意力
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L610-L620](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L610-L620)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L610-L620
class BertEncoder(nn.Module):

@@ -106,10 +106,10 @@ class BertEncoder(nn.Module):
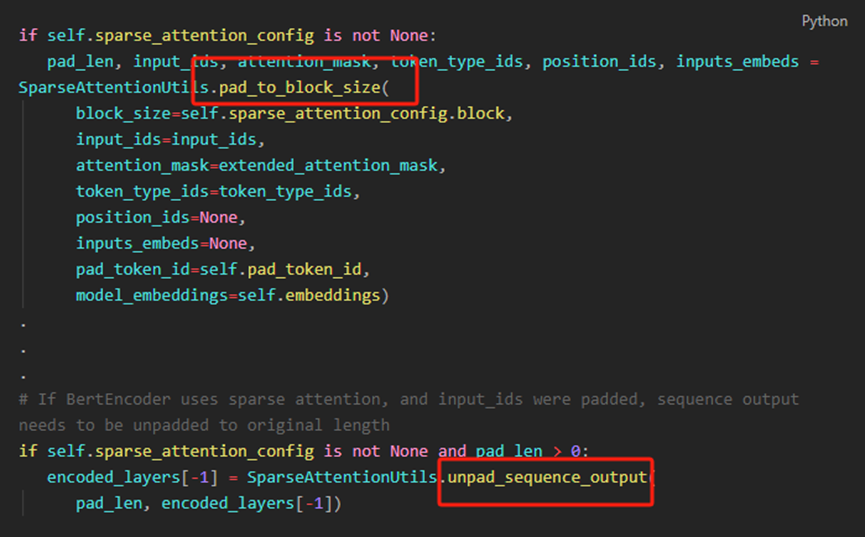
您可能需要对input_ids和attention_mask的序列维度进行填充,使其成为稀疏块大小的倍数,用在模型forward里
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1067-L1093](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L1067-L1093)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1067-L1093
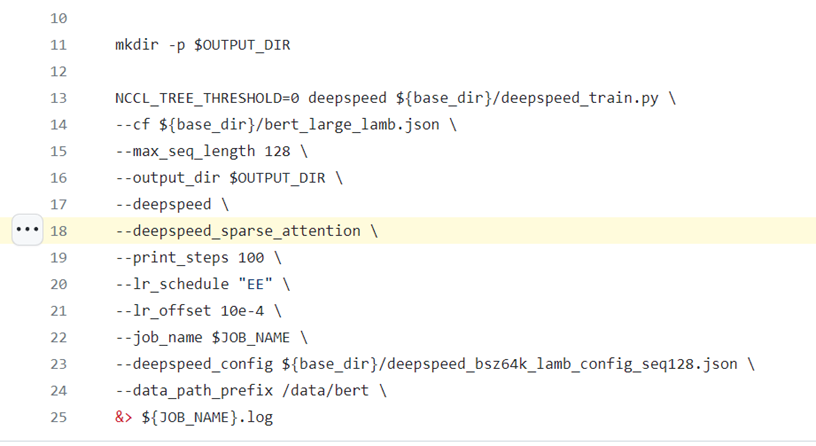
-要使用DeepSpeed Sparse Attention,需要在启动脚本中通过--deepspeed_sparse_attention参数启用它,见[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh#L18](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh" \l "L18)
+要使用DeepSpeed Sparse Attention,需要在启动脚本中通过--deepspeed_sparse_attention参数启用它,见https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh#L18
# 超快稠密transformer核(Ultra-fast dense transformer kernels)
@@ -162,7 +162,7 @@ Deepspeed发布时重点宣传了transformer核,跟ZeRO-2并列,主要作用
以BingBertGlue训练代码为例,
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/BingBertGlue/nvidia/modelingpreln_layerdrop.py#L582-L604](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/BingBertGlue/nvidia/modelingpreln_layerdrop.py" \l "L582-L604)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/BingBertGlue/nvidia/modelingpreln_layerdrop.py#L582-L604
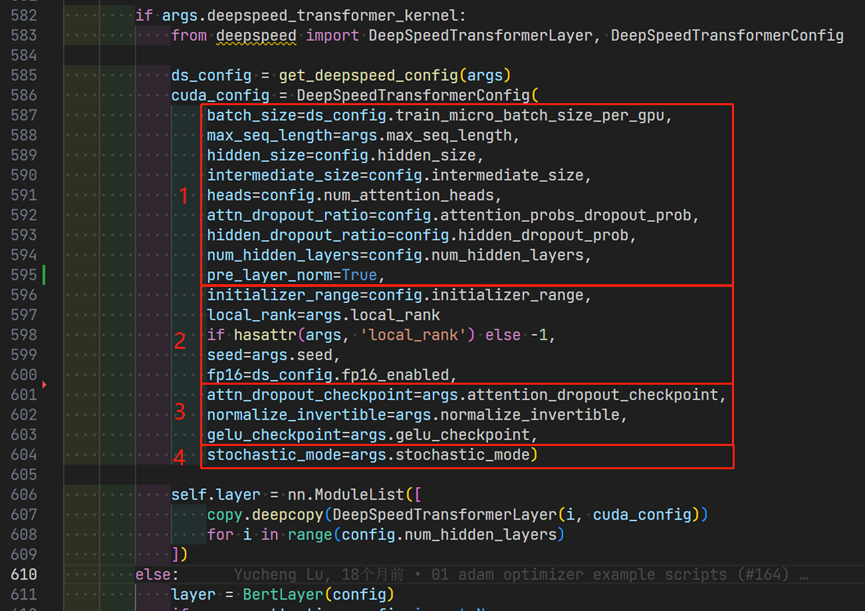
参数主要分为4个大类:
@@ -253,7 +253,7 @@ comm_backend_name用于指示要使用的后端实现。您可以通过将comm_b
由于1位压缩不能代表精确的零,因此,如果参数在训练过程中具有恒定的零梯度,则压缩误差将继续在动量中积累。例如,对于BERT预训练seq长度128,Bert.embeddings.position_embeddings.Weight在其梯度和动量129至512中具有恒定的零,因为它只能学习到seq长度128,而模型则支持到seq长度512.因此,在1位Adam V2中,我们增加了动量mask的支持,以指定那些在其梯度中具有恒定零的参数。有关如何配置此动量mask,请参见以下示例脚本。
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_train.py#L426-L453](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_train.py" \l "L426-L453)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_train.py#L426-L453
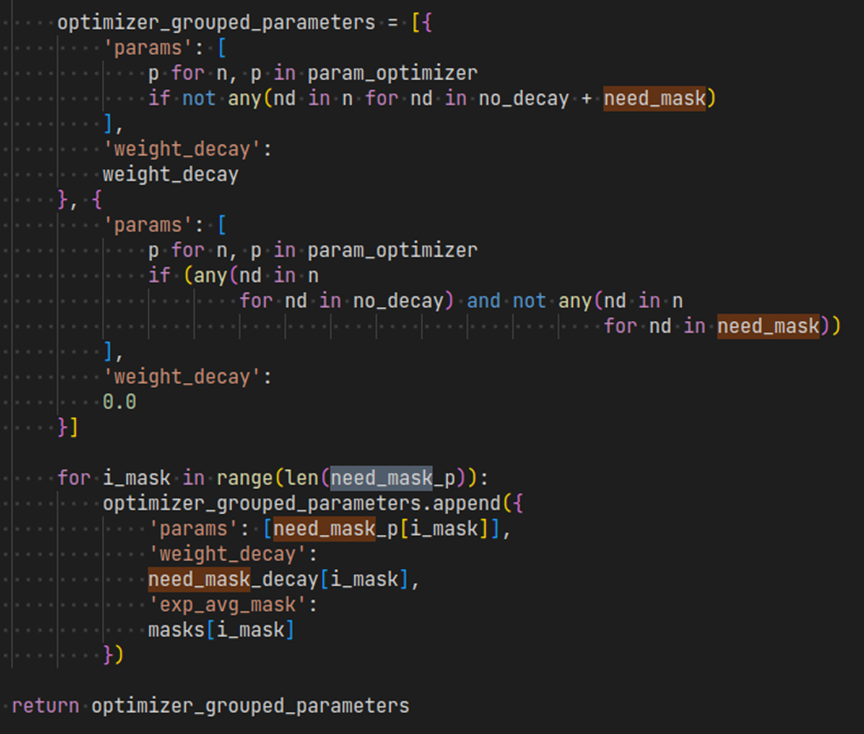
@@ -337,7 +337,7 @@ deepspeed启动命令行:
如果在DeepSpeed初始化时传递了LoRA模型,那么DeepSpeed引擎将识别LoRA冻结参数。然而,流行的实现是初始化一个基本模型,然后再转换为LoRA模型。在这种情况下,用户需要在LoRA模型转换后显式调用DeepSpeed引擎。这只需要一行代码。下面显示了一个训练脚本的示例片段
-[https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/mixed_precision_zeropp.md#training-script-changes](https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/mixed_precision_zeropp.md" \l "training-script-changes)
+https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/mixed_precision_zeropp.md#training-script-changes

@@ -347,7 +347,7 @@ deepspeed启动命令行:
PEFT模型的使用非常方便,只需要按照原本的方式实例化模型,然后设置一下LoRA的config,调用一下get_peft_model方法,就获得了在原模型基础上的PEFT模型,对于LoRA策略来讲,就是在预训练参数矩阵W的基础上增加了矩阵分解的旁支。在下面的例子中,选择了attention中的q和v的部分做LoRA。
-[https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L174-L184](https://github.com/tloen/alpaca-lora/blob/main/finetune.py" \l "L174-L184)
+https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L174-L184

@@ -363,13 +363,13 @@ PEFT模型的使用非常方便,只需要按照原本的方式实例化模型
模型训练完成后,可以调用PEFT重写的save_pretrained函数保存权重,该方法只会保存LoRA训练的部分,因此权重文件特别小
-[https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L273-L275](https://github.com/tloen/alpaca-lora/blob/main/finetune.py" \l "L273-L275)
+https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L273-L275

推理:
-[https://github.com/tloen/alpaca-lora/blob/main/generate.py#L26-L52](https://github.com/tloen/alpaca-lora/blob/8bb8579e403dc78e37fe81ffbb253c413007323f/generate.py" \l "L26-L52)
+https://github.com/tloen/alpaca-lora/blob/main/generate.py#L26-L52

diff --git a/blogBase.json b/blogBase.json
index f6e48f7..9d3e678 100644
--- a/blogBase.json
+++ b/blogBase.json
@@ -1 +1 @@
-{"singlePage": [], "startSite": "10/10/2024", "filingNum": "", "onePageListNum": 15, "commentLabelColor": "#006b75", "yearColorList": ["#bc4c00", "#0969da", "#1f883d", "#A333D0"], "i18n": "CN", "themeMode": "manual", "dayTheme": "light", "nightTheme": "dark", "urlMode": "pinyin", "script": "", "style": "", "head": "", "indexScript": "", "indexStyle": "", "bottomText": "\u8f6c\u8f7d\u8bf7\u6ce8\u660e\u51fa\u5904", "showPostSource": 0, "iconList": {}, "UTC": 8, "rssSplit": "sentence", "exlink": {}, "needComment": 1, "allHead": "", "title": "AlgoScope", "subTitle": "\u5b66\u672f\u516b\u6212\u7231\u8336\u6b47", "avatarUrl": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "GMEEK_VERSION": "last", "email": "zhaowenyi7@gmail.com", "postListJson": {"P2": {"htmlDir": "docs/post/tong-ji-xia-zhuan-ma-zhe-8-nian-wo-mai-guo-de-shu.html", "labels": ["\u6280\u672f"], "postTitle": "\u7edf\u8ba1\u4e0b\u8f6c\u7801\u8fd98\u5e74\u6211\u4e70\u8fc7\u7684\u4e66", "postUrl": "post/tong-ji-xia-zhuan-ma-zhe-8-nian-wo-mai-guo-de-shu.html", "postSourceUrl": "https://github.com/algo-scope/algo-scope.github.io/issues/2", "commentNum": 0, "wordCount": 6523, "description": "\u7ffb\u4e86\u6dd8\u5b9d\u4eac\u4e1c\u5f53\u5f53\u7684\u8d2d\u7269\u8bb0\u5f55\uff0c\u5356\u4e66\u57fa\u672c\u90fd\u662f\u5728\u591a\u6293\u9c7c\u4e0a\u6240\u4ee5\u4e5f\u80fd\u67e5\u5230\uff0c\u6309\u7167\u8d2d\u4e70\u65f6\u95f4\u6392\u5e8f\u3002", "top": 0, "createdAt": 1728666201, "style": "", "script": "", "head": "", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "createdDate": "2024-10-12", "dateLabelColor": "#bc4c00"}, "P3": {"htmlDir": "docs/post/shen-ti-shi-ge-ming-de-ben-qian.html", "labels": ["\u5065\u5eb7"], "postTitle": "\u8eab\u4f53\u662f\u9769\u547d\u7684\u672c\u94b1", "postUrl": "post/shen-ti-shi-ge-ming-de-ben-qian.html", "postSourceUrl": "https://github.com/algo-scope/algo-scope.github.io/issues/3", "commentNum": 0, "wordCount": 3514, "description": "## \u8170\u95f4\u76d8\u7a81\u51fa\r\n\r\n2017\u5e74\u6211\u5728\u8bfb\u7814\u65f6\u6253\u7fbd\u6bdb\u7403\u7528\u529b\u8fc7\u731b\uff0c\u52a0\u4e0a\u4e4b\u524d\u5e73\u65f6\u559c\u6b22\u9a7c\u7740\u80cc\u6709\u8170\u808c\u52b3\u635f\uff0c\u6709\u5929\u65e9\u4e0a\u8d77\u5e8a\u65f6\u7a81\u7136\u611f\u89c9\u817f\u4e0a\u62bd\u62bd\u7740\u75bc\u3002", "top": 0, "createdAt": 1728832742, "style": "", "script": "", "head": "", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "createdDate": "2024-10-13", "dateLabelColor": "#bc4c00"}, "P4": {"htmlDir": "docs/post/DeepSpeed-xun-lian-you-hua-yuan-li.html", "labels": ["\u6280\u672f"], "postTitle": "DeepSpeed\u8bad\u7ec3\u4f18\u5316\u539f\u7406", "postUrl": "post/DeepSpeed-xun-lian-you-hua-yuan-li.html", "postSourceUrl": "https://github.com/algo-scope/algo-scope.github.io/issues/4", "commentNum": 0, "wordCount": 22658, "description": "# \u7a00\u758f\u6ce8\u610f\u529b\uff08Sparse Attention\uff09\r\n\r\n\u57fa\u4e8e\u6ce8\u610f\u529b\u7684\u6df1\u5ea6\u5b66\u4e60\u6a21\u578b\u4f8b\u5982Transformer\uff0c\u5728\u6355\u6349\u8f93\u5165\u5e8f\u5217\u4e2dtoken\u4e4b\u95f4\u7684\u5173\u7cfb\u65b9\u9762\u975e\u5e38\u6709\u6548\uff0c\u5373\u4f7f\u8ddd\u79bb\u8f83\u8fdc\u3002", "top": 0, "createdAt": 1729059253, "style": "", "script": "", "head": "", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "createdDate": "2024-10-16", "dateLabelColor": "#bc4c00"}}, "singeListJson": {}, "labelColorDict": {"bug": "#d73a4a", "documentation": "#0075ca", "duplicate": "#cfd3d7", "enhancement": "#a2eeef", "good first issue": "#7057ff", "help wanted": "#008672", "invalid": "#e4e669", "question": "#d876e3", "wontfix": "#ffffff", "\u5065\u5eb7": "#5319e7", "\u6280\u672f": "#15ECA6"}, "displayTitle": "AlgoScope", "faviconUrl": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "primerCSS": "", "homeUrl": "https://algo-scope.github.io", "prevUrl": "disabled", "nextUrl": "disabled"}
\ No newline at end of file
+{"singlePage": [], "startSite": "10/10/2024", "filingNum": "", "onePageListNum": 15, "commentLabelColor": "#006b75", "yearColorList": ["#bc4c00", "#0969da", "#1f883d", "#A333D0"], "i18n": "CN", "themeMode": "manual", "dayTheme": "light", "nightTheme": "dark", "urlMode": "pinyin", "script": "", "style": "", "head": "", "indexScript": "", "indexStyle": "", "bottomText": "\u8f6c\u8f7d\u8bf7\u6ce8\u660e\u51fa\u5904", "showPostSource": 0, "iconList": {}, "UTC": 8, "rssSplit": "sentence", "exlink": {}, "needComment": 1, "allHead": "", "title": "AlgoScope", "subTitle": "\u5b66\u672f\u516b\u6212\u7231\u8336\u6b47", "avatarUrl": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "GMEEK_VERSION": "last", "email": "zhaowenyi7@gmail.com", "postListJson": {"P2": {"htmlDir": "docs/post/tong-ji-xia-zhuan-ma-zhe-8-nian-wo-mai-guo-de-shu.html", "labels": ["\u6280\u672f"], "postTitle": "\u7edf\u8ba1\u4e0b\u8f6c\u7801\u8fd98\u5e74\u6211\u4e70\u8fc7\u7684\u4e66", "postUrl": "post/tong-ji-xia-zhuan-ma-zhe-8-nian-wo-mai-guo-de-shu.html", "postSourceUrl": "https://github.com/algo-scope/algo-scope.github.io/issues/2", "commentNum": 0, "wordCount": 6523, "description": "\u7ffb\u4e86\u6dd8\u5b9d\u4eac\u4e1c\u5f53\u5f53\u7684\u8d2d\u7269\u8bb0\u5f55\uff0c\u5356\u4e66\u57fa\u672c\u90fd\u662f\u5728\u591a\u6293\u9c7c\u4e0a\u6240\u4ee5\u4e5f\u80fd\u67e5\u5230\uff0c\u6309\u7167\u8d2d\u4e70\u65f6\u95f4\u6392\u5e8f\u3002", "top": 0, "createdAt": 1728666201, "style": "", "script": "", "head": "", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "createdDate": "2024-10-12", "dateLabelColor": "#bc4c00"}, "P3": {"htmlDir": "docs/post/shen-ti-shi-ge-ming-de-ben-qian.html", "labels": ["\u5065\u5eb7"], "postTitle": "\u8eab\u4f53\u662f\u9769\u547d\u7684\u672c\u94b1", "postUrl": "post/shen-ti-shi-ge-ming-de-ben-qian.html", "postSourceUrl": "https://github.com/algo-scope/algo-scope.github.io/issues/3", "commentNum": 0, "wordCount": 3514, "description": "## \u8170\u95f4\u76d8\u7a81\u51fa\r\n\r\n2017\u5e74\u6211\u5728\u8bfb\u7814\u65f6\u6253\u7fbd\u6bdb\u7403\u7528\u529b\u8fc7\u731b\uff0c\u52a0\u4e0a\u4e4b\u524d\u5e73\u65f6\u559c\u6b22\u9a7c\u7740\u80cc\u6709\u8170\u808c\u52b3\u635f\uff0c\u6709\u5929\u65e9\u4e0a\u8d77\u5e8a\u65f6\u7a81\u7136\u611f\u89c9\u817f\u4e0a\u62bd\u62bd\u7740\u75bc\u3002", "top": 0, "createdAt": 1728832742, "style": "", "script": "", "head": "", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "createdDate": "2024-10-13", "dateLabelColor": "#bc4c00"}, "P4": {"htmlDir": "docs/post/DeepSpeed-xun-lian-you-hua-yuan-li.html", "labels": ["\u6280\u672f"], "postTitle": "DeepSpeed\u8bad\u7ec3\u4f18\u5316\u539f\u7406", "postUrl": "post/DeepSpeed-xun-lian-you-hua-yuan-li.html", "postSourceUrl": "https://github.com/algo-scope/algo-scope.github.io/issues/4", "commentNum": 0, "wordCount": 21238, "description": "# \u7a00\u758f\u6ce8\u610f\u529b\uff08Sparse Attention\uff09\r\n\r\n\u57fa\u4e8e\u6ce8\u610f\u529b\u7684\u6df1\u5ea6\u5b66\u4e60\u6a21\u578b\u4f8b\u5982Transformer\uff0c\u5728\u6355\u6349\u8f93\u5165\u5e8f\u5217\u4e2dtoken\u4e4b\u95f4\u7684\u5173\u7cfb\u65b9\u9762\u975e\u5e38\u6709\u6548\uff0c\u5373\u4f7f\u8ddd\u79bb\u8f83\u8fdc\u3002", "top": 0, "createdAt": 1729059253, "style": "", "script": "", "head": "", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "createdDate": "2024-10-16", "dateLabelColor": "#bc4c00"}}, "singeListJson": {}, "labelColorDict": {"bug": "#d73a4a", "documentation": "#0075ca", "duplicate": "#cfd3d7", "enhancement": "#a2eeef", "good first issue": "#7057ff", "help wanted": "#008672", "invalid": "#e4e669", "question": "#d876e3", "wontfix": "#ffffff", "\u5065\u5eb7": "#5319e7", "\u6280\u672f": "#15ECA6"}, "displayTitle": "AlgoScope", "faviconUrl": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "ogImage": "https://raw.githubusercontent.com/algo-scope/imgBed/main/imgs/logo.png", "primerCSS": "", "homeUrl": "https://algo-scope.github.io", "prevUrl": "disabled", "nextUrl": "disabled"}
\ No newline at end of file
diff --git a/docs/post/DeepSpeed-xun-lian-you-hua-yuan-li.html b/docs/post/DeepSpeed-xun-lian-you-hua-yuan-li.html
index 4234ef5..e6bf35a 100644
--- a/docs/post/DeepSpeed-xun-lian-you-hua-yuan-li.html
+++ b/docs/post/DeepSpeed-xun-lian-you-hua-yuan-li.html
@@ -93,7 +93,7 @@ 性能表现
代码示例
以微软的bing_bert 训练代码为例,
1、 编写sparse_attention配置文件,后面要传入get_sparse_attention_config函数
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json#L24-L33](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json" \l "L24-L33)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json#L24-L33

通过修改配置中的mode可以使用任何支持的稀疏结构更新 DeepSpeed 配置文件,并相应地设置参数,mode有多个实现,对应多种不同的SA结构:
SparsityConfig:这个模块是所有稀疏结构的父类,包含所有稀疏结构的共享特性,mode中没有这个选项,但包含它的参数。
@@ -154,21 +154,21 @@ 代码示例
上述mode的配置具体加载到代码中后的示例:
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L79-L109](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L79-L109)
+
https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L79-L109

2、 将上一步的稀疏注意力配置通过get_sparse_attention_config函数读取,传入模型初始化
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1024-L1032](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L1024-L1032)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1024-L1032
class BertModel(BertPreTrainedModel):

3、encoder模型初始化时的注意力层更新为稀疏注意力
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L610-L620](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L610-L620)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L610-L620
class BertEncoder(nn.Module):

4、 输入数据pad和unpad
您可能需要对input_ids和attention_mask的序列维度进行填充,使其成为稀疏块大小的倍数,用在模型forward里
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1067-L1093](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py" \l "L1067-L1093)
+
https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/nvidia/modelingpreln_layerdrop.py#L1067-L1093

-要使用DeepSpeed Sparse Attention,需要在启动脚本中通过--deepspeed_sparse_attention参数启用它,见[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh#L18](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh" \l "L18)
+
要使用DeepSpeed Sparse Attention,需要在启动脚本中通过--deepspeed_sparse_attention参数启用它,见https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh#L18

超快稠密transformer核(Ultra-fast dense transformer kernels)
实现原理
@@ -199,7 +199,7 @@ 性能表现
图9 训练速度对比
代码示例
以BingBertGlue训练代码为例,
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/BingBertGlue/nvidia/modelingpreln_layerdrop.py#L582-L604](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/BingBertGlue/nvidia/modelingpreln_layerdrop.py" \l "L582-L604)
+
https://github.com/microsoft/DeepSpeedExamples/blob/master/training/BingBertGlue/nvidia/modelingpreln_layerdrop.py#L582-L604

参数主要分为4个大类:
@@ -269,7 +269,7 @@ 代码示例
cuda_aware用于基于MPI的实现,以表明基础MPI库支持CUDA-AWARE-AWARE通信。此功能仅在具有Infiniband InterConnect和Cuda-Awance MPI库(如MVAPICH2-GDR或OPENMPI)的系统上支持此。将cuda_aware设置为false将允许对基于以太网的系统进行训练。但是,通信将在通信之前和之后使用发件人以及CPU和GPU缓冲区之间的接收器侧内存副本进行。
comm_backend_name用于指示要使用的后端实现。您可以通过将comm_backend_name设置为“ NCCL”和“ MPI”来在NCCL和基于MPI的实现之间进行选择。
由于1位压缩不能代表精确的零,因此,如果参数在训练过程中具有恒定的零梯度,则压缩误差将继续在动量中积累。例如,对于BERT预训练seq长度128,Bert.embeddings.position_embeddings.Weight在其梯度和动量129至512中具有恒定的零,因为它只能学习到seq长度128,而模型则支持到seq长度512.因此,在1位Adam V2中,我们增加了动量mask的支持,以指定那些在其梯度中具有恒定零的参数。有关如何配置此动量mask,请参见以下示例脚本。
-[https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_train.py#L426-L453](https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_train.py" \l "L426-L453)
+https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_train.py#L426-L453

0/1 Adam
0/1 Adam优化器,它可以提高在通信受限集群上的模型训练速度,特别适用于通信稠密型的大型模型。例如,它可以在不影响端到端模型准确性的情况下,将BERT-large预训练的总体通信量减少多达26倍。与1-bit Adam优化器相比,0/1 Adam通过自适应方差状态冻结提供了一种更灵活的压缩通信方式。此外,它还允许计算节点在训练过程中使用一种称为1-bit同步的技术跳过通信轮次,而不会影响收敛速度。我们有一篇论文详细介绍了技术细节(https://arxiv.org/abs/2202.06009),包括算法、系统实现和评估结果。
@@ -320,12 +320,12 @@ 代码示例

通过命令行或者配置文件,将LoRA配置传入训练脚本
如果在DeepSpeed初始化时传递了LoRA模型,那么DeepSpeed引擎将识别LoRA冻结参数。然而,流行的实现是初始化一个基本模型,然后再转换为LoRA模型。在这种情况下,用户需要在LoRA模型转换后显式调用DeepSpeed引擎。这只需要一行代码。下面显示了一个训练脚本的示例片段
-[https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/mixed_precision_zeropp.md#training-script-changes](https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/mixed_precision_zeropp.md" \l "training-script-changes)
+https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/mixed_precision_zeropp.md#training-script-changes

转换方法:
使用Parameter-Efficient Fine-Tuning (PEFT),是huggingface开发的一个python工具,项目地址:https://github.com/huggingface/peft,可以很方便地实现将普通的大模型变成用于支持轻量级fine-tune的模型,使用非常便捷。
PEFT模型的使用非常方便,只需要按照原本的方式实例化模型,然后设置一下LoRA的config,调用一下get_peft_model方法,就获得了在原模型基础上的PEFT模型,对于LoRA策略来讲,就是在预训练参数矩阵W的基础上增加了矩阵分解的旁支。在下面的例子中,选择了attention中的q和v的部分做LoRA。
-[https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L174-L184](https://github.com/tloen/alpaca-lora/blob/main/finetune.py" \l "L174-L184)
+https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L174-L184

其中,LoRA参数直接写在训练代码里:
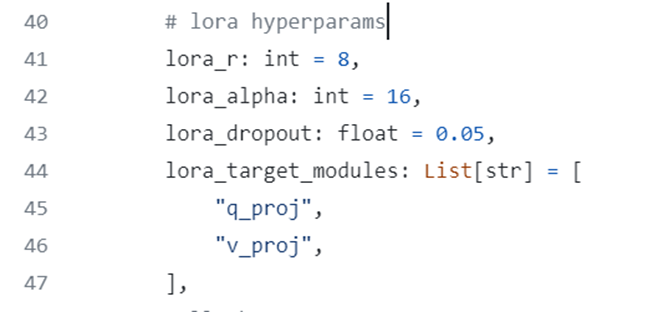
@@ -333,10 +333,10 @@ 代码示例
可以通过 model.print_trainable_parameters() 来打印lora训练的参数量,可以看到微调时只训练了0.16%的参数

模型训练完成后,可以调用PEFT重写的save_pretrained函数保存权重,该方法只会保存LoRA训练的部分,因此权重文件特别小
-[https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L273-L275](https://github.com/tloen/alpaca-lora/blob/main/finetune.py" \l "L273-L275)
+https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L273-L275

推理:
-[https://github.com/tloen/alpaca-lora/blob/main/generate.py#L26-L52](https://github.com/tloen/alpaca-lora/blob/8bb8579e403dc78e37fe81ffbb253c413007323f/generate.py" \l "L26-L52)
+https://github.com/tloen/alpaca-lora/blob/main/generate.py#L26-L52

model先加载预训练模型,然后再通过PEFT加载LoRA权重,执行后续推理。
转载请注明出处