
The Arcalot community develops tools, plugins, and libraries that you can use either standalone as a library, and/or via a user interface or CLI. You can run the tools locally, remotely, or as part of a bigger system. Arcalot:
-
The Arcalot community is dedicated to developing modular tools, plugins, and libraries +with flexible implementations to be used independently or as complete end-to-end +solutions. We believe in enabling automation and portability of complex tasks and in +pre-validating actions to avoid costly re-runs due to late failures and incompatible +data.

Arcaflow is a workflow engine consisting of three main components:
+
Arcaflow is a workflow orchestration system consisting of three main components:
It allows you to click and drag plugins into a workflow for your systems and, if needed, feed the resulting data back into the UI for further analysis. You can also use it just to generate a workflow with parallel and subsequent tasks via the command line. There is a range of supported plugins, written either in Go or Python.
-
Arcalog can assist you with or automate your root cause analysis in CI or other log systems either as a standalone tool or by embedding it into your applications.
-It also provides additional tooling to download jobs from various log systems or add your own log files for analysis.
-
+
Arcaflow is highly-flexible and portable, helping you to build +pipelines of actions via plugins. Plugin steps typically perform one action well, +creating or manipulating data that is returned in a machine-readable format. Data is +validated according to schemas as it passes through the pipeline in order to clearly +diagnose type mismatch problems early. Arcaflow runs on your laptop, a jump host, or in +a CI system, requiring only the Arcaflow engine binary, a workflow definition in YAML, +and a compatible container runtime.
+Arcaflow allows you to encapsulate and version-control expertise, making potentially +very complex workflows easily portable among environments and automation systems. With +an Arcaflow workflow, you can carefully craft a pipeline of actions that serves your +direct needs and share that workflow virtually unchanged for others to run in different +environments and CI/CD systems.
+An ever-growing catalog of +official plugins +are maintained within the Arcalot organization and are available as +versioned containers from Quay.io. You can also +build your own containerized plugins using the the Arcaflow SDK, available for +Python and +Golang. We encourage you to +contribute your plugins to the community, and you can start by adding them to the +plugins incubator repo via a +pull request.
+
We work hard to bring the documentation to the user, meaning that you should find a lot +of relevant documentation in the context of what you may be working on via readme files, +be it the engine, the SDK, a plugin, a workflow, or a sub-component. Comprehensive +documentation, developer references, and quickstart guides will always be located in the +arcalot.io pages.
You can find our general community health files like our code of conduct and contribution guidelines in the .github repository. If you have any questions or suggestions, please use the issues in the respective repository or contribute to the discussions.
-If you would like to contribute, check out the issues in the individual repositories, our project boards where we organize our work, and our Arcalot Round Table.
+We invite you to contribute! Check out the Issues in the individual repositories for +ideas on where to get involved, or consider contributing a new plugin by starting with +our python plugin template repository. +Outside contributions and pull requests are of course always welcome.
+If you want to get more involved with contributions, maintenance, and governance, +consider joining the +Arcalot Round Table (ART), our central +community body. The ART currently holds bi-weekly video conference meetings. Please +reach out to one of our +ART chairs +for more information.
+You can find our general community health files like our code of conduct and +contribution guidelines in the .github repository. +If you have any questions or suggestions, please use the Issues in the respective +repository.
diff --git a/search/search_index.json b/search/search_index.json index 3e690cb..907ffc2 100644 --- a/search/search_index.json +++ b/search/search_index.json @@ -1 +1 @@ -{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Arcalot","text":"The Arcalot community develops tools, plugins, and libraries that you can use either standalone as a library, and/or via a user interface or CLI. You can run the tools locally, remotely, or as part of a bigger system. Arcalot:
Arcaflow is a workflow engine consisting of three main components:
It allows you to click and drag plugins into a workflow for your systems and, if needed, feed the resulting data back into the UI for further analysis. You can also use it just to generate a workflow with parallel and subsequent tasks via the command line. There is a range of supported plugins, written either in Go or Python.
"},{"location":"#arcalog","title":"Arcalog","text":"Arcalog can assist you with or automate your root cause analysis in CI or other log systems either as a standalone tool or by embedding it into your applications.
It also provides additional tooling to download jobs from various log systems or add your own log files for analysis.
"},{"location":"#community","title":"Community","text":"You can find our general community health files like our code of conduct and contribution guidelines in the .github repository. If you have any questions or suggestions, please use the issues in the respective repository or contribute to the discussions.
If you would like to contribute, check out the issues in the individual repositories, our project boards where we organize our work, and our Arcalot Round Table.
"},{"location":"arcaflow/","title":"Arcaflow: The noble workflow engine","text":"Arcaflow is a workflow engine that lets you run individual steps and pass data between them. The data is validated according to a schema along the way to make sure there is no corrupt data. Arcaflow runs on your laptop, a jump host, or in a CI system and deploys plugins as containers on target systems via Docker, Podman, or Kubernetes.
Did you know?
In Docker/Kubernetes, Arcaflow only needs network access to the API, not the plugin container itself. You can safely place a restrictive firewall on most plugins.
Use casesArcaflow is a good fit to:
You can use Arcaflow for many things. We use it for:
Get started \u00bb Contribute \u00bb
Shipping expertiseGood workflows take time and expertise to develop. Often these workflows evolve organically into bespoke scripts and/or application stacks, and knowledge transfer or the ability to run the workflows in new environments can be very difficult. Arcaflow addresses this problem by focusing on being the plumbing for the workflow, standardizing on a plugin architecture for all actions, minimizing dependencies, focusing on quality, and enforcing strong typing for data passing.
Arcaflow\u2019s design can drastically simplify much of the workflow creation process, and it allows the workflow author to ensure the workflow is locked in end-to-end. A complete workflow can be version-controlled as a simple YAML file and in most cases can be expected to run in exactly the same way in any compatible environment.
Not a CI systemArcaflow is not designed to run as a persistent service nor to record workflow histories, and in most cases it is probably not the best tool to set up or manage infrastructure. For end-to-end CI needs, you should leverage a system that provides these and other features (possibly something from the Alternatives list below).
Arcaflow is, however, an excellent companion to a CI system. In many cases, building complex workflows completely within a CI environment can effectively lock you into that system because the workflow may not be easily portable outside of it or run independently by a user. An Arcaflow workflow can be easily integrated into most CI systems, so a workflow that you define once may be moved in most cases without modification to different environments or run directly by users.
AlternativesIt\u2019s important that you pick the right tool for the job. Sometimes, you need something simple. Sometimes, you want something persistent that keeps track of the workflows you run over time. We have collected some common and well-known open source workflow and workflow-like engines into this list and have provided some comparisons to help you find the right tool for your needs.
Here are some of the features that make Arcaflow a unique solution to the below alternatives:
Ansible is an IT automation and configuration management system. It handles configuration management, application deployment, cloud provisioning, ad-hoc task execution, network automation, and multi-node orchestration. Ansible makes complex changes like zero-downtime rolling updates with load balancers easy.
How are Arcaflow and Ansible similar?
How is Ansible different?
Airflow is a platform to programmatically author, schedule, and monitor workflows. It is a deployed workflow engine written in Python.
How are Arcaflow and Airflow similar?
How is Airflow different?
Argo Workflows is a container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo Workflows is implemented as a Kubernetes CRD (Custom Resource Definition).
How are Arcaflow and Argo Workflows similar?
How is Argo Workflows different?
Conductor is a platform created by Netflix to orchestrate workflows that span across microservices.
How are Arcaflow and Conductor similar?
How is Conductor different?
Tekton is a framework for creating CI/CD systems, allowing developers to build, test, and deploy across cloud providers and on-premise systems.
How are Arcaflow and Tekton similar?
How is Tekton different?
qDup allows shell commands to be queued up across multiple servers to coordinate performance tests. It is designed to follow the same workflow as a user at a terminal so that commands can be performed with or without qDup. Commands are grouped into re-usable scripts that are mapped to different hosts by roles.
How are Arcaflow and qDup similar?
How is qDup different?
In order to use Arcaflow, you will need a container engine on your computer. For the purposes of this guide, we\u2019ll assume you are using Docker or Podman.
"},{"location":"arcaflow/getting-started/#step-2-get-the-engine","title":"Step 2: Get the engine","text":"Head on over to the GitHub releases page and download the latest release.
"},{"location":"arcaflow/getting-started/#step-3-create-your-first-plugin","title":"Step 3: Create your first plugin","text":"Let\u2019s create a simple hello-world plugin in Python. We\u2019ll publish the code here, you can find the details in the Python plugin guide.
plugin.py#!/usr/local/bin/python3\nimport dataclasses\nimport sys\nfrom arcaflow_plugin_sdk import plugin\n\n\n@dataclasses.dataclass\nclass InputParams:\n name: str\n\n\n@dataclasses.dataclass\nclass SuccessOutput:\n message: str\n\n\n@plugin.step(\n id=\"hello-world\",\n name=\"Hello world!\",\n description=\"Says hello :)\",\n outputs={\"success\": SuccessOutput},\n)\ndef hello_world(params: InputParams):\n return \"success\", SuccessOutput(f\"Hello, {params.name}\")\n\n\nif __name__ == \"__main__\":\n sys.exit(\n plugin.run(\n plugin.build_schema(\n hello_world,\n )\n )\n )\nTip
Further reading: Creating your first Python plugin
"},{"location":"arcaflow/getting-started/#step-4-build-the-plugin","title":"Step 4: Build the plugin","text":"Next, let\u2019s create a Dockerfile and build a container image:
Dockerfile
FROM python:alpine\n\nADD plugin.py /\nRUN chmod +x /plugin.py && pip install arcaflow_plugin_sdk\n\nENTRYPOINT [\"/plugin.py\"]\nCMD []\ndocker build -t example-plugin .\npodman build -t example-plugin .\nTip
Further reading: Packaging plugins
Did you know?
While Arcaflow is a workflow engine, plugins can be run independently via the command line. Try running your containerized hello-world plugin directly.
DockerPodmanecho \"name: Arca Lot\" | docker run -i --rm example-plugin -f -\necho \"name: Arca Lot\" | podman run -i --rm example-plugin -f -\nLet\u2019s start with something simple: we\u2019ll incorporate the plugin above into a workflow. Let\u2019s create a workflow.yaml in an empty directory
version: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n name:\n type:\n type_id: string\nsteps:\n greet:\n plugin:\n deployment_type: image \n src: example-plugin\n input:\n name: !expr $.input.name\noutput:\n message: !expr $.steps.greet.outputs.success.message\nTip
Further reading: Creating workflows
"},{"location":"arcaflow/getting-started/#step-6-create-an-input-file","title":"Step 6: Create an input file","text":"Now, let\u2019s create an input file for our workflow named input.yaml:
name: Arca Lot\nYou will need an Arcaflow config.yaml file to prevent Arcaflow from trying to pull the container image.
Tip
Without a config file, the default behavior of Arcaflow is to run with docker and to always pull plugin container images for the workflow.
DockerPodman config.yamldeployer:\n type: docker\n deployment:\n # Make sure we don't try to pull the image we have locally\n imagePullPolicy: Never\ndeployer:\n type: podman\n deployment:\n # Make sure we don't try to pull the image we have locally\n imagePullPolicy: Never\nTip
Further reading: Setting up Arcaflow
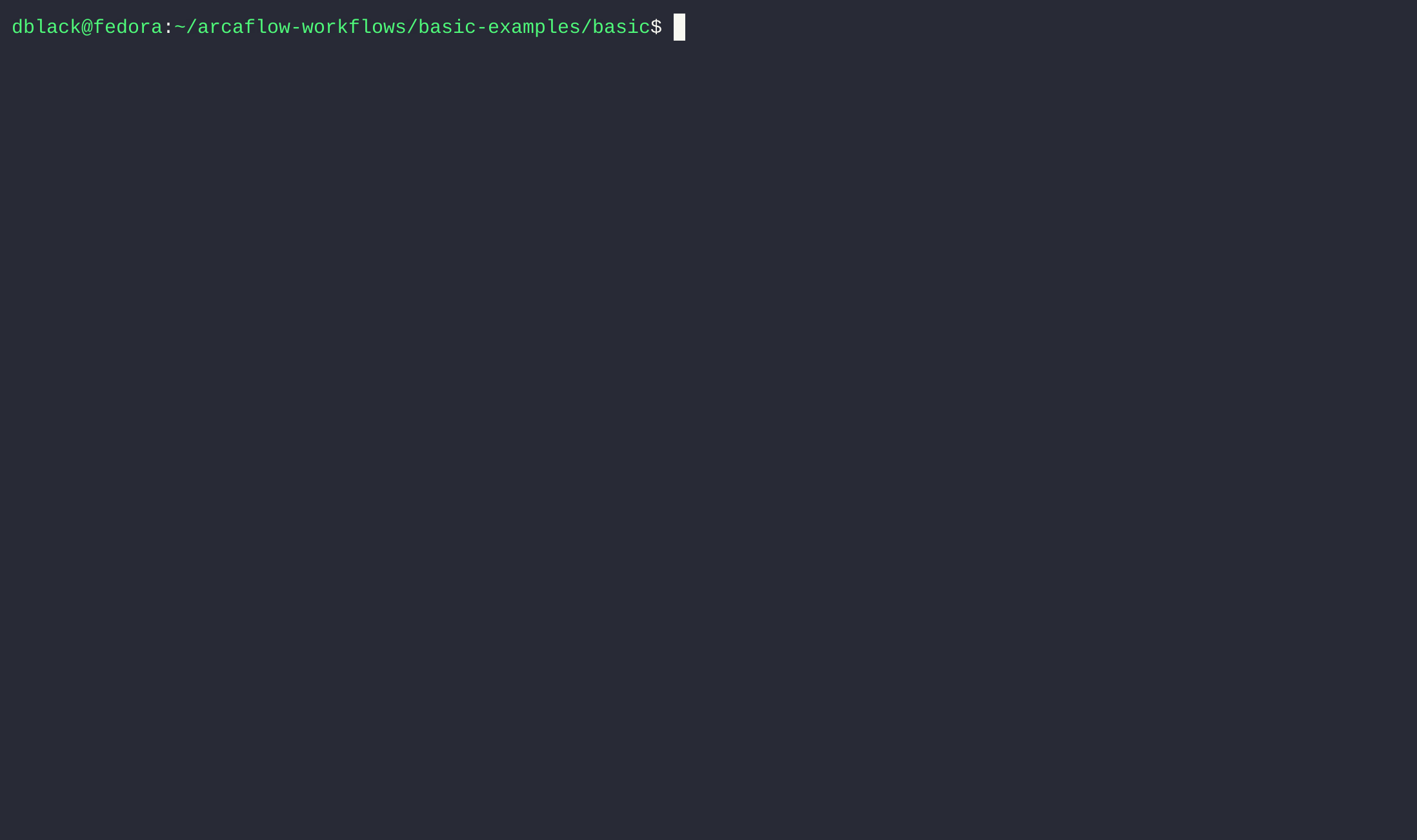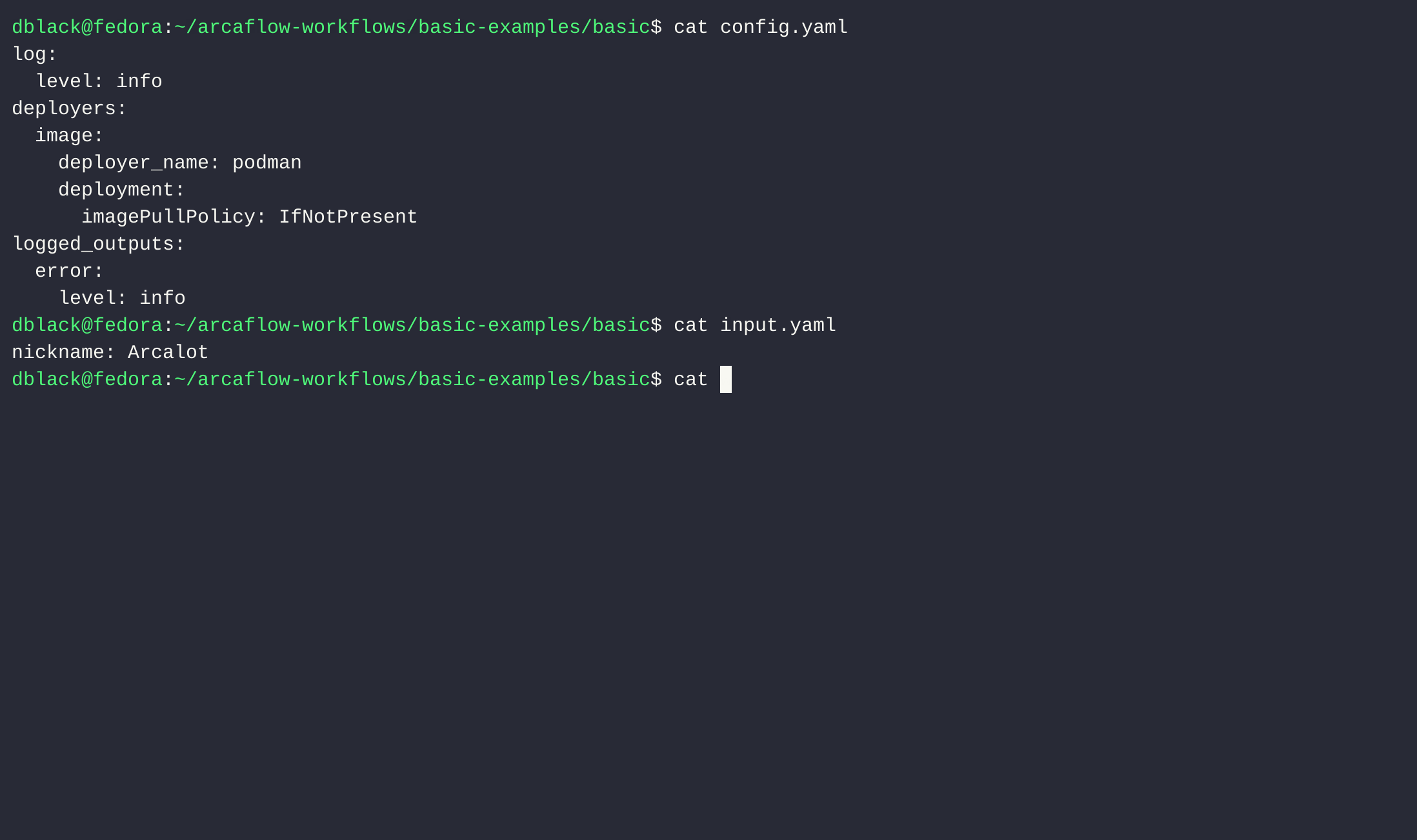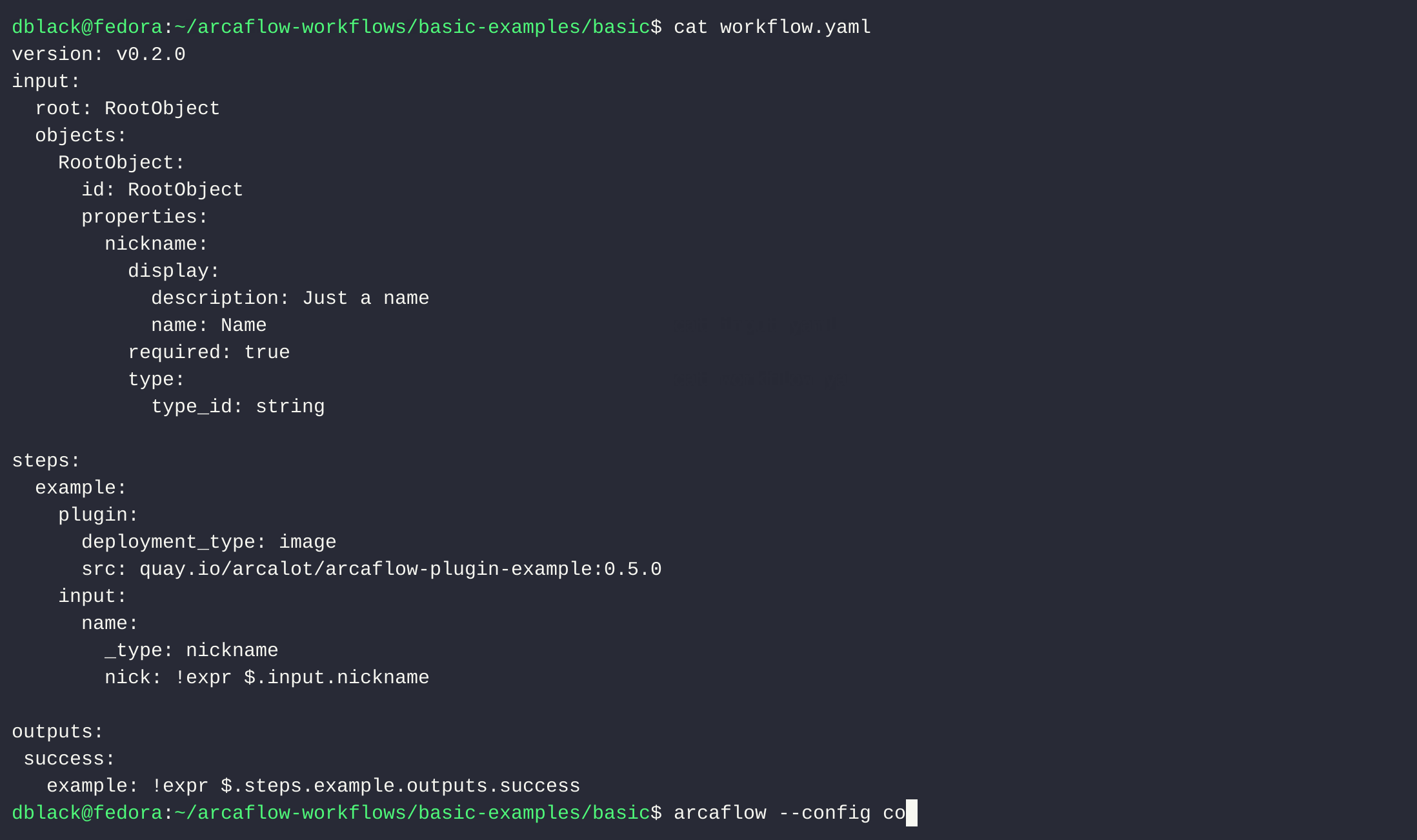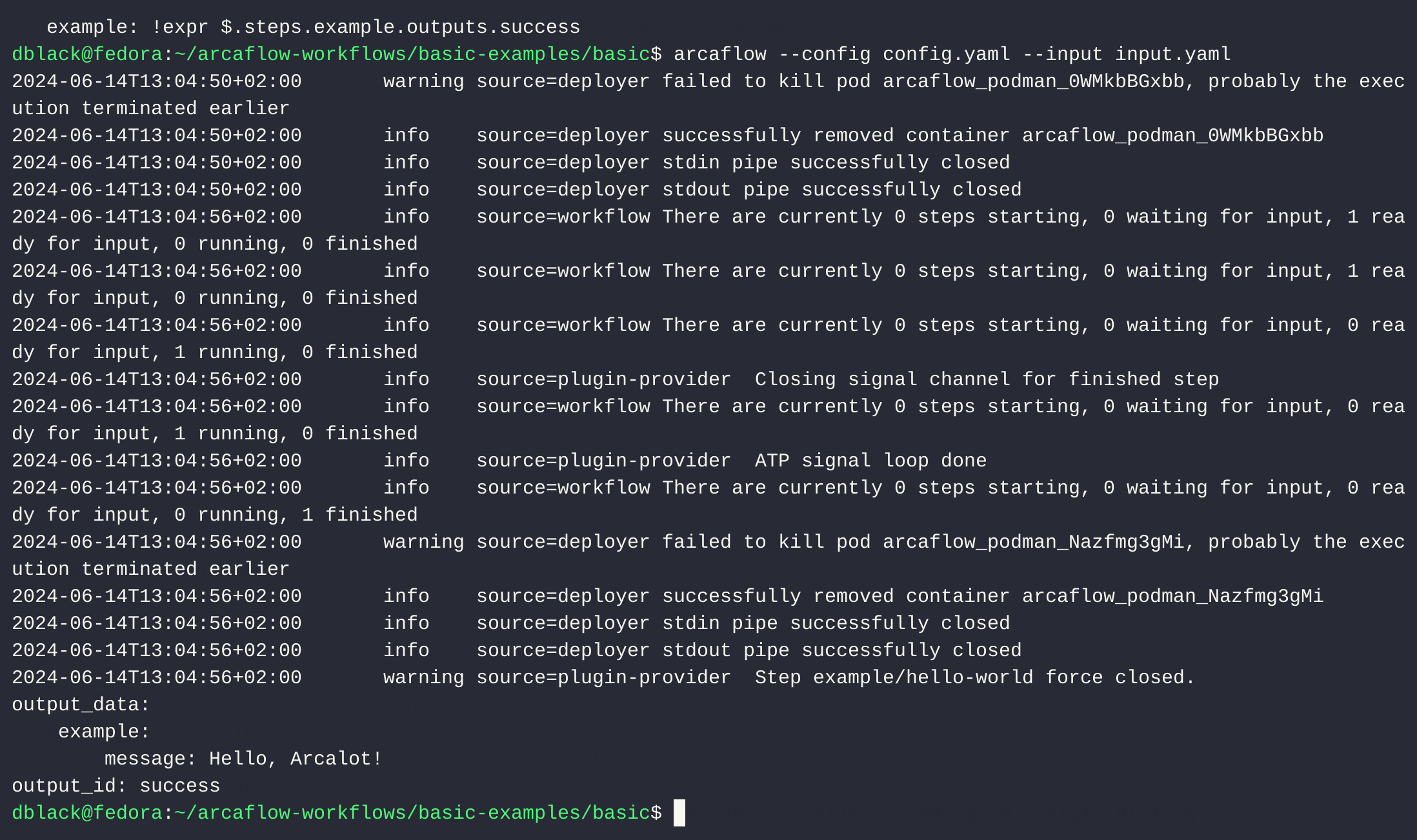
"},{"location":"arcaflow/getting-started/#step-7-run-the-workflow","title":"Step 7: Run the workflow","text":"Finally, let\u2019s run our workflow. Make sure you are in the directory where the workflow is located.
Linux/MacOSWindows/path/to/arcaflow -input input.yaml -config config.yaml\nC:\\path\\to\\arcaflow.exe -input input.yaml -config config.yaml\nIf everything went well, after a few seconds you should see logs messages similar to the ones shown below:
2023-03-22T11:25:58+01:00 info Loading plugins locally to determine schemas...\n2023-03-22T11:25:58+01:00 info Deploying example-plugin...\n2023-03-22T11:25:58+01:00 info Creating container from image example-plugin...\n2023-03-22T11:25:59+01:00 info Container started.\n2023-03-22T11:25:59+01:00 info Schema for example-plugin obtained.\n2023-03-22T11:25:59+01:00 info Schema loading complete.\n2023-03-22T11:25:59+01:00 info Building dependency tree...\n2023-03-22T11:25:59+01:00 info Dependency tree complete.\n2023-03-22T11:25:59+01:00 info Dependency tree Mermaid:\nflowchart TD\nsubgraph input\ninput.name\nend\ninput.name-->steps.greet\nsteps.greet-->steps.greet.outputs.success\nsteps.greet.outputs.success-->output\n2023-03-22T11:25:59+01:00 info Starting step greet...\n2023-03-22T11:25:59+01:00 info Creating container from image example-plugin...\n2023-03-22T11:26:00+01:00 info Container started.\n2023-03-22T11:26:00+01:00 info Step greet is now running...\n2023-03-22T11:26:00+01:00 info Step greet is now executing ATP...\n2023-03-22T11:26:00+01:00 info Step \"greet\" has finished with output success.\nmessage: Hello, Arca Lot\nAs you can see, the last line of the output is the output data from the workflow.
Did you know?
Arcaflow provides Mermaid markdown in the workflow output that allows you to quickly visualize the workflow in a graphic format. You can grab the Mermaid graph you see in the output and put it into the Mermaid editor.
Mermaid markdownMermaid rendered flowchartflowchart TD\nsubgraph input\ninput.name\nend\ninput.name-->steps.greet\nsteps.greet-->steps.greet.outputs.success\nsteps.greet.outputs.success-->output\nflowchart TD\nsubgraph input\ninput.name\nend\ninput.name-->steps.greet\nsteps.greet-->steps.greet.outputs.success\nsteps.greet.outputs.success-->outputTip
Further reading: Running Arcaflow
"},{"location":"arcaflow/getting-started/#next-steps","title":"Next steps","text":"Congratulations, you are now an Arcaflow user! Here are some things you can do next to start working with plugins and workflows:
Hungry for more? Keep digging into our docs::
Contribute to Arcaflow \u00bb
"},{"location":"arcaflow/concepts/","title":"Concepts","text":"This section of the documentation deals with theoretical concepts around Arcaflow. Fear not, it\u2019s not a university exam, but simply a description on how we designed Arcaflow the way we did and why we did so.
ArchitectureGet started with a primer on the core architecture of Arcaflow.
Read more about architecture \u00bb
TypingWe believe in strong and static typing to avoid bugs, so Arcaflow has its own typing system.
Read more about typing \u00bb
PluginsArcaflow is interoperable between several programming languages. Currently, we provide SDKs for Python and Go.
Read more about plugins \u00bb
WorkflowsArcaflow runs several steps and connects them together into a workflow.
Read more about workflows \u00bb
Flow control (WIP)In the future, we want to add the ability to perform loops, dynamic parallelization, etc.
Read more about flow control \u00bb
"},{"location":"arcaflow/concepts/architecture/","title":"Arcaflow architecture","text":"The Arcaflow architecture consists of the following 2 keys elements:
The engine is responsible for the orchestration of the workflow steps. It has several duties:
The engine itself is designed to be run from a command line interface, possibly as a webserver, but is not designed to run in a redundant fashion. Instead of implementing redundancy itself, the engine will receive support to execute workflows in third party systems, such as Kafka.
A stretch goal for the engine is to make it fully embeddable, possibly with in-binary workflows and execution images to make them easily to ship in network-restricted environments.
"},{"location":"arcaflow/concepts/architecture/#plugins","title":"Plugins","text":"Plugins provide execution for one or more steps for a workflow. The job of a plugin is to do one thing and do it well. A plugin provides a thin layer over third party tools, or its own implementation of features. Its main job is to provide accurate input and output schema information to the engine and transform the data as needed.
For example, a plugin may output unformatted text, which a plugin has to parse and build a machine-readable data structure for that information. This reformatting of data allows the engine to pipe data between steps and reliably check the data for faults.
The current plan is to provide plugin SDKs for Python, GO, and Rust (in that order).
"},{"location":"arcaflow/concepts/architecture/#typing","title":"Typing","text":"A core element of the Arcaflow system is the typing system. Each plugin and the engine itself will provide a machine-readable data structure that describes what inputs are expected and what outputs may be produced. If you are familiar with JSON schema or OpenAPI, this is similar, and Arcaflow can produce those schema documents. However, the Arcaflow system is stricter than those industry standards to optimize for performance and simpler implementation in all supported programming languages.
"},{"location":"arcaflow/concepts/architecture/#executing-workflows","title":"Executing workflows","text":"Arcaflow workflows are orchestrated in the Engine, while plugins can be run locally or remotely on container engines. This lends itself to a Git-based workflow:
flowchart LR\n subgraph laptop[Your laptop]\n direction LR\n\n ui(UI)\n engine(Engine)\n git(Git)\n\n ui -- Workflow --> engine\n ui -- Workflow --> git -- Workflow --> engine\n engine -- Execution results --> ui\n end\n\n subgraph docker[Docker/Podman<br>on your laptop]\n direction LR\n\n plugins1(Plugin)\n\n engine -- Step execution --> plugins1\n end\n engine -- Launch plugin --> docker\n\n subgraph k8s[Kubernetes]\n direction LR\n\n plugins2(Plugin)\n\n engine -- Step execution --> plugins2\n end\n engine -- Launch plugin --> k8s\n\n apis(Other APIs)\n plugins1 --> apis\n plugins2 --> apis Arcaflow is designed as an interoperable system between programming languages. Therefore, plugins are started as external processes and the communication with the plugin takes place over its standard input and output. The Arcaflow Engine passes data between the plugins as required by the workflow file.
In the vast majority of cases, plugins run inside a container, while the Arcaflow Engine itself does not. This allows Arcaflow to pass data between several Kubernetes clusters, local plugins, or even run plugins via Podman over SSH. These capabilities are built into the Arcaflow Engine with the help of deployers.
Since Arcaflow has an internal typing system, each plugin must declare at the start what input data it requires and what outputs it produces. This allows the Engine to verify that the workflow can be run, and that no invalid data is being used. If invalid data is detected, the workflow is aborted to prevent latent defects in the data.
In summary, you can think of Arcaflow as a strongly (and at some time in the future possibly statically) typed system for executing workflows, where individual plugins run in containers across several systems.
"},{"location":"arcaflow/concepts/typing/","title":"Typing system","text":"Let\u2019s say you are creating a system that measures performance. But, uh-oh! A bug has struck! Instead of returning a number, a plugin returns an empty string. Would you want that converted to a numeric 0 for a metric? Or worse yet, would you want a negative number resulting from a bug to make it into your metrics? Would you want to collect metrics for years just to find out they are all wrong?
If the answer is no, then the typing system is here to help. Each plugin or workflow in Arcaflow is required to explicitly state what data types it accepts for its fields, and what their boundaries are. When a plugin then violates its own rules, the engine makes sure that corrupt data isn\u2019t used any further.
For example, let\u2019s look at the definition of an integer:
type_id: integer\nmin: 10\nmax: 128\nIt\u2019s so simple, but it already prevents a lot of bugs: non-integers, numbers out of range.
But wait! A typing system can do more for you. For example, we can automatically generate a nice documentation from it. Let\u2019s take this object as an example:
type_id: object\nid: name\nproperties:\n name:\n type:\n type_id: string\n min: 1\n max: 256\n display:\n name: \"Name\"\n description: \"The name of the user.\"\n icon: |\n <svg ...></svg>\nThat\u2019s all it takes to render a nice form field or automatic documentation. You can read more about creating types in the plugins section or the workflows section, or see the complete typing reference in the Contributing guide.
"},{"location":"arcaflow/concepts/workflows/","title":"Arcaflow Workflows (concept)","text":"Tip
This document describes the concept of Arcaflow Workflows. We describe the process of writing a workflow in this section
"},{"location":"arcaflow/concepts/workflows/#steps","title":"Steps","text":"Workflows are a way to describe a sequence or parallel execution of individual steps. The steps are provided exclusively by plugins. The simplest workflow looks like this:
stateDiagram-v2\n [*] --> Step\n Step --> [*]However, this is only true if the step only has one output. Most steps will at least have two possible outputs, for success and error states:
stateDiagram-v2\n [*] --> Step\n Step --> [*]: yes\n Step --> [*]: noPlugins can declare as many outputs as needed, with custom names. The workflow engine doesn\u2019t make a distinction based on the names, all outputs are treated equal for execution.
An important rule is that one step must always end in exactly one output. No step must end without an output, and no step can end in more than one output. This provides a mechanism to direct the flow of the workflow execution.
Plugins must also explicitly declare what parameters they expect as input for the step, and the data types of these and what parameters they will produce as output.
"},{"location":"arcaflow/concepts/workflows/#interconnecting-steps","title":"Interconnecting steps","text":"When two steps are connected, they will be executed after each other:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n Step1 --> Step2\n Step2 --> [*]Similarly, when two steps are not directly connected, they may be executed in parallel:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n [*] --> Step2\n Step1 --> [*]\n Step2 --> [*]You can use the interconnection to direct the flow of step outputs:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n Step3: Step 3\n [*] --> Step1\n Step1 --> Step2: success\n Step1 --> Step3: error\n Step2 --> [*]\n Step3 --> [*]When two steps are connected, you have the ability to pass data between them. Emblematically described:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n Step1 --> Step2: input_1 = $.steps.step1.outputs.success\n Step2 --> [*]The data type of the input on Step 2 in this case must match the result of the expression. If the data type does not match, the workflow will not be executed.
"},{"location":"arcaflow/concepts/workflows/#undefined-inputs","title":"Undefined inputs","text":"Step inputs can either be required or optional. When a step input is required, it must be configured or the workflow will fail to execute. However, there are cases when the inputs cannot be determined from previous steps. In this case, the workflow start can be connected and the required inputs can be obtained from the user when running the workflow:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n [*] --> Step2: input_1 = $.input.option_1\n Step1 --> Step2: input_2 = $.steps.step1.outputs.success\n Step2 --> [*]This is typically the case when credentials, such as database access, etc. are required.
"},{"location":"arcaflow/concepts/workflows/#outputs","title":"Outputs","text":"The output for each step is preserved for later inspection. However, the workflow can explicitly declare outputs. These outputs are usable in scripted environments as a direct output of the workflow:
stateDiagram-v2\n [*] --> Step\n Step --> [*]: output_1 = $.steps.step1.outputs.successBackground processes
Each plugin will only be invoked once, allowing plugins to run background processes, such as server applications. The plugins must handle SIGINT and SIGTERM events properly.
"},{"location":"arcaflow/concepts/workflows/#flow-control-wip","title":"Flow control (WIP)","text":"The workflow contains several flow control operations. These flow control operations are not implemented by plugins, but are part of the workflow engine itself.
"},{"location":"arcaflow/concepts/workflows/#foreach","title":"Foreach","text":"The foreach flow control allows you to loop over a sub-workflow with a list of input objects.
stateDiagram-v2\n [*] --> ForEach\n state ForEach {\n [*] --> loop_list_input\n loop_list_input --> sub_workflow\n sub_workflow --> loop_list_input\n state sub_workflow {\n [*] --> Step1\n Step1 --> [*]\n }\n sub_workflow --> [*]: Sub Output\n }\n ForEach --> [*]: OutputWarning
The features below are in-development and not yet implemented in the released codebase.
"},{"location":"arcaflow/concepts/workflows/#abort","title":"Abort","text":"The abort flow control is a quick way to exit out of a workflow. This is useful when entering a terminal error state and the workflow output data would be useless anyway.
stateDiagram-v2\n [*] --> Step1\n Step1 --> Abort: Output 1\n Step1 --> Step2: Output 2\n Step2 --> [*]However, this is only required if you want to abort the workflow immediately. If you want an error case to result in the workflow failing, but whatever steps can be finished being finished, you can leave error outputs unconnected.
"},{"location":"arcaflow/concepts/workflows/#do-while","title":"Do-while","text":"A do-while block will execute the steps in it as long as a certain condition is met. The condition is derived from the output of the step or steps executed inside the loop:
stateDiagram-v2\n [*] --> DoWhile\n state DoWhile {\n [*] --> Step1\n Step1 --> [*]: output_1_condition=$.step1.output_1.finished == false \n }\n DoWhile --> [*]If the step declares multiple outputs, multiple conditions are possible. The do-while block will also have multiple outputs:
stateDiagram-v2\n [*] --> DoWhile\n state DoWhile {\n [*] --> Step1\n Step1 --> [*]: Output 1 condition\n Step1 --> [*]: Output 2 condition \n }\n DoWhile --> [*]: Output 1\n DoWhile --> [*]: Output 2You may decide to only allow exit from a loop if one of the two outputs is satisfied:
stateDiagram-v2\n [*] --> DoWhile\n state DoWhile {\n [*] --> Step1\n Step1 --> Step1: Output 1\n Step1 --> [*]: Output 2\n }\n DoWhile --> [*]: Output 1A condition is a flow control operation that redirects the flow one way or another based on an expression. You can also create multiple branches to create a switch-case effect.
stateDiagram-v2\n state if_state <<choice>>\n Step1: Step 1\n [*] --> Step1\n Step1 --> if_state\n Step2: Step 2\n Step3: Step 3\n if_state --> Step2: $.step1.output_1 == true\n if_state --> Step3: $.step1.output_1 == falseThe multiply flow control operation is useful when you need to dynamically execute sub-workflows in parallel based on an input condition. You can, for example, use this to run a workflow step on multiple or all Kubernetes nodes.
stateDiagram-v2\n Lookup: Lookup Kubernetes hosts\n [*] --> Lookup\n Lookup --> Multiply\n state Multiply {\n [*] --> Stresstest\n Stresstest --> [*]\n }\n Multiply --> [*]The output of a Multiply operation will be a map, keyed with a string that is configured from the input.
Tip
You can think of a Multiply step like a for-each loop, but the steps being executed in parallel.
"},{"location":"arcaflow/concepts/workflows/#synchronize","title":"Synchronize","text":"The synchronize step attempts to synchronize the execution of subsequent steps for a specified key. The key must be a constant and cannot be obtained from an input expression.
stateDiagram-v2\n [*] --> Step1\n [*] --> Step2\n Synchronize1: Synchronize (key=a)\n Synchronize2: Synchronize (key=a)\n Step1 --> Synchronize1\n Step2 --> Synchronize2\n Synchronize1 --> Step3\n Synchronize2 --> Step4\n Step3 --> [*]\n Step4 --> [*]First of all, welcome to the Arca Lot! Whether you are a beginner or a seasoned veteran, your contributions are most appreciated. Thank you!
Now, let\u2019s get you started. There are a number of ways you can contribute on GitHub, please check the Arcaflow project board for open issues. Additionally, here are a few repos you can contribute to:
Repository What you can do here arcalot.github.io Improve the documentation arcaflow-plugin-sdk-go Improve the Go SDK arcaflow-plugin-sdk-python Improve the Python SDK arcaflow-engine Improve the Arcaflow Engine arcaflow-engine-deployer-kubernetes Improve the Kubernetes deployment of plugins arcaflow-engine-deployer-docker Improve the Docker deployment of plugins arcaflow-engine-deployer-podman Improve the Podman deployment of plugins arcaflow-expressions Improve the Arcaflow expression language arcaflow-plugin-image-builder Improve the Arcaflow plugin packaging arcaflow-plugin-* Improve the officially supported pluginsIf you want to contribute regularly, why not join the Arcalot Round Table by reading our charter and signing up as a member? That way you get a voice in the decisions we make!
"},{"location":"arcaflow/contributing/#license","title":"License","text":"All code in Arcaflow is licensed under the Apache 2.0 license. The documentation is licensed under CC-BY-4.0. Please make sure you read and understand these licenses before contributing. If you are contributing on behalf of your employer, please make sure you have permission to do so.
"},{"location":"arcaflow/contributing/#principles","title":"Principles","text":"While we don\u2019t deal in absolutes (only a Sith would do that) we hold ourselves to a few key principles. There are plenty of things where we could do better in these areas, so if you find something, please open an issue. It\u2019s important!
"},{"location":"arcaflow/contributing/#the-principle-of-the-least-surprise","title":"The principle of the least surprise","text":"Sometimes, things are just hard to make user-friendly. If presented with two choices, we will always pick the one that doesn\u2019t break expectations. What would an average user expect to happen without reading the documentation? If something surprised you, please open a bug.
"},{"location":"arcaflow/contributing/#the-principle-of-nice-error-messages","title":"The principle of nice error messages","text":"When using Arcaflow, you should never be confronted with a stack trace. Error messages should always explain what went wrong and how to fix it. We know, this is a tall order, but if you see an error message that is not helpful, please open a bug.
"},{"location":"arcaflow/contributing/#the-principle-of-intern-friendliness","title":"The principle of intern-friendliness","text":"There is enough software out in the wild that requires months of training and is really hard to get into. Arcaflow isn\u2019t the easiest to learn either, see the whole typing system thing, but nevertheless, the software should be written in such a way that an intern with minimal training can sit down and do something useful with it. If something is unnecessarily hard or undocumented, you guessed it, please open a bug.
"},{"location":"arcaflow/contributing/#the-principle-of-typing","title":"The principle of typing","text":"We believe that strong and static typing can save us from bugs. This applies to programming languages just as much as it applies to workflows. We aim to make a system tell us that something is wrong before we spent several hours running it.
"},{"location":"arcaflow/contributing/#the-principle-of-testing","title":"The principle of testing","text":"Bugs? Yeah, we have those, and we want fewer of them. Since we are a community effort, we can\u2019t afford a large QA team to test through everything manually before a release. Therefore, it\u2019s doubly important that we have automated tests that run on every change. Furthermore, we want our tests to run quickly and without additional setup time. You should be able to run go test or python -m unittest discover and get a result within a few seconds at most. This makes it more likely that a contributor will run the tests and contribute new tests instead of waiting for CI to sort it out.
Every software is\u2026 pardon our French: crap. Ours is no exception. The difference is how big and how stinky the piles are. We aim to make the piles small, well-defined and as stink-less as possible. If we need to replace a pile with another pile, it should be easy to do so.
Translated to software engineering, we create APIs between our piles components. These APIs can be in the form of code, or in the form of a GitHub Actions workflow. A non-leaky API helps us replace one side of the API without touching the other.
"},{"location":"arcaflow/contributing/#the-principle-of-kindness-to-our-future-self","title":"The principle of kindness to our future self","text":"Writing code should be fun, most of us got into this industry because we enjoyed creating something. We want to keep this joy of creation. What kills the enthusiasm fastest is having to slog through endless pieces of obtuse code, spending hours and hours trying to accomplish a one-line change. When we write code, we want to be kind to our future selves. That\u2019s why we not only write documentation and tests for our users, we also create these for ourselves and our peers.
"},{"location":"arcaflow/contributing/deployers/","title":"Arcaflow Deployers Development Guide","text":"The Arcaflow Engine relies on deployers to execute containers. Deployers provide a binary-safe transparent tunnel of communication between a plugin and the engine. (Typically, this will be done via standard input/output, but other deployers are possible.)
The Engine and the plugin communicate via the Arcaflow Transport Protocol over this tunnel, but the deployer is unaware of the method of this communication.
Deployers are written in Go and must implement the deployer interface. Deployers are not dynamically pluggable, they must also be added to the engine code to be usable.
"},{"location":"arcaflow/contributing/engine/","title":"Arcaflow Engine Development Guide","text":"Warning
The engine is currently undergoing a major refactor. This page describes the engine post-refactor.
The Arcaflow engine is responsible for parsing a YAML workflow and executing it. It goes through several phases during execution.
"},{"location":"arcaflow/contributing/engine/#yaml-loading-phase","title":"YAML loading phase","text":"During the YAML loading phase, the engine loads the workflow YAML as raw data containing YAML nodes. We need the raw YAML nodes to access the YAML tags, which we use to turn the structure into expressions. The resulting data structure of this phase is a structure consisting of maps, lists, strings, and expression objects.
YAML
YAML, at its core, only knows three data types: maps, lists, and strings. Additionally, each entry can have a tag in the form of !foo or !!foo.
Once the YAML is loaded, we can take the data created and parse the workflow. This will validate the input definition and the basic step definitions and provide a more structured data. However, at this point the plugin schemas are not known yet, so any data structure related to steps is accepted as-is.
"},{"location":"arcaflow/contributing/engine/#schema-loading","title":"Schema loading","text":"The engine has an API to provide step types. These step types have the ability to provide a lifecycle and load their schema. In case of plugins, this means that the plugin is fired up briefly and its schema is queried. (See Deployers.)
"},{"location":"arcaflow/contributing/engine/#dag-construction","title":"DAG construction","text":"Once the schema is loaded, the Directed Acyclic Graph can be constructed from the expressions. Each lifecycle stage input is combed for expressions and a DAG is built.
"},{"location":"arcaflow/contributing/engine/#static-code-analysis-future","title":"Static code analysis (future)","text":"The expression library already has the facilities to inspect types, which will, in the future, provide us the ability to perform a static code analysis on the workflow. This will guarantee users that a workflow can be executed without typing problems.
"},{"location":"arcaflow/contributing/engine/#workflow-execution","title":"Workflow execution","text":"When the DAG is complete and contains no cycles, the workflow execution can proceed. The execution cycle queries lifecycle nodes that have no more inbound dependencies and runs the lifecycle. When a lifecycle stage finishes, the corresponding nodes are removed from the DAG, freeing up other nodes for execution.
"},{"location":"arcaflow/contributing/expressions/","title":"Arcaflow Expressions Development Guide","text":"The expressions library provides the engine and other potential users with a simple way to compile expressions and provide typing information about an expression result.
The library consists of two parts: the internal parser/AST and the API layer.
"},{"location":"arcaflow/contributing/expressions/#the-parser-ast","title":"The Parser / AST","text":"The expressions parser constructs an Abstract Syntax Tree from the expression which can then be walked by the API layer. The AST consists of the following node types:
"},{"location":"arcaflow/contributing/expressions/#dot-notation","title":"Dot Notation","text":"Let\u2019s say you have an expression foo.bar. The dot notation node is the dot in the middle. The left subtree of the dot will be the entire expression left of the dot, while the right subtree will be everything to the right.
Bracket expressions are expressions in the form of foo[bar]. The left subtree will represent the expression to the left of the brackets (foo in the example), while the right subtree will represent the subexpression within the brackets (bar in the example).
Binary operations include all of the operations that have a left and right subtree that do not have a special node representing them (dot notation and bracket expression are examples of special cases). Binary operations are represented by a node containing an operation and the subtrees to which the operation is applied.
"},{"location":"arcaflow/contributing/expressions/#unary-operations","title":"Unary Operations","text":"Unary operations include boolean complement ! and numeric negation -. Unary operations are represented by a node containing an operation and the subtree to which the operation is applied. Unlike binary operations, unary operations have only one subtree.
Identifiers come in two forms:
$ references the root of the data structure.^\\w+$. This may be used for accessing object fields or as function identifiers.The API layer provides three functions:
All three functions walk the AST above and construct the required data.
"},{"location":"arcaflow/contributing/plugin-protocol/","title":"Arcaflow Plugin protocol specification (ATP)","text":"Arcaflow runs plugins locally in a container using Docker or Podman, or remotely in Kubernetes. Each plugin must be containerized and communicates with the engine over standard input/output. This document outlines the protocol the engine and the plugins use to communicate.
Hint
You do not need this page if you only intend to implement a plugin with the SDK!
"},{"location":"arcaflow/contributing/plugin-protocol/#execution-model","title":"Execution model","text":"A single plugin execution is intended to run a single task and not more. This simplifies the code since there is no need to try and clean up after each task. Each plugin is executed in a container and must communicate with the engine over standard input/output. Furthermore, the plugin must add a handler for SIGTERM and properly clean up if there are services running in the background.
Each plugin is executed at the start of the workflow, or workflow block, and is terminated only at the end of the current workflow or workflow block. The plugin can safely rely on being able to start a service in the background and then keeping it running until the SIGTERM comes to shut down the container.
However, the plugin must, under no circumstances, start doing work until the engine sends the command to do so. This includes starting any services inside the container or outside. This restriction is necessary to be able to launch the plugin with minimal resource consumption locally on the engine host to fetch the schema.
The plugin execution is divided into three major steps.
SIGTERM to the plugin. The plugin has up to 30 seconds to shut down. The SIGTERM may come at any time, even while the work is still running, and the plugin must appropriately shut down. If the work is not complete, it is important that the plugin does not send error output to STDOUT. If the plugin fails to stop by itself within 30 seconds, the plugin container is forcefully stopped.As a data transport protocol, we use CBOR messages RFC 8949 back to back due to their self-delimiting nature. This section provides the entire protocol as JSON schema below.
"},{"location":"arcaflow/contributing/plugin-protocol/#step-0-the-start-output-message","title":"Step 0: The \u201cstart output\u201d message","text":"Because Kubernetes has no clean way of capturing an output right at the start, the initial step of the plugin execution involves the engine sending an empty CBOR message (None or Nil) to the plugin. This indicates, that the plugin may start its output now.
The \u201cHello\u201d message is a way for the plugin to introduce itself and present its steps and schema. Transcribed to JSON, a message of this kind would look as follows:
{\n \"version\": 1,\n \"steps\": {\n \"step-id-1\": {\n \"name\": \"Step 1\",\n \"description\": \"This is the first step\",\n \"input\": {\n \"schema\": {\n // Input schema\n }\n },\n \"outputs\": {\n \"output-id-1\": {\n \"name\": \"Name for this output kind\",\n \"description\": \"Description for this output\",\n \"schema\": {\n // Output schema\n }\n }\n }\n }\n }\n}\nThe schemas must describe the data structure the plugin expects. For a simple hello world input would look as follows:
{\n \"type\": \"object\",\n \"properties\": {\n \"name\": {\n \"type\": \"string\"\n }\n }\n}\nThe full schema is described below in the Schema section.
"},{"location":"arcaflow/contributing/plugin-protocol/#step-2-start-work-message","title":"Step 2: Start work message","text":"The \u201cstart work\u201d message has the following parameters in CBOR:
{\n \"id\": \"id-of-the-step-to-execute\",\n \"config\": {\n // Input parameters according to schema here\n }\n}\nThe plugin must respond with a CBOR message of the following format:
{\n \"status\": \"started\"\n}\nIf the plugin execution ended unexpectedly, the plugin should crash and output a reasonable error message to the standard error. The plugin must exit with a non-zero exit status to notify the engine that the execution failed.
"},{"location":"arcaflow/contributing/plugin-protocol/#step-3b-output","title":"Step 3/b: Output","text":"When the plugin has executed successfully, it must emit a CBOR message to the standard output:
{\n \"output_id\": \"id-of-the-declared-output\",\n \"output_data\": {\n // Result data of the plugin\n },\n \"debug_logs\": \"Unstructured logs here for debugging as a string.\"\n}\nThis section contains the exact schema that the plugin sends to the engine.
Type:scope Root object: Schema Properties steps (map[string, reference[Step]]) Name: Steps Description: Steps this schema supports. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Step] Referenced object: Step (see in the Objects section below) Objects AnySchema (object) Type: object Properties None
BoolSchema (object) Type: object Properties None
Display (object) Type: object Properties description (string) Name: Description Description: Description for this item if needed. Required: No Minimum: 1 Examples \"Please select the fruit you would like.\"\nstring) Name: Icon Description: SVG icon for this item. Must have the declared size of 64x64, must not include additional namespaces, and must not reference external resources. Required: No Minimum: 1 Examples \"<svg ...></svg>\"\nstring) Name: Name Description: Short text serving as a name or title for this item. Required: No Minimum: 1 Examples \"Fruit\"\nobject) Type: object Properties max (float) Name: Maximum Description: Maximum value for this float (inclusive). Required: No Examples 16.0\nfloat) Name: Minimum Description: Minimum value for this float (inclusive). Required: No Examples 5.0\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum value for this int (inclusive). Required: No Minimum: 0 Examples 5\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties units (reference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nmap[int, reference[Display]]) Name: Values Description: Possible values for this field. Required: Yes | Minimum items: | 1 |\nint Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\"1024\": {\"name\": \"kB\"}, \"1048576\": {\"name\": \"MB\"}}\nobject) Type: object Properties items (one of[string]) Name: Items Description: ReflectedType definition for items in this list. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\nobject) Type: object Properties keys (one of[string]) Name: Keys Description: ReflectedType definition for keys in this map. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\none of[string]) Name: Values Description: ReflectedType definition for values in this map. Required: No Object (object) Type: object Properties id (string) Name: ID Description: Unique identifier for this object within the current scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ properties (map[string, reference[Property]]) Name: Properties Description: Properties of this object. Required: Yes Key type Type: string Minimum: 1 Value type Type: reference[Property] Referenced object: Property (see in the Objects section below) OneOfIntSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[int, one of[string]]) Name: Types Required: No Key type Type: int Value type Type: one of[string] OneOfStringSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[string, one of[string]]) Name: Types Required: No Key type Type: string Value type Type: one of[string] Pattern (object) Type: object Properties None
Property (object) Type: object Properties conflicts (list[string]) Name: Conflicts Description: The current property cannot be set if any of the listed properties are set. Required: No List Items Type: string default (string) Name: Default Description: Default value for this property in JSON encoding. The value must be unserializable by the type specified in the type field. Required: No display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) examples (list[string]) Name: Examples Description: Example values for this property, encoded as JSON. Required: No List Items Type: string required (bool) Name: Required Description: When set to true, the value for this field must be provided under all circumstances. Required: No Defaulttrue\nlist[string]) Name: Required if Description: Sets the current property to required if any of the properties in this list are set. Required: No List Items Type: string required_if_not (list[string]) Name: Required if not Description: Sets the current property to be required if none of the properties in this list are set. Required: No List Items Type: string type (one of[string]) Name: Type Description: Type definition for this field. Required: Yes Ref (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) id (string) Name: ID Description: Referenced object ID. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Schema (object) Type: object Properties steps (map[string, reference[Step]]) Name: Steps Description: Steps this schema supports. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Step] Referenced object: Step (see in the Objects section below) Scope (object) Type: object Properties objects (map[string, reference[Object]]) Name: Objects Description: A set of referencable objects. These objects may contain references themselves. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Object] Referenced object: Object (see in the Objects section below) root (string) Name: Root object Description: ID of the root object of the scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Step (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) id (string) Name: ID Description: Machine identifier for this step. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ input (reference[Scope]) Name: Input Description: Input data schema. Required: Yes Referenced object: Scope (see in the Objects section below) outputs (map[string, reference[StepOutput]]) Name: Input Description: Input data schema. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[StepOutput] Referenced object: StepOutput (see in the Objects section below) StepOutput (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) error (bool) Name: Error Description: If set to true, this output will be treated as an error output. Required: No Defaultfalse\nreference[Scope]) Name: Schema Description: Data schema for this particular output. Required: Yes Referenced object: Scope (see in the Objects section below) String (object) Type: object Properties max (int) Name: Maximum Description: Maximum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 16\nint) Name: Minimum Description: Minimum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 5\npattern) Name: Pattern Description: Regular expression this string must match. Required: No Examples \"^[a-zA-Z]+$\"\nobject) Type: object Properties values (map[string, reference[Display]]) Name: Values Description: Mapping where the left side of the map holds the possible value and the right side holds the display value for forms, etc. Required: Yes | Minimum items: | 1 |\nstring Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\n \"apple\": {\n \"name\": \"Apple\"\n },\n \"orange\": {\n \"name\": \"Orange\"\n }\n}\nobject) Type: object Properties name_long_plural (string) Name: Name long (plural) Description: Longer name for this UnitDefinition in plural form. Required: Yes Examples \"bytes\",\"characters\"\nstring) Name: Name long (singular) Description: Longer name for this UnitDefinition in singular form. Required: Yes Examples \"byte\",\"character\"\nstring) Name: Name short (plural) Description: Shorter name for this UnitDefinition in plural form. Required: Yes Examples \"B\",\"chars\"\nstring) Name: Name short (singular) Description: Shorter name for this UnitDefinition in singular form. Required: Yes Examples \"B\",\"char\"\nobject) Type: object Properties base_unit (reference[Unit]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: Yes Referenced object: Unit (see in the Objects section below) Examples {\n \"name_short_singular\": \"B\",\n \"name_short_plural\": \"B\",\n \"name_long_singular\": \"byte\",\n \"name_long_plural\": \"bytes\"\n}\nmap[int, reference[Unit]]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: No Key type Type: int Value type Type: reference[Unit] Referenced object: Unit (see in the Objects section below) Examples {\n \"1024\": {\n \"name_short_singular\": \"kB\",\n \"name_short_plural\": \"kB\",\n \"name_long_singular\": \"kilobyte\",\n \"name_long_plural\": \"kilobytes\"\n },\n \"1048576\": {\n \"name_short_singular\": \"MB\",\n \"name_short_plural\": \"MB\",\n \"name_long_singular\": \"megabyte\",\n \"name_long_plural\": \"megabytes\"\n }\n}\nArcaflow takes a departure from the classic run-and-pray approach of running workloads and validates workflows before executing them. To do this, Arcaflow starts the plugins as needed before the workflow is run and queries them for their schema. This schema will contain information about what kind of input a plugin requests and what kind of outputs it can produce.
A plugin can support multiple workflow steps and must provide information about the data types in its input and output for each step. A step can have exactly one input format, but may declare more than one output.
The type system is inspired by JSON schema and OpenAPI, but it is more restrictive due to the need to efficiently serialize workloads over various formats.
"},{"location":"arcaflow/contributing/typing/#types","title":"Types","text":"The typing system supports the following data types.
null, nil, or None), or a default value.null, nil, or None).null, nil, or None).true or false and cannot take any other values.The typing system also contains more in-depth validation than just simple types:
"},{"location":"arcaflow/contributing/typing/#strings","title":"Strings","text":"Strings can have a minimum or maximum length, as well as validation against a regular expression.
"},{"location":"arcaflow/contributing/typing/#ints-floats","title":"Ints, floats","text":"Number types can have a minimum and maximum value (inclusive).
"},{"location":"arcaflow/contributing/typing/#booleans","title":"Booleans","text":"Boolean types can take a value of either true or false, but when unserializing from YAML or JSON formats, strings or int values of true, yes, on, enable, enabled, 1, false, no, off, disable, disabled or 0 are also accepted.
Lists and maps can have constraints on the minimum or maximum number of items in them (inclusive).
"},{"location":"arcaflow/contributing/typing/#objects","title":"Objects","text":"Object fields can have several constraints:
required_if has a list of other fields that, if set, make the current field required.required_if_not has a list of other fields that, if none are set, make the current field required.conflicts has a list of other fields that cannot be set together with the current field.When you need to create a list of multiple object types, or simply have an either-or choice between two object types, you can use the OneOf type. This field uses an already existing field of the underlying objects, or adds an extra field to the schema to distinguish between the different types. Translated to JSON, you might see something like this:
{\n \"_type\": \"Greeter\",\n \"message\": \"Hello world!\"\n}\nObjects, on their own, cannot create circular references. It is not possible to create two objects that refer to each other. That\u2019s where scopes and refs come into play. Scopes hold a list of objects, identified by an ID. Refs inside the scope (for example, in an object property) can refer to these IDs. Every scope has a root object, which will be used to provide its \u201cobject-like\u201d features, such as a list of fields.
For example:
objects:\n my_root_object:\n id: my_root_object\n properties:\n ...\nroot: my_root_object\nMultiple scopes can be nested into each other. The ref always refers to the closest scope up the tree. Multiple scopes can be used when combining objects from several sources (e.g. several plugins) into one schema to avoid conflicting ID assignments.
"},{"location":"arcaflow/contributing/typing/#any","title":"Any","text":"Any accepts any primitive type (string, int, float, bool, map, list) but no patterns, objects, etc. This type is severely limited in its ability to validate data and should only be used in exceptional cases when there is no other way to describe a schema.
"},{"location":"arcaflow/contributing/typing/#metadata","title":"Metadata","text":"Object fields can also declare metadata that will help with creating user interfaces for the object. These fields are:
For display purposes, the type system is designed so that it can infer the intent of the data. We wish to communicate the following intents:
We explicitly document the following inference rules, which will probably change in the future.
This section explains how a scope object looks like. The plugin protocol contains a few more types that are used when communicating a schema.
Type:scope Root object: Scope Properties objects (map[string, reference[Object]]) Name: Objects Description: A set of referencable objects. These objects may contain references themselves. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Object] Referenced object: Object (see in the Objects section below) root (string) Name: Root object Description: ID of the root object of the scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Objects AnySchema (object) Type: object Properties None
BoolSchema (object) Type: object Properties None
Display (object) Type: object Properties description (string) Name: Description Description: Description for this item if needed. Required: No Minimum: 1 Examples \"Please select the fruit you would like.\"\nstring) Name: Icon Description: SVG icon for this item. Must have the declared size of 64x64, must not include additional namespaces, and must not reference external resources. Required: No Minimum: 1 Examples \"<svg ...></svg>\"\nstring) Name: Name Description: Short text serving as a name or title for this item. Required: No Minimum: 1 Examples \"Fruit\"\nobject) Type: object Properties max (float) Name: Maximum Description: Maximum value for this float (inclusive). Required: No Examples 16.0\nfloat) Name: Minimum Description: Minimum value for this float (inclusive). Required: No Examples 5.0\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum value for this int (inclusive). Required: No Minimum: 0 Examples 5\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties units (reference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nmap[int, reference[Display]]) Name: Values Description: Possible values for this field. Required: Yes | Minimum items: | 1 |\nint Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\"1024\": {\"name\": \"kB\"}, \"1048576\": {\"name\": \"MB\"}}\nobject) Type: object Properties items (one of[string]) Name: Items Description: ReflectedType definition for items in this list. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\nobject) Type: object Properties keys (one of[string]) Name: Keys Description: ReflectedType definition for keys in this map. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\none of[string]) Name: Values Description: ReflectedType definition for values in this map. Required: No Object (object) Type: object Properties id (string) Name: ID Description: Unique identifier for this object within the current scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ properties (map[string, reference[Property]]) Name: Properties Description: Properties of this object. Required: Yes Key type Type: string Minimum: 1 Value type Type: reference[Property] Referenced object: Property (see in the Objects section below) OneOfIntSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[int, one of[string]]) Name: Types Required: No Key type Type: int Value type Type: one of[string] OneOfStringSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[string, one of[string]]) Name: Types Required: No Key type Type: string Value type Type: one of[string] Pattern (object) Type: object Properties None
Property (object) Type: object Properties conflicts (list[string]) Name: Conflicts Description: The current property cannot be set if any of the listed properties are set. Required: No List Items Type: string default (string) Name: Default Description: Default value for this property in JSON encoding. The value must be unserializable by the type specified in the type field. Required: No display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) examples (list[string]) Name: Examples Description: Example values for this property, encoded as JSON. Required: No List Items Type: string required (bool) Name: Required Description: When set to true, the value for this field must be provided under all circumstances. Required: No Defaulttrue\nlist[string]) Name: Required if Description: Sets the current property to required if any of the properties in this list are set. Required: No List Items Type: string required_if_not (list[string]) Name: Required if not Description: Sets the current property to be required if none of the properties in this list are set. Required: No List Items Type: string type (one of[string]) Name: Type Description: Type definition for this field. Required: Yes Ref (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) id (string) Name: ID Description: Referenced object ID. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Scope (object) Type: object Properties objects (map[string, reference[Object]]) Name: Objects Description: A set of referencable objects. These objects may contain references themselves. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Object] Referenced object: Object (see in the Objects section below) root (string) Name: Root object Description: ID of the root object of the scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ String (object) Type: object Properties max (int) Name: Maximum Description: Maximum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 16\nint) Name: Minimum Description: Minimum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 5\npattern) Name: Pattern Description: Regular expression this string must match. Required: No Examples \"^[a-zA-Z]+$\"\nobject) Type: object Properties values (map[string, reference[Display]]) Name: Values Description: Mapping where the left side of the map holds the possible value and the right side holds the display value for forms, etc. Required: Yes | Minimum items: | 1 |\nstring Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\n \"apple\": {\n \"name\": \"Apple\"\n },\n \"orange\": {\n \"name\": \"Orange\"\n }\n}\nobject) Type: object Properties name_long_plural (string) Name: Name long (plural) Description: Longer name for this UnitDefinition in plural form. Required: Yes Examples \"bytes\",\"characters\"\nstring) Name: Name long (singular) Description: Longer name for this UnitDefinition in singular form. Required: Yes Examples \"byte\",\"character\"\nstring) Name: Name short (plural) Description: Shorter name for this UnitDefinition in plural form. Required: Yes Examples \"B\",\"chars\"\nstring) Name: Name short (singular) Description: Shorter name for this UnitDefinition in singular form. Required: Yes Examples \"B\",\"char\"\nobject) Type: object Properties base_unit (reference[Unit]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: Yes Referenced object: Unit (see in the Objects section below) Examples {\n \"name_short_singular\": \"B\",\n \"name_short_plural\": \"B\",\n \"name_long_singular\": \"byte\",\n \"name_long_plural\": \"bytes\"\n}\nmap[int, reference[Unit]]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: No Key type Type: int Value type Type: reference[Unit] Referenced object: Unit (see in the Objects section below) Examples {\n \"1024\": {\n \"name_short_singular\": \"kB\",\n \"name_short_plural\": \"kB\",\n \"name_long_singular\": \"kilobyte\",\n \"name_long_plural\": \"kilobytes\"\n },\n \"1048576\": {\n \"name_short_singular\": \"MB\",\n \"name_short_plural\": \"MB\",\n \"name_long_singular\": \"megabyte\",\n \"name_long_plural\": \"megabytes\"\n }\n}\nArcaflow supports writing plugins in any language, and we provide pre-made libraries for Python and Go.
Plugins in Arcaflow run in containers, so you can use dependencies and libraries.
Writing plugins in PythonPython is the easiest language to start writing plugins in, you simply need to write a few dataclasses and a function and that\u2019s already a working plugin.
Read more about Python plugins \u00bb
Writing plugins in GoGo is the programming language of the engine. Writing plugins in Go is more complicated than Python because you will need to provide both the structs and the Arcaflow schema. We recommend Go for plugins that interact with Kubernetes.
Read more about Go plugins \u00bb
Packaging pluginsTo use plugins with Arcaflow, you will need to package them into a container image. You can, of course, write your own Dockerfile, but we provide a handy utility called Carpenter to automate the process.
Read more about packaging \u00bb
"},{"location":"arcaflow/plugins/packaging/","title":"Packaging Arcaflow plugins","text":"Arcaflow plugins are distributed using container images. Whatever programming language you are using, you will need to package it up into a container image and distribute it via a container registry.
"},{"location":"arcaflow/plugins/packaging/#the-manual-method","title":"The manual method","text":"Currently, we only support the manual method for non-Arcalot plugins. However, it\u2019s very simple. First, create a Dockerfile for your programming language:
PythonGoWith Python, the Dockerfile heavily depends on which build tool you are using. Here we are demonstrating the usage using pip.
FROM python:alpine\n\n# Add the plugin contents\nADD . /plugin\n# Set the working directory\nWORKDIR /plugin\n\n# Install the dependencies. Customize this\n# to your Python package manager.\nRUN pip install -r requirements.txt\n\n# Set this to your .py file\nENTRYPOINT [\"/usr/local/bin/python3\", /plugin/plugin.py\"]\n# Make sure this stays empty!\nCMD []\nFor Go plugins we recommend a multi-stage build so the source code doesn\u2019t unnecessarily bloat the image. (Keep in mind, for some libraries you will need to include at least a LICENSE and possibly a NOTICE file in the image.)
FROM golang AS build\n# Add the plugin contents\nADD . /plugin\n# Set the working directory\nWORKDIR /plugin\n# Build your image\nENV CGO_ENABLED=0\nRUN go build -o plugin\n\n# Start from an empty image\nFROM scratch\n# Copy the built binary\nCOPY --from=build /plugin/plugin /plugin\n# Set the entry point\nENTRYPOINT [\"/plugin\"]\n# Make sure this stays empty!\nCMD []\nThat\u2019s it! Now you can run your build:
docker build -t example.com/your-namespace/your-plugin:latest .\ndocker push example.com/your-namespace/your-plugin:latest\nIn contrast to Python, Go doesn\u2019t contain enough language elements to infer the types and validation from Go types. Therefore, in order to use Go you both need to create the data structures (e.g. struct) and write the schema by hand. Therefore, we recommend Python for writing plugins.
For writing Go plugins, you will need:
If you have these three, you can get started with your first plugin.
"},{"location":"arcaflow/plugins/go/first/","title":"Writing your first Go plugin","text":"In order to create a Go plugin, you will need to create a Go module project (go mod init) and install the Arcaflow SDK using go get go.flow.arcalot.io/pluginsdk.
Writing a Go plugin consists of the following 4 parts:
First, we define an input data model. This must be a struct.
type Input struct {\n Name string `json:\"name\"`\n}\nNote
The Arcaflow serialization does not use the built-in Go JSON marshaling, so any additional tags like omitempty, or yaml tags are ignored.
In addition to the struct above, we must also define a schema for the input data structure:
// We define a separate scope, so we can add sub-objects later.\nvar inputSchema = schema.NewScopeSchema(\n // Struct-mapped object schemas are object definitions that are mapped to a specific struct (Input)\n schema.NewStructMappedObjectSchema[Input](\n // ID for the object:\n \"input\",\n // Properties of the object:\n map[string]*schema.PropertySchema{\n \"name\": schema.NewPropertySchema(\n // Type properties:\n schema.NewStringSchema(nil, nil, nil),\n // Display metadata:\n schema.NewDisplayValue(\n schema.PointerTo(\"Name\"),\n schema.PointerTo(\"Name of the person to greet.\"),\n nil,\n ),\n // Required:\n true,\n // Required if:\n []string{},\n // Required if not:\n []string{},\n // Conflicts:\n []string{},\n // Default value, JSON encoded:\n nil,\n //Examples:\n nil,\n )\n },\n ),\n)\nThe output data model is similar to the input. First, we define our output struct:
type Output struct {\n Message string `json:\"message\"`\n}\nThen, we have to describe the schema for this output similar to the input:
var outputSchema = schema.NewScopeSchema(\n schema.NewStructMappedObjectSchema[Output](\n \"output\",\n map[string]*schema.PropertySchema{\n \"message\": schema.NewPropertySchema(\n schema.NewStringSchema(nil, nil, nil),\n schema.NewDisplayValue(\n schema.PointerTo(\"Message\"),\n schema.PointerTo(\"The resulting message.\"),\n nil,\n ),\n true,\n nil,\n nil,\n nil,\n nil,\n nil,\n )\n },\n ),\n)\nNow we can create a callable function. This function will always take one input and produce an output ID (e.g. \"success\") and an output data structure. This allows you to return one of multiple possible outputs.
func greet(input Input) (string, any) {\n return \"success\", Output{\n fmt.Sprintf(\"Hello, %s!\", input.Name), \n }\n}\nFinally, we can incorporate this function into a step schema:
var greetSchema = schema.NewCallableSchema(\n schema.NewCallableStep[Input](\n // ID of the function:\n \"greet\",\n // Add the input schema:\n inputSchema,\n map[string]*schema.StepOutputSchema{\n // Define possible outputs:\n \"success\": schema.NewStepOutputSchema(\n // Add the output schema:\n outputSchema,\n schema.NewDisplayValue(\n schema.PointerTo(\"Success\"),\n schema.PointerTo(\"Successfully created message.\"),\n nil,\n ),\n false,\n ),\n },\n // Metadata for the function:\n schema.NewDisplayValue(\n schema.PointerTo(\"Greet\"),\n schema.PointerTo(\"Greets the user.\"),\n nil,\n ),\n // Reference the function\n greet,\n )\n)\nFinally, we need to create our main function to run the plugin:
package main\n\nimport (\n \"go.flow.arcalot.io/pluginsdk/plugin\"\n)\n\nfunc main() {\n plugin.Run(greetSchema)\n}\nGo plugins currently cannot run as CLI tools, so you will have to use this plugin in conjunction with the Arcaflow Engine. However, you can dump the schema by running:
go run yourplugin.go --schema\nOnce you are finished with your first plugin, you should read the section about writing a schema.
"},{"location":"arcaflow/plugins/go/schema/","title":"Writing a schema in Go","text":"In contrast to Python, the Go SDK does not have the ability to infer the schema from the code of a plugin. The Go language does not have enough information to provide enough information.
Therefore, schemas in Go need to be written by hand. This document will explain the details and intricacies of writing a Go schema by hand.
"},{"location":"arcaflow/plugins/go/schema/#typed-vs-untyped-serialization","title":"Typed vs. untyped serialization","text":"Since Go is a strongly and statically typed language, there are two ways to serialize and unserialize a type.
The untyped serialization functions (Serialize, Unserialize) always result in an any type (interface{} for pre-1.18 code) and you will have to perform a type assertion to get the type you can actually work with.
The typed serialization functions (SerializeType, UnserializeType) result in a specific type, but cannot be used in lists, maps, etc. due to the lack of language features, such as covariance.
In practice, you will always use untyped functions when writing a plugin, typed functions are only useful for writing Arcaflow Engine code.
"},{"location":"arcaflow/plugins/go/schema/#strings","title":"Strings","text":"You can define a string by calling schema.NewStringSchema(). It has 3 parameters:
*int64)*int64)*regexp.Regexp)It will result in a *StringSchema, which also complies with the schema.String interface. It unserializes from a string, integer, float to a string and serializes back to a string.
Tip
You can easily convert a value to a pointer by using the schema.PointerTo() function.
You can define a regular expression pattern by calling schema.NewPatternSchema(). It has no parameters and will result in a *PatternSchema, which also complies with the schema.Pattern interface. It unserializes from a string to a *regexp.Regexp and serializes back to a string.
Integers in Are always 64-bit signed integers. You can define an integer type with the schema.NewIntSchema() function. It takes the following parameters:
*int64)*int64)*UnitsDefinition, see Units)When unserializing from a string, or another int or float type, the SDK will attempt to parse it as an integer. When serializing, the integer type will always be serialized as an integer.
"},{"location":"arcaflow/plugins/go/schema/#floating-point-numbers","title":"Floating point numbers","text":"Floating point numbers are always stored as 64-bit floating point numbers. You can define a float type with the schema.NewFloatSchema() function. It takes the following parameters:
*float64)*float64)*UnitsDefinition, see Units)When unserializing from a string, or another int or float type, the SDK will attempt to parse it as a float. When serializing, the float type will always be serialized as a float.
"},{"location":"arcaflow/plugins/go/schema/#booleans","title":"Booleans","text":"You can define a boolean by calling schema.NewBoolSchema(). It has no parameters and will result in a *BoolSchema, which also complies with the schema.Bool interface.
It converts both integers and strings to boolean if possible. The following values are accepted as true or false, respectively:
1yesyontrueenableenabled0nonofffalsedisabledisabledBoolean types will always serialize to bool.
Go doesn\u2019t have any built-in enums, so Arcaflow supports int64 and string-based enums. You can define an int enum by calling the schema.NewIntEnumSchema() function. It takes the following parameters:
map[int64]*DisplayValue of values. The keys are the valid values in the enum. The values are display values, which can also be nil if no special display properties are desired.*UnitsDefinition, see Units)Strings can be defined by using the schema.NewStringEnumSchema() function, which only takes the first parameter with string keys.
Both functions return a *EnumSchema[string|int64], which also complies with the Enum[string|int64] interface.
Lists come in two variants: typed and untyped. (See Typed vs. Untyped.) You can create an untyped list by calling schema.NewListSchema() and a typed list by calling schema.NewTypedListSchema(). Both have the following parameters:
*int64)*int64)The result is a *ListSchema for untyped lists, and a *TypedListSchema for typed lists, which also satisfy their corresponding interfaces.
Maps, like lists, come in two variants: typed and untyped. (See Typed vs. Untyped.) You can create an untyped map by calling schema.NewMapSchema() and a typed map by calling schema.NewTypedMapSchema(). They both have the following parameters:
string, int, or an enum thereof.*int64)*int64)The functions return a *schema.MapSchema and *schema.TypedMapSchema, respectively, which satisfy their corresponding interfaces.
Objects come in not two, but three variants: untyped, struct-mapped, and typed. (See Typed vs. Untyped.) Untyped objects unserialize to a map[string]any, whereas struct-mapped objects are bound to a struct, but behave like untyped objects. Typed objects are bound to a struct and are typed. In plugins, you will always want to use struct-mapped object schemas.
You can create objects with the following functions:
schema.NewObjectSchema for untyped objects.schema.NewStructMappedObjectSchema for struct-mapped objects.schema.NewTypedObject for typed objects.They all have two parameters:
Properties of objects are always untyped. You can create a property by calling schema.NewPropertySchema() and it has the following parameters:
bool)[]string)[]string)[]string)*string)[]string)Sometimes, objects need to have circular references to each other. That\u2019s where scopes help. Scopes behave like objects, but act as a container for Refs. They contain a root object and additional objects that can be referenced by ID.
You can create a scope by calling schema.NewScopeSchema(). It takes the following parameters:
Warning
When using scopes, you must call ApplyScope on the outermost scope once you have constructed your type tree, otherwise references won\u2019t work.
Refs are references to objects in the current scope. You can create a ref by calling schema.NewRefSchema(). It takes two parameters:
Sometimes, a field must be able to hold more than one type of item. That\u2019s where one-of types come into play. They behave like objects, but have a special field called the discriminator which differentiates between the different possible types. This discriminator field can either be an integer or a string.
You can use schema.NewOneOfIntSchema() to create an integer-based one-of type and schema.NewOneOfStringSchema() to create a string-based one. They both accept two parameters:
map[int64|string]Object, which holds the discriminator values and their corresponding objects (these can be refs or scopes too).string holding the name of the discriminator field.The objects in the map are allowed to skip the discriminator field, but if they use it, it must have the same type as listed here.
"},{"location":"arcaflow/plugins/go/schema/#any","title":"Any","text":"The \u201cany\u201d type allows any primitive type to pass through. However, this comes with severe limitations and the data cannot be validated, so its use is discouraged. You can create an AnySchema by calling schema.NewAnySchema(). This function has no parameters.
Several types, for example properties, accept a display value. This is a value designed to be rendered as a form field. It has three parameters:
Display types are always optional (can be nil) and you can create one by calling schema.NewDisplayValue()
Units make it easier to parse and display numeric values. For example, if you have an integer representing nanoseconds, you may want to parse strings like 5m30s. This is similar to the duration type in Go, but with the capabilities of defining your own units.
Units have two parameters: the base type and multipliers. You can define a unit type by calling schema.NewUnits() and provide the base unit and multipliers by calling schema.NewUnit().
var u = schema.NewUnits(\n // Base unit:\n NewUnit(\n // Short name, singular\n \"B\",\n // Short name, plural\n \"B\",\n // Long name, singular\n \"byte\",\n // Long name, plural\n \"bytes\",\n ),\n // Multipliers\n map[int64]*UnitDefinition{\n 1024: NewUnit(\n \"kB\",\n \"kB\",\n \"kilobyte\",\n \"kilobytes\",\n ),\n //...\n },\n)\nYou can use the built-in schema.UnitBytes, schema.UnitDurationNanoseconds, and schema.UnitDurationSeconds units for your plugins.
If you want to create an Arcaflow plugin in Python, you will need three things:
If you have these three, you can get started with your first plugin.
"},{"location":"arcaflow/plugins/python/data-model/","title":"Creating a Python data model","text":"Every plugin needs a schema to represent its expected inputs and outputs in a machine-readable format. The schema strong typing is a core design element of Arcaflow, enabling us to build portable workflows that compartmentalize failure conditions and avoid data errors.
When creating a data model for Arcaflow plugins in Python, everything starts with dataclasses. They allow Arcaflow to get information about the data types of individual fields in your class:
plugin.pyimport dataclasses\n\n\n@dataclasses.dataclass\nclass MyDataModel:\n some_field: str\n other_field: int\nHowever, Arcaflow doesn\u2019t support all Python data types. You pick from the following list:
strintfloatboolre.Patterntyping.List[othertype]typing.Dict[keytype, valuetype]typing.Union[onedataclass, anotherdataclass]typing.AnyYou can read more about the individual types in the data types section
"},{"location":"arcaflow/plugins/python/data-model/#optional-parameters","title":"Optional parameters","text":"You can also declare any parameter as optional, like this:
plugin.py@dataclasses.dataclass\nclass MyClass:\n param: typing.Optional[int] = None\nNote that adding typing.Optional is not enough, you must specify the default value.
You can specify desired validations for each field like this:
plugin.py@dataclasses.dataclass\nclass MyClass:\n param: typing.Annotated[int, schema.name(\"Param\")]\nTip
Annotated objects are preferred as a best practice for a documented schema, and are expected for any officially-supported community plugins.
You can use the following annotations to add metadata to your fields:
schema.id adds a serialized field name for the current field (e.g. one containing dashes, which is not valid in Python)schema.name adds a human-readable name to the parameter. This can be used to present a form field.schema.description adds a long-form description to the field.schema.example adds an example value to the field. You can repeat this annotation multiple times. The example must be provided as primitive types (no dataclasses).You can also add validations to the fields. The following annotations are valid for all data types:
schema.required_if specifies a field that causes the current field to be required. If the other field is empty, the current field is not required. You can repeat this annotation multiple times. (Make sure to use the optional annotation above.)schema.required_if_not specifies a field that, if not filled, causes the current field to be required. You can repeat this annotation multiple times.(Make sure to use the optional annotation above.)schema.conflicts specifies a field that cannot be used together with the current field. You can repeat this annotation multiple times. (Make sure to use the optional annotation above.)Additionally, some data types have their own validations and metadata, such as schema.min, schema.max, schema.pattern, or schema.units.
Note
When combining typing.Annotated with typing.Optional, the default value is assigned to the Annotated object, not to the Optional object.
@dataclasses.dataclass\nclass MyClass:\n param: typing.Annotated[\n typing.Optional[int],\n schema.name(\"Param\")\n ] = None\nStrings are, as the name suggests, strings of human-readable characters. You can specify them in your dataclass like this:
some_field: str\nAdditionally, you can apply the following validations:
schema.min() specifies the minimum length of the string if the field is set.schema.max() specifies the maximum length of the string if the field is set.schema.pattern() specifies the regular expression the string must match if the field is set.Integers are 64-bit signed whole numbers. You can specify them in your dataclass like this:
some_field: int\nAdditionally, you can apply the following validations and metadata:
schema.min() specifies the minimum number if the field is set.schema.max() specifies the maximum number if the field is set.schema.units() specifies the units for this field (e.g. bytes). See Units.Floating point numbers are 64-bit signed fractions. You can specify them in your dataclass like this:
some_field: float\nWarning
Floating point numbers are inaccurate! Make sure to transmit numbers requiring accuracy as integers!
Additionally, you can apply the following validations and metadata:
schema.min() specifies the minimum number if the field is set.schema.max() specifies the maximum number if the field is set.schema.units() specifies the units for this field (e.g. bytes). See Units.Booleans are True or False values. You can specify them in your dataclass like this:
some_field: bool\nBooleans have no additional validations or metadata.
"},{"location":"arcaflow/plugins/python/data-model/#enums","title":"Enums","text":"Enums, short for enumerations, are used to define a set of named values as unique constants. They provide a way to represent a fixed number of possible values for a variable, parameter, or property. In Python, an enum is declared as a class, but doesn\u2019t behave as a normal class. Instead, the \u201cattributes\u201d of the class act as independent \u201cmember\u201d or \u201cenumeration member\u201d objects, each of which has a name and a constant value.
By using enums, you can give meaningful names to distinct values, making the code more self-explanatory and providing a convenient way to work with sets of related constants.
In an Arcaflow schema, an Enum type provides a list of valid values for a field. The Enum must define a set of members with unique values, all of which are either strings or integers.
You can specify an enum with string values like this:
import enum\n\n\nclass MyEnum(enum.Enum):\n Value1 = \"value 1\"\n Value2 = \"value 2\"\n\nmy_field: MyEnum\nmy_field of MyEnum.Value1. You can specify an Enum class with integer values like this:
import enum\n\nclass MyEnum(enum.Enum):\n Value1 = 1\n Value2 = 2\n\nmy_field: MyEnum\nThe my_field variable is a variable of type MyEnum. It can store one of the defined enumeration members (Value1 or Value2). An input value of 1 in this case will result in the plugin receiving a value for my_field of MyEnum.Value1.
value = MyEnum.Value1\nNote
Enumeration members are \u201csingleton\u201d objects which have a single instance. In Python, you should compare enumeration members using is rather than == (for example, variable is MyEnum.Value1). The values of an Enum used in an Arcaflow schema must have values of string or integer data type.
Tip
Enums aren\u2019t dataclasses, but can be used as the type of dataclass attributes.
Warning
Do not mix integers and strings in the same enum! The values for each Enum type must all be strings, or all integers.
"},{"location":"arcaflow/plugins/python/data-model/#patterns","title":"Patterns","text":"When you need to hold regular expressions, you can use a pattern field. This is tied to the Python regular expressions library. You can specify a pattern field like this:
import re\n\nmy_field: re.Pattern\nPattern fields have no additional validations or metadata.
Note
If you are looking for a way to do pattern/regex matching for a string you will need to use the schema.pattern() validation which specifies the regular expression, to which the string must match.
The below example declares that the first_name variable must only have uppercase and lowercase alphabets.
plugin.py@dataclasses.dataclass\nclass MyClass:\n first_name: typing.Annotated[\n str,\n schema.min(2),\n schema.pattern(re.compile(\"^[a-zA-Z]+$\")),\n schema.example(\"Arca\"),\n schema.name(\"First name\")\n ]\nWhen you want to make a list in Arcaflow, you always need to specify its contents. You can do that like this:
my_field: typing.List[str]\nLists can have the following validations:
schema.min() specifies the minimum number of items in the list.schema.max() specifies the maximum number of items in the list.Tip
Items in lists can also be annotated with validations.
"},{"location":"arcaflow/plugins/python/data-model/#dicts","title":"Dicts","text":"Dicts (maps in Arcaflow) are key-value pairs. You need to specify both the key and the value type. You can do that as follows:
my_field: typing.Dict[str, str]\nLists can have the following validations:
schema.min() specifies the minimum number of items in the list.schema.max() specifies the maximum number of items in the list.Tip
Items in dicts can also be annotated with validations.
"},{"location":"arcaflow/plugins/python/data-model/#union-types","title":"Union types","text":"Union types (one-of in Arcaflow) allow you to specify two or more possible objects (dataclasses) that can be in a specific place. The only requirement is that there must be a common field (discriminator) and each dataclass must have a unique value for this field. If you do not add this field to your dataclasses, it will be added automatically for you.
For example:
import typing\nimport dataclasses\n\n\n@dataclasses.dataclass\nclass FullName:\n first_name: str\n last_name: str\n\n\n@dataclasses.dataclass\nclass Nickname:\n nickname: str\n\n\nname: typing.Annotated[\n typing.Union[\n typing.Annotated[FullName, schema.discriminator_value(\"full\")],\n typing.Annotated[Nickname, schema.discriminator_value(\"nick\")]\n ], schema.discriminator(\"name_type\")]\nTip
The schema.discriminator and schema.discriminator_value annotations are optional. If you do not specify them, a discriminator will be generated for you.
Any types allow you to pass through any primitive data (no dataclasses). However, this comes with severe limitations as far as validation and use in workflows is concerned, so this type should only be used in limited cases. For example, if you would like to create a plugin that inserts data into an ElasticSearch database the \u201cany\u201d type would be appropriate here.
You can define an \u201cany\u201d type like this:
my_data: typing.Any\nIntegers and floats can have unit metadata associated with them. For example, a field may contain a unit description like this:
time: typing.Annotated[int, schema.units(schema.UNIT_TIME)]\nIn this case, a string like 5m30s will automatically be parsed into nanoseconds. Integers will pass through without conversion. You can also define your own unit types. At minimum, you need to specify the base type (nanoseconds in this case), and you can specify multipliers:
my_units = schema.Units(\n schema.Unit(\n # Short, singular\n \"ns\",\n # Short, plural\n \"ns\",\n # Long, singular\n \"nanosecond\",\n # Long, plural\n \"nanoseconds\"\n ),\n {\n 1000: schema.Unit(\n \"ms\",\n \"ms\",\n \"microsecond\",\n \"microseconds\"\n ),\n # ...\n }\n)\nYou can then use this description in your schema.units annotations. Additionally, you can also use it to convert an integer or float into its string representation with the my_units.format_short or my_units.format_long functions. If you need to parse a string yourself, you can use my_units.parse.
A number of unit types are built-in to the python SDK for convenience:
UNIT_BYTE - Bytes and 2^10 multiples (kilo-, mega-, giga-, tera-, peta-)UNIT_TIME - Nanoseconds and human-friendly multiples (microseconds, seconds, minutes, hours, days)UNIT_CHARACTER - Character notations (char, chars, character, characters)UNIT_PERCENT - Percentage notations (%, percent)Instead of using your plugin as a standalone tool or in conjunction with Arcaflow, you can also embed your plugin into your existing Python application. To do that you simply build a schema and then call the schema yourself. You can pass raw data as an input, and you\u2019ll get the benefit of schema validation.
myapp.pyfrom arcaflow_plugin_sdk import plugin\nimport my_arcaflow_plugin\n\n# Build your schema with the step functions passed\nschema = plugin.build_schema(my_arcaflow_plugin.hello_world)\n\n# Which step from the plugin we want to execute\nstep_id = \"hello_world\"\n\n# Input parameters. Note, these must be a dict, not a dataclass\nstep_params = {\n \"name\": \"Arca Lot\",\n}\n\n# Execute the step\noutput_id, output_data = schema(step_id, step_params)\n\n# Print which kind of result we have\npprint.pprint(output_id)\n\n# Print the result data\npprint.pprint(output_data)\nHowever, the example above requires you to provide the data as a dict, not a dataclass, and it will also return a dict as an output object. Sometimes, you may want to use a partial approach, where you only use part of the SDK. In this case, you can change your code to run any of the following functions, in order:
serialization.load_from_file() to load a YAML or JSON file into a dictyourschema.unserialize_input() to turn a dict into a dataclass needed for your stepsyourschema.call_step() to run a step with the unserialized dataclassyourschema.serialize_output() to turn the output dataclass into a dictmy-field?","text":"Dataclasses don\u2019t support dashes in parameters. You can work around this by defining the id annotation:
@dataclasses.dataclass\nclass MyData:\n my_field: typing.Annotated[\n str,\n schema.id(\"my-field\"),\n ]\nYou can extend Python\u2019s JSON encoder to support dataclasses. If that doesn\u2019t suit your needs, you can use this SDK to convert the dataclasses to their basic representations and then write that to your JSON or YAML file. First, add this outside of your step:
my_object_schema = plugin.build_object_schema(MyDataclass)\nInside your step function you can then dump the data from your input
def my_step(params: MyParams):\n yaml_contents = yaml.dump(my_object_schema.serialize(params.some_param))\nThis requires a bit of trickery. First, we build a schema from the dataclass representing the row or entry in the list:
my_row_schema = plugin.build_object_schema(MyRow)\nThen you can create a list schema:
my_list_schema = schema.ListType(my_row_schema)\nYou can now unserialize a list obtained from the YAML or JSON file:
my_data = my_list_schema.unserialize(json.loads(...))\nIn this guide you will learn how to write a basic \u201cHello World\u201d plugin for Arcaflow and then run it without the engine as a standalone tool. In order to proceed this tutorial, you will need to install Python version 3.9 or higher on your machine. The tutorial will make use of the Arcaflow Python SDK to provide the required functionality.
"},{"location":"arcaflow/plugins/python/first/#step-1-setting-up-your-environment","title":"Step 1: Setting up your environment","text":"If you have Python installed, you will need to set up your environment. You can use any dependency manager you like, but here are three methods to get you started quickly.
Official plugins
If you wish to contribute an official Arcaflow plugin on GitHub, please use Poetry. For simplicity, we only accept Poetry plugins.
From the template repositoryUsing pipUsing Poetrypython3.10 --version\npython3.9 --version\npython3 --version\npython --version\npython -m venv venv\nsource venv/bin/activate\npip install -r requirements.txt\nrequirements.txt with the following content: arcaflow-plugin-sdk\npython3.10 --version\npython3.9 --version\npython3 --version\npython --version\npython -m venv venv\nsource venv/bin/activate\npip install -r requirements.txt\npoetry new your-plugin\nyour-plugin.which python3.10\nwhich python3.9\nwhich python3\nwhich python\npoetry env use /path/to/your/python3.9\npyproject.toml file has the following lines: [tool.poetry.dependencies]\npython = \"^3.9\"\npoetry add arcaflow-plugin-sdk\npoetry shell\nNow you are ready to start hacking away at your plugin! You can open the example_plugin.py file and follow along, or you can create a new Python file and write the code.
Plugins in Arcaflow must explain how they want their input data and what kind of output they produce. Let\u2019s start with the input data model. In our case, we want to ask the user for a name. Normally, you would write this in Python:
plugin.pydef hello_world(name):\n return f\"Hello, {name}\"\nHowever, that\u2019s not how the Arcaflow SDK works. You must always specify the data type of any variable. Additionally, every function can only have one input, and it must be a dataclass.
So, let\u2019s change the code a little:
plugin.pyimport dataclasses\n\n\n@dataclasses.dataclass\nclass InputParams:\n name: str\n\ndef hello_world(params: InputParams):\n # ...\nSo far so good, but we are not done yet. The output also has special rules. One plugin function can have more than one possible output, so you need to say which output it is, and you need to also return a dataclass.
For example:
plugin.pyimport dataclasses\n\n\n@dataclasses.dataclass\nclass InputParams:\n name: str\n\n\n@dataclasses.dataclass\nclass SuccessOutput:\n message: str\n\n\ndef hello_world(params: InputParams):\n return \"success\", SuccessOutput(f\"Hello, {params.name}\")\nTip
If your plugin has a problem, you could create and return an ErrorOutput instead. In the Arcaflow workflow you can then handle each output separately.
Of course, Arcaflow doesn\u2019t know what to do with this code yet. You will need to add a decorator to the hello_world function in order to give Arcaflow the necessary information:
from arcaflow_plugin_sdk import plugin\n\n\n@plugin.step(\n id=\"hello-world\",\n name=\"Hello world!\",\n description=\"Says hello :)\",\n outputs={\"success\": SuccessOutput},\n)\ndef hello_world(params: InputParams):\n # ...\nLet\u2019s go through the parameters:
id provides the step identifier. If your plugin provides more than one step function, you need to specify this in your workflow.name provides the human-readable name of the plugin step. This will help render a user interface for the workflow.description is a longer description for the function and may contain line breaks.outputs specifies the possible outputs and the dataclasses associated with these outputs. This is important so Arcaflow knows what to expect.Tip
If you want, you can specify the function return type like this, but Arcaflow won\u2019t use it:
def hello_world(params: InputParams) -> typing.Tuple[str, ...]:\nThere is one more piece missing to run a plugin: the calling code. Add the following to your file:
plugin.pyimport sys\nfrom arcaflow_plugin_sdk import plugin\n\n\nif __name__ == \"__main__\":\n sys.exit(\n plugin.run(\n plugin.build_schema(\n # List your step functions here:\n hello_world,\n )\n )\n )\nNow your plugin is ready. You can package it up for a workflow, or you can run it as a standalone tool from the command line:
python example_plugin.py -f input-data.yaml\nYou will need to provide the input data in YAML format:
input-data.yamlname: Arca Lot\nTip
If your plugin provides more than one step function, you can specify the correct one to use with the -s parameter.
Tip
To prevent output from breaking the functionality when attached to the Arcaflow Engine, the SDK hides any output your step function writes to the standard output or standard error. You can use the --debug flag to show any output on the standard error in standalone mode.
Tip
You can generate a JSON schema file for your step input by running
python example_plugin.py --json-schema input >example.schema.json\nIf you are using the YAML plugin for VSCode, add the following line to the top of your input file for code completion:
# yaml-language-server: $schema=example.schema.json\nIn order to create an actually useful plugin, you will want to create a data model for your plugin. Once the data model is complete, you should look into packaging your plugin.
"},{"location":"arcaflow/plugins/python/official/","title":"Creating official Arcaflow plugins","text":"Official Arcaflow plugins have more stringent requirements than normal. This document describes how to create a plugin that conforms to those requirements.
"},{"location":"arcaflow/plugins/python/official/#development-environment","title":"Development environment","text":"Official Python plugins are standardized on Poetry and a Linux-based development environment.
"},{"location":"arcaflow/plugins/python/official/#installing-poetry","title":"Installing Poetry","text":"First, please ensure your python3 executable is at least version 3.9.
$ python3 --version\nPython 3.9.15\n$ dnf -y install python3.9\n$ apt-get -y install python3.9\nTip
If the python3 command doesn\u2019t work for you, but python3.9 does, you can alias the command:
$ alias python3=\"python3.9\"\nInstall Poetry using one of their supported methods for your environment.
Warning
Make sure to install Poetry into exactly one Python executable on your system. If something goes wrong with your package\u2019s Python virtual environment, you do not want to also spend time figuring out which Poetry executable is responsible for it.
Now, verify your Poetry version.
$ poetry --version\nPoetry (version 1.2.2)\nCreate your plugin project, plugin-project, and change directory into the project root. You should see a directory structure similar to this with the following files.
$ poetry new plugin-project\nCreated package plugin_project in plugin-project\n\n$ tree plugin-project\nplugin-project\n\u251c\u2500\u2500 plugin_project\n\u2502\u00a0\u00a0 \u2514\u2500\u2500 __init__.py\n\u251c\u2500\u2500 pyproject.toml\n\u251c\u2500\u2500 README.md\n\u2514\u2500\u2500 tests\n \u2514\u2500\u2500 __init__.py\n\n2 directories, 4 files\n\n$ cd plugin-project\nEnsure python3 is at least 3.9.
$ python3 --version\nPython 3.9.15\nSet Poetry to use your Python that is at least 3.9.
$ poetry env use $(which python3)\nCheck that your pyproject.toml is using at least Python 3.9 by looking for the following line.
[tool.poetry.dependencies]\npython = \"^3.9\"\nAdd the arcaflow plugin sdk for python as a software dependency for your Python project.
$ poetry add arcaflow-plugin-sdk-python\nYou should now have a poetry.lock file in your project root. Poetry maintains the state of your pyproject.toml, and its exact software dependencies as hashes in the poetry.lock file.
To build an official plugin container image we use the carpenter workflow on GitHub Actions. This workflow calls the Arcaflow image builder to build the image and perform all validations necessary.
In order to successfully run the build, you should add the following files from the template repository:
DockerfileLICENSE.flake8Additionally, you need to add tests to your project, write a README.md, and make sure that the code directory matches your project name.
Some plugins work well as libraries too. You can publish Arcaflow plugins on PyPI.
To push an official package to PyPI, please contact an Arcalot chair to create an API token on PyPI and set up a CI environment. For testing purposes you can use TestPyPI.
You can configure Poetry to use this API token by calling:
$ poetry config pypi-token.<any name> <PYPI API TOKEN>\nAlternatively, you can also use environment variables:
$ export POETRY_PYPI_TOKEN_PYPI=my-token\n$ export POETRY_HTTP_BASIC_PYPI_USERNAME=<username>\n$ export POETRY_HTTP_BASIC_PYPI_PASSWORD=<password>\nYou can generate distribution archives by typing:
$ poetry build\nYou can then test publishing:
$ poetry publish --dry-run\n\nPublishing arcaflow-plugin-template-python (0.1.0) to PyPI\n- Uploading arcaflow_plugin_template_python-0.1.0-py3-none-any.whl 100%\n- Uploading arcaflow_plugin_template_python-0.1.0.tar.gz 100%\nRemove the --dry-run to actually publish or call poetry publish --build to run it in one go.
If you want to skip the automatic schema generation described in previous chapters, you can also create a schema by hand.
Warning
This process is complicated, requires providing redundant information and should be avoided if at all possible. We recommend creating a data model using dataclasses, decorators and annotations.
We start by defining a schema:
from arcaflow_plugin_sdk import schema\nfrom typing import Dict\n\nsteps: Dict[str, schema.StepSchema]\n\ns = schema.Schema(\n steps,\n)\nThe steps parameter here must be a dict, where the key is the step ID and the value is the step schema. So, let\u2019s create a step schema:
from arcaflow_plugin_sdk import schema\n\nstep_schema = schema.StepSchema(\n id = \"pod\",\n name = \"Pod scenario\",\n description = \"Kills pods\",\n input = input_schema,\n outputs = outputs,\n handler = my_handler_func\n)\nLet\u2019s go in order:
input must be a schema of the type schema.ObjectType. This describes the single parameter that will be passed to my_handler_func.outputs describe a Dict[str, schema.ObjectType], where the key is the ID for the returned output type, while the value describes the output schema.handler function takes one parameter, the object described in input and must return a tuple of a string and the output object. Here the ID uniquely identifies which output is intended, for example success and error, while the second parameter in the tuple must match the outputs declaration.That\u2019s it! Now all that\u2019s left is to define the ObjectType and any sub-objects.
The ObjectType is intended as a backing type for dataclasses. For example:
t = schema.ObjectType(\n TestClass,\n {\n \"a\": schema.Field(\n type=schema.StringType(),\n required=True,\n ),\n \"b\": schema.Field(\n type=schema.IntType(),\n required=True,\n )\n }\n)\nThe fields support the following parameters:
type: underlying type schema for the field (required)name: name for the current fielddescription: description for the current fieldrequired: marks the field as requiredrequired_if: a list of other fields that, if filled, will also cause the current field to be requiredrequired_if_not: a list of other fields that, if not set, will cause the current field to be requiredconflicts: a list of other fields that cannot be set together with the current fieldSometimes it is necessary to create circular references. This is where the ScopeType and the RefType comes into play. Scopes contain a list of objects that can be referenced by their ID, but one object is special: the root object of the scope. The RefType, on the other hand, is there to reference objects in a scope.
Currently, the Python implementation passes the scope to the ref type directly, but the important rule is that ref types always reference their nearest scope up the tree. Do not create references that aim at scopes not directly above the ref!
For example:
@dataclasses.dataclass\nclass OneOfData1:\n a: str\n\n@dataclasses.dataclass\nclass OneOfData2:\n b: OneOfData1\n\nscope = schema.ScopeType(\n {\n \"OneOfData1\": schema.ObjectType(\n OneOfData1,\n {\n \"a\": schema.Field(\n schema.StringType()\n )\n }\n ),\n },\n # Root object of scopes\n \"OneOfData2\",\n)\n\nscope.objects[\"OneOfData2\"] = schema.ObjectType(\n OneOfData2,\n {\n \"b\": schema.Field(\n schema.RefType(\"OneOfData1\", scope)\n )\n }\n)\nAs you can see, this API is not easy to use and is likely to change in the future.
"},{"location":"arcaflow/plugins/python/schema/#oneoftype","title":"OneOfType","text":"The OneOfType allows you to create a type that is a combination of other ObjectTypes. When a value is deserialized, a special discriminator field is consulted to figure out which type is actually being sent.
This discriminator field may be present in the underlying type. If it is, the type must match the declaration in the AnyOfType.
For example:
@dataclasses.dataclass\nclass OneOfData1:\n type: str\n a: str\n\n@dataclasses.dataclass\nclass OneOfData2:\n b: int\n\nscope = schema.ScopeType(\n {\n \"OneOfData1\": schema.ObjectType(\n OneOfData1,\n {\n # Here the discriminator field is also present in the underlying type\n \"type\": schema.Field(\n schema.StringType(),\n ),\n \"a\": schema.Field(\n schema.StringType()\n )\n }\n ),\n \"OneOfData2\": schema.ObjectType(\n OneOfData2,\n {\n \"b\": schema.Field(\n schema.IntType()\n )\n }\n )\n },\n # Root object of scopes\n \"OneOfData1\",\n)\n\ns = schema.OneOfStringType(\n {\n # Option 1\n \"a\": schema.RefType(\n # The RefType resolves against the scope.\n \"OneOfData1\",\n scope\n ),\n # Option 2\n \"b\": schema.RefType(\n \"OneOfData2\",\n scope\n ),\n },\n # Pass the scope this type belongs do\n scope,\n # Discriminator field\n \"type\",\n)\n\nserialized_data = s.serialize(OneOfData1(\n \"a\",\n \"Hello world!\"\n))\npprint.pprint(serialized_data)\nNote, that the OneOfTypes take all object-like elements, such as refs, objects, or scopes.
"},{"location":"arcaflow/plugins/python/schema/#stringtype","title":"StringType","text":"String types indicate that the underlying type is a string.
t = schema.StringType()\nThe string type supports the following parameters:
min_length: minimum length for the string (inclusive)max_length: maximum length for the string (inclusive)pattern: regular expression the string must matchThe pattern type indicates that the field must contain a regular expression. It will be decoded as re.Pattern.
t = schema.PatternType()\nThe pattern type has no parameters.
"},{"location":"arcaflow/plugins/python/schema/#inttype","title":"IntType","text":"The int type indicates that the underlying type is an integer.
t = schema.IntType()\nThe int type supports the following parameters:
min: minimum value for the number (inclusive).max: minimum value for the number (inclusive).The float type indicates that the underlying type is a floating point number.
t = schema.FloatType()\nThe float type supports the following parameters:
min: minimum value for the number (inclusive).max: minimum value for the number (inclusive).The bool type indicates that the underlying value is a boolean. When unserializing, this type also supports string and integer values of true, yes, on, enable, enabled, 1, false, no, off, disable, disabled or 0.
The enum type creates a type from an existing enum:
class MyEnum(Enum):\n A = \"a\"\n B = \"b\"\n\nt = schema.EnumType(MyEnum)\nThe enum type has no further parameters.
"},{"location":"arcaflow/plugins/python/schema/#listtype","title":"ListType","text":"The list type describes a list of items. The item type must be described:
t = schema.ListType(\n schema.StringType()\n)\nThe list type supports the following extra parameters:
min: The minimum number of items in the list (inclusive)max: The maximum number of items in the list (inclusive)The map type describes a key-value type (dict). You must specify both the key and the value type:
t = schema.MapType(\n schema.StringType(),\n schema.StringType()\n)\nThe map type supports the following extra parameters:
min: The minimum number of items in the map (inclusive)max: The maximum number of items in the map (inclusive)The \u201cany\u201d type allows any primitive type to pass through. However, this comes with severe limitations and the data cannot be validated, so its use is discouraged. You can create an AnyType by simply doing this:
t = schema.AnyType()\nIf you create the schema by hand, you can add the following code to your plugin:
if __name__ == \"__main__\":\n sys.exit(plugin.run(your_schema))\nYou can then run your plugin as described in the writing your first plugin section.
"},{"location":"arcaflow/plugins/python/testing/","title":"Testing your Python plugin","text":"When writing your first plugin, you will probably want to test it manually. However, as development progresses, you should switch to automated testing. Automated testing makes sure your plugins don\u2019t break when you introduce changes.
This page describes the following test scenarios:
Manual testing is easy: prepare a test input file in YAML format, then run the plugin as a command line tool. For example, the hello world plugin would take this input:
name: Arca Lot\nYou could then run the example plugin:
python example_plugin -f my-input-file.yaml\nThe plugin will run and present you with the output.
Tip
If you have more than one step, don\u2019t forget to pass the -s step-id parameter.
Tip
To prevent output from breaking the functionality when attached to the Arcaflow Engine, the SDK hides any output your step function writes to the standard output or standard error. You can use the --debug flag to show any output on the standard error in standalone mode.
You can use any test framework you like for your serialization test, we\u2019ll demonstrate with unittest as it is included directly in Python. The key to this test is to call plugin.test_object_serialization() with an instance of your dataclass that you want to test:
class ExamplePluginTest(unittest.TestCase):\n def test_serialization(self):\n self.assertTrue(plugin.test_object_serialization(\n example_plugin.PodScenarioResults(\n [\n example_plugin.Pod(\n namespace=\"default\",\n name=\"nginx-asdf\"\n )\n ]\n )\n ))\nRemember, you need to call this function with an instance containing actual data, not just the class name.
The test function will first serialize, then unserialize your data and check if it\u2019s the same. If you want to use a manually created schema, you can do so, too:
class ExamplePluginTest(unittest.TestCase):\n def test_serialization(self):\n plugin.test_object_serialization(\n example_plugin.PodScenarioResults(\n #...\n ),\n schema.ObjectType(\n #...\n )\n )\nFunctional tests don\u2019t have anything special about them. You can directly call your code with your dataclasses as parameters, and check the return. This works best on auto-generated schemas with the @plugin.step decorator. See below for manually created schemas.
class ExamplePluginTest(unittest.TestCase):\n def test_functional(self):\n input = example_plugin.PodScenarioParams()\n\n output_id, output_data = example_plugin.pod_scenario(input)\n\n # Check if the output is always an error, as it is the case for the example plugin.\n self.assertEqual(\"error\", output_id)\n self.assertEqual(\n output_data,\n example_plugin.PodScenarioError(\n \"Cannot kill pod .* in namespace .*, function not implemented\"\n )\n )\nIf you created your schema manually, the best way to write your tests is to include the schema in your test. This will automatically validate both the input and the output, making sure they conform to your schema. For example:
class ExamplePluginTest(unittest.TestCase):\n def test_functional(self):\n step_schema = schema.StepSchema(\n #...\n handler = example_plugin.pod_scenario,\n )\n input = example_plugin.PodScenarioParams()\n\n output_id, output_data = step_schema(input)\n\n # Check if the output is always an error, as it is the case for the example plugin.\n self.assertEqual(\"error\", output_id)\n self.assertEqual(\n output_data,\n example_plugin.PodScenarioError(\n \"Cannot kill pod .* in namespace .*, function not implemented\"\n )\n )\nRunning Arcaflow is simple! You will need three things:
Please start by setting up Arcaflow.
"},{"location":"arcaflow/running/running/","title":"Running Arcaflow","text":"Before you proceed, you will need to perform the following steps:
/path/to/arcaflow -input path/to/input.yaml\nc:\\path\\to\\arcaflow.exe -input path/to/input.yaml\nYou can pass the following additional options to Arcaflow:
Option Description-config /path/to/config.yaml Set an Arcaflow configuration file. (See the configuration guide.) -context /path/to/workflow/dir Set a different workflow directory. (Defaults to the current directory.) -workflow workflow.yaml Set a different workflow file. (Defaults to workflow.yaml.)"},{"location":"arcaflow/running/running/#execution","title":"Execution","text":"Once you start Arcaflow, it will perform the following three phases:
Note
The loading phase only reads the plugin schemas; it does not run any of the functional steps of the plugins.
Tip
You can redirect the standard output to capture the output data and still read the log messages on the standard error.
"},{"location":"arcaflow/running/setup/","title":"Setting up Arcaflow","text":"In order to use Arcaflow, you will need to download the Arcaflow Engine. You can simply unpack and run it, no need for installing it.
On Linux and macOS, you may need to run chmod +x on the engine binary.
If you are using Docker as the local deployer (see below), you generally do not need to perform any extra configuration.
If you wish to customize Arcaflow, you can pass a YAML configuration file to Arcaflow with the -config your-arcaflow-config.yaml parameter.
The Arcaflow Engine needs a local container deployer to temporarily run plugins and read their schema. We recommend either Docker (default) or Podman for this purpose. You can use a Kubernetes cluster for this purpose too, but a local container engine is the better choice for performance reasons.
You can then change the deployer type like this:
config.yamldeployer:\n type: podman\n # Deployer-specific options \nDocker is the default local deployer. You can configure it like this:
config.yamldeployer:\n type: docker\n connection:\n # Change this to point to a TCP-based Docker socket\n host: host-to-docker \n # Add a certificates here. This is usually needed in TCP mode.\n cacert: |\n Add your CA cert PEM here\n cert: |\n Add your client cert PEM here.\n key: |\n Add your client key PEM here.\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n network:\n # Add your network config here\n platform:\n # Add your platform config here\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Connection (object) Type: object Properties cacert (string) Name: CA certificate Description: CA certificate in PEM format to verify the Dockerd server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name for Dockerd. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z0-9./:_-]+$ Default\"npipe:////./pipe/docker_engine\"\n'unix:///var/run/docker.sock'\n\u201d
'npipe:////./pipe/docker_engine'\nstring) Name: Client key Description: Client private key in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nobject) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (map[string, string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[A-Z0-9_]+$ Value type Type: string Maximum: 32760 Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nreference[NetworkConfig]) Name: Network configuration Description: Provides information about the container networking for the plugin. Required: No Referenced object: NetworkConfig (see in the Objects section below) platform (reference[PlatformConfig]) Name: Platform configuration Description: Provides information about the container host platform for the plugin. Required: No Referenced object: PlatformConfig (see in the Objects section below) HostConfig (object) Type: object Properties CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) NetworkConfig (object) Type: object Properties None
PlatformConfig (object) Type: object Properties None
PortBinding (object) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nIf you want to use Podman as your local deployer instead of Docker, you can do so like this:
config.yamldeployer:\n type: podman\n podman:\n # Change where Podman is. (You can use this to point to a shell script\n path: /path/to/your/podman\n # Change the network mode\n networkMode: host\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) Objects Config (object) Type: object Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) ContainerConfig (object) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (list[string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+=.+$ Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nobject) Type: object Properties Binds (list[string]) Name: Volume Bindings Description: Volumes Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+:.+$ CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) Podman (object) Type: object Properties cgroupNs (string) Name: CGroup namespace Description: Provides the Cgroup Namespace settings for the container Required: No Must match pattern: ^host|ns:/proc/\\d+/ns/cgroup|container:.+|private$ containerName (string) Name: Container Name Description: Provides name of the container Required: No Must match pattern: ^.*$ imageArchitecture (string) Name: Podman image Architecture Description: Provides Podman Image Architecture Required: No Must match pattern: ^.*$ Default\"amd64\"\nstring) Name: Podman Image OS Description: Provides Podman Image Operating System Required: No Must match pattern: ^.*$ Default\"linux\"\nstring) Name: Network Mode Description: Provides network settings for the container Required: No Must match pattern: ^bridge:.*|host|none$ path (string) Name: Podman path Description: Provides the path of podman executable Required: No Must match pattern: ^.*$ Default\"podman\"\nobject) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ Kubernetes can be used as the \u201clocal\u201d deployer, but this is typically not recommended for performance reasons. You can set up the Kubernetes deployer like this:
config.yamldeployer:\n type: kubernetes\n connection:\n host: localhost:6443\n cert: |\n Add your client cert in PEM format here.\n key: |\n Add your client key in PEM format here.\n cacert: |\n Add the server CA cert in PEM format here.\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects AWSElasticBlockStoreVolumeSource (object) Type: object Properties None
AzureDiskVolumeSource (object) Type: object Properties None
AzureFileVolumeSource (object) Type: object Properties None
CSIVolumeSource (object) Type: object Properties None
CephFSVolumeSource (object) Type: object Properties None
CinderVolumeSource (object) Type: object Properties None
Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) ConfigMapVolumeSource (object) Type: object Properties None
Connection (object) Type: object Properties bearerToken (string) Name: Bearer token Description: Bearer token to authenticate against the Kubernetes API with. Required: No burst (int) Name: Burst Description: Burst value for query throttling. Required: No Minimum: 0 Default10\nstring) Name: CA certificate Description: CA certificate in PEM format to verify Kubernetes server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name and port of the Kubernetes server Required: No Default\"kubernetes.default.svc\"\nstring) Name: Client key Description: Client private key in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nstring) Name: Password Description: Password for basic authentication. Required: No path (string) Name: Path Description: Path to the API server. Required: No Default\"/api\"\nfloat) Name: QPS Description: Queries Per Second allowed against the API. Required: No Minimum: 0 Units: queries Default5.0\nstring) Name: TLS server name Description: Expected TLS server name to verify in the certificate. Required: No username (string) Name: Username Description: Username for basic authentication. Required: No Container (object) Type: object Properties args (list[string]) Name: Arguments Description: Arguments to the entypoint (command). Required: No List Items Type: string command (list[string]) Name: Command Description: Override container entry point. Not executed with a shell. Required: No Minimum items: 1 List Items Type: string env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) image (string) Name: Image Description: Container image to use for this container. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9_\\-:./]+$ imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ securityContext (object) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 workingDir (string) Name: Working directory Description: Override the container working directory. Required: No DownwardAPIVolumeSource (object) Type: object Properties None
EmptyDirVolumeSource (object) Type: object Properties medium (string) Name: Medium Description: How to store the empty directory Required: No Minimum: 1 Must match pattern: ^(|Memory|HugePages|HugePages-.*)$ EnvFromSource (object) Type: object Properties configMapRef (object) Name: Config map source Description: Populates the source from a config map. Required: No Properties name (string) Name: Name Description: Name of the referenced config map. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the config map must be defined. Required: No prefix (string) Name: Prefix Description: An optional identifier to prepend to each key in the ConfigMap. Required: No Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ secretRef (object) Name: Secret source Description: Populates the source from a secret. Required: No Properties name (string) Name: Name Description: Name of the referenced secret. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the secret must be defined. Required: No EphemeralVolumeSource (object) Type: object Properties None
FCVolumeSource (object) Type: object Properties None
FlexVolumeSource (object) Type: object Properties None
FlockerVolumeSource (object) Type: object Properties None
GCEPersistentDiskVolumeSource (object) Type: object Properties None
GlusterfsVolumeSource (object) Type: object Properties None
HostPathVolumeSource (object) Type: object Properties path (string) Name: Path Description: Path to the directory on the host. Required: Yes Minimum: 1 Examples \"/srv/volume1\"\nenum[string]) Name: Type Description: Type of the host path. Required: No Values BlockDevice Block deviceCharDevice Character deviceDirectory DirectoryDirectoryOrCreate Create directory if not foundFile FileFileOrCreate Create file if not foundSocket Socketobject) Type: object Properties None
NFSVolumeSource (object) Type: object Properties None
ObjectMeta (object) Type: object Properties annotations (map[string, string]) Name: Annotations Description: Kubernetes annotations to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ generateName (string) Name: Name prefix Description: Name prefix to generate pod names from. Required: No labels (map[string, string]) Name: Labels Description: Kubernetes labels to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ name (string) Name: Name Description: Pod name. Required: No namespace (string) Name: Namespace Description: Kubernetes namespace to deploy in. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"default\"\nobject) Type: object Properties None
PhotonPersistentDiskVolumeSource (object) Type: object Properties None
Pod (object) Type: object Properties metadata (reference[ObjectMeta]) Name: Metadata Description: Pod metadata. Required: No Referenced object: ObjectMeta (see in the Objects section below) spec (reference[PodSpec]) Name: Specification Description: Pod specification. Required: No Referenced object: PodSpec (see in the Objects section below) PodSpec (object) Type: object Properties affinity (object) Name: Affinity rules Description: Affinity rules. Required: No Properties podAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ podAntiAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ containers (list[reference[Container]]) Name: Containers Description: A list of containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) initContainers (list[reference[Container]]) Name: Init containers Description: A list of initialization containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) nodeSelector (map[string, string]) Name: Labels Description: Node labels you want the target node to have. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ pluginContainer (object) Name: Plugin container Description: The container to run the plugin in. Required: Yes Properties env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"arcaflow-plugin-container\"\nobject) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 volumes (list[reference[Volume]]) Name: Volumes Description: A list of volumes that can be mounted by containers belonging to the pod. Required: No List Items Type: reference[Volume] Referenced object: Volume (see in the Objects section below) PortworxVolumeSource (object) Type: object Properties None
ProjectedVolumeSource (object) Type: object Properties None
QuobyteVolumeSource (object) Type: object Properties None
RBDVolumeSource (object) Type: object Properties None
ScaleIOVolumeSource (object) Type: object Properties None
SecretVolumeSource (object) Type: object Properties None
StorageOSVolumeSource (object) Type: object Properties None
Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nobject) Type: object Properties awsElasticBlockStore (reference[AWSElasticBlockStoreVolumeSource]) Name: AWS EBS Description: AWS Elastic Block Storage. Required: No Referenced object: AWSElasticBlockStoreVolumeSource (see in the Objects section below) azureDisk (reference[AzureDiskVolumeSource]) Name: Azure Data Disk Description: Mount an Azure Data Disk as a volume. Required: No Referenced object: AzureDiskVolumeSource (see in the Objects section below) azureFile (reference[AzureFileVolumeSource]) Name: Azure File Description: Mount an Azure File Service mount. Required: No Referenced object: AzureFileVolumeSource (see in the Objects section below) cephfs (reference[CephFSVolumeSource]) Name: CephFS Description: Mount a CephFS volume. Required: No Referenced object: CephFSVolumeSource (see in the Objects section below) cinder (reference[CinderVolumeSource]) Name: Cinder Description: Mount a cinder volume attached and mounted on the host machine. Required: No Referenced object: CinderVolumeSource (see in the Objects section below) configMap (reference[ConfigMapVolumeSource]) Name: ConfigMap Description: Mount a ConfigMap as a volume. Required: No Referenced object: ConfigMapVolumeSource (see in the Objects section below) csi (reference[CSIVolumeSource]) Name: CSI Volume Description: Mount a volume using a CSI driver. Required: No Referenced object: CSIVolumeSource (see in the Objects section below) downwardAPI (reference[DownwardAPIVolumeSource]) Name: Downward API Description: Specify a volume that the pod should mount itself. Required: No Referenced object: DownwardAPIVolumeSource (see in the Objects section below) emptyDir (reference[EmptyDirVolumeSource]) Name: Empty directory Description: Temporary empty directory. Required: No Referenced object: EmptyDirVolumeSource (see in the Objects section below) ephemeral (reference[EphemeralVolumeSource]) Name: Ephemeral Description: Mount a volume that is handled by a cluster storage driver. Required: No Referenced object: EphemeralVolumeSource (see in the Objects section below) fc (reference[FCVolumeSource]) Name: Fibre Channel Description: Mount a Fibre Channel volume that's attached to the host machine. Required: No Referenced object: FCVolumeSource (see in the Objects section below) flexVolume (reference[FlexVolumeSource]) Name: Flex Description: Mount a generic volume provisioned/attached using an exec based plugin. Required: No Referenced object: FlexVolumeSource (see in the Objects section below) flocker (reference[FlockerVolumeSource]) Name: Flocker Description: Mount a Flocker volume. Required: No Referenced object: FlockerVolumeSource (see in the Objects section below) gcePersistentDisk (reference[GCEPersistentDiskVolumeSource]) Name: GCE disk Description: Google Cloud disk. Required: No Referenced object: GCEPersistentDiskVolumeSource (see in the Objects section below) glusterfs (reference[GlusterfsVolumeSource]) Name: GlusterFS Description: Mount a Gluster volume. Required: No Referenced object: GlusterfsVolumeSource (see in the Objects section below) hostPath (reference[HostPathVolumeSource]) Name: Host path Description: Mount volume from the host. Required: No Referenced object: HostPathVolumeSource (see in the Objects section below) iscsi (reference[ISCSIVolumeSource]) Name: iSCSI Description: Mount an iSCSI volume. Required: No Referenced object: ISCSIVolumeSource (see in the Objects section below) name (string) Name: Name Description: The name this volume can be referenced by. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ nfs (reference[NFSVolumeSource]) Name: NFS Description: Mount an NFS share. Required: No Referenced object: NFSVolumeSource (see in the Objects section below) persistentVolumeClaim (reference[PersistentVolumeClaimVolumeSource]) Name: Persistent Volume Claim Description: Mount a Persistent Volume Claim. Required: No Referenced object: PersistentVolumeClaimVolumeSource (see in the Objects section below) photonPersistentDisk (reference[PhotonPersistentDiskVolumeSource]) Name: PhotonController persistent disk Description: Mount a PhotonController persistent disk as a volume. Required: No Referenced object: PhotonPersistentDiskVolumeSource (see in the Objects section below) portworxVolume (reference[PortworxVolumeSource]) Name: Portworx Volume Description: Mount a Portworx volume. Required: No Referenced object: PortworxVolumeSource (see in the Objects section below) projected (reference[ProjectedVolumeSource]) Name: Projected Description: Projected items for all in one resources secrets, configmaps, and downward API. Required: No Referenced object: ProjectedVolumeSource (see in the Objects section below) quobyte (reference[QuobyteVolumeSource]) Name: quobyte Description: Mount Quobyte volume from the host. Required: No Referenced object: QuobyteVolumeSource (see in the Objects section below) rbd (reference[RBDVolumeSource]) Name: Rados Block Device Description: Mount a Rados Block Device. Required: No Referenced object: RBDVolumeSource (see in the Objects section below) scaleIO (reference[ScaleIOVolumeSource]) Name: ScaleIO Persistent Volume Description: Mount a ScaleIO persistent volume. Required: No Referenced object: ScaleIOVolumeSource (see in the Objects section below) secret (reference[SecretVolumeSource]) Name: Secret Description: Mount a Kubernetes secret. Required: No Referenced object: SecretVolumeSource (see in the Objects section below) storageos (reference[StorageOSVolumeSource]) Name: StorageOS Volume Description: Mount a StorageOS volume. Required: No Referenced object: StorageOSVolumeSource (see in the Objects section below) vsphereVolume (reference[VsphereVirtualDiskVolumeSource]) Name: vSphere Virtual Disk Description: Mount a vSphere Virtual Disk as a volume. Required: No Referenced object: VsphereVirtualDiskVolumeSource (see in the Objects section below) VsphereVirtualDiskVolumeSource (object) Type: object Properties None
"},{"location":"arcaflow/running/setup/#logging","title":"Logging","text":"Logging is useful when you need more information about what is happening while you run a workload.
"},{"location":"arcaflow/running/setup/#basic-logging","title":"Basic logging","text":"Here is the syntax for setting the log level: config.yaml
log:\n level: info\nOptions for the level are:
debug: Extra verbosity useful to developersinfo: General infowarning: Something went wrong, and you should know about iterror: Something failed. This inf o should help you figure out whyThis sets which types of log output are shown or hidden. debug shows everything, while error shows the least, only showing error output. Each output shows more, rather than just its type, so debug, info, and warning still show error output.
Step logging is useful for getting output from failed steps, or general debugging. It is not recommended that you rely on this long term, as there may be better methods of debugging failed workflows.
To make the workflow output just error level logs when a step fails, set it as shown: config.yaml
logged_outputs:\n error:\n level: error\nTip
The standard name for the output path when a step fails is called error, which happens to also be the name of the log level here, but these are independent values.
You can specify multiple types of outputs and their log levels. For example, if you also want to output success steps as debug, set it as shown: config.yaml
logged_outputs:\n error:\n level: error\n success:\n level: debug\nNote: If you set the level lower than the general log level shown above, it will not show up in the output.
"},{"location":"arcaflow/workflows/","title":"Creating Arcaflow workflows","text":"Arcaflow workflows consist of four parts:
VersionThe schema version must be at the root of your workflow file. It indicates the semantic version of the workflow file structure being used.
Learn more about versioning \u00bb
InputsThe input section of a workflow is much like a plugin schema: it describes the data model of the workflow itself. This is useful because the input can be validated ahead of time. Any input data can then be referenced by the individual plugin steps.
Learn more about inputs \u00bb
StepsSteps hold the individual parts of the workflow. You can feed data from one step to the next, or feed data from the input to a step.
Learn more about steps \u00bb
OutputsOutputs hold the final result of a workflow. Outputs can reference outputs of steps.
Learn more about output \u00bb
Schema NamesLearn more about our schema naming conventions \u00bb
"},{"location":"arcaflow/workflows/expressions/","title":"Arcaflow expressions","text":"Arcaflow expressions were inspired by JSONPath but have diverged from the syntax. You can use expressions in a workflow YAML like this:
some_value: !expr $.your.expression.here\nThis page explains the language elements of expressions.
Warning
Expressions in workflow definitions must be prefixed with !expr, otherwise their literal value will be taken as a string.
Literals represent constant values in an expression.
"},{"location":"arcaflow/workflows/expressions/#string-values","title":"String values","text":"Normal string literals start and end with a matched pair of either single quotes (') or double quotes (\") and have zero or more characters between the quotes.
Strings may contain special characters. In normal strings, these characters are represented by \u201cescape sequences\u201d consisting of a backslash followed by another character. Since a backslash therefore has a special meaning, in order to represent a literal backslash character, it must be preceded by another backslash. Similarly, in a string delimited by double quotes, a double quote occurring inside the string must be escaped to prevent it from marking the end of the string. The same is true for single quotes occurring inside a string delimited by single quotes. However, you do not need to escape double quotes in a single-quoted string nor single-quotes in a double-quoted string.
Here is the list of supported escape characters:
Escape Result\\\\ \\ backslash character \\t tab character \\n newline character \\r carriage return character \\b backspace character \\\" \" double quote character \\' ' single quote character \\0 null character For example, to have the following text represented in a single string:
test test2/\\
You would need the expression \"test\\ntest2/\\\\\"
When expressing string literals in YAML, be aware that YAML has its own rules around the use of quotation marks.
For example, to include a double-quoted string in an expression, you must either add single quotes around the expression or use block flow scalars. Inside a single-quoted string, an apostrophe needs to be preceded by another apostrophe to indicate that it does not terminate the string.
Here is an example of the following value represented in a few of the various ways:
Here\u2019s an apostrophe and \u201cembedded quotes\u201d.
Inlined with single quotes:
some_value_1: !expr '\"Here''s an apostrophe and \\\"embedded quotes\\\".\"'\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.Inlined with double quotes:
some_value_2: !expr \"'Here\\\\'s an apostrophe and \\\"embedded quotes\\\".'\"\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.\\\\ is replaced with a single backslash; \\\" is replaced with a literal \"; With Block Flow Scalar:
some_value_1: !expr |-\n 'Here\\'s an apostrophe and \"embedded quotes\".'\nsome_value_2: !expr |-\n \"Here's an apostrophe and \\\"embedded quotes\\\".\"\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.|) causes the YAML processor to pass the contents of the string without modification.-) after the vertical bar causes the trailing newline to be omitted from the end of the string.some_value_1 do not need to be escaped nor do the single quotes in some_value_2.See Raw string values to see how to do this without escaping.
"},{"location":"arcaflow/workflows/expressions/#raw-string-values","title":"Raw string values","text":"Raw string literals start and end with backtick characters \u201c`\u201c.
In a raw string, all characters are interpreted literally. This means that you can use ' and \" characters without escaping them, and backslashes are treated like any other character. However, backtick characters cannot appear in a raw string.
Here is an example of the following value represented using raw strings:
Here\u2019s an apostrophe and \u201cembedded quotes\u201d.
Inlined:
some_value: !expr '`Here''s an apostrophe and \"embedded quotes\".`'\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.With Block Flow Scalar:
some_value: !expr |-\n `Here's an apostrophe and \"embedded quotes\".`\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.|) causes the YAML processor to pass the contents of the string without modification.-) after the vertical bar causes the trailing newline to be omitted from the end of the string.Integers are whole numbers expressed as sequences of base-10 digits.
Integer literals may not start with 0, unless the value is 0. For example, 001 is not a valid integer literal.
Examples:
01503Negative values are constructed by applying the negation operator (-) to a literal numeric value.
Floating point literals are non-negative double-precision floating point numbers.
Supported formats include:
1.1 or 1.5.0e5 and 5.0E-5Negative values are constructed by applying the negation operator (-) to a literal numeric value.
Boolean literals have two valid values:
truefalseNo other values are valid boolean literals. The values are case-sensitive.
"},{"location":"arcaflow/workflows/expressions/#root-reference","title":"Root reference","text":"The $ character always references the root of the data structure. Let\u2019s take this data structure:
foo:\n bar: Hello world!\nYou can reference the text like this:
$.foo.bar\nThe dot notation allows you to reference fields of an object.
For example, if you have an object on the root data structure named \u201ca\u201d with the field \u201cb\u201d in it, you can access it with:
$.a.b\nThe bracket accessor is used for referencing values in maps or lists.
"},{"location":"arcaflow/workflows/expressions/#list-access","title":"List access","text":"For list access, you specify the index of the value you want to access. The index should be an expression yielding a non-negative integer value, where zero corresponds to the first value in the list.
If you have a list named foo:
foo:\n - Hello world!\nYou can access the first value with the expression:
$.foo[0]\nGiving the output \"Hello world!\"
Maps, also known as dictionaries in some languages, are key-value pair data structures.
To use a map in an expression, the expression to the left of the brackets must be a reference to a map. That is then followed by a pair of brackets with a sub-expression between them. That sub-expression must evaluate to a valid key in the map.
Here is an example of a map with string keys and integer values. The map is stored in a field called foo in the root-level object:
foo:\n a: 1\n b: 2\nGiven the map shown above, the following expression would yield a value of 2:
$.foo[\"b\"]\nThe engine provides predefined functions for use in expressions. These provide transformations beyond what is available from operators.
Functions:
function definition return type descriptionintToFloat(integer) float Converts an integer value into the equivalent floating point value. floatToInt(float) integer Converts a floating point value into an integer value by discarding the fraction, rounding toward zero to the nearest integer.Special cases:\u00a0 +Inf yields the maximum 64-bit integer (9223372036854775807)\u00a0 -Inf and NaN yield the minimum 64-bit integer (-9223372036854775808)For example, 5.5 yields 5, and -1.9 yields -1 intToString(integer) string Returns a string containing the base-10 representation of the input.For example, an input of 55 yields \"55\" floatToString(float) string Returns a string containing the base-10 representation of the input.For example, an input of 5000.5 yields \"5000.5\" floatToFormattedString(float, string, integer) string Returns a string containing the input in the specified format with the specified precision.\u00a0 Param 1: the floating point input value\u00a0 Param 2: the format specifier: \"e\", \"E\", \"f\", \"g\", \"G\"\u00a0 Param 3: the number of digitsSpecifying -1 for the precision will produce the minimum number of digits required to represent the value exactly. (See the Go runtime documentation for details.) boolToString(boolean) string Returns \"true\" for true, and \"false\" for false. stringToInt(string) integer Interprets the string as a base-10 integer. Returns an error if the input is not a valid integer. stringToFloat(string) float Converts the input string to a double-precision floating-point number.Accepts floating-point numbers as defined by the Go syntax for floating point literals. If the input is well-formed and near a valid floating-point number, returns the nearest floating-point number rounded using IEEE754 unbiased rounding. Returns an error when an invalid input is received. stringToBool(string) boolean Interprets the input as a boolean.Accepts \"1\", \"t\", and \"true\" as true and \"0\", \"f\", and \"false\" as false (case is not significant). Returns an error for any other input. ceil(float) float Returns the least integer value greater than or equal to the input.Special cases are:\u00a0 ceil(\u00b10.0) = \u00b10.0\u00a0 ceil(\u00b1Inf) = \u00b1Inf\u00a0 ceil(NaN) = NaNFor example ceil(1.5) yields 2.0, and ceil(-1.5) yields -1.0 floor(float) float Returns the greatest integer value less than or equal to the input.Special cases are:\u00a0 floor(\u00b10.0) = \u00b10.0\u00a0 floor(\u00b1Inf) = \u00b1Inf\u00a0 floor(NaN) = NaNFor example floor(1.5) yields 1.0, and floor(-1.5) yields -2.0 round(float) float Returns the nearest integer to the input, rounding half away from zero.Special cases are:\u00a0 round(\u00b10.0) = \u00b10.0\u00a0 round(\u00b1Inf) = \u00b1Inf\u00a0 round(NaN) = NaNFor example round(1.5) yields 2.0, and round(-1.5) yields -2.0 abs(float) float Returns the absolute value of the input.Special cases are:\u00a0 abs(\u00b1Inf) = +Inf\u00a0 abs(NaN) = NaN toLower(string) string Returns the input with Unicode letters mapped to their lower case. toUpper(string) string Returns the input with Unicode letters mapped to their upper case. splitString(string, string) list[string] Returns a list of the substrings which appear between instances of the specified separator; the separator instances are not included in the resulting list elements; adjacent occurrences of separator instances as well as instances appearing at the beginning or ending of the input will produce empty string list elements.\u00a0 Param 1: The string to split.\u00a0 Param 2: The separator. readFile(string) string Returns the contents of a file as a UTF-8 character string, given a file path string. Relative file paths are resolved from the Arcaflow process working directory. Shell environment variables are not expanded. bindConstants(list[any], any) list[object] Returns a list of objects each containing two properties: an item property which contains the corresponding item from the list in the first parameter; and, a constant property which contains the value of the second input parameter. The output list items will have a generated schema name as described in Generated Schema Names. For usage see this example. A function is used in an expression by referencing its name followed by a comma-separated list of zero or more argument expressions enclosed in parentheses.
Example:
thisIsAFunction(\"this is a string literal for the first parameter\", $.a.b)\nBinary Operations have an expression to the left and right, with an operator in between. The order of operations determines which operators are evaluated first. See Order of Operations
The types of the left and right operand expressions must match. To convert between types, see the list of available functions. The type of the resulting expression is the same as the type of its operands.
Operator Description+ Addition/Concatenation - Subtraction * Multiplication / Division % Modulus ^ Exponentiation == Equal To != Not Equal To > Greater Than < Less Than >= Greater Than or Equal To <= Less Than or Equal To && Logical And \\|\\| Logical Or"},{"location":"arcaflow/workflows/expressions/#additionconcatenation","title":"Addition/Concatenation","text":"This operator has different behavior depending on the type.
"},{"location":"arcaflow/workflows/expressions/#string-concatenation","title":"String Concatenation","text":"When the + operator is used with two strings, it concatenates them together. For example, the expression \"a\" + \"b\" would output the string \"ab\".
When the + operator is used with numerical operands, it adds them together. The operator requires numerical operands with the same type. You cannot mix float and integer operands. For example, the expression 2 + 2 would output the integer 4.
When the - operator is applied to numerical operands, the result is the value of the right operand subtracted from the value of the left. The operator requires numerical operands with the same type. You cannot mix float and integer operands.
For example, the expression 6 - 4 would output the integer 2. The expression $.a - $.b would evaluate the values of a and b within the root, and subtract the value of $.b from $.a.
When the * operator is used with numerical operands, it multiplies them. The operator requires numerical operands with the same type.
For example, the expression 3 * 3 would output the integer 9.
When the / operator is used with numerical operands, it outputs the value of the left expression divided by the value of the right. The operator requires numerical operands with the same type.
The result of integer division is rounded towards zero. If a non-integral result is required, or if different rounding logic is required, convert the inputs into floating point numbers with the intToFloat function. Different types of rounding can be performed on floating point numbers with the functions ceil, floor, and round.
For example, the expression -3 / 2 would yield the integer value -1.
When the % operator is used with numerical operands, it evaluates to the remainder when the value of the left expression is divided by the value of the right. The operator requires numerical operands with the same type.
For example, the expression 5 % 3 would output the integer 2.
The ^ operator outputs the result of the left side raised to the power of the right side. The operator requires numerical operands with the same type.
The mathematical expression 23 is represented in the expression language as 2^3, which would output the integer 8.
The == operator evaluates to true if the values of the left and right operands are the same. Both operands must have the same type. You may use functions to convert between types \u2013 see functions for more type conversions. The operator supports the types integer, float, string, and boolean.
For example, 2 == 2 results in true, and \"a\" == \"b\" results in false. 1 == 1.0 would result in a type error.
The != operator is the inverse of the == operator. It evaluates to false if the values of the left and right operands are the same. Both operands must have the same type. You may use functions to convert between types \u2013 see functions for more type conversions. The operator supports the types integer, float, string, and boolean.
For example, 2 != 2 results in false, and \"a\" != \"b\" results in true. 1 != 1.0 would result in a type error.
The > operator outputs true if the left side is greater than the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For an integer example, the expression 3 > 3 would output the boolean false, and 4 > 3 would output true. For a string example, the expression \"a\" > \"b\" would output false.
The < operator outputs true if the left side is less than the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For an integer example, the expression 3 < 3 would output the boolean false, and 1 < 2 would output true. For a string example, the expression \"a\" < \"b\" would output true.
The >= operator outputs true if the left side is greater than or equal to (not less than) the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For an integer example, the expression 3 >= 3 would output the boolean true, 3 >= 4 would output false, and 4 >= 3 would output true.
The <= operator outputs true if the left side is less than or equal to (not greater than) the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For example, the expression 3 <= 3 would output the boolean true, 3 <= 4 would output true, and 4 <= 3 would output false.
The && operator returns true if both the left and right sides are true, and false otherwise. This operator requires boolean operands. Note: The operation does not \u201cshort-circuit\u201d \u2013 both the left and right expressions are evaluated before the comparison takes place.
All cases:
Left Right&& true true true true false false false true false false false false"},{"location":"arcaflow/workflows/expressions/#logical-or","title":"Logical OR","text":"The || operator returns true if either or both of the left and right sides are true, and false otherwise. This operator requires boolean operands. Note: The operation does not \u201cshort-circuit\u201d \u2013 both the left and right expressions are evaluated before the comparison takes place.
All cases:
Left Right\\|\\| true true true true false true false true true false false false"},{"location":"arcaflow/workflows/expressions/#unary-operations","title":"Unary Operations","text":"Unary operations are operations that have one input. The operator is applied to the expression which follows it.
Operator Description - Negation ! Logical complement"},{"location":"arcaflow/workflows/expressions/#negation","title":"Negation","text":"The - operator negates the value of the expression which follows it.
This operation requires numeric input.
Examples with integer literals: -5, - 5 Example with a float literal: -50.0 Example with a reference: -$.foo Example with parentheses and a sub-expression: -(5 + 5)
The ! operator logically inverts the value of the expression which follows it.
This operation requires boolean input.
Example with a boolean literal: !true Example with a reference: !$.foo
Parentheses are used to force precedence in the expression. They do not do anything implicitly (for example, there is no implied multiplication).
For example, the expression 5 + 5 * 5 evaluates the 5 * 5 before the +, resulting in 5 + 25, and finally 30. If you want the 5 + 5 to be run first, you must use parentheses. That gives you the expression (5 + 5) * 5, resulting in 10 * 5, and finally 50.
The order of operations is designed to match mathematics and most programming languages.
Order (highest to lowest; operators listed on the same line are evaluated in the order they appear in the expression):
-)())^)*) and division (/)+) and subtraction (-)binary equality and inequality (all equal)
==) !=) >) <) >=) <=)logical complement (!)
&&)||).) and bracket access ([])More information on the expression language is available in the development guide.
"},{"location":"arcaflow/workflows/expressions/#examples","title":"Examples","text":""},{"location":"arcaflow/workflows/expressions/#referencing-inputs","title":"Referencing inputs","text":"Pass a workflow input directly to a plugin input
workflow.yamlversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n name:\n type:\n type_id: string\n\nsteps:\n step_a:\n plugin:\n deployment_type: image\n src: quay.io/some/container/image\n input:\n some:\n key: !expr $.input.name\nPass output from one plugin to the input of another plugin
workflow.yamlversion: v0.2.0\nsteps:\n step_a:\n plugin: \n deployment_type: image\n src: quay.io/some/container/image\n input: {}\n\n step_b:\n plugin:\n deployment_type: image \n src: quay.io/some/container/image\n input:\n some:\n key: !expr $.steps.step_a.outputs.success.some_value\nrepeated_inputs: \n hostname: mogo\nvarying_inputs:\n - cpu_load: 10\n - cpu_load: 20\n - cpu_load: 40\n - cpu_load: 60\nversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n repeated_inputs:\n type:\n type_id: ref\n id: RepeatedValues\n varying_inputs:\n type:\n type_id: list\n items:\n id: SubRootObject\n type_id: ref\n RepeatedValues:\n id: RepeatedValues\n properties:\n hostname:\n type:\n type_id: string\n SubRootObject:\n id: SubRootObject\n properties:\n cpu_load:\n type:\n type_id: integer \n\nsteps:\n example:\n plugin:\n deployment_type: image \n src: quay.io/some/container/image\n input: !expr 'bindConstants($.input.varying_inputs, $.input.repeated_inputs)'\nIn this case, we do not need to know the schema name of the type output generated by bindConstants(). If you need to reference the schema of the list items returned by bindConstants(), see Generated Schema Name.
Flow control allows the workflow author to build a workflow with a decision tree based on supported flow logic. These flow control operations are not implemented by plugins, but are part of the workflow engine itself.
"},{"location":"arcaflow/workflows/flow-control/#foreach-loops","title":"Foreach Loops","text":"Foreach loops allow for running a sub-workflow with iterative inputs from a parent workflow. A sub-workflow is a complete Arcaflow workflow file with its own input and output schemas as described in this section. The inputs for the sub-workflow are provided as a list, where each list item is an object that matches the sub-workflow input schema.
Tip
A complete functional example is available in the arcaflow-workflows repository.
In the parent workflow file, the author can define an input schema with the list that will contain the input object that will be passed to the sub-workflow. For example:
workflow.yamlinput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n loop:\n type:\n type_id: list\n items:\n type_id: object\n id: loop_id\n properties:\n loop_id:\n type:\n type_id: integer\n param_1:\n type:\n type_id: integer\n param_2:\n type:\n type_id: string\nThen in the steps section of the workflow, the sub-workflow can be defined as a step with the loop list object from above passed to its input.
The parameters for the sub-workflow step are:
kind - The type of loop (currently only foreach is supported)items - A list of objects to pass to the sub-workflow (the expression language allows to pass this from the input schema per the above example)workflow - The file name for the sub-workflow (this should be in the same directory as the parent workflow)parallelism - The number of sub-workflow loop iterations that will run in parallelsteps:\n sub_workflow_loop:\n kind: foreach\n items: !expr $.input.loop\n workflow: sub-workflow.yaml\n parallelism: 1\nThe input yaml file for the above parent workflow would provide the list of objects to loop over as in this example:
input.yamlloop:\n - loop_id: 1\n param_1: 10\n param_2: \"a\"\n - loop_id: 2\n param_1: 20\n param_2: \"b\"\n - loop_id: 3\n param_1: 30\n param_2: \"c\"\nThe sub-workflow file then has its complete schema and set of steps as in this example:
sub-workflow.yamlversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n loop_id:\n type:\n type_id: integer\n param_1:\n type:\n type_id: integer\n param_2:\n type:\n type_id: string\nsteps:\n my_plugin:\n plugin: \n deployment_type: image\n src: path/to/my_plugin:1\n input:\n param_1: !expr $.input.param_1\n my_other_plugin:\n plugin: \n deployment_type: image\n src: path/to/my_other_plugin:1\n input:\n param_2: !expr $.input.param_2\noutputs:\n success:\n loop_id: !expr $.input.loop_id\n my_plugin: !expr $.steps.my_plugin.outputs.success\n my_other_plugin: !expr $.steps.my_other_plugin.outputs.success\nbindConstants()","text":"The builtin function bindConstants() allows you to avoid repeating input variables for a foreach subworkflow. In the example below, the input variable name\u2019s value is repeated across each iteration in this input. This results in a more repetitive input and schema definition. This section will show you how to simplify it.
bindConstants()","text":"input-repeated.yamliterations:\n - loop_id: 1\n repeated_inputs:\n name: mogo\n ratio: 3.14\n - loop_id: 2\n repeated_inputs:\n name: mogo\n ratio: 3.14\n - loop_id: 3\n repeated_inputs:\n name: mogo\n ratio: 3.14\n - loop_id: 4\n repeated_inputs:\n name: mogo\n ratio: 3.14\nversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n iterations:\n type:\n type_id: list\n items:\n id: SubRootObject\n type_id: ref\n namespace: $.steps.foreach_loop.execute.inputs.items\n\nsteps:\n foreach_loop:\n kind: foreach\n items: !expr $.input.iterations\n workflow: subworkflow.yaml\n parallelism: 1\n\noutputs:\n success:\n fab_four: !expr $.steps.foreach_loop.outputs.success.data\nversion: v0.2.0\ninput:\n root: SubRootObject\n objects:\n SubRootObject:\n id: SubRootObject\n properties:\n loop_id:\n type:\n type_id: integer\n repeated_inputs:\n type:\n type_id: ref\n id: RepeatedInputs\n RepeatedInputs:\n id: RepeatedInputs\n properties:\n name:\n type:\n type_id: string\n ratio:\n type:\n type_id: float \n\nsteps:\n example:\n plugin:\n deployment_type: image\n src: quay.io/arcalot/arcaflow-plugin-template-python:0.4.0\n input:\n name: !expr $.input.repeated_inputs.name\n\noutputs:\n success:\n loop_id: !expr $.input.loop_id\n ratio: !expr $.input.repeated_inputs.ratio\n beatle: !expr $.steps.example.outputs.success\nHere we restructure the input, factoring out the repeated name and ratio entries in the list and placing them into a single field; we will use bindConstants() to construct the foreach list with repeated entries.
repeated_inputs: \n name: mogo\n ratio: 3.14\niterations:\n - loop_id: 1\n - loop_id: 2\n - loop_id: 3\n - loop_id: 4\nTo use the generated values from bindConstants(), a new schema representing these bound values must be added to the input schema section of our subworkflow.yaml, input. This new schema\u2019s ID will be the ID of the schema that defines the items in your list, in this case SubRootObject and the schema name that defines your repeated inputs, in this case RepeatedValues, for more information see Generated Schema Names. This creates our new schema ID, SubRootObject__RepeatedValues. You are required to use this schema ID because it is generated from the names of your other schemas.
steps:\n foreach_loop:\n kind: foreach\n items: !expr 'bindConstants($.input.iterations, $.input.repeated_inputs)'\n workflow: subworkflow.yaml\n parallelism: 1\nTo use bindConstants() with an outputSchema in your workflow, you need to reference the schema of the list items returned by bindConstants(), see Generated Schema Name.
See the full workflow.
"},{"location":"arcaflow/workflows/input/","title":"Writing workflow inputs","text":"The input section of a workflow is much like a plugin schema: it describes the data model of the workflow itself. This is useful because the input can be validated ahead of time. Any input data can then be referenced by the individual steps.
Tip
The workflow input schema is analogous to the plugin input schema in that it defines the expected inputs and formats. But a workflow author has the freedom to define the schema independently of the plugin schema \u2013 This means that objects can be named and documented differently, catering to the workflow user, and input validation can happen before a plugin is loaded.
The workflow inputs start with a scope object. As an overview, a scope looks like this:
workflow.yamlinput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n name:\n type:\n type_id: string\n # Other properties of the root object\n # Other objects that can be referenced here\nThis corresponds to the following workflow input:
workflow_input.yamlname: Arca Lot\nAdmittedly, this looks complicated, but read on, it will become clear very quickly.
"},{"location":"arcaflow/workflows/input/#objects","title":"Objects","text":"Let\u2019s start with objects. Objects are like structs or classes in programming. They have two properties: an ID and a list of properties. The basic structure looks like this:
some_object:\n id: some_object\n properties:\n # Properties here\nNow you need to define a property. Let\u2019s say, we want to define a string with the name of the user. You can do this as follows:
type_id: object\nid: some_object\nproperties:\nname:\n type:\n type_id: string\nNotice, that the type_id field is indented. That\u2019s because the type field describes a string type, which has additional parameters. For example:
type_id: object\nid: some_object\nproperties:\nname:\n type:\n type_id: string\n min: 1 # Minimum length for the string\nThere are also additional attributes of the property itself. For example:
type_id: object\nid: some_object\nproperties:\nname:\n type:\n type_id: string\n min: 1 # Minimum length for the string\n display:\n name: Name\n description: Name of the user.\n conflicts:\n - full_name\nProperties have the following attributes:
Attribute Type Descriptiondisplay Display Display metadata of the property. See Display values. required bool If set to true, the field must always be filled. required_if []string List of other properties that, if filled, lead to the current property being required. required_if_not []string List of other properties that, if not filled, lead to the current property being required. conflicts []string List of other properties that conflict the current property. default string Default value for this property, JSON-encoded. examples []string Examples for the current property, JSON-encoded. Note
Unlike the plugin schema where an unassigned default value is set to None, for the workflow schema you simply omit the default to leave it unassigned.
Scopes behave like objects, but they serve an additional purpose. Suppose, object A had a property of the object type B, but now you needed to reference back to object A. Without references, there would be no way to do this.
OpenAPI and JSON Schema have a similar concept, but in those systems all references are global. This presents a problem when merging schemas. For example, both Docker and Kubernetes have an object called Volume. These objects would need to be renamed when both configurations are in one schema.
Arcaflow has a different solution: every plugin, every part of a workflow has its own scope. When a reference is found in a scope, it always relates to its own scope. This way, references don\u2019t get mixed.
Let\u2019s take a simple example: a scope with objects A and B, referencing each other.
type_id: scope\nroot: A\nobjects:\n A:\n type_id: object\n id: A\n properties:\n b:\n type:\n type_id: ref\n id: B\n required: false\n B:\n type_id: object\n id: B\n properties:\n a:\n type:\n type_id: ref\n id: A\n required: false\nThis you can create a circular dependency between these objects without needing to copy-paste their properties.
Additionally, refs have an extra display property, which references a Display value to provide context for the reference.
Strings are, as the name suggests, strings of human-readable characters. They have the following properties:
type_id: string\nmin: # Minimum number of characters. Optional.\nmax: # Maximum number of characters. Optional.\npattern: # Regular expression this string must match. Optional.\nPatterns are special kinds of strings that hold regular expressions.
type_id: pattern\nIntegers are similar to strings, but they don\u2019t have a pattern field but have a units field. (See Units.)
type_id: integer\nmin: # Minimum value. Optional.\nmax: # Maximum value. Optional.\nunits:\n # Units definition. Optional.\nFloating point numbers are similar to integers.
type_id: float\nmin: # Minimum value. Optional.\nmax: # Maximum value. Optional.\nunits:\n # Units definition. Optional.\nEnums only allow a fixed set of values. String enums map string keys to a display value. (See Display values.)
type_id: enum_string\nvalues:\n red:\n name: Red\n yellow:\n name: Yellow\nEnums only allow a fixed set of values. Integer enums map integer keys to a display value. (See Display values.)
type_id: enum_integer\nvalues:\n 1:\n name: Red\n 2:\n name: Yellow\nBooleans can hold a true or false value.
type_id: bool\nLists hold items of a specific type. You can also define their minimum and maximum size.
type_id: list\nitems:\n type_id: type of the items\n # Other definitions for list items\nmin: 1 # Minimum number of items in the list (optional)\nmax: 2 # maximum number of items in the list (optional)\nMaps are key-value mappings. You must define both the key and value types, whereas keys can only be strings, integers, string enums, or integer enums.
type_id: map\nkeys:\n type_id: string\nvalues:\n type_id: string\nmin: 1 # Minimum number of items in the map (optional)\nmax: 2 # maximum number of items in the map (optional)\nOne-of types allow you to specify multiple alternative objects, scopes, or refs. However, these objects must contain a common field (discriminator) and each value for that field must correspond to exactly one object type.
Tip
If the common field is not specified in the possible objects, it is implicitly added. If it is specified, however, it must match the discriminator type.
type_id: one_of_string\ndiscriminator_field_name: object_type # Defaults to: _type\ntypes:\n a:\n type_id: object\n id: A\n properties:\n # Properties of object A.\n b:\n type_id: object\n id: B\n properties:\n # Properties of object B\nWe can now use the following value as an input:
object_type: a\n# Other values for object A\nIn contrast, you can specify object_type as b and that will cause the unserialization to run with the properties of object B.
One-of types allow you to specify multiple alternative objects, scopes, or refs. However, these objects must contain a common field (discriminator) and each value for that field must correspond to exactly one object type.
Tip
If the common field is not specified in the possible objects, it is implicitly added. If it is specified, however, it must match the discriminator type.
type_id: one_of_int\ndiscriminator_field_name: object_type # Defaults to: _type\ntypes:\n 1:\n type_id: object\n id: A\n properties:\n # Properties of object A.\n 2:\n type_id: object\n id: B\n properties:\n # Properties of object B\nWe can now use the following value as an input:
object_type: 1\n# Other values for object A\nIn contrast, you can specify object_type as 2 and that will cause the unserialization to run with the properties of object B.
Any types allow any data to pass through without validation. We do not recommend using the \u201cany\u201d type due to its lack of validation and the risk to cause runtime errors. Only use any types if you can truly handle any data that is passed.
type_id: any\nDisplay values are all across the Arcaflow schema. They are useful to provide human-readable descriptions of properties, refs, etc. that can be used to generate nice, human-readable documentation, user interfaces, etc. They are always optional and consist of the following 3 fields:
name: Short name\ndescription: Longer description of what the item does, possibly in multiple lines.\nicon: |\n <svg ...></svg> # SVG icon, 64x64 pixels, without doctype and external references.\nUnits make it easier to parse and display numeric values. For example, if you have an integer representing nanoseconds, you may want to parse strings like 5m30s.
Units have two parameters: a base unit description and multipliers. For example:
base_unit:\n name_short_singular: B\n name_short_plural: B\n name_long_singular: byte\n name_long_plural: bytes\nmultipliers:\n 1024:\n name_short_singular: kB\n name_short_plural: kB\n name_long_singular: kilobyte\n name_long_plural: kilobytes\n # ...\nOutputs in Arcaflow serve a dual purpose:
You can define an output simply with expressions. Outputs generally include desired output parameters from individual steps, but may also include data from inputs or even static values.
output:\n some_key:\n some_other_key: !expr $.steps.some_step.outputs.success.some_value\n foo: !expr $.inputs.bar\n arca: \"flow\"\nArcaflow can produce multiple output groups for a workflow. These output groups are mutually exclusive to each other.
A common example of two mutually exclusive events could be the availability of your data storage service. Let\u2019s assume the service is either available, or unavailable (the unavailable state also includes any states where an error is thrown during data insertion). Multiple workflow outputs allows you to plan for these two events.
In this example taken from the Arcaflow Workflows project, the success output collects the data from the specified steps and inserts it into data storage. The no-indexing output collects the data, the error logs, and does not store the data.
outputs:\n success:\n pcp: !expr $.steps.pcp.outputs.success\n sysbench: !expr $.steps.sysbench.outputs.success\n metadata: !expr $.steps.metadata.outputs.success\n opensearch: !expr $.steps.opensearch.outputs.success\n no-indexing:\n pcp: !expr $.steps.pcp.outputs.success\n sysbench: !expr $.steps.sysbench.outputs.success\n metadata: !expr $.steps.metadata.outputs.success\n no-index: !expr $.steps.opensearch.outputs.error\nSchemas that are not composed within an ObjectSchema do not have an Object ID. They use a stringified version of their TypeID for their schema name.
The name of a ListSchema is the name of the schema of its element type prefixed with list_. For lists of lists, the schema name is the name of the inner list schema prefixed with an additional list_.
The name of an ObjectSchema is its Object ID. A ListSchema that has an ObjectSchema as its item value uses the name of that ObjectSchema.
ScopeSchemas do not use a schema name.RefSchemas use the schema name of the type to which they point.The name of the schema for the value returned by a given call to bindConstants() is generated from the names of the schemas of the parameters to the call. Because the output of this function is always a list, the list_ prefix is omitted from the schema name, and only the schema name of the list\u2019s items is used. The name is formed by concatenating the name of the schema of the first parameter\u2019s list items with the name of the schema of the second parameter, separated by a double underscore __.
If your input is complete, you can now turn to writing your workflow steps. You can connect workflow steps by using expressions. For example, if step A has an input that needs data from step B, Arcaflow will automatically run step B first.
To define a step type, you can do the following:
workflow.yamlversion: v0.2.0\nsteps:\n step_a: # Specify any ID here you want to reference the step by\n plugin: \n deployment_type: image\n src: quay.io/some/container/image # This must be an Arcaflow-compatible image\n input: # specify input values as a data structure, mixing in expressions as needed\n some:\n key: !expr $.steps.step_b.outputs.success.some_value \n step_b:\n plugin: \n deployment_type: image\n src: quay.io/some/container/image\n input:\n some:\n key: !expr $.input.some_value # Reference an input value\nPlugin steps run Arcaflow plugins in containers. They can use Docker, Podman, or Kubernetes as deployers. If no deployer is specified in the workflow, the plugin will use the local deployer.
Plugin steps have the following properties:
Property Descriptionplugin Full name of the container image to run. This must be an Arcaflow-compatible container image. step If a plugin provides more than one possible step, you can specify the step ID here. deploy Configuration for the deployer. (See below.) This can contain expressions, so you can dynamically specify deployment parameters. input Input data for the plugin. This can contain expressions, so you can dynamically define inputs. You can reference plugin outputs in the format of $.steps.your_step_id.outputs.your_plugin_output_id.some_variable.
The deploy key for plugins lets you control how the plugin container is deployed. You can use expressions to use other plugins (e.g. the kubeconfig plugin) to generate the deployment configuration and feed it into other steps.
You can configure the Docker deployer like this:
version: v0.2.0\nstep:\n your_step_id:\n plugin: ...\n input: ...\n deploy: # You can use expressions here\n deployer_name: docker\n connection:\n # Change this to point to a TCP-based Docker socket\n host: host-to-docker\n # Add a certificates here. This is usually needed in TCP mode.\n cacert: |\n Add your CA cert PEM here\n cert: |\n Add your client cert PEM here.\n key: |\n Add your client key PEM here.\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n network:\n # Add your network config here\n platform:\n # Add your platform config here\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Connection (object) Type: object Properties cacert (string) Name: CA certificate Description: CA certificate in PEM format to verify the Dockerd server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name for Dockerd. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z0-9./:_-]+$ Default\"npipe:////./pipe/docker_engine\"\n'unix:///var/run/docker.sock'\n\u201d
'npipe:////./pipe/docker_engine'\nstring) Name: Client key Description: Client private key in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nobject) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (map[string, string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[A-Z0-9_]+$ Value type Type: string Maximum: 32760 Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nreference[NetworkConfig]) Name: Network configuration Description: Provides information about the container networking for the plugin. Required: No Referenced object: NetworkConfig (see in the Objects section below) platform (reference[PlatformConfig]) Name: Platform configuration Description: Provides information about the container host platform for the plugin. Required: No Referenced object: PlatformConfig (see in the Objects section below) HostConfig (object) Type: object Properties CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) NetworkConfig (object) Type: object Properties None
PlatformConfig (object) Type: object Properties None
PortBinding (object) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nIf you want to use Podman as your local deployer, you can do so like this:
version: v0.2.0\nstep:\n your_step_id:\n plugin: ...\n input: ...\n deploy: # You can use expressions here\n deployer_name: podman\n podman:\n # Change where Podman is. (You can use this to point to a shell script\n path: /path/to/your/podman\n # Change the network mode\n networkMode: host\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) Objects Config (object) Type: object Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) ContainerConfig (object) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (list[string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+=.+$ Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nobject) Type: object Properties Binds (list[string]) Name: Volume Bindings Description: Volumes Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+:.+$ CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) Podman (object) Type: object Properties cgroupNs (string) Name: CGroup namespace Description: Provides the Cgroup Namespace settings for the container Required: No Must match pattern: ^host|ns:/proc/\\d+/ns/cgroup|container:.+|private$ containerName (string) Name: Container Name Description: Provides name of the container Required: No Must match pattern: ^.*$ imageArchitecture (string) Name: Podman image Architecture Description: Provides Podman Image Architecture Required: No Must match pattern: ^.*$ Default\"amd64\"\nstring) Name: Podman Image OS Description: Provides Podman Image Operating System Required: No Must match pattern: ^.*$ Default\"linux\"\nstring) Name: Network Mode Description: Provides network settings for the container Required: No Must match pattern: ^bridge:.*|host|none$ path (string) Name: Podman path Description: Provides the path of podman executable Required: No Must match pattern: ^.*$ Default\"podman\"\nobject) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ The Kubernetes deployer deploys on top of Kubernetes. You can set up the deployer like this:
version: v0.2.0\nstep:\n your_step_id:\n plugin: ...\n input: ...\n deploy: # You can use expressions here\n deployer_name: kubernetes\n connection:\n host: localhost:6443\n cert: |\n Add your client cert in PEM format here.\n key: |\n Add your client key in PEM format here.\n cacert: |\n Add the server CA cert in PEM format here.\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects AWSElasticBlockStoreVolumeSource (object) Type: object Properties None
AzureDiskVolumeSource (object) Type: object Properties None
AzureFileVolumeSource (object) Type: object Properties None
CSIVolumeSource (object) Type: object Properties None
CephFSVolumeSource (object) Type: object Properties None
CinderVolumeSource (object) Type: object Properties None
Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) ConfigMapVolumeSource (object) Type: object Properties None
Connection (object) Type: object Properties bearerToken (string) Name: Bearer token Description: Bearer token to authenticate against the Kubernetes API with. Required: No burst (int) Name: Burst Description: Burst value for query throttling. Required: No Minimum: 0 Default10\nstring) Name: CA certificate Description: CA certificate in PEM format to verify Kubernetes server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name and port of the Kubernetes server Required: No Default\"kubernetes.default.svc\"\nstring) Name: Client key Description: Client private key in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nstring) Name: Password Description: Password for basic authentication. Required: No path (string) Name: Path Description: Path to the API server. Required: No Default\"/api\"\nfloat) Name: QPS Description: Queries Per Second allowed against the API. Required: No Minimum: 0 Units: queries Default5.0\nstring) Name: TLS server name Description: Expected TLS server name to verify in the certificate. Required: No username (string) Name: Username Description: Username for basic authentication. Required: No Container (object) Type: object Properties args (list[string]) Name: Arguments Description: Arguments to the entypoint (command). Required: No List Items Type: string command (list[string]) Name: Command Description: Override container entry point. Not executed with a shell. Required: No Minimum items: 1 List Items Type: string env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) image (string) Name: Image Description: Container image to use for this container. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9_\\-:./]+$ imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ securityContext (object) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 workingDir (string) Name: Working directory Description: Override the container working directory. Required: No DownwardAPIVolumeSource (object) Type: object Properties None
EmptyDirVolumeSource (object) Type: object Properties medium (string) Name: Medium Description: How to store the empty directory Required: No Minimum: 1 Must match pattern: ^(|Memory|HugePages|HugePages-.*)$ EnvFromSource (object) Type: object Properties configMapRef (object) Name: Config map source Description: Populates the source from a config map. Required: No Properties name (string) Name: Name Description: Name of the referenced config map. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the config map must be defined. Required: No prefix (string) Name: Prefix Description: An optional identifier to prepend to each key in the ConfigMap. Required: No Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ secretRef (object) Name: Secret source Description: Populates the source from a secret. Required: No Properties name (string) Name: Name Description: Name of the referenced secret. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the secret must be defined. Required: No EphemeralVolumeSource (object) Type: object Properties None
FCVolumeSource (object) Type: object Properties None
FlexVolumeSource (object) Type: object Properties None
FlockerVolumeSource (object) Type: object Properties None
GCEPersistentDiskVolumeSource (object) Type: object Properties None
GlusterfsVolumeSource (object) Type: object Properties None
HostPathVolumeSource (object) Type: object Properties path (string) Name: Path Description: Path to the directory on the host. Required: Yes Minimum: 1 Examples \"/srv/volume1\"\nenum[string]) Name: Type Description: Type of the host path. Required: No Values BlockDevice Block deviceCharDevice Character deviceDirectory DirectoryDirectoryOrCreate Create directory if not foundFile FileFileOrCreate Create file if not foundSocket Socketobject) Type: object Properties None
NFSVolumeSource (object) Type: object Properties None
ObjectMeta (object) Type: object Properties annotations (map[string, string]) Name: Annotations Description: Kubernetes annotations to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ generateName (string) Name: Name prefix Description: Name prefix to generate pod names from. Required: No labels (map[string, string]) Name: Labels Description: Kubernetes labels to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ name (string) Name: Name Description: Pod name. Required: No namespace (string) Name: Namespace Description: Kubernetes namespace to deploy in. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"default\"\nobject) Type: object Properties None
PhotonPersistentDiskVolumeSource (object) Type: object Properties None
Pod (object) Type: object Properties metadata (reference[ObjectMeta]) Name: Metadata Description: Pod metadata. Required: No Referenced object: ObjectMeta (see in the Objects section below) spec (reference[PodSpec]) Name: Specification Description: Pod specification. Required: No Referenced object: PodSpec (see in the Objects section below) PodSpec (object) Type: object Properties affinity (object) Name: Affinity rules Description: Affinity rules. Required: No Properties podAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ podAntiAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ containers (list[reference[Container]]) Name: Containers Description: A list of containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) initContainers (list[reference[Container]]) Name: Init containers Description: A list of initialization containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) nodeSelector (map[string, string]) Name: Labels Description: Node labels you want the target node to have. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ pluginContainer (object) Name: Plugin container Description: The container to run the plugin in. Required: Yes Properties env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"arcaflow-plugin-container\"\nobject) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 volumes (list[reference[Volume]]) Name: Volumes Description: A list of volumes that can be mounted by containers belonging to the pod. Required: No List Items Type: reference[Volume] Referenced object: Volume (see in the Objects section below) PortworxVolumeSource (object) Type: object Properties None
ProjectedVolumeSource (object) Type: object Properties None
QuobyteVolumeSource (object) Type: object Properties None
RBDVolumeSource (object) Type: object Properties None
ScaleIOVolumeSource (object) Type: object Properties None
SecretVolumeSource (object) Type: object Properties None
StorageOSVolumeSource (object) Type: object Properties None
Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nobject) Type: object Properties awsElasticBlockStore (reference[AWSElasticBlockStoreVolumeSource]) Name: AWS EBS Description: AWS Elastic Block Storage. Required: No Referenced object: AWSElasticBlockStoreVolumeSource (see in the Objects section below) azureDisk (reference[AzureDiskVolumeSource]) Name: Azure Data Disk Description: Mount an Azure Data Disk as a volume. Required: No Referenced object: AzureDiskVolumeSource (see in the Objects section below) azureFile (reference[AzureFileVolumeSource]) Name: Azure File Description: Mount an Azure File Service mount. Required: No Referenced object: AzureFileVolumeSource (see in the Objects section below) cephfs (reference[CephFSVolumeSource]) Name: CephFS Description: Mount a CephFS volume. Required: No Referenced object: CephFSVolumeSource (see in the Objects section below) cinder (reference[CinderVolumeSource]) Name: Cinder Description: Mount a cinder volume attached and mounted on the host machine. Required: No Referenced object: CinderVolumeSource (see in the Objects section below) configMap (reference[ConfigMapVolumeSource]) Name: ConfigMap Description: Mount a ConfigMap as a volume. Required: No Referenced object: ConfigMapVolumeSource (see in the Objects section below) csi (reference[CSIVolumeSource]) Name: CSI Volume Description: Mount a volume using a CSI driver. Required: No Referenced object: CSIVolumeSource (see in the Objects section below) downwardAPI (reference[DownwardAPIVolumeSource]) Name: Downward API Description: Specify a volume that the pod should mount itself. Required: No Referenced object: DownwardAPIVolumeSource (see in the Objects section below) emptyDir (reference[EmptyDirVolumeSource]) Name: Empty directory Description: Temporary empty directory. Required: No Referenced object: EmptyDirVolumeSource (see in the Objects section below) ephemeral (reference[EphemeralVolumeSource]) Name: Ephemeral Description: Mount a volume that is handled by a cluster storage driver. Required: No Referenced object: EphemeralVolumeSource (see in the Objects section below) fc (reference[FCVolumeSource]) Name: Fibre Channel Description: Mount a Fibre Channel volume that's attached to the host machine. Required: No Referenced object: FCVolumeSource (see in the Objects section below) flexVolume (reference[FlexVolumeSource]) Name: Flex Description: Mount a generic volume provisioned/attached using an exec based plugin. Required: No Referenced object: FlexVolumeSource (see in the Objects section below) flocker (reference[FlockerVolumeSource]) Name: Flocker Description: Mount a Flocker volume. Required: No Referenced object: FlockerVolumeSource (see in the Objects section below) gcePersistentDisk (reference[GCEPersistentDiskVolumeSource]) Name: GCE disk Description: Google Cloud disk. Required: No Referenced object: GCEPersistentDiskVolumeSource (see in the Objects section below) glusterfs (reference[GlusterfsVolumeSource]) Name: GlusterFS Description: Mount a Gluster volume. Required: No Referenced object: GlusterfsVolumeSource (see in the Objects section below) hostPath (reference[HostPathVolumeSource]) Name: Host path Description: Mount volume from the host. Required: No Referenced object: HostPathVolumeSource (see in the Objects section below) iscsi (reference[ISCSIVolumeSource]) Name: iSCSI Description: Mount an iSCSI volume. Required: No Referenced object: ISCSIVolumeSource (see in the Objects section below) name (string) Name: Name Description: The name this volume can be referenced by. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ nfs (reference[NFSVolumeSource]) Name: NFS Description: Mount an NFS share. Required: No Referenced object: NFSVolumeSource (see in the Objects section below) persistentVolumeClaim (reference[PersistentVolumeClaimVolumeSource]) Name: Persistent Volume Claim Description: Mount a Persistent Volume Claim. Required: No Referenced object: PersistentVolumeClaimVolumeSource (see in the Objects section below) photonPersistentDisk (reference[PhotonPersistentDiskVolumeSource]) Name: PhotonController persistent disk Description: Mount a PhotonController persistent disk as a volume. Required: No Referenced object: PhotonPersistentDiskVolumeSource (see in the Objects section below) portworxVolume (reference[PortworxVolumeSource]) Name: Portworx Volume Description: Mount a Portworx volume. Required: No Referenced object: PortworxVolumeSource (see in the Objects section below) projected (reference[ProjectedVolumeSource]) Name: Projected Description: Projected items for all in one resources secrets, configmaps, and downward API. Required: No Referenced object: ProjectedVolumeSource (see in the Objects section below) quobyte (reference[QuobyteVolumeSource]) Name: quobyte Description: Mount Quobyte volume from the host. Required: No Referenced object: QuobyteVolumeSource (see in the Objects section below) rbd (reference[RBDVolumeSource]) Name: Rados Block Device Description: Mount a Rados Block Device. Required: No Referenced object: RBDVolumeSource (see in the Objects section below) scaleIO (reference[ScaleIOVolumeSource]) Name: ScaleIO Persistent Volume Description: Mount a ScaleIO persistent volume. Required: No Referenced object: ScaleIOVolumeSource (see in the Objects section below) secret (reference[SecretVolumeSource]) Name: Secret Description: Mount a Kubernetes secret. Required: No Referenced object: SecretVolumeSource (see in the Objects section below) storageos (reference[StorageOSVolumeSource]) Name: StorageOS Volume Description: Mount a StorageOS volume. Required: No Referenced object: StorageOSVolumeSource (see in the Objects section below) vsphereVolume (reference[VsphereVirtualDiskVolumeSource]) Name: vSphere Virtual Disk Description: Mount a vSphere Virtual Disk as a volume. Required: No Referenced object: VsphereVirtualDiskVolumeSource (see in the Objects section below) VsphereVirtualDiskVolumeSource (object) Type: object Properties None
"},{"location":"arcaflow/workflows/versioning/","title":"Workflow schema versions","text":""},{"location":"arcaflow/workflows/versioning/#valid-version-string","title":"Valid version string","text":"All workflow schema versions conform to semantic version 2.0.0 with a major, minor, and patch version. In this document, since the prepended v is unnecessary it is not used. However, it is required as a value for the version key in your workflow file.
Invalid version string for workflow.yaml.
version: 0.2.0\ninput:\nsteps:\noutputs:\nValid version string for workflow.yaml.
version: v0.2.0\ninput:\nsteps:\noutputs:\nFor the configuration file, config.yaml, two types of deployers are now possible, image and python, so deployer has become deployers. Effectively, the type key has become the deployer_name key. The deployer_name key and value are required which means you must also have either the image key or the python key.
deployers:\n image:\n deployer_name: docker|podman|kubernetes\n python:\n deployer_name: python\nFor your workflow file, workflow.yaml, the version key and value are required, and they must be at the root of the file.
version: v0.2.0\ninputs: {}\nsteps: {}\noutputs: {}\nArcalog is still in early development. A scientific paper describing the project is available as a preprint.
The README contains a guide on how to use Arcalog to gather data as well as how to use the --http flag to run a minimal user interface for downloading individual build IDs from Prow.
Pre-release developer documentation is also available if you want to use the early pre-release version of Arcalog to embed the data gathering steps into your own application.
"}]} \ No newline at end of file +{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Arcalot","text":"The Arcalot community is dedicated to developing modular tools, plugins, and libraries with flexible implementations to be used independently or as complete end-to-end solutions. We believe in enabling automation and portability of complex tasks and in pre-validating actions to avoid costly re-runs due to late failures and incompatible data.
"},{"location":"#arcaflow","title":"Arcaflow","text":"Arcaflow is a workflow orchestration system consisting of three main components:
Arcaflow is highly-flexible and portable, helping you to build pipelines of actions via plugins. Plugin steps typically perform one action well, creating or manipulating data that is returned in a machine-readable format. Data is validated according to schemas as it passes through the pipeline in order to clearly diagnose type mismatch problems early. Arcaflow runs on your laptop, a jump host, or in a CI system, requiring only the Arcaflow engine binary, a workflow definition in YAML, and a compatible container runtime.
Arcaflow allows you to encapsulate and version-control expertise, making potentially very complex workflows easily portable among environments and automation systems. With an Arcaflow workflow, you can carefully craft a pipeline of actions that serves your direct needs and share that workflow virtually unchanged for others to run in different environments and CI/CD systems.
An ever-growing catalog of official plugins are maintained within the Arcalot organization and are available as versioned containers from Quay.io. You can also build your own containerized plugins using the the Arcaflow SDK, available for Python and Golang. We encourage you to contribute your plugins to the community, and you can start by adding them to the plugins incubator repo via a pull request.
"},{"location":"#documentation","title":"Documentation","text":"We work hard to bring the documentation to the user, meaning that you should find a lot of relevant documentation in the context of what you may be working on via readme files, be it the engine, the SDK, a plugin, a workflow, or a sub-component. Comprehensive documentation, developer references, and quickstart guides will always be located in the arcalot.io pages.
"},{"location":"#community","title":"Community","text":"We invite you to contribute! Check out the Issues in the individual repositories for ideas on where to get involved, or consider contributing a new plugin by starting with our python plugin template repository. Outside contributions and pull requests are of course always welcome.
If you want to get more involved with contributions, maintenance, and governance, consider joining the Arcalot Round Table (ART), our central community body. The ART currently holds bi-weekly video conference meetings. Please reach out to one of our ART chairs for more information.
You can find our general community health files like our code of conduct and contribution guidelines in the .github repository. If you have any questions or suggestions, please use the Issues in the respective repository.
"},{"location":"arcaflow/","title":"Arcaflow: The noble workflow engine","text":"Arcaflow is a workflow engine that lets you run individual steps and pass data between them. The data is validated according to a schema along the way to make sure there is no corrupt data. Arcaflow runs on your laptop, a jump host, or in a CI system and deploys plugins as containers on target systems via Docker, Podman, or Kubernetes.
Did you know?
In Docker/Kubernetes, Arcaflow only needs network access to the API, not the plugin container itself. You can safely place a restrictive firewall on most plugins.
Use casesArcaflow is a good fit to:
You can use Arcaflow for many things. We use it for:
Get started \u00bb Contribute \u00bb
Shipping expertiseGood workflows take time and expertise to develop. Often these workflows evolve organically into bespoke scripts and/or application stacks, and knowledge transfer or the ability to run the workflows in new environments can be very difficult. Arcaflow addresses this problem by focusing on being the plumbing for the workflow, standardizing on a plugin architecture for all actions, minimizing dependencies, focusing on quality, and enforcing strong typing for data passing.
Arcaflow\u2019s design can drastically simplify much of the workflow creation process, and it allows the workflow author to ensure the workflow is locked in end-to-end. A complete workflow can be version-controlled as a simple YAML file and in most cases can be expected to run in exactly the same way in any compatible environment.
Not a CI systemArcaflow is not designed to run as a persistent service nor to record workflow histories, and in most cases it is probably not the best tool to set up or manage infrastructure. For end-to-end CI needs, you should leverage a system that provides these and other features (possibly something from the Alternatives list below).
Arcaflow is, however, an excellent companion to a CI system. In many cases, building complex workflows completely within a CI environment can effectively lock you into that system because the workflow may not be easily portable outside of it or run independently by a user. An Arcaflow workflow can be easily integrated into most CI systems, so a workflow that you define once may be moved in most cases without modification to different environments or run directly by users.
AlternativesIt\u2019s important that you pick the right tool for the job. Sometimes, you need something simple. Sometimes, you want something persistent that keeps track of the workflows you run over time. We have collected some common and well-known open source workflow and workflow-like engines into this list and have provided some comparisons to help you find the right tool for your needs.
Here are some of the features that make Arcaflow a unique solution to the below alternatives:
Ansible is an IT automation and configuration management system. It handles configuration management, application deployment, cloud provisioning, ad-hoc task execution, network automation, and multi-node orchestration. Ansible makes complex changes like zero-downtime rolling updates with load balancers easy.
How are Arcaflow and Ansible similar?
How is Ansible different?
Airflow is a platform to programmatically author, schedule, and monitor workflows. It is a deployed workflow engine written in Python.
How are Arcaflow and Airflow similar?
How is Airflow different?
Argo Workflows is a container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo Workflows is implemented as a Kubernetes CRD (Custom Resource Definition).
How are Arcaflow and Argo Workflows similar?
How is Argo Workflows different?
Conductor is a platform created by Netflix to orchestrate workflows that span across microservices.
How are Arcaflow and Conductor similar?
How is Conductor different?
Tekton is a framework for creating CI/CD systems, allowing developers to build, test, and deploy across cloud providers and on-premise systems.
How are Arcaflow and Tekton similar?
How is Tekton different?
qDup allows shell commands to be queued up across multiple servers to coordinate performance tests. It is designed to follow the same workflow as a user at a terminal so that commands can be performed with or without qDup. Commands are grouped into re-usable scripts that are mapped to different hosts by roles.
How are Arcaflow and qDup similar?
How is qDup different?
In order to use Arcaflow, you will need a container engine on your computer. For the purposes of this guide, we\u2019ll assume you are using Docker or Podman.
"},{"location":"arcaflow/getting-started/#step-2-get-the-engine","title":"Step 2: Get the engine","text":"Head on over to the GitHub releases page and download the latest release.
"},{"location":"arcaflow/getting-started/#step-3-create-your-first-plugin","title":"Step 3: Create your first plugin","text":"Let\u2019s create a simple hello-world plugin in Python. We\u2019ll publish the code here, you can find the details in the Python plugin guide.
plugin.py#!/usr/local/bin/python3\nimport dataclasses\nimport sys\nfrom arcaflow_plugin_sdk import plugin\n\n\n@dataclasses.dataclass\nclass InputParams:\n name: str\n\n\n@dataclasses.dataclass\nclass SuccessOutput:\n message: str\n\n\n@plugin.step(\n id=\"hello-world\",\n name=\"Hello world!\",\n description=\"Says hello :)\",\n outputs={\"success\": SuccessOutput},\n)\ndef hello_world(params: InputParams):\n return \"success\", SuccessOutput(f\"Hello, {params.name}\")\n\n\nif __name__ == \"__main__\":\n sys.exit(\n plugin.run(\n plugin.build_schema(\n hello_world,\n )\n )\n )\nTip
Further reading: Creating your first Python plugin
"},{"location":"arcaflow/getting-started/#step-4-build-the-plugin","title":"Step 4: Build the plugin","text":"Next, let\u2019s create a Dockerfile and build a container image:
Dockerfile
FROM python:alpine\n\nADD plugin.py /\nRUN chmod +x /plugin.py && pip install arcaflow_plugin_sdk\n\nENTRYPOINT [\"/plugin.py\"]\nCMD []\ndocker build -t example-plugin .\npodman build -t example-plugin .\nTip
Further reading: Packaging plugins
Did you know?
While Arcaflow is a workflow engine, plugins can be run independently via the command line. Try running your containerized hello-world plugin directly.
DockerPodmanecho \"name: Arca Lot\" | docker run -i --rm example-plugin -f -\necho \"name: Arca Lot\" | podman run -i --rm example-plugin -f -\nLet\u2019s start with something simple: we\u2019ll incorporate the plugin above into a workflow. Let\u2019s create a workflow.yaml in an empty directory
version: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n name:\n type:\n type_id: string\nsteps:\n greet:\n plugin:\n deployment_type: image \n src: example-plugin\n input:\n name: !expr $.input.name\noutput:\n message: !expr $.steps.greet.outputs.success.message\nTip
Further reading: Creating workflows
"},{"location":"arcaflow/getting-started/#step-6-create-an-input-file","title":"Step 6: Create an input file","text":"Now, let\u2019s create an input file for our workflow named input.yaml:
name: Arca Lot\nYou will need an Arcaflow config.yaml file to prevent Arcaflow from trying to pull the container image.
Tip
Without a config file, the default behavior of Arcaflow is to run with docker and to always pull plugin container images for the workflow.
DockerPodman config.yamldeployer:\n type: docker\n deployment:\n # Make sure we don't try to pull the image we have locally\n imagePullPolicy: Never\ndeployer:\n type: podman\n deployment:\n # Make sure we don't try to pull the image we have locally\n imagePullPolicy: Never\nTip
Further reading: Setting up Arcaflow
"},{"location":"arcaflow/getting-started/#step-7-run-the-workflow","title":"Step 7: Run the workflow","text":"Finally, let\u2019s run our workflow. Make sure you are in the directory where the workflow is located.
Linux/MacOSWindows/path/to/arcaflow -input input.yaml -config config.yaml\nC:\\path\\to\\arcaflow.exe -input input.yaml -config config.yaml\nIf everything went well, after a few seconds you should see logs messages similar to the ones shown below:
2023-03-22T11:25:58+01:00 info Loading plugins locally to determine schemas...\n2023-03-22T11:25:58+01:00 info Deploying example-plugin...\n2023-03-22T11:25:58+01:00 info Creating container from image example-plugin...\n2023-03-22T11:25:59+01:00 info Container started.\n2023-03-22T11:25:59+01:00 info Schema for example-plugin obtained.\n2023-03-22T11:25:59+01:00 info Schema loading complete.\n2023-03-22T11:25:59+01:00 info Building dependency tree...\n2023-03-22T11:25:59+01:00 info Dependency tree complete.\n2023-03-22T11:25:59+01:00 info Dependency tree Mermaid:\nflowchart TD\nsubgraph input\ninput.name\nend\ninput.name-->steps.greet\nsteps.greet-->steps.greet.outputs.success\nsteps.greet.outputs.success-->output\n2023-03-22T11:25:59+01:00 info Starting step greet...\n2023-03-22T11:25:59+01:00 info Creating container from image example-plugin...\n2023-03-22T11:26:00+01:00 info Container started.\n2023-03-22T11:26:00+01:00 info Step greet is now running...\n2023-03-22T11:26:00+01:00 info Step greet is now executing ATP...\n2023-03-22T11:26:00+01:00 info Step \"greet\" has finished with output success.\nmessage: Hello, Arca Lot\nAs you can see, the last line of the output is the output data from the workflow.
Did you know?
Arcaflow provides Mermaid markdown in the workflow output that allows you to quickly visualize the workflow in a graphic format. You can grab the Mermaid graph you see in the output and put it into the Mermaid editor.
Mermaid markdownMermaid rendered flowchartflowchart TD\nsubgraph input\ninput.name\nend\ninput.name-->steps.greet\nsteps.greet-->steps.greet.outputs.success\nsteps.greet.outputs.success-->output\nflowchart TD\nsubgraph input\ninput.name\nend\ninput.name-->steps.greet\nsteps.greet-->steps.greet.outputs.success\nsteps.greet.outputs.success-->outputTip
Further reading: Running Arcaflow
"},{"location":"arcaflow/getting-started/#next-steps","title":"Next steps","text":"Congratulations, you are now an Arcaflow user! Here are some things you can do next to start working with plugins and workflows:
Hungry for more? Keep digging into our docs::
Contribute to Arcaflow \u00bb
"},{"location":"arcaflow/concepts/","title":"Concepts","text":"This section of the documentation deals with theoretical concepts around Arcaflow. Fear not, it\u2019s not a university exam, but simply a description on how we designed Arcaflow the way we did and why we did so.
ArchitectureGet started with a primer on the core architecture of Arcaflow.
Read more about architecture \u00bb
TypingWe believe in strong and static typing to avoid bugs, so Arcaflow has its own typing system.
Read more about typing \u00bb
PluginsArcaflow is interoperable between several programming languages. Currently, we provide SDKs for Python and Go.
Read more about plugins \u00bb
WorkflowsArcaflow runs several steps and connects them together into a workflow.
Read more about workflows \u00bb
Flow control (WIP)In the future, we want to add the ability to perform loops, dynamic parallelization, etc.
Read more about flow control \u00bb
"},{"location":"arcaflow/concepts/architecture/","title":"Arcaflow architecture","text":"The Arcaflow architecture consists of the following 2 keys elements:
The engine is responsible for the orchestration of the workflow steps. It has several duties:
The engine itself is designed to be run from a command line interface, possibly as a webserver, but is not designed to run in a redundant fashion. Instead of implementing redundancy itself, the engine will receive support to execute workflows in third party systems, such as Kafka.
A stretch goal for the engine is to make it fully embeddable, possibly with in-binary workflows and execution images to make them easily to ship in network-restricted environments.
"},{"location":"arcaflow/concepts/architecture/#plugins","title":"Plugins","text":"Plugins provide execution for one or more steps for a workflow. The job of a plugin is to do one thing and do it well. A plugin provides a thin layer over third party tools, or its own implementation of features. Its main job is to provide accurate input and output schema information to the engine and transform the data as needed.
For example, a plugin may output unformatted text, which a plugin has to parse and build a machine-readable data structure for that information. This reformatting of data allows the engine to pipe data between steps and reliably check the data for faults.
The current plan is to provide plugin SDKs for Python, GO, and Rust (in that order).
"},{"location":"arcaflow/concepts/architecture/#typing","title":"Typing","text":"A core element of the Arcaflow system is the typing system. Each plugin and the engine itself will provide a machine-readable data structure that describes what inputs are expected and what outputs may be produced. If you are familiar with JSON schema or OpenAPI, this is similar, and Arcaflow can produce those schema documents. However, the Arcaflow system is stricter than those industry standards to optimize for performance and simpler implementation in all supported programming languages.
"},{"location":"arcaflow/concepts/architecture/#executing-workflows","title":"Executing workflows","text":"Arcaflow workflows are orchestrated in the Engine, while plugins can be run locally or remotely on container engines. This lends itself to a Git-based workflow:
flowchart LR\n subgraph laptop[Your laptop]\n direction LR\n\n ui(UI)\n engine(Engine)\n git(Git)\n\n ui -- Workflow --> engine\n ui -- Workflow --> git -- Workflow --> engine\n engine -- Execution results --> ui\n end\n\n subgraph docker[Docker/Podman<br>on your laptop]\n direction LR\n\n plugins1(Plugin)\n\n engine -- Step execution --> plugins1\n end\n engine -- Launch plugin --> docker\n\n subgraph k8s[Kubernetes]\n direction LR\n\n plugins2(Plugin)\n\n engine -- Step execution --> plugins2\n end\n engine -- Launch plugin --> k8s\n\n apis(Other APIs)\n plugins1 --> apis\n plugins2 --> apis Arcaflow is designed as an interoperable system between programming languages. Therefore, plugins are started as external processes and the communication with the plugin takes place over its standard input and output. The Arcaflow Engine passes data between the plugins as required by the workflow file.
In the vast majority of cases, plugins run inside a container, while the Arcaflow Engine itself does not. This allows Arcaflow to pass data between several Kubernetes clusters, local plugins, or even run plugins via Podman over SSH. These capabilities are built into the Arcaflow Engine with the help of deployers.
Since Arcaflow has an internal typing system, each plugin must declare at the start what input data it requires and what outputs it produces. This allows the Engine to verify that the workflow can be run, and that no invalid data is being used. If invalid data is detected, the workflow is aborted to prevent latent defects in the data.
In summary, you can think of Arcaflow as a strongly (and at some time in the future possibly statically) typed system for executing workflows, where individual plugins run in containers across several systems.
"},{"location":"arcaflow/concepts/typing/","title":"Typing system","text":"Let\u2019s say you are creating a system that measures performance. But, uh-oh! A bug has struck! Instead of returning a number, a plugin returns an empty string. Would you want that converted to a numeric 0 for a metric? Or worse yet, would you want a negative number resulting from a bug to make it into your metrics? Would you want to collect metrics for years just to find out they are all wrong?
If the answer is no, then the typing system is here to help. Each plugin or workflow in Arcaflow is required to explicitly state what data types it accepts for its fields, and what their boundaries are. When a plugin then violates its own rules, the engine makes sure that corrupt data isn\u2019t used any further.
For example, let\u2019s look at the definition of an integer:
type_id: integer\nmin: 10\nmax: 128\nIt\u2019s so simple, but it already prevents a lot of bugs: non-integers, numbers out of range.
But wait! A typing system can do more for you. For example, we can automatically generate a nice documentation from it. Let\u2019s take this object as an example:
type_id: object\nid: name\nproperties:\n name:\n type:\n type_id: string\n min: 1\n max: 256\n display:\n name: \"Name\"\n description: \"The name of the user.\"\n icon: |\n <svg ...></svg>\nThat\u2019s all it takes to render a nice form field or automatic documentation. You can read more about creating types in the plugins section or the workflows section, or see the complete typing reference in the Contributing guide.
"},{"location":"arcaflow/concepts/workflows/","title":"Arcaflow Workflows (concept)","text":"Tip
This document describes the concept of Arcaflow Workflows. We describe the process of writing a workflow in this section
"},{"location":"arcaflow/concepts/workflows/#steps","title":"Steps","text":"Workflows are a way to describe a sequence or parallel execution of individual steps. The steps are provided exclusively by plugins. The simplest workflow looks like this:
stateDiagram-v2\n [*] --> Step\n Step --> [*]However, this is only true if the step only has one output. Most steps will at least have two possible outputs, for success and error states:
stateDiagram-v2\n [*] --> Step\n Step --> [*]: yes\n Step --> [*]: noPlugins can declare as many outputs as needed, with custom names. The workflow engine doesn\u2019t make a distinction based on the names, all outputs are treated equal for execution.
An important rule is that one step must always end in exactly one output. No step must end without an output, and no step can end in more than one output. This provides a mechanism to direct the flow of the workflow execution.
Plugins must also explicitly declare what parameters they expect as input for the step, and the data types of these and what parameters they will produce as output.
"},{"location":"arcaflow/concepts/workflows/#interconnecting-steps","title":"Interconnecting steps","text":"When two steps are connected, they will be executed after each other:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n Step1 --> Step2\n Step2 --> [*]Similarly, when two steps are not directly connected, they may be executed in parallel:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n [*] --> Step2\n Step1 --> [*]\n Step2 --> [*]You can use the interconnection to direct the flow of step outputs:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n Step3: Step 3\n [*] --> Step1\n Step1 --> Step2: success\n Step1 --> Step3: error\n Step2 --> [*]\n Step3 --> [*]When two steps are connected, you have the ability to pass data between them. Emblematically described:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n Step1 --> Step2: input_1 = $.steps.step1.outputs.success\n Step2 --> [*]The data type of the input on Step 2 in this case must match the result of the expression. If the data type does not match, the workflow will not be executed.
"},{"location":"arcaflow/concepts/workflows/#undefined-inputs","title":"Undefined inputs","text":"Step inputs can either be required or optional. When a step input is required, it must be configured or the workflow will fail to execute. However, there are cases when the inputs cannot be determined from previous steps. In this case, the workflow start can be connected and the required inputs can be obtained from the user when running the workflow:
stateDiagram-v2\n Step1: Step 1\n Step2: Step 2\n [*] --> Step1\n [*] --> Step2: input_1 = $.input.option_1\n Step1 --> Step2: input_2 = $.steps.step1.outputs.success\n Step2 --> [*]This is typically the case when credentials, such as database access, etc. are required.
"},{"location":"arcaflow/concepts/workflows/#outputs","title":"Outputs","text":"The output for each step is preserved for later inspection. However, the workflow can explicitly declare outputs. These outputs are usable in scripted environments as a direct output of the workflow:
stateDiagram-v2\n [*] --> Step\n Step --> [*]: output_1 = $.steps.step1.outputs.successBackground processes
Each plugin will only be invoked once, allowing plugins to run background processes, such as server applications. The plugins must handle SIGINT and SIGTERM events properly.
"},{"location":"arcaflow/concepts/workflows/#flow-control-wip","title":"Flow control (WIP)","text":"The workflow contains several flow control operations. These flow control operations are not implemented by plugins, but are part of the workflow engine itself.
"},{"location":"arcaflow/concepts/workflows/#foreach","title":"Foreach","text":"The foreach flow control allows you to loop over a sub-workflow with a list of input objects.
stateDiagram-v2\n [*] --> ForEach\n state ForEach {\n [*] --> loop_list_input\n loop_list_input --> sub_workflow\n sub_workflow --> loop_list_input\n state sub_workflow {\n [*] --> Step1\n Step1 --> [*]\n }\n sub_workflow --> [*]: Sub Output\n }\n ForEach --> [*]: OutputWarning
The features below are in-development and not yet implemented in the released codebase.
"},{"location":"arcaflow/concepts/workflows/#abort","title":"Abort","text":"The abort flow control is a quick way to exit out of a workflow. This is useful when entering a terminal error state and the workflow output data would be useless anyway.
stateDiagram-v2\n [*] --> Step1\n Step1 --> Abort: Output 1\n Step1 --> Step2: Output 2\n Step2 --> [*]However, this is only required if you want to abort the workflow immediately. If you want an error case to result in the workflow failing, but whatever steps can be finished being finished, you can leave error outputs unconnected.
"},{"location":"arcaflow/concepts/workflows/#do-while","title":"Do-while","text":"A do-while block will execute the steps in it as long as a certain condition is met. The condition is derived from the output of the step or steps executed inside the loop:
stateDiagram-v2\n [*] --> DoWhile\n state DoWhile {\n [*] --> Step1\n Step1 --> [*]: output_1_condition=$.step1.output_1.finished == false \n }\n DoWhile --> [*]If the step declares multiple outputs, multiple conditions are possible. The do-while block will also have multiple outputs:
stateDiagram-v2\n [*] --> DoWhile\n state DoWhile {\n [*] --> Step1\n Step1 --> [*]: Output 1 condition\n Step1 --> [*]: Output 2 condition \n }\n DoWhile --> [*]: Output 1\n DoWhile --> [*]: Output 2You may decide to only allow exit from a loop if one of the two outputs is satisfied:
stateDiagram-v2\n [*] --> DoWhile\n state DoWhile {\n [*] --> Step1\n Step1 --> Step1: Output 1\n Step1 --> [*]: Output 2\n }\n DoWhile --> [*]: Output 1A condition is a flow control operation that redirects the flow one way or another based on an expression. You can also create multiple branches to create a switch-case effect.
stateDiagram-v2\n state if_state <<choice>>\n Step1: Step 1\n [*] --> Step1\n Step1 --> if_state\n Step2: Step 2\n Step3: Step 3\n if_state --> Step2: $.step1.output_1 == true\n if_state --> Step3: $.step1.output_1 == falseThe multiply flow control operation is useful when you need to dynamically execute sub-workflows in parallel based on an input condition. You can, for example, use this to run a workflow step on multiple or all Kubernetes nodes.
stateDiagram-v2\n Lookup: Lookup Kubernetes hosts\n [*] --> Lookup\n Lookup --> Multiply\n state Multiply {\n [*] --> Stresstest\n Stresstest --> [*]\n }\n Multiply --> [*]The output of a Multiply operation will be a map, keyed with a string that is configured from the input.
Tip
You can think of a Multiply step like a for-each loop, but the steps being executed in parallel.
"},{"location":"arcaflow/concepts/workflows/#synchronize","title":"Synchronize","text":"The synchronize step attempts to synchronize the execution of subsequent steps for a specified key. The key must be a constant and cannot be obtained from an input expression.
stateDiagram-v2\n [*] --> Step1\n [*] --> Step2\n Synchronize1: Synchronize (key=a)\n Synchronize2: Synchronize (key=a)\n Step1 --> Synchronize1\n Step2 --> Synchronize2\n Synchronize1 --> Step3\n Synchronize2 --> Step4\n Step3 --> [*]\n Step4 --> [*]First of all, welcome to the Arca Lot! Whether you are a beginner or a seasoned veteran, your contributions are most appreciated. Thank you!
Now, let\u2019s get you started. There are a number of ways you can contribute on GitHub, please check the Arcaflow project board for open issues. Additionally, here are a few repos you can contribute to:
Repository What you can do here arcalot.github.io Improve the documentation arcaflow-plugin-sdk-go Improve the Go SDK arcaflow-plugin-sdk-python Improve the Python SDK arcaflow-engine Improve the Arcaflow Engine arcaflow-engine-deployer-kubernetes Improve the Kubernetes deployment of plugins arcaflow-engine-deployer-docker Improve the Docker deployment of plugins arcaflow-engine-deployer-podman Improve the Podman deployment of plugins arcaflow-expressions Improve the Arcaflow expression language arcaflow-plugin-image-builder Improve the Arcaflow plugin packaging arcaflow-plugin-* Improve the officially supported pluginsIf you want to contribute regularly, why not join the Arcalot Round Table by reading our charter and signing up as a member? That way you get a voice in the decisions we make!
"},{"location":"arcaflow/contributing/#license","title":"License","text":"All code in Arcaflow is licensed under the Apache 2.0 license. The documentation is licensed under CC-BY-4.0. Please make sure you read and understand these licenses before contributing. If you are contributing on behalf of your employer, please make sure you have permission to do so.
"},{"location":"arcaflow/contributing/#principles","title":"Principles","text":"While we don\u2019t deal in absolutes (only a Sith would do that) we hold ourselves to a few key principles. There are plenty of things where we could do better in these areas, so if you find something, please open an issue. It\u2019s important!
"},{"location":"arcaflow/contributing/#the-principle-of-the-least-surprise","title":"The principle of the least surprise","text":"Sometimes, things are just hard to make user-friendly. If presented with two choices, we will always pick the one that doesn\u2019t break expectations. What would an average user expect to happen without reading the documentation? If something surprised you, please open a bug.
"},{"location":"arcaflow/contributing/#the-principle-of-nice-error-messages","title":"The principle of nice error messages","text":"When using Arcaflow, you should never be confronted with a stack trace. Error messages should always explain what went wrong and how to fix it. We know, this is a tall order, but if you see an error message that is not helpful, please open a bug.
"},{"location":"arcaflow/contributing/#the-principle-of-intern-friendliness","title":"The principle of intern-friendliness","text":"There is enough software out in the wild that requires months of training and is really hard to get into. Arcaflow isn\u2019t the easiest to learn either, see the whole typing system thing, but nevertheless, the software should be written in such a way that an intern with minimal training can sit down and do something useful with it. If something is unnecessarily hard or undocumented, you guessed it, please open a bug.
"},{"location":"arcaflow/contributing/#the-principle-of-typing","title":"The principle of typing","text":"We believe that strong and static typing can save us from bugs. This applies to programming languages just as much as it applies to workflows. We aim to make a system tell us that something is wrong before we spent several hours running it.
"},{"location":"arcaflow/contributing/#the-principle-of-testing","title":"The principle of testing","text":"Bugs? Yeah, we have those, and we want fewer of them. Since we are a community effort, we can\u2019t afford a large QA team to test through everything manually before a release. Therefore, it\u2019s doubly important that we have automated tests that run on every change. Furthermore, we want our tests to run quickly and without additional setup time. You should be able to run go test or python -m unittest discover and get a result within a few seconds at most. This makes it more likely that a contributor will run the tests and contribute new tests instead of waiting for CI to sort it out.
Every software is\u2026 pardon our French: crap. Ours is no exception. The difference is how big and how stinky the piles are. We aim to make the piles small, well-defined and as stink-less as possible. If we need to replace a pile with another pile, it should be easy to do so.
Translated to software engineering, we create APIs between our piles components. These APIs can be in the form of code, or in the form of a GitHub Actions workflow. A non-leaky API helps us replace one side of the API without touching the other.
"},{"location":"arcaflow/contributing/#the-principle-of-kindness-to-our-future-self","title":"The principle of kindness to our future self","text":"Writing code should be fun, most of us got into this industry because we enjoyed creating something. We want to keep this joy of creation. What kills the enthusiasm fastest is having to slog through endless pieces of obtuse code, spending hours and hours trying to accomplish a one-line change. When we write code, we want to be kind to our future selves. That\u2019s why we not only write documentation and tests for our users, we also create these for ourselves and our peers.
"},{"location":"arcaflow/contributing/deployers/","title":"Arcaflow Deployers Development Guide","text":"The Arcaflow Engine relies on deployers to execute containers. Deployers provide a binary-safe transparent tunnel of communication between a plugin and the engine. (Typically, this will be done via standard input/output, but other deployers are possible.)
The Engine and the plugin communicate via the Arcaflow Transport Protocol over this tunnel, but the deployer is unaware of the method of this communication.
Deployers are written in Go and must implement the deployer interface. Deployers are not dynamically pluggable, they must also be added to the engine code to be usable.
"},{"location":"arcaflow/contributing/engine/","title":"Arcaflow Engine Development Guide","text":"Warning
The engine is currently undergoing a major refactor. This page describes the engine post-refactor.
The Arcaflow engine is responsible for parsing a YAML workflow and executing it. It goes through several phases during execution.
"},{"location":"arcaflow/contributing/engine/#yaml-loading-phase","title":"YAML loading phase","text":"During the YAML loading phase, the engine loads the workflow YAML as raw data containing YAML nodes. We need the raw YAML nodes to access the YAML tags, which we use to turn the structure into expressions. The resulting data structure of this phase is a structure consisting of maps, lists, strings, and expression objects.
YAML
YAML, at its core, only knows three data types: maps, lists, and strings. Additionally, each entry can have a tag in the form of !foo or !!foo.
Once the YAML is loaded, we can take the data created and parse the workflow. This will validate the input definition and the basic step definitions and provide a more structured data. However, at this point the plugin schemas are not known yet, so any data structure related to steps is accepted as-is.
"},{"location":"arcaflow/contributing/engine/#schema-loading","title":"Schema loading","text":"The engine has an API to provide step types. These step types have the ability to provide a lifecycle and load their schema. In case of plugins, this means that the plugin is fired up briefly and its schema is queried. (See Deployers.)
"},{"location":"arcaflow/contributing/engine/#dag-construction","title":"DAG construction","text":"Once the schema is loaded, the Directed Acyclic Graph can be constructed from the expressions. Each lifecycle stage input is combed for expressions and a DAG is built.
"},{"location":"arcaflow/contributing/engine/#static-code-analysis-future","title":"Static code analysis (future)","text":"The expression library already has the facilities to inspect types, which will, in the future, provide us the ability to perform a static code analysis on the workflow. This will guarantee users that a workflow can be executed without typing problems.
"},{"location":"arcaflow/contributing/engine/#workflow-execution","title":"Workflow execution","text":"When the DAG is complete and contains no cycles, the workflow execution can proceed. The execution cycle queries lifecycle nodes that have no more inbound dependencies and runs the lifecycle. When a lifecycle stage finishes, the corresponding nodes are removed from the DAG, freeing up other nodes for execution.
"},{"location":"arcaflow/contributing/expressions/","title":"Arcaflow Expressions Development Guide","text":"The expressions library provides the engine and other potential users with a simple way to compile expressions and provide typing information about an expression result.
The library consists of two parts: the internal parser/AST and the API layer.
"},{"location":"arcaflow/contributing/expressions/#the-parser-ast","title":"The Parser / AST","text":"The expressions parser constructs an Abstract Syntax Tree from the expression which can then be walked by the API layer. The AST consists of the following node types:
"},{"location":"arcaflow/contributing/expressions/#dot-notation","title":"Dot Notation","text":"Let\u2019s say you have an expression foo.bar. The dot notation node is the dot in the middle. The left subtree of the dot will be the entire expression left of the dot, while the right subtree will be everything to the right.
Bracket expressions are expressions in the form of foo[bar]. The left subtree will represent the expression to the left of the brackets (foo in the example), while the right subtree will represent the subexpression within the brackets (bar in the example).
Binary operations include all of the operations that have a left and right subtree that do not have a special node representing them (dot notation and bracket expression are examples of special cases). Binary operations are represented by a node containing an operation and the subtrees to which the operation is applied.
"},{"location":"arcaflow/contributing/expressions/#unary-operations","title":"Unary Operations","text":"Unary operations include boolean complement ! and numeric negation -. Unary operations are represented by a node containing an operation and the subtree to which the operation is applied. Unlike binary operations, unary operations have only one subtree.
Identifiers come in two forms:
$ references the root of the data structure.^\\w+$. This may be used for accessing object fields or as function identifiers.The API layer provides three functions:
All three functions walk the AST above and construct the required data.
"},{"location":"arcaflow/contributing/plugin-protocol/","title":"Arcaflow Plugin protocol specification (ATP)","text":"Arcaflow runs plugins locally in a container using Docker or Podman, or remotely in Kubernetes. Each plugin must be containerized and communicates with the engine over standard input/output. This document outlines the protocol the engine and the plugins use to communicate.
Hint
You do not need this page if you only intend to implement a plugin with the SDK!
"},{"location":"arcaflow/contributing/plugin-protocol/#execution-model","title":"Execution model","text":"A single plugin execution is intended to run a single task and not more. This simplifies the code since there is no need to try and clean up after each task. Each plugin is executed in a container and must communicate with the engine over standard input/output. Furthermore, the plugin must add a handler for SIGTERM and properly clean up if there are services running in the background.
Each plugin is executed at the start of the workflow, or workflow block, and is terminated only at the end of the current workflow or workflow block. The plugin can safely rely on being able to start a service in the background and then keeping it running until the SIGTERM comes to shut down the container.
However, the plugin must, under no circumstances, start doing work until the engine sends the command to do so. This includes starting any services inside the container or outside. This restriction is necessary to be able to launch the plugin with minimal resource consumption locally on the engine host to fetch the schema.
The plugin execution is divided into three major steps.
SIGTERM to the plugin. The plugin has up to 30 seconds to shut down. The SIGTERM may come at any time, even while the work is still running, and the plugin must appropriately shut down. If the work is not complete, it is important that the plugin does not send error output to STDOUT. If the plugin fails to stop by itself within 30 seconds, the plugin container is forcefully stopped.As a data transport protocol, we use CBOR messages RFC 8949 back to back due to their self-delimiting nature. This section provides the entire protocol as JSON schema below.
"},{"location":"arcaflow/contributing/plugin-protocol/#step-0-the-start-output-message","title":"Step 0: The \u201cstart output\u201d message","text":"Because Kubernetes has no clean way of capturing an output right at the start, the initial step of the plugin execution involves the engine sending an empty CBOR message (None or Nil) to the plugin. This indicates, that the plugin may start its output now.
The \u201cHello\u201d message is a way for the plugin to introduce itself and present its steps and schema. Transcribed to JSON, a message of this kind would look as follows:
{\n \"version\": 1,\n \"steps\": {\n \"step-id-1\": {\n \"name\": \"Step 1\",\n \"description\": \"This is the first step\",\n \"input\": {\n \"schema\": {\n // Input schema\n }\n },\n \"outputs\": {\n \"output-id-1\": {\n \"name\": \"Name for this output kind\",\n \"description\": \"Description for this output\",\n \"schema\": {\n // Output schema\n }\n }\n }\n }\n }\n}\nThe schemas must describe the data structure the plugin expects. For a simple hello world input would look as follows:
{\n \"type\": \"object\",\n \"properties\": {\n \"name\": {\n \"type\": \"string\"\n }\n }\n}\nThe full schema is described below in the Schema section.
"},{"location":"arcaflow/contributing/plugin-protocol/#step-2-start-work-message","title":"Step 2: Start work message","text":"The \u201cstart work\u201d message has the following parameters in CBOR:
{\n \"id\": \"id-of-the-step-to-execute\",\n \"config\": {\n // Input parameters according to schema here\n }\n}\nThe plugin must respond with a CBOR message of the following format:
{\n \"status\": \"started\"\n}\nIf the plugin execution ended unexpectedly, the plugin should crash and output a reasonable error message to the standard error. The plugin must exit with a non-zero exit status to notify the engine that the execution failed.
"},{"location":"arcaflow/contributing/plugin-protocol/#step-3b-output","title":"Step 3/b: Output","text":"When the plugin has executed successfully, it must emit a CBOR message to the standard output:
{\n \"output_id\": \"id-of-the-declared-output\",\n \"output_data\": {\n // Result data of the plugin\n },\n \"debug_logs\": \"Unstructured logs here for debugging as a string.\"\n}\nThis section contains the exact schema that the plugin sends to the engine.
Type:scope Root object: Schema Properties steps (map[string, reference[Step]]) Name: Steps Description: Steps this schema supports. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Step] Referenced object: Step (see in the Objects section below) Objects AnySchema (object) Type: object Properties None
BoolSchema (object) Type: object Properties None
Display (object) Type: object Properties description (string) Name: Description Description: Description for this item if needed. Required: No Minimum: 1 Examples \"Please select the fruit you would like.\"\nstring) Name: Icon Description: SVG icon for this item. Must have the declared size of 64x64, must not include additional namespaces, and must not reference external resources. Required: No Minimum: 1 Examples \"<svg ...></svg>\"\nstring) Name: Name Description: Short text serving as a name or title for this item. Required: No Minimum: 1 Examples \"Fruit\"\nobject) Type: object Properties max (float) Name: Maximum Description: Maximum value for this float (inclusive). Required: No Examples 16.0\nfloat) Name: Minimum Description: Minimum value for this float (inclusive). Required: No Examples 5.0\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum value for this int (inclusive). Required: No Minimum: 0 Examples 5\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties units (reference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nmap[int, reference[Display]]) Name: Values Description: Possible values for this field. Required: Yes | Minimum items: | 1 |\nint Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\"1024\": {\"name\": \"kB\"}, \"1048576\": {\"name\": \"MB\"}}\nobject) Type: object Properties items (one of[string]) Name: Items Description: ReflectedType definition for items in this list. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\nobject) Type: object Properties keys (one of[string]) Name: Keys Description: ReflectedType definition for keys in this map. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\none of[string]) Name: Values Description: ReflectedType definition for values in this map. Required: No Object (object) Type: object Properties id (string) Name: ID Description: Unique identifier for this object within the current scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ properties (map[string, reference[Property]]) Name: Properties Description: Properties of this object. Required: Yes Key type Type: string Minimum: 1 Value type Type: reference[Property] Referenced object: Property (see in the Objects section below) OneOfIntSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[int, one of[string]]) Name: Types Required: No Key type Type: int Value type Type: one of[string] OneOfStringSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[string, one of[string]]) Name: Types Required: No Key type Type: string Value type Type: one of[string] Pattern (object) Type: object Properties None
Property (object) Type: object Properties conflicts (list[string]) Name: Conflicts Description: The current property cannot be set if any of the listed properties are set. Required: No List Items Type: string default (string) Name: Default Description: Default value for this property in JSON encoding. The value must be unserializable by the type specified in the type field. Required: No display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) examples (list[string]) Name: Examples Description: Example values for this property, encoded as JSON. Required: No List Items Type: string required (bool) Name: Required Description: When set to true, the value for this field must be provided under all circumstances. Required: No Defaulttrue\nlist[string]) Name: Required if Description: Sets the current property to required if any of the properties in this list are set. Required: No List Items Type: string required_if_not (list[string]) Name: Required if not Description: Sets the current property to be required if none of the properties in this list are set. Required: No List Items Type: string type (one of[string]) Name: Type Description: Type definition for this field. Required: Yes Ref (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) id (string) Name: ID Description: Referenced object ID. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Schema (object) Type: object Properties steps (map[string, reference[Step]]) Name: Steps Description: Steps this schema supports. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Step] Referenced object: Step (see in the Objects section below) Scope (object) Type: object Properties objects (map[string, reference[Object]]) Name: Objects Description: A set of referencable objects. These objects may contain references themselves. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Object] Referenced object: Object (see in the Objects section below) root (string) Name: Root object Description: ID of the root object of the scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Step (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) id (string) Name: ID Description: Machine identifier for this step. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ input (reference[Scope]) Name: Input Description: Input data schema. Required: Yes Referenced object: Scope (see in the Objects section below) outputs (map[string, reference[StepOutput]]) Name: Input Description: Input data schema. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[StepOutput] Referenced object: StepOutput (see in the Objects section below) StepOutput (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) error (bool) Name: Error Description: If set to true, this output will be treated as an error output. Required: No Defaultfalse\nreference[Scope]) Name: Schema Description: Data schema for this particular output. Required: Yes Referenced object: Scope (see in the Objects section below) String (object) Type: object Properties max (int) Name: Maximum Description: Maximum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 16\nint) Name: Minimum Description: Minimum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 5\npattern) Name: Pattern Description: Regular expression this string must match. Required: No Examples \"^[a-zA-Z]+$\"\nobject) Type: object Properties values (map[string, reference[Display]]) Name: Values Description: Mapping where the left side of the map holds the possible value and the right side holds the display value for forms, etc. Required: Yes | Minimum items: | 1 |\nstring Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\n \"apple\": {\n \"name\": \"Apple\"\n },\n \"orange\": {\n \"name\": \"Orange\"\n }\n}\nobject) Type: object Properties name_long_plural (string) Name: Name long (plural) Description: Longer name for this UnitDefinition in plural form. Required: Yes Examples \"bytes\",\"characters\"\nstring) Name: Name long (singular) Description: Longer name for this UnitDefinition in singular form. Required: Yes Examples \"byte\",\"character\"\nstring) Name: Name short (plural) Description: Shorter name for this UnitDefinition in plural form. Required: Yes Examples \"B\",\"chars\"\nstring) Name: Name short (singular) Description: Shorter name for this UnitDefinition in singular form. Required: Yes Examples \"B\",\"char\"\nobject) Type: object Properties base_unit (reference[Unit]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: Yes Referenced object: Unit (see in the Objects section below) Examples {\n \"name_short_singular\": \"B\",\n \"name_short_plural\": \"B\",\n \"name_long_singular\": \"byte\",\n \"name_long_plural\": \"bytes\"\n}\nmap[int, reference[Unit]]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: No Key type Type: int Value type Type: reference[Unit] Referenced object: Unit (see in the Objects section below) Examples {\n \"1024\": {\n \"name_short_singular\": \"kB\",\n \"name_short_plural\": \"kB\",\n \"name_long_singular\": \"kilobyte\",\n \"name_long_plural\": \"kilobytes\"\n },\n \"1048576\": {\n \"name_short_singular\": \"MB\",\n \"name_short_plural\": \"MB\",\n \"name_long_singular\": \"megabyte\",\n \"name_long_plural\": \"megabytes\"\n }\n}\nArcaflow takes a departure from the classic run-and-pray approach of running workloads and validates workflows before executing them. To do this, Arcaflow starts the plugins as needed before the workflow is run and queries them for their schema. This schema will contain information about what kind of input a plugin requests and what kind of outputs it can produce.
A plugin can support multiple workflow steps and must provide information about the data types in its input and output for each step. A step can have exactly one input format, but may declare more than one output.
The type system is inspired by JSON schema and OpenAPI, but it is more restrictive due to the need to efficiently serialize workloads over various formats.
"},{"location":"arcaflow/contributing/typing/#types","title":"Types","text":"The typing system supports the following data types.
null, nil, or None), or a default value.null, nil, or None).null, nil, or None).true or false and cannot take any other values.The typing system also contains more in-depth validation than just simple types:
"},{"location":"arcaflow/contributing/typing/#strings","title":"Strings","text":"Strings can have a minimum or maximum length, as well as validation against a regular expression.
"},{"location":"arcaflow/contributing/typing/#ints-floats","title":"Ints, floats","text":"Number types can have a minimum and maximum value (inclusive).
"},{"location":"arcaflow/contributing/typing/#booleans","title":"Booleans","text":"Boolean types can take a value of either true or false, but when unserializing from YAML or JSON formats, strings or int values of true, yes, on, enable, enabled, 1, false, no, off, disable, disabled or 0 are also accepted.
Lists and maps can have constraints on the minimum or maximum number of items in them (inclusive).
"},{"location":"arcaflow/contributing/typing/#objects","title":"Objects","text":"Object fields can have several constraints:
required_if has a list of other fields that, if set, make the current field required.required_if_not has a list of other fields that, if none are set, make the current field required.conflicts has a list of other fields that cannot be set together with the current field.When you need to create a list of multiple object types, or simply have an either-or choice between two object types, you can use the OneOf type. This field uses an already existing field of the underlying objects, or adds an extra field to the schema to distinguish between the different types. Translated to JSON, you might see something like this:
{\n \"_type\": \"Greeter\",\n \"message\": \"Hello world!\"\n}\nObjects, on their own, cannot create circular references. It is not possible to create two objects that refer to each other. That\u2019s where scopes and refs come into play. Scopes hold a list of objects, identified by an ID. Refs inside the scope (for example, in an object property) can refer to these IDs. Every scope has a root object, which will be used to provide its \u201cobject-like\u201d features, such as a list of fields.
For example:
objects:\n my_root_object:\n id: my_root_object\n properties:\n ...\nroot: my_root_object\nMultiple scopes can be nested into each other. The ref always refers to the closest scope up the tree. Multiple scopes can be used when combining objects from several sources (e.g. several plugins) into one schema to avoid conflicting ID assignments.
"},{"location":"arcaflow/contributing/typing/#any","title":"Any","text":"Any accepts any primitive type (string, int, float, bool, map, list) but no patterns, objects, etc. This type is severely limited in its ability to validate data and should only be used in exceptional cases when there is no other way to describe a schema.
"},{"location":"arcaflow/contributing/typing/#metadata","title":"Metadata","text":"Object fields can also declare metadata that will help with creating user interfaces for the object. These fields are:
For display purposes, the type system is designed so that it can infer the intent of the data. We wish to communicate the following intents:
We explicitly document the following inference rules, which will probably change in the future.
This section explains how a scope object looks like. The plugin protocol contains a few more types that are used when communicating a schema.
Type:scope Root object: Scope Properties objects (map[string, reference[Object]]) Name: Objects Description: A set of referencable objects. These objects may contain references themselves. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Object] Referenced object: Object (see in the Objects section below) root (string) Name: Root object Description: ID of the root object of the scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Objects AnySchema (object) Type: object Properties None
BoolSchema (object) Type: object Properties None
Display (object) Type: object Properties description (string) Name: Description Description: Description for this item if needed. Required: No Minimum: 1 Examples \"Please select the fruit you would like.\"\nstring) Name: Icon Description: SVG icon for this item. Must have the declared size of 64x64, must not include additional namespaces, and must not reference external resources. Required: No Minimum: 1 Examples \"<svg ...></svg>\"\nstring) Name: Name Description: Short text serving as a name or title for this item. Required: No Minimum: 1 Examples \"Fruit\"\nobject) Type: object Properties max (float) Name: Maximum Description: Maximum value for this float (inclusive). Required: No Examples 16.0\nfloat) Name: Minimum Description: Minimum value for this float (inclusive). Required: No Examples 5.0\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum value for this int (inclusive). Required: No Minimum: 0 Examples 5\nreference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nobject) Type: object Properties units (reference[Units]) Name: Units Description: Units this number represents. Required: No Referenced object: Units (see in the Objects section below) Examples { \"base_unit\": { \"name_short_singular\": \"%\", \"name_short_plural\": \"%\", \"name_long_singular\": \"percent\", \"name_long_plural\": \"percent\" }}\nmap[int, reference[Display]]) Name: Values Description: Possible values for this field. Required: Yes | Minimum items: | 1 |\nint Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\"1024\": {\"name\": \"kB\"}, \"1048576\": {\"name\": \"MB\"}}\nobject) Type: object Properties items (one of[string]) Name: Items Description: ReflectedType definition for items in this list. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\nobject) Type: object Properties keys (one of[string]) Name: Keys Description: ReflectedType definition for keys in this map. Required: No max (int) Name: Maximum Description: Maximum value for this int (inclusive). Required: No Minimum: 0 Examples 16\nint) Name: Minimum Description: Minimum number of items in this list.. Required: No Minimum: 0 Examples 5\none of[string]) Name: Values Description: ReflectedType definition for values in this map. Required: No Object (object) Type: object Properties id (string) Name: ID Description: Unique identifier for this object within the current scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ properties (map[string, reference[Property]]) Name: Properties Description: Properties of this object. Required: Yes Key type Type: string Minimum: 1 Value type Type: reference[Property] Referenced object: Property (see in the Objects section below) OneOfIntSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[int, one of[string]]) Name: Types Required: No Key type Type: int Value type Type: one of[string] OneOfStringSchema (object) Type: object Properties discriminator_field_name (string) Name: Discriminator field name Description: Name of the field used to discriminate between possible values. If this field is present on any of the component objects it must also be an int. Required: No Examples \"_type\"\nmap[string, one of[string]]) Name: Types Required: No Key type Type: string Value type Type: one of[string] Pattern (object) Type: object Properties None
Property (object) Type: object Properties conflicts (list[string]) Name: Conflicts Description: The current property cannot be set if any of the listed properties are set. Required: No List Items Type: string default (string) Name: Default Description: Default value for this property in JSON encoding. The value must be unserializable by the type specified in the type field. Required: No display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) examples (list[string]) Name: Examples Description: Example values for this property, encoded as JSON. Required: No List Items Type: string required (bool) Name: Required Description: When set to true, the value for this field must be provided under all circumstances. Required: No Defaulttrue\nlist[string]) Name: Required if Description: Sets the current property to required if any of the properties in this list are set. Required: No List Items Type: string required_if_not (list[string]) Name: Required if not Description: Sets the current property to be required if none of the properties in this list are set. Required: No List Items Type: string type (one of[string]) Name: Type Description: Type definition for this field. Required: Yes Ref (object) Type: object Properties display (reference[Display]) Name: Display Description: Name, description and icon. Required: No Referenced object: Display (see in the Objects section below) id (string) Name: ID Description: Referenced object ID. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Scope (object) Type: object Properties objects (map[string, reference[Object]]) Name: Objects Description: A set of referencable objects. These objects may contain references themselves. Required: Yes Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ Value type Type: reference[Object] Referenced object: Object (see in the Objects section below) root (string) Name: Root object Description: ID of the root object of the scope. Required: Yes Minimum: 1 Maximum: 255 Must match pattern: ^[$@a-zA-Z0-9-_]+$ String (object) Type: object Properties max (int) Name: Maximum Description: Maximum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 16\nint) Name: Minimum Description: Minimum length for this string (inclusive). Required: No Minimum: 0 Units: characters Examples 5\npattern) Name: Pattern Description: Regular expression this string must match. Required: No Examples \"^[a-zA-Z]+$\"\nobject) Type: object Properties values (map[string, reference[Display]]) Name: Values Description: Mapping where the left side of the map holds the possible value and the right side holds the display value for forms, etc. Required: Yes | Minimum items: | 1 |\nstring Value type Type: reference[Display] Referenced object: Display (see in the Objects section below) Examples {\n \"apple\": {\n \"name\": \"Apple\"\n },\n \"orange\": {\n \"name\": \"Orange\"\n }\n}\nobject) Type: object Properties name_long_plural (string) Name: Name long (plural) Description: Longer name for this UnitDefinition in plural form. Required: Yes Examples \"bytes\",\"characters\"\nstring) Name: Name long (singular) Description: Longer name for this UnitDefinition in singular form. Required: Yes Examples \"byte\",\"character\"\nstring) Name: Name short (plural) Description: Shorter name for this UnitDefinition in plural form. Required: Yes Examples \"B\",\"chars\"\nstring) Name: Name short (singular) Description: Shorter name for this UnitDefinition in singular form. Required: Yes Examples \"B\",\"char\"\nobject) Type: object Properties base_unit (reference[Unit]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: Yes Referenced object: Unit (see in the Objects section below) Examples {\n \"name_short_singular\": \"B\",\n \"name_short_plural\": \"B\",\n \"name_long_singular\": \"byte\",\n \"name_long_plural\": \"bytes\"\n}\nmap[int, reference[Unit]]) Name: Base UnitDefinition Description: The base UnitDefinition is the smallest UnitDefinition of scale for this set of UnitsDefinition. Required: No Key type Type: int Value type Type: reference[Unit] Referenced object: Unit (see in the Objects section below) Examples {\n \"1024\": {\n \"name_short_singular\": \"kB\",\n \"name_short_plural\": \"kB\",\n \"name_long_singular\": \"kilobyte\",\n \"name_long_plural\": \"kilobytes\"\n },\n \"1048576\": {\n \"name_short_singular\": \"MB\",\n \"name_short_plural\": \"MB\",\n \"name_long_singular\": \"megabyte\",\n \"name_long_plural\": \"megabytes\"\n }\n}\nArcaflow supports writing plugins in any language, and we provide pre-made libraries for Python and Go.
Plugins in Arcaflow run in containers, so you can use dependencies and libraries.
Writing plugins in PythonPython is the easiest language to start writing plugins in, you simply need to write a few dataclasses and a function and that\u2019s already a working plugin.
Read more about Python plugins \u00bb
Writing plugins in GoGo is the programming language of the engine. Writing plugins in Go is more complicated than Python because you will need to provide both the structs and the Arcaflow schema. We recommend Go for plugins that interact with Kubernetes.
Read more about Go plugins \u00bb
Packaging pluginsTo use plugins with Arcaflow, you will need to package them into a container image. You can, of course, write your own Dockerfile, but we provide a handy utility called Carpenter to automate the process.
Read more about packaging \u00bb
"},{"location":"arcaflow/plugins/packaging/","title":"Packaging Arcaflow plugins","text":"Arcaflow plugins are distributed using container images. Whatever programming language you are using, you will need to package it up into a container image and distribute it via a container registry.
"},{"location":"arcaflow/plugins/packaging/#the-manual-method","title":"The manual method","text":"Currently, we only support the manual method for non-Arcalot plugins. However, it\u2019s very simple. First, create a Dockerfile for your programming language:
PythonGoWith Python, the Dockerfile heavily depends on which build tool you are using. Here we are demonstrating the usage using pip.
FROM python:alpine\n\n# Add the plugin contents\nADD . /plugin\n# Set the working directory\nWORKDIR /plugin\n\n# Install the dependencies. Customize this\n# to your Python package manager.\nRUN pip install -r requirements.txt\n\n# Set this to your .py file\nENTRYPOINT [\"/usr/local/bin/python3\", /plugin/plugin.py\"]\n# Make sure this stays empty!\nCMD []\nFor Go plugins we recommend a multi-stage build so the source code doesn\u2019t unnecessarily bloat the image. (Keep in mind, for some libraries you will need to include at least a LICENSE and possibly a NOTICE file in the image.)
FROM golang AS build\n# Add the plugin contents\nADD . /plugin\n# Set the working directory\nWORKDIR /plugin\n# Build your image\nENV CGO_ENABLED=0\nRUN go build -o plugin\n\n# Start from an empty image\nFROM scratch\n# Copy the built binary\nCOPY --from=build /plugin/plugin /plugin\n# Set the entry point\nENTRYPOINT [\"/plugin\"]\n# Make sure this stays empty!\nCMD []\nThat\u2019s it! Now you can run your build:
docker build -t example.com/your-namespace/your-plugin:latest .\ndocker push example.com/your-namespace/your-plugin:latest\nIn contrast to Python, Go doesn\u2019t contain enough language elements to infer the types and validation from Go types. Therefore, in order to use Go you both need to create the data structures (e.g. struct) and write the schema by hand. Therefore, we recommend Python for writing plugins.
For writing Go plugins, you will need:
If you have these three, you can get started with your first plugin.
"},{"location":"arcaflow/plugins/go/first/","title":"Writing your first Go plugin","text":"In order to create a Go plugin, you will need to create a Go module project (go mod init) and install the Arcaflow SDK using go get go.flow.arcalot.io/pluginsdk.
Writing a Go plugin consists of the following 4 parts:
First, we define an input data model. This must be a struct.
type Input struct {\n Name string `json:\"name\"`\n}\nNote
The Arcaflow serialization does not use the built-in Go JSON marshaling, so any additional tags like omitempty, or yaml tags are ignored.
In addition to the struct above, we must also define a schema for the input data structure:
// We define a separate scope, so we can add sub-objects later.\nvar inputSchema = schema.NewScopeSchema(\n // Struct-mapped object schemas are object definitions that are mapped to a specific struct (Input)\n schema.NewStructMappedObjectSchema[Input](\n // ID for the object:\n \"input\",\n // Properties of the object:\n map[string]*schema.PropertySchema{\n \"name\": schema.NewPropertySchema(\n // Type properties:\n schema.NewStringSchema(nil, nil, nil),\n // Display metadata:\n schema.NewDisplayValue(\n schema.PointerTo(\"Name\"),\n schema.PointerTo(\"Name of the person to greet.\"),\n nil,\n ),\n // Required:\n true,\n // Required if:\n []string{},\n // Required if not:\n []string{},\n // Conflicts:\n []string{},\n // Default value, JSON encoded:\n nil,\n //Examples:\n nil,\n )\n },\n ),\n)\nThe output data model is similar to the input. First, we define our output struct:
type Output struct {\n Message string `json:\"message\"`\n}\nThen, we have to describe the schema for this output similar to the input:
var outputSchema = schema.NewScopeSchema(\n schema.NewStructMappedObjectSchema[Output](\n \"output\",\n map[string]*schema.PropertySchema{\n \"message\": schema.NewPropertySchema(\n schema.NewStringSchema(nil, nil, nil),\n schema.NewDisplayValue(\n schema.PointerTo(\"Message\"),\n schema.PointerTo(\"The resulting message.\"),\n nil,\n ),\n true,\n nil,\n nil,\n nil,\n nil,\n nil,\n )\n },\n ),\n)\nNow we can create a callable function. This function will always take one input and produce an output ID (e.g. \"success\") and an output data structure. This allows you to return one of multiple possible outputs.
func greet(input Input) (string, any) {\n return \"success\", Output{\n fmt.Sprintf(\"Hello, %s!\", input.Name), \n }\n}\nFinally, we can incorporate this function into a step schema:
var greetSchema = schema.NewCallableSchema(\n schema.NewCallableStep[Input](\n // ID of the function:\n \"greet\",\n // Add the input schema:\n inputSchema,\n map[string]*schema.StepOutputSchema{\n // Define possible outputs:\n \"success\": schema.NewStepOutputSchema(\n // Add the output schema:\n outputSchema,\n schema.NewDisplayValue(\n schema.PointerTo(\"Success\"),\n schema.PointerTo(\"Successfully created message.\"),\n nil,\n ),\n false,\n ),\n },\n // Metadata for the function:\n schema.NewDisplayValue(\n schema.PointerTo(\"Greet\"),\n schema.PointerTo(\"Greets the user.\"),\n nil,\n ),\n // Reference the function\n greet,\n )\n)\nFinally, we need to create our main function to run the plugin:
package main\n\nimport (\n \"go.flow.arcalot.io/pluginsdk/plugin\"\n)\n\nfunc main() {\n plugin.Run(greetSchema)\n}\nGo plugins currently cannot run as CLI tools, so you will have to use this plugin in conjunction with the Arcaflow Engine. However, you can dump the schema by running:
go run yourplugin.go --schema\nOnce you are finished with your first plugin, you should read the section about writing a schema.
"},{"location":"arcaflow/plugins/go/schema/","title":"Writing a schema in Go","text":"In contrast to Python, the Go SDK does not have the ability to infer the schema from the code of a plugin. The Go language does not have enough information to provide enough information.
Therefore, schemas in Go need to be written by hand. This document will explain the details and intricacies of writing a Go schema by hand.
"},{"location":"arcaflow/plugins/go/schema/#typed-vs-untyped-serialization","title":"Typed vs. untyped serialization","text":"Since Go is a strongly and statically typed language, there are two ways to serialize and unserialize a type.
The untyped serialization functions (Serialize, Unserialize) always result in an any type (interface{} for pre-1.18 code) and you will have to perform a type assertion to get the type you can actually work with.
The typed serialization functions (SerializeType, UnserializeType) result in a specific type, but cannot be used in lists, maps, etc. due to the lack of language features, such as covariance.
In practice, you will always use untyped functions when writing a plugin, typed functions are only useful for writing Arcaflow Engine code.
"},{"location":"arcaflow/plugins/go/schema/#strings","title":"Strings","text":"You can define a string by calling schema.NewStringSchema(). It has 3 parameters:
*int64)*int64)*regexp.Regexp)It will result in a *StringSchema, which also complies with the schema.String interface. It unserializes from a string, integer, float to a string and serializes back to a string.
Tip
You can easily convert a value to a pointer by using the schema.PointerTo() function.
You can define a regular expression pattern by calling schema.NewPatternSchema(). It has no parameters and will result in a *PatternSchema, which also complies with the schema.Pattern interface. It unserializes from a string to a *regexp.Regexp and serializes back to a string.
Integers in Are always 64-bit signed integers. You can define an integer type with the schema.NewIntSchema() function. It takes the following parameters:
*int64)*int64)*UnitsDefinition, see Units)When unserializing from a string, or another int or float type, the SDK will attempt to parse it as an integer. When serializing, the integer type will always be serialized as an integer.
"},{"location":"arcaflow/plugins/go/schema/#floating-point-numbers","title":"Floating point numbers","text":"Floating point numbers are always stored as 64-bit floating point numbers. You can define a float type with the schema.NewFloatSchema() function. It takes the following parameters:
*float64)*float64)*UnitsDefinition, see Units)When unserializing from a string, or another int or float type, the SDK will attempt to parse it as a float. When serializing, the float type will always be serialized as a float.
"},{"location":"arcaflow/plugins/go/schema/#booleans","title":"Booleans","text":"You can define a boolean by calling schema.NewBoolSchema(). It has no parameters and will result in a *BoolSchema, which also complies with the schema.Bool interface.
It converts both integers and strings to boolean if possible. The following values are accepted as true or false, respectively:
1yesyontrueenableenabled0nonofffalsedisabledisabledBoolean types will always serialize to bool.
Go doesn\u2019t have any built-in enums, so Arcaflow supports int64 and string-based enums. You can define an int enum by calling the schema.NewIntEnumSchema() function. It takes the following parameters:
map[int64]*DisplayValue of values. The keys are the valid values in the enum. The values are display values, which can also be nil if no special display properties are desired.*UnitsDefinition, see Units)Strings can be defined by using the schema.NewStringEnumSchema() function, which only takes the first parameter with string keys.
Both functions return a *EnumSchema[string|int64], which also complies with the Enum[string|int64] interface.
Lists come in two variants: typed and untyped. (See Typed vs. Untyped.) You can create an untyped list by calling schema.NewListSchema() and a typed list by calling schema.NewTypedListSchema(). Both have the following parameters:
*int64)*int64)The result is a *ListSchema for untyped lists, and a *TypedListSchema for typed lists, which also satisfy their corresponding interfaces.
Maps, like lists, come in two variants: typed and untyped. (See Typed vs. Untyped.) You can create an untyped map by calling schema.NewMapSchema() and a typed map by calling schema.NewTypedMapSchema(). They both have the following parameters:
string, int, or an enum thereof.*int64)*int64)The functions return a *schema.MapSchema and *schema.TypedMapSchema, respectively, which satisfy their corresponding interfaces.
Objects come in not two, but three variants: untyped, struct-mapped, and typed. (See Typed vs. Untyped.) Untyped objects unserialize to a map[string]any, whereas struct-mapped objects are bound to a struct, but behave like untyped objects. Typed objects are bound to a struct and are typed. In plugins, you will always want to use struct-mapped object schemas.
You can create objects with the following functions:
schema.NewObjectSchema for untyped objects.schema.NewStructMappedObjectSchema for struct-mapped objects.schema.NewTypedObject for typed objects.They all have two parameters:
Properties of objects are always untyped. You can create a property by calling schema.NewPropertySchema() and it has the following parameters:
bool)[]string)[]string)[]string)*string)[]string)Sometimes, objects need to have circular references to each other. That\u2019s where scopes help. Scopes behave like objects, but act as a container for Refs. They contain a root object and additional objects that can be referenced by ID.
You can create a scope by calling schema.NewScopeSchema(). It takes the following parameters:
Warning
When using scopes, you must call ApplyScope on the outermost scope once you have constructed your type tree, otherwise references won\u2019t work.
Refs are references to objects in the current scope. You can create a ref by calling schema.NewRefSchema(). It takes two parameters:
Sometimes, a field must be able to hold more than one type of item. That\u2019s where one-of types come into play. They behave like objects, but have a special field called the discriminator which differentiates between the different possible types. This discriminator field can either be an integer or a string.
You can use schema.NewOneOfIntSchema() to create an integer-based one-of type and schema.NewOneOfStringSchema() to create a string-based one. They both accept two parameters:
map[int64|string]Object, which holds the discriminator values and their corresponding objects (these can be refs or scopes too).string holding the name of the discriminator field.The objects in the map are allowed to skip the discriminator field, but if they use it, it must have the same type as listed here.
"},{"location":"arcaflow/plugins/go/schema/#any","title":"Any","text":"The \u201cany\u201d type allows any primitive type to pass through. However, this comes with severe limitations and the data cannot be validated, so its use is discouraged. You can create an AnySchema by calling schema.NewAnySchema(). This function has no parameters.
Several types, for example properties, accept a display value. This is a value designed to be rendered as a form field. It has three parameters:
Display types are always optional (can be nil) and you can create one by calling schema.NewDisplayValue()
Units make it easier to parse and display numeric values. For example, if you have an integer representing nanoseconds, you may want to parse strings like 5m30s. This is similar to the duration type in Go, but with the capabilities of defining your own units.
Units have two parameters: the base type and multipliers. You can define a unit type by calling schema.NewUnits() and provide the base unit and multipliers by calling schema.NewUnit().
var u = schema.NewUnits(\n // Base unit:\n NewUnit(\n // Short name, singular\n \"B\",\n // Short name, plural\n \"B\",\n // Long name, singular\n \"byte\",\n // Long name, plural\n \"bytes\",\n ),\n // Multipliers\n map[int64]*UnitDefinition{\n 1024: NewUnit(\n \"kB\",\n \"kB\",\n \"kilobyte\",\n \"kilobytes\",\n ),\n //...\n },\n)\nYou can use the built-in schema.UnitBytes, schema.UnitDurationNanoseconds, and schema.UnitDurationSeconds units for your plugins.
If you want to create an Arcaflow plugin in Python, you will need three things:
If you have these three, you can get started with your first plugin.
"},{"location":"arcaflow/plugins/python/data-model/","title":"Creating a Python data model","text":"Every plugin needs a schema to represent its expected inputs and outputs in a machine-readable format. The schema strong typing is a core design element of Arcaflow, enabling us to build portable workflows that compartmentalize failure conditions and avoid data errors.
When creating a data model for Arcaflow plugins in Python, everything starts with dataclasses. They allow Arcaflow to get information about the data types of individual fields in your class:
plugin.pyimport dataclasses\n\n\n@dataclasses.dataclass\nclass MyDataModel:\n some_field: str\n other_field: int\nHowever, Arcaflow doesn\u2019t support all Python data types. You pick from the following list:
strintfloatboolre.Patterntyping.List[othertype]typing.Dict[keytype, valuetype]typing.Union[onedataclass, anotherdataclass]typing.AnyYou can read more about the individual types in the data types section
"},{"location":"arcaflow/plugins/python/data-model/#optional-parameters","title":"Optional parameters","text":"You can also declare any parameter as optional, like this:
plugin.py@dataclasses.dataclass\nclass MyClass:\n param: typing.Optional[int] = None\nNote that adding typing.Optional is not enough, you must specify the default value.
You can specify desired validations for each field like this:
plugin.py@dataclasses.dataclass\nclass MyClass:\n param: typing.Annotated[int, schema.name(\"Param\")]\nTip
Annotated objects are preferred as a best practice for a documented schema, and are expected for any officially-supported community plugins.
You can use the following annotations to add metadata to your fields:
schema.id adds a serialized field name for the current field (e.g. one containing dashes, which is not valid in Python)schema.name adds a human-readable name to the parameter. This can be used to present a form field.schema.description adds a long-form description to the field.schema.example adds an example value to the field. You can repeat this annotation multiple times. The example must be provided as primitive types (no dataclasses).You can also add validations to the fields. The following annotations are valid for all data types:
schema.required_if specifies a field that causes the current field to be required. If the other field is empty, the current field is not required. You can repeat this annotation multiple times. (Make sure to use the optional annotation above.)schema.required_if_not specifies a field that, if not filled, causes the current field to be required. You can repeat this annotation multiple times.(Make sure to use the optional annotation above.)schema.conflicts specifies a field that cannot be used together with the current field. You can repeat this annotation multiple times. (Make sure to use the optional annotation above.)Additionally, some data types have their own validations and metadata, such as schema.min, schema.max, schema.pattern, or schema.units.
Note
When combining typing.Annotated with typing.Optional, the default value is assigned to the Annotated object, not to the Optional object.
@dataclasses.dataclass\nclass MyClass:\n param: typing.Annotated[\n typing.Optional[int],\n schema.name(\"Param\")\n ] = None\nStrings are, as the name suggests, strings of human-readable characters. You can specify them in your dataclass like this:
some_field: str\nAdditionally, you can apply the following validations:
schema.min() specifies the minimum length of the string if the field is set.schema.max() specifies the maximum length of the string if the field is set.schema.pattern() specifies the regular expression the string must match if the field is set.Integers are 64-bit signed whole numbers. You can specify them in your dataclass like this:
some_field: int\nAdditionally, you can apply the following validations and metadata:
schema.min() specifies the minimum number if the field is set.schema.max() specifies the maximum number if the field is set.schema.units() specifies the units for this field (e.g. bytes). See Units.Floating point numbers are 64-bit signed fractions. You can specify them in your dataclass like this:
some_field: float\nWarning
Floating point numbers are inaccurate! Make sure to transmit numbers requiring accuracy as integers!
Additionally, you can apply the following validations and metadata:
schema.min() specifies the minimum number if the field is set.schema.max() specifies the maximum number if the field is set.schema.units() specifies the units for this field (e.g. bytes). See Units.Booleans are True or False values. You can specify them in your dataclass like this:
some_field: bool\nBooleans have no additional validations or metadata.
"},{"location":"arcaflow/plugins/python/data-model/#enums","title":"Enums","text":"Enums, short for enumerations, are used to define a set of named values as unique constants. They provide a way to represent a fixed number of possible values for a variable, parameter, or property. In Python, an enum is declared as a class, but doesn\u2019t behave as a normal class. Instead, the \u201cattributes\u201d of the class act as independent \u201cmember\u201d or \u201cenumeration member\u201d objects, each of which has a name and a constant value.
By using enums, you can give meaningful names to distinct values, making the code more self-explanatory and providing a convenient way to work with sets of related constants.
In an Arcaflow schema, an Enum type provides a list of valid values for a field. The Enum must define a set of members with unique values, all of which are either strings or integers.
You can specify an enum with string values like this:
import enum\n\n\nclass MyEnum(enum.Enum):\n Value1 = \"value 1\"\n Value2 = \"value 2\"\n\nmy_field: MyEnum\nmy_field of MyEnum.Value1. You can specify an Enum class with integer values like this:
import enum\n\nclass MyEnum(enum.Enum):\n Value1 = 1\n Value2 = 2\n\nmy_field: MyEnum\nThe my_field variable is a variable of type MyEnum. It can store one of the defined enumeration members (Value1 or Value2). An input value of 1 in this case will result in the plugin receiving a value for my_field of MyEnum.Value1.
value = MyEnum.Value1\nNote
Enumeration members are \u201csingleton\u201d objects which have a single instance. In Python, you should compare enumeration members using is rather than == (for example, variable is MyEnum.Value1). The values of an Enum used in an Arcaflow schema must have values of string or integer data type.
Tip
Enums aren\u2019t dataclasses, but can be used as the type of dataclass attributes.
Warning
Do not mix integers and strings in the same enum! The values for each Enum type must all be strings, or all integers.
"},{"location":"arcaflow/plugins/python/data-model/#patterns","title":"Patterns","text":"When you need to hold regular expressions, you can use a pattern field. This is tied to the Python regular expressions library. You can specify a pattern field like this:
import re\n\nmy_field: re.Pattern\nPattern fields have no additional validations or metadata.
Note
If you are looking for a way to do pattern/regex matching for a string you will need to use the schema.pattern() validation which specifies the regular expression, to which the string must match.
The below example declares that the first_name variable must only have uppercase and lowercase alphabets.
plugin.py@dataclasses.dataclass\nclass MyClass:\n first_name: typing.Annotated[\n str,\n schema.min(2),\n schema.pattern(re.compile(\"^[a-zA-Z]+$\")),\n schema.example(\"Arca\"),\n schema.name(\"First name\")\n ]\nWhen you want to make a list in Arcaflow, you always need to specify its contents. You can do that like this:
my_field: typing.List[str]\nLists can have the following validations:
schema.min() specifies the minimum number of items in the list.schema.max() specifies the maximum number of items in the list.Tip
Items in lists can also be annotated with validations.
"},{"location":"arcaflow/plugins/python/data-model/#dicts","title":"Dicts","text":"Dicts (maps in Arcaflow) are key-value pairs. You need to specify both the key and the value type. You can do that as follows:
my_field: typing.Dict[str, str]\nLists can have the following validations:
schema.min() specifies the minimum number of items in the list.schema.max() specifies the maximum number of items in the list.Tip
Items in dicts can also be annotated with validations.
"},{"location":"arcaflow/plugins/python/data-model/#union-types","title":"Union types","text":"Union types (one-of in Arcaflow) allow you to specify two or more possible objects (dataclasses) that can be in a specific place. The only requirement is that there must be a common field (discriminator) and each dataclass must have a unique value for this field. If you do not add this field to your dataclasses, it will be added automatically for you.
For example:
import typing\nimport dataclasses\n\n\n@dataclasses.dataclass\nclass FullName:\n first_name: str\n last_name: str\n\n\n@dataclasses.dataclass\nclass Nickname:\n nickname: str\n\n\nname: typing.Annotated[\n typing.Union[\n typing.Annotated[FullName, schema.discriminator_value(\"full\")],\n typing.Annotated[Nickname, schema.discriminator_value(\"nick\")]\n ], schema.discriminator(\"name_type\")]\nTip
The schema.discriminator and schema.discriminator_value annotations are optional. If you do not specify them, a discriminator will be generated for you.
Any types allow you to pass through any primitive data (no dataclasses). However, this comes with severe limitations as far as validation and use in workflows is concerned, so this type should only be used in limited cases. For example, if you would like to create a plugin that inserts data into an ElasticSearch database the \u201cany\u201d type would be appropriate here.
You can define an \u201cany\u201d type like this:
my_data: typing.Any\nIntegers and floats can have unit metadata associated with them. For example, a field may contain a unit description like this:
time: typing.Annotated[int, schema.units(schema.UNIT_TIME)]\nIn this case, a string like 5m30s will automatically be parsed into nanoseconds. Integers will pass through without conversion. You can also define your own unit types. At minimum, you need to specify the base type (nanoseconds in this case), and you can specify multipliers:
my_units = schema.Units(\n schema.Unit(\n # Short, singular\n \"ns\",\n # Short, plural\n \"ns\",\n # Long, singular\n \"nanosecond\",\n # Long, plural\n \"nanoseconds\"\n ),\n {\n 1000: schema.Unit(\n \"ms\",\n \"ms\",\n \"microsecond\",\n \"microseconds\"\n ),\n # ...\n }\n)\nYou can then use this description in your schema.units annotations. Additionally, you can also use it to convert an integer or float into its string representation with the my_units.format_short or my_units.format_long functions. If you need to parse a string yourself, you can use my_units.parse.
A number of unit types are built-in to the python SDK for convenience:
UNIT_BYTE - Bytes and 2^10 multiples (kilo-, mega-, giga-, tera-, peta-)UNIT_TIME - Nanoseconds and human-friendly multiples (microseconds, seconds, minutes, hours, days)UNIT_CHARACTER - Character notations (char, chars, character, characters)UNIT_PERCENT - Percentage notations (%, percent)Instead of using your plugin as a standalone tool or in conjunction with Arcaflow, you can also embed your plugin into your existing Python application. To do that you simply build a schema and then call the schema yourself. You can pass raw data as an input, and you\u2019ll get the benefit of schema validation.
myapp.pyfrom arcaflow_plugin_sdk import plugin\nimport my_arcaflow_plugin\n\n# Build your schema with the step functions passed\nschema = plugin.build_schema(my_arcaflow_plugin.hello_world)\n\n# Which step from the plugin we want to execute\nstep_id = \"hello_world\"\n\n# Input parameters. Note, these must be a dict, not a dataclass\nstep_params = {\n \"name\": \"Arca Lot\",\n}\n\n# Execute the step\noutput_id, output_data = schema(step_id, step_params)\n\n# Print which kind of result we have\npprint.pprint(output_id)\n\n# Print the result data\npprint.pprint(output_data)\nHowever, the example above requires you to provide the data as a dict, not a dataclass, and it will also return a dict as an output object. Sometimes, you may want to use a partial approach, where you only use part of the SDK. In this case, you can change your code to run any of the following functions, in order:
serialization.load_from_file() to load a YAML or JSON file into a dictyourschema.unserialize_input() to turn a dict into a dataclass needed for your stepsyourschema.call_step() to run a step with the unserialized dataclassyourschema.serialize_output() to turn the output dataclass into a dictmy-field?","text":"Dataclasses don\u2019t support dashes in parameters. You can work around this by defining the id annotation:
@dataclasses.dataclass\nclass MyData:\n my_field: typing.Annotated[\n str,\n schema.id(\"my-field\"),\n ]\nYou can extend Python\u2019s JSON encoder to support dataclasses. If that doesn\u2019t suit your needs, you can use this SDK to convert the dataclasses to their basic representations and then write that to your JSON or YAML file. First, add this outside of your step:
my_object_schema = plugin.build_object_schema(MyDataclass)\nInside your step function you can then dump the data from your input
def my_step(params: MyParams):\n yaml_contents = yaml.dump(my_object_schema.serialize(params.some_param))\nThis requires a bit of trickery. First, we build a schema from the dataclass representing the row or entry in the list:
my_row_schema = plugin.build_object_schema(MyRow)\nThen you can create a list schema:
my_list_schema = schema.ListType(my_row_schema)\nYou can now unserialize a list obtained from the YAML or JSON file:
my_data = my_list_schema.unserialize(json.loads(...))\nIn this guide you will learn how to write a basic \u201cHello World\u201d plugin for Arcaflow and then run it without the engine as a standalone tool. In order to proceed this tutorial, you will need to install Python version 3.9 or higher on your machine. The tutorial will make use of the Arcaflow Python SDK to provide the required functionality.
"},{"location":"arcaflow/plugins/python/first/#step-1-setting-up-your-environment","title":"Step 1: Setting up your environment","text":"If you have Python installed, you will need to set up your environment. You can use any dependency manager you like, but here are three methods to get you started quickly.
Official plugins
If you wish to contribute an official Arcaflow plugin on GitHub, please use Poetry. For simplicity, we only accept Poetry plugins.
From the template repositoryUsing pipUsing Poetrypython3.10 --version\npython3.9 --version\npython3 --version\npython --version\npython -m venv venv\nsource venv/bin/activate\npip install -r requirements.txt\nrequirements.txt with the following content: arcaflow-plugin-sdk\npython3.10 --version\npython3.9 --version\npython3 --version\npython --version\npython -m venv venv\nsource venv/bin/activate\npip install -r requirements.txt\npoetry new your-plugin\nyour-plugin.which python3.10\nwhich python3.9\nwhich python3\nwhich python\npoetry env use /path/to/your/python3.9\npyproject.toml file has the following lines: [tool.poetry.dependencies]\npython = \"^3.9\"\npoetry add arcaflow-plugin-sdk\npoetry shell\nNow you are ready to start hacking away at your plugin! You can open the example_plugin.py file and follow along, or you can create a new Python file and write the code.
Plugins in Arcaflow must explain how they want their input data and what kind of output they produce. Let\u2019s start with the input data model. In our case, we want to ask the user for a name. Normally, you would write this in Python:
plugin.pydef hello_world(name):\n return f\"Hello, {name}\"\nHowever, that\u2019s not how the Arcaflow SDK works. You must always specify the data type of any variable. Additionally, every function can only have one input, and it must be a dataclass.
So, let\u2019s change the code a little:
plugin.pyimport dataclasses\n\n\n@dataclasses.dataclass\nclass InputParams:\n name: str\n\ndef hello_world(params: InputParams):\n # ...\nSo far so good, but we are not done yet. The output also has special rules. One plugin function can have more than one possible output, so you need to say which output it is, and you need to also return a dataclass.
For example:
plugin.pyimport dataclasses\n\n\n@dataclasses.dataclass\nclass InputParams:\n name: str\n\n\n@dataclasses.dataclass\nclass SuccessOutput:\n message: str\n\n\ndef hello_world(params: InputParams):\n return \"success\", SuccessOutput(f\"Hello, {params.name}\")\nTip
If your plugin has a problem, you could create and return an ErrorOutput instead. In the Arcaflow workflow you can then handle each output separately.
Of course, Arcaflow doesn\u2019t know what to do with this code yet. You will need to add a decorator to the hello_world function in order to give Arcaflow the necessary information:
from arcaflow_plugin_sdk import plugin\n\n\n@plugin.step(\n id=\"hello-world\",\n name=\"Hello world!\",\n description=\"Says hello :)\",\n outputs={\"success\": SuccessOutput},\n)\ndef hello_world(params: InputParams):\n # ...\nLet\u2019s go through the parameters:
id provides the step identifier. If your plugin provides more than one step function, you need to specify this in your workflow.name provides the human-readable name of the plugin step. This will help render a user interface for the workflow.description is a longer description for the function and may contain line breaks.outputs specifies the possible outputs and the dataclasses associated with these outputs. This is important so Arcaflow knows what to expect.Tip
If you want, you can specify the function return type like this, but Arcaflow won\u2019t use it:
def hello_world(params: InputParams) -> typing.Tuple[str, ...]:\nThere is one more piece missing to run a plugin: the calling code. Add the following to your file:
plugin.pyimport sys\nfrom arcaflow_plugin_sdk import plugin\n\n\nif __name__ == \"__main__\":\n sys.exit(\n plugin.run(\n plugin.build_schema(\n # List your step functions here:\n hello_world,\n )\n )\n )\nNow your plugin is ready. You can package it up for a workflow, or you can run it as a standalone tool from the command line:
python example_plugin.py -f input-data.yaml\nYou will need to provide the input data in YAML format:
input-data.yamlname: Arca Lot\nTip
If your plugin provides more than one step function, you can specify the correct one to use with the -s parameter.
Tip
To prevent output from breaking the functionality when attached to the Arcaflow Engine, the SDK hides any output your step function writes to the standard output or standard error. You can use the --debug flag to show any output on the standard error in standalone mode.
Tip
You can generate a JSON schema file for your step input by running
python example_plugin.py --json-schema input >example.schema.json\nIf you are using the YAML plugin for VSCode, add the following line to the top of your input file for code completion:
# yaml-language-server: $schema=example.schema.json\nIn order to create an actually useful plugin, you will want to create a data model for your plugin. Once the data model is complete, you should look into packaging your plugin.
"},{"location":"arcaflow/plugins/python/official/","title":"Creating official Arcaflow plugins","text":"Official Arcaflow plugins have more stringent requirements than normal. This document describes how to create a plugin that conforms to those requirements.
"},{"location":"arcaflow/plugins/python/official/#development-environment","title":"Development environment","text":"Official Python plugins are standardized on Poetry and a Linux-based development environment.
"},{"location":"arcaflow/plugins/python/official/#installing-poetry","title":"Installing Poetry","text":"First, please ensure your python3 executable is at least version 3.9.
$ python3 --version\nPython 3.9.15\n$ dnf -y install python3.9\n$ apt-get -y install python3.9\nTip
If the python3 command doesn\u2019t work for you, but python3.9 does, you can alias the command:
$ alias python3=\"python3.9\"\nInstall Poetry using one of their supported methods for your environment.
Warning
Make sure to install Poetry into exactly one Python executable on your system. If something goes wrong with your package\u2019s Python virtual environment, you do not want to also spend time figuring out which Poetry executable is responsible for it.
Now, verify your Poetry version.
$ poetry --version\nPoetry (version 1.2.2)\nCreate your plugin project, plugin-project, and change directory into the project root. You should see a directory structure similar to this with the following files.
$ poetry new plugin-project\nCreated package plugin_project in plugin-project\n\n$ tree plugin-project\nplugin-project\n\u251c\u2500\u2500 plugin_project\n\u2502\u00a0\u00a0 \u2514\u2500\u2500 __init__.py\n\u251c\u2500\u2500 pyproject.toml\n\u251c\u2500\u2500 README.md\n\u2514\u2500\u2500 tests\n \u2514\u2500\u2500 __init__.py\n\n2 directories, 4 files\n\n$ cd plugin-project\nEnsure python3 is at least 3.9.
$ python3 --version\nPython 3.9.15\nSet Poetry to use your Python that is at least 3.9.
$ poetry env use $(which python3)\nCheck that your pyproject.toml is using at least Python 3.9 by looking for the following line.
[tool.poetry.dependencies]\npython = \"^3.9\"\nAdd the arcaflow plugin sdk for python as a software dependency for your Python project.
$ poetry add arcaflow-plugin-sdk-python\nYou should now have a poetry.lock file in your project root. Poetry maintains the state of your pyproject.toml, and its exact software dependencies as hashes in the poetry.lock file.
To build an official plugin container image we use the carpenter workflow on GitHub Actions. This workflow calls the Arcaflow image builder to build the image and perform all validations necessary.
In order to successfully run the build, you should add the following files from the template repository:
DockerfileLICENSE.flake8Additionally, you need to add tests to your project, write a README.md, and make sure that the code directory matches your project name.
Some plugins work well as libraries too. You can publish Arcaflow plugins on PyPI.
To push an official package to PyPI, please contact an Arcalot chair to create an API token on PyPI and set up a CI environment. For testing purposes you can use TestPyPI.
You can configure Poetry to use this API token by calling:
$ poetry config pypi-token.<any name> <PYPI API TOKEN>\nAlternatively, you can also use environment variables:
$ export POETRY_PYPI_TOKEN_PYPI=my-token\n$ export POETRY_HTTP_BASIC_PYPI_USERNAME=<username>\n$ export POETRY_HTTP_BASIC_PYPI_PASSWORD=<password>\nYou can generate distribution archives by typing:
$ poetry build\nYou can then test publishing:
$ poetry publish --dry-run\n\nPublishing arcaflow-plugin-template-python (0.1.0) to PyPI\n- Uploading arcaflow_plugin_template_python-0.1.0-py3-none-any.whl 100%\n- Uploading arcaflow_plugin_template_python-0.1.0.tar.gz 100%\nRemove the --dry-run to actually publish or call poetry publish --build to run it in one go.
If you want to skip the automatic schema generation described in previous chapters, you can also create a schema by hand.
Warning
This process is complicated, requires providing redundant information and should be avoided if at all possible. We recommend creating a data model using dataclasses, decorators and annotations.
We start by defining a schema:
from arcaflow_plugin_sdk import schema\nfrom typing import Dict\n\nsteps: Dict[str, schema.StepSchema]\n\ns = schema.Schema(\n steps,\n)\nThe steps parameter here must be a dict, where the key is the step ID and the value is the step schema. So, let\u2019s create a step schema:
from arcaflow_plugin_sdk import schema\n\nstep_schema = schema.StepSchema(\n id = \"pod\",\n name = \"Pod scenario\",\n description = \"Kills pods\",\n input = input_schema,\n outputs = outputs,\n handler = my_handler_func\n)\nLet\u2019s go in order:
input must be a schema of the type schema.ObjectType. This describes the single parameter that will be passed to my_handler_func.outputs describe a Dict[str, schema.ObjectType], where the key is the ID for the returned output type, while the value describes the output schema.handler function takes one parameter, the object described in input and must return a tuple of a string and the output object. Here the ID uniquely identifies which output is intended, for example success and error, while the second parameter in the tuple must match the outputs declaration.That\u2019s it! Now all that\u2019s left is to define the ObjectType and any sub-objects.
The ObjectType is intended as a backing type for dataclasses. For example:
t = schema.ObjectType(\n TestClass,\n {\n \"a\": schema.Field(\n type=schema.StringType(),\n required=True,\n ),\n \"b\": schema.Field(\n type=schema.IntType(),\n required=True,\n )\n }\n)\nThe fields support the following parameters:
type: underlying type schema for the field (required)name: name for the current fielddescription: description for the current fieldrequired: marks the field as requiredrequired_if: a list of other fields that, if filled, will also cause the current field to be requiredrequired_if_not: a list of other fields that, if not set, will cause the current field to be requiredconflicts: a list of other fields that cannot be set together with the current fieldSometimes it is necessary to create circular references. This is where the ScopeType and the RefType comes into play. Scopes contain a list of objects that can be referenced by their ID, but one object is special: the root object of the scope. The RefType, on the other hand, is there to reference objects in a scope.
Currently, the Python implementation passes the scope to the ref type directly, but the important rule is that ref types always reference their nearest scope up the tree. Do not create references that aim at scopes not directly above the ref!
For example:
@dataclasses.dataclass\nclass OneOfData1:\n a: str\n\n@dataclasses.dataclass\nclass OneOfData2:\n b: OneOfData1\n\nscope = schema.ScopeType(\n {\n \"OneOfData1\": schema.ObjectType(\n OneOfData1,\n {\n \"a\": schema.Field(\n schema.StringType()\n )\n }\n ),\n },\n # Root object of scopes\n \"OneOfData2\",\n)\n\nscope.objects[\"OneOfData2\"] = schema.ObjectType(\n OneOfData2,\n {\n \"b\": schema.Field(\n schema.RefType(\"OneOfData1\", scope)\n )\n }\n)\nAs you can see, this API is not easy to use and is likely to change in the future.
"},{"location":"arcaflow/plugins/python/schema/#oneoftype","title":"OneOfType","text":"The OneOfType allows you to create a type that is a combination of other ObjectTypes. When a value is deserialized, a special discriminator field is consulted to figure out which type is actually being sent.
This discriminator field may be present in the underlying type. If it is, the type must match the declaration in the AnyOfType.
For example:
@dataclasses.dataclass\nclass OneOfData1:\n type: str\n a: str\n\n@dataclasses.dataclass\nclass OneOfData2:\n b: int\n\nscope = schema.ScopeType(\n {\n \"OneOfData1\": schema.ObjectType(\n OneOfData1,\n {\n # Here the discriminator field is also present in the underlying type\n \"type\": schema.Field(\n schema.StringType(),\n ),\n \"a\": schema.Field(\n schema.StringType()\n )\n }\n ),\n \"OneOfData2\": schema.ObjectType(\n OneOfData2,\n {\n \"b\": schema.Field(\n schema.IntType()\n )\n }\n )\n },\n # Root object of scopes\n \"OneOfData1\",\n)\n\ns = schema.OneOfStringType(\n {\n # Option 1\n \"a\": schema.RefType(\n # The RefType resolves against the scope.\n \"OneOfData1\",\n scope\n ),\n # Option 2\n \"b\": schema.RefType(\n \"OneOfData2\",\n scope\n ),\n },\n # Pass the scope this type belongs do\n scope,\n # Discriminator field\n \"type\",\n)\n\nserialized_data = s.serialize(OneOfData1(\n \"a\",\n \"Hello world!\"\n))\npprint.pprint(serialized_data)\nNote, that the OneOfTypes take all object-like elements, such as refs, objects, or scopes.
"},{"location":"arcaflow/plugins/python/schema/#stringtype","title":"StringType","text":"String types indicate that the underlying type is a string.
t = schema.StringType()\nThe string type supports the following parameters:
min_length: minimum length for the string (inclusive)max_length: maximum length for the string (inclusive)pattern: regular expression the string must matchThe pattern type indicates that the field must contain a regular expression. It will be decoded as re.Pattern.
t = schema.PatternType()\nThe pattern type has no parameters.
"},{"location":"arcaflow/plugins/python/schema/#inttype","title":"IntType","text":"The int type indicates that the underlying type is an integer.
t = schema.IntType()\nThe int type supports the following parameters:
min: minimum value for the number (inclusive).max: minimum value for the number (inclusive).The float type indicates that the underlying type is a floating point number.
t = schema.FloatType()\nThe float type supports the following parameters:
min: minimum value for the number (inclusive).max: minimum value for the number (inclusive).The bool type indicates that the underlying value is a boolean. When unserializing, this type also supports string and integer values of true, yes, on, enable, enabled, 1, false, no, off, disable, disabled or 0.
The enum type creates a type from an existing enum:
class MyEnum(Enum):\n A = \"a\"\n B = \"b\"\n\nt = schema.EnumType(MyEnum)\nThe enum type has no further parameters.
"},{"location":"arcaflow/plugins/python/schema/#listtype","title":"ListType","text":"The list type describes a list of items. The item type must be described:
t = schema.ListType(\n schema.StringType()\n)\nThe list type supports the following extra parameters:
min: The minimum number of items in the list (inclusive)max: The maximum number of items in the list (inclusive)The map type describes a key-value type (dict). You must specify both the key and the value type:
t = schema.MapType(\n schema.StringType(),\n schema.StringType()\n)\nThe map type supports the following extra parameters:
min: The minimum number of items in the map (inclusive)max: The maximum number of items in the map (inclusive)The \u201cany\u201d type allows any primitive type to pass through. However, this comes with severe limitations and the data cannot be validated, so its use is discouraged. You can create an AnyType by simply doing this:
t = schema.AnyType()\nIf you create the schema by hand, you can add the following code to your plugin:
if __name__ == \"__main__\":\n sys.exit(plugin.run(your_schema))\nYou can then run your plugin as described in the writing your first plugin section.
"},{"location":"arcaflow/plugins/python/testing/","title":"Testing your Python plugin","text":"When writing your first plugin, you will probably want to test it manually. However, as development progresses, you should switch to automated testing. Automated testing makes sure your plugins don\u2019t break when you introduce changes.
This page describes the following test scenarios:
Manual testing is easy: prepare a test input file in YAML format, then run the plugin as a command line tool. For example, the hello world plugin would take this input:
name: Arca Lot\nYou could then run the example plugin:
python example_plugin -f my-input-file.yaml\nThe plugin will run and present you with the output.
Tip
If you have more than one step, don\u2019t forget to pass the -s step-id parameter.
Tip
To prevent output from breaking the functionality when attached to the Arcaflow Engine, the SDK hides any output your step function writes to the standard output or standard error. You can use the --debug flag to show any output on the standard error in standalone mode.
You can use any test framework you like for your serialization test, we\u2019ll demonstrate with unittest as it is included directly in Python. The key to this test is to call plugin.test_object_serialization() with an instance of your dataclass that you want to test:
class ExamplePluginTest(unittest.TestCase):\n def test_serialization(self):\n self.assertTrue(plugin.test_object_serialization(\n example_plugin.PodScenarioResults(\n [\n example_plugin.Pod(\n namespace=\"default\",\n name=\"nginx-asdf\"\n )\n ]\n )\n ))\nRemember, you need to call this function with an instance containing actual data, not just the class name.
The test function will first serialize, then unserialize your data and check if it\u2019s the same. If you want to use a manually created schema, you can do so, too:
class ExamplePluginTest(unittest.TestCase):\n def test_serialization(self):\n plugin.test_object_serialization(\n example_plugin.PodScenarioResults(\n #...\n ),\n schema.ObjectType(\n #...\n )\n )\nFunctional tests don\u2019t have anything special about them. You can directly call your code with your dataclasses as parameters, and check the return. This works best on auto-generated schemas with the @plugin.step decorator. See below for manually created schemas.
class ExamplePluginTest(unittest.TestCase):\n def test_functional(self):\n input = example_plugin.PodScenarioParams()\n\n output_id, output_data = example_plugin.pod_scenario(input)\n\n # Check if the output is always an error, as it is the case for the example plugin.\n self.assertEqual(\"error\", output_id)\n self.assertEqual(\n output_data,\n example_plugin.PodScenarioError(\n \"Cannot kill pod .* in namespace .*, function not implemented\"\n )\n )\nIf you created your schema manually, the best way to write your tests is to include the schema in your test. This will automatically validate both the input and the output, making sure they conform to your schema. For example:
class ExamplePluginTest(unittest.TestCase):\n def test_functional(self):\n step_schema = schema.StepSchema(\n #...\n handler = example_plugin.pod_scenario,\n )\n input = example_plugin.PodScenarioParams()\n\n output_id, output_data = step_schema(input)\n\n # Check if the output is always an error, as it is the case for the example plugin.\n self.assertEqual(\"error\", output_id)\n self.assertEqual(\n output_data,\n example_plugin.PodScenarioError(\n \"Cannot kill pod .* in namespace .*, function not implemented\"\n )\n )\nRunning Arcaflow is simple! You will need three things:
Please start by setting up Arcaflow.
"},{"location":"arcaflow/running/running/","title":"Running Arcaflow","text":"Before you proceed, you will need to perform the following steps:
/path/to/arcaflow -input path/to/input.yaml\nc:\\path\\to\\arcaflow.exe -input path/to/input.yaml\nYou can pass the following additional options to Arcaflow:
Option Description-config /path/to/config.yaml Set an Arcaflow configuration file. (See the configuration guide.) -context /path/to/workflow/dir Set a different workflow directory. (Defaults to the current directory.) -workflow workflow.yaml Set a different workflow file. (Defaults to workflow.yaml.)"},{"location":"arcaflow/running/running/#execution","title":"Execution","text":"Once you start Arcaflow, it will perform the following three phases:
Note
The loading phase only reads the plugin schemas; it does not run any of the functional steps of the plugins.
Tip
You can redirect the standard output to capture the output data and still read the log messages on the standard error.
"},{"location":"arcaflow/running/setup/","title":"Setting up Arcaflow","text":"In order to use Arcaflow, you will need to download the Arcaflow Engine. You can simply unpack and run it, no need for installing it.
On Linux and macOS, you may need to run chmod +x on the engine binary.
If you are using Docker as the local deployer (see below), you generally do not need to perform any extra configuration.
If you wish to customize Arcaflow, you can pass a YAML configuration file to Arcaflow with the -config your-arcaflow-config.yaml parameter.
The Arcaflow Engine needs a local container deployer to temporarily run plugins and read their schema. We recommend either Docker (default) or Podman for this purpose. You can use a Kubernetes cluster for this purpose too, but a local container engine is the better choice for performance reasons.
You can then change the deployer type like this:
config.yamldeployer:\n type: podman\n # Deployer-specific options \nDocker is the default local deployer. You can configure it like this:
config.yamldeployer:\n type: docker\n connection:\n # Change this to point to a TCP-based Docker socket\n host: host-to-docker \n # Add a certificates here. This is usually needed in TCP mode.\n cacert: |\n Add your CA cert PEM here\n cert: |\n Add your client cert PEM here.\n key: |\n Add your client key PEM here.\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n network:\n # Add your network config here\n platform:\n # Add your platform config here\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Connection (object) Type: object Properties cacert (string) Name: CA certificate Description: CA certificate in PEM format to verify the Dockerd server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name for Dockerd. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z0-9./:_-]+$ Default\"npipe:////./pipe/docker_engine\"\n'unix:///var/run/docker.sock'\n\u201d
'npipe:////./pipe/docker_engine'\nstring) Name: Client key Description: Client private key in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nobject) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (map[string, string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[A-Z0-9_]+$ Value type Type: string Maximum: 32760 Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nreference[NetworkConfig]) Name: Network configuration Description: Provides information about the container networking for the plugin. Required: No Referenced object: NetworkConfig (see in the Objects section below) platform (reference[PlatformConfig]) Name: Platform configuration Description: Provides information about the container host platform for the plugin. Required: No Referenced object: PlatformConfig (see in the Objects section below) HostConfig (object) Type: object Properties CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) NetworkConfig (object) Type: object Properties None
PlatformConfig (object) Type: object Properties None
PortBinding (object) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nIf you want to use Podman as your local deployer instead of Docker, you can do so like this:
config.yamldeployer:\n type: podman\n podman:\n # Change where Podman is. (You can use this to point to a shell script\n path: /path/to/your/podman\n # Change the network mode\n networkMode: host\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) Objects Config (object) Type: object Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) ContainerConfig (object) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (list[string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+=.+$ Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nobject) Type: object Properties Binds (list[string]) Name: Volume Bindings Description: Volumes Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+:.+$ CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) Podman (object) Type: object Properties cgroupNs (string) Name: CGroup namespace Description: Provides the Cgroup Namespace settings for the container Required: No Must match pattern: ^host|ns:/proc/\\d+/ns/cgroup|container:.+|private$ containerName (string) Name: Container Name Description: Provides name of the container Required: No Must match pattern: ^.*$ imageArchitecture (string) Name: Podman image Architecture Description: Provides Podman Image Architecture Required: No Must match pattern: ^.*$ Default\"amd64\"\nstring) Name: Podman Image OS Description: Provides Podman Image Operating System Required: No Must match pattern: ^.*$ Default\"linux\"\nstring) Name: Network Mode Description: Provides network settings for the container Required: No Must match pattern: ^bridge:.*|host|none$ path (string) Name: Podman path Description: Provides the path of podman executable Required: No Must match pattern: ^.*$ Default\"podman\"\nobject) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ Kubernetes can be used as the \u201clocal\u201d deployer, but this is typically not recommended for performance reasons. You can set up the Kubernetes deployer like this:
config.yamldeployer:\n type: kubernetes\n connection:\n host: localhost:6443\n cert: |\n Add your client cert in PEM format here.\n key: |\n Add your client key in PEM format here.\n cacert: |\n Add the server CA cert in PEM format here.\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects AWSElasticBlockStoreVolumeSource (object) Type: object Properties None
AzureDiskVolumeSource (object) Type: object Properties None
AzureFileVolumeSource (object) Type: object Properties None
CSIVolumeSource (object) Type: object Properties None
CephFSVolumeSource (object) Type: object Properties None
CinderVolumeSource (object) Type: object Properties None
Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) ConfigMapVolumeSource (object) Type: object Properties None
Connection (object) Type: object Properties bearerToken (string) Name: Bearer token Description: Bearer token to authenticate against the Kubernetes API with. Required: No burst (int) Name: Burst Description: Burst value for query throttling. Required: No Minimum: 0 Default10\nstring) Name: CA certificate Description: CA certificate in PEM format to verify Kubernetes server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name and port of the Kubernetes server Required: No Default\"kubernetes.default.svc\"\nstring) Name: Client key Description: Client private key in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nstring) Name: Password Description: Password for basic authentication. Required: No path (string) Name: Path Description: Path to the API server. Required: No Default\"/api\"\nfloat) Name: QPS Description: Queries Per Second allowed against the API. Required: No Minimum: 0 Units: queries Default5.0\nstring) Name: TLS server name Description: Expected TLS server name to verify in the certificate. Required: No username (string) Name: Username Description: Username for basic authentication. Required: No Container (object) Type: object Properties args (list[string]) Name: Arguments Description: Arguments to the entypoint (command). Required: No List Items Type: string command (list[string]) Name: Command Description: Override container entry point. Not executed with a shell. Required: No Minimum items: 1 List Items Type: string env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) image (string) Name: Image Description: Container image to use for this container. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9_\\-:./]+$ imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ securityContext (object) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 workingDir (string) Name: Working directory Description: Override the container working directory. Required: No DownwardAPIVolumeSource (object) Type: object Properties None
EmptyDirVolumeSource (object) Type: object Properties medium (string) Name: Medium Description: How to store the empty directory Required: No Minimum: 1 Must match pattern: ^(|Memory|HugePages|HugePages-.*)$ EnvFromSource (object) Type: object Properties configMapRef (object) Name: Config map source Description: Populates the source from a config map. Required: No Properties name (string) Name: Name Description: Name of the referenced config map. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the config map must be defined. Required: No prefix (string) Name: Prefix Description: An optional identifier to prepend to each key in the ConfigMap. Required: No Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ secretRef (object) Name: Secret source Description: Populates the source from a secret. Required: No Properties name (string) Name: Name Description: Name of the referenced secret. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the secret must be defined. Required: No EphemeralVolumeSource (object) Type: object Properties None
FCVolumeSource (object) Type: object Properties None
FlexVolumeSource (object) Type: object Properties None
FlockerVolumeSource (object) Type: object Properties None
GCEPersistentDiskVolumeSource (object) Type: object Properties None
GlusterfsVolumeSource (object) Type: object Properties None
HostPathVolumeSource (object) Type: object Properties path (string) Name: Path Description: Path to the directory on the host. Required: Yes Minimum: 1 Examples \"/srv/volume1\"\nenum[string]) Name: Type Description: Type of the host path. Required: No Values BlockDevice Block deviceCharDevice Character deviceDirectory DirectoryDirectoryOrCreate Create directory if not foundFile FileFileOrCreate Create file if not foundSocket Socketobject) Type: object Properties None
NFSVolumeSource (object) Type: object Properties None
ObjectMeta (object) Type: object Properties annotations (map[string, string]) Name: Annotations Description: Kubernetes annotations to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ generateName (string) Name: Name prefix Description: Name prefix to generate pod names from. Required: No labels (map[string, string]) Name: Labels Description: Kubernetes labels to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ name (string) Name: Name Description: Pod name. Required: No namespace (string) Name: Namespace Description: Kubernetes namespace to deploy in. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"default\"\nobject) Type: object Properties None
PhotonPersistentDiskVolumeSource (object) Type: object Properties None
Pod (object) Type: object Properties metadata (reference[ObjectMeta]) Name: Metadata Description: Pod metadata. Required: No Referenced object: ObjectMeta (see in the Objects section below) spec (reference[PodSpec]) Name: Specification Description: Pod specification. Required: No Referenced object: PodSpec (see in the Objects section below) PodSpec (object) Type: object Properties affinity (object) Name: Affinity rules Description: Affinity rules. Required: No Properties podAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ podAntiAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ containers (list[reference[Container]]) Name: Containers Description: A list of containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) initContainers (list[reference[Container]]) Name: Init containers Description: A list of initialization containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) nodeSelector (map[string, string]) Name: Labels Description: Node labels you want the target node to have. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ pluginContainer (object) Name: Plugin container Description: The container to run the plugin in. Required: Yes Properties env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"arcaflow-plugin-container\"\nobject) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 volumes (list[reference[Volume]]) Name: Volumes Description: A list of volumes that can be mounted by containers belonging to the pod. Required: No List Items Type: reference[Volume] Referenced object: Volume (see in the Objects section below) PortworxVolumeSource (object) Type: object Properties None
ProjectedVolumeSource (object) Type: object Properties None
QuobyteVolumeSource (object) Type: object Properties None
RBDVolumeSource (object) Type: object Properties None
ScaleIOVolumeSource (object) Type: object Properties None
SecretVolumeSource (object) Type: object Properties None
StorageOSVolumeSource (object) Type: object Properties None
Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nobject) Type: object Properties awsElasticBlockStore (reference[AWSElasticBlockStoreVolumeSource]) Name: AWS EBS Description: AWS Elastic Block Storage. Required: No Referenced object: AWSElasticBlockStoreVolumeSource (see in the Objects section below) azureDisk (reference[AzureDiskVolumeSource]) Name: Azure Data Disk Description: Mount an Azure Data Disk as a volume. Required: No Referenced object: AzureDiskVolumeSource (see in the Objects section below) azureFile (reference[AzureFileVolumeSource]) Name: Azure File Description: Mount an Azure File Service mount. Required: No Referenced object: AzureFileVolumeSource (see in the Objects section below) cephfs (reference[CephFSVolumeSource]) Name: CephFS Description: Mount a CephFS volume. Required: No Referenced object: CephFSVolumeSource (see in the Objects section below) cinder (reference[CinderVolumeSource]) Name: Cinder Description: Mount a cinder volume attached and mounted on the host machine. Required: No Referenced object: CinderVolumeSource (see in the Objects section below) configMap (reference[ConfigMapVolumeSource]) Name: ConfigMap Description: Mount a ConfigMap as a volume. Required: No Referenced object: ConfigMapVolumeSource (see in the Objects section below) csi (reference[CSIVolumeSource]) Name: CSI Volume Description: Mount a volume using a CSI driver. Required: No Referenced object: CSIVolumeSource (see in the Objects section below) downwardAPI (reference[DownwardAPIVolumeSource]) Name: Downward API Description: Specify a volume that the pod should mount itself. Required: No Referenced object: DownwardAPIVolumeSource (see in the Objects section below) emptyDir (reference[EmptyDirVolumeSource]) Name: Empty directory Description: Temporary empty directory. Required: No Referenced object: EmptyDirVolumeSource (see in the Objects section below) ephemeral (reference[EphemeralVolumeSource]) Name: Ephemeral Description: Mount a volume that is handled by a cluster storage driver. Required: No Referenced object: EphemeralVolumeSource (see in the Objects section below) fc (reference[FCVolumeSource]) Name: Fibre Channel Description: Mount a Fibre Channel volume that's attached to the host machine. Required: No Referenced object: FCVolumeSource (see in the Objects section below) flexVolume (reference[FlexVolumeSource]) Name: Flex Description: Mount a generic volume provisioned/attached using an exec based plugin. Required: No Referenced object: FlexVolumeSource (see in the Objects section below) flocker (reference[FlockerVolumeSource]) Name: Flocker Description: Mount a Flocker volume. Required: No Referenced object: FlockerVolumeSource (see in the Objects section below) gcePersistentDisk (reference[GCEPersistentDiskVolumeSource]) Name: GCE disk Description: Google Cloud disk. Required: No Referenced object: GCEPersistentDiskVolumeSource (see in the Objects section below) glusterfs (reference[GlusterfsVolumeSource]) Name: GlusterFS Description: Mount a Gluster volume. Required: No Referenced object: GlusterfsVolumeSource (see in the Objects section below) hostPath (reference[HostPathVolumeSource]) Name: Host path Description: Mount volume from the host. Required: No Referenced object: HostPathVolumeSource (see in the Objects section below) iscsi (reference[ISCSIVolumeSource]) Name: iSCSI Description: Mount an iSCSI volume. Required: No Referenced object: ISCSIVolumeSource (see in the Objects section below) name (string) Name: Name Description: The name this volume can be referenced by. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ nfs (reference[NFSVolumeSource]) Name: NFS Description: Mount an NFS share. Required: No Referenced object: NFSVolumeSource (see in the Objects section below) persistentVolumeClaim (reference[PersistentVolumeClaimVolumeSource]) Name: Persistent Volume Claim Description: Mount a Persistent Volume Claim. Required: No Referenced object: PersistentVolumeClaimVolumeSource (see in the Objects section below) photonPersistentDisk (reference[PhotonPersistentDiskVolumeSource]) Name: PhotonController persistent disk Description: Mount a PhotonController persistent disk as a volume. Required: No Referenced object: PhotonPersistentDiskVolumeSource (see in the Objects section below) portworxVolume (reference[PortworxVolumeSource]) Name: Portworx Volume Description: Mount a Portworx volume. Required: No Referenced object: PortworxVolumeSource (see in the Objects section below) projected (reference[ProjectedVolumeSource]) Name: Projected Description: Projected items for all in one resources secrets, configmaps, and downward API. Required: No Referenced object: ProjectedVolumeSource (see in the Objects section below) quobyte (reference[QuobyteVolumeSource]) Name: quobyte Description: Mount Quobyte volume from the host. Required: No Referenced object: QuobyteVolumeSource (see in the Objects section below) rbd (reference[RBDVolumeSource]) Name: Rados Block Device Description: Mount a Rados Block Device. Required: No Referenced object: RBDVolumeSource (see in the Objects section below) scaleIO (reference[ScaleIOVolumeSource]) Name: ScaleIO Persistent Volume Description: Mount a ScaleIO persistent volume. Required: No Referenced object: ScaleIOVolumeSource (see in the Objects section below) secret (reference[SecretVolumeSource]) Name: Secret Description: Mount a Kubernetes secret. Required: No Referenced object: SecretVolumeSource (see in the Objects section below) storageos (reference[StorageOSVolumeSource]) Name: StorageOS Volume Description: Mount a StorageOS volume. Required: No Referenced object: StorageOSVolumeSource (see in the Objects section below) vsphereVolume (reference[VsphereVirtualDiskVolumeSource]) Name: vSphere Virtual Disk Description: Mount a vSphere Virtual Disk as a volume. Required: No Referenced object: VsphereVirtualDiskVolumeSource (see in the Objects section below) VsphereVirtualDiskVolumeSource (object) Type: object Properties None
"},{"location":"arcaflow/running/setup/#logging","title":"Logging","text":"Logging is useful when you need more information about what is happening while you run a workload.
"},{"location":"arcaflow/running/setup/#basic-logging","title":"Basic logging","text":"Here is the syntax for setting the log level: config.yaml
log:\n level: info\nOptions for the level are:
debug: Extra verbosity useful to developersinfo: General infowarning: Something went wrong, and you should know about iterror: Something failed. This inf o should help you figure out whyThis sets which types of log output are shown or hidden. debug shows everything, while error shows the least, only showing error output. Each output shows more, rather than just its type, so debug, info, and warning still show error output.
Step logging is useful for getting output from failed steps, or general debugging. It is not recommended that you rely on this long term, as there may be better methods of debugging failed workflows.
To make the workflow output just error level logs when a step fails, set it as shown: config.yaml
logged_outputs:\n error:\n level: error\nTip
The standard name for the output path when a step fails is called error, which happens to also be the name of the log level here, but these are independent values.
You can specify multiple types of outputs and their log levels. For example, if you also want to output success steps as debug, set it as shown: config.yaml
logged_outputs:\n error:\n level: error\n success:\n level: debug\nNote: If you set the level lower than the general log level shown above, it will not show up in the output.
"},{"location":"arcaflow/workflows/","title":"Creating Arcaflow workflows","text":"Arcaflow workflows consist of four parts:
VersionThe schema version must be at the root of your workflow file. It indicates the semantic version of the workflow file structure being used.
Learn more about versioning \u00bb
InputsThe input section of a workflow is much like a plugin schema: it describes the data model of the workflow itself. This is useful because the input can be validated ahead of time. Any input data can then be referenced by the individual plugin steps.
Learn more about inputs \u00bb
StepsSteps hold the individual parts of the workflow. You can feed data from one step to the next, or feed data from the input to a step.
Learn more about steps \u00bb
OutputsOutputs hold the final result of a workflow. Outputs can reference outputs of steps.
Learn more about output \u00bb
Schema NamesLearn more about our schema naming conventions \u00bb
"},{"location":"arcaflow/workflows/expressions/","title":"Arcaflow expressions","text":"Arcaflow expressions were inspired by JSONPath but have diverged from the syntax. You can use expressions in a workflow YAML like this:
some_value: !expr $.your.expression.here\nThis page explains the language elements of expressions.
Warning
Expressions in workflow definitions must be prefixed with !expr, otherwise their literal value will be taken as a string.
Literals represent constant values in an expression.
"},{"location":"arcaflow/workflows/expressions/#string-values","title":"String values","text":"Normal string literals start and end with a matched pair of either single quotes (') or double quotes (\") and have zero or more characters between the quotes.
Strings may contain special characters. In normal strings, these characters are represented by \u201cescape sequences\u201d consisting of a backslash followed by another character. Since a backslash therefore has a special meaning, in order to represent a literal backslash character, it must be preceded by another backslash. Similarly, in a string delimited by double quotes, a double quote occurring inside the string must be escaped to prevent it from marking the end of the string. The same is true for single quotes occurring inside a string delimited by single quotes. However, you do not need to escape double quotes in a single-quoted string nor single-quotes in a double-quoted string.
Here is the list of supported escape characters:
Escape Result\\\\ \\ backslash character \\t tab character \\n newline character \\r carriage return character \\b backspace character \\\" \" double quote character \\' ' single quote character \\0 null character For example, to have the following text represented in a single string:
test test2/\\
You would need the expression \"test\\ntest2/\\\\\"
When expressing string literals in YAML, be aware that YAML has its own rules around the use of quotation marks.
For example, to include a double-quoted string in an expression, you must either add single quotes around the expression or use block flow scalars. Inside a single-quoted string, an apostrophe needs to be preceded by another apostrophe to indicate that it does not terminate the string.
Here is an example of the following value represented in a few of the various ways:
Here\u2019s an apostrophe and \u201cembedded quotes\u201d.
Inlined with single quotes:
some_value_1: !expr '\"Here''s an apostrophe and \\\"embedded quotes\\\".\"'\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.Inlined with double quotes:
some_value_2: !expr \"'Here\\\\'s an apostrophe and \\\"embedded quotes\\\".'\"\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.\\\\ is replaced with a single backslash; \\\" is replaced with a literal \"; With Block Flow Scalar:
some_value_1: !expr |-\n 'Here\\'s an apostrophe and \"embedded quotes\".'\nsome_value_2: !expr |-\n \"Here's an apostrophe and \\\"embedded quotes\\\".\"\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.|) causes the YAML processor to pass the contents of the string without modification.-) after the vertical bar causes the trailing newline to be omitted from the end of the string.some_value_1 do not need to be escaped nor do the single quotes in some_value_2.See Raw string values to see how to do this without escaping.
"},{"location":"arcaflow/workflows/expressions/#raw-string-values","title":"Raw string values","text":"Raw string literals start and end with backtick characters \u201c`\u201c.
In a raw string, all characters are interpreted literally. This means that you can use ' and \" characters without escaping them, and backslashes are treated like any other character. However, backtick characters cannot appear in a raw string.
Here is an example of the following value represented using raw strings:
Here\u2019s an apostrophe and \u201cembedded quotes\u201d.
Inlined:
some_value: !expr '`Here''s an apostrophe and \"embedded quotes\".`'\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.With Block Flow Scalar:
some_value: !expr |-\n `Here's an apostrophe and \"embedded quotes\".`\nTip
!expr tag indicates to the YAML processor that the value is an Arca expression.|) causes the YAML processor to pass the contents of the string without modification.-) after the vertical bar causes the trailing newline to be omitted from the end of the string.Integers are whole numbers expressed as sequences of base-10 digits.
Integer literals may not start with 0, unless the value is 0. For example, 001 is not a valid integer literal.
Examples:
01503Negative values are constructed by applying the negation operator (-) to a literal numeric value.
Floating point literals are non-negative double-precision floating point numbers.
Supported formats include:
1.1 or 1.5.0e5 and 5.0E-5Negative values are constructed by applying the negation operator (-) to a literal numeric value.
Boolean literals have two valid values:
truefalseNo other values are valid boolean literals. The values are case-sensitive.
"},{"location":"arcaflow/workflows/expressions/#root-reference","title":"Root reference","text":"The $ character always references the root of the data structure. Let\u2019s take this data structure:
foo:\n bar: Hello world!\nYou can reference the text like this:
$.foo.bar\nThe dot notation allows you to reference fields of an object.
For example, if you have an object on the root data structure named \u201ca\u201d with the field \u201cb\u201d in it, you can access it with:
$.a.b\nThe bracket accessor is used for referencing values in maps or lists.
"},{"location":"arcaflow/workflows/expressions/#list-access","title":"List access","text":"For list access, you specify the index of the value you want to access. The index should be an expression yielding a non-negative integer value, where zero corresponds to the first value in the list.
If you have a list named foo:
foo:\n - Hello world!\nYou can access the first value with the expression:
$.foo[0]\nGiving the output \"Hello world!\"
Maps, also known as dictionaries in some languages, are key-value pair data structures.
To use a map in an expression, the expression to the left of the brackets must be a reference to a map. That is then followed by a pair of brackets with a sub-expression between them. That sub-expression must evaluate to a valid key in the map.
Here is an example of a map with string keys and integer values. The map is stored in a field called foo in the root-level object:
foo:\n a: 1\n b: 2\nGiven the map shown above, the following expression would yield a value of 2:
$.foo[\"b\"]\nThe engine provides predefined functions for use in expressions. These provide transformations beyond what is available from operators.
Functions:
function definition return type descriptionintToFloat(integer) float Converts an integer value into the equivalent floating point value. floatToInt(float) integer Converts a floating point value into an integer value by discarding the fraction, rounding toward zero to the nearest integer.Special cases:\u00a0 +Inf yields the maximum 64-bit integer (9223372036854775807)\u00a0 -Inf and NaN yield the minimum 64-bit integer (-9223372036854775808)For example, 5.5 yields 5, and -1.9 yields -1 intToString(integer) string Returns a string containing the base-10 representation of the input.For example, an input of 55 yields \"55\" floatToString(float) string Returns a string containing the base-10 representation of the input.For example, an input of 5000.5 yields \"5000.5\" floatToFormattedString(float, string, integer) string Returns a string containing the input in the specified format with the specified precision.\u00a0 Param 1: the floating point input value\u00a0 Param 2: the format specifier: \"e\", \"E\", \"f\", \"g\", \"G\"\u00a0 Param 3: the number of digitsSpecifying -1 for the precision will produce the minimum number of digits required to represent the value exactly. (See the Go runtime documentation for details.) boolToString(boolean) string Returns \"true\" for true, and \"false\" for false. stringToInt(string) integer Interprets the string as a base-10 integer. Returns an error if the input is not a valid integer. stringToFloat(string) float Converts the input string to a double-precision floating-point number.Accepts floating-point numbers as defined by the Go syntax for floating point literals. If the input is well-formed and near a valid floating-point number, returns the nearest floating-point number rounded using IEEE754 unbiased rounding. Returns an error when an invalid input is received. stringToBool(string) boolean Interprets the input as a boolean.Accepts \"1\", \"t\", and \"true\" as true and \"0\", \"f\", and \"false\" as false (case is not significant). Returns an error for any other input. ceil(float) float Returns the least integer value greater than or equal to the input.Special cases are:\u00a0 ceil(\u00b10.0) = \u00b10.0\u00a0 ceil(\u00b1Inf) = \u00b1Inf\u00a0 ceil(NaN) = NaNFor example ceil(1.5) yields 2.0, and ceil(-1.5) yields -1.0 floor(float) float Returns the greatest integer value less than or equal to the input.Special cases are:\u00a0 floor(\u00b10.0) = \u00b10.0\u00a0 floor(\u00b1Inf) = \u00b1Inf\u00a0 floor(NaN) = NaNFor example floor(1.5) yields 1.0, and floor(-1.5) yields -2.0 round(float) float Returns the nearest integer to the input, rounding half away from zero.Special cases are:\u00a0 round(\u00b10.0) = \u00b10.0\u00a0 round(\u00b1Inf) = \u00b1Inf\u00a0 round(NaN) = NaNFor example round(1.5) yields 2.0, and round(-1.5) yields -2.0 abs(float) float Returns the absolute value of the input.Special cases are:\u00a0 abs(\u00b1Inf) = +Inf\u00a0 abs(NaN) = NaN toLower(string) string Returns the input with Unicode letters mapped to their lower case. toUpper(string) string Returns the input with Unicode letters mapped to their upper case. splitString(string, string) list[string] Returns a list of the substrings which appear between instances of the specified separator; the separator instances are not included in the resulting list elements; adjacent occurrences of separator instances as well as instances appearing at the beginning or ending of the input will produce empty string list elements.\u00a0 Param 1: The string to split.\u00a0 Param 2: The separator. readFile(string) string Returns the contents of a file as a UTF-8 character string, given a file path string. Relative file paths are resolved from the Arcaflow process working directory. Shell environment variables are not expanded. bindConstants(list[any], any) list[object] Returns a list of objects each containing two properties: an item property which contains the corresponding item from the list in the first parameter; and, a constant property which contains the value of the second input parameter. The output list items will have a generated schema name as described in Generated Schema Names. For usage see this example. A function is used in an expression by referencing its name followed by a comma-separated list of zero or more argument expressions enclosed in parentheses.
Example:
thisIsAFunction(\"this is a string literal for the first parameter\", $.a.b)\nBinary Operations have an expression to the left and right, with an operator in between. The order of operations determines which operators are evaluated first. See Order of Operations
The types of the left and right operand expressions must match. To convert between types, see the list of available functions. The type of the resulting expression is the same as the type of its operands.
Operator Description+ Addition/Concatenation - Subtraction * Multiplication / Division % Modulus ^ Exponentiation == Equal To != Not Equal To > Greater Than < Less Than >= Greater Than or Equal To <= Less Than or Equal To && Logical And \\|\\| Logical Or"},{"location":"arcaflow/workflows/expressions/#additionconcatenation","title":"Addition/Concatenation","text":"This operator has different behavior depending on the type.
"},{"location":"arcaflow/workflows/expressions/#string-concatenation","title":"String Concatenation","text":"When the + operator is used with two strings, it concatenates them together. For example, the expression \"a\" + \"b\" would output the string \"ab\".
When the + operator is used with numerical operands, it adds them together. The operator requires numerical operands with the same type. You cannot mix float and integer operands. For example, the expression 2 + 2 would output the integer 4.
When the - operator is applied to numerical operands, the result is the value of the right operand subtracted from the value of the left. The operator requires numerical operands with the same type. You cannot mix float and integer operands.
For example, the expression 6 - 4 would output the integer 2. The expression $.a - $.b would evaluate the values of a and b within the root, and subtract the value of $.b from $.a.
When the * operator is used with numerical operands, it multiplies them. The operator requires numerical operands with the same type.
For example, the expression 3 * 3 would output the integer 9.
When the / operator is used with numerical operands, it outputs the value of the left expression divided by the value of the right. The operator requires numerical operands with the same type.
The result of integer division is rounded towards zero. If a non-integral result is required, or if different rounding logic is required, convert the inputs into floating point numbers with the intToFloat function. Different types of rounding can be performed on floating point numbers with the functions ceil, floor, and round.
For example, the expression -3 / 2 would yield the integer value -1.
When the % operator is used with numerical operands, it evaluates to the remainder when the value of the left expression is divided by the value of the right. The operator requires numerical operands with the same type.
For example, the expression 5 % 3 would output the integer 2.
The ^ operator outputs the result of the left side raised to the power of the right side. The operator requires numerical operands with the same type.
The mathematical expression 23 is represented in the expression language as 2^3, which would output the integer 8.
The == operator evaluates to true if the values of the left and right operands are the same. Both operands must have the same type. You may use functions to convert between types \u2013 see functions for more type conversions. The operator supports the types integer, float, string, and boolean.
For example, 2 == 2 results in true, and \"a\" == \"b\" results in false. 1 == 1.0 would result in a type error.
The != operator is the inverse of the == operator. It evaluates to false if the values of the left and right operands are the same. Both operands must have the same type. You may use functions to convert between types \u2013 see functions for more type conversions. The operator supports the types integer, float, string, and boolean.
For example, 2 != 2 results in false, and \"a\" != \"b\" results in true. 1 != 1.0 would result in a type error.
The > operator outputs true if the left side is greater than the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For an integer example, the expression 3 > 3 would output the boolean false, and 4 > 3 would output true. For a string example, the expression \"a\" > \"b\" would output false.
The < operator outputs true if the left side is less than the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For an integer example, the expression 3 < 3 would output the boolean false, and 1 < 2 would output true. For a string example, the expression \"a\" < \"b\" would output true.
The >= operator outputs true if the left side is greater than or equal to (not less than) the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For an integer example, the expression 3 >= 3 would output the boolean true, 3 >= 4 would output false, and 4 >= 3 would output true.
The <= operator outputs true if the left side is less than or equal to (not greater than) the right side, and false otherwise. The operator requires numerical or string operands. The type must be the same for both operands. String operands are compared using the lexicographical order of the charset.
For example, the expression 3 <= 3 would output the boolean true, 3 <= 4 would output true, and 4 <= 3 would output false.
The && operator returns true if both the left and right sides are true, and false otherwise. This operator requires boolean operands. Note: The operation does not \u201cshort-circuit\u201d \u2013 both the left and right expressions are evaluated before the comparison takes place.
All cases:
Left Right&& true true true true false false false true false false false false"},{"location":"arcaflow/workflows/expressions/#logical-or","title":"Logical OR","text":"The || operator returns true if either or both of the left and right sides are true, and false otherwise. This operator requires boolean operands. Note: The operation does not \u201cshort-circuit\u201d \u2013 both the left and right expressions are evaluated before the comparison takes place.
All cases:
Left Right\\|\\| true true true true false true false true true false false false"},{"location":"arcaflow/workflows/expressions/#unary-operations","title":"Unary Operations","text":"Unary operations are operations that have one input. The operator is applied to the expression which follows it.
Operator Description - Negation ! Logical complement"},{"location":"arcaflow/workflows/expressions/#negation","title":"Negation","text":"The - operator negates the value of the expression which follows it.
This operation requires numeric input.
Examples with integer literals: -5, - 5 Example with a float literal: -50.0 Example with a reference: -$.foo Example with parentheses and a sub-expression: -(5 + 5)
The ! operator logically inverts the value of the expression which follows it.
This operation requires boolean input.
Example with a boolean literal: !true Example with a reference: !$.foo
Parentheses are used to force precedence in the expression. They do not do anything implicitly (for example, there is no implied multiplication).
For example, the expression 5 + 5 * 5 evaluates the 5 * 5 before the +, resulting in 5 + 25, and finally 30. If you want the 5 + 5 to be run first, you must use parentheses. That gives you the expression (5 + 5) * 5, resulting in 10 * 5, and finally 50.
The order of operations is designed to match mathematics and most programming languages.
Order (highest to lowest; operators listed on the same line are evaluated in the order they appear in the expression):
-)())^)*) and division (/)+) and subtraction (-)binary equality and inequality (all equal)
==) !=) >) <) >=) <=)logical complement (!)
&&)||).) and bracket access ([])More information on the expression language is available in the development guide.
"},{"location":"arcaflow/workflows/expressions/#examples","title":"Examples","text":""},{"location":"arcaflow/workflows/expressions/#referencing-inputs","title":"Referencing inputs","text":"Pass a workflow input directly to a plugin input
workflow.yamlversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n name:\n type:\n type_id: string\n\nsteps:\n step_a:\n plugin:\n deployment_type: image\n src: quay.io/some/container/image\n input:\n some:\n key: !expr $.input.name\nPass output from one plugin to the input of another plugin
workflow.yamlversion: v0.2.0\nsteps:\n step_a:\n plugin: \n deployment_type: image\n src: quay.io/some/container/image\n input: {}\n\n step_b:\n plugin:\n deployment_type: image \n src: quay.io/some/container/image\n input:\n some:\n key: !expr $.steps.step_a.outputs.success.some_value\nrepeated_inputs: \n hostname: mogo\nvarying_inputs:\n - cpu_load: 10\n - cpu_load: 20\n - cpu_load: 40\n - cpu_load: 60\nversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n repeated_inputs:\n type:\n type_id: ref\n id: RepeatedValues\n varying_inputs:\n type:\n type_id: list\n items:\n id: SubRootObject\n type_id: ref\n RepeatedValues:\n id: RepeatedValues\n properties:\n hostname:\n type:\n type_id: string\n SubRootObject:\n id: SubRootObject\n properties:\n cpu_load:\n type:\n type_id: integer \n\nsteps:\n example:\n plugin:\n deployment_type: image \n src: quay.io/some/container/image\n input: !expr 'bindConstants($.input.varying_inputs, $.input.repeated_inputs)'\nIn this case, we do not need to know the schema name of the type output generated by bindConstants(). If you need to reference the schema of the list items returned by bindConstants(), see Generated Schema Name.
Flow control allows the workflow author to build a workflow with a decision tree based on supported flow logic. These flow control operations are not implemented by plugins, but are part of the workflow engine itself.
"},{"location":"arcaflow/workflows/flow-control/#foreach-loops","title":"Foreach Loops","text":"Foreach loops allow for running a sub-workflow with iterative inputs from a parent workflow. A sub-workflow is a complete Arcaflow workflow file with its own input and output schemas as described in this section. The inputs for the sub-workflow are provided as a list, where each list item is an object that matches the sub-workflow input schema.
Tip
A complete functional example is available in the arcaflow-workflows repository.
In the parent workflow file, the author can define an input schema with the list that will contain the input object that will be passed to the sub-workflow. For example:
workflow.yamlinput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n loop:\n type:\n type_id: list\n items:\n type_id: object\n id: loop_id\n properties:\n loop_id:\n type:\n type_id: integer\n param_1:\n type:\n type_id: integer\n param_2:\n type:\n type_id: string\nThen in the steps section of the workflow, the sub-workflow can be defined as a step with the loop list object from above passed to its input.
The parameters for the sub-workflow step are:
kind - The type of loop (currently only foreach is supported)items - A list of objects to pass to the sub-workflow (the expression language allows to pass this from the input schema per the above example)workflow - The file name for the sub-workflow (this should be in the same directory as the parent workflow)parallelism - The number of sub-workflow loop iterations that will run in parallelsteps:\n sub_workflow_loop:\n kind: foreach\n items: !expr $.input.loop\n workflow: sub-workflow.yaml\n parallelism: 1\nThe input yaml file for the above parent workflow would provide the list of objects to loop over as in this example:
input.yamlloop:\n - loop_id: 1\n param_1: 10\n param_2: \"a\"\n - loop_id: 2\n param_1: 20\n param_2: \"b\"\n - loop_id: 3\n param_1: 30\n param_2: \"c\"\nThe sub-workflow file then has its complete schema and set of steps as in this example:
sub-workflow.yamlversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n loop_id:\n type:\n type_id: integer\n param_1:\n type:\n type_id: integer\n param_2:\n type:\n type_id: string\nsteps:\n my_plugin:\n plugin: \n deployment_type: image\n src: path/to/my_plugin:1\n input:\n param_1: !expr $.input.param_1\n my_other_plugin:\n plugin: \n deployment_type: image\n src: path/to/my_other_plugin:1\n input:\n param_2: !expr $.input.param_2\noutputs:\n success:\n loop_id: !expr $.input.loop_id\n my_plugin: !expr $.steps.my_plugin.outputs.success\n my_other_plugin: !expr $.steps.my_other_plugin.outputs.success\nbindConstants()","text":"The builtin function bindConstants() allows you to avoid repeating input variables for a foreach subworkflow. In the example below, the input variable name\u2019s value is repeated across each iteration in this input. This results in a more repetitive input and schema definition. This section will show you how to simplify it.
bindConstants()","text":"input-repeated.yamliterations:\n - loop_id: 1\n repeated_inputs:\n name: mogo\n ratio: 3.14\n - loop_id: 2\n repeated_inputs:\n name: mogo\n ratio: 3.14\n - loop_id: 3\n repeated_inputs:\n name: mogo\n ratio: 3.14\n - loop_id: 4\n repeated_inputs:\n name: mogo\n ratio: 3.14\nversion: v0.2.0\ninput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n iterations:\n type:\n type_id: list\n items:\n id: SubRootObject\n type_id: ref\n namespace: $.steps.foreach_loop.execute.inputs.items\n\nsteps:\n foreach_loop:\n kind: foreach\n items: !expr $.input.iterations\n workflow: subworkflow.yaml\n parallelism: 1\n\noutputs:\n success:\n fab_four: !expr $.steps.foreach_loop.outputs.success.data\nversion: v0.2.0\ninput:\n root: SubRootObject\n objects:\n SubRootObject:\n id: SubRootObject\n properties:\n loop_id:\n type:\n type_id: integer\n repeated_inputs:\n type:\n type_id: ref\n id: RepeatedInputs\n RepeatedInputs:\n id: RepeatedInputs\n properties:\n name:\n type:\n type_id: string\n ratio:\n type:\n type_id: float \n\nsteps:\n example:\n plugin:\n deployment_type: image\n src: quay.io/arcalot/arcaflow-plugin-template-python:0.4.0\n input:\n name: !expr $.input.repeated_inputs.name\n\noutputs:\n success:\n loop_id: !expr $.input.loop_id\n ratio: !expr $.input.repeated_inputs.ratio\n beatle: !expr $.steps.example.outputs.success\nHere we restructure the input, factoring out the repeated name and ratio entries in the list and placing them into a single field; we will use bindConstants() to construct the foreach list with repeated entries.
repeated_inputs: \n name: mogo\n ratio: 3.14\niterations:\n - loop_id: 1\n - loop_id: 2\n - loop_id: 3\n - loop_id: 4\nTo use the generated values from bindConstants(), a new schema representing these bound values must be added to the input schema section of our subworkflow.yaml, input. This new schema\u2019s ID will be the ID of the schema that defines the items in your list, in this case SubRootObject and the schema name that defines your repeated inputs, in this case RepeatedValues, for more information see Generated Schema Names. This creates our new schema ID, SubRootObject__RepeatedValues. You are required to use this schema ID because it is generated from the names of your other schemas.
steps:\n foreach_loop:\n kind: foreach\n items: !expr 'bindConstants($.input.iterations, $.input.repeated_inputs)'\n workflow: subworkflow.yaml\n parallelism: 1\nTo use bindConstants() with an outputSchema in your workflow, you need to reference the schema of the list items returned by bindConstants(), see Generated Schema Name.
See the full workflow.
"},{"location":"arcaflow/workflows/input/","title":"Writing workflow inputs","text":"The input section of a workflow is much like a plugin schema: it describes the data model of the workflow itself. This is useful because the input can be validated ahead of time. Any input data can then be referenced by the individual steps.
Tip
The workflow input schema is analogous to the plugin input schema in that it defines the expected inputs and formats. But a workflow author has the freedom to define the schema independently of the plugin schema \u2013 This means that objects can be named and documented differently, catering to the workflow user, and input validation can happen before a plugin is loaded.
The workflow inputs start with a scope object. As an overview, a scope looks like this:
workflow.yamlinput:\n root: RootObject\n objects:\n RootObject:\n id: RootObject\n properties:\n name:\n type:\n type_id: string\n # Other properties of the root object\n # Other objects that can be referenced here\nThis corresponds to the following workflow input:
workflow_input.yamlname: Arca Lot\nAdmittedly, this looks complicated, but read on, it will become clear very quickly.
"},{"location":"arcaflow/workflows/input/#objects","title":"Objects","text":"Let\u2019s start with objects. Objects are like structs or classes in programming. They have two properties: an ID and a list of properties. The basic structure looks like this:
some_object:\n id: some_object\n properties:\n # Properties here\nNow you need to define a property. Let\u2019s say, we want to define a string with the name of the user. You can do this as follows:
type_id: object\nid: some_object\nproperties:\nname:\n type:\n type_id: string\nNotice, that the type_id field is indented. That\u2019s because the type field describes a string type, which has additional parameters. For example:
type_id: object\nid: some_object\nproperties:\nname:\n type:\n type_id: string\n min: 1 # Minimum length for the string\nThere are also additional attributes of the property itself. For example:
type_id: object\nid: some_object\nproperties:\nname:\n type:\n type_id: string\n min: 1 # Minimum length for the string\n display:\n name: Name\n description: Name of the user.\n conflicts:\n - full_name\nProperties have the following attributes:
Attribute Type Descriptiondisplay Display Display metadata of the property. See Display values. required bool If set to true, the field must always be filled. required_if []string List of other properties that, if filled, lead to the current property being required. required_if_not []string List of other properties that, if not filled, lead to the current property being required. conflicts []string List of other properties that conflict the current property. default string Default value for this property, JSON-encoded. examples []string Examples for the current property, JSON-encoded. Note
Unlike the plugin schema where an unassigned default value is set to None, for the workflow schema you simply omit the default to leave it unassigned.
Scopes behave like objects, but they serve an additional purpose. Suppose, object A had a property of the object type B, but now you needed to reference back to object A. Without references, there would be no way to do this.
OpenAPI and JSON Schema have a similar concept, but in those systems all references are global. This presents a problem when merging schemas. For example, both Docker and Kubernetes have an object called Volume. These objects would need to be renamed when both configurations are in one schema.
Arcaflow has a different solution: every plugin, every part of a workflow has its own scope. When a reference is found in a scope, it always relates to its own scope. This way, references don\u2019t get mixed.
Let\u2019s take a simple example: a scope with objects A and B, referencing each other.
type_id: scope\nroot: A\nobjects:\n A:\n type_id: object\n id: A\n properties:\n b:\n type:\n type_id: ref\n id: B\n required: false\n B:\n type_id: object\n id: B\n properties:\n a:\n type:\n type_id: ref\n id: A\n required: false\nThis you can create a circular dependency between these objects without needing to copy-paste their properties.
Additionally, refs have an extra display property, which references a Display value to provide context for the reference.
Strings are, as the name suggests, strings of human-readable characters. They have the following properties:
type_id: string\nmin: # Minimum number of characters. Optional.\nmax: # Maximum number of characters. Optional.\npattern: # Regular expression this string must match. Optional.\nPatterns are special kinds of strings that hold regular expressions.
type_id: pattern\nIntegers are similar to strings, but they don\u2019t have a pattern field but have a units field. (See Units.)
type_id: integer\nmin: # Minimum value. Optional.\nmax: # Maximum value. Optional.\nunits:\n # Units definition. Optional.\nFloating point numbers are similar to integers.
type_id: float\nmin: # Minimum value. Optional.\nmax: # Maximum value. Optional.\nunits:\n # Units definition. Optional.\nEnums only allow a fixed set of values. String enums map string keys to a display value. (See Display values.)
type_id: enum_string\nvalues:\n red:\n name: Red\n yellow:\n name: Yellow\nEnums only allow a fixed set of values. Integer enums map integer keys to a display value. (See Display values.)
type_id: enum_integer\nvalues:\n 1:\n name: Red\n 2:\n name: Yellow\nBooleans can hold a true or false value.
type_id: bool\nLists hold items of a specific type. You can also define their minimum and maximum size.
type_id: list\nitems:\n type_id: type of the items\n # Other definitions for list items\nmin: 1 # Minimum number of items in the list (optional)\nmax: 2 # maximum number of items in the list (optional)\nMaps are key-value mappings. You must define both the key and value types, whereas keys can only be strings, integers, string enums, or integer enums.
type_id: map\nkeys:\n type_id: string\nvalues:\n type_id: string\nmin: 1 # Minimum number of items in the map (optional)\nmax: 2 # maximum number of items in the map (optional)\nOne-of types allow you to specify multiple alternative objects, scopes, or refs. However, these objects must contain a common field (discriminator) and each value for that field must correspond to exactly one object type.
Tip
If the common field is not specified in the possible objects, it is implicitly added. If it is specified, however, it must match the discriminator type.
type_id: one_of_string\ndiscriminator_field_name: object_type # Defaults to: _type\ntypes:\n a:\n type_id: object\n id: A\n properties:\n # Properties of object A.\n b:\n type_id: object\n id: B\n properties:\n # Properties of object B\nWe can now use the following value as an input:
object_type: a\n# Other values for object A\nIn contrast, you can specify object_type as b and that will cause the unserialization to run with the properties of object B.
One-of types allow you to specify multiple alternative objects, scopes, or refs. However, these objects must contain a common field (discriminator) and each value for that field must correspond to exactly one object type.
Tip
If the common field is not specified in the possible objects, it is implicitly added. If it is specified, however, it must match the discriminator type.
type_id: one_of_int\ndiscriminator_field_name: object_type # Defaults to: _type\ntypes:\n 1:\n type_id: object\n id: A\n properties:\n # Properties of object A.\n 2:\n type_id: object\n id: B\n properties:\n # Properties of object B\nWe can now use the following value as an input:
object_type: 1\n# Other values for object A\nIn contrast, you can specify object_type as 2 and that will cause the unserialization to run with the properties of object B.
Any types allow any data to pass through without validation. We do not recommend using the \u201cany\u201d type due to its lack of validation and the risk to cause runtime errors. Only use any types if you can truly handle any data that is passed.
type_id: any\nDisplay values are all across the Arcaflow schema. They are useful to provide human-readable descriptions of properties, refs, etc. that can be used to generate nice, human-readable documentation, user interfaces, etc. They are always optional and consist of the following 3 fields:
name: Short name\ndescription: Longer description of what the item does, possibly in multiple lines.\nicon: |\n <svg ...></svg> # SVG icon, 64x64 pixels, without doctype and external references.\nUnits make it easier to parse and display numeric values. For example, if you have an integer representing nanoseconds, you may want to parse strings like 5m30s.
Units have two parameters: a base unit description and multipliers. For example:
base_unit:\n name_short_singular: B\n name_short_plural: B\n name_long_singular: byte\n name_long_plural: bytes\nmultipliers:\n 1024:\n name_short_singular: kB\n name_short_plural: kB\n name_long_singular: kilobyte\n name_long_plural: kilobytes\n # ...\nOutputs in Arcaflow serve a dual purpose:
You can define an output simply with expressions. Outputs generally include desired output parameters from individual steps, but may also include data from inputs or even static values.
output:\n some_key:\n some_other_key: !expr $.steps.some_step.outputs.success.some_value\n foo: !expr $.inputs.bar\n arca: \"flow\"\nArcaflow can produce multiple output groups for a workflow. These output groups are mutually exclusive to each other.
A common example of two mutually exclusive events could be the availability of your data storage service. Let\u2019s assume the service is either available, or unavailable (the unavailable state also includes any states where an error is thrown during data insertion). Multiple workflow outputs allows you to plan for these two events.
In this example taken from the Arcaflow Workflows project, the success output collects the data from the specified steps and inserts it into data storage. The no-indexing output collects the data, the error logs, and does not store the data.
outputs:\n success:\n pcp: !expr $.steps.pcp.outputs.success\n sysbench: !expr $.steps.sysbench.outputs.success\n metadata: !expr $.steps.metadata.outputs.success\n opensearch: !expr $.steps.opensearch.outputs.success\n no-indexing:\n pcp: !expr $.steps.pcp.outputs.success\n sysbench: !expr $.steps.sysbench.outputs.success\n metadata: !expr $.steps.metadata.outputs.success\n no-index: !expr $.steps.opensearch.outputs.error\nSchemas that are not composed within an ObjectSchema do not have an Object ID. They use a stringified version of their TypeID for their schema name.
The name of a ListSchema is the name of the schema of its element type prefixed with list_. For lists of lists, the schema name is the name of the inner list schema prefixed with an additional list_.
The name of an ObjectSchema is its Object ID. A ListSchema that has an ObjectSchema as its item value uses the name of that ObjectSchema.
ScopeSchemas do not use a schema name.RefSchemas use the schema name of the type to which they point.The name of the schema for the value returned by a given call to bindConstants() is generated from the names of the schemas of the parameters to the call. Because the output of this function is always a list, the list_ prefix is omitted from the schema name, and only the schema name of the list\u2019s items is used. The name is formed by concatenating the name of the schema of the first parameter\u2019s list items with the name of the schema of the second parameter, separated by a double underscore __.
If your input is complete, you can now turn to writing your workflow steps. You can connect workflow steps by using expressions. For example, if step A has an input that needs data from step B, Arcaflow will automatically run step B first.
To define a step type, you can do the following:
workflow.yamlversion: v0.2.0\nsteps:\n step_a: # Specify any ID here you want to reference the step by\n plugin: \n deployment_type: image\n src: quay.io/some/container/image # This must be an Arcaflow-compatible image\n input: # specify input values as a data structure, mixing in expressions as needed\n some:\n key: !expr $.steps.step_b.outputs.success.some_value \n step_b:\n plugin: \n deployment_type: image\n src: quay.io/some/container/image\n input:\n some:\n key: !expr $.input.some_value # Reference an input value\nPlugin steps run Arcaflow plugins in containers. They can use Docker, Podman, or Kubernetes as deployers. If no deployer is specified in the workflow, the plugin will use the local deployer.
Plugin steps have the following properties:
Property Descriptionplugin Full name of the container image to run. This must be an Arcaflow-compatible container image. step If a plugin provides more than one possible step, you can specify the step ID here. deploy Configuration for the deployer. (See below.) This can contain expressions, so you can dynamically specify deployment parameters. input Input data for the plugin. This can contain expressions, so you can dynamically define inputs. You can reference plugin outputs in the format of $.steps.your_step_id.outputs.your_plugin_output_id.some_variable.
The deploy key for plugins lets you control how the plugin container is deployed. You can use expressions to use other plugins (e.g. the kubeconfig plugin) to generate the deployment configuration and feed it into other steps.
You can configure the Docker deployer like this:
version: v0.2.0\nstep:\n your_step_id:\n plugin: ...\n input: ...\n deploy: # You can use expressions here\n deployer_name: docker\n connection:\n # Change this to point to a TCP-based Docker socket\n host: host-to-docker\n # Add a certificates here. This is usually needed in TCP mode.\n cacert: |\n Add your CA cert PEM here\n cert: |\n Add your client cert PEM here.\n key: |\n Add your client key PEM here.\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n network:\n # Add your network config here\n platform:\n # Add your platform config here\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Connection (object) Type: object Properties cacert (string) Name: CA certificate Description: CA certificate in PEM format to verify the Dockerd server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name for Dockerd. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z0-9./:_-]+$ Default\"npipe:////./pipe/docker_engine\"\n'unix:///var/run/docker.sock'\n\u201d
'npipe:////./pipe/docker_engine'\nstring) Name: Client key Description: Client private key in PEM format to authenticate against the Dockerd with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nobject) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (map[string, string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No Key type Type: string Minimum: 1 Maximum: 255 Must match pattern: ^[A-Z0-9_]+$ Value type Type: string Maximum: 32760 Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nreference[NetworkConfig]) Name: Network configuration Description: Provides information about the container networking for the plugin. Required: No Referenced object: NetworkConfig (see in the Objects section below) platform (reference[PlatformConfig]) Name: Platform configuration Description: Provides information about the container host platform for the plugin. Required: No Referenced object: PlatformConfig (see in the Objects section below) HostConfig (object) Type: object Properties CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) NetworkConfig (object) Type: object Properties None
PlatformConfig (object) Type: object Properties None
PortBinding (object) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nIf you want to use Podman as your local deployer, you can do so like this:
version: v0.2.0\nstep:\n your_step_id:\n plugin: ...\n input: ...\n deploy: # You can use expressions here\n deployer_name: podman\n podman:\n # Change where Podman is. (You can use this to point to a shell script\n path: /path/to/your/podman\n # Change the network mode\n networkMode: host\n deployment:\n # For more options here see: https://docs.docker.com/engine/api/v1.42/#tag/Container/operation/ContainerCreate\n container:\n # Add your container config here.\n host:\n # Add your host config here.\n imagePullPolicy: Always|IfNotPresent|Never\n timeouts:\n # HTTP timeout\n http: 5s\nscope Root object: Config Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) Objects Config (object) Type: object Properties deployment (reference[Deployment]) Name: Deployment Description: Deployment configuration for the plugin. Required: No Referenced object: Deployment (see in the Objects section below) podman (reference[Podman]) Name: Podman Description: Podman CLI configuration Required: No Referenced object: Podman (see in the Objects section below) ContainerConfig (object) Type: object Properties Domainname (string) Name: Domain name Description: Domain name for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ Env (list[string]) Name: Environment variables Description: Environment variables to set on the plugin container. Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+=.+$ Hostname (string) Name: Hostname Description: Hostname for the plugin container. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-zA-Z0-9-_.]+$ MacAddress (string) Name: MAC address Description: Media Access Control address for the container. Required: No Must match pattern: ^[a-fA-F0-9]{2}(:[a-fA-F0-9]{2}){5}$ NetworkDisabled (bool) Name: Disable network Description: Disable container networking completely. Required: No User (string) Name: Username Description: User that will run the command inside the container. Optionally, a group can be specified in the user:group format. Required: No Minimum: 1 Maximum: 255 Must match pattern: ^[a-z_][a-z0-9_-]*[$]?(:[a-z_][a-z0-9_-]*[$]?)$ Deployment (object) Type: object Properties container (reference[ContainerConfig]) Name: Container configuration Description: Provides information about the container for the plugin. Required: No Referenced object: ContainerConfig (see in the Objects section below) host (reference[HostConfig]) Name: Host configuration Description: Provides information about the container host for the plugin. Required: No Referenced object: HostConfig (see in the Objects section below) imagePullPolicy (enum[string]) Name: Image pull policy Description: When to pull the plugin image. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nobject) Type: object Properties Binds (list[string]) Name: Volume Bindings Description: Volumes Required: No List Items Type: string Minimum: 1 Maximum: 32760 Must match pattern: ^.+:.+$ CapAdd (list[string]) Name: Add capabilities Description: Add capabilities to the container. Required: No List Items Type: string CapDrop (list[string]) Name: Drop capabilities Description: Drop capabilities from the container. Required: No List Items Type: string CgroupnsMode (enum[string]) Name: CGroup namespace mode Description: CGroup namespace mode to use for the container. Required: No Values host Hostprivate Privatelist[string]) Name: DNS servers Description: DNS servers to use for lookup. Required: No List Items Type: string DnsOptions (list[string]) Name: DNS options Description: DNS options to look for. Required: No List Items Type: string DnsSearch (list[string]) Name: DNS search Description: DNS search domain. Required: No List Items Type: string ExtraHosts (list[string]) Name: Extra hosts Description: Extra hosts entries to add Required: No List Items Type: string NetworkMode (string) Name: Network mode Description: Specifies either the network mode, the container network to attach to, or a name of a Docker network to use. Required: No Must match pattern: ^(none|bridge|host|container:[a-zA-Z0-9][a-zA-Z0-9_.-]+|[a-zA-Z0-9][a-zA-Z0-9_.-]+)$ Examples \"none\"\n\u201d
\"bridge\"\n\"host\"\n\"container:container-name\"\n\"network-name\"\nmap[string, list[reference[PortBinding]]]) Name: Port bindings Description: Ports to expose on the host machine. Ports are specified in the format of portnumber/protocol. Required: No Key type Type: string Must match pattern: ^[0-9]+(/[a-zA-Z0-9]+)$ Value type Type: list[reference[PortBinding]] List Items Type: reference[PortBinding] Referenced object: PortBinding (see in the Objects section below) Podman (object) Type: object Properties cgroupNs (string) Name: CGroup namespace Description: Provides the Cgroup Namespace settings for the container Required: No Must match pattern: ^host|ns:/proc/\\d+/ns/cgroup|container:.+|private$ containerName (string) Name: Container Name Description: Provides name of the container Required: No Must match pattern: ^.*$ imageArchitecture (string) Name: Podman image Architecture Description: Provides Podman Image Architecture Required: No Must match pattern: ^.*$ Default\"amd64\"\nstring) Name: Podman Image OS Description: Provides Podman Image Operating System Required: No Must match pattern: ^.*$ Default\"linux\"\nstring) Name: Network Mode Description: Provides network settings for the container Required: No Must match pattern: ^bridge:.*|host|none$ path (string) Name: Podman path Description: Provides the path of podman executable Required: No Must match pattern: ^.*$ Default\"podman\"\nobject) Type: object Properties HostIP (string) Name: Host IP Required: No HostPort (string) Name: Host port Required: No Must match pattern: ^0-9+$ The Kubernetes deployer deploys on top of Kubernetes. You can set up the deployer like this:
version: v0.2.0\nstep:\n your_step_id:\n plugin: ...\n input: ...\n deploy: # You can use expressions here\n deployer_name: kubernetes\n connection:\n host: localhost:6443\n cert: |\n Add your client cert in PEM format here.\n key: |\n Add your client key in PEM format here.\n cacert: |\n Add the server CA cert in PEM format here.\nscope Root object: Config Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) Objects AWSElasticBlockStoreVolumeSource (object) Type: object Properties None
AzureDiskVolumeSource (object) Type: object Properties None
AzureFileVolumeSource (object) Type: object Properties None
CSIVolumeSource (object) Type: object Properties None
CephFSVolumeSource (object) Type: object Properties None
CinderVolumeSource (object) Type: object Properties None
Config (object) Type: object Properties connection (reference[Connection]) Name: Connection Description: Docker connection information. Required: No Referenced object: Connection (see in the Objects section below) pod (reference[Pod]) Name: Pod Description: Pod configuration for the plugin. Required: No Referenced object: Pod (see in the Objects section below) timeouts (reference[Timeouts]) Name: Timeouts Description: Timeouts for the Docker connection. Required: No Referenced object: Timeouts (see in the Objects section below) ConfigMapVolumeSource (object) Type: object Properties None
Connection (object) Type: object Properties bearerToken (string) Name: Bearer token Description: Bearer token to authenticate against the Kubernetes API with. Required: No burst (int) Name: Burst Description: Burst value for query throttling. Required: No Minimum: 0 Default10\nstring) Name: CA certificate Description: CA certificate in PEM format to verify Kubernetes server certificate against. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Client certificate Description: Client certificate in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN CERTIFICATE-----(\\s*.*\\s*)*-----END CERTIFICATE-----\\s*$ Examples \"-----BEGIN CERTIFICATE-----\\nMIIB4TCCAYugAwIBAgIUCHhhffY1lzezGatYMR02gpEJChkwDQYJKoZIhvcNAQEL\\nBQAwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgMClNvbWUtU3RhdGUxITAfBgNVBAoM\\nGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZDAeFw0yMjA5MjgwNTI4MTJaFw0yMzA5\\nMjgwNTI4MTJaMEUxCzAJBgNVBAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEw\\nHwYDVQQKDBhJbnRlcm5ldCBXaWRnaXRzIFB0eSBMdGQwXDANBgkqhkiG9w0BAQEF\\nAANLADBIAkEArr89f2kggSO/yaCB6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1\\nnEiPnLbzDDgMU8KCPAMhI7JpYRlHnipxWwIDAQABo1MwUTAdBgNVHQ4EFgQUiZ6J\\nDwuF9QCh1vwQGXs2MutuQ9EwHwYDVR0jBBgwFoAUiZ6JDwuF9QCh1vwQGXs2Mutu\\nQ9EwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQsFAANBAFYIFM27BDiG725d\\nVkhRblkvZzeRHhcwtDOQTC9d8M/LymN2y0nHSlJCZm/Lo/aH8viSY1vi1GSHfDz7\\nTlfe8gs=\\n-----END CERTIFICATE-----\\n\"\nstring) Name: Host Description: Host name and port of the Kubernetes server Required: No Default\"kubernetes.default.svc\"\nstring) Name: Client key Description: Client private key in PEM format to authenticate against Kubernetes with. Required: No Minimum: 1 Must match pattern: ^\\s*-----BEGIN ([A-Z]+) PRIVATE KEY-----(\\s*.*\\s*)*-----END ([A-Z]+) PRIVATE KEY-----\\s*$ Examples \"-----BEGIN PRIVATE KEY-----\\nMIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEArr89f2kggSO/yaCB\\n6EwIQeT6ZptBoX0ZvCMI+DpkCwqOS5fwRbj1nEiPnLbzDDgMU8KCPAMhI7JpYRlH\\nnipxWwIDAQABAkBybu/x0MElcGi2u/J2UdwScsV7je5Tt12z82l7TJmZFFJ8RLmc\\nrh00Gveb4VpGhd1+c3lZbO1mIT6v3vHM9A0hAiEA14EW6b+99XYza7+5uwIDuiM+\\nBz3pkK+9tlfVXE7JyKsCIQDPlYJ5xtbuT+VvB3XOdD/VWiEqEmvE3flV0417Rqha\\nEQIgbyxwNpwtEgEtW8untBrA83iU2kWNRY/z7ap4LkuS+0sCIGe2E+0RmfqQsllp\\nicMvM2E92YnykCNYn6TwwCQSJjRxAiEAo9MmaVlK7YdhSMPo52uJYzd9MQZJqhq+\\nlB1ZGDx/ARE=\\n-----END PRIVATE KEY-----\\n\"\nstring) Name: Password Description: Password for basic authentication. Required: No path (string) Name: Path Description: Path to the API server. Required: No Default\"/api\"\nfloat) Name: QPS Description: Queries Per Second allowed against the API. Required: No Minimum: 0 Units: queries Default5.0\nstring) Name: TLS server name Description: Expected TLS server name to verify in the certificate. Required: No username (string) Name: Username Description: Username for basic authentication. Required: No Container (object) Type: object Properties args (list[string]) Name: Arguments Description: Arguments to the entypoint (command). Required: No List Items Type: string command (list[string]) Name: Command Description: Override container entry point. Not executed with a shell. Required: No Minimum items: 1 List Items Type: string env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) image (string) Name: Image Description: Container image to use for this container. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9_\\-:./]+$ imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ securityContext (object) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 workingDir (string) Name: Working directory Description: Override the container working directory. Required: No DownwardAPIVolumeSource (object) Type: object Properties None
EmptyDirVolumeSource (object) Type: object Properties medium (string) Name: Medium Description: How to store the empty directory Required: No Minimum: 1 Must match pattern: ^(|Memory|HugePages|HugePages-.*)$ EnvFromSource (object) Type: object Properties configMapRef (object) Name: Config map source Description: Populates the source from a config map. Required: No Properties name (string) Name: Name Description: Name of the referenced config map. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the config map must be defined. Required: No prefix (string) Name: Prefix Description: An optional identifier to prepend to each key in the ConfigMap. Required: No Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ secretRef (object) Name: Secret source Description: Populates the source from a secret. Required: No Properties name (string) Name: Name Description: Name of the referenced secret. Required: Yes Minimum: 1 optional (bool) Name: Optional Description: Specify whether the secret must be defined. Required: No EphemeralVolumeSource (object) Type: object Properties None
FCVolumeSource (object) Type: object Properties None
FlexVolumeSource (object) Type: object Properties None
FlockerVolumeSource (object) Type: object Properties None
GCEPersistentDiskVolumeSource (object) Type: object Properties None
GlusterfsVolumeSource (object) Type: object Properties None
HostPathVolumeSource (object) Type: object Properties path (string) Name: Path Description: Path to the directory on the host. Required: Yes Minimum: 1 Examples \"/srv/volume1\"\nenum[string]) Name: Type Description: Type of the host path. Required: No Values BlockDevice Block deviceCharDevice Character deviceDirectory DirectoryDirectoryOrCreate Create directory if not foundFile FileFileOrCreate Create file if not foundSocket Socketobject) Type: object Properties None
NFSVolumeSource (object) Type: object Properties None
ObjectMeta (object) Type: object Properties annotations (map[string, string]) Name: Annotations Description: Kubernetes annotations to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ generateName (string) Name: Name prefix Description: Name prefix to generate pod names from. Required: No labels (map[string, string]) Name: Labels Description: Kubernetes labels to appy. See https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ for details. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ name (string) Name: Name Description: Pod name. Required: No namespace (string) Name: Namespace Description: Kubernetes namespace to deploy in. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"default\"\nobject) Type: object Properties None
PhotonPersistentDiskVolumeSource (object) Type: object Properties None
Pod (object) Type: object Properties metadata (reference[ObjectMeta]) Name: Metadata Description: Pod metadata. Required: No Referenced object: ObjectMeta (see in the Objects section below) spec (reference[PodSpec]) Name: Specification Description: Pod specification. Required: No Referenced object: PodSpec (see in the Objects section below) PodSpec (object) Type: object Properties affinity (object) Name: Affinity rules Description: Affinity rules. Required: No Properties podAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ podAntiAffinity (object) Name: Pod Affinity Description: The pod affinity rules. Required: No Properties requiredDuringSchedulingIgnoredDuringExecution (list[object]) Name: Required During Scheduling Ignored During Execution Description: Hard pod affinity rules. Required: No Minimum items: 1 List Items Type: object Properties labelSelector (object) Name: MatchExpressions Description: Expressions for the label selector. Required: No Properties matchExpressions (list[object]) Name: MatchExpression Description: Expression for the label selector. Required: No Minimum items: 1 List Items Type: object Properties key (string) Name: Key Description: Key for the label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ operator (string) Name: Operator Description: Logical operator for Kubernetes to use when interpreting the rules. You can use In, NotIn, Exists, DoesNotExist, Gt and Lt. Required: No Maximum: 253 Must match pattern: In|NotIn|Exists|DoesNotExist|Gt|Lt values (list[string]) Name: Values Description: Values for the label that the system uses to denote the domain. Required: No Minimum items: 1 List Items Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ topologyKey (string) Name: TopologyKey Description: Key for the node label that the system uses to denote the domain. Required: No Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_./][a-zA-Z0-9]+)*[a-zA-Z0-9])$ containers (list[reference[Container]]) Name: Containers Description: A list of containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) initContainers (list[reference[Container]]) Name: Init containers Description: A list of initialization containers belonging to the pod. Required: No List Items Type: reference[Container] Referenced object: Container (see in the Objects section below) nodeSelector (map[string, string]) Name: Labels Description: Node labels you want the target node to have. Required: No Key type Type: string Must match pattern: ^(|([a-zA-Z](|[a-zA-Z\\-.]{0,251}[a-zA-Z0-9]))/)([a-zA-Z](|[a-zA-Z\\\\-]{0,61}[a-zA-Z0-9]))$ Value type Type: string Maximum: 63 Must match pattern: ^(|[a-zA-Z0-9]+(|[-_.][a-zA-Z0-9]+)*[a-zA-Z0-9])$ pluginContainer (object) Name: Plugin container Description: The container to run the plugin in. Required: Yes Properties env (list[object]) Name: Environment Description: Environment variables for this container. Required: No List Items Type: object Properties name (string) Name: Name Description: Environment variables name. Required: Yes Minimum: 1 Must match pattern: ^[a-zA-Z0-9-._]+$ value (string) Name: Value Description: Value for the environment variable. Required: No valueFrom (reference[EnvFromSource]) Name: Value source Description: Load the environment variable from a secret or config map. Required: No Referenced object: EnvFromSource (see in the Objects section below) envFrom (list[reference[EnvFromSource]]) Name: Environment sources Description: List of sources to populate the environment variables from. Required: No List Items Type: reference[EnvFromSource] Referenced object: EnvFromSource (see in the Objects section below) imagePullPolicy (enum[string]) Name: Volume device Description: Mount a raw block device within the container. Required: No Values Always AlwaysIfNotPresent If not presentNever Never\"IfNotPresent\"\nstring) Name: Name Description: Name for the container. Each container in a pod must have a unique name. Required: No Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ Default\"arcaflow-plugin-container\"\nobject) Name: Volume device Description: Mount a raw block device within the container. Required: No Properties capabilities (object) Name: Capabilities Description: Add or drop POSIX capabilities. Required: No Properties add (list[string]) Name: Add Description: Add POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ drop (list[string]) Name: Drop Description: Drop POSIX capabilities. Required: No List Items Type: string Minimum: 1 Must match pattern: ^[A-Z_]+$ privileged (bool) Name: Privileged Description: Run the container in privileged mode. Required: No volumeDevices (list[object]) Name: Volume device Description: Mount a raw block device within the container. Required: No List Items Type: object Properties devicePath (string) Name: Device path Description: Path inside the container the device will be mapped to. Required: Yes Minimum: 1 name (string) Name: Name Description: Must match the persistent volume claim in the pod. Required: Yes Minimum: 1 volumeMounts (list[object]) Name: Volume mounts Description: Pod volumes to mount on this container. Required: No List Items Type: object Properties mountPath (string) Name: Mount path Description: Path to mount the volume on inside the container. Required: Yes Minimum: 1 name (string) Name: Volume name Description: Must match the pod volume to mount. Required: Yes Minimum: 1 readOnly (bool) Name: Read only Description: Mount volume as read-only. Required: No Defaultfalse\nstring) Name: Subpath Description: Path from the volume to mount. Required: No Minimum: 1 volumes (list[reference[Volume]]) Name: Volumes Description: A list of volumes that can be mounted by containers belonging to the pod. Required: No List Items Type: reference[Volume] Referenced object: Volume (see in the Objects section below) PortworxVolumeSource (object) Type: object Properties None
ProjectedVolumeSource (object) Type: object Properties None
QuobyteVolumeSource (object) Type: object Properties None
RBDVolumeSource (object) Type: object Properties None
ScaleIOVolumeSource (object) Type: object Properties None
SecretVolumeSource (object) Type: object Properties None
StorageOSVolumeSource (object) Type: object Properties None
Timeouts (object) Type: object Properties http (int) Name: HTTP Description: HTTP timeout for the Docker API. Required: No Minimum: 100000000 Units: nanoseconds Default\"15s\"\nobject) Type: object Properties awsElasticBlockStore (reference[AWSElasticBlockStoreVolumeSource]) Name: AWS EBS Description: AWS Elastic Block Storage. Required: No Referenced object: AWSElasticBlockStoreVolumeSource (see in the Objects section below) azureDisk (reference[AzureDiskVolumeSource]) Name: Azure Data Disk Description: Mount an Azure Data Disk as a volume. Required: No Referenced object: AzureDiskVolumeSource (see in the Objects section below) azureFile (reference[AzureFileVolumeSource]) Name: Azure File Description: Mount an Azure File Service mount. Required: No Referenced object: AzureFileVolumeSource (see in the Objects section below) cephfs (reference[CephFSVolumeSource]) Name: CephFS Description: Mount a CephFS volume. Required: No Referenced object: CephFSVolumeSource (see in the Objects section below) cinder (reference[CinderVolumeSource]) Name: Cinder Description: Mount a cinder volume attached and mounted on the host machine. Required: No Referenced object: CinderVolumeSource (see in the Objects section below) configMap (reference[ConfigMapVolumeSource]) Name: ConfigMap Description: Mount a ConfigMap as a volume. Required: No Referenced object: ConfigMapVolumeSource (see in the Objects section below) csi (reference[CSIVolumeSource]) Name: CSI Volume Description: Mount a volume using a CSI driver. Required: No Referenced object: CSIVolumeSource (see in the Objects section below) downwardAPI (reference[DownwardAPIVolumeSource]) Name: Downward API Description: Specify a volume that the pod should mount itself. Required: No Referenced object: DownwardAPIVolumeSource (see in the Objects section below) emptyDir (reference[EmptyDirVolumeSource]) Name: Empty directory Description: Temporary empty directory. Required: No Referenced object: EmptyDirVolumeSource (see in the Objects section below) ephemeral (reference[EphemeralVolumeSource]) Name: Ephemeral Description: Mount a volume that is handled by a cluster storage driver. Required: No Referenced object: EphemeralVolumeSource (see in the Objects section below) fc (reference[FCVolumeSource]) Name: Fibre Channel Description: Mount a Fibre Channel volume that's attached to the host machine. Required: No Referenced object: FCVolumeSource (see in the Objects section below) flexVolume (reference[FlexVolumeSource]) Name: Flex Description: Mount a generic volume provisioned/attached using an exec based plugin. Required: No Referenced object: FlexVolumeSource (see in the Objects section below) flocker (reference[FlockerVolumeSource]) Name: Flocker Description: Mount a Flocker volume. Required: No Referenced object: FlockerVolumeSource (see in the Objects section below) gcePersistentDisk (reference[GCEPersistentDiskVolumeSource]) Name: GCE disk Description: Google Cloud disk. Required: No Referenced object: GCEPersistentDiskVolumeSource (see in the Objects section below) glusterfs (reference[GlusterfsVolumeSource]) Name: GlusterFS Description: Mount a Gluster volume. Required: No Referenced object: GlusterfsVolumeSource (see in the Objects section below) hostPath (reference[HostPathVolumeSource]) Name: Host path Description: Mount volume from the host. Required: No Referenced object: HostPathVolumeSource (see in the Objects section below) iscsi (reference[ISCSIVolumeSource]) Name: iSCSI Description: Mount an iSCSI volume. Required: No Referenced object: ISCSIVolumeSource (see in the Objects section below) name (string) Name: Name Description: The name this volume can be referenced by. Required: Yes Maximum: 253 Must match pattern: ^[a-z0-9]($|[a-z0-9\\-_]*[a-z0-9])$ nfs (reference[NFSVolumeSource]) Name: NFS Description: Mount an NFS share. Required: No Referenced object: NFSVolumeSource (see in the Objects section below) persistentVolumeClaim (reference[PersistentVolumeClaimVolumeSource]) Name: Persistent Volume Claim Description: Mount a Persistent Volume Claim. Required: No Referenced object: PersistentVolumeClaimVolumeSource (see in the Objects section below) photonPersistentDisk (reference[PhotonPersistentDiskVolumeSource]) Name: PhotonController persistent disk Description: Mount a PhotonController persistent disk as a volume. Required: No Referenced object: PhotonPersistentDiskVolumeSource (see in the Objects section below) portworxVolume (reference[PortworxVolumeSource]) Name: Portworx Volume Description: Mount a Portworx volume. Required: No Referenced object: PortworxVolumeSource (see in the Objects section below) projected (reference[ProjectedVolumeSource]) Name: Projected Description: Projected items for all in one resources secrets, configmaps, and downward API. Required: No Referenced object: ProjectedVolumeSource (see in the Objects section below) quobyte (reference[QuobyteVolumeSource]) Name: quobyte Description: Mount Quobyte volume from the host. Required: No Referenced object: QuobyteVolumeSource (see in the Objects section below) rbd (reference[RBDVolumeSource]) Name: Rados Block Device Description: Mount a Rados Block Device. Required: No Referenced object: RBDVolumeSource (see in the Objects section below) scaleIO (reference[ScaleIOVolumeSource]) Name: ScaleIO Persistent Volume Description: Mount a ScaleIO persistent volume. Required: No Referenced object: ScaleIOVolumeSource (see in the Objects section below) secret (reference[SecretVolumeSource]) Name: Secret Description: Mount a Kubernetes secret. Required: No Referenced object: SecretVolumeSource (see in the Objects section below) storageos (reference[StorageOSVolumeSource]) Name: StorageOS Volume Description: Mount a StorageOS volume. Required: No Referenced object: StorageOSVolumeSource (see in the Objects section below) vsphereVolume (reference[VsphereVirtualDiskVolumeSource]) Name: vSphere Virtual Disk Description: Mount a vSphere Virtual Disk as a volume. Required: No Referenced object: VsphereVirtualDiskVolumeSource (see in the Objects section below) VsphereVirtualDiskVolumeSource (object) Type: object Properties None
"},{"location":"arcaflow/workflows/versioning/","title":"Workflow schema versions","text":""},{"location":"arcaflow/workflows/versioning/#valid-version-string","title":"Valid version string","text":"All workflow schema versions conform to semantic version 2.0.0 with a major, minor, and patch version. In this document, since the prepended v is unnecessary it is not used. However, it is required as a value for the version key in your workflow file.
Invalid version string for workflow.yaml.
version: 0.2.0\ninput:\nsteps:\noutputs:\nValid version string for workflow.yaml.
version: v0.2.0\ninput:\nsteps:\noutputs:\nFor the configuration file, config.yaml, two types of deployers are now possible, image and python, so deployer has become deployers. Effectively, the type key has become the deployer_name key. The deployer_name key and value are required which means you must also have either the image key or the python key.
deployers:\n image:\n deployer_name: docker|podman|kubernetes\n python:\n deployer_name: python\nFor your workflow file, workflow.yaml, the version key and value are required, and they must be at the root of the file.
version: v0.2.0\ninputs: {}\nsteps: {}\noutputs: {}\nArcalog is still in early development. A scientific paper describing the project is available as a preprint.
The README contains a guide on how to use Arcalog to gather data as well as how to use the --http flag to run a minimal user interface for downloading individual build IDs from Prow.
Pre-release developer documentation is also available if you want to use the early pre-release version of Arcalog to embed the data gathering steps into your own application.
"}]} \ No newline at end of file diff --git a/sitemap.xml b/sitemap.xml index d7d773e..8f725da 100644 --- a/sitemap.xml +++ b/sitemap.xml @@ -2,197 +2,197 @@