Schizophrenia is a chronic and serious mental disorder which affects how a person thinks, feels, and behaves. Although there have been many studies about psychological and behavioral manifestations of schizophrenia, neuroscientists have yet to determine a set of corresponding neurological biomarkers for this disorder. A functional magnetic resonance imaging (fMRI) can help determine non-invasive biomarkers for schizophrenia in brain function[1][2] and one such fMRI analysis technique called, dynamic functional network connectivity (dFNC)[3][4][10], uses K-Means clustering to characterize time-varying connectivity between functional networks. Researchers have worked on finding correlation between schizophrenia and dFNC[1][2][5][6], but little work has been done with the choice of clustering algorithm[7][9]. Therefore, in this project, we have studied how modifying the clustering technique in the dFNC pipeline can yield dynamic states from fMRI data that impact the accuracy of classifying schizophrenia[8].
We experimented with DBSCAN, Hiearcharial Clustering, Gaussian Mixture Models, and Bayesian Gaussian Mixture Models clustering methods on subject connectivity matrices produced from fMRI data, and each algorithm's cluster assignments as features for SVMs, MLP, Nearest Neighbor, and other supervised classification algorithms to classify schizophrenia.
Section II describes the fMRI data used in our experimentation, while Section III summarizes the aforementioned clustering and classification algorithms used in the pipeline. Section IV compares the accuracy of these classifiers, along with presenting a series of charts that analyze the cluster assignments produced on the fMRI data.
All datasets used in this project are derivatives of fMRI data (functional magnetic resonance imaging), which is data measuring brain activity to track a patient's thought processs over a predefined time period.
We derive our own synthetic dataset in order to test out our clusterers and classifiers on a simulated dataset for sanity checking their implementation.
The data set was generated by a seed set of
For each subject, we generate a source signal of sime
For each class, we simulate baseline signal noise from a normal distribution, which the relevant source signal being added to that baseline.
Formally a single subjects signal within a window of size W is given as:
where
The probability for entering from state
The addition of noise, and the fact that windows are created with a size
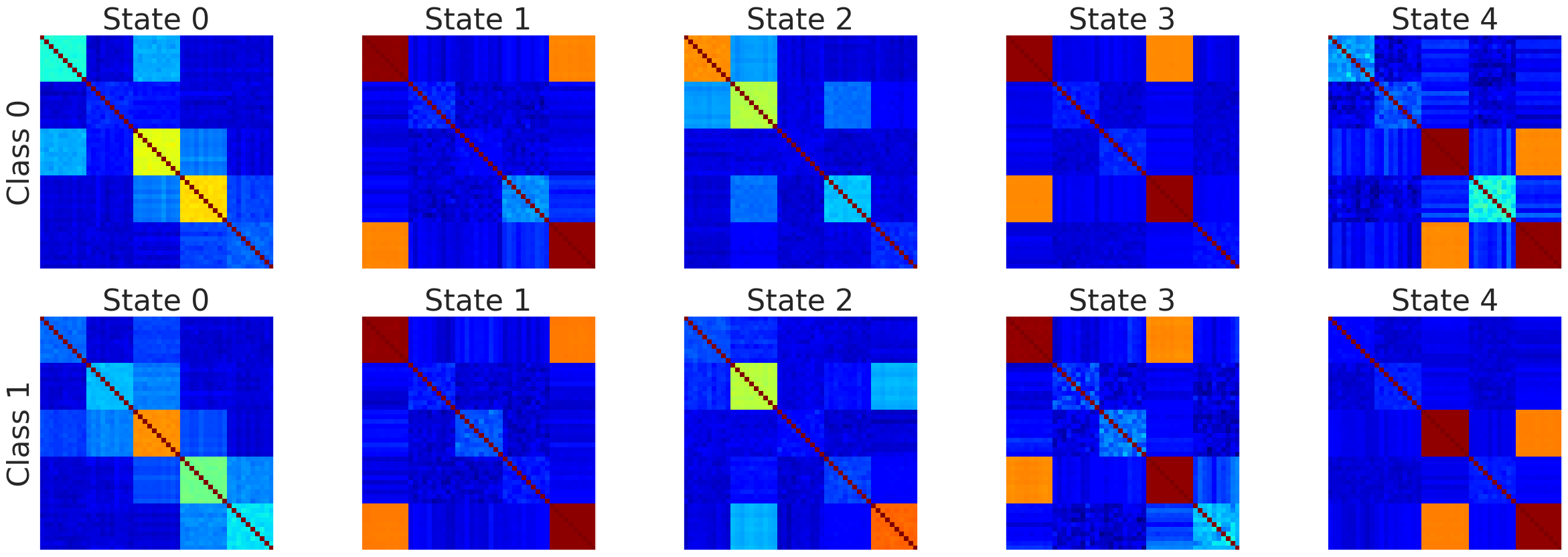
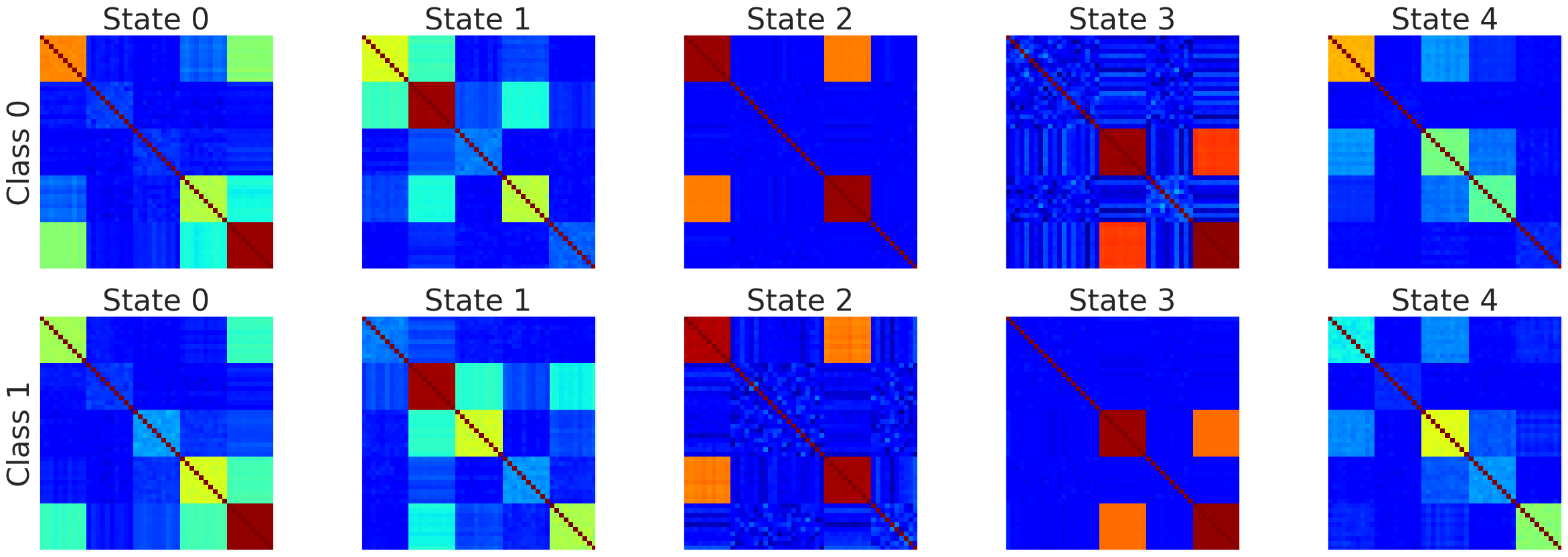
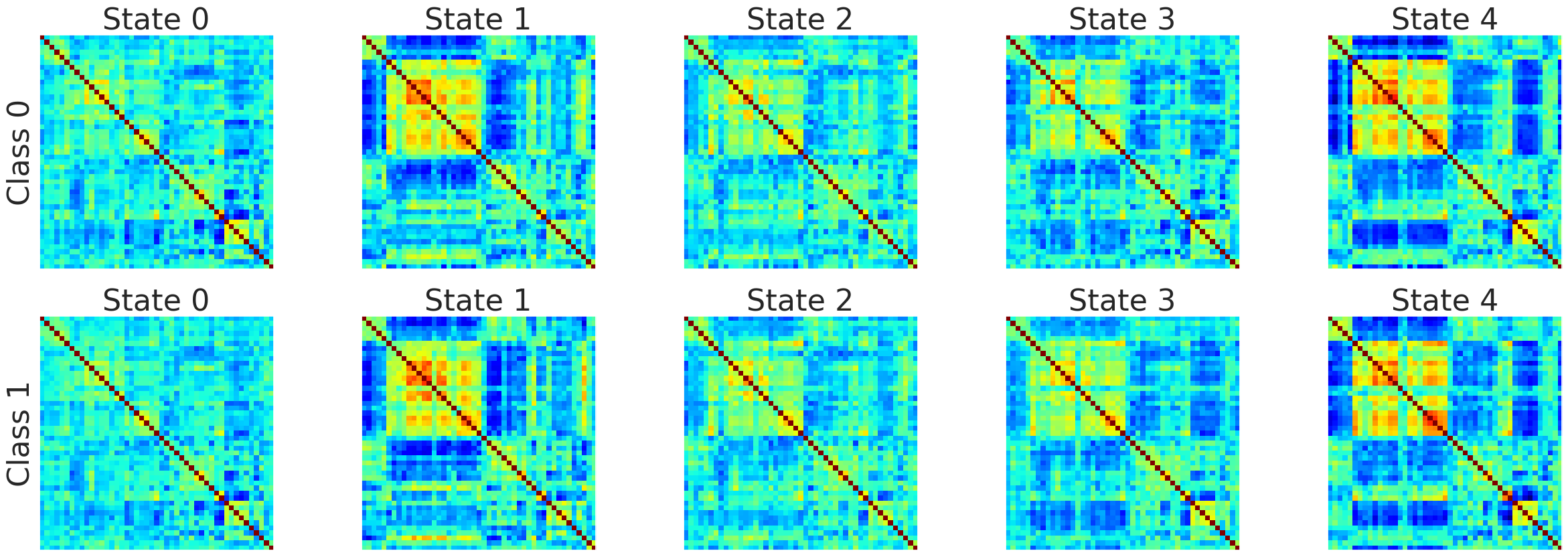
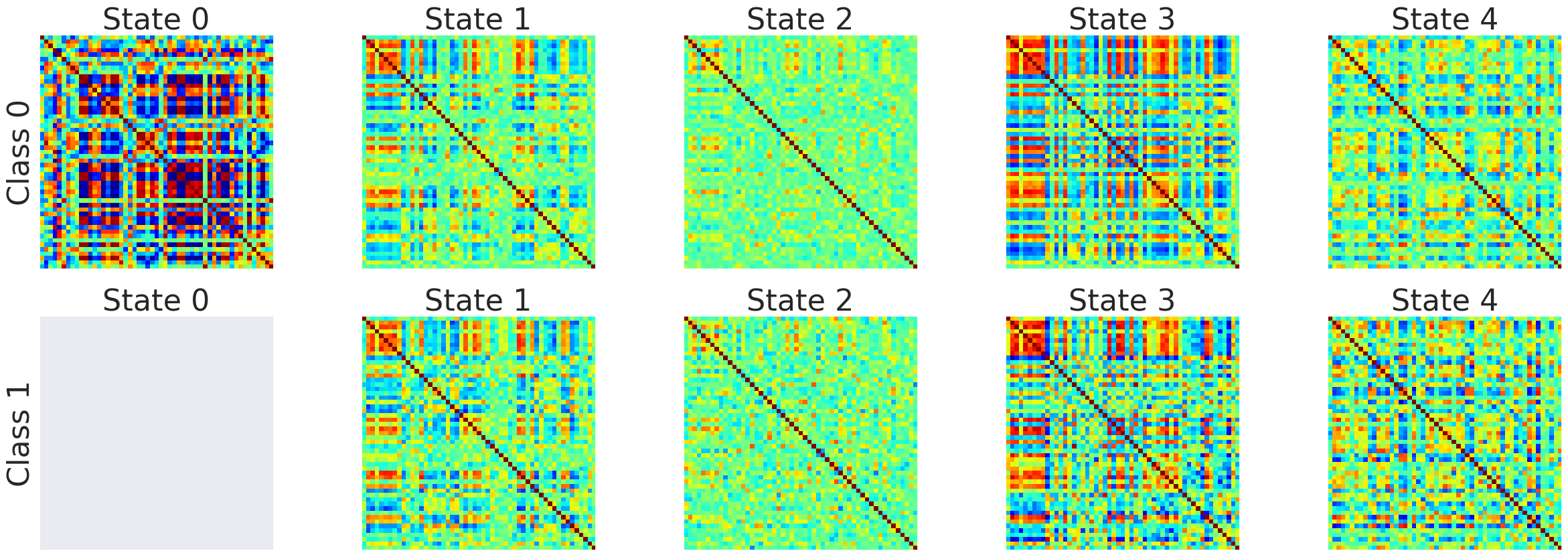
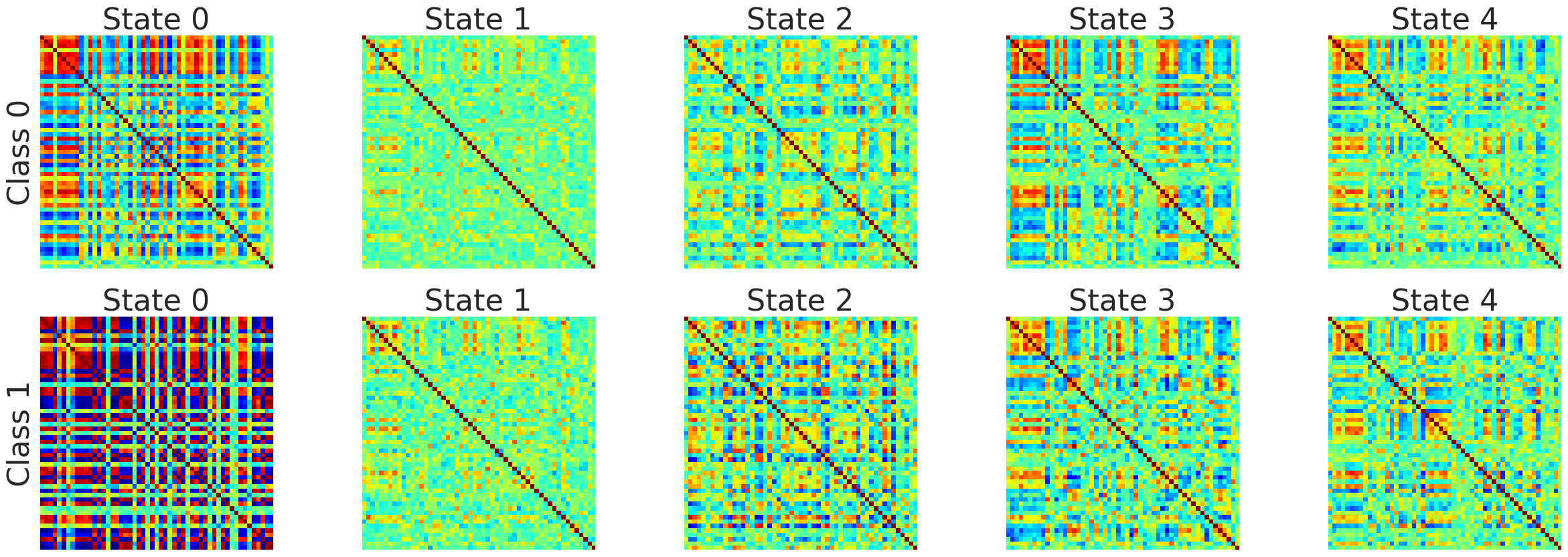
For example the following connectivity matrices were computed from randomly selected subjects from each class, for each state:
| Class | State 0 | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|---|
| 0 | 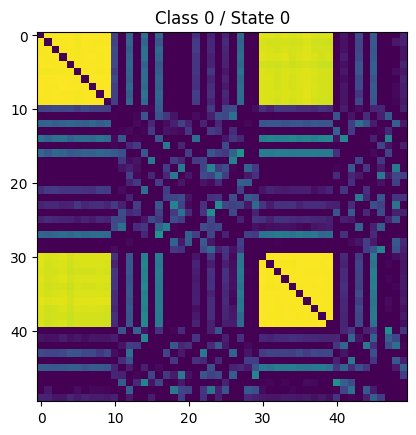 |
 |
 |
 |
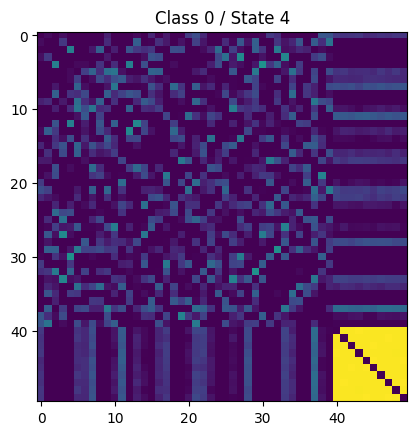 |
| 1 | 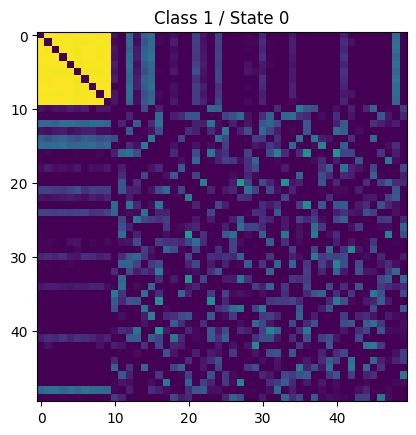 |
 |
 |
 |
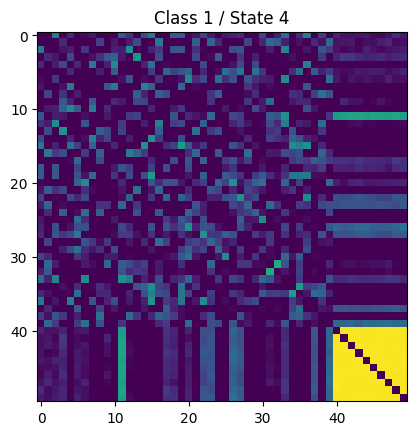 |
For our simulation we generate
The parameters for
| Class Parameter | State 0 | State 1 | State 2 | State 3 | State 4 |
|---|---|---|---|---|---|
| 0.4 | 0.1 | 0.1 | 0.3 | 0.1 | |
| $P_(c=1,k)% | 0.1 | 0.1 | 0.3 | 0.1 | 0.4 |
We use derivatives from the Phase 3 Dataset of FBIRN (Functional Biomedical Infromatics Research Network Data Repository), which specifically focuses on brain activity maps from patients with schizophrenia. This dataset includes 186 healthy controls and 176 indivduals from schizophrenia from around the United States. Subject participants in this dataset are between the ages of 18-62.
We also use derivatives from the UCLA Consortium for Neuropsychiatric Phenomics archives, which includes neuroimages for roughly 272 participants. The subject population consists of roughly 272 healthy controls, as well as participants with a diagnosis of schizophrenia (50 subjects). Subject participants in this dataset range from 21 to 50 years
.png?raw=True)
As is standard in Dynamic Functional Network Connectivity, Group Independent Component Analysis of subject images is used to compute a set of
For all data-sets we chose a sliding window of size
We computed correlation coefficients across the components, within each time series window to form the FNC matrix with entries
Through this process, we generat a total of
We implemented 5 different clustering algorithms as part of the dFNC pipeline: K-Means, DBSCAN, Gaussian Mixture Models, Bayesian Gaussian Mixture Models, and Agglomerative Hierarchical Clustering.
For K-Means, GMM, bGMM, and Agglomerative clustering, we measured the elbow criterion on a range of 2-9 components. We measured both the correlation-distance dispersion, as is recommended in Damaraju et al. 2014 [], as well as the silhouette measure. The results from this analysis are included below. In general, we found either unclear or multiple elbows in the range
| Gaussian | Fbirn | UCLA |
|---|---|---|
 |
 |
 |
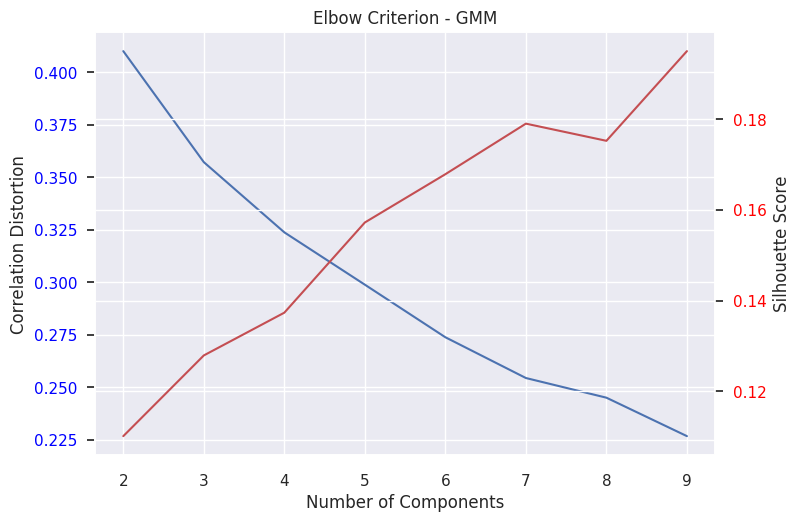 |
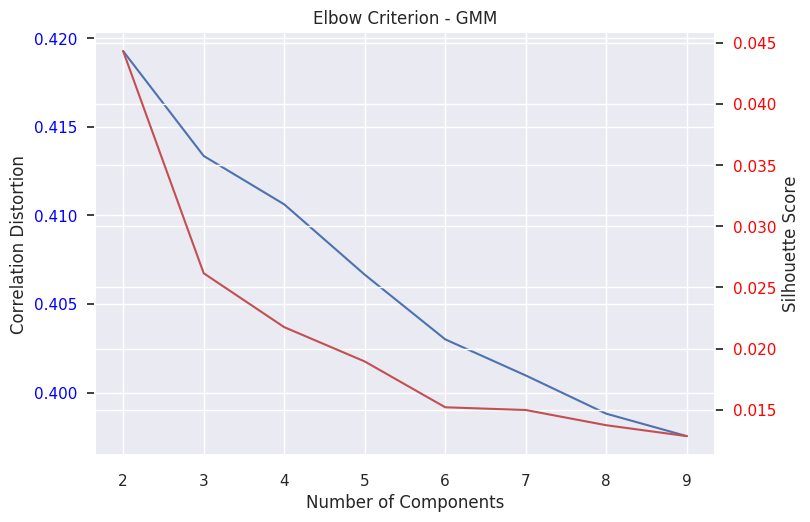 |
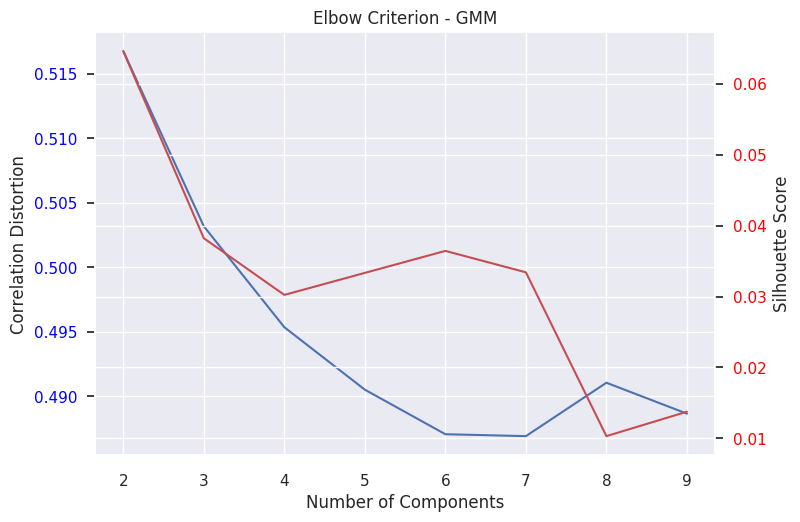 |
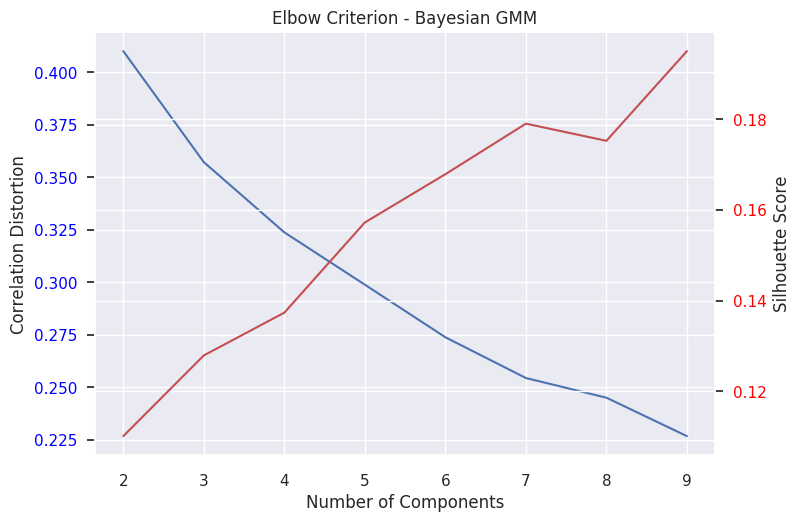 |
 |
 |
 |
 |
 |
As features for generation, we follow the precedent in [], and compute means of clusters for each class, and use these centers to form a regression matrix of size
For our evaluation metric, we used the Area-Under the "Receiving Operating Characteric" (ROC) curve, or AUC.
We performed a Grid-Search over all available parameters for each of the classifiers available in Polyssifier. For each set of training data used for cross-validation, we trained the grid-search separately, and took the parameters with the highest AUC.
In order to evaluate the predictive capacities of the features produced by each clustering algorithm, we performed a two-tailed t-test comparing healthy and schizophrenic patients.
The first t-test compared cluster assignments for each patient across the time domain where each time slot represented a feature of the dataset. For each time slot, the average cluster assignment for all the healthy control patients was compared to the average cluster assignment for all the schizophrenic patients. We tested for statistically different averages at each time point using a p-value of 0.10.
The results displayed below highlight the points in time when there was less that a 10% chance that the observed difference in a healthy control's cluster assignment and a schizophrenic's cluster assignment was due to normal random variation. In theory, the more points of significance across time the more likely a trained model would accurately diagnose a subject. The results indicated that both K-Means and Gaussian Mixture Models failed to produce statistically different cluster assignments across time. The Bayesian Gaussian Mixture Model produced some significant differences while the Hierarchical clustering was significant at every time point.
We initially believed that Hierarchical clustering would outperform all the other clustering algorithms, but the subsequent testing with supervised learning models refuted this hypothesis.

Given the lack of improvement in accuracy across all clustering algorithms, we believed that training supervised models using time points as features would require much more data for successful classification. Using time slots as features meant that there were 130 features in the data. Since there were only 267 patients in the UCLA data set, it was surmised that the dimensionality of the data was too high. To reduce the dimensionality of the datasets, the beta coefficients were calculated reducing the number of training features form 130 to 10.

We performed the same t-test calculations for the generated beta features. Each clustering algorithm produced statistically different beta coefficients between healthy and schizophrenic patients. With the reduced dimensionality of the data, we successfully improved the accuracy of our diagnoses across all supervised learning algorithms for each clustering algorithm. These results are discussed later in the report.
For all results, the Area Under Curve (AUC) metric was used since we were trying to classify two possible outcomes. Patients were with either healthy or had schizophrenia. AUC scores near 0.50 meant that the models randomly diagnosed patients as healthy or schizophrenic. This represented the worst possible outcome. Any model with and AUC scores between 0.40 and 0.60 was deemed a failed model. AUC scores near 1.0 meant that diagnoses were accurate with few false positives (high specificity) and few false negatives (high recall). There were no observed models that completely reversed the diagnoses with AUC scores near 0.0.
We initially trained the supervised learning algorithms using simulated Gaussian datasets since we did not have access to the real patient data until later in the semester. We first trained the supervised learning models without any clustering in order to establish a baseline AUC scores for our clustering algorithms to improve upon. These baseline results are displayed below.

The key result from this experiment was that without any clustering, no supervised learning algorithm could consistently achieve AUC score above 0.60. Some learners such as the Multilayer Perceptron, Passive Aggressive Classifier, and Bernoulli Naive Bayes surprisingly scored below 0.40 suggesting that they consistently misdiagnose patients. We attributed these results as being due to random error.
After establishing the baseline AUC scores, we performed clustering and beta feature generation for the simulated Gaussian datasets. Using these clustered and reduced datasets, we trained across the same classifiers to for each clustering algorithm (K-Means, Gaussian Mixture Model, Bayesian Gaussian Mixture Model, DBSCAN, and Hierarchical). The results are displayed below.
| Clustering Algorithm | Multilayer Perceptron | Nearest Neighbors | SVM | Random Forest | Extra Trees | Gradient Boost | Logistic Regression | Passive Aggressive Classifier |
|---|---|---|---|---|---|---|---|---|
| kmeans | 0.972 ± 0.026 | 0.96 ± 0.021 | 0.972 ± 0.023 | 0.962 ± 0.027 | 0.966 ± 0.024 | 0.954 ± 0.031 | 0.971 ± 0.022 | 0.974 ± 0.02 |
| gmm | 0.963 ± 0.028 | 0.954 ± 0.03 | 0.972 ± 0.025 | 0.967 ± 0.022 | 0.976 ± 0.017 | 0.928 ± 0.046 | 0.962 ± 0.028 | 0.97 ± 0.024 |
| bgmm | 0.966 ± 0.023 | 0.949 ± 0.028 | 0.974 ± 0.027 | 0.966 ± 0.026 | 0.963 ± 0.028 | 0.962 ± 0.03 | 0.974 ± 0.02 | 0.972 ± 0.024 |
| dbscan | 0.971 ± 0.024 | 0.952 ± 0.025 | 0.972 ± 0.022 | 0.961 ± 0.024 | 0.965 ± 0.023 | 0.962 ± 0.022 | 0.967 ± 0.025 | 0.968 ± 0.026 |
| hierarchical | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.0 | 1.0 ± 0.001 | 1.0 ± 0.0 | 1.0 ± 0.0 |
| Clustering Algorithm | Perceptron | Gaussian Process | Ada Boost | Voting | Bernoulli Naive Bayes | Bagging | Decision Tree |
|---|---|---|---|---|---|---|---|
| kmeans | 0.947 ± 0.062 | 0.955 ± 0.027 | 0.957 ± 0.032 | 0.92 ± 0.037 | 0.948 ± 0.022 | 0.941 ± 0.035 | 0.938 ± 0.036 |
| gmm | 0.962 ± 0.028 | 0.952 ± 0.029 | 0.955 ± 0.031 | 0.92 ± 0.045 | 0.938 ± 0.028 | 0.917 ± 0.036 | 0.923 ± 0.033 |
| bgmm | 0.969 ± 0.029 | 0.955 ± 0.029 | 0.958 ± 0.029 | 0.923 ± 0.045 | 0.949 ± 0.028 | 0.931 ± 0.043 | 0.933 ± 0.026 |
| dbscan | 0.957 ± 0.035 | 0.96 ± 0.032 | 0.967 ± 0.028 | 0.913 ± 0.034 | 0.93 ± 0.031 | 0.93 ± 0.036 | 0.943 ± 0.022 |
| hierarchical | 1.0 ± 0.0 | 1.0 ± 0.001 | 0.999 ± 0.002 | 0.993 ± 0.014 | 0.991 ± 0.009 | 0.983 ± 0.016 | 0.969 ± 0.035 |
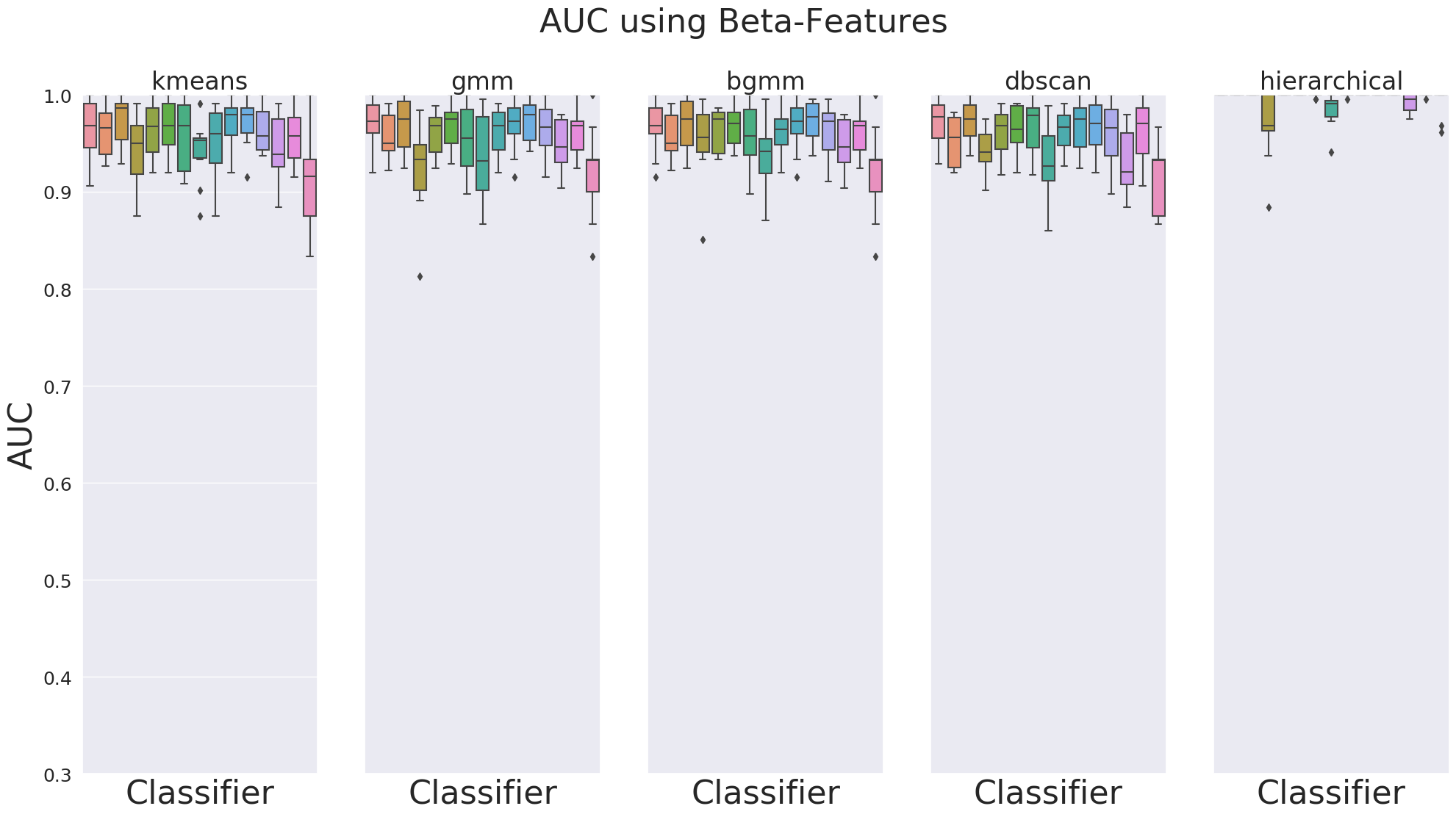

The clustering combined with the beta feature generation dramatically improved the AUC scores on the simulated Gaussian datasets. All clustering algorithms produced AUC scores above 0.90 with standard deviations below 0.05 across all supervised models. The hierarchical clustering even produced perfect predictions. These results confirmed our suspicions that in order to accurately diagnose patients, we needed to perform clustering and reduce the number of features we trained our models on. These initial results using simulated data helped us tremendously when deploying our models on real patient data.



Visualization of clusters with KMeans clustering in 2-d and 3-d with Gaussian Simulated Data

Visualization of clusters with GMM clustering in 2-d and 3-d with Gaussian Simulated Data


Visualization of clusters with BGMM clustering in 2-d and 3-d with Gaussian Simulated Data



Visualization of clusters with DBSCAN clustering in 2-d and 3-d with Gaussian Simulated Data

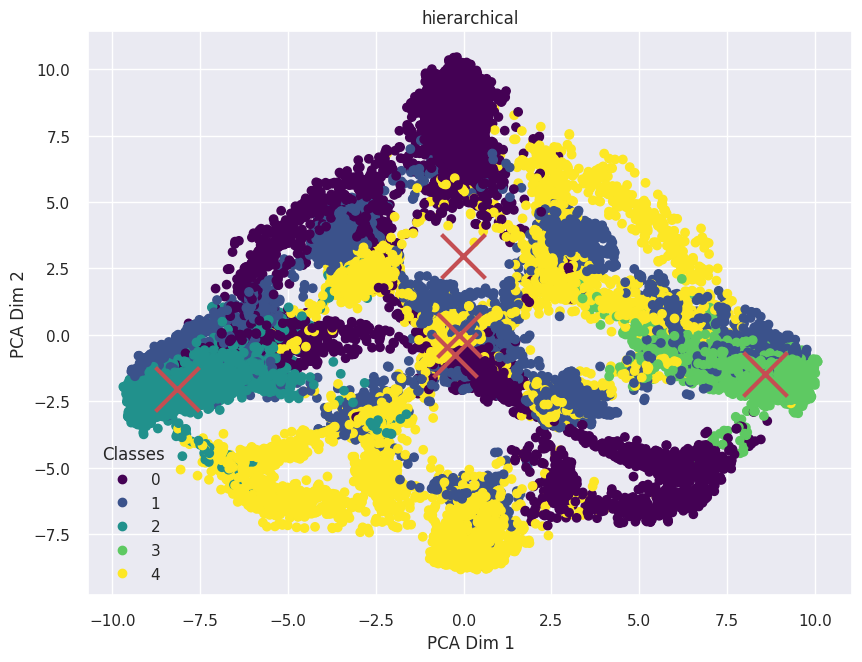
Visualization of clusters with Hierarchical clustering in 2-d and 3-d with Gaussian Simulated Data
We trained the FBIRN dataset in same manner as the simulated Guassian dataset. First, we trained the the supervised learning models without any clustering or beta feature generation to establish a baseline accuracy. As expected, the classifiers failed to consistently achieve AUC scores outside of the 0.40-0.60 range suggesting that all the models produced random diagnoses. The baseline results are displayed below.

Next we trained the models on the FBIRN data using only cluster assignments. No beta features were generated to reduce the dimensionality of the dataset. The results are displayed below.

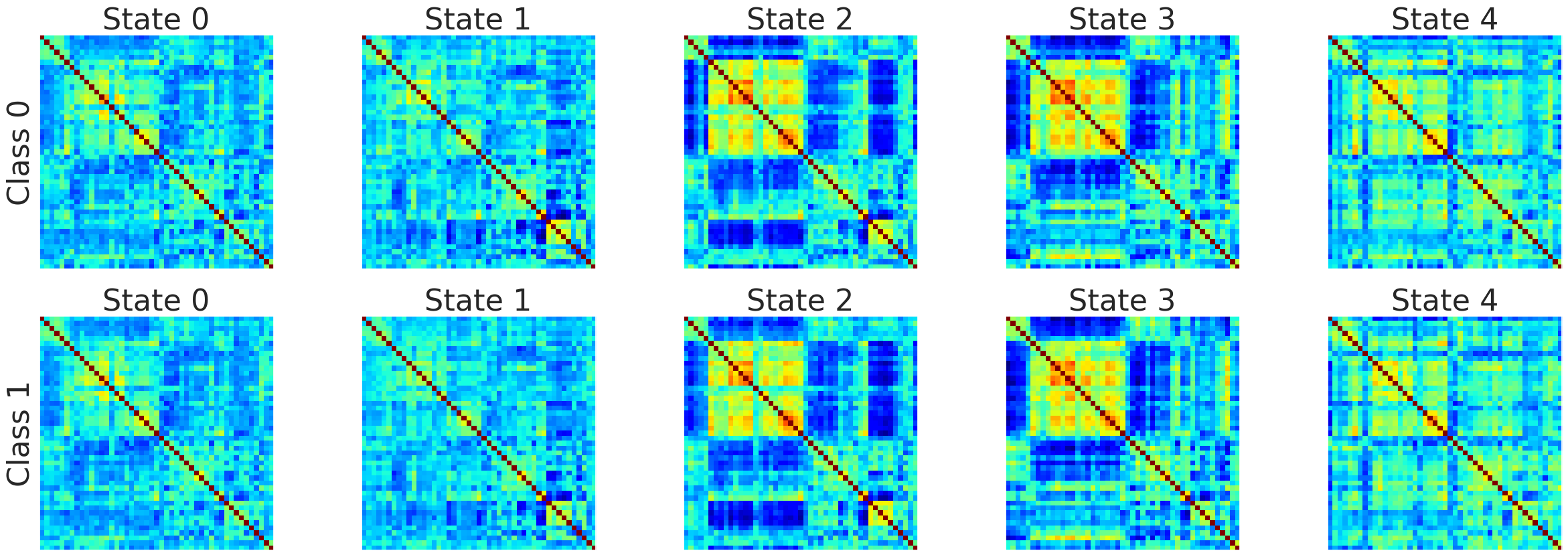
The results indicated that most clustering algorithms could lift the AUC scores to an average of 0.70 with the exclusion the Voting learner. K-Means, Gaussian Mixture Models, Bayesian Gaussian Mixture Model all produced similar AUC scores suggesting that each clustering algorithm discovered the same centroids in the FBIRN data. DBSCAN failed to find a sufficient number of centroids in the FBIRN data to improve AUC scores. DBSCAN only found 2 centroids as opposed to 5 centroids found by all other clustering algorithms.
Regardless, none of these models achieved a high enough score to be used in a clinical environment. We surmised that the number of features in the datasets needed to be reduced from cluster assignments over time to beta features in order for the supervised learning models to accurately diagnose patients.
After generating the beta feature, we obtained much higher AUC score across all the clustering algorithms. The final results for the FBIRN dataset are displayed below.
| Clustering Algorithm | SVM | Multilayer Perceptron | Logistic Regression | Passive Aggressive Classifier | Perceptron | Random Forest | Extra Trees |
|---|---|---|---|---|---|---|---|
| kmeans | 0.952 ± 0.036 | 0.92 ± 0.065 | 0.944 ± 0.039 | 0.945 ± 0.035 | 0.902 ± 0.043 | 0.871 ± 0.038 | 0.853 ± 0.04 |
| gmm | 0.936 ± 0.054 | 0.946 ± 0.038 | 0.943 ± 0.038 | 0.929 ± 0.031 | 0.882 ± 0.04 | 0.885 ± 0.022 | 0.874 ± 0.026 |
| bgmm | 0.955 ± 0.037 | 0.932 ± 0.042 | 0.945 ± 0.038 | 0.939 ± 0.038 | 0.896 ± 0.074 | 0.86 ± 0.039 | 0.87 ± 0.056 |
| dbscan | 0.883 ± 0.027 | 0.893 ± 0.031 | 0.892 ± 0.033 | 0.884 ± 0.027 | 0.828 ± 0.064 | 0.805 ± 0.064 | 0.806 ± 0.058 |
| hierarchical | 0.957 ± 0.032 | 0.954 ± 0.038 | 0.953 ± 0.038 | 0.951 ± 0.032 | 0.891 ± 0.098 | 0.881 ± 0.032 | 0.872 ± 0.048 |

The reduced number of training features increased the accuracy of all the learners with Support Vector Machines obtaining the highest accuracy across all clustering algorithms. Only DBSCAN failed to get above an average AUC score of 0.90 for Support Vector Machines and Hierarchical Clustering obtained this highest score of 0.957.
Gaussian Mixture Models and Bayesian Mixture Models showed slight improvement over K-Means clustering. DBSCAN did not outperform K-Means, but it did improve to an AUC score of 0.883 following beta feature generation. In short, Hierarchical Clustering performed the best when classifying the FBIRN dataset.


Visualization of clusters with KMeans clustering in 2-d and 3-d with FBirn Data



Visualization of clusters with GMM clustering in 2-d and 3-d with FBirn Data
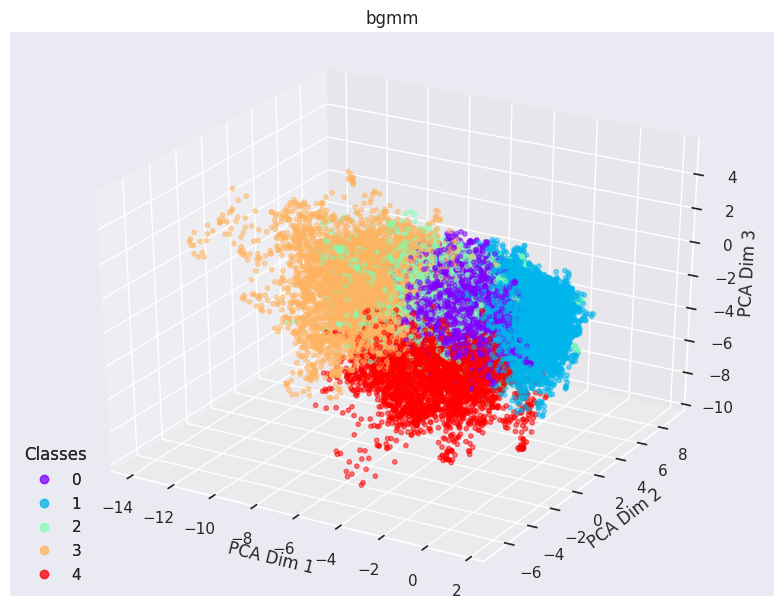

Visualization of clusters with BGMM clustering in 2-d and 3-d with FBirn Data



Visualization of clusters with DBSCAN clustering in 2-d and 3-d with FBirn Data


Visualization of clusters with Hierarchical clustering in 2-d and 3-d with FBirn Data
Following the training of the FBIRN dataset, we began training the UCLA dataset. First, we used performed to clustering to establish a baseline to compare the clustering algorithms against. The results are displayed below.

Surprisingly, the UCLA was much easier to classify without any clustering nor beta feature generation. This AUC scores were within 0.70 and 0.80 region which meant that using dFNC alone enabled supervised learning models could somewhat classify healthy and schizophrenic patients. To uncover why this was the case, we decided to plot PCAs for the dFNC windows and label the points according to whether a patient had schizophrenia or not.
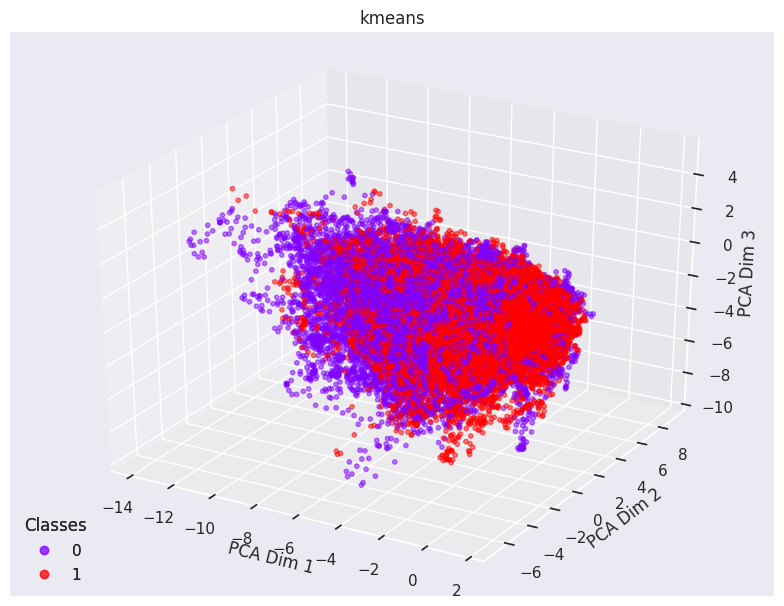
 Visualisation of dFNC before clustering for FBIRN and UCLA datasets.
Visualisation of dFNC before clustering for FBIRN and UCLA datasets.
We noticed that the PCA feature space of the UCLA dataset was much more separable than the FBIRN dataset. Note how the FBIRN data has much more mixing of healthy and schizophrenic patients over the PCA dimensions of dFNC. We believed that this led to the relatively higher AUC scores for the UCLA dataset before clustering algorithms were applied.
After analyzing the relatively high AUC scores of the UCLA datasets, we performed our usual analysis. We applied our clustering algorithms and trained our supervised learning models on the beat features. The final results are displayed below.
| Clustering Algorithm | SVM | Multilayer Perceptron | Logistic Regression | Passive Aggressive Classifier | Perceptron | Extra Trees | Random Forest |
|---|---|---|---|---|---|---|---|
| kmeans | 0.907 ± 0.057 | 0.907 ± 0.057 | 0.904 ± 0.06 | 0.896 ± 0.08 | 0.799 ± 0.116 | 0.724 ± 0.168 | 0.746 ± 0.133 |
| gmm | 0.91 ± 0.059 | 0.909 ± 0.07 | 0.908 ± 0.071 | 0.885 ± 0.087 | 0.886 ± 0.058 | 0.795 ± 0.095 | 0.785 ± 0.108 |
| bgmm | 0.909 ± 0.075 | 0.907 ± 0.081 | 0.908 ± 0.08 | 0.877 ± 0.105 | 0.879 ± 0.081 | 0.741 ± 0.157 | 0.705 ± 0.166 |
| dbscan | 0.409 ± 0.118 | 0.467 ± 0.131 | 0.69 ± 0.096 | 0.667 ± 0.122 | 0.5 ± 0.0 | 0.643 ± 0.171 | 0.649 ± 0.125 |
| hierarchical | 0.886 ± 0.054 | 0.889 ± 0.07 | 0.9 ± 0.069 | 0.883 ± 0.071 | 0.826 ± 0.122 | 0.829 ± 0.099 | 0.792 ± 0.114 |

Accuracy from the baseline cases with AUC scores on average increasing from 0.70. to 0.90 for multiple learners such as Support Vector Machines and Multilayer Perceptron. Interestingly not all learners improved their AUC scores even after performing the clustering and beta feature generation. For instance, the DBSCAN reduced the AUC scores from the baseline 0.70 to 0.50. We believe that the DBSCAN's sensitivity to hyperparameter changes led it to over classify different clusters leading to poor classification results. Furthermore, there was increased variability in the AUC scores especially for Decision Tree, Random Forest, and Bagging.
In brief, all the clustering algorithms with the exclusion of DBSCAN showed improvement over KMeans clustering and the baseline case of no clustering. The Gaussian Mixture Model had the highest accuracy beating out Hierarchical Clustering which performed the best on the FBIRN dataset.

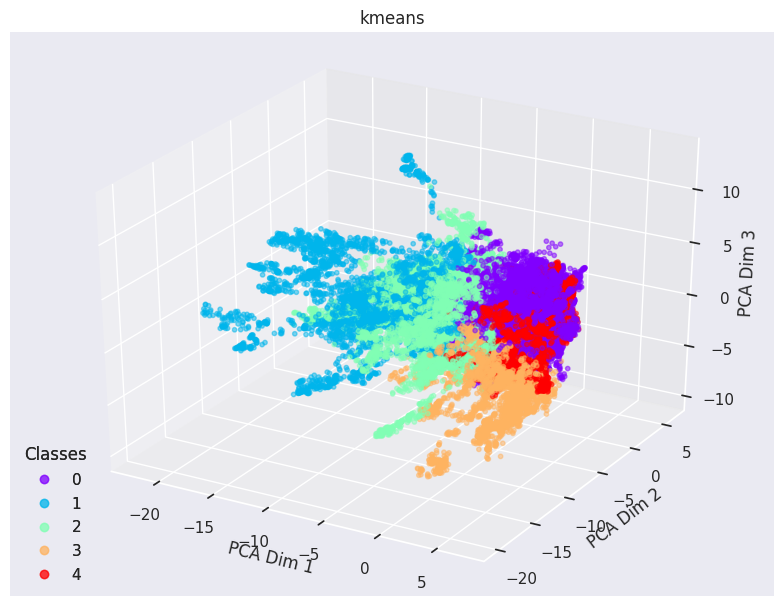
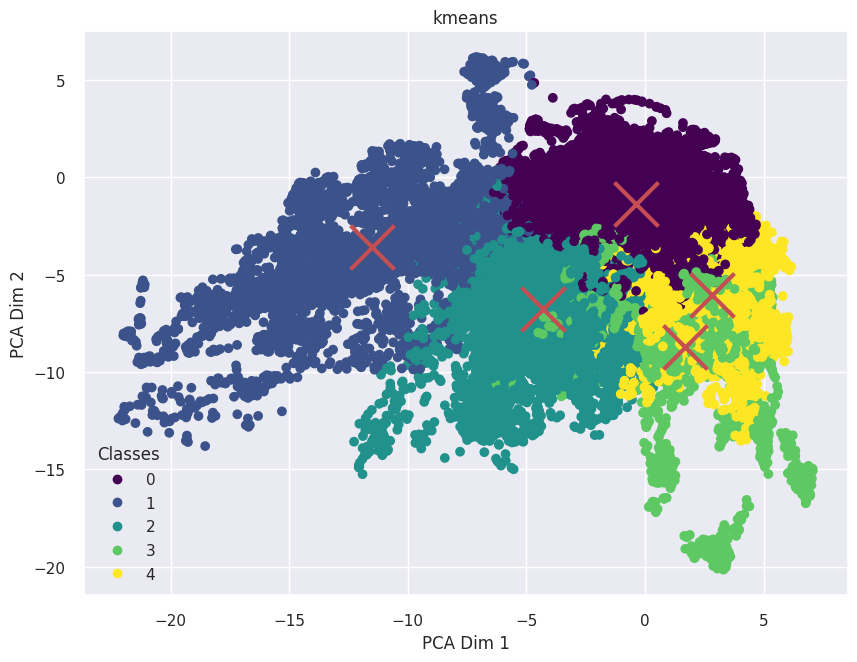
Visualization of clusters with KMeans clustering in 2-d and 3-d with UCLA Data


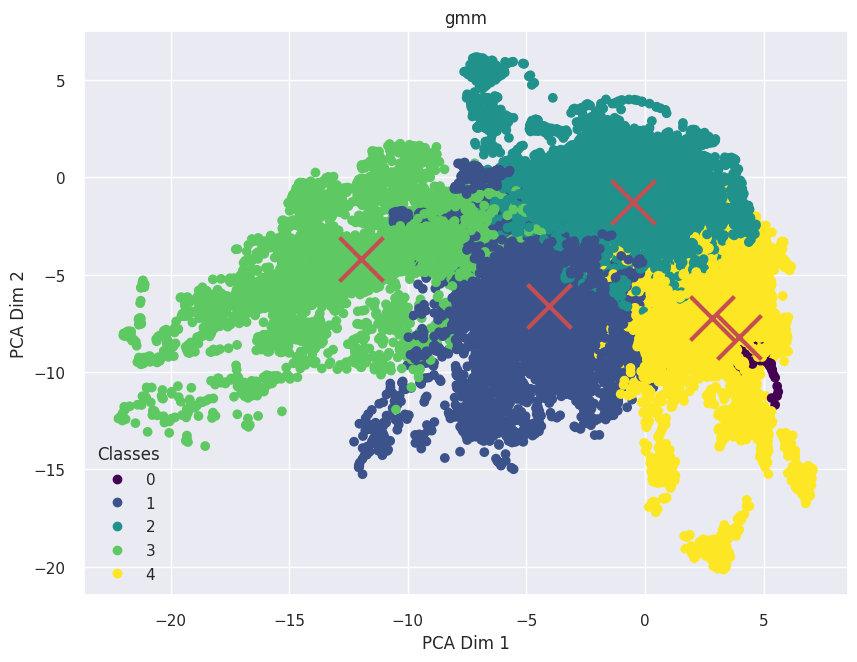
Visualization of clusters with GMM clustering in 2-d and 3-d with UCLA Data


Visualization of clusters with BGMM clustering in 2-d and 3-d with UCLA Data



Visualization of clusters with DBSCAN clustering in 2-d and 3-d with UCLA Data


Visualization of clusters with Hierarchical clustering in 2-d and 3-d with UCLA Data
dFNCluster implements Dynamic Functional Network Connectivity (dFNC) with several clustering algorithms, and actively compares the performance of classification under different clustering algorithms and hyper-parameters.
First, install git submodules
git submodule update --init --recursive
This project has been tested in Python 3.6+
It is recommended you use a conda virtual environment.
conda create -y --name dfncluster
and install requirements via pip
pip install -r requirements.txt
You can run main.py with the arguments given below, or look at them by running python main.py --help
usage: main.py [-h] [--dataset DATASET] [--remake_data REMAKE_DATA]
[--clusterer CLUSTERER] [--window_size WINDOW_SIZE]
[--time_index TIME_INDEX] [--clusterer_params CLUSTERER_PARAMS]
[--classifier_params CLASSIFIER_PARAMS] [--outdir OUTDIR]
[--dfnc DFNC] [--classify CLASSIFY] [--subset_size SUBSET_SIZE]
[--dfnc_outfile DFNC_OUTFILE] [--seed SEED] [--k K]
optional arguments:
-h, --help show this help message and exit
--dataset DATASET <str> the data set to use. Options are fbirn, simtb,
gaussian; DEFAULT=fbirn
--remake_data REMAKE_DATA
<bool> whether or not to remake the data set;
DEFAULT=False
--clusterer CLUSTERER
<str> the clusterer to use. Options are kmeans, bgmm,
gmm, dbscan; DEFAULT=kmeans
--window_size WINDOW_SIZE
<int> the size of the dFNC window; DEFAULT=22
--time_index TIME_INDEX
<int> the dimension in which dFNC windows will be
computed; DEFAULT=1
--clusterer_params CLUSTERER_PARAMS
<str(dict)> dict to be loaded for classifier
params(JSON); DEFAULT="{}"
--classifier_params CLASSIFIER_PARAMS
<str(dict)> dict to be loaded for classifier params
(JSON); DEFAULT="{}"
--outdir OUTDIR <str> Name of the results directory. Saving hierarchy
is: results/<outdir>; DEFAULT=FNCOnly
--dfnc DFNC <bool> Do or do not run dFNC; DEFAULT=True
--classify CLASSIFY <bool> Do or do not do classification; DEFAULT=True
--subset_size SUBSET_SIZE
<float [0,1]> percentage of data to use; DEFAULT=1.0
(all data)
--dfnc_outfile DFNC_OUTFILE
<str> The filename for saving dFNC results;
DEFAULT=dfnc.npy
--seed SEED <int> Seed for numpy RNG. Used for random generation
of the data set, or for controlling randomness in
Clusterings.; DEFAULT=None (do not use seed)
--k K <int> number of folds for k-fold cross-validation
To generate a data set from SKlearn for testing purposes, you can generate one of the datasets in data/SklearnDatasets.
For example, the moons data set can be generated as follows:
PYTHONPATH=. python data/SklearnDatasets/Moons/Moons.py
which will save moons.npy in the data/SklearnDatasets/Moons directory.
The following datasets have been included as examples:
- Moons
- Classification (sklearn.datasets.make_classification)
- Blobs (sklearn.datasets.make_blobs)
- MNIST (sklearn.datasets.fetch_openml(name='mnist_...)
- Iris (sklearn.datasets.load_iris)
To run with the pre-computed ICA Timecourses from real data, run the following
first, untar the data
cd data/MatDatasets/FbirnTC
tar -xzf subjects.tar.gz
back in the dfncluster directory, build the data set, which serializes the data set object as a pickled npy file
PYTHONPATH=. python data/MatDatasets/FbirnTC/FbirnTC.py
And run the main function, which performs dFNC analysis, and classification using cluster assignments, and raw states for comparison
PYTHONPATH=. python main.py
To run with the pre-computed ICA Timecourses, run the following
first, untar the simulated data
cd data/MatDatasets/OmegaSim
tar -xzf subjects.tar.gz
back in the dfncluster directory, build the simulations data set, which serializes the data set object as a pickled npy file
PYTHONPATH=. python data/MatDatasets/OmegaSim/OmegaSim.py
To run on a subset of the simulated data set, you can either edit data.csv in the data directory, and rebuild, or copy that directory under a new name, edit, rebuild and point main.py to the new data set.
[1]. Eswar Damaraju et al. “Dynamic functional connectivity analysis reveals transient states of dyscon-nectivity in schizophrenia”. In:NeuroImage: Clinical5 (2014), pp. 298–308.
[2]. Mustafa S Salman et al. “Group ICA for identifying biomarkers in schizophrenia:‘Adaptive’networks viaspatially constrained ICA show more sensitivity to group differences than spatio-temporal regression”.In:NeuroImage: Clinical22 (2019), p. 101747.
[3]. Elena A Allen et al. “Tracking whole-brain connectivity dynamics in the resting state”. In:Cerebralcortex24.3 (2014), pp. 663–676.
[4]. D. Zhi et al., "Abnormal Dynamic Functional Network Connectivity and Graph Theoretical Analysis in Major Depressive Disorder," 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, 2018, pp. 558-561.
[5]. U Sakoglu, AM Michael, and VD Calhoun. “Classification of schizophrenia patients vs healthy controlswith dynamic functional network connectivity”. In:Neuroimage47.1 (2009), S39–41.
[6]. Unal Sako ̆glu et al. “A method for evaluating dynamic functional network connectivity and task-modulation: application to schizophrenia”. In:Magnetic Resonance Materials in Physics, Biology andMedicine23.5-6 (2010), pp. 351–366.
[7]. V. M. Vergara, A. Abrol, F. A. Espinoza and V. D. Calhoun, "Selection of Efficient Clustering Index to Estimate the Number of Dynamic Brain States from Functional Network Connectivity*," 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 2019, pp. 632-635.
[8]. D. K. Saha, A. Abrol, E. Damaraju, B. Rashid, S. M. Plis and V. D. Calhoun, “Classification As a Criterion to Select Model Order For Dynamic Functional Connectivity States in Rest-fMRI Data,” 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 2019, pp. 1602-1605.
[9]. Pedregosa et al. “2.3. Clustering.” Scikit, scikit-learn.org/stable/modules/clustering.html.
[10]. Rashid, Barnaly, et al. “Classification of Schizophrenia and Bipolar Patients Using Static and Dynamic Resting-State FMRI Brain Connectivity.” NeuroImage, vol. 134, 2016, pp. 645–657., doi:10.1016/j.neuroimage.2016.04.051.