diff --git a/zh/_blog.yml b/zh/_blog.yml
index 698e40dbb9..d2ce2396a6 100644
--- a/zh/_blog.yml
+++ b/zh/_blog.yml
@@ -1427,6 +1427,17 @@
- llm
- training
+- local: quanto-introduction
+ title: "Quanto:PyTorch 量化工具包"
+ author: dacorvo
+ thumbnail: /blog/assets/169_quanto_intro/thumbnail.png
+ date: March 18, 2024
+ tags:
+ - guide
+ - quantization
+ - transformers
+ - diffusers
+
- local: cloudflare-workers-ai
title: 为 Hugging Face 用户带来无服务器 GPU 推理服务
author: philschmid
@@ -1437,4 +1448,3 @@
- cloudflare
- llm
- inference
-
\ No newline at end of file
diff --git a/zh/quanto-introduction.md b/zh/quanto-introduction.md
new file mode 100644
index 0000000000..ceb593b22e
--- /dev/null
+++ b/zh/quanto-introduction.md
@@ -0,0 +1,229 @@
+---
+title: "Quanto:PyTorch 量化工具包"
+thumbnail: /blog/assets/169_quanto_intro/thumbnail.png
+authors:
+- user: dacorvo
+- user: ybelkada
+- user: marcsun13
+translators:
+- user: MatrixYao
+- user: zhongdongy
+ proofreader: true
+---
+
+# Quanto: PyTorch 量化工具包
+
+量化技术通过用低精度数据类型 (如 8 位整型 (int8) ) 来表示深度学习模型的权重和激活,以减少传统深度学习模型使用 32 位浮点 (float32) 表示权重和激活所带来的计算和内存开销。
+
+减少位宽意味着模型的内存占用更低,这对在消费设备上部署大语言模型至关重要。量化技术也使得我们可以针对较低位宽数据类型进行特殊的计算优化,例如 CUDA 设备有针对 `int8` 或 `float8` 矩阵乘法的硬件优化。
+
+市面上有许多可用于量化 PyTorch 深度学习模型的开源库,它们各有特色及局限。通常来讲,每个库都仅实现了针对特定模型或设备的特性,因而普适性不强。此外,尽管各个库的设计原理大致相同,但不幸的是,它们彼此之间却互不兼容。
+
+因此,[quanto](https://github.com/huggingface/quanto) 库应运而出,其旨在提供一个多功能的 PyTorch 量化工具包。目前 quanto 包含如下特性:
+
+- 在 eager 模式下可用 (适用于无法成图的模型),
+- 生成的量化模型可以运行于任何设备 (包括 CUDA 设备和 MPS 设备) 上,
+- 自动插入量化和反量化结点,
+- 自动插入量化后的 `torch.nn.functional` 算子,
+- 自动插入量化后的 `torch.nn` 模块 (具体支持列表见下文),
+- 提供无缝的模型量化工作流,支持包含静态量化、动态量化在内的多种模型量化方案,
+- 支持将量化模型序列化为 `state_dict` ,
+- 不仅支持 `int8` 权重,还支持 `int2` 以及 `int4` ,
+- 不仅支持 `int8` 激活,还支持 `float8` 。
+
+最近,出现了很多仅专注于大语言模型 (LLM) 的量化算法,而 [quanto](https://github.com/huggingface/quanto) 的目标为那些适用于任何模态的、易用的量化方案 (如线性量化,分组量化等) 提供简单易用的量化原语。
+
+我们无意取代其他量化库,而是想通过新算法的实现门槛来促进创新,使得大家能够轻松地实现新模块,抑或是轻松组合现有模块来实现新算法。
+
+毫无疑问,量化很困难。当前,如要实现模型的无缝量化,需要大家对 PyTorch 的内部结构有深入了解。但不用担心,[quanto](https://github.com/huggingface/quanto) 的目标就是为你完成大部分繁重的工作,以便你可以集中精力在最重要的事情上,即: 探索低比特 AI 从而找出惠及 GPU 穷人的解决方案。
+
+## 量化工作流
+
+大家可以 pip 安装 `quanto` 包。
+
+```sh
+pip install quanto
+```
+
+[quanto](https://github.com/huggingface/quanto) 没有对动态和静态量化进行明确区分。因为静态量化可以首先对模型进行动态量化,随后再将权重 `冻结` 为静态值的方式来完成。
+
+典型的量化工作流包括以下步骤:
+
+**1. 量化**
+
+将标准浮点模型转换为动态量化模型。
+
+```python
+quantize(model, weights=quanto.qint8, activations=quanto.qint8)
+```
+
+此时,我们会对模型的浮点权重进行动态量化以用于后续推理。
+
+**2. 校准 (如果上一步未量化激活,则可选)**
+
+`quanto` 支持校准模式。在校准过程中,我们会给量化模型传一些代表性样本,并在此过程中记录各算子激活的统计信息 (如取值范围)。
+
+```python
+with calibration(momentum=0.9):
+ model(samples)
+```
+
+上述代码会自动使能量化模块的激活量化功能。
+
+**3. 微调,即量化感知训练 (可选)**
+
+如果模型的性能下降太多,可以尝试将其微调几轮以恢复原浮点模型的性能。
+
+```python
+model.train()
+for batch_idx, (data, target) in enumerate(train_loader):
+ data, target = data.to(device), target.to(device)
+ optimizer.zero_grad()
+ output = model(data).dequantize()
+ loss = torch.nn.functional.nll_loss(output, target)
+ loss.backward()
+ optimizer.step()
+```
+
+**4. 冻结整型权重**
+
+模型冻结后,其浮点权重将替换为量化后的整型权重。
+
+```python
+freeze(model)
+```
+
+请参阅 [该例](https://github.com/huggingface/quanto/tree/main/examples) 以深入了解量化工作流程。你还可以查看此 [notebook](https://colab.research.google.com/drive/1qB6yXt650WXBWqroyQIegB-yrWKkiwhl?usp=sharing),其提供了一个完整的用 `quanto` 量化 BLOOM 模型的例子。
+
+## 效果
+
+下面我们列出了一些初步结果,我们还在紧锣密鼓地更新以进一步提高量化模型的准确性和速度。但从这些初步结果中,我们仍能看出 `quanto` 的巨大潜力。
+
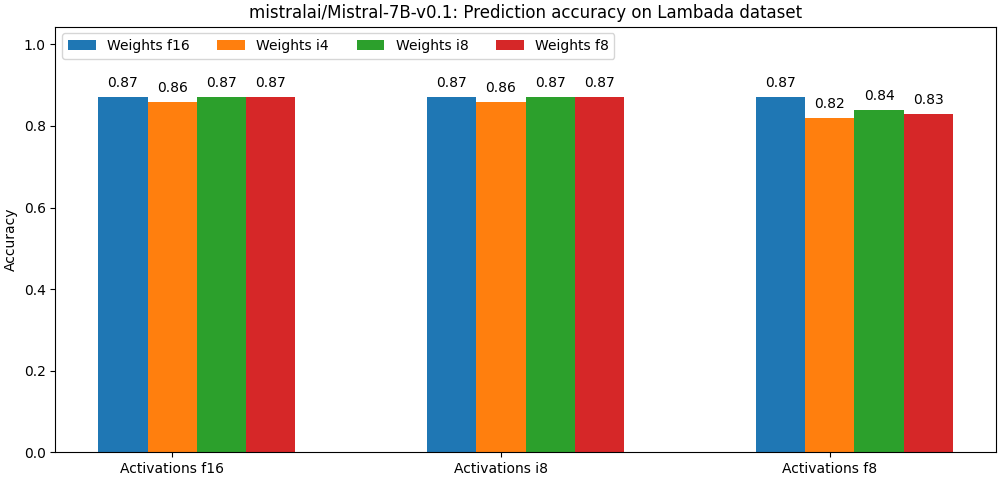
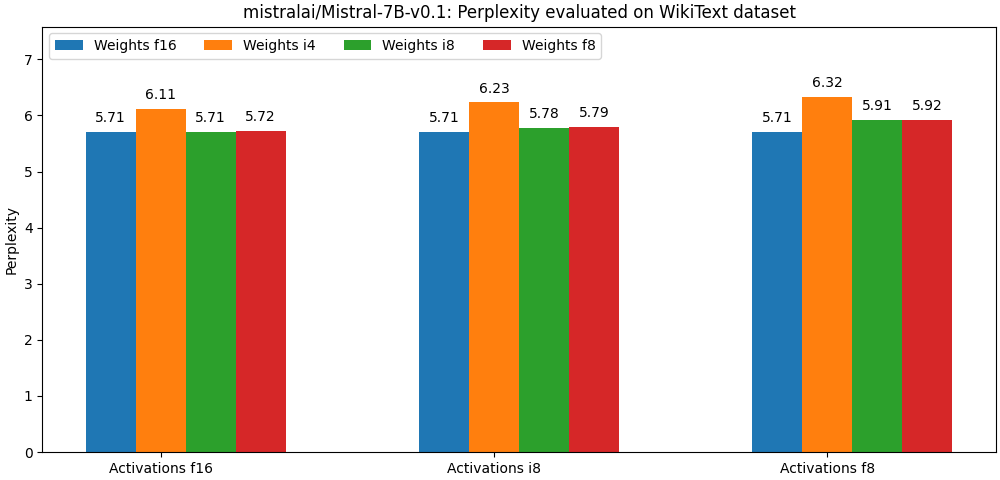
+下面两幅图评估了 [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) 在不同的量化参数下的准确度。注意: 每组的第一根柱子均表示非量化模型。
+
+
+
+
+
+
+
+
+
+
+
+
+
+上述结果均未使用任何高级训后量化算法 (如 [hqq](https://mobiusml.github.io/hqq_blog/) 或 [AWQ](https://github.com/mit-han-lab/llm-awq))。
+
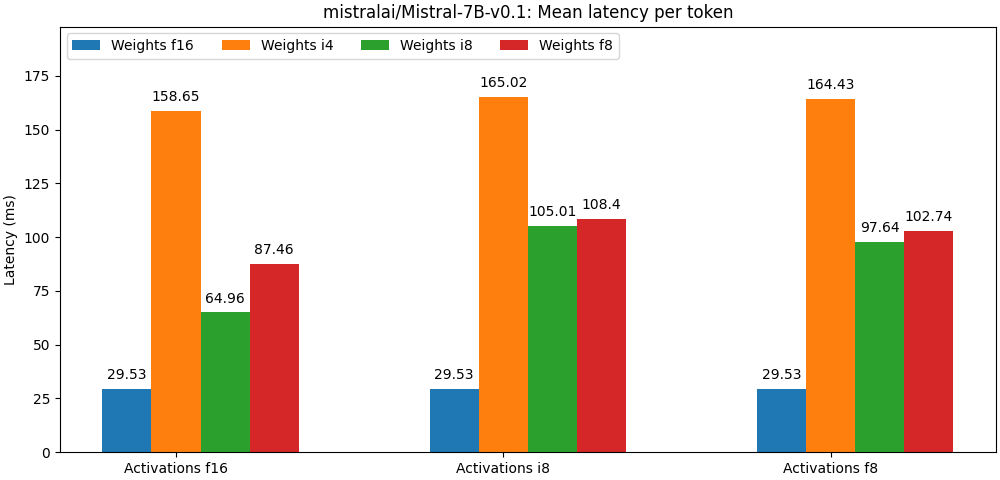
+下图给出了在英伟达 A100 GPU 上测到的词元延迟。
+
+
+
+
+
+
+
+这些测试结果都尚未利用任何优化的矩阵乘法算子。可以看到,量化位宽越低,开销越大。我们正在持续改进 [quanto](https://github.com/huggingface/quanto),以增加更多的优化器和优化算子,请持续关注我们的性能演进。
+
+请参阅 [quanto 基准测试](https://github.com/huggingface/quanto/tree/main/bench/) 以了解在不同模型架构及配置下的详细结果。
+
+## 集成进 `transformers`
+
+我们已将 `quanto` 无缝集成至 Hugging Face [transformers](https://github.com/huggingface/transformers) 库中。你可以通过给 `from_pretrained` API 传 `QuantoConfig` 参数来对任何模型进行量化!
+
+目前,你需要使用最新版本的 [accelerate](https://github.com/huggingface/accelerate) 以确保完全兼容。
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
+
+model_id = "facebook/opt-125m"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+quantization_config = QuantoConfig(weights="int8")
+
+quantized_model = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ quantization_config= quantization_config
+)
+```
+
+你只需在 `QuantoConfig` 中设置相应的参数即可将模型的权重/激活量化成 `int8` 、 `float8` 、 `int4` 或 `int2` ; 还可将激活量化成 `int8` 或 `float8` 。如若设成 `float8` ,你需要有一个支持 `float8` 精度的硬件,否则当执行 matmul (仅当量化权重时) 时,我们会默认将权重和激活都转成 `torch.float32` 或 `torch.float16` (具体视模型的原始精度而定) 再计算。目前 `MPS` 设备不支持 `float8` , `torch` 会直接抛出错误。
+
+`quanto` 与设备无关,这意味着无论用的是 CPU/GPU 还是 MPS (Apple 的芯片),你都可以对模型进行量化并运行它。
+
+`quanto` 也可与 `torch.compile` 结合使用。你可以先用 `quanto` 量化模型,然后用 `torch.compile` 来编译它以加快其推理速度。如果涉及动态量化 (即使用量化感知训练或对激活进行动态量化),该功能可能无法开箱即用。因此,请确保在使用 `transformers` API 创建 `QuantoConfig` 时,设置 `activations=None` 。
+
+`quanto` 可用于量化任何模态的模型!下面展示了如何使用 `quanto` 将 `openai/whisper-large-v3` 模型量化至 `int8` 。
+
+```python
+from transformers import AutoModelForSpeechSeq2Seq
+
+model_id = "openai/whisper-large-v3"
+quanto_config = QuantoConfig(weights="int8")
+
+model = AutoModelForSpeechSeq2Seq.from_pretrained(
+ model_id,
+ torch_dtype=torch.float16,
+ device_map="cuda",
+ quantization_config=quanto_config
+)
+```
+
+你可查阅此 [notebook](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing#scrollTo=IHbdLXAg53JL),以详细了解如何在 `transformers` 中正确使用 `quanto` !
+
+## 实现细节
+
+### 量化张量
+
+`quanto` 的核心是一些 Tensor 子类,其主要做下面两件事:
+- 将源张量按最优`比例` 投影至给定量化数据类型的取值范围内。
+- 将投影后的值映射至目标数据类型。
+
+当目标类型是浮点型时,映射由 PyTorch 原生转换接口 (即 `Tensor.to()` ) 完成。而当目标类型是整型时,映射可以用一个简单的舍入操作 (即 `torch.round()` ) 来完成。
+
+投影的目标是提高数据类型转换的精确度,具体可以通过最小化以下两个值来达成:
+- 饱和值的个数 (即有多少个数最终映射为目标数据类型的最小值/最大值),
+- 归零值的个数 (即有多少个数因为小于目标数据类型可以表示的最小数字,所以被映射成了 0)。
+
+为了提高效率起见, `8 比特` 量化时,我们使用对称投影,即以零点为中心进行投影。一般而言,对称量化张量与许多标准算子兼容。
+
+在使用较低位宽的量化 (如 `int2` 或 `int4` ) 时,一般使用的是仿射投影。此时,会多一个 `zeropoint` 参数以对齐投影值和原值的零点。这种方法对量化范围的覆盖度会好些。仿射量化张量通常更难与标准算子兼容,因此一般需要自定义很多算子。
+
+### 量化 `torch.nn` 模块
+
+`quanto` 实现了一种通用机制,以用能够处理 `quanto` 张量的 `quanto` 模块替换相应的 `torch` 模块 ( `torch.nn.Module` )。
+
+`quanto` 模块会动态对 `weights` 进行数据类型转换,直至模型被冻结,这在一定程度上会减慢推理速度,但如果需要微调模型 (即量化感知训练),则这么做是需要的。
+
+此外,我们并未量化 `bias` 参数,因为它们比 `weights` 小得多,并且对加法进行量化很难获得太多加速。
+
+我们动态地将激活量化至固定取值范围 (默认范围为 `[-1, 1]` ),并通过校准过程决定最佳的比例 (使用二阶动量更新法)。
+
+我们支持以下模块的量化版:
+
+- [Linear](https://pytorch.org/docs/stable/generated/torch.nn.Linear.html) (QLinear)。仅量化权重,不量化偏置。输入和输出可量化。
+- [Conv2d](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html) (QConv2D)。仅量化权重,不量化偏置。输入和输出可量化。
+- [LayerNorm](https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html)。权重和偏至均 **不** 量化。输出可量化。
+
+### 定制算子
+
+得益于 PyTorch 出色的调度机制,[quanto](https://github.com/huggingface/quanto) 支持在 [transformers](https://github.com/huggingface/transformers) 或 [diffusers](https://github.com/huggingface/diffusers) 的模型中最常用的函数,无需过多修改模型代码即可启用量化张量。
+
+大多数“调度”功能可通过标准的 PyTorch API 的组合来完成。但一些复杂的函数仍需要使用 `torch.ops.quanto` 命名空间下的自定义操作。其中一个例子是低位宽的融合矩阵乘法。
+
+### 训后量化优化
+
+[quanto](https://github.com/huggingface/quanto) 中尚未支持高级的训后量化算法,但该库足够通用,因此与大多数 PTQ 优化算法兼容,如 [hqq](https://mobiusml.github.io/hqq_blog/)、[AWQ](https://github.com/mit-han-lab/llm-awq) 等。
+
+展望未来,我们计划无缝集成这些最流行的算法。
+
+## 为 Quanto 作出贡献
+
+我们非常欢迎大家对 [quanto](https://github.com/huggingface/quanto) 作出贡献,尤其欢迎以下几类贡献:
+
+- 实现更多针对特定设备的 [quanto](https://github.com/huggingface/quanto) 优化算子,
+- 支持更多的 PTQ 优化算法,
+- 扩大量化张量可调度操作的覆盖面。
\ No newline at end of file