diff --git a/quanto-introduction.md b/quanto-introduction.md
index a3eedee1e6..7d3775c6d8 100644
--- a/quanto-introduction.md
+++ b/quanto-introduction.md
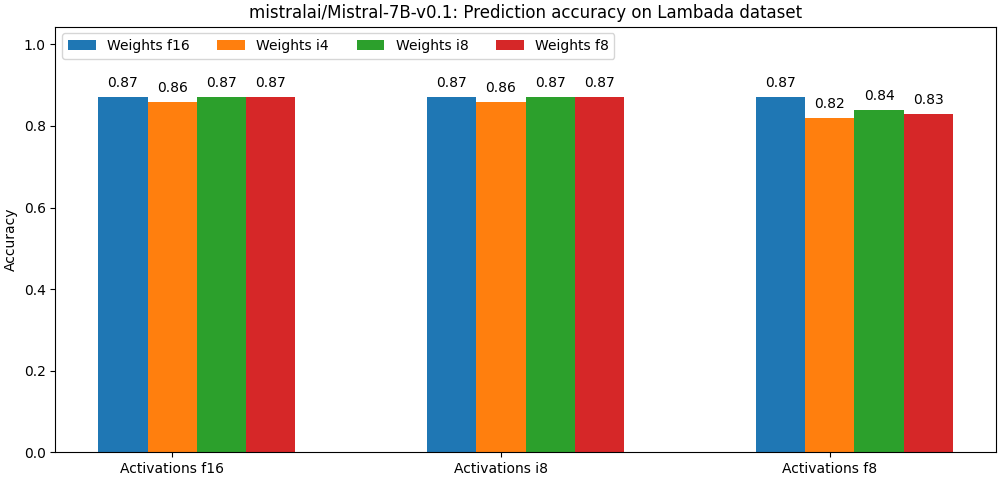
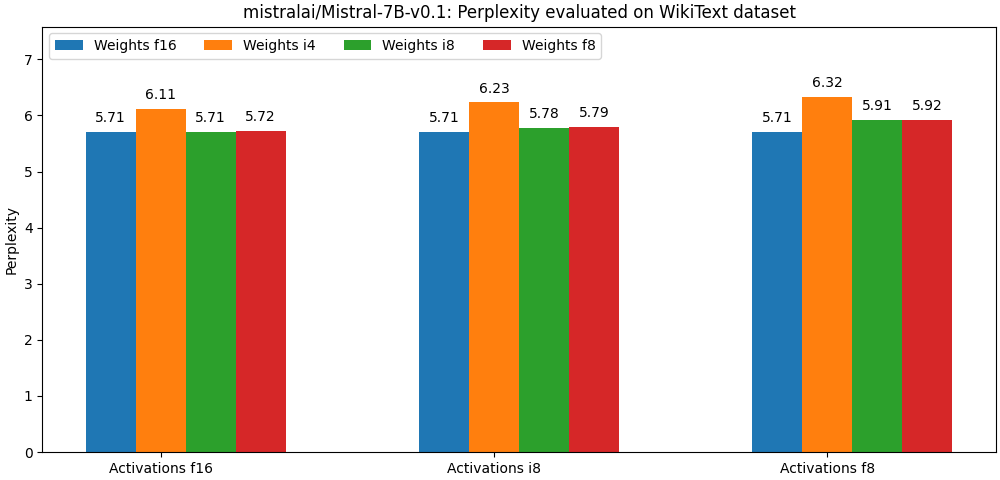
@@ -108,14 +108,14 @@ Note: the first bar in each group always corresponds to the non-quantized model.
-

+
-

+
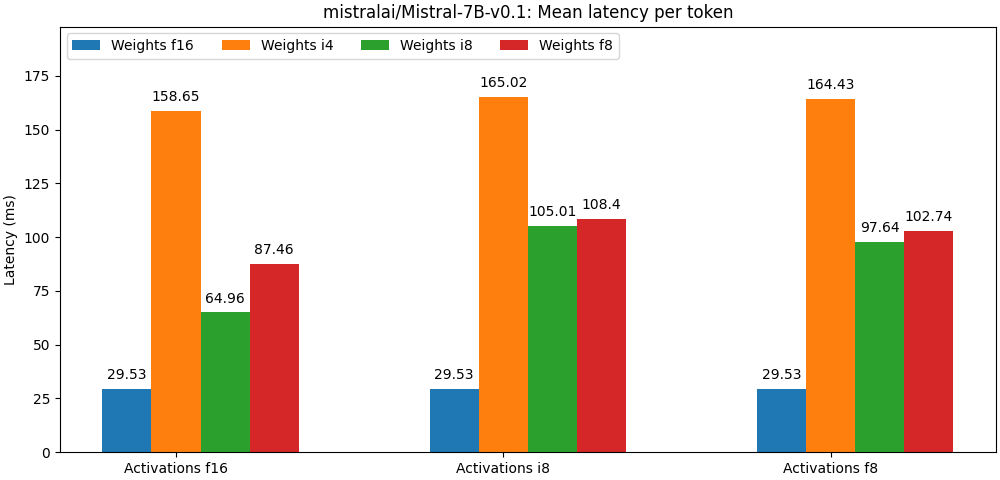
@@ -126,7 +126,7 @@ The graph below gives the latency per-token measured on an NVIDIA A100 GPU.
-

+