SetFit models#
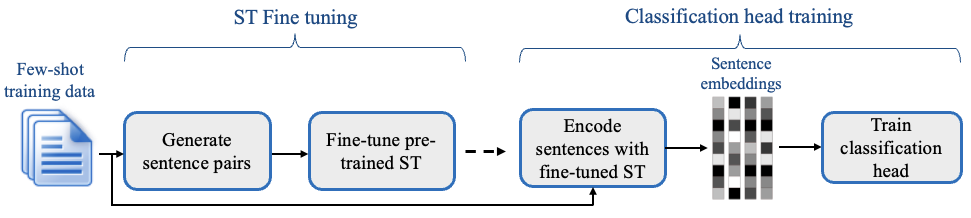
+You can use SetFit in stormtrooper for training efficient zero and few-shot learning models from sentence transformers.
+SetFit uses a prompt-free approach, needs way smaller models, and is thus faster to train, and more employable in high-performance settings for inference.
+ +
+Since this requires the setfit package we recommend you install stormtrooper with its optional dependencies.
+pip install stormtrooper[setfit]
+from stormtrooper.setfit import SetFitZeroShotClassifier, SetFitFewShotClassifier
+
+sample_text = "It is the Electoral College's responsibility to elect the president."
+
+labels = ["politics", "science", "other"]
+Here’s a zero shot example:
+model = SetFitZeroShotClassifier().fit(None, labels)
+predictions = model.predict([sample_text])
+assert list(predictions) == ["politics"]
+And a few shot example:
+few_shot_examples = [
+ "Joe Biden is the president.",
+ "Liquid water was found on the moon.",
+ "Jerry likes football."
+]
+
+model = SetFitFewShotClassifier().fit(few_shot_examples, labels)
+predictions = model.predict([sample_text])
+assert list(predictions) == ["politics"]
+API reference#
+-
+
- +class stormtrooper.setfit.SetFitZeroShotClassifier(model_name: str = 'sentence-transformers/all-MiniLM-L6-v2', sample_size: int = 8, device: str = 'cpu')# +
Scikit-learn compatible zero shot classification +with SetFit and sentence transformers.
+-
+
- Parameters: +
-
+
model_name (
str, default'sentence-transformers/all-MiniLM-L6-v2') – Name of sentence transformer on HuggingFace Hub.
+sample_size (
int, default8) – Number of training samples to generate.
+device (
str, default'cpu') – Indicates which device should be used for classification. +Models are by default run on CPU.
+
+
-
+
- +classes_# +
Class names learned from the labels.
+-
+
- Type: +
+arrayofstr
+
-
+
- +fit(X, y: Iterable[str])# +
Learns class labels.
+-
+
- Parameters: +
-
+
X (
Any) – Ignored
+y (
iterableofstr) – Iterable of class labels. +Should at least contain a representative sample +of potential labels.
+
+- Returns: +
Fitted model.
+
+- Return type: +
+self
+
-
+
- +partial_fit(X, y: Iterable[str])# +
Learns class labels. +Can learn new labels if new are encountered in the data.
+-
+
- Parameters: +
-
+
X (
Any) – Ignored
+y (
iterableofstr) – Iterable of class labels.
+
+- Returns: +
Fitted model.
+
+- Return type: +
+self
+
-
+
- +predict(X: Iterable[str]) ndarray# +
Predicts most probable class label for given texts.
+-
+
- Parameters: +
X (
+iterableofstr) – Texts to label.
+- Returns: +
Array of string class labels.
+
+- Return type: +
+arrayofshape (n_texts)
+
-
+
- +class stormtrooper.setfit.SetFitFewShotClassifier(model_name: str = 'sentence-transformers/all-MiniLM-L6-v2', device: str = 'cpu')# +
Scikit-learn compatible few shot classification +with SetFit and sentence transformers.
+-
+
- Parameters: +
-
+
model_name (
str, default'sentence-transformers/all-MiniLM-L6-v2') – Name of sentence transformer on HuggingFace Hub.
+device (
str, default'cpu') – Indicates which device should be used for classification. +Models are by default run on CPU.
+
+
-
+
- +classes_# +
Class names learned from the labels.
+-
+
- Type: +
+arrayofstr
+
-
+
- +fit(X: Iterable[str], y: Iterable[str])# +
Learns class labels.
+-
+
- Parameters: +
-
+
X (
iterableofstr) – Examples to pass into the few-shot prompt.
+y (
iterableofstr) – Iterable of class labels.
+
+- Returns: +
Fitted model.
+
+- Return type: +
+self
+
-
+
- +predict(X: Iterable[str]) ndarray# +
Predicts most probable class label for given texts.
+-
+
- Parameters: +
X (
+iterableofstr) – Texts to label.
+- Returns: +
Array of string class labels.
+
+- Return type: +
+arrayofshape (n_texts)
+