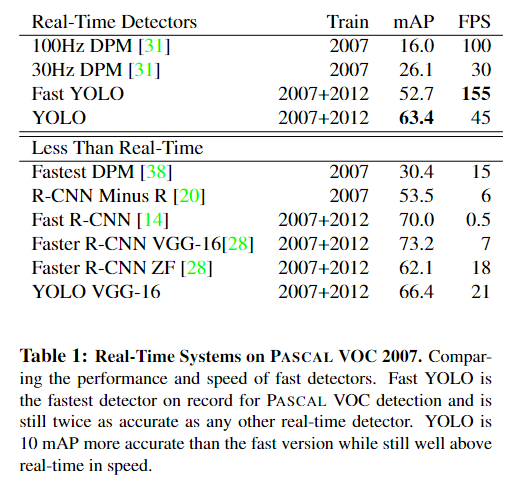
之前的目标检测算法如R-CNN都包含两个步骤:
- 检测目标位置(生成检测矩形框)
- 使用分类器对矩形框进行分类
分类完之后还需要进行一些后处理,比如对重复的矩形框进行消除,整个pipeline相对比较复杂,难以优化。

将整张图片作为网络的输入,直接在输出层对BBox的位置和类别进行回归。
- Resize image:将输入图片resize到448x448。
- Run ConvNet:使用CNN提取特征,FC层输出分类和回归结果。
- Non-max Suppression:非极大值抑制筛选出最终的结果。
YOLO V1将对象检测重新定义为一个单一的回归问题,直接从图像像素到边界框坐标和类概率。只需在图像上看一次(YOLO)即可预测存在哪些对象以及它们在哪里。单个卷积网络同时预测多个边界框和这些框的类概率。YOLO对全图像进行训练,并直接优化检测性能。
与传统的目标检测方法相比,这种统一的模型有几个优点。
- 速度非常快。将检测框定为回归问题,因此我们不需要复杂的pipeline。
- YOLO对图像进行全局推理。与基于滑动窗口和区域建议(region proposal-based)的技术不同,YOLO在训练和测试期间看到整个图像,因此它隐式地编码关于类及其外观的上下文信息。
- YOLO的泛化性能更好。
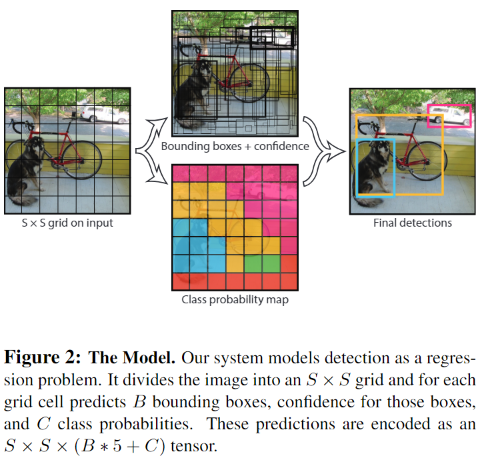
首先将输入图片分成$S × S$个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
每个网格需要预测B个BBox的位置信息和confidence(置信度),一个BBox对应着四个位置信息(x,y,w,h)和一个confidence信息。其中$(x,y)$是BBox中心点的位置,$(w,h)$是BBox的宽和高,这是相对于整张图片的。$(x,y,w,h)$相对于单元格归一化到0-1之间。例如图片的宽是width,高为height,BBox中心所在的网格坐标为$x_0,y_0$,则BBox的实际坐标为 $$ x/(width/S)-x_0,y/(height/S)-y_0 $$
置信度confidence分数反映了模型对BBox包含目标对象的可能性,以及它认为BBox预测的准确性。前者记为$Pr(object)$,后者用$IOU^{truth}{pred}$。$Confidence=Pr(object) * IOU^{truth}{pred}$。
每个网格除了预测B个BBox外,还要预测$C$个类别概率:$Pr(Class_i | Object)$,表示由该单元格负责预测的BBox中的目标属于各类的概率,不管该单元格预测多少个BBox,该单元格值预测一组类别概率值。
对于每个bounding box的class-specific confidence score: $$ \begin{array}{c}{{P r(c l a s s_{i}|o b j e c t)*c o n f i d e n c e=}}\ {{P r(o b j e c t)*I O{U}{p r e d}^{t r u t h}=P r(c l a s s{i})*I O{U}_{p r e d}^{t r u t h}}}\end{array} $$ 每张图片会输出一个$S \times S \times (B *5+C)$的向量。

-
网络整体由24个卷积层+2个全连接层组成
-
输入图像大小为448448,经过若干个卷积层与池化层,变为$7 * 7 * 1024$张量(图一中倒数第三个立方体),最后经过两层全连接层,输出张量维度为$7 * 730$
-
网络输出张量维度
- 7*7的含义
77是指图片被分成了77个格子,如下所示:

在Yolo中,如果一个物体的中心点,落在了某个格子中,那么这个格子将负责预测这个物体。这句话怎么理解,用上图举例,设左下角格子假设坐标为 (1,1),小狗所在的最小包围矩形框的中心,落在了 (2,3) 这个格子中。那么77个格子中,(2,3) 这个格子负责预测小狗,而那些没有物体中心点落进来的格子,则不负责预测任何物体。这个设定就好比该网络在一开始,就将整个图片上的预测任务进行了分工,一共设定77个按照方阵列队的检测人员,每个人员负责检测一个物体,大家的分工界线,就是看被检测物体的中心点落在谁的格子里。当然,是77还是99,是上图中的参数S,可以自己修改,精度和性能会随之有些变化。
- 30的含义
刚才设定了49个检测人员,那么每个人员负责检测的内容,就是这里的30(注意,30是张量最后一维的长度)。在Yolo v1论文中,30是由$(4+1)*2+20$得到的。其中4+1是矩形框的中心点坐标$x,y$,长宽$w,h$以及是否属于被检测物体的置信度$c$;2是一个格子共回归两个矩形框。20表示有20个物体类别。
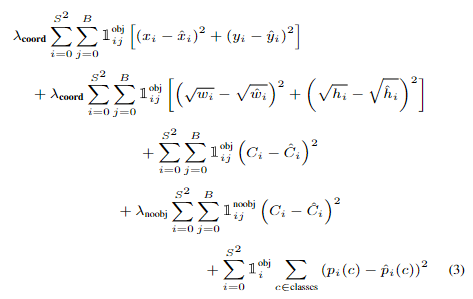
- 所有的损失都是使用平方和误差
- 预测矩形框的中心点:$(x,y)$。损失函数中的第一行 ,其中$1^{obj}_{ij}$表示单元格是否包含目标物体。若包含则=1,否为为0.也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响
- 预测矩形框的宽高:$(w,h)$。损失函数的第二行。$1^{obj}_{ij}$含义同上。这里取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
- 置信度C。损失函数的第三、四行。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值。
- 物体类别概率:损失函数第5行。对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。