diff --git a/01_csrd.py b/01_csrd.py
index e73f863..4f56331 100644
--- a/01_csrd.py
+++ b/01_csrd.py
@@ -1,18 +1,11 @@
# Databricks notebook source
# MAGIC %md
-# MAGIC ## CSRD directive
+# MAGIC ## Parsing CSRD directive
# COMMAND ----------
# MAGIC %md
-# MAGIC On July 31, 2023, the European Commission adopted the [European Sustainability Reporting Standards](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:L_202302772) (ESRS), which were published in the Official Journal of the European Union in December 2023. Drafted by the European Financial Reporting Advisory Group (EFRAG), the standards provide supplementary guidance for companies within the scope of the [E.U. Corporate Sustainability Reporting Directive](https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32022L2464) (CSRD). The adoption of the CSRD, along with the supporting ESRS, is intended to increase the breadth of nonfinancial information reported by companies and to ensure that the information reported is consistent, relevant, comparable, reliable, and easy to access.
-# MAGIC
-# MAGIC Source: [Deloitte](https://dart.deloitte.com/USDART/home/publications/deloitte/heads-up/2023/csrd-corporate-sustainability-reporting-directive-faqs)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC Though the CSRD compliance poses a data quality challenge to firms trying to collect and report this information for the first time, the directive itself (as per many regulatory documents) may be source of confusion / concerns and subject to interpretation. In this exercise, we want to demonstrate generative AI to navigate through the complexities of regulatory documents and the CSRD initiative specifically. We aim at programmatically extracting chapters / articles / paragraphs from the CSRD initiative (available below) and provide users with solid foundations to build GenAI solutions in the context of regulatory compliance.
+# MAGIC We aim at programmatically extracting chapters / articles / paragraphs from the CSRD initiative (link below) and provide users with solid foundations to build more advanced GenAI applications in the context of regulatory compliance.
# MAGIC
# MAGIC https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:02013L0034-20240109&qid=1712714544806
@@ -29,19 +22,17 @@
# COMMAND ----------
# MAGIC %md
-# MAGIC
-# MAGIC ### Parsing strategy
-# MAGIC
-# MAGIC We may apply different data strategies to extract chapters and articles from the CSRD directive. The simplest approach would be to extract raw content and extract chunks that could feed our vector database. Whilst this would certainly be the easiest route, we would naively split text in the middle of potentially critical articles, not ensuring strict understanding of each sections. As a consequence, and even if we apply a context window across multiple chunks a model may be tempted to "infer" missing words and generate content not 100% in line with regulatory text.
-# MAGIC
-# MAGIC A second approach may be to read text as a whole and let generative AI capabilities extract specific sections and articles for us. Whilst this offer an ease of use and certainly in line with future direction of generative AI, we could possibly leave text at the interpretation of AI rather than relying on pure fact.
-# MAGIC
-# MAGIC Instead, we went down the "boring" and "outdated" approach of scraping our document manually. Efforts done upfront will certainly pay off later when extracting facts around well defined chapter, articles, paragraphs and citations, acting as a compliance assistant through Q&A capabilities or operation workflow.
+# MAGIC We may apply different data strategies to extract chapters and articles from the CSRD directive. The simplest approach would be to extract raw content and extract chunks that could feed our vector database. Whilst this would certainly be the easiest route, we would naively split text in the middle of potentially critical articles, not ensuring strict understanding of each sections. As a consequence, and even if we apply a context window across multiple chunks a model may be tempted to "infer" missing words and generate content not 100% in line with regulatory text.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC A second approach may be to read text as a whole and let generative AI capabilities extract specific sections and articles for us. Whilst this offer an ease of use and certainly in line with future direction of generative AI, we could possibly leave text at the interpretation of AI rather than relying on facts we could find as-is in the original documentation.
# COMMAND ----------
# MAGIC %md
-# MAGIC We make use of the Beautiful soup library to navigate HTML content. Relatively complex, this HTML structure can be manually inspected through a browser / developer tool as per screenshot below.
+# MAGIC Instead, we went down the "boring" and "outdated" approach of scraping documents manually. Efforts done upfront will certainly pay off later when extracting facts around chapters, articles, paragraphs and citations. We make use of the [Beautiful soup](https://beautiful-soup-4.readthedocs.io/en/latest/) library to navigate HTML content. Relatively complex, this HTML structure can be manually inspected through a browser / developer tool as per screenshot below.
# MAGIC
# MAGIC 
@@ -129,7 +120,7 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC Finally, we could extract the hierarchy of content, from chapter, to articles and paragraph.
+# MAGIC Finally, we could extract the full content hierarchy from the CSRD directive, from chapter to articles and paragraph.
# COMMAND ----------
@@ -152,12 +143,11 @@ def get_paragraphs(article_section):
# MAGIC %md
# MAGIC ## Knowledge Graph
-# MAGIC Our content follows a tree structure, where each chapter may have multiple articles and each article having multiple paragraphs. A graph structure becomes a logical representation of our data.
+# MAGIC Our content follows a tree structure where each chapter has multiple articles and each article has multiple paragraphs. A graph structure becomes a logical representation of our data. We leverage [NetworkX](https://networkx.org/) libary for that purpose.
# COMMAND ----------
import networkx as nx
-import textwrap
CSRD = nx.DiGraph()
CSRD.add_node('CSRD', title=directive_name, label='CSRD', group='DIRECTIVE')
@@ -184,7 +174,7 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC One can extract our graph nodes and manually investigate its content, further validating our parsing logic earlier.
+# MAGIC We can easily access any given document in our graph and manually investigate its content, further validating our parsing logic earlier.
# COMMAND ----------
@@ -197,7 +187,7 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC Stored as a graph, the same can easily be visualized to get a better understanding of the problem at hand. Our directive contains ~ 350 nodes where each node is connected to maximum 1 parent (tree structure), as represented below
+# MAGIC Stored as a graph, the same can easily be visualized to get a better understanding of the problem at hand. Our directive contains ~ 350 nodes where each node is connected to maximum 1 parent (expected from a tree structure), as represented below. Zoom in and hover some nodes to access their actual text content.
# COMMAND ----------
@@ -207,7 +197,7 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC With our graph stored in memory, one can easily access a given content through its natural identifier, in the form of `chapter-article-paragraph` coordinate.
+# MAGIC We created our graph identifiers so that we can access a given paragraph through their unique ID, expressed in the form of `chapter-article-paragraph` coordinate.
# COMMAND ----------
@@ -220,7 +210,7 @@ def get_paragraphs(article_section):
# MAGIC %md
# MAGIC ## Indexing content
-# MAGIC Though representing our CSRD as a graph was visually compelling, it offers little to no search capability. At the age of generative AI, one may have to search content for a given question / query, hence perfect fit for vector store capability.
+# MAGIC Though representing our CSRD as a graph was visually compelling, it offers no semantic search capability. In this section, we will further index our graph data to offer search functionality for a given question / query.
# COMMAND ----------
@@ -246,7 +236,11 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC In production settings, we highly encourage users to leverage Databricks vector store capability, linking a record down to the actual binary file (PDF) available on your volume, hence part of your same governance strategy. In the context of a solution accelerator, we decided to limit the infra requirement and provide similar capabilities in memory, hence leveraging in memory vector store such as FAISS. We leverage databricks Pay as token capability for embedding, representing each paragraph as vector document.
+# MAGIC In production settings, we highly encourage users to leverage [Databricks vector store](https://docs.databricks.com/en/generative-ai/vector-search.html) capability, linking records down to the actual binary file that may have been previously stored on your volume, hence part of a unified governance strategy.
+# MAGIC
+# MAGIC In the context of a solution accelerator, we decided to limit the infrastructure requirements (volume creation, table creation, DLT pipelines, etc.) and provide entry level capabilities, in memory, leveraging FAISS as our vector store and leveraging out-of-the-box foundation models provided by Databricks.
+# MAGIC
+# MAGIC For more information on E2E applications, please refer to [DB Demo](https://www.databricks.com/resources/demos/tutorials/data-science-and-ai/lakehouse-ai-deploy-your-llm-chatbot).
# COMMAND ----------
@@ -255,6 +249,11 @@ def get_paragraphs(article_section):
# COMMAND ----------
+# MAGIC %md
+# MAGIC We leverage langchain framework for its ease of use, converting our graph content as a set of langchain documents.
+
+# COMMAND ----------
+
from langchain.docstore.document import Document
documents = []
@@ -275,7 +274,7 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC We can now retrieve content based on semantic search. Given a question, part of text, or simple keywords, we can retrieve specific facts that we link back to actual paragraphs in our CSRD directive. This will become our foundation to our RAG strategy later. The example below returns the best matching paragraph with a relevance score.
+# MAGIC We can now retrieve content based on similarity search. Given a question, part of a text, or simple keywords, we retrieve specific facts, articles and paragraph that we can trace back to our CSRD directive. This will become the foundation to our RAG strategy later. The example below returns the best matching paragraph with a relevance score given a user question.
# COMMAND ----------
@@ -288,7 +287,7 @@ def get_paragraphs(article_section):
# MAGIC %md
# MAGIC ## Foundational model
-# MAGIC It is expected that foundational models like DBRX that learned knowledge from trillion of tokens may already know some of the relevant context for generic questions.
+# MAGIC It is expected that foundational models like DBRX, Llama 3, Mixtral or OpenAI that learned knowledge from trillion of tokens may already know some of the relevant context for generic questions. However, it would be cavalier to ask specific questions to our model and solely rely on its foundational knowledge. In the context of regulatory compliance, we cannot afford for a model to "make things up" or return information as "best guess", regardless of how convincing its answer might be.
# COMMAND ----------
@@ -297,20 +296,20 @@ def get_paragraphs(article_section):
# COMMAND ----------
-# MAGIC %md
-# MAGIC However, it would be cavalier to ask specific questions to our model and solely rely on its foundational knowledge. In the context of regulatory compliance, we cannot afford for a model to "make things up" or return information as "best guess", regardless of how convincing its answer might be. The following question might yield well formed answer that may seem convincing to the naked eye, but definitely lacks substance and quality required, certainly failing to cite actual facts based on articles / paragraphs.
+query = 'Which disclosures will be subject to assurance, and what level of assurance is required?'
+displayHTML(llm_html(query, chat_model.invoke(query).content))
# COMMAND ----------
-query = 'Which disclosures will be subject to assurance, and what level of assurance is required?'
-displayHTML(llm_html(query, chat_model.invoke(query).content))
+# MAGIC %md
+# MAGIC The question above might yield a well formed answer that may seem convincing to the naked eye, but definitely lacks substance and the quality required for regulatory compliance. Instead of a POV we may take at its face value, it would certainly be comfortable to cite actual facts and reference existing articles / paragraphs from a trusted source (such as the directive itself).
# COMMAND ----------
# MAGIC %md
# MAGIC
# MAGIC ## RAG strategy
-# MAGIC Instead, we should prompt a model to search for specific knowledge provided as a context, knowledge that we acquired throughout the first part of our notebook. This creates our foundation for RAG framework. The main premise behind RAG is the injection of context (or knowledge) to the LLM in order to yield more accurate responses from it
+# MAGIC Instead, we should prompt a model to search for specific knowledge, knowledge that we acquired throughout the first part of our notebook. This creates our foundation for RAG. In this section, we will design a simple prompt and "chain" our vector store logic with actual model inference.
# COMMAND ----------
@@ -351,7 +350,7 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC Please note that prompts might be designed in a way that provides user with better clarity and / or confidence as well as safeguarding model against malicious or offensive use. This, however, is not part of this solution for simplicity sake. We invite users to explore our [DB Demo](https://www.databricks.com/resources/demos/tutorials/data-science-and-ai/lakehouse-ai-deploy-your-llm-chatbot) that covers the basics + advanced use of RAG. A good example would be to restrict our model to only answer questions that are CSRD related.
+# MAGIC Prompts must be designed in a way that provides user with better clarity and / or confidence as well as safeguarding model against malicious or offensive use. This, however, is not part of this solution but invite users to explore our [DB Demo](https://www.databricks.com/resources/demos/tutorials/data-science-and-ai/lakehouse-ai-deploy-your-llm-chatbot) that covers the basics to most advanced use of RAG. A good example would be to restrict our model to only answer questions that are CSRD related, possibly linking multiple chains together.
# COMMAND ----------
@@ -362,13 +361,13 @@ def get_paragraphs(article_section):
# COMMAND ----------
# MAGIC %md
-# MAGIC In this example, we could let our model formulate a point of view based on actual facts we can trust. For the purpose of that demo, we simply represent output as a form of a notebook. In real life scenario, offering that capability would require building chat bot UI outside of a notebook based environment (not in the scope here).
+# MAGIC In this example, we let our model formulate a point of view based on actual facts we can trust. For the purpose of that demo, we represented output as a form of a notebook. In real life scenario, offering that capability as a chat interface would require building a UI and application server outside of a notebook based environment (outside of the scope here).
# COMMAND ----------
# MAGIC %md
# MAGIC ## Extracting references
-# MAGIC It is expected that regulatory documents (or legal documents) might contain multiple definitions and cross references to other articles, paragraphs or other regulations. Whilst we kept the scope of this demo to the CSRD initiative only, our document might contain many cross references that would be needed to formulate an objective view with objective facts.
+# MAGIC It is expected that regulatory documents (or legal documents) might contain multiple definitions and cross references to other articles, paragraphs or other regulations. Whilst we kept the scope of this demo to the CSRD initiative only, our document might already contain many cross references that would be needed to formulate an objective view with objective facts.
# COMMAND ----------
@@ -391,6 +390,11 @@ def get_paragraphs(article_section):
# COMMAND ----------
+# MAGIC %md
+# MAGIC This is a perfect example where large language model reasoning capabilities might shine. By designing a simple prompt and parsing logic, one can extract references to other articles and paragraph we know exist in our graph structure.
+
+# COMMAND ----------
+
def parse_references(txt, graph):
node_ids = []
references = re.findall('(\d+[a-z]?)\-(\d+[a-z]?)', txt)
@@ -416,6 +420,11 @@ def parse_references(txt, graph):
# COMMAND ----------
+# MAGIC %md
+# MAGIC Modern foundational models such as DBRX are able to follow our prompting instructions, returning references to other articles we know exist. In the example below, we return cross references to Chapter 6, article 29 and paragraph 2.
+
+# COMMAND ----------
+
references = parse_references(answer, CSRD)
displayHTML(references_html('CSRD §{}'.format(f'{chapter}.{article}.{paragraph}'), test_node['title'], references))
@@ -443,6 +452,11 @@ def parse_references(txt, graph):
# COMMAND ----------
+# MAGIC %md
+# MAGIC Unfortunately for us, regulatory documents are complex and show high number of connections between different paragraphs and articles. We might want to visualize the resulting graph to grasp its newly acquired complexity.
+
+# COMMAND ----------
+
from copy import deepcopy
CSRD_references = deepcopy(CSRD)
for i, x in reference_df.iterrows():
@@ -455,8 +469,14 @@ def parse_references(txt, graph):
# COMMAND ----------
+# MAGIC %md
+# MAGIC We directly get a sense of the regulatory complexity of the CSRD directive. Each "clique" represented here may be source of confusion for whoever does not have a legal background.
+
+# COMMAND ----------
+
# MAGIC %md
# MAGIC ## Compliance assistant
+# MAGIC In this section, we want to leverage our newly acquired knowledge of article references to further augment the accuracy and relevance of a regulatory assistant. Being able to traverse our graph and navigating through references and definitions might present opportunities for businesses, better adhering to regulatory guideline by further understanding its legal terms. A first approach might be to expand the capabilities of a vector store by linking content to its actual connections.
# COMMAND ----------
@@ -515,6 +535,11 @@ def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerFor
# COMMAND ----------
+# MAGIC %md
+# MAGIC In the example below, the same question was triggering additional content retrieval that could be used to return a more objective and accurate information.
+
+# COMMAND ----------
+
question = {"query": 'Which disclosures will be subject to assurance, and what level of assurance is required?'}
answer = chain_kg.invoke(question)
displayHTML(rag_kg_html(question['query'], answer['result'], answer['source_documents']))
@@ -522,3 +547,9 @@ def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerFor
# COMMAND ----------
# MAGIC %md
+# MAGIC The downside, however, is that our graph is highly connected, resulting in far too much content being returned (even when limiting traversal to maximum 1 hop). Though modern models can handle larger context window (32k tokens for DBRX), a model might not be able to fully exploit each information returned (tend to ignore context not at the beigining or end of the context window). An alternative scenario would be to probe our vector store recursively, formulating an answer by ensuring full comprehension of each of the returned definitions.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Multi stage reasoning
diff --git a/README.md b/README.md
index 3434164..bf96ae7 100644
--- a/README.md
+++ b/README.md
@@ -1,16 +1,20 @@
 -[](https://docs.databricks.com/release-notes/runtime/CHANGE_ME.html)
-[](https://databricks.com/try-databricks)
+[](https://docs.databricks.com/release-notes/runtime/CHANGE_ME.html)
+[](https://databricks.com/try-databricks)
+[](https://databricks.com/try-databricks)
-## Business Problem
-WHAT IS THE BUSINESS PROBLEM ADDRESSED BY THIS SOLUTION
+
+## CSRD assistant
+*On July 31, 2023, the European Commission adopted the [European Sustainability Reporting Standards](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:L_202302772) (ESRS), which were published in the Official Journal of the European Union in December 2023. Drafted by the European Financial Reporting Advisory Group (EFRAG), the standards provide supplementary guidance for companies within the scope of the [E.U. Corporate Sustainability Reporting Directive](https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32022L2464) (CSRD). The adoption of the CSRD, along with the supporting ESRS, is intended to increase the breadth of nonfinancial information reported by companies and to ensure that the information reported is consistent, relevant, comparable, reliable, and easy to access. Source: [Deloitte](https://dart.deloitte.com/USDART/home/publications/deloitte/heads-up/2023/csrd-corporate-sustainability-reporting-directive-faqs)*
+
+Though the CSRD compliance poses a data quality challenge to firms trying to collect and report this information for the first time, the directive itself (as per many regulatory documents) may be source of confusion / concerns and subject to interpretation. In this exercise, we want to demonstrate generative AI abilities to navigate through the complexities of regulatory documentation.
## Reference Architecture
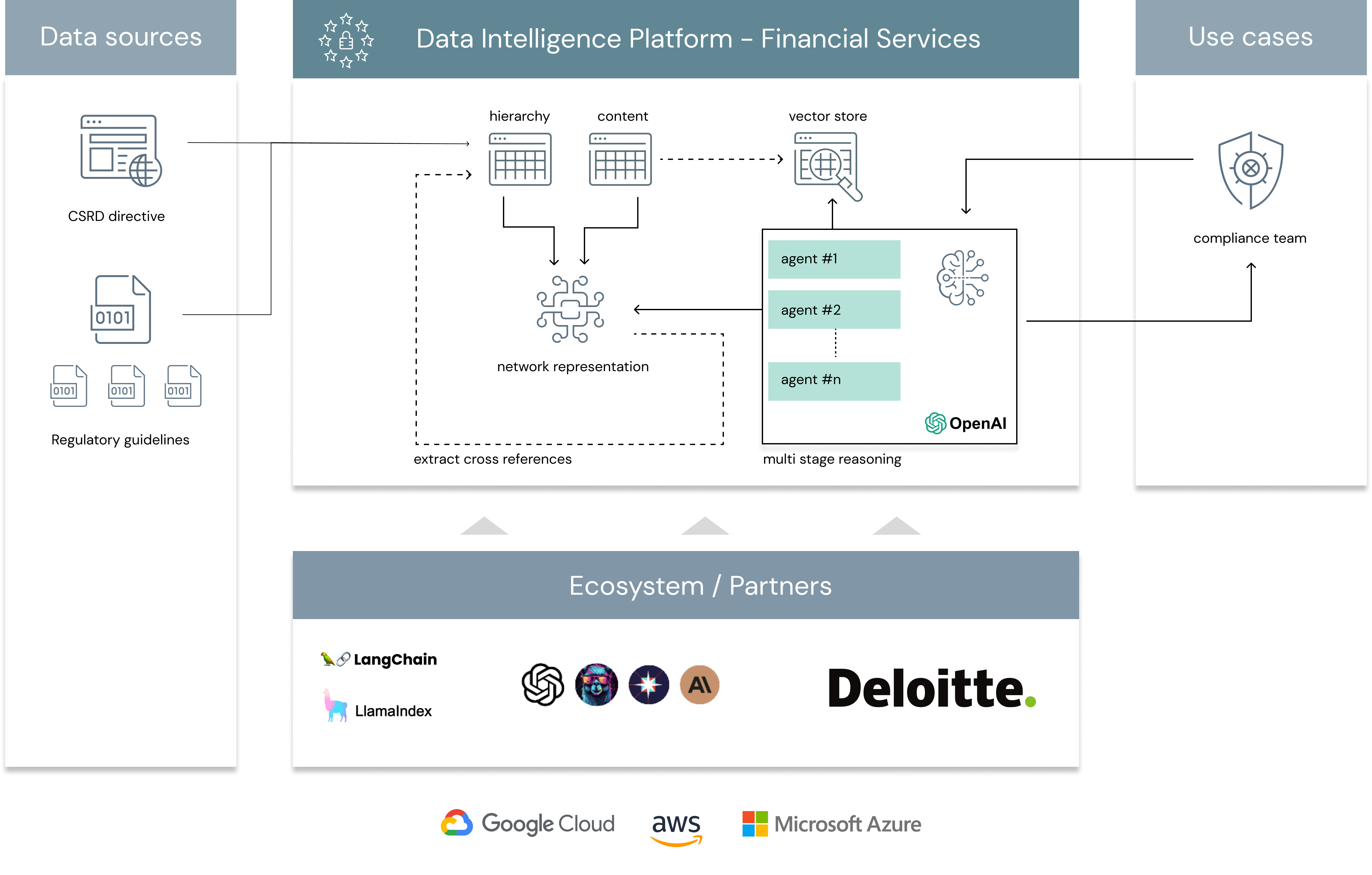
-IMAGE TO REFERENCE ARCHITECTURE
+
## Authors
-
+
## Project support
@@ -24,3 +28,9 @@ Any issues discovered through the use of this project should be filed as GitHub
| library | description | license | source |
|----------------------------------------|-------------------------|------------|-----------------------------------------------------|
+|beautifulsoup4|Parsing HTML|MIT|https://pypi.org/project/beautifulsoup4/|
+|networkx|Graph library|BSD|https://pypi.org/project/networkx/|
+|pyvis|Graph visualization|BSD|https://pypi.org/project/pyvis/|
+|faiss-cpu|In memory vector store|MIT|https://pypi.org/project/faiss-cpu/|
+|langchain|LLM framework|MIT|https://pypi.org/project/langchain/|
+|SQLAlchemy|Database abstraction|MIT|https://pypi.org/project/SQLAlchemy/|
\ No newline at end of file
-[](https://docs.databricks.com/release-notes/runtime/CHANGE_ME.html)
-[](https://databricks.com/try-databricks)
+[](https://docs.databricks.com/release-notes/runtime/CHANGE_ME.html)
+[](https://databricks.com/try-databricks)
+[](https://databricks.com/try-databricks)
-## Business Problem
-WHAT IS THE BUSINESS PROBLEM ADDRESSED BY THIS SOLUTION
+
+## CSRD assistant
+*On July 31, 2023, the European Commission adopted the [European Sustainability Reporting Standards](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:L_202302772) (ESRS), which were published in the Official Journal of the European Union in December 2023. Drafted by the European Financial Reporting Advisory Group (EFRAG), the standards provide supplementary guidance for companies within the scope of the [E.U. Corporate Sustainability Reporting Directive](https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32022L2464) (CSRD). The adoption of the CSRD, along with the supporting ESRS, is intended to increase the breadth of nonfinancial information reported by companies and to ensure that the information reported is consistent, relevant, comparable, reliable, and easy to access. Source: [Deloitte](https://dart.deloitte.com/USDART/home/publications/deloitte/heads-up/2023/csrd-corporate-sustainability-reporting-directive-faqs)*
+
+Though the CSRD compliance poses a data quality challenge to firms trying to collect and report this information for the first time, the directive itself (as per many regulatory documents) may be source of confusion / concerns and subject to interpretation. In this exercise, we want to demonstrate generative AI abilities to navigate through the complexities of regulatory documentation.
## Reference Architecture
-IMAGE TO REFERENCE ARCHITECTURE
+
## Authors
-
+
## Project support
@@ -24,3 +28,9 @@ Any issues discovered through the use of this project should be filed as GitHub
| library | description | license | source |
|----------------------------------------|-------------------------|------------|-----------------------------------------------------|
+|beautifulsoup4|Parsing HTML|MIT|https://pypi.org/project/beautifulsoup4/|
+|networkx|Graph library|BSD|https://pypi.org/project/networkx/|
+|pyvis|Graph visualization|BSD|https://pypi.org/project/pyvis/|
+|faiss-cpu|In memory vector store|MIT|https://pypi.org/project/faiss-cpu/|
+|langchain|LLM framework|MIT|https://pypi.org/project/langchain/|
+|SQLAlchemy|Database abstraction|MIT|https://pypi.org/project/SQLAlchemy/|
\ No newline at end of file