diff --git a/.github/CODEOWNERS b/.github/CODEOWNERS
new file mode 100644
index 0000000000..8cfd604b39
--- /dev/null
+++ b/.github/CODEOWNERS
@@ -0,0 +1,11 @@
+# See https://help.github.com/articles/about-codeowners/ for syntax
+
+# Core Engineering will be the default owners for everything
+# in the repo. Unless a later match takes precedence,
+# @deepset-ai/core-engineering will be requested for review
+# when someone opens a pull request.
+* @deepset-ai/core-engineering
+
+# Documentation
+*.md @deepset-ai/documentation @deepset-ai/core-engineering
+/tutorials/ @deepset-ai/documentation @deepset-ai/core-engineering
diff --git a/.github/utils/code_and_docs.sh b/.github/utils/code_and_docs.sh
deleted file mode 100755
index 8d33294865..0000000000
--- a/.github/utils/code_and_docs.sh
+++ /dev/null
@@ -1,26 +0,0 @@
-#!/bin/bash
-
-echo "========== Apply Black ========== "
-black .
-echo
-
-echo "========== Convert tutorial notebooks into webpages ========== "
-python .github/utils/convert_notebooks_into_webpages.py
-echo
-
-echo "========== Generate OpenAPI docs ========== "
-python .github/utils/generate_openapi_specs.py
-echo
-
-echo "========== Generate JSON schema ========== "
-python .github/utils/generate_json_schema.py
-echo
-
-echo "========== Generate the API documentation ========== "
-set -e # Fails on any error in the following loop
-cd docs/_src/api/api/
-for file in ../pydoc/* ; do
- echo "Processing" $file
- pydoc-markdown "$file"
-done
-echo
diff --git a/.github/utils/convert_notebooks_into_webpages.py b/.github/utils/convert_notebooks_into_webpages.py
old mode 100644
new mode 100755
index e3d3474660..55d4753099
--- a/.github/utils/convert_notebooks_into_webpages.py
+++ b/.github/utils/convert_notebooks_into_webpages.py
@@ -1,3 +1,5 @@
+#!/usr/bin/env python3
+
import re
from nbconvert import MarkdownExporter
@@ -142,7 +144,7 @@
id: "tutorial17md"
--->""",
18: """
-# Better Retrieval via "Dense Passage Retrieval"
+# Better Retrieval via "Embedding Retrieval"
-[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb)
+[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb)
### Importance of Retrievers
@@ -28,40 +28,33 @@ Family of algorithms based on counting the occurrences of words (bag-of-words) r
#### Dense
-These retrievers use neural network models to create "dense" embedding vectors. Within this family there are two different approaches:
+These retrievers use neural network models to create "dense" embedding vectors. Within this family, there are two different approaches:
-a) Single encoder: Use a **single model** to embed both query and passage.
-b) Dual-encoder: Use **two models**, one to embed the query and one to embed the passage
-
-Recent work suggests that dual encoders work better, likely because they can deal better with the different nature of query and passage (length, style, syntax ...).
+a) Single encoder: Use a **single model** to embed both the query and the passage.
+b) Dual-encoder: Use **two models**, one to embed the query and one to embed the passage.
**Examples**: REALM, DPR, Sentence-Transformers
-**Pros**: Captures semantinc similarity instead of "word matches" (e.g. synonyms, related topics ...)
-
-**Cons**: Computationally more heavy, initial training of model
-
+**Pros**: Captures semantic similarity instead of "word matches" (for example, synonyms, related topics).
-### "Dense Passage Retrieval"
+**Cons**: Computationally more heavy to use, initial training of the model (though this is less of an issue nowadays as many pre-trained models are available and most of the time, it's not needed to train the model).
-In this Tutorial, we want to highlight one "Dense Dual-Encoder" called Dense Passage Retriever.
-It was introduced by Karpukhin et al. (2020, https://arxiv.org/abs/2004.04906.
-Original Abstract:
+### Embedding Retrieval
-_"Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks."_
+In this Tutorial, we use an `EmbeddingRetriever` with [Sentence Transformers](https://www.sbert.net/index.html) models.
-Paper: https://arxiv.org/abs/2004.04906
-Original Code: https://fburl.com/qa-dpr
+These models are trained to embed similar sentences close to each other in a shared embedding space.
+Some models have been fine-tuned on massive Information Retrieval data and can be used to retrieve documents based on a short query (for example, `multi-qa-mpnet-base-dot-v1`). There are others that are more suited to semantic similarity tasks where you are trying to find the most similar documents to a given document (for example, `all-mpnet-base-v2`). There are even models that are multilingual (for example, `paraphrase-multilingual-mpnet-base-v2`). For a good overview of different models with their evaluation metrics, see the [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html#) in the Sentence Transformers documentation.
-*Use this* [link](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb) *to open the notebook in Google Colab.*
+*Use this* [link](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb) *to open the notebook in Google Colab.*
-### Prepare environment
+### Prepare the Environment
-#### Colab: Enable the GPU runtime
-Make sure you enable the GPU runtime to experience decent speed in this tutorial.
+#### Colab: Enable the GPU Runtime
+Make sure you enable the GPU runtime to experience decent speed in this tutorial.
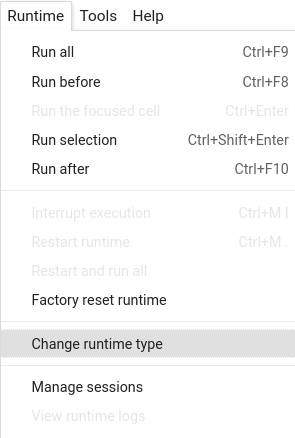
**Runtime -> Change Runtime type -> Hardware accelerator -> GPU**
 @@ -82,6 +75,21 @@ Make sure you enable the GPU runtime to experience decent speed in this tutorial
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers
@@ -151,34 +159,28 @@ document_store.write_documents(docs)
#### Retriever
-**Here:** We use a `DensePassageRetriever`
+**Here:** We use an `EmbeddingRetriever`.
**Alternatives:**
-- The `BM25Retriever`with custom queries (e.g. boosting) and filters
-- Use `EmbeddingRetriever` to find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT)
-- Use `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging
+- `BM25Retriever` with custom queries (for example, boosting) and filters
+- `DensePassageRetriever` which uses two encoder models, one to embed the query and one to embed the passage, and then compares the embedding for retrieval
+- `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging
```python
-from haystack.nodes import DensePassageRetriever
+from haystack.nodes import EmbeddingRetriever
-retriever = DensePassageRetriever(
+retriever = EmbeddingRetriever(
document_store=document_store,
- query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
- passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
- max_seq_len_query=64,
- max_seq_len_passage=256,
- batch_size=16,
- use_gpu=True,
- embed_title=True,
- use_fast_tokenizers=True,
+ embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
+ model_format="sentence_transformers",
)
# Important:
-# Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all
+# Now that we initialized the Retriever, we need to call update_embeddings() to iterate over all
# previously indexed documents and update their embedding representation.
-# While this can be a time consuming operation (depending on corpus size), it only needs to be done once.
-# At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.
+# While this can be a time consuming operation (depending on the corpus size), it only needs to be done once.
+# At query time, we only need to embed the query and compare it to the existing document embeddings, which is very fast.
document_store.update_embeddings(retriever)
```
@@ -234,7 +236,8 @@ print_answers(prediction, details="minimum")
This [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany
-We bring NLP to the industry via open source!
+We bring NLP to the industry via open source!
+
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
diff --git a/docs/_src/tutorials/tutorials/7.md b/docs/_src/tutorials/tutorials/7.md
index cbb4d541ee..c22882b00d 100644
--- a/docs/_src/tutorials/tutorials/7.md
+++ b/docs/_src/tutorials/tutorials/7.md
@@ -43,6 +43,21 @@ Here are the packages and imports that we'll need:
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
from typing import List
diff --git a/docs/_src/tutorials/tutorials/8.md b/docs/_src/tutorials/tutorials/8.md
index 7d8d091708..cb78d48b11 100644
--- a/docs/_src/tutorials/tutorials/8.md
+++ b/docs/_src/tutorials/tutorials/8.md
@@ -45,6 +45,21 @@ This tutorial will show you all the tools that Haystack provides to help you cas
# !tar -xvf xpdf-tools-mac-4.03.tar.gz && sudo cp xpdf-tools-mac-4.03/bin64/pdftotext /usr/local/bin
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
# Here are the imports we need
diff --git a/docs/_src/tutorials/tutorials/9.md b/docs/_src/tutorials/tutorials/9.md
index 9490af9dc9..d77e5da173 100644
--- a/docs/_src/tutorials/tutorials/9.md
+++ b/docs/_src/tutorials/tutorials/9.md
@@ -24,6 +24,21 @@ This tutorial will guide you through the steps required to create a retriever th
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
# Here are some imports that we'll need
diff --git a/docs/img/ci-failure-example-instructions.png b/docs/img/ci-failure-example-instructions.png
new file mode 100644
index 0000000000..db485a201f
Binary files /dev/null and b/docs/img/ci-failure-example-instructions.png differ
diff --git a/docs/img/ci-failure-example.png b/docs/img/ci-failure-example.png
new file mode 100644
index 0000000000..9fc44df66f
Binary files /dev/null and b/docs/img/ci-failure-example.png differ
diff --git a/docs/img/ci-success.png b/docs/img/ci-success.png
new file mode 100644
index 0000000000..304609e20d
Binary files /dev/null and b/docs/img/ci-success.png differ
diff --git a/docs/img/fork_action_config.png b/docs/img/fork_action_config.png
deleted file mode 100644
index 253d841382..0000000000
Binary files a/docs/img/fork_action_config.png and /dev/null differ
diff --git a/docs/pydoc/__init__.py b/docs/pydoc/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/docs/pydoc/renderers.py b/docs/pydoc/renderers.py
new file mode 100644
index 0000000000..5c76bdb4a1
--- /dev/null
+++ b/docs/pydoc/renderers.py
@@ -0,0 +1,49 @@
+import sys
+import io
+import dataclasses
+import docspec
+import typing as t
+from pathlib import Path
+from pydoc_markdown.interfaces import Context, Renderer
+from pydoc_markdown.contrib.renderers.markdown import MarkdownRenderer
+
+
+README_FRONTMATTER = """---
+title: {title}
+excerpt: {excerpt}
+category: {category}
+---
+
+"""
+
+
+@dataclasses.dataclass
+class ReadmeRenderer(Renderer):
+ """
+ This custom Renderer is heavily based on the `MarkdownRenderer`,
+ it just prepends a front matter so that the output can be published
+ directly to readme.io.
+ """
+
+ # These settings will be used in the front matter output
+ title: str
+ category: str
+ excerpt: str
+ # This exposes a special `markdown` settings value that can be used to pass
+ # parameters to the underlying `MarkdownRenderer`
+ markdown: MarkdownRenderer = dataclasses.field(default_factory=MarkdownRenderer)
+
+ def init(self, context: Context) -> None:
+ self.markdown.init(context)
+
+ def render(self, modules: t.List[docspec.Module]) -> None:
+ if self.markdown.filename is None:
+ sys.stdout.write(self._frontmatter())
+ self.markdown.render_to_stream(modules, sys.stdout)
+ else:
+ with io.open(self.markdown.filename, "w", encoding=self.markdown.encoding) as fp:
+ fp.write(self._frontmatter())
+ self.markdown.render_to_stream(modules, t.cast(t.TextIO, fp))
+
+ def _frontmatter(self) -> str:
+ return README_FRONTMATTER.format(title=self.title, category=self.category, excerpt=self.excerpt)
diff --git a/haystack/__init__.py b/haystack/__init__.py
index 8b0d9900ef..eca24ef531 100644
--- a/haystack/__init__.py
+++ b/haystack/__init__.py
@@ -12,14 +12,9 @@
__version__: str = str(metadata.version("farm-haystack"))
-# This configuration must be done before any import to apply to all submodules
+# Logging is not configured here on purpose, see https://github.com/deepset-ai/haystack/issues/2485
import logging
-logging.basicConfig(
- format="%(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.WARNING
-)
-logging.getLogger("haystack").setLevel(logging.INFO)
-
import pandas as pd
from haystack.schema import Document, Answer, Label, MultiLabel, Span, EvaluationResult
diff --git a/haystack/document_stores/__init__.py b/haystack/document_stores/__init__.py
index 1491a2f8d3..6ed752c961 100644
--- a/haystack/document_stores/__init__.py
+++ b/haystack/document_stores/__init__.py
@@ -12,8 +12,11 @@
elasticsearch_index_to_document_store,
open_search_index_to_document_store,
)
-from haystack.document_stores.opensearch import OpenSearchDocumentStore, OpenDistroElasticsearchDocumentStore
+OpenSearchDocumentStore = safe_import("haystack.document_stores.opensearch", "OpenSearchDocumentStore", "opensearch")
+OpenDistroElasticsearchDocumentStore = safe_import(
+ "haystack.document_stores.opensearch", "OpenDistroElasticsearchDocumentStore", "opensearch"
+)
SQLDocumentStore = safe_import("haystack.document_stores.sql", "SQLDocumentStore", "sql")
FAISSDocumentStore = safe_import("haystack.document_stores.faiss", "FAISSDocumentStore", "faiss")
PineconeDocumentStore = safe_import("haystack.document_stores.pinecone", "PineconeDocumentStore", "pinecone")
diff --git a/haystack/document_stores/memory.py b/haystack/document_stores/memory.py
index c86144c771..760df00ccc 100644
--- a/haystack/document_stores/memory.py
+++ b/haystack/document_stores/memory.py
@@ -10,7 +10,7 @@
from tqdm import tqdm
from haystack.schema import Document, Label
-from haystack.errors import DuplicateDocumentError
+from haystack.errors import DuplicateDocumentError, DocumentStoreError
from haystack.document_stores import BaseDocumentStore
from haystack.document_stores.base import get_batches_from_generator
from haystack.modeling.utils import initialize_device_settings
@@ -448,8 +448,11 @@ def update_embeddings(
) as progress_bar:
for document_batch in batched_documents:
embeddings = retriever.embed_documents(document_batch) # type: ignore
- assert len(document_batch) == len(embeddings)
-
+ if not len(document_batch) == len(embeddings):
+ raise DocumentStoreError(
+ "The number of embeddings does not match the number of documents in the batch "
+ f"({len(embeddings)} != {len(document_batch)})"
+ )
if embeddings[0].shape[0] != self.embedding_dim:
raise RuntimeError(
f"Embedding dim. of model ({embeddings[0].shape[0]})"
diff --git a/haystack/document_stores/opensearch.py b/haystack/document_stores/opensearch.py
index 2ad78a3a11..e6d9d17518 100644
--- a/haystack/document_stores/opensearch.py
+++ b/haystack/document_stores/opensearch.py
@@ -7,25 +7,25 @@
from tqdm.auto import tqdm
try:
- from elasticsearch.helpers import bulk
- from elasticsearch.exceptions import RequestError
-except (ImportError, ModuleNotFoundError) as ie:
+ from opensearchpy import OpenSearch, Urllib3HttpConnection, RequestsHttpConnection, NotFoundError, RequestError
+ from opensearchpy.helpers import bulk
+except (ImportError, ModuleNotFoundError) as e:
from haystack.utils.import_utils import _optional_component_not_installed
- _optional_component_not_installed(__name__, "elasticsearch", ie)
+ _optional_component_not_installed(__name__, "opensearch", e)
from haystack.schema import Document
from haystack.document_stores.base import get_batches_from_generator
from haystack.document_stores.filter_utils import LogicalFilterClause
+from haystack.errors import DocumentStoreError
-from .elasticsearch import ElasticsearchDocumentStore
-
+from .elasticsearch import BaseElasticsearchDocumentStore, prepare_hosts
logger = logging.getLogger(__name__)
-class OpenSearchDocumentStore(ElasticsearchDocumentStore):
+class OpenSearchDocumentStore(BaseElasticsearchDocumentStore):
def __init__(
self,
scheme: str = "https", # Mind this different default param
@@ -131,18 +131,45 @@ def __init__(
Synonym or Synonym_graph to handle synonyms, including multi-word synonyms correctly during the analysis process.
More info at https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-graph-tokenfilter.html
"""
+ # These parameters aren't used by Opensearch at the moment but could be in the future, see
+ # https://github.com/opensearch-project/security/issues/1504. Let's not deprecate them for
+ # now but send a warning to the user.
+ if api_key or api_key_id:
+ logger.warning("api_key and api_key_id will be ignored by the Opensearch client")
+
+ # Base constructor needs the client to be ready, create it before calling super()
+ client = self._init_client(
+ host=host,
+ port=port,
+ username=username,
+ password=password,
+ aws4auth=aws4auth,
+ scheme=scheme,
+ ca_certs=ca_certs,
+ verify_certs=verify_certs,
+ timeout=timeout,
+ use_system_proxy=use_system_proxy,
+ )
+
+ # Test the connection
+ try:
+ client.indices.get(index)
+ except NotFoundError:
+ # We don't know which permissions the user has but we can assume they can write to the given index, so
+ # if we get a NotFoundError it means at least the connection is working.
+ pass
+ except Exception as e:
+ # If we get here, there's something fundamentally wrong with the connection and we can't continue
+ raise ConnectionError(
+ f"Initial connection to Opensearch failed with error '{e}'\n"
+ f"Make sure an Opensearch instance is running at `{host}` and that it has finished booting (can take > 30s)."
+ )
+
self.embeddings_field_supports_similarity = False
self.similarity_to_space_type = {"cosine": "cosinesimil", "dot_product": "innerproduct", "l2": "l2"}
self.space_type_to_similarity = {v: k for k, v in self.similarity_to_space_type.items()}
super().__init__(
- scheme=scheme,
- username=username,
- password=password,
- host=host,
- port=port,
- api_key_id=api_key_id,
- api_key=api_key,
- aws4auth=aws4auth,
+ client=client,
index=index,
label_index=label_index,
search_fields=search_fields,
@@ -153,13 +180,10 @@ def __init__(
custom_mapping=custom_mapping,
excluded_meta_data=excluded_meta_data,
analyzer=analyzer,
- ca_certs=ca_certs,
- verify_certs=verify_certs,
recreate_index=recreate_index,
create_index=create_index,
refresh_type=refresh_type,
similarity=similarity,
- timeout=timeout,
return_embedding=return_embedding,
duplicate_documents=duplicate_documents,
index_type=index_type,
@@ -167,9 +191,65 @@ def __init__(
skip_missing_embeddings=skip_missing_embeddings,
synonyms=synonyms,
synonym_type=synonym_type,
- use_system_proxy=use_system_proxy,
)
+ @classmethod
+ def _init_client(
+ cls,
+ host: Union[str, List[str]],
+ port: Union[int, List[int]],
+ username: str,
+ password: str,
+ aws4auth,
+ scheme: str,
+ ca_certs: Optional[str],
+ verify_certs: bool,
+ timeout: int,
+ use_system_proxy: bool,
+ ) -> OpenSearch:
+ """
+ Create an instance of the Opensearch client
+ """
+ hosts = prepare_hosts(host, port)
+ connection_class = Urllib3HttpConnection
+ if use_system_proxy:
+ connection_class = RequestsHttpConnection
+
+ if username:
+ # standard http_auth
+ client = OpenSearch(
+ hosts=hosts,
+ http_auth=(username, password),
+ scheme=scheme,
+ ca_certs=ca_certs,
+ verify_certs=verify_certs,
+ timeout=timeout,
+ connection_class=connection_class,
+ )
+ elif aws4auth:
+ # Sign requests to Opensearch with IAM credentials
+ # see https://docs.aws.amazon.com/opensearch-service/latest/developerguide/request-signing.html#request-signing-python
+ client = OpenSearch(
+ hosts=hosts,
+ http_auth=aws4auth,
+ connection_class=RequestsHttpConnection,
+ use_ssl=True,
+ verify_certs=True,
+ timeout=timeout,
+ )
+ else:
+ # no authentication needed
+ client = OpenSearch(
+ hosts=hosts,
+ scheme=scheme,
+ ca_certs=ca_certs,
+ verify_certs=verify_certs,
+ timeout=timeout,
+ connection_class=connection_class,
+ )
+
+ return client
+
def query_by_embedding(
self,
query_emb: np.ndarray,
@@ -264,10 +344,12 @@ def query_by_embedding(
return_embedding = self.return_embedding
if not self.embedding_field:
- raise RuntimeError("Please specify arg `embedding_field` in ElasticsearchDocumentStore()")
+ raise DocumentStoreError("Please set a valid `embedding_field` for OpenSearchDocumentStore")
# +1 in similarity to avoid negative numbers (for cosine sim)
body: Dict[str, Any] = {"size": top_k, "query": self._get_vector_similarity_query(query_emb, top_k)}
if filters:
+ if not "bool" in body["query"]:
+ body["query"]["bool"] = {}
body["query"]["bool"]["filter"] = LogicalFilterClause.parse(filters).convert_to_elasticsearch()
excluded_meta_data: Optional[list] = None
@@ -317,7 +399,7 @@ def _create_document_index(self, index_name: str, headers: Optional[Dict[str, st
search_field in mappings["properties"]
and mappings["properties"][search_field]["type"] != "text"
):
- raise Exception(
+ raise DocumentStoreError(
f"The search_field '{search_field}' of index '{index_id}' with type '{mappings['properties'][search_field]['type']}' "
f"does not have the right type 'text' to be queried in fulltext search. Please use only 'text' type properties as search_fields or use another index. "
f"This error might occur if you are trying to use haystack 1.0 and above with an existing elasticsearch index created with a previous version of haystack. "
@@ -335,7 +417,7 @@ def _create_document_index(self, index_name: str, headers: Optional[Dict[str, st
else:
# bad embedding field
if mappings["properties"][self.embedding_field]["type"] != "knn_vector":
- raise Exception(
+ raise DocumentStoreError(
f"The '{index_id}' index in OpenSearch already has a field called '{self.embedding_field}'"
f" with the type '{mappings['properties'][self.embedding_field]['type']}'. Please update the "
f"document_store to use a different name for the embedding_field parameter."
@@ -527,7 +609,7 @@ def clone_embedding_field(
):
mapping = self.client.indices.get(self.index, headers=headers)[self.index]["mappings"]
if new_embedding_field in mapping["properties"]:
- raise Exception(
+ raise DocumentStoreError(
f"{new_embedding_field} already exists with mapping {mapping['properties'][new_embedding_field]}"
)
mapping["properties"][new_embedding_field] = self._get_embedding_field_mapping(similarity=similarity)
diff --git a/haystack/document_stores/sql.py b/haystack/document_stores/sql.py
index 7ada22beee..5248801cdc 100644
--- a/haystack/document_stores/sql.py
+++ b/haystack/document_stores/sql.py
@@ -21,7 +21,7 @@
ForeignKeyConstraint,
)
from sqlalchemy.ext.declarative import declarative_base
- from sqlalchemy.orm import relationship, sessionmaker
+ from sqlalchemy.orm import relationship, sessionmaker, validates
from sqlalchemy.sql import case, null
except (ImportError, ModuleNotFoundError) as ie:
from haystack.utils.import_utils import _optional_component_not_installed
@@ -73,6 +73,17 @@ class MetaDocumentORM(ORMBase):
{},
) # type: ignore
+ valid_metadata_types = (str, int, float, bool, bytes, bytearray, type(None))
+
+ @validates("value")
+ def validate_value(self, key, value):
+ if not isinstance(value, self.valid_metadata_types):
+ raise TypeError(
+ f"Discarded metadata '{self.name}', since it has invalid type: {type(value).__name__}.\n"
+ f"SQLDocumentStore can accept and cast to string only the following types: {', '.join([el.__name__ for el in self.valid_metadata_types])}"
+ )
+ return value
+
class LabelORM(ORMBase):
__tablename__ = "label"
@@ -386,7 +397,12 @@ def write_documents(
for doc in document_objects[i : i + batch_size]:
meta_fields = doc.meta or {}
vector_id = meta_fields.pop("vector_id", None)
- meta_orms = [MetaDocumentORM(name=key, value=value) for key, value in meta_fields.items()]
+ meta_orms = []
+ for key, value in meta_fields.items():
+ try:
+ meta_orms.append(MetaDocumentORM(name=key, value=value))
+ except TypeError as ex:
+ logger.error(f"Document {doc.id} - {ex}")
doc_mapping = {
"id": doc.id,
"content": doc.to_dict()["content"],
diff --git a/haystack/document_stores/weaviate.py b/haystack/document_stores/weaviate.py
index f24c83ce60..3dc8f51cc1 100644
--- a/haystack/document_stores/weaviate.py
+++ b/haystack/document_stores/weaviate.py
@@ -11,7 +11,7 @@
try:
import weaviate
- from weaviate import client, AuthClientPassword
+ from weaviate import client, AuthClientPassword, gql
except (ImportError, ModuleNotFoundError) as ie:
from haystack.utils.import_utils import _optional_component_not_installed
@@ -814,8 +814,10 @@ def query(
query: Optional[str] = None,
filters: Optional[Dict[str, Union[Dict, List, str, int, float, bool]]] = None,
top_k: int = 10,
+ all_terms_must_match: bool = False,
custom_query: Optional[str] = None,
index: Optional[str] = None,
+ headers: Optional[Dict[str, str]] = None,
scale_score: bool = True,
) -> List[Document]:
"""
@@ -887,36 +889,95 @@ def query(
}
```
:param top_k: How many documents to return per query.
+ :param all_terms_must_match: Not used in Weaviate.
:param custom_query: Custom query that will executed using query.raw method, for more details refer
https://weaviate.io/developers/weaviate/current/graphql-references/filters.html
:param index: The name of the index in the DocumentStore from which to retrieve documents
+ :param headers: Not used in Weaviate.
:param scale_score: Whether to scale the similarity score to the unit interval (range of [0,1]).
If true (default) similarity scores (e.g. cosine or dot_product) which naturally have a different value range will be scaled to a range of [0,1], where 1 means extremely relevant.
Otherwise raw similarity scores (e.g. cosine or dot_product) will be used.
"""
+ if headers:
+ raise NotImplementedError("Weaviate does not support Custom HTTP headers!")
+
+ if all_terms_must_match:
+ raise NotImplementedError("The `all_terms_must_match` option is not supported in Weaviate!")
+
index = self._sanitize_index_name(index) or self.index
# Build the properties to retrieve from Weaviate
properties = self._get_current_properties(index)
properties.append("_additional {id, certainty, vector}")
- if custom_query:
- query_output = self.weaviate_client.query.raw(custom_query)
- elif filters:
- filter_dict = LogicalFilterClause.parse(filters).convert_to_weaviate()
- query_output = (
- self.weaviate_client.query.get(class_name=index, properties=properties)
- .with_where(filter_dict)
- .with_limit(top_k)
- .do()
- )
+ if query is None:
+
+ # Retrieval via custom query, no BM25
+ if custom_query:
+ query_output = self.weaviate_client.query.raw(custom_query)
+
+ # Naive retrieval without BM25, only filtering
+ elif filters:
+ filter_dict = LogicalFilterClause.parse(filters).convert_to_weaviate()
+ query_output = (
+ self.weaviate_client.query.get(class_name=index, properties=properties)
+ .with_where(filter_dict)
+ .with_limit(top_k)
+ .do()
+ )
+ else:
+ raise NotImplementedError(
+ "Weaviate does not support the retrieval of records without specifying a query or a filter!"
+ )
+
+ # Default Retrieval via BM25 using the user's query on `self.content_field`
else:
- raise NotImplementedError(
- "Weaviate does not support inverted index text query. However, "
- "it allows to search by filters example : {'content': 'some text'} or "
- "use a custom GraphQL query in text format!"
+ logger.warning(
+ "As of v1.14.1 Weaviate's BM25 retrieval is still in experimental phase, "
+ "so use it with care! To turn on the BM25 experimental feature in Weaviate "
+ "you need to start it with the `ENABLE_EXPERIMENTAL_BM25='true'` "
+ "environmental variable."
)
+ # Retrieval with BM25 AND filtering
+ if filters:
+ raise NotImplementedError(
+ "Weaviate currently (v1.14.1) does not support filters WITH inverted index text query (eg BM25)!"
+ )
+
+ # Once Weaviate starts supporting filters with BM25:
+ # filter_dict = LogicalFilterClause.parse(filters).convert_to_weaviate()
+ # gql_query = weaviate.gql.get.GetBuilder(class_name=index,
+ # properties=properties,
+ # connection=self.weaviate_client) \
+ # .with_near_vector({'vector': [0, 0]}) \
+ # .with_where(filter_dict) \
+ # .with_limit(top_k) \
+ # .build()
+
+ # BM25 retrieval without filtering
+ gql_query = (
+ gql.get.GetBuilder(class_name=index, properties=properties, connection=self.weaviate_client)
+ .with_near_vector({"vector": [0, 0]})
+ .with_limit(top_k)
+ .build()
+ )
+
+ # Build the BM25 part of the GQL manually.
+ # Currently the GetBuilder of the Weaviate-client (v3.6.0)
+ # does not support the BM25 part of GQL building, so
+ # the BM25 part needs to be added manually.
+ # The BM25 query needs to be provided all lowercase while
+ # the functionality is in experimental mode in Weaviate,
+ # see https://app.slack.com/client/T0181DYT9KN/C017EG2SL3H/thread/C017EG2SL3H-1658790227.208119
+ bm25_gql_query = f"""bm25: {{
+ query: "{query.replace('"', ' ').lower()}",
+ properties: ["{self.content_field}"]
+ }}"""
+ gql_query = gql_query.replace("nearVector: {vector: [0, 0]}", bm25_gql_query)
+
+ query_output = self.weaviate_client.query.raw(gql_query)
+
results = []
if query_output and "data" in query_output and "Get" in query_output.get("data"):
if query_output.get("data").get("Get").get(index):
@@ -1238,10 +1299,19 @@ def delete_documents(
index = self._sanitize_index_name(index) or self.index
if not filters and not ids:
+ # Delete the existing index, then create an empty new one
self._create_schema_and_index(index, recreate_index=True)
+ return
+
+ # Create index if it doesn't exist yet
+ self._create_schema_and_index(index, recreate_index=False)
+
+ if ids and not filters:
+ for id in ids:
+ self.weaviate_client.data_object.delete(id)
+
else:
- # create index if it doesn't exist yet
- self._create_schema_and_index(index, recreate_index=False)
+ # Use filters to restrict list of retrieved documents, before checking these against provided ids
docs_to_delete = self.get_all_documents(index, filters=filters)
if ids:
docs_to_delete = [doc for doc in docs_to_delete if doc.id in ids]
diff --git a/haystack/errors.py b/haystack/errors.py
index 88d6de4222..bc81faf0f8 100644
--- a/haystack/errors.py
+++ b/haystack/errors.py
@@ -35,6 +35,13 @@ def __repr__(self):
return str(self)
+class ModelingError(HaystackError):
+ """Exception for issues raised by the modeling module"""
+
+ def __init__(self, message: Optional[str] = None, docs_link: Optional[str] = "https://haystack.deepset.ai/"):
+ super().__init__(message=message, docs_link=docs_link)
+
+
class PipelineError(HaystackError):
"""Exception for issues raised within a pipeline"""
diff --git a/haystack/json-schemas/haystack-pipeline-master.schema.json b/haystack/json-schemas/haystack-pipeline-master.schema.json
index f85d8c62ab..16644ec408 100644
--- a/haystack/json-schemas/haystack-pipeline-master.schema.json
+++ b/haystack/json-schemas/haystack-pipeline-master.schema.json
@@ -239,10 +239,41 @@
"type": "string"
}
},
- "replicas": {
- "title": "replicas",
- "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
- "type": "integer"
+ "serve_deployment_kwargs": {
+ "title": "serve_deployment_kwargs",
+ "description": "Arguments to be passed to the Ray Serve `deployment()` method (only for Ray pipelines)",
+ "type": "object",
+ "properties": {
+ "num_replicas": {
+ "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
+ "type": "integer"
+ },
+ "version": {
+ "type": "string"
+ },
+ "prev_version": {
+ "type": "string"
+ },
+ "init_args": {
+ "type": "array"
+ },
+ "init_kwargs": {
+ "type": "object"
+ },
+ "router_prefix": {
+ "type": "string"
+ },
+ "ray_actor_options": {
+ "type": "object"
+ },
+ "user_config": {
+ "type": {}
+ },
+ "max_concurrent_queries": {
+ "type": "integer"
+ }
+ },
+ "additionalProperties": true
}
},
"required": [
@@ -285,7 +316,7 @@
"items": {
"not": {
"required": [
- "replicas"
+ "serve_deployment_kwargs"
]
}
}
@@ -2116,11 +2147,6 @@
"default": true,
"type": "boolean"
},
- "infer_tokenizer_classes": {
- "title": "Infer Tokenizer Classes",
- "default": false,
- "type": "boolean"
- },
"similarity_function": {
"title": "Similarity Function",
"default": "dot_product",
@@ -3572,6 +3598,18 @@
"default": true,
"type": "boolean"
},
+ "tokenizer_model_folder": {
+ "title": "Tokenizer Model Folder",
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "string",
+ "format": "path"
+ }
+ ]
+ },
"language": {
"title": "Language",
"default": "en",
@@ -3742,6 +3780,11 @@
"batch_size": {
"title": "Batch Size",
"type": "integer"
+ },
+ "sep_token": {
+ "title": "Sep Token",
+ "default": "",
+ "type": "string"
}
},
"additionalProperties": false,
@@ -4326,11 +4369,6 @@
"default": true,
"type": "boolean"
},
- "infer_tokenizer_classes": {
- "title": "Infer Tokenizer Classes",
- "default": false,
- "type": "boolean"
- },
"similarity_function": {
"title": "Similarity Function",
"default": "dot_product",
@@ -4375,6 +4413,11 @@
"title": "Scale Score",
"default": true,
"type": "boolean"
+ },
+ "use_fast": {
+ "title": "Use Fast",
+ "default": true,
+ "type": "boolean"
}
},
"required": [
diff --git a/haystack/modeling/data_handler/data_silo.py b/haystack/modeling/data_handler/data_silo.py
index 435e1ef686..f7237b8d28 100644
--- a/haystack/modeling/data_handler/data_silo.py
+++ b/haystack/modeling/data_handler/data_silo.py
@@ -812,7 +812,16 @@ def _run_teacher(self, batch: dict) -> List[torch.Tensor]:
"""
Run the teacher model on the given batch.
"""
- return self.teacher.inferencer.model(**batch)
+ params = {
+ "input_ids": batch["input_ids"],
+ "segment_ids": batch["segment_ids"],
+ "padding_mask": batch["padding_mask"],
+ }
+ if "output_hidden_states" in batch.keys():
+ params["output_hidden_states"] = batch["output_hidden_states"]
+ if "output_attentions" in batch.keys():
+ params["output_attentions"] = batch["output_attentions"]
+ return self.teacher.inferencer.model(**params)
def _pass_batches(
self,
diff --git a/haystack/modeling/data_handler/processor.py b/haystack/modeling/data_handler/processor.py
index dd90a00a46..e9584bddc3 100644
--- a/haystack/modeling/data_handler/processor.py
+++ b/haystack/modeling/data_handler/processor.py
@@ -1,4 +1,4 @@
-from typing import Optional, Dict, List, Union, Any, Iterable
+from typing import Optional, Dict, List, Union, Any, Iterable, Type
import os
import json
@@ -16,9 +16,11 @@
import requests
from tqdm import tqdm
from torch.utils.data import TensorDataset
+import transformers
+from transformers import PreTrainedTokenizer
from haystack.modeling.model.tokenization import (
- Tokenizer,
+ get_tokenizer,
tokenize_batch_question_answering,
tokenize_with_metadata,
truncate_sequences,
@@ -176,11 +178,9 @@ def load_from_dir(cls, load_dir: str):
"Loading tokenizer from deprecated config. "
"If you used `custom_vocab` or `never_split_chars`, this won't work anymore."
)
- tokenizer = Tokenizer.load(
- load_dir, tokenizer_class=config["tokenizer"], do_lower_case=config["lower_case"]
- )
+ tokenizer = get_tokenizer(load_dir, tokenizer_class=config["tokenizer"], do_lower_case=config["lower_case"])
else:
- tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["tokenizer"])
+ tokenizer = get_tokenizer(load_dir, tokenizer_class=config["tokenizer"])
# we have to delete the tokenizer string from config, because we pass it as Object
del config["tokenizer"]
@@ -216,7 +216,7 @@ def convert_from_transformers(
**kwargs,
):
tokenizer_args = tokenizer_args or {}
- tokenizer = Tokenizer.load(
+ tokenizer = get_tokenizer(
tokenizer_name_or_path,
tokenizer_class=tokenizer_class,
use_fast=use_fast,
@@ -308,7 +308,9 @@ def file_to_dicts(self, file: str) -> List[dict]:
raise NotImplementedError()
@abstractmethod
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
raise NotImplementedError()
@abstractmethod
@@ -445,7 +447,9 @@ def __init__(
"using the default task or add a custom task later via processor.add_task()"
)
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Convert input dictionaries into a pytorch dataset for Question Answering.
For this we have an internal representation called "baskets".
@@ -492,7 +496,7 @@ def file_to_dicts(self, file: str) -> List[dict]:
return dicts
# TODO use Input Objects instead of this function, remove Natural Questions (NQ) related code
- def convert_qa_input_dict(self, infer_dict: dict):
+ def convert_qa_input_dict(self, infer_dict: dict) -> Dict[str, Any]:
"""Input dictionaries in QA can either have ["context", "qas"] (internal format) as keys or
["text", "questions"] (api format). This function converts the latter into the former. It also converts the
is_impossible field to answer_type so that NQ and SQuAD dicts have the same format.
@@ -929,9 +933,15 @@ def load_from_dir(cls, load_dir: str):
# read config
processor_config_file = Path(load_dir) / "processor_config.json"
config = json.load(open(processor_config_file))
- # init tokenizer
- query_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["query_tokenizer"], subfolder="query")
- passage_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["passage_tokenizer"], subfolder="passage")
+ # init tokenizers
+ query_tokenizer_class: Type[PreTrainedTokenizer] = getattr(transformers, config["query_tokenizer"])
+ query_tokenizer = query_tokenizer_class.from_pretrained(
+ pretrained_model_name_or_path=load_dir, subfolder="query"
+ )
+ passage_tokenizer_class: Type[PreTrainedTokenizer] = getattr(transformers, config["passage_tokenizer"])
+ passage_tokenizer = passage_tokenizer_class.from_pretrained(
+ pretrained_model_name_or_path=load_dir, subfolder="passage"
+ )
# we have to delete the tokenizer string from config, because we pass it as Object
del config["query_tokenizer"]
@@ -978,7 +988,9 @@ def save(self, save_dir: Union[str, Path]):
with open(output_config_file, "w") as file:
json.dump(config, file)
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Convert input dictionaries into a pytorch dataset for TextSimilarity (e.g. DPR).
For conversion we have an internal representation called "baskets".
@@ -1334,9 +1346,9 @@ def load_from_dir(cls, load_dir: str):
processor_config_file = Path(load_dir) / "processor_config.json"
config = json.load(open(processor_config_file))
# init tokenizer
- query_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["query_tokenizer"], subfolder="query")
- passage_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["passage_tokenizer"], subfolder="passage")
- table_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["table_tokenizer"], subfolder="table")
+ query_tokenizer = get_tokenizer(load_dir, tokenizer_class=config["query_tokenizer"], subfolder="query")
+ passage_tokenizer = get_tokenizer(load_dir, tokenizer_class=config["passage_tokenizer"], subfolder="passage")
+ table_tokenizer = get_tokenizer(load_dir, tokenizer_class=config["table_tokenizer"], subfolder="table")
# we have to delete the tokenizer string from config, because we pass it as Object
del config["query_tokenizer"]
@@ -1488,7 +1500,9 @@ def _read_multimodal_dpr_json(self, file: str, max_samples: Optional[int] = None
standard_dicts.append(sample)
return standard_dicts
- def dataset_from_dicts(self, dicts: List[Dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Convert input dictionaries into a pytorch dataset for TextSimilarity.
For conversion we have an internal representation called "baskets".
@@ -1836,7 +1850,9 @@ def __init__(
def file_to_dicts(self, file: str) -> List[Dict]:
raise NotImplementedError
- def dataset_from_dicts(self, dicts, indices=None, return_baskets=False, debug=False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
self.baskets = []
# Tokenize in batches
texts = [x["text"] for x in dicts]
@@ -1958,7 +1974,7 @@ def load_from_dir(cls, load_dir: str):
processor_config_file = Path(load_dir) / "processor_config.json"
config = json.load(open(processor_config_file))
# init tokenizer
- tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["tokenizer"])
+ tokenizer = get_tokenizer(load_dir, tokenizer_class=config["tokenizer"])
# we have to delete the tokenizer string from config, because we pass it as Object
del config["tokenizer"]
@@ -1979,7 +1995,9 @@ def convert_labels(self, dictionary: Dict):
ret: Dict = {}
return ret
- def dataset_from_dicts(self, dicts: List[Dict], indices=None, return_baskets: bool = False, debug: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Function to convert input dictionaries containing text into a torch dataset.
For normal operation with Language Models it calls the superclass' TextClassification.dataset_from_dicts method.
@@ -2067,7 +2085,9 @@ def file_to_dicts(self, file: str) -> List[dict]:
dicts.append({"text": line})
return dicts
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
if return_baskets:
raise NotImplementedError("return_baskets is not supported by UnlabeledTextProcessor")
texts = [dict_["text"] for dict_ in dicts]
diff --git a/haystack/modeling/data_handler/samples.py b/haystack/modeling/data_handler/samples.py
index 443295ea64..6335490ec7 100644
--- a/haystack/modeling/data_handler/samples.py
+++ b/haystack/modeling/data_handler/samples.py
@@ -1,4 +1,4 @@
-from typing import Union, Optional, List
+from typing import Any, Union, Optional, List, Dict
import logging
import numpy as np
@@ -13,7 +13,13 @@ class Sample:
the human readable clear_text. Over the course of data preprocessing, this object is populated
with tokenized and featurized versions of the data."""
- def __init__(self, id: str, clear_text: dict, tokenized: Optional[dict] = None, features: Optional[dict] = None):
+ def __init__(
+ self,
+ id: str,
+ clear_text: dict,
+ tokenized: Optional[dict] = None,
+ features: Optional[Union[Dict[str, Any], List[Dict[str, Any]]]] = None,
+ ):
"""
:param id: The unique id of the sample
:param clear_text: A dictionary containing various human readable fields (e.g. text, label).
diff --git a/haystack/modeling/evaluation/eval.py b/haystack/modeling/evaluation/eval.py
index 4cdba7409f..028227462b 100644
--- a/haystack/modeling/evaluation/eval.py
+++ b/haystack/modeling/evaluation/eval.py
@@ -8,6 +8,7 @@
from haystack.modeling.evaluation.metrics import compute_metrics, compute_report_metrics
from haystack.modeling.model.adaptive_model import AdaptiveModel
+from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
from haystack.utils.experiment_tracking import Tracker as tracker
from haystack.modeling.visual import BUSH_SEP
@@ -69,7 +70,26 @@ def eval(
with torch.no_grad():
- logits = model.forward(**batch)
+ if isinstance(model, AdaptiveModel):
+ logits = model.forward(
+ input_ids=batch.get("input_ids", None),
+ segment_ids=batch.get("segment_ids", None),
+ padding_mask=batch.get("padding_mask", None),
+ output_hidden_states=batch.get("output_hidden_states", False),
+ output_attentions=batch.get("output_attentions", False),
+ )
+ elif isinstance(model, BiAdaptiveModel):
+ logits = model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )
+ else:
+ logits = model.forward(**batch)
+
losses_per_head = model.logits_to_loss_per_head(logits=logits, **batch)
preds = model.logits_to_preds(logits=logits, **batch)
labels = model.prepare_labels(**batch)
diff --git a/haystack/modeling/infer.py b/haystack/modeling/infer.py
index 85b828b22b..adfddf1d50 100644
--- a/haystack/modeling/infer.py
+++ b/haystack/modeling/infer.py
@@ -470,11 +470,7 @@ def _get_predictions(self, dataset: Dataset, tensor_names: List, baskets):
with torch.no_grad():
logits = self.model.forward(**batch)
preds = self.model.formatted_preds(
- logits=logits,
- samples=batch_samples,
- tokenizer=self.processor.tokenizer,
- return_class_probs=self.return_class_probs,
- **batch,
+ logits=logits, samples=batch_samples, padding_mask=batch.get("padding_mask", None)
)
preds_all += preds
return preds_all
@@ -511,7 +507,13 @@ def _get_predictions_and_aggregate(self, dataset: Dataset, tensor_names: List, b
with torch.no_grad():
# Aggregation works on preds, not logits. We want as much processing happening in one batch + on GPU
# So we transform logits to preds here as well
- logits = self.model.forward(**batch)
+ logits = self.model.forward(
+ input_ids=batch["input_ids"],
+ segment_ids=batch["segment_ids"],
+ padding_mask=batch["padding_mask"],
+ output_hidden_states=batch.get("output_hidden_states", False),
+ output_attentions=batch.get("output_attentions", False),
+ )
# preds = self.model.logits_to_preds(logits, **batch)[0] (This must somehow be useful for SQuAD)
preds = self.model.logits_to_preds(logits, **batch)
unaggregated_preds_all.append(preds)
diff --git a/haystack/modeling/model/adaptive_model.py b/haystack/modeling/model/adaptive_model.py
index ac126e485b..1d01dc4671 100644
--- a/haystack/modeling/model/adaptive_model.py
+++ b/haystack/modeling/model/adaptive_model.py
@@ -13,7 +13,7 @@
from transformers.convert_graph_to_onnx import convert, quantize as quantize_model
from haystack.modeling.data_handler.processor import Processor
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, LanguageModel
from haystack.modeling.model.prediction_head import PredictionHead, QuestionAnsweringHead
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -196,7 +196,7 @@ def __init__(
super(AdaptiveModel, self).__init__() # type: ignore
self.device = device
self.language_model = language_model.to(device)
- self.lm_output_dims = language_model.get_output_dims()
+ self.lm_output_dims = language_model.output_dims
self.prediction_heads = nn.ModuleList([ph.to(device) for ph in prediction_heads])
self.fit_heads_to_lm()
self.dropout = nn.Dropout(embeds_dropout_prob)
@@ -262,7 +262,6 @@ def load( # type: ignore
load_dir: Union[str, Path],
device: Union[str, torch.device],
strict: bool = True,
- lm_name: Optional[str] = None,
processor: Optional[Processor] = None,
):
"""
@@ -277,17 +276,12 @@ def load( # type: ignore
:param load_dir: Location where the AdaptiveModel is stored.
:param device: To which device we want to sent the model, either torch.device("cpu") or torch.device("cuda").
- :param lm_name: The name to assign to the loaded language model.
:param strict: Whether to strictly enforce that the keys loaded from saved model match the ones in
the PredictionHead (see torch.nn.module.load_state_dict()).
:param processor: Processor to populate prediction head with information coming from tasks.
"""
device = torch.device(device)
- # Language Model
- if lm_name:
- language_model = LanguageModel.load(load_dir, haystack_lm_name=lm_name)
- else:
- language_model = LanguageModel.load(load_dir)
+ language_model = get_language_model(load_dir)
# Prediction heads
_, ph_config_files = cls._get_prediction_head_files(load_dir)
@@ -334,7 +328,9 @@ def convert_from_transformers(
:return: AdaptiveModel
"""
- lm = LanguageModel.load(model_name_or_path, revision=revision, use_auth_token=use_auth_token, **kwargs)
+ lm = get_language_model(
+ model_name_or_path, revision=revision, use_auth_token=use_auth_token, model_kwargs=kwargs
+ )
if task_type is None:
# Infer task type from config
architecture = lm.model.config.architectures[0]
@@ -462,31 +458,44 @@ def prepare_labels(self, **kwargs):
all_labels.append(labels)
return all_labels
- def forward(self, output_hidden_states: bool = False, output_attentions: bool = False, **kwargs):
+ def forward(
+ self,
+ input_ids: torch.Tensor,
+ segment_ids: torch.Tensor,
+ padding_mask: torch.Tensor,
+ output_hidden_states: bool = False,
+ output_attentions: bool = False,
+ ):
"""
Push data through the whole model and returns logits. The data will
propagate through the language model and each of the attached prediction heads.
- :param kwargs: Holds all arguments that need to be passed to the language model
- and prediction head(s).
+ :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
+ :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
+ first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
+ It is a tensor of shape [batch_size, max_seq_len].
+ :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len].
:param output_hidden_states: Whether to output hidden states
:param output_attentions: Whether to output attentions
:return: All logits as torch.tensor or multiple tensors.
"""
# Run forward pass of language model
output_tuple = self.language_model.forward(
- **kwargs, output_hidden_states=output_hidden_states, output_attentions=output_attentions
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ attention_mask=padding_mask,
+ output_hidden_states=output_hidden_states,
+ output_attentions=output_attentions,
)
- if output_hidden_states:
- if output_attentions:
- sequence_output, pooled_output, hidden_states, attentions = output_tuple
- else:
- sequence_output, pooled_output, hidden_states = output_tuple
+ if output_hidden_states and output_attentions:
+ sequence_output, pooled_output, hidden_states, attentions = output_tuple
+ elif output_hidden_states:
+ sequence_output, pooled_output, hidden_states = output_tuple
+ elif output_attentions:
+ sequence_output, pooled_output, attentions = output_tuple
else:
- if output_attentions:
- sequence_output, pooled_output, attentions = output_tuple
- else:
- sequence_output, pooled_output = output_tuple
+ sequence_output, pooled_output = output_tuple
# Run forward pass of (multiple) prediction heads using the output from above
all_logits = []
if len(self.prediction_heads) > 0:
@@ -509,12 +518,11 @@ def forward(self, output_hidden_states: bool = False, output_attentions: bool =
# just return LM output (e.g. useful for extracting embeddings at inference time)
all_logits.append((sequence_output, pooled_output))
+ if output_hidden_states and output_attentions:
+ return all_logits, hidden_states, attentions
if output_hidden_states:
- if output_attentions:
- return all_logits, hidden_states, attentions
- else:
- return all_logits, hidden_states
- elif output_attentions:
+ return all_logits, hidden_states
+ if output_attentions:
return all_logits, attentions
return all_logits
@@ -570,7 +578,7 @@ def verify_vocab_size(self, vocab_size: int):
msg = (
f"Vocab size of tokenizer {vocab_size} doesn't match with model {model_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size == model_vocab_len, msg
diff --git a/haystack/modeling/model/biadaptive_model.py b/haystack/modeling/model/biadaptive_model.py
index e960fb01dd..d80f009578 100644
--- a/haystack/modeling/model/biadaptive_model.py
+++ b/haystack/modeling/model/biadaptive_model.py
@@ -6,9 +6,10 @@
import torch
from torch import nn
+from transformers import DPRContextEncoder, DPRQuestionEncoder, AutoModel
from haystack.modeling.data_handler.processor import Processor
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, LanguageModel
from haystack.modeling.model.prediction_head import PredictionHead, TextSimilarityHead
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -28,8 +29,11 @@ def loss_per_head_sum(
class BiAdaptiveModel(nn.Module):
- """PyTorch implementation containing all the modelling needed for your NLP task. Combines 2 language
- models for representation of 2 sequences and a prediction head. Allows for gradient flow back to the 2 language model components."""
+ """
+ PyTorch implementation containing all the modelling needed for your NLP task.
+ Combines 2 language models for representation of 2 sequences and a prediction head.
+ Allows for gradient flow back to the 2 language model components.
+ """
def __init__(
self,
@@ -74,9 +78,9 @@ def __init__(
self.device = device
self.language_model1 = language_model1.to(device)
- self.lm1_output_dims = language_model1.get_output_dims()
+ self.lm1_output_dims = language_model1.output_dims
self.language_model2 = language_model2.to(device)
- self.lm2_output_dims = language_model2.get_output_dims()
+ self.lm2_output_dims = language_model2.output_dims
self.dropout1 = nn.Dropout(embeds_dropout_prob)
self.dropout2 = nn.Dropout(embeds_dropout_prob)
self.prediction_heads = nn.ModuleList([ph.to(device) for ph in prediction_heads])
@@ -140,13 +144,13 @@ def load(
"""
# Language Model
if lm1_name:
- language_model1 = LanguageModel.load(os.path.join(load_dir, lm1_name))
+ language_model1 = get_language_model(os.path.join(load_dir, lm1_name))
else:
- language_model1 = LanguageModel.load(load_dir)
+ language_model1 = get_language_model(load_dir)
if lm2_name:
- language_model2 = LanguageModel.load(os.path.join(load_dir, lm2_name))
+ language_model2 = get_language_model(os.path.join(load_dir, lm2_name))
else:
- language_model2 = LanguageModel.load(load_dir)
+ language_model2 = get_language_model(load_dir)
# Prediction heads
ph_config_files = cls._get_prediction_head_files(load_dir)
@@ -258,7 +262,15 @@ def prepare_labels(self, **kwargs):
all_labels.append(labels)
return all_labels
- def forward(self, **kwargs):
+ def forward(
+ self,
+ query_input_ids: Optional[torch.Tensor] = None,
+ query_segment_ids: Optional[torch.Tensor] = None,
+ query_attention_mask: Optional[torch.Tensor] = None,
+ passage_input_ids: Optional[torch.Tensor] = None,
+ passage_segment_ids: Optional[torch.Tensor] = None,
+ passage_attention_mask: Optional[torch.Tensor] = None,
+ ):
"""
Push data through the whole model and returns logits. The data will propagate through
the first language model and second language model based on the tensor names and both the
@@ -269,7 +281,14 @@ def forward(self, **kwargs):
"""
# Run forward pass of both language models
- pooled_output = self.forward_lm(**kwargs)
+ pooled_output = self.forward_lm(
+ query_input_ids=query_input_ids,
+ query_segment_ids=query_segment_ids,
+ query_attention_mask=query_attention_mask,
+ passage_input_ids=passage_input_ids,
+ passage_segment_ids=passage_segment_ids,
+ passage_attention_mask=passage_attention_mask,
+ )
# Run forward pass of (multiple) prediction heads using the output from above
all_logits = []
@@ -304,7 +323,15 @@ def forward(self, **kwargs):
return all_logits
- def forward_lm(self, **kwargs):
+ def forward_lm(
+ self,
+ query_input_ids: Optional[torch.Tensor] = None,
+ query_segment_ids: Optional[torch.Tensor] = None,
+ query_attention_mask: Optional[torch.Tensor] = None,
+ passage_input_ids: Optional[torch.Tensor] = None,
+ passage_segment_ids: Optional[torch.Tensor] = None,
+ passage_attention_mask: Optional[torch.Tensor] = None,
+ ):
"""
Forward pass for the BiAdaptive model.
@@ -312,11 +339,23 @@ def forward_lm(self, **kwargs):
:return: 2 tensors of pooled_output from the 2 language models.
"""
pooled_output = [None, None]
- if "query_input_ids" in kwargs.keys():
- pooled_output1, hidden_states1 = self.language_model1(**kwargs)
+
+ if query_input_ids is not None and query_segment_ids is not None and query_attention_mask is not None:
+ pooled_output1, _ = self.language_model1(
+ input_ids=query_input_ids, segment_ids=query_segment_ids, attention_mask=query_attention_mask
+ )
pooled_output[0] = pooled_output1
- if "passage_input_ids" in kwargs.keys():
- pooled_output2, hidden_states2 = self.language_model2(**kwargs)
+
+ if passage_input_ids is not None and passage_segment_ids is not None and passage_attention_mask is not None:
+
+ max_seq_len = passage_input_ids.shape[-1]
+ passage_input_ids = passage_input_ids.view(-1, max_seq_len)
+ passage_attention_mask = passage_attention_mask.view(-1, max_seq_len)
+ passage_segment_ids = passage_segment_ids.view(-1, max_seq_len)
+
+ pooled_output2, _ = self.language_model2(
+ input_ids=passage_input_ids, segment_ids=passage_segment_ids, attention_mask=passage_attention_mask
+ )
pooled_output[1] = pooled_output2
return tuple(pooled_output)
@@ -350,7 +389,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int):
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model1_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size1 == model1_vocab_len, msg
@@ -359,7 +398,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int):
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model2_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size2 == model2_vocab_len, msg
@@ -395,8 +434,6 @@ def _get_prediction_head_files(cls, load_dir: Union[str, Path]):
return config_files
def convert_to_transformers(self):
- from transformers import DPRContextEncoder, DPRQuestionEncoder, AutoModel
-
if len(self.prediction_heads) != 1:
raise ValueError(
f"Currently conversion only works for models with a SINGLE prediction head. "
@@ -458,12 +495,8 @@ def convert_from_transformers(
:type processor: Processor
:return: AdaptiveModel
"""
- lm1 = LanguageModel.load(
- pretrained_model_name_or_path=model_name_or_path1, language_model_class="DPRQuestionEncoder"
- )
- lm2 = LanguageModel.load(
- pretrained_model_name_or_path=model_name_or_path2, language_model_class="DPRContextEncoder"
- )
+ lm1 = get_language_model(pretrained_model_name_or_path=model_name_or_path1)
+ lm2 = get_language_model(pretrained_model_name_or_path=model_name_or_path2)
prediction_head = TextSimilarityHead(similarity_function=similarity_function)
# TODO Infer type of head automatically from config
if task_type == "text_similarity":
diff --git a/haystack/modeling/model/language_model.py b/haystack/modeling/model/language_model.py
index 1247a5dcf6..34a4565768 100644
--- a/haystack/modeling/model/language_model.py
+++ b/haystack/modeling/model/language_model.py
@@ -17,47 +17,47 @@
Acknowledgements: Many of the modeling parts here come from the great transformers repository: https://github.com/huggingface/transformers.
Thanks for the great work!
"""
-from __future__ import absolute_import, division, print_function, unicode_literals
-from typing import Optional, Dict, Any, Union
+from typing import Type, Optional, Dict, Any, Union, List
+
+import re
import json
import logging
import os
+from abc import ABC, abstractmethod
from pathlib import Path
from functools import wraps
import numpy as np
import torch
from torch import nn
import transformers
-from transformers import (
- BertModel,
- BertConfig,
- RobertaModel,
- RobertaConfig,
- XLNetModel,
- XLNetConfig,
- AlbertModel,
- AlbertConfig,
- XLMRobertaModel,
- XLMRobertaConfig,
- DistilBertModel,
- DistilBertConfig,
- ElectraModel,
- ElectraConfig,
- CamembertModel,
- CamembertConfig,
- BigBirdModel,
- BigBirdConfig,
- DebertaV2Model,
- DebertaV2Config,
-)
+from transformers import PretrainedConfig, PreTrainedModel
from transformers import AutoModel, AutoConfig
from transformers.modeling_utils import SequenceSummary
+from haystack.errors import ModelingError
+
logger = logging.getLogger(__name__)
+LANGUAGE_HINTS = (
+ ("german", "german"),
+ ("english", "english"),
+ ("chinese", "chinese"),
+ ("indian", "indian"),
+ ("french", "french"),
+ ("camembert", "french"),
+ ("polish", "polish"),
+ ("spanish", "spanish"),
+ ("umberto", "italian"),
+ ("multilingual", "multilingual"),
+)
+
+#: Names of the attributes in various model configs which refer to the number of dimensions in the output vectors
+OUTPUT_DIM_NAMES = ["dim", "hidden_size", "d_model"]
+
+
def silence_transformers_logs(from_pretrained_func):
"""
A wrapper that raises the log level of Transformers to
@@ -82,240 +82,77 @@ def quiet_from_pretrained_func(cls, *args, **kwargs):
return quiet_from_pretrained_func
-# These are the names of the attributes in various model configs which refer to the number of dimensions
-# in the output vectors
-OUTPUT_DIM_NAMES = ["dim", "hidden_size", "d_model"]
-
# TODO analyse if LMs can be completely used through HF transformers
-class LanguageModel(nn.Module):
+class LanguageModel(nn.Module, ABC):
"""
- The parent class for any kind of model that can embed language into a semantic vector space. Practically
- speaking, these models read in tokenized sentences and return vectors that capture the meaning of sentences
- or of tokens.
+ The parent class for any kind of model that can embed language into a semantic vector space.
+ These models read in tokenized sentences and return vectors that capture the meaning of sentences or of tokens.
"""
- subclasses: dict = {}
+ def __init__(self, model_type: str):
+ super().__init__()
+ self._output_dims = None
+ self.name = model_type
- def __init_subclass__(cls, **kwargs):
- """
- This automatically keeps track of all available subclasses.
- Enables generic load() or all specific LanguageModel implementation.
- """
- super().__init_subclass__(**kwargs)
- cls.subclasses[cls.__name__] = cls
+ @property
+ def encoder(self):
+ return self.model.encoder
- def forward(self, input_ids: torch.Tensor, segment_ids: torch.Tensor, padding_mask: torch.Tensor, **kwargs):
+ @abstractmethod
+ def forward(
+ self,
+ input_ids: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor], # DistilBERT does not use them, see DistilBERTLanguageModel
+ output_hidden_states: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ return_dict: bool = False,
+ ):
raise NotImplementedError
- @classmethod
- def load(
- cls,
- pretrained_model_name_or_path: Union[Path, str],
- language: str = None,
- use_auth_token: Union[bool, str] = None,
- **kwargs,
- ):
+ @property
+ def output_hidden_states(self):
"""
- Load a pretrained language model by doing one of the following:
-
- 1. Specifying its name and downloading the model.
- 2. Pointing to the directory the model is saved in.
-
- Available remote models:
-
- * bert-base-uncased
- * bert-large-uncased
- * bert-base-cased
- * bert-large-cased
- * bert-base-multilingual-uncased
- * bert-base-multilingual-cased
- * bert-base-chinese
- * bert-base-german-cased
- * roberta-base
- * roberta-large
- * xlnet-base-cased
- * xlnet-large-cased
- * xlm-roberta-base
- * xlm-roberta-large
- * albert-base-v2
- * albert-large-v2
- * distilbert-base-german-cased
- * distilbert-base-multilingual-cased
- * google/electra-small-discriminator
- * google/electra-base-discriminator
- * google/electra-large-discriminator
- * facebook/dpr-question_encoder-single-nq-base
- * facebook/dpr-ctx_encoder-single-nq-base
-
- See all supported model variations at: https://huggingface.co/models.
-
- The appropriate language model class is inferred automatically from model configuration
- or can be manually supplied using `language_model_class`.
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
- :param revision: The version of the model to use from the Hugging Face model hub. This can be a tag name, a branch name, or a commit hash.
- :param language_model_class: (Optional) Name of the language model class to load (for example `Bert`).
+ Controls whether the model outputs the hidden states or not
"""
- n_added_tokens = kwargs.pop("n_added_tokens", 0)
- language_model_class = kwargs.pop("language_model_class", None)
- kwargs["revision"] = kwargs.get("revision", None)
- logger.info("LOADING MODEL")
- logger.info("=============")
- config_file = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(config_file):
- logger.info(f"Model found locally at {pretrained_model_name_or_path}")
- # it's a local directory in Haystack format
- config = json.load(open(config_file))
- language_model = cls.subclasses[config["name"]].load(pretrained_model_name_or_path)
- else:
- logger.info(f"Could not find {pretrained_model_name_or_path} locally.")
- logger.info(f"Looking on Transformers Model Hub (in local cache and online)...")
- if language_model_class is None:
- language_model_class = cls.get_language_model_class(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
-
- if language_model_class:
- language_model = cls.subclasses[language_model_class].load(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- language_model = None
-
- if not language_model:
- raise Exception(
- f"Model not found for {pretrained_model_name_or_path}. Either supply the local path for a saved "
- f"model or one of bert/roberta/xlnet/albert/distilbert models that can be downloaded from remote. "
- f"Ensure that the model class name can be inferred from the directory name when loading a "
- f"Transformers' model."
- )
- logger.info(f"Loaded {pretrained_model_name_or_path}")
+ self.encoder.config.output_hidden_states = True
- # resize embeddings in case of custom vocab
- if n_added_tokens != 0:
- # TODO verify for other models than BERT
- model_emb_size = language_model.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
- vocab_size = model_emb_size + n_added_tokens
- logger.info(
- f"Resizing embedding layer of LM from {model_emb_size} to {vocab_size} to cope with custom vocab."
- )
- language_model.model.resize_token_embeddings(vocab_size)
- # verify
- model_emb_size = language_model.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
- assert vocab_size == model_emb_size
-
- return language_model
-
- @staticmethod
- def get_language_model_class(model_name_or_path, use_auth_token: Union[str, bool] = None, **kwargs):
- # it's transformers format (either from model hub or local)
- model_name_or_path = str(model_name_or_path)
-
- config = AutoConfig.from_pretrained(model_name_or_path, use_auth_token=use_auth_token, **kwargs)
- model_type = config.model_type
- if model_type == "xlm-roberta":
- language_model_class = "XLMRoberta"
- elif model_type == "roberta":
- if "mlm" in model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- language_model_class = "Roberta"
- elif model_type == "camembert":
- language_model_class = "Camembert"
- elif model_type == "albert":
- language_model_class = "Albert"
- elif model_type == "distilbert":
- language_model_class = "DistilBert"
- elif model_type == "bert":
- language_model_class = "Bert"
- elif model_type == "xlnet":
- language_model_class = "XLNet"
- elif model_type == "electra":
- language_model_class = "Electra"
- elif model_type == "dpr":
- if config.architectures[0] == "DPRQuestionEncoder":
- language_model_class = "DPRQuestionEncoder"
- elif config.architectures[0] == "DPRContextEncoder":
- language_model_class = "DPRContextEncoder"
- elif config.archictectures[0] == "DPRReader":
- raise NotImplementedError("DPRReader models are currently not supported.")
- elif model_type == "big_bird":
- language_model_class = "BigBird"
- elif model_type == "deberta-v2":
- language_model_class = "DebertaV2"
- else:
- # Fall back to inferring type from model name
- logger.warning(
- "Could not infer LanguageModel class from config. Trying to infer "
- "LanguageModel class from model name."
- )
- language_model_class = LanguageModel._infer_language_model_class_from_string(model_name_or_path)
-
- return language_model_class
-
- @staticmethod
- def _infer_language_model_class_from_string(model_name_or_path):
- # If inferring Language model class from config doesn't succeed,
- # fall back to inferring Language model class from model name.
- if "xlm" in model_name_or_path.lower() and "roberta" in model_name_or_path.lower():
- language_model_class = "XLMRoberta"
- elif "bigbird" in model_name_or_path.lower():
- language_model_class = "BigBird"
- elif "roberta" in model_name_or_path.lower():
- language_model_class = "Roberta"
- elif "codebert" in model_name_or_path.lower():
- if "mlm" in model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- language_model_class = "Roberta"
- elif "camembert" in model_name_or_path.lower() or "umberto" in model_name_or_path.lower():
- language_model_class = "Camembert"
- elif "albert" in model_name_or_path.lower():
- language_model_class = "Albert"
- elif "distilbert" in model_name_or_path.lower():
- language_model_class = "DistilBert"
- elif "bert" in model_name_or_path.lower():
- language_model_class = "Bert"
- elif "xlnet" in model_name_or_path.lower():
- language_model_class = "XLNet"
- elif "electra" in model_name_or_path.lower():
- language_model_class = "Electra"
- elif "word2vec" in model_name_or_path.lower() or "glove" in model_name_or_path.lower():
- language_model_class = "WordEmbedding_LM"
- elif "minilm" in model_name_or_path.lower():
- language_model_class = "Bert"
- elif "dpr-question_encoder" in model_name_or_path.lower():
- language_model_class = "DPRQuestionEncoder"
- elif "dpr-ctx_encoder" in model_name_or_path.lower():
- language_model_class = "DPRContextEncoder"
- else:
- language_model_class = None
+ @output_hidden_states.setter
+ def output_hidden_states(self, value: bool):
+ """
+ Sets the model to output the hidden states or not
+ """
+ self.encoder.config.output_hidden_states = value
- return language_model_class
+ @property
+ def output_dims(self):
+ """
+ The output dimension of this language model
+ """
+ if self._output_dims:
+ return self._output_dims
- def get_output_dims(self):
- config = self.model.config
for odn in OUTPUT_DIM_NAMES:
- if odn in dir(config):
- return getattr(config, odn)
- raise Exception("Could not infer the output dimensions of the language model")
-
- def freeze(self, layers):
- """To be implemented"""
- raise NotImplementedError()
+ try:
+ value = getattr(self.model.config, odn, None)
+ if value:
+ self._output_dims = value
+ return value
+ except AttributeError as e:
+ raise ModelingError("Can't get the output dimension before loading the model.")
- def unfreeze(self):
- """To be implemented"""
- raise NotImplementedError()
+ raise ModelingError("Could not infer the output dimensions of the language model.")
- def save_config(self, save_dir):
+ def save_config(self, save_dir: Union[Path, str]):
+ """
+ Save the configuration of the language model in Haystack format.
+ """
save_filename = Path(save_dir) / "language_model_config.json"
+ setattr(self.model.config, "name", self.name)
+ setattr(self.model.config, "language", self.language)
+
+ string = self.model.config.to_json_string()
with open(save_filename, "w") as file:
- setattr(self.model.config, "name", self.__class__.__name__)
- setattr(self.model.config, "language", self.language)
- # For DPR models, transformers overwrites the model_type with the one set in DPRConfig
- # Therefore, we copy the model_type from the model config to DPRConfig
- if self.__class__.__name__ == "DPRQuestionEncoder" or self.__class__.__name__ == "DPRContextEncoder":
- setattr(transformers.DPRConfig, "model_type", self.model.config.model_type)
- string = self.model.config.to_json_string()
file.write(string)
def save(self, save_dir: Union[str, Path], state_dict: Dict[Any, Any] = None):
@@ -327,43 +164,16 @@ def save(self, save_dir: Union[str, Path], state_dict: Dict[Any, Any] = None):
"""
# Save Weights
save_name = Path(save_dir) / "language_model.bin"
- model_to_save = (
- self.model.module if hasattr(self.model, "module") else self.model
- ) # Only save the model it-self
+ model_to_save = self.model.module if hasattr(self.model, "module") else self.model # Only save the model itself
if not state_dict:
state_dict = model_to_save.state_dict()
torch.save(state_dict, save_name)
self.save_config(save_dir)
- @classmethod
- def _get_or_infer_language_from_name(cls, language, name):
- if language is not None:
- return language
- else:
- return cls._infer_language_from_name(name)
-
- @classmethod
- def _infer_language_from_name(cls, name):
- known_languages = ("german", "english", "chinese", "indian", "french", "polish", "spanish", "multilingual")
- matches = [lang for lang in known_languages if lang in name]
- if "camembert" in name:
- language = "french"
- logger.info(f"Automatically detected language from language model name: {language}")
- elif "umberto" in name:
- language = "italian"
- logger.info(f"Automatically detected language from language model name: {language}")
- elif len(matches) == 0:
- language = "english"
- elif len(matches) > 1:
- language = matches[0]
- else:
- language = matches[0]
- logger.info(f"Automatically detected language from language model name: {language}")
-
- return language
-
- def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask=None, input_ids=None, **kwargs):
+ def formatted_preds(
+ self, logits, samples, ignore_first_token: bool = True, padding_mask: torch.Tensor = None
+ ) -> List[Dict[str, Any]]:
"""
Extracting vectors from a language model (for example, for extracting sentence embeddings).
You can use different pooling strategies and layers by specifying them in the object attributes
@@ -382,7 +192,7 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
:return: A list of dictionaries containing predictions, for example: [{"context": "some text", "vec": [-0.01, 0.5 ...]}].
"""
if not hasattr(self, "extraction_layer") or not hasattr(self, "extraction_strategy"):
- raise ValueError(
+ raise ModelingError(
"`extraction_layer` or `extraction_strategy` not specified for LM. "
"Make sure to set both, e.g. via Inferencer(extraction_strategy='cls_token', extraction_layer=-1)`"
)
@@ -394,12 +204,15 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
# aggregate vectors
if self.extraction_strategy == "pooled":
if self.extraction_layer != -1:
- raise ValueError(
- f"Pooled output only works for the last layer, but got extraction_layer = {self.extraction_layer}. Please set `extraction_layer=-1`.)"
+ raise ModelingError(
+ f"Pooled output only works for the last layer, but got extraction_layer={self.extraction_layer}. "
+ "Please set `extraction_layer=-1`"
)
vecs = pooled_output.cpu().numpy()
+
elif self.extraction_strategy == "per_token":
vecs = sequence_output.cpu().numpy()
+
elif self.extraction_strategy == "reduce_mean":
vecs = self._pool_tokens(
sequence_output, padding_mask, self.extraction_strategy, ignore_first_token=ignore_first_token
@@ -411,7 +224,9 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
elif self.extraction_strategy == "cls_token":
vecs = sequence_output[:, 0, :].cpu().numpy()
else:
- raise NotImplementedError
+ raise NotImplementedError(
+ f"This extraction strategy ({self.extraction_strategy}) is not supported by Haystack."
+ )
preds = []
for vec, sample in zip(vecs, samples):
@@ -421,7 +236,9 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
preds.append(pred)
return preds
- def _pool_tokens(self, sequence_output, padding_mask, strategy, ignore_first_token):
+ def _pool_tokens(
+ self, sequence_output: torch.Tensor, padding_mask: torch.Tensor, strategy: str, ignore_first_token: bool
+ ):
token_vecs = sequence_output.cpu().numpy()
# we only take the aggregated value of non-padding tokens
padding_mask = padding_mask.cpu().numpy()
@@ -439,30 +256,22 @@ def _pool_tokens(self, sequence_output, padding_mask, strategy, ignore_first_tok
return pooled_vecs
-class Bert(LanguageModel):
+class HFLanguageModel(LanguageModel):
"""
- A BERT model that wraps Hugging Face's implementation
+ A model that wraps Hugging Face's implementation
(https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1810.04805.
"""
- def __init__(self):
- super(Bert, self).__init__()
- self.model = None
- self.name = "bert"
-
- @classmethod
- def from_scratch(cls, vocab_size, name="bert", language="en"):
- bert = cls()
- bert.name = name
- bert.language = language
- config = BertConfig(vocab_size=vocab_size)
- bert.model = BertModel(config)
- return bert
-
- @classmethod
@silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
+ def __init__(
+ self,
+ pretrained_model_name_or_path: Union[Path, str],
+ model_type: str,
+ language: str = None,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
+ ):
"""
Load a pretrained model by supplying one of the following:
@@ -470,362 +279,110 @@ def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = N
* A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
* A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
- :param pretrained_model_name_or_path: The path of the saved pretrained model or the name of the model.
- """
- bert = cls()
- if "haystack_lm_name" in kwargs:
- bert.name = kwargs["haystack_lm_name"]
- else:
- bert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- bert_config = BertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- bert.model = BertModel.from_pretrained(haystack_lm_model, config=bert_config, **kwargs)
- bert.language = bert.model.config.language
- else:
- # Pytorch-transformer Style
- bert.model = BertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- bert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return bert
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the BERT model.
-
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence. Can also return hidden states and attentions if specified using the arguments `output_hidden_states` and `output_attentions`.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class Albert(LanguageModel):
- """
- An ALBERT model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- """
-
- def __init__(self):
- super(Albert, self).__init__()
- self.model = None
- self.name = "albert"
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one of the following:
-
- * The name of a remote model on s3 (for example: "albert-base").
- * A local path of a model trained using transformers (for example: "some_dir/huggingface_model")
- * A local path of a model trained using Haystack (for example: "some_dir/Haystack_model")
-
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- albert = cls()
- if "haystack_lm_name" in kwargs:
- albert.name = kwargs["haystack_lm_name"]
- else:
- albert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = AlbertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- albert.model = AlbertModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- albert.language = albert.model.config.language
- else:
- # Huggingface transformer Style
- albert.model = AlbertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- albert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return albert
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the Albert model.
-
- :param input_ids: The IDs of each token in the input sequence. Is a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class Roberta(LanguageModel):
- """
- A roberta model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1907.11692
- """
-
- def __init__(self):
- super(Roberta, self).__init__()
- self.model = None
- self.name = "roberta"
+ You can also use `get_language_model()` for a uniform interface across different model types.
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
+ :param pretrained_model_name_or_path: The path of the saved pretrained model or the name of the model.
+ :param model_type: the HuggingFace class name prefix (for example 'Bert', 'Roberta', etc...)
+ :param language: the model's language ('multilingual' is also accepted)
+ :param use_auth_token: the HF token or False
"""
- Load a language model by supplying one of the following:
+ super().__init__(model_type=model_type)
- * The name of a remote model on s3 (for example: "roberta-base").
- * A local path of a model trained using transformers (for example: "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example: "some_dir/haystack_model").
+ config_class: PretrainedConfig = getattr(transformers, model_type + "Config", None)
+ model_class: PreTrainedModel = getattr(transformers, model_type + "Model", None)
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example: "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- roberta = cls()
- if "haystack_lm_name" in kwargs:
- roberta.name = kwargs["haystack_lm_name"]
- else:
- roberta.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
if os.path.exists(haystack_lm_config):
# Haystack style
- config = RobertaConfig.from_pretrained(haystack_lm_config)
haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- roberta.model = RobertaModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- roberta.language = roberta.model.config.language
+ model_config = config_class.from_pretrained(haystack_lm_config)
+ self.model = model_class.from_pretrained(
+ haystack_lm_model, config=model_config, use_auth_token=use_auth_token, **(model_kwargs or {})
+ )
+ self.language = self.model.config.language
else:
- # Huggingface transformer Style
- roberta.model = RobertaModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- roberta.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return roberta
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the Roberta model.
-
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class XLMRoberta(LanguageModel):
- """
- A roberta model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1907.11692
- """
-
- def __init__(self):
- super(XLMRoberta, self).__init__()
- self.model = None
- self.name = "xlm_roberta"
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one fo the following:
-
- * The name of a remote model on s3 (for example: "xlm-roberta-base")
- * A local path of a model trained using transformers (for example: "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example: "some_dir/haystack_model").
+ # Pytorch-transformer Style
+ self.model = model_class.from_pretrained(
+ str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **(model_kwargs or {})
+ )
+ self.language = language or _guess_language(str(pretrained_model_name_or_path))
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example, "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- xlm_roberta = cls()
- if "haystack_lm_name" in kwargs:
- xlm_roberta.name = kwargs["haystack_lm_name"]
- else:
- xlm_roberta.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = XLMRobertaConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- xlm_roberta.model = XLMRobertaModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- xlm_roberta.language = xlm_roberta.model.config.language
- else:
- # Huggingface transformer Style
- xlm_roberta.model = XLMRobertaModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- xlm_roberta.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return xlm_roberta
+ # resize embeddings in case of custom vocab
+ if n_added_tokens != 0:
+ # TODO verify for other models than BERT
+ model_emb_size = self.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
+ vocab_size = model_emb_size + n_added_tokens
+ logger.info(
+ f"Resizing embedding layer of LM from {model_emb_size} to {vocab_size} to cope with custom vocab."
+ )
+ self.model.resize_token_embeddings(vocab_size)
+ # verify
+ model_emb_size = self.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
+ assert vocab_size == model_emb_size
def forward(
self,
input_ids: torch.Tensor,
+ attention_mask: torch.Tensor,
segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
- **kwargs,
+ return_dict: bool = False,
):
"""
- Perform the forward pass of the XLMRoberta model.
+ Perform the forward pass of the model.
:param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
:param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
+ :param attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len]. Different models call this parameter differently (padding/attention mask).
:param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
:param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
+ :return: Embeddings for each token in the input sequence. Can also return hidden states and attentions if specified using the arguments `output_hidden_states` and `output_attentions`.
"""
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class DistilBert(LanguageModel):
+ if hasattr(self, "encoder"): # Not all models have an encoder
+ if output_hidden_states is None:
+ output_hidden_states = self.model.encoder.config.output_hidden_states
+ if output_attentions is None:
+ output_attentions = self.model.encoder.config.output_attentions
+
+ params = {}
+ if input_ids is not None:
+ params["input_ids"] = input_ids
+ if segment_ids is not None:
+ # Some models don't take this (see DistilBERT)
+ params["token_type_ids"] = segment_ids
+ if attention_mask is not None:
+ params["attention_mask"] = attention_mask
+ if output_hidden_states:
+ params["output_hidden_states"] = output_hidden_states
+ if output_attentions:
+ params["output_attentions"] = output_attentions
+
+ return self.model(**params, return_dict=return_dict)
+
+
+class HFLanguageModelWithPooler(HFLanguageModel):
"""
- A DistilBERT model that wraps Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
+ A model that wraps Hugging Face's implementation
+ (https://github.com/huggingface/transformers) to fit the LanguageModel class,
+ with an extra pooler.
NOTE:
- - DistilBert doesn’t have `token_type_ids`, you don’t need to indicate which
- token belongs to which segment. Just separate your segments with the separation
- token `tokenizer.sep_token` (or [SEP]).
- - Unlike the other BERT variants, DistilBert does not output the
- `pooled_output`. An additional pooler is initialized.
+ - Unlike the other BERT variants, these don't output the `pooled_output`. An additional pooler is initialized.
"""
- def __init__(self):
- super(DistilBert, self).__init__()
- self.model = None
- self.name = "distilbert"
- self.pooler = None
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
+ def __init__(
+ self,
+ pretrained_model_name_or_path: Union[Path, str],
+ model_type: str,
+ language: str = None,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
+ ):
"""
Load a pretrained model by supplying one of the following:
@@ -835,840 +392,576 @@ def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = N
:param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
"""
- distilbert = cls()
- if "haystack_lm_name" in kwargs:
- distilbert.name = kwargs["haystack_lm_name"]
- else:
- distilbert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = DistilBertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- distilbert.model = DistilBertModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- distilbert.language = distilbert.model.config.language
- else:
- # Pytorch-transformer Style
- distilbert.model = DistilBertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- distilbert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = distilbert.model.config
+ super().__init__(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ model_type=model_type,
+ language=language,
+ n_added_tokens=n_added_tokens,
+ use_auth_token=use_auth_token,
+ model_kwargs=model_kwargs,
+ )
+ config = self.model.config
- # DistilBERT does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
+ # These models do not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
# The pooler takes the first hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
# We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
# feed everything to the prediction head
- config.summary_last_dropout = 0
- config.summary_type = "first"
- config.summary_activation = "tanh"
- distilbert.pooler = SequenceSummary(config)
- distilbert.pooler.apply(distilbert.model._init_weights)
- return distilbert
-
- def forward( # type: ignore
- self,
- input_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the DistilBERT model.
-
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- pooled_output = self.pooler(output_tuple[0])
- return (output_tuple[0], pooled_output) + output_tuple[1:]
-
- def enable_hidden_states_output(self):
- self.model.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.config.output_hidden_states = False
-
-
-class XLNet(LanguageModel):
- """
- A XLNet model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1906.08237
- """
+ sequence_summary_config = POOLER_PARAMETERS.get(self.name.lower(), {})
+ for key, value in sequence_summary_config.items():
+ setattr(config, key, value)
- def __init__(self):
- super(XLNet, self).__init__()
- self.model = None
- self.name = "xlnet"
- self.pooler = None
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one of the following:
-
- * The name of a remote model on s3 (for example, "xlnet-base-cased").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * Alocal path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example, "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- xlnet = cls()
- if "haystack_lm_name" in kwargs:
- xlnet.name = kwargs["haystack_lm_name"]
- else:
- xlnet.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = XLNetConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- xlnet.model = XLNetModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- xlnet.language = xlnet.model.config.language
- else:
- # Pytorch-transformer Style
- xlnet.model = XLNetModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- xlnet.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = xlnet.model.config
- # XLNet does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
- # The pooler takes the last hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
- # We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
- # feed everything to the prediction head
- config.summary_last_dropout = 0
- xlnet.pooler = SequenceSummary(config)
- xlnet.pooler.apply(xlnet.model._init_weights)
- return xlnet
+ self.pooler = SequenceSummary(config)
+ self.pooler.apply(self.model._init_weights)
def forward(
self,
input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor],
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
- **kwargs,
+ return_dict: bool = False,
):
"""
- Perform the forward pass of the XLNet model.
+ Perform the forward pass of the model.
:param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
:param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
+ It is a tensor of shape [batch_size, max_seq_len]. Optional, some models don't need it (DistilBERT for example)
+ :param padding_mask/attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len]. Different models call this parameter differently (padding/attention mask).
:param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
:param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
:return: Embeddings for each token in the input sequence.
"""
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- # Note: XLNet has a couple of special input tensors for pretraining / text generation (perm_mask, target_mapping ...)
- # We will need to implement them, if we wanna support LM adaptation
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
+ output_tuple = super().forward(
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ attention_mask=attention_mask,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
- return_dict=False,
+ return_dict=return_dict,
)
- # XLNet also only returns the sequence_output (one vec per token)
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- # TODO verify that this is really doing correct pooling
pooled_output = self.pooler(output_tuple[0])
return (output_tuple[0], pooled_output) + output_tuple[1:]
- def enable_hidden_states_output(self):
- self.model.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.output_hidden_states = False
-
-class Electra(LanguageModel):
+class HFLanguageModelNoSegmentIds(HFLanguageModelWithPooler):
"""
- ELECTRA is a new pre-training approach which trains two transformer models:
- the generator and the discriminator. The generator replaces tokens in a sequence,
- and is therefore trained as a masked language model. The discriminator, which is
- the model we're interested in, tries to identify which tokens were replaced by
- the generator in the sequence.
-
- The ELECTRA model here wraps Hugging Face's implementation
+ A model that wraps Hugging Face's implementation of a model that does not need segment ids.
(https://github.com/huggingface/transformers) to fit the LanguageModel class.
- NOTE:
- - Electra does not output the `pooled_output`. An additional pooler is initialized.
+ These are for now kept in a separate subclass to show a proper warning.
"""
- def __init__(self):
- super(Electra, self).__init__()
- self.model = None
- self.name = "electra"
- self.pooler = None
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a pretrained model by supplying one of the following
-
- * The name of a remote model on s3 (for example, "google/electra-base-discriminator").
- * A local path of a model trained using transformers ("some_dir/huggingface_model").
- * A local path of a model trained using Haystack ("some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
- """
- electra = cls()
- if "haystack_lm_name" in kwargs:
- electra.name = kwargs["haystack_lm_name"]
- else:
- electra.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = ElectraConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- electra.model = ElectraModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- electra.language = electra.model.config.language
- else:
- # Transformers Style
- electra.model = ElectraModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- electra.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = electra.model.config
-
- # ELECTRA does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
- # The pooler takes the first hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
- # We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
- # feed everything to the prediction head.
- # Note: ELECTRA uses gelu as activation (BERT uses tanh instead)
- config.summary_last_dropout = 0
- config.summary_type = "first"
- config.summary_activation = "gelu"
- config.summary_use_proj = False
- electra.pooler = SequenceSummary(config)
- electra.pooler.apply(electra.model._init_weights)
- return electra
-
def forward(
self,
input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
- **kwargs,
+ return_dict: bool = False,
):
"""
- Perform the forward pass of the ELECTRA model.
+ Perform the forward pass of the model.
:param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
+ :param attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len]. Different models call this parameter differently (padding/attention mask).
+ :param segment_ids: Unused. See DistilBERT documentation.
:param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
:param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
+ :return: Embeddings for each token in the input sequence. Can also return hidden states and attentions if
+ specified using the arguments `output_hidden_states` and `output_attentions`.
"""
- output_tuple = self.model(input_ids, token_type_ids=segment_ids, attention_mask=padding_mask, return_dict=False)
-
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
+ if segment_ids is not None:
+ logging.warning(f"`segment_ids` is not None, but {self.name} does not use them. They will be ignored.")
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
+ return super().forward(
+ input_ids=input_ids,
+ segment_ids=None,
+ attention_mask=attention_mask,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
+ return_dict=return_dict,
)
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- pooled_output = self.pooler(output_tuple[0])
- return (output_tuple[0], pooled_output) + output_tuple[1:]
-
- def disable_hidden_states_output(self):
- self.model.config.output_hidden_states = False
-
-
-class Camembert(Roberta):
- """
- A Camembert model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- """
-
- def __init__(self):
- super(Camembert, self).__init__()
- self.model = None
- self.name = "camembert"
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one of the following:
-
- * The name of a remote model on s3 (for example, "camembert-base").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example, "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- camembert = cls()
- if "haystack_lm_name" in kwargs:
- camembert.name = kwargs["haystack_lm_name"]
- else:
- camembert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = CamembertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- camembert.model = CamembertModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- camembert.language = camembert.model.config.language
- else:
- # Huggingface transformer Style
- camembert.model = CamembertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- camembert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return camembert
-class DPRQuestionEncoder(LanguageModel):
+class DPREncoder(LanguageModel):
"""
- A DPRQuestionEncoder model that wraps Hugging Face's implementation.
+ A DPREncoder model that wraps Hugging Face's implementation.
"""
- def __init__(self):
- super(DPRQuestionEncoder, self).__init__()
- self.model = None
- self.name = "dpr_question_encoder"
-
- @classmethod
@silence_transformers_logs
- def load(
- cls,
+ def __init__(
+ self,
pretrained_model_name_or_path: Union[Path, str],
+ model_type: str,
language: str = None,
- use_auth_token: Union[str, bool] = None,
- **kwargs,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
):
"""
Load a pretrained model by supplying one of the following:
-
* The name of a remote model on s3 (for example, "facebook/dpr-question_encoder-single-nq-base").
* A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
* A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
:param pretrained_model_name_or_path: The path of the base pretrained language model whose weights are used to initialize DPRQuestionEncoder.
- """
- dpr_question_encoder = cls()
- if "haystack_lm_name" in kwargs:
- dpr_question_encoder.name = kwargs["haystack_lm_name"]
- else:
- dpr_question_encoder.name = pretrained_model_name_or_path
+ :param model_type: the type of model (see `HUGGINGFACE_TO_HAYSTACK`)
+ :param model_kwargs: any kwarg to pass to the model at init
+ :param language: the model's language. If not given, it will be inferred. Defaults to english.
+ :param n_added_tokens: unused for `DPREncoder`
+ :param use_auth_token: useful if the model is from the HF Hub and private
+ :param model_kwargs: any kwarg to pass to the model at init
+ """
+ super().__init__(model_type=model_type)
+ self.role = "question" if "question" in model_type.lower() else "context"
+ self._encoder = None
+
+ model_classname = f"DPR{self.role.capitalize()}Encoder"
+ try:
+ model_class: Type[PreTrainedModel] = getattr(transformers, model_classname)
+ except AttributeError as e:
+ raise ModelingError(f"Model class of type '{model_classname}' not found.")
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
if os.path.exists(haystack_lm_config):
- # Haystack style
- original_model_config = AutoConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
-
- if original_model_config.model_type == "dpr":
- dpr_config = transformers.DPRConfig.from_pretrained(haystack_lm_config)
- dpr_question_encoder.model = transformers.DPRQuestionEncoder.from_pretrained(
- haystack_lm_model, config=dpr_config, **kwargs
- )
- else:
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_question_encoder.model = transformers.DPRQuestionEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- language_model_class = cls.get_language_model_class(haystack_lm_config, use_auth_token, **kwargs)
- dpr_question_encoder.model.base_model.bert_model = (
- cls.subclasses[language_model_class].load(str(pretrained_model_name_or_path)).model
- )
- dpr_question_encoder.language = dpr_question_encoder.model.config.language
- else:
- original_model_config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token
+ self._init_model_haystack_style(
+ haystack_lm_config=haystack_lm_config,
+ model_name_or_path=pretrained_model_name_or_path,
+ model_class=model_class,
+ model_kwargs=model_kwargs or {},
+ use_auth_token=use_auth_token,
)
- if original_model_config.model_type == "dpr":
- # "pretrained dpr model": load existing pretrained DPRQuestionEncoder model
- dpr_question_encoder.model = transformers.DPRQuestionEncoder.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **kwargs
- )
- else:
- # "from scratch": load weights from different architecture (e.g. bert) into DPRQuestionEncoder
- # but keep config values from original architecture
- # TODO test for architectures other than BERT, e.g. Electra
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_question_encoder.model = transformers.DPRQuestionEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- dpr_question_encoder.model.base_model.bert_model = AutoModel.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **original_config_dict
- )
- dpr_question_encoder.language = cls._get_or_infer_language_from_name(
- language, pretrained_model_name_or_path
+ else:
+ self._init_model_transformers_style(
+ model_name_or_path=pretrained_model_name_or_path,
+ model_class=model_class,
+ model_kwargs=model_kwargs or {},
+ use_auth_token=use_auth_token,
+ language=language,
)
- return dpr_question_encoder
-
- def save(self, save_dir: Union[str, Path], state_dict: Optional[Dict[Any, Any]] = None):
+ def _init_model_haystack_style(
+ self,
+ haystack_lm_config: Path,
+ model_name_or_path: Union[str, Path],
+ model_class: Type[PreTrainedModel],
+ model_kwargs: Dict[str, Any],
+ use_auth_token: Optional[Union[str, bool]] = None,
+ ):
"""
- Save the model `state_dict` and its configuration file so that it can be loaded again.
+ Init a Haystack-style DPR model.
- :param save_dir: The directory in which the model should be saved.
- :param state_dict: A dictionary containing the whole state of the module including names of layers.
- By default, the unchanged state dictionary of the module is used.
+ :param haystack_lm_config: path to the language model config file
+ :param model_name_or_path: name or path of the model to load
+ :param model_class: The HuggingFace model class name
+ :param model_kwargs: any kwarg to pass to the model at init
+ :param use_auth_token: useful if the model is from the HF Hub and private
"""
- model_to_save = self.model.module if hasattr(self.model, "module") else self.model # Only save the model itself
+ original_model_config = AutoConfig.from_pretrained(haystack_lm_config)
+ haystack_lm_model = Path(model_name_or_path) / "language_model.bin"
- if self.model.config.model_type != "dpr" and model_to_save.base_model_prefix.startswith("question_"):
- state_dict = model_to_save.state_dict()
- if state_dict:
- keys = state_dict.keys()
- for key in list(keys):
- new_key = key
- if key.startswith("question_encoder.bert_model.model."):
- new_key = key.split("_encoder.bert_model.model.", 1)[1]
- elif key.startswith("question_encoder.bert_model."):
- new_key = key.split("_encoder.bert_model.", 1)[1]
- state_dict[new_key] = state_dict.pop(key)
+ original_model_type = original_model_config.model_type
+ if original_model_type and "dpr" in original_model_type.lower():
+ dpr_config = transformers.DPRConfig.from_pretrained(haystack_lm_config)
+ self.model = model_class.from_pretrained(haystack_lm_model, config=dpr_config, **model_kwargs)
- super(DPRQuestionEncoder, self).save(save_dir=save_dir, state_dict=state_dict)
+ else:
+ self.model = self._init_model_through_config(
+ model_config=original_model_config, model_class=model_class, model_kwargs=model_kwargs
+ )
+ original_model_type = capitalize_model_type(original_model_type)
+ language_model_class = get_language_model_class(original_model_type)
+ if not language_model_class:
+ raise ValueError(
+ f"The type of model supplied ({model_name_or_path} , "
+ f"({original_model_type}) is not supported by Haystack. "
+ f"Supported model categories are: {', '.join(HUGGINGFACE_TO_HAYSTACK.keys())}"
+ )
+ # Instantiate the class for this model
+ self.model.base_model.bert_model = language_model_class(
+ pretrained_model_name_or_path=model_name_or_path,
+ model_type=original_model_type,
+ use_auth_token=use_auth_token,
+ **model_kwargs,
+ ).model
- def forward( # type: ignore
+ self.language = self.model.config.language
+
+ def _init_model_transformers_style(
self,
- query_input_ids: torch.Tensor,
- query_segment_ids: torch.Tensor,
- query_attention_mask: torch.Tensor,
- **kwargs,
+ model_name_or_path: Union[str, Path],
+ model_class: Type[PreTrainedModel],
+ model_kwargs: Dict[str, Any],
+ use_auth_token: Optional[Union[str, bool]] = None,
+ language: Optional[str] = None,
):
"""
- Perform the forward pass of the DPRQuestionEncoder model.
+ Init a Transformers-style DPR model.
- :param query_input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param query_segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param query_attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :return: Embeddings for each token in the input sequence.
+ :param model_name_or_path: name or path of the model to load
+ :param model_class: The HuggingFace model class name
+ :param model_kwargs: any kwarg to pass to the model at init
+ :param use_auth_token: useful if the model is from the HF Hub and private
+ :param language: the model's language. If not given, it will be inferred. Defaults to english.
"""
- output_tuple = self.model(
- input_ids=query_input_ids,
- token_type_ids=query_segment_ids,
- attention_mask=query_attention_mask,
- return_dict=True,
- )
- if self.model.question_encoder.config.output_hidden_states == True:
- pooled_output, all_hidden_states = output_tuple.pooler_output, output_tuple.hidden_states
- return pooled_output, all_hidden_states
+ original_model_config = AutoConfig.from_pretrained(model_name_or_path, use_auth_token=use_auth_token)
+ if "dpr" in original_model_config.model_type.lower():
+ # "pretrained dpr model": load existing pretrained DPRQuestionEncoder model
+ self.model = model_class.from_pretrained(
+ str(model_name_or_path), use_auth_token=use_auth_token, **model_kwargs
+ )
else:
- pooled_output = output_tuple.pooler_output
- return pooled_output, None
-
- def enable_hidden_states_output(self):
- self.model.question_encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.question_encoder.config.output_hidden_states = False
-
-
-class DPRContextEncoder(LanguageModel):
- """
- A DPRContextEncoder model that wraps Hugging Face's implementation.
- """
-
- def __init__(self):
- super(DPRContextEncoder, self).__init__()
- self.model = None
- self.name = "dpr_context_encoder"
+ # "from scratch": load weights from different architecture (e.g. bert) into DPRQuestionEncoder
+ # but keep config values from original architecture
+ # TODO test for architectures other than BERT, e.g. Electra
+ self.model = self._init_model_through_config(
+ model_config=original_model_config, model_class=model_class, model_kwargs=model_kwargs
+ )
+ self.model.base_model.bert_model = AutoModel.from_pretrained(
+ str(model_name_or_path), use_auth_token=use_auth_token, **vars(original_model_config)
+ )
+ self.language = language or _guess_language(str(model_name_or_path))
- @classmethod
- @silence_transformers_logs
- def load(
- cls,
- pretrained_model_name_or_path: Union[Path, str],
- language: str = None,
- use_auth_token: Union[str, bool] = None,
- **kwargs,
+ def _init_model_through_config(
+ self, model_config: AutoConfig, model_class: Type[PreTrainedModel], model_kwargs: Optional[Dict[str, Any]]
):
"""
- Load a pretrained model by supplying one of the following:
-
- * The name of a remote model on s3 (for example, "facebook/dpr-ctx_encoder-single-nq-base").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: The path of the base pretrained language model whose weights are used to initialize DPRContextEncoder.
+ Init a DPR model using a config object.
"""
- dpr_context_encoder = cls()
- if "haystack_lm_name" in kwargs:
- dpr_context_encoder.name = kwargs["haystack_lm_name"]
- else:
- dpr_context_encoder.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
-
- if os.path.exists(haystack_lm_config):
- # Haystack style
- original_model_config = AutoConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
+ if model_config.model_type.lower() != "bert":
+ logger.warning(
+ f"Using a model of type '{model_config.model_type}' which might be incompatible with DPR encoders. "
+ f"Only Bert-based encoders are supported. They need input_ids, token_type_ids, attention_mask as input tensors."
+ )
+ config_dict = vars(model_config)
+ if model_kwargs:
+ config_dict.update(model_kwargs)
+ return model_class(config=transformers.DPRConfig(**config_dict))
- if original_model_config.model_type == "dpr":
- dpr_config = transformers.DPRConfig.from_pretrained(haystack_lm_config)
- dpr_context_encoder.model = transformers.DPRContextEncoder.from_pretrained(
- haystack_lm_model, config=dpr_config, use_auth_token=use_auth_token, **kwargs
- )
- else:
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_context_encoder.model = transformers.DPRContextEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- language_model_class = cls.get_language_model_class(haystack_lm_config, **kwargs)
- dpr_context_encoder.model.base_model.bert_model = (
- cls.subclasses[language_model_class]
- .load(str(pretrained_model_name_or_path), use_auth_token=use_auth_token)
- .model
- )
- dpr_context_encoder.language = dpr_context_encoder.model.config.language
+ @property
+ def encoder(self):
+ if not self._encoder:
+ self._encoder = self.model.question_encoder if self.role == "question" else self.model.ctx_encoder
+ return self._encoder
- else:
- # Pytorch-transformer Style
- original_model_config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token
- )
- if original_model_config.model_type == "dpr":
- # "pretrained dpr model": load existing pretrained DPRContextEncoder model
- dpr_context_encoder.model = transformers.DPRContextEncoder.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **kwargs
- )
- else:
- # "from scratch": load weights from different architecture (e.g. bert) into DPRContextEncoder
- # but keep config values from original architecture
- # TODO test for architectures other than BERT, e.g. Electra
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_context_encoder.model = transformers.DPRContextEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- dpr_context_encoder.model.base_model.bert_model = AutoModel.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **original_config_dict
- )
- dpr_context_encoder.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
+ def save_config(self, save_dir: Union[Path, str]) -> None:
+ """
+ Save the configuration of the language model in Haystack format.
- return dpr_context_encoder
+ :param save_dir: the path to save the model at
+ """
+ # For DPR models, transformers overwrites the model_type with the one set in DPRConfig
+ # Therefore, we copy the model_type from the model config to DPRConfig
+ setattr(transformers.DPRConfig, "model_type", self.model.config.model_type)
+ super().save_config(save_dir=save_dir)
- def save(self, save_dir: Union[str, Path], state_dict: Optional[Dict[Any, Any]] = None):
+ def save(self, save_dir: Union[str, Path], state_dict: Optional[Dict[Any, Any]] = None) -> None:
"""
Save the model `state_dict` and its configuration file so that it can be loaded again.
:param save_dir: The directory in which the model should be saved.
- :param state_dict: A dictionary containing the whole state of the module including names of layers. By default, the unchanged state dictionary of the module is used.
+ :param state_dict: A dictionary containing the whole state of the module including names of layers.
+ By default, the unchanged state dictionary of the module is used.
"""
- model_to_save = (
- self.model.module if hasattr(self.model, "module") else self.model
- ) # Only save the model it-self
+ model_to_save = self.model.module if hasattr(self.model, "module") else self.model # Only save the model itself
+
+ if "dpr" not in self.model.config.model_type.lower():
+ prefix = "question" if self.role == "question" else "ctx"
- if self.model.config.model_type != "dpr" and model_to_save.base_model_prefix.startswith("ctx_"):
state_dict = model_to_save.state_dict()
if state_dict:
- keys = state_dict.keys()
- for key in list(keys):
+ for key in list(state_dict.keys()): # list() here performs a copy and allows editing the dict
new_key = key
- if key.startswith("ctx_encoder.bert_model.model."):
+
+ if key.startswith(f"{prefix}_encoder.bert_model.model."):
new_key = key.split("_encoder.bert_model.model.", 1)[1]
- elif key.startswith("ctx_encoder.bert_model."):
+
+ elif key.startswith(f"{prefix}_encoder.bert_model."):
new_key = key.split("_encoder.bert_model.", 1)[1]
+
state_dict[new_key] = state_dict.pop(key)
- super(DPRContextEncoder, self).save(save_dir=save_dir, state_dict=state_dict)
+ super().save(save_dir=save_dir, state_dict=state_dict)
- def forward( # type: ignore
+ def forward(
self,
- passage_input_ids: torch.Tensor,
- passage_segment_ids: torch.Tensor,
- passage_attention_mask: torch.Tensor,
- **kwargs,
+ input_ids: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor],
+ output_hidden_states: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ return_dict: bool = True,
):
"""
- Perform the forward pass of the DPRContextEncoder model.
+ Perform the forward pass of the DPR encoder model.
- :param passage_input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, number_of_hard_negative_passages, max_seq_len].
- :param passage_segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
+ :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, number_of_hard_negative, max_seq_len].
+ :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
It is a tensor of shape [batch_size, number_of_hard_negative_passages, max_seq_len].
- :param passage_attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ :param attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
of shape [batch_size, number_of_hard_negative_passages, max_seq_len].
+ :param output_hidden_states: whether to add the hidden states along with the pooled output
+ :param output_attentions: unused
:return: Embeddings for each token in the input sequence.
"""
- max_seq_len = passage_input_ids.shape[-1]
- passage_input_ids = passage_input_ids.view(-1, max_seq_len)
- passage_segment_ids = passage_segment_ids.view(-1, max_seq_len)
- passage_attention_mask = passage_attention_mask.view(-1, max_seq_len)
- output_tuple = self.model(
- input_ids=passage_input_ids,
- token_type_ids=passage_segment_ids,
- attention_mask=passage_attention_mask,
- return_dict=True,
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.encoder.config.output_hidden_states
)
- if self.model.ctx_encoder.config.output_hidden_states == True:
- pooled_output, all_hidden_states = output_tuple.pooler_output, output_tuple.hidden_states
- return pooled_output, all_hidden_states
- else:
- pooled_output = output_tuple.pooler_output
- return pooled_output, None
-
- def enable_hidden_states_output(self):
- self.model.ctx_encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.ctx_encoder.config.output_hidden_states = False
+ model_output = self.model(
+ input_ids=input_ids,
+ token_type_ids=segment_ids,
+ attention_mask=attention_mask,
+ output_hidden_states=output_hidden_states,
+ output_attentions=False,
+ return_dict=return_dict,
+ )
-class BigBird(LanguageModel):
+ if output_hidden_states:
+ return model_output.pooler_output, model_output.hidden_states
+ return model_output.pooler_output, None
+
+
+#: Match the name of the HuggingFace Model class to the corresponding Haystack wrapper
+HUGGINGFACE_TO_HAYSTACK: Dict[str, Union[Type[HFLanguageModel], Type[DPREncoder]]] = {
+ "Auto": HFLanguageModel,
+ "Albert": HFLanguageModel,
+ "Bert": HFLanguageModel,
+ "BigBird": HFLanguageModel,
+ "Camembert": HFLanguageModel,
+ "Codebert": HFLanguageModel,
+ "DebertaV2": HFLanguageModelWithPooler,
+ "DistilBert": HFLanguageModelNoSegmentIds,
+ "DPRContextEncoder": DPREncoder,
+ "DPRQuestionEncoder": DPREncoder,
+ "Electra": HFLanguageModelWithPooler,
+ "GloVe": HFLanguageModel,
+ "MiniLM": HFLanguageModel,
+ "Roberta": HFLanguageModel,
+ "Umberto": HFLanguageModel,
+ "Word2Vec": HFLanguageModel,
+ "WordEmbedding_LM": HFLanguageModel,
+ "XLMRoberta": HFLanguageModel,
+ "XLNet": HFLanguageModelWithPooler,
+}
+#: HF Capitalization pairs
+HUGGINGFACE_CAPITALIZE = {
+ "xlm-roberta": "XLMRoberta",
+ "deberta-v2": "DebertaV2",
+ **{k.lower(): k for k in HUGGINGFACE_TO_HAYSTACK.keys()},
+}
+
+#: Regex to match variants of the HF class name, to enhance our mode type guessing abilities.
+NAME_HINTS: Dict[str, str] = {
+ "xlm.*roberta": "XLMRoberta",
+ "roberta.*xml": "XLMRoberta",
+ "codebert.*mlm": "Roberta",
+ "mlm.*codebert": "Roberta",
+ "[dpr]?.*question.*encoder": "DPRQuestionEncoder",
+ "[dpr]?.*query.*encoder": "DPRQuestionEncoder",
+ "[dpr]?.*passage.*encoder": "DPRContextEncoder",
+ "[dpr]?.*context.*encoder": "DPRContextEncoder",
+ "[dpr]?.*ctx.*encoder": "DPRContextEncoder",
+ "deberta-v2": "DebertaV2",
+}
+
+#: Parameters or the pooler of models that don't have their own pooler
+POOLER_PARAMETERS: Dict[str, Dict[str, Any]] = {
+ "DistilBert": {"summary_last_dropout": 0, "summary_type": "first", "summary_activation": "tanh"},
+ "XLNet": {"summary_last_dropout": 0},
+ "Electra": {
+ "summary_last_dropout": 0,
+ "summary_type": "first",
+ "summary_activation": "gelu",
+ "summary_use_proj": False,
+ },
+ "DebertaV2": {
+ "summary_last_dropout": 0,
+ "summary_type": "first",
+ "summary_activation": "tanh",
+ "summary_use_proj": False,
+ },
+}
+
+
+def capitalize_model_type(model_type: str) -> str:
"""
- A BERT model that wraps Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1810.04805
+ Returns the proper capitalized version of the model type, that can be used to
+ retrieve the model class from transformers.
+ :param model_type: the model_type as found in the config file
+ :return: the capitalized version of the model type, or the original name of not found.
"""
+ return HUGGINGFACE_CAPITALIZE.get(model_type.lower(), model_type)
- def __init__(self):
- super(BigBird, self).__init__()
- self.model = None
- self.name = "big_bird"
-
- @classmethod
- def from_scratch(cls, vocab_size, name="big_bird", language="en"):
- big_bird = cls()
- big_bird.name = name
- big_bird.language = language
- config = BigBirdConfig(vocab_size=vocab_size)
- big_bird.model = BigBirdModel(config)
- return big_bird
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a pretrained model by supplying one of the following:
- * The name of a remote model on s3 (for example, "bert-base-cased").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
- """
- big_bird = cls()
- if "haystack_lm_name" in kwargs:
- big_bird.name = kwargs["haystack_lm_name"]
- else:
- big_bird.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- big_bird_config = BigBirdConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- big_bird.model = BigBirdModel.from_pretrained(haystack_lm_model, config=big_bird_config, **kwargs)
- big_bird.language = big_bird.model.config.language
- else:
- # Pytorch-transformer Style
- big_bird.model = BigBirdModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- big_bird.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return big_bird
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the BigBird model.
+def is_supported_model(model_type: Optional[str]):
+ """
+ Returns whether the model type is supported by Haystack
+ :param model_type: the model_type as found in the config file
+ :return: whether the model type is supported by the Haystack
+ """
+ return model_type and model_type.lower() in HUGGINGFACE_CAPITALIZE
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
+def get_language_model_class(model_type: str) -> Optional[Type[Union[HFLanguageModel, DPREncoder]]]:
+ """
+ Returns the corresponding Haystack LanguageModel subclass.
+ :param model_type: the model_type , properly capitalized (see `capitalize_model_type()`)
+ :return: the wrapper class, or `None` if `model_type` was `None` or was not recognized.
+ Lower case model_type values will return `None` as well
+ """
+ return HUGGINGFACE_TO_HAYSTACK.get(model_type)
+
+
+def get_language_model(
+ pretrained_model_name_or_path: Union[Path, str],
+ language: str = None,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ revision: Optional[str] = None,
+ autoconfig_kwargs: Optional[Dict[str, Any]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
+) -> LanguageModel:
+ """
+ Load a pretrained language model by doing one of the following:
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
+ 1. Specifying its name and downloading the model.
+ 2. Pointing to the directory the model is saved in.
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
+ See all supported model variations at: https://huggingface.co/models.
+ The appropriate language model class is inferred automatically from model configuration.
-class DebertaV2(LanguageModel):
+ :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
+ :param language: The language of the model (i.e english etc).
+ :param n_added_tokens: The number of added tokens to the model.
+ :param use_auth_token: Whether to use the huggingface auth token for private repos or not.
+ :param revision: The version of the model to use from the Hugging Face model hub. This can be a tag name,
+ a branch name, or a commit hash.
+ :param autoconfig_kwargs: Additional keyword arguments to pass to the autoconfig function.
+ :param model_kwargs: Additional keyword arguments to pass to the lamguage model constructor.
"""
- This is a wrapper around the DebertaV2 model from Hugging Face's transformers library.
- It is also compatible with DebertaV3 as DebertaV3 only changes the pretraining procedure.
- NOTE:
- - DebertaV2 does not output the `pooled_output`. An additional pooler is initialized.
- """
+ if not pretrained_model_name_or_path or not isinstance(pretrained_model_name_or_path, (str, Path)):
+ raise ValueError(f"{pretrained_model_name_or_path} is not a valid pretrained_model_name_or_path parameter")
- def __init__(self):
- super().__init__()
- self.model = None
- self.name = "deberta-v2"
- self.pooler = None
+ config_file = Path(pretrained_model_name_or_path) / "language_model_config.json"
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a pretrained model by supplying one of the following:
+ model_type = None
+ config_file_exists = os.path.exists(config_file)
+ if config_file_exists:
+ # it's a local directory in Haystack format
+ config = json.load(open(config_file))
+ model_type = config["name"]
- * A remote name from the Hugging Face's model hub (for example: microsoft/deberta-v3-base).
- * A local path of a model trained using transformers (for example: some_dir/huggingface_model).
- * A local path of a model trained using Haystack (for example: some_dir/haystack_model).
+ if not model_type:
+ model_type = _get_model_type(
+ pretrained_model_name_or_path,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ autoconfig_kwargs=autoconfig_kwargs,
+ )
- :param pretrained_model_name_or_path: The path to the saved pretrained model or the name of the model.
- """
- debertav2 = cls()
- if "haystack_lm_name" in kwargs:
- debertav2.name = kwargs["haystack_lm_name"]
- else:
- debertav2.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = DebertaV2Config.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- debertav2.model = DebertaV2Model.from_pretrained(haystack_lm_model, config=config, **kwargs)
- debertav2.language = debertav2.model.config.language
- else:
- # Transformers Style
- debertav2.model = DebertaV2Model.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- debertav2.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = debertav2.model.config
+ if not model_type:
+ logger.error(
+ f"Model type not understood for '{pretrained_model_name_or_path}' "
+ f"({model_type if model_type else 'model_type not set'}). "
+ "Either supply the local path for a saved model, "
+ "or the name of a model that can be downloaded from the Model Hub. "
+ "Ensure that the model class name can be inferred from the directory name "
+ "when loading a Transformers model."
+ )
+ logger.error(f"Using the AutoModel class for '{pretrained_model_name_or_path}'. This can cause crashes!")
+ model_type = "Auto"
+
+ # Find the class corresponding to this model type
+ model_type = capitalize_model_type(model_type)
+ language_model_class = get_language_model_class(model_type)
+ if not language_model_class:
+ raise ValueError(
+ f"The type of model supplied ({model_type}) is not supported by Haystack or was not correctly identified. "
+ f"Supported model types are: {', '.join(HUGGINGFACE_TO_HAYSTACK.keys())}"
+ )
- # DebertaV2 does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
- # The pooler takes the first hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
- # We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
- # feed everything to the prediction head.
- config.summary_last_dropout = 0
- config.summary_type = "first"
- config.summary_activation = "tanh"
- config.summary_use_proj = False
- debertav2.pooler = SequenceSummary(config)
- debertav2.pooler.apply(debertav2.model._init_weights)
- return debertav2
+ logger.info(f" * LOADING MODEL: '{pretrained_model_name_or_path}' {'(' + model_type + ')' if model_type else ''}")
+
+ # Instantiate the class for this model
+ language_model = language_model_class(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ model_type=model_type,
+ language=language,
+ n_added_tokens=n_added_tokens,
+ use_auth_token=use_auth_token,
+ model_kwargs=model_kwargs,
+ )
+ logger.info(
+ f"Loaded '{pretrained_model_name_or_path}' ({model_type} model) "
+ f"from {'local file system' if config_file_exists else 'model hub'}."
+ )
+ return language_model
+
+
+def _get_model_type(
+ model_name_or_path: Union[str, Path],
+ use_auth_token: Optional[Union[str, bool]] = None,
+ revision: Optional[str] = None,
+ autoconfig_kwargs: Optional[Dict[str, Any]] = None,
+) -> Optional[str]:
+ """
+ Given a model name, try to use AutoConfig to understand which model type it is.
+ In case it's not successful, tries to infer the type from the name of the model.
+ """
+ model_name_or_path = str(model_name_or_path)
+
+ model_type: Optional[str] = None
+ # Use AutoConfig to understand the model class
+ try:
+ config = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path=model_name_or_path,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ **(autoconfig_kwargs or {}),
+ )
+ model_type = config.model_type
+ # if unsupported model, try to infer from config.architectures
+ if not is_supported_model(model_type) and config.architectures:
+ model_type = config.architectures[0] if is_supported_model(config.architectures[0]) else None
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the DebertaV2 model.
+ except Exception as e:
+ logger.error(f"AutoConfig failed to load on '{model_name_or_path}': {str(e)}")
- :param input_ids: The IDs of each token in the input sequence. Is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- output_tuple = self.model(input_ids, token_type_ids=segment_ids, attention_mask=padding_mask, return_dict=False)
+ if not model_type:
+ logger.warning("Could not infer the model type from its config. Looking for clues in the model name.")
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
+ # Look for other patterns and variation that hints at the model type
+ for regex, model_name in NAME_HINTS.items():
+ if re.match(f".*{regex}.*", model_name_or_path):
+ model_type = model_name
+ break
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
+ if model_type and model_type.lower() == "roberta" and "mlm" in model_name_or_path.lower():
+ logger.error(
+ f"MLM part of codebert is currently not supported in Haystack: '{model_name_or_path}' may crash later."
)
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- pooled_output = self.pooler(output_tuple[0])
- return (output_tuple[0], pooled_output) + output_tuple[1:]
- def disable_hidden_states_output(self):
- self.model.config.output_hidden_states = False
+ return model_type
+
+
+def _guess_language(name: str) -> str:
+ """
+ Looks for clues about the model language in the model name.
+ """
+ languages = [lang for hint, lang in LANGUAGE_HINTS if hint.lower() in name.lower()]
+ if len(languages) > 0:
+ language = languages[0]
+ else:
+ language = "english"
+ logger.info(f"Auto-detected model language: {language}")
+ return language
diff --git a/haystack/modeling/model/tokenization.py b/haystack/modeling/model/tokenization.py
index 3c0ed9a961..9467d38132 100644
--- a/haystack/modeling/model/tokenization.py
+++ b/haystack/modeling/model/tokenization.py
@@ -12,308 +12,65 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""
-Tokenization classes.
-"""
-from __future__ import absolute_import, division, print_function, unicode_literals
-from typing import Dict, Any, Tuple, Optional, List, Union
+
+from typing import Dict, Any, Union, Tuple, Optional, List
import re
import logging
import numpy as np
-from transformers import (
- AutoTokenizer,
- AlbertTokenizer,
- AlbertTokenizerFast,
- BertTokenizer,
- BertTokenizerFast,
- DistilBertTokenizer,
- DistilBertTokenizerFast,
- ElectraTokenizer,
- ElectraTokenizerFast,
- RobertaTokenizer,
- RobertaTokenizerFast,
- XLMRobertaTokenizer,
- XLMRobertaTokenizerFast,
- XLNetTokenizer,
- XLNetTokenizerFast,
- CamembertTokenizer,
- CamembertTokenizerFast,
- DPRContextEncoderTokenizer,
- DPRContextEncoderTokenizerFast,
- DPRQuestionEncoderTokenizer,
- DPRQuestionEncoderTokenizerFast,
- BigBirdTokenizer,
- BigBirdTokenizerFast,
- DebertaV2Tokenizer,
- DebertaV2TokenizerFast,
-)
-from transformers import AutoConfig
+from transformers import AutoTokenizer, PreTrainedTokenizer, RobertaTokenizer
+from haystack.errors import ModelingError
from haystack.modeling.data_handler.samples import SampleBasket
logger = logging.getLogger(__name__)
-# Special characters used by the different tokenizers to indicate start of word / whitespace
+#: Special characters used by the different tokenizers to indicate start of word / whitespace
SPECIAL_TOKENIZER_CHARS = r"^(##|Ġ|▁)"
-# TODO analyse if tokenizers can be completely used through HF transformers
-class Tokenizer:
+
+def get_tokenizer(
+ pretrained_model_name_or_path: str,
+ revision: str = None,
+ use_fast: bool = True,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ **kwargs,
+) -> PreTrainedTokenizer:
"""
- Simple Wrapper for Tokenizers from the transformers package. Enables loading of different Tokenizer classes with a uniform interface.
+ Enables loading of different Tokenizer classes with a uniform interface.
+ Right now it always returns an instance of `AutoTokenizer`.
+
+ :param pretrained_model_name_or_path: The path of the saved pretrained model or its name (e.g. `bert-base-uncased`)
+ :param revision: The version of model to use from the HuggingFace model hub. Can be tag name, branch name, or commit hash.
+ :param use_fast: Indicate if Haystack should try to load the fast version of the tokenizer (True) or use the Python one (False). Defaults to True.
+ :param use_auth_token: The auth_token to use in `PretrainedTokenizer.from_pretrained()`, or False
+ :param kwargs: other kwargs to pass on to `PretrainedTokenizer.from_pretrained()`
+ :return: AutoTokenizer instance
"""
+ model_name_or_path = str(pretrained_model_name_or_path)
- @classmethod
- def load(
- cls,
- pretrained_model_name_or_path,
- revision=None,
- tokenizer_class=None,
- use_fast=True,
- use_auth_token: Union[bool, str] = None,
- **kwargs,
- ):
- """
- Enables loading of different Tokenizer classes with a uniform interface. Either infer the class from
- model config or define it manually via `tokenizer_class`.
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name (e.g. `bert-base-uncased`)
- :type pretrained_model_name_or_path: str
- :param revision: The version of model to use from the HuggingFace model hub. Can be tag name, branch name, or commit hash.
- :type revision: str
- :param tokenizer_class: (Optional) Name of the tokenizer class to load (e.g. `BertTokenizer`)
- :type tokenizer_class: str
- :param use_fast: (Optional, False by default) Indicate if Haystack should try to load the fast version of the tokenizer (True) or
- use the Python one (False).
- Only DistilBERT, BERT and Electra fast tokenizers are supported.
- :type use_fast: bool
- :param kwargs:
- :return: Tokenizer
- """
- pretrained_model_name_or_path = str(pretrained_model_name_or_path)
- kwargs["revision"] = revision
-
- if tokenizer_class is None:
- tokenizer_class = cls._infer_tokenizer_class(pretrained_model_name_or_path, use_auth_token=use_auth_token)
-
- logger.debug(f"Loading tokenizer of type '{tokenizer_class}'")
- # return appropriate tokenizer object
- ret = None
- if "AutoTokenizer" in tokenizer_class:
- ret = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, use_fast=use_fast, **kwargs)
- elif "AlbertTokenizer" in tokenizer_class:
- if use_fast:
- ret = AlbertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = AlbertTokenizer.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- elif "XLMRobertaTokenizer" in tokenizer_class:
- if use_fast:
- ret = XLMRobertaTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = XLMRobertaTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "RobertaTokenizer" in tokenizer_class:
- if use_fast:
- ret = RobertaTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = RobertaTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DistilBertTokenizer" in tokenizer_class:
- if use_fast:
- ret = DistilBertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DistilBertTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "BertTokenizer" in tokenizer_class:
- if use_fast:
- ret = BertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = BertTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "XLNetTokenizer" in tokenizer_class:
- if use_fast:
- ret = XLNetTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = XLNetTokenizer.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- elif "ElectraTokenizer" in tokenizer_class:
- if use_fast:
- ret = ElectraTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = ElectraTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "CamembertTokenizer" in tokenizer_class:
- if use_fast:
- ret = CamembertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = CamembertTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DPRQuestionEncoderTokenizer" in tokenizer_class:
- if use_fast:
- ret = DPRQuestionEncoderTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DPRQuestionEncoderTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DPRContextEncoderTokenizer" in tokenizer_class:
- if use_fast:
- ret = DPRContextEncoderTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DPRContextEncoderTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "BigBirdTokenizer" in tokenizer_class:
- if use_fast:
- ret = BigBirdTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = BigBirdTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DebertaV2Tokenizer" in tokenizer_class:
- if use_fast:
- ret = DebertaV2TokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DebertaV2Tokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- if ret is None:
- raise Exception("Unable to load tokenizer")
- return ret
-
- @staticmethod
- def _infer_tokenizer_class(pretrained_model_name_or_path, use_auth_token: Union[bool, str] = None):
- # Infer Tokenizer from model type in config
- try:
- config = AutoConfig.from_pretrained(pretrained_model_name_or_path, use_auth_token=use_auth_token)
- except OSError:
- # Haystack model (no 'config.json' file)
- try:
- config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path + "/language_model_config.json", use_auth_token=use_auth_token
- )
- except Exception as e:
- logger.warning("No config file found. Trying to infer Tokenizer type from model name")
- tokenizer_class = Tokenizer._infer_tokenizer_class_from_string(pretrained_model_name_or_path)
- return tokenizer_class
-
- model_type = config.model_type
-
- if model_type == "xlm-roberta":
- tokenizer_class = "XLMRobertaTokenizer"
- elif model_type == "roberta":
- if "mlm" in pretrained_model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- tokenizer_class = "RobertaTokenizer"
- elif model_type == "camembert":
- tokenizer_class = "CamembertTokenizer"
- elif model_type == "albert":
- tokenizer_class = "AlbertTokenizer"
- elif model_type == "distilbert":
- tokenizer_class = "DistilBertTokenizer"
- elif model_type == "bert":
- tokenizer_class = "BertTokenizer"
- elif model_type == "xlnet":
- tokenizer_class = "XLNetTokenizer"
- elif model_type == "electra":
- tokenizer_class = "ElectraTokenizer"
- elif model_type == "dpr":
- if config.architectures[0] == "DPRQuestionEncoder":
- tokenizer_class = "DPRQuestionEncoderTokenizer"
- elif config.architectures[0] == "DPRContextEncoder":
- tokenizer_class = "DPRContextEncoderTokenizer"
- elif config.architectures[0] == "DPRReader":
- raise NotImplementedError("DPRReader models are currently not supported.")
- elif model_type == "big_bird":
- tokenizer_class = "BigBirdTokenizer"
- elif model_type == "deberta-v2":
- tokenizer_class = "DebertaV2Tokenizer"
- else:
- # Fall back to inferring type from model name
- logger.warning(
- "Could not infer Tokenizer type from config. Trying to infer Tokenizer type from model name."
- )
- tokenizer_class = Tokenizer._infer_tokenizer_class_from_string(pretrained_model_name_or_path)
-
- return tokenizer_class
-
- @staticmethod
- def _infer_tokenizer_class_from_string(pretrained_model_name_or_path):
- # If inferring tokenizer class from config doesn't succeed,
- # fall back to inferring tokenizer class from model name.
- if "albert" in pretrained_model_name_or_path.lower():
- tokenizer_class = "AlbertTokenizer"
- elif "bigbird" in pretrained_model_name_or_path.lower():
- tokenizer_class = "BigBirdTokenizer"
- elif "xlm-roberta" in pretrained_model_name_or_path.lower():
- tokenizer_class = "XLMRobertaTokenizer"
- elif "roberta" in pretrained_model_name_or_path.lower():
- tokenizer_class = "RobertaTokenizer"
- elif "codebert" in pretrained_model_name_or_path.lower():
- if "mlm" in pretrained_model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- tokenizer_class = "RobertaTokenizer"
- elif "camembert" in pretrained_model_name_or_path.lower() or "umberto" in pretrained_model_name_or_path.lower():
- tokenizer_class = "CamembertTokenizer"
- elif "distilbert" in pretrained_model_name_or_path.lower():
- tokenizer_class = "DistilBertTokenizer"
- elif (
- "debertav2" in pretrained_model_name_or_path.lower() or "debertav3" in pretrained_model_name_or_path.lower()
- ):
- tokenizer_class = "DebertaV2Tokenizer"
- elif "bert" in pretrained_model_name_or_path.lower():
- tokenizer_class = "BertTokenizer"
- elif "xlnet" in pretrained_model_name_or_path.lower():
- tokenizer_class = "XLNetTokenizer"
- elif "electra" in pretrained_model_name_or_path.lower():
- tokenizer_class = "ElectraTokenizer"
- elif "minilm" in pretrained_model_name_or_path.lower():
- tokenizer_class = "BertTokenizer"
- elif "dpr-question_encoder" in pretrained_model_name_or_path.lower():
- tokenizer_class = "DPRQuestionEncoderTokenizer"
- elif "dpr-ctx_encoder" in pretrained_model_name_or_path.lower():
- tokenizer_class = "DPRContextEncoderTokenizer"
- else:
- tokenizer_class = "AutoTokenizer"
+ if "mlm" in model_name_or_path.lower():
+ logging.error("MLM part of codebert is currently not supported in Haystack. Proceed at your own risk.")
+
+ params = {}
+ if any(tokenizer_type in model_name_or_path for tokenizer_type in ["albert", "xlnet"]):
+ params["keep_accents"] = True
- return tokenizer_class
+ return AutoTokenizer.from_pretrained(
+ pretrained_model_name_or_path=model_name_or_path,
+ revision=revision,
+ use_fast=use_fast,
+ use_auth_token=use_auth_token,
+ **params,
+ **kwargs,
+ )
-def tokenize_batch_question_answering(pre_baskets, tokenizer, indices):
+def tokenize_batch_question_answering(
+ pre_baskets: List[Dict[str, Any]], tokenizer: PreTrainedTokenizer, indices: List[Any]
+) -> List[SampleBasket]:
"""
Tokenizes text data for question answering tasks. Tokenization means splitting words into subwords, depending on the
tokenizer's vocabulary.
@@ -322,16 +79,20 @@ def tokenize_batch_question_answering(pre_baskets, tokenizer, indices):
- Then we tokenize each question individually
- We construct dicts with question and corresponding document text + tokens + offsets + ids
- :param pre_baskets: input dicts with QA info #todo change to input objects
+ :param pre_baskets: input dicts with QA info #TODO change to input objects
:param tokenizer: tokenizer to be used
- :param indices: list, indices used during multiprocessing so that IDs assigned to our baskets are unique
+ :param indices: indices used during multiprocessing so that IDs assigned to our baskets are unique
:return: baskets, list containing question and corresponding document information
"""
- assert len(indices) == len(pre_baskets)
- assert tokenizer.is_fast, (
- "Processing QA data is only supported with fast tokenizers for now.\n"
- "Please load Tokenizers with 'use_fast=True' option."
- )
+ if not len(indices) == len(pre_baskets):
+ raise ValueError("indices and pre_baskets must have the same length")
+
+ if not tokenizer.is_fast:
+ raise ModelingError(
+ "Processing QA data is only supported with fast tokenizers for now."
+ "Please load Tokenizers with 'use_fast=True' option."
+ )
+
baskets = []
# # Tokenize texts in batch mode
texts = [d["context"] for d in pre_baskets]
@@ -385,80 +146,13 @@ def tokenize_batch_question_answering(pre_baskets, tokenizer, indices):
def _get_start_of_word_QA(word_ids):
- words = np.array(word_ids)
- start_of_word_single = [1] + list(np.ediff1d(words))
- return start_of_word_single
-
-
-def tokenize_with_metadata(text: str, tokenizer) -> Dict[str, Any]:
- """
- Performing tokenization while storing some important metadata for each token:
-
- * offsets: (int) Character index where the token begins in the original text
- * start_of_word: (bool) If the token is the start of a word. Particularly helpful for NER and QA tasks.
-
- We do this by first doing whitespace tokenization and then applying the model specific tokenizer to each "word".
-
- .. note:: We don't assume to preserve exact whitespaces in the tokens!
- This means: tabs, new lines, multiple whitespace etc will all resolve to a single " ".
- This doesn't make a difference for BERT + XLNet but it does for RoBERTa.
- For RoBERTa it has the positive effect of a shorter sequence length, but some information about whitespace
- type is lost which might be helpful for certain NLP tasks ( e.g tab for tables).
-
- :param text: Text to tokenize
- :param tokenizer: Tokenizer (e.g. from Tokenizer.load())
- :return: Dictionary with "tokens", "offsets" and "start_of_word"
- """
- # normalize all other whitespace characters to " "
- # Note: using text.split() directly would destroy the offset,
- # since \n\n\n would be treated similarly as a single \n
- text = re.sub(r"\s", " ", text)
- # Fast Tokenizers return offsets, so we don't need to calculate them ourselves
- if tokenizer.is_fast:
- # tokenized = tokenizer(text, return_offsets_mapping=True, return_special_tokens_mask=True)
- tokenized2 = tokenizer.encode_plus(text, return_offsets_mapping=True, return_special_tokens_mask=True)
-
- tokens2 = tokenized2["input_ids"]
- offsets2 = np.array([x[0] for x in tokenized2["offset_mapping"]])
- # offsets2 = [x[0] for x in tokenized2["offset_mapping"]]
- words = np.array(tokenized2.encodings[0].words)
-
- # TODO check for validity for all tokenizer and special token types
- words[0] = -1
- words[-1] = words[-2]
- words += 1
- start_of_word2 = [0] + list(np.ediff1d(words))
- #######
-
- # start_of_word3 = []
- # last_word = -1
- # for word_id in tokenized2.encodings[0].words:
- # if word_id is None or word_id == last_word:
- # start_of_word3.append(0)
- # else:
- # start_of_word3.append(1)
- # last_word = word_id
-
- tokenized_dict = {"tokens": tokens2, "offsets": offsets2, "start_of_word": start_of_word2}
- else:
- # split text into "words" (here: simple whitespace tokenizer).
- words = text.split(" ")
- word_offsets = []
- cumulated = 0
- for idx, word in enumerate(words):
- word_offsets.append(cumulated)
- cumulated += len(word) + 1 # 1 because we so far have whitespace tokenizer
-
- # split "words" into "subword tokens"
- tokens, offsets, start_of_word = _words_to_tokens(words, word_offsets, tokenizer)
- tokenized_dict = {"tokens": tokens, "offsets": offsets, "start_of_word": start_of_word}
- return tokenized_dict
+ return [1] + list(np.ediff1d(np.array(word_ids)))
def truncate_sequences(
seq_a: list,
seq_b: Optional[list],
- tokenizer,
+ tokenizer: AutoTokenizer,
max_seq_len: int,
truncation_strategy: str = "longest_first",
with_special_tokens: bool = True,
@@ -467,21 +161,27 @@ def truncate_sequences(
"""
Reduces a single sequence or a pair of sequences to a maximum sequence length.
The sequences can contain tokens or any other elements (offsets, masks ...).
- If `with_special_tokens` is enabled, it'll remove some additional tokens to have exactly enough space for later adding special tokens (CLS, SEP etc.)
+ If `with_special_tokens` is enabled, it'll remove some additional tokens to have exactly
+ enough space for later adding special tokens (CLS, SEP etc.)
Supported truncation strategies:
- - longest_first: (default) Iteratively reduce the inputs sequence until the input is under max_length starting from the longest one at each token (when there is a pair of input sequences). Overflowing tokens only contains overflow from the first sequence.
- - only_first: Only truncate the first sequence. raise an error if the first sequence is shorter or equal to than num_tokens_to_remove.
+ - longest_first: (default) Iteratively reduce the inputs sequence until the input is under
+ max_length starting from the longest one at each token (when there is a pair of input sequences).
+ Overflowing tokens only contains overflow from the first sequence.
+ - only_first: Only truncate the first sequence. raise an error if the first sequence is
+ shorter or equal to than num_tokens_to_remove.
- only_second: Only truncate the second sequence
- do_not_truncate: Does not truncate (raise an error if the input sequence is longer than max_length)
:param seq_a: First sequence of tokens/offsets/...
:param seq_b: Optional second sequence of tokens/offsets/...
- :param tokenizer: Tokenizer (e.g. from Tokenizer.load())
+ :param tokenizer: Tokenizer (e.g. from get_tokenizer))
:param max_seq_len:
- :param truncation_strategy: how the sequence(s) should be truncated down. Default: "longest_first" (see above for other options).
- :param with_special_tokens: If true, it'll remove some additional tokens to have exactly enough space for later adding special tokens (CLS, SEP etc.)
+ :param truncation_strategy: how the sequence(s) should be truncated down.
+ Default: "longest_first" (see above for other options).
+ :param with_special_tokens: If true, it'll remove some additional tokens to have exactly enough space
+ for later adding special tokens (CLS, SEP etc.)
:param stride: optional stride of the window during truncation
:return: truncated seq_a, truncated seq_b, overflowing tokens
"""
@@ -503,59 +203,119 @@ def truncate_sequences(
return (seq_a, seq_b, overflowing_tokens)
-def _words_to_tokens(words, word_offsets, tokenizer):
+#
+# FIXME this is a relic from FARM. If there's the occasion, remove it!
+#
+def tokenize_with_metadata(text: str, tokenizer: PreTrainedTokenizer) -> Dict[str, Any]:
+ """
+ Performing tokenization while storing some important metadata for each token:
+
+ * offsets: (int) Character index where the token begins in the original text
+ * start_of_word: (bool) If the token is the start of a word. Particularly helpful for NER and QA tasks.
+
+ We do this by first doing whitespace tokenization and then applying the model specific tokenizer to each "word".
+
+ .. note:: We don't assume to preserve exact whitespaces in the tokens!
+ This means: tabs, new lines, multiple whitespace etc will all resolve to a single " ".
+ This doesn't make a difference for BERT + XLNet but it does for RoBERTa.
+ For RoBERTa it has the positive effect of a shorter sequence length, but some information about whitespace
+ type is lost which might be helpful for certain NLP tasks ( e.g tab for tables).
+
+ :param text: Text to tokenize
+ :param tokenizer: Tokenizer (e.g. from get_tokenizer))
+ :return: Dictionary with "tokens", "offsets" and "start_of_word"
+ """
+ # normalize all other whitespace characters to " "
+ # Note: using text.split() directly would destroy the offset,
+ # since \n\n\n would be treated similarly as a single \n
+ text = re.sub(r"\s", " ", text)
+
+ words: Union[List[str], np.ndarray] = []
+ word_offsets: Union[List[int], np.ndarray] = []
+ start_of_word: List[Union[int, bool]] = []
+
+ # Fast Tokenizers return offsets, so we don't need to calculate them ourselves
+ if tokenizer.is_fast:
+ # tokenized = tokenizer(text, return_offsets_mapping=True, return_special_tokens_mask=True)
+ tokenized = tokenizer.encode_plus(text, return_offsets_mapping=True, return_special_tokens_mask=True)
+
+ tokens = tokenized["input_ids"]
+ offsets = np.array([x[0] for x in tokenized["offset_mapping"]])
+ # offsets2 = [x[0] for x in tokenized2["offset_mapping"]]
+ words = np.array(tokenized.encodings[0].words)
+
+ # TODO check for validity for all tokenizer and special token types
+ words[0] = -1
+ words[-1] = words[-2]
+ words += 1
+ start_of_word = [0] + list(np.ediff1d(words))
+ return {"tokens": tokens, "offsets": offsets, "start_of_word": start_of_word}
+
+ # split text into "words" (here: simple whitespace tokenizer).
+ words = text.split(" ")
+ cumulated = 0
+ for word in words:
+ word_offsets.append(cumulated)
+ cumulated += len(word) + 1 # 1 because we so far have whitespace tokenizer
+
+ # split "words" into "subword tokens"
+ tokens, offsets, start_of_word = _words_to_tokens(words, word_offsets, tokenizer) # type: ignore
+ return {"tokens": tokens, "offsets": offsets, "start_of_word": start_of_word}
+
+
+# Note: only used by tokenize_with_metadata()
+def _words_to_tokens(
+ words: List[str], word_offsets: List[int], tokenizer: PreTrainedTokenizer
+) -> Tuple[List[str], List[int], List[bool]]:
"""
Tokenize "words" into subword tokens while keeping track of offsets and if a token is the start of a word.
:param words: list of words.
- :type words: list
:param word_offsets: Character indices where each word begins in the original text
- :type word_offsets: list
- :param tokenizer: Tokenizer (e.g. from Tokenizer.load())
- :return: tokens, offsets, start_of_word
+ :param tokenizer: Tokenizer (e.g. from get_tokenizer))
+ :return: Tuple of (tokens, offsets, start_of_word)
"""
- tokens = []
- token_offsets = []
- start_of_word = []
- idx = 0
- for w, w_off in zip(words, word_offsets):
- idx += 1
- if idx % 500000 == 0:
- logger.info(idx)
+ tokens: List[str] = []
+ token_offsets: List[int] = []
+ start_of_word: List[bool] = []
+ index = 0
+ for index, (word, word_offset) in enumerate(zip(words, word_offsets)):
+ if index % 500000 == 0:
+ logger.info(index)
# Get (subword) tokens of single word.
# empty / pure whitespace
- if len(w) == 0:
+ if len(word) == 0:
continue
# For the first word of a text: we just call the regular tokenize function.
# For later words: we need to call it with add_prefix_space=True to get the same results with roberta / gpt2 tokenizer
# see discussion here. https://github.com/huggingface/transformers/issues/1196
if len(tokens) == 0:
- tokens_word = tokenizer.tokenize(w)
+ tokens_word = tokenizer.tokenize(word)
else:
if type(tokenizer) == RobertaTokenizer:
- tokens_word = tokenizer.tokenize(w, add_prefix_space=True)
+ tokens_word = tokenizer.tokenize(word, add_prefix_space=True)
else:
- tokens_word = tokenizer.tokenize(w)
+ tokens_word = tokenizer.tokenize(word)
# Sometimes the tokenizer returns no tokens
if len(tokens_word) == 0:
continue
tokens += tokens_word
# get global offset for each token in word + save marker for first tokens of a word
- first_tok = True
- for tok in tokens_word:
- token_offsets.append(w_off)
+ first_token = True
+ for token in tokens_word:
+ token_offsets.append(word_offset)
# Depending on the tokenizer type special chars are added to distinguish tokens with preceeding
# whitespace (=> "start of a word"). We need to get rid of these to calculate the original length of the token
- orig_tok = re.sub(SPECIAL_TOKENIZER_CHARS, "", tok)
+ original_token = re.sub(SPECIAL_TOKENIZER_CHARS, "", token)
# Don't use length of unk token for offset calculation
- if orig_tok == tokenizer.special_tokens_map["unk_token"]:
- w_off += 1
+ if original_token == tokenizer.special_tokens_map["unk_token"]:
+ word_offset += 1
else:
- w_off += len(orig_tok)
- if first_tok:
+ word_offset += len(original_token)
+ if first_token:
start_of_word.append(True)
- first_tok = False
+ first_token = False
else:
start_of_word.append(False)
diff --git a/haystack/modeling/model/triadaptive_model.py b/haystack/modeling/model/triadaptive_model.py
index 9d3e8cfe63..9a76dab0d3 100644
--- a/haystack/modeling/model/triadaptive_model.py
+++ b/haystack/modeling/model/triadaptive_model.py
@@ -7,7 +7,7 @@
from torch import nn
from haystack.modeling.data_handler.processor import Processor
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, LanguageModel
from haystack.modeling.model.prediction_head import PredictionHead
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -87,11 +87,11 @@ def __init__(
super(TriAdaptiveModel, self).__init__()
self.device = device
self.language_model1 = language_model1.to(device)
- self.lm1_output_dims = language_model1.get_output_dims()
+ self.lm1_output_dims = language_model1.output_dims
self.language_model2 = language_model2.to(device)
- self.lm2_output_dims = language_model2.get_output_dims()
+ self.lm2_output_dims = language_model2.output_dims
self.language_model3 = language_model3.to(device)
- self.lm3_output_dims = language_model3.get_output_dims()
+ self.lm3_output_dims = language_model3.output_dims
self.dropout1 = nn.Dropout(embeds_dropout_prob)
self.dropout2 = nn.Dropout(embeds_dropout_prob)
self.dropout3 = nn.Dropout(embeds_dropout_prob)
@@ -165,17 +165,17 @@ def load(
"""
# Language Model
if lm1_name:
- language_model1 = LanguageModel.load(os.path.join(load_dir, lm1_name))
+ language_model1 = get_language_model(os.path.join(load_dir, lm1_name))
else:
- language_model1 = LanguageModel.load(load_dir)
+ language_model1 = get_language_model(load_dir)
if lm2_name:
- language_model2 = LanguageModel.load(os.path.join(load_dir, lm2_name))
+ language_model2 = get_language_model(os.path.join(load_dir, lm2_name))
else:
- language_model2 = LanguageModel.load(load_dir)
+ language_model2 = get_language_model(load_dir)
if lm3_name:
- language_model3 = LanguageModel.load(os.path.join(load_dir, lm3_name))
+ language_model3 = get_language_model(os.path.join(load_dir, lm3_name))
else:
- language_model3 = LanguageModel.load(load_dir)
+ language_model3 = get_language_model(load_dir)
# Prediction heads
ph_config_files = cls._get_prediction_head_files(load_dir)
@@ -294,19 +294,30 @@ def forward_lm(self, **kwargs):
pooled_output = [None, None]
# Forward pass for the queries
if "query_input_ids" in kwargs.keys():
- pooled_output1, hidden_states1 = self.language_model1(**kwargs)
+ pooled_output1, _ = self.language_model1(
+ input_ids=kwargs.get("query_input_ids"),
+ segment_ids=kwargs.get("query_segment_ids"),
+ attention_mask=kwargs.get("query_attention_mask"),
+ output_hidden_states=False,
+ output_attentions=False,
+ )
pooled_output[0] = pooled_output1
+
# Forward pass for text passages and tables
if "passage_input_ids" in kwargs.keys():
table_mask = torch.flatten(kwargs["is_table"]) == True
+
# Current batch consists of only tables
if all(table_mask):
- pooled_output2, hidden_states2 = self.language_model3(
+ pooled_output2, _ = self.language_model3(
passage_input_ids=kwargs["passage_input_ids"],
passage_segment_ids=kwargs["table_segment_ids"],
passage_attention_mask=kwargs["passage_attention_mask"],
+ output_hidden_states=False,
+ output_attentions=False,
)
pooled_output[1] = pooled_output2
+
# Current batch consists of tables and texts
elif any(table_mask):
@@ -320,17 +331,31 @@ def forward_lm(self, **kwargs):
table_input_ids = passage_input_ids[table_mask]
table_segment_ids = table_segment_ids[table_mask]
table_attention_mask = passage_attention_mask[table_mask]
- pooled_output_tables, _ = self.language_model3(table_input_ids, table_segment_ids, table_attention_mask)
+
+ pooled_output_tables, _ = self.language_model3(
+ input_ids=table_input_ids,
+ segment_ids=table_segment_ids,
+ attention_mask=table_attention_mask,
+ output_hidden_states=False,
+ output_attentions=False,
+ )
text_input_ids = passage_input_ids[~table_mask]
text_segment_ids = passage_segment_ids[~table_mask]
text_attention_mask = passage_attention_mask[~table_mask]
- pooled_output_text, _ = self.language_model2(text_input_ids, text_segment_ids, text_attention_mask)
+
+ pooled_output_text, _ = self.language_model2(
+ input_ids=text_input_ids,
+ segment_ids=text_segment_ids,
+ attention_mask=text_attention_mask,
+ output_hidden_states=False,
+ output_attentions=False,
+ )
last_table_idx = 0
last_text_idx = 0
combined_outputs = []
- for idx, mask in enumerate(table_mask):
+ for mask in table_mask:
if mask:
combined_outputs.append(pooled_output_tables[last_table_idx])
last_table_idx += 1
@@ -345,9 +370,22 @@ def forward_lm(self, **kwargs):
), "Passage embedding model and table embedding model use different embedding sizes"
pooled_output_combined = combined_outputs.view(-1, embedding_size)
pooled_output[1] = pooled_output_combined
+
# Current batch consists of only texts
else:
- pooled_output2, hidden_states2 = self.language_model2(**kwargs)
+ # Make input two-dimensional
+ max_seq_len = kwargs["passage_input_ids"].shape[-1]
+ input_ids = kwargs["passage_input_ids"].view(-1, max_seq_len)
+ attention_mask = kwargs["passage_attention_mask"].view(-1, max_seq_len)
+ segment_ids = kwargs["passage_segment_ids"].view(-1, max_seq_len)
+
+ pooled_output2, _ = self.language_model2(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ segment_ids=segment_ids,
+ output_hidden_states=False,
+ output_attentions=False,
+ )
pooled_output[1] = pooled_output2
return tuple(pooled_output)
@@ -382,7 +420,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int, vocab_size3: int
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model1_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size1 == model1_vocab_len, msg
@@ -391,7 +429,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int, vocab_size3: int
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model2_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size2 == model2_vocab_len, msg
@@ -400,7 +438,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int, vocab_size3: int
msg = (
f"Vocab size of tokenizer {vocab_size3} doesn't match with model {model3_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size3 == model1_vocab_len, msg
diff --git a/haystack/modeling/training/base.py b/haystack/modeling/training/base.py
index 67a126c2fd..1ea3ec02ec 100644
--- a/haystack/modeling/training/base.py
+++ b/haystack/modeling/training/base.py
@@ -17,8 +17,8 @@
from haystack.modeling.data_handler.data_silo import DataSilo, DistillationDataSilo
from haystack.modeling.evaluation.eval import Evaluator
from haystack.modeling.model.adaptive_model import AdaptiveModel
+from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
from haystack.modeling.model.optimization import get_scheduler
-from haystack.modeling.model.language_model import DebertaV2
from haystack.modeling.utils import GracefulKiller
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -251,8 +251,8 @@ def train(self):
vocab_size1=len(self.data_silo.processor.query_tokenizer),
vocab_size2=len(self.data_silo.processor.passage_tokenizer),
)
- elif not isinstance(
- self.model.language_model, DebertaV2
+ elif (
+ self.model.language_model.name != "debertav2"
): # DebertaV2 has mismatched vocab size on purpose (see https://github.com/huggingface/transformers/issues/12428)
self.model.verify_vocab_size(vocab_size=len(self.data_silo.processor.tokenizer))
self.model.train()
@@ -372,7 +372,24 @@ def train(self):
def compute_loss(self, batch: dict, step: int) -> torch.Tensor:
# Forward & backward pass through model
- logits = self.model.forward(**batch)
+ if isinstance(self.model, AdaptiveModel):
+ logits = self.model.forward(
+ input_ids=batch["input_ids"], segment_ids=None, padding_mask=batch["padding_mask"]
+ )
+
+ elif isinstance(self.model, BiAdaptiveModel):
+ logits = self.model.forward(
+ query_input_ids=batch["query_input_ids"],
+ query_segment_ids=batch["query_segment_ids"],
+ query_attention_mask=batch["query_attention_mask"],
+ passage_input_ids=batch["passage_input_ids"],
+ passage_segment_ids=batch["passage_segment_ids"],
+ passage_attention_mask=batch["passage_attention_mask"],
+ )
+
+ else:
+ logits = self.model.forward(**batch)
+
per_sample_loss = self.model.logits_to_loss(logits=logits, global_step=self.global_step, **batch)
return self.backward_propagate(per_sample_loss, step)
@@ -767,7 +784,15 @@ def compute_loss(self, batch: dict, step: int) -> torch.Tensor:
keys = list(batch.keys())
keys = [key for key in keys if key.startswith("teacher_output")]
teacher_logits = [batch.pop(key) for key in keys]
- logits = self.model.forward(**batch)
+
+ logits = self.model.forward(
+ input_ids=batch.get("input_ids"),
+ segment_ids=batch.get("segment_ids"),
+ padding_mask=batch.get("padding_mask"),
+ output_hidden_states=batch.get("output_hidden_states"),
+ output_attentions=batch.get("output_attentions"),
+ )
+
student_loss = self.model.logits_to_loss(logits=logits, global_step=self.global_step, **batch)
distillation_loss = self.distillation_loss_fn(
student_logits=logits[0] / self.temperature, teacher_logits=teacher_logits[0] / self.temperature
@@ -899,7 +924,16 @@ def __init__(
self.loss = DataParallel(self.loss).to(device)
def compute_loss(self, batch: dict, step: int) -> torch.Tensor:
- return self.backward_propagate(torch.sum(self.loss(batch)), step)
+ return self.backward_propagate(
+ torch.sum(
+ self.loss(
+ input_ids=batch.get("input_ids"),
+ segment_ids=batch.get("segment_ids"),
+ padding_mask=batch.get("padding_mask"),
+ )
+ ),
+ step,
+ )
class DistillationLoss(Module):
@@ -945,14 +979,23 @@ def __init__(self, model: Union[DataParallel, AdaptiveModel], teacher_model: Mod
else:
self.dim_mappings.append(None)
- def forward(self, batch):
+ def forward(self, input_ids: torch.Tensor, segment_ids: torch.Tensor, padding_mask: torch.Tensor):
with torch.no_grad():
_, teacher_hidden_states, teacher_attentions = self.teacher_model.forward(
- **batch, output_attentions=True, output_hidden_states=True
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ padding_mask=padding_mask,
+ output_attentions=True,
+ output_hidden_states=True,
)
-
- _, hidden_states, attentions = self.model.forward(**batch, output_attentions=True, output_hidden_states=True)
- loss = torch.tensor(0.0, device=batch["input_ids"].device)
+ _, hidden_states, attentions = self.model.forward(
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ padding_mask=padding_mask,
+ output_attentions=True,
+ output_hidden_states=True,
+ )
+ loss = torch.tensor(0.0, device=input_ids.device)
# calculating attention loss
for student_attention, teacher_attention, dim_mapping in zip(
diff --git a/haystack/modeling/visual.py b/haystack/modeling/visual.py
index e45f4d7786..d2084bdc5e 100644
--- a/haystack/modeling/visual.py
+++ b/haystack/modeling/visual.py
@@ -91,7 +91,7 @@
"""
WORKER_M = r""" 0
-/|\
+/|\
/'\ """
WORKER_F = r""" 0
diff --git a/haystack/nodes/_json_schema.py b/haystack/nodes/_json_schema.py
index 17de407f27..f16ceaf0c9 100644
--- a/haystack/nodes/_json_schema.py
+++ b/haystack/nodes/_json_schema.py
@@ -289,10 +289,25 @@ def get_json_schema(filename: str, version: str, modules: List[str] = ["haystack
"type": "array",
"items": {"type": "string"},
},
- "replicas": {
- "title": "replicas",
- "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
- "type": "integer",
+ "serve_deployment_kwargs": {
+ "title": "serve_deployment_kwargs",
+ "description": "Arguments to be passed to the Ray Serve `deployment()` method (only for Ray pipelines)",
+ "type": "object",
+ "properties": {
+ "num_replicas": {
+ "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
+ "type": "integer",
+ },
+ "version": {"type": "string"},
+ "prev_version": {"type": "string"},
+ "init_args": {"type": "array"},
+ "init_kwargs": {"type": "object"},
+ "router_prefix": {"type": "string"},
+ "ray_actor_options": {"type": "object"},
+ "user_config": {"type": {}},
+ "max_concurrent_queries": {"type": "integer"},
+ },
+ "additionalProperties": True,
},
},
"required": ["name", "inputs"],
@@ -315,7 +330,9 @@ def get_json_schema(filename: str, version: str, modules: List[str] = ["haystack
"properties": {
"pipelines": {
"title": "Pipelines",
- "items": {"properties": {"nodes": {"items": {"not": {"required": ["replicas"]}}}}},
+ "items": {
+ "properties": {"nodes": {"items": {"not": {"required": ["serve_deployment_kwargs"]}}}}
+ },
}
},
},
diff --git a/haystack/nodes/answer_generator/transformers.py b/haystack/nodes/answer_generator/transformers.py
index 494429ec70..6bc68f79e3 100644
--- a/haystack/nodes/answer_generator/transformers.py
+++ b/haystack/nodes/answer_generator/transformers.py
@@ -229,7 +229,8 @@ def predict(self, query: str, documents: List[Document], top_k: Optional[int] =
passage_embeddings = self._prepare_passage_embeddings(docs=documents, embeddings=flat_docs_dict["embedding"])
# Query tokenization
- input_dict = self.tokenizer.prepare_seq2seq_batch(src_texts=[query], return_tensors="pt")
+ input_dict = self.tokenizer(text=[query], return_tensors="pt", padding="longest", truncation=True)
+
input_ids = input_dict["input_ids"].to(self.devices[0])
# Query embedding
query_embedding = self.model.question_encoder(input_ids)[0]
diff --git a/haystack/nodes/connector/crawler.py b/haystack/nodes/connector/crawler.py
index 16f703d5e1..f89fad0beb 100644
--- a/haystack/nodes/connector/crawler.py
+++ b/haystack/nodes/connector/crawler.py
@@ -13,7 +13,7 @@
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
- from selenium.common.exceptions import StaleElementReferenceException
+ from selenium.common.exceptions import StaleElementReferenceException, WebDriverException
from selenium import webdriver
except (ImportError, ModuleNotFoundError) as ie:
from haystack.utils.import_utils import _optional_component_not_installed
@@ -22,6 +22,7 @@
from haystack.nodes.base import BaseComponent
from haystack.schema import Document
+from haystack.errors import NodeError
logger = logging.getLogger(__name__)
@@ -94,15 +95,15 @@ def __init__(
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(service=Service("chromedriver"), options=options)
- except:
- raise Exception(
+ except WebDriverException as exc:
+ raise NodeError(
"""
\'chromium-driver\' needs to be installed manually when running colab. Follow the below given commands:
!apt-get update
!apt install chromium-driver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
If it has already been installed, please check if it has been copied to the right directory i.e. to \'/usr/bin\'"""
- )
+ ) from exc
else:
logger.info("'chrome-driver' will be automatically installed.")
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
diff --git a/haystack/nodes/preprocessor/base.py b/haystack/nodes/preprocessor/base.py
index 61bd7667ea..c8cabf94ec 100644
--- a/haystack/nodes/preprocessor/base.py
+++ b/haystack/nodes/preprocessor/base.py
@@ -1,6 +1,7 @@
from typing import List, Optional, Union
from abc import abstractmethod
+
from haystack.nodes.base import BaseComponent
from haystack.schema import Document
diff --git a/haystack/nodes/preprocessor/preprocessor.py b/haystack/nodes/preprocessor/preprocessor.py
index 7a4d7cd824..eebb98b8c8 100644
--- a/haystack/nodes/preprocessor/preprocessor.py
+++ b/haystack/nodes/preprocessor/preprocessor.py
@@ -5,6 +5,8 @@
from itertools import chain
from typing import List, Optional, Generator, Set, Union
import warnings
+from pathlib import Path
+from pickle import UnpicklingError
import nltk
from more_itertools import windowed
@@ -51,6 +53,7 @@ def __init__(
split_length: int = 200,
split_overlap: int = 0,
split_respect_sentence_boundary: bool = True,
+ tokenizer_model_folder: Optional[Union[str, Path]] = None,
language: str = "en",
id_hash_keys: Optional[List[str]] = None,
):
@@ -75,6 +78,7 @@ def __init__(
to True, the individual split will always have complete sentences &
the number of words will be <= split_length.
:param language: The language used by "nltk.tokenize.sent_tokenize" in iso639 format. Available options: "en", "es", "de", "fr" & many more.
+ :param tokenizer_model_folder: Path to the folder containing the NTLK PunktSentenceTokenizer models, if loading a model from a local path. Leave empty otherwise.
:param id_hash_keys: Generate the document id from a custom list of strings that refer to the document's
attributes. If you want to ensure you don't have duplicate documents in your DocumentStore but texts are
not unique, you can modify the metadata and pass e.g. `"meta"` to this field (e.g. [`"content"`, `"meta"`]).
@@ -95,7 +99,8 @@ def __init__(
self.split_length = split_length
self.split_overlap = split_overlap
self.split_respect_sentence_boundary = split_respect_sentence_boundary
- self.language = iso639_to_nltk.get(language, language)
+ self.language = language
+ self.tokenizer_model_folder = tokenizer_model_folder
self.print_log: Set[str] = set()
self.id_hash_keys = id_hash_keys
@@ -229,6 +234,11 @@ def clean(
# Mainly needed for type checking
if not isinstance(document, Document):
raise HaystackError("Document must not be of type 'dict' but of type 'Document'.")
+
+ if type(document.content) is not str:
+ logger.error("Document content is not of type str. Nothing to clean.")
+ return document
+
text = document.content
if clean_header_footer:
text = self._find_and_remove_header_footer(
@@ -286,11 +296,16 @@ def split(
if split_respect_sentence_boundary and split_by != "word":
raise NotImplementedError("'split_respect_sentence_boundary=True' is only compatible with split_by='word'.")
+ if type(document.content) is not str:
+ logger.error("Document content is not of type str. Nothing to split.")
+ return [document]
+
text = document.content
if split_respect_sentence_boundary and split_by == "word":
# split by words ensuring no sub sentence splits
- sentences = nltk.tokenize.sent_tokenize(text, language=self.language)
+ sentences = self._split_sentences(text)
+
word_count = 0
list_splits = []
current_slice: List[str] = []
@@ -334,7 +349,7 @@ def split(
if split_by == "passage":
elements = text.split("\n\n")
elif split_by == "sentence":
- elements = nltk.tokenize.sent_tokenize(text, language=self.language)
+ elements = self._split_sentences(text)
elif split_by == "word":
elements = text.split(" ")
else:
@@ -444,3 +459,50 @@ def _find_longest_common_ngram(
# no common sequence found
longest = ""
return longest if longest.strip() else None
+
+ def _split_sentences(self, text: str) -> List[str]:
+ """
+ Tokenize text into sentences.
+ :param text: str, text to tokenize
+ :return: list[str], list of sentences
+ """
+ sentences = []
+
+ language_name = iso639_to_nltk.get(self.language)
+
+ # Try to load a custom model from 'tokenizer_model_path'
+ if self.tokenizer_model_folder is not None:
+ tokenizer_model_path = Path(self.tokenizer_model_folder).absolute() / f"{self.language}.pickle"
+ try:
+ sentence_tokenizer = nltk.data.load(f"file:{str(tokenizer_model_path)}", format="pickle")
+ sentences = sentence_tokenizer.tokenize(text)
+ except LookupError:
+ logger.exception(f"PreProcessor couldn't load sentence tokenizer from {str(tokenizer_model_path)}")
+ except (UnpicklingError, ValueError) as e:
+ logger.exception(
+ f"PreProcessor couldn't determine model format of sentence tokenizer at {str(tokenizer_model_path)}."
+ )
+ if sentences:
+ return sentences
+
+ # NLTK failed to split, fallback to the default model or to English
+ if language_name is not None:
+ logger.error(
+ f"PreProcessor couldn't find custom sentence tokenizer model for {self.language}. Using default {self.language} model."
+ )
+ return nltk.tokenize.sent_tokenize(text, language=language_name)
+
+ logger.error(
+ f"PreProcessor couldn't find default or custom sentence tokenizer model for {self.language}. Using English instead."
+ )
+ return nltk.tokenize.sent_tokenize(text, language="english")
+
+ # Use a default NLTK model
+ if language_name is not None:
+ return nltk.tokenize.sent_tokenize(text, language=language_name)
+
+ logger.error(
+ f"PreProcessor couldn't find default sentence tokenizer model for {self.language}. Using English instead. "
+ "You may train your own model and use the 'tokenizer_model_folder' parameter."
+ )
+ return nltk.tokenize.sent_tokenize(text, language="english")
diff --git a/haystack/nodes/question_generator/question_generator.py b/haystack/nodes/question_generator/question_generator.py
index 7ca6a47735..e9b667e5e9 100644
--- a/haystack/nodes/question_generator/question_generator.py
+++ b/haystack/nodes/question_generator/question_generator.py
@@ -39,6 +39,7 @@ def __init__(
prompt="generate questions:",
num_queries_per_doc=1,
batch_size: Optional[int] = None,
+ sep_token: str = "",
):
"""
Uses the valhalla/t5-base-e2e-qg model by default. This class supports any question generation model that is
@@ -68,6 +69,7 @@ def __init__(
self.prompt = prompt
self.num_queries_per_doc = num_queries_per_doc
self.batch_size = batch_size
+ self.sep_token = self.tokenizer.sep_token or sep_token
def run(self, documents: List[Document]): # type: ignore
generated_questions = []
@@ -81,12 +83,15 @@ def run(self, documents: List[Document]): # type: ignore
def run_batch(self, documents: Union[List[Document], List[List[Document]]], batch_size: Optional[int] = None): # type: ignore
generated_questions = []
if isinstance(documents[0], Document):
- questions = self.generate_batch(texts=[d.content for d in documents if isinstance(d, Document)])
+ questions = self.generate_batch(
+ texts=[d.content for d in documents if isinstance(d, Document)], batch_size=batch_size
+ )
questions_iterator = questions # type: ignore
documents_iterator = documents
else:
questions = self.generate_batch(
- texts=[[d.content for d in doc_list] for doc_list in documents if isinstance(doc_list, list)]
+ texts=[[d.content for d in doc_list] for doc_list in documents if isinstance(doc_list, list)],
+ batch_size=batch_size,
)
questions_iterator = itertools.chain.from_iterable(questions) # type: ignore
documents_iterator = itertools.chain.from_iterable(documents) # type: ignore
@@ -127,12 +132,11 @@ def generate(self, text: str) -> List[str]:
num_return_sequences=self.num_queries_per_doc,
)
- string_output = self.tokenizer.batch_decode(tokens_output)
- string_output = [cur_output.replace("", "").replace("", "") for cur_output in string_output]
+ string_output = self.tokenizer.batch_decode(tokens_output, skip_special_tokens=True)
ret = []
for split in string_output:
- for question in split.split(""):
+ for question in split.split(self.sep_token):
question = question.strip()
if question and question not in ret:
ret.append(question)
@@ -196,8 +200,7 @@ def generate_batch(
num_return_sequences=self.num_queries_per_doc,
)
- string_output = self.tokenizer.batch_decode(tokens_output)
- string_output = [cur_output.replace("", "").replace("", "") for cur_output in string_output]
+ string_output = self.tokenizer.batch_decode(tokens_output, skip_special_tokens=True)
all_string_outputs.extend(string_output)
# Group predictions together by split
@@ -223,7 +226,7 @@ def generate_batch(
for doc in group:
doc_preds = []
for split in doc:
- for question in split.split(""):
+ for question in split.split(self.sep_token):
question = question.strip()
if question and question not in doc_preds:
doc_preds.append(question)
diff --git a/haystack/nodes/retriever/dense.py b/haystack/nodes/retriever/dense.py
index b608a39301..fa651123be 100644
--- a/haystack/nodes/retriever/dense.py
+++ b/haystack/nodes/retriever/dense.py
@@ -13,15 +13,20 @@
from torch.utils.data.sampler import SequentialSampler
import pandas as pd
from huggingface_hub import hf_hub_download
-from transformers import AutoConfig
+from transformers import (
+ AutoConfig,
+ DPRContextEncoderTokenizerFast,
+ DPRQuestionEncoderTokenizerFast,
+ DPRContextEncoderTokenizer,
+ DPRQuestionEncoderTokenizer,
+)
from haystack.errors import HaystackError
from haystack.schema import Document
from haystack.document_stores import BaseDocumentStore
from haystack.nodes.retriever.base import BaseRetriever
from haystack.nodes.retriever._embedding_encoder import _EMBEDDING_ENCODERS
-from haystack.modeling.model.tokenization import Tokenizer
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, DPREncoder
from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
from haystack.modeling.model.triadaptive_model import TriAdaptiveModel
from haystack.modeling.model.prediction_head import TextSimilarityHead
@@ -57,7 +62,6 @@ def __init__(
batch_size: int = 16,
embed_title: bool = True,
use_fast_tokenizers: bool = True,
- infer_tokenizer_classes: bool = False,
similarity_function: str = "dot_product",
global_loss_buffer_size: int = 150000,
progress_bar: bool = True,
@@ -102,8 +106,6 @@ def __init__(
before writing them to the DocumentStore like this:
{"text": "my text", "meta": {"name": "my title"}}.
:param use_fast_tokenizers: Whether to use fast Rust tokenizers
- :param infer_tokenizer_classes: Whether to infer tokenizer class from the model config / name.
- If `False`, the class always loads `DPRQuestionEncoderTokenizer` and `DPRContextEncoderTokenizer`.
:param similarity_function: Which function to apply for calculating the similarity of query and passage embeddings during training.
Options: `dot_product` (Default) or `cosine`
:param global_loss_buffer_size: Buffer size for all_gather() in DDP.
@@ -151,39 +153,29 @@ def __init__(
"This can be set when initializing the DocumentStore"
)
- self.infer_tokenizer_classes = infer_tokenizer_classes
- tokenizers_default_classes = {"query": "DPRQuestionEncoderTokenizer", "passage": "DPRContextEncoderTokenizer"}
- if self.infer_tokenizer_classes:
- tokenizers_default_classes["query"] = None # type: ignore
- tokenizers_default_classes["passage"] = None # type: ignore
-
# Init & Load Encoders
- self.query_tokenizer = Tokenizer.load(
+ self.query_tokenizer = DPRQuestionEncoderTokenizerFast.from_pretrained(
pretrained_model_name_or_path=query_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["query"],
use_auth_token=use_auth_token,
)
- self.query_encoder = LanguageModel.load(
+ self.query_encoder = DPREncoder(
pretrained_model_name_or_path=query_embedding_model,
- revision=model_version,
- language_model_class="DPRQuestionEncoder",
+ model_type="DPRQuestionEncoder",
use_auth_token=use_auth_token,
)
- self.passage_tokenizer = Tokenizer.load(
+ self.passage_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
pretrained_model_name_or_path=passage_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["passage"],
use_auth_token=use_auth_token,
)
- self.passage_encoder = LanguageModel.load(
+ self.passage_encoder = DPREncoder(
pretrained_model_name_or_path=passage_embedding_model,
- revision=model_version,
- language_model_class="DPRContextEncoder",
+ model_type="DPRContextEncoder",
use_auth_token=use_auth_token,
)
@@ -493,12 +485,19 @@ def _get_predictions(self, dicts):
leave=False,
disable=disable_tqdm,
) as progress_bar:
- for batch in data_loader:
- batch = {key: batch[key].to(self.devices[0]) for key in batch}
+ for raw_batch in data_loader:
+ batch = {key: raw_batch[key].to(self.devices[0]) for key in raw_batch}
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = self.model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = self.model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -550,7 +549,6 @@ def embed_documents(self, docs: List[Document]) -> List[np.ndarray]:
for d in docs
]
embeddings = self._get_predictions(passages)["passages"]
-
return embeddings
def train(
@@ -726,7 +724,6 @@ def load(
similarity_function: str = "dot_product",
query_encoder_dir: str = "query_encoder",
passage_encoder_dir: str = "passage_encoder",
- infer_tokenizer_classes: bool = False,
):
"""
Load DensePassageRetriever from the specified directory.
@@ -743,7 +740,6 @@ def load(
embed_title=embed_title,
use_fast_tokenizers=use_fast_tokenizers,
similarity_function=similarity_function,
- infer_tokenizer_classes=infer_tokenizer_classes,
)
logger.info(f"DPR model loaded from {load_dir}")
@@ -774,13 +770,13 @@ def __init__(
batch_size: int = 16,
embed_meta_fields: List[str] = ["name", "section_title", "caption"],
use_fast_tokenizers: bool = True,
- infer_tokenizer_classes: bool = False,
similarity_function: str = "dot_product",
global_loss_buffer_size: int = 150000,
progress_bar: bool = True,
devices: Optional[List[Union[str, torch.device]]] = None,
use_auth_token: Optional[Union[str, bool]] = None,
scale_score: bool = True,
+ use_fast: bool = True,
):
"""
Init the Retriever incl. the two encoder models from a local or remote model checkpoint.
@@ -805,8 +801,6 @@ def __init__(
performance if your titles contain meaningful information for retrieval
(topic, entities etc.).
:param use_fast_tokenizers: Whether to use fast Rust tokenizers
- :param infer_tokenizer_classes: Whether to infer tokenizer class from the model config / name.
- If `False`, the class always loads `DPRQuestionEncoderTokenizer` and `DPRContextEncoderTokenizer`.
:param similarity_function: Which function to apply for calculating the similarity of query and passage embeddings during training.
Options: `dot_product` (Default) or `cosine`
:param global_loss_buffer_size: Buffer size for all_gather() in DDP.
@@ -824,6 +818,7 @@ def __init__(
:param scale_score: Whether to scale the similarity score to the unit interval (range of [0,1]).
If true (default) similarity scores (e.g. cosine or dot_product) which naturally have a different value range will be scaled to a range of [0,1], where 1 means extremely relevant.
Otherwise raw similarity scores (e.g. cosine or dot_product) will be used.
+ :param use_fast: Whether to use the fast version of DPR tokenizers or fallback to the standard version. Defaults to True.
"""
super().__init__()
@@ -855,59 +850,40 @@ def __init__(
"This can be set when initializing the DocumentStore"
)
- self.infer_tokenizer_classes = infer_tokenizer_classes
- tokenizers_default_classes = {
- "query": "DPRQuestionEncoderTokenizer",
- "passage": "DPRContextEncoderTokenizer",
- "table": "DPRContextEncoderTokenizer",
- }
- if self.infer_tokenizer_classes:
- tokenizers_default_classes["query"] = None # type: ignore
- tokenizers_default_classes["passage"] = None # type: ignore
- tokenizers_default_classes["table"] = None # type: ignore
+ query_tokenizer_class = DPRQuestionEncoderTokenizerFast if use_fast else DPRQuestionEncoderTokenizer
+ passage_tokenizer_class = DPRContextEncoderTokenizerFast if use_fast else DPRContextEncoderTokenizer
+ table_tokenizer_class = DPRContextEncoderTokenizerFast if use_fast else DPRContextEncoderTokenizer
# Init & Load Encoders
- self.query_tokenizer = Tokenizer.load(
- pretrained_model_name_or_path=query_embedding_model,
+ self.query_tokenizer = query_tokenizer_class.from_pretrained(
+ query_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["query"],
use_auth_token=use_auth_token,
)
- self.query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=query_embedding_model,
- revision=model_version,
- language_model_class="DPRQuestionEncoder",
- use_auth_token=use_auth_token,
+ self.query_encoder = get_language_model(
+ pretrained_model_name_or_path=query_embedding_model, revision=model_version, use_auth_token=use_auth_token
)
- self.passage_tokenizer = Tokenizer.load(
- pretrained_model_name_or_path=passage_embedding_model,
+ self.passage_tokenizer = passage_tokenizer_class.from_pretrained(
+ passage_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["passage"],
use_auth_token=use_auth_token,
)
- self.passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=passage_embedding_model,
- revision=model_version,
- language_model_class="DPRContextEncoder",
- use_auth_token=use_auth_token,
+ self.passage_encoder = get_language_model(
+ pretrained_model_name_or_path=passage_embedding_model, revision=model_version, use_auth_token=use_auth_token
)
- self.table_tokenizer = Tokenizer.load(
- pretrained_model_name_or_path=table_embedding_model,
+ self.table_tokenizer = table_tokenizer_class.from_pretrained(
+ table_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["table"],
use_auth_token=use_auth_token,
)
- self.table_encoder = LanguageModel.load(
- pretrained_model_name_or_path=table_embedding_model,
- revision=model_version,
- language_model_class="DPRContextEncoder",
- use_auth_token=use_auth_token,
+ self.table_encoder = get_language_model(
+ pretrained_model_name_or_path=table_embedding_model, revision=model_version, use_auth_token=use_auth_token
)
self.processor = TableTextSimilarityProcessor(
@@ -1419,7 +1395,6 @@ def load(
query_encoder_dir: str = "query_encoder",
passage_encoder_dir: str = "passage_encoder",
table_encoder_dir: str = "table_encoder",
- infer_tokenizer_classes: bool = False,
):
"""
Load TableTextRetriever from the specified directory.
@@ -1439,7 +1414,6 @@ def load(
embed_meta_fields=embed_meta_fields,
use_fast_tokenizers=use_fast_tokenizers,
similarity_function=similarity_function,
- infer_tokenizer_classes=infer_tokenizer_classes,
)
logger.info(f"TableTextRetriever model loaded from {load_dir}")
diff --git a/haystack/nodes/translator/transformers.py b/haystack/nodes/translator/transformers.py
index c653c05e52..e77705d148 100644
--- a/haystack/nodes/translator/transformers.py
+++ b/haystack/nodes/translator/transformers.py
@@ -119,9 +119,14 @@ def translate(
else:
text_for_translator: List[str] = [query] # type: ignore
- batch = self.tokenizer.prepare_seq2seq_batch(
- src_texts=text_for_translator, return_tensors="pt", max_length=self.max_seq_len
+ batch = self.tokenizer(
+ text=text_for_translator,
+ return_tensors="pt",
+ max_length=self.max_seq_len,
+ padding="longest",
+ truncation=True,
).to(self.devices[0])
+
generated_output = self.model.generate(**batch)
translated_texts = self.tokenizer.batch_decode(
generated_output, skip_special_tokens=True, clean_up_tokenization_spaces=self.clean_up_tokenization_spaces
diff --git a/haystack/pipelines/config.py b/haystack/pipelines/config.py
index b958397598..99ea05e6e9 100644
--- a/haystack/pipelines/config.py
+++ b/haystack/pipelines/config.py
@@ -179,7 +179,12 @@ def build_component_dependency_graph(
return graph
-def validate_yaml(path: Path, strict_version_check: bool = False, overwrite_with_env_variables: bool = True):
+def validate_yaml(
+ path: Path,
+ strict_version_check: bool = False,
+ overwrite_with_env_variables: bool = True,
+ extras: Optional[str] = None,
+):
"""
Ensures that the given YAML file can be loaded without issues.
@@ -197,16 +202,20 @@ def validate_yaml(path: Path, strict_version_check: bool = False, overwrite_with
to change index name param for an ElasticsearchDocumentStore, an env
variable 'MYDOCSTORE_PARAMS_INDEX=documents-2021' can be set. Note that an
`_` sign must be used to specify nested hierarchical properties.
+ :param extras: which values are allowed in the `extras` field (for example, `ray`). If None, does not allow the `extras` field at all.
:return: None if validation is successful
:raise: `PipelineConfigError` in case of issues.
"""
pipeline_config = read_pipeline_config_from_yaml(path)
- validate_config(pipeline_config=pipeline_config, strict_version_check=strict_version_check)
+ validate_config(pipeline_config=pipeline_config, strict_version_check=strict_version_check, extras=extras)
logging.debug(f"'{path}' contains valid Haystack pipelines.")
def validate_config(
- pipeline_config: Dict[str, Any], strict_version_check: bool = False, overwrite_with_env_variables: bool = True
+ pipeline_config: Dict[str, Any],
+ strict_version_check: bool = False,
+ overwrite_with_env_variables: bool = True,
+ extras: Optional[str] = None,
):
"""
Ensures that the given YAML file can be loaded without issues.
@@ -225,10 +234,11 @@ def validate_config(
to change index name param for an ElasticsearchDocumentStore, an env
variable 'MYDOCSTORE_PARAMS_INDEX=documents-2021' can be set. Note that an
`_` sign must be used to specify nested hierarchical properties.
+ :param extras: which values are allowed in the `extras` field (for example, `ray`). If None, does not allow the `extras` field at all.
:return: None if validation is successful
:raise: `PipelineConfigError` in case of issues.
"""
- validate_schema(pipeline_config=pipeline_config, strict_version_check=strict_version_check)
+ validate_schema(pipeline_config=pipeline_config, strict_version_check=strict_version_check, extras=extras)
for pipeline_definition in pipeline_config["pipelines"]:
component_definitions = get_component_definitions(
@@ -237,7 +247,7 @@ def validate_config(
validate_pipeline_graph(pipeline_definition=pipeline_definition, component_definitions=component_definitions)
-def validate_schema(pipeline_config: Dict, strict_version_check: bool = False) -> None:
+def validate_schema(pipeline_config: Dict, strict_version_check: bool = False, extras: Optional[str] = None) -> None:
"""
Check that the YAML abides the JSON schema, so that every block
of the pipeline configuration file contains all required information
@@ -248,11 +258,20 @@ def validate_schema(pipeline_config: Dict, strict_version_check: bool = False) -
:param pipeline_config: the configuration to validate
:param strict_version_check: whether to fail in case of a version mismatch (throws a warning otherwise)
+ :param extras: which values are allowed in the `extras` field (for example, `ray`). If None, does not allow the `extras` field at all.
:return: None if validation is successful
:raise: `PipelineConfigError` in case of issues.
"""
validate_config_strings(pipeline_config)
+ # Check that the extras are respected
+ extras_in_config = pipeline_config.get("extras", None)
+ if (not extras and extras_in_config) or (extras and extras_in_config not in extras):
+ raise PipelineConfigError(
+ f"Cannot use this class to load a YAML with 'extras: {extras_in_config}'. "
+ "Use the proper class, for example 'RayPipeline'."
+ )
+
# Check for the version manually (to avoid validation errors)
pipeline_version = pipeline_config.get("version", None)
diff --git a/haystack/pipelines/ray.py b/haystack/pipelines/ray.py
index e326bb8aff..98e4c5c1e9 100644
--- a/haystack/pipelines/ray.py
+++ b/haystack/pipelines/ray.py
@@ -32,7 +32,7 @@ class RayPipeline(Pipeline):
Pipeline can be independently scaled. For instance, an extractive QA Pipeline deployment can have three replicas
of the Reader and a single replica for the Retriever. This way, you can use your resources more efficiently by horizontally scaling Components.
- To set the number of replicas, add `replicas` in the YAML configuration for the node in a pipeline:
+ To set the number of replicas, add `num_replicas` in the YAML configuration for the node in a pipeline:
```yaml
| components:
@@ -43,8 +43,9 @@ class RayPipeline(Pipeline):
| type: RayPipeline
| nodes:
| - name: ESRetriever
- | replicas: 2 # number of replicas to create on the Ray cluster
| inputs: [ Query ]
+ | serve_deployment_kwargs:
+ | num_replicas: 2 # number of replicas to create on the Ray cluster
```
A Ray Pipeline can only be created with a YAML Pipeline configuration.
@@ -61,14 +62,20 @@ class RayPipeline(Pipeline):
YAML definitions of Ray pipelines are validated at load. For more information, see [YAML File Definitions](https://haystack-website-git-fork-fstau-dev-287-search-deepset-overnice.vercel.app/components/pipelines#yaml-file-definitions).
"""
- def __init__(self, address: str = None, ray_args: Optional[Dict[str, Any]] = None):
+ def __init__(
+ self,
+ address: str = None,
+ ray_args: Optional[Dict[str, Any]] = None,
+ serve_args: Optional[Dict[str, Any]] = None,
+ ):
"""
:param address: The IP address for the Ray cluster. If set to `None`, a local Ray instance is started.
:param kwargs: Optional parameters for initializing Ray.
+ :param serve_args: Optional parameters for initializing Ray Serve.
"""
ray_args = ray_args or {}
ray.init(address=address, **ray_args)
- serve.start()
+ self._serve_controller_client = serve.start(**serve_args)
super().__init__()
@classmethod
@@ -80,14 +87,15 @@ def load_from_config(
strict_version_check: bool = False,
address: Optional[str] = None,
ray_args: Optional[Dict[str, Any]] = None,
+ serve_args: Optional[Dict[str, Any]] = None,
):
- validate_config(pipeline_config, strict_version_check=strict_version_check)
+ validate_config(pipeline_config, strict_version_check=strict_version_check, extras="ray")
pipeline_definition = get_pipeline_definition(pipeline_config=pipeline_config, pipeline_name=pipeline_name)
component_definitions = get_component_definitions(
pipeline_config=pipeline_config, overwrite_with_env_variables=overwrite_with_env_variables
)
- pipeline = cls(address=address, ray_args=ray_args or {})
+ pipeline = cls(address=address, ray_args=ray_args or {}, serve_args=serve_args or {})
for node_config in pipeline_definition["nodes"]:
if pipeline.root_node is None:
@@ -101,8 +109,12 @@ def load_from_config(
name = node_config["name"]
component_type = component_definitions[name]["type"]
component_class = BaseComponent.get_subclass(component_type)
- replicas = next(node for node in pipeline_definition["nodes"] if node["name"] == name).get("replicas", 1)
- handle = cls._create_ray_deployment(component_name=name, pipeline_config=pipeline_config, replicas=replicas)
+ serve_deployment_kwargs = next(node for node in pipeline_definition["nodes"] if node["name"] == name).get(
+ "serve_deployment_kwargs", {}
+ )
+ handle = cls._create_ray_deployment(
+ component_name=name, pipeline_config=pipeline_config, serve_deployment_kwargs=serve_deployment_kwargs
+ )
pipeline._add_ray_deployment_in_graph(
handle=handle,
name=name,
@@ -121,6 +133,7 @@ def load_from_yaml( # type: ignore
address: Optional[str] = None,
strict_version_check: bool = False,
ray_args: Optional[Dict[str, Any]] = None,
+ serve_args: Optional[Dict[str, Any]] = None,
):
"""
Load Pipeline from a YAML file defining the individual components and how they're tied together to form
@@ -154,7 +167,8 @@ def load_from_yaml( # type: ignore
| nodes:
| - name: MyESRetriever
| inputs: [Query]
- | replicas: 2 # number of replicas to create on the Ray cluster
+ | serve_deployment_kwargs:
+ | num_replicas: 2 # number of replicas to create on the Ray cluster
| - name: MyReader
| inputs: [MyESRetriever]
```
@@ -170,6 +184,7 @@ def load_from_yaml( # type: ignore
variable 'MYDOCSTORE_PARAMS_INDEX=documents-2021' can be set. Note that an
`_` sign must be used to specify nested hierarchical properties.
:param address: The IP address for the Ray cluster. If set to None, a local Ray instance is started.
+ :param serve_args: Optional parameters for initializing Ray Serve.
"""
pipeline_config = read_pipeline_config_from_yaml(path)
return RayPipeline.load_from_config(
@@ -179,19 +194,27 @@ def load_from_yaml( # type: ignore
strict_version_check=strict_version_check,
address=address,
ray_args=ray_args,
+ serve_args=serve_args,
)
@classmethod
- def _create_ray_deployment(cls, component_name: str, pipeline_config: dict, replicas: int = 1):
+ def _create_ray_deployment(
+ cls, component_name: str, pipeline_config: dict, serve_deployment_kwargs: Optional[Dict[str, Any]] = {}
+ ):
"""
Create a Ray Deployment for the Component.
:param component_name: Class name of the Haystack Component.
:param pipeline_config: The Pipeline config YAML parsed as a dict.
- :param replicas: By default, a single replica of the component is created. It can be
- configured by setting `replicas` parameter in the Pipeline YAML.
+ :param serve_deployment_kwargs: An optional dictionary of arguments to be supplied to the
+ `ray.serve.deployment()` method, like `num_replicas`, `ray_actor_options`,
+ `max_concurrent_queries`, etc. See potential values in the
+ Ray Serve API docs (https://docs.ray.io/en/latest/serve/package-ref.html)
+ under the `ray.serve.deployment()` method
"""
- RayDeployment = serve.deployment(_RayDeploymentWrapper, name=component_name, num_replicas=replicas) # type: ignore
+ RayDeployment = serve.deployment(
+ _RayDeploymentWrapper, name=component_name, **serve_deployment_kwargs # type: ignore
+ )
RayDeployment.deploy(pipeline_config, component_name)
handle = RayDeployment.get_handle()
return handle
diff --git a/haystack/schema.py b/haystack/schema.py
index 8343819b94..1ec21b8e47 100644
--- a/haystack/schema.py
+++ b/haystack/schema.py
@@ -1,4 +1,5 @@
from __future__ import annotations
+import csv
import typing
from typing import Any, Optional, Dict, List, Union
@@ -1346,12 +1347,15 @@ def _build_document_metrics_df(
metrics_df = pd.DataFrame.from_records(metrics, index=documents["multilabel_id"].unique())
return metrics_df
- def save(self, out_dir: Union[str, Path]):
+ def save(self, out_dir: Union[str, Path], **to_csv_kwargs):
"""
Saves the evaluation result.
The result of each node is saved in a separate csv with file name {node_name}.csv to the out_dir folder.
:param out_dir: Path to the target folder the csvs will be saved.
+ :param to_csv_kwargs: kwargs to be passed to pd.DataFrame.to_csv(). See https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_csv.html.
+ This method uses different default values than pd.DataFrame.to_csv() for the following parameters:
+ index=False, quoting=csv.QUOTE_NONNUMERIC (to avoid problems with \r chars)
"""
out_dir = out_dir if isinstance(out_dir, Path) else Path(out_dir)
logger.info(f"Saving evaluation results to {out_dir}")
@@ -1359,29 +1363,45 @@ def save(self, out_dir: Union[str, Path]):
out_dir.mkdir(parents=True)
for node_name, df in self.node_results.items():
target_path = out_dir / f"{node_name}.csv"
- df.to_csv(target_path, index=False, header=True)
+ default_to_csv_kwargs = {
+ "index": False,
+ "quoting": csv.QUOTE_NONNUMERIC, # avoids problems with \r chars in texts by enclosing all string values in quotes
+ }
+ to_csv_kwargs = {**default_to_csv_kwargs, **to_csv_kwargs}
+ df.to_csv(target_path, **to_csv_kwargs)
@classmethod
- def load(cls, load_dir: Union[str, Path]):
+ def load(cls, load_dir: Union[str, Path], **read_csv_kwargs):
"""
Loads the evaluation result from disk. Expects one csv file per node. See save() for further information.
:param load_dir: The directory containing the csv files.
+ :param read_csv_kwargs: kwargs to be passed to pd.read_csv(). See https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html.
+ This method uses different default values than pd.read_csv() for the following parameters:
+ header=0, converters=CONVERTERS
+ where CONVERTERS is a dictionary mapping all array typed columns to ast.literal_eval.
"""
load_dir = load_dir if isinstance(load_dir, Path) else Path(load_dir)
csv_files = [file for file in load_dir.iterdir() if file.is_file() and file.suffix == ".csv"]
cols_to_convert = [
+ "filters",
"gold_document_ids",
+ "gold_custom_document_ids",
"gold_contexts",
"gold_answers",
+ "gold_documents_id_match",
"gold_offsets_in_documents",
"gold_answers_exact_match",
"gold_answers_f1",
- "gold_answers_document_id_match",
- "gold_context_similarity",
+ "gold_answers_sas",
+ "gold_answers_match",
+ "gold_contexts_similarity",
+ "offsets_in_document",
]
converters = dict.fromkeys(cols_to_convert, ast.literal_eval)
- node_results = {file.stem: pd.read_csv(file, header=0, converters=converters) for file in csv_files}
+ default_read_csv_kwargs = {"converters": converters, "header": 0}
+ read_csv_kwargs = {**default_read_csv_kwargs, **read_csv_kwargs}
+ node_results = {file.stem: pd.read_csv(file, **read_csv_kwargs) for file in csv_files}
# backward compatibility mappings
for df in node_results.values():
df.rename(columns={"gold_document_contents": "gold_contexts", "content": "context"}, inplace=True)
diff --git a/haystack/utils/deepsetcloud.py b/haystack/utils/deepsetcloud.py
index dbda39c084..0c906e35b9 100644
--- a/haystack/utils/deepsetcloud.py
+++ b/haystack/utils/deepsetcloud.py
@@ -30,6 +30,8 @@ class PipelineStatus(Enum):
UNDEPLOYMENT_IN_PROGRESS: str = "UNDEPLOYMENT_IN_PROGRESS"
DEPLOYMENT_SCHEDULED: str = "DEPLOYMENT_SCHEDULED"
UNDEPLOYMENT_SCHEDULED: str = "UNDEPLOYMENT_SCHEDULED"
+ DEPLOYMENT_FAILED: str = "DEPLOYMENT_FAILED"
+ UNDEPLOYMENT_FAILED: str = "UNDEPLOYMENT_FAILED"
UKNOWN: str = "UNKNOWN"
@classmethod
@@ -38,12 +40,18 @@ def from_str(cls, status_string: str) -> "PipelineStatus":
SATISFIED_STATES_KEY = "satisfied_states"
+FAILED_STATES_KEY = "failed_states"
VALID_INITIAL_STATES_KEY = "valid_initial_states"
VALID_TRANSITIONING_STATES_KEY = "valid_transitioning_states"
PIPELINE_STATE_TRANSITION_INFOS: Dict[PipelineStatus, Dict[str, List[PipelineStatus]]] = {
PipelineStatus.UNDEPLOYED: {
SATISFIED_STATES_KEY: [PipelineStatus.UNDEPLOYED],
- VALID_INITIAL_STATES_KEY: [PipelineStatus.DEPLOYED, PipelineStatus.DEPLOYED_UNHEALTHY],
+ FAILED_STATES_KEY: [PipelineStatus.UNDEPLOYMENT_FAILED],
+ VALID_INITIAL_STATES_KEY: [
+ PipelineStatus.DEPLOYED,
+ PipelineStatus.DEPLOYMENT_FAILED,
+ PipelineStatus.UNDEPLOYMENT_FAILED,
+ ],
VALID_TRANSITIONING_STATES_KEY: [
PipelineStatus.UNDEPLOYMENT_SCHEDULED,
PipelineStatus.UNDEPLOYMENT_IN_PROGRESS,
@@ -51,7 +59,12 @@ def from_str(cls, status_string: str) -> "PipelineStatus":
},
PipelineStatus.DEPLOYED: {
SATISFIED_STATES_KEY: [PipelineStatus.DEPLOYED, PipelineStatus.DEPLOYED_UNHEALTHY],
- VALID_INITIAL_STATES_KEY: [PipelineStatus.UNDEPLOYED],
+ FAILED_STATES_KEY: [PipelineStatus.DEPLOYMENT_FAILED],
+ VALID_INITIAL_STATES_KEY: [
+ PipelineStatus.UNDEPLOYED,
+ PipelineStatus.DEPLOYMENT_FAILED,
+ PipelineStatus.UNDEPLOYMENT_FAILED,
+ ],
VALID_TRANSITIONING_STATES_KEY: [PipelineStatus.DEPLOYMENT_SCHEDULED, PipelineStatus.DEPLOYMENT_IN_PROGRESS],
},
}
@@ -624,9 +637,11 @@ def deploy(
)
logger.info(f"Try it out using the following curl command:\n{curl_cmd}")
- elif status == PipelineStatus.DEPLOYED_UNHEALTHY:
- logger.warning(
- f"Deployment of pipeline config '{pipeline_config_name}' succeeded. But '{pipeline_config_name}' is unhealthy."
+ elif status == PipelineStatus.DEPLOYMENT_FAILED:
+ raise DeepsetCloudError(
+ f"Deployment of pipeline config '{pipeline_config_name}' failed. "
+ "This might be caused by an exception in deepset Cloud or a runtime error in the pipeline. "
+ "You can try to run this pipeline locally first."
)
elif status in [PipelineStatus.UNDEPLOYMENT_IN_PROGRESS, PipelineStatus.UNDEPLOYMENT_SCHEDULED]:
raise DeepsetCloudError(
@@ -705,6 +720,7 @@ def _transition_pipeline_state(
transition_info = PIPELINE_STATE_TRANSITION_INFOS[target_state]
satisfied_states = transition_info[SATISFIED_STATES_KEY]
+ failed_states = transition_info[FAILED_STATES_KEY]
valid_transitioning_states = transition_info[VALID_TRANSITIONING_STATES_KEY]
valid_initial_states = transition_info[VALID_INITIAL_STATES_KEY]
@@ -717,6 +733,12 @@ def _transition_pipeline_state(
f"Pipeline config '{pipeline_config_name}' is in invalid state '{status.value}' to be transitioned to '{target_state.value}'."
)
+ if status in failed_states:
+ logger.warning(
+ f"Pipeline config '{pipeline_config_name}' is in a failed state '{status}'. This might be caused by a previous error during (un)deployment. "
+ + f"Trying to transition from '{status}' to '{target_state}'..."
+ )
+
if target_state == PipelineStatus.DEPLOYED:
res = self._deploy(pipeline_config_name=pipeline_config_name, workspace=workspace, headers=headers)
status = PipelineStatus.from_str(res["status"])
diff --git a/pyproject.toml b/pyproject.toml
index d586fb17b0..9bebb99ec7 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -72,7 +72,7 @@ disable = [
"use-list-literal",
-
+
# To review later
"cyclic-import",
@@ -90,6 +90,7 @@ minversion = "6.0"
addopts = "--strict-markers"
markers = [
"integration: integration tests",
+ "unit: unit tests",
"generator: generator tests",
"summarizer: summarizer tests",
@@ -106,5 +107,6 @@ markers = [
"faiss: uses FAISS",
"milvus: requires a Milvus 2 setup",
"milvus1: requires a Milvus 1 container",
+ "opensearch"
]
log_cli = true
\ No newline at end of file
diff --git a/rest_api/controller/document.py b/rest_api/controller/document.py
index 2b0dbc368e..198d7301dc 100644
--- a/rest_api/controller/document.py
+++ b/rest_api/controller/document.py
@@ -4,10 +4,11 @@
from fastapi import FastAPI, APIRouter
from haystack.document_stores import BaseDocumentStore
+from haystack.schema import Document
from rest_api.utils import get_app, get_pipelines
from rest_api.config import LOG_LEVEL
-from rest_api.schema import FilterRequest, DocumentSerialized
+from rest_api.schema import FilterRequest
logging.getLogger("haystack").setLevel(LOG_LEVEL)
@@ -19,7 +20,7 @@
document_store: BaseDocumentStore = get_pipelines().get("document_store", None)
-@router.post("/documents/get_by_filters", response_model=List[DocumentSerialized], response_model_exclude_none=True)
+@router.post("/documents/get_by_filters", response_model=List[Document], response_model_exclude_none=True)
def get_documents(filters: FilterRequest):
"""
This endpoint allows you to retrieve documents contained in your document store.
diff --git a/rest_api/controller/feedback.py b/rest_api/controller/feedback.py
index 0c3bb349ba..532b8e25d4 100644
--- a/rest_api/controller/feedback.py
+++ b/rest_api/controller/feedback.py
@@ -6,7 +6,7 @@
from fastapi import FastAPI, APIRouter
from haystack.schema import Label
from haystack.document_stores import BaseDocumentStore
-from rest_api.schema import FilterRequest, LabelSerialized, CreateLabelSerialized
+from rest_api.schema import FilterRequest, CreateLabelSerialized
from rest_api.utils import get_app, get_pipelines
@@ -18,7 +18,7 @@
@router.post("/feedback")
-def post_feedback(feedback: Union[LabelSerialized, CreateLabelSerialized]):
+def post_feedback(feedback: CreateLabelSerialized):
"""
This endpoint allows the API user to submit feedback on an answer for a particular query.
@@ -35,7 +35,7 @@ def post_feedback(feedback: Union[LabelSerialized, CreateLabelSerialized]):
document_store.write_labels([label])
-@router.get("/feedback", response_model=List[LabelSerialized])
+@router.get("/feedback", response_model=List[Label])
def get_feedback():
"""
This endpoint allows the API user to retrieve all the feedback that has been submitted
diff --git a/rest_api/controller/search.py b/rest_api/controller/search.py
index f8a716baec..8931465606 100644
--- a/rest_api/controller/search.py
+++ b/rest_api/controller/search.py
@@ -4,7 +4,6 @@
import logging
import time
import json
-from numpy import ndarray
from pydantic import BaseConfig
from fastapi import FastAPI, APIRouter
@@ -84,11 +83,6 @@ def _process_request(pipeline, request) -> Dict[str, Any]:
if not "answers" in result:
result["answers"] = []
- # if any of the documents contains an embedding as an ndarray the latter needs to be converted to list of float
- for document in result["documents"]:
- if isinstance(document.embedding, ndarray):
- document.embedding = document.embedding.tolist()
-
logger.info(
json.dumps({"request": request, "response": result, "time": f"{(time.time() - start_time):.2f}"}, default=str)
)
diff --git a/rest_api/schema.py b/rest_api/schema.py
index 87d4230b37..986ffcf826 100644
--- a/rest_api/schema.py
+++ b/rest_api/schema.py
@@ -1,6 +1,8 @@
from __future__ import annotations
from typing import Dict, List, Optional, Union
+import numpy as np
+import pandas as pd
try:
from typing import Literal
@@ -10,50 +12,40 @@
from pydantic import BaseModel, Field, Extra
from pydantic import BaseConfig
-from haystack.schema import Answer, Document, Label
+from haystack.schema import Answer, Document
BaseConfig.arbitrary_types_allowed = True
+BaseConfig.json_encoders = {np.ndarray: lambda x: x.tolist(), pd.DataFrame: lambda x: x.to_dict(orient="records")}
-PrimitiveType = Union[str, int, float, bool]
+PrimitiveType = Union[str, int, float, bool]
-class QueryRequest(BaseModel):
- query: str
- params: Optional[dict] = None
- debug: Optional[bool] = False
+class RequestBaseModel(BaseModel):
class Config:
# Forbid any extra fields in the request to avoid silent failures
extra = Extra.forbid
-class FilterRequest(BaseModel):
- filters: Optional[Dict[str, Union[PrimitiveType, List[PrimitiveType], Dict[str, PrimitiveType]]]] = None
-
-
-class AnswerSerialized(Answer):
- context: Optional[str] = None
-
-
-class DocumentSerialized(Document):
- content: str
- embedding: Optional[List[float]] # type: ignore
+class QueryRequest(RequestBaseModel):
+ query: str
+ params: Optional[dict] = None
+ debug: Optional[bool] = False
-class LabelSerialized(Label, BaseModel):
- document: DocumentSerialized
- answer: Optional[AnswerSerialized] = None
+class FilterRequest(RequestBaseModel):
+ filters: Optional[Dict[str, Union[PrimitiveType, List[PrimitiveType], Dict[str, PrimitiveType]]]] = None
-class CreateLabelSerialized(BaseModel):
+class CreateLabelSerialized(RequestBaseModel):
id: Optional[str] = None
query: str
- document: DocumentSerialized
+ document: Document
is_correct_answer: bool
is_correct_document: bool
origin: Literal["user-feedback", "gold-label"]
- answer: Optional[AnswerSerialized] = None
+ answer: Optional[Answer] = None
no_answer: Optional[bool] = None
pipeline_id: Optional[str] = None
created_at: Optional[str] = None
@@ -61,13 +53,9 @@ class CreateLabelSerialized(BaseModel):
meta: Optional[dict] = None
filters: Optional[dict] = None
- class Config:
- # Forbid any extra fields in the request to avoid silent failures
- extra = Extra.forbid
-
class QueryResponse(BaseModel):
query: str
- answers: List[AnswerSerialized] = []
- documents: List[DocumentSerialized] = []
+ answers: List[Answer] = []
+ documents: List[Document] = []
debug: Optional[Dict] = Field(None, alias="_debug")
diff --git a/rest_api/test/test_rest_api.py b/rest_api/test/test_rest_api.py
index 6d9a7fcb29..f358e41d99 100644
--- a/rest_api/test/test_rest_api.py
+++ b/rest_api/test/test_rest_api.py
@@ -5,6 +5,8 @@
from textwrap import dedent
from unittest import mock
from unittest.mock import MagicMock
+import numpy as np
+import pandas as pd
import pytest
from fastapi.testclient import TestClient
@@ -125,7 +127,7 @@ def get_all_documents_generator(self, *args, **kwargs) -> Generator[Document, No
pass
def get_all_labels(self, *args, **kwargs) -> List[Label]:
- self.mocker.get_all_labels(*args, **kwargs)
+ return self.mocker.get_all_labels(*args, **kwargs)
def get_document_by_id(self, *args, **kwargs) -> Optional[Document]:
pass
@@ -176,7 +178,7 @@ def feedback():
"score": None,
"id": "fc18c987a8312e72a47fb1524f230bb0",
"meta": {},
- "embedding": None,
+ "embedding": [0.1, 0.2, 0.3],
},
"answer": {
"answer": "Adobe Systems",
@@ -366,6 +368,57 @@ def test_query_with_bool_in_params(client):
assert response_json["answers"] == []
+def test_query_with_embeddings(client):
+ with mock.patch("rest_api.controller.search.query_pipeline") as mocked_pipeline:
+ # `run` must return a dictionary containing a `query` key
+ mocked_pipeline.run.return_value = {
+ "query": TEST_QUERY,
+ "documents": [
+ Document(
+ content="test",
+ content_type="text",
+ score=0.9,
+ meta={"test_key": "test_value"},
+ embedding=np.array([0.1, 0.2, 0.3]),
+ )
+ ],
+ }
+ response = client.post(url="/query", json={"query": TEST_QUERY})
+ assert 200 == response.status_code
+ assert len(response.json()["documents"]) == 1
+ assert response.json()["documents"][0]["content"] == "test"
+ assert response.json()["documents"][0]["content_type"] == "text"
+ assert response.json()["documents"][0]["embedding"] == [0.1, 0.2, 0.3]
+ # Ensure `run` was called with the expected parameters
+ mocked_pipeline.run.assert_called_with(query=TEST_QUERY, params={}, debug=False)
+
+
+def test_query_with_dataframe(client):
+ with mock.patch("rest_api.controller.search.query_pipeline") as mocked_pipeline:
+ # `run` must return a dictionary containing a `query` key
+ mocked_pipeline.run.return_value = {
+ "query": TEST_QUERY,
+ "documents": [
+ Document(
+ content=pd.DataFrame.from_records([{"col1": "text_1", "col2": 1}, {"col1": "text_2", "col2": 2}]),
+ content_type="table",
+ score=0.9,
+ meta={"test_key": "test_value"},
+ )
+ ],
+ }
+ response = client.post(url="/query", json={"query": TEST_QUERY})
+ assert 200 == response.status_code
+ assert len(response.json()["documents"]) == 1
+ assert response.json()["documents"][0]["content"] == [
+ {"col1": "text_1", "col2": 1},
+ {"col1": "text_2", "col2": 2},
+ ]
+ assert response.json()["documents"][0]["content_type"] == "table"
+ # Ensure `run` was called with the expected parameters
+ mocked_pipeline.run.assert_called_with(query=TEST_QUERY, params={}, debug=False)
+
+
def test_write_feedback(client, feedback):
response = client.post(url="/feedback", json=feedback)
assert 200 == response.status_code
@@ -376,9 +429,8 @@ def test_write_feedback(client, feedback):
assert len(labels) == 1
# Ensure all the items that were in `feedback` are also part of
# the stored label (which has several more keys)
- label = labels[0].to_dict()
- for k, v in feedback.items():
- assert label[k] == v
+ label = labels[0]
+ assert label == Label.from_dict(feedback)
def test_write_feedback_without_id(client, feedback):
@@ -395,9 +447,11 @@ def test_write_feedback_without_id(client, feedback):
assert label["id"]
-def test_get_feedback(client):
+def test_get_feedback(client, feedback):
+ MockDocumentStore.mocker.get_all_labels.return_value = [Label.from_dict(feedback)]
response = client.get("/feedback")
assert response.status_code == 200
+ assert Label.from_dict(response.json()[0]) == Label.from_dict(feedback)
MockDocumentStore.mocker.get_all_labels.assert_called_once()
diff --git a/setup.cfg b/setup.cfg
index 3f0d9b3c41..32e7e19e74 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -101,7 +101,7 @@ install_requires =
# context matching
rapidfuzz>=2.0.15,<3
-
+
# Schema validation
jsonschema
@@ -141,7 +141,7 @@ only-milvus =
milvus =
farm-haystack[sql,only-milvus]
weaviate =
- weaviate-client==3.3.3
+ weaviate-client==3.6.0
only-pinecone =
pinecone-client
pinecone =
@@ -150,19 +150,22 @@ graphdb =
SPARQLWrapper
inmemorygraph =
SPARQLWrapper
+opensearch =
+ opensearch-py>=2
docstores =
- farm-haystack[faiss,milvus,weaviate,graphdb,inmemorygraph,pinecone]
+ farm-haystack[faiss,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]
docstores-gpu =
- farm-haystack[faiss-gpu,milvus,weaviate,graphdb,inmemorygraph,pinecone]
+ farm-haystack[faiss-gpu,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]
audio =
+ pyworld<=0.2.12; python_version >= '3.10'
espnet
espnet-model-zoo
pydub
beir =
beir; platform_system != 'Windows'
crawler =
- selenium !=4.1.4 # due to https://github.com/SeleniumHQ/selenium/issues/10612
+ selenium>=4.0.0,!=4.1.4 # Avoid 4.1.4 due to https://github.com/SeleniumHQ/selenium/issues/10612
webdriver-manager
preprocessing =
beautifulsoup4
@@ -185,8 +188,10 @@ ray =
aiorwlock>=1.3.0,<2
colab =
- grpcio==1.43.0
+ grpcio==1.47.0
+ requests>=2.25 # Needed to avoid dependency conflict with crawler https://github.com/deepset-ai/haystack/pull/2921
dev =
+ pre-commit
# Type check
mypy
typing_extensions; python_version < '3.8'
@@ -201,7 +206,7 @@ dev =
# Linting
pylint
# Code formatting
- black[jupyter]
+ black[jupyter]==22.6.0
# Documentation
pydoc-markdown==4.5.1 # FIXME Unpin!
mkdocs
diff --git a/test/conftest.py b/test/conftest.py
index 451f3ee59b..02a8ff95f3 100644
--- a/test/conftest.py
+++ b/test/conftest.py
@@ -146,7 +146,17 @@ def pytest_collection_modifyitems(config, items):
keywords.extend(i.split("-"))
else:
keywords.append(i)
- for cur_doc_store in ["elasticsearch", "faiss", "sql", "memory", "milvus1", "milvus", "weaviate", "pinecone"]:
+ for cur_doc_store in [
+ "elasticsearch",
+ "faiss",
+ "sql",
+ "memory",
+ "milvus1",
+ "milvus",
+ "weaviate",
+ "pinecone",
+ "opensearch",
+ ]:
if cur_doc_store in keywords and cur_doc_store not in document_store_types_to_run:
skip_docstore = pytest.mark.skip(
reason=f'{cur_doc_store} is disabled. Enable via pytest --document_store_type="{cur_doc_store}"'
diff --git a/test/document_stores/test_document_store.py b/test/document_stores/test_document_store.py
index 6af5edeb85..79361f065e 100644
--- a/test/document_stores/test_document_store.py
+++ b/test/document_stores/test_document_store.py
@@ -389,14 +389,14 @@ def test_get_documents_by_id(document_store: BaseDocumentStore):
def test_get_document_count(document_store: BaseDocumentStore):
documents = [
- {"content": "text1", "id": "1", "meta_field_for_count": "a"},
+ {"content": "text1", "id": "1", "meta_field_for_count": "c"},
{"content": "text2", "id": "2", "meta_field_for_count": "b"},
{"content": "text3", "id": "3", "meta_field_for_count": "b"},
{"content": "text4", "id": "4", "meta_field_for_count": "b"},
]
document_store.write_documents(documents)
assert document_store.get_document_count() == 4
- assert document_store.get_document_count(filters={"meta_field_for_count": ["a"]}) == 1
+ assert document_store.get_document_count(filters={"meta_field_for_count": ["c"]}) == 1
assert document_store.get_document_count(filters={"meta_field_for_count": ["b"]}) == 3
@@ -453,6 +453,30 @@ def test_write_document_meta(document_store: BaseDocumentStore):
assert document_store.get_document_by_id("4").meta["meta_field"] == "test4"
+@pytest.mark.parametrize("document_store", ["sql"], indirect=True)
+def test_write_document_sql_invalid_meta(document_store: BaseDocumentStore):
+ documents = [
+ {
+ "content": "dict_with_invalid_meta",
+ "valid_meta_field": "test1",
+ "invalid_meta_field": [1, 2, 3],
+ "name": "filename1",
+ "id": "1",
+ },
+ Document(
+ content="document_object_with_invalid_meta",
+ meta={"valid_meta_field": "test2", "invalid_meta_field": [1, 2, 3], "name": "filename2"},
+ id="2",
+ ),
+ ]
+ document_store.write_documents(documents)
+ documents_in_store = document_store.get_all_documents()
+ assert len(documents_in_store) == 2
+
+ assert document_store.get_document_by_id("1").meta == {"name": "filename1", "valid_meta_field": "test1"}
+ assert document_store.get_document_by_id("2").meta == {"name": "filename2", "valid_meta_field": "test2"}
+
+
def test_write_document_index(document_store: BaseDocumentStore):
document_store.delete_index("haystack_test_one")
document_store.delete_index("haystack_test_two")
diff --git a/test/document_stores/test_opensearch.py b/test/document_stores/test_opensearch.py
index 73172fb762..899ceb42c8 100644
--- a/test/document_stores/test_opensearch.py
+++ b/test/document_stores/test_opensearch.py
@@ -1,12 +1,760 @@
import sys
+import logging
+
+from unittest.mock import MagicMock
import pytest
+import numpy as np
+
+from haystack.document_stores.opensearch import (
+ OpenSearch,
+ OpenSearchDocumentStore,
+ OpenDistroElasticsearchDocumentStore,
+ RequestsHttpConnection,
+ Urllib3HttpConnection,
+ RequestError,
+ tqdm,
+)
+from haystack.schema import Document, Label, Answer
+from haystack.errors import DocumentStoreError
+
+# Being all the tests in this module, ideally we wouldn't need a marker here,
+# but this is to allow this test suite to be skipped when running (e.g.)
+# `pytest test/document_stores --document-store-type=faiss`
+class TestOpenSearchDocumentStore:
+
+ # Constants
+
+ query_emb = np.ndarray(shape=(2, 2), dtype=float)
+ index_name = "myindex"
+
+ # Fixtures
+
+ @pytest.fixture
+ def ds(self):
+ """
+ This fixture provides a working document store and takes care of removing the indices when done
+ """
+ index_name = __name__
+ labels_index_name = f"{index_name}_labels"
+ ds = OpenSearchDocumentStore(index=index_name, label_index=labels_index_name, port=9201, create_index=True)
+ yield ds
+ ds.delete_index(index_name)
+ ds.delete_index(labels_index_name)
+
+ @pytest.fixture
+ def mocked_document_store(self):
+ """
+ The fixture provides an instance of a slightly customized
+ OpenSearchDocumentStore equipped with a mocked client
+ """
+
+ class DSMock(OpenSearchDocumentStore):
+ # We mock a subclass to avoid messing up the actual class object
+ pass
+
+ DSMock._init_client = MagicMock()
+ DSMock.client = MagicMock()
+ return DSMock()
+
+ @pytest.fixture
+ def mocked_open_search_init(self, monkeypatch):
+ mocked_init = MagicMock(return_value=None)
+ monkeypatch.setattr(OpenSearch, "__init__", mocked_init)
+ return mocked_init
+
+ @pytest.fixture
+ def _init_client_params(self):
+ """
+ The fixture provides the required arguments to call OpenSearchDocumentStore._init_client
+ """
+ return {
+ "host": "localhost",
+ "port": 9999,
+ "username": "user",
+ "password": "pass",
+ "aws4auth": None,
+ "scheme": "http",
+ "ca_certs": "ca_certs",
+ "verify_certs": True,
+ "timeout": 42,
+ "use_system_proxy": True,
+ }
+
+ @pytest.fixture
+ def documents(self):
+ documents = []
+ for i in range(3):
+ documents.append(
+ Document(
+ content=f"A Foo Document {i}",
+ meta={"name": f"name_{i}", "year": "2020", "month": "01"},
+ embedding=np.random.rand(768).astype(np.float32),
+ )
+ )
+
+ documents.append(
+ Document(
+ content=f"A Bar Document {i}",
+ meta={"name": f"name_{i}", "year": "2021", "month": "02"},
+ embedding=np.random.rand(768).astype(np.float32),
+ )
+ )
+
+ documents.append(
+ Document(
+ content=f"Document {i} without embeddings",
+ meta={"name": f"name_{i}", "no_embedding": True, "month": "03"},
+ )
+ )
+
+ return documents
+
+ @pytest.fixture
+ def index(self):
+ return {
+ "aliases": {},
+ "mappings": {
+ "properties": {
+ "age": {"type": "integer"},
+ "occupation": {"type": "text"},
+ "vec": {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "engine": "nmslib",
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ },
+ }
+ },
+ "settings": {
+ "index": {
+ "creation_date": "1658337984559",
+ "number_of_shards": "1",
+ "number_of_replicas": "1",
+ "uuid": "jU5KPBtXQHOaIn2Cm2d4jg",
+ "version": {"created": "135238227"},
+ "provided_name": "fooindex",
+ }
+ },
+ }
+
+ @pytest.fixture
+ def labels(self, documents):
+ labels = []
+ for i, d in enumerate(documents):
+ labels.append(
+ Label(
+ query="query",
+ document=d,
+ is_correct_document=True,
+ is_correct_answer=False,
+ # create a mix set of labels
+ origin="user-feedback" if i % 2 else "gold-label",
+ answer=None if not i else Answer(f"the answer is {i}"),
+ )
+ )
+ return labels
+
+ # Integration tests
+
+ @pytest.mark.integration
+ def test___init__(self):
+ OpenSearchDocumentStore(index="default_index", port=9201, create_index=True)
+
+ @pytest.mark.integration
+ def test_write_documents(self, ds, documents):
+ ds.write_documents(documents)
+ docs = ds.get_all_documents()
+ assert len(docs) == len(documents)
+ for i, doc in enumerate(docs):
+ expected = documents[i]
+ assert doc.id == expected.id
+
+ @pytest.mark.integration
+ def test_write_labels(self, ds, labels):
+ ds.write_labels(labels)
+ assert ds.get_all_labels() == labels
+
+ @pytest.mark.integration
+ def test_recreate_index(self, ds, documents, labels):
+ ds.write_documents(documents)
+ ds.write_labels(labels)
+
+ # Create another document store on top of the previous one
+ ds = OpenSearchDocumentStore(index=ds.index, label_index=ds.label_index, recreate_index=True, port=9201)
+ assert len(ds.get_all_documents(index=ds.index)) == 0
+ assert len(ds.get_all_labels(index=ds.label_index)) == 0
+
+ @pytest.mark.integration
+ def test_clone_embedding_field(self, ds, documents):
+ cloned_field_name = "cloned"
+ ds.write_documents(documents)
+ ds.clone_embedding_field(cloned_field_name, "cosine")
+ for doc in ds.get_all_documents():
+ meta = doc.to_dict()["meta"]
+ if "no_embedding" in meta:
+ # docs with no embedding should be ignored
+ assert cloned_field_name not in meta
+ else:
+ # docs with an original embedding should have the new one
+ assert cloned_field_name in meta
+
+ # Unit tests
+
+ @pytest.mark.unit
+ def test___init___api_key_raises_warning(self, mocked_document_store, caplog):
+ with caplog.at_level(logging.WARN, logger="haystack.document_stores.opensearch"):
+ mocked_document_store.__init__(api_key="foo")
+ mocked_document_store.__init__(api_key_id="bar")
+ mocked_document_store.__init__(api_key="foo", api_key_id="bar")
+
+ assert len(caplog.records) == 3
+ for r in caplog.records:
+ assert r.levelname == "WARNING"
+
+ @pytest.mark.unit
+ def test___init___connection_test_fails(self, mocked_document_store):
+ failing_client = MagicMock()
+ failing_client.indices.get.side_effect = Exception("The client failed!")
+ mocked_document_store._init_client.return_value = failing_client
+ with pytest.raises(ConnectionError):
+ mocked_document_store.__init__()
+
+ @pytest.mark.unit
+ def test___init___client_params(self, mocked_open_search_init, _init_client_params):
+ """
+ Ensure the Opensearch-py client was initialized with the right params
+ """
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ assert mocked_open_search_init.called
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs == {
+ "hosts": [{"host": "localhost", "port": 9999}],
+ "http_auth": ("user", "pass"),
+ "scheme": "http",
+ "ca_certs": "ca_certs",
+ "verify_certs": True,
+ "timeout": 42,
+ "connection_class": RequestsHttpConnection,
+ }
+
+ @pytest.mark.unit
+ def test__init_client_use_system_proxy_use_sys_proxy(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["use_system_proxy"] = False
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["connection_class"] == Urllib3HttpConnection
+
+ @pytest.mark.unit
+ def test__init_client_use_system_proxy_dont_use_sys_proxy(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["use_system_proxy"] = True
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["connection_class"] == RequestsHttpConnection
+
+ @pytest.mark.unit
+ def test__init_client_auth_methods_username_password(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["username"] = "user"
+ _init_client_params["aws4auth"] = None
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["http_auth"] == ("user", "pass")
+
+ @pytest.mark.unit
+ def test__init_client_auth_methods_aws_iam(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["username"] = ""
+ _init_client_params["aws4auth"] = "foo"
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["http_auth"] == "foo"
+
+ @pytest.mark.unit
+ def test__init_client_auth_methods_no_auth(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["username"] = ""
+ _init_client_params["aws4auth"] = None
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert "http_auth" not in kwargs
+
+ @pytest.mark.unit
+ def test_query_by_embedding_raises_if_missing_field(self, mocked_document_store):
+ mocked_document_store.embedding_field = ""
+ with pytest.raises(DocumentStoreError):
+ mocked_document_store.query_by_embedding(self.query_emb)
+
+ @pytest.mark.unit
+ def test_query_by_embedding_filters(self, mocked_document_store):
+ expected_filters = {"type": "article", "date": {"$gte": "2015-01-01", "$lt": "2021-01-01"}}
+ mocked_document_store.query_by_embedding(self.query_emb, filters=expected_filters)
+ # Assert the `search` method on the client was called with the filters we provided
+ _, kwargs = mocked_document_store.client.search.call_args
+ actual_filters = kwargs["body"]["query"]["bool"]["filter"]
+ assert actual_filters["bool"]["must"] == [
+ {"term": {"type": "article"}},
+ {"range": {"date": {"gte": "2015-01-01", "lt": "2021-01-01"}}},
+ ]
+
+ @pytest.mark.unit
+ def test_query_by_embedding_return_embedding_false(self, mocked_document_store):
+ mocked_document_store.return_embedding = False
+ mocked_document_store.query_by_embedding(self.query_emb)
+ # assert the resulting body is consistent with the `excluded_meta_data` value
+ _, kwargs = mocked_document_store.client.search.call_args
+ assert kwargs["body"]["_source"] == {"excludes": ["embedding"]}
+
+ @pytest.mark.unit
+ def test_query_by_embedding_excluded_meta_data_return_embedding_true(self, mocked_document_store):
+ """
+ Test that when `return_embedding==True` the field should NOT be excluded even if it
+ was added to `excluded_meta_data`
+ """
+ mocked_document_store.return_embedding = True
+ mocked_document_store.excluded_meta_data = ["foo", "embedding"]
+ mocked_document_store.query_by_embedding(self.query_emb)
+ _, kwargs = mocked_document_store.client.search.call_args
+ # we expect "embedding" was removed from the final query
+ assert kwargs["body"]["_source"] == {"excludes": ["foo"]}
+
+ @pytest.mark.unit
+ def test_query_by_embedding_excluded_meta_data_return_embedding_false(self, mocked_document_store):
+ """
+ Test that when `return_embedding==False`, the final query excludes the `embedding` field
+ even if it wasn't explicitly added to `excluded_meta_data`
+ """
+ mocked_document_store.return_embedding = False
+ mocked_document_store.excluded_meta_data = ["foo"]
+ mocked_document_store.query_by_embedding(self.query_emb)
+ # assert the resulting body is consistent with the `excluded_meta_data` value
+ _, kwargs = mocked_document_store.client.search.call_args
+ assert kwargs["body"]["_source"] == {"excludes": ["foo", "embedding"]}
+
+ @pytest.mark.unit
+ def test__create_document_index_with_alias(self, mocked_document_store, caplog):
+ mocked_document_store.client.indices.exists_alias.return_value = True
+
+ with caplog.at_level(logging.DEBUG, logger="haystack.document_stores.opensearch"):
+ mocked_document_store._create_document_index(self.index_name)
+
+ assert f"Index name {self.index_name} is an alias." in caplog.text
+
+ @pytest.mark.unit
+ def test__create_document_index_wrong_mapping_raises(self, mocked_document_store, index):
+ """
+ Ensure the method raises if we specify a field in `search_fields` that's not text
+ """
+ mocked_document_store.search_fields = ["age"]
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ with pytest.raises(Exception, match=f"The search_field 'age' of index '{self.index_name}' with type 'integer'"):
+ mocked_document_store._create_document_index(self.index_name)
+
+ @pytest.mark.unit
+ def test__create_document_index_create_mapping_if_missing(self, mocked_document_store, index):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "doesnt_have_a_mapping"
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # Assert the expected body was passed to the client
+ _, kwargs = mocked_document_store.client.indices.put_mapping.call_args
+ assert kwargs["index"] == self.index_name
+ assert "doesnt_have_a_mapping" in kwargs["body"]["properties"]
+
+ @pytest.mark.unit
+ def test__create_document_index_with_bad_field_raises(self, mocked_document_store, index):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "age" # this is mapped as integer
+
+ with pytest.raises(
+ Exception, match=f"The '{self.index_name}' index in OpenSearch already has a field called 'age'"
+ ):
+ mocked_document_store._create_document_index(self.index_name)
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_but_no_method(self, mocked_document_store, index):
+ """
+ We call the method passing a properly mapped field but without the `method` specified in the mapping
+ """
+ del index["mappings"]["properties"]["vec"]["method"]
+ # FIXME: the method assumes this key is present but it might not always be the case. This test has to pass
+ # without the following line:
+ index["settings"]["index"]["knn.space_type"] = "innerproduct"
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+
+ mocked_document_store._create_document_index(self.index_name)
+ # FIXME: when `method` is missing from the field mapping, embeddings_field_supports_similarity is always
+ # False but I'm not sure this is by design
+ assert mocked_document_store.embeddings_field_supports_similarity is False
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_similarity(self, mocked_document_store, index):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.similarity = "dot_product"
+
+ mocked_document_store._create_document_index(self.index_name)
+ assert mocked_document_store.embeddings_field_supports_similarity is True
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_similarity_mismatch(
+ self, mocked_document_store, index, caplog
+ ):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.similarity = "foo_bar"
+
+ with caplog.at_level(logging.WARN, logger="haystack.document_stores.opensearch"):
+ mocked_document_store._create_document_index(self.index_name)
+ assert "Embedding field 'vec' is optimized for similarity 'dot_product'." in caplog.text
+ assert mocked_document_store.embeddings_field_supports_similarity is False
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_hnsw_default(
+ self, mocked_document_store, index
+ ):
+ """
+ Test default values when `knn.algo_param` is missing from the index settings
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "hnsw"
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # assert the resulting body is contains the adjusted params
+ _, kwargs = mocked_document_store.client.indices.put_settings.call_args
+ assert kwargs["body"] == {"knn.algo_param.ef_search": 20}
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_hnsw(self, mocked_document_store, index):
+ """
+ Test a value of `knn.algo_param` that needs to be adjusted
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "hnsw"
+ index["settings"]["index"]["knn.algo_param"] = {"ef_search": 999}
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # assert the resulting body is contains the adjusted params
+ _, kwargs = mocked_document_store.client.indices.put_settings.call_args
+ assert kwargs["body"] == {"knn.algo_param.ef_search": 20}
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_flat_default(
+ self, mocked_document_store, index
+ ):
+ """
+ If `knn.algo_param` is missing, default value needs no adjustments
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "flat"
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ mocked_document_store.client.indices.put_settings.assert_not_called
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_hnsw(self, mocked_document_store, index):
+ """
+ Test a value of `knn.algo_param` that needs to be adjusted
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "flat"
+ index["settings"]["index"]["knn.algo_param"] = {"ef_search": 999}
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # assert the resulting body is contains the adjusted params
+ _, kwargs = mocked_document_store.client.indices.put_settings.call_args
+ assert kwargs["body"] == {"knn.algo_param.ef_search": 512}
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_custom_mapping(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.custom_mapping = {"mappings": {"properties": {"a_number": {"type": "integer"}}}}
+
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {"mappings": {"properties": {"a_number": {"type": "integer"}}}}
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_no_mapping(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {
+ "mappings": {
+ "dynamic_templates": [
+ {"strings": {"mapping": {"type": "keyword"}, "match_mapping_type": "string", "path_match": "*"}}
+ ],
+ "properties": {
+ "content": {"type": "text"},
+ "embedding": {
+ "dimension": 768,
+ "method": {
+ "engine": "nmslib",
+ "name": "hnsw",
+ "parameters": {"ef_construction": 512, "m": 16},
+ "space_type": "innerproduct",
+ },
+ "type": "knn_vector",
+ },
+ "name": {"type": "keyword"},
+ },
+ },
+ "settings": {"analysis": {"analyzer": {"default": {"type": "standard"}}}, "index": {"knn": True}},
+ }
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_no_mapping_with_synonyms(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.search_fields = ["occupation"]
+ mocked_document_store.synonyms = ["foo"]
+
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {
+ "mappings": {
+ "properties": {
+ "name": {"type": "keyword"},
+ "content": {"type": "text", "analyzer": "synonym"},
+ "occupation": {"type": "text", "analyzer": "synonym"},
+ "embedding": {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ },
+ },
+ "dynamic_templates": [
+ {"strings": {"path_match": "*", "match_mapping_type": "string", "mapping": {"type": "keyword"}}}
+ ],
+ },
+ "settings": {
+ "analysis": {
+ "analyzer": {
+ "default": {"type": "standard"},
+ "synonym": {"tokenizer": "whitespace", "filter": ["lowercase", "synonym"]},
+ },
+ "filter": {"synonym": {"type": "synonym", "synonyms": ["foo"]}},
+ },
+ "index": {"knn": True},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_no_mapping_with_embedding_field(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "hnsw"
+
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {
+ "mappings": {
+ "properties": {
+ "name": {"type": "keyword"},
+ "content": {"type": "text"},
+ "vec": {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 80, "m": 64},
+ },
+ },
+ },
+ "dynamic_templates": [
+ {"strings": {"path_match": "*", "match_mapping_type": "string", "mapping": {"type": "keyword"}}}
+ ],
+ },
+ "settings": {
+ "analysis": {"analyzer": {"default": {"type": "standard"}}},
+ "index": {"knn": True, "knn.algo_param.ef_search": 20},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__create_document_index_client_failure(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.client.indices.create.side_effect = RequestError
+
+ with pytest.raises(RequestError):
+ mocked_document_store._create_document_index(self.index_name)
+
+ @pytest.mark.unit
+ def test__get_embedding_field_mapping_flat(self, mocked_document_store):
+ mocked_document_store.index_type = "flat"
+
+ assert mocked_document_store._get_embedding_field_mapping("dot_product") == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__get_embedding_field_mapping_hnsw(self, mocked_document_store):
+ mocked_document_store.index_type = "hnsw"
+
+ assert mocked_document_store._get_embedding_field_mapping("dot_product") == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 80, "m": 64},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__get_embedding_field_mapping_wrong(self, mocked_document_store, caplog):
+ mocked_document_store.index_type = "foo"
+
+ with caplog.at_level(logging.ERROR, logger="haystack.document_stores.opensearch"):
+ retval = mocked_document_store._get_embedding_field_mapping("dot_product")
+
+ assert "Please set index_type to either 'flat' or 'hnsw'" in caplog.text
+ assert retval == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {"space_type": "innerproduct", "name": "hnsw", "engine": "nmslib"},
+ }
+
+ @pytest.mark.unit
+ def test__create_label_index_already_exists(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = True
+
+ mocked_document_store._create_label_index("foo")
+ mocked_document_store.client.indices.create.assert_not_called()
+
+ @pytest.mark.unit
+ def test__create_label_index_client_error(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.client.indices.create.side_effect = RequestError
+
+ with pytest.raises(RequestError):
+ mocked_document_store._create_label_index("foo")
+
+ @pytest.mark.unit
+ def test__get_vector_similarity_query_support_true(self, mocked_document_store):
+ mocked_document_store.embedding_field = "FooField"
+ mocked_document_store.embeddings_field_supports_similarity = True
+
+ assert mocked_document_store._get_vector_similarity_query(self.query_emb, 3) == {
+ "bool": {"must": [{"knn": {"FooField": {"vector": self.query_emb.tolist(), "k": 3}}}]}
+ }
+
+ @pytest.mark.unit
+ def test__get_vector_similarity_query_support_false(self, mocked_document_store):
+ mocked_document_store.embedding_field = "FooField"
+ mocked_document_store.embeddings_field_supports_similarity = False
+ mocked_document_store.similarity = "dot_product"
+
+ assert mocked_document_store._get_vector_similarity_query(self.query_emb, 3) == {
+ "script_score": {
+ "query": {"match_all": {}},
+ "script": {
+ "source": "knn_score",
+ "lang": "knn",
+ "params": {
+ "field": "FooField",
+ "query_value": self.query_emb.tolist(),
+ "space_type": "innerproduct",
+ },
+ },
+ }
+ }
+
+ @pytest.mark.unit
+ def test__get_raw_similarity_score_dot(self, mocked_document_store):
+ mocked_document_store.similarity = "dot_product"
+ assert mocked_document_store._get_raw_similarity_score(2) == 1
+ assert mocked_document_store._get_raw_similarity_score(-2) == 1.5
+
+ @pytest.mark.unit
+ def test__get_raw_similarity_score_l2(self, mocked_document_store):
+ mocked_document_store.similarity = "l2"
+ assert mocked_document_store._get_raw_similarity_score(1) == 0
+
+ @pytest.mark.unit
+ def test__get_raw_similarity_score_cosine(self, mocked_document_store):
+ mocked_document_store.similarity = "cosine"
+ mocked_document_store.embeddings_field_supports_similarity = True
+ assert mocked_document_store._get_raw_similarity_score(1) == 1
+ mocked_document_store.embeddings_field_supports_similarity = False
+ assert mocked_document_store._get_raw_similarity_score(1) == 0
+
+ @pytest.mark.unit
+ def test_clone_embedding_field_duplicate_mapping(self, mocked_document_store, index):
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.index = self.index_name
+ with pytest.raises(Exception, match="age already exists with mapping"):
+ mocked_document_store.clone_embedding_field("age", "cosine")
+
+ @pytest.mark.unit
+ def test_clone_embedding_field_update_mapping(self, mocked_document_store, index, monkeypatch):
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.index = self.index_name
-from haystack.document_stores import OpenSearchDocumentStore
+ # Mock away tqdm and the batch logic so we can test the mapping update alone
+ mocked_document_store._get_all_documents_in_index = MagicMock(return_value=[])
+ monkeypatch.setattr(tqdm, "__new__", MagicMock())
-pytestmark = pytest.mark.skipif(sys.platform in ["win32", "cygwin"], reason="Opensearch not running on Windows CI")
+ mocked_document_store.clone_embedding_field("a_field", "cosine")
+ _, kwargs = mocked_document_store.client.indices.put_mapping.call_args
+ assert kwargs["body"]["properties"]["a_field"] == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "cosinesimil",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ }
-@pytest.mark.elasticsearch
-def test_init_opensearch_client():
- OpenSearchDocumentStore(index="test_index", port=9201)
+class TestOpenDistroElasticsearchDocumentStore:
+ @pytest.mark.unit
+ def test_deprecation_notice(self, monkeypatch, caplog):
+ klass = OpenDistroElasticsearchDocumentStore
+ monkeypatch.setattr(klass, "_init_client", MagicMock())
+ with caplog.at_level(logging.WARN, logger="haystack.document_stores.opensearch"):
+ klass()
+ assert caplog.record_tuples == [
+ (
+ "haystack.document_stores.opensearch",
+ logging.WARN,
+ "Open Distro for Elasticsearch has been replaced by OpenSearch! See https://opensearch.org/faq/ for details. We recommend using the OpenSearchDocumentStore instead.",
+ )
+ ]
diff --git a/test/document_stores/test_weaviate.py b/test/document_stores/test_weaviate.py
index 1c020ce85f..4ec0abaeda 100644
--- a/test/document_stores/test_weaviate.py
+++ b/test/document_stores/test_weaviate.py
@@ -1,4 +1,5 @@
import uuid
+from unittest.mock import MagicMock
import numpy as np
import pytest
@@ -6,7 +7,6 @@
from haystack.schema import Document
from ..conftest import get_document_store
-
embedding_dim = 768
@@ -97,8 +97,12 @@ def test_query_by_embedding(document_store_with_docs):
@pytest.mark.parametrize("document_store_with_docs", ["weaviate"], indirect=True)
def test_query(document_store_with_docs):
query_text = "My name is Carla and I live in Berlin"
+ docs = document_store_with_docs.query(query_text)
+ assert len(docs) == 3
+
+ # BM25 retrieval WITH filters is not yet supported as of Weaviate v1.14.1
with pytest.raises(Exception):
- docs = document_store_with_docs.query(query_text)
+ docs = document_store_with_docs.query(query_text, filters={"name": ["filename2"]})
docs = document_store_with_docs.query(filters={"name": ["filename2"]})
assert len(docs) == 1
@@ -119,3 +123,24 @@ def test_get_all_documents_unaffected_by_QUERY_MAXIMUM_RESULTS(document_store_wi
monkeypatch.setattr(document_store_with_docs, "get_document_count", lambda **kwargs: 13_000)
docs = document_store_with_docs.get_all_documents()
assert len(docs) == 3
+
+
+@pytest.mark.weaviate
+@pytest.mark.parametrize("document_store_with_docs", ["weaviate"], indirect=True)
+def test_deleting_by_id_or_by_filters(document_store_with_docs):
+ # This test verifies that deleting an object by its ID does not first require fetching all documents. This fixes
+ # a bug, as described in https://github.com/deepset-ai/haystack/issues/2898
+ document_store_with_docs.get_all_documents = MagicMock(wraps=document_store_with_docs.get_all_documents)
+
+ assert document_store_with_docs.get_document_count() == 3
+
+ # Delete a document by its ID. This should bypass the get_all_documents() call
+ document_store_with_docs.delete_documents(ids=[DOCUMENTS_XS[0]["id"]])
+ document_store_with_docs.get_all_documents.assert_not_called()
+ assert document_store_with_docs.get_document_count() == 2
+
+ document_store_with_docs.get_all_documents.reset_mock()
+ # Delete a document with filters. Prove that using the filters will go through get_all_documents()
+ document_store_with_docs.delete_documents(filters={"name": ["filename2"]})
+ document_store_with_docs.get_all_documents.assert_called()
+ assert document_store_with_docs.get_document_count() == 1
diff --git a/test/modeling/test_modeling_dpr.py b/test/modeling/test_dpr.py
similarity index 86%
rename from test/modeling/test_modeling_dpr.py
rename to test/modeling/test_dpr.py
index c6a30c0212..af1cf0e91a 100644
--- a/test/modeling/test_modeling_dpr.py
+++ b/test/modeling/test_dpr.py
@@ -1,3 +1,6 @@
+from typing import Tuple
+
+import os
import logging
from pathlib import Path
@@ -6,13 +9,14 @@
import torch
from torch.utils.data import SequentialSampler
from tqdm import tqdm
+from transformers import DPRQuestionEncoder
from haystack.modeling.data_handler.dataloader import NamedDataLoader
from haystack.modeling.data_handler.processor import TextSimilarityProcessor
from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
-from haystack.modeling.model.language_model import LanguageModel, DPRContextEncoder, DPRQuestionEncoder
+from haystack.modeling.model.language_model import get_language_model, DPREncoder
from haystack.modeling.model.prediction_head import TextSimilarityHead
-from haystack.modeling.model.tokenization import Tokenizer
+from haystack.modeling.model.tokenization import get_tokenizer
from haystack.modeling.utils import set_all_seeds, initialize_device_settings
@@ -24,10 +28,10 @@ def test_dpr_modules(caplog=None):
devices, n_gpu = initialize_device_settings(use_cuda=True)
# 1.Create question and passage tokenizers
- query_tokenizer = Tokenizer.load(
+ query_tokenizer = get_tokenizer(
pretrained_model_name_or_path="facebook/dpr-question_encoder-single-nq-base", do_lower_case=True, use_fast=True
)
- passage_tokenizer = Tokenizer.load(
+ passage_tokenizer = get_tokenizer(
pretrained_model_name_or_path="facebook/dpr-ctx_encoder-single-nq-base", do_lower_case=True, use_fast=True
)
@@ -46,17 +50,15 @@ def test_dpr_modules(caplog=None):
num_hard_negatives=1,
)
- question_language_model = LanguageModel.load(
+ question_language_model = DPREncoder(
pretrained_model_name_or_path="bert-base-uncased",
- language_model_class="DPRQuestionEncoder",
- hidden_dropout_prob=0,
- attention_probs_dropout_prob=0,
+ model_type="DPRQuestionEncoder",
+ model_kwargs={"hidden_dropout_prob": 0, "attention_probs_dropout_prob": 0},
)
- passage_language_model = LanguageModel.load(
+ passage_language_model = DPREncoder(
pretrained_model_name_or_path="bert-base-uncased",
- language_model_class="DPRContextEncoder",
- hidden_dropout_prob=0,
- attention_probs_dropout_prob=0,
+ model_type="DPRContextEncoder",
+ model_kwargs={"hidden_dropout_prob": 0, "attention_probs_dropout_prob": 0},
)
prediction_head = TextSimilarityHead(similarity_function="dot_product")
@@ -75,8 +77,8 @@ def test_dpr_modules(caplog=None):
assert type(model) == BiAdaptiveModel
assert type(processor) == TextSimilarityProcessor
- assert type(question_language_model) == DPRQuestionEncoder
- assert type(passage_language_model) == DPRContextEncoder
+ assert type(question_language_model) == DPREncoder
+ assert type(passage_language_model) == DPREncoder
# check embedding layer weights
assert list(model.named_parameters())[0][1][0, 0].item() - -0.010200000368058681 < 0.0001
@@ -131,9 +133,17 @@ def test_dpr_modules(caplog=None):
torch.eq(features["passage_attention_mask"][0][1].nonzero().cpu().squeeze(), torch.tensor(list(range(143))))
)
+ features_query = {key.replace("query_", ""): value for key, value in features.items() if key.startswith("query_")}
+ features_passage = {
+ key.replace("passage_", ""): value for key, value in features.items() if key.startswith("passage_")
+ }
+ max_seq_len = features_passage.get("input_ids").shape[-1]
+ features_passage = {key: value.view(-1, max_seq_len) for key, value in features_passage.items()}
+
# test model encodings
- query_vector = model.language_model1(**features)[0]
- passage_vector = model.language_model2(**features)[0]
+ query_vector = model.language_model1(**features_query)[0]
+ passage_vector = model.language_model2(**features_passage)[0]
+
assert torch.all(
torch.le(
query_vector[0, :10].cpu()
@@ -157,7 +167,14 @@ def test_dpr_modules(caplog=None):
)
# test logits and loss
- embeddings = model(**features)
+ embeddings = model(
+ query_input_ids=features.get("query_input_ids", None),
+ query_segment_ids=features.get("query_segment_ids", None),
+ query_attention_mask=features.get("query_attention_mask", None),
+ passage_input_ids=features.get("passage_input_ids", None),
+ passage_segment_ids=features.get("passage_segment_ids", None),
+ passage_attention_mask=features.get("passage_attention_mask", None),
+ )
query_emb, passage_emb = embeddings[0]
assert torch.all(torch.eq(query_emb.cpu(), query_vector.cpu()))
assert torch.all(torch.eq(passage_emb.cpu(), passage_vector.cpu()))
@@ -343,9 +360,9 @@ def test_dpr_processor(embed_title, passage_ids, passage_attns, use_fast, num_ha
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=use_fast)
+ query_tokenizer = get_tokenizer(query_tok, use_fast=use_fast)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=use_fast)
+ passage_tokenizer = get_tokenizer(passage_tok, use_fast=use_fast)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -400,9 +417,9 @@ def test_dpr_processor_empty_title(use_fast, embed_title):
}
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=use_fast)
+ query_tokenizer = get_tokenizer(query_tok, use_fast=use_fast)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=use_fast)
+ passage_tokenizer = get_tokenizer(passage_tok, use_fast=use_fast)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -485,9 +502,9 @@ def test_dpr_problematic():
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -516,9 +533,9 @@ def test_dpr_query_only():
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -578,9 +595,9 @@ def test_dpr_context_only():
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -629,9 +646,9 @@ def test_dpr_processor_save_load(tmp_path):
}
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -646,9 +663,10 @@ def test_dpr_processor_save_load(tmp_path):
metric="text_similarity_metric",
shuffle_negatives=False,
)
- processor.save(save_dir=f"{tmp_path}/testsave/dpr_processor")
+ save_dir = f"{tmp_path}/testsave/dpr_processor"
+ processor.save(save_dir=save_dir)
dataset, tensor_names, _ = processor.dataset_from_dicts(dicts=[d], return_baskets=False)
- loadedprocessor = TextSimilarityProcessor.load_from_dir(load_dir=f"{tmp_path}/testsave/dpr_processor")
+ loadedprocessor = TextSimilarityProcessor.load_from_dir(load_dir=save_dir)
dataset2, tensor_names, _ = loadedprocessor.dataset_from_dicts(dicts=[d], return_baskets=False)
assert np.array_equal(dataset.tensors[0], dataset2.tensors[0])
@@ -667,7 +685,7 @@ def test_dpr_processor_save_load(tmp_path):
{"query": "facebook/dpr-question_encoder-single-nq-base", "passage": "facebook/dpr-ctx_encoder-single-nq-base"},
],
)
-def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_model):
+def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path: Path, query_and_passage_model: Tuple[str, str]):
"""
This test compares 1) a model that was loaded from model hub with
2) a model from model hub that was saved to disk and then loaded from disk and
@@ -679,7 +697,24 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
"passages": [
{
"title": "Etalab",
- "text": "Etalab est une administration publique française qui fait notamment office de Chief Data Officer de l'État et coordonne la conception et la mise en œuvre de sa stratégie dans le domaine de la donnée (ouverture et partage des données publiques ou open data, exploitation des données et intelligence artificielle...). Ainsi, Etalab développe et maintient le portail des données ouvertes du gouvernement français data.gouv.fr. Etalab promeut également une plus grande ouverture l'administration sur la société (gouvernement ouvert) : transparence de l'action publique, innovation ouverte, participation citoyenne... elle promeut l’innovation, l’expérimentation, les méthodes de travail ouvertes, agiles et itératives, ainsi que les synergies avec la société civile pour décloisonner l’administration et favoriser l’adoption des meilleures pratiques professionnelles dans le domaine du numérique. À ce titre elle étudie notamment l’opportunité de recourir à des technologies en voie de maturation issues du monde de la recherche. Cette entité chargée de l'innovation au sein de l'administration doit contribuer à l'amélioration du service public grâce au numérique. Elle est rattachée à la Direction interministérielle du numérique, dont les missions et l’organisation ont été fixées par le décret du 30 octobre 2019. Dirigé par Laure Lucchesi depuis 2016, elle rassemble une équipe pluridisciplinaire d'une trentaine de personnes.",
+ "text": "Etalab est une administration publique française qui fait notamment office "
+ "de Chief Data Officer de l'État et coordonne la conception et la mise en œuvre "
+ "de sa stratégie dans le domaine de la donnée (ouverture et partage des données "
+ "publiques ou open data, exploitation des données et intelligence artificielle...). "
+ "Ainsi, Etalab développe et maintient le portail des données ouvertes du gouvernement "
+ "français data.gouv.fr. Etalab promeut également une plus grande ouverture "
+ "l'administration sur la société (gouvernement ouvert) : transparence de l'action "
+ "publique, innovation ouverte, participation citoyenne... elle promeut l’innovation, "
+ "l’expérimentation, les méthodes de travail ouvertes, agiles et itératives, ainsi que "
+ "les synergies avec la société civile pour décloisonner l’administration et favoriser "
+ "l’adoption des meilleures pratiques professionnelles dans le domaine du numérique. "
+ "À ce titre elle étudie notamment l’opportunité de recourir à des technologies en voie "
+ "de maturation issues du monde de la recherche. Cette entité chargée de l'innovation "
+ "au sein de l'administration doit contribuer à l'amélioration du service public grâce "
+ "au numérique. Elle est rattachée à la Direction interministérielle du numérique, dont "
+ "les missions et l’organisation ont été fixées par le décret du 30 octobre 2019. Dirigé "
+ "par Laure Lucchesi depuis 2016, elle rassemble une équipe pluridisciplinaire d'une "
+ "trentaine de personnes.",
"label": "positive",
"external_id": "1",
}
@@ -689,16 +724,12 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# load model from model hub
query_embedding_model = query_and_passage_model["query"]
passage_embedding_model = query_and_passage_model["passage"]
- query_tokenizer = Tokenizer.load(
+ query_tokenizer = get_tokenizer(
pretrained_model_name_or_path=query_embedding_model
) # tokenizer class is inferred automatically
- query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=query_embedding_model, language_model_class="DPRQuestionEncoder"
- )
- passage_tokenizer = Tokenizer.load(pretrained_model_name_or_path=passage_embedding_model)
- passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=passage_embedding_model, language_model_class="DPRContextEncoder"
- )
+ query_encoder = get_language_model(pretrained_model_name_or_path=query_embedding_model)
+ passage_tokenizer = get_tokenizer(pretrained_model_name_or_path=passage_embedding_model)
+ passage_encoder = get_language_model(pretrained_model_name_or_path=passage_embedding_model)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
@@ -737,18 +768,14 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
passage_tokenizer.save_pretrained(save_dir + f"/{passage_encoder_dir}")
# load model from disk
- loaded_query_tokenizer = Tokenizer.load(
+ loaded_query_tokenizer = get_tokenizer(
pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir, use_fast=True
) # tokenizer class is inferred automatically
- loaded_query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir, language_model_class="DPRQuestionEncoder"
- )
- loaded_passage_tokenizer = Tokenizer.load(
+ loaded_query_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir)
+ loaded_passage_tokenizer = get_tokenizer(
pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir, use_fast=True
)
- loaded_passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir, language_model_class="DPRContextEncoder"
- )
+ loaded_passage_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
loaded_processor = TextSimilarityProcessor(
query_tokenizer=loaded_query_tokenizer,
@@ -794,12 +821,19 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
all_embeddings = {"query": [], "passages": []}
model.eval()
- for i, batch in enumerate(tqdm(data_loader, desc=f"Creating Embeddings", unit=" Batches", disable=True)):
+ for batch in tqdm(data_loader, desc=f"Creating Embeddings", unit=" Batches", disable=True):
batch = {key: batch[key].to(device) for key in batch}
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -826,7 +860,14 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = loaded_model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = loaded_model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings2["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -849,16 +890,12 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
loaded_passage_tokenizer.save_pretrained(save_dir + f"/{passage_encoder_dir}")
# load model from disk
- query_tokenizer = Tokenizer.load(
+ query_tokenizer = get_tokenizer(
pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir
) # tokenizer class is inferred automatically
- query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir, language_model_class="DPRQuestionEncoder"
- )
- passage_tokenizer = Tokenizer.load(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
- passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir, language_model_class="DPRContextEncoder"
- )
+ query_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir)
+ passage_tokenizer = get_tokenizer(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
+ passage_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
@@ -910,7 +947,14 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = loaded_model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = loaded_model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings3["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -942,9 +986,9 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
#
# device, n_gpu = initialize_device_settings(use_cuda=False)
#
-# query_tokenizer = Tokenizer.load(pretrained_model_name_or_path=question_lang_model,
+# query_tokenizer = get_tokenizer(pretrained_model_name_or_path=question_lang_model,
# do_lower_case=do_lower_case, use_fast=use_fast)
-# passage_tokenizer = Tokenizer.load(pretrained_model_name_or_path=passage_lang_model,
+# passage_tokenizer = get_tokenizer(pretrained_model_name_or_path=passage_lang_model,
# do_lower_case=do_lower_case, use_fast=use_fast)
# label_list = ["hard_negative", "positive"]
#
@@ -965,9 +1009,9 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
#
# data_silo = DataSilo(processor=processor, batch_size=batch_size, distributed=False)
#
-# question_language_model = LanguageModel.load(pretrained_model_name_or_path=question_lang_model,
+# question_language_model = get_language_model(pretrained_model_name_or_path=question_lang_model,
# language_model_class="DPRQuestionEncoder")
-# passage_language_model = LanguageModel.load(pretrained_model_name_or_path=passage_lang_model,
+# passage_language_model = get_language_model(pretrained_model_name_or_path=passage_lang_model,
# language_model_class="DPRContextEncoder")
#
# prediction_head = TextSimilarityHead(similarity_function=similarity_function)
@@ -1038,9 +1082,3 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# )
#
# trainer2.train()
-
-
-if __name__ == "__main__":
- # test_dpr_training()
- test_dpr_context_only()
- # test_dpr_modules()
diff --git a/test/modeling/test_modeling_inference.py b/test/modeling/test_inference.py
similarity index 100%
rename from test/modeling/test_modeling_inference.py
rename to test/modeling/test_inference.py
diff --git a/test/modeling/test_language.py b/test/modeling/test_language.py
new file mode 100644
index 0000000000..844f2302b7
--- /dev/null
+++ b/test/modeling/test_language.py
@@ -0,0 +1,34 @@
+import pytest
+
+from haystack.modeling.model.language_model import get_language_model
+
+
+@pytest.mark.parametrize(
+ "pretrained_model_name_or_path, lm_class",
+ [
+ ("google/bert_uncased_L-2_H-128_A-2", "HFLanguageModel"),
+ ("google/electra-small-generator", "HFLanguageModelWithPooler"),
+ ("distilbert-base-uncased", "HFLanguageModelNoSegmentIds"),
+ ("deepset/bert-small-mm_retrieval-passage_encoder", "DPREncoder"),
+ ],
+)
+def test_basic_loading(pretrained_model_name_or_path, lm_class):
+ lm = get_language_model(pretrained_model_name_or_path)
+ mod = __import__("haystack.modeling.model.language_model", fromlist=[lm_class])
+ klass = getattr(mod, lm_class)
+ assert isinstance(lm, klass)
+
+
+def test_basic_loading_unknown_model():
+ with pytest.raises(OSError):
+ get_language_model("model_that_doesnt_exist")
+
+
+def test_basic_loading_with_empty_string():
+ with pytest.raises(ValueError):
+ get_language_model("")
+
+
+def test_basic_loading_invalid_params():
+ with pytest.raises(ValueError):
+ get_language_model(None)
diff --git a/test/modeling/test_modeling_prediction_head.py b/test/modeling/test_prediction_head.py
similarity index 87%
rename from test/modeling/test_modeling_prediction_head.py
rename to test/modeling/test_prediction_head.py
index e607bce7cc..368afc5022 100644
--- a/test/modeling/test_modeling_prediction_head.py
+++ b/test/modeling/test_prediction_head.py
@@ -1,7 +1,7 @@
import logging
from haystack.modeling.model.adaptive_model import AdaptiveModel
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model
from haystack.modeling.model.prediction_head import QuestionAnsweringHead
from haystack.modeling.utils import set_all_seeds, initialize_device_settings
@@ -14,7 +14,7 @@ def test_prediction_head_load_save(tmp_path, caplog=None):
devices, n_gpu = initialize_device_settings(use_cuda=False)
lang_model = "bert-base-german-cased"
- language_model = LanguageModel.load(lang_model)
+ language_model = get_language_model(lang_model)
prediction_head = QuestionAnsweringHead()
model = AdaptiveModel(
diff --git a/test/modeling/test_modeling_processor.py b/test/modeling/test_processor.py
similarity index 98%
rename from test/modeling/test_modeling_processor.py
rename to test/modeling/test_processor.py
index 8744aeb6cb..79308d80f8 100644
--- a/test/modeling/test_modeling_processor.py
+++ b/test/modeling/test_processor.py
@@ -4,7 +4,7 @@
from transformers import AutoTokenizer
from haystack.modeling.data_handler.processor import SquadProcessor
-from haystack.modeling.model.tokenization import Tokenizer
+from haystack.modeling.model.tokenization import get_tokenizer
from ..conftest import SAMPLES_PATH
@@ -24,7 +24,7 @@ def test_dataset_from_dicts_qa_inference(caplog=None):
sample_types = ["answer-wrong", "answer-offset-wrong", "noanswer", "vanilla"]
for model in models:
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=model, use_fast=True)
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model)
processor = SquadProcessor(tokenizer, max_seq_len=256, data_dir=None)
for sample_type in sample_types:
@@ -251,7 +251,7 @@ def test_dataset_from_dicts_qa_labelconversion(caplog=None):
sample_types = ["answer-wrong", "answer-offset-wrong", "noanswer", "vanilla"]
for model in models:
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=model, use_fast=True)
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model)
processor = SquadProcessor(tokenizer, max_seq_len=256, data_dir=None)
for sample_type in sample_types:
diff --git a/test/modeling/test_modeling_processor_saving_loading.py b/test/modeling/test_processor_save_load.py
similarity index 89%
rename from test/modeling/test_modeling_processor_saving_loading.py
rename to test/modeling/test_processor_save_load.py
index 8972422364..154b303f70 100644
--- a/test/modeling/test_modeling_processor_saving_loading.py
+++ b/test/modeling/test_processor_save_load.py
@@ -2,7 +2,7 @@
from pathlib import Path
from haystack.modeling.data_handler.processor import SquadProcessor
-from haystack.modeling.model.tokenization import Tokenizer
+from haystack.modeling.model.tokenization import get_tokenizer
from haystack.modeling.utils import set_all_seeds
import torch
@@ -16,7 +16,7 @@ def test_processor_saving_loading(tmp_path, caplog):
set_all_seeds(seed=42)
lang_model = "roberta-base"
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False)
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=lang_model, do_lower_case=False)
processor = SquadProcessor(
tokenizer=tokenizer,
diff --git a/test/modeling/test_modeling_question_answering.py b/test/modeling/test_question_answering.py
similarity index 100%
rename from test/modeling/test_modeling_question_answering.py
rename to test/modeling/test_question_answering.py
diff --git a/test/modeling/test_tokenization.py b/test/modeling/test_tokenization.py
index 486b338f77..5758eeedec 100644
--- a/test/modeling/test_tokenization.py
+++ b/test/modeling/test_tokenization.py
@@ -1,500 +1,325 @@
-import logging
-import pytest
+from typing import Tuple
+
import re
-from transformers import (
- BertTokenizer,
- BertTokenizerFast,
- RobertaTokenizer,
- RobertaTokenizerFast,
- XLNetTokenizer,
- XLNetTokenizerFast,
- ElectraTokenizerFast,
-)
+
+import pytest
+import numpy as np
+from unittest.mock import MagicMock
from tokenizers.pre_tokenizers import WhitespaceSplit
-from haystack.modeling.model.tokenization import Tokenizer
+import haystack
+from haystack.modeling.model.tokenization import get_tokenizer
-import numpy as np
+
+BERT = "bert-base-cased"
+ROBERTA = "roberta-base"
+XLNET = "xlnet-base-cased"
+
+TOKENIZERS_TO_TEST = [BERT, ROBERTA, XLNET]
+TOKENIZERS_TO_TEST_WITH_TOKEN_MARKER = [(BERT, "##"), (ROBERTA, "Ġ"), (XLNET, "▁")]
-TEXTS = [
- "This is a sentence",
- "Der entscheidende Pass",
- "This is a sentence with multiple spaces",
- "力加勝北区ᴵᴺᵀᵃছজটডণত",
- "Thiso text is included tolod makelio sure Unicodeel is handled properly:",
- "This is a sentence...",
- "Let's see all on this text and. !23# neverseenwordspossible",
- """This is a sentence.
- With linebreak""",
- """Sentence with multiple
+REGULAR_SENTENCE = "This is a sentence"
+GERMAN_SENTENCE = "Der entscheidende Pass"
+OTHER_ALPHABETS = "力加勝北区ᴵᴺᵀᵃছজটডণত"
+GIBBERISH_SENTENCE = "Thiso text is included tolod makelio sure Unicodeel is handled properly:"
+SENTENCE_WITH_ELLIPSIS = "This is a sentence..."
+SENTENCE_WITH_LINEBREAK_1 = "and another one\n\n\nwithout space"
+SENTENCE_WITH_LINEBREAK_2 = """This is a sentence.
+ With linebreak"""
+SENTENCE_WITH_LINEBREAKS = """Sentence
+ with
+ multiple
newlines
- """,
- "and another one\n\n\nwithout space",
- "This is a sentence with tab",
- "This is a sentence with multiple tabs",
-]
-
-
-def test_basic_loading(caplog):
- caplog.set_level(logging.CRITICAL)
- # slow tokenizers
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="bert-base-cased", do_lower_case=True, use_fast=False)
- assert type(tokenizer) == BertTokenizer
- assert tokenizer.basic_tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="xlnet-base-cased", do_lower_case=True, use_fast=False)
- assert type(tokenizer) == XLNetTokenizer
- assert tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="roberta-base", use_fast=False)
- assert type(tokenizer) == RobertaTokenizer
-
- # fast tokenizers
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="bert-base-cased", do_lower_case=True)
- assert type(tokenizer) == BertTokenizerFast
- assert tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="xlnet-base-cased", do_lower_case=True)
- assert type(tokenizer) == XLNetTokenizerFast
- assert tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="roberta-base")
- assert type(tokenizer) == RobertaTokenizerFast
-
-
-def test_bert_tokenizer_all_meta(caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_model = "bert-base-cased"
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False)
-
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- tokenized = tokenizer.tokenize(basic_text)
- assert tokenized == [
- "Some",
- "Text",
- "with",
- "never",
- "##see",
- "##nto",
- "##ken",
- "##s",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- ]
+ """
+SENTENCE_WITH_EXCESS_WHITESPACE = "This is a sentence with multiple spaces"
+SENTENCE_WITH_TABS = "This is a sentence with multiple tabs"
+SENTENCE_WITH_CUSTOM_TOKEN = "Let's see all on this text and. !23# neverseenwordspossible"
- encoded_batch = tokenizer.encode_plus(basic_text)
- encoded = encoded_batch.encodings[0]
- words = np.array(encoded.words)
- words[words == None] = -1
- start_of_word_single = [False] + list(np.ediff1d(words) > 0)
- assert encoded.tokens == [
- "[CLS]",
- "Some",
- "Text",
- "with",
- "never",
- "##see",
- "##nto",
- "##ken",
- "##s",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- "[SEP]",
- ]
- assert [x[0] for x in encoded.offsets] == [
- 0,
- 0,
- 5,
- 10,
- 15,
- 20,
- 23,
- 26,
- 29,
- 31,
- 36,
- 37,
- 40,
- 41,
- 42,
- 44,
- 48,
- 50,
- 58,
- 59,
- 64,
- 65,
- 69,
- 70,
- 72,
- 0,
- ]
- assert start_of_word_single == [
- False,
- True,
- True,
- True,
- True,
- False,
- False,
- False,
- False,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- False,
- False,
- ]
+class AutoTokenizer:
+ mocker: MagicMock = MagicMock()
-def test_save_load(tmp_path, caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_names = ["bert-base-cased", "roberta-base", "xlnet-base-cased"]
- tokenizers = []
- for lang_name in lang_names:
- if "xlnet" in lang_name.lower():
- t = Tokenizer.load(lang_name, lower_case=False, use_fast=True, from_slow=True)
- else:
- t = Tokenizer.load(lang_name, lower_case=False)
- t.add_tokens(new_tokens=["neverseentokens"])
- tokenizers.append(t)
-
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- for tokenizer in tokenizers:
- tokenizer_type = tokenizer.__class__.__name__
- save_dir = f"{tmp_path}/testsave/{tokenizer_type}"
- tokenizer.save_pretrained(save_dir)
- tokenizer_loaded = Tokenizer.load(save_dir, tokenizer_class=tokenizer_type)
- encoded_before = tokenizer.encode_plus(basic_text).encodings[0]
- encoded_after = tokenizer_loaded.encode_plus(basic_text).encodings[0]
- data_before = {
- "tokens": encoded_before.tokens,
- "offsets": encoded_before.offsets,
- "words": encoded_before.words,
- }
- data_after = {"tokens": encoded_after.tokens, "offsets": encoded_after.offsets, "words": encoded_after.words}
- assert data_before == data_after
-
-
-@pytest.mark.parametrize("model_name", ["bert-base-german-cased", "google/electra-small-discriminator"])
-def test_fast_tokenizer_with_examples(caplog, model_name):
- fast_tokenizer = Tokenizer.load(model_name, lower_case=False, use_fast=True)
- tokenizer = Tokenizer.load(model_name, lower_case=False, use_fast=False)
-
- for text in TEXTS:
- # plain tokenize function
- tokenized = tokenizer.tokenize(text)
- fast_tokenized = fast_tokenizer.tokenize(text)
-
- assert tokenized == fast_tokenized
-
-
-def test_all_tokenizer_on_special_cases(caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_names = ["bert-base-cased", "roberta-base", "xlnet-base-cased"]
-
- tokenizers = []
- for lang_name in lang_names:
- if "roberta" in lang_name:
- add_prefix_space = True
- else:
- add_prefix_space = False
- t = Tokenizer.load(lang_name, lower_case=False, add_prefix_space=add_prefix_space)
- tokenizers.append(t)
-
- texts = [
- "This is a sentence",
- "Der entscheidende Pass",
- "力加勝北区ᴵᴺᵀᵃছজটডণত",
- "Thiso text is included tolod makelio sure Unicodeel is handled properly:",
- "This is a sentence...",
- "Let's see all on this text and. !23# neverseenwordspossible" "This is a sentence with multiple spaces",
- """This is a sentence.
- With linebreak""",
- """Sentence with multiple
- newlines
- """,
- "and another one\n\n\nwithout space",
- "This is a sentence with multiple tabs",
- ]
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ cls.mocker.from_pretrained(*args, **kwargs)
+ return cls()
- expected_to_fail = {(2, 1), (2, 5)}
-
- for i_tok, tokenizer in enumerate(tokenizers):
- for i_text, text in enumerate(texts):
- # Important: we don't assume to preserve whitespaces after tokenization.
- # This means: \t, \n " " etc will all resolve to a single " ".
- # This doesn't make a difference for BERT + XLNet but it does for roBERTa
-
- test_passed = True
-
- # 1. original tokenize function from transformer repo on full sentence
- standardized_whitespace_text = " ".join(text.split()) # remove multiple whitespaces
- tokenized = tokenizer.tokenize(standardized_whitespace_text)
-
- # 2. Our tokenization method using a pretokenizer which can normalize multiple white spaces
- # This approach is used in NER
- pre_tokenizer = WhitespaceSplit()
- words_and_spans = pre_tokenizer.pre_tokenize_str(text)
- words = [x[0] for x in words_and_spans]
- word_spans = [x[1] for x in words_and_spans]
-
- encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
-
- # verify that tokenization on full sequence is the same as the one on "whitespace tokenized words"
- if encoded.tokens != tokenized:
- test_passed = False
-
- # token offsets are originally relative to the beginning of the word
- # These lines convert them so they are relative to the beginning of the sentence
- token_offsets = []
- for ((start, end), w_index) in zip(encoded.offsets, encoded.words):
- word_start_ch = word_spans[w_index][0]
- token_offsets.append((start + word_start_ch, end + word_start_ch))
-
- # verify that offsets align back to original text
- if text == "力加勝北区ᴵᴺᵀᵃছজটডণত":
- # contains [UNK] that are impossible to match back to original text space
- continue
- for tok, (start, end) in zip(encoded.tokens, token_offsets):
- # subword-tokens have special chars depending on model type. In order to align with original text we need to get rid of them
- tok = re.sub(r"^(##|Ġ|▁)", "", tok)
- # tok = tokenizer.decode(tokenizer.convert_tokens_to_ids(tok))
- original_tok = text[start:end]
- if tok != original_tok:
- test_passed = False
- if (i_tok, i_text) in expected_to_fail:
- assert not test_passed, f"Behaviour of {tokenizer.__class__.__name__} has changed on text {text}'"
- else:
- assert test_passed, f"Behaviour of {tokenizer.__class__.__name__} has changed on text {text}'"
-
-
-def test_bert_custom_vocab(caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_model = "bert-base-cased"
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False)
-
- # deprecated: tokenizer.add_custom_vocab("samples/tokenizer/custom_vocab.txt")
- tokenizer.add_tokens(new_tokens=["neverseentokens"])
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- # original tokenizer from transformer repo
- tokenized = tokenizer.tokenize(basic_text)
- assert tokenized == [
- "Some",
- "Text",
- "with",
- "neverseentokens",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- ]
+@pytest.fixture(autouse=True)
+def mock_autotokenizer(request, monkeypatch):
+ # Do not patch integration tests
+ if "integration" in request.keywords:
+ return
+ monkeypatch.setattr(haystack.modeling.model.tokenization, "AutoTokenizer", AutoTokenizer)
+
+
+def convert_offset_from_word_reference_to_text_reference(offsets, words, word_spans):
+ """
+ Token offsets are originally relative to the beginning of the word
+ We make them relative to the beginning of the sentence.
+
+ Not a fixture, just a utility.
+ """
+ token_offsets = []
+ for ((start, end), word_index) in zip(offsets, words):
+ word_start = word_spans[word_index][0]
+ token_offsets.append((start + word_start, end + word_start))
+ return token_offsets
+
+
+#
+# Unit tests
+#
+
+
+def test_get_tokenizer_str():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path="test-model-name")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path="test-model-name", revision=None, use_fast=True, use_auth_token=None
+ )
- # ours with metadata
- encoded = tokenizer.encode_plus(basic_text, add_special_tokens=False).encodings[0]
- offsets = [x[0] for x in encoded.offsets]
- start_of_word_single = [True] + list(np.ediff1d(encoded.words) > 0)
- assert encoded.tokens == tokenized
- assert offsets == [0, 5, 10, 15, 31, 36, 37, 40, 41, 42, 44, 48, 50, 58, 59, 64, 65, 69, 70, 72]
- assert start_of_word_single == [
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- False,
- ]
+def test_get_tokenizer_path(tmp_path):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=tmp_path / "test-path")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path=str(tmp_path / "test-path"), revision=None, use_fast=True, use_auth_token=None
+ )
-def test_fast_bert_custom_vocab(caplog):
- caplog.set_level(logging.CRITICAL)
- lang_model = "bert-base-cased"
+def test_get_tokenizer_keep_accents():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path="test-model-name-albert")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path="test-model-name-albert",
+ revision=None,
+ use_fast=True,
+ use_auth_token=None,
+ keep_accents=True,
+ )
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False, use_fast=True)
- # deprecated: tokenizer.add_custom_vocab("samples/tokenizer/custom_vocab.txt")
+def test_get_tokenizer_mlm_warning(caplog):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path="test-model-name-mlm")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path="test-model-name-mlm", revision=None, use_fast=True, use_auth_token=None
+ )
+ assert "MLM part of codebert is currently not supported in Haystack".lower() in caplog.text.lower()
+
+
+#
+# Integration tests
+#
+
+
+@pytest.mark.integration
+@pytest.mark.parametrize("model_name", TOKENIZERS_TO_TEST)
+def test_save_load(tmp_path, model_name: str):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False)
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+
tokenizer.add_tokens(new_tokens=["neverseentokens"])
+ original_encoding = tokenizer.encode_plus(text)
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- # original tokenizer from transformer repo
- tokenized = tokenizer.tokenize(basic_text)
- assert tokenized == [
- "Some",
- "Text",
- "with",
- "neverseentokens",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- ]
+ save_dir = tmp_path / "saved_tokenizer"
+ tokenizer.save_pretrained(save_dir)
- # ours with metadata
- encoded = tokenizer.encode_plus(basic_text, add_special_tokens=False).encodings[0]
- offsets = [x[0] for x in encoded.offsets]
- start_of_word_single = [True] + list(np.ediff1d(encoded.words) > 0)
- assert encoded.tokens == tokenized
- assert offsets == [0, 5, 10, 15, 31, 36, 37, 40, 41, 42, 44, 48, 50, 58, 59, 64, 65, 69, 70, 72]
- assert start_of_word_single == [
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- False,
- ]
+ tokenizer_loaded = get_tokenizer(pretrained_model_name_or_path=save_dir)
+ new_encoding = tokenizer_loaded.encode_plus(text)
+ assert original_encoding == new_encoding
+
+
+@pytest.mark.integration
+def test_tokenize_custom_vocab_bert():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
+ tokenizer.add_tokens(new_tokens=["neverseentokens"])
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+ tokenized = tokenizer.tokenize(text)
+ assert (
+ tokenized == f"Some Text with neverseentokens plus ! 215 ? # . and a combined - token _ with / ch ##ars".split()
+ )
+
+
+@pytest.mark.integration
@pytest.mark.parametrize(
- "model_name, tokenizer_type",
- [("bert-base-german-cased", BertTokenizerFast), ("google/electra-small-discriminator", ElectraTokenizerFast)],
+ "edge_case",
+ [
+ REGULAR_SENTENCE,
+ OTHER_ALPHABETS,
+ GIBBERISH_SENTENCE,
+ SENTENCE_WITH_ELLIPSIS,
+ SENTENCE_WITH_LINEBREAK_1,
+ SENTENCE_WITH_LINEBREAK_2,
+ SENTENCE_WITH_LINEBREAKS,
+ SENTENCE_WITH_EXCESS_WHITESPACE,
+ SENTENCE_WITH_TABS,
+ ],
)
-def test_fast_tokenizer_type(caplog, model_name, tokenizer_type):
- caplog.set_level(logging.CRITICAL)
+@pytest.mark.parametrize("model_name", TOKENIZERS_TO_TEST)
+def test_tokenization_on_edge_cases_full_sequence_tokenization(model_name: str, edge_case: str):
+ """
+ Verify that tokenization on full sequence is the same as the one on "whitespace tokenized words"
+ """
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False, add_prefix_space=True)
- tokenizer = Tokenizer.load(model_name, use_fast=True)
- assert type(tokenizer) is tokenizer_type
+ pre_tokenizer = WhitespaceSplit()
+ words_and_spans = pre_tokenizer.pre_tokenize_str(edge_case)
+ words = [x[0] for x in words_and_spans]
+ encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
+ expected_tokenization = tokenizer.tokenize(" ".join(edge_case.split())) # remove multiple whitespaces
-# See discussion in https://github.com/deepset-ai/FARM/pull/624 for reason to remove the test
-# def test_fast_bert_tokenizer_strip_accents(caplog):
-# caplog.set_level(logging.CRITICAL)
-#
-# tokenizer = Tokenizer.load("dbmdz/bert-base-german-uncased",
-# use_fast=True,
-# strip_accents=False)
-# assert type(tokenizer) is BertTokenizerFast
-# assert tokenizer.do_lower_case
-# assert tokenizer._tokenizer._parameters['strip_accents'] is False
+ assert encoded.tokens == expected_tokenization
+
+
+@pytest.mark.integration
+@pytest.mark.parametrize("edge_case", [SENTENCE_WITH_CUSTOM_TOKEN, GERMAN_SENTENCE])
+@pytest.mark.parametrize("model_name", [t for t in TOKENIZERS_TO_TEST if t != ROBERTA])
+def test_tokenization_on_edge_cases_full_sequence_tokenization_roberta_exceptions(model_name: str, edge_case: str):
+ """
+ Verify that tokenization on full sequence is the same as the one on "whitespace tokenized words".
+ These test cases work for all tokenizers under test except for RoBERTa.
+ """
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False, add_prefix_space=True)
+ pre_tokenizer = WhitespaceSplit()
+ words_and_spans = pre_tokenizer.pre_tokenize_str(edge_case)
+ words = [x[0] for x in words_and_spans]
-def test_fast_electra_tokenizer(caplog):
- caplog.set_level(logging.CRITICAL)
+ encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
+ expected_tokenization = tokenizer.tokenize(" ".join(edge_case.split())) # remove multiple whitespaces
- tokenizer = Tokenizer.load("dbmdz/electra-base-german-europeana-cased-discriminator", use_fast=True)
- assert type(tokenizer) is ElectraTokenizerFast
+ assert encoded.tokens == expected_tokenization
-@pytest.mark.parametrize("model_name", ["bert-base-cased", "distilbert-base-uncased", "deepset/electra-base-squad2"])
-def test_detokenization_in_fast_tokenizers(model_name):
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=model_name, use_fast=True)
- for text in TEXTS:
- encoded = tokenizer.encode_plus(text, add_special_tokens=False).encodings[0]
+@pytest.mark.integration
+@pytest.mark.parametrize(
+ "edge_case",
+ [
+ REGULAR_SENTENCE,
+ # OTHER_ALPHABETS, # contains [UNK] that are impossible to match back to original text space
+ GIBBERISH_SENTENCE,
+ SENTENCE_WITH_ELLIPSIS,
+ SENTENCE_WITH_LINEBREAK_1,
+ SENTENCE_WITH_LINEBREAK_2,
+ SENTENCE_WITH_LINEBREAKS,
+ SENTENCE_WITH_EXCESS_WHITESPACE,
+ SENTENCE_WITH_TABS,
+ ],
+)
+@pytest.mark.parametrize("model_name,marker", TOKENIZERS_TO_TEST_WITH_TOKEN_MARKER)
+def test_tokenization_on_edge_cases_full_sequence_verify_spans(model_name: str, marker: str, edge_case: str):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False, add_prefix_space=True)
+
+ pre_tokenizer = WhitespaceSplit()
+ words_and_spans = pre_tokenizer.pre_tokenize_str(edge_case)
+ words = [x[0] for x in words_and_spans]
+ word_spans = [x[1] for x in words_and_spans]
+
+ encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
+
+ # subword-tokens have special chars depending on model type. To align with original text we get rid of them
+ tokens = [token.replace(marker, "") for token in encoded.tokens]
+ token_offsets = convert_offset_from_word_reference_to_text_reference(encoded.offsets, encoded.words, word_spans)
+
+ for token, (start, end) in zip(tokens, token_offsets):
+ assert token == edge_case[start:end]
+
+
+@pytest.mark.integration
+@pytest.mark.parametrize(
+ "edge_case",
+ [
+ REGULAR_SENTENCE,
+ GERMAN_SENTENCE,
+ SENTENCE_WITH_EXCESS_WHITESPACE,
+ OTHER_ALPHABETS,
+ GIBBERISH_SENTENCE,
+ SENTENCE_WITH_ELLIPSIS,
+ SENTENCE_WITH_CUSTOM_TOKEN,
+ SENTENCE_WITH_LINEBREAK_1,
+ SENTENCE_WITH_LINEBREAK_2,
+ SENTENCE_WITH_LINEBREAKS,
+ SENTENCE_WITH_TABS,
+ ],
+)
+def test_detokenization_for_bert(edge_case):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
- detokenized = " ".join(encoded.tokens)
- detokenized = re.sub(r"(^|\s+)(##)", "", detokenized)
+ encoded = tokenizer.encode_plus(edge_case, add_special_tokens=False).encodings[0]
- detokenized_ids = tokenizer(detokenized, add_special_tokens=False)["input_ids"]
- detokenized_tokens = [tokenizer.decode([tok_id]).strip() for tok_id in detokenized_ids]
+ detokenized = " ".join(encoded.tokens)
+ detokenized = re.sub(r"(^|\s+)(##)", "", detokenized)
- assert encoded.tokens == detokenized_tokens
+ detokenized_ids = tokenizer(detokenized, add_special_tokens=False)["input_ids"]
+ detokenized_tokens = [tokenizer.decode([tok_id]).strip() for tok_id in detokenized_ids]
+ assert encoded.tokens == detokenized_tokens
-if __name__ == "__main__":
- test_all_tokenizer_on_special_cases()
+
+@pytest.mark.integration
+def test_encode_plus_for_bert():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+
+ encoded_batch = tokenizer.encode_plus(text)
+ encoded = encoded_batch.encodings[0]
+
+ words = np.array(encoded.words)
+ words[0] = -1
+ words[-1] = -1
+
+ print(words.tolist())
+
+ tokens = encoded.tokens
+ offsets = [x[0] for x in encoded.offsets]
+ start_of_word = [False] + list(np.ediff1d(words) > 0)
+
+ assert list(zip(tokens, offsets, start_of_word)) == [
+ ("[CLS]", 0, False),
+ ("Some", 0, True),
+ ("Text", 5, True),
+ ("with", 10, True),
+ ("never", 15, True),
+ ("##see", 20, False),
+ ("##nto", 23, False),
+ ("##ken", 26, False),
+ ("##s", 29, False),
+ ("plus", 31, True),
+ ("!", 36, True),
+ ("215", 37, True),
+ ("?", 40, True),
+ ("#", 41, True),
+ (".", 42, True),
+ ("and", 44, True),
+ ("a", 48, True),
+ ("combined", 50, True),
+ ("-", 58, True),
+ ("token", 59, True),
+ ("_", 64, True),
+ ("with", 65, True),
+ ("/", 69, True),
+ ("ch", 70, True),
+ ("##ars", 72, False),
+ ("[SEP]", 0, False),
+ ]
+
+
+@pytest.mark.integration
+def test_tokenize_custom_vocab_bert():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
+
+ tokenizer.add_tokens(new_tokens=["neverseentokens"])
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+
+ tokenized = tokenizer.tokenize(text)
+
+ encoded = tokenizer.encode_plus(text, add_special_tokens=False).encodings[0]
+ offsets = [x[0] for x in encoded.offsets]
+ start_of_word_single = [True] + list(np.ediff1d(encoded.words) > 0)
+
+ assert encoded.tokens == tokenized
+ assert offsets == [0, 5, 10, 15, 31, 36, 37, 40, 41, 42, 44, 48, 50, 58, 59, 64, 65, 69, 70, 72]
+ assert start_of_word_single == [True] * 19 + [False]
diff --git a/test/nodes/test_audio.py b/test/nodes/test_audio.py
index 774a61409f..1fdaf31b7f 100644
--- a/test/nodes/test_audio.py
+++ b/test/nodes/test_audio.py
@@ -1,7 +1,14 @@
import os
+import pytest
import numpy as np
-import soundfile as sf
+
+try:
+ import soundfile as sf
+
+ soundfile_not_found = False
+except:
+ soundfile_not_found = True
from haystack.schema import Span, Answer, SpeechAnswer, Document, SpeechDocument
from haystack.nodes.audio import AnswerToSpeech, DocumentToSpeech
@@ -10,111 +17,108 @@
from ..conftest import SAMPLES_PATH
-def test_text_to_speech_audio_data():
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
- audio_data = text2speech.text_to_audio_data(text="answer")
-
- assert np.allclose(expected_audio_data, audio_data, atol=0.001)
-
-
-def test_text_to_speech_audio_file(tmp_path):
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
- audio_file = text2speech.text_to_audio_file(text="answer", generated_audio_dir=tmp_path / "test_audio")
- assert os.path.exists(audio_file)
- assert np.allclose(expected_audio_data, sf.read(audio_file)[0], atol=0.001)
-
-
-def test_text_to_speech_compress_audio(tmp_path):
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
- audio_file = text2speech.text_to_audio_file(
- text="answer", generated_audio_dir=tmp_path / "test_audio", audio_format="mp3"
- )
- assert os.path.exists(audio_file)
- assert audio_file.suffix == ".mp3"
- # FIXME find a way to make sure the compressed audio is similar enough to the wav version.
- # At a manual inspection, the code seems to be working well.
-
-
-def test_text_to_speech_naming_function(tmp_path):
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
- audio_file = text2speech.text_to_audio_file(
- text="answer", generated_audio_dir=tmp_path / "test_audio", audio_naming_function=lambda text: text
- )
- assert os.path.exists(audio_file)
- assert audio_file.name == expected_audio_file.name
- assert np.allclose(sf.read(expected_audio_file)[0], sf.read(audio_file)[0], atol=0.001)
-
-
-def test_answer_to_speech(tmp_path):
- text_answer = Answer(
- answer="answer",
- type="extractive",
- context="the context for this answer is here",
- offsets_in_document=[Span(31, 37)],
- offsets_in_context=[Span(21, 27)],
- meta={"some_meta": "some_value"},
- )
- expected_audio_answer = SAMPLES_PATH / "audio" / "answer.wav"
- expected_audio_context = SAMPLES_PATH / "audio" / "the context for this answer is here.wav"
-
- answer2speech = AnswerToSpeech(
- generated_audio_dir=tmp_path / "test_audio",
- audio_params={"audio_naming_function": lambda text: text},
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- results, _ = answer2speech.run(answers=[text_answer])
-
- audio_answer: SpeechAnswer = results["answers"][0]
- assert isinstance(audio_answer, SpeechAnswer)
- assert audio_answer.type == "generative"
- assert audio_answer.answer_audio.name == expected_audio_answer.name
- assert audio_answer.context_audio.name == expected_audio_context.name
- assert audio_answer.answer == "answer"
- assert audio_answer.context == "the context for this answer is here"
- assert audio_answer.offsets_in_document == [Span(31, 37)]
- assert audio_answer.offsets_in_context == [Span(21, 27)]
- assert audio_answer.meta["some_meta"] == "some_value"
- assert audio_answer.meta["audio_format"] == "wav"
-
- assert np.allclose(sf.read(audio_answer.answer_audio)[0], sf.read(expected_audio_answer)[0], atol=0.001)
- assert np.allclose(sf.read(audio_answer.context_audio)[0], sf.read(expected_audio_context)[0], atol=0.001)
-
-
-def test_document_to_speech(tmp_path):
- text_doc = Document(
- content="this is the content of the document", content_type="text", meta={"name": "test_document.txt"}
- )
- expected_audio_content = SAMPLES_PATH / "audio" / "this is the content of the document.wav"
-
- doc2speech = DocumentToSpeech(
- generated_audio_dir=tmp_path / "test_audio",
- audio_params={"audio_naming_function": lambda text: text},
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- results, _ = doc2speech.run(documents=[text_doc])
-
- audio_doc: SpeechDocument = results["documents"][0]
- assert isinstance(audio_doc, SpeechDocument)
- assert audio_doc.content_type == "audio"
- assert audio_doc.content_audio.name == expected_audio_content.name
- assert audio_doc.content == "this is the content of the document"
- assert audio_doc.meta["name"] == "test_document.txt"
- assert audio_doc.meta["audio_format"] == "wav"
-
- assert np.allclose(sf.read(audio_doc.content_audio)[0], sf.read(expected_audio_content)[0], atol=0.001)
+@pytest.mark.skipif(soundfile_not_found, reason="soundfile not found")
+class TestTextToSpeech:
+ def test_text_to_speech_audio_data(self):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
+ audio_data = text2speech.text_to_audio_data(text="answer")
+
+ assert np.allclose(expected_audio_data, audio_data, atol=0.001)
+
+ def test_text_to_speech_audio_file(self, tmp_path):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
+ audio_file = text2speech.text_to_audio_file(text="answer", generated_audio_dir=tmp_path / "test_audio")
+ assert os.path.exists(audio_file)
+ assert np.allclose(expected_audio_data, sf.read(audio_file)[0], atol=0.001)
+
+ def test_text_to_speech_compress_audio(self, tmp_path):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
+ audio_file = text2speech.text_to_audio_file(
+ text="answer", generated_audio_dir=tmp_path / "test_audio", audio_format="mp3"
+ )
+ assert os.path.exists(audio_file)
+ assert audio_file.suffix == ".mp3"
+ # FIXME find a way to make sure the compressed audio is similar enough to the wav version.
+ # At a manual inspection, the code seems to be working well.
+
+ def test_text_to_speech_naming_function(self, tmp_path):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
+ audio_file = text2speech.text_to_audio_file(
+ text="answer", generated_audio_dir=tmp_path / "test_audio", audio_naming_function=lambda text: text
+ )
+ assert os.path.exists(audio_file)
+ assert audio_file.name == expected_audio_file.name
+ assert np.allclose(sf.read(expected_audio_file)[0], sf.read(audio_file)[0], atol=0.001)
+
+ def test_answer_to_speech(self, tmp_path):
+ text_answer = Answer(
+ answer="answer",
+ type="extractive",
+ context="the context for this answer is here",
+ offsets_in_document=[Span(31, 37)],
+ offsets_in_context=[Span(21, 27)],
+ meta={"some_meta": "some_value"},
+ )
+ expected_audio_answer = SAMPLES_PATH / "audio" / "answer.wav"
+ expected_audio_context = SAMPLES_PATH / "audio" / "the context for this answer is here.wav"
+
+ answer2speech = AnswerToSpeech(
+ generated_audio_dir=tmp_path / "test_audio",
+ audio_params={"audio_naming_function": lambda text: text},
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ results, _ = answer2speech.run(answers=[text_answer])
+
+ audio_answer: SpeechAnswer = results["answers"][0]
+ assert isinstance(audio_answer, SpeechAnswer)
+ assert audio_answer.type == "generative"
+ assert audio_answer.answer_audio.name == expected_audio_answer.name
+ assert audio_answer.context_audio.name == expected_audio_context.name
+ assert audio_answer.answer == "answer"
+ assert audio_answer.context == "the context for this answer is here"
+ assert audio_answer.offsets_in_document == [Span(31, 37)]
+ assert audio_answer.offsets_in_context == [Span(21, 27)]
+ assert audio_answer.meta["some_meta"] == "some_value"
+ assert audio_answer.meta["audio_format"] == "wav"
+
+ assert np.allclose(sf.read(audio_answer.answer_audio)[0], sf.read(expected_audio_answer)[0], atol=0.001)
+ assert np.allclose(sf.read(audio_answer.context_audio)[0], sf.read(expected_audio_context)[0], atol=0.001)
+
+ def test_document_to_speech(self, tmp_path):
+ text_doc = Document(
+ content="this is the content of the document", content_type="text", meta={"name": "test_document.txt"}
+ )
+ expected_audio_content = SAMPLES_PATH / "audio" / "this is the content of the document.wav"
+
+ doc2speech = DocumentToSpeech(
+ generated_audio_dir=tmp_path / "test_audio",
+ audio_params={"audio_naming_function": lambda text: text},
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ results, _ = doc2speech.run(documents=[text_doc])
+
+ audio_doc: SpeechDocument = results["documents"][0]
+ assert isinstance(audio_doc, SpeechDocument)
+ assert audio_doc.content_type == "audio"
+ assert audio_doc.content_audio.name == expected_audio_content.name
+ assert audio_doc.content == "this is the content of the document"
+ assert audio_doc.meta["name"] == "test_document.txt"
+ assert audio_doc.meta["audio_format"] == "wav"
+
+ assert np.allclose(sf.read(audio_doc.content_audio)[0], sf.read(expected_audio_content)[0], atol=0.001)
diff --git a/test/nodes/test_preprocessor.py b/test/nodes/test_preprocessor.py
index 6859002491..45a614d8c6 100644
--- a/test/nodes/test_preprocessor.py
+++ b/test/nodes/test_preprocessor.py
@@ -1,5 +1,6 @@
import sys
from pathlib import Path
+import os
import pytest
@@ -9,6 +10,10 @@
from ..conftest import SAMPLES_PATH
+
+NLTK_TEST_MODELS = SAMPLES_PATH.absolute() / "preprocessor" / "nltk_models"
+
+
TEXT = """
This is a sample sentence in paragraph_1. This is a sample sentence in paragraph_1. This is a sample sentence in
paragraph_1. This is a sample sentence in paragraph_1. This is a sample sentence in paragraph_1.
@@ -21,20 +26,90 @@
in the sentence.
"""
+LEGAL_TEXT_PT = """
+A Lei nº 9.514/1997, que instituiu a alienação fiduciária de
+bens imóveis, é norma especial e posterior ao Código de Defesa do
+Consumidor – CDC. Em tais circunstâncias, o inadimplemento do
+devedor fiduciante enseja a aplicação da regra prevista nos arts. 26 e 27
+da lei especial” (REsp 1.871.911/SP, rel. Min. Nancy Andrighi, DJe
+25/8/2020).
+
+A Emenda Constitucional n. 35 alterou substancialmente esse mecanismo,
+ao determinar, na nova redação conferida ao art. 53: “§ 3º Recebida a
+denúncia contra o Senador ou Deputado, por crime ocorrido após a
+diplomação, o Supremo Tribunal Federal dará ciência à Casa respectiva, que,
+por iniciativa de partido político nela representado e pelo voto da maioria de
+seus membros, poderá, até a decisão final, sustar o andamento da ação”.
+Vale ressaltar, contudo, que existem, antes do encaminhamento ao
+Presidente da República, os chamados autógrafos. Os autógrafos ocorrem já
+com o texto definitivamente aprovado pelo Plenário ou pelas comissões,
+quando for o caso. Os autógrafos devem reproduzir com absoluta fidelidade a
+redação final aprovada. O projeto aprovado será encaminhado em autógrafos
+ao Presidente da República. O tema encontra-se regulamentado pelo art. 200
+do RICD e arts. 328 a 331 do RISF.
+"""
+
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 15), (10, 2)])
+def test_preprocess_sentence_split(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
-def test_preprocess_sentence_split():
document = Document(content=TEXT)
preprocessor = PreProcessor(
- split_length=1, split_overlap=0, split_by="sentence", split_respect_sentence_boundary=False
+ split_length=split_length, split_overlap=0, split_by="sentence", split_respect_sentence_boundary=False
)
documents = preprocessor.process(document)
- assert len(documents) == 15
+ assert len(documents) == expected_documents_count
+
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 15), (10, 2)])
+def test_preprocess_sentence_split_custom_models_wrong_file_format(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+
+ document = Document(content=TEXT)
+ preprocessor = PreProcessor(
+ split_length=split_length,
+ split_overlap=0,
+ split_by="sentence",
+ split_respect_sentence_boundary=False,
+ tokenizer_model_folder=NLTK_TEST_MODELS / "wrong",
+ language="en",
+ )
+ documents = preprocessor.process(document)
+ assert len(documents) == expected_documents_count
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 15), (10, 2)])
+def test_preprocess_sentence_split_custom_models_non_default_language(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+
+ document = Document(content=TEXT)
+ preprocessor = PreProcessor(
+ split_length=split_length,
+ split_overlap=0,
+ split_by="sentence",
+ split_respect_sentence_boundary=False,
+ language="ca",
+ )
+ documents = preprocessor.process(document)
+ assert len(documents) == expected_documents_count
+
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 8), (8, 1)])
+def test_preprocess_sentence_split_custom_models(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+
+ document = Document(content=LEGAL_TEXT_PT)
preprocessor = PreProcessor(
- split_length=10, split_overlap=0, split_by="sentence", split_respect_sentence_boundary=False
+ split_length=split_length,
+ split_overlap=0,
+ split_by="sentence",
+ split_respect_sentence_boundary=False,
+ language="pt",
+ tokenizer_model_folder=NLTK_TEST_MODELS,
)
documents = preprocessor.process(document)
- assert len(documents) == 2
+ assert len(documents) == expected_documents_count
def test_preprocess_word_split():
@@ -64,19 +139,16 @@ def test_preprocess_word_split():
assert len(documents) == 15
-def test_preprocess_passage_split():
- document = Document(content=TEXT)
- preprocessor = PreProcessor(
- split_length=1, split_overlap=0, split_by="passage", split_respect_sentence_boundary=False
- )
- documents = preprocessor.process(document)
- assert len(documents) == 3
+@pytest.mark.parametrize("split_length_and_results", [(1, 3), (2, 2)])
+def test_preprocess_passage_split(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+ document = Document(content=TEXT)
preprocessor = PreProcessor(
- split_length=2, split_overlap=0, split_by="passage", split_respect_sentence_boundary=False
+ split_length=split_length, split_overlap=0, split_by="passage", split_respect_sentence_boundary=False
)
documents = preprocessor.process(document)
- assert len(documents) == 2
+ assert len(documents) == expected_documents_count
@pytest.mark.skipif(sys.platform in ["win32", "cygwin"], reason="FIXME Footer not detected correctly on Windows")
diff --git a/test/nodes/test_question_generator.py b/test/nodes/test_question_generator.py
index 52a6712c64..1813c5be1c 100644
--- a/test/nodes/test_question_generator.py
+++ b/test/nodes/test_question_generator.py
@@ -1,10 +1,12 @@
+import pytest
+
from haystack.pipelines import (
QuestionAnswerGenerationPipeline,
QuestionGenerationPipeline,
RetrieverQuestionGenerationPipeline,
)
+from haystack.nodes.question_generator import QuestionGenerator
from haystack.schema import Document
-import pytest
text = 'The Living End are an Australian punk rockabilly band from Melbourne, formed in 1994. Since 2002, the line-up consists of Chris Cheney (vocals, guitar), Scott Owen (double bass, vocals), and Andy Strachan (drums). The band rose to fame in 1997 after the release of their EP Second Solution / Prisoner of Society, which peaked at No. 4 on the Australian ARIA Singles Chart. They have released eight studio albums, two of which reached the No. 1 spot on the ARIA Albums Chart: The Living End (October 1998) and State of Emergency (February 2006). They have also achieved chart success in the U.S. and the United Kingdom. The Band was nominated 27 times and won five awards at the Australian ARIA Music Awards ceremonies: "Highest Selling Single" for Second Solution / Prisoner of Society (1998), "Breakthrough Artist – Album" and "Best Group" for The Living End (1999), as well as "Best Rock Album" for White Noise (2008) and The Ending Is Just the Beginning Repeating (2011). In October 2010, their debut album was listed in the book "100 Best Australian Albums". Australian musicologist Ian McFarlane described the group as "one of Australia’s premier rock acts. By blending a range of styles (punk, rockabilly and flat out rock) with great success, The Living End has managed to produce anthemic choruses and memorable songs in abundance".'
diff --git a/test/nodes/test_retriever.py b/test/nodes/test_retriever.py
index cc3c5c4edb..c5081b1e5e 100644
--- a/test/nodes/test_retriever.py
+++ b/test/nodes/test_retriever.py
@@ -11,6 +11,7 @@
from elasticsearch import Elasticsearch
from haystack.document_stores import WeaviateDocumentStore
+from haystack.nodes.retriever.base import BaseRetriever
from haystack.schema import Document
from haystack.document_stores.elasticsearch import ElasticsearchDocumentStore
from haystack.document_stores.faiss import FAISSDocumentStore
@@ -49,7 +50,7 @@
],
indirect=True,
)
-def test_retrieval(retriever_with_docs, document_store_with_docs):
+def test_retrieval(retriever_with_docs: BaseRetriever, document_store_with_docs: BaseDocumentStore):
if not isinstance(retriever_with_docs, (BM25Retriever, FilterRetriever, TfidfRetriever)):
document_store_with_docs.update_embeddings(retriever_with_docs)
@@ -344,9 +345,9 @@ def sum_params(model):
def test_table_text_retriever_training(document_store):
retriever = TableTextRetriever(
document_store=document_store,
- query_embedding_model="prajjwal1/bert-tiny",
- passage_embedding_model="prajjwal1/bert-tiny",
- table_embedding_model="prajjwal1/bert-tiny",
+ query_embedding_model="deepset/bert-small-mm_retrieval-question_encoder",
+ passage_embedding_model="deepset/bert-small-mm_retrieval-passage_encoder",
+ table_embedding_model="deepset/bert-small-mm_retrieval-table_encoder",
use_gpu=False,
)
diff --git a/test/pipelines/test_pipeline.py b/test/pipelines/test_pipeline.py
index 0a5365432e..0d3e09eabd 100644
--- a/test/pipelines/test_pipeline.py
+++ b/test/pipelines/test_pipeline.py
@@ -1313,6 +1313,100 @@ def test_deploy_on_deepset_cloud_invalid_state_in_progress():
)
+@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
+@responses.activate
+def test_failed_deploy_on_deepset_cloud():
+ if MOCK_DC:
+ responses.add(
+ method=responses.POST,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline/deploy",
+ json={"status": "DEPLOYMENT_SCHEDULED"},
+ status=200,
+ )
+
+ # status will be first undeployed, after deploy() it's in progress twice and the third time deployment failed
+ status_flow = ["UNDEPLOYED", "DEPLOYMENT_IN_PROGRESS", "DEPLOYMENT_IN_PROGRESS", "DEPLOYMENT_FAILED"]
+ for status in status_flow:
+ responses.add(
+ method=responses.GET,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline",
+ json={"status": status},
+ status=200,
+ )
+ with pytest.raises(
+ DeepsetCloudError,
+ match=f"Deployment of pipeline config 'test_new_non_existing_pipeline' failed. "
+ "This might be caused by an exception in deepset Cloud or a runtime error in the pipeline. "
+ "You can try to run this pipeline locally first.",
+ ):
+ Pipeline.deploy_on_deepset_cloud(
+ pipeline_config_name="test_new_non_existing_pipeline", api_endpoint=DC_API_ENDPOINT, api_key=DC_API_KEY
+ )
+
+
+@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
+@responses.activate
+def test_unexpected_failed_deploy_on_deepset_cloud():
+ if MOCK_DC:
+ responses.add(
+ method=responses.POST,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline/deploy",
+ json={"status": "DEPLOYMENT_SCHEDULED"},
+ status=200,
+ )
+
+ # status will be first undeployed, after deploy() it's in deployment failed
+ status_flow = ["UNDEPLOYED", "DEPLOYMENT_FAILED"]
+ for status in status_flow:
+ responses.add(
+ method=responses.GET,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline",
+ json={"status": status},
+ status=200,
+ )
+ with pytest.raises(
+ DeepsetCloudError,
+ match=f"Deployment of pipeline config 'test_new_non_existing_pipeline' failed. "
+ "This might be caused by an exception in deepset Cloud or a runtime error in the pipeline. "
+ "You can try to run this pipeline locally first.",
+ ):
+ Pipeline.deploy_on_deepset_cloud(
+ pipeline_config_name="test_new_non_existing_pipeline", api_endpoint=DC_API_ENDPOINT, api_key=DC_API_KEY
+ )
+
+
+@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
+@responses.activate
+def test_deploy_on_deepset_cloud_with_failed_start_state(caplog):
+ if MOCK_DC:
+ responses.add(
+ method=responses.POST,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline/deploy",
+ json={"status": "DEPLOYMENT_SCHEDULED"},
+ status=200,
+ )
+
+ # status will be first in failed (but not invalid) state, after deploy() it's in progress twice and third time deployed
+ status_flow = ["DEPLOYMENT_FAILED", "DEPLOYMENT_IN_PROGRESS", "DEPLOYMENT_IN_PROGRESS", "DEPLOYED"]
+ for status in status_flow:
+ responses.add(
+ method=responses.GET,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline",
+ json={"status": status},
+ status=200,
+ )
+
+ with caplog.at_level(logging.WARNING):
+ Pipeline.deploy_on_deepset_cloud(
+ pipeline_config_name="test_new_non_existing_pipeline", api_endpoint=DC_API_ENDPOINT, api_key=DC_API_KEY
+ )
+ assert (
+ "Pipeline config 'test_new_non_existing_pipeline' is in a failed state 'PipelineStatus.DEPLOYMENT_FAILED'."
+ in caplog.text
+ )
+ assert "This might be caused by a previous error during (un)deployment." in caplog.text
+
+
@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
@responses.activate
def test_undeploy_on_deepset_cloud_invalid_state_in_progress():
diff --git a/test/pipelines/test_pipeline_yaml.py b/test/pipelines/test_pipeline_yaml.py
index 353ec48dc6..64c9bcaa00 100644
--- a/test/pipelines/test_pipeline_yaml.py
+++ b/test/pipelines/test_pipeline_yaml.py
@@ -1021,3 +1021,10 @@ def test_save_yaml_overwrite(tmp_path):
with open(tmp_path / "saved_pipeline.yml", "r") as saved_yaml:
content = saved_yaml.read()
assert content != ""
+
+
+def test_load_yaml_ray_args_in_pipeline(tmp_path):
+ with pytest.raises(PipelineConfigError) as e:
+ pipeline = Pipeline.load_from_yaml(
+ SAMPLES_PATH / "pipeline" / "ray.haystack-pipeline.yml", pipeline_name="ray_query_pipeline"
+ )
diff --git a/test/pipelines/test_ray.py b/test/pipelines/test_ray.py
index 5a4171f907..17f996d206 100644
--- a/test/pipelines/test_ray.py
+++ b/test/pipelines/test_ray.py
@@ -14,6 +14,7 @@ def shutdown_ray():
try:
import ray
+ ray.serve.shutdown()
ray.shutdown()
except:
pass
@@ -21,15 +22,20 @@ def shutdown_ray():
@pytest.mark.integration
@pytest.mark.parametrize("document_store_with_docs", ["elasticsearch"], indirect=True)
-def test_load_pipeline(document_store_with_docs):
+@pytest.mark.parametrize("serve_detached", [True, False])
+def test_load_pipeline(document_store_with_docs, serve_detached):
pipeline = RayPipeline.load_from_yaml(
SAMPLES_PATH / "pipeline" / "ray.haystack-pipeline.yml",
pipeline_name="ray_query_pipeline",
ray_args={"num_cpus": 8},
+ serve_args={"detached": serve_detached},
)
prediction = pipeline.run(query="Who lives in Berlin?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}})
+ assert pipeline._serve_controller_client._detached == serve_detached
assert ray.serve.get_deployment(name="ESRetriever").num_replicas == 2
assert ray.serve.get_deployment(name="Reader").num_replicas == 1
+ assert ray.serve.get_deployment(name="ESRetriever").max_concurrent_queries == 17
+ assert ray.serve.get_deployment(name="ESRetriever").ray_actor_options["num_cpus"] == 0.5
assert prediction["query"] == "Who lives in Berlin?"
assert prediction["answers"][0].answer == "Carla"
diff --git a/test/samples/pipeline/ray.haystack-pipeline.yml b/test/samples/pipeline/ray.haystack-pipeline.yml
index 8dd4489af4..e89ec98ded 100644
--- a/test/samples/pipeline/ray.haystack-pipeline.yml
+++ b/test/samples/pipeline/ray.haystack-pipeline.yml
@@ -40,7 +40,13 @@ pipelines:
- name: ray_query_pipeline
nodes:
- name: ESRetriever
- replicas: 2
inputs: [ Query ]
+ serve_deployment_kwargs:
+ num_replicas: 2
+ version: Twenty
+ ray_actor_options:
+ # num_gpus: 0.25 # we have no GPU to test this
+ num_cpus: 0.5
+ max_concurrent_queries: 17
- name: Reader
inputs: [ ESRetriever ]
diff --git a/test/samples/preprocessor/nltk_models/pt.pickle b/test/samples/preprocessor/nltk_models/pt.pickle
new file mode 100644
index 0000000000..445ce95213
Binary files /dev/null and b/test/samples/preprocessor/nltk_models/pt.pickle differ
diff --git a/test/samples/preprocessor/nltk_models/wrong/en.pickle b/test/samples/preprocessor/nltk_models/wrong/en.pickle
new file mode 100644
index 0000000000..5edf856308
--- /dev/null
+++ b/test/samples/preprocessor/nltk_models/wrong/en.pickle
@@ -0,0 +1,2 @@
+This is a text file, not a real PunktSentenceTokenizer model.
+Loading it should not work on sentence tokenizer.
\ No newline at end of file
diff --git a/test/samples/squad/tiny_augmented.json b/test/samples/squad/tiny_augmented.json
index 2c29add194..c906c383e8 100644
--- a/test/samples/squad/tiny_augmented.json
+++ b/test/samples/squad/tiny_augmented.json
@@ -1 +1 @@
-{"data": [{"title": "test1", "paragraphs": [{"context": "my name is carla \u2014 me danced together with abdul - berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my grandmother is baba and i met together with you ka jakarta", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my sister is carla & i live upstairs with friends boom berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "the name is harry and i worked together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "whose aunt is carla and i sang together paula abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "suppose is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "what is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "where is the test for", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "suppose defines for test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "these constitutes a social that", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}], "topics": [{"title": "test1", "paragraphs": [{"context": "my name is carla \u2014 me danced together with abdul - berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my grandmother is baba and i met together with you ka jakarta", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my sister is carla & i live upstairs with friends boom berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "the name is harry and i worked together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "whose aunt is carla and i sang together paula abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "suppose is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "what is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "where is the test for", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "suppose defines for test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "these constitutes a social that", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}]}
\ No newline at end of file
+{"data": [{"title": "test1", "paragraphs": [{"context": "maiden father is carla and i lives together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my dad is carla and i lived comfortably at abdul rahman manhattan", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my mum ... carla and maria perform exclusively with myself karim berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "last wife , carla because i live now beside abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my name is carla and i live together with abdul hamid berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "thus is another test .", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another mathematical context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "there is dynamic test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}], "topics": [{"title": "test1", "paragraphs": [{"context": "maiden father is carla and i lives together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my dad is carla and i lived comfortably at abdul rahman manhattan", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my mum ... carla and maria perform exclusively with myself karim berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "last wife , carla because i live now beside abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my name is carla and i live together with abdul hamid berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "thus is another test .", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another mathematical context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "there is dynamic test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}]}
\ No newline at end of file
diff --git a/tutorials/Tutorial10_Knowledge_Graph.ipynb b/tutorials/Tutorial10_Knowledge_Graph.ipynb
index e40e04d00c..507ab40adf 100644
--- a/tutorials/Tutorial10_Knowledge_Graph.ipynb
+++ b/tutorials/Tutorial10_Knowledge_Graph.ipynb
@@ -39,6 +39,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,inmemorygraph]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial10_Knowledge_Graph.py b/tutorials/Tutorial10_Knowledge_Graph.py
index ebc696561d..70ab063b83 100644
--- a/tutorials/Tutorial10_Knowledge_Graph.py
+++ b/tutorials/Tutorial10_Knowledge_Graph.py
@@ -1,5 +1,13 @@
-import os
import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
+import os
import subprocess
import time
from pathlib import Path
@@ -8,8 +16,6 @@
from haystack.document_stores import GraphDBKnowledgeGraph, InMemoryKnowledgeGraph
from haystack.utils import fetch_archive_from_http
-logger = logging.getLogger(__name__)
-
def tutorial10_knowledge_graph():
# Let's first fetch some triples that we want to store in our knowledge graph
@@ -34,7 +40,7 @@ def tutorial10_knowledge_graph():
print(f"The last triple stored in the knowledge graph is: {kg.get_all_triples()[-1]}")
print(f"There are {len(kg.get_all_triples())} triples stored in the knowledge graph.")
- # ALTERNATIVE PATH USING GraphDB as knowledge graph
+ # ALTERNATIVE PATH USING GraphDB as knowledge graph
# LAUNCH_GRAPHDB = os.environ.get("LAUNCH_GRAPHDB", True)
# # Start a GraphDB server
# if LAUNCH_GRAPHDB:
diff --git a/tutorials/Tutorial11_Pipelines.ipynb b/tutorials/Tutorial11_Pipelines.ipynb
index 6e7fa8f55e..692be31501 100644
--- a/tutorials/Tutorial11_Pipelines.ipynb
+++ b/tutorials/Tutorial11_Pipelines.ipynb
@@ -90,6 +90,40 @@
"!pip install pygraphviz"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/tutorials/Tutorial11_Pipelines.py b/tutorials/Tutorial11_Pipelines.py
index 994f203cf9..78078c3dfc 100644
--- a/tutorials/Tutorial11_Pipelines.py
+++ b/tutorials/Tutorial11_Pipelines.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.utils import (
clean_wiki_text,
print_answers,
diff --git a/tutorials/Tutorial12_LFQA.ipynb b/tutorials/Tutorial12_LFQA.ipynb
index a11dc9aa06..ee4a2dc6bf 100644
--- a/tutorials/Tutorial12_LFQA.ipynb
+++ b/tutorials/Tutorial12_LFQA.ipynb
@@ -56,6 +56,40 @@
"!pip install -q git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial12_LFQA.py b/tutorials/Tutorial12_LFQA.py
index 1a9724bc41..e14c21e87d 100644
--- a/tutorials/Tutorial12_LFQA.py
+++ b/tutorials/Tutorial12_LFQA.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.utils import convert_files_to_docs, fetch_archive_from_http, clean_wiki_text
from haystack.nodes import Seq2SeqGenerator
diff --git a/tutorials/Tutorial13_Question_generation.ipynb b/tutorials/Tutorial13_Question_generation.ipynb
index a7dc74e03e..9868de1c3d 100644
--- a/tutorials/Tutorial13_Question_generation.ipynb
+++ b/tutorials/Tutorial13_Question_generation.ipynb
@@ -54,6 +54,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial13_Question_generation.py b/tutorials/Tutorial13_Question_generation.py
index cd2e102618..cea723ebf1 100644
--- a/tutorials/Tutorial13_Question_generation.py
+++ b/tutorials/Tutorial13_Question_generation.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from tqdm import tqdm
from haystack.nodes import QuestionGenerator, BM25Retriever, FARMReader, TransformersTranslator
from haystack.document_stores import ElasticsearchDocumentStore
diff --git a/tutorials/Tutorial14_Query_Classifier.ipynb b/tutorials/Tutorial14_Query_Classifier.ipynb
index 8d72e4491e..17f1430264 100644
--- a/tutorials/Tutorial14_Query_Classifier.ipynb
+++ b/tutorials/Tutorial14_Query_Classifier.ipynb
@@ -89,6 +89,40 @@
"!pip install pygraphviz"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/tutorials/Tutorial14_Query_Classifier.py b/tutorials/Tutorial14_Query_Classifier.py
index 615a561bc3..30f360a18b 100644
--- a/tutorials/Tutorial14_Query_Classifier.py
+++ b/tutorials/Tutorial14_Query_Classifier.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.utils import (
fetch_archive_from_http,
convert_files_to_docs,
diff --git a/tutorials/Tutorial15_TableQA.ipynb b/tutorials/Tutorial15_TableQA.ipynb
index dcea18bc68..5b46e830a6 100644
--- a/tutorials/Tutorial15_TableQA.ipynb
+++ b/tutorials/Tutorial15_TableQA.ipynb
@@ -39,6 +39,40 @@
"!nvidia-smi"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -3303,7 +3337,10 @@
"metadata": {},
"source": [
"## Adding tables from PDFs\n",
- "It can sometimes be hard to provide your data in form of a pandas DataFrame. For this case, we provide the `ParsrConverter` wrapper that can help you to convert, for example, a PDF file into a document that you can index."
+ "It can sometimes be hard to provide your data in form of a pandas DataFrame. For this case, we provide the `ParsrConverter` wrapper that can help you to convert, for example, a PDF file into a document that you can index.\n",
+ "\n",
+ "**Attention: `parsr` needs a docker environment for execution, but Colab doesn't support docker.**\n",
+ "**If you have a local docker environment, you can uncomment and run the following cells.**"
]
},
{
@@ -3312,10 +3349,10 @@
"metadata": {},
"outputs": [],
"source": [
- "import time\n",
+ "# import time\n",
"\n",
- "!docker run -d -p 3001:3001 axarev/parsr\n",
- "time.sleep(30)"
+ "# !docker run -d -p 3001:3001 axarev/parsr\n",
+ "# time.sleep(30)"
]
},
{
@@ -3324,7 +3361,7 @@
"metadata": {},
"outputs": [],
"source": [
- "!wget https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf"
+ "# !wget https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf"
]
},
{
@@ -3333,13 +3370,13 @@
"metadata": {},
"outputs": [],
"source": [
- "from haystack.nodes import ParsrConverter\n",
+ "# from haystack.nodes import ParsrConverter\n",
"\n",
- "converter = ParsrConverter()\n",
+ "# converter = ParsrConverter()\n",
"\n",
- "docs = converter.convert(\"table.pdf\")\n",
+ "# docs = converter.convert(\"table.pdf\")\n",
"\n",
- "tables = [doc for doc in docs if doc.content_type == \"table\"]"
+ "# tables = [doc for doc in docs if doc.content_type == \"table\"]"
]
},
{
@@ -3356,7 +3393,7 @@
}
],
"source": [
- "print(tables)"
+ "# print(tables)"
]
},
{
@@ -3409,4 +3446,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
diff --git a/tutorials/Tutorial15_TableQA.py b/tutorials/Tutorial15_TableQA.py
index c22717f6a0..94b8720d3c 100644
--- a/tutorials/Tutorial15_TableQA.py
+++ b/tutorials/Tutorial15_TableQA.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
import os
import json
import time
diff --git a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb
index ca8baee532..37adfd6085 100644
--- a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb
+++ b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb
@@ -56,6 +56,40 @@
"!pip install pygraphviz"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": 1,
diff --git a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py
index 74613dcd32..6660371a53 100644
--- a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py
+++ b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py
@@ -18,9 +18,17 @@
# Here are the imports we need
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores.elasticsearch import ElasticsearchDocumentStore
from haystack.nodes import PreProcessor, TransformersDocumentClassifier, FARMReader, BM25Retriever
-from haystack.schema import Document
from haystack.utils import convert_files_to_docs, fetch_archive_from_http, print_answers, launch_es
diff --git a/tutorials/Tutorial17_Audio.ipynb b/tutorials/Tutorial17_Audio.ipynb
index 23f3590ea1..460e29c96c 100644
--- a/tutorials/Tutorial17_Audio.ipynb
+++ b/tutorials/Tutorial17_Audio.ipynb
@@ -64,6 +64,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,audio]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/tutorials/Tutorial17_Audio.py b/tutorials/Tutorial17_Audio.py
index 71f7edbd3b..7d04970bce 100755
--- a/tutorials/Tutorial17_Audio.py
+++ b/tutorials/Tutorial17_Audio.py
@@ -6,6 +6,15 @@
# In this tutorial, we're going to see how to use `AnswerToSpeech` to convert answers
# into audio files.
#
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.utils import fetch_archive_from_http, launch_es, print_answers
from haystack.nodes import FARMReader, BM25Retriever
diff --git a/tutorials/Tutorial18_GPL.ipynb b/tutorials/Tutorial18_GPL.ipynb
index 843b894315..d642f2de27 100644
--- a/tutorials/Tutorial18_GPL.ipynb
+++ b/tutorials/Tutorial18_GPL.ipynb
@@ -81,6 +81,40 @@
}
}
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial18_GPL.py b/tutorials/Tutorial18_GPL.py
index 0229746361..e5affe9a5f 100644
--- a/tutorials/Tutorial18_GPL.py
+++ b/tutorials/Tutorial18_GPL.py
@@ -37,6 +37,15 @@
- 94.13 HIV is transmitted via sex or sharing needles
"""
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from sentence_transformers import SentenceTransformer, util
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from datasets import load_dataset
diff --git a/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb b/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb
index 5d442a3dc7..2b145a5b8f 100644
--- a/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb
+++ b/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb
@@ -63,15 +63,54 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
"outputs": [],
"source": [
"from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers\n",
"from haystack.nodes import FARMReader, TransformersReader"
- ]
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
},
{
"cell_type": "markdown",
diff --git a/tutorials/Tutorial1_Basic_QA_Pipeline.py b/tutorials/Tutorial1_Basic_QA_Pipeline.py
index e666921738..f6f5b58c62 100755
--- a/tutorials/Tutorial1_Basic_QA_Pipeline.py
+++ b/tutorials/Tutorial1_Basic_QA_Pipeline.py
@@ -10,14 +10,20 @@
# marvellous seven kingdoms.
import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers, launch_es
from haystack.nodes import FARMReader, TransformersReader, BM25Retriever
def tutorial1_basic_qa_pipeline():
- logger = logging.getLogger(__name__)
-
# ## Document Store
#
# Haystack finds answers to queries within the documents stored in a `DocumentStore`. The current implementations of
diff --git a/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb b/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb
index 5b457c54e3..a67ae56f2d 100644
--- a/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb
+++ b/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb
@@ -59,20 +59,54 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
"metadata": {
"collapsed": false,
"pycharm": {
"name": "#%%\n"
}
- },
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
"outputs": [],
"source": [
"from haystack.nodes import FARMReader\n",
"from haystack.utils import fetch_archive_from_http"
- ]
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
},
{
"cell_type": "markdown",
diff --git a/tutorials/Tutorial2_Finetune_a_model_on_your_data.py b/tutorials/Tutorial2_Finetune_a_model_on_your_data.py
index a110078f33..7f90a31eed 100755
--- a/tutorials/Tutorial2_Finetune_a_model_on_your_data.py
+++ b/tutorials/Tutorial2_Finetune_a_model_on_your_data.py
@@ -7,6 +7,15 @@
#
# This tutorial shows you how to fine-tune a pretrained model on your own dataset.
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.nodes import FARMReader
from haystack.utils import augment_squad, fetch_archive_from_http
diff --git a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb
index 316d587e28..b079778b27 100644
--- a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb
+++ b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb
@@ -59,6 +59,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": 3,
diff --git a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py
index d37fc130ef..84ebbbf90a 100644
--- a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py
+++ b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py
@@ -6,6 +6,15 @@
#
# If you are interested in more feature-rich Elasticsearch, then please refer to the Tutorial 1.
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import InMemoryDocumentStore, SQLDocumentStore
from haystack.nodes import FARMReader, TransformersReader, TfidfRetriever
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers
diff --git a/tutorials/Tutorial4_FAQ_style_QA.ipynb b/tutorials/Tutorial4_FAQ_style_QA.ipynb
index d24aaecddf..c78bd5ff10 100644
--- a/tutorials/Tutorial4_FAQ_style_QA.ipynb
+++ b/tutorials/Tutorial4_FAQ_style_QA.ipynb
@@ -67,6 +67,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -80,8 +114,7 @@
"from haystack.document_stores import ElasticsearchDocumentStore\n",
"\n",
"from haystack.nodes import EmbeddingRetriever\n",
- "import pandas as pd\n",
- "import requests"
+ "import pandas as pd"
]
},
{
diff --git a/tutorials/Tutorial4_FAQ_style_QA.py b/tutorials/Tutorial4_FAQ_style_QA.py
index 2d3b416b1c..8bcc719975 100755
--- a/tutorials/Tutorial4_FAQ_style_QA.py
+++ b/tutorials/Tutorial4_FAQ_style_QA.py
@@ -1,12 +1,17 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.nodes import EmbeddingRetriever
from haystack.utils import launch_es, print_answers, fetch_archive_from_http
import pandas as pd
-import requests
-import logging
-import subprocess
-import time
def tutorial4_faq_style_qa():
diff --git a/tutorials/Tutorial5_Evaluation.ipynb b/tutorials/Tutorial5_Evaluation.ipynb
index 65b377a617..095c4b8b1c 100644
--- a/tutorials/Tutorial5_Evaluation.ipynb
+++ b/tutorials/Tutorial5_Evaluation.ipynb
@@ -75,6 +75,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/tutorials/Tutorial5_Evaluation.py b/tutorials/Tutorial5_Evaluation.py
index 9e5e729543..24acfff195 100644
--- a/tutorials/Tutorial5_Evaluation.py
+++ b/tutorials/Tutorial5_Evaluation.py
@@ -1,4 +1,12 @@
import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
import tempfile
from pathlib import Path
@@ -16,9 +24,6 @@
from haystack.schema import Answer, Document, EvaluationResult, Label, MultiLabel, Span
-logger = logging.getLogger(__name__)
-
-
def tutorial5_evaluation():
# make sure these indices do not collide with existing ones, the indices will be wiped clean before data is inserted
diff --git a/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb b/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb
deleted file mode 100644
index 2989bfc8c7..0000000000
--- a/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb
+++ /dev/null
@@ -1,2761 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "bEH-CRbeA6NU"
- },
- "source": [
- "# Better Retrieval via \"Dense Passage Retrieval\"\n",
- "\n",
- "[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb)\n",
- "\n",
- "### Importance of Retrievers\n",
- "\n",
- "The Retriever has a huge impact on the performance of our overall search pipeline.\n",
- "\n",
- "\n",
- "### Different types of Retrievers\n",
- "#### Sparse\n",
- "Family of algorithms based on counting the occurrences of words (bag-of-words) resulting in very sparse vectors with length = vocab size.\n",
- "\n",
- "**Examples**: BM25, TF-IDF\n",
- "\n",
- "**Pros**: Simple, fast, well explainable\n",
- "\n",
- "**Cons**: Relies on exact keyword matches between query and text\n",
- " \n",
- "\n",
- "#### Dense\n",
- "These retrievers use neural network models to create \"dense\" embedding vectors. Within this family there are two different approaches: \n",
- "\n",
- "a) Single encoder: Use a **single model** to embed both query and passage. \n",
- "b) Dual-encoder: Use **two models**, one to embed the query and one to embed the passage\n",
- "\n",
- "Recent work suggests that dual encoders work better, likely because they can deal better with the different nature of query and passage (length, style, syntax ...). \n",
- "\n",
- "**Examples**: REALM, DPR, Sentence-Transformers\n",
- "\n",
- "**Pros**: Captures semantinc similarity instead of \"word matches\" (e.g. synonyms, related topics ...)\n",
- "\n",
- "**Cons**: Computationally more heavy, initial training of model\n",
- "\n",
- "\n",
- "### \"Dense Passage Retrieval\"\n",
- "\n",
- "In this Tutorial, we want to highlight one \"Dense Dual-Encoder\" called Dense Passage Retriever. \n",
- "It was introduced by Karpukhin et al. (2020, https://arxiv.org/abs/2004.04906. \n",
- "\n",
- "Original Abstract: \n",
- "\n",
- "_\"Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.\"_\n",
- "\n",
- "Paper: https://arxiv.org/abs/2004.04906 \n",
- "Original Code: https://fburl.com/qa-dpr \n",
- "\n",
- "\n",
- "*Use this* [link](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb) *to open the notebook in Google Colab.*\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "3K27Y5FbA6NV"
- },
- "source": [
- "### Prepare environment\n",
- "\n",
- "#### Colab: Enable the GPU runtime\n",
- "Make sure you enable the GPU runtime to experience decent speed in this tutorial. \n",
- "**Runtime -> Change Runtime type -> Hardware accelerator -> GPU**\n",
- "\n",
- "
@@ -82,6 +75,21 @@ Make sure you enable the GPU runtime to experience decent speed in this tutorial
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers
@@ -151,34 +159,28 @@ document_store.write_documents(docs)
#### Retriever
-**Here:** We use a `DensePassageRetriever`
+**Here:** We use an `EmbeddingRetriever`.
**Alternatives:**
-- The `BM25Retriever`with custom queries (e.g. boosting) and filters
-- Use `EmbeddingRetriever` to find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT)
-- Use `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging
+- `BM25Retriever` with custom queries (for example, boosting) and filters
+- `DensePassageRetriever` which uses two encoder models, one to embed the query and one to embed the passage, and then compares the embedding for retrieval
+- `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging
```python
-from haystack.nodes import DensePassageRetriever
+from haystack.nodes import EmbeddingRetriever
-retriever = DensePassageRetriever(
+retriever = EmbeddingRetriever(
document_store=document_store,
- query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
- passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
- max_seq_len_query=64,
- max_seq_len_passage=256,
- batch_size=16,
- use_gpu=True,
- embed_title=True,
- use_fast_tokenizers=True,
+ embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
+ model_format="sentence_transformers",
)
# Important:
-# Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all
+# Now that we initialized the Retriever, we need to call update_embeddings() to iterate over all
# previously indexed documents and update their embedding representation.
-# While this can be a time consuming operation (depending on corpus size), it only needs to be done once.
-# At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.
+# While this can be a time consuming operation (depending on the corpus size), it only needs to be done once.
+# At query time, we only need to embed the query and compare it to the existing document embeddings, which is very fast.
document_store.update_embeddings(retriever)
```
@@ -234,7 +236,8 @@ print_answers(prediction, details="minimum")
This [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany
-We bring NLP to the industry via open source!
+We bring NLP to the industry via open source!
+
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
diff --git a/docs/_src/tutorials/tutorials/7.md b/docs/_src/tutorials/tutorials/7.md
index cbb4d541ee..c22882b00d 100644
--- a/docs/_src/tutorials/tutorials/7.md
+++ b/docs/_src/tutorials/tutorials/7.md
@@ -43,6 +43,21 @@ Here are the packages and imports that we'll need:
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
from typing import List
diff --git a/docs/_src/tutorials/tutorials/8.md b/docs/_src/tutorials/tutorials/8.md
index 7d8d091708..cb78d48b11 100644
--- a/docs/_src/tutorials/tutorials/8.md
+++ b/docs/_src/tutorials/tutorials/8.md
@@ -45,6 +45,21 @@ This tutorial will show you all the tools that Haystack provides to help you cas
# !tar -xvf xpdf-tools-mac-4.03.tar.gz && sudo cp xpdf-tools-mac-4.03/bin64/pdftotext /usr/local/bin
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
# Here are the imports we need
diff --git a/docs/_src/tutorials/tutorials/9.md b/docs/_src/tutorials/tutorials/9.md
index 9490af9dc9..d77e5da173 100644
--- a/docs/_src/tutorials/tutorials/9.md
+++ b/docs/_src/tutorials/tutorials/9.md
@@ -24,6 +24,21 @@ This tutorial will guide you through the steps required to create a retriever th
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
```
+## Logging
+
+We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+Example log message:
+INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+
+
+```python
+import logging
+
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+```
+
```python
# Here are some imports that we'll need
diff --git a/docs/img/ci-failure-example-instructions.png b/docs/img/ci-failure-example-instructions.png
new file mode 100644
index 0000000000..db485a201f
Binary files /dev/null and b/docs/img/ci-failure-example-instructions.png differ
diff --git a/docs/img/ci-failure-example.png b/docs/img/ci-failure-example.png
new file mode 100644
index 0000000000..9fc44df66f
Binary files /dev/null and b/docs/img/ci-failure-example.png differ
diff --git a/docs/img/ci-success.png b/docs/img/ci-success.png
new file mode 100644
index 0000000000..304609e20d
Binary files /dev/null and b/docs/img/ci-success.png differ
diff --git a/docs/img/fork_action_config.png b/docs/img/fork_action_config.png
deleted file mode 100644
index 253d841382..0000000000
Binary files a/docs/img/fork_action_config.png and /dev/null differ
diff --git a/docs/pydoc/__init__.py b/docs/pydoc/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/docs/pydoc/renderers.py b/docs/pydoc/renderers.py
new file mode 100644
index 0000000000..5c76bdb4a1
--- /dev/null
+++ b/docs/pydoc/renderers.py
@@ -0,0 +1,49 @@
+import sys
+import io
+import dataclasses
+import docspec
+import typing as t
+from pathlib import Path
+from pydoc_markdown.interfaces import Context, Renderer
+from pydoc_markdown.contrib.renderers.markdown import MarkdownRenderer
+
+
+README_FRONTMATTER = """---
+title: {title}
+excerpt: {excerpt}
+category: {category}
+---
+
+"""
+
+
+@dataclasses.dataclass
+class ReadmeRenderer(Renderer):
+ """
+ This custom Renderer is heavily based on the `MarkdownRenderer`,
+ it just prepends a front matter so that the output can be published
+ directly to readme.io.
+ """
+
+ # These settings will be used in the front matter output
+ title: str
+ category: str
+ excerpt: str
+ # This exposes a special `markdown` settings value that can be used to pass
+ # parameters to the underlying `MarkdownRenderer`
+ markdown: MarkdownRenderer = dataclasses.field(default_factory=MarkdownRenderer)
+
+ def init(self, context: Context) -> None:
+ self.markdown.init(context)
+
+ def render(self, modules: t.List[docspec.Module]) -> None:
+ if self.markdown.filename is None:
+ sys.stdout.write(self._frontmatter())
+ self.markdown.render_to_stream(modules, sys.stdout)
+ else:
+ with io.open(self.markdown.filename, "w", encoding=self.markdown.encoding) as fp:
+ fp.write(self._frontmatter())
+ self.markdown.render_to_stream(modules, t.cast(t.TextIO, fp))
+
+ def _frontmatter(self) -> str:
+ return README_FRONTMATTER.format(title=self.title, category=self.category, excerpt=self.excerpt)
diff --git a/haystack/__init__.py b/haystack/__init__.py
index 8b0d9900ef..eca24ef531 100644
--- a/haystack/__init__.py
+++ b/haystack/__init__.py
@@ -12,14 +12,9 @@
__version__: str = str(metadata.version("farm-haystack"))
-# This configuration must be done before any import to apply to all submodules
+# Logging is not configured here on purpose, see https://github.com/deepset-ai/haystack/issues/2485
import logging
-logging.basicConfig(
- format="%(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.WARNING
-)
-logging.getLogger("haystack").setLevel(logging.INFO)
-
import pandas as pd
from haystack.schema import Document, Answer, Label, MultiLabel, Span, EvaluationResult
diff --git a/haystack/document_stores/__init__.py b/haystack/document_stores/__init__.py
index 1491a2f8d3..6ed752c961 100644
--- a/haystack/document_stores/__init__.py
+++ b/haystack/document_stores/__init__.py
@@ -12,8 +12,11 @@
elasticsearch_index_to_document_store,
open_search_index_to_document_store,
)
-from haystack.document_stores.opensearch import OpenSearchDocumentStore, OpenDistroElasticsearchDocumentStore
+OpenSearchDocumentStore = safe_import("haystack.document_stores.opensearch", "OpenSearchDocumentStore", "opensearch")
+OpenDistroElasticsearchDocumentStore = safe_import(
+ "haystack.document_stores.opensearch", "OpenDistroElasticsearchDocumentStore", "opensearch"
+)
SQLDocumentStore = safe_import("haystack.document_stores.sql", "SQLDocumentStore", "sql")
FAISSDocumentStore = safe_import("haystack.document_stores.faiss", "FAISSDocumentStore", "faiss")
PineconeDocumentStore = safe_import("haystack.document_stores.pinecone", "PineconeDocumentStore", "pinecone")
diff --git a/haystack/document_stores/memory.py b/haystack/document_stores/memory.py
index c86144c771..760df00ccc 100644
--- a/haystack/document_stores/memory.py
+++ b/haystack/document_stores/memory.py
@@ -10,7 +10,7 @@
from tqdm import tqdm
from haystack.schema import Document, Label
-from haystack.errors import DuplicateDocumentError
+from haystack.errors import DuplicateDocumentError, DocumentStoreError
from haystack.document_stores import BaseDocumentStore
from haystack.document_stores.base import get_batches_from_generator
from haystack.modeling.utils import initialize_device_settings
@@ -448,8 +448,11 @@ def update_embeddings(
) as progress_bar:
for document_batch in batched_documents:
embeddings = retriever.embed_documents(document_batch) # type: ignore
- assert len(document_batch) == len(embeddings)
-
+ if not len(document_batch) == len(embeddings):
+ raise DocumentStoreError(
+ "The number of embeddings does not match the number of documents in the batch "
+ f"({len(embeddings)} != {len(document_batch)})"
+ )
if embeddings[0].shape[0] != self.embedding_dim:
raise RuntimeError(
f"Embedding dim. of model ({embeddings[0].shape[0]})"
diff --git a/haystack/document_stores/opensearch.py b/haystack/document_stores/opensearch.py
index 2ad78a3a11..e6d9d17518 100644
--- a/haystack/document_stores/opensearch.py
+++ b/haystack/document_stores/opensearch.py
@@ -7,25 +7,25 @@
from tqdm.auto import tqdm
try:
- from elasticsearch.helpers import bulk
- from elasticsearch.exceptions import RequestError
-except (ImportError, ModuleNotFoundError) as ie:
+ from opensearchpy import OpenSearch, Urllib3HttpConnection, RequestsHttpConnection, NotFoundError, RequestError
+ from opensearchpy.helpers import bulk
+except (ImportError, ModuleNotFoundError) as e:
from haystack.utils.import_utils import _optional_component_not_installed
- _optional_component_not_installed(__name__, "elasticsearch", ie)
+ _optional_component_not_installed(__name__, "opensearch", e)
from haystack.schema import Document
from haystack.document_stores.base import get_batches_from_generator
from haystack.document_stores.filter_utils import LogicalFilterClause
+from haystack.errors import DocumentStoreError
-from .elasticsearch import ElasticsearchDocumentStore
-
+from .elasticsearch import BaseElasticsearchDocumentStore, prepare_hosts
logger = logging.getLogger(__name__)
-class OpenSearchDocumentStore(ElasticsearchDocumentStore):
+class OpenSearchDocumentStore(BaseElasticsearchDocumentStore):
def __init__(
self,
scheme: str = "https", # Mind this different default param
@@ -131,18 +131,45 @@ def __init__(
Synonym or Synonym_graph to handle synonyms, including multi-word synonyms correctly during the analysis process.
More info at https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-graph-tokenfilter.html
"""
+ # These parameters aren't used by Opensearch at the moment but could be in the future, see
+ # https://github.com/opensearch-project/security/issues/1504. Let's not deprecate them for
+ # now but send a warning to the user.
+ if api_key or api_key_id:
+ logger.warning("api_key and api_key_id will be ignored by the Opensearch client")
+
+ # Base constructor needs the client to be ready, create it before calling super()
+ client = self._init_client(
+ host=host,
+ port=port,
+ username=username,
+ password=password,
+ aws4auth=aws4auth,
+ scheme=scheme,
+ ca_certs=ca_certs,
+ verify_certs=verify_certs,
+ timeout=timeout,
+ use_system_proxy=use_system_proxy,
+ )
+
+ # Test the connection
+ try:
+ client.indices.get(index)
+ except NotFoundError:
+ # We don't know which permissions the user has but we can assume they can write to the given index, so
+ # if we get a NotFoundError it means at least the connection is working.
+ pass
+ except Exception as e:
+ # If we get here, there's something fundamentally wrong with the connection and we can't continue
+ raise ConnectionError(
+ f"Initial connection to Opensearch failed with error '{e}'\n"
+ f"Make sure an Opensearch instance is running at `{host}` and that it has finished booting (can take > 30s)."
+ )
+
self.embeddings_field_supports_similarity = False
self.similarity_to_space_type = {"cosine": "cosinesimil", "dot_product": "innerproduct", "l2": "l2"}
self.space_type_to_similarity = {v: k for k, v in self.similarity_to_space_type.items()}
super().__init__(
- scheme=scheme,
- username=username,
- password=password,
- host=host,
- port=port,
- api_key_id=api_key_id,
- api_key=api_key,
- aws4auth=aws4auth,
+ client=client,
index=index,
label_index=label_index,
search_fields=search_fields,
@@ -153,13 +180,10 @@ def __init__(
custom_mapping=custom_mapping,
excluded_meta_data=excluded_meta_data,
analyzer=analyzer,
- ca_certs=ca_certs,
- verify_certs=verify_certs,
recreate_index=recreate_index,
create_index=create_index,
refresh_type=refresh_type,
similarity=similarity,
- timeout=timeout,
return_embedding=return_embedding,
duplicate_documents=duplicate_documents,
index_type=index_type,
@@ -167,9 +191,65 @@ def __init__(
skip_missing_embeddings=skip_missing_embeddings,
synonyms=synonyms,
synonym_type=synonym_type,
- use_system_proxy=use_system_proxy,
)
+ @classmethod
+ def _init_client(
+ cls,
+ host: Union[str, List[str]],
+ port: Union[int, List[int]],
+ username: str,
+ password: str,
+ aws4auth,
+ scheme: str,
+ ca_certs: Optional[str],
+ verify_certs: bool,
+ timeout: int,
+ use_system_proxy: bool,
+ ) -> OpenSearch:
+ """
+ Create an instance of the Opensearch client
+ """
+ hosts = prepare_hosts(host, port)
+ connection_class = Urllib3HttpConnection
+ if use_system_proxy:
+ connection_class = RequestsHttpConnection
+
+ if username:
+ # standard http_auth
+ client = OpenSearch(
+ hosts=hosts,
+ http_auth=(username, password),
+ scheme=scheme,
+ ca_certs=ca_certs,
+ verify_certs=verify_certs,
+ timeout=timeout,
+ connection_class=connection_class,
+ )
+ elif aws4auth:
+ # Sign requests to Opensearch with IAM credentials
+ # see https://docs.aws.amazon.com/opensearch-service/latest/developerguide/request-signing.html#request-signing-python
+ client = OpenSearch(
+ hosts=hosts,
+ http_auth=aws4auth,
+ connection_class=RequestsHttpConnection,
+ use_ssl=True,
+ verify_certs=True,
+ timeout=timeout,
+ )
+ else:
+ # no authentication needed
+ client = OpenSearch(
+ hosts=hosts,
+ scheme=scheme,
+ ca_certs=ca_certs,
+ verify_certs=verify_certs,
+ timeout=timeout,
+ connection_class=connection_class,
+ )
+
+ return client
+
def query_by_embedding(
self,
query_emb: np.ndarray,
@@ -264,10 +344,12 @@ def query_by_embedding(
return_embedding = self.return_embedding
if not self.embedding_field:
- raise RuntimeError("Please specify arg `embedding_field` in ElasticsearchDocumentStore()")
+ raise DocumentStoreError("Please set a valid `embedding_field` for OpenSearchDocumentStore")
# +1 in similarity to avoid negative numbers (for cosine sim)
body: Dict[str, Any] = {"size": top_k, "query": self._get_vector_similarity_query(query_emb, top_k)}
if filters:
+ if not "bool" in body["query"]:
+ body["query"]["bool"] = {}
body["query"]["bool"]["filter"] = LogicalFilterClause.parse(filters).convert_to_elasticsearch()
excluded_meta_data: Optional[list] = None
@@ -317,7 +399,7 @@ def _create_document_index(self, index_name: str, headers: Optional[Dict[str, st
search_field in mappings["properties"]
and mappings["properties"][search_field]["type"] != "text"
):
- raise Exception(
+ raise DocumentStoreError(
f"The search_field '{search_field}' of index '{index_id}' with type '{mappings['properties'][search_field]['type']}' "
f"does not have the right type 'text' to be queried in fulltext search. Please use only 'text' type properties as search_fields or use another index. "
f"This error might occur if you are trying to use haystack 1.0 and above with an existing elasticsearch index created with a previous version of haystack. "
@@ -335,7 +417,7 @@ def _create_document_index(self, index_name: str, headers: Optional[Dict[str, st
else:
# bad embedding field
if mappings["properties"][self.embedding_field]["type"] != "knn_vector":
- raise Exception(
+ raise DocumentStoreError(
f"The '{index_id}' index in OpenSearch already has a field called '{self.embedding_field}'"
f" with the type '{mappings['properties'][self.embedding_field]['type']}'. Please update the "
f"document_store to use a different name for the embedding_field parameter."
@@ -527,7 +609,7 @@ def clone_embedding_field(
):
mapping = self.client.indices.get(self.index, headers=headers)[self.index]["mappings"]
if new_embedding_field in mapping["properties"]:
- raise Exception(
+ raise DocumentStoreError(
f"{new_embedding_field} already exists with mapping {mapping['properties'][new_embedding_field]}"
)
mapping["properties"][new_embedding_field] = self._get_embedding_field_mapping(similarity=similarity)
diff --git a/haystack/document_stores/sql.py b/haystack/document_stores/sql.py
index 7ada22beee..5248801cdc 100644
--- a/haystack/document_stores/sql.py
+++ b/haystack/document_stores/sql.py
@@ -21,7 +21,7 @@
ForeignKeyConstraint,
)
from sqlalchemy.ext.declarative import declarative_base
- from sqlalchemy.orm import relationship, sessionmaker
+ from sqlalchemy.orm import relationship, sessionmaker, validates
from sqlalchemy.sql import case, null
except (ImportError, ModuleNotFoundError) as ie:
from haystack.utils.import_utils import _optional_component_not_installed
@@ -73,6 +73,17 @@ class MetaDocumentORM(ORMBase):
{},
) # type: ignore
+ valid_metadata_types = (str, int, float, bool, bytes, bytearray, type(None))
+
+ @validates("value")
+ def validate_value(self, key, value):
+ if not isinstance(value, self.valid_metadata_types):
+ raise TypeError(
+ f"Discarded metadata '{self.name}', since it has invalid type: {type(value).__name__}.\n"
+ f"SQLDocumentStore can accept and cast to string only the following types: {', '.join([el.__name__ for el in self.valid_metadata_types])}"
+ )
+ return value
+
class LabelORM(ORMBase):
__tablename__ = "label"
@@ -386,7 +397,12 @@ def write_documents(
for doc in document_objects[i : i + batch_size]:
meta_fields = doc.meta or {}
vector_id = meta_fields.pop("vector_id", None)
- meta_orms = [MetaDocumentORM(name=key, value=value) for key, value in meta_fields.items()]
+ meta_orms = []
+ for key, value in meta_fields.items():
+ try:
+ meta_orms.append(MetaDocumentORM(name=key, value=value))
+ except TypeError as ex:
+ logger.error(f"Document {doc.id} - {ex}")
doc_mapping = {
"id": doc.id,
"content": doc.to_dict()["content"],
diff --git a/haystack/document_stores/weaviate.py b/haystack/document_stores/weaviate.py
index f24c83ce60..3dc8f51cc1 100644
--- a/haystack/document_stores/weaviate.py
+++ b/haystack/document_stores/weaviate.py
@@ -11,7 +11,7 @@
try:
import weaviate
- from weaviate import client, AuthClientPassword
+ from weaviate import client, AuthClientPassword, gql
except (ImportError, ModuleNotFoundError) as ie:
from haystack.utils.import_utils import _optional_component_not_installed
@@ -814,8 +814,10 @@ def query(
query: Optional[str] = None,
filters: Optional[Dict[str, Union[Dict, List, str, int, float, bool]]] = None,
top_k: int = 10,
+ all_terms_must_match: bool = False,
custom_query: Optional[str] = None,
index: Optional[str] = None,
+ headers: Optional[Dict[str, str]] = None,
scale_score: bool = True,
) -> List[Document]:
"""
@@ -887,36 +889,95 @@ def query(
}
```
:param top_k: How many documents to return per query.
+ :param all_terms_must_match: Not used in Weaviate.
:param custom_query: Custom query that will executed using query.raw method, for more details refer
https://weaviate.io/developers/weaviate/current/graphql-references/filters.html
:param index: The name of the index in the DocumentStore from which to retrieve documents
+ :param headers: Not used in Weaviate.
:param scale_score: Whether to scale the similarity score to the unit interval (range of [0,1]).
If true (default) similarity scores (e.g. cosine or dot_product) which naturally have a different value range will be scaled to a range of [0,1], where 1 means extremely relevant.
Otherwise raw similarity scores (e.g. cosine or dot_product) will be used.
"""
+ if headers:
+ raise NotImplementedError("Weaviate does not support Custom HTTP headers!")
+
+ if all_terms_must_match:
+ raise NotImplementedError("The `all_terms_must_match` option is not supported in Weaviate!")
+
index = self._sanitize_index_name(index) or self.index
# Build the properties to retrieve from Weaviate
properties = self._get_current_properties(index)
properties.append("_additional {id, certainty, vector}")
- if custom_query:
- query_output = self.weaviate_client.query.raw(custom_query)
- elif filters:
- filter_dict = LogicalFilterClause.parse(filters).convert_to_weaviate()
- query_output = (
- self.weaviate_client.query.get(class_name=index, properties=properties)
- .with_where(filter_dict)
- .with_limit(top_k)
- .do()
- )
+ if query is None:
+
+ # Retrieval via custom query, no BM25
+ if custom_query:
+ query_output = self.weaviate_client.query.raw(custom_query)
+
+ # Naive retrieval without BM25, only filtering
+ elif filters:
+ filter_dict = LogicalFilterClause.parse(filters).convert_to_weaviate()
+ query_output = (
+ self.weaviate_client.query.get(class_name=index, properties=properties)
+ .with_where(filter_dict)
+ .with_limit(top_k)
+ .do()
+ )
+ else:
+ raise NotImplementedError(
+ "Weaviate does not support the retrieval of records without specifying a query or a filter!"
+ )
+
+ # Default Retrieval via BM25 using the user's query on `self.content_field`
else:
- raise NotImplementedError(
- "Weaviate does not support inverted index text query. However, "
- "it allows to search by filters example : {'content': 'some text'} or "
- "use a custom GraphQL query in text format!"
+ logger.warning(
+ "As of v1.14.1 Weaviate's BM25 retrieval is still in experimental phase, "
+ "so use it with care! To turn on the BM25 experimental feature in Weaviate "
+ "you need to start it with the `ENABLE_EXPERIMENTAL_BM25='true'` "
+ "environmental variable."
)
+ # Retrieval with BM25 AND filtering
+ if filters:
+ raise NotImplementedError(
+ "Weaviate currently (v1.14.1) does not support filters WITH inverted index text query (eg BM25)!"
+ )
+
+ # Once Weaviate starts supporting filters with BM25:
+ # filter_dict = LogicalFilterClause.parse(filters).convert_to_weaviate()
+ # gql_query = weaviate.gql.get.GetBuilder(class_name=index,
+ # properties=properties,
+ # connection=self.weaviate_client) \
+ # .with_near_vector({'vector': [0, 0]}) \
+ # .with_where(filter_dict) \
+ # .with_limit(top_k) \
+ # .build()
+
+ # BM25 retrieval without filtering
+ gql_query = (
+ gql.get.GetBuilder(class_name=index, properties=properties, connection=self.weaviate_client)
+ .with_near_vector({"vector": [0, 0]})
+ .with_limit(top_k)
+ .build()
+ )
+
+ # Build the BM25 part of the GQL manually.
+ # Currently the GetBuilder of the Weaviate-client (v3.6.0)
+ # does not support the BM25 part of GQL building, so
+ # the BM25 part needs to be added manually.
+ # The BM25 query needs to be provided all lowercase while
+ # the functionality is in experimental mode in Weaviate,
+ # see https://app.slack.com/client/T0181DYT9KN/C017EG2SL3H/thread/C017EG2SL3H-1658790227.208119
+ bm25_gql_query = f"""bm25: {{
+ query: "{query.replace('"', ' ').lower()}",
+ properties: ["{self.content_field}"]
+ }}"""
+ gql_query = gql_query.replace("nearVector: {vector: [0, 0]}", bm25_gql_query)
+
+ query_output = self.weaviate_client.query.raw(gql_query)
+
results = []
if query_output and "data" in query_output and "Get" in query_output.get("data"):
if query_output.get("data").get("Get").get(index):
@@ -1238,10 +1299,19 @@ def delete_documents(
index = self._sanitize_index_name(index) or self.index
if not filters and not ids:
+ # Delete the existing index, then create an empty new one
self._create_schema_and_index(index, recreate_index=True)
+ return
+
+ # Create index if it doesn't exist yet
+ self._create_schema_and_index(index, recreate_index=False)
+
+ if ids and not filters:
+ for id in ids:
+ self.weaviate_client.data_object.delete(id)
+
else:
- # create index if it doesn't exist yet
- self._create_schema_and_index(index, recreate_index=False)
+ # Use filters to restrict list of retrieved documents, before checking these against provided ids
docs_to_delete = self.get_all_documents(index, filters=filters)
if ids:
docs_to_delete = [doc for doc in docs_to_delete if doc.id in ids]
diff --git a/haystack/errors.py b/haystack/errors.py
index 88d6de4222..bc81faf0f8 100644
--- a/haystack/errors.py
+++ b/haystack/errors.py
@@ -35,6 +35,13 @@ def __repr__(self):
return str(self)
+class ModelingError(HaystackError):
+ """Exception for issues raised by the modeling module"""
+
+ def __init__(self, message: Optional[str] = None, docs_link: Optional[str] = "https://haystack.deepset.ai/"):
+ super().__init__(message=message, docs_link=docs_link)
+
+
class PipelineError(HaystackError):
"""Exception for issues raised within a pipeline"""
diff --git a/haystack/json-schemas/haystack-pipeline-master.schema.json b/haystack/json-schemas/haystack-pipeline-master.schema.json
index f85d8c62ab..16644ec408 100644
--- a/haystack/json-schemas/haystack-pipeline-master.schema.json
+++ b/haystack/json-schemas/haystack-pipeline-master.schema.json
@@ -239,10 +239,41 @@
"type": "string"
}
},
- "replicas": {
- "title": "replicas",
- "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
- "type": "integer"
+ "serve_deployment_kwargs": {
+ "title": "serve_deployment_kwargs",
+ "description": "Arguments to be passed to the Ray Serve `deployment()` method (only for Ray pipelines)",
+ "type": "object",
+ "properties": {
+ "num_replicas": {
+ "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
+ "type": "integer"
+ },
+ "version": {
+ "type": "string"
+ },
+ "prev_version": {
+ "type": "string"
+ },
+ "init_args": {
+ "type": "array"
+ },
+ "init_kwargs": {
+ "type": "object"
+ },
+ "router_prefix": {
+ "type": "string"
+ },
+ "ray_actor_options": {
+ "type": "object"
+ },
+ "user_config": {
+ "type": {}
+ },
+ "max_concurrent_queries": {
+ "type": "integer"
+ }
+ },
+ "additionalProperties": true
}
},
"required": [
@@ -285,7 +316,7 @@
"items": {
"not": {
"required": [
- "replicas"
+ "serve_deployment_kwargs"
]
}
}
@@ -2116,11 +2147,6 @@
"default": true,
"type": "boolean"
},
- "infer_tokenizer_classes": {
- "title": "Infer Tokenizer Classes",
- "default": false,
- "type": "boolean"
- },
"similarity_function": {
"title": "Similarity Function",
"default": "dot_product",
@@ -3572,6 +3598,18 @@
"default": true,
"type": "boolean"
},
+ "tokenizer_model_folder": {
+ "title": "Tokenizer Model Folder",
+ "anyOf": [
+ {
+ "type": "string"
+ },
+ {
+ "type": "string",
+ "format": "path"
+ }
+ ]
+ },
"language": {
"title": "Language",
"default": "en",
@@ -3742,6 +3780,11 @@
"batch_size": {
"title": "Batch Size",
"type": "integer"
+ },
+ "sep_token": {
+ "title": "Sep Token",
+ "default": "",
+ "type": "string"
}
},
"additionalProperties": false,
@@ -4326,11 +4369,6 @@
"default": true,
"type": "boolean"
},
- "infer_tokenizer_classes": {
- "title": "Infer Tokenizer Classes",
- "default": false,
- "type": "boolean"
- },
"similarity_function": {
"title": "Similarity Function",
"default": "dot_product",
@@ -4375,6 +4413,11 @@
"title": "Scale Score",
"default": true,
"type": "boolean"
+ },
+ "use_fast": {
+ "title": "Use Fast",
+ "default": true,
+ "type": "boolean"
}
},
"required": [
diff --git a/haystack/modeling/data_handler/data_silo.py b/haystack/modeling/data_handler/data_silo.py
index 435e1ef686..f7237b8d28 100644
--- a/haystack/modeling/data_handler/data_silo.py
+++ b/haystack/modeling/data_handler/data_silo.py
@@ -812,7 +812,16 @@ def _run_teacher(self, batch: dict) -> List[torch.Tensor]:
"""
Run the teacher model on the given batch.
"""
- return self.teacher.inferencer.model(**batch)
+ params = {
+ "input_ids": batch["input_ids"],
+ "segment_ids": batch["segment_ids"],
+ "padding_mask": batch["padding_mask"],
+ }
+ if "output_hidden_states" in batch.keys():
+ params["output_hidden_states"] = batch["output_hidden_states"]
+ if "output_attentions" in batch.keys():
+ params["output_attentions"] = batch["output_attentions"]
+ return self.teacher.inferencer.model(**params)
def _pass_batches(
self,
diff --git a/haystack/modeling/data_handler/processor.py b/haystack/modeling/data_handler/processor.py
index dd90a00a46..e9584bddc3 100644
--- a/haystack/modeling/data_handler/processor.py
+++ b/haystack/modeling/data_handler/processor.py
@@ -1,4 +1,4 @@
-from typing import Optional, Dict, List, Union, Any, Iterable
+from typing import Optional, Dict, List, Union, Any, Iterable, Type
import os
import json
@@ -16,9 +16,11 @@
import requests
from tqdm import tqdm
from torch.utils.data import TensorDataset
+import transformers
+from transformers import PreTrainedTokenizer
from haystack.modeling.model.tokenization import (
- Tokenizer,
+ get_tokenizer,
tokenize_batch_question_answering,
tokenize_with_metadata,
truncate_sequences,
@@ -176,11 +178,9 @@ def load_from_dir(cls, load_dir: str):
"Loading tokenizer from deprecated config. "
"If you used `custom_vocab` or `never_split_chars`, this won't work anymore."
)
- tokenizer = Tokenizer.load(
- load_dir, tokenizer_class=config["tokenizer"], do_lower_case=config["lower_case"]
- )
+ tokenizer = get_tokenizer(load_dir, tokenizer_class=config["tokenizer"], do_lower_case=config["lower_case"])
else:
- tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["tokenizer"])
+ tokenizer = get_tokenizer(load_dir, tokenizer_class=config["tokenizer"])
# we have to delete the tokenizer string from config, because we pass it as Object
del config["tokenizer"]
@@ -216,7 +216,7 @@ def convert_from_transformers(
**kwargs,
):
tokenizer_args = tokenizer_args or {}
- tokenizer = Tokenizer.load(
+ tokenizer = get_tokenizer(
tokenizer_name_or_path,
tokenizer_class=tokenizer_class,
use_fast=use_fast,
@@ -308,7 +308,9 @@ def file_to_dicts(self, file: str) -> List[dict]:
raise NotImplementedError()
@abstractmethod
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
raise NotImplementedError()
@abstractmethod
@@ -445,7 +447,9 @@ def __init__(
"using the default task or add a custom task later via processor.add_task()"
)
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Convert input dictionaries into a pytorch dataset for Question Answering.
For this we have an internal representation called "baskets".
@@ -492,7 +496,7 @@ def file_to_dicts(self, file: str) -> List[dict]:
return dicts
# TODO use Input Objects instead of this function, remove Natural Questions (NQ) related code
- def convert_qa_input_dict(self, infer_dict: dict):
+ def convert_qa_input_dict(self, infer_dict: dict) -> Dict[str, Any]:
"""Input dictionaries in QA can either have ["context", "qas"] (internal format) as keys or
["text", "questions"] (api format). This function converts the latter into the former. It also converts the
is_impossible field to answer_type so that NQ and SQuAD dicts have the same format.
@@ -929,9 +933,15 @@ def load_from_dir(cls, load_dir: str):
# read config
processor_config_file = Path(load_dir) / "processor_config.json"
config = json.load(open(processor_config_file))
- # init tokenizer
- query_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["query_tokenizer"], subfolder="query")
- passage_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["passage_tokenizer"], subfolder="passage")
+ # init tokenizers
+ query_tokenizer_class: Type[PreTrainedTokenizer] = getattr(transformers, config["query_tokenizer"])
+ query_tokenizer = query_tokenizer_class.from_pretrained(
+ pretrained_model_name_or_path=load_dir, subfolder="query"
+ )
+ passage_tokenizer_class: Type[PreTrainedTokenizer] = getattr(transformers, config["passage_tokenizer"])
+ passage_tokenizer = passage_tokenizer_class.from_pretrained(
+ pretrained_model_name_or_path=load_dir, subfolder="passage"
+ )
# we have to delete the tokenizer string from config, because we pass it as Object
del config["query_tokenizer"]
@@ -978,7 +988,9 @@ def save(self, save_dir: Union[str, Path]):
with open(output_config_file, "w") as file:
json.dump(config, file)
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Convert input dictionaries into a pytorch dataset for TextSimilarity (e.g. DPR).
For conversion we have an internal representation called "baskets".
@@ -1334,9 +1346,9 @@ def load_from_dir(cls, load_dir: str):
processor_config_file = Path(load_dir) / "processor_config.json"
config = json.load(open(processor_config_file))
# init tokenizer
- query_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["query_tokenizer"], subfolder="query")
- passage_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["passage_tokenizer"], subfolder="passage")
- table_tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["table_tokenizer"], subfolder="table")
+ query_tokenizer = get_tokenizer(load_dir, tokenizer_class=config["query_tokenizer"], subfolder="query")
+ passage_tokenizer = get_tokenizer(load_dir, tokenizer_class=config["passage_tokenizer"], subfolder="passage")
+ table_tokenizer = get_tokenizer(load_dir, tokenizer_class=config["table_tokenizer"], subfolder="table")
# we have to delete the tokenizer string from config, because we pass it as Object
del config["query_tokenizer"]
@@ -1488,7 +1500,9 @@ def _read_multimodal_dpr_json(self, file: str, max_samples: Optional[int] = None
standard_dicts.append(sample)
return standard_dicts
- def dataset_from_dicts(self, dicts: List[Dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Convert input dictionaries into a pytorch dataset for TextSimilarity.
For conversion we have an internal representation called "baskets".
@@ -1836,7 +1850,9 @@ def __init__(
def file_to_dicts(self, file: str) -> List[Dict]:
raise NotImplementedError
- def dataset_from_dicts(self, dicts, indices=None, return_baskets=False, debug=False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
self.baskets = []
# Tokenize in batches
texts = [x["text"] for x in dicts]
@@ -1958,7 +1974,7 @@ def load_from_dir(cls, load_dir: str):
processor_config_file = Path(load_dir) / "processor_config.json"
config = json.load(open(processor_config_file))
# init tokenizer
- tokenizer = Tokenizer.load(load_dir, tokenizer_class=config["tokenizer"])
+ tokenizer = get_tokenizer(load_dir, tokenizer_class=config["tokenizer"])
# we have to delete the tokenizer string from config, because we pass it as Object
del config["tokenizer"]
@@ -1979,7 +1995,9 @@ def convert_labels(self, dictionary: Dict):
ret: Dict = {}
return ret
- def dataset_from_dicts(self, dicts: List[Dict], indices=None, return_baskets: bool = False, debug: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
"""
Function to convert input dictionaries containing text into a torch dataset.
For normal operation with Language Models it calls the superclass' TextClassification.dataset_from_dicts method.
@@ -2067,7 +2085,9 @@ def file_to_dicts(self, file: str) -> List[dict]:
dicts.append({"text": line})
return dicts
- def dataset_from_dicts(self, dicts: List[dict], indices: Optional[List[int]] = None, return_baskets: bool = False):
+ def dataset_from_dicts(
+ self, dicts: List[Dict], indices: List[int] = [], return_baskets: bool = False, debug: bool = False
+ ):
if return_baskets:
raise NotImplementedError("return_baskets is not supported by UnlabeledTextProcessor")
texts = [dict_["text"] for dict_ in dicts]
diff --git a/haystack/modeling/data_handler/samples.py b/haystack/modeling/data_handler/samples.py
index 443295ea64..6335490ec7 100644
--- a/haystack/modeling/data_handler/samples.py
+++ b/haystack/modeling/data_handler/samples.py
@@ -1,4 +1,4 @@
-from typing import Union, Optional, List
+from typing import Any, Union, Optional, List, Dict
import logging
import numpy as np
@@ -13,7 +13,13 @@ class Sample:
the human readable clear_text. Over the course of data preprocessing, this object is populated
with tokenized and featurized versions of the data."""
- def __init__(self, id: str, clear_text: dict, tokenized: Optional[dict] = None, features: Optional[dict] = None):
+ def __init__(
+ self,
+ id: str,
+ clear_text: dict,
+ tokenized: Optional[dict] = None,
+ features: Optional[Union[Dict[str, Any], List[Dict[str, Any]]]] = None,
+ ):
"""
:param id: The unique id of the sample
:param clear_text: A dictionary containing various human readable fields (e.g. text, label).
diff --git a/haystack/modeling/evaluation/eval.py b/haystack/modeling/evaluation/eval.py
index 4cdba7409f..028227462b 100644
--- a/haystack/modeling/evaluation/eval.py
+++ b/haystack/modeling/evaluation/eval.py
@@ -8,6 +8,7 @@
from haystack.modeling.evaluation.metrics import compute_metrics, compute_report_metrics
from haystack.modeling.model.adaptive_model import AdaptiveModel
+from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
from haystack.utils.experiment_tracking import Tracker as tracker
from haystack.modeling.visual import BUSH_SEP
@@ -69,7 +70,26 @@ def eval(
with torch.no_grad():
- logits = model.forward(**batch)
+ if isinstance(model, AdaptiveModel):
+ logits = model.forward(
+ input_ids=batch.get("input_ids", None),
+ segment_ids=batch.get("segment_ids", None),
+ padding_mask=batch.get("padding_mask", None),
+ output_hidden_states=batch.get("output_hidden_states", False),
+ output_attentions=batch.get("output_attentions", False),
+ )
+ elif isinstance(model, BiAdaptiveModel):
+ logits = model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )
+ else:
+ logits = model.forward(**batch)
+
losses_per_head = model.logits_to_loss_per_head(logits=logits, **batch)
preds = model.logits_to_preds(logits=logits, **batch)
labels = model.prepare_labels(**batch)
diff --git a/haystack/modeling/infer.py b/haystack/modeling/infer.py
index 85b828b22b..adfddf1d50 100644
--- a/haystack/modeling/infer.py
+++ b/haystack/modeling/infer.py
@@ -470,11 +470,7 @@ def _get_predictions(self, dataset: Dataset, tensor_names: List, baskets):
with torch.no_grad():
logits = self.model.forward(**batch)
preds = self.model.formatted_preds(
- logits=logits,
- samples=batch_samples,
- tokenizer=self.processor.tokenizer,
- return_class_probs=self.return_class_probs,
- **batch,
+ logits=logits, samples=batch_samples, padding_mask=batch.get("padding_mask", None)
)
preds_all += preds
return preds_all
@@ -511,7 +507,13 @@ def _get_predictions_and_aggregate(self, dataset: Dataset, tensor_names: List, b
with torch.no_grad():
# Aggregation works on preds, not logits. We want as much processing happening in one batch + on GPU
# So we transform logits to preds here as well
- logits = self.model.forward(**batch)
+ logits = self.model.forward(
+ input_ids=batch["input_ids"],
+ segment_ids=batch["segment_ids"],
+ padding_mask=batch["padding_mask"],
+ output_hidden_states=batch.get("output_hidden_states", False),
+ output_attentions=batch.get("output_attentions", False),
+ )
# preds = self.model.logits_to_preds(logits, **batch)[0] (This must somehow be useful for SQuAD)
preds = self.model.logits_to_preds(logits, **batch)
unaggregated_preds_all.append(preds)
diff --git a/haystack/modeling/model/adaptive_model.py b/haystack/modeling/model/adaptive_model.py
index ac126e485b..1d01dc4671 100644
--- a/haystack/modeling/model/adaptive_model.py
+++ b/haystack/modeling/model/adaptive_model.py
@@ -13,7 +13,7 @@
from transformers.convert_graph_to_onnx import convert, quantize as quantize_model
from haystack.modeling.data_handler.processor import Processor
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, LanguageModel
from haystack.modeling.model.prediction_head import PredictionHead, QuestionAnsweringHead
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -196,7 +196,7 @@ def __init__(
super(AdaptiveModel, self).__init__() # type: ignore
self.device = device
self.language_model = language_model.to(device)
- self.lm_output_dims = language_model.get_output_dims()
+ self.lm_output_dims = language_model.output_dims
self.prediction_heads = nn.ModuleList([ph.to(device) for ph in prediction_heads])
self.fit_heads_to_lm()
self.dropout = nn.Dropout(embeds_dropout_prob)
@@ -262,7 +262,6 @@ def load( # type: ignore
load_dir: Union[str, Path],
device: Union[str, torch.device],
strict: bool = True,
- lm_name: Optional[str] = None,
processor: Optional[Processor] = None,
):
"""
@@ -277,17 +276,12 @@ def load( # type: ignore
:param load_dir: Location where the AdaptiveModel is stored.
:param device: To which device we want to sent the model, either torch.device("cpu") or torch.device("cuda").
- :param lm_name: The name to assign to the loaded language model.
:param strict: Whether to strictly enforce that the keys loaded from saved model match the ones in
the PredictionHead (see torch.nn.module.load_state_dict()).
:param processor: Processor to populate prediction head with information coming from tasks.
"""
device = torch.device(device)
- # Language Model
- if lm_name:
- language_model = LanguageModel.load(load_dir, haystack_lm_name=lm_name)
- else:
- language_model = LanguageModel.load(load_dir)
+ language_model = get_language_model(load_dir)
# Prediction heads
_, ph_config_files = cls._get_prediction_head_files(load_dir)
@@ -334,7 +328,9 @@ def convert_from_transformers(
:return: AdaptiveModel
"""
- lm = LanguageModel.load(model_name_or_path, revision=revision, use_auth_token=use_auth_token, **kwargs)
+ lm = get_language_model(
+ model_name_or_path, revision=revision, use_auth_token=use_auth_token, model_kwargs=kwargs
+ )
if task_type is None:
# Infer task type from config
architecture = lm.model.config.architectures[0]
@@ -462,31 +458,44 @@ def prepare_labels(self, **kwargs):
all_labels.append(labels)
return all_labels
- def forward(self, output_hidden_states: bool = False, output_attentions: bool = False, **kwargs):
+ def forward(
+ self,
+ input_ids: torch.Tensor,
+ segment_ids: torch.Tensor,
+ padding_mask: torch.Tensor,
+ output_hidden_states: bool = False,
+ output_attentions: bool = False,
+ ):
"""
Push data through the whole model and returns logits. The data will
propagate through the language model and each of the attached prediction heads.
- :param kwargs: Holds all arguments that need to be passed to the language model
- and prediction head(s).
+ :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
+ :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
+ first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
+ It is a tensor of shape [batch_size, max_seq_len].
+ :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len].
:param output_hidden_states: Whether to output hidden states
:param output_attentions: Whether to output attentions
:return: All logits as torch.tensor or multiple tensors.
"""
# Run forward pass of language model
output_tuple = self.language_model.forward(
- **kwargs, output_hidden_states=output_hidden_states, output_attentions=output_attentions
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ attention_mask=padding_mask,
+ output_hidden_states=output_hidden_states,
+ output_attentions=output_attentions,
)
- if output_hidden_states:
- if output_attentions:
- sequence_output, pooled_output, hidden_states, attentions = output_tuple
- else:
- sequence_output, pooled_output, hidden_states = output_tuple
+ if output_hidden_states and output_attentions:
+ sequence_output, pooled_output, hidden_states, attentions = output_tuple
+ elif output_hidden_states:
+ sequence_output, pooled_output, hidden_states = output_tuple
+ elif output_attentions:
+ sequence_output, pooled_output, attentions = output_tuple
else:
- if output_attentions:
- sequence_output, pooled_output, attentions = output_tuple
- else:
- sequence_output, pooled_output = output_tuple
+ sequence_output, pooled_output = output_tuple
# Run forward pass of (multiple) prediction heads using the output from above
all_logits = []
if len(self.prediction_heads) > 0:
@@ -509,12 +518,11 @@ def forward(self, output_hidden_states: bool = False, output_attentions: bool =
# just return LM output (e.g. useful for extracting embeddings at inference time)
all_logits.append((sequence_output, pooled_output))
+ if output_hidden_states and output_attentions:
+ return all_logits, hidden_states, attentions
if output_hidden_states:
- if output_attentions:
- return all_logits, hidden_states, attentions
- else:
- return all_logits, hidden_states
- elif output_attentions:
+ return all_logits, hidden_states
+ if output_attentions:
return all_logits, attentions
return all_logits
@@ -570,7 +578,7 @@ def verify_vocab_size(self, vocab_size: int):
msg = (
f"Vocab size of tokenizer {vocab_size} doesn't match with model {model_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size == model_vocab_len, msg
diff --git a/haystack/modeling/model/biadaptive_model.py b/haystack/modeling/model/biadaptive_model.py
index e960fb01dd..d80f009578 100644
--- a/haystack/modeling/model/biadaptive_model.py
+++ b/haystack/modeling/model/biadaptive_model.py
@@ -6,9 +6,10 @@
import torch
from torch import nn
+from transformers import DPRContextEncoder, DPRQuestionEncoder, AutoModel
from haystack.modeling.data_handler.processor import Processor
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, LanguageModel
from haystack.modeling.model.prediction_head import PredictionHead, TextSimilarityHead
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -28,8 +29,11 @@ def loss_per_head_sum(
class BiAdaptiveModel(nn.Module):
- """PyTorch implementation containing all the modelling needed for your NLP task. Combines 2 language
- models for representation of 2 sequences and a prediction head. Allows for gradient flow back to the 2 language model components."""
+ """
+ PyTorch implementation containing all the modelling needed for your NLP task.
+ Combines 2 language models for representation of 2 sequences and a prediction head.
+ Allows for gradient flow back to the 2 language model components.
+ """
def __init__(
self,
@@ -74,9 +78,9 @@ def __init__(
self.device = device
self.language_model1 = language_model1.to(device)
- self.lm1_output_dims = language_model1.get_output_dims()
+ self.lm1_output_dims = language_model1.output_dims
self.language_model2 = language_model2.to(device)
- self.lm2_output_dims = language_model2.get_output_dims()
+ self.lm2_output_dims = language_model2.output_dims
self.dropout1 = nn.Dropout(embeds_dropout_prob)
self.dropout2 = nn.Dropout(embeds_dropout_prob)
self.prediction_heads = nn.ModuleList([ph.to(device) for ph in prediction_heads])
@@ -140,13 +144,13 @@ def load(
"""
# Language Model
if lm1_name:
- language_model1 = LanguageModel.load(os.path.join(load_dir, lm1_name))
+ language_model1 = get_language_model(os.path.join(load_dir, lm1_name))
else:
- language_model1 = LanguageModel.load(load_dir)
+ language_model1 = get_language_model(load_dir)
if lm2_name:
- language_model2 = LanguageModel.load(os.path.join(load_dir, lm2_name))
+ language_model2 = get_language_model(os.path.join(load_dir, lm2_name))
else:
- language_model2 = LanguageModel.load(load_dir)
+ language_model2 = get_language_model(load_dir)
# Prediction heads
ph_config_files = cls._get_prediction_head_files(load_dir)
@@ -258,7 +262,15 @@ def prepare_labels(self, **kwargs):
all_labels.append(labels)
return all_labels
- def forward(self, **kwargs):
+ def forward(
+ self,
+ query_input_ids: Optional[torch.Tensor] = None,
+ query_segment_ids: Optional[torch.Tensor] = None,
+ query_attention_mask: Optional[torch.Tensor] = None,
+ passage_input_ids: Optional[torch.Tensor] = None,
+ passage_segment_ids: Optional[torch.Tensor] = None,
+ passage_attention_mask: Optional[torch.Tensor] = None,
+ ):
"""
Push data through the whole model and returns logits. The data will propagate through
the first language model and second language model based on the tensor names and both the
@@ -269,7 +281,14 @@ def forward(self, **kwargs):
"""
# Run forward pass of both language models
- pooled_output = self.forward_lm(**kwargs)
+ pooled_output = self.forward_lm(
+ query_input_ids=query_input_ids,
+ query_segment_ids=query_segment_ids,
+ query_attention_mask=query_attention_mask,
+ passage_input_ids=passage_input_ids,
+ passage_segment_ids=passage_segment_ids,
+ passage_attention_mask=passage_attention_mask,
+ )
# Run forward pass of (multiple) prediction heads using the output from above
all_logits = []
@@ -304,7 +323,15 @@ def forward(self, **kwargs):
return all_logits
- def forward_lm(self, **kwargs):
+ def forward_lm(
+ self,
+ query_input_ids: Optional[torch.Tensor] = None,
+ query_segment_ids: Optional[torch.Tensor] = None,
+ query_attention_mask: Optional[torch.Tensor] = None,
+ passage_input_ids: Optional[torch.Tensor] = None,
+ passage_segment_ids: Optional[torch.Tensor] = None,
+ passage_attention_mask: Optional[torch.Tensor] = None,
+ ):
"""
Forward pass for the BiAdaptive model.
@@ -312,11 +339,23 @@ def forward_lm(self, **kwargs):
:return: 2 tensors of pooled_output from the 2 language models.
"""
pooled_output = [None, None]
- if "query_input_ids" in kwargs.keys():
- pooled_output1, hidden_states1 = self.language_model1(**kwargs)
+
+ if query_input_ids is not None and query_segment_ids is not None and query_attention_mask is not None:
+ pooled_output1, _ = self.language_model1(
+ input_ids=query_input_ids, segment_ids=query_segment_ids, attention_mask=query_attention_mask
+ )
pooled_output[0] = pooled_output1
- if "passage_input_ids" in kwargs.keys():
- pooled_output2, hidden_states2 = self.language_model2(**kwargs)
+
+ if passage_input_ids is not None and passage_segment_ids is not None and passage_attention_mask is not None:
+
+ max_seq_len = passage_input_ids.shape[-1]
+ passage_input_ids = passage_input_ids.view(-1, max_seq_len)
+ passage_attention_mask = passage_attention_mask.view(-1, max_seq_len)
+ passage_segment_ids = passage_segment_ids.view(-1, max_seq_len)
+
+ pooled_output2, _ = self.language_model2(
+ input_ids=passage_input_ids, segment_ids=passage_segment_ids, attention_mask=passage_attention_mask
+ )
pooled_output[1] = pooled_output2
return tuple(pooled_output)
@@ -350,7 +389,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int):
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model1_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size1 == model1_vocab_len, msg
@@ -359,7 +398,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int):
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model2_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size2 == model2_vocab_len, msg
@@ -395,8 +434,6 @@ def _get_prediction_head_files(cls, load_dir: Union[str, Path]):
return config_files
def convert_to_transformers(self):
- from transformers import DPRContextEncoder, DPRQuestionEncoder, AutoModel
-
if len(self.prediction_heads) != 1:
raise ValueError(
f"Currently conversion only works for models with a SINGLE prediction head. "
@@ -458,12 +495,8 @@ def convert_from_transformers(
:type processor: Processor
:return: AdaptiveModel
"""
- lm1 = LanguageModel.load(
- pretrained_model_name_or_path=model_name_or_path1, language_model_class="DPRQuestionEncoder"
- )
- lm2 = LanguageModel.load(
- pretrained_model_name_or_path=model_name_or_path2, language_model_class="DPRContextEncoder"
- )
+ lm1 = get_language_model(pretrained_model_name_or_path=model_name_or_path1)
+ lm2 = get_language_model(pretrained_model_name_or_path=model_name_or_path2)
prediction_head = TextSimilarityHead(similarity_function=similarity_function)
# TODO Infer type of head automatically from config
if task_type == "text_similarity":
diff --git a/haystack/modeling/model/language_model.py b/haystack/modeling/model/language_model.py
index 1247a5dcf6..34a4565768 100644
--- a/haystack/modeling/model/language_model.py
+++ b/haystack/modeling/model/language_model.py
@@ -17,47 +17,47 @@
Acknowledgements: Many of the modeling parts here come from the great transformers repository: https://github.com/huggingface/transformers.
Thanks for the great work!
"""
-from __future__ import absolute_import, division, print_function, unicode_literals
-from typing import Optional, Dict, Any, Union
+from typing import Type, Optional, Dict, Any, Union, List
+
+import re
import json
import logging
import os
+from abc import ABC, abstractmethod
from pathlib import Path
from functools import wraps
import numpy as np
import torch
from torch import nn
import transformers
-from transformers import (
- BertModel,
- BertConfig,
- RobertaModel,
- RobertaConfig,
- XLNetModel,
- XLNetConfig,
- AlbertModel,
- AlbertConfig,
- XLMRobertaModel,
- XLMRobertaConfig,
- DistilBertModel,
- DistilBertConfig,
- ElectraModel,
- ElectraConfig,
- CamembertModel,
- CamembertConfig,
- BigBirdModel,
- BigBirdConfig,
- DebertaV2Model,
- DebertaV2Config,
-)
+from transformers import PretrainedConfig, PreTrainedModel
from transformers import AutoModel, AutoConfig
from transformers.modeling_utils import SequenceSummary
+from haystack.errors import ModelingError
+
logger = logging.getLogger(__name__)
+LANGUAGE_HINTS = (
+ ("german", "german"),
+ ("english", "english"),
+ ("chinese", "chinese"),
+ ("indian", "indian"),
+ ("french", "french"),
+ ("camembert", "french"),
+ ("polish", "polish"),
+ ("spanish", "spanish"),
+ ("umberto", "italian"),
+ ("multilingual", "multilingual"),
+)
+
+#: Names of the attributes in various model configs which refer to the number of dimensions in the output vectors
+OUTPUT_DIM_NAMES = ["dim", "hidden_size", "d_model"]
+
+
def silence_transformers_logs(from_pretrained_func):
"""
A wrapper that raises the log level of Transformers to
@@ -82,240 +82,77 @@ def quiet_from_pretrained_func(cls, *args, **kwargs):
return quiet_from_pretrained_func
-# These are the names of the attributes in various model configs which refer to the number of dimensions
-# in the output vectors
-OUTPUT_DIM_NAMES = ["dim", "hidden_size", "d_model"]
-
# TODO analyse if LMs can be completely used through HF transformers
-class LanguageModel(nn.Module):
+class LanguageModel(nn.Module, ABC):
"""
- The parent class for any kind of model that can embed language into a semantic vector space. Practically
- speaking, these models read in tokenized sentences and return vectors that capture the meaning of sentences
- or of tokens.
+ The parent class for any kind of model that can embed language into a semantic vector space.
+ These models read in tokenized sentences and return vectors that capture the meaning of sentences or of tokens.
"""
- subclasses: dict = {}
+ def __init__(self, model_type: str):
+ super().__init__()
+ self._output_dims = None
+ self.name = model_type
- def __init_subclass__(cls, **kwargs):
- """
- This automatically keeps track of all available subclasses.
- Enables generic load() or all specific LanguageModel implementation.
- """
- super().__init_subclass__(**kwargs)
- cls.subclasses[cls.__name__] = cls
+ @property
+ def encoder(self):
+ return self.model.encoder
- def forward(self, input_ids: torch.Tensor, segment_ids: torch.Tensor, padding_mask: torch.Tensor, **kwargs):
+ @abstractmethod
+ def forward(
+ self,
+ input_ids: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor], # DistilBERT does not use them, see DistilBERTLanguageModel
+ output_hidden_states: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ return_dict: bool = False,
+ ):
raise NotImplementedError
- @classmethod
- def load(
- cls,
- pretrained_model_name_or_path: Union[Path, str],
- language: str = None,
- use_auth_token: Union[bool, str] = None,
- **kwargs,
- ):
+ @property
+ def output_hidden_states(self):
"""
- Load a pretrained language model by doing one of the following:
-
- 1. Specifying its name and downloading the model.
- 2. Pointing to the directory the model is saved in.
-
- Available remote models:
-
- * bert-base-uncased
- * bert-large-uncased
- * bert-base-cased
- * bert-large-cased
- * bert-base-multilingual-uncased
- * bert-base-multilingual-cased
- * bert-base-chinese
- * bert-base-german-cased
- * roberta-base
- * roberta-large
- * xlnet-base-cased
- * xlnet-large-cased
- * xlm-roberta-base
- * xlm-roberta-large
- * albert-base-v2
- * albert-large-v2
- * distilbert-base-german-cased
- * distilbert-base-multilingual-cased
- * google/electra-small-discriminator
- * google/electra-base-discriminator
- * google/electra-large-discriminator
- * facebook/dpr-question_encoder-single-nq-base
- * facebook/dpr-ctx_encoder-single-nq-base
-
- See all supported model variations at: https://huggingface.co/models.
-
- The appropriate language model class is inferred automatically from model configuration
- or can be manually supplied using `language_model_class`.
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
- :param revision: The version of the model to use from the Hugging Face model hub. This can be a tag name, a branch name, or a commit hash.
- :param language_model_class: (Optional) Name of the language model class to load (for example `Bert`).
+ Controls whether the model outputs the hidden states or not
"""
- n_added_tokens = kwargs.pop("n_added_tokens", 0)
- language_model_class = kwargs.pop("language_model_class", None)
- kwargs["revision"] = kwargs.get("revision", None)
- logger.info("LOADING MODEL")
- logger.info("=============")
- config_file = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(config_file):
- logger.info(f"Model found locally at {pretrained_model_name_or_path}")
- # it's a local directory in Haystack format
- config = json.load(open(config_file))
- language_model = cls.subclasses[config["name"]].load(pretrained_model_name_or_path)
- else:
- logger.info(f"Could not find {pretrained_model_name_or_path} locally.")
- logger.info(f"Looking on Transformers Model Hub (in local cache and online)...")
- if language_model_class is None:
- language_model_class = cls.get_language_model_class(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
-
- if language_model_class:
- language_model = cls.subclasses[language_model_class].load(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- language_model = None
-
- if not language_model:
- raise Exception(
- f"Model not found for {pretrained_model_name_or_path}. Either supply the local path for a saved "
- f"model or one of bert/roberta/xlnet/albert/distilbert models that can be downloaded from remote. "
- f"Ensure that the model class name can be inferred from the directory name when loading a "
- f"Transformers' model."
- )
- logger.info(f"Loaded {pretrained_model_name_or_path}")
+ self.encoder.config.output_hidden_states = True
- # resize embeddings in case of custom vocab
- if n_added_tokens != 0:
- # TODO verify for other models than BERT
- model_emb_size = language_model.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
- vocab_size = model_emb_size + n_added_tokens
- logger.info(
- f"Resizing embedding layer of LM from {model_emb_size} to {vocab_size} to cope with custom vocab."
- )
- language_model.model.resize_token_embeddings(vocab_size)
- # verify
- model_emb_size = language_model.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
- assert vocab_size == model_emb_size
-
- return language_model
-
- @staticmethod
- def get_language_model_class(model_name_or_path, use_auth_token: Union[str, bool] = None, **kwargs):
- # it's transformers format (either from model hub or local)
- model_name_or_path = str(model_name_or_path)
-
- config = AutoConfig.from_pretrained(model_name_or_path, use_auth_token=use_auth_token, **kwargs)
- model_type = config.model_type
- if model_type == "xlm-roberta":
- language_model_class = "XLMRoberta"
- elif model_type == "roberta":
- if "mlm" in model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- language_model_class = "Roberta"
- elif model_type == "camembert":
- language_model_class = "Camembert"
- elif model_type == "albert":
- language_model_class = "Albert"
- elif model_type == "distilbert":
- language_model_class = "DistilBert"
- elif model_type == "bert":
- language_model_class = "Bert"
- elif model_type == "xlnet":
- language_model_class = "XLNet"
- elif model_type == "electra":
- language_model_class = "Electra"
- elif model_type == "dpr":
- if config.architectures[0] == "DPRQuestionEncoder":
- language_model_class = "DPRQuestionEncoder"
- elif config.architectures[0] == "DPRContextEncoder":
- language_model_class = "DPRContextEncoder"
- elif config.archictectures[0] == "DPRReader":
- raise NotImplementedError("DPRReader models are currently not supported.")
- elif model_type == "big_bird":
- language_model_class = "BigBird"
- elif model_type == "deberta-v2":
- language_model_class = "DebertaV2"
- else:
- # Fall back to inferring type from model name
- logger.warning(
- "Could not infer LanguageModel class from config. Trying to infer "
- "LanguageModel class from model name."
- )
- language_model_class = LanguageModel._infer_language_model_class_from_string(model_name_or_path)
-
- return language_model_class
-
- @staticmethod
- def _infer_language_model_class_from_string(model_name_or_path):
- # If inferring Language model class from config doesn't succeed,
- # fall back to inferring Language model class from model name.
- if "xlm" in model_name_or_path.lower() and "roberta" in model_name_or_path.lower():
- language_model_class = "XLMRoberta"
- elif "bigbird" in model_name_or_path.lower():
- language_model_class = "BigBird"
- elif "roberta" in model_name_or_path.lower():
- language_model_class = "Roberta"
- elif "codebert" in model_name_or_path.lower():
- if "mlm" in model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- language_model_class = "Roberta"
- elif "camembert" in model_name_or_path.lower() or "umberto" in model_name_or_path.lower():
- language_model_class = "Camembert"
- elif "albert" in model_name_or_path.lower():
- language_model_class = "Albert"
- elif "distilbert" in model_name_or_path.lower():
- language_model_class = "DistilBert"
- elif "bert" in model_name_or_path.lower():
- language_model_class = "Bert"
- elif "xlnet" in model_name_or_path.lower():
- language_model_class = "XLNet"
- elif "electra" in model_name_or_path.lower():
- language_model_class = "Electra"
- elif "word2vec" in model_name_or_path.lower() or "glove" in model_name_or_path.lower():
- language_model_class = "WordEmbedding_LM"
- elif "minilm" in model_name_or_path.lower():
- language_model_class = "Bert"
- elif "dpr-question_encoder" in model_name_or_path.lower():
- language_model_class = "DPRQuestionEncoder"
- elif "dpr-ctx_encoder" in model_name_or_path.lower():
- language_model_class = "DPRContextEncoder"
- else:
- language_model_class = None
+ @output_hidden_states.setter
+ def output_hidden_states(self, value: bool):
+ """
+ Sets the model to output the hidden states or not
+ """
+ self.encoder.config.output_hidden_states = value
- return language_model_class
+ @property
+ def output_dims(self):
+ """
+ The output dimension of this language model
+ """
+ if self._output_dims:
+ return self._output_dims
- def get_output_dims(self):
- config = self.model.config
for odn in OUTPUT_DIM_NAMES:
- if odn in dir(config):
- return getattr(config, odn)
- raise Exception("Could not infer the output dimensions of the language model")
-
- def freeze(self, layers):
- """To be implemented"""
- raise NotImplementedError()
+ try:
+ value = getattr(self.model.config, odn, None)
+ if value:
+ self._output_dims = value
+ return value
+ except AttributeError as e:
+ raise ModelingError("Can't get the output dimension before loading the model.")
- def unfreeze(self):
- """To be implemented"""
- raise NotImplementedError()
+ raise ModelingError("Could not infer the output dimensions of the language model.")
- def save_config(self, save_dir):
+ def save_config(self, save_dir: Union[Path, str]):
+ """
+ Save the configuration of the language model in Haystack format.
+ """
save_filename = Path(save_dir) / "language_model_config.json"
+ setattr(self.model.config, "name", self.name)
+ setattr(self.model.config, "language", self.language)
+
+ string = self.model.config.to_json_string()
with open(save_filename, "w") as file:
- setattr(self.model.config, "name", self.__class__.__name__)
- setattr(self.model.config, "language", self.language)
- # For DPR models, transformers overwrites the model_type with the one set in DPRConfig
- # Therefore, we copy the model_type from the model config to DPRConfig
- if self.__class__.__name__ == "DPRQuestionEncoder" or self.__class__.__name__ == "DPRContextEncoder":
- setattr(transformers.DPRConfig, "model_type", self.model.config.model_type)
- string = self.model.config.to_json_string()
file.write(string)
def save(self, save_dir: Union[str, Path], state_dict: Dict[Any, Any] = None):
@@ -327,43 +164,16 @@ def save(self, save_dir: Union[str, Path], state_dict: Dict[Any, Any] = None):
"""
# Save Weights
save_name = Path(save_dir) / "language_model.bin"
- model_to_save = (
- self.model.module if hasattr(self.model, "module") else self.model
- ) # Only save the model it-self
+ model_to_save = self.model.module if hasattr(self.model, "module") else self.model # Only save the model itself
if not state_dict:
state_dict = model_to_save.state_dict()
torch.save(state_dict, save_name)
self.save_config(save_dir)
- @classmethod
- def _get_or_infer_language_from_name(cls, language, name):
- if language is not None:
- return language
- else:
- return cls._infer_language_from_name(name)
-
- @classmethod
- def _infer_language_from_name(cls, name):
- known_languages = ("german", "english", "chinese", "indian", "french", "polish", "spanish", "multilingual")
- matches = [lang for lang in known_languages if lang in name]
- if "camembert" in name:
- language = "french"
- logger.info(f"Automatically detected language from language model name: {language}")
- elif "umberto" in name:
- language = "italian"
- logger.info(f"Automatically detected language from language model name: {language}")
- elif len(matches) == 0:
- language = "english"
- elif len(matches) > 1:
- language = matches[0]
- else:
- language = matches[0]
- logger.info(f"Automatically detected language from language model name: {language}")
-
- return language
-
- def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask=None, input_ids=None, **kwargs):
+ def formatted_preds(
+ self, logits, samples, ignore_first_token: bool = True, padding_mask: torch.Tensor = None
+ ) -> List[Dict[str, Any]]:
"""
Extracting vectors from a language model (for example, for extracting sentence embeddings).
You can use different pooling strategies and layers by specifying them in the object attributes
@@ -382,7 +192,7 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
:return: A list of dictionaries containing predictions, for example: [{"context": "some text", "vec": [-0.01, 0.5 ...]}].
"""
if not hasattr(self, "extraction_layer") or not hasattr(self, "extraction_strategy"):
- raise ValueError(
+ raise ModelingError(
"`extraction_layer` or `extraction_strategy` not specified for LM. "
"Make sure to set both, e.g. via Inferencer(extraction_strategy='cls_token', extraction_layer=-1)`"
)
@@ -394,12 +204,15 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
# aggregate vectors
if self.extraction_strategy == "pooled":
if self.extraction_layer != -1:
- raise ValueError(
- f"Pooled output only works for the last layer, but got extraction_layer = {self.extraction_layer}. Please set `extraction_layer=-1`.)"
+ raise ModelingError(
+ f"Pooled output only works for the last layer, but got extraction_layer={self.extraction_layer}. "
+ "Please set `extraction_layer=-1`"
)
vecs = pooled_output.cpu().numpy()
+
elif self.extraction_strategy == "per_token":
vecs = sequence_output.cpu().numpy()
+
elif self.extraction_strategy == "reduce_mean":
vecs = self._pool_tokens(
sequence_output, padding_mask, self.extraction_strategy, ignore_first_token=ignore_first_token
@@ -411,7 +224,9 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
elif self.extraction_strategy == "cls_token":
vecs = sequence_output[:, 0, :].cpu().numpy()
else:
- raise NotImplementedError
+ raise NotImplementedError(
+ f"This extraction strategy ({self.extraction_strategy}) is not supported by Haystack."
+ )
preds = []
for vec, sample in zip(vecs, samples):
@@ -421,7 +236,9 @@ def formatted_preds(self, logits, samples, ignore_first_token=True, padding_mask
preds.append(pred)
return preds
- def _pool_tokens(self, sequence_output, padding_mask, strategy, ignore_first_token):
+ def _pool_tokens(
+ self, sequence_output: torch.Tensor, padding_mask: torch.Tensor, strategy: str, ignore_first_token: bool
+ ):
token_vecs = sequence_output.cpu().numpy()
# we only take the aggregated value of non-padding tokens
padding_mask = padding_mask.cpu().numpy()
@@ -439,30 +256,22 @@ def _pool_tokens(self, sequence_output, padding_mask, strategy, ignore_first_tok
return pooled_vecs
-class Bert(LanguageModel):
+class HFLanguageModel(LanguageModel):
"""
- A BERT model that wraps Hugging Face's implementation
+ A model that wraps Hugging Face's implementation
(https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1810.04805.
"""
- def __init__(self):
- super(Bert, self).__init__()
- self.model = None
- self.name = "bert"
-
- @classmethod
- def from_scratch(cls, vocab_size, name="bert", language="en"):
- bert = cls()
- bert.name = name
- bert.language = language
- config = BertConfig(vocab_size=vocab_size)
- bert.model = BertModel(config)
- return bert
-
- @classmethod
@silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
+ def __init__(
+ self,
+ pretrained_model_name_or_path: Union[Path, str],
+ model_type: str,
+ language: str = None,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
+ ):
"""
Load a pretrained model by supplying one of the following:
@@ -470,362 +279,110 @@ def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = N
* A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
* A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
- :param pretrained_model_name_or_path: The path of the saved pretrained model or the name of the model.
- """
- bert = cls()
- if "haystack_lm_name" in kwargs:
- bert.name = kwargs["haystack_lm_name"]
- else:
- bert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- bert_config = BertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- bert.model = BertModel.from_pretrained(haystack_lm_model, config=bert_config, **kwargs)
- bert.language = bert.model.config.language
- else:
- # Pytorch-transformer Style
- bert.model = BertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- bert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return bert
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the BERT model.
-
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence. Can also return hidden states and attentions if specified using the arguments `output_hidden_states` and `output_attentions`.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class Albert(LanguageModel):
- """
- An ALBERT model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- """
-
- def __init__(self):
- super(Albert, self).__init__()
- self.model = None
- self.name = "albert"
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one of the following:
-
- * The name of a remote model on s3 (for example: "albert-base").
- * A local path of a model trained using transformers (for example: "some_dir/huggingface_model")
- * A local path of a model trained using Haystack (for example: "some_dir/Haystack_model")
-
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- albert = cls()
- if "haystack_lm_name" in kwargs:
- albert.name = kwargs["haystack_lm_name"]
- else:
- albert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = AlbertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- albert.model = AlbertModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- albert.language = albert.model.config.language
- else:
- # Huggingface transformer Style
- albert.model = AlbertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- albert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return albert
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the Albert model.
-
- :param input_ids: The IDs of each token in the input sequence. Is a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class Roberta(LanguageModel):
- """
- A roberta model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1907.11692
- """
-
- def __init__(self):
- super(Roberta, self).__init__()
- self.model = None
- self.name = "roberta"
+ You can also use `get_language_model()` for a uniform interface across different model types.
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
+ :param pretrained_model_name_or_path: The path of the saved pretrained model or the name of the model.
+ :param model_type: the HuggingFace class name prefix (for example 'Bert', 'Roberta', etc...)
+ :param language: the model's language ('multilingual' is also accepted)
+ :param use_auth_token: the HF token or False
"""
- Load a language model by supplying one of the following:
+ super().__init__(model_type=model_type)
- * The name of a remote model on s3 (for example: "roberta-base").
- * A local path of a model trained using transformers (for example: "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example: "some_dir/haystack_model").
+ config_class: PretrainedConfig = getattr(transformers, model_type + "Config", None)
+ model_class: PreTrainedModel = getattr(transformers, model_type + "Model", None)
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example: "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- roberta = cls()
- if "haystack_lm_name" in kwargs:
- roberta.name = kwargs["haystack_lm_name"]
- else:
- roberta.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
if os.path.exists(haystack_lm_config):
# Haystack style
- config = RobertaConfig.from_pretrained(haystack_lm_config)
haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- roberta.model = RobertaModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- roberta.language = roberta.model.config.language
+ model_config = config_class.from_pretrained(haystack_lm_config)
+ self.model = model_class.from_pretrained(
+ haystack_lm_model, config=model_config, use_auth_token=use_auth_token, **(model_kwargs or {})
+ )
+ self.language = self.model.config.language
else:
- # Huggingface transformer Style
- roberta.model = RobertaModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- roberta.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return roberta
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the Roberta model.
-
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class XLMRoberta(LanguageModel):
- """
- A roberta model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1907.11692
- """
-
- def __init__(self):
- super(XLMRoberta, self).__init__()
- self.model = None
- self.name = "xlm_roberta"
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one fo the following:
-
- * The name of a remote model on s3 (for example: "xlm-roberta-base")
- * A local path of a model trained using transformers (for example: "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example: "some_dir/haystack_model").
+ # Pytorch-transformer Style
+ self.model = model_class.from_pretrained(
+ str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **(model_kwargs or {})
+ )
+ self.language = language or _guess_language(str(pretrained_model_name_or_path))
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example, "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- xlm_roberta = cls()
- if "haystack_lm_name" in kwargs:
- xlm_roberta.name = kwargs["haystack_lm_name"]
- else:
- xlm_roberta.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = XLMRobertaConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- xlm_roberta.model = XLMRobertaModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- xlm_roberta.language = xlm_roberta.model.config.language
- else:
- # Huggingface transformer Style
- xlm_roberta.model = XLMRobertaModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- xlm_roberta.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return xlm_roberta
+ # resize embeddings in case of custom vocab
+ if n_added_tokens != 0:
+ # TODO verify for other models than BERT
+ model_emb_size = self.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
+ vocab_size = model_emb_size + n_added_tokens
+ logger.info(
+ f"Resizing embedding layer of LM from {model_emb_size} to {vocab_size} to cope with custom vocab."
+ )
+ self.model.resize_token_embeddings(vocab_size)
+ # verify
+ model_emb_size = self.model.resize_token_embeddings(new_num_tokens=None).num_embeddings
+ assert vocab_size == model_emb_size
def forward(
self,
input_ids: torch.Tensor,
+ attention_mask: torch.Tensor,
segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
- **kwargs,
+ return_dict: bool = False,
):
"""
- Perform the forward pass of the XLMRoberta model.
+ Perform the forward pass of the model.
:param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
:param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
+ :param attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len]. Different models call this parameter differently (padding/attention mask).
:param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
:param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
+ :return: Embeddings for each token in the input sequence. Can also return hidden states and attentions if specified using the arguments `output_hidden_states` and `output_attentions`.
"""
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
-
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
-
-
-class DistilBert(LanguageModel):
+ if hasattr(self, "encoder"): # Not all models have an encoder
+ if output_hidden_states is None:
+ output_hidden_states = self.model.encoder.config.output_hidden_states
+ if output_attentions is None:
+ output_attentions = self.model.encoder.config.output_attentions
+
+ params = {}
+ if input_ids is not None:
+ params["input_ids"] = input_ids
+ if segment_ids is not None:
+ # Some models don't take this (see DistilBERT)
+ params["token_type_ids"] = segment_ids
+ if attention_mask is not None:
+ params["attention_mask"] = attention_mask
+ if output_hidden_states:
+ params["output_hidden_states"] = output_hidden_states
+ if output_attentions:
+ params["output_attentions"] = output_attentions
+
+ return self.model(**params, return_dict=return_dict)
+
+
+class HFLanguageModelWithPooler(HFLanguageModel):
"""
- A DistilBERT model that wraps Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
+ A model that wraps Hugging Face's implementation
+ (https://github.com/huggingface/transformers) to fit the LanguageModel class,
+ with an extra pooler.
NOTE:
- - DistilBert doesn’t have `token_type_ids`, you don’t need to indicate which
- token belongs to which segment. Just separate your segments with the separation
- token `tokenizer.sep_token` (or [SEP]).
- - Unlike the other BERT variants, DistilBert does not output the
- `pooled_output`. An additional pooler is initialized.
+ - Unlike the other BERT variants, these don't output the `pooled_output`. An additional pooler is initialized.
"""
- def __init__(self):
- super(DistilBert, self).__init__()
- self.model = None
- self.name = "distilbert"
- self.pooler = None
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
+ def __init__(
+ self,
+ pretrained_model_name_or_path: Union[Path, str],
+ model_type: str,
+ language: str = None,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
+ ):
"""
Load a pretrained model by supplying one of the following:
@@ -835,840 +392,576 @@ def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = N
:param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
"""
- distilbert = cls()
- if "haystack_lm_name" in kwargs:
- distilbert.name = kwargs["haystack_lm_name"]
- else:
- distilbert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = DistilBertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- distilbert.model = DistilBertModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- distilbert.language = distilbert.model.config.language
- else:
- # Pytorch-transformer Style
- distilbert.model = DistilBertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- distilbert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = distilbert.model.config
+ super().__init__(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ model_type=model_type,
+ language=language,
+ n_added_tokens=n_added_tokens,
+ use_auth_token=use_auth_token,
+ model_kwargs=model_kwargs,
+ )
+ config = self.model.config
- # DistilBERT does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
+ # These models do not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
# The pooler takes the first hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
# We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
# feed everything to the prediction head
- config.summary_last_dropout = 0
- config.summary_type = "first"
- config.summary_activation = "tanh"
- distilbert.pooler = SequenceSummary(config)
- distilbert.pooler.apply(distilbert.model._init_weights)
- return distilbert
-
- def forward( # type: ignore
- self,
- input_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the DistilBERT model.
-
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- pooled_output = self.pooler(output_tuple[0])
- return (output_tuple[0], pooled_output) + output_tuple[1:]
-
- def enable_hidden_states_output(self):
- self.model.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.config.output_hidden_states = False
-
-
-class XLNet(LanguageModel):
- """
- A XLNet model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1906.08237
- """
+ sequence_summary_config = POOLER_PARAMETERS.get(self.name.lower(), {})
+ for key, value in sequence_summary_config.items():
+ setattr(config, key, value)
- def __init__(self):
- super(XLNet, self).__init__()
- self.model = None
- self.name = "xlnet"
- self.pooler = None
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one of the following:
-
- * The name of a remote model on s3 (for example, "xlnet-base-cased").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * Alocal path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example, "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- xlnet = cls()
- if "haystack_lm_name" in kwargs:
- xlnet.name = kwargs["haystack_lm_name"]
- else:
- xlnet.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = XLNetConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- xlnet.model = XLNetModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- xlnet.language = xlnet.model.config.language
- else:
- # Pytorch-transformer Style
- xlnet.model = XLNetModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- xlnet.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = xlnet.model.config
- # XLNet does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
- # The pooler takes the last hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
- # We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
- # feed everything to the prediction head
- config.summary_last_dropout = 0
- xlnet.pooler = SequenceSummary(config)
- xlnet.pooler.apply(xlnet.model._init_weights)
- return xlnet
+ self.pooler = SequenceSummary(config)
+ self.pooler.apply(self.model._init_weights)
def forward(
self,
input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor],
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
- **kwargs,
+ return_dict: bool = False,
):
"""
- Perform the forward pass of the XLNet model.
+ Perform the forward pass of the model.
:param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
:param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
+ It is a tensor of shape [batch_size, max_seq_len]. Optional, some models don't need it (DistilBERT for example)
+ :param padding_mask/attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len]. Different models call this parameter differently (padding/attention mask).
:param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
:param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
:return: Embeddings for each token in the input sequence.
"""
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
-
- # Note: XLNet has a couple of special input tensors for pretraining / text generation (perm_mask, target_mapping ...)
- # We will need to implement them, if we wanna support LM adaptation
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
+ output_tuple = super().forward(
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ attention_mask=attention_mask,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
- return_dict=False,
+ return_dict=return_dict,
)
- # XLNet also only returns the sequence_output (one vec per token)
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- # TODO verify that this is really doing correct pooling
pooled_output = self.pooler(output_tuple[0])
return (output_tuple[0], pooled_output) + output_tuple[1:]
- def enable_hidden_states_output(self):
- self.model.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.output_hidden_states = False
-
-class Electra(LanguageModel):
+class HFLanguageModelNoSegmentIds(HFLanguageModelWithPooler):
"""
- ELECTRA is a new pre-training approach which trains two transformer models:
- the generator and the discriminator. The generator replaces tokens in a sequence,
- and is therefore trained as a masked language model. The discriminator, which is
- the model we're interested in, tries to identify which tokens were replaced by
- the generator in the sequence.
-
- The ELECTRA model here wraps Hugging Face's implementation
+ A model that wraps Hugging Face's implementation of a model that does not need segment ids.
(https://github.com/huggingface/transformers) to fit the LanguageModel class.
- NOTE:
- - Electra does not output the `pooled_output`. An additional pooler is initialized.
+ These are for now kept in a separate subclass to show a proper warning.
"""
- def __init__(self):
- super(Electra, self).__init__()
- self.model = None
- self.name = "electra"
- self.pooler = None
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a pretrained model by supplying one of the following
-
- * The name of a remote model on s3 (for example, "google/electra-base-discriminator").
- * A local path of a model trained using transformers ("some_dir/huggingface_model").
- * A local path of a model trained using Haystack ("some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
- """
- electra = cls()
- if "haystack_lm_name" in kwargs:
- electra.name = kwargs["haystack_lm_name"]
- else:
- electra.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = ElectraConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- electra.model = ElectraModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- electra.language = electra.model.config.language
- else:
- # Transformers Style
- electra.model = ElectraModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- electra.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = electra.model.config
-
- # ELECTRA does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
- # The pooler takes the first hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
- # We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
- # feed everything to the prediction head.
- # Note: ELECTRA uses gelu as activation (BERT uses tanh instead)
- config.summary_last_dropout = 0
- config.summary_type = "first"
- config.summary_activation = "gelu"
- config.summary_use_proj = False
- electra.pooler = SequenceSummary(config)
- electra.pooler.apply(electra.model._init_weights)
- return electra
-
def forward(
self,
input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
- **kwargs,
+ return_dict: bool = False,
):
"""
- Perform the forward pass of the ELECTRA model.
+ Perform the forward pass of the model.
:param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
+ :param attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ of shape [batch_size, max_seq_len]. Different models call this parameter differently (padding/attention mask).
+ :param segment_ids: Unused. See DistilBERT documentation.
:param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
:param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
+ :return: Embeddings for each token in the input sequence. Can also return hidden states and attentions if
+ specified using the arguments `output_hidden_states` and `output_attentions`.
"""
- output_tuple = self.model(input_ids, token_type_ids=segment_ids, attention_mask=padding_mask, return_dict=False)
-
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
+ if segment_ids is not None:
+ logging.warning(f"`segment_ids` is not None, but {self.name} does not use them. They will be ignored.")
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
+ return super().forward(
+ input_ids=input_ids,
+ segment_ids=None,
+ attention_mask=attention_mask,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
+ return_dict=return_dict,
)
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- pooled_output = self.pooler(output_tuple[0])
- return (output_tuple[0], pooled_output) + output_tuple[1:]
-
- def disable_hidden_states_output(self):
- self.model.config.output_hidden_states = False
-
-
-class Camembert(Roberta):
- """
- A Camembert model that wraps the Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- """
-
- def __init__(self):
- super(Camembert, self).__init__()
- self.model = None
- self.name = "camembert"
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a language model by supplying one of the following:
-
- * The name of a remote model on s3 (for example, "camembert-base").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: Name or path of a model.
- :param language: (Optional) The language the model was trained for (for example, "german").
- If not supplied, Haystack tries to infer it from the model name.
- :return: Language Model
- """
- camembert = cls()
- if "haystack_lm_name" in kwargs:
- camembert.name = kwargs["haystack_lm_name"]
- else:
- camembert.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = CamembertConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- camembert.model = CamembertModel.from_pretrained(haystack_lm_model, config=config, **kwargs)
- camembert.language = camembert.model.config.language
- else:
- # Huggingface transformer Style
- camembert.model = CamembertModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- camembert.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return camembert
-class DPRQuestionEncoder(LanguageModel):
+class DPREncoder(LanguageModel):
"""
- A DPRQuestionEncoder model that wraps Hugging Face's implementation.
+ A DPREncoder model that wraps Hugging Face's implementation.
"""
- def __init__(self):
- super(DPRQuestionEncoder, self).__init__()
- self.model = None
- self.name = "dpr_question_encoder"
-
- @classmethod
@silence_transformers_logs
- def load(
- cls,
+ def __init__(
+ self,
pretrained_model_name_or_path: Union[Path, str],
+ model_type: str,
language: str = None,
- use_auth_token: Union[str, bool] = None,
- **kwargs,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
):
"""
Load a pretrained model by supplying one of the following:
-
* The name of a remote model on s3 (for example, "facebook/dpr-question_encoder-single-nq-base").
* A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
* A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
:param pretrained_model_name_or_path: The path of the base pretrained language model whose weights are used to initialize DPRQuestionEncoder.
- """
- dpr_question_encoder = cls()
- if "haystack_lm_name" in kwargs:
- dpr_question_encoder.name = kwargs["haystack_lm_name"]
- else:
- dpr_question_encoder.name = pretrained_model_name_or_path
+ :param model_type: the type of model (see `HUGGINGFACE_TO_HAYSTACK`)
+ :param model_kwargs: any kwarg to pass to the model at init
+ :param language: the model's language. If not given, it will be inferred. Defaults to english.
+ :param n_added_tokens: unused for `DPREncoder`
+ :param use_auth_token: useful if the model is from the HF Hub and private
+ :param model_kwargs: any kwarg to pass to the model at init
+ """
+ super().__init__(model_type=model_type)
+ self.role = "question" if "question" in model_type.lower() else "context"
+ self._encoder = None
+
+ model_classname = f"DPR{self.role.capitalize()}Encoder"
+ try:
+ model_class: Type[PreTrainedModel] = getattr(transformers, model_classname)
+ except AttributeError as e:
+ raise ModelingError(f"Model class of type '{model_classname}' not found.")
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
if os.path.exists(haystack_lm_config):
- # Haystack style
- original_model_config = AutoConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
-
- if original_model_config.model_type == "dpr":
- dpr_config = transformers.DPRConfig.from_pretrained(haystack_lm_config)
- dpr_question_encoder.model = transformers.DPRQuestionEncoder.from_pretrained(
- haystack_lm_model, config=dpr_config, **kwargs
- )
- else:
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_question_encoder.model = transformers.DPRQuestionEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- language_model_class = cls.get_language_model_class(haystack_lm_config, use_auth_token, **kwargs)
- dpr_question_encoder.model.base_model.bert_model = (
- cls.subclasses[language_model_class].load(str(pretrained_model_name_or_path)).model
- )
- dpr_question_encoder.language = dpr_question_encoder.model.config.language
- else:
- original_model_config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token
+ self._init_model_haystack_style(
+ haystack_lm_config=haystack_lm_config,
+ model_name_or_path=pretrained_model_name_or_path,
+ model_class=model_class,
+ model_kwargs=model_kwargs or {},
+ use_auth_token=use_auth_token,
)
- if original_model_config.model_type == "dpr":
- # "pretrained dpr model": load existing pretrained DPRQuestionEncoder model
- dpr_question_encoder.model = transformers.DPRQuestionEncoder.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **kwargs
- )
- else:
- # "from scratch": load weights from different architecture (e.g. bert) into DPRQuestionEncoder
- # but keep config values from original architecture
- # TODO test for architectures other than BERT, e.g. Electra
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_question_encoder.model = transformers.DPRQuestionEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- dpr_question_encoder.model.base_model.bert_model = AutoModel.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **original_config_dict
- )
- dpr_question_encoder.language = cls._get_or_infer_language_from_name(
- language, pretrained_model_name_or_path
+ else:
+ self._init_model_transformers_style(
+ model_name_or_path=pretrained_model_name_or_path,
+ model_class=model_class,
+ model_kwargs=model_kwargs or {},
+ use_auth_token=use_auth_token,
+ language=language,
)
- return dpr_question_encoder
-
- def save(self, save_dir: Union[str, Path], state_dict: Optional[Dict[Any, Any]] = None):
+ def _init_model_haystack_style(
+ self,
+ haystack_lm_config: Path,
+ model_name_or_path: Union[str, Path],
+ model_class: Type[PreTrainedModel],
+ model_kwargs: Dict[str, Any],
+ use_auth_token: Optional[Union[str, bool]] = None,
+ ):
"""
- Save the model `state_dict` and its configuration file so that it can be loaded again.
+ Init a Haystack-style DPR model.
- :param save_dir: The directory in which the model should be saved.
- :param state_dict: A dictionary containing the whole state of the module including names of layers.
- By default, the unchanged state dictionary of the module is used.
+ :param haystack_lm_config: path to the language model config file
+ :param model_name_or_path: name or path of the model to load
+ :param model_class: The HuggingFace model class name
+ :param model_kwargs: any kwarg to pass to the model at init
+ :param use_auth_token: useful if the model is from the HF Hub and private
"""
- model_to_save = self.model.module if hasattr(self.model, "module") else self.model # Only save the model itself
+ original_model_config = AutoConfig.from_pretrained(haystack_lm_config)
+ haystack_lm_model = Path(model_name_or_path) / "language_model.bin"
- if self.model.config.model_type != "dpr" and model_to_save.base_model_prefix.startswith("question_"):
- state_dict = model_to_save.state_dict()
- if state_dict:
- keys = state_dict.keys()
- for key in list(keys):
- new_key = key
- if key.startswith("question_encoder.bert_model.model."):
- new_key = key.split("_encoder.bert_model.model.", 1)[1]
- elif key.startswith("question_encoder.bert_model."):
- new_key = key.split("_encoder.bert_model.", 1)[1]
- state_dict[new_key] = state_dict.pop(key)
+ original_model_type = original_model_config.model_type
+ if original_model_type and "dpr" in original_model_type.lower():
+ dpr_config = transformers.DPRConfig.from_pretrained(haystack_lm_config)
+ self.model = model_class.from_pretrained(haystack_lm_model, config=dpr_config, **model_kwargs)
- super(DPRQuestionEncoder, self).save(save_dir=save_dir, state_dict=state_dict)
+ else:
+ self.model = self._init_model_through_config(
+ model_config=original_model_config, model_class=model_class, model_kwargs=model_kwargs
+ )
+ original_model_type = capitalize_model_type(original_model_type)
+ language_model_class = get_language_model_class(original_model_type)
+ if not language_model_class:
+ raise ValueError(
+ f"The type of model supplied ({model_name_or_path} , "
+ f"({original_model_type}) is not supported by Haystack. "
+ f"Supported model categories are: {', '.join(HUGGINGFACE_TO_HAYSTACK.keys())}"
+ )
+ # Instantiate the class for this model
+ self.model.base_model.bert_model = language_model_class(
+ pretrained_model_name_or_path=model_name_or_path,
+ model_type=original_model_type,
+ use_auth_token=use_auth_token,
+ **model_kwargs,
+ ).model
- def forward( # type: ignore
+ self.language = self.model.config.language
+
+ def _init_model_transformers_style(
self,
- query_input_ids: torch.Tensor,
- query_segment_ids: torch.Tensor,
- query_attention_mask: torch.Tensor,
- **kwargs,
+ model_name_or_path: Union[str, Path],
+ model_class: Type[PreTrainedModel],
+ model_kwargs: Dict[str, Any],
+ use_auth_token: Optional[Union[str, bool]] = None,
+ language: Optional[str] = None,
):
"""
- Perform the forward pass of the DPRQuestionEncoder model.
+ Init a Transformers-style DPR model.
- :param query_input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param query_segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param query_attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :return: Embeddings for each token in the input sequence.
+ :param model_name_or_path: name or path of the model to load
+ :param model_class: The HuggingFace model class name
+ :param model_kwargs: any kwarg to pass to the model at init
+ :param use_auth_token: useful if the model is from the HF Hub and private
+ :param language: the model's language. If not given, it will be inferred. Defaults to english.
"""
- output_tuple = self.model(
- input_ids=query_input_ids,
- token_type_ids=query_segment_ids,
- attention_mask=query_attention_mask,
- return_dict=True,
- )
- if self.model.question_encoder.config.output_hidden_states == True:
- pooled_output, all_hidden_states = output_tuple.pooler_output, output_tuple.hidden_states
- return pooled_output, all_hidden_states
+ original_model_config = AutoConfig.from_pretrained(model_name_or_path, use_auth_token=use_auth_token)
+ if "dpr" in original_model_config.model_type.lower():
+ # "pretrained dpr model": load existing pretrained DPRQuestionEncoder model
+ self.model = model_class.from_pretrained(
+ str(model_name_or_path), use_auth_token=use_auth_token, **model_kwargs
+ )
else:
- pooled_output = output_tuple.pooler_output
- return pooled_output, None
-
- def enable_hidden_states_output(self):
- self.model.question_encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.question_encoder.config.output_hidden_states = False
-
-
-class DPRContextEncoder(LanguageModel):
- """
- A DPRContextEncoder model that wraps Hugging Face's implementation.
- """
-
- def __init__(self):
- super(DPRContextEncoder, self).__init__()
- self.model = None
- self.name = "dpr_context_encoder"
+ # "from scratch": load weights from different architecture (e.g. bert) into DPRQuestionEncoder
+ # but keep config values from original architecture
+ # TODO test for architectures other than BERT, e.g. Electra
+ self.model = self._init_model_through_config(
+ model_config=original_model_config, model_class=model_class, model_kwargs=model_kwargs
+ )
+ self.model.base_model.bert_model = AutoModel.from_pretrained(
+ str(model_name_or_path), use_auth_token=use_auth_token, **vars(original_model_config)
+ )
+ self.language = language or _guess_language(str(model_name_or_path))
- @classmethod
- @silence_transformers_logs
- def load(
- cls,
- pretrained_model_name_or_path: Union[Path, str],
- language: str = None,
- use_auth_token: Union[str, bool] = None,
- **kwargs,
+ def _init_model_through_config(
+ self, model_config: AutoConfig, model_class: Type[PreTrainedModel], model_kwargs: Optional[Dict[str, Any]]
):
"""
- Load a pretrained model by supplying one of the following:
-
- * The name of a remote model on s3 (for example, "facebook/dpr-ctx_encoder-single-nq-base").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: The path of the base pretrained language model whose weights are used to initialize DPRContextEncoder.
+ Init a DPR model using a config object.
"""
- dpr_context_encoder = cls()
- if "haystack_lm_name" in kwargs:
- dpr_context_encoder.name = kwargs["haystack_lm_name"]
- else:
- dpr_context_encoder.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
-
- if os.path.exists(haystack_lm_config):
- # Haystack style
- original_model_config = AutoConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
+ if model_config.model_type.lower() != "bert":
+ logger.warning(
+ f"Using a model of type '{model_config.model_type}' which might be incompatible with DPR encoders. "
+ f"Only Bert-based encoders are supported. They need input_ids, token_type_ids, attention_mask as input tensors."
+ )
+ config_dict = vars(model_config)
+ if model_kwargs:
+ config_dict.update(model_kwargs)
+ return model_class(config=transformers.DPRConfig(**config_dict))
- if original_model_config.model_type == "dpr":
- dpr_config = transformers.DPRConfig.from_pretrained(haystack_lm_config)
- dpr_context_encoder.model = transformers.DPRContextEncoder.from_pretrained(
- haystack_lm_model, config=dpr_config, use_auth_token=use_auth_token, **kwargs
- )
- else:
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_context_encoder.model = transformers.DPRContextEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- language_model_class = cls.get_language_model_class(haystack_lm_config, **kwargs)
- dpr_context_encoder.model.base_model.bert_model = (
- cls.subclasses[language_model_class]
- .load(str(pretrained_model_name_or_path), use_auth_token=use_auth_token)
- .model
- )
- dpr_context_encoder.language = dpr_context_encoder.model.config.language
+ @property
+ def encoder(self):
+ if not self._encoder:
+ self._encoder = self.model.question_encoder if self.role == "question" else self.model.ctx_encoder
+ return self._encoder
- else:
- # Pytorch-transformer Style
- original_model_config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token
- )
- if original_model_config.model_type == "dpr":
- # "pretrained dpr model": load existing pretrained DPRContextEncoder model
- dpr_context_encoder.model = transformers.DPRContextEncoder.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **kwargs
- )
- else:
- # "from scratch": load weights from different architecture (e.g. bert) into DPRContextEncoder
- # but keep config values from original architecture
- # TODO test for architectures other than BERT, e.g. Electra
- if original_model_config.model_type != "bert":
- logger.warning(
- f"Using a model of type '{original_model_config.model_type}' which might be incompatible with DPR encoders."
- f"Bert based encoders are supported that need input_ids,token_type_ids,attention_mask as input tensors."
- )
- original_config_dict = vars(original_model_config)
- original_config_dict.update(kwargs)
- dpr_context_encoder.model = transformers.DPRContextEncoder(
- config=transformers.DPRConfig(**original_config_dict)
- )
- dpr_context_encoder.model.base_model.bert_model = AutoModel.from_pretrained(
- str(pretrained_model_name_or_path), use_auth_token=use_auth_token, **original_config_dict
- )
- dpr_context_encoder.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
+ def save_config(self, save_dir: Union[Path, str]) -> None:
+ """
+ Save the configuration of the language model in Haystack format.
- return dpr_context_encoder
+ :param save_dir: the path to save the model at
+ """
+ # For DPR models, transformers overwrites the model_type with the one set in DPRConfig
+ # Therefore, we copy the model_type from the model config to DPRConfig
+ setattr(transformers.DPRConfig, "model_type", self.model.config.model_type)
+ super().save_config(save_dir=save_dir)
- def save(self, save_dir: Union[str, Path], state_dict: Optional[Dict[Any, Any]] = None):
+ def save(self, save_dir: Union[str, Path], state_dict: Optional[Dict[Any, Any]] = None) -> None:
"""
Save the model `state_dict` and its configuration file so that it can be loaded again.
:param save_dir: The directory in which the model should be saved.
- :param state_dict: A dictionary containing the whole state of the module including names of layers. By default, the unchanged state dictionary of the module is used.
+ :param state_dict: A dictionary containing the whole state of the module including names of layers.
+ By default, the unchanged state dictionary of the module is used.
"""
- model_to_save = (
- self.model.module if hasattr(self.model, "module") else self.model
- ) # Only save the model it-self
+ model_to_save = self.model.module if hasattr(self.model, "module") else self.model # Only save the model itself
+
+ if "dpr" not in self.model.config.model_type.lower():
+ prefix = "question" if self.role == "question" else "ctx"
- if self.model.config.model_type != "dpr" and model_to_save.base_model_prefix.startswith("ctx_"):
state_dict = model_to_save.state_dict()
if state_dict:
- keys = state_dict.keys()
- for key in list(keys):
+ for key in list(state_dict.keys()): # list() here performs a copy and allows editing the dict
new_key = key
- if key.startswith("ctx_encoder.bert_model.model."):
+
+ if key.startswith(f"{prefix}_encoder.bert_model.model."):
new_key = key.split("_encoder.bert_model.model.", 1)[1]
- elif key.startswith("ctx_encoder.bert_model."):
+
+ elif key.startswith(f"{prefix}_encoder.bert_model."):
new_key = key.split("_encoder.bert_model.", 1)[1]
+
state_dict[new_key] = state_dict.pop(key)
- super(DPRContextEncoder, self).save(save_dir=save_dir, state_dict=state_dict)
+ super().save(save_dir=save_dir, state_dict=state_dict)
- def forward( # type: ignore
+ def forward(
self,
- passage_input_ids: torch.Tensor,
- passage_segment_ids: torch.Tensor,
- passage_attention_mask: torch.Tensor,
- **kwargs,
+ input_ids: torch.Tensor,
+ attention_mask: torch.Tensor,
+ segment_ids: Optional[torch.Tensor],
+ output_hidden_states: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ return_dict: bool = True,
):
"""
- Perform the forward pass of the DPRContextEncoder model.
+ Perform the forward pass of the DPR encoder model.
- :param passage_input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, number_of_hard_negative_passages, max_seq_len].
- :param passage_segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
+ :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, number_of_hard_negative, max_seq_len].
+ :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
It is a tensor of shape [batch_size, number_of_hard_negative_passages, max_seq_len].
- :param passage_attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
+ :param attention_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
of shape [batch_size, number_of_hard_negative_passages, max_seq_len].
+ :param output_hidden_states: whether to add the hidden states along with the pooled output
+ :param output_attentions: unused
:return: Embeddings for each token in the input sequence.
"""
- max_seq_len = passage_input_ids.shape[-1]
- passage_input_ids = passage_input_ids.view(-1, max_seq_len)
- passage_segment_ids = passage_segment_ids.view(-1, max_seq_len)
- passage_attention_mask = passage_attention_mask.view(-1, max_seq_len)
- output_tuple = self.model(
- input_ids=passage_input_ids,
- token_type_ids=passage_segment_ids,
- attention_mask=passage_attention_mask,
- return_dict=True,
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.encoder.config.output_hidden_states
)
- if self.model.ctx_encoder.config.output_hidden_states == True:
- pooled_output, all_hidden_states = output_tuple.pooler_output, output_tuple.hidden_states
- return pooled_output, all_hidden_states
- else:
- pooled_output = output_tuple.pooler_output
- return pooled_output, None
-
- def enable_hidden_states_output(self):
- self.model.ctx_encoder.config.output_hidden_states = True
-
- def disable_hidden_states_output(self):
- self.model.ctx_encoder.config.output_hidden_states = False
+ model_output = self.model(
+ input_ids=input_ids,
+ token_type_ids=segment_ids,
+ attention_mask=attention_mask,
+ output_hidden_states=output_hidden_states,
+ output_attentions=False,
+ return_dict=return_dict,
+ )
-class BigBird(LanguageModel):
+ if output_hidden_states:
+ return model_output.pooler_output, model_output.hidden_states
+ return model_output.pooler_output, None
+
+
+#: Match the name of the HuggingFace Model class to the corresponding Haystack wrapper
+HUGGINGFACE_TO_HAYSTACK: Dict[str, Union[Type[HFLanguageModel], Type[DPREncoder]]] = {
+ "Auto": HFLanguageModel,
+ "Albert": HFLanguageModel,
+ "Bert": HFLanguageModel,
+ "BigBird": HFLanguageModel,
+ "Camembert": HFLanguageModel,
+ "Codebert": HFLanguageModel,
+ "DebertaV2": HFLanguageModelWithPooler,
+ "DistilBert": HFLanguageModelNoSegmentIds,
+ "DPRContextEncoder": DPREncoder,
+ "DPRQuestionEncoder": DPREncoder,
+ "Electra": HFLanguageModelWithPooler,
+ "GloVe": HFLanguageModel,
+ "MiniLM": HFLanguageModel,
+ "Roberta": HFLanguageModel,
+ "Umberto": HFLanguageModel,
+ "Word2Vec": HFLanguageModel,
+ "WordEmbedding_LM": HFLanguageModel,
+ "XLMRoberta": HFLanguageModel,
+ "XLNet": HFLanguageModelWithPooler,
+}
+#: HF Capitalization pairs
+HUGGINGFACE_CAPITALIZE = {
+ "xlm-roberta": "XLMRoberta",
+ "deberta-v2": "DebertaV2",
+ **{k.lower(): k for k in HUGGINGFACE_TO_HAYSTACK.keys()},
+}
+
+#: Regex to match variants of the HF class name, to enhance our mode type guessing abilities.
+NAME_HINTS: Dict[str, str] = {
+ "xlm.*roberta": "XLMRoberta",
+ "roberta.*xml": "XLMRoberta",
+ "codebert.*mlm": "Roberta",
+ "mlm.*codebert": "Roberta",
+ "[dpr]?.*question.*encoder": "DPRQuestionEncoder",
+ "[dpr]?.*query.*encoder": "DPRQuestionEncoder",
+ "[dpr]?.*passage.*encoder": "DPRContextEncoder",
+ "[dpr]?.*context.*encoder": "DPRContextEncoder",
+ "[dpr]?.*ctx.*encoder": "DPRContextEncoder",
+ "deberta-v2": "DebertaV2",
+}
+
+#: Parameters or the pooler of models that don't have their own pooler
+POOLER_PARAMETERS: Dict[str, Dict[str, Any]] = {
+ "DistilBert": {"summary_last_dropout": 0, "summary_type": "first", "summary_activation": "tanh"},
+ "XLNet": {"summary_last_dropout": 0},
+ "Electra": {
+ "summary_last_dropout": 0,
+ "summary_type": "first",
+ "summary_activation": "gelu",
+ "summary_use_proj": False,
+ },
+ "DebertaV2": {
+ "summary_last_dropout": 0,
+ "summary_type": "first",
+ "summary_activation": "tanh",
+ "summary_use_proj": False,
+ },
+}
+
+
+def capitalize_model_type(model_type: str) -> str:
"""
- A BERT model that wraps Hugging Face's implementation
- (https://github.com/huggingface/transformers) to fit the LanguageModel class.
- Paper: https://arxiv.org/abs/1810.04805
+ Returns the proper capitalized version of the model type, that can be used to
+ retrieve the model class from transformers.
+ :param model_type: the model_type as found in the config file
+ :return: the capitalized version of the model type, or the original name of not found.
"""
+ return HUGGINGFACE_CAPITALIZE.get(model_type.lower(), model_type)
- def __init__(self):
- super(BigBird, self).__init__()
- self.model = None
- self.name = "big_bird"
-
- @classmethod
- def from_scratch(cls, vocab_size, name="big_bird", language="en"):
- big_bird = cls()
- big_bird.name = name
- big_bird.language = language
- config = BigBirdConfig(vocab_size=vocab_size)
- big_bird.model = BigBirdModel(config)
- return big_bird
-
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a pretrained model by supplying one of the following:
- * The name of a remote model on s3 (for example, "bert-base-cased").
- * A local path of a model trained using transformers (for example, "some_dir/huggingface_model").
- * A local path of a model trained using Haystack (for example, "some_dir/haystack_model").
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
- """
- big_bird = cls()
- if "haystack_lm_name" in kwargs:
- big_bird.name = kwargs["haystack_lm_name"]
- else:
- big_bird.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Pytorch-Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- big_bird_config = BigBirdConfig.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- big_bird.model = BigBirdModel.from_pretrained(haystack_lm_model, config=big_bird_config, **kwargs)
- big_bird.language = big_bird.model.config.language
- else:
- # Pytorch-transformer Style
- big_bird.model = BigBirdModel.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- big_bird.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- return big_bird
-
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the BigBird model.
+def is_supported_model(model_type: Optional[str]):
+ """
+ Returns whether the model type is supported by Haystack
+ :param model_type: the model_type as found in the config file
+ :return: whether the model type is supported by the Haystack
+ """
+ return model_type and model_type.lower() in HUGGINGFACE_CAPITALIZE
- :param input_ids: The IDs of each token in the input sequence. It's a tensor of shape [batch_size, max_seq_len].
- :param segment_ids: The ID of the segment. For example, in next sentence prediction, the tokens in the
- first sentence are marked with 0 and the tokens in the second sentence are marked with 1.
- It is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
- output_tuple = self.model(
- input_ids,
- token_type_ids=segment_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
- return_dict=False,
- )
- return output_tuple
+def get_language_model_class(model_type: str) -> Optional[Type[Union[HFLanguageModel, DPREncoder]]]:
+ """
+ Returns the corresponding Haystack LanguageModel subclass.
+ :param model_type: the model_type , properly capitalized (see `capitalize_model_type()`)
+ :return: the wrapper class, or `None` if `model_type` was `None` or was not recognized.
+ Lower case model_type values will return `None` as well
+ """
+ return HUGGINGFACE_TO_HAYSTACK.get(model_type)
+
+
+def get_language_model(
+ pretrained_model_name_or_path: Union[Path, str],
+ language: str = None,
+ n_added_tokens: int = 0,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ revision: Optional[str] = None,
+ autoconfig_kwargs: Optional[Dict[str, Any]] = None,
+ model_kwargs: Optional[Dict[str, Any]] = None,
+) -> LanguageModel:
+ """
+ Load a pretrained language model by doing one of the following:
- def enable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = True
+ 1. Specifying its name and downloading the model.
+ 2. Pointing to the directory the model is saved in.
- def disable_hidden_states_output(self):
- self.model.encoder.config.output_hidden_states = False
+ See all supported model variations at: https://huggingface.co/models.
+ The appropriate language model class is inferred automatically from model configuration.
-class DebertaV2(LanguageModel):
+ :param pretrained_model_name_or_path: The path of the saved pretrained model or its name.
+ :param language: The language of the model (i.e english etc).
+ :param n_added_tokens: The number of added tokens to the model.
+ :param use_auth_token: Whether to use the huggingface auth token for private repos or not.
+ :param revision: The version of the model to use from the Hugging Face model hub. This can be a tag name,
+ a branch name, or a commit hash.
+ :param autoconfig_kwargs: Additional keyword arguments to pass to the autoconfig function.
+ :param model_kwargs: Additional keyword arguments to pass to the lamguage model constructor.
"""
- This is a wrapper around the DebertaV2 model from Hugging Face's transformers library.
- It is also compatible with DebertaV3 as DebertaV3 only changes the pretraining procedure.
- NOTE:
- - DebertaV2 does not output the `pooled_output`. An additional pooler is initialized.
- """
+ if not pretrained_model_name_or_path or not isinstance(pretrained_model_name_or_path, (str, Path)):
+ raise ValueError(f"{pretrained_model_name_or_path} is not a valid pretrained_model_name_or_path parameter")
- def __init__(self):
- super().__init__()
- self.model = None
- self.name = "deberta-v2"
- self.pooler = None
+ config_file = Path(pretrained_model_name_or_path) / "language_model_config.json"
- @classmethod
- @silence_transformers_logs
- def load(cls, pretrained_model_name_or_path: Union[Path, str], language: str = None, **kwargs):
- """
- Load a pretrained model by supplying one of the following:
+ model_type = None
+ config_file_exists = os.path.exists(config_file)
+ if config_file_exists:
+ # it's a local directory in Haystack format
+ config = json.load(open(config_file))
+ model_type = config["name"]
- * A remote name from the Hugging Face's model hub (for example: microsoft/deberta-v3-base).
- * A local path of a model trained using transformers (for example: some_dir/huggingface_model).
- * A local path of a model trained using Haystack (for example: some_dir/haystack_model).
+ if not model_type:
+ model_type = _get_model_type(
+ pretrained_model_name_or_path,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ autoconfig_kwargs=autoconfig_kwargs,
+ )
- :param pretrained_model_name_or_path: The path to the saved pretrained model or the name of the model.
- """
- debertav2 = cls()
- if "haystack_lm_name" in kwargs:
- debertav2.name = kwargs["haystack_lm_name"]
- else:
- debertav2.name = pretrained_model_name_or_path
- # We need to differentiate between loading model using Haystack format and Transformers format
- haystack_lm_config = Path(pretrained_model_name_or_path) / "language_model_config.json"
- if os.path.exists(haystack_lm_config):
- # Haystack style
- config = DebertaV2Config.from_pretrained(haystack_lm_config)
- haystack_lm_model = Path(pretrained_model_name_or_path) / "language_model.bin"
- debertav2.model = DebertaV2Model.from_pretrained(haystack_lm_model, config=config, **kwargs)
- debertav2.language = debertav2.model.config.language
- else:
- # Transformers Style
- debertav2.model = DebertaV2Model.from_pretrained(str(pretrained_model_name_or_path), **kwargs)
- debertav2.language = cls._get_or_infer_language_from_name(language, pretrained_model_name_or_path)
- config = debertav2.model.config
+ if not model_type:
+ logger.error(
+ f"Model type not understood for '{pretrained_model_name_or_path}' "
+ f"({model_type if model_type else 'model_type not set'}). "
+ "Either supply the local path for a saved model, "
+ "or the name of a model that can be downloaded from the Model Hub. "
+ "Ensure that the model class name can be inferred from the directory name "
+ "when loading a Transformers model."
+ )
+ logger.error(f"Using the AutoModel class for '{pretrained_model_name_or_path}'. This can cause crashes!")
+ model_type = "Auto"
+
+ # Find the class corresponding to this model type
+ model_type = capitalize_model_type(model_type)
+ language_model_class = get_language_model_class(model_type)
+ if not language_model_class:
+ raise ValueError(
+ f"The type of model supplied ({model_type}) is not supported by Haystack or was not correctly identified. "
+ f"Supported model types are: {', '.join(HUGGINGFACE_TO_HAYSTACK.keys())}"
+ )
- # DebertaV2 does not provide a pooled_output by default. Therefore, we need to initialize an extra pooler.
- # The pooler takes the first hidden representation & feeds it to a dense layer of (hidden_dim x hidden_dim).
- # We don't want a dropout in the end of the pooler, since we do that already in the adaptive model before we
- # feed everything to the prediction head.
- config.summary_last_dropout = 0
- config.summary_type = "first"
- config.summary_activation = "tanh"
- config.summary_use_proj = False
- debertav2.pooler = SequenceSummary(config)
- debertav2.pooler.apply(debertav2.model._init_weights)
- return debertav2
+ logger.info(f" * LOADING MODEL: '{pretrained_model_name_or_path}' {'(' + model_type + ')' if model_type else ''}")
+
+ # Instantiate the class for this model
+ language_model = language_model_class(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ model_type=model_type,
+ language=language,
+ n_added_tokens=n_added_tokens,
+ use_auth_token=use_auth_token,
+ model_kwargs=model_kwargs,
+ )
+ logger.info(
+ f"Loaded '{pretrained_model_name_or_path}' ({model_type} model) "
+ f"from {'local file system' if config_file_exists else 'model hub'}."
+ )
+ return language_model
+
+
+def _get_model_type(
+ model_name_or_path: Union[str, Path],
+ use_auth_token: Optional[Union[str, bool]] = None,
+ revision: Optional[str] = None,
+ autoconfig_kwargs: Optional[Dict[str, Any]] = None,
+) -> Optional[str]:
+ """
+ Given a model name, try to use AutoConfig to understand which model type it is.
+ In case it's not successful, tries to infer the type from the name of the model.
+ """
+ model_name_or_path = str(model_name_or_path)
+
+ model_type: Optional[str] = None
+ # Use AutoConfig to understand the model class
+ try:
+ config = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path=model_name_or_path,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ **(autoconfig_kwargs or {}),
+ )
+ model_type = config.model_type
+ # if unsupported model, try to infer from config.architectures
+ if not is_supported_model(model_type) and config.architectures:
+ model_type = config.architectures[0] if is_supported_model(config.architectures[0]) else None
- def forward(
- self,
- input_ids: torch.Tensor,
- segment_ids: torch.Tensor,
- padding_mask: torch.Tensor,
- output_hidden_states: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- **kwargs,
- ):
- """
- Perform the forward pass of the DebertaV2 model.
+ except Exception as e:
+ logger.error(f"AutoConfig failed to load on '{model_name_or_path}': {str(e)}")
- :param input_ids: The IDs of each token in the input sequence. Is a tensor of shape [batch_size, max_seq_len].
- :param padding_mask: A mask that assigns 1 to valid input tokens and 0 to padding tokens
- of shape [batch_size, max_seq_len].
- :param output_hidden_states: When set to `True`, outputs hidden states in addition to the embeddings.
- :param output_attentions: When set to `True`, outputs attentions in addition to the embeddings.
- :return: Embeddings for each token in the input sequence.
- """
- output_tuple = self.model(input_ids, token_type_ids=segment_ids, attention_mask=padding_mask, return_dict=False)
+ if not model_type:
+ logger.warning("Could not infer the model type from its config. Looking for clues in the model name.")
- if output_hidden_states is None:
- output_hidden_states = self.model.encoder.config.output_hidden_states
- if output_attentions is None:
- output_attentions = self.model.encoder.config.output_attentions
+ # Look for other patterns and variation that hints at the model type
+ for regex, model_name in NAME_HINTS.items():
+ if re.match(f".*{regex}.*", model_name_or_path):
+ model_type = model_name
+ break
- output_tuple = self.model(
- input_ids,
- attention_mask=padding_mask,
- output_hidden_states=output_hidden_states,
- output_attentions=output_attentions,
+ if model_type and model_type.lower() == "roberta" and "mlm" in model_name_or_path.lower():
+ logger.error(
+ f"MLM part of codebert is currently not supported in Haystack: '{model_name_or_path}' may crash later."
)
- # We need to manually aggregate that to get a pooled output (one vec per seq)
- pooled_output = self.pooler(output_tuple[0])
- return (output_tuple[0], pooled_output) + output_tuple[1:]
- def disable_hidden_states_output(self):
- self.model.config.output_hidden_states = False
+ return model_type
+
+
+def _guess_language(name: str) -> str:
+ """
+ Looks for clues about the model language in the model name.
+ """
+ languages = [lang for hint, lang in LANGUAGE_HINTS if hint.lower() in name.lower()]
+ if len(languages) > 0:
+ language = languages[0]
+ else:
+ language = "english"
+ logger.info(f"Auto-detected model language: {language}")
+ return language
diff --git a/haystack/modeling/model/tokenization.py b/haystack/modeling/model/tokenization.py
index 3c0ed9a961..9467d38132 100644
--- a/haystack/modeling/model/tokenization.py
+++ b/haystack/modeling/model/tokenization.py
@@ -12,308 +12,65 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""
-Tokenization classes.
-"""
-from __future__ import absolute_import, division, print_function, unicode_literals
-from typing import Dict, Any, Tuple, Optional, List, Union
+
+from typing import Dict, Any, Union, Tuple, Optional, List
import re
import logging
import numpy as np
-from transformers import (
- AutoTokenizer,
- AlbertTokenizer,
- AlbertTokenizerFast,
- BertTokenizer,
- BertTokenizerFast,
- DistilBertTokenizer,
- DistilBertTokenizerFast,
- ElectraTokenizer,
- ElectraTokenizerFast,
- RobertaTokenizer,
- RobertaTokenizerFast,
- XLMRobertaTokenizer,
- XLMRobertaTokenizerFast,
- XLNetTokenizer,
- XLNetTokenizerFast,
- CamembertTokenizer,
- CamembertTokenizerFast,
- DPRContextEncoderTokenizer,
- DPRContextEncoderTokenizerFast,
- DPRQuestionEncoderTokenizer,
- DPRQuestionEncoderTokenizerFast,
- BigBirdTokenizer,
- BigBirdTokenizerFast,
- DebertaV2Tokenizer,
- DebertaV2TokenizerFast,
-)
-from transformers import AutoConfig
+from transformers import AutoTokenizer, PreTrainedTokenizer, RobertaTokenizer
+from haystack.errors import ModelingError
from haystack.modeling.data_handler.samples import SampleBasket
logger = logging.getLogger(__name__)
-# Special characters used by the different tokenizers to indicate start of word / whitespace
+#: Special characters used by the different tokenizers to indicate start of word / whitespace
SPECIAL_TOKENIZER_CHARS = r"^(##|Ġ|▁)"
-# TODO analyse if tokenizers can be completely used through HF transformers
-class Tokenizer:
+
+def get_tokenizer(
+ pretrained_model_name_or_path: str,
+ revision: str = None,
+ use_fast: bool = True,
+ use_auth_token: Optional[Union[str, bool]] = None,
+ **kwargs,
+) -> PreTrainedTokenizer:
"""
- Simple Wrapper for Tokenizers from the transformers package. Enables loading of different Tokenizer classes with a uniform interface.
+ Enables loading of different Tokenizer classes with a uniform interface.
+ Right now it always returns an instance of `AutoTokenizer`.
+
+ :param pretrained_model_name_or_path: The path of the saved pretrained model or its name (e.g. `bert-base-uncased`)
+ :param revision: The version of model to use from the HuggingFace model hub. Can be tag name, branch name, or commit hash.
+ :param use_fast: Indicate if Haystack should try to load the fast version of the tokenizer (True) or use the Python one (False). Defaults to True.
+ :param use_auth_token: The auth_token to use in `PretrainedTokenizer.from_pretrained()`, or False
+ :param kwargs: other kwargs to pass on to `PretrainedTokenizer.from_pretrained()`
+ :return: AutoTokenizer instance
"""
+ model_name_or_path = str(pretrained_model_name_or_path)
- @classmethod
- def load(
- cls,
- pretrained_model_name_or_path,
- revision=None,
- tokenizer_class=None,
- use_fast=True,
- use_auth_token: Union[bool, str] = None,
- **kwargs,
- ):
- """
- Enables loading of different Tokenizer classes with a uniform interface. Either infer the class from
- model config or define it manually via `tokenizer_class`.
-
- :param pretrained_model_name_or_path: The path of the saved pretrained model or its name (e.g. `bert-base-uncased`)
- :type pretrained_model_name_or_path: str
- :param revision: The version of model to use from the HuggingFace model hub. Can be tag name, branch name, or commit hash.
- :type revision: str
- :param tokenizer_class: (Optional) Name of the tokenizer class to load (e.g. `BertTokenizer`)
- :type tokenizer_class: str
- :param use_fast: (Optional, False by default) Indicate if Haystack should try to load the fast version of the tokenizer (True) or
- use the Python one (False).
- Only DistilBERT, BERT and Electra fast tokenizers are supported.
- :type use_fast: bool
- :param kwargs:
- :return: Tokenizer
- """
- pretrained_model_name_or_path = str(pretrained_model_name_or_path)
- kwargs["revision"] = revision
-
- if tokenizer_class is None:
- tokenizer_class = cls._infer_tokenizer_class(pretrained_model_name_or_path, use_auth_token=use_auth_token)
-
- logger.debug(f"Loading tokenizer of type '{tokenizer_class}'")
- # return appropriate tokenizer object
- ret = None
- if "AutoTokenizer" in tokenizer_class:
- ret = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, use_fast=use_fast, **kwargs)
- elif "AlbertTokenizer" in tokenizer_class:
- if use_fast:
- ret = AlbertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = AlbertTokenizer.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- elif "XLMRobertaTokenizer" in tokenizer_class:
- if use_fast:
- ret = XLMRobertaTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = XLMRobertaTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "RobertaTokenizer" in tokenizer_class:
- if use_fast:
- ret = RobertaTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = RobertaTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DistilBertTokenizer" in tokenizer_class:
- if use_fast:
- ret = DistilBertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DistilBertTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "BertTokenizer" in tokenizer_class:
- if use_fast:
- ret = BertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = BertTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "XLNetTokenizer" in tokenizer_class:
- if use_fast:
- ret = XLNetTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = XLNetTokenizer.from_pretrained(
- pretrained_model_name_or_path, keep_accents=True, use_auth_token=use_auth_token, **kwargs
- )
- elif "ElectraTokenizer" in tokenizer_class:
- if use_fast:
- ret = ElectraTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = ElectraTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "CamembertTokenizer" in tokenizer_class:
- if use_fast:
- ret = CamembertTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = CamembertTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DPRQuestionEncoderTokenizer" in tokenizer_class:
- if use_fast:
- ret = DPRQuestionEncoderTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DPRQuestionEncoderTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DPRContextEncoderTokenizer" in tokenizer_class:
- if use_fast:
- ret = DPRContextEncoderTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DPRContextEncoderTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "BigBirdTokenizer" in tokenizer_class:
- if use_fast:
- ret = BigBirdTokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = BigBirdTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- elif "DebertaV2Tokenizer" in tokenizer_class:
- if use_fast:
- ret = DebertaV2TokenizerFast.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- else:
- ret = DebertaV2Tokenizer.from_pretrained(
- pretrained_model_name_or_path, use_auth_token=use_auth_token, **kwargs
- )
- if ret is None:
- raise Exception("Unable to load tokenizer")
- return ret
-
- @staticmethod
- def _infer_tokenizer_class(pretrained_model_name_or_path, use_auth_token: Union[bool, str] = None):
- # Infer Tokenizer from model type in config
- try:
- config = AutoConfig.from_pretrained(pretrained_model_name_or_path, use_auth_token=use_auth_token)
- except OSError:
- # Haystack model (no 'config.json' file)
- try:
- config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path + "/language_model_config.json", use_auth_token=use_auth_token
- )
- except Exception as e:
- logger.warning("No config file found. Trying to infer Tokenizer type from model name")
- tokenizer_class = Tokenizer._infer_tokenizer_class_from_string(pretrained_model_name_or_path)
- return tokenizer_class
-
- model_type = config.model_type
-
- if model_type == "xlm-roberta":
- tokenizer_class = "XLMRobertaTokenizer"
- elif model_type == "roberta":
- if "mlm" in pretrained_model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- tokenizer_class = "RobertaTokenizer"
- elif model_type == "camembert":
- tokenizer_class = "CamembertTokenizer"
- elif model_type == "albert":
- tokenizer_class = "AlbertTokenizer"
- elif model_type == "distilbert":
- tokenizer_class = "DistilBertTokenizer"
- elif model_type == "bert":
- tokenizer_class = "BertTokenizer"
- elif model_type == "xlnet":
- tokenizer_class = "XLNetTokenizer"
- elif model_type == "electra":
- tokenizer_class = "ElectraTokenizer"
- elif model_type == "dpr":
- if config.architectures[0] == "DPRQuestionEncoder":
- tokenizer_class = "DPRQuestionEncoderTokenizer"
- elif config.architectures[0] == "DPRContextEncoder":
- tokenizer_class = "DPRContextEncoderTokenizer"
- elif config.architectures[0] == "DPRReader":
- raise NotImplementedError("DPRReader models are currently not supported.")
- elif model_type == "big_bird":
- tokenizer_class = "BigBirdTokenizer"
- elif model_type == "deberta-v2":
- tokenizer_class = "DebertaV2Tokenizer"
- else:
- # Fall back to inferring type from model name
- logger.warning(
- "Could not infer Tokenizer type from config. Trying to infer Tokenizer type from model name."
- )
- tokenizer_class = Tokenizer._infer_tokenizer_class_from_string(pretrained_model_name_or_path)
-
- return tokenizer_class
-
- @staticmethod
- def _infer_tokenizer_class_from_string(pretrained_model_name_or_path):
- # If inferring tokenizer class from config doesn't succeed,
- # fall back to inferring tokenizer class from model name.
- if "albert" in pretrained_model_name_or_path.lower():
- tokenizer_class = "AlbertTokenizer"
- elif "bigbird" in pretrained_model_name_or_path.lower():
- tokenizer_class = "BigBirdTokenizer"
- elif "xlm-roberta" in pretrained_model_name_or_path.lower():
- tokenizer_class = "XLMRobertaTokenizer"
- elif "roberta" in pretrained_model_name_or_path.lower():
- tokenizer_class = "RobertaTokenizer"
- elif "codebert" in pretrained_model_name_or_path.lower():
- if "mlm" in pretrained_model_name_or_path.lower():
- raise NotImplementedError("MLM part of codebert is currently not supported in Haystack")
- tokenizer_class = "RobertaTokenizer"
- elif "camembert" in pretrained_model_name_or_path.lower() or "umberto" in pretrained_model_name_or_path.lower():
- tokenizer_class = "CamembertTokenizer"
- elif "distilbert" in pretrained_model_name_or_path.lower():
- tokenizer_class = "DistilBertTokenizer"
- elif (
- "debertav2" in pretrained_model_name_or_path.lower() or "debertav3" in pretrained_model_name_or_path.lower()
- ):
- tokenizer_class = "DebertaV2Tokenizer"
- elif "bert" in pretrained_model_name_or_path.lower():
- tokenizer_class = "BertTokenizer"
- elif "xlnet" in pretrained_model_name_or_path.lower():
- tokenizer_class = "XLNetTokenizer"
- elif "electra" in pretrained_model_name_or_path.lower():
- tokenizer_class = "ElectraTokenizer"
- elif "minilm" in pretrained_model_name_or_path.lower():
- tokenizer_class = "BertTokenizer"
- elif "dpr-question_encoder" in pretrained_model_name_or_path.lower():
- tokenizer_class = "DPRQuestionEncoderTokenizer"
- elif "dpr-ctx_encoder" in pretrained_model_name_or_path.lower():
- tokenizer_class = "DPRContextEncoderTokenizer"
- else:
- tokenizer_class = "AutoTokenizer"
+ if "mlm" in model_name_or_path.lower():
+ logging.error("MLM part of codebert is currently not supported in Haystack. Proceed at your own risk.")
+
+ params = {}
+ if any(tokenizer_type in model_name_or_path for tokenizer_type in ["albert", "xlnet"]):
+ params["keep_accents"] = True
- return tokenizer_class
+ return AutoTokenizer.from_pretrained(
+ pretrained_model_name_or_path=model_name_or_path,
+ revision=revision,
+ use_fast=use_fast,
+ use_auth_token=use_auth_token,
+ **params,
+ **kwargs,
+ )
-def tokenize_batch_question_answering(pre_baskets, tokenizer, indices):
+def tokenize_batch_question_answering(
+ pre_baskets: List[Dict[str, Any]], tokenizer: PreTrainedTokenizer, indices: List[Any]
+) -> List[SampleBasket]:
"""
Tokenizes text data for question answering tasks. Tokenization means splitting words into subwords, depending on the
tokenizer's vocabulary.
@@ -322,16 +79,20 @@ def tokenize_batch_question_answering(pre_baskets, tokenizer, indices):
- Then we tokenize each question individually
- We construct dicts with question and corresponding document text + tokens + offsets + ids
- :param pre_baskets: input dicts with QA info #todo change to input objects
+ :param pre_baskets: input dicts with QA info #TODO change to input objects
:param tokenizer: tokenizer to be used
- :param indices: list, indices used during multiprocessing so that IDs assigned to our baskets are unique
+ :param indices: indices used during multiprocessing so that IDs assigned to our baskets are unique
:return: baskets, list containing question and corresponding document information
"""
- assert len(indices) == len(pre_baskets)
- assert tokenizer.is_fast, (
- "Processing QA data is only supported with fast tokenizers for now.\n"
- "Please load Tokenizers with 'use_fast=True' option."
- )
+ if not len(indices) == len(pre_baskets):
+ raise ValueError("indices and pre_baskets must have the same length")
+
+ if not tokenizer.is_fast:
+ raise ModelingError(
+ "Processing QA data is only supported with fast tokenizers for now."
+ "Please load Tokenizers with 'use_fast=True' option."
+ )
+
baskets = []
# # Tokenize texts in batch mode
texts = [d["context"] for d in pre_baskets]
@@ -385,80 +146,13 @@ def tokenize_batch_question_answering(pre_baskets, tokenizer, indices):
def _get_start_of_word_QA(word_ids):
- words = np.array(word_ids)
- start_of_word_single = [1] + list(np.ediff1d(words))
- return start_of_word_single
-
-
-def tokenize_with_metadata(text: str, tokenizer) -> Dict[str, Any]:
- """
- Performing tokenization while storing some important metadata for each token:
-
- * offsets: (int) Character index where the token begins in the original text
- * start_of_word: (bool) If the token is the start of a word. Particularly helpful for NER and QA tasks.
-
- We do this by first doing whitespace tokenization and then applying the model specific tokenizer to each "word".
-
- .. note:: We don't assume to preserve exact whitespaces in the tokens!
- This means: tabs, new lines, multiple whitespace etc will all resolve to a single " ".
- This doesn't make a difference for BERT + XLNet but it does for RoBERTa.
- For RoBERTa it has the positive effect of a shorter sequence length, but some information about whitespace
- type is lost which might be helpful for certain NLP tasks ( e.g tab for tables).
-
- :param text: Text to tokenize
- :param tokenizer: Tokenizer (e.g. from Tokenizer.load())
- :return: Dictionary with "tokens", "offsets" and "start_of_word"
- """
- # normalize all other whitespace characters to " "
- # Note: using text.split() directly would destroy the offset,
- # since \n\n\n would be treated similarly as a single \n
- text = re.sub(r"\s", " ", text)
- # Fast Tokenizers return offsets, so we don't need to calculate them ourselves
- if tokenizer.is_fast:
- # tokenized = tokenizer(text, return_offsets_mapping=True, return_special_tokens_mask=True)
- tokenized2 = tokenizer.encode_plus(text, return_offsets_mapping=True, return_special_tokens_mask=True)
-
- tokens2 = tokenized2["input_ids"]
- offsets2 = np.array([x[0] for x in tokenized2["offset_mapping"]])
- # offsets2 = [x[0] for x in tokenized2["offset_mapping"]]
- words = np.array(tokenized2.encodings[0].words)
-
- # TODO check for validity for all tokenizer and special token types
- words[0] = -1
- words[-1] = words[-2]
- words += 1
- start_of_word2 = [0] + list(np.ediff1d(words))
- #######
-
- # start_of_word3 = []
- # last_word = -1
- # for word_id in tokenized2.encodings[0].words:
- # if word_id is None or word_id == last_word:
- # start_of_word3.append(0)
- # else:
- # start_of_word3.append(1)
- # last_word = word_id
-
- tokenized_dict = {"tokens": tokens2, "offsets": offsets2, "start_of_word": start_of_word2}
- else:
- # split text into "words" (here: simple whitespace tokenizer).
- words = text.split(" ")
- word_offsets = []
- cumulated = 0
- for idx, word in enumerate(words):
- word_offsets.append(cumulated)
- cumulated += len(word) + 1 # 1 because we so far have whitespace tokenizer
-
- # split "words" into "subword tokens"
- tokens, offsets, start_of_word = _words_to_tokens(words, word_offsets, tokenizer)
- tokenized_dict = {"tokens": tokens, "offsets": offsets, "start_of_word": start_of_word}
- return tokenized_dict
+ return [1] + list(np.ediff1d(np.array(word_ids)))
def truncate_sequences(
seq_a: list,
seq_b: Optional[list],
- tokenizer,
+ tokenizer: AutoTokenizer,
max_seq_len: int,
truncation_strategy: str = "longest_first",
with_special_tokens: bool = True,
@@ -467,21 +161,27 @@ def truncate_sequences(
"""
Reduces a single sequence or a pair of sequences to a maximum sequence length.
The sequences can contain tokens or any other elements (offsets, masks ...).
- If `with_special_tokens` is enabled, it'll remove some additional tokens to have exactly enough space for later adding special tokens (CLS, SEP etc.)
+ If `with_special_tokens` is enabled, it'll remove some additional tokens to have exactly
+ enough space for later adding special tokens (CLS, SEP etc.)
Supported truncation strategies:
- - longest_first: (default) Iteratively reduce the inputs sequence until the input is under max_length starting from the longest one at each token (when there is a pair of input sequences). Overflowing tokens only contains overflow from the first sequence.
- - only_first: Only truncate the first sequence. raise an error if the first sequence is shorter or equal to than num_tokens_to_remove.
+ - longest_first: (default) Iteratively reduce the inputs sequence until the input is under
+ max_length starting from the longest one at each token (when there is a pair of input sequences).
+ Overflowing tokens only contains overflow from the first sequence.
+ - only_first: Only truncate the first sequence. raise an error if the first sequence is
+ shorter or equal to than num_tokens_to_remove.
- only_second: Only truncate the second sequence
- do_not_truncate: Does not truncate (raise an error if the input sequence is longer than max_length)
:param seq_a: First sequence of tokens/offsets/...
:param seq_b: Optional second sequence of tokens/offsets/...
- :param tokenizer: Tokenizer (e.g. from Tokenizer.load())
+ :param tokenizer: Tokenizer (e.g. from get_tokenizer))
:param max_seq_len:
- :param truncation_strategy: how the sequence(s) should be truncated down. Default: "longest_first" (see above for other options).
- :param with_special_tokens: If true, it'll remove some additional tokens to have exactly enough space for later adding special tokens (CLS, SEP etc.)
+ :param truncation_strategy: how the sequence(s) should be truncated down.
+ Default: "longest_first" (see above for other options).
+ :param with_special_tokens: If true, it'll remove some additional tokens to have exactly enough space
+ for later adding special tokens (CLS, SEP etc.)
:param stride: optional stride of the window during truncation
:return: truncated seq_a, truncated seq_b, overflowing tokens
"""
@@ -503,59 +203,119 @@ def truncate_sequences(
return (seq_a, seq_b, overflowing_tokens)
-def _words_to_tokens(words, word_offsets, tokenizer):
+#
+# FIXME this is a relic from FARM. If there's the occasion, remove it!
+#
+def tokenize_with_metadata(text: str, tokenizer: PreTrainedTokenizer) -> Dict[str, Any]:
+ """
+ Performing tokenization while storing some important metadata for each token:
+
+ * offsets: (int) Character index where the token begins in the original text
+ * start_of_word: (bool) If the token is the start of a word. Particularly helpful for NER and QA tasks.
+
+ We do this by first doing whitespace tokenization and then applying the model specific tokenizer to each "word".
+
+ .. note:: We don't assume to preserve exact whitespaces in the tokens!
+ This means: tabs, new lines, multiple whitespace etc will all resolve to a single " ".
+ This doesn't make a difference for BERT + XLNet but it does for RoBERTa.
+ For RoBERTa it has the positive effect of a shorter sequence length, but some information about whitespace
+ type is lost which might be helpful for certain NLP tasks ( e.g tab for tables).
+
+ :param text: Text to tokenize
+ :param tokenizer: Tokenizer (e.g. from get_tokenizer))
+ :return: Dictionary with "tokens", "offsets" and "start_of_word"
+ """
+ # normalize all other whitespace characters to " "
+ # Note: using text.split() directly would destroy the offset,
+ # since \n\n\n would be treated similarly as a single \n
+ text = re.sub(r"\s", " ", text)
+
+ words: Union[List[str], np.ndarray] = []
+ word_offsets: Union[List[int], np.ndarray] = []
+ start_of_word: List[Union[int, bool]] = []
+
+ # Fast Tokenizers return offsets, so we don't need to calculate them ourselves
+ if tokenizer.is_fast:
+ # tokenized = tokenizer(text, return_offsets_mapping=True, return_special_tokens_mask=True)
+ tokenized = tokenizer.encode_plus(text, return_offsets_mapping=True, return_special_tokens_mask=True)
+
+ tokens = tokenized["input_ids"]
+ offsets = np.array([x[0] for x in tokenized["offset_mapping"]])
+ # offsets2 = [x[0] for x in tokenized2["offset_mapping"]]
+ words = np.array(tokenized.encodings[0].words)
+
+ # TODO check for validity for all tokenizer and special token types
+ words[0] = -1
+ words[-1] = words[-2]
+ words += 1
+ start_of_word = [0] + list(np.ediff1d(words))
+ return {"tokens": tokens, "offsets": offsets, "start_of_word": start_of_word}
+
+ # split text into "words" (here: simple whitespace tokenizer).
+ words = text.split(" ")
+ cumulated = 0
+ for word in words:
+ word_offsets.append(cumulated)
+ cumulated += len(word) + 1 # 1 because we so far have whitespace tokenizer
+
+ # split "words" into "subword tokens"
+ tokens, offsets, start_of_word = _words_to_tokens(words, word_offsets, tokenizer) # type: ignore
+ return {"tokens": tokens, "offsets": offsets, "start_of_word": start_of_word}
+
+
+# Note: only used by tokenize_with_metadata()
+def _words_to_tokens(
+ words: List[str], word_offsets: List[int], tokenizer: PreTrainedTokenizer
+) -> Tuple[List[str], List[int], List[bool]]:
"""
Tokenize "words" into subword tokens while keeping track of offsets and if a token is the start of a word.
:param words: list of words.
- :type words: list
:param word_offsets: Character indices where each word begins in the original text
- :type word_offsets: list
- :param tokenizer: Tokenizer (e.g. from Tokenizer.load())
- :return: tokens, offsets, start_of_word
+ :param tokenizer: Tokenizer (e.g. from get_tokenizer))
+ :return: Tuple of (tokens, offsets, start_of_word)
"""
- tokens = []
- token_offsets = []
- start_of_word = []
- idx = 0
- for w, w_off in zip(words, word_offsets):
- idx += 1
- if idx % 500000 == 0:
- logger.info(idx)
+ tokens: List[str] = []
+ token_offsets: List[int] = []
+ start_of_word: List[bool] = []
+ index = 0
+ for index, (word, word_offset) in enumerate(zip(words, word_offsets)):
+ if index % 500000 == 0:
+ logger.info(index)
# Get (subword) tokens of single word.
# empty / pure whitespace
- if len(w) == 0:
+ if len(word) == 0:
continue
# For the first word of a text: we just call the regular tokenize function.
# For later words: we need to call it with add_prefix_space=True to get the same results with roberta / gpt2 tokenizer
# see discussion here. https://github.com/huggingface/transformers/issues/1196
if len(tokens) == 0:
- tokens_word = tokenizer.tokenize(w)
+ tokens_word = tokenizer.tokenize(word)
else:
if type(tokenizer) == RobertaTokenizer:
- tokens_word = tokenizer.tokenize(w, add_prefix_space=True)
+ tokens_word = tokenizer.tokenize(word, add_prefix_space=True)
else:
- tokens_word = tokenizer.tokenize(w)
+ tokens_word = tokenizer.tokenize(word)
# Sometimes the tokenizer returns no tokens
if len(tokens_word) == 0:
continue
tokens += tokens_word
# get global offset for each token in word + save marker for first tokens of a word
- first_tok = True
- for tok in tokens_word:
- token_offsets.append(w_off)
+ first_token = True
+ for token in tokens_word:
+ token_offsets.append(word_offset)
# Depending on the tokenizer type special chars are added to distinguish tokens with preceeding
# whitespace (=> "start of a word"). We need to get rid of these to calculate the original length of the token
- orig_tok = re.sub(SPECIAL_TOKENIZER_CHARS, "", tok)
+ original_token = re.sub(SPECIAL_TOKENIZER_CHARS, "", token)
# Don't use length of unk token for offset calculation
- if orig_tok == tokenizer.special_tokens_map["unk_token"]:
- w_off += 1
+ if original_token == tokenizer.special_tokens_map["unk_token"]:
+ word_offset += 1
else:
- w_off += len(orig_tok)
- if first_tok:
+ word_offset += len(original_token)
+ if first_token:
start_of_word.append(True)
- first_tok = False
+ first_token = False
else:
start_of_word.append(False)
diff --git a/haystack/modeling/model/triadaptive_model.py b/haystack/modeling/model/triadaptive_model.py
index 9d3e8cfe63..9a76dab0d3 100644
--- a/haystack/modeling/model/triadaptive_model.py
+++ b/haystack/modeling/model/triadaptive_model.py
@@ -7,7 +7,7 @@
from torch import nn
from haystack.modeling.data_handler.processor import Processor
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, LanguageModel
from haystack.modeling.model.prediction_head import PredictionHead
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -87,11 +87,11 @@ def __init__(
super(TriAdaptiveModel, self).__init__()
self.device = device
self.language_model1 = language_model1.to(device)
- self.lm1_output_dims = language_model1.get_output_dims()
+ self.lm1_output_dims = language_model1.output_dims
self.language_model2 = language_model2.to(device)
- self.lm2_output_dims = language_model2.get_output_dims()
+ self.lm2_output_dims = language_model2.output_dims
self.language_model3 = language_model3.to(device)
- self.lm3_output_dims = language_model3.get_output_dims()
+ self.lm3_output_dims = language_model3.output_dims
self.dropout1 = nn.Dropout(embeds_dropout_prob)
self.dropout2 = nn.Dropout(embeds_dropout_prob)
self.dropout3 = nn.Dropout(embeds_dropout_prob)
@@ -165,17 +165,17 @@ def load(
"""
# Language Model
if lm1_name:
- language_model1 = LanguageModel.load(os.path.join(load_dir, lm1_name))
+ language_model1 = get_language_model(os.path.join(load_dir, lm1_name))
else:
- language_model1 = LanguageModel.load(load_dir)
+ language_model1 = get_language_model(load_dir)
if lm2_name:
- language_model2 = LanguageModel.load(os.path.join(load_dir, lm2_name))
+ language_model2 = get_language_model(os.path.join(load_dir, lm2_name))
else:
- language_model2 = LanguageModel.load(load_dir)
+ language_model2 = get_language_model(load_dir)
if lm3_name:
- language_model3 = LanguageModel.load(os.path.join(load_dir, lm3_name))
+ language_model3 = get_language_model(os.path.join(load_dir, lm3_name))
else:
- language_model3 = LanguageModel.load(load_dir)
+ language_model3 = get_language_model(load_dir)
# Prediction heads
ph_config_files = cls._get_prediction_head_files(load_dir)
@@ -294,19 +294,30 @@ def forward_lm(self, **kwargs):
pooled_output = [None, None]
# Forward pass for the queries
if "query_input_ids" in kwargs.keys():
- pooled_output1, hidden_states1 = self.language_model1(**kwargs)
+ pooled_output1, _ = self.language_model1(
+ input_ids=kwargs.get("query_input_ids"),
+ segment_ids=kwargs.get("query_segment_ids"),
+ attention_mask=kwargs.get("query_attention_mask"),
+ output_hidden_states=False,
+ output_attentions=False,
+ )
pooled_output[0] = pooled_output1
+
# Forward pass for text passages and tables
if "passage_input_ids" in kwargs.keys():
table_mask = torch.flatten(kwargs["is_table"]) == True
+
# Current batch consists of only tables
if all(table_mask):
- pooled_output2, hidden_states2 = self.language_model3(
+ pooled_output2, _ = self.language_model3(
passage_input_ids=kwargs["passage_input_ids"],
passage_segment_ids=kwargs["table_segment_ids"],
passage_attention_mask=kwargs["passage_attention_mask"],
+ output_hidden_states=False,
+ output_attentions=False,
)
pooled_output[1] = pooled_output2
+
# Current batch consists of tables and texts
elif any(table_mask):
@@ -320,17 +331,31 @@ def forward_lm(self, **kwargs):
table_input_ids = passage_input_ids[table_mask]
table_segment_ids = table_segment_ids[table_mask]
table_attention_mask = passage_attention_mask[table_mask]
- pooled_output_tables, _ = self.language_model3(table_input_ids, table_segment_ids, table_attention_mask)
+
+ pooled_output_tables, _ = self.language_model3(
+ input_ids=table_input_ids,
+ segment_ids=table_segment_ids,
+ attention_mask=table_attention_mask,
+ output_hidden_states=False,
+ output_attentions=False,
+ )
text_input_ids = passage_input_ids[~table_mask]
text_segment_ids = passage_segment_ids[~table_mask]
text_attention_mask = passage_attention_mask[~table_mask]
- pooled_output_text, _ = self.language_model2(text_input_ids, text_segment_ids, text_attention_mask)
+
+ pooled_output_text, _ = self.language_model2(
+ input_ids=text_input_ids,
+ segment_ids=text_segment_ids,
+ attention_mask=text_attention_mask,
+ output_hidden_states=False,
+ output_attentions=False,
+ )
last_table_idx = 0
last_text_idx = 0
combined_outputs = []
- for idx, mask in enumerate(table_mask):
+ for mask in table_mask:
if mask:
combined_outputs.append(pooled_output_tables[last_table_idx])
last_table_idx += 1
@@ -345,9 +370,22 @@ def forward_lm(self, **kwargs):
), "Passage embedding model and table embedding model use different embedding sizes"
pooled_output_combined = combined_outputs.view(-1, embedding_size)
pooled_output[1] = pooled_output_combined
+
# Current batch consists of only texts
else:
- pooled_output2, hidden_states2 = self.language_model2(**kwargs)
+ # Make input two-dimensional
+ max_seq_len = kwargs["passage_input_ids"].shape[-1]
+ input_ids = kwargs["passage_input_ids"].view(-1, max_seq_len)
+ attention_mask = kwargs["passage_attention_mask"].view(-1, max_seq_len)
+ segment_ids = kwargs["passage_segment_ids"].view(-1, max_seq_len)
+
+ pooled_output2, _ = self.language_model2(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ segment_ids=segment_ids,
+ output_hidden_states=False,
+ output_attentions=False,
+ )
pooled_output[1] = pooled_output2
return tuple(pooled_output)
@@ -382,7 +420,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int, vocab_size3: int
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model1_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size1 == model1_vocab_len, msg
@@ -391,7 +429,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int, vocab_size3: int
msg = (
f"Vocab size of tokenizer {vocab_size1} doesn't match with model {model2_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size2 == model2_vocab_len, msg
@@ -400,7 +438,7 @@ def verify_vocab_size(self, vocab_size1: int, vocab_size2: int, vocab_size3: int
msg = (
f"Vocab size of tokenizer {vocab_size3} doesn't match with model {model3_vocab_len}. "
"If you added a custom vocabulary to the tokenizer, "
- "make sure to supply 'n_added_tokens' to LanguageModel.load() and BertStyleLM.load()"
+ "make sure to supply 'n_added_tokens' to get_language_model() and BertStyleLM.load()"
)
assert vocab_size3 == model1_vocab_len, msg
diff --git a/haystack/modeling/training/base.py b/haystack/modeling/training/base.py
index 67a126c2fd..1ea3ec02ec 100644
--- a/haystack/modeling/training/base.py
+++ b/haystack/modeling/training/base.py
@@ -17,8 +17,8 @@
from haystack.modeling.data_handler.data_silo import DataSilo, DistillationDataSilo
from haystack.modeling.evaluation.eval import Evaluator
from haystack.modeling.model.adaptive_model import AdaptiveModel
+from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
from haystack.modeling.model.optimization import get_scheduler
-from haystack.modeling.model.language_model import DebertaV2
from haystack.modeling.utils import GracefulKiller
from haystack.utils.experiment_tracking import Tracker as tracker
@@ -251,8 +251,8 @@ def train(self):
vocab_size1=len(self.data_silo.processor.query_tokenizer),
vocab_size2=len(self.data_silo.processor.passage_tokenizer),
)
- elif not isinstance(
- self.model.language_model, DebertaV2
+ elif (
+ self.model.language_model.name != "debertav2"
): # DebertaV2 has mismatched vocab size on purpose (see https://github.com/huggingface/transformers/issues/12428)
self.model.verify_vocab_size(vocab_size=len(self.data_silo.processor.tokenizer))
self.model.train()
@@ -372,7 +372,24 @@ def train(self):
def compute_loss(self, batch: dict, step: int) -> torch.Tensor:
# Forward & backward pass through model
- logits = self.model.forward(**batch)
+ if isinstance(self.model, AdaptiveModel):
+ logits = self.model.forward(
+ input_ids=batch["input_ids"], segment_ids=None, padding_mask=batch["padding_mask"]
+ )
+
+ elif isinstance(self.model, BiAdaptiveModel):
+ logits = self.model.forward(
+ query_input_ids=batch["query_input_ids"],
+ query_segment_ids=batch["query_segment_ids"],
+ query_attention_mask=batch["query_attention_mask"],
+ passage_input_ids=batch["passage_input_ids"],
+ passage_segment_ids=batch["passage_segment_ids"],
+ passage_attention_mask=batch["passage_attention_mask"],
+ )
+
+ else:
+ logits = self.model.forward(**batch)
+
per_sample_loss = self.model.logits_to_loss(logits=logits, global_step=self.global_step, **batch)
return self.backward_propagate(per_sample_loss, step)
@@ -767,7 +784,15 @@ def compute_loss(self, batch: dict, step: int) -> torch.Tensor:
keys = list(batch.keys())
keys = [key for key in keys if key.startswith("teacher_output")]
teacher_logits = [batch.pop(key) for key in keys]
- logits = self.model.forward(**batch)
+
+ logits = self.model.forward(
+ input_ids=batch.get("input_ids"),
+ segment_ids=batch.get("segment_ids"),
+ padding_mask=batch.get("padding_mask"),
+ output_hidden_states=batch.get("output_hidden_states"),
+ output_attentions=batch.get("output_attentions"),
+ )
+
student_loss = self.model.logits_to_loss(logits=logits, global_step=self.global_step, **batch)
distillation_loss = self.distillation_loss_fn(
student_logits=logits[0] / self.temperature, teacher_logits=teacher_logits[0] / self.temperature
@@ -899,7 +924,16 @@ def __init__(
self.loss = DataParallel(self.loss).to(device)
def compute_loss(self, batch: dict, step: int) -> torch.Tensor:
- return self.backward_propagate(torch.sum(self.loss(batch)), step)
+ return self.backward_propagate(
+ torch.sum(
+ self.loss(
+ input_ids=batch.get("input_ids"),
+ segment_ids=batch.get("segment_ids"),
+ padding_mask=batch.get("padding_mask"),
+ )
+ ),
+ step,
+ )
class DistillationLoss(Module):
@@ -945,14 +979,23 @@ def __init__(self, model: Union[DataParallel, AdaptiveModel], teacher_model: Mod
else:
self.dim_mappings.append(None)
- def forward(self, batch):
+ def forward(self, input_ids: torch.Tensor, segment_ids: torch.Tensor, padding_mask: torch.Tensor):
with torch.no_grad():
_, teacher_hidden_states, teacher_attentions = self.teacher_model.forward(
- **batch, output_attentions=True, output_hidden_states=True
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ padding_mask=padding_mask,
+ output_attentions=True,
+ output_hidden_states=True,
)
-
- _, hidden_states, attentions = self.model.forward(**batch, output_attentions=True, output_hidden_states=True)
- loss = torch.tensor(0.0, device=batch["input_ids"].device)
+ _, hidden_states, attentions = self.model.forward(
+ input_ids=input_ids,
+ segment_ids=segment_ids,
+ padding_mask=padding_mask,
+ output_attentions=True,
+ output_hidden_states=True,
+ )
+ loss = torch.tensor(0.0, device=input_ids.device)
# calculating attention loss
for student_attention, teacher_attention, dim_mapping in zip(
diff --git a/haystack/modeling/visual.py b/haystack/modeling/visual.py
index e45f4d7786..d2084bdc5e 100644
--- a/haystack/modeling/visual.py
+++ b/haystack/modeling/visual.py
@@ -91,7 +91,7 @@
"""
WORKER_M = r""" 0
-/|\
+/|\
/'\ """
WORKER_F = r""" 0
diff --git a/haystack/nodes/_json_schema.py b/haystack/nodes/_json_schema.py
index 17de407f27..f16ceaf0c9 100644
--- a/haystack/nodes/_json_schema.py
+++ b/haystack/nodes/_json_schema.py
@@ -289,10 +289,25 @@ def get_json_schema(filename: str, version: str, modules: List[str] = ["haystack
"type": "array",
"items": {"type": "string"},
},
- "replicas": {
- "title": "replicas",
- "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
- "type": "integer",
+ "serve_deployment_kwargs": {
+ "title": "serve_deployment_kwargs",
+ "description": "Arguments to be passed to the Ray Serve `deployment()` method (only for Ray pipelines)",
+ "type": "object",
+ "properties": {
+ "num_replicas": {
+ "description": "How many replicas Ray should create for this node (only for Ray pipelines)",
+ "type": "integer",
+ },
+ "version": {"type": "string"},
+ "prev_version": {"type": "string"},
+ "init_args": {"type": "array"},
+ "init_kwargs": {"type": "object"},
+ "router_prefix": {"type": "string"},
+ "ray_actor_options": {"type": "object"},
+ "user_config": {"type": {}},
+ "max_concurrent_queries": {"type": "integer"},
+ },
+ "additionalProperties": True,
},
},
"required": ["name", "inputs"],
@@ -315,7 +330,9 @@ def get_json_schema(filename: str, version: str, modules: List[str] = ["haystack
"properties": {
"pipelines": {
"title": "Pipelines",
- "items": {"properties": {"nodes": {"items": {"not": {"required": ["replicas"]}}}}},
+ "items": {
+ "properties": {"nodes": {"items": {"not": {"required": ["serve_deployment_kwargs"]}}}}
+ },
}
},
},
diff --git a/haystack/nodes/answer_generator/transformers.py b/haystack/nodes/answer_generator/transformers.py
index 494429ec70..6bc68f79e3 100644
--- a/haystack/nodes/answer_generator/transformers.py
+++ b/haystack/nodes/answer_generator/transformers.py
@@ -229,7 +229,8 @@ def predict(self, query: str, documents: List[Document], top_k: Optional[int] =
passage_embeddings = self._prepare_passage_embeddings(docs=documents, embeddings=flat_docs_dict["embedding"])
# Query tokenization
- input_dict = self.tokenizer.prepare_seq2seq_batch(src_texts=[query], return_tensors="pt")
+ input_dict = self.tokenizer(text=[query], return_tensors="pt", padding="longest", truncation=True)
+
input_ids = input_dict["input_ids"].to(self.devices[0])
# Query embedding
query_embedding = self.model.question_encoder(input_ids)[0]
diff --git a/haystack/nodes/connector/crawler.py b/haystack/nodes/connector/crawler.py
index 16f703d5e1..f89fad0beb 100644
--- a/haystack/nodes/connector/crawler.py
+++ b/haystack/nodes/connector/crawler.py
@@ -13,7 +13,7 @@
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
- from selenium.common.exceptions import StaleElementReferenceException
+ from selenium.common.exceptions import StaleElementReferenceException, WebDriverException
from selenium import webdriver
except (ImportError, ModuleNotFoundError) as ie:
from haystack.utils.import_utils import _optional_component_not_installed
@@ -22,6 +22,7 @@
from haystack.nodes.base import BaseComponent
from haystack.schema import Document
+from haystack.errors import NodeError
logger = logging.getLogger(__name__)
@@ -94,15 +95,15 @@ def __init__(
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(service=Service("chromedriver"), options=options)
- except:
- raise Exception(
+ except WebDriverException as exc:
+ raise NodeError(
"""
\'chromium-driver\' needs to be installed manually when running colab. Follow the below given commands:
!apt-get update
!apt install chromium-driver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
If it has already been installed, please check if it has been copied to the right directory i.e. to \'/usr/bin\'"""
- )
+ ) from exc
else:
logger.info("'chrome-driver' will be automatically installed.")
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
diff --git a/haystack/nodes/preprocessor/base.py b/haystack/nodes/preprocessor/base.py
index 61bd7667ea..c8cabf94ec 100644
--- a/haystack/nodes/preprocessor/base.py
+++ b/haystack/nodes/preprocessor/base.py
@@ -1,6 +1,7 @@
from typing import List, Optional, Union
from abc import abstractmethod
+
from haystack.nodes.base import BaseComponent
from haystack.schema import Document
diff --git a/haystack/nodes/preprocessor/preprocessor.py b/haystack/nodes/preprocessor/preprocessor.py
index 7a4d7cd824..eebb98b8c8 100644
--- a/haystack/nodes/preprocessor/preprocessor.py
+++ b/haystack/nodes/preprocessor/preprocessor.py
@@ -5,6 +5,8 @@
from itertools import chain
from typing import List, Optional, Generator, Set, Union
import warnings
+from pathlib import Path
+from pickle import UnpicklingError
import nltk
from more_itertools import windowed
@@ -51,6 +53,7 @@ def __init__(
split_length: int = 200,
split_overlap: int = 0,
split_respect_sentence_boundary: bool = True,
+ tokenizer_model_folder: Optional[Union[str, Path]] = None,
language: str = "en",
id_hash_keys: Optional[List[str]] = None,
):
@@ -75,6 +78,7 @@ def __init__(
to True, the individual split will always have complete sentences &
the number of words will be <= split_length.
:param language: The language used by "nltk.tokenize.sent_tokenize" in iso639 format. Available options: "en", "es", "de", "fr" & many more.
+ :param tokenizer_model_folder: Path to the folder containing the NTLK PunktSentenceTokenizer models, if loading a model from a local path. Leave empty otherwise.
:param id_hash_keys: Generate the document id from a custom list of strings that refer to the document's
attributes. If you want to ensure you don't have duplicate documents in your DocumentStore but texts are
not unique, you can modify the metadata and pass e.g. `"meta"` to this field (e.g. [`"content"`, `"meta"`]).
@@ -95,7 +99,8 @@ def __init__(
self.split_length = split_length
self.split_overlap = split_overlap
self.split_respect_sentence_boundary = split_respect_sentence_boundary
- self.language = iso639_to_nltk.get(language, language)
+ self.language = language
+ self.tokenizer_model_folder = tokenizer_model_folder
self.print_log: Set[str] = set()
self.id_hash_keys = id_hash_keys
@@ -229,6 +234,11 @@ def clean(
# Mainly needed for type checking
if not isinstance(document, Document):
raise HaystackError("Document must not be of type 'dict' but of type 'Document'.")
+
+ if type(document.content) is not str:
+ logger.error("Document content is not of type str. Nothing to clean.")
+ return document
+
text = document.content
if clean_header_footer:
text = self._find_and_remove_header_footer(
@@ -286,11 +296,16 @@ def split(
if split_respect_sentence_boundary and split_by != "word":
raise NotImplementedError("'split_respect_sentence_boundary=True' is only compatible with split_by='word'.")
+ if type(document.content) is not str:
+ logger.error("Document content is not of type str. Nothing to split.")
+ return [document]
+
text = document.content
if split_respect_sentence_boundary and split_by == "word":
# split by words ensuring no sub sentence splits
- sentences = nltk.tokenize.sent_tokenize(text, language=self.language)
+ sentences = self._split_sentences(text)
+
word_count = 0
list_splits = []
current_slice: List[str] = []
@@ -334,7 +349,7 @@ def split(
if split_by == "passage":
elements = text.split("\n\n")
elif split_by == "sentence":
- elements = nltk.tokenize.sent_tokenize(text, language=self.language)
+ elements = self._split_sentences(text)
elif split_by == "word":
elements = text.split(" ")
else:
@@ -444,3 +459,50 @@ def _find_longest_common_ngram(
# no common sequence found
longest = ""
return longest if longest.strip() else None
+
+ def _split_sentences(self, text: str) -> List[str]:
+ """
+ Tokenize text into sentences.
+ :param text: str, text to tokenize
+ :return: list[str], list of sentences
+ """
+ sentences = []
+
+ language_name = iso639_to_nltk.get(self.language)
+
+ # Try to load a custom model from 'tokenizer_model_path'
+ if self.tokenizer_model_folder is not None:
+ tokenizer_model_path = Path(self.tokenizer_model_folder).absolute() / f"{self.language}.pickle"
+ try:
+ sentence_tokenizer = nltk.data.load(f"file:{str(tokenizer_model_path)}", format="pickle")
+ sentences = sentence_tokenizer.tokenize(text)
+ except LookupError:
+ logger.exception(f"PreProcessor couldn't load sentence tokenizer from {str(tokenizer_model_path)}")
+ except (UnpicklingError, ValueError) as e:
+ logger.exception(
+ f"PreProcessor couldn't determine model format of sentence tokenizer at {str(tokenizer_model_path)}."
+ )
+ if sentences:
+ return sentences
+
+ # NLTK failed to split, fallback to the default model or to English
+ if language_name is not None:
+ logger.error(
+ f"PreProcessor couldn't find custom sentence tokenizer model for {self.language}. Using default {self.language} model."
+ )
+ return nltk.tokenize.sent_tokenize(text, language=language_name)
+
+ logger.error(
+ f"PreProcessor couldn't find default or custom sentence tokenizer model for {self.language}. Using English instead."
+ )
+ return nltk.tokenize.sent_tokenize(text, language="english")
+
+ # Use a default NLTK model
+ if language_name is not None:
+ return nltk.tokenize.sent_tokenize(text, language=language_name)
+
+ logger.error(
+ f"PreProcessor couldn't find default sentence tokenizer model for {self.language}. Using English instead. "
+ "You may train your own model and use the 'tokenizer_model_folder' parameter."
+ )
+ return nltk.tokenize.sent_tokenize(text, language="english")
diff --git a/haystack/nodes/question_generator/question_generator.py b/haystack/nodes/question_generator/question_generator.py
index 7ca6a47735..e9b667e5e9 100644
--- a/haystack/nodes/question_generator/question_generator.py
+++ b/haystack/nodes/question_generator/question_generator.py
@@ -39,6 +39,7 @@ def __init__(
prompt="generate questions:",
num_queries_per_doc=1,
batch_size: Optional[int] = None,
+ sep_token: str = "",
):
"""
Uses the valhalla/t5-base-e2e-qg model by default. This class supports any question generation model that is
@@ -68,6 +69,7 @@ def __init__(
self.prompt = prompt
self.num_queries_per_doc = num_queries_per_doc
self.batch_size = batch_size
+ self.sep_token = self.tokenizer.sep_token or sep_token
def run(self, documents: List[Document]): # type: ignore
generated_questions = []
@@ -81,12 +83,15 @@ def run(self, documents: List[Document]): # type: ignore
def run_batch(self, documents: Union[List[Document], List[List[Document]]], batch_size: Optional[int] = None): # type: ignore
generated_questions = []
if isinstance(documents[0], Document):
- questions = self.generate_batch(texts=[d.content for d in documents if isinstance(d, Document)])
+ questions = self.generate_batch(
+ texts=[d.content for d in documents if isinstance(d, Document)], batch_size=batch_size
+ )
questions_iterator = questions # type: ignore
documents_iterator = documents
else:
questions = self.generate_batch(
- texts=[[d.content for d in doc_list] for doc_list in documents if isinstance(doc_list, list)]
+ texts=[[d.content for d in doc_list] for doc_list in documents if isinstance(doc_list, list)],
+ batch_size=batch_size,
)
questions_iterator = itertools.chain.from_iterable(questions) # type: ignore
documents_iterator = itertools.chain.from_iterable(documents) # type: ignore
@@ -127,12 +132,11 @@ def generate(self, text: str) -> List[str]:
num_return_sequences=self.num_queries_per_doc,
)
- string_output = self.tokenizer.batch_decode(tokens_output)
- string_output = [cur_output.replace("", "").replace("", "") for cur_output in string_output]
+ string_output = self.tokenizer.batch_decode(tokens_output, skip_special_tokens=True)
ret = []
for split in string_output:
- for question in split.split(""):
+ for question in split.split(self.sep_token):
question = question.strip()
if question and question not in ret:
ret.append(question)
@@ -196,8 +200,7 @@ def generate_batch(
num_return_sequences=self.num_queries_per_doc,
)
- string_output = self.tokenizer.batch_decode(tokens_output)
- string_output = [cur_output.replace("", "").replace("", "") for cur_output in string_output]
+ string_output = self.tokenizer.batch_decode(tokens_output, skip_special_tokens=True)
all_string_outputs.extend(string_output)
# Group predictions together by split
@@ -223,7 +226,7 @@ def generate_batch(
for doc in group:
doc_preds = []
for split in doc:
- for question in split.split(""):
+ for question in split.split(self.sep_token):
question = question.strip()
if question and question not in doc_preds:
doc_preds.append(question)
diff --git a/haystack/nodes/retriever/dense.py b/haystack/nodes/retriever/dense.py
index b608a39301..fa651123be 100644
--- a/haystack/nodes/retriever/dense.py
+++ b/haystack/nodes/retriever/dense.py
@@ -13,15 +13,20 @@
from torch.utils.data.sampler import SequentialSampler
import pandas as pd
from huggingface_hub import hf_hub_download
-from transformers import AutoConfig
+from transformers import (
+ AutoConfig,
+ DPRContextEncoderTokenizerFast,
+ DPRQuestionEncoderTokenizerFast,
+ DPRContextEncoderTokenizer,
+ DPRQuestionEncoderTokenizer,
+)
from haystack.errors import HaystackError
from haystack.schema import Document
from haystack.document_stores import BaseDocumentStore
from haystack.nodes.retriever.base import BaseRetriever
from haystack.nodes.retriever._embedding_encoder import _EMBEDDING_ENCODERS
-from haystack.modeling.model.tokenization import Tokenizer
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model, DPREncoder
from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
from haystack.modeling.model.triadaptive_model import TriAdaptiveModel
from haystack.modeling.model.prediction_head import TextSimilarityHead
@@ -57,7 +62,6 @@ def __init__(
batch_size: int = 16,
embed_title: bool = True,
use_fast_tokenizers: bool = True,
- infer_tokenizer_classes: bool = False,
similarity_function: str = "dot_product",
global_loss_buffer_size: int = 150000,
progress_bar: bool = True,
@@ -102,8 +106,6 @@ def __init__(
before writing them to the DocumentStore like this:
{"text": "my text", "meta": {"name": "my title"}}.
:param use_fast_tokenizers: Whether to use fast Rust tokenizers
- :param infer_tokenizer_classes: Whether to infer tokenizer class from the model config / name.
- If `False`, the class always loads `DPRQuestionEncoderTokenizer` and `DPRContextEncoderTokenizer`.
:param similarity_function: Which function to apply for calculating the similarity of query and passage embeddings during training.
Options: `dot_product` (Default) or `cosine`
:param global_loss_buffer_size: Buffer size for all_gather() in DDP.
@@ -151,39 +153,29 @@ def __init__(
"This can be set when initializing the DocumentStore"
)
- self.infer_tokenizer_classes = infer_tokenizer_classes
- tokenizers_default_classes = {"query": "DPRQuestionEncoderTokenizer", "passage": "DPRContextEncoderTokenizer"}
- if self.infer_tokenizer_classes:
- tokenizers_default_classes["query"] = None # type: ignore
- tokenizers_default_classes["passage"] = None # type: ignore
-
# Init & Load Encoders
- self.query_tokenizer = Tokenizer.load(
+ self.query_tokenizer = DPRQuestionEncoderTokenizerFast.from_pretrained(
pretrained_model_name_or_path=query_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["query"],
use_auth_token=use_auth_token,
)
- self.query_encoder = LanguageModel.load(
+ self.query_encoder = DPREncoder(
pretrained_model_name_or_path=query_embedding_model,
- revision=model_version,
- language_model_class="DPRQuestionEncoder",
+ model_type="DPRQuestionEncoder",
use_auth_token=use_auth_token,
)
- self.passage_tokenizer = Tokenizer.load(
+ self.passage_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
pretrained_model_name_or_path=passage_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["passage"],
use_auth_token=use_auth_token,
)
- self.passage_encoder = LanguageModel.load(
+ self.passage_encoder = DPREncoder(
pretrained_model_name_or_path=passage_embedding_model,
- revision=model_version,
- language_model_class="DPRContextEncoder",
+ model_type="DPRContextEncoder",
use_auth_token=use_auth_token,
)
@@ -493,12 +485,19 @@ def _get_predictions(self, dicts):
leave=False,
disable=disable_tqdm,
) as progress_bar:
- for batch in data_loader:
- batch = {key: batch[key].to(self.devices[0]) for key in batch}
+ for raw_batch in data_loader:
+ batch = {key: raw_batch[key].to(self.devices[0]) for key in raw_batch}
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = self.model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = self.model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -550,7 +549,6 @@ def embed_documents(self, docs: List[Document]) -> List[np.ndarray]:
for d in docs
]
embeddings = self._get_predictions(passages)["passages"]
-
return embeddings
def train(
@@ -726,7 +724,6 @@ def load(
similarity_function: str = "dot_product",
query_encoder_dir: str = "query_encoder",
passage_encoder_dir: str = "passage_encoder",
- infer_tokenizer_classes: bool = False,
):
"""
Load DensePassageRetriever from the specified directory.
@@ -743,7 +740,6 @@ def load(
embed_title=embed_title,
use_fast_tokenizers=use_fast_tokenizers,
similarity_function=similarity_function,
- infer_tokenizer_classes=infer_tokenizer_classes,
)
logger.info(f"DPR model loaded from {load_dir}")
@@ -774,13 +770,13 @@ def __init__(
batch_size: int = 16,
embed_meta_fields: List[str] = ["name", "section_title", "caption"],
use_fast_tokenizers: bool = True,
- infer_tokenizer_classes: bool = False,
similarity_function: str = "dot_product",
global_loss_buffer_size: int = 150000,
progress_bar: bool = True,
devices: Optional[List[Union[str, torch.device]]] = None,
use_auth_token: Optional[Union[str, bool]] = None,
scale_score: bool = True,
+ use_fast: bool = True,
):
"""
Init the Retriever incl. the two encoder models from a local or remote model checkpoint.
@@ -805,8 +801,6 @@ def __init__(
performance if your titles contain meaningful information for retrieval
(topic, entities etc.).
:param use_fast_tokenizers: Whether to use fast Rust tokenizers
- :param infer_tokenizer_classes: Whether to infer tokenizer class from the model config / name.
- If `False`, the class always loads `DPRQuestionEncoderTokenizer` and `DPRContextEncoderTokenizer`.
:param similarity_function: Which function to apply for calculating the similarity of query and passage embeddings during training.
Options: `dot_product` (Default) or `cosine`
:param global_loss_buffer_size: Buffer size for all_gather() in DDP.
@@ -824,6 +818,7 @@ def __init__(
:param scale_score: Whether to scale the similarity score to the unit interval (range of [0,1]).
If true (default) similarity scores (e.g. cosine or dot_product) which naturally have a different value range will be scaled to a range of [0,1], where 1 means extremely relevant.
Otherwise raw similarity scores (e.g. cosine or dot_product) will be used.
+ :param use_fast: Whether to use the fast version of DPR tokenizers or fallback to the standard version. Defaults to True.
"""
super().__init__()
@@ -855,59 +850,40 @@ def __init__(
"This can be set when initializing the DocumentStore"
)
- self.infer_tokenizer_classes = infer_tokenizer_classes
- tokenizers_default_classes = {
- "query": "DPRQuestionEncoderTokenizer",
- "passage": "DPRContextEncoderTokenizer",
- "table": "DPRContextEncoderTokenizer",
- }
- if self.infer_tokenizer_classes:
- tokenizers_default_classes["query"] = None # type: ignore
- tokenizers_default_classes["passage"] = None # type: ignore
- tokenizers_default_classes["table"] = None # type: ignore
+ query_tokenizer_class = DPRQuestionEncoderTokenizerFast if use_fast else DPRQuestionEncoderTokenizer
+ passage_tokenizer_class = DPRContextEncoderTokenizerFast if use_fast else DPRContextEncoderTokenizer
+ table_tokenizer_class = DPRContextEncoderTokenizerFast if use_fast else DPRContextEncoderTokenizer
# Init & Load Encoders
- self.query_tokenizer = Tokenizer.load(
- pretrained_model_name_or_path=query_embedding_model,
+ self.query_tokenizer = query_tokenizer_class.from_pretrained(
+ query_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["query"],
use_auth_token=use_auth_token,
)
- self.query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=query_embedding_model,
- revision=model_version,
- language_model_class="DPRQuestionEncoder",
- use_auth_token=use_auth_token,
+ self.query_encoder = get_language_model(
+ pretrained_model_name_or_path=query_embedding_model, revision=model_version, use_auth_token=use_auth_token
)
- self.passage_tokenizer = Tokenizer.load(
- pretrained_model_name_or_path=passage_embedding_model,
+ self.passage_tokenizer = passage_tokenizer_class.from_pretrained(
+ passage_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["passage"],
use_auth_token=use_auth_token,
)
- self.passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=passage_embedding_model,
- revision=model_version,
- language_model_class="DPRContextEncoder",
- use_auth_token=use_auth_token,
+ self.passage_encoder = get_language_model(
+ pretrained_model_name_or_path=passage_embedding_model, revision=model_version, use_auth_token=use_auth_token
)
- self.table_tokenizer = Tokenizer.load(
- pretrained_model_name_or_path=table_embedding_model,
+ self.table_tokenizer = table_tokenizer_class.from_pretrained(
+ table_embedding_model,
revision=model_version,
do_lower_case=True,
use_fast=use_fast_tokenizers,
- tokenizer_class=tokenizers_default_classes["table"],
use_auth_token=use_auth_token,
)
- self.table_encoder = LanguageModel.load(
- pretrained_model_name_or_path=table_embedding_model,
- revision=model_version,
- language_model_class="DPRContextEncoder",
- use_auth_token=use_auth_token,
+ self.table_encoder = get_language_model(
+ pretrained_model_name_or_path=table_embedding_model, revision=model_version, use_auth_token=use_auth_token
)
self.processor = TableTextSimilarityProcessor(
@@ -1419,7 +1395,6 @@ def load(
query_encoder_dir: str = "query_encoder",
passage_encoder_dir: str = "passage_encoder",
table_encoder_dir: str = "table_encoder",
- infer_tokenizer_classes: bool = False,
):
"""
Load TableTextRetriever from the specified directory.
@@ -1439,7 +1414,6 @@ def load(
embed_meta_fields=embed_meta_fields,
use_fast_tokenizers=use_fast_tokenizers,
similarity_function=similarity_function,
- infer_tokenizer_classes=infer_tokenizer_classes,
)
logger.info(f"TableTextRetriever model loaded from {load_dir}")
diff --git a/haystack/nodes/translator/transformers.py b/haystack/nodes/translator/transformers.py
index c653c05e52..e77705d148 100644
--- a/haystack/nodes/translator/transformers.py
+++ b/haystack/nodes/translator/transformers.py
@@ -119,9 +119,14 @@ def translate(
else:
text_for_translator: List[str] = [query] # type: ignore
- batch = self.tokenizer.prepare_seq2seq_batch(
- src_texts=text_for_translator, return_tensors="pt", max_length=self.max_seq_len
+ batch = self.tokenizer(
+ text=text_for_translator,
+ return_tensors="pt",
+ max_length=self.max_seq_len,
+ padding="longest",
+ truncation=True,
).to(self.devices[0])
+
generated_output = self.model.generate(**batch)
translated_texts = self.tokenizer.batch_decode(
generated_output, skip_special_tokens=True, clean_up_tokenization_spaces=self.clean_up_tokenization_spaces
diff --git a/haystack/pipelines/config.py b/haystack/pipelines/config.py
index b958397598..99ea05e6e9 100644
--- a/haystack/pipelines/config.py
+++ b/haystack/pipelines/config.py
@@ -179,7 +179,12 @@ def build_component_dependency_graph(
return graph
-def validate_yaml(path: Path, strict_version_check: bool = False, overwrite_with_env_variables: bool = True):
+def validate_yaml(
+ path: Path,
+ strict_version_check: bool = False,
+ overwrite_with_env_variables: bool = True,
+ extras: Optional[str] = None,
+):
"""
Ensures that the given YAML file can be loaded without issues.
@@ -197,16 +202,20 @@ def validate_yaml(path: Path, strict_version_check: bool = False, overwrite_with
to change index name param for an ElasticsearchDocumentStore, an env
variable 'MYDOCSTORE_PARAMS_INDEX=documents-2021' can be set. Note that an
`_` sign must be used to specify nested hierarchical properties.
+ :param extras: which values are allowed in the `extras` field (for example, `ray`). If None, does not allow the `extras` field at all.
:return: None if validation is successful
:raise: `PipelineConfigError` in case of issues.
"""
pipeline_config = read_pipeline_config_from_yaml(path)
- validate_config(pipeline_config=pipeline_config, strict_version_check=strict_version_check)
+ validate_config(pipeline_config=pipeline_config, strict_version_check=strict_version_check, extras=extras)
logging.debug(f"'{path}' contains valid Haystack pipelines.")
def validate_config(
- pipeline_config: Dict[str, Any], strict_version_check: bool = False, overwrite_with_env_variables: bool = True
+ pipeline_config: Dict[str, Any],
+ strict_version_check: bool = False,
+ overwrite_with_env_variables: bool = True,
+ extras: Optional[str] = None,
):
"""
Ensures that the given YAML file can be loaded without issues.
@@ -225,10 +234,11 @@ def validate_config(
to change index name param for an ElasticsearchDocumentStore, an env
variable 'MYDOCSTORE_PARAMS_INDEX=documents-2021' can be set. Note that an
`_` sign must be used to specify nested hierarchical properties.
+ :param extras: which values are allowed in the `extras` field (for example, `ray`). If None, does not allow the `extras` field at all.
:return: None if validation is successful
:raise: `PipelineConfigError` in case of issues.
"""
- validate_schema(pipeline_config=pipeline_config, strict_version_check=strict_version_check)
+ validate_schema(pipeline_config=pipeline_config, strict_version_check=strict_version_check, extras=extras)
for pipeline_definition in pipeline_config["pipelines"]:
component_definitions = get_component_definitions(
@@ -237,7 +247,7 @@ def validate_config(
validate_pipeline_graph(pipeline_definition=pipeline_definition, component_definitions=component_definitions)
-def validate_schema(pipeline_config: Dict, strict_version_check: bool = False) -> None:
+def validate_schema(pipeline_config: Dict, strict_version_check: bool = False, extras: Optional[str] = None) -> None:
"""
Check that the YAML abides the JSON schema, so that every block
of the pipeline configuration file contains all required information
@@ -248,11 +258,20 @@ def validate_schema(pipeline_config: Dict, strict_version_check: bool = False) -
:param pipeline_config: the configuration to validate
:param strict_version_check: whether to fail in case of a version mismatch (throws a warning otherwise)
+ :param extras: which values are allowed in the `extras` field (for example, `ray`). If None, does not allow the `extras` field at all.
:return: None if validation is successful
:raise: `PipelineConfigError` in case of issues.
"""
validate_config_strings(pipeline_config)
+ # Check that the extras are respected
+ extras_in_config = pipeline_config.get("extras", None)
+ if (not extras and extras_in_config) or (extras and extras_in_config not in extras):
+ raise PipelineConfigError(
+ f"Cannot use this class to load a YAML with 'extras: {extras_in_config}'. "
+ "Use the proper class, for example 'RayPipeline'."
+ )
+
# Check for the version manually (to avoid validation errors)
pipeline_version = pipeline_config.get("version", None)
diff --git a/haystack/pipelines/ray.py b/haystack/pipelines/ray.py
index e326bb8aff..98e4c5c1e9 100644
--- a/haystack/pipelines/ray.py
+++ b/haystack/pipelines/ray.py
@@ -32,7 +32,7 @@ class RayPipeline(Pipeline):
Pipeline can be independently scaled. For instance, an extractive QA Pipeline deployment can have three replicas
of the Reader and a single replica for the Retriever. This way, you can use your resources more efficiently by horizontally scaling Components.
- To set the number of replicas, add `replicas` in the YAML configuration for the node in a pipeline:
+ To set the number of replicas, add `num_replicas` in the YAML configuration for the node in a pipeline:
```yaml
| components:
@@ -43,8 +43,9 @@ class RayPipeline(Pipeline):
| type: RayPipeline
| nodes:
| - name: ESRetriever
- | replicas: 2 # number of replicas to create on the Ray cluster
| inputs: [ Query ]
+ | serve_deployment_kwargs:
+ | num_replicas: 2 # number of replicas to create on the Ray cluster
```
A Ray Pipeline can only be created with a YAML Pipeline configuration.
@@ -61,14 +62,20 @@ class RayPipeline(Pipeline):
YAML definitions of Ray pipelines are validated at load. For more information, see [YAML File Definitions](https://haystack-website-git-fork-fstau-dev-287-search-deepset-overnice.vercel.app/components/pipelines#yaml-file-definitions).
"""
- def __init__(self, address: str = None, ray_args: Optional[Dict[str, Any]] = None):
+ def __init__(
+ self,
+ address: str = None,
+ ray_args: Optional[Dict[str, Any]] = None,
+ serve_args: Optional[Dict[str, Any]] = None,
+ ):
"""
:param address: The IP address for the Ray cluster. If set to `None`, a local Ray instance is started.
:param kwargs: Optional parameters for initializing Ray.
+ :param serve_args: Optional parameters for initializing Ray Serve.
"""
ray_args = ray_args or {}
ray.init(address=address, **ray_args)
- serve.start()
+ self._serve_controller_client = serve.start(**serve_args)
super().__init__()
@classmethod
@@ -80,14 +87,15 @@ def load_from_config(
strict_version_check: bool = False,
address: Optional[str] = None,
ray_args: Optional[Dict[str, Any]] = None,
+ serve_args: Optional[Dict[str, Any]] = None,
):
- validate_config(pipeline_config, strict_version_check=strict_version_check)
+ validate_config(pipeline_config, strict_version_check=strict_version_check, extras="ray")
pipeline_definition = get_pipeline_definition(pipeline_config=pipeline_config, pipeline_name=pipeline_name)
component_definitions = get_component_definitions(
pipeline_config=pipeline_config, overwrite_with_env_variables=overwrite_with_env_variables
)
- pipeline = cls(address=address, ray_args=ray_args or {})
+ pipeline = cls(address=address, ray_args=ray_args or {}, serve_args=serve_args or {})
for node_config in pipeline_definition["nodes"]:
if pipeline.root_node is None:
@@ -101,8 +109,12 @@ def load_from_config(
name = node_config["name"]
component_type = component_definitions[name]["type"]
component_class = BaseComponent.get_subclass(component_type)
- replicas = next(node for node in pipeline_definition["nodes"] if node["name"] == name).get("replicas", 1)
- handle = cls._create_ray_deployment(component_name=name, pipeline_config=pipeline_config, replicas=replicas)
+ serve_deployment_kwargs = next(node for node in pipeline_definition["nodes"] if node["name"] == name).get(
+ "serve_deployment_kwargs", {}
+ )
+ handle = cls._create_ray_deployment(
+ component_name=name, pipeline_config=pipeline_config, serve_deployment_kwargs=serve_deployment_kwargs
+ )
pipeline._add_ray_deployment_in_graph(
handle=handle,
name=name,
@@ -121,6 +133,7 @@ def load_from_yaml( # type: ignore
address: Optional[str] = None,
strict_version_check: bool = False,
ray_args: Optional[Dict[str, Any]] = None,
+ serve_args: Optional[Dict[str, Any]] = None,
):
"""
Load Pipeline from a YAML file defining the individual components and how they're tied together to form
@@ -154,7 +167,8 @@ def load_from_yaml( # type: ignore
| nodes:
| - name: MyESRetriever
| inputs: [Query]
- | replicas: 2 # number of replicas to create on the Ray cluster
+ | serve_deployment_kwargs:
+ | num_replicas: 2 # number of replicas to create on the Ray cluster
| - name: MyReader
| inputs: [MyESRetriever]
```
@@ -170,6 +184,7 @@ def load_from_yaml( # type: ignore
variable 'MYDOCSTORE_PARAMS_INDEX=documents-2021' can be set. Note that an
`_` sign must be used to specify nested hierarchical properties.
:param address: The IP address for the Ray cluster. If set to None, a local Ray instance is started.
+ :param serve_args: Optional parameters for initializing Ray Serve.
"""
pipeline_config = read_pipeline_config_from_yaml(path)
return RayPipeline.load_from_config(
@@ -179,19 +194,27 @@ def load_from_yaml( # type: ignore
strict_version_check=strict_version_check,
address=address,
ray_args=ray_args,
+ serve_args=serve_args,
)
@classmethod
- def _create_ray_deployment(cls, component_name: str, pipeline_config: dict, replicas: int = 1):
+ def _create_ray_deployment(
+ cls, component_name: str, pipeline_config: dict, serve_deployment_kwargs: Optional[Dict[str, Any]] = {}
+ ):
"""
Create a Ray Deployment for the Component.
:param component_name: Class name of the Haystack Component.
:param pipeline_config: The Pipeline config YAML parsed as a dict.
- :param replicas: By default, a single replica of the component is created. It can be
- configured by setting `replicas` parameter in the Pipeline YAML.
+ :param serve_deployment_kwargs: An optional dictionary of arguments to be supplied to the
+ `ray.serve.deployment()` method, like `num_replicas`, `ray_actor_options`,
+ `max_concurrent_queries`, etc. See potential values in the
+ Ray Serve API docs (https://docs.ray.io/en/latest/serve/package-ref.html)
+ under the `ray.serve.deployment()` method
"""
- RayDeployment = serve.deployment(_RayDeploymentWrapper, name=component_name, num_replicas=replicas) # type: ignore
+ RayDeployment = serve.deployment(
+ _RayDeploymentWrapper, name=component_name, **serve_deployment_kwargs # type: ignore
+ )
RayDeployment.deploy(pipeline_config, component_name)
handle = RayDeployment.get_handle()
return handle
diff --git a/haystack/schema.py b/haystack/schema.py
index 8343819b94..1ec21b8e47 100644
--- a/haystack/schema.py
+++ b/haystack/schema.py
@@ -1,4 +1,5 @@
from __future__ import annotations
+import csv
import typing
from typing import Any, Optional, Dict, List, Union
@@ -1346,12 +1347,15 @@ def _build_document_metrics_df(
metrics_df = pd.DataFrame.from_records(metrics, index=documents["multilabel_id"].unique())
return metrics_df
- def save(self, out_dir: Union[str, Path]):
+ def save(self, out_dir: Union[str, Path], **to_csv_kwargs):
"""
Saves the evaluation result.
The result of each node is saved in a separate csv with file name {node_name}.csv to the out_dir folder.
:param out_dir: Path to the target folder the csvs will be saved.
+ :param to_csv_kwargs: kwargs to be passed to pd.DataFrame.to_csv(). See https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_csv.html.
+ This method uses different default values than pd.DataFrame.to_csv() for the following parameters:
+ index=False, quoting=csv.QUOTE_NONNUMERIC (to avoid problems with \r chars)
"""
out_dir = out_dir if isinstance(out_dir, Path) else Path(out_dir)
logger.info(f"Saving evaluation results to {out_dir}")
@@ -1359,29 +1363,45 @@ def save(self, out_dir: Union[str, Path]):
out_dir.mkdir(parents=True)
for node_name, df in self.node_results.items():
target_path = out_dir / f"{node_name}.csv"
- df.to_csv(target_path, index=False, header=True)
+ default_to_csv_kwargs = {
+ "index": False,
+ "quoting": csv.QUOTE_NONNUMERIC, # avoids problems with \r chars in texts by enclosing all string values in quotes
+ }
+ to_csv_kwargs = {**default_to_csv_kwargs, **to_csv_kwargs}
+ df.to_csv(target_path, **to_csv_kwargs)
@classmethod
- def load(cls, load_dir: Union[str, Path]):
+ def load(cls, load_dir: Union[str, Path], **read_csv_kwargs):
"""
Loads the evaluation result from disk. Expects one csv file per node. See save() for further information.
:param load_dir: The directory containing the csv files.
+ :param read_csv_kwargs: kwargs to be passed to pd.read_csv(). See https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html.
+ This method uses different default values than pd.read_csv() for the following parameters:
+ header=0, converters=CONVERTERS
+ where CONVERTERS is a dictionary mapping all array typed columns to ast.literal_eval.
"""
load_dir = load_dir if isinstance(load_dir, Path) else Path(load_dir)
csv_files = [file for file in load_dir.iterdir() if file.is_file() and file.suffix == ".csv"]
cols_to_convert = [
+ "filters",
"gold_document_ids",
+ "gold_custom_document_ids",
"gold_contexts",
"gold_answers",
+ "gold_documents_id_match",
"gold_offsets_in_documents",
"gold_answers_exact_match",
"gold_answers_f1",
- "gold_answers_document_id_match",
- "gold_context_similarity",
+ "gold_answers_sas",
+ "gold_answers_match",
+ "gold_contexts_similarity",
+ "offsets_in_document",
]
converters = dict.fromkeys(cols_to_convert, ast.literal_eval)
- node_results = {file.stem: pd.read_csv(file, header=0, converters=converters) for file in csv_files}
+ default_read_csv_kwargs = {"converters": converters, "header": 0}
+ read_csv_kwargs = {**default_read_csv_kwargs, **read_csv_kwargs}
+ node_results = {file.stem: pd.read_csv(file, **read_csv_kwargs) for file in csv_files}
# backward compatibility mappings
for df in node_results.values():
df.rename(columns={"gold_document_contents": "gold_contexts", "content": "context"}, inplace=True)
diff --git a/haystack/utils/deepsetcloud.py b/haystack/utils/deepsetcloud.py
index dbda39c084..0c906e35b9 100644
--- a/haystack/utils/deepsetcloud.py
+++ b/haystack/utils/deepsetcloud.py
@@ -30,6 +30,8 @@ class PipelineStatus(Enum):
UNDEPLOYMENT_IN_PROGRESS: str = "UNDEPLOYMENT_IN_PROGRESS"
DEPLOYMENT_SCHEDULED: str = "DEPLOYMENT_SCHEDULED"
UNDEPLOYMENT_SCHEDULED: str = "UNDEPLOYMENT_SCHEDULED"
+ DEPLOYMENT_FAILED: str = "DEPLOYMENT_FAILED"
+ UNDEPLOYMENT_FAILED: str = "UNDEPLOYMENT_FAILED"
UKNOWN: str = "UNKNOWN"
@classmethod
@@ -38,12 +40,18 @@ def from_str(cls, status_string: str) -> "PipelineStatus":
SATISFIED_STATES_KEY = "satisfied_states"
+FAILED_STATES_KEY = "failed_states"
VALID_INITIAL_STATES_KEY = "valid_initial_states"
VALID_TRANSITIONING_STATES_KEY = "valid_transitioning_states"
PIPELINE_STATE_TRANSITION_INFOS: Dict[PipelineStatus, Dict[str, List[PipelineStatus]]] = {
PipelineStatus.UNDEPLOYED: {
SATISFIED_STATES_KEY: [PipelineStatus.UNDEPLOYED],
- VALID_INITIAL_STATES_KEY: [PipelineStatus.DEPLOYED, PipelineStatus.DEPLOYED_UNHEALTHY],
+ FAILED_STATES_KEY: [PipelineStatus.UNDEPLOYMENT_FAILED],
+ VALID_INITIAL_STATES_KEY: [
+ PipelineStatus.DEPLOYED,
+ PipelineStatus.DEPLOYMENT_FAILED,
+ PipelineStatus.UNDEPLOYMENT_FAILED,
+ ],
VALID_TRANSITIONING_STATES_KEY: [
PipelineStatus.UNDEPLOYMENT_SCHEDULED,
PipelineStatus.UNDEPLOYMENT_IN_PROGRESS,
@@ -51,7 +59,12 @@ def from_str(cls, status_string: str) -> "PipelineStatus":
},
PipelineStatus.DEPLOYED: {
SATISFIED_STATES_KEY: [PipelineStatus.DEPLOYED, PipelineStatus.DEPLOYED_UNHEALTHY],
- VALID_INITIAL_STATES_KEY: [PipelineStatus.UNDEPLOYED],
+ FAILED_STATES_KEY: [PipelineStatus.DEPLOYMENT_FAILED],
+ VALID_INITIAL_STATES_KEY: [
+ PipelineStatus.UNDEPLOYED,
+ PipelineStatus.DEPLOYMENT_FAILED,
+ PipelineStatus.UNDEPLOYMENT_FAILED,
+ ],
VALID_TRANSITIONING_STATES_KEY: [PipelineStatus.DEPLOYMENT_SCHEDULED, PipelineStatus.DEPLOYMENT_IN_PROGRESS],
},
}
@@ -624,9 +637,11 @@ def deploy(
)
logger.info(f"Try it out using the following curl command:\n{curl_cmd}")
- elif status == PipelineStatus.DEPLOYED_UNHEALTHY:
- logger.warning(
- f"Deployment of pipeline config '{pipeline_config_name}' succeeded. But '{pipeline_config_name}' is unhealthy."
+ elif status == PipelineStatus.DEPLOYMENT_FAILED:
+ raise DeepsetCloudError(
+ f"Deployment of pipeline config '{pipeline_config_name}' failed. "
+ "This might be caused by an exception in deepset Cloud or a runtime error in the pipeline. "
+ "You can try to run this pipeline locally first."
)
elif status in [PipelineStatus.UNDEPLOYMENT_IN_PROGRESS, PipelineStatus.UNDEPLOYMENT_SCHEDULED]:
raise DeepsetCloudError(
@@ -705,6 +720,7 @@ def _transition_pipeline_state(
transition_info = PIPELINE_STATE_TRANSITION_INFOS[target_state]
satisfied_states = transition_info[SATISFIED_STATES_KEY]
+ failed_states = transition_info[FAILED_STATES_KEY]
valid_transitioning_states = transition_info[VALID_TRANSITIONING_STATES_KEY]
valid_initial_states = transition_info[VALID_INITIAL_STATES_KEY]
@@ -717,6 +733,12 @@ def _transition_pipeline_state(
f"Pipeline config '{pipeline_config_name}' is in invalid state '{status.value}' to be transitioned to '{target_state.value}'."
)
+ if status in failed_states:
+ logger.warning(
+ f"Pipeline config '{pipeline_config_name}' is in a failed state '{status}'. This might be caused by a previous error during (un)deployment. "
+ + f"Trying to transition from '{status}' to '{target_state}'..."
+ )
+
if target_state == PipelineStatus.DEPLOYED:
res = self._deploy(pipeline_config_name=pipeline_config_name, workspace=workspace, headers=headers)
status = PipelineStatus.from_str(res["status"])
diff --git a/pyproject.toml b/pyproject.toml
index d586fb17b0..9bebb99ec7 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -72,7 +72,7 @@ disable = [
"use-list-literal",
-
+
# To review later
"cyclic-import",
@@ -90,6 +90,7 @@ minversion = "6.0"
addopts = "--strict-markers"
markers = [
"integration: integration tests",
+ "unit: unit tests",
"generator: generator tests",
"summarizer: summarizer tests",
@@ -106,5 +107,6 @@ markers = [
"faiss: uses FAISS",
"milvus: requires a Milvus 2 setup",
"milvus1: requires a Milvus 1 container",
+ "opensearch"
]
log_cli = true
\ No newline at end of file
diff --git a/rest_api/controller/document.py b/rest_api/controller/document.py
index 2b0dbc368e..198d7301dc 100644
--- a/rest_api/controller/document.py
+++ b/rest_api/controller/document.py
@@ -4,10 +4,11 @@
from fastapi import FastAPI, APIRouter
from haystack.document_stores import BaseDocumentStore
+from haystack.schema import Document
from rest_api.utils import get_app, get_pipelines
from rest_api.config import LOG_LEVEL
-from rest_api.schema import FilterRequest, DocumentSerialized
+from rest_api.schema import FilterRequest
logging.getLogger("haystack").setLevel(LOG_LEVEL)
@@ -19,7 +20,7 @@
document_store: BaseDocumentStore = get_pipelines().get("document_store", None)
-@router.post("/documents/get_by_filters", response_model=List[DocumentSerialized], response_model_exclude_none=True)
+@router.post("/documents/get_by_filters", response_model=List[Document], response_model_exclude_none=True)
def get_documents(filters: FilterRequest):
"""
This endpoint allows you to retrieve documents contained in your document store.
diff --git a/rest_api/controller/feedback.py b/rest_api/controller/feedback.py
index 0c3bb349ba..532b8e25d4 100644
--- a/rest_api/controller/feedback.py
+++ b/rest_api/controller/feedback.py
@@ -6,7 +6,7 @@
from fastapi import FastAPI, APIRouter
from haystack.schema import Label
from haystack.document_stores import BaseDocumentStore
-from rest_api.schema import FilterRequest, LabelSerialized, CreateLabelSerialized
+from rest_api.schema import FilterRequest, CreateLabelSerialized
from rest_api.utils import get_app, get_pipelines
@@ -18,7 +18,7 @@
@router.post("/feedback")
-def post_feedback(feedback: Union[LabelSerialized, CreateLabelSerialized]):
+def post_feedback(feedback: CreateLabelSerialized):
"""
This endpoint allows the API user to submit feedback on an answer for a particular query.
@@ -35,7 +35,7 @@ def post_feedback(feedback: Union[LabelSerialized, CreateLabelSerialized]):
document_store.write_labels([label])
-@router.get("/feedback", response_model=List[LabelSerialized])
+@router.get("/feedback", response_model=List[Label])
def get_feedback():
"""
This endpoint allows the API user to retrieve all the feedback that has been submitted
diff --git a/rest_api/controller/search.py b/rest_api/controller/search.py
index f8a716baec..8931465606 100644
--- a/rest_api/controller/search.py
+++ b/rest_api/controller/search.py
@@ -4,7 +4,6 @@
import logging
import time
import json
-from numpy import ndarray
from pydantic import BaseConfig
from fastapi import FastAPI, APIRouter
@@ -84,11 +83,6 @@ def _process_request(pipeline, request) -> Dict[str, Any]:
if not "answers" in result:
result["answers"] = []
- # if any of the documents contains an embedding as an ndarray the latter needs to be converted to list of float
- for document in result["documents"]:
- if isinstance(document.embedding, ndarray):
- document.embedding = document.embedding.tolist()
-
logger.info(
json.dumps({"request": request, "response": result, "time": f"{(time.time() - start_time):.2f}"}, default=str)
)
diff --git a/rest_api/schema.py b/rest_api/schema.py
index 87d4230b37..986ffcf826 100644
--- a/rest_api/schema.py
+++ b/rest_api/schema.py
@@ -1,6 +1,8 @@
from __future__ import annotations
from typing import Dict, List, Optional, Union
+import numpy as np
+import pandas as pd
try:
from typing import Literal
@@ -10,50 +12,40 @@
from pydantic import BaseModel, Field, Extra
from pydantic import BaseConfig
-from haystack.schema import Answer, Document, Label
+from haystack.schema import Answer, Document
BaseConfig.arbitrary_types_allowed = True
+BaseConfig.json_encoders = {np.ndarray: lambda x: x.tolist(), pd.DataFrame: lambda x: x.to_dict(orient="records")}
-PrimitiveType = Union[str, int, float, bool]
+PrimitiveType = Union[str, int, float, bool]
-class QueryRequest(BaseModel):
- query: str
- params: Optional[dict] = None
- debug: Optional[bool] = False
+class RequestBaseModel(BaseModel):
class Config:
# Forbid any extra fields in the request to avoid silent failures
extra = Extra.forbid
-class FilterRequest(BaseModel):
- filters: Optional[Dict[str, Union[PrimitiveType, List[PrimitiveType], Dict[str, PrimitiveType]]]] = None
-
-
-class AnswerSerialized(Answer):
- context: Optional[str] = None
-
-
-class DocumentSerialized(Document):
- content: str
- embedding: Optional[List[float]] # type: ignore
+class QueryRequest(RequestBaseModel):
+ query: str
+ params: Optional[dict] = None
+ debug: Optional[bool] = False
-class LabelSerialized(Label, BaseModel):
- document: DocumentSerialized
- answer: Optional[AnswerSerialized] = None
+class FilterRequest(RequestBaseModel):
+ filters: Optional[Dict[str, Union[PrimitiveType, List[PrimitiveType], Dict[str, PrimitiveType]]]] = None
-class CreateLabelSerialized(BaseModel):
+class CreateLabelSerialized(RequestBaseModel):
id: Optional[str] = None
query: str
- document: DocumentSerialized
+ document: Document
is_correct_answer: bool
is_correct_document: bool
origin: Literal["user-feedback", "gold-label"]
- answer: Optional[AnswerSerialized] = None
+ answer: Optional[Answer] = None
no_answer: Optional[bool] = None
pipeline_id: Optional[str] = None
created_at: Optional[str] = None
@@ -61,13 +53,9 @@ class CreateLabelSerialized(BaseModel):
meta: Optional[dict] = None
filters: Optional[dict] = None
- class Config:
- # Forbid any extra fields in the request to avoid silent failures
- extra = Extra.forbid
-
class QueryResponse(BaseModel):
query: str
- answers: List[AnswerSerialized] = []
- documents: List[DocumentSerialized] = []
+ answers: List[Answer] = []
+ documents: List[Document] = []
debug: Optional[Dict] = Field(None, alias="_debug")
diff --git a/rest_api/test/test_rest_api.py b/rest_api/test/test_rest_api.py
index 6d9a7fcb29..f358e41d99 100644
--- a/rest_api/test/test_rest_api.py
+++ b/rest_api/test/test_rest_api.py
@@ -5,6 +5,8 @@
from textwrap import dedent
from unittest import mock
from unittest.mock import MagicMock
+import numpy as np
+import pandas as pd
import pytest
from fastapi.testclient import TestClient
@@ -125,7 +127,7 @@ def get_all_documents_generator(self, *args, **kwargs) -> Generator[Document, No
pass
def get_all_labels(self, *args, **kwargs) -> List[Label]:
- self.mocker.get_all_labels(*args, **kwargs)
+ return self.mocker.get_all_labels(*args, **kwargs)
def get_document_by_id(self, *args, **kwargs) -> Optional[Document]:
pass
@@ -176,7 +178,7 @@ def feedback():
"score": None,
"id": "fc18c987a8312e72a47fb1524f230bb0",
"meta": {},
- "embedding": None,
+ "embedding": [0.1, 0.2, 0.3],
},
"answer": {
"answer": "Adobe Systems",
@@ -366,6 +368,57 @@ def test_query_with_bool_in_params(client):
assert response_json["answers"] == []
+def test_query_with_embeddings(client):
+ with mock.patch("rest_api.controller.search.query_pipeline") as mocked_pipeline:
+ # `run` must return a dictionary containing a `query` key
+ mocked_pipeline.run.return_value = {
+ "query": TEST_QUERY,
+ "documents": [
+ Document(
+ content="test",
+ content_type="text",
+ score=0.9,
+ meta={"test_key": "test_value"},
+ embedding=np.array([0.1, 0.2, 0.3]),
+ )
+ ],
+ }
+ response = client.post(url="/query", json={"query": TEST_QUERY})
+ assert 200 == response.status_code
+ assert len(response.json()["documents"]) == 1
+ assert response.json()["documents"][0]["content"] == "test"
+ assert response.json()["documents"][0]["content_type"] == "text"
+ assert response.json()["documents"][0]["embedding"] == [0.1, 0.2, 0.3]
+ # Ensure `run` was called with the expected parameters
+ mocked_pipeline.run.assert_called_with(query=TEST_QUERY, params={}, debug=False)
+
+
+def test_query_with_dataframe(client):
+ with mock.patch("rest_api.controller.search.query_pipeline") as mocked_pipeline:
+ # `run` must return a dictionary containing a `query` key
+ mocked_pipeline.run.return_value = {
+ "query": TEST_QUERY,
+ "documents": [
+ Document(
+ content=pd.DataFrame.from_records([{"col1": "text_1", "col2": 1}, {"col1": "text_2", "col2": 2}]),
+ content_type="table",
+ score=0.9,
+ meta={"test_key": "test_value"},
+ )
+ ],
+ }
+ response = client.post(url="/query", json={"query": TEST_QUERY})
+ assert 200 == response.status_code
+ assert len(response.json()["documents"]) == 1
+ assert response.json()["documents"][0]["content"] == [
+ {"col1": "text_1", "col2": 1},
+ {"col1": "text_2", "col2": 2},
+ ]
+ assert response.json()["documents"][0]["content_type"] == "table"
+ # Ensure `run` was called with the expected parameters
+ mocked_pipeline.run.assert_called_with(query=TEST_QUERY, params={}, debug=False)
+
+
def test_write_feedback(client, feedback):
response = client.post(url="/feedback", json=feedback)
assert 200 == response.status_code
@@ -376,9 +429,8 @@ def test_write_feedback(client, feedback):
assert len(labels) == 1
# Ensure all the items that were in `feedback` are also part of
# the stored label (which has several more keys)
- label = labels[0].to_dict()
- for k, v in feedback.items():
- assert label[k] == v
+ label = labels[0]
+ assert label == Label.from_dict(feedback)
def test_write_feedback_without_id(client, feedback):
@@ -395,9 +447,11 @@ def test_write_feedback_without_id(client, feedback):
assert label["id"]
-def test_get_feedback(client):
+def test_get_feedback(client, feedback):
+ MockDocumentStore.mocker.get_all_labels.return_value = [Label.from_dict(feedback)]
response = client.get("/feedback")
assert response.status_code == 200
+ assert Label.from_dict(response.json()[0]) == Label.from_dict(feedback)
MockDocumentStore.mocker.get_all_labels.assert_called_once()
diff --git a/setup.cfg b/setup.cfg
index 3f0d9b3c41..32e7e19e74 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -101,7 +101,7 @@ install_requires =
# context matching
rapidfuzz>=2.0.15,<3
-
+
# Schema validation
jsonschema
@@ -141,7 +141,7 @@ only-milvus =
milvus =
farm-haystack[sql,only-milvus]
weaviate =
- weaviate-client==3.3.3
+ weaviate-client==3.6.0
only-pinecone =
pinecone-client
pinecone =
@@ -150,19 +150,22 @@ graphdb =
SPARQLWrapper
inmemorygraph =
SPARQLWrapper
+opensearch =
+ opensearch-py>=2
docstores =
- farm-haystack[faiss,milvus,weaviate,graphdb,inmemorygraph,pinecone]
+ farm-haystack[faiss,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]
docstores-gpu =
- farm-haystack[faiss-gpu,milvus,weaviate,graphdb,inmemorygraph,pinecone]
+ farm-haystack[faiss-gpu,milvus,weaviate,graphdb,inmemorygraph,pinecone,opensearch]
audio =
+ pyworld<=0.2.12; python_version >= '3.10'
espnet
espnet-model-zoo
pydub
beir =
beir; platform_system != 'Windows'
crawler =
- selenium !=4.1.4 # due to https://github.com/SeleniumHQ/selenium/issues/10612
+ selenium>=4.0.0,!=4.1.4 # Avoid 4.1.4 due to https://github.com/SeleniumHQ/selenium/issues/10612
webdriver-manager
preprocessing =
beautifulsoup4
@@ -185,8 +188,10 @@ ray =
aiorwlock>=1.3.0,<2
colab =
- grpcio==1.43.0
+ grpcio==1.47.0
+ requests>=2.25 # Needed to avoid dependency conflict with crawler https://github.com/deepset-ai/haystack/pull/2921
dev =
+ pre-commit
# Type check
mypy
typing_extensions; python_version < '3.8'
@@ -201,7 +206,7 @@ dev =
# Linting
pylint
# Code formatting
- black[jupyter]
+ black[jupyter]==22.6.0
# Documentation
pydoc-markdown==4.5.1 # FIXME Unpin!
mkdocs
diff --git a/test/conftest.py b/test/conftest.py
index 451f3ee59b..02a8ff95f3 100644
--- a/test/conftest.py
+++ b/test/conftest.py
@@ -146,7 +146,17 @@ def pytest_collection_modifyitems(config, items):
keywords.extend(i.split("-"))
else:
keywords.append(i)
- for cur_doc_store in ["elasticsearch", "faiss", "sql", "memory", "milvus1", "milvus", "weaviate", "pinecone"]:
+ for cur_doc_store in [
+ "elasticsearch",
+ "faiss",
+ "sql",
+ "memory",
+ "milvus1",
+ "milvus",
+ "weaviate",
+ "pinecone",
+ "opensearch",
+ ]:
if cur_doc_store in keywords and cur_doc_store not in document_store_types_to_run:
skip_docstore = pytest.mark.skip(
reason=f'{cur_doc_store} is disabled. Enable via pytest --document_store_type="{cur_doc_store}"'
diff --git a/test/document_stores/test_document_store.py b/test/document_stores/test_document_store.py
index 6af5edeb85..79361f065e 100644
--- a/test/document_stores/test_document_store.py
+++ b/test/document_stores/test_document_store.py
@@ -389,14 +389,14 @@ def test_get_documents_by_id(document_store: BaseDocumentStore):
def test_get_document_count(document_store: BaseDocumentStore):
documents = [
- {"content": "text1", "id": "1", "meta_field_for_count": "a"},
+ {"content": "text1", "id": "1", "meta_field_for_count": "c"},
{"content": "text2", "id": "2", "meta_field_for_count": "b"},
{"content": "text3", "id": "3", "meta_field_for_count": "b"},
{"content": "text4", "id": "4", "meta_field_for_count": "b"},
]
document_store.write_documents(documents)
assert document_store.get_document_count() == 4
- assert document_store.get_document_count(filters={"meta_field_for_count": ["a"]}) == 1
+ assert document_store.get_document_count(filters={"meta_field_for_count": ["c"]}) == 1
assert document_store.get_document_count(filters={"meta_field_for_count": ["b"]}) == 3
@@ -453,6 +453,30 @@ def test_write_document_meta(document_store: BaseDocumentStore):
assert document_store.get_document_by_id("4").meta["meta_field"] == "test4"
+@pytest.mark.parametrize("document_store", ["sql"], indirect=True)
+def test_write_document_sql_invalid_meta(document_store: BaseDocumentStore):
+ documents = [
+ {
+ "content": "dict_with_invalid_meta",
+ "valid_meta_field": "test1",
+ "invalid_meta_field": [1, 2, 3],
+ "name": "filename1",
+ "id": "1",
+ },
+ Document(
+ content="document_object_with_invalid_meta",
+ meta={"valid_meta_field": "test2", "invalid_meta_field": [1, 2, 3], "name": "filename2"},
+ id="2",
+ ),
+ ]
+ document_store.write_documents(documents)
+ documents_in_store = document_store.get_all_documents()
+ assert len(documents_in_store) == 2
+
+ assert document_store.get_document_by_id("1").meta == {"name": "filename1", "valid_meta_field": "test1"}
+ assert document_store.get_document_by_id("2").meta == {"name": "filename2", "valid_meta_field": "test2"}
+
+
def test_write_document_index(document_store: BaseDocumentStore):
document_store.delete_index("haystack_test_one")
document_store.delete_index("haystack_test_two")
diff --git a/test/document_stores/test_opensearch.py b/test/document_stores/test_opensearch.py
index 73172fb762..899ceb42c8 100644
--- a/test/document_stores/test_opensearch.py
+++ b/test/document_stores/test_opensearch.py
@@ -1,12 +1,760 @@
import sys
+import logging
+
+from unittest.mock import MagicMock
import pytest
+import numpy as np
+
+from haystack.document_stores.opensearch import (
+ OpenSearch,
+ OpenSearchDocumentStore,
+ OpenDistroElasticsearchDocumentStore,
+ RequestsHttpConnection,
+ Urllib3HttpConnection,
+ RequestError,
+ tqdm,
+)
+from haystack.schema import Document, Label, Answer
+from haystack.errors import DocumentStoreError
+
+# Being all the tests in this module, ideally we wouldn't need a marker here,
+# but this is to allow this test suite to be skipped when running (e.g.)
+# `pytest test/document_stores --document-store-type=faiss`
+class TestOpenSearchDocumentStore:
+
+ # Constants
+
+ query_emb = np.ndarray(shape=(2, 2), dtype=float)
+ index_name = "myindex"
+
+ # Fixtures
+
+ @pytest.fixture
+ def ds(self):
+ """
+ This fixture provides a working document store and takes care of removing the indices when done
+ """
+ index_name = __name__
+ labels_index_name = f"{index_name}_labels"
+ ds = OpenSearchDocumentStore(index=index_name, label_index=labels_index_name, port=9201, create_index=True)
+ yield ds
+ ds.delete_index(index_name)
+ ds.delete_index(labels_index_name)
+
+ @pytest.fixture
+ def mocked_document_store(self):
+ """
+ The fixture provides an instance of a slightly customized
+ OpenSearchDocumentStore equipped with a mocked client
+ """
+
+ class DSMock(OpenSearchDocumentStore):
+ # We mock a subclass to avoid messing up the actual class object
+ pass
+
+ DSMock._init_client = MagicMock()
+ DSMock.client = MagicMock()
+ return DSMock()
+
+ @pytest.fixture
+ def mocked_open_search_init(self, monkeypatch):
+ mocked_init = MagicMock(return_value=None)
+ monkeypatch.setattr(OpenSearch, "__init__", mocked_init)
+ return mocked_init
+
+ @pytest.fixture
+ def _init_client_params(self):
+ """
+ The fixture provides the required arguments to call OpenSearchDocumentStore._init_client
+ """
+ return {
+ "host": "localhost",
+ "port": 9999,
+ "username": "user",
+ "password": "pass",
+ "aws4auth": None,
+ "scheme": "http",
+ "ca_certs": "ca_certs",
+ "verify_certs": True,
+ "timeout": 42,
+ "use_system_proxy": True,
+ }
+
+ @pytest.fixture
+ def documents(self):
+ documents = []
+ for i in range(3):
+ documents.append(
+ Document(
+ content=f"A Foo Document {i}",
+ meta={"name": f"name_{i}", "year": "2020", "month": "01"},
+ embedding=np.random.rand(768).astype(np.float32),
+ )
+ )
+
+ documents.append(
+ Document(
+ content=f"A Bar Document {i}",
+ meta={"name": f"name_{i}", "year": "2021", "month": "02"},
+ embedding=np.random.rand(768).astype(np.float32),
+ )
+ )
+
+ documents.append(
+ Document(
+ content=f"Document {i} without embeddings",
+ meta={"name": f"name_{i}", "no_embedding": True, "month": "03"},
+ )
+ )
+
+ return documents
+
+ @pytest.fixture
+ def index(self):
+ return {
+ "aliases": {},
+ "mappings": {
+ "properties": {
+ "age": {"type": "integer"},
+ "occupation": {"type": "text"},
+ "vec": {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "engine": "nmslib",
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ },
+ }
+ },
+ "settings": {
+ "index": {
+ "creation_date": "1658337984559",
+ "number_of_shards": "1",
+ "number_of_replicas": "1",
+ "uuid": "jU5KPBtXQHOaIn2Cm2d4jg",
+ "version": {"created": "135238227"},
+ "provided_name": "fooindex",
+ }
+ },
+ }
+
+ @pytest.fixture
+ def labels(self, documents):
+ labels = []
+ for i, d in enumerate(documents):
+ labels.append(
+ Label(
+ query="query",
+ document=d,
+ is_correct_document=True,
+ is_correct_answer=False,
+ # create a mix set of labels
+ origin="user-feedback" if i % 2 else "gold-label",
+ answer=None if not i else Answer(f"the answer is {i}"),
+ )
+ )
+ return labels
+
+ # Integration tests
+
+ @pytest.mark.integration
+ def test___init__(self):
+ OpenSearchDocumentStore(index="default_index", port=9201, create_index=True)
+
+ @pytest.mark.integration
+ def test_write_documents(self, ds, documents):
+ ds.write_documents(documents)
+ docs = ds.get_all_documents()
+ assert len(docs) == len(documents)
+ for i, doc in enumerate(docs):
+ expected = documents[i]
+ assert doc.id == expected.id
+
+ @pytest.mark.integration
+ def test_write_labels(self, ds, labels):
+ ds.write_labels(labels)
+ assert ds.get_all_labels() == labels
+
+ @pytest.mark.integration
+ def test_recreate_index(self, ds, documents, labels):
+ ds.write_documents(documents)
+ ds.write_labels(labels)
+
+ # Create another document store on top of the previous one
+ ds = OpenSearchDocumentStore(index=ds.index, label_index=ds.label_index, recreate_index=True, port=9201)
+ assert len(ds.get_all_documents(index=ds.index)) == 0
+ assert len(ds.get_all_labels(index=ds.label_index)) == 0
+
+ @pytest.mark.integration
+ def test_clone_embedding_field(self, ds, documents):
+ cloned_field_name = "cloned"
+ ds.write_documents(documents)
+ ds.clone_embedding_field(cloned_field_name, "cosine")
+ for doc in ds.get_all_documents():
+ meta = doc.to_dict()["meta"]
+ if "no_embedding" in meta:
+ # docs with no embedding should be ignored
+ assert cloned_field_name not in meta
+ else:
+ # docs with an original embedding should have the new one
+ assert cloned_field_name in meta
+
+ # Unit tests
+
+ @pytest.mark.unit
+ def test___init___api_key_raises_warning(self, mocked_document_store, caplog):
+ with caplog.at_level(logging.WARN, logger="haystack.document_stores.opensearch"):
+ mocked_document_store.__init__(api_key="foo")
+ mocked_document_store.__init__(api_key_id="bar")
+ mocked_document_store.__init__(api_key="foo", api_key_id="bar")
+
+ assert len(caplog.records) == 3
+ for r in caplog.records:
+ assert r.levelname == "WARNING"
+
+ @pytest.mark.unit
+ def test___init___connection_test_fails(self, mocked_document_store):
+ failing_client = MagicMock()
+ failing_client.indices.get.side_effect = Exception("The client failed!")
+ mocked_document_store._init_client.return_value = failing_client
+ with pytest.raises(ConnectionError):
+ mocked_document_store.__init__()
+
+ @pytest.mark.unit
+ def test___init___client_params(self, mocked_open_search_init, _init_client_params):
+ """
+ Ensure the Opensearch-py client was initialized with the right params
+ """
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ assert mocked_open_search_init.called
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs == {
+ "hosts": [{"host": "localhost", "port": 9999}],
+ "http_auth": ("user", "pass"),
+ "scheme": "http",
+ "ca_certs": "ca_certs",
+ "verify_certs": True,
+ "timeout": 42,
+ "connection_class": RequestsHttpConnection,
+ }
+
+ @pytest.mark.unit
+ def test__init_client_use_system_proxy_use_sys_proxy(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["use_system_proxy"] = False
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["connection_class"] == Urllib3HttpConnection
+
+ @pytest.mark.unit
+ def test__init_client_use_system_proxy_dont_use_sys_proxy(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["use_system_proxy"] = True
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["connection_class"] == RequestsHttpConnection
+
+ @pytest.mark.unit
+ def test__init_client_auth_methods_username_password(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["username"] = "user"
+ _init_client_params["aws4auth"] = None
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["http_auth"] == ("user", "pass")
+
+ @pytest.mark.unit
+ def test__init_client_auth_methods_aws_iam(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["username"] = ""
+ _init_client_params["aws4auth"] = "foo"
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert kwargs["http_auth"] == "foo"
+
+ @pytest.mark.unit
+ def test__init_client_auth_methods_no_auth(self, mocked_open_search_init, _init_client_params):
+ _init_client_params["username"] = ""
+ _init_client_params["aws4auth"] = None
+ OpenSearchDocumentStore._init_client(**_init_client_params)
+ _, kwargs = mocked_open_search_init.call_args
+ assert "http_auth" not in kwargs
+
+ @pytest.mark.unit
+ def test_query_by_embedding_raises_if_missing_field(self, mocked_document_store):
+ mocked_document_store.embedding_field = ""
+ with pytest.raises(DocumentStoreError):
+ mocked_document_store.query_by_embedding(self.query_emb)
+
+ @pytest.mark.unit
+ def test_query_by_embedding_filters(self, mocked_document_store):
+ expected_filters = {"type": "article", "date": {"$gte": "2015-01-01", "$lt": "2021-01-01"}}
+ mocked_document_store.query_by_embedding(self.query_emb, filters=expected_filters)
+ # Assert the `search` method on the client was called with the filters we provided
+ _, kwargs = mocked_document_store.client.search.call_args
+ actual_filters = kwargs["body"]["query"]["bool"]["filter"]
+ assert actual_filters["bool"]["must"] == [
+ {"term": {"type": "article"}},
+ {"range": {"date": {"gte": "2015-01-01", "lt": "2021-01-01"}}},
+ ]
+
+ @pytest.mark.unit
+ def test_query_by_embedding_return_embedding_false(self, mocked_document_store):
+ mocked_document_store.return_embedding = False
+ mocked_document_store.query_by_embedding(self.query_emb)
+ # assert the resulting body is consistent with the `excluded_meta_data` value
+ _, kwargs = mocked_document_store.client.search.call_args
+ assert kwargs["body"]["_source"] == {"excludes": ["embedding"]}
+
+ @pytest.mark.unit
+ def test_query_by_embedding_excluded_meta_data_return_embedding_true(self, mocked_document_store):
+ """
+ Test that when `return_embedding==True` the field should NOT be excluded even if it
+ was added to `excluded_meta_data`
+ """
+ mocked_document_store.return_embedding = True
+ mocked_document_store.excluded_meta_data = ["foo", "embedding"]
+ mocked_document_store.query_by_embedding(self.query_emb)
+ _, kwargs = mocked_document_store.client.search.call_args
+ # we expect "embedding" was removed from the final query
+ assert kwargs["body"]["_source"] == {"excludes": ["foo"]}
+
+ @pytest.mark.unit
+ def test_query_by_embedding_excluded_meta_data_return_embedding_false(self, mocked_document_store):
+ """
+ Test that when `return_embedding==False`, the final query excludes the `embedding` field
+ even if it wasn't explicitly added to `excluded_meta_data`
+ """
+ mocked_document_store.return_embedding = False
+ mocked_document_store.excluded_meta_data = ["foo"]
+ mocked_document_store.query_by_embedding(self.query_emb)
+ # assert the resulting body is consistent with the `excluded_meta_data` value
+ _, kwargs = mocked_document_store.client.search.call_args
+ assert kwargs["body"]["_source"] == {"excludes": ["foo", "embedding"]}
+
+ @pytest.mark.unit
+ def test__create_document_index_with_alias(self, mocked_document_store, caplog):
+ mocked_document_store.client.indices.exists_alias.return_value = True
+
+ with caplog.at_level(logging.DEBUG, logger="haystack.document_stores.opensearch"):
+ mocked_document_store._create_document_index(self.index_name)
+
+ assert f"Index name {self.index_name} is an alias." in caplog.text
+
+ @pytest.mark.unit
+ def test__create_document_index_wrong_mapping_raises(self, mocked_document_store, index):
+ """
+ Ensure the method raises if we specify a field in `search_fields` that's not text
+ """
+ mocked_document_store.search_fields = ["age"]
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ with pytest.raises(Exception, match=f"The search_field 'age' of index '{self.index_name}' with type 'integer'"):
+ mocked_document_store._create_document_index(self.index_name)
+
+ @pytest.mark.unit
+ def test__create_document_index_create_mapping_if_missing(self, mocked_document_store, index):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "doesnt_have_a_mapping"
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # Assert the expected body was passed to the client
+ _, kwargs = mocked_document_store.client.indices.put_mapping.call_args
+ assert kwargs["index"] == self.index_name
+ assert "doesnt_have_a_mapping" in kwargs["body"]["properties"]
+
+ @pytest.mark.unit
+ def test__create_document_index_with_bad_field_raises(self, mocked_document_store, index):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "age" # this is mapped as integer
+
+ with pytest.raises(
+ Exception, match=f"The '{self.index_name}' index in OpenSearch already has a field called 'age'"
+ ):
+ mocked_document_store._create_document_index(self.index_name)
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_but_no_method(self, mocked_document_store, index):
+ """
+ We call the method passing a properly mapped field but without the `method` specified in the mapping
+ """
+ del index["mappings"]["properties"]["vec"]["method"]
+ # FIXME: the method assumes this key is present but it might not always be the case. This test has to pass
+ # without the following line:
+ index["settings"]["index"]["knn.space_type"] = "innerproduct"
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+
+ mocked_document_store._create_document_index(self.index_name)
+ # FIXME: when `method` is missing from the field mapping, embeddings_field_supports_similarity is always
+ # False but I'm not sure this is by design
+ assert mocked_document_store.embeddings_field_supports_similarity is False
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_similarity(self, mocked_document_store, index):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.similarity = "dot_product"
+
+ mocked_document_store._create_document_index(self.index_name)
+ assert mocked_document_store.embeddings_field_supports_similarity is True
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_similarity_mismatch(
+ self, mocked_document_store, index, caplog
+ ):
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.similarity = "foo_bar"
+
+ with caplog.at_level(logging.WARN, logger="haystack.document_stores.opensearch"):
+ mocked_document_store._create_document_index(self.index_name)
+ assert "Embedding field 'vec' is optimized for similarity 'dot_product'." in caplog.text
+ assert mocked_document_store.embeddings_field_supports_similarity is False
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_hnsw_default(
+ self, mocked_document_store, index
+ ):
+ """
+ Test default values when `knn.algo_param` is missing from the index settings
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "hnsw"
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # assert the resulting body is contains the adjusted params
+ _, kwargs = mocked_document_store.client.indices.put_settings.call_args
+ assert kwargs["body"] == {"knn.algo_param.ef_search": 20}
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_hnsw(self, mocked_document_store, index):
+ """
+ Test a value of `knn.algo_param` that needs to be adjusted
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "hnsw"
+ index["settings"]["index"]["knn.algo_param"] = {"ef_search": 999}
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # assert the resulting body is contains the adjusted params
+ _, kwargs = mocked_document_store.client.indices.put_settings.call_args
+ assert kwargs["body"] == {"knn.algo_param.ef_search": 20}
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_flat_default(
+ self, mocked_document_store, index
+ ):
+ """
+ If `knn.algo_param` is missing, default value needs no adjustments
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "flat"
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ mocked_document_store.client.indices.put_settings.assert_not_called
+
+ @pytest.mark.unit
+ def test__create_document_index_with_existing_mapping_adjust_params_hnsw(self, mocked_document_store, index):
+ """
+ Test a value of `knn.algo_param` that needs to be adjusted
+ """
+ mocked_document_store.client.indices.exists.return_value = True
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "flat"
+ index["settings"]["index"]["knn.algo_param"] = {"ef_search": 999}
+
+ mocked_document_store._create_document_index(self.index_name)
+
+ # assert the resulting body is contains the adjusted params
+ _, kwargs = mocked_document_store.client.indices.put_settings.call_args
+ assert kwargs["body"] == {"knn.algo_param.ef_search": 512}
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_custom_mapping(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.custom_mapping = {"mappings": {"properties": {"a_number": {"type": "integer"}}}}
+
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {"mappings": {"properties": {"a_number": {"type": "integer"}}}}
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_no_mapping(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {
+ "mappings": {
+ "dynamic_templates": [
+ {"strings": {"mapping": {"type": "keyword"}, "match_mapping_type": "string", "path_match": "*"}}
+ ],
+ "properties": {
+ "content": {"type": "text"},
+ "embedding": {
+ "dimension": 768,
+ "method": {
+ "engine": "nmslib",
+ "name": "hnsw",
+ "parameters": {"ef_construction": 512, "m": 16},
+ "space_type": "innerproduct",
+ },
+ "type": "knn_vector",
+ },
+ "name": {"type": "keyword"},
+ },
+ },
+ "settings": {"analysis": {"analyzer": {"default": {"type": "standard"}}}, "index": {"knn": True}},
+ }
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_no_mapping_with_synonyms(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.search_fields = ["occupation"]
+ mocked_document_store.synonyms = ["foo"]
+
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {
+ "mappings": {
+ "properties": {
+ "name": {"type": "keyword"},
+ "content": {"type": "text", "analyzer": "synonym"},
+ "occupation": {"type": "text", "analyzer": "synonym"},
+ "embedding": {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ },
+ },
+ "dynamic_templates": [
+ {"strings": {"path_match": "*", "match_mapping_type": "string", "mapping": {"type": "keyword"}}}
+ ],
+ },
+ "settings": {
+ "analysis": {
+ "analyzer": {
+ "default": {"type": "standard"},
+ "synonym": {"tokenizer": "whitespace", "filter": ["lowercase", "synonym"]},
+ },
+ "filter": {"synonym": {"type": "synonym", "synonyms": ["foo"]}},
+ },
+ "index": {"knn": True},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__create_document_index_no_index_no_mapping_with_embedding_field(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.embedding_field = "vec"
+ mocked_document_store.index_type = "hnsw"
+
+ mocked_document_store._create_document_index(self.index_name)
+ _, kwargs = mocked_document_store.client.indices.create.call_args
+ assert kwargs["body"] == {
+ "mappings": {
+ "properties": {
+ "name": {"type": "keyword"},
+ "content": {"type": "text"},
+ "vec": {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 80, "m": 64},
+ },
+ },
+ },
+ "dynamic_templates": [
+ {"strings": {"path_match": "*", "match_mapping_type": "string", "mapping": {"type": "keyword"}}}
+ ],
+ },
+ "settings": {
+ "analysis": {"analyzer": {"default": {"type": "standard"}}},
+ "index": {"knn": True, "knn.algo_param.ef_search": 20},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__create_document_index_client_failure(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.client.indices.create.side_effect = RequestError
+
+ with pytest.raises(RequestError):
+ mocked_document_store._create_document_index(self.index_name)
+
+ @pytest.mark.unit
+ def test__get_embedding_field_mapping_flat(self, mocked_document_store):
+ mocked_document_store.index_type = "flat"
+
+ assert mocked_document_store._get_embedding_field_mapping("dot_product") == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__get_embedding_field_mapping_hnsw(self, mocked_document_store):
+ mocked_document_store.index_type = "hnsw"
+
+ assert mocked_document_store._get_embedding_field_mapping("dot_product") == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "innerproduct",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 80, "m": 64},
+ },
+ }
+
+ @pytest.mark.unit
+ def test__get_embedding_field_mapping_wrong(self, mocked_document_store, caplog):
+ mocked_document_store.index_type = "foo"
+
+ with caplog.at_level(logging.ERROR, logger="haystack.document_stores.opensearch"):
+ retval = mocked_document_store._get_embedding_field_mapping("dot_product")
+
+ assert "Please set index_type to either 'flat' or 'hnsw'" in caplog.text
+ assert retval == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {"space_type": "innerproduct", "name": "hnsw", "engine": "nmslib"},
+ }
+
+ @pytest.mark.unit
+ def test__create_label_index_already_exists(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = True
+
+ mocked_document_store._create_label_index("foo")
+ mocked_document_store.client.indices.create.assert_not_called()
+
+ @pytest.mark.unit
+ def test__create_label_index_client_error(self, mocked_document_store):
+ mocked_document_store.client.indices.exists.return_value = False
+ mocked_document_store.client.indices.create.side_effect = RequestError
+
+ with pytest.raises(RequestError):
+ mocked_document_store._create_label_index("foo")
+
+ @pytest.mark.unit
+ def test__get_vector_similarity_query_support_true(self, mocked_document_store):
+ mocked_document_store.embedding_field = "FooField"
+ mocked_document_store.embeddings_field_supports_similarity = True
+
+ assert mocked_document_store._get_vector_similarity_query(self.query_emb, 3) == {
+ "bool": {"must": [{"knn": {"FooField": {"vector": self.query_emb.tolist(), "k": 3}}}]}
+ }
+
+ @pytest.mark.unit
+ def test__get_vector_similarity_query_support_false(self, mocked_document_store):
+ mocked_document_store.embedding_field = "FooField"
+ mocked_document_store.embeddings_field_supports_similarity = False
+ mocked_document_store.similarity = "dot_product"
+
+ assert mocked_document_store._get_vector_similarity_query(self.query_emb, 3) == {
+ "script_score": {
+ "query": {"match_all": {}},
+ "script": {
+ "source": "knn_score",
+ "lang": "knn",
+ "params": {
+ "field": "FooField",
+ "query_value": self.query_emb.tolist(),
+ "space_type": "innerproduct",
+ },
+ },
+ }
+ }
+
+ @pytest.mark.unit
+ def test__get_raw_similarity_score_dot(self, mocked_document_store):
+ mocked_document_store.similarity = "dot_product"
+ assert mocked_document_store._get_raw_similarity_score(2) == 1
+ assert mocked_document_store._get_raw_similarity_score(-2) == 1.5
+
+ @pytest.mark.unit
+ def test__get_raw_similarity_score_l2(self, mocked_document_store):
+ mocked_document_store.similarity = "l2"
+ assert mocked_document_store._get_raw_similarity_score(1) == 0
+
+ @pytest.mark.unit
+ def test__get_raw_similarity_score_cosine(self, mocked_document_store):
+ mocked_document_store.similarity = "cosine"
+ mocked_document_store.embeddings_field_supports_similarity = True
+ assert mocked_document_store._get_raw_similarity_score(1) == 1
+ mocked_document_store.embeddings_field_supports_similarity = False
+ assert mocked_document_store._get_raw_similarity_score(1) == 0
+
+ @pytest.mark.unit
+ def test_clone_embedding_field_duplicate_mapping(self, mocked_document_store, index):
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.index = self.index_name
+ with pytest.raises(Exception, match="age already exists with mapping"):
+ mocked_document_store.clone_embedding_field("age", "cosine")
+
+ @pytest.mark.unit
+ def test_clone_embedding_field_update_mapping(self, mocked_document_store, index, monkeypatch):
+ mocked_document_store.client.indices.get.return_value = {self.index_name: index}
+ mocked_document_store.index = self.index_name
-from haystack.document_stores import OpenSearchDocumentStore
+ # Mock away tqdm and the batch logic so we can test the mapping update alone
+ mocked_document_store._get_all_documents_in_index = MagicMock(return_value=[])
+ monkeypatch.setattr(tqdm, "__new__", MagicMock())
-pytestmark = pytest.mark.skipif(sys.platform in ["win32", "cygwin"], reason="Opensearch not running on Windows CI")
+ mocked_document_store.clone_embedding_field("a_field", "cosine")
+ _, kwargs = mocked_document_store.client.indices.put_mapping.call_args
+ assert kwargs["body"]["properties"]["a_field"] == {
+ "type": "knn_vector",
+ "dimension": 768,
+ "method": {
+ "space_type": "cosinesimil",
+ "name": "hnsw",
+ "engine": "nmslib",
+ "parameters": {"ef_construction": 512, "m": 16},
+ },
+ }
-@pytest.mark.elasticsearch
-def test_init_opensearch_client():
- OpenSearchDocumentStore(index="test_index", port=9201)
+class TestOpenDistroElasticsearchDocumentStore:
+ @pytest.mark.unit
+ def test_deprecation_notice(self, monkeypatch, caplog):
+ klass = OpenDistroElasticsearchDocumentStore
+ monkeypatch.setattr(klass, "_init_client", MagicMock())
+ with caplog.at_level(logging.WARN, logger="haystack.document_stores.opensearch"):
+ klass()
+ assert caplog.record_tuples == [
+ (
+ "haystack.document_stores.opensearch",
+ logging.WARN,
+ "Open Distro for Elasticsearch has been replaced by OpenSearch! See https://opensearch.org/faq/ for details. We recommend using the OpenSearchDocumentStore instead.",
+ )
+ ]
diff --git a/test/document_stores/test_weaviate.py b/test/document_stores/test_weaviate.py
index 1c020ce85f..4ec0abaeda 100644
--- a/test/document_stores/test_weaviate.py
+++ b/test/document_stores/test_weaviate.py
@@ -1,4 +1,5 @@
import uuid
+from unittest.mock import MagicMock
import numpy as np
import pytest
@@ -6,7 +7,6 @@
from haystack.schema import Document
from ..conftest import get_document_store
-
embedding_dim = 768
@@ -97,8 +97,12 @@ def test_query_by_embedding(document_store_with_docs):
@pytest.mark.parametrize("document_store_with_docs", ["weaviate"], indirect=True)
def test_query(document_store_with_docs):
query_text = "My name is Carla and I live in Berlin"
+ docs = document_store_with_docs.query(query_text)
+ assert len(docs) == 3
+
+ # BM25 retrieval WITH filters is not yet supported as of Weaviate v1.14.1
with pytest.raises(Exception):
- docs = document_store_with_docs.query(query_text)
+ docs = document_store_with_docs.query(query_text, filters={"name": ["filename2"]})
docs = document_store_with_docs.query(filters={"name": ["filename2"]})
assert len(docs) == 1
@@ -119,3 +123,24 @@ def test_get_all_documents_unaffected_by_QUERY_MAXIMUM_RESULTS(document_store_wi
monkeypatch.setattr(document_store_with_docs, "get_document_count", lambda **kwargs: 13_000)
docs = document_store_with_docs.get_all_documents()
assert len(docs) == 3
+
+
+@pytest.mark.weaviate
+@pytest.mark.parametrize("document_store_with_docs", ["weaviate"], indirect=True)
+def test_deleting_by_id_or_by_filters(document_store_with_docs):
+ # This test verifies that deleting an object by its ID does not first require fetching all documents. This fixes
+ # a bug, as described in https://github.com/deepset-ai/haystack/issues/2898
+ document_store_with_docs.get_all_documents = MagicMock(wraps=document_store_with_docs.get_all_documents)
+
+ assert document_store_with_docs.get_document_count() == 3
+
+ # Delete a document by its ID. This should bypass the get_all_documents() call
+ document_store_with_docs.delete_documents(ids=[DOCUMENTS_XS[0]["id"]])
+ document_store_with_docs.get_all_documents.assert_not_called()
+ assert document_store_with_docs.get_document_count() == 2
+
+ document_store_with_docs.get_all_documents.reset_mock()
+ # Delete a document with filters. Prove that using the filters will go through get_all_documents()
+ document_store_with_docs.delete_documents(filters={"name": ["filename2"]})
+ document_store_with_docs.get_all_documents.assert_called()
+ assert document_store_with_docs.get_document_count() == 1
diff --git a/test/modeling/test_modeling_dpr.py b/test/modeling/test_dpr.py
similarity index 86%
rename from test/modeling/test_modeling_dpr.py
rename to test/modeling/test_dpr.py
index c6a30c0212..af1cf0e91a 100644
--- a/test/modeling/test_modeling_dpr.py
+++ b/test/modeling/test_dpr.py
@@ -1,3 +1,6 @@
+from typing import Tuple
+
+import os
import logging
from pathlib import Path
@@ -6,13 +9,14 @@
import torch
from torch.utils.data import SequentialSampler
from tqdm import tqdm
+from transformers import DPRQuestionEncoder
from haystack.modeling.data_handler.dataloader import NamedDataLoader
from haystack.modeling.data_handler.processor import TextSimilarityProcessor
from haystack.modeling.model.biadaptive_model import BiAdaptiveModel
-from haystack.modeling.model.language_model import LanguageModel, DPRContextEncoder, DPRQuestionEncoder
+from haystack.modeling.model.language_model import get_language_model, DPREncoder
from haystack.modeling.model.prediction_head import TextSimilarityHead
-from haystack.modeling.model.tokenization import Tokenizer
+from haystack.modeling.model.tokenization import get_tokenizer
from haystack.modeling.utils import set_all_seeds, initialize_device_settings
@@ -24,10 +28,10 @@ def test_dpr_modules(caplog=None):
devices, n_gpu = initialize_device_settings(use_cuda=True)
# 1.Create question and passage tokenizers
- query_tokenizer = Tokenizer.load(
+ query_tokenizer = get_tokenizer(
pretrained_model_name_or_path="facebook/dpr-question_encoder-single-nq-base", do_lower_case=True, use_fast=True
)
- passage_tokenizer = Tokenizer.load(
+ passage_tokenizer = get_tokenizer(
pretrained_model_name_or_path="facebook/dpr-ctx_encoder-single-nq-base", do_lower_case=True, use_fast=True
)
@@ -46,17 +50,15 @@ def test_dpr_modules(caplog=None):
num_hard_negatives=1,
)
- question_language_model = LanguageModel.load(
+ question_language_model = DPREncoder(
pretrained_model_name_or_path="bert-base-uncased",
- language_model_class="DPRQuestionEncoder",
- hidden_dropout_prob=0,
- attention_probs_dropout_prob=0,
+ model_type="DPRQuestionEncoder",
+ model_kwargs={"hidden_dropout_prob": 0, "attention_probs_dropout_prob": 0},
)
- passage_language_model = LanguageModel.load(
+ passage_language_model = DPREncoder(
pretrained_model_name_or_path="bert-base-uncased",
- language_model_class="DPRContextEncoder",
- hidden_dropout_prob=0,
- attention_probs_dropout_prob=0,
+ model_type="DPRContextEncoder",
+ model_kwargs={"hidden_dropout_prob": 0, "attention_probs_dropout_prob": 0},
)
prediction_head = TextSimilarityHead(similarity_function="dot_product")
@@ -75,8 +77,8 @@ def test_dpr_modules(caplog=None):
assert type(model) == BiAdaptiveModel
assert type(processor) == TextSimilarityProcessor
- assert type(question_language_model) == DPRQuestionEncoder
- assert type(passage_language_model) == DPRContextEncoder
+ assert type(question_language_model) == DPREncoder
+ assert type(passage_language_model) == DPREncoder
# check embedding layer weights
assert list(model.named_parameters())[0][1][0, 0].item() - -0.010200000368058681 < 0.0001
@@ -131,9 +133,17 @@ def test_dpr_modules(caplog=None):
torch.eq(features["passage_attention_mask"][0][1].nonzero().cpu().squeeze(), torch.tensor(list(range(143))))
)
+ features_query = {key.replace("query_", ""): value for key, value in features.items() if key.startswith("query_")}
+ features_passage = {
+ key.replace("passage_", ""): value for key, value in features.items() if key.startswith("passage_")
+ }
+ max_seq_len = features_passage.get("input_ids").shape[-1]
+ features_passage = {key: value.view(-1, max_seq_len) for key, value in features_passage.items()}
+
# test model encodings
- query_vector = model.language_model1(**features)[0]
- passage_vector = model.language_model2(**features)[0]
+ query_vector = model.language_model1(**features_query)[0]
+ passage_vector = model.language_model2(**features_passage)[0]
+
assert torch.all(
torch.le(
query_vector[0, :10].cpu()
@@ -157,7 +167,14 @@ def test_dpr_modules(caplog=None):
)
# test logits and loss
- embeddings = model(**features)
+ embeddings = model(
+ query_input_ids=features.get("query_input_ids", None),
+ query_segment_ids=features.get("query_segment_ids", None),
+ query_attention_mask=features.get("query_attention_mask", None),
+ passage_input_ids=features.get("passage_input_ids", None),
+ passage_segment_ids=features.get("passage_segment_ids", None),
+ passage_attention_mask=features.get("passage_attention_mask", None),
+ )
query_emb, passage_emb = embeddings[0]
assert torch.all(torch.eq(query_emb.cpu(), query_vector.cpu()))
assert torch.all(torch.eq(passage_emb.cpu(), passage_vector.cpu()))
@@ -343,9 +360,9 @@ def test_dpr_processor(embed_title, passage_ids, passage_attns, use_fast, num_ha
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=use_fast)
+ query_tokenizer = get_tokenizer(query_tok, use_fast=use_fast)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=use_fast)
+ passage_tokenizer = get_tokenizer(passage_tok, use_fast=use_fast)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -400,9 +417,9 @@ def test_dpr_processor_empty_title(use_fast, embed_title):
}
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=use_fast)
+ query_tokenizer = get_tokenizer(query_tok, use_fast=use_fast)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=use_fast)
+ passage_tokenizer = get_tokenizer(passage_tok, use_fast=use_fast)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -485,9 +502,9 @@ def test_dpr_problematic():
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -516,9 +533,9 @@ def test_dpr_query_only():
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -578,9 +595,9 @@ def test_dpr_context_only():
]
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -629,9 +646,9 @@ def test_dpr_processor_save_load(tmp_path):
}
query_tok = "facebook/dpr-question_encoder-single-nq-base"
- query_tokenizer = Tokenizer.load(query_tok, use_fast=True)
+ query_tokenizer = get_tokenizer(query_tok)
passage_tok = "facebook/dpr-ctx_encoder-single-nq-base"
- passage_tokenizer = Tokenizer.load(passage_tok, use_fast=True)
+ passage_tokenizer = get_tokenizer(passage_tok)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
passage_tokenizer=passage_tokenizer,
@@ -646,9 +663,10 @@ def test_dpr_processor_save_load(tmp_path):
metric="text_similarity_metric",
shuffle_negatives=False,
)
- processor.save(save_dir=f"{tmp_path}/testsave/dpr_processor")
+ save_dir = f"{tmp_path}/testsave/dpr_processor"
+ processor.save(save_dir=save_dir)
dataset, tensor_names, _ = processor.dataset_from_dicts(dicts=[d], return_baskets=False)
- loadedprocessor = TextSimilarityProcessor.load_from_dir(load_dir=f"{tmp_path}/testsave/dpr_processor")
+ loadedprocessor = TextSimilarityProcessor.load_from_dir(load_dir=save_dir)
dataset2, tensor_names, _ = loadedprocessor.dataset_from_dicts(dicts=[d], return_baskets=False)
assert np.array_equal(dataset.tensors[0], dataset2.tensors[0])
@@ -667,7 +685,7 @@ def test_dpr_processor_save_load(tmp_path):
{"query": "facebook/dpr-question_encoder-single-nq-base", "passage": "facebook/dpr-ctx_encoder-single-nq-base"},
],
)
-def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_model):
+def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path: Path, query_and_passage_model: Tuple[str, str]):
"""
This test compares 1) a model that was loaded from model hub with
2) a model from model hub that was saved to disk and then loaded from disk and
@@ -679,7 +697,24 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
"passages": [
{
"title": "Etalab",
- "text": "Etalab est une administration publique française qui fait notamment office de Chief Data Officer de l'État et coordonne la conception et la mise en œuvre de sa stratégie dans le domaine de la donnée (ouverture et partage des données publiques ou open data, exploitation des données et intelligence artificielle...). Ainsi, Etalab développe et maintient le portail des données ouvertes du gouvernement français data.gouv.fr. Etalab promeut également une plus grande ouverture l'administration sur la société (gouvernement ouvert) : transparence de l'action publique, innovation ouverte, participation citoyenne... elle promeut l’innovation, l’expérimentation, les méthodes de travail ouvertes, agiles et itératives, ainsi que les synergies avec la société civile pour décloisonner l’administration et favoriser l’adoption des meilleures pratiques professionnelles dans le domaine du numérique. À ce titre elle étudie notamment l’opportunité de recourir à des technologies en voie de maturation issues du monde de la recherche. Cette entité chargée de l'innovation au sein de l'administration doit contribuer à l'amélioration du service public grâce au numérique. Elle est rattachée à la Direction interministérielle du numérique, dont les missions et l’organisation ont été fixées par le décret du 30 octobre 2019. Dirigé par Laure Lucchesi depuis 2016, elle rassemble une équipe pluridisciplinaire d'une trentaine de personnes.",
+ "text": "Etalab est une administration publique française qui fait notamment office "
+ "de Chief Data Officer de l'État et coordonne la conception et la mise en œuvre "
+ "de sa stratégie dans le domaine de la donnée (ouverture et partage des données "
+ "publiques ou open data, exploitation des données et intelligence artificielle...). "
+ "Ainsi, Etalab développe et maintient le portail des données ouvertes du gouvernement "
+ "français data.gouv.fr. Etalab promeut également une plus grande ouverture "
+ "l'administration sur la société (gouvernement ouvert) : transparence de l'action "
+ "publique, innovation ouverte, participation citoyenne... elle promeut l’innovation, "
+ "l’expérimentation, les méthodes de travail ouvertes, agiles et itératives, ainsi que "
+ "les synergies avec la société civile pour décloisonner l’administration et favoriser "
+ "l’adoption des meilleures pratiques professionnelles dans le domaine du numérique. "
+ "À ce titre elle étudie notamment l’opportunité de recourir à des technologies en voie "
+ "de maturation issues du monde de la recherche. Cette entité chargée de l'innovation "
+ "au sein de l'administration doit contribuer à l'amélioration du service public grâce "
+ "au numérique. Elle est rattachée à la Direction interministérielle du numérique, dont "
+ "les missions et l’organisation ont été fixées par le décret du 30 octobre 2019. Dirigé "
+ "par Laure Lucchesi depuis 2016, elle rassemble une équipe pluridisciplinaire d'une "
+ "trentaine de personnes.",
"label": "positive",
"external_id": "1",
}
@@ -689,16 +724,12 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# load model from model hub
query_embedding_model = query_and_passage_model["query"]
passage_embedding_model = query_and_passage_model["passage"]
- query_tokenizer = Tokenizer.load(
+ query_tokenizer = get_tokenizer(
pretrained_model_name_or_path=query_embedding_model
) # tokenizer class is inferred automatically
- query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=query_embedding_model, language_model_class="DPRQuestionEncoder"
- )
- passage_tokenizer = Tokenizer.load(pretrained_model_name_or_path=passage_embedding_model)
- passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=passage_embedding_model, language_model_class="DPRContextEncoder"
- )
+ query_encoder = get_language_model(pretrained_model_name_or_path=query_embedding_model)
+ passage_tokenizer = get_tokenizer(pretrained_model_name_or_path=passage_embedding_model)
+ passage_encoder = get_language_model(pretrained_model_name_or_path=passage_embedding_model)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
@@ -737,18 +768,14 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
passage_tokenizer.save_pretrained(save_dir + f"/{passage_encoder_dir}")
# load model from disk
- loaded_query_tokenizer = Tokenizer.load(
+ loaded_query_tokenizer = get_tokenizer(
pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir, use_fast=True
) # tokenizer class is inferred automatically
- loaded_query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir, language_model_class="DPRQuestionEncoder"
- )
- loaded_passage_tokenizer = Tokenizer.load(
+ loaded_query_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir)
+ loaded_passage_tokenizer = get_tokenizer(
pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir, use_fast=True
)
- loaded_passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir, language_model_class="DPRContextEncoder"
- )
+ loaded_passage_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
loaded_processor = TextSimilarityProcessor(
query_tokenizer=loaded_query_tokenizer,
@@ -794,12 +821,19 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
all_embeddings = {"query": [], "passages": []}
model.eval()
- for i, batch in enumerate(tqdm(data_loader, desc=f"Creating Embeddings", unit=" Batches", disable=True)):
+ for batch in tqdm(data_loader, desc=f"Creating Embeddings", unit=" Batches", disable=True):
batch = {key: batch[key].to(device) for key in batch}
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -826,7 +860,14 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = loaded_model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = loaded_model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings2["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -849,16 +890,12 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
loaded_passage_tokenizer.save_pretrained(save_dir + f"/{passage_encoder_dir}")
# load model from disk
- query_tokenizer = Tokenizer.load(
+ query_tokenizer = get_tokenizer(
pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir
) # tokenizer class is inferred automatically
- query_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir, language_model_class="DPRQuestionEncoder"
- )
- passage_tokenizer = Tokenizer.load(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
- passage_encoder = LanguageModel.load(
- pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir, language_model_class="DPRContextEncoder"
- )
+ query_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / query_encoder_dir)
+ passage_tokenizer = get_tokenizer(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
+ passage_encoder = get_language_model(pretrained_model_name_or_path=Path(save_dir) / passage_encoder_dir)
processor = TextSimilarityProcessor(
query_tokenizer=query_tokenizer,
@@ -910,7 +947,14 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# get logits
with torch.no_grad():
- query_embeddings, passage_embeddings = loaded_model.forward(**batch)[0]
+ query_embeddings, passage_embeddings = loaded_model.forward(
+ query_input_ids=batch.get("query_input_ids", None),
+ query_segment_ids=batch.get("query_segment_ids", None),
+ query_attention_mask=batch.get("query_attention_mask", None),
+ passage_input_ids=batch.get("passage_input_ids", None),
+ passage_segment_ids=batch.get("passage_segment_ids", None),
+ passage_attention_mask=batch.get("passage_attention_mask", None),
+ )[0]
if query_embeddings is not None:
all_embeddings3["query"].append(query_embeddings.cpu().numpy())
if passage_embeddings is not None:
@@ -942,9 +986,9 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
#
# device, n_gpu = initialize_device_settings(use_cuda=False)
#
-# query_tokenizer = Tokenizer.load(pretrained_model_name_or_path=question_lang_model,
+# query_tokenizer = get_tokenizer(pretrained_model_name_or_path=question_lang_model,
# do_lower_case=do_lower_case, use_fast=use_fast)
-# passage_tokenizer = Tokenizer.load(pretrained_model_name_or_path=passage_lang_model,
+# passage_tokenizer = get_tokenizer(pretrained_model_name_or_path=passage_lang_model,
# do_lower_case=do_lower_case, use_fast=use_fast)
# label_list = ["hard_negative", "positive"]
#
@@ -965,9 +1009,9 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
#
# data_silo = DataSilo(processor=processor, batch_size=batch_size, distributed=False)
#
-# question_language_model = LanguageModel.load(pretrained_model_name_or_path=question_lang_model,
+# question_language_model = get_language_model(pretrained_model_name_or_path=question_lang_model,
# language_model_class="DPRQuestionEncoder")
-# passage_language_model = LanguageModel.load(pretrained_model_name_or_path=passage_lang_model,
+# passage_language_model = get_language_model(pretrained_model_name_or_path=passage_lang_model,
# language_model_class="DPRContextEncoder")
#
# prediction_head = TextSimilarityHead(similarity_function=similarity_function)
@@ -1038,9 +1082,3 @@ def test_dpr_processor_save_load_non_bert_tokenizer(tmp_path, query_and_passage_
# )
#
# trainer2.train()
-
-
-if __name__ == "__main__":
- # test_dpr_training()
- test_dpr_context_only()
- # test_dpr_modules()
diff --git a/test/modeling/test_modeling_inference.py b/test/modeling/test_inference.py
similarity index 100%
rename from test/modeling/test_modeling_inference.py
rename to test/modeling/test_inference.py
diff --git a/test/modeling/test_language.py b/test/modeling/test_language.py
new file mode 100644
index 0000000000..844f2302b7
--- /dev/null
+++ b/test/modeling/test_language.py
@@ -0,0 +1,34 @@
+import pytest
+
+from haystack.modeling.model.language_model import get_language_model
+
+
+@pytest.mark.parametrize(
+ "pretrained_model_name_or_path, lm_class",
+ [
+ ("google/bert_uncased_L-2_H-128_A-2", "HFLanguageModel"),
+ ("google/electra-small-generator", "HFLanguageModelWithPooler"),
+ ("distilbert-base-uncased", "HFLanguageModelNoSegmentIds"),
+ ("deepset/bert-small-mm_retrieval-passage_encoder", "DPREncoder"),
+ ],
+)
+def test_basic_loading(pretrained_model_name_or_path, lm_class):
+ lm = get_language_model(pretrained_model_name_or_path)
+ mod = __import__("haystack.modeling.model.language_model", fromlist=[lm_class])
+ klass = getattr(mod, lm_class)
+ assert isinstance(lm, klass)
+
+
+def test_basic_loading_unknown_model():
+ with pytest.raises(OSError):
+ get_language_model("model_that_doesnt_exist")
+
+
+def test_basic_loading_with_empty_string():
+ with pytest.raises(ValueError):
+ get_language_model("")
+
+
+def test_basic_loading_invalid_params():
+ with pytest.raises(ValueError):
+ get_language_model(None)
diff --git a/test/modeling/test_modeling_prediction_head.py b/test/modeling/test_prediction_head.py
similarity index 87%
rename from test/modeling/test_modeling_prediction_head.py
rename to test/modeling/test_prediction_head.py
index e607bce7cc..368afc5022 100644
--- a/test/modeling/test_modeling_prediction_head.py
+++ b/test/modeling/test_prediction_head.py
@@ -1,7 +1,7 @@
import logging
from haystack.modeling.model.adaptive_model import AdaptiveModel
-from haystack.modeling.model.language_model import LanguageModel
+from haystack.modeling.model.language_model import get_language_model
from haystack.modeling.model.prediction_head import QuestionAnsweringHead
from haystack.modeling.utils import set_all_seeds, initialize_device_settings
@@ -14,7 +14,7 @@ def test_prediction_head_load_save(tmp_path, caplog=None):
devices, n_gpu = initialize_device_settings(use_cuda=False)
lang_model = "bert-base-german-cased"
- language_model = LanguageModel.load(lang_model)
+ language_model = get_language_model(lang_model)
prediction_head = QuestionAnsweringHead()
model = AdaptiveModel(
diff --git a/test/modeling/test_modeling_processor.py b/test/modeling/test_processor.py
similarity index 98%
rename from test/modeling/test_modeling_processor.py
rename to test/modeling/test_processor.py
index 8744aeb6cb..79308d80f8 100644
--- a/test/modeling/test_modeling_processor.py
+++ b/test/modeling/test_processor.py
@@ -4,7 +4,7 @@
from transformers import AutoTokenizer
from haystack.modeling.data_handler.processor import SquadProcessor
-from haystack.modeling.model.tokenization import Tokenizer
+from haystack.modeling.model.tokenization import get_tokenizer
from ..conftest import SAMPLES_PATH
@@ -24,7 +24,7 @@ def test_dataset_from_dicts_qa_inference(caplog=None):
sample_types = ["answer-wrong", "answer-offset-wrong", "noanswer", "vanilla"]
for model in models:
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=model, use_fast=True)
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model)
processor = SquadProcessor(tokenizer, max_seq_len=256, data_dir=None)
for sample_type in sample_types:
@@ -251,7 +251,7 @@ def test_dataset_from_dicts_qa_labelconversion(caplog=None):
sample_types = ["answer-wrong", "answer-offset-wrong", "noanswer", "vanilla"]
for model in models:
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=model, use_fast=True)
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model)
processor = SquadProcessor(tokenizer, max_seq_len=256, data_dir=None)
for sample_type in sample_types:
diff --git a/test/modeling/test_modeling_processor_saving_loading.py b/test/modeling/test_processor_save_load.py
similarity index 89%
rename from test/modeling/test_modeling_processor_saving_loading.py
rename to test/modeling/test_processor_save_load.py
index 8972422364..154b303f70 100644
--- a/test/modeling/test_modeling_processor_saving_loading.py
+++ b/test/modeling/test_processor_save_load.py
@@ -2,7 +2,7 @@
from pathlib import Path
from haystack.modeling.data_handler.processor import SquadProcessor
-from haystack.modeling.model.tokenization import Tokenizer
+from haystack.modeling.model.tokenization import get_tokenizer
from haystack.modeling.utils import set_all_seeds
import torch
@@ -16,7 +16,7 @@ def test_processor_saving_loading(tmp_path, caplog):
set_all_seeds(seed=42)
lang_model = "roberta-base"
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False)
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=lang_model, do_lower_case=False)
processor = SquadProcessor(
tokenizer=tokenizer,
diff --git a/test/modeling/test_modeling_question_answering.py b/test/modeling/test_question_answering.py
similarity index 100%
rename from test/modeling/test_modeling_question_answering.py
rename to test/modeling/test_question_answering.py
diff --git a/test/modeling/test_tokenization.py b/test/modeling/test_tokenization.py
index 486b338f77..5758eeedec 100644
--- a/test/modeling/test_tokenization.py
+++ b/test/modeling/test_tokenization.py
@@ -1,500 +1,325 @@
-import logging
-import pytest
+from typing import Tuple
+
import re
-from transformers import (
- BertTokenizer,
- BertTokenizerFast,
- RobertaTokenizer,
- RobertaTokenizerFast,
- XLNetTokenizer,
- XLNetTokenizerFast,
- ElectraTokenizerFast,
-)
+
+import pytest
+import numpy as np
+from unittest.mock import MagicMock
from tokenizers.pre_tokenizers import WhitespaceSplit
-from haystack.modeling.model.tokenization import Tokenizer
+import haystack
+from haystack.modeling.model.tokenization import get_tokenizer
-import numpy as np
+
+BERT = "bert-base-cased"
+ROBERTA = "roberta-base"
+XLNET = "xlnet-base-cased"
+
+TOKENIZERS_TO_TEST = [BERT, ROBERTA, XLNET]
+TOKENIZERS_TO_TEST_WITH_TOKEN_MARKER = [(BERT, "##"), (ROBERTA, "Ġ"), (XLNET, "▁")]
-TEXTS = [
- "This is a sentence",
- "Der entscheidende Pass",
- "This is a sentence with multiple spaces",
- "力加勝北区ᴵᴺᵀᵃছজটডণত",
- "Thiso text is included tolod makelio sure Unicodeel is handled properly:",
- "This is a sentence...",
- "Let's see all on this text and. !23# neverseenwordspossible",
- """This is a sentence.
- With linebreak""",
- """Sentence with multiple
+REGULAR_SENTENCE = "This is a sentence"
+GERMAN_SENTENCE = "Der entscheidende Pass"
+OTHER_ALPHABETS = "力加勝北区ᴵᴺᵀᵃছজটডণত"
+GIBBERISH_SENTENCE = "Thiso text is included tolod makelio sure Unicodeel is handled properly:"
+SENTENCE_WITH_ELLIPSIS = "This is a sentence..."
+SENTENCE_WITH_LINEBREAK_1 = "and another one\n\n\nwithout space"
+SENTENCE_WITH_LINEBREAK_2 = """This is a sentence.
+ With linebreak"""
+SENTENCE_WITH_LINEBREAKS = """Sentence
+ with
+ multiple
newlines
- """,
- "and another one\n\n\nwithout space",
- "This is a sentence with tab",
- "This is a sentence with multiple tabs",
-]
-
-
-def test_basic_loading(caplog):
- caplog.set_level(logging.CRITICAL)
- # slow tokenizers
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="bert-base-cased", do_lower_case=True, use_fast=False)
- assert type(tokenizer) == BertTokenizer
- assert tokenizer.basic_tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="xlnet-base-cased", do_lower_case=True, use_fast=False)
- assert type(tokenizer) == XLNetTokenizer
- assert tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="roberta-base", use_fast=False)
- assert type(tokenizer) == RobertaTokenizer
-
- # fast tokenizers
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="bert-base-cased", do_lower_case=True)
- assert type(tokenizer) == BertTokenizerFast
- assert tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="xlnet-base-cased", do_lower_case=True)
- assert type(tokenizer) == XLNetTokenizerFast
- assert tokenizer.do_lower_case == True
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path="roberta-base")
- assert type(tokenizer) == RobertaTokenizerFast
-
-
-def test_bert_tokenizer_all_meta(caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_model = "bert-base-cased"
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False)
-
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- tokenized = tokenizer.tokenize(basic_text)
- assert tokenized == [
- "Some",
- "Text",
- "with",
- "never",
- "##see",
- "##nto",
- "##ken",
- "##s",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- ]
+ """
+SENTENCE_WITH_EXCESS_WHITESPACE = "This is a sentence with multiple spaces"
+SENTENCE_WITH_TABS = "This is a sentence with multiple tabs"
+SENTENCE_WITH_CUSTOM_TOKEN = "Let's see all on this text and. !23# neverseenwordspossible"
- encoded_batch = tokenizer.encode_plus(basic_text)
- encoded = encoded_batch.encodings[0]
- words = np.array(encoded.words)
- words[words == None] = -1
- start_of_word_single = [False] + list(np.ediff1d(words) > 0)
- assert encoded.tokens == [
- "[CLS]",
- "Some",
- "Text",
- "with",
- "never",
- "##see",
- "##nto",
- "##ken",
- "##s",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- "[SEP]",
- ]
- assert [x[0] for x in encoded.offsets] == [
- 0,
- 0,
- 5,
- 10,
- 15,
- 20,
- 23,
- 26,
- 29,
- 31,
- 36,
- 37,
- 40,
- 41,
- 42,
- 44,
- 48,
- 50,
- 58,
- 59,
- 64,
- 65,
- 69,
- 70,
- 72,
- 0,
- ]
- assert start_of_word_single == [
- False,
- True,
- True,
- True,
- True,
- False,
- False,
- False,
- False,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- False,
- False,
- ]
+class AutoTokenizer:
+ mocker: MagicMock = MagicMock()
-def test_save_load(tmp_path, caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_names = ["bert-base-cased", "roberta-base", "xlnet-base-cased"]
- tokenizers = []
- for lang_name in lang_names:
- if "xlnet" in lang_name.lower():
- t = Tokenizer.load(lang_name, lower_case=False, use_fast=True, from_slow=True)
- else:
- t = Tokenizer.load(lang_name, lower_case=False)
- t.add_tokens(new_tokens=["neverseentokens"])
- tokenizers.append(t)
-
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- for tokenizer in tokenizers:
- tokenizer_type = tokenizer.__class__.__name__
- save_dir = f"{tmp_path}/testsave/{tokenizer_type}"
- tokenizer.save_pretrained(save_dir)
- tokenizer_loaded = Tokenizer.load(save_dir, tokenizer_class=tokenizer_type)
- encoded_before = tokenizer.encode_plus(basic_text).encodings[0]
- encoded_after = tokenizer_loaded.encode_plus(basic_text).encodings[0]
- data_before = {
- "tokens": encoded_before.tokens,
- "offsets": encoded_before.offsets,
- "words": encoded_before.words,
- }
- data_after = {"tokens": encoded_after.tokens, "offsets": encoded_after.offsets, "words": encoded_after.words}
- assert data_before == data_after
-
-
-@pytest.mark.parametrize("model_name", ["bert-base-german-cased", "google/electra-small-discriminator"])
-def test_fast_tokenizer_with_examples(caplog, model_name):
- fast_tokenizer = Tokenizer.load(model_name, lower_case=False, use_fast=True)
- tokenizer = Tokenizer.load(model_name, lower_case=False, use_fast=False)
-
- for text in TEXTS:
- # plain tokenize function
- tokenized = tokenizer.tokenize(text)
- fast_tokenized = fast_tokenizer.tokenize(text)
-
- assert tokenized == fast_tokenized
-
-
-def test_all_tokenizer_on_special_cases(caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_names = ["bert-base-cased", "roberta-base", "xlnet-base-cased"]
-
- tokenizers = []
- for lang_name in lang_names:
- if "roberta" in lang_name:
- add_prefix_space = True
- else:
- add_prefix_space = False
- t = Tokenizer.load(lang_name, lower_case=False, add_prefix_space=add_prefix_space)
- tokenizers.append(t)
-
- texts = [
- "This is a sentence",
- "Der entscheidende Pass",
- "力加勝北区ᴵᴺᵀᵃছজটডণত",
- "Thiso text is included tolod makelio sure Unicodeel is handled properly:",
- "This is a sentence...",
- "Let's see all on this text and. !23# neverseenwordspossible" "This is a sentence with multiple spaces",
- """This is a sentence.
- With linebreak""",
- """Sentence with multiple
- newlines
- """,
- "and another one\n\n\nwithout space",
- "This is a sentence with multiple tabs",
- ]
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ cls.mocker.from_pretrained(*args, **kwargs)
+ return cls()
- expected_to_fail = {(2, 1), (2, 5)}
-
- for i_tok, tokenizer in enumerate(tokenizers):
- for i_text, text in enumerate(texts):
- # Important: we don't assume to preserve whitespaces after tokenization.
- # This means: \t, \n " " etc will all resolve to a single " ".
- # This doesn't make a difference for BERT + XLNet but it does for roBERTa
-
- test_passed = True
-
- # 1. original tokenize function from transformer repo on full sentence
- standardized_whitespace_text = " ".join(text.split()) # remove multiple whitespaces
- tokenized = tokenizer.tokenize(standardized_whitespace_text)
-
- # 2. Our tokenization method using a pretokenizer which can normalize multiple white spaces
- # This approach is used in NER
- pre_tokenizer = WhitespaceSplit()
- words_and_spans = pre_tokenizer.pre_tokenize_str(text)
- words = [x[0] for x in words_and_spans]
- word_spans = [x[1] for x in words_and_spans]
-
- encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
-
- # verify that tokenization on full sequence is the same as the one on "whitespace tokenized words"
- if encoded.tokens != tokenized:
- test_passed = False
-
- # token offsets are originally relative to the beginning of the word
- # These lines convert them so they are relative to the beginning of the sentence
- token_offsets = []
- for ((start, end), w_index) in zip(encoded.offsets, encoded.words):
- word_start_ch = word_spans[w_index][0]
- token_offsets.append((start + word_start_ch, end + word_start_ch))
-
- # verify that offsets align back to original text
- if text == "力加勝北区ᴵᴺᵀᵃছজটডণত":
- # contains [UNK] that are impossible to match back to original text space
- continue
- for tok, (start, end) in zip(encoded.tokens, token_offsets):
- # subword-tokens have special chars depending on model type. In order to align with original text we need to get rid of them
- tok = re.sub(r"^(##|Ġ|▁)", "", tok)
- # tok = tokenizer.decode(tokenizer.convert_tokens_to_ids(tok))
- original_tok = text[start:end]
- if tok != original_tok:
- test_passed = False
- if (i_tok, i_text) in expected_to_fail:
- assert not test_passed, f"Behaviour of {tokenizer.__class__.__name__} has changed on text {text}'"
- else:
- assert test_passed, f"Behaviour of {tokenizer.__class__.__name__} has changed on text {text}'"
-
-
-def test_bert_custom_vocab(caplog):
- caplog.set_level(logging.CRITICAL)
-
- lang_model = "bert-base-cased"
-
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False)
-
- # deprecated: tokenizer.add_custom_vocab("samples/tokenizer/custom_vocab.txt")
- tokenizer.add_tokens(new_tokens=["neverseentokens"])
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- # original tokenizer from transformer repo
- tokenized = tokenizer.tokenize(basic_text)
- assert tokenized == [
- "Some",
- "Text",
- "with",
- "neverseentokens",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- ]
+@pytest.fixture(autouse=True)
+def mock_autotokenizer(request, monkeypatch):
+ # Do not patch integration tests
+ if "integration" in request.keywords:
+ return
+ monkeypatch.setattr(haystack.modeling.model.tokenization, "AutoTokenizer", AutoTokenizer)
+
+
+def convert_offset_from_word_reference_to_text_reference(offsets, words, word_spans):
+ """
+ Token offsets are originally relative to the beginning of the word
+ We make them relative to the beginning of the sentence.
+
+ Not a fixture, just a utility.
+ """
+ token_offsets = []
+ for ((start, end), word_index) in zip(offsets, words):
+ word_start = word_spans[word_index][0]
+ token_offsets.append((start + word_start, end + word_start))
+ return token_offsets
+
+
+#
+# Unit tests
+#
+
+
+def test_get_tokenizer_str():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path="test-model-name")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path="test-model-name", revision=None, use_fast=True, use_auth_token=None
+ )
- # ours with metadata
- encoded = tokenizer.encode_plus(basic_text, add_special_tokens=False).encodings[0]
- offsets = [x[0] for x in encoded.offsets]
- start_of_word_single = [True] + list(np.ediff1d(encoded.words) > 0)
- assert encoded.tokens == tokenized
- assert offsets == [0, 5, 10, 15, 31, 36, 37, 40, 41, 42, 44, 48, 50, 58, 59, 64, 65, 69, 70, 72]
- assert start_of_word_single == [
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- False,
- ]
+def test_get_tokenizer_path(tmp_path):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=tmp_path / "test-path")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path=str(tmp_path / "test-path"), revision=None, use_fast=True, use_auth_token=None
+ )
-def test_fast_bert_custom_vocab(caplog):
- caplog.set_level(logging.CRITICAL)
- lang_model = "bert-base-cased"
+def test_get_tokenizer_keep_accents():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path="test-model-name-albert")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path="test-model-name-albert",
+ revision=None,
+ use_fast=True,
+ use_auth_token=None,
+ keep_accents=True,
+ )
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=lang_model, do_lower_case=False, use_fast=True)
- # deprecated: tokenizer.add_custom_vocab("samples/tokenizer/custom_vocab.txt")
+def test_get_tokenizer_mlm_warning(caplog):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path="test-model-name-mlm")
+ tokenizer.mocker.from_pretrained.assert_called_with(
+ pretrained_model_name_or_path="test-model-name-mlm", revision=None, use_fast=True, use_auth_token=None
+ )
+ assert "MLM part of codebert is currently not supported in Haystack".lower() in caplog.text.lower()
+
+
+#
+# Integration tests
+#
+
+
+@pytest.mark.integration
+@pytest.mark.parametrize("model_name", TOKENIZERS_TO_TEST)
+def test_save_load(tmp_path, model_name: str):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False)
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+
tokenizer.add_tokens(new_tokens=["neverseentokens"])
+ original_encoding = tokenizer.encode_plus(text)
- basic_text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
-
- # original tokenizer from transformer repo
- tokenized = tokenizer.tokenize(basic_text)
- assert tokenized == [
- "Some",
- "Text",
- "with",
- "neverseentokens",
- "plus",
- "!",
- "215",
- "?",
- "#",
- ".",
- "and",
- "a",
- "combined",
- "-",
- "token",
- "_",
- "with",
- "/",
- "ch",
- "##ars",
- ]
+ save_dir = tmp_path / "saved_tokenizer"
+ tokenizer.save_pretrained(save_dir)
- # ours with metadata
- encoded = tokenizer.encode_plus(basic_text, add_special_tokens=False).encodings[0]
- offsets = [x[0] for x in encoded.offsets]
- start_of_word_single = [True] + list(np.ediff1d(encoded.words) > 0)
- assert encoded.tokens == tokenized
- assert offsets == [0, 5, 10, 15, 31, 36, 37, 40, 41, 42, 44, 48, 50, 58, 59, 64, 65, 69, 70, 72]
- assert start_of_word_single == [
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- True,
- False,
- ]
+ tokenizer_loaded = get_tokenizer(pretrained_model_name_or_path=save_dir)
+ new_encoding = tokenizer_loaded.encode_plus(text)
+ assert original_encoding == new_encoding
+
+
+@pytest.mark.integration
+def test_tokenize_custom_vocab_bert():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
+ tokenizer.add_tokens(new_tokens=["neverseentokens"])
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+ tokenized = tokenizer.tokenize(text)
+ assert (
+ tokenized == f"Some Text with neverseentokens plus ! 215 ? # . and a combined - token _ with / ch ##ars".split()
+ )
+
+
+@pytest.mark.integration
@pytest.mark.parametrize(
- "model_name, tokenizer_type",
- [("bert-base-german-cased", BertTokenizerFast), ("google/electra-small-discriminator", ElectraTokenizerFast)],
+ "edge_case",
+ [
+ REGULAR_SENTENCE,
+ OTHER_ALPHABETS,
+ GIBBERISH_SENTENCE,
+ SENTENCE_WITH_ELLIPSIS,
+ SENTENCE_WITH_LINEBREAK_1,
+ SENTENCE_WITH_LINEBREAK_2,
+ SENTENCE_WITH_LINEBREAKS,
+ SENTENCE_WITH_EXCESS_WHITESPACE,
+ SENTENCE_WITH_TABS,
+ ],
)
-def test_fast_tokenizer_type(caplog, model_name, tokenizer_type):
- caplog.set_level(logging.CRITICAL)
+@pytest.mark.parametrize("model_name", TOKENIZERS_TO_TEST)
+def test_tokenization_on_edge_cases_full_sequence_tokenization(model_name: str, edge_case: str):
+ """
+ Verify that tokenization on full sequence is the same as the one on "whitespace tokenized words"
+ """
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False, add_prefix_space=True)
- tokenizer = Tokenizer.load(model_name, use_fast=True)
- assert type(tokenizer) is tokenizer_type
+ pre_tokenizer = WhitespaceSplit()
+ words_and_spans = pre_tokenizer.pre_tokenize_str(edge_case)
+ words = [x[0] for x in words_and_spans]
+ encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
+ expected_tokenization = tokenizer.tokenize(" ".join(edge_case.split())) # remove multiple whitespaces
-# See discussion in https://github.com/deepset-ai/FARM/pull/624 for reason to remove the test
-# def test_fast_bert_tokenizer_strip_accents(caplog):
-# caplog.set_level(logging.CRITICAL)
-#
-# tokenizer = Tokenizer.load("dbmdz/bert-base-german-uncased",
-# use_fast=True,
-# strip_accents=False)
-# assert type(tokenizer) is BertTokenizerFast
-# assert tokenizer.do_lower_case
-# assert tokenizer._tokenizer._parameters['strip_accents'] is False
+ assert encoded.tokens == expected_tokenization
+
+
+@pytest.mark.integration
+@pytest.mark.parametrize("edge_case", [SENTENCE_WITH_CUSTOM_TOKEN, GERMAN_SENTENCE])
+@pytest.mark.parametrize("model_name", [t for t in TOKENIZERS_TO_TEST if t != ROBERTA])
+def test_tokenization_on_edge_cases_full_sequence_tokenization_roberta_exceptions(model_name: str, edge_case: str):
+ """
+ Verify that tokenization on full sequence is the same as the one on "whitespace tokenized words".
+ These test cases work for all tokenizers under test except for RoBERTa.
+ """
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False, add_prefix_space=True)
+ pre_tokenizer = WhitespaceSplit()
+ words_and_spans = pre_tokenizer.pre_tokenize_str(edge_case)
+ words = [x[0] for x in words_and_spans]
-def test_fast_electra_tokenizer(caplog):
- caplog.set_level(logging.CRITICAL)
+ encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
+ expected_tokenization = tokenizer.tokenize(" ".join(edge_case.split())) # remove multiple whitespaces
- tokenizer = Tokenizer.load("dbmdz/electra-base-german-europeana-cased-discriminator", use_fast=True)
- assert type(tokenizer) is ElectraTokenizerFast
+ assert encoded.tokens == expected_tokenization
-@pytest.mark.parametrize("model_name", ["bert-base-cased", "distilbert-base-uncased", "deepset/electra-base-squad2"])
-def test_detokenization_in_fast_tokenizers(model_name):
- tokenizer = Tokenizer.load(pretrained_model_name_or_path=model_name, use_fast=True)
- for text in TEXTS:
- encoded = tokenizer.encode_plus(text, add_special_tokens=False).encodings[0]
+@pytest.mark.integration
+@pytest.mark.parametrize(
+ "edge_case",
+ [
+ REGULAR_SENTENCE,
+ # OTHER_ALPHABETS, # contains [UNK] that are impossible to match back to original text space
+ GIBBERISH_SENTENCE,
+ SENTENCE_WITH_ELLIPSIS,
+ SENTENCE_WITH_LINEBREAK_1,
+ SENTENCE_WITH_LINEBREAK_2,
+ SENTENCE_WITH_LINEBREAKS,
+ SENTENCE_WITH_EXCESS_WHITESPACE,
+ SENTENCE_WITH_TABS,
+ ],
+)
+@pytest.mark.parametrize("model_name,marker", TOKENIZERS_TO_TEST_WITH_TOKEN_MARKER)
+def test_tokenization_on_edge_cases_full_sequence_verify_spans(model_name: str, marker: str, edge_case: str):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=model_name, do_lower_case=False, add_prefix_space=True)
+
+ pre_tokenizer = WhitespaceSplit()
+ words_and_spans = pre_tokenizer.pre_tokenize_str(edge_case)
+ words = [x[0] for x in words_and_spans]
+ word_spans = [x[1] for x in words_and_spans]
+
+ encoded = tokenizer.encode_plus(words, is_split_into_words=True, add_special_tokens=False).encodings[0]
+
+ # subword-tokens have special chars depending on model type. To align with original text we get rid of them
+ tokens = [token.replace(marker, "") for token in encoded.tokens]
+ token_offsets = convert_offset_from_word_reference_to_text_reference(encoded.offsets, encoded.words, word_spans)
+
+ for token, (start, end) in zip(tokens, token_offsets):
+ assert token == edge_case[start:end]
+
+
+@pytest.mark.integration
+@pytest.mark.parametrize(
+ "edge_case",
+ [
+ REGULAR_SENTENCE,
+ GERMAN_SENTENCE,
+ SENTENCE_WITH_EXCESS_WHITESPACE,
+ OTHER_ALPHABETS,
+ GIBBERISH_SENTENCE,
+ SENTENCE_WITH_ELLIPSIS,
+ SENTENCE_WITH_CUSTOM_TOKEN,
+ SENTENCE_WITH_LINEBREAK_1,
+ SENTENCE_WITH_LINEBREAK_2,
+ SENTENCE_WITH_LINEBREAKS,
+ SENTENCE_WITH_TABS,
+ ],
+)
+def test_detokenization_for_bert(edge_case):
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
- detokenized = " ".join(encoded.tokens)
- detokenized = re.sub(r"(^|\s+)(##)", "", detokenized)
+ encoded = tokenizer.encode_plus(edge_case, add_special_tokens=False).encodings[0]
- detokenized_ids = tokenizer(detokenized, add_special_tokens=False)["input_ids"]
- detokenized_tokens = [tokenizer.decode([tok_id]).strip() for tok_id in detokenized_ids]
+ detokenized = " ".join(encoded.tokens)
+ detokenized = re.sub(r"(^|\s+)(##)", "", detokenized)
- assert encoded.tokens == detokenized_tokens
+ detokenized_ids = tokenizer(detokenized, add_special_tokens=False)["input_ids"]
+ detokenized_tokens = [tokenizer.decode([tok_id]).strip() for tok_id in detokenized_ids]
+ assert encoded.tokens == detokenized_tokens
-if __name__ == "__main__":
- test_all_tokenizer_on_special_cases()
+
+@pytest.mark.integration
+def test_encode_plus_for_bert():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+
+ encoded_batch = tokenizer.encode_plus(text)
+ encoded = encoded_batch.encodings[0]
+
+ words = np.array(encoded.words)
+ words[0] = -1
+ words[-1] = -1
+
+ print(words.tolist())
+
+ tokens = encoded.tokens
+ offsets = [x[0] for x in encoded.offsets]
+ start_of_word = [False] + list(np.ediff1d(words) > 0)
+
+ assert list(zip(tokens, offsets, start_of_word)) == [
+ ("[CLS]", 0, False),
+ ("Some", 0, True),
+ ("Text", 5, True),
+ ("with", 10, True),
+ ("never", 15, True),
+ ("##see", 20, False),
+ ("##nto", 23, False),
+ ("##ken", 26, False),
+ ("##s", 29, False),
+ ("plus", 31, True),
+ ("!", 36, True),
+ ("215", 37, True),
+ ("?", 40, True),
+ ("#", 41, True),
+ (".", 42, True),
+ ("and", 44, True),
+ ("a", 48, True),
+ ("combined", 50, True),
+ ("-", 58, True),
+ ("token", 59, True),
+ ("_", 64, True),
+ ("with", 65, True),
+ ("/", 69, True),
+ ("ch", 70, True),
+ ("##ars", 72, False),
+ ("[SEP]", 0, False),
+ ]
+
+
+@pytest.mark.integration
+def test_tokenize_custom_vocab_bert():
+ tokenizer = get_tokenizer(pretrained_model_name_or_path=BERT, do_lower_case=False)
+
+ tokenizer.add_tokens(new_tokens=["neverseentokens"])
+ text = "Some Text with neverseentokens plus !215?#. and a combined-token_with/chars"
+
+ tokenized = tokenizer.tokenize(text)
+
+ encoded = tokenizer.encode_plus(text, add_special_tokens=False).encodings[0]
+ offsets = [x[0] for x in encoded.offsets]
+ start_of_word_single = [True] + list(np.ediff1d(encoded.words) > 0)
+
+ assert encoded.tokens == tokenized
+ assert offsets == [0, 5, 10, 15, 31, 36, 37, 40, 41, 42, 44, 48, 50, 58, 59, 64, 65, 69, 70, 72]
+ assert start_of_word_single == [True] * 19 + [False]
diff --git a/test/nodes/test_audio.py b/test/nodes/test_audio.py
index 774a61409f..1fdaf31b7f 100644
--- a/test/nodes/test_audio.py
+++ b/test/nodes/test_audio.py
@@ -1,7 +1,14 @@
import os
+import pytest
import numpy as np
-import soundfile as sf
+
+try:
+ import soundfile as sf
+
+ soundfile_not_found = False
+except:
+ soundfile_not_found = True
from haystack.schema import Span, Answer, SpeechAnswer, Document, SpeechDocument
from haystack.nodes.audio import AnswerToSpeech, DocumentToSpeech
@@ -10,111 +17,108 @@
from ..conftest import SAMPLES_PATH
-def test_text_to_speech_audio_data():
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
- audio_data = text2speech.text_to_audio_data(text="answer")
-
- assert np.allclose(expected_audio_data, audio_data, atol=0.001)
-
-
-def test_text_to_speech_audio_file(tmp_path):
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
- audio_file = text2speech.text_to_audio_file(text="answer", generated_audio_dir=tmp_path / "test_audio")
- assert os.path.exists(audio_file)
- assert np.allclose(expected_audio_data, sf.read(audio_file)[0], atol=0.001)
-
-
-def test_text_to_speech_compress_audio(tmp_path):
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
- audio_file = text2speech.text_to_audio_file(
- text="answer", generated_audio_dir=tmp_path / "test_audio", audio_format="mp3"
- )
- assert os.path.exists(audio_file)
- assert audio_file.suffix == ".mp3"
- # FIXME find a way to make sure the compressed audio is similar enough to the wav version.
- # At a manual inspection, the code seems to be working well.
-
-
-def test_text_to_speech_naming_function(tmp_path):
- text2speech = TextToSpeech(
- model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
- audio_file = text2speech.text_to_audio_file(
- text="answer", generated_audio_dir=tmp_path / "test_audio", audio_naming_function=lambda text: text
- )
- assert os.path.exists(audio_file)
- assert audio_file.name == expected_audio_file.name
- assert np.allclose(sf.read(expected_audio_file)[0], sf.read(audio_file)[0], atol=0.001)
-
-
-def test_answer_to_speech(tmp_path):
- text_answer = Answer(
- answer="answer",
- type="extractive",
- context="the context for this answer is here",
- offsets_in_document=[Span(31, 37)],
- offsets_in_context=[Span(21, 27)],
- meta={"some_meta": "some_value"},
- )
- expected_audio_answer = SAMPLES_PATH / "audio" / "answer.wav"
- expected_audio_context = SAMPLES_PATH / "audio" / "the context for this answer is here.wav"
-
- answer2speech = AnswerToSpeech(
- generated_audio_dir=tmp_path / "test_audio",
- audio_params={"audio_naming_function": lambda text: text},
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- results, _ = answer2speech.run(answers=[text_answer])
-
- audio_answer: SpeechAnswer = results["answers"][0]
- assert isinstance(audio_answer, SpeechAnswer)
- assert audio_answer.type == "generative"
- assert audio_answer.answer_audio.name == expected_audio_answer.name
- assert audio_answer.context_audio.name == expected_audio_context.name
- assert audio_answer.answer == "answer"
- assert audio_answer.context == "the context for this answer is here"
- assert audio_answer.offsets_in_document == [Span(31, 37)]
- assert audio_answer.offsets_in_context == [Span(21, 27)]
- assert audio_answer.meta["some_meta"] == "some_value"
- assert audio_answer.meta["audio_format"] == "wav"
-
- assert np.allclose(sf.read(audio_answer.answer_audio)[0], sf.read(expected_audio_answer)[0], atol=0.001)
- assert np.allclose(sf.read(audio_answer.context_audio)[0], sf.read(expected_audio_context)[0], atol=0.001)
-
-
-def test_document_to_speech(tmp_path):
- text_doc = Document(
- content="this is the content of the document", content_type="text", meta={"name": "test_document.txt"}
- )
- expected_audio_content = SAMPLES_PATH / "audio" / "this is the content of the document.wav"
-
- doc2speech = DocumentToSpeech(
- generated_audio_dir=tmp_path / "test_audio",
- audio_params={"audio_naming_function": lambda text: text},
- transformers_params={"seed": 777, "always_fix_seed": True},
- )
- results, _ = doc2speech.run(documents=[text_doc])
-
- audio_doc: SpeechDocument = results["documents"][0]
- assert isinstance(audio_doc, SpeechDocument)
- assert audio_doc.content_type == "audio"
- assert audio_doc.content_audio.name == expected_audio_content.name
- assert audio_doc.content == "this is the content of the document"
- assert audio_doc.meta["name"] == "test_document.txt"
- assert audio_doc.meta["audio_format"] == "wav"
-
- assert np.allclose(sf.read(audio_doc.content_audio)[0], sf.read(expected_audio_content)[0], atol=0.001)
+@pytest.mark.skipif(soundfile_not_found, reason="soundfile not found")
+class TestTextToSpeech:
+ def test_text_to_speech_audio_data(self):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
+ audio_data = text2speech.text_to_audio_data(text="answer")
+
+ assert np.allclose(expected_audio_data, audio_data, atol=0.001)
+
+ def test_text_to_speech_audio_file(self, tmp_path):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_data, _ = sf.read(SAMPLES_PATH / "audio" / "answer.wav")
+ audio_file = text2speech.text_to_audio_file(text="answer", generated_audio_dir=tmp_path / "test_audio")
+ assert os.path.exists(audio_file)
+ assert np.allclose(expected_audio_data, sf.read(audio_file)[0], atol=0.001)
+
+ def test_text_to_speech_compress_audio(self, tmp_path):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
+ audio_file = text2speech.text_to_audio_file(
+ text="answer", generated_audio_dir=tmp_path / "test_audio", audio_format="mp3"
+ )
+ assert os.path.exists(audio_file)
+ assert audio_file.suffix == ".mp3"
+ # FIXME find a way to make sure the compressed audio is similar enough to the wav version.
+ # At a manual inspection, the code seems to be working well.
+
+ def test_text_to_speech_naming_function(self, tmp_path):
+ text2speech = TextToSpeech(
+ model_name_or_path="espnet/kan-bayashi_ljspeech_vits",
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ expected_audio_file = SAMPLES_PATH / "audio" / "answer.wav"
+ audio_file = text2speech.text_to_audio_file(
+ text="answer", generated_audio_dir=tmp_path / "test_audio", audio_naming_function=lambda text: text
+ )
+ assert os.path.exists(audio_file)
+ assert audio_file.name == expected_audio_file.name
+ assert np.allclose(sf.read(expected_audio_file)[0], sf.read(audio_file)[0], atol=0.001)
+
+ def test_answer_to_speech(self, tmp_path):
+ text_answer = Answer(
+ answer="answer",
+ type="extractive",
+ context="the context for this answer is here",
+ offsets_in_document=[Span(31, 37)],
+ offsets_in_context=[Span(21, 27)],
+ meta={"some_meta": "some_value"},
+ )
+ expected_audio_answer = SAMPLES_PATH / "audio" / "answer.wav"
+ expected_audio_context = SAMPLES_PATH / "audio" / "the context for this answer is here.wav"
+
+ answer2speech = AnswerToSpeech(
+ generated_audio_dir=tmp_path / "test_audio",
+ audio_params={"audio_naming_function": lambda text: text},
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ results, _ = answer2speech.run(answers=[text_answer])
+
+ audio_answer: SpeechAnswer = results["answers"][0]
+ assert isinstance(audio_answer, SpeechAnswer)
+ assert audio_answer.type == "generative"
+ assert audio_answer.answer_audio.name == expected_audio_answer.name
+ assert audio_answer.context_audio.name == expected_audio_context.name
+ assert audio_answer.answer == "answer"
+ assert audio_answer.context == "the context for this answer is here"
+ assert audio_answer.offsets_in_document == [Span(31, 37)]
+ assert audio_answer.offsets_in_context == [Span(21, 27)]
+ assert audio_answer.meta["some_meta"] == "some_value"
+ assert audio_answer.meta["audio_format"] == "wav"
+
+ assert np.allclose(sf.read(audio_answer.answer_audio)[0], sf.read(expected_audio_answer)[0], atol=0.001)
+ assert np.allclose(sf.read(audio_answer.context_audio)[0], sf.read(expected_audio_context)[0], atol=0.001)
+
+ def test_document_to_speech(self, tmp_path):
+ text_doc = Document(
+ content="this is the content of the document", content_type="text", meta={"name": "test_document.txt"}
+ )
+ expected_audio_content = SAMPLES_PATH / "audio" / "this is the content of the document.wav"
+
+ doc2speech = DocumentToSpeech(
+ generated_audio_dir=tmp_path / "test_audio",
+ audio_params={"audio_naming_function": lambda text: text},
+ transformers_params={"seed": 777, "always_fix_seed": True},
+ )
+ results, _ = doc2speech.run(documents=[text_doc])
+
+ audio_doc: SpeechDocument = results["documents"][0]
+ assert isinstance(audio_doc, SpeechDocument)
+ assert audio_doc.content_type == "audio"
+ assert audio_doc.content_audio.name == expected_audio_content.name
+ assert audio_doc.content == "this is the content of the document"
+ assert audio_doc.meta["name"] == "test_document.txt"
+ assert audio_doc.meta["audio_format"] == "wav"
+
+ assert np.allclose(sf.read(audio_doc.content_audio)[0], sf.read(expected_audio_content)[0], atol=0.001)
diff --git a/test/nodes/test_preprocessor.py b/test/nodes/test_preprocessor.py
index 6859002491..45a614d8c6 100644
--- a/test/nodes/test_preprocessor.py
+++ b/test/nodes/test_preprocessor.py
@@ -1,5 +1,6 @@
import sys
from pathlib import Path
+import os
import pytest
@@ -9,6 +10,10 @@
from ..conftest import SAMPLES_PATH
+
+NLTK_TEST_MODELS = SAMPLES_PATH.absolute() / "preprocessor" / "nltk_models"
+
+
TEXT = """
This is a sample sentence in paragraph_1. This is a sample sentence in paragraph_1. This is a sample sentence in
paragraph_1. This is a sample sentence in paragraph_1. This is a sample sentence in paragraph_1.
@@ -21,20 +26,90 @@
in the sentence.
"""
+LEGAL_TEXT_PT = """
+A Lei nº 9.514/1997, que instituiu a alienação fiduciária de
+bens imóveis, é norma especial e posterior ao Código de Defesa do
+Consumidor – CDC. Em tais circunstâncias, o inadimplemento do
+devedor fiduciante enseja a aplicação da regra prevista nos arts. 26 e 27
+da lei especial” (REsp 1.871.911/SP, rel. Min. Nancy Andrighi, DJe
+25/8/2020).
+
+A Emenda Constitucional n. 35 alterou substancialmente esse mecanismo,
+ao determinar, na nova redação conferida ao art. 53: “§ 3º Recebida a
+denúncia contra o Senador ou Deputado, por crime ocorrido após a
+diplomação, o Supremo Tribunal Federal dará ciência à Casa respectiva, que,
+por iniciativa de partido político nela representado e pelo voto da maioria de
+seus membros, poderá, até a decisão final, sustar o andamento da ação”.
+Vale ressaltar, contudo, que existem, antes do encaminhamento ao
+Presidente da República, os chamados autógrafos. Os autógrafos ocorrem já
+com o texto definitivamente aprovado pelo Plenário ou pelas comissões,
+quando for o caso. Os autógrafos devem reproduzir com absoluta fidelidade a
+redação final aprovada. O projeto aprovado será encaminhado em autógrafos
+ao Presidente da República. O tema encontra-se regulamentado pelo art. 200
+do RICD e arts. 328 a 331 do RISF.
+"""
+
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 15), (10, 2)])
+def test_preprocess_sentence_split(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
-def test_preprocess_sentence_split():
document = Document(content=TEXT)
preprocessor = PreProcessor(
- split_length=1, split_overlap=0, split_by="sentence", split_respect_sentence_boundary=False
+ split_length=split_length, split_overlap=0, split_by="sentence", split_respect_sentence_boundary=False
)
documents = preprocessor.process(document)
- assert len(documents) == 15
+ assert len(documents) == expected_documents_count
+
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 15), (10, 2)])
+def test_preprocess_sentence_split_custom_models_wrong_file_format(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+
+ document = Document(content=TEXT)
+ preprocessor = PreProcessor(
+ split_length=split_length,
+ split_overlap=0,
+ split_by="sentence",
+ split_respect_sentence_boundary=False,
+ tokenizer_model_folder=NLTK_TEST_MODELS / "wrong",
+ language="en",
+ )
+ documents = preprocessor.process(document)
+ assert len(documents) == expected_documents_count
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 15), (10, 2)])
+def test_preprocess_sentence_split_custom_models_non_default_language(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+
+ document = Document(content=TEXT)
+ preprocessor = PreProcessor(
+ split_length=split_length,
+ split_overlap=0,
+ split_by="sentence",
+ split_respect_sentence_boundary=False,
+ language="ca",
+ )
+ documents = preprocessor.process(document)
+ assert len(documents) == expected_documents_count
+
+
+@pytest.mark.parametrize("split_length_and_results", [(1, 8), (8, 1)])
+def test_preprocess_sentence_split_custom_models(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+
+ document = Document(content=LEGAL_TEXT_PT)
preprocessor = PreProcessor(
- split_length=10, split_overlap=0, split_by="sentence", split_respect_sentence_boundary=False
+ split_length=split_length,
+ split_overlap=0,
+ split_by="sentence",
+ split_respect_sentence_boundary=False,
+ language="pt",
+ tokenizer_model_folder=NLTK_TEST_MODELS,
)
documents = preprocessor.process(document)
- assert len(documents) == 2
+ assert len(documents) == expected_documents_count
def test_preprocess_word_split():
@@ -64,19 +139,16 @@ def test_preprocess_word_split():
assert len(documents) == 15
-def test_preprocess_passage_split():
- document = Document(content=TEXT)
- preprocessor = PreProcessor(
- split_length=1, split_overlap=0, split_by="passage", split_respect_sentence_boundary=False
- )
- documents = preprocessor.process(document)
- assert len(documents) == 3
+@pytest.mark.parametrize("split_length_and_results", [(1, 3), (2, 2)])
+def test_preprocess_passage_split(split_length_and_results):
+ split_length, expected_documents_count = split_length_and_results
+ document = Document(content=TEXT)
preprocessor = PreProcessor(
- split_length=2, split_overlap=0, split_by="passage", split_respect_sentence_boundary=False
+ split_length=split_length, split_overlap=0, split_by="passage", split_respect_sentence_boundary=False
)
documents = preprocessor.process(document)
- assert len(documents) == 2
+ assert len(documents) == expected_documents_count
@pytest.mark.skipif(sys.platform in ["win32", "cygwin"], reason="FIXME Footer not detected correctly on Windows")
diff --git a/test/nodes/test_question_generator.py b/test/nodes/test_question_generator.py
index 52a6712c64..1813c5be1c 100644
--- a/test/nodes/test_question_generator.py
+++ b/test/nodes/test_question_generator.py
@@ -1,10 +1,12 @@
+import pytest
+
from haystack.pipelines import (
QuestionAnswerGenerationPipeline,
QuestionGenerationPipeline,
RetrieverQuestionGenerationPipeline,
)
+from haystack.nodes.question_generator import QuestionGenerator
from haystack.schema import Document
-import pytest
text = 'The Living End are an Australian punk rockabilly band from Melbourne, formed in 1994. Since 2002, the line-up consists of Chris Cheney (vocals, guitar), Scott Owen (double bass, vocals), and Andy Strachan (drums). The band rose to fame in 1997 after the release of their EP Second Solution / Prisoner of Society, which peaked at No. 4 on the Australian ARIA Singles Chart. They have released eight studio albums, two of which reached the No. 1 spot on the ARIA Albums Chart: The Living End (October 1998) and State of Emergency (February 2006). They have also achieved chart success in the U.S. and the United Kingdom. The Band was nominated 27 times and won five awards at the Australian ARIA Music Awards ceremonies: "Highest Selling Single" for Second Solution / Prisoner of Society (1998), "Breakthrough Artist – Album" and "Best Group" for The Living End (1999), as well as "Best Rock Album" for White Noise (2008) and The Ending Is Just the Beginning Repeating (2011). In October 2010, their debut album was listed in the book "100 Best Australian Albums". Australian musicologist Ian McFarlane described the group as "one of Australia’s premier rock acts. By blending a range of styles (punk, rockabilly and flat out rock) with great success, The Living End has managed to produce anthemic choruses and memorable songs in abundance".'
diff --git a/test/nodes/test_retriever.py b/test/nodes/test_retriever.py
index cc3c5c4edb..c5081b1e5e 100644
--- a/test/nodes/test_retriever.py
+++ b/test/nodes/test_retriever.py
@@ -11,6 +11,7 @@
from elasticsearch import Elasticsearch
from haystack.document_stores import WeaviateDocumentStore
+from haystack.nodes.retriever.base import BaseRetriever
from haystack.schema import Document
from haystack.document_stores.elasticsearch import ElasticsearchDocumentStore
from haystack.document_stores.faiss import FAISSDocumentStore
@@ -49,7 +50,7 @@
],
indirect=True,
)
-def test_retrieval(retriever_with_docs, document_store_with_docs):
+def test_retrieval(retriever_with_docs: BaseRetriever, document_store_with_docs: BaseDocumentStore):
if not isinstance(retriever_with_docs, (BM25Retriever, FilterRetriever, TfidfRetriever)):
document_store_with_docs.update_embeddings(retriever_with_docs)
@@ -344,9 +345,9 @@ def sum_params(model):
def test_table_text_retriever_training(document_store):
retriever = TableTextRetriever(
document_store=document_store,
- query_embedding_model="prajjwal1/bert-tiny",
- passage_embedding_model="prajjwal1/bert-tiny",
- table_embedding_model="prajjwal1/bert-tiny",
+ query_embedding_model="deepset/bert-small-mm_retrieval-question_encoder",
+ passage_embedding_model="deepset/bert-small-mm_retrieval-passage_encoder",
+ table_embedding_model="deepset/bert-small-mm_retrieval-table_encoder",
use_gpu=False,
)
diff --git a/test/pipelines/test_pipeline.py b/test/pipelines/test_pipeline.py
index 0a5365432e..0d3e09eabd 100644
--- a/test/pipelines/test_pipeline.py
+++ b/test/pipelines/test_pipeline.py
@@ -1313,6 +1313,100 @@ def test_deploy_on_deepset_cloud_invalid_state_in_progress():
)
+@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
+@responses.activate
+def test_failed_deploy_on_deepset_cloud():
+ if MOCK_DC:
+ responses.add(
+ method=responses.POST,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline/deploy",
+ json={"status": "DEPLOYMENT_SCHEDULED"},
+ status=200,
+ )
+
+ # status will be first undeployed, after deploy() it's in progress twice and the third time deployment failed
+ status_flow = ["UNDEPLOYED", "DEPLOYMENT_IN_PROGRESS", "DEPLOYMENT_IN_PROGRESS", "DEPLOYMENT_FAILED"]
+ for status in status_flow:
+ responses.add(
+ method=responses.GET,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline",
+ json={"status": status},
+ status=200,
+ )
+ with pytest.raises(
+ DeepsetCloudError,
+ match=f"Deployment of pipeline config 'test_new_non_existing_pipeline' failed. "
+ "This might be caused by an exception in deepset Cloud or a runtime error in the pipeline. "
+ "You can try to run this pipeline locally first.",
+ ):
+ Pipeline.deploy_on_deepset_cloud(
+ pipeline_config_name="test_new_non_existing_pipeline", api_endpoint=DC_API_ENDPOINT, api_key=DC_API_KEY
+ )
+
+
+@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
+@responses.activate
+def test_unexpected_failed_deploy_on_deepset_cloud():
+ if MOCK_DC:
+ responses.add(
+ method=responses.POST,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline/deploy",
+ json={"status": "DEPLOYMENT_SCHEDULED"},
+ status=200,
+ )
+
+ # status will be first undeployed, after deploy() it's in deployment failed
+ status_flow = ["UNDEPLOYED", "DEPLOYMENT_FAILED"]
+ for status in status_flow:
+ responses.add(
+ method=responses.GET,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline",
+ json={"status": status},
+ status=200,
+ )
+ with pytest.raises(
+ DeepsetCloudError,
+ match=f"Deployment of pipeline config 'test_new_non_existing_pipeline' failed. "
+ "This might be caused by an exception in deepset Cloud or a runtime error in the pipeline. "
+ "You can try to run this pipeline locally first.",
+ ):
+ Pipeline.deploy_on_deepset_cloud(
+ pipeline_config_name="test_new_non_existing_pipeline", api_endpoint=DC_API_ENDPOINT, api_key=DC_API_KEY
+ )
+
+
+@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
+@responses.activate
+def test_deploy_on_deepset_cloud_with_failed_start_state(caplog):
+ if MOCK_DC:
+ responses.add(
+ method=responses.POST,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline/deploy",
+ json={"status": "DEPLOYMENT_SCHEDULED"},
+ status=200,
+ )
+
+ # status will be first in failed (but not invalid) state, after deploy() it's in progress twice and third time deployed
+ status_flow = ["DEPLOYMENT_FAILED", "DEPLOYMENT_IN_PROGRESS", "DEPLOYMENT_IN_PROGRESS", "DEPLOYED"]
+ for status in status_flow:
+ responses.add(
+ method=responses.GET,
+ url=f"{DC_API_ENDPOINT}/workspaces/default/pipelines/test_new_non_existing_pipeline",
+ json={"status": status},
+ status=200,
+ )
+
+ with caplog.at_level(logging.WARNING):
+ Pipeline.deploy_on_deepset_cloud(
+ pipeline_config_name="test_new_non_existing_pipeline", api_endpoint=DC_API_ENDPOINT, api_key=DC_API_KEY
+ )
+ assert (
+ "Pipeline config 'test_new_non_existing_pipeline' is in a failed state 'PipelineStatus.DEPLOYMENT_FAILED'."
+ in caplog.text
+ )
+ assert "This might be caused by a previous error during (un)deployment." in caplog.text
+
+
@pytest.mark.usefixtures(deepset_cloud_fixture.__name__)
@responses.activate
def test_undeploy_on_deepset_cloud_invalid_state_in_progress():
diff --git a/test/pipelines/test_pipeline_yaml.py b/test/pipelines/test_pipeline_yaml.py
index 353ec48dc6..64c9bcaa00 100644
--- a/test/pipelines/test_pipeline_yaml.py
+++ b/test/pipelines/test_pipeline_yaml.py
@@ -1021,3 +1021,10 @@ def test_save_yaml_overwrite(tmp_path):
with open(tmp_path / "saved_pipeline.yml", "r") as saved_yaml:
content = saved_yaml.read()
assert content != ""
+
+
+def test_load_yaml_ray_args_in_pipeline(tmp_path):
+ with pytest.raises(PipelineConfigError) as e:
+ pipeline = Pipeline.load_from_yaml(
+ SAMPLES_PATH / "pipeline" / "ray.haystack-pipeline.yml", pipeline_name="ray_query_pipeline"
+ )
diff --git a/test/pipelines/test_ray.py b/test/pipelines/test_ray.py
index 5a4171f907..17f996d206 100644
--- a/test/pipelines/test_ray.py
+++ b/test/pipelines/test_ray.py
@@ -14,6 +14,7 @@ def shutdown_ray():
try:
import ray
+ ray.serve.shutdown()
ray.shutdown()
except:
pass
@@ -21,15 +22,20 @@ def shutdown_ray():
@pytest.mark.integration
@pytest.mark.parametrize("document_store_with_docs", ["elasticsearch"], indirect=True)
-def test_load_pipeline(document_store_with_docs):
+@pytest.mark.parametrize("serve_detached", [True, False])
+def test_load_pipeline(document_store_with_docs, serve_detached):
pipeline = RayPipeline.load_from_yaml(
SAMPLES_PATH / "pipeline" / "ray.haystack-pipeline.yml",
pipeline_name="ray_query_pipeline",
ray_args={"num_cpus": 8},
+ serve_args={"detached": serve_detached},
)
prediction = pipeline.run(query="Who lives in Berlin?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}})
+ assert pipeline._serve_controller_client._detached == serve_detached
assert ray.serve.get_deployment(name="ESRetriever").num_replicas == 2
assert ray.serve.get_deployment(name="Reader").num_replicas == 1
+ assert ray.serve.get_deployment(name="ESRetriever").max_concurrent_queries == 17
+ assert ray.serve.get_deployment(name="ESRetriever").ray_actor_options["num_cpus"] == 0.5
assert prediction["query"] == "Who lives in Berlin?"
assert prediction["answers"][0].answer == "Carla"
diff --git a/test/samples/pipeline/ray.haystack-pipeline.yml b/test/samples/pipeline/ray.haystack-pipeline.yml
index 8dd4489af4..e89ec98ded 100644
--- a/test/samples/pipeline/ray.haystack-pipeline.yml
+++ b/test/samples/pipeline/ray.haystack-pipeline.yml
@@ -40,7 +40,13 @@ pipelines:
- name: ray_query_pipeline
nodes:
- name: ESRetriever
- replicas: 2
inputs: [ Query ]
+ serve_deployment_kwargs:
+ num_replicas: 2
+ version: Twenty
+ ray_actor_options:
+ # num_gpus: 0.25 # we have no GPU to test this
+ num_cpus: 0.5
+ max_concurrent_queries: 17
- name: Reader
inputs: [ ESRetriever ]
diff --git a/test/samples/preprocessor/nltk_models/pt.pickle b/test/samples/preprocessor/nltk_models/pt.pickle
new file mode 100644
index 0000000000..445ce95213
Binary files /dev/null and b/test/samples/preprocessor/nltk_models/pt.pickle differ
diff --git a/test/samples/preprocessor/nltk_models/wrong/en.pickle b/test/samples/preprocessor/nltk_models/wrong/en.pickle
new file mode 100644
index 0000000000..5edf856308
--- /dev/null
+++ b/test/samples/preprocessor/nltk_models/wrong/en.pickle
@@ -0,0 +1,2 @@
+This is a text file, not a real PunktSentenceTokenizer model.
+Loading it should not work on sentence tokenizer.
\ No newline at end of file
diff --git a/test/samples/squad/tiny_augmented.json b/test/samples/squad/tiny_augmented.json
index 2c29add194..c906c383e8 100644
--- a/test/samples/squad/tiny_augmented.json
+++ b/test/samples/squad/tiny_augmented.json
@@ -1 +1 @@
-{"data": [{"title": "test1", "paragraphs": [{"context": "my name is carla \u2014 me danced together with abdul - berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my grandmother is baba and i met together with you ka jakarta", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my sister is carla & i live upstairs with friends boom berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "the name is harry and i worked together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "whose aunt is carla and i sang together paula abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "suppose is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "what is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "where is the test for", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "suppose defines for test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "these constitutes a social that", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}], "topics": [{"title": "test1", "paragraphs": [{"context": "my name is carla \u2014 me danced together with abdul - berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my grandmother is baba and i met together with you ka jakarta", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my sister is carla & i live upstairs with friends boom berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "the name is harry and i worked together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "whose aunt is carla and i sang together paula abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "suppose is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "what is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "where is the test for", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "suppose defines for test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "these constitutes a social that", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}]}
\ No newline at end of file
+{"data": [{"title": "test1", "paragraphs": [{"context": "maiden father is carla and i lives together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my dad is carla and i lived comfortably at abdul rahman manhattan", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my mum ... carla and maria perform exclusively with myself karim berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "last wife , carla because i live now beside abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my name is carla and i live together with abdul hamid berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "thus is another test .", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another mathematical context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "there is dynamic test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}], "topics": [{"title": "test1", "paragraphs": [{"context": "maiden father is carla and i lives together with friends in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my dad is carla and i lived comfortably at abdul rahman manhattan", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my mum ... carla and maria perform exclusively with myself karim berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "last wife , carla because i live now beside abdul in berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}, {"context": "my name is carla and i live together with abdul hamid berlin", "qas": [{"answers": [], "id": 7211011040021040393, "question": "Who lives in Berlin?", "is_impossible": false}]}]}, {"title": "test2", "paragraphs": [{"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "thus is another test .", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another mathematical context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "this is another test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}, {"context": "there is dynamic test context", "qas": [{"answers": [], "id": -5782547119306399562, "question": "The model can't answer this", "is_impossible": false}]}]}]}
\ No newline at end of file
diff --git a/tutorials/Tutorial10_Knowledge_Graph.ipynb b/tutorials/Tutorial10_Knowledge_Graph.ipynb
index e40e04d00c..507ab40adf 100644
--- a/tutorials/Tutorial10_Knowledge_Graph.ipynb
+++ b/tutorials/Tutorial10_Knowledge_Graph.ipynb
@@ -39,6 +39,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,inmemorygraph]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial10_Knowledge_Graph.py b/tutorials/Tutorial10_Knowledge_Graph.py
index ebc696561d..70ab063b83 100644
--- a/tutorials/Tutorial10_Knowledge_Graph.py
+++ b/tutorials/Tutorial10_Knowledge_Graph.py
@@ -1,5 +1,13 @@
-import os
import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
+import os
import subprocess
import time
from pathlib import Path
@@ -8,8 +16,6 @@
from haystack.document_stores import GraphDBKnowledgeGraph, InMemoryKnowledgeGraph
from haystack.utils import fetch_archive_from_http
-logger = logging.getLogger(__name__)
-
def tutorial10_knowledge_graph():
# Let's first fetch some triples that we want to store in our knowledge graph
@@ -34,7 +40,7 @@ def tutorial10_knowledge_graph():
print(f"The last triple stored in the knowledge graph is: {kg.get_all_triples()[-1]}")
print(f"There are {len(kg.get_all_triples())} triples stored in the knowledge graph.")
- # ALTERNATIVE PATH USING GraphDB as knowledge graph
+ # ALTERNATIVE PATH USING GraphDB as knowledge graph
# LAUNCH_GRAPHDB = os.environ.get("LAUNCH_GRAPHDB", True)
# # Start a GraphDB server
# if LAUNCH_GRAPHDB:
diff --git a/tutorials/Tutorial11_Pipelines.ipynb b/tutorials/Tutorial11_Pipelines.ipynb
index 6e7fa8f55e..692be31501 100644
--- a/tutorials/Tutorial11_Pipelines.ipynb
+++ b/tutorials/Tutorial11_Pipelines.ipynb
@@ -90,6 +90,40 @@
"!pip install pygraphviz"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/tutorials/Tutorial11_Pipelines.py b/tutorials/Tutorial11_Pipelines.py
index 994f203cf9..78078c3dfc 100644
--- a/tutorials/Tutorial11_Pipelines.py
+++ b/tutorials/Tutorial11_Pipelines.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.utils import (
clean_wiki_text,
print_answers,
diff --git a/tutorials/Tutorial12_LFQA.ipynb b/tutorials/Tutorial12_LFQA.ipynb
index a11dc9aa06..ee4a2dc6bf 100644
--- a/tutorials/Tutorial12_LFQA.ipynb
+++ b/tutorials/Tutorial12_LFQA.ipynb
@@ -56,6 +56,40 @@
"!pip install -q git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial12_LFQA.py b/tutorials/Tutorial12_LFQA.py
index 1a9724bc41..e14c21e87d 100644
--- a/tutorials/Tutorial12_LFQA.py
+++ b/tutorials/Tutorial12_LFQA.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.utils import convert_files_to_docs, fetch_archive_from_http, clean_wiki_text
from haystack.nodes import Seq2SeqGenerator
diff --git a/tutorials/Tutorial13_Question_generation.ipynb b/tutorials/Tutorial13_Question_generation.ipynb
index a7dc74e03e..9868de1c3d 100644
--- a/tutorials/Tutorial13_Question_generation.ipynb
+++ b/tutorials/Tutorial13_Question_generation.ipynb
@@ -54,6 +54,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial13_Question_generation.py b/tutorials/Tutorial13_Question_generation.py
index cd2e102618..cea723ebf1 100644
--- a/tutorials/Tutorial13_Question_generation.py
+++ b/tutorials/Tutorial13_Question_generation.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from tqdm import tqdm
from haystack.nodes import QuestionGenerator, BM25Retriever, FARMReader, TransformersTranslator
from haystack.document_stores import ElasticsearchDocumentStore
diff --git a/tutorials/Tutorial14_Query_Classifier.ipynb b/tutorials/Tutorial14_Query_Classifier.ipynb
index 8d72e4491e..17f1430264 100644
--- a/tutorials/Tutorial14_Query_Classifier.ipynb
+++ b/tutorials/Tutorial14_Query_Classifier.ipynb
@@ -89,6 +89,40 @@
"!pip install pygraphviz"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/tutorials/Tutorial14_Query_Classifier.py b/tutorials/Tutorial14_Query_Classifier.py
index 615a561bc3..30f360a18b 100644
--- a/tutorials/Tutorial14_Query_Classifier.py
+++ b/tutorials/Tutorial14_Query_Classifier.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.utils import (
fetch_archive_from_http,
convert_files_to_docs,
diff --git a/tutorials/Tutorial15_TableQA.ipynb b/tutorials/Tutorial15_TableQA.ipynb
index dcea18bc68..5b46e830a6 100644
--- a/tutorials/Tutorial15_TableQA.ipynb
+++ b/tutorials/Tutorial15_TableQA.ipynb
@@ -39,6 +39,40 @@
"!nvidia-smi"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -3303,7 +3337,10 @@
"metadata": {},
"source": [
"## Adding tables from PDFs\n",
- "It can sometimes be hard to provide your data in form of a pandas DataFrame. For this case, we provide the `ParsrConverter` wrapper that can help you to convert, for example, a PDF file into a document that you can index."
+ "It can sometimes be hard to provide your data in form of a pandas DataFrame. For this case, we provide the `ParsrConverter` wrapper that can help you to convert, for example, a PDF file into a document that you can index.\n",
+ "\n",
+ "**Attention: `parsr` needs a docker environment for execution, but Colab doesn't support docker.**\n",
+ "**If you have a local docker environment, you can uncomment and run the following cells.**"
]
},
{
@@ -3312,10 +3349,10 @@
"metadata": {},
"outputs": [],
"source": [
- "import time\n",
+ "# import time\n",
"\n",
- "!docker run -d -p 3001:3001 axarev/parsr\n",
- "time.sleep(30)"
+ "# !docker run -d -p 3001:3001 axarev/parsr\n",
+ "# time.sleep(30)"
]
},
{
@@ -3324,7 +3361,7 @@
"metadata": {},
"outputs": [],
"source": [
- "!wget https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf"
+ "# !wget https://www.w3.org/WAI/WCAG21/working-examples/pdf-table/table.pdf"
]
},
{
@@ -3333,13 +3370,13 @@
"metadata": {},
"outputs": [],
"source": [
- "from haystack.nodes import ParsrConverter\n",
+ "# from haystack.nodes import ParsrConverter\n",
"\n",
- "converter = ParsrConverter()\n",
+ "# converter = ParsrConverter()\n",
"\n",
- "docs = converter.convert(\"table.pdf\")\n",
+ "# docs = converter.convert(\"table.pdf\")\n",
"\n",
- "tables = [doc for doc in docs if doc.content_type == \"table\"]"
+ "# tables = [doc for doc in docs if doc.content_type == \"table\"]"
]
},
{
@@ -3356,7 +3393,7 @@
}
],
"source": [
- "print(tables)"
+ "# print(tables)"
]
},
{
@@ -3409,4 +3446,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
diff --git a/tutorials/Tutorial15_TableQA.py b/tutorials/Tutorial15_TableQA.py
index c22717f6a0..94b8720d3c 100644
--- a/tutorials/Tutorial15_TableQA.py
+++ b/tutorials/Tutorial15_TableQA.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
import os
import json
import time
diff --git a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb
index ca8baee532..37adfd6085 100644
--- a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb
+++ b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.ipynb
@@ -56,6 +56,40 @@
"!pip install pygraphviz"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": 1,
diff --git a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py
index 74613dcd32..6660371a53 100644
--- a/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py
+++ b/tutorials/Tutorial16_Document_Classifier_at_Index_Time.py
@@ -18,9 +18,17 @@
# Here are the imports we need
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores.elasticsearch import ElasticsearchDocumentStore
from haystack.nodes import PreProcessor, TransformersDocumentClassifier, FARMReader, BM25Retriever
-from haystack.schema import Document
from haystack.utils import convert_files_to_docs, fetch_archive_from_http, print_answers, launch_es
diff --git a/tutorials/Tutorial17_Audio.ipynb b/tutorials/Tutorial17_Audio.ipynb
index 23f3590ea1..460e29c96c 100644
--- a/tutorials/Tutorial17_Audio.ipynb
+++ b/tutorials/Tutorial17_Audio.ipynb
@@ -64,6 +64,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,audio]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/tutorials/Tutorial17_Audio.py b/tutorials/Tutorial17_Audio.py
index 71f7edbd3b..7d04970bce 100755
--- a/tutorials/Tutorial17_Audio.py
+++ b/tutorials/Tutorial17_Audio.py
@@ -6,6 +6,15 @@
# In this tutorial, we're going to see how to use `AnswerToSpeech` to convert answers
# into audio files.
#
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.utils import fetch_archive_from_http, launch_es, print_answers
from haystack.nodes import FARMReader, BM25Retriever
diff --git a/tutorials/Tutorial18_GPL.ipynb b/tutorials/Tutorial18_GPL.ipynb
index 843b894315..d642f2de27 100644
--- a/tutorials/Tutorial18_GPL.ipynb
+++ b/tutorials/Tutorial18_GPL.ipynb
@@ -81,6 +81,40 @@
}
}
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial18_GPL.py b/tutorials/Tutorial18_GPL.py
index 0229746361..e5affe9a5f 100644
--- a/tutorials/Tutorial18_GPL.py
+++ b/tutorials/Tutorial18_GPL.py
@@ -37,6 +37,15 @@
- 94.13 HIV is transmitted via sex or sharing needles
"""
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from sentence_transformers import SentenceTransformer, util
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from datasets import load_dataset
diff --git a/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb b/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb
index 5d442a3dc7..2b145a5b8f 100644
--- a/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb
+++ b/tutorials/Tutorial1_Basic_QA_Pipeline.ipynb
@@ -63,15 +63,54 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
"outputs": [],
"source": [
"from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers\n",
"from haystack.nodes import FARMReader, TransformersReader"
- ]
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
},
{
"cell_type": "markdown",
diff --git a/tutorials/Tutorial1_Basic_QA_Pipeline.py b/tutorials/Tutorial1_Basic_QA_Pipeline.py
index e666921738..f6f5b58c62 100755
--- a/tutorials/Tutorial1_Basic_QA_Pipeline.py
+++ b/tutorials/Tutorial1_Basic_QA_Pipeline.py
@@ -10,14 +10,20 @@
# marvellous seven kingdoms.
import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers, launch_es
from haystack.nodes import FARMReader, TransformersReader, BM25Retriever
def tutorial1_basic_qa_pipeline():
- logger = logging.getLogger(__name__)
-
# ## Document Store
#
# Haystack finds answers to queries within the documents stored in a `DocumentStore`. The current implementations of
diff --git a/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb b/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb
index 5b457c54e3..a67ae56f2d 100644
--- a/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb
+++ b/tutorials/Tutorial2_Finetune_a_model_on_your_data.ipynb
@@ -59,20 +59,54 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
"metadata": {
"collapsed": false,
"pycharm": {
"name": "#%%\n"
}
- },
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
"outputs": [],
"source": [
"from haystack.nodes import FARMReader\n",
"from haystack.utils import fetch_archive_from_http"
- ]
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
},
{
"cell_type": "markdown",
diff --git a/tutorials/Tutorial2_Finetune_a_model_on_your_data.py b/tutorials/Tutorial2_Finetune_a_model_on_your_data.py
index a110078f33..7f90a31eed 100755
--- a/tutorials/Tutorial2_Finetune_a_model_on_your_data.py
+++ b/tutorials/Tutorial2_Finetune_a_model_on_your_data.py
@@ -7,6 +7,15 @@
#
# This tutorial shows you how to fine-tune a pretrained model on your own dataset.
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.nodes import FARMReader
from haystack.utils import augment_squad, fetch_archive_from_http
diff --git a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb
index 316d587e28..b079778b27 100644
--- a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb
+++ b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.ipynb
@@ -59,6 +59,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": 3,
diff --git a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py
index d37fc130ef..84ebbbf90a 100644
--- a/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py
+++ b/tutorials/Tutorial3_Basic_QA_Pipeline_without_Elasticsearch.py
@@ -6,6 +6,15 @@
#
# If you are interested in more feature-rich Elasticsearch, then please refer to the Tutorial 1.
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import InMemoryDocumentStore, SQLDocumentStore
from haystack.nodes import FARMReader, TransformersReader, TfidfRetriever
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers
diff --git a/tutorials/Tutorial4_FAQ_style_QA.ipynb b/tutorials/Tutorial4_FAQ_style_QA.ipynb
index d24aaecddf..c78bd5ff10 100644
--- a/tutorials/Tutorial4_FAQ_style_QA.ipynb
+++ b/tutorials/Tutorial4_FAQ_style_QA.ipynb
@@ -67,6 +67,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -80,8 +114,7 @@
"from haystack.document_stores import ElasticsearchDocumentStore\n",
"\n",
"from haystack.nodes import EmbeddingRetriever\n",
- "import pandas as pd\n",
- "import requests"
+ "import pandas as pd"
]
},
{
diff --git a/tutorials/Tutorial4_FAQ_style_QA.py b/tutorials/Tutorial4_FAQ_style_QA.py
index 2d3b416b1c..8bcc719975 100755
--- a/tutorials/Tutorial4_FAQ_style_QA.py
+++ b/tutorials/Tutorial4_FAQ_style_QA.py
@@ -1,12 +1,17 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.nodes import EmbeddingRetriever
from haystack.utils import launch_es, print_answers, fetch_archive_from_http
import pandas as pd
-import requests
-import logging
-import subprocess
-import time
def tutorial4_faq_style_qa():
diff --git a/tutorials/Tutorial5_Evaluation.ipynb b/tutorials/Tutorial5_Evaluation.ipynb
index 65b377a617..095c4b8b1c 100644
--- a/tutorials/Tutorial5_Evaluation.ipynb
+++ b/tutorials/Tutorial5_Evaluation.ipynb
@@ -75,6 +75,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/tutorials/Tutorial5_Evaluation.py b/tutorials/Tutorial5_Evaluation.py
index 9e5e729543..24acfff195 100644
--- a/tutorials/Tutorial5_Evaluation.py
+++ b/tutorials/Tutorial5_Evaluation.py
@@ -1,4 +1,12 @@
import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
import tempfile
from pathlib import Path
@@ -16,9 +24,6 @@
from haystack.schema import Answer, Document, EvaluationResult, Label, MultiLabel, Span
-logger = logging.getLogger(__name__)
-
-
def tutorial5_evaluation():
# make sure these indices do not collide with existing ones, the indices will be wiped clean before data is inserted
diff --git a/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb b/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb
deleted file mode 100644
index 2989bfc8c7..0000000000
--- a/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb
+++ /dev/null
@@ -1,2761 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "bEH-CRbeA6NU"
- },
- "source": [
- "# Better Retrieval via \"Dense Passage Retrieval\"\n",
- "\n",
- "[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb)\n",
- "\n",
- "### Importance of Retrievers\n",
- "\n",
- "The Retriever has a huge impact on the performance of our overall search pipeline.\n",
- "\n",
- "\n",
- "### Different types of Retrievers\n",
- "#### Sparse\n",
- "Family of algorithms based on counting the occurrences of words (bag-of-words) resulting in very sparse vectors with length = vocab size.\n",
- "\n",
- "**Examples**: BM25, TF-IDF\n",
- "\n",
- "**Pros**: Simple, fast, well explainable\n",
- "\n",
- "**Cons**: Relies on exact keyword matches between query and text\n",
- " \n",
- "\n",
- "#### Dense\n",
- "These retrievers use neural network models to create \"dense\" embedding vectors. Within this family there are two different approaches: \n",
- "\n",
- "a) Single encoder: Use a **single model** to embed both query and passage. \n",
- "b) Dual-encoder: Use **two models**, one to embed the query and one to embed the passage\n",
- "\n",
- "Recent work suggests that dual encoders work better, likely because they can deal better with the different nature of query and passage (length, style, syntax ...). \n",
- "\n",
- "**Examples**: REALM, DPR, Sentence-Transformers\n",
- "\n",
- "**Pros**: Captures semantinc similarity instead of \"word matches\" (e.g. synonyms, related topics ...)\n",
- "\n",
- "**Cons**: Computationally more heavy, initial training of model\n",
- "\n",
- "\n",
- "### \"Dense Passage Retrieval\"\n",
- "\n",
- "In this Tutorial, we want to highlight one \"Dense Dual-Encoder\" called Dense Passage Retriever. \n",
- "It was introduced by Karpukhin et al. (2020, https://arxiv.org/abs/2004.04906. \n",
- "\n",
- "Original Abstract: \n",
- "\n",
- "_\"Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.\"_\n",
- "\n",
- "Paper: https://arxiv.org/abs/2004.04906 \n",
- "Original Code: https://fburl.com/qa-dpr \n",
- "\n",
- "\n",
- "*Use this* [link](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb) *to open the notebook in Google Colab.*\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "3K27Y5FbA6NV"
- },
- "source": [
- "### Prepare environment\n",
- "\n",
- "#### Colab: Enable the GPU runtime\n",
- "Make sure you enable the GPU runtime to experience decent speed in this tutorial. \n",
- "**Runtime -> Change Runtime type -> Hardware accelerator -> GPU**\n",
- "\n",
- " "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 357
- },
- "colab_type": "code",
- "id": "JlZgP8q1A6NW",
- "outputId": "c893ac99-b7a0-4d49-a8eb-1a9951d364d9"
- },
- "outputs": [],
- "source": [
- "# Make sure you have a GPU running\n",
- "!nvidia-smi"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000
- },
- "colab_type": "code",
- "id": "NM36kbRFA6Nc",
- "outputId": "af1a9d85-9557-4d68-ea87-a01f00c584f9"
- },
- "outputs": [],
- "source": [
- "# Install the latest release of Haystack in your own environment\n",
- "#! pip install farm-haystack\n",
- "\n",
- "# Install the latest master of Haystack\n",
- "!pip install --upgrade pip\n",
- "!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "xmRuhTQ7A6Nh"
- },
- "outputs": [],
- "source": [
- "from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers\n",
- "from haystack.nodes import FARMReader, TransformersReader"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "q3dSo7ZtA6Nl"
- },
- "source": [
- "### Document Store\n",
- "\n",
- "#### Option 1: FAISS\n",
- "\n",
- "FAISS is a library for efficient similarity search on a cluster of dense vectors.\n",
- "The `FAISSDocumentStore` uses a SQL(SQLite in-memory be default) database under-the-hood\n",
- "to store the document text and other meta data. The vector embeddings of the text are\n",
- "indexed on a FAISS Index that later is queried for searching answers.\n",
- "The default flavour of FAISSDocumentStore is \"Flat\" but can also be set to \"HNSW\" for\n",
- "faster search at the expense of some accuracy. Just set the faiss_index_factor_str argument in the constructor.\n",
- "For more info on which suits your use case: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 51
- },
- "colab_type": "code",
- "id": "1cYgDJmrA6Nv",
- "outputId": "a8aa6da1-9acf-43b1-fa3c-200123e9bdce",
- "pycharm": {
- "name": "#%%\n"
- }
- },
- "outputs": [],
- "source": [
- "from haystack.document_stores import FAISSDocumentStore\n",
- "\n",
- "document_store = FAISSDocumentStore(faiss_index_factory_str=\"Flat\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%% md\n"
- }
- },
- "source": [
- "#### Option 2: Milvus\n",
- "\n",
- "Milvus is an open source database library that is also optimized for vector similarity searches like FAISS.\n",
- "Like FAISS it has both a \"Flat\" and \"HNSW\" mode but it outperforms FAISS when it comes to dynamic data management.\n",
- "It does require a little more setup, however, as it is run through Docker and requires the setup of some config files.\n",
- "See [their docs](https://milvus.io/docs/v1.0.0/milvus_docker-cpu.md) for more details."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- },
- "outputs": [],
- "source": [
- "# Milvus cannot be run on COlab, so this cell is commented out.\n",
- "# To run Milvus you need Docker (versions below 2.0.0) or a docker-compose (versions >= 2.0.0), neither of which is available on Colab.\n",
- "# See Milvus' documentation for more details: https://milvus.io/docs/install_standalone-docker.md\n",
- "\n",
- "# !pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[milvus]\n",
- "\n",
- "# from haystack.utils import launch_milvus\n",
- "# from haystack.document_stores import MilvusDocumentStore\n",
- "\n",
- "# launch_milvus()\n",
- "# document_store = MilvusDocumentStore()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "06LatTJBA6N0",
- "pycharm": {
- "name": "#%% md\n"
- }
- },
- "source": [
- "### Cleaning & indexing documents\n",
- "\n",
- "Similarly to the previous tutorials, we download, convert and index some Game of Thrones articles to our DocumentStore"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 156
- },
- "colab_type": "code",
- "id": "iqKnu6wxA6N1",
- "outputId": "bb5dcc7b-b65f-49ed-db0b-842981af213b",
- "pycharm": {
- "name": "#%%\n"
- }
- },
- "outputs": [],
- "source": [
- "# Let's first get some files that we want to use\n",
- "doc_dir = \"data/tutorial6\"\n",
- "s3_url = \"https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt6.zip\"\n",
- "fetch_archive_from_http(url=s3_url, output_dir=doc_dir)\n",
- "\n",
- "# Convert files to dicts\n",
- "docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)\n",
- "\n",
- "# Now, let's write the dicts containing documents to our DB.\n",
- "document_store.write_documents(docs)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "wgjedxx_A6N6"
- },
- "source": [
- "### Initialize Retriever, Reader & Pipeline\n",
- "\n",
- "#### Retriever\n",
- "\n",
- "**Here:** We use a `DensePassageRetriever`\n",
- "\n",
- "**Alternatives:**\n",
- "\n",
- "- The `BM25Retriever`with custom queries (e.g. boosting) and filters\n",
- "- Use `EmbeddingRetriever` to find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT)\n",
- "- Use `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000,
- "referenced_widgets": [
- "20affb86c4574e3a9829136fdfe40470",
- "7f8c2c86bbb74a18ac8bd24046d99d34",
- "84311c037c6e44b5b621237f59f027a0",
- "05d793fc179746e9b74cbcbc1a3389eb",
- "ad2ce6a8b4f844ac93b425f1261c131f",
- "bb45d5e4c9944fcd87b408e2fbfea440",
- "248d02e01dea4a63a3296e28e4537eaf",
- "74a9c43eb61a43aa973194b0b70e18f5",
- "58fc3339f13644aea1d4c6d8e1d43a65",
- "460bef2bfa7d4aa480639095555577ac",
- "8553a48fb3144739b99fa04adf8b407c",
- "babe35bb292f4010b64104b2b5bc92af",
- "887412c45ce744efbcc875b563770c29",
- "b4b950d899df4e3fbed9255b281e988a",
- "89535c589aa64648b82a9794a2888e78",
- "f35430501bb14fba8dbd5fb797c2e509",
- "eb5d93a8416a437e9cb039650756ac74",
- "5b8d5975d2674e7e9ada64e77c463c0a",
- "4afa2be1c2c5483f932a42ea4a7897af",
- "0e7186eeb5fa47d89c8c111ebe43c5af",
- "fa946133dfcc4a6ebc6fef2ef9dd92f7",
- "518b6a993e42490297289f2328d0270a",
- "cea074a636d34a75b311569fc3f0b3ab",
- "2630fd2fa91d498796af6d7d8d73aba4"
- ]
- },
- "colab_type": "code",
- "id": "kFwiPP60A6N7",
- "outputId": "07249856-3222-4898-9246-68e9ecbf5a1b",
- "pycharm": {
- "is_executing": true
- }
- },
- "outputs": [],
- "source": [
- "from haystack.nodes import DensePassageRetriever\n",
- "\n",
- "retriever = DensePassageRetriever(\n",
- " document_store=document_store,\n",
- " query_embedding_model=\"facebook/dpr-question_encoder-single-nq-base\",\n",
- " passage_embedding_model=\"facebook/dpr-ctx_encoder-single-nq-base\",\n",
- " max_seq_len_query=64,\n",
- " max_seq_len_passage=256,\n",
- " batch_size=16,\n",
- " use_gpu=True,\n",
- " embed_title=True,\n",
- " use_fast_tokenizers=True,\n",
- ")\n",
- "# Important:\n",
- "# Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all\n",
- "# previously indexed documents and update their embedding representation.\n",
- "# While this can be a time consuming operation (depending on corpus size), it only needs to be done once.\n",
- "# At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.\n",
- "document_store.update_embeddings(retriever)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "rnVR28OXA6OA"
- },
- "source": [
- "#### Reader\n",
- "\n",
- "Similar to previous Tutorials we now initalize our reader.\n",
- "\n",
- "Here we use a FARMReader with the *deepset/roberta-base-squad2* model (see: https://huggingface.co/deepset/roberta-base-squad2)\n",
- "\n",
- "\n",
- "\n",
- "##### FARMReader"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 739,
- "referenced_widgets": [
- "3d273d2d3b25435ba4eb4ffd8e812b6f",
- "5104b7cddf6d4d0f92d3dd142b9f4c42",
- "e0510255a31d448497af3ca0f4915cb4",
- "670270fd06274932adad4d42c8a1912e",
- "6ca292cd3f46417ea296684e48863af9",
- "75578e0466cd4b84ba7dfee1028ae4cd",
- "cbe09b984b804402b1fe82739cbc375c",
- "4fd0caca56bd415b8c31860ba542145a",
- "9960be4cc1c64905917b5fd7ea6bb294",
- "2f3d901b3acb4841a4b03b2c5cd4393b",
- "04644b74bb2a45a7a6fcf86151b5bf8c",
- "5efa895c53284b72adec629a6fc59fa9",
- "182e5db14fac427b90380b5213f57825",
- "243600e420f449089c1b5ed0d2715339",
- "466222c8b2e1403ca69c8130423f0a8b",
- "a458be4cc49240e4b9bc1c95c05551e8",
- "d9ee08fa621d4b558bd1a415e3ee6f62",
- "1b905c5551b940ed9bc5320e1e5a9213",
- "64fc7775a84e425c8082a545f7c2a0c1",
- "66cd72dae82d434a87b638236784fd4b",
- "36b1b48aea02494a8bc94020a15d7417",
- "5934bc4db2a94c20b5c55f1c017024ab",
- "f9289caeac404087ad4973a646e3a117",
- "7e121f0fdb1746c094bff218a4f623ab",
- "98781635b86244aca5d22be4280c32de",
- "e148b28d946549a9b5eb09294ebe124e",
- "4b8b29c1b1a243808de4cc1cae3f6bd6",
- "bbef597f804e4ca580aee665399a3bc1",
- "345f49b2b42c40278478d30e8a691768",
- "e3724385769d443cb4ea39b92e0b2abd",
- "d05fbb94014840cab4584c4781a590c1",
- "b8d52b604dad43c18ba00c935b961422",
- "e625a32fc81b42fb9e0fff7ce766fcdc",
- "885390f24e08495db6a1febd661531e0",
- "c2a614f48e974fb8b13a3c5d7cafaed6",
- "ada8fa1c88954ef8b839f29090de9e79",
- "427b07b356e44c68b47178b277aaa16f",
- "1b4166bda5ae48aa8539e0fa5521007a",
- "fd30d43909874239b2183c5fb61241fe",
- "09a647660cf94131a1c140d06eb293ab",
- "3e482e9ef4d34d93b4ba4f7f07b0e44f",
- "66450cab654d40ae8ed1c32fa733397a",
- "aa4becf2e33d4f1e9fdac70236d48f6e",
- "78d087ed952e429b97eb3d8fcdc7c8ec",
- "5020846874ae473bbfa7038fe98de474",
- "08c736f4ad424330a82df1b5dc047b2c",
- "9169ca606bf64d41aa08fb42876bd2ab",
- "c8f1f7e8462d4d14a507816f67953eae"
- ]
- },
- "colab_type": "code",
- "id": "fyIuWVwhA6OB",
- "outputId": "33113253-8b95-4604-f9e5-1aa28ee66a91"
- },
- "outputs": [],
- "source": [
- "# Load a local model or any of the QA models on\n",
- "# Hugging Face's model hub (https://huggingface.co/models)\n",
- "\n",
- "reader = FARMReader(model_name_or_path=\"deepset/roberta-base-squad2\", use_gpu=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "unhLD18yA6OF"
- },
- "source": [
- "### Pipeline\n",
- "\n",
- "With a Haystack `Pipeline` you can stick together your building blocks to a search pipeline.\n",
- "Under the hood, `Pipelines` are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.\n",
- "To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the `ExtractiveQAPipeline` that combines a retriever and a reader to answer our questions.\n",
- "You can learn more about `Pipelines` in the [docs](https://haystack.deepset.ai/docs/latest/pipelinesmd)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "TssPQyzWA6OG"
- },
- "outputs": [],
- "source": [
- "from haystack.pipelines import ExtractiveQAPipeline\n",
- "\n",
- "pipe = ExtractiveQAPipeline(reader, retriever)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "bXlBBxKXA6OL"
- },
- "source": [
- "## Voilà! Ask a question!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 275
- },
- "colab_type": "code",
- "id": "Zi97Hif2A6OM",
- "outputId": "5eb9363d-ba92-45d5-c4d0-63ada3073f02"
- },
- "outputs": [],
- "source": [
- "# You can configure how many candidates the reader and retriever shall return\n",
- "# The higher top_k for retriever, the better (but also the slower) your answers.\n",
- "prediction = pipe.run(\n",
- " query=\"Who created the Dothraki vocabulary?\", params={\"Retriever\": {\"top_k\": 10}, \"Reader\": {\"top_k\": 5}}\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "print_answers(prediction, details=\"minimum\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "collapsed": false
- },
- "source": [
- "## About us\n",
- "\n",
- "This [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany\n",
- "\n",
- "We bring NLP to the industry via open source! \n",
- "Our focus: Industry specific language models & large scale QA systems. \n",
- " \n",
- "Some of our other work: \n",
- "- [German BERT](https://deepset.ai/german-bert)\n",
- "- [GermanQuAD and GermanDPR](https://deepset.ai/germanquad)\n",
- "- [FARM](https://github.com/deepset-ai/FARM)\n",
- "\n",
- "Get in touch:\n",
- "[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)\n",
- "\n",
- "By the way: [we're hiring!](https://www.deepset.ai/jobs)"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [],
- "name": "Tutorial6_Better_Retrieval_via_DPR.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.6.9"
- },
- "widgets": {
- "application/vnd.jupyter.widget-state+json": {
- "04644b74bb2a45a7a6fcf86151b5bf8c": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_243600e420f449089c1b5ed0d2715339",
- "max": 498637366,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_182e5db14fac427b90380b5213f57825",
- "value": 498637366
- }
- },
- "05d793fc179746e9b74cbcbc1a3389eb": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_74a9c43eb61a43aa973194b0b70e18f5",
- "placeholder": "",
- "style": "IPY_MODEL_248d02e01dea4a63a3296e28e4537eaf",
- "value": " 232k/232k [00:00<00:00, 628kB/s]"
- }
- },
- "08c736f4ad424330a82df1b5dc047b2c": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "09a647660cf94131a1c140d06eb293ab": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "0e7186eeb5fa47d89c8c111ebe43c5af": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_2630fd2fa91d498796af6d7d8d73aba4",
- "placeholder": "",
- "style": "IPY_MODEL_cea074a636d34a75b311569fc3f0b3ab",
- "value": " 438M/438M [00:13<00:00, 31.7MB/s]"
- }
- },
- "182e5db14fac427b90380b5213f57825": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "1b4166bda5ae48aa8539e0fa5521007a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1b905c5551b940ed9bc5320e1e5a9213": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "20affb86c4574e3a9829136fdfe40470": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_84311c037c6e44b5b621237f59f027a0",
- "IPY_MODEL_05d793fc179746e9b74cbcbc1a3389eb"
- ],
- "layout": "IPY_MODEL_7f8c2c86bbb74a18ac8bd24046d99d34"
- }
- },
- "243600e420f449089c1b5ed0d2715339": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "248d02e01dea4a63a3296e28e4537eaf": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "2630fd2fa91d498796af6d7d8d73aba4": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "2f3d901b3acb4841a4b03b2c5cd4393b": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "345f49b2b42c40278478d30e8a691768": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "36b1b48aea02494a8bc94020a15d7417": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "3d273d2d3b25435ba4eb4ffd8e812b6f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_e0510255a31d448497af3ca0f4915cb4",
- "IPY_MODEL_670270fd06274932adad4d42c8a1912e"
- ],
- "layout": "IPY_MODEL_5104b7cddf6d4d0f92d3dd142b9f4c42"
- }
- },
- "3e482e9ef4d34d93b4ba4f7f07b0e44f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_aa4becf2e33d4f1e9fdac70236d48f6e",
- "IPY_MODEL_78d087ed952e429b97eb3d8fcdc7c8ec"
- ],
- "layout": "IPY_MODEL_66450cab654d40ae8ed1c32fa733397a"
- }
- },
- "427b07b356e44c68b47178b277aaa16f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "460bef2bfa7d4aa480639095555577ac": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "466222c8b2e1403ca69c8130423f0a8b": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "4afa2be1c2c5483f932a42ea4a7897af": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_518b6a993e42490297289f2328d0270a",
- "max": 437983985,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_fa946133dfcc4a6ebc6fef2ef9dd92f7",
- "value": 437983985
- }
- },
- "4b8b29c1b1a243808de4cc1cae3f6bd6": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_e3724385769d443cb4ea39b92e0b2abd",
- "max": 456318,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_345f49b2b42c40278478d30e8a691768",
- "value": 456318
- }
- },
- "4fd0caca56bd415b8c31860ba542145a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5020846874ae473bbfa7038fe98de474": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "5104b7cddf6d4d0f92d3dd142b9f4c42": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "518b6a993e42490297289f2328d0270a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "58fc3339f13644aea1d4c6d8e1d43a65": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_8553a48fb3144739b99fa04adf8b407c",
- "IPY_MODEL_babe35bb292f4010b64104b2b5bc92af"
- ],
- "layout": "IPY_MODEL_460bef2bfa7d4aa480639095555577ac"
- }
- },
- "5934bc4db2a94c20b5c55f1c017024ab": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5b8d5975d2674e7e9ada64e77c463c0a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5efa895c53284b72adec629a6fc59fa9": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_a458be4cc49240e4b9bc1c95c05551e8",
- "placeholder": "",
- "style": "IPY_MODEL_466222c8b2e1403ca69c8130423f0a8b",
- "value": " 499M/499M [00:23<00:00, 21.1MB/s]"
- }
- },
- "64fc7775a84e425c8082a545f7c2a0c1": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_5934bc4db2a94c20b5c55f1c017024ab",
- "max": 898822,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_36b1b48aea02494a8bc94020a15d7417",
- "value": 898822
- }
- },
- "66450cab654d40ae8ed1c32fa733397a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "66cd72dae82d434a87b638236784fd4b": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_7e121f0fdb1746c094bff218a4f623ab",
- "placeholder": "",
- "style": "IPY_MODEL_f9289caeac404087ad4973a646e3a117",
- "value": " 899k/899k [00:01<00:00, 684kB/s]"
- }
- },
- "670270fd06274932adad4d42c8a1912e": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_4fd0caca56bd415b8c31860ba542145a",
- "placeholder": "",
- "style": "IPY_MODEL_cbe09b984b804402b1fe82739cbc375c",
- "value": " 559/559 [00:00<00:00, 2.78kB/s]"
- }
- },
- "6ca292cd3f46417ea296684e48863af9": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "74a9c43eb61a43aa973194b0b70e18f5": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "75578e0466cd4b84ba7dfee1028ae4cd": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "78d087ed952e429b97eb3d8fcdc7c8ec": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_c8f1f7e8462d4d14a507816f67953eae",
- "placeholder": "",
- "style": "IPY_MODEL_9169ca606bf64d41aa08fb42876bd2ab",
- "value": " 189/189 [00:00<00:00, 409B/s]"
- }
- },
- "7e121f0fdb1746c094bff218a4f623ab": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "7f8c2c86bbb74a18ac8bd24046d99d34": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "84311c037c6e44b5b621237f59f027a0": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_bb45d5e4c9944fcd87b408e2fbfea440",
- "max": 231508,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ad2ce6a8b4f844ac93b425f1261c131f",
- "value": 231508
- }
- },
- "8553a48fb3144739b99fa04adf8b407c": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_b4b950d899df4e3fbed9255b281e988a",
- "max": 437986065,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_887412c45ce744efbcc875b563770c29",
- "value": 437986065
- }
- },
- "885390f24e08495db6a1febd661531e0": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "887412c45ce744efbcc875b563770c29": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "89535c589aa64648b82a9794a2888e78": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "9169ca606bf64d41aa08fb42876bd2ab": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "98781635b86244aca5d22be4280c32de": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_4b8b29c1b1a243808de4cc1cae3f6bd6",
- "IPY_MODEL_bbef597f804e4ca580aee665399a3bc1"
- ],
- "layout": "IPY_MODEL_e148b28d946549a9b5eb09294ebe124e"
- }
- },
- "9960be4cc1c64905917b5fd7ea6bb294": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_04644b74bb2a45a7a6fcf86151b5bf8c",
- "IPY_MODEL_5efa895c53284b72adec629a6fc59fa9"
- ],
- "layout": "IPY_MODEL_2f3d901b3acb4841a4b03b2c5cd4393b"
- }
- },
- "a458be4cc49240e4b9bc1c95c05551e8": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "aa4becf2e33d4f1e9fdac70236d48f6e": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_08c736f4ad424330a82df1b5dc047b2c",
- "max": 189,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_5020846874ae473bbfa7038fe98de474",
- "value": 189
- }
- },
- "ad2ce6a8b4f844ac93b425f1261c131f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "ada8fa1c88954ef8b839f29090de9e79": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_09a647660cf94131a1c140d06eb293ab",
- "placeholder": "",
- "style": "IPY_MODEL_fd30d43909874239b2183c5fb61241fe",
- "value": " 150/150 [00:01<00:00, 119B/s]"
- }
- },
- "b4b950d899df4e3fbed9255b281e988a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "b8d52b604dad43c18ba00c935b961422": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "babe35bb292f4010b64104b2b5bc92af": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_f35430501bb14fba8dbd5fb797c2e509",
- "placeholder": "",
- "style": "IPY_MODEL_89535c589aa64648b82a9794a2888e78",
- "value": " 438M/438M [00:13<00:00, 32.3MB/s]"
- }
- },
- "bb45d5e4c9944fcd87b408e2fbfea440": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "bbef597f804e4ca580aee665399a3bc1": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_b8d52b604dad43c18ba00c935b961422",
- "placeholder": "",
- "style": "IPY_MODEL_d05fbb94014840cab4584c4781a590c1",
- "value": " 456k/456k [00:02<00:00, 166kB/s]"
- }
- },
- "c2a614f48e974fb8b13a3c5d7cafaed6": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_1b4166bda5ae48aa8539e0fa5521007a",
- "max": 150,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_427b07b356e44c68b47178b277aaa16f",
- "value": 150
- }
- },
- "c8f1f7e8462d4d14a507816f67953eae": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "cbe09b984b804402b1fe82739cbc375c": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "cea074a636d34a75b311569fc3f0b3ab": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "d05fbb94014840cab4584c4781a590c1": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "d9ee08fa621d4b558bd1a415e3ee6f62": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_64fc7775a84e425c8082a545f7c2a0c1",
- "IPY_MODEL_66cd72dae82d434a87b638236784fd4b"
- ],
- "layout": "IPY_MODEL_1b905c5551b940ed9bc5320e1e5a9213"
- }
- },
- "e0510255a31d448497af3ca0f4915cb4": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_75578e0466cd4b84ba7dfee1028ae4cd",
- "max": 559,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_6ca292cd3f46417ea296684e48863af9",
- "value": 559
- }
- },
- "e148b28d946549a9b5eb09294ebe124e": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "e3724385769d443cb4ea39b92e0b2abd": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "e625a32fc81b42fb9e0fff7ce766fcdc": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_c2a614f48e974fb8b13a3c5d7cafaed6",
- "IPY_MODEL_ada8fa1c88954ef8b839f29090de9e79"
- ],
- "layout": "IPY_MODEL_885390f24e08495db6a1febd661531e0"
- }
- },
- "eb5d93a8416a437e9cb039650756ac74": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_4afa2be1c2c5483f932a42ea4a7897af",
- "IPY_MODEL_0e7186eeb5fa47d89c8c111ebe43c5af"
- ],
- "layout": "IPY_MODEL_5b8d5975d2674e7e9ada64e77c463c0a"
- }
- },
- "f35430501bb14fba8dbd5fb797c2e509": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f9289caeac404087ad4973a646e3a117": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "fa946133dfcc4a6ebc6fef2ef9dd92f7": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "fd30d43909874239b2183c5fb61241fe": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- }
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 1
-}
\ No newline at end of file
diff --git a/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb
new file mode 100644
index 0000000000..9c53563aa1
--- /dev/null
+++ b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb
@@ -0,0 +1,450 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bEH-CRbeA6NU"
+ },
+ "source": [
+ "# Better Retrieval via \"Embedding Retrieval\"\n",
+ "\n",
+ "[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb)\n",
+ "\n",
+ "### Importance of Retrievers\n",
+ "\n",
+ "The Retriever has a huge impact on the performance of our overall search pipeline.\n",
+ "\n",
+ "\n",
+ "### Different types of Retrievers\n",
+ "#### Sparse\n",
+ "Family of algorithms based on counting the occurrences of words (bag-of-words) resulting in very sparse vectors with length = vocab size.\n",
+ "\n",
+ "**Examples**: BM25, TF-IDF\n",
+ "\n",
+ "**Pros**: Simple, fast, well explainable\n",
+ "\n",
+ "**Cons**: Relies on exact keyword matches between query and text\n",
+ " \n",
+ "\n",
+ "#### Dense\n",
+ "These retrievers use neural network models to create \"dense\" embedding vectors. Within this family, there are two different approaches:\n",
+ "\n",
+ "a) Single encoder: Use a **single model** to embed both the query and the passage.\n",
+ "b) Dual-encoder: Use **two models**, one to embed the query and one to embed the passage.\n",
+ "\n",
+ "**Examples**: REALM, DPR, Sentence-Transformers\n",
+ "\n",
+ "**Pros**: Captures semantic similarity instead of \"word matches\" (for example, synonyms, related topics).\n",
+ "\n",
+ "**Cons**: Computationally more heavy to use, initial training of the model (though this is less of an issue nowadays as many pre-trained models are available and most of the time, it's not needed to train the model).\n",
+ "\n",
+ "\n",
+ "### Embedding Retrieval\n",
+ "\n",
+ "In this Tutorial, we use an `EmbeddingRetriever` with [Sentence Transformers](https://www.sbert.net/index.html) models.\n",
+ "\n",
+ "These models are trained to embed similar sentences close to each other in a shared embedding space.\n",
+ "\n",
+ "Some models have been fine-tuned on massive Information Retrieval data and can be used to retrieve documents based on a short query (for example, `multi-qa-mpnet-base-dot-v1`). There are others that are more suited to semantic similarity tasks where you are trying to find the most similar documents to a given document (for example, `all-mpnet-base-v2`). There are even models that are multilingual (for example, `paraphrase-multilingual-mpnet-base-v2`). For a good overview of different models with their evaluation metrics, see the [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html#) in the Sentence Transformers documentation.\n",
+ "\n",
+ "*Use this* [link](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb) *to open the notebook in Google Colab.*\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3K27Y5FbA6NV"
+ },
+ "source": [
+ "### Prepare the Environment\n",
+ "\n",
+ "#### Colab: Enable the GPU Runtime\n",
+ "Make sure you enable the GPU runtime to experience decent speed in this tutorial.\n",
+ "**Runtime -> Change Runtime type -> Hardware accelerator -> GPU**\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "JlZgP8q1A6NW"
+ },
+ "outputs": [],
+ "source": [
+ "# Make sure you have a GPU running\n",
+ "!nvidia-smi"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "NM36kbRFA6Nc"
+ },
+ "outputs": [],
+ "source": [
+ "# Install the latest release of Haystack in your own environment\n",
+ "#! pip install farm-haystack\n",
+ "\n",
+ "# Install the latest master of Haystack\n",
+ "!pip install --upgrade pip\n",
+ "!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "id": "GbM2ml-ozqLX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "id": "kQWEUUMnzqLX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xmRuhTQ7A6Nh"
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers\n",
+ "from haystack.nodes import FARMReader, TransformersReader"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "q3dSo7ZtA6Nl"
+ },
+ "source": [
+ "### Document Store\n",
+ "\n",
+ "#### Option 1: FAISS\n",
+ "\n",
+ "FAISS is a library for efficient similarity search on a cluster of dense vectors.\n",
+ "The `FAISSDocumentStore` uses a SQL(SQLite in-memory be default) database under-the-hood\n",
+ "to store the document text and other meta data. The vector embeddings of the text are\n",
+ "indexed on a FAISS Index that later is queried for searching answers.\n",
+ "The default flavour of FAISSDocumentStore is \"Flat\" but can also be set to \"HNSW\" for\n",
+ "faster search at the expense of some accuracy. Just set the faiss_index_factor_str argument in the constructor.\n",
+ "For more info on which suits your use case: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1cYgDJmrA6Nv",
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.document_stores import FAISSDocumentStore\n",
+ "\n",
+ "document_store = FAISSDocumentStore(faiss_index_factory_str=\"Flat\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "id": "s4HK5l0qzqLZ"
+ },
+ "source": [
+ "#### Option 2: Milvus\n",
+ "\n",
+ "Milvus is an open source database library that is also optimized for vector similarity searches like FAISS.\n",
+ "Like FAISS it has both a \"Flat\" and \"HNSW\" mode but it outperforms FAISS when it comes to dynamic data management.\n",
+ "It does require a little more setup, however, as it is run through Docker and requires the setup of some config files.\n",
+ "See [their docs](https://milvus.io/docs/v1.0.0/milvus_docker-cpu.md) for more details."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "id": "2Ur4h-E3zqLZ"
+ },
+ "outputs": [],
+ "source": [
+ "# Milvus cannot be run on COlab, so this cell is commented out.\n",
+ "# To run Milvus you need Docker (versions below 2.0.0) or a docker-compose (versions >= 2.0.0), neither of which is available on Colab.\n",
+ "# See Milvus' documentation for more details: https://milvus.io/docs/install_standalone-docker.md\n",
+ "\n",
+ "# !pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[milvus]\n",
+ "\n",
+ "# from haystack.utils import launch_milvus\n",
+ "# from haystack.document_stores import MilvusDocumentStore\n",
+ "\n",
+ "# launch_milvus()\n",
+ "# document_store = MilvusDocumentStore()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "06LatTJBA6N0",
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "### Cleaning & indexing documents\n",
+ "\n",
+ "Similarly to the previous tutorials, we download, convert and index some Game of Thrones articles to our DocumentStore"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iqKnu6wxA6N1",
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Let's first get some files that we want to use\n",
+ "doc_dir = \"data/tutorial6\"\n",
+ "s3_url = \"https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt6.zip\"\n",
+ "fetch_archive_from_http(url=s3_url, output_dir=doc_dir)\n",
+ "\n",
+ "# Convert files to dicts\n",
+ "docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)\n",
+ "\n",
+ "# Now, let's write the dicts containing documents to our DB.\n",
+ "document_store.write_documents(docs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wgjedxx_A6N6"
+ },
+ "source": [
+ "### Initialize Retriever, Reader & Pipeline\n",
+ "\n",
+ "#### Retriever\n",
+ "\n",
+ "**Here:** We use an `EmbeddingRetriever`.\n",
+ "\n",
+ "**Alternatives:**\n",
+ "\n",
+ "- `BM25Retriever` with custom queries (for example, boosting) and filters\n",
+ "- `DensePassageRetriever` which uses two encoder models, one to embed the query and one to embed the passage, and then compares the embedding for retrieval\n",
+ "- `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "kFwiPP60A6N7",
+ "pycharm": {
+ "is_executing": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.nodes import EmbeddingRetriever\n",
+ "\n",
+ "retriever = EmbeddingRetriever(\n",
+ " document_store=document_store,\n",
+ " embedding_model=\"sentence-transformers/multi-qa-mpnet-base-dot-v1\",\n",
+ " model_format=\"sentence_transformers\",\n",
+ ")\n",
+ "# Important:\n",
+ "# Now that we initialized the Retriever, we need to call update_embeddings() to iterate over all\n",
+ "# previously indexed documents and update their embedding representation.\n",
+ "# While this can be a time consuming operation (depending on the corpus size), it only needs to be done once.\n",
+ "# At query time, we only need to embed the query and compare it to the existing document embeddings, which is very fast.\n",
+ "document_store.update_embeddings(retriever)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rnVR28OXA6OA"
+ },
+ "source": [
+ "#### Reader\n",
+ "\n",
+ "Similar to previous Tutorials we now initalize our reader.\n",
+ "\n",
+ "Here we use a FARMReader with the *deepset/roberta-base-squad2* model (see: https://huggingface.co/deepset/roberta-base-squad2)\n",
+ "\n",
+ "\n",
+ "\n",
+ "##### FARMReader"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fyIuWVwhA6OB"
+ },
+ "outputs": [],
+ "source": [
+ "# Load a local model or any of the QA models on\n",
+ "# Hugging Face's model hub (https://huggingface.co/models)\n",
+ "\n",
+ "reader = FARMReader(model_name_or_path=\"deepset/roberta-base-squad2\", use_gpu=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "unhLD18yA6OF"
+ },
+ "source": [
+ "### Pipeline\n",
+ "\n",
+ "With a Haystack `Pipeline` you can stick together your building blocks to a search pipeline.\n",
+ "Under the hood, `Pipelines` are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.\n",
+ "To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the `ExtractiveQAPipeline` that combines a retriever and a reader to answer our questions.\n",
+ "You can learn more about `Pipelines` in the [docs](https://haystack.deepset.ai/docs/latest/pipelinesmd)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TssPQyzWA6OG"
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.pipelines import ExtractiveQAPipeline\n",
+ "\n",
+ "pipe = ExtractiveQAPipeline(reader, retriever)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bXlBBxKXA6OL"
+ },
+ "source": [
+ "## Voilà! Ask a question!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Zi97Hif2A6OM"
+ },
+ "outputs": [],
+ "source": [
+ "# You can configure how many candidates the reader and retriever shall return\n",
+ "# The higher top_k for retriever, the better (but also the slower) your answers.\n",
+ "prediction = pipe.run(\n",
+ " query=\"Who created the Dothraki vocabulary?\", params={\"Retriever\": {\"top_k\": 10}, \"Reader\": {\"top_k\": 5}}\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pI0wrHylzqLa"
+ },
+ "outputs": [],
+ "source": [
+ "print_answers(prediction, details=\"minimum\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false,
+ "id": "kXE84-2_zqLa"
+ },
+ "source": [
+ "## About us\n",
+ "\n",
+ "This [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany\n",
+ "\n",
+ "We bring NLP to the industry via open source!\n",
+ " \n",
+ "Our focus: Industry specific language models & large scale QA systems. \n",
+ " \n",
+ "Some of our other work: \n",
+ "- [German BERT](https://deepset.ai/german-bert)\n",
+ "- [GermanQuAD and GermanDPR](https://deepset.ai/germanquad)\n",
+ "- [FARM](https://github.com/deepset-ai/FARM)\n",
+ "\n",
+ "Get in touch:\n",
+ "[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)\n",
+ "\n",
+ "By the way: [we're hiring!](https://www.deepset.ai/jobs)"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.9"
+ },
+ "gpuClass": "standard"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/tutorials/Tutorial6_Better_Retrieval_via_DPR.py b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.py
old mode 100755
new mode 100644
similarity index 77%
rename from tutorials/Tutorial6_Better_Retrieval_via_DPR.py
rename to tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.py
index 911d36eeee..605205cffa
--- a/tutorials/Tutorial6_Better_Retrieval_via_DPR.py
+++ b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.py
@@ -1,9 +1,18 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import FAISSDocumentStore, MilvusDocumentStore
from haystack.utils import clean_wiki_text, print_answers, launch_milvus, convert_files_to_docs, fetch_archive_from_http
-from haystack.nodes import FARMReader, DensePassageRetriever
+from haystack.nodes import FARMReader, EmbeddingRetriever
-def tutorial6_better_retrieval_via_dpr():
+def tutorial6_better_retrieval_via_embedding_retrieval():
# OPTION 1: FAISS is a library for efficient similarity search on a cluster of dense vectors.
# The FAISSDocumentStore uses a SQL(SQLite in-memory be default) document store under-the-hood
# to store the document text and other meta data. The vector embeddings of the text are
@@ -37,23 +46,17 @@ def tutorial6_better_retrieval_via_dpr():
document_store.write_documents(docs)
### Retriever
- retriever = DensePassageRetriever(
+ retriever = EmbeddingRetriever(
document_store=document_store,
- query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
- passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
- max_seq_len_query=64,
- max_seq_len_passage=256,
- batch_size=2,
- use_gpu=True,
- embed_title=True,
- use_fast_tokenizers=True,
+ embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
+ model_format="sentence_transformers",
)
# Important:
- # Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all
+ # Now that we initialized the Retriever, we need to call update_embeddings() to iterate over all
# previously indexed documents and update their embedding representation.
- # While this can be a time consuming operation (depending on corpus size), it only needs to be done once.
- # At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.
+ # While this can be a time consuming operation (depending on the corpus size), it only needs to be done once.
+ # At query time, we only need to embed the query and compare it to the existing document embeddings, which is very fast.
document_store.update_embeddings(retriever)
### Reader
@@ -78,7 +81,7 @@ def tutorial6_better_retrieval_via_dpr():
if __name__ == "__main__":
- tutorial6_better_retrieval_via_dpr()
+ tutorial6_better_retrieval_via_embedding_retrieval()
# This Haystack script was made with love by deepset in Berlin, Germany
# Haystack: https://github.com/deepset-ai/haystack
diff --git a/tutorials/Tutorial7_RAG_Generator.ipynb b/tutorials/Tutorial7_RAG_Generator.ipynb
index ebfd62f368..56ae3289ad 100644
--- a/tutorials/Tutorial7_RAG_Generator.ipynb
+++ b/tutorials/Tutorial7_RAG_Generator.ipynb
@@ -75,6 +75,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial7_RAG_Generator.py b/tutorials/Tutorial7_RAG_Generator.py
index bc946ec2d0..a841371f62 100644
--- a/tutorials/Tutorial7_RAG_Generator.py
+++ b/tutorials/Tutorial7_RAG_Generator.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from typing import List
import requests
import pandas as pd
diff --git a/tutorials/Tutorial8_Preprocessing.ipynb b/tutorials/Tutorial8_Preprocessing.ipynb
index 0b73814d49..91e462b469 100644
--- a/tutorials/Tutorial8_Preprocessing.ipynb
+++ b/tutorials/Tutorial8_Preprocessing.ipynb
@@ -74,6 +74,40 @@
"# !tar -xvf xpdf-tools-mac-4.03.tar.gz && sudo cp xpdf-tools-mac-4.03/bin64/pdftotext /usr/local/bin"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": 2,
diff --git a/tutorials/Tutorial8_Preprocessing.py b/tutorials/Tutorial8_Preprocessing.py
index f7a3a8a4fb..9659e1a378 100644
--- a/tutorials/Tutorial8_Preprocessing.py
+++ b/tutorials/Tutorial8_Preprocessing.py
@@ -17,6 +17,15 @@
This tutorial will show you all the tools that Haystack provides to help you cast your data into the right format.
"""
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
# Here are the imports we need
from pathlib import Path
diff --git a/tutorials/Tutorial9_DPR_training.ipynb b/tutorials/Tutorial9_DPR_training.ipynb
index d6f2b22792..5152eafc97 100644
--- a/tutorials/Tutorial9_DPR_training.ipynb
+++ b/tutorials/Tutorial9_DPR_training.ipynb
@@ -36,6 +36,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial9_DPR_training.py b/tutorials/Tutorial9_DPR_training.py
index ca298657ed..7509abd5a7 100644
--- a/tutorials/Tutorial9_DPR_training.py
+++ b/tutorials/Tutorial9_DPR_training.py
@@ -1,11 +1,22 @@
-def tutorial9_dpr_training():
- # Training Your Own "Dense Passage Retrieval" Model
+# Training Your Own "Dense Passage Retrieval" Model
+
+# Here are some imports that we'll need
+
+import logging
- # Here are some imports that we'll need
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
- from haystack.nodes import DensePassageRetriever
- from haystack.utils import fetch_archive_from_http
- from haystack.document_stores import InMemoryDocumentStore
+from haystack.nodes import DensePassageRetriever
+from haystack.utils import fetch_archive_from_http
+from haystack.document_stores import InMemoryDocumentStore
+
+
+def tutorial9_dpr_training():
# Download original DPR data
# WARNING: the train set is 7.4GB and the dev set is 800MB
"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 357
- },
- "colab_type": "code",
- "id": "JlZgP8q1A6NW",
- "outputId": "c893ac99-b7a0-4d49-a8eb-1a9951d364d9"
- },
- "outputs": [],
- "source": [
- "# Make sure you have a GPU running\n",
- "!nvidia-smi"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000
- },
- "colab_type": "code",
- "id": "NM36kbRFA6Nc",
- "outputId": "af1a9d85-9557-4d68-ea87-a01f00c584f9"
- },
- "outputs": [],
- "source": [
- "# Install the latest release of Haystack in your own environment\n",
- "#! pip install farm-haystack\n",
- "\n",
- "# Install the latest master of Haystack\n",
- "!pip install --upgrade pip\n",
- "!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "xmRuhTQ7A6Nh"
- },
- "outputs": [],
- "source": [
- "from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers\n",
- "from haystack.nodes import FARMReader, TransformersReader"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "q3dSo7ZtA6Nl"
- },
- "source": [
- "### Document Store\n",
- "\n",
- "#### Option 1: FAISS\n",
- "\n",
- "FAISS is a library for efficient similarity search on a cluster of dense vectors.\n",
- "The `FAISSDocumentStore` uses a SQL(SQLite in-memory be default) database under-the-hood\n",
- "to store the document text and other meta data. The vector embeddings of the text are\n",
- "indexed on a FAISS Index that later is queried for searching answers.\n",
- "The default flavour of FAISSDocumentStore is \"Flat\" but can also be set to \"HNSW\" for\n",
- "faster search at the expense of some accuracy. Just set the faiss_index_factor_str argument in the constructor.\n",
- "For more info on which suits your use case: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 51
- },
- "colab_type": "code",
- "id": "1cYgDJmrA6Nv",
- "outputId": "a8aa6da1-9acf-43b1-fa3c-200123e9bdce",
- "pycharm": {
- "name": "#%%\n"
- }
- },
- "outputs": [],
- "source": [
- "from haystack.document_stores import FAISSDocumentStore\n",
- "\n",
- "document_store = FAISSDocumentStore(faiss_index_factory_str=\"Flat\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%% md\n"
- }
- },
- "source": [
- "#### Option 2: Milvus\n",
- "\n",
- "Milvus is an open source database library that is also optimized for vector similarity searches like FAISS.\n",
- "Like FAISS it has both a \"Flat\" and \"HNSW\" mode but it outperforms FAISS when it comes to dynamic data management.\n",
- "It does require a little more setup, however, as it is run through Docker and requires the setup of some config files.\n",
- "See [their docs](https://milvus.io/docs/v1.0.0/milvus_docker-cpu.md) for more details."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "collapsed": false,
- "pycharm": {
- "name": "#%%\n"
- }
- },
- "outputs": [],
- "source": [
- "# Milvus cannot be run on COlab, so this cell is commented out.\n",
- "# To run Milvus you need Docker (versions below 2.0.0) or a docker-compose (versions >= 2.0.0), neither of which is available on Colab.\n",
- "# See Milvus' documentation for more details: https://milvus.io/docs/install_standalone-docker.md\n",
- "\n",
- "# !pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[milvus]\n",
- "\n",
- "# from haystack.utils import launch_milvus\n",
- "# from haystack.document_stores import MilvusDocumentStore\n",
- "\n",
- "# launch_milvus()\n",
- "# document_store = MilvusDocumentStore()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "06LatTJBA6N0",
- "pycharm": {
- "name": "#%% md\n"
- }
- },
- "source": [
- "### Cleaning & indexing documents\n",
- "\n",
- "Similarly to the previous tutorials, we download, convert and index some Game of Thrones articles to our DocumentStore"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 156
- },
- "colab_type": "code",
- "id": "iqKnu6wxA6N1",
- "outputId": "bb5dcc7b-b65f-49ed-db0b-842981af213b",
- "pycharm": {
- "name": "#%%\n"
- }
- },
- "outputs": [],
- "source": [
- "# Let's first get some files that we want to use\n",
- "doc_dir = \"data/tutorial6\"\n",
- "s3_url = \"https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt6.zip\"\n",
- "fetch_archive_from_http(url=s3_url, output_dir=doc_dir)\n",
- "\n",
- "# Convert files to dicts\n",
- "docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)\n",
- "\n",
- "# Now, let's write the dicts containing documents to our DB.\n",
- "document_store.write_documents(docs)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "wgjedxx_A6N6"
- },
- "source": [
- "### Initialize Retriever, Reader & Pipeline\n",
- "\n",
- "#### Retriever\n",
- "\n",
- "**Here:** We use a `DensePassageRetriever`\n",
- "\n",
- "**Alternatives:**\n",
- "\n",
- "- The `BM25Retriever`with custom queries (e.g. boosting) and filters\n",
- "- Use `EmbeddingRetriever` to find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT)\n",
- "- Use `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000,
- "referenced_widgets": [
- "20affb86c4574e3a9829136fdfe40470",
- "7f8c2c86bbb74a18ac8bd24046d99d34",
- "84311c037c6e44b5b621237f59f027a0",
- "05d793fc179746e9b74cbcbc1a3389eb",
- "ad2ce6a8b4f844ac93b425f1261c131f",
- "bb45d5e4c9944fcd87b408e2fbfea440",
- "248d02e01dea4a63a3296e28e4537eaf",
- "74a9c43eb61a43aa973194b0b70e18f5",
- "58fc3339f13644aea1d4c6d8e1d43a65",
- "460bef2bfa7d4aa480639095555577ac",
- "8553a48fb3144739b99fa04adf8b407c",
- "babe35bb292f4010b64104b2b5bc92af",
- "887412c45ce744efbcc875b563770c29",
- "b4b950d899df4e3fbed9255b281e988a",
- "89535c589aa64648b82a9794a2888e78",
- "f35430501bb14fba8dbd5fb797c2e509",
- "eb5d93a8416a437e9cb039650756ac74",
- "5b8d5975d2674e7e9ada64e77c463c0a",
- "4afa2be1c2c5483f932a42ea4a7897af",
- "0e7186eeb5fa47d89c8c111ebe43c5af",
- "fa946133dfcc4a6ebc6fef2ef9dd92f7",
- "518b6a993e42490297289f2328d0270a",
- "cea074a636d34a75b311569fc3f0b3ab",
- "2630fd2fa91d498796af6d7d8d73aba4"
- ]
- },
- "colab_type": "code",
- "id": "kFwiPP60A6N7",
- "outputId": "07249856-3222-4898-9246-68e9ecbf5a1b",
- "pycharm": {
- "is_executing": true
- }
- },
- "outputs": [],
- "source": [
- "from haystack.nodes import DensePassageRetriever\n",
- "\n",
- "retriever = DensePassageRetriever(\n",
- " document_store=document_store,\n",
- " query_embedding_model=\"facebook/dpr-question_encoder-single-nq-base\",\n",
- " passage_embedding_model=\"facebook/dpr-ctx_encoder-single-nq-base\",\n",
- " max_seq_len_query=64,\n",
- " max_seq_len_passage=256,\n",
- " batch_size=16,\n",
- " use_gpu=True,\n",
- " embed_title=True,\n",
- " use_fast_tokenizers=True,\n",
- ")\n",
- "# Important:\n",
- "# Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all\n",
- "# previously indexed documents and update their embedding representation.\n",
- "# While this can be a time consuming operation (depending on corpus size), it only needs to be done once.\n",
- "# At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.\n",
- "document_store.update_embeddings(retriever)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "rnVR28OXA6OA"
- },
- "source": [
- "#### Reader\n",
- "\n",
- "Similar to previous Tutorials we now initalize our reader.\n",
- "\n",
- "Here we use a FARMReader with the *deepset/roberta-base-squad2* model (see: https://huggingface.co/deepset/roberta-base-squad2)\n",
- "\n",
- "\n",
- "\n",
- "##### FARMReader"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 739,
- "referenced_widgets": [
- "3d273d2d3b25435ba4eb4ffd8e812b6f",
- "5104b7cddf6d4d0f92d3dd142b9f4c42",
- "e0510255a31d448497af3ca0f4915cb4",
- "670270fd06274932adad4d42c8a1912e",
- "6ca292cd3f46417ea296684e48863af9",
- "75578e0466cd4b84ba7dfee1028ae4cd",
- "cbe09b984b804402b1fe82739cbc375c",
- "4fd0caca56bd415b8c31860ba542145a",
- "9960be4cc1c64905917b5fd7ea6bb294",
- "2f3d901b3acb4841a4b03b2c5cd4393b",
- "04644b74bb2a45a7a6fcf86151b5bf8c",
- "5efa895c53284b72adec629a6fc59fa9",
- "182e5db14fac427b90380b5213f57825",
- "243600e420f449089c1b5ed0d2715339",
- "466222c8b2e1403ca69c8130423f0a8b",
- "a458be4cc49240e4b9bc1c95c05551e8",
- "d9ee08fa621d4b558bd1a415e3ee6f62",
- "1b905c5551b940ed9bc5320e1e5a9213",
- "64fc7775a84e425c8082a545f7c2a0c1",
- "66cd72dae82d434a87b638236784fd4b",
- "36b1b48aea02494a8bc94020a15d7417",
- "5934bc4db2a94c20b5c55f1c017024ab",
- "f9289caeac404087ad4973a646e3a117",
- "7e121f0fdb1746c094bff218a4f623ab",
- "98781635b86244aca5d22be4280c32de",
- "e148b28d946549a9b5eb09294ebe124e",
- "4b8b29c1b1a243808de4cc1cae3f6bd6",
- "bbef597f804e4ca580aee665399a3bc1",
- "345f49b2b42c40278478d30e8a691768",
- "e3724385769d443cb4ea39b92e0b2abd",
- "d05fbb94014840cab4584c4781a590c1",
- "b8d52b604dad43c18ba00c935b961422",
- "e625a32fc81b42fb9e0fff7ce766fcdc",
- "885390f24e08495db6a1febd661531e0",
- "c2a614f48e974fb8b13a3c5d7cafaed6",
- "ada8fa1c88954ef8b839f29090de9e79",
- "427b07b356e44c68b47178b277aaa16f",
- "1b4166bda5ae48aa8539e0fa5521007a",
- "fd30d43909874239b2183c5fb61241fe",
- "09a647660cf94131a1c140d06eb293ab",
- "3e482e9ef4d34d93b4ba4f7f07b0e44f",
- "66450cab654d40ae8ed1c32fa733397a",
- "aa4becf2e33d4f1e9fdac70236d48f6e",
- "78d087ed952e429b97eb3d8fcdc7c8ec",
- "5020846874ae473bbfa7038fe98de474",
- "08c736f4ad424330a82df1b5dc047b2c",
- "9169ca606bf64d41aa08fb42876bd2ab",
- "c8f1f7e8462d4d14a507816f67953eae"
- ]
- },
- "colab_type": "code",
- "id": "fyIuWVwhA6OB",
- "outputId": "33113253-8b95-4604-f9e5-1aa28ee66a91"
- },
- "outputs": [],
- "source": [
- "# Load a local model or any of the QA models on\n",
- "# Hugging Face's model hub (https://huggingface.co/models)\n",
- "\n",
- "reader = FARMReader(model_name_or_path=\"deepset/roberta-base-squad2\", use_gpu=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "unhLD18yA6OF"
- },
- "source": [
- "### Pipeline\n",
- "\n",
- "With a Haystack `Pipeline` you can stick together your building blocks to a search pipeline.\n",
- "Under the hood, `Pipelines` are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.\n",
- "To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the `ExtractiveQAPipeline` that combines a retriever and a reader to answer our questions.\n",
- "You can learn more about `Pipelines` in the [docs](https://haystack.deepset.ai/docs/latest/pipelinesmd)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "TssPQyzWA6OG"
- },
- "outputs": [],
- "source": [
- "from haystack.pipelines import ExtractiveQAPipeline\n",
- "\n",
- "pipe = ExtractiveQAPipeline(reader, retriever)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "colab_type": "text",
- "id": "bXlBBxKXA6OL"
- },
- "source": [
- "## Voilà! Ask a question!"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 275
- },
- "colab_type": "code",
- "id": "Zi97Hif2A6OM",
- "outputId": "5eb9363d-ba92-45d5-c4d0-63ada3073f02"
- },
- "outputs": [],
- "source": [
- "# You can configure how many candidates the reader and retriever shall return\n",
- "# The higher top_k for retriever, the better (but also the slower) your answers.\n",
- "prediction = pipe.run(\n",
- " query=\"Who created the Dothraki vocabulary?\", params={\"Retriever\": {\"top_k\": 10}, \"Reader\": {\"top_k\": 5}}\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "print_answers(prediction, details=\"minimum\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "collapsed": false
- },
- "source": [
- "## About us\n",
- "\n",
- "This [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany\n",
- "\n",
- "We bring NLP to the industry via open source! \n",
- "Our focus: Industry specific language models & large scale QA systems. \n",
- " \n",
- "Some of our other work: \n",
- "- [German BERT](https://deepset.ai/german-bert)\n",
- "- [GermanQuAD and GermanDPR](https://deepset.ai/germanquad)\n",
- "- [FARM](https://github.com/deepset-ai/FARM)\n",
- "\n",
- "Get in touch:\n",
- "[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)\n",
- "\n",
- "By the way: [we're hiring!](https://www.deepset.ai/jobs)"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [],
- "name": "Tutorial6_Better_Retrieval_via_DPR.ipynb",
- "provenance": []
- },
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.6.9"
- },
- "widgets": {
- "application/vnd.jupyter.widget-state+json": {
- "04644b74bb2a45a7a6fcf86151b5bf8c": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_243600e420f449089c1b5ed0d2715339",
- "max": 498637366,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_182e5db14fac427b90380b5213f57825",
- "value": 498637366
- }
- },
- "05d793fc179746e9b74cbcbc1a3389eb": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_74a9c43eb61a43aa973194b0b70e18f5",
- "placeholder": "",
- "style": "IPY_MODEL_248d02e01dea4a63a3296e28e4537eaf",
- "value": " 232k/232k [00:00<00:00, 628kB/s]"
- }
- },
- "08c736f4ad424330a82df1b5dc047b2c": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "09a647660cf94131a1c140d06eb293ab": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "0e7186eeb5fa47d89c8c111ebe43c5af": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_2630fd2fa91d498796af6d7d8d73aba4",
- "placeholder": "",
- "style": "IPY_MODEL_cea074a636d34a75b311569fc3f0b3ab",
- "value": " 438M/438M [00:13<00:00, 31.7MB/s]"
- }
- },
- "182e5db14fac427b90380b5213f57825": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "1b4166bda5ae48aa8539e0fa5521007a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "1b905c5551b940ed9bc5320e1e5a9213": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "20affb86c4574e3a9829136fdfe40470": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_84311c037c6e44b5b621237f59f027a0",
- "IPY_MODEL_05d793fc179746e9b74cbcbc1a3389eb"
- ],
- "layout": "IPY_MODEL_7f8c2c86bbb74a18ac8bd24046d99d34"
- }
- },
- "243600e420f449089c1b5ed0d2715339": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "248d02e01dea4a63a3296e28e4537eaf": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "2630fd2fa91d498796af6d7d8d73aba4": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "2f3d901b3acb4841a4b03b2c5cd4393b": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "345f49b2b42c40278478d30e8a691768": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "36b1b48aea02494a8bc94020a15d7417": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "3d273d2d3b25435ba4eb4ffd8e812b6f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_e0510255a31d448497af3ca0f4915cb4",
- "IPY_MODEL_670270fd06274932adad4d42c8a1912e"
- ],
- "layout": "IPY_MODEL_5104b7cddf6d4d0f92d3dd142b9f4c42"
- }
- },
- "3e482e9ef4d34d93b4ba4f7f07b0e44f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_aa4becf2e33d4f1e9fdac70236d48f6e",
- "IPY_MODEL_78d087ed952e429b97eb3d8fcdc7c8ec"
- ],
- "layout": "IPY_MODEL_66450cab654d40ae8ed1c32fa733397a"
- }
- },
- "427b07b356e44c68b47178b277aaa16f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "460bef2bfa7d4aa480639095555577ac": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "466222c8b2e1403ca69c8130423f0a8b": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "4afa2be1c2c5483f932a42ea4a7897af": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_518b6a993e42490297289f2328d0270a",
- "max": 437983985,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_fa946133dfcc4a6ebc6fef2ef9dd92f7",
- "value": 437983985
- }
- },
- "4b8b29c1b1a243808de4cc1cae3f6bd6": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_e3724385769d443cb4ea39b92e0b2abd",
- "max": 456318,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_345f49b2b42c40278478d30e8a691768",
- "value": 456318
- }
- },
- "4fd0caca56bd415b8c31860ba542145a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5020846874ae473bbfa7038fe98de474": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "5104b7cddf6d4d0f92d3dd142b9f4c42": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "518b6a993e42490297289f2328d0270a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "58fc3339f13644aea1d4c6d8e1d43a65": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_8553a48fb3144739b99fa04adf8b407c",
- "IPY_MODEL_babe35bb292f4010b64104b2b5bc92af"
- ],
- "layout": "IPY_MODEL_460bef2bfa7d4aa480639095555577ac"
- }
- },
- "5934bc4db2a94c20b5c55f1c017024ab": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5b8d5975d2674e7e9ada64e77c463c0a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "5efa895c53284b72adec629a6fc59fa9": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_a458be4cc49240e4b9bc1c95c05551e8",
- "placeholder": "",
- "style": "IPY_MODEL_466222c8b2e1403ca69c8130423f0a8b",
- "value": " 499M/499M [00:23<00:00, 21.1MB/s]"
- }
- },
- "64fc7775a84e425c8082a545f7c2a0c1": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_5934bc4db2a94c20b5c55f1c017024ab",
- "max": 898822,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_36b1b48aea02494a8bc94020a15d7417",
- "value": 898822
- }
- },
- "66450cab654d40ae8ed1c32fa733397a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "66cd72dae82d434a87b638236784fd4b": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_7e121f0fdb1746c094bff218a4f623ab",
- "placeholder": "",
- "style": "IPY_MODEL_f9289caeac404087ad4973a646e3a117",
- "value": " 899k/899k [00:01<00:00, 684kB/s]"
- }
- },
- "670270fd06274932adad4d42c8a1912e": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_4fd0caca56bd415b8c31860ba542145a",
- "placeholder": "",
- "style": "IPY_MODEL_cbe09b984b804402b1fe82739cbc375c",
- "value": " 559/559 [00:00<00:00, 2.78kB/s]"
- }
- },
- "6ca292cd3f46417ea296684e48863af9": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "74a9c43eb61a43aa973194b0b70e18f5": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "75578e0466cd4b84ba7dfee1028ae4cd": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "78d087ed952e429b97eb3d8fcdc7c8ec": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_c8f1f7e8462d4d14a507816f67953eae",
- "placeholder": "",
- "style": "IPY_MODEL_9169ca606bf64d41aa08fb42876bd2ab",
- "value": " 189/189 [00:00<00:00, 409B/s]"
- }
- },
- "7e121f0fdb1746c094bff218a4f623ab": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "7f8c2c86bbb74a18ac8bd24046d99d34": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "84311c037c6e44b5b621237f59f027a0": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_bb45d5e4c9944fcd87b408e2fbfea440",
- "max": 231508,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_ad2ce6a8b4f844ac93b425f1261c131f",
- "value": 231508
- }
- },
- "8553a48fb3144739b99fa04adf8b407c": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_b4b950d899df4e3fbed9255b281e988a",
- "max": 437986065,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_887412c45ce744efbcc875b563770c29",
- "value": 437986065
- }
- },
- "885390f24e08495db6a1febd661531e0": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "887412c45ce744efbcc875b563770c29": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "89535c589aa64648b82a9794a2888e78": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "9169ca606bf64d41aa08fb42876bd2ab": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "98781635b86244aca5d22be4280c32de": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_4b8b29c1b1a243808de4cc1cae3f6bd6",
- "IPY_MODEL_bbef597f804e4ca580aee665399a3bc1"
- ],
- "layout": "IPY_MODEL_e148b28d946549a9b5eb09294ebe124e"
- }
- },
- "9960be4cc1c64905917b5fd7ea6bb294": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_04644b74bb2a45a7a6fcf86151b5bf8c",
- "IPY_MODEL_5efa895c53284b72adec629a6fc59fa9"
- ],
- "layout": "IPY_MODEL_2f3d901b3acb4841a4b03b2c5cd4393b"
- }
- },
- "a458be4cc49240e4b9bc1c95c05551e8": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "aa4becf2e33d4f1e9fdac70236d48f6e": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_08c736f4ad424330a82df1b5dc047b2c",
- "max": 189,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_5020846874ae473bbfa7038fe98de474",
- "value": 189
- }
- },
- "ad2ce6a8b4f844ac93b425f1261c131f": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "ada8fa1c88954ef8b839f29090de9e79": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_09a647660cf94131a1c140d06eb293ab",
- "placeholder": "",
- "style": "IPY_MODEL_fd30d43909874239b2183c5fb61241fe",
- "value": " 150/150 [00:01<00:00, 119B/s]"
- }
- },
- "b4b950d899df4e3fbed9255b281e988a": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "b8d52b604dad43c18ba00c935b961422": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "babe35bb292f4010b64104b2b5bc92af": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_f35430501bb14fba8dbd5fb797c2e509",
- "placeholder": "",
- "style": "IPY_MODEL_89535c589aa64648b82a9794a2888e78",
- "value": " 438M/438M [00:13<00:00, 32.3MB/s]"
- }
- },
- "bb45d5e4c9944fcd87b408e2fbfea440": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "bbef597f804e4ca580aee665399a3bc1": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HTMLModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HTMLModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HTMLView",
- "description": "",
- "description_tooltip": null,
- "layout": "IPY_MODEL_b8d52b604dad43c18ba00c935b961422",
- "placeholder": "",
- "style": "IPY_MODEL_d05fbb94014840cab4584c4781a590c1",
- "value": " 456k/456k [00:02<00:00, 166kB/s]"
- }
- },
- "c2a614f48e974fb8b13a3c5d7cafaed6": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_1b4166bda5ae48aa8539e0fa5521007a",
- "max": 150,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_427b07b356e44c68b47178b277aaa16f",
- "value": 150
- }
- },
- "c8f1f7e8462d4d14a507816f67953eae": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "cbe09b984b804402b1fe82739cbc375c": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "cea074a636d34a75b311569fc3f0b3ab": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "d05fbb94014840cab4584c4781a590c1": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "d9ee08fa621d4b558bd1a415e3ee6f62": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_64fc7775a84e425c8082a545f7c2a0c1",
- "IPY_MODEL_66cd72dae82d434a87b638236784fd4b"
- ],
- "layout": "IPY_MODEL_1b905c5551b940ed9bc5320e1e5a9213"
- }
- },
- "e0510255a31d448497af3ca0f4915cb4": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "FloatProgressModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "FloatProgressModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "ProgressView",
- "bar_style": "success",
- "description": "Downloading: 100%",
- "description_tooltip": null,
- "layout": "IPY_MODEL_75578e0466cd4b84ba7dfee1028ae4cd",
- "max": 559,
- "min": 0,
- "orientation": "horizontal",
- "style": "IPY_MODEL_6ca292cd3f46417ea296684e48863af9",
- "value": 559
- }
- },
- "e148b28d946549a9b5eb09294ebe124e": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "e3724385769d443cb4ea39b92e0b2abd": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "e625a32fc81b42fb9e0fff7ce766fcdc": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_c2a614f48e974fb8b13a3c5d7cafaed6",
- "IPY_MODEL_ada8fa1c88954ef8b839f29090de9e79"
- ],
- "layout": "IPY_MODEL_885390f24e08495db6a1febd661531e0"
- }
- },
- "eb5d93a8416a437e9cb039650756ac74": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "HBoxModel",
- "state": {
- "_dom_classes": [],
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "HBoxModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/controls",
- "_view_module_version": "1.5.0",
- "_view_name": "HBoxView",
- "box_style": "",
- "children": [
- "IPY_MODEL_4afa2be1c2c5483f932a42ea4a7897af",
- "IPY_MODEL_0e7186eeb5fa47d89c8c111ebe43c5af"
- ],
- "layout": "IPY_MODEL_5b8d5975d2674e7e9ada64e77c463c0a"
- }
- },
- "f35430501bb14fba8dbd5fb797c2e509": {
- "model_module": "@jupyter-widgets/base",
- "model_name": "LayoutModel",
- "state": {
- "_model_module": "@jupyter-widgets/base",
- "_model_module_version": "1.2.0",
- "_model_name": "LayoutModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "LayoutView",
- "align_content": null,
- "align_items": null,
- "align_self": null,
- "border": null,
- "bottom": null,
- "display": null,
- "flex": null,
- "flex_flow": null,
- "grid_area": null,
- "grid_auto_columns": null,
- "grid_auto_flow": null,
- "grid_auto_rows": null,
- "grid_column": null,
- "grid_gap": null,
- "grid_row": null,
- "grid_template_areas": null,
- "grid_template_columns": null,
- "grid_template_rows": null,
- "height": null,
- "justify_content": null,
- "justify_items": null,
- "left": null,
- "margin": null,
- "max_height": null,
- "max_width": null,
- "min_height": null,
- "min_width": null,
- "object_fit": null,
- "object_position": null,
- "order": null,
- "overflow": null,
- "overflow_x": null,
- "overflow_y": null,
- "padding": null,
- "right": null,
- "top": null,
- "visibility": null,
- "width": null
- }
- },
- "f9289caeac404087ad4973a646e3a117": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- },
- "fa946133dfcc4a6ebc6fef2ef9dd92f7": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "ProgressStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "ProgressStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "bar_color": null,
- "description_width": "initial"
- }
- },
- "fd30d43909874239b2183c5fb61241fe": {
- "model_module": "@jupyter-widgets/controls",
- "model_name": "DescriptionStyleModel",
- "state": {
- "_model_module": "@jupyter-widgets/controls",
- "_model_module_version": "1.5.0",
- "_model_name": "DescriptionStyleModel",
- "_view_count": null,
- "_view_module": "@jupyter-widgets/base",
- "_view_module_version": "1.2.0",
- "_view_name": "StyleView",
- "description_width": ""
- }
- }
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 1
-}
\ No newline at end of file
diff --git a/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb
new file mode 100644
index 0000000000..9c53563aa1
--- /dev/null
+++ b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb
@@ -0,0 +1,450 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bEH-CRbeA6NU"
+ },
+ "source": [
+ "# Better Retrieval via \"Embedding Retrieval\"\n",
+ "\n",
+ "[](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb)\n",
+ "\n",
+ "### Importance of Retrievers\n",
+ "\n",
+ "The Retriever has a huge impact on the performance of our overall search pipeline.\n",
+ "\n",
+ "\n",
+ "### Different types of Retrievers\n",
+ "#### Sparse\n",
+ "Family of algorithms based on counting the occurrences of words (bag-of-words) resulting in very sparse vectors with length = vocab size.\n",
+ "\n",
+ "**Examples**: BM25, TF-IDF\n",
+ "\n",
+ "**Pros**: Simple, fast, well explainable\n",
+ "\n",
+ "**Cons**: Relies on exact keyword matches between query and text\n",
+ " \n",
+ "\n",
+ "#### Dense\n",
+ "These retrievers use neural network models to create \"dense\" embedding vectors. Within this family, there are two different approaches:\n",
+ "\n",
+ "a) Single encoder: Use a **single model** to embed both the query and the passage.\n",
+ "b) Dual-encoder: Use **two models**, one to embed the query and one to embed the passage.\n",
+ "\n",
+ "**Examples**: REALM, DPR, Sentence-Transformers\n",
+ "\n",
+ "**Pros**: Captures semantic similarity instead of \"word matches\" (for example, synonyms, related topics).\n",
+ "\n",
+ "**Cons**: Computationally more heavy to use, initial training of the model (though this is less of an issue nowadays as many pre-trained models are available and most of the time, it's not needed to train the model).\n",
+ "\n",
+ "\n",
+ "### Embedding Retrieval\n",
+ "\n",
+ "In this Tutorial, we use an `EmbeddingRetriever` with [Sentence Transformers](https://www.sbert.net/index.html) models.\n",
+ "\n",
+ "These models are trained to embed similar sentences close to each other in a shared embedding space.\n",
+ "\n",
+ "Some models have been fine-tuned on massive Information Retrieval data and can be used to retrieve documents based on a short query (for example, `multi-qa-mpnet-base-dot-v1`). There are others that are more suited to semantic similarity tasks where you are trying to find the most similar documents to a given document (for example, `all-mpnet-base-v2`). There are even models that are multilingual (for example, `paraphrase-multilingual-mpnet-base-v2`). For a good overview of different models with their evaluation metrics, see the [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html#) in the Sentence Transformers documentation.\n",
+ "\n",
+ "*Use this* [link](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb) *to open the notebook in Google Colab.*\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3K27Y5FbA6NV"
+ },
+ "source": [
+ "### Prepare the Environment\n",
+ "\n",
+ "#### Colab: Enable the GPU Runtime\n",
+ "Make sure you enable the GPU runtime to experience decent speed in this tutorial.\n",
+ "**Runtime -> Change Runtime type -> Hardware accelerator -> GPU**\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "JlZgP8q1A6NW"
+ },
+ "outputs": [],
+ "source": [
+ "# Make sure you have a GPU running\n",
+ "!nvidia-smi"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "NM36kbRFA6Nc"
+ },
+ "outputs": [],
+ "source": [
+ "# Install the latest release of Haystack in your own environment\n",
+ "#! pip install farm-haystack\n",
+ "\n",
+ "# Install the latest master of Haystack\n",
+ "!pip install --upgrade pip\n",
+ "!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "id": "GbM2ml-ozqLX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "id": "kQWEUUMnzqLX"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xmRuhTQ7A6Nh"
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers\n",
+ "from haystack.nodes import FARMReader, TransformersReader"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "q3dSo7ZtA6Nl"
+ },
+ "source": [
+ "### Document Store\n",
+ "\n",
+ "#### Option 1: FAISS\n",
+ "\n",
+ "FAISS is a library for efficient similarity search on a cluster of dense vectors.\n",
+ "The `FAISSDocumentStore` uses a SQL(SQLite in-memory be default) database under-the-hood\n",
+ "to store the document text and other meta data. The vector embeddings of the text are\n",
+ "indexed on a FAISS Index that later is queried for searching answers.\n",
+ "The default flavour of FAISSDocumentStore is \"Flat\" but can also be set to \"HNSW\" for\n",
+ "faster search at the expense of some accuracy. Just set the faiss_index_factor_str argument in the constructor.\n",
+ "For more info on which suits your use case: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1cYgDJmrA6Nv",
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.document_stores import FAISSDocumentStore\n",
+ "\n",
+ "document_store = FAISSDocumentStore(faiss_index_factory_str=\"Flat\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "id": "s4HK5l0qzqLZ"
+ },
+ "source": [
+ "#### Option 2: Milvus\n",
+ "\n",
+ "Milvus is an open source database library that is also optimized for vector similarity searches like FAISS.\n",
+ "Like FAISS it has both a \"Flat\" and \"HNSW\" mode but it outperforms FAISS when it comes to dynamic data management.\n",
+ "It does require a little more setup, however, as it is run through Docker and requires the setup of some config files.\n",
+ "See [their docs](https://milvus.io/docs/v1.0.0/milvus_docker-cpu.md) for more details."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "id": "2Ur4h-E3zqLZ"
+ },
+ "outputs": [],
+ "source": [
+ "# Milvus cannot be run on COlab, so this cell is commented out.\n",
+ "# To run Milvus you need Docker (versions below 2.0.0) or a docker-compose (versions >= 2.0.0), neither of which is available on Colab.\n",
+ "# See Milvus' documentation for more details: https://milvus.io/docs/install_standalone-docker.md\n",
+ "\n",
+ "# !pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[milvus]\n",
+ "\n",
+ "# from haystack.utils import launch_milvus\n",
+ "# from haystack.document_stores import MilvusDocumentStore\n",
+ "\n",
+ "# launch_milvus()\n",
+ "# document_store = MilvusDocumentStore()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "06LatTJBA6N0",
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "### Cleaning & indexing documents\n",
+ "\n",
+ "Similarly to the previous tutorials, we download, convert and index some Game of Thrones articles to our DocumentStore"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "iqKnu6wxA6N1",
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Let's first get some files that we want to use\n",
+ "doc_dir = \"data/tutorial6\"\n",
+ "s3_url = \"https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt6.zip\"\n",
+ "fetch_archive_from_http(url=s3_url, output_dir=doc_dir)\n",
+ "\n",
+ "# Convert files to dicts\n",
+ "docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)\n",
+ "\n",
+ "# Now, let's write the dicts containing documents to our DB.\n",
+ "document_store.write_documents(docs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wgjedxx_A6N6"
+ },
+ "source": [
+ "### Initialize Retriever, Reader & Pipeline\n",
+ "\n",
+ "#### Retriever\n",
+ "\n",
+ "**Here:** We use an `EmbeddingRetriever`.\n",
+ "\n",
+ "**Alternatives:**\n",
+ "\n",
+ "- `BM25Retriever` with custom queries (for example, boosting) and filters\n",
+ "- `DensePassageRetriever` which uses two encoder models, one to embed the query and one to embed the passage, and then compares the embedding for retrieval\n",
+ "- `TfidfRetriever` in combination with a SQL or InMemory Document store for simple prototyping and debugging"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "kFwiPP60A6N7",
+ "pycharm": {
+ "is_executing": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.nodes import EmbeddingRetriever\n",
+ "\n",
+ "retriever = EmbeddingRetriever(\n",
+ " document_store=document_store,\n",
+ " embedding_model=\"sentence-transformers/multi-qa-mpnet-base-dot-v1\",\n",
+ " model_format=\"sentence_transformers\",\n",
+ ")\n",
+ "# Important:\n",
+ "# Now that we initialized the Retriever, we need to call update_embeddings() to iterate over all\n",
+ "# previously indexed documents and update their embedding representation.\n",
+ "# While this can be a time consuming operation (depending on the corpus size), it only needs to be done once.\n",
+ "# At query time, we only need to embed the query and compare it to the existing document embeddings, which is very fast.\n",
+ "document_store.update_embeddings(retriever)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rnVR28OXA6OA"
+ },
+ "source": [
+ "#### Reader\n",
+ "\n",
+ "Similar to previous Tutorials we now initalize our reader.\n",
+ "\n",
+ "Here we use a FARMReader with the *deepset/roberta-base-squad2* model (see: https://huggingface.co/deepset/roberta-base-squad2)\n",
+ "\n",
+ "\n",
+ "\n",
+ "##### FARMReader"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "fyIuWVwhA6OB"
+ },
+ "outputs": [],
+ "source": [
+ "# Load a local model or any of the QA models on\n",
+ "# Hugging Face's model hub (https://huggingface.co/models)\n",
+ "\n",
+ "reader = FARMReader(model_name_or_path=\"deepset/roberta-base-squad2\", use_gpu=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "unhLD18yA6OF"
+ },
+ "source": [
+ "### Pipeline\n",
+ "\n",
+ "With a Haystack `Pipeline` you can stick together your building blocks to a search pipeline.\n",
+ "Under the hood, `Pipelines` are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.\n",
+ "To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the `ExtractiveQAPipeline` that combines a retriever and a reader to answer our questions.\n",
+ "You can learn more about `Pipelines` in the [docs](https://haystack.deepset.ai/docs/latest/pipelinesmd)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "TssPQyzWA6OG"
+ },
+ "outputs": [],
+ "source": [
+ "from haystack.pipelines import ExtractiveQAPipeline\n",
+ "\n",
+ "pipe = ExtractiveQAPipeline(reader, retriever)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bXlBBxKXA6OL"
+ },
+ "source": [
+ "## Voilà! Ask a question!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Zi97Hif2A6OM"
+ },
+ "outputs": [],
+ "source": [
+ "# You can configure how many candidates the reader and retriever shall return\n",
+ "# The higher top_k for retriever, the better (but also the slower) your answers.\n",
+ "prediction = pipe.run(\n",
+ " query=\"Who created the Dothraki vocabulary?\", params={\"Retriever\": {\"top_k\": 10}, \"Reader\": {\"top_k\": 5}}\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pI0wrHylzqLa"
+ },
+ "outputs": [],
+ "source": [
+ "print_answers(prediction, details=\"minimum\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": false,
+ "id": "kXE84-2_zqLa"
+ },
+ "source": [
+ "## About us\n",
+ "\n",
+ "This [Haystack](https://github.com/deepset-ai/haystack/) notebook was made with love by [deepset](https://deepset.ai/) in Berlin, Germany\n",
+ "\n",
+ "We bring NLP to the industry via open source!\n",
+ " \n",
+ "Our focus: Industry specific language models & large scale QA systems. \n",
+ " \n",
+ "Some of our other work: \n",
+ "- [German BERT](https://deepset.ai/german-bert)\n",
+ "- [GermanQuAD and GermanDPR](https://deepset.ai/germanquad)\n",
+ "- [FARM](https://github.com/deepset-ai/FARM)\n",
+ "\n",
+ "Get in touch:\n",
+ "[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)\n",
+ "\n",
+ "By the way: [we're hiring!](https://www.deepset.ai/jobs)"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "Tutorial6_Better_Retrieval_via_Embedding_Retrieval.ipynb",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.9"
+ },
+ "gpuClass": "standard"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/tutorials/Tutorial6_Better_Retrieval_via_DPR.py b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.py
old mode 100755
new mode 100644
similarity index 77%
rename from tutorials/Tutorial6_Better_Retrieval_via_DPR.py
rename to tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.py
index 911d36eeee..605205cffa
--- a/tutorials/Tutorial6_Better_Retrieval_via_DPR.py
+++ b/tutorials/Tutorial6_Better_Retrieval_via_Embedding_Retrieval.py
@@ -1,9 +1,18 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from haystack.document_stores import FAISSDocumentStore, MilvusDocumentStore
from haystack.utils import clean_wiki_text, print_answers, launch_milvus, convert_files_to_docs, fetch_archive_from_http
-from haystack.nodes import FARMReader, DensePassageRetriever
+from haystack.nodes import FARMReader, EmbeddingRetriever
-def tutorial6_better_retrieval_via_dpr():
+def tutorial6_better_retrieval_via_embedding_retrieval():
# OPTION 1: FAISS is a library for efficient similarity search on a cluster of dense vectors.
# The FAISSDocumentStore uses a SQL(SQLite in-memory be default) document store under-the-hood
# to store the document text and other meta data. The vector embeddings of the text are
@@ -37,23 +46,17 @@ def tutorial6_better_retrieval_via_dpr():
document_store.write_documents(docs)
### Retriever
- retriever = DensePassageRetriever(
+ retriever = EmbeddingRetriever(
document_store=document_store,
- query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
- passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
- max_seq_len_query=64,
- max_seq_len_passage=256,
- batch_size=2,
- use_gpu=True,
- embed_title=True,
- use_fast_tokenizers=True,
+ embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
+ model_format="sentence_transformers",
)
# Important:
- # Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all
+ # Now that we initialized the Retriever, we need to call update_embeddings() to iterate over all
# previously indexed documents and update their embedding representation.
- # While this can be a time consuming operation (depending on corpus size), it only needs to be done once.
- # At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.
+ # While this can be a time consuming operation (depending on the corpus size), it only needs to be done once.
+ # At query time, we only need to embed the query and compare it to the existing document embeddings, which is very fast.
document_store.update_embeddings(retriever)
### Reader
@@ -78,7 +81,7 @@ def tutorial6_better_retrieval_via_dpr():
if __name__ == "__main__":
- tutorial6_better_retrieval_via_dpr()
+ tutorial6_better_retrieval_via_embedding_retrieval()
# This Haystack script was made with love by deepset in Berlin, Germany
# Haystack: https://github.com/deepset-ai/haystack
diff --git a/tutorials/Tutorial7_RAG_Generator.ipynb b/tutorials/Tutorial7_RAG_Generator.ipynb
index ebfd62f368..56ae3289ad 100644
--- a/tutorials/Tutorial7_RAG_Generator.ipynb
+++ b/tutorials/Tutorial7_RAG_Generator.ipynb
@@ -75,6 +75,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial7_RAG_Generator.py b/tutorials/Tutorial7_RAG_Generator.py
index bc946ec2d0..a841371f62 100644
--- a/tutorials/Tutorial7_RAG_Generator.py
+++ b/tutorials/Tutorial7_RAG_Generator.py
@@ -1,3 +1,12 @@
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
from typing import List
import requests
import pandas as pd
diff --git a/tutorials/Tutorial8_Preprocessing.ipynb b/tutorials/Tutorial8_Preprocessing.ipynb
index 0b73814d49..91e462b469 100644
--- a/tutorials/Tutorial8_Preprocessing.ipynb
+++ b/tutorials/Tutorial8_Preprocessing.ipynb
@@ -74,6 +74,40 @@
"# !tar -xvf xpdf-tools-mac-4.03.tar.gz && sudo cp xpdf-tools-mac-4.03/bin64/pdftotext /usr/local/bin"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": 2,
diff --git a/tutorials/Tutorial8_Preprocessing.py b/tutorials/Tutorial8_Preprocessing.py
index f7a3a8a4fb..9659e1a378 100644
--- a/tutorials/Tutorial8_Preprocessing.py
+++ b/tutorials/Tutorial8_Preprocessing.py
@@ -17,6 +17,15 @@
This tutorial will show you all the tools that Haystack provides to help you cast your data into the right format.
"""
+import logging
+
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
+
# Here are the imports we need
from pathlib import Path
diff --git a/tutorials/Tutorial9_DPR_training.ipynb b/tutorials/Tutorial9_DPR_training.ipynb
index d6f2b22792..5152eafc97 100644
--- a/tutorials/Tutorial9_DPR_training.ipynb
+++ b/tutorials/Tutorial9_DPR_training.ipynb
@@ -36,6 +36,40 @@
"!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]"
]
},
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Logging\n",
+ "\n",
+ "We configure how logging messages should be displayed and which log level should be used before importing Haystack.\n",
+ "Example log message:\n",
+ "INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt\n",
+ "Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "\n",
+ "logging.basicConfig(format=\"%(levelname)s - %(name)s - %(message)s\", level=logging.WARNING)\n",
+ "logging.getLogger(\"haystack\").setLevel(logging.INFO)"
+ ],
+ "metadata": {
+ "collapsed": false,
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ }
+ },
{
"cell_type": "code",
"execution_count": null,
diff --git a/tutorials/Tutorial9_DPR_training.py b/tutorials/Tutorial9_DPR_training.py
index ca298657ed..7509abd5a7 100644
--- a/tutorials/Tutorial9_DPR_training.py
+++ b/tutorials/Tutorial9_DPR_training.py
@@ -1,11 +1,22 @@
-def tutorial9_dpr_training():
- # Training Your Own "Dense Passage Retrieval" Model
+# Training Your Own "Dense Passage Retrieval" Model
+
+# Here are some imports that we'll need
+
+import logging
- # Here are some imports that we'll need
+# We configure how logging messages should be displayed and which log level should be used before importing Haystack.
+# Example log message:
+# INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt
+# Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
+logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
+logging.getLogger("haystack").setLevel(logging.INFO)
- from haystack.nodes import DensePassageRetriever
- from haystack.utils import fetch_archive_from_http
- from haystack.document_stores import InMemoryDocumentStore
+from haystack.nodes import DensePassageRetriever
+from haystack.utils import fetch_archive_from_http
+from haystack.document_stores import InMemoryDocumentStore
+
+
+def tutorial9_dpr_training():
# Download original DPR data
# WARNING: the train set is 7.4GB and the dev set is 800MB