diff --git a/CHANGELOG.md b/CHANGELOG.md
index 20bc0566..8f974485 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,5 +1,10 @@
# Changelog
-# v0.1.0
+## v0.1.1
+- Multiple bug fixes
+- Added `third_party` folder for `pytorch_sac` and `dmc2gym`
+- Library now available in `pypi`
+
+## v0.1.0
Initial release
\ No newline at end of file
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 00000000..8686035f
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,6 @@
+include LICENSE README.md
+include requirements/*.txt
+include mbrl/examples/conf/*.yaml
+include mbrl/examples/conf/algorithm/*.yaml
+include mbrl/examples/conf/dynamics_model/*.yaml
+include mbrl/examples/conf/overrides/*.yaml
\ No newline at end of file
diff --git a/README.md b/README.md
index 39065eb1..12b55341 100644
--- a/README.md
+++ b/README.md
@@ -1,3 +1,4 @@
+[
[](https://github.com/facebookresearch/mbrl-lib/actions?query=workflow%3ACI)
[](https://github.com/facebookresearch/mbrl-lib/tree/master/LICENSE)
[](https://www.python.org/downloads/release/python-360/)
@@ -6,7 +7,7 @@
# MBRL-Lib
-``mbrl-lib`` is a toolbox for facilitating development of
+``mbrl`` is a toolbox for facilitating development of
Model-Based Reinforcement Learning algorithms. It provides easily interchangeable
modeling and planning components, and a set of utility functions that allow writing
model-based RL algorithms with only a few lines of code.
@@ -17,43 +18,28 @@ See also our companion [paper](https://arxiv.org/abs/2104.10159).
### Installation
-``mbrl-lib`` is a Python 3.7+ library. To install it, clone the repository,
+#### Standard Installation
- git clone https://github.com/facebookresearch/mbrl-lib.git
-
-then run
+``mbrl`` requires Python 3.7+ library and [PyTorch (>= 1.7)](https://pytorch.org).
+To install the latest stable version, run
- cd mbrl-lib
- pip install -e .
+ pip install mbrl
-If you are interested in contributing, please install the developer tools as well
+#### Developer installation
+If you are interested in modifying the library, clone the repository and set up
+a development environment as follows
+ git clone https://github.com/facebookresearch/mbrl-lib.git
pip install -e ".[dev]"
-Finally, make sure your Python environment has
-[PyTorch (>= 1.7)](https://pytorch.org) installed with the appropriate
-CUDA configuration for your system.
-
-For testing your installation, run
+And test it by running the following from the root folder of the repository
python -m pytest tests/core
python -m pytest tests/algorithms
-### Mujoco
-
-Mujoco is a popular library for testing RL methods. Installing Mujoco is not
-required to use most of the components and utilities in MBRL-Lib, but if you
-have a working Mujoco installation (and license) and want to test MBRL-Lib
-on it, please run
-
- pip install -r requirements/mujoco.txt
-
-and to test our mujoco-related utilities, run
-
- python -m pytest tests/mujoco
### Basic example
-As a starting point, check out our [tutorial notebook](notebooks/pets_example.ipynb)
+As a starting point, check out our [tutorial notebook](https://github.com/facebookresearch/mbrl-lib/tree/master/notebooks/pets_example.ipynb)
on how to write the PETS algorithm
([Chua et al., NeurIPS 2018](https://arxiv.org/pdf/1805.12114.pdf))
using our toolbox, and running it on a continuous version of the cartpole
@@ -62,20 +48,23 @@ environment.
## Provided algorithm implementations
MBRL-Lib provides implementations of popular MBRL algorithms
as examples of how to use this library. You can find them in the
-[mbrl/algorithms](mbrl/algorithms) folder. Currently, we have implemented
-[PETS](mbrl/algorithms/pets.py) and [MBPO](mbrl/algorithms/mbpo.py), and
+[mbrl/algorithms](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/algorithms) folder. Currently, we have implemented
+[PETS](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/algorithms/pets.py) and [MBPO](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/algorithms/mbpo.py), and
we plan to keep increasing this list in the near future.
The implementations rely on [Hydra](https://github.com/facebookresearch/hydra)
to handle configuration. You can see the configuration files in
-[this](conf) folder. The [overrides](conf/overrides) subfolder contains
+[this](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/examples/conf)
+folder.
+The [overrides](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/examples/conf/overrides)
+subfolder contains
environment specific configurations for each environment, overriding the
default configurations with the best hyperparameter values we have found so far
for each combination of algorithm and environment. You can run training
by passing the desired override option via command line.
For example, to run MBPO on the gym version of HalfCheetah, you should call
```python
-python main.py algorithm=mbpo overrides=mbpo_halfcheetah
+python -m mbrl.examples.main algorithm=mbpo overrides=mbpo_halfcheetah
```
By default, all algorithms will save results in a csv file called `results.csv`,
inside a folder whose path looks like
@@ -90,20 +79,27 @@ such as the type of dynamics model
(e.g., `dynamics_model=basic_ensemble`), or the number of models in the ensemble
(e.g., `dynamics_model.model.ensemble_size=some-number`). To learn more about
all the available options, take a look at the provided
-[configuration files](conf).
+[configuration files](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/examples/conf).
-Note that running the provided examples and `main.py` requires Mujoco, but
+### Note
+Running the provided examples requires Mujoco, but
you can try out the library components (and algorithms) on other environments
-by creating your own entry script and Hydra configuration.
+by creating your own entry script and Hydra configuration (see [examples].
+
+If you do have a working Mujoco installation (and license), you can check
+that it works correctly with our library by running
+(also requires [`dm_control`](https://github.com/deepmind/dm_control)).
+
+ python -m pytest tests/mujoco
## Visualization tools
Our library also contains a set of
-[visualization](mbrl/diagnostics) tools, meant to facilitate diagnostics and
-development of models and controllers. These currently require Mujoco installation, but we are
-planning to add more support and extensions in the future. Currently,
-the following tools are provided:
+[visualization](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/diagnostics) tools, meant to facilitate diagnostics and
+development of models and controllers. These currently require a Mujoco
+installation (see previous subsection), but we are planning to add support for other environments
+and extensions in the future. Currently, the following tools are provided:
-* [``Visualizer``](visualize_model_preds.py): Creates a video to qualitatively
+* ``Visualizer``: Creates a video to qualitatively
assess model predictions over a rolling horizon. Specifically, it runs a
user specified policy in a given environment, and at each time step, computes
the model's predicted observation/rewards over a lookahead horizon for the
@@ -116,35 +112,35 @@ assess model predictions over a rolling horizon. Specifically, it runs a
be trained independently. The following gif shows an example of 200 steps
of pre-trained MBPO policy on Inverted Pendulum environment.
- 
+ 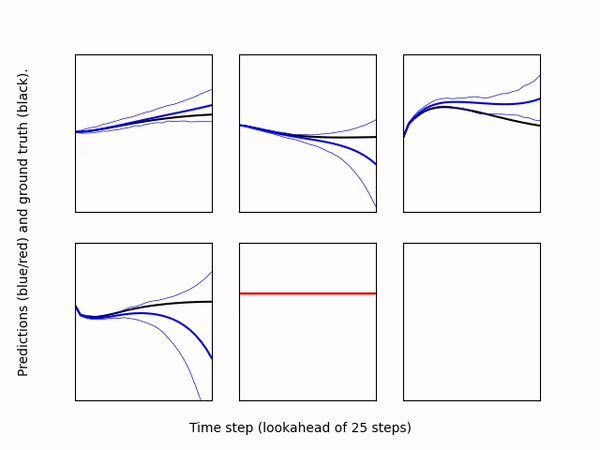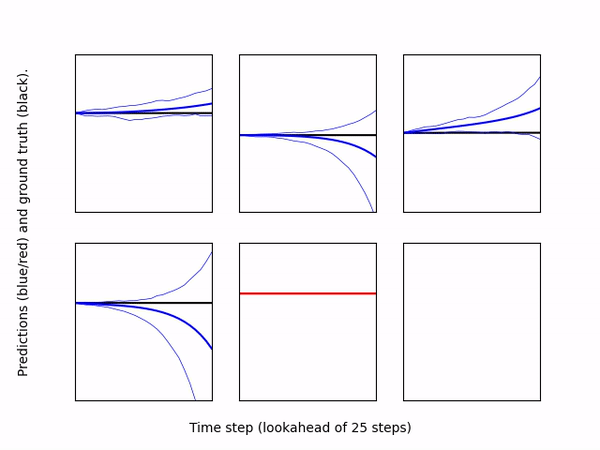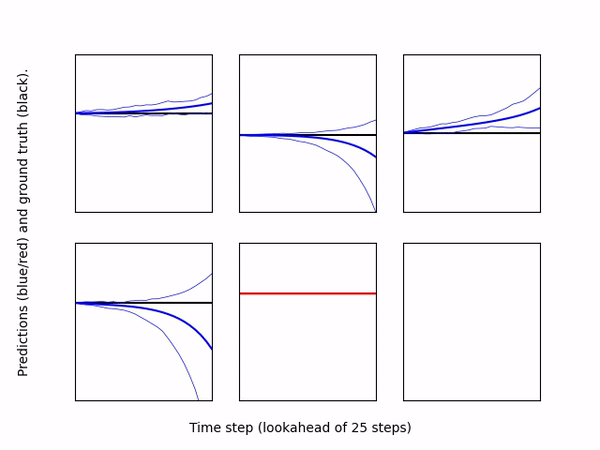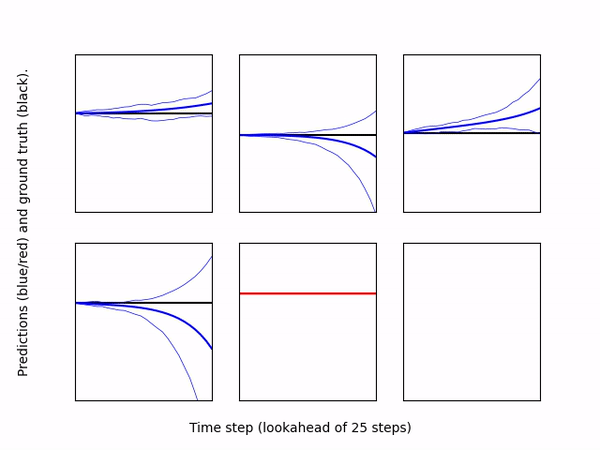
-* [``DatasetEvaluator``](eval_model_on_dataset.py): Loads a pre-trained model
+* ``DatasetEvaluator``: Loads a pre-trained model
and a dataset (can be loaded from separate directories), and computes
predictions of the model for each output dimension. The evaluator then
creates a scatter plot for each dimension comparing the ground truth output
vs. the model's prediction. If the model is an ensemble, the plot shows the
mean prediction as well as the individual predictions of each ensemble member.
- 
+ 
-* [``FineTuner``](finetune_model_with_controller.py): Can be used to train a
+* ``FineTuner``: Can be used to train a
model on a dataset produced by a given agent/controller. The model and agent
can be loaded from separate directories, and the fine tuner will roll the
environment for some number of steps using actions obtained from the
controller. The final model and dataset will then be saved under directory
"model_dir/diagnostics/subdir", where `subdir` is provided by the user.
-* [``True Dynamics Multi-CPU Controller``](control_env.py): This script can run
+* ``True Dynamics Multi-CPU Controller``: This script can run
a trajectory optimizer agent on the true environment using Python's
multiprocessing. Each environment runs in its own CPU, which can significantly
speed up costly sampling algorithm such as CEM. The controller will also save
a video if the ``render`` argument is passed. Below is an example on
HalfCheetah-v2 using CEM for trajectory optimization.
- 
+ 
Note that the tools above require Mujoco installation, and are specific to
-models of type [``OneDimTransitionRewardModel``](../models/one_dim_tr_model.py).
+models of type [``OneDimTransitionRewardModel``](https://github.com/facebookresearch/mbrl-lib/tree/master/mbrl/models/one_dim_tr_model.py).
We are planning to extend this in the future; if you have useful suggestions
don't hesitate to raise an issue or submit a pull request!
@@ -153,7 +149,7 @@ Please check out our **[documentation](https://facebookresearch.github.io/mbrl-l
and don't hesitate to raise issues or contribute if anything is unclear!
## License
-`mbrl-lib` is released under the MIT license. See [LICENSE](LICENSE) for
+`mbrl` is released under the MIT license. See [LICENSE](LICENSE) for
additional details about it. See also our
[Terms of Use](https://opensource.facebook.com/legal/terms) and
[Privacy Policy](https://opensource.facebook.com/legal/privacy).
diff --git a/docs/index.rst b/docs/index.rst
index 47658062..202e41d8 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -1,6 +1,6 @@
Documentation for mbrl-lib
========================================
-``mbrl-lib`` is library to facilitate research on Model-Based Reinforcement Learning.
+``mbrl`` is library to facilitate research on Model-Based Reinforcement Learning.
Getting started
===============
@@ -8,52 +8,33 @@ Getting started
Installation
------------
-``mbrl-lib`` is a Python 3.7+ library. To install it, clone the repository,
+Standard Installation
+^^^^^^^^^^^^^^^^^^^^^
+``mbrl`` requires Python 3.7+ and `PyTorch (>= 1.7) `_.
-.. code-block:: bash
-
- git clone https://github.com/facebookresearch/mbrl-lib.git
-
-then run
+To install the latest stable version, run
.. code-block:: bash
- cd mbrl-lib
- pip install -e .
+ pip install mbrl
-If you also want the developer tools for contributing, run
+Development Installation
+^^^^^^^^^^^^^^^^^^^^^^^^
+If you are interested in modifying parts of the library, you can clone the repository
+and set up a development environment, as follows
.. code-block:: bash
+ git clone https://github.com/facebookresearch/mbrl-lib.git
pip install -e ".[dev]"
-Finally, make sure your Python environment has
-`PyTorch (>= 1.7) `_ installed with the appropriate CUDA configuration
-for your system.
-
-
-To test your installation, run
+And test it by running
.. code-block:: bash
python -m pytest tests/core
+ python -m pytest tests/algorithms
-Mujoco
-------
-Mujoco is a popular library for testing RL methods. Installing Mujoco is not
-required to use most of the components and utilities in MBRL-Lib, but if you
-have a working Mujoco installation (and license) and want to test MBRL-Lib
-on it, you please install
-
-.. code-block:: bash
-
- pip install -r requirements/mujoco.txt
-
-and to test our mujoco-related utilities, run
-
-.. code-block:: bash
-
- python -m pytest tests/mujoco
Basic Example
-------------
diff --git a/mbrl/__init__.py b/mbrl/__init__.py
index e43ef635..25a5bce2 100644
--- a/mbrl/__init__.py
+++ b/mbrl/__init__.py
@@ -2,4 +2,4 @@
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
-__version__ = "0.1.0"
+__version__ = "0.1.1"
diff --git a/mbrl/algorithms/__init__.py b/mbrl/algorithms/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/mbrl/algorithms/mbpo.py b/mbrl/algorithms/mbpo.py
index 8eec8224..91290444 100644
--- a/mbrl/algorithms/mbpo.py
+++ b/mbrl/algorithms/mbpo.py
@@ -9,12 +9,12 @@
import hydra.utils
import numpy as np
import omegaconf
-import pytorch_sac.utils
import torch
import mbrl.constants
import mbrl.models
import mbrl.planning
+import mbrl.third_party.pytorch_sac as pytorch_sac
import mbrl.types
import mbrl.util
import mbrl.util.common
diff --git a/conf/algorithm/mbpo.yaml b/mbrl/examples/conf/algorithm/mbpo.yaml
similarity index 88%
rename from conf/algorithm/mbpo.yaml
rename to mbrl/examples/conf/algorithm/mbpo.yaml
index 8282e55d..7feac08a 100644
--- a/conf/algorithm/mbpo.yaml
+++ b/mbrl/examples/conf/algorithm/mbpo.yaml
@@ -15,7 +15,7 @@ num_eval_episodes: 1
# SAC Agent configuration
# --------------------------------------------
agent:
- _target_: pytorch_sac.agent.sac.SACAgent
+ _target_: mbrl.third_party.pytorch_sac.agent.sac.SACAgent
obs_dim: ??? # to be specified later
action_dim: ??? # to be specified later
action_range: ??? # to be specified later
@@ -38,14 +38,14 @@ agent:
target_entropy: ${overrides.sac_target_entropy}
double_q_critic:
- _target_: pytorch_sac.agent.critic.DoubleQCritic
+ _target_: mbrl.third_party.pytorch_sac.agent.critic.DoubleQCritic
obs_dim: ${algorithm.agent.obs_dim}
action_dim: ${algorithm.agent.action_dim}
hidden_dim: 1024
hidden_depth: ${overrides.sac_hidden_depth}
diag_gaussian_actor:
- _target_: pytorch_sac.agent.actor.DiagGaussianActor
+ _target_: mbrl.third_party.pytorch_sac.agent.actor.DiagGaussianActor
obs_dim: ${algorithm.agent.obs_dim}
action_dim: ${algorithm.agent.action_dim}
hidden_depth: ${overrides.sac_hidden_depth}
diff --git a/conf/algorithm/pets.yaml b/mbrl/examples/conf/algorithm/pets.yaml
similarity index 100%
rename from conf/algorithm/pets.yaml
rename to mbrl/examples/conf/algorithm/pets.yaml
diff --git a/conf/dynamics_model/basic_ensemble.yaml b/mbrl/examples/conf/dynamics_model/basic_ensemble.yaml
similarity index 100%
rename from conf/dynamics_model/basic_ensemble.yaml
rename to mbrl/examples/conf/dynamics_model/basic_ensemble.yaml
diff --git a/conf/dynamics_model/gaussian_mlp.yaml b/mbrl/examples/conf/dynamics_model/gaussian_mlp.yaml
similarity index 100%
rename from conf/dynamics_model/gaussian_mlp.yaml
rename to mbrl/examples/conf/dynamics_model/gaussian_mlp.yaml
diff --git a/conf/dynamics_model/gaussian_mlp_ensemble.yaml b/mbrl/examples/conf/dynamics_model/gaussian_mlp_ensemble.yaml
similarity index 100%
rename from conf/dynamics_model/gaussian_mlp_ensemble.yaml
rename to mbrl/examples/conf/dynamics_model/gaussian_mlp_ensemble.yaml
diff --git a/conf/main.yaml b/mbrl/examples/conf/main.yaml
similarity index 100%
rename from conf/main.yaml
rename to mbrl/examples/conf/main.yaml
diff --git a/conf/overrides/mbpo_ant.yaml b/mbrl/examples/conf/overrides/mbpo_ant.yaml
similarity index 100%
rename from conf/overrides/mbpo_ant.yaml
rename to mbrl/examples/conf/overrides/mbpo_ant.yaml
diff --git a/conf/overrides/mbpo_cartpole.yaml b/mbrl/examples/conf/overrides/mbpo_cartpole.yaml
similarity index 100%
rename from conf/overrides/mbpo_cartpole.yaml
rename to mbrl/examples/conf/overrides/mbpo_cartpole.yaml
diff --git a/conf/overrides/mbpo_halfcheetah.yaml b/mbrl/examples/conf/overrides/mbpo_halfcheetah.yaml
similarity index 100%
rename from conf/overrides/mbpo_halfcheetah.yaml
rename to mbrl/examples/conf/overrides/mbpo_halfcheetah.yaml
diff --git a/conf/overrides/mbpo_hopper.yaml b/mbrl/examples/conf/overrides/mbpo_hopper.yaml
similarity index 100%
rename from conf/overrides/mbpo_hopper.yaml
rename to mbrl/examples/conf/overrides/mbpo_hopper.yaml
diff --git a/conf/overrides/mbpo_humanoid.yaml b/mbrl/examples/conf/overrides/mbpo_humanoid.yaml
similarity index 100%
rename from conf/overrides/mbpo_humanoid.yaml
rename to mbrl/examples/conf/overrides/mbpo_humanoid.yaml
diff --git a/conf/overrides/mbpo_inv_pendulum.yaml b/mbrl/examples/conf/overrides/mbpo_inv_pendulum.yaml
similarity index 100%
rename from conf/overrides/mbpo_inv_pendulum.yaml
rename to mbrl/examples/conf/overrides/mbpo_inv_pendulum.yaml
diff --git a/conf/overrides/mbpo_pusher.yaml b/mbrl/examples/conf/overrides/mbpo_pusher.yaml
similarity index 100%
rename from conf/overrides/mbpo_pusher.yaml
rename to mbrl/examples/conf/overrides/mbpo_pusher.yaml
diff --git a/conf/overrides/mbpo_walker.yaml b/mbrl/examples/conf/overrides/mbpo_walker.yaml
similarity index 100%
rename from conf/overrides/mbpo_walker.yaml
rename to mbrl/examples/conf/overrides/mbpo_walker.yaml
diff --git a/conf/overrides/pets_cartpole.yaml b/mbrl/examples/conf/overrides/pets_cartpole.yaml
similarity index 100%
rename from conf/overrides/pets_cartpole.yaml
rename to mbrl/examples/conf/overrides/pets_cartpole.yaml
diff --git a/conf/overrides/pets_halfcheetah.yaml b/mbrl/examples/conf/overrides/pets_halfcheetah.yaml
similarity index 100%
rename from conf/overrides/pets_halfcheetah.yaml
rename to mbrl/examples/conf/overrides/pets_halfcheetah.yaml
diff --git a/conf/overrides/pets_hopper.yaml b/mbrl/examples/conf/overrides/pets_hopper.yaml
similarity index 100%
rename from conf/overrides/pets_hopper.yaml
rename to mbrl/examples/conf/overrides/pets_hopper.yaml
diff --git a/conf/overrides/pets_inv_pendulum.yaml b/mbrl/examples/conf/overrides/pets_inv_pendulum.yaml
similarity index 100%
rename from conf/overrides/pets_inv_pendulum.yaml
rename to mbrl/examples/conf/overrides/pets_inv_pendulum.yaml
diff --git a/conf/overrides/pets_pusher.yaml b/mbrl/examples/conf/overrides/pets_pusher.yaml
similarity index 100%
rename from conf/overrides/pets_pusher.yaml
rename to mbrl/examples/conf/overrides/pets_pusher.yaml
diff --git a/conf/overrides/pets_reacher.yaml b/mbrl/examples/conf/overrides/pets_reacher.yaml
similarity index 100%
rename from conf/overrides/pets_reacher.yaml
rename to mbrl/examples/conf/overrides/pets_reacher.yaml
diff --git a/main.py b/mbrl/examples/main.py
similarity index 100%
rename from main.py
rename to mbrl/examples/main.py
diff --git a/mbrl/planning/core.py b/mbrl/planning/core.py
index fc0635d4..0da2a616 100644
--- a/mbrl/planning/core.py
+++ b/mbrl/planning/core.py
@@ -132,8 +132,11 @@ def load_agent(agent_path: Union[str, pathlib.Path], env: gym.Env) -> Agent:
agent_path = pathlib.Path(agent_path)
cfg = omegaconf.OmegaConf.load(agent_path / ".hydra" / "config.yaml")
- if cfg.algorithm.agent._target_ == "pytorch_sac.agent.sac.SACAgent":
- import pytorch_sac
+ if (
+ cfg.algorithm.agent._target_
+ == "mbrl.third_party.pytorch_sac.agent.sac.SACAgent"
+ ):
+ import mbrl.third_party.pytorch_sac as pytorch_sac
from .sac_wrapper import SACAgent
diff --git a/mbrl/planning/sac_wrapper.py b/mbrl/planning/sac_wrapper.py
index 30255f84..66579843 100644
--- a/mbrl/planning/sac_wrapper.py
+++ b/mbrl/planning/sac_wrapper.py
@@ -3,10 +3,11 @@
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import numpy as np
-import pytorch_sac
-import pytorch_sac.utils
import torch
+import mbrl.third_party.pytorch_sac as pytorch_sac
+import mbrl.third_party.pytorch_sac.utils as pytorch_sac_utils
+
from .core import Agent
@@ -40,5 +41,5 @@ def act(
Returns:
(np.ndarray): the action.
"""
- with pytorch_sac.utils.eval_mode(), torch.no_grad():
+ with pytorch_sac_utils.eval_mode(), torch.no_grad():
return self.sac_agent.act(obs, sample=sample, batched=batched)
diff --git a/mbrl/third_party/__init__.py b/mbrl/third_party/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/mbrl/third_party/dmc2gym/LICENSE b/mbrl/third_party/dmc2gym/LICENSE
new file mode 100644
index 00000000..4f5235d7
--- /dev/null
+++ b/mbrl/third_party/dmc2gym/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2020 Denis Yarats
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/mbrl/third_party/dmc2gym/README.md b/mbrl/third_party/dmc2gym/README.md
new file mode 100644
index 00000000..ae71cfe8
--- /dev/null
+++ b/mbrl/third_party/dmc2gym/README.md
@@ -0,0 +1,25 @@
+# OpenAI Gym wrapper for the DeepMind Control Suite.
+A lightweight wrapper around the DeepMind Control Suite that provides the standard OpenAI Gym interface. The wrapper allows to specify the following:
+* Reliable random seed initialization that will ensure deterministic behaviour.
+* Setting ```from_pixels=True``` converts proprioceptive observations into image-based. In additional, you can choose the image dimensions, by setting ```height``` and ```width```.
+* Action space normalization bound each action's coordinate into the ```[-1, 1]``` range.
+* Setting ```frame_skip``` argument lets to perform action repeat.
+
+
+### Instalation
+```
+pip install git+git://github.com/denisyarats/dmc2gym.git
+```
+
+### Usage
+```python
+import dmc2gym
+
+env = dmc2gym.make(domain_name='point_mass', task_name='easy', seed=1)
+
+done = False
+obs = env.reset()
+while not done:
+ action = env.action_space.sample()
+ obs, reward, done, info = env.step(action)
+```
diff --git a/mbrl/third_party/dmc2gym/__init__.py b/mbrl/third_party/dmc2gym/__init__.py
new file mode 100644
index 00000000..07b89084
--- /dev/null
+++ b/mbrl/third_party/dmc2gym/__init__.py
@@ -0,0 +1,54 @@
+import gym
+from gym.envs.registration import register
+
+
+def make(
+ domain_name,
+ task_name,
+ seed=1,
+ visualize_reward=True,
+ from_pixels=False,
+ height=84,
+ width=84,
+ camera_id=0,
+ frame_skip=1,
+ episode_length=1000,
+ environment_kwargs=None,
+ time_limit=None,
+ channels_first=True,
+):
+ env_id = "dmc_%s_%s_%s-v1" % (domain_name, task_name, seed)
+
+ if from_pixels:
+ assert (
+ not visualize_reward
+ ), "cannot use visualize reward when learning from pixels"
+
+ # shorten episode length
+ max_episode_steps = (episode_length + frame_skip - 1) // frame_skip
+
+ if not env_id in gym.envs.registry.env_specs:
+ task_kwargs = {}
+ if seed is not None:
+ task_kwargs["random"] = seed
+ if time_limit is not None:
+ task_kwargs["time_limit"] = time_limit
+ register(
+ id=env_id,
+ entry_point="mbrl.third_party.dmc2gym.wrappers:DMCWrapper",
+ kwargs=dict(
+ domain_name=domain_name,
+ task_name=task_name,
+ task_kwargs=task_kwargs,
+ environment_kwargs=environment_kwargs,
+ visualize_reward=visualize_reward,
+ from_pixels=from_pixels,
+ height=height,
+ width=width,
+ camera_id=camera_id,
+ frame_skip=frame_skip,
+ channels_first=channels_first,
+ ),
+ max_episode_steps=max_episode_steps,
+ )
+ return gym.make(env_id)
diff --git a/mbrl/third_party/dmc2gym/setup.py b/mbrl/third_party/dmc2gym/setup.py
new file mode 100644
index 00000000..0f6226a1
--- /dev/null
+++ b/mbrl/third_party/dmc2gym/setup.py
@@ -0,0 +1,17 @@
+import os
+
+from setuptools import find_packages, setup
+
+setup(
+ name="dmc2gym",
+ version="1.0.0",
+ author="Denis Yarats",
+ description=("a gym like wrapper for dm_control"),
+ license="",
+ keywords="gym dm_control openai deepmind",
+ packages=find_packages(),
+ install_requires=[
+ "gym",
+ "dm_control",
+ ],
+)
diff --git a/mbrl/third_party/dmc2gym/wrappers.py b/mbrl/third_party/dmc2gym/wrappers.py
new file mode 100644
index 00000000..3cb248ca
--- /dev/null
+++ b/mbrl/third_party/dmc2gym/wrappers.py
@@ -0,0 +1,164 @@
+import numpy as np
+from dm_control import suite
+from dm_env import specs
+from gym import core, spaces
+
+
+def _spec_to_box(spec):
+ def extract_min_max(s):
+ assert s.dtype == np.float64 or s.dtype == np.float32
+ dim = np.int(np.prod(s.shape))
+ if type(s) == specs.Array:
+ bound = np.inf * np.ones(dim, dtype=np.float32)
+ return -bound, bound
+ elif type(s) == specs.BoundedArray:
+ zeros = np.zeros(dim, dtype=np.float32)
+ return s.minimum + zeros, s.maximum + zeros
+
+ mins, maxs = [], []
+ for s in spec:
+ mn, mx = extract_min_max(s)
+ mins.append(mn)
+ maxs.append(mx)
+ low = np.concatenate(mins, axis=0)
+ high = np.concatenate(maxs, axis=0)
+ assert low.shape == high.shape
+ return spaces.Box(low, high, dtype=np.float32)
+
+
+def _flatten_obs(obs):
+ obs_pieces = []
+ for v in obs.values():
+ flat = np.array([v]) if np.isscalar(v) else v.ravel()
+ obs_pieces.append(flat)
+ return np.concatenate(obs_pieces, axis=0)
+
+
+class DMCWrapper(core.Env):
+ def __init__(
+ self,
+ domain_name,
+ task_name,
+ task_kwargs=None,
+ visualize_reward={},
+ from_pixels=False,
+ height=84,
+ width=84,
+ camera_id=0,
+ frame_skip=1,
+ environment_kwargs=None,
+ channels_first=True,
+ ):
+ assert (
+ "random" in task_kwargs
+ ), "please specify a seed, for deterministic behaviour"
+ self._from_pixels = from_pixels
+ self._height = height
+ self._width = width
+ self._camera_id = camera_id
+ self._frame_skip = frame_skip
+ self._channels_first = channels_first
+
+ # create task
+ self._env = suite.load(
+ domain_name=domain_name,
+ task_name=task_name,
+ task_kwargs=task_kwargs,
+ visualize_reward=visualize_reward,
+ environment_kwargs=environment_kwargs,
+ )
+
+ # true and normalized action spaces
+ self._true_action_space = _spec_to_box([self._env.action_spec()])
+ self._norm_action_space = spaces.Box(
+ low=-1.0, high=1.0, shape=self._true_action_space.shape, dtype=np.float32
+ )
+
+ # create observation space
+ if from_pixels:
+ shape = [3, height, width] if channels_first else [height, width, 3]
+ self._observation_space = spaces.Box(
+ low=0, high=255, shape=shape, dtype=np.uint8
+ )
+ else:
+ self._observation_space = _spec_to_box(
+ self._env.observation_spec().values()
+ )
+
+ self._state_space = _spec_to_box(self._env.observation_spec().values())
+
+ self.current_state = None
+
+ # set seed
+ self.seed(seed=task_kwargs.get("random", 1))
+
+ def __getattr__(self, name):
+ return getattr(self._env, name)
+
+ def _get_obs(self, time_step):
+ if self._from_pixels:
+ obs = self.render(
+ height=self._height, width=self._width, camera_id=self._camera_id
+ )
+ if self._channels_first:
+ obs = obs.transpose(2, 0, 1).copy()
+ else:
+ obs = _flatten_obs(time_step.observation)
+ return obs
+
+ def _convert_action(self, action):
+ action = action.astype(np.float64)
+ true_delta = self._true_action_space.high - self._true_action_space.low
+ norm_delta = self._norm_action_space.high - self._norm_action_space.low
+ action = (action - self._norm_action_space.low) / norm_delta
+ action = action * true_delta + self._true_action_space.low
+ action = action.astype(np.float32)
+ return action
+
+ @property
+ def observation_space(self):
+ return self._observation_space
+
+ @property
+ def state_space(self):
+ return self._state_space
+
+ @property
+ def action_space(self):
+ return self._norm_action_space
+
+ def seed(self, seed):
+ self._true_action_space.seed(seed)
+ self._norm_action_space.seed(seed)
+ self._observation_space.seed(seed)
+
+ def step(self, action):
+ assert self._norm_action_space.contains(action)
+ action = self._convert_action(action)
+ assert self._true_action_space.contains(action)
+ reward = 0
+ extra = {"internal_state": self._env.physics.get_state().copy()}
+
+ for _ in range(self._frame_skip):
+ time_step = self._env.step(action)
+ reward += time_step.reward or 0
+ done = time_step.last()
+ if done:
+ break
+ obs = self._get_obs(time_step)
+ self.current_state = _flatten_obs(time_step.observation)
+ extra["discount"] = time_step.discount
+ return obs, reward, done, extra
+
+ def reset(self):
+ time_step = self._env.reset()
+ self.current_state = _flatten_obs(time_step.observation)
+ obs = self._get_obs(time_step)
+ return obs
+
+ def render(self, mode="rgb_array", height=None, width=None, camera_id=0):
+ assert mode == "rgb_array", "only support rgb_array mode, given %s" % mode
+ height = height or self._height
+ width = width or self._width
+ camera_id = camera_id or self._camera_id
+ return self._env.physics.render(height=height, width=width, camera_id=camera_id)
diff --git a/mbrl/third_party/pytorch_sac/LICENSE b/mbrl/third_party/pytorch_sac/LICENSE
new file mode 100644
index 00000000..bb03a07d
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2019 Denis Yarats
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/mbrl/third_party/pytorch_sac/README.md b/mbrl/third_party/pytorch_sac/README.md
new file mode 100644
index 00000000..4337796e
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/README.md
@@ -0,0 +1,36 @@
+# Soft Actor-Critic (SAC) implementation in PyTorch
+
+This is PyTorch implementation of Soft Actor-Critic (SAC) [[ArXiv]](https://arxiv.org/abs/1812.05905).
+
+If you use this code in your research project please cite us as:
+```
+@misc{pytorch_sac,
+ author = {Yarats, Denis and Kostrikov, Ilya},
+ title = {Soft Actor-Critic (SAC) implementation in PyTorch},
+ year = {2020},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/denisyarats/pytorch_sac}},
+}
+```
+
+## Requirements
+We assume you have access to a gpu that can run CUDA 9.2. Then, the simplest way to install all required dependencies is to create an anaconda environment and activate it:
+```
+conda env create -f conda_env.yml
+source activate pytorch_sac
+```
+
+## Instructions
+To train an SAC agent on the `cheetah run` task run:
+```
+python train.py env=cheetah_run
+```
+This will produce `exp` folder, where all the outputs are going to be stored including train/eval logs, tensorboard blobs, and evaluation episode videos. One can attacha tensorboard to monitor training by running:
+```
+tensorboard --logdir exp
+```
+
+## Results
+An extensive benchmarking of SAC on the DM Control Suite against D4PG. We plot an average performance of SAC over 5 seeds together with p95 confidence intervals. Importantly, we keep the hyperparameters fixed across all the tasks. Note that results for D4PG are reported after 10^8 steps and taken from the original paper.
+
diff --git a/mbrl/third_party/pytorch_sac/__init__.py b/mbrl/third_party/pytorch_sac/__init__.py
new file mode 100644
index 00000000..46d7a61f
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/__init__.py
@@ -0,0 +1,7 @@
+from .agent import Agent
+from .agent.sac import SACAgent
+from .logger import Logger
+from .replay_buffer import ReplayBuffer
+from .video import VideoRecorder
+
+__all__ = ["ReplayBuffer", "Agent", "SACAgent", "Logger", "VideoRecorder"]
diff --git a/mbrl/third_party/pytorch_sac/agent/__init__.py b/mbrl/third_party/pytorch_sac/agent/__init__.py
new file mode 100644
index 00000000..758eb1a9
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/agent/__init__.py
@@ -0,0 +1,19 @@
+import abc
+
+
+class Agent(object):
+ def reset(self):
+ """For state-full agents this function performs reseting at the beginning of each episode."""
+ pass
+
+ @abc.abstractmethod
+ def train(self, training=True):
+ """Sets the agent in either training or evaluation mode."""
+
+ @abc.abstractmethod
+ def update(self, replay_buffer, logger, step):
+ """Main function of the agent that performs learning."""
+
+ @abc.abstractmethod
+ def act(self, obs, sample=False, batched=False):
+ """Issues an action given an observation."""
diff --git a/mbrl/third_party/pytorch_sac/agent/actor.py b/mbrl/third_party/pytorch_sac/agent/actor.py
new file mode 100644
index 00000000..149876d1
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/agent/actor.py
@@ -0,0 +1,92 @@
+import math
+
+import torch
+import torch.nn.functional as F
+from torch import distributions as pyd
+from torch import nn
+
+from mbrl.third_party.pytorch_sac import utils
+
+
+class TanhTransform(pyd.transforms.Transform):
+ domain = pyd.constraints.real
+ codomain = pyd.constraints.interval(-1.0, 1.0)
+ bijective = True
+ sign = +1
+
+ def __init__(self, cache_size=1):
+ super().__init__(cache_size=cache_size)
+
+ @staticmethod
+ def atanh(x):
+ return 0.5 * (x.log1p() - (-x).log1p())
+
+ def __eq__(self, other):
+ return isinstance(other, TanhTransform)
+
+ def _call(self, x):
+ return x.tanh()
+
+ def _inverse(self, y):
+ # We do not clamp to the boundary here as it may degrade the performance of certain algorithms.
+ # one should use `cache_size=1` instead
+ return self.atanh(y)
+
+ def log_abs_det_jacobian(self, x, y):
+ # We use a formula that is more numerically stable, see details in the following link
+ # https://github.com/tensorflow/probability/commit/ef6bb176e0ebd1cf6e25c6b5cecdd2428c22963f#diff-e120f70e92e6741bca649f04fcd907b7
+ return 2.0 * (math.log(2.0) - x - F.softplus(-2.0 * x))
+
+
+class SquashedNormal(pyd.transformed_distribution.TransformedDistribution):
+ def __init__(self, loc, scale):
+ self.loc = loc
+ self.scale = scale
+
+ self.base_dist = pyd.Normal(loc, scale)
+ transforms = [TanhTransform()]
+ super().__init__(self.base_dist, transforms)
+
+ @property
+ def mean(self):
+ mu = self.loc
+ for tr in self.transforms:
+ mu = tr(mu)
+ return mu
+
+
+class DiagGaussianActor(nn.Module):
+ """torch.distributions implementation of an diagonal Gaussian policy."""
+
+ def __init__(self, obs_dim, action_dim, hidden_dim, hidden_depth, log_std_bounds):
+ super().__init__()
+
+ self.log_std_bounds = log_std_bounds
+ self.trunk = utils.mlp(obs_dim, hidden_dim, 2 * action_dim, hidden_depth)
+
+ self.outputs = dict()
+ self.apply(utils.weight_init)
+
+ def forward(self, obs):
+ mu, log_std = self.trunk(obs).chunk(2, dim=-1)
+
+ # constrain log_std inside [log_std_min, log_std_max]
+ log_std = torch.tanh(log_std)
+ log_std_min, log_std_max = self.log_std_bounds
+ log_std = log_std_min + 0.5 * (log_std_max - log_std_min) * (log_std + 1)
+
+ std = log_std.exp()
+
+ self.outputs["mu"] = mu
+ self.outputs["std"] = std
+
+ dist = SquashedNormal(mu, std)
+ return dist
+
+ def log(self, logger, step):
+ for k, v in self.outputs.items():
+ logger.log_histogram(f"train_actor/{k}_hist", v, step)
+
+ for i, m in enumerate(self.trunk):
+ if type(m) == nn.Linear:
+ logger.log_param(f"train_actor/fc{i}", m, step)
diff --git a/mbrl/third_party/pytorch_sac/agent/critic.py b/mbrl/third_party/pytorch_sac/agent/critic.py
new file mode 100644
index 00000000..7941d563
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/agent/critic.py
@@ -0,0 +1,40 @@
+import torch
+from torch import nn
+
+from mbrl.third_party.pytorch_sac import utils
+
+
+class DoubleQCritic(nn.Module):
+ """Critic network, employes double Q-learning."""
+
+ def __init__(self, obs_dim, action_dim, hidden_dim, hidden_depth):
+ super().__init__()
+
+ self.Q1 = utils.mlp(obs_dim + action_dim, hidden_dim, 1, hidden_depth)
+ self.Q2 = utils.mlp(obs_dim + action_dim, hidden_dim, 1, hidden_depth)
+
+ self.outputs = dict()
+ self.apply(utils.weight_init)
+
+ def forward(self, obs, action):
+ assert obs.size(0) == action.size(0)
+
+ obs_action = torch.cat([obs, action], dim=-1)
+ q1 = self.Q1(obs_action)
+ q2 = self.Q2(obs_action)
+
+ self.outputs["q1"] = q1
+ self.outputs["q2"] = q2
+
+ return q1, q2
+
+ def log(self, logger, step):
+ for k, v in self.outputs.items():
+ logger.log_histogram(f"train_critic/{k}_hist", v, step)
+
+ assert len(self.Q1) == len(self.Q2)
+ for i, (m1, m2) in enumerate(zip(self.Q1, self.Q2)):
+ assert type(m1) == type(m2)
+ if type(m1) is nn.Linear:
+ logger.log_param(f"train_critic/q1_fc{i}", m1, step)
+ logger.log_param(f"train_critic/q2_fc{i}", m2, step)
diff --git a/mbrl/third_party/pytorch_sac/agent/sac.py b/mbrl/third_party/pytorch_sac/agent/sac.py
new file mode 100644
index 00000000..86f3041b
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/agent/sac.py
@@ -0,0 +1,171 @@
+import pathlib
+
+import hydra
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+from mbrl.third_party.pytorch_sac import utils
+from mbrl.third_party.pytorch_sac.agent import Agent
+
+
+class SACAgent(Agent):
+ """SAC algorithm."""
+
+ def __init__(
+ self,
+ obs_dim,
+ action_dim,
+ action_range,
+ device,
+ critic_cfg,
+ actor_cfg,
+ discount,
+ init_temperature,
+ alpha_lr,
+ alpha_betas,
+ actor_lr,
+ actor_betas,
+ actor_update_frequency,
+ critic_lr,
+ critic_betas,
+ critic_tau,
+ critic_target_update_frequency,
+ batch_size,
+ learnable_temperature,
+ target_entropy=None,
+ ):
+ super().__init__()
+
+ self.action_range = action_range
+ self.device = torch.device(device)
+ self.discount = discount
+ self.critic_tau = critic_tau
+ self.actor_update_frequency = actor_update_frequency
+ self.critic_target_update_frequency = critic_target_update_frequency
+ self.batch_size = batch_size
+ self.learnable_temperature = learnable_temperature
+
+ self.critic = hydra.utils.instantiate(critic_cfg).to(self.device)
+ self.critic_target = hydra.utils.instantiate(critic_cfg).to(self.device)
+ self.critic_target.load_state_dict(self.critic.state_dict())
+
+ self.actor = hydra.utils.instantiate(actor_cfg).to(self.device)
+
+ self.log_alpha = torch.tensor(np.log(init_temperature)).to(self.device)
+ self.log_alpha.requires_grad = True
+ # default target entropy to -|A|
+ self.target_entropy = target_entropy if target_entropy else -action_dim
+
+ # optimizers
+ self.actor_optimizer = torch.optim.Adam(
+ self.actor.parameters(), lr=actor_lr, betas=actor_betas
+ )
+
+ self.critic_optimizer = torch.optim.Adam(
+ self.critic.parameters(), lr=critic_lr, betas=critic_betas
+ )
+
+ self.log_alpha_optimizer = torch.optim.Adam(
+ [self.log_alpha], lr=alpha_lr, betas=alpha_betas
+ )
+
+ self.train()
+ self.critic_target.train()
+
+ def train(self, training=True):
+ self.training = training
+ self.actor.train(training)
+ self.critic.train(training)
+
+ @property
+ def alpha(self):
+ return self.log_alpha.exp()
+
+ def act(self, obs, sample=False, batched=False):
+ obs = torch.FloatTensor(obs).to(self.device)
+ if not batched:
+ obs = obs.unsqueeze(0)
+ dist = self.actor(obs)
+ action = dist.sample() if sample else dist.mean
+ action = action.clamp(*self.action_range)
+ if not batched:
+ assert action.ndim == 2 and action.shape[0] == 1
+ return utils.to_np(action[0])
+ assert action.ndim == 2
+ return utils.to_np(action)
+
+ def update_critic(self, obs, action, reward, next_obs, not_done, logger, step):
+ dist = self.actor(next_obs)
+ next_action = dist.rsample()
+ log_prob = dist.log_prob(next_action).sum(-1, keepdim=True)
+ target_Q1, target_Q2 = self.critic_target(next_obs, next_action)
+ target_V = torch.min(target_Q1, target_Q2) - self.alpha.detach() * log_prob
+ target_Q = reward + (not_done * self.discount * target_V)
+ target_Q = target_Q.detach()
+
+ # get current Q estimates
+ current_Q1, current_Q2 = self.critic(obs, action)
+ critic_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(
+ current_Q2, target_Q
+ )
+ logger.log("train_critic/loss", critic_loss, step)
+
+ # Optimize the critic
+ self.critic_optimizer.zero_grad()
+ critic_loss.backward()
+ self.critic_optimizer.step()
+
+ self.critic.log(logger, step)
+
+ def update_actor_and_alpha(self, obs, logger, step):
+ dist = self.actor(obs)
+ action = dist.rsample()
+ log_prob = dist.log_prob(action).sum(-1, keepdim=True)
+ actor_Q1, actor_Q2 = self.critic(obs, action)
+
+ actor_Q = torch.min(actor_Q1, actor_Q2)
+ actor_loss = (self.alpha.detach() * log_prob - actor_Q).mean()
+
+ logger.log("train_actor/loss", actor_loss, step)
+ logger.log("train_actor/target_entropy", self.target_entropy, step)
+ logger.log("train_actor/entropy", -log_prob.mean(), step)
+
+ # optimize the actor
+ self.actor_optimizer.zero_grad()
+ actor_loss.backward()
+ self.actor_optimizer.step()
+
+ self.actor.log(logger, step)
+
+ if self.learnable_temperature:
+ self.log_alpha_optimizer.zero_grad()
+ alpha_loss = (
+ self.alpha * (-log_prob - self.target_entropy).detach()
+ ).mean()
+ logger.log("train_alpha/loss", alpha_loss, step)
+ logger.log("train_alpha/value", self.alpha, step)
+ alpha_loss.backward()
+ self.log_alpha_optimizer.step()
+
+ def update(self, replay_buffer, logger, step):
+ obs, action, reward, next_obs, not_done, not_done_no_max = replay_buffer.sample(
+ self.batch_size
+ )
+
+ logger.log("train/batch_reward", reward.mean(), step)
+
+ self.update_critic(obs, action, reward, next_obs, not_done_no_max, logger, step)
+
+ if step % self.actor_update_frequency == 0:
+ self.update_actor_and_alpha(obs, logger, step)
+
+ if step % self.critic_target_update_frequency == 0:
+ utils.soft_update_params(self.critic, self.critic_target, self.critic_tau)
+
+ def save(self, save_dir):
+ critic_path = save_dir / "critic.pth"
+ actor_path = save_dir / "actor.pth"
+
+ torch.save(self.critic.state_dict(), critic_path)
+ torch.save(self.actor.state_dict(), actor_path)
diff --git a/mbrl/third_party/pytorch_sac/conda_env.yml b/mbrl/third_party/pytorch_sac/conda_env.yml
new file mode 100644
index 00000000..eb790e69
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/conda_env.yml
@@ -0,0 +1,17 @@
+name: pytorch_sac
+channels:
+ - defaults
+dependencies:
+ - python=3.6
+ - pytorch
+ - cudatoolkit=9.2
+ - absl-py
+ - pyparsing
+ - pip:
+ - termcolor
+ - git+git://github.com/deepmind/dm_control.git
+ - git+git://github.com/denisyarats/dmc2gym.git
+ - tb-nightly
+ - imageio
+ - imageio-ffmpeg
+ - hydra-core
diff --git a/mbrl/third_party/pytorch_sac/config/agent/sac.yaml b/mbrl/third_party/pytorch_sac/config/agent/sac.yaml
new file mode 100644
index 00000000..a2c7d94f
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/config/agent/sac.yaml
@@ -0,0 +1,37 @@
+# @package _global_
+agent:
+ _target_: pytorch_sac.agent.sac.SACAgent
+ obs_dim: ??? # to be specified later
+ action_dim: ??? # to be specified later
+ action_range: ??? # to be specified later
+ device: ${device}
+ critic_cfg: ${double_q_critic}
+ actor_cfg: ${diag_gaussian_actor}
+ discount: 0.99
+ init_temperature: 0.1
+ alpha_lr: 1e-4
+ alpha_betas: [0.9, 0.999]
+ actor_lr: 1e-4
+ actor_betas: [0.9, 0.999]
+ actor_update_frequency: 1
+ critic_lr: 1e-4
+ critic_betas: [0.9, 0.999]
+ critic_tau: 0.005
+ critic_target_update_frequency: 2
+ batch_size: 1024
+ learnable_temperature: true
+
+double_q_critic:
+ _target_: pytorch_sac.agent.critic.DoubleQCritic
+ obs_dim: ${agent.obs_dim}
+ action_dim: ${agent.action_dim}
+ hidden_dim: 1024
+ hidden_depth: 2
+
+diag_gaussian_actor:
+ _target_: pytorch_sac.agent.actor.DiagGaussianActor
+ obs_dim: ${agent.obs_dim}
+ action_dim: ${agent.action_dim}
+ hidden_depth: 2
+ hidden_dim: 1024
+ log_std_bounds: [-5, 2]
\ No newline at end of file
diff --git a/mbrl/third_party/pytorch_sac/config/train.yaml b/mbrl/third_party/pytorch_sac/config/train.yaml
new file mode 100644
index 00000000..b89719ba
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/config/train.yaml
@@ -0,0 +1,34 @@
+defaults:
+ - agent: sac
+
+env: cheetah_run
+
+# this needs to be specified manually
+experiment: test_exp
+
+num_train_steps: 1e6
+replay_buffer_capacity: ${num_train_steps}
+
+num_seed_steps: 5000
+
+eval_frequency: 10000
+num_eval_episodes: 10
+
+device: cuda
+
+# logger
+log_frequency: 10000
+log_save_tb: true
+
+# video recorder
+save_video: true
+
+
+seed: 1
+
+exp_name: default
+
+## hydra configuration
+hydra:
+ run:
+ dir: ./exp/${exp_name}/${env}/${now:%Y.%m.%d}/${now:%H%M}_sac_${experiment}
\ No newline at end of file
diff --git a/mbrl/third_party/pytorch_sac/figures/dm_control.png b/mbrl/third_party/pytorch_sac/figures/dm_control.png
new file mode 100644
index 00000000..b06df901
Binary files /dev/null and b/mbrl/third_party/pytorch_sac/figures/dm_control.png differ
diff --git a/mbrl/third_party/pytorch_sac/logger.py b/mbrl/third_party/pytorch_sac/logger.py
new file mode 100644
index 00000000..a9d747b5
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/logger.py
@@ -0,0 +1,212 @@
+import csv
+import os
+import shutil
+from collections import defaultdict
+
+import numpy as np
+import torch
+from termcolor import colored
+from torch.utils.tensorboard import SummaryWriter
+
+COMMON_TRAIN_FORMAT = [
+ ("episode", "E", "int"),
+ ("step", "S", "int"),
+ ("episode_reward", "R", "float"),
+ ("duration", "D", "time"),
+]
+
+COMMON_EVAL_FORMAT = [
+ ("episode", "E", "int"),
+ ("step", "S", "int"),
+ ("episode_reward", "R", "float"),
+]
+
+
+AGENT_TRAIN_FORMAT = {
+ "sac": [
+ ("batch_reward", "BR", "float"),
+ ("actor_loss", "ALOSS", "float"),
+ ("critic_loss", "CLOSS", "float"),
+ ("alpha_loss", "TLOSS", "float"),
+ ("alpha_value", "TVAL", "float"),
+ ("actor_entropy", "AENT", "float"),
+ ]
+}
+
+
+class AverageMeter(object):
+ def __init__(self):
+ self._sum = 0
+ self._count = 0
+
+ def update(self, value, n=1):
+ self._sum += value
+ self._count += n
+
+ def value(self):
+ return self._sum / max(1, self._count)
+
+
+class MetersGroup(object):
+ def __init__(self, file_name, formating):
+ self._csv_file_name = self._prepare_file(file_name, "csv")
+ self._formating = formating
+ self._meters = defaultdict(AverageMeter)
+ self._csv_file = open(self._csv_file_name, "w")
+ self._csv_writer = None
+
+ def _prepare_file(self, prefix, suffix):
+ file_name = f"{prefix}.{suffix}"
+ if os.path.exists(file_name):
+ os.remove(file_name)
+ return file_name
+
+ def log(self, key, value, n=1):
+ self._meters[key].update(value, n)
+
+ def _prime_meters(self):
+ data = dict()
+ for key, meter in self._meters.items():
+ if key.startswith("train"):
+ key = key[len("train") + 1 :]
+ else:
+ key = key[len("eval") + 1 :]
+ key = key.replace("/", "_")
+ data[key] = meter.value()
+ return data
+
+ def _dump_to_csv(self, data):
+ if self._csv_writer is None:
+ self._csv_writer = csv.DictWriter(
+ self._csv_file, fieldnames=sorted(data.keys()), restval=0.0
+ )
+ self._csv_writer.writeheader()
+ self._csv_writer.writerow(data)
+ self._csv_file.flush()
+
+ def _format(self, key, value, ty):
+ if ty == "int":
+ value = int(value)
+ return f"{key}: {value}"
+ elif ty == "float":
+ return f"{key}: {value:.04f}"
+ elif ty == "time":
+ return f"{key}: {value:04.1f} s"
+ else:
+ raise ValueError(f"invalid format type: {ty}")
+
+ def _dump_to_console(self, data, prefix):
+ prefix = colored(prefix, "yellow" if prefix == "train" else "green")
+ pieces = [f"| {prefix: <14}"]
+ for key, disp_key, ty in self._formating:
+ value = data.get(key, 0)
+ pieces.append(self._format(disp_key, value, ty))
+ print(" | ".join(pieces))
+
+ def dump(self, step, prefix, save=True):
+ if len(self._meters) == 0:
+ return
+ if save:
+ data = self._prime_meters()
+ data["step"] = step
+ self._dump_to_csv(data)
+ self._dump_to_console(data, prefix)
+ self._meters.clear()
+
+
+class Logger(object):
+ def __init__(
+ self,
+ log_dir,
+ save_tb=False,
+ log_frequency=10000,
+ agent="sac",
+ train_format=None,
+ eval_format=None,
+ ):
+ self._log_dir = log_dir
+ self._log_frequency = log_frequency
+ if save_tb:
+ tb_dir = os.path.join(log_dir, "tb")
+ if os.path.exists(tb_dir):
+ try:
+ shutil.rmtree(tb_dir)
+ except:
+ print("logger.py warning: Unable to remove tb directory")
+ pass
+ self._sw = SummaryWriter(tb_dir)
+ else:
+ self._sw = None
+ if not train_format:
+ # each agent has specific output format for training
+ assert agent in AGENT_TRAIN_FORMAT
+ train_format = COMMON_TRAIN_FORMAT + AGENT_TRAIN_FORMAT[agent]
+ eval_format = eval_format if eval_format else COMMON_EVAL_FORMAT
+ self._train_mg = MetersGroup(
+ os.path.join(log_dir, f"{agent}_train"), formating=train_format
+ )
+ self._eval_mg = MetersGroup(
+ os.path.join(log_dir, f"{agent}_eval"), formating=eval_format
+ )
+
+ def _should_log(self, step, log_frequency):
+ log_frequency = log_frequency or self._log_frequency
+ return step % log_frequency == 0
+
+ def _try_sw_log(self, key, value, step):
+ if self._sw is not None:
+ self._sw.add_scalar(key, value, step)
+
+ def _try_sw_log_video(self, key, frames, step):
+ if self._sw is not None:
+ frames = torch.from_numpy(np.array(frames))
+ frames = frames.unsqueeze(0)
+ self._sw.add_video(key, frames, step, fps=30)
+
+ def _try_sw_log_histogram(self, key, histogram, step):
+ if self._sw is not None:
+ self._sw.add_histogram(key, histogram, step)
+
+ def log(self, key, value, step, n=1, log_frequency=1):
+ if not self._should_log(step, log_frequency):
+ return
+ assert key.startswith("train") or key.startswith("eval")
+ if type(value) == torch.Tensor:
+ value = value.item()
+ self._try_sw_log(key, value / n, step)
+ mg = self._train_mg if key.startswith("train") else self._eval_mg
+ mg.log(key, value, n)
+
+ def log_param(self, key, param, step, log_frequency=None):
+ if not self._should_log(step, log_frequency):
+ return
+ self.log_histogram(key + "_w", param.weight.data, step)
+ if hasattr(param.weight, "grad") and param.weight.grad is not None:
+ self.log_histogram(key + "_w_g", param.weight.grad.data, step)
+ if hasattr(param, "bias") and hasattr(param.bias, "data"):
+ self.log_histogram(key + "_b", param.bias.data, step)
+ if hasattr(param.bias, "grad") and param.bias.grad is not None:
+ self.log_histogram(key + "_b_g", param.bias.grad.data, step)
+
+ def log_video(self, key, frames, step, log_frequency=None):
+ if not self._should_log(step, log_frequency):
+ return
+ assert key.startswith("train") or key.startswith("eval")
+ self._try_sw_log_video(key, frames, step)
+
+ def log_histogram(self, key, histogram, step, log_frequency=None):
+ if not self._should_log(step, log_frequency):
+ return
+ assert key.startswith("train") or key.startswith("eval")
+ self._try_sw_log_histogram(key, histogram, step)
+
+ def dump(self, step, save=True, ty=None):
+ if ty is None:
+ self._train_mg.dump(step, "train", save)
+ self._eval_mg.dump(step, "eval", save)
+ elif ty == "eval":
+ self._eval_mg.dump(step, "eval", save)
+ elif ty == "train":
+ self._train_mg.dump(step, "train", save)
+ else:
+ raise ValueError(f"invalid log type: {ty}")
diff --git a/mbrl/third_party/pytorch_sac/replay_buffer.py b/mbrl/third_party/pytorch_sac/replay_buffer.py
new file mode 100644
index 00000000..67c47ef1
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/replay_buffer.py
@@ -0,0 +1,81 @@
+import numpy as np
+import torch
+
+
+class ReplayBuffer(object):
+ """Buffer to store environment transitions."""
+
+ def __init__(self, obs_shape, action_shape, capacity, device):
+ self.capacity = capacity
+ self.device = device
+
+ # the proprioceptive obs is stored as float32, pixels obs as uint8
+ obs_dtype = np.float32 if len(obs_shape) == 1 else np.uint8
+
+ self.obses = np.empty((capacity, *obs_shape), dtype=obs_dtype)
+ self.next_obses = np.empty((capacity, *obs_shape), dtype=obs_dtype)
+ self.actions = np.empty((capacity, *action_shape), dtype=np.float32)
+ self.rewards = np.empty((capacity, 1), dtype=np.float32)
+ self.not_dones = np.empty((capacity, 1), dtype=np.float32)
+ self.not_dones_no_max = np.empty((capacity, 1), dtype=np.float32)
+
+ self.idx = 0
+ self.last_save = 0
+ self.full = False
+
+ def __len__(self):
+ return self.capacity if self.full else self.idx
+
+ def add(self, obs, action, reward, next_obs, done, done_no_max):
+ np.copyto(self.obses[self.idx], obs)
+ np.copyto(self.actions[self.idx], action)
+ np.copyto(self.rewards[self.idx], reward)
+ np.copyto(self.next_obses[self.idx], next_obs)
+ np.copyto(self.not_dones[self.idx], not done)
+ np.copyto(self.not_dones_no_max[self.idx], not done_no_max)
+
+ self.idx = (self.idx + 1) % self.capacity
+ self.full = self.full or self.idx == 0
+
+ def add_batch(self, obs, action, reward, next_obs, done, done_no_max):
+ def copy_from_to(buffer_start, batch_start, how_many):
+ buffer_slice = slice(buffer_start, buffer_start + how_many)
+ batch_slice = slice(batch_start, batch_start + how_many)
+ np.copyto(self.obses[buffer_slice], obs[batch_slice])
+ np.copyto(self.actions[buffer_slice], action[batch_slice])
+ np.copyto(self.rewards[buffer_slice], reward[batch_slice])
+ np.copyto(self.next_obses[buffer_slice], next_obs[batch_slice])
+ np.copyto(self.not_dones[buffer_slice], np.logical_not(done[batch_slice]))
+ np.copyto(
+ self.not_dones_no_max[buffer_slice],
+ np.logical_not(done_no_max[batch_slice]),
+ )
+
+ _batch_start = 0
+ buffer_end = self.idx + len(obs)
+ if buffer_end > self.capacity:
+ copy_from_to(self.idx, _batch_start, self.capacity - self.idx)
+ _batch_start = self.capacity - self.idx
+ self.idx = 0
+ self.full = True
+
+ _how_many = len(obs) - _batch_start
+ copy_from_to(self.idx, _batch_start, _how_many)
+ self.idx = (self.idx + _how_many) % self.capacity
+ self.full = self.full or self.idx == 0
+
+ def sample(self, batch_size):
+ idxs = np.random.randint(
+ 0, self.capacity if self.full else self.idx, size=batch_size
+ )
+
+ obses = torch.as_tensor(self.obses[idxs], device=self.device).float()
+ actions = torch.as_tensor(self.actions[idxs], device=self.device)
+ rewards = torch.as_tensor(self.rewards[idxs], device=self.device)
+ next_obses = torch.as_tensor(self.next_obses[idxs], device=self.device).float()
+ not_dones = torch.as_tensor(self.not_dones[idxs], device=self.device)
+ not_dones_no_max = torch.as_tensor(
+ self.not_dones_no_max[idxs], device=self.device
+ )
+
+ return obses, actions, rewards, next_obses, not_dones, not_dones_no_max
diff --git a/mbrl/third_party/pytorch_sac/setup.py b/mbrl/third_party/pytorch_sac/setup.py
new file mode 100644
index 00000000..d1b35e9d
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/setup.py
@@ -0,0 +1,21 @@
+import re
+
+from setuptools import find_packages, setup
+
+install_requires = [line.rstrip() for line in open("requirements/main.txt", "r")]
+
+with open("README.md", "r") as f:
+ long_description = f.read()
+
+setup(
+ name="pytorch_sac",
+ version="0.0.1",
+ author="Denis Yarats",
+ long_description=long_description,
+ long_description_content_type="text/markdown",
+ url="https://github.com/denisyarats/pytorch_sac",
+ packages=find_packages(),
+ install_requires=install_requires,
+ include_package_data=True,
+ zip_safe=False,
+)
diff --git a/mbrl/third_party/pytorch_sac/train.py b/mbrl/third_party/pytorch_sac/train.py
new file mode 100755
index 00000000..220795c3
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/train.py
@@ -0,0 +1,139 @@
+#!/usr/bin/env python3
+import os
+import pathlib
+import time
+
+import hydra
+import numpy as np
+import torch
+from pytorch_sac import utils
+from pytorch_sac.logger import Logger
+from pytorch_sac.replay_buffer import ReplayBuffer
+from pytorch_sac.video import VideoRecorder
+
+
+class Workspace(object):
+ def __init__(self, cfg):
+ self.work_dir = os.getcwd()
+ print(f"workspace: {self.work_dir}")
+
+ self.cfg = cfg
+
+ self.logger = Logger(
+ self.work_dir,
+ save_tb=cfg.log_save_tb,
+ log_frequency=cfg.log_frequency,
+ agent="sac",
+ )
+
+ utils.set_seed_everywhere(cfg.seed)
+ self.device = torch.device(cfg.device)
+ self.env = utils.make_env(cfg)
+
+ cfg.agent.obs_dim = self.env.observation_space.shape[0]
+ cfg.agent.action_dim = self.env.action_space.shape[0]
+ cfg.agent.action_range = [
+ float(self.env.action_space.low.min()),
+ float(self.env.action_space.high.max()),
+ ]
+ self.agent = hydra.utils.instantiate(cfg.agent)
+
+ self.replay_buffer = ReplayBuffer(
+ self.env.observation_space.shape,
+ self.env.action_space.shape,
+ int(cfg.replay_buffer_capacity),
+ self.device,
+ )
+
+ self.video_recorder = VideoRecorder(self.work_dir if cfg.save_video else None)
+ self.step = 0
+
+ def evaluate(self):
+ average_episode_reward = 0
+ for episode in range(self.cfg.num_eval_episodes):
+ obs = self.env.reset()
+ self.agent.reset()
+ self.video_recorder.init(enabled=(episode == 0))
+ done = False
+ episode_reward = 0
+ while not done:
+ with utils.eval_mode(self.agent):
+ action = self.agent.act(obs, sample=False)
+ obs, reward, done, _ = self.env.step(action)
+ self.video_recorder.record(self.env)
+ episode_reward += reward
+
+ average_episode_reward += episode_reward
+ self.video_recorder.save(f"{self.step}.mp4")
+ average_episode_reward /= self.cfg.num_eval_episodes
+ self.logger.log("eval/episode_reward", average_episode_reward, self.step)
+ self.logger.dump(self.step)
+ return average_episode_reward
+
+ def run(self):
+ episode, episode_reward, done = 0, 0, True
+ start_time = time.time()
+ best_eval_score = -np.inf
+ while self.step < self.cfg.num_train_steps:
+ if done:
+ if self.step > 0:
+ self.logger.log(
+ "train/duration", time.time() - start_time, self.step
+ )
+ start_time = time.time()
+ self.logger.dump(
+ self.step, save=(self.step > self.cfg.num_seed_steps)
+ )
+
+ self.logger.log("train/episode_reward", episode_reward, self.step)
+
+ obs = self.env.reset()
+ self.agent.reset()
+ done = False
+ episode_reward = 0
+ episode_step = 0
+ episode += 1
+
+ self.logger.log("train/episode", episode, self.step)
+
+ # sample action for data collection
+ if self.step < self.cfg.num_seed_steps:
+ action = self.env.action_space.sample()
+ else:
+ with utils.eval_mode(self.agent):
+ action = self.agent.act(obs, sample=True)
+
+ # run training update
+ if self.step >= self.cfg.num_seed_steps:
+ self.agent.update(self.replay_buffer, self.logger, self.step)
+
+ next_obs, reward, done, _ = self.env.step(action)
+
+ # allow infinite bootstrap
+ done = float(done)
+ done_no_max = 0 if episode_step + 1 == self.env._max_episode_steps else done
+ episode_reward += reward
+
+ self.replay_buffer.add(obs, action, reward, next_obs, done, done_no_max)
+
+ obs = next_obs
+ episode_step += 1
+ self.step += 1
+
+ # evaluate agent periodically
+ if self.step % self.cfg.eval_frequency == 0:
+ self.logger.log("eval/episode", episode, self.step)
+ score = self.evaluate()
+ if score > best_eval_score:
+ best_eval_score = score
+ self.agent.save(pathlib.Path(self.work_dir))
+
+
+@hydra.main(config_path="config/train.yaml")
+def main(cfg):
+ workspace = Workspace(cfg)
+ workspace.run()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/mbrl/third_party/pytorch_sac/utils.py b/mbrl/third_party/pytorch_sac/utils.py
new file mode 100644
index 00000000..53a6c999
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/utils.py
@@ -0,0 +1,136 @@
+import math
+import os
+import random
+from collections import deque
+
+import gym
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import distributions as pyd
+from torch import nn
+
+
+def make_env(cfg):
+ """Helper function to create dm_control or gym environment"""
+
+ if "gym___" in cfg.env:
+ env = gym.make(cfg.env.split("___")[1])
+ else:
+ import mbrl.third_party.dmc2gym as dmc2gym
+
+ if cfg.env == "ball_in_cup_catch":
+ domain_name = "ball_in_cup"
+ task_name = "catch"
+ else:
+ domain_name = cfg.env.split("_")[0]
+ task_name = "_".join(cfg.env.split("_")[1:])
+
+ env = dmc2gym.make(
+ domain_name=domain_name,
+ task_name=task_name,
+ seed=cfg.seed,
+ visualize_reward=True,
+ )
+ env.seed(cfg.seed)
+ assert env.action_space.low.min() >= -1
+ assert env.action_space.high.max() <= 1
+
+ return env
+
+
+class eval_mode(object):
+ def __init__(self, *models):
+ self.models = models
+
+ def __enter__(self):
+ self.prev_states = []
+ for model in self.models:
+ self.prev_states.append(model.training)
+ model.train(False)
+
+ def __exit__(self, *args):
+ for model, state in zip(self.models, self.prev_states):
+ model.train(state)
+ return False
+
+
+class train_mode(object):
+ def __init__(self, *models):
+ self.models = models
+
+ def __enter__(self):
+ self.prev_states = []
+ for model in self.models:
+ self.prev_states.append(model.training)
+ model.train(True)
+
+ def __exit__(self, *args):
+ for model, state in zip(self.models, self.prev_states):
+ model.train(state)
+ return False
+
+
+def soft_update_params(net, target_net, tau):
+ for param, target_param in zip(net.parameters(), target_net.parameters()):
+ target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
+
+
+def set_seed_everywhere(seed):
+ torch.manual_seed(seed)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(seed)
+ np.random.seed(seed)
+ random.seed(seed)
+
+
+def make_dir(*path_parts):
+ dir_path = os.path.join(*path_parts)
+ try:
+ os.mkdir(dir_path)
+ except OSError:
+ pass
+ return dir_path
+
+
+def weight_init(m):
+ """Custom weight init for Conv2D and Linear layers."""
+ if isinstance(m, nn.Linear):
+ nn.init.orthogonal_(m.weight.data)
+ if hasattr(m.bias, "data"):
+ m.bias.data.fill_(0.0)
+
+
+class MLP(nn.Module):
+ def __init__(
+ self, input_dim, hidden_dim, output_dim, hidden_depth, output_mod=None
+ ):
+ super().__init__()
+ self.trunk = mlp(input_dim, hidden_dim, output_dim, hidden_depth, output_mod)
+ self.apply(weight_init)
+
+ def forward(self, x):
+ return self.trunk(x)
+
+
+def mlp(input_dim, hidden_dim, output_dim, hidden_depth, output_mod=None):
+ if hidden_depth == 0:
+ mods = [nn.Linear(input_dim, output_dim)]
+ else:
+ mods = [nn.Linear(input_dim, hidden_dim), nn.ReLU(inplace=True)]
+ for i in range(hidden_depth - 1):
+ mods += [nn.Linear(hidden_dim, hidden_dim), nn.ReLU(inplace=True)]
+ mods.append(nn.Linear(hidden_dim, output_dim))
+ if output_mod is not None:
+ mods.append(output_mod)
+ trunk = nn.Sequential(*mods)
+ return trunk
+
+
+def to_np(t):
+ if t is None:
+ return None
+ elif t.nelement() == 0:
+ return np.array([])
+ else:
+ return t.cpu().detach().numpy()
diff --git a/mbrl/third_party/pytorch_sac/video.py b/mbrl/third_party/pytorch_sac/video.py
new file mode 100644
index 00000000..dfe33eeb
--- /dev/null
+++ b/mbrl/third_party/pytorch_sac/video.py
@@ -0,0 +1,34 @@
+import os
+
+import imageio
+
+from mbrl.third_party.pytorch_sac import utils
+
+
+class VideoRecorder(object):
+ def __init__(self, root_dir, height=256, width=256, camera_id=0, fps=30):
+ self.save_dir = utils.make_dir(root_dir, "video") if root_dir else None
+ self.height = height
+ self.width = width
+ self.camera_id = camera_id
+ self.fps = fps
+ self.frames = []
+
+ def init(self, enabled=True):
+ self.frames = []
+ self.enabled = self.save_dir is not None and enabled
+
+ def record(self, env):
+ if self.enabled:
+ frame = env.render(
+ mode="rgb_array",
+ height=self.height,
+ width=self.width,
+ camera_id=self.camera_id,
+ )
+ self.frames.append(frame)
+
+ def save(self, file_name):
+ if self.enabled:
+ path = os.path.join(self.save_dir, file_name)
+ imageio.mimsave(path, self.frames, fps=self.fps)
diff --git a/mbrl/util/mujoco.py b/mbrl/util/mujoco.py
index 0e6735cf..63b9d549 100644
--- a/mbrl/util/mujoco.py
+++ b/mbrl/util/mujoco.py
@@ -5,14 +5,11 @@
from typing import Optional, Tuple, Union, cast
import gym
-import gym.envs.mujoco
import gym.wrappers
import numpy as np
import omegaconf
import torch
-import mbrl.env
-import mbrl.env.mujoco_envs
import mbrl.planning
import mbrl.types
@@ -64,7 +61,8 @@ def make_env(
``cfg.learned_rewards == True``).
"""
if "dmcontrol___" in cfg.overrides.env:
- import dmc2gym.wrappers
+ import mbrl.env
+ import mbrl.third_party.dmc2gym as dmc2gym
domain, task = cfg.overrides.env.split("___")[1].split("--")
term_fn = getattr(mbrl.env.termination_fns, domain)
@@ -74,6 +72,8 @@ def make_env(
reward_fn = getattr(mbrl.env.reward_fns, cfg.overrides.term_fn, None)
env = dmc2gym.make(domain_name=domain, task_name=task)
elif "gym___" in cfg.overrides.env:
+ import mbrl.env
+
env = gym.make(cfg.overrides.env.split("___")[1])
term_fn = getattr(mbrl.env.termination_fns, cfg.overrides.term_fn)
if hasattr(cfg.overrides, "reward_fn") and cfg.overrides.reward_fn is not None:
@@ -81,6 +81,8 @@ def make_env(
else:
reward_fn = getattr(mbrl.env.reward_fns, cfg.overrides.term_fn, None)
else:
+ import mbrl.env.mujoco_envs
+
if cfg.overrides.env == "cartpole_continuous":
env = mbrl.env.cartpole_continuous.CartPoleEnv()
term_fn = mbrl.env.termination_fns.cartpole
@@ -144,13 +146,15 @@ def make_env_from_str(env_name: str) -> gym.Env:
(gym.Env): the created environment.
"""
if "dmcontrol___" in env_name:
- import dmc2gym.wrappers
+ import mbrl.third_party.dmc2gym as dmc2gym
domain, task = env_name.split("___")[1].split("--")
env = dmc2gym.make(domain_name=domain, task_name=task)
elif "gym___" in env_name:
env = gym.make(env_name.split("___")[1])
else:
+ import mbrl.env.mujoco_envs
+
if env_name == "cartpole_continuous":
env = mbrl.env.cartpole_continuous.CartPoleEnv()
elif env_name == "pets_halfcheetah":
@@ -201,17 +205,14 @@ def __init__(self, env: gym.wrappers.TimeLimit):
self._elapsed_steps = 0
self._step_count = 0
- if isinstance(self._env.env, gym.envs.mujoco.MujocoEnv):
+ if "gym.envs.mujoco" in self._env.env.__class__.__module__:
self._enter_method = self._enter_mujoco_gym
self._exit_method = self._exit_mujoco_gym
+ elif "mbrl.third_party.dmc2gym" in self._env.env.__class__.__module__:
+ self._enter_method = self._enter_dmcontrol
+ self._exit_method = self._exit_dmcontrol
else:
- import dmc2gym.wrappers
-
- if isinstance(self._env.env, dmc2gym.wrappers.DMCWrapper):
- self._enter_method = self._enter_dmcontrol
- self._exit_method = self._exit_dmcontrol
- else:
- raise RuntimeError("Tried to freeze an unsupported environment.")
+ raise RuntimeError("Tried to freeze an unsupported environment.")
def _enter_mujoco_gym(self):
self._init_state = (
@@ -260,25 +261,22 @@ def get_current_state(env: gym.wrappers.TimeLimit) -> Tuple:
environments it returns `physics.get_state().copy()`, elapsed steps and step_count.
"""
- if isinstance(env.env, gym.envs.mujoco.MujocoEnv):
+ if "gym.envs.mujoco" in env.env.__class__.__module__:
state = (
env.env.data.qpos.ravel().copy(),
env.env.data.qvel.ravel().copy(),
)
elapsed_steps = env._elapsed_steps
return state, elapsed_steps
+ elif "mbrl.third_party.dmc2gym" in env.env.__class__.__module__:
+ state = env.env._env.physics.get_state().copy()
+ elapsed_steps = env._elapsed_steps
+ step_count = env.env._env._step_count
+ return state, elapsed_steps, step_count
else:
- import dmc2gym.wrappers
-
- if isinstance(env.env, dmc2gym.wrappers.DMCWrapper):
- state = env.env._env.physics.get_state().copy()
- elapsed_steps = env._elapsed_steps
- step_count = env.env._env._step_count
- return state, elapsed_steps, step_count
- else:
- raise NotImplementedError(
- "Only gym mujoco and dm_control environments supported by get_current_state."
- )
+ raise NotImplementedError(
+ "Only gym mujoco and dm_control environments supported."
+ )
def set_env_state(state: Tuple, env: gym.wrappers.TimeLimit):
@@ -293,19 +291,18 @@ def set_env_state(state: Tuple, env: gym.wrappers.TimeLimit):
state (tuple): see :func:`get_current_state` for a description.
env (:class:`gym.wrappers.TimeLimit`): the environment.
"""
- if isinstance(env.env, gym.envs.mujoco.MujocoEnv):
+ if "gym.envs.mujoco" in env.env.__class__.__module__:
env.set_state(*state[0])
env._elapsed_steps = state[1]
+ elif "mbrl.third_party.dmc2gym" in env.env.__class__.__module__:
+ with env.env._env.physics.reset_context():
+ env.env._env.physics.set_state(state[0])
+ env._elapsed_steps = state[1]
+ env.env._env._step_count = state[2]
else:
- import dmc2gym.wrappers
-
- if isinstance(env.env, dmc2gym.wrappers.DMCWrapper):
- with env.env._env.physics.reset_context():
- env.env._env.physics.set_state(state[0])
- env._elapsed_steps = state[1]
- env.env._env._step_count = state[2]
- else:
- raise NotImplementedError
+ raise NotImplementedError(
+ "Only gym mujoco and dm_control environments supported."
+ )
def rollout_mujoco_env(
diff --git a/pyproyect.toml b/pyproyect.toml
new file mode 100644
index 00000000..43e6846b
--- /dev/null
+++ b/pyproyect.toml
@@ -0,0 +1,20 @@
+[build-system]
+requires = [
+ "setuptools>=42",
+ "wheel"
+]
+build-backend = "setuptools.build_meta"
+
+[tool.black]
+line-length = 88
+exclude = '''
+(
+ /(
+ .eggs # exclude a few common directories in the
+ | .git # root of the project
+ | .mypy_cache
+ | docs
+ | *personal*
+ )
+)
+'''
\ No newline at end of file
diff --git a/requirements/main.txt b/requirements/main.txt
index 09e34775..5b83e4da 100644
--- a/requirements/main.txt
+++ b/requirements/main.txt
@@ -8,4 +8,3 @@ gym==0.17.2
jupyter>=1.0.0
pytest>=6.0.1
sk-video>=1.1.10
-pytorch_sac@git+https://github.com/luisenp/pytorch_sac.git
diff --git a/requirements/mujoco.txt b/requirements/mujoco.txt
deleted file mode 100644
index 30ec1056..00000000
--- a/requirements/mujoco.txt
+++ /dev/null
@@ -1,3 +0,0 @@
-mujoco-py>=2.0.0
-dm_control @ git+https://github.com/deepmind/dm_control.git
-dmc2gym @ git+https://github.com/denisyarats/dmc2gym.git
diff --git a/setup.cfg b/setup.cfg
index 3818ecb5..2c7ef07c 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -7,6 +7,8 @@ per-file-ignores =
mbrl/diagnostics/__init__.py:F401
mbrl/env/mujoco_envs.py:F401
tests/*:F401
+exclude =
+ mbrl/third_party/*
[mypy]
python_version = 3.7
diff --git a/setup.py b/setup.py
index a4efb972..e260abe9 100644
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,6 @@
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
from pathlib import Path
-import re
from setuptools import setup, find_packages
@@ -19,28 +18,28 @@ def parse_requirements_file(path):
init_str = Path("mbrl/__init__.py").read_text()
-match = re.search(r"^__version__ = \"(?P[\w\.]+?)\"$", init_str, re.MULTILINE)
-assert match is not None, "Could not find version in mbrl/__init__.py"
-version = match.group("version")
+version = init_str.split("__version__ = ")[1].rstrip().strip('"')
setup(
- name="mbrl_lib",
+ name="mbrl",
version=version,
author="Facebook AI Research",
- author_email="lep@fb.com",
+ description="A PyTorch library for model-based reinforcement learning research",
long_description=long_description,
long_description_content_type="text/markdown",
url="https://github.com/facebookresearch/mbrl-lib",
packages=find_packages(),
classifiers=[
- "License :: MIT License",
+ "License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
],
install_requires=reqs_main,
- extras_require={"dev": reqs_main + reqs_dev},
+ extras_require={
+ "dev": reqs_main + reqs_dev,
+ },
include_package_data=True,
python_requires=">=3.7",
zip_safe=False,
diff --git a/tests/algorithms/test_algorithms.py b/tests/algorithms/test_algorithms.py
index 380c6bae..384b0b0a 100644
--- a/tests/algorithms/test_algorithms.py
+++ b/tests/algorithms/test_algorithms.py
@@ -3,6 +3,7 @@
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import os
+import pathlib
import random
import tempfile
@@ -22,11 +23,12 @@
_NUM_TRIALS_MBPO = 10
_REW_C = 0.001
_INITIAL_EXPLORE = 500
+_CONF_DIR = pathlib.Path("mbrl") / "examples" / "conf"
# Not optimal, but the prob. of observing this by random seems to be < 1e-5
_TARGET_REWARD = -10 * _REW_C
-_REPO_DIR = os.getcwd()
+_REPO_DIR = pathlib.Path(os.getcwd())
_DIR = tempfile.TemporaryDirectory()
_SILENT = True
@@ -74,11 +76,11 @@ def mock_reward_fn(action, obs):
# TODO replace this using pytest fixture
def _check_pets(model_type):
- with open(os.path.join(_REPO_DIR, "conf/algorithm/pets.yaml"), "r") as f:
+ with open(_REPO_DIR / _CONF_DIR / "algorithm" / "pets.yaml", "r") as f:
algorithm_cfg = yaml.safe_load(f)
with open(
- os.path.join(_REPO_DIR, f"conf/dynamics_model/{model_type}.yaml"), "r"
+ _REPO_DIR / _CONF_DIR / "dynamics_model" / f"{model_type}.yaml", "r"
) as f:
model_cfg = yaml.safe_load(f)
@@ -132,11 +134,12 @@ def test_pets_basic_ensemble_deterministic_mlp():
def test_mbpo():
- with open(os.path.join(_REPO_DIR, "conf/algorithm/mbpo.yaml"), "r") as f:
+ with open(_REPO_DIR / _CONF_DIR / "algorithm" / "mbpo.yaml", "r") as f:
algorithm_cfg = yaml.safe_load(f)
with open(
- os.path.join(_REPO_DIR, "conf/dynamics_model/gaussian_mlp_ensemble.yaml"), "r"
+ _REPO_DIR / _CONF_DIR / "dynamics_model" / "gaussian_mlp_ensemble.yaml",
+ "r",
) as f:
model_cfg = yaml.safe_load(f)
diff --git a/tests/core/test_replay_buffer.py b/tests/core/test_replay_buffer.py
index c8f9f913..8bff90fd 100644
--- a/tests/core/test_replay_buffer.py
+++ b/tests/core/test_replay_buffer.py
@@ -4,9 +4,9 @@
# LICENSE file in the root directory of this source tree.
import numpy as np
import pytest
-import pytorch_sac.replay_buffer as sac_buffer
import torch
+import mbrl.third_party.pytorch_sac.replay_buffer as sac_buffer
import mbrl.util.replay_buffer as replay_buffer
from mbrl.types import TransitionBatch
diff --git a/tests/mujoco/test_diagnostics.py b/tests/mujoco/test_diagnostics.py
index 861897b2..4aed4697 100644
--- a/tests/mujoco/test_diagnostics.py
+++ b/tests/mujoco/test_diagnostics.py
@@ -17,7 +17,7 @@
import mbrl.planning as planning
import mbrl.util.common
-_REPO_DIR = os.getcwd()
+_REPO_DIR = pathlib.Path(os.getcwd())
_DIR = tempfile.TemporaryDirectory()
_HYDRA_DIR = pathlib.Path(_DIR.name) / ".hydra"
pathlib.Path.mkdir(_HYDRA_DIR)
@@ -27,10 +27,12 @@
_ENV = gym.make(_ENV_NAME)
_OBS_SHAPE = _ENV.observation_space.shape
_ACT_SHAPE = _ENV.action_space.shape
+_CONF_DIR = pathlib.Path("mbrl") / "examples" / "conf"
# Creating config files
with open(
- os.path.join(_REPO_DIR, "conf/dynamics_model/gaussian_mlp_ensemble.yaml"), "r"
+ _REPO_DIR / _CONF_DIR / "dynamics_model" / "gaussian_mlp_ensemble.yaml",
+ "r",
) as f:
_MODEL_CFG = yaml.safe_load(f)
@@ -52,8 +54,8 @@
"device": "cuda:0" if torch.cuda.is_available() else "cpu",
}
-# Config file for loafing a pytorch_sac agent
-with open(os.path.join(_REPO_DIR, "conf/algorithm/mbpo.yaml"), "r") as f:
+# Config file for loading a pytorch_sac agent
+with open(_REPO_DIR / _CONF_DIR / "algorithm" / "mbpo.yaml", "r") as f:
_MBPO__ALGO_CFG = yaml.safe_load(f)
_MBPO_CFG_DICT = _CFG_DICT.copy()
_MBPO_CFG_DICT["algorithm"] = _MBPO__ALGO_CFG
@@ -75,7 +77,7 @@
)
# Extend default config file with information for a trajectory optimizer agent
-with open(os.path.join(_REPO_DIR, "conf/algorithm/pets.yaml"), "r") as f:
+with open(_REPO_DIR / _CONF_DIR / "algorithm" / "pets.yaml", "r") as f:
_PETS_ALGO_CFG = yaml.safe_load(f)
_CFG_DICT["algorithm"].update(_PETS_ALGO_CFG)
_CFG_DICT["algorithm"]["learned_rewards"] = True
diff --git a/tests/mujoco/test_util.py b/tests/mujoco/test_util.py
index 451d5c31..a6f45d1c 100644
--- a/tests/mujoco/test_util.py
+++ b/tests/mujoco/test_util.py
@@ -2,11 +2,11 @@
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
-import dmc2gym
import gym
import numpy as np
import pytest
+import mbrl.third_party.dmc2gym as dmc2gym
import mbrl.util.mujoco