diff --git a/.all-contributorsrc b/.all-contributorsrc
index 9bcfc017..a3b6732b 100644
--- a/.all-contributorsrc
+++ b/.all-contributorsrc
@@ -41,6 +41,13 @@
"profile": "https://github.com/shanzehbatool",
"contributions": []
},
+ {
+ "login": "mpstewart1",
+ "name": "Matthew Stewart",
+ "avatar_url": "https://avatars.githubusercontent.com/mpstewart1",
+ "profile": "https://github.com/mpstewart1",
+ "contributions": []
+ },
{
"login": "JaredP94",
"name": "Jared Ping",
@@ -48,13 +55,6 @@
"profile": "https://github.com/JaredP94",
"contributions": []
},
- {
- "login": "ishapira1",
- "name": "ishapira",
- "avatar_url": "https://avatars.githubusercontent.com/ishapira1",
- "profile": "https://github.com/ishapira1",
- "contributions": []
- },
{
"login": "eliasab16",
"name": "eliasab16",
@@ -63,17 +63,17 @@
"contributions": []
},
{
- "login": "NaN",
- "name": "Maximilian Lam",
- "avatar_url": "https://www.gravatar.com/avatar/7c34633d1ec9625618e54ca802a6eeca?d=identicon&s=100",
- "profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
+ "login": "ishapira1",
+ "name": "ishapira",
+ "avatar_url": "https://avatars.githubusercontent.com/ishapira1",
+ "profile": "https://github.com/ishapira1",
"contributions": []
},
{
- "login": "mpstewart1",
- "name": "Matthew Stewart",
- "avatar_url": "https://avatars.githubusercontent.com/mpstewart1",
- "profile": "https://github.com/mpstewart1",
+ "login": "NaN",
+ "name": "Maximilian Lam",
+ "avatar_url": "https://www.gravatar.com/avatar/fa9de66acd58daa5b4580f804c8e3554?d=identicon&s=100",
+ "profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
{
@@ -90,13 +90,6 @@
"profile": "https://github.com/jaysonzlin",
"contributions": []
},
- {
- "login": "18jeffreyma",
- "name": "Jeffrey Ma",
- "avatar_url": "https://avatars.githubusercontent.com/18jeffreyma",
- "profile": "https://github.com/18jeffreyma",
- "contributions": []
- },
{
"login": "sophiacho1",
"name": "Sophia Cho",
@@ -104,6 +97,13 @@
"profile": "https://github.com/sophiacho1",
"contributions": []
},
+ {
+ "login": "18jeffreyma",
+ "name": "Jeffrey Ma",
+ "avatar_url": "https://avatars.githubusercontent.com/18jeffreyma",
+ "profile": "https://github.com/18jeffreyma",
+ "contributions": []
+ },
{
"login": "korneelf1",
"name": "Korneel Van den Berghe",
@@ -111,6 +111,13 @@
"profile": "https://github.com/korneelf1",
"contributions": []
},
+ {
+ "login": "zishenwan",
+ "name": "Zishen",
+ "avatar_url": "https://avatars.githubusercontent.com/zishenwan",
+ "profile": "https://github.com/zishenwan",
+ "contributions": []
+ },
{
"login": "alxrod",
"name": "Alex Rodriguez",
@@ -118,6 +125,13 @@
"profile": "https://github.com/alxrod",
"contributions": []
},
+ {
+ "login": "srivatsankrishnan",
+ "name": "Srivatsan Krishnan",
+ "avatar_url": "https://avatars.githubusercontent.com/srivatsankrishnan",
+ "profile": "https://github.com/srivatsankrishnan",
+ "contributions": []
+ },
{
"login": "andreamurillomtz",
"name": "Andrea Murillo",
@@ -126,10 +140,10 @@
"contributions": []
},
{
- "login": "srivatsankrishnan",
- "name": "Srivatsan Krishnan",
- "avatar_url": "https://avatars.githubusercontent.com/srivatsankrishnan",
- "profile": "https://github.com/srivatsankrishnan",
+ "login": "ma3mool",
+ "name": "Abdulrahman Mahmoud",
+ "avatar_url": "https://avatars.githubusercontent.com/ma3mool",
+ "profile": "https://github.com/ma3mool",
"contributions": []
},
{
@@ -149,17 +163,10 @@
{
"login": "NaN",
"name": "Aghyad Deeb",
- "avatar_url": "https://www.gravatar.com/avatar/f36cbf06b5d628db59b1474bebfea781?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/14fc01e7ce71f4cfebeceff24b191fc6?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
- {
- "login": "zishenwan",
- "name": "Zishen",
- "avatar_url": "https://avatars.githubusercontent.com/zishenwan",
- "profile": "https://github.com/zishenwan",
- "contributions": []
- },
{
"login": "DivyaAmirtharaj",
"name": "Divya",
@@ -168,17 +175,10 @@
"contributions": []
},
{
- "login": "jared-ni",
- "name": "Jared Ni",
- "avatar_url": "https://avatars.githubusercontent.com/jared-ni",
- "profile": "https://github.com/jared-ni",
- "contributions": []
- },
- {
- "login": "ELSuitorHarvard",
- "name": "ELSuitorHarvard",
- "avatar_url": "https://avatars.githubusercontent.com/ELSuitorHarvard",
- "profile": "https://github.com/ELSuitorHarvard",
+ "login": "MichaelSchnebly",
+ "name": "Michael Schnebly",
+ "avatar_url": "https://avatars.githubusercontent.com/MichaelSchnebly",
+ "profile": "https://github.com/MichaelSchnebly",
"contributions": []
},
{
@@ -188,6 +188,13 @@
"profile": "https://github.com/Ekhao",
"contributions": []
},
+ {
+ "login": "jared-ni",
+ "name": "Jared Ni",
+ "avatar_url": "https://avatars.githubusercontent.com/jared-ni",
+ "profile": "https://github.com/jared-ni",
+ "contributions": []
+ },
{
"login": "oishib",
"name": "oishib",
@@ -196,10 +203,10 @@
"contributions": []
},
{
- "login": "MichaelSchnebly",
- "name": "Michael Schnebly",
- "avatar_url": "https://avatars.githubusercontent.com/MichaelSchnebly",
- "profile": "https://github.com/MichaelSchnebly",
+ "login": "ELSuitorHarvard",
+ "name": "ELSuitorHarvard",
+ "avatar_url": "https://avatars.githubusercontent.com/ELSuitorHarvard",
+ "profile": "https://github.com/ELSuitorHarvard",
"contributions": []
},
{
@@ -210,10 +217,10 @@
"contributions": []
},
{
- "login": "jaywonchung",
- "name": "Jae-Won Chung",
- "avatar_url": "https://avatars.githubusercontent.com/jaywonchung",
- "profile": "https://github.com/jaywonchung",
+ "login": "leo47007",
+ "name": "YU SHUN, HSIAO",
+ "avatar_url": "https://avatars.githubusercontent.com/leo47007",
+ "profile": "https://github.com/leo47007",
"contributions": []
},
{
@@ -224,24 +231,17 @@
"contributions": []
},
{
- "login": "jzhou1318",
- "name": "Jennifer Zhou",
- "avatar_url": "https://avatars.githubusercontent.com/jzhou1318",
- "profile": "https://github.com/jzhou1318",
- "contributions": []
- },
- {
- "login": "marcozennaro",
- "name": "Marco Zennaro",
- "avatar_url": "https://avatars.githubusercontent.com/marcozennaro",
- "profile": "https://github.com/marcozennaro",
+ "login": "jaywonchung",
+ "name": "Jae-Won Chung",
+ "avatar_url": "https://avatars.githubusercontent.com/jaywonchung",
+ "profile": "https://github.com/jaywonchung",
"contributions": []
},
{
- "login": "pongtr",
- "name": "Pong Trairatvorakul",
- "avatar_url": "https://avatars.githubusercontent.com/pongtr",
- "profile": "https://github.com/pongtr",
+ "login": "colbybanbury",
+ "name": "Colby Banbury",
+ "avatar_url": "https://avatars.githubusercontent.com/colbybanbury",
+ "profile": "https://github.com/colbybanbury",
"contributions": []
},
{
@@ -251,6 +251,13 @@
"profile": "https://github.com/eurashin",
"contributions": []
},
+ {
+ "login": "AditiR-42",
+ "name": "Aditi Raju",
+ "avatar_url": "https://avatars.githubusercontent.com/AditiR-42",
+ "profile": "https://github.com/AditiR-42",
+ "contributions": []
+ },
{
"login": "ShvetankPrakash",
"name": "Shvetank Prakash",
@@ -259,24 +266,38 @@
"contributions": []
},
{
- "login": "colbybanbury",
- "name": "Colby Banbury",
- "avatar_url": "https://avatars.githubusercontent.com/colbybanbury",
- "profile": "https://github.com/colbybanbury",
+ "login": "arbass22",
+ "name": "Andrew Bass",
+ "avatar_url": "https://avatars.githubusercontent.com/arbass22",
+ "profile": "https://github.com/arbass22",
"contributions": []
},
{
- "login": "AditiR-42",
- "name": "Aditi Raju",
- "avatar_url": "https://avatars.githubusercontent.com/AditiR-42",
- "profile": "https://github.com/AditiR-42",
+ "login": "marcozennaro",
+ "name": "Marco Zennaro",
+ "avatar_url": "https://avatars.githubusercontent.com/marcozennaro",
+ "profile": "https://github.com/marcozennaro",
"contributions": []
},
{
- "login": "arbass22",
- "name": "Andrew Bass",
- "avatar_url": "https://avatars.githubusercontent.com/arbass22",
- "profile": "https://github.com/arbass22",
+ "login": "jzhou1318",
+ "name": "Jennifer Zhou",
+ "avatar_url": "https://avatars.githubusercontent.com/jzhou1318",
+ "profile": "https://github.com/jzhou1318",
+ "contributions": []
+ },
+ {
+ "login": "pongtr",
+ "name": "Pong Trairatvorakul",
+ "avatar_url": "https://avatars.githubusercontent.com/pongtr",
+ "profile": "https://github.com/pongtr",
+ "contributions": []
+ },
+ {
+ "login": "BrunoScaglione",
+ "name": "Bruno Scaglione",
+ "avatar_url": "https://avatars.githubusercontent.com/BrunoScaglione",
+ "profile": "https://github.com/BrunoScaglione",
"contributions": []
},
{
@@ -300,6 +321,13 @@
"profile": "https://github.com/gnodipac886",
"contributions": []
},
+ {
+ "login": "abigailswallow",
+ "name": "abigailswallow",
+ "avatar_url": "https://avatars.githubusercontent.com/abigailswallow",
+ "profile": "https://github.com/abigailswallow",
+ "contributions": []
+ },
{
"login": "jessicaquaye",
"name": "Jessica Quaye",
@@ -324,7 +352,7 @@
{
"login": "NaN",
"name": "Annie Laurie Cook",
- "avatar_url": "https://www.gravatar.com/avatar/f1ebb6908872dcd6a2f10790eb14e44d?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/38b1f271710b4e194fb990f3af181f89?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
@@ -350,23 +378,23 @@
"contributions": []
},
{
- "login": "abigailswallow",
- "name": "abigailswallow",
- "avatar_url": "https://avatars.githubusercontent.com/abigailswallow",
- "profile": "https://github.com/abigailswallow",
+ "login": "NaN",
+ "name": "Yu-Shun Hsiao",
+ "avatar_url": "https://www.gravatar.com/avatar/ef3a35266c587a9b2c1bbf4e3be600b2?d=identicon&s=100",
+ "profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
{
"login": "NaN",
"name": "Costin-Andrei Oncescu",
- "avatar_url": "https://www.gravatar.com/avatar/44fb0390f4701d5b8888b9d48e1f16a8?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/1b784ecc7b8ac6875182287b7036fa7a?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
{
"login": "NaN",
"name": "Batur Arslan",
- "avatar_url": "https://www.gravatar.com/avatar/669bb20b25d4988d6ba52f11ea7cac91?d=identicon&s=100",
+ "avatar_url": "https://www.gravatar.com/avatar/a0acef9d1ad19d971be2d7f11e4b74ed?d=identicon&s=100",
"profile": "https://github.com/harvard-edge/cs249r_book/graphs/contributors",
"contributions": []
},
diff --git a/README.md b/README.md
index eab4fad9..a11a53c2 100644
--- a/README.md
+++ b/README.md
@@ -1,7 +1,7 @@
# MACHINE LEARNING SYSTEMS with TinyML
-  +
+ 
@@ -62,71 +62,77 @@ Please note that the cs249r project is released with a [Contributor Code of Cond

Shanzeh Batool
|
+ 
Matthew Stewart
|

Jared Ping
|
- 
ishapira
|

eliasab16
|
- 
Maximilian Lam
|
-
Matthew Stewart
|
+
ishapira
|
+ 
Maximilian Lam
|

Marcelo Rovai
|

Jayson Lin
|
- 
Jeffrey Ma
|

Sophia Cho
|
+
Jeffrey Ma
|

Korneel Van den Berghe
|
+ 
Zishen
|

Alex Rodriguez
|
- 
Andrea Murillo
|

Srivatsan Krishnan
|
- 
arnaumarin
|
- 
Aghyad Deeb
|
+
Andrea Murillo
|
+ 
Abdulrahman Mahmoud
|
- 
Aghyad Deeb
|
-
Zishen
|
+
arnaumarin
|
+
Aghyad Deeb
|
+ 
Aghyad Deeb
|

Divya
|
- 
Jared Ni
|
- 
ELSuitorHarvard
|
+ 
Michael Schnebly
|

Emil Njor
|
+
Jared Ni
|

oishib
|
-
Michael Schnebly
|
+
ELSuitorHarvard
|

Henry Bae
|
- 
Jae-Won Chung
|
+ 
YU SHUN, HSIAO
|

Mark Mazumder
|
- 
Jennifer Zhou
|
- 
Marco Zennaro
|
- 
Pong Trairatvorakul
|
+
Jae-Won Chung
|
+ 
Colby Banbury
|

eurashin
|
- 
Shvetank Prakash
|
-
Colby Banbury
|

Aditi Raju
|
+
Shvetank Prakash
|

Andrew Bass
|
- 
Alex Oesterling
|
+
Marco Zennaro
|
+
Jennifer Zhou
|
+
Pong Trairatvorakul
|
+ 
Bruno Scaglione
|
+
Alex Oesterling
|

Gauri Jain
|

Eric D
|
+
+
+ 
abigailswallow
|

Jessica Quaye
|

Jason Yik
|

happyappledog
|
+ 
Annie Laurie Cook
|
- 
Annie Laurie Cook
|

Curren Iyer
|

Shreya Johri
|

Sonia Murthy
|
-
abigailswallow
|
+ 
Yu-Shun Hsiao
|
+ 
Costin-Andrei Oncescu
|
- 
Costin-Andrei Oncescu
|
- 
Batur Arslan
|
+ 
Batur Arslan
|

Vijay Edupuganti
|

The Random DIY
|

Emeka Ezike
|
diff --git a/_quarto.yml b/_quarto.yml
index b18130cf..b8864724 100644
--- a/_quarto.yml
+++ b/_quarto.yml
@@ -39,7 +39,7 @@ book:
back-to-top-navigation: true
favicon: favicon.png
- cover-image: cover-image.png
+ cover-image: cover-image-transparent.png
cover-image-alt: "Cover image."
sidebar:
@@ -159,7 +159,7 @@ bibliography:
format:
epub:
toc: true
- epub-cover-image: cover-image.png
+ epub-cover-image: cover-image-white.png
html:
reference-location: margin
@@ -247,7 +247,7 @@ format:
\begin{titlepage}
\centering
- \includegraphics[width=\textwidth]{cover-image.png} % Adjust the size and path to your image
+ \includegraphics[width=\textwidth]{cover-image-white.png} % Adjust the size and path to your image
{{\huge\bfseries Machine Learning Systems}\\[1em] \Large with TinyML\par}
diff --git a/contents/ai_for_good/ai_for_good.bib b/contents/ai_for_good/ai_for_good.bib
index bc2d5d4a..f50928c1 100644
--- a/contents/ai_for_good/ai_for_good.bib
+++ b/contents/ai_for_good/ai_for_good.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@inproceedings{altayeb2022classifying,
author = {Altayeb, Moez and Zennaro, Marco and Rovai, Marcelo},
booktitle = {Proceedings of the 2022 ACM Conference on Information Technology for Social Good},
@@ -7,7 +10,8 @@ @inproceedings{altayeb2022classifying
source = {Crossref},
title = {Classifying mosquito wingbeat sound using {TinyML}},
url = {https://doi.org/10.1145/3524458.3547258},
- year = {2022}
+ year = {2022},
+ month = sep,
}
@inproceedings{bamoumen2022tinyml,
@@ -20,7 +24,8 @@ @inproceedings{bamoumen2022tinyml
source = {Crossref},
title = {How {TinyML} Can be Leveraged to Solve Environmental Problems: {A} Survey},
url = {https://doi.org/10.1109/3ict56508.2022.9990661},
- year = {2022}
+ year = {2022},
+ month = nov,
}
@article{duisterhof2019learning,
@@ -29,7 +34,7 @@ @article{duisterhof2019learning
title = {Learning to seek: {Autonomous} source seeking with deep reinforcement learning onboard a nano drone microcontroller},
url = {https://arxiv.org/abs/1909.11236},
volume = {abs/1909.11236},
- year = {2019}
+ year = {2019},
}
@inproceedings{duisterhof2021sniffy,
@@ -42,7 +47,8 @@ @inproceedings{duisterhof2021sniffy
source = {Crossref},
title = {Sniffy Bug: {A} Fully Autonomous Swarm of Gas-Seeking Nano Quadcopters in Cluttered Environments},
url = {https://doi.org/10.1109/iros51168.2021.9636217},
- year = {2021}
+ year = {2021},
+ month = sep,
}
@article{jia2023life,
@@ -57,7 +63,8 @@ @article{jia2023life
title = {Life-threatening ventricular arrhythmia detection challenge in implantable cardioverter{\textendash}defibrillators},
url = {https://doi.org/10.1038/s42256-023-00659-9},
volume = {5},
- year = {2023}
+ year = {2023},
+ month = may,
}
@inproceedings{ooko2021tinyml,
@@ -70,7 +77,8 @@ @inproceedings{ooko2021tinyml
source = {Crossref},
title = {{TinyML} in Africa: {Opportunities} and Challenges},
url = {https://doi.org/10.1109/gcwkshps52748.2021.9682107},
- year = {2021}
+ year = {2021},
+ month = dec,
}
@article{ramcharan2017deep,
@@ -84,15 +92,16 @@ @article{ramcharan2017deep
title = {Deep Learning for Image-Based Cassava Disease Detection},
url = {https://doi.org/10.3389/fpls.2017.01852},
volume = {8},
- year = {2017}
+ year = {2017},
+ month = oct,
}
@misc{rao2021,
author = {Rao, Ravi},
journal = {www.wevolver.com},
- month = {Dec},
+ month = dec,
url = {https://www.wevolver.com/article/tinyml-unlocks-new-possibilities-for-sustainable-development-technologies},
- year = {2021}
+ year = {2021},
}
@article{seyedzadeh2018machine,
@@ -107,7 +116,8 @@ @article{seyedzadeh2018machine
title = {Machine learning for estimation of building energy consumption and performance: {A} review},
url = {https://doi.org/10.1186/s40327-018-0064-7},
volume = {6},
- year = {2018}
+ year = {2018},
+ month = oct,
}
@article{tirtalistyani2022indonesia,
@@ -122,13 +132,14 @@ @article{tirtalistyani2022indonesia
title = {{Indonesia} Rice Irrigation System: {Time} for Innovation},
url = {https://doi.org/10.3390/su141912477},
volume = {14},
- year = {2022}
+ year = {2022},
+ month = sep,
}
@misc{vectorborne,
howpublished = {https://www.who.int/news-room/fact-sheets/detail/vector-borne-diseases},
note = {(Accessed on 10/17/2023)},
- title = {Vector-borne diseases}
+ title = {Vector-borne diseases},
}
@misc{verma2022elephant,
@@ -137,7 +148,7 @@ @misc{verma2022elephant
journal = {Hackster.io},
title = {Elephant {AI}},
url = {https://www.hackster.io/dual\_boot/elephant-ai-ba71e9},
- year = {2022}
+ year = {2022},
}
@article{vinuesa2020role,
@@ -152,7 +163,8 @@ @article{vinuesa2020role
title = {The role of artificial intelligence in achieving the Sustainable Development Goals},
url = {https://doi.org/10.1038/s41467-019-14108-y},
volume = {11},
- year = {2020}
+ year = {2020},
+ month = jan,
}
@inproceedings{zennaro2022tinyml,
@@ -160,5 +172,5 @@ @inproceedings{zennaro2022tinyml
booktitle = {The UN 7th Multi-stakeholder Forum on Science, Technology and Innovation for the Sustainable Development Goals},
pages = {2022--05},
title = {{TinyML:} {Applied} {AI} for development},
- year = {2022}
+ year = {2022},
}
diff --git a/contents/ai_for_good/ai_for_good.qmd b/contents/ai_for_good/ai_for_good.qmd
index 6fd2f082..4a95787e 100644
--- a/contents/ai_for_good/ai_for_good.qmd
+++ b/contents/ai_for_good/ai_for_good.qmd
@@ -10,21 +10,21 @@ Resources: [Slides](#sec-ai-for-good-resource), [Labs](#sec-ai-for-good-resource

-By aligning AI progress with human values, goals, and ethics, the ultimate goal of ML systems (at any scale) is to be a technology that reflects human principles and aspirations. Initiatives under "AI for Good" promote the development of AI to tackle the [UN Sustainable Development Goals](https://www.undp.org/sustainable-development-goals) (SDGs) using embedded AI technologies, expanding access to AI education, amongst other things. While it is now clear that AI will be an instrumental part of progress towards the SDGs, its adoption and impact are limited by the immense power consumption, strong connectivity requirements and high costs of cloud-based deployments. TinyML, allowing ML models to run on low-cost and low-power microcontrollers, can circumvent many of these issues.
+By aligning AI progress with human values, goals, and ethics, the ultimate goal of ML systems (at any scale) is to be a technology that reflects human principles and aspirations. Initiatives under "AI for Good" promote the development of AI to tackle the [UN Sustainable Development Goals](https://www.undp.org/sustainable-development-goals) (SDGs) using embedded AI technologies, expanding access to AI education, amongst other things. While it is now clear that AI will be an instrumental part of progress towards the SDGs, its adoption and impact are limited by the immense power consumption, strong connectivity requirements, and high costs of cloud-based deployments. TinyML can circumvent many of these issues by allowing ML models to run on low-cost and low-power microcontrollers.
-> The "AI for Good" movement plays a critical role in cultivating a future where an AI-empowered society is more just, sustainable, and prosperous for all of humanity.
+> The "AI for Good" movement is critical in cultivating a future where an AI-empowered society is more just, sustainable, and prosperous for all humanity.
::: {.callout-tip}
## Learning Objectives
-* Understand how TinyML can help advance the UN Sustainable Development Goals in areas like health, agriculture, education, and the environment.
+* Understand how TinyML can help advance the UN Sustainable Development Goals in health, agriculture, education, and the environment.
* Recognize the versatility of TinyML for enabling localized, low-cost solutions tailored to community needs.
-* Consider challenges of adopting TinyML globally such as limited training, data constraints, accessibility, and cultural barriers.
+* Consider the challenges of adopting TinyML globally, such as limited training, data constraints, accessibility, and cultural barriers.
-* Appreciate the importance of collaborative, ethical approaches to develop and deploy TinyML to best serve local contexts.
+* Appreciate the importance of collaborative, ethical approaches to develop and deploy TinyML to serve local contexts best.
* Recognize the potential of TinyML, if responsibly implemented, to promote equity and empower underserved populations worldwide.
@@ -35,54 +35,54 @@ By aligning AI progress with human values, goals, and ethics, the ultimate goal
To give ourselves a framework around which to think about AI for social good, we will be following the UN Sustainable Development Goals (SDGs). The UN SDGs are a collection of 17 global goals, shown in @fig-sdg, adopted by the United Nations in 2015 as part of the 2030 Agenda for Sustainable Development. The SDGs address global challenges related to poverty, inequality, climate change, environmental degradation, prosperity, and peace and justice.
-What is special about SDGs is that they are a collection of interlinked objectives designed to serve as a "shared blueprint for peace and prosperity for people and the planet, now and into the future.". The SDGs emphasize the interconnected environmental, social and economic aspects of sustainable development by putting sustainability at their center.
+What is special about the SDGs is that they are a collection of interlinked objectives designed to serve as a "shared blueprint for peace and prosperity for people and the planet, now and into the future." The SDGs emphasize sustainable development's interconnected environmental, social, and economic aspects by putting sustainability at their center.
-A recent study [@vinuesa2020role] highlights the influence of AI on all aspects of sustainable development, in particular on the 17 Sustainable Development Goals (SDGs) and 169 targets internationally defined in the 2030 Agenda for Sustainable Development. The study shows that AI can act as an enabler for 134 targets through technological improvements, but it also highlights the challenges of AI on some targets. When considering AI and societal outcomes, the study shows that AI can benefit 67 targets, but it also warns about the issues related to the implementation of AI in countries with different cultural values and wealth.
+A recent study [@vinuesa2020role] highlights the influence of AI on all aspects of sustainable development, particularly on the 17 Sustainable Development Goals (SDGs) and 169 targets internationally defined in the 2030 Agenda for Sustainable Development. The study shows that AI can act as an enabler for 134 targets through technological improvements, but it also highlights the challenges of AI on some targets. The study shows that AI can benefit 67 targets when considering AI and societal outcomes. Still, it also warns about the issues related to the implementation of AI in countries with different cultural values and wealth.
.](https://www.un.org/sustainabledevelopment/wp-content/uploads/2015/12/english_SDG_17goals_poster_all_languages_with_UN_emblem_1.png){#fig-sdg}
-In the context of our book, here is how TinyML could potentially help advance at least _some_ of these SDG goals.
+In our book's context, TinyML could help advance at least some of these SDG goals.
-* **Goal 1 - No Poverty**: TinyML could help provide low-cost solutions for tasks like crop monitoring to improve agricultural yields in developing countries.
+* **Goal 1 - No Poverty:** TinyML could help provide low-cost solutions for crop monitoring to improve agricultural yields in developing countries.
-* **Goal 2 - Zero Hunger**: TinyML could enable localized and precise crop health monitoring and disease detection to reduce crop losses.
+* **Goal 2 - Zero Hunger:** TinyML could enable localized and precise crop health monitoring and disease detection to reduce crop losses.
-* **Goal 3 - Good Health and Wellbeing**: TinyML could help enable low-cost medical diagnosis tools for early detection and prevention of diseases in remote areas.
+* **Goal 3 - Good Health and Wellbeing:** TinyML could help enable low-cost medical diagnosis tools for early detection and prevention of diseases in remote areas.
-* **Goal 6 - Clean Water and Sanitation**: TinyML could monitor water quality and detect contaminants to ensure access to clean drinking water.
+* **Goal 6 - Clean Water and Sanitation:** TinyML could monitor water quality and detect contaminants to ensure Access to clean drinking water.
-* **Goal 7 - Affordable and Clean Energy**: TinyML could optimize energy consumption and enable predictive maintenance for renewable energy infrastructure.
+* **Goal 7 - Affordable and Clean Energy:** TinyML could optimize energy consumption and enable predictive maintenance for renewable energy infrastructure.
-* **Goal 11 - Sustainable Cities and Communities**: TinyML could enable intelligent traffic management, air quality monitoring, and optimized resource management in smart cities.
+* **Goal 11 - Sustainable Cities and Communities:** TinyML could enable intelligent traffic management, air quality monitoring, and optimized resource management in smart cities.
-* **Goal 13 - Climate Action**: TinyML could monitor deforestation and track reforestation efforts. It could also help predict extreme weather events.
+* **Goal 13 - Climate Action:** TinyML could monitor deforestation and track reforestation efforts. It could also help predict extreme weather events.
-The portability, lower power requirements, and real-time analytics enabled by TinyML make it well-suited for addressing several sustainability challenges faced by developing regions. Widespread deployment of power solutions has the potential to provide localized and cost-effective monitoring to help achieve some of the UN SDGs. In the rest of the sections, we will dive into the details of how TinyML is useful across many of the sectors that have the potential to address the UN SDGs.
+The portability, lower power requirements, and real-time analytics enabled by TinyML make it well-suited for addressing several sustainability challenges developing regions face. The widespread deployment of power solutions has the potential to provide localized and cost-effective monitoring to help achieve some of the UN's SDGs. In the rest of the sections, we will dive into how TinyML is useful across many sectors that can address the UN SDGs.
## Agriculture
-Agriculture is essential to achieving many of the UN Sustainable Development Goals, including eradicating hunger and malnutrition, promoting economic growth, and using natural resources sustainably. TinyML can be a valuable tool to help advance sustainable agriculture, especially for smallholder farmers in developing regions.
+Agriculture is essential to achieving many of the UN Sustainable Development Goals, including eradicating Hunger and malnutrition, promoting economic growth, and using natural resources sustainably. TinyML can be a valuable tool to help advance sustainable agriculture, especially for smallholder farmers in developing regions.
-TinyML solutions can provide real-time monitoring and data analytics for crop health and growing conditions - all without reliance on connectivity infrastructure. For example, low-cost camera modules connected to microcontrollers can monitor for disease, pests, and nutritional deficiencies. TinyML algorithms can analyze the images to detect issues early before they spread and damage yields. This kind of precision monitoring can optimize inputs like water, fertilizer, and pesticides - improving efficiency and sustainability.
+TinyML solutions can provide real-time monitoring and data analytics for crop health and growing conditions - all without reliance on connectivity infrastructure. For example, low-cost camera modules connected to microcontrollers can monitor for disease, pests, and nutritional deficiencies. TinyML algorithms can analyze the images to detect issues early before they spread and damage yields. Precision monitoring can optimize inputs like water, fertilizer, and pesticides - improving efficiency and sustainability.
-Other sensors like GPS units and accelerometers can track microclimate conditions, soil humidity, and livestock wellbeing. Local real-time data helps farmers respond and adapt better to changes in the field. TinyML analytics at the edge avoids lag, network disruptions, and high data costs of cloud-based systems. And localized systems allow for customization to specific crops, diseases, and regional issues.
+Other sensors, such as GPS units and accelerometers, can track microclimate conditions, soil humidity, and livestock wellbeing. Local real-time data helps farmers respond and adapt better to changes in the field. TinyML analytics at the edge avoids lag, network disruptions, and the high data costs of cloud-based systems. Localized systems allow customization of specific crops, diseases, and regional issues.
Widespread TinyML applications can help digitize smallholder farms to increase productivity, incomes, and resilience. The low cost of hardware and minimal connectivity requirements make solutions accessible. Projects across the developing world have shown the benefits:
-* Microsoft's [FarmBeats](https://www.microsoft.com/en-us/research/project/farmbeats-iot-agriculture/) project is an end-to-end approach to enable data-driven farming by using low-cost sensors, drones, and vision and machine learning algorithms. The project aims to solve the problem of limited adoption of technology in farming due to the lack of power and internet connectivity in farms and the farmers' limited technology savviness. The project's goal is to increase farm productivity and reduce costs by coupling data with the farmer's knowledge and intuition about their farm. The project has been successful in enabling actionable insights from data by building artificial intelligence (AI) or machine learning (ML) models based on fused data sets.
+* Microsoft's [FarmBeats](https://www.microsoft.com/en-us/research/project/farmbeats-iot-agriculture/) project is an end-to-end approach to enable data-driven farming by using low-cost sensors, drones, and vision and machine learning algorithms. The project aims to solve the problem of limited adoption of technology in farming due to the need for more power and internet connectivity in farms and the farmers' limited technology savviness. The project aims to increase farm productivity and reduce costs by coupling data with farmers' knowledge and intuition about their farms. The project has successfully enabled actionable insights from data by building artificial intelligence (AI) or machine learning (ML) models based on fused data sets.
-* In Sub-Saharan Africa, off-the-shelf cameras and edge AI cut cassava losses to disease from 40% down to 5%, protecting a staple crop [@ramcharan2017deep].
+* In Sub-Saharan Africa, off-the-shelf cameras and edge AI have cut cassava disease losses from 40% to 5%, protecting a staple crop [@ramcharan2017deep].
* In Indonesia, sensors monitor microclimates across rice paddies, optimizing water usage even with erratic rains [@tirtalistyani2022indonesia].
-With greater investment and integration into rural advisory services, TinyML could transform small-scale agriculture and improve livelihoods for farmers worldwide. The technology effectively brings the benefits of precision agriculture to disconnected regions most in need.
+With greater investment and integration into rural advisory services, TinyML could transform small-scale agriculture and improve farmers' livelihoods worldwide. The technology effectively brings the benefits of precision agriculture to disconnected regions most in need.
:::{#exr-agri .callout-exercise collapse="true"}
### Crop Yield Modeling
-This exercise teaches you how to predict crop yields in Nepal by combining satellite data (Sentinel-2), climate data (WorldClim), and on-the-ground measurements. You'll use a machine learning algorithm called XGBoost Regressor to build a model, split the data for training and testing, and fine-tune the model parameters for the best performance. This notebook lays the foundation to implement TinyML in the agriculture domain – consider how you could adapt this process for smaller datasets, fewer features, and simplified models to make it compatible with the power and memory constraints of TinyML devices.
+This exercise teaches you how to predict crop yields in Nepal by combining satellite data (Sentinel-2), climate data (WorldClim), and on-the-ground measurements. You'll use a machine learning algorithm called XGBoost Regressor to build a model, split the data for training and testing, and fine-tune the model parameters for the best performance. This notebook lays the foundation for implementing TinyML in the agriculture domain. Consider how you could adapt this process for smaller datasets, fewer features, and simplified models to make it compatible with the power and memory constraints of TinyML devices.
[](https://colab.research.google.com/github/developmentseed/sat-ml-training/blob/main/_notebooks/2020-07-29-Crop_yield_modeling_with_XGBoost.ipynb#scrollTo=GQd7ELsRWkBI)
:::
@@ -91,9 +91,9 @@ This exercise teaches you how to predict crop yields in Nepal by combining satel
### Expanding Access
-Universal health coverage and quality care remain out of reach for millions worldwide. A shortage of medical professionals severely limits access to even basic diagnosis and treatment in many regions. Additionally, healthcare infrastructure like clinics, hospitals, and utilities to power complex equipment are lacking. These gaps disproportionately impact marginalized communities, exacerbating health disparities.
+Universal health coverage and quality care remain out of reach for millions worldwide. In many regions, more medical professionals are required to Access basic diagnosis and treatment. Additionally, healthcare infrastructure like clinics, hospitals, and utilities to power complex equipment needs to be improved. These gaps disproportionately impact marginalized communities, exacerbating health disparities.
-TinyML offers a promising technological solution to help expand access to quality healthcare globally. TinyML refers to the ability to deploy machine learning algorithms on microcontrollers, tiny chips with processing power, memory, and connectivity. TinyML enables real-time data analysis and intelligence in low-powered, compact devices.
+TinyML offers a promising technological solution to help expand Access to quality healthcare globally. TinyML refers to the ability to deploy machine learning algorithms on microcontrollers, tiny chips with processing power, memory, and connectivity. TinyML enables real-time data analysis and intelligence in low-powered, compact devices.
This creates opportunities for transformative medical tools that are portable, affordable, and accessible. TinyML software and hardware can be optimized to run even in resource-constrained environments. For example, a TinyML system could analyze symptoms or make diagnostic predictions using minimal computing power, no continuous internet connectivity, and a battery or solar power source. These capabilities can bring medical-grade screening and monitoring directly to underserved patients.
@@ -101,11 +101,11 @@ This creates opportunities for transformative medical tools that are portable, a
Early detection of diseases is one major application. Small sensors paired with TinyML software can identify symptoms before conditions escalate or visible signs appear. For instance, [cough monitors](https://stradoslabs.com/cough-monitoring-and-respiratory-trial-data-collection-landing) with embedded machine learning can pick up on acoustic patterns indicative of respiratory illness, malaria, or tuberculosis. Detecting diseases at onset improves outcomes and reduces healthcare costs.
-A detailed example could be given for using TinyML to monitor pneumonia in children. Pneumonia is a leading cause of death for children under 5, and detecting it early is critical. A startup called [Respira Labs](https://www.samayhealth.com/) has developed a low-cost wearable audio sensor that uses TinyML algorithms to analyze coughs and identify symptoms of respiratory illnesses like pneumonia. The device contains a microphone sensor and microcontroller that runs a neural network model trained to classify respiratory sounds. It can identify features like wheezing, crackling, and stridor that may indicate pneumonia. The device is designed to be highly accessible - it has a simple strap, requires no battery or charging, and results are provided through LED lights and audio cues.
+A detailed example could be given for TinyML monitoring pneumonia in children. Pneumonia is a leading cause of death for children under 5, and detecting it early is critical. A startup called [Respira Labs](https://www.samayhealth.com/) has developed a low-cost wearable audio sensor that uses TinyML algorithms to analyze coughs and identify symptoms of respiratory illnesses like pneumonia. The device contains a microphone sensor and microcontroller that runs a neural network model trained to classify respiratory sounds. It can identify features like wheezing, crackling, and stridor that may indicate pneumonia. The device is designed to be highly accessible - it has a simple strap, requires no battery or charging, and results are provided through LED lights and audio cues.
-Another example involves researchers at UNIFEI in Brazil who have developed a low-cost device that leverages TinyML to monitor heart rhythms. Their innovative solution addresses a critical need - atrial fibrillation and other heart rhythm abnormalities often go undiagnosed due to the prohibitive cost and limited availability of screening tools. The device overcomes these barriers through its ingenious design. It uses an off-the-shelf microcontroller that costs only a few dollars, along with a basic pulse sensor. By minimizing complexity, the device becomes accessible to under-resourced populations. The TinyML algorithm running locally on the microcontroller analyzes pulse data in real time to detect irregular heart rhythms. This life-saving heart monitoring device demonstrates how TinyML enables powerful AI capabilities to be deployed in cost-effective, user-friendly designs.
+Another example involves researchers at UNIFEI in Brazil who have developed a low-cost device that leverages TinyML to monitor heart rhythms. Their innovative solution addresses a critical need - atrial fibrillation and other heart rhythm abnormalities often go undiagnosed due to the prohibitive cost and limited availability of screening tools. The device overcomes these barriers through its ingenious design. It uses an off-the-shelf microcontroller that costs only a few dollars, along with a basic pulse sensor. By minimizing complexity, the device becomes accessible to under-resourced populations. The TinyML algorithm running locally on the microcontroller analyzes pulse data in real-time to detect irregular heart rhythms. This life-saving heart monitoring device demonstrates how TinyML enables powerful AI capabilities to be deployed in cost-effective, user-friendly designs.
-TinyML's versatility also shows promise for tackling infectious diseases. Researchers have proposed applying TinyML to identify malaria-spreading mosquitoes by their wingbeat sounds. When equipped with microphones, small microcontrollers can run advanced audio classification models to determine mosquito species. This compact, low-power solution produces results in real time, suitable for remote field use. By making entomology analytics affordable and accessible, TinyML could revolutionize monitoring of insects that endanger human health. From heart disease to malaria, TinyML is expanding healthcare access for vulnerable communities.
+TinyML's versatility also shows promise for tackling infectious diseases. Researchers have proposed applying TinyML to identify malaria-spreading mosquitoes by their wingbeat sounds. When equipped with microphones, small microcontrollers can run advanced audio classification models to determine mosquito species. This compact, low-power solution produces results in real time, suitable for remote field use. By making entomology analytics affordable and accessible, TinyML could revolutionize monitoring insects that endanger human health. TinyML is expanding healthcare access for vulnerable communities from heart disease to malaria.
### Infectious Disease Control
@@ -115,15 +115,15 @@ Traditional monitoring methods are expensive, labor-intensive, and difficult to
A collaborative research team from the University of Khartoum and the ICTP is exploring an innovative solution using TinyML. In a recent paper, they presented a low-cost device that can identify disease-spreading mosquito species through their wing beat sounds [@altayeb2022classifying].
-This portable, self-contained system shows great promise for entomology. The researchers suggest it could revolutionize insect monitoring and vector control strategies in remote areas. By providing cheaper, easier mosquito analytics, TinyML could significantly bolster malaria eradication efforts. Its versatility and minimal power needs make it ideal for field use in isolated, off-grid regions with scarce resources but high disease burden.
+This portable, self-contained system shows great promise for entomology. The researchers suggest it could revolutionize insect monitoring and vector control strategies in remote areas. TinyML could significantly bolster malaria eradication efforts by providing cheaper, easier mosquito analytics. Its versatility and minimal power needs make it ideal for field use in isolated, off-grid regions with scarce resources but high disease burden.
### TinyML Design Contest in Healthcare
The first TinyML contest in healthcare, TDC'22 [@jia2023life], was held in 2022 to motivate participating teams to design AI/ML algorithms for detecting life-threatening ventricular arrhythmias (VAs) and deploy them on Implantable Cardioverter Defibrillators (ICDs). VAs are the main cause of sudden cardiac death (SCD). People at high risk of SCD rely on the ICD to deliver proper and timely defibrillation treatment (i.e., shocking the heart back into normal rhythm) when experiencing life-threatening VAs.
-An on-device algorithm for early and timely life-threatening VA detection will increase the chances of survival. The proposed AI/ML algorithm needed to be deployed and executed on an extremely low-power and resource-constrained microcontroller (MCU) (a $10 development board with an ARM Cortex-M4 core at 80 MHz, 256 kB of flash memory and 64 kB of SRAM). The submitted designs were evaluated by metrics measured on the MCU for (1) detection performance; (2) inference latency; and (3) memory occupation by the program of AI/ML algorithms.
+An on-device algorithm for early and timely life-threatening VA detection will increase the chances of survival. The proposed AI/ML algorithm needed to be deployed and executed on an extremely low-power and resource-constrained microcontroller (MCU) (a $10 development board with an ARM Cortex-M4 core at 80 MHz, 256 kB of flash memory and 64 kB of SRAM). The submitted designs were evaluated by metrics measured on the MCU for (1) detection performance, (2) inference latency, and (3) memory occupation by the program of AI/ML algorithms.
-The champion, GaTech EIC Lab, obtained 0.972 in $F_\beta$ (F1 score with a higher weight to recall), 1.747 ms in latency and 26.39 kB in memory footprint with a deep neural network. An ICD with an on-device VA detection algorithm was [implanted in a clinical trial](https://youtu.be/vx2gWzAr85A?t=2359).
+The champion, GaTech EIC Lab, obtained 0.972 in $F_\beta$ (F1 score with a higher weight to recall), 1.747 ms in latency, and 26.39 kB in memory footprint with a deep neural network. An ICD with an on-device VA detection algorithm was [implanted in a clinical trial](https://youtu.be/vx2gWzAr85A?t=2359).
:::{#exr-hc .callout-exercise collapse="true"}
@@ -136,27 +136,27 @@ In this exercise, you'll learn about Named Entity Recognition (NER), a powerful
## Science
-In many scientific fields, researchers are limited by the quality and resolution of data they can collect. They often must infer the true parameters of interest indirectly, using approximate correlations and models built on sparse data points. This constrains the accuracy of scientific understanding and predictions.
+In many scientific fields, researchers are limited by the quality and resolution of data they can collect. They often must indirectly infer the true parameters of interest using approximate correlations and models built on sparse data points. This constrains the accuracy of scientific understanding and predictions.
-The emergence of TinyML opens new possibilities for gathering high-fidelity scientific measurements. With embedded machine learning, tiny low-cost sensors can automatically process and analyze data locally in real time. This creates intelligent sensor networks that capture nuanced data at much greater scales and frequencies.
+The emergence of TinyML opens new possibilities for gathering high-fidelity scientific measurements. With embedded machine learning, tiny, low-cost sensors can automatically process and analyze data locally in real-time. This creates intelligent sensor networks that capture nuanced data at much greater scales and frequencies.
-For example, monitoring environmental conditions to model climate change remains a challenge due to the lack of widespread, continuous data. The Ribbit Project from UC Berkeley is pioneering a crowdsourced TinyML solution [@rao2021]. They developed an open-source CO2 sensor that uses an onboard microcontroller to process the gas measurements. By distributing hundreds of these low-cost sensors, an extensive dataset can be aggregated. The TinyML devices compensate for environmental factors and provide granular, accurate readings not possible previously.
+For example, monitoring environmental conditions to model climate change remains challenging due to the need for widespread, continuous data. The Ribbit Project from UC Berkeley is pioneering a crowdsourced TinyML solution [@rao2021]. They developed an open-source CO2 sensor that uses an onboard microcontroller to process the gas measurements. An extensive dataset can be aggregated by distributing hundreds of these low-cost sensors. The TinyML devices compensate for environmental factors and provide previously impossible, granular, accurate readings.
-The potential to massively scale out intelligent sensing via TinyML has profound scientific implications. From ecology to cosmology, higher resolution data can lead to new discoveries and predictive capabilities. Other applications could include seismic sensors for earthquake early warning systems, distributed weather monitors to track microclimate changes, and acoustic sensors to study animal populations.
+The potential to massively scale out intelligent sensing via TinyML has profound scientific implications. Higher-resolution data can lead to discoveries and predictive capabilities in fields ranging from ecology to cosmology. Other applications could include seismic sensors for earthquake early warning systems, distributed weather monitors to track microclimate changes, and acoustic sensors to study animal populations.
-As sensors and algorithms continue improving, TinyML networks may generate more detailed maps of natural systems than ever before. Democratizing the collection of scientific data can accelerate research and understanding across disciplines. But it also raises new challenges around data quality, privacy, and modeling unknowns. Overall, TinyML signifies a growing convergence of AI and the natural sciences to answer fundamental questions.
+As sensors and algorithms continue improving, TinyML networks may generate more detailed maps of natural systems than ever before. Democratizing the collection of scientific data can accelerate research and understanding across disciplines. However, it raises new challenges around data quality, privacy, and modeling unknowns. TinyML signifies a growing convergence of AI and the natural sciences to answer fundamental questions.
## Conservation and Environment
-TinyML is emerging as a powerful tool for environmental conservation and sustainability efforts. Recent research has highlighted numerous applications of tiny machine learning across domains like wildlife monitoring, natural resource management, and tracking climate change.
+TinyML is emerging as a powerful tool for environmental conservation and sustainability efforts. Recent research has highlighted numerous applications of tiny machine learning in domains such as wildlife monitoring, natural resource management, and tracking climate change.
-One example is using TinyML for real-time wildlife tracking and protection. Researchers have developed [Smart Wildlife Tracker](https://www.hackster.io/dhruvsheth_/eletect-tinyml-and-iot-based-smart-wildlife-tracker-c03e5a) devices that leverage TinyML algorithms to detect poaching activities. The collars contain sensors like cameras, microphones, and GPS to continuously monitor the surrounding environment. Embedded machine learning models analyze the audio and visual data to identify threats like nearby humans or gunshots. Early poaching detection gives wildlife rangers critical information to intervene and take action.
+One example is using TinyML for real-time wildlife tracking and protection. Researchers have developed [Smart Wildlife Tracker](https://www.hackster.io/dhruvsheth_/eletect-tinyml-and-iot-based-smart-wildlife-tracker-c03e5a) devices that leverage TinyML algorithms to detect poaching activities. The collars contain sensors like cameras, microphones, and GPS to monitor the surrounding environment continuously. Embedded machine learning models analyze the audio and visual data to identify threats like nearby humans or gunshots. Early poaching detection gives wildlife rangers critical information to intervene and take action.
Other projects apply TinyML to study animal behavior through sensors. The smart wildlife collar uses accelerometers and acoustic monitoring to track elephant movements, communication, and moods [@verma2022elephant]. The low-power TinyML collar devices transmit rich data on elephant activities while avoiding burdensome Battery changes. This helps researchers unobtrusively observe elephant populations to inform conservation strategies.
On a broader scale, distributed TinyML devices are envisioned to create dense sensor networks for environmental modeling. Hundreds of low-cost air quality monitors could map pollution across cities. Underwater sensors may detect toxins and give early warning of algal blooms. Such applications underscore TinyML's versatility in ecology, climatology, and sustainability.
-A survey on how TinyML can be used to solve environmental issues has been published by researchers from Moulay Ismail University of Meknes in Morocco [@bamoumen2022tinyml]. However, thoughtfully assessing benefits, risks, and equitable access will be vital as TinyML expands environmental research and conservation. With ethical consideration of impacts, TinyML offers data-driven solutions to protect biodiversity, natural resources, and our planet as a whole.
+Researchers from Moulay Ismail University of Meknes in Morocco [@bamoumen2022tinyml] have published a survey on how TinyML can be used to solve environmental issues. However, thoughtfully assessing benefits, risks, and equitable Access will be vital as TinyML expands environmental research and conservation. With ethical consideration of impacts, TinyML offers data-driven solutions to protect biodiversity, natural resources, and our planet.
## Disaster Response
@@ -164,15 +164,19 @@ In disaster response, speed and safety are paramount. But rubble and wreckage cr
When buildings collapse after earthquakes, small drones can prove invaluable. Equipped with TinyML navigation algorithms, micro-sized drones like the [CrazyFlie](https://www.bitcraze.io/) can traverse cramped voids and map pathways beyond human reach [@duisterhof2019learning]. Obstacle avoidance allows the drones to weave through unstable debris. This autonomous mobility lets them rapidly sweep areas humans cannot access.
+The video below presents the [@duisterhof2019learning] paper on deep reinforcement learning using drones for source-seeking.
+
{{< video https://www.youtube.com/watch?v=wmVKbX7MOnU >}}
Crucially, onboard sensors and TinyML processors analyze real-time data to identify signs of survivors. Thermal cameras detect body heat, microphones pick up calls for help, and gas sensors warn of leaks [@duisterhof2021sniffy]. Processing data locally using TinyML allows for quick interpretation to guide rescue efforts. As conditions evolve, the drones can adapt by adjusting their search patterns and priorities.
+The following video is an overview of autonomous drones for gas leak detection.
+
{{< video https://www.youtube.com/watch?v=hj_SBSpK5qg >}}
-Additionally, coordinated swarms of drones unlock new capabilities. By collaborating and sharing insights, drone teams achieve a comprehensive view of the situation. Blanketing disaster sites allows TinyML algorithms to fuse and analyze data from multiple vantage points. This amplifies situational awareness beyond individual drones [@duisterhof2021sniffy].
+Additionally, coordinated swarms of drones unlock new capabilities. By collaborating and sharing insights, drone teams comprehensively view the situation. Blanketing disaster sites allows TinyML algorithms to fuse and analyze data from multiple vantage points, amplifying situational awareness beyond individual drones [@duisterhof2021sniffy].
-Most importantly, initial drone reconnaissance enhances safety for human responders. Keeping rescue teams at a safe distance until drone surveys assess hazards saves lives. Once secured, drones can guide precise placement of personnel.
+Most importantly, initial drone reconnaissance enhances safety for human responders. Keeping rescue teams at a safe distance until drone surveys assess hazards saves lives. Once secured, drones can guide precise personnel placement.
By combining agile mobility, real-time data, and swarm coordination, TinyML-enabled drones promise to transform disaster response. Their versatility, speed, and safety make them a vital asset for rescue efforts in dangerous, inaccessible environments. Integrating autonomous drones with traditional methods can accelerate responses when it matters most.
@@ -180,29 +184,31 @@ By combining agile mobility, real-time data, and swarm coordination, TinyML-enab
TinyML holds immense potential to help address challenges in developing regions, but realizing its benefits requires focused education and capacity building. Recognizing this need, academic researchers have spearheaded outreach initiatives to spread TinyML education globally.
-In 2020, Harvard University, Columbia University, the International Centre for Theoretical Physics (ICTP), and UNIFEI jointly founded the TinyML for Developing Communities (TinyML4D) network [@zennaro2022tinyml]. This network aims to empower universities and researchers in developing countries to harness TinyML for local impact.
+In 2020, Harvard University, Columbia University, the International Centre for Theoretical Physics (ICTP), and UNIFEI jointly founded the TinyML for Developing Communities (TinyML4D) network [@zennaro2022tinyml]. This network empowers universities and researchers in developing countries to harness TinyML for local impact.
-A core focus is expanding access to applied machine learning education. The TinyML4D network provides training, curricula, and lab resources to members. Hands-on workshops and data collection projects give students practical experience. Through conferences and academic collaborations, members can share best practices and build a community.
+A core focus is expanding Access to applied machine learning education. The TinyML4D network provides training, curricula, and lab resources to members. Hands-on workshops and data collection projects give students practical experience. Members can share best practices and build a community through conferences and academic collaborations.
-The network prioritizes enabling locally-relevant TinyML solutions. Projects address challenges like agriculture, health, and environmental monitoring based on community needs. For example, a member university in Rwanda developed a low-cost flood monitoring system using TinyML and sensors.
+The network prioritizes enabling locally relevant TinyML solutions. Projects address challenges like agriculture, health, and environmental monitoring based on community needs. For example, a member university in Rwanda developed a low-cost flood monitoring system using TinyML and sensors.
-To date, TinyML4D includes over 50 member institutions across Africa, Asia, and Latin America. But greater investments and industry partnerships are needed to reach all underserved regions. The ultimate vision is training new generations to ethically apply TinyML for sustainable development. Outreach efforts today lay the foundation to democratize transformative technology for the future.
+TinyML4D includes over 50 member institutions across Africa, Asia, and Latin America. However, greater investments and industry partnerships are needed to reach all underserved regions. The ultimate vision is training new generations to ethically apply TinyML for sustainable development. Outreach efforts today lay the foundation for democratizing transformative technology for the future.
## Accessibility
Technology has immense potential to break down barriers faced by people with disabilities and bridge gaps in accessibility. TinyML specifically opens new possibilities for developing intelligent, personalized assistive devices.
-With machine learning algorithms running locally on microcontrollers, compact accessibility tools can operate in real-time without reliance on connectivity. The [National Institute on Deafness and Other Communication Disorders (NIDCD)](https://www.nidcd.nih.gov/health/statistics/quick-statistics-hearing) states that 20% of the world's population has some form of hearing loss. Hearing aids leveraging TinyML could recognize multiple speakers and amplify the voice of a chosen target in crowded rooms. This allows people with hearing impairments to focus on specific conversations.
+With machine learning algorithms running locally on microcontrollers, compact accessibility tools can operate in real time without reliance on connectivity. The [National Institute on Deafness and Other Communication Disorders (NIDCD)](https://www.nidcd.nih.gov/health/statistics/quick-statistics-hearing) states that 20% of the world's population has some form of hearing loss. Hearing aids leveraging TinyML could recognize multiple speakers and amplify the voice of a chosen target in crowded rooms. This allows people with hearing impairments to focus on specific conversations.
+
+Similarly, mobility devices could use on-device vision processing to identify obstacles and terrain characteristics. This enables enhanced navigation and safety for the visually impaired. Companies like [Envision](https://www.letsenvision.com/) are developing smart glasses, converting visual information into speech, with embedded TinyML to guide blind people by detecting objects, text, and traffic signals.
-Similarly, mobility devices could use on-device vision processing to identify obstacles and terrain characteristics. This enables enhanced navigation and safety for the visually impaired. Companies like [Envision](https://www.letsenvision.com/) are developing smart glasses, converting visual information into speech, with embedded TinyML to guide the blind by detecting objects, text, and traffic signals.
+The video below shows the different real-life use cases of the Envision visual aid glasses.
{{< video https://www.youtube.com/watch?v=oGWinIKDOdc >}}
-TinyML could even power responsive prosthetic limbs. By analyzing nerve signals and sensory data like muscle tension, prosthetics and exoskeletons with embedded ML can move and adjust grip dynamically. This makes control more natural and intuitive. Companies are creating affordable, everyday bionic hands using TinyML. And for those with speech difficulties, voice-enabled devices with TinyML can generate personalized vocal outputs from non-verbal inputs. Pairs by Anthropic translates gestures into natural speech tailored for individual users.
+TinyML could even power responsive prosthetic limbs. By analyzing nerve signals and sensory data like muscle tension, prosthetics and exoskeletons with embedded ML can move and adjust grip dynamically, making control more natural and intuitive. Companies are creating affordable, everyday bionic hands using TinyML. For those with speech difficulties, voice-enabled devices with TinyML can generate personalized vocal outputs from non-verbal inputs. Pairs by Anthropic translates gestures into natural speech tailored for individual users.
By enabling more customizable assistive tech, TinyML makes services more accessible and tailored to individual needs. And through translation and interpretation applications, TinyML can break down communication barriers. Apps like Microsoft Translator offer real-time translation powered by TinyML algorithms.
-With thoughtful and inclusive design, TinyML promises more autonomy and dignity for people with disabilities. But developers should engage communities directly, avoid compromising privacy, and consider affordability to maximize benefit. Overall, TinyML has huge potential to contribute to a more just, equitable world.
+With its thoughtful and inclusive design, TinyML promises more autonomy and dignity for people with disabilities. However, developers should engage communities directly, avoid compromising privacy, and consider affordability to maximize the benefits. TinyML has huge potential to contribute to a more just, equitable world.
## Infrastructure and Urban Planning
@@ -210,38 +216,38 @@ As urban populations swell, cities face immense challenges in efficiently managi
Machine learning models can learn to predict and regulate energy usage based on occupancy patterns. Miniaturized sensors placed throughout buildings can provide granular, real-time data on space utilization, temperature, and more [@seyedzadeh2018machine]. This visibility allows TinyML systems to minimize waste by optimizing heating, cooling, lighting, etc.
-These examples demonstrate TinyML's huge potential for efficient, sustainable city infrastructure. But urban planners must consider privacy, security, and accessibility to ensure responsible adoption. With careful implementation, TinyML could profoundly modernize urban life.
+These examples demonstrate TinyML's huge potential for efficient, sustainable city infrastructure. However, urban planners must consider privacy, security, and accessibility to ensure responsible adoption. With careful implementation, TinyML could profoundly modernize urban life.
## Challenges and Considerations
-While TinyML presents immense opportunities, thoughtful consideration of challenges and ethical implications will be critical as adoption spreads globally. Researchers have highlighted key factors to address, especially in deploying TinyML in developing regions.
+While TinyML presents immense opportunities, thoughtful consideration of challenges and ethical implications will be critical as adoption spreads globally. Researchers have highlighted key factors to address, especially when deploying TinyML in developing regions.
-A foremost challenge is limited access to training and hardware [@ooko2021tinyml]. Few educational programs exist tailored to TinyML, and emerging economies often lack a robust electronics supply chain. Thorough training and partnerships will be needed to nurture expertise and avail devices to underserved communities. Initiatives like the TinyML4D network help provide structured learning pathways.
+A foremost challenge is limited Access to training and hardware [@ooko2021tinyml]. Only educational programs exist tailored to TinyML, and emerging economies often need a robust electronics supply chain. Thorough training and partnerships will be needed to nurture expertise and make devices available to underserved communities. Initiatives like the TinyML4D network help provide structured learning pathways.
-Data limitations also pose hurdles. TinyML models require quality localized datasets, but these are scarce in under-resourced environments. Creating frameworks to ethically crowdsource data could address this. But data collection should benefit local communities directly, not just extract value.
+Data limitations also pose hurdles. TinyML models require quality localized datasets, which are scarce in under-resourced environments. Creating frameworks to crowdsource data ethically could address this. However, data collection should benefit local communities directly, not just extract value.
-Optimizing power usage and connectivity will be vital for sustainability. TinyML's low power needs make it ideal for off-grid use cases. Integrating battery or solar can enable continuous operation. Adapting devices for low-bandwidth transmission where internet is limited also maximizes impact.
+Optimizing power usage and connectivity will be vital for sustainability. TinyML's low power needs make it ideal for off-grid use cases. Integrating battery or solar can enable continuous operation. Adapting devices for low-bandwidth transmission where the internet is limited also maximizes impact.
Cultural and language barriers further complicate adoption. User interfaces and devices should account for all literacy levels and avoid excluding subgroups. Voice-controllable solutions in local dialects can enhance accessibility.
-Addressing these challenges requires holistic partnerships, funding, and policy support. But inclusively and ethically scaling TinyML has monumental potential to uplift disadvantaged populations worldwide. With thoughtful implementation, the technology could profoundly democratize opportunity.
+Addressing these challenges requires holistic partnerships, funding, and policy support. However, inclusively and ethically scaling TinyML has monumental potential to uplift disadvantaged populations worldwide. With thoughtful implementation, the technology could profoundly democratize opportunity.
## Conclusion
-TinyML presents a tremendous opportunity to harness the power of artificial intelligence to advance the UN Sustainable Development Goals and drive social impact globally. As highlighted through the examples across sectors like healthcare, agriculture, conservation and more, embedded machine learning unlocks new capabilities for low-cost, accessible solutions tailored to local contexts. TinyML circumvents barriers like poor infrastructure, limited connectivity, and high costs that often exclude developing communities from emerging technology.
+TinyML presents a tremendous opportunity to harness the power of artificial intelligence to advance the UN Sustainable Development Goals and drive social impact globally, as highlighted by examples across sectors like healthcare, agriculture, conservation, and more; embedded machine learning unlocks new capabilities for low-cost, accessible solutions tailored to local contexts. TinyML circumvents barriers like poor infrastructure, limited connectivity, and high costs that often exclude developing communities from emerging technology.
-However, realizing TinyML's full potential requires holistic collaboration. Researchers, policymakers, companies and local stakeholders must work together to provide training, establish ethical frameworks, co-design solutions, and adapt them to community needs. Only through inclusive development and deployment can TinyML deliver on its promise to bridge inequities and uplift vulnerable populations without leaving any behind.
+However, realizing TinyML's full potential requires holistic collaboration. Researchers, policymakers, companies, and local stakeholders must collaborate to provide training, establish ethical frameworks, co-design solutions, and adapt them to community needs. Through inclusive development and deployment, TinyML can deliver on its promise to bridge inequities and uplift vulnerable populations without leaving any behind.
-If cultivated responsibly, TinyML could democratize opportunity and accelerate progress on global priorities from poverty alleviation to climate resilience. The technology represents a new wave of applied AI to empower societies, promote sustainability, and propel all of humanity collectively towards greater justice, prosperity and peace. TinyML provides a glimpse into an AI-enabled future that is accessible to all.
+If cultivated responsibly, TinyML could democratize opportunity and accelerate progress on global priorities from poverty alleviation to climate resilience. The technology represents a new wave of applied AI to empower societies, promote sustainability, and propel humanity toward greater justice, prosperity, and peace. TinyML provides a glimpse into an AI-enabled future that is accessible to all.
## Resources {#sec-ai-for-good-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will be adding new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [TinyML for Social Impact.](https://docs.google.com/presentation/d/1gkA6pAPUjPWND9ODgnfhCVzbwVYXdrkTpXsJdZ7hJHY/edit#slide=id.ge94401e7d6_0_81)
@@ -258,7 +264,7 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/benchmarking/benchmarking.bib b/contents/benchmarking/benchmarking.bib
index 2866fe58..c0f9dce1 100644
--- a/contents/benchmarking/benchmarking.bib
+++ b/contents/benchmarking/benchmarking.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@inproceedings{adolf2016fathom,
author = {Adolf, Robert and Rama, Saketh and Reagen, Brandon and Wei, Gu-yeon and Brooks, David},
booktitle = {2016 IEEE International Symposium on Workload Characterization (IISWC)},
@@ -8,21 +11,24 @@ @inproceedings{adolf2016fathom
source = {Crossref},
title = {Fathom: {Reference} workloads for modern deep learning methods},
url = {https://doi.org/10.1109/iiswc.2016.7581275},
- year = {2016}
+ year = {2016},
+ month = sep,
}
@inproceedings{antol2015vqa,
- author = {Stanislaw Antol and Aishwarya Agrawal and Jiasen Lu and Margaret Mitchell and Dhruv Batra and C. Lawrence Zitnick and Devi Parikh},
+ author = {Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Dhruv and Zitnick, C. Lawrence and Parikh, Devi},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/iccv/AntolALMBZP15.bib},
- booktitle = {2015 {IEEE} International Conference on Computer Vision, {ICCV} 2015, Santiago, Chile, December 7-13, 2015},
- doi = {10.1109/ICCV.2015.279},
+ booktitle = {2015 IEEE International Conference on Computer Vision (ICCV)},
+ doi = {10.1109/iccv.2015.279},
pages = {2425--2433},
- publisher = {{IEEE} Computer Society},
+ publisher = {IEEE},
timestamp = {Wed, 24 May 2017 01:00:00 +0200},
- title = {{VQA:} Visual Question Answering},
- url = {https://doi.org/10.1109/ICCV.2015.279},
- year = {2015}
+ title = {{VQA:} {Visual} Question Answering},
+ url = {https://doi.org/10.1109/iccv.2015.279},
+ year = {2015},
+ source = {Crossref},
+ month = dec,
}
@article{banbury2020benchmarking,
@@ -31,7 +37,7 @@ @article{banbury2020benchmarking
title = {Benchmarking tinyml systems: {Challenges} and direction},
url = {https://arxiv.org/abs/2003.04821},
volume = {abs/2003.04821},
- year = {2020}
+ year = {2020},
}
@article{beyer2020we,
@@ -40,33 +46,35 @@ @article{beyer2020we
title = {Are we done with imagenet?},
url = {https://arxiv.org/abs/2006.07159},
volume = {abs/2006.07159},
- year = {2020}
+ year = {2020},
}
@inproceedings{brown2020language,
- author = {Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert{-}Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei},
+ author = {Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and Winter, Clemens and Hesse, Christopher and Chen, Mark and Sigler, Eric and Litwin, Mateusz and Gray, Scott and Chess, Benjamin and Clark, Jack and Berner, Christopher and McCandlish, Sam and Radford, Alec and Sutskever, Ilya and Amodei, Dario},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/BrownMRSKDNSSAA20.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Tue, 19 Jan 2021 00:00:00 +0100},
title = {Language Models are Few-Shot Learners},
url = {https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html},
- year = {2020}
+ year = {2020},
}
@inproceedings{chu2021discovering,
- author = {Grace Chu and Okan Arikan and Gabriel Bender and Weijun Wang and Achille Brighton and Pieter{-}Jan Kindermans and Hanxiao Liu and Berkin Akin and Suyog Gupta and Andrew Howard},
+ author = {Chu, Grace and Arikan, Okan and Bender, Gabriel and Wang, Weijun and Brighton, Achille and Kindermans, Pieter-Jan and Liu, Hanxiao and Akin, Berkin and Gupta, Suyog and Howard, Andrew},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/ChuABWBKLAG021.bib},
- booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition Workshops, {CVPR} Workshops 2021, virtual, June 19-25, 2021},
- doi = {10.1109/CVPRW53098.2021.00337},
+ booktitle = {2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
+ doi = {10.1109/cvprw53098.2021.00337},
pages = {3022--3031},
- publisher = {Computer Vision Foundation / {IEEE}},
+ publisher = {IEEE},
timestamp = {Mon, 18 Jul 2022 01:00:00 +0200},
title = {Discovering Multi-Hardware Mobile Models via Architecture Search},
- url = {https://openaccess.thecvf.com/content/CVPR2021W/ECV/html/Chu\_Discovering\_Multi-Hardware\_Mobile\_Models\_via\_Architecture\_Search\_CVPRW\_2021\_paper.html},
- year = {2021}
+ url = {https://doi.org/10.1109/cvprw53098.2021.00337},
+ year = {2021},
+ source = {Crossref},
+ month = jun,
}
@article{coleman2017dawnbench,
@@ -81,20 +89,21 @@ @article{coleman2017dawnbench
title = {Analysis of {DAWNBench,} a Time-to-Accuracy Machine Learning Performance Benchmark},
url = {https://doi.org/10.1145/3352020.3352024},
volume = {53},
- year = {2019}
+ year = {2019},
+ month = jul,
}
@inproceedings{coleman2022similarity,
- author = {Cody Coleman and Edward Chou and Julian Katz{-}Samuels and Sean Culatana and Peter Bailis and Alexander C. Berg and Robert D. Nowak and Roshan Sumbaly and Matei Zaharia and I. Zeki Yalniz},
+ author = {Coleman, Cody and Chou, Edward and Katz-Samuels, Julian and Culatana, Sean and Bailis, Peter and Berg, Alexander C. and Nowak, Robert D. and Sumbaly, Roshan and Zaharia, Matei and Yalniz, I. Zeki},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/aaai/ColemanCKCBBNSZ22.bib},
- booktitle = {Thirty-Sixth {AAAI} Conference on Artificial Intelligence, {AAAI} 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, {IAAI} 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, {EAAI} 2022 Virtual Event, February 22 - March 1, 2022},
+ booktitle = {Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022 Virtual Event, February 22 - March 1, 2022},
pages = {6402--6410},
- publisher = {{AAAI} Press},
+ publisher = {AAAI Press},
timestamp = {Mon, 11 Jul 2022 01:00:00 +0200},
title = {Similarity Search for Efficient Active Learning and Search of Rare Concepts},
url = {https://ojs.aaai.org/index.php/AAAI/article/view/20591},
- year = {2022}
+ year = {2022},
}
@article{david2021tensorflow,
@@ -103,7 +112,7 @@ @article{david2021tensorflow
pages = {800--811},
title = {Tensorflow lite micro: {Embedded} machine learning for tinyml systems},
volume = {3},
- year = {2021}
+ year = {2021},
}
@article{davies2018loihi,
@@ -118,19 +127,21 @@ @article{davies2018loihi
title = {Loihi: {A} Neuromorphic Manycore Processor with On-Chip Learning},
url = {https://doi.org/10.1109/mm.2018.112130359},
volume = {38},
- year = {2018}
+ year = {2018},
+ month = jan,
}
@inproceedings{devlin2018bert,
+ author = {Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
address = {Minneapolis, Minnesota},
- author = {Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
- booktitle = {Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)},
- doi = {10.18653/v1/N19-1423},
+ booktitle = {Proceedings of the 2019 Conference of the North},
+ doi = {10.18653/v1/n19-1423},
pages = {4171--4186},
publisher = {Association for Computational Linguistics},
- title = {{BERT}: Pre-training of Deep Bidirectional Transformers for Language Understanding},
- url = {https://aclanthology.org/N19-1423},
- year = {2019}
+ title = {{BERT:} {Pre-training} of Deep Bidirectional Transformers for Language Understanding},
+ url = {https://doi.org/10.18653/v1/n19-1423},
+ year = {2019},
+ source = {Crossref},
}
@article{gaviria2022dollar,
@@ -145,21 +156,24 @@ @article{gaviria2022dollar
title = {{MLPerf:} {An} Industry Standard Benchmark Suite for Machine Learning Performance},
url = {https://doi.org/10.1109/mm.2020.2974843},
volume = {40},
- year = {2020}
+ year = {2020},
+ month = mar,
}
@inproceedings{hendrycks2021natural,
- author = {Dan Hendrycks and Kevin Zhao and Steven Basart and Jacob Steinhardt and Dawn Song},
+ author = {Hendrycks, Dan and Zhao, Kevin and Basart, Steven and Steinhardt, Jacob and Song, Dawn},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/HendrycksZBSS21.bib},
- booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition, {CVPR} 2021, virtual, June 19-25, 2021},
- doi = {10.1109/CVPR46437.2021.01501},
+ booktitle = {2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr46437.2021.01501},
pages = {15262--15271},
- publisher = {Computer Vision Foundation / {IEEE}},
+ publisher = {IEEE},
timestamp = {Mon, 18 Jul 2022 01:00:00 +0200},
title = {Natural Adversarial Examples},
- url = {https://openaccess.thecvf.com/content/CVPR2021/html/Hendrycks\_Natural\_Adversarial\_Examples\_CVPR\_2021\_paper.html},
- year = {2021}
+ url = {https://doi.org/10.1109/cvpr46437.2021.01501},
+ year = {2021},
+ source = {Crossref},
+ month = jun,
}
@inproceedings{ignatov2018ai,
@@ -171,35 +185,37 @@ @inproceedings{ignatov2018ai
source = {Crossref},
title = {{AI} Benchmark: {All} About Deep Learning on Smartphones in 2019},
url = {https://doi.org/10.1109/iccvw.2019.00447},
- year = {2019}
+ year = {2019},
+ month = oct,
}
@inproceedings{kiela2021dynabench,
+ author = {Kiela, Douwe and Bartolo, Max and Nie, Yixin and Kaushik, Divyansh and Geiger, Atticus and Wu, Zhengxuan and Vidgen, Bertie and Prasad, Grusha and Singh, Amanpreet and Ringshia, Pratik and Ma, Zhiyi and Thrush, Tristan and Riedel, Sebastian and Waseem, Zeerak and Stenetorp, Pontus and Jia, Robin and Bansal, Mohit and Potts, Christopher and Williams, Adina},
address = {Online},
- author = {Kiela, Douwe and Bartolo, Max and Nie, Yixin and Kaushik, Divyansh and Geiger, Atticus and Wu, Zhengxuan and Vidgen, Bertie and Prasad, Grusha and Singh, Amanpreet and Ringshia, Pratik and Ma, Zhiyi and Thrush, Tristan and Riedel, Sebastian and Waseem, Zeerak and Stenetorp, Pontus and Jia, Robin and Bansal, Mohit and Potts, Christopher and Williams, Adina},
booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
doi = {10.18653/v1/2021.naacl-main.324},
pages = {4110--4124},
publisher = {Association for Computational Linguistics},
- title = {Dynabench: Rethinking Benchmarking in {NLP}},
- url = {https://aclanthology.org/2021.naacl-main.324},
- year = {2021}
+ title = {Dynabench: {Rethinking} Benchmarking in {NLP}},
+ url = {https://doi.org/10.18653/v1/2021.naacl-main.324},
+ year = {2021},
+ source = {Crossref},
}
@inproceedings{koh2021wilds,
- author = {Pang Wei Koh and Shiori Sagawa and Henrik Marklund and Sang Michael Xie and Marvin Zhang and Akshay Balsubramani and Weihua Hu and Michihiro Yasunaga and Richard Lanas Phillips and Irena Gao and Tony Lee and Etienne David and Ian Stavness and Wei Guo and Berton Earnshaw and Imran S. Haque and Sara M. Beery and Jure Leskovec and Anshul Kundaje and Emma Pierson and Sergey Levine and Chelsea Finn and Percy Liang},
+ author = {Koh, Pang Wei and Sagawa, Shiori and Marklund, Henrik and Xie, Sang Michael and Zhang, Marvin and Balsubramani, Akshay and Hu, Weihua and Yasunaga, Michihiro and Phillips, Richard Lanas and Gao, Irena and Lee, Tony and David, Etienne and Stavness, Ian and Guo, Wei and Earnshaw, Berton and Haque, Imran S. and Beery, Sara M. and Leskovec, Jure and Kundaje, Anshul and Pierson, Emma and Levine, Sergey and Finn, Chelsea and Liang, Percy},
+ editor = {Meila, Marina and Zhang, Tong},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/icml/KohSMXZBHYPGLDS21.bib},
- booktitle = {Proceedings of the 38th International Conference on Machine Learning, {ICML} 2021, 18-24 July 2021, Virtual Event},
- editor = {Marina Meila and Tong Zhang},
+ booktitle = {Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event},
pages = {5637--5664},
- publisher = {{PMLR}},
+ publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
timestamp = {Tue, 13 Dec 2022 00:00:00 +0100},
title = {{WILDS:} {A} Benchmark of in-the-Wild Distribution Shifts},
url = {http://proceedings.mlr.press/v139/koh21a.html},
volume = {139},
- year = {2021}
+ year = {2021},
}
@inproceedings{lin2014microsoft,
@@ -208,20 +224,20 @@ @inproceedings{lin2014microsoft
organization = {Springer},
pages = {740--755},
title = {Microsoft coco: {Common} objects in context},
- year = {2014}
+ year = {2014},
}
@inproceedings{lundberg2017unified,
- author = {Scott M. Lundberg and Su{-}In Lee},
+ author = {Lundberg, Scott M. and Lee, Su-In},
+ editor = {Guyon, Isabelle and von Luxburg, Ulrike and Bengio, Samy and Wallach, Hanna M. and Fergus, Rob and Vishwanathan, S. V. N. and Garnett, Roman},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/LundbergL17.bib},
- booktitle = {Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, {USA}},
- editor = {Isabelle Guyon and Ulrike von Luxburg and Samy Bengio and Hanna M. Wallach and Rob Fergus and S. V. N. Vishwanathan and Roman Garnett},
+ booktitle = {Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA},
pages = {4765--4774},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
title = {A Unified Approach to Interpreting Model Predictions},
url = {https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html},
- year = {2017}
+ year = {2017},
}
@article{maass1997networks,
@@ -236,7 +252,8 @@ @article{maass1997networks
title = {Networks of spiking neurons: {The} third generation of neural network models},
url = {https://doi.org/10.1016/s0893-6080(97)00011-7},
volume = {10},
- year = {1997}
+ year = {1997},
+ month = dec,
}
@article{mattson2020mlperf,
@@ -251,7 +268,8 @@ @article{mattson2020mlperf
title = {{MLPerf:} {An} Industry Standard Benchmark Suite for Machine Learning Performance},
url = {https://doi.org/10.1109/mm.2020.2974843},
volume = {40},
- year = {2020}
+ year = {2020},
+ month = mar,
}
@article{modha2023neural,
@@ -266,7 +284,8 @@ @article{modha2023neural
title = {Neural inference at the frontier of energy, space, and time},
url = {https://doi.org/10.1126/science.adh1174},
volume = {382},
- year = {2023}
+ year = {2023},
+ month = oct,
}
@inproceedings{reddi2020mlperf,
@@ -279,7 +298,8 @@ @inproceedings{reddi2020mlperf
source = {Crossref},
title = {{MLPerf} Inference Benchmark},
url = {https://doi.org/10.1109/isca45697.2020.00045},
- year = {2020}
+ year = {2020},
+ month = may,
}
@inproceedings{ribeiro2016should,
@@ -287,7 +307,7 @@ @inproceedings{ribeiro2016should
booktitle = {Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining},
pages = {1135--1144},
title = {{\textquotedblright} Why should i trust you?{\textquotedblright} Explaining the predictions of any classifier},
- year = {2016}
+ year = {2016},
}
@article{schuman2022opportunities,
@@ -302,7 +322,8 @@ @article{schuman2022opportunities
title = {Opportunities for neuromorphic computing algorithms and applications},
url = {https://doi.org/10.1038/s43588-021-00184-y},
volume = {2},
- year = {2022}
+ year = {2022},
+ month = jan,
}
@article{warden2018speech,
@@ -311,21 +332,23 @@ @article{warden2018speech
title = {Speech commands: {A} dataset for limited-vocabulary speech recognition},
url = {https://arxiv.org/abs/1804.03209},
volume = {abs/1804.03209},
- year = {2018}
+ year = {2018},
}
@inproceedings{xie2020adversarial,
- author = {Cihang Xie and Mingxing Tan and Boqing Gong and Jiang Wang and Alan L. Yuille and Quoc V. Le},
+ author = {Xie, Cihang and Tan, Mingxing and Gong, Boqing and Wang, Jiang and Yuille, Alan L. and Le, Quoc V.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/XieTGWYL20.bib},
- booktitle = {2020 {IEEE/CVF} Conference on Computer Vision and Pattern Recognition, {CVPR} 2020, Seattle, WA, USA, June 13-19, 2020},
- doi = {10.1109/CVPR42600.2020.00090},
+ booktitle = {2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr42600.2020.00090},
pages = {816--825},
- publisher = {{IEEE}},
+ publisher = {IEEE},
timestamp = {Tue, 13 Oct 2020 01:00:00 +0200},
title = {Adversarial Examples Improve Image Recognition},
- url = {https://doi.org/10.1109/CVPR42600.2020.00090},
- year = {2020}
+ url = {https://doi.org/10.1109/cvpr42600.2020.00090},
+ year = {2020},
+ source = {Crossref},
+ month = jun,
}
@article{xu2023demystifying,
@@ -334,14 +357,14 @@ @article{xu2023demystifying
title = {Demystifying {CLIP} Data},
url = {https://arxiv.org/abs/2309.16671},
volume = {abs/2309.16671},
- year = {2023}
+ year = {2023},
}
@misc{yik2023neurobench,
- archiveprefix = {arXiv},
author = {Yik, Jason and Ahmed, Soikat Hasan and Ahmed, Zergham and Anderson, Brian and Andreou, Andreas G. and Bartolozzi, Chiara and Basu, Arindam and den Blanken, Douwe and Bogdan, Petrut and Bohte, Sander and Bouhadjar, Younes and Buckley, Sonia and Cauwenberghs, Gert and Corradi, Federico and de Croon, Guido and Danielescu, Andreea and Daram, Anurag and Davies, Mike and Demirag, Yigit and Eshraghian, Jason and Forest, Jeremy and Furber, Steve and Furlong, Michael and Gilra, Aditya and Indiveri, Giacomo and Joshi, Siddharth and Karia, Vedant and Khacef, Lyes and Knight, James C. and Kriener, Laura and Kubendran, Rajkumar and Kudithipudi, Dhireesha and Lenz, Gregor and Manohar, Rajit and Mayr, Christian and Michmizos, Konstantinos and Muir, Dylan and Neftci, Emre and Nowotny, Thomas and Ottati, Fabrizio and Ozcelikkale, Ayca and Pacik-Nelson, Noah and Panda, Priyadarshini and Pao-Sheng, Sun and Payvand, Melika and Pehle, Christian and Petrovici, Mihai A. and Posch, Christoph and Renner, Alpha and Sandamirskaya, Yulia and Schaefer, Clemens JS and van Schaik, Andr\'e and Schemmel, Johannes and Schuman, Catherine and Seo, Jae-sun and Sheik, Sadique and Shrestha, Sumit Bam and Sifalakis, Manolis and Sironi, Amos and Stewart, Kenneth and Stewart, Terrence C. and Stratmann, Philipp and Tang, Guangzhi and Timcheck, Jonathan and Verhelst, Marian and Vineyard, Craig M. and Vogginger, Bernhard and Yousefzadeh, Amirreza and Zhou, Biyan and Zohora, Fatima Tuz and Frenkel, Charlotte and Reddi, Vijay Janapa},
+ archiveprefix = {arXiv},
eprint = {2304.04640},
primaryclass = {cs.AI},
title = {{NeuroBench:} {Advancing} Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking},
- year = {2023}
+ year = {2023},
}
diff --git a/contents/benchmarking/benchmarking.qmd b/contents/benchmarking/benchmarking.qmd
index 2bd20a85..e01bb8e9 100644
--- a/contents/benchmarking/benchmarking.qmd
+++ b/contents/benchmarking/benchmarking.qmd
@@ -10,7 +10,7 @@ Resources: [Slides](#sec-benchmarking-ai-resource), [Labs](#sec-benchmarking-ai-

-Benchmarking is a critical part of developing and deploying machine learning systems, especially for TinyML applications. Benchmarks allow developers to measure and compare the performance of different model architectures, training procedures, and deployment strategies. This provides key insights into which approaches work best for the problem at hand and the constraints of the deployment environment.
+Benchmarking is critical to developing and deploying machine learning systems, especially TinyML applications. Benchmarks allow developers to measure and compare the performance of different model architectures, training procedures, and deployment strategies. This provides key insights into which approaches work best for the problem at hand and the constraints of the deployment environment.
This chapter will provide an overview of popular ML benchmarks, best practices for benchmarking, and how to use benchmarks to improve model development and system performance. It aims to provide developers with the right tools and knowledge to effectively benchmark and optimize their systems, especially for TinyML systems.
@@ -25,98 +25,98 @@ This chapter will provide an overview of popular ML benchmarks, best practices f
* Become familiar with the key components of an AI benchmark, including datasets, tasks, metrics, baselines, reproducibility rules, and more.
-* Understand the distinction between training and inference, and how each phase warrants specialized ML systems benchmarking.
+* Understand the distinction between training and inference and how each phase warrants specialized ML systems benchmarking.
* Learn about system benchmarking concepts like throughput, latency, power, and computational efficiency.
-* Appreciate the evolution of model benchmarking from accuracy to more holistic metrics like fairness, robustness and real-world applicability.
+* Appreciate the evolution of model benchmarking from accuracy to more holistic metrics like fairness, robustness, and real-world applicability.
-* Recognize the growing role of data benchmarking in evaluating issues like bias, noise, balance and diversity.
+* Recognize the growing role of data benchmarking in evaluating issues like bias, noise, balance, and diversity.
-* Understand the limitations of evaluating models, data, and systems in isolation, and the emerging need for integrated benchmarking.
+* Understand the limitations of evaluating models, data, and systems in isolation and the emerging need for integrated benchmarking.
:::
## Introduction {#sec-benchmarking-ai}
-Benchmarking provides the essential measurements needed to drive progress in machine learning and to truly understand system performance. As the physicist Lord Kelvin famously said, "To measure is to know." Benchmarks give us the ability to know the capabilities of different models, software, and hardware quantitatively. They allow ML developers to measure the inference time, memory usage, power consumption, and other metrics that characterize a system. Moreover, benchmarks create standardized processes for measurement, enabling fair comparisons across different solutions.
+Benchmarking provides the essential measurements needed to drive machine learning progress and truly understand system performance. As the physicist Lord Kelvin famously said, "To measure is to know." Benchmarks allow us to quantitatively know the capabilities of different models, software, and hardware. They allow ML developers to measure the inference time, memory usage, power consumption, and other metrics that characterize a system. Moreover, benchmarks create standardized processes for measurement, enabling fair comparisons across different solutions.
When benchmarks are maintained over time, they become instrumental in capturing progress across generations of algorithms, datasets, and hardware. The models and techniques that set new records on ML benchmarks from one year to the next demonstrate tangible improvements in what's possible for on-device machine learning. By using benchmarks to measure, ML practitioners can know the real-world capabilities of their systems and have confidence that each step reflects genuine progress towards the state-of-the-art.
Benchmarking has several important goals and objectives that guide its implementation for machine learning systems.
-* **Performance assessment.** This involves evaluating key metrics like the speed, accuracy, and efficiency of a given model. For instance, in a TinyML context, it is crucial to benchmark how quickly a voice assistant can recognize commands, as this evaluates real-time performance.
+* **Performance assessment.** This involves evaluating key metrics like a given model's speed, accuracy, and efficiency. For instance, in a TinyML context, it is crucial to benchmark how quickly a voice assistant can recognize commands, as this evaluates real-time performance.
-* **Resource evaluation.** This means assessing the model's impact on critical system resources including battery life, memory usage, and computational overhead. A relevant example is comparing the battery drain of two different image recognition algorithms running on a wearable device.
+* **Resource evaluation.** This means assessing the model's impact on critical system resources, including battery life, memory usage, and computational overhead. A relevant example is comparing the battery drain of two different image recognition algorithms running on a wearable device.
* **Validation and verification.** Benchmarking helps ensure the system functions correctly and meets specified requirements. One way is by checking the accuracy of an algorithm, like a heart rate monitor on a smartwatch, against readings from medical-grade equipment as a form of clinical validation.
* **Competitive analysis.** This enables comparing solutions against competing offerings in the market. For example, benchmarking a custom object detection model versus common TinyML benchmarks like MobileNet and Tiny-YOLO.
-* **Credibility.** Accurate benchmarks uphold the credibility of AI solutions and the organizations that develop them. They demonstrate a commitment to transparency, honesty, and quality, which is essential in building trust with users and stakeholders.
+* **Credibility.** Accurate benchmarks uphold the credibility of AI solutions and the organizations that develop them. They demonstrate a commitment to transparency, honesty, and quality, which are essential in building trust with users and stakeholders.
-* **Regulation and Standardization**. As the AI industry continues to grow, there is an increasing need for regulation and standardization to ensure that AI solutions are safe, ethical, and effective. Accurate and reliable benchmarks are an essential component of this regulatory framework, as they provide the data and evidence needed to assess compliance with industry standards and legal requirements.
+* **Regulation and Standardization**. As the AI industry continues to grow, there is an increasing need for regulation and standardization to ensure that AI solutions are safe, ethical, and effective. Accurate and reliable benchmarks are essential to this regulatory framework, as they provide the data and evidence needed to assess compliance with industry standards and legal requirements.
-This chapter will cover the 3 types of benchmarks in AI, the standard metrics, tools, and techniques designers use to optimize their systems, and the challenges and trends in benchmarking.
+This chapter will cover the 3 types of AI benchmarks, the standard metrics, tools, and techniques designers use to optimize their systems, and the challenges and trends in benchmarking.
## Historical Context
### Standard Benchmarks
-The evolution of benchmarks in computing vividly illustrates the industry's relentless pursuit of excellence and innovation. In the early days of computing during the 1960s and 1970s, benchmarks were rudimentary and designed for mainframe computers. For example, the [Whetstone benchmark](https://en.wikipedia.org/wiki/Whetstone_(benchmark)), named after the Whetstone ALGOL compiler, was one of the first standardized tests to measure floating-point arithmetic performance of a CPU. These pioneering benchmarks prompted manufacturers to refine their architectures and algorithms to achieve better benchmark scores.
+The evolution of benchmarks in computing vividly illustrates the industry's relentless pursuit of excellence and innovation. In the early days of computing during the 1960s and 1970s, benchmarks were rudimentary and designed for mainframe computers. For example, the [Whetstone benchmark](https://en.wikipedia.org/wiki/Whetstone_(benchmark)), named after the Whetstone ALGOL compiler, was one of the first standardized tests to measure the floating-point arithmetic performance of a CPU. These pioneering benchmarks prompted manufacturers to refine their architectures and algorithms to achieve better benchmark scores.
-The 1980s marked a significant shift with the rise of personal computers. As companies like IBM, Apple, and Commodore competed for market share, and so benchmarks became critical tools to enable fair competition. The [SPEC CPU benchmarks](https://www.spec.org/cpu/), introduced by the [System Performance Evaluation Cooperative (SPEC)](https://www.spec.org/), established standardized tests allowing objective comparisons between different machines. This standardization created a competitive environment, pushing silicon manufacturers and system creators to enhance their hardware and software offerings continually.
+The 1980s marked a significant shift with the rise of personal computers. As companies like IBM, Apple, and Commodore competed for market share, and so benchmarks became critical tools to enable fair competition. The [SPEC CPU benchmarks](https://www.spec.org/cpu/), introduced by the [System Performance Evaluation Cooperative (SPEC)](https://www.spec.org/), established standardized tests allowing objective comparisons between different machines. This standardization created a competitive environment, pushing silicon manufacturers and system creators to continually enhance their hardware and software offerings.
-With the 1990s came the era of graphics-intensive applications and video games. The need for benchmarks to evaluate graphics card performance led to the creation of [3DMark](https://www.3dmark.com/) by Futuremark. As gamers and professionals sought high-performance graphics cards, companies like NVIDIA and AMD were driven to rapid innovation, leading to major advancements in GPU technology like programmable shaders.
+The 1990s brought the era of graphics-intensive applications and video games. The need for benchmarks to evaluate graphics card performance led to Futuremark's creation of [3DMark](https://www.3dmark.com/). As gamers and professionals sought high-performance graphics cards, companies like NVIDIA and AMD were driven to rapid innovation, leading to major advancements in GPU technology like programmable shaders.
-The 2000s saw a surge in mobile phones and portable devices like tablets. With portability came the challenge of balancing performance and power consumption. Benchmarks like [MobileMark](https://bapco.com/products/mobilemark-2014/) by BAPCo evaluated not just speed but also battery life. This drove companies to develop more energy-efficient System-on-Chips (SOCs), leading to the emergence of architectures like ARM that prioritized power efficiency.
+The 2000s saw a surge in mobile phones and portable devices like tablets. With portability came the challenge of balancing performance and power consumption. Benchmarks like [MobileMark](https://bapco.com/products/mobilemark-2014/) by BAPCo evaluated speed and battery life. This drove companies to develop more energy-efficient System-on-Chips (SOCs), leading to the emergence of architectures like ARM that prioritized power efficiency.
-The recent decade's focus has shifted towards cloud computing, big data, and artificial intelligence. Cloud services providers like Amazon Web Services and Google Cloud compete on performance, scalability, and cost-effectiveness. Tailored cloud benchmarks like [CloudSuite](http://cloudsuite.ch/) have become essential, driving providers to optimize their infrastructure for better services.
+The focus of the recent decade has shifted towards cloud computing, big data, and artificial intelligence. Cloud service providers like Amazon Web Services and Google Cloud compete on performance, scalability, and cost-effectiveness. Tailored cloud benchmarks like [CloudSuite](http://cloudsuite.ch/) have become essential, driving providers to optimize their infrastructure for better services.
### Custom Benchmarks
-In addition to industry-standard benchmarks, there are custom benchmarks that are specifically designed to meet the unique requirements of a particular application or task. They are tailored to the specific needs of the user or developer, ensuring that the performance metrics are directly relevant to the intended use of the AI model or system. Custom benchmarks can be created by individual organizations, researchers, or developers, and are often used in conjunction with industry standard benchmarks to provide a comprehensive evaluation of AI performance.
+In addition to industry-standard benchmarks, there are custom benchmarks specifically designed to meet the unique requirements of a particular application or task. They are tailored to the specific needs of the user or developer, ensuring that the performance metrics are directly relevant to the intended use of the AI model or system. Custom benchmarks can be created by individual organizations, researchers, or developers and are often used in conjunction with industry-standard benchmarks to provide a comprehensive evaluation of AI performance.
-For example, a hospital could develop a benchmark to assess an AI model for predicting patient readmission. This benchmark would incorporate metrics relevant to the hospital's patient population like demographics, medical history, and social factors. Similarly, a financial institution's fraud detection benchmark could focus on identifying fraudulent transactions accurately while minimizing false positives. In automotive, an autonomous vehicle benchmark may prioritize performance in diverse conditions, responding to obstacles, and safety. Retailers could benchmark recommendation systems using click-through rate, conversion rate, and customer satisfaction. Manufacturing companies might benchmark quality control systems on defect identification, efficiency, and waste reduction. In each industry, custom benchmarks provide organizations with evaluation criteria tailored to their unique needs and context. This allows for more meaningful assessment of how well AI systems meet requirements.
+For example, a hospital could develop a benchmark to assess an AI model for predicting patient readmission. This benchmark would incorporate metrics relevant to the hospital's patient population, like demographics, medical history, and social factors. Similarly, a financial institution's fraud detection benchmark could focus on identifying fraudulent transactions accurately while minimizing false positives. In automotive, an autonomous vehicle benchmark may prioritize performance in diverse conditions, responding to obstacles, and safety. Retailers could benchmark recommendation systems using click-through rate, conversion rate, and customer satisfaction. Manufacturing companies might benchmark quality control systems on defect identification, efficiency, and waste reduction. In each industry, custom benchmarks provide organizations with evaluation criteria tailored to their unique needs and context. This allows for a more meaningful assessment of how well AI systems meet requirements.
-The advantage of custom benchmarks lies in their flexibility and relevance. They can be designed to test specific aspects of performance that are critical to the success of the AI solution in its intended application. This allows for a more targeted and accurate assessment of the AI model or system's capabilities. Custom benchmarks also provide valuable insights into the performance of AI solutions in real-world scenarios, which can be crucial for identifying potential issues and areas for improvement.
+The advantage of custom benchmarks lies in their flexibility and relevance. They can be designed to test specific performance aspects critical to the success of the AI solution in its intended application. This allows for a more targeted and accurate assessment of the AI model or system's capabilities. Custom benchmarks also provide valuable insights into the performance of AI solutions in real-world scenarios, which can be crucial for identifying potential issues and areas for improvement.
-In AI, benchmarks play a crucial role in driving progress and innovation. While benchmarks have long been used in computing, their application to machine learning is relatively recent. AI-focused benchmarks aim to provide standardized metrics to evaluate and compare the performance of different algorithms, model architectures, and hardware platforms.
+In AI, benchmarks play a crucial role in driving progress and innovation. While benchmarks have long been used in computing, their application to machine learning is relatively recent. AI-focused benchmarks provide standardized metrics to evaluate and compare the performance of different algorithms, model architectures, and hardware platforms.
### Community Consensus
A key prerogative for any benchmark to be impactful is that it must reflect the shared priorities and values of the broader research community. Benchmarks designed in isolation risk failing to gain acceptance if they overlook key metrics considered important by leading groups. Through collaborative development with open participation from academic labs, companies, and other stakeholders, benchmarks can incorporate collective input on critical capabilities worth measuring. This helps ensure the benchmarks evaluate aspects the community agrees are essential to advance the field. The process of reaching alignment on tasks and metrics itself supports converging on what matters most.
-Furthermore, benchmarks published with broad co-authorship from respected institutions carry authority and validity that convinces the community to adopt them as trusted standards. Benchmarks perceived as biased by particular corporate or institutional interests breed skepticism. Ongoing community engagement through workshops and challenges is also key after initial release, and that is what, for instance, led to the success of ImageNet. As research rapidly progresses, collective participation enables continual refinement and expansion of benchmarks over time.
+Furthermore, benchmarks published with broad co-authorship from respected institutions carry authority and validity that convinces the community to adopt them as trusted standards. Benchmarks perceived as biased by particular corporate or institutional interests breed skepticism. Ongoing community engagement through workshops and challenges is also key after the initial release, and that is what, for instance, led to the success of ImageNet. As research progresses, collective participation enables continual refinement and expansion of benchmarks over time.
-Finally, community-developed benchmarks released with open access accelerate adoption and consistent implementation. Shared open source code, documentation, models and infrastructure lower barriers for groups to benchmark solutions on an equal footing using standardized implementations. This consistency is critical for fair comparisons. Without coordination, labs and companies may implement benchmarks differently, reducing result reproducibility.
+Finally, community-developed benchmarks released with open access accelerate adoption and consistent implementation. We shared open-source code, documentation, models, and infrastructure to lower barriers for groups to benchmark solutions on an equal footing using standardized implementations. This consistency is critical for fair comparisons. Without coordination, labs and companies may implement benchmarks differently, reducing result reproducibility.
-Community consensus brings benchmarks lasting relevance while fragmentation causes confusion. Through collaborative development and transparent operation, benchmarks can become authoritative standards for tracking progress. Several of the benchmarks that we discuss in this chapter were developed and built by the community, for the community, and that is what ultimately led to their success.
+Community consensus brings benchmarks lasting relevance, while fragmentation confuses. Through collaborative development and transparent operation, benchmarks can become authoritative standards for tracking progress. Several of the benchmarks that we discuss in this chapter were developed and built by the community, for the community, and that is what ultimately led to their success.
## AI Benchmarks: System, Model, and Data
-As AI systems grow in complexity and ubiquity, the need for comprehensive benchmarking becomes paramount. Within this context, benchmarks are often classified into three primary categories: Hardware, Model, and Data. Let's delve into why each of these buckets is essential and the significance of evaluating AI from these three distinct dimensions:
+The need for comprehensive benchmarking becomes paramount as AI systems grow in complexity and ubiquity. Within this context, benchmarks are often classified into three primary categories: Hardware, Model, and Data. Let's delve into why each of these buckets is essential and the significance of evaluating AI from these three distinct dimensions:
### System Benchmarks
-AI computations, especially those in deep learning, are resource-intensive. The hardware on which these computations run plays an important role in determining the speed, efficiency, and scalability of AI solutions. Consequently, hardware benchmarks help evaluate the performance of CPUs, GPUs, TPUs, and other accelerators in the context of AI tasks. By understanding hardware performance, developers can make informed choices about which hardware platforms are best suited for specific AI applications. Furthermore, hardware manufacturers use these benchmarks to identify areas for improvement, driving innovation in AI-specific chip designs.
+AI computations, especially those in deep learning, are resource-intensive. The hardware on which these computations run plays an important role in determining AI solutions' speed, efficiency, and scalability. Consequently, hardware benchmarks help evaluate the performance of CPUs, GPUs, TPUs, and other accelerators in AI tasks. By understanding hardware performance, developers can choose which hardware platforms best suit specific AI applications. Furthermore, hardware manufacturers use these benchmarks to identify areas for improvement, driving innovation in AI-specific chip designs.
### Model Benchmarks
-The architecture, size, and complexity of AI models vary widely. Different models have different computational demands and offer varying levels of accuracy and efficiency. Model benchmarks help us assess the performance of various AI architectures on standardized tasks. They provide insights into the speed, accuracy, and resource demands of different models. By benchmarking models, researchers can identify best-performing architectures for specific tasks, guiding the AI community towards more efficient and effective solutions. Additionally, these benchmarks aid in tracking the progress of AI research, showcasing advancements in model design and optimization.
+The architecture, size, and complexity of AI models vary widely. Different models have different computational demands and offer varying levels of accuracy and efficiency. Model benchmarks help us assess the performance of various AI architectures on standardized tasks. They provide insights into different models' speed, accuracy, and resource demands. By benchmarking models, researchers can identify best-performing architectures for specific tasks, guiding the AI community towards more efficient and effective solutions. Additionally, these benchmarks aid in tracking the progress of AI research, showcasing advancements in model design and optimization.
### Data Benchmarks
-AI, particularly machine learning, is inherently data-driven. The quality, size, and diversity of data influence the training efficacy and generalization capability of AI models. Data benchmarks focus on the datasets used in AI training and evaluation. They provide standardized datasets that the community can use to train and test models, ensuring a level playing field for comparisons. Moreover, these benchmarks highlight challenges in data quality, diversity, and representation, pushing the community to address biases and gaps in AI training data. By understanding data benchmarks, researchers can also gauge how models might perform in real-world scenarios, ensuring robustness and reliability.
+AI, particularly machine learning, is inherently data-driven. The quality, size, and diversity of data influence AI models' training efficacy and generalization capability. Data benchmarks focus on the datasets used in AI training and evaluation. They provide standardized datasets the community can use to train and test models, ensuring a level playing field for comparisons. Moreover, these benchmarks highlight data quality, diversity, and representation challenges, pushing the community to address biases and gaps in AI training data. By understanding data benchmarks, researchers can also gauge how models might perform in real-world scenarios, ensuring robustness and reliability.
-In the remainder of the sections, we will go through each of these benchmark types. The focus will be an in-depth exploration of system benchmarks, as these are critical to understanding and advancing machine learning system performance. We will cover model and data benchmarks briefly for a comprehensive perspective, but the emphasis and majority of the content will be devoted to system benchmarks.
+In the remainder of the sections, we will discuss each of these benchmark types. The focus will be an in-depth exploration of system benchmarks, as these are critical to understanding and advancing machine learning system performance. We will briefly cover model and data benchmarks for a comprehensive perspective, but the emphasis and majority of the content will be devoted to system benchmarks.
## System Benchmarking
### Granularity
-Machine learning system benchmarking provides a structured and systematic approach to assess how well a system is performing across various dimensions. Given the complexity of ML systems, we can dissect their performance through different levels of granularity and obtain a comprehensive view of the system's efficiency, identify potential bottlenecks, and pinpoint areas for improvement. To this end, there are various types of benchmarks that have evolved over the years and continue to persist.
+Machine learning system benchmarking provides a structured and systematic approach to assessing a system's performance across various dimensions. Given the complexity of ML systems, we can dissect their performance through different levels of granularity and obtain a comprehensive view of the system's efficiency, identify potential bottlenecks, and pinpoint areas for improvement. To this end, various types of benchmarks have evolved over the years and continue to persist.
@fig-granularity illustrates the different layers of granularity of an ML system. At the application level, end-to-end benchmarks assess the overall system performance, considering factors like data preprocessing, model training, and inference. While at the model layer, benchmarks focus on assessing the efficiency and accuracy of specific models. This includes evaluating how well models generalize to new data and their computational efficiency during training and inference. Furthermore, benchmarking can extend to hardware and software infrastructure, examining the performance of individual components like GPUs or TPUs.
@@ -125,21 +125,21 @@ Machine learning system benchmarking provides a structured and systematic approa
#### Micro Benchmarks
-Micro-benchmarks in AI are specialized, focusing on the evaluation of distinct components or specific operations within a broader machine learning process. These benchmarks zero in on individual tasks, offering insights into the computational demands of a particular neural network layer, the efficiency of a unique optimization technique, or the throughput of a specific activation function. For instance, practitioners might use micro-benchmarks to measure the computational time required by a convolutional layer in a deep learning model or to evaluate the speed of data preprocessing that feeds data into the model. Such granular assessments are instrumental in fine-tuning and optimizing discrete aspects of AI models, ensuring that each component operates at its peak potential.
+Micro-benchmarks in AI are specialized, evaluating distinct components or specific operations within a broader machine learning process. These benchmarks zero in on individual tasks, offering insights into the computational demands of a particular neural network layer, the efficiency of a unique optimization technique, or the throughput of a specific activation function. For instance, practitioners might use micro-benchmarks to measure the computational time required by a convolutional layer in a deep learning model or to evaluate the speed of data preprocessing that feeds data into the model. Such granular assessments are instrumental in fine-tuning and optimizing discrete aspects of AI models, ensuring that each component operates at its peak potential.
-These types of microbenchmarks include that zoom into very specific operations or components of the AI pipeline, such as the following:
+These types of microbenchmarks include zooming into very specific operations or components of the AI pipeline, such as the following:
* **Tensor Operations:** Libraries like [cuDNN](https://developer.nvidia.com/cudnn) (by NVIDIA) often have benchmarks to measure the performance of individual tensor operations, such as convolutions or matrix multiplications, which are foundational to deep learning computations.
* **Activation Functions:** Benchmarks that measure the speed and efficiency of various activation functions like ReLU, Sigmoid, or Tanh in isolation.
-* **Layer Benchmarks:** Evaluations of the computational efficiency of distinct neural network layers, such as a LSTM layer or a Transformer block, when operating on standardized input sizes.
+* **Layer Benchmarks:** Evaluations of the computational efficiency of distinct neural network layers, such as LSTM or Transformer blocks, when operating on standardized input sizes.
-Example: [DeepBench](https://github.com/baidu-research/DeepBench), introduced by Baidu, is a good example of something that asseses the above. DeepBench assesses the performance of basic operations in deep learning models, providing insights into how different hardware platforms handle neural network training and inference.
+Example: [DeepBench](https://github.com/baidu-research/DeepBench), introduced by Baidu, is a good example of something that assesses the above. DeepBench assesses the performance of basic operations in deep learning models, providing insights into how different hardware platforms handle neural network training and inference.
:::{#exr-cuda .callout-exercise collapse="true"}
### System Benchmarking - Tensor Operations
-Ever wondered how your image filters get so fast? Special libraries like cuDNN supercharge those calculations on certain hardware. In this Colab, we're gonna use cuDNN with PyTorch to speed up image filtering. Think of it like a tiny benchmark, showing how the right software can unlock your GPU's power!
+Ever wonder how your image filters get so fast? Special libraries like cuDNN supercharge those calculations on certain hardware. In this Colab, we'll use cuDNN with PyTorch to speed up image filtering. Think of it as a tiny benchmark, showing how the right software can unlock your GPU's power!
[](https://colab.research.google.com/github/RyanHartzell/cudnn-image-filtering/blob/master/notebooks/CuDNN%20Image%20Filtering%20Tutorial%20Using%20PyTorch.ipynb#scrollTo=1sWeXdYsATrr)
@@ -147,7 +147,7 @@ Ever wondered how your image filters get so fast? Special libraries like cuDNN s
#### Macro Benchmarks
-Macro-benchmarks provide a holistic view, assessing the end-to-end performance of entire machine learning models or comprehensive AI systems. Rather than focusing on individual operations, macro-benchmarks evaluate the collective efficacy of models under real-world scenarios or tasks. For example, a macro-benchmark might assess the complete performance of a deep learning model undertaking image classification on a dataset like [ImageNet](https://www.image-net.org/). This includes gauging accuracy, computational speed, and resource consumption. Similarly, one might measure the cumulative time and resources needed to train a natural language processing model on extensive text corpora or evaluate the performance of an entire recommendation system, from data ingestion to final user-specific outputs.
+Macro benchmarks provide a holistic view, assessing the end-to-end performance of entire machine learning models or comprehensive AI systems. Rather than focusing on individual operations, macro-benchmarks evaluate the collective efficacy of models under real-world scenarios or tasks. For example, a macro-benchmark might assess the complete performance of a deep learning model undertaking image classification on a dataset like [ImageNet](https://www.image-net.org/). This includes gauging accuracy, computational speed, and resource consumption. Similarly, one might measure the cumulative time and resources needed to train a natural language processing model on extensive text corpora or evaluate the performance of an entire recommendation system, from data ingestion to final user-specific outputs.
Examples: These benchmarks evaluate the AI model:
@@ -155,29 +155,29 @@ Examples: These benchmarks evaluate the AI model:
* [EEMBC's MLMark](https://github.com/eembc/mlmark): A benchmarking suite for evaluating the performance and power efficiency of embedded devices running machine learning workloads. This benchmark provides insights into how different hardware platforms handle tasks like image recognition or audio processing.
-* [AI-Benchmark](https://ai-benchmark.com/)(@ignatov2018ai): A benchmarking tool designed for Android devices, it valuates the performance of AI tasks on mobile devices, encompassing various real-world scenarios like image recognition, face parsing, and optical character recognition.
+* [AI-Benchmark](https://ai-benchmark.com/)(@ignatov2018ai): A benchmarking tool designed for Android devices, it evaluates the performance of AI tasks on mobile devices, encompassing various real-world scenarios like image recognition, face parsing, and optical character recognition.
#### End-to-end Benchmarks
-End-to-End Benchmarks provide an all-inclusive evaluation that extends beyond the boundaries of the AI model itself. Instead of focusing solely on the computational efficiency or accuracy of a machine learning model, these benchmarks encompass the entire pipeline of an AI system. This includes initial data pre-processing, the core model's performance, post-processing of the model's outputs, and even other integral components like storage and network interactions.
+End-to-end benchmarks provide an all-inclusive evaluation that extends beyond the boundaries of the AI model itself. Instead of focusing solely on a machine learning model's computational efficiency or accuracy, these benchmarks encompass the entire pipeline of an AI system. This includes initial data preprocessing, the core model's performance, post-processing of the model's outputs, and other integral components like storage and network interactions.
-Data pre-processing is the first stage in many AI systems, transforming raw data into a format suitable for model training or inference. The efficiency, scalability, and accuracy of these pre-processing steps are vital for the overall system's performance. End-to-end benchmarks assess this phase, ensuring that data cleaning, normalization, augmentation, or any other transformation process doesn't become a bottleneck.
+Data preprocessing is the first stage in many AI systems, transforming raw data into a format suitable for model training or inference. These preprocessing steps' efficiency, scalability, and accuracy are vital for the overall system's performance. End-to-end benchmarks assess this phase, ensuring that data cleaning, normalization, augmentation, or any other transformation process doesn't become a bottleneck.
The post-processing phase also takes center stage. This involves interpreting the model's raw outputs, possibly converting scores into meaningful categories, filtering results, or even integrating with other systems. In real-world applications, this phase is crucial for delivering actionable insights, and end-to-end benchmarks ensure it's both efficient and effective.
-Beyond the core AI operations, other system components play an important role in the overall performance and user experience. Storage solutions, be it cloud-based, on-premises, or hybrid, can significantly impact data retrieval and storage times, especially with vast AI datasets. Similarly, network interactions, vital for cloud-based AI solutions or distributed systems, can become performance bottlenecks if not optimized. End-to-end benchmarks holistically evaluate these components, ensuring that the entire system, from data retrieval to final output delivery, operates seamlessly.
+Beyond the core AI operations, other system components are important in the overall performance and user experience. Storage solutions, whether cloud-based, on-premises, or hybrid, can significantly impact data retrieval and storage times, especially with vast AI datasets. Similarly, network interactions, vital for cloud-based AI solutions or distributed systems, can become performance bottlenecks if not optimized. End-to-end benchmarks holistically evaluate these components, ensuring that the entire system operates seamlessly, from data retrieval to final output delivery.
-To date, there are no public, end to end benchmarks that take into account the role of data storage, network and compute performance. Arguably, MLPerf Training and Inference, come close to the idea of an end to end benchmark but they are exclusively focused on ML model performance and do not represent real world deployment scenarios of how models are used in the field. Nonetheless, they provide a very useful signal that helps assess AI system performance.
+To date, there are no public, end-to-end benchmarks that take into account the role of data storage, network, and compute performance. Arguably, MLPerf Training and Inference come close to the idea of an end-to-end benchmark, but they are exclusively focused on ML model performance and do not represent real-world deployment scenarios of how models are used in the field. Nonetheless, they provide a very useful signal that helps assess AI system performance.
Given the inherent specificity of end-to-end benchmarking, it is typically performed internally at a company by instrumenting real production deployments of AI. This allows engineers to have a realistic understanding and breakdown of the performance, but given the sensitivity and specificity of the information, it is rarely reported outside of the company.
#### Understanding the Trade-offs
-Different issues arise at different stages of an AI system. Micro-benchmarks help in fine-tuning individual components, macro-benchmarks aid in refining model architectures or algorithms, and end-to-end benchmarks guide the optimization of the entire workflow. By understanding where a problem lies, developers can apply targeted optimizations.
+Different issues arise at different stages of an AI system. Micro-benchmarks help fine-tune individual components, macro-benchmarks aid in refining model architectures or algorithms, and end-to-end benchmarks guide the optimization of the entire workflow. By understanding where a problem lies, developers can apply targeted optimizations.
Moreover, while individual components of an AI system might perform optimally in isolation, bottlenecks can emerge when they interact. End-to-end benchmarks, in particular, are crucial to ensure that the entire system, when operating collectively, meets desired performance and efficiency standards.
-Finally, by discerning where performance bottlenecks or inefficiencies lie, organizations can make informed decisions on where to allocate resources. For instance, if micro-benchmarks reveal inefficiencies in specific tensor operations, investments can be directed towards specialized hardware accelerators. Conversely, if end-to-end benchmarks indicate data retrieval issues, investments might be channeled towards better storage solutions.
+Finally, organizations can make informed decisions on where to allocate resources by discerning performance bottlenecks or inefficiencies. For instance, if micro-benchmarks reveal inefficiencies in specific tensor operations, investments can be directed toward specialized hardware accelerators. Conversely, if end-to-end benchmarks indicate data retrieval issues, investments might be channeled toward better storage solutions.
### Benchmark Components
@@ -185,7 +185,7 @@ At its core, an AI benchmark is more than just a test or a score; it's a compreh
#### Standardized Datasets
-Datasets serve as the foundation for most AI benchmarks. They provide a consistent set of data on which models are trained and evaluated, ensuring a level playing field for comparisons.
+Datasets serve as the foundation for most AI benchmarks. They provide a consistent data set on which models are trained and evaluated, ensuring a level playing field for comparisons.
Example: ImageNet, a large-scale dataset containing millions of labeled images spanning thousands of categories, is a popular benchmarking standard for image classification tasks.
@@ -193,13 +193,13 @@ Example: ImageNet, a large-scale dataset containing millions of labeled images s
A benchmark should have a clear objective or task that models aim to achieve. This task defines the problem the AI system is trying to solve.
-Example: For natural language processing benchmarks, tasks might include sentiment analysis, named entity recognition, or machine translation.
+Example: Tasks for natural language processing benchmarks might include sentiment analysis, named entity recognition, or machine translation.
#### Evaluation Metrics
Once a task is defined, benchmarks require metrics to quantify performance. These metrics offer objective measures to compare different models or systems.
-In classification tasks, metrics like accuracy, precision, recall, and [F1 score](https://en.wikipedia.org/wiki/F-score) are commonly used. For regression tasks, mean squared error or mean absolute error might be employed.
+In classification tasks, metrics like accuracy, precision, recall, and [F1 score](https://en.wikipedia.org/wiki/F-score) are commonly used. Mean squared or absolute errors might be employed for regression tasks.
#### Baseline Models
@@ -221,7 +221,7 @@ Example: Mobile AI benchmarks might specify that tests were conducted at room te
#### Reproducibility Rules
-To ensure benchmarks are credible and can be replicated by others in the community, they often include detailed protocols, covering everything from random seeds used to exact hyperparameters.
+To ensure benchmarks are credible and can be replicated by others in the community, they often include detailed protocols covering everything from random seeds used to exact hyperparameters.
Example: A benchmark for a reinforcement learning task might detail the exact training episodes, exploration-exploitation ratios, and reward structures used.
@@ -229,7 +229,7 @@ Example: A benchmark for a reinforcement learning task might detail the exact tr
Beyond raw scores or metrics, benchmarks often provide guidelines or context to interpret results, helping practitioners understand the broader implications.
-Example: A benchmark might highlight that while Model A scored higher than Model B in accuracy, Model B offers better real-time performance, making it more suitable for time-sensitive applications.
+Example: A benchmark might highlight that while Model A scored higher than Model B in accuracy, it offers better real-time performance, making it more suitable for time-sensitive applications.
### Training vs. Inference
@@ -237,63 +237,63 @@ The development life cycle of a machine learning model involves two critical pha
Benchmarking the training phase provides insights into how different model architectures, hyperparameter values, and optimization algorithms impact the time and resources needed to train the model. For instance, benchmarking shows how neural network depth affects training time on a given dataset. Benchmarking also reveals how hardware accelerators like GPUs and TPUs can speed up training.
-On the other hand, benchmarking inference evaluates model performance in real-world conditions after deployment. Key metrics include latency, throughput, memory footprint, and power consumption. Inference benchmarking determines if an model meets the requirements of its target application regarding response time and device constraints, which is typically the focus of TinyML but we will discuss these broadly to make sure we have a general understanding.
+On the other hand, benchmarking inference evaluates model performance in real-world conditions after deployment. Key metrics include latency, throughput, memory footprint, and power consumption. Inference benchmarking determines if a model meets the requirements of its target application regarding response time and device constraints, which is typically the focus of TinyML. However, we will discuss these broadly to ensure a general understanding.
### Training Benchmarks
-Training represents the phase where raw data is processed and ingested by the system to adjust and refine its parameters. Therefore, it is not just an algorithmic activity but also involves system-level considerations, including data pipelines, storage, computing resources, and orchestration mechanisms. The goal is to ensure that the ML system can efficiently learn from data, optimizing both the model's performance and the system's resource utilization.
+Training represents the phase where the system processes and ingests raw data to adjust and refine its parameters. Therefore, it is an algorithmic activity and involves system-level considerations, including data pipelines, storage, computing resources, and orchestration mechanisms. The goal is to ensure that the ML system can efficiently learn from data, optimizing both the model's performance and the system's resource utilization.
#### Purpose
From an ML systems perspective, training benchmarks evaluate how well the system scales with increasing data volumes and computational demands. It's about understanding the interplay between hardware, software, and the data pipeline in the training process.
-Consider a distributed ML system designed to train on vast datasets, like those used in large-scale e-commerce product recommendations. A training benchmark would assess how efficiently the system scales across multiple nodes, how it manages data sharding, and how it handles failures or node drop-offs during the training process.
+Consider a distributed ML system designed to train on vast datasets, like those used in large-scale e-commerce product recommendations. A training benchmark would assess how efficiently the system scales across multiple nodes, manage data sharding and handle failures or node drop-offs during training.
Training benchmarks evaluate CPU, GPU, memory, and network utilization during the training phase, guiding system optimizations. When training a model in a cloud-based ML system, it's crucial to understand how resources are being utilized. Are GPUs being fully leveraged? Is there unnecessary memory overhead? Benchmarks can highlight bottlenecks or inefficiencies in resource utilization, leading to cost savings and performance improvements.
-Training an ML model is contingent on the timely and efficient delivery of data. Benchmarks in this context would also assess the efficiency of data pipelines, data preprocessing speed, and storage retrieval times. For real-time analytics systems, like those used in fraud detection, the speed at which training data is ingested, preprocessed, and fed into the model can be critical. Benchmarks would evaluate the latency of data pipelines, the efficiency of storage systems (like SSDs vs. HDDs), and the speed of data augmentation or transformation tasks.
+Training an ML model is contingent on timely and efficient data delivery. Benchmarks in this context would also assess the efficiency of data pipelines, data preprocessing speed, and storage retrieval times. For real-time analytics systems, like those used in fraud detection, the speed at which training data is ingested, preprocessed, and fed into the model can be critical. Benchmarks would evaluate the latency of data pipelines, the efficiency of storage systems (like SSDs vs. HDDs), and the speed of data augmentation or transformation tasks.
#### Metrics
-Training metrics, when viewed from a systems perspective, offer insights that transcend the conventional algorithmic performance indicators. These metrics not only measure the model's learning efficacy but also gauge the efficiency, scalability, and robustness of the entire ML system during the training phase. Let's delve deeper into these metrics and their significance.
+When viewed from a systems perspective, training metrics offer insights that transcend conventional algorithmic performance indicators. These metrics measure the model's learning efficacy and gauge the efficiency, scalability, and robustness of the entire ML system during the training phase. Let's delve deeper into these metrics and their significance.
The following metrics are often considered important:
-1. **Training Time:** The time taken to train a model from scratch until it reaches a satisfactory performance level. It is a direct measure of the computational resources required to train a model. For example, [Google's BERT](https://arxiv.org/abs/1810.04805)(@devlin2018bert) model is a natural language processing model that requires several days to train on a massive corpus of text data using multiple GPUs. The long training time is a significant challenge in terms of resource consumption and cost.
+1. **Training Time:** The time it takes to train a model from scratch until it reaches a satisfactory performance level. It directly measures the computational resources required to train a model. For example, [Google's BERT](https://arxiv.org/abs/1810.04805)(@devlin2018bert) is a natural language processing model that requires several days to train on a massive corpus of text data using multiple GPUs. The long training time is a significant resource consumption and cost challenge.
-2. **Scalability:** How well the training process can handle increases in data size or model complexity. Scalability can be assessed by measuring training time, memory usage, and other resource consumption as data size or model complexity increases. [OpenAI's GPT-3](https://arxiv.org/abs/2005.14165)(@brown2020language) model has 175 billion parameters, making it one of the largest language models in existence. Training GPT-3 required extensive engineering efforts to scale up the training process to handle the massive model size. This involved the use of specialized hardware, distributed training, and other techniques to ensure that the model could be trained efficiently.
+2. **Scalability:** How well the training process can handle increases in data size or model complexity. Scalability can be assessed by measuring training time, memory usage, and other resource consumption as data size or model complexity increases. [OpenAI's GPT-3](https://arxiv.org/abs/2005.14165)(@brown2020language) model has 175 billion parameters, making it one of the largest language models in existence. Training GPT-3 required extensive engineering efforts to scale the training process to handle the massive model size. This involved using specialized hardware, distributed training, and other techniques to ensure the model could be trained efficiently.
3. **Resource Utilization:** The extent to which the training process utilizes available computational resources such as CPU, GPU, memory, and disk I/O. High resource utilization can indicate an efficient training process, while low utilization can suggest bottlenecks or inefficiencies. For instance, training a convolutional neural network (CNN) for image classification requires significant GPU resources. Utilizing multi-GPU setups and optimizing the training code for GPU acceleration can greatly improve resource utilization and training efficiency.
-4. **Memory Consumption:** The amount of memory used by the training process. Memory consumption can be a limiting factor for training large models or datasets. As an example, Google researchers faced significant memory consumption challenges when training BERT. The model has hundreds of millions of parameters, which require large amounts of memory to store. The researchers had to develop techniques to reduce memory consumption, such as gradient checkpointing and model parallelism.
+4. **Memory Consumption:** The amount of memory the training process uses. Memory consumption can be a limiting factor for training large models or datasets. For example, Google researchers faced significant memory consumption challenges when training BERT. The model has hundreds of millions of parameters, requiring large amounts of memory. The researchers had to develop techniques to reduce memory consumption, such as gradient checkpointing and model parallelism.
-5. **Energy Consumption:** The amount of energy consumed during the training process. As machine learning models become larger and more complex, energy consumption has become an important consideration. Training large machine learning models can consume significant amounts of energy, leading to a large carbon footprint. For instance, the training of OpenAI's GPT-3 was estimated to have a carbon footprint equivalent to traveling by car for 700,000 kilometers.
+5. ** Energy Consumption: ** The energy consumed during training. As machine learning models become more complex, energy consumption has become an important consideration. Training large machine learning models can consume significant energy, leading to a large carbon footprint. For instance, the training of OpenAI's GPT-3 was estimated to have a carbon footprint equivalent to traveling by car for 700,000 kilometers.
-6. **Throughput:** The number of training samples processed per unit time. Higher throughput generally indicates a more efficient training process. When training a recommendation system for an e-commerce platform, the throughput is an important metric to consider. A high throughput ensures that the model can process large volumes of user interaction data in a timely manner, which is crucial for maintaining the relevance and accuracy of the recommendations. But it's also important to understand how to balance throughput with latency bounds. Therefore, often there is a latency-bounded throughput constraint that's imposed on service-level agreements for datacenter application deployments.
+6. **Throughput:** The number of training samples processed per unit time. Higher throughput generally indicates a more efficient training process. The throughput is an important metric to consider when training a recommendation system for an e-commerce platform. A high throughput ensures that the model can process large volumes of user interaction data promptly, which is crucial for maintaining the relevance and accuracy of the recommendations. But it's also important to understand how to balance throughput with latency bounds. Therefore, a latency-bounded throughput constraint is often imposed on service-level agreements for data center application deployments.
-7. **Cost:** The cost of training a model, which can include both computational and human resources. Cost is an important factor when considering the practicality and feasibility of training large or complex models. The cost of training large language models like GPT-3 is estimated to be in the range of millions of dollars. This cost includes computational resources, electricity, and human resources required for model development and training.
+7. **Cost:** The cost of training a model can include both computational and human resources. Cost is important when considering the practicality and feasibility of training large or complex models. Training large language models like GPT-3 is estimated to cost millions of dollars. This cost includes computational, electricity and human resources required for model development and training.
-8. **Fault Tolerance and Robustness:** The ability of the training process to handle failures or errors without crashing or producing incorrect results. This is important for ensuring the reliability of the training process. In a real-world scenario, where a machine learning model is being trained on a distributed system, network failures or hardware malfunctions can occur. In recent years, for instance, it has become abundantly clear that faults that arise from silent data corruption have emerged as a major issue. A fault-tolerant and robust training process can recover from such failures without compromising the integrity of the model.
+8. **Fault Tolerance and Robustness:** The ability of the training process to handle failures or errors without crashing or producing incorrect results. This is important for ensuring the reliability of the training process. Network failures or hardware malfunctions can occur in a real-world scenario where a machine-learning model is being trained on a distributed system. In recent years, it has become abundantly clear that faults arising from silent data corruption have emerged as a major issue. A fault-tolerant and robust training process can recover from such failures without compromising the model's integrity.
-9. **Ease of Use and Flexibility:** The ease with which the training process can be set up and used, as well as its flexibility in handling different types of data and models. In companies like Google, efficiency can sometimes be measured in terms of the number of Software Engineer (SWE) years saved since that translates directly to impact. Ease of use and flexibility can reduce the time and effort required to train a model. TensorFlow and PyTorch are popular machine learning frameworks that provide user-friendly interfaces and flexible APIs for building and training machine learning models. These frameworks support a wide range of model architectures and are equipped with tools that simplify the training process.
+9. **Ease of Use and Flexibility:** The ease with which the training process can be set up and used and its flexibility in handling different types of data and models. In companies like Google, efficiency can sometimes be measured by the number of Software Engineer (SWE) years saved since that translates directly to impact. Ease of use and flexibility can reduce the time and effort required to train a model. TensorFlow and PyTorch are popular machine-learning frameworks that provide user-friendly interfaces and flexible APIs for building and training machine-learning models. These frameworks support many model architectures and are equipped with tools that simplify the training process.
-10. **Reproducibility:** The ability to reproduce the results of the training process. Reproducibility is important for verifying the correctness and validity of a model. However, there are often variations due to stochastic network characteristics and this makes it hard to reproduce the precise behavior of applications being trained, and this can present a challenge for benchmarking.
+10. **Reproducibility:** The ability to reproduce the training process results. Reproducibility is important for verifying a model's correctness and validity. However, variations due to stochastic network characteristics often make it hard to reproduce the precise behavior of applications being trained, which can present a challenge for benchmarking.
-By benchmarking for these types of metrics, we can obtain a comprehensive view of the performance and efficiency of the training process from a systems' perspective, which can help identify areas for improvement and ensure that resources are used effectively.
+By benchmarking for these types of metrics, we can obtain a comprehensive view of the training process's performance and efficiency from a systems perspective. This can help identify areas for improvement and ensure that resources are used effectively.
#### Tasks
-Selecting a handful of representative tasks for benchmarking machine learning systems is challenging because machine learning is applied to a diverse range of domains, each with its own unique characteristics and requirements. Here are some of the challenges faced in selecting representative tasks:
+Selecting a handful of representative tasks for benchmarking machine learning systems is challenging because machine learning is applied to various domains with unique characteristics and requirements. Here are some of the challenges faced in selecting representative tasks:
1. **Diversity of Applications:** Machine learning is used in numerous fields such as healthcare, finance, natural language processing, computer vision, and many more. Each field has specific tasks that may not be representative of other fields. For example, image classification tasks in computer vision may not be relevant to financial fraud detection.
-2. **Variability in Data Types and Quality:** Different tasks require different types of data, such as text, images, videos, or numerical data. The quality and availability of data can vary greatly between tasks, making it difficult to select tasks that are representative of the general challenges faced in machine learning.
-3. **Task Complexity and Difficulty:** The complexity of tasks varies greatly, with some tasks being relatively straightforward, while others are highly complex and require sophisticated models and techniques. Selecting representative tasks that cover the range of complexities encountered in machine learning is a challenge.
-4. **Ethical and Privacy Concerns:** Some tasks may involve sensitive or private data, such as medical records or personal information. These tasks may have ethical and privacy concerns that need to be addressed, which can make them less suitable as representative tasks for benchmarking.
-5. **Scalability and Resource Requirements:** Different tasks may have different scalability and resource requirements. Some tasks may require extensive computational resources, while others can be performed with minimal resources. Selecting tasks that are representative of the general resource requirements in machine learning is difficult.
-6. **Evaluation Metrics:** The metrics used to evaluate the performance of machine learning models vary between tasks. Some tasks may have well-established evaluation metrics, while others may lack clear or standardized metrics. This can make it challenging to compare performance across different tasks.
-7. **Generalizability of Results:** The results obtained from benchmarking on a specific task may not be generalizable to other tasks. This means that the performance of a machine learning system on a selected task may not be indicative of its performance on other tasks.
+2. **Variability in Data Types and Quality:** Different tasks require different data types, such as text, images, videos, or numerical data. Data quality and availability can vary greatly between tasks, making it difficult to select tasks that are representative of the general challenges faced in machine learning.
+3. **Task Complexity and Difficulty:** The complexity of tasks varies greatly. Some are relatively straightforward, while others are highly complex and require sophisticated models and techniques. Selecting representative tasks that cover the complexities encountered in machine learning is challenging.
+4. **Ethical and Privacy Concerns:** Some tasks may involve sensitive or private data, such as medical records or personal information. These tasks may have ethical and privacy concerns that need to be addressed, making them less suitable as representative tasks for benchmarking.
+5. **Scalability and Resource Requirements:** Different tasks may have different scalability and resource requirements. Some tasks may require extensive computational resources, while others can be performed with minimal resources. Selecting tasks that represent the general resource requirements in machine learning is difficult.
+6. **Evaluation Metrics:** The metrics used to evaluate the performance of machine learning models vary between tasks. Some tasks may have well-established evaluation metrics, while others lack clear or standardized metrics. This can make it challenging to compare performance across different tasks.
+7. **Generalizability of Results:** The results obtained from benchmarking on a specific task may not be generalizable to other tasks. This means that a machine learning system's performance on a selected task may not be indicative of its performance on other tasks.
-It is important to carefully consider these factors when designing benchmarks to ensure that they are meaningful and relevant to the diverse range of tasks encountered in machine learning.
+It is important to carefully consider these factors when designing benchmarks to ensure they are meaningful and relevant to the diverse range of tasks encountered in machine learning.
#### Benchmarks
@@ -301,7 +301,7 @@ Here are some original works that laid the fundamental groundwork for developing
*[MLPerf Training Benchmark](https://github.com/mlcommons/training)*
-MLPerf is a suite of benchmarks designed to measure the performance of machine learning hardware, software, and services. The MLPerf Training benchmark [@mattson2020mlperf] focuses on the time it takes to train models to a target quality metric. It includes a diverse set of workloads, such as image classification, object detection, translation, and reinforcement learning.
+MLPerf is a suite of benchmarks designed to measure the performance of machine learning hardware, software, and services. The MLPerf Training benchmark [@mattson2020mlperf] focuses on the time it takes to train models to a target quality metric. It includes diverse workloads, such as image classification, object detection, translation, and reinforcement learning.
Metrics:
@@ -311,17 +311,17 @@ Metrics:
*[DAWNBench](https://dawn.cs.stanford.edu/benchmark/)*
-DAWNBench [@coleman2017dawnbench] is a benchmark suite that focuses on end-to-end deep learning training time and inference performance. It includes common tasks such as image classification and question answering.
+DAWNBench [@coleman2017dawnbench] is a benchmark suite focusing on end-to-end deep learning training time and inference performance. It includes common tasks such as image classification and question answering.
Metrics:
* Time to train to target accuracy
* Inference latency
-* Cost (in terms of cloud compute and storage resources)
+* Cost (in terms of cloud computing and storage resources)
*[Fathom](https://github.com/rdadolf/fathom)*
-Fathom [@adolf2016fathom] is a benchmark from Harvard University that includes a diverse set of workloads to evaluate the performance of deep learning models. It includes common tasks such as image classification, speech recognition, and language modeling.
+Fathom [@adolf2016fathom] is a benchmark from Harvard University that evaluates the performance of deep learning models using a diverse set of workloads. These include common tasks such as image classification, speech recognition, and language modeling.
Metrics:
@@ -345,53 +345,53 @@ By measuring these metrics, we can assess the performance and efficiency of the
### Inference Benchmarks
-Inference in machine learning refers to the process of using a trained model to make predictions on new, unseen data. It is the phase where the model applies its learned knowledge to solve the problem it was designed for, such as classifying images, recognizing speech, or translating text.
+Inference in machine learning refers to using a trained model to make predictions on new, unseen data. It is the phase where the model applies its learned knowledge to solve the problem it was designed for, such as classifying images, recognizing speech, or translating text.
#### Purpose
-When we build machine learning models, our ultimate goal is to deploy them in real-world applications where they can provide accurate and reliable predictions on new, unseen data. This process of using a trained model to make predictions is known as inference. The real-world performance of a machine learning model can differ significantly from its performance on training or validation datasets, which makes benchmarking inference a crucial step in the development and deployment of machine learning models.
+When we build machine learning models, our ultimate goal is to deploy them in real-world applications where they can provide accurate and reliable predictions on new, unseen data. This process of using a trained model to make predictions is known as inference. A machine learning model's real-world performance can differ significantly from its performance on training or validation datasets, which makes benchmarking inference a crucial step in the development and deployment of machine learning models.
-Benchmarking inference allows us to evaluate how well a machine learning model performs in real-world scenarios. This evaluation ensures that the model is practical and reliable when deployed in applications, providing a more comprehensive understanding of the model's behavior with real data. Additionally, benchmarking can help identify potential bottlenecks or limitations in the model's performance. For example, if a model takes too long to make a prediction, it may be impractical for real-time applications such as autonomous driving or voice assistants.
+Benchmarking inference allows us to evaluate how well a machine-learning model performs in real-world scenarios. This evaluation ensures that the model is practical and reliable when deployed in applications, providing a more comprehensive understanding of the model's behavior with real data. Additionally, benchmarking can help identify potential bottlenecks or limitations in the model's performance. For example, if a model takes less time to predict, it may be impractical for real-time applications such as autonomous driving or voice assistants.
-Resource efficiency is another critical aspect of inference, as it can be computationally intensive and require significant memory and processing power. Benchmarking helps ensure that the model is efficient in terms of resource usage, which is particularly important for edge devices with limited computational capabilities, such as smartphones or IoT devices. Moreover, benchmarking allows us to compare the performance of our model with competing models or previous versions of the same model. This comparison is essential for making informed decisions about which model to deploy in a specific application.
+Resource efficiency is another critical aspect of inference, as it can be computationally intensive and require significant memory and processing power. Benchmarking helps ensure that the model is efficient regarding resource usage, which is particularly important for edge devices with limited computational capabilities, such as smartphones or IoT devices. Moreover, benchmarking allows us to compare the performance of our model with competing models or previous versions of the same model. This comparison is essential for making informed decisions about which model to deploy in a specific application.
-Finally, ensuring that the model's predictions are not only accurate but also consistent across different data points is vital. Benchmarking helps verify the model's accuracy and consistency, ensuring that it meets the application's requirements. It also assesses the robustness of the model, ensuring that it can handle real-world data variability and still make accurate predictions.
+Finally, it is vital to ensure that the model's predictions are not only accurate but also consistent across different data points. Benchmarking helps verify the model's accuracy and consistency, ensuring that it meets the application's requirements. It also assesses the model's robustness, ensuring that it can handle real-world data variability and still make accurate predictions.
#### Metrics
-1. **Accuracy:** Accuracy is one of the most vital metrics when benchmarking machine learning models, quantifying the proportion of correct predictions made by the model compared to the true values or labels. For example, in the case of a spam detection model that can correctly classify 95 out of 100 email messages as spam or not spam, the accuracy of this model would be calculated as 95%.
+1. **Accuracy:** Accuracy is one of the most vital metrics when benchmarking machine learning models. It quantifies the proportion of correct predictions made by the model compared to the true values or labels. For example, if a spam detection model can correctly classify 95 out of 100 email messages as spam or not, its accuracy would be calculated as 95%.
-2. **Latency:** Latency is a performance metric that calculates the time lag or delay occurring between the receipt of an input and the production of the corresponding output by the machine learning system. An example that clearly depicts latency is a real-time translation application; if there exists a half-second delay from the moment a user inputs a sentence to the time the translated text is displayed by the app, then the system's latency is 0.5 seconds.
+2. **Latency:** Latency is a performance metric that calculates the time lag or delay between the input receipt and the production of the corresponding output by the machine learning system. An example that clearly depicts latency is a real-time translation application; if a half-second delay exists from the moment a user inputs a sentence to the time the app displays the translated text, then the system's latency is 0.5 seconds.
-3. **Latency-Bounded Throughput:** Latency-bounded throughput is a valuable metric that combines the aspects of latency and throughput, measuring the maximum throughput of a system while still meeting a specified latency constraint. For example, in a video streaming application that utilizes a machine learning model to automatically generate and display subtitles, latency-bounded throughput would measure how many video frames the system can process per second (throughput) while ensuring that the subtitles are displayed with no more than a 1-second delay (latency). This metric is particularly important in real-time applications where meeting latency requirements is crucial to the user experience.
+3. **Latency-Bounded Throughput:** Latency-bounded throughput is a valuable metric that combines the aspects of latency and throughput, measuring the maximum throughput of a system while still meeting a specified latency constraint. For example, in a video streaming application that utilizes a machine learning model to generate and display subtitles automatically, latency-bounded throughput would measure how many video frames the system can process per second (throughput) while ensuring that the subtitles are displayed with no more than a 1-second delay (latency). This metric is particularly important in real-time applications where meeting latency requirements is crucial to the user experience.
-4. **Throughput:** Throughput assesses the system's capacity by measuring the total number of inferences or predictions a machine learning model can handle within a specific unit of time. Consider a speech recognition system that employs a Recurrent Neural Network (RNN) as its underlying model; if this system is capable of processing and understanding 50 different audio clips in a minute, then its throughput rate stands at 50 clips per minute.
+4. **Throughput:** Throughput assesses the system's capacity by measuring the number of inferences or predictions a machine learning model can handle within a specific unit of time. Consider a speech recognition system that employs a Recurrent Neural Network (RNN) as its underlying model; if this system can process and understand 50 different audio clips in a minute, then its throughput rate stands at 50 clips per minute.
-5. **Inference Time:** Inference time is a crucial metric that measures the duration a machine learning system, such as a Convolutional Neural Network (CNN) used in image recognition tasks, takes to process an input and generate a prediction or output. For instance, if a CNN takes approximately 2 milliseconds to accurately identify and label a cat within a given photo, then its inference time is said to be 2 milliseconds.
+5. **Inference Time:** Inference time is a crucial metric that measures the duration a machine learning system, such as a Convolutional Neural Network (CNN) used in image recognition tasks, takes to process an input and generate a prediction or output. For instance, if a CNN takes approximately 2 milliseconds to identify and label a cat within a given photo accurately, then its inference time is said to be 2 milliseconds.
6. **Energy Efficiency:** Energy efficiency is a metric that determines the amount of energy consumed by the machine learning model to perform a single inference. A prime example of this would be a natural language processing model built on a Transformer network architecture; if it utilizes 0.1 Joules of energy to translate a sentence from English to French, its energy efficiency is measured at 0.1 Joules per inference.
-7. **Memory Usage:** Memory usage quantifies the volume of RAM needed by a machine learning model to carry out inference tasks. A relevant example to illustrate this would be a face recognition system that is based on a CNN; if such a system requires 150 MB of RAM to process and recognize faces within an image, then its memory usage is 150 MB.
+7. **Memory Usage:** Memory usage quantifies the volume of RAM needed by a machine learning model to carry out inference tasks. A relevant example to illustrate this would be a face recognition system based on a CNN; if such a system requires 150 MB of RAM to process and recognize faces within an image, its memory usage is 150 MB.
#### Tasks
-By and large, the challenges in picking representative tasks for benchmarking inference machine learning systems are somewhat of the same taxonomy as what we have provided for training. Nevertheless, to be pedantic, let's discuss those in the context of inference machine learning systems.
+The challenges in picking representative tasks for benchmarking inference machine learning systems are, by and large, somewhat similar to the taxonomy we have provided for training. Nevertheless, to be pedantic, let's discuss those in the context of inference machine learning systems.
-1. **Diversity of Applications:** Inference machine learning is employed across numerous domains such as healthcare, finance, entertainment, security, and more. Each domain has its unique tasks, and what's representative in one domain might not be in another. For example, an inference task for predicting stock prices in the financial domain might not be representative of image recognition tasks in the medical domain.
+1. **Diversity of Applications:** Inference machine learning is employed across numerous domains such as healthcare, finance, entertainment, security, and more. Each domain has unique tasks, and what's representative in one domain might not be in another. For example, an inference task for predicting stock prices in the financial domain might differ from image recognition tasks in the medical domain.
-2. **Variability in Data Types:** Different inference tasks require different types of data -- text, images, videos, numerical data, etc. Ensuring that benchmarks address the wide variety of data types used in real-world applications is challenging. For example, voice recognition systems process audio data, which is vastly different from the visual data processed by facial recognition systems.
+2. **Variability in Data Types:** Different inference tasks require different types of data—text, images, videos, numerical data, etc. Ensuring that benchmarks address the wide variety of data types used in real-world applications is challenging. For example, voice recognition systems process audio data, which is vastly different from the visual data processed by facial recognition systems.
3. **Task Complexity:** The complexity of inference tasks can differ immensely, from basic classification tasks to intricate tasks requiring state-of-the-art models. For example, differentiating between two categories (binary classification) is typically simpler than detecting hundreds of object types in a crowded scene.
4. **Real-time Requirements:** Some applications demand immediate or real-time responses, while others may allow for some delay. In autonomous driving, real-time object detection and decision-making are paramount, whereas a recommendation engine for a shopping website might tolerate slight delays.
-5. **Scalability Concerns:** Given the varied scale of applications, from edge devices to cloud-based servers, tasks must represent the diverse computational environments where inference occurs. For example, an inference task running on a smartphone's limited resources is quite different from one running on a powerful cloud server.
+5. **Scalability Concerns:** Given the varied scale of applications, from edge devices to cloud-based servers, tasks must represent the diverse computational environments where inference occurs. For example, an inference task running on a smartphone's limited resources differs from a powerful cloud server.
-6. **Evaluation Metrics Diversity:** Depending on the task, the metrics to evaluate performance can differ significantly. Finding a common ground or universally accepted metric for diverse tasks is a challenge. For example, precision and recall might be vital for a medical diagnosis task, whereas throughput (inferences per second) might be more crucial for video processing tasks.
+6. **Evaluation Metrics Diversity:** The metrics used to evaluate performance can differ significantly depending on the task. Finding a common ground or universally accepted metric for diverse tasks is challenging. For example, precision and recall might be vital for a medical diagnosis task, whereas throughput (inferences per second) might be more crucial for video processing tasks.
-7. **Ethical and Privacy Concerns:** Especially in sensitive areas like facial recognition or personal data processing, there are concerns related to ethics and privacy. These concerns can impact the selection and nature of tasks used for benchmarking. For example, using real-world facial data for benchmarking can raise privacy issues, whereas synthetic data might not replicate real-world challenges.
+7. **Ethical and Privacy Concerns:** Concerns related to ethics and privacy exist, especially in sensitive areas like facial recognition or personal data processing. These concerns can impact the selection and nature of tasks used for benchmarking. For example, using real-world facial data for benchmarking can raise privacy issues, whereas synthetic data might not replicate real-world challenges.
-8. **Hardware Diversity:** With a wide range of devices from GPUs, CPUs, TPUs, to custom ASICs used for inference, ensuring that tasks are representative across varied hardware is challenging. For example, a task optimized for inference on a GPU might perform sub-optimally on an edge device.
+8. **Hardware Diversity:** With a wide range of devices from GPUs, CPUs, and TPUs to custom ASICs used for inference, ensuring that tasks are representative across varied hardware is challenging. For example, a task optimized for inference on a GPU might perform sub-optimally on an edge device.
#### Benchmarks
@@ -399,7 +399,7 @@ Here are some original works that laid the fundamental groundwork for developing
*[MLPerf Inference Benchmark](https://github.com/mlcommons/inference)*
-MLPerf Inference is a comprehensive suite of benchmarks that assess the performance of machine learning models during the inference phase. It encompasses a variety of workloads including image classification, object detection, and natural language processing, aiming to provide standardized and insightful metrics for evaluating different inference systems.
+MLPerf Inference is a comprehensive benchmark suite that assesses machine learning models' performance during the inference phase. It encompasses a variety of workloads, including image classification, object detection, and natural language processing, aiming to provide standardized and insightful metrics for evaluating different inference systems.
Metrics:
@@ -423,7 +423,7 @@ Metrics:
*[OpenVINO toolkit](https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html)*
-OpenVINO toolkit provides a benchmark tool to measure the performance of deep learning models for a variety of tasks such as image classification, object detection, and facial recognition on Intel hardware. It offers detailed insights into the inference performance of the models on different hardware configurations.
+OpenVINO toolkit provides a benchmark tool to measure the performance of deep learning models for various tasks, such as image classification, object detection, and facial recognition, on Intel hardware. It offers detailed insights into the models' inference performance on different hardware configurations.
Metrics:
@@ -438,7 +438,7 @@ Consider a scenario where we want to evaluate the inference performance of an ob
Task: The task is to perform real-time object detection on video streams, detecting and identifying objects such as vehicles, pedestrians, and traffic signs.
-Benchmark: We can use the AI Benchmark for this task as it focuses on evaluating inference performance on edge devices, which is suitable for our scenario.
+Benchmark: We can use the AI Benchmark for this task as it evaluates inference performance on edge devices, which suits our scenario.
Metrics: We will measure the following metrics:
@@ -461,101 +461,101 @@ Get ready to put your AI models to the ultimate test! MLPerf is like the Olympic
### Benchmark Example
-In order to properly illustrate the components of a systems benchmark, we can look at the keyword spotting benchmark in MLPerf Tiny and explain the motivation behind each decision.
+To properly illustrate the components of a systems benchmark, we can look at the keyword spotting benchmark in MLPerf Tiny and explain the motivation behind each decision.
#### Task
-Keyword spotting was selected as a task because it is a common usecase in TinyML that has been well established for years. Additionally the typical hardware used for keyword spotting differs substantially from the offerings of other benchmarks such as MLPerf Inference's speech recognition task.
+Keyword spotting was selected as a task because it is a common use case in TinyML that has been well-established for years. Additionally, the typical hardware used for keyword spotting differs substantially from the offerings of other benchmarks, such as MLPerf Inference's speech recognition task.
#### Dataset
-[Google Speech Commands](https://www.tensorflow.org/datasets/catalog/speech_commands)(@warden2018speech) was selected as the best dataset to represent the task. The dataset is well established in the research community and has permissive licensing which allows it to be easily used in a benchmark.
+[Google Speech Commands](https://www.tensorflow.org/datasets/catalog/speech_commands)(@warden2018speech) was selected as the best dataset to represent the task. The dataset is well-established in the research community and has permissive licensing, allowing it to be easily used in a benchmark.
#### Model
-The next core component is the model which will act as the primary workload for the benchmark. The model should be well established as a solution to the selected task and not necessarily the state of the art solution. The model selected is a simple depthwise seperable convolution model. This architecture is not the state of the art solution to the task, but it is well established and not designed for a specific hardware platform like many of the state of the art solutions. The benchmark also establishes a reference training recipe, despite being an inference benchmark, in order to be fully reproducible and transparent.
+The next core component is the model, which will act as the primary workload for the benchmark. The model should be well established as a solution to the selected task rather than a state-of-the-art solution. The model selected is a simple depthwise separable convolution model. This architecture is not the state-of-the-art solution to the task, but it is well-established and not designed for a specific hardware platform like many state-of-the-art solutions. Despite being an inference benchmark, the benchmark also establishes a reference training recipe to be fully reproducible and transparent.
#### Metrics
-Latency was selected as the primary metric for the benchmark, as keyword spotting systems need to react quickly to maintain user satisfaction. Additionally, given that TinyML systems are often battery powered, energy consumption is measured to ensure the hardware platform is efficient. The accuracy of the model is also measure to ensure that the optimizations applied by a submitter, such as quantization, don't degrade the accuracy beyond a threshold.
+Latency was selected as the primary metric for the benchmark, as keyword spotting systems need to react quickly to maintain user satisfaction. Additionally, given that TinyML systems are often battery-powered, energy consumption is measured to ensure the hardware platform is efficient. The accuracy of the model is also measured to ensure that the optimizations applied by a submitter, such as quantization, don't degrade the accuracy beyond a threshold.
#### Benchmark Harness
-MLPerf Tiny uses [EEMBCs EnergyRunner benchmark harness](https://github.com/eembc/energyrunner) to load the inputs to the model and to isolate and measure the energy consumption of the device. When measuring energy consumption it's critical to select a harness that is accurate at the expected power levels of the devices under test, and simple enough to not become a burden for participants of the benchmark.
+MLPerf Tiny uses [EEMBCs EnergyRunner benchmark harness](https://github.com/eembc/energyrunner) to load the inputs to the model and isolate and measure the device's energy consumption. When measuring energy consumption, it's critical to select a harness that is accurate at the expected power levels of the devices under test and simple enough not to become a burden for the benchmark participants.
#### Baseline Submission
-Baseline submissions are critical for contextualizing results and acting as a reference point to help participants get started. The baseline submission should prioritize simplicity and readability over state of the art performance. The keyword spotting baseline uses a standard [STM microcontroller](https://www.st.com/en/microcontrollers-microprocessors.html) as it's hardware and [TensorFlow Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers)(@david2021tensorflow) as it's inference framework.
+Baseline submissions are critical for contextualizing results and as a reference point to help participants get started. The baseline submission should prioritize simplicity and readability over state-of-the-art performance. The keyword spotting baseline uses a standard [STM microcontroller](https://www.st.com/en/microcontrollers-microprocessors.html) as its hardware and [TensorFlow Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers)(@david2021tensorflow) as its inference framework.
### Challenges and Limitations
While benchmarking provides a structured methodology for performance evaluation in complex domains like artificial intelligence and computing, the process also poses several challenges. If not properly addressed, these challenges can undermine the credibility and accuracy of benchmarking results. Some of the predominant difficulties faced in benchmarking include the following:
-* Incomplete problem coverage - Benchmark tasks may not fully represent the problem space. For instance, common image classification datasets like [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) have limited diversity in image types. Algorithms tuned for such benchmarks may fail to generalize well to real-world datasets.
+* Incomplete problem coverage—Benchmark tasks may not fully represent the problem space. For instance, common image classification datasets like [CIFAR-10](https://www.cs.toronto.edu/kriz/cifar.html) have limited diversity in image types. Algorithms tuned for such benchmarks may fail to generalize well to real-world datasets.
* Statistical insignificance - Benchmarks must have enough trials and data samples to produce statistically significant results. For example, benchmarking an OCR model on only a few text scans may not adequately capture its true error rates.
-* Limited reproducibility - Varying hardware, software versions, codebases and other factors can reduce reproducibility of benchmark results. MLPerf addresses this by providing reference implementations and environment specification.
-* Misalignment with end goals - Benchmarks focusing only on speed or accuracy metrics may misalign with real-world objectives like cost and power efficiency. Benchmarks must reflect all critical performance axes.
-* Rapid staleness - Due to the fast pace of advancements in AI and computing, benchmarks and their datasets can become outdated quickly. Maintaining up-to-date benchmarks is thus a persistent challenge.
+* Limited reproducibility—Varying hardware, software versions, codebases, and other factors can reduce the reproducibility of benchmark results. MLPerf addresses this by providing reference implementations and environment specifications.
+* Misalignment with end goals - Benchmarks focusing only on speed or accuracy metrics may misalign real-world objectives like cost and power efficiency. Benchmarks must reflect all critical performance axes.
+* Rapid staleness—Due to the rapid pace of advancements in AI and computing, benchmarks and their datasets can quickly become outdated. Maintaining up-to-date benchmarks is thus a persistent challenge.
-But of all these, perhaps the most important challenge is dealing with benchmark engineering.
+But of all these, the most important challenge is benchmark engineering.
#### Hardware Lottery
-The ["hardware lottery"](https://arxiv.org/abs/2009.06489) in benchmarking machine learning systems refers to the situation where the success or efficiency of a machine learning model is significantly influenced by the compatibility of the model with the underlying hardware [@chu2021discovering]. In other words, some models perform exceptionally well because they are a good fit for the particular characteristics or capabilities of the hardware on which they are run, rather than because they are intrinsically superior models. @fig-hardware-lottery demonstrates the performance of different models on different hardware: notice how (follow the big yellow arrow) the Mobilenet V3 Large model (in green) has the lowest latency among all models when run unquantized on the Pixel4 CPU while it performs the worst on Pixel4 DSP Qualcomm Snapdragon 855. Unfortunately, the hardware used is often omitted from papers or given only brief mentions, making reproducing results difficult if not impossible.
+The ["hardware lottery"](https://arxiv.org/abs/2009.06489) in benchmarking machine learning systems refers to the situation where the success or efficiency of a machine learning model is significantly influenced by the compatibility of the model with the underlying hardware [@chu2021discovering]. In other words, some models perform exceptionally well because they are a good fit for the particular characteristics or capabilities of the hardware they are run on rather than because they are intrinsically superior models. @fig-hardware-lottery demonstrates the performance of different models on different hardware: notice how (follow the big yellow arrow) the Mobilenet V3 Large model (in green) has the lowest latency among all models when run unquantized on the Pixel4 CPU. At the same time, it performs the worst on Pixel4 DSP Qualcomm Snapdragon 855. Unfortunately, the hardware used is often omitted from papers or only briefly mentioned, making reproducing results difficult, if possible.
{#fig-hardware-lottery}
-For instance, certain machine learning models may be designed and optimized to take advantage of parallel processing capabilities of specific hardware accelerators, such as Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs). As a result, these models might show superior performance when benchmarked on such hardware, compared to other models that are not optimized for the hardware.
+For instance, certain machine learning models may be designed and optimized to take advantage of the parallel processing capabilities of specific hardware accelerators, such as Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs). As a result, these models might show superior performance when benchmarked on such hardware compared to other models that are not optimized for the hardware.
-For example, a 2018 paper introduced a new convolutional neural network architecture for image classification that achieved state-of-the-art accuracy on ImageNet. However, the paper only mentioned that the model was trained on 8 GPUs, without specifying the model, memory size, or other relevant details. A follow-up study tried to reproduce the results but found that training the same model on commonly available GPUs achieved 10% lower accuracy, even after hyperparameter tuning. The original hardware likely had far higher memory bandwidth and compute power. As another example, training times for large language models can vary drastically based on the GPUs used.
+For example, a 2018 paper introduced a new convolutional neural network architecture for image classification that achieved state-of-the-art accuracy on ImageNet. However, the paper only mentioned that the model was trained on 8 GPUs without specifying the model, memory size, or other relevant details. A follow-up study tried to reproduce the results but found that training the same model on commonly available GPUs achieved 10% lower accuracy, even after hyperparameter tuning. The original hardware likely had far higher memory bandwidth and compute power. As another example, training times for large language models can vary drastically based on the GPUs used.
-The "hardware lottery" can introduce challenges and biases in benchmarking machine learning systems, as the performance of the model is not solely dependent on the model's architecture or algorithm, but also on the compatibility and synergies with the underlying hardware. This can make it difficult to fairly compare different models and to identify the best model based on its intrinsic merits. It can also lead to a situation where the community converges on models that are a good fit for the popular hardware of the day, potentially overlooking other models that might be superior but are not compatible with the current hardware trends.
+The "hardware lottery" can introduce challenges and biases in benchmarking machine learning systems, as the model's performance is not solely dependent on the model's architecture or algorithm but also on the compatibility and synergies with the underlying hardware. This can make it difficult to compare different models fairly and to identify the best model based on its intrinsic merits. It can also lead to a situation where the community converges on models that are a good fit for the popular hardware of the day, potentially overlooking other models that might be superior but incompatible with the current hardware trends.
#### Benchmark Engineering
-Hardware lottery occurs when a machine learning model unintentionally performs exceptionally well or poorly on a specific hardware setup due to unforeseen compatibility or incompatibility. The model is not explicitly designed or optimized for that particular hardware by the developers or engineers; rather, it happens to align or (mis)align with the hardware's capabilities or limitations. In this case, the performance of the model on the hardware is a byproduct of coincidence rather than design.
+Hardware lottery occurs when a machine learning model unintentionally performs exceptionally well or poorly on a specific hardware setup due to unforeseen compatibility or incompatibility. The model is not explicitly designed or optimized for that particular hardware by the developers or engineers; rather, it happens to align or (mis)align with the hardware's capabilities or limitations. In this case, the model's performance on the hardware is a byproduct of coincidence rather than design.
-In contrast to the accidental hardware lottery, benchmark engineering involves deliberately optimizing or designing a machine learning model to perform exceptionally well on specific hardware, often to win benchmarks or competitions. This intentional optimization might include tweaking the model's architecture, algorithms, or parameters to take full advantage of the hardware's features and capabilities.
+In contrast to the accidental hardware lottery, benchmark engineering involves deliberately optimizing or designing a machine learning model to perform exceptionally well on specific hardware, often to win benchmarks or competitions. This intentional optimization might include tweaking the model's architecture, algorithms, or parameters to exploit the hardware's features and capabilities fully.
#### Problem
-Benchmark engineering refers to the process of tweaking or modifying an AI system to optimize its performance on specific benchmark tests, often at the expense of generalizability or real-world performance. This can include adjusting hyperparameters, training data, or other aspects of the system specifically to achieve high scores on benchmark metrics, without necessarily improving the overall functionality or utility of the system.
+Benchmark engineering refers to tweaking or modifying an AI system to optimize performance on specific benchmark tests, often at the expense of generalizability or real-world performance. This can include adjusting hyperparameters, training data, or other aspects of the system specifically to achieve high scores on benchmark metrics without necessarily improving the overall functionality or utility of the system.
-The motivation behind benchmark engineering often stems from the desire to achieve high performance scores for marketing or competitive purposes. High benchmark scores can be used to demonstrate the superiority of an AI system compared to competitors, and can be a key selling point for potential users or investors. This pressure to perform well on benchmarks can sometimes lead to the prioritization of benchmark-specific optimizations over more holistic improvements to the system.
+The motivation behind benchmark engineering often stems from the desire to achieve high-performance scores for marketing or competitive purposes. High benchmark scores can demonstrate the superiority of an AI system compared to competitors and can be a key selling point for potential users or investors. This pressure to perform well on benchmarks sometimes leads to prioritizing benchmark-specific optimizations over more holistic improvements to the system.
-It can lead to a number of risks and challenges. One of the primary risks is that the AI system may not perform as well in real-world applications as the benchmark scores suggest. This can lead to user dissatisfaction, reputational damage, and potential safety or ethical concerns. Furthermore, benchmark engineering can contribute to a lack of transparency and accountability in the AI community, as it can be difficult to discern how much of an AI system's performance is due to genuine improvements versus benchmark-specific optimizations.
+It can lead to several risks and challenges. One of the primary risks is that the AI system may perform better in real-world applications than the benchmark scores suggest. This can lead to user dissatisfaction, reputational damage, and potential safety or ethical concerns. Furthermore, benchmark engineering can contribute to a lack of transparency and accountability in the AI community, as it can be difficult to discern how much of an AI system's performance is due to genuine improvements versus benchmark-specific optimizations.
-To mitigate the risks associated with benchmark engineering, it is important for the AI community to prioritize transparency and accountability. This can include clearly disclosing any optimizations or adjustments made specifically for benchmark tests, as well as providing more comprehensive evaluations of AI systems that include real-world performance metrics in addition to benchmark scores. Additionally, it is important for researchers and developers to prioritize holistic improvements to AI systems that improve their generalizability and functionality across a range of applications, rather than focusing solely on benchmark-specific optimizations.
+The AI community must prioritize transparency and accountability to mitigate the risks associated with benchmark engineering. This can include disclosing any optimizations or adjustments made specifically for benchmark tests and providing more comprehensive evaluations of AI systems that include real-world performance metrics and benchmark scores. Researchers and developers must prioritize holistic improvements to AI systems that improve their generalizability and functionality across various applications rather than focusing solely on benchmark-specific optimizations.
#### Issues
-One of the primary problems with benchmark engineering is that it can compromise the real-world performance of AI systems. When developers focus on optimizing their systems to achieve high scores on specific benchmark tests, they may neglect other important aspects of system performance that are crucial in real-world applications. For example, an AI system designed for image recognition might be engineered to perform exceptionally well on a benchmark test that includes a specific set of images, but struggle to accurately recognize images that are slightly different from those in the test set.
+One of the primary problems with benchmark engineering is that it can compromise the real-world performance of AI systems. When developers focus on optimizing their systems to achieve high scores on specific benchmark tests, they may neglect other important system performance aspects crucial in real-world applications. For example, an AI system designed for image recognition might be engineered to perform exceptionally well on a benchmark test that includes a specific set of images but needs help to recognize images slightly different from those in the test set accurately.
-Another issue with benchmark engineering is that it can result in AI systems that lack generalizability. In other words, while the system may perform well on the benchmark test, it may not be able to handle a diverse range of inputs or scenarios. For instance, an AI model developed for natural language processing might be engineered to achieve high scores on a benchmark test that includes a specific type of text, but fail to accurately process text that falls outside of that specific type.
+Another area for improvement with benchmark engineering is that it can result in AI systems that lack generalizability. In other words, while the system may perform well on the benchmark test, it may need help handling a diverse range of inputs or scenarios. For instance, an AI model developed for natural language processing might be engineered to achieve high scores on a benchmark test that includes a specific type of text but fails to process text that falls outside of that specific type accurately.
-It can also lead to misleading results. When AI systems are engineered to perform well on benchmark tests, the results may not accurately reflect the true capabilities of the system. This can be problematic for users or investors who rely on benchmark scores to make informed decisions about which AI systems to use or invest in. For example, an AI system that has been engineered to achieve high scores on a benchmark test for speech recognition might not actually be capable of accurately recognizing speech in real-world situations, leading users or investors to make decisions based on inaccurate information.
+It can also lead to misleading results. When AI systems are engineered to perform well on benchmark tests, the results may not accurately reflect the system's true capabilities. This can be problematic for users or investors who rely on benchmark scores to make informed decisions about which AI systems to use or invest in. For example, an AI system engineered to achieve high scores on a benchmark test for speech recognition might need to be more capable of accurately recognizing speech in real-world situations, leading users or investors to make decisions based on inaccurate information.
#### Mitigation
-There are several ways to mitigate benchmark engineering. Transparency in the benchmarking process is crucial to maintaining the accuracy and reliability of benchmarks. This involves clearly disclosing the methodologies, data sets, and evaluation criteria used in benchmark tests, as well as any optimizations or adjustments made to the AI system for the purpose of the benchmark.
+There are several ways to mitigate benchmark engineering. Transparency in the benchmarking process is crucial to maintaining benchmark accuracy and reliability. This involves clearly disclosing the methodologies, data sets, and evaluation criteria used in benchmark tests, as well as any optimizations or adjustments made to the AI system for the purpose of the benchmark.
-One way to achieve transparency is through the use of open-source benchmarks. Open-source benchmarks are made publicly available, allowing researchers, developers, and other stakeholders to review, critique, and contribute to the benchmark, thereby ensuring its accuracy and reliability. This collaborative approach also facilitates the sharing of best practices and the development of more robust and comprehensive benchmarks.
+One way to achieve transparency is through the use of open-source benchmarks. Open-source benchmarks are made publicly available, allowing researchers, developers, and other stakeholders to review, critique, and contribute to them, thereby ensuring their accuracy and reliability. This collaborative approach also facilitates sharing best practices and developing more robust and comprehensive benchmarks.
-One example is the MLPerf Tiny. It's an open-source framework designed to make it easy to compare different solutions in the world of TinyML. Its modular design allows components to be swapped out for comparison or improvement. The reference implementations, shown in green and orange in @fig-ml-perf, act as the baseline for results. TinyML often needs optimization across the entire system, and users can contribute by focusing on specific parts, like quantization. The modular benchmark design allows users to showcase their contributions' competitive advantage by modifying a reference implementation. In short, MLPerf Tiny offers a flexible and modular way to assess and enhance TinyML applications, making it easier to compare and improve different aspects of the technology.
+One example is the MLPerf Tiny. It's an open-source framework designed to make it easy to compare different solutions in the world of TinyML. Its modular design allows components to be swapped out for comparison or improvement. The reference implementations, shown in green and orange in @fig-ml-perf, act as the baseline for results. TinyML often needs optimization across the entire system, and users can contribute by focusing on specific parts, like quantization. The modular benchmark design allows users to showcase their contributions and competitive advantage by modifying a reference implementation. In short, MLPerf Tiny offers a flexible and modular way to assess and enhance TinyML applications, making it easier to compare and improve different aspects of the technology.
{#fig-ml-perf}
-Another method for achieving transparency is through peer review of benchmarks. This involves having independent experts review and validate the benchmark's methodology, data sets, and results to ensure their credibility and reliability. Peer review can provide a valuable means of verifying the accuracy of benchmark tests and can help to build confidence in the results.
+Another method for achieving transparency is through peer review of benchmarks. This involves having independent experts review and validate the benchmark's methodology, data sets, and results to ensure their credibility and reliability. Peer review can provide a valuable means of verifying the accuracy of benchmark tests and help build confidence in the results.
-Standardization of benchmarks is another important solution to mitigate benchmark engineering. Standardized benchmarks provide a common framework for evaluating AI systems, ensuring consistency and comparability across different systems and applications. This can be achieved through the development of industry-wide standards and best practices for benchmarking, as well as through the use of common metrics and evaluation criteria.
+Standardization of benchmarks is another important solution to mitigate benchmark engineering. Standardized benchmarks provide a common framework for evaluating AI systems, ensuring consistency and comparability across different systems and applications. This can be achieved by developing industry-wide standards and best practices for benchmarking and through common metrics and evaluation criteria.
-Third-party verification of results can also be a valuable tool in mitigating benchmark engineering. This involves having an independent third party verify the results of a benchmark test to ensure their credibility and reliability. Third-party verification can help to build confidence in the results and can provide a valuable means of validating the performance and capabilities of AI systems.
+Third-party verification of results can also be valuable in mitigating benchmark engineering. This involves having an independent third party verify the results of a benchmark test to ensure their credibility and reliability. Third-party verification can build confidence in the results and provide a valuable means of validating the performance and capabilities of AI systems.
## Model Benchmarking
-Benchmarking machine learning models is important for determining the effectiveness and efficiency of various machine learning algorithms in solving specific tasks or problems. By analyzing the results obtained from benchmarking, developers and researchers can identify the strengths and weaknesses of their models, leading to more informed decisions on model selection and further optimization.
+Benchmarking machine learning models is important for determining the effectiveness and efficiency of various machine learning algorithms in solving specific tasks or problems. By analyzing the results obtained from benchmarking, developers and researchers can identify their models' strengths and weaknesses, leading to more informed decisions on model selection and further optimization.
-The evolution and progress of machine learning models are intrinsically linked to the availability and quality of data sets. In the world of machine learning, data acts as the raw material that powers the algorithms, allowing them to learn, adapt, and ultimately perform tasks that were traditionally the domain of humans. Therefore, it is important to understand this history.
+The evolution and progress of machine learning models are intrinsically linked to the availability and quality of data sets. In machine learning, data acts as the raw material that powers the algorithms, allowing them to learn, adapt, and ultimately perform tasks that were traditionally the domain of humans. Therefore, it is important to understand this history.
### Historical Context
@@ -563,13 +563,13 @@ Machine learning datasets have a rich history and have evolved significantly ove
#### MNIST (1998)
-The [MNIST dataset](https://www.tensorflow.org/datasets/catalog/mnist), created by Yann LeCun, Corinna Cortes, and Christopher J.C. Burges in 1998, can be considered a cornerstone in the history of machine learning datasets. It consists of 70,000 labeled 28x28 pixel grayscale images of handwritten digits (0-9). MNIST has been widely used for benchmarking algorithms in image processing and machine learning, serving as a starting point for many researchers and practitioners in the field. @fig-mnist shows some examples of the handwritten digits.
+The [MNIST dataset](https://www.tensorflow.org/datasets/catalog/mnist), created by Yann LeCun, Corinna Cortes, and Christopher J.C. Burges in 1998, can be considered a cornerstone in the history of machine learning datasets. It comprises 70,000 labeled 28x28 pixel grayscale images of handwritten digits (0-9). MNIST has been widely used for benchmarking algorithms in image processing and machine learning as a starting point for many researchers and practitioners. @fig-mnist shows some examples of handwritten digits.
](images/png/mnist.png){#fig-mnist}
#### ImageNet (2009)
-Fast forward to 2009, and we see the introduction of the [ImageNet dataset](https://www.tensorflow.org/datasets/catalog/imagenet2012), which marked a significant leap in the scale and complexity of datasets. ImageNet consists of over 14 million labeled images spanning more than 20,000 categories. It was developed by Fei-Fei Li and her team with the goal of advancing research in object recognition and computer vision. The dataset became synonymous with the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), an annual competition that played a crucial role in the development of deep learning models, including the famous AlexNet in 2012.
+Fast forward to 2009, and we see the introduction of the [ImageNet dataset](https://www.tensorflow.org/datasets/catalog/imagenet2012), which marked a significant leap in the scale and complexity of datasets. ImageNet consists of over 14 million labeled images spanning more than 20,000 categories. Fei-Fei Li and her team developed it to advance object recognition and computer vision research. The dataset became synonymous with the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), an annual competition crucial in developing deep learning models, including the famous AlexNet in 2012.
#### COCO (2014)
@@ -579,168 +579,168 @@ The [Common Objects in Context (COCO) dataset](https://cocodataset.org/)(@lin201
#### GPT-3 (2020)
-While the above examples primarily focus on image datasets, there have been significant developments in text datasets as well. One notable example is GPT-3 [@brown2020language], developed by OpenAI. GPT-3 is a language model trained on a diverse range of internet text. Although the dataset used to train GPT-3 is not publicly available, the model itself, consisting of 175 billion parameters, is a testament to the scale and complexity of modern machine learning datasets and models.
+While the above examples primarily focus on image datasets, there have also been significant developments in text datasets. One notable example is GPT-3 [@brown2020language], developed by OpenAI. GPT-3 is a language model trained on diverse internet text. Although the dataset used to train GPT-3 is not publicly available, the model itself, consisting of 175 billion parameters, is a testament to the scale and complexity of modern machine learning datasets and models.
#### Present and Future
-Today, we have a plethora of datasets spanning various domains, including healthcare, finance, social sciences, and more. The following characteristics are how we can taxonomize the space and growth of machine learning datasets that fuel model development.
+Today, we have a plethora of datasets spanning various domains, including healthcare, finance, social sciences, and more. The following characteristics help us taxonomize the space and growth of machine learning datasets that fuel model development.
-1. **Diversity of Data Sets:** The variety of data sets available to researchers and engineers has expanded dramatically over the years, covering a wide range of fields, including natural language processing, image recognition, and more. This diversity has fueled the development of specialized machine learning models tailored to specific tasks, such as translation, speech recognition, and facial recognition.
+1. **Diversity of Data Sets:** The variety of data sets available to researchers and engineers has expanded dramatically, covering many fields, including natural language processing, image recognition, and more. This diversity has fueled the development of specialized machine-learning models tailored to specific tasks, such as translation, speech recognition, and facial recognition.
2. **Volume of Data:** The sheer volume of data that has become available in the digital age has also played a crucial role in advancing machine learning models. Large data sets enable models to capture the complexity and nuances of real-world phenomena, leading to more accurate and reliable predictions.
3. **Quality and Cleanliness of Data:** The quality of data is another critical factor that influences the performance of machine learning models. Clean, well-labeled, and unbiased data sets are essential for training models that are robust and fair.
-4. **Open Access to Data:** The availability of open-access data sets has also contributed significantly to the progress in machine learning. Open data allows researchers from around the world to collaborate, share insights, and build upon each other's work, leading to faster innovation and development of more advanced models.
+4. **Open Access to Data:** The availability of open-access data sets has also contributed significantly to machine learning's progress. Open data allows researchers from around the world to collaborate, share insights, and build upon each other's work, leading to faster innovation and the development of more advanced models.
-5. **Ethics and Privacy Concerns:** As data sets continue to grow in size and complexity, ethical considerations and privacy concerns become increasingly important. There is an ongoing debate about the balance between leveraging data for machine learning advancements and protecting individuals' privacy rights.
+5. **Ethics and Privacy Concerns:** As data sets grow in size and complexity, ethical considerations and privacy concerns become increasingly important. There is an ongoing debate about the balance between leveraging data for machine learning advancements and protecting individuals' privacy rights.
-The development of machine learning models is heavily reliant on the availability of diverse, large, high-quality, and open-access data sets. As we move forward, addressing the ethical considerations and privacy concerns associated with the use of large data sets is crucial to ensure that machine learning technologies benefit society as a whole. There is a growing awareness that data acts as the rocket fuel for machine learning, driving and fueling the development of machine learning models. Consequently, an increasing amount of focus is being placed on the development of the data sets themselves. We will explore this in further detail in the data benchmarking section.
+The development of machine learning models relies heavily on the availability of diverse, large, high-quality, and open-access data sets. As we move forward, addressing the ethical considerations and privacy concerns associated with using large data sets is crucial to ensure that machine learning technologies benefit society. There is a growing awareness that data acts as the rocket fuel for machine learning, driving and fueling the development of machine learning models. Consequently, more focus is being placed on developing the data sets themselves. We will explore this in further detail in the data benchmarking section.
### Model Metrics
-The evolution of machine learning model evaluation has witnessed a transition from a narrow focus on accuracy to a more comprehensive approach that takes into account a range of factors, from ethical considerations and real-world applicability to practical constraints like model size and efficiency. This shift reflects the maturation of the field as machine learning models are increasingly applied in diverse and complex real-world scenarios.
+Machine learning model evaluation has evolved from a narrow focus on accuracy to a more comprehensive approach considering a range of factors, from ethical considerations and real-world applicability to practical constraints like model size and efficiency. This shift reflects the field's maturation as machine learning models are increasingly applied in diverse, complex real-world scenarios.
#### Accuracy
-Accuracy is one of the most intuitive and commonly used metrics for evaluating machine learning models. At its core, accuracy measures the proportion of correct predictions made by the model out of all predictions. As an example, imagine we have developed a machine learning model to classify images as either containing a cat or not. If we test this model on a dataset of 100 images, and it correctly identifies 90 of them, we would calculate its accuracy as 90%.
+Accuracy is one of the most intuitive and commonly used metrics for evaluating machine learning models. At its core, accuracy measures the proportion of correct predictions made by the model out of all predictions. For example, imagine we have developed a machine learning model to classify images as either containing a cat or not. If we test this model on a dataset of 100 images, and it correctly identifies 90 of them, we would calculate its accuracy as 90%.
-In the initial stages of machine learning, accuracy was often the primary, if not the only, metric considered when evaluating model performance. This is perhaps understandable, given its straightforward nature and ease of interpretation. However, as the field has progressed, the limitations of relying solely on accuracy have become more apparent.
+In the initial stages of machine learning, accuracy was often the primary, if not the only, metric considered when evaluating model performance. This is understandable, given its straightforward nature and ease of interpretation. However, as the field has progressed, the limitations of relying solely on accuracy have become more apparent.
-Consider the example of a medical diagnosis model that has an accuracy of 95%. While at first glance this may seem impressive, we must delve deeper to fully assess the model's performance. If the model fails to accurately diagnose severe conditions that, while rare, can have severe consequences, its high accuracy may not be as meaningful. A pertinent example of this is [Google's retinopathy machine learning model](https://about.google/intl/ALL_us/stories/seeingpotential/), which was designed to diagnose diabetic retinopathy and diabetic macular edema from retinal photographs.
+Consider the example of a medical diagnosis model with an accuracy of 95%. While at first glance this may seem impressive, we must delve deeper to assess the model's performance fully. Suppose the model fails to accurately diagnose severe conditions that, while rare, can have severe consequences; its high accuracy may not be as meaningful. A pertinent example of this is [Google's retinopathy machine learning model](https://about.google/intl/ALL_us/stories/seeingpotential/), which was designed to diagnose diabetic retinopathy and diabetic macular edema from retinal photographs.
-The Google model demonstrated impressive accuracy levels in lab settings, but when deployed in real-world clinical environments in Thailand, [it faced significant challenges](https://www.technologyreview.com/2020/04/27/1000658/google-medical-ai-accurate-lab-real-life-clinic-covid-diabetes-retina-disease/). In the real-world setting, the model encountered diverse patient populations, varying image quality, and a range of different medical conditions that it had not been exposed to during its training. Consequently, its performance was compromised, and it struggled to maintain the same levels of accuracy that had been observed in lab settings. This example serves as a clear reminder that while high accuracy is an important and desirable attribute for a medical diagnosis model, it must be evaluated in conjunction with other factors, such as the model's ability to generalize to different populations and handle diverse and unpredictable real-world conditions, to truly understand its value and potential impact on patient care.
+The Google model demonstrated impressive accuracy levels in lab settings. Still, when deployed in real-world clinical environments in Thailand, [it faced significant challenges](https://www.technologyreview.com/2020/04/27/1000658/google-medical-ai-accurate-lab-real-life-clinic-covid-diabetes-retina-disease/). In the real-world setting, the model encountered diverse patient populations, varying image quality, and a range of different medical conditions that it had not been exposed to during its training. Consequently, its performance could have been better, and it struggled to maintain the same accuracy levels observed in lab settings. This example serves as a clear reminder that while high accuracy is an important and desirable attribute for a medical diagnosis model, it must be evaluated in conjunction with other factors, such as the model's ability to generalize to different populations and handle diverse and unpredictable real-world conditions, to understand its value and potential impact on patient care truly.
-Similarly, if the model performs well on average but exhibits significant disparities in performance across different demographic groups, this too would be a cause for concern.
+Similarly, if the model performs well on average but exhibits significant disparities in performance across different demographic groups, this, too, would be cause for concern.
-The evolution of machine learning has thus seen a shift towards a more holistic approach to model evaluation, taking into account not just accuracy, but also other crucial factors such as fairness, transparency, and real-world applicability. A prime example of this is the [Gender Shades project](http://gendershades.org/) at MIT Media Lab, led by Joy Buolamwini, which highlighted significant racial and gender biases in commercial facial recognition systems. The project evaluated the performance of three facial recognition technologies developed by IBM, Microsoft, and Face++ and found that they all exhibited biases, performing better on lighter-skinned and male faces compared to darker-skinned and female faces.
+The evolution of machine learning has thus seen a shift towards a more holistic approach to model evaluation, taking into account not just accuracy, but also other crucial factors such as fairness, transparency, and real-world applicability. A prime example is the [Gender Shades project](http://gendershades.org/) at MIT Media Lab, led by Joy Buolamwini, highlighting significant racial and gender biases in commercial facial recognition systems. The project evaluated the performance of three facial recognition technologies developed by IBM, Microsoft, and Face++. It found that they all exhibited biases, performing better on lighter-skinned and male faces compared to darker-skinned and female faces.
-While accuracy remains a fundamental and valuable metric for evaluating machine learning models, it is clear that a more comprehensive approach is required to fully assess a model's performance. This means considering additional metrics that account for fairness, transparency, and real-world applicability, as well as conducting rigorous testing across diverse datasets to uncover and mitigate any potential biases. The move towards a more holistic approach to model evaluation reflects the maturation of the field and its increasing recognition of the real-world implications and ethical considerations associated with deploying machine learning models.
+While accuracy remains a fundamental and valuable metric for evaluating machine learning models, a more comprehensive approach is required to fully assess a model's performance. This means considering additional metrics that account for fairness, transparency, and real-world applicability, as well as conducting rigorous testing across diverse datasets to uncover and mitigate any potential biases. The move towards a more holistic approach to model evaluation reflects the maturation of the field and its increasing recognition of the real-world implications and ethical considerations associated with deploying machine learning models.
#### Fairness
Fairness in machine learning models is a multifaceted and critical aspect that requires careful attention, particularly in high-stakes applications that significantly affect people's lives, such as in loan approval processes, hiring, and criminal justice. It refers to the equitable treatment of all individuals, irrespective of their demographic or social attributes such as race, gender, age, or socioeconomic status.
-When evaluating models, simply relying on accuracy can be insufficient and potentially misleading. For instance, consider a loan approval model that boasts a 95% accuracy rate. While this figure may appear impressive at first glance, it does not reveal how the model performs across different demographic groups. If this model consistently discriminates against a particular group, its accuracy is less commendable, and its fairness comes into question.
+Simply relying on accuracy can be insufficient and potentially misleading when evaluating models. For instance, consider a loan approval model with a 95% accuracy rate. While this figure may appear impressive at first glance, it does not reveal how the model performs across different demographic groups. If this model consistently discriminates against a particular group, its accuracy is less commendable, and its fairness is questioned.
-Discrimination can manifest in various forms, such as direct discrimination, where a model explicitly uses sensitive attributes like race or gender in its decision-making process, or indirect discrimination, where seemingly neutral variables correlate with sensitive attributes, indirectly influencing the model's outcomes. An infamous example of the latter is the COMPAS tool used in the US criminal justice system, which exhibited racial biases in predicting recidivism rates, despite not explicitly using race as a variable.
+Discrimination can manifest in various forms, such as direct discrimination, where a model explicitly uses sensitive attributes like race or gender in its decision-making process, or indirect discrimination, where seemingly neutral variables correlate with sensitive attributes, indirectly influencing the model's outcomes. An infamous example of the latter is the COMPAS tool used in the US criminal justice system, which exhibited racial biases in predicting recidivism rates despite not explicitly using race as a variable.
-Addressing fairness involves careful examination of the model's performance across diverse groups, identification of potential biases, and rectification of disparities through corrective measures such as re-balancing datasets, adjusting model parameters, and implementing fairness-aware algorithms. Researchers and practitioners are continuously developing metrics and methodologies tailored to specific use cases to evaluate fairness in real-world scenarios. For example, disparate impact analysis, demographic parity, and equal opportunity are some of the metrics employed to assess fairness.
+Addressing fairness involves careful examination of the model's performance across diverse groups, identifying potential biases, and rectifying disparities through corrective measures such as re-balancing datasets, adjusting model parameters, and implementing fairness-aware algorithms. Researchers and practitioners continuously develop metrics and methodologies tailored to specific use cases to evaluate fairness in real-world scenarios. For example, disparate impact analysis, demographic parity, and equal opportunity are some of the metrics employed to assess fairness.
Additionally, transparency and interpretability of models are fundamental to achieving fairness. Understanding how a model makes decisions can reveal potential biases and enable stakeholders to hold developers accountable. Open-source tools like [AI Fairness 360](https://ai-fairness-360.org/) by IBM and [Fairness Indicators](https://www.tensorflow.org/tfx/guide/fairness_indicators) by TensorFlow are being developed to facilitate fairness assessments and mitigation of biases in machine learning models.
-Ensuring fairness in machine learning models particularly in applications that significantly impact people's lives. It requires rigorous evaluation of the model's performance across diverse groups, careful identification and mitigation of biases, and implementation of transparency and interpretability measures. By addressing fairness in a comprehensive manner, we can work towards developing machine learning models that are equitable, just, and beneficial for society as a whole.
+Ensuring fairness in machine learning models, particularly in applications that significantly impact people's lives, requires rigorous evaluation of the model's performance across diverse groups, careful identification and mitigation of biases, and implementation of transparency and interpretability measures. By comprehensively addressing fairness, we can work towards developing machine learning models that are equitable, just, and beneficial for society.
#### Complexity
##### Parameters*
-In the initial stages of machine learning, model benchmarking often relied on parameter counts as a proxy for model complexity. The rationale was that more parameters typically lead to a more complex model, which should, in turn, deliver better performance. However, this approach has proven to be inadequate as it doesn't account for the computational cost associated with processing a large number of parameters.
+In the initial stages of machine learning, model benchmarking often relied on parameter counts as a proxy for model complexity. The rationale was that more parameters typically lead to a more complex model, which should, in turn, deliver better performance. However, this approach has proven inadequate as it needs to account for the computational cost associated with processing many parameters.
-For example, GPT-3, developed by OpenAI, is a language model that boasts an astounding 175 billion parameters. While it achieves state-of-the-art performance on a variety of natural language processing tasks, its size and the computational resources required to run it make it impractical for deployment in many real-world scenarios, especially those with limited computational capabilities.
+For example, GPT-3, developed by OpenAI, is a language model that boasts an astounding 175 billion parameters. While it achieves state-of-the-art performance on various natural language processing tasks, its size and the computational resources required to run it make it impractical for deployment in many real-world scenarios, especially those with limited computational capabilities.
-The reliance on parameter counts as a proxy for model complexity also fails to consider the efficiency of the model. A model with fewer parameters might be just as effective, if not more so, than a model with a higher parameter count if it is optimized for efficiency. For instance, MobileNets, developed by Google, are a family of models designed specifically for mobile and edge devices. They utilize depth-wise separable convolutions to reduce the number of parameters and computational cost, while still achieving competitive performance.
+Relying on parameter counts as a proxy for model complexity also fails to consider the model's efficiency. If optimized for efficiency, a model with fewer parameters might be just as effective, if not more so, than a model with a higher parameter count. For instance, MobileNets, developed by Google, is a family of models designed specifically for mobile and edge devices. They utilize depth-wise separable convolutions to reduce the number of parameters and computational costs while still achieving competitive performance.
-In light of these limitations, the field has moved towards a more holistic approach to model benchmarking that considers not just parameter counts, but also other crucial factors such as floating-point operations per second (FLOPs), memory consumption, and latency. FLOPs, in particular, have emerged as an important metric as they provide a more accurate representation of the computational load a model imposes. This shift towards a more comprehensive approach to model benchmarking reflects a recognition of the need to balance performance with practicality, ensuring that models are not just effective, but also efficient and deployable in real-world scenarios.
+In light of these limitations, the field has moved towards a more holistic approach to model benchmarking that considers parameter counts and other crucial factors such as floating-point operations per second (FLOPs), memory consumption, and latency. FLOPs, in particular, have emerged as an important metric as they provide a more accurate representation of the computational load a model imposes. This shift towards a more comprehensive approach to model benchmarking reflects a recognition of the need to balance performance with practicality, ensuring that models are effective, efficient, and deployable in real-world scenarios.
##### FLOPS
-The size of a machine learning model is an essential aspect that directly impacts its usability in practical scenarios, especially when computational resources are limited. Traditionally, the number of parameters in a model was often used as a proxy for its size, with the underlying assumption being that more parameters would translate to better performance. However, this simplistic view does not consider the computational cost associated with processing these parameters. This is where the concept of floating-point operations per second (FLOPs) comes into play, providing a more accurate representation of the computational load a model imposes.
+The size of a machine learning model is an essential aspect that directly impacts its usability in practical scenarios, especially when computational resources are limited. Traditionally, the number of parameters in a model was often used as a proxy for its size, with the underlying assumption being that more parameters would translate to better performance. However, this simplistic view does not consider the computational cost of processing these parameters. This is where the concept of floating-point operations per second (FLOPs) comes into play, providing a more accurate representation of the computational load a model imposes.
-FLOPs measure the number of floating-point operations a model performs to generate a prediction. For example, a model with a high number of FLOPs requires substantial computational resources to process the vast number of operations, which may render it impractical for certain applications. Conversely, a model with a lower FLOP count is more lightweight and can be easily deployed in scenarios where computational resources are limited.
+FLOPs measure the number of floating-point operations a model performs to generate a prediction. A model with many FLOPs requires substantial computational resources to process the vast number of operations, which may render it impractical for certain applications. Conversely, a model with a lower FLOP count is more lightweight and can be easily deployed in scenarios where computational resources are limited.
-Let's consider an example. BERT [Bidirectional Encoder Representations from Transformers](@devlin2018bert), a popular natural language processing model, has over 340 million parameters, making it a large model with high accuracy and impressive performance across a range of tasks. However, the sheer size of BERT, coupled with its high FLOP count, makes it a computationally intensive model that may not be suitable for real-time applications or deployment on edge devices with limited computational capabilities.
+Let's consider an example. BERT [Bidirectional Encoder Representations from Transformers](@devlin2018bert), a popular natural language processing model, has over 340 million parameters, making it a large model with high accuracy and impressive performance across various tasks. However, the sheer size of BERT, coupled with its high FLOP count, makes it a computationally intensive model that may not be suitable for real-time applications or deployment on edge devices with limited computational capabilities.
-In light of this, there has been a growing interest in developing smaller models that can achieve similar performance levels as their larger counterparts while being more efficient in terms of computational load. DistilBERT, for instance, is a smaller version of BERT that retains 97% of its performance while being 40% smaller in terms of parameter count. The reduction in size also translates to a lower FLOP count, making DistilBERT a more practical choice for resource-constrained scenarios.
+In light of this, there has been a growing interest in developing smaller models that can achieve similar performance levels as their larger counterparts while being more efficient in computational load. DistilBERT, for instance, is a smaller version of BERT that retains 97% of its performance while being 40% smaller in terms of parameter count. The size reduction also translates to a lower FLOP count, making DistilBERT a more practical choice for resource-constrained scenarios.
-To sum up, while parameter count provides a useful indication of model size, it is not a comprehensive metric as it does not consider the computational cost associated with processing these parameters. FLOPs, on the other hand, offer a more accurate representation of a model's computational load and are thus an essential consideration when deploying machine learning models in real-world scenarios, particularly when computational resources are limited. The evolution from relying solely on parameter count to also considering FLOPs signifies a maturation in the field, reflecting a greater awareness of the practical constraints and challenges associated with deploying machine learning models in diverse settings.
+In summary, while parameter count provides a useful indication of model size, it is not a comprehensive metric as it needs to consider the computational cost associated with processing these parameters. FLOPs, on the other hand, offer a more accurate representation of a model's computational load and are thus an essential consideration when deploying machine learning models in real-world scenarios, particularly when computational resources are limited. The evolution from relying solely on parameter count to considering FLOPs signifies a maturation in the field, reflecting a greater awareness of the practical constraints and challenges of deploying machine learning models in diverse settings.
##### Efficiency
-Efficiency metrics, such as memory consumption and latency/throughput, have also gained prominence. These metrics are particularly crucial when deploying models on edge devices or in real-time applications, as they measure how quickly a model can process data and how much memory it requires. In this context, Pareto curves are often used to visualize the trade-off between different metrics, helping stakeholders make informed decisions about which model is best suited to their needs.
+Efficiency metrics, such as memory consumption and latency/throughput, have also gained prominence. These metrics are particularly crucial when deploying models on edge devices or in real-time applications, as they measure how quickly a model can process data and how much memory it requires. In this context, Pareto curves are often used to visualize the trade-off between different metrics, helping stakeholders decide which model best suits their needs.
### Lessons Learned
-Model benchmarking has offered us several valuable insights that can be leveraged to drive innovation in system benchmarks. The progression of machine learning models has been profoundly influenced by the advent of leaderboards and the open-source availability of models and datasets. These elements have served as significant catalysts, propelling innovation and accelerating the integration of cutting-edge models into production environments. However, these are not the only contributors to the development of machine learning benchmarks, as we will explore further.
+Model benchmarking has offered us several valuable insights that can be leveraged to drive innovation in system benchmarks. The progression of machine learning models has been profoundly influenced by the advent of leaderboards and the open-source availability of models and datasets. These elements have served as significant catalysts, propelling innovation and accelerating the integration of cutting-edge models into production environments. However, as we will explore further, these are not the only contributors to the development of machine learning benchmarks.
-Leaderboards play a vital role in providing an objective and transparent method for researchers and practitioners to evaluate the efficacy of different models, ranking them based on their performance in benchmarks. This system fosters a competitive environment, encouraging the development of models that are not only accurate but also efficient. The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is a prime example of this, with its annual leaderboard significantly contributing to the development of groundbreaking models such as AlexNet.
+Leaderboards play a vital role in providing an objective and transparent method for researchers and practitioners to evaluate the efficacy of different models, ranking them based on their performance in benchmarks. This system fosters a competitive environment, encouraging the development of models that are not only accurate but also efficient. The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is a prime example of this, with its annual leaderboard significantly contributing to developing groundbreaking models such as AlexNet.
-Open-source access to state-of-the-art models and datasets further democratizes the field of machine learning, facilitating collaboration among researchers and practitioners worldwide. This open access accelerates the process of testing, validation, and deployment of new models in production environments, as evidenced by the widespread adoption of models like BERT and GPT-3 in various applications, from natural language processing to more complex, multi-modal tasks.
+Open-source access to state-of-the-art models and datasets further democratizes machine learning, facilitating collaboration among researchers and practitioners worldwide. This open access accelerates the process of testing, validation, and deployment of new models in production environments, as evidenced by the widespread adoption of models like BERT and GPT-3 in various applications, from natural language processing to more complex, multi-modal tasks.
-Community collaboration platforms like Kaggle have revolutionized the field by hosting competitions that unite data scientists from across the globe to solve intricate problems, with specific benchmarks serving as the goalposts for innovation and model development.
+Community collaboration platforms like Kaggle have revolutionized the field by hosting competitions that unite data scientists from across the globe to solve intricate problems. Specific benchmarks serve as the goalposts for innovation and model development.
Moreover, the availability of diverse and high-quality datasets is paramount in training and testing machine learning models. Datasets such as ImageNet have played an instrumental role in the evolution of image recognition models, while extensive text datasets have facilitated advancements in natural language processing models.
-Lastly, the contributions of academic and research institutions cannot be overstated. Their role in publishing research papers, sharing findings at conferences, and fostering collaboration between various institutions has significantly contributed to the advancement of machine learning models and benchmarks.
+Lastly, the contributions of academic and research institutions must be supported. Their role in publishing research papers, sharing findings at conferences, and fostering collaboration between various institutions has significantly contributed to advancing machine learning models and benchmarks.
#### Emerging Trends
-As machine learning models become more sophisticated, so do the benchmarks required to accurately assess them. There are several emerging benchmarks and datasets that are gaining popularity due to their ability to evaluate models in more complex and realistic scenarios:
+As machine learning models become more sophisticated, so do the benchmarks required to assess them accurately. There are several emerging benchmarks and datasets that are gaining popularity due to their ability to evaluate models in more complex and realistic scenarios:
-**Multimodal Datasets:** These datasets contain multiple types of data, such as text, images, and audio, to better represent real-world situations. An example is the VQA (Visual Question Answering) dataset [@antol2015vqa], where models are tested on their ability to answer text-based questions about images.
+**Multimodal Datasets:** These datasets contain multiple data types, such as text, images, and audio, to represent real-world situations better. An example is the VQA (Visual Question Answering) dataset [@antol2015vqa], where models' ability to answer text-based questions about images is tested.
-**Fairness and Bias Evaluation:** There is an increasing focus on creating benchmarks that assess the fairness and bias of machine learning models. Examples include the [AI Fairness 360](https://ai-fairness-360.org/) toolkit, which offers a comprehensive set of metrics and datasets for evaluating bias in models.
+**Fairness and Bias Evaluation:** There is an increasing focus on creating benchmarks assessing machine learning models' fairness and bias. Examples include the [AI Fairness 360](https://ai-fairness-360.org/) toolkit, which offers a comprehensive set of metrics and datasets for evaluating bias in models.
-**Out-of-Distribution Generalization**: Testing how well models perform on data that is different from the original training distribution. This evaluates the model's ability to generalize to new, unseen data. Example benchmarks are Wilds [@koh2021wilds], RxRx, and ANC-Bench.
+**Out-of-Distribution Generalization:** Testing how well models perform on data different from the original training distribution. This evaluates the model's ability to generalize to new, unseen data. Example benchmarks are Wilds [@koh2021wilds], RxRx, and ANC-Bench.
**Adversarial Robustness:** Evaluating model performance under adversarial attacks or perturbations to the input data. This tests the model's robustness. Example benchmarks are ImageNet-A [@hendrycks2021natural], ImageNet-C [@xie2020adversarial], and CIFAR-10.1.
-**Real-World Performance:** Testing models on real-world datasets that closely match end tasks, rather than just canned benchmark datasets. Examples are medical imaging datasets for healthcare tasks or actual customer support chat logs for dialogue systems.
+**Real-World Performance:** Testing models on real-world datasets that closely match end tasks rather than just canned benchmark datasets. Examples are medical imaging datasets for healthcare tasks or customer support chat logs for dialogue systems.
-**Energy and Compute Efficiency:** Benchmarks that measure the computational resources required to achieve a particular accuracy. This evaluates the model's efficiency. Examples are MLPerf and Greenbench, and these were already discussed in the Systems benchmarking section.
+**Energy and Compute Efficiency:** Benchmarks that measure the computational resources required to achieve a particular accuracy. This evaluates the model's Efficiency. Examples are MLPerf and Greenbench, already discussed in the Systems benchmarking section.
**Interpretability and Explainability:** Benchmarks that assess how easy it is to understand and explain a model's internal logic and predictions. Example metrics are faithfulness to input gradients and coherence of explanations.
### Limitations and Challenges
-While model benchmarks are an essential tool in the assessment of machine learning models, there are several limitations and challenges that should be addressed to ensure that they accurately reflect a model's performance in real-world scenarios.
+While model benchmarks are an essential tool in assessing machine learning models, several limitations and challenges should be addressed to ensure that they accurately reflect a model's performance in real-world scenarios.
-**Dataset does not Correspond to Real-World Scenarios:** Often, the data used in model benchmarks is cleaned and preprocessed to such an extent that it may not accurately represent the data that a model would encounter in real-world applications. This idealized version of the data can lead to overestimations of a model's performance. In the case of the ImageNet dataset, the images are well-labeled and categorized, but in a real-world scenario, a model may need to deal with images that are blurry, poorly lit, or taken from awkward angles. This discrepancy can significantly affect the model's performance.
+**Dataset does not Correspond to Real-World Scenarios:** Often, the data used in model benchmarks is cleaned and preprocessed to such an extent that it may need to accurately represent the data that a model would encounter in real-world applications. This idealized data version can lead to overestimating a model's performance. In the case of the ImageNet dataset, the images are well-labeled and categorized. Still, in a real-world scenario, a model may need to deal with blurry images that could be better lit or taken from awkward angles. This discrepancy can significantly affect the model's performance.
-**Sim2Real Gap:** The Sim2Real gap refers to the difference in performance of a model when transitioning from a simulated environment to a real-world environment. This gap is often observed in robotics, where a robot trained in a simulated environment struggles to perform tasks in the real world due to the complexity and unpredictability of real-world environments. A robot trained to pick up objects in a simulated environment may struggle to perform the same task in the real world because the simulated environment does not accurately represent the complexities of real-world physics, lighting, and object variability.
+**Sim2Real Gap:** The Sim2Real gap refers to the difference in the performance of a model when transitioning from a simulated environment to a real-world environment. This gap is often observed in robotics, where a robot trained in a simulated environment struggles to perform tasks in the real world due to the complexity and unpredictability of real-world environments. A robot trained to pick up objects in a simulated environment may need help to perform the same task in the real world because the simulated environment does not accurately represent the complexities of real-world physics, lighting, and object variability.
**Challenges in Creating Datasets:** Creating a dataset for model benchmarking is a challenging task that requires careful consideration of various factors such as data quality, diversity, and representation. As discussed in the data engineering section, ensuring that the data is clean, unbiased, and representative of the real-world scenario is crucial for the accuracy and reliability of the benchmark. For example, when creating a dataset for a healthcare-related task, it is important to ensure that the data is representative of the entire population and not biased towards a particular demographic. This ensures that the model performs well across diverse patient populations.
-Model benchmarks are essential in measuring the capability of a model architecture in solving a fixed task, but it is important to address the limitations and challenges associated with them. This includes ensuring that the dataset accurately represents real-world scenarios, addressing the Sim2Real gap, and overcoming the challenges associated with creating unbiased and representative datasets. By addressing these challenges, and many others, we can ensure that model benchmarks provide a more accurate and reliable assessment of a model's performance in real-world applications.
+Model benchmarks are essential in measuring the capability of a model architecture in solving a fixed task, but it is important to address the limitations and challenges associated with them. This includes ensuring that the dataset accurately represents real-world scenarios, addressing the Sim2Real gap, and overcoming the challenges of creating unbiased and representative datasets. By addressing these challenges and many others, we can ensure that model benchmarks provide a more accurate and reliable assessment of a model's performance in real-world applications.
-The [Speech Commands dataset](https://arxiv.org/pdf/1804.03209.pdf), and its successor [MSWC](https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/fe131d7f5a6b38b23cc967316c13dae2-Paper-round2.pdf), are common benchmarks for one of the quintessential TinyML applications, keyword spotting. Speech Commands establish streaming error metrics beyond the standard top-1 classification accuracy that are more relevant to the keyword spotting use case. Use case relevant metrics are what elevates a dataset to a model benchmark.
+The [Speech Commands dataset](https://arxiv.org/pdf/1804.03209.pdf) and its successor [MSWC](https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/fe131d7f5a6b38b23cc967316c13dae2-Paper-round2.pdf), are common benchmarks for one of the quintessential TinyML applications, keyword spotting. Speech commands establish streaming error metrics beyond the standard top-1 classification accuracy more relevant to the keyword spotting use case. Using case-relevant metrics is what elevates a dataset to a model benchmark.
## Data Benchmarking
-For the past several years, the field of AI has been focused on developing increasingly sophisticated machine learning models like large language models. The goal has been to create models capable of human-level or superhuman performance on a wide range of tasks by training them on massive datasets. This model-centric approach produced rapid progress, with models attaining state-of-the-art results on many established benchmarks. @fig-superhuman-perf shows the performance of AI systems relative to human performance (marked by the horizontal line at 0) across five applications: handwriting recognition, speech recognition, image recognition, reading comprehension, and language udnerstanding. Over the past decade, the AI performance has surpassed that of humans.
+For the past several years, AI has focused on developing increasingly sophisticated machine learning models like large language models. The goal has been to create models capable of human-level or superhuman performance on a wide range of tasks by training them on massive datasets. This model-centric approach produced rapid progress, with models attaining state-of-the-art results on many established benchmarks. @fig-superhuman-perf shows the performance of AI systems relative to human performance (marked by the horizontal line at 0) across five applications: handwriting recognition, speech recognition, image recognition, reading comprehension, and language understanding. Over the past decade, the AI performance has surpassed that of humans.
-However, there are growing concerns about issues like bias, safety, and robustness that persist even in models that achieve high accuracy on standard benchmarks. Additionally, some popular datasets used for evaluating models are beginning to saturate, with models reaching near perfect performance on existing test splits [@kiela2021dynabench]. As a simple example, there are test images in the classic MNIST handwritten digit dataset which may look indecipherable to most human evaluators, but nonetheless were assigned a label when the dataset was created - models which happen to agree with those labels may appear to exhibit superhuman performance but instead may only be capturing idiosyncrasies of the labeling and acquisition process from the dataset's creation in 1994. In the same spirit, computer vision researchers now ask "Are we done with ImageNet?" [@beyer2020we]. This highlights limitations in the conventional model-centric approach of optimizing accuracy on fixed datasets through architectural innovations.
+However, growing concerns about issues like bias, safety, and robustness persist even in models that achieve high accuracy on standard benchmarks. Additionally, some popular datasets used for evaluating models are beginning to saturate, with models reaching near-perfect performance on existing test splits [@kiela2021dynabench]. As a simple example, there are test images in the classic MNIST handwritten digit dataset that may look indecipherable to most human evaluators but were assigned a label when the dataset was created - models that happen to agree with those labels may appear to exhibit superhuman performance but instead may only be capturing idiosyncrasies of the labeling and acquisition process from the dataset's creation in 1994. In the same spirit, computer vision researchers now ask, "Are we done with ImageNet?" [@beyer2020we]. This highlights limitations in the conventional model-centric approach of optimizing accuracy on fixed datasets through architectural innovations.
{#fig-superhuman-perf}
-An alternative paradigm is emerging called data-centric AI. Rather than treating data as static and focusing narrowly on model performance, this approach recognizes that models are only as good as their training data. So the emphasis shifts to curating high-quality datasets that better reflect real-world complexity, developing more informative evaluation benchmarks, and carefully considering how data is sampled, preprocessed, and augmented. The goal is to optimize model behavior by improving the data, rather than just optimizing metrics on flawed datasets. Data-centric AI critically examines and enhances the data itself to produce beneficial AI. This reflects an important evolution in mindset as the field addresses the shortcomings of narrow benchmarking.
+An alternative paradigm is emerging called data-centric AI. Rather than treating data as static and focusing narrowly on model performance, this approach recognizes that models are only as good as their training data. So, the emphasis shifts to curating high-quality datasets that better reflect real-world complexity, developing more informative evaluation benchmarks, and carefully considering how data is sampled, preprocessed, and augmented. The goal is to optimize model behavior by improving the data rather than just optimizing metrics on flawed datasets. Data-centric AI critically examines and enhances the data itself to produce beneficial AI. This reflects an important evolution in mindset as the field addresses the shortcomings of narrow benchmarking.
-In this section, we will explore the key differences between model-centric and data-centric approaches to AI. This distinction has important implications for how we benchmark AI systems. Specifically, we will see how a focus on data quality and efficiency can directly improve machine learning performance, as an alternative to solely optimizing model architectures. The data-centric approach recognizes that models are only as good as their training data. So enhancing data curation, evaluation benchmarks, and data handling processes can produce AI systems that are safer, fairer, and more robust. Rethinking benchmarking to prioritize data alongside models represents an important evolution as the field aims to deliver trustworthy real-world impact.
+This section will explore the key differences between model-centric and data-centric approaches to AI. This distinction has important implications for how we benchmark AI systems. Specifically, we will see how focusing on data quality and Efficiency can directly improve machine learning performance as an alternative to optimizing model architectures solely. The data-centric approach recognizes that models are only as good as their training data. So, enhancing data curation, evaluation benchmarks, and data handling processes can produce AI systems that are safer, fairer, and more robust. Rethinking benchmarking to prioritize data alongside models represents an important evolution as the field aims to deliver trustworthy real-world impact.
### Limitations of Model-Centric AI
-In the model-centric AI era, a prominent characteristic was the development of complex model architectures. Researchers and practitioners dedicated substantial effort to devise sophisticated and intricate models in the quest for superior performance. This frequently involved the incorporation of additional layers and the fine-tuning of a multitude of hyperparameters to achieve incremental improvements in accuracy. Concurrently, there was a significant emphasis on leveraging advanced algorithms. These algorithms, often at the forefront of the latest research, were employed to enhance the performance of AI models. The primary aim of these algorithms was to optimize the learning process of models, thereby extracting maximal information from the training data.
+In the model-centric AI era, a prominent characteristic was the development of complex model architectures. Researchers and practitioners dedicated substantial effort to devising sophisticated and intricate models in the quest for superior performance. This frequently involved the incorporation of additional layers and the fine-tuning of a multitude of hyperparameters to achieve incremental improvements in accuracy. Concurrently, there was a significant emphasis on leveraging advanced algorithms. These algorithms, often at the forefront of the latest research, were employed to enhance the performance of AI models. The primary aim of these algorithms was to optimize the learning process of models, thereby extracting maximal information from the training data.
-While the model-centric approach has been central to many advancements in AI, it has several shortcomings. First, the development of complex model architectures can often lead to overfitting. This is where the model performs well on the training data but fails to generalize to new, unseen data. The additional layers and complexity can capture noise in the training data as if it were a real pattern, which harms the model's performance on new data.
+While the model-centric approach has been central to many advancements in AI, it has several areas for improvement. First, the development of complex model architectures can often lead to overfitting. This is when the model performs well on the training data but needs to generalize to new, unseen data. The additional layers and complexity can capture noise in the training data as if it were a real pattern, harming the model's performance on new data.
-Second, the reliance on advanced algorithms can sometimes obscure the real understanding of a model's functioning. These algorithms often act as a black box, making it difficult to interpret how the model is making decisions. This lack of transparency can be a significant hurdle, especially in critical applications such as healthcare and finance, where understanding the model's decision-making process is crucial.
+Second, relying on advanced algorithms can sometimes obscure the real understanding of a model's functioning. These algorithms often act as a black box, making it difficult to interpret how the model is making decisions. This lack of transparency can be a significant hurdle, especially in critical applications such as healthcare and finance, where understanding the model's decision-making process is crucial.
-Third, the emphasis on achieving state-of-the-art results on benchmark datasets can sometimes be misleading. These datasets are often not fully representative of the complexities and variability found in real-world data. A model that performs well on a benchmark dataset may not necessarily generalize well to new, unseen data in a real-world application. This discrepancy can lead to a false sense of confidence in the model's capabilities and hinder its practical applicability.
+Third, the emphasis on achieving state-of-the-art results on benchmark datasets can sometimes be misleading. These datasets need to represent the complexities and variability of real-world data more fully. A model that performs well on a benchmark dataset may not necessarily generalize well to new, unseen data in a real-world application. This discrepancy can lead to false confidence in the model's capabilities and hinder its practical applicability.
-Lastly, the model-centric approach often relies on large labeled datasets for training. However, in many real-world scenarios, obtaining such datasets is difficult and costly. This reliance on large datasets also limits the applicability of AI in domains where data is scarce or expensive to label.
+Lastly, the model-centric approach often relies on large labeled datasets for training. However, obtaining such datasets takes time and effort in many real-world scenarios. This reliance on large datasets also limits AI's applicability in domains where data is scarce or expensive to label.
-As a result of the above reasons, and many more, the AI community is shifting to a more data-centric approach. Rather than focusing just on model architecture, researchers are now prioritizing curating high-quality datasets, developing better evaluation benchmarks, and considering how data is sampled and preprocessed. The key idea is that models are only as good as their training data. So focusing on getting the right data will allow us to develop AI systems that are more fair, safe, and aligned with human values. This data-centric shift represents an important change in mindset as AI progresses.
+As a result of the above reasons, and many more, the AI community is shifting to a more data-centric approach. Rather than focusing just on model architecture, researchers are now prioritizing curating high-quality datasets, developing better evaluation benchmarks, and considering how data is sampled and preprocessed. The key idea is that models are only as good as their training data. So, focusing on getting the right data will allow us to develop AI systems that are more fair, safe, and aligned with human values. This data-centric shift represents an important change in mindset as AI progresses.
### The Shift Toward Data-centric AI
-Data-centric AI is a paradigm that emphasizes the importance of high-quality, well-labeled, and diverse datasets in the development of AI models. In contrast to the model-centric approach, which focuses on refining and iterating on the model architecture and algorithm to improve performance, data-centric AI prioritizes the quality of the input data as the primary driver of improved model performance. High-quality data is [clean, well-labeled](https://landing.ai/blog/tips-for-a-data-centric-ai-approach/), and representative of the real-world scenarios the model will encounter. In contrast, low-quality data can lead to poor model performance, regardless of the complexity or sophistication of the model architecture.
+Data-centric AI is a paradigm that emphasizes the importance of high-quality, well-labeled, and diverse datasets in developing AI models. In contrast to the model-centric approach, which focuses on refining and iterating on the model architecture and algorithm to improve performance, data-centric AI prioritizes the quality of the input data as the primary driver of improved model performance. High-quality data is [clean, well-labeled](https://landing.ai/blog/tips-for-a-data-centric-ai-approach/) and representative of the real-world scenarios the model will encounter. In contrast, low-quality data can lead to poor model performance, regardless of the complexity or sophistication of the model architecture.
Data-centric AI puts a strong emphasis on the cleaning and labeling of data. Cleaning involves the removal of outliers, handling missing values, and addressing other data inconsistencies. Labeling, on the other hand, involves assigning meaningful and accurate labels to the data. Both these processes are crucial in ensuring that the AI model is trained on accurate and relevant data. Another important aspect of the data-centric approach is data augmentation. This involves artificially increasing the size and diversity of the dataset by applying various transformations to the data, such as rotation, scaling, and flipping training images. Data augmentation helps in improving the model's robustness and generalization capabilities.
-There are several benefits to adopting a data-centric approach to AI development. First and foremost, it leads to improved model performance and generalization capabilities. By ensuring that the model is trained on high-quality, diverse data, the model is better able to generalize to new, unseen data [@gaviria2022dollar].
+There are several benefits to adopting a data-centric approach to AI development. First and foremost, it leads to improved model performance and generalization capabilities. By ensuring that the model is trained on high-quality, diverse data, the model can better generalize to new, unseen data [@gaviria2022dollar].
-Additionally, a data-centric approach can often lead to simpler models that are easier to interpret and maintain. This is because the emphasis is on the data, rather than the model architecture, meaning that simpler models can achieve high performance when trained on high-quality data.
+Additionally, a data-centric approach can often lead to simpler models that are easier to interpret and maintain. This is because the emphasis is on the data rather than the model architecture, meaning simpler models can achieve high performance when trained on high-quality data.
The shift towards data-centric AI represents a significant paradigm shift. By prioritizing the quality of the input data, this approach aims to improve model performance and generalization capabilities, ultimately leading to more robust and reliable AI systems. As we continue to advance in our understanding and application of AI, the data-centric approach is likely to play an important role in shaping the future of this field.
@@ -748,72 +748,72 @@ The shift towards data-centric AI represents a significant paradigm shift. By pr
Data benchmarking aims to evaluate common issues in datasets, such as identifying label errors, noisy features, representation imbalance (for example, out of the 1000 classes in Imagenet-1K, there are over 100 categories which are just types of dogs), class imbalance (where some classes have many more samples than others), whether models trained on a given dataset can generalize to out-of-distribution features, or what types of biases might exist in a given dataset [@gaviria2022dollar]. In its simplest form, data benchmarking aims to improve accuracy on a test set by removing noisy or mislabeled training samples while keeping the model architecture fixed. Recent competitions in data benchmarking have invited participants to submit novel augmentation strategies and active learning techniques.
-Data-centric techniques continue to gain attention in benchmarking, especially as foundation models are increasingly trained on self-supervised objectives. Compared to smaller datasets like Imagenet-1K, massive datasets commonly used in self-supervised learning such as Common Crawl, OpenImages, and LAION-5B contain an order of magnitude higher amounts of noise, duplicates, bias, and potentially offensive data.
+Data-centric techniques continue to gain attention in benchmarking, especially as foundation models are increasingly trained on self-supervised objectives. Compared to smaller datasets like Imagenet-1K, massive datasets commonly used in self-supervised learning, such as Common Crawl, OpenImages, and LAION-5B, contain higher amounts of noise, duplicates, bias, and potentially offensive data.
-[DataComp](https://www.datacomp.ai/) is a recently-launched dataset competition which targets evaluation of large corpora. DataComp focuses on language-image pairs used to train CLIP models. The introductory whitepaper finds that, when the total compute budget for training is held constant, the best-performing CLIP models on downstream tasks such as ImageNet classification are trained on just 30% of the available training sample pool. This suggests that proper filtering of large corpora is critical to improving the accuracy of foundation models. Similarly, Demystifying CLIP Data [@xu2023demystifying] asks whether the success of CLIP is attributable to the architecture or the dataset.
+[DataComp](https://www.datacomp.ai/) is a recently launched dataset competition that targets the evaluation of large corpora. DataComp focuses on language-image pairs used to train CLIP models. The introductory whitepaper finds that when the total compute budget for training is constant, the best-performing CLIP models on downstream tasks, such as ImageNet classification, are trained on just 30% of the available training sample pool. This suggests that proper filtering of large corpora is critical to improving the accuracy of foundation models. Similarly, Demystifying CLIP Data [@xu2023demystifying] asks whether the success of CLIP is attributable to the architecture or the dataset.
-[DataPerf](https://www.dataperf.org/) is another recent effort which focuses on benchmarking data in a wide range of modalities. DataPerf provides rounds of online competition to spur improvement in datasets. The inaugural offering launched with challenges in vision, speech, acquisition, debugging, and text prompting for image generation.
+[DataPerf](https://www.dataperf.org/) is another recent effort focusing on benchmarking data in various modalities. DataPerf provides rounds of online competition to spur improvement in datasets. The inaugural offering launched with challenges in vision, speech, acquisition, debugging, and text prompting for image generation.
### Data Efficiency
-As machine learning models grow larger and more complex and compute resources more scarce in the face of rising demand, it becomes challenging to meet the requirements for computation even with the largest machine learning fleets. To overcome these challenges and ensure machine learning system scalability, it is necessary to explore novel opportunities that augment conventional approaches to resource scaling.
+As machine learning models grow larger and more complex and compute resources become more scarce in the face of rising demand, it becomes challenging to meet the computation requirements even with the largest machine learning fleets. To overcome these challenges and ensure machine learning system scalability, it is necessary to explore novel opportunities that augment conventional approaches to resource scaling.
-Improving data quality can be a useful method to significantly impact machine learning system performance. One of the primary benefits of enhancing data quality is the potential to reduce the size of the training dataset while still maintaining, or even improving, model performance. This reduction in data size has a direct relationship to the amount of training time required, thereby allowing models to converge more quickly and efficiently. But achieving this balance between data quality and dataset size is a challenging task that requires the development of sophisticated methods, algorithms, and techniques.
+Improving data quality can be a useful method to impact machine learning system performance significantly. One of the primary benefits of enhancing data quality is the potential to reduce the size of the training dataset while still maintaining or even improving model performance. This data size reduction directly relates to the amount of training time required, thereby allowing models to converge more quickly and efficiently. Achieving this balance between data quality and dataset size is a challenging task that requires the development of sophisticated methods, algorithms, and techniques.
-There are several approaches that can be taken to improve data quality. These methods include and are not limited to the following:
+Several approaches can be taken to improve data quality. These methods include and are not limited to the following:
* **Data Cleaning:** This involves handling missing values, correcting errors, and removing outliers. Clean data ensures that the model is not learning from noise or inaccuracies.
-* **Data Interpretability and Explainability:** Common techniques include LIME [@ribeiro2016should] which provides insight into the decision boundaries of classifiers, and Shapley values [@lundberg2017unified] which estimate the importance of individual samples in contributing to a model's predictions.
+* **Data Interpretability and Explainability:** Common techniques include LIME [@ribeiro2016should], which provides insight into the decision boundaries of classifiers, and Shapley values [@lundberg2017unified], which estimate the importance of individual samples in contributing to a model's predictions.
* **Feature Engineering:** Transforming or creating new features can significantly improve model performance by providing more relevant information for learning.
* **Data Augmentation:** Augmenting data by creating new samples through various transformations can help improve model robustness and generalization.
* **Active Learning:** This is a semi-supervised learning approach where the model actively queries a human oracle to label the most informative samples [@coleman2022similarity]. This ensures that the model is trained on the most relevant data.
-* Dimensionality Reduction: Techniques like PCA can be used to reduce the number of features in a dataset, thereby reducing complexity and training time.
+* Dimensionality Reduction: Techniques like PCA can reduce the number of features in a dataset, thereby reducing complexity and training time.
-There are many other methods in the wild. But the goal is the same. By refining the dataset and ensuring it is of the highest quality, we can directly reduce the training time required for models to converge. However, achieving this requires the development and implementation of sophisticated methods, algorithms, and techniques that can clean, preprocess, and augment data while retaining the most informative samples. This is an ongoing challenge that will require continued research and innovation in the field of machine learning.
+There are many other methods in the wild. But the goal is the same. Refining the dataset and ensuring it is of the highest quality can reduce the training time required for models to converge. However, achieving this requires developing and implementing sophisticated methods, algorithms, and techniques that can clean, preprocess, and augment data while retaining the most informative samples. This is an ongoing challenge that will require continued research and innovation in the field of machine learning.
## The Trifecta
-While system, model, and data benchmarks have traditionally been studied in isolation, there is a growing recognition that to fully understand and advance AI we must take a more holistic view. By iterating between benchmarking systems, models, and datasets together, novel insights may emerge that are not apparent when these components are analyzed separately. System performance impacts model accuracy, model capabilities drive data needs, and data characteristics shape system requirements.
+While system, model, and data benchmarks have traditionally been studied in isolation, there is a growing recognition that to understand and advance AI fully, we must take a more holistic view. By iterating between benchmarking systems, models, and datasets together, novel insights that are not apparent when these components are analyzed separately may emerge. System performance impacts model accuracy, model capabilities drive data needs, and data characteristics shape system requirements.
-Benchmarking the triad of system, model, and data in an integrated fashion will likely lead to new discoveries about the co-design of AI systems, the generalization properties of models, and the role of data curation and quality in enabling performance. Rather than narrow benchmarks of individual components, the future of AI requires benchmarks that evaluate the symbiotic relationship between computing platforms, algorithms, and training data. This systems-level perspective will be critical to overcoming current limitations and unlocking the next level of AI capabilities.
+Benchmarking the triad of system, model, and data in an integrated fashion will likely lead to discoveries about the co-design of AI systems, the generalization properties of models, and the role of data curation and quality in enabling performance. Rather than narrow benchmarks of individual components, the future of AI requires benchmarks that evaluate the symbiotic relationship between computing platforms, algorithms, and training data. This systems-level perspective will be critical to overcoming current limitations and unlocking the next level of AI capabilities.
-@fig-benchmarking-trifecta illustrates the many potential ways to interplay data benchmarking, model benchmarking, and system infrastructure benchmarking together. Through exploring these intricate interactions, we are likely to uncover new optimization opportunities and capabilities for enhancement. The triad of data, model, and system benchmarks offers a rich space for co-design and co-optimization.
+@fig-benchmarking-trifecta illustrates the many potential ways to interplay data benchmarking, model benchmarking, and system infrastructure benchmarking together. Exploring these intricate interactions is likely to uncover new optimization opportunities and enhancement capabilities. The data, model, and system benchmark triad offers a rich space for co-design and co-optimization.
{#fig-benchmarking-trifecta}
-While this integrated perspective represents an emerging trend, the field has much more to discover about the synergies and trade-offs between these different components. As we iteratively benchmark combinations of data, models, and systems, entirely new insights will emerge that remain hidden when these elements are studied in isolation. This multi-faceted benchmarking approach charting the intersections of data, algorithms, and hardware promises to be a fruitful avenue for major progress in AI, even though it is still in its early stages.
+While this integrated perspective represents an emerging trend, the field has much more to discover about the synergies and trade-offs between these components. As we iteratively benchmark combinations of data, models, and systems, new insights that remain hidden when these elements are studied in isolation will emerge. This multifaceted benchmarking approach charting the intersections of data, algorithms, and hardware promises to be a fruitful avenue for major progress in AI, even though it is still in its early stages.
## Benchmarks for Emerging Technologies
-Emerging technologies can be particularly challenging to design benchmarks for given their significant differences from existing techniques. Standard benchmarks used for existing technologies may not highlight the key features of the new approach, while completely new benchmarks may be seen as contrived to favor the emerging technology over others, or yet may be so different from existing benchmarks that they cannot be understood and lose insightful value. Thus, benchmarks for emerging technologies must balance around fairness, applicability, and ease of comparison with existing benchmarks.
+Given their significant differences from existing techniques, emerging technologies can be particularly challenging to design benchmarks for. Standard benchmarks used for existing technologies may not highlight the key features of the new approach. In contrast, new benchmarks may be seen as contrived to favor the emerging technology over others. They may be so different from existing benchmarks that they cannot be understood and lose insightful value. Thus, benchmarks for emerging technologies must balance fairness, applicability, and ease of comparison with existing benchmarks.
-An example emerging technology where benchmarking has proven to be especially difficult is in [Neuromorphic Computing](@sec-neuromorphic). Using the brain as a source of inspiration for scalable, robust, and energy-efficient general intelligence, neuromorphic computing [@schuman2022opportunities] directly incorporates biologically realistic mechanisms in both computing algorithms and hardware, such as spiking neural networks [@maass1997networks] and non-von Neumann architectures for executing them [@davies2018loihi; @modha2023neural]. From a full-stack perspective of models, training techniques, and hardware systems, neuromorphic computing differs from conventional hardware and AI, thus there is a key challenge towards developing benchmarks which are fair and useful for guiding the technology.
+An example of emerging technology where benchmarking has proven to be especially difficult is in [Neuromorphic Computing](@sec-neuromorphic). Using the brain as a source of inspiration for scalable, robust, and energy-efficient general intelligence, neuromorphic computing [@schuman2022opportunities] directly incorporates biologically realistic mechanisms in both computing algorithms and hardware, such as spiking neural networks [@maass1997networks] and non-von Neumann architectures for executing them [@davies2018loihi; @modha2023neural]. From a full-stack perspective of models, training techniques, and hardware systems, neuromorphic computing differs from conventional hardware and AI. Thus, there is a key challenge in developing fair and useful benchmarks for guiding the technology.
-An ongoing initiative towards developing standard neuromorphic benchmarks is NeuroBench [@yik2023neurobench]. In order to suitably benchmark neuromorphics, NeuroBench follows high-level principles of _inclusiveness_ through task and metric applicability to both neuromorphic and non-neuromorphic solutions, _actionability_ of implementation using common tooling, and _iterative_ updates to continue to ensure relevance as the field rapidly grows. NeuroBench and other benchmarks for emerging technologies provide critical guidance for future techniques which may be necessary as the scaling limits of existing approaches draw nearer.
+An ongoing initiative to develop standard neuromorphic benchmarks is NeuroBench [@yik2023neurobench]. To suitably benchmark neuromorphic, NeuroBench follows high-level principles of _inclusiveness_ through task and metric applicability to both neuromorphic and non-neuromorphic solutions, _actionability_ of implementation using common tooling, and _iterative_ updates to continue to ensure relevance as the field rapidly grows. NeuroBench and other benchmarks for emerging technologies provide critical guidance for future techniques, which may be necessary as the scaling limits of existing approaches draw nearer.
## Conclusion
What gets measured gets improved. This chapter has explored the multifaceted nature of benchmarking spanning systems, models, and data. Benchmarking is important to advancing AI by providing the essential measurements to track progress.
-ML system benchmarks enable optimization across metrics like speed, efficiency, and scalability. Model benchmarks drive innovation through standardized tasks and metrics beyond just accuracy. And data benchmarks highlight issues of quality, balance and representation.
+ML system benchmarks enable optimization across speed, Efficiency, and scalability metrics. Model benchmarks drive innovation through standardized tasks and metrics beyond accuracy. Data benchmarks highlight issues of quality, balance, and representation.
-Importantly, evaluating these components in isolation has limitations. The future will likely see more integrated benchmarking that explores the interplay between system benchmarks, model benchmarks and data benchmarks. This view promises new insights into the co-design of data, algorithms and infrastructure.
+Importantly, evaluating these components in isolation has limitations. In the future, more integrated benchmarking will likely be used to explore the interplay between system, model, and data benchmarks. This view promises new insights into co-designing data, algorithms, and infrastructure.
-As AI grows more complex, comprehensive benchmarking becomes even more critical. Standards must continuously evolve to measure new capabilities and reveal limitations. Close collaboration between industry, academics and national labls etc. is essential to develop benchmarks that are rigorous, transparent and socially beneficial.
+As AI grows more complex, comprehensive benchmarking becomes even more critical. Standards must continuously evolve to measure new capabilities and reveal limitations. Close collaboration between industry, academics, national labels, etc., is essential to developing benchmarks that are rigorous, transparent, and socially beneficial.
-Benchmarking provides the compass to guide progress in AI. By persistently measuring and openly sharing results, we can navigate towards systems that are performant, robust and trustworthy. If AI is to properly serve societal and human needs, it must be benchmarked with humanity's best interests in mind. To this end, there are emerging areas such as benchmarking the safety of AI systems but that's for another day and perhaps something we can discuss further in Generative AI!
+Benchmarking provides the compass to guide progress in AI. By persistently measuring and openly sharing results, we can navigate toward performant, robust, and trustworthy systems. If AI is to serve societal and human needs properly, it must be benchmarked with humanity's best interests in mind. To this end, there are emerging areas, such as benchmarking the safety of AI systems, but that's for another day and something we can discuss further in Generative AI!
Benchmarking is a continuously evolving topic. The article [The Olympics of AI: Benchmarking Machine Learning Systems](https://towardsdatascience.com/the-olympics-of-ai-benchmarking-machine-learning-systems-c4b2051fbd2b) covers several emerging subfields in AI benchmarking, including robotics, extended reality, and neuromorphic computing that we encourage the reader to pursue.
## Resources {#sec-benchmarking-ai-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Why is benchmarking important?](https://docs.google.com/presentation/d/17udz3gxeYF3r3X1r4ePwu1I9H8ljb53W3ktFSmuDlGs/edit?usp=drive_link&resourcekey=0-Espn0a0x81kl2txL_jIWjw)
@@ -834,7 +834,7 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/case_studies.qmd b/contents/case_studies.qmd
index 9a3ad48f..1cecb6e1 100644
--- a/contents/case_studies.qmd
+++ b/contents/case_studies.qmd
@@ -4,6 +4,6 @@
## Learning Objectives
-* Coming soon.
+*Coming soon.*
:::
diff --git a/contents/contributors.qmd b/contents/contributors.qmd
index 08d97fcc..425182d9 100644
--- a/contents/contributors.qmd
+++ b/contents/contributors.qmd
@@ -76,71 +76,77 @@ We extend our sincere thanks to the diverse group of individuals who have genero
Shanzeh Batool
|
+
Matthew Stewart
|
Jared Ping
|
-
ishapira
|
eliasab16
|
-
Maximilian Lam
|
-
Matthew Stewart
|
+
ishapira
|
+
Maximilian Lam
|
Marcelo Rovai
|
Jayson Lin
|
-
Jeffrey Ma
|
Sophia Cho
|
+
Jeffrey Ma
|
Korneel Van den Berghe
|
+
Zishen
|
Alex Rodriguez
|
-
Andrea Murillo
|
Srivatsan Krishnan
|
-
arnaumarin
|
-
Aghyad Deeb
|
+
Andrea Murillo
|
+
Abdulrahman Mahmoud
|
-
Aghyad Deeb
|
-
Zishen
|
+
arnaumarin
|
+
Aghyad Deeb
|
+
Aghyad Deeb
|
Divya
|
-
Jared Ni
|
-
ELSuitorHarvard
|
+
Michael Schnebly
|
Emil Njor
|
+
Jared Ni
|
oishib
|
-
Michael Schnebly
|
+
ELSuitorHarvard
|
Henry Bae
|
-
Jae-Won Chung
|
+
YU SHUN, HSIAO
|
Mark Mazumder
|
-
Jennifer Zhou
|
-
Marco Zennaro
|
-
Pong Trairatvorakul
|
+
Jae-Won Chung
|
+
Colby Banbury
|
eurashin
|
-
Shvetank Prakash
|
-
Colby Banbury
|
Aditi Raju
|
+
Shvetank Prakash
|
Andrew Bass
|
-
Alex Oesterling
|
+
Marco Zennaro
|
+
Jennifer Zhou
|
+
Pong Trairatvorakul
|
+
Bruno Scaglione
|
+
Alex Oesterling
|
Gauri Jain
|
Eric D
|
+
+
+
abigailswallow
|
Jessica Quaye
|
Jason Yik
|
happyappledog
|
+
Annie Laurie Cook
|
-
Annie Laurie Cook
|
Curren Iyer
|
Shreya Johri
|
Sonia Murthy
|
-
abigailswallow
|
+
Yu-Shun Hsiao
|
+
Costin-Andrei Oncescu
|
-
Costin-Andrei Oncescu
|
-
Batur Arslan
|
+
Batur Arslan
|
Vijay Edupuganti
|
The Random DIY
|
Emeka Ezike
|
diff --git a/contents/conventions.qmd b/contents/conventions.qmd
index 55d14716..8628a841 100644
--- a/contents/conventions.qmd
+++ b/contents/conventions.qmd
@@ -2,66 +2,66 @@
Please follow these conventions as you contribute to this online book:
-1. **Clear Structure and Organization**:
+1. **Clear Structure and Organization:**
- - **Chapter Outlines**: Begin each chapter with an outline that provides an
+ - **Chapter Outlines:** Begin each chapter with an outline that provides an
overview of the topics covered.
- - **Sequential Numbering**: Utilize sequential numbering for chapters,
+ - **Sequential Numbering:** Utilize sequential numbering for chapters,
sections, and subsections to facilitate easy reference.
-2. **Accessible Language**:
+2. **Accessible Language:**
- - **Glossary**: Include a glossary that defines technical terms and jargon.
- - **Consistent Terminology**: Maintain consistent use of terminology
+ - **Glossary:** Include a glossary that defines technical terms and jargon.
+ - **Consistent Terminology:** Maintain consistent use of terminology
throughout the book to avoid confusion.
-3. **Learning Aids**:
+3. **Learning Aids:**
- - **Diagrams and Figures**: Employ diagrams, figures, and tables to visually
+ - **Diagrams and Figures:** Employ diagrams, figures, and tables to visually
convey complex concepts.
- - **Sidebars**: Use sidebars for additional information, anecdotes, or to
+ - **Sidebars:** Use sidebars for additional information, anecdotes, or to
provide real-world context to the theoretical content.
-4. **Interactive Elements**:
+4. **Interactive Elements:**
- - **Exercises and Projects**: Integrate exercises and projects at the end of
+ - **Exercises and Projects:** Integrate exercises and projects at the end of
each chapter to encourage active learning and practical application of
concepts.
- - **Case Studies**: Incorporate case studies to provide a deeper
+ - **Case Studies:** Incorporate case studies to provide a deeper
understanding of how principles are applied in real-world situations.
-5. **References and Further Reading**:
+5. **References and Further Reading:**
- - **Bibliography**: Include a bibliography at the end of each chapter for
+ - **Bibliography:** Include a bibliography at the end of each chapter for
readers who wish to delve deeper into specific topics.
- - **Citations**: Maintain a consistent style for citations, adhering to
+ - **Citations:** Maintain a consistent style for citations, adhering to
recognized academic standards like APA, MLA, or Chicago.
-6. **Supporting Materials**:
+6. **Supporting Materials:**
- - **Supplementary Online Resources**: Provide links to supplementary online
+ - **Supplementary Online Resources:** Provide links to supplementary online
resources, such as video lectures, webinars, or interactive modules.
- - **Datasets and Code Repositories**: Share datasets and code repositories
+ - **Datasets and Code Repositories:** Share datasets and code repositories
for hands-on practice, particularly for sections dealing with algorithms
and applications.
-7. **Feedback and Community Engagement**:
+7. **Feedback and Community Engagement:**
- - **Forums and Discussion Groups**: Establish forums or discussion groups
+ - **Forums and Discussion Groups:** Establish forums or discussion groups
where readers can interact, ask questions, and share knowledge.
- - **Open Review Process**: Implement an open review process, inviting
+ - **Open Review Process:** Implement an open review process, inviting
feedback from the community to continuously improve the content.
-8. **Inclusivity and Accessibility**:
+8. **Inclusivity and Accessibility:**
- - **Inclusive Language**: Utilize inclusive language that respects diversity
+ - **Inclusive Language:** Utilize inclusive language that respects diversity
and promotes equality.
- - **Accessible Formats**: Ensure the textbook is available in accessible
+ - **Accessible Formats:** Ensure the textbook is available in accessible
formats, including audio and Braille, to cater to readers with
disabilities.
-9. **Index**:
- - **Comprehensive Index**: Include a comprehensive index at the end of the
+9. **Index:**
+ - **Comprehensive Index:** Include a comprehensive index at the end of the
book to help readers quickly locate specific information.
Implementing these conventions can contribute to creating a textbook that is
diff --git a/contents/copyright.qmd b/contents/copyright.qmd
index 52a34b0e..3f619368 100644
--- a/contents/copyright.qmd
+++ b/contents/copyright.qmd
@@ -1,6 +1,6 @@
# Copyright {.unnumbered}
-This book is open-source and developed collaboratively through GitHub. Unless otherwise stated, this work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0). You can find the full text of the license [here](https://creativecommons.org/licenses/by-sa/4.0/).
+This book is open-source and developed collaboratively through GitHub. Unless otherwise stated, this work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 CC BY-SA 4.0). You can find the full text of the license [here](https://creativecommons.org/licenses/by-nc-sa/4.0).
Contributors to this project have dedicated their contributions to the public domain or under the same open license as the original project. While the contributions are collaborative, each contributor retains copyright in their respective contributions.
diff --git a/contents/data_engineering/data_engineering.bib b/contents/data_engineering/data_engineering.bib
index 9565b12a..a4d6ab8f 100644
--- a/contents/data_engineering/data_engineering.bib
+++ b/contents/data_engineering/data_engineering.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@article{aledhari2020federated,
author = {Aledhari, Mohammed and Razzak, Rehma and Parizi, Reza M. and Saeed, Fahad},
bdsk-url-1 = {https://doi.org/10.1109/access.2020.3013541},
@@ -10,33 +13,36 @@ @article{aledhari2020federated
title = {Federated Learning: {A} Survey on Enabling Technologies, Protocols, and Applications},
url = {https://doi.org/10.1109/access.2020.3013541},
volume = {8},
- year = {2020}
+ year = {2020},
}
@inproceedings{ardila2020common,
+ author = {Ardila, Rosana and Branson, Megan and Davis, Kelly and Kohler, Michael and Meyer, Josh and Henretty, Michael and Morais, Reuben and Saunders, Lindsay and Tyers, Francis and Weber, Gregor},
address = {Marseille, France},
- author = {Ardila, Rosana and Branson, Megan and Davis, Kelly and Kohler, Michael and Meyer, Josh and Henretty, Michael and Morais, Reuben and Saunders, Lindsay and Tyers, Francis and Weber, Gregor},
booktitle = {Proceedings of the Twelfth Language Resources and Evaluation Conference},
isbn = {979-10-95546-34-4},
language = {English},
pages = {4218--4222},
publisher = {European Language Resources Association},
- title = {Common Voice: A Massively-Multilingual Speech Corpus},
+ title = {Common Voice: {A} Massively-Multilingual Speech Corpus},
url = {https://aclanthology.org/2020.lrec-1.520},
- year = {2020}
+ year = {2020},
}
@article{bender2018data,
+ author = {Bender, Emily M. and Friedman, Batya},
address = {Cambridge, MA},
- author = {Bender, Emily M. and Friedman, Batya},
- doi = {10.1162/tacl\_a\_00041},
+ doi = {10.1162/tacl_a_00041},
journal = {Transactions of the Association for Computational Linguistics},
pages = {587--604},
- publisher = {MIT Press},
- title = {Data Statements for Natural Language Processing: Toward Mitigating System Bias and Enabling Better Science},
- url = {https://aclanthology.org/Q18-1041},
+ publisher = {MIT Press - Journals},
+ title = {Data Statements for Natural Language Processing: {Toward} Mitigating System Bias and Enabling Better Science},
+ url = {https://doi.org/10.1162/tacl_a_00041},
volume = {6},
- year = {2018}
+ year = {2018},
+ source = {Crossref},
+ issn = {2307-387X},
+ month = dec,
}
@article{chapelle2009semisupervised,
@@ -52,7 +58,8 @@ @article{chapelle2009semisupervised
title = {Semi-Supervised Learning {(Chapelle,} {O.} et al., Eds.; 2006) {[Book} reviews]},
url = {https://doi.org/10.1109/tnn.2009.2015974},
volume = {20},
- year = {2009}
+ year = {2009},
+ month = mar,
}
@article{gebru2021datasheets,
@@ -68,14 +75,15 @@ @article{gebru2021datasheets
title = {Datasheets for datasets},
url = {https://doi.org/10.1145/3458723},
volume = {64},
- year = {2021}
+ year = {2021},
+ month = nov,
}
@misc{googleinformation,
author = {Google},
bdsk-url-1 = {https://blog.google/documents/83/},
title = {Information quality content moderation},
- url = {https://blog.google/documents/83/}
+ url = {https://blog.google/documents/83/},
}
@incollection{holland2020dataset,
@@ -90,7 +98,7 @@ @incollection{holland2020dataset
subtitle = {A Framework to Drive Higher Data Quality Standards},
title = {The Dataset Nutrition Label},
url = {https://doi.org/10.5040/9781509932771.ch-001},
- year = {2020}
+ year = {2020},
}
@inproceedings{johnsonroberson2017driving,
@@ -103,7 +111,8 @@ @inproceedings{johnsonroberson2017driving
source = {Crossref},
title = {Driving in the Matrix: {Can} virtual worlds replace human-generated annotations for real world tasks?},
url = {https://doi.org/10.1109/icra.2017.7989092},
- year = {2017}
+ year = {2017},
+ month = may,
}
@article{krishnan2022selfsupervised,
@@ -119,7 +128,8 @@ @article{krishnan2022selfsupervised
title = {Self-supervised learning in medicine and healthcare},
url = {https://doi.org/10.1038/s41551-022-00914-1},
volume = {6},
- year = {2022}
+ year = {2022},
+ month = aug,
}
@article{northcutt2021pervasive,
@@ -128,7 +138,7 @@ @article{northcutt2021pervasive
doi = {https://doi.org/10.48550/arXiv.2103.14749 arXiv-issued DOI via DataCite},
journal = {arXiv},
title = {Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks},
- year = {2021}
+ year = {2021},
}
@inproceedings{pushkarna2022data,
@@ -141,7 +151,8 @@ @inproceedings{pushkarna2022data
source = {Crossref},
title = {Data Cards: {Purposeful} and Transparent Dataset Documentation for Responsible {AI}},
url = {https://doi.org/10.1145/3531146.3533231},
- year = {2022}
+ year = {2022},
+ month = jun,
}
@inproceedings{ratner2018snorkel,
@@ -154,19 +165,26 @@ @inproceedings{ratner2018snorkel
subtitle = {Weak Supervision for Multi-Task Learning},
title = {Snorkel {MeTaL}},
url = {https://doi.org/10.1145/3209889.3209898},
- year = {2018}
+ year = {2018},
+ month = jun,
}
-@inproceedings{victor2019machine,
- author = {Victor S. Sheng and Jing Zhang},
+@article{victor2019machine,
+ author = {Sheng, Victor S. and Zhang, Jing},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/aaai/Sheng019.bib},
- booktitle = {The Thirty-Third {AAAI} Conference on Artificial Intelligence, {AAAI} 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, {IAAI} 2019, The Ninth {AAAI} Symposium on Educational Advances in Artificial Intelligence, {EAAI} 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019},
+ booktitle = {The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019},
doi = {10.1609/aaai.v33i01.33019837},
pages = {9837--9843},
- publisher = {{AAAI} Press},
+ publisher = {Association for the Advancement of Artificial Intelligence (AAAI)},
timestamp = {Wed, 25 Sep 2019 01:00:00 +0200},
title = {Machine Learning with Crowdsourcing: {A} Brief Summary of the Past Research and Future Directions},
url = {https://doi.org/10.1609/aaai.v33i01.33019837},
- year = {2019}
+ year = {2019},
+ number = {01},
+ source = {Crossref},
+ volume = {33},
+ journal = {Proceedings of the AAAI Conference on Artificial Intelligence},
+ issn = {2374-3468, 2159-5399},
+ month = jul,
}
diff --git a/contents/data_engineering/data_engineering.qmd b/contents/data_engineering/data_engineering.qmd
index 98dfeee9..bb6334bb 100644
--- a/contents/data_engineering/data_engineering.qmd
+++ b/contents/data_engineering/data_engineering.qmd
@@ -10,22 +10,22 @@ Resources: [Slides](#sec-data-engineering-resource), [Labs](#sec-data-engineerin

-Data is the lifeblood of AI systems. Without good data, even the most advanced machine learning algorithms will fail. In this section, we will dive into the intricacies of building high-quality datasets to fuel our AI models. Data engineering encompasses the processes of collecting, storing, processing, and managing data for training machine learning models.
+Data is the lifeblood of AI systems. Without good data, even the most advanced machine-learning algorithms will not succeed. This section will dive into the intricacies of building high-quality datasets to fuel our AI models. Data engineering involves collecting, storing, processing, and managing data to train machine learning models.
::: {.callout-tip}
## Learning Objectives
-* Understand the importance of clearly defining the problem statement and objectives when embarking on a ML project.
+* Understand the importance of clearly defining the problem statement and objectives when embarking on an ML project.
-* Recognize various data sourcing techniques like web scraping, crowdsourcing, and synthetic data generation, along with their advantages and limitations.
+* Recognize various data sourcing techniques, such as web scraping, crowdsourcing, and synthetic data generation, along with their advantages and limitations.
* Appreciate the need for thoughtful data labeling, using manual or AI-assisted approaches, to create high-quality training datasets.
-* Briefly learn different methods for storing and managing data such as databases, data warehouses, and data lakes.
+* Briefly learn different methods for storing and managing data, such as databases, data warehouses, and data lakes.
-* Comprehend the role of transparency through metadata and dataset documentation, as well as tracking data provenance to facilitate ethics, auditing, and reproducibility.
+* Comprehend the role of transparency through metadata and dataset documentation and tracking data provenance to facilitate ethics, auditing, and reproducibility.
* Understand how licensing protocols govern legal data access and usage, necessitating careful compliance.
@@ -36,33 +36,33 @@ Data is the lifeblood of AI systems. Without good data, even the most advanced m
## Introduction
-Dataset creators face complex privacy and representation challenges when building high-quality training data, especially for sensitive domains like healthcare. Legally, creators may need to remove direct identifiers like names and ages. Even without legal obligations, removing such information can help build user trust. However, excessive anonymization can compromise dataset utility. Techniques like differential privacy$^{1}$, aggregation, and reducing detail provide alternatives to balance privacy and utility, but have downsides. Creators must strike a thoughtful balance based on use case.
+Dataset creators face complex privacy and representation challenges when building high-quality training data, especially for sensitive domains like healthcare. Legally, creators may need to remove direct identifiers like names and ages. Even without legal obligations, removing such information can help build user trust. However, excessive anonymization can compromise dataset utility. Techniques like differential privacy$^{1}$, aggregation, and reducing detail provide alternatives to balance privacy and utility but have downsides. Creators must strike a thoughtful balance based on the use case.
-Looking beyond privacy, creators need to proactively assess and address representation gaps that could introduce model biases. It is crucial yet insufficient to ensure diversity across individual variables like gender, race, and accent. Combinations of characteristics also require assessment, as models can struggle when certain intersections are absent. For example, a medical dataset could have balanced gender, age, and diagnosis data individually, but lack enough cases capturing elderly women with a specific condition. Such [higher-order gaps](https://blog.google/technology/health/healthcare-ai-systems-put-people-center/) are not immediately obvious but can critically impact model performance.
+Looking beyond privacy, creators need to proactively assess and address representation gaps that could introduce model biases. It is crucial yet insufficient to ensure diversity across individual variables like gender, race, and accent. Combinations of characteristics also require assessment, as models can only work when certain intersections are present. For example, a medical dataset could have balanced gender, age, and diagnosis data individually, but it lacks enough cases to capture older women with a specific condition. Such [higher-order gaps](https://blog.google/technology/health/healthcare-ai-systems-put-people-center/) are not immediately obvious but can critically impact model performance.
-Creating useful, ethical training data requires holistic consideration of privacy risks and representation gaps. Perfect solutions are elusive. However, conscientious data engineering practices like anonymization, aggregation, undersampling overrepresented groups, and synthesized data generation can help balance competing needs. This facilitates models that are both accurate and socially responsible. Cross-functional collaboration and external audits can also strengthen training data. The challenges are multifaceted, but surmountable with thoughtful effort.
+Creating useful, ethical training data requires holistic consideration of privacy risks and representation gaps. Perfect solutions are elusive. However, conscientious data engineering practices like anonymization, aggregation, undersampling of overrepresented groups, and synthesized data generation can help balance competing needs. This facilitates models that are both accurate and socially responsible. Cross-functional collaboration and external audits can also strengthen training data. The challenges are multifaceted but surmountable with thoughtful effort.
-We begin by discussing data collection: Where do we source data, and how do we gather it? Options range from scraping the web, accessing APIs, utilizing sensors and IoT devices, to conducting surveys and gathering user input. These methods reflect real-world practices. Next, we delve into data labeling, including considerations for human involvement. We'll discuss the trade-offs and limitations of human labeling and explore emerging methods for automated labeling. Following that, we'll address data cleaning and preprocessing, a crucial yet frequently undervalued step in preparing raw data for AI model training. Data augmentation comes next, a strategy for enhancing limited datasets by generating synthetic samples. This is particularly pertinent for embedded systems, as many use cases don't have extensive data repositories readily available for curation. Synthetic data generation emerges as a viable alternative, though it comes with its own set of advantages and disadvantages. We'll also touch upon dataset versioning, emphasizing the importance of tracking data modifications over time. Data is ever-evolving; hence, it's imperative to devise strategies for managing and storing expansive datasets. By the end of this section, you'll possess a comprehensive understanding of the entire data pipeline, from collection to storage, essential for operationalizing AI systems. Let's embark on this journey!
+We begin by discussing data collection: Where do we source data, and how do we gather it? Options range from scraping the web, accessing APIs, and utilizing sensors and IoT devices to conducting surveys and gathering user input. These methods reflect real-world practices. Next, we delve into data labeling, including considerations for human involvement. We'll discuss the tradeoffs and limitations of human labeling and explore emerging methods for automated labeling. Following that, we'll address data cleaning and preprocessing, a crucial yet frequently undervalued step in preparing raw data for AI model training. Data augmentation comes next, a strategy for enhancing limited datasets by generating synthetic samples. This is particularly pertinent for embedded systems, as many use cases need extensive data repositories readily available for curation. Synthetic data generation emerges as a viable alternative, though it has its own advantages and disadvantages. We'll also touch upon dataset versioning, emphasizing the importance of tracking data modifications over time. Data is ever-evolving; hence, it's imperative to devise strategies for managing and storing expansive datasets. By the end of this section, you'll possess a comprehensive understanding of the entire data pipeline, from collection to storage, essential for operationalizing AI systems. Let's embark on this journey!
## Problem Definition
-In many domains of machine learning, while sophisticated algorithms take center stage, the fundamental importance of data quality is often overlooked. This neglect gives rise to ["Data Cascades"](https://research.google/pubs/pub49953/) (see @fig-cascades) - events where lapses in data quality compound, leading to negative downstream consequences such as flawed predictions, project terminations, and even potential harm to communities.
+In many machine learning domains, sophisticated algorithms take center stage, while the fundamental importance of data quality is often overlooked. This neglect gives rise to ["Data Cascades"](https://research.google/pubs/pub49953/) (see @fig-cascades)—events where lapses in data quality compound, leading to negative downstream consequences such as flawed predictions, project terminations, and even potential harm to communities.
{#fig-cascades}
-Despite many ML professionals recognizing the importance of data, numerous practitioners report facing these cascades. This highlights a systemic issue: while the allure of developing advanced models remains, data is often underappreciated.
+Despite many ML professionals recognizing the importance of data, numerous practitioners report facing these cascades. This highlights a systemic issue: while the allure of developing advanced models remains, data often needs to be more appreciated.
-Take, for example, Keyword Spotting (KWS) (see @fig-keywords). KWS serves as a prime example of TinyML in action and is a critical technology behind voice-enabled interfaces on endpoint devices such as smartphones. Typically functioning as lightweight wake-word engines, these systems are consistently active, listening for a specific phrase to trigger further actions. When we say the phrases "Ok Google" or "Alexa," this initiates a process on a microcontroller embedded within the device. Despite their limited resources, these microcontrollers play an important role in enabling seamless voice interactions with devices, often operating in environments with high levels of ambient noise. The uniqueness of the wake-word helps minimize false positives, ensuring that the system is not triggered inadvertently.
+Take, for example, Keyword Spotting (KWS) (see @fig-keywords). KWS is a prime example of TinyML in action and is a critical technology behind voice-enabled interfaces on endpoint devices such as smartphones. Typically functioning as lightweight wake-word engines, these systems are consistently active, listening for a specific phrase to trigger further actions. When we say "OK, Google" or "Alexa," this initiates a process on a microcontroller embedded within the device. Despite their limited resources, these microcontrollers play an important role in enabling seamless voice interactions with devices, often operating in environments with high ambient noise. The uniqueness of the wake word helps minimize false positives, ensuring that the system is not triggered inadvertently.
-It is important to appreciate that these keyword spotting technologies are not isolated; they integrate seamlessly into larger systems, processing signals continuously while managing low power consumption. These systems extend beyond simple keyword recognition, evolving to facilitate diverse sound detections, such as the breaking of glass. This evolution is geared towards creating intelligent devices capable of understanding and responding to a myriad of vocal commands, heralding a future where even household appliances can be controlled through voice interactions.
+It is important to appreciate that these keyword-spotting technologies are not isolated; they integrate seamlessly into larger systems, processing signals continuously while managing low power consumption. These systems extend beyond simple keyword recognition, evolving to facilitate diverse sound detections, such as glass breaking. This evolution is geared towards creating intelligent devices capable of understanding and responding to vocal commands, heralding a future where even household appliances can be controlled through voice interactions.
{#fig-keywords}
-Building a reliable KWS model is not a straightforward task. It demands a deep understanding of the deployment scenario, encompassing where and how these devices will operate. For instance, a KWS model's effectiveness is not just about recognizing a word; it's about discerning it among various accents and background noises, whether in a bustling cafe or amid the blaring sound of a television in a living room or a kitchen where these devices are commonly found. It's about ensuring that a whispered "Alexa" in the dead of night or a shouted "Ok Google" in a noisy marketplace are both recognized with equal precision.
+Building a reliable KWS model is a complex task. It demands a deep understanding of the deployment scenario, encompassing where and how these devices will operate. For instance, a KWS model's effectiveness is not just about recognizing a word; it's about discerning it among various accents and background noises, whether in a bustling cafe or amid the blaring sound of a television in a living room or a kitchen where these devices are commonly found. It's about ensuring that a whispered "Alexa" in the dead of night or a shouted "OK Google" in a noisy marketplace are recognized with equal precision.
-Moreover, many of the current KWS voice assistants support a limited number of languages, leaving a substantial portion of the world's linguistic diversity unrepresented. This limitation is partly due to the difficulty in gathering and monetizing data for languages spoken by smaller populations. The long-tail distribution of languages implies that many languages have limited data available, making the development of supportive technologies challenging.
+Moreover, many current KWS voice assistants support a limited number of languages, leaving a substantial portion of the world's linguistic diversity unrepresented. This limitation is partly due to the difficulty in gathering and monetizing data for languages spoken by smaller populations. The long-tail distribution of languages implies that many languages have limited data, making the development of supportive technologies challenging.
-This level of accuracy and robustness hinges on the availability of data, quality of data, ability to label the data correctly, and ensuring transparency of the data for the end user-all before the data is used to train the model. But it all begins with a clear understanding of the problem statement or definition.
+This level of accuracy and robustness hinges on the availability and quality of data, the ability to label the data correctly, and the transparency of the data for the end user before it is used to train the model. However, it all begins with clearly understanding the problem statement or definition.
Generally, in ML, problem definition has a few key steps:
@@ -78,12 +78,13 @@ Generally, in ML, problem definition has a few key steps:
6. Followed by finally doing the data collection.
-Laying a solid foundation for a project is essential for its trajectory and eventual success. Central to this foundation is first identifying a clear problem, such as ensuring that voice commands in voice assistance systems are recognized consistently across varying environments. Clear objectives, like creating representative datasets for diverse scenarios, provide a unified direction. Benchmarks, such as system accuracy in keyword detection, offer measurable outcomes to gauge progress. Engaging with stakeholders, from end-users to investors, provides invaluable insights and ensures alignment with market needs. Additionally, when delving into areas like voice assistance, understanding platform constraints is pivotal. Embedded systems, such as microcontrollers, come with inherent limitations in processing power, memory, and energy efficiency. Recognizing these limitations ensures that functionalities, like keyword detection, are tailored to operate optimally, balancing performance with resource conservation.
+A solid project foundation is essential for its trajectory and eventual success. Central to this foundation is first identifying a clear problem, such as ensuring that voice commands in voice assistance systems are recognized consistently across varying environments. Clear objectives, like creating representative datasets for diverse scenarios, provide a unified direction. Benchmarks, such as system accuracy in keyword detection, offer measurable outcomes to gauge progress. Engaging with stakeholders, from end-users to investors, provides invaluable insights and ensures alignment with market needs.
+Additionally, understanding platform constraints is pivotal when delving into areas like voice assistance. Embedded systems, such as microcontrollers, come with inherent processing power, memory, and energy efficiency limitations. Recognizing these limitations ensures that functionalities, like keyword detection, are tailored to operate optimally, balancing performance with resource conservation.
In this context, using KWS as an example, we can break each of the steps out as follows:
1. **Identifying the Problem:**
- At its core, KWS aims to detect specific keywords amidst a sea of ambient sounds and other spoken words. The primary problem is to design a system that can recognize these keywords with high accuracy, low latency, and minimal false positives or negatives, especially when deployed on devices with limited computational resources.
+ At its core, KWS aims to detect specific keywords amidst ambient sounds and other spoken words. The primary problem is to design a system that can recognize these keywords with high accuracy, low latency, and minimal false positives or negatives, especially when deployed on devices with limited computational resources.
2. **Setting Clear Objectives:**
The objectives for a KWS system might include:
@@ -100,15 +101,15 @@ In this context, using KWS as an example, we can break each of the steps out as
* Power Consumption: Average power used during keyword detection.
4. **Stakeholder Engagement and Understanding:**
- Engage with stakeholders, which might include device manufacturers, hardware and software developers, and end-users. Understand their needs, capabilities, and constraints. For instance:
+ Engage with stakeholders, which include device manufacturers, hardware and software developers, and end-users. Understand their needs, capabilities, and constraints. For instance:
* Device manufacturers might prioritize low power consumption.
* Software developers might emphasize ease of integration.
* End-users would prioritize accuracy and responsiveness.
5. **Understanding the Constraints and Limitations of Embedded Systems:**
Embedded devices come with their own set of challenges:
- * Memory Limitations: KWS models need to be lightweight to fit within the memory constraints of embedded devices. Typically, KWS models might need to be as small as 16KB to fit in the always-on island of the SoC. Moreover, this is just the model size. Additional application code for pre-processing may also need to fit within the memory constraints.
- * Processing Power: The computational capabilities of embedded devices are limited (few hundred MHz of clock speed), so the KWS model must be optimized for efficiency.
+ * Memory Limitations: KWS models must be lightweight to fit within the memory constraints of embedded devices. Typically, KWS models need to be as small as 16KB to fit in the always-on island of the SoC. Moreover, this is just the model size. Additional application code for preprocessing may also need to fit within the memory constraints.
+ * Processing Power: The computational capabilities of embedded devices are limited (a few hundred MHz of clock speed), so the KWS model must be optimized for efficiency.
* Power Consumption: Since many embedded devices are battery-powered, the KWS system must be power-efficient.
* Environmental Challenges: Devices might be deployed in various environments, from quiet bedrooms to noisy industrial settings. The KWS system must be robust enough to function effectively across these scenarios.
@@ -125,7 +126,7 @@ In this context, using KWS as an example, we can break each of the steps out as
### Keyword Spotting with TensorFlow Lite Micro
-Explore a hands-on guide for building and deploying Keyword Spotting (KWS) systems using TensorFlow Lite Micro. Follow steps from data collection to model training and finally deployment to microcontrollers. Learn to create efficient KWS models that recognize specific keywords amidst background noise. Perfect for those interested in machine learning on embedded systems. Unlock the potential of voice-enabled devices with TensorFlow Lite Micro!
+Explore a hands-on guide for building and deploying Keyword Spotting (KWS) systems using TensorFlow Lite Micro. Follow steps from data collection to model training and deployment to microcontrollers. Learn to create efficient KWS models that recognize specific keywords amidst background noise. Perfect for those interested in machine learning on embedded systems. Unlock the potential of voice-enabled devices with TensorFlow Lite Micro!
[](https://colab.research.google.com/drive/17I7GL8WTieGzXYKRtQM2FrFi3eLQIrOM)
:::
@@ -134,17 +135,17 @@ The current chapter underscores the essential role of data quality in ML, using
## Data Sourcing
-The quality and diversity of data gathered is important for developing accurate and robust AI systems. Sourcing high-quality training data requires careful consideration of the objectives, resources, and ethical implications. Data can be obtained from various sources depending on the needs of the project:
+The quality and diversity of data gathered are important for developing accurate and robust AI systems. Sourcing high-quality training data requires careful consideration of the objectives, resources, and ethical implications. Data can be obtained from various sources depending on the needs of the project:
### Pre-existing datasets
-Platforms like [Kaggle](https://www.kaggle.com/) and [UCI Machine Learning Repository](https://archive.ics.uci.edu/) provide a convenient starting point. Pre-existing datasets are a valuable resource for researchers, developers, and businesses alike. One of their primary advantages is cost-efficiency. Creating a dataset from scratch can be both time-consuming and expensive, so having access to ready-made data can save significant resources. Moreover, many of these datasets, like [ImageNet](https://www.image-net.org/), have become standard benchmarks in the machine learning community, allowing for consistent performance comparisons across different models and algorithms. This availability of data means that experiments can be started immediately without any delays associated with data collection and preprocessing. In a fast moving field like ML, this expediency is important.
+Platforms like [Kaggle](https://www.kaggle.com/) and [UCI Machine Learning Repository](https://archive.ics.uci.edu/) provide a convenient starting point. Pre-existing datasets are valuable for researchers, developers, and businesses. One of their primary advantages is cost efficiency. Creating a dataset from scratch can be time-consuming and expensive, so accessing ready-made data can save significant resources. Moreover, many datasets, like [ImageNet](https://www.image-net.org/), have become standard benchmarks in the machine learning community, allowing for consistent performance comparisons across different models and algorithms. This data availability means that experiments can be started immediately without any data collection and preprocessing delays. In a fast-moving field like ML, this practicality is important.
-The quality assurance that comes with popular pre-existing datasets is important to consider because several datasets have errors in them. For instance, [the ImageNet dataset was found to have over 6.4% errors](https://arxiv.org/abs/2103.14749). Given their widespread use, any errors or biases in these datasets are often identified and rectified by the community. This assurance is especially beneficial for students and newcomers to the field, as they can focus on learning and experimentation without worrying about data integrity. Supporting documentation that often accompanies existing datasets is invaluable, though this generally applies only to widely used datasets. Good documentation provides insights into the data collection process, variable definitions, and sometimes even offers baseline model performances. This information not only aids understanding but also promotes reproducibility in research, a cornerstone of scientific integrity; currently there is a crisis around [improving reproducibility in machine learning systems](https://arxiv.org/abs/2003.12206). When other researchers have access to the same data, they can validate findings, test new hypotheses, or apply different methodologies, thus allowing us to build on each other's work more rapidly.
+The quality assurance that comes with popular pre-existing datasets is important to consider because several datasets have errors in them. For instance, [the ImageNet dataset was found to have over 6.4% errors](https://arxiv.org/abs/2103.14749). Given their widespread use, the community often identifies and rectifies any errors or biases in these datasets. This assurance is especially beneficial for students and newcomers to the field, as they can focus on learning and experimentation without worrying about data integrity. Supporting documentation often accompanying existing datasets is invaluable, though this generally applies only to widely used datasets. Good documentation provides insights into the data collection process and variable definitions and sometimes even offers baseline model performances. This information not only aids understanding but also promotes reproducibility in research, a cornerstone of scientific integrity; currently, there is a crisis around [improving reproducibility in machine learning systems](https://arxiv.org/abs/2003.12206). When other researchers have access to the same data, they can validate findings, test new hypotheses, or apply different methodologies, thus allowing us to build on each other's work more rapidly.
-While platforms like Kaggle and UCI Machine Learning Repository are invaluable resources, it's essential to understand the context in which the data was collected. Researchers should be wary of potential overfitting when using popular datasets, as multiple models might have been trained on them, leading to inflated performance metrics. Sometimes these [datasets do not reflect the real-world data](https://venturebeat.com/uncategorized/3-big-problems-with-datasets-in-ai-and-machine-learning/).
+While platforms like Kaggle and UCI Machine Learning Repository are invaluable resources, it's essential to understand the context in which the data was collected. Researchers should be wary of potential overfitting when using popular datasets, as multiple models might have been trained on them, leading to inflated performance metrics. Sometimes, these [datasets do not reflect the real-world data](https://venturebeat.com/uncategorized/3-big-problems-with-datasets-in-ai-and-machine-learning/).
-In addition, bias, validity, and reproducibility issues may exist in these datasets and in recent years there is a growing awareness of these issues. Furthermore, using the same dataset to train different models as shown in the figure below can sometimes create misalignment, where the models do not accurately reflect the real world (see @fig-misalignment).
+In addition, bias, validity, and reproducibility issues may exist in these datasets, and there has been a growing awareness of these issues in recent years. Furthermore, using the same dataset to train different models, as shown in the figure below, can sometimes create misalignment, where the models do not accurately reflect the real world (see @fig-misalignment).
{#fig-misalignment}
@@ -152,23 +153,23 @@ In addition, bias, validity, and reproducibility issues may exist in these datas
Web scraping refers to automated techniques for extracting data from websites. It typically involves sending HTTP requests to web servers, retrieving HTML content, and parsing that content to extract relevant information. Popular tools and frameworks for web scraping include Beautiful Soup, Scrapy, and Selenium. These tools offer different functionalities, from parsing HTML content to automating web browser interactions, especially for websites that load content dynamically using JavaScript.
-Web scraping can be an effective way to gather large datasets for training machine learning models, particularly when human-labeled data is scarce. For computer vision research, web scraping enables the collection of massive volumes of images and videos. Researchers have used this technique to build influential datasets like [ImageNet](https://www.image-net.org/) and [OpenImages](https://storage.googleapis.com/openimages/web/index.html). For example, one could scrape e-commerce sites to amass product photos for object recognition, or social media platforms to collect user uploads for facial analysis. Even before ImageNet, Stanford's [LabelMe](https://people.csail.mit.edu/torralba/publications/labelmeApplications.pdf) project scraped Flickr for over 63,000 annotated images covering hundreds of object categories.
+Web scraping can effectively gather large datasets for training machine learning models, particularly when human-labeled data is scarce. For computer vision research, web scraping enables the collection of massive volumes of images and videos. Researchers have used this technique to build influential datasets like [ImageNet](https://www.image-net.org/) and [OpenImages](https://storage.googleapis.com/openimages/web/index.html). For example, one could scrape e-commerce sites to amass product photos for object recognition or social media platforms to collect user uploads for facial analysis. Even before ImageNet, Stanford's [LabelMe](https://people.csail.mit.edu/torralba/publications/labelmeApplications.pdf) project scraped Flickr for over 63,000 annotated images covering hundreds of object categories.
-Beyond computer vision, web scraping supports the gathering of textual data for natural language tasks. Researchers can scrape news sites for sentiment analysis data, forums, and review sites for dialogue systems research, or social media for topic modeling. For example, the training data for chatbot ChatGPT was obtained by scraping much of the public internet. GitHub repositories were scraped to train GitHub's Copilot AI coding assistant.
+Beyond computer vision, web scraping supports gathering textual data for natural language tasks. Researchers can scrape news sites for sentiment analysis data, forums and review sites for dialogue systems research, or social media for topic modeling. For example, the training data for chatbot ChatGPT was obtained by scraping much of the public Internet. GitHub repositories were scraped to train GitHub's Copilot AI coding assistant.
-Web scraping can also collect structured data like stock prices, weather data, or product information for analytical applications. Once data is scraped, it is essential to store it in a structured manner, often using databases or data warehouses. Proper data management ensures the usability of the scraped data for future analysis and applications.
+Web scraping can also collect structured data, such as stock prices, weather data, or product information, for analytical applications. Once data is scraped, it is essential to store it in a structured manner, often using databases or data warehouses. Proper data management ensures the usability of the scraped data for future analysis and applications.
-However, while web scraping offers numerous advantages, there are significant limitations and ethical considerations to bear in mind. Not all websites permit scraping, and violating these restrictions can lead to legal repercussions. It is also unethical and potentially illegal to scrape copyrighted material or private communications. Ethical web scraping mandates adherence to a website's 'robots.txt' file, which outlines the sections of the site that can be accessed and scraped by automated bots.
+However, while web scraping offers numerous advantages, there are significant limitations and ethical considerations to bear. Not all websites permit scraping, and violating these restrictions can lead to legal repercussions. Scraping copyrighted material or private communications is also unethical and potentially illegal. Ethical web scraping mandates adherence to a website's 'robots.txt' file, which outlines the sections of the site that can be accessed and scraped by automated bots.
-To deter automated scraping, many websites implement rate limits. If a bot sends too many requests in a short period, it might be temporarily blocked, restricting the speed of data access. Additionally, the dynamic nature of web content means that data scraped at different intervals might lack consistency, posing challenges for longitudinal studies. Though there are emerging trends like [Web Navigation](https://arxiv.org/abs/1812.09195) where machine learning algorithms can automatically navigate the website to access the dynamic content.
+To deter automated scraping, many websites implement rate limits. If a bot sends too many requests in a short period, it might be temporarily blocked, restricting the speed of data access. Additionally, the dynamic nature of web content means that data scraped at different intervals might need more consistency, posing challenges for longitudinal studies. However, there are emerging trends like [Web Navigation](https://arxiv.org/abs/1812.09195) where machine learning algorithms can automatically navigate the website to access the dynamic content.
-For niche subjects, the volume of pertinent data available for scraping might be limited. For example, while scraping for common topics like images of cats and dogs might yield abundant data, searching for rare medical conditions might not be as fruitful. Moreover, the data obtained through scraping is often unstructured and noisy, necessitating thorough preprocessing and cleaning. It is crucial to understand that not all scraped data will be of high quality or accuracy. Employing verification methods, such as cross-referencing with alternate data sources, can enhance data reliability.
+The volume of pertinent data available for scraping might be limited for niche subjects. For example, while scraping for common topics like images of cats and dogs might yield abundant data, searching for rare medical conditions might be less fruitful. Moreover, the data obtained through scraping is often unstructured and noisy, necessitating thorough preprocessing and cleaning. It is crucial to understand that not all scraped data will be of high quality or accuracy. Employing verification methods, such as cross-referencing with alternate data sources, can enhance data reliability.
Privacy concerns arise when scraping personal data, emphasizing the need for anonymization. Therefore, it is paramount to adhere to a website's Terms of Service, confine data collection to public domains, and ensure the anonymity of any personal data acquired.
-While web scraping can be a scalable method to amass large training datasets for AI systems, its applicability is confined to specific data types. For example, sourcing data for Inertial Measurement Units (IMU) for gesture recognition is not straightforward through web scraping. At most, one might be able to scrape an existing dataset.
+While web scraping can be a scalable method to amass large training datasets for AI systems, its applicability is confined to specific data types. For example, web scraping makes sourcing data for Inertial Measurement Units (IMU) for gesture recognition more complex. At most, one can scrape an existing dataset.
-Web scraping can yield inconsistent or inaccurate data. For example, the photo in @fig-traffic-light shows up when you search 'traffic light' on Google images. It is an image from 1914 that shows outdated traffic lights, which are also barely discernible because of the image's poor quality.
+Web scraping can yield inconsistent or inaccurate data. For example, the photo in @fig-traffic-light shows up when you search for 'traffic light' on Google Images. It is an image from 1914 that shows outdated traffic lights, which are also barely discernible because of the image's poor quality.
](images/jpg/1914_traffic.jpeg){#fig-traffic-light}
@@ -176,42 +177,42 @@ Web scraping can yield inconsistent or inaccurate data. For example, the photo i
### Web Scraping
-Discover the power of web scraping with Python using libraries like Beautiful Soup and Pandas. In this exercise, we'll scrape Python documentation for function names and descriptions, and explore NBA player stats. By the end, you'll have the skills to extract and analyze data from real-world websites. Ready to dive in? Access the Google Colab notebook below and start practicing!
+Discover the power of web scraping with Python using libraries like Beautiful Soup and Pandas. This exercise will scrape Python documentation for function names and descriptions and explore NBA player stats. By the end, you'll have the skills to extract and analyze data from real-world websites. Ready to dive in? Access the Google Colab notebook below and start practicing!
[](https://colab.research.google.com/github/Andy-Pham-72/Web-Scraping-with-BeautifulSoup-and-Pandas/blob/master/Web_scraping_with_beautiful_soup_and_pandas_complete.ipynb)
:::
### Crowdsourcing
-Crowdsourcing for datasets is the practice of obtaining data by using the services of a large number of people, either from a specific community or the general public, typically via the internet. Instead of relying on a small team or specific organization to collect or label data, crowdsourcing leverages the collective effort of a vast, distributed group of participants. Services like Amazon Mechanical Turk enable the distribution of annotation tasks to a large, diverse workforce. This facilitates the collection of labels for complex tasks like sentiment analysis or image recognition that specifically require human judgment.
+Crowdsourcing for datasets is the practice of obtaining data using the services of many people, either from a specific community or the general public, typically via the Internet. Instead of relying on a small team or specific organization to collect or label data, crowdsourcing leverages the collective effort of a vast, distributed group of participants. Services like Amazon Mechanical Turk enable the distribution of annotation tasks to a large, diverse workforce. This facilitates the collection of labels for complex tasks like sentiment analysis or image recognition requiring human judgment.
-Crowdsourcing has emerged as an effective approach for many data collection and problem-solving needs. One major advantage of crowdsourcing is scalability-by distributing tasks to a large, global pool of contributors on digital platforms, projects can process huge volumes of data in a short time frame. This makes crowdsourcing ideal for large-scale data labeling, collection, and analysis.
+Crowdsourcing has emerged as an effective approach for data collection and problem-solving. One major advantage of crowdsourcing is scalability—by distributing tasks to a large, global pool of contributors on digital platforms, projects can process huge volumes of data quickly. This makes crowdsourcing ideal for large-scale data labeling, collection, and analysis.
-In addition, crowdsourcing taps into a diverse group of participants, bringing a wide range of perspectives, cultural insights, and language abilities that can enrich data and enhance creative problem-solving in ways that a more homogenous group may not. Because crowdsourcing draws from a large audience beyond traditional channels, it also tends to be more cost-effective than conventional methods, especially for simpler microtasks.
+In addition, crowdsourcing taps into a diverse group of participants, bringing a wide range of perspectives, cultural insights, and language abilities that can enrich data and enhance creative problem-solving in ways that a more homogenous group may not. Because crowdsourcing draws from a large audience beyond traditional channels, it is more cost-effective than conventional methods, especially for simpler microtasks.
-Crowdsourcing platforms also allow for great flexibility, as task parameters can be adjusted in real-time based on initial results. This creates a feedback loop for iterative improvements to the data collection process. Complex jobs can be broken down into microtasks and distributed to multiple people, with cross-validation of results by assigning redundant versions of the same task. Ultimately, when thoughtfully managed, crowdsourcing enables community engagement around a collaborative project, where participants find reward in contributing.
+Crowdsourcing platforms also allow for great flexibility, as task parameters can be adjusted in real time based on initial results. This creates a feedback loop for iterative improvements to the data collection process. Complex jobs can be broken down into microtasks and distributed to multiple people, with results cross-validated by assigning redundant versions of the same task. When thoughtfully managed, crowdsourcing enables community engagement around a collaborative project, where participants find reward in contributing.
-However, while crowdsourcing offers numerous advantages, it's essential to approach it with a clear strategy. While it provides access to a diverse set of annotators, it also introduces variability in the quality of annotations. Additionally, platforms like Mechanical Turk might not always capture a complete demographic spectrum; often tech-savvy individuals are overrepresented, while children and the elderly may be underrepresented. It's crucial to provide clear instructions and possibly even training for the annotators. Periodic checks and validations of the labeled data can help maintain quality. This ties back to the topic of clear Problem Definition that we discussed earlier. Crowdsourcing for datasets also requires careful attention to ethical considerations. It's crucial to ensure that participants are informed about how their data will be used and that their privacy is protected. Quality control through detailed protocols, transparency in sourcing, and auditing is essential to ensure reliable outcomes.
+However, while crowdsourcing offers numerous advantages, it's essential to approach it with a clear strategy. While it provides access to a diverse set of annotators, it also introduces variability in the quality of annotations. Additionally, platforms like Mechanical Turk might not always capture a complete demographic spectrum; often, tech-savvy individuals are overrepresented, while children and older people may be underrepresented. Providing clear instructions and training for the annotators is crucial. Periodic checks and validations of the labeled data help maintain quality. This ties back to the topic of clear Problem Definition that we discussed earlier. Crowdsourcing for datasets also requires careful attention to ethical considerations. It's crucial to ensure that participants are informed about how their data will be used and that their privacy is protected. Quality control through detailed protocols, transparency in sourcing, and auditing is essential to ensure reliable outcomes.
-For TinyML, crowdsourcing can pose some unique challenges. TinyML devices are highly specialized for particular tasks within tight constraints. As a result, the data they require tends to be very specific. It may be difficult to obtain such specialized data from a general audience through crowdsourcing. For example, TinyML applications often rely on data collected from certain sensors or hardware. Crowdsourcing would require participants to have access to very specific and consistent devices - like microphones with the same sampling rates. Even for simple audio tasks like keyword spotting, these hardware nuances present obstacles.
+For TinyML, crowdsourcing can pose some unique challenges. TinyML devices are highly specialized for particular tasks within tight constraints. As a result, the data they require tends to be very specific. Obtaining such specialized data from a general audience may be difficult through crowdsourcing. For example, TinyML applications often rely on data collected from certain sensors or hardware. Crowdsourcing would require participants to have access to very specific and consistent devices - like microphones, with the same sampling rates. These hardware nuances present obstacles even for simple audio tasks like keyword spotting.
-Beyond hardware, the data itself needs high granularity and quality given the limitations of TinyML. It can be hard to ensure this when crowdsourcing from those unfamiliar with the application's context and requirements. There are also potential issues around privacy, real-time collection, standardization, and technical expertise. Moreover, the narrow nature of many TinyML tasks makes accurate data labeling difficult without the proper understanding. Participants may struggle to provide reliable annotations without full context.
+Beyond hardware, the data itself needs high granularity and quality, given the limitations of TinyML. It can be hard to ensure this when crowdsourcing from those unfamiliar with the application's context and requirements. There are also potential issues around privacy, real-time collection, standardization, and technical expertise. Moreover, the narrow nature of many TinyML tasks makes accurate data labeling easier with the proper understanding. Participants may need full context to provide reliable annotations.
Thus, while crowdsourcing can work well in many cases, the specialized needs of TinyML introduce unique data challenges. Careful planning is required for guidelines, targeting, and quality control. For some applications, crowdsourcing may be feasible, but others may require more focused data collection efforts to obtain relevant, high-quality training data.
### Synthetic Data
-Synthetic data generation can be useful for addressing some of the limitations of data collection. It involves creating data that wasn't originally captured or observed, but is generated using algorithms, simulations, or other techniques to resemble real-world data (@fig-synthetic-data). It has become a valuable tool in various fields, particularly in scenarios where real-world data is scarce, expensive, or ethically challenging to obtain (e.g., TinyML). Various techniques, such as Generative Adversarial Networks (GANs), can produce high-quality synthetic data that is almost indistinguishable from real data. These techniques have advanced significantly, making synthetic data generation increasingly realistic and reliable.
+Synthetic data generation can be useful for addressing some of the data collection limitations. It involves creating data that wasn't originally captured or observed but is generated using algorithms, simulations, or other techniques to resemble real-world data (@fig-synthetic-data). It has become a valuable tool in various fields, particularly when real-world data is scarce, expensive, or ethically challenging (e.g., TinyML). Various techniques, such as Generative Adversarial Networks (GANs), can produce high-quality synthetic data almost indistinguishable from real data. These techniques have advanced significantly, making synthetic data generation increasingly realistic and reliable.
-In many domains, especially emerging ones, there may not be enough real-world data available for analysis or training machine learning models. Synthetic data can fill this gap by producing large volumes of data that mimic real-world scenarios. For instance, detecting the sound of breaking glass might be challenging in security applications where a TinyML device is trying to identify break-ins. Collecting real-world data would require breaking numerous windows, which is impractical and costly.
+More real-world data may need to be available for analysis or training machine learning models in many domains, especially emerging ones. Synthetic data can fill this gap by producing large volumes of data that mimic real-world scenarios. For instance, detecting the sound of breaking glass might be challenging in security applications where a TinyML device is trying to identify break-ins. Collecting real-world data would require breaking numerous windows, which is impractical and costly.
-Moreover, in machine learning, especially in deep learning, having a diverse dataset is crucial. Synthetic data can augment existing datasets by introducing variations, thereby enhancing the robustness of models. For example, SpecAugment is an excellent data augmentation technique for Automatic Speech Recognition (ASR) systems.
+Moreover, having a diverse dataset is crucial in machine learning, especially in deep learning. Synthetic data can augment existing datasets by introducing variations, thereby enhancing the robustness of models. For example, SpecAugment is an excellent data augmentation technique for Automatic Speech Recognition (ASR) systems.
-Privacy and confidentiality is also a big issue. Datasets containing sensitive or personal information pose privacy concerns when shared or used. Synthetic data, being artificially generated, doesn't have these direct ties to real individuals, allowing for safer use while preserving essential statistical properties.
+Privacy and confidentiality are also big issues. Datasets containing sensitive or personal information pose privacy concerns when shared or used. Synthetic data, being artificially generated, doesn't have these direct ties to real individuals, allowing for safer use while preserving essential statistical properties.
-Generating synthetic data, especially once the generation mechanisms have been established, can be a more cost-effective alternative. In the aforementioned security application scenario, synthetic data eliminates the need for breaking multiple windows to gather relevant data.
+Generating synthetic data, especially once the generation mechanisms have been established, can be a more cost-effective alternative. Synthetic data eliminates the need to break multiple windows to gather relevant data in the security above application scenario.
-Many embedded use-cases deal with unique situations, such as manufacturing plants, that are difficult to simulate. Synthetic data allows researchers complete control over the data generation process, enabling the creation of specific scenarios or conditions that are challenging to capture in real life.
+Many embedded use cases deal with unique situations, such as manufacturing plants, that are difficult to simulate. Synthetic data allows researchers complete control over the data generation process, enabling the creation of specific scenarios or conditions that are challenging to capture in real life.
While synthetic data offers numerous advantages, it is essential to use it judiciously. Care must be taken to ensure that the generated data accurately represents the underlying real-world distributions and does not introduce unintended biases.
@@ -220,47 +221,35 @@ While synthetic data offers numerous advantages, it is essential to use it judic
:::{#exr-sd .callout-exercise collapse="true"}
### Synthetic Data
-Let us learn about synthetic data generation using Generative Adversarial Networks (GANs) on tabular data. We'll take a hands-on approach, diving into the workings of the CTGAN model and applying it to the Synthea dataset from the healthcare domain. From data preprocessing to model training and evaluation, we'll go step-by-step, learning how to create synthetic data and assess its quality and unlock the potential of GANs for data augmentation and real-world applications.
+Let us learn about synthetic data generation using Generative Adversarial Networks (GANs) on tabular data. We'll take a hands-on approach, diving into the workings of the CTGAN model and applying it to the Synthea dataset from the healthcare domain. From data preprocessing to model training and evaluation, we'll go step-by-step, learning how to create synthetic data, assess its quality, and unlock the potential of GANs for data augmentation and real-world applications.
[](https://colab.research.google.com/drive/1nwbvkg32sOUC69zATCfXOygFUBeo0dsx?usp=sharing#scrollTo=TkwYknr44eFn)
:::
## Data Storage
-Data sourcing and data storage go hand-in-hand and it is necessary to store data in a format that facilitates easy access and processing. Depending on the use case, there are various kinds of data storage systems that can be used to store your datasets. Some examples are shown in @tbl-databases.
+Data sourcing and data storage go hand in hand, and data must be stored in a format that facilitates easy access and processing. Depending on the use case, various kinds of data storage systems can be used to store your datasets. Some examples are shown in @tbl-databases.
- ----------------------------------------------------------------------------
- **Database** **Data Warehouse** **Data Lake**
- -------------- ------------------- --------------------- -------------------
- **Purpose** Operational and Analytical Analytical
- transactional
+| **Database** | **Data Warehouse** | **Data Lake** |
+|------------------------------------|--------------------------|------------------------|
+| **Purpose** | Operational and transactional | Analytical |
+| **Data type** | Structured | Structured, semi-structured, and/or unstructured |
+| **Scale** | Small to large volumes of data | Large volumes of integrated data | Large volumes of diverse data |
+| **Examples** | MySQL | Google BigQuery, Amazon Redshift, Microsoft Azure Synapse, Google Cloud Storage, AWS S3, Azure Data Lake Storage |
- **Data type** Structured Structured Structured,
- semi-structured
- and/or unstructured
+ : Comparative overview of the database, data warehouse, and data lake. {#tbl-databases}
- **Scale** Small to large Large volumes of Large volumes of
- volumes of data integrated data diverse data
+The stored data is often accompanied by metadata, defined as 'data about data .'It provides detailed contextual information about the data, such as means of data creation, time of creation, attached data use license, etc. For example, [[Hugging Face]{.underline}](https://huggingface.co/) has [[Dataset Cards]{.underline}](https://huggingface.co/docs/hub/datasets-cards). To promote responsible data use, dataset creators should disclose potential biases through the dataset cards. These cards can educate users about a dataset's contents and limitations. The cards also give vital context on appropriate dataset usage by highlighting biases and other important details. Having this type of metadata can also allow fast retrieval if structured properly. Once the model is developed and deployed to edge devices, the storage systems can continue to store incoming data, model updates, or analytical results.
-**Examples** MySQL Google BigQuery, Google Cloud
- Amazon Redshift, Storage, AWS S3,
- Microsoft Azure Azure Data Lake
- Synapse. Storage
- ----------------------------------------------------------------------------
-
- : Comparative overview of database, data warehouse, and data lake. {#tbl-databases}
-
-The stored data is often accompanied by metadata, which is defined as 'data about data'. It provides detailed contextual information about the data, such as means of data creation, time of creation, attached data use license etc. For example, [[Hugging Face]{.underline}](https://huggingface.co/) has [[Dataset Cards]{.underline}](https://huggingface.co/docs/hub/datasets-cards). To promote responsible data use, dataset creators should disclose potential biases through the dataset cards. These cards can educate users about a dataset\'s contents and limitations. The cards also give vital context on appropriate dataset usage by highlighting biases and other important details. Having this type of metadata can also allow fast retrieval if structured properly. Once the model is developed and deployed to edge devices, the storage systems can continue to store incoming data, model updates or analytical results.
-
-**Data Governance:** With a large amount of data storage, it is also imperative to have policies and practices (i.e., data governance) that helps manage data during its life cycle, from acquisition to disposal. Data governance frames the way data is managed and includes making pivotal decisions about data access and control (@fig-governance). It involves exercising authority and making decisions concerning data, with the aim to uphold its quality, ensure compliance, maintain security, and derive value. Data governance is operationalized through the development of policies, incentives, and penalties, cultivating a culture that perceives data as a valuable asset. Specific procedures and assigned authorities are implemented to safeguard data quality and monitor its utilization and the related risks.
+**Data Governance:** With a large amount of data storage, it is also imperative to have policies and practices (i.e., data governance) that help manage data during its life cycle, from acquisition to disposal. Data governance frames how data is managed and includes making pivotal decisions about data access and control (@fig-governance). It involves exercising authority and making decisions concerning data to uphold its quality, ensure compliance, maintain security, and derive value. Data governance is operationalized by developing policies, incentives, and penalties, cultivating a culture that perceives data as a valuable asset. Specific procedures and assigned authorities are implemented to safeguard data quality and monitor its utilization and related risks.
Data governance utilizes three integrative approaches: planning and control, organizational, and risk-based.
* **The planning and control approach**, common in IT, aligns business and technology through annual cycles and continuous adjustments, focusing on policy-driven, auditable governance.
-* **The organizational approach** emphasizes structure, establishing authoritative roles like Chief Data Officers, ensuring responsibility and accountability in governance.
+* **The organizational approach** emphasizes structure, establishing authoritative roles like Chief Data Officers and ensuring responsibility and accountability in governance.
-* **The risk-based approach**, intensified by AI advancements, focuses on identifying and managing inherent risks in data and algorithms, especially addressing AI-specific issues through regular assessments and proactive risk management strategies, allowing for incidental and preventive actions to mitigate undesired algorithm impacts.
+* **The risk-based approach**, intensified by AI advancements, focuses on identifying and managing inherent risks in data and algorithms. It especially addresses AI-specific issues through regular assessments and proactive risk management strategies, allowing for incidental and preventive actions to mitigate undesired algorithm impacts.
)](images/jpg/data_governance.jpg){#fig-governance}
@@ -268,51 +257,51 @@ Some examples of data governance across different sectors include:
* **Medicine:** [[Health Information Exchanges(HIEs)]{.underline}](https://www.healthit.gov/topic/health-it-and-health-information-exchange-basics/what-hie) enable the sharing of health information across different healthcare providers to improve patient care. They implement strict data governance practices to maintain data accuracy, integrity, privacy, and security, complying with regulations such as the [[Health Insurance Portability and Accountability Act (HIPAA)]{.underline}](https://www.cdc.gov/phlp/publications/topic/hipaa.html). Governance policies ensure that patient data is only shared with authorized entities and that patients can control access to their information.
-* **Finance:** [[Basel III Framework]{.underline}](https://www.bis.org/bcbs/basel3.htm) is an international regulatory framework for banks. It ensures that banks establish clear policies, practices, and responsibilities for data management, ensuring data accuracy, completeness, and timeliness. Not only does it enable banks to meet regulatory compliance, it also prevents financial crises by more effective management of risks.
+* ** Finance: ** [[Basel III Framework] .underline] (https://www.bis.org/bcbs/basel3.htm) is an international regulatory framework for banks. It ensures that banks establish clear policies, practices, and responsibilities for data management, ensuring data accuracy, completeness, and timeliness. Not only does it enable banks to meet regulatory compliance, but it also prevents financial crises by more effectively managing risks.
-* **Government:** Governments agencies managing citizen data, public records, and administrative information implement data governance to manage data transparently and securely. Social Security System in the US, and Aadhar system in India are good examples of such governance systems.
+* **Government:** Government agencies managing citizen data, public records, and administrative information implement data governance to manage data transparently and securely. The Social Security System in the US and the Aadhar system in India are good examples of such governance systems.
**Special data storage considerations for TinyML**
***Efficient Audio Storage Formats:*** Keyword spotting systems need specialized audio storage formats to enable quick keyword searching in audio data. Traditional formats like WAV and MP3 store full audio waveforms, which require extensive processing to search through. Keyword spotting uses compressed storage optimized for snippet-based search. One approach is to store compact acoustic features instead of raw audio. Such a workflow would involve:
-* **Extracting acoustic features:** Mel-frequency cepstral coefficients (MFCCs) are commonly used to represent important audio characteristics.
+* **Extracting acoustic features:** Mel-frequency cepstral coefficients (MFCCs) commonly represent important audio characteristics.
-* **Creating Embeddings:** Embeddings transform extracted acoustic features into continuous vector spaces, enabling more compact and representative data storage. This representation is essential in converting high-dimensional data, like audio, into a format that's more manageable and efficient for computation and storage.
+* **Creating Embeddings:** Embeddings transform extracted acoustic features into continuous vector spaces, enabling more compact and representative data storage. This representation is essential in converting high-dimensional data, like audio, into a more manageable and efficient format for computation and storage.
-* **Vector quantization:** This technique is used to represent high-dimensional data, like embeddings, with lower-dimensional vectors, reducing storage needs. Initially, a codebook is generated from the training data to define a set of code vectors representing the original data vectors. Subsequently, each data vector is matched to the nearest codeword according to the codebook, ensuring minimal loss of information.
+* **Vector quantization:** This technique represents high-dimensional data, like embeddings, with lower-dimensional vectors, reducing storage needs. Initially, a codebook is generated from the training data to define a set of code vectors representing the original data vectors. Subsequently, each data vector is matched to the nearest codeword according to the codebook, ensuring minimal information loss.
* **Sequential storage:** The audio is fragmented into short frames, and the quantized features (or embeddings) for each frame are stored sequentially to maintain the temporal order, preserving the coherence and context of the audio data.
This format enables decoding the features frame-by-frame for keyword matching. Searching the features is faster than decompressing the full audio.
-***Selective Network Output Storage:*** Another technique for reducing storage is to discard the intermediate audio features stored during training, but not required during inference. The network is run on the full audio during training, however, only the final outputs are stored during inference. In a recent study (Rybakov et al. 2018), the authors discuss adaptation of the model's intermediate data storage structure to incorporate the nature of streaming models that are prevalent in TinyML applications.
+***Selective Network Output Storage:*** Another technique for reducing storage is to discard the intermediate audio features stored during training but not required during inference. The network is run on full audio during training. However, only the final outputs are stored during inference.
## Data Processing
-Data processing refers to the steps involved in transforming raw data into a format that is suitable for feeding into machine learning algorithms. It is a crucial stage in any ML workflow, yet often overlooked. Without proper data processing, ML models are unlikely to achieve optimal performance. "Data preparation accounts for about 60-80% of the work of a data scientist." @fig-data-engineering shows a breakdown of a data scientist's time allocation, highlighting the significant portion spent on data cleaning and organizing.
+Data processing refers to the steps involved in transforming raw data into a format suitable for feeding into machine learning algorithms. It is a crucial stage in any ML workflow, yet often overlooked. With proper data processing, ML models are likely to achieve optimal performance. "Data preparation accounts for about 60-80% of the work of a data scientist." @fig-data-engineering shows a breakdown of a data scientist's time allocation, highlighting the significant portion spent on data cleaning and organizing.
{#fig-data-engineering}
-Proper data cleaning is a crucial step that directly impacts model performance. Real-world data is often dirty - it contains errors, missing values, noise, anomalies, and inconsistencies. Data cleaning involves detecting and fixing these issues to prepare high-quality data for modeling. By carefully selecting appropriate techniques, data scientists can improve model accuracy, reduce overfitting, and enable algorithms to learn more robust patterns. Overall, thoughtful data processing allows machine learning systems to better uncover insights and make predictions from real-world data.
+Proper data cleaning is a crucial step that directly impacts model performance. Real-world data is often dirty, containing errors, missing values, noise, anomalies, and inconsistencies. Data cleaning involves detecting and fixing these issues to prepare high-quality data for modeling. By carefully selecting appropriate techniques, data scientists can improve model accuracy, reduce overfitting, and enable algorithms to learn more robust patterns. Overall, thoughtful data processing allows machine learning systems to uncover insights better and make predictions from real-world data.
-Data often comes from diverse sources and can be unstructured or semi-structured. Thus, it's essential to process and standardize it, ensuring it adheres to a uniform format. Such transformations may include:
+Data often comes from diverse sources and can be unstructured or semi-structured. Thus, processing and standardizing it is essential, ensuring it adheres to a uniform format. Such transformations may include:
* Normalizing numerical variables
* Encoding categorical variables
* Using techniques like dimensionality reduction
-Data validation serves a broader role than just ensuring adherence to certain standards like preventing temperature values from falling below absolute zero. These types of issues arise in TinyML because sensors may malfunction or temporarily produce incorrect readings, such transients are not uncommon. Therefore, it is imperative to catch data errors early before they propagate through the data pipeline. Rigorous validation processes, including verifying the initial annotation practices, detecting outliers, and handling missing values through techniques like mean imputation, contribute directly to the quality of datasets. This, in turn, impacts the performance, fairness, and safety of the models trained on them.
+Data validation serves a broader role than ensuring adherence to certain standards, like preventing temperature values from falling below absolute zero. These issues arise in TinyML because sensors may malfunction or temporarily produce incorrect readings; such transients are not uncommon. Therefore, it is imperative to catch data errors early before propagating through the data pipeline. Rigorous validation processes, including verifying the initial annotation practices, detecting outliers, and handling missing values through techniques like mean imputation, contribute directly to the quality of datasets. This, in turn, impacts the performance, fairness, and safety of the models trained on them.
{#fig-data-engineering-kws2}
-Let's take a look at an example of a data processing pipeline (see @fig-data-engineering-kws2). In the context of TinyML, the Multilingual Spoken Words Corpus (MSWC) is an example of data processing pipelines-systematic and automated workflows for data transformation, storage, and processing. By streamlining the data flow, from raw data to usable datasets, data pipelines enhance productivity and facilitate the rapid development of machine learning models. The MSWC is an expansive and expanding collection of audio recordings of spoken words in 50 different languages, which are collectively used by over 5 billion people. This dataset is intended for academic study and business uses in areas like keyword identification and speech-based search. It is openly licensed under Creative Commons Attribution 4.0 for broad usage.
+Let's look at an example of a data processing pipeline (see @fig-data-engineering-kws2). In the context of TinyML, the Multilingual Spoken Words Corpus (MSWC) is an example of data processing pipelines-systematic and automated workflows for data transformation, storage, and processing. By streamlining the data flow, from raw data to usable datasets, data pipelines enhance productivity and facilitate the rapid development of machine learning models. The MSWC is an expansive and expanding collection of audio recordings of spoken words in 50 languages, which over 5 billion people use collectively. This dataset is intended for academic study and business uses in keyword identification and speech-based search. It is openly licensed under Creative Commons Attribution 4.0 for broad usage.
-The MSWC used a [forced alignment](https://montreal-forced-aligner.readthedocs.io/en/latest/) method to automatically extract individual word recordings to train keyword-spotting models from the [Common Voice](https://commonvoice.mozilla.org/) project, which features crowdsourced sentence-level recordings. Forced alignment refers to a group of long-standing methods in speech processing that are used to predict when speech phenomena like syllables, words, or sentences start and end within an audio recording. In the MSWC data, crowd-sourced recordings often feature background noises, such as static and wind. Depending on the model's requirements, these noises can be removed or intentionally retained.
+The MSWC used a [forced alignment](https://montreal-forced-aligner.readthedocs.io/en/latest/) method to automatically extract individual word recordings to train keyword-spotting models from the [Common Voice](https://commonvoice.mozilla.org/) project, which features crowdsourced sentence-level recordings. Forced alignment refers to long-standing methods in speech processing that predict when speech phenomena like syllables, words, or sentences start and end within an audio recording. In the MSWC data, crowdsourced recordings often feature background noises, such as static and wind. Depending on the model's requirements, these noises can be removed or intentionally retained.
Maintaining the integrity of the data infrastructure is a continuous endeavor. This encompasses data storage, security, error handling, and stringent version control. Periodic updates are crucial, especially in dynamic realms like keyword spotting, to adjust to evolving linguistic trends and device integrations.
-There is a boom of data processing pipelines, these are commonly found in ML operations toolchains, which we will discuss in the MLOps chapter. Briefly, these include frameworks like MLOps by Google Cloud. It provides methods for automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment, and infrastructure management, and there are several mechanisms that specifically focus on data processing which is an integral part of these systems.
+There is a boom in data processing pipelines, commonly found in ML operations toolchains, which we will discuss in the MLOps chapter. Briefly, these include frameworks like MLOps by Google Cloud. It provides methods for automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment, and infrastructure management. Several mechanisms focus on data processing, an integral part of these systems.
:::{#exr-dp .callout-exercise collapse="true"}
@@ -325,7 +314,7 @@ Let us explore two significant projects in speech data processing and machine le
## Data Labeling
-Data labeling is an important step in creating high-quality training datasets for machine learning models. Labels provide the ground truth information that allows models to learn relationships between inputs and desired outputs. This section covers key considerations around selecting label types, formats, and content to capture the necessary information for given tasks. It discusses common annotation approaches, from manual labeling to crowdsourcing to AI-assisted methods, and best practices for ensuring label quality through training, guidelines, and quality checks. Ethical treatment of human annotators is also something we emphasize. The integration of AI to accelerate and augment human annotation is also explored. Understanding labeling needs, challenges, and strategies is essential for constructing reliable, useful datasets that can train performant, trustworthy machine learning systems.
+Data labeling is important in creating high-quality training datasets for machine learning models. Labels provide ground truth information, allowing models to learn relationships between inputs and desired outputs. This section covers key considerations for selecting label types, formats, and content to capture the necessary information for tasks. It discusses common annotation approaches, from manual labeling to crowdsourcing to AI-assisted methods, and best practices for ensuring label quality through training, guidelines, and quality checks. We also emphasize the ethical treatment of human annotators. The integration of AI to accelerate and augment human annotation is also explored. Understanding labeling needs, challenges, and strategies are essential for constructing reliable, useful datasets to train performant, trustworthy machine learning systems.
### Label Types
@@ -333,114 +322,115 @@ Labels capture information about key tasks or concepts. Common label types (see
{#fig-labels}
-Unless focused on self-supervised learning, a dataset will likely provide labels addressing one or more tasks of interest. Dataset creators must consider what information labels should capture and how they can practically obtain the necessary labels, given their unique resource constraints. Creators must first decide what type(s) of content labels should capture. For example, a creator interested in car detection would want to label cars in their dataset. Still, they might also consider whether to simultaneously collect labels for other tasks that the dataset could potentially be used for in the future, such as pedestrian detection.
+Unless focused on self-supervised learning, a dataset will likely provide labels addressing one or more tasks of interest. Given their unique resource constraints, dataset creators must consider what information labels should capture and how they can practically obtain the necessary labels. Creators must first decide what type(s) of content labels should capture. For example, a creator interested in car detection would want to label cars in their dataset. Still, they might also consider whether to simultaneously collect labels for other tasks that the dataset could potentially be used for, such as pedestrian detection.
-Additionally, annotators can potentially provide metadata that provides insight into how the dataset represents different characteristics of interest (see: Data Transparency). The Common Voice dataset, for example, includes various types of metadata that provide information about the speakers, recordings, and dataset quality for each language represented (@ardila2020common). They include demographic splits showing the number of recordings by speaker age range and gender. This allows us to see the breakdown of who contributed recordings for each language. They also include statistics like average recording duration and total hours of validated recordings. These give insights into the nature and size of the datasets for each language. Additionally, quality control metrics like the percentage of recordings that have been validated are useful to know how complete and clean the datasets are. The metadata also includes normalized demographic splits scaled to 100% for comparison across languages. This highlights representation differences between higher and lower resource languages.
+Additionally, annotators can provide metadata that provides insight into how the dataset represents different characteristics of interest (see @sec-data-transparency). The Common Voice dataset, for example, includes various types of metadata that provide information about the speakers, recordings, and dataset quality for each language represented (@ardila2020common). They include demographic splits showing the number of recordings by speaker age range and gender. This allows us to see who contributed recordings for each language. They also include statistics like average recording duration and total hours of validated recordings. These give insights into the nature and size of the datasets for each language.
+Additionally, quality control metrics like the percentage of recordings that have been validated are useful to know how complete and clean the datasets are. The metadata also includes normalized demographic splits scaled to 100% for comparison across languages. This highlights representation differences between higher and lower resource languages.
-Next, creators must determine the format of those labels. For example, a creator interested in car detection might choose between binary classification labels that say whether a car is present, bounding boxes that show the general locations of any cars, or pixel-wise segmentation labels that show the exact location of each car. Their choice of label format may depend both on their use case and their resource constraints, as finer-grained labels are typically more expensive and time-consuming to acquire.
+Next, creators must determine the format of those labels. For example, a creator interested in car detection might choose between binary classification labels that say whether a car is present, bounding boxes that show the general locations of any cars, or pixel-wise segmentation labels that show the exact location of each car. Their choice of label format may depend on their use case and resource constraints, as finer-grained labels are typically more expensive and time-consuming to acquire.
### Annotation Methods
-Common annotation approaches include manual labeling, crowdsourcing, and semi-automated techniques. Manual labeling by experts yields high quality but lacks scalability. Crowdsourcing enables distributed annotation by non-experts, often through dedicated platforms (@victor2019machine). Weakly supervised and programmatic methods can reduce manual effort by heuristically or automatically generating labels (@ratner2018snorkel)
+Common annotation approaches include manual labeling, crowdsourcing, and semi-automated techniques. Manual labeling by experts yields high quality but needs more scalability. Crowdsourcing enables non-experts to distribute annotation, often through dedicated platforms (@victor2019machine). Weakly supervised and programmatic methods can reduce manual effort by heuristically or automatically generating labels (@ratner2018snorkel)
-After deciding on their labels' desired content and format, creators begin the annotation process. To collect large numbers of labels from human annotators, creators frequently rely on dedicated annotation platforms, which can connect them to teams of human annotators. When using these platforms, creators may have little insight to annotators' backgrounds and levels of experience with topics of interest. However, some platforms offer access to annotators with specific expertise (e.g. doctors).
+After deciding on their labels' desired content and format, creators begin the annotation process. To collect large numbers of labels from human annotators, creators frequently rely on dedicated annotation platforms, which can connect them to teams of human annotators. When using these platforms, creators may need more insight into annotators' backgrounds and experience levels with topics of interest. However, some platforms offer access to annotators with specific expertise (e.g., doctors).
### Ensuring Label Quality
-There is no guarantee that the data labels are actually correct. @fig-hard-labels shows some examples of hard labeling cases. It is possible that despite the best instructions being given to labelers, they still mislabel some images (@northcutt2021pervasive). Strategies like quality checks, training annotators, and collecting multiple labels per datapoint can help ensure label quality. For ambiguous tasks, multiple annotators can help identify controversial datapoints and quantify disagreement levels.
+There is no guarantee that the data labels are correct. @fig-hard-labels shows some examples of hard labeling cases. Despite the best instructions given to labelers, they still mislabel some images (@ northcutt2021pervasive). Strategies like quality checks, training annotators, and collecting multiple labels per data point can help ensure label quality. Multiple annotators can help identify controversial data points and quantify disagreement levels for ambiguous tasks.
{#fig-hard-labels}
-When working with human annotators, it is important to offer fair compensation and otherwise prioritize ethical treatment, as annotators can be exploited or otherwise harmed during the labeling process (Perrigo, 2023). For example, if a dataset is likely to contain disturbing content, annotators may benefit from having the option to view images in grayscale (@googleinformation).
+When working with human annotators, offering fair compensation and otherwise prioritizing ethical treatment is important, as annotators can be exploited or otherwise harmed during the labeling process (Perrigo, 2023). For example, if a dataset is likely to contain disturbing content, annotators may benefit from having the option to view images in grayscale (@googleinformation).
### AI-Assisted Annotation
-ML has an insatiable demand for data. Therefore, no amount of data is sufficient data. This raises the question of how we can get more labeled data. Rather than always generating and curating data manually, we can rely on existing AI models to help label datasets more quickly and cheaply, though often with lower quality than human annotation. This can be done in various ways (see @fig-weak-supervision for examples), such as the following:
+ML has an insatiable demand for data. Therefore, more data is needed. This raises the question of how we can get more labeled data. Rather than always generating and curating data manually, we can rely on existing AI models to help label datasets more quickly and cheaply, though often with lower quality than human annotation. This can be done in various ways (see @fig-weak-supervision for examples), such as the following:
* **Pre-annotation:** AI models can generate preliminary labels for a dataset using methods such as semi-supervised learning (@chapelle2009semisupervised), which humans can then review and correct. This can save a significant amount of time, especially for large datasets.
* **Active learning:** AI models can identify the most informative data points in a dataset, which can then be prioritized for human annotation. This can help improve the labeled dataset's quality while reducing the overall annotation time.
-* **Quality control:** AI models can be used to identify and flag potential errors in human annotations. This can help to ensure the accuracy and consistency of the labeled dataset.
+* **Quality control:** AI models can identify and flag potential errors in human annotations, helping to ensure the accuracy and consistency of the labeled dataset.
Here are some examples of how AI-assisted annotation has been proposed to be useful:
-* **Medical imaging:** AI-assisted annotation is being used to label medical images, such as MRI scans and X-rays (@krishnan2022selfsupervised). Carefully annotating medical datasets is extremely challenging, especially at scale, since domain experts are both scarce and it becomes a costly effort. This can help to train AI models to diagnose diseases and other medical conditions more accurately and efficiently.
+* **Medical imaging:** AI-assisted annotation labels medical images, such as MRI scans and X-rays (@krishnan2022selfsupervised). Carefully annotating medical datasets is extremely challenging, especially at scale, since domain experts are scarce and become costly. This can help to train AI models to diagnose diseases and other medical conditions more accurately and efficiently.
* **Self-driving cars:** AI-assisted annotation is being used to label images and videos from self-driving cars. This can help to train AI models to identify objects on the road, such as other vehicles, pedestrians, and traffic signs.
-* **Social media:** AI-assisted annotation is being used to label social media posts, such as images and videos. This can help to train AI models to identify and classify different types of content, such as news, advertising, and personal posts.
+* **Social media:** AI-assisted annotation labels social media posts like images and videos. This can help to train AI models to identify and classify different types of content, such as news, advertising, and personal posts.
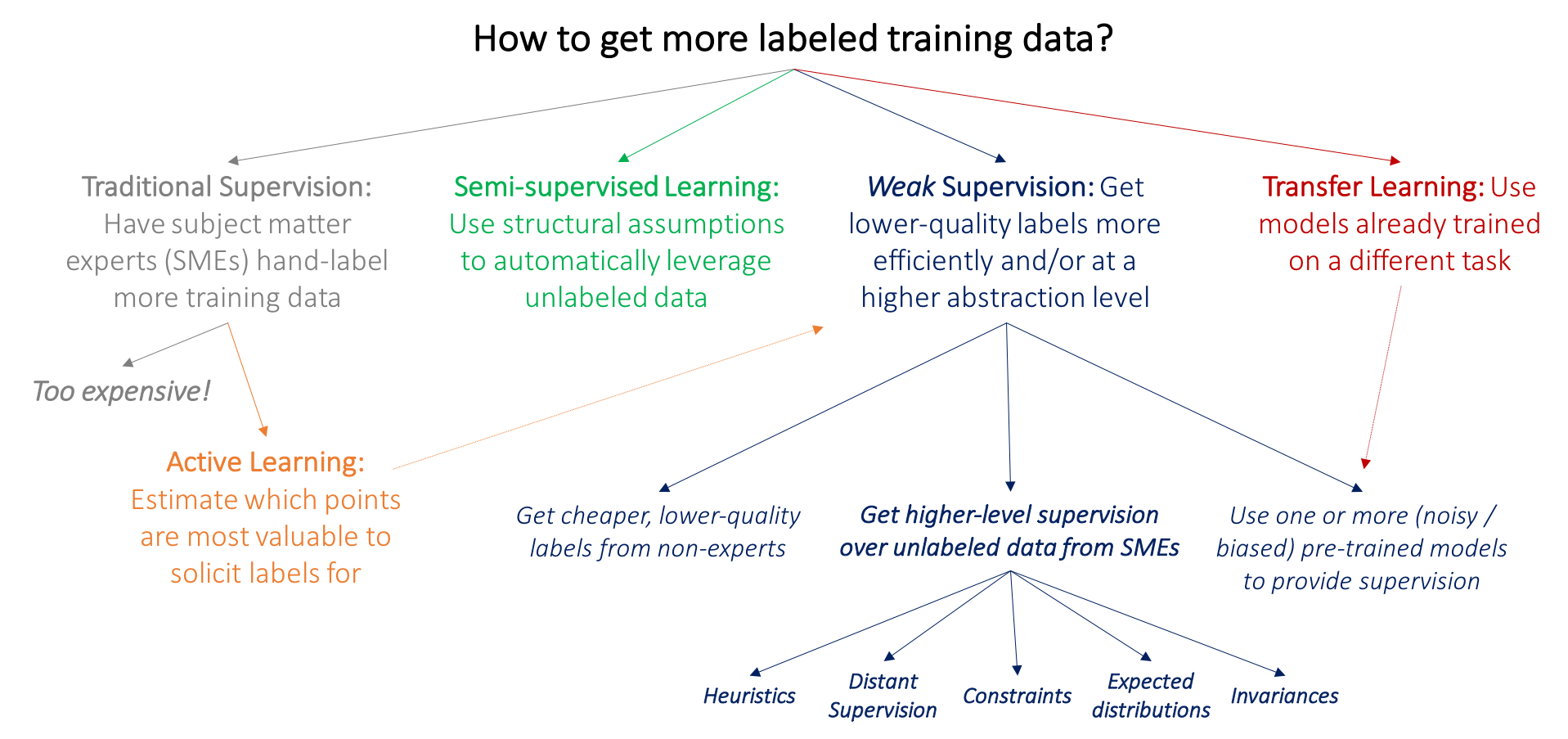{#fig-weak-supervision}
## Data Version Control
-Production systems are perpetually inundated with fluctuating and escalating volumes of data, prompting the rapid emergence of numerous data replicas. This proliferating data serves as the foundation for training machine learning models. For instance, a global sales company engaged in sales forecasting continuously receives consumer behavior data. Similarly, healthcare systems formulating predictive models for disease diagnosis are consistently acquiring new patient data. TinyML applications, such as keyword spotting, are highly data hungry in terms of the amount of data generated. Consequently, meticulous tracking of data versions and the corresponding model performance is imperative.
+Production systems are perpetually inundated with fluctuating and escalating volumes of data, prompting the rapid emergence of numerous data replicas. This increasing data serves as the foundation for training machine learning models. For instance, a global sales company engaged in sales forecasting continuously receives consumer behavior data. Similarly, healthcare systems formulating predictive models for disease diagnosis are consistently acquiring new patient data. TinyML applications, such as keyword spotting, are highly data-hungry regarding the amount of data generated. Consequently, meticulous tracking of data versions and the corresponding model performance is imperative.
-Data Version Control offers a structured methodology to handle alterations and versions of datasets efficiently. It facilitates the monitoring of modifications, preserves multiple versions, and guarantees reproducibility and traceability in data-centric projects. Furthermore, data version control provides the versatility to review and utilize specific versions as needed, ensuring that each stage of the data processing and model development can be revisited and audited with precision and ease. It has a variety of practical uses -
+Data Version Control offers a structured methodology to handle alterations and versions of datasets efficiently. It facilitates monitoring modifications, preserves multiple versions, and guarantees reproducibility and traceability in data-centric projects. Furthermore, data version control provides the versatility to review and utilize specific versions as needed, ensuring that each stage of the data processing and model development can be revisited and audited precisely and easily. It has a variety of practical uses -
-**Risk Management:** Data version control allows transparency and accountability by tracking versions of the dataset.
+**Risk Management:** Data version control allows transparency and accountability by tracking dataset versions.
-**Collaboration and Efficiency:** Easy access to different versions of the dataset in one place can improve data sharing of specific checkpoints, and enable efficient collaboration.
+**Collaboration and Efficiency:** Easy access to different dataset versions in one place can improve data sharing of specific checkpoints and enable efficient collaboration.
-**Reproducibility:** Data version control allows for tracking the performance of models with respect to different versions of the data,
+**Reproducibility:** Data version control allows for tracking the performance of models concerning different versions of the data,
and therefore enabling reproducibility.
**Key Concepts**
* **Commits:** It is an immutable snapshot of the data at a specific point in time, representing a unique version. Every commit is associated with a unique identifier to allow
-* **Branches:** Branching allows developers and data scientists to diverge from the main line of development and continue to work independently without affecting other branches. This is especially useful when experimenting with new features or models, enabling parallel development and experimentation without the risk of corrupting the stable, main branch.
+* **Branches:** Branching allows developers and data scientists to diverge from the main development line and continue to work independently without affecting other branches. This is especially useful when experimenting with new features or models, enabling parallel development and experimentation without the risk of corrupting the stable main branch.
* **Merges:** Merges help to integrate changes from different branches while maintaining the integrity of the data.
-With data version control in place, we are able to track the changes as shown in @fig-data-version-ctrl, reproduce previous results by reverting to older versions, and collaborate safely by branching off and isolating the changes.
+With data version control in place, we can track the changes shown in @fig-data-version-ctrl, reproduce previous results by reverting to older versions, and collaborate safely by branching off and isolating the changes.
{#fig-data-version-ctrl}
**Popular Data Version Control Systems**
-[**[DVC]{.underline}**](https://dvc.org/doc): It stands for Data Version Control in short, and is an open-source, lightweight tool that works on top of github and supports all kinds of data format. It can seamlessly integrate into the Git workflow, if Git is being used for managing code. It captures the versions of data and models in the Git commits, while storing them on premises or on cloud (e.g. AWS, Google Cloud, Azure). These data and models (e.g. ML artifacts) are defined in the metadata files, which get updated in every commit. It can allow metrics tracking of models on different versions of the data.
+[**[DVC]{.underline}**](https://dvc.org/doc): It stands for Data Version Control in short and is an open-source, lightweight tool that works on top of Git Hub and supports all kinds of data formats. It can seamlessly integrate into the workflow if Git is used to manage code. It captures the versions of data and models in the Git commits while storing them on-premises or on the cloud (e.g., AWS, Google Cloud, Azure). These data and models (e.g., ML artifacts) are defined in the metadata files, which get updated in every commit. It can allow metrics tracking of models on different versions of the data.
-**[[lakeFS]{.underline}](https://docs.lakefs.io/):** It is an open-source tool that supports the data version control on data lakes. It supports many git-like operations such as branching and merging of data, as well as reverting to previous versions of the data. It also has a unique UI feature which allows exploration and management of data much easier.
+**[[lakeFS]{.underline}](https://docs.lakefs.io/):** It is an open-source tool that supports the data version control on data lakes. It supports many git-like operations, such as branching and merging of data, as well as reverting to previous versions of the data. It also has a unique UI feature, making exploring and managing data much easier.
-**[[Git LFS]{.underline}](https://git-lfs.com/):** It is useful for data version control on smaller sized datasets. It uses Git's inbuilt branching and merging features, but is limited in terms of tracking metrics, reverting to previous versions or integration with data lakes.
+**[[Git LFS]{.underline}](https://git-lfs.com/):** It is useful for data version control on smaller-sized datasets. It uses Git's inbuilt branching and merging features but is limited in tracking metrics, reverting to previous versions, or integrating with data lakes.
## Optimizing Data for Embedded AI
-Creators working on embedded systems may have unusual priorities when cleaning their datasets. On the one hand, models may be developed for unusually specific use cases, requiring heavy filtering of datasets. While other natural language models may be capable of turning any speech to text, a model for an embedded system may be focused on a single limited task, such as detecting a keyword. As a result, creators may aggressively filter out large amounts of data because they do not address the task of interest. Additionally, an embedded AI system may be tied to specific hardware devices or environments. For example, a video model may need to process images from a single type of camera, which will only be mounted on doorbells in residential neighborhoods. In this scenario, creators may discard images if they came from a different kind of camera, show the wrong type of scenery, or were taken from the wrong height or angle.
+Creators working on embedded systems may have unusual priorities when cleaning their datasets. On the one hand, models may be developed for unusually specific use cases, requiring heavy filtering of datasets. While other natural language models may be capable of turning any speech into text, a model for an embedded system may be focused on a single limited task, such as detecting a keyword. As a result, creators may aggressively filter out large amounts of data because they need to address the task of interest. An embedded AI system may also be tied to specific hardware devices or environments. For example, a video model may need to process images from a single type of camera, which will only be mounted on doorbells in residential neighborhoods. In this scenario, creators may discard images if they came from a different kind of camera, show the wrong type of scenery, or were taken from the wrong height or angle.
-On the other hand, embedded AI systems are often expected to provide especially accurate performance in unpredictable real-world settings. This may lead creators to design datasets specifically to represent variations in potential inputs and promote model robustness. As a result, they may define a narrow scope for their project but then aim for deep coverage within those bounds. For example, creators of the doorbell model mentioned above might try to cover variations in data arising from:
+On the other hand, embedded AI systems are often expected to provide especially accurate performance in unpredictable real-world settings. This may lead creators to design datasets to represent variations in potential inputs and promote model robustness. As a result, they may define a narrow scope for their project but then aim for deep coverage within those bounds. For example, creators of the doorbell model mentioned above might try to cover variations in data arising from:
-* Geographically, socially and architecturally diverse neighborhoods
+* Geographically, socially, and architecturally diverse neighborhoods
* Different types of artificial and natural lighting
* Different seasons and weather conditions
-* Obstructions (e.g. raindrops or delivery boxes obscuring the camera's view)
+* Obstructions (e.g., raindrops or delivery boxes obscuring the camera's view)
-As described above, creators may consider crowdsourcing or synthetically generating data to include these different kinds of variations.
+As described above, creators may consider crowdsourcing or synthetically generating data to include these variations.
-## Data Transparency
+## Data Transparency {#sec-data-transparency}
-By providing clear, detailed documentation, creators can help developers understand how best to use their datasets. Several groups have suggested standardized documentation formats for datasets, such as Data Cards (@pushkarna2022data), datasheets (@gebru2021datasheets), data statements (@bender2018data), or Data Nutrition Labels (@holland2020dataset). When releasing a dataset, creators may describe what kinds of data they collected, how they collected and labeled it, and what kinds of use cases may be a good or poor fit for the dataset. Quantitatively, it may be appropriate to provide a breakdown of how well the dataset represents different groups (e.g. different gender groups, different cameras).
+By providing clear, detailed documentation, creators can help developers understand how best to use their datasets. Several groups have suggested standardized documentation formats for datasets, such as Data Cards (@pushkarna2022data), datasheets (@gebru2021datasheets), data statements (@bender2018data), or Data Nutrition Labels (@holland2020dataset). When releasing a dataset, creators may describe what kinds of data they collected, how they collected and labeled it, and what kinds of use cases may be a good or poor fit for the dataset. Quantitatively, it may be appropriate to show how well the dataset represents different groups (e.g., different gender groups, different cameras).
-@fig-data-card shows an example of a data card for a computer vision (CV) dataset. It includes some basic information about the dataset and instructions on how to use or not to use the dataset, including known biases.
+@fig-data-card shows an example of a data card for a computer vision (CV) dataset. It includes some basic information about the dataset and instructions on how to use it, including known biases.
{#fig-data-card}
-Keeping track of data provenance-essentially the origins and the journey of each data point through the data pipeline-is not merely a good practice but an essential requirement for data quality. Data provenance contributes significantly to the transparency of machine learning systems. Transparent systems make it easier to scrutinize data points, enabling better identification and rectification of errors, biases, or inconsistencies. For instance, if a ML model trained on medical data is underperforming in particular areas, tracing back the data provenance can help identify whether the issue is with the data collection methods, the demographic groups represented in the data, or other factors. This level of transparency doesn't just help in debugging the system but also plays a crucial role in enhancing the overall data quality. By improving the reliability and credibility of the dataset, data provenance also enhances the model's performance and its acceptability among end-users.
+Keeping track of data provenance- essentially the origins and the journey of each data point through the data pipeline- is not merely a good practice but an essential requirement for data quality. Data provenance contributes significantly to the transparency of machine learning systems. Transparent systems make it easier to scrutinize data points, enabling better identification and rectification of errors, biases, or inconsistencies. For instance, if an ML model trained on medical data is underperforming in particular areas, tracing the provenance can help identify whether the issue is with the data collection methods, the demographic groups represented in the data or other factors. This level of transparency doesn't just help debug the system but also plays a crucial role in enhancing the overall data quality. By improving the reliability and credibility of the dataset, data provenance also enhances the model's performance and its acceptability among end-users.
-When producing documentation, creators should also clearly specify how users can access the dataset and how the dataset will be maintained over time. For example, users may need to undergo training or receive special permission from the creators before accessing a dataset containing protected information, as is the case with many medical datasets. In some cases, users may not be permitted to directly access the data and must instead submit their model to be trained on the dataset creators' hardware, following a federated learning setup (@aledhari2020federated). Creators may also describe how long the dataset will remain accessible, how the users can submit feedback on any errors that they discover, and whether there are plans to update the dataset.
+When producing documentation, creators should also specify how users can access the dataset and how the dataset will be maintained over time. For example, users may need to undergo training or receive special permission from the creators before accessing a protected information dataset, as with many medical datasets. In some cases, users may not access the data directly. Instead, they must submit their model to be trained on the dataset creators' hardware, following a federated learning setup (@aledhari2020federated). Creators may also describe how long the dataset will remain accessible, how the users can submit feedback on any errors they discover, and whether there are plans to update the dataset.
-Some laws and regulations promote also data transparency through new requirements for organizations:
+Some laws and regulations also promote data transparency through new requirements for organizations:
-* General Data Protection Regulation (GDPR) in European Union: It establishes strict requirements for processing and protecting personal data of EU citizens. It mandates plain language privacy policies that clearly explain what data is collected, why it is used, how long it is stored, and with whom it is shared. GDPR also mandates that privacy notices must include details on legal basis for processing, data transfers, retention periods, rights to access and deletion, and contact info for data controllers.
-* California's Consumer Privacy Act (CCPA): CCPA requires clear privacy policies and opt-out rights for the sale of personal data. Significantly, it also establishes rights for consumers to request their specific data be disclosed. Businesses must provide copies of collected personal information along with details on what it is used for, what categories are collected, and what third parties receive it. Consumers can identify data points they believe are inaccurate. The law represents a major step forward in empowering personal data access.
+* General Data Protection Regulation (GDPR) in the European Union: It establishes strict requirements for processing and protecting the personal data of EU citizens. It mandates plain-language privacy policies that clearly explain what data is collected, why it is used, how long it is stored, and with whom it is shared. GDPR also mandates that privacy notices must include details on the legal basis for processing, data transfers, retention periods, rights to access and deletion, and contact info for data controllers.
+* California's Consumer Privacy Act (CCPA): CCPA requires clear privacy policies and opt-out rights to sell personal data. Significantly, it also establishes rights for consumers to request their specific data be disclosed. Businesses must provide copies of collected personal information and details on what it is used for, what categories are collected, and what third parties receive. Consumers can identify data points they believe need to be more accurate. The law represents a major step forward in empowering personal data access.
-There are several current challenges in ensuring data transparency, especially because it requires significant time and financial resources. Data systems are also quite complex, and full transparency can be difficult to achieve in these cases. Full transparency may also overwhelm the consumers with too much detail. And finally, it is also important to balance the tradeoff between transparency and privacy.
+Ensured data transparency presents several challenges, especially because it requires significant time and financial resources. Data systems are also quite complex, and full transparency can take time. Full transparency may also overwhelm consumers with too much detail. Finally, it is also important to balance the tradeoff between transparency and privacy.
## Licensing
Many high-quality datasets either come from proprietary sources or contain copyrighted information. This introduces licensing as a challenging legal domain. Companies eager to train ML systems must engage in negotiations to obtain licenses that grant legal access to these datasets. Furthermore, licensing terms can impose restrictions on data applications and sharing methods. Failure to comply with these licenses can have severe consequences.
-For instance, ImageNet, one of the most extensively utilized datasets for computer vision research, is a case in point. A majority of its images were procured from public online sources without obtaining explicit permissions, sparking ethical concerns (Prabhu and Birhane, 2020). Accessing the ImageNet dataset for corporations requires registration and adherence to its terms of use, which restricts commercial usage ([[ImageNet]{.underline}](https://www.image-net.org/#), 2021). Major players like Google and Microsoft invest significantly in licensing datasets to enhance their ML vision systems. However, the cost factor restricts accessibility for researchers from smaller companies with constrained budgets.
+For instance, ImageNet, one of the most extensively utilized datasets for computer vision research, is a case in point. Most of its images were procured from public online sources without explicit permission, sparking ethical concerns (Prabhu and Birhane, 2020). Accessing the ImageNet dataset for corporations requires registration and adherence to its terms of use, which restricts commercial usage ([[ImageNet]{.underline}](https://www.image-net.org/#), 2021). Major players like Google and Microsoft invest significantly in licensing datasets to enhance their ML vision systems. However, the cost factor restricts accessibility for researchers from smaller companies with constrained budgets.
-The legal domain of data licensing has seen major cases that help define parameters of fair use. A prominent example is _Authors Guild, Inc. v. Google, Inc._ This 2005 lawsuit alleged that Google\'s book scanning project infringed copyrights by displaying snippets without permission. However, the courts ultimately ruled in Google\'s favor, upholding fair use based on the transformative nature of creating a searchable index and showing limited text excerpts. This precedent provides some legal grounds for arguing fair use protections apply to indexing datasets and generating representative samples for machine learning. However, restrictions specified in licenses remain binding, so comprehensive analysis of licensing terms is critical. The case demonstrates why negotiations with data providers are important to enable legal usage within acceptable bounds.
+The legal domain of data licensing has seen major cases that help define fair use parameters. A prominent example is _Authors Guild, Inc. v. Google, Inc._ This 2005 lawsuit alleged that Google's book scanning project infringed copyrights by displaying snippets without permission. However, the courts ultimately ruled in Google's favor, upholding fair use based on the transformative nature of creating a searchable index and showing limited text excerpts. This precedent provides some legal grounds for arguing fair use protections apply to indexing datasets and generating representative samples for machine learning. However, license restrictions remain binding, so a comprehensive analysis of licensing terms is critical. The case demonstrates why negotiations with data providers are important to enable legal usage within acceptable bounds.
**New Data Regulations and Their Implications**
@@ -452,32 +442,32 @@ New data regulations also impact licensing practices. The legislative landscape
3. Emphasizes data quality, transparency, human oversight, and accountability.
-Additionally, the EU Act addresses the ethical dimensions and operational challenges in sectors such as healthcare and finance. Key elements include the prohibition of AI systems posing \"unacceptable\" risks, stringent conditions for high-risk systems, and minimal obligations for \"limited risk\" AI systems. The proposed European AI Board will oversee and ensure efficient regulation implementation.
+Additionally, the EU Act addresses the ethical dimensions and operational challenges in sectors such as healthcare and finance. Key elements include the prohibition of AI systems posing \"unacceptable\" risks, stringent conditions for high-risk systems, and minimal obligations for \"limited risk\" AI systems. The proposed European AI Board will oversee and ensure the implementation of efficient regulation.
**Challenges in Assembling ML Training Datasets**
-Complex licensing issues around proprietary data, copyright law, and privacy regulations all constrain options for assembling ML training datasets. But expanding accessibility through more open licensing or public-private data collaborations could greatly accelerate industry progress and ethical standards.
+Complex licensing issues around proprietary data, copyright law, and privacy regulations constrain options for assembling ML training datasets. However, expanding accessibility through more open licensing or public-private data collaborations could greatly accelerate industry progress and ethical standards.
-In some cases, certain portions of a dataset may need to be removed or obscured in order to comply with data usage agreements or protect sensitive information. For example, a dataset of user information may have names, contact details, and other identifying data that may need to be removed from the dataset, this is well after the dataset has already been actively sourced and used for training models. Similarly, a dataset that includes copyrighted content or trade secrets may need to have those portions filtered out before being distributed. Laws such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Amended Act on the Protection of Personal Information ([[APPI]{.underline}](https://www.ppc.go.jp/files/pdf/280222_amendedlaw.pdf)) have been passed to guarantee the right to be forgotten. These regulations legally require model providers to erase user data upon request.
+Sometimes, certain portions of a dataset may need to be removed or obscured to comply with data usage agreements or protect sensitive information. For example, a dataset of user information may have names, contact details, and other identifying data that may need to be removed from the dataset; this is well after the dataset has already been actively sourced and used for training models. Similarly, a dataset that includes copyrighted content or trade secrets may need to filter out those portions before being distributed. Laws such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Amended Act on the Protection of Personal Information ([[APPI]{.underline}](https://www.ppc.go.jp/files/pdf/280222_amendedlaw.pdf)) have been passed to guarantee the right to be forgotten. These regulations legally require model providers to erase user data upon request.
-Data collectors and providers need to be able to take appropriate measures to de-identify or filter out any proprietary, licensed, confidential, or regulated information as needed. In some cases, the users may explicitly request that their data be removed.
+Data collectors and providers need to be able to take appropriate measures to de-identify or filter out any proprietary, licensed, confidential, or regulated information as needed. Sometimes, the users may explicitly request that their data be removed.
-Having the ability to update the dataset by removing data from the dataset will enable the dataset creators to uphold legal and ethical obligations around data usage and privacy. However, the ability to remove data has some important limitations. We need to think about the fact that some models may have already been trained on the dataset and there is no clear or known way to eliminate a particular data sample\'s effect from the trained network. There is no erase mechanism. Thus, this begs the question, should the model be re-trained from scratch each time a sample is removed? That\'s a costly option. Once data has been used to train a model, simply removing it from the original dataset may not fully eliminate its impact on the model\'s behavior. New research is needed around the effects of data removal on already-trained models and whether full retraining is necessary to avoid retaining artifacts of deleted data. This presents an important consideration when balancing data licensing obligations with efficiency and practicality in an evolving, deployed ML system.
+The ability to update the dataset by removing data from the dataset will enable the creators to uphold legal and ethical obligations around data usage and privacy. However, the ability to remove data has some important limitations. We must consider that some models may have already been trained on the dataset, and there is no clear or known way to eliminate a particular data sample's effect from the trained network. There is no erase mechanism. Thus, this begs the question, should the model be retrained from scratch each time a sample is removed? That's a costly option. Once data has been used to train a model, simply removing it from the original dataset may not fully eliminate its impact on the model's behavior. New research is needed around the effects of data removal on already-trained models and whether full retraining is necessary to avoid retaining artifacts of deleted data. This presents an important consideration when balancing data licensing obligations with efficiency and practicality in an evolving, deployed ML system.
-Dataset licensing is a multifaceted domain intersecting technology, ethics, and law. As the world around us evolves, understanding these intricacies becomes paramount for anyone building datasets during data engineering.
+Dataset licensing is a multifaceted domain that intersects technology, ethics, and law. Understanding these intricacies becomes paramount for anyone building datasets during data engineering as the world evolves.
## Conclusion
-Data is the fundamental building block of AI systems. Without quality data, even the most advanced machine learning algorithms will fail. Data engineering encompasses the end-to-end process of collecting, storing, processing and managing data to fuel the development of machine learning models. It begins with clearly defining the core problem and objectives, which guides effective data collection. Data can be sourced from diverse means including existing datasets, web scraping, crowdsourcing and synthetic data generation. Each approach involves tradeoffs between factors like cost, speed, privacy and specificity. Once data is collected, thoughtful labeling through manual or AI-assisted annotation enables the creation of high-quality training datasets. Proper storage in databases, warehouses or lakes facilitates easy access and analysis. Metadata provides contextual details about the data. Data processing transforms raw data into a clean, consistent format ready for machine learning model development. Throughout this pipeline, transparency through documentation and provenance tracking is crucial for ethics, auditability and reproducibility. Data licensing protocols also govern legal data access and use. Key challenges in data engineering include privacy risks, representation gaps, legal restrictions around proprietary data, and the need to balance competing constraints like speed versus quality. By thoughtfully engineering high-quality training data, machine learning practitioners can develop accurate, robust and responsible AI systems, including for embedded and TinyML applications.
+Data is the fundamental building block of AI systems. Without quality data, even the most advanced machine learning algorithms will fail. Data engineering encompasses the end-to-end process of collecting, storing, processing, and managing data to fuel the development of machine learning models. It begins with clearly defining the core problem and objectives, which guides effective data collection. Data can be sourced from diverse means, including existing datasets, web scraping, crowdsourcing, and synthetic data generation. Each approach involves tradeoffs between cost, speed, privacy, and specificity. Once data is collected, thoughtful labeling through manual or AI-assisted annotation enables the creation of high-quality training datasets. Proper storage in databases, warehouses, or lakes facilitates easy access and analysis. Metadata provides contextual details about the data. Data processing transforms raw data into a clean, consistent format for machine learning model development. Throughout this pipeline, transparency through documentation and provenance tracking is crucial for ethics, auditability, and reproducibility. Data licensing protocols also govern legal data access and use. Key challenges in data engineering include privacy risks, representation gaps, legal restrictions around proprietary data, and the need to balance competing constraints like speed versus quality. By thoughtfully engineering high-quality training data, machine learning practitioners can develop accurate, robust, and responsible AI systems, including embedded and TinyML applications.
## Resources {#sec-data-engineering-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Data Engineering: Overview.](https://docs.google.com/presentation/d/1nuNFjB99ccE6hqFeAmRRbhoEoSjBgJXGr9u6cvwnXgM/edit#slide=id.p19)
@@ -491,14 +481,14 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
* [Responsible Data Collection.](https://docs.google.com/presentation/d/1vcmuhLVNFT2asKSCSGh_Ix9ht0mJZxMii8MufEMQhFA/edit?resourcekey=0-_pYLcW5aF3p3Bvud0PPQNg#slide=id.ga4ca29c69e_0_195)
-* Data Anamoly Detection:
- * [Anamoly Detection: Overview.](https://docs.google.com/presentation/d/1R8A_5zKDZDZOdAb1XF9ovIOUTLWSIuFWDs20-avtxbM/edit?resourcekey=0-pklEaPv8PmLQ3ZzRYgRNxw#slide=id.g94db9f9f78_0_2)
-
- * [Anamoly Detection: Challenges.](https://docs.google.com/presentation/d/1JZxx2kLaO1a8O6z6rRVFpK0DN-8VMkaSrNnmk_VGbI4/edit#slide=id.g53eb988857_0_91)
+* Data Anomaly Detection:
+ * [Anamoly Detection: Overview.](https://docs.google.com/presentation/d/1R8A_5zKDZDZOdAb1XF9ovIOUTLWSIuFWDs20-avtxbM/edit?resourcekey=0-pklEaPv8PmLQ3ZzRYgRNxw#slide=id.g94db9f9f78_0_2)
+
+ * [Anamoly Detection: Challenges.](https://docs.google.com/presentation/d/1JZxx2kLaO1a8O6z6rRVFpK0DN-8VMkaSrNnmk_VGbI4/edit#slide=id.g53eb988857_0_91)
- * [Anamoly Detection: Datasets.](https://docs.google.com/presentation/d/1wPDhp4RxVrOonp6pU0Capk0LWXZOGZ3x9BzW_VjpTQw/edit?resourcekey=0-y6wKAnuxrLWqhleq9ruLOA#slide=id.g53eb988857_0_91)
+ * [Anamoly Detection: Datasets.](https://docs.google.com/presentation/d/1wPDhp4RxVrOonp6pU0Capk0LWXZOGZ3x9BzW_VjpTQw/edit?resourcekey=0-y6wKAnuxrLWqhleq9ruLOA#slide=id.g53eb988857_0_91)
- * [Anamoly Detection: using Autoencoders.](https://docs.google.com/presentation/d/1Q4h7XrayNRIP0r52Hlk5VjxRcli-GY2xmyZ53nCd6CI/edit#slide=id.g53eb988857_0_91)
+ * [Anamoly Detection: using Autoencoders.](https://docs.google.com/presentation/d/1Q4h7XrayNRIP0r52Hlk5VjxRcli-GY2xmyZ53nCd6CI/edit#slide=id.g53eb988857_0_91)
:::
@@ -520,7 +510,7 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/dl_primer/dl_primer.bib b/contents/dl_primer/dl_primer.bib
index a62cccf9..0486c4f7 100644
--- a/contents/dl_primer/dl_primer.bib
+++ b/contents/dl_primer/dl_primer.bib
@@ -1,10 +1,13 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@article{bank2023autoencoders,
author = {Bank, Dor and Koenigstein, Noam and Giryes, Raja},
journal = {Machine Learning for Data Science Handbook: Data Mining and Knowledge Discovery Handbook},
pages = {353--374},
publisher = {Springer},
title = {Autoencoders},
- year = {2023}
+ year = {2023},
}
@article{goodfellow2020generative,
@@ -19,13 +22,14 @@ @article{goodfellow2020generative
title = {Generative adversarial networks},
url = {https://doi.org/10.1145/3422622},
volume = {63},
- year = {2020}
+ year = {2020},
+ month = oct,
}
@inproceedings{jouppi2017datacenter,
+ author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
abstract = {Many architects believe that major improvements in cost-energy-performance must now come from domain-specific hardware. This paper evaluates a custom ASIC{\textemdash}called a Tensor Processing Unit (TPU) {\textemdash} deployed in datacenters since 2015 that accelerates the inference phase of neural networks (NN). The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory. The TPU's deterministic execution model is a better match to the 99th-percentile response-time requirement of our NN applications than are the time-varying optimizations of CPUs and GPUs that help average throughput more than guaranteed latency. The lack of such features helps explain why, despite having myriad MACs and a big memory, the TPU is relatively small and low power. We compare the TPU to a server-class Intel Haswell CPU and an Nvidia K80 GPU, which are contemporaries deployed in the same datacenters. Our workload, written in the high-level TensorFlow framework, uses production NN applications (MLPs, CNNs, and LSTMs) that represent 95\% of our datacenters' NN inference demand. Despite low utilization for some applications, the TPU is on average about 15X {\textendash} 30X faster than its contemporary GPU or CPU, with TOPS/Watt about 30X {\textendash} 80X higher. Moreover, using the CPU's GDDR5 memory in the TPU would triple achieved TOPS and raise TOPS/Watt to nearly 70X the GPU and 200X the CPU.},
address = {New York, NY, USA},
- author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
bdsk-url-1 = {https://doi.org/10.1145/3079856.3080246},
booktitle = {Proceedings of the 44th Annual International Symposium on Computer Architecture},
doi = {10.1145/3079856.3080246},
@@ -39,27 +43,28 @@ @inproceedings{jouppi2017datacenter
source = {Crossref},
title = {In-Datacenter Performance Analysis of a Tensor Processing Unit},
url = {https://doi.org/10.1145/3079856.3080246},
- year = {2017}
+ year = {2017},
+ month = jun,
}
@inproceedings{krizhevsky2012imagenet,
- author = {Alex Krizhevsky and Ilya Sutskever and Geoffrey E. Hinton},
+ author = {Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E.},
+ editor = {Bartlett, Peter L. and Pereira, Fernando C. N. and Burges, Christopher J. C. and Bottou, L\'eon and Weinberger, Kilian Q.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/KrizhevskySH12.bib},
booktitle = {Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States},
- editor = {Peter L. Bartlett and Fernando C. N. Pereira and Christopher J. C. Burges and L{\'{e}}on Bottou and Kilian Q. Weinberger},
pages = {1106--1114},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
- title = {ImageNet Classification with Deep Convolutional Neural Networks},
+ title = {{ImageNet} Classification with Deep Convolutional Neural Networks},
url = {https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html},
- year = {2012}
+ year = {2012},
}
@book{rosenblatt1957perceptron,
author = {Rosenblatt, Frank},
publisher = {Cornell Aeronautical Laboratory},
title = {The perceptron, a perceiving and recognizing automaton Project Para},
- year = {1957}
+ year = {1957},
}
@article{rumelhart1986learning,
@@ -74,18 +79,14 @@ @article{rumelhart1986learning
title = {Learning representations by back-propagating errors},
url = {https://doi.org/10.1038/323533a0},
volume = {323},
- year = {1986}
+ year = {1986},
+ month = oct,
}
-@inproceedings{vaswani2017attention,
- author = {Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin},
- bibsource = {dblp computer science bibliography, https://dblp.org},
- biburl = {https://dblp.org/rec/conf/nips/VaswaniSPUJGKP17.bib},
- booktitle = {Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, {USA}},
- editor = {Isabelle Guyon and Ulrike von Luxburg and Samy Bengio and Hanna M. Wallach and Rob Fergus and S. V. N. Vishwanathan and Roman Garnett},
- pages = {5998--6008},
- timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
- title = {Attention is All you Need},
- url = {https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html},
- year = {2017}
+@article{vaswani2017attention,
+ title={Attention is all you need},
+ author={Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {\L}ukasz and Polosukhin, Illia},
+ journal={Advances in neural information processing systems},
+ volume={30},
+ year={2017}
}
diff --git a/contents/dl_primer/dl_primer.qmd b/contents/dl_primer/dl_primer.qmd
index b6ba898a..02e62a7f 100644
--- a/contents/dl_primer/dl_primer.qmd
+++ b/contents/dl_primer/dl_primer.qmd
@@ -8,9 +8,9 @@ bibliography: dl_primer.bib
Resources: [Slides](#sec-deep-learning-primer-resource), [Labs](#sec-deep-learning-primer-resource), [Exercises](#sec-deep-learning-primer-resource)
:::
-
+
-This section offers a brief introduction to deep learning, starting with an overview of its history, applications, and relevance to embedded AI systems. It examines the core concepts like neural networks, highlighting key components like perceptrons, multilayer perceptrons, activation functions, and computational graphs. The primer also briefly explores major deep learning architecture, contrasting their applications and uses. Additionally, it compares deep learning to traditional machine learning to equip readers with the general conceptual building blocks to make informed choices between deep learning and traditional ML techniques based on problem constraints, setting the stage for more advanced techniques and applications that will follow in subsequent chapters.
+This section briefly introduces deep learning, starting with an overview of its history, applications, and relevance to embedded AI systems. It examines the core concepts like neural networks, highlighting key components like perceptrons, multilayer perceptrons, activation functions, and computational graphs. The primer also briefly explores major deep learning architecture, contrasting their applications and uses. Additionally, it compares deep learning to traditional machine learning to equip readers with the general conceptual building blocks to make informed choices between deep learning and traditional ML techniques based on problem constraints, setting the stage for more advanced techniques and applications that will follow in subsequent chapters.
::: {.callout-tip}
@@ -22,7 +22,7 @@ This section offers a brief introduction to deep learning, starting with an over
* Comparison between deep learning and traditional machine learning approaches across various dimensions.
-* Acquire the basic conceptual building blocks to delve deeper into advanced deep learning techniques and applications.
+* Acquire the basic conceptual building blocks to delve deeper into advanced deep-learning techniques and applications.
:::
@@ -33,7 +33,7 @@ This section offers a brief introduction to deep learning, starting with an over
Deep learning, a specialized area within machine learning and artificial intelligence (AI), utilizes algorithms modeled after the structure and function of the human brain, known as artificial neural networks. This field is a foundational element in AI, driving progress in diverse sectors such as computer vision, natural language processing, and self-driving vehicles. Its significance in embedded AI systems is highlighted by its capability to handle intricate calculations and predictions, optimizing the limited resources in embedded settings.
-](./images/png/ai_dl_progress_nvidia.png)
+](images/png/ai_dl_progress_nvidia.png)
### Brief History of Deep Learning
@@ -41,49 +41,49 @@ The idea of deep learning has origins in early artificial neural networks. It ha
The term "deep learning" became prominent in the 2000s, characterized by advances in computational power and data accessibility. Important milestones include the successful training of deep networks like AlexNet [@krizhevsky2012imagenet] by [Geoffrey Hinton](https://amturing.acm.org/award_winners/hinton_4791679.cfm), a leading figure in AI, and the renewed focus on neural networks as effective tools for data analysis and modeling.
-In recent times, deep learning has seen exponential growth, transforming various industries. Computational growth followed an 18-month doubling pattern from 1952 to 2010, which then accelerated to a 6-month cycle from 2010 to 2022, as shown in @fig-trends. Concurrently, we saw the emergence of large-scale models between 2015 and 2022, appearing 2 to 3 orders of magnitude faster and following a 10-month doubling cycle.
+Deep learning has recently seen exponential growth, transforming various industries. Computational growth followed an 18-month doubling pattern from 1952 to 2010, which then accelerated to a 6-month cycle from 2010 to 2022, as shown in @fig-trends. Concurrently, we saw the emergence of large-scale models between 2015 and 2022, appearing 2 to 3 orders of magnitude faster and following a 10-month doubling cycle.
{#fig-trends}
Multiple factors have contributed to this surge, including advancements in computational power, the abundance of big data, and improvements in algorithmic designs. First, the growth of computational capabilities, especially the arrival of Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) [@jouppi2017datacenter], has significantly sped up the training and inference times of deep learning models. These hardware improvements have enabled the construction and training of more complex, deeper networks than what was possible in earlier years.
-Second, the digital revolution has yielded a wealth of big data, offering rich material for deep learning models to learn from and excel in tasks such as image and speech recognition, language translation, and game playing. The presence of large, labeled datasets has been key in refining and successfully deploying deep learning applications in real-world settings.
+Second, the digital revolution has yielded a wealth of big data, offering rich material for deep learning models to learn from and excel in tasks such as image and speech recognition, language translation, and game playing. Large, labeled datasets have been key in refining and successfully deploying deep learning applications in real-world settings.
-Additionally, collaborations and open-source efforts have nurtured a dynamic community of researchers and practitioners, accelerating advancements in deep learning techniques. Innovations like deep reinforcement learning, transfer learning, and generative adversarial networks have broadened the scope of what is achievable with deep learning, opening new possibilities in various sectors including healthcare, finance, transportation, and entertainment.
+Additionally, collaborations and open-source efforts have nurtured a dynamic community of researchers and practitioners, accelerating advancements in deep learning techniques. Innovations like deep reinforcement learning, transfer learning, and generative adversarial networks have broadened the scope of what is achievable with deep learning, opening new possibilities in various sectors, including healthcare, finance, transportation, and entertainment.
-Organizations around the world recognize the transformative potential of deep learning and are investing heavily in research and development to leverage its capabilities in providing innovative solutions, optimizing operations, and creating new business opportunities. As deep learning continues its upward trajectory, it is set to redefine how we interact with technology, enhancing convenience, safety, and connectivity in our lives.
+Organizations worldwide recognize deep learning's transformative potential and invest heavily in research and development to leverage its capabilities in providing innovative solutions, optimizing operations, and creating new business opportunities. As deep learning continues its upward trajectory, it is set to redefine how we interact with technology, enhancing convenience, safety, and connectivity in our lives.
### Applications of Deep Learning
-Deep learning finds extensive use across numerous industries today. In finance, it is employed for stock market prediction, risk assessment, and fraud detection. In marketing, it is used for customer segmentation, personalization, and content optimization. In healthcare, machine learning aids in diagnosis, treatment planning, and patient monitoring. The transformative impact on society is evident.
+Deep learning is extensively used across numerous industries today. In finance, it is employed for stock market prediction, risk assessment, and fraud detection. Marketing uses it for customer segmentation, personalization, and content optimization. In healthcare, machine learning aids in diagnosis, treatment planning, and patient monitoring. The transformative impact on society is evident.
-For instance, deep learning algorithms can predict stock market trends, guiding investment strategies and enhancing financial decisions. Similarly, in healthcare, deep learning can make medical predictions that improve patient diagnosis and save lives. The benefits are clear: machine learning not only predicts with greater accuracy than humans but also does so much more quickly.
+For instance, deep learning algorithms can predict stock market trends, guide investment strategies, and enhance financial decisions. Similarly, in healthcare, deep learning can make medical predictions that improve patient diagnosis and save lives. The benefits are clear: machine learning predicts with greater accuracy than humans and does so much more quickly.
-In manufacturing, deep learning has had a significant impact. By continuously learning from vast amounts of data collected during the manufacturing process, companies can boost productivity while minimizing waste through improved efficiency. This financial benefit for companies translates to better quality products at lower prices for customers. Machine learning enables manufacturers to continually refine their processes, producing higher quality goods more efficiently than ever before.
+In manufacturing, deep learning has had a significant impact. By continuously learning from vast amounts of data collected during manufacturing, companies can boost productivity while minimizing waste through improved efficiency. This financial benefit for companies translates to better quality products at lower customer prices. Machine learning enables manufacturers to continually refine their processes, producing higher quality goods more efficiently than ever.
-Deep learning also enhances everyday products like Netflix recommendations and Google Translate text translations. Moreover, it helps companies like Amazon and Uber reduce customer service costs by swiftly identifying dissatisfied customers.
+Deep learning enhances everyday products like Netflix recommendations and Google Translate text translations. Moreover, it helps companies like Amazon and Uber reduce customer service costs by swiftly identifying dissatisfied customers.
### Relevance to Embedded AI
-Embedded AI, the integration of AI algorithms directly into hardware devices, naturally gains from the capabilities of deep learning. The combination of deep learning algorithms and embedded systems has laid the groundwork for intelligent, autonomous devices capable of advanced on-device data processing and analysis. Deep learning aids in extracting complex patterns and information from input data, serving as an essential tool in the development of smart embedded systems, from household appliances to industrial machinery. This collaboration aims to usher in a new era of intelligent, interconnected devices that can learn and adapt to user behavior and environmental conditions, optimizing performance and offering unprecedented levels of convenience and efficiency.
+Embedded AI, the integration of AI algorithms directly into hardware devices, naturally gains from deep learning capabilities. Combining deep learning algorithms and embedded systems has laid the groundwork for intelligent, autonomous devices capable of advanced on-device data processing and analysis. Deep learning aids in extracting complex patterns and information from input data, which is essential in developing smart embedded systems, from household appliances to industrial machinery. This collaboration aims to usher in a new era of intelligent, interconnected devices that can learn and adapt to user behavior and environmental conditions, optimizing performance and offering unprecedented convenience and efficiency.
## Neural Networks
-Deep learning draws inspiration from the neural networks of the human brain to create patterns used in decision-making. This section delves into the foundational concepts that make up deep learning, providing insights into the more complex topics discussed later in this primer.
+Deep learning draws inspiration from the human brain's neural networks to create decision-making patterns. This section delves into the foundational concepts of deep learning, providing insights into the more complex topics discussed later in this primer.
-Neural networks serve as the foundation of deep learning, inspired by the biological neural networks in the human brain to process and analyze data hierarchically. Below, we examine the primary components and structures commonly found in neural networks.
+Neural networks serve as the foundation of deep learning, inspired by the biological neural networks in the human brain to process and analyze data hierarchically. Below, we examine the primary components and structures in neural networks.
### Perceptrons
-The perceptron is the basic unit or node that serves as the foundation for more complex structures. A perceptron takes various inputs, applies weights and a bias to these inputs, and then uses an activation function to produce an output.
+The Perceptron is the basic unit or node that is the foundation for more complex structures. It takes various inputs, applies weights and biases to them, and then uses an activation function to produce an output.
-)](./images/png/Rosenblattperceptron.png){#fig-perceptron}
+)](images/png/Rosenblattperceptron.png){#fig-perceptron}
-Conceived in the 1950s, perceptrons paved the way for the development of more intricate neural networks and have been a fundamental building block in the field of deep learning.
+Conceived in the 1950s, perceptrons paved the way for developing more intricate neural networks and have been a fundamental building block in deep learning.
-### Multi-layer Perceptrons
+### Multilayer Perceptrons
-Multi-layer perceptrons (MLPs) are an evolution of the single-layer perceptron model, featuring multiple layers of nodes connected in a feedforward manner. These layers include an input layer for data reception, several hidden layers for data processing, and an output layer for final result generation. MLPs are skilled at identifying non-linear relationships and use a backpropagation technique for training, where weights are optimized through a gradient descent algorithm.
+Multilayer perceptrons (MLPs) are an evolution of the single-layer perceptron model, featuring multiple layers of nodes connected in a feedforward manner. These layers include an input layer for data reception, several hidden layers for data processing, and an output layer for final result generation. MLPs are skilled at identifying non-linear relationships and use a backpropagation technique for training, where weights are optimized through a gradient descent algorithm.
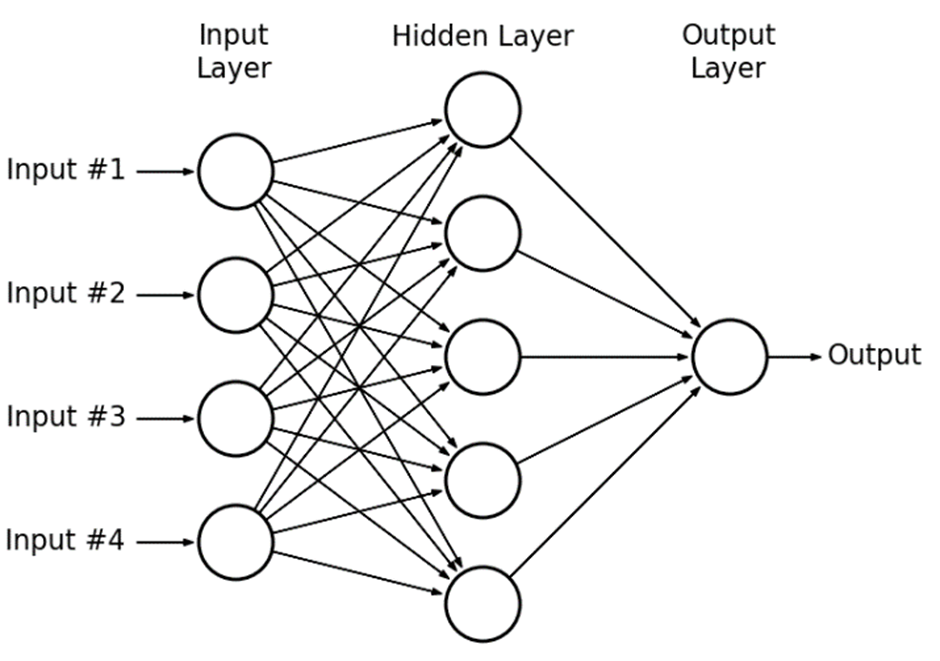{width=70%}
@@ -91,14 +91,17 @@ Multi-layer perceptrons (MLPs) are an evolution of the single-layer perceptron m
The forward pass is the initial phase where data moves through the network from the input to the output layer. During this phase, each layer performs specific computations on the input data, using weights and biases before passing the resulting values to subsequent layers. The final output of this phase is used to compute the loss, indicating the difference between the predicted output and actual target values.
+The video below explains how neural networks work using handwritten digit recognition as an example application. It also touches on the math underlying neural nets.
+
{{< video https://www.youtube.com/embed/aircAruvnKk?si=qfkBf8MJjC2WSyw3 >}}
#### Backward Pass (Backpropagation)
-Backpropagation is a key algorithm in training deep neural networks. This phase involves calculating the gradient of the loss function concerning each weight by using the chain rule, effectively moving backward through the network. The gradients calculated in this step guide the adjustment of weights with the objective of minimizing the loss function, thereby enhancing the network's performance with each iteration of training.
+Backpropagation is a key algorithm in training deep neural networks. This phase involves calculating the gradient of the loss function concerning each weight using the chain rule, effectively moving backward through the network. The gradients calculated in this step guide the adjustment of weights to minimize the loss function, thereby enhancing the network's performance with each iteration of training.
-Grasping these foundational concepts paves the way to understanding more intricate deep learning architectures and techniques, fostering the development of more sophisticated and efficacious applications, especially within the realm of embedded AI systems.
+Grasping these foundational concepts paves the way to understanding more intricate deep learning architectures and techniques, fostering the development of more sophisticated and productive applications, especially within embedded AI systems.
+The following two videos build upon the previous one. They cover gradient descent and backpropagation in neural networks.
{{< video https://www.youtube.com/watch?v=IHZwWFHWa-w&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=2 >}}
@@ -106,45 +109,45 @@ Grasping these foundational concepts paves the way to understanding more intrica
### Model Architectures
-Deep learning architectures refer to the various structured approaches that dictate how neurons and layers are organized and interact in neural networks. These architectures have evolved to tackle different problems and data types effectively. This section offers an overview of some well-known deep learning architectures and their characteristics.
+Deep learning architectures refer to the various structured approaches that dictate how neurons and layers are organized and interact in neural networks. These architectures have evolved to tackle different problems and data types effectively. This section overviews some well-known deep learning architectures and their characteristics.
-#### Multi-Layer Perceptrons (MLPs)
+#### Multilayer Perceptrons (MLPs)
-MLPs are basic deep learning architectures, comprising three or more layers: an input layer, one or more hidden layers, and an output layer. These layers are fully connected, meaning each neuron in a layer is linked to every neuron in the preceding and following layers. MLPs can model intricate functions and are used in a broad array of tasks, such as regression, classification, and pattern recognition. Their capacity to learn non-linear relationships through backpropagation makes them a versatile instrument in the deep learning toolkit.
+MLPs are basic deep learning architectures comprising three layers: an input layer, one or more hidden layers, and an output layer. These layers are fully connected, meaning each neuron in a layer is linked to every neuron in the preceding and following layers. MLPs can model intricate functions and are used in various tasks, such as regression, classification, and pattern recognition. Their capacity to learn non-linear relationships through backpropagation makes them a versatile instrument in the deep learning toolkit.
In embedded AI systems, MLPs can function as compact models for simpler tasks like sensor data analysis or basic pattern recognition, where computational resources are limited. Their ability to learn non-linear relationships with relatively less complexity makes them a suitable choice for embedded systems.
:::{#exr-mlp .callout-exercise collapse="true"}
-### Multi-Layer Perceptrons (MLPs)
+### Multilayer Perceptrons (MLPs)
-Get ready to dive into the exciting world of deep learning and TinyML! We've just covered the core building blocks of neural networks, from simple perceptrons to complex architectures. Now, you'll get to apply these concepts in practical examples. In the provided Colab notebooks, you'll explore:
+Get ready to dive into the exciting world of deep learning and TinyML! We've just covered the core building blocks of neural networks, from simple perceptrons to complex architectures. Now, you'll get to apply these concepts in practical examples. In the provided Colab notebooks, you'll explore:
-**Predicting house prices:** Learn how neural networks can analyze housing data to estimate property values.
+**Predicting house prices:** Learn how neural networks can analyze housing data to estimate property values.
[](https://colab.research.google.com/github/Mjrovai/UNIFEI-IESTI01-TinyML-2022.1/blob/main/00_Curse_Folder/1_Fundamentals/Class_07/TF_Boston_Housing_Regression.ipynb)
-**Image Classification:** Discover how to build a network capable of understanding the famous MNIST handwritten digit dataset.
+**Image Classification:** Discover how to build a network to understand the famous MNIST handwritten digit dataset.
[](https://colab.research.google.com/github/Mjrovai/UNIFEI-IESTI01-TinyML-2022.1/blob/main/00_Curse_Folder/1_Fundamentals/Class_09/TF_MNIST_Classification_v2.ipynb)
-**Real-world medical diagnosis:** Use deep learning to tackle the important task of breast cancer classification.
+**Real-world medical diagnosis:** Use deep learning to tackle the important task of breast cancer classification.
[](https://colab.research.google.com/github/Mjrovai/UNIFEI-IESTI01-TinyML-2022.1/blob/main/00_Curse_Folder/1_Fundamentals/Class_13/docs/WDBC_Project/Breast_Cancer_Classification.ipynb)
-Are you excited to start building? Let's go!
+Are you excited to start building? Let's go!
:::
#### Convolutional Neural Networks (CNNs)
-CNNs are mainly used in image and video recognition tasks. This architecture employs convolutional layers that apply a series of filters to the input data to identify features like edges, corners, and textures. A typical CNN also includes pooling layers to reduce the spatial dimensions of the data, and fully connected layers for classification. CNNs have proven highly effective in tasks such as image recognition, object detection, and computer vision applications.
+CNNs are mainly used in image and video recognition tasks. This architecture employs convolutional layers that filter input data to identify features like edges, corners, and textures. A typical CNN also includes pooling layers to reduce the spatial dimensions of the data and fully connected layers for classification. CNNs have proven highly effective in image recognition, object detection, and computer vision applications.
-In embedded AI, CNNs are crucial for image and video recognition tasks, where real-time processing is often needed. They can be optimized for embedded systems by using techniques like quantization and pruning to minimize memory usage and computational demands, enabling efficient object detection and facial recognition functionalities in devices with limited computational resources.
+In embedded AI, CNNs are crucial for image and video recognition tasks, where real-time processing is often needed. They can be optimized for embedded systems using techniques like quantization and pruning to minimize memory usage and computational demands, enabling efficient object detection and facial recognition functionalities in devices with limited computational resources.
:::{#exr-cnn .callout-exercise collapse="true"}
### Convolutional Neural Networks (CNNs)
-We discussed that CNNs excel at identifying features in images, making them ideal for tasks like object classification. Now, you'll get to put this knowledge into action! This Colab notebook focuses on building a CNN to classify images from the CIFAR-10 dataset, which includes objects like airplanes, cars, and animals. You'll learn about the key differences between CIFAR-10 and the MNIST dataset we explored earlier, and how these differences influence model choice. By the end of this notebook, you'll have a grasp of CNNs for image recognition and be well on your way to becoming a TinyML expert!
-
+We discussed that CNNs excel at identifying image features, making them ideal for tasks like object classification. Now, you'll get to put this knowledge into action! This Colab notebook focuses on building a CNN to classify images from the CIFAR-10 dataset, which includes objects like airplanes, cars, and animals. You'll learn about the key differences between CIFAR-10 and the MNIST dataset we explored earlier and how these differences influence model choice. By the end of this notebook, you'll have a grasp of CNNs for image recognition and be well on your way to becoming a TinyML expert!
+
[](https://colab.research.google.com/github/Mjrovai/UNIFEI-IESTI01-TinyML-2022.1/blob/main/00_Curse_Folder/1_Fundamentals/Class_11/CNN_Cifar_10.ipynb)
:::
@@ -153,7 +156,7 @@ We discussed that CNNs excel at identifying features in images, making them idea
RNNs are suitable for sequential data analysis, like time series forecasting and natural language processing. In this architecture, connections between nodes form a directed graph along a temporal sequence, allowing information to be carried across sequences through hidden state vectors. Variants of RNNs include Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), designed to capture longer dependencies in sequence data.
-In embedded systems, these networks can be used in voice recognition systems, predictive maintenance, or in IoT devices where sequential data patterns are common. Optimizations specific to embedded platforms can assist in managing their typically high computational and memory requirements.
+These networks can be used in voice recognition systems, predictive maintenance, or IoT devices where sequential data patterns are common. Optimizations specific to embedded platforms can assist in managing their typically high computational and memory requirements.
#### Generative Adversarial Networks (GANs)
@@ -163,7 +166,7 @@ In embedded settings, GANs could be used for on-device data augmentation to enha
#### Autoencoders
-Autoencoders are neural networks used for data compression and noise reduction [@bank2023autoencoders]. They are structured to encode input data into a lower-dimensional representation and then decode it back to its original form. Variants like Variational Autoencoders (VAEs) introduce probabilistic layers that allow for generative properties, finding applications in image generation and anomaly detection.
+Autoencoders are neural networks for data compression and noise reduction [@bank2023autoencoders]. They are structured to encode input data into a lower-dimensional representation and then decode it back to its original form. Variants like Variational Autoencoders (VAEs) introduce probabilistic layers that allow for generative properties, finding applications in image generation and anomaly detection.
Using autoencoders can help in efficient data transmission and storage, improving the overall performance of embedded systems with limited computational and memory resources.
@@ -171,13 +174,13 @@ Using autoencoders can help in efficient data transmission and storage, improvin
Transformer networks have emerged as a powerful architecture, especially in natural language processing [@vaswani2017attention]. These networks use self-attention mechanisms to weigh the influence of different input words on each output word, enabling parallel computation and capturing intricate patterns in data. Transformer networks have led to state-of-the-art results in tasks like language translation, summarization, and text generation.
-These networks can be optimized to perform language-related tasks directly on-device. For example, transformers can be used in embedded systems for real-time translation services or voice-assisted interfaces, where latency and computational efficiency are crucial. Techniques such as model distillation can be employed to deploy these networks on embedded devices with limited resources.
+These networks can be optimized to perform language-related tasks directly on the device. For example, transformers can be used in embedded systems for real-time translation services or voice-assisted interfaces, where latency and computational efficiency are crucial. Techniques such as model distillation can be employed to deploy these networks on embedded devices with limited resources.
-Each of these architectures serves specific purposes and excels in different domains, offering a rich toolkit for addressing diverse problems in the realm of embedded AI systems. Understanding the nuances of these architectures is crucial in designing effective and efficient deep learning models for various applications.
+These architectures serve specific purposes and excel in different domains, offering a rich toolkit for addressing diverse problems in embedded AI systems. Understanding the nuances of these architectures is crucial in designing effective and efficient deep learning models for various applications.
### Traditional ML vs Deep Learning
-To succinctly highlight the differences, a comparative table illustrates the contrasting characteristics between traditional ML and deep learning:
+To briefly highlight the differences, @tbl-mlvsdl illustrates the contrasting characteristics between traditional ML and deep learning:
| Aspect | Traditional ML | Deep Learning |
|----------------------------|-----------------------------------------------------|--------------------------------------------------------|
@@ -188,25 +191,27 @@ To succinctly highlight the differences, a comparative table illustrates the con
| Interpretability | High (clear insights into decision pathways) | Low (complex layered structures, "black box" nature) |
| Maintenance | Easier (simple to update and maintain) | Complex (requires more efforts in maintenance and updates) |
+: Comparison of traditional machine learning and deep learning. {#tbl-mlvsdl}
+
### Choosing Traditional ML vs. DL
#### Data Availability and Volume
-* **Amount of Data**: Traditional machine learning algorithms, such as decision trees or Naive Bayes, are often more suitable when data availability is limited, offering robust predictions even with smaller datasets. This is particularly true in cases like medical diagnostics for disease prediction and customer segmentation in marketing.
-
-* **Data Diversity and Quality**: Traditional machine learning algorithms are flexible in handling various data types and often require less preprocessing compared to deep learning models. They may also be more robust in situations with noisy data.
+* **Amount of Data:** Traditional machine learning algorithms, such as decision trees or Naive Bayes, are often more suitable when data availability is limited. They offer robust predictions even with smaller datasets. This is particularly true in medical diagnostics for disease prediction and customer segmentation in marketing.
+
+* **Data Diversity and Quality:** Traditional machine learning algorithms often work well with structured data (the input to the model is a set of features, ideally independent of each other) but may require significant preprocessing effort (i.e., feature engineering). On the other hand, deep learning takes the approach of automatically performing feature engineering as part of the model architecture. This approach enables the construction of end-to-end models capable of directly mapping from unstructured input data (such as text, audio, and images) to the desired output without relying on simplistic heuristics that have limited effectiveness. However, this results in larger models demanding more data and computational resources. In noisy data, the necessity for larger datasets is further emphasized when utilizing Deep Learning.
#### Complexity of the Problem
-* **Problem Granularity**: Problems that are simple to moderately complex, which may involve linear or polynomial relationships between variables, often find a better fit with traditional machine learning methods.
-
-* **Hierarchical Feature Representation**: Deep learning models are excellent in tasks that require hierarchical feature representation, such as image and speech recognition. However, not all problems require this level of complexity, and traditional machine learning algorithms may sometimes offer simpler and equally effective solutions.
+* **Problem Granularity:** Problems that are simple to moderately complex, which may involve linear or polynomial relationships between variables, often find a better fit with traditional machine learning methods.
+
+* **Hierarchical Feature Representation:** Deep learning models are excellent in tasks that require hierarchical feature representation, such as image and speech recognition. However, not all problems require this complexity, and traditional machine learning algorithms may sometimes offer simpler and equally effective solutions.
#### Hardware and Computational Resources
-* **Resource Constraints**: The availability of computational resources often influences the choice between traditional ML and deep learning. The former is generally less resource-intensive and thus preferable in environments with hardware limitations or budget constraints.
-
-* **Scalability and Speed**: Traditional machine learning algorithms, like support vector machines (SVM), often allow for faster training times and easier scalability, particularly beneficial in projects with tight timelines and growing data volumes.
+* **Resource Constraints:** The availability of computational resources often influences the choice between traditional ML and deep learning. The former is generally less resource-intensive and thus preferable in environments with hardware limitations or budget constraints.
+
+* **Scalability and Speed:** Traditional machine learning algorithms, like support vector machines (SVM), often allow for faster training times and easier scalability, which is particularly beneficial in projects with tight timelines and growing data volumes.
#### Regulatory Compliance
@@ -214,39 +219,39 @@ Regulatory compliance is crucial in various industries, requiring adherence to g
#### Interpretability
-Understanding the decision-making process is easier with traditional machine learning techniques compared to deep learning models, which function as "black boxes," making it challenging to trace decision pathways.
+Understanding the decision-making process is easier with traditional machine learning techniques than deep learning models, which function as "black boxes," making it challenging to trace decision pathways.
### Making an Informed Choice
Given the constraints of embedded AI systems, understanding the differences between traditional ML techniques and deep learning becomes essential. Both avenues offer unique advantages, and their distinct characteristics often dictate the choice of one over the other in different scenarios.
-Despite this, deep learning has been steadily outperforming traditional machine learning methods in several key areas due to a combination of abundant data, computational advancements, and proven effectiveness in complex tasks.
+Despite this, deep learning has steadily outperformed traditional machine learning methods in several key areas due to abundant data, computational advancements, and proven effectiveness in complex tasks.
Here are some specific reasons why we focus on deep learning in this text:
-1. **Superior Performance in Complex Tasks**: Deep learning models, particularly deep neural networks, excel in tasks where the relationships between data points are incredibly intricate. Tasks like image and speech recognition, language translation, and playing complex games like Go and Chess have seen significant advancements primarily through deep learning algorithms.
+1. **Superior Performance in Complex Tasks:** Deep learning models, particularly deep neural networks, excel in tasks where the relationships between data points are incredibly intricate. Tasks like image and speech recognition, language translation, and playing complex games like Go and Chess have seen significant advancements primarily through deep learning algorithms.
-2. **Efficient Handling of Unstructured Data**: Unlike traditional machine learning methods, deep learning can process unstructured data more effectively. This is crucial in today's data landscape, where a large majority of data is unstructured, such as text, images, and videos.
+2. **Efficient Handling of Unstructured Data:** Unlike traditional machine learning methods, deep learning can more effectively process unstructured data. This is crucial in today's data landscape, where the vast majority of data, such as text, images, and videos, is unstructured.
-3. **Leveraging Big Data**: With the availability of big data, deep learning models have the capacity to continually learn and improve. These models excel at utilizing large datasets to enhance their predictive accuracy, a limitation in traditional machine learning approaches.
+3. **Leveraging Big Data:** With the availability of big data, deep learning models can learn and improve continually. These models excel at utilizing large datasets to enhance their predictive accuracy, a limitation in traditional machine-learning approaches.
-4. **Hardware Advancements and Parallel Computing**: The advent of powerful GPUs and the availability of cloud computing platforms have enabled the rapid training of deep learning models. These advancements have addressed one of the significant challenges of deep learning-the need for substantial computational resources.
+4. **Hardware Advancements and Parallel Computing:** The advent of powerful GPUs and the availability of cloud computing platforms have enabled the rapid training of deep learning models. These advancements have addressed one of deep learning's significant challenges: the need for substantial computational resources.
-5. **Dynamic Adaptability and Continuous Learning**: Deep learning models can adapt to new information or data dynamically. They can be trained to generalize their learning to new, unseen data, which is crucial in rapidly evolving fields like autonomous driving or real-time language translation.
+5. **Dynamic Adaptability and Continuous Learning:** Deep learning models can dynamically adapt to new information or data. They can be trained to generalize their learning to new, unseen data, crucial in rapidly evolving fields like autonomous driving or real-time language translation.
-While deep learning has gained significant traction, it's essential to understand that traditional machine learning is far from obsolete. As we delve deeper into the intricacies of deep learning, we will also highlight situations where traditional machine learning methods may be more appropriate due to their simplicity, efficiency, and interpretability. By focusing on deep learning in this text, we aim to equip readers with the knowledge and tools needed to tackle modern, complex problems across various domains, while also providing insights into the comparative advantages and appropriate application scenarios for both deep learning and traditional machine learning techniques.
+While deep learning has gained significant traction, it's essential to understand that traditional machine learning is still relevant. As we delve deeper into the intricacies of deep learning, we will also highlight situations where traditional machine learning methods may be more appropriate due to their simplicity, efficiency, and interpretability. By focusing on deep learning in this text, we aim to equip readers with the knowledge and tools to tackle modern, complex problems across various domains while also providing insights into the comparative advantages and appropriate application scenarios for deep learning and traditional machine learning techniques.
## Conclusion
-Deep learning has risen as a potent set of techniques for addressing intricate pattern recognition and prediction challenges. Starting with an overview, we outlined the fundamental concepts and principles governing deep learning, laying the groundwork for more advanced studies.
+Deep learning has become a potent set of techniques for addressing intricate pattern recognition and prediction challenges. Starting with an overview, we outlined the fundamental concepts and principles governing deep learning, laying the groundwork for more advanced studies.
-Central to deep learning, we explored the basic ideas of neural networks, the powerful computational models inspired by the human brain's interconnected neuron structure. This exploration allowed us to appreciate the capabilities and potential of neural networks in creating sophisticated algorithms capable of learning and adapting from data.
+Central to deep learning, we explored the basic ideas of neural networks, powerful computational models inspired by the human brain's interconnected neuron structure. This exploration allowed us to appreciate neural networks' capabilities and potential in creating sophisticated algorithms capable of learning and adapting from data.
-Understanding the role of libraries and frameworks was a key part of our discussion, offering insights into the tools that can facilitate the development and deployment of deep learning models. These resources not only ease the implementation of neural networks but also open avenues for innovation and optimization.
+Understanding the role of libraries and frameworks was a key part of our discussion. We offered insights into the tools that can facilitate developing and deploying deep learning models. These resources ease the implementation of neural networks and open avenues for innovation and optimization.
-Next, we tackled the challenges one might face when embedding deep learning algorithms within embedded systems, providing a critical perspective on the complexities and considerations that come with bringing AI to edge devices.
+Next, we tackled the challenges one might face when embedding deep learning algorithms within embedded systems, providing a critical perspective on the complexities and considerations of bringing AI to edge devices.
-Furthermore, we delved into an examination of the limitations of deep learning. Through a series of discussions, we unraveled the challenges faced in deep learning applications and outlined scenarios where traditional machine learning might outperform deep learning. These sections are crucial for fostering a balanced view of the capabilities and limitations of deep learning.
+Furthermore, we examined deep learning's limitations. Through discussions, we unraveled the challenges faced in deep learning applications and outlined scenarios where traditional machine learning might outperform deep learning. These sections are crucial for fostering a balanced view of deep learning's capabilities and limitations.
In this primer, we have equipped you with the knowledge to make informed choices between deploying traditional machine learning or deep learning techniques, depending on the unique demands and constraints of a specific problem.
@@ -254,12 +259,12 @@ As we conclude this chapter, we hope you are now well-equipped with the basic "l
## Resources {#sec-deep-learning-primer-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will be adding new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Past, Present, and Future of ML.](https://docs.google.com/presentation/d/16ensKAKBG8DOUHF4f5thTJklVGTadxjm3kPkdoPyabI/edit#slide=id.g94db9f9f78_0_2)
@@ -292,5 +297,5 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
:::{.callout-lab collapse="false"}
# Labs
-Coming soon.
-:::
+*Coming soon.*
+:::
\ No newline at end of file
diff --git a/contents/dsp_spectral_features_block/dsp_spectral_features_block.bib b/contents/dsp_spectral_features_block/dsp_spectral_features_block.bib
index e69de29b..00614696 100644
--- a/contents/dsp_spectral_features_block/dsp_spectral_features_block.bib
+++ b/contents/dsp_spectral_features_block/dsp_spectral_features_block.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/dsp_spectral_features_block/dsp_spectral_features_block.qmd b/contents/dsp_spectral_features_block/dsp_spectral_features_block.qmd
index df8a646b..5b7daade 100644
--- a/contents/dsp_spectral_features_block/dsp_spectral_features_block.qmd
+++ b/contents/dsp_spectral_features_block/dsp_spectral_features_block.qmd
@@ -16,15 +16,15 @@ But how does it work under the hood? Let's dig into it.
Extracting features from a dataset captured with inertial sensors, such as accelerometers, involves processing and analyzing the raw data. Accelerometers measure the acceleration of an object along one or more axes (typically three, denoted as X, Y, and Z). These measurements can be used to understand various aspects of the object's motion, such as movement patterns and vibrations. Here's a high-level overview of the process:
-**Data collection**: First, we need to gather data from the accelerometers. Depending on the application, data may be collected at different sampling rates. It's essential to ensure that the sampling rate is high enough to capture the relevant dynamics of the studied motion (the sampling rate should be at least double the maximum relevant frequency present in the signal).
+**Data collection:** First, we need to gather data from the accelerometers. Depending on the application, data may be collected at different sampling rates. It's essential to ensure that the sampling rate is high enough to capture the relevant dynamics of the studied motion (the sampling rate should be at least double the maximum relevant frequency present in the signal).
-**Data preprocessing**: Raw accelerometer data can be noisy and contain errors or irrelevant information. Preprocessing steps, such as filtering and normalization, can help clean and standardize the data, making it more suitable for feature extraction.
+**Data preprocessing:** Raw accelerometer data can be noisy and contain errors or irrelevant information. Preprocessing steps, such as filtering and normalization, can help clean and standardize the data, making it more suitable for feature extraction.
> The Studio does not perform normalization or standardization, so sometimes, when working with Sensor Fusion, it could be necessary to perform this step before uploading data to the Studio. This is particularly crucial in sensor fusion projects, as seen in this tutorial, [Sensor Data Fusion with Spresense and CommonSense](https://docs.edgeimpulse.com/experts/air-quality-and-environmental-projects/environmental-sensor-fusion-commonsense).
-**Segmentation**: Depending on the nature of the data and the application, dividing the data into smaller segments or **windows** may be necessary. This can help focus on specific events or activities within the dataset, making feature extraction more manageable and meaningful. The **window size** and overlap (**window span**) choice depend on the application and the frequency of the events of interest. As a rule of thumb, we should try to capture a couple of "data cycles."
+**Segmentation:** Depending on the nature of the data and the application, dividing the data into smaller segments or **windows** may be necessary. This can help focus on specific events or activities within the dataset, making feature extraction more manageable and meaningful. The **window size** and overlap (**window span**) choice depend on the application and the frequency of the events of interest. As a rule of thumb, we should try to capture a couple of "data cycles."
-**Feature extraction**: Once the data is preprocessed and segmented, you can extract features that describe the motion's characteristics. Some typical features extracted from accelerometer data include:
+**Feature extraction:** Once the data is preprocessed and segmented, you can extract features that describe the motion's characteristics. Some typical features extracted from accelerometer data include:
- **Time-domain** features describe the data's [statistical properties](https://www.mdpi.com/1424-8220/22/5/2012) within each segment, such as mean, median, standard deviation, skewness, kurtosis, and zero-crossing rate.
- **Frequency-domain** features are obtained by transforming the data into the frequency domain using techniques like the [Fast Fourier Transform (FFT)](https://en.wikipedia.org/wiki/Fast_Fourier_transform). Some typical frequency-domain features include the power spectrum, spectral energy, dominant frequencies (amplitude and frequency), and spectral entropy.
@@ -361,7 +361,7 @@ plt.legend(loc='upper right')
plt.xlabel('Frequency (Hz)')
#plt.ylabel('PSD [V**2/Hz]')
plt.ylabel('Power')
-plt.title('Power spectrum P(f) using Welch\'s method')
+plt.title('Power spectrum P(f) using Welch's method')
plt.grid()
plt.box(False)
plt.show()
diff --git a/contents/efficient_ai/efficient_ai.bib b/contents/efficient_ai/efficient_ai.bib
index d3e52144..c737e486 100644
--- a/contents/efficient_ai/efficient_ai.bib
+++ b/contents/efficient_ai/efficient_ai.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@book{barroso2019datacenter,
author = {Barroso, Luiz Andr\'e and H\"olzle, Urs and Ranganathan, Parthasarathy},
doi = {10.1007/978-3-031-01761-2},
@@ -8,37 +11,39 @@ @book{barroso2019datacenter
subtitle = {Designing Warehouse-Scale Machines},
title = {The Datacenter as a Computer},
url = {https://doi.org/10.1007/978-3-031-01761-2},
- year = {2019}
+ year = {2019},
}
@article{chowdhery2019visual,
- author = {Chowdhery, Aakanksha and Warden, Pete and Shlens, Jonathon and Howard, Andrew and Rhodes, Rocky},
- journal = {arXiv preprint arXiv:1906.05721},
- title = {Visual wake words dataset},
- year = {2019}
+ title={Visual wake words dataset},
+ author={Chowdhery, Aakanksha and Warden, Pete and Shlens, Jonathon and Howard, Andrew and Rhodes, Rocky},
+ journal={arXiv preprint arXiv:1906.05721},
+ year={2019}
}
@misc{han2016deep,
- archiveprefix = {arXiv},
author = {Han, Song and Mao, Huizi and Dally, William J.},
+ archiveprefix = {arXiv},
eprint = {1510.00149},
primaryclass = {cs.CV},
title = {Deep Compression: {Compressing} Deep Neural Networks with Pruning, Trained Quantization and {Huffman} Coding},
- year = {2016}
+ year = {2016},
}
@inproceedings{he2016deep,
- author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
+ author = {He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/HeZRS16.bib},
- booktitle = {2016 {IEEE} Conference on Computer Vision and Pattern Recognition, {CVPR} 2016, Las Vegas, NV, USA, June 27-30, 2016},
- doi = {10.1109/CVPR.2016.90},
+ booktitle = {2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr.2016.90},
pages = {770--778},
- publisher = {{IEEE} Computer Society},
+ publisher = {IEEE},
timestamp = {Wed, 17 Apr 2019 01:00:00 +0200},
title = {Deep Residual Learning for Image Recognition},
- url = {https://doi.org/10.1109/CVPR.2016.90},
- year = {2016}
+ url = {https://doi.org/10.1109/cvpr.2016.90},
+ year = {2016},
+ source = {Crossref},
+ month = jun,
}
@misc{howard2017mobilenets,
@@ -47,15 +52,20 @@ @misc{howard2017mobilenets
title = {{MobileNets:} {Efficient} Convolutional Neural Networks for Mobile Vision Applications},
url = {https://arxiv.org/abs/1704.04861},
volume = {abs/1704.04861},
- year = {2017}
+ year = {2017},
}
@inproceedings{hu2018squeeze,
author = {Hu, Jie and Shen, Li and Sun, Gang},
- booktitle = {Proceedings of the IEEE conference on computer vision and pattern recognition},
+ booktitle = {2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {7132--7141},
- title = {Squeeze-and-excitation networks},
- year = {2018}
+ title = {Squeeze-and-Excitation Networks},
+ year = {2018},
+ doi = {10.1109/cvpr.2018.00745},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/cvpr.2018.00745},
+ publisher = {IEEE},
+ month = jun,
}
@article{iandola2016squeezenet,
@@ -64,13 +74,13 @@ @article{iandola2016squeezenet
title = {{SqueezeNet:} {Alexnet-level} accuracy with 50x fewer parameters and 0.5 {MB} model size},
url = {https://arxiv.org/abs/1602.07360},
volume = {abs/1602.07360},
- year = {2016}
+ year = {2016},
}
@inproceedings{jouppi2017datacenter,
+ author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
abstract = {Many architects believe that major improvements in cost-energy-performance must now come from domain-specific hardware. This paper evaluates a custom ASIC{\textemdash}called a Tensor Processing Unit (TPU) {\textemdash} deployed in datacenters since 2015 that accelerates the inference phase of neural networks (NN). The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory. The TPU's deterministic execution model is a better match to the 99th-percentile response-time requirement of our NN applications than are the time-varying optimizations of CPUs and GPUs that help average throughput more than guaranteed latency. The lack of such features helps explain why, despite having myriad MACs and a big memory, the TPU is relatively small and low power. We compare the TPU to a server-class Intel Haswell CPU and an Nvidia K80 GPU, which are contemporaries deployed in the same datacenters. Our workload, written in the high-level TensorFlow framework, uses production NN applications (MLPs, CNNs, and LSTMs) that represent 95\% of our datacenters' NN inference demand. Despite low utilization for some applications, the TPU is on average about 15X {\textendash} 30X faster than its contemporary GPU or CPU, with TOPS/Watt about 30X {\textendash} 80X higher. Moreover, using the CPU's GDDR5 memory in the TPU would triple achieved TOPS and raise TOPS/Watt to nearly 70X the GPU and 200X the CPU.},
address = {New York, NY, USA},
- author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
bdsk-url-1 = {https://doi.org/10.1145/3079856.3080246},
booktitle = {Proceedings of the 44th Annual International Symposium on Computer Architecture},
doi = {10.1145/3079856.3080246},
@@ -84,7 +94,8 @@ @inproceedings{jouppi2017datacenter
source = {Crossref},
title = {In-Datacenter Performance Analysis of a Tensor Processing Unit},
url = {https://doi.org/10.1145/3079856.3080246},
- year = {2017}
+ year = {2017},
+ month = jun,
}
@article{lecun1989optimal,
@@ -92,7 +103,7 @@ @article{lecun1989optimal
journal = {Adv Neural Inf Process Syst},
title = {Optimal brain damage},
volume = {2},
- year = {1989}
+ year = {1989},
}
@article{li2019edge,
@@ -107,54 +118,74 @@ @article{li2019edge
title = {Edge {AI:} {On-demand} Accelerating Deep Neural Network Inference via Edge Computing},
url = {https://doi.org/10.1109/twc.2019.2946140},
volume = {19},
- year = {2020}
+ year = {2020},
+ month = jan,
}
@inproceedings{lin2014microsoft,
- author = {Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence},
- booktitle = {Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13},
+ author = {Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll\'ar, Piotr and Zitnick, C Lawrence},
+ booktitle = {Computer Vision{\textendash}ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13},
organization = {Springer},
pages = {740--755},
- title = {Microsoft coco: Common objects in context},
- year = {2014}
+ title = {Microsoft coco: {Common} objects in context},
+ year = {2014},
}
@article{russakovsky2015imagenet,
- author = {Russakovsky, Olga and Deng, Jia and Su, Hao and Krause, Jonathan and Satheesh, Sanjeev and Ma, Sean and Huang, Zhiheng and Karpathy, Andrej and Khosla, Aditya and Bernstein, Michael and others},
- journal = {International journal of computer vision},
+ author = {Russakovsky, Olga and Deng, Jia and Su, Hao and Krause, Jonathan and Satheesh, Sanjeev and Ma, Sean and Huang, Zhiheng and Karpathy, Andrej and Khosla, Aditya and Bernstein, Michael and Berg, Alexander C. and Fei-Fei, Li},
+ journal = {Int. J. Comput. Vision},
pages = {211--252},
- publisher = {Springer},
- title = {Imagenet large scale visual recognition challenge},
+ publisher = {Springer Science and Business Media LLC},
+ title = {{ImageNet} Large Scale Visual Recognition Challenge},
volume = {115},
- year = {2015}
+ year = {2015},
+ doi = {10.1007/s11263-015-0816-y},
+ number = {3},
+ source = {Crossref},
+ url = {https://doi.org/10.1007/s11263-015-0816-y},
+ issn = {0920-5691, 1573-1405},
+ month = apr,
}
@article{schizas2022tinyml,
- author = {Schizas, Nikolaos and Karras, Aristeidis and Karras, Christos and Sioutas, Spyros},
- journal = {Future Internet},
- title = {TinyML for Ultra-Low Power AI and Large Scale IoT Deployments: A Systematic Review},
- doi = {https://doi.org/10.3390/fi14120363},
- year = {2022}
+ author = {Schizas, Nikolaos and Karras, Aristeidis and Karras, Christos and Sioutas, Spyros},
+ journal = {Future Internet},
+ title = {{TinyML} for Ultra-Low Power {AI} and Large Scale {IoT} Deployments: {A} Systematic Review},
+ doi = {10.3390/fi14120363},
+ year = {2022},
+ number = {12},
+ source = {Crossref},
+ url = {https://doi.org/10.3390/fi14120363},
+ volume = {14},
+ publisher = {MDPI AG},
+ issn = {1999-5903},
+ pages = {363},
+ month = dec,
}
@article{warden2018speech,
author = {Warden, Pete},
journal = {arXiv preprint arXiv:1804.03209},
- title = {Speech commands: A dataset for limited-vocabulary speech recognition},
- year = {2018}
+ title = {Speech commands: {A} dataset for limited-vocabulary speech recognition},
+ year = {2018},
}
@book{warden2019tinyml,
author = {Warden, Pete and Situnayake, Daniel},
publisher = {O'Reilly Media},
title = {Tinyml: {Machine} learning with tensorflow lite on arduino and ultra-low-power microcontrollers},
- year = {2019}
+ year = {2019},
}
@inproceedings{xie2017aggregated,
- author = {Xie, Saining and Girshick, Ross and Doll{\'a}r, Piotr and Tu, Zhuowen and He, Kaiming},
- booktitle = {Proceedings of the IEEE conference on computer vision and pattern recognition},
+ author = {Xie, Saining and Girshick, Ross and Dollar, Piotr and Tu, Zhuowen and He, Kaiming},
+ booktitle = {2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {1492--1500},
- title = {Aggregated residual transformations for deep neural networks},
- year = {2017}
+ title = {Aggregated Residual Transformations for Deep Neural Networks},
+ year = {2017},
+ doi = {10.1109/cvpr.2017.634},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/cvpr.2017.634},
+ publisher = {IEEE},
+ month = jul,
}
diff --git a/contents/efficient_ai/efficient_ai.qmd b/contents/efficient_ai/efficient_ai.qmd
index 7aaea470..07b30230 100644
--- a/contents/efficient_ai/efficient_ai.qmd
+++ b/contents/efficient_ai/efficient_ai.qmd
@@ -8,9 +8,9 @@ bibliography: efficient_ai.bib
Resources: [Slides](#sec-efficient-ai-resource), [Labs](#sec-efficient-ai-resource), [Exercises](#sec-efficient-ai-resource)
:::
-
+
-Efficiency in artificial intelligence (AI) is not simply a luxury; it is a necessity. In this chapter, we dive into the key concepts that underpin efficiency in AI systems. The computational demands placed on neural networks can be daunting, even for the most minimal of systems. For AI to be seamlessly integrated into everyday devices and essential systems, it must perform optimally within the constraints of limited resources, all while maintaining its efficacy. The pursuit of efficiency guarantees that AI models are streamlined, rapid, and sustainable, thereby widening their applicability across a diverse array of platforms and scenarios.
+Efficiency in artificial intelligence (AI) is not simply a luxury but a necessity. In this chapter, we dive into the key concepts underpinning AI systems' efficiency. The computational demands on neural networks can be daunting, even for minimal systems. For AI to be seamlessly integrated into everyday devices and essential systems, it must perform optimally within the constraints of limited resources while maintaining its efficacy. The pursuit of efficiency guarantees that AI models are streamlined, rapid, and sustainable, thereby widening their applicability across various platforms and scenarios.
::: {.callout-tip}
@@ -26,118 +26,120 @@ Efficiency in artificial intelligence (AI) is not simply a luxury; it is a neces
- Appreciate the significance of numerics and their representations.
-- Appreciate that we need to understand nuances of model comparison beyond accuracy.
+- We appreciate that we need to understand the nuances of model comparison beyond accuracy.
-- Recognize efficiency encompasses technology, costs, environment, ethics.
+- Recognize efficiency encompasses technology, costs, environment, and ethics.
:::
-The focus is on gaining a conceptual understanding of the motivations and significance of the various strategies for achieving efficient AI, both in terms of techniques and a holistic perspective. Subsequent chapters will dive into the nitty gritty details on these various concepts.
+The focus is on gaining a conceptual understanding of the motivations and significance of the various strategies for achieving efficient AI, both in terms of techniques and a holistic perspective. Subsequent chapters will dive into the nitty-gritty details of these various concepts.
## Introduction
-Training models can consume a significant amount of energy, sometimes equivalent to the carbon footprint of sizable industrial processes. We will cover some of these sustainability details in the [AI Sustainability](../sustainable_ai/sustainable_ai.qmd) chapter. On the deployment side, if these models are not optimized for efficiency, they can quickly drain device batteries, demand excessive memory, or fall short of real-time processing needs. Through this introduction, our objective is to elucidate the nuances of efficiency, setting the groundwork for a comprehensive exploration in the subsequent chapters.
+Training models can consume significant energy, sometimes equivalent to the carbon footprint of sizable industrial processes. We will cover some of these sustainability details in the [AI Sustainability](../sustainable_ai/sustainable_ai.qmd) chapter. On the deployment side, if these models are not optimized for efficiency, they can quickly drain device batteries, demand excessive memory, or fall short of real-time processing needs. Through this introduction, we aim to elucidate the nuances of efficiency, setting the groundwork for a comprehensive exploration in the subsequent chapters.
## The Need for Efficient AI
-Efficiency takes on different connotations based on where AI computations occur. Let's take a brief moment to revisit and differentiate between Cloud, Edge, and TinyML in terms of efficiency.
+Efficiency takes on different connotations depending on where AI computations occur. Let's revisit and differentiate between Cloud, Edge, and TinyML in terms of efficiency.
{#fig-platforms}
-For cloud AI, traditional AI models often ran in the large-scale data centers equipped with powerful GPUs and TPUs [@barroso2019datacenter]. Here, efficiency pertains to optimizing computational resources, reducing costs, and ensuring timely data processing and return. However, relying on the cloud introduced latency, especially when dealing with large data streams that needed to be uploaded, processed, and then downloaded.
+For cloud AI, traditional AI models often run in large-scale data centers equipped with powerful GPUs and TPUs [@barroso2019datacenter]. Here, efficiency pertains to optimizing computational resources, reducing costs, and ensuring timely data processing and return. However, relying on the cloud introduced latency, especially when dealing with large data streams that must be uploaded, processed, and downloaded.
-For edge AI, edge computing brought AI closer to the data source, processing information directly on local devices like smartphones, cameras, or industrial machines [@li2019edge]. Here, efficiency encompasses quick real-time responses and reduced data transmission needs. The constraints, however, are tighter-these devices, while more powerful than microcontrollers, have limited computational power compared to cloud setups.
+For edge AI, edge computing brings AI closer to the data source, processing information directly on local devices like smartphones, cameras, or industrial machines [@li2019edge]. Here, efficiency encompasses quick real-time responses and reduced data transmission needs. The constraints, however, are tighter—these devices, while more powerful than microcontrollers, have limited computational power compared to cloud setups.
-Pushing the frontier even further is TinyML, where AI models run on microcontrollers or extremely resource-constrained environments. The difference in performance for processors and memory between TinyML and cloud or mobile systems can be several orders of magnitude [@warden2019tinyml]. Efficiency in TinyML is about ensuring models are lightweight enough to fit on these devices, use minimal energy (critical for battery-powered devices), and still perform their tasks effectively.
+Pushing the frontier even further is TinyML, where AI models run on microcontrollers or extremely resource-constrained environments. The difference in processor and memory performance between TinyML and cloud or mobile systems can be several orders of magnitude [@warden2019tinyml]. Efficiency in TinyML is about ensuring models are lightweight enough to fit on these devices, use minimal energy (critical for battery-powered devices), and still perform their tasks effectively.
-The spectrum from Cloud to TinyML represents a shift from vast, centralized computational resources to distributed, localized, and constrained environments. As we transition from one to the other, the challenges and strategies related to efficiency evolve, underlining the need for specialized approaches tailored to each scenario. Having underscored the need for efficient AI, especially within the context of TinyML, we will transition to exploring the methodologies devised to meet these challenges. The following sections outline at a high level the main concepts that we will dwelve into deeper at a later point. As we delve into these strategies, we will demonstrate the breadth and depth of innovation needed to achieve efficient AI.
+The spectrum from Cloud to TinyML represents a shift from vast, centralized computational resources to distributed, localized, and constrained environments. As we transition from one to the other, the challenges and strategies related to efficiency evolve, underlining the need for specialized approaches tailored to each scenario. Having underscored the need for efficient AI, especially within the context of TinyML, we will transition to exploring the methodologies devised to meet these challenges. The following sections outline the main concepts we will delve deeper into later. We will demonstrate the breadth and depth of innovation needed to achieve efficient AI as we delve into these strategies.
## Efficient Model Architectures
Choosing the right model architecture is as crucial as optimizing it. In recent years, researchers have explored some novel architectures that can have inherently fewer parameters while maintaining strong performance.
-**MobileNets**: MobileNets are a class of efficient models for mobile and embedded vision applications [@howard2017mobilenets]. The key idea that led to the success of MobileNets is the use of depth-wise separable convolutions which significantly reduce the number of parameters and computations in the network. MobileNetV2 and V3 further enhance this design with the introduction of inverted residuals and linear bottlenecks.
+**MobileNets:** MobileNets are efficient mobile and embedded vision application models [@howard2017mobilenets]. The key idea that led to their success is the use of depth-wise separable convolutions, which significantly reduce the number of parameters and computations in the network. MobileNetV2 and V3 further enhance this design by introducing inverted residuals and linear bottlenecks.
-**SqueezeNet**: SqueezeNet is a class of ML models known for its smaller size without sacrificing accuracy. It achieves this by using a "fire module" that reduces the number of input channels to 3x3 filters, thus reducing the parameters [@iandola2016squeezenet]. Moreover, it employs delayed downsampling to increase the accuracy by maintaining a larger feature map.
+**SqueezeNet:** SqueezeNet is a class of ML models known for its smaller size without sacrificing accuracy. It achieves this by using a "fire module" that reduces the number of input channels to 3x3 filters, thus reducing the parameters [@iandola2016squeezenet]. Moreover, it employs delayed downsampling to increase the accuracy by maintaining a larger feature map.
-**ResNet variants**: The Residual Network (ResNet) architecture allows introduced skip connections, or shortcuts [@he2016deep]. Some variants of ResNet are designed to be more efficient. For instance, ResNet-SE incorporates the "squeeze and excitation" mechanism to recalibrate feature maps [@hu2018squeeze], while ResNeXt offers grouped convolutions for efficiency [@xie2017aggregated].
+**ResNet variants:** The Residual Network (ResNet) architecture allows for the introduction of skip connections or shortcuts [@he2016deep]. Some variants of ResNet are designed to be more efficient. For instance, ResNet-SE incorporates the "squeeze and excitation" mechanism to recalibrate feature maps [@hu2018squeeze], while ResNeXt offers grouped convolutions for efficiency [@xie2017aggregated].
## Efficient Model Compression
-Model compression methods are very important for bringing deep learning models to devices with limited resources. These techniques reduce the size, energy consumption, and computational demands of models without a significant loss in accuracy. At a high level, the methods can briefly be binned into the following fundamental methods:
+Model compression methods are very important for bringing deep learning models to devices with limited resources. These techniques reduce models' size, energy consumption, and computational demands without significantly losing accuracy. At a high level, the methods can briefly be binned into the following fundamental methods:
-**Pruning**: This is akin to trimming the branches of a tree. This was first thought of in the [Optimal Brain Damage](https://proceedings.neurips.cc/paper/1989/file/6c9882bbac1c7093bd25041881277658-Paper.pdf) paper [@lecun1989optimal]. This was later popularized in the context of deep learning by @han2016deep. In pruning, certain weights or even entire neurons are removed from the network, based on specific criteria. This can significantly reduce the model size. There are various strategies, like weight pruning, neuron pruning, and structured pruning. We will explore these in more detail in @sec-pruning. In the example in @fig-pruning, removing some of the nodes in the inner layers reduces the numbers of edges between the nodes and, in turn, the size of the model.
+**Pruning:** This is akin to trimming the branches of a tree. This was first thought of in the [Optimal Brain Damage](https://proceedings.neurips.cc/paper/1989/file/6c9882bbac1c7093bd25041881277658-Paper.pdf) paper [@lecun1989optimal]. This was later popularized in the context of deep learning by @han2016deep. Certain weights or even entire neurons are removed from the network in pruning based on specific criteria. This can significantly reduce the model size. Various strategies include weight pruning, neuron pruning, and structured pruning. We will explore these in more detail in @sec-pruning. In the example in @fig-pruning, removing some of the nodes in the inner layers reduces the number of edges between the nodes and, in turn, the model's size.
{#fig-pruning}
-**Quantization**: Quantization is the process of constraining an input from a large set to output in a smaller set, primarily in deep learning, this means reducing the number of bits that represent the weights and biases of the model. For example, using 16-bit or 8-bit representations instead of 32-bit can reduce model size and speed up computations, with a minor trade-off in accuracy. We will explore these in more detail in @sec-quant. @fig-quantization shows an example of quantization by rounding to the closest number. The conversion from 32-bit floating point to 16-bit reduces the memory usage by 50%. And going from 32-bit to 8-bit integer, memory is reduced by 75%. While the loss in numeric precision, and consequently model performance, is minor, the memory usage efficiency is very significant.
+**Quantization:** quantization is the process of constraining an input from a large set to output in a smaller set, primarily in deep learning; this means reducing the number of bits that represent the weights and biases of the model. For example, using 16-bit or 8-bit representations instead of 32-bit can reduce the model size and speed up computations, with a minor trade-off in accuracy. We will explore these in more detail in @sec-quant. @fig-quantization shows an example of quantization by rounding to the closest number. The conversion from 32-bit floating point to 16-bit reduces the memory usage by 50%. And going from 32-bit to 8-bit Integer, memory is reduced by 75%. While the loss in numeric precision, and consequently model performance, is minor, the memory usage efficiency is very significant.
{#fig-quantization}
-**Knowledge Distillation**: Knowledge distillation involves training a smaller model (student) to replicate the behavior of a larger model (teacher). The idea is to transfer the knowledge from the cumbersome model to the lightweight one, so the smaller model attains performance close to its larger counterpart but with significantly fewer parameters. We will explore knowledge distillation in more detail in the @sec-kd.
+**Knowledge Distillation:** Knowledge distillation involves training a smaller model (student) to replicate the behavior of a larger model (teacher). The idea is to transfer the knowledge from the cumbersome model to the lightweight one. Hence, the smaller model attains performance close to its larger counterpart but with significantly fewer parameters. We will explore knowledge distillation in more detail in the @sec-kd.
## Efficient Inference Hardware
-[Training](../training/training.qmd) an AI model is an intensive task that requires powerful hardware and can take hours to weeks, but inference needs to be as fast as possible, especially in real-time applications. This is where efficient inference hardware comes into play. By optimizing the hardware specifically for inference tasks, we can achieve rapid response times and power-efficient operation, especially crucial for edge devices and embedded systems.
+[Training](../training/training.qmd): An AI model is an intensive task that requires powerful hardware and can take hours to weeks, but inference needs to be as fast as possible, especially in real-time applications. This is where efficient inference hardware comes into play. We can achieve rapid response times and power-efficient operation by optimizing the hardware specifically for inference tasks, which is especially crucial for edge devices and embedded systems.
-**TPUs (Tensor Processing Units)**: [TPUs](https://cloud.google.com/tpu) are custom-built ASICs (Application-Specific Integrated Circuits) by Google to accelerate machine learning workloads [@jouppi2017datacenter]. They are optimized for tensor operations, offering high throughput for low-precision arithmetic, and are designed specifically for neural network machine learning. TPUs deliver a significant acceleration in model training and inference as compared to general-purpose GPU/CPUs. This boost means faster model training and real-time or near-real-time inference capabilities, crucial for applications like voice search and augmented reality.
+**TPUs (Tensor Processing Units):** [TPUs](https://cloud.google.com/tpu) are custom-built ASICs (Application-Specific Integrated Circuits) by Google to accelerate machine learning workloads [@jouppi2017datacenter]. They are optimized for tensor operations, offering high throughput for low-precision arithmetic, and are designed specifically for neural network machine learning. TPUs significantly accelerate model training and inference compared to general-purpose GPU/CPUs. This boost means faster model training and real-time or near-real-time inference capabilities, which are crucial for applications like voice search and augmented reality.
-[Edge TPUs](https://cloud.google.com/edge-tpu) are a smaller, power-efficient version of Google's TPUs, tailored for edge devices. They provide fast on-device ML inferencing for TensorFlow Lite models. Edge TPUs allow for low-latency, high-efficiency inference on edge devices like smartphones, IoT devices, and embedded systems. This means AI capabilities can be deployed in real-time applications without needing to communicate with a central server, thus saving bandwidth and reducing latency. Consider the table in @fig-edge-tpu-perf. It shows the performance differences of running different models on CPUs versus a Coral USB accelerator. The Coral USB accelerator is an accessory by Google's Coral AI platform that lets developrs connect Edge TPUs to Linux computers. Running inference on the Edge TPUs was 70 to 100 times faster than on CPUs.
+[Edge TPUs](https://cloud.google.com/edge-tpu) are a smaller, power-efficient version of Google's TPUs tailored for edge devices. They provide fast on-device ML inferencing for TensorFlow Lite models. Edge TPUs allow for low-latency, high-efficiency inference on edge devices like smartphones, IoT devices, and embedded systems. AI capabilities can be deployed in real-time applications without communicating with a central server, thus saving bandwidth and reducing latency. Consider the table in @fig-edge-tpu-perf. It shows the performance differences between running different models on CPUs versus a Coral USB accelerator. The Coral USB accelerator is an accessory by Google's Coral AI platform that lets developers connect Edge TPUs to Linux computers. Running inference on the Edge TPUs was 70 to 100 times faster than on CPUs.
-](images/png/tflite_edge_tpu_perf.png){#fig-edge-tpu-perf}
+](images/png/tflite_edge_tpu_perf.png){#fig-edge-tpu-perf}
-**NN Accelerators**: Fixed function neural network accelerators are hardware accelerators designed explicitly for neural network computations. These can be standalone chips or part of a larger system-on-chip (SoC) solution. By optimizing the hardware for the specific operations that neural networks require, such as matrix multiplications and convolutions, NN accelerators can achieve faster inference times and lower power consumption compared to general-purpose CPUs and GPUs. They are especially beneficial in TinyML devices with power or thermal constraints, such as smartwatches, micro-drones, or robotics.
+**NN Accelerators:** Fixed-function neural network accelerators are hardware accelerators designed explicitly for neural network computations. They can be standalone chips or part of a larger system-on-chip (SoC) solution. By optimizing the hardware for the specific operations that neural networks require, such as matrix multiplications and convolutions, NN accelerators can achieve faster inference times and lower power consumption than general-purpose CPUs and GPUs. They are especially beneficial in TinyML devices with power or thermal constraints, such as smartwatches, micro-drones, or robotics.
-But these are all but the most common place examples, there are a number of other types of hardware that are emerging that have the potential to offer signficiant advantages for inference. These include but are not limited to neuromorphic hardware, photonic computing, and so forth. In [@sec-aihw] we will explore these in greater detail.
+But these are all but the most common examples. A number of other types of hardware are emerging that have the potential to offer significant advantages for inference. These include, but are not limited to, neuromorphic hardware, photonic computing, etc. In [@sec-aihw], we will explore these in greater detail.
-Efficient hardware for inference not only speeds up the process but also saves energy, extends battery life, and can operate in real-time conditions. As AI continues to be integrated into a myriad of applications---from smart cameras to voice assistants---the role of optimized hardware will only become more prominent. By leveraging these specialized hardware components, developers and engineers can bring the power of AI to devices and situations that were previously unthinkable.
+Efficient hardware for inference speeds up the process, saves energy, extends battery life, and can operate in real-time conditions. As AI continues to be integrated into myriad applications- from smart cameras to voice assistants- the role of optimized hardware will only become more prominent. By leveraging these specialized hardware components, developers and engineers can bring the power of AI to devices and situations that were previously unthinkable.
## Efficient Numerics
-Machine learning, and especially deep learning, involves enormous amounts of computation. Models can have millions to billions of parameters, and these are often trained on vast datasets. Every operation, every multiplication or addition, demands computational resources. Therefore, the precision of the numbers used in these operations can have a significant impact on the computational speed, energy consumption, and memory requirements. This is where the concept of efficient numerics comes into play.
+Machine learning, and especially deep learning, involves enormous amounts of computation. Models can have millions to billions of parameters, often trained on vast datasets. Every operation, every multiplication or addition, demands computational resources. Therefore, the precision of the numbers used in these operations can significantly impact the computational speed, energy consumption, and memory requirements. This is where the concept of efficient numerics comes into play.
### Numerical Formats
There are many different types of numerics. Numerics have a long history in computing systems.
-**Floating point**: Known as single-precision floating-point, FP32 utilizes 32 bits to represent a number, incorporating its sign, exponent, and fraction. FP32 is widely adopted in many deep learning frameworks and offers a balance between accuracy and computational requirements. It's prevalent in the training phase for many neural networks due to its sufficient precision in capturing minute details during weight updates.
+**Floating point:** Known as single-precision floating-point, FP32 utilizes 32 bits to represent a number, incorporating its sign, exponent, and fraction. FP32 is widely adopted in many deep learning frameworks and balances accuracy and computational requirements. It's prevalent in the training phase for many neural networks due to its sufficient precision in capturing minute details during weight updates.
-Also known as half-precision floating point, FP16 uses 16 bits to represent a number, including its sign, exponent, and fraction. FP16 offers a good balance between precision and memory savings. It's particularly popular in deep learning training on GPUs that support mixed-precision arithmetic, combining the speed benefits of FP16 with the precision of FP32 where needed.
+Also known as half-precision floating point, FP16 uses 16 bits to represent a number, including its sign, exponent, and fraction. It offers a good balance between precision and memory savings. FP16 is particularly popular in deep learning training on GPUs that support mixed-precision arithmetic, combining the speed benefits of FP16 with the precision of FP32 where needed.
-There are also several other numerical formats that fall into an exotic calss. An exotic example is BF16, or Brain Floating Point. It is a 16-bit numerical format that is designed explicitly for deep learning applications. It's a compromise between FP32 and FP16, retaining the 8-bit exponent from FP32 while reducing the mantissa to 7 bits (as compared to FP32's 23-bit mantissa). This structure prioritizes range over precision. BF16 has been shown to achieve training results that are comparable in accuracy to FP32 while using significantly less memory and computational resources. This makes it suitable not just for inference but also for training deep neural networks.
+Several other numerical formats fall into an exotic class. An exotic example is BF16 or Brain Floating Point. It is a 16-bit numerical format designed explicitly for deep learning applications. It's a compromise between FP32 and FP16, retaining the 8-bit exponent from FP32 while reducing the mantissa to 7 bits (as compared to FP32's 23-bit mantissa). This structure prioritizes range over precision. BF16 has achieved training results comparable in accuracy to FP32 while using significantly less memory and computational resources. This makes it suitable not just for inference but also for training deep neural networks.
By retaining the 8-bit exponent of FP32, BF16 offers a similar range, which is crucial for deep learning tasks where certain operations can result in very large or very small numbers. At the same time, by truncating precision, BF16 allows for reduced memory and computational requirements compared to FP32. BF16 has emerged as a promising middle ground in the landscape of numerical formats for deep learning, providing an efficient and effective alternative to the more traditional FP32 and FP16 formats.
](https://storage.googleapis.com/gweb-cloudblog-publish/images/Three_floating-point_formats.max-624x261.png){#fig-fp-formats}
-**Integer**: These are integer representations using 8, 4, and 2 bits. They are often used during the inference phase of neural networks, where the weights and activations of the model are quantized to these lower precisions. Integer representations are deterministic and offer significant speed and memory advantages over floating-point representations. For many inference tasks, especially on edge devices, the slight loss in accuracy due to quantization is often acceptable given the efficiency gains. An extreme form of integer numerics is for binary neural networks (BNNs), where weights and activations are constrained to one of two values: either +1 or -1.
+**Integer:** These are integer representations using 8, 4, and 2 bits. They are often used during the inference phase of neural networks, where the weights and activations of the model are quantized to these lower precisions. Integer representations are deterministic and offer significant speed and memory advantages over floating-point representations. For many inference tasks, especially on edge devices, the slight loss in accuracy due to quantization is often acceptable, given the efficiency gains. An extreme form of integer numerics is for binary neural networks (BNNs), where weights and activations are constrained to one of two values: +1 or -1.
-**Variable bit widths**: Beyond the standard widths, research is ongoing into extremely low bit-width numerics, even down to binary or ternary representations. Extremely low bit-width operations can offer significant speedups and reduce power consumption even further. While challenges remain in maintaining model accuracy with such drastic quantization, advances continue to be made in this area.
+**Variable bit widths:** Beyond the standard widths, research is ongoing into extremely low bit-width numerics, even down to binary or ternary representations. Extremely low bit-width operations can offer significant speedups and further reduce power consumption. While challenges remain in maintaining model accuracy with such drastic quantization, advances continue to be made in this area.
-Efficient numerics is not just about reducing the bit-width of numbers but understanding the trade-offs between accuracy and efficiency. As machine learning models become more pervasive, especially in real-world, resource-constrained environments, the focus on efficient numerics will continue to grow. By thoughtfully selecting and leveraging the appropriate numeric precision, one can achieve robust model performance while optimizing for speed, memory, and energy. The table below summarizes them.
+Efficient numerics is not just about reducing the bit-width of numbers but understanding the trade-offs between accuracy and efficiency. As machine learning models become more pervasive, especially in real-world, resource-constrained environments, the focus on efficient numerics will continue to grow. By thoughtfully selecting and leveraging the appropriate numeric precision, one can achieve robust model performance while optimizing for speed, memory, and energy. @tbl-precision summarizes these trade-offs.
| Precision | Pros | Cons |
|------------|-----------------------------------------------------------|--------------------------------------------------|
| **FP32** (Floating Point 32-bit) | Standard precision used in most deep learning frameworks.
High accuracy due to ample representational capacity.
Well-suited for training | High memory usage.
Slower inference times compared to quantized models.
Higher energy consumption. |
| **FP16** (Floating Point 16-bit) | Reduces memory usage compared to FP32.
Speeds up computations on hardware that supports FP16.
Often used in mixed-precision training to balance speed and accuracy. | Lower representational capacity compared to FP32.
Risk of numerical instability in some models or layers. |
| **INT8** (8-bit Integer) | Significantly reduced memory footprint compared to floating-point representations.
Faster inference if hardware supports INT8 computations.
Suitable for many post-training quantization scenarios. | Quantization can lead to some accuracy loss.
Requires careful calibration during quantization to minimize accuracy degradation. |
-| **INT4** (4-bit Integer) | Even lower memory usage than INT8.
Further speed-up potential for inference. | Higher risk of accuracy loss compared to INT8.
Calibration during quantization becomes more critical. |
+| **INT4** (4-bit Integer) | Even lower memory usage than INT8.< br//> Further speedup potential for inference. | Higher risk of accuracy loss compared to INT8.
Calibration during quantization becomes more critical. |
| **Binary** | Minimal memory footprint (only 1 bit per parameter).
Extremely fast inference due to bitwise operations.
Power efficient. | Significant accuracy drop for many tasks.
Complex training dynamics due to extreme quantization. |
-| **Ternary** | Low memory usage but slightly more than binary.
Offers a middle ground between representation and efficiency. | Accuracy might still be lower than higher precision models.
Training dynamics can be complex. |
+| **Ternary** | Low memory usage but slightly more than binary.
Offers a middle ground between representation and efficiency. | accuracy might still be lower than that of higher precision models.
Training dynamics can be complex. |
+
+: Comparing precision levels in deep learning. {#tbl-precision}
### Efficiency Benefits
-Numerical efficiency matters for machine learning workloads for a number of reasons:
+Numerical efficiency matters for machine learning workloads for several reasons:
-**Computational Efficiency**: High-precision computations (like FP32 or FP64) can be slow and resource-intensive. By reducing numeric precision, one can achieve faster computation times, especially on specialized hardware that supports lower precision.
+** Computational Efficiency :** High-precision computations (like FP32 or FP64) can be slow and resource-intensive. Reducing numeric precision can achieve faster computation times, especially on specialized hardware that supports lower precision.
-**Memory Efficiency**: Storage requirements decrease with reduced numeric precision. For instance, FP16 requires half the memory of FP32. This is crucial when deploying models to edge devices with limited memory or when working with very large models.
+**Memory Efficiency:** Storage requirements decrease with reduced numeric precision. For instance, FP16 requires half the memory of FP32. This is crucial when deploying models to edge devices with limited memory or working with large models.
-**Power Efficiency**: Lower precision computations often consume less power, which is especially important for battery-operated devices.
+**Power Efficiency:** Lower precision computations often consume less power, which is especially important for battery-operated devices.
-**Noise Introduction**: Interestingly, the noise introduced by using lower precision can sometimes act as a regularizer, helping to prevent overfitting in some models.
+**Noise Introduction:** Interestingly, the noise introduced using lower precision can sometimes act as a regularizer, helping to prevent overfitting in some models.
-**Hardware Acceleration**: Many modern AI accelerators and GPUs are optimized for lower precision operations, leveraging the efficiency benefits of such numerics.
+**Hardware Acceleration:** Many modern AI accelerators and GPUs are optimized for lower precision operations, leveraging the efficiency benefits of such numerics.
## Evaluating Models
@@ -145,52 +147,52 @@ It's worth noting that the actual benefits and trade-offs can vary based on the
### Efficiency Metrics
-To guide this process systematically, it is important to have a deep understanding of model evaluation methods. When assessing AI models' effectiveness and suitability for various applications, efficiency metrics come to the forefront.
+A deep understanding of model evaluation methods is important to guide this process systematically. When assessing AI models' effectiveness and suitability for various applications, efficiency metrics come to the forefront.
-**FLOPs (Floating Point Operations)** gauge the computational demands of a model. For instance, a modern neural network like BERT has billions of FLOPs, which might be manageable on a powerful cloud server but would be taxing on a smartphone. Higher FLOPs can lead to more prolonged inference times and more significant power drain, especially on devices without specialized hardware accelerators. Hence, for real-time applications such as video streaming or gaming, models with lower FLOPs might be more desirable.
+**FLOPs (Floating Point Operations)** gauge a model's computational demands. For instance, a modern neural network like BERT has billions of FLOPs, which might be manageable on a powerful cloud server but would be taxing on a smartphone. Higher FLOPs can lead to more prolonged inference times and significant power drain, especially on devices without specialized hardware accelerators. Hence, for real-time applications such as video streaming or gaming, models with lower FLOPs might be more desirable.
-**Memory Usage** pertains to how much storage the model requires, which affects both the storage and RAM of the deploying device. Consider deploying a model onto a smartphone: a model that occupies several gigabytes of space not only consumes precious storage but might also be slower due to the need to load large weights into memory. This becomes especially crucial for edge devices like security cameras or drones, where minimal memory footprints are vital for both storage and rapid data processing.
+**Memory Usage** pertains to how much storage the model requires, affecting both the deploying device's storage and RAM. Consider deploying a model onto a smartphone: a model that occupies several gigabytes of space not only consumes precious storage but might also be slower due to the need to load large weights into memory. This becomes especially crucial for edge devices like security cameras or drones, where minimal memory footprints are vital for storage and rapid data processing.
-**Power Consumption** becomes especially crucial for devices that rely on batteries. For instance, a wearable health monitor using a power-hungry model could drain its battery in hours, rendering it impractical for continuous health monitoring. As we move toward an era dominated by IoT devices, where many devices operate on battery power, optimizing models for low power consumption becomes essential.
+**Power Consumption** becomes especially crucial for devices that rely on batteries. For instance, a wearable health monitor using a power-hungry model could drain its battery in hours, rendering it impractical for continuous health monitoring. Optimizing models for low power consumption becomes essential as we move toward an era dominated by IoT devices, where many devices operate on battery power.
**Inference Time** is about how swiftly a model can produce results. In applications like autonomous driving, where split-second decisions are the difference between safety and calamity, models must operate rapidly. If a self-driving car's model takes even a few seconds too long to recognize an obstacle, the consequences could be dire. Hence, ensuring a model's inference time aligns with the real-time demands of its application is paramount.
-In essence, these efficiency metrics are more than mere numbers-they dictate where and how a model can be effectively deployed. A model might boast high accuracy, but if its FLOPs, memory usage, power consumption, or inference time make it unsuitable for its intended platform or real-world scenarios, its practical utility becomes limited.
+In essence, these efficiency metrics are more than numbers dictating where and how a model can be effectively deployed. A model might boast high accuracy, but if its FLOPs, memory usage, power consumption, or inference time make it unsuitable for its intended platform or real-world scenarios, its practical utility becomes limited.
### Efficiency Comparisons
-There is an abundance of models in the ecosystem, each boasting its unique strengths and idiosyncrasies. However, pure model accuracy figures or training and inference speeds don't paint the complete picture. When we dive deeper into comparative analyses, several critical nuances emerge.
+The ecosystem contains an abundance of models, each boasting its unique strengths and idiosyncrasies. However, pure model accuracy figures or training and inference speeds paint a partial picture. When we dive deeper into comparative analyses, several critical nuances emerge.
-Often, we encounter the delicate balance between accuracy and efficiency. For instance, while a dense deep learning model and a lightweight MobileNet variant might both excel in image classification, their computational demands could be at two extremes. This differentiation is especially pronounced when comparing deployments on resource-abundant cloud servers versus constrained TinyML devices. In many real-world scenarios, the marginal gains in accuracy could be overshadowed by the inefficiencies of a resource-intensive model.
+Often, we encounter the delicate balance between accuracy and efficiency. For instance, while a dense, deep learning model and a lightweight MobileNet variant might excel in image classification, their computational demands could be at two extremes. This differentiation is especially pronounced when comparing deployments on resource-abundant cloud servers versus constrained TinyML devices. In many real-world scenarios, the marginal gains in accuracy could be overshadowed by the inefficiencies of a resource-intensive model.
-Moreover, the optimal model choice isn't always universal but often depends on the specifics of an application. Consider object detection: a model that excels in general scenarios might falter in niche environments like detecting manufacturing defects on a factory floor. This adaptability-or the lack of it-can dictate a model's real-world utility.
+Moreover, the optimal model choice is only sometimes universal but often depends on the specifics of an application. Consider object detection: a model that excels in general scenarios that might falter in niche environments, such as when detecting manufacturing defects on a factory floor. This adaptability- or the lack of it- can dictate a model's real-world utility.
-Another important consideration is the relationship between model complexity and its practical benefits. Take voice-activated assistants as an example such as "Alexa" or "OK Google." While a complex model might demonstrate a marginally superior understanding of user speech, if it's slower to respond than a simpler counterpart, the user experience could be compromised. Thus, adding layers or parameters doesn't always equate to better real-world outcomes.
+Another important consideration is the relationship between model complexity and its practical benefits. Take voice-activated assistants, such as "Alexa" or "OK Google." While a complex model might demonstrate a marginally superior understanding of user speech if it's slower to respond than a simpler counterpart, the user experience could be compromised. Thus, adding layers or parameters only sometimes equates to better real-world outcomes.
-Furthermore, while benchmark datasets, such as ImageNet [@russakovsky2015imagenet], COCO [@lin2014microsoft], Visual Wake Words [@chowdhery2019visual], Google Speech Commands [@warden2018speech], etc. provide a standardized performance metric, they might not capture the diversity and unpredictability of real-world data. Two facial recognition models with similar benchmark scores might exhibit varied competencies when faced with diverse ethnic backgrounds or challenging lighting conditions. Such disparities underscore the importance of robustness and consistency across varied data. For example, @fig-stoves from the Dollar Street dataset shows stove images across extreme monthly incomes. So if a model was trained on pictures of stoves found in wealth countries only, it will fail to recognize stoves from poorer regions.
+Furthermore, while benchmark datasets, such as ImageNet [@russakovsky2015imagenet], COCO [@lin2014microsoft], Visual Wake Words [@chowdhery2019visual], Google Speech Commands [@warden2018speech], etc. provide a standardized performance metric, they might not capture the diversity and unpredictability of real-world data. Two facial recognition models with similar benchmark scores might exhibit varied competencies when faced with diverse ethnic backgrounds or challenging lighting conditions. Such disparities underscore the importance of robustness and consistency across varied data. For example, @fig-stoves from the Dollar Street dataset shows stove images across extreme monthly incomes. So, if a model was trained on pictures of stoves found in wealthy countries only, it would fail to recognize stoves from poorer regions.
-{#fig-stoves}
+{#fig-stoves}
-In essence, a thorough comparative analysis transcends numerical metrics. It's a holistic assessment, intertwined with real-world applications, costs, and the intricate subtleties that each model brings to the table. This is why it becomes important to have standard benchmarks and metrics that are widely established and adopted by the community.
+In essence, a thorough comparative analysis transcends numerical metrics. It's a holistic assessment intertwined with real-world applications, costs, and the intricate subtleties that each model brings to the table. This is why having standard benchmarks and metrics widely established and adopted by the community becomes important.
## Conclusion
-Efficient AI is extremely important as we push towards broader and more diverse real-world deployment of machine learning. This chapter provided an overview, exploring the various methodologies and considerations behind achieving efficient AI, starting with the fundamental need, similarities and differences across cloud, edge, and TinyML systems.
+Efficient AI is extremely important as we push towards broader and more diverse real-world deployment of machine learning. This chapter provided an overview, exploring the various methodologies and considerations behind achieving efficient AI, starting with the fundamental need, similarities, and differences across cloud, Edge, and TinyML systems.
-We saw that efficient model architectures can be useful for optimizations. Model compression techniques such as pruning, quantization, and knowledge distillation exist to help reduce computational demands and memory footprint without significantly impacting accuracy. Specialized hardware like TPUs and NN accelerators offer optimized silicon for the operations and data flow of neural networks. And efficient numerics strike a balance between precision and efficiency, enabling models to attain robust performance using minimal resources. In the subsequent chapters, we will dive deeper into each of these different topics and explore them in great depth and detail.
+We saw that efficient model architectures can be useful for optimizations. Model compression techniques such as pruning, quantization, and knowledge distillation exist to help reduce computational demands and memory footprint without significantly impacting accuracy. Specialized hardware like TPUs and NN accelerators offer optimized silicon for neural network operations and data flow. Efficient numerics balance precision and efficiency, enabling models to attain robust performance using minimal resources. In the subsequent chapters, we will explore these different topics in depth and in detail.
-Together, these form a holistic framework for efficient AI. But the journey doesn't end here. Achieving optimally efficient intelligence requires continued research and innovation. As models become more sophisticated, datasets grow larger, and applications diversify into specialized domains, efficiency must evolve in lockstep. Measuring real-world impact would need nuanced benchmarks and standardized metrics beyond simplistic accuracy figures.
+Together, these form a holistic framework for efficient AI. But the journey doesn't end here. Achieving optimally efficient intelligence requires continued research and innovation. As models become more sophisticated, datasets grow, and applications diversify into specialized domains, efficiency must evolve in lockstep. Measuring real-world impact requires nuanced benchmarks and standardized metrics beyond simplistic accuracy figures.
-Moreover, efficient AI expands beyond technological optimization but also encompasses costs, environmental impact, and ethical considerations for the broader societal good. As AI permeates across industries and daily lives, a comprehensive outlook on efficiency underpins its sustainable and responsible progress. The subsequent chapters will build upon these foundational concepts, providing actionable insights and hands-on best practices for developing and deploying efficient AI solutions.
+Moreover, efficient AI expands beyond technological optimization and encompasses costs, environmental impact, and ethical considerations for the broader societal good. As AI permeates industries and daily lives, a comprehensive outlook on efficiency underpins its sustainable and responsible progress. The subsequent chapters will build upon these foundational concepts, providing actionable insights and hands-on best practices for developing and deploying efficient AI solutions.
## Resources {#sec-efficient-ai-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Deploying on Edge Devices: challenges and techniques.](https://docs.google.com/presentation/d/1tvSiOfQ1lYPXsvHcFVs8R1lYZPei_Nb7/edit?usp=drive_link&ouid=102419556060649178683&rtpof=true&sd=true)
@@ -204,13 +206,13 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
-Coming soon.
+*Coming soon.*
:::
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/ethics.qmd b/contents/ethics.qmd
index 7935f9f9..b1ec63bd 100644
--- a/contents/ethics.qmd
+++ b/contents/ethics.qmd
@@ -3,7 +3,7 @@
::: {.callout-tip}
## Learning Objectives
-* coming soon.
+*Coming soon.*
:::
diff --git a/contents/foreword.qmd b/contents/foreword.qmd
index a41c28b5..0f82c3f7 100644
--- a/contents/foreword.qmd
+++ b/contents/foreword.qmd
@@ -56,21 +56,21 @@ Here's a closer look at what each chapter covers:
To get the most out of this book, consider the following structured approach:
-1. **Basic Knowledge (Chapters 1-4)**: Start by building a strong foundation with the initial chapters, which provide an introduction to embedded AI and cover core topics like embedded systems and deep learning.
+1. **Basic Knowledge (Chapters 1-4):** Start by building a strong foundation with the initial chapters, which provide an introduction to embedded AI and cover core topics like embedded systems and deep learning.
-2. **Development Process (Chapters 5-10)**: With that foundation, move on to the chapters focused on practical aspects of the AI model building process like workflows, data engineering, training, optimizations and frameworks.
+2. **Development Process (Chapters 5-10):** With that foundation, move on to the chapters focused on practical aspects of the AI model building process like workflows, data engineering, training, optimizations and frameworks.
-3. **Deployment and Monitoring (Chapters 11-14)**: These chapters offer insights into effectively deploying AI on devices and monitoring the operationalization through methods like benchmarking and on-device learning.
+3. **Deployment and Monitoring (Chapters 11-14):** These chapters offer insights into effectively deploying AI on devices and monitoring the operationalization through methods like benchmarking and on-device learning.
-4. **Responsible and Emerging AI (Chapters 15-18)**: Critically examine topics like ethics, security, sustainability and cutting edge techniques in AI as you conclude the learning journey.
+4. **Responsible and Emerging AI (Chapters 15-18):** Critically examine topics like ethics, security, sustainability and cutting edge techniques in AI as you conclude the learning journey.
-5. **Interconnected Learning**: While designed for progressive learning, feel free to navigate chapters based on your interests and needs.
+5. **Interconnected Learning:** While designed for progressive learning, feel free to navigate chapters based on your interests and needs.
-6. **Practical Applications**: Relate theory to real-world applications by engaging with case studies and hands-on exercises throughout.
+6. **Practical Applications:** Relate theory to real-world applications by engaging with case studies and hands-on exercises throughout.
-7. **Discussion and Networking**: Participate in forums and groups to debate concepts and share insights.
+7. **Discussion and Networking:** Participate in forums and groups to debate concepts and share insights.
-8. **Revisit and Reflect**: Revisiting chapters can reinforce learnings and offer new perspectives on concepts.
+8. **Revisit and Reflect:** Revisiting chapters can reinforce learnings and offer new perspectives on concepts.
By adopting this structured yet flexible approach, you're setting the stage for a fulfilling and enriching learning experience.
diff --git a/contents/frameworks/frameworks.bib b/contents/frameworks/frameworks.bib
index 71a37a67..3bc1c371 100644
--- a/contents/frameworks/frameworks.bib
+++ b/contents/frameworks/frameworks.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@inproceedings{abadi2016tensorflow,
author = {Yu, Yuan and Abadi, Mart{\'\i}n and Barham, Paul and Brevdo, Eugene and Burrows, Mike and Davis, Andy and Dean, Jeff and Ghemawat, Sanjay and Harley, Tim and Hawkins, Peter and Isard, Michael and Kudlur, Manjunath and Monga, Rajat and Murray, Derek and Zheng, Xiaoqiang},
booktitle = {Proceedings of the Thirteenth EuroSys Conference},
@@ -7,35 +10,36 @@ @inproceedings{abadi2016tensorflow
source = {Crossref},
title = {Dynamic control flow in large-scale machine learning},
url = {https://doi.org/10.1145/3190508.3190551},
- year = {2018}
+ year = {2018},
+ month = apr,
}
@misc{al2016theano,
- archiveprefix = {arXiv},
author = {Team, The Theano Development and Al-Rfou, Rami and Alain, Guillaume and Almahairi, Amjad and Angermueller, Christof and Bahdanau, Dzmitry and Ballas, Nicolas and Bastien, Fr\'ed\'eric and Bayer, Justin and Belikov, Anatoly and Belopolsky, Alexander and Bengio, Yoshua and Bergeron, Arnaud and Bergstra, James and Bisson, Valentin and Snyder, Josh Bleecher and Bouchard, Nicolas and Boulanger-Lewandowski, Nicolas and Bouthillier, Xavier and de Br\'ebisson, Alexandre and Breuleux, Olivier and Carrier, Pierre-Luc and Cho, Kyunghyun and Chorowski, Jan and Christiano, Paul and Cooijmans, Tim and C\^ot\'e, Marc-Alexandre and C\^ot\'e, Myriam and Courville, Aaron and Dauphin, Yann N. and Delalleau, Olivier and Demouth, Julien and Desjardins, Guillaume and Dieleman, Sander and Dinh, Laurent and Ducoffe, M\'elanie and Dumoulin, Vincent and Kahou, Samira Ebrahimi and Erhan, Dumitru and Fan, Ziye and Firat, Orhan and Germain, Mathieu and Glorot, Xavier and Goodfellow, Ian and Graham, Matt and Gulcehre, Caglar and Hamel, Philippe and Harlouchet, Iban and Heng, Jean-Philippe and Hidasi, Bal\'azs and Honari, Sina and Jain, Arjun and Jean, S\'ebastien and Jia, Kai and Korobov, Mikhail and Kulkarni, Vivek and Lamb, Alex and Lamblin, Pascal and Larsen, Eric and Laurent, C\'esar and Lee, Sean and Lefrancois, Simon and Lemieux, Simon and L\'eonard, Nicholas and Lin, Zhouhan and Livezey, Jesse A. and Lorenz, Cory and Lowin, Jeremiah and Ma, Qianli and Manzagol, Pierre-Antoine and Mastropietro, Olivier and McGibbon, Robert T. and Memisevic, Roland and van Merri\"enboer, Bart and Michalski, Vincent and Mirza, Mehdi and Orlandi, Alberto and Pal, Christopher and Pascanu, Razvan and Pezeshki, Mohammad and Raffel, Colin and Renshaw, Daniel and Rocklin, Matthew and Romero, Adriana and Roth, Markus and Sadowski, Peter and Salvatier, John and Savard, Fran\c{c}ois and Schl\"uter, Jan and Schulman, John and Schwartz, Gabriel and Serban, Iulian Vlad and Serdyuk, Dmitriy and Shabanian, Samira and Simon, \'Etienne and Spieckermann, Sigurd and Subramanyam, S. Ramana and Sygnowski, Jakub and Tanguay, J\'er\'emie and van Tulder, Gijs and Turian, Joseph and Urban, Sebastian and Vincent, Pascal and Visin, Francesco and de Vries, Harm and Warde-Farley, David and Webb, Dustin J. and Willson, Matthew and Xu, Kelvin and Xue, Lijun and Yao, Li and Zhang, Saizheng and Zhang, Ying},
+ archiveprefix = {arXiv},
eprint = {1605.02688},
primaryclass = {cs.SC},
title = {Theano: {A} Python framework for fast computation of mathematical expressions},
- year = {2016}
+ year = {2016},
}
@inproceedings{brown2020language,
- author = {Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert{-}Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei},
+ author = {Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and Winter, Clemens and Hesse, Christopher and Chen, Mark and Sigler, Eric and Litwin, Mateusz and Gray, Scott and Chess, Benjamin and Clark, Jack and Berner, Christopher and McCandlish, Sam and Radford, Alec and Sutskever, Ilya and Amodei, Dario},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/BrownMRSKDNSSAA20.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Tue, 19 Jan 2021 00:00:00 +0100},
title = {Language Models are Few-Shot Learners},
url = {https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html},
- year = {2020}
+ year = {2020},
}
@article{chollet2018keras,
author = {Chollet, Fran\c{c}ois},
journal = {March 9th},
title = {Introduction to keras},
- year = {2018}
+ year = {2018},
}
@article{david2021tensorflow,
@@ -44,48 +48,52 @@ @article{david2021tensorflow
pages = {800--811},
title = {Tensorflow lite micro: {Embedded} machine learning for tinyml systems},
volume = {3},
- year = {2021}
+ year = {2021},
}
@inproceedings{dean2012large,
- author = {Jeffrey Dean and Greg Corrado and Rajat Monga and Kai Chen and Matthieu Devin and Quoc V. Le and Mark Z. Mao and Marc'Aurelio Ranzato and Andrew W. Senior and Paul A. Tucker and Ke Yang and Andrew Y. Ng},
+ author = {Dean, Jeffrey and Corrado, Greg and Monga, Rajat and Chen, Kai and Devin, Matthieu and Le, Quoc V. and Mao, Mark Z. and Ranzato, Marc'Aurelio and Senior, Andrew W. and Tucker, Paul A. and Yang, Ke and Ng, Andrew Y.},
+ editor = {Bartlett, Peter L. and Pereira, Fernando C. N. and Burges, Christopher J. C. and Bottou, L\'eon and Weinberger, Kilian Q.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/DeanCMCDLMRSTYN12.bib},
booktitle = {Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States},
- editor = {Peter L. Bartlett and Fernando C. N. Pereira and Christopher J. C. Burges and L{\'{e}}on Bottou and Kilian Q. Weinberger},
pages = {1232--1240},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
title = {Large Scale Distributed Deep Networks},
url = {https://proceedings.neurips.cc/paper/2012/hash/6aca97005c68f1206823815f66102863-Abstract.html},
- year = {2012}
+ year = {2012},
}
@inproceedings{deng2009imagenet,
- author = {Jia Deng and Wei Dong and Richard Socher and Li{-}Jia Li and Kai Li and Fei{-}Fei Li},
+ author = {Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Li, Fei-Fei},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/DengDSLL009.bib},
- booktitle = {2009 {IEEE} Computer Society Conference on Computer Vision and Pattern Recognition {(CVPR} 2009), 20-25 June 2009, Miami, Florida, {USA}},
- doi = {10.1109/CVPR.2009.5206848},
+ booktitle = {2009 IEEE Conference on Computer Vision and Pattern Recognition},
+ doi = {10.1109/cvpr.2009.5206848},
pages = {248--255},
- publisher = {{IEEE} Computer Society},
+ publisher = {IEEE},
timestamp = {Fri, 27 Mar 2020 00:00:00 +0100},
- title = {ImageNet: {A} large-scale hierarchical image database},
- url = {https://doi.org/10.1109/CVPR.2009.5206848},
- year = {2009}
+ title = {{ImageNet:} {A} large-scale hierarchical image database},
+ url = {https://doi.org/10.1109/cvpr.2009.5206848},
+ year = {2009},
+ source = {Crossref},
+ month = jun,
}
@inproceedings{he2016deep,
- author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
+ author = {He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/HeZRS16.bib},
- booktitle = {2016 {IEEE} Conference on Computer Vision and Pattern Recognition, {CVPR} 2016, Las Vegas, NV, USA, June 27-30, 2016},
- doi = {10.1109/CVPR.2016.90},
+ booktitle = {2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr.2016.90},
pages = {770--778},
- publisher = {{IEEE} Computer Society},
+ publisher = {IEEE},
timestamp = {Wed, 17 Apr 2019 01:00:00 +0200},
title = {Deep Residual Learning for Image Recognition},
- url = {https://doi.org/10.1109/CVPR.2016.90},
- year = {2016}
+ url = {https://doi.org/10.1109/cvpr.2016.90},
+ year = {2016},
+ source = {Crossref},
+ month = jun,
}
@inproceedings{jia2014caffe,
@@ -98,20 +106,21 @@ @inproceedings{jia2014caffe
subtitle = {Convolutional Architecture for Fast Feature Embedding},
title = {Caffe},
url = {https://doi.org/10.1145/2647868.2654889},
- year = {2014}
+ year = {2014},
+ month = nov,
}
@inproceedings{krizhevsky2012imagenet,
- author = {Alex Krizhevsky and Ilya Sutskever and Geoffrey E. Hinton},
+ author = {Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E.},
+ editor = {Bartlett, Peter L. and Pereira, Fernando C. N. and Burges, Christopher J. C. and Bottou, L\'eon and Weinberger, Kilian Q.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/KrizhevskySH12.bib},
booktitle = {Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States},
- editor = {Peter L. Bartlett and Fernando C. N. Pereira and Christopher J. C. Burges and L{\'{e}}on Bottou and Kilian Q. Weinberger},
pages = {1106--1114},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
- title = {ImageNet Classification with Deep Convolutional Neural Networks},
+ title = {{ImageNet} Classification with Deep Convolutional Neural Networks},
url = {https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html},
- year = {2012}
+ year = {2012},
}
@inproceedings{kung1979systolic,
@@ -121,7 +130,7 @@ @inproceedings{kung1979systolic
pages = {256--282},
title = {Systolic arrays (for {VLSI)}},
volume = {1},
- year = {1979}
+ year = {1979},
}
@article{lai2018cmsis,
@@ -130,20 +139,20 @@ @article{lai2018cmsis
title = {Cmsis-nn: {Efficient} neural network kernels for arm cortex-m cpus},
url = {https://arxiv.org/abs/1801.06601},
volume = {abs/1801.06601},
- year = {2018}
+ year = {2018},
}
@inproceedings{li2014communication,
- author = {Mu Li and David G. Andersen and Alexander J. Smola and Kai Yu},
+ author = {Li, Mu and Andersen, David G. and Smola, Alexander J. and Yu, Kai},
+ editor = {Ghahramani, Zoubin and Welling, Max and Cortes, Corinna and Lawrence, Neil D. and Weinberger, Kilian Q.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/LiASY14.bib},
booktitle = {Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada},
- editor = {Zoubin Ghahramani and Max Welling and Corinna Cortes and Neil D. Lawrence and Kilian Q. Weinberger},
pages = {19--27},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
title = {Communication Efficient Distributed Machine Learning with the Parameter Server},
url = {https://proceedings.neurips.cc/paper/2014/hash/1ff1de774005f8da13f42943881c655f-Abstract.html},
- year = {2014}
+ year = {2014},
}
@article{li2017learning,
@@ -158,48 +167,53 @@ @article{li2017learning
title = {Learning without Forgetting},
url = {https://doi.org/10.1109/tpami.2017.2773081},
volume = {40},
- year = {2018}
+ year = {2018},
+ month = dec,
}
@inproceedings{lin2020mcunet,
- author = {Ji Lin and Wei{-}Ming Chen and Yujun Lin and John Cohn and Chuang Gan and Song Han},
+ author = {Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Cohn, John and Gan, Chuang and Han, Song},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/LinCLCG020.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Thu, 11 Feb 2021 00:00:00 +0100},
- title = {MCUNet: Tiny Deep Learning on IoT Devices},
+ title = {{MCUNet:} {Tiny} Deep Learning on {IoT} Devices},
url = {https://proceedings.neurips.cc/paper/2020/hash/86c51678350f656dcc7f490a43946ee5-Abstract.html},
- year = {2020}
+ year = {2020},
}
@inproceedings{mcmahan2023communicationefficient,
- author = {Brendan McMahan and Eider Moore and Daniel Ramage and Seth Hampson and Blaise Ag{\"{u}}era y Arcas},
+ author = {McMahan, Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and y Arcas, Blaise Ag\"uera},
+ editor = {Singh, Aarti and Zhu, Xiaojin (Jerry)},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/aistats/McMahanMRHA17.bib},
- booktitle = {Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, {AISTATS} 2017, 20-22 April 2017, Fort Lauderdale, FL, {USA}},
- editor = {Aarti Singh and Xiaojin (Jerry) Zhu},
+ booktitle = {Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA},
pages = {1273--1282},
- publisher = {{PMLR}},
+ publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
timestamp = {Wed, 03 Apr 2019 01:00:00 +0200},
title = {Communication-Efficient Learning of Deep Networks from Decentralized Data},
url = {http://proceedings.mlr.press/v54/mcmahan17a.html},
volume = {54},
- year = {2017}
+ year = {2017},
}
@inproceedings{paszke2019pytorch,
- author = {Adam Paszke and Sam Gross and Francisco Massa and Adam Lerer and James Bradbury and Gregory Chanan and Trevor Killeen and Zeming Lin and Natalia Gimelshein and Luca Antiga and Alban Desmaison and Andreas K{\"{o}}pf and Edward Yang and Zachary DeVito and Martin Raison and Alykhan Tejani and Sasank Chilamkurthy and Benoit Steiner and Lu Fang and Junjie Bai and Soumith Chintala},
+ author = {Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and Chauhan, Geeta and Chourdia, Anjali and Constable, Will and Desmaison, Alban and DeVito, Zachary and Ellison, Elias and Feng, Will and Gong, Jiong and Gschwind, Michael and Hirsh, Brian and Huang, Sherlock and Kalambarkar, Kshiteej and Kirsch, Laurent and Lazos, Michael and Lezcano, Mario and Liang, Yanbo and Liang, Jason and Lu, Yinghai and Luk, C. K. and Maher, Bert and Pan, Yunjie and Puhrsch, Christian and Reso, Matthias and Saroufim, Mark and Siraichi, Marcos Yukio and Suk, Helen and Zhang, Shunting and Suo, Michael and Tillet, Phil and Zhao, Xu and Wang, Eikan and Zhou, Keren and Zou, Richard and Wang, Xiaodong and Mathews, Ajit and Wen, William and Chanan, Gregory and Wu, Peng and Chintala, Soumith},
+ editor = {Wallach, Hanna M. and Larochelle, Hugo and Beygelzimer, Alina and d'Alch\'e-Buc, Florence and Fox, Emily B. and Garnett, Roman},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/PaszkeGMLBCKLGA19.bib},
- booktitle = {Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada},
- editor = {Hanna M. Wallach and Hugo Larochelle and Alina Beygelzimer and Florence d'Alch{\'{e}}{-}Buc and Emily B. Fox and Roman Garnett},
+ booktitle = {Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2},
pages = {8024--8035},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
- title = {PyTorch: An Imperative Style, High-Performance Deep Learning Library},
- url = {https://proceedings.neurips.cc/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html},
- year = {2019}
+ title = {{PyTorch} 2: {Faster} Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation},
+ url = {https://doi.org/10.1145/3620665.3640366},
+ year = {2024},
+ doi = {10.1145/3620665.3640366},
+ source = {Crossref},
+ publisher = {ACM},
+ month = apr,
}
@inproceedings{seide2016cntk,
@@ -212,7 +226,8 @@ @inproceedings{seide2016cntk
subtitle = {Microsoft's Open-Source Deep-Learning Toolkit},
title = {Cntk},
url = {https://doi.org/10.1145/2939672.2945397},
- year = {2016}
+ year = {2016},
+ month = aug,
}
@inproceedings{tokui2015chainer,
@@ -226,5 +241,6 @@ @inproceedings{tokui2015chainer
title = {Chainer},
url = {https://doi.org/10.1145/3292500.3330756},
volume = {5},
- year = {2019}
+ year = {2019},
+ month = jul,
}
diff --git a/contents/frameworks/frameworks.qmd b/contents/frameworks/frameworks.qmd
index 04871432..a3ee4f46 100644
--- a/contents/frameworks/frameworks.qmd
+++ b/contents/frameworks/frameworks.qmd
@@ -8,11 +8,11 @@ bibliography: frameworks.bib
Resources: [Slides](#sec-ai-frameworks-resource), [Labs](#sec-ai-frameworks-resource), [Exercises](#sec-ai-frameworks-resource)
:::
-
+
-In this chapter, we explore the landscape of AI frameworks that serve as the foundation for developing machine learning systems. AI frameworks provide the essential tools, libraries, and environments necessary to design, train, and deploy machine learning models. We delve into the evolutionary trajectory of these frameworks, dissect the workings of TensorFlow, and provide insights into the core components and advanced features that define these frameworks.
+This chapter explores the landscape of AI frameworks that serve as the foundation for developing machine learning systems. AI frameworks provide the tools, libraries, and environments to design, train, and deploy machine learning models. We delve into the evolutionary trajectory of these frameworks, dissect the workings of TensorFlow, and provide insights into the core components and advanced features that define these frameworks.
-Furthermore, we investigate the specialization of frameworks tailored to specific needs, the emergence of frameworks specifically designed for embedded AI, and the criteria for selecting the most suitable framework for your project. This exploration will be rounded off by a glimpse into the future trends that are expected to shape the landscape of ML frameworks in the coming years.
+Furthermore, we investigate the specialization of frameworks tailored to specific needs, the emergence of frameworks specifically designed for embedded AI, and the criteria for selecting the most suitable framework for your project. This exploration will be rounded off by a glimpse into the future trends expected to shape the landscape of ML frameworks in the coming years.
::: {.callout-tip}
@@ -21,48 +21,48 @@ Furthermore, we investigate the specialization of frameworks tailored to specifi
* Understand the evolution and capabilities of major machine learning frameworks. This includes graph execution models, programming paradigms, hardware acceleration support, and how they have expanded over time.
-* Learn the core components and functionality of frameworks like computational graphs, data pipelines, optimization algorithms, training loops, etc. that enable efficient model building.
+* Learn frameworks' core components and functionality, such as computational graphs, data pipelines, optimization algorithms, training loops, etc., that enable efficient model building.
-* Compare frameworks across different environments like cloud, edge, and TinyML. Learn how frameworks specialize based on computational constraints and hardware.
+* Compare frameworks across different environments, such as cloud, edge, and TinyML. Learn how frameworks specialize based on computational constraints and hardware.
-* Dive deeper into embedded and TinyML focused frameworks like TensorFlow Lite Micro, CMSIS-NN, TinyEngine etc. and how they optimize for microcontrollers.
+* Dive deeper into embedded and TinyML-focused frameworks like TensorFlow Lite Micro, CMSIS-NN, TinyEngine, etc., and how they optimize for microcontrollers.
-* Explore model conversion and deployment considerations when choosing a framework, including aspects like latency, memory usage, and hardware support.
+* When choosing a framework, explore model conversion and deployment considerations, including latency, memory usage, and hardware support.
-* Evaluate key factors in selecting the right framework like performance, hardware compatibility, community support, ease of use, etc. based on the specific project needs and constraints.
+* Evaluate key factors in selecting the right framework, like performance, hardware compatibility, community support, ease of use, etc., based on the specific project needs and constraints.
-* Understand the limitations of current frameworks and potential future trends like using ML to improve frameworks, decomposed ML systems, and high performance compilers.
+* Understand the limitations of current frameworks and potential future trends, such as using ML to improve frameworks, decomposed ML systems, and high-performance compilers.
:::
## Introduction
-Machine learning frameworks provide the tools and infrastructure to efficiently build, train, and deploy machine learning models. In this chapter, we will explore the evolution and key capabilities of major frameworks like [TensorFlow (TF)](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/), and specialized frameworks for embedded devices. We will dive into the components like computational graphs, optimization algorithms, hardware acceleration, and more that enable developers to quickly construct performant models. Understanding these frameworks is essential to leverage the power of deep learning across the spectrum from cloud to edge devices.
+Machine learning frameworks provide the tools and infrastructure to efficiently build, train, and deploy machine learning models. In this chapter, we will explore the evolution and key capabilities of major frameworks like [TensorFlow (TF)](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/), and specialized frameworks for embedded devices. We will dive into the components like computational graphs, optimization algorithms, hardware acceleration, and more that enable developers to construct performant models quickly. Understanding these frameworks is essential to leverage the power of deep learning across the spectrum from cloud to edge devices.
ML frameworks handle much of the complexity of model development through high-level APIs and domain-specific languages that allow practitioners to quickly construct models by combining pre-made components and abstractions. For example, frameworks like TensorFlow and PyTorch provide Python APIs to define neural network architectures using layers, optimizers, datasets, and more. This enables rapid iteration compared to coding every model detail from scratch.
-A key capability offered by frameworks is distributed training engines that can scale model training across clusters of GPUs and TPUs. This makes it feasible to train state-of-the-art models with billions or trillions of parameters on vast datasets. Frameworks also integrate with specialized hardware like NVIDIA GPUs to further accelerate training via optimizations like parallelization and efficient matrix operations.
+A key capability framework offered is distributed training engines that can scale model training across clusters of GPUs and TPUs. This makes it feasible to train state-of-the-art models with billions or trillions of parameters on vast datasets. Frameworks also integrate with specialized hardware like NVIDIA GPUs to further accelerate training via optimizations like parallelization and efficient matrix operations.
In addition, frameworks simplify deploying finished models into production through tools like [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving) for scalable model serving and [TensorFlow Lite](https://www.tensorflow.org/lite) for optimization on mobile and edge devices. Other valuable capabilities include visualization, model optimization techniques like quantization and pruning, and monitoring metrics during training.
-Leading open source frameworks like TensorFlow, PyTorch, and [MXNet](https://mxnet.apache.org/versions/1.9.1/) power much of AI research and development today. Commercial offerings like [Amazon SageMaker](https://aws.amazon.com/pm/sagemaker/) and [Microsoft Azure Machine Learning](https://azure.microsoft.com/en-us/free/machine-learning/search/?ef_id=_k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&gad=1&gclid=CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE) integrate these open source frameworks with proprietary capabilities and enterprise tools.
+They were leading open-source frameworks like TensorFlow, PyTorch, and [MXNet](https://mxnet.apache.org/versions/1.9.1/), which power much of AI research and development today. Commercial offerings like [Amazon SageMaker](https://aws.amazon.com/pm/sagemaker/) and [Microsoft Azure Machine Learning](https://azure.microsoft.com/en-us/free/machine-learning/search/?ef_id=_k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&OCID=AIDcmm5edswduu_SEM__k_CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE_k_&gad=1&gclid=CjwKCAjws9ipBhB1EiwAccEi1JVOThls797Sj3Li96_GYjoJQDx_EWaXNsDaEWeFbIaRkESUCkq64xoCSmwQAvD_BwE) integrate these open source frameworks with proprietary capabilities and enterprise tools.
-Machine learning engineers and practitioners leverage these robust frameworks to focus on high-value tasks like model architecture, feature engineering, and hyperparameter tuning instead of infrastructure. The goal is to efficiently build and deploy performant models that solve real-world problems.
+Machine learning engineers and practitioners leverage these robust frameworks to focus on high-value tasks like model architecture, feature engineering, and hyperparameter tuning instead of infrastructure. The goal is to build and deploy performant models that solve real-world problems efficiently.
-In this chapter, we will explore today\'s leading cloud frameworks and how they have adapted models and tools specifically for embedded and edge deployment. We will compare programming models, supported hardware, optimization capabilities, and more to fully understand how frameworks enable scalable machine learning from the cloud to the edge.
+This chapter, we will explore today's leading cloud frameworks and how they have adapted models and tools specifically for embedded and edge deployment. We will compare programming models, supported hardware, optimization capabilities, and more to fully understand how frameworks enable scalable machine learning from the cloud to the edge.
## Framework Evolution
-Machine learning frameworks have evolved significantly over time to meet the diverse needs of machine learning practitioners and advancements in AI techniques. A few decades ago, building and training machine learning models required extensive low-level coding and infrastructure. Machine learning frameworks have evolved considerably over the past decade to meet the expanding needs of practitioners and rapid advances in deep learning techniques. Early neural network research was constrained by insufficient data and compute power. Building and training machine learning models required extensive low-level coding and infrastructure. But the release of large datasets like [ImageNet](https://www.image-net.org/) [@deng2009imagenet] and advancements in parallel GPU computing unlocked the potential for far deeper neural networks.
+Machine learning frameworks have evolved significantly to meet the diverse needs of machine learning practitioners and advancements in AI techniques. A few decades ago, building and training machine learning models required extensive low-level coding and infrastructure. Machine learning frameworks have evolved considerably over the past decade to meet the expanding needs of practitioners and rapid advances in deep learning techniques. Insufficient data and computing power constrained early neural network research. Building and training machine learning models required extensive low-level coding and infrastructure. However, the release of large datasets like [ImageNet](https://www.image-net.org/) [@deng2009imagenet] and advancements in parallel GPU computing unlocked the potential for far deeper neural networks.
-The first ML frameworks, [Theano](https://pypi.org/project/Theano/#:~:text=Theano is a Python library,a similar interface to NumPy's.) by @al2016theano and [Caffe](https://caffe.berkeleyvision.org/) by @jia2014caffe, were developed by academic institutions (Montreal Institute for Learning Algorithms, Berkeley Vision and Learning Center). Amid a growing interest in deep learning due to state-of-the-art performance of AlexNet @krizhevsky2012imagenet on the ImageNet dataset, private companies and individuals began developing ML frameworks, resulting in frameworks such as [Keras](https://keras.io/) by @chollet2018keras, [Chainer](https://chainer.org/) by @tokui2015chainer, TensorFlow from Google [@abadi2016tensorflow], [CNTK](https://learn.microsoft.com/en-us/cognitive-toolkit/) by Microsoft [@seide2016cntk], and PyTorch by Facebook [@paszke2019pytorch].
+The first ML frameworks, [Theano](https://pypi.org/project/Theano/#:~:text=Theano is a Python library, a similar interface to NumPy's.) by @al2016theano and [Caffe](https://caffe.berkeleyvision.org/) by @jia2014caffe, were developed by academic institutions (Montreal Institute for Learning Algorithms, Berkeley Vision and Learning Center). Amid growing interest in deep learning due to state-of-the-art performance of AlexNet @krizhevsky2012imagenet on the ImageNet dataset, private companies and individuals began developing ML frameworks, resulting in frameworks such as [Keras](https://keras.io/) by @chollet2018keras, [Chainer](https://chainer.org/) by @tokui2015chainer, TensorFlow from Google [@abadi2016tensorflow], [CNTK](https://learn.microsoft.com/en-us/cognitive-toolkit/) by Microsoft [@seide2016cntk], and PyTorch by Facebook [@paszke2019pytorch].
-Many of these ML frameworks can be divided into categories, namely high-level vs. low-level frameworks and static vs. dynamic computational graph frameworks. High-level frameworks provide a higher level of abstraction than low-level frameworks. That is, high-level frameworks have pre-built functions and modules for common ML tasks, such as creating, training, and evaluating common ML models as well as preprocessing data, engineering features, and visualizing data, which low-level frameworks do not have. Thus, high-level frameworks may be easier to use, but are not as customizable as low-level frameworks (i.e. users of low-level frameworks can define custom layers, loss functions, optimization algorithms, etc.). Examples of high-level frameworks include TensorFlow/Keras and PyTorch. Examples of low-level ML frameworks include TensorFlow with low-level APIs, Theano, Caffe, Chainer, and CNTK.
+Many of these ML frameworks can be divided into high-level vs. low-level frameworks and static vs. dynamic computational graph frameworks. High-level frameworks provide a higher level of abstraction than low-level frameworks. High-level frameworks have pre-built functions and modules for common ML tasks, such as creating, training, and evaluating common ML models, preprocessing data, engineering features, and visualizing data, which low-level frameworks do not have. Thus, high-level frameworks may be easier to use but are less customizable than low-level frameworks (i.e., users of low-level frameworks can define custom layers, loss functions, optimization algorithms, etc.). Examples of high-level frameworks include TensorFlow/Keras and PyTorch. Examples of low-level ML frameworks include TensorFlow with low-level APIs, Theano, Caffe, Chainer, and CNTK.
-Frameworks like Theano and Caffe used static computational graphs which required rigidly defining the full model architecture upfront. Static graphs require upfront declaration and limit flexibility. Dynamic graphs construct on-the-fly for more iterative development. But around 2016, frameworks began adopting dynamic graphs like PyTorch and TensorFlow 2.0 which can construct graphs on-the-fly. This provides greater flexibility for model development. We will discuss these concepts and details later on in the AI Training section.
+Frameworks like Theano and Caffe used static computational graphs, which required rigidly defining the full model architecture upfront. Static graphs require upfront declaration and limit flexibility. Dynamic graphs are constructed on the fly for more iterative development. However, around 2016, frameworks began adopting dynamic graphs like PyTorch and TensorFlow 2.0, which can construct graphs on the fly. This provides greater flexibility for model development. We will discuss these concepts and details later in the AI Training section.
-The development of these frameworks facilitated an explosion in model size and complexity over time---from early multilayer perceptrons and convolutional networks to modern transformers with billions or trillions of parameters. In 2016, ResNet models by @he2016deep achieved record ImageNet accuracy with over 150 layers and 25 million parameters. Then in 2020, the GPT-3 language model from OpenAI [@brown2020language] pushed parameters to an astonishing 175 billion using model parallelism in frameworks to train across thousands of GPUs and TPUs.
+The development of these frameworks facilitated an explosion in model size and complexity over time---from early multilayer perceptrons and convolutional networks to modern transformers with billions or trillions of parameters. In 2016, ResNet models by @he2016deep achieved record ImageNet accuracy with over 150 layers and 25 million parameters. Then, in 2020, the GPT-3 language model from OpenAI [@brown2020language] pushed parameters to an astonishing 175 billion using model parallelism in frameworks to train across thousands of GPUs and TPUs.
Each generation of frameworks unlocked new capabilities that powered advancement:
@@ -72,29 +72,29 @@ Each generation of frameworks unlocked new capabilities that powered advancement
* PyTorch (2016) provided imperative programming and dynamic graphs for flexible experimentation.
-* TensorFlow 2.0 (2019) made eager execution default for intuitiveness and debugging.
+* TensorFlow 2.0 (2019) defaulted eager execution for intuitiveness and debugging.
* TensorFlow Graphics (2020) added 3D data structures to handle point clouds and meshes.
-In recent years, there has been a convergence on the frameworks. @fig-ml-framework shows that TensorFlow and PyTorch have become the overwhelmingly dominant ML frameworks, representing more than 95% of ML frameworks used in research and production. Keras was integrated into TensorFlow in 2019; Preferred Networks transitioned Chainer to PyTorch in 2019; and Microsoft stopped actively developing CNTK in 2022 in favor of supporting PyTorch on Windows.
+In recent years, the frameworks have converged. @fig-ml-framework shows that TensorFlow and PyTorch have become the overwhelmingly dominant ML frameworks, representing more than 95% of ML frameworks used in research and production. Keras was integrated into TensorFlow in 2019; Preferred Networks transitioned Chainer to PyTorch in 2019; and Microsoft stopped actively developing CNTK in 2022 to support PyTorch on Windows.
{#fig-ml-framework}
-However, a one-size-fits-all approach does not work well across the spectrum from cloud to tiny edge devices. Different frameworks represent various philosophies around graph execution, declarative versus imperative APIs, and more. Declarative defines what the program should do while imperative focuses on how it should do it step-by-step. For instance, TensorFlow uses graph execution and declarative-style modeling while PyTorch adopts eager execution and imperative modeling for more Pythonic flexibility. Each approach carries tradeoffs that we will discuss later in the Basic Components section.
+However, a one-size-fits-all approach only works well across the spectrum from cloud to tiny edge devices. Different frameworks represent various philosophies around graph execution, declarative versus imperative APIs, and more. Declaratives define what the program should do, while imperatives focus on how it should be done step-by-step. For instance, TensorFlow uses graph execution and declarative-style modeling, while PyTorch adopts eager execution and imperative modeling for more Pythonic flexibility. Each approach carries tradeoffs, which we will discuss later in the Basic Components section.
-Today\'s advanced frameworks enable practitioners to develop and deploy increasingly complex models - a key driver of innovation in the AI field. But they continue to evolve and expand their capabilities for the next generation of machine learning. To understand how these systems continue to evolve, we will dive deeper into TensorFlow as an example of how the framework grew in complexity over time.
+Today's advanced frameworks enable practitioners to develop and deploy increasingly complex models - a key driver of innovation in the AI field. However, they continue to evolve and expand their capabilities for the next generation of machine learning. To understand how these systems continue to evolve, we will dive deeper into TensorFlow as an example of how the framework grew in complexity over time.
## DeepDive into TensorFlow
TensorFlow was developed by the Google Brain team and was released as an open-source software library on November 9, 2015. It was designed for numerical computation using data flow graphs and has since become popular for a wide range of machine learning and deep learning applications.
-TensorFlow is both a training and inference framework and provides built-in functionality to handle everything from model creation and training, to deployment (@fig-tensorflow-architecture). Since its initial development, the TensorFlow ecosystem has grown to include many different "varieties" of TensorFlow that are each intended to allow users to support ML on different platforms. In this section, we will mainly discuss only the core package.
+TensorFlow is a training and inference framework that provides built-in functionality to handle everything from model creation and training to deployment (@fig-tensorflow-architecture). Since its initial development, the TensorFlow ecosystem has grown to include many different "varieties" of TensorFlow, each intended to allow users to support ML on different platforms. In this section, we will mainly discuss only the core package.
### TF Ecosystem
-1. [TensorFlow Core](https://www.tensorflow.org/tutorials): primary package that most developers engage with. It provides a comprehensive, flexible platform for defining, training, and deploying machine learning models. It includes tf.keras as its high-level API.
+1. [TensorFlow Core](https://www.tensorflow.org/tutorials): primary package that most developers engage with. It provides a comprehensive, flexible platform for defining, training, and deploying machine learning models. It includes tf—keras as its high-level API.
-2. [TensorFlow Lite](https://www.tensorflow.org/lite): designed for deploying lightweight models on mobile, embedded, and edge devices. It offers tools to convert TensorFlow models to a more compact format suitable for limited-resource devices and provides optimized pre-trained models for mobile.
+2. [TensorFlow Lite] (https://www.tensorflow.org/lite): designed for deploying lightweight models on mobile, embedded, and edge devices. It offers tools to convert TensorFlow models to a more compact format suitable for limited-resource devices and provides optimized pre-trained models for mobile.
3. [TensorFlow.js](https://www.tensorflow.org/js): JavaScript library that allows training and deployment of machine learning models directly in the browser or on Node.js. It also provides tools for porting pre-trained TensorFlow models to the browser-friendly format.
@@ -108,7 +108,7 @@ TensorFlow is both a training and inference framework and provides built-in func
8. [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving): framework designed for serving and deploying machine learning models for inference in production environments. It provides tools for versioning and dynamically updating deployed models without service interruption.
-9. [TensorFlow Extended (TFX)](https://www.tensorflow.org/tfx): end-to-end platform designed to deploy and manage machine learning pipelines in production settings. TFX encompasses components for data validation, preprocessing, model training, validation, and serving.
+9. [TensorFlow Extended (TFX)](https://www.tensorflow.org/tfx): end-to-end platform designed to deploy and manage machine learning pipelines in production settings. TFX encompasses data validation, preprocessing, model training, validation, and serving components.
)](images/png/tensorflow.png){#fig-tensorflow-architecture}
@@ -116,15 +116,15 @@ TensorFlow was developed to address the limitations of DistBelief [@abadi2016ten
The Parameter Server (PS) architecture is a popular design for distributing the training of machine learning models, especially deep neural networks, across multiple machines. The fundamental idea is to separate the storage and management of model parameters from the computation used to update these parameters:
-**Storage**: The storage and management of model parameters were handled by the stateful parameter server processes. Given the large scale of models and the distributed nature of the system, these parameters were sharded across multiple parameter servers. Each server maintained a portion of the model parameters, making it \"stateful\" as it had to maintain and manage this state across the training process.
+**Storage:** The stateful parameter server processes handled the storage and management of model parameters. Given the large scale of models and the system's distributed nature, these parameters were sharded across multiple parameter servers. Each server maintained a portion of the model parameters, making it \"stateful\" as it had to maintain and manage this state across the training process.
-**Computation**: The worker processes, which could be run in parallel, were stateless and purely computational, processing data and computing gradients without maintaining any state or long-term memory [@li2014communication].
+**Computation:** The worker processes, which could be run in parallel, were stateless and purely computational. They processed data and computed gradients without maintaining any state or long-term memory [@li2014communication].
:::{#exr-tfc .callout-exercise collapse="true"}
### TensorFlow Core
-Let's get a comprehensive understanding of core machine learning algorithms using TensorFlow and their practical applications in data analysis and predictive modeling. We will start with linear regression to predict survival rates from the Titanic dataset. Then using TensorFlow, we will construct classifiers to identify different species of flowers based on their attributes. Next, we will use K-Means algorithm and its application in segmenting datasets into cohesive clusters. Finally, we will apply hidden markov models (HMM), in order to foresee weather patterns.
+Let's comprehensively understand core machine learning algorithms using TensorFlow and their practical applications in data analysis and predictive modeling. We will start with linear regression to predict survival rates from the Titanic dataset. Then, using TensorFlow, we will construct classifiers to identify different species of flowers based on their attributes. Next, we will use the K-Means algorithm and its application in segmenting datasets into cohesive clusters. Finally, we will apply hidden Markov models (HMM) to foresee weather patterns.
[](https://colab.research.google.com/drive/15Cyy2H7nT40sGR7TBN5wBvgTd57mVKay#scrollTo=IEeIRxlbx0wY)
:::
@@ -133,8 +133,8 @@ Let's get a comprehensive understanding of core machine learning algorithms usin
### TensorFlow Lite
-Here we will see how to build a miniature machine learning model for microcontrollers. We will get to build a mini neural network, streamlined to learn from data, even with limited resources and optimize for deployment by shrinking our model for efficient use on microcontrollers.
-TensorFlow Lite, a powerful technology derived from TensorFlow, shrinks models for tiny devices and helps enable on-device features like image recognition in smart devices and is used in edge computing to allow for faster analysis and decisions in devices processing data locally.
+Here, we will see how to build a miniature machine-learning model for microcontrollers. We will build a mini neural network that is streamlined to learn from data even with limited resources and optimized for deployment by shrinking our model for efficient use on microcontrollers.
+TensorFlow Lite, a powerful technology derived from TensorFlow, shrinks models for tiny devices and helps enable on-device features like image recognition in smart devices. It is used in edge computing to allow for faster analysis and decisions in devices processing data locally.
[](https://colab.research.google.com/github/Mjrovai/UNIFEI-IESTI01-TinyML-2022.1/blob/main/00_Curse_Folder/2_Applications_Deploy/Class_16/TFLite-Micro-Hello-World/train_TFL_Micro_hello_world_model.ipynb)
:::
@@ -143,55 +143,55 @@ DistBelief and its architecture defined above were crucial in enabling distribut
### Static Computation Graph
-In the parameter server architecture, model parameters are distributed across various parameter servers. Since DistBelief was primarily designed for the neural network paradigm, parameters corresponded to a fixed structure of the neural network. If the computation graph were dynamic, the distribution and coordination of parameters would become significantly more complicated. For example, a change in the graph might require the initialization of new parameters or the removal of existing ones, complicating the management and synchronization tasks of the parameter servers. This made it harder to implement models outside the neural framework or models that required dynamic computation graphs.
+Model parameters are distributed across various parameter servers in the parameter server architecture. Since DistBelief was primarily designed for the neural network paradigm, parameters corresponded to a fixed neural network structure. If the computation graph were dynamic, the distribution and coordination of parameters would become significantly more complicated. For example, a change in the graph might require the initialization of new parameters or the removal of existing ones, complicating the management and synchronization tasks of the parameter servers. This made it harder to implement models outside the neural framework or models that required dynamic computation graphs.
-TensorFlow was designed to be a more general computation framework where the computation is expressed as a data flow graph. This allows for a wider variety of machine learning models and algorithms outside of just neural networks, and provides flexibility in refining models.
+TensorFlow was designed as a more general computation framework that expresses computation as a data flow graph. This allows for a wider variety of machine learning models and algorithms outside of neural networks and provides flexibility in refining models.
### Usability & Deployment
-The parameter server model involves a clear delineation of roles (worker nodes and parameter servers), and is optimized for data center deployments which might not be optimal for all use cases. For instance, on edge devices or in other non-data center environments, this division introduces overheads or complexities.
+The parameter server model delineates roles (worker nodes and parameter servers) and is optimized for data center deployments, which might only be optimal for some use cases. For instance, this division introduces overheads or complexities on edge devices or in other non-data center environments.
-TensorFlow was built to run on multiple platforms, from mobile devices and edge devices, to cloud infrastructure. It also aimed to provide ease of use between local and distributed training, and to be more lightweight, and developer friendly.
+TensorFlow was built to run on multiple platforms, from mobile devices and edge devices to cloud infrastructure. It also aimed to be lighter and developer-friendly and to provide ease of use between local and distributed training.
### Architecture Design
-Rather than using the parameter server architecture, TensorFlow instead deploys tasks across a cluster. These tasks are named processes that can communicate over a network, and each can execute TensorFlow\'s core construct: the dataflow graph, and interface with various computing devices (like CPUs or GPUs). This graph is a directed representation where nodes symbolize computational operations, and edges depict the tensors (data) flowing between these operations.
+Rather than using the parameter server architecture, TensorFlow deploys tasks across a cluster. These tasks are named processes that can communicate over a network, and each can execute TensorFlow's core construct, the dataflow graph, and interface with various computing devices (like CPUs or GPUs). This graph is a directed representation where nodes symbolize computational operations, and edges depict the tensors (data) flowing between these operations.
-Despite the absence of traditional parameter servers, some tasks, called "PS tasks", still perform the role of storing and managing parameters, reminiscent of parameter servers in other systems. The remaining tasks, which usually handle computation, data processing, and gradient calculations, are referred to as \"worker tasks.\" TensorFlow\'s PS tasks can execute any computation representable by the dataflow graph, meaning they aren\'t just limited to parameter storage, and the computation can be distributed. This capability makes them significantly more versatile and gives users the power to program the PS tasks using the standard TensorFlow interface, the same one they\'d use to define their models. As mentioned above, dataflow graphs' structure also makes it inherently good for parallelism allowing for processing of large datasets.
+Despite the absence of traditional parameter servers, some "PS tasks" still store and manage parameters reminiscent of parameter servers in other systems. The remaining tasks, which usually handle computation, data processing, and gradient calculations, are referred to as \"worker tasks.\" TensorFlow's PS tasks can execute any computation representable by the dataflow graph, meaning they aren't just limited to parameter storage, and the computation can be distributed. This capability makes them significantly more versatile and gives users the power to program the PS tasks using the standard TensorFlow interface, the same one they'd use to define their models. As mentioned above, dataflow graphs' structure also makes them inherently good for parallelism, allowing for the processing of large datasets.
### Built-in Functionality & Keras
-TensorFlow includes libraries to help users develop and deploy more use-case specific models, and since this framework is open-source, this list continues to grow. These libraries address the entire ML development life-cycle: data preparation, model building, deployment, as well as responsible AI.
+TensorFlow includes libraries to help users develop and deploy more use-case-specific models, and since this framework is open-source, this list continues to grow. These libraries address the entire ML development lifecycle: data preparation, model building, deployment, and responsible AI.
-Additionally, one of TensorFlow's biggest advantages is its integration with Keras, though as we will cover in the next section, Pytorch recently also added a Keras integration. Keras is another ML framework that was built to be extremely user-friendly and as a result has a high level of abstraction. We will cover Keras in more depth later in this chapter, but when discussing its integration with TensorFlow, the most important thing to note is that it was originally built to be backend agnostic. This means users could abstract away these complexities, offering a cleaner, more intuitive way to define and train models without worrying about compatibility issues with different backends. TensorFlow users had some complaints about the usability and readability of TensorFlow's API, so as TF gained prominence it integrated Keras as its high-level API. This integration offered major benefits to TensorFlow users since it introduced more intuitive readability, and portability of models while still taking advantage of powerful backend features, Google support, and infrastructure to deploy models on various platforms.
+One of TensorFlow's biggest advantages is its integration with Keras, though, as we will cover in the next section, Pytorch recently added a Keras integration. Keras is another ML framework built to be extremely user-friendly and, as a result, has a high level of abstraction. We will cover Keras in more depth later in this chapter. However, when discussing its integration with TensorFlow, it was important to note that it was originally built to be backend-agnostic. This means users could abstract away these complexities, offering a cleaner, more intuitive way to define and train models without worrying about compatibility issues with different backends. TensorFlow users had some complaints about the usability and readability of TensorFlow's API, so as TF gained prominence, it integrated Keras as its high-level API. This integration offered major benefits to TensorFlow users since it introduced more intuitive readability and portability of models while still taking advantage of powerful backend features, Google support, and infrastructure to deploy models on various platforms.
:::{#exr-k .callout-exercise collapse="true"}
### Exploring Keras: Building, Training, and Evaluating Neural Networks
-Here, we'll learn how to use Keras, a high-level neural networks API, for model development and training. We will explore the functional API for concise model building, understand loss and metric classes for model evaluation, and use built-in optimizers to update model parameters during training. Additionally, we'll discover how to define custom layers and metrics tailored to our needs. Lastly, we'll delve into Keras' training loops to streamline the process of training neural networks on large datasets. This knowledge will empower us to build and optimize neural network models across various applications in machine learning and artificial intelligence.
+Here, we'll learn how to use Keras, a high-level neural network API, for model development and training. We will explore the functional API for concise model building, understand loss and metric classes for model evaluation, and use built-in optimizers to update model parameters during training. Additionally, we'll discover how to define custom layers and metrics tailored to our needs. Lastly, we'll delve into Keras' training loops to streamline the process of training neural networks on large datasets. This knowledge will empower us to build and optimize neural network models across various machine learning and artificial intelligence applications.
[](https://colab.research.google.com/drive/1UCJt8EYjlzCs1H1d1X0iDGYJsHKwu-NO#scrollTo=fxINLLGitX_n)
:::
### Limitations and Challenges
-TensorFlow is one of the most popular deep learning frameworks but does have criticisms and weaknesses-- mostly focusing on usability, and resource usage. The rapid pace of updates through its support from Google, while advantageous, has sometimes led to issues of backward compatibility, deprecated functions, and shifting documentation. Additionally, even with the Keras implementation, the syntax and learning curve of TensorFlow can be difficult for new users. One major critique of TensorFlow is its high overhead and memory consumption due to the range of built in libraries and support. Some of these concerns can be addressed by using pared down versions, but can still be limiting in resource-constrained environments.
+TensorFlow is one of the most popular deep learning frameworks but has criticisms and weaknesses, mostly focusing on usability and resource usage. While advantageous, the rapid pace of updates through its support from Google has sometimes led to backward compatibility issues, deprecated functions, and shifting documentation. Additionally, even with the Keras implementation, TensorFlow's syntax and learning curve can be difficult for new users. One major critique of TensorFlow is its high overhead and memory consumption due to the range of built-in libraries and support. Some of these concerns can be addressed using pared-down versions, but they can still be limited in resource-constrained environments.
### PyTorch vs. TensorFlow
-PyTorch and TensorFlow have established themselves as frontrunners in the industry. Both frameworks offer robust functionalities, but they differ in terms of their design philosophies, ease of use, ecosystem, and deployment capabilities.
+PyTorch and TensorFlow have established themselves as frontrunners in the industry. Both frameworks offer robust functionalities but differ in design philosophies, ease of use, ecosystem, and deployment capabilities.
-**Design Philosophy and Programming Paradigm:** PyTorch uses a dynamic computational graph, termed as eager execution. This makes it intuitive and facilitates debugging since operations are executed immediately and can be inspected on-the-fly. In comparison, earlier versions of TensorFlow were centered around a static computational graph, which required the graph\'s complete definition before execution. However, TensorFlow 2.0 introduced eager execution by default, making it more aligned with PyTorch in this regard. PyTorch\'s dynamic nature and Python based approach has enabled its simplicity and flexibility, particularly for rapid prototyping. TensorFlow\'s static graph approach in its earlier versions had a steeper learning curve; the introduction of TensorFlow 2.0, with its Keras integration as the high-level API, has significantly simplified the development process.
+**Design Philosophy and Programming Paradigm:** PyTorch uses a dynamic computational graph termed eager execution. This makes it intuitive and facilitates debugging since operations are executed immediately and can be inspected on the fly. In comparison, earlier versions of TensorFlow were centered around a static computational graph, which required the graph's complete definition before execution. However, TensorFlow 2.0 introduced eager execution by default, making it more aligned with PyTorch. PyTorch's dynamic nature and Python-based approach have enabled its simplicity and flexibility, particularly for rapid prototyping. TensorFlow's static graph approach in its earlier versions had a steeper learning curve; the introduction of TensorFlow 2.0, with its Keras integration as the high-level API, has significantly simplified the development process.
-**Deployment:** PyTorch is heavily favored in research environments, deploying PyTorch models in production settings was traditionally challenging. However, with the introduction of TorchScript and the TorchServe tool, deployment has become more feasible. One of TensorFlow\'s strengths lies in its scalability and deployment capabilities, especially on embedded and mobile platforms with TensorFlow Lite. TensorFlow Serving and TensorFlow.js further facilitate deployment in various environments, thus giving it a broader reach in the ecosystem.
+**Deployment:** PyTorch is heavily favored in research environments; deploying PyTorch models in production settings was traditionally challenging. However, deployment has become more feasible with the introduction of TorchScript and the TorchServe tool. One of TensorFlow's strengths lies in its scalability and deployment capabilities, especially on embedded and mobile platforms with TensorFlow Lite. TensorFlow Serving and TensorFlow.js further facilitate deployment in various environments, thus giving it a broader reach in the ecosystem.
-**Performance:** Both frameworks offer efficient hardware acceleration for their operations. However, TensorFlow has a slightly more robust optimization workflow, such as the XLA (Accelerated Linear Algebra) compiler, which can further boost performance. Its static computational graph, in the early versions, was also advantageous for certain optimizations.
+**Performance:** Both frameworks offer efficient hardware acceleration for their operations. However, TensorFlow has a slightly more robust optimization workflow, such as the XLA (Accelerated Linear Algebra) compiler, which can further boost performance. Its static computational graph was also advantageous for certain optimizations in the early versions.
-**Ecosystem:** PyTorch has a growing ecosystem with tools like TorchServe for serving models and libraries like TorchVision, TorchText, and TorchAudio for specific domains. As we mentioned earlier, TensorFlow has a broad and mature ecosystem. TensorFlow Extended (TFX) provides an end-to-end platform for deploying production machine learning pipelines. Other tools and libraries include TensorFlow Lite, TensorFlow.js, TensorFlow Hub, and TensorFlow Serving.
+**Ecosystem:** PyTorch has a growing ecosystem with tools like TorchServe for serving models and libraries like TorchVision, TorchText, and TorchAudio for specific domains. As we mentioned earlier, TensorFlow has a broad and mature ecosystem. TensorFlow Extended (TFX) provides an end-to-end platform for deploying production machine learning pipelines. Other tools and libraries include TensorFlow Lite, TensorFlow.js, TensorFlow Hub, and TensorFlow Serving.
-Here's a summarizing comparative analysis:
+@tbl-pytorch_vs_tf provides a comparative analysis:
| Feature/Aspect | PyTorch | TensorFlow |
|-----------------------------|------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
@@ -201,51 +201,53 @@ Here's a summarizing comparative analysis:
| Ecosystem | TorchServe, TorchVision, TorchText, TorchAudio | TensorFlow Extended (TFX), TensorFlow Lite, TensorFlow.js, TensorFlow Hub, TensorFlow Serving |
| Ease of Use | Preferred for its Pythonic approach and rapid prototyping | Initially steep learning curve; Simplified with Keras in TensorFlow 2.0 |
+: Comparison of PyTorch and TensorFlow. {#tbl-pytorch_vs_tf}
+
## Basic Framework Components
### Tensor data structures
-To understand tensors, let us start from the familiar concepts in linear algebra. As demonstrated in @fig-tensor-data-structure, vectors can be represented as a stack of numbers in a 1-dimensional array. Matrices follow the same idea, and one can think of them as many vectors being stacked on each other, making it 2 dimensional. Higher dimensional tensors work the same way. A 3-dimensional tensor is simply a set of matrices stacked on top of each other in another direction. Therefore, vectors and matrices can be considered special cases of tensors, with 1D and 2D dimensions respectively.
+To understand tensors, let us start from the familiar concepts in linear algebra. As demonstrated in @fig-tensor-data-structure, vectors can be represented as a stack of numbers in a 1-dimensional array. Matrices follow the same idea, and one can think of them as many vectors stacked on each other, making them 2 dimensional. Higher dimensional tensors work the same way. A 3-dimensional tensor is simply a set of matrices stacked on each other in another direction. Therefore, vectors and matrices can be considered special cases of tensors with 1D and 2D dimensions, respectively.
{#fig-tensor-data-structure}
-Defining formally, in machine learning, tensors are a multi-dimensional array of numbers. The number of dimensions defines the rank of the tensor. As a generalization of linear algebra, the study of tensors is called multilinear algebra. There are noticeable similarities between matrices and higher ranked tensors. First, it is possible to extend the definitions given in linear algebra to tensors, such as with eigenvalues, eigenvectors, and rank (in the linear algebra sense) . Furthermore, with the way that we have defined tensors, it is possible to turn higher dimensional tensors into matrices. This turns out to be very critical in practice, as multiplication of abstract representations of higher dimensional tensors are often completed by first converting them into matrices for multiplication.
+Defining formally, in machine learning, tensors are a multi-dimensional array of numbers. The number of dimensions defines the rank of the tensor. As a generalization of linear algebra, the study of tensors is called multilinear algebra. There are noticeable similarities between matrices and higher-ranked tensors. First, extending the definitions given in linear algebra to tensors, such as with eigenvalues, eigenvectors, and rank (in the linear algebra sense), is possible. Furthermore, with the way we have defined tensors, it is possible to turn higher dimensional tensors into matrices. This is critical in practice, as the multiplication of abstract representations of higher dimensional tensors is often completed by first converting them into matrices for multiplication.
-Tensors offer a flexible data structure with its ability to represent data in higher dimensions. For example, to represent color image data, for each of the pixel values (in 2 dimensions), one needs the color values for red, green and blue. With tensors, it is easy to contain image data in a single 3-dimensional tensor with each of the numbers within it representing a certain color value in the certain location of the image. Extending even further, if we wanted to store a series of images, we can simply extend the dimensions such that the new dimension (to create a 4-dimensional tensor) represents the different images that we have. This is exactly what the famous [MNIST](https://www.tensorflow.org/datasets/catalog/mnist) dataset does, loading a single 4-dimensional tensor when one calls to load the dataset, allowing a compact representation of all the data in one place.
+Tensors offer a flexible data structure that can represent data in higher dimensions. For example, to represent color image data, for each pixel value (in 2 dimensions), one needs the color values for red, green, and blue. With tensors, it is easy to contain image data in a single 3-dimensional tensor, with each number within it representing a certain color value in a certain location of the image. Extending even further, if we wanted to store a series of images, we could extend the dimensions such that the new dimension (to create a 4-dimensional tensor) represents our different images. This is exactly what the famous [MNIST](https://www.tensorflow.org/datasets/catalog/mnist) dataset does, loading a single 4-dimensional tensor when one calls to load the dataset, allowing a compact representation of all the data in one place.
### Computational graphs
#### Graph Definition
-Computational graphs are a key component of deep learning frameworks like TensorFlow and PyTorch. They allow us to express complex neural network architectures in a way that can be efficiently executed and differentiated. A computational graph consists of a directed acyclic graph (DAG) where each node represents an operation or variable, and edges represent data dependencies between them.
+Computational graphs are a key component of deep learning frameworks like TensorFlow and PyTorch. They allow us to express complex neural network architectures efficiently and differentiatedly. A computational graph consists of a directed acyclic graph (DAG) where each node represents an operation or variable, and edges represent data dependencies between them.
-For example, a node might represent a matrix multiplication operation, taking two input matrices (or tensors) and producing an output matrix (or tensor). To visualize this, consider the simple example in @fig-computational-graph. The directed acyclic graph above computes $z = x \times y$, where each of the variables are just numbers.
+For example, a node might represent a matrix multiplication operation, taking two input matrices (or tensors) and producing an output matrix (or tensor). To visualize this, consider the simple example in @fig-computational-graph. The directed acyclic graph above computes $z = x \times y$, where each variable is just numbers.
{#fig-computational-graph width="50%" height="auto" align="center"}
-Underneath the hood, the computational graphs represent abstractions for common layers like convolutional, pooling, recurrent, and dense layers, with data including activations, weights, biases, are represented in tensors. Convolutional layers form the backbone of CNN models for computer vision. They detect spatial patterns in input data through learned filters. Recurrent layers like LSTMs and GRUs enable processing sequential data for tasks like language translation. Attention layers are used in transformers to draw global context from the entire input.
+Underneath the hood, the computational graphs represent abstractions for common layers like convolutional, pooling, recurrent, and dense layers, with data including activations, weights, and biases represented in tensors. Convolutional layers form the backbone of CNN models for computer vision. They detect spatial patterns in input data through learned filters. Recurrent layers like LSTMs and GRUs enable sequential data processing for tasks like language translation. Attention layers are used in transformers to draw global context from the entire input.
-Broadly speaking, layers are higher level abstractions that define computations on top of those tensors. For example, a Dense layer performs a matrix multiplication and addition between input/weight/bias tensors. Note that a layer operates on tensors as inputs and outputs and the layer itself is not a tensor. Some key differences:
+Layers are higher-level abstractions that define computations on top of those tensors. For example, a Dense layer performs a matrix multiplication and addition between input/weight/bias tensors. Note that a layer operates on tensors as inputs and outputs; the layer is not a tensor. Some key differences:
* Layers contain states like weights and biases. Tensors are stateless, just holding data.
* Layers can modify internal state during training. Tensors are immutable/read-only.
-* Layers are higher level abstractions. Tensors are lower level, directly representing data and math operations.
+* Layers are higher-level abstractions. Tensors are at a lower level and directly represent data and math operations.
* Layers define fixed computation patterns. Tensors flow between layers during execution.
* Layers are used indirectly when building models. Tensors flow between layers during execution.
-So while tensors are a core data structure that layers consume and produce, layers have additional functionality for defining parameterized operations and training. While a layer configures tensor operations under the hood, the layer itself remains distinct from the tensor objects. The layer abstraction makes building and training neural networks much more intuitive. This sort of abstraction enables developers to build models by stacking these layers together, without having to implement the layer logic themselves. For example, calling `tf.keras.layers.Conv2D` in TensorFlow creates a convolutional layer. The framework handles computing the convolutions, managing parameters, etc. This simplifies model development, allowing developers to focus on architecture rather than low-level implementations. Layer abstractions utilize highly optimized implementations for performance. They also enable portability, as the same architecture can run on different hardware backends like GPUs and TPUs.
+So, while tensors are a core data structure that layers consume and produce, layers have additional functionality for defining parameterized operations and training. While a layer configures tensor operations under the hood, the layer remains distinct from the tensor objects. The layer abstraction makes building and training neural networks much more intuitive. This abstraction enables developers to build models by stacking these layers together without implementing the layer logic. For example, calling `tf.keras.layers.Conv2D` in TensorFlow creates a convolutional layer. The framework handles computing the convolutions, managing parameters, etc. This simplifies model development, allowing developers to focus on architecture rather than low-level implementations. Layer abstractions utilize highly optimized implementations for performance. They also enable portability, as the same architecture can run on different hardware backends like GPUs and TPUs.
-In addition, computational graphs include activation functions like ReLU, sigmoid, and tanh that are essential to neural networks and many frameworks provide these as standard abstractions. These functions introduce non-linearities that enable models to approximate complex functions. Frameworks provide these as simple, pre-defined operations that can be used when constructing models. For example, tf.nn.relu in TensorFlow. This abstraction enables flexibility, as developers can easily swap activation functions for tuning performance. Pre-defined activations are also optimized by the framework for faster execution.
+In addition, computational graphs include activation functions like ReLU, sigmoid, and tanh that are essential to neural networks, and many frameworks provide these as standard abstractions. These functions introduce non-linearities that enable models to approximate complex functions. Frameworks provide these as simple, predefined operations that can be used when constructing models, for example, if.nn.relu in TensorFlow. This abstraction enables flexibility, as developers can easily swap activation functions for tuning performance. Predefined activations are also optimized by the framework for faster execution.
-In recent years, models like ResNets and MobileNets have emerged as popular architectures, with current frameworks pre-packaging these as computational graphs. Rather than worrying about the fine details, developers can utilize them as a starting point, customizing as needed by substituting layers. This simplifies and speeds up model development, avoiding reinventing architectures from scratch. Pre-defined models include well-tested, optimized implementations that ensure good performance. Their modular design also enables transferring learned features to new tasks via transfer learning. In essence, these pre-defined architectures provide high-performance building blocks to quickly create robust models.
+In recent years, models like ResNets and MobileNets have emerged as popular architectures, with current frameworks pre-packaging these as computational graphs. Rather than worrying about the fine details, developers can utilize them as a starting point, customizing as needed by substituting layers. This simplifies and speeds up model development, avoiding reinventing architectures from scratch. Predefined models include well-tested, optimized implementations that ensure good performance. Their modular design also enables transferring learned features to new tasks via transfer learning. These predefined architectures provide high-performance building blocks to create robust models quickly.
-These layer abstractions, activation functions, and predefined architectures provided by the frameworks are what constitute a computational graph. When a user defines a layer in a framework (e.g. tf.keras.layers.Dense()), the framework is configuring computational graph nodes and edges to represent that layer. The layer parameters like weights and biases become variables in the graph. The layer computations become operation nodes (such as the x and y in the figure above). When you call an activation function like tf.nn.relu(), the framework adds a ReLU operation node to the graph. Predefined architectures are just pre-configured subgraphs that can be inserted into your model\'s graph. Thus, model definition via high-level abstractions creates a computational graph. The layers, activations, and architectures we use become graph nodes and edges.
+These layer abstractions, activation functions, and predefined architectures the frameworks provide constitute a computational graph. When a user defines a layer in a framework (e.g., tf.keras.layers.Dense()), the framework configures computational graph nodes and edges to represent that layer. The layer parameters like weights and biases become variables in the graph. The layer computations become operation nodes (such as the x and y in the figure above). When you call an activation function like tf.nn.relu(), the framework adds a ReLU operation node to the graph. Predefined architectures are just pre-configured subgraphs that can be inserted into your model's graph. Thus, model definition via high-level abstractions creates a computational graph—the layers, activations, and architectures we use become graph nodes and edges.
-When we define a neural network architecture in a framework, we are implicitly constructing a computational graph. The framework uses this graph to determine operations to run during training and inference. Computational graphs bring several advantages over raw code and that's one of the core functionalities that is offered by a good ML framework:
+We implicitly construct a computational graph when defining a neural network architecture in a framework. The framework uses this graph to determine operations to run during training and inference. Computational graphs bring several advantages over raw code, and that's one of the core functionalities that is offered by a good ML framework:
* Explicit representation of data flow and operations
@@ -257,13 +259,13 @@ When we define a neural network architecture in a framework, we are implicitly c
* Portability - graph can be serialized, saved, and restored later
-Computational graphs are the fundamental building blocks of ML frameworks. Model definition via high-level abstractions creates a computational graph. The layers, activations, and architectures we use become graph nodes and edges. The framework compilers and optimizers operate on this graph to generate executable code. Essentially, the abstractions provide a developer-friendly API for building computational graphs. Under the hood, it\'s still graphs all the way down! So while you may not directly manipulate graphs as a framework user, they enable your high-level model specifications to be efficiently executed. The abstractions simplify model-building while computational graphs make it possible.
+Computational graphs are the fundamental building blocks of ML frameworks. Model definition via high-level abstractions creates a computational graph—the layers, activations, and architectures we use become graph nodes and edges. The framework compilers and optimizers operate on this graph to generate executable code. The abstractions provide a developer-friendly API for building computational graphs. Under the hood, it's still graphs down! So, while you may not directly manipulate graphs as a framework user, they enable your high-level model specifications to be efficiently executed. The abstractions simplify model-building, while computational graphs make it possible.
#### Static vs. Dynamic Graphs
Deep learning frameworks have traditionally followed one of two approaches for expressing computational graphs.
-**Static graphs (declare-then-execute):** With this model, the entire computational graph must be defined upfront before it can be run. All operations and data dependencies must be specified during the declaration phase. TensorFlow originally followed this static approach - models were defined in a separate context, then a session was created to run them. The benefit of static graphs is they allow more aggressive optimization, since the framework can see the full graph. But it also tends to be less flexible for research and interactivity. Changes to the graph require re-declaring the full model.
+**Static graphs (declare-then-execute):** With this model, the entire computational graph must be defined upfront before running it. All operations and data dependencies must be specified during the declaration phase. TensorFlow originally followed this static approach - models were defined in a separate context, and then a session was created to run them. The benefit of static graphs is they allow more aggressive optimization since the framework can see the full graph. However, it also tends to be less flexible for research and interactivity. Changes to the graph require re-declaring the full model.
For example:
@@ -272,20 +274,20 @@ x = tf.placeholder(tf.float32)
y = tf.matmul(x, weights) + biases
```
-The model is defined separately from execution, like building a blueprint. For TensorFlow 1.x, this is done using tf.Graph(). All ops and variables must be declared upfront. Subsequently, the graph is compiled and optimized before running. Execution is done later by feeding in tensor values.
+The model is defined separately from execution, like building a blueprint. For TensorFlow 1. x, this is done using tf.Graph(). All ops and variables must be declared upfront. Subsequently, the graph is compiled and optimized before running. Execution is done later by feeding in tensor values.
-**Dynamic graphs (define-by-run):** In contrast to declare (all) first and then execute, the graph is built dynamically as execution happens. There is no separate declaration phase - operations execute immediately as they are defined. This style is more imperative and flexible, facilitating experimentation.
+**Dynamic graphs (define-by-run):** Unlike declaring (all) first and then executing, the graph is built dynamically as execution happens. There is no separate declaration phase - operations execute immediately as defined. This style is imperative and flexible, facilitating experimentation.
-PyTorch uses dynamic graphs, building the graph on-the-fly as execution happens. For example, consider the following code snippet, where the graph is built as the execution is taking place:
+PyTorch uses dynamic graphs, building the graph on the fly as execution happens. For example, consider the following code snippet, where the graph is built as the execution is taking place:
```{.python}
x = torch.randn(4,784)
y = torch.matmul(x, weights) + biases
```
-In the above example, there are no separate compile/build/run phases. Ops define and execute immediately. With dynamic graphs, definition is intertwined with execution. This provides a more intuitive, interactive workflow. But the downside is less potential for optimizations, since the framework only sees the graph as it is built.
+The above example does not have separate compile/build/run phases. Ops define and execute immediately. With dynamic graphs, the definition is intertwined with execution, providing a more intuitive, interactive workflow. However, the downside is that there is less potential for optimization since the framework only sees the graph as it is built.
-Recently, however, the distinction has blurred as frameworks adopt both modes. TensorFlow 2.0 defaults to dynamic graph mode, while still letting users work with static graphs when needed. Dynamic declaration makes frameworks easier to use, while static models provide optimization benefits. The ideal framework offers both options.
+Recently, however, the distinction has blurred as frameworks adopt both modes. TensorFlow 2.0 defaults to dynamic graph mode while letting users work with static graphs when needed. Dynamic declaration makes frameworks easier to use, while static models provide optimization benefits. The ideal framework offers both options.
Static graph declaration provides optimization opportunities but less interactivity. While dynamic execution offers flexibility and ease of use, it may have performance overhead. Here is a table comparing the pros and cons of static vs dynamic execution graphs:
@@ -296,81 +298,81 @@ Static graph declaration provides optimization opportunities but less interactiv
### Data Pipeline Tools
-Computational graphs can only be as good as the data they learn from and work on. Therefore, feeding training data efficiently is crucial for optimizing deep neural networks performance, though it is often overlooked as one of the core functionalities. Many modern AI frameworks provide specialized pipelines to ingest, process, and augment datasets for model training.
+Computational graphs can only be as good as the data they learn from and work on. Therefore, feeding training data efficiently is crucial for optimizing deep neural network performance, though it is often overlooked as one of the core functionalities. Many modern AI frameworks provide specialized pipelines to ingest, process, and augment datasets for model training.
#### Data Loaders
-At the core of these pipelines are data loaders, which handle reading examples from storage formats like CSV files or image folders. Reading training examples from sources like files, databases, object storage, etc. is the job of the data loaders. Deep learning models require diverse data formats depending on the application. Among the popular formats are CSV: A versatile, simple format often used for tabular data. TFRecord: TensorFlow\'s proprietary format, optimized for performance. Parquet: Columnar storage, offering efficient data compression and retrieval. JPEG/PNG: Commonly used for image data. WAV/MP3: Prevalent formats for audio data. For instance, `tf.data` is TensorFlows's dataloading pipeline: .
+These pipelines' cores are data loaders, which handle reading examples from storage formats like CSV files or image folders. Reading training examples from sources like files, databases, object storage, etc., is the job of the data loaders. Deep learning models require diverse data formats depending on the application. Among the popular formats is CSV, a versatile, simple format often used for tabular data. TFRecord: TensorFlow's proprietary format, optimized for performance. Parquet: Columnar storage, offering efficient data compression and retrieval. JPEG/PNG: Commonly used for image data. WAV/MP3: Prevalent formats for audio data. For instance, `tf.data` is TensorFlows's dataloading pipeline: .
-Data loaders batch examples to leverage vectorization support in hardware. Batching refers to grouping multiple data points for simultaneous processing, leveraging the vectorized computation capabilities of hardware like GPUs. While typical batch sizes range from 32-512 examples, the optimal size often depends on the memory footprint of the data and the specific hardware constraints. Advanced loaders can stream virtually unlimited datasets from disk and cloud storage. Streaming large datasets from disk or networks instead of loading fully into memory. This enables virtually unlimited dataset sizes.
+Data loaders batch examples to leverage vectorization support in hardware. Batching refers to grouping multiple data points for simultaneous processing, leveraging the vectorized computation capabilities of hardware like GPUs. While typical batch sizes range from 32 to 512 examples, the optimal size often depends on the data's memory footprint and the specific hardware constraints. Advanced loaders can stream virtually unlimited datasets from disk and cloud storage. They stream large datasets from disks or networks instead of fully loading them into memory, enabling unlimited dataset sizes.
-Data loaders can also shuffle data across epochs for randomization, and preprocess features in parallel with model training to expedite the training process. Randomly shuffling the order of examples between training epochs reduces bias and improves generalization.
+Data loaders can also shuffle data across epochs for randomization and preprocess features in parallel with model training to expedite the training process. Randomly shuffling the order of examples between training epochs reduces bias and improves generalization.
-Data loaders also support caching and prefetching strategies to optimize data delivery for fast, smooth model training. Caching preprocessed batches in memory so they can be reused efficiently during multiple training steps. Caching these batches in memory eliminates redundant processing. Prefetching, on the other hand, involves preloading subsequent batches, ensuring that the model never idles waiting for data.
+Data loaders also support caching and prefetching strategies to optimize data delivery for fast, smooth model training. Caching preprocessed batches in memory allows them to be reused efficiently during multiple training steps and eliminates redundant processing. Prefetching, conversely, involves preloading subsequent batches, ensuring that the model never idles waiting for data.
### Data Augmentation
-Besides loading, data augmentation expands datasets synthetically. Augmentations apply random transformations like flipping, cropping, rotating, altering color, adding noise etc. for images. For audio, common augmentations involve mixing clips with background noise, or modulating speed/pitch/volume.
+Besides loading, data augmentation expands datasets synthetically. Augmentations apply random transformations for images like flipping, cropping, rotating, altering color, adding noise, etc. For audio, common augmentations involve mixing clips with background noise or modulating speed/pitch/volume.
-Augmentations increase variation in the training data. Frameworks like TensorFlow and PyTorch simplify applying random augmentations each epoch by integrating into the data pipeline.By programmatically increasing variation in the training data distribution, augmentations reduce overfitting and improve model generalization.
+Augmentations increase variation in the training data. Frameworks like TensorFlow and PyTorch simplify applying random augmentations each epoch by integrating them into the data pipeline. By programmatically increasing variation in the training data distribution, augmentations reduce Overfitting and improve model generalization.
-Many frameworks make it easy to integrate augmentations into the data pipeline so they are applied on-the-fly each epoch. Together, performant data loaders and extensive augmentations enable practitioners to feed massive, varied datasets to neural networks efficiently. Hands-off data pipelines represent a significant improvement in usability and productivity. They allow developers to focus more on model architecture and less on data wrangling when training deep learning models.
+Many frameworks simplify integrating augmentations into the data pipeline, applying them on the fly each epoch. Together, performant data loaders and extensive augmentations enable practitioners to feed massive, varied datasets to neural networks efficiently. Hands-off data pipelines represent a significant improvement in usability and productivity. They allow developers to focus more on model architecture and less on data wrangling when training deep learning models.
### Optimization Algorithms
-Training a neural network is fundamentally an iterative process that seeks to minimize a loss function. At its core, the goal is to fine-tune the model weights and parameters to produce predictions as close as possible to the true target labels. Machine learning frameworks have greatly streamlined this process by offering extensive support in three critical areas: loss functions, optimization algorithms, and regularization techniques.
+Training a neural network is fundamentally an iterative process that seeks to minimize a loss function. The goal is to fine-tune the model weights and parameters to produce predictions close to the true target labels. Machine learning frameworks have greatly streamlined this process by offering extensive support in three critical areas: loss functions, optimization algorithms, and regularization techniques.
-Loss Functions are useful to quantify the difference between the model\'s predictions and the true values. Different datasets require a different loss function to perform properly, as the loss function tells the computer the "objective" for it to aim to. Commonly used loss functions are Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks.
+Loss Functions are useful to quantify the difference between the model's predictions and the true values. Different datasets require a different loss function to perform properly, as the loss function tells the computer the "objective" for it to aim. Commonly used loss functions are Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks.
-To demonstrate some of the loss functions, imagine that you have a set of inputs and the corresponding outputs, $Y_n$ that denotes the output of $n$'th value. The inputs are fed into the model, and the model outputs a prediction, which we can call $\hat{Y_n}$. With the predicted value and the real value, we can for example use the MSE to calculate the loss function:
+To demonstrate some of the loss functions, imagine you have a set of inputs and the corresponding outputs, $Y_n$, that denote the output of $n$'th value. The inputs are fed into the model, and the model outputs a prediction, which we can call $\hat{Y_n}$. With the predicted value and the real value, we can, for example, use the MSE to calculate the loss function:
$$MSE = \frac{1}{N}\sum_{n=1}^{N}(Y_n - \hat{Y_n})^2$$
-If the problem is a classification problem, we do not want to use the MSE, since the distance between the predicted value and the real value does not have significant meaning. For example, if one wants to recognize handwritten models, while 9 is further away from 2, it does not mean that the model is more wrong by making the prediction. Therefore, we use the cross-entropy loss function, which is defined as:
+If the problem is a classification problem, we do not want to use the MSE since the distance between the predicted value and the real value does not have significant meaning. For example, if one wants to recognize handwritten models, while 9 is further away from 2, it does not mean that the model is wrong in making the prediction. Therefore, we use the cross-entropy loss function, which is defined as:
$$Cross-Entropy = -\sum_{n=1}^{N}Y_n\log(\hat{Y_n})$$
-Once the loss like above is computed, we need methods to adjust the model\'s parameters to reduce this loss or error during the training process. To do so, current frameworks use a gradient based approach, where it computes how much changes tuning the weights in a certain way changes the value of the loss function. Knowing this gradient, the model moves in the direction that reduces the gradient. There are many challenges associated with this, however, primarily stemming from the fact that the optimization problem is not convex, making it very easy to solve, and more details about this will come in the AI Training section. Modern frameworks come equipped with efficient implementations of several optimization algorithms, many of which are variants of gradient descent algorithms with stochastic methods and adaptive learning rates. More information with clear examples can be found in the AI Training section.
+Once a loss like the above is computed, we need methods to adjust the model's parameters to reduce this loss or error during the training process. To do so, current frameworks use a gradient-based approach, which computes how much changes tuning the weights in a certain way changes the value of the loss function. Knowing this gradient, the model moves in the direction that reduces the gradient. Many challenges are associated with this, primarily stemming from the fact that the optimization problem could not be more, making it very easy to solve. More details about this will come in the AI Training section. Modern frameworks come equipped with efficient implementations of several optimization algorithms, many of which are variants of gradient descent algorithms with stochastic methods and adaptive learning rates. More information with clear examples can be found in the AI Training section.
-Last but not least, overly complex models tend to overfit, meaning they perform well on the training data but fail to generalize to new, unseen data (see Overfitting). To counteract this, regularization methods are employed to penalize model complexity and encourage it to learn simpler patterns. Dropout for instance randomly sets a fraction of input units to 0 at each update during training, which helps prevent overfitting.
+Lastly, overly complex models tend to overfit, meaning they perform well on the training data but must generalize to new, unseen data (see Overfitting). To counteract this, regularization methods are employed to penalize model complexity and encourage it to learn simpler patterns. Dropout randomly sets a fraction of input units to 0 at each update during training, which helps prevent Overfitting.
-However, there are cases where the problem is more complex than what the model can represent, and this may result in underfitting. Therefore, choosing the right model architecture is also a critical step in the training process. Further heuristics and techniques are discussed in the AI Training section.
+However, there are cases where the problem is more complex than the model can represent, which may result in underfitting. Therefore, choosing the right model architecture is also a critical step in the training process. Further heuristics and techniques are discussed in the AI Training section.
-Frameworks also provide efficient implementations of gradient descent, Adagrad, Adadelta, and Adam. Adding regularization like dropout and L1/L2 penalties prevents overfitting during training. Batch normalization accelerates training by normalizing inputs to layers.
+Frameworks also efficiently implement gradient descent, Adagrad, Adadelta, and Adam. Adding regularization, such as dropout and L1/L2 penalties, prevents Overfitting during training. Batch normalization accelerates training by normalizing inputs to layers.
### Model Training Support
-Before training a defined neural network model, a compilation step is required. During this step, the high-level architecture of the neural network is transformed into an optimized, executable format. This process comprises several steps. The construction of the computational graph is the first step. It represents all the mathematical operations and data flow within the model. We discussed this earlier.
+A compilation step is required before training a defined neural network model. During this step, the neural network's high-level architecture is transformed into an optimized, executable format. This process comprises several steps. The first step is to construct the computational graph, which represents all the mathematical operations and data flow within the model. We discussed this earlier.
-During training, the focus is on executing the computational graph. Every parameter within the graph, such as weights and biases, is assigned an initial value. This value might be random or based on a predefined logic, depending on the chosen initialization method.
+During training, the focus is on executing the computational graph. Every parameter within the graph, such as weights and biases, is assigned an initial value. Depending on the chosen initialization method, this value might be random or based on a predefined logic.
-The next critical step is memory allocation. Essential memory is reserved for the model\'s operations on both CPUs and GPUs, ensuring efficient data processing. The model\'s operations are then mapped to the available hardware resources, particularly GPUs or TPUs, to expedite computation. Once compilation is finalized, the model is prepared for training.
+The next critical step is memory allocation. Essential memory is reserved for the model's operations on both CPUs and GPUs, ensuring efficient data processing. The model's operations are then mapped to the available hardware resources, particularly GPUs or TPUs, to expedite computation. Once the compilation is finalized, the model is prepared for training.
-The training process employs various tools to enhance efficiency. Batch processing is commonly used to maximize computational throughput. Techniques like vectorization enable operations on entire data arrays, rather than proceeding element-wise, which bolsters speed. Optimizations such as kernel fusion (refer to the Optimizations chapter) amalgamate multiple operations into a single action, minimizing computational overhead. Operations can also be segmented into phases, facilitating the concurrent processing of different mini-batches at various stages.
+The training process employs various tools to enhance efficiency. Batch processing is commonly used to maximize computational throughput. Techniques like vectorization enable operations on entire data arrays rather than proceeding element-wise, which bolsters speed. Optimizations such as kernel fusion (refer to the Optimizations chapter) amalgamate multiple operations into a single action, minimizing computational overhead. Operations can also be segmented into phases, facilitating the concurrent processing of different mini-batches at various stages.
-Frameworks consistently checkpoint the state, preserving intermediate model versions during training. This ensures that if an interruption occurs, the progress isn\'t wholly lost, and training can recommence from the last checkpoint. Additionally, the system vigilantly monitors the model\'s performance against a validation data set. Should the model begin to overfit (that is, if its performance on the validation set declines), training is automatically halted, conserving computational resources and time.
+Frameworks consistently checkpoint the state, preserving intermediate model versions during training. This ensures that progress is recovered if an interruption occurs, and training can be recommenced from the last checkpoint. Additionally, the system vigilantly monitors the model's performance against a validation data set. Should the model begin to overfit (if its performance on the validation set declines), training is automatically halted, conserving computational resources and time.
-ML frameworks incorporate a blend of model compilation, enhanced batch processing methods, and utilities such as checkpointing and early stopping. These resources manage the complex aspects of performance, enabling practitioners to zero in on model development and training. As a result, developers experience both speed and ease when utilizing the capabilities of neural networks.
+ML frameworks incorporate a blend of model compilation, enhanced batch processing methods, and utilities such as checkpointing and early stopping. These resources manage the complex aspects of performance, enabling practitioners to zero in on model development and training. As a result, developers experience both speed and ease when utilizing neural networks' capabilities.
### Validation and Analysis
-After training deep learning models, frameworks provide utilities to evaluate performance and gain insights into the models\' workings. These tools enable disciplined experimentation and debugging.
+After training deep learning models, frameworks provide utilities to evaluate performance and gain insights into the models' workings. These tools enable disciplined experimentation and debugging.
#### Evaluation Metrics
Frameworks include implementations of common evaluation metrics for validation:
-* Accuracy - Fraction of correct predictions overall. Widely used for classification.
+* Accuracy - Fraction of correct predictions overall. They are widely used for classification.
-* Precision - Of positive predictions, how many were actually positive. Useful for imbalanced datasets.
+* Precision - Of positive predictions, how many were positive. Useful for imbalanced datasets.
-* Recall - Of actual positives, how many did we predict correctly. Measures completeness.
+* Recall - Of actual positives, how many did we predict correctly? Measures completeness.
* F1-score - Harmonic mean of precision and recall. Combines both metrics.
-* AUC-ROC - Area under ROC curve. Used for classification threshold analysis.
+* AUC-ROC - Area under ROC curve. They are used for classification threshold analysis.
-* MAP - Mean Average Precision. Evaluates ranked predictions in retrieval/detection.
+* MAP - Mean Average Precision. Evaluate ranked predictions in retrieval/detection.
* Confusion Matrix - Matrix that shows the true positives, true negatives, false positives, and false negatives. Provides a more detailed view of classification performance.
@@ -380,7 +382,7 @@ These metrics quantify model performance on validation data for comparison.
Visualization tools provide insight into models:
-* Loss curves - Plot training and validation loss over time to spot overfitting.
+* Loss curves - Plot training and validation loss over time to spot Overfitting.
* Activation grids - Illustrate features learned by convolutional filters.
@@ -392,21 +394,21 @@ Tools like [TensorBoard](https://www.tensorflow.org/tensorboard/scalars_and_kera
### Differentiable programming
-With the machine learning training methods such as backpropagation relying on the change in the loss function with respect to the change in weights (which essentially is the definition of derivatives), the ability to quickly and efficiently train large machine learning models rely on the computer's ability to take derivatives. This makes differentiable programming one of the most important elements of a machine learning framework.
+Machine learning training methods such as backpropagation rely on the change in the loss function with respect to the change in weights (which essentially is the definition of derivatives). Thus, the ability to quickly and efficiently train large machine learning models relies on the computer's ability to take derivatives. This makes differentiable programming one of the most important elements of a machine learning framework.
-There are primarily four methods that we can use to make computers take derivatives. First, we can manually figure out the derivatives by hand and input them to the computer. One can see that this would quickly become a nightmare with many layers of neural networks, if we had to compute all the derivatives in the backpropagation steps by hand. Another method is symbolic differentiation using computer algebra systems such as Mathematica, but this can introduce a layer of inefficiency, as there needs to be a level of abstraction to take derivatives. Numerical derivatives, the practice of approximating gradients using finite difference methods, suffer from many problems including high computational costs, and larger grid size can lead to a significant amount of errors. This leads to automatic differentiation, which exploits the primitive functions that computers use to represent operations to obtain an exact derivative. With automatic differentiation, computational complexity of computing the gradient is proportional to computing the function itself. Intricacies of automatic differentiation are not dealt with by end users now, but resources to learn more can be found widely, such as from [here](https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf). Automatic differentiation and differentiable programming today is ubiquitous and is done efficiently and automatically by modern machine learning frameworks.
+We can use four primary methods to make computers take derivatives. First, we can manually figure out the derivatives by hand and input them into the computer. This would quickly become a nightmare with many layers of neural networks if we had to compute all the derivatives in the backpropagation steps by hand. Another method is symbolic differentiation using computer algebra systems such as Mathematica, which can introduce a layer of inefficiency, as there needs to be a level of abstraction to take derivatives. Numerical derivatives, the practice of approximating gradients using finite difference methods, suffer from many problems, including high computational costs and larger grid sizes, leading to many errors. This leads to automatic differentiation, which exploits the primitive functions that computers use to represent operations to obtain an exact derivative. With automatic differentiation, the computational complexity of computing the gradient is proportional to computing the function itself. Intricacies of automatic differentiation are not dealt with by end users now, but resources to learn more can be found widely, such as from [here](https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf). Today's automatic differentiation and differentiable programming are ubiquitous and are done efficiently and automatically by modern machine learning frameworks.
### Hardware Acceleration
-The trend to continuously train and deploy larger machine learning models has essentially made hardware acceleration support a necessity for machine learning platforms (@fig-hardware-accelerator). Deep layers of neural networks require many matrix multiplications, which attracts hardware that can compute matrix operations fast and in parallel. In this landscape, two types of hardware architectures, the [GPU and TPU](https://cloud.google.com/tpu/docs/intro-to-tpu), have emerged as leading choices for training machine learning models.
+The trend to continuously train and deploy larger machine-learning models has made hardware acceleration support necessary for machine-learning platforms (@fig-hardware-accelerator). Deep layers of neural networks require many matrix multiplications, which attract hardware that can compute matrix operations quickly and in parallel. In this landscape, two hardware architectures, the [GPU and TPU](https://cloud.google.com/tpu/docs/intro-to-tpu), have emerged as leading choices for training machine learning models.
-The use of hardware accelerators began with [AlexNet](https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf), which paved the way for future works to utilize GPUs as hardware accelerators for training computer vision models. GPUs, or Graphics Processing Units, excel in handling a large number of computations at once, making them ideal for the matrix operations that are central to neural network training. Their architecture, designed for rendering graphics, turns out to be perfect for the kind of mathematical operations required in machine learning. While they are very useful for machine learning tasks and have been implemented in many hardware platforms, GPU's are still general purpose in that they can be used for other applications.
+The use of hardware accelerators began with [AlexNet](https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf), which paved the way for future works to utilize GPUs as hardware accelerators for training computer vision models. GPUs, or Graphics Processing Units, excel in handling many computations at once, making them ideal for the matrix operations central to neural network training. Their architecture, designed for rendering graphics, is perfect for the mathematical operations required in machine learning. While they are very useful for machine learning tasks and have been implemented in many hardware platforms, GPUs are still general purpose in that they can be used for other applications.
-On the other hand, [Tensor Processing Units](https://cloud.google.com/tpu/docs/intro-to-tpu) (TPU) are hardware units designed specifically for neural networks. They focus on the multiply and accumulate (MAC) operation, and their hardware essentially consists of a large hardware matrix that contains elements efficiently computing the MAC operation. This concept called the [systolic array architecture](https://www.eecs.harvard.edu/~htk/publication/1982-kung-why-systolic-architecture.pdf), was pioneered by @kung1979systolic, but has proven to be a useful structure to efficiently compute matrix products and other operations within neural networks (such as convolutions).
+On the other hand, [Tensor Processing Units](https://cloud.google.com/tpu/docs/intro-to-tpu) (TPU) are hardware units designed specifically for neural networks. They focus on the multiply and accumulate (MAC) operation, and their hardware consists of a large hardware matrix that contains elements that efficiently compute the MAC operation. This concept, called the [systolic array architecture](https://www.eecs.harvard.edu/~htk/publication/1982-kung-why-systolic-architecture.pdf), was pioneered by @kung1979systolic, but has proven to be a useful structure to efficiently compute matrix products and other operations within neural networks (such as convolutions).
-While TPU's can drastically reduce training times, it also has disadvantages. For example, many operations within the machine learning frameworks (primarily TensorFlow here since the TPU directly integrates with it) are not supported with the TPU's. It also cannot support custom custom operations from the machine learning frameworks, and the network design must closely align to the hardware capabilities.
+While TPUs can drastically reduce training times, they also have disadvantages. For example, many operations within the machine learning frameworks (primarily TensorFlow here since the TPU directly integrates with it) are not supported by TPUs. They cannot also support custom operations from the machine learning frameworks, and the network design must closely align with the hardware capabilities.
-Today, NVIDIA GPUs dominate training, aided by software libraries like [CUDA](https://developer.nvidia.com/cuda-toolkit), [cuDNN](https://developer.nvidia.com/cudnn), and [TensorRT.](https://developer.nvidia.com/tensorrt#:~:text=NVIDIA TensorRT-LLM is an,knowledge of C++ or CUDA.) Frameworks also tend to include optimizations to maximize performance on these hardware types, like pruning unimportant connections and fusing layers. Combining these techniques with hardware acceleration provides greater efficiency. For inference, hardware is increasingly moving towards optimized ASICs and SoCs. Google\'s TPUs accelerate models in data centers. Apple, Qualcomm, and others now produce AI-focused mobile chips. The NVIDIA Jetson family targets autonomous robots.
+Today, NVIDIA GPUs dominate training, aided by software libraries like [CUDA](https://developer.nvidia.com/cuda-toolkit), [cuDNN](https://developer.nvidia.com/cudnn), and [TensorRT.](https://developer.nvidia.com/tensorrt#:~:text=NVIDIA TensorRT-LLM is an,knowledge of C++ or CUDA.) Frameworks also include optimizations to maximize performance on these hardware types, like pruning unimportant connections and fusing layers. Combining these techniques with hardware acceleration provides greater efficiency. For inference, hardware is increasingly moving towards optimized ASICs and SoCs. Google's TPUs accelerate models in data centers. Apple, Qualcomm, and others now produce AI-focused mobile chips. The NVIDIA Jetson family targets autonomous robots.
)](images/png/hardware_accelerator.png){#fig-hardware-accelerator}
@@ -414,69 +416,69 @@ Today, NVIDIA GPUs dominate training, aided by software libraries like [CUDA](ht
### Distributed training
-As machine learning models have become larger over the years, it has become essential for large models to utilize multiple computing nodes in the training process. This process, called distributed learning, has allowed for higher training capabilities, but has also imposed challenges in implementation.
+As machine learning models have become larger over the years, it has become essential for large models to utilize multiple computing nodes in the training process. This process, distributed learning, has allowed for higher training capabilities but has also imposed challenges in implementation.
-We can consider three different ways to spread the work of training machine learning models to multiple computing nodes. Input data partitioning, referring to multiple processors running the same model on different input partitions. This is the easiest to implement that is available for many machine learning frameworks. The more challenging distribution of work comes with model parallelism, which refers to multiple computing nodes working on different parts of the model, and pipelined model parallelism, which refers to multiple computing nodes working on different layers of the model on the same input. The latter two mentioned here are active research areas.
+We can consider three different ways to spread the work of training machine learning models to multiple computing nodes. Input data partitioning refers to multiple processors running the same model on different input partitions. This is the easiest implementation and is available for many machine learning frameworks. The more challenging distribution of work comes with model parallelism, which refers to multiple computing nodes working on different parts of the model, and pipelined model parallelism, which refers to multiple computing nodes working on different layers of the model on the same input. The latter two mentioned here are active research areas.
ML frameworks that support distributed learning include TensorFlow (through its [tf.distribute](https://www.tensorflow.org/api_docs/python/tf/distribute) module), PyTorch (through its [torch.nn.DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) and [torch.nn.DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) modules), and MXNet (through its [gluon](https://mxnet.apache.org/versions/1.9.1/api/python/docs/api/gluon/index.html) API).
### Model Conversion
-Machine learning models have various methods to be represented in order to be used within different frameworks and for different device types. For example, a model can be converted to be compatible with inference frameworks within the mobile device. The default format for TensorFlow models is checkpoint files containing weights and architectures, which are needed in case we have to retrain the models. But for mobile deployment, models are typically converted to TensorFlow Lite format. TensorFlow Lite uses a compact flatbuffer representation and optimizations for fast inference on mobile hardware, discarding all the unnecessary baggage associated with training metadata such as checkpoint file structures.
+Machine learning models have various methods to be represented and used within different frameworks and for different device types. For example, a model can be converted to be compatible with inference frameworks within the mobile device. The default format for TensorFlow models is checkpoint files containing weights and architectures, which are needed to retrain the models. However, models are typically converted to TensorFlow Lite format for mobile deployment. TensorFlow Lite uses a compact flat buffer representation and optimizations for fast inference on mobile hardware, discarding all the unnecessary baggage associated with training metadata, such as checkpoint file structures.
-The default format for TensorFlow models is checkpoint files containing weights and architectures. For mobile deployment, models are typically converted to TensorFlow Lite format. TensorFlow Lite uses a compact flatbuffer representation and optimizations for fast inference on mobile hardware.
+The default format for TensorFlow models is checkpoint files containing weights and architectures. For mobile deployment, models are typically converted to TensorFlow Lite format. TensorFlow Lite uses a compact flat buffer representation and optimizations for fast inference on mobile hardware.
-Model optimizations like quantization (see [Optimizations](../optimizations/optimizations.qmd) chapter) can further optimize models for target architectures like mobile. This reduces precision of weights and activations to `uint8` or `int8` for a smaller footprint and faster execution with supported hardware accelerators. For post-training quantization, TensorFlow\'s converter handles analysis and conversion automatically.
+Model optimizations like quantization (see [Optimizations](../optimizations/optimizations.qmd) chapter) can further optimize models for target architectures like mobile. This reduces the precision of weights and activations to `uint8` or `int8` for a smaller footprint and faster execution with supported hardware accelerators. For post-training quantization, TensorFlow's converter handles analysis and conversion automatically.
-Frameworks like TensorFlow simplify deploying trained models to mobile and embedded IoT devices through easy conversion APIs for TFLite format and quantization. Ready-to-use conversion enables high performance inference on mobile without manual optimization burden. Besides TFLite, other common targets include TensorFlow.js for web deployment, TensorFlow Serving for cloud services, and TensorFlow Hub for transfer learning. TensorFlow\'s conversion utilities handle these scenarios to streamline end-to-end workflows.
+Frameworks like TensorFlow simplify deploying trained models to mobile and embedded IoT devices through easy conversion APIs for TFLite format and quantization. Ready-to-use conversion enables high-performance inference on mobile without a manual optimization burden. Besides TFLite, other common targets include TensorFlow.js for web deployment, TensorFlow Serving for cloud services, and TensorFlow Hub for transfer learning. TensorFlow's conversion utilities handle these scenarios to streamline end-to-end workflows.
More information about model conversion in TensorFlow is linked [here](https://www.tensorflow.org/lite/models/convert).
### AutoML, No-Code/Low-Code ML
-In many cases, machine learning can have a relatively high barrier of entry compared to other fields. To successfully train and deploy models, one needs to have a critical understanding of a variety of disciplines, from data science (data processing, data cleaning), model structures (hyperparameter tuning, neural network architecture), hardware (acceleration, parallel processing), and more depending on the problem at hand. The complexity of these problems have led to the introduction to frameworks such as AutoML, which aims to make "Machine learning available for non-Machine Learning exports" and to "automate research in machine learning". They have constructed AutoWEKA, which aids in the complex process of hyperparameter selection, as well as Auto-sklearn and Auto-pytorch, an extension of AutoWEKA into the popular sklearn and PyTorch Libraries.
+In many cases, machine learning can have a relatively high barrier of entry compared to other fields. To successfully train and deploy models, one needs to have a critical understanding of a variety of disciplines, from data science (data processing, data cleaning), model structures (hyperparameter tuning, neural network architecture), hardware (acceleration, parallel processing), and more depending on the problem at hand. The complexity of these problems has led to the introduction of frameworks such as AutoML, which aims to make "Machine learning available for non-Machine Learning exports" and to "automate research in machine learning." They have constructed AutoWEKA, which aids in the complex process of hyperparameter selection, and Auto-sklearn and Auto-pytorch, an extension of AutoWEKA into the popular sklearn and PyTorch Libraries.
-While these works of automating parts of machine learning tasks are underway, others have focused on constructing machine learning models easier by deploying no-code/low code machine learning, utilizing a drag and drop interface with an easy to navigate user interface. Companies such as Apple, Google, and Amazon have already created these easy to use platforms to allow users to construct machine learning models that can integrate to their ecosystem.
+While these efforts to automate parts of machine learning tasks are underway, others have focused on making machine learning models easier by deploying no-code/low-code machine learning, utilizing a drag-and-drop interface with an easy-to-navigate user interface. Companies such as Apple, Google, and Amazon have already created these easy-to-use platforms to allow users to construct machine learning models that can integrate into their ecosystem.
-These steps to remove barrier to entry continue to democratize machine learning and make it easier to access for beginners and simplify workflow for experts.
+These steps to remove barriers to entry continue to democratize machine learning, make it easier for beginners to access, and simplify workflow for experts.
### Advanced Learning Methods
#### Transfer Learning
-Transfer learning is the practice of using knowledge gained from a pretrained model to train and improve performance of a model that is for a different task. For example, datasets that have been trained on ImageNet datasets such as MobileNet and ResNet can help classify other image datasets. To do so, one may freeze the pretrained model, utilizing it as a feature extractor to train a much smaller model that is built on top of the feature extraction. One can also fine tune the entire model to fit the new task.
+Transfer learning is the practice of using knowledge gained from a pre-trained model to train and improve the performance of a model for a different task. For example, datasets trained on ImageNet datasets such as MobileNet and ResNet can help classify other image datasets. To do so, one may freeze the pre-trained model, utilizing it as a feature extractor to train a much smaller model built on top of the feature extraction. One can also fine-tune the entire model to fit the new task.
-Transfer learning has a series of challenges, in that the modified model may not be able to conduct its original tasks after transfer learning. Papers such as ["Learning without Forgetting"](https://browse.arxiv.org/pdf/1606.09282.pdf) by @li2017learning aims to address these challenges and have been implemented in modern machine learning platforms.
+Transfer learning has challenges, such as the modified model's inability to conduct its original tasks after transfer learning. Papers such as ["Learning without Forgetting"](https://browse.arxiv.org/pdf/1606.09282.pdf) by @li2017learning aims to address these challenges and have been implemented in modern machine learning platforms.
#### Federated Learning
-Consider the problem of labeling items that are present in a photo from personal devices. One may consider moving the image data from the devices to a central server, where a single model will train Using these image data provided by the devices. However, this presents many potential challenges. First, with many devices one needs a massive network infrastructure to move and store data from these devices to a central location. With the number of devices that are present today this is often not feasible, and very costly. Furthermore, there are privacy challenges associated with moving personal data, such as Photos central servers.
+Consider the problem of labeling items in a photo from personal devices and moving the image data from the devices to a central server, where a single model will train Using the image data provided by the devices. However, this presents many potential challenges. First, with many devices, one needs a massive network infrastructure to move and store data from these devices to a central location. With the number of devices present today, this is often not feasible and very costly. Furthermore, privacy challenges like those of Photos central servers are associated with moving personal data.
-Federated learning by @mcmahan2023communicationefficient is a form of distributed computing that resolves these issues by distributing the models into personal devices for them to be trained on device (@fig-federated-learning). At the beginning, a base global model is trained on a central server to be distributed to all devices. Using this base model, the devices individually compute the gradients and send them back to the central hub. Intuitively this is the transfer of model parameters instead of the data itself. This innovative approach allows the model to be trained with many different datasets (which, in our example, would be the set of images that are on personal devices), without the need to transfer a large amount of potentially sensitive data. However, federated learning also comes with a series of challenges.
+Federated learning by @mcmahan2023communicationefficient is a form of distributed computing that resolves these issues by distributing the models into personal devices for them to be trained on devices (@fig-federated-learning). Initially, a base global model is trained on a central server to be distributed to all devices. Using this base model, the devices individually compute the gradients and send them back to the central hub. Intuitively, this transfers model parameters instead of the data itself. This innovative approach allows the model to be trained with many different datasets (in our example, the set of images on personal devices) without transferring a large amount of potentially sensitive data. However, federated learning also comes with a series of challenges.
-In many real-world situations, data collected from devices may not come with suitable labels. This issue is compounded by the fact that users, who are often the primary source of data, can be unreliable. This unreliability means that even when data is labeled, there's no guarantee of its accuracy or relevance. Furthermore, each user's data is unique, resulting in a significant variance in the data generated by different users. This non-IID nature of data, coupled with the unbalanced data production where some users generate more data than others, can adversely impact the performance of the global model. Researchers have worked to compensate for this, such as by adding a proximal term to achieve a balance between the local and global model, and adding a frozen [global hypersphere classifier](https://arxiv.org/abs/2207.09413).
+Data collected from devices may come with something other than suitable labels in many real-world situations. Users compound this issue; the primary data source can often be unreliable. This unreliability means that even when data is labeled, its accuracy or relevance is not guaranteed. Furthermore, each user's data is unique, resulting in a significant variance in the data generated by different users. This non-IID nature of data, coupled with the unbalanced data production where some users generate more data than others, can adversely impact the performance of the global model. Researchers have worked to compensate for this by adding a proximal term to balance the local and global model and adding a frozen [global hypersphere classifier](https://arxiv.org/abs/2207.09413).
-There are additional challenges associated with federated learning. The number of mobile device owners can far exceed the average number of training samples on each device, leading to substantial communication overhead. This issue is particularly pronounced in the context of mobile networks, which are often used for such communication and can be unstable. This instability can result in delayed or failed transmission of model updates, thereby affecting the overall training process.
+Additional challenges are associated with federated learning. The number of mobile device owners can far exceed the average number of training samples on each device, leading to substantial communication overhead. This issue is particularly pronounced in the context of mobile networks, which are often used for such communication and can be unstable. This instability can result in delayed or failed transmission of model updates, thereby affecting the overall training process.
-The heterogeneity of device resources is another hurdle. Devices participating in Federated Learning can have varying computational powers and memory capacities. This diversity makes it challenging to design algorithms that are efficient across all devices. Privacy and security issues are not a guarantee for federated learning. Techniques such as inversion gradient attacks can be used to extract information about the training data from the model parameters. Despite these challenges, the large amount of potential benefits continue to make it a popular research area. Open source programs such as [Flower](https://flower.dev/) have been developed to make it simpler to implement federated learning with a variety of machine learning frameworks.
+The heterogeneity of device resources is another hurdle. Devices participating in Federated Learning can have varying computational powers and memory capacities. This diversity makes it challenging to design efficient algorithms across all devices. Privacy and security issues are not a guarantee for federated learning. Techniques such as inversion gradient attacks can extract information about the training data from the model parameters. Despite these challenges, the many potential benefits continue to make it a popular research area. Open source programs such as [Flower](https://flower.dev/) have been developed to simplify implementing federated learning with various machine learning frameworks.
)](images/png/federated_learning.png){#fig-federated-learning}
## Framework Specialization
-Thus far, we have talked about ML frameworks generally. However, typically frameworks are optimized based on the target environment\'s computational capabilities and application requirements, ranging from the cloud to the edge to tiny devices. Choosing the right framework is crucial based on the target environment for deployment. This section provides an overview of the major types of AI frameworks tailored for cloud, edge, and TinyML environments to help understand the similarities and differences between these different ecosystems.
+Thus far, we have talked about ML frameworks generally. However, typically, frameworks are optimized based on the target environment's computational capabilities and application requirements, ranging from the cloud to the edge to tiny devices. Choosing the right framework is crucial based on the target environment for deployment. This section provides an overview of the major types of AI frameworks tailored for cloud, edge, and TinyML environments to help understand the similarities and differences between these ecosystems.
### Cloud
-Cloud-based AI frameworks assume access to ample computational power, memory, and storage resources in the cloud. They generally support both training and inference. Cloud-based AI frameworks are suited for applications where data can be sent to the cloud for processing, such as cloud-based AI services, large-scale data analytics, and web applications. Popular cloud AI frameworks include the ones we mentioned earlier such as TensorFlow, PyTorch, MXNet, Keras, and others. These frameworks utilize technologies like GPUs, TPUs, distributed training, and AutoML to deliver scalable AI. Concepts like model serving, MLOps, and AIOps relate to the operationalization of AI in the cloud. Cloud AI powers services like Google Cloud AI and enables transfer learning using pre-trained models.
+Cloud-based AI frameworks assume access to ample computational power, memory, and storage resources in the cloud. They generally support both training and inference. Cloud-based AI frameworks are suited for applications where data can be sent to the cloud for processing, such as cloud-based AI services, large-scale data analytics, and web applications. Popular cloud AI frameworks include the ones we mentioned earlier, such as TensorFlow, PyTorch, MXNet, Keras, etc. These frameworks utilize GPUs, TPUs, distributed training, and AutoML to deliver scalable AI. Concepts like model serving, MLOps, and AIOps relate to the operationalization of AI in the cloud. Cloud AI powers services like Google Cloud AI and enables transfer learning using pre-trained models.
### Edge
-Edge AI frameworks are tailored for deploying AI models on edge devices, such as IoT devices, smartphones, and edge servers. Edge AI frameworks are optimized for devices with moderate computational resources, offering a balance between power and performance. Edge AI frameworks are ideal for applications requiring real-time or near-real-time processing, including robotics, autonomous vehicles, and smart devices. Key edge AI frameworks include TensorFlow Lite, PyTorch Mobile, CoreML, and others. They employ optimizations like model compression, quantization, and efficient neural network architectures. Hardware support includes CPUs, GPUs, NPUs and accelerators like the Edge TPU. Edge AI enables use cases like mobile vision, speech recognition, and real-time anomaly detection.
+Edge AI frameworks are tailored to deploy AI models on IoT devices, smartphones, and edge servers. Edge AI frameworks are optimized for devices with moderate computational resources, balancing power and performance. Edge AI frameworks are ideal for applications requiring real-time or near-real-time processing, including robotics, autonomous vehicles, and smart devices. Key edge AI frameworks include TensorFlow Lite, PyTorch Mobile, CoreML, and others. They employ optimizations like model compression, quantization, and efficient neural network architectures. Hardware support includes CPUs, GPUs, NPUs, and accelerators like the Edge TPU. Edge AI enables use cases like mobile vision, speech recognition, and real-time anomaly detection.
### Embedded
-TinyML frameworks are specialized for deploying AI models on extremely resource-constrained devices, specifically microcontrollers and sensors within the IoT ecosystem. TinyML frameworks are designed for devices with severely limited resources, emphasizing minimal memory and power consumption. TinyML frameworks are specialized for use cases on resource-constrained IoT devices for applications such as predictive maintenance, gesture recognition, and environmental monitoring. Major TinyML frameworks include TensorFlow Lite Micro, uTensor, and ARM NN. They optimize complex models to fit within kilobytes of memory through techniques like quantization-aware training and reduced precision. TinyML allows intelligent sensing across battery-powered devices, enabling collaborative learning via federated learning. The choice of framework involves balancing model performance and computational constraints of the target platform, whether cloud, edge or TinyML. Here is a summary table comparing the major AI frameworks across cloud, edge, and TinyML environments:
+TinyML frameworks are specialized for deploying AI models on extremely resource-constrained devices, specifically microcontrollers and sensors within the IoT ecosystem. TinyML frameworks are designed for devices with limited resources, emphasizing minimal memory and power consumption. TinyML frameworks are specialized for use cases on resource-constrained IoT devices for predictive maintenance, gesture recognition, and environmental monitoring applications. Major TinyML frameworks include TensorFlow Lite Micro, uTensor, and ARM NN. They optimize complex models to fit within kilobytes of memory through techniques like quantization-aware training and reduced precision. TinyML allows intelligent sensing across battery-powered devices, enabling collaborative learning via federated learning. The choice of framework involves balancing model performance and computational constraints of the target platform, whether cloud, edge, or TinyML. @tbl-ml_frameworks compares the major AI frameworks across cloud, edge, and TinyML environments:
| Framework Type | Examples | Key Technologies | Use Cases |
|----------------|-----------------------------------|-------------------------------------------------------------------------|------------------------------------------------------|
@@ -484,85 +486,87 @@ TinyML frameworks are specialized for deploying AI models on extremely resource-
| Edge AI | TensorFlow Lite, PyTorch Mobile, Core ML | Model optimization, compression, quantization, efficient NN architectures | Mobile apps, robots, autonomous systems, real-time processing |
| TinyML | TensorFlow Lite Micro, uTensor, ARM NN | Quantization-aware training, reduced precision, neural architecture search | IoT sensors, wearables, predictive maintenance, gesture recognition |
+: Comparison of framework types for Cloud AI, Edge AI, and TinyML. {#tbl-ml_frameworks}
+
**Key differences:**
* Cloud AI leverages massive computational power for complex models using GPUs/TPUs and distributed training
* Edge AI optimizes models to run locally on resource-constrained edge devices.
-* TinyML fits models into extremely low memory and compute environments like microcontrollers
+* TinyML fits models into extremely low memory and computes environments like microcontrollers
## Embedded AI Frameworks {#sec-ai_frameworks_embedded}
### Resource Constraints
-Embedded systems face severe resource constraints that pose unique challenges for deploying machine learning models compared to traditional computing platforms. For example, microcontroller units (MCUs) commonly used in IoT devices often have:
+Embedded systems face severe resource constraints that pose unique challenges when deploying machine learning models compared to traditional computing platforms. For example, microcontroller units (MCUs) commonly used in IoT devices often have:
-* **RAM** in the range of tens of kilobytes to a few megabytes. The popular [ESP8266 MCU](https://www.espressif.com/en/products/socs/esp8266) has around 80KB RAM available to developers. This contrasts with 8GB or more on typical laptops and desktops today.
+* **RAM** ranges from tens of kilobytes to a few megabytes. The popular [ESP8266 MCU](https://www.espressif.com/en/products/socs/esp8266) has around 80KB RAM available to developers. This contrasts with 8GB or more on typical laptops and desktops today.
-* **Flash storage** ranging from hundreds of kilobytes to a few megabytes. The Arduino Uno microcontroller provides just 32KB of storage for code. Standard computers today have disk storage in the order of terabytes.
+* **Flash storage** ranges from hundreds of kilobytes to a few megabytes. The Arduino Uno microcontroller provides just 32KB of code storage. Standard computers today have disk storage in the order of terabytes.
* **Processing power** from just a few MHz to approximately 200MHz. The ESP8266 operates at 80MHz. This is several orders of magnitude slower than multi-GHz multi-core CPUs in servers and high-end laptops.
-These tight constraints make training machine learning models directly on microcontrollers infeasible in most cases. The limited RAM precludes handling large datasets for training. Energy usage for training would also quickly deplete battery-powered devices. Instead, models are trained on resource-rich systems and deployed on microcontrollers for optimized inference. But even inference poses challenges:
+These tight constraints often make training machine learning models directly on microcontrollers infeasible. The limited RAM precludes handling large datasets for training. Energy usage for training would also quickly deplete battery-powered devices. Instead, models are trained on resource-rich systems and deployed on microcontrollers for optimized inference. But even inference poses challenges:
-1. **Model Size:** AI models are too large to fit on embedded and IoT devices. This necessitates the need for model compression techniques, such as quantization, pruning, and knowledge distillation. Additionally, as we will see, many of the frameworks used by developers for AI development have large amounts of overhead, and built in libraries that embedded systems can't support.
+1. **Model Size:** AI models are too large to fit on embedded and IoT devices. This necessitates model compression techniques, such as quantization, pruning, and knowledge distillation. Additionally, as we will see, many of the frameworks used by developers for AI development have large amounts of overhead and built-in libraries that embedded systems can't support.
-2. **Complexity of Tasks:** With only tens of KBs to a few MBs of RAM, IoT devices and embedded systems are constrained in the complexity of tasks they can handle. Tasks that require large datasets or sophisticated algorithms-- for example LLMs-- which would run smoothly on traditional computing platforms, might be infeasible on embedded systems without compression or other optimization techniques due to memory limitations.
+2. **Complexity of Tasks:** With only tens of KBs to a few MBs of RAM, IoT devices and embedded systems are constrained in the complexity of tasks they can handle. Tasks that require large datasets or sophisticated algorithms—for example, LLMs—that would run smoothly on traditional computing platforms might be infeasible on embedded systems without compression or other optimization techniques due to memory limitations.
-3. **Data Storage and Processing:** Embedded systems often process data in real-time and might not store large amounts of data locally. Conversely, traditional computing systems can hold and process large datasets in memory, enabling faster data operations and analysis as well as real-time updates.
+3. **Data Storage and Processing:** Embedded systems often process data in real time and might only store small amounts locally. Conversely, traditional computing systems can hold and process large datasets in memory, enabling faster data operations analysis and real-time updates.
-4. **Security and Privacy:** Limited memory also restricts the complexity of security algorithms and protocols, data encryption, reverse engineering protections, and more that can be implemented on the device. This can potentially make some IoT devices more vulnerable to attacks.
+4. **Security and Privacy:** Limited memory also restricts the complexity of security algorithms and protocols, data encryption, reverse engineering protections, and more that can be implemented on the device. This could make some IoT devices more vulnerable to attacks.
-Consequently, specialized software optimizations and ML frameworks tailored for microcontrollers are necessary to work within these tight resource bounds. Clever optimization techniques like quantization, pruning and knowledge distillation compress models to fit within limited memory (see Optimizations section). Learnings from neural architecture search help guide model designs.
+Consequently, specialized software optimizations and ML frameworks tailored for microcontrollers must work within these tight resource bounds. Clever optimization techniques like quantization, pruning, and knowledge distillation compress models to fit within limited memory (see Optimizations section). Learnings from neural architecture search help guide model designs.
-Hardware improvements like dedicated ML accelerators on microcontrollers also help alleviate constraints. For instance, [Qualcomm's Hexagon DSP](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) provides acceleration for TensorFlow Lite models on Snapdragon mobile chips. [Google's Edge TPU](https://cloud.google.com/edge-tpu) packs ML performance into a tiny ASIC for edge devices. [ARM Ethos-U55](https://www.arm.com/products/silicon-ip-cpu/ethos/ethos-u55) offers efficient inference on Cortex-M class microcontrollers. These customized ML chips unlock advanced capabilities for resource-constrained applications.
+Hardware improvements like dedicated ML accelerators on microcontrollers also help alleviate constraints. For instance, [Qualcomm's Hexagon DSP](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) accelerates TensorFlow Lite models on Snapdragon mobile chips. [Google's Edge TPU](https://cloud.google.com/edge-tpu) packs ML performance into a tiny ASIC for edge devices. [ARM Ethos-U55](https://www.arm.com/products/silicon-ip-cpu/ethos/ethos-u55) offers efficient inference on Cortex-M class microcontrollers. These customized ML chips unlock advanced capabilities for resource-constrained applications.
-Generally, due to the limited processing power, it's almost always infeasible to train AI models on IoT or embedded systems. Instead, models are trained on powerful traditional computers (often with GPUs) and then deployed on the embedded device for inference. TinyML specifically deals with this, ensuring models are lightweight enough for real-time inference on these constrained devices.
+Due to limited processing power, it's almost always infeasible to train AI models on IoT or embedded systems. Instead, models are trained on powerful traditional computers (often with GPUs) and then deployed on the embedded device for inference. TinyML specifically deals with this, ensuring models are lightweight enough for real-time inference on these constrained devices.
### Frameworks & Libraries
-Embedded AI frameworks are software tools and libraries designed to enable AI and ML capabilities on embedded systems. These frameworks are essential for bringing AI to IoT devices, robotics, and other edge computing platforms and they are designed to work where computational resources, memory, and power consumption are limited.
+Embedded AI frameworks are software tools and libraries designed to enable AI and ML capabilities on embedded systems. These frameworks are essential for bringing AI to IoT devices, robotics, and other edge computing platforms, and they are designed to work where computational resources, memory, and power consumption are limited.
### Challenges
-While embedded systems present an enormous opportunity for deploying machine learning to enable intelligent capabilities at the edge, these resource-constrained environments also pose significant challenges. Unlike typical cloud or desktop environments rich with computational resources, embedded devices introduce severe constraints around memory, processing power, energy efficiency, and specialized hardware. As a result, existing machine learning techniques and frameworks designed for server clusters with abundant resources do not directly translate to embedded systems. This section uncovers some of the challenges and opportunities for embedded systems and ML frameworks.
+While embedded systems present an enormous opportunity for deploying machine learning to enable intelligent capabilities at the edge, these resource-constrained environments pose significant challenges. Unlike typical cloud or desktop environments rich with computational resources, embedded devices introduce severe constraints around memory, processing power, energy efficiency, and specialized hardware. As a result, existing machine learning techniques and frameworks designed for server clusters with abundant resources do not directly translate to embedded systems. This section uncovers some of the challenges and opportunities for embedded systems and ML frameworks.
#### Fragmented Ecosystem
-The lack of a unified ML framework led to a highly fragmented ecosystem. Engineers at companies like [STMicroelectronics](https://www.st.com/), [NXP Semiconductors](https://www.nxp.com/), and [Renesas](https://www.renesas.com/) had to develop custom solutions tailored to their specific microcontroller and DSP architectures. These ad-hoc frameworks required extensive manual optimization for each low-level hardware platform. This made porting models extremely difficult, requiring redevelopment for new Arm, RISC-V or proprietary architectures.
+The lack of a unified ML framework led to a highly fragmented ecosystem. Engineers at companies like [STMicroelectronics](https://www.st.com/), [NXP Semiconductors](https://www.nxp.com/), and [Renesas](https://www.renesas.com/) had to develop custom solutions tailored to their specific microcontroller and DSP architectures. These ad-hoc frameworks required extensive manual optimization for each low-level hardware platform. This made porting models extremely difficult, requiring redevelopment for new Arm, RISC-V, or proprietary architectures.
#### Disparate Hardware Needs
-Without a shared framework, there was no standard way to assess hardware's capabilities. Vendors like Intel, Qualcomm and NVIDIA created integrated solutions blending model, software and hardware improvements. This made it hard to discern the sources of performance gains - whether new chip designs like Intel's low-power x86 cores or software optimizations were responsible. A standard framework was needed so vendors could evaluate their hardware's capabilities in a fair, reproducible way.
+Without a shared framework, there was no standard way to assess hardware's capabilities. Vendors like Intel, Qualcomm, and NVIDIA created integrated solutions, blending models and improving software and hardware. This made it hard to discern the sources of performance gains - whether new chip designs like Intel's low-power x86 cores or software optimizations were responsible. A standard framework was needed so vendors could evaluate their hardware's capabilities fairly and reproducibly.
#### Lack of Portability
-Adapting models trained in common frameworks like TensorFlow or PyTorch to run efficiently on microcontrollers was very challenging without standardized tools. It required time-consuming manual translation of models to run on specialized DSPs from companies like CEVA or low-power Arm M-series cores. There were no turnkey tools enabling portable deployment across different architectures.
+With standardized tools, adapting models trained in common frameworks like TensorFlow or PyTorch to run efficiently on microcontrollers was easier. It required time-consuming manual translation of models to run on specialized DSPs from companies like CEVA or low-power Arm M-series cores. No turnkey tools were enabling portable deployment across different architectures.
#### Incomplete Infrastructure
-The infrastructure to support key model development workflows was lacking. There was minimal support for compression techniques to fit large models within constrained memory budgets. Tools for quantization to lower precision for faster inference were missing. Standardized APIs for integration into applications were incomplete. Essential functionality like on-device debugging, metrics, and performance profiling was absent. These gaps increased the cost and difficulty of embedded ML development.
+The infrastructure to support key model development workflows needed to be improved. More support is needed for compression techniques to fit large models within constrained memory budgets. Tools for quantization to lower precision for faster inference were missing. Standardized APIs for integration into applications were incomplete. Essential functionality like on-device debugging, metrics, and performance profiling was absent. These gaps increased the cost and difficulty of embedded ML development.
#### No Standard Benchmark
-Without unified benchmarks, there was no standard way to assess and compare the capabilities of different hardware platforms from vendors like NVIDIA, Arm and Ambiq Micro. Existing evaluations relied on proprietary benchmarks tailored to showcased strengths of particular chips. This made it impossible to objectively measure hardware improvements in a fair, neutral manner. This topic is discussed in more detail in the [Benchmarking AI](../benchmarking/benchmarking.qmd) chapter.
+Without unified benchmarks, there was no standard way to assess and compare the capabilities of different hardware platforms from vendors like NVIDIA, Arm, and Ambiq Micro. Existing evaluations relied on proprietary benchmarks tailored to showcase the strengths of particular chips. This made it impossible to measure hardware improvements objectively in a fair, neutral manner. The [Benchmarking AI](../benchmarking/benchmarking. cmd) chapter discusses this topic in more detail.
#### Minimal Real-World Testing
-Much of the benchmarks relied on synthetic data. Rigorously testing models on real-world embedded applications was difficult without standardized datasets and benchmarks. This raised questions on how performance claims would translate to real-world usage. More extensive testing was needed to validate chips in actual use cases.
+Much of the benchmarks relied on synthetic data. Rigorously testing models on real-world embedded applications was difficult without standardized datasets and benchmarks, raising questions about how performance claims would translate to real-world usage. More extensive testing was needed to validate chips in actual use cases.
-The lack of shared frameworks and infrastructure slowed TinyML adoption, hampering the integration of ML into embedded products. Recent standardized frameworks have begun addressing these issues through improved portability, performance profiling, and benchmarking support. But ongoing innovation is still needed to enable seamless, cost-effective deployment of AI to edge devices.
+The lack of shared frameworks and infrastructure slowed TinyML adoption, hampering the integration of ML into embedded products. Recent standardized frameworks have begun addressing these issues through improved portability, performance profiling, and benchmarking support. However, ongoing innovation is still needed to enable seamless, cost-effective deployment of AI to edge devices.
#### Summary
-The absence of standardized frameworks, benchmarks, and infrastructure for embedded ML has traditionally hampered adoption. However, recent progress has been made in developing shared frameworks like TensorFlow Lite Micro and benchmark suites like MLPerf Tiny that aim to accelerate the proliferation of TinyML solutions. But overcoming the fragmentation and difficulty of embedded deployment remains an ongoing process.
+The absence of standardized frameworks, benchmarks, and infrastructure for embedded ML has traditionally hampered adoption. However, recent progress has been made in developing shared frameworks like TensorFlow Lite Micro and benchmark suites like MLPerf Tiny that aim to accelerate the proliferation of TinyML solutions. However, overcoming the fragmentation and difficulty of embedded deployment remains an ongoing process.
## Examples
-Machine learning deployment on microcontrollers and other embedded devices often requires specially optimized software libraries and frameworks to work within the tight constraints of memory, compute, and power. Several options exist for performing inference on such resource-limited hardware, each with their own approach to optimizing model execution. This section will explore the key characteristics and design principles behind TFLite Micro, TinyEngine, and CMSIS-NN, providing insight into how each framework tackles the complex problem of high-accuracy yet efficient neural network execution on microcontrollers. They showcase different approaches for implementing efficient TinyML frameworks.
+Machine learning deployment on microcontrollers and other embedded devices often requires specially optimized software libraries and frameworks to work within tight memory, compute, and power constraints. Several options exist for performing inference on such resource-limited hardware, each with its approach to optimizing model execution. This section will explore the key characteristics and design principles behind TFLite Micro, TinyEngine, and CMSIS-NN, providing insight into how each framework tackles the complex problem of high-accuracy yet efficient neural network execution on microcontrollers. It will also showcase different approaches for implementing efficient TinyML frameworks.
-The table summarizes the key differences and similarities between these three specialized machine learning inference frameworks for embedded systems and microcontrollers.
+@tbl-compare_frameworks summarizes the key differences and similarities between these three specialized machine-learning inference frameworks for embedded systems and microcontrollers.
| Framework | TensorFlow Lite Micro | TinyEngine | CMSIS-NN |
|------------------------|:----------------------------:|:--------------------------------------:|:--------------------------------------:|
@@ -576,7 +580,9 @@ The table summarizes the key differences and similarities between these three sp
| **Optimization Approach** | Some code generation features | Specialized kernels, operator fusion | Architecture-specific assembly optimizations |
| **Key Benefits** | Flexibility, portability, ease of updating models | Maximizes performance, optimized memory usage | Hardware acceleration, standardized API, portability |
-In the following sections, we will dive into understanding each of these in greater detail.
+: Comparison of frameworks: TensorFlow Lite Micro, TinyEngine, and CMSIS-NN {#tbl-compare_frameworks}
+
+We will understand each of these in greater detail in the following sections.
### Interpreter
@@ -586,7 +592,7 @@ Traditional interpreters often have significant branching overhead, which can re
An alternative to an interpreter-based inference engine is to generate native code from a model during export. This can improve performance, but it sacrifices portability and flexibility, as the generated code needs recompilation for each target platform and must be replaced entirely to modify a model.
-TFLM strikes a balance between the simplicity of code compilation and the flexibility of an interpreter-based approach by incorporating certain code-generation features. For example, the library can be constructed solely from source files, offering much of the compilation simplicity associated with code generation while retaining the benefits of an interpreter-based model execution framework.
+TFLM balances the simplicity of code compilation and the flexibility of an interpreter-based approach by incorporating certain code-generation features. For example, the library can be constructed solely from source files, offering much of the compilation simplicity associated with code generation while retaining the benefits of an interpreter-based model execution framework.
An interpreter-based approach offers several benefits over code generation for machine learning inference on embedded devices:
@@ -602,33 +608,33 @@ TensorFlow Lite Micro is a powerful and flexible framework for machine learning
### Compiler-based
-[TinyEngine](https://github.com/mit-han-lab/tinyengine) by is an ML inference framework designed specifically for resource-constrained microcontrollers. It employs several optimizations to enable high-accuracy neural network execution within the tight constraints of memory, compute, and storage on microcontrollers [@lin2020mcunet].
+[TinyEngine](https://github.com/mit-han-lab/tinyengine) is an ML inference framework designed specifically for resource-constrained microcontrollers. It employs several optimizations to enable high-accuracy neural network execution within the tight constraints of memory, computing, and storage on microcontrollers [@lin2020mcunet].
-While inference frameworks like TFLite Micro use interpreters to execute the neural network graph dynamically at runtime, this adds significant overhead in terms of memory usage to store metadata, interpretation latency, and lack of optimizations, although TFLite argues that the overhead is small. TinyEngine eliminates this overhead by employing a code generation approach. During compilation, it analyzes the network graph and generates specialized code to execute just that model. This code is natively compiled into the application binary, avoiding runtime interpretation costs.
+While inference frameworks like TFLite Micro use interpreters to execute the neural network graph dynamically at runtime, this adds significant overhead regarding memory usage to store metadata, interpretation latency, and lack of optimizations. However, TFLite argues that the overhead is small. TinyEngine eliminates this overhead by employing a code generation approach. It analyzes the network graph during compilation and generates specialized code to execute just that model. This code is natively compiled into the application binary, avoiding runtime interpretation costs.
-Conventional ML frameworks schedule memory per layer, trying to minimize usage for each layer separately. TinyEngine does model-level scheduling instead, analyzing memory usage across layers. It allocates a common buffer size based on the max memory needs of all layers. This buffer is then shared efficiently across layers to increase data reuse.
+Conventional ML frameworks schedule memory per layer, trying to minimize usage for each layer separately. TinyEngine does model-level scheduling instead of analyzing memory usage across layers. It allocates a common buffer size based on the maximum memory needs of all layers. This buffer is then shared efficiently across layers to increase data reuse.
-TinyEngine also specializes the kernels for each layer through techniques like tiling, unrolling, and fusing operators. For example, it will generate unrolled compute kernels with the exact number of loops needed for a 3x3 or 5x5 convolution. These specialized kernels extract maximum performance from the microcontroller hardware. It uses depthwise convolutions that are optimized to minimize memory allocations by computing each channel\'s output in-place over the input channel data. This technique exploits the channel-separable nature of depthwise convolutions to reduce peak memory size.
+TinyEngine also specializes in the kernels for each layer through techniques like tiling, unrolling, and fusing operators. For example, it will generate unrolled compute kernels with the number of loops needed for a 3x3 or 5x5 convolution. These specialized kernels extract maximum performance from the microcontroller hardware. It uses optimized depthwise convolutions to minimize memory allocations by computing each channel's output in place over the input channel data. This technique exploits the channel-separable nature of depthwise convolutions to reduce peak memory size.
-Similar to TFLite Micro, the compiled TinyEngine binary only includes ops needed for a specific model rather than all possible operations. This results in a very small binary footprint, keeping code size low for memory-constrained devices.
+Like TFLite Micro, the compiled TinyEngine binary only includes ops needed for a specific model rather than all possible operations. This results in a very small binary footprint, keeping code size low for memory-constrained devices.
-One difference between TFLite Micro and TinyEngine is that the latter is co-designed with "TinyNAS," an architecture search method for microcontroller models, similar to differential NAS for microcontrollers. The efficiency of TinyEngine allows exploring larger and more accurate models through NAS. It also provides feedback to TinyNAS on which models can fit within the hardware constraints.
+One difference between TFLite Micro and TinyEngine is that the latter is co-designed with "TinyNAS," an architecture search method for microcontroller models similar to differential NAS for microcontrollers. TinyEngine's efficiency allows for exploring larger and more accurate models through NAS. It also provides feedback to TinyNAS on which models can fit within the hardware constraints.
-Through all these various custom techniques like static compilation, model-based scheduling, specialized kernels, and co-design with NAS, TinyEngine enables high-accuracy deep learning inference within the tight resource constraints of microcontrollers.
+Through various custom techniques, such as static compilation, model-based scheduling, specialized kernels, and co-design with NAS, TinyEngine enables high-accuracy deep learning inference within microcontrollers' tight resource constraints.
### Library
-[CMSIS-NN](https://www.keil.com/pack/doc/CMSIS/NN/html/index.html), standing for Cortex Microcontroller Software Interface Standard for Neural Networks, is a software library devised by ARM. It offers a standardized interface for deploying neural network inference on microcontrollers and embedded systems, with a particular focus on optimization for ARM Cortex-M processors [@lai2018cmsis].
+[CMSIS-NN](https://www.keil.com/pack/doc/CMSIS/NN/html/index.html), standing for Cortex Microcontroller Software Interface Standard for Neural Networks, is a software library devised by ARM. It offers a standardized interface for deploying neural network inference on microcontrollers and embedded systems, focusing on optimization for ARM Cortex-M processors [@lai2018cmsis].
-**Neural Network Kernels:** CMSIS-NN is equipped with highly efficient kernels that handle fundamental neural network operations such as convolution, pooling, fully connected layers, and activation functions. It caters to a broad range of neural network models by supporting both floating-point and fixed-point arithmetic. The latter is especially beneficial for resource-constrained devices as it curtails memory and computational requirements (Quantization).
+**Neural Network Kernels:** CMSIS-NN has highly efficient kernels that handle fundamental neural network operations such as convolution, pooling, fully connected layers, and activation functions. It caters to a broad range of neural network models by supporting floating and fixed-point arithmetic. The latter is especially beneficial for resource-constrained devices as it curtails memory and computational requirements (Quantization).
-**Hardware Acceleration:** CMSIS-NN harnesses the power of Single Instruction, Multiple Data (SIMD) instructions available on many Cortex-M processors. This allows for parallel processing of multiple data elements within a single instruction, thereby boosting computational efficiency. Certain Cortex-M processors feature Digital Signal Processing (DSP) extensions that CMSIS-NN can exploit for accelerated neural network execution. The library also incorporates assembly-level optimizations tailored to specific microcontroller architectures to further enhance performance.
+**Hardware Acceleration:** CMSIS-NN harnesses the power of Single Instruction, Multiple Data (SIMD) instructions available on many Cortex-M processors. This allows for parallel processing of multiple data elements within a single instruction, thereby boosting computational efficiency. Certain Cortex-M processors feature Digital Signal Processing (DSP) extensions that CMSIS-NN can exploit for accelerated neural network execution. The library also incorporates assembly-level optimizations tailored to specific microcontroller architectures to enhance performance further.
**Standardized API:** CMSIS-NN offers a consistent and abstracted API that protects developers from the complexities of low-level hardware details. This makes the integration of neural network models into applications simpler. It may also encompass tools or utilities for converting popular neural network model formats into a format that is compatible with CMSIS-NN.
-**Memory Management:** CMSIS-NN provides functions for efficient memory allocation and management, which is vital in embedded systems where memory resources are scarce. It ensures optimal memory usage during inference and in some instances, allows for in-place operations to further decrease memory overhead.
+**Memory Management:** CMSIS-NN provides functions for efficient memory allocation and management, which is vital in embedded systems where memory resources are scarce. It ensures optimal memory usage during inference and, in some instances, allows in-place operations to decrease memory overhead.
-**Portability**: CMSIS-NN is designed with portability in mind across various Cortex-M processors. This enables developers to write code that can operate on different microcontrollers without significant modifications.
+**Portability:** CMSIS-NN is designed for portability across various Cortex-M processors. This enables developers to write code that can operate on different microcontrollers without significant modifications.
**Low Latency:** CMSIS-NN minimizes inference latency, making it an ideal choice for real-time applications where swift decision-making is paramount.
@@ -636,39 +642,39 @@ Through all these various custom techniques like static compilation, model-based
## Choosing the Right Framework
-Choosing the right machine learning framework for a given application requires carefully evaluating models, hardware, and software considerations. By analyzing these three aspects - models, hardware, and software - ML engineers can select the optimal framework and customize as needed for efficient and performant on-device ML applications. The goal is to balance model complexity, hardware limitations, and software integration to design a tailored ML pipeline for embedded and edge devices.
+Choosing the right machine learning framework for a given application requires carefully evaluating models, hardware, and software considerations. By analyzing these three aspects—models, hardware, and software—ML engineers can select the optimal framework and customize it as needed for efficient and performant on-device ML applications. The goal is to balance model complexity, hardware limitations, and software integration to design a tailored ML pipeline for embedded and edge devices.
{#fig-tf-comparison width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - General"}
### Model
-TensorFlow supports significantly more ops than TensorFlow Lite and TensorFlow Lite Micro as it is typically used for research or cloud deployment, which require a large number of and more flexibility with operators (ops) (@fig-tf-comparison). TensorFlow Lite supports select ops for on-device training, whereas TensorFlow Micro does not. TensorFlow Lite also supports dynamic shapes and quantization aware training, but TensorFlow Micro does not. In contrast, TensorFlow Lite and TensorFlow Micro offer native quantization tooling and support, where quantization refers to the process of transforming an ML program into an approximated representation with available lower precision operations.
+TensorFlow supports significantly more ops than TensorFlow Lite and TensorFlow Lite Micro as it is typically used for research or cloud deployment, which require a large number of and more flexibility with operators (ops) (@fig-tf-comparison). TensorFlow Lite supports select ops for on-device training, whereas TensorFlow Micro does not. TensorFlow Lite also supports dynamic shapes and quantization-aware training, but TensorFlow Micro does not. In contrast, TensorFlow Lite and TensorFlow Micro offer native quantization tooling and support, where quantization refers to transforming an ML program into an approximated representation with available lower precision operations.
### Software
{#fig-tf-sw-comparison width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - Model"}
-TensorFlow Lite Micro does not have OS support, while TensorFlow and TensorFlow Lite do, in order to reduce memory overhead, make startup times faster, and consume less energy (@fig-tf-sw-comparison). TensorFlow Lite Micro can be used in conjunction with real-time operating systems (RTOS) like FreeRTOS, Zephyr, and Mbed OS. TensorFlow Lite and TensorFlow Lite Micro support model memory mapping, allowing models to be directly accessed from flash storage rather than loaded into RAM, whereas TensorFlow does not. TensorFlow and TensorFlow Lite support accelerator delegation to schedule code to different accelerators, whereas TensorFlow Lite Micro does not, as embedded systems tend not to have a rich array of specialized accelerators.
+TensorFlow Lite Micro does not have OS support, while TensorFlow and TensorFlow Lite do, to reduce memory overhead, make startup times faster, and consume less energy (@fig-tf-sw-comparison). TensorFlow Lite Micro can be used in conjunction with real-time operating systems (RTOS) like FreeRTOS, Zephyr, and Mbed OS. TensorFlow Lite and TensorFlow Lite Micro support model memory mapping, allowing models to be directly accessed from flash storage rather than loaded into RAM, whereas TensorFlow does not. TensorFlow and TensorFlow Lite support accelerator delegation to schedule code to different accelerators, whereas TensorFlow Lite Micro does not, as embedded systems tend to have a limited array of specialized accelerators.
### Hardware
{#fig-tf-hw-comparison width="100%" height="auto" align="center" caption="TensorFlow Framework Comparison - Hardware"}
-TensorFlow Lite and TensorFlow Lite Micro have significantly smaller base binary sizes and base memory footprints compared to TensorFlow (@fig-tf-hw-comparison). For example, a typical TensorFlow Lite Micro binary is less than 200KB, whereas TensorFlow is much larger. This is due to the resource-constrained environments of embedded systems. TensorFlow provides support for x86, TPUs, and GPUs like NVIDIA, AMD, and Intel. TensorFlow Lite provides support for Arm Cortex A and x86 processors commonly used in mobile and tablets. The latter is stripped out of all the training logic that is not necessary for ondevice deployment. TensorFlow Lite Micro provides support for microcontroller-focused Arm Cortex M cores like M0, M3, M4, and M7, as well as DSPs like Hexagon and SHARC and MCUs like STM32, NXP Kinetis, Microchip AVR.
+TensorFlow Lite and TensorFlow Lite Micro have significantly smaller base binary sizes and memory footprints than TensorFlow (@fig-tf-hw-comparison). For example, a typical TensorFlow Lite Micro binary is less than 200KB, whereas TensorFlow is much larger. This is due to the resource-constrained environments of embedded systems. TensorFlow supports x86, TPUs, and GPUs like NVIDIA, AMD, and Intel. TensorFlow Lite supports Arm Cortex-A and x86 processors commonly used on mobile phones and tablets. The latter is stripped of all the unnecessary training logic for on-device deployment. TensorFlow Lite Micro provides support for microcontroller-focused Arm Cortex M cores like M0, M3, M4, and M7, as well as DSPs like Hexagon and SHARC and MCUs like STM32, NXP Kinetis, Microchip AVR.
-Selecting the appropriate AI framework is essential to ensure that embedded systems can efficiently execute AI models. There are key factors to consider when choosing a machine learning framework, with a focus on ease of use, community support, performance, scalability, integration with data engineering tools, and integration with model optimization tools. By understanding these factors, you can make informed decisions and maximize the potential of your machine learning initiatives.
+Selecting the appropriate AI framework is essential to ensure that embedded systems can efficiently execute AI models. Key factors to consider when choosing a machine learning framework are ease of use, community support, performance, scalability, integration with data engineering tools, and integration with model optimization tools. By understanding these factors, you can make informed decisions and maximize the potential of your machine-learning initiatives.
### Other Factors
-When evaluating AI frameworks for embedded systems, several other key factors beyond models, hardware, and software should be considered.
+Several other key factors beyond models, hardware, and software should be considered when evaluating AI frameworks for embedded systems.
#### Performance
-Performance is critical in embedded systems where computational resources are limited. Evaluate the framework\'s ability to optimize model inference for embedded hardware. Factors such as model quantization and hardware acceleration support play a crucial role in achieving efficient inference.
+Performance is critical in embedded systems where computational resources are limited. Evaluate the framework's ability to optimize model inference for embedded hardware. Model quantization and hardware acceleration support are crucial in achieving efficient inference.
#### Scalability
-Scalability is essential when considering the potential growth of an embedded AI project. The framework should support the deployment of models on a variety of embedded devices, from microcontrollers to more powerful processors. It should also handle both small-scale and large-scale deployments seamlessly.
+Scalability is essential when considering the potential growth of an embedded AI project. The framework should support the deployment of models on various embedded devices, from microcontrollers to more powerful processors. It should also seamlessly handle both small-scale and large-scale deployments.
#### Integration with Data Engineering Tools
@@ -676,15 +682,15 @@ Data engineering tools are essential for data preprocessing and pipeline managem
#### Integration with Model Optimization Tools
-Model optimization is crucial to ensure that AI models are well-suited for embedded deployment. Evaluate whether the framework integrates with model optimization tools, such as TensorFlow Lite Converter or ONNX Runtime, to facilitate model quantization and size reduction.
+Model optimization ensures that AI models are well-suited for embedded deployment. Evaluate whether the framework integrates with model optimization tools like TensorFlow Lite Converter or ONNX Runtime to facilitate model quantization and size reduction.
#### Ease of Use
-The ease of use of an AI framework significantly impacts development efficiency. A framework with a user-friendly interface and clear documentation reduces the learning curve for developers. Consideration should be given to whether the framework supports high-level APIs, allowing developers to focus on model design rather than low-level implementation details. This factor is incredibly important for embedded systems, which have less features that typical developers might be accustomed to.
+The ease of use of an AI framework significantly impacts development efficiency. A framework with a user-friendly interface and clear documentation reduces developers' learning curve. Consideration should be given to whether the framework supports high-level APIs, allowing developers to focus on model design rather than low-level implementation details. This factor is incredibly important for embedded systems, which have fewer features than typical developers might be accustomed to.
#### Community Support
-Community support plays another essential factor. Frameworks with active and engaged communities often have well-maintained codebases, receive regular updates, and provide valuable forums for problem-solving. As a result, community support plays into Ease of Use as well because it ensures that developers have access to a wealth of resources, including tutorials and example projects. Community support provides some assurance that the framework will continue to be supported for future updates. There are only a handful of frameworks that cater to TinyML needs. Of that, TensorFlow Lite Micro is the most popular and has the most community support.
+Community support plays another essential factor. Frameworks with active and engaged communities often have well-maintained codebases, receive regular updates, and provide valuable forums for problem-solving. As a result, community support also plays into Ease of Use because it ensures that developers have access to a wealth of resources, including tutorials and example projects. Community support provides some assurance that the framework will continue to be supported for future updates. There are only a few frameworks that cater to TinyML needs. TensorFlow Lite Micro is the most popular and has the most community support.
## Future Trends in ML Frameworks
@@ -694,7 +700,7 @@ Currently, the ML system stack consists of four abstractions (@fig-mlsys-stack),
{#fig-mlsys-stack align="center" caption="Four Abstractions in Current ML System Stack"}
-This has led to vertical (i.e. between abstraction levels) and horizontal (i.e. library-driven vs. compilation-driven approaches to tensor computation) boundaries, which hinder innovation for ML. Future work in ML frameworks can look toward breaking these boundaries. In December 2021, [Apache TVM](https://tvm.apache.org/2021/12/15/tvm-unity) Unity was proposed, which aimed to facilitate interactions between the different abstraction levels (as well as the people behind them, such as ML scientists, ML engineers, and hardware engineers) and co-optimize decisions in all four abstraction levels.
+This has led to vertical (i.e., between abstraction levels) and horizontal (i.e., library-driven vs. compilation-driven approaches to tensor computation) boundaries, which hinder innovation for ML. Future work in ML frameworks can look toward breaking these boundaries. In December 2021, [Apache TVM](https://tvm.apache.org/2021/12/15/tvm-unity) Unity was proposed, which aimed to facilitate interactions between the different abstraction levels (as well as the people behind them, such as ML scientists, ML engineers, and hardware engineers) and co-optimize decisions in all four abstraction levels.
### High-Performance Compilers & Libraries
@@ -714,22 +720,22 @@ We can also use ML to improve ML frameworks in the future. Some current uses of
In summary, selecting the optimal framework requires thoroughly evaluating options against criteria like usability, community support, performance, hardware compatibility, and model conversion abilities. There is no universal best solution, as the right framework depends on the specific constraints and use case.
-For extremely resource constrained microcontroller-based platforms, TensorFlow Lite Micro currently provides a strong starting point. Its comprehensive optimization tooling like quantization mapping and kernel optimizations enables high performance on devices like Arm Cortex-M and RISC-V processors. The active developer community ensures accessible technical support. Seamless integration with TensorFlow for training and converting models makes the workflow cohesive.
+TensorFlow Lite Micro currently provides a strong starting point for extremely resource-constrained microcontroller-based platforms. Its comprehensive optimization tooling, such as quantization mapping and kernel optimizations, enables high performance on devices like Arm Cortex-M and RISC-V processors. The active developer community ensures accessible technical support. Seamless integration with TensorFlow for training and converting models makes the workflow cohesive.
-For platforms with more capable CPUs like Cortex-A, TensorFlow Lite for Microcontrollers expand possibilities. They provide greater flexibility for custom and advanced models beyond the core operators in TFLite Micro. However, this comes at the cost of a larger memory footprint. These frameworks are ideal for automotive systems, drones, and more powerful edge devices that can benefit from greater model sophistication.
+For platforms with more capable CPUs like Cortex-A, TensorFlow Lite for Microcontrollers expands possibilities. It provides greater flexibility for custom and advanced models beyond the core operators in TFLite Micro. However, this comes at the cost of a larger memory footprint. These frameworks are ideal for automotive systems, drones, and more powerful edge devices that can benefit from greater model sophistication.
-Frameworks specifically built for specialized hardware like CMSIS-NN on Cortex-M processors can further maximize performance, but sacrifice portability. Integrated frameworks from processor vendors tailor the stack to their architectures. This can unlock the full potential of their chips but lock you into their ecosystem.
+Frameworks specifically built for specialized hardware like CMSIS-NN on Cortex-M processors can further maximize performance but sacrifice portability. Integrated frameworks from processor vendors tailor the stack to their architectures, unlocking the full potential of their chips but locking you into their ecosystem.
-Ultimately, choosing the right framework involves finding the best match between its capabilities and the requirements of the target platform. This requires balancing tradeoffs between performance needs, hardware constraints, model complexity, and other factors. Thoroughly assessing intended models, use cases, and evaluating options against key metrics will guide developers towards picking the ideal framework for their embedded ML application.
+Ultimately, choosing the right framework involves finding the best match between its capabilities and the requirements of the target platform. This requires balancing tradeoffs between performance needs, hardware constraints, model complexity, and other factors. Thoroughly assessing intended models and use cases and evaluating options against key metrics will guide developers in picking the ideal framework for their embedded ML application.
## Resources {#sec-ai-frameworks-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Why do we need frameworks?](https://docs.google.com/presentation/d/1zbnsihiO68oIUE04TVJEcDQ_Kyec4mhdQkIG6xoR0DY/edit#slide=id.p1)
@@ -768,7 +774,7 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/generative_ai/generative_ai.bib b/contents/generative_ai/generative_ai.bib
index e69de29b..00614696 100644
--- a/contents/generative_ai/generative_ai.bib
+++ b/contents/generative_ai/generative_ai.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/generative_ai/generative_ai.qmd b/contents/generative_ai/generative_ai.qmd
index 771a0f4a..f74caf27 100644
--- a/contents/generative_ai/generative_ai.qmd
+++ b/contents/generative_ai/generative_ai.qmd
@@ -10,7 +10,7 @@ bibliography: generative_ai.bib
## Learning Objectives
-* coming soon.
+*Coming soon.*
:::
diff --git a/contents/hw_acceleration/hw_acceleration.bib b/contents/hw_acceleration/hw_acceleration.bib
index c9152d12..41bebdb2 100644
--- a/contents/hw_acceleration/hw_acceleration.bib
+++ b/contents/hw_acceleration/hw_acceleration.bib
@@ -1,7 +1,16 @@
-@article{gwennap_certus-nx_nodate,
- author = {Gwennap, Linley},
- language = {en},
- title = {Certus-{NX} Innovates General-Purpose {FPGAs}}
+%comment{This file was created with betterbib v5.0.11.}
+
+
+@inproceedings{Li2020Additive,
+ author = {Li, Yuhang and Dong, Xin and Wang, Wei},
+ bibsource = {dblp computer science bibliography, https://dblp.org},
+ biburl = {https://dblp.org/rec/conf/iclr/LiDW20.bib},
+ booktitle = {8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020},
+ publisher = {OpenReview.net},
+ timestamp = {Tue, 18 Aug 2020 01:00:00 +0200},
+ title = {Additive Powers-of-Two Quantization: {An} Efficient Non-uniform Discretization for Neural Networks},
+ url = {https://openreview.net/forum?id=BkgXT24tDS},
+ year = {2020},
}
@inproceedings{adolf2016fathom,
@@ -14,19 +23,26 @@ @inproceedings{adolf2016fathom
source = {Crossref},
title = {Fathom: {Reference} workloads for modern deep learning methods},
url = {https://doi.org/10.1109/iiswc.2016.7581275},
- year = {2016}
+ year = {2016},
+ month = sep,
}
@inproceedings{agnesina2023autodmp,
author = {Agnesina, Anthony and Rajvanshi, Puranjay and Yang, Tian and Pradipta, Geraldo and Jiao, Austin and Keller, Ben and Khailany, Brucek and Ren, Haoxing},
booktitle = {Proceedings of the 2023 International Symposium on Physical Design},
pages = {149--157},
- title = {AutoDMP: Automated dreamplace-based macro placement},
- year = {2023}
+ title = {{AutoDMP}},
+ year = {2023},
+ doi = {10.1145/3569052.3578923},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3569052.3578923},
+ publisher = {ACM},
+ subtitle = {Automated DREAMPlace-based Macro Placement},
+ month = mar,
}
@article{asit2021accelerating,
- author = {Asit K. Mishra and Jorge Albericio Latorre and Jeff Pool and Darko Stosic and Dusan Stosic and Ganesh Venkatesh and Chong Yu and Paulius Micikevicius},
+ author = {Mishra, Asit K. and Latorre, Jorge Albericio and Pool, Jeff and Stosic, Darko and Stosic, Dusan and Venkatesh, Ganesh and Yu, Chong and Micikevicius, Paulius},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-08378.bib},
eprint = {2104.08378},
@@ -36,7 +52,7 @@ @article{asit2021accelerating
title = {Accelerating Sparse Deep Neural Networks},
url = {https://arxiv.org/abs/2104.08378},
volume = {abs/2104.08378},
- year = {2021}
+ year = {2021},
}
@article{bains2020business,
@@ -51,15 +67,21 @@ @article{bains2020business
title = {The business of building brains},
url = {https://doi.org/10.1038/s41928-020-0449-1},
volume = {3},
- year = {2020}
+ year = {2020},
+ month = jul,
}
@inproceedings{bhardwaj2020comprehensive,
- author = {Bhardwaj, Kshitij and Havasi, Marton and Yao, Yuan and Brooks, David M and Hern{\'a}ndez-Lobato, Jos{\'e} Miguel and Wei, Gu-Yeon},
+ author = {Bhardwaj, Kshitij and Havasi, Marton and Yao, Yuan and Brooks, David M. and Hern\'andez-Lobato, Jos\'e Miguel and Wei, Gu-Yeon},
booktitle = {Proceedings of the ACM/IEEE International Symposium on Low Power Electronics and Design},
pages = {145--150},
- title = {A comprehensive methodology to determine optimal coherence interfaces for many-accelerator SoCs},
- year = {2020}
+ title = {A comprehensive methodology to determine optimal coherence interfaces for many-accelerator {SoCs}},
+ year = {2020},
+ doi = {10.1145/3370748.3406564},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3370748.3406564},
+ publisher = {ACM},
+ month = aug,
}
@article{biggs2021natively,
@@ -74,7 +96,8 @@ @article{biggs2021natively
title = {A natively flexible 32-bit Arm microprocessor},
url = {https://doi.org/10.1038/s41586-021-03625-w},
volume = {595},
- year = {2021}
+ year = {2021},
+ month = jul,
}
@article{binkert2011gem5,
@@ -89,19 +112,20 @@ @article{binkert2011gem5
title = {The gem5 simulator},
url = {https://doi.org/10.1145/2024716.2024718},
volume = {39},
- year = {2011}
+ year = {2011},
+ month = may,
}
@inproceedings{brown2020language,
- author = {Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert{-}Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei},
+ author = {Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and Winter, Clemens and Hesse, Christopher and Chen, Mark and Sigler, Eric and Litwin, Mateusz and Gray, Scott and Chess, Benjamin and Clark, Jack and Berner, Christopher and McCandlish, Sam and Radford, Alec and Sutskever, Ilya and Amodei, Dario},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/BrownMRSKDNSSAA20.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Tue, 19 Jan 2021 00:00:00 +0100},
title = {Language Models are Few-Shot Learners},
url = {https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html},
- year = {2020}
+ year = {2020},
}
@article{burr2016recent,
@@ -116,7 +140,8 @@ @article{burr2016recent
title = {Recent Progress in Phase-{Change\ensuremath{<}?Pub} \_newline {?\ensuremath{>}Memory} Technology},
url = {https://doi.org/10.1109/jetcas.2016.2547718},
volume = {6},
- year = {2016}
+ year = {2016},
+ month = jun,
}
@inproceedings{chen2018tvm,
@@ -124,13 +149,13 @@ @inproceedings{chen2018tvm
booktitle = {13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18)},
pages = {578--594},
title = {{TVM:} {An} automated End-to-End optimizing compiler for deep learning},
- year = {2018}
+ year = {2018},
}
@article{cheng2017survey,
author = {Cheng, Yu and Wang, Duo and Zhou, Pan and Zhang, Tao},
doi = {10.1109/msp.2017.2765695},
- issn = {1053-5888},
+ issn = {1053-5888, 1558-0792},
journal = {IEEE Signal Process Mag.},
number = {1},
pages = {126--136},
@@ -139,7 +164,8 @@ @article{cheng2017survey
title = {Model Compression and Acceleration for Deep Neural Networks: {The} Principles, Progress, and Challenges},
url = {https://doi.org/10.1109/msp.2017.2765695},
volume = {35},
- year = {2018}
+ year = {2018},
+ month = jan,
}
@article{chi2016prime,
@@ -155,7 +181,8 @@ @article{chi2016prime
title = {Prime},
url = {https://doi.org/10.1145/3007787.3001140},
volume = {44},
- year = {2016}
+ year = {2016},
+ month = jun,
}
@article{chua1971memristor,
@@ -170,7 +197,7 @@ @article{chua1971memristor
title = {Memristor-The missing circuit element},
url = {https://doi.org/10.1109/tct.1971.1083337},
volume = {18},
- year = {1971}
+ year = {1971},
}
@article{davies2018loihi,
@@ -185,7 +212,8 @@ @article{davies2018loihi
title = {Loihi: {A} Neuromorphic Manycore Processor with On-Chip Learning},
url = {https://doi.org/10.1109/mm.2018.112130359},
volume = {38},
- year = {2018}
+ year = {2018},
+ month = jan,
}
@article{davies2021advancing,
@@ -200,7 +228,8 @@ @article{davies2021advancing
title = {Advancing Neuromorphic Computing With Loihi: {A} Survey of Results and Outlook},
url = {https://doi.org/10.1109/jproc.2021.3067593},
volume = {109},
- year = {2021}
+ year = {2021},
+ month = may,
}
@article{dongarra2009evolution,
@@ -209,7 +238,7 @@ @article{dongarra2009evolution
pages = {3--4},
title = {The evolution of high performance computing on system z},
volume = {53},
- year = {2009}
+ year = {2009},
}
@article{duarte2022fastml,
@@ -218,7 +247,7 @@ @article{duarte2022fastml
title = {{FastML} Science Benchmarks: {Accelerating} Real-Time Scientific Edge Machine Learning},
url = {https://arxiv.org/abs/2207.07958},
volume = {abs/2207.07958},
- year = {2022}
+ year = {2022},
}
@article{eshraghian2023training,
@@ -234,7 +263,8 @@ @article{eshraghian2023training
title = {Training Spiking Neural Networks Using Lessons From Deep Learning},
url = {https://doi.org/10.1109/jproc.2023.3308088},
volume = {111},
- year = {2023}
+ year = {2023},
+ month = sep,
}
@article{farah2005neuroethics,
@@ -249,7 +279,8 @@ @article{farah2005neuroethics
title = {Neuroethics: {The} practical and the philosophical},
url = {https://doi.org/10.1016/j.tics.2004.12.001},
volume = {9},
- year = {2005}
+ year = {2005},
+ month = jan,
}
@inproceedings{fowers2018configurable,
@@ -262,7 +293,8 @@ @inproceedings{fowers2018configurable
source = {Crossref},
title = {A Configurable Cloud-Scale {DNN} Processor for Real-Time {AI}},
url = {https://doi.org/10.1109/isca.2018.00012},
- year = {2018}
+ year = {2018},
+ month = jun,
}
@article{furber2016large,
@@ -277,7 +309,8 @@ @article{furber2016large
title = {Large-scale neuromorphic computing systems},
url = {https://doi.org/10.1088/1741-2560/13/5/051001},
volume = {13},
- year = {2016}
+ year = {2016},
+ month = aug,
}
@article{gale2019state,
@@ -286,7 +319,7 @@ @article{gale2019state
title = {The state of sparsity in deep neural networks},
url = {https://arxiv.org/abs/1902.09574},
volume = {abs/1902.09574},
- year = {2019}
+ year = {2019},
}
@inproceedings{gannot1994verilog,
@@ -301,7 +334,7 @@ @inproceedings{gannot1994verilog
title = {Verilog {HDL} based {FPGA} design},
url = {https://doi.org/10.1109/ivc.1994.323743},
volume = {},
- year = {1994}
+ year = {1994},
}
@article{gates2009flexible,
@@ -316,7 +349,8 @@ @article{gates2009flexible
title = {Flexible Electronics},
url = {https://doi.org/10.1126/science.1171230},
volume = {323},
- year = {2009}
+ year = {2009},
+ month = mar,
}
@article{goodyear2017social,
@@ -331,13 +365,20 @@ @article{goodyear2017social
title = {Social media, apps and wearable technologies: {Navigating} ethical dilemmas and procedures},
url = {https://doi.org/10.1080/2159676x.2017.1303790},
volume = {9},
- year = {2017}
+ year = {2017},
+ month = mar,
+}
+
+@article{gwennap_certus-nx_nodate,
+ author = {Gwennap, Linley},
+ language = {en},
+ title = {Certus-{NX} Innovates General-Purpose {FPGAs}},
}
@article{gwennapcertusnx,
author = {Gwennap, Linley},
language = {en},
- title = {Certus-{NX} Innovates General-Purpose {FPGAs}}
+ title = {Certus-{NX} Innovates General-Purpose {FPGAs}},
}
@article{haensch2018next,
@@ -352,7 +393,8 @@ @article{haensch2018next
title = {The Next Generation of Deep Learning Hardware: {Analog} Computing},
url = {https://doi.org/10.1109/jproc.2018.2871057},
volume = {107},
- year = {2019}
+ year = {2019},
+ month = jan,
}
@article{hazan2021neuromorphic,
@@ -366,12 +408,13 @@ @article{hazan2021neuromorphic
title = {Neuromorphic Analog Implementation of Neural Engineering Framework-Inspired Spiking Neuron for High-Dimensional Representation},
url = {https://doi.org/10.3389/fnins.2021.627221},
volume = {15},
- year = {2021}
+ year = {2021},
+ month = feb,
}
@article{hennessy2019golden,
- abstract = {Innovations like domain-specific hardware, enhanced security, open instruction sets, and agile chip development will lead the way.},
author = {Hennessy, John L. and Patterson, David A.},
+ abstract = {Innovations like domain-specific hardware, enhanced security, open instruction sets, and agile chip development will lead the way.},
copyright = {http://www.acm.org/publications/policies/copyright\_policy\#Background},
doi = {10.1145/3282307},
issn = {0001-0782, 1557-7317},
@@ -384,7 +427,8 @@ @article{hennessy2019golden
title = {A new golden age for computer architecture},
url = {https://doi.org/10.1145/3282307},
volume = {62},
- year = {2019}
+ year = {2019},
+ month = jan,
}
@misc{howard2017mobilenets,
@@ -393,7 +437,7 @@ @misc{howard2017mobilenets
title = {{MobileNets:} {Efficient} Convolutional Neural Networks for Mobile Vision Applications},
url = {https://arxiv.org/abs/1704.04861},
volume = {abs/1704.04861},
- year = {2017}
+ year = {2017},
}
@article{huang2010pseudo,
@@ -408,56 +452,63 @@ @article{huang2010pseudo
title = {Pseudo-{CMOS:} {A} Design Style for Low-Cost and Robust Flexible Electronics},
url = {https://doi.org/10.1109/ted.2010.2088127},
volume = {58},
- year = {2011}
+ year = {2011},
+ month = jan,
}
-@inproceedings{ignatov2018ai,
- author = {Ignatov, Andrey and Timofte, Radu and Kulik, Andrei and Yang, Seungsoo and Wang, Ke and Baum, Felix and Wu, Max and Xu, Lirong and Van Gool, Luc},
- booktitle = {2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW)},
- doi = {10.1109/iccvw.2019.00447},
- pages = {0--0},
- publisher = {IEEE},
+@article{huang2022flexible,
+ author = {Huang, Shihua and Waeijen, Luc and Corporaal, Henk},
+ title = {How Flexible is Your Computing System?},
+ journal = {ACM Trans. Embedded Comput. Syst.},
+ volume = {21},
+ number = {4},
+ pages = {1--41},
+ year = {2022},
+ publisher = {Association for Computing Machinery (ACM)},
+ doi = {10.1145/3524861},
source = {Crossref},
- title = {{AI} Benchmark: {All} About Deep Learning on Smartphones in 2019},
- url = {https://doi.org/10.1109/iccvw.2019.00447},
- year = {2019}
+ url = {https://doi.org/10.1145/3524861},
+ issn = {1539-9087, 1558-3465},
+ month = jul,
}
@article{ignatov2018ai,
- abstract = {Over the last years, the computational power of mobile devices such as smartphones and tablets has grown dramatically, reaching the level of desktop computers available not long ago. While standard smartphone apps are no longer a problem for them, there is still a group of tasks that can easily challenge even high-end devices, namely running artificial intelligence algorithms. In this paper, we present a study of the current state of deep learning in the Android ecosystem and describe available frameworks, programming models and the limitations of running AI on smartphones. We give an overview of the hardware acceleration resources available on four main mobile chipset platforms: Qualcomm, HiSilicon, MediaTek and Samsung. Additionally, we present the real-world performance results of different mobile SoCs collected with AI Benchmark that are covering all main existing hardware configurations.},
author = {Ignatov, Andrey and Timofte, Radu and Chou, William and Wang, Ke and Wu, Max and Hartley, Tim and Van Gool, Luc},
+ abstract = {Over the last years, the computational power of mobile devices such as smartphones and tablets has grown dramatically, reaching the level of desktop computers available not long ago. While standard smartphone apps are no longer a problem for them, there is still a group of tasks that can easily challenge even high-end devices, namely running artificial intelligence algorithms. In this paper, we present a study of the current state of deep learning in the Android ecosystem and describe available frameworks, programming models and the limitations of running AI on smartphones. We give an overview of the hardware acceleration resources available on four main mobile chipset platforms: Qualcomm, HiSilicon, MediaTek and Samsung. Additionally, we present the real-world performance results of different mobile SoCs collected with AI Benchmark that are covering all main existing hardware configurations.},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV) Workshops},
pages = {0--0},
publisher = {arXiv},
title = {{AI} Benchmark: {Running} deep neural networks on Android smartphones},
- year = {2018}
+ year = {2018},
}
@inproceedings{imani2016resistive,
author = {Imani, Mohsen and Rahimi, Abbas and S. Rosing, Tajana},
booktitle = {Proceedings of the 2016 Design, Automation \& Test in Europe Conference \& Exhibition (DATE)},
- doi = {10.3850/9783981537079\_0454},
+ doi = {10.3850/9783981537079_0454},
organization = {IEEE},
pages = {1327--1332},
publisher = {Research Publishing Services},
source = {Crossref},
title = {Resistive Configurable Associative Memory for Approximate Computing},
- url = {https://doi.org/10.3850/9783981537079\_0454},
- year = {2016}
+ url = {https://doi.org/10.3850/9783981537079_0454},
+ year = {2016},
}
@inproceedings{jacob2018quantization,
- author = {Benoit Jacob and Skirmantas Kligys and Bo Chen and Menglong Zhu and Matthew Tang and Andrew G. Howard and Hartwig Adam and Dmitry Kalenichenko},
+ author = {Jacob, Benoit and Kligys, Skirmantas and Chen, Bo and Zhu, Menglong and Tang, Matthew and Howard, Andrew and Adam, Hartwig and Kalenichenko, Dmitry},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/JacobKCZTHAK18.bib},
- booktitle = {2018 {IEEE} Conference on Computer Vision and Pattern Recognition, {CVPR} 2018, Salt Lake City, UT, USA, June 18-22, 2018},
- doi = {10.1109/CVPR.2018.00286},
+ booktitle = {2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ doi = {10.1109/cvpr.2018.00286},
pages = {2704--2713},
- publisher = {{IEEE} Computer Society},
+ publisher = {IEEE},
timestamp = {Wed, 06 Feb 2019 00:00:00 +0100},
title = {Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference},
- url = {http://openaccess.thecvf.com/content\_cvpr\_2018/html/Jacob\_Quantization\_and\_Training\_CVPR\_2018\_paper.html},
- year = {2018}
+ url = {https://doi.org/10.1109/cvpr.2018.00286},
+ year = {2018},
+ source = {Crossref},
+ month = jun,
}
@misc{jia2018dissecting,
@@ -466,26 +517,26 @@ @misc{jia2018dissecting
title = {Dissecting the {NVIDIA} {Volta} {GPU} Architecture via Microbenchmarking},
url = {https://arxiv.org/abs/1804.06826},
volume = {abs/1804.06826},
- year = {2018}
+ year = {2018},
}
@inproceedings{jia2019beyond,
- author = {Zhihao Jia and Matei Zaharia and Alex Aiken},
+ author = {Jia, Zhihao and Zaharia, Matei and Aiken, Alex},
+ editor = {Talwalkar, Ameet and Smith, Virginia and Zaharia, Matei},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/mlsys/JiaZA19.bib},
booktitle = {Proceedings of Machine Learning and Systems 2019, MLSys 2019, Stanford, CA, USA, March 31 - April 2, 2019},
- editor = {Ameet Talwalkar and Virginia Smith and Matei Zaharia},
publisher = {mlsys.org},
timestamp = {Thu, 18 Jun 2020 01:00:00 +0200},
title = {Beyond Data and Model Parallelism for Deep Neural Networks},
url = {https://proceedings.mlsys.org/book/265.pdf},
- year = {2019}
+ year = {2019},
}
@inproceedings{jouppi2017datacenter,
+ author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
abstract = {Many architects believe that major improvements in cost-energy-performance must now come from domain-specific hardware. This paper evaluates a custom ASIC{\textemdash}called a Tensor Processing Unit (TPU) {\textemdash} deployed in datacenters since 2015 that accelerates the inference phase of neural networks (NN). The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory. The TPU's deterministic execution model is a better match to the 99th-percentile response-time requirement of our NN applications than are the time-varying optimizations of CPUs and GPUs that help average throughput more than guaranteed latency. The lack of such features helps explain why, despite having myriad MACs and a big memory, the TPU is relatively small and low power. We compare the TPU to a server-class Intel Haswell CPU and an Nvidia K80 GPU, which are contemporaries deployed in the same datacenters. Our workload, written in the high-level TensorFlow framework, uses production NN applications (MLPs, CNNs, and LSTMs) that represent 95\% of our datacenters' NN inference demand. Despite low utilization for some applications, the TPU is on average about 15X {\textendash} 30X faster than its contemporary GPU or CPU, with TOPS/Watt about 30X {\textendash} 80X higher. Moreover, using the CPU's GDDR5 memory in the TPU would triple achieved TOPS and raise TOPS/Watt to nearly 70X the GPU and 200X the CPU.},
address = {New York, NY, USA},
- author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
bdsk-url-1 = {https://doi.org/10.1145/3079856.3080246},
booktitle = {Proceedings of the 44th Annual International Symposium on Computer Architecture},
doi = {10.1145/3079856.3080246},
@@ -499,13 +550,14 @@ @inproceedings{jouppi2017datacenter
source = {Crossref},
title = {In-Datacenter Performance Analysis of a Tensor Processing Unit},
url = {https://doi.org/10.1145/3079856.3080246},
- year = {2017}
+ year = {2017},
+ month = jun,
}
@inproceedings{jouppi2017indatacenter,
+ author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
abstract = {Many architects believe that major improvements in cost-energy-performance must now come from domain-specific hardware. This paper evaluates a custom ASIC{\textemdash}called a Tensor Processing Unit (TPU) {\textemdash} deployed in datacenters since 2015 that accelerates the inference phase of neural networks (NN). The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory. The TPU's deterministic execution model is a better match to the 99th-percentile response-time requirement of our NN applications than are the time-varying optimizations of CPUs and GPUs that help average throughput more than guaranteed latency. The lack of such features helps explain why, despite having myriad MACs and a big memory, the TPU is relatively small and low power. We compare the TPU to a server-class Intel Haswell CPU and an Nvidia K80 GPU, which are contemporaries deployed in the same datacenters. Our workload, written in the high-level TensorFlow framework, uses production NN applications (MLPs, CNNs, and LSTMs) that represent 95\% of our datacenters' NN inference demand. Despite low utilization for some applications, the TPU is on average about 15X {\textendash} 30X faster than its contemporary GPU or CPU, with TOPS/Watt about 30X {\textendash} 80X higher. Moreover, using the CPU's GDDR5 memory in the TPU would triple achieved TOPS and raise TOPS/Watt to nearly 70X the GPU and 200X the CPU.},
address = {New York, NY, USA},
- author = {Jouppi, Norman P. and Young, Cliff and Patil, Nishant and Patterson, David and Agrawal, Gaurav and Bajwa, Raminder and Bates, Sarah and Bhatia, Suresh and Boden, Nan and Borchers, Al and Boyle, Rick and Cantin, Pierre-luc and Chao, Clifford and Clark, Chris and Coriell, Jeremy and Daley, Mike and Dau, Matt and Dean, Jeffrey and Gelb, Ben and Ghaemmaghami, Tara Vazir and Gottipati, Rajendra and Gulland, William and Hagmann, Robert and Ho, C. Richard and Hogberg, Doug and Hu, John and Hundt, Robert and Hurt, Dan and Ibarz, Julian and Jaffey, Aaron and Jaworski, Alek and Kaplan, Alexander and Khaitan, Harshit and Killebrew, Daniel and Koch, Andy and Kumar, Naveen and Lacy, Steve and Laudon, James and Law, James and Le, Diemthu and Leary, Chris and Liu, Zhuyuan and Lucke, Kyle and Lundin, Alan and MacKean, Gordon and Maggiore, Adriana and Mahony, Maire and Miller, Kieran and Nagarajan, Rahul and Narayanaswami, Ravi and Ni, Ray and Nix, Kathy and Norrie, Thomas and Omernick, Mark and Penukonda, Narayana and Phelps, Andy and Ross, Jonathan and Ross, Matt and Salek, Amir and Samadiani, Emad and Severn, Chris and Sizikov, Gregory and Snelham, Matthew and Souter, Jed and Steinberg, Dan and Swing, Andy and Tan, Mercedes and Thorson, Gregory and Tian, Bo and Toma, Horia and Tuttle, Erick and Vasudevan, Vijay and Walter, Richard and Wang, Walter and Wilcox, Eric and Yoon, Doe Hyun},
bdsk-url-1 = {https://doi.org/10.1145/3079856.3080246},
booktitle = {Proceedings of the 44th Annual International Symposium on Computer Architecture},
doi = {10.1145/3079856.3080246},
@@ -519,14 +571,15 @@ @inproceedings{jouppi2017indatacenter
source = {Crossref},
title = {In-Datacenter Performance Analysis of a Tensor Processing Unit},
url = {https://doi.org/10.1145/3079856.3080246},
- year = {2017}
+ year = {2017},
+ month = jun,
}
@inproceedings{jouppi2023tpu,
+ author = {Jouppi, Norm and Kurian, George and Li, Sheng and Ma, Peter and Nagarajan, Rahul and Nai, Lifeng and Patil, Nishant and Subramanian, Suvinay and Swing, Andy and Towles, Brian and Young, Clifford and Zhou, Xiang and Zhou, Zongwei and Patterson, David A},
abstract = {In response to innovations in machine learning (ML) models, production workloads changed radically and rapidly. TPU v4 is the fifth Google domain specific architecture (DSA) and its third supercomputer for such ML models. Optical circuit switches (OCSes) dynamically reconfigure its interconnect topology to improve scale, availability, utilization, modularity, deployment, security, power, and performance; users can pick a twisted 3D torus topology if desired. Much cheaper, lower power, and faster than Infiniband, OCSes and underlying optical components are lt;5\% of system cost and lt;3\% of system power. Each TPU v4 includes SparseCores, dataflow processors that accelerate models that rely on embeddings by 5x{\textendash}7x yet use only 5\% of die area and power. Deployed since 2020, TPU v4 outperforms TPU v3 by 2.1x and improves performance/Watt by 2.7x. The TPU v4 supercomputer is 4x larger at 4096 chips and thus nearly 10x faster overall, which along with OCS flexibility and availability allows a large language model to train at an average of ~60\% of peak FLOPS/second. For similar sized systems, it is ~4.3x{\textendash}4.5x faster than the Graphcore IPU Bow and is 1.2x{\textendash}1.7x faster and uses 1.3x{\textendash}1.9x less power than the Nvidia A100. TPU v4s inside the energy-optimized warehouse scale computers of Google Cloud use ~2{\textendash}6x less energy and produce ~20x less CO2e than contemporary DSAs in typical on-premise data centers.},
address = {New York, NY, USA},
articleno = {82},
- author = {Jouppi, Norm and Kurian, George and Li, Sheng and Ma, Peter and Nagarajan, Rahul and Nai, Lifeng and Patil, Nishant and Subramanian, Suvinay and Swing, Andy and Towles, Brian and Young, Clifford and Zhou, Xiang and Zhou, Zongwei and Patterson, David A},
bdsk-url-1 = {https://doi.org/10.1145/3579371.3589350},
booktitle = {Proceedings of the 50th Annual International Symposium on Computer Architecture},
doi = {10.1145/3579371.3589350},
@@ -539,7 +592,8 @@ @inproceedings{jouppi2023tpu
source = {Crossref},
title = {{TPU} v4: {An} Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings},
url = {https://doi.org/10.1145/3579371.3589350},
- year = {2023}
+ year = {2023},
+ month = jun,
}
@inproceedings{kao2020confuciux,
@@ -547,25 +601,36 @@ @inproceedings{kao2020confuciux
booktitle = {2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO)},
organization = {IEEE},
pages = {622--636},
- title = {Confuciux: Autonomous hardware resource assignment for dnn accelerators using reinforcement learning},
- year = {2020}
+ title = {{ConfuciuX:} {Autonomous} Hardware Resource Assignment for {DNN} Accelerators using Reinforcement Learning},
+ year = {2020},
+ doi = {10.1109/micro50266.2020.00058},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/micro50266.2020.00058},
+ publisher = {IEEE},
+ month = oct,
}
@inproceedings{kao2020gamma,
author = {Kao, Sheng-Chun and Krishna, Tushar},
booktitle = {Proceedings of the 39th International Conference on Computer-Aided Design},
pages = {1--9},
- title = {Gamma: Automating the hw mapping of dnn models on accelerators via genetic algorithm},
- year = {2020}
+ title = {Gamma},
+ year = {2020},
+ doi = {10.1145/3400302.3415639},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3400302.3415639},
+ publisher = {ACM},
+ subtitle = {automating the HW mapping of DNN models on accelerators via genetic algorithm},
+ month = nov,
}
@misc{krishnan2022multiagent,
+ author = {Krishnan, Srivatsan and Jaques, Natasha and Omidshafiei, Shayegan and Zhang, Dan and Gur, Izzeddin and Reddi, Vijay Janapa and Faust, Aleksandra},
archiveprefix = {arXiv},
- author = {Srivatsan Krishnan and Natasha Jaques and Shayegan Omidshafiei and Dan Zhang and Izzeddin Gur and Vijay Janapa Reddi and Aleksandra Faust},
eprint = {2211.16385},
primaryclass = {cs.AR},
title = {Multi-Agent Reinforcement Learning for Microprocessor Design Space Exploration},
- year = {2022}
+ year = {2022},
}
@inproceedings{krishnan2023archgym,
@@ -577,7 +642,8 @@ @inproceedings{krishnan2023archgym
source = {Crossref},
title = {{ArchGym:} {An} Open-Source Gymnasium for Machine Learning Assisted Architecture Design},
url = {https://doi.org/10.1145/3579371.3589049},
- year = {2023}
+ year = {2023},
+ month = jun,
}
@article{kwon2022flexible,
@@ -591,19 +657,8 @@ @article{kwon2022flexible
title = {Flexible sensors and machine learning for heart monitoring},
url = {https://doi.org/10.1016/j.nanoen.2022.107632},
volume = {102},
- year = {2022}
-}
-
-@inproceedings{Li2020Additive,
- author = {Yuhang Li and Xin Dong and Wei Wang},
- bibsource = {dblp computer science bibliography, https://dblp.org},
- biburl = {https://dblp.org/rec/conf/iclr/LiDW20.bib},
- booktitle = {8th International Conference on Learning Representations, {ICLR} 2020, Addis Ababa, Ethiopia, April 26-30, 2020},
- publisher = {OpenReview.net},
- timestamp = {Tue, 18 Aug 2020 01:00:00 +0200},
- title = {Additive Powers-of-Two Quantization: An Efficient Non-uniform Discretization for Neural Networks},
- url = {https://openreview.net/forum?id=BkgXT24tDS},
- year = {2020}
+ year = {2022},
+ month = nov,
}
@inproceedings{lin2022ondevice,
@@ -614,19 +669,20 @@ @inproceedings{lin2022ondevice
source = {Crossref},
title = {{PockEngine:} {Sparse} and Efficient Fine-tuning in a Pocket},
url = {https://doi.org/10.1145/3613424.3614307},
- year = {2023}
+ year = {2023},
+ month = oct,
}
@article{lin2023awq,
author = {Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Dang, Xingyu and Han, Song},
journal = {arXiv},
title = {{AWQ:} {Activation-aware} Weight Quantization for {LLM} Compression and Acceleration},
- year = {2023}
+ year = {2023},
}
@article{lindholm2008nvidia,
- abstract = {To enable flexible, programmable graphics and high-performance computing, NVIDIA has developed the Tesla scalable unified graphics and parallel computing architecture. Its scalable parallel array of processors is massively multithreaded and programmable in C or via graphics APIs.},
author = {Lindholm, Erik and Nickolls, John and Oberman, Stuart and Montrym, John},
+ abstract = {To enable flexible, programmable graphics and high-performance computing, NVIDIA has developed the Tesla scalable unified graphics and parallel computing architecture. Its scalable parallel array of processors is massively multithreaded and programmable in C or via graphics APIs.},
bdsk-url-1 = {https://ieeexplore.ieee.org/document/4523358},
bdsk-url-2 = {https://doi.org/10.1109/MM.2008.31},
doi = {10.1109/mm.2008.31},
@@ -642,7 +698,8 @@ @article{lindholm2008nvidia
url = {https://doi.org/10.1109/mm.2008.31},
urldate = {2023-11-07},
volume = {28},
- year = {2008}
+ year = {2008},
+ month = mar,
}
@article{loh20083dstacked,
@@ -657,7 +714,8 @@ @article{loh20083dstacked
title = {{3D}-Stacked Memory Architectures for Multi-core Processors},
url = {https://doi.org/10.1145/1394608.1382159},
volume = {36},
- year = {2008}
+ year = {2008},
+ month = jun,
}
@inproceedings{luebke2008cuda,
@@ -672,7 +730,8 @@ @inproceedings{luebke2008cuda
title = {{CUDA:} {Scalable} parallel programming for high-performance scientific computing},
url = {https://doi.org/10.1109/isbi.2008.4541126},
volume = {},
- year = {2008}
+ year = {2008},
+ month = may,
}
@article{maass1997networks,
@@ -687,7 +746,8 @@ @article{maass1997networks
title = {Networks of spiking neurons: {The} third generation of neural network models},
url = {https://doi.org/10.1016/s0893-6080(97)00011-7},
volume = {10},
- year = {1997}
+ year = {1997},
+ month = dec,
}
@article{markovic2020physics,
@@ -702,7 +762,8 @@ @article{markovic2020physics
title = {Physics for neuromorphic computing},
url = {https://doi.org/10.1038/s42254-020-0208-2},
volume = {2},
- year = {2020}
+ year = {2020},
+ month = jul,
}
@article{mattson2020mlperf,
@@ -717,7 +778,8 @@ @article{mattson2020mlperf
title = {{MLPerf:} {An} Industry Standard Benchmark Suite for Machine Learning Performance},
url = {https://doi.org/10.1109/mm.2020.2974843},
volume = {40},
- year = {2020}
+ year = {2020},
+ month = mar,
}
@article{miller2000optical,
@@ -732,18 +794,24 @@ @article{miller2000optical
title = {Optical interconnects to silicon},
url = {https://doi.org/10.1109/2944.902184},
volume = {6},
- year = {2000}
+ year = {2000},
+ month = nov,
}
@article{mirhoseini2021graph,
- author = {Mirhoseini, Azalia and Goldie, Anna and Yazgan, Mustafa and Jiang, Joe Wenjie and Songhori, Ebrahim and Wang, Shen and Lee, Young-Joon and Johnson, Eric and Pathak, Omkar and Nazi, Azade and others},
+ author = {Mirhoseini, Azalia and Goldie, Anna and Yazgan, Mustafa and Jiang, Joe Wenjie and Songhori, Ebrahim and Wang, Shen and Lee, Young-Joon and Johnson, Eric and Pathak, Omkar and Nazi, Azade and Pak, Jiwoo and Tong, Andy and Srinivasa, Kavya and Hang, William and Tuncer, Emre and Le, Quoc V. and Laudon, James and Ho, Richard and Carpenter, Roger and Dean, Jeff},
journal = {Nature},
number = {7862},
pages = {207--212},
- publisher = {Nature Publishing Group},
+ publisher = {Springer Science and Business Media LLC},
title = {A graph placement methodology for fast chip design},
volume = {594},
- year = {2021}
+ year = {2021},
+ doi = {10.1038/s41586-021-03544-w},
+ source = {Crossref},
+ url = {https://doi.org/10.1038/s41586-021-03544-w},
+ issn = {0028-0836, 1476-4687},
+ month = jun,
}
@article{mittal2021survey,
@@ -757,7 +825,8 @@ @article{mittal2021survey
title = {A survey of {SRAM}-based in-memory computing techniques and applications},
url = {https://doi.org/10.1016/j.sysarc.2021.102276},
volume = {119},
- year = {2021}
+ year = {2021},
+ month = oct,
}
@article{modha2023neural,
@@ -772,7 +841,8 @@ @article{modha2023neural
title = {Neural inference at the frontier of energy, space, and time},
url = {https://doi.org/10.1126/science.adh1174},
volume = {382},
- year = {2023}
+ year = {2023},
+ month = oct,
}
@inproceedings{munshi2009opencl,
@@ -787,7 +857,8 @@ @inproceedings{munshi2009opencl
title = {The {OpenCL} specification},
url = {https://doi.org/10.1109/hotchips.2009.7478342},
volume = {},
- year = {2009}
+ year = {2009},
+ month = aug,
}
@article{musk2019integrated,
@@ -802,7 +873,8 @@ @article{musk2019integrated
title = {An Integrated Brain-Machine Interface Platform With Thousands of Channels},
url = {https://doi.org/10.2196/16194},
volume = {21},
- year = {2019}
+ year = {2019},
+ month = oct,
}
@article{norrie2021design,
@@ -818,19 +890,20 @@ @article{norrie2021design
title = {The Design Process for Google's Training Chips: {Tpuv2} and {TPUv3}},
url = {https://doi.org/10.1109/mm.2021.3058217},
volume = {41},
- year = {2021}
+ year = {2021},
+ month = mar,
}
@book{patterson2016computer,
author = {Patterson, David A and Hennessy, John L},
publisher = {Morgan kaufmann},
title = {Computer organization and design {ARM} edition: {The} hardware software interface},
- year = {2016}
+ year = {2016},
}
@article{putnam2014reconfigurable,
- abstract = {Datacenter workloads demand high computational capabilities, flexibility, power efficiency, and low cost. It is challenging to improve all of these factors simultaneously. To advance datacenter capabilities beyond what commodity server designs can provide, we have designed and built a composable, reconfigurablefabric to accelerate portions of large-scale software services. Each instantiation of the fabric consists of a 6x8 2-D torus of high-end Stratix V FPGAs embedded into a half-rack of 48 machines. One FPGA is placed into each server, accessible through PCIe, and wired directly to other FPGAs with pairs of 10 Gb SAS cables In this paper, we describe a medium-scale deployment of this fabric on a bed of 1,632 servers, and measure its efficacy in accelerating the Bing web search engine. We describe the requirements and architecture of the system, detail the critical engineering challenges and solutions needed to make the system robust in the presence of failures, and measure the performance, power, and resilience of the system when ranking candidate documents. Under high load, the largescale reconfigurable fabric improves the ranking throughput of each server by a factor of 95\% for a fixed latency distribution{\textemdash} or, while maintaining equivalent throughput, reduces the tail latency by 29\%},
author = {Putnam, Andrew and Caulfield, Adrian M. and Chung, Eric S. and Chiou, Derek and Constantinides, Kypros and Demme, John and Esmaeilzadeh, Hadi and Fowers, Jeremy and Gopal, Gopi Prashanth and Gray, Jan and Haselman, Michael and Hauck, Scott and Heil, Stephen and Hormati, Amir and Kim, Joo-Young and Lanka, Sitaram and Larus, James and Peterson, Eric and Pope, Simon and Smith, Aaron and Thong, Jason and Xiao, Phillip Yi and Burger, Doug},
+ abstract = {Datacenter workloads demand high computational capabilities, flexibility, power efficiency, and low cost. It is challenging to improve all of these factors simultaneously. To advance datacenter capabilities beyond what commodity server designs can provide, we have designed and built a composable, reconfigurablefabric to accelerate portions of large-scale software services. Each instantiation of the fabric consists of a 6x8 2-D torus of high-end Stratix V FPGAs embedded into a half-rack of 48 machines. One FPGA is placed into each server, accessible through PCIe, and wired directly to other FPGAs with pairs of 10 Gb SAS cables In this paper, we describe a medium-scale deployment of this fabric on a bed of 1,632 servers, and measure its efficacy in accelerating the Bing web search engine. We describe the requirements and architecture of the system, detail the critical engineering challenges and solutions needed to make the system robust in the presence of failures, and measure the performance, power, and resilience of the system when ranking candidate documents. Under high load, the largescale reconfigurable fabric improves the ranking throughput of each server by a factor of 95\% for a fixed latency distribution{\textemdash} or, while maintaining equivalent throughput, reduces the tail latency by 29\%},
bdsk-url-1 = {https://dl.acm.org/doi/10.1145/2678373.2665678},
bdsk-url-2 = {https://doi.org/10.1145/2678373.2665678},
doi = {10.1145/2678373.2665678},
@@ -845,24 +918,27 @@ @article{putnam2014reconfigurable
url = {https://doi.org/10.1145/2678373.2665678},
urldate = {2023-11-07},
volume = {42},
- year = {2014}
+ year = {2014},
+ month = jun,
}
@inproceedings{rajat2009largescale,
- author = {Rajat Raina and Anand Madhavan and Andrew Y. Ng},
+ author = {Raina, Rajat and Madhavan, Anand and Ng, Andrew Y.},
+ editor = {Danyluk, Andrea Pohoreckyj and Bottou, L\'eon and Littman, Michael L.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/icml/RainaMN09.bib},
- booktitle = {Proceedings of the 26th Annual International Conference on Machine Learning, {ICML} 2009, Montreal, Quebec, Canada, June 14-18, 2009},
+ booktitle = {Proceedings of the 26th Annual International Conference on Machine Learning},
doi = {10.1145/1553374.1553486},
- editor = {Andrea Pohoreckyj Danyluk and L{\'{e}}on Bottou and Michael L. Littman},
pages = {873--880},
- publisher = {{ACM}},
- series = {{ACM} International Conference Proceeding Series},
+ publisher = {ACM},
+ series = {ACM International Conference Proceeding Series},
timestamp = {Wed, 14 Nov 2018 00:00:00 +0100},
title = {Large-scale deep unsupervised learning using graphics processors},
url = {https://doi.org/10.1145/1553374.1553486},
volume = {382},
- year = {2009}
+ year = {2009},
+ source = {Crossref},
+ month = jun,
}
@article{ranganathan2011from,
@@ -877,16 +953,22 @@ @article{ranganathan2011from
title = {From Microprocessors to Nanostores: {Rethinking} Data-Centric Systems},
url = {https://doi.org/10.1109/mc.2011.18},
volume = {44},
- year = {2011}
+ year = {2011},
+ month = jan,
}
@inproceedings{reagen2017case,
- author = {Reagen, Brandon and Hern{\'a}ndez-Lobato, Jos{\'e} Miguel and Adolf, Robert and Gelbart, Michael and Whatmough, Paul and Wei, Gu-Yeon and Brooks, David},
+ author = {Reagen, Brandon and Hernandez-Lobato, Jose Miguel and Adolf, Robert and Gelbart, Michael and Whatmough, Paul and Wei, Gu-Yeon and Brooks, David},
booktitle = {2017 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED)},
organization = {IEEE},
pages = {1--6},
- title = {A case for efficient accelerator design space exploration via bayesian optimization},
- year = {2017}
+ title = {A case for efficient accelerator design space exploration via {Bayesian} optimization},
+ year = {2017},
+ doi = {10.1109/islped.2017.8009208},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/islped.2017.8009208},
+ publisher = {IEEE},
+ month = jul,
}
@inproceedings{reddi2020mlperf,
@@ -899,7 +981,8 @@ @inproceedings{reddi2020mlperf
source = {Crossref},
title = {{MLPerf} Inference Benchmark},
url = {https://doi.org/10.1109/isca45697.2020.00045},
- year = {2020}
+ year = {2020},
+ month = may,
}
@article{roskies2002neuroethics,
@@ -914,7 +997,8 @@ @article{roskies2002neuroethics
title = {Neuroethics for the New Millenium},
url = {https://doi.org/10.1016/s0896-6273(02)00763-8},
volume = {35},
- year = {2002}
+ year = {2002},
+ month = jul,
}
@article{samajdar2018scale,
@@ -923,7 +1007,7 @@ @article{samajdar2018scale
title = {Scale-sim: {Systolic} cnn accelerator simulator},
url = {https://arxiv.org/abs/1811.02883},
volume = {abs/1811.02883},
- year = {2018}
+ year = {2018},
}
@article{schuman2022opportunities,
@@ -938,13 +1022,14 @@ @article{schuman2022opportunities
title = {Opportunities for neuromorphic computing algorithms and applications},
url = {https://doi.org/10.1038/s43588-021-00184-y},
volume = {2},
- year = {2022}
+ year = {2022},
+ month = jan,
}
@misc{segal1999opengl,
author = {Segal, Mark and Akeley, Kurt},
title = {The {OpenGL} graphics system: {A} specification (version 1.1)},
- year = {1999}
+ year = {1999},
}
@article{segura2018ethical,
@@ -959,7 +1044,8 @@ @article{segura2018ethical
title = {Ethical Implications of User Perceptions of Wearable Devices},
url = {https://doi.org/10.1007/s11948-017-9872-8},
volume = {24},
- year = {2017}
+ year = {2017},
+ month = feb,
}
@article{shastri2021photonics,
@@ -974,7 +1060,8 @@ @article{shastri2021photonics
title = {Photonics for artificial intelligence and neuromorphic computing},
url = {https://doi.org/10.1038/s41566-020-00754-y},
volume = {15},
- year = {2021}
+ year = {2021},
+ month = jan,
}
@inproceedings{suda2016throughput,
@@ -986,28 +1073,14 @@ @inproceedings{suda2016throughput
source = {Crossref},
title = {Throughput-Optimized {OpenCL}-based {FPGA} Accelerator for Large-Scale Convolutional Neural Networks},
url = {https://doi.org/10.1145/2847263.2847276},
- year = {2016}
+ year = {2016},
+ month = feb,
}
@article{sze2017efficient,
author = {Sze, Vivienne and Chen, Yu-Hsin and Yang, Tien-Ju and Emer, Joel S.},
- doi = {10.1109/jproc.2017.2761740},
- issn = {0018-9219, 1558-2256},
- journal = {Proc. IEEE},
- number = {12},
- pages = {2295--2329},
- publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
- source = {Crossref},
- title = {Efficient Processing of Deep Neural Networks: {A} Tutorial and Survey},
- url = {https://doi.org/10.1109/jproc.2017.2761740},
- volume = {105},
- year = {2017}
-}
-
-@article{sze2017efficient,
abstract = {Deep neural networks (DNNs) are currently widely used for many artificial intelligence (AI) applications including computer vision, speech recognition, and robotics. While DNNs deliver state-of-the-art accuracy on many AI tasks, it comes at the cost of high computational complexity. Accordingly, techniques that enable efficient processing of DNNs to improve energy efficiency and throughput without sacrificing application accuracy or increasing hardware cost are critical to the wide deployment of DNNs in AI systems. This article aims to provide a comprehensive tutorial and survey about the recent advances towards the goal of enabling efficient processing of DNNs. Specifically, it will provide an overview of DNNs, discuss various hardware platforms and architectures that support DNNs, and highlight key trends in reducing the computation cost of DNNs either solely via hardware design changes or via joint hardware design and DNN algorithm changes. It will also summarize various development resources that enable researchers and practitioners to quickly get started in this field, and highlight important benchmarking metrics and design considerations that should be used for evaluating the rapidly growing number of DNN hardware designs, optionally including algorithmic co-designs, being proposed in academia and industry. The reader will take away the following concepts from this article: understand the key design considerations for DNNs; be able to evaluate different DNN hardware implementations with benchmarks and comparison metrics; understand the trade-offs between various hardware architectures and platforms; be able to evaluate the utility of various DNN design techniques for efficient processing; and understand recent implementation trends and opportunities.},
archiveprefix = {arXiv},
- author = {Sze, Vivienne and Chen, Yu-Hsin and Yang, Tien-Ju and Emer, Joel S.},
copyright = {http://arxiv.org/licenses/nonexclusive-distrib/1.0/},
doi = {10.1109/jproc.2017.2761740},
eprint = {1703.09039},
@@ -1021,7 +1094,8 @@ @article{sze2017efficient
title = {Efficient Processing of Deep Neural Networks: {A} Tutorial and Survey},
url = {https://doi.org/10.1109/jproc.2017.2761740},
volume = {105},
- year = {2017}
+ year = {2017},
+ month = dec,
}
@article{tang2022soft,
@@ -1035,7 +1109,8 @@ @article{tang2022soft
title = {Soft bioelectronics for cardiac interfaces},
url = {https://doi.org/10.1063/5.0069516},
volume = {3},
- year = {2022}
+ year = {2022},
+ month = jan,
}
@article{tang2023flexible,
@@ -1050,16 +1125,17 @@ @article{tang2023flexible
title = {Flexible brain{\textendash}computer interfaces},
url = {https://doi.org/10.1038/s41928-022-00913-9},
volume = {6},
- year = {2023}
+ year = {2023},
+ month = feb,
}
@inproceedings{valenzuela2000genetic,
author = {Valenzuela, Christine L and Wang, Pearl Y},
- booktitle = {Parallel Problem Solving from Nature PPSN VI: 6th International Conference Paris, France, September 18--20, 2000 Proceedings 6},
+ booktitle = {Parallel Problem Solving from Nature PPSN VI: 6th International Conference Paris, France, September 18{\textendash}20, 2000 Proceedings 6},
organization = {Springer},
pages = {671--680},
- title = {A genetic algorithm for VLSI floorplanning},
- year = {2000}
+ title = {A genetic algorithm for {VLSI} floorplanning},
+ year = {2000},
}
@article{verma2019memory,
@@ -1074,7 +1150,7 @@ @article{verma2019memory
title = {In-Memory Computing: {Advances} and Prospects},
url = {https://doi.org/10.1109/mssc.2019.2922889},
volume = {11},
- year = {2019}
+ year = {2019},
}
@article{vivet2021intact,
@@ -1090,21 +1166,24 @@ @article{vivet2021intact
title = {{IntAct:} {A} 96-Core Processor With Six Chiplets {3D}-Stacked on an Active Interposer With Distributed Interconnects and Integrated Power Management},
url = {https://doi.org/10.1109/jssc.2020.3036341},
volume = {56},
- year = {2021}
+ year = {2021},
+ month = jan,
}
@inproceedings{wang2020apq,
- author = {Tianzhe Wang and Kuan Wang and Han Cai and Ji Lin and Zhijian Liu and Hanrui Wang and Yujun Lin and Song Han},
+ author = {Wang, Tianzhe and Wang, Kuan and Cai, Han and Lin, Ji and Liu, Zhijian and Wang, Hanrui and Lin, Yujun and Han, Song},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/WangWCLL0LH20.bib},
- booktitle = {2020 {IEEE/CVF} Conference on Computer Vision and Pattern Recognition, {CVPR} 2020, Seattle, WA, USA, June 13-19, 2020},
- doi = {10.1109/CVPR42600.2020.00215},
+ booktitle = {2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr42600.2020.00215},
pages = {2075--2084},
- publisher = {{IEEE}},
+ publisher = {IEEE},
timestamp = {Tue, 22 Dec 2020 00:00:00 +0100},
- title = {{APQ:} Joint Search for Network Architecture, Pruning and Quantization Policy},
- url = {https://doi.org/10.1109/CVPR42600.2020.00215},
- year = {2020}
+ title = {{APQ:} {Joint} Search for Network Architecture, Pruning and Quantization Policy},
+ url = {https://doi.org/10.1109/cvpr42600.2020.00215},
+ year = {2020},
+ source = {Crossref},
+ month = jun,
}
@book{weik1955survey,
@@ -1112,7 +1191,7 @@ @book{weik1955survey
language = {en},
publisher = {Ballistic Research Laboratories},
title = {A Survey of Domestic Electronic Digital Computing Systems},
- year = {1955}
+ year = {1955},
}
@article{wong2012metal,
@@ -1127,12 +1206,13 @@ @article{wong2012metal
title = {{Metal{\textendash}Oxide} {RRAM}},
url = {https://doi.org/10.1109/jproc.2012.2190369},
volume = {100},
- year = {2012}
+ year = {2012},
+ month = jun,
}
@article{xiong2021mribased,
- abstract = {Brain tumor segmentation is a challenging problem in medical image processing and analysis. It is a very time-consuming and error-prone task. In order to reduce the burden on physicians and improve the segmentation accuracy, the computer-aided detection (CAD) systems need to be developed. Due to the powerful feature learning ability of the deep learning technology, many deep learning-based methods have been applied to the brain tumor segmentation CAD systems and achieved satisfactory accuracy. However, deep learning neural networks have high computational complexity, and the brain tumor segmentation process consumes significant time. Therefore, in order to achieve the high segmentation accuracy of brain tumors and obtain the segmentation results efficiently, it is very demanding to speed up the segmentation process of brain tumors.},
author = {Xiong, Siyu and Wu, Guoqing and Fan, Xitian and Feng, Xuan and Huang, Zhongcheng and Cao, Wei and Zhou, Xuegong and Ding, Shijin and Yu, Jinhua and Wang, Lingli and Shi, Zhifeng},
+ abstract = {Brain tumor segmentation is a challenging problem in medical image processing and analysis. It is a very time-consuming and error-prone task. In order to reduce the burden on physicians and improve the segmentation accuracy, the computer-aided detection (CAD) systems need to be developed. Due to the powerful feature learning ability of the deep learning technology, many deep learning-based methods have been applied to the brain tumor segmentation CAD systems and achieved satisfactory accuracy. However, deep learning neural networks have high computational complexity, and the brain tumor segmentation process consumes significant time. Therefore, in order to achieve the high segmentation accuracy of brain tumors and obtain the segmentation results efficiently, it is very demanding to speed up the segmentation process of brain tumors.},
bdsk-url-1 = {https://doi.org/10.1186/s12859-021-04347-6},
doi = {10.1186/s12859-021-04347-6},
issn = {1471-2105},
@@ -1146,7 +1226,8 @@ @article{xiong2021mribased
url = {https://doi.org/10.1186/s12859-021-04347-6},
urldate = {2023-11-07},
volume = {22},
- year = {2021}
+ year = {2021},
+ month = sep,
}
@article{xiu2019time,
@@ -1161,7 +1242,7 @@ @article{xiu2019time
title = {Time Moore: {Exploiting} {Moore's} Law From The Perspective of Time},
url = {https://doi.org/10.1109/mssc.2018.2882285},
volume = {11},
- year = {2019}
+ year = {2019},
}
@article{young2018recent,
@@ -1176,23 +1257,28 @@ @article{young2018recent
title = {Recent Trends in Deep Learning Based Natural Language Processing {[Review} Article]},
url = {https://doi.org/10.1109/mci.2018.2840738},
volume = {13},
- year = {2018}
+ year = {2018},
+ month = aug,
}
@article{yu2023rl,
+ author = {Qian, Yu and Zhou, Xuegong and Zhou, Hao and Wang, Lingli},
abstract = {Logic synthesis is a crucial step in electronic design automation tools. The rapid developments of reinforcement learning (RL) have enabled the automated exploration of logic synthesis. Existing RL based methods may lead to data inefficiency, and the exploration approaches for FPGA and ASIC technology mapping in recent works lack the flexibility of the learning process. This work proposes ESE, a reinforcement learning based framework to efficiently learn the logic synthesis process. The framework supports the modeling of logic optimization and technology mapping for FPGA and ASIC. The optimization for the execution time of the synthesis script is also considered. For the modeling of FPGA mapping, the logic optimization and technology mapping are combined to be learned in a flexible way. For the modeling of ASIC mapping, the standard cell based optimization and LUT optimization operations are incorporated into the ASIC synthesis flow. To improve the utilization of samples, the Proximal Policy Optimization model is adopted. Furthermore, the framework is enhanced by supporting MIG based synthesis exploration. Experiments show that for FPGA technology mapping on the VTR benchmark, the average LUT-Level-Product and script runtime are improved by more than 18.3\% and 12.4\% respectively than previous works. For ASIC mapping on the EPFL benchmark, the average Area-Delay-Product is improved by 14.5\%.},
address = {New York, NY, USA},
- author = {Qian, Yu and Zhou, Xuegong and Zhou, Hao and Wang, Lingli},
doi = {10.1145/3632174},
- issn = {1084-4309},
+ issn = {1084-4309, 1557-7309},
journal = {ACM Trans. Des. Autom. Electron. Syst.},
keywords = {technology mapping, Majority-Inverter Graph, And-Inverter Graph, Reinforcement learning, logic optimization},
- month = {nov},
+ month = jan,
note = {Just Accepted},
- publisher = {Association for Computing Machinery},
+ publisher = {Association for Computing Machinery (ACM)},
title = {An Efficient Reinforcement Learning Based Framework for Exploring Logic Synthesis},
url = {https://doi.org/10.1145/3632174},
- year = {2023}
+ year = {2024},
+ number = {2},
+ source = {Crossref},
+ volume = {29},
+ pages = {1--33},
}
@inproceedings{zhang2015fpga,
@@ -1201,25 +1287,47 @@ @inproceedings{zhang2015fpga
pages = {161--170},
title = {{FPGA}-based Accelerator Design for Deep Convolutional Neural Networks Proceedings of the 2015 {ACM}},
volume = {15},
- year = {2015}
+ year = {2015},
}
@inproceedings{zhang2022fullstack,
- abstract = {The rapidly-changing deep learning landscape presents a unique opportunity for building inference accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. In this paper, we analyze bottlenecks in state-of-the-art vision and natural language processing (NLP) models, including EfficientNet and BERT, and use FAST to design accelerators capable of addressing these bottlenecks. FAST-generated accelerators optimized for single workloads improve Perf/TDP by 3.7\texttimes{} on average across all benchmarks compared to TPU-v3. A FAST-generated accelerator optimized for serving a suite of workloads improves Perf/TDP by 2.4\texttimes{} on average compared to TPU-v3. Our return on investment analysis shows that FAST-generated accelerators can potentially be practical for moderate-sized datacenter deployments.},
- address = {New York, NY, USA},
author = {Zhang, Dan and Huda, Safeen and Songhori, Ebrahim and Prabhu, Kartik and Le, Quoc and Goldie, Anna and Mirhoseini, Azalia},
+ abstract = {The rapidly-changing deep learning landscape presents a unique opportunity for building inference accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. In this paper, we analyze bottlenecks in state-of-the-art vision and natural language processing (NLP) models, including EfficientNet and BERT, and use FAST to design accelerators capable of addressing these bottlenecks. FAST-generated accelerators optimized for single workloads improve Perf/TDP by 3.7{\texttimes} on average across all benchmarks compared to TPU-v3. A FAST-generated accelerator optimized for serving a suite of workloads improves Perf/TDP by 2.4{\texttimes} on average compared to TPU-v3. Our return on investment analysis shows that FAST-generated accelerators can potentially be practical for moderate-sized datacenter deployments.},
+ address = {New York, NY, USA},
booktitle = {Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems},
doi = {10.1145/3503222.3507767},
isbn = {9781450392051},
keywords = {design space exploration, hardware-software codesign, tensor processing unit, machine learning, operation fusion},
location = {Lausanne, Switzerland},
numpages = {16},
- pages = {27-42},
- publisher = {Association for Computing Machinery},
+ pages = {27--42},
+ publisher = {ACM},
series = {ASPLOS '22},
- title = {A Full-Stack Search Technique for Domain Optimized Deep Learning Accelerators},
+ title = {A full-stack search technique for domain optimized deep learning accelerators},
url = {https://doi.org/10.1145/3503222.3507767},
- year = {2022}
+ year = {2022},
+ source = {Crossref},
+ month = feb,
+}
+
+@inproceedings{zhangfast,
+ author = {Zhang, Dan and Huda, Safeen and Songhori, Ebrahim and Prabhu, Kartik and Le, Quoc and Goldie, Anna and Mirhoseini, Azalia},
+ title = {A full-stack search technique for domain optimized deep learning accelerators},
+ year = {2022},
+ isbn = {9781450392051},
+ publisher = {ACM},
+ address = {New York, NY, USA},
+ url = {https://doi.org/10.1145/3503222.3507767},
+ doi = {10.1145/3503222.3507767},
+ abstract = {The rapidly-changing deep learning landscape presents a unique opportunity for building inference accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. In this paper, we analyze bottlenecks in state-of-the-art vision and natural language processing (NLP) models, including EfficientNet and BERT, and use FAST to design accelerators capable of addressing these bottlenecks. FAST-generated accelerators optimized for single workloads improve Perf/TDP by 3.7{\texttimes} on average across all benchmarks compared to TPU-v3. A FAST-generated accelerator optimized for serving a suite of workloads improves Perf/TDP by 2.4{\texttimes} on average compared to TPU-v3. Our return on investment analysis shows that FAST-generated accelerators can potentially be practical for moderate-sized datacenter deployments.},
+ booktitle = {Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems},
+ pages = {27--42},
+ numpages = {16},
+ keywords = {design space exploration, hardware-software codesign, tensor processing unit, machine learning, operation fusion},
+ location = {Lausanne, Switzerland},
+ series = {ASPLOS '22},
+ source = {Crossref},
+ month = feb,
}
@article{zhou2022photonic,
@@ -1234,15 +1342,21 @@ @article{zhou2022photonic
title = {Photonic matrix multiplication lights up photonic accelerator and beyond},
url = {https://doi.org/10.1038/s41377-022-00717-8},
volume = {11},
- year = {2022}
+ year = {2022},
+ month = feb,
}
@inproceedings{zhou2023area,
- author = {Zhou, Guanglei and Anderson, Jason H},
+ author = {Zhou, Guanglei and Anderson, Jason H.},
booktitle = {Proceedings of the 28th Asia and South Pacific Design Automation Conference},
pages = {159--165},
- title = {Area-Driven FPGA Logic Synthesis Using Reinforcement Learning},
- year = {2023}
+ title = {Area-Driven {FPGA} Logic Synthesis Using Reinforcement Learning},
+ year = {2023},
+ doi = {10.1145/3566097.3567894},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3566097.3567894},
+ publisher = {ACM},
+ month = jan,
}
@inproceedings{zhu2018benchmarking,
@@ -1255,34 +1369,6 @@ @inproceedings{zhu2018benchmarking
source = {Crossref},
title = {Benchmarking and Analyzing Deep Neural Network Training},
url = {https://doi.org/10.1109/iiswc.2018.8573476},
- year = {2018}
-}
-
-@inproceedings{zhangfast,
-author = {Zhang, Dan and Huda, Safeen and Songhori, Ebrahim and Prabhu, Kartik and Le, Quoc and Goldie, Anna and Mirhoseini, Azalia},
-title = {A Full-Stack Search Technique for Domain Optimized Deep Learning Accelerators},
-year = {2022},
-isbn = {9781450392051},
-publisher = {Association for Computing Machinery},
-address = {New York, NY, USA},
-url = {https://doi.org/10.1145/3503222.3507767},
-doi = {10.1145/3503222.3507767},
-abstract = {The rapidly-changing deep learning landscape presents a unique opportunity for building inference accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. In this paper, we analyze bottlenecks in state-of-the-art vision and natural language processing (NLP) models, including EfficientNet and BERT, and use FAST to design accelerators capable of addressing these bottlenecks. FAST-generated accelerators optimized for single workloads improve Perf/TDP by 3.7\texttimes{} on average across all benchmarks compared to TPU-v3. A FAST-generated accelerator optimized for serving a suite of workloads improves Perf/TDP by 2.4\texttimes{} on average compared to TPU-v3. Our return on investment analysis shows that FAST-generated accelerators can potentially be practical for moderate-sized datacenter deployments.},
-booktitle = {Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems},
-pages = {27-42},
-numpages = {16},
-keywords = {design space exploration, hardware-software codesign, tensor processing unit, machine learning, operation fusion},
-location = {Lausanne, Switzerland},
-series = {ASPLOS '22}
+ year = {2018},
+ month = sep,
}
-
-@article{huang2022flexible,
- title={How Flexible is Your Computing System?},
- author={Huang, Shihua and Waeijen, Luc and Corporaal, Henk},
- journal={ACM Transactions on Embedded Computing Systems (TECS)},
- volume={21},
- number={4},
- pages={1--41},
- year={2022},
- publisher={ACM New York, NY}
-}
\ No newline at end of file
diff --git a/contents/hw_acceleration/hw_acceleration.qmd b/contents/hw_acceleration/hw_acceleration.qmd
index e402d557..ae267674 100644
--- a/contents/hw_acceleration/hw_acceleration.qmd
+++ b/contents/hw_acceleration/hw_acceleration.qmd
@@ -8,9 +8,9 @@ bibliography: hw_acceleration.bib
Resources: [Slides](#sec-ai-acceleration-resource), [Labs](#sec-ai-acceleration-resource), [Exercises](#sec-ai-acceleration-resource)
:::
-
+
-Machine learning has emerged as a transformative technology across many industries. However, deploying ML capabilities in real-world edge devices faces challenges due to limited computing resources. Specialized hardware acceleration has become essential to enable high-performance machine learning under these constraints. Hardware accelerators optimize compute-intensive operations like inference using custom silicon optimized for matrix multiplications. This provides dramatic speedups over general-purpose CPUs, unlocking real-time execution of advanced models on size, weight and power-constrained devices.
+Machine learning has emerged as a transformative technology across many industries. However, deploying ML capabilities in real-world edge devices faces challenges due to limited computing resources. Specialized hardware acceleration is essential to enable high-performance machine learning under these constraints. Hardware accelerators optimize compute-intensive operations like inference using custom silicon optimized for matrix multiplications. This provides dramatic speedups over general-purpose CPUs, unlocking real-time execution of advanced models on size, weight, and power-constrained devices.
This chapter provides essential background on hardware acceleration techniques for embedded machine learning and their tradeoffs. The goal is to equip readers to make informed hardware selections and software optimizations to develop performant on-device ML capabilities.
@@ -22,13 +22,13 @@ This chapter provides essential background on hardware acceleration techniques f
* Survey key accelerator options like GPUs, TPUs, FPGAs, and ASICs and their tradeoffs
-* Learn about programming models, frameworks, compilers for AI accelerators
+* Learn about programming models, frameworks, and compilers for AI accelerators
* Appreciate the importance of benchmarking and metrics for hardware evaluation
* Recognize the role of hardware-software co-design in building efficient systems
-* Gain exposure to cutting-edge research directions like neuromorphics and quantum computing
+* Gain exposure to cutting-edge research directions like neuromorphic and quantum computing
* Understand how ML is beginning to augment and enhance hardware design
@@ -36,11 +36,11 @@ This chapter provides essential background on hardware acceleration techniques f
## Introduction
-Machine learning has emerged as a transformative technology across many industries, enabling systems to learn and improve from data. To deploy machine learning capabilities in real-world environments, there is a growing demand for embedded ML solutions - where models are built into edge devices like smartphones, home appliances and autonomous vehicles. However, these edge devices have limited computing resources compared to data center servers.
+Machine learning has emerged as a transformative technology across many industries, enabling systems to learn and improve from data. There is a growing demand for embedded ML solutions to deploy machine learning capabilities in real-world environments - where models are built into edge devices like smartphones, home appliances, and autonomous vehicles. However, these edge devices have limited computing resources compared to data center servers.
-To enable high-performance machine learning on resource-constrained edge devices, specialized hardware acceleration has become essential. Hardware acceleration refers to using custom silicon chips and architectures to offload compute-intensive ML operations from the main processor. In neural networks, the most intensive computations are the matrix multiplications during inference. Hardware accelerators can optimize these matrix operations, providing 10-100x speedups over general-purpose CPUs. This acceleration unlocks the ability to run advanced neural network models in real-time on devices with size, weight and power constraints.
+Specialized hardware acceleration enables high-performance machine learning on resource-constrained edge devices. Hardware acceleration refers to using custom silicon chips and architectures to offload compute-intensive ML operations from the main processor. In neural networks, the most intensive computations are the matrix multiplications during inference. Hardware accelerators can optimize these matrix operations, providing 10-100x speedups over general-purpose CPUs. This acceleration unlocks the ability to run advanced neural network models on devices with size, weight, and power constraints in real-time.
-This chapter overviews hardware acceleration techniques for embedded machine learning and their design tradeoffs. The goal of this chapter is to equip readers with essential background on embedded ML acceleration. This will enable informed hardware selection and software optimization to develop high-performance machine learning capabilities on edge devices.
+This chapter overviews hardware acceleration techniques for embedded machine learning and their design tradeoffs. Its goal is to equip readers with an essential background in embedded ML acceleration. This will enable informed hardware selection and software optimization to develop high-performance machine learning capabilities on edge devices.
## Background and Basics
@@ -48,53 +48,53 @@ This chapter overviews hardware acceleration techniques for embedded machine lea
The origins of hardware acceleration date back to the 1960s, with the advent of floating point math co-processors to offload calculations from the main CPU. One early example was the [Intel 8087](https://en.wikipedia.org/wiki/Intel_8087) chip released in 1980 to accelerate floating point operations for the 8086 processor. This established the practice of using specialized processors to handle math-intensive workloads efficiently.
-In the 1990s, the first [graphics processing units (GPUs)](https://en.wikipedia.org/wiki/History_of_the_graphics_processor) emerged to process graphics pipelines for rendering and gaming rapidly. Nvidia's [GeForce 256](https://en.wikipedia.org/wiki/GeForce_256) in 1999 was one of the earliest programmable GPUs capable of running custom software algorithms. GPUs exemplify domain-specific fixed-function accelerators as well as evolving into parallel programmable accelerators.
+In the 1990s, the first [graphics processing units (GPUs)](https://en.wikipedia.org/wiki/History_of_the_graphics_processor) emerged to process graphics pipelines for rendering and gaming rapidly. Nvidia's [GeForce 256](https://en.wikipedia.org/wiki/GeForce_256) in 1999 was one of the earliest programmable GPUs capable of running custom software algorithms. GPUs exemplify domain-specific fixed-function accelerators and evolve into parallel programmable accelerators.
In the 2000s, GPUs were applied to general-purpose computing under [GPGPU](https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units). Their high memory bandwidth and computational throughput made them well-suited for math-intensive workloads. This included breakthroughs in using GPUs to accelerate training of deep learning models such as [AlexNet](https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html) in 2012.
-In recent years, Google's [Tensor Processing Units (TPUs)](https://en.wikipedia.org/wiki/Tensor_processing_unit) represent customized ASICs specifically architected for matrix multiplication in deep learning. Their optimized tensor cores achieve higher TeraOPS/watt than CPUs or GPUs during inference. Ongoing innovation includes model compression techniques like [pruning](https://arxiv.org/abs/1506.02626) and [quantization](https://arxiv.org/abs/1609.07061) to fit larger neural networks on edge devices.
+In recent years, Google's [Tensor Processing Units (TPUs)](https://en.wikipedia.org/wiki/Tensor_processing_unit) represent customized ASICs specifically architected for matrix multiplication in deep learning. During inference, their optimized tensor cores achieve higher TeraOPS/watt than CPUs or GPUs. Ongoing innovation includes model compression techniques like [pruning](https://arxiv.org/abs/1506.02626) and [quantization](https://arxiv.org/abs/1609.07061) to fit larger neural networks on edge devices.
This evolution demonstrates how hardware acceleration has focused on solving compute-intensive bottlenecks, from floating point math to graphics to matrix multiplication for ML. Understanding this history provides a crucial context for specialized AI accelerators today.
### The Need for Acceleration
-The evolution of hardware acceleration is closely tied to the broader history of computing. In the early decades, chip design was governed by Moore's Law and Dennard Scaling, which observed that the number of transistors on an integrated circuit double every year and that as transistors become smaller their peformance (speed) increased while power density (power per unit area) remains constant, respectively. These two laws were held through the single-core era. @fig-moore-dennard shows the trends of different microprocessor metrics. As the figure denotes, Dennard Scaling fails around the mid-2000s, notice how the clock speed (frequency) remains almost constant even as the number of transistors kept increasing.
+The evolution of hardware acceleration is closely tied to the broader history of computing. In the early decades, chip design was governed by Moore's Law and Dennard Scaling, which observed that the number of transistors on an integrated circuit doubled yearly, and their performance (speed) increased as transistors became smaller. At the same time, power density (power per unit area) remains constant. These two laws were held through the single-core era. @fig-moore-dennard shows the trends of different microprocessor metrics. As the figure denotes, Dennard Scaling fails around the mid-2000s; notice how the clock speed (frequency) remains almost constant even as the number of transistors keeps increasing.
-However, as @patterson2016computer describe, technological constraints eventually forced a transition to the multicore era, with chips containing multiple processing cores to deliver gains in performance. As power limitations prevented further scaling, this led to "dark silicon" ([Dark Silicon](https://en.wikipedia.org/wiki/Dark_silicon)) where not all chip areas could be simultaneously active [@xiu2019time].
+However, as @patterson2016computer describes, technological constraints eventually forced a transition to the multicore era, with chips containing multiple processing cores to deliver performance gains. Power limitations prevented further scaling, which led to "dark silicon" ([Dark Silicon](https://en.wikipedia.org/wiki/Dark_silicon)), where not all chip areas could be simultaneously active [@xiu2019time].
-The concept of dark silicon emerged as a consequence of these constraints. "Dark silicon" refers to portions of the chip that cannot be powered on at the same time due to thermal and power limitations. Essentially, as the density of transistors increased, the proportion of the chip that could be actively used without overheating or exceeding power budgets shrank.
+The concept of dark silicon emerged as a consequence of these constraints. "Dark silicon" refers to portions of the chip that cannot be powered simultaneously due to thermal and power limitations. Essentially, as the density of transistors increased, the proportion of the chip that could be actively used without overheating or exceeding power budgets shrank.
This phenomenon meant that while chips had more transistors, not all could be operational simultaneously, limiting potential performance gains. This power crisis necessitated a shift to the accelerator era, with specialized hardware units tailored for specific tasks to maximize efficiency. The explosion in AI workloads further drove demand for customized accelerators. Enabling factors included new programming languages, software tools, and manufacturing advances.
.](images/png/hwai_40yearsmicrotrenddata.png){#fig-moore-dennard}
-Fundamentally, hardware accelerators are evaluated on performance, power, and silicon area (PPA). The nature of the target application - whether memory-bound or compute-bound - heavily influences the design. For example, memory-bound workloads demand high bandwidth and low latency access, while compute-bound applications require maximal computational throughput.
+Fundamentally, hardware accelerators are evaluated on performance, power, and silicon area (PPA)—the nature of the target application—whether memory-bound or compute-bound—heavily influences the design. For example, memory-bound workloads demand high bandwidth and low latency access, while compute-bound applications require maximal computational throughput.
### General Principles
-The design of specialized hardware accelerators involves navigating complex trade-offs between performance, power efficiency, silicon area, and workload-specific optimizations. This section outlines core considerations and methodologies for achieving an optimal balance based on application requirements and hardware constraints.
+The design of specialized hardware accelerators involves navigating complex tradeoffs between performance, power efficiency, silicon area, and workload-specific optimizations. This section outlines core considerations and methodologies for achieving an optimal balance based on application requirements and hardware constraints.
#### Performance Within Power Budgets
-Performance refers to the throughput of computational work per unit time, commonly measured in floating point operations per second (FLOPS) or frames per second (FPS). Higher performance enables completing more work, but power consumption rises with activity.
+Performance refers to the throughput of computational work per unit of time, commonly measured in floating point operations per second (FLOPS) or frames per second (FPS). Higher performance enables completing more work, but power consumption rises with activity.
-Hardware accelerators aim to maximize performance within set power budgets. This requires careful balancing of parallelism, clock frequency of the chip, operating voltage of the chip, workload optimization and other techniques to maximize operations per watt.
+Hardware accelerators aim to maximize performance within set power budgets. This requires careful balancing of parallelism, the chip's clock frequency, the operating voltage, workload optimization, and other techniques to maximize operations per watt.
* **Performance** = Throughput * Efficiency
* **Throughput** ~= Parallelism * Clock Frequency
* **Efficiency** = Operations / Watt
-For example, GPUs achieve high throughput via massively parallel architectures. However, their efficiency is lower than customized application-specific integrated circuits (ASICs) like Google's TPU that optimize for a specific workload.
+For example, GPUs achieve high throughput via massively parallel architectures. However, their efficiency is lower than that of customized application-specific integrated circuits (ASICs) like Google's TPU, which optimize for a specific workload.
#### Managing Silicon Area and Costs
Chip area directly impacts manufacturing cost. Larger die sizes require more materials, lower yields, and higher defect rates. Mulit-die packages help scale designs but add packaging complexity. Silicon area depends on:
-* **Computational resources** - e.g. number of cores, memory, caches
+* **Computational resources** - e.g., number of cores, memory, caches
* **Manufacturing process node** - smaller transistors enable higher density
* **Programming model** - programmed accelerators require more flexibility
-Accelerator design involves squeezing maximim performance within area constraints. Techniques like pruning and compression help fit larger models on chip.
+Accelerator design involves squeezing maximum performance within area constraints. Techniques like pruning and compression help fit larger models on the chip.
#### Workload-Specific Optimizations
@@ -106,33 +106,33 @@ The target workload dictates optimal accelerator architectures. Some of the key
* **Data parallelism:** Multiple replicated compute units allow parallel execution.
* **Pipelining:** Overlapped execution of operations increases throughput.
-Understanding workload characteristics enables customized acceleration. For example, convolutional neural networks use sliding window operations that are optimally mapped to spatial arrays of processing elements.
+Understanding workload characteristics enables customized acceleration. For example, convolutional neural networks use sliding window operations optimally mapped to spatial arrays of processing elements.
-By navigating these architectural tradeoffs, hardware accelerators can deliver massive performance gains and enable emerging applications in AI, graphics, scientific computing and other domains.
+By navigating these architectural tradeoffs, hardware accelerators can deliver massive performance gains and enable emerging applications in AI, graphics, scientific computing, and other domains.
#### Sustainable Hardware Design
In recent years, AI sustainability has become a pressing concern driven by two key factors - the exploding scale of AI workloads and their associated energy consumption.
-First, the size of AI models and datasets has rapidly grown. For example, the amount of compute used to train state-of-the-art models doubles every 3.5 months based on OpenAI's AI compute trends. This exponential growth requires massive computational resources in data centers.
+First, the size of AI models and datasets has rapidly grown. For example, based on OpenAI's AI computing trends, the amount of computing used to train state-of-the-art models doubles every 3.5 months. This exponential growth requires massive computational resources in data centers.
-Second, the energy usage of AI training and inference presents sustainability challenges. Data centers running AI applications now consume substantial amounts of energy, contributing to high carbon emissions. It's estimated that training a large AI model can have a carbon footprint of 626,000 pounds of CO2 equivalent, almost 5 times the lifetime emissions of an average car.
+Second, the energy usage of AI training and inference presents sustainability challenges. Data centers running AI applications consume substantial energy, contributing to high carbon emissions. It's estimated that training a large AI model can have a carbon footprint of 626,000 pounds of CO2 equivalent, almost 5 times the lifetime emissions of an average car.
-As a result, AI research and practice must prioritize energy efficiency and carbon impact alongside accuracy. There is increasing focus on model efficiency, data center design, hardware optimization and other solutions to improve sustainability. Striking a balance between AI progress and environmental responsibility has emerged as a key consideration and an area of active research across the field.
+As a result, AI research and practice must prioritize energy efficiency and carbon impact alongside accuracy. There is an increasing focus on model efficiency, data center design, hardware optimization, and other solutions to improve sustainability. Striking a balance between AI progress and environmental responsibility has emerged as a key consideration and an area of active research across the field.
The scale of AI systems is expected to keep growing. Developing sustainable AI is crucial for managing the environmental footprint and enabling widespread beneficial deployment of this transformative technology.
-We will learn about [Sustainable AI](../sustainable_ai/sustainable_ai.qmd) in a later chapter where we will go into more detail about it.
+We will learn about [Sustainable AI](../sustainable_ai/sustainable_ai. cmd) in a later chapter, where we will discuss it in more detail.
## Accelerator Types {#sec-aihw}
-Hardware accelerators can take on many forms. They can exist as a widget (like the [Neural Engine in the Apple M1 chip](https://www.apple.com/newsroom/2020/11/apple-unleashes-m1/)) or as entire chips specially designed to perform certain tasks very well. In this section, we will examine processors for machine learning workloads along the spectrum from highly specialized ASICs to more general-purpose CPUs. We first focus on custom hardware purpose-built for AI to understand the most extreme optimizations possible when design constraints are removed. This establishes a ceiling for performance and efficiency.
+Hardware accelerators can take on many forms. They can exist as a widget (like the [Neural Engine in the Apple M1 chip](https://www.apple.com/newsroom/2020/11/apple-unleashes-m1/)) or as entire chips specially designed to perform certain tasks very well. This section will examine processors for machine learning workloads along the spectrum from highly specialized ASICs to more general-purpose CPUs. We first focus on custom hardware purpose-built for AI to understand the most extreme optimizations possible when design constraints are removed. This establishes a ceiling for performance and efficiency.
-We then progressively consider more programmable and adaptable architectures with discussions of GPUs and FPGAs. These make tradeoffs in customization to maintain flexibility. Finally, we cover general-purpose CPUs which sacrifice optimizations for a particular workload in exchange for versatile programmability across applications.
+We then progressively consider more programmable and adaptable architectures, discussing GPUs and FPGAs. These make tradeoffs in customization to maintain flexibility. Finally, we cover general-purpose CPUs that sacrifice optimizations for a particular workload in exchange for versatile programmability across applications.
-By structuring the analysis along this spectrum, we aim to illustrate the fundamental tradeoffs in accelerator design between utilization, efficiency, programmability, and flexibility. The optimal balance point depends on the constraints and requirements of the target application. This spectrum perspective provides a framework for reasoning about hardware choices for machine learning and the capabilities required at each level of specialization.
+By structuring the analysis along this spectrum, we aim to illustrate the fundamental tradeoffs between utilization, efficiency, programmability, and flexibility in accelerator design. The optimal balance point depends on the constraints and requirements of the target application. This spectrum perspective provides a framework for reasoning about hardware choices for machine learning and the capabilities required at each level of specialization.
-@fig-design-tradeoffs illustrates the complex interplay between flexibility, performance, functional diversity, and area of architecture design. Notice how the ASIC is on the bottom-right corner, with minimal area, flexibility, and power consumption and maximal performance, due to its highly specialized application-specific nature. A key tradeoff is functinoal diversity vs performance: general purpose architechtures can serve diverse applications but their application performance is degraded as compared to more customized architectures.
+@fig-design-tradeoffs illustrates the complex interplay between flexibility, performance, functional diversity, and area of architecture design. Notice how the ASIC is in the bottom-right corner, with minimal area, flexibility, power consumption, and maximal performance due to its highly specialized application-specific nature. A key tradeoff is functional diversity vs. performance: general-purpose architectures can serve diverse applications, but their application performance could be better compared to more customized architectures.
The progression begins with the most specialized option, ASICs purpose-built for AI, to ground our understanding in the maximum possible optimizations before expanding to more generalizable architectures. This structured approach aims to elucidate the accelerator design space.
@@ -140,29 +140,29 @@ The progression begins with the most specialized option, ASICs purpose-built for
### Application-Specific Integrated Circuits (ASICs)
-An Application-Specific Integrated Circuit (ASIC) is a type of [integrated circuit](https://en.wikipedia.org/wiki/Integrated_circuit) (IC) that is custom-designed for a specific application or workload, rather than for general-purpose use. Unlike CPUs and GPUs, ASICs do not support multiple applications or workloads. Rather, they are optimized to perform a single task extremely efficiently. The Google TPU is an example of an ASIC.
+An Application-Specific Integrated Circuit (ASIC) is a type of [integrated circuit](https://en.wikipedia.org/wiki/Integrated_circuit) (IC) that is custom-designed for a specific application or workload rather than for general-purpose use. Unlike CPUs and GPUs, ASICs do not support multiple applications or workloads. Rather, they are optimized to perform a single task extremely efficiently. The Google TPU is an example of an ASIC.
-ASICs achieve this efficiency by tailoring every aspect of the chip design - the underlying logic gates, electronic components, architecture, memory, I/O, and manufacturing process - specifically for the target application. This level of customization allows removing any unnecessary logic or functionality required for general computation. The result is an IC that maximizes performance and power efficiency on the desired workload. The efficiency gains from application-specific hardware are so substantial that these software-centric firms are dedicating enormous engineering resources to designing customized ASICs.
+ASICs achieve this efficiency by tailoring every aspect of the chip design - the underlying logic gates, electronic components, architecture, memory, I/O, and manufacturing process - specifically for the target application. This level of customization allows removing any unnecessary logic or functionality required for general computation. The result is an IC that maximizes performance and power efficiency on the desired workload. The efficiency gains from application-specific hardware are so substantial that these software-centric firms dedicate enormous engineering resources to designing customized ASICs.
The rise of more complex machine learning algorithms has made the performance advantages enabled by tailored hardware acceleration a key competitive differentiator, even for companies traditionally concentrated on software engineering. ASICs have become a high-priority investment for major cloud providers aiming to offer faster AI computation.
#### Advantages
-ASICs provide significant benefits over general purpose processors like CPUs and GPUs due to their customized nature. The key advantages include the following.
+Due to their customized nature, ASICs provide significant benefits over general-purpose processors like CPUs and GPUs. The key advantages include the following.
##### Maximized Performance and Efficiency
-The most fundamental advantage of ASICs is the ability to maximize performance and power efficiency by customizing the hardware architecture specifically for the target application. Every transistor and design aspect is optimized for the desired workload - no unnecessary logic or overhead is needed to support generic computation.
+The most fundamental advantage of ASICs is maximizing performance and power efficiency by customizing the hardware architecture specifically for the target application. Every transistor and design aspect is optimized for the desired workload - no unnecessary logic or overhead is needed to support generic computation.
-For example, [Google's Tensor Processing Units (TPUs)](https://cloud.google.com/tpu/docs/intro-to-tpu) contain architectures tailored exactly for the matrix multiplication operations used in neural networks. To design the TPU ASICs, Google's engineering teams need to clearly define the chip specifications, write the architecture description using Hardware Description Languages like [Verilog](https://www.verilog.com/), synthesize the design to map it to hardware components, and carefully place-and-route transistors and wires based on the fabrication process design rules. This complex design process, known as very-large-scale integration (VLSI), allows them to build an IC optimized just for machine learning workloads.
+For example, [Google's Tensor Processing Units (TPUs)](https://cloud.google.com/tpu/docs/intro-to-tpu) contain architectures tailored exactly for the matrix multiplication operations used in neural networks. To design the TPU ASICs, Google's engineering teams need to define the chip specifications clearly, write the architecture description using Hardware Description Languages like [Verilog](https://www.verilog.com/), synthesize the design to map it to hardware components, and carefully place-and-route transistors and wires based on the fabrication process design rules. This complex design process, known as very-large-scale integration (VLSI), allows them to build an optimized IC for machine learning workloads.
-As a result, TPU ASICs achieve over an order of magnitude higher efficiency in operations per watt than general purpose GPUs on ML workloads by maximizing performance and minimizing power consumption through a full-stack custom hardware design.
+As a result, TPU ASICs achieve over an order of magnitude higher efficiency in operations per watt than general-purpose GPUs on ML workloads by maximizing performance and minimizing power consumption through a full-stack custom hardware design.
##### Specialized On-Chip Memory
-ASICs incorporate on-chip SRAM and caches specifically optimized to feed data to the computational units. For example, Apple's M1 system-on-a-chip contains special low-latency SRAM to accelerate the performance of its Neural Engine machine learning hardware. Large local memory with high bandwidth enables keeping data as close as possible to the processing elements. This provides tremendous speed advantages compared to off-chip DRAM access, which is up to 100x slower.
+ASICs incorporate on-chip SRAM and caches specifically optimized to feed data to the computational units. For example, Apple's M1 system-on-a-chip contains special low-latency SRAM to accelerate the performance of its Neural Engine machine learning hardware. Large local memory with high bandwidth enables data to be kept close to the processing elements. This provides tremendous speed advantages compared to off-chip DRAM access, which can be up to 100x slower.
-Data locality and optimizing memory hierarchy is crucial for both high throughput and low power.Below is a table "Numbers Everyone Should Know" from [Jeff Dean](https://research.google/people/jeff/).
+Data locality and optimizing memory hierarchy are crucial for high throughput and low power. Below is a table, "Numbers Everyone Should Know," from [Jeff Dean](https://research.google/people/jeff/).
| Operation | Latency | Notes |
|-|-|-|
@@ -183,45 +183,45 @@ Data locality and optimizing memory hierarchy is crucial for both high throughpu
##### Custom Datatypes and Operations
-Unlike general purpose processors, ASICs can be designed to natively support custom datatypes like INT4 or bfloat16 that are widely used in ML models. For instance, Nvidia's Ampere GPU architecture has dedicated bfloat16 Tensor Cores to accelerate AI workloads. Low precision datatypes enable higher arithmetic density and performance. ASICs can also directly incorporate non-standard operations common in ML algorithms as primitive operations - for example, natively supporting activation functions like ReLU makes execution more efficient. We encourage you to refer to the Efficient Numeric Representations chapter for additional details.
+Unlike general-purpose processors, ASICs can be designed to natively support custom datatypes like INT4 or bfloat16, which are widely used in ML models. For instance, Nvidia's Ampere GPU architecture has dedicated bfloat16 Tensor Cores to accelerate AI workloads. Low-precision datatypes enable higher arithmetic density and performance. ASICs can also directly incorporate non-standard operations common in ML algorithms as primitive operations - for example, natively supporting activation functions like ReLU makes execution more efficient. Please refer to the Efficient Numeric Representations chapter for additional details.
##### High Parallelism
-ASIC architectures can leverage much higher parallelism tuned for the target workload versus general purpose CPUs or GPUs. More computational units tailored for the application means more operations execute simultaneously. Highly parallel ASICs achieve tremendous throughput for data parallel workloads like neural network inference.
+ASIC architectures can leverage higher parallelism tuned for the target workload versus general-purpose CPUs or GPUs. More computational units tailored for the application mean more operations execute simultaneously. Highly parallel ASICs achieve tremendous throughput for data parallel workloads like neural network inference.
##### Advanced Process Nodes
-Cutting edge manufacturing processes allow packing more transistors into smaller die areas, increasing density. ASICs designed specifically for high volume applications can better amortize the costs of bleeding edge process nodes.
+Cutting-edge manufacturing processes allow more transistors to be packed into smaller die areas, increasing density. ASICs designed specifically for high-volume applications can better amortize the costs of cutting-edge process nodes.
#### Disadvantages
##### Long Design Timelines
-The engineering process of designing and validating an ASIC can take 2-3 years. Synthesizing the architecture using hardware description languages, taping out the chip layout, and fabricating the silicon on advanced process nodes involves long development cycles. For example, to tape out a 7nm chip, teams need to carefully define specifications, write the architecture in HDL, synthesize the logic gates, place components, route all interconnections, and finalize the layout to send for fabrication. This very large scale integration (VLSI) flow means ASIC design and manufacturing can traditionally take 2-5 years.
+The engineering process of designing and validating an ASIC can take 2-3 years. Synthesizing the architecture using hardware description languages, taping out the chip layout, and fabricating the silicon on advanced process nodes involve long development cycles. For example, to tape out a 7nm chip, teams need to define specifications carefully, write the architecture in HDL, synthesize the logic gates, place components, route all interconnections, and finalize the layout to send for fabrication. This very large-scale integration (VLSI) flow means ASIC design and manufacturing can traditionally take 2-5 years.
There are a few key reasons why the long design timelines of ASICs, often 2-3 years, can be challenging for machine learning workloads:
-* **ML algorithms evolve rapidly:** New model architectures, training techniques, and network optimizations are constantly emerging. For example, Transformers became hugely popular in NLP in just the last few years. By the time an ASIC finishes tapeout, the optimal architecture for a workload may have changed.
+* **ML algorithms evolve rapidly:** New model architectures, training techniques, and network optimizations are constantly emerging. For example, Transformers became hugely popular in NLP last few years. When an ASIC finishes tapeout, the optimal architecture for a workload may have changed.
* **Datasets grow quickly:** ASICs designed for certain model sizes or datatypes can become undersized relative to demand. For instance, natural language models are scaling exponentially with more data and parameters. A chip designed for BERT might not accommodate GPT-3.
-* **ML applications change frequently:** The industry focus shifts between computer vision, speech, NLP, recommender systems etc. An ASIC optimized for image classification may have less relevance in a few years.
+* **ML applications change frequently:** The industry focus shifts between computer vision, speech, NLP, recommender systems, etc. An ASIC optimized for image classification may have less relevance in a few years.
* **Faster design cycles with GPUs/FPGAs:** Programmable accelerators like GPUs can adapt much quicker by upgrading software libraries and frameworks. New algorithms can be deployed without hardware changes.
-* **Time-to-market needs:** Getting a competitive edge in ML requires rapidly experimenting with new ideas and deploying them. Waiting several years for an ASIC is not aligned with fast iteration.
+* **Time-to-market needs:** Getting a competitive edge in ML requires rapidly experimenting with and deploying new ideas. Waiting several years for an ASIC is different from fast iteration.
-The pace of innovation in ML is not well matched to the multi-year timescale for ASIC development. Significant engineering efforts are required to extend ASIC lifespan through modular architectures, process scaling, model compression, and other techniques. But the rapid evolution of ML makes fixed function hardware challenging.
+The pace of innovation in ML needs to be better matched to the multi-year timescale for ASIC development. Significant engineering efforts are required to extend ASIC lifespan through modular architectures, process scaling, model compression, and other techniques. However, the rapid evolution of ML makes fixed-function hardware challenging.
##### High Non-Recurring Engineering Costs
-The fixed costs of taking an ASIC from design to high volume manufacturing can be very capital intensive, often tens of millions of dollars. Photomask fabrication for taping out chips in advanced process nodes, packaging, and one-time engineering efforts are expensive. For instance, a 7nm chip tapeout alone could cost tens of millions of dollars. The high non-recurring engineering (NRE) investment narrows ASIC viability to high-volume production use cases where the upfront cost can be amortized.
+The fixed costs of taking an ASIC from design to high-volume manufacturing can be very capital-intensive, often tens of millions of dollars. Photomask fabrication for taping out chips in advanced process nodes, packaging, and one-time engineering efforts is expensive. For instance, a 7nm chip tape-out alone could cost millions. The high non-recurring engineering (NRE) investment narrows ASIC viability to high-volume production use cases where the upfront cost can be amortized.
##### Complex Integration and Programming
-ASICs require extensive software integration work including drivers, compilers, OS support, and debugging tools. They also need expertise in electrical and thermal packaging. Additionally, programming ASIC architectures efficiently can involve challenges like workload partitioning and scheduling across many parallel units. The customized nature necessitates significant integration efforts to turn raw hardware into fully operational accelerators.
+ASICs require extensive software integration work, including drivers, compilers, OS support, and debugging tools. They also need expertise in electrical and thermal packaging. Additionally, efficiently programming ASIC architectures can involve challenges like workload partitioning and scheduling across many parallel units. The customized nature necessitates significant integration efforts to turn raw hardware into fully operational accelerators.
While ASICs provide massive efficiency gains on target applications by tailoring every aspect of the hardware design to one specific task, their fixed nature results in tradeoffs in flexibility and development costs compared to programmable accelerators, which must be weighed based on the application.
### Field-Programmable Gate Arrays (FPGAs)
-FPGAs are programmable integrated circuits that can be reconfigured for different applications. Their customizable nature provides advantages for accelerating AI algorithms compared to fixed ASICs or inflexible GPUs. While Google, Meta, and NVIDIA which are looking at putting ASICs in data centers, Microsoft deployed FPGAs in their data centers [@putnam2014reconfigurable] in 2011 to efficiently serve diverse data center workloads.
+FPGAs are programmable integrated circuits that can be reconfigured for different applications. Their customizable nature provides advantages for accelerating AI algorithms compared to fixed ASICs or inflexible GPUs. While Google, Meta, and NVIDIA are considering putting ASICs in data centers, Microsoft deployed FPGAs in its data centers [@putnam2014reconfigurable] in 2011 to efficiently serve diverse data center workloads.
#### Advantages
@@ -229,13 +229,13 @@ FPGAs provide several benefits over GPUs and ASICs for accelerating machine lear
##### Flexibility Through Reconfigurable Fabric
-The key advantage of FPGAs is the ability to reconfigure the underlying fabric to implement custom architectures optimized for different models, unlike fixed-function ASICs. For example, quant trading firms use FPGAs to accelerate their algorithms because they change frequently, and the low NRE cost of FPGAs is more viable than taping out new ASICs. @fig-different-fpgas contains a table comparison of three different FPGAs.
+The key advantage of FPGAs is the ability to reconfigure the underlying fabric to implement custom architectures optimized for different models, unlike fixed-function ASICs. For example, quant trading firms use FPGAs to accelerate their algorithms because they change frequently, and the low NRE cost of FPGAs is more viable than tapping out new ASICs. @fig-different-fpgas contains a table comparing three different FPGAs.
{#fig-different-fpgas}
-FPGAs are composed of basic building blocks - configurable logic blocks, RAM blocks, and interconnects. Vendors provide a base amount of these resources, and engineers program the chips by compiling HDL code into bitstreams that rearrange the fabric into different configurations. This makes FPGAs adaptable as algorithms evolve.
+FPGAs comprise basic building blocks - configurable logic blocks, RAM blocks, and interconnects. Vendors provide a base amount of these resources, and engineers program the chips by compiling HDL code into bitstreams that rearrange the fabric into different configurations. This makes FPGAs adaptable as algorithms evolve.
-While FPGAs may not achieve the utmost performance and efficiency of workload-specific ASICs, their programmability provides more flexibility as algorithms change. This adaptability makes FPGAs a compelling choice for accelerating evolving machine learning applications. For machine learning workloads, Microsoft has deployed FPGAs in its Azure data centers to serve diverse applications, instead of using ASICs. The programmability enables optimization across changing ML models.
+While FPGAs may not achieve the utmost performance and efficiency of workload-specific ASICs, their programmability provides more flexibility as algorithms change. This adaptability makes FPGAs a compelling choice for accelerating evolving machine learning applications. Microsoft has deployed FPGAs in its Azure data centers for machine learning workloads to serve diverse applications instead of ASICs. The programmability enables optimization across changing ML models.
##### Customized Parallelism and Pipelining
@@ -243,45 +243,45 @@ FPGA architectures can leverage spatial parallelism and pipelining by tailoring
##### Low Latency On-Chip Memory
-Large amounts of high bandwidth on-chip memory enables localized storage for weights and activations. For instance, Xilinx Versal FPGAs contain 32MB of low latency RAM blocks along with dual-channel DDR4 interfaces for external memory. Bringing memory physically closer to the compute units reduces access latency. This provides significant speed advantages over GPUs that must traverse PCIe or other system buses to reach off-chip GDDR6 memory.
+Large amounts of high-bandwidth on-chip memory enable localized storage for weights and activations. For instance, Xilinx Versal FPGAs contain 32MB of low-latency RAM blocks and dual-channel DDR4 interfaces for external memory. Bringing memory physically closer to the compute units reduces access latency. This provides significant speed advantages over GPUs that traverse PCIe or other system buses to reach off-chip GDDR6 memory.
##### Native Support for Low Precision
-A key advantage of FPGAs is the ability to natively implement any bit width for arithmetic units, such as INT4 or bfloat16 used in quantized ML models. For example, Intel's Stratix 10 NX FPGAs have dedicated INT8 cores that can achieve up to 143 INT8 TOPS at ~1 TOPS/W [Intel Stratix 10 NX FPGA
+A key advantage of FPGAs is the ability to natively implement any bit width for arithmetic units, such as INT4 or bfloat16, used in quantized ML models. For example, Intel's Stratix 10 NX FPGAs have dedicated INT8 cores that can achieve up to 143 INT8 TOPS at ~1 TOPS/W [Intel Stratix 10 NX FPGA
](https://www.intel.com/content/www/us/en/products/details/fpga/stratix/10/nx.html). Lower bit widths increase arithmetic density and performance. FPGAs can even support mixed precision or dynamic precision tuning at runtime.
-#### Disadvatages
+#### Disadvantages
##### Lower Peak Throughput than ASICs
-FPGAs cannot match the raw throughput numbers of ASICs customized for a specific model and precision. The overheads of the reconfigurable fabric compared to fixed function hardware result in lower peak performance. For example, the TPU v5e pods allow up to 256 chips to be connected with more than 100 petaOps of INT8 performance while FPGAs can offer up to 143 INT8 TOPS or 286 INT4 TOPS [Intel Stratix 10 NX FPGA
+FPGAs cannot match the raw throughput numbers of ASICs customized for a specific model and precision. The overheads of the reconfigurable fabric compared to fixed function hardware result in lower peak performance. For example, the TPU v5e pods allow up to 256 chips to be connected with more than 100 petaOps of INT8 performance, while FPGAs can offer up to 143 INT8 TOPS or 286 INT4 TOPS [Intel Stratix 10 NX FPGA
](https://www.intel.com/content/www/us/en/products/details/fpga/stratix/10/nx.html).
-This is because FPGAs are composed of basic building blocks - configurable logic blocks, RAM blocks, and interconnects. Vendors provide a set amount of these resources. To program FPGAs, engineers write HDL code and compile into bitstreams that rearrange the fabric, which has inherent overheads versus an ASIC purpose-built for one computation.
+This is because FPGAs comprise basic building blocks—configurable logic blocks, RAM blocks, and interconnects. Vendors provide a set amount of these resources. To program FPGAs, engineers write HDL code and compile it into bitstreams that rearrange the fabric, which has inherent overheads versus an ASIC purpose-built for one computation.
##### Programming Complexity
-To optimize FPGA performance, engineers must program the architectures in low-level hardware description languages like Verilog or VHDL. This requires hardware design expertise and longer development cycles versus higher level software frameworks like TensorFlow. Maximizing utilization can be challenging despite advances in high-level synthesis from C/C++.
+To optimize FPGA performance, engineers must program the architectures in low-level hardware description languages like Verilog or VHDL. This requires hardware design expertise and longer development cycles than higher-level software frameworks like TensorFlow. Maximizing utilization can be challenging despite advances in high-level synthesis from C/C++.
##### Reconfiguration Overheads
-To change FPGA configurations requires reloading a new bitstream, which has considerable latency and storage size costs. For example, partial reconfiguration on Xilinx FPGAs can take 100s of milliseconds. This makes dynamically swapping architectures in real-time infeasible. The bitstream storage also consumes on-chip memory.
+Changing FPGA configurations requires reloading a new bitstream, which has considerable latency and storage size costs. For example, partial reconfiguration on Xilinx FPGAs can take 100s of milliseconds. This makes dynamically swapping architectures in real-time infeasible. The bitstream storage also consumes on-chip memory.
##### Diminishing Gains on Advanced Nodes
-While smaller process nodes benefit ASICs greatly, they provide less advantages for FPGAs. At 7nm and below, effects like process variation, thermal constraints, and aging disproportionately impact FPGA performance. The overheads of configurable fabric also diminish gains vs fixed function ASICs.
+While smaller process nodes greatly benefit ASICs, they provide fewer advantages for FPGAs. At 7nm and below, effects like process variation, thermal constraints, and aging disproportionately impact FPGA performance. The overheads of the configurable fabric also diminish gains compared to fixed-function ASICs.
##### Case Study
-FPGAs have found widespread application in various fields, including medical imaging, robotics, and finance, where they excel in handling computationally intensive machine learning tasks. In the context of medical imaging, an illustrative example is the application of FPGAs for brain tumor segmentation, a traditionally time-consuming and error-prone process. For instance, Xiong et al. developed a quantized segmentation accelerator, which they retrained using the BraTS19 and BraTS20 datasets. Their work yielded remarkable results, achieving over 5x and 44x performance improvements, as well as 11x and 82x energy efficiency gains compared to GPU and CPU implementations, respectively [@xiong2021mribased].
+FPGAs have found widespread application in various fields, including medical imaging, robotics, and finance, where they excel in handling computationally intensive machine learning tasks. In medical imaging, an illustrative example is the application of FPGAs for brain tumor segmentation, a traditionally time-consuming and error-prone process. For instance, Xiong et al. developed a quantized segmentation accelerator, which they retrained using the BraTS19 and BraTS20 datasets. Their work yielded remarkable results, achieving over 5x and 44x performance improvements and 11x and 82x energy efficiency gains compared to GPU and CPU implementations, respectively [@xiong2021mribased].
### Digital Signal Processors (DSPs)
-The first digital signal processor core was built in 1948 by Texas Instruments ([The Evolution of Audio DSPs](https://audioxpress.com/article/the-evolution-of-audio-dsps)). Traditionally, DSPs would have logic to allow them to directly access digital/audio data in memory, perform an arithmetic operation (multiply-add-accumulate-MAC-was one of the most common operations) and then write the result back to memory. The DSP would also include specialized analog components to retrieve said digital/audio data.
+The first digital signal processor core was built in 1948 by Texas Instruments ([The Evolution of Audio DSPs](https://audioxpress.com/article/the-evolution-of-audio-dsps)). Traditionally, DSPs would have logic to directly access digital/audio data in memory, perform an arithmetic operation (multiply-add-accumulate-MAC was one of the most common operations), and then write the result back to memory. The DSP would include specialized analog components to retrieve digital/audio data.
-Once we entered the smartphone era, DSPs started encompassing more sophisticated tasks. They required Bluetooth, Wi-Fi, and cellular connectivity. Media also became much more complex. Today, it's not common to have entire chips dedicated to just DSP, but a System on Chip would include DSPs in addition to general-purpose CPUs. For example, Qualcomm's [Hexagon Digital Signal Processor](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) claims to be a "world-class processor with both CPU and DSP functionality to support deeply embedded processing needs of the mobile platform for both multimedia and modem functions." [Google Tensors](https://blog.google/products/pixel/google-tensor-g3-pixel-8/), the chip in the Google Pixel phones, also includes both CPUs and specialized DSP engines.
+Once we entered the smartphone era, DSPs started encompassing more sophisticated tasks. They required Bluetooth, Wi-Fi, and cellular connectivity. Media also became much more complex. Today, it's rare to have entire chips dedicated to just DSP, but a System on Chip would include DSPs and general-purpose CPUs. For example, Qualcomm's [Hexagon Digital Signal Processor](https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor) claims to be a "world-class processor with both CPU and DSP functionality to support deeply embedded processing needs of the mobile platform for both multimedia and modem functions." [Google Tensors](https://blog.google/products/pixel/google-tensor-g3-pixel-8/), the chip in the Google Pixel phones, also includes CPUs and specialized DSP engines.
-#### Advatages
+#### Advantages
DSPs architecturally provide advantages in vector math throughput, low latency memory access, power efficiency, and support for diverse datatypes - making them well-suited for embedded ML acceleration.
@@ -299,11 +299,11 @@ DSPs are engineered to provide high performance per watt on digital signal workl
##### Support for Integer and Floating Point Math
-Unlike GPUs which excel at single or half precision, DSPs can natively support both 8/16-bit integer and 32-bit floating point datatypes used across ML models. Some DSPs even support dot product acceleration at INT8 precision for quantized neural networks.
+Unlike GPUs that excel at single or half precision, DSPs can natively support 8/16-bit integer and 32-bit floating point datatypes used across ML models. Some DSPs support dot product acceleration at INT8 precision for quantized neural networks.
-#### Disadvatages
+#### Disadvantages
-DSPs make architectural tradeoffs that limit peak throughput, precision, and model capacity compared to other AI accelerators. But their advantages in power efficiency and integer math make them a strong edge compute option. So while DSPs provide some benefits over CPUs, they also come with limitations for machine learning workloads:
+DSPs make architectural tradeoffs that limit peak throughput, precision, and model capacity compared to other AI accelerators. However, their advantages in power efficiency and integer math make them a strong edge computing option. So, while DSPs provide some benefits over CPUs, they also come with limitations for machine learning workloads:
##### Lower Peak Throughput than ASICs/GPUs
@@ -311,7 +311,7 @@ DSPs cannot match the raw computational throughput of GPUs or customized ASICs d
##### Slower Double Precision Performance
-Most DSPs are not optimized for higher precision floating point needed in some ML models. Their dot product engines focus on INT8/16 and FP32 which provides better power efficiency. But 64-bit floating point throughput is much lower. This can limit usage in models requiring high precision.
+Most DSPs must be optimized for the higher precision floating point needed in some ML models. Their dot product engines focus on INT8/16 and FP32, which provide better power efficiency. However, 64-bit floating point throughput is much lower, which can limit usage in models requiring high precision.
##### Constrained Model Capacity
@@ -319,65 +319,65 @@ The limited on-chip memory of DSPs constrains the model sizes that can be run. L
##### Programming Complexity
-Efficiently programming DSP architectures requires expertise in parallel programming and optimizing data access patterns. Their specialized microarchitectures have more learning curve than high-level software frameworks. This makes development more complex.
+Efficient programming of DSP architectures requires expertise in parallel programming and optimizing data access patterns. Their specialized microarchitectures have a steeper learning curve than high-level software frameworks, making development more complex.
### Graphics Processing Units (GPUs)
-The term graphics processing unit existed since at least the 1980s. There had always been a demand for graphics hardware in both video game consoles (high demand, needed to be relatively lower cost) and scientific simulations (lower demand, but needed higher resolution, could be at a high price point).
+The term graphics processing unit has existed since at least the 1980s. There had always been a demand for graphics hardware in video game consoles (high demand, needed to be relatively lower cost) and scientific simulations (lower demand, but higher resolution, could be at a high price point).
-The term was popularized, however, in 1999 when NVIDIA launched the GeForce 256 mainly targeting the PC games market sector [@lindholm2008nvidia]. As PC games became more sophisticated, NVIDIA GPUs became more programmable over time as well. Soon, users realized they could take advantage of this programmability and run a variety of non-graphics related workloads on GPUs and benefit from the underlying architecture. And so, starting in the late 2000s, GPUs became general-purpose graphics processing units or GP-GPUs.
+The term was popularized, however, in 1999 when NVIDIA launched the GeForce 256, mainly targeting the PC games market sector [@lindholm2008nvidia]. As PC games became more sophisticated, NVIDIA GPUs became more programmable. Soon, users realized they could take advantage of this programmability, run various non-graphics-related workloads on GPUs, and benefit from the underlying architecture. And so, in the late 2000s, GPUs became general-purpose graphics processing units or GP-GPUs.
[Intel Arc Graphics](https://www.intel.com/content/www/us/en/products/details/fpga/stratix/10/nx.html) and [AMD Radeon RX](https://www.amd.com/en/graphics/radeon-rx-graphics) have also developed their GPUs over time.
-#### Advatages
+#### Advantages
##### High Computational Throughput
-The key advantage of GPUs is their ability to perform massively parallel floating point calculations optimized for computer graphics and linear algebra [@rajat2009largescale]. Modern GPUs like Nvidia's A100 offers up to 19.5 teraflops of FP32 performance with 6912 CUDA cores and 40GB of graphics memory that is tightly coupled with 1.6TB/s of graphics memory bandwidth.
+The key advantage of GPUs is their ability to perform massively parallel floating-point calculations optimized for computer graphics and linear algebra [@rajat2009largescale]. Modern GPUs like Nvidia's A100 offer up to 19.5 teraflops of FP32 performance with 6912 CUDA cores and 40GB of graphics memory tightly coupled with 1.6TB/s of graphics memory bandwidth.
-This raw throughput stems from the highly parallel streaming multiprocessor (SM) architecture tailored for data-parallel workloads [@jia2019beyond]. Each SM contains hundreds of scalar cores optimized for float32/64 math. With thousands of SMs on chip, GPUs are purpose-built for matrix multiplication and vector operations used throughout neural networks.
+This raw throughput stems from the highly parallel streaming multiprocessor (SM) architecture tailored for data-parallel workloads [@jia2019beyond]. Each SM contains hundreds of scalar cores optimized for float32/64 math. With thousands of SMs on a chip, GPUs are purpose-built for matrix multiplication and vector operations used throughout neural networks.
For example, Nvidia's latest [H100](https://www.nvidia.com/en-us/data-center/h100/) GPU provides 4000 TFLOPs of FP8, 2000 TFLOPs of FP16, 1000 TFLOPs of TF32, 67 TFLOPs of FP32 and 34 TFLOPs of FP64 Compute performance, which can dramatically accelerate large batch training on models like BERT, GPT-3, and other transformer architectures. The scalable parallelism of GPUs is key to speeding up computationally intensive deep learning.
##### Mature Software Ecosystem
-Nvidia provides extensive runtime libraries like [cuDNN](https://developer.nvidia.com/cudnn) and [cuBLAS](https://developer.nvidia.com/cublas) that are highly optimized for deep learning primitives. Frameworks like TensorFlow and PyTorch integrate with these libraries to enable GPU acceleration with no direct programming. CUDA provides lower-level control for custom computations.
+Nvidia provides extensive runtime libraries like [cuDNN](https://developer.nvidia.com/cudnn) and [cuBLAS](https://developer.nvidia.com/cublas) that are highly optimized for deep learning primitives. Frameworks like TensorFlow and PyTorch integrate with these libraries to enable GPU acceleration without direct programming. CUDA provides lower-level control for custom computations.
-This ecosystem enables quickly leveraging GPUs via high-level Python without GPU programming expertise. Known workflows and abstractions provide a convenient on-ramp for scaling up deep learning experiments. The software maturity supplements the throughput advantages.
+This ecosystem enables quick leveraging of GPUs via high-level Python without GPU programming expertise. Known workflows and abstractions provide a convenient on-ramp for scaling up deep learning experiments. The software maturity supplements the throughput advantages.
##### Broad Availability
-The economies of scale of graphics processing make GPUs broadly accessible in data centers, cloud platforms like AWS and GCP, and desktop workstations. Their availability in research environments has provided a convenient platform for ML experimentation and innovation. For example, nearly every state-of-the-art deep learning result has involved GPU acceleration because of this ubiquity. The broad access supplements the software maturity to make GPUs the standard ML accelerator.
+The economies of scale of graphics processing make GPUs broadly accessible in data centers, cloud platforms like AWS and GCP, and desktop workstations. Their availability in research environments has provided a convenient ML experimentation and innovation platform. For example, nearly every state-of-the-art deep learning result has involved GPU acceleration because of this ubiquity. The broad access supplements the software maturity to make GPUs the standard ML accelerator.
##### Programmable Architecture
-While not fully flexible as FPGAs, GPUs do provide programmability via CUDA and shader languages to customize computations. Developers can optimize data access patterns, create new ops, and tune precisions for evolving models and algorithms.
+While not as flexible as FPGAs, GPUs provide programmability via CUDA and shader languages to customize computations. Developers can optimize data access patterns, create new ops, and tune precisions for evolving models and algorithms.
-#### Disadvatages
+#### Disadvantages
-While GPUs have become the standard accelerator for deep learning, their architecture also comes with some key downsides.
+While GPUs have become the standard accelerator for deep learning, their architecture has some key downsides.
##### Less Efficient than Custom ASICs
The statement "GPUs are less efficient than ASICs" could spark intense debate within the ML/AI field and cause this book to explode.
-Typically, GPUs are perceived as less efficient than ASICs because the latter are custom-built for specific tasks and thus can operate more efficiently by design. GPUs, with their general-purpose architecture, are inherently more versatile and programmable, catering to a broad spectrum of computational tasks beyond ML/AI.
+Typically, GPUs are perceived as less efficient than ASICs because the latter are custom-built for specific tasks and thus can operate more efficiently by design. With their general-purpose architecture, GPUs are inherently more versatile and programmable, catering to a broad spectrum of computational tasks beyond ML/AI.
-However, modern GPUs, however, have evolved to include specialized hardware support for essential AI operations, such as generalized matrix multiplication (GEMM) and other matrix operations, native support for quantization, native support for pruning which are critical for running ML models effectively. These enhancements have significantly improved the efficiency of GPUs for AI tasks, to the point where they can rival the performance of ASICs for certain applications.
+However, modern GPUs have evolved to include specialized hardware support for essential AI operations, such as generalized matrix multiplication (GEMM) and other matrix operations, native support for quantization, and native support for pruning, which are critical for running ML models effectively. These enhancements have significantly improved the efficiency of GPUs for AI tasks to the point where they can rival the performance of ASICs for certain applications.
-Consequently, some might argue that contemporary GPUs represent a convergence of sorts, incorporating specialized, ASIC-like capabilities within a flexible, general-purpose processing framework. This adaptability has blurred the lines between the two types of hardware, with GPUs offering a strong balance of specialization and programmability that is well-suited to the dynamic needs of ML/AI research and development.
+Consequently, contemporary GPUs are convergent, incorporating specialized ASIC-like capabilities within a flexible, general-purpose processing framework. This adaptability has blurred the lines between the two types of hardware. GPUs offer a strong balance of specialization and programmability that is well-suited to the dynamic needs of ML/AI research and development.
##### High Memory Bandwidth Needs
-The massively parallel architecture requires tremendous memory bandwidth to supply thousands of cores as shown in Figure 1. For example, the Nvidia A100 GPU requires 1.6TB/sec to fully saturate its compute. GPUs rely on wide 384-bit memory buses to high bandwidth GDDR6 RAM, but even the fastest GDDR6 tops out around 1 TB/sec. This dependence on external DRAM incurs latency and power overheads.
+The massively parallel architecture requires tremendous memory bandwidth to supply thousands of cores, as shown in Figure 1. For example, the Nvidia A100 GPU requires 1.6TB/sec to fully saturate its computer. GPUs rely on wide 384-bit memory buses to high-bandwidth GDDR6 RAM, but even the fastest GDDR6 tops out at around 1 TB/sec. This dependence on external DRAM incurs latency and power overheads.
##### Programming Complexity
-While tools like CUDA help, optimally mapping and partitioning ML workloads across the massively parallel GPU architecture remains challenging. Achieving both high utilization and memory locality requires low-level tuning [@jia2018dissecting]. Abstractions like TensorFlow can leave performance on the table.
+While tools like CUDA help, optimally mapping and partitioning ML workloads across the massively parallel GPU architecture remains challenging, achieving both high utilization and memory locality requires low-level tuning [@jia2018dissecting]. Abstractions like TensorFlow can leave performance on the table.
##### Limited On-Chip Memory
-GPUs have relatively small on-chip memory caches compared to the large working set requirements of ML models during training. They are reliant on high bandwidth access to external DRAM, which ASICs minimize with large on-chip SRAM.
+GPUs have relatively small on-chip memory caches compared to ML models' large working set requirements during training. They rely on high bandwidth access to external DRAM, which ASICs minimize with large on-chip SRAM.
##### Fixed Architecture
@@ -385,29 +385,29 @@ Unlike FPGAs, the fundamental GPU architecture cannot be altered post-manufactur
#### Case Study
-The recent groundbreaking research conducted by OpenAI [@brown2020language] with their GPT-3 model. GPT-3, a language model consisting of 175 billion parameters, demonstrated unprecedented language understanding and generation capabilities. Its training, which would have taken months on conventional CPUs, was accomplished in a matter of days using powerful GPUs, thus pushing the boundaries of natural language processing (NLP) capabilities.
+The recent groundbreaking research conducted by OpenAI [@brown2020language] with their GPT-3 model. GPT-3, a language model with 175 billion parameters, demonstrated unprecedented language understanding and generation capabilities. Its training, which would have taken months on conventional CPUs, was accomplished in a matter of days using powerful GPUs, thus pushing the boundaries of natural language processing (NLP) capabilities.
### Central Processing Units (CPUs)
-The term CPUs has a long history that dates back to 1955 [@weik1955survey] while the first microprocessor CPU-the Intel 4004-was invented in 1971 ([Who Invented the Microprocessor?](https://computerhistory.org/blog/who-invented-the-microprocessor/)). Compilers compile high-level programming languages like Python, Java, or C to assembly instructions (x86, ARM, RISC-V, etc.) for CPUs to process. The set of instructions a CPU understands is called the "instruction set" and must be agreed upon by both the hardware and software running atop it (See section 5 for a more in-depth description on instruction set architectures-ISAs).
+The term CPUs has a long history that dates back to 1955 [@weik1955survey] while the first microprocessor CPU-the Intel 4004-was invented in 1971 ([Who Invented the Microprocessor?](https://computerhistory.org/blog/who-invented-the-microprocessor/)). Compilers compile high-level programming languages like Python, Java, or C to assemble instructions (x86, ARM, RISC-V, etc.) for CPUs to process. The set of instructions a CPU understands is called the "instruction set." It must be agreed upon by both the hardware and software running atop it (See section 5 for a more in-depth description of instruction set architectures-ISAs).
An overview of significant developments in CPUs:
-* **Single-core Era (1950s- 2000):** This era is known for seeing aggressive microarchitectural improvements. Techniques like speculative execution (executing an instruction before the previous one was done), out-of-order execution (re-ordering instructions to be more effective), and wider issue widths (executing multiple instructions at once) were implemented to increase instruction throughput. The term "System on Chip" also originated in this era as different analog components (components designed with transistors) and digital components (components designed with hardware description languages that are mapped to transistors) were put on the same platform to achieve some task.
-* **Multi-core Era (2000s):** Driven by the decrease of Moore's Law, this era is marked by scaling the number of cores within a CPU. Now tasks can be split across many different cores each with its own datapath and control unit. Many of the issues arising in this era pertained to how to share certain resources, which resources to share, and how to maintain coherency and consistency across all the cores.
-* **Sea of accelerators (2010s):** Again, driven by the decrease of Moore's law, this era is marked by offloading more complicated tasks to accelerators (widgets) attached the the main datapath in CPUs. It's common to see accelerators dedicated to various AI workloads, as well as image/digital processing, and cryptography. In these designs, CPUs are often described more as arbiters, deciding which tasks should be processed rather than doing the processing itself. Any task could still be run on the CPU rather than the accelerators, but the CPU would generally be slower. However, the cost of designing and especially programming the accelerator became be a non-trivial hurdle that led to a spike of interest in design-specific libraries (DSLs).
-* **Presence in data centers:** Although we often hear that GPUs dominate the data center marker, CPUs are still well suited for tasks that don't inherently possess a large amount of parallelism. CPUs often handle serial and small tasks and coordinate the data center as a whole.
+* ** Single-core Era (1950s- 2000): ** This era is known for aggressive microarchitectural improvements. Techniques like speculative execution (executing an instruction before the previous one was done), out-of-order execution (re-ordering instructions to be more effective), and wider issue widths (executing multiple instructions at once) were implemented to increase instruction throughput. The term "System on Chip" also originated in this era as different analog components (components designed with transistors) and digital components (components designed with hardware description languages that are mapped to transistors) were put on the same platform to achieve some task.
+* **Multicore Era (2000s):** Driven by the decrease of Moore's Law, this era is marked by scaling the number of cores within a CPU. Now, tasks can be split across many different cores, each with its own datapath and control unit. Many of the issues in this era pertained to how to share certain resources, which resources to share, and how to maintain coherency and consistency across all the cores.
+* **Sea of accelerators (2010s):** Again, driven by the decrease of Moore's law, this era is marked by offloading more complicated tasks to accelerators (widgets) attached to the main datapath in CPUs. It's common to see accelerators dedicated to various AI workloads, as well as image/digital processing, and cryptography. In these designs, CPUs are often described more as judges, deciding which tasks should be processed rather than doing the processing itself. Any task could still be run on the CPU rather than the accelerators, but the CPU would generally be slower. However, the cost of designing and programming the accelerator became a non-trivial hurdle that sparked interest in design-specific libraries (DSLs).
+* **Presence in data centers:** Although we often hear that GPUs dominate the data center marker, CPUs are still well suited for tasks that don't inherently possess a large amount of parallelism. CPUs often handle serial and small tasks and coordinate the data center.
* **On the edge:** Given the tighter resource constraints on the edge, edge CPUs often only implement a subset of the techniques developed in the sing-core era because these optimizations tend to be heavy on power and area consumption. Edge CPUs still maintain a relatively simple datapath with limited memory capacities.
-Traditionally, CPUs have been synonymous with general-purpose computing-a term that has also changed as the "average" workload a consumer would run changes over time. For example, floating point components were once considered reserved for "scientific computing" so it was usually implemented as a co-processor (a modular component that worked in tandem with the datapath) and seldom deployed to average consumers. Compare this attitude to today, where FPUs are built into every datapath.
+Traditionally, CPUs have been synonymous with general-purpose computing, a term that has also changed as the "average" workload a consumer would run changes over time. For example, floating point components were once considered reserved for "scientific computing," they were usually implemented as a co-processor (a modular component that worked with the datapath) and seldom deployed to average consumers. Compare this attitude to today, where FPUs are built into every datapath.
-#### Advatages
+#### Advantages
-While limited in raw throughput, general-purpose CPUs do provide some practical benefits for AI acceleration.
+While raw throughput is limited, general-purpose CPUs provide practical AI acceleration benefits.
##### General Programmability
-CPUs support diverse workloads beyond ML, providing flexible general-purpose programmability. This versatility comes from their standardized instruction sets and mature compiler ecosystems that allow running any application from databases and web servers to analytics pipelines [@hennessy2019golden].
+CPUs support diverse workloads beyond ML, providing flexible general-purpose programmability. This versatility comes from their standardized instruction sets and mature compiler ecosystems, which allow running any application, from databases and web servers to analytics pipelines [@hennessy2019golden].
This avoids the need for dedicated ML accelerators and enables leveraging existing CPU-based infrastructure for basic ML deployment. For example, X86 servers from vendors like Intel and AMD can run common ML frameworks using Python and TensorFlow packages alongside other enterprise workloads.
@@ -415,29 +415,29 @@ This avoids the need for dedicated ML accelerators and enables leveraging existi
For decades, highly optimized math libraries like [BLAS](https://www.netlib.org/blas/), [LAPACK](https://hpc.llnl.gov/software/mathematical-software/lapack#:~:text=The%20Linear%20Algebra%20PACKage%20(LAPACK,problems%2C%20and%20singular%20value%20decomposition.)), and [FFTW](https://www.fftw.org/) have leveraged vectorized instructions and multithreading on CPUs [@dongarra2009evolution]. Major ML frameworks like PyTorch, TensorFlow, and SciKit-Learn are designed to integrate seamlessly with these CPU math kernels.
-Hardware vendors like Intel and AMD also provide low-level libraries to fully optimize performance for deep learning primitives ([AI Inference Acceleration on CPUs](https://www.intel.com/content/www/us/en/developer/articles/technical/ai-inference-acceleration-on-intel-cpus.html#gs.0w9qn2)). This robust, mature software ecosystem allows quickly deploying ML on existing CPU infrastructure.
+Hardware vendors like Intel and AMD also provide low-level libraries to optimize performance for deep learning primitives fully ([AI Inference Acceleration on CPUs](https://www.intel.com/content/www/us/en/developer/articles/technical/ai-inference-acceleration-on-intel-cpus.html#gs.0w9qn2)). This robust, mature software ecosystem allows quickly deploying ML on existing CPU infrastructure.
##### Wide Availability
The economies of scale of CPU manufacturing, driven by demand across many markets like PCs, servers, and mobile, make them ubiquitously available. Intel CPUs, for example, have powered most servers for decades [@ranganathan2011from]. This wide availability in data centers reduces hardware costs for basic ML deployment.
-Even small embedded devices typically integrate some CPU, enabling edge inference. The ubiquity reduces need for purchasing specialized ML accelerators in many situations.
+Even small embedded devices typically integrate some CPU, enabling edge inference. The ubiquity reduces the need to purchase specialized ML accelerators in many situations.
##### Low Power for Inference
-Optimizations like vector extensions in ARM Neon and Intel AVX provide power efficient integer and floating point throughput optimized for "bursty" workloads like inference [@ignatov2018ai]. While slower than GPUs, CPU inference can be deployed in power-constrained environments. For example, ARM's Cortex-M CPUs now deliver over 1 TOPS of INT8 performance under 1W, enabling keyword spotting and vision applications on edge devices ([ARM](https://community.arm.com/arm-community-blogs/b/architectures-and-processors-blog/posts/armv8_2d00_m-based-processor-software-development-hints-and-tips)).
+Optimizations like ARM Neon and Intel AVX vector extensions provide power-efficient integer and floating point throughput optimized for "bursty" workloads such as inference [@ignatov2018ai]. While slower than GPUs, CPU inference can be deployed in power-constrained environments. For example, ARM's Cortex-M CPUs now deliver over 1 TOPS of INT8 performance under 1W, enabling keyword spotting and vision applications on edge devices ([ARM](https://community.arm.com/arm-community-blogs/b/architectures-and-processors-blog/posts/armv8_2d00_m-based-processor-software-development-hints-and-tips)).
-#### Disadvatages
+#### Disadvantages
-While providing some advantages, general-purpose CPUs also come with limitations for AI workloads.
+While providing some advantages, general-purpose CPUs also have limitations for AI workloads.
##### Lower Throughput than Accelerators
-CPUs lack the specialized architectures for massively parallel processing that GPUs and other accelerators provide. Their general-purpose design results in lower computational throughput for the highly parallelizable math operations common in ML models [@jouppi2017datacenter].
+CPUs lack the specialized architectures for massively parallel processing that GPUs and other accelerators provide. Their general-purpose design reduces computational throughput for the highly parallelizable math operations common in ML models [@jouppi2017datacenter].
##### Not Optimized for Data Parallelism
-The architectures of CPUs are not specifically optimized for data parallel workloads inherent to AI [@sze2017efficient]. They allocate substantial silicon area to instruction decoding, speculative execution, caching, and flow control that provide little benefit for the array operations used in neural networks ([AI Inference Acceleration on CPUs](https://www.intel.com/content/www/us/en/developer/articles/technical/ai-inference-acceleration-on-intel-cpus.html#gs.0w9qn2)). However, modern CPUs are equipped with vector instructions like [AVX-512](https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/what-is-intel-avx-512.html) specifically to accelerate certain key operations like matrix multiplication.
+The architectures of CPUs are not specifically optimized for data parallel workloads inherent to AI [@sze2017efficient]. They allocate substantial silicon area to instruction decoding, speculative execution, caching, and flow control that provides little benefit for the array operations used in neural networks ([AI Inference Acceleration on CPUs](https://www.intel.com/content/www/us/en/developer/articles/technical/ai-inference-acceleration-on-intel-cpus.html#gs.0w9qn2)). However, modern CPUs are equipped with vector instructions like [AVX-512](https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/what-is-intel-avx-512.html) specifically to accelerate certain key operations like matrix multiplication.
GPU streaming multiprocessors, for example, devote most transistors to floating point units instead of complex branch prediction logic. This specialization allows much higher utilization for ML math.
@@ -447,83 +447,83 @@ CPUs suffer from higher latency accessing main memory relative to GPUs and other
##### Power Inefficiency Under Heavy Workloads
-While suitable for intermittent inference, sustaining near-peak throughput for training results in inefficient power consumption on CPUs, especially mobile CPUs [@ignatov2018ai]. Accelerators explicitly optimize the dataflow, memory, and computation for sustained ML workloads. For training large models, CPUs are energy-inefficient.
+While suitable for intermittent inference, sustaining near-peak throughput for training results in inefficient power consumption on CPUs, especially mobile CPUs [@ignatov2018ai]. Accelerators explicitly optimize the data flow, memory, and computation for sustained ML workloads. CPUs are energy-inefficient for training large models.
### Comparison
| Accelerator | Description | Key Advantages | Key Disadvantages |
|-|-|-|-|
-| ASICs | Custom ICs designed for target workload like AI inference | Maximizes perf/watt.
Optimized for tensor ops
Low latency on-chip memory | Fixed architecture lacks flexibility
High NRE cost
Long design cycles |
+| ASICs | Custom ICs designed for target workloads like AI inference | Maximizes perf/watt.
Optimized for tensor ops
Low latency on-chip memory | Fixed architecture lacks flexibility
High NRE cost
Long design cycles |
| FPGAs | Reconfigurable fabric with programmable logic and routing | Flexible architecture
Low latency memory access | Lower perf/watt than ASICs
Complex programming |
| GPUs | Originally for graphics, now used for neural network acceleration | High throughput
Parallel scalability
Software ecosystem with CUDA | Not as power efficient as ASICs.
Require high memory bandwidth |
| CPUs | General purpose processors | Programmability
Ubiquitous availability | Lower performance for AI workloads |
-In general, CPUs provide a readily available baseline, GPUs deliver broadly accessible acceleration, FPGAs offer programmability, and ASICs maximize efficiency for fixed functions. The optimal choice depends on the scale, cost, flexibility and other requirements of the target application.
+In general, CPUs provide a readily available baseline, GPUs deliver broadly accessible acceleration, FPGAs offer programmability, and ASICs maximize efficiency for fixed functions. The optimal choice depends on the target application's scale, cost, flexibility, and other requirements.
-Although first developed for data center deployment, where [cite some benefit that google cites], Google has also put considerable effort into developing Edge TPUs. These Edge TPUs maintain the inspiration from systolic arrays but are tailored to the limited resources accessible at the edge.
+Although first developed for data center deployment, where [cite some benefit that Google cites], Google has also put considerable effort into developing Edge TPUs. These Edge TPUs maintain the inspiration from systolic arrays but are tailored to the limited resources accessible at the edge.
## Hardware-Software Co-Design
Hardware-software co-design is based on the principle that AI systems achieve optimal performance and efficiency when the hardware and software components are designed in tight integration. This involves an iterative, collaborative design cycle where the hardware architecture and software algorithms are concurrently developed and refined with continuous feedback between teams.
-For example, a new neural network model may be prototyped on an FPGA-based accelerator platform to obtain real performance data early in the design process. These results provide feedback to both the hardware designers on potential optimizations as well as the software developers on refinements to the model or framework to better leverage the hardware capabilities. This level of synergy is difficult to achieve with the common practice of software being developed independently to deploy on fixed commodity hardware.
+For example, a new neural network model may be prototyped on an FPGA-based accelerator platform to obtain real performance data early in the design process. These results provide feedback to the hardware designers on potential optimizations and the software developers on refinements to the model or framework to better leverage the hardware capabilities. This level of synergy is difficult to achieve with the common practice of software being developed independently to deploy on fixed commodity hardware.
-Co-design is particularly critical for embedded AI systems which face significant resource constraints like low power budgets, limited memory and compute capacity, and real-time latency requirements. Tight integration between algorithm developers and hardware architects helps unlock optimizations across the stack to meet these restrictions. Enabling techniques include algorithmic improvements like neural architecture search and pruning along with hardware advances like specialized dataflows and memory hierarchies.
+Co-design is critical for embedded AI systems facing significant resource constraints like low power budgets, limited memory and compute capacity, and real-time latency requirements. Tight integration between algorithm developers and hardware architects helps unlock optimizations across the stack to meet these restrictions. Enabling techniques include algorithmic improvements like neural architecture search and pruning and hardware advances like specialized dataflows and memory hierarchies.
By bringing hardware and software design together, rather than developing them separately, holistic optimizations can be made that maximize performance and efficiency. The next sections provide more details on specific co-design approaches.
### The Need for Co-Design
-There are several key factors that make a collaborative hardware-software co-design approach essential for building efficient AI systems.
+Several key factors make a collaborative hardware-software co-design approach essential for building efficient AI systems.
#### Increasing Model Size and Complexity
-State-of-the-art AI models have been rapidly growing in size, enabled by advances in neural architecture design and availability of large datasets. For example, the GPT-3 language model contains 175 billion parameters [@brown2020language], requiring huge computational resources for training. This explosion in model complexity necessitates co-design to develop efficient hardware and algorithms in tandem. Techniques like model compression [@cheng2017survey] and quantization must be co-optimized with the hardware architecture.
+State-of-the-art AI models have been rapidly growing in size, enabled by advances in neural architecture design and the availability of large datasets. For example, the GPT-3 language model contains 175 billion parameters [@brown2020language], requiring huge computational resources for training. This explosion in model complexity necessitates co-design to develop efficient hardware and algorithms in tandem. Techniques like model compression [@cheng2017survey] and quantization must be co-optimized with the hardware architecture.
#### Constraints of Embedded Deployment
-Deploying AI applications on edge devices like mobile phones or smart home appliances introduces significant constraints on resources such as energy, memory, and silicon area [@sze2017efficient]. To enable real-time inference under these restrictions requires co-exploring hardware optimizations like specialized dataflows and compression with efficient neural network design and pruning techniques. Co-design maximizes performance within the tight deployment constraints.
+Deploying AI applications on edge devices like mobile phones or smart home appliances introduces significant constraints on energy, memory, and silicon area [@sze2017efficient]. Enable real-time inference under these restrictions requires co-exploring hardware optimizations like specialized dataflows and compression with efficient neural network design and pruning techniques. Co-design maximizes performance within tight deployment constraints.
#### Rapid Evolution of AI Algorithms
-The field of AI is evolving extremely rapidly, with new model architectures, training methodologies, and software frameworks constantly emerging. For example, Transformers have become hugely popular for NLP just in the last few years [@young2018recent]. Keeping pace with these algorithmic innovations requires hardware-software co-design to quickly adapt platforms and avoid accrued technical debt.
+AI is rapidly evolving, with new model architectures, training methodologies, and software frameworks constantly emerging. For example, Transformers have recently become hugely popular for NLP [@young2018recent]. Keeping pace with these algorithmic innovations requires hardware-software co-design to adapt platforms and avoid accrued technical debt quickly.
#### Complex Hardware-Software Interactions
-There are many subtle interactions and tradeoffs between hardware architectural choices and software optimizations that have significant impacts on overall efficiency. For instance, techniques like tensor partitioning and batching affect parallelism. Data access patterns impact memory utilization. Co-design provides a cross-layer perspective to unravel these dependencies.
+Many subtle interactions and tradeoffs between hardware architectural choices and software optimizations significantly impact overall efficiency. For instance, techniques like tensor partitioning and batching affect parallelism and data access patterns impact memory utilization. Co-design provides a cross-layer perspective to unravel these dependencies.
#### Need for Specialization
-AI workloads benefit from specialized operations like low precision math and customized memory hierarchies. This motivates incorporating custom hardware tailored to neural network algorithms rather than relying solely on flexible software running on generic hardware [@sze2017efficient]. But to realize the benefits, the software stack must explicitly target the custom hardware operations.
+AI workloads benefit from specialized operations like low-precision math and customized memory hierarchies. This motivates incorporating custom hardware tailored to neural network algorithms rather than relying solely on flexible software running on generic hardware [@sze2017efficient]. However, the software stack must explicitly target custom hardware operations to realize the benefits.
#### Demand for Higher Efficiency
-With growing model complexity, there are diminishing returns and overhead from optimizing only the hardware or software in isolation [@putnam2014reconfigurable]. Inevitable tradeoffs arise that require a global optimization across layers. Jointly co-designing hardware and software provides large compound efficiency gains.
+With growing model complexity, diminishing returns and overhead from optimizing only the hardware or software in isolation [@putnam2014reconfigurable] arise. Inevitable tradeoffs arise that require global optimization across layers. Jointly co-designing hardware and software provides large compound efficiency gains.
### Principles of Hardware-Software Co-Design
-To build high-performance and efficient AI systems, there must be tight integration and co-optimization between the underlying hardware architecture and software stack. Neither can be designed in isolation - maximizing their synergies requires a holistic approach known as hardware-software co-design.
+The underlying hardware architecture and software stack must be tightly integrated and co-optimized to build high-performance and efficient AI systems. Neither can be designed in isolation; maximizing their synergies requires a holistic approach known as hardware-software co-design.
The key goal is tailoring the hardware capabilities to match the algorithms and workloads run by the software. This requires a feedback loop between hardware architects and software developers to converge on optimized solutions. Several techniques enable effective co-design:
#### Hardware-Aware Software Optimization
-The software stack can be optimized to better leverage the underlying hardware capabilities:
+The software stack can be optimized to leverage the underlying hardware capabilities better:
* **Parallelism:** Parallelize matrix computations like convolution or attention layers to maximize throughput on vector engines.
* **Memory Optimization:** Tune data layouts to improve cache locality based on hardware profiling. This maximizes reuse and minimizes expensive DRAM access.
-* **Compression:** Lerverage sparsity in the models to reduce storage space as well as save on computation by zero-skipping operations.
-* **Custom Operations:** Incorporate specialized ops like low precision INT4 or bfloat16 into models to capitalize on dedicated hardware support.
+* **Compression:** Use sparsity in the models to reduce storage space and save on computation by zero-skipping operations.
+* **Custom Operations:** Incorporate specialized operations like low-precision INT4 or bfloat16 into models to capitalize on dedicated hardware support.
* **Dataflow Mapping:** Explicitly map model stages to computational units to optimize data movement on hardware.
#### Algorithm-Driven Hardware Specialization
-Hardware can be tailored to better suit the characteristics of ML algorithms:
+Hardware can be tailored to suit the characteristics of ML algorithms better:
* **Custom Datatypes:** Support low precision INT8/4 or bfloat16 in hardware for higher arithmetic density.
* **On-Chip Memory:** Increase SRAM bandwidth and lower access latency to match model memory access patterns.
* **Domain-Specific Ops:** Add hardware units for key ML functions like FFTs or matrix multiplication to reduce latency and energy.
-* **Model Profiling:** Use model simulation and profiling to identify computational hotspots and guide hardware optimization.
+* **Model Profiling:** Use model simulation and profiling to identify computational hotspots and optimize hardware.
The key is collaborative feedback - insights from hardware profiling
guide software optimizations, while algorithmic advances inform hardware
@@ -532,27 +532,27 @@ efficiency gains compared to isolated efforts.
#### Algorithm-Hardware Co-exploration
-Jointly exploring innovations in neural network architectures along with custom hardware design is a powerful co-design technique. This allows finding ideal pairings tailored to each other's strengths [@sze2017efficient].
+A powerful co-design technique involves jointly exploring innovations in neural network architectures and custom hardware design. This allows for finding ideal pairings tailored to each other's strengths [@sze2017efficient].
For instance, the shift to mobile architectures like MobileNets [@howard2017mobilenets] was guided by edge device constraints like model size and latency. The quantization [@jacob2018quantization] and pruning techniques [@gale2019state] that unlocked these efficient models became possible thanks to hardware accelerators with native low-precision integer support and pruning support [@asit2021accelerating].
-Attention-based models have thrived on massively parallel GPUs and ASICs where their computation maps well spatially, as opposed to RNN architectures reliant on sequential processing. Co-evolution of algorithms and hardware unlocked new capabilities.
+Attention-based models have thrived on massively parallel GPUs and ASICs, where their computation maps well spatially, as opposed to RNN architectures, which rely on sequential processing. The co-evolution of algorithms and hardware unlocked new capabilities.
-Effective co-exploration requires close collaboration between algorithm researchers and hardware architects. Rapid prototyping on FPGAs [@zhang2015fpga] or specialized AI simulators allows quickly evaluating different pairings of model architectures and hardware designs pre-silicon.
+Effective co-exploration requires close collaboration between algorithm researchers and hardware architects. Rapid prototyping on FPGAs [@zhang2015fpga] or specialized AI simulators allows quick evaluation of different pairings of model architectures and hardware designs pre-silicon.
-For example, Google's TPU architecture evolved in conjunction with optimizations to TensorFlow models to maximize performance on image classification. This tight feedback loop yielded models tailored for the TPU that would have been unlikely in isolation.
+For example, Google's TPU architecture evolved with optimizations to TensorFlow models to maximize performance on image classification. This tight feedback loop yielded models tailored for the TPU that would have been unlikely in isolation.
-Studies have shown 2-5x higher performance and efficiency gains with algorithm-hardware co-exploration compared to isolated algorithm or hardware optimization efforts [@suda2016throughput]. Parallelizing the joint development also reduces time-to-deployment.
+Studies have shown 2-5x higher performance and efficiency gains with algorithm-hardware co-exploration than isolated algorithm or hardware optimization efforts [@suda2016throughput]. Parallelizing the joint development also reduces time-to-deployment.
-Overall, exploring the tight interdependencies between model innovation and hardware advances unlocks opportunities not visible when tackled sequentially. This synergistic co-design yields solutions greater than the sum of their parts.
+Overall, exploring the tight interdependencies between model innovation and hardware advances unlocks opportunities that must be visible when tackled sequentially. This synergistic co-design yields solutions greater than the sum of their parts.
### Challenges
-While collaborative co-design can improve efficiency, adaptability, and time-to-market, it also comes with engineering and organizational challenges.
+While collaborative co-design can improve efficiency, adaptability, and time to market, it also has engineering and organizational challenges.
#### Increased Prototyping Costs
-More extensive prototyping is required to evaluate different hardware-software pairings. The need for rapid, iterative prototypes on FPGAs or emulators increases validation overhead. For example, Microsoft found more prototypes needed for co-design of an AI accelerator versus sequential design [@fowers2018configurable].
+More extensive prototyping is required to evaluate different hardware-software pairings. The need for rapid, iterative prototypes on FPGAs or emulators increases validation overhead. For example, Microsoft found that more prototypes were needed to co-design an AI accelerator than sequential design [@fowers2018configurable].
#### Team and Organizational Hurdles
@@ -560,7 +560,7 @@ Co-design requires close coordination between traditionally disconnected hardwar
#### Simulation and Modeling Complexity
-Capturing subtle interactions between hardware and software layers for joint simulation and modeling adds significant complexity. Full cross-layer abstractions are difficult to construct quantitatively pre-implementation. This makes holistic optimizations harder to quantify ahead of time.
+Capturing subtle interactions between hardware and software layers for joint simulation and modeling adds significant complexity. Full cross-layer abstractions are difficult to construct quantitatively before implementation, making holistic optimizations harder to quantify ahead of time.
#### Over-Specialization Risks
@@ -568,11 +568,11 @@ Tight co-design bears the risk of overfitting optimizations to current algorithm
#### Adoption Challenges
-Engineers comfortable with established discrete hardware or software design practices may resist adopting unfamiliar collaborative workflows. Projects could face friction in transitioning to co-design, despite long-term benefits.
+Engineers comfortable with established discrete hardware or software design practices may only accept familiar collaborative workflows. Despite the long-term benefits, projects could face friction in transitioning to co-design.
## Software for AI Hardware
-At this time it should be obvious that specialized hardware accelerators like GPUs, TPUs, and FPGAs are essential to delivering high-performance artificial intelligence applications. But to leverage these hardware platforms effectively, an extensive software stack is required, spanning the entire development and deployment lifecycle. Frameworks and libraries form the backbone of AI hardware, offering sets of robust, pre-built code, algorithms, and functions specifically optimized to perform a wide array of AI tasks on the different hardware. They are designed to simplify the complexities involved in utilizing the hardware from scratch, which can be time-consuming and prone to error. Software plays an important role in the following:
+Specialized hardware accelerators like GPUs, TPUs, and FPGAs are essential to delivering high-performance artificial intelligence applications. However, an extensive software stack is required to leverage these hardware platforms effectively, spanning the entire development and deployment lifecycle. Frameworks and libraries form the backbone of AI hardware, offering sets of robust, pre-built code, algorithms, and functions specifically optimized to perform various AI tasks on different hardware. They are designed to simplify the complexities of utilizing the hardware from scratch, which can be time-consuming and prone to error. Software plays an important role in the following:
* Providing programming abstractions and models like CUDA and OpenCL to map computations onto accelerators.
* Integrating accelerators into popular deep learning frameworks like TensorFlow and PyTorch.
@@ -580,26 +580,25 @@ At this time it should be obvious that specialized hardware accelerators like GP
* Simulation platforms to model hardware and software together.
* Infrastructure to manage deployment on accelerators.
-
-This expansive software ecosystem is as important as the hardware itself in delivering performant and efficient AI applications. This section provides an overview of the tools available at each layer of the stack to enable developers to build and run AI systems powered by hardware acceleration.
+This expansive software ecosystem is as important as the hardware in delivering performant and efficient AI applications. This section overviews the tools available at each stack layer to enable developers to build and run AI systems powered by hardware acceleration.
### Programming Models {#sec-programming-models}
Programming models provide abstractions to map computations and data onto heterogeneous hardware accelerators:
* **[CUDA](https://developer.nvidia.com/cuda-toolkit):** Nvidia's parallel programming model to leverage GPUs using extensions to languages like C/C++. Allows launching kernels across GPU cores [@luebke2008cuda].
-* **[OpenCL](https://www.khronos.org/opencl/):** Open standard for writing programs spanning CPUs, GPUs, FPGAs and other accelerators. Specifies a heterogeneous computing framework [@munshi2009opencl].
+* **[OpenCL](https://www.khronos.org/opencl/):** Open standard for writing programs spanning CPUs, GPUs, FPGAs, and other accelerators. Specifies a heterogeneous computing framework [@munshi2009opencl].
* **[OpenGL/WebGL](https://www.opengl.org):** 3D graphics programming interfaces that can map general-purpose code to GPU cores [@segal1999opengl].
-* **[Verilog](https://www.verilog.com)/VHDL**: Hardware description languages (HDLs) used to configure FPGAs as AI accelerators by specifying digital circuits [@gannot1994verilog].
-* **[TVM](https://tvm.apache.org):** Compiler framework providing Python frontend to optimize and map deep learning models onto diverse hardware back-ends [@chen2018tvm].
+* **[Verilog](https://www.verilog.com)/VHDL:** Hardware description languages (HDLs) used to configure FPGAs as AI accelerators by specifying digital circuits [@gannot1994verilog].
+* **[TVM](https://tvm.apache.org):** A Compiler framework providing a Python frontend to optimize and map deep learning models onto diverse hardware backends [@chen2018tvm].
-Key challenges include expressing parallelism, managing memory across devices, and matching algorithms to hardware capabilities. Abstractions must balance portability with allowing hardware customization. Programming models enable developers to harness accelerators without hardware expertise. More of these details are discussed in the [AI frameworks](../frameworks/frameworks.qmd) section.
+Key challenges include expressing parallelism, managing memory across devices, and matching algorithms to hardware capabilities. Abstractions must balance portability with allowing hardware customization. Programming models enable developers to harness accelerators without hardware expertise. These details are discussed in the [AI frameworks](../frameworks/frameworks.qmd) section.
:::{#exr-tvm .callout-exercise collapse="true"}
### Software for AI Hardware - TVM
-We've learned that fancy AI hardware needs special software to work its magic. TVM is like a super-smart translator, turning your code into instructions that accelerators understand. In this Colab, we'll use TVM to make a pretend accelerator called VTA do matrix multiplication super fast. Ready to see how software powers up hardware?
+We've learned that fancy AI hardware needs special software to work magic. TVM is like a super-smart translator, turning your code into instructions that accelerators understand. In this Colab, we'll use TVM to make a pretend accelerator called VTA do matrix multiplication super fast. Ready to see how software powers up hardware?
[](https://colab.research.google.com/github/uwsampl/tutorial/blob/master/notebook/04a_TVM_Tutorial_VTA_Mat_Mult.ipynb)
@@ -607,83 +606,83 @@ We've learned that fancy AI hardware needs special software to work its magic. T
### Libraries and Runtimes
-Specialized libraries and runtimes provide software abstractions to access and maximize utilization of AI accelerators:
+Specialized libraries and runtimes provide software abstractions to access and maximize the utilization of AI accelerators:
-* **Math Libraries:** Highly optimized implementations of linear algebra primitives like GEMM, FFTs, convolutions etc. tailored to target hardware. [Nvidia cuBLAS](https://developer.nvidia.com/cublas), [Intel MKL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html), and [Arm compute libraries](https://www.arm.com/technologies/compute-library) are examples.
-* **Framework Integrations:** Libraries to accelerate deep learning frameworks like TensorFlow, PyTorch, and MXNet on supported hardware. For example, [cuDNN](https://developer.nvidia.com/cudnn) for accelerating CNNs on Nvidia GPUs.
-* **Runtimes:** Software to handle execution on accelerators, including scheduling, synchronization, memory management and other tasks. [Nvidia TensorRT](https://developer.nvidia.com/tensorrt) is an inference optimizer and runtime.
+* **Math Libraries:** Highly optimized implementations of linear algebra primitives like GEMM, FFTs, convolutions, etc., tailored to the target hardware. [Nvidia cuBLAS](https://developer.nvidia.com/cublas), [Intel MKL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html), and [Arm compute libraries](https://www.arm.com/technologies/compute-library) are examples.
+* **Framework Integrations:** Libraries to accelerate deep learning frameworks like TensorFlow, PyTorch, and MXNet on supported hardware. For example, [cuDNN](https://developer.nvidia.com/cudnn) accelerates CNNs on Nvidia GPUs.
+* **Runtimes:** Software to handle accelerator execution, including scheduling, synchronization, memory management, and other tasks. [Nvidia TensorRT](https://developer.nvidia.com/tensorrt) is an inference optimizer and runtime.
* **Drivers and Firmware:** Low-level software to interface with hardware, initialize devices, and handle execution. Vendors like Xilinx provide drivers for their accelerator boards.
For instance, PyTorch integrators use cuDNN and cuBLAS libraries to accelerate training on Nvidia GPUs. The TensorFlow XLA runtime optimizes and compiles models for accelerators like TPUs. Drivers initialize devices and offload operations.
-The challenges include efficiently partitioning and scheduling workloads across heterogeneous devices like multi-GPU nodes. Runtimes must also minimize overhead of data transfers and synchronization.
+The challenges include efficiently partitioning and scheduling workloads across heterogeneous devices like multi-GPU nodes. Runtimes must also minimize the overhead of data transfers and synchronization.
-Libraries, runtimes and drivers provide optimized building blocks that deep learning developers can leverage to tap into accelerator performance without hardware programming expertise. Their optimization is essential for production deployments.
+Libraries, runtimes, and drivers provide optimized building blocks that deep learning developers can leverage to tap into accelerator performance without hardware programming expertise. Their optimization is essential for production deployments.
### Optimizing Compilers
-Optimizing compilers play a key role in extracting maximum performance and efficiency from hardware accelerators for AI workloads. They apply optimizations spanning algorithmic changes, graph-level transformations, and low-level code generation.
+Optimizing compilers is key in extracting maximum performance and efficiency from hardware accelerators for AI workloads. They apply optimizations spanning algorithmic changes, graph-level transformations, and low-level code generation.
* **Algorithm Optimization:** Techniques like quantization, pruning, and neural architecture search to enhance model efficiency and match hardware capabilities.
* **Graph Optimizations:** Graph-level optimizations like operator fusion, rewriting, and layout transformations to optimize performance on target hardware.
* **Code Generation:** Generating optimized low-level code for accelerators from high-level models and frameworks.
-For example, the TVM open compiler stack applies quantization for a BERT model targeting Arm GPUs. It fuses pointwise convolution operations and transforms weight layout to optimize memory access. Finally it emits optimized OpenGL code to run the workload on the GPU.
+For example, the TVM open compiler stack applies quantization for a BERT model targeting Arm GPUs. It fuses pointwise convolution operations and transforms the weight layout to optimize memory access. Finally, it emits optimized OpenGL code to run the GPU workload.
Key compiler optimizations include maximizing parallelism, improving data locality and reuse, minimizing memory footprint, and exploiting custom hardware operations. Compilers build and optimize machine learning workloads holistically across hardware components like CPUs, GPUs, and other accelerators.
-However, efficiently mapping complex models introduces challenges like efficiently partitioning workloads across heterogeneous devices. Production-level compilers also require extensive time tuning on representative workloads. Still, optimizing compilers are indispensable in unlocking the full capabilities of AI accelerators.
+However, efficiently mapping complex models introduces challenges like efficiently partitioning workloads across heterogeneous devices. Production-level compilers also require extensive time tuning on representative workloads. Still, optimizing compilers is indispensable in unlocking the full capabilities of AI accelerators.
### Simulation and Modeling
Simulation software is important in hardware-software co-design. It enables joint modeling of proposed hardware architectures and software stacks:
* **Hardware Simulation:** Platforms like [Gem5](https://www.gem5.org) allow detailed simulation of hardware components like pipelines, caches, interconnects, and memory hierarchies. Engineers can model hardware changes without physical prototyping [@binkert2011gem5].
-* **Software Simulation:** Compiler stacks like [TVM](https://tvm.apache.org) support simulation of machine learning workloads to estimate performance on target hardware architectures. This assists with software optimizations.
+* **Software Simulation:** Compiler stacks like [TVM](https://tvm.apache.org) support the simulation of machine learning workloads to estimate performance on target hardware architectures. This assists with software optimizations.
* **Co-simulation:** Unified platforms like the SCALE-Sim [@samajdar2018scale] integrate hardware and software simulation into a single tool. This enables what-if analysis to quantify the system-level impacts of cross-layer optimizations early in the design cycle.
-For example, an FPGA-based AI accelerator design could be simulated using Verilog hardware description language and synthesized into a Gem5 model. Verilog is well-suited for describing the digital logic and interconnects that make up the accelerator architecture. Using Verilog allows the designer to specify the datapaths, control logic, on-chip memories, and other components that will be implemented in the FPGA fabric. Once the Verilog design is complete, it can be synthesized into a model that simulates the behavior of the hardware, such as using the Gem5 simulator. Gem5 is useful for this task because it allows modeling of full systems including processors, caches, buses, and custom accelerators. Gem5 supports interfacing Verilog models of hardware to the simulation, enabling unified system modeling.
+For example, an FPGA-based AI accelerator design could be simulated using Verilog hardware description language and synthesized into a Gem5 model. Verilog is well-suited for describing the digital logic and interconnects of the accelerator architecture. Verilog allows the designer to specify the datapaths, control logic, on-chip memories, and other components implemented in the FPGA fabric. Once the Verilog design is complete, it can be synthesized into a model that simulates the behavior of the hardware, such as using the Gem5 simulator. Gem5 is useful for this task because it allows the modeling of full systems, including processors, caches, buses, and custom accelerators. Gem5 supports interfacing Verilog models of hardware to the simulation, enabling unified system modeling.
-The synthesized FPGA accelerator model could then have ML workloads simulated using TVM compiled onto it within the Gem5 environment for unified modeling. TVM allows optimized compilation of ML models onto heterogeneous hardware like FPGAs. Running TVM-compiled workloads on the accelerator within the Gem5 simulation provides an integrated way to validate and refine the hardware design, software stack, and system integration before ever needing to physically realize the accelerator on a real FPGA.
+The synthesized FPGA accelerator model could then have ML workloads simulated using TVM compiled onto it within the Gem5 environment for unified modeling. TVM allows optimized compilation of ML models onto heterogeneous hardware like FPGAs. Running TVM-compiled workloads on the accelerator within the Gem5 simulation provides an integrated way to validate and refine the hardware design, software stack, and system integration before physically realizing the accelerator on a real FPGA.
This type of co-simulation provides estimations of overall metrics like throughput, latency, and power to guide co-design before expensive physical prototyping. They also assist with partitioning optimizations between hardware and software to guide design tradeoffs.
-However, limitations exist in accurately modeling subtle low-level interactions between components. Quantified simulations are an estimate but cannot wholly replace physical prototypes and testing. Still, unified simulation and modeling provides invaluable early insights into system-level optimization opportunities during the co-deign process.
+However, accuracy in modeling subtle low-level interactions between components is limited. Quantified simulations are estimates but cannot wholly replace physical prototypes and testing. Still, unified simulation and modeling provide invaluable early insights into system-level optimization opportunities during the co-design process.
## Benchmarking AI Hardware
-Benchmarking is a critical process that quantifies and compares the performance of various hardware platforms designed to speed up artificial intelligence applications. It guides purchasing decisions, development focus, and performance optimization efforts for both hardware manufacturers and software developers.
+Benchmarking is a critical process that quantifies and compares the performance of various hardware platforms designed to speed up artificial intelligence applications. It guides purchasing decisions, development focus, and performance optimization efforts for hardware manufacturers and software developers.
-The [benchmarking chapter](../benchmarking/benchmarking.qmd) explores this topic in great detail and why it has become an indispensable part of the AI hardware development cycle and how it impacts the broader technology landscape. Here, we will briefly review the main concepts but refer you to the chapter for more details.
+The [benchmarking chapter](../benchmarking/benchmarking. cmd) explores this topic in great detail, explaining why it has become an indispensable part of the AI hardware development cycle and how it impacts the broader technology landscape. Here, we will briefly review the main concepts, but we recommend that you refer to the chapter for more details.
-Benchmarking suites such as MLPerf, Fathom, and AI Benchmark offer a set of standardized tests that can be used across different hardware platforms. These suites measure AI accelerator performance across various neural networks and machine learning tasks, from basic image classification to complex language processing. By providing a common ground for comparison, they help ensure that performance claims are consistent and verifiable. These "tools" are applied not only to guide the development of hardware but also to ensure that the software stack leverages the full potential of the underlying architecture.
+Benchmarking suites such as MLPerf, Fathom, and AI Benchmark offer a set of standardized tests that can be used across different hardware platforms. These suites measure AI accelerator performance across various neural networks and machine learning tasks, from basic image classification to complex language processing. Providing a common ground for Comparison, they help ensure that performance claims are consistent and verifiable. These "tools" are applied not only to guide the development of hardware but also to ensure that the software stack leverages the full potential of the underlying architecture.
-* **MLPerf**: Includes a broad set of benchmarks covering both training [@mattson2020mlperf] and inference [@reddi2020mlperf] for a range of machine learning tasks.
-* **Fathom**: Focuses on core operations found in deep learning models, emphasizing their execution on different architectures [@adolf2016fathom].
-* **AI Benchmark**: Targets mobile and consumer devices, assessing AI performance in end-user applications [@ignatov2018ai].
+* **MLPerf:** Includes a broad set of benchmarks covering both training [@mattson2020mlperf] and inference [@reddi2020mlperf] for a range of machine learning tasks.
+* **Fathom:** Focuses on core operations in deep learning models, emphasizing their execution on different architectures [@adolf2016fathom].
+* **AI Benchmark:** Targets mobile and consumer devices, assessing AI performance in end-user applications [@ignatov2018ai].
Benchmarks also have performance metrics that are the quantifiable measures used to evaluate the effectiveness of AI accelerators. These metrics provide a comprehensive view of an accelerator's capabilities and are used to guide the design and selection process for AI systems. Common metrics include:
-* **Throughput**: Usually measured in operations per second, this metric indicates the volume of computations an accelerator can handle.
-* **Latency**: The time delay from input to output in a system, vital for real-time processing tasks.
-* **Energy Efficiency**: Calculated as computations per watt, representing the trade-off between performance and power consumption.
-* **Cost Efficiency**: This evaluates the cost of operation relative to performance, an essential metric for budget-conscious deployments.
-* **Accuracy**: Particularly in inference tasks, the precision of computations is critical and sometimes balanced against speed.
-* **Scalability**: The ability of the system to maintain performance gains as the computational load scales up.
+* **Throughput:** Usually measured in operations per second, this metric indicates the volume of computations an accelerator can handle.
+* **Latency:** The time delay from input to output in a system is vital for real-time processing tasks.
+* **Energy Efficiency:** Calculated as computations per watt, representing the tradeoff between performance and power consumption.
+* **Cost Efficiency:** This evaluates the cost of operation relative to performance, an essential metric for budget-conscious deployments.
+* **Accuracy:** In inference tasks, the precision of computations is critical and sometimes balanced against speed.
+* **Scalability:** The ability of the system to maintain performance gains as the computational load scales up.
-Benchmark results give insights beyond just numbers - they can reveal bottlenecks in the software and hardware stack. For example, benchmarks may show how increased batch size improves GPU utilization by providing more parallelism. Or how compiler optimizations boost TPU performance. These learnings enable continuous optimization [@jia2019beyond].
+Benchmark results give insights beyond just numbers—they can reveal bottlenecks in the software and hardware stack. For example, benchmarks may show how increased batch size improves GPU utilization by providing more parallelism or how compiler optimizations boost TPU performance. These learnings enable continuous optimization [@jia2019beyond].
-Standardized benchmarking provides quantified, comparable evaluation of AI accelerators to inform design, purchasing, and optimization. But real-world performance validation remains essential as well [@zhu2018benchmarking].
+Standardized benchmarking provides a quantified, comparable evaluation of AI accelerators to inform design, purchasing, and optimization. However, real-world performance validation remains essential as well [@zhu2018benchmarking].
## Challenges and Solutions
-AI accelerators offer impressive performance improvements, but their integration into the broader AI landscape is often hindered by significant portability and compatibility challenges. The crux of the issue lies in the diversity of the AI ecosystem - a vast array of machine learning accelerators, frameworks and programming languages exists, each with its unique features and requirements.
+AI accelerators offer impressive performance improvements, but significant portability and compatibility challenges often need to be improved in their integration into the broader AI landscape. The crux of the issue lies in the diversity of the AI ecosystem—a vast array of machine learning accelerators, frameworks, and programming languages exist, each with its unique features and requirements.
### Portability/Compatibility Issues
-Developers frequently encounter difficulties when attempting to transfer their AI models from one hardware environment to another. For example, a machine learning model developed for a desktop environment in Python using the PyTorch framework, optimized for an Nvidia GPU, may not easily transition to a more constrained device such as the Arduino Nano 33 BLE. This complexity stems from stark differences in programming requirements - Python and PyTorch on the desktop versus a C++ environment on an Arduino, not to mention the shift from x86 architecture to ARM ISA.
+Developers frequently encounter difficulties transferring their AI models from one hardware environment to another. For example, a machine learning model developed for a desktop environment in Python using the PyTorch framework, optimized for an Nvidia GPU, may not easily transition to a more constrained device such as the Arduino Nano 33 BLE. This complexity stems from stark differences in programming requirements - Python and PyTorch on the desktop versus a C++ environment on an Arduino, not to mention the shift from x86 architecture to ARM ISA.
-These divergences highlight the intricacy of portability within AI systems. Moreover, the rapid advancement in AI algorithms and models means that hardware accelerators must continually adapt, creating a moving target for compatibility. The absence of universal standards and interfaces compounds the issue, making it challenging to deploy AI solutions consistently across various devices and platforms.
+These divergences highlight the intricacy of portability within AI systems. Moreover, the rapid advancement in AI algorithms and models means that hardware accelerators must continually adapt, creating a moving target for compatibility. The absence of universal standards and interfaces compounds the issue, making deploying AI solutions consistently across various devices and platforms challenging.
#### Solutions and Strategies
@@ -691,35 +690,35 @@ To address these hurdles, the AI industry is moving towards several solutions:
##### Standardization Initiatives
-The [Open Neural Network Exchange (ONNX)](https://onnx.ai/) is at the forefront of this pursuit, proposing an open and shared ecosystem that promotes model interchangeability. ONNX facilitates the use of AI models across various frameworks, allowing for models trained in one environment to be efficiently deployed in another, which significantly reduces the need for time-consuming rewrites or adjustments.
+The [Open Neural Network Exchange (ONNX)](https://onnx.ai/) is at the forefront of this pursuit, proposing an open and shared ecosystem that promotes model interchangeability. ONNX facilitates the use of AI models across various frameworks, allowing models trained in one environment to be efficiently deployed in another, significantly reducing the need for time-consuming rewrites or adjustments.
##### Cross-Platform Frameworks
-Complementing the standardization efforts, cross-platform frameworks such as TensorFlow Lite and PyTorch Mobile have been developed specifically to create cohesion between diverse computational environments ranging from desktops to mobile and embedded devices. These frameworks offer streamlined, lightweight versions of their parent frameworks, ensuring compatibility and functional integrity across different hardware types without sacrificing performance. This ensures that developers can create applications with the confidence that they will work on a multitude of devices, bridging a gap that has traditionally posed a considerable challenge in AI development.
+Complementing the standardization efforts, cross-platform frameworks such as TensorFlow Lite and PyTorch Mobile have been developed specifically to create cohesion between diverse computational environments ranging from desktops to mobile and embedded devices. These frameworks offer streamlined, lightweight versions of their parent frameworks, ensuring compatibility and functional integrity across different hardware types without sacrificing performance. This ensures that developers can create applications with the confidence that they will work on many devices, bridging a gap that has traditionally posed a considerable challenge in AI development.
##### Hardware-agnostic Platforms
-The rise of hardware-agnostic platforms has also played an important role in democratizing the use of AI. By creating environments where AI applications can be executed on various accelerators, these platforms remove the burden of hardware-specific coding from developers. This abstraction not only simplifies the development process but also opens up new possibilities for innovation and application deployment, free from the constraints of hardware specifications.
+The rise of hardware-agnostic platforms has also played an important role in democratizing the use of AI. By creating environments where AI applications can be executed on various accelerators, these platforms remove the burden of hardware-specific coding from developers. This abstraction simplifies the development process and opens up new possibilities for innovation and application deployment, free from the constraints of hardware specifications.
##### Advanced Compilation Tools
-In addition, the advent of advanced compilation tools like TVM-an end-to-end tensor compiler-offers an optimized path through the jungle of diverse hardware architectures. TVM equips developers with the means to fine-tune machine learning models for a broad spectrum of computational substrates, ensuring optimal performance and avoiding the need for manual model adjustment each time there is a shift in the underlying hardware.
+In addition, the advent of advanced compilation tools like TVM, an end-to-end tensor compiler, offers an optimized path through the jungle of diverse hardware architectures. TVM equips developers with the means to fine-tune machine learning models for a broad spectrum of computational substrates, ensuring optimal performance and avoiding manual model adjustment each time there is a shift in the underlying hardware.
##### Community and Industry Collaboration
-The collaboration between open-source communities and industry consortia cannot be understated. These collective bodies are instrumental in forming shared standards and best practices that all developers and manufacturers can adhere to. Such collaboration fosters a more unified and synergistic AI ecosystem, significantly diminishing the prevalence of portability issues and smoothing the path toward global AI integration and advancement. Through these combined efforts, the field of AI is steadily moving toward a future where seamless model deployment across various platforms becomes a standard, rather than an exception.
+The collaboration between open-source communities and industry consortia cannot be understated. These collective bodies are instrumental in forming shared standards and best practices that all developers and manufacturers can adhere to. Such collaboration fosters a more unified and synergistic AI ecosystem, significantly diminishing the prevalence of portability issues and smoothing the path toward global AI integration and advancement. Through these combined efforts, AI is steadily moving toward a future where seamless model deployment across various platforms becomes a standard rather than an exception.
-Solving the portability challenges is crucial for the AI field to realize the full potential of hardware accelerators in a dynamic and diverse technological landscape. It requires a concerted effort from hardware manufacturers, software developers, and standard bodies to create a more interoperable and flexible environment. With continued innovation and collaboration, the AI community can pave the way for seamless integration and deployment of AI models across a multitude of platforms.
+Solving the portability challenges is crucial for the AI field to realize the full potential of hardware accelerators in a dynamic and diverse technological landscape. It requires a concerted effort from hardware manufacturers, software developers, and standard bodies to create a more interoperable and flexible environment. With continued innovation and collaboration, the AI community can pave the way for seamless integration and deployment of AI models across many platforms.
### Power Consumption Concerns
-Power consumption is a crucial issue in the development and operation of data center AI accelerators, like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) [@jouppi2017indatacenter] [@norrie2021design] [@jouppi2023tpu]. These powerful components are the backbone of contemporary AI infrastructure, but their high energy demands contribute to the environmental impact of technology and drive up operational costs significantly. As data processing needs become more complex, with the popularity of AI and deep learning increasing, there's a pressing demand for GPUs and TPUs that can deliver the necessary computational power more efficiently. The impact of such advancements is two-fold: they can lower the environmental footprint of these technologies and also reduce the cost of running AI applications.
+Power consumption is a crucial issue in the development and operation of data center AI accelerators, like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) [@jouppi2017indatacenter] [@norrie2021design] [@jouppi2023tpu]. These powerful components are the backbone of contemporary AI infrastructure, but their high energy demands contribute to the environmental impact of technology and drive up operational costs significantly. As data processing needs become more complex, with the popularity of AI and deep learning increasing, there's a pressing demand for GPUs and TPUs that can deliver the necessary computational power more efficiently. The impact of such advancements is two-fold: they can lower these technologies' environmental footprint and reduce the cost of running AI applications.
Emerging hardware technologies are at the cusp of revolutionizing power efficiency in this sector. Photonic computing, for instance, uses light rather than electricity to carry information, offering a promise of high-speed processing with a fraction of the power usage. We delve deeper into this and other innovative technologies in the "Emerging Hardware Technologies" section, exploring their potential to address current power consumption challenges.
-At the edge of the network, AI accelerators are engineered to process data on devices like smartphones, IoT sensors, and smart wearables. These devices often work under severe power limitations, necessitating a careful balancing act between performance and power usage. A high-performance AI model may provide quick results but at the cost of depleting battery life swiftly and increasing thermal output, which may affect the device's functionality and durability. The stakes are higher for devices deployed in remote or hard-to-reach areas, where consistent power supply cannot be guaranteed, underscoring the need for low-power consuming solutions.
+At the edge of the network, AI accelerators are engineered to process data on devices like smartphones, IoT sensors, and smart wearables. These devices often work under severe power limitations, necessitating a careful balancing act between performance and power usage. A high-performance AI model may provide quick results but at the cost of depleting battery life swiftly and increasing thermal output, which may affect the device's functionality and durability. The stakes are higher for devices deployed in remote or hard-to-reach areas, where consistent power supply cannot be guaranteed, underscoring the need for low-power-consuming solutions.
-The challenge of power efficiency at the edge is further compounded by latency issues. Edge AI applications in fields such as autonomous driving and healthcare monitoring require not just speed but also precision and reliability, as delays in processing can lead to serious safety risks. For these applications, developers are compelled to optimize both the AI algorithms and the hardware design to strike an optimal balance between power consumption and latency.
+Latency issues further compound the challenge of power efficiency at the edge. Edge AI applications in fields such as autonomous driving and healthcare monitoring require speed, precision, and reliability, as delays in processing can lead to serious safety risks. For these applications, developers must optimize both the AI algorithms and the hardware design to strike an optimal balance between power consumption and latency.
This optimization effort is not just about making incremental improvements to existing technologies; it's about rethinking how and where we process AI tasks. By designing AI accelerators that are both power-efficient and capable of quick processing, we can ensure these devices serve their intended purposes without unnecessary energy use or compromised performance. Such developments could propel the widespread adoption of AI across various sectors, enabling smarter, safer, and more sustainable use of technology.
@@ -727,51 +726,53 @@ This optimization effort is not just about making incremental improvements to ex
Resource constraints also pose a significant challenge for Edge AI accelerators, as these specialized hardware and software solutions must deliver robust performance within the limitations of edge devices. Due to power and size limitations, edge AI accelerators often have restricted computation, memory, and storage capacity [@lin2022ondevice]. This scarcity of resources necessitates a careful allocation of processing capabilities to execute machine learning models efficiently.
-Moreover, managing constrained resources demands innovative approaches, including model quantization [@lin2023awq] [@Li2020Additive], pruning [@wang2020apq], and optimizing inference pipelines. Edge AI accelerators must strike a delicate balance between providing meaningful AI functionality and not exhausting the available resources, all while maintaining low power consumption. Overcoming these resource constraints is crucial to ensure the successful deployment of AI at the edge, where many applications, from IoT to mobile devices, rely on the efficient use of limited hardware resources to deliver real-time and intelligent decision-making.
+Moreover, managing constrained resources demands innovative approaches, including model quantization [@lin2023awq] [@Li2020Additive], pruning [@wang2020apq], and optimizing inference pipelines. Edge AI accelerators must strike a delicate balance between providing meaningful AI functionality and not exhausting available resources while maintaining low power consumption. Overcoming these resource constraints is crucial to ensure the successful deployment of AI at the edge, where many applications, from IoT to mobile devices, rely on efficiently using limited hardware resources to deliver real-time and intelligent decision-making.
## Emerging Technologies
-Thus far we have discussed AI hardware technology in the context of conventional von Neumann architecture design and CMOS-based implementation. These specialized AI chips offer benefits like higher throughput and power efficiency but rely on traditional computing principles. The relentless growth in demand for AI compute power is driving innovations in integration methods for AI hardware.
+Thus far, we have discussed AI hardware technology in the context of conventional von Neumann architecture design and CMOS-based implementation. These specialized AI chips offer benefits like higher throughput and power efficiency but rely on traditional computing principles. The relentless growth in demand for AI computing power is driving innovations in integration methods for AI hardware.
-Two leading approaches have emerged for maximizing compute density - wafer-scale integration and chiplet-based architectures, which we will discuss in this section. Looking much further ahead, we will look into emerging technologies that diverge from conventional architectures and adopt fundamentally different approaches for AI-specialized computing.
+Two leading approaches have emerged for maximizing compute density—wafer-scale integration and chiplet-based architectures—which we will discuss in this section. Looking much further ahead, we will examine emerging technologies that diverge from conventional architectures and adopt fundamentally different approaches for AI-specialized computing.
-Some of these unconventional paradigms include neuromorphic computing which mimics biological neural networks, quantum computing that leverages quantum mechanical effects, and optical computing utilizing photons instead of electrons. Beyond novel computing substrates, new device technologies are enabling additional gains through better memory and interconnect.
+Some of these unconventional paradigms include neuromorphic computing, which mimics biological neural networks; quantum computing, which leverages quantum mechanical effects; and optical computing, which utilizes photons instead of electrons. Beyond novel computing substrates, new device technologies are enabling additional gains through better memory and interconnecting.
Examples include memristors for in-memory computing and nanophotonics for integrated photonic communication. Together, these technologies offer the potential for orders of magnitude improvements in speed, efficiency, and scalability compared to current AI hardware. We will examine these in this section.
### Integration Methods
-Integration methods refer to the approaches used to combine and interconnect the various computational and memory components in an AI chip or system. The goal of integration is to maximize performance, power efficiency, and density by closely linking the key processing elements.
+Integration methods refer to the approaches used to combine and interconnect an AI chip or system's various computational and memory components. By closely linking the key processing elements, integration aims to maximize performance, power efficiency, and density.
-In the past, AI compute was primarily performed on CPUs and GPUs built using conventional integration methods. These discrete components were manufactured separately then connected together on a board. However, this loose integration creates bottlenecks like data transfer overheads.
+In the past, AI computing was primarily performed on CPUs and GPUs built using conventional integration methods. These discrete components were manufactured separately and connected together on a board. However, this loose integration creates bottlenecks, such as data transfer overheads.
-As AI workloads have grown, there is increasing demand for tighter integration between compute, memory, and communication elements. Some key drivers of integration include:
+As AI workloads have grown, there is increasing demand for tighter integration between computing, memory, and communication elements. Some key drivers of integration include:
* **Minimizing data movement:** Tight integration reduces latency and power for moving data between components. This improves efficiency.
-* **Customization:** Tailoring all components of a system to AI workloads allows optimizations throughout the hardware stack.
-* **Parallelism:** Integrating a large number of processing elements enables massively parallel computation.
-* **Density:** Tighter integration allows packing more transistors and memory into a given area.
+* **Customization:** Tailoring all system components to AI workloads allows optimizations throughout the hardware stack.
+* **Parallelism:** Integrating many processing elements enables massively parallel computation.
+* **Density:** Tighter integration allows more transistors and memory to be packed into a given area.
* **Cost:** Economies of scale from large integrated systems can reduce costs.
In response, new manufacturing techniques like wafer-scale fabrication and advanced packaging now allow much higher levels of integration. The goal is to create unified, specialized AI compute complexes tailored for deep learning and other AI algorithms. Tighter integration is key to delivering the performance and efficiency needed for the next generation of AI.
#### Wafer-scale AI
-Wafer-scale AI takes an extremely integrated approach, manufacturing an entire silicon wafer as one gigantic chip. This differs drastically from conventional CPUs and GPUs which cut each wafer into many smaller individual chips. @fig-wafer-scale shows a comparison between Cerebras Wafer Scale Engine 2, which's the largest chip ever built, and the largest GPU. While some GPUs may contain billions of transistors, they still pale in comparison to the scale of a wafer-size chip with over a trillion transistors.
+Wafer-scale AI takes an extremely integrated approach, manufacturing an entire silicon wafer as one gigantic chip. This differs drastically from conventional CPUs and GPUs, which cut each wafer into many smaller individual chips. @fig-wafer-scale shows a comparison between Cerebras Wafer Scale Engine 2, which is the largest chip ever built, and the largest GPU. While some GPUs may contain billions of transistors, they still pale in Comparison to the scale of a wafer-size chip with over a trillion transistors.
The wafer-scale approach also diverges from more modular system-on-chip designs that still have discrete components communicating by bus. Instead, wafer-scale AI enables full customization and tight integration of computation, memory, and interconnects across the entire die.
.](images/png/aimage1.png){#fig-wafer-scale}
-By designing the wafer as one integrated logic unit, data transfer between elements is minimized. This provides lower latency and power consumption compared to discrete system-on-chip or chiplet designs. While chiplets can offer flexibility by mixing and matching components, communication between chiplets is a challenge. The monolithic nature of wafer-scale integration eliminates these inter-chip communication bottlenecks.
+By designing the wafer as one integrated logic unit, data transfer between elements is minimized. This provides lower latency and power consumption than discrete system-on-chip or chiplet designs. While chiplets can offer flexibility by mixing and matching components, communication between chiplets is challenging. The monolithic nature of wafer-scale integration eliminates these inter-chip communication bottlenecks.
+
+However, the ultra-large-scale also poses difficulties for manufacturability and yield with wafer-scale designs. Defects in any region of the wafer can make (certain parts of) the chip unusable. Specialized lithography techniques are required to produce such large dies. So, wafer-scale integration pursues the maximum performance gains from integration but requires overcoming substantial fabrication challenges.
-However, the ultra-large scale also poses difficulties for manufacturability and yield with wafer-scale designs. Defects in any region of the wafer can make (certian parts of) the chip unusable. And specialized lithography techniques are required to produce such large dies. So wafer-scale integration pursues the maximum performance gains from integration but requires overcoming substantial fabrication challenges. The following video will provide additional context.
+The following video will provide additional context.
{{< video https://www.youtube.com/watch?v=Fcob512SJz0 >}}
#### Chiplets for AI
-Chiplet design refers to a semiconductor architecture in which a single integrated circuit (IC) is constructed from multiple smaller, individual components known as chiplets. Each chiplet is a self-contained functional block, typically specialized for a specific task or functionality. These chiplets are then interconnected on a larger substrate or package to create a complete, cohesive system. @fig-chiplet illustrates this concept. For AI hardware, chiplets enable mixing different types of chips optimized for tasks like matrix multiplication, data movement, analog I/O, and specialized memories. This heterogeneous integration differs greatly from wafer-scale integration where all logic is manufactured as one monolithic chip. Companies like Intel and AMD have adopted chiplet design for their CPUs.
+Chiplet design refers to a semiconductor architecture in which a single integrated circuit (IC) is constructed from multiple smaller, individual components known as chiplets. Each chiplet is a self-contained functional block, typically specialized for a specific task or functionality. These chiplets are then interconnected on a larger substrate or package to create a cohesive system. @fig-chiplet illustrates this concept. For AI hardware, chiplets enable the mixing of different types of chips optimized for tasks like matrix multiplication, data movement, analog I/O, and specialized memories. This heterogeneous integration differs greatly from wafer-scale integration, where all logic is manufactured as one monolithic chip. Companies like Intel and AMD have adopted chiplet designs for their CPUs.
Chiplets are interconnected using advanced packaging techniques like high-density substrate interposers, 2.5D/3D stacking, and wafer-level packaging. This allows combining chiplets fabricated with different process nodes, specialized memories, and various optimized AI engines.
@@ -779,8 +780,8 @@ Chiplets are interconnected using advanced packaging techniques like high-densit
Some key advantages of using chiplets for AI include:
-* **Flexibility:** Flexibility: Chiplets allow combining different chip types, process nodes, and memories tailored for each function. This is more modular versus a fixed wafer-scale design.
-* **Yield:** Smaller chiplets have higher yield than a gigantic wafer-scale chip. Defects are contained to individual chiplets.
+* **Flexibility:** Flexibility: Chiplets allow for the combination of different chip types, process nodes, and memories tailored for each function. This is more modular versus a fixed wafer-scale design.
+* **Yield:** Smaller chiplets have a higher yield than a gigantic wafer-scale chip. Defects are contained in individual chiplets.
* **Cost:** Leverages existing manufacturing capabilities versus requiring specialized new processes. Reduces costs by reusing mature fabrication.
* **Compatibility:** Can integrate with more conventional system architectures like PCIe and standard DDR memory interfaces.
@@ -790,93 +791,95 @@ However, chiplets also face integration and performance challenges:
* Added latency when communicating between chiplets versus monolithic integration. Requires optimization for low-latency interconnect.
* Advanced packaging adds complexity versus wafer-scale integration, though this is arguable.
-The key objective of chiplets is finding the right balance between modular flexibility and integration density for optimal AI performance. Chiplets aim for efficient AI acceleration while working within the constraints of conventional manufacturing techniques. Overall, chiplets take a middle path between the extremes of wafer-scale integration and fully discrete components. This provides practical benefits but may sacrifice some computational density and efficiency versus a theoretical wafer-size system.
+The key objective of chiplets is finding the right balance between modular flexibility and integration density for optimal AI performance. Chiplets aim for efficient AI acceleration while working within the constraints of conventional manufacturing techniques. Chiplets take a middle path between the extremes of wafer-scale integration and fully discrete components. This provides practical benefits but may sacrifice some computational density and efficiency versus a theoretical wafer-size system.
### Neuromorphic Computing {#sec-neuromorphic}
-Neuromorphic computing is an emerging field aiming to emulate the efficiency and robustness of biological neural systems for machine learning applications. A key difference from classical Von Neumann architectures is the merging of memory and processing in the same circuit [@schuman2022opportunities; @markovic2020physics; @furber2016large], as illustrated in @fig-neuromorphic. This integrated approach is inspired by the structure of the brain. A key advantage is the potential for orders of magnitude improvement in energy efficient computation compared to conventional AI hardware. For example, some estimates project 100x-1000x gains in energy efficiency versus current GPU-based systems for equivalent workloads.
+Neuromorphic computing is an emerging field aiming to emulate the efficiency and robustness of biological neural systems for machine learning applications. A key difference from classical Von Neumann architectures is the merging of memory and processing in the same circuit [@schuman2022opportunities; @markovic2020physics; @furber2016large], as illustrated in @fig-neuromorphic. The structure of the brain inspires this integrated approach. A key advantage is the potential for orders of magnitude improvement in energy-efficient computation compared to conventional AI hardware. For example, estimates project 100x-1000x gains in energy efficiency versus current GPU-based systems for equivalent workloads.
{#fig-neuromorphic}
-Intel and IBM are leading commercial efforts in neuromorphic hardware. Intel's Loihi and Loihi 2 chips [@davies2018loihi; @davies2021advancing] offer programmable neuromorphic cores with on-chip learning. IBM's Northpole [@modha2023neural] device comprises more than 100 million magnetic tunnel junction synapses and 68 billion transistors. These specialized chips deliver benefits like low power consumption for edge inference.
+Intel and IBM are leading commercial efforts in neuromorphic hardware. Intel's Loihi and Loihi 2 chips [@davies2018loihi; @davies2021advancing] offer programmable neuromorphic cores with on-chip learning. IBM's Northpole [@modha2023neural] device comprises over 100 million magnetic tunnel junction synapses and 68 billion transistors. These specialized chips deliver benefits like low power consumption for edge inference.
-Spiking neural networks (SNNs) [@maass1997networks] are computational models suited for neuromorphic hardware. Unlike deep neural networks that communicate via continuous values, SNNs use discrete spikes more akin to biological neurons. This allows efficient event-based computation rather than constant processing. Additionally, SNNs take into account temporal characteristics of input data in addition to spatial characteristics. This better mimics biological neural networks, where timing of neuronal spikes plays an important role. However, training SNNs remains challenging due to the added temporal complexity. @fig-spiking provides an overview of the spiking methodlogy: (a) Diagram of a neuron; (b) Measuring an action potential propagated along the axon of a neuron. Only the action potential is detectable along the axon; (c) The neuron's spike is approximated with a binary representation; (d) Event-Driven Processing; (e) Active Pixel Sensor and Dynamic Vision Sensor. You can also watch the video linked below for a more detailed explanation.
+Spiking neural networks (SNNs) [@maass1997networks] are computational models for neuromorphic hardware. Unlike deep neural networks communicating via continuous values, SNNs use discrete spikes that are more akin to biological neurons. This allows efficient event-based computation rather than constant processing. Additionally, SNNs consider the temporal and spatial characteristics of input data. This better mimics biological neural networks, where the timing of neuronal spikes plays an important role. However, training SNNs remains challenging due to the added temporal complexity. @fig-spiking provides an overview of the spiking methodology: (a) Diagram of a neuron; (b) Measuring an action potential propagated along the axon of a neuron. Only the action potential is detectable along the axon; (c) The neuron's spike is approximated with a binary representation; (d) Event-Driven Processing; (e) Active Pixel Sensor and Dynamic Vision Sensor.
+
+You can also watch the video linked below for a more detailed explanation.
{#fig-spiking}
{{< video https://www.youtube.com/watch?v=yihk_8XnCzg >}}
-Specialized nanoelectronic devices called memristors [@chua1971memristor] serve as the synaptic components in neuromorphic systems. Memristors act as non-volatile memory with adjustable conductance, emulating the plasticity of real synapses. By combining memory and processing functions, memristors enable in-situ learning without separate data transfers. However, memristor technology has not yet reached maturity and scalability for commercial hardware.
+Specialized nanoelectronic devices called memristors [@chua1971memristor] are synaptic components in neuromorphic systems. Memristors act as nonvolatile memory with adjustable conductance, emulating the plasticity of real synapses. Memristors enable in-situ learning without separate data transfers by combining memory and processing functions. However, memristor technology has yet to reach maturity and scalability for commercial hardware.
-Recently, the integration of photonics with neuromorphic computing [@shastri2021photonics] has emerged as an active research area. Using light for computation and communication allows high speeds and reduced energy consumption. However, fully realizing photonic neuromorphic systems requires overcoming design and integration challenges.
+The integration of photonics with neuromorphic computing [@shastri2021photonics] has recently emerged as an active research area. Using light for computation and communication allows high speeds and reduced energy consumption. However, fully realizing photonic neuromorphic systems requires overcoming design and integration challenges.
-Neuromorphic computing offers promising capabilities for efficient edge inference but still faces obstacles around training algorithms, nanodevice integration, and system design. Ongoing multidisciplinary research across computer science, engineering, materials science, and physics will be key to unlocking the full potential of this technology for AI use cases.
+Neuromorphic computing offers promising capabilities for efficient edge inference but faces obstacles around training algorithms, nanodevice integration, and system design. Ongoing multidisciplinary research across computer science, engineering, materials science, and physics will be key to unlocking this technology's full potential for AI use cases.
### Analog Computing
Analog computing is an emerging approach that uses analog signals and components like capacitors, inductors, and amplifiers rather than digital logic for computing. It represents information as continuous electrical signals instead of discrete 0s and 1s. This allows the computation to directly reflect the analog nature of real-world data, avoiding digitization errors and overhead.
-Analog computing has generated renewed interest for efficient AI hardware, particularly for inference directly on low-power edge devices. Operations like multiplication and summation at the core of neural networks can be performed with very low energy consumption using analog circuits. This makes analog well-suited for deploying ML models on energy-constrained end nodes. Startups like Mythic are developing analog AI accelerators.
+Analog computing has generated renewed interest in efficient AI hardware, particularly for inference directly on low-power edge devices. Analog circuits, such as multiplication and summation at the core of neural networks, can be used with very low energy consumption. This makes analog well-suited for deploying ML models on energy-constrained end nodes. Startups like Mythic are developing analog AI accelerators.
-While analog computing was popular in early computers, the boom of digital logic led to its decline. However, analog is compelling for niche applications requiring extreme efficiency [@haensch2018next]. It contrasts with digital neuromorphic approaches that still use digital spikes for computation. Analog may allow lower precision computation but requires expertise in analog circuit design. Tradeoffs around precision, programming complexity, and fabrication costs remain active areas of research.
+While analog computing was popular in early computers, the boom of digital logic led to its decline. However, analog is compelling for niche applications requiring extreme efficiency [@haensch2018next]. It contrasts with digital neuromorphic approaches that still use digital spikes for computation. Analog may allow lower precision computation but requires expertise in analog circuit design. Tradeoffs around precision, programming complexity, and fabrication costs remain active research areas.
-Neuromorphic computing, which aims to emulate biological neural systems for efficient ML inference, can for instance use analog circuits to implement the key components and behaviors of brains. For example, researchers have designed analog circuits to model neurons and synapses using capacitors, transistors, and operational amplifiers [@hazan2021neuromorphic]. The capacitors can exhibit the spiking dynamics of biological neurons, while the amplifiers and transistors provide weighted summation of inputs to mimic dendrites. Variable resistor technologies like memristors can realize analog synapses with spike-timing dependent plasticity - the ability to strengthen or weaken connections based on spiking activity.
+Neuromorphic computing, which aims to emulate biological neural systems for efficient ML inference, can use analog circuits to implement the key components and behaviors of brains. For example, researchers have designed analog circuits to model neurons and synapses using capacitors, transistors, and operational amplifiers [@hazan2021neuromorphic]. The capacitors can exhibit the spiking dynamics of biological neurons, while the amplifiers and transistors provide a weighted summation of inputs to mimic dendrites. Variable resistor technologies like memristors can realize analog synapses with spike-timing-dependent plasticity, which can strengthen or weaken connections based on spiking activity.
-Startups like SynSense have developed analog neuromorphic chips containing these biomimetic components [@bains2020business]. This analog approach results in very low power consumption and high scalability for edge devices versus complex digital SNN implementations.
+Startups like SynSense have developed analog neuromorphic chips containing these biomimetic components [@bains2020business]. This analog approach results in low power consumption and high scalability for edge devices versus complex digital SNN implementations.
-However, training analog SNNs on chip remains an open challenge. Overall, analog realization is a promising technique for delivering the efficiency, scalability, and biological plausibility envisioned with neuromorphic computing. The physics of analog components combined with neural architecture design could enable large improvements in inference efficiency over conventional digital neural networks.
+However, training analog SNNs on chips remains an open challenge. Overall, analog realization is a promising technique for delivering the efficiency, scalability, and biological plausibility envisioned with neuromorphic computing. The physics of analog components combined with neural architecture design could improve inference efficiency over conventional digital neural networks.
### Flexible Electronics
While much of the new hardware technology in the ML workspace has been focused on optimizing and making systems more efficient, there's a parallel trajectory aiming to adapt hardware for specific applications [@gates2009flexible; @musk2019integrated; @tang2023flexible; @tang2022soft; @kwon2022flexible]. One such avenue is the development of flexible electronics for AI use cases.
-Flexible electronics refer to electronic circuits and devices fabricated on flexible plastic or polymer substrates rather than rigid silicon. This allows the electronics to bend, twist, and conform to irregular shapes, unlike conventional rigid boards and chips. @fig-flexible-device shows an example of a flexible device prototype that wirelessly measures body temperature, which can be seamlessly integrated into clothing or skin patches. The flexibility and bendability of emerging electronic materials allows them to be integrated into thin, lightweight form factors well-suited for embedded AI and TinyML applications.
+Flexible electronics refer to electronic circuits and devices fabricated on flexible plastic or polymer substrates rather than rigid silicon. Unlike conventional rigid boards and chips, this allows the electronics to bend, twist, and conform to irregular shapes. @fig-flexible-device shows an example of a flexible device prototype that wirelessly measures body temperature, which can be seamlessly integrated into clothing or skin patches. The flexibility and bendability of emerging electronic materials allow them to be integrated into thin, lightweight form factors that are well-suited for embedded AI and TinyML applications.
-Flexible AI hardware can conform to curvy surfaces and operate efficiently with microwatt power budgets. Flexibility also enables rollable or foldable form factors to minimize device footprint and weight, which is ideal for small, portable smart devices and wearables incorporating TinyML. Another key advantage of flexible electronics compared to conventional technologies is lower manufacturing costs and simpler fabrication processes, which could democratize access to these technologies. While silicon masks and fabrication costs typically cost millions of dollars, flexible hardware typically costs only tens of cents to manufacture [@huang2010pseudo; @biggs2021natively]. The potential to fabricate flexible electronics directly onto plastic films using high-throughput printing and coating processes can reduce costs and improve manufacturability at scale versus rigid AI chips [@musk2019integrated].
+Flexible AI hardware can conform to curvy surfaces and operate efficiently with microwatt power budgets. Flexibility also enables rollable or foldable form factors to minimize device footprint and weight, ideal for small, portable smart devices and wearables incorporating TinyML. Another key advantage of flexible electronics compared to conventional technologies is lower manufacturing costs and simpler fabrication processes, which could democratize access to these technologies. While silicon masks and fabrication costs typically cost millions of dollars, flexible hardware typically costs only tens of cents to manufacture [@huang2010pseudo; @biggs2021natively]. The potential to fabricate flexible electronics directly onto plastic films using high-throughput printing and coating processes can reduce costs and improve manufacturability at scale versus rigid AI chips [@musk2019integrated].
{#fig-flexible-device}
-The field is enabled by advances in organic semiconductors and nanomaterials that can be deposited on thin, flexible films. However, fabrication remains challenging compared to mature silicon processes. Flexible circuits typically exhibit lower performance than rigid equivalents right now. Still, they promise to transform electronics into lightweight, bendable materials.
+The field is enabled by advances in organic semiconductors and nanomaterials that can be deposited on thin, flexible films. However, fabrication remains challenging compared to mature silicon processes. Flexible circuits currently typically exhibit lower performance than rigid equivalents. Still, they promise to transform electronics into lightweight, bendable materials.
-Flexible electronics use cases are well-suited for intimate integration with the human body. Potential medical AI applications include biointegrated sensors, soft assistive robots, and implants to monitor or stimulate the nervous system intelligently. Specifically, flexible electrode arrays could enable higher density, less invasive neural interfaces compared to rigid equivalents.
+Flexible electronics use cases are well-suited for intimate integration with the human body. Potential medical AI applications include bio-integrated sensors, soft assistive robots, and implants that monitor or stimulate the nervous system intelligently. Specifically, flexible electrode arrays could enable higher-density, less-invasive neural interfaces compared to rigid equivalents.
-Therefore, flexible electronics are ushering in a new era of wearables and body sensors, largely due to innovations in organic transistors. These components allow for more lightweight and bendable electronics, which are ideal for wearables, electronic skin, and body-conforming medical devices.
+Therefore, flexible electronics are ushering in a new era of wearables and body sensors, largely due to innovations in organic transistors. These components allow for more lightweight and bendable electronics, ideal for wearables, electronic skin, and body-conforming medical devices.
-In terms of biocompatibility, they are well-suited for bioelectronic devices, opening avenues for applications in both brain and cardiac interfaces. For example, research in flexible brain--computer interfaces and soft bioelectronics for cardiac applications demonstrates the potential for wide-ranging medical applications.
+They are well-suited for bioelectronic devices in terms of biocompatibility, opening avenues for applications in brain and cardiac interfaces. For example, research in flexible brain-computer interfaces and soft bioelectronics for cardiac applications demonstrates the potential for wide-ranging medical applications.
-Companies and research institutions are not only developing and investing great amounts of resources in flexible electrodes, as showcased in Neuralink's work [@musk2019integrated], but are also pushing the boundaries to integrate machine learning models within the systems [@kwon2022flexible]. These smart sensors aim for a seamless, long-lasting symbiosis with the human body.
+Companies and research institutions are not only developing and investing great amounts of resources in flexible electrodes, as showcased in Neuralink's work [@musk2019integrated]. Still, they are also pushing the boundaries to integrate machine learning models within the systems [@kwon2022flexible]. These smart sensors aim for a seamless, long-lasting symbiosis with the human body.
-Ethically, the incorporation of smart, machine-learning-driven sensors within the body raises important questions. Issues surrounding data privacy, informed consent, and the long-term societal implications of such technologies are the focus of ongoing work in neuroethics and bioethics [@segura2018ethical; @goodyear2017social; @farah2005neuroethics; @roskies2002neuroethics]. The field is progressing at a pace that necessitates parallel advancements in ethical frameworks to guide the responsible development and deployment of these technologies. Overall, while there are limitations and ethical hurdles to overcome, the prospects for flexible electronics are expansive and hold immense promise for future research and applications.
+Ethically, incorporating smart, machine-learning-driven sensors within the body raises important questions. Issues surrounding data privacy, informed consent, and the long-term societal implications of such technologies are the focus of ongoing work in neuroethics and bioethics [@segura2018ethical; @goodyear2017social; @farah2005neuroethics; @roskies2002neuroethics]. The field is progressing at a pace that necessitates parallel advancements in ethical frameworks to guide the responsible development and deployment of these technologies. While there are limitations and ethical hurdles to overcome, the prospects for flexible electronics are expansive and hold immense promise for future research and applications.
### Memory Technologies
-Memory technologies are critical to AI hardware, but conventional DDR DRAM and SRAM create bottlenecks. AI workloads require high bandwidth (>1 TB/s) and extreme scientific applications of AI require extremely low latency (<50 ns) to feed data to compute units [@duarte2022fastml], high density (>128Gb) to store large model parameters and data sets, and excellent energy efficiency (<100 fJ/b) for embedded use [@verma2019memory]. New memories are needed to meet these demands. Emerging options include several new technologies:
+Memory technologies are critical to AI hardware, but conventional DDR DRAM and SRAM create bottlenecks. AI workloads require high bandwidth (>1 TB/s). Extreme scientific applications of AI require extremely low latency (<50 ns) to feed data to compute units [@duarte2022fastml], high density (>128Gb) to store large model parameters and data sets, and excellent energy efficiency (<100 fJ/b) for embedded use [@verma2019memory]. New memories are needed to meet these demands. Emerging options include several new technologies:
* Resistive RAM (ReRAM) can improve density with simple, passive arrays. However, challenges around variability remain [@chi2016prime].
-* Phase change memory (PCM) exploits the unique properties of chalcogenide glass. Crystalline and amorphous phases have different resistances. Intel's Optane DCPMM provides fast (100ns), high endurance PCM. But challenges include limited write cycles and high reset current [@burr2016recent].
+* Phase change memory (PCM) exploits the unique properties of chalcogenide glass. Crystalline and amorphous phases have different resistances. Intel's Optane DCPMM provides fast (100ns), high endurance PCM. However, challenges include limited write cycles and high reset current [@burr2016recent].
* 3D stacking can also boost memory density and bandwidth by vertically integrating memory layers with TSV interconnects [@loh20083dstacked]. For example, HBM provides 1024-bit wide interfaces.
-New memory technologies are critical to unlock the next level of AI hardware performance and efficiency through their innovative cell architectures and materials. Realizing their benefits in commercial systems remains an ongoing challenge.
+New memory technologies, with their innovative cell architectures and materials, are critical to unlocking the next level of AI hardware performance and efficiency. Realizing their benefits in commercial systems remains an ongoing challenge.
-In-Memory Computing is gaining traction as a promising avenue for optimizing machine learning and high-performance computing workloads. At its core, the technology co-locates data storage and computation to improve energy efficiency and reduce latency [@verma2019memory; @mittal2021survey,@wong2012metal]. Two key technologies under this umbrella are Resistive RAM (ReRAM) and Processing-In-Memory (PIM).
+In-memory computing is gaining traction as a promising avenue for optimizing machine learning and high-performance computing workloads. At its core, the technology co-locates data storage and computation to improve energy efficiency and reduce latency [@verma2019memory; @mittal2021survey,@wong2012metal]. Two key technologies under this umbrella are Resistive RAM (ReRAM) and Processing-In-Memory (PIM).
-ReRAM [@wong2012metal] and PIM [@chi2016prime] serve as the backbone for in-memory computing by storing and computing data in the same location. ReRAM focuses on issues of uniformity, endurance, retention, multibit operation, and scalability. On the other hand, PIM involves CPU units integrated directly into memory arrays, specialized for tasks like matrix multiplication which are central in AI computations.
+ReRAM [@wong2012metal] and PIM [@chi2016prime] are the backbones for in-memory computing, storing and computing data in the same location. ReRAM focuses on issues of uniformity, endurance, retention, multi-bit operation, and scalability. On the other hand, PIM involves CPU units integrated directly into memory arrays, specialized for tasks like matrix multiplication, which are central in AI computations.
These technologies find applications in AI workloads and high-performance computing, where the synergy of storage and computation can lead to significant performance gains. The architecture is particularly useful for compute-intensive tasks common in machine learning models.
-While in-memory computing technologies like ReRAM and PIM offer exciting prospects for efficiency and performance, they come with their own set of challenges such as issues with data uniformity and scalability in ReRAM [@imani2016resistive]. Nonetheless, the field is ripe for innovation, and addressing these limitations can potentially open new frontiers in both AI and high-performance computing.
+While in-memory computing technologies like ReRAM and PIM offer exciting prospects for efficiency and performance, they come with their own challenges, such as data uniformity and scalability issues in ReRAM [@imani2016resistive]. Nonetheless, the field is ripe for innovation, and addressing these limitations can open new frontiers in AI and high-performance computing.
### Optical Computing
-In AI acceleration, a burgeoning area of interest lies in novel technologies that deviate from traditional paradigms. Some emerging technologies mentioned above such as flexible electronics, in-memory computing or even neuromorphics computing are close to becoming a reality, given their ground-breaking innovations and applications. One of the promising and leading the next-gen frontiers are optical computing technologies [@miller2000optical,@zhou2022photonic ]. Companies like [[LightMatter]](https://lightmatter.co/) are pioneering the use of light photonics for calculations, thereby utilizing photons instead of electrons for data transmission and computation.
+In AI acceleration, a burgeoning area of interest lies in novel technologies that deviate from traditional paradigms. Some emerging technologies mentioned above, such as flexible electronics, in-memory computing, or even neuromorphic computing, are close to becoming a reality, given their ground-breaking innovations and applications. One of the promising and leading next-gen frontiers is optical computing technologies [@miller2000optical,@zhou2022photonic ]. Companies like [[LightMatter]](https://lightmatter.co/) are pioneering the use of light photonics for calculations, thereby utilizing photons instead of electrons for data transmission and computation.
-Optical computing utilizes photons and photonic devices rather than traditional electronic circuits for computing and data processing. It takes inspiration from fiber optic communication links that already rely on light for fast, efficient data transfer [@shastri2021photonics]. Light can propagate with much less loss compared to electrons in semiconductors, enabling inherent speed and efficiency benefits.
+Optical computing utilizes photons and photonic devices rather than traditional electronic circuits for computing and data processing. It takes inspiration from fiber optic communication links that rely on light for fast, efficient data transfer [@shastri2021photonics]. Light can propagate with much less loss than semiconductors' electrons, enabling inherent speed and efficiency benefits.
Some specific advantages of optical computing include:
* **High throughput:** Photons can transmit with bandwidths >100 Tb/s using wavelength division multiplexing.
-* **Low latency:** Photons interact on femtosecond timescales, millions of times faster than silicon transistors.
-* **Parallelism:** Multiple data signals can propagate through the same optical medium simultaneously.
+* **Low latency:** Photons interact on femtosecond timescales, millions faster than silicon transistors.
+* **Parallelism:** Multiple data signals can propagate simultaneously through the same optical medium.
* **Low power:** Photonic circuits utilizing waveguides and resonators can achieve complex logic and memory with only microwatts of power.
However, optical computing currently faces significant challenges:
@@ -887,133 +890,135 @@ However, optical computing currently faces significant challenges:
* Immature integration methods to combine photonics with traditional CMOS chips.
* Complex programming models required to handle parallelism.
-As a result, optical computing is still in the very early research stage despite its promising potential. But technical breakthroughs could enable it to complement electronics and unlock performance gains for AI workloads. Companies like Lightmatter are pioneering early optical AI accelerators. Long term, it could represent a revolutionary computing substrate if key challenges are overcome.
+As a result, optical computing is still in the very early research stage despite its promising potential. However, technical breakthroughs could enable it to complement electronics and unlock performance gains for AI workloads. Companies like Lightmatter are pioneering early optical AI accelerators. In the long term, if key challenges are overcome, it could represent a revolutionary computing substrate.
### Quantum Computing
-Quantum computers leverage unique phenomena of quantum physics like superposition and entanglement to represent and process information in ways not possible classically. Instead of binary bits, the fundamental unit is the quantum bit or qubit. Unlike classical bits limited to 0 or 1, qubits can exist in a superposition of both states simultaneously due to quantum effects.
+Quantum computers leverage unique phenomena of quantum physics, like superposition and entanglement, to represent and process information in ways not possible classically. Instead of binary bits, the fundamental unit is the quantum bit or qubit. Unlike classical bits, which are limited to 0 or 1, qubits can exist simultaneously in a superposition of both states due to quantum effects.
Multiple qubits can also be entangled, leading to exponential information density but introducing probabilistic results. Superposition enables parallel computation on all possible states, while entanglement allows nonlocal correlations between qubits.
Quantum algorithms carefully manipulate these inherently quantum mechanical effects to solve problems like optimization or search more efficiently than their classical counterparts in theory.
* Faster training of deep neural networks by exploiting quantum parallelism for linear algebra operations.
-* Efficient quantum ML algorithms making use of the unique capabilities of qubits.
+* Efficient quantum ML algorithms make use of the unique capabilities of qubits.
* Quantum neural networks with inherent quantum effects baked into the model architecture.
* Quantum optimizers leveraging quantum annealing or adiabatic algorithms for combinatorial optimization problems.
However, quantum states are fragile and prone to errors that require error-correcting protocols. The non-intuitive nature of quantum programming also introduces challenges not present in classical computing.
-* Noisy and fragile quantum bits difficult to scale up. The largest quantum computer today has less than 100 qubits.
+* Noisy and fragile quantum bits are difficult to scale up. The largest quantum computer today has less than 100 qubits.
* Restricted set of available quantum gates and circuits relative to classical programming.
* Lack of datasets and benchmarks to evaluate quantum ML in practical domains.
While meaningful quantum advantage for ML remains far off, active research at companies like [D-Wave](https://www.dwavesys.com/company/about-d-wave/), [Rigetti](https://www.rigetti.com/), and [IonQ](https://ionq.com/) is advancing quantum computer engineering and quantum algorithms. Major technology companies like Google, [IBM](https://www.ibm.com/quantum?utm_content=SRCWW&p1=Search&p4C700050385964705&p5=e&gclid=Cj0KCQjw-pyqBhDmARIsAKd9XIPD9U1Sjez_S0z5jeDDE4nRyd6X_gtVDUKJ-HIolx2vOc599KgW8gAaAv8gEALw_wcB&gclsrc=aw.ds), and Microsoft are actively exploring quantum computing. Google recently announced a 72-qubit quantum processor called [Bristlecone](https://blog.research.google/2018/03/a-preview-of-bristlecone-googles-new.html) and plans to build a 49-qubit commercial quantum system. Microsoft also has an active research program in topological quantum computing and collaborates with quantum startup [IonQ](https://ionq.com/)
-Quantum techniques may first make inroads for optimization before more generalized ML adoption. Realizing the full potential of quantum ML awaits major milestones in quantum hardware development and ecosystem maturity.
+Quantum techniques may first make inroads into optimization before more generalized ML adoption. Realizing quantum ML's full potential awaits major milestones in quantum hardware development and ecosystem maturity.
## Future Trends
-In this chapter, the primary focus has been on the design of specialized hardware optimized for machine learning workloads and algorithms. This discussion encompassed the tailored architectures of GPUs and TPUs for neural network training and inference. However, an emerging research direction is the leveraging machine learning in facilitating the hardware design process itself.
+In this chapter, the primary focus has been on designing specialized hardware optimized for machine learning workloads and algorithms. This discussion encompassed the tailored architectures of GPUs and TPUs for neural network training and inference. However, an emerging research direction is leveraging machine learning to facilitate the hardware design process itself.
-The hardware design process involves many complex stages, including specification, high-level modeling, simulation, synthesis, verification, prototyping, and fabrication. Traditionally, much of this process requires extensive human expertise, effort, and time. However, recent advances in machine learning are enabling parts of the hardware design workflow to be automated and enhanced using ML techniques.
+The hardware design process involves many complex stages, including specification, high-level modeling, simulation, synthesis, verification, prototyping, and fabrication. Much of this process traditionally requires extensive human expertise, effort, and time. However, recent advances in machine learning are enabling parts of the hardware design workflow to be automated and enhanced using ML techniques.
Some examples of how ML is transforming hardware design include:
* **Automated circuit synthesis using reinforcement learning:** Rather than hand-crafting transistor-level designs, ML agents such as reinforcement learning can learn to connect logic gates and generate circuit layouts automatically. This can accelerate the time-consuming synthesis process.
-* **ML-based hardware simulation and emulation:** Deep neural network models can be trained to predict how a hardware design will perform under different conditions. For instance, deep learning models can be trained to predict cycle count for given workloads. This allows fast and accurate simulation compared to traditional RTL simulations.
-* **Automated chip floorplanning using ML algorithms:** Chip floorplanning, which involves optimally placing different components on a die. Evolutionary algorithms like genetic algorithms and other ML algorithms like reinforcement leanring are used explore floorplan options. This can significantly improve manual floorplanning placements in terms of faster turnaround time and also quality of placements.
-* **ML-driven architecture optimization:** Novel hardware architectures, like those for efficient ML accelerators, can be automatically generated and optimized by searching the architectural design space. Machine leanring algorithms can be used for effectively searching large architectural design space.
+* **ML-based hardware simulation and emulation:** Deep neural network models can be trained to predict how a hardware design will perform under different conditions. For instance, deep learning models can be trained to predict cycle counts for given workloads. This allows faster and more accurate simulation than traditional RTL simulations.
+* **Automated chip floorplanning using ML algorithms:** Chip floorplanning involves optimally placing different components on a die. Evolutionary algorithms like genetic algorithms and other ML algorithms like reinforcement learning are used to explore floorplan options. This can significantly improve manual floorplanning placements in terms of faster turnaround time and quality of placements.
+* **ML-driven architecture optimization:** Novel hardware architectures, like those for efficient ML accelerators, can be automatically generated and optimized by searching the architectural design space. Machine learning algorithms can effectively search large architectural design spaces.
-Applying ML to hardware design automation holds enormous promise to make the process faster, cheaper, and more efficient. It opens up design possibilities that would be extremely difficult through manual design. The use of ML in hardware design is an area of active research and early deployment, and we will study the techniques involved and their transformative potential.
+Applying ML to hardware design automation holds enormous promise to make the process faster, cheaper, and more efficient. It opens up design possibilities that would require more than manual design. The use of ML in hardware design is an area of active research and early deployment, and we will study the techniques involved and their transformative potential.
### ML for Hardware Design Automation
-A major opportunity for machine learning in hardware design is automating parts of the complex and tedious design workflow. Hardware design automation (HDA) broadly refers to using ML techniques like reinforcement learning, genetic algorithms, and neural networks to automate tasks like synthesis, verification, floorplanning, and more. A few examples of where ML for HDA shows real promise:
+A major opportunity for machine learning in hardware design is automating parts of the complex and tedious design workflow. Hardware design automation (HDA) broadly refers to using ML techniques like reinforcement learning, genetic algorithms, and neural networks to automate tasks like synthesis, verification, floorplanning, and more. Here are a few examples of where ML for HDA shows real promise:
-* **Automated circuit synthesis:** Circuit synthesis involves converting a high-level description of desired logic into an optimized gate-level netlist implementation. This complex process has many design considerations and tradeoffs. ML agents can be trained through reinforcement learning (@yu2023rl,@zhou2023area) to explore the design space and output optimized syntheses automatically. Startups like [Symbiotic EDA](https://www.symbioticeda.com/) are bringing this technology to market.
-* **Automated chip floorplanning:** Floorplanning refers to strategically placing different components on a chip die area. Search algorithms like genetic algorithms (@valenzuela2000genetic), reinforcement learning (@mirhoseini2021graph, @agnesina2023autodmp) can be used to automate floorplan optimization to minimize wire length, power consumption, and other objectives. These automated ML-assisted floorplanners are extremely valuable as chip complexity increases.
+* **Automated circuit synthesis:** Circuit synthesis involves converting a high-level description of desired logic into an optimized gate-level netlist implementation. This complex process has many design considerations and tradeoffs. ML agents can be trained through reinforcement learning (@yu2023rl,@zhou2023area) to explore the design space and automatically output optimized syntheses. Startups like [Symbiotic EDA](https://www.symbioticeda.com/) are bringing this technology to market.
+* **Automated chip floorplanning:** Floorplanning refers to strategically placing different components on a chip die area. Search algorithms like genetic algorithms (@valenzuela2000genetic) and reinforcement learning (@mirhoseini2021graph, @agnesina2023autodmp) can be used to automate floorplan optimization to minimize wire length, power consumption, and other objectives. These automated ML-assisted floor planners are extremely valuable as chip complexity increases.
* **ML hardware simulators:** Training deep neural network models to predict how hardware designs will perform as simulators can accelerate the simulation process by over 100x compared to traditional architectural and RTL simulations.
-* **Automated code translation:** Converting hardware description languages like Verilog to optimized RTL implementations is critical but time-consuming. ML models can be trained to act as translator agents and automate parts of this process.
+* **Automated code translation:** Converting hardware description languages like Verilog to optimized RTL implementations is critical but time-consuming. ML models can be trained to act as translator agents and automate this process.
The benefits of HDA using ML are reduced design time, superior optimizations, and exploration of design spaces too complex for manual approaches. This can accelerate hardware development and lead to better designs.
-Challenges include limits of ML generalization, the black-box nature of some techniques, and accuracy tradeoffs. But research is rapidly advancing to address these issues and make HDA ML solutions robust and reliable for production use. HDA provides a major avenue for ML to transform hardware design.
+Challenges include limits of ML generalization, the black-box nature of some techniques, and accuracy tradeoffs. However, research is rapidly advancing to address these issues and make HDA ML solutions robust and reliable for production use. HDA provides a major avenue for ML to transform hardware design.
### ML-Based Hardware Simulation and Verification
Simulating and verifying hardware designs is critical before manufacturing to ensure the design behaves as intended. Traditional approaches like register-transfer level (RTL) simulation are complex and time-consuming. ML introduces new opportunities to enhance hardware simulation and verification. Some examples include:
* **Surrogate modeling for simulation:** Highly accurate surrogate models of a design can be built using neural networks. These models predict outputs from inputs much faster than RTL simulation, enabling fast design space exploration. Companies like Ansys use this technique.
-* **ML simulators:** Large neural network models can be trained on RTL simulations to learn to mimic the functionality of a hardware design. Once trained, the NN model can act as a highly efficient simulator to use for regression testing and other tasks. [Graphcore](https://www.graphcore.ai/posts/ai-for-simulation-how-graphcore-is-helping-transform-traditional-hpc) has demonstrated over 100x speedup with this approach.
-* **Formal verification using ML:** Formal verification mathematically proves properties about a design. ML techniques can help generate verification properties and can learn to solve the complex formal proofs needed. This automates parts of this challenging process. Startups like Cortical.io are bringing ML formal verification solutions to market.
+* **ML simulators:** Large neural network models can be trained on RTL simulations to learn to mimic the functionality of a hardware design. Once trained, the NN model can be a highly efficient simulator for regression testing and other tasks. [Graphcore](https://www.graphcore.ai/posts/ai-for-simulation-how-graphcore-is-helping-transform-traditional-hpc) has demonstrated over 100x speedup with this approach.
+* **Formal verification using ML:** Formal verification mathematically proves properties about a design. ML techniques can help generate verification properties and learn to solve the complex formal proofs needed, automating parts of this challenging process. Startups like Cortical.io are bringing formal ML verification solutions to the market.
* **Bug detection:** ML models can be trained to process hardware designs and identify potential issues. This assists human designers in inspecting complex designs and finding bugs. Facebook has shown bug detection models for their server hardware.
-The key benefits of applying ML to simulation and verification are faster design validation turnaround times, more rigorous testing, and reduced human effort. Challenges include verifying ML model correctness and handling corner cases. ML promises to significantly accelerate testing workflows.
+The key benefits of applying ML to simulation and verification are faster design validation turnaround times, more rigorous testing, and reduced human effort. Challenges include verifying ML model correctness and handling corner cases. ML promises to accelerate testing workflows significantly.
### ML for Efficient Hardware Architectures
-Designing hardware architectures optimized for performance, power, and efficiency is a key goal. ML introduces new techniques to automate and enhance architecture design space exploration for both general-purpose and specialized hardware like ML accelerators. Some promising examples include:
+A key goal is designing hardware architectures optimized for performance, power, and efficiency. ML introduces new techniques to automate and enhance architecture design space exploration for general-purpose and specialized hardware like ML accelerators. Some promising examples include:
* **Architecture search for hardware:** Search techniques like evolutionary algorithms (@kao2020gamma), Bayesian optimization (@reagen2017case, @bhardwaj2020comprehensive), reinforcement learning (@kao2020confuciux, @krishnan2022multiagent) can automatically generate novel hardware architectures by mutating and mixing design attributes like cache size, number of parallel units, memory bandwidth, and so on. This allows for efficient navigation of large design spaces.
* **Predictive modeling for optimization:** - ML models can be trained to predict hardware performance, power, and efficiency metrics for a given architecture. These become "surrogate models" (@krishnan2023archgym) for fast optimization and space exploration by substituting lengthy simulations.
* **Specialized accelerator optimization:** - For specialized chips like tensor processing units for AI, automated architecture search techniques based on ML algorithms (@zhang2022fullstack) show promise for finding fast, efficient designs.
-The benefits of using ML include superior design space exploration, automated optimization, and reduced manual effort. Challenges include long training times for some techniques and local optima limitations. But ML for hardware architecture holds great potential for unlocking performance and efficiency gains.
+The benefits of using ML include superior design space exploration, automated optimization, and reduced manual effort. Challenges include long training times for some techniques and local optima limitations. However, ML for hardware architecture holds great potential for unlocking performance and efficiency gains.
### ML to Optimize Manufacturing and Reduce Defects
-Once a hardware design is complete, it moves to manufacturing. But variability and defects during manufacturing can impact yields and quality. ML techniques are now being applied to improve fabrication processes and reduce defects. Some examples include:
+Once a hardware design is complete, it moves to manufacturing. However, variability and defects during manufacturing can impact yields and quality. ML techniques are now being applied to improve fabrication processes and reduce defects. Some examples include:
-* **Predictive maintenance:** ML models can analyze equipment sensor data over time and identify signals that predict maintenance needs before failure. This enables proactive upkeep that can come in very handy in the costly fabrication process.
+* **Predictive maintenance:** ML models can analyze equipment sensor data over time and identify signals that predict maintenance needs before failure. This enables proactive upkeep, which can be very handy in the costly fabrication process.
* **Process optimization:** Supervised learning models can be trained on process data to identify factors that lead to low yields. The models can then optimize parameters to improve yields, throughput, or consistency.
-* **Yield prediction:** By analyzing test data from fabricated designs using techniques like regression trees, ML models can predict yields early in production. This allows process adjustments.
+* **Yield prediction:** By analyzing test data from fabricated designs using techniques like regression trees, ML models can predict yields early in production, allowing process adjustments.
* **Defect detection:** Computer vision ML techniques can be applied to images of designs to identify defects invisible to the human eye. This enables precision quality control and root cause analysis.
-* **Proactive failure analysis:** - By analyzing structured and unstructured process data, ML models can help predict, diagnose, and prevent issues that lead to downstream defects and failures.
+* **Proactive failure analysis:** - ML models can help predict, diagnose, and prevent issues that lead to downstream defects and failures by analyzing structured and unstructured process data.
-Applying ML to manufacturing enables process optimization, real-time quality control, predictive maintenance, and ultimately higher yields. Challenges include managing complex manufacturing data and variations. But ML is poised to transform semiconductor manufacturing.
+Applying ML to manufacturing enables process optimization, real-time quality control, predictive maintenance, and higher yields. Challenges include managing complex manufacturing data and variations. But ML is poised to transform semiconductor manufacturing.
### Toward Foundation Models for Hardware Design
As we have seen, machine learning is opening up new possibilities across the hardware design workflow, from specification to manufacturing. However, current ML techniques are still narrow in scope and require extensive domain-specific engineering. The long-term vision is the development of general artificial intelligence systems that can be applied with versatility across hardware design tasks.
-To fully realize this vision, investment and research are needed to develop foundation models for hardware design. These are unified, general-purpose ML models and architectures that can learn complex hardware design skills with the right training data and objectives.
+To fully realize this vision, investment, and research are needed to develop foundation models for hardware design. These are unified, general-purpose ML models and architectures that can learn complex hardware design skills with the right training data and objectives.
-Realizing foundation models for end-to-end hardware design will require:
+Realizing foundation models for end-to-end hardware design will require the following:
-* Accumulation of large, high-quality, labeled datasets across hardware design stages to train foundation models.
+* Accumulate large, high-quality, labeled datasets across hardware design stages to train foundation models.
* Advances in multi-modal, multi-task ML techniques to handle the diversity of hardware design data and tasks.
* Interfaces and abstraction layers to connect foundation models to existing design flows and tools.
* Development of simulation environments and benchmarks to train and test foundation models on hardware design capabilities.
-* Methods to explain and interpret the design decisions and optimizations made by ML models for trust and verification.
+* Methods to explain and interpret ML models' design decisions and optimizations for trust and verification.
* Compilation techniques to optimize foundation models for efficient deployment across hardware platforms.
While significant research remains, foundation models represent the most transformative long-term goal for imbuing AI into the hardware design process. Democratizing hardware design via versatile, automated ML systems promises to unlock a new era of optimized, efficient, and innovative chip design. The journey ahead is filled with open challenges and opportunities.
-We encourage you to read [Architecture 2.0](https://www.sigarch.org/architecture-2-0-why-computer-architects-need-a-data-centric-ai-gymnasium/) if ML-aided computer architecture design [@krishnan2023archgym] interests you. Alternatively, you can watch the below video.
+If you are interested in ML-aided computer architecture design [@krishnan2023archgym], we encourage you to read [Architecture 2.0](https://www.sigarch.org/architecture-2-0-why-computer-architects-need-a-data-centric-ai-gymnasium/).
+
+Alternatively, you can watch the below video.
{{< video https://www.youtube.com/watch?v=F5Eieaz7u1I&ab_channel=OpenComputeProject >}}
## Conclusion
-Specialized hardware acceleration has become indispensable for enabling performant and efficient artificial intelligence applications as models and datasets explode in complexity. In this chapter, we examined the limitations of general-purpose processors like CPUs for AI workloads. Their lack of parallelism and computational throughput cannot train or run state-of-the-art deep neural networks quickly. These motivations have driven innovations in customized accelerators.
+Specialized hardware acceleration has become indispensable for enabling performant and efficient artificial intelligence applications as models and datasets explode in complexity. This chapter examined the limitations of general-purpose processors like CPUs for AI workloads. Their lack of parallelism and computational throughput cannot train or run state-of-the-art deep neural networks quickly. These motivations have driven innovations in customized accelerators.
-We surveyed GPUs, TPUs, FPGAs and ASICs specifically designed for the math-intensive operations inherent to neural networks. By covering this spectrum of options, we aimed to provide a framework for reasoning through accelerator selection based on constraints around flexibility, performance, power, cost, and other factors.
+We surveyed GPUs, TPUs, FPGAs, and ASICs specifically designed for the math-intensive operations inherent to neural networks. By covering this spectrum of options, we aimed to provide a framework for reasoning through accelerator selection based on constraints around flexibility, performance, power, cost, and other factors.
-We also explored the role of software in actively enabling and optimizing AI acceleration. This spans programming abstractions, frameworks, compilers and simulators. We discussed hardware-software co-design as a proactive methodology for building more holistic AI systems by closely integrating algorithm innovation and hardware advances.
+We also explored the role of software in actively enabling and optimizing AI acceleration. This spans programming abstractions, frameworks, compilers, and simulators. We discussed hardware-software co-design as a proactive methodology for building more holistic AI systems by closely integrating algorithm innovation and hardware advances.
But there is so much more to come! Exciting frontiers like analog computing, optical neural networks, and quantum machine learning represent active research directions that could unlock orders of magnitude improvements in efficiency, speed, and scale compared to present paradigms.
-In the end, specialized hardware acceleration remains indispensable for unlocking the performance and efficiency necessary to fulfill the promise of artificial intelligence from cloud to edge. We hope this chapter actively provided useful background and insights into the rapid innovation occurring in this domain.
+Ultimately, specialized hardware acceleration remains indispensable for unlocking the performance and efficiency necessary to fulfill the promise of artificial intelligence from cloud to edge. We hope this chapter provides useful background and insights into the rapid innovation occurring in this domain.
## Resources {#sec-ai-acceleration-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-Coming soon.
+*Coming soon.*
:::
:::{.callout-exercise collapse="false"}
@@ -1025,5 +1030,5 @@ Coming soon.
:::{.callout-lab collapse="false"}
# Labs
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/image_classification/image_classification.bib b/contents/image_classification/image_classification.bib
index e69de29b..00614696 100644
--- a/contents/image_classification/image_classification.bib
+++ b/contents/image_classification/image_classification.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/image_classification/image_classification.qmd b/contents/image_classification/image_classification.qmd
index fc182948..73c1d975 100644
--- a/contents/image_classification/image_classification.qmd
+++ b/contents/image_classification/image_classification.qmd
@@ -497,22 +497,22 @@ Catching the opportunity, the same trained model was deployed on the ESP-CAM, th
Before we finish, consider that Computer Vision is more than just image classification. For example, you can develop Edge Machine Learning projects around vision in several areas, such as:
-- **Autonomous Vehicles**: Use sensor fusion, lidar data, and computer vision algorithms to navigate and make decisions.
+- **Autonomous Vehicles:** Use sensor fusion, lidar data, and computer vision algorithms to navigate and make decisions.
-- **Healthcare**: Automated diagnosis of diseases through MRI, X-ray, and CT scan image analysis
+- **Healthcare:** Automated diagnosis of diseases through MRI, X-ray, and CT scan image analysis
-- **Retail**: Automated checkout systems that identify products as they pass through a scanner.
+- **Retail:** Automated checkout systems that identify products as they pass through a scanner.
-- **Security and Surveillance**: Facial recognition, anomaly detection, and object tracking in real-time video feeds.
+- **Security and Surveillance:** Facial recognition, anomaly detection, and object tracking in real-time video feeds.
-- **Augmented Reality**: Object detection and classification to overlay digital information in the real world.
+- **Augmented Reality:** Object detection and classification to overlay digital information in the real world.
-- **Industrial Automation**: Visual inspection of products, predictive maintenance, and robot and drone guidance.
+- **Industrial Automation:** Visual inspection of products, predictive maintenance, and robot and drone guidance.
-- **Agriculture**: Drone-based crop monitoring and automated harvesting.
+- **Agriculture:** Drone-based crop monitoring and automated harvesting.
-- **Natural Language Processing**: Image captioning and visual question answering.
+- **Natural Language Processing:** Image captioning and visual question answering.
-- **Gesture Recognition**: For gaming, sign language translation, and human-machine interaction.
+- **Gesture Recognition:** For gaming, sign language translation, and human-machine interaction.
-- **Content Recommendation**: Image-based recommendation systems in e-commerce.
+- **Content Recommendation:** Image-based recommendation systems in e-commerce.
diff --git a/contents/introduction/images/png/21st_computer.png b/contents/introduction/images/png/21st_computer.png
new file mode 100644
index 00000000..2e49f628
Binary files /dev/null and b/contents/introduction/images/png/21st_computer.png differ
diff --git a/contents/introduction/images/png/cover_introduction.png b/contents/introduction/images/png/cover_introduction.png
new file mode 100644
index 00000000..b2f96850
Binary files /dev/null and b/contents/introduction/images/png/cover_introduction.png differ
diff --git a/contents/introduction/introduction.bib b/contents/introduction/introduction.bib
index b7a052cc..d4ae204a 100644
--- a/contents/introduction/introduction.bib
+++ b/contents/introduction/introduction.bib
@@ -1,10 +1,18 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@article{weiser1991computer,
- title={The Computer for the 21 st Century},
- author={Weiser, Mark},
- journal={Scientific american},
- volume={265},
- number={3},
- pages={94--105},
- year={1991},
- publisher={JSTOR}
+ author = {Weiser, Mark},
+ title = {The Computer for the 21st Century},
+ journal = {Sci. Am.},
+ volume = {265},
+ number = {3},
+ pages = {94--104},
+ year = {1991},
+ publisher = {Springer Science and Business Media LLC},
+ doi = {10.1038/scientificamerican0991-94},
+ source = {Crossref},
+ url = {https://doi.org/10.1038/scientificamerican0991-94},
+ issn = {0036-8733},
+ month = sep,
}
diff --git a/contents/introduction/introduction.qmd b/contents/introduction/introduction.qmd
index 46c2607a..8196a6a4 100644
--- a/contents/introduction/introduction.qmd
+++ b/contents/introduction/introduction.qmd
@@ -4,20 +4,22 @@ bibliography: introduction.bib
# Introduction
-In the early 1990s, [Mark Weiser](https://en.wikipedia.org/wiki/Mark_Weiser), a pioneering computer scientist, introduced the world to a revolutionary concept that would forever change the way we interact with technology. He envisioned a future where computing would be so seamlessly integrated into our environments that it would become an invisible, integral part of daily life. This vision, which he termed "ubiquitous computing," promised a world where technology would serve us without demanding our constant attention or interaction. Fast forward to today, and we find ourselves on the cusp of realizing Weiser's vision, thanks to the advent and proliferation of machine learning systems.
+
-Ubiquitous computing [@weiser1991computer], as imagined by Weiser, is not merely about embedding processors in everyday objects; it is about imbuing our environment with a form of intelligence that anticipates our needs and acts on our behalf, enhancing our experiences without our explicit command. The key to this ubiquitous intelligence lies in the development and deployment of machine learning systems at the edge of our networks.
+In the early 1990s, [Mark Weiser](https://en.wikipedia.org/wiki/Mark_Weiser), a pioneering computer scientist, introduced the world to a revolutionary concept that would forever change how we interact with technology. He envisioned a future where computing would be so seamlessly integrated into our environments that it would become an invisible, integral part of daily life. This vision, which he termed "ubiquitous computing," promised a world where technology would serve us without demanding our constant attention or interaction. Fast forward to today, and we find ourselves on the cusp of realizing Weiser's vision, thanks to the advent and proliferation of machine learning systems.
-Machine learning, a subset of artificial intelligence, enables computers to learn from and make decisions based on data, rather than following explicitly programmed instructions. When deployed at the edge—closer to where data is generated and actions are taken—machine learning systems can process information in real-time, responding to environmental changes and user inputs with minimal latency. This capability is critical for applications where timing is crucial, such as autonomous vehicles, real-time language translation, and smart healthcare devices.
+Ubiquitous computing [@weiser1991computer], as Weiser imagined, is not merely about embedding processors in everyday objects; it is about imbuing our environment with a form of intelligence that anticipates our needs and acts on our behalf, enhancing our experiences without our explicit command. The key to this ubiquitous intelligence lies in developing and deploying machine learning systems at the edge of our networks.
-The migration of machine learning from centralized data centers to the edge of networks marks a significant evolution in computing architecture. This shift is driven by the need for speed, privacy, and reduced bandwidth consumption. By processing data locally, edge-based machine learning systems can make quick decisions without the need to constantly communicate with a central server. This not only speeds up response times but also conserves bandwidth and enhances privacy by limiting the amount of data that needs to be transmitted over the network.
+Machine learning, a subset of artificial intelligence, enables computers to learn from and make decisions based on data rather than following explicitly programmed instructions. When deployed at the edge—closer to where data is generated, and actions are taken—machine learning systems can process information in real-time, responding to environmental changes and user inputs with minimal latency. This capability is critical for applications where timing is crucial, such as autonomous vehicles, real-time language translation, and smart healthcare devices.
-Moreover, the ability to deploy machine learning models in diverse environments has led to an explosion of innovative applications. From smart cities that optimize traffic flow in real-time to agricultural drones that monitor crop health and apply treatments precisely where needed, machine learning at the edge is enabling a level of contextual awareness and responsiveness that was previously unimaginable.
+The migration of machine learning from centralized data centers to the edge of networks marks a significant evolution in computing architecture. The need for speed, privacy, and reduced bandwidth consumption drives this shift. By processing data locally, edge-based machine learning systems can make quick decisions without constantly communicating with a central server. This speeds up response times, conserves bandwidth, and enhances privacy by limiting the amount of data transmitted over the network.
-Despite the promise of ubiquitous intelligence, deploying machine learning systems at the edge is not without its challenges. These systems must operate within the constraints of limited processing power, memory, and energy availability, often in environments that are far from the controlled conditions of data centers. Additionally, ensuring the privacy and security of the data these systems process is a paramount concern, particularly in applications that handle sensitive personal information.
+Moreover, the ability to deploy machine learning models in diverse environments has led to an explosion of innovative applications. From smart cities that optimize traffic flow in real-time to agricultural drones that monitor crop health and apply treatments precisely where needed, machine learning at the edge enables a level of contextual awareness and responsiveness that was previously unimaginable.
-Developing machine learning models that are efficient enough to run at the edge while still delivering accurate and reliable results requires innovative approaches to model design, training, and deployment. Researchers and engineers are exploring techniques such as model compression, federated learning, and transfer learning to address these challenges.
+Despite the promise of ubiquitous intelligence, deploying machine learning systems at the edge is challenging. These systems must operate within the constraints of limited processing power, memory, and energy availability, often in environments far from the controlled conditions of data centers. Additionally, ensuring the privacy and security of the data in these systems processes is paramount, particularly in applications that handle sensitive personal information.
-As we stand on the threshold of Weiser's vision of ubiquitous computing, it is clear that machine learning systems are the key to unlocking this future. By embedding intelligence in the fabric of our environment, these systems have the potential to make our interactions with technology more natural and intuitive than ever before. As we continue to push the boundaries of what's possible with machine learning at the edge, we move closer to a world where technology quietly enhances our lives, without ever getting in the way.
+Developing machine learning models that are efficient enough to run at the edge while delivering accurate and reliable results requires innovative model design, training, and deployment approaches. Researchers and engineers are exploring techniques such as model compression, federated learning, and transfer learning to address these challenges.
-In this book, we will explore the technical foundations of machine learning systems, the challenges of deploying these systems at the edge, and the vast array of applications they enable. Join us as we embark on a journey into the future of ubiquitous intelligence, where the seamless integration of technology into our daily lives transforms the very essence of how we live, work, and interact with the world around us.
+As we stand on the threshold of Weiser's vision of ubiquitous computing, machine learning systems are clear as the key to unlocking this future. By embedding intelligence in the fabric of our environment, these systems have the potential to make our interactions with technology more natural and intuitive than ever before. As we continue to push the boundaries of what's possible with machine learning at the edge, we move closer to a world where technology quietly enhances our lives without ever getting in the way.
+
+In this book, we will explore the technical foundations of machine learning systems, the challenges of deploying these systems at the edge, and the vast array of applications they enable. Join us as we embark on a journey into the future of ubiquitous intelligence, where the seamless integration of technology into our daily lives transforms the essence of how we live, work, and interact with the world around us.
diff --git a/contents/kws_feature_eng/kws_feature_eng.bib b/contents/kws_feature_eng/kws_feature_eng.bib
index e69de29b..00614696 100644
--- a/contents/kws_feature_eng/kws_feature_eng.bib
+++ b/contents/kws_feature_eng/kws_feature_eng.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/kws_feature_eng/kws_feature_eng.qmd b/contents/kws_feature_eng/kws_feature_eng.qmd
index 3d73b025..e27bd15b 100644
--- a/contents/kws_feature_eng/kws_feature_eng.qmd
+++ b/contents/kws_feature_eng/kws_feature_eng.qmd
@@ -24,29 +24,29 @@ Here a typical KWS Process using MFCC Feature Converter:
#### Applications of KWS:
-- **Voice Assistants**: In devices like Amazon's Alexa or Google Home, KWS is used to detect the wake word ("Alexa" or "Hey Google") to activate the device.
-- **Voice-Activated Controls**: In automotive or industrial settings, KWS can be used to initiate specific commands like "Start engine" or "Turn off lights."
-- **Security Systems**: Voice-activated security systems may use KWS to authenticate users based on a spoken passphrase.
-- **Telecommunication Services**: Customer service lines may use KWS to route calls based on spoken keywords.
+- **Voice Assistants:** In devices like Amazon's Alexa or Google Home, KWS is used to detect the wake word ("Alexa" or "Hey Google") to activate the device.
+- **Voice-Activated Controls:** In automotive or industrial settings, KWS can be used to initiate specific commands like "Start engine" or "Turn off lights."
+- **Security Systems:** Voice-activated security systems may use KWS to authenticate users based on a spoken passphrase.
+- **Telecommunication Services:** Customer service lines may use KWS to route calls based on spoken keywords.
#### Differences from General Speech Recognition:
-- **Computational Efficiency**: KWS is usually designed to be less computationally intensive than full speech recognition, as it only needs to recognize a small set of phrases.
-- **Real-time Processing**: KWS often operates in real-time and is optimized for low-latency detection of keywords.
-- **Resource Constraints**: KWS models are often designed to be lightweight, so they can run on devices with limited computational resources, like microcontrollers or mobile phones.
-- **Focused Task**: While general speech recognition models are trained to handle a broad range of vocabulary and accents, KWS models are fine-tuned to recognize specific keywords, often in noisy environments accurately.
+- **Computational Efficiency:** KWS is usually designed to be less computationally intensive than full speech recognition, as it only needs to recognize a small set of phrases.
+- **Real-time Processing:** KWS often operates in real-time and is optimized for low-latency detection of keywords.
+- **Resource Constraints:** KWS models are often designed to be lightweight, so they can run on devices with limited computational resources, like microcontrollers or mobile phones.
+- **Focused Task:** While general speech recognition models are trained to handle a broad range of vocabulary and accents, KWS models are fine-tuned to recognize specific keywords, often in noisy environments accurately.
## Introduction to Audio Signals
Understanding the basic properties of audio signals is crucial for effective feature extraction and, ultimately, for successfully applying machine learning algorithms in audio classification tasks. Audio signals are complex waveforms that capture fluctuations in air pressure over time. These signals can be characterized by several fundamental attributes: sampling rate, frequency, and amplitude.
-- **Frequency and Amplitude**: [Frequency](https://en.wikipedia.org/wiki/Audio_frequency) refers to the number of oscillations a waveform undergoes per unit time and is also measured in Hz. In the context of audio signals, different frequencies correspond to different pitches. [Amplitude](https://en.wikipedia.org/wiki/Amplitude), on the other hand, measures the magnitude of the oscillations and correlates with the loudness of the sound. Both frequency and amplitude are essential features that capture audio signals' tonal and rhythmic qualities.
+- **Frequency and Amplitude:** [Frequency](https://en.wikipedia.org/wiki/Audio_frequency) refers to the number of oscillations a waveform undergoes per unit time and is also measured in Hz. In the context of audio signals, different frequencies correspond to different pitches. [Amplitude](https://en.wikipedia.org/wiki/Amplitude), on the other hand, measures the magnitude of the oscillations and correlates with the loudness of the sound. Both frequency and amplitude are essential features that capture audio signals' tonal and rhythmic qualities.
-- **Sampling Rate**: The [sampling rate](https://en.wikipedia.org/wiki/Sampling_(signal_processing)), often denoted in Hertz (Hz), defines the number of samples taken per second when digitizing an analog signal. A higher sampling rate allows for a more accurate digital representation of the signal but also demands more computational resources for processing. Typical sampling rates include 44.1 kHz for CD-quality audio and 16 kHz or 8 kHz for speech recognition tasks. Understanding the trade-offs in selecting an appropriate sampling rate is essential for balancing accuracy and computational efficiency. In general, with TinyML projects, we work with 16KHz. Altough music tones can be heard at frequencies up to 20 kHz, voice maxes out at 8 kHz. Traditional telephone systems use an 8 kHz sampling frequency.
+- **Sampling Rate:** The [sampling rate](https://en.wikipedia.org/wiki/Sampling_(signal_processing)), often denoted in Hertz (Hz), defines the number of samples taken per second when digitizing an analog signal. A higher sampling rate allows for a more accurate digital representation of the signal but also demands more computational resources for processing. Typical sampling rates include 44.1 kHz for CD-quality audio and 16 kHz or 8 kHz for speech recognition tasks. Understanding the trade-offs in selecting an appropriate sampling rate is essential for balancing accuracy and computational efficiency. In general, with TinyML projects, we work with 16KHz. Altough music tones can be heard at frequencies up to 20 kHz, voice maxes out at 8 kHz. Traditional telephone systems use an 8 kHz sampling frequency.
> For an accurate representation of the signal, the sampling rate must be at least twice the highest frequency present in the signal.
-- **Time Domain vs. Frequency Domain**: Audio signals can be analyzed in the time and frequency domains. In the time domain, a signal is represented as a waveform where the amplitude is plotted against time. This representation helps to observe temporal features like onset and duration but the signal's tonal characteristics are not well evidenced. Conversely, a frequency domain representation provides a view of the signal's constituent frequencies and their respective amplitudes, typically obtained via a Fourier Transform. This is invaluable for tasks that require understanding the signal's spectral content, such as identifying musical notes or speech phonemes (our case).
+- **Time Domain vs. Frequency Domain:** Audio signals can be analyzed in the time and frequency domains. In the time domain, a signal is represented as a waveform where the amplitude is plotted against time. This representation helps to observe temporal features like onset and duration but the signal's tonal characteristics are not well evidenced. Conversely, a frequency domain representation provides a view of the signal's constituent frequencies and their respective amplitudes, typically obtained via a Fourier Transform. This is invaluable for tasks that require understanding the signal's spectral content, such as identifying musical notes or speech phonemes (our case).
The image below shows the words `YES` and `NO` with typical representations in the Time (Raw Audio) and Frequency domains:
@@ -60,15 +60,15 @@ Using raw audio data for Keyword Spotting (KWS), for example, on TinyML devices
Here are some additional details of the critical issues associated with using raw audio:
-- **High Dimensionality**: Audio signals, especially those sampled at high rates, result in large amounts of data. For example, a 1-second audio clip sampled at 16 kHz will have 16,000 individual data points. High-dimensional data increases computational complexity, leading to longer training times and higher computational costs, making it impractical for resource-constrained environments. Furthermore, the wide dynamic range of audio signals requires a significant amount of bits per sample, while conveying little useful information.
+- **High Dimensionality:** Audio signals, especially those sampled at high rates, result in large amounts of data. For example, a 1-second audio clip sampled at 16 kHz will have 16,000 individual data points. High-dimensional data increases computational complexity, leading to longer training times and higher computational costs, making it impractical for resource-constrained environments. Furthermore, the wide dynamic range of audio signals requires a significant amount of bits per sample, while conveying little useful information.
-- **Temporal Dependencies**: Raw audio signals have temporal structures that simple machine learning models may find hard to capture. While recurrent neural networks like [LSTMs](https://annals-csis.org/Volume_18/drp/pdf/185.pdf) can model such dependencies, they are computationally intensive and tricky to train on tiny devices.
+- **Temporal Dependencies:** Raw audio signals have temporal structures that simple machine learning models may find hard to capture. While recurrent neural networks like [LSTMs](https://annals-csis.org/Volume_18/drp/pdf/185.pdf) can model such dependencies, they are computationally intensive and tricky to train on tiny devices.
-- **Noise and Variability**: Raw audio signals often contain background noise and other non-essential elements affecting model performance. Additionally, the same sound can have different characteristics based on various factors such as distance from the microphone, the orientation of the sound source, and acoustic properties of the environment, adding to the complexity of the data.
+- **Noise and Variability:** Raw audio signals often contain background noise and other non-essential elements affecting model performance. Additionally, the same sound can have different characteristics based on various factors such as distance from the microphone, the orientation of the sound source, and acoustic properties of the environment, adding to the complexity of the data.
-- **Lack of Semantic Meaning**: Raw audio doesn't inherently contain semantically meaningful features for classification tasks. Features like pitch, tempo, and spectral characteristics, which can be crucial for speech recognition, are not directly accessible from raw waveform data.
+- **Lack of Semantic Meaning:** Raw audio doesn't inherently contain semantically meaningful features for classification tasks. Features like pitch, tempo, and spectral characteristics, which can be crucial for speech recognition, are not directly accessible from raw waveform data.
-- **Signal Redundancy**: Audio signals often contain redundant information, with certain portions of the signal contributing little to no value to the task at hand. This redundancy can make learning inefficient and potentially lead to overfitting.
+- **Signal Redundancy:** Audio signals often contain redundant information, with certain portions of the signal contributing little to no value to the task at hand. This redundancy can make learning inefficient and potentially lead to overfitting.
For these reasons, feature extraction techniques such as Mel-frequency Cepstral Coefficients (MFCCs), Mel-Frequency Energies (MFEs), and simple Spectograms are commonly used to transform raw audio data into a more manageable and informative format. These features capture the essential characteristics of the audio signal while reducing dimensionality and noise, facilitating more effective machine learning.
@@ -88,10 +88,10 @@ The image below shows the words `YES` and `NO` in their MFCC representation:
MFCCs are crucial for several reasons, particularly in the context of Keyword Spotting (KWS) and TinyML:
-- **Dimensionality Reduction**: MFCCs capture essential spectral characteristics of the audio signal while significantly reducing the dimensionality of the data, making it ideal for resource-constrained TinyML applications.
-- **Robustness**: MFCCs are less susceptible to noise and variations in pitch and amplitude, providing a more stable and robust feature set for audio classification tasks.
-- **Human Auditory System Modeling**: The Mel scale in MFCCs approximates the human ear's response to different frequencies, making them practical for speech recognition where human-like perception is desired.
-- **Computational Efficiency**: The process of calculating MFCCs is computationally efficient, making it well-suited for real-time applications on hardware with limited computational resources.
+- **Dimensionality Reduction:** MFCCs capture essential spectral characteristics of the audio signal while significantly reducing the dimensionality of the data, making it ideal for resource-constrained TinyML applications.
+- **Robustness:** MFCCs are less susceptible to noise and variations in pitch and amplitude, providing a more stable and robust feature set for audio classification tasks.
+- **Human Auditory System Modeling:** The Mel scale in MFCCs approximates the human ear's response to different frequencies, making them practical for speech recognition where human-like perception is desired.
+- **Computational Efficiency:** The process of calculating MFCCs is computationally efficient, making it well-suited for real-time applications on hardware with limited computational resources.
In summary, MFCCs offer a balance of information richness and computational efficiency, making them popular for audio classification tasks, particularly in constrained environments like TinyML.
@@ -99,11 +99,11 @@ In summary, MFCCs offer a balance of information richness and computational effi
The computation of Mel-frequency Cepstral Coefficients (MFCCs) involves several key steps. Let's walk through these, which are particularly important for Keyword Spotting (KWS) tasks on TinyML devices.
-- **Pre-emphasis**: The first step is pre-emphasis, which is applied to accentuate the high-frequency components of the audio signal and balance the frequency spectrum. This is achieved by applying a filter that amplifies the difference between consecutive samples. The formula for pre-emphasis is: y(t) = x(t) - $\alpha$ x(t-1) , where $\alpha$ is the pre-emphasis factor, typically around 0.97.
+- **Pre-emphasis:** The first step is pre-emphasis, which is applied to accentuate the high-frequency components of the audio signal and balance the frequency spectrum. This is achieved by applying a filter that amplifies the difference between consecutive samples. The formula for pre-emphasis is: y(t) = x(t) - $\alpha$ x(t-1) , where $\alpha$ is the pre-emphasis factor, typically around 0.97.
-- **Framing**: Audio signals are divided into short frames (the *frame length*), usually 20 to 40 milliseconds. This is based on the assumption that frequencies in a signal are stationary over a short period. Framing helps in analyzing the signal in such small time slots. The *frame stride* (or step) will displace one frame and the adjacent. Those steps could be sequential or overlapped.
+- **Framing:** Audio signals are divided into short frames (the *frame length*), usually 20 to 40 milliseconds. This is based on the assumption that frequencies in a signal are stationary over a short period. Framing helps in analyzing the signal in such small time slots. The *frame stride* (or step) will displace one frame and the adjacent. Those steps could be sequential or overlapped.
-- **Windowing**: Each frame is then windowed to minimize the discontinuities at the frame boundaries. A commonly used window function is the Hamming window. Windowing prepares the signal for a Fourier transform by minimizing the edge effects. The image below shows three frames (10, 20, and 30) and the time samples after windowing (note that the frame length and frame stride are 20 ms):
+- **Windowing:** Each frame is then windowed to minimize the discontinuities at the frame boundaries. A commonly used window function is the Hamming window. Windowing prepares the signal for a Fourier transform by minimizing the edge effects. The image below shows three frames (10, 20, and 30) and the time samples after windowing (note that the frame length and frame stride are 20 ms):
{fig-align="center" width="6.5in"}
@@ -113,11 +113,11 @@ The computation of Mel-frequency Cepstral Coefficients (MFCCs) involves several
{fig-align="center" width="6.5in"}
-- **Mel Filter Banks**: The frequency domain is then mapped to the [Mel scale](https://en.wikipedia.org/wiki/Mel_scale), which approximates the human ear's response to different frequencies. The idea is to extract more features (more filter banks) in the lower frequencies and less in the high frequencies. Thus, it performs well on sounds distinguished by the human ear. Typically, 20 to 40 triangular filters extract the Mel-frequency energies. These energies are then log-transformed to convert multiplicative factors into additive ones, making them more suitable for further processing.
+- **Mel Filter Banks:** The frequency domain is then mapped to the [Mel scale](https://en.wikipedia.org/wiki/Mel_scale), which approximates the human ear's response to different frequencies. The idea is to extract more features (more filter banks) in the lower frequencies and less in the high frequencies. Thus, it performs well on sounds distinguished by the human ear. Typically, 20 to 40 triangular filters extract the Mel-frequency energies. These energies are then log-transformed to convert multiplicative factors into additive ones, making them more suitable for further processing.
{fig-align="center" width="6.5in"}
-- **Discrete Cosine Transform (DCT)**: The last step is to apply the [Discrete Cosine Transform (DCT)](https://en.wikipedia.org/wiki/Discrete_cosine_transform) to the log Mel energies. The DCT helps to decorrelate the energies, effectively compressing the data and retaining only the most discriminative features. Usually, the first 12-13 DCT coefficients are retained, forming the final MFCC feature vector.
+- **Discrete Cosine Transform (DCT):** The last step is to apply the [Discrete Cosine Transform (DCT)](https://en.wikipedia.org/wiki/Discrete_cosine_transform) to the log Mel energies. The DCT helps to decorrelate the energies, effectively compressing the data and retaining only the most discriminative features. Usually, the first 12-13 DCT coefficients are retained, forming the final MFCC feature vector.
{fig-align="center" width="6.5in"}
@@ -135,15 +135,15 @@ In general, MFCCs are more focused on capturing the envelope of the power spectr
#### MFCCs are particularly strong for:
-1. **Speech Recognition**: MFCCs are excellent for identifying phonetic content in speech signals.
-2. **Speaker Identification**: They can be used to distinguish between different speakers based on voice characteristics.
-3. **Emotion Recognition**: MFCCs can capture the nuanced variations in speech indicative of emotional states.
-4. **Keyword Spotting**: Especially in TinyML, where low computational complexity and small feature size are crucial.
+1. **Speech Recognition:** MFCCs are excellent for identifying phonetic content in speech signals.
+2. **Speaker Identification:** They can be used to distinguish between different speakers based on voice characteristics.
+3. **Emotion Recognition:** MFCCs can capture the nuanced variations in speech indicative of emotional states.
+4. **Keyword Spotting:** Especially in TinyML, where low computational complexity and small feature size are crucial.
#### Spectrograms or MFEs are often more suitable for:
-1. **Music Analysis**: Spectrograms can capture harmonic and timbral structures in music, which is essential for tasks like genre classification, instrument recognition, or music transcription.
-2. **Environmental Sound Classification**: In recognizing non-speech, environmental sounds (e.g., rain, wind, traffic), the full spectrogram can provide more discriminative features.
-3. **Birdsong Identification**: The intricate details of bird calls are often better captured using spectrograms.
-4. **Bioacoustic Signal Processing**: In applications like dolphin or bat call analysis, the fine-grained frequency information in a spectrogram can be essential.
-5. **Audio Quality Assurance**: Spectrograms are often used in professional audio analysis to identify unwanted noises, clicks, or other artifacts.
+1. **Music Analysis:** Spectrograms can capture harmonic and timbral structures in music, which is essential for tasks like genre classification, instrument recognition, or music transcription.
+2. **Environmental Sound Classification:** In recognizing non-speech, environmental sounds (e.g., rain, wind, traffic), the full spectrogram can provide more discriminative features.
+3. **Birdsong Identification:** The intricate details of bird calls are often better captured using spectrograms.
+4. **Bioacoustic Signal Processing:** In applications like dolphin or bat call analysis, the fine-grained frequency information in a spectrogram can be essential.
+5. **Audio Quality Assurance:** Spectrograms are often used in professional audio analysis to identify unwanted noises, clicks, or other artifacts.
diff --git a/contents/kws_nicla/kws_nicla.bib b/contents/kws_nicla/kws_nicla.bib
index e69de29b..00614696 100644
--- a/contents/kws_nicla/kws_nicla.bib
+++ b/contents/kws_nicla/kws_nicla.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/labs.qmd b/contents/labs.qmd
index 5ec80c65..4d56afc4 100644
--- a/contents/labs.qmd
+++ b/contents/labs.qmd
@@ -1,7 +1,7 @@
# LABS
-The following labs provide a unique opportunity to gain hands-on experience deploying tinyML models onto real embedded devices. In contrast to working with large models that require data center-scale resources, these labs allow you to interact directly with the hardware and software, giving you a tangible understanding of the challenges and opportunities in embedded AI.
+The following labs provide a unique opportunity to gain hands-on experience deploying TinyML models onto real embedded devices. In contrast to working with large models that require data center-scale resources, these labs allow you to interact directly with the hardware and software, giving you a tangible understanding of the challenges and opportunities in embedded AI.
-From setting up the [Nicla Vision](https://store.arduino.cc/products/nicla-vision) board to implementing computer vision, audio processing, and motion classification tasks using tools like [TensorFlow Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers) and Arduino firmware, you'll develop practical skills in deploying efficient AI models on resource-constrained devices. By completing these labs, you'll appreciate the beauty of tinyML—the ability to hold cutting-edge AI technology in the palm of your hand. This hands-on perspective is invaluable for understanding the end-to-end workflow of embedded AI systems and will prepare you for real-world applications where model efficiency, robustness, and responsiveness are paramount. In the future, we plan to add a few other platforms. Please stay tuned!
+From setting up the [Nicla Vision](https://store.arduino.cc/products/nicla-vision) board to implementing computer vision, audio processing, and motion classification tasks using tools like [TensorFlow Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers) and Arduino firmware, you'll develop practical skills in deploying efficient AI models on resource-constrained devices. By completing these labs, you'll appreciate the beauty of TinyML—the ability to hold cutting-edge AI technology in the palm of your hand. This hands-on perspective is invaluable for understanding the end-to-end workflow of embedded AI systems and will prepare you for real-world applications where model efficiency, robustness, and responsiveness are paramount. In the future, we plan to add a few other platforms. Please stay tuned!
These lab exercises are the contributions of [Marcelo Rovai](https://github.com/Mjrovai).
\ No newline at end of file
diff --git a/contents/ml_systems/ml_systems.bib b/contents/ml_systems/ml_systems.bib
index 66e945e3..bea5df32 100644
--- a/contents/ml_systems/ml_systems.bib
+++ b/contents/ml_systems/ml_systems.bib
@@ -1,6 +1,9 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@misc{armcomfuture,
author = {ARM.com},
howpublished = {https://www.arm.com/company/news/2023/02/arm-announces-q3-fy22-results},
note = {(Accessed on 09/16/2023)},
- title = {The future is being built on Arm: {Market} diversification continues to drive strong royalty and licensing growth as ecosystem reaches quarter of a trillion chips milestone {\textendash} Arm{\textregistered}}
+ title = {The future is being built on Arm: {Market} diversification continues to drive strong royalty and licensing growth as ecosystem reaches quarter of a trillion chips milestone {\textendash} Arm{\textregistered}},
}
diff --git a/contents/ml_systems/ml_systems.qmd b/contents/ml_systems/ml_systems.qmd
index fa8cccae..83328cec 100644
--- a/contents/ml_systems/ml_systems.qmd
+++ b/contents/ml_systems/ml_systems.qmd
@@ -8,33 +8,33 @@ bibliography: ml_systems.bib
Resources: [Slides](#sec-ml-systems-resource), [Labs](#sec-ml-systems-resource), [Exercises](#sec-ml-systems-resource)
:::
-
+
-In the domain of machine learning (ML) systems, computing systems serve as the bedrock, providing a robust platform where intelligent algorithms can function both efficiently and effectively. Defined by their specialized roles and real-time computational capabilities, these systems act as the convergence point where data and computation intersect on a micro-scale. Tailored to meet the demands of specific tasks, they excel in optimizing performance, energy usage, and spatial efficiency-key considerations in the successful implementation of ML systems.c
+Machine learning (ML) systems, built on the foundation of computing systems, hold the potential to transform our world. These systems, with their specialized roles and real-time computational capabilities, represent a critical junction where data and computation meet on a micro-scale. They are specifically tailored to optimize performance, energy usage, and spatial efficiency—key factors essential for the successful implementation of ML systems.
-As we journey further into this chapter, we will demystify the intricate yet captivating realm of embedded systems, gaining insights into their structural design, operational features, and the crucial part they play in enabling ML systems applications. From an introduction to the fundamentals of microcontroller units to a deep dive into the interfaces and peripherals that amplify their capabilities, this chapter aims to be a comprehensive guide for understanding the nuanced aspects of embedded systems within the ML systems landscape.
+As this chapter progresses, we will explore embedded systems' complex and fascinating world. We'll gain insights into their structural design and operational features and understand their pivotal role in powering ML applications. Starting with the basics of microcontroller units, we will examine the interfaces and peripherals that enhance their functionalities. This chapter is designed to be a comprehensive guide elucidating the nuanced aspects of embedded systems within the ML systems framework.
::: {.callout-tip}
## Learning Objectives
-* Acquire a comprehensive understanding of ML systems, including their definitions, architecture, and programming languages, with a focus on the evolution and significance of TinyML.
+* Acquire a comprehensive understanding of ML systems, including their definitions, architecture, and programming languages, focusing on the evolution and significance of TinyML.
-* Explore the design and operational principles of ML systems, including microcontroller versus microprocessor use, memory management, System on Chip (SoC) integration, and the development and deployment of machine learning models.
+* Explore the design and operational principles of ML systems, including the use of a microcontroller rather than a microprocessor, memory management, System-on-chip (SoC) integration, and the development and deployment of machine learning models.
-* Examine the interfaces, power management, and real-time operating characteristics essential for efficient ML systems, alongside considerations for energy efficiency, reliability, and security.
+* Examine the interfaces, power management, and real-time operating characteristics essential for efficient ML systems alongside energy efficiency, reliability, and security considerations.
-* Investigate the distinctions, benefits, challenges, and use cases for Cloud ML, Edge ML, and TinyML, emphasizing the selection of the appropriate machine learning approach based on specific application needs and the evolving landscape of embedded systems in machine learning.
+* Investigate the distinctions, benefits, challenges, and use cases for Cloud ML, Edge ML, and TinyML, emphasizing selecting the appropriate machine learning approach based on specific application needs and the evolving landscape of embedded systems in machine learning.
:::
## Machine Learning Systems
-ML is rapidly evolving, with new paradigms emerging that are reshaping how these algorithms are developed, trained, and deployed. In particular, the area of embedded machine learning is experiencing significant innovation, driven by the proliferation of smart sensors, edge devices, and microcontrollers. This chapter explores the landscape of embedded machine learning, covering the key approaches of Cloud ML, Edge ML, and TinyML (@fig-cloud-edge-tinyml-comparison).
+ML is rapidly evolving, with new paradigms reshaping how models are developed, trained, and deployed. One such paradigm is embedded machine learning, which is experiencing significant innovation driven by the proliferation of smart sensors, edge devices, and microcontrollers. Embedded machine learning refers to the integration of machine learning algorithms into the hardware of a device, enabling real-time data processing and analysis without relying on cloud connectivity. This chapter explores the landscape of embedded machine learning, covering the key approaches of Cloud ML, Edge ML, and TinyML (@fig-cloud-edge-tinyml-comparison).
{#fig-cloud-edge-tinyml-comparison}
-We begin by outlining the features or characteristics, benefits, challenges, and use cases for each embedded ML variant. This provides context on where these technologies do well and where they face limitations. We then bring all three approaches together into a comparative analysis, evaluating them across critical parameters like latency, privacy, computational demands, and more. This side-by-side perspective highlights the unique strengths and tradeoffs involved in selecting among these strategies.
+We begin by outlining each embedded ML variant's features or characteristics, benefits, challenges, and use cases. This provides context on where these technologies do well and where they face limitations. We then combine all three approaches into a comparative analysis, evaluating them across critical parameters like latency, privacy, computational demands, and more. This side-by-side perspective highlights the unique strengths and tradeoffs of selecting these strategies.
Next, we trace the evolution timeline of embedded systems and machine learning, from the origins of wireless sensor networks to the integration of ML algorithms into microcontrollers. This historical lens enriches our understanding of the rapid pace of advancement in this domain. Finally, practical hands-on exercises offer an opportunity to experiment first-hand with embedded computer vision applications.
@@ -44,11 +44,11 @@ By the end of this multipronged exploration of embedded ML, you will possess the
### Characteristics
-Cloud ML is a specialized branch of the broader machine learning field that operates within cloud computing environments. It offers a virtual platform for the development, training, and deployment of machine learning models, providing both flexibility and scalability.
+Cloud ML is a specialized branch of the broader machine learning field within cloud computing environments. It offers a virtual platform for developing, training, and deploying machine learning models, providing flexibility and scalability.
-At its foundation, Cloud ML utilizes a powerful blend of high-capacity servers, expansive storage solutions, and robust networking architectures, all located in data centers around the world (@fig-cloudml-example). This setup centralizes computational resources, simplifying the management and scaling of machine learning projects.
+At its foundation, Cloud ML utilizes a powerful blend of high-capacity servers, expansive storage solutions, and robust networking architectures, all located in data centers worldwide (@fig-cloudml-example). This setup centralizes computational resources, simplifying the management and scaling of machine learning projects.
-The cloud environment excels in data processing and model training, designed to manage large data volumes and complex computations. Models crafted in Cloud ML can leverage vast amounts of data, processed and analyzed centrally, thereby enhancing the model's learning and predictive performance.
+The cloud environment excels in data processing and model training and is designed to manage large data volumes and complex computations. Models crafted in Cloud ML can leverage vast amounts of data, processed and analyzed centrally, thereby enhancing the model's learning and predictive performance.
)](images/png/cloud_ml_tpu.png){#fig-cloudml-example}
@@ -58,27 +58,27 @@ Cloud ML is synonymous with immense computational power, adept at handling compl
A key advantage of Cloud ML is its dynamic scalability. As data volumes or computational needs grow, the infrastructure can adapt seamlessly, ensuring consistent performance.
-Cloud ML platforms often offer a wide array of advanced tools and algorithms. Developers can utilize these resources to accelerate the building, training, and deployment of sophisticated models, thereby fostering innovation.
+Cloud ML platforms often offer a wide array of advanced tools and algorithms. Developers can utilize these resources to accelerate the building, training, and deploying sophisticated models, fostering innovation.
### Challenges
Despite its capabilities, Cloud ML can face latency issues, especially in applications that require real-time responses. The time taken to send data to centralized servers and back can introduce delays, a significant drawback in time-sensitive scenarios.
-Centralizing data processing and storage can also create vulnerabilities in data privacy and security. Data centers become attractive targets for cyber-attacks, requiring substantial investments in security measures to protect sensitive data.
+Centralizing data processing and storage can also create data privacy and security vulnerabilities. Data centers become attractive targets for cyber-attacks, requiring substantial investments in security measures to protect sensitive data.
-Additionally, as data processing needs escalate, so do the costs of using cloud services. Organizations dealing with large data volumes may encounter rising costs, potentially affecting the long-term scalability and feasibility of their operations.
+Additionally, as data processing needs escalate, so do the costs of using cloud services. Organizations dealing with large data volumes may encounter rising costs, which could affect the long-term scalability and feasibility of their operations.
### Example Use Cases
-Cloud ML plays an important role in powering virtual assistants like Siri and Alexa. These systems harness the cloud's computational prowess to analyze and process voice inputs, delivering intelligent and personalized responses to users.
+Cloud ML is important in powering virtual assistants like Siri and Alexa. These systems harness the cloud's computational prowess to analyze and process voice inputs, delivering intelligent and personalized responses to users.
-It also serves as the foundation for advanced recommendation systems in platforms like Netflix and Amazon. These systems sift through extensive datasets to identify patterns and preferences, offering personalized content or product suggestions to boost user engagement.
+It also provides the foundation for advanced recommendation systems in platforms like Netflix and Amazon. These systems sift through extensive datasets to identify patterns and preferences, offering personalized content or product suggestions to boost user engagement.
-In the financial realm, Cloud ML has been instrumental in creating robust fraud detection systems. These systems scrutinize vast amounts of transactional data to flag potential fraudulent activities, enabling timely interventions and reducing financial risks.
+In the financial realm, Cloud ML has created robust fraud detection systems. These systems scrutinize vast amounts of transactional data to flag potential fraudulent activities, enabling timely interventions and reducing financial risks.
-In summary, it's virtually impossible to navigate the internet today without encountering some form of Cloud ML, either directly or indirectly. From the personalized ads that appear on your social media feed to the predictive text features in email services, Cloud ML is deeply integrated into our online experiences. It powers smart algorithms that recommend products on e-commerce sites, fine-tunes search engines to deliver accurate results, and even automates the tagging and categorization of photos on platforms like Facebook.
+In summary, it's virtually impossible to navigate the internet today without encountering some form of Cloud ML, directly or indirectly. From the personalized ads on your social media feed to the predictive text features in email services, Cloud ML is deeply integrated into our online experiences. It powers smart algorithms that recommend products on e-commerce sites, fine-tunes search engines to deliver accurate results, and even automates the tagging and categorization of photos on platforms like Facebook.
-Furthermore, Cloud ML bolsters user security through anomaly detection systems that monitor for unusual activities, potentially shielding users from cyber threats. Essentially, it acts as the unseen powerhouse, continuously operating behind the scenes to refine, secure, and personalize our digital interactions, making the modern internet a more intuitive and user-friendly environment.
+Furthermore, Cloud ML bolsters user security through anomaly detection systems that monitor for unusual activities, potentially shielding users from cyber threats. It acts as the unseen powerhouse, continuously operating behind the scenes to refine, secure, and personalize our digital interactions, making the modern internet a more intuitive and user-friendly environment.
## Edge ML
@@ -86,11 +86,11 @@ Furthermore, Cloud ML bolsters user security through anomaly detection systems t
**Definition of Edge ML**
-Edge Machine Learning (Edge ML) is the practice of running machine learning algorithms directly on endpoint devices or closer to where the data is generated, rather than relying on centralized cloud servers. This approach aims to bring computation closer to the data source, reducing the need to send large volumes of data over networks, which often results in lower latency and improved data privacy.
+Edge Machine Learning (Edge ML) runs machine learning algorithms directly on endpoint devices or closer to where the data is generated rather than relying on centralized cloud servers. This approach aims to bring computation closer to the data source, reducing the need to send large volumes of data over networks, often resulting in lower latency and improved data privacy.
**Decentralized Data Processing**
-In Edge ML, data processing happens in a decentralized fashion. Instead of sending data to remote servers, the data is processed locally on devices like smartphones, tablets, or IoT devices (@fig-edgeml-example). This local processing allows devices to make quick decisions based on the data they collect, without having to rely heavily on a central server's resources. This decentralization is particularly important in real-time applications where even a slight delay can have significant consequences.
+In Edge ML, data processing happens in a decentralized fashion. Instead of sending data to remote servers, the data is processed locally on devices like smartphones, tablets, or IoT devices (@fig-edgeml-example). This local processing allows devices to make quick decisions based on the data they collect without relying heavily on a central server's resources. This decentralization is particularly important in real-time applications where even a slight delay can have significant consequences.
**Local Data Storage and Computation**
@@ -102,47 +102,47 @@ Local data storage and computation are key features of Edge ML. This setup ensur
**Reduced Latency**
-One of the main advantages of Edge ML is the significant reduction in latency compared to Cloud ML. In situations where milliseconds count, such as in autonomous vehicles where quick decision-making can mean the difference between safety and an accident, this reduced latency can be a critical benefit.
+One of Edge ML's main advantages is the significant latency reduction compared to Cloud ML. This reduced latency can be a critical benefit in situations where milliseconds count, such as in autonomous vehicles, where quick decision-making can mean the difference between safety and an accident.
**Enhanced Data Privacy**
-Edge ML also offers improved data privacy, as data is primarily stored and processed locally. This minimizes the risk of data breaches that are more common in centralized data storage solutions. This means sensitive information can be kept more secure, as it's not sent over networks where it could potentially be intercepted.
+Edge ML also offers improved data privacy, as data is primarily stored and processed locally. This minimizes the risk of data breaches that are more common in centralized data storage solutions. Sensitive information can be kept more secure, as it's not sent over networks that could be intercepted.
**Lower Bandwidth Usage**
-Operating closer to the data source means that less data needs to be sent over networks, reducing bandwidth usage. This can result in cost savings and efficiency gains, especially in environments where bandwidth is limited or costly.
+Operating closer to the data source means less data must be sent over networks, reducing bandwidth usage. This can result in cost savings and efficiency gains, especially in environments where bandwidth is limited or costly.
### Challenges
**Limited Computational Resources Compared to Cloud ML**
-However, Edge ML is not without its challenges. One of the main concerns is the limited computational resources compared to cloud-based solutions. Endpoint devices may not have the same processing power or storage capacity as cloud servers, which can limit the complexity of the machine learning models that can be deployed.
+However, Edge ML has its challenges. One of the main concerns is the limited computational resources compared to cloud-based solutions. Endpoint devices may have a different processing power or storage capacity than cloud servers, limiting the complexity of the machine learning models that can be deployed.
**Complexity in Managing Edge Nodes**
-Managing a network of edge nodes can introduce complexity, especially when it comes to coordination, updates, and maintenance. Ensuring that all nodes are operating seamlessly and are up-to-date with the latest algorithms and security protocols can be a logistical challenge.
+Managing a network of edge nodes can introduce complexity, especially regarding coordination, updates, and maintenance. Ensuring all nodes operate seamlessly and are up-to-date with the latest algorithms and security protocols can be a logistical challenge.
**Security Concerns at the Edge Nodes**
-While Edge ML offers enhanced data privacy, edge nodes can sometimes be more vulnerable to physical and cyber-attacks. Developing robust security protocols that protect data at each node, without compromising the system's efficiency, remains a significant challenge in deploying Edge ML solutions.
+While Edge ML offers enhanced data privacy, edge nodes can sometimes be more vulnerable to physical and cyber-attacks. Developing robust security protocols that protect data at each node without compromising the system's efficiency remains a significant challenge in deploying Edge ML solutions.
### Example Use Cases
-Edge ML has a wide range of applications, from autonomous vehicles and smart homes to industrial IoT. These examples were chosen to highlight scenarios where real-time data processing, reduced latency, and enhanced privacy are not just beneficial but often critical to the operation and success of these technologies. They serve to demonstrate the pivotal role that Edge ML can play in driving advancements in various sectors, fostering innovation, and paving the way for more intelligent, responsive, and adaptive systems.
+Edge ML has many applications, from autonomous vehicles and smart homes to industrial IoT. These examples were chosen to highlight scenarios where real-time data processing, reduced latency, and enhanced privacy are not just beneficial but often critical to the operation and success of these technologies. They demonstrate the pivotal role that Edge ML can play in driving advancements in various sectors, fostering innovation, and paving the way for more intelligent, responsive, and adaptive systems.
**Autonomous Vehicles**
-Autonomous vehicles stand as a prime example of Edge ML's potential. These vehicles rely heavily on real-time data processing to navigate and make decisions. Localized machine learning models assist in quickly analyzing data from various sensors to make immediate driving decisions, essentially ensuring safety and smooth operation.
+Autonomous vehicles stand as a prime example of Edge ML's potential. These vehicles rely heavily on real-time data processing to navigate and make decisions. Localized machine learning models assist in quickly analyzing data from various sensors to make immediate driving decisions, ensuring safety and smooth operation.
**Smart Homes and Buildings**
-In smart homes and buildings, Edge ML plays a crucial role in efficiently managing various systems, from lighting and heating to security. By processing data locally, these systems can operate more responsively and in harmony with the occupants' habits and preferences, creating a more comfortable living environment.
+Edge ML plays a crucial role in efficiently managing various systems in smart homes and buildings, from lighting and heating to security. By processing data locally, these systems can operate more responsively and harmoniously with the occupants' habits and preferences, creating a more comfortable living environment.
**Industrial IoT**
-The Industrial Internet of Things (IoT) leverages Edge ML to monitor and control complex industrial processes. Here, machine learning models can analyze data from numerous sensors in real-time, enabling predictive maintenance, optimizing operations, and enhancing safety measures. This brings about a revolution in industrial automation and efficiency.
+The Industrial Internet of Things (IoT) leverages Edge ML to monitor and control complex industrial processes. Here, machine learning models can analyze data from numerous sensors in real-time, enabling predictive maintenance, optimizing operations, and enhancing safety measures. This revolution in industrial automation and efficiency.
-The applicability of Edge ML is vast and not limited to these examples. Various other sectors, including healthcare, agriculture, and urban planning, are exploring and integrating Edge ML to develop solutions that are both innovative and responsive to real-world needs and challenges, heralding a new era of smart, interconnected systems.
+The applicability of Edge ML is vast and not limited to these examples. Various other sectors, including healthcare, agriculture, and urban planning, are exploring and integrating Edge ML to develop innovative solutions responsive to real-world needs and challenges, heralding a new era of smart, interconnected systems.
## Tiny ML
@@ -150,23 +150,23 @@ The applicability of Edge ML is vast and not limited to these examples. Various
**Definition of TinyML**
-TinyML sits at the crossroads of embedded systems and machine learning, representing a burgeoning field that brings smart algorithms directly to tiny microcontrollers and sensors. These microcontrollers operate under severe resource constraints, particularly in terms of memory, storage, and computational power (see a TinyML kit example in @fig-tinyml-example).
+TinyML sits at the crossroads of embedded systems and machine learning, representing a burgeoning field that brings smart algorithms directly to tiny microcontrollers and sensors. These microcontrollers operate under severe resource constraints, particularly regarding memory, storage, and computational power (see a TinyML kit example in @fig-tinyml-example).
**On-Device Machine Learning**
-In TinyML, the focus is on on-device machine learning. This means that machine learning models are not just deployed but also trained right on the device, eliminating the need for external servers or cloud infrastructures. This allows TinyML to enable intelligent decision-making right where the data is generated, making real-time insights and actions possible, even in settings where connectivity is limited or unavailable.
+In TinyML, the focus is on on-device machine learning. This means that machine learning models are deployed and trained on the device, eliminating the need for external servers or cloud infrastructures. This allows TinyML to enable intelligent decision-making right where the data is generated, making real-time insights and actions possible, even in settings where connectivity is limited or unavailable.
**Low Power and Resource-Constrained Environments**
-TinyML excels in low-power and resource-constrained settings. These environments require solutions that are highly optimized to function within the available resources. TinyML meets this need through specialized algorithms and models designed to deliver decent performance while consuming minimal energy, thus ensuring extended operational periods, even in battery-powered devices.
+TinyML excels in low-power and resource-constrained settings. These environments require highly optimized solutions that function within the available resources. TinyML meets this need through specialized algorithms and models designed to deliver decent performance while consuming minimal energy, thus ensuring extended operational periods, even in battery-powered devices.
-))](images/jpg/tiny_ml.jpg){#fig-tinyml-example}
+))](images/jpg/tiny_ml.jpg){#fig-tinyml-example}
:::{#exr-tinyml .callout-exercise collapse="true"}
### TinyML with Arduino
-Get ready to bring machine learning to the smallest of devices! In the embedded machine learning world, TinyML is where resource constraints meet ingenuity. This Colab notebook will walk you through building a gesture recognition model specifically designed to run on an Arduino board. You'll learn how to train a small but effective neural network, optimize it for minimal memory usage, and actually deploy it to your microcontroller. If you're excited about making everyday objects smarter, this is where it begins!
+Get ready to bring machine learning to the smallest of devices! In the embedded machine learning world, TinyML is where resource constraints meet ingenuity. This Colab notebook will walk you through building a gesture recognition model designed on an Arduino board. You'll learn how to train a small but effective neural network, optimize it for minimal memory usage, and deploy it to your microcontroller. If you're excited about making everyday objects smarter, this is where it begins!
[](https://colab.research.google.com/github/arduino/ArduinoTensorFlowLiteTutorials/blob/master/GestureToEmoji/arduino_tinyml_workshop.ipynb)
@@ -180,31 +180,31 @@ One of the standout benefits of TinyML is its ability to offer ultra-low latency
**High Data Security**
-TinyML inherently enhances data security. Because data processing and analysis happen on the device itself, the risk of data interception during transmission is virtually eliminated. This localized approach to data management ensures that sensitive information stays on the device, thereby strengthening user data security.
+TinyML inherently enhances data security. Because data processing and analysis happen on the device, the risk of data interception during transmission is virtually eliminated. This localized approach to data management ensures that sensitive information stays on the device, strengthening user data security.
**Energy Efficiency**
-TinyML operates within an energy-efficient framework, a necessity given the resource-constrained environments in which it functions. By employing lean algorithms and optimized computational methods, TinyML ensures that devices can execute complex tasks without rapidly depleting battery life, making it a sustainable option for long-term deployments.
+TinyML operates within an energy-efficient framework, a necessity given its resource-constrained environments. By employing lean algorithms and optimized computational methods, TinyML ensures that devices can execute complex tasks without rapidly depleting battery life, making it a sustainable option for long-term deployments.
### Challenges
**Limited Computational Capabilities**
-However, the shift to TinyML comes with its set of hurdles. The primary limitation is the constrained computational capabilities of the devices. The need to operate within such limits means that deployed models must be simplified, which could affect the accuracy and sophistication of the solutions.
+However, the shift to TinyML comes with its set of hurdles. The primary limitation is the devices' constrained computational capabilities. The need to operate within such limits means that deployed models must be simplified, which could affect the accuracy and sophistication of the solutions.
**Complex Development Cycle**
-TinyML also introduces a complicated development cycle. Crafting models that are both lightweight and effective demands a deep understanding of machine learning principles, along with expertise in embedded systems. This complexity calls for a collaborative development approach, where multi-domain expertise is essential for success.
+TinyML also introduces a complicated development cycle. Crafting lightweight and effective models demands a deep understanding of machine learning principles and expertise in embedded systems. This complexity calls for a collaborative development approach, where multi-domain expertise is essential for success.
**Model Optimization and Compression**
-A central challenge in TinyML is model optimization and compression. Creating machine learning models that can operate effectively within the limited memory and computational power of microcontrollers requires innovative approaches to model design. Developers often face the challenge of striking a delicate balance, optimizing models to maintain effectiveness while fitting within stringent resource constraints.
+A central challenge in TinyML is model optimization and compression. Creating machine learning models that can operate effectively within the limited memory and computational power of microcontrollers requires innovative approaches to model design. Developers often face the challenge of striking a delicate balance and optimizing models to maintain effectiveness while fitting within stringent resource constraints.
### Example Use Cases
**Wearable Devices**
-In wearables, TinyML opens the door to smarter, more responsive gadgets. From fitness trackers offering real-time workout feedback to smart glasses processing visual data on the fly, TinyML is transforming how we engage with wearable tech, delivering personalized experiences directly from the device.
+In wearables, TinyML opens the door to smarter, more responsive gadgets. From fitness trackers offering real-time workout feedback to smart glasses processing visual data on the fly, TinyML transforms how we engage with wearable tech, delivering personalized experiences directly from the device.
**Predictive Maintenance**
@@ -212,17 +212,17 @@ In industrial settings, TinyML plays a significant role in predictive maintenanc
**Anomaly Detection**
-TinyML can be employed to create anomaly detection models that identify unusual data patterns. For instance, a smart factory could use TinyML to monitor industrial processes and spot anomalies, helping prevent accidents and improve product quality. Similarly, a security company could use TinyML to monitor network traffic for unusual patterns, aiding in the detection and prevention of cyber attacks. In healthcare, TinyML could monitor patient data for anomalies, aiding early disease detection and better patient treatment.
+TinyML can be employed to create anomaly detection models that identify unusual data patterns. For instance, a smart factory could use TinyML to monitor industrial processes and spot anomalies, helping prevent accidents and improve product quality. Similarly, a security company could use TinyML to monitor network traffic for unusual patterns, aiding in detecting and preventing cyber-attacks. TinyML could monitor patient data for anomalies in healthcare, aiding early disease detection and better patient treatment.
**Environmental Monitoring**
-In the field of environmental monitoring, TinyML enables real-time data analysis from various field-deployed sensors. These could range from air quality monitoring in cities to wildlife tracking in protected areas. Through TinyML, data can be processed locally, allowing for quick responses to changing conditions and providing a nuanced understanding of environmental patterns, crucial for informed decision-making.
+In environmental monitoring, TinyML enables real-time data analysis from various field-deployed sensors. These could range from city air quality monitoring to wildlife tracking in protected areas. Through TinyML, data can be processed locally, allowing for quick responses to changing conditions and providing a nuanced understanding of environmental patterns, crucial for informed decision-making.
-In summary, TinyML serves as a trailblazer in the evolution of machine learning, fostering innovation across various fields by bringing intelligence directly to the edge. Its potential to transform our interaction with technology and the world is immense, promising a future where devices are not just connected but also intelligent, capable of making real-time decisions and responses.
+In summary, TinyML serves as a trailblazer in the evolution of machine learning, fostering innovation across various fields by bringing intelligence directly to the edge. Its potential to transform our interaction with technology and the world is immense, promising a future where devices are connected, intelligent, and capable of making real-time decisions and responses.
## Comparison
-Up to this point, we've explored each of the different ML variants individually. Now, let's bring them all together for a comprehensive view. Below is a table offering a comparative analysis of Cloud ML, Edge ML, and TinyML based on various features and aspects. This comparison aims to provide a clear perspective on the unique advantages and distinguishing factors of each, aiding in making informed decisions based on the specific needs and constraints of a given application or project.
+Up to this point, we've explored each of the different ML variants individually. Now, let's bring them all together for a comprehensive view. @tbl-big_vs_tiny offers a comparative analysis of Cloud ML, Edge ML, and TinyML based on various features and aspects. This comparison aims to provide a clear perspective on the unique advantages and distinguishing factors, aiding in making informed decisions based on the specific needs and constraints of a given application or project.
| Feature/Aspect | Cloud ML | Edge ML | TinyML |
|--------------------------|--------------------------------------------------------|------------------------------------------------------|------------------------------------------------------|
@@ -238,22 +238,24 @@ Up to this point, we've explored each of the different ML variants individually.
| **Application Examples** | Big Data Analysis, Virtual Assistants | Autonomous Vehicles, Smart Homes | Wearables, Sensor Networks |
| **Development Complexity** | Moderate to High (Requires knowledge in cloud computing) | Moderate (Requires knowledge in local network setup) | Moderate to High (Requires expertise in embedded systems)|
+: Comparison of feature aspects across Cloud ML, Edge ML, and TinyML. {#tbl-big_vs_tiny}
+
## Conclusion
-In this chapter, we've offered a panoramic view of the evolving landscape of machine learning, covering cloud, edge, and tiny ML paradigms. Cloud-based machine learning leverages the immense computational resources of cloud platforms to enable powerful and accurate models but comes with its own set of limitations, including latency and privacy concerns. Edge ML mitigates these limitations by bringing ML inference directly to edge devices, offering lower latency and reduced connectivity needs. TinyML takes this a step further by miniaturizing ML models to run directly on highly resource-constrained devices, opening up a new category of intelligent applications.
+In this chapter, we've offered a panoramic view of the evolving landscape of machine learning, covering cloud, edge, and tiny ML paradigms. Cloud-based machine learning leverages the immense computational resources of cloud platforms to enable powerful and accurate models but comes with limitations, including latency and privacy concerns. Edge ML mitigates these limitations by bringing inference directly to edge devices, offering lower latency and reduced connectivity needs. TinyML takes this further by miniaturizing ML models to run directly on highly resource-constrained devices, opening up a new category of intelligent applications.
-Each approach comes with its own set of trade-offs, including model complexity, latency, privacy, and hardware costs. Over time, we anticipate a convergence of these embedded ML approaches, with cloud pre-training facilitating more sophisticated edge and tiny ML implementations. Advances like federated learning and on-device learning will also enable embedded devices to refine their models by learning from real-world data.
+Each approach has its tradeoffs, including model complexity, latency, privacy, and hardware costs. Over time, we anticipate converging these embedded ML approaches, with cloud pre-training facilitating more sophisticated edge and tiny ML implementations. Advances like federated learning and on-device learning will enable embedded devices to refine their models by learning from real-world data.
-The embedded ML landscape is in a state of rapid evolution, poised to enable intelligent applications across a broad spectrum of devices and use cases. This chapter serves as a snapshot of the current state of embedded ML, and as algorithms, hardware, and connectivity continue to improve, we can expect embedded devices of all sizes to become increasingly capable, unlocking transformative new applications for artificial intelligence.
+The embedded ML landscape is rapidly evolving and poised to enable intelligent applications across a broad spectrum of devices and use cases. This chapter serves as a snapshot of the current state of embedded ML. As algorithms, hardware, and connectivity continue to improve, we can expect embedded devices of all sizes to become increasingly capable, unlocking transformative new applications for artificial intelligence.
## Resources {#sec-ml-systems-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will be adding new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Embedded Systems Overview.](https://docs.google.com/presentation/d/1Lgrn7bddHYxyrOmk0JfSVmEBimRePqI7WSliUKRPK9E/edit?resourcekey=0-c5JvfDeqHIdV9A5RMAMAyw#slide=id.g94db9f9f78_0_8)
@@ -281,13 +283,13 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
-Coming soon.
+*Coming soon.*
:::
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/motion_classify_ad/motion_classify_ad.bib b/contents/motion_classify_ad/motion_classify_ad.bib
index e69de29b..00614696 100644
--- a/contents/motion_classify_ad/motion_classify_ad.bib
+++ b/contents/motion_classify_ad/motion_classify_ad.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/motion_classify_ad/motion_classify_ad.qmd b/contents/motion_classify_ad/motion_classify_ad.qmd
index b29aef7f..01fd760c 100644
--- a/contents/motion_classify_ad/motion_classify_ad.qmd
+++ b/contents/motion_classify_ad/motion_classify_ad.qmd
@@ -27,7 +27,7 @@ By the end of this tutorial, you'll have a working prototype that can classify d
## IMU Installation and testing
-For this project, we will use an accelerometer. As discussed in the Hands-On Tutorial, *Setup Nicla Vision*, the Nicla Vision Board has an onboard **6-axis IMU**: 3D gyroscope and 3D accelerometer, the [LSM6DSOX](https://www.st.com/resource/en/datasheet/lsm6dsox.pdf). Let's verify if the [LSM6DSOX IMU library](https://github.com/arduino-libraries/Arduino_LSM6DSOX) is installed. If not, install it.
+For this project, we will use an accelerometer. As discussed in the Hands-On Tutorial, *Setup Nicla Vision*, the Nicla Vision Board has an onboard **6-axis IMU:** 3D gyroscope and 3D accelerometer, the [LSM6DSOX](https://www.st.com/resource/en/datasheet/lsm6dsox.pdf). Let's verify if the [LSM6DSOX IMU library](https://github.com/arduino-libraries/Arduino_LSM6DSOX) is installed. If not, install it.
{fig-align="center" width="6.5in"}
@@ -39,15 +39,15 @@ Next, go to `Examples > Arduino_LSM6DSOX > SimpleAccelerometer` and run the acce
Choosing an appropriate sampling frequency is crucial for capturing the motion characteristics you're interested in studying. The Nyquist-Shannon sampling theorem states that the sampling rate should be at least twice the highest frequency component in the signal to reconstruct it properly. In the context of motion classification and anomaly detection for transportation, the choice of sampling frequency would depend on several factors:
-1. **Nature of the Motion**: Different types of transportation (terrestrial, maritime, etc.) may involve different ranges of motion frequencies. Faster movements may require higher sampling frequencies.
+1. **Nature of the Motion:** Different types of transportation (terrestrial, maritime, etc.) may involve different ranges of motion frequencies. Faster movements may require higher sampling frequencies.
-2. **Hardware Limitations**: The Arduino Nicla Vision board and any associated sensors may have limitations on how fast they can sample data.
+2. **Hardware Limitations:** The Arduino Nicla Vision board and any associated sensors may have limitations on how fast they can sample data.
-3. **Computational Resources**: Higher sampling rates will generate more data, which might be computationally intensive, especially critical in a TinyML environment.
+3. **Computational Resources:** Higher sampling rates will generate more data, which might be computationally intensive, especially critical in a TinyML environment.
-4. **Battery Life**: A higher sampling rate will consume more power. If the system is battery-operated, this is an important consideration.
+4. **Battery Life:** A higher sampling rate will consume more power. If the system is battery-operated, this is an important consideration.
-5. **Data Storage**: More frequent sampling will require more storage space, another crucial consideration for embedded systems with limited memory.
+5. **Data Storage:** More frequent sampling will require more storage space, another crucial consideration for embedded systems with limited memory.
In many human activity recognition tasks, **sampling rates of around 50 Hz to 100 Hz** are commonly used. Given that we are simulating transportation scenarios, which are generally not high-frequency events, a sampling rate in that range (50-100 Hz) might be a reasonable starting point.
@@ -335,13 +335,13 @@ Now you should try different movements with your board (similar to those done du
{fig-align="center" width="6.5in"}
-- **maritime and terrestrial**:
+- **maritime and terrestrial:**
{fig-align="center" width="6.5in"}
Note that in all situations above, the value of the `anomaly score` was smaller than 0.0. Try a new movement that was not part of the original dataset, for example, "rolling" the Nicla, facing the camera upside-down, as a container falling from a boat or even a boat accident:
-- **anomaly detection**:
+- **anomaly detection:**
{fig-align="center" width="6.5in"}
@@ -363,45 +363,45 @@ Before we finish, consider that Movement Classification and Object Detection can
#### Industrial and Manufacturing
-- **Predictive Maintenance**: Detecting anomalies in machinery motion to predict failures before they occur.
-- **Quality Control**: Monitoring the motion of assembly lines or robotic arms for precision assessment and deviation detection from the standard motion pattern.
-- **Warehouse Logistics**: Managing and tracking the movement of goods with automated systems that classify different types of motion and detect anomalies in handling.
+- **Predictive Maintenance:** Detecting anomalies in machinery motion to predict failures before they occur.
+- **Quality Control:** Monitoring the motion of assembly lines or robotic arms for precision assessment and deviation detection from the standard motion pattern.
+- **Warehouse Logistics:** Managing and tracking the movement of goods with automated systems that classify different types of motion and detect anomalies in handling.
#### Healthcare
-- **Patient Monitoring**: Detecting falls or abnormal movements in the elderly or those with mobility issues.
-- **Rehabilitation**: Monitoring the progress of patients recovering from injuries by classifying motion patterns during physical therapy sessions.
-- **Activity Recognition**: Classifying types of physical activity for fitness applications or patient monitoring.
+- **Patient Monitoring:** Detecting falls or abnormal movements in the elderly or those with mobility issues.
+- **Rehabilitation:** Monitoring the progress of patients recovering from injuries by classifying motion patterns during physical therapy sessions.
+- **Activity Recognition:** Classifying types of physical activity for fitness applications or patient monitoring.
#### Consumer Electronics
-- **Gesture Control**: Interpreting specific motions to control devices, such as turning on lights with a hand wave.
-- **Gaming**: Enhancing gaming experiences with motion-controlled inputs.
+- **Gesture Control:** Interpreting specific motions to control devices, such as turning on lights with a hand wave.
+- **Gaming:** Enhancing gaming experiences with motion-controlled inputs.
#### Transportation and Logistics
-- **Vehicle Telematics**: Monitoring vehicle motion for unusual behavior such as hard braking, sharp turns, or accidents.
-- **Cargo Monitoring**: Ensuring the integrity of goods during transport by detecting unusual movements that could indicate tampering or mishandling.
+- **Vehicle Telematics:** Monitoring vehicle motion for unusual behavior such as hard braking, sharp turns, or accidents.
+- **Cargo Monitoring:** Ensuring the integrity of goods during transport by detecting unusual movements that could indicate tampering or mishandling.
#### Smart Cities and Infrastructure
-- **Structural Health Monitoring**: Detecting vibrations or movements within structures that could indicate potential failures or maintenance needs.
-- **Traffic Management**: Analyzing the flow of pedestrians or vehicles to improve urban mobility and safety.
+- **Structural Health Monitoring:** Detecting vibrations or movements within structures that could indicate potential failures or maintenance needs.
+- **Traffic Management:** Analyzing the flow of pedestrians or vehicles to improve urban mobility and safety.
#### Security and Surveillance
-- **Intruder Detection**: Detecting motion patterns typical of unauthorized access or other security breaches.
-- **Wildlife Monitoring**: Detecting poachers or abnormal animal movements in protected areas.
+- **Intruder Detection:** Detecting motion patterns typical of unauthorized access or other security breaches.
+- **Wildlife Monitoring:** Detecting poachers or abnormal animal movements in protected areas.
#### Agriculture
-- **Equipment Monitoring**: Tracking the performance and usage of agricultural machinery.
-- **Animal Behavior Analysis**: Monitoring livestock movements to detect behaviors indicating health issues or stress.
+- **Equipment Monitoring:** Tracking the performance and usage of agricultural machinery.
+- **Animal Behavior Analysis:** Monitoring livestock movements to detect behaviors indicating health issues or stress.
#### Environmental Monitoring
-- **Seismic Activity**: Detecting irregular motion patterns that precede earthquakes or other geologically relevant events.
-- **Oceanography**: Studying wave patterns or marine movements for research and safety purposes.
+- **Seismic Activity:** Detecting irregular motion patterns that precede earthquakes or other geologically relevant events.
+- **Oceanography:** Studying wave patterns or marine movements for research and safety purposes.
### Nicla 3D case
diff --git a/contents/niclav_sys/niclav_sys.bib b/contents/niclav_sys/niclav_sys.bib
index e69de29b..00614696 100644
--- a/contents/niclav_sys/niclav_sys.bib
+++ b/contents/niclav_sys/niclav_sys.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/niclav_sys/niclav_sys.qmd b/contents/niclav_sys/niclav_sys.qmd
index d473eac0..127656dc 100644
--- a/contents/niclav_sys/niclav_sys.qmd
+++ b/contents/niclav_sys/niclav_sys.qmd
@@ -34,13 +34,13 @@ Memory is crucial for embedded machine learning projects. The NiclaV board can h
### Sensors
-- **Camera**: A GC2145 2 MP Color CMOS Camera.
+- **Camera:** A GC2145 2 MP Color CMOS Camera.
-- **Microphone**: The `MP34DT05` is an ultra-compact, low-power, omnidirectional, digital MEMS microphone built with a capacitive sensing element and the IC interface.
+- **Microphone:** The `MP34DT05` is an ultra-compact, low-power, omnidirectional, digital MEMS microphone built with a capacitive sensing element and the IC interface.
-- **6-Axis IMU**: 3D gyroscope and 3D accelerometer data from the `LSM6DSOX` 6-axis IMU.
+- **6-Axis IMU:** 3D gyroscope and 3D accelerometer data from the `LSM6DSOX` 6-axis IMU.
-- **Time of Flight Sensor**: The `VL53L1CBV0FY` Time-of-Flight sensor adds accurate and low power-ranging capabilities to the Nicla Vision. The invisible near-infrared VCSEL laser (including the analog driver) is encapsulated with receiving optics in an all-in-one small module below the camera.
+- **Time of Flight Sensor:** The `VL53L1CBV0FY` Time-of-Flight sensor adds accurate and low power-ranging capabilities to the Nicla Vision. The invisible near-infrared VCSEL laser (including the analog driver) is encapsulated with receiving optics in an all-in-one small module below the camera.
## Arduino IDE Installation
@@ -173,9 +173,9 @@ In [GitHub](https://github.com/Mjrovai/Arduino_Nicla_Vision), you can find the P
The code can be split into two parts:
-- **Setup**: Where the libraries are imported, initialized and the variables are defined and initiated.
+- **Setup:** Where the libraries are imported, initialized and the variables are defined and initiated.
-- **Loop**: (while loop) part of the code that runs continually. The image (*img* variable) is captured (one frame). Each of those frames can be used for inference in Machine Learning Applications.
+- **Loop:** (while loop) part of the code that runs continually. The image (*img* variable) is captured (one frame). Each of those frames can be used for inference in Machine Learning Applications.
To interrupt the program execution, press the red `[X]` button.
diff --git a/contents/object_detection_fomo/object_detection_fomo.bib b/contents/object_detection_fomo/object_detection_fomo.bib
index e69de29b..00614696 100644
--- a/contents/object_detection_fomo/object_detection_fomo.bib
+++ b/contents/object_detection_fomo/object_detection_fomo.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/ondevice_learning/ondevice_learning.bib b/contents/ondevice_learning/ondevice_learning.bib
index 1316b2d8..afc583f7 100644
--- a/contents/ondevice_learning/ondevice_learning.bib
+++ b/contents/ondevice_learning/ondevice_learning.bib
@@ -1,6 +1,9 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@inproceedings{abadi2016deep,
- address = {New York, NY, USA},
author = {Abadi, Martin and Chu, Andy and Goodfellow, Ian and McMahan, H. Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li},
+ address = {New York, NY, USA},
booktitle = {Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security},
date-added = {2023-11-22 18:06:03 -0500},
date-modified = {2023-11-22 18:08:42 -0500},
@@ -12,19 +15,20 @@ @inproceedings{abadi2016deep
source = {Crossref},
title = {Deep Learning with Differential Privacy},
url = {https://doi.org/10.1145/2976749.2978318},
- year = {2016}
+ year = {2016},
+ month = oct,
}
@inproceedings{cai2020tinytl,
- author = {Han Cai and Chuang Gan and Ligeng Zhu and Song Han},
+ author = {Cai, Han and Gan, Chuang and Zhu, Ligeng and Han, Song},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/CaiGZ020.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Tue, 19 Jan 2021 00:00:00 +0100},
- title = {TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning},
+ title = {{TinyTL:} {Reduce} Memory, Not Parameters for Efficient On-Device Learning},
url = {https://proceedings.neurips.cc/paper/2020/hash/81f7acabd411274fcf65ce2070ed568a-Abstract.html},
- year = {2020}
+ year = {2020},
}
@article{chen2016training,
@@ -33,7 +37,7 @@ @article{chen2016training
title = {Training deep nets with sublinear memory cost},
url = {https://arxiv.org/abs/1604.06174},
volume = {abs/1604.06174},
- year = {2016}
+ year = {2016},
}
@inproceedings{chen2018tvm,
@@ -41,7 +45,7 @@ @inproceedings{chen2018tvm
booktitle = {13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18)},
pages = {578--594},
title = {{TVM:} {An} automated End-to-End optimizing compiler for deep learning},
- year = {2018}
+ year = {2018},
}
@article{chen2023learning,
@@ -56,7 +60,8 @@ @article{chen2023learning
title = {Learning domain-heterogeneous speaker recognition systems with personalized continual federated learning},
url = {https://doi.org/10.1186/s13636-023-00299-2},
volume = {2023},
- year = {2023}
+ year = {2023},
+ month = sep,
}
@article{david2021tensorflow,
@@ -65,7 +70,7 @@ @article{david2021tensorflow
pages = {800--811},
title = {Tensorflow lite micro: {Embedded} machine learning for tinyml systems},
volume = {3},
- year = {2021}
+ year = {2021},
}
@article{desai2016five,
@@ -74,7 +79,7 @@ @article{desai2016five
pages = {28},
title = {Five Safes: {Designing} data access for research},
volume = {1601},
- year = {2016}
+ year = {2016},
}
@article{dhar2021survey,
@@ -90,7 +95,8 @@ @article{dhar2021survey
title = {A Survey of On-Device Machine Learning},
url = {https://doi.org/10.1145/3450494},
volume = {2},
- year = {2021}
+ year = {2021},
+ month = jul,
}
@article{dwork2014algorithmic,
@@ -105,7 +111,7 @@ @article{dwork2014algorithmic
title = {The Algorithmic Foundations of Differential Privacy},
url = {https://doi.org/10.1561/0400000042},
volume = {9},
- year = {2013}
+ year = {2013},
}
@article{esteva2017dermatologist,
@@ -120,20 +126,21 @@ @article{esteva2017dermatologist
title = {Dermatologist-level classification of skin cancer with deep neural networks},
url = {https://doi.org/10.1038/nature21056},
volume = {542},
- year = {2017}
+ year = {2017},
+ month = jan,
}
@inproceedings{gruslys2016memory,
- author = {Audrunas Gruslys and R{\'{e}}mi Munos and Ivo Danihelka and Marc Lanctot and Alex Graves},
+ author = {Gruslys, Audrunas and Munos, R\'emi and Danihelka, Ivo and Lanctot, Marc and Graves, Alex},
+ editor = {Lee, Daniel D. and Sugiyama, Masashi and von Luxburg, Ulrike and Guyon, Isabelle and Garnett, Roman},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/GruslysMDLG16.bib},
booktitle = {Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain},
- editor = {Daniel D. Lee and Masashi Sugiyama and Ulrike von Luxburg and Isabelle Guyon and Roman Garnett},
pages = {4125--4133},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
title = {Memory-Efficient Backpropagation Through Time},
url = {https://proceedings.neurips.cc/paper/2016/hash/a501bebf79d570651ff601788ea9d16d-Abstract.html},
- year = {2016}
+ year = {2016},
}
@inproceedings{hong2023publishing,
@@ -146,20 +153,21 @@ @inproceedings{hong2023publishing
source = {Crossref},
title = {Publishing Efficient On-device Models Increases Adversarial Vulnerability},
url = {https://doi.org/10.1109/satml54575.2023.00026},
- year = {2023}
+ year = {2023},
+ month = feb,
}
@inproceedings{kairouz2015secure,
- author = {Peter Kairouz and Sewoong Oh and Pramod Viswanath},
+ author = {Kairouz, Peter and Oh, Sewoong and Viswanath, Pramod},
+ editor = {Cortes, Corinna and Lawrence, Neil D. and Lee, Daniel D. and Sugiyama, Masashi and Garnett, Roman},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/KairouzOV15.bib},
booktitle = {Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada},
- editor = {Corinna Cortes and Neil D. Lawrence and Daniel D. Lee and Masashi Sugiyama and Roman Garnett},
pages = {2008--2016},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
title = {Secure Multi-party Differential Privacy},
url = {https://proceedings.neurips.cc/paper/2015/hash/a01610228fe998f515a72dd730294d87-Abstract.html},
- year = {2015}
+ year = {2015},
}
@article{karargyris2023federated,
@@ -174,7 +182,8 @@ @article{karargyris2023federated
title = {Federated benchmarking of medical artificial intelligence with {MedPerf}},
url = {https://doi.org/10.1038/s42256-023-00652-2},
volume = {5},
- year = {2023}
+ year = {2023},
+ month = jul,
}
@article{kwon2023tinytrain,
@@ -183,32 +192,32 @@ @article{kwon2023tinytrain
title = {{TinyTrain:} {Deep} Neural Network Training at the Extreme Edge},
url = {https://arxiv.org/abs/2307.09988},
volume = {abs/2307.09988},
- year = {2023}
+ year = {2023},
}
@inproceedings{li2016lightrnn,
- author = {Xiang Li and Tao Qin and Jian Yang and Tie{-}Yan Liu},
+ author = {Li, Xiang and Qin, Tao and Yang, Jian and Liu, Tie-Yan},
+ editor = {Lee, Daniel D. and Sugiyama, Masashi and von Luxburg, Ulrike and Guyon, Isabelle and Garnett, Roman},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/LiQYHL16.bib},
booktitle = {Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain},
- editor = {Daniel D. Lee and Masashi Sugiyama and Ulrike von Luxburg and Isabelle Guyon and Roman Garnett},
pages = {4385--4393},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
- title = {LightRNN: Memory and Computation-Efficient Recurrent Neural Networks},
+ title = {{LightRNN:} {Memory} and Computation-Efficient Recurrent Neural Networks},
url = {https://proceedings.neurips.cc/paper/2016/hash/c3e4035af2a1cde9f21e1ae1951ac80b-Abstract.html},
- year = {2016}
+ year = {2016},
}
@inproceedings{lin2020mcunet,
- author = {Ji Lin and Wei{-}Ming Chen and Yujun Lin and John Cohn and Chuang Gan and Song Han},
+ author = {Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Cohn, John and Gan, Chuang and Han, Song},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/LinCLCG020.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Thu, 11 Feb 2021 00:00:00 +0100},
- title = {MCUNet: Tiny Deep Learning on IoT Devices},
+ title = {{MCUNet:} {Tiny} Deep Learning on {IoT} Devices},
url = {https://proceedings.neurips.cc/paper/2020/hash/86c51678350f656dcc7f490a43946ee5-Abstract.html},
- year = {2020}
+ year = {2020},
}
@article{lin2022device,
@@ -217,7 +226,7 @@ @article{lin2022device
pages = {22941--22954},
title = {On-device training under 256kb memory},
volume = {35},
- year = {2022}
+ year = {2022},
}
@article{moshawrab2023reviewing,
@@ -232,7 +241,8 @@ @article{moshawrab2023reviewing
title = {Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives},
url = {https://doi.org/10.3390/electronics12102287},
volume = {12},
- year = {2023}
+ year = {2023},
+ month = may,
}
@inproceedings{nguyen2023re,
@@ -244,7 +254,8 @@ @inproceedings{nguyen2023re
source = {Crossref},
title = {Re-Thinking Model Inversion Attacks Against Deep Neural Networks},
url = {https://doi.org/10.1109/cvpr52729.2023.01572},
- year = {2023}
+ year = {2023},
+ month = jun,
}
@article{pan2009survey,
@@ -259,7 +270,8 @@ @article{pan2009survey
title = {A Survey on Transfer Learning},
url = {https://doi.org/10.1109/tkde.2009.191},
volume = {22},
- year = {2010}
+ year = {2010},
+ month = oct,
}
@inproceedings{rouhani2017tinydl,
@@ -272,7 +284,8 @@ @inproceedings{rouhani2017tinydl
source = {Crossref},
title = {{TinyDL:} {Just-in-time} deep learning solution for constrained embedded systems},
url = {https://doi.org/10.1109/iscas.2017.8050343},
- year = {2017}
+ year = {2017},
+ month = may,
}
@inproceedings{shi2022data,
@@ -284,7 +297,8 @@ @inproceedings{shi2022data
source = {Crossref},
title = {Data selection for efficient model update in federated learning},
url = {https://doi.org/10.1145/3517207.3526980},
- year = {2022}
+ year = {2022},
+ month = apr,
}
@article{wu2022sustainable,
@@ -293,7 +307,7 @@ @article{wu2022sustainable
pages = {795--813},
title = {Sustainable ai: {Environmental} implications, challenges and opportunities},
volume = {4},
- year = {2022}
+ year = {2022},
}
@article{xu2023federated,
@@ -302,7 +316,7 @@ @article{xu2023federated
title = {Federated Learning of Gboard Language Models with Differential Privacy},
url = {https://arxiv.org/abs/2305.18465},
volume = {abs/2305.18465},
- year = {2023}
+ year = {2023},
}
@inproceedings{yang2023online,
@@ -315,7 +329,8 @@ @inproceedings{yang2023online
source = {Crossref},
title = {Online Model Compression for Federated Learning with Large Models},
url = {https://doi.org/10.1109/icassp49357.2023.10097124},
- year = {2023}
+ year = {2023},
+ month = jun,
}
@article{zhao2018federated,
@@ -324,25 +339,22 @@ @article{zhao2018federated
title = {Federated learning with non-iid data},
url = {https://arxiv.org/abs/1806.00582},
volume = {abs/1806.00582},
- year = {2018}
+ year = {2018},
}
@article{zhuang2021comprehensive,
- author={Zhuang, Fuzhen and Qi, Zhiyuan and Duan, Keyu and Xi, Dongbo and Zhu, Yongchun and Zhu, Hengshu and Xiong, Hui and He, Qing},
- journal={Proceedings of the IEEE},
- title={A Comprehensive Survey on Transfer Learning},
- year={2021},
- volume={109},
- number={1},
- pages={43-76},
- keywords={Transfer learning;Semisupervised learning;Data models;Covariance matrices;Machine learning;Adaptation models;Domain adaptation;interpretation;machine learning;transfer learning},
- doi={10.1109/JPROC.2020.3004555}
+ author = {Zhuang, Fuzhen and Qi, Zhiyuan and Duan, Keyu and Xi, Dongbo and Zhu, Yongchun and Zhu, Hengshu and Xiong, Hui and He, Qing},
+ journal = {Proc. IEEE},
+ title = {A Comprehensive Survey on Transfer Learning},
+ year = {2021},
+ volume = {109},
+ number = {1},
+ pages = {43--76},
+ keywords = {Transfer learning;Semisupervised learning;Data models;Covariance matrices;Machine learning;Adaptation models;Domain adaptation;interpretation;machine learning;transfer learning},
+ doi = {10.1109/jproc.2020.3004555},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/jproc.2020.3004555},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ issn = {0018-9219, 1558-2256},
+ month = jan,
}
-
-@inproceedings{cai2020tinytl,
- title = {TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning},
- author = {Cai, Han and Gan, Chuang and Zhu, Ligeng and Han, Song},
- booktitle = {Advances in Neural Information Processing Systems},
- volume = {33},
- year = {2020}
-}
\ No newline at end of file
diff --git a/contents/ondevice_learning/ondevice_learning.qmd b/contents/ondevice_learning/ondevice_learning.qmd
index af6ca68e..ec184b0e 100644
--- a/contents/ondevice_learning/ondevice_learning.qmd
+++ b/contents/ondevice_learning/ondevice_learning.qmd
@@ -8,9 +8,9 @@ bibliography: ondevice_learning.bib
Resources: [Slides](#sec-on-device-learning-resource), [Labs](#sec-on-device-learning-resource), [Exercises](#sec-on-device-learning-resource)
:::
-
+
-On-device Learning represents a significant innovation for embedded and edge IoT devices, enabling models to train and update directly on small local devices. This contrasts with traditional methods where models are trained on expansive cloud computing resources before deployment. With On-Device Learning, devices like smart speakers, wearables, and industrial sensors can refine models in real-time based on local data, without needing to transmit data externally. For example, a voice-enabled smart speaker could learn and adapt to its owner's speech patterns and vocabulary right on the device. But there is no such thing as free lunch, therefore in this chapter, we will discuss both the benefits and the limitations of on-device learning.
+On-device Learning represents a significant innovation for embedded and edge IoT devices, enabling models to train and update directly on small local devices. This contrasts with traditional methods, where models are trained on expansive cloud computing resources before deployment. With On-Device Learning, devices like smart speakers, wearables, and industrial sensors can refine models in real-time based on local data without needing to transmit data externally. For example, a voice-enabled smart speaker could learn and adapt to its owner's speech patterns and vocabulary right on the device. However, there is no such thing as a free lunch; therefore, in this chapter, we will discuss both the benefits and the limitations of on-device learning.
::: {.callout-tip}
@@ -31,9 +31,9 @@ On-device Learning represents a significant innovation for embedded and edge IoT
## Introduction
-On-device Learning refers to the process of training ML models directly on the device where they are deployed, as opposed to traditional methods where models are trained on powerful servers and then deployed to devices. This method is particularly relevant to TinyML, where ML systems are integrated into tiny, resource-constrained devices.
+On-device Learning refers to training ML models directly on the device where they are deployed, as opposed to traditional methods where models are trained on powerful servers and then deployed to devices. This method is particularly relevant to TinyML, where ML systems are integrated into tiny, resource-constrained devices.
-An example of On-Device Learning can be seen in a smart thermostat that adapts to user behavior over time. Initially, the thermostat may have a generic model that understands basic patterns of usage. However, as it is exposed to more data, such as the times the user is home or away, preferred temperatures, and external weather conditions, the thermostat can refine its model directly on the device to provide a personalized experience for the user. This is all done without the need to send data back to a central server for processing.
+An example of On-Device Learning can be seen in a smart thermostat that adapts to user behavior over time. Initially, the thermostat may have a generic model that understands basic usage patterns. However, as it is exposed to more data, such as the times the user is home or away, preferred temperatures, and external weather conditions, the thermostat can refine its model directly on the device to provide a personalized experience. This is all done without sending data back to a central server for processing.
Another example is in predictive text on smartphones. As users type, the phone learns from the user's language patterns and suggests words or phrases that are likely to be used next. This learning happens directly on the device, and the model updates in real-time as more data is collected. A widely used real-world example of on-device learning is Gboard. On an Android phone, Gboard learns from typing and dictation patterns to enhance the experience for all users. On-device learning is also called federated learning. @fig-federated-cycle shows the cycle of federated learning on mobile devices: A. the device learns from user patterns; B. local model updates are communicated to the cloud; C. the cloud server updates the global model and sends the new model to all the devices.
@@ -41,11 +41,11 @@ Another example is in predictive text on smartphones. As users type, the phone l
## Advantages and Limitations
-On-Device Learning provides a number of advantages over traditional cloud-based ML. By keeping data and models on the device, it eliminates the need for costly data transmission and addresses privacy concerns. This allows for more personalized, responsive experiences as the model can adapt in real-time to user behavior.
+On-device learning provides several advantages over traditional cloud-based ML. By keeping data and models on the device, it eliminates the need for costly data transmission and addresses privacy concerns. This allows for more personalized, responsive experiences, as the model can adapt in real-time to user behavior.
-However, On-Device Learning also comes with tradeoffs. The limited compute resources on consumer devices can make it challenging to run complex models locally. Datasets are also more restricted since they consist only of user-generated data from a single device. Additionally, updating models requires pushing out new versions rather than seamless cloud updates.
+However, On-Device Learning also comes with tradeoffs. The limited computing resources on consumer devices can make it challenging to run complex models locally. Datasets are also more restricted since they consist only of user-generated data from a single device. Additionally, updating models requires pushing out new versions rather than seamless cloud updates.
-On-Device Learning opens up new capabilities by enabling offline AI while maintaining user privacy. But it requires carefully managing model and data complexity within the constraints of consumer devices. Finding the right balance between localization and cloud offloading is key to delivering optimized on-device experiences.
+On-device learning opens up new capabilities by enabling offline AI while maintaining user privacy. However, it requires carefully managing model and data complexity within the constraints of consumer devices. Finding the right balance between localization and cloud offloading is key to optimizing on-device experiences.
### Benefits
@@ -53,36 +53,36 @@ On-Device Learning opens up new capabilities by enabling offline AI while mainta
One of the significant advantages of on-device learning is the enhanced privacy and security of user data. For instance, consider a smartwatch that monitors sensitive health metrics such as heart rate and blood pressure. By processing data and adapting models directly on the device, the biometric data remains localized, circumventing the need to transmit raw data to cloud servers where it could be susceptible to breaches.
-Server breaches are far from rare, with millions of records compromised annually. For example, the 2017 Equifax breach exposed the personal data of 147 million people. By keeping data on the device, the risk of such exposures is drastically minimized. On-device learning acts as a safeguard against unauthorized access from various threats, including malicious actors, insider threats, and accidental exposure, by eliminating reliance on centralized cloud storage.
+Server breaches are far from rare, with millions of records compromised annually. For example, the 2017 Equifax breach exposed the personal data of 147 million people. By keeping data on the device, the risk of such exposures is drastically minimized. On-device learning eliminates reliance on centralized cloud storage and safeguards against unauthorized access from various threats, including malicious actors, insider threats, and accidental exposure.
Regulations like the Health Insurance Portability and Accountability Act ([HIPAA](https://www.cdc.gov/phlp/publications/topic/hipaa.html)) and the General Data Protection Regulation ([GDPR](https://gdpr.eu/tag/gdpr/)) mandate stringent data privacy requirements that on-device learning adeptly addresses. By ensuring data remains localized and is not transferred to other systems, on-device learning facilitates [compliance with these regulations](https://www.researchgate.net/publication/321515854_The_EU_General_Data_Protection_Regulation_GDPR_A_Practical_Guide).
-On-device learning is not just beneficial for individual users; it has significant implications for organizations and sectors dealing with highly sensitive data. For instance, within the military, on-device learning empowers frontline systems to adapt models and function independently of connections to central servers that could potentially be compromised. By localizing data processing and learning, critical and sensitive information is staunchly protected. However, this comes with the trade-off that individual devices take on more value and may incentivize theft or destruction, as they become sole carriers of specialized AI models. Care must be taken to secure devices themselves when transitioning to on-device learning.
+On-device learning is not just beneficial for individual users; it has significant implications for organizations and sectors dealing with highly sensitive data. For instance, within the military, on-device learning empowers frontline systems to adapt models and function independently of connections to central servers that could potentially be compromised. Critical and sensitive information is staunchly protected by localizing data processing and learning. However, this comes with the tradeoff that individual devices take on more value and may incentivize theft or destruction as they become the sole carriers of specialized AI models. Care must be taken to secure devices themselves when transitioning to on-device learning.
-It is also important in preserving the privacy, security, and regulatory compliance of personal and sensitive data. Training and operating models locally, as opposed to in the cloud, substantially augments privacy measures, ensuring that user data is safeguarded from potential threats.
+It is also important to preserve the privacy, security, and regulatory compliance of personal and sensitive data. Instead of in the cloud, training and operating models locally substantially augment privacy measures, ensuring that user data is safeguarded from potential threats.
-However, this is not entirely intuitive because on-device learning could instead open systems up to new privacy attacks.
-With valuable data summaries and model updates permanently stored on individual devices, it may be much harder to physically and digitally protect them compared to a large computing cluster. While on-device learning reduces the amount of data compromised in any one breach, it could also introduce new dangers by dispersing sensitive information across many decentralized endpoints. Careful security practices are still essential for on-device systems.
+However, this is only partially intuitive because on-device learning could instead open systems up to new privacy attacks.
+With valuable data summaries and model updates permanently stored on individual devices, it may be much harder to physically and digitally protect them than a large computing cluster. While on-device learning reduces the amount of data compromised in any one breach, it could also introduce new dangers by dispersing sensitive information across many decentralized endpoints. Careful security practices are still essential for on-device systems.
#### Regulatory Compliance
On-device learning helps address major privacy regulations like ([GDPR](https://gdpr.eu/tag/gdpr/)) and [CCPA](https://oag.ca.gov/privacy/ccpa). These regulations require data localization, restricting cross-border data transfers to approved countries with adequate controls. GDPR also mandates privacy by design and consent requirements for data collection. By keeping data processing and model training localized on-device, sensitive user data is not transferred across borders. This avoids major compliance headaches for organizations.
-For example, a healthcare provider monitoring patient vitals with wearables would have to ensure cross-border data transfers comply with HIPAA and GDPR if using the cloud. Determining which country's laws apply and securing approvals for international data flows introduces legal and engineering burdens. With on-device learning, no data leaves the device, simplifying compliance. The time and resources spent on compliance are reduced significantly.
+For example, a healthcare provider monitoring patient vitals with wearables must ensure cross-border data transfers comply with HIPAA and GDPR if using the cloud. Determining which country's laws apply and securing approvals for international data flows introduces legal and engineering burdens. With on-device learning, no data leaves the device, simplifying compliance. The time and resources spent on compliance are reduced significantly.
-Industries like healthcare, finance and government with highly regulated data can benefit greatly from on-device learning. By localizing data and learning, regulatory requirements on privacy and data sovereignty are more easily met. On-device solutions provide an efficient way to build compliant AI applications.
+Industries like healthcare, finance, and government, which have highly regulated data, can benefit greatly from on-device learning. By localizing data and learning, regulatory privacy and data sovereignty requirements are more easily met. On-device solutions provide an efficient way to build compliant AI applications.
Major privacy regulations impose restrictions on cross-border data movement that on-device learning inherently addresses through localized processing. This reduces the compliance burden for organizations working with regulated data.
#### Reduced Bandwidth, Costs, and Increased Efficiency
-One major advantage of on-device learning is the significant reduction in bandwidth usage and associated cloud infrastructure costs. By keeping data localized for model training, rather than transmitting raw data to the cloud, on-device learning can result in substantial savings in bandwidth. For instance, a network of cameras analyzing video footage can achieve up to significant reductions in data transfer by training models on-device rather than streaming all video footage to the cloud for processing.
+One major advantage of on-device learning is the significant reduction in bandwidth usage and associated cloud infrastructure costs. By keeping data localized for model training rather than transmitting raw data to the cloud, on-device learning can result in substantial bandwidth savings. For instance, a network of cameras analyzing video footage can achieve significant reductions in data transfer by training models on-device rather than streaming all video footage to the cloud for processing.
-This reduction in data transmission not only saves bandwidth but also translates to lower costs for servers, networking, and data storage in the cloud. Large organizations, which might spend millions on cloud infrastructure to train models on device data, can experience dramatic cost reductions through on-device learning. In the era of Generative AI, where [costs have been escalating significantly](https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems), finding ways to keep expenses down has become increasingly important.
+This reduction in data transmission saves bandwidth and translates to lower costs for servers, networking, and data storage in the cloud. Large organizations, which might spend millions on cloud infrastructure to train models on-device data, can experience dramatic cost reductions through on-device learning. In the era of Generative AI, where [costs have been escalating significantly](https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems), finding ways to keep expenses down has become increasingly important.
-Furthermore, the energy and environmental costs associated with running large server farms are also diminished. Data centers are known to consume vast amounts of energy, contributing to greenhouse gas emissions. By reducing the need for extensive cloud-based infrastructure, on-device learning plays a part in mitigating the environmental impact of data processing [@wu2022sustainable].
+Furthermore, the energy and environmental costs of running large server farms are also diminished. Data centers consume vast amounts of energy, contributing to greenhouse gas emissions. By reducing the need for extensive cloud-based infrastructure, on-device learning plays a part in mitigating the environmental impact of data processing [@wu2022sustainable].
-Specifically for endpoint applications, on-device learning minimizes the number of network API calls needed to run inference through a cloud provider. For applications with millions of users, the cumulative costs associated with bandwidth and API calls can quickly escalate. In contrast, performing training and inferences locally is considerably more efficient and cost-effective. On-device learning has been shown to reduce training memory requirements, drastically improve memory efficiency, and reduce up to 20% in per-iteration latency under the state-of-the-art optimizations [@dhar2021survey].
+Specifically for endpoint applications, on-device learning minimizes the number of network API calls needed to run inference through a cloud provider. The cumulative costs associated with bandwidth and API calls can quickly escalate for applications with millions of users. In contrast, performing training and inferences locally is considerably more efficient and cost-effective. Under state-of-the-art optimizations, on-device learning has been shown to reduce training memory requirements, drastically improve memory efficiency, and reduce up to 20% in per-iteration latency [@dhar2021survey].
Another key benefit of on-device learning is the potential for IoT devices to continuously adapt their ML model to new data for continuous, lifelong learning. On-device models can quickly become outdated as user behavior, data patterns, and preferences change. Continuous learning enables the model to efficiently adapt to new data and improvements and maintain high model performance over time.
@@ -90,39 +90,39 @@ Another key benefit of on-device learning is the potential for IoT devices to co
### Limitations
-While traditional cloud-based ML systems have access to nearly endless computing resources, on-device learning is often restricted by the limitations in computational and storage power of the edge device that the model is trained on. By definition, an [edge device](http://arxiv.org/abs/1911.00623) is a device with restrained computing, memory, and energy resources, that cannot be easily increased or decreased. Thus, the reliance on edge devices can restrict the complexity, efficiency, and size of on-device ML models.
+While traditional cloud-based ML systems have access to nearly endless computing resources, on-device learning is often restricted by the limitations in computational and storage power of the edge device that the model is trained on. By definition, an [edge device](http://arxiv.org/abs/1911.00623) is a device with restrained computing, memory, and energy resources that cannot be easily increased or decreased. Thus, the reliance on edge devices can restrict the complexity, efficiency, and size of on-device ML models.
#### Compute resources
-Traditional cloud-based ML systems utilize large servers with multiple high-end GPUs or TPUs that provide nearly endless computational power and memory. For example, services like Amazon Web Services (AWS) [EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html) allow configuring clusters of GPU instances for massively parallel training.
+Traditional cloud-based ML systems utilize large servers with multiple high-end GPUs or TPUs, providing nearly endless computational power and memory. For example, services like Amazon Web Services (AWS) [EC2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html) allow configuring clusters of GPU instances for massively parallel training.
-In contrast, on-device learning is restricted by the hardware limitations of the edge device it runs on. Edge devices refer to endpoints like smartphones, embedded electronics, and IoT devices. By definition, these devices have highly restrained computing, memory, and energy resources compared to the cloud.
+In contrast, on-device learning is restricted by the hardware limitations of the edge device on which it runs. Edge devices refer to endpoints like smartphones, embedded electronics, and IoT devices. By definition, these devices have highly restrained computing, memory, and energy resources compared to the cloud.
-For example, a typical smartphone or Raspberry Pi may only have a few CPU cores, a few GB of RAM, and a small battery. Even more resource-constrained are TinyML microcontroller devices such as the [Arduino Nano BLE Sense](https://store-usa.arduino.cc/products/arduino-nano-33-ble-sense). The resources are fixed on these devices and can't easily be increased on demand like scaling cloud infrastructure. This reliance on edge devices directly restricts the complexity, efficiency, and size of models that can be deployed for on-device training:
+For example, a typical smartphone or Raspberry Pi may only have a few CPU cores, a few GB of RAM, and a small battery. Even more resource-constrained are TinyML microcontroller devices such as the [Arduino Nano BLE Sense](https://store-usa.arduino.cc/products/arduino-nano-33-ble-sense). The resources are fixed on these devices and can't easily be increased on demand, such as scaling cloud infrastructure. This reliance on edge devices directly restricts the complexity, efficiency, and size of models that can be deployed for on-device training:
-* **Complexity**: Limits on memory, computing, and power restrict model architecture design, constraining the number of layers and parameters.
-* **Efficiency**: Models must be heavily optimized through methods like quantization and pruning to run faster and consume less energy.
-* **Size**: Actual model files must be compressed as much as possible to fit within the storage limitations of edge devices.
+* **Complexity:** Limits on memory, computing, and power restrict model architecture design, constraining the number of layers and parameters.
+* **Efficiency:** Models must be heavily optimized through methods like quantization and pruning to run faster and consume less energy.
+* **Size:** Actual model files must be compressed as much as possible to fit within the storage limitations of edge devices.
-Thus, while the cloud offers endless scalability, on-device learning must operate within the tight resource constraints of endpoint hardware. This requires careful co-design of streamlined models, training methods, and optimizations tailored specifically for edge devices.
+Thus, while the cloud offers endless scalability, on-device learning must operate within the tight resource constraints of endpoint hardware. This requires careful codesign of streamlined models, training methods, and optimizations tailored specifically for edge devices.
#### Dataset Size, Accuracy, and Generalization
-In addition to limited computing resources, on-device learning is also constrained in terms of the dataset available for training models.
+In addition to limited computing resources, on-device learning is also constrained by the dataset available for training models.
In the cloud, models are trained on massive, diverse datasets like ImageNet or Common Crawl. For example, ImageNet contains over 14 million images carefully categorized across thousands of classes.
-On-device learning instead relies on smaller, decentralized data silos unique to each device. A smartphone camera roll may contain only thousands of photos centered around a user's specific interests and environments.
+On-device learning instead relies on smaller, decentralized data silos unique to each device. A smartphone camera roll may contain only thousands of photos of users' interests and environments.
-This decentralized data leads to a lack of IID (independent and identically distributed) data. For instance, two friends may take many photos of the same places and objects, meaning their data distributions are highly correlated rather than independent.
+This decentralized data leads to a need for IID (independent and identically distributed) data. For instance, two friends may take many photos of the same places and objects, meaning their data distributions are highly correlated rather than independent.
Reasons data may be non-IID in on-device settings:
-* **User heterogeneity**: different users have different interests and environments.
-* **Device differences:** sensors, regions, and demographics affect data.
+* **User heterogeneity:** Different users have different interests and environments.
+* **Device differences:** Sensors, regions, and demographics affect data.
* **Temporal effects:** time of day, seasonal impacts on data.
-The effectiveness of ML relies heavily on large, diverse training data. With small, localized datasets, on-device models may fail to generalize across different user populations and environments. For example, a disease detection model trained only on images from a single hospital would not generalize well to other patient demographics. Without extensive, diverse medical images, the model's real-world performance would suffer. Thus, while cloud-based learning leverages massive datasets, on-device learning relies on much smaller, decentralized data silos unique to each user.
+The effectiveness of ML relies heavily on large, diverse training data. With small, localized datasets, on-device models may fail to generalize across different user populations and environments. For example, a disease detection model trained only on images from a single hospital would not generalize well to other patient demographics. Withel's real-world performance would only improve with extensive, diverse medical improvement. Thus, while cloud-based learning leverages massive datasets, on-device learning relies on much smaller, decentralized data silos unique to each user.
The limited data and optimizations required for on-device learning can negatively impact model accuracy and generalization:
@@ -156,23 +156,23 @@ Correspondingly, there are three approaches to adapting existing ML algorithms o
* Modifying optimizations to reduce training resource requirements
* Creating new storage-efficient data representations
-In the following section, we will review these on-device learning adaptation methods. More details on model optimizations can be found in the [Model Optimizations](../optimizations/optimizations.qmd) chapter.
+In the following section, we will review these on-device learning adaptation methods. The [Model Optimizations](../optimizations/optimizations.qmd) chapter provides more details on model optimizations.
### Reducing Model Complexity
-In this section, we will briefly discuss ways to reduce model complexity to adapt ML models on-device. For details of reducing model complexity, please refer to the Model Optimization Chapter.
+In this section, we will briefly discuss ways to reduce model complexity when adapting ML models on-device. For details on reducing model complexity, please refer to the Model Optimization Chapter.
#### Traditional ML Algorithms
-Due to the compute and memory limitations of edge devices, select traditional ML algorithms are great candidates for on-device learning applications due to their lightweight nature. Some example algorithms with low resource footprints include Naive Bayes Classifier, Support Vector Machines (SVMs), Linear Regression, Logistic Regression, and select Decision Tree algorithms.
+Due to edge devices' computing and memory limitations, select traditional ML algorithms are great candidates for on-device learning applications due to their lightweight nature. Some example algorithms with low resource footprints include Naive Bayes Classifiers, Support Vector Machines (SVMs), Linear Regression, Logistic Regression, and select Decision Tree algorithms.
-With some refinements, these classical ML algorithms can be adapted to specific hardware architectures and perform simple tasks, and their low performance requirements make it easy to integrate continuous learning even on edge devices.
+With some refinements, these classical ML algorithms can be adapted to specific hardware architectures and perform simple tasks. Their low-performance requirements make it easy to integrate continuous learning even on edge devices.
#### Pruning
-Pruning is a technique used to reduce the size and complexity of an ML model to improve their efficiency and generalization performance. This is beneficial for training models on edge devices, where we want to minimize the resource usage while maintaining competitive accuracy.
+Pruning is a technique for reducing the size and complexity of an ML model to improve its efficiency and generalization performance. This is beneficial for training models on edge devices, where we want to minimize resource usage while maintaining competitive accuracy.
-The primary goal of pruning is to remove parts of the model that do not contribute significantly to its predictive power while retaining the most informative aspects. In the context of decision trees, pruning involves removing some of the branches (subtrees) from the tree, leading to a smaller and simpler tree. In the context of DNN, pruning is used to reduce the number of neurons (units) or connections in the network, as shown in @fig-ondevice-pruning.
+The primary goal of pruning is to remove parts of the model that do not contribute significantly to its predictive power while retaining the most informative aspects. In the context of decision trees, pruning involves removing some branches (subtrees) from the tree, leading to a smaller and simpler tree. In the context of DNN, pruning is used to reduce the number of neurons (units) or connections in the network, as shown in @fig-ondevice-pruning.
{#fig-ondevice-pruning}
@@ -182,43 +182,43 @@ Traditional cloud-based DNN frameworks have too much memory overhead to be used
Traditional cloud-based DNN frameworks have too much memory overhead to be used on-device. For example, deep learning systems like PyTorch and TensorFlow require hundreds of megabytes of memory overhead when training models such as MobilenetV2-w0.35, and the overhead scales as the number of training parameters increases.
-Current research for lightweight DNNs mostly explore CNN architectures. Several bare-metal frameworks designed for running Neural Network on MCUs by keeping computational overhead and memory footprint low also exist. Some examples include MNN, TVM, and TensorFlow Lite. However, they can only perform inference during forward pass and lack support for back-propagation. While these models are designed for edge deployment, their reduction in model weights and architectural connections led to reduced resource requirements for continuous learning.
+Current research for lightweight DNNs mostly explores CNN architectures. Several bare-metal frameworks designed for running Neural Networks on MCUs by keeping computational overhead and memory footprint low also exist. Some examples include MNN, TVM, and TensorFlow Lite. However, they can only perform inference during forward passes and lack support for backpropagation. While these models are designed for edge deployment, their reduction in model weights and architectural connections led to reduced resource requirements for continuous learning.
-The tradeoff between performance and model support is clear when adapting the most popular DNN systems. How do we adapt existing DNN models to resource-constrained settings while maintaining support for back-propagation and continuous learning? Latest research suggests algorithm and system codesign techniques that help reduce the resource consumption of ML training on edge devices. Utilizing techniques such as quantization-aware scaling (QAS), sparse updates, and other cutting edge techniques, on-device learning is possible on embedded systems with a few hundred kilobytes of RAM without additional memory while maintaining [high accuracy](http://arxiv.org/abs/2206.15472).
+The tradeoff between performance and model support is clear when adapting the most popular DNN systems. How do we adapt existing DNN models to resource-constrained settings while maintaining support for backpropagation and continuous learning? The latest research suggests algorithm and system codesign techniques that help reduce the resource consumption of ML training on edge devices. Utilizing techniques such as quantization-aware scaling (QAS), sparse updates, and other cutting-edge techniques, on-device learning is possible on embedded systems with a few hundred kilobytes of RAM without additional memory while maintaining [high accuracy](http://arxiv.org/abs/2206.15472).
### Modifying Optimization Processes
-Choosing the right optimization strategy is important for DNN training on-device, since this allows for the finding of a good local minimum. This optimization strategy must also consider limited memory and power since training occurs on-device.
+Choosing the right optimization strategy is important for DNN training on a device since this allows for finding a good local minimum. Since training occurs on a device, this strategy must also consider limited memory and power.
#### Quantization-Aware Scaling
Quantization is a common method for reducing the memory footprint of DNN training. Although this could introduce new errors, these errors can be mitigated by designing a model to characterize this statistical error. For example, models could use stochastic rounding or introduce the quantization error into the gradient updates.
-A specific algorithmic technique is Quantization-Aware Scaling (QAS), used to improve the performance of neural networks on low-precision hardware, such as edge devices and mobile devices or TinyML systems, by adjusting the scale factors during the quantization process.
+A specific algorithmic technique is Quantization-Aware Scaling (QAS), which improves the performance of neural networks on low-precision hardware, such as edge devices, mobile devices, or TinyML systems, by adjusting the scale factors during the quantization process.
-As we discussed in the Model Optimizations chapter, quantization is the process of mapping a continuous range of values to a discrete set of values. In the context of neural networks, quantization often involves reducing the precision of the weights and activations from 32-bit floating point to lower-precision formats such as 8-bit integers. This reduction in precision can significantly reduce the computational cost and memory footprint of the model, making it suitable for deployment on low-precision hardware. @fig-float-int-quantization is an example of float to integer quatization.
+As we discussed in the Model Optimizations chapter, quantization is the process of mapping a continuous range of values to a discrete set of values. In the context of neural networks, quantization often involves reducing the precision of the weights and activations from 32-bit floating point to lower-precision formats such as 8-bit integers. This reduction in precision can significantly reduce the computational cost and memory footprint of the model, making it suitable for deployment on low-precision hardware. @fig-float-int-quantization is an example of float-to-integer quantization.
](images/png/ondevice_quantization_matrix.png){#fig-float-int-quantization}
-However, the quantization process can also introduce quantization errors that can degrade the performance of the model. Quantization-aware scaling is a technique that aims to minimize these errors by adjusting the scale factors used in the quantization process.
+However, the quantization process can also introduce quantization errors that can degrade the model's performance. Quantization-aware scaling is a technique that aims to minimize these errors by adjusting the scale factors used in the quantization process.
The QAS process involves two main steps:
-* **Quantization-aware training:** In this step, the neural network is trained with quantization in mind, using simulated quantization to mimic the effects of quantization during the forward and backward passes. This allows the model to learn to compensate for the quantization errors and improve its performance on low-precision hardware. Refer to QAT section in Model Optimizations for details.
+* **Quantization-aware training:** In this step, the neural network is trained with quantization in mind, using simulated quantization to mimic the effects of quantization during the forward and backward passes. This allows the model to learn to compensate for the quantization errors and improve its performance on low-precision hardware. Refer to the QAT section in Model Optimizations for details.
-* **Quantization and scaling:** After training, the model is quantized to low-precision format, and the scale factors are adjusted to minimize the quantization errors. The scale factors are chosen based on the distribution of the weights and activations in the model, and are adjusted to ensure that the quantized values are within the range of the low-precision format.
+* **Quantization and scaling:** After training, the model is quantized to a low-precision format, and the scale factors are adjusted to minimize the quantization errors. The scale factors are chosen based on the distribution of the weights and activations in the model and are adjusted to ensure that the quantized values are within the range of the low-precision format.
-QAS is used to overcome the difficulties of optimizing models on tiny devices. Without needing hyperparamter tuning. QAS automatically scales tensor gradients with various bit-precisions. This in turn stabilizes the training process and matches the accuracy of floating-point precision.
+QAS is used to overcome the difficulties of optimizing models on tiny devices without needing hyperparameter tuning; QAS automatically scales tensor gradients with various bit precisions. This stabilizes the training process and matches the accuracy of floating-point precision.
#### Sparse Updates
-Although QAS enables optimizing a quantized model, it uses a large amount of memory that is unrealistic for on-device training. So spare update is used to reduce the memory footprint of full backward computation. Instead of pruning weights for inference, sparse update prunes the gradient during backwards propagation to update the model sparsely. In other words, sparse update skips computing gradients of less important layers and sub-tensors.
+Although QAS enables the optimization of a quantized model, it uses a large amount of memory, which is unrealistic for on-device training. So, spare updates are used to reduce the memory footprint of full backward computation. Instead of pruning weights for inference, sparse update prunes the gradient during backward propagation to update the model sparsely. In other words, sparse update skips computing gradients of less important layers and sub-tensors.
However, determining the optimal sparse update scheme given a constraining memory budget can be challenging due to the large search space. For example, the MCUNet model has 43 convolutional layers and a search space of approximately 1030. One technique to address this issue is contribution analysis. Contribution analysis measures the accuracy improvement from biases (updating the last few biases compared to only updating the classifier) and weights (updating the weight of one extra layer compared to only having a bias update). By trying to maximize these improvements, contribution analysis automatically derives an optimal sparse update scheme for enabling on-device training.
#### Layer-Wise Training
-Other methods besides quantization can help optimize routines. One such method is layer-wise training. A significant memory consumer of DNN training is the end-to-end back-propagation. This requires all intermediate feature maps to be stored so the model can calculate gradients. An alternative to this approach that reduces the memory footprint of DNN training is sequential layer-by-layer training [@chen2016training]. Instead of training end-to-end, training a single layer at a time helps avoid having to store intermediate feature maps.
+Other methods besides quantization can help optimize routines. One such method is layer-wise training. A significant memory consumer of DNN training is end-to-end backpropagation, which requires all intermediate feature maps to be stored so the model can calculate gradients. An alternative to this approach that reduces the memory footprint of DNN training is sequential layer-by-layer training [@chen2016training]. Instead of training end-to-end, training a single layer at a time helps avoid having to store intermediate feature maps.
#### Trading Computation for Memory
@@ -226,7 +226,7 @@ The strategy of trading computation for memory involves releasing some of the me
### Developing New Data Representations
-The dimensionality and volume of the training data can significantly impact on-device adaptation. So another technique for adapting models onto resource-cosntrained devices is to represent datasets in a more efficient way.
+The dimensionality and volume of the training data can significantly impact on-device adaptation. So, another technique for adapting models onto resource-constrained devices is to represent datasets more efficiently.
#### Data Compression
@@ -236,19 +236,19 @@ Other more common methods of data compression focus on reducing the dimensionali
## Transfer Learning
-Transfer learning is a ML technique where a model developed for a particular task is reused as the starting point for a model on a second task. In the context of on-device AI, transfer learning allows us to leverage pre-trained models that have already learned useful representations from large datasets, and fine-tune them for specific tasks using smaller datasets directly on the device. This can significantly reduce the computational resources and time required for training models from scratch.
+Transfer learning is an ML technique in which a model developed for a particular task is reused as the starting point for a model on a second task. In the context of on-device AI, transfer learning allows us to leverage pre-trained models that have already learned useful representations from large datasets and finetune them for specific tasks using smaller datasets directly on the device. This can significantly reduce the computational resources and time required for training models from scratch.
-@fig-transfer-learning-apps includes some intuitive examples of transfer learning from the real world. For instance, if you can ride a bicycle, then you probably know how to balance yourself on two-wheel vehicles. Then, it would be easier for you to learn how to ride a motorcyle than it would be for someone who cannot ride a bicycle.
+@fig-transfer-learning-apps includes some intuitive examples of transfer learning from the real world. For instance, if you can ride a bicycle, you know how to balance yourself on two-wheel vehicles. Then, it would be easier for you to learn how to ride a motorcycle than it would be for someone who cannot ride a bicycle.
{#fig-transfer-learning-apps}
Let's take the example of a smart sensor application that uses on-device AI to recognize objects in images captured by the device. Traditionally, this would require sending the image data to a server, where a large neural network model processes the data and sends back the results. With on-device AI, the model is stored and runs directly on-device, eliminating the need to send data to a server.
-If we want to customize the model for the on-device characteristics, training a neural network model from scratch on the device would however be impractical due to the limited computational resources and battery life. This is where transfer learning comes in. Instead of training a model from scratch, we can take a pre-trained model, such as a convolutional neural network (CNN) or a transformer network that has been trained on a large dataset of images, and fine-tune it for our specific object recognition task. This fine-tuning can be done directly on the device using a smaller dataset of images relevant to the task. By leveraging the pre-trained model, we can reduce the computational resources and time required for training, while still achieving high accuracy for the object recognition task.
+If we want to customize the model for the on-device characteristics, training a neural network model from scratch on the device would be impractical due to the limited computational resources and battery life. This is where transfer learning comes in. Instead of training a model from scratch, we can take a pre-trained model, such as a convolutional neural network (CNN) or a transformer network trained on a large dataset of images, and finetune it for our specific object recognition task. This finetuning can be done directly on the device using a smaller dataset of images relevant to the task. By leveraging the pre-trained model, we can reduce the computational resources and time required for training while still achieving high accuracy for the object recognition task.
-Transfer learning plays an important role in making on-device AI practical by allowing us to leverage pre-trained models and fine-tune them for specific tasks, thereby reducing the computational resources and time required for training. The combination of on-device AI and transfer learning opens up new possibilities for AI applications that are more privacy-conscious and responsive to user needs.
+Transfer learning is important in making on-device AI practical by allowing us to leverage pre-trained models and finetune them for specific tasks, thereby reducing the computational resources and time required for training. The combination of on-device AI and transfer learning opens up new possibilities for AI applications that are more privacy-conscious and responsive to user needs.
-Transfer learning has revolutionized the way models are developed and deployed, both in the cloud and at the edge. Transfer learning is being used in the real world. One such example is the use of transfer learning to develop AI models that can detect and diagnose diseases from medical images, such as X-rays, MRI scans, and CT scans. For example, researchers at Stanford University developed a transfer learning model that can detect cancer in skin images with an accuracy of 97% [@esteva2017dermatologist]. This model was pre-trained on 1.28 million images to classify a broad range of objects, then specialized for cancer detection by training on a dermatologist-curated dataset of skin images.
+Transfer learning has revolutionized the way models are developed and deployed, both in the cloud and at the edge. Transfer learning is being used in the real world. One such example is the use of transfer learning to develop AI models that can detect and diagnose diseases from medical images, such as X-rays, MRI scans, and CT scans. For example, researchers at Stanford University developed a transfer learning model that can detect cancer in skin images with an accuracy of 97% [@esteva2017dermatologist]. This model was pre-trained on 1.28 million images to classify a broad range of objects and then specialized for cancer detection by training on a dermatologist-curated dataset of skin images.
Implementation in production scenarios can be broadly categorized into two stages: pre-deployment and post-deployment.
@@ -257,50 +257,50 @@ Implementation in production scenarios can be broadly categorized into two stage
In the pre-deployment stage, transfer learning acts as a catalyst to expedite the development process. Here's how it typically works: Imagine we are creating a system to recognize different breeds of dogs. Rather than starting from scratch, we can utilize a pre-trained model that has already mastered the broader task of recognizing animals in images.
-This pre-trained model serves as a solid foundation and contains a wealth of knowledge acquired from extensive data. We then fine-tune this model using a specialized dataset containing images of various dog breeds. This fine-tuning process tailors the model to our specific need --- identifying dog breeds with precision. Once fine-tuned and validated to meet performance criteria, this specialized model is then ready for deployment.
+This pre-trained model serves as a solid foundation and contains a wealth of knowledge acquired from extensive data. We then finetune this model using a specialized dataset containing images of various dog breeds. This finetuning process tailors the model to our specific need --- precisely identifying dog breeds. Once finetuned and validated to meet performance criteria, this specialized model is then ready for deployment.
Here's how it works in practice:
* **Start with a Pre-Trained Model:** Begin by selecting a model that has already been trained on a comprehensive dataset, usually related to a general task. This model serves as the foundation for the task at hand.
-* **Fine-Tuning:** The pre-trained model is then fine-tuned on a smaller, more specialized dataset that is specific to the desired task. This step allows the model to adapt and specialize its knowledge to the specific requirements of the application.
-* **Validation:** After fine-tuning, the model is validated to ensure it meets the performance criteria for the specialized task.
+* **Finetuning:** The pre-trained model is then finetuned on a smaller, more specialized dataset specific to the desired task. This step allows the model to adapt and specialize its knowledge to the specific requirements of the application.
+* **Validation:** After finetuning, the model is validated to ensure it meets the performance criteria for the specialized task.
* **Deployment:** Once validated, the specialized model is then deployed into the production environment.
This method significantly reduces the time and computational resources required to train a model from scratch [@pan2009survey]. By adopting transfer learning, embedded systems can achieve high accuracy on specialized tasks without the need to gather extensive data or expend significant computational resources on training from the ground up.
### Post-Deployment Adaptation
-Deployment to a device need not mark the culmination of a ML model's educational trajectory. With the advent of transfer learning, we open the doors to the deployment of adaptive ML models to real-world scenarios, catering to the personalized needs of users.
+Deployment to a device need not mark the culmination of an ML model's educational trajectory. With the advent of transfer learning, we open the doors to the deployment of adaptive ML models in real-world scenarios, catering to users' personalized needs.
-Consider a real-world application where a parent wishes to identify their child in a collection of images from a school event on their smartphone. In this scenario, the parent is faced with the challenge of locating their child amidst images of many other children. Here, transfer learning can be employed to fine-tune an embedded system's model to this unique and specialized task. Initially, the system might use a generic model trained to recognize faces in images. However, with transfer learning, the system can adapt this model to recognize the specific features of the user's child.
+Consider a real-world application where a parent wishes to identify their child in a collection of images from a school event on their smartphone. In this scenario, the parent is faced with the challenge of locating their child amidst images of many other children. Transfer learning can be employed here to finetune an embedded system's model to this unique and specialized task. Initially, the system might use a generic model trained to recognize faces in images. However, with transfer learning, the system can adapt this model to recognize the specific features of the user's child.
Here's how it works:
1. **Data Collection:** The embedded system gathers images that include the child, ideally with the parent's input to ensure accuracy and relevance. This can be done directly on the device, maintaining the user's data privacy.
-2. **Model Fine-Tuning:** The pre-existing face recognition model, which has been trained on a large and diverse dataset, is then fine-tuned using the newly collected images of the child. This process adapts the model to recognize the child's specific facial features, distinguishing them from other children in the images.
+2. **Model Finetuning:** The pre-existing face recognition model, which has been trained on a large and diverse dataset, is then finetuned using the newly collected images of the child. This process adapts the model to recognize the child's specific facial features, distinguishing them from other children in the images.
3. **Validation:** The refined model is then validated to ensure it accurately recognizes the child in various images. This can involve the parent verifying the model's performance and providing feedback for further improvements.
4. **Deployment:** Once validated, the adapted model is deployed on the device, enabling the parent to easily identify their child in images without having to sift through them manually.
-This on-the-fly customization enhances the model's efficacy for the individual user, ensuring that they benefit from ML personalization. This is in part how iPhotos or Google photos works when they ask us to recognize a face and then based on that information they index all the photos by that face. Because the learning and adaptation occur on the device itself, there are no risks to personal privacy. The parent's images are not uploaded to a cloud server or shared with third parties, protecting the family's privacy while still reaping the benefits of a personalized ML model. This approach represents a significant step forward in the quest to provide users with tailored ML solutions that respect and uphold their privacy.
+This on-the-fly customization enhances the model's efficacy for the individual user, ensuring that they benefit from ML personalization. This is, in part, how iPhotos or Google Photos works when they ask us to recognize a face, and then, based on that information, they index all the photos by that face. Because the learning and adaptation occur on the device itself, there are no risks to personal privacy. The parent's images are not uploaded to a cloud server or shared with third parties, protecting the family's privacy while still reaping the benefits of a personalized ML model. This approach represents a significant step forward in the quest to provide users with tailored ML solutions that respect and uphold their privacy.
### Benefits
-Transfer learning has become an important technique in the field of ML and artificial intelligence, and it is particularly valuable for several reasons.
+Transfer learning has become an important technique in ML and artificial intelligence, and it is particularly valuable for several reasons.
-1. **Data Scarcity:** In many real-world scenarios, acquiring a sufficiently large labeled dataset for training a ML model from scratch is challenging. Transfer learning mitigates this issue by allowing the use of pre-trained models that have already learned valuable features from a vast dataset.
+1. **Data Scarcity:** In many real-world scenarios, acquiring a sufficiently large labeled dataset to train an ML model from scratch is challenging. Transfer learning mitigates this issue by allowing the use of pre-trained models that have already learned valuable features from a vast dataset.
2. **Computational Expense:** Training a model from scratch requires significant computational resources and time, especially for complex models like deep neural networks. By using transfer learning, we can leverage the computation that has already been done during the training of the source model, thereby saving both time and computational power.
3. **Limited Annotated Data:** For some specific tasks, there might be ample raw data available, but the process of labeling that data for supervised learning can be costly and time-consuming. Transfer learning enables us to utilize pre-trained models that have been trained on a related task with labeled data, hence requiring less annotated data for the new task.
There are advantages to reusing the features:
-1. **Hierarchical Feature Learning:** Deep learning models, particularly Convolutional Neural Networks (CNNs), have the ability to learn hierarchical features. Lower layers typically learn generic features like edges and shapes, while higher layers learn more complex and task-specific features. Transfer learning allows us to reuse the generic features learned by a model and fine-tune the higher layers for our specific task.
+1. **Hierarchical Feature Learning:** Deep learning models, particularly Convolutional Neural Networks (CNNs), can learn hierarchical features. Lower layers typically learn generic features like edges and shapes, while higher layers learn more complex and task-specific features. Transfer learning allows us to reuse the generic features learned by a model and finetune the higher layers for our specific task.
2. **Boosting Performance:** Transfer learning has been proven to boost the performance of models on tasks with limited data. The knowledge gained from the source task can provide a valuable starting point and lead to faster convergence and improved accuracy on the target task.
:::{#exr-tlb .callout-exercise collapse="true"}
### Transfer Learning
-Imagine training an AI to recognize flowers like a pro, but without needing a million flower pictures! That's the power of transfer learning. In this Colab, we'll take an AI that already knows about images and teach it to become a flower expert with way less effort. Get ready to make your AI smarter, not harder!
+Imagine training an AI to recognize flowers like a pro, but without needing a million flower pictures! That's the power of transfer learning. In this Colab, we'll take an AI that already knows about images and teach it to become a flower expert with less effort. Get ready to make your AI smarter, not harder!
[](https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/images/transfer_learning.ipynb?force_kitty_mode=1&force_corgi_mode=1)
@@ -308,13 +308,13 @@ Imagine training an AI to recognize flowers like a pro, but without needing a mi
### Core Concepts
-Understanding the core concepts of transfer learning is essential for effectively utilizing this powerful approach in ML. Here we'll break down some of the main principles and components that underlie the process of transfer learning.
+Understanding the core concepts of transfer learning is essential for effectively utilizing this powerful approach in ML. Here, we'll break down some of the main principles and components that underlie the process of transfer learning.
#### Source and Target Tasks
In transfer learning, there are two main tasks involved: the source task and the target task. The source task is the task for which the model has already been trained and has learned valuable information. The target task is the new task we want the model to perform. The goal of transfer learning is to leverage the knowledge gained from the source task to improve performance on the target task.
-If we have a model trained to recognize various fruits in images (source task), and we want to create a new model to recognize different vegetables in images (target task), we can use transfer learning to leverage the knowledge gained during the fruit recognition task to improve the performance of the vegetable recognition model.
+Suppose we have a model trained to recognize various fruits in images (source task), and we want to create a new model to recognize different vegetables in images (target task). In that case, we can use transfer learning to leverage the knowledge gained during the fruit recognition task to improve the performance of the vegetable recognition model.
#### Representation Transfer
@@ -322,13 +322,13 @@ Representation transfer is about transferring the learned representations (featu
* **Instance Transfer:** This involves reusing the data instances from the source task in the target task.
* **Feature-Representation Transfer:** This involves transferring the learned feature representations from the source task to the target task.
-* **Parameter Transfer:** This involves transferring the learned parameters (weights) of the model from the source task to the target task.
+* **Parameter Transfer:** This involves transferring the model's learned parameters (weights) from the source task to the target task.
In natural language processing, a model trained to understand the syntax and grammar of a language (source task) can have its learned representations transferred to a new model designed to perform sentiment analysis (target task).
-#### Fine-Tuning
+#### Finetuning
-Fine-tuning is the process of adjusting the parameters of a pre-trained model to adapt it to the target task. This typically involves updating the weights of the model's layers, especially the last few layers, to make the model more relevant for the new task. In image classification, a model pre-trained on a general dataset like ImageNet (source task) can be fine-tuned by adjusting the weights of its layers to perform well on a specific classification task, like recognizing specific animal species (target task).
+Finetuning is the process of adjusting the parameters of a pre-trained model to adapt it to the target task. This typically involves updating the weights of the model's layers, especially the last few layers, to make the model more relevant for the new task. In image classification, a model pre-trained on a general dataset like ImageNet (source task) can be finetuned by adjusting the weights of its layers to perform well on a specific classification task, like recognizing specific animal species (target task).
#### Feature Extractions
@@ -340,7 +340,7 @@ Transfer learning can be classified into three main types based on the nature of
#### Inductive Transfer Learning
-In inductive transfer learning, the goal is to learn the target predictive function with the help of source data. It typically involves fine-tuning a pre-trained model on the target task with available labeled data. A common example of inductive transfer learning is image classification tasks. For instance, a model pre-trained on the ImageNet dataset (source task) can be fine-tuned to classify specific types of birds (target task) using a smaller labeled dataset of bird images.
+In inductive transfer learning, the goal is to learn the target predictive function with the help of source data. It typically involves finetuning a pre-trained model on the target task with available labeled data. A common example of inductive transfer learning is image classification tasks. For instance, a model pre-trained on the ImageNet dataset (source task) can be finetuned to classify specific types of birds (target task) using a smaller labeled dataset of bird images.
#### Transductive Transfer Learning
@@ -350,15 +350,15 @@ Transductive transfer learning involves using source and target data, but only t
Unsupervised transfer learning is used when the source and target tasks are related, but there is no labeled data available for the target task. The goal is to leverage the knowledge gained from the source task to improve performance on the target task, even without labeled data. An example of unsupervised transfer learning is topic modeling in text data. A model trained to extract topics from news articles (source task) can be adapted to extract topics from social media posts (target task) without needing labeled data for the social media posts.
-#### Comparison and Trade-offs
+#### Comparison and Tradeoffs
-By leveraging these different types of transfer learning, practitioners can choose the approach that best fits the nature of their tasks and available data, ultimately leading to more effective and efficient ML models. So in summary:
+By leveraging these different types of transfer learning, practitioners can choose the approach that best fits the nature of their tasks and available data, ultimately leading to more effective and efficient ML models. So, in summary:
* **Inductive:** different source and target tasks, different domains
* **Transductive:** different source and target tasks, same domain
* **Unsupervised:** unlabeled source data, transfers feature representations
-Here's a matrix that outlines in a bit more detail the similarities and differences between the types of transfer learning:
+@tbl-tltypes presents a matrix that outlines in a bit more detail the similarities and differences between the types of transfer learning:
| | Inductive Transfer Learning | Transductive Transfer Learning | Unsupervised Transfer Learning |
|------------------------------|-----------------------------|--------------------------------|---------------------------------|
@@ -368,6 +368,8 @@ Here's a matrix that outlines in a bit more detail the similarities and differen
| **Objective** | Improve target task performance with source data | Transfer knowledge from source to target domain | Leverage source task to improve target task performance without labeled data |
| **Example** | ImageNet to bird classification | Sentiment analysis in different languages | Topic modeling for different text data |
+: Comparison of transfer learning types. {#tbl-tltypes}
+
### Constraints and Considerations
When engaging in transfer learning, there are several factors that must be considered to ensure successful knowledge transfer and model performance. Here's a breakdown of some key factors:
@@ -382,7 +384,7 @@ Task similarity refers to how closely related the source and target tasks are. S
#### Data Quality and Quantity
-The quality and quantity of data available for the target task can significantly impact the success of transfer learning. More and high-quality data can result in better model performance. If we have a large dataset with clear, well-labeled images for our target task of recognizing specific bird species, the transfer learning process is likely to be more successful than if we have a small, noisy dataset.
+The quality and quantity of data available for the target task can significantly impact the success of transfer learning. More high-quality data can result in better model performance. Suppose we have a large dataset with clear, well-labeled images to recognize specific bird species. In that case, the transfer learning process will likely be more successful than if we have a small, noisy dataset.
#### Feature Space Overlap
@@ -390,11 +392,11 @@ Feature space overlap refers to how well the features learned by the source mode
#### Model Complexity
-The complexity of the source model can also impact the success of transfer learning. Sometimes, a simpler model might transfer better than a complex one, as it is less likely to overfit the source task. A simple convolutional neural network (CNN) model trained on image data (source task) may transfer more successfully to a new image classification task (target task) than a complex CNN with many layers, as the simpler model is less likely to overfit the source task.
+The complexity of the source model can also impact the success of transfer learning. Sometimes, a simpler model might transfer better than a complex one, as it is less likely to overfit the source task. For example, a simple convolutional neural network (CNN) model trained on image data (source task) may transfer more successfully to a new image classification task (target task) than a complex CNN with many layers, as the simpler model is less likely to overfit the source task.
-By considering these factors, ML practitioners can make informed decisions about when and how to utilize transfer learning, ultimately leading to more successful model performance on the target task. The success of transfer learning hinges on the degree of similarity between the source and target domains. There is risk of overfitting, especially when fine-tuning occurs on a limited dataset. On the computational front, it is worth noting that certain pre-trained models, owing to their size, might not comfortably fit into the memory constraints of some devices or may run prohibitively slowly. Over time, as data evolves, there is potential for model drift, indicating the need for periodic re-training or ongoing adaptation.
+By considering these factors, ML practitioners can make informed decisions about when and how to utilize transfer learning, ultimately leading to more successful model performance on the target task. The success of transfer learning hinges on the degree of similarity between the source and target domains. Overfitting is risky, especially when finetuning occurs on a limited dataset. On the computational front, certain pre-trained models, owing to their size, might not comfortably fit into the memory constraints of some devices or may run prohibitively slowly. Over time, as data evolves, there is potential for model drift, indicating the need for periodic re-training or ongoing adaptation.
-Learn more about transfer learning in the video below:
+Learn more about transfer learning in the video below.
{{< video https://www.youtube.com/watch?v=FQM13HkEfBk >}}
@@ -402,77 +404,77 @@ Learn more about transfer learning in the video below:
Federated Learning Overview
-The modern internet is full of large networks of connected devices. Whether it's cell phones, thermostats, smart speakers or any number of other IOT products, countless edge devices are a goldmine for hyper-personalized, rich data. However, with that rich data comes an assortment of problems with information transfer and privacy. Constructing a training dataset in the cloud from these devices would involve high volumes of bandwidth and cost inefficient data transfer and violate user's privacy.
+The modern internet is full of large networks of connected devices. Whether it's cell phones, thermostats, smart speakers, or other IOT products, countless edge devices are a goldmine for hyper-personalized, rich data. However, with that rich data comes an assortment of problems with information transfer and privacy. Constructing a training dataset in the cloud from these devices would involve high volumes of bandwidth, cost-efficient data transfer, and violation of users' privacy.
Federated learning offers a solution to these problems: train models partially on the edge devices and only communicate model updates to the cloud. In 2016, a team from Google designed architecture for federated learning that attempts to address these problems.
-In their initial paper Google outlines a principle federated learning algorithm called FederatedAveraging, shown in @fig-federated-avg-algo. Specifically, FederatedAveraging performs stochastic gradient descent (SGD) over several different edge devices. In this process, each device calculates a gradient $g_k = \nabla F_k(w_t)$ which is then applied to update the server side weights as (with $\eta$ as learning rate across $k$ clients):
+In their initial paper, Google outlines a principle federated learning algorithm called FederatedAveraging, which is shown in @fig-federated-avg-algo. Specifically, FederatedAveraging performs stochastic gradient descent (SGD) over several different edge devices. In this process, each device calculates a gradient $g_k = \nabla F_k(w_t)$ which is then applied to update the server-side weights as (with $\eta$ as learning rate across $k$ clients):
$$
w_{t+1} \rightarrow w_t - \eta \sum_{k=1}^{K} \frac{n_k}{n}g_k
$$
-This boils down the basic algorithm for federated learning on the right. For each round of training, the server takes a random set of the client devices and calls each client to train on its local batch using the most recent server side weights. Those weights then get returned to the server where they are collected individually then averaged to update the global model weights.
+This summarizes the basic algorithm for federated learning on the right. For each round of training, the server takes a random set of client devices and calls each client to train on its local batch using the most recent server-side weights. Those weights are then returned to the server, where they are collected individually and averaged to update the global model weights.
).](images/png/ondevice_fed_averaging.png){#fig-federated-avg-algo}
-With this proposed structure, there are a few key vectors for optimizing federated learning further. We will outline each in the following subsections.
+With this proposed structure, there are a few key vectors for further optimizing federated learning. We will outline each in the following subsections.
-The following video is an overview of federated learning:
+The following video is an overview of federated learning.
{{< video https://www.youtube.com/watch?v=zqv1eELa7fs >}}
### Communication Efficiency
-One of the key bottlenecks in federated learning is communication. Every time a client trains the model, they must communicate back to the server their updates. Similarly, once the server has averaged all the updates, it must send them back to the client. On large networks of millions of devices, this incurs huge bandwidth and resource cost. As the field of federated learning advances, a few optimizations have been developed to minimize this communication. To address the footprint of the model, researchers have developed model compression techniques. In the client server protocol, federated learning can also minimize communication through selective sharing of updates on clients. Finally, efficient aggregation techniques can also streamline the communication process.
+One of the key bottlenecks in federated learning is communication. Every time a client trains the model, they must communicate their updates back to the server. Similarly, once the server has averaged all the updates, it must send them back to the client. This incurs huge bandwidth and resource costs on large networks of millions of devices. As the field of federated learning advances, a few optimizations have been developed to minimize this communication. To address the footprint of the model, researchers have developed model compression techniques. In the client-server protocol, federated learning can also minimize communication through the selective sharing of updates on clients. Finally, efficient aggregation techniques can also streamline the communication process.
### Model Compression
-In standard federated learning, the server must communicate the entire model to each client and then the client must send back all of the updated weights. This means that the easiest way to reduce both the memory and communication footprint on the client is to minimize the size of the model needed to be communicated. To do this, we can employ all of the previously discussed model optimization strategies.
+In standard federated learning, the server communicates the entire model to each client, and then the client sends back all of the updated weights. This means that the easiest way to reduce the client's memory and communication footprint is to minimize the size of the model needed to be communicated. We can employ all of the previously discussed model optimization strategies to do this.
-In 2022, another team at Google proposed wherein each client communicates via a compressed format and decompresses the model on the fly for training [@yang2023online], allocating and deallocating the full memory for the model only for a short period while training. The model is compressed through a range of various quantization strategies elaborated upon in their paper. Meanwhile the server can update the uncompressed model, decompressing and applying updates as they come in.
+In 2022, another team at Google proposed that each client communicates via a compressed format and decompresses the model on the fly for training [@yang2023online], allocating and deallocating the full memory for the model only for a short period while training. The model is compressed through a range of various quantization strategies elaborated upon in their paper. Meanwhile, the server can update the uncompressed model by decompressing and applying updates as they come in.
### Selective Update Sharing
-There are a breadth of methods for selectively sharing updates. The general principle is that reducing the portion of the model that the clients are training on the edge reduces the memory necessary for training and the size of communication to the server. In basic federated learning, the client trains the entire model. This means that when a client sends an update to the server it has gradients for every weight in the network.
+There are many methods for selectively sharing updates. The general principle is that reducing the portion of the model that the clients are training on the edge reduces the memory necessary for training and the size of communication to the server. In basic federated learning, the client trains the entire model. This means that when a client sends an update to the server, it has gradients for every weight in the network.
-However, we cannot just reduce communication by sending pieces of those gradients to the server from each client because the gradients are part of an entire update required to improve the model. Instead, you need to architecturally design the model such that the clients each train only a small portion of the broader model, reducing the total communication while still gaining the benefit of training on client data. A paper [@shi2022data] from the University of Sheffield applies this concept to a CNN by splitting the global model into two parts: an upper and lower part as shown in @chen2023learning.
+However, we cannot just reduce communication by sending pieces of those gradients from each client to the server because the gradients are part of an entire update required to improve the model. Instead, you need to architecturally design the model such that each client trains only a small portion of the broader model, reducing the total communication while still gaining the benefit of training on client data. A paper [@shi2022data] from the University of Sheffield applies this concept to a CNN by splitting the global model into two parts: an upper and a lower part, as shown in @chen2023learning.
).](images/png/ondevice_split_model.png){#fig-split-model}
- The lower part is designed to focus on generic features in the dataset while the upper part trained on those generic features is designed to be more sensitive to the activation maps. This means that the lower part of the model is trained through standard federated averaging across all of the clients. Meanwhile, the upper part of the model is trained entirely on the server side from the activation maps generated by the clients. This approach drastically reduces communication for the model while still making the network robust to various types of input found in the data on the client devices.
+ The lower part is designed to focus on generic features in the dataset, while the upper part, trained on those generic features, is designed to be more sensitive to the activation maps. This means that the lower part of the model is trained through standard federated averaging across all of the clients. Meanwhile, the upper part of the model is trained entirely on the server side from the activation maps generated by the clients. This approach drastically reduces communication for the model while still making the network robust to various types of input found in the data on the client devices.
### Optimized Aggregation
-In addition to reducing the communication overhead, optimizing the aggregation function can improve model training speed and accuracy in certain federated learning use cases. While the standard for aggregation is just averaging, there are various other approaches which can improve model efficiency, accuracy, and security. One alternative is clipped averaging which clips the model updates within a specific range. Another strategy to preserve security is differential privacy average aggregation. This approach integrates differential privacy into the aggregations tep to protect client identities. Each client adds a layer of random noise to their updates before communicating to the server. The server then updates the server with the noisy updates, meaning that the amount of noise needs to be tuned carefully to balance privacy and accuracy.
+In addition to reducing the communication overhead, optimizing the aggregation function can improve model training speed and accuracy in certain federated learning use cases. While the standard for aggregation is just averaging, various other approaches can improve model efficiency, accuracy, and security. One alternative is clipped averaging, which clips the model updates within a specific range. Another strategy to preserve security is differential privacy average aggregation. This approach integrates differential privacy into the aggregations tep to protect client identities. Each client adds a layer of random noise to their updates before communicating to the server. The server then updates the server with the noisy updates, meaning that the amount of noise needs to be tuned carefully to balance privacy and accuracy.
-In addition to security enhancing aggregation methods, there are several modifications to the aggregation methods that can improve training speed and performance by adding client metadata along with the weight updates. Momentum aggregation is a technique which helps address the convergence problem. In federated learning, client data can be extremely heterogeneous depending on the different environments devices are in. That means that many models with heterogeneous data may struggle to converge. Each client stores a momentum term locally which tracks the pace of change over several updates. With clients communicating this momentum, the server can factor in the rate of change of each update when changing the global model to accelerate convergence. Similarly, weighted aggregation can factoro in the client performance or other parameters like device type or network connection strength to adjust the weight with which the server should incorporate the model updates. Further description of specific aggregation algorithms are described by @moshawrab2023reviewing.
+In addition to security-enhancing aggregation methods, there are several modifications to the aggregation methods that can improve training speed and performance by adding client metadata along with the weight updates. Momentum aggregation is a technique that helps address the convergence problem. In federated learning, client data can be extremely heterogeneous depending on the different environments in which the devices are used. That means that many models with heterogeneous data may need help to converge. Each client stores a momentum term locally, which tracks the pace of change over several updates. With clients communicating this momentum, the server can factor in the rate of change of each update when changing the global model to accelerate convergence. Similarly, weighted aggregation can factor in the client performance or other parameters like device type or network connection strength to adjust the weight with which the server should incorporate the model updates. Further description of specific aggregation algorithms is described by @moshawrab2023reviewing.
### Handling non-IID Data
-When using federated learning to train a model across many client devices, it is convenient to consider the data to be independent and identically distributed (IID) across all clients. When data is IID, the model will converge faster and perform better because each local update on any given client is more representative of the broader dataset. This makes aggregation straightforward as you can directly average all clients. However, this is not how data often appears in the real world. Consider a few of the following ways in which data may be non-IID:
+When using federated learning to train a model across many client devices, it is convenient to consider the data to be independent and identically distributed (IID) across all clients. When data is IID, the model will converge faster and perform better because each local update on any given client is more representative of the broader dataset. This makes aggregation straightforward, as you can directly average all clients. However, this differs from how data often appears in the real world. Consider a few of the following ways in which data may be non-IID:
-* If you are learning on a set of health-monitor devices, different device models could mean different sensor qualities and properties. This means that low quality sensors and devices may produce data, and therefore model updates distinctly different than high quality ones
+* If you are learning on a set of health-monitor devices, different device models could mean different sensor qualities and properties. This means that low-quality sensors and devices may produce data, and therefore, model updates distinctly different than high-quality ones
-* A smart keyboard trained to perform autocorrect. If you have a disproportionate amount of devices from a certain region the slang, sentence structure, or even language they were using could skew more model updates towards a certain style of typing
+* A smart keyboard trained to perform autocorrect. If you have a disproportionate amount of devices from a certain region, the slang, sentence structure, or even language they were using could skew more model updates towards a certain style of typing
-* If you have wildlife sensors in remote areas, connectivity may not be equally distributed causing some clients in certain regions to be able to send more model updates than others. If those regions have different wildlife activity from certain species, that could skew the updates toward those animals
+* If you have wildlife sensors in remote areas, connectivity may not be equally distributed, causing some clients in certain regions to be unable to send more model updates than others. If those regions have different wildlife activity from certain species, that could skew the updates toward those animals
There are a few approaches to addressing non-IID data in federated learning. One approach would be to change the aggregation algorithm. If you use a weighted aggregation algorithm, you can adjust based on different client properties like region, sensor properties, or connectivity [@zhao2018federated].
### Client Selection
-Considering all of the factors influencing the efficacy of federated learning like IID data and communication, client selection is key component to ensuring a system trains well. Selecting the wrong clients can skew the dataset, resulting in non-IID data. Similarly, choosing clients randomly with bad network connections can slow down communication. Therefore, when selecting the right subset of clients, several key characteristics must be considered.
+Considering all of the factors influencing the efficacy of federated learning, like IID data and communication, client selection is a key component to ensuring a system trains well. Selecting the wrong clients can skew the dataset, resulting in non-IID data. Similarly, choosing clients randomly with bad network connections can slow down communication. Therefore, several key characteristics must be considered when selecting the right subset of clients.
-When selecting clients, there are three main components to consider: data heterogeneity, resource allocation, and communication cost. To address data heterogeneity, we can select for clients on the previously proposed metrics in the non-IID section. In federated learning, all devices may not have the same amount of compute, resulting in some being more inefficient at training than others. When selecting a subset of clients for training, one must consider a balance of data heterogeneity and available resources. In an ideal scenario, you can always select the subset of clients with the greatest resources. However, this may skew your dataset so a balance must be struck. Communication differences add another layer to this, you do not want to be bottlenecked by waiting for devices with poor connections to transmit their entire updates. Therefore, you must also consider choosing a subset of diverse yet well-connected devices.
+When selecting clients, there are three main components to consider: data heterogeneity, resource allocation, and communication cost. We can select clients on the previously proposed metrics in the non-IID section to address data heterogeneity. In federated learning, all devices may have different amounts of computing, resulting in some being more inefficient at training than others. When selecting a subset of clients for training, one must consider a balance of data heterogeneity and available resources. In an ideal scenario, you can always select the subset of clients with the greatest resources. However, this may skew your dataset, so a balance must be struck. Communication differences add another layer; you want to avoid being bottlenecked by waiting for devices with poor connections to transmit all their updates. Therefore, you must also consider choosing a subset of diverse yet well-connected devices.
### An Example of Deployed Federated Learning: G board
-A primary example of a deployed federated learning system is Google's Keyboard, Gboard, for android devices. In their implementation of federated learning for the keyboard, Google focused on employing differential privacy techniques to protect the user's data and identity. Gboard leverages language models for several key features such as Next Word Prediction (NWP), Smart Compose (SC), and On-The-Fly rescoring (OTF) [@xu2023federated], as shown in @fig-gboard-features.
+A primary example of a deployed federated learning system is Google's Keyboard, Gboard, for Android devices. In implementing federated learning for the keyboard, Google focused on employing differential privacy techniques to protect the user's data and identity. Gboard leverages language models for several key features, such as Next Word Prediction (NWP), Smart Compose (SC), and On-The-Fly rescoring (OTF) [@xu2023federated], as shown in @fig-gboard-features.
-NWP will anticipate the next word the user is trying to type based on the previous one. SC gives inline suggestions to speed up the typing based on each character. OTF will re-rank the proposed next words based on the active typing process. All three of these models need to run quickly on the edge and federated learning can accelerate training on the users' data. However, uploading every word a user typed to the cloud for training would be a massive privacy violation. Therefore, federated learning with an emphasis on differential privacy protects the user while still enabling a better user experience.
+NWP will anticipate the next word the user tries to type based on the previous one. SC gives inline suggestions to speed up the typing based on each character. OTF will re-rank the proposed next words based on the active typing process. All three of these models need to run quickly on the edge, and federated learning can accelerate training on the users' data. However, uploading every word a user typed to the cloud for training would be a massive privacy violation. Therefore, federated learning emphasizes differential privacy, which protects the user while enabling a better user experience.
).](images/png/ondevice_gboard_example.png){#fig-gboard-features}
-To accomplish this goal, Google employed their algorithm DP-FTRL which provides a formal guarantee that trained models will not memorize specific user data or identities. The system desgined of the algorithm is shown in @fig-differential-privacy. DP-FTRL combined with secure aggregation, a strategy of encrypting model updates, provides an optimal balance of privacy and utility. Furthermore, adaptive clipping is applied in the aggregation process to limit the impact of individual users on the global model (step 3 in @fig-differential-privacy). Through a combination of all of these techniques, Google can continuously refine their keyboard while preserving user privacy in a formally provable way.
+To accomplish this goal, Google employed its algorithm DP-FTRL, which provides a formal guarantee that trained models will not memorize specific user data or identities. The algorithm system design is shown in @fig-differential-privacy. DP-FTRL, combined with secure aggregation, encrypts model updates and provides an optimal balance of privacy and utility. Furthermore, adaptive clipping is applied in the aggregation process to limit the impact of individual users on the global model (step 3 in @fig-differential-privacy). By combining all these techniques, Google can continuously refine its keyboard while preserving user privacy in a formally provable way.
).](images/png/ondevice_gboard_approach.png){#fig-differential-privacy}
@@ -480,7 +482,7 @@ To accomplish this goal, Google employed their algorithm DP-FTRL which provides
### Federated Learning - Text Generation
-Ever used those smart keyboards suggesting the next word? With federated learning, we can make them even better without sacrificing privacy. In this Colab, we'll teach an AI to predict words by training on text data spread across devices. Get ready to make your typing even smoother!
+Have you ever used those smart keyboards to suggest the next word? With federated learning, we can make them even better without sacrificing privacy. In this Colab, we'll teach an AI to predict words by training on text data spread across devices. Get ready to make your typing even smoother!
[](https://colab.research.google.com/github/tensorflow/federated/blob/main/docs/tutorials/federated_learning_for_text_generation.ipynb)
@@ -490,7 +492,7 @@ Ever used those smart keyboards suggesting the next word? With federated learni
### Federated Learning - Image Classification
-Want to train an image-savvy AI without sending your photos to the cloud? Federated learning is the answer! In this Colab, we'll train a model across multiple devices, each learning from its own images. Privacy protected, teamwork makes the AI dream work!
+Want to train an image-savvy AI without sending your photos to the cloud? Federated learning is the answer! In this Colab, we'll train a model across multiple devices, each learning from its images. Privacy is protected, and teamwork makes the AI dream work!
[](https://colab.research.google.com/github/tensorflow/federated/blob/v0.5.0/docs/tutorials/federated_learning_for_image_classification.ipynb)
@@ -498,19 +500,19 @@ Want to train an image-savvy AI without sending your photos to the cloud? Federa
### Benchmarking for Federated Learning: MedPerf
-One of the richest examples of data on the edge is medical devices. These devices store some of the most personal data on users but offer huge advances in personalized treatment and better accuracy in medical AI. Given these two factors, medical devices are the perfect use case for federated learning. [MedPerf](https://doi.org/10.1038/s42256-023-00652-2) is an open source platform used to benchmark models using federated evaluation [@karargyris2023federated]. Instead of just training models via federated learning, MedPerf takes the model to edge devices to test it against personalized data while preserving privacy. In this way a benchmark committee can evaluate various models in the real world on edge devices while still preserving patient anonymity.
+One of the richest examples of data on the edge is medical devices. These devices store some of the most personal data on users but offer huge advances in personalized treatment and better accuracy in medical AI. Given these two factors, medical devices are the perfect use case for federated learning. [MedPerf](https://doi.org/10.1038/s42256-023-00652-2) is an open-source platform used to benchmark models using federated evaluation [@karargyris2023federated]. Instead of just training models via federated learning, MedPerf takes the model to edge devices to test it against personalized data while preserving privacy. In this way, a benchmark committee can evaluate various models in the real world on edge devices while still preserving patient anonymity.
## Security Concerns
Performing ML model training and adaptation on end-user devices also introduces security risks that must be addressed. Some key security concerns include:
-* **Exposure of private data**: Training data may be leaked or stolen from devices
-* **Data poisoning**: Adversaries can manipulate training data to degrade model performance
-* **Model extraction**: Attackers may attempt to steal trained model parameters
-* **Membership inference**: Models may reveal participation of specific users' data
-* **Evasion attacks**: Specially crafted inputs can cause misclassification
+* **Exposure of private data:** Training data may be leaked or stolen from devices
+* **Data poisoning:** Adversaries can manipulate training data to degrade model performance
+* **Model extraction:** Attackers may attempt to steal trained model parameters
+* **Membership inference:** Models may reveal the participation of specific users' data
+* **Evasion attacks:** Specially crafted inputs can cause misclassification
-Any system that performs learning on-device introduces security concerns, as it may expose vulnerabilities in larger scale models. There are numerous security risks associated with any ML model, but these risks have specific consequences for on-device learning. Fortunately, there are methods to mitigate these risks to improve the real-world performance of on-device learning.
+Any system that performs learning on-device introduces security concerns, as it may expose vulnerabilities in larger-scale models. Numerous security risks are associated with any ML model, but these risks have specific consequences for on-device learning. Fortunately, there are methods to mitigate these risks and improve the real-world performance of on-device learning.
### Data Poisoning
@@ -520,36 +522,36 @@ Several data poisoning attack techniques exist:
* **Label Flipping:** It involves applying incorrect labels to samples. For instance, in image classification, cat photos may be labeled as dogs to confuse the model. Flipping even [10% of labels](https://proceedings.mlr.press/v139/schwarzschild21a.html) can have significant consequences on the model.
* **Data Insertion:** It introduces fake or distorted inputs into the training set. This could include pixelated images, noisy audio, or garbled text.
-* **Logic Corruption:** This alters the underlying [patterns](https://www.worldscientific.com/doi/10.1142/S0218001414600027) in data to mislead the model. In sentiment analysis, highly negative reviews may be marked positive through this technique. For this reason, recent surveys have shown that many companies are more [afraid of data poisoning](https://proceedings.mlr.press/v139/schwarzschild21a.html) than other adversarial ML concerns.
+* ** Logic Corruption: ** This alters the underlying [patterns] (https://www.worldscientific.com/doi/10.1142/S0218001414600027) in data to mislead the model. In sentiment analysis, highly negative reviews may be marked positive through this technique. For this reason, recent surveys have shown that many companies are more [afraid of data poisoning](https://proceedings.mlr.press/v139/schwarzschild21a.html) than other adversarial ML concerns.
-What makes data poisoning alarming is how it exploits the discrepancy between curated datasets and live training data. Consider a cat photo dataset collected from the internet. In the weeks later when this data trains a model on-device, new cat photos on the web differ significantly.
+What makes data poisoning alarming is how it exploits the discrepancy between curated datasets and live training data. Consider a cat photo dataset collected from the internet. In the weeks later, when this data trains a model on-device, new cat photos on the web differ significantly.
With data poisoning, attackers purchase domains and upload content that influences a portion of the training data. Even small data changes significantly impact the model's learned behavior. Consequently, poisoning can instill racist, sexist, or other harmful biases if unchecked.
[Microsoft Tay](https://en.wikipedia.org/wiki/Tay_(chatbot)) was a chatbot launched by Microsoft in 2016. It was designed to learn from its interactions with users on social media platforms like Twitter. Unfortunately, Microsoft Tay became a prime example of data poisoning in ML models. Within 24 hours of its launch, Microsoft had to take Tay offline because it had started producing offensive and inappropriate messages, including hate speech and racist comments. This occurred because some users on social media intentionally fed Tay with harmful and offensive input, which the chatbot then learned from and incorporated into its responses.
-This incident is a clear example of data poisoning because malicious actors intentionally manipulated the data used to train and inform the chatbot's responses. The data poisoning resulted in the chatbot adopting harmful biases and producing output that was not intended by its developers. It demonstrates how even small amounts of maliciously crafted data can have a significant impact on the behavior of ML models, and highlights the importance of implementing robust data filtering and validation mechanisms to prevent such incidents from occurring.
+This incident is a clear example of data poisoning because malicious actors intentionally manipulated the data used to train and inform the chatbot's responses. The data poisoning resulted in the chatbot adopting harmful biases and producing output that its developers did not intend. It demonstrates how even small amounts of maliciously crafted data can significantly impact the behavior of ML models and highlights the importance of implementing robust data filtering and validation mechanisms to prevent such incidents from occurring.
-The real-world impacts of such biases could be dangerous. Rigorous data validation, anomaly detection, and tracking of data provenance are critical defensive measures. Adopting frameworks like Five Safes ensures models are trained on high-quality, representative data [@desai2016five].
+Such biases could have dangerous real-world impacts. Rigorous data validation, anomaly detection, and tracking of data provenance are critical defensive measures. Adopting frameworks like Five Safes ensures models are trained on high-quality, representative data [@desai2016five].
-Data poisoning is a pressing concern for secure on-device learning, since data at the endpoint cannot be easily monitored in real-time and if models are allowed to adapt on their own then we run the risk of the device acting malicously. But continued research in adversarial ML aims to develop robust solutions to detect and mitigate such data attacks.
+Data poisoning is a pressing concern for secure on-device learning since data at the endpoint cannot be easily monitored in real-time. If models are allowed to adapt on their own, then we run the risk of the device acting maliciously. However, continued research in adversarial ML aims to develop robust solutions to detect and mitigate such data attacks.
### Adversarial Attacks
-During the training phase, attackers might inject malicious data into the training dataset, which can subtly alter the model's behavior. For example, an attacker could add images of cats that are labeled as dogs into a dataset used to train an image classification model. If done cleverly, the model's accuracy might not significantly drop, and the attack could go unnoticed. The model would then incorrectly classify some cats as dogs, which could have consequences depending on the application.
+During the training phase, attackers might inject malicious data into the training dataset, which can subtly alter the model's behavior. For example, an attacker could add images of cats labeled as dogs to a dataset used to train an image classification model. If done cleverly, the model's accuracy might not significantly drop, and the attack could be noticed. The model would then incorrectly classify some cats as dogs, which could have consequences depending on the application.
In an embedded security camera system, for instance, this could allow an intruder to avoid detection by wearing a specific pattern that the model has been tricked into classifying as non-threatening.
-During the inference phase, attackers can use adversarial examples to fool the model. Adversarial examples are inputs that have been slightly altered in a way that causes the model to make incorrect predictions. For instance, an attacker might add a small amount of noise to an image in a way that causes a face recognition system to misidentify a person. These attacks can be particularly concerning in applications where safety is at stake, such as autonomous vehicles. In the example you mentioned, the researchers were able to cause a traffic sign recognition system to misclassify a stop sign as a speed sign. This type of misclassification could potentially lead to accidents if it occurred in a real-world autonomous driving system.
+During the inference phase, attackers can use adversarial examples to fool the model. Adversarial examples are inputs that have been slightly altered in a way that causes the model to make incorrect predictions. For instance, an attacker might add a small amount of noise to an image in a way that causes a face recognition system to misidentify a person. These attacks can be particularly concerning in applications where safety is at stake, such as autonomous vehicles. In the example you mentioned, the researchers were able to cause a traffic sign recognition system to misclassify a stop sign as a speed sign. This type of misclassification could lead to accidents if it occurred in a real-world autonomous driving system.
To mitigate these risks, several defenses can be employed:
* **Data Validation and Sanitization:** Before incorporating new data into the training dataset, it should be thoroughly validated and sanitized to ensure it is not malicious.
* **Adversarial Training:** The model can be trained on adversarial examples to make it more robust to these types of attacks.
* **Input Validation:** During inference, inputs should be validated to ensure they have not been manipulated to create adversarial examples.
-* **Regular Auditing and Monitoring:** Regularly auditing and monitoring the model's behavior can help to detect and mitigate adversarial attacks. In the context of tiny ML systems, this is easier said than done, because it is often hard to monitor embedded ML systems at the endpoint due to communication bandwidth limitations and so forth, which we will discuss in the MLOps chapter.
+* **Regular Auditing and Monitoring:** Regularly auditing and monitoring the model's behavior can help detect and mitigate adversarial attacks. However, this is easier said than done in the context of tiny ML systems. It is often hard to monitor embedded ML systems at the endpoint due to communication bandwidth limitations, which we will discuss in the MLOps chapter.
-By understanding the potential risks and implementing these defenses, we can help to secure on-device training at the endpoint/edge and mitigate the impact of adversarial attacks. Most people easily confuse data poisoning and adversarial attacks. So here is a table comparing data poisoning and adversarial attacks:
+By understanding the potential risks and implementing these defenses, we can help secure on-device training at the endpoint/edge and mitigate the impact of adversarial attacks. Most people easily confuse data poisoning and adversarial attacks. So @tbl-attacks compares data poisoning and adversarial attacks:
| Aspect | Data Poisoning | Adversarial Attacks |
|--------------------|-----------------------------------------|-------------------------------------------|
@@ -561,13 +563,15 @@ By understanding the potential risks and implementing these defenses, we can hel
| **Potential Effects** | Model learns incorrect patterns and makes incorrect predictions | Immediate and potentially dangerous incorrect predictions |
| **Applications Affected** | Any ML model | Autonomous vehicles, security systems, etc |
+: Comparison of data poisoning and adversarial attacks. {#tbl-attacks}
+
### Model Inversion
-Model inversion attacks are a privacy threat to on-device machine learning models trained on sensitive user data [@nguyen2023re]. Understanding this attack vector and mitigation strategies will be important for building secure and ethical on-device AI. For example, imagine an iPhone app uses on-device learning to categorize photos in your camera roll into groups like "beach", "food", or "selfies" for easier searching.
+Model inversion attacks are a privacy threat to on-device machine learning models trained on sensitive user data [@nguyen2023re]. Understanding this attack vector and mitigation strategies will be important for building secure and ethical on-device AI. For example, imagine an iPhone app that uses on-device learning to categorize photos in your camera roll into groups like "beach," "food," or "selfies" for easier searching.
-The on-device model may be pretrained by Apple on a dataset of iCloud photos from consenting users. A malicious attacker could attempt to extract parts of those original iCloud training photos using model inversion. Specifically, the attacker feeds crafted synthetic inputs into the on-device photo classifier. By tweaking the synthetic inputs and observing how the model categorizes them, they can refine the inputs until they reconstruct copies of the original training data - like a beach photo from a user's iCloud. Now the attacker has breached that user's privacy by obtaining one of their personal photos without consent. This demonstrates why model inversion is dangerous - it can potentially leak highly sensitive training data.
+The on-device model may be trained by Apple on a dataset of iCloud photos from consenting users. A malicious attacker could attempt to extract parts of those original iCloud training photos using model inversion. Specifically, the attacker feeds crafted synthetic inputs into the on-device photo classifier. By tweaking the synthetic inputs and observing how the model categorizes them, they can refine the inputs until they reconstruct copies of the original training data - like a beach photo from a user's iCloud. Now, the attacker has breached that user's privacy by obtaining one of their photos without consent. This demonstrates why model inversion is dangerous - it can potentially leak highly sensitive training data.
-Photos are an especially high-risk data type because they often contain identifiable people, location information, and private moments. But the same attack methodology could apply to other personal data like audio recordings, text messages, or users' health data.
+Photos are an especially high-risk data type because they often contain identifiable people, location information, and private moments. However, the same attack methodology could apply to other personal data, such as audio recordings, text messages, or users' health data.
To defend against model inversion, one would need to take precautions like adding noise to the model outputs or using privacy-preserving machine learning techniques like [federated learning](@sec-fl) to train the on-device model. The goal is to prevent attackers from being able to reconstruct the original training data.
@@ -577,39 +581,39 @@ While data poisoning and adversarial attacks are common concerns for ML models i
There are three primary types of security risks specific to on-device learning:
-* **Transfer-Based Attacks**: These attacks exploit the transferability property between a surrogate model (an approximation of the target model, similar to an on-device model) and a remote target model (the original full-scale model). Attackers generate adversarial examples using the surrogate model, which can then be used to deceive the target model. For example, imagine an on-device model designed to identify spam emails. An attacker could use this model to generate a spam email that is not detected by the larger, full-scale email filtering system.
+* **Transfer-Based Attacks:** These attacks exploit the transferability property between a surrogate model (an approximation of the target model, similar to an on-device model) and a remote target model (the original full-scale model). Attackers generate adversarial examples using the surrogate model, which can then be used to deceive the target model. For example, imagine an on-device model designed to identify spam emails. An attacker could use this model to generate a spam email that is not detected by the larger, full-scale filtering system.
-* **Optimization-Based Attacks**: These attacks generate adversarial examples for transfer-based attacks using some form of objective function, and iteratively modify inputs to achieve the desired outcome. Gradient estimation attacks, for example, approximate the model's gradient using query outputs (such as softmax confidence scores), while gradient-free attacks use the model's final decision (the predicted class) to approximate the gradient, albeit requiring many more queries.
+* **Optimization-Based Attacks:** These attacks generate adversarial examples for transfer-based attacks using some form of the objective function and iteratively modify inputs to achieve the desired outcome. Gradient estimation attacks, for example, approximate the model's gradient using query outputs (such as softmax confidence scores), while gradient-free attacks use the model's final decision (the predicted class) to approximate the gradient, albeit requiring many more queries.
-* **Query Attacks with Transfer Priors**: These attacks combine elements of transfer-based and optimization-based attacks. They reverse engineer on-device models to serve as surrogates for the target full-scale model. In other words, attackers use the smaller on-device model to understand how the larger model works, and then use this knowledge to attack the full-scale model.
+* **Query Attacks with Transfer Priors:** These attacks combine elements of transfer-based and optimization-based attacks. They reverse engineer on-device models to serve as surrogates for the target full-scale model. In other words, attackers use the smaller on-device model to understand how the larger model works and then use this knowledge to attack the full-scale model.
By understanding these specific risks associated with on-device learning, we can develop more robust security protocols to protect both on-device and full-scale models from potential attacks.
### Mitigation of On-Device Learning Risks
-To mitigate the numerous security risks associated with on-device learning, a variety of methods can be employed. These methods may be specific to the type of attack or serve as a general tool to bolster security.
+Various methods can be employed to mitigate the numerous security risks associated with on-device learning. These methods may be specific to the type of attack or serve as a general tool to bolster security.
-One strategy to reduce security risks is to diminish the similarity between on-device models and full-scale models, thereby reducing transferability by up to 90%. This method, known as similarity-unpairing, addresses the problem that arises when adversaries exploit the input-gradient similarity between the two models. By fine-tuning the full-scale model to create a new version with similar accuracy but different input gradients, we can then construct the on-device model by quantizing this updated full-scale model. This unpairing reduces the vulnerability of on-device models by limiting the exposure of the original full-scale model. Importantly, the order of finetuning and quantization can be varied while still achieving risk mitigation [@hong2023publishing].
+One strategy to reduce security risks is to diminish the similarity between on-device models and full-scale models, thereby reducing transferability by up to 90%. This method, known as similarity-unpairing, addresses the problem that arises when adversaries exploit the input-gradient similarity between the two models. By finetuning the full-scale model to create a new version with similar accuracy but different input gradients, we can construct the on-device model by quantizing this updated full-scale model. This unpairing reduces the vulnerability of on-device models by limiting the exposure of the original full-scale model. Importantly, the order of finetuning and quantization can be varied while still achieving risk mitigation [@hong2023publishing].
To tackle data poisoning, it is imperative to source datasets from trusted and reliable [vendors](https://www.eetimes.com/cybersecurity-threats-loom-over-endpoint-ai-systems/?_gl=1%2A17zgs0d%2A_ga%2AMTY0MzA1MTAyNS4xNjk4MDgyNzc1%2A_ga_ZLV02RYCZ8%2AMTY5ODA4Mjc3NS4xLjAuMTY5ODA4Mjc3NS42MC4wLjA).
-In combating adversarial attacks, several strategies can be employed. A proactive approach involves generating adversarial examples and incorporating them into the model's training dataset, thereby fortifying the model against such attacks. Tools like [CleverHans](http://github.com/cleverhans-lab/cleverhans), an open-source training library, are instrumental in creating adversarial examples. Defense distillation is another effective strategy, wherein the on-device model outputs probabilities of different classifications rather than definitive decisions [@hong2023publishing], making it more challenging for adversarial examples to exploit the model.
+Several strategies can be employed to combat adversarial attacks. A proactive approach involves generating adversarial examples and incorporating them into the model's training dataset, thereby fortifying the model against such attacks. Tools like [CleverHans](http://github.com/cleverhans-lab/cleverhans), an open-source training library, are instrumental in creating adversarial examples. Defense distillation is another effective strategy, wherein the on-device model outputs probabilities of different classifications rather than definitive decisions [@hong2023publishing], making it more challenging for adversarial examples to exploit the model.
The theft of intellectual property is another significant concern when deploying on-device models. Intellectual property theft is a concern when deploying on-device models, as adversaries may attempt to reverse-engineer the model to steal the underlying technology. To safeguard against intellectual property theft, the binary executable of the trained model should be stored on a microcontroller unit with encrypted software and secured physical interfaces of the chip. Furthermore, the final dataset used for training the model should be kept [private](https://www.eetimes.com/cybersecurity-threats-loom-over-endpoint-ai-systems/?_gl=1%2A17zgs0d%2A_ga%2AMTY0MzA1MTAyNS4xNjk4MDgyNzc1%2A_ga_ZLV02RYCZ8%2AMTY5ODA4Mjc3NS4xLjAuMTY5ODA4Mjc3NS42MC4wLjA).
Furthermore, on-device models often utilize well-known or open-source datasets, such as MobileNet's Visual Wake Words. As such, it is important to maintain the [privacy of the final dataset](http://arxiv.org/abs/2212.13700) used for training the model. Additionally, protecting the data augmentation process and incorporating specific use cases can minimize the risk of reverse-engineering an on-device model.
-Lastly, the Adversarial Threat Landscape for Artificial-Intelligence Systems ([ATLAS](https://atlas.mitre.org/)) serves as a valuable matrix tool that helps assess the risk profile of on-device models, empowering developers to identify and [mitigate](https://www.eetimes.com/cybersecurity-threats-loom-over-endpoint-ai-systems/?_gl=1%2A17zgs0d%2A_ga%2AMTY0MzA1MTAyNS4xNjk4MDgyNzc1%2A_ga_ZLV02RYCZ8%2AMTY5ODA4Mjc3NS4xLjAuMTY5ODA4Mjc3NS42MC4wLjA) potential risks proactively.
+Lastly, the Adversarial Threat Landscape for Artificial Intelligence Systems ([ATLAS](https://atlas.mitre.org/)) serves as a valuable matrix tool that helps assess the risk profile of on-device models, empowering developers to identify and [mitigate](https://www.eetimes.com/cybersecurity-threats-loom-over-endpoint-ai-systems/?_gl=1%2A17zgs0d%2A_ga%2AMTY0MzA1MTAyNS4xNjk4MDgyNzc1%2A_ga_ZLV02RYCZ8%2AMTY5ODA4Mjc3NS4xLjAuMTY5ODA4Mjc3NS42MC4wLjA) potential risks proactively.
### Securing Training Data
-There are a variety of different ways to secure on-device training data. Each of these concepts in itself is really deep and could be worth a class by itself. So here we'll briefly allude to those concepts so you're aware about what to learn further.
+There are various ways to secure on-device training data. Each concept is really deep and could be worth a class by itself. So here, we'll briefly allude to those concepts so you're aware of what to learn further.
#### Encryption
-Encryption serves as the first line of defense for training data. This involves implementing end-to-end encryption for both local storage on devices and communication channels to prevent unauthorized access to raw training data. Trusted execution environments, such as [Intel SGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html) and [ARM TrustZone](https://www.arm.com/technologies/trustzone-for-cortex-a#:~:text=Arm%20TrustZone%20technology%20offers%20an,trust%20based%20on%20PSA%20guidelines.), are essential for facilitating secure training on encrypted data.
+Encryption serves as the first line of defense for training data. This involves implementing end-to-end encryption for local storage on devices and communication channels to prevent unauthorized access to raw training data. Trusted execution environments, such as [Intel SGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html) and [ARM TrustZone](https://www.arm.com/technologies/trustzone-for-cortex-a#:~:text=Arm%20TrustZone%20technology%20offers%20an,trust%20based%20on%20PSA%20guidelines.), are essential for facilitating secure training on encrypted data.
-Additionally, when aggregating updates from multiple devices, secure multi-party computation protocols can be employed to enhance security [@kairouz2015secure]. A practical application of this is in collaborative on-device learning, where cryptographic privacy-preserving aggregation of user model updates can be implemented. This technique effectively hides individual user data even during the aggregation phase.
+Additionally, when aggregating updates from multiple devices, secure multi-party computation protocols can be employed to enhance security [@kairouz2015secure]; a practical application of this is in collaborative on-device learning, where cryptographic privacy-preserving aggregation of user model updates can be implemented. This technique effectively hides individual user data even during the aggregation phase.
#### Differential Privacy
@@ -617,7 +621,7 @@ Differential privacy is another crucial strategy for protecting training data. B
#### Anomaly Detection
-Anomaly detection plays an important role in identifying and mitigating potential data poisoning attacks. This can be achieved through statistical analyses like Principal Component Analysis (PCA) and clustering, which help to detect deviations in aggregated training data. Time-series methods such as [Cumulative Sum (CUSUM)](https://en.wikipedia.org/wiki/CUSUM) charts are useful for identifying shifts indicative of potential poisoning. Comparing current data distributions with previously seen clean data distributions can also help to flag anomalies. Moreover, suspected poisoned batches should be removed from the training update aggregation process. For example, spot checks on subsets of training images on devices can be conducted using photoDNA hashes to identify poisoned inputs.
+Anomaly detection plays an important role in identifying and mitigating potential data poisoning attacks. This can be achieved through statistical analyses like Principal Component Analysis (PCA) and clustering, which help to detect deviations in aggregated training data. Time-series methods such as [Cumulative Sum (CUSUM)](https://en.wikipedia.org/wiki/CUSUM) charts are useful for identifying shifts indicative of potential poisoning. Comparing current data distributions with previously seen clean data distributions can also help to flag anomalies. Moreover, suspected poisoned batches should be removed from the training update aggregation process. For example, spot checks on subsets of training images on devices can be conducted using [photoDNA](https://www.microsoft.com/en-us/photodna) hashes to identify poisoned inputs.
#### Input Data Validation
@@ -627,11 +631,11 @@ Lastly, input data validation is essential for ensuring the integrity and validi
Embedded inference frameworks like TF-Lite Micro [@david2021tensorflow], TVM [@chen2018tvm], and MCUNet [@lin2020mcunet] provide a slim runtime for running neural network models on microcontrollers and other resource-constrained devices. However, they don't support on-device training. Training requires its own set of specialized tools due to the impact of quantization on gradient calculation and the memory footprint of backpropagation [@lin2022device].
-In recent years, there are a handful of tools and frameworks that have started to emerge that enable on-device training, and these include Tiny Training Engine [@lin2022device], TinyTL [@cai2020tinytl], and TinyTrain [@kwon2023tinytrain].
+In recent years, a handful of tools and frameworks have started to emerge that enable on-device training. These include Tiny Training Engine [@lin2022device], TinyTL [@cai2020tinytl], and TinyTrain [@kwon2023tinytrain].
### Tiny Training Engine
-Tiny Training Engine (TTE) uses several techniques to optimize memory usage and speed up the training process. An overview of the TTE workflow is shown in @fig-tte-workflow. First, TTE offloads the automatic differentiation to compile time instead of runtime. This significantly reduces overhead during training. Second, TTE performs graph optimization like pruning and sparse updates to reduce memory requirements and accelerate computations.
+Tiny Training Engine (TTE) uses several techniques to optimize memory usage and speed up the training process. An overview of the TTE workflow is shown in @fig-tte-workflow. First, TTE offloads the automatic differentiation to compile time instead of runtime, significantly reducing overhead during training. Second, TTE performs graph optimization like pruning and sparse updates to reduce memory requirements and accelerate computations.
{#fig-tte-workflow}
@@ -646,29 +650,29 @@ Specifically, TTE follows four main steps:
Tiny Transfer Learning (TinyTL) enables memory-efficient on-device training through a technique called weight freezing. During training, much of the memory bottleneck comes from storing intermediate activations and updating the weights in the neural network.
-To reduce this memory overhead, TinyTL freezes the majority of the weights so they do not need to be updated during training. This eliminates the need to store intermediate activations for frozen parts of the network. TinyTL only fine-tunes the bias terms, which are much smaller than the weights. An overview of TinyTL workflow is shown in @fig-tinytl-workflow.
+To reduce this memory overhead, TinyTL freezes the majority of the weights so they do not need to be updated during training. This eliminates the need to store intermediate activations for frozen parts of the network. TinyTL only finetunes the bias terms, which are much smaller than the weights. An overview of TinyTL workflow is shown in @fig-tinytl-workflow.
{#fig-tinytl-workflow}
-Freezing weights is applicable not just to fully-connected layers but also to convolutional and normalization layers. However, only adapting the biases limits the model's ability to learn and adapt to new data.
+Freezing weights apply to fully connected layers as well as convolutional and normalization layers. However, only adapting the biases limits the model's ability to learn and adapt to new data.
To increase adaptability without much additional memory, TinyTL uses a small residual learning model. This refines the intermediate feature maps to produce better outputs, even with fixed weights. The residual model introduces minimal overhead - less than 3.8% on top of the base model.
-By freezing most weights TinyTL significantly cuts down memory usage during on-device training. The residual model then allows it to still adapt and learn effectively for the task. The combined approach provides memory-efficient on-device training with minimal impact on model accuracy.
+By freezing most weights, TinyTL significantly reduces memory usage during on-device training. The residual model then allows it to adapt and learn effectively for the task. The combined approach provides memory-efficient on-device training with minimal impact on model accuracy.
### Tiny Train
TinyTrain significantly reduces the time required for on-device training by selectively updating only certain parts of the model. It does this using a technique called task-adaptive sparse updating, as shown in @fig-tiny-train.
-Based on the user data, memory, and compute available on the device, TinyTrain dynamically chooses which layers of the neural network to update during training. This layer selection is optimized to reduce computation and memory usage while maintaining high accuracy.
+Based on the user data, memory, and computing available on the device, TinyTrain dynamically chooses which neural network layers to update during training. This layer selection is optimized to reduce computation and memory usage while maintaining high accuracy.
{#fig-tiny-train}
More specifically, TinyTrain first does offline pretraining of the model. During pretraining, it not only trains the model on the task data but also meta-trains the model. Meta-training means training the model on metadata about the training process itself. This meta-learning improves the model's ability to adapt accurately even when limited data is available for the target task.
-Then, during the online adaptation stage when the model is being customized on the device, TinyTrain performs task-adaptive sparse updates. Using the criteria around the device's capabilities, it selects only certain layers to update through backpropagation. The layers are chosen to balance accuracy, memory usage, and computation time.
+Then, during the online adaptation stage, when the model is being customized on the device, TinyTrain performs task-adaptive sparse updates. Using the criteria around the device's capabilities, it selects only certain layers to update through backpropagation. The layers are chosen to balance accuracy, memory usage, and computation time.
-By sparsely updating layers tailored to the device and task, TinyTrain is able to significantly reduce on-device training time and resource usage. The offline meta-training also improves accuracy when adapting with limited data. Together, these methods enable fast, efficient, and accurate on-device training.
+By sparsely updating layers tailored to the device and task, TinyTrain significantly reduces on-device training time and resource usage. The offline meta-training also improves accuracy when adapting to limited data. Together, these methods enable fast, efficient, and accurate on-device training.
### Comparison
@@ -696,7 +700,7 @@ In conclusion, on-device learning stands at the forefront of TinyML, promising a
## Resources {#sec-on-device-learning-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
@@ -710,7 +714,7 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
* [TFLite Quantization-Aware Training.](https://docs.google.com/presentation/d/1eSOyAOu8Vg_VfIHZ9gWRVjWnmFTOcZ4FavaNMc4reHQ/edit#slide=id.p1)
* Transfer Learning:
- * [Transfer Learning: with Visual Wake Words exaple.](https://docs.google.com/presentation/d/1kVev1WwXG2MrpEMmRbiPjTBwQ6CSCE_K84SUlSbuUPM/edit#slide=id.ga654406365_0_127)
+ * [Transfer Learning: with Visual Wake Words example.](https://docs.google.com/presentation/d/1kVev1WwXG2MrpEMmRbiPjTBwQ6CSCE_K84SUlSbuUPM/edit#slide=id.ga654406365_0_127)
* [On-device Training and Transfer Learning.](https://docs.google.com/presentation/d/1wou3qW4kXttufz6hR5lXAcZ3kXlwkl1O/edit?usp=sharing&ouid=102419556060649178683&rtpof=true&sd=true)
@@ -747,5 +751,5 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/ops/ops.bib b/contents/ops/ops.bib
index 946765e8..34f3b122 100644
--- a/contents/ops/ops.bib
+++ b/contents/ops/ops.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@article{attia2018noninvasive,
author = {Attia, Zachi I. and Sugrue, Alan and Asirvatham, Samuel J. and Ackerman, Michael J. and Kapa, Suraj and Friedman, Paul A. and Noseworthy, Peter A.},
bdsk-url-1 = {https://doi.org/10.1371/journal.pone.0201059},
@@ -11,7 +14,8 @@ @article{attia2018noninvasive
title = {Noninvasive assessment of dofetilide plasma concentration using a deep learning (neural network) analysis of the surface electrocardiogram: {A} proof of concept study},
url = {https://doi.org/10.1371/journal.pone.0201059},
volume = {13},
- year = {2018}
+ year = {2018},
+ month = aug,
}
@article{chen2023framework,
@@ -25,7 +29,8 @@ @article{chen2023framework
source = {Crossref},
title = {A framework for integrating artificial intelligence for clinical care with continuous therapeutic monitoring},
url = {https://doi.org/10.1038/s41551-023-01115-0},
- year = {2023}
+ year = {2023},
+ month = nov,
}
@article{guo2019mobile,
@@ -41,7 +46,8 @@ @article{guo2019mobile
title = {Mobile Photoplethysmographic Technology to Detect Atrial Fibrillation},
url = {https://doi.org/10.1016/j.jacc.2019.08.019},
volume = {74},
- year = {2019}
+ year = {2019},
+ month = nov,
}
@article{janapa2023edge,
@@ -49,7 +55,7 @@ @article{janapa2023edge
journal = {Proceedings of Machine Learning and Systems},
title = {Edge Impulse: {An} {MLOps} Platform for Tiny Machine Learning},
volume = {5},
- year = {2023}
+ year = {2023},
}
@article{li2021noninvasive,
@@ -65,7 +71,8 @@ @article{li2021noninvasive
title = {Non-invasive Monitoring of Three Glucose Ranges Based On {ECG} By Using {DBSCAN}-{CNN}},
url = {https://doi.org/10.1109/jbhi.2021.3072628},
volume = {25},
- year = {2021}
+ year = {2021},
+ month = sep,
}
@article{liu2022monitoring,
@@ -83,12 +90,13 @@ @article{liu2022monitoring
title = {Monitoring gait at home with radio waves in Parkinson{\textquoteright}s disease: {A} marker of severity, progression, and medication response},
url = {https://doi.org/10.1126/scitranslmed.adc9669},
volume = {14},
- year = {2022}
+ year = {2022},
+ month = sep,
}
@article{psoma2023wearable,
- article-number = {719},
author = {Psoma, Sotiria D. and Kanthou, Chryso},
+ article-number = {719},
bdsk-url-1 = {https://www.mdpi.com/2079-6374/13/7/719},
bdsk-url-2 = {https://doi.org/10.3390/bios13070719},
doi = {10.3390/bios13070719},
@@ -102,8 +110,27 @@ @article{psoma2023wearable
title = {Wearable Insulin Biosensors for Diabetes Management: {Advances} and Challenges},
url = {https://doi.org/10.3390/bios13070719},
volume = {13},
- year = {2023}
-}}
+ year = {2023},
+ month = jul,
+}
+
+@inproceedings{sambasivan2021,
+ author = {Sambasivan, Nithya and Kapania, Shivani and Highfill, Hannah and Akrong, Diana and Paritosh, Praveen and Aroyo, Lora M},
+ title = {{{\textquotedblleft}Everyone} wants to do the model work, not the data work{\textquotedblright}: {Data} Cascades in High-Stakes {AI}},
+ year = {2021},
+ isbn = {9781450380966},
+ publisher = {ACM},
+ address = {New York, NY, USA},
+ url = {https://doi.org/10.1145/3411764.3445518},
+ doi = {10.1145/3411764.3445518},
+ booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
+ articleno = {39},
+ numpages = {15},
+ location = {conf-loc, cityYokohama/city, countryJapan/country, /conf-loc},
+ series = {CHI '21},
+ source = {Crossref},
+ month = may,
+}
@inproceedings{sculley2015hidden,
author = {Sambasivan, Nithya and Kapania, Shivani and Highfill, Hannah and Akrong, Diana and Paritosh, Praveen and Aroyo, Lora M},
@@ -113,7 +140,17 @@ @inproceedings{sculley2015hidden
source = {Crossref},
title = {{{\textquotedblleft}Everyone} wants to do the model work, not the data work{\textquotedblright}: {Data} Cascades in High-Stakes {AI}},
url = {https://doi.org/10.1145/3411764.3445518},
- year = {2021}
+ year = {2021},
+ month = may,
+}
+
+@manual{stm2021l4,
+ organization = {STMicroelectronics},
+ title = {{Stm32L4Q5Ag}},
+ number = {DS12902},
+ year = {2021},
+ month = nov,
+ note = {Rev. 3},
}
@article{zhang2017highly,
@@ -130,30 +167,6 @@ @article{zhang2017highly
title = {Highly wearable cuff-less blood pressure and heart rate monitoring with single-arm electrocardiogram and photoplethysmogram signals},
url = {https://doi.org/10.1186/s12938-017-0317-z},
volume = {16},
- year = {2017}
-}
-
-@inproceedings{sambasivan2021,
- author = {Sambasivan, Nithya and Kapania, Shivani and Highfill, Hannah and Akrong, Diana and Paritosh, Praveen and Aroyo, Lora M},
- title = {Everyone wants to do the model work, not the data work: Data Cascades in High-Stakes AI},
- year = {2021},
- isbn = {9781450380966},
- publisher = {Association for Computing Machinery},
- address = {New York, NY, USA},
- url = {https://doi.org/10.1145/3411764.3445518},
- doi = {10.1145/3411764.3445518},
- booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
- articleno = {39},
- numpages = {15},
- location = {, Yokohama, Japan, },
- series = {CHI '21}
+ year = {2017},
+ month = feb,
}
-
-@manual{stm2021l4,
- organization = "STMicroelectronics",
- title = "STM32L4Q5AG",
- number = "DS12902",
- year = 2021,
- month = 11,
- note = "Rev. 3"
-}
\ No newline at end of file
diff --git a/contents/ops/ops.qmd b/contents/ops/ops.qmd
index 72706eab..8f93d3f6 100644
--- a/contents/ops/ops.qmd
+++ b/contents/ops/ops.qmd
@@ -8,15 +8,15 @@ bibliography: ops.bib
Resources: [Slides](#sec-embedded-aiops-resource), [Labs](#sec-embedded-aiops-resource), [Exercises](#sec-embedded-aiops-resource)
:::
-
+
-This chapter explores the practices and architectures needed to effectively develop, deploy, and manage ML models across their entire lifecycle. We examine the various phases of the ML process including data collection, model training, evaluation, deployment, and monitoring. The importance of automation, collaboration, and continuous improvement is also discussed. We contrast different environments for ML model deployment, from cloud servers to embedded edge devices, and analyze their distinct constraints. Through concrete examples, we demonstrate how to tailor ML system design and operations for reliable and optimized model performance in any target environment. The goal is to provide readers with a comprehensive understanding of ML model management so they can successfully build and run ML applications that sustainably deliver value.
+This chapter explores the practices and architectures needed to effectively develop, deploy, and manage ML models across their entire lifecycle. We examine the various phases of the ML process, including data collection, model training, evaluation, deployment, and monitoring. The importance of automation, collaboration, and continuous improvement is also discussed. We contrast different environments for ML model deployment, from cloud servers to embedded edge devices, and analyze their distinct constraints. We demonstrate how to tailor ML system design and operations through concrete examples for reliable and optimized model performance in any target environment. The goal is to provide readers with a comprehensive understanding of ML model management so they can successfully build and run ML applications that sustainably deliver value.
::: {.callout-tip}
## Learning Objectives
-* Understand what is MLOps and why it is needed
+* Understand what MLOps is and why it is needed
* Learn the architectural patterns for traditional MLOps
@@ -35,50 +35,50 @@ This chapter explores the practices and architectures needed to effectively deve
## Introduction
-Machine Learning Operations (MLOps), is a systematic approach that combines machine learning (ML), data science, and software engineering to automate the end-to-end ML lifecycle. This includes everything from data preparation and model training to deployment and maintenance. MLOps ensures that ML models are developed, deployed, and maintained efficiently and effectively.
+Machine Learning Operations (MLOps) is a systematic approach that combines machine learning (ML), data science, and software engineering to automate the end-to-end ML lifecycle. This includes everything from data preparation and model training to deployment and maintenance. MLOps ensures that ML models are developed, deployed, and maintained efficiently and effectively.
-Let's start by taking a general example (i.e., non-edge ML) case. Consider a ridesharing company that wants to deploy a machine-learning model to predict rider demand in real time. The data science team spends months developing a model, but when it's time to deploy, they realize it needs to be compatible with the engineering team's production environment. Deploying the model requires rebuilding it from scratch - costing weeks of additional work. This is where MLOps comes in.
+Let's start by taking a general example (i.e., non-edge ML) case. Consider a ridesharing company that wants to deploy a machine-learning model to predict real-time rider demand. The data science team spends months developing a model, but when it's time to deploy, they realize it needs to be compatible with the engineering team's production environment. Deploying the model requires rebuilding it from scratch, which costs weeks of additional work. This is where MLOps comes in.
-With MLOps, there are protocols and tools in place to ensure that the model developed by the data science team can be seamlessly deployed and integrated into the production environment. In essence, MLOps removes friction during the development, deployment, and maintenance of ML systems. It improves collaboration between teams through defined workflows and interfaces. MLOps also accelerates iteration speed by enabling continuous delivery for ML models.
+With MLOps, protocols, and tools, the model developed by the data science team can be seamlessly deployed and integrated into the production environment. In essence, MLOps removes friction during the development, deployment, and maintenance of ML systems. It improves collaboration between teams through defined workflows and interfaces. MLOps also accelerates iteration speed by enabling continuous delivery for ML models.
For the ridesharing company, implementing MLOps means their demand prediction model can be frequently retrained and deployed based on new incoming data. This keeps the model accurate despite changing rider behavior. MLOps also allows the company to experiment with new modeling techniques since models can be quickly tested and updated.
-Other MLOps benefits include enhanced model lineage tracking, reproducibility, and auditing. Cataloging ML workflows and standardizing artifacts - such as logging model versions, tracking data lineage, and packaging models and parameters - enables deeper insight into model provenance. Standardizing these artifacts facilitates tracing a model back to its origins, replicating the model development process, and examining how a model version has changed over time. This also facilitates regulation compliance, which is especially critical in regulated industries like healthcare and finance where being able to audit and explain models is important.
+Other MLOps benefits include enhanced model lineage tracking, reproducibility, and auditing. Cataloging ML workflows and standardizing artifacts - such as logging model versions, tracking data lineage, and packaging models and parameters - enables deeper insight into model provenance. Standardizing these artifacts facilitates tracing a model back to its origins, replicating the model development process, and examining how a model version has changed over time. This also facilitates regulation compliance, which is especially critical in regulated industries like healthcare and finance, where being able to audit and explain models is important.
-Major organizations adopt MLOps to boost productivity, increase collaboration, and accelerate ML outcomes. It provides the frameworks, tools, and best practices to manage ML systems throughout their lifecycle effectively. This results in better-performing models, faster time-to-value, and sustained competitive advantage. As we explore MLOps further, consider how implementing these practices can help address embedded ML challenges today and in the future.
+Major organizations adopt MLOps to boost productivity, increase collaboration, and accelerate ML outcomes. It provides the frameworks, tools, and best practices to effectively manage ML systems throughout their lifecycle. This results in better-performing models, faster time-to-value, and sustained competitive advantage. As we explore MLOps further, consider how implementing these practices can help address embedded ML challenges today and in the future.
## Historical Context
-MLOps has its roots in DevOps, which is a set of practices that combines software development (Dev) and IT operations (Ops) to shorten the development lifecycle and provide continuous delivery of high-quality software. The parallels between MLOps and DevOps are evident in their focus on automation, collaboration, and continuous improvement. In both cases, the goal is to break down silos between different teams (developers, operations, and, in the case of MLOps, data scientists and ML engineers) and to create a more streamlined and efficient process. It is useful to understand the history of this evolution to better understand MLOps in the context of traditional systems.
+MLOps has its roots in DevOps, a set of practices combining software development (Dev) and IT operations (Ops) to shorten the development lifecycle and provide continuous delivery of high-quality software. The parallels between MLOps and DevOps are evident in their focus on automation, collaboration, and continuous improvement. In both cases, the goal is to break down silos between different teams (developers, operations, and, in the case of MLOps, data scientists and ML engineers) and to create a more streamlined and efficient process. It is useful to understand the history of this evolution better to understand MLOps in the context of traditional systems.
### DevOps
-The term "DevOps" was first coined in 2009 by [Patrick Debois](https://www.jedi.be/), a consultant and Agile practitioner. Debois organized the first [DevOpsDays](https://www.devopsdays.org/) conference in Ghent, Belgium, in 2009, which brought together development and operations professionals to discuss ways to improve collaboration and automate processes.
+The term "DevOps" was first coined in 2009 by [Patrick Debois](https://www.jedi.be/), a consultant and Agile practitioner. Debois organized the first [DevOpsDays](https://www.devopsdays.org/) conference in Ghent, Belgium, in 2009. The conference brought together development and operations professionals to discuss ways to improve collaboration and automate processes.
-DevOps has its roots in the [Agile](https://agilemanifesto.org/) movement, which began in the early 2000s. Agile provided the foundation for a more collaborative approach to software development and emphasized small, iterative releases. However, Agile primarily focused on collaboration between development teams. As Agile methodologies became more popular, organizations realized the need to extend this collaboration to operations teams as well.
+DevOps has its roots in the [Agile](https://agilemanifesto.org/) movement, which began in the early 2000s. Agile provided the foundation for a more collaborative approach to software development and emphasized small, iterative releases. However, Agile primarily focuses on collaboration between development teams. As Agile methodologies became more popular, organizations realized the need to extend this collaboration to operations teams.
-The siloed nature of development and operations teams often led to inefficiencies, conflicts, and delays in software delivery. This need for better collaboration and integration between these teams led to the [DevOps](https://www.atlassian.com/devops) movement. In a sense, DevOps can be seen as an extension of the Agile principles to include operations teams.
+The siloed nature of development and operations teams often led to inefficiencies, conflicts, and delays in software delivery. This need for better collaboration and integration between these teams led to the [DevOps](https://www.atlassian.com/devops) movement. DevOps can be seen as an extension of the Agile principles, including operations teams.
-The key principles of DevOps include collaboration, automation, continuous integration and delivery, and feedback. DevOps focuses on automating the entire software delivery pipeline, from development to deployment. It aims to improve the collaboration between development and operations teams, utilizing tools like [Jenkins](https://www.jenkins.io/), [Docker](https://www.docker.com/), and [Kubernetes](https://kubernetes.io/) to streamline the development lifecycle.
+The key principles of DevOps include collaboration, automation, continuous integration, delivery, and feedback. DevOps focuses on automating the entire software delivery pipeline, from development to deployment. It aims to improve the collaboration between development and operations teams, utilizing tools like [Jenkins](https://www.jenkins.io/), [Docker](https://www.docker.com/), and [Kubernetes](https://kubernetes.io/) to streamline the development lifecycle.
-While Agile and DevOps share common principles around collaboration and feedback, DevOps specifically targets the integration of development and IT operations - expanding Agile beyond just development teams. It introduces practices and tools to automate software delivery and enhance the speed and quality of software releases.
+While Agile and DevOps share common principles around collaboration and feedback, DevOps specifically targets integrating development and IT operations - expanding Agile beyond just development teams. It introduces practices and tools to automate software delivery and enhance the speed and quality of software releases.
### MLOps
-[MLOps](https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning), on the other hand, stands for MLOps, and it extends the principles of DevOps to the ML lifecycle. MLOps aims to automate and streamline the end-to-end ML lifecycle, from data preparation and model development to deployment and monitoring. The main focus of MLOps is to facilitate collaboration between data scientists, data engineers, and IT operations, and to automate the deployment, monitoring, and management of ML models. Some key factors led to the rise of MLOps.
+[MLOps](https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning), on the other hand, stands for MLOps, and it extends the principles of DevOps to the ML lifecycle. MLOps aims to automate and streamline the end-to-end ML lifecycle, from data preparation and model development to deployment and monitoring. The main focus of MLOps is to facilitate collaboration between data scientists, data engineers, and IT operations and to automate the deployment, monitoring, and management of ML models. Some key factors led to the rise of MLOps.
* **Data drift:** Data drift degrades model performance over time, motivating the need for rigorous monitoring and automated retraining procedures provided by MLOps.
-* **Reproducibility:** The lack of reproducibility in machine learning experiments motivated the need for MLOps systems to track code, data, and environment variables to enable reproducible ML workflows.
+* **Reproducibility:** The lack of reproducibility in machine learning experiments motivated MLOps systems to track code, data, and environment variables to enable reproducible ML workflows.
* **Explainability:** The black box nature and lack of explainability of complex models motivated the need for MLOps capabilities to increase model transparency and explainability.
* **Monitoring:** The inability to reliably monitor model performance post-deployment highlighted the need for MLOps solutions with robust model performance instrumentation and alerting.
* **Friction:** The friction in manually retraining and deploying models motivated the need for MLOps systems that automate machine learning deployment pipelines.
-* **Optimization:** The complexity of configuring infrastructure for machine learning motivated the need for MLOps platforms with optimized, ready-made ML infrastructure.
+* **Optimization:** The complexity of configuring machine learning infrastructure motivated the need for MLOps platforms with optimized, ready-made ML infrastructure.
-While both DevOps and MLOps share the common goal of automating and streamlining processes, they differ in their focus and challenges. DevOps primarily deals with the challenges of software development and IT operations. In contrast, MLOps deals with the additional complexities of managing ML models, such as [data versioning](https://dvc.org/), [model versioning](https://dvc.org/), and [model monitoring](https://www.fiddler.ai/). MLOps also requires collaboration between various stakeholders, including data scientists, data engineers, and IT operations.
+While DevOps and MLOps share the common goal of automating and streamlining processes, their focus and challenges differ. DevOps primarily deals with the challenges of software development and IT operations. In contrast, MLOps deals with the additional complexities of managing ML models, such as [data versioning](https://dvc.org/), [model versioning](https://dvc.org/), and [model monitoring](https://www.fiddler.ai/). MLOps also requires stakeholder collaboration, including data scientists, engineers, and IT operations.
While DevOps and MLOps share similarities in their goals and principles, they differ in their focus and challenges. DevOps focuses on improving the collaboration between development and operations teams and automating software delivery. In contrast, MLOps focuses on streamlining and automating the ML lifecycle and facilitating collaboration between data scientists, data engineers, and IT operations.
-Here is a table that summarizes them side by side.
+@tbl-mlops compares and summarizes them side by side.
| Aspect | DevOps | MLOps |
|----------------------|----------------------------------|--------------------------------------|
@@ -88,7 +88,9 @@ Here is a table that summarizes them side by side.
| **Primary Concerns** | Code integration, Testing, Release management, Automation, Infrastructure as code | Data management, Model versioning, Experiment tracking, Model deployment, Scalability of ML workflows |
| **Typical Outcomes** | Faster and more reliable software releases, Improved collaboration between development and operations teams | Efficient management and deployment of machine learning models, Enhanced collaboration between data scientists and engineers |
-Learn more about ML Lifecycles through a case study featuring speech recognition:
+: Comparison of DevOps and MLOps. {#tbl-mlops}
+
+Learn more about ML Lifecycles through a case study featuring speech recognition.
{{< video https://www.youtube.com/watch?v=YJsRD_hU4tc&list=PLkDaE6sCZn6GMoA0wbpJLi3t34Gd8l0aK&index=3 >}}
@@ -104,15 +106,15 @@ Teams actively track changes to datasets over time using version control with [G
Teams meticulously label and annotate data using labeling software like [LabelStudio](https://labelstud.io/), which enables distributed teams to work on tagging datasets together. As the target variables and labeling conventions evolve, teams maintain accessibility to earlier versions.
-Teams store the raw dataset and all derived assets on cloud storage services like [Amazon S3](https://aws.amazon.com/s3/) or [Google Cloud Storage](https://cloud.google.com/storage) which provide scalable, resilient storage with versioning capabilities. Teams can set granular access permissions.
+Teams store the raw dataset and all derived assets on cloud storage services like [Amazon S3](https://aws.amazon.com/s3/) or [Google Cloud Storage](https://cloud.google.com/storage). These services provide scalable, resilient storage with versioning capabilities. Teams can set granular access permissions.
-Robust data pipelines created by teams automate the extraction, joining, cleansing and transformation of raw data into analysis-ready datasets. [Prefect](https://www.prefect.io/), [Apache Airflow](https://airflow.apache.org/), [dbt](https://www.getdbt.com/) are workflow orchestrators that allow engineers to develop flexible, reusable data processing pipelines.
+Robust data pipelines created by teams automate raw data extraction, joining, cleansing, and transformation into analysis-ready datasets. [Prefect](https://www.prefect.io/), [Apache Airflow](https://airflow.apache.org/), and [dbt](https://www.getdbt.com/) are workflow orchestrators that allow engineers to develop flexible, reusable data processing pipelines.
For instance, a pipeline may ingest data from [PostgreSQL](https://www.postgresql.org/) databases, REST APIs, and CSVs stored on S3. It can filter, deduplicate, and aggregate the data, handle errors, and save the output to S3. The pipeline can also push the transformed data into a feature store like [Tecton](https://www.tecton.ai/) or [Feast](https://feast.dev/) for low-latency access.
-In an industrial predictive maintenance use case, sensor data is ingested from devices into S3. A Prefect pipeline processes the sensor data, joining it with maintenance records. The enriched dataset is stored in Feast so models can easily retrieve the latest data for training and predictions.
+In an industrial predictive maintenance use case, sensor data is ingested from devices into S3. A perfect pipeline processes the sensor data, joining it with maintenance records. The enriched dataset is stored in Feast so models can easily retrieve the latest data for training and predictions.
-Here is a short overview of data pipelines:
+The video below is a short overview of data pipelines.
{{< video https://www.youtube.com/watch?v=gz-44N3MMOA&list=PLkDaE6sCZn6GMoA0wbpJLi3t34Gd8l0aK&index=33 >}}
@@ -122,39 +124,39 @@ Continuous integration and continuous delivery (CI/CD) pipelines actively automa
CI/CD pipelines orchestrate key steps, including checking out new code changes, transforming data, training and registering new models, validation testing, containerization, deploying to environments like staging clusters, and promoting to production. Teams leverage popular CI/CD solutions like [Jenkins](https://www.jenkins.io/), [CircleCI](https://circleci.com/) and [GitHub Actions](https://github.com/features/actions) to execute these MLOps pipelines, while [Prefect](https://www.prefect.io/), [Metaflow](https://metaflow.org/) and [Kubeflow](https://www.kubeflow.org/) offer ML-focused options.
-@fig-ci-cd illustrates a CI/CD pipeline specifically tailored for MLOps. The process starts with a dataset and feature repository (on the left), which feeds into a dataset ingestion stage. Post-ingestion, the data undergoes validation to ensure its quality before being transformed for training. Parallel to this, a retraining trigger can initiate the pipeline based on specified criteria. The data then passes through a model training/tuning phase within a data processing engine, followed by model evaluation and validation. Once validated, the model is registered and stored in a machine learning metadata and artifact repository. The final stage involves deploying the trained model back into the dataset and feature repository, thereby creating a cyclical process for continuous improvement and deployment of machine learning models
+@fig-ci-cd illustrates a CI/CD pipeline specifically tailored for MLOps. The process starts with a dataset and feature repository (on the left), which feeds into a dataset ingestion stage. Post-ingestion, the data undergoes validation to ensure its quality before being transformed for training. Parallel to this, a retraining trigger can initiate the pipeline based on specified criteria. The data then passes through a model training/tuning phase within a data processing engine, followed by model evaluation and validation. Once validated, the model is registered and stored in a machine learning metadata and artifact repository. The final stage involves deploying the trained model back into the dataset and feature repository, thereby creating a cyclical process for continuous improvement and deployment of machine learning models.
{#fig-ci-cd}
For example, when a data scientist checks improvements to an image classification model into a [GitHub](https://github.com/) repository, this actively triggers a Jenkins CI/CD pipeline. The pipeline reruns data transformations and model training on the latest data, tracking experiments with [MLflow](https://mlflow.org/). After automated validation testing, teams deploy the model container to a [Kubernetes](https://kubernetes.io/) staging cluster for further QA. Once approved, Jenkins facilitates a phased rollout of the model to production with [canary deployments](https://kubernetes.io/docs/concepts/cluster-administration/manage-deployment/#canary-deployments) to catch any issues. If anomalies are detected, the pipeline enables teams to roll back to the previous model version gracefully.
-By connecting the disparate steps from development to deployment under continuous automation, CI/CD pipelines empower teams to iterate and deliver ML models rapidly. Integrating MLOps tools like MLflow enhances model packaging, versioning, and pipeline traceability. CI/CD is integral for progressing models beyond prototypes into sustainable business systems.
+CI/CD pipelines empower teams to iterate and deliver ML models rapidly by connecting the disparate steps from development to deployment under continuous automation. Integrating MLOps tools like MLflow enhances model packaging, versioning, and pipeline traceability. CI/CD is integral for progressing models beyond prototypes into sustainable business systems.
### Model Training
-In the model training phase, data scientists actively experiment with different ML architectures and algorithms to create optimized models that effectively extract insights and patterns from data. MLOps introduces best practices and automation to make this iterative process more efficient and reproducible.
+In the model training phase, data scientists actively experiment with different ML architectures and algorithms to create optimized models that extract insights and patterns from data. MLOps introduces best practices and automation to make this iterative process more efficient and reproducible.
-Modern ML frameworks like [TensorFlow](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/) and [Keras](https://keras.io/) provide pre-built components that simplify designing neural networks and other model architectures. Data scientists leverage built-in modules for layers, activations, losses, etc. and high-level APIs like Keras to focus more on model architecture.
+Modern ML frameworks like [TensorFlow](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/) and [Keras](https://keras.io/) provide pre-built components that simplify designing neural networks and other model architectures. Data scientists leverage built-in modules for layers, activations, losses, etc., and high-level APIs like Keras to focus more on model architecture.
MLOps enables teams to package model training code into reusable, tracked scripts and notebooks. As models are developed, capabilities like [hyperparameter tuning](https://cloud.google.com/ai-platform/training/docs/hyperparameter-tuning-overview), [neural architecture search](https://arxiv.org/abs/1808.05377) and [automatic feature selection](https://scikit-learn.org/stable/modules/feature_selection.html) rapidly iterate to find the best-performing configurations.
-Teams put training code under version control using Git and host it in repositories like GitHub to track changes over time. This allows seamless collaboration between data scientists.
+Teams use Git to version control training code and host it in repositories like GitHub to track changes over time. This allows seamless collaboration between data scientists.
-Notebooks like [Jupyter](https://jupyter.org/) make an excellent environment for interactive model development. The notebooks contain data ingestion, preprocessing, model declaration, training loop, evaluation, and export code in one reproducible document.
+Notebooks like [Jupyter](https://jupyter.org/) create an excellent interactive model development environment. The notebooks contain data ingestion, preprocessing, model declaration, training loop, evaluation, and export code in one reproducible document.
Finally, teams orchestrate model training as part of a CI/CD pipeline for automation. For instance, a Jenkins pipeline can trigger a Python script to load new training data, retrain a TensorFlow classifier, evaluate model metrics, and automatically register the model if performance thresholds are met.
An example workflow has a data scientist using a PyTorch notebook to develop a CNN model for image classification. The [fastai](https://www.fast.ai/) library provides high-level APIs to simplify training CNNs on image datasets. The notebook trains the model on sample data, evaluates accuracy metrics, and tunes hyperparameters like learning rate and layers to optimize performance. This reproducible notebook is version-controlled and integrated into a retraining pipeline.
-Automating and standardizing model training empowers teams to accelerate experimentation and achieve the rigor needed for production of ML systems.
+Automating and standardizing model training empowers teams to accelerate experimentation and achieve the rigor needed to produce ML systems.
### Model Evaluation
-Before deploying models, teams perform rigorous evaluation and testing to validate meeting performance benchmarks and readiness for release. MLOps introduces best practices around model validation, auditing and [canary testing](https://martinfowler.com/bliki/CanaryRelease.html).
+Before deploying models, teams perform rigorous evaluation and testing to validate meeting performance benchmarks and readiness for release. MLOps introduces best practices around model validation, auditing, and [canary testing](https://martinfowler.com/bliki/CanaryRelease.html).
-Teams typically evaluate models against holdout [test datasets](https://en.wikipedia.org/wiki/Training,_validation,_and_test_sets) not used during training. The test data originates from the same distribution as production data. Teams calculate metrics like [accuracy](https://en.wikipedia.org/wiki/Accuracy_and_precision), [AUC](https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Area_under_the_curve), [precision](https://en.wikipedia.org/wiki/Precision_and_recall), [recall](https://en.wikipedia.org/wiki/Precision_and_recall), and [F1 score](https://en.wikipedia.org/wiki/F1_score).
+Teams typically evaluate models against holdout [test datasets](https://en.wikipedia.org/wiki/Training,_validation,_and_test_sets) that are not used during training. The test data originates from the same distribution as production data. Teams calculate metrics like [accuracy](https://en.wikipedia.org/wiki/Accuracy_and_precision), [AUC](https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Area_under_the_curve), [precision](https://en.wikipedia.org/wiki/Precision_and_recall), [recall](https://en.wikipedia.org/wiki/Precision_and_recall), and [F1 score](https://en.wikipedia.org/wiki/F1_score).
-Teams also track the same metrics over time against test data samples. If evaluation data comes from live production streams, this catches [data drifts](https://www.ibm.com/cloud/learn/data-drift) over time that degrade model performance.
+Teams also track the same metrics over time against test data samples. If evaluation data comes from live production streams, this catches [data drifts](https://www.ibm.com/cloud/learn/data-drift) that degrade model performance over time.
Human oversight for model release remains important. Data scientists review performance across key segments and slices. Error analysis helps identify model weaknesses to guide enhancement. Teams apply [fairness](https://developers.google.com/machine-learning/fairness-overview) and [bias detection](https://developers.google.com/machine-learning/fairness-overview) techniques.
@@ -162,39 +164,39 @@ Canary testing releases a model to a small subset of users to evaluate real-worl
For example, a retailer evaluates a personalized product recommendation model against historical test data, reviewing accuracy and diversity metrics. Teams also calculate metrics on live customer data over time, detecting decreased accuracy over the last 2 weeks. Before full rollout, the new model is released to 5% of web traffic to ensure no degradation.
-Automating evaluation and canary releases reduces deployment risks. But human review remains critical to assess less quantifiable dynamics of model behavior. Rigorous pre-deployment validation provides confidence in putting models into production.
+Automating evaluation and canary releases reduces deployment risks. However, human review still needs to be more critical to assess less quantifiable dynamics of model behavior. Rigorous pre-deployment validation provides confidence in putting models into production.
### Model Deployment
-To reliably deploy ML models to production, teams need to properly package, test and track them. MLOps introduces frameworks and procedures to actively version, deploy, monitor and update models in sustainable ways.
+Teams need to properly package, test, and track ML models to reliably deploy them to production. MLOps introduces frameworks and procedures for actively versioning, deploying, monitoring, and updating models in sustainable ways.
-Teams containerize models using [Docker](https://www.docker.com/) which bundles code, libraries and dependencies into a standardized unit. Containers enable smooth portability across environments.
+Teams containerize models using [Docker](https://www.docker.com/), which bundles code, libraries, and dependencies into a standardized unit. Containers enable smooth portability across environments.
-Frameworks like [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving) and [BentoML](https://bentoml.org/) help serve predictions from deployed models via performance-optimized APIs. These frameworks handle versioning, scaling and monitoring.
+Frameworks like [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving) and [BentoML](https://bentoml.org/) help serve predictions from deployed models via performance-optimized APIs. These frameworks handle versioning, scaling, and monitoring.
Teams first deploy updated models to staging or QA environments for testing before full production rollout. Shadow or canary deployments route a sample of traffic to test model variants. Teams incrementally increase access to new models.
Teams build robust rollback procedures in case issues emerge. Rollbacks revert to the last known good model version. Integration with CI/CD pipelines simplifies redeployment if needed.
-Teams carefully track model artifacts like scripts, weights, logs and metrics for each version with ML metadata tools like [MLflow](https://mlflow.org/). This maintains lineage and auditability.
+Teams carefully track model artifacts, such as scripts, weights, logs, and metrics, for each version with ML metadata tools like [MLflow](https://mlflow.org/). This maintains lineage and auditability.
-For example, a retailer containerizes a product recommendation model in TensorFlow Serving and deploys it to a [Kubernetes](https://kubernetes.io/) staging cluster. After monitoring and approving performance on sample traffic, Kubernetes shifts 10% of production traffic to the new model. If no issues are detected after a few days, the new model takes over 100% of traffic. But teams keep the previous version accessible for rollback if needed.
+For example, a retailer containerizes a product recommendation model in TensorFlow Serving and deploys it to a [Kubernetes](https://kubernetes.io/) staging cluster. After monitoring and approving performance on sample traffic, Kubernetes shifts 10% of production traffic to the new model. If no issues are detected after a few days, the new model takes over 100% of traffic. However, teams should keep the previous version accessible for rollback if needed.
Model deployment processes enable teams to make ML systems resilient in production by accounting for all transition states.
### Infrastructure Management
-MLOps teams heavily leverage [infrastructure as code (IaC)](https://www.infoworld.com/article/3271126/what-is-iac-infrastructure-as-code-explained.html) tools and robust cloud architectures to actively manage the resources needed for development, training and deployment of ML systems.
+MLOps teams heavily leverage [infrastructure as code (IaC)](https://www.infoworld.com/article/3271126/what-is-iac-infrastructure-as-code-explained.html) tools and robust cloud architectures to actively manage the resources needed for development, training, and deployment of ML systems.
Teams use IaC tools like [Terraform](https://www.terraform.io/), [CloudFormation](https://aws.amazon.com/cloudformation/) and [Ansible](https://www.ansible.com/) to programmatically define, provision and update infrastructure in a version controlled manner. For MLOps, teams widely use Terraform to spin up resources on [AWS](https://aws.amazon.com/), [GCP](https://cloud.google.com/) and [Azure](https://azure.microsoft.com/).
-For model building and training, teams dynamically provision compute resources like GPU servers, container clusters, storage and databases through Terraform as needed by data scientists. Code encapsulates and preserves infrastructure definitions.
+For model building and training, teams dynamically provision computing resources like GPU servers, container clusters, storage, and databases through Terraform as needed by data scientists. Code encapsulates and preserves infrastructure definitions.
-Containers and orchestrators like Docker and Kubernetes provide means for teams to package models and reliably deploy them across different environments. Containers can be predictably spun up or down automatically based on demand.
+Containers and orchestrators like Docker and Kubernetes allow teams to package models and reliably deploy them across different environments. Containers can be predictably spun up or down automatically based on demand.
By leveraging cloud elasticity, teams scale resources up and down to meet spikes in workloads like hyperparameter tuning jobs or spikes in prediction requests. [Auto-scaling](https://aws.amazon.com/autoscaling/) enables optimized cost efficiency.
-Infrastructure spans on-prem, cloud and edge devices. A robust technology stack provides flexibility and resilience. Monitoring tools give teams observability into resource utilization.
+Infrastructure spans on-prem, cloud, and edge devices. A robust technology stack provides flexibility and resilience. Monitoring tools allow teams to observe resource utilization.
For example, a Terraform config may deploy a GCP Kubernetes cluster to host trained TensorFlow models exposed as prediction microservices. The cluster scales up pods to handle increased traffic. CI/CD integration seamlessly rolls out new model containers.
@@ -202,19 +204,19 @@ Carefully managing infrastructure through IaC and monitoring enables teams to pr
### Monitoring
-MLOps teams actively maintain robust monitoring to sustain visibility into ML models deployed in production. Monitoring continuously provides insights into model and system performance so teams can rapidly detect and address issues to minimize disruption.
+MLOps teams actively maintain robust monitoring to sustain visibility into ML models deployed in production. Continuous monitoring provides insights into model and system performance so teams can rapidly detect and address issues to minimize disruption.
-Teams actively monitor key model aspects including analyzing samples of live predictions to track metrics like accuracy and [confusion matrix](https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html) over time.
+Teams actively monitor key model aspects, including analyzing samples of live predictions to track metrics like accuracy and [confusion matrix](https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html) over time.
-When monitoring performance, it is important for teams to profile incoming data to check for model drift - a steady decline in model accuracy over time after production deployment. Model drift can occur in one of two ways: [concept drift](https://en.wikipedia.org/wiki/Concept_drift) and data drift. Concept drift refers to a fundamental change observed in the relationship between the input data and the target outcomes. For instance, as the COVID-19 pandemic progressed e-commerce and retail sites had to correct their model recommendations, since purchase data was overwhelmingly skewed towards items like hand sanitizer. Data drift describes changes in the distribution of data over time. For example, image recognition algorithms used in self-driving cars will need to account for seasonality in observing their surroundings. Teams also track application performance metrics like latency and errors for model integrations.
+When monitoring performance, teams must profile incoming data to check for model drift - a steady decline in model accuracy after production deployment. Model drift can occur in two ways: [concept drift](https://en.wikipedia.org/wiki/Concept_drift) and data drift. Concept drift refers to a fundamental change observed in the relationship between the input data and the target outcomes. For instance, as the COVID-19 pandemic progressed, e-commerce and retail sites had to correct their model recommendations since purchase data was overwhelmingly skewed towards items like hand sanitizer. Data drift describes changes in the distribution of data over time. For example, image recognition algorithms used in self-driving cars must account for seasonality in observing their surroundings. Teams also track application performance metrics like latency and errors for model integrations.
-From an infrastructure perspective, teams monitor for capacity issues like high CPU, memory and disk utilization as well as system outages. Tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/) and [Elastic](https://www.elastic.co/) enable teams to actively collect, analyze, query and visualize diverse monitoring metrics. Dashboards make dynamics highly visible.
+From an infrastructure perspective, teams monitor for capacity issues like high CPU, memory, and disk utilization and system outages. Tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Elastic](https://www.elastic.co/) enable teams to actively collect, analyze, query, and visualize diverse monitoring metrics. Dashboards make dynamics highly visible.
Teams configure alerting for key monitoring metrics like accuracy declines and system faults to enable proactively responding to events that threaten reliability. For example, drops in model accuracy trigger alerts for teams to investigate potential data drift and retrain models using updated, representative data samples.
-Comprehensive monitoring enables teams to maintain confidence in model and system health after deployment. It empowers teams to catch and resolve deviations through data-driven alerts and dashboards preemptively. Active monitoring is essential for maintaining highly available, trustworthy ML systems.
+After deployment, comprehensive monitoring enables teams to maintain confidence in model and system health. It empowers teams to catch and resolve deviations preemptively through data-driven alerts and dashboards. Active monitoring is essential for maintaining highly available, trustworthy ML systems.
-Watch the video below to learn more about monitoring:
+Watch the video below to learn more about monitoring.
{{< video https://www.youtube.com/watch?v=hq_XyP9y0xg&list=PLkDaE6sCZn6GMoA0wbpJLi3t34Gd8l0aK&index=7 >}}
@@ -222,41 +224,41 @@ Watch the video below to learn more about monitoring:
MLOps teams actively establish proper governance practices as a critical component. Governance provides oversight into ML models to ensure they are trustworthy, ethical, and compliant. Without governance, significant risks exist of models behaving in dangerous or prohibited ways when deployed in applications and business processes.
-MLOps governance employs techniques to provide transparency into model predictions, performance, and behavior throughout the ML lifecycle. Explainability methods like [SHAP](https://github.com/slundberg/shap) and [LIME](https://github.com/marcotcr/lime) help auditors understand why models make certain predictions by highlighting influential input features behind decisions. [Bias detection](https://developers.google.com/machine-learning/fairness-overview) analyzes model performance across different demographic groups defined by attributes like age, gender and ethnicity to detect any systematic skews. Teams perform rigorous testing procedures on representative datasets to validate model performance before deployment.
+MLOps governance employs techniques to provide transparency into model predictions, performance, and behavior throughout the ML lifecycle. Explainability methods like [SHAP](https://github.com/slundberg/shap) and [LIME](https://github.com/marcotcr/lime) help auditors understand why models make certain predictions by highlighting influential input features behind decisions. [Bias detection](https://developers.google.com/machine-learning/fairness-overview) analyzes model performance across different demographic groups defined by attributes like age, gender, and ethnicity to detect any systematic skews. Teams perform rigorous testing procedures on representative datasets to validate model performance before deployment.
-Once in production, teams monitor [concept drift](https://en.wikipedia.org/wiki/Concept_drift) to track if predictive relationships change over time in ways that degrade model accuracy. Teams analyze production logs to uncover patterns in the types of errors models generate. Documentation about data provenance, development procedures, and evaluation metrics provides additional visibility.
+Once in production, teams monitor [concept drift](https://en.wikipedia.org/wiki/Concept_drift) to determine whether predictive relationships change over time in ways that degrade model accuracy. Teams also analyze production logs to uncover patterns in the types of errors models generate. Documentation about data provenance, development procedures, and evaluation metrics provides additional visibility.
-Platforms like [Watson OpenScale](https://www.ibm.com/cloud/watson-openscale) incorporate governance capabilities like bias monitoring and explainability directly into model building, testing and production monitoring. The key focus areas of governance are transparency, fairness, and compliance. This minimizes risks of models behaving incorrectly or dangerously when integrated into business processes. Embedding governance practices into MLOps workflows enables teams to ensure trustworthy AI.
+Platforms like [Watson OpenScale](https://www.ibm.com/cloud/watson-openscale) incorporate governance capabilities like bias monitoring and explainability directly into model building, testing, and production monitoring. The key focus areas of governance are transparency, fairness, and compliance. This minimizes the risks of models behaving incorrectly or dangerously when integrated into business processes. Embedding governance practices into MLOps workflows enables teams to ensure trustworthy AI.
### Communication & Collaboration
-MLOps actively breaks down silos and enables free flow of information and insights between teams through all ML lifecycle stages. Tools like [MLflow](https://mlflow.org/), [Weights & Biases](https://wandb.ai/), and data contexts provide traceability and visibility to improve collaboration.
+MLOps actively breaks down silos and enables the free flow of information and insights between teams through all ML lifecycle stages. Tools like [MLflow](https://mlflow.org/), [Weights & Biases](https://wandb.ai/), and data contexts provide traceability and visibility to improve collaboration.
-Teams use MLflow to systematize tracking of model experiments, versions, and artifacts. Experiments can be programmatically logged from data science notebooks and training jobs. The model registry provides a central hub for teams to store production-ready models before deployment, with metadata like descriptions, metrics, tags and lineage. Integrations with [Github](https://github.com/), [GitLab](https://about.gitlab.com/) facilitate code change triggers.
+Teams use MLflow to systematize tracking of model experiments, versions, and artifacts. Experiments can be programmatically logged from data science notebooks and training jobs. The model registry provides a central hub for teams to store production-ready models before deployment, with metadata like descriptions, metrics, tags, and lineage. Integrations with [Github](https://github.com/), [GitLab](https://about.gitlab.com/) facilitate code change triggers.
Weights & Biases provides collaborative tools tailored to ML teams. Data scientists log experiments, visualize metrics like loss curves, and share experimentation insights with colleagues. Comparison dashboards highlight model differences. Teams discuss progress and next steps.
-Establishing shared data contexts - glossaries, [data dictionaries](https://en.wikipedia.org/wiki/Data_dictionary), schema references - ensures alignment on data meaning and usage across roles. Documentation aids understanding for those without direct data access.
+Establishing shared data contexts—glossaries, [data dictionaries](https://en.wikipedia.org/wiki/Data_dictionary), and schema references—ensures alignment on data meaning and usage across roles. Documentation aids understanding for those without direct data access.
For example, a data scientist may use Weights & Biases to analyze an anomaly detection model experiment and share the evaluation results with other team members to discuss improvements. The final model can then be registered with MLflow before handing off for deployment.
-Enabling transparency, traceability and communication via MLOps empowers teams to remove bottlenecks and accelerate delivery of impactful ML systems.
+Enabling transparency, traceability, and communication via MLOps empowers teams to remove bottlenecks and accelerate the delivery of impactful ML systems.
-The following video covers key challenges in model deployment, including concept drift, model drift, and software engineering issues:
+The following video covers key challenges in model deployment, including concept drift, model drift, and software engineering issues.
{{< video https://www.youtube.com/watch?v=UyEtTyeahus&list=PLkDaE6sCZn6GMoA0wbpJLi3t34Gd8l0aK&index=5 >}}
## Hidden Technical Debt in ML Systems
-Technical debt is an increasingly pressing issue for ML systems (see Figure 14.2). This metaphor, originally proposed in the 1990s, likens the long-term costs of quick software development to financial debt. Just as some financial debt powers beneficial growth, carefully managed technical debt enables rapid iteration. However, left unchecked, accumulating technical debt can outweigh any gains.
+Technical debt is increasingly pressing for ML systems (see Figure 14.2). This metaphor, originally proposed in the 1990s, likens the long-term costs of quick software development to financial debt. Just as some financial debt powers beneficial growth, carefully managed technical debt enables rapid iteration. However, left unchecked, accumulating technical debt can outweigh any gains.
-@fig-technical-debt illustrates the various components that contribute to hidden technical debt in ML systems. It shows the interconnected nature of configuration, data collection, and feature extraction, which are foundational to the ML codebase. The box sizes indicate the proportion of the entire system represented by each component. In industry ML systems, the code for the model algorithm makes up only a very tiny fraction (see the small black box in the middle as compared to all the other large boxes). The complexity of ML systems and the fast-paced nature of the industry make it very easy to accumulate technical debt.
+@fig-technical-debt illustrates the various components contributing to ML systems' hidden technical debt. It shows the interconnected nature of configuration, data collection, and feature extraction, which is foundational to the ML codebase. The box sizes indicate the proportion of the entire system represented by each component. In industry ML systems, the code for the model algorithm makes up only a tiny fraction (see the small black box in the middle compared to all the other large boxes). The complexity of ML systems and the fast-paced nature of the industry make it very easy to accumulate technical debt.
{#fig-technical-debt}
### Model Boundary Erosion
-Unlike traditional software, ML lacks clear boundaries between components as seen in the diagram above. This erosion of abstraction creates entanglements that exacerbate technical debt in several ways:
+Unlike traditional software, ML lacks clear boundaries between components, as seen in the diagram above. This erosion of abstraction creates entanglements that exacerbate technical debt in several ways:
### Entanglement
@@ -264,18 +266,18 @@ Tight coupling between ML model components makes isolating changes difficult. Mo
### Correction Cascades
-![Figure 14.3: The flowchart depicts the concept of correction cascades in the ML workflow, from problem statement to model deployment. The arcs represent the potential iterative corrections needed at each stage of the workflow, with different colors corresponding to distinct issues such as interacting with physical world brittleness, inadequate application-domain expertise, conflicting reward systems, and poor cross-organizational documentation. The red arrows indicate the impact of cascades, which can lead to significant revisions in the model development process, while the dotted red line represents the drastic measure of abandoning the process to restart. This visual emphasizes the complex, interconnected nature of ML system development and the importance of addressing these issues early in the development cycle to mitigate their amplifying effects downstream. [@sculley2015hidden]](images/png/data_cascades.png)
+![Figure 14.3: The flowchart depicts the concept of correction cascades in the ML workflow, from problem statement to model deployment. The arcs represent the potential iterative corrections needed at each workflow stage, with different colors corresponding to distinct issues such as interacting with physical world brittleness, inadequate application-domain expertise, conflicting reward systems, and poor cross-organizational documentation. The red arrows indicate the impact of cascades, which can lead to significant revisions in the model development process. In contrast, the dotted red line represents the drastic measure of abandoning the process to restart. This visual emphasizes the complex, interconnected nature of ML system development and the importance of addressing these issues early in the development cycle to mitigate their amplifying effects downstream. [@sculley2015hidden]](images/png/data_cascades.png)
Building models sequentially creates risky dependencies where later models rely on earlier ones. For example, taking an existing model and fine-tuning it for a new use case seems efficient. However, this bakes in assumptions from the original model that may eventually need correction.
-There are several factors that inform the decision to build models sequentially or not:
+Several factors inform the decision to build models sequentially or not:
-* **Dataset size and rate of growth:** With small, static datasets, it often makes sense to fine-tune existing models. For large, growing datasets, training custom models from scratch allows more flexibility to account for new data.
-* **Available computing resources:** Fine-tuning requires less resources than training large models from scratch. With limited resources, leveraging existing models may be the only feasible approach.
+* **Dataset size and rate of growth:** With small, static datasets, fine-tuning existing models often makes sense. For large, growing datasets, training custom models from scratch allows more flexibility to account for new data.
+* **Available computing resources:** Fine-tuning requires fewer resources than training large models from scratch. With limited resources, leveraging existing models may be the only feasible approach.
-While fine-tuning can be efficient, modifying foundational components later becomes extremely costly due to the cascading effects on subsequent models. Careful thought should be given to identifying points where introducing fresh model architectures, even with large resource requirements, can avoid correction cascades down the line (see Figure 14.3). There are still scenarios where sequential model building makes sense, so it entails weighing these tradeoffs around efficiency, flexibility, and technical debt.
+While fine-tuning can be efficient, modifying foundational components later becomes extremely costly due to the cascading effects on subsequent models. Careful thought should be given to identifying where introducing fresh model architectures, even with large resource requirements, can avoid correction cascades down the line (see Figure 14.3). There are still scenarios where sequential model building makes sense, which entails weighing these tradeoffs around efficiency, flexibility, and technical debt.
-@fig-data-cascades-debt depicts the concept of correction cascades in the ML workflow, from problem statement to model deployment. The arcs represent the potential iterative corrections needed at each stage of the workflow, with different colors corresponding to distinct issues such as interacting with physical world brittleness, inadequate application-domain expertise, conflicting reward systems, and poor cross-organizational documentation. The red arrows indicate the impact of cascades, which can lead to significant revisions in the model development process, while the dotted red line represents the drastic measure of abandoning the process to restart. This visual emphasizes the complex, interconnected nature of ML system development and the importance of addressing these issues early in the development cycle to mitigate their amplifying effects downstream.
+@fig-data-cascades-debt depicts the concept of correction cascades in the ML workflow, from problem statement to model deployment. The arcs represent the potential iterative corrections needed at each stage of the workflow, with different colors corresponding to distinct issues such as interacting with physical world brittleness, inadequate application-domain expertise, conflicting reward systems, and poor cross-organizational documentation. The red arrows indicate the impact of cascades, which can lead to significant revisions in the model development process. In contrast, the dotted red line represents the drastic measure of abandoning the process to restart. This visual emphasizes the complex, interconnected nature of ML system development and the importance of addressing these issues early in the development cycle to mitigate their amplifying effects downstream.
{#fig-data-cascades-debt}
@@ -283,49 +285,49 @@ While fine-tuning can be efficient, modifying foundational components later beco
Once ML model predictions are made available, many downstream systems may silently consume them as inputs for further processing. However, the original model was not designed to accommodate this broad reuse. Due to the inherent opacity of ML systems, it becomes impossible to fully analyze the impact of the model's outputs as inputs elsewhere. Changes to the model can then have expensive and dangerous consequences by breaking undiscovered dependencies.
-Undeclared consumers can also enable hidden feedback loops if their outputs indirectly influence the original model's training data. Mitigations include restricting access to predictions, defining strict service contracts, and monitoring for signs of un-modelled influences. Architecting ML systems to encapsulate and isolate their effects limits the risks from unanticipated propagation.
+Undeclared consumers can also enable hidden feedback loops if their outputs indirectly influence the original model's training data. Mitigations include restricting access to predictions, defining strict service contracts, and monitoring for signs of un-modelled influences. Architecting ML systems to encapsulate and isolate their effects limits the risks of unanticipated propagation.
### Data Dependency Debt
-Data dependency debt refers to unstable and underutilized data dependencies which can have detrimental and hard to detect repercussions. While this is a key contributor to tech debt for traditional software, those systems can benefit from the use of widely available tools for static analysis by compilers and linkers to identify dependencies of these types. ML systems lack similar tooling.
+Data dependency debt refers to unstable and underutilized data dependencies, which can have detrimental and hard-to-detect repercussions. While this is a key contributor to tech debt for traditional software, those systems can benefit from the use of widely available tools for static analysis by compilers and linkers to identify dependencies of these types. ML systems need similar tooling.
-One mitigation for unstable data dependencies is to use versioning which ensures the stability of inputs but comes with the cost of managing multiple sets of data and the potential for staleness of the data. A mitigation for underutilized data dependencies is to conduct exhaustive leave-one-feature-out evaluation.
+One mitigation for unstable data dependencies is to use versioning, which ensures the stability of inputs but comes with the cost of managing multiple sets of data and the potential for staleness. Another mitigation for underutilized data dependencies is to conduct exhaustive leave-one-feature-out evaluation.
### Analysis Debt from Feedback Loops
-Unlike traditional software, ML systems can change their own behavior over time, making it difficult to analyze pre-deployment. This debt manifests in feedback loops, both direct and hidden.
+Unlike traditional software, ML systems can change their behavior over time, making it difficult to analyze pre-deployment. This debt manifests in feedback loops, both direct and hidden.
-Direct feedback loops occur when a model influences its own future inputs, such as by recommending products to users that in turn shape future training data. Hidden loops arise indirectly between models, such as two systems that interact via real-world environments. Gradual feedback loops are especially hard to detect. These loops lead to analysis debt---the inability to fully predict how a model will act after release. They undermine pre-deployment validation by enabling unmodeled self-influence.
+Direct feedback loops occur when a model influences its future inputs, such as by recommending products to users that, in turn, shape future training data. Hidden loops arise indirectly between models, such as two systems that interact via real-world environments. Gradual feedback loops are especially hard to detect. These loops lead to analysis debt—the inability to predict how a model will act fully after release. They undermine pre-deployment validation by enabling unmodeled self-influence.
-Careful monitoring and canary deployments help detect feedback. But fundamental challenges remain in understanding complex model interactions. Architectural choices that reduce entanglement and coupling mitigate analysis debt's compounding effect.
+Careful monitoring and canary deployments help detect feedback. However, fundamental challenges remain in understanding complex model interactions. Architectural choices that reduce entanglement and coupling mitigate analysis debt's compounding effect.
### Pipeline Jungles
-ML workflows often lack standardized interfaces between components. This leads teams to incrementally "glue" together pipelines with custom code. What emerges are "pipeline jungles"---tangled preprocessing steps that are brittle and resist change. Avoiding modifications to these messy pipelines causes teams to experiment through alternate prototypes. Soon, multiple ways of doing everything proliferate. The lack of abstractions and interfaces then impedes sharing, reuse, and efficiency.
+ML workflows often need more standardized interfaces between components. This leads teams to incrementally "glue" together pipelines with custom code. What emerges are "pipeline jungles"---tangled preprocessing steps that are brittle and resist change. Avoiding modifications to these messy pipelines causes teams to experiment through alternate prototypes. Soon, multiple ways of doing everything proliferate. The need for abstractions and interfaces then impedes sharing, reuse, and efficiency.
-Technical debt accumulates as one-off pipelines solidify into legacy constraints. Teams sink time into managing idiosyncratic code rather than maximizing model performance. Architectural principles like modularity and encapsulation are needed to establish clean interfaces. Shared abstractions enable interchangeable components, prevent lock-in, and promote best practice diffusion across teams. Breaking free of pipeline jungles ultimately requires enforcing standards that prevent accretion of abstraction debt. The benefits of interfaces and APIs that tame complexity outweigh the transitional costs.
+Technical debt accumulates as one-off pipelines solidify into legacy constraints. Teams sink time into managing idiosyncratic code rather than maximizing model performance. Architectural principles like modularity and encapsulation are needed to establish clean interfaces. Shared abstractions enable interchangeable components, prevent lock-in, and promote best-practice diffusion across teams. Breaking free of pipeline jungles ultimately requires enforcing standards that prevent the accretion of abstraction debt. The benefits of interfaces and APIs that tame complexity outweigh the transitional costs.
### Configuration Debt
-ML systems involve extensive configuration of hyperparameters, architectures, and other tuning parameters. However, configuration is often an afterthought, lacking rigor and testing. Ad hoc configurations proliferate, amplified by the many knobs available for tuning complex ML models.
+ML systems involve extensive configuration of hyperparameters, architectures, and other tuning parameters. However, the configuration is often an afterthought, needing more rigor and testing—ad hoc configurations increase, amplified by the many knobs available for tuning complex ML models.
-This accumulation of technical debt has several consequences. Fragile and outdated configurations lead to hidden dependencies and bugs that cause production failures. Knowledge about optimal configurations is isolated rather than shared, leading to redundant work. Reproducing and comparing results becomes difficult when configuration lacks documentation. Legacy constraints accrete as teams fear changing poorly understood configurations.
+This accumulation of technical debt has several consequences. Fragile and outdated configurations lead to hidden dependencies and bugs that cause production failures. Knowledge about optimal configurations is isolated rather than shared, leading to redundant work. Reproducing and comparing results becomes difficult when configurations lack documentation. Legacy constraints accumulate as teams fear changing poorly understood configurations.
-Addressing configuration debt requires establishing standards to document, test, validate, and centrally store configurations. Investing in more automated approaches such as hyperparameter optimization and architecture search reduces dependence on manual tuning. Better configuration hygiene makes iterative improvement more tractable by preventing complexity from compounding endlessly. The key is recognizing configuration as an integral part of the ML system lifecycle rather than an ad hoc afterthought.
+Addressing configuration debt requires establishing standards to document, test, validate, and centrally store configurations. Investing in more automated approaches, such as hyperparameter optimization and architecture search, reduces dependence on manual tuning. Better configuration hygiene makes iterative improvement more tractable by preventing complexity from compounding endlessly. The key is recognizing configuration as an integral part of the ML system lifecycle rather than an ad hoc afterthought.
### The Changing World
-ML systems operate in dynamic real-world environments. Thresholds and decisions that are initially effective become outdated as the world evolves. But legacy constraints make it difficult to adapt systems to reflect changing populations, usage patterns, and other shifting contextual factors.
+ML systems operate in dynamic real-world environments. Thresholds and decisions that are initially effective become outdated as the world evolves. However, legacy constraints make adapting systems to changing populations, usage patterns, and other shifting contextual factors difficult.
This debt manifests in two main ways. First, preset thresholds and heuristics require constant re-evaluation and tuning as their optimal values drift. Second, validating systems through static unit and integration tests fails when inputs and behaviors are moving targets.
-Responding to a changing world in real-time with legacy ML systems is challenging. Technical debt accumulates as assumptions decay. The lack of modular architecture and ability to dynamically update components without side effects exacerbates these issues.
+Responding to a changing world in real-time with legacy ML systems is challenging. Technical debt accumulates as assumptions decay. The lack of modular architecture and the ability to dynamically update components without side effects exacerbates these issues.
-Mitigating this requires building in configurability, monitoring, and modular updatability. Online learning where models continuously adapt, as well as robust feedback loops to training pipelines, help automatically tune to the world. But anticipating and architecting for change is essential to prevent erosion of real-world performance over time.
+Mitigating this requires building in configurability, monitoring, and modular updatability. Online learning, where models continuously adapt and robust feedback loops to training pipelines, helps automatically tune to the world. However, anticipating and architecting for change is essential to prevent erosion of real-world performance over time.
### Navigating Technical Debt in Early Stages
-It is understandable that technical debt accumulates naturally in early stages of model development. When aiming to build MVP models quickly, teams often lack complete information on what components will reach scale or require modification. Some deferred work is expected.
+Understandably, technical debt accumulates naturally in the early stages of model development. When aiming to build MVP models quickly, teams often need more complete information on what components will reach scale or require modification. Some deferred work is expected.
However, even scrappy initial systems should follow principles like "Flexible Foundations" to avoid painting themselves into corners:
@@ -334,52 +336,52 @@ However, even scrappy initial systems should follow principles like "Flexible Fo
* Abstraction layers hide implementation details that may shift over time
* Containerized model serving keeps options open on deployment requirements
-Decisions that seem expedient in the moment can seriously limit future flexibility. For example, baking key business logic into model code rather than keeping it separate makes subsequent model changes extremely difficult.
+Decisions that seem reasonable at the moment can seriously limit future flexibility. For example, baking key business logic into model code rather than keeping it separate makes subsequent model changes extremely difficult.
With thoughtful design, though, it is possible to build quickly at first while retaining degrees of freedom to improve. As the system matures, prudent break points emerge where introducing fresh architectures proactively avoids massive rework down the line. This balances urgent timelines with reducing future correction cascades.
### Summary
-Although financial debt is a good metaphor to understand the tradeoffs, it differs from technical debt in its measurability. Technical debt lacks the ability to be fully tracked and quantified. This makes it hard for teams to navigate the tradeoffs between moving quickly and inherently introducing more debt versus taking the time to pay down that debt.
+Although financial debt is a good metaphor for understanding tradeoffs, it differs from technical debt's measurability. Technical debt needs to be fully tracked and quantified. This makes it hard for teams to navigate the tradeoffs between moving quickly and inherently introducing more debt versus taking the time to pay down that debt.
-The [Hidden Technical Debt of Machine Learning Systems](https://papers.nips.cc/paper_files/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf) paper spreads awareness of the nuances of ML system specific tech debt and encourages additional development in the broad area of maintainable ML.
+The [Hidden Technical Debt of Machine Learning Systems](https://papers.nips.cc/paper_files/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf) paper spreads awareness of the nuances of ML system-specific tech debt. It encourages additional development in the broad area of maintainable ML.
## Roles and Responsibilities
-Given the vastness of MLOps, successfully implementing ML systems requires diverse skills and close collaboration between people with different areas of expertise. While data scientists build the core ML models, it takes cross-functional teamwork to successfully deploy these models into production environments and enable them to deliver business value in a sustainable way.
+Given the vastness of MLOps, successfully implementing ML systems requires diverse skills and close collaboration between people with different areas of expertise. While data scientists build the core ML models, it takes cross-functional teamwork to successfully deploy these models into production environments and enable them to deliver sustainable business value.
-MLOps provides the framework and practices for coordinating the efforts of various roles involved in developing, deploying and running MLg systems. Bridging traditional silos between data, engineering and operations teams is key to MLOps success. Enabling seamless collaboration through the machine learning lifecycle accelerates benefit realization while ensuring long-term reliability and performance of ML models.
+MLOps provides the framework and practices for coordinating the efforts of various roles involved in developing, deploying, and running MLG systems. Bridging traditional silos between data, engineering, and operations teams is key to MLOp's success. Enabling seamless collaboration through the machine learning lifecycle accelerates benefit realization while ensuring ML models' long-term reliability and performance.
-We will look at some of the key roles involved in MLOps and their primary responsibilities. Understanding the breadth of skills needed to operationalize ML models provides guidance on assembling MLOps teams. It also clarifies how the workflows between different roles fit together under the overarching MLOps methodology.
+We will look at some key roles involved in MLOps and their primary responsibilities. Understanding the breadth of skills needed to operationalize ML models guides assembling MLOps teams. It also clarifies how the workflows between roles fit under the overarching MLOps methodology.
### Data Engineers
Data engineers are responsible for building and maintaining the data infrastructure and pipelines that feed data to ML models. They ensure data is smoothly moved from source systems into the storage, processing, and feature engineering environments needed for ML model development and deployment. Their main responsibilities include:
-* Migrating raw data from on-prem databases, sensors, apps into cloud-based data lakes like Amazon S3 or Google Cloud Storage. This provides cost-efficient, scalable storage.
-* Building data pipelines with workflow schedulers like Apache Airflow, Prefect, dbt. These extract data from sources, transform and validate data, and load it into destinations like data warehouses, feature stores or directly for model training.
-* Transforming messy raw data into structured, analysis-ready datasets. This includes handling null or malformed values, deduplicating, joining disparate data sources, aggregating data and engineering new features.
+* Migrating raw data from on-prem databases, sensors, and apps into cloud-based data lakes like Amazon S3 or Google Cloud Storage. This provides cost-efficient, scalable storage.
+* Building data pipelines with workflow schedulers like Apache Airflow, Prefect, and dbt. These extract data from sources, transform and validate data, and load it into destinations like data warehouses, feature stores, or directly for model training.
+* Transforming messy, raw data into structured, analysis-ready datasets. This includes handling null or malformed values, deduplicating, joining disparate data sources, aggregating data, and engineering new features.
* Maintaining data infrastructure components like cloud data warehouses ([Snowflake](https://www.snowflake.com/en/data-cloud/workloads/data-warehouse/), [Redshift](https://aws.amazon.com/redshift/), [BigQuery](https://cloud.google.com/bigquery?hl=en)), data lakes, and metadata management systems. Provisioning and optimizing data processing systems.
-* Establishing data versioning, backup and archival processes for ML datasets and features. Enforcing data governance policies.
+* Establishing data versioning, backup, and archival processes for ML datasets and features and enforcing data governance policies.
For example, a manufacturing firm may use Apache Airflow pipelines to extract sensor data from PLCs on the factory floor into an Amazon S3 data lake. The data engineers would then process this raw data to filter, clean, and join it with product metadata. These pipeline outputs would then load into a Snowflake data warehouse from which features can be read for model training and prediction.
-The data engineering team builds and sustains the data foundation for reliable model development and operations. Their work enables data scientists and ML engineers to focus on building, training and deploying ML models at scale.
+The data engineering team builds and sustains the data foundation for reliable model development and operations. Their work enables data scientists and ML engineers to focus on building, training, and deploying ML models at scale.
### Data Scientists
-The job of the data scientists is to focus on the research, experimentation, development and continuous improvement of ML models. They leverage their expertise in statistics, modeling and algorithms to create high-performing models. Their main responsibilities include:
+The job of the data scientists is to focus on the research, experimentation, development, and continuous improvement of ML models. They leverage their expertise in statistics, modeling, and algorithms to create high-performing models. Their main responsibilities include:
-* Working with business and data teams to identify opportunities where ML can add value. Framing the problem and defining success metrics.
-* Performing exploratory data analysis to understand relationships in data and derive insights. Identifying relevant features for modeling.
-* Researching and experimenting with different ML algorithms and model architectures based on the problem and data characteristics. Leveraging libraries like TensorFlow, PyTorch, Keras.
-* Training and fine-tuning models by tuning hyperparameters, adjusting neural network architectures, feature engineering, etc. to maximize performance.
-* Evaluating model performance through metrics like accuracy, AUC, F1 scores. Performing error analysis to identify areas for improvement.
-* Developing new model versions by incorporating new data, testing different approaches, and optimizing model behavior. Maintaining documentation and lineage for models.
+* Working with business and data teams to identify opportunities where ML can add value, framing the problem, and defining success metrics.
+* Performing exploratory data analysis to understand relationships in data, derive insights, and identify relevant features for modeling.
+* Researching and experimenting with different ML algorithms and model architectures based on the problem and data characteristics and leveraging libraries like TensorFlow, PyTorch, and Keras.
+* To maximize performance, train and fine-tune models by tuning hyperparameters, adjusting neural network architectures, feature engineering, etc.
+* Evaluating model performance through metrics like accuracy, AUC, and F1 scores and performing error analysis to identify areas for improvement.
+* Developing new model versions by incorporating new data, testing different approaches, optimizing model behavior, and maintaining documentation and lineage for models.
-For example, a data scientist may leverage TensorFlow and [TensorFlow Probability](https://www.tensorflow.org/probability) to develop a demand forecasting model for retail inventory planning. They would iterate on different sequence models like LSTMs and experiment with features derived from product, sales and seasonal data. The model would be evaluated based on error metrics versus actual demand before deployment. The data scientist monitors performance and retrains/enhances the model as new data comes in.
+For example, a data scientist may leverage TensorFlow and [TensorFlow Probability](https://www.tensorflow.org/probability) to develop a demand forecasting model for retail inventory planning. They would iterate on different sequence models like LSTMs and experiment with features derived from product, sales, and seasonal data. The model would be evaluated based on error metrics versus actual demand before deployment. The data scientist monitors performance and retrains/enhances the model as new data comes in.
-Data scientists drive model creation, improvement and innovation through their expertise in ML techniques. They collaborate closely with other roles to ensure models create maximum business impact.
+Data scientists drive model creation, improvement, and innovation through their expertise in ML techniques. They collaborate closely with other roles to ensure models create maximum business impact.
### ML Engineers
@@ -387,11 +389,11 @@ ML engineers enable models data scientists develop to be productized and deploye
* Taking prototype models from data scientists and hardening them for production environments through coding best practices.
* Building APIs and microservices for model deployment using tools like [Flask](https://flask.palletsprojects.com/en/3.0.x/), [FastAPI](https://fastapi.tiangolo.com/). Containerizing models with Docker.
-* Managing model versions and sinaging new models into production using CI/CD pipelines. Implementing canary releases, A/B tests, and rollback procedures.
-* Optimizing model performance for high scalability, low latency and cost-efficiency. Leveraging compression, quantization, multi-model serving.
-* Monitoring models once in production and ensuring continued reliability and accuracy. Retraining models periodically.
+* Manage model versions, sync new models into production using CI/CD pipelines, and implement canary releases, A/B tests, and rollback procedures.
+* Optimizing model performance for high scalability, low latency, and cost efficiency. Leveraging compression, quantization, and multi-model serving.
+* Monitor models once in production and ensure continued reliability and accuracy. Retraining models periodically.
-For example, a ML engineer may take a TensorFlow fraud detection model developed by data scientists and containerize it using TensorFlow Serving for scalable deployment. The model would be integrated into the company's transaction processing pipeline via APIs. The ML engineer implements a model registry and CI/CD pipeline using MLFlow and Jenkins to reliably deploy model updates. The ML engineers would then monitor the running model for continued performance using tools like Prometheus and Grafana. If model accuracy drops, they initiate retraining and deployment of a new model version.
+For example, an ML engineer may take a TensorFlow fraud detection model developed by data scientists and containerize it using TensorFlow Serving for scalable deployment. The model would be integrated into the company's transaction processing pipeline via APIs. The ML engineer implements a model registry and CI/CD pipeline using MLFlow and Jenkins to deploy model updates reliably. The ML engineers then monitor the running model for continued performance using tools like Prometheus and Grafana. If model accuracy drops, they initiate retraining and deployment of a new model version.
The ML engineering team enables data science models to progress smoothly into sustainable and robust production systems. Their expertise in building modular, monitored systems delivers continuous business value.
@@ -399,75 +401,75 @@ The ML engineering team enables data science models to progress smoothly into su
DevOps engineers enable MLOps by building and managing the underlying infrastructure for developing, deploying, and monitoring ML models. They provide the cloud architecture and automation pipelines. Their main responsibilities include:
-* Provisioning and managing cloud infrastructure for ML workflows using IaC tools like Terraform, Docker, Kubernetes.
-* Developing CI/CD pipelines for model retraining, validation, and deployment. Integrating ML tools into the pipeline like MLflow, Kubeflow.
+* Provisioning and managing cloud infrastructure for ML workflows using IaC tools like Terraform, Docker, and Kubernetes.
+* Developing CI/CD pipelines for model retraining, validation, and deployment. Integrating ML tools into the pipeline, such as MLflow and Kubeflow.
* Monitoring model and infrastructure performance using tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), [ELK stack](https://aws.amazon.com/what-is/elk-stack/). Building alerts and dashboards.
-* Implementing governance practices around model development, testing, and promotion. Enabling reproducibility and traceability.
-* Embedding ML models within applications. Exposing models via APIs and microservices for integration.
-* Optimizing infrastructure performance and costs. Leveraging autoscaling, spot instances, and availability across regions.
+* Implement governance practices around model development, testing, and promotion to enable reproducibility and traceability.
+* Embedding ML models within applications. They are exposing models via APIs and microservices for integration.
+* Optimizing infrastructure performance and costs and leveraging autoscaling, spot instances, and availability across regions.
-For example, a DevOps engineer provisions a Kubernetes cluster on AWS using Terraform to run ML training jobs and online deployment. They build a CI/CD pipeline in Jenkins which triggers model retraining if new data is available. After automated testing, the model is registered with MLflow and deployed in the Kubernetes cluster. The engineer then monitors cluster health, container resource usage, and API latency using Prometheus and Grafana.
+For example, a DevOps engineer provisions a Kubernetes cluster on AWS using Terraform to run ML training jobs and online deployment. They build a CI/CD pipeline in Jenkins, which triggers model retraining if new data is available. After automated testing, the model is registered with MLflow and deployed in the Kubernetes cluster. The engineer then monitors cluster health, container resource usage, and API latency using Prometheus and Grafana.
-The DevOps team enables rapid experimentation and reliable deployments for ML through expertise in cloud, automation, and monitoring. Their work maximizes model impact while minimizing technical debt.
+The DevOps team enables rapid experimentation and reliable deployments for ML through cloud, automation, and monitoring expertise. Their work maximizes model impact while minimizing technical debt.
### Project Managers
-Project managers play a vital role in MLOps by coordinating the activities between the different teams involved in delivering ML projects. They help drive alignment, accountability, and accelerated results. Their main responsibilities include:
+Project managers play a vital role in MLOps by coordinating the activities between the teams involved in delivering ML projects. They help drive alignment, accountability, and accelerated results. Their main responsibilities include:
-* Working with stakeholders to define project goals, success metrics, timelines and budgets. Outlining specifications and scope.
-* Creating a project plan spanning activities like data acquisition, model development, infrastructure setup, deployment, and monitoring.
-* Coordinating design, development and testing efforts between data engineers, data scientists, ML engineers and DevOps roles.
-* Tracking progress and milestones. Identifying roadblocks and resolving through corrective actions. Managing risks and issues.
-* Facilitating communication through status reports, meetings, workshops, documentation. Enabling seamless collaboration.
-* Driving adherence to timelines and budget. Escalating anticipated overruns or shortfalls for mitigation.
+* Working with stakeholders to define project goals, success metrics, timelines, and budgets; outlining specifications and scope.
+* Creating a project plan spanning data acquisition, model development, infrastructure setup, deployment, and monitoring.
+* Coordinating design, development, and testing efforts between data engineers, data scientists, ML engineers, and DevOps roles.
+* Tracking progress and milestones, identifying roadblocks and resolving them through corrective actions, and managing risks and issues.
+* Facilitating communication through status reports, meetings, workshops, and documentation and enabling seamless collaboration.
+* Driving adherence to timelines and budget and escalating anticipated overruns or shortfalls for mitigation.
-For example, a project manager would create a project plan for the development and ongoing enhancement of a customer churn prediction model. They coordinate between data engineers building data pipelines, data scientists experimenting with models, ML engineers productionalizing models, and DevOps setting up deployment infrastructure. The project manager tracks progress via milestones like dataset preparation, model prototyping, deployment, and monitoring. They surface any risks, delays or budget issues to enact preventive solutions.
+For example, a project manager would create a project plan for developing and enhancing a customer churn prediction model. They coordinate between data engineers building data pipelines, data scientists experimenting with models, ML engineers productionalizing models, and DevOps setting up deployment infrastructure. The project manager tracks progress via milestones like dataset preparation, model prototyping, deployment, and monitoring. To enact preventive solutions, they surface any risks, delays, or budget issues.
-Skilled project managers enable MLOps teams to work synergistically to deliver maximum business value from ML investments rapidly. Their leadership and organization align with diverse teams.
+Skilled project managers enable MLOps teams to work synergistically to rapidly deliver maximum business value from ML investments. Their leadership and organization align with diverse teams.
## Embedded System Challenges
-We will briefly review the challenges with embedded systems so taht it sets the context for the specific challenges that emerge with embedded MLOps that we will discuss in the following section.
+We will briefly review the challenges with embedded systems so that it sets the context for the specific challenges that emerge with embedded MLOps, which we will discuss in the following section.
### Limited Compute Resources
-Embedded devices like microcontrollers and mobile phones have much more constrained compute power compared to data center machines or GPUs. A typical microcontroller may have only KB of RAM, MHz of CPU speed, and no GPU. For example, a microcontroller in a smartwatch may only have a 32-bit processor running at 120MHz with 320KB of RAM [@stm2021l4]. This allows relatively simple ML models like small linear regressions or random forests, but more complex deep neural networks would be infeasible. Strategies to mitigate this include quantization, pruning, efficient model architectures, and offloading certain computations to the cloud when connectivity allows.
+Embedded devices like microcontrollers and mobile phones have much more constrained computing power than data center machines or GPUs. A typical microcontroller may have only KB of RAM, MHz CPU speed, and no GPU. For example, a microcontroller in a smartwatch may only have a 32-bit processor running at 120MHz with 320KB of RAM [@stm2021l4]. This allows simple ML models like small linear regressions or random forests, but more complex deep neural networks would be infeasible. Strategies to mitigate this include quantization, pruning, efficient model architectures, and offloading certain computations to the cloud when connectivity allows.
### Constrained Memory
-With limited memory, storing large ML models and datasets directly on embedded devices is often infeasible. For example, a deep neural network model can easily take hundreds of MB, which exceeds the storage capacity of many embedded systems. Consider this example. A wildlife camera that captures images to detect animals may have only a 2GB memory card. This is insufficient to store a deep learning model for image classification that is often hundreds of MB in size. Consequently, this requires optimization of memory usage through methods like weights compression, lower-precision numerics, and streaming inference pipelines.
+Storing large ML models and datasets directly on embedded devices is often infeasible with limited memory. For example, a deep neural network model can easily take hundreds of MB, which exceeds the storage capacity of many embedded systems. Consider this example. A wildlife camera that captures images to detect animals may have only a 2GB memory card. More is needed to store a deep learning model for image classification that is often hundreds of MB in size. Consequently, this requires optimization of memory usage through weights compression, lower-precision numerics, and streaming inference pipelines.
### Intermittent Connectivity
-Many embedded devices operate in remote environments without reliable internet connectivity. This means we cannot rely on constant cloud access for convenient retraining, monitoring, and deployment. Instead, we need smart scheduling and caching strategies to optimize for intermittent connections. For example, a model predicting crop yield on a remote farm may need to make predictions daily, but only have connectivity to the cloud once a week when the farmer drives into town. The model needs to operate independently in between connections.
+Many embedded devices operate in remote environments without reliable internet connectivity. We must rely on something other than constant cloud access for convenient retraining, monitoring, and deployment. Instead, we need smart scheduling and caching strategies to optimize for intermittent connections. For example, a model predicting crop yield on a remote farm may need to make predictions daily but only have connectivity to the cloud once a week when the farmer drives into town. The model needs to operate independently in between connections.
### Power Limitations
-Embedded devices like phones, wearables, and remote sensors are battery-powered. Continual inference and communication can quickly drain those batteries, limiting functionality. For example, a smart collar tagging endangered animals runs on a small battery. Continuously running a GPS tracking model would drain the battery within days. The collar has to carefully schedule when to activate the model. Thus, embedded ML has to carefully manage tasks to conserve power. Techniques include optimized hardware accelerators, prediction caching, and adaptive model execution.
+Embedded devices like phones, wearables, and remote sensors are battery-powered. Continual inference and communication can quickly drain those batteries, limiting functionality. For example, a smart collar tagging endangered animals runs on a small battery. Continuously running a GPS tracking model would drain the battery within days. The collar has to schedule when to activate the model carefully. Thus, embedded ML has to manage tasks carefully to conserve power. Techniques include optimized hardware accelerators, prediction caching, and adaptive model execution.
### Fleet Management
-For mass-produced embedded devices, there can be millions of units deployed in the field to orchestrate updates for. Hypothetically, updating a fraud detection model on 100 million (future smart) credit cards requires securely pushing updates to each distributed device rather than a centralized data center. Such distributed scale makes fleet-wide management much harder than a centralized server cluster. It requires intelligent protocols for over-the-air updates, handling connectivity issues, and monitoring resource constraints across devices.
+For mass-produced embedded devices, millions of units can be deployed in the field to orchestrate updates. Hypothetically, updating a fraud detection model on 100 million (future smart) credit cards requires securely pushing updates to each distributed device rather than a centralized data center. Such a distributed scale makes fleet-wide management much harder than a centralized server cluster. It requires intelligent protocols for over-the-air updates, handling connectivity issues, and monitoring resource constraints across devices.
### On-Device Data Collection
-Collecting useful training data requires engineering both the sensors on device as well as the software pipelines. This is unlike servers where we can pull data from external sources. Challenges include handling sensor noise. Sensors on an industrial machine detect vibrations and temperature to predict maintenance needs. This requires tuning the sensors and sampling rates to capture useful data.
+Collecting useful training data requires engineering both the sensors on the device and the software pipelines. This is unlike servers, where we can pull data from external sources. Challenges include handling sensor noise. Sensors on an industrial machine detect vibrations and temperature to predict maintenance needs. This requires tuning the sensors and sampling rates to capture useful data.
### Device-Specific Personalization
-A smart speaker learns an individual user's voice patterns and speech cadence to improve recognition accuracy, all while protecting privacy. Adapting ML models to specific devices and users is important but this poses privacy challenges. On-device learning allows personalization without transmitting as much private data. But balancing model improvement, privacy preservation, and constraints requires novel techniques.
+A smart speaker learns an individual user's voice patterns and speech cadence to improve recognition accuracy while protecting privacy. Adapting ML models to specific devices and users is important, but this poses privacy challenges. On-device learning allows personalization without transmitting as much private data. However, balancing model improvement, privacy preservation, and constraints requires novel techniques.
### Safety Considerations
-For extremely large embedded ML in systems like self-driving vehicles, there are serious safety risks if not engineered carefully. Self-driving cars must undergo extensive track testing in simulated rain, snow, and obstacle scenarios to ensure safe operation before deployment. This requires extensive validation, fail-safes, simulators, and standards compliance before deployment.
+If extremely large embedded ML in systems like self-driving vehicles is not engineered carefully, there are serious safety risks. To ensure safe operation before deployment, self-driving cars must undergo extensive track testing in simulated rain, snow, and obstacle scenarios. This requires extensive validation, fail-safes, simulators, and standards compliance before deployment.
### Diverse Hardware Targets
-There are a diverse range of embedded processors including ARM, x86, specialized AI accelerators, FPGAs etc. Supporting this heterogeneity makes deployment challenging. We need strategies like standardized frameworks, extensive testing, and allowing model tuning for each platform. For example, an object detection model needs efficient implementations across embedded devices like a Raspberry Pi, Nvidia Jetson, and Google Edge TPU.
+There is a diverse range of embedded processors, including ARM, x86, specialized AI accelerators, FPGAs, etc. Supporting this heterogeneity makes deployment challenging. We need strategies like standardized frameworks, extensive testing, and model tuning for each platform. For example, an object detection model needs efficient implementations across embedded devices like a Raspberry Pi, Nvidia Jetson, and Google Edge TPU.
### Testing Coverage
-Rigorously testing edge cases is difficult with constrained embedded resources for simulation. But exhaustive testing is critical in systems like self-driving cars. Exhaustively testing an autopilot model requires millions of simulated kilometers exposing it to extremely rare events like sensor failures. Therefore, strategies like synthetic data generation, distributed simulation, and chaos engineering help improve coverage.
+Rigorously testing edge cases is difficult with constrained embedded simulation resources, but exhaustive testing is critical in systems like self-driving cars. Exhaustively testing an autopilot model requires millions of simulated kilometers, exposing it to rare events like sensor failures. Therefore, strategies like synthetic data generation, distributed simulation, and chaos engineering help improve coverage.
### Concept Drift Detection
@@ -475,17 +477,17 @@ With limited monitoring data from each remote device, detecting changes in the i
## Traditional MLOps vs. Embedded MLOps
-In traditional MLOps, ML models are typically deployed in cloud-based or server environments, where resources like computing power and memory are abundant. These environments facilitate the smooth operation of complex models that require significant computational resources. For instance, a cloud-based image recognition model might be used by a social media platform to tag photos with relevant labels automatically. In this case, the model can leverage the extensive resources available in the cloud to process vast data efficiently.
+In traditional MLOps, ML models are typically deployed in cloud-based or server environments, with abundant resources like computing power and memory. These environments facilitate the smooth operation of complex models that require significant computational resources. For instance, a cloud-based image recognition model might be used by a social media platform to tag photos with relevant labels automatically. In this case, the model can leverage the extensive resources available in the cloud to efficiently process vast amounts of data.
-On the other hand, embedded MLOps involves deploying ML models on embedded systems, specialized computing systems designed to perform specific functions within larger systems. Embedded systems are typically characterized by their limited computational resources and power. For example, a ML model might be embedded in a smart thermostat to optimize heating and cooling based on the user's preferences and habits. In this case, the model must be optimized to run efficiently on the thermostat's limited hardware, without compromising its performance or accuracy.
+On the other hand, embedded MLOps involves deploying ML models on embedded systems, specialized computing systems designed to perform specific functions within larger systems. Embedded systems are typically characterized by their limited computational resources and power. For example, an ML model might be embedded in a smart thermostat to optimize heating and cooling based on the user's preferences and habits. The model must be optimized to run efficiently on the thermostat's limited hardware without compromising its performance or accuracy.
-The key difference between traditional and embedded MLOps lies in the resource constraints of embedded systems. While traditional MLOps can leverage abundant cloud or server resources, embedded MLOps must contend with the hardware limitations on which the model is deployed. This requires careful optimization and fine-tuning of the model to ensure it can deliver accurate and valuable insights within the constraints of the embedded system.
+The key difference between traditional and embedded MLOps lies in the embedded system's resource constraints. While traditional MLOps can leverage abundant cloud or server resources, embedded MLOps must contend with the hardware limitations on which the model is deployed. This requires careful optimization and fine-tuning of the model to ensure it can deliver accurate and valuable insights within the embedded system's constraints.
-Furthermore, embedded MLOps must consider the unique challenges posed by integrating ML models with other components of the embedded system. For example, the model must be compatible with the system's software and hardware and must be able to interface seamlessly with other components, such as sensors or actuators. This requires a deep understanding of both ML and embedded systems, as well as close collaboration between data scientists, engineers, and other stakeholders.
+Furthermore, embedded MLOps must consider the unique challenges posed by integrating ML models with other embedded system components. For example, the model must be compatible with the system's software and hardware and must be able to interface seamlessly with other components, such as sensors or actuators. This requires a deep understanding of both ML and embedded systems and close collaboration between data scientists, engineers, and other stakeholders.
-So, while traditional MLOps and embedded MLOps share the common goal of deploying and maintaining ML models in production environments, the unique challenges posed by embedded systems require a specialized approach. Embedded MLOps must carefully balance the need for model accuracy and performance with the constraints of the hardware on which the model is deployed. This requires a deep understanding of both ML and embedded systems, as well as close collaboration between various stakeholders to ensure the successful integration of ML models into embedded systems.
+So, while traditional MLOps and embedded MLOps share the common goal of deploying and maintaining ML models in production environments, the unique challenges posed by embedded systems require a specialized approach. Embedded MLOps must carefully balance the need for model accuracy and performance with the constraints of the hardware on which the model is deployed. This requires a deep understanding of both ML and embedded systems and close collaboration between various stakeholders to ensure the successful integration of ML models into embedded systems.
-This time we will group the subtopics under broader categories to streamline the structure of our thought process on MLOps. This structure will help you understand how different aspects of MLOps are interconnected and why each is important for the efficient operation of ML systems as we discuss the challenges in the context of embedded systems.
+This time, we will group the subtopics under broader categories to streamline the structure of our thought process on MLOps. This structure will help you understand how different aspects of MLOps are interconnected and why each is important for the efficient operation of ML systems as we discuss the challenges in the context of embedded systems.
* Model Lifecycle Management
* Data Management: Handling data ingestion, validation, and version control.
@@ -494,9 +496,9 @@ This time we will group the subtopics under broader categories to streamline the
* Model Deployment: Approaches for deploying models into production environments.
* Development and Operations Integration
- * CI/CD Pipelines: Integrating ML models into continuous integration and continuous deployment pipelines.
+ * CI/CD Pipelines: Integrating ML models into continuous integration and deployment pipelines.
* Infrastructure Management: Setting up and maintaining the infrastructure required for training and deploying models.
- * Communication & Collaboration: Ensuring smooth communication and collaboration practices between data scientists, ML engineers, and operations teams.
+ * Communication & Collaboration: Ensuring smooth communication and collaboration between data scientists, ML engineers, and operations teams.
* Operational Excellence
* Monitoring: Techniques for monitoring model performance, data drift, and operational health.
@@ -508,47 +510,47 @@ This time we will group the subtopics under broader categories to streamline the
In traditional centralized MLOps, data is aggregated into large datasets and data lakes, then processed on cloud or on-prem servers. However, embedded MLOps relies on decentralized data from local on-device sensors. Devices collect smaller batches of incremental data, often noisy and unstructured. With connectivity constraints, this data cannot always be instantly transmitted to the cloud and needs to be intelligently cached and processed at the edge.
-Embedded devices can only preprocess and clean data minimally before transmission due to limited on-device compute. Early filtering and processing occurs at edge gateways to reduce transmission loads. While leveraging cloud storage, more processing and storage happens at the edge to account for intermittent connectivity. Devices identify and transmit only the most critical subsets of data to the cloud.
+Due to limited on-device computing, embedded devices can only preprocess and clean data minimally before transmission. Early filtering and processing occur at edge gateways to reduce transmission loads. While leveraging cloud storage, more processing and storage happen at the edge to account for intermittent connectivity. Devices identify and transmit only the most critical subsets of data to the cloud.
-Labeling also faces challenges without centralized data access, requiring more automated techniques like federated learning where devices collaboratively label peers' data. With personal edge devices, data privacy and regulations are critical concerns. Data collection, transmission and storage must be secure and compliant.
+Labeling also needs centralized data access, requiring more automated techniques like federated learning, where devices collaboratively label peers' data. With personal edge devices, data privacy and regulations are critical concerns. Data collection, transmission, and storage must be secure and compliant.
-For instance, a smartwatch may collect step count, heart rate, GPS coordinates throughout the day. This data is cached locally and transmitted to an edge gateway when WiFi is available. The gateway processes and filters data before syncing relevant subsets with the cloud platform to retrain models.
+For instance, a smartwatch may collect the day's step count, heart rate, and GPS coordinates. This data is cached locally and transmitted to an edge gateway when WiFi is available—the gateway processes and filters data before syncing relevant subsets with the cloud platform to retrain models.
#### Model Training
-In traditional centralized MLOps, models are trained using abundant data via deep learning on high-powered cloud GPU servers. However, embedded MLOps faces severe constraints on model complexity, data availability and compute resources for training.
+In traditional centralized MLOps, models are trained using abundant data via deep learning on high-powered cloud GPU servers. However, embedded MLOps need more support in model complexity, data availability, and computing resources for training.
-The volume of aggregated data is much lower, often requiring techniques like federated learning across devices to create training sets. The specialized nature of edge data also limits public datasets for pre-training. With privacy concerns, data samples need to be tightly controlled and anonymized where possible.
+The volume of aggregated data is much lower, often requiring techniques like federated learning across devices to create training sets. The specialized nature of edge data also limits public datasets for pre-training. With privacy concerns, data samples must be tightly controlled and anonymized where possible.
-Furthermore, the models themselves need to use simplified architectures optimized for low-power edge hardware. There is no access to high-end GPUs for intensive deep learning given the compute limitations. Training leverages lower-powered edge servers and clusters with distributed approaches to spread load.
+Furthermore, the models must use simplified architectures optimized for low-power edge hardware. Given the computing limitations, high-end GPUs are inaccessible for intensive deep learning. Training leverages lower-powered edge servers and clusters with distributed approaches to spread load.
-To mitigate data scarcity and irregularity, strategies like transfer learning become essential (see Figure 14.5). Models can pre-train on large public datasets, then fine-tune the training on limited domain-specific edge data. Even incremental on-device learning to customize models helps overcome the decentralized nature of embedded data. The lack of broad labeled data also motivates semi-supervised techniques.
+Strategies like transfer learning become essential to mitigate data scarcity and irregularity (see Figure 14.5). Models can pre-train on large public datasets and then finetune the training on limited domain-specific edge data. Even incremental on-device learning to customize models helps overcome the decentralized nature of embedded data. The lack of broad labeled data also motivates semi-supervised techniques.
-@fig-transfer-learning-mlops illustrates the concept of transfer learning in model training within an MLOps framework. It showcases a neural network where the initial layers (W_{A1} to W_{A4}), which are responsible for general feature extraction, are frozen (indicated by the green dashed line), meaning their weights are not updated during training. This reuse of pre-trained layers accelerates learning by utilizing knowledge gained from previous tasks. The latter layers (W_{A5} to W_{A7}), depicted beyond the blue dashed line, are fine-tuned for the specific task at hand, focusing on task-specific feature learning. This approach allows the model to adapt to the new task using fewer resources and potentially achieve higher performance on specialized tasks by reusing the general features learned from a broader dataset.
+@fig-transfer-learning-mlops illustrates the concept of transfer learning in model training within an MLOps framework. It showcases a neural network where the initial layers (W_{A1} to W_{A4}), which are responsible for general feature extraction, are frozen (indicated by the green dashed line), meaning their weights are not updated during training. This reuse of pre-trained layers accelerates learning by utilizing knowledge gained from previous tasks. The latter layers (W_{A5} to W_{A7}), depicted beyond the blue dashed line, are finetuned for the specific task at hand, focusing on task-specific feature learning. This approach allows the model to adapt to the new task using fewer resources and potentially achieve higher performance on specialized tasks by reusing the general features learned from a broader dataset.
{#fig-transfer-learning-mlops}
-For example, a smart home assistant may pre-train an audio recognition model on public YouTube clips which helps bootstrap with general knowledge. It then transfer learns on a small sample of home data to classify customized appliances and events, specializing the model. The model distills down into a lightweight neural network optimized for microphone-enabled devices across the home.
+For example, a smart home assistant may pre-train an audio recognition model on public YouTube clips, which helps bootstrap with general knowledge. It then transfers learning to a small sample of home data to classify customized appliances and events, specializing in the model. The model transforms into a lightweight neural network optimized for microphone-enabled devices across the home.
-So embedded MLOps faces acute challenges in constructing training datasets, designing efficient models, and distributing compute for model development compared to traditional settings. Careful adaptation such as transfer learning and distributed training is required to train models given the embedded constraints.
+So, embedded MLOps face acute challenges in constructing training datasets, designing efficient models, and distributing compute for model development compared to traditional settings. Given the embedded constraints, careful adaptation, such as transfer learning and distributed training, is required to train models.
#### Model Evaluation
-In traditional centralized MLOps, models are evaluated primarily on accuracy metrics using holdout test datasets. However, embedded MLOps requires more holistic evaluation accounting for system constraints beyond just accuracy.
+In traditional centralized MLOps, models are evaluated primarily using accuracy metrics and holdout test datasets. However, embedded MLOps require a more holistic evaluation that accounts for system constraints beyond accuracy.
-Models need to be tested early and often on real deployed edge hardware covering diverse configurations. In addition to accuracy, factors like latency, CPU usage, memory footprint and power consumption are critical evaluation criteria. Models are selected based on tradeoffs between these metrics to meet edge device constraints.
+Models must be tested early and often on deployed edge hardware covering diverse configurations. In addition to accuracy, factors like latency, CPU usage, memory footprint, and power consumption are critical evaluation criteria. Models are selected based on tradeoffs between these metrics to meet edge device constraints.
-Data drift must also be monitored - where models trained on cloud data degrade in accuracy over time on local edge data. Embedded data often has more variability than centralized training sets. Evaluating models across diverse operational edge data samples is key. But sometimes getting the data for monitoring the drift can be challenging if these devices are in the wild and communication is a barrier.
+Data drift must also be monitored - where models trained on cloud data degrade in accuracy over time on local edge data. Embedded data often has more variability than centralized training sets. Evaluating models across diverse operational edge data samples is key. But sometimes, getting the data for monitoring the drift can be challenging if these devices are in the wild and communication is a barrier.
Ongoing monitoring provides visibility into real-world performance post-deployment, revealing bottlenecks not caught during testing. For instance, a smart camera model update may be canary tested on 100 cameras first and rolled back if degraded accuracy is observed before expanding to all 5000 cameras.
#### Model Deployment
-In traditional MLOps, new model versions are directly deployed onto servers via API endpoints. However, embedded devices require optimized delivery mechanisms to receive updated models. Over-the-air (OTA) updates provide a standardized approach to wirelessly distribute new software or firmware releases to embedded devices. Rather than direct API access, OTA packages allow remotely deploying models and dependencies as pre-built bundles. As an alternative, [federated learning](@sec-fl) allows model updates without direct access to raw training data. This decentralized approach has potential for continuous model improvement, but currently lacks robust MLOps platforms.
+In traditional MLOps, new model versions are directly deployed onto servers via API endpoints. However, embedded devices require optimized delivery mechanisms to receive updated models. Over-the-air (OTA) updates provide a standardized approach to wirelessly distributing new software or firmware releases to embedded devices. Rather than direct API access, OTA packages allow remote deploying models and dependencies as pre-built bundles. Alternatively, [federated learning](@sec-fl) allows model updates without direct access to raw training data. This decentralized approach has the potential for continuous model improvement but needs robust MLOps platforms.
-For deeply embedded devices lacking connectivity, model delivery relies on physical interfaces like USB or UART serial connections. The model packaging still follows similar principles to OTA updates, but the deployment mechanism is tailored for the capabilities of the edge hardware. Moreover, specialized OTA protocols optimized for IoT networks are often used rather than standard WiFi or Bluetooth protocols. Key factors include efficiency, reliability, security, and telemetry like progress tracking. Solutions like [Mender.io](https://mender.io/) provide embedded-focused OTA services handling differential updates across device fleets.
+Model delivery relies on physical interfaces like USB or UART serial connections for deeply embedded devices lacking connectivity. The model packaging still follows similar principles to OTA updates, but the deployment mechanism is tailored to the capabilities of the edge hardware. Moreover, specialized OTA protocols optimized for IoT networks are often used rather than standard WiFi or Bluetooth protocols. Key factors include efficiency, reliability, security, and telemetry, such as progress tracking—solutions like [Mender. Io](https://mender.io/) provides embedded-focused OTA services handling differential updates across device fleets.
-@fig-model-lifecycle presents an overview of Model Lifecycle Management in an MLOps context, illustrating the flow from development (top left) to deployment and monitoring (bottom right). The process begins with ML Development, where code and configurations are version-controlled. Data and model management are central to the process, involving datasets and feature repositories. Continuous training, model conversion, and model registry are key stages in the operationalization of training. Model deployment includes serving the model and managing serving logs. Alerting mechanisms are in place to flag issues, which feed into continuous monitoring to ensure model performance and reliability over time. This integrated approach ensures that models are not only developed but also maintained effectively throughout their lifecycle.
+@fig-model-lifecycle presents an overview of Model Lifecycle Management in an MLOps context, illustrating the flow from development (top left) to deployment and monitoring (bottom right). The process begins with ML Development, where code and configurations are version-controlled. Data and model management are central to the process, involving datasets and feature repositories. Continuous training, model conversion, and model registry are key stages in the operationalization of training. The model deployment includes serving the model and managing serving logs. Alerting mechanisms are in place to flag issues, which feed into continuous monitoring to ensure model performance and reliability over time. This integrated approach ensures that models are developed and maintained effectively throughout their lifecycle.
{#fig-model-lifecycle}
@@ -556,77 +558,77 @@ For deeply embedded devices lacking connectivity, model delivery relies on physi
#### CI/CD Pipelines
-In traditional MLOps, robust CI/CD infrastructure like Jenkins and Kubernetes enables automating pipelines for large-scale model deployment. However, embedded MLOps lacks this centralized infrastructure and needs more tailored CI/CD workflows for edge devices.
+In traditional MLOps, robust CI/CD infrastructure like Jenkins and Kubernetes enables pipeline automation for large-scale model deployment. However, embedded MLOps need this centralized infrastructure and more tailored CI/CD workflows for edge devices.
-Building CI/CD pipelines has to account for a fragmented landscape of diverse hardware, firmware versions and connectivity constraints. There is no standard platform on which to orchestrate pipelines and tooling support is more limited.
+Building CI/CD pipelines has to account for a fragmented landscape of diverse hardware, firmware versions, and connectivity constraints. There is no standard platform to orchestrate pipelines, and tooling support is more limited.
-Testing needs to cover this wide spectrum of target embedded devices early, which is difficult without centralized access. Companies must invest significant effort into acquiring and managing test infrastructure across the heterogeneous embedded ecosystem.
+Testing must cover this wide spectrum of target embedded devices early, which is difficult without centralized access. Companies must invest significant effort into acquiring and managing test infrastructure across the heterogeneous embedded ecosystem.
-Over-the-air updates require setting up specialized servers to securely distribute model bundles to devices in the field. Rollout and rollback procedures must be carefully tailored for particular device families.
+Over-the-air updates require setting up specialized servers to distribute model bundles securely to devices in the field. Rollout and rollback procedures must also be carefully tailored for particular device families.
-With traditional CI/CD tools less applicable, embedded MLOps relies more on custom scripts and integration. Companies take varied approaches from open source frameworks to fully in-house solutions. Tight integration between developers, edge engineers and end customers establishes trusted release processes.
+With traditional CI/CD tools less applicable, embedded MLOps rely more on custom scripts and integration. Companies take varied approaches, from open-source frameworks to fully in-house solutions. Tight integration between developers, edge engineers, and end customers establishes trusted release processes.
-Therefore, embedded MLOps can't leverage centralized cloud infrastructure for CI/CD. Companies cobble together custom pipelines, testing infrastructure and OTA delivery to deploy models across fragmented and disconnected edge systems.
+Therefore, embedded MLOps can't leverage centralized cloud infrastructure for CI/CD. Companies combine custom pipelines, testing infrastructure, and OTA delivery to deploy models across fragmented and disconnected edge systems.
#### Infrastructure Management
-In traditional centralized MLOps, infrastructure entails provisioning cloud servers, GPUs and high-bandwidth networks for intensive workloads like model training and serving predictions at scale. However, embedded MLOps requires more heterogeneous infrastructure spanning edge devices, gateways, and cloud.
+In traditional centralized MLOps, infrastructure entails provisioning cloud servers, GPUs, and high-bandwidth networks for intensive workloads like model training and serving predictions at scale. However, embedded MLOps require more heterogeneous infrastructure spanning edge devices, gateways, and the cloud.
-Edge devices like sensors capture and preprocess data locally before intermittent transmission to avoid overloading networks. Gateways aggregate and process data from devices before sending select subsets to the cloud for training and analysis. The cloud provides centralized management and supplemental compute.
+Edge devices like sensors capture and preprocess data locally before intermittent transmission to avoid overloading networks—gateways aggregate and process device data before sending select subsets to the cloud for training and analysis. The cloud provides centralized management and supplemental computing.
-This infrastructure needs tight integration, balancing processing and communication loads. Network bandwidth is limited, requiring careful data filtering and compression. Edge compute capabilities are modest compared to the cloud, imposing optimization constraints.
+This infrastructure needs tight integration and balancing processing and communication loads. Network bandwidth is limited, requiring careful data filtering and compression. Edge computing capabilities are modest compared to the cloud, imposing optimization constraints.
-Managing secure OTA updates across large device fleets presents challenges at the edge. Rollouts must be incremental and rollback-ready for quick mitigation. Updating edge infrastructure requires coordination given decentralized environments.
+Managing secure OTA updates across large device fleets presents challenges at the edge. Rollouts must be incremental and rollback-ready for quick mitigation. Given decentralized environments, updating edge infrastructure requires coordination.
For example, an industrial plant may perform basic signal processing on sensors before sending data to an on-prem gateway. The gateway handles data aggregation, infrastructure monitoring, and OTA updates. Only curated data is transmitted to the cloud for advanced analytics and model retraining.
-In summary, embedded MLOps requires holistic management of distributed infrastructure spanning constrained edge, gateways, and centralized cloud. Workloads are balanced across tiers while accounting for connectivity, compute and security challenges.
+Embedded MLOps requires holistic management of distributed infrastructure spanning constrained edge, gateways, and centralized cloud. Workloads are balanced across tiers while accounting for connectivity, computing, and security challenges.
#### Communication & Collaboration
-In traditional MLOps, collaboration tends to be centered around data scientists, ML engineers and DevOps teams. But embedded MLOps requires tighter cross-functional coordination between additional roles to address system constraints.
+In traditional MLOps, collaboration tends to center around data scientists, ML engineers, and DevOps teams. However, embedded MLOps require tighter cross-functional coordination between additional roles to address system constraints.
Edge engineers optimize model architectures for target hardware environments. They provide feedback to data scientists during development so models fit device capabilities early on. Similarly, product teams define operational requirements informed by end-user contexts.
-With more stakeholders across the embedded ecosystem, communication channels must facilitate information sharing between centralized and remote teams. Issue tracking and project management ensures alignment.
+With more stakeholders across the embedded ecosystem, communication channels must facilitate information sharing between centralized and remote teams. Issue tracking and project management ensure alignment.
-Collaborative tools optimize models for particular devices. Data scientists can log issues replicated from field devices so models specialize on niche data. Remote device access aids debugging and data collection.
+Collaborative tools optimize models for particular devices. Data scientists can log issues replicated from field devices so models specialize in niche data. Remote device access aids debugging and data collection.
-For example, data scientists may collaborate with field teams managing fleets of wind turbines to retrieve operational data samples. This data is used to specialize models detecting anomalies specific to that turbine class. Model updates are first tested in simulations then reviewed by engineers before field deployment.
+For example, data scientists may collaborate with field teams managing fleets of wind turbines to retrieve operational data samples. This data is used to specialize models detecting anomalies specific to that turbine class. Model updates are tested in simulations and reviewed by engineers before field deployment.
-In essence, embedded MLOps mandates continuous coordination between data scientists, engineers, end customers and other stakeholders throughout the ML lifecycle. Only through close collaboration can models be tailored and optimized for targeted edge devices.
+Embedded MLOps mandates continuous coordination between data scientists, engineers, end customers, and other stakeholders throughout the ML lifecycle. Through close collaboration, models can be tailored and optimized for targeted edge devices.
### Operational Excellence
#### Monitoring
-In traditional MLOps, monitoring focuses on tracking model accuracy, performance metrics and data drift centrally. But embedded MLOps must account for decentralized monitoring across diverse edge devices and environments.
+Traditional MLOps monitoring focuses on centrally tracking model accuracy, performance metrics, and data drift. However, embedded MLOps must account for decentralized monitoring across diverse edge devices and environments.
-Edge devices require optimized data collection to transmit key monitoring metrics without overloading networks. Metrics help assess model performance, data patterns, resource usage and other behaviors on remote devices.
+Edge devices require optimized data collection to transmit key monitoring metrics without overloading networks. Metrics help assess model performance, data patterns, resource usage, and other behaviors on remote devices.
With limited connectivity, more analysis occurs at the edge before aggregating insights centrally. Gateways play a key role in monitoring fleet health and coordinating software updates. Confirmed indicators are eventually propagated to the cloud.
-Broad device coverage is challenging but critical. Issues specific to certain device types may arise so monitoring needs to cover the full spectrum. Canary deployments help trial monitoring processes before scaling.
+Broad device coverage is challenging but critical. Issues specific to certain device types may arise, so monitoring needs to cover the full spectrum. Canary deployments help trial monitoring processes before scaling.
-Anomaly detection identifies incidents requiring rolling back models or retraining on new data. But interpreting alerts requires understanding unique device contexts based on input from engineers and customers.
+Anomaly detection identifies incidents requiring rolling back models or retraining on new data. However, interpreting alerts requires understanding unique device contexts based on input from engineers and customers.
-For example, an automaker may monitor autonomous vehicles for indicators of model degradation using caching, aggregation and real-time streams. Engineers assess when identified anomalies warrant OTA updates to improve models based on factors like location and vehicle age.
+For example, an automaker may monitor autonomous vehicles for indicators of model degradation using caching, aggregation, and real-time streams. Engineers assess when identified anomalies warrant OTA updates to improve models based on factors like location and vehicle age.
-Embedded MLOps monitoring provides observability into model and system performance across decentralized edge environments. Careful data collection, analysis and collaboration delivers meaningful insights to maintain reliability.
+Embedded MLOps monitoring provides observability into model and system performance across decentralized edge environments. Careful data collection, analysis, and collaboration deliver meaningful insights to maintain reliability.
#### Governance
-In traditional MLOps, governance focuses on model explainability, fairness and compliance for centralized systems. But embedded MLOps must also address device-level governance challenges around data privacy, security and safety.
+In traditional MLOps, governance focuses on model explainability, fairness, and compliance for centralized systems. However, embedded MLOps must also address device-level governance challenges related to data privacy, security, and safety.
With sensors collecting personal and sensitive data, local data governance on devices is critical. Data access controls, anonymization, and encrypted caching help address privacy risks and compliance like HIPAA and GDPR. Updates must maintain security patches and settings.
-Safety governance considers the physical impacts of flawed device behavior. Failures could cause unsafe conditions in vehicles, factories and critical systems. Redundancy, fail-safes and warning systems help mitigate risks.
+Safety governance considers the physical impacts of flawed device behavior. Failures could cause unsafe conditions in vehicles, factories, and critical systems. Redundancy, fail-safes, and warning systems help mitigate risks.
-Traditional governance like bias monitoring and model explainability remains imperative but is harder to implement for embedded AI. Peeking into black-box models on low-power devices poses challenges.
+Traditional governance, such as bias monitoring and model explainability, remains imperative but is harder to implement for embedded AI. Peeking into black-box models on low-power devices also poses challenges.
-For example, a medical device may scrub personal data on-device before transmission. Strict data governance protocols approve model updates. Model explainability is limited but the focus is detecting anomalous behavior. Backup systems prevent failures.
+For example, a medical device may scrub personal data on the device before transmission. Strict data governance protocols approve model updates. Model explainability is limited, but the focus is on detecting anomalous behavior. Backup systems prevent failures.
-In essence, embedded MLOps governance must span the dimensions of privacy, security, safety, transparency, and ethics. Specialized techniques and team collaboration are needed to help establish trust and accountability within decentralized environments.
+Embedded MLOps governance must encompass privacy, security, safety, transparency, and ethics. Specialized techniques and team collaboration are needed to help establish trust and accountability within decentralized environments.
### Comparison
@@ -642,92 +644,92 @@ Here is a comparison table highlighting similarities and differences between Tra
| Infrastructure | Dynamic cloud infrastructure | Heterogeneous edge/cloud infrastructure |
| Collaboration | Shared experiment tracking and model registry | Collaboration for device-specific optimization |
-So while Embedded MLOps shares foundational MLOps principles, it faces unique constraints to tailor workflows and infrastructure specifically for resource-constrained edge devices.
+So, while Embedded MLOps shares foundational MLOps principles, it faces unique constraints in tailoring workflows and infrastructure specifically for resource-constrained edge devices.
## Commercial Offerings
-While no replacement for understanding the principles, there are an increasing number of commercial offerings that help ease the burden of building ML pipelines and integrating tools together to build, test, deploy, and monitor ML models in production.
+While understanding the principles is not a substitute for understanding them, an increasing number of commercial offerings help ease the burden of building ML pipelines and integrating tools to build, test, deploy, and monitor ML models in production.
### Traditional MLOps
-Google, Microsoft, and Amazon all offer their own version of managed ML services. These include services that manage model training and experimentation, model hosting and scaling, and monitoring. These offerings are available via an API and client SDKs, as well as through web UIs. While it is possible to build your own end-to-end MLOps solutions using pieces from each, the greatest ease of use benefits come by staying within a single provider ecosystem to take advantage of interservice integrations.
+Google, Microsoft, and Amazon offer their version of managed ML services. These include services that manage model training and experimentation, model hosting and scaling, and monitoring. These offerings are available via an API and client SDKs, as well as through web UIs. While it is possible to build your own end-to-end MLOps solutions using pieces from each, the greatest ease of use benefits come by staying within a single provider ecosystem to take advantage of interservice integrations.
-I will provide a quick overview of the services offered that fit into each part of the MLOps life cycle described above, providing examples of offerings from different providers. The space is moving very quickly; new companies and products are entering the scene very rapidly, and these are not meant to serve as an endorsement of a particular company's offering.
+I will provide a quick overview of the services that fit into each part of the MLOps life cycle described above, providing examples of offerings from different providers. The space is moving very quickly; new companies and products are entering the scene very rapidly, and these are not meant to serve as an endorsement of a particular company's offering.
#### Data Management
-Data storage and versioning are table stakes for any commercial offering and most take advantage of existing general purpose storage solutions such as S3. Others use more specialized options such as a git-based storage (Example: [Hugging Face's Dataset Hub](https://huggingface.co/datasets) This is an area where providers make it easy to support their competitors' data storage options, as they don't want this to be a barrier for adoptions of the rest of their MLOps services. For example, Vertex AI's training pipeline seamlessly supports datasets stored in S3, Google Cloud Buckets, or Hugging Face's Dataset Hub.
+Data storage and versioning are table stakes for any commercial offering, and most take advantage of existing general-purpose storage solutions such as S3. Others use more specialized options such as git-based storage (Example: [Hugging Face's Dataset Hub](https://huggingface.co/datasets) This is an area where providers make it easy to support their competitors' data storage options, as they don't want this to be a barrier for adoptions of the rest of their MLOps services. For example, Vertex AI's training pipeline seamlessly supports datasets stored in S3, Google Cloud Buckets, or Hugging Face's Dataset Hub.
#### Model Training
-Managed training services are where cloud providers really shine, as they provide on demand access to hardware that is out of reach for most smaller companies. They bill only for hardware during training time, and this puts GPU accelerated training within reach of even the smallest developer teams. The level of control that developers have over their training workflow can vary widely depending on their needs. Some providers have services that provide little more than access to the resources and rely on the developer to manage the training loop, logging, and model storage themselves. Other services are as simple as pointing to a base model and a labeled data set to kick off a fully managed fine tuning job (example: [Vertex AI Fine Tuning](https://cloud.google.com/vertex-ai/docs/generative-ai/models/tune-models)).
+Managed training services are where cloud providers shine, as they provide on-demand access to hardware that is out of reach for most smaller companies. They bill only for hardware during training time, putting GPU-accelerated training within reach of even the smallest developer teams. The control developers have over their training workflow can vary widely depending on their needs. Some providers have services that provide little more than access to the resources and rely on the developer to manage the training loop, logging, and model storage themselves. Other services are as simple as pointing to a base model and a labeled data set to kick off a fully managed finetuning job (example: [Vertex AI Fine Tuning](https://cloud.google.com/vertex-ai/docs/generative-ai/models/tune-models)).
-A word of warning: As of 2023, GPU hardware demand well exceeds the supply and as a result cloud providers are rationing access to their GPUs, and in some data center regions may be unavailable or require long term contracts.
+A word of warning: As of 2023, GPU hardware demand well exceeds supply, and as a result, cloud providers are rationing access to their GPUs. In some data center regions, GPUs may be unavailable or require long-term contracts.
#### Model Evaluation
-Model evaluation tasks typically involve monitoring the accuracy, latency, and resource usage of models in both the testing and production phases. Unlike in embedded systems, ML models deployed to the cloud benefit from constant internet connectivity and virtually unlimited logging capacities. As a result it is often feasible to capture and log every request and response. This makes replaying or generating synthetic requests to enable comparison across different models and versions tractable.
+Model evaluation tasks typically involve monitoring models' accuracy, latency, and resource usage in both the testing and production phases. Unlike embedded systems, ML models deployed to the cloud benefit from constant internet connectivity and unlimited logging capacities. As a result, it is often feasible to capture and log every request and response. This makes replaying or generating synthetic requests to compare different models and versions tractable.
-Some providers also offer services that automate the experiment tracking of modifying model hyperparameters. They track the runs, performance, and generated artifacts from these model training runs. Example: [WeightsAndBiases](https://wandb.ai/)
+Some providers also offer services that automate the experiment tracking of modifying model hyperparameters. They track the runs and performance and generate artifacts from these model training runs. Example: [WeightsAndBiases](https://wandb.ai/)
#### Model Deployment
-Each provider typically has a service referred to as a "model registry" where training models are stored and accessed. Often these registries may also provide access to base models that are either open source or provided by larger technology companies (or in some cases like [LLAMA](https://ai.meta.com/llama/), both!). These model registries are a common place to compare all of the models and their versions together to allow easy decision making on which to pick for a given use case. Example: [Vertex AI's model registry](https://cloud.google.com/vertex-ai/docs/model-registry/introduction)
+Each provider typically has a service referred to as a "model registry," where training models are stored and accessed. Often, these registries may also provide access to base models that are either open source or provided by larger technology companies (or, in some cases, like [LLAMA](https://ai.meta.com/llama/), both!). These model registries are a common place to compare all the models and their versions to allow easy decision-making on which to pick for a given use case. Example: [Vertex AI's model registry](https://cloud.google.com/vertex-ai/docs/model-registry/introduction)
-From the model registry it is quick and simple to deploy a model to an inference endpoint, which handles the resource provisioning, model weight downloading, and hosting of a given model. These services typically give access to the model via a REST API where inference requests can be sent. Depending on the model type, the specific required resources can be configured, such as which type of GPU accelerator may be needed to hit the desired performance. Some providers may also offer serverless inference, or batch inference options that do not need a persistent endpoint for accessing the model. Example: [AWS SageMaker Inference](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html)
+From the model registry, deploying a model to an inference endpoint is quick and simple, and it handles the resource provisioning, model weight downloading, and hosting of a given model. These services typically give access to the model via a REST API where inference requests can be sent. Depending on the model type, specific resources can be configured, such as which type of GPU accelerator may be needed to hit the desired performance. Some providers may also offer serverless inference or batch inference options that do not need a persistent endpoint to access the model. Example: [AWS SageMaker Inference](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html)
### Embedded MLOps
-Despite the proliferation of new ML Ops tools in response to the increase in demand, the challenges described earlier have constrained the availability of such tools in embedded systems environments. More recently, new tools such as Edge Impulse [@janapa2023edge] have made the development process somewhat easier, as we'll describe below.
+Despite the proliferation of new ML Ops tools in response to the increase in demand, the challenges described earlier have constrained the availability of such tools in embedded systems environments. More recently, new tools such as Edge Impulse [@janapa2023edge] have made the development process somewhat easier, as described below.
#### Edge Impulse
-[Edge Impulse](https://edgeimpulse.com/) is an end-to-end development platform for creating and deploying machine learning models onto edge devices such as microcontrollers and small processors. It aims to make embedded machine learning more accessible to software developers through its easy-to-use web interface and integrated tools for data collection, model development, optimization and deployment. It's key capabilities include:
+[Edge Impulse](https://edgeimpulse.com/) is an end-to-end development platform for creating and deploying machine learning models onto edge devices such as microcontrollers and small processors. It aims to make embedded machine learning more accessible to software developers through its easy-to-use web interface and integrated tools for data collection, model development, optimization, and deployment. Its key capabilities include the following:
-* Intuitive drag and drop workflow for building ML models without coding required
-* Tools for acquiring, labeling, visualizing and preprocessing data from sensors
-* Choice of model architectures including neural networks and unsupervised learning
+* Intuitive drag-and-drop workflow for building ML models without coding required
+* Tools for acquiring, labeling, visualizing, and preprocessing data from sensors
+* Choice of model architectures, including neural networks and unsupervised learning
* Model optimization techniques to balance performance metrics and hardware constraints
-* Seamless deployment onto edge devices through compilation, SDKs and benchmarks
+* Seamless deployment onto edge devices through compilation, SDKs, and benchmarks
* Collaboration features for teams and integration with other platforms
-With Edge Impulse, developers with limited data science expertise can develop specialized ML models that run efficiently within small computing environments. It provides a comprehensive solution for creating embedded intelligence and taking machine learning to the edge.
+With Edge Impulse, developers with limited data science expertise can develop specialized ML models that run efficiently within small computing environments. It provides a comprehensive solution for creating embedded intelligence and advancing machine learning.
##### User Interface
-Edge Impulse was designed with seven key principles in mind: accessibility, end-to-end capabilities, a data-centric approach, iterativeness, extensibility, team orientation, and community support. The intuitive user interface, shown in @fig-edge-impulse-ui, guides developers at all experience levels through uploading data, selecting a model architecture, training the model, and deploying it across relevant hardware platforms. It should be noted that, like any tool, Edge Impulse is intended to assist with, not replace, foundational considerations such as determining if ML is an appropriate solution or acquiring the requisite domain expertise for a given application.
+Edge Impulse was designed with seven key principles: accessibility, end-to-end capabilities, a data-centric approach, interactiveness, extensibility, team orientation, and community support. The intuitive user interface, shown in @fig-edge-impulse-ui, guides developers at all experience levels through uploading data, selecting a model architecture, training the model, and deploying it across relevant hardware platforms. It should be noted that, like any tool, Edge Impulse is intended to assist with, not replace, foundational considerations such as determining if ML is an appropriate solution or acquiring the requisite domain expertise for a given application.
{#fig-edge-impulse-ui}
-What makes Edge Impulse notable is its comprehensive yet intuitive end-to-end workflow. Developers start by uploading their data, either through file upload or command line interface (CLI) tools, after which they can examine raw samples and visualize the distribution of data in the training and test splits. Next, users can pick from a variety of preprocessing "blocks" to facilitate digital signal processing (DSP). While default parameter values are provided, users have the option to customize the parameters as needed, with considerations around memory and latency displayed. Users can easily choose their neural network architecture - without any code needed.
+What makes Edge Impulse notable is its comprehensive yet intuitive end-to-end workflow. Developers start by uploading their data through file upload or command line interface (CLI) tools, after which they can examine raw samples and visualize the data distribution in the training and test splits. Next, users can pick from various preprocessing "blocks" to facilitate digital signal processing (DSP). While default parameter values are provided, users can customize the parameters as needed, with considerations around memory and latency displayed. Users can easily choose their neural network architecture - without any code needed.
-Thanks to the platform's visual editor, users can customize the components of the architecture and the specific parameters, all while ensuring that the model is still trainable. Users can also leverage unsupervised learning algorithms, such as K-means clustering and Gaussian mixture models (GMM).
+Thanks to the platform's visual editor, users can customize the architecture's components and specific parameters while ensuring that the model is still trainable. Users can also leverage unsupervised learning algorithms, such as K-means clustering and Gaussian mixture models (GMM).
##### Optimizations
-To accommodate the resource constraints of TinyML applications, Edge Impulse provides a confusion matrix summarizing key performance metrics including per-class accuracy and F1 scores. The platform elucidates the tradeoffs between model performance, size, and latency using simulations in [Renode](https://renode.io/) and device-specific benchmarking. For streaming data use cases, a performance calibration tool leverages a genetic algorithm to find ideal post-processing configurations balancing false acceptance and false rejection rates. To optimize models, techniques like quantization, code optimization, and device-specific optimization are available. For deployment, models can be compiled in appropriate formats for target edge devices. Native firmware SDKs also enable direct data collection on devices.
+To accommodate the resource constraints of TinyML applications, Edge Impulse provides a confusion matrix summarizing key performance metrics, including per-class accuracy and F1 scores. The platform elucidates the tradeoffs between model performance, size, and latency using simulations in [Renode](https://renode.io/) and device-specific benchmarking. For streaming data use cases, a performance calibration tool leverages a genetic algorithm to find ideal post-processing configurations balancing false acceptance and false rejection rates. Techniques like quantization, code optimization, and device-specific optimization are available to optimize models. For deployment, models can be compiled in appropriate formats for target edge devices. Native firmware SDKs also enable direct data collection on devices.
-In addition to streamlining development, Edge Impulse scales the modeling process itself. A key capability is the [EON Tuner](https://docs.edgeimpulse.com/docs/edge-impulse-studio/eon-tuner), an automated machine learning (AutoML) tool that assists users in hyperparameter tuning based on system constraints. It runs a random search to quickly generate configurations for digital signal processing and training steps. The resulting models are displayed for the user to select based on relevant performance, memory, and latency metrics. For data, active learning facilitates training on a small labeled subset then manually or automatically labeling new samples based on proximity to existing classes. This expands data efficiency.
+In addition to streamlining development, Edge Impulse scales the modeling process itself. A key capability is the [EON Tuner](https://docs.edgeimpulse.com/docs/edge-impulse-studio/eon-tuner), an automated machine learning (AutoML) tool that assists users in hyperparameter tuning based on system constraints. It runs a random search to generate configurations for digital signal processing and training steps quickly. The resulting models are displayed for the user to select based on relevant performance, memory, and latency metrics. For data, active learning facilitates training on a small labeled subset, followed by manually or automatically labeling new samples based on proximity to existing classes. This expands data efficiency.
##### Use Cases
Beyond the accessibility of the platform itself, the Edge Impulse team has expanded the knowledge base of the embedded ML ecosystem. The platform lends itself to academic environments, having been used in online courses and on-site workshops globally. Numerous case studies featuring industry and research use cases have been published, most notably [Oura Ring](https://ouraring.com/), which uses ML to identify sleep patterns. The team has made repositories open source on GitHub, facilitating community growth. Users can also make projects public to share techniques and download libraries to share via Apache. Organization-level access enables collaboration on workflows.
-Overall, Edge Impulse is uniquely comprehensive and integrateable for developer workflows. Larger platforms like Google and Microsoft focus more on cloud versus embedded systems. TinyMLOps frameworks such as Neuton AI and Latent AI offer some functionality but lack Edge Impulse's end-to-end capabilities. TensorFlow Lite Micro is the standard inference engine due to flexibility, open source status, and TensorFlow integration but uses more memory and storage than Edge Impulse's EON Compiler. Other platforms are outdated, academic-focused, or less versatile. In summary, Edge Impulse aims to streamline and scale embedded ML through an accessible, automated platform.
+Overall, Edge Impulse is uniquely comprehensive and integrateable for developer workflows. Larger platforms like Google and Microsoft focus more on cloud versus embedded systems. TinyMLOps frameworks such as Neuton AI and Latent AI offer some functionality but lack Edge Impulse's end-to-end capabilities. TensorFlow Lite Micro is the standard inference engine due to flexibility, open source status, and TensorFlow integration, but it uses more memory and storage than Edge Impulse's EON Compiler. Other platforms need to be updated, academic-focused, or more versatile. In summary, Edge Impulse aims to streamline and scale embedded ML through an accessible, automated platform.
#### Limitations
-While Edge Impulse provides an accessible pipeline for embedded ML, there are still important limitations and risks to consider. A key challenge is data quality and availability - the models are only as good as the data used to train them. Users must have sufficient labeled samples that capture the breadth of expected operating conditions and failure modes. Labeled anomalies and outliers are critical yet time-consuming to collect and identify. Insufficient or biased data leads to poor model performance regardless of the tool's capabilities.
+While Edge Impulse provides an accessible pipeline for embedded ML, important limitations and risks remain. A key challenge is data quality and availability - the models are only as good as the data used to train them. Users must have sufficient labeled samples that capture the breadth of expected operating conditions and failure modes. Labeled anomalies and outliers are critical yet time-consuming to collect and identify. Insufficient or biased data leads to poor model performance regardless of the tool's capabilities.
-There are also inherent challenges in deploying to low-powered devices. Optimized models may still be too resource intensive for ultra-low power MCUs. Striking the right balance of compression versus accuracy takes some experimentation. The tool simplifies but doesn't eliminate the need for foundational ML and signal processing expertise. Embedded environments also constrain debugging and interpretability compared to the cloud.
+Deploying low-powered devices also presents inherent challenges. Optimized models may still need to be more resource-intensive for ultra-low-power MCUs. Striking the right balance of compression versus accuracy takes some experimentation. The tool simplifies but still needs to eliminate the need for foundational ML and signal processing expertise. Embedded environments also constrain debugging and interpretability compared to the cloud.
-While impressive results are achievable, users shouldn't view Edge Impulse as a "Push Button ML" solution. Careful project scoping, data collection, model evaluation and testing is still essential. As with any development tool, reasonable expectations and diligence in application are advised. But for developers willing to invest the requisite data science and engineering effort, Edge Impulse can accelerate embedded ML prototyping and deployment.
+While impressive results are achievable, users shouldn't view Edge Impulse as a "Push Button ML" solution. Careful project scoping, data collection, model evaluation, and testing are still essential. As with any development tool, reasonable expectations and diligence in application are advised. However, Edge Impulse can accelerate embedded ML prototyping and deployment for developers willing to invest the requisite data science and engineering effort.
:::{#exr-ei .callout-exercise collapse="true"}
### Edge Impulse
-Ready to level up your tiny machine learning projects? Let's combine the power of Edge Impulse with the awesome visualizations of Weights & Biases (WandB). In this Colab, you'll learn how to track your model's training progress like a pro! Imagine seeing cool graphs of your model getting smarter, comparing different versions, and making sure your AI is performing its best even on tiny devices.
+Ready to level up your tiny machine-learning projects? Let's combine the power of Edge Impulse with the awesome visualizations of Weights & Biases (WandB). In this Colab, you'll learn to track your model's training progress like a pro! Imagine seeing cool graphs of your model getting smarter, comparing different versions, and ensuring your AI performs its best even on tiny devices.
[](https://colab.research.google.com/github/edgeimpulse/notebooks/blob/main/notebooks/python-sdk-with-wandb.ipynb#scrollTo=7583a486-afd6-42d8-934b-fdb33a6f3362)
@@ -737,63 +739,64 @@ Ready to level up your tiny machine learning projects? Let's combine the power o
### Oura Ring
-The [Oura Ring](https://ouraring.com/) is a wearable that, when placed on the user's finger, can measure activity, sleep, and recovery. Using sensors to track physiological metrics, the device uses embedded ML to predict the stages of sleep. To establish a baseline of legitimacy in the industry, Oura conducted a correlation experiment to evaluate the success of the device in predicting sleep stages against a baseline study, resulting in a solid 62% correlation compared to the baseline of 82-83%. Thus, the team set out to determine how they could improve their performance even further.
+The [Oura Ring](https://ouraring.com/) is a wearable that can measure activity, sleep, and recovery when placed on the user's finger. Using sensors to track physiological metrics, the device uses embedded ML to predict the stages of sleep. To establish a baseline of legitimacy in the industry, Oura conducted a correlation experiment to evaluate the device's success in predicting sleep stages against a baseline study. This resulted in a solid 62% correlation compared to the 82-83% baseline. Thus, the team set out to determine how to improve their performance even further.
-The first challenge was to obtain better data, in terms of both quantity and quality. They could host a larger study to get a more comprehensive data set, but the data would be noisy and at such a large scale that it would be difficult to aggregate, scrub, and analyze. This is where Edge Impulse comes in.
+The first challenge was to obtain better data in terms of both quantity and quality. They could host a larger study to get a more comprehensive data set, but the data would be so noisy and large that it would be difficult to aggregate, scrub, and analyze. This is where Edge Impulse comes in.
-Oura was able to host a massive sleep study of 100 men and women between the ages of 15 and 73 across three continents (Asia, Europe, North America). In addition to wearing the Oura Ring, participants were responsible for undergoing the industry standard PSG testing, which provided a "label" for this data set. With 440 nights of sleep from 106 participants, the data set totaled 3,444 hours in length across Ring and PSG data. With Edge Impulse, Oura was able to easily upload and consolidate the data from different sources into a private S3 bucket. They were also able to set up a Data Pipeline to merge data samples into individual files, as well as preprocess the data without having to conduct manual scrubbing.
+We hosted a massive sleep study of 100 men and women between the ages of 15 and 73 across three continents (Asia, Europe, and North America). In addition to wearing the Oura Ring, participants were responsible for undergoing the industry standard PSG testing, which provided a "label" for this data set. With 440 nights of sleep from 106 participants, the data set totaled 3,444 hours in length across Ring and PSG data. With Edge Impulse, Oura could easily upload and consolidate data from different sources into a private S3 bucket. They were also able to set up a Data Pipeline to merge data samples into individual files and preprocess the data without having to conduct manual scrubbing.
-Because of the time saved on data processing thanks to Edge Impulse, the Oura team was able to focus on the key drivers of their prediction. In fact, they ended up only extracting three types of sensor data: heart rate, motion, and body temperature. After partitioning the data using five-fold cross validation and classifying sleep stage, the team was able to achieve a correlation of 79% - just a few percentage points off the standard. They were able to readily deploy two types of models for sleep detection: one simplified using just the ring's accelerometer and one more comprehensive leveraging Autonomic Nervous System (ANS)-mediated peripheral signals and circadian features. With Edge Impulse, they plan to conduct further analyses of different activity types and leverage the scalability of the platform to continue to experiment with different sources of data and subsets of features extracted.
+Because of the time saved on data processing thanks to Edge Impulse, the Oura team could focus on the key drivers of their prediction. They only extracted three types of sensor data: heart rate, motion, and body temperature. After partitioning the data using five-fold cross-validation and classifying sleep stages, the team achieved a correlation of 79% - just a few percentage points off the standard. They readily deployed two types of sleep detection models: one simplified using just the ring's accelerometer and one more comprehensive leveraging Autonomic Nervous System (ANS)-mediated peripheral signals and circadian features. With Edge Impulse, they plan to conduct further analyses of different activity types and leverage the platform's scalability to continue experimenting with different data sources and subsets of extracted features.
-While most ML research focuses on the model-dominant steps such as training and finetuning, this case study underscores the importance of a holistic approach to ML Ops, where even the initial steps of data aggregation and preprocessing have a fundamental impact on successful outcomes.
+While most ML research focuses on model-dominant steps such as training and finetuning, this case study underscores the importance of a holistic approach to ML Ops, where even the initial steps of data aggregation and preprocessing fundamentally impact successful outcomes.
### ClinAIOps
-Let's take a look at MLOps in the context of medical health monitoring to better understand how MLOps "matures" in the context of a real world deployment. Specifically, let's consider continuous therapeutic monitoring (CTM) enabled by wearable devices and sensors , providing the opportunity for more frequent and personalized adjustments to treatments by capturing detailed physiological data from patients.
+Let's look at MLOps in the context of medical health monitoring to better understand how MLOps "matures" in a real-world deployment. Specifically, let's consider continuous therapeutic monitoring (CTM) enabled by wearable devices and sensors. CTM captures detailed physiological data from patients, providing the opportunity for more frequent and personalized adjustments to treatments.
-Wearable ML enabled sensors enable continuous physiological and activity monitoring outside of clinics, opening up possibilities for timely, data-driven adjustments of therapies. For example, wearable insulin biosensors [@psoma2023wearable] and wrist-worn ECG sensors for glucose monitoring [@li2021noninvasive] can automate insulin dosing for diabetes, wrist-worn ECG and PPG sensors can adjust blood thinners based on atrial fibrillation patterns [@attia2018noninvasive; @guo2019mobile], and accelerometers tracking gait can trigger preventative care for declining mobility in the elderly [@liu2022monitoring]. The variety of signals that can now be captured passively and continuously allows therapy titration and optimization tailored to each patient's changing needs. By closing the loop between physiological sensing and therapeutic response with TinyML and ondevice learning, wearables are poised to transform many areas of personalized medicine.
+Wearable ML-enabled sensors enable continuous physiological and activity monitoring outside clinics, opening up possibilities for timely, data-driven therapy adjustments. For example, wearable insulin biosensors [@psoma2023wearable] and wrist-worn ECG sensors for glucose monitoring [@li2021noninvasive] can automate insulin dosing for diabetes, wrist-worn ECG and PPG sensors can adjust blood thinners based on atrial fibrillation patterns [@attia2018noninvasive; @guo2019mobile], and accelerometers tracking gait can trigger preventative care for declining mobility in the elderly [@liu2022monitoring]. The variety of signals that can now be captured passively and continuously allows therapy titration and optimization tailored to each patient's changing needs. By closing the loop between physiological sensing and therapeutic response with TinyML and on-device learning, wearables are poised to transform many areas of personalized medicine.
-ML holds great promise in analyzing CTM data to provide data-driven recommendations for therapy adjustments. But simply deploying AI models in silos, without integrating them properly into clinical workflows and decision making, can lead to poor adoption or suboptimal outcomes. In other words, thinking about MLOps alone is simply insufficient to make them useful in practice. What is needed are frameworks to seamlessly incorporate AI and CTM into real-world clinical practice as this study shows.
+ML holds great promise in analyzing CTM data to provide data-driven recommendations for therapy adjustments. But simply deploying AI models in silos, without integrating them properly into clinical workflows and decision-making, can lead to poor adoption or suboptimal outcomes. In other words, thinking about MLOps alone is insufficient to make them useful in practice. This study shows that frameworks are needed to incorporate AI and CTM into real-world clinical practice seamlessly.
-This case study analyzes "ClinAIOps" as a model for embedded ML operations in complex clinical environments [@chen2023framework]. We provide an overview of the framework and why it's needed, walk through an application example, and discuss key implementation challenges related to model monitoring, workflow integration, and stakeholder incentives. Analyzing real-world examples like ClinAIOps illuminates crucial principles and best practices needed for reliable and effective AI Ops across many domains.
+This case study analyzes "ClinAIOps" as a model for embedded ML operations in complex clinical environments [@chen2023framework]. We provide an overview of the framework and why it's needed, walk through an application example, and discuss key implementation challenges related to model monitoring, workflow integration, and stakeholder incentives. Analyzing real-world examples like ClinAIOps illuminates crucial principles and best practices for reliable and effective AI Ops across many domains.
Traditional MLOps frameworks are insufficient for integrating continuous therapeutic monitoring (CTM) and AI in clinical settings for a few key reasons:
-* MLOps focuses on the ML model lifecycle - training, deployment, monitoring. But healthcare involves coordinating multiple human stakeholders - patients, clinicians - not just models.
+* MLOps focuses on the ML model lifecycle—training, deployment, monitoring. But healthcare involves coordinating multiple human stakeholders—patients and clinicians—not just models.
-* MLOps aims to automate IT system monitoring and management. But optimizing patient health requires personalized care and human oversight, not just automation.
+* MLOps aims to automate IT system monitoring and management. However, optimizing patient health requires personalized care and human oversight, not just automation.
* CTM and healthcare delivery are complex sociotechnical systems with many moving parts. MLOps doesn't provide a framework for coordinating human and AI decision-making.
-* There are ethical considerations regarding healthcare AI that require human judgment, oversight and accountability. MLOps frameworks lack processes for ethical oversight.
+* Ethical considerations regarding healthcare AI require human judgment, oversight, and accountability. MLOps frameworks lack processes for ethical oversight.
-* Patient health data is highly sensitive and regulated. MLOps alone doesn't ensure handling of protected health information to privacy and regulatory standards.
+* Patient health data is highly sensitive and regulated. MLOps alone doesn't ensure the handling of protected health information to privacy and regulatory standards.
* Clinical validation of AI-guided treatment plans is essential for provider adoption. MLOps doesn't incorporate domain-specific evaluation of model recommendations.
* Optimizing healthcare metrics like patient outcomes requires aligning stakeholder incentives and workflows, which pure tech-focused MLOps overlooks.
-Thus, effectively integrating AI/ML and CTM in clinical practice requires more than just model and data pipelines, but coordinating complex human-AI collaborative decision making, which ClinAIOps aims to address via its multi-stakeholder feedback loops.
+Thus, effectively integrating AI/ML and CTM in clinical practice requires more than just model and data pipelines; it requires coordinating complex human-AI collaborative decision-making, which ClinAIOps aims to address via its multi-stakeholder feedback loops.
#### Feedback Loops
-The ClinAIOps framework, shown in @fig-clinaiops, provides these mechanisms through three feedback loops. The loops are useful for coordinating the insights from continuous physiological monitoring, clinician expertise, and AI guidance via feedback loops, enabling data-driven precision medicine while maintaining human accountability. ClinAIOps provides a model for effective human-AI symbiosis in healthcare: the patient is at the center, providing health challenges and goals which inform the therapy regimen; the clinician oversees this regimen, giving inputs for adjustments based on continuous monitoring data and health reports from the patient; whereas AI developers play a crucial role by creating systems that generate alerts for therapy updates, which are then vetted by the clinician.
+The ClinAIOps framework, shown in @fig-clinaiops, provides these mechanisms through three feedback loops. The loops are useful for coordinating the insights from continuous physiological monitoring, clinician expertise, and AI guidance via feedback loops, enabling data-driven precision medicine while maintaining human accountability. ClinAIOps provides a model for effective human-AI symbiosis in healthcare: the patient is at the center, providing health challenges and goals that inform the therapy regimen; the clinician oversees this regimen, giving inputs for adjustments based on continuous monitoring data and health reports from the patient; whereas AI developers play a crucial role by creating systems that generate alerts for therapy updates, which the clinician then vets.
-These feedback loops which we will discuss below help maintain clinician responsibility and control over treatment plans, by reviewing AI suggestions before they impact patients. They help dynamically customize AI model behavior and outputs to each patient's changing health status. They help improve model accuracy and clinical utility over time by learning from clinician and patient responses. They facilitate shared decision-making and personalized care during patient-clinician interactions. They enable rapid optimization of therapies based on frequent patient data that clinicians cannot manually analyze.
+These feedback loops, which we will discuss below, help maintain clinician responsibility and control over treatment plans by reviewing AI suggestions before they impact patients. They help dynamically customize AI model behavior and outputs to each patient's changing health status. They help improve model accuracy and clinical utility over time by learning from clinician and patient responses. They facilitate shared decision-making and personalized care during patient-clinician interactions. They enable rapid optimization of therapies based on frequent patient data that clinicians cannot manually analyze.
{#fig-clinaiops}
##### Patient-AI Loop
-The patient-AI loop enables frequent therapy optimization driven by continuous physiological monitoring. Patients are prescribed wearables like smartwatches or skin patches to passively collect relevant health signals. For example, a diabetic patient could have a continuous glucose monitor, or a heart disease patient may wear an ECG patch. The patient's longitudinal health data streams are analyzed by an AI model in context of their electronic medical records - their diagnoses, lab tests, medications, and demographics. The AI model suggests adjustments to the treatment regimen tailored to that individual, like changing a medication dose or administration schedule. Minor adjustments within a pre-approved safe range can be made by the patient independently, while major changes are reviewed by the clinician first. This tight feedback between the patient's physiology and AI-guided therapy allows data-driven, timely optimizations like automated insulin dosing recommendations based on real-time glucose levels for diabetes patients.
+The patient-AI loop enables frequent therapy optimization driven by continuous physiological monitoring. Patients are prescribed wearables like smartwatches or skin patches to collect relevant health signals passively. For example, a diabetic patient could have a continuous glucose monitor, or a heart disease patient may wear an ECG patch. An AI model analyzes the patient's longitudinal health data streams in the context of their electronic medical records - their diagnoses, lab tests, medications, and demographics. The AI model suggests adjustments to the treatment regimen tailored to that individual, like changing a medication dose or administration schedule. Minor adjustments within a pre-approved safe range can be made by the patient independently, while major changes are reviewed by the clinician first. This tight feedback between the patient's physiology and AI-guided therapy allows data-driven, timely optimizations like automated insulin dosing recommendations based on real-time glucose levels for diabetes patients.
##### Clinician-AI Loop
-The clinician-AI loop allows clinical oversight over AI-generated recommendations to ensure safety and accountability. The AI model provides the clinician with treatment recommendations, along with easily reviewed summaries of the relevant patient data the suggestions are based on. For instance, an AI may suggest lowering a hypertension patient's blood pressure medication dose based on continuously low readings. The clinician can choose to accept, reject, or modify the AI's proposed prescription changes. This clinician feedback further trains and improves the model. Additionally, the clinician sets the bounds for the types and extents of treatment changes the AI can autonomously recommend to patients. By reviewing AI suggestions, the clinician maintains ultimate treatment authority based on their clinical judgment and accountability. This loop allows them to efficiently oversee patient cases with AI assistance.
+The clinician-AI loop allows clinical oversight over AI-generated recommendations to ensure safety and accountability. The AI model provides the clinician with treatment recommendations and easily reviewed summaries of the relevant patient data on which the suggestions are based. For instance, an AI may suggest lowering a hypertension patient's blood pressure medication dose based on continuously low readings. The clinician can accept, reject, or modify the AI's proposed prescription changes. This clinician feedback further trains and improves the model.
+Additionally, the clinician sets the bounds for the types and extent of treatment changes the AI can autonomously recommend to patients. By reviewing AI suggestions, the clinician maintains ultimate treatment authority based on their clinical judgment and accountability. This loop allows them to oversee patient cases with AI assistance efficiently.
##### Patient-Clinician Loop
-Instead of routine data collection, the clinician can focus on interpreting high-level data patterns and collaborating with the patient to set health goals and priorities. The AI assistance will also free up clinician time, allowing them to focus more deeply on listening to patients' stories and concerns. For instance, the clinician may discuss diet and exercise changes with a diabetes patient to improve their glucose control based on their continuous monitoring data. Appointment frequency can also be dynamically adjusted based on patient progress rather than following a fixed calendar. Freed from basic data gathering, the clinician can provide coaching and care customized to each patient informed by their continuous health data. The patient-clinician relationship is made more productive and personalized.
+Instead of routine data collection, the clinician can focus on interpreting high-level data patterns and collaborating with the patient to set health goals and priorities. The AI assistance will also free up clinicians' time, allowing them to focus more deeply on listening to patients' stories and concerns. For instance, the clinician may discuss diet and exercise changes with a diabetes patient to improve their glucose control based on their continuous monitoring data. Appointment frequency can also be dynamically adjusted based on patient progress rather than following a fixed calendar. Freed from basic data gathering, the clinician can provide coaching and care customized to each patient informed by their continuous health data. The patient-clinician relationship is made more productive and personalized.
#### Hypertension Example
@@ -801,43 +804,43 @@ Let's consider an example. According to the Centers for Disease Control and Prev
##### Data Collection
-The data collected would include continuous blood pressure monitoring using a wrist-worn device equipped with photoplethysmography (PPG) and electrocardiography (ECG) sensors to estimate blood pressure [@zhang2017highly]. The wearable would also track the patient's physical activity via embedded accelerometers. The patient would log any antihypertensive medications they take, along with the time and dose. Additionally, the patient's demographic details and medical history from their electronic health record (EHR) would be incorporated. This multimodal real-world data provides valuable context for the AI model to analyze the patient's blood pressure patterns, activity levels, medication adherence, and responses to therapy.
+The data collected would include continuous blood pressure monitoring using a wrist-worn device equipped with photoplethysmography (PPG) and electrocardiography (ECG) sensors to estimate blood pressure [@zhang2017highly]. The wearable would also track the patient's physical activity via embedded accelerometers. The patient would log any antihypertensive medications they take, along with the time and dose. The patient's demographic details and medical history from their electronic health record (EHR) would also be incorporated. This multimodal real-world data provides valuable context for the AI model to analyze the patient's blood pressure patterns, activity levels, medication adherence, and responses to therapy.
##### AI Model
-The on-device AI model would analyze the patient's continuous blood pressure trends, circadian patterns, physical activity levels, medication adherence behaviors, and other context. It would use ML to predict optimal antihypertensive medication doses and timing to control the individual's blood pressure. The model would send dosage change recommendations directly to the patient for minor adjustments, or to the reviewing clinician for approval for more significant modifications. By observing clinician feedback on its recommendations, as well as evaluating the resulting blood pressure outcomes in patients, the AI model could be continually retrained and improved to enhance performance. The goal is fully personalized blood pressure management optimized for each patient's needs and responses.
+The on-device AI model would analyze the patient's continuous blood pressure trends, circadian patterns, physical activity levels, medication adherence behaviors, and other contexts. It would use ML to predict optimal antihypertensive medication doses and timing to control the individual's blood pressure. The model would send dosage change recommendations directly to the patient for minor adjustments or to the reviewing clinician for approval for more significant modifications. By observing clinician feedback on its recommendations and evaluating the resulting blood pressure outcomes in patients, the AI model could be continually retrained and improved to enhance performance. The goal is fully personalized blood pressure management optimized for each patient's needs and responses.
##### Patient-AI Loop
-In the Patient-AI loop, the hypertensive patient would receive notifications on their wearable device or tethered smartphone app recommending adjustments to their antihypertensive medications. For minor dose changes within a pre-defined safe range, the patient could independently implement the AI model's suggested adjustment to their regimen. However, for more significant modifications, the patient would need to obtain clinician approval before changing their dosage. By providing personalized and timely medication recommendations, this automates an element of hypertension self-management for the patient. It can improve their adherence to the regimen as well as treatment outcomes. The patient is empowered to leverage AI insights to better control their blood pressure.
+In the Patient-AI loop, the hypertensive patient would receive notifications on their wearable device or tethered smartphone app recommending adjustments to their antihypertensive medications. For minor dose changes within a pre-defined safe range, the patient could independently implement the AI model's suggested adjustment to their regimen. However, the patient must obtain clinician approval before changing their dosage for more significant modifications. Providing personalized and timely medication recommendations automates an element of hypertension self-management for the patient. It can improve their adherence to the regimen as well as treatment outcomes. The patient is empowered to leverage AI insights to control their blood pressure better.
##### Clinician-AI Loop
-In the Clinician-AI loop, the provider would receive summaries of the patient's continuous blood pressure trends and visualizations of their medication taking patterns and adherence. They review the AI model's suggested antihypertensive dosage changes and decide whether to approve, reject, or modify the recommendations before they reach the patient. The clinician also specifies the boundaries for how much the AI can independently recommend changing dosages without clinician oversight. If the patient's blood pressure is trending at dangerous levels, the system alerts the clinician so they can promptly intervene and adjust medications or request an emergency room visit. By keeping the clinician in charge of approving major treatment changes, this loop maintains accountability and safety while allowing the clinician to harness AI insights.
+In the Clinician-AI loop, the provider would receive summaries of the patient's continuous blood pressure trends and visualizations of their medication-taking patterns and adherence. They review the AI model's suggested antihypertensive dosage changes and decide whether to approve, reject, or modify the recommendations before they reach the patient. The clinician also specifies the boundaries for how much the AI can independently recommend changing dosages without clinician oversight. If the patient's blood pressure is trending at dangerous levels, the system alerts the clinician so they can promptly intervene and adjust medications or request an emergency room visit. This loop maintains accountability and safety while allowing the clinician to harness AI insights by keeping the clinician in charge of approving major treatment changes.
##### Patient-Clinician Loop
-In the Patient-Clinician loop, shown in @fig-interactive-loop, the in-person visits would focus less on collecting data or basic medication adjustments. Instead, the clinician could interpret high-level trends and patterns in the patient's continuous monitoring data and have focused discussions about diet, exercise, stress management, and other lifestyle changes to holistically improve their blood pressure control. The frequency of appointments could be dynamically optimized based on the patient's stability rather than following a fixed calendar. Since the clinician would not need to review all the granular data, they could concentrate on delivering personalized care and recommendations during visits. With continuous monitoring and AI-assisted optimization of medications between visits, the clinician-patient relationship focuses on overall wellness goals and becomes more impactful. This proactive and tailored data-driven approach can help avoid hypertension complications like stroke, heart failure, and other threats to patient health and wellbeing.
+In the Patient-Clinician loop, shown in @fig-interactive-loop, the in-person visits would focus less on collecting data or basic medication adjustments. Instead, the clinician could interpret high-level trends and patterns in the patient's continuous monitoring data and have focused discussions about diet, exercise, stress management, and other lifestyle changes to improve their blood pressure control holistically. The frequency of appointments could be dynamically optimized based on the patient's stability rather than following a fixed calendar. Since the clinician would not need to review all the granular data, they could concentrate on delivering personalized care and recommendations during visits. With continuous monitoring and AI-assisted optimization of medications between visits, the clinician-patient relationship focuses on overall wellness goals and becomes more impactful. This proactive and tailored data-driven approach can help avoid hypertension complications like stroke, heart failure, and other threats to patient health and well-being.
{#fig-interactive-loop}
#### MLOps vs. ClinAIOps
-The hypertension example illustrates well why traditional MLOps is insufficient for many real-world AI applications, and why frameworks like ClinAIOps are needed instead.
+The hypertension example illustrates well why traditional MLOps are insufficient for many real-world AI applications and why frameworks like ClinAIOps are needed instead.
-With hypertension, simply developing and deploying an ML model for adjusting medications would fail without considering the broader clinical context. The patient, clinician, and health system each have concerns that shape adoption. And the AI model cannot optimize blood pressure outcomes alone - it requires integrating with workflows, behaviors, and incentives.
+With hypertension, simply developing and deploying an ML model for adjusting medications would only succeed if it considered the broader clinical context. The patient, clinician, and health system have concerns about shaping adoption. The AI model cannot optimize blood pressure outcomes alone—it requires integrating with workflows, behaviors, and incentives.
* Some key gaps the example highlights in a pure MLOps approach:
-* The model itself would lack the real-world patient data at scale to reliably recommend treatments. ClinAIOps enables this through collecting feedback from clinicians and patients via continuous monitoring.
-* Clinicians would not trust model recommendations without transparency, explainability, and accountability. ClinAIOps keeps the clinician in the loop to build confidence.
+* The model itself would lack the real-world patient data at scale to recommend treatments reliably. ClinAIOps enables this by collecting feedback from clinicians and patients via continuous monitoring.
+* Clinicians would only trust model recommendations with transparency, explainability, and accountability. ClinAIOps keeps the clinician in the loop to build confidence.
* Patients need personalized coaching and motivation - not just AI notifications. The ClinAIOps patient-clinician loop facilitates this.
-* Sensor reliability and data accuracy would be insufficient without clinical oversight. ClinAIOps validates recommendations.
-* Liability for treatment outcomes is unclear with just an ML model. ClinAIOps maintains human accountability.
-* Health systems would lack incentive to change workflows without demonstrating value. ClinAIOps aligns stakeholders.
+* Sensor reliability and data accuracy would only be sufficient with clinical oversight. ClinAIOps validates recommendations.
+* Liability for treatment outcomes must be clarified with just an ML model. ClinAIOps maintains human accountability.
+* Health systems would need to demonstrate value to change workflows. ClinAIOps aligns stakeholders.
-The hypertension case clearly shows the need to look beyond just training and deploying a performant ML model to considering the entire human-AI socio-technical system. This is the key gap ClinAIOps aims to address over traditional MLOps. Put another way, traditional MLOps is overly tech-focused on automating ML model development and deployment, while ClinAIOps incorporates clinical context and human-AI coordination through multi-stakeholder feedback loops.
+The hypertension case clearly shows the need to look beyond training and deploying a performant ML model to consider the entire human-AI sociotechnical system. This is the key gap ClinAIOps aims to address over traditional MLOps. Traditional MLOps is overly tech-focused on automating ML model development and deployment, while ClinAIOps incorporates clinical context and human-AI coordination through multi-stakeholder feedback loops.
-Here is a table comparing them. The point of this table is to highlight how when MLOps is put into practice, we need to think about more than just ML models.
+@tbl-clinical_ops compares them. This table highlights how, when MLOps is implemented, we need to consider more than just ML models.
| | Traditional MLOps | ClinAIOps |
|-|-------------------|------------------|
@@ -850,23 +853,25 @@ Here is a table comparing them. The point of this table is to highlight how when
| Model validation | Testing model performance metrics | Clinical evaluation of recommendations |
| Implementation | Focuses on technical integration | Aligns incentives of human stakeholders |
+: Comparison of MLOps versus AI operations for clinical use. {#@tbl-clinical_ops}
+
#### Summary
-In complex domains like healthcare, successfully deploying AI requires moving beyond a narrow focus on just training and deploying performant ML models. As illustrated through the hypertension example, real-world integration of AI necessitates coordinating diverse stakeholders, aligning incentives, validating recommendations, and maintaining accountability. Frameworks like ClinAIOps, which facilitate collaborative human-AI decision making through integrated feedback loops, are needed to address these multifaceted challenges. Rather than just automating tasks, AI must augment human capabilities and clinical workflows. This allows AI to deliver a positive impact on patient outcomes, population health, and healthcare efficiency.
+In complex domains like healthcare, successfully deploying AI requires moving beyond a narrow focus on training and deploying performant ML models. As illustrated through the hypertension example, real-world integration of AI necessitates coordinating diverse stakeholders, aligning incentives, validating recommendations, and maintaining accountability. Frameworks like ClinAIOps, which facilitate collaborative human-AI decision-making through integrated feedback loops, are needed to address these multifaceted challenges. Rather than just automating tasks, AI must augment human capabilities and clinical workflows. This allows AI to positively impact patient outcomes, population health, and healthcare efficiency.
## Conclusion
Embedded ML is poised to transform many industries by enabling AI capabilities directly on edge devices like smartphones, sensors, and IoT hardware. However, developing and deploying TinyML models on resource-constrained embedded systems poses unique challenges compared to traditional cloud-based MLOps.
-This chapter provided an in-depth analysis of key differences between traditional and embedded MLOps across the model lifecycle, development workflows, infrastructure management, and operational practices. We discussed how factors like intermittent connectivity, decentralized data, and limited on-device compute necessitate innovative techniques like federated learning, on-device inference, and model optimization. Architectural patterns like cross-device learning and hierarchical edge-cloud infrastructure help mitigate constraints.
+This chapter provided an in-depth analysis of key differences between traditional and embedded MLOps across the model lifecycle, development workflows, infrastructure management, and operational practices. We discussed how factors like intermittent connectivity, decentralized data, and limited on-device computing necessitate innovative techniques like federated learning, on-device inference, and model optimization. Architectural patterns like cross-device learning and hierarchical edge-cloud infrastructure help mitigate constraints.
-Through concrete examples like Oura Ring and ClinAIOps, we demonstrated applied principles for embedded MLOps. The case studies highlighted critical considerations beyond just core ML engineering, like aligning stakeholder incentives, maintaining accountability, and coordinating human-AI decision making. This underscores the need for a holistic approach spanning both technical and human elements.
+Through concrete examples like Oura Ring and ClinAIOps, we demonstrated applied principles for embedded MLOps. The case studies highlighted critical considerations beyond core ML engineering, like aligning stakeholder incentives, maintaining accountability, and coordinating human-AI decision-making. This underscores the need for a holistic approach spanning both technical and human elements.
-While embedded MLOps faces impediments, emerging tools like Edge Impulse and lessons from pioneers help accelerate TinyML innovation. A solid understanding of foundational MLOps principles tailored to embedded environments will empower more organizations to overcome constraints and deliver distributed AI capabilities. As frameworks and best practices mature, seamlessly integrating ML into edge devices and processes will transform industries through localized intelligence.
+While embedded MLOps face impediments, emerging tools like Edge Impulse and lessons from pioneers help accelerate TinyML innovation. A solid understanding of foundational MLOps principles tailored to embedded environments will empower more organizations to overcome constraints and deliver distributed AI capabilities. As frameworks and best practices mature, seamlessly integrating ML into edge devices and processes will transform industries through localized intelligence.
## Resources {#sec-embedded-aiops-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
@@ -887,7 +892,7 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
* [Scaling TinyML: Challenges and Opportunities.](https://docs.google.com/presentation/d/1VxwhVztoTk3eG04FD9fFNpj2lVrVjYYPJi3jBz0O_mo/edit?resourcekey=0-bV7CCIPr7SxZf2p61oB_CA#slide=id.g94db9f9f78_0_2)
-* Training Operationalizatios:
+* Training Operationalization:
* [Training Ops: CI/CD trigger.](https://docs.google.com/presentation/d/1YyRY6lOzdC7NjutJSvl_VXYu29qwHKqx0y98zAUCJCU/edit?resourcekey=0-PTh1FxqkQyhOO0bKKHBldQ#slide=id.g94db9f9f78_0_2)
* [Continuous Integration.](https://docs.google.com/presentation/d/1poGgYTH44X0dVGwG9FGIyVwot4EET_jJOt-4kgcQawo/edit?usp=drive_link)
@@ -907,7 +912,7 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
* [Challenges for Scaling TinyML Deployment: Part 1.](https://docs.google.com/presentation/d/1mw5FFERf5r-q8R7iyNf6kx2MMcwNOTBd5WwFOj8Zs20/edit?resourcekey=0-u80KeJio3iIWco00crGD9g#slide=id.gdc4defd718_0_0)
- * [Challenges for Scaling TinyML Deploymnet: Part 2.](https://docs.google.com/presentation/d/1NB63wTHoEPGSn--KqFu1vjHx3Ild9AOhpBbflJP-k7I/edit?usp=drive_link&resourcekey=0-MsEi1Lba2dpl0G-bzakHJQ)
+ * [Challenges for Scaling TinyML Deployment: Part 2.](https://docs.google.com/presentation/d/1NB63wTHoEPGSn--KqFu1vjHx3Ild9AOhpBbflJP-k7I/edit?usp=drive_link&resourcekey=0-MsEi1Lba2dpl0G-bzakHJQ)
* [Model Deployment Impact on MLOps.](https://docs.google.com/presentation/d/1A0pfm55s03dFbYKKFRV-x7pRCm_2-VpoIM0O9kW0TAA/edit?usp=drive_link&resourcekey=0--O2AFFmVzAmz5KO0mJeVHA)
@@ -926,5 +931,5 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/optimizations/optimizations.bib b/contents/optimizations/optimizations.bib
index 2964e4d4..ca44d62b 100644
--- a/contents/optimizations/optimizations.bib
+++ b/contents/optimizations/optimizations.bib
@@ -1,65 +1,73 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@inproceedings{benmeziane2021hardwareaware,
author = {Benmeziane, Hadjer and El Maghraoui, Kaoutar and Ouarnoughi, Hamza and Niar, Smail and Wistuba, Martin and Wang, Naigang},
+ editor = {Zhou, Zhi-Hua},
bdsk-url-1 = {https://doi.org/10.24963/ijcai.2021/592},
booktitle = {Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence},
doi = {10.24963/ijcai.2021/592},
- editor = {Zhou, Zhi-Hua},
note = {Survey Track},
pages = {4322--4329},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
source = {Crossref},
title = {Hardware-Aware Neural Architecture Search: {Survey} and Taxonomy},
url = {https://doi.org/10.24963/ijcai.2021/592},
- year = {2021}
+ year = {2021},
+ month = aug,
}
@inproceedings{cai2018proxylessnas,
- author = {Han Cai and Ligeng Zhu and Song Han},
+ author = {Cai, Han and Zhu, Ligeng and Han, Song},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/iclr/CaiZH19.bib},
- booktitle = {7th International Conference on Learning Representations, {ICLR} 2019, New Orleans, LA, USA, May 6-9, 2019},
+ booktitle = {7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019},
publisher = {OpenReview.net},
timestamp = {Tue, 24 Nov 2020 00:00:00 +0100},
- title = {ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware},
+ title = {{ProxylessNAS:} {Direct} Neural Architecture Search on Target Task and Hardware},
url = {https://openreview.net/forum?id=HylVB3AqYm},
- year = {2019}
+ year = {2019},
}
@inproceedings{chu2021discovering,
- author = {Grace Chu and Okan Arikan and Gabriel Bender and Weijun Wang and Achille Brighton and Pieter{-}Jan Kindermans and Hanxiao Liu and Berkin Akin and Suyog Gupta and Andrew Howard},
+ author = {Chu, Grace and Arikan, Okan and Bender, Gabriel and Wang, Weijun and Brighton, Achille and Kindermans, Pieter-Jan and Liu, Hanxiao and Akin, Berkin and Gupta, Suyog and Howard, Andrew},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/ChuABWBKLAG021.bib},
- booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition Workshops, {CVPR} Workshops 2021, virtual, June 19-25, 2021},
- doi = {10.1109/CVPRW53098.2021.00337},
+ booktitle = {2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
+ doi = {10.1109/cvprw53098.2021.00337},
pages = {3022--3031},
- publisher = {Computer Vision Foundation / {IEEE}},
+ publisher = {IEEE},
timestamp = {Mon, 18 Jul 2022 01:00:00 +0200},
title = {Discovering Multi-Hardware Mobile Models via Architecture Search},
- url = {https://openaccess.thecvf.com/content/CVPR2021W/ECV/html/Chu\_Discovering\_Multi-Hardware\_Mobile\_Models\_via\_Architecture\_Search\_CVPRW\_2021\_paper.html},
- year = {2021}
+ url = {https://doi.org/10.1109/cvprw53098.2021.00337},
+ year = {2021},
+ source = {Crossref},
+ month = jun,
}
@inproceedings{dong2022splitnets,
- author = {Xin Dong and Barbara De Salvo and Meng Li and Chiao Liu and Zhongnan Qu and H. T. Kung and Ziyun Li},
+ author = {Dong, Xin and De Salvo, Barbara and Li, Meng and Liu, Chiao and Qu, Zhongnan and Kung, H.T. and Li, Ziyun},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/DongSLLQ0L22.bib},
- booktitle = {{IEEE/CVF} Conference on Computer Vision and Pattern Recognition, {CVPR} 2022, New Orleans, LA, USA, June 18-24, 2022},
- doi = {10.1109/CVPR52688.2022.01223},
+ booktitle = {2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr52688.2022.01223},
pages = {12549--12559},
- publisher = {{IEEE}},
+ publisher = {IEEE},
timestamp = {Sun, 22 Jan 2023 00:00:00 +0100},
- title = {SplitNets: Designing Neural Architectures for Efficient Distributed Computing on Head-Mounted Systems},
- url = {https://doi.org/10.1109/CVPR52688.2022.01223},
- year = {2022}
+ title = {{SplitNets:} {Designing} Neural Architectures for Efficient Distributed Computing on Head-Mounted Systems},
+ url = {https://doi.org/10.1109/cvpr52688.2022.01223},
+ year = {2022},
+ source = {Crossref},
+ month = jun,
}
@misc{fahim2021hls4ml,
- archiveprefix = {arXiv},
author = {Fahim, Farah and Hawks, Benjamin and Herwig, Christian and Hirschauer, James and Jindariani, Sergo and Tran, Nhan and Carloni, Luca P. and Guglielmo, Giuseppe Di and Harris, Philip and Krupa, Jeffrey and Rankin, Dylan and Valentin, Manuel Blanco and Hester, Josiah and Luo, Yingyi and Mamish, John and Orgrenci-Memik, Seda and Aarrestad, Thea and Javed, Hamza and Loncar, Vladimir and Pierini, Maurizio and Pol, Adrian Alan and Summers, Sioni and Duarte, Javier and Hauck, Scott and Hsu, Shih-Chieh and Ngadiuba, Jennifer and Liu, Mia and Hoang, Duc and Kreinar, Edward and Wu, Zhenbin},
+ archiveprefix = {arXiv},
eprint = {2103.05579},
primaryclass = {cs.LG},
title = {hls4ml: {An} Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices},
- year = {2021}
+ year = {2021},
}
@misc{gholami2021survey,
@@ -68,7 +76,7 @@ @misc{gholami2021survey
title = {A Survey of Quantization Methods for Efficient Neural Network Inference)},
url = {https://arxiv.org/abs/2103.13630},
volume = {abs/2103.13630},
- year = {2021}
+ year = {2021},
}
@misc{google2023three,
@@ -77,7 +85,7 @@ @misc{google2023three
title = {Three Floating Point Formats},
url = {https://storage.googleapis.com/gweb-cloudblog-publish/images/Three\_floating-point\_formats.max-624x261.png},
urldate = {2023-10-20},
- year = {2023}
+ year = {2023},
}
@inproceedings{gordon2018morphnet,
@@ -89,7 +97,8 @@ @inproceedings{gordon2018morphnet
source = {Crossref},
title = {{MorphNet:} {Fast} \& Simple Resource-Constrained Structure Learning of Deep Networks},
url = {https://doi.org/10.1109/cvpr.2018.00171},
- year = {2018}
+ year = {2018},
+ month = jun,
}
@misc{gu2023deep,
@@ -98,16 +107,28 @@ @misc{gu2023deep
title = {Deep Learning Model Compression (ii) by Ivy Gu Medium},
url = {https://ivygdy.medium.com/deep-learning-model-compression-ii-546352ea9453},
urldate = {2023-10-20},
- year = {2023}
+ year = {2023},
}
-@misc{han2015deep,
- author = {Han and Mao and Dally},
- journal = {ArXiv preprint},
- title = {Deep Compression: {Compressing} Deep Neural Networks with Pruning, Trained Quantization and {Huffman} Coding},
- url = {https://arxiv.org/abs/1510.00149},
- volume = {abs/1510.00149},
- year = {2015}
+@article{han2015deep,
+ title={Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding},
+ author={Han, Song and Mao, Huizi and Dally, William J},
+ journal={arXiv preprint arXiv:1510.00149},
+ year={2015}
+}
+
+@article{hawks2021psandqs,
+ author = {Hawks, Benjamin and Duarte, Javier and Fraser, Nicholas J. and Pappalardo, Alessandro and Tran, Nhan and Umuroglu, Yaman},
+ title = {Ps and Qs: {Quantization-aware} Pruning for Efficient Low Latency Neural Network Inference},
+ volume = {4},
+ issn = {2624-8212},
+ url = {https://doi.org/10.3389/frai.2021.676564},
+ doi = {10.3389/frai.2021.676564},
+ journal = {Frontiers in Artificial Intelligence},
+ publisher = {Frontiers Media SA},
+ year = {2021},
+ month = jul,
+ source = {Crossref},
}
@misc{hegde2023introduction,
@@ -116,12 +137,12 @@ @misc{hegde2023introduction
title = {An Introduction to Separable Convolutions - Analytics Vidhya},
url = {https://www.analyticsvidhya.com/blog/2021/11/an-introduction-to-separable-convolutions/},
urldate = {2023-10-20},
- year = {2023}
+ year = {2023},
}
@misc{hinton2015distilling,
- archiveprefix = {arXiv},
author = {Hinton, Geoffrey},
+ archiveprefix = {arXiv},
doi = {10.1002/0471743984.vse0673},
eprint = {1503.02531},
isbn = {9780471332305, 9780471743989},
@@ -130,7 +151,8 @@ @misc{hinton2015distilling
source = {Crossref},
title = {Van {Nostrand's} Scientific Encyclopedia},
url = {https://doi.org/10.1002/0471743984.vse0673},
- year = {2005}
+ year = {2005},
+ month = oct,
}
@misc{howard2017mobilenets,
@@ -139,7 +161,7 @@ @misc{howard2017mobilenets
title = {{MobileNets:} {Efficient} Convolutional Neural Networks for Mobile Vision Applications},
url = {https://arxiv.org/abs/1704.04861},
volume = {abs/1704.04861},
- year = {2017}
+ year = {2017},
}
@article{iandola2016squeezenet,
@@ -148,16 +170,16 @@ @article{iandola2016squeezenet
title = {{SqueezeNet:} {Alexnet-level} accuracy with 50x fewer parameters and 0.5 {MB} model size},
url = {https://arxiv.org/abs/1602.07360},
volume = {abs/1602.07360},
- year = {2016}
+ year = {2016},
}
@misc{intellabs2023knowledge,
author = {IntelLabs},
- bdsk-url-1 = {https://intellabs.github.io/distiller/knowledge_distillation.html},
+ bdsk-url-1 = {https://intellabs.github.io/distiller/knowledge\_distillation.html},
title = {Knowledge Distillation - Neural Network Distiller},
url = {https://intellabs.github.io/distiller/knowledge_distillation.html},
urldate = {2023-10-20},
- year = {2023}
+ year = {2023},
}
@misc{isscc2014computings,
@@ -166,28 +188,35 @@ @misc{isscc2014computings
title = {Computing's energy problem (and what we can do about it)},
url = {https://ieeexplore.ieee.org/document/6757323},
urldate = {2014-03-06},
- year = {2014}
+ year = {2014},
}
@misc{jiang2019accuracy,
+ author = {Hu, Yang and Jiang, Jie and Zhang, Lifu and Shi, Yunfeng and Shi, Jian},
archiveprefix = {arXiv},
- author = {Jiang, Weiwen and Zhang, Xinyi and Sha, Edwin H. -M. and Yang, Lei and Zhuge, Qingfeng and Shi, Yiyu and Hu, Jingtong},
eprint = {1901.11211},
primaryclass = {cs.DC},
- title = {Accuracy vs. Efficiency: {Achieving} Both through {FPGA}-Implementation Aware Neural Architecture Search},
- year = {2019}
+ title = {Halide Perovskite Semiconductors},
+ year = {2023},
+ doi = {10.1002/9783527829026.ch13},
+ source = {Crossref},
+ url = {https://doi.org/10.1002/9783527829026.ch13},
+ publisher = {Wiley},
+ isbn = {9783527348091, 9783527829026},
+ pages = {351--375},
+ month = dec,
}
@inproceedings{jonathan2019lottery,
- author = {Jonathan Frankle and Michael Carbin},
+ author = {Frankle, Jonathan and Carbin, Michael},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/iclr/FrankleC19.bib},
- booktitle = {7th International Conference on Learning Representations, {ICLR} 2019, New Orleans, LA, USA, May 6-9, 2019},
+ booktitle = {7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019},
publisher = {OpenReview.net},
timestamp = {Thu, 25 Jul 2019 01:00:00 +0200},
- title = {The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks},
+ title = {The Lottery Ticket Hypothesis: {Finding} Sparse, Trainable Neural Networks},
url = {https://openreview.net/forum?id=rJl-b3RcF7},
- year = {2019}
+ year = {2019},
}
@article{koren2009matrix,
@@ -195,19 +224,24 @@ @article{koren2009matrix
journal = {Computer},
number = {8},
pages = {30--37},
- publisher = {IEEE},
- title = {Matrix factorization techniques for recommender systems},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ title = {Matrix Factorization Techniques for Recommender Systems},
volume = {42},
- year = {2009}
+ year = {2009},
+ doi = {10.1109/mc.2009.263},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/mc.2009.263},
+ issn = {0018-9162},
+ month = aug,
}
@misc{krishna2023raman,
- archiveprefix = {arXiv},
author = {Krishna, Adithya and Nudurupati, Srikanth Rohit and G, Chandana D and Dwivedi, Pritesh and van Schaik, Andr\'e and Mehendale, Mahesh and Thakur, Chetan Singh},
+ archiveprefix = {arXiv},
eprint = {2306.06493},
primaryclass = {cs.NE},
title = {{RAMAN:} {A} Re-configurable and Sparse {TinyML} Accelerator for Inference on Edge},
- year = {2023}
+ year = {2023},
}
@misc{krishnamoorthi2018quantizing,
@@ -216,30 +250,30 @@ @misc{krishnamoorthi2018quantizing
title = {Quantizing deep convolutional networks for efficient inference: {A} whitepaper},
url = {https://arxiv.org/abs/1806.08342},
volume = {abs/1806.08342},
- year = {2018}
+ year = {2018},
}
@misc{kung2018packing,
- archiveprefix = {arXiv},
author = {Kung, H. T. and McDanel, Bradley and Zhang, Sai Qian},
+ archiveprefix = {arXiv},
eprint = {1811.04770},
primaryclass = {cs.LG},
title = {Packing Sparse Convolutional Neural Networks for Efficient Systolic Array Implementations: {Column} Combining Under Joint Optimization},
- year = {2018}
+ year = {2018},
}
@misc{kuzmin2022fp8,
- archiveprefix = {arXiv},
author = {Kuzmin, Andrey and Baalen, Mart Van and Ren, Yuwei and Nagel, Markus and Peters, Jorn and Blankevoort, Tijmen},
+ archiveprefix = {arXiv},
eprint = {2208.09225},
primaryclass = {cs.LG},
title = {{FP8} Quantization: {The} Power of the Exponent},
- year = {2022}
+ year = {2022},
}
@article{kwon2021hardwaresoftware,
- article-number = {11073},
author = {Kwon, Jisu and Park, Daejin},
+ article-number = {11073},
bdsk-url-1 = {https://www.mdpi.com/2076-3417/11/22/11073},
bdsk-url-2 = {https://doi.org/10.3390/app112211073},
doi = {10.3390/app112211073},
@@ -252,28 +286,29 @@ @article{kwon2021hardwaresoftware
title = {{Hardware/Software} Co-Design for {TinyML} Voice-Recognition Application on Resource Frugal Edge Devices},
url = {https://doi.org/10.3390/app112211073},
volume = {11},
- year = {2021}
+ year = {2021},
+ month = nov,
}
@misc{lai2018cmsisnn,
- archiveprefix = {arXiv},
author = {Lai, Liangzhen and Suda, Naveen and Chandra, Vikas},
+ archiveprefix = {arXiv},
eprint = {1801.06601},
primaryclass = {cs.NE},
title = {{CMSIS}-{NN:} {Efficient} Neural Network Kernels for Arm Cortex-M {CPUs}},
- year = {2018}
+ year = {2018},
}
@inproceedings{lin2020mcunet,
- author = {Ji Lin and Wei{-}Ming Chen and Yujun Lin and John Cohn and Chuang Gan and Song Han},
+ author = {Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Cohn, John and Gan, Chuang and Han, Song},
+ editor = {Larochelle, Hugo and Ranzato, Marc'Aurelio and Hadsell, Raia and Balcan, Maria-Florina and Lin, Hsuan-Tien},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/LinCLCG020.bib},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual},
- editor = {Hugo Larochelle and Marc'Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin},
timestamp = {Thu, 11 Feb 2021 00:00:00 +0100},
- title = {MCUNet: Tiny Deep Learning on IoT Devices},
+ title = {{MCUNet:} {Tiny} Deep Learning on {IoT} Devices},
url = {https://proceedings.neurips.cc/paper/2020/hash/86c51678350f656dcc7f490a43946ee5-Abstract.html},
- year = {2020}
+ year = {2020},
}
@misc{lin2023awq,
@@ -282,21 +317,26 @@ @misc{lin2023awq
title = {{AWQ:} {Activation-aware} Weight Quantization for {LLM} Compression and Acceleration},
url = {https://arxiv.org/abs/2306.00978},
volume = {abs/2306.00978},
- year = {2023}
+ year = {2023},
}
@inproceedings{prakash2022cfu,
author = {Prakash, Shvetank and Callahan, Tim and Bushagour, Joseph and Banbury, Colby and Green, Alan V. and Warden, Pete and Ansell, Tim and Reddi, Vijay Janapa},
journal = {ArXiv preprint},
title = {{CFU} Playground: {Full-stack} Open-Source Framework for Tiny Machine Learning {(TinyML)} Acceleration on {FPGAs}},
- url = {https://arxiv.org/abs/2201.01863},
+ url = {https://doi.org/10.1109/ispass57527.2023.00024},
volume = {abs/2201.01863},
- year = {2022}
+ year = {2023},
+ doi = {10.1109/ispass57527.2023.00024},
+ source = {Crossref},
+ booktitle = {2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)},
+ publisher = {IEEE},
+ month = apr,
}
@article{qi2021efficient,
- abstract = {Nowadays, deep neural networks (DNNs) have been rapidly deployed to realize a number of functionalities like sensing, imaging, classification, recognition, etc. However, the computational-intensive requirement of DNNs makes it difficult to be applicable for resource-limited Internet of Things (IoT) devices. In this paper, we propose a novel pruning-based paradigm that aims to reduce the computational cost of DNNs, by uncovering a more compact structure and learning the effective weights therein, on the basis of not compromising the expressive capability of DNNs. In particular, our algorithm can achieve efficient end-to-end training that transfers a redundant neural network to a compact one with a specifically targeted compression rate directly. We comprehensively evaluate our approach on various representative benchmark datasets and compared with typical advanced convolutional neural network (CNN) architectures. The experimental results verify the superior performance and robust effectiveness of our scheme. For example, when pruning VGG on CIFAR-10, our proposed scheme is able to significantly reduce its FLOPs (floating-point operations) and number of parameters with a proportion of 76.2\% and 94.1\%, respectively, while still maintaining a satisfactory accuracy. To sum up, our scheme could facilitate the integration of DNNs into the common machine-learning-based IoT framework and establish distributed training of neural networks in both cloud and edge.},
author = {Qi, Chen and Shen, Shibo and Li, Rongpeng and Zhao, Zhifeng and Liu, Qing and Liang, Jing and Zhang, Honggang},
+ abstract = {Nowadays, deep neural networks (DNNs) have been rapidly deployed to realize a number of functionalities like sensing, imaging, classification, recognition, etc. However, the computational-intensive requirement of DNNs makes it difficult to be applicable for resource-limited Internet of Things (IoT) devices. In this paper, we propose a novel pruning-based paradigm that aims to reduce the computational cost of DNNs, by uncovering a more compact structure and learning the effective weights therein, on the basis of not compromising the expressive capability of DNNs. In particular, our algorithm can achieve efficient end-to-end training that transfers a redundant neural network to a compact one with a specifically targeted compression rate directly. We comprehensively evaluate our approach on various representative benchmark datasets and compared with typical advanced convolutional neural network (CNN) architectures. The experimental results verify the superior performance and robust effectiveness of our scheme. For example, when pruning VGG on CIFAR-10, our proposed scheme is able to significantly reduce its FLOPs (floating-point operations) and number of parameters with a proportion of 76.2\% and 94.1\%, respectively, while still maintaining a satisfactory accuracy. To sum up, our scheme could facilitate the integration of DNNs into the common machine-learning-based IoT framework and establish distributed training of neural networks in both cloud and edge.},
bdsk-url-1 = {https://doi.org/10.1186/s13634-021-00744-4},
doi = {10.1186/s13634-021-00744-4},
file = {Full Text PDF:/Users/jeffreyma/Zotero/storage/AGWCC5VS/Qi et al. - 2021 - An efficient pruning scheme of deep neural network.pdf:application/pdf},
@@ -308,47 +348,50 @@ @article{qi2021efficient
title = {An efficient pruning scheme of deep neural networks for Internet of Things applications},
url = {https://doi.org/10.1186/s13634-021-00744-4},
volume = {2021},
- year = {2021}
+ year = {2021},
+ month = jun,
}
@article{sheng2019qbert,
- author = {Sheng Shen and
-Zhen Dong and
-Jiayu Ye and
-Linjian Ma and
-Zhewei Yao and
-Amir Gholami and
-Michael W. Mahoney and
-Kurt Keutzer},
+ author = {Shen, Sheng and Dong, Zhen and Ye, Jiayu and Ma, Linjian and Yao, Zhewei and Gholami, Amir and Mahoney, Michael W. and Keutzer, Kurt},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/journals/corr/abs-1909-05840.bib},
eprint = {1909.05840},
eprinttype = {arXiv},
- journal = {CoRR},
+ journal = {Proceedings of the AAAI Conference on Artificial Intelligence},
timestamp = {Wed, 18 Sep 2019 10:38:36 +0200},
- title = {{Q-BERT:} Hessian Based Ultra Low Precision Quantization of {BERT}},
- url = {http://arxiv.org/abs/1909.05840},
- volume = {abs/1909.05840},
- year = {2019}
+ title = {Q-{BERT:} {Hessian} Based Ultra Low Precision Quantization of {BERT}},
+ url = {https://doi.org/10.1609/aaai.v34i05.6409},
+ volume = {34},
+ year = {2020},
+ doi = {10.1609/aaai.v34i05.6409},
+ number = {05},
+ source = {Crossref},
+ publisher = {Association for the Advancement of Artificial Intelligence (AAAI)},
+ issn = {2374-3468, 2159-5399},
+ pages = {8815--8821},
+ month = apr,
}
@inproceedings{tan2019mnasnet,
- author = {Mingxing Tan and Bo Chen and Ruoming Pang and Vijay Vasudevan and Mark Sandler and Andrew Howard and Quoc V. Le},
+ author = {Tan, Mingxing and Chen, Bo and Pang, Ruoming and Vasudevan, Vijay and Sandler, Mark and Howard, Andrew and Le, Quoc V.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/TanCPVSHL19.bib},
- booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition, {CVPR} 2019, Long Beach, CA, USA, June 16-20, 2019},
- doi = {10.1109/CVPR.2019.00293},
+ booktitle = {2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr.2019.00293},
pages = {2820--2828},
- publisher = {Computer Vision Foundation / {IEEE}},
+ publisher = {IEEE},
timestamp = {Tue, 12 Jan 2021 00:00:00 +0100},
- title = {MnasNet: Platform-Aware Neural Architecture Search for Mobile},
- url = {http://openaccess.thecvf.com/content\_CVPR\_2019/html/Tan\_MnasNet\_Platform-Aware\_Neural\_Architecture\_Search\_for\_Mobile\_CVPR\_2019\_paper.html},
- year = {2019}
+ title = {{MnasNet:} {Platform-aware} Neural Architecture Search for Mobile},
+ url = {https://doi.org/10.1109/cvpr.2019.00293},
+ year = {2019},
+ source = {Crossref},
+ month = jun,
}
@misc{tan2020efficientnet,
- archiveprefix = {arXiv},
author = {Tan, Mingxing and Le, Quoc V.},
+ archiveprefix = {arXiv},
doi = {10.1002/9781394205639.ch6},
eprint = {1905.11946},
isbn = {9781394205608, 9781394205639},
@@ -358,36 +401,38 @@ @misc{tan2020efficientnet
source = {Crossref},
title = {Demystifying Deep Learning},
url = {https://doi.org/10.1002/9781394205639.ch6},
- year = {2023}
+ year = {2023},
+ month = dec,
}
@misc{ultimate,
bdsk-url-1 = {https://deci.ai/quantization-and-quantization-aware-training/},
title = {The Ultimate Guide to Deep Learning Model Quantization and Quantization-Aware Training},
- url = {https://deci.ai/quantization-and-quantization-aware-training/}
+ url = {https://deci.ai/quantization-and-quantization-aware-training/},
}
-@misc{vaswani2023attention,
- archiveprefix = {arXiv},
- author = {Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin},
- eprint = {1706.03762},
- primaryclass = {cs.CL},
- title = {Attention Is All You Need},
- year = {2023}
+@article{vaswani2017attention,
+ title={Attention is all you need},
+ author={Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {\L}ukasz and Polosukhin, Illia},
+ journal={Advances in neural information processing systems},
+ volume={30},
+ year={2017}
}
@inproceedings{wu2019fbnet,
- author = {Bichen Wu and Xiaoliang Dai and Peizhao Zhang and Yanghan Wang and Fei Sun and Yiming Wu and Yuandong Tian and Peter Vajda and Yangqing Jia and Kurt Keutzer},
+ author = {Wu, Bichen and Keutzer, Kurt and Dai, Xiaoliang and Zhang, Peizhao and Wang, Yanghan and Sun, Fei and Wu, Yiming and Tian, Yuandong and Vajda, Peter and Jia, Yangqing},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/cvpr/WuDZWSWTVJK19.bib},
- booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition, {CVPR} 2019, Long Beach, CA, USA, June 16-20, 2019},
- doi = {10.1109/CVPR.2019.01099},
+ booktitle = {2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ doi = {10.1109/cvpr.2019.01099},
pages = {10734--10742},
- publisher = {Computer Vision Foundation / {IEEE}},
+ publisher = {IEEE},
timestamp = {Mon, 20 Jan 2020 00:00:00 +0100},
- title = {FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search},
- url = {http://openaccess.thecvf.com/content\_CVPR\_2019/html/Wu\_FBNet\_Hardware-Aware\_Efficient\_ConvNet\_Design\_via\_Differentiable\_Neural\_Architecture\_Search\_CVPR\_2019\_paper.html},
- year = {2019}
+ title = {{FBNet:} {Hardware-aware} Efficient {ConvNet} Design via Differentiable Neural Architecture Search},
+ url = {https://doi.org/10.1109/cvpr.2019.01099},
+ year = {2019},
+ source = {Crossref},
+ month = jun,
}
@misc{wu2020integer,
@@ -396,7 +441,7 @@ @misc{wu2020integer
title = {Integer Quantization for Deep Learning Inference: {Principles} and Empirical Evaluation)},
url = {https://arxiv.org/abs/2004.09602},
volume = {abs/2004.09602},
- year = {2020}
+ year = {2020},
}
@misc{xiao2022smoothquant,
@@ -405,30 +450,30 @@ @misc{xiao2022smoothquant
title = {{SmoothQuant:} {Accurate} and Efficient Post-Training Quantization for Large Language Models},
url = {https://arxiv.org/abs/2211.10438},
volume = {abs/2211.10438},
- year = {2022}
+ year = {2022},
}
@misc{xinyu,
- abstract = {Some simple examples for showing how to use tensor decomposition to reconstruct fluid dynamics},
author = {Xinyu, Chen},
- bdsk-url-1 = {https://medium.com/}
+ abstract = {Some simple examples for showing how to use tensor decomposition to reconstruct fluid dynamics},
+ bdsk-url-1 = {https://medium.com/},
}
@inproceedings{xu2018alternating,
- author = {Chen Xu and Jianqiang Yao and Zhouchen Lin and Wenwu Ou and Yuanbin Cao and Zhirong Wang and Hongbin Zha},
+ author = {Xu, Chen and Yao, Jianqiang and Lin, Zhouchen and Ou, Wenwu and Cao, Yuanbin and Wang, Zhirong and Zha, Hongbin},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/iclr/XuYLOCWZ18.bib},
- booktitle = {6th International Conference on Learning Representations, {ICLR} 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings},
+ booktitle = {6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings},
publisher = {OpenReview.net},
timestamp = {Thu, 25 Jul 2019 01:00:00 +0200},
title = {Alternating Multi-bit Quantization for Recurrent Neural Networks},
url = {https://openreview.net/forum?id=S19dR9x0b},
- year = {2018}
+ year = {2018},
}
@misc{yang2020coexploration,
- archiveprefix = {arXiv},
author = {Ho Yoon, Jung and Jung, Hyung-Suk and Hwan Lee, Min and Hwan Kim, Gun and Ji Song, Seul and Yeong Seok, Jun and Jean Yoon, Kyung and Seong Hwang, Cheol and Besland, M.-P. and Tranchant, J. and Souchier, E. and Moreau, P. and Salmon, S. and Corraze, B. and Janod, E. and Cario, L. and Zazpe, Ra\'ul and Ungureanu, Mariana and Llopis, Roger and Golmar, Federico and Stoliar, Pablo and Casanova, F\'elix and Eduardo Hueso, Luis and Hermes, C. and Wimmer, M. and Menzel, S. and Fleck, K. and Rana, V. and Salinga, M. and B\"ottger, U. and Bruchhaus, R. and Wuttig, M. and Waser, R. and Lentz, F. and Hermes, C. and R\"osgen, B. and Selle, T. and Bruchhaus, R. and Rana, V. and Waser, R. and Marchewka, Astrid and Menzel, Stephan and B\"ottger, Ulrich and Waser, Rainer and Hoskins, Brian and Alibart, Fabien and Strukov, Dmitri and Pellegrino, Luca and Manca, Nicola and Kanki, Teruo and Tanaka, Hidekazu and Biasotti, Michele and Bellingeri, Emilio and Sergio Siri, Antonio and Marr\'e, Daniele and M. Padilha, Antonio Claudio and Martini Dalpian, Gustavo and Reily Rocha, Alexandre and Prodromakis, Themistoklis and Salaoru, Iulia and Khiat, Ali and Toumazou, Christopher and Gale, Ella M. and Madhavan, A. and Adam, G. and Alibart, F. and Gao, L. and Strukov, D. B. and Wamwangi, D. and Welnic, W. and Wuttig, M. and Gholipour, Behrad and Huang, Chung-Che and Anastasopoulos, Alexandros and Al-Saab, Feras and Hayden, Brian E. and Hewak, Daniel W. and Lan, Rui and Endo, Rie and Kuwahara, Masashi and Kobayashi, Yoshinao and Susa, Masahiro and Baumeister, Paul and Wortmann, Daniel and Bl\"ugel, Stefan and Mazzarello, Riccardo and Li, Yan and Zhang, Wei and Ronneberger, Ider and Simon, Ronnie and Gallus, Jens and Bessas, Dimitrios and Sergueev, Ilya and Wille, Hans-Christian and Pierre Hermann, Rapha\"el and Luckas, Jennifer and Rausch, Pascal and Krebs, Daniel and Zalden, Peter and Boltz, Janika and Raty, Jean-Yves and Salinga, Martin and Longeaud, Christophe and Wuttig, Matthias and Kim, Haeri and Kim, Dong-Wook and Phark, Soo-Hyon and Hong, Seungbum and Park, C. and Herpers, A. and Bruchhaus, R. and Verbeeck, J. and Egoavil, R. and Borgatti, F. and Panaccione, G. and Offi, F. and Dittmann, R. and Clima, Sergiu and Sankaran, Kiroubanand and Mees, Maarten and Yin Chen, Yang and Goux, Ludovic and Govoreanu, Bogdan and Wouters, Dirk J. and Kittl, Jorge and Jurczak, Malgorzata and Pourtois, Geoffrey and Calka, P. and Martinez, E. and Delaye, V. and Lafond, D. and Audoit, G. and Mariolle, D. and Chevalier, N. and Grampeix, H. and Cagli, C. and Jousseaume, V. and Guedj, C. and Shrestha, Pragya and Ochia, Adaku and Cheung, Kin. P. and Campbell, Jason and Baumgart, Helmut and Harris, Gary and Scherff, Malte and Meyer, Bjoern and Scholz, Julius and Hoffmann, Joerg and Jooss, Christian and Xiao, Bo and Tada, Tomofumi and Gu, Tingkun and Tawara, Arihiro and Watanabe, Satoshi and Young, Tai-Fa and Yang, Ya-Liang and Chang, Ting-Chang and Hsu, Kuang-Ting and Chen, Chao-Yu and Burkert, A and Valov, I. and Staikov, G. and Waser, R. and van den Hurk, Jan and Valov, Ilia and Waser, Rainer and Valov, Ilia and Tappertzhofen, Stefan and van der Hurk, Jan and Waser, Rainer and Adam, G. and Alibart, F. and Gao, L. and Hoskins, B. and Strukov, D. B. and Jean Yoon, Kyung and Ji Song, Seul and Kim, Gun Hwan and Seok, Jun Yeong and Ho Yoon, Jeong and Seong Hwang, Cheol and Yoon, Jung Ho and Yoon, Kyung Jin and Shuai, Yao and Wu, Chuangui and Zhang, Wanli and Zhou, Shengqiang and B\"urger, Danilo and Slesazeck, Stefan and Mikolajick, Thomas and Helm, Manfred and Schmidt, Heidemarie and Gale, Ella and Pearson, David and Kitson, Stephen and Adamatzky, Andrew and Costello, Ben de Lacy and Lehtonen, Eero and Poikonen, Jussi and Laiho, Mika and Kanerva, Pentti and Lim, Hyungkwang and Jang, Ho-won and Jeong, Doo Seok and Cao, Xun and Jiang, Meng and Zhang, Feng and Liu, Xinjun and Jin, Ping and Zhang, Kai and Tangirala, Madhavi and Shrestha, Pragya and Baumgart, Helmut and Kittiwatanakul, Salinporn and Lu, Jiwei and Wolf, Stuart and Pallem, Venkateswara and Dussarrat, Christian and Pinto, S. and Krishna, R. and Dias, C. and Pimentel, G. and Oliveira, G. N. P. and Teixeira, J. M. and Aguiar, P. and Titus, E. and Gracio, J. and Ventura, J. and Araujo, J. P.},
+ archiveprefix = {arXiv},
doi = {10.1002/9783527667703.ch67},
eprint = {2002.04116},
isbn = {9783527411917, 9783527667703},
@@ -438,20 +483,21 @@ @misc{yang2020coexploration
source = {Crossref},
title = {Frontiers in Electronic Materials},
url = {https://doi.org/10.1002/9783527667703.ch67},
- year = {2012}
+ year = {2012},
+ month = jun,
}
@inproceedings{zhang2019autoshrink,
- author = {Tunhou Zhang and Hsin{-}Pai Cheng and Zhenwen Li and Feng Yan and Chengyu Huang and Hai Helen Li and Yiran Chen},
+ author = {Zhang, Tunhou and Cheng, Hsin-Pai and Li, Zhenwen and Yan, Feng and Huang, Chengyu and Li, Hai Helen and Chen, Yiran},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/aaai/ZhangCL0HLC20.bib},
- booktitle = {The Thirty-Fourth {AAAI} Conference on Artificial Intelligence, {AAAI} 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, {IAAI} 2020, The Tenth {AAAI} Symposium on Educational Advances in Artificial Intelligence, {EAAI} 2020, New York, NY, USA, February 7-12, 2020},
+ booktitle = {The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020},
pages = {6829--6836},
- publisher = {{AAAI} Press},
+ publisher = {AAAI Press},
timestamp = {Tue, 02 Feb 2021 00:00:00 +0100},
- title = {AutoShrink: {A} Topology-Aware {NAS} for Discovering Efficient Neural Architecture},
+ title = {{AutoShrink:} {A} Topology-Aware {NAS} for Discovering Efficient Neural Architecture},
url = {https://aaai.org/ojs/index.php/AAAI/article/view/6163},
- year = {2020}
+ year = {2020},
}
@inproceedings{zhang2020fast,
@@ -462,27 +508,15 @@ @inproceedings{zhang2020fast
source = {Crossref},
title = {Fast Hardware-Aware Neural Architecture Search},
url = {https://doi.org/10.1109/cvprw50498.2020.00354},
- year = {2020}
+ year = {2020},
+ month = jun,
}
@misc{zhou2021analognets,
- archiveprefix = {arXiv},
author = {Zhou, Chuteng and Redondo, Fernando Garcia and B\"uchel, Julian and Boybat, Irem and Comas, Xavier Timoneda and Nandakumar, S. R. and Das, Shidhartha and Sebastian, Abu and Gallo, Manuel Le and Whatmough, Paul N.},
+ archiveprefix = {arXiv},
eprint = {2111.06503},
primaryclass = {cs.AR},
title = {{AnalogNets:} {Ml-hw} Co-Design of Noise-robust {TinyML} Models and Always-On Analog Compute-in-Memory Accelerator},
- year = {2021}
-}
-
-@article{hawks2021psandqs,
- title = {Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference},
- volume = {4},
- ISSN = {2624-8212},
- url = {http://dx.doi.org/10.3389/frai.2021.676564},
- DOI = {10.3389/frai.2021.676564},
- journal = {Frontiers in Artificial Intelligence},
- publisher = {Frontiers Media SA},
- author = {Hawks, Benjamin and Duarte, Javier and Fraser, Nicholas J. and Pappalardo, Alessandro and Tran, Nhan and Umuroglu, Yaman},
year = {2021},
- month = jul
-}
\ No newline at end of file
+}
diff --git a/contents/optimizations/optimizations.qmd b/contents/optimizations/optimizations.qmd
index 8bb15d42..6041b9a1 100644
--- a/contents/optimizations/optimizations.qmd
+++ b/contents/optimizations/optimizations.qmd
@@ -8,7 +8,7 @@ bibliography: optimizations.bib
Resources: [Slides](#sec-model-optimizations-resource), [Labs](#sec-model-optimizations-resource), [Exercises](#sec-model-optimizations-resource)
:::
-
+
When machine learning models are deployed on systems, especially on resource-constrained embedded systems, the optimization of models is a necessity. While machine learning inherently often demands substantial computational resources, the systems are inherently limited in memory, processing power, and energy. This chapter will dive into the art and science of optimizing machine learning models to ensure they are lightweight, efficient, and effective when deployed in TinyML scenarios.
@@ -148,7 +148,7 @@ Unstructured pruning has some advantages over structured pruning: removing indiv
Unstructured pruning, while offering the potential for significant model size reduction and enhanced deployability, brings with it challenges related to managing sparse representations and ensuring computational efficiency. It is particularly useful in scenarios where achieving the highest possible model compression is paramount and where the deployment environment can handle sparse computations efficiently.
-The following compact table provides a concise comparison between structured and unstructured pruning. In this table, aspects related to the nature and architecture of the pruned model (Definition, Model Regularity, and Compression Level) are grouped together, followed by aspects related to computational considerations (Computational Efficiency and Hardware Compatibility), and ending with aspects related to the implementation and adaptation of the pruned model (Implementation Complexity and Fine-Tuning Complexity). Both pruning strategies offer unique advantages and challenges, and the selection between them should be influenced by specific project and deployment requirements.
+@tbl-pruning_methods provides a concise comparison between structured and unstructured pruning. In this table, aspects related to the nature and architecture of the pruned model (Definition, Model Regularity, and Compression Level) are grouped together, followed by aspects related to computational considerations (Computational Efficiency and Hardware Compatibility), and ending with aspects related to the implementation and adaptation of the pruned model (Implementation Complexity and Fine-Tuning Complexity). Both pruning strategies offer unique advantages and challenges, as shown in @tbl-pruning_methods, and the selection between them should be influenced by specific project and deployment requirements.
| **Aspect** | **Structured Pruning** | **Unstructured Pruning** |
|------------------------------|------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------|
@@ -160,6 +160,8 @@ The following compact table provides a concise comparison between structured and
| **Implementation Complexity**| Often simpler to implement and manage due to maintaining network structure | Can be complex to manage and compute due to sparse representations |
| **Fine-Tuning Complexity** | May require less complex fine-tuning strategies post-pruning | Might necessitate more complex retraining or fine-tuning strategies post-pruning |
+: Comparing structured versus unstructured pruning strategies. {#tbl-pruning_methods}
+
{#fig-structured-unstructured}
#### Lottery Ticket Hypothesis
@@ -381,7 +383,7 @@ Precision, delineating the exactness with which a number is represented, bifurca
**Double Precision (Float64):** Allocating 64 bits, double precision (e.g., 3.141592653589793) provides heightened accuracy, albeit demanding augmented memory and computational resources. In scientific computations, where precision is paramount, variables like π might be represented with Float64.
-**Single Precision (Float32)**: With 32 bits at its disposal, single precision (e.g., 3.1415927) strikes a balance between numerical accuracy and memory conservation. In ML, Float32 might be employed to store weights during training to maintain a reasonable level of precision.
+**Single Precision (Float32):** With 32 bits at its disposal, single precision (e.g., 3.1415927) strikes a balance between numerical accuracy and memory conservation. In ML, Float32 might be employed to store weights during training to maintain a reasonable level of precision.
**Half Precision (Float16):** Constrained to 16 bits, half precision (e.g., 3.14) curtails memory usage and can expedite computations, albeit sacrificing numerical accuracy and range. In ML, especially during inference on resource-constrained devices, Float16 might be utilized to reduce the model's memory footprint.
@@ -613,7 +615,7 @@ Upon deciding the type of clipping range, it is essential to tighten the range t
{#fig-quantization-granularity}
1. Layerwise Quantization: This approach determines the clipping range by considering all of the weights in the convolutional filters of a layer. Then, the same clipping range is used for all convolutional filters. It's the simplest to implement, and, as such, it often results in sub-optimal accuracy due the wide variety of differing ranges between filters. For example, a convolutional kernel with a narrower range of parameters loses its quantization resolution due to another kernel in the same layer having a wider range.
-2. Groupwise Quantization: This approach groups different channels inside a layer to calculate the clipping range. This method can be helpful when the distribution of parameters across a single convolution/activation varies a lot. In practice, this method was useful in Q-BERT [@sheng2019qbert] for quantizing Transformer [@vaswani2023attention] models that consist of fully-connected attention layers. The downside with this approach comes with the extra cost of accounting for different scaling factors.
+2. Groupwise Quantization: This approach groups different channels inside a layer to calculate the clipping range. This method can be helpful when the distribution of parameters across a single convolution/activation varies a lot. In practice, this method was useful in Q-BERT [@sheng2019qbert] for quantizing Transformer [@vaswani2017attention] models that consist of fully-connected attention layers. The downside with this approach comes with the extra cost of accounting for different scaling factors.
3. Channelwise Quantization: This popular method uses a fixed range for each convolutional filter that is independent of other channels. Because each channel is assigned a dedicated scaling factor, this method ensures a higher quantization resolution and often results in higher accuracy.
4. Sub-channelwise Quantization: Taking channelwise quantization to the extreme, this method determines the clipping range with respect to any groups of parameters in a convolution or fully-connected layer. It may result in considerable overhead since different scaling factors need to be taken into account when processing a single convolution or fully-connected layer.
@@ -707,6 +709,8 @@ In addition to being an indispensable technique for many edge processors, quanti
Thus, quantization combined with efficient low-precision logic and dedicated deep learning accelerators, has been one crucial driving force for the evolution of such edge processors.
+The video below is a lecture on quantization and the different quantization methods.
+
{{< video https://www.youtube.com/watch?v=AlASZb93rrc >}}
## Efficient Hardware Implementation {#sec-model_ops_hw}
@@ -982,5 +986,5 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/privacy_security/privacy_security.bib b/contents/privacy_security/privacy_security.bib
index caca7414..2a3edc3e 100644
--- a/contents/privacy_security/privacy_security.bib
+++ b/contents/privacy_security/privacy_security.bib
@@ -1,6 +1,184 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
+@inproceedings{Asonov2004Keyboard,
+ author = {Asonov, D. and Agrawal, R.},
+ booktitle = {IEEE Symposium on Security and Privacy, 2004. Proceedings. 2004},
+ date-added = {2023-11-22 17:05:39 -0500},
+ date-modified = {2023-11-22 17:06:45 -0500},
+ doi = {10.1109/secpri.2004.1301311},
+ organization = {IEEE},
+ pages = {3--11},
+ publisher = {IEEE},
+ source = {Crossref},
+ title = {Keyboard acoustic emanations},
+ url = {https://doi.org/10.1109/secpri.2004.1301311},
+ year = {2004},
+}
+
+@inproceedings{Biega2020Oper,
+ author = {Biega, Asia J. and Potash, Peter and Daum\'e, Hal and Diaz, Fernando and Finck, Mich\`ele},
+ editor = {Huang, Jimmy and Chang, Yi and Cheng, Xueqi and Kamps, Jaap and Murdock, Vanessa and Wen, Ji-Rong and Liu, Yiqun},
+ bibsource = {dblp computer science bibliography, https://dblp.org},
+ biburl = {https://dblp.org/rec/conf/sigir/BiegaPDDF20.bib},
+ booktitle = {Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval},
+ doi = {10.1145/3397271.3401034},
+ pages = {399--408},
+ publisher = {ACM},
+ timestamp = {Thu, 03 Sep 2020 01:00:00 +0200},
+ title = {Operationalizing the Legal Principle of Data Minimization for Personalization},
+ url = {https://doi.org/10.1145/3397271.3401034},
+ year = {2020},
+ source = {Crossref},
+ month = jul,
+}
+
+@article{Burnet1989Spycatcher,
+ author = {Burnet, David and Thomas, Richard},
+ date-added = {2023-11-22 17:03:00 -0500},
+ date-modified = {2023-11-22 17:04:44 -0500},
+ doi = {10.2307/1410360},
+ issn = {0263-323X},
+ journal = {J. Law Soc.},
+ number = {2},
+ pages = {210},
+ publisher = {JSTOR},
+ source = {Crossref},
+ title = {Spycatcher: {The} Commodification of Truth},
+ url = {https://doi.org/10.2307/1410360},
+ volume = {16},
+ year = {1989},
+}
+
+@inproceedings{Dwork2006Theory,
+ author = {Dwork, Cynthia and McSherry, Frank and Nissim, Kobbi and Smith, Adam},
+ editor = {Halevi, Shai and Rabin, Tal},
+ address = {Berlin, Heidelberg},
+ booktitle = {Theory of Cryptography},
+ date-added = {2023-11-22 18:04:12 -0500},
+ date-modified = {2023-11-22 18:05:20 -0500},
+ pages = {265--284},
+ publisher = {Springer Berlin Heidelberg},
+ title = {Calibrating Noise to Sensitivity in Private Data Analysis},
+ year = {2006},
+}
+
+@article{Gao2020Physical,
+ author = {Gao, Yansong and Al-Sarawi, Said F. and Abbott, Derek},
+ date-added = {2023-11-22 17:52:20 -0500},
+ date-modified = {2023-11-22 17:54:56 -0500},
+ doi = {10.1038/s41928-020-0372-5},
+ issn = {2520-1131},
+ journal = {Nature Electronics},
+ number = {2},
+ pages = {81--91},
+ publisher = {Springer Science and Business Media LLC},
+ source = {Crossref},
+ title = {Physical unclonable functions},
+ url = {https://doi.org/10.1038/s41928-020-0372-5},
+ volume = {3},
+ year = {2020},
+ month = feb,
+}
+
+@article{Gupta2023ChatGPT,
+ author = {Gupta, Maanak and Akiri, Charankumar and Aryal, Kshitiz and Parker, Eli and Praharaj, Lopamudra},
+ date-added = {2023-11-22 18:01:41 -0500},
+ date-modified = {2023-11-22 18:02:55 -0500},
+ doi = {10.1109/access.2023.3300381},
+ issn = {2169-3536},
+ journal = {\#IEEE\_O\_ACC\#},
+ pages = {80218--80245},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ source = {Crossref},
+ title = {From {ChatGPT} to {ThreatGPT:} {Impact} of Generative {AI} in Cybersecurity and Privacy},
+ url = {https://doi.org/10.1109/access.2023.3300381},
+ volume = {11},
+ year = {2023},
+}
+
+@article{Kocher2011Intro,
+ author = {Kocher, Paul and Jaffe, Joshua and Jun, Benjamin and Rohatgi, Pankaj},
+ date-added = {2023-11-22 16:58:42 -0500},
+ date-modified = {2023-11-22 17:00:36 -0500},
+ doi = {10.1007/s13389-011-0006-y},
+ issn = {2190-8508, 2190-8516},
+ journal = {Journal of Cryptographic Engineering},
+ number = {1},
+ pages = {5--27},
+ publisher = {Springer Science and Business Media LLC},
+ source = {Crossref},
+ title = {Introduction to differential power analysis},
+ url = {https://doi.org/10.1007/s13389-011-0006-y},
+ volume = {1},
+ year = {2011},
+ month = mar,
+}
+
+@inproceedings{Kocher2018spectre,
+ author = {Kocher, Paul and Horn, Jann and Fogh, Anders and Genkin, Daniel and Gruss, Daniel and Haas, Werner and Hamburg, Mike and Lipp, Moritz and Mangard, Stefan and Prescher, Thomas and Schwarz, Michael and Yarom, Yuval},
+ booktitle = {2019 IEEE Symposium on Security and Privacy (SP)},
+ date-added = {2023-11-22 16:33:35 -0500},
+ date-modified = {2023-11-22 16:34:01 -0500},
+ doi = {10.1109/sp.2019.00002},
+ publisher = {IEEE},
+ source = {Crossref},
+ title = {Spectre Attacks: {Exploiting} Speculative Execution},
+ url = {https://doi.org/10.1109/sp.2019.00002},
+ year = {2019},
+ month = may,
+}
+
+@article{Li2020Federated,
+ author = {Li, Tian and Sahu, Anit Kumar and Talwalkar, Ameet and Smith, Virginia},
+ date-added = {2023-11-22 19:15:13 -0500},
+ date-modified = {2023-11-22 19:17:19 -0500},
+ doi = {10.1109/msp.2020.2975749},
+ issn = {1053-5888, 1558-0792},
+ journal = {IEEE Signal Process Mag.},
+ number = {3},
+ pages = {50--60},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ source = {Crossref},
+ title = {Federated Learning: {Challenges,} Methods, and Future Directions},
+ url = {https://doi.org/10.1109/msp.2020.2975749},
+ volume = {37},
+ year = {2020},
+ month = may,
+}
+
+@inproceedings{Lipp2018meltdown,
+ author = {Kocher, Paul and Horn, Jann and Fogh, Anders and Genkin, Daniel and Gruss, Daniel and Haas, Werner and Hamburg, Mike and Lipp, Moritz and Mangard, Stefan and Prescher, Thomas and Schwarz, Michael and Yarom, Yuval},
+ booktitle = {2019 IEEE Symposium on Security and Privacy (SP)},
+ date-added = {2023-11-22 16:32:26 -0500},
+ date-modified = {2023-11-22 16:33:08 -0500},
+ doi = {10.1109/sp.2019.00002},
+ publisher = {IEEE},
+ source = {Crossref},
+ title = {Spectre Attacks: {Exploiting} Speculative Execution},
+ url = {https://doi.org/10.1109/sp.2019.00002},
+ year = {2019},
+ month = may,
+}
+
+@inproceedings{Rashmi2018Secure,
+ author = {R.V., Rashmi and A., Karthikeyan},
+ booktitle = {2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA)},
+ date-added = {2023-11-22 17:50:16 -0500},
+ date-modified = {2023-11-22 17:51:39 -0500},
+ doi = {10.1109/iceca.2018.8474730},
+ pages = {291--298},
+ publisher = {IEEE},
+ source = {Crossref},
+ title = {Secure boot of Embedded Applications - A Review},
+ url = {https://doi.org/10.1109/iceca.2018.8474730},
+ year = {2018},
+ month = mar,
+}
+
@inproceedings{abadi2016deep,
- address = {New York, NY, USA},
author = {Abadi, Martin and Chu, Andy and Goodfellow, Ian and McMahan, H. Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li},
+ address = {New York, NY, USA},
booktitle = {Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security},
date-added = {2023-11-22 18:06:03 -0500},
date-modified = {2023-11-22 18:08:42 -0500},
@@ -12,7 +190,8 @@ @inproceedings{abadi2016deep
source = {Crossref},
title = {Deep Learning with Differential Privacy},
url = {https://doi.org/10.1145/2976749.2978318},
- year = {2016}
+ year = {2016},
+ month = oct,
}
@inproceedings{agrawal2003side,
@@ -25,21 +204,24 @@ @inproceedings{agrawal2003side
source = {Crossref},
title = {{Trojan} Detection using {IC} Fingerprinting},
url = {https://doi.org/10.1109/sp.2007.36},
- year = {2007}
+ year = {2007},
+ month = may,
}
@inproceedings{ahmed2020headless,
- author = {Ahmed Abdelkader and Michael J. Curry and Liam Fowl and Tom Goldstein and Avi Schwarzschild and Manli Shu and Christoph Studer and Chen Zhu},
+ author = {Abdelkader, Ahmed and Curry, Michael J. and Fowl, Liam and Goldstein, Tom and Schwarzschild, Avi and Shu, Manli and Studer, Christoph and Zhu, Chen},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/icassp/AbdelkaderCFGSS20.bib},
- booktitle = {2020 {IEEE} International Conference on Acoustics, Speech and Signal Processing, {ICASSP} 2020, Barcelona, Spain, May 4-8, 2020},
- doi = {10.1109/ICASSP40776.2020.9053181},
+ booktitle = {ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
+ doi = {10.1109/icassp40776.2020.9053181},
pages = {3087--3091},
- publisher = {{IEEE}},
+ publisher = {IEEE},
timestamp = {Thu, 23 Jul 2020 01:00:00 +0200},
- title = {Headless Horseman: Adversarial Attacks on Transfer Learning Models},
- url = {https://doi.org/10.1109/ICASSP40776.2020.9053181},
- year = {2020}
+ title = {Headless Horseman: {Adversarial} Attacks on Transfer Learning Models},
+ url = {https://doi.org/10.1109/icassp40776.2020.9053181},
+ year = {2020},
+ source = {Crossref},
+ month = may,
}
@inproceedings{amiel2006fault,
@@ -50,7 +232,7 @@ @inproceedings{amiel2006fault
organization = {Springer},
pages = {223--236},
title = {Fault analysis of {DPA}-resistant algorithms},
- year = {2006}
+ year = {2006},
}
@inproceedings{antonakakis2017understanding,
@@ -58,22 +240,7 @@ @inproceedings{antonakakis2017understanding
booktitle = {26th USENIX security symposium (USENIX Security 17)},
pages = {1093--1110},
title = {Understanding the mirai botnet},
- year = {2017}
-}
-
-@inproceedings{Asonov2004Keyboard,
- author = {Asonov, D. and Agrawal, R.},
- booktitle = {IEEE Symposium on Security and Privacy, 2004. Proceedings. 2004},
- date-added = {2023-11-22 17:05:39 -0500},
- date-modified = {2023-11-22 17:06:45 -0500},
- doi = {10.1109/secpri.2004.1301311},
- organization = {IEEE},
- pages = {3--11},
- publisher = {IEEE},
- source = {Crossref},
- title = {Keyboard acoustic emanations},
- url = {https://doi.org/10.1109/secpri.2004.1301311},
- year = {2004}
+ year = {2017},
}
@article{ateniese2015hacking,
@@ -90,7 +257,7 @@ @article{ateniese2015hacking
title = {Hacking smart machines with smarter ones: {How} to extract meaningful data from machine learning classifiers},
url = {https://doi.org/10.1504/ijsn.2015.071829},
volume = {10},
- year = {2015}
+ year = {2015},
}
@inproceedings{barenghi2010low,
@@ -105,34 +272,20 @@ @inproceedings{barenghi2010low
source = {Crossref},
title = {Low voltage fault attacks to {AES}},
url = {https://doi.org/10.1109/hst.2010.5513121},
- year = {2010}
-}
-
-@inproceedings{Biega2020Oper,
- author = {Asia J. Biega and Peter Potash and Hal Daum{\'{e}} III and Fernando Diaz and Mich{\`{e}}le Finck},
- bibsource = {dblp computer science bibliography, https://dblp.org},
- biburl = {https://dblp.org/rec/conf/sigir/BiegaPDDF20.bib},
- booktitle = {Proceedings of the 43rd International {ACM} {SIGIR} conference on research and development in Information Retrieval, {SIGIR} 2020, Virtual Event, China, July 25-30, 2020},
- doi = {10.1145/3397271.3401034},
- editor = {Jimmy Huang and Yi Chang and Xueqi Cheng and Jaap Kamps and Vanessa Murdock and Ji{-}Rong Wen and Yiqun Liu},
- pages = {399--408},
- publisher = {{ACM}},
- timestamp = {Thu, 03 Sep 2020 01:00:00 +0200},
- title = {Operationalizing the Legal Principle of Data Minimization for Personalization},
- url = {https://doi.org/10.1145/3397271.3401034},
- year = {2020}
+ year = {2010},
+ month = jun,
}
@inproceedings{biggio2012poisoning,
- author = {Battista Biggio and Blaine Nelson and Pavel Laskov},
+ author = {Biggio, Battista and Nelson, Blaine and Laskov, Pavel},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/icml/BiggioNL12.bib},
- booktitle = {Proceedings of the 29th International Conference on Machine Learning, {ICML} 2012, Edinburgh, Scotland, UK, June 26 - July 1, 2012},
+ booktitle = {Proceedings of the 29th International Conference on Machine Learning, ICML 2012, Edinburgh, Scotland, UK, June 26 - July 1, 2012},
publisher = {icml.cc / Omnipress},
timestamp = {Wed, 03 Apr 2019 01:00:00 +0200},
title = {Poisoning Attacks against Support Vector Machines},
url = {http://icml.cc/2012/papers/880.pdf},
- year = {2012}
+ year = {2012},
}
@article{breier2018deeplaser,
@@ -141,24 +294,7 @@ @article{breier2018deeplaser
title = {Deeplaser: {Practical} fault attack on deep neural networks},
url = {https://arxiv.org/abs/1806.05859},
volume = {abs/1806.05859},
- year = {2018}
-}
-
-@article{Burnet1989Spycatcher,
- author = {Burnet, David and Thomas, Richard},
- date-added = {2023-11-22 17:03:00 -0500},
- date-modified = {2023-11-22 17:04:44 -0500},
- doi = {10.2307/1410360},
- issn = {0263-323X},
- journal = {J. Law Soc.},
- number = {2},
- pages = {210},
- publisher = {JSTOR},
- source = {Crossref},
- title = {Spycatcher: {The} Commodification of Truth},
- url = {https://doi.org/10.2307/1410360},
- volume = {16},
- year = {1989}
+ year = {2018},
}
@article{cavoukian2009privacy,
@@ -167,7 +303,7 @@ @article{cavoukian2009privacy
date-modified = {2023-11-22 17:56:58 -0500},
journal = {Office of the Information and Privacy Commissioner},
title = {Privacy by design},
- year = {2009}
+ year = {2009},
}
@book{dhanjani2015abusing,
@@ -180,20 +316,7 @@ @book{dhanjani2015abusing
source = {Crossref},
title = {The Internet of Things},
url = {https://doi.org/10.7551/mitpress/10277.001.0001},
- year = {2015}
-}
-
-@inproceedings{Dwork2006Theory,
- address = {Berlin, Heidelberg},
- author = {Dwork, Cynthia and McSherry, Frank and Nissim, Kobbi and Smith, Adam},
- booktitle = {Theory of Cryptography},
- date-added = {2023-11-22 18:04:12 -0500},
- date-modified = {2023-11-22 18:05:20 -0500},
- editor = {Halevi, Shai and Rabin, Tal},
- pages = {265--284},
- publisher = {Springer Berlin Heidelberg},
- title = {Calibrating Noise to Sensitivity in Private Data Analysis},
- year = {2006}
+ year = {2015},
}
@article{eldan2023whos,
@@ -202,7 +325,7 @@ @article{eldan2023whos
title = {Who's Harry Potter? Approximate Unlearning in {LLMs}},
url = {https://arxiv.org/abs/2310.02238},
volume = {abs/2310.02238},
- year = {2023}
+ year = {2023},
}
@article{eykholt2018robust,
@@ -211,7 +334,7 @@ @article{eykholt2018robust
title = {Robust Physical-World Attacks on Deep Learning Models},
url = {https://arxiv.org/abs/1707.08945},
volume = {abs/1707.08945},
- year = {2017}
+ year = {2017},
}
@article{farwell2011stuxnet,
@@ -228,7 +351,8 @@ @article{farwell2011stuxnet
title = {Stuxnet and the Future of Cyber War},
url = {https://doi.org/10.1080/00396338.2011.555586},
volume = {53},
- year = {2011}
+ year = {2011},
+ month = jan,
}
@inproceedings{gandolfi2001electromagnetic,
@@ -239,24 +363,7 @@ @inproceedings{gandolfi2001electromagnetic
organization = {Springer},
pages = {251--261},
title = {Electromagnetic analysis: {Concrete} results},
- year = {2001}
-}
-
-@article{Gao2020Physical,
- author = {Gao, Yansong and Al-Sarawi, Said F. and Abbott, Derek},
- date-added = {2023-11-22 17:52:20 -0500},
- date-modified = {2023-11-22 17:54:56 -0500},
- doi = {10.1038/s41928-020-0372-5},
- issn = {2520-1131},
- journal = {Nature Electronics},
- number = {2},
- pages = {81--91},
- publisher = {Springer Science and Business Media LLC},
- source = {Crossref},
- title = {Physical unclonable functions},
- url = {https://doi.org/10.1038/s41928-020-0372-5},
- volume = {3},
- year = {2020}
+ year = {2001},
}
@inproceedings{gnad2017voltage,
@@ -271,7 +378,8 @@ @inproceedings{gnad2017voltage
source = {Crossref},
title = {Voltage drop-based fault attacks on {FPGAs} using valid bitstreams},
url = {https://doi.org/10.23919/fpl.2017.8056840},
- year = {2017}
+ year = {2017},
+ month = sep,
}
@article{goodfellow2020generative,
@@ -286,23 +394,8 @@ @article{goodfellow2020generative
title = {Generative adversarial networks},
url = {https://doi.org/10.1145/3422622},
volume = {63},
- year = {2020}
-}
-
-@article{Gupta2023ChatGPT,
- author = {Gupta, Maanak and Akiri, Charankumar and Aryal, Kshitiz and Parker, Eli and Praharaj, Lopamudra},
- date-added = {2023-11-22 18:01:41 -0500},
- date-modified = {2023-11-22 18:02:55 -0500},
- doi = {10.1109/access.2023.3300381},
- issn = {2169-3536},
- journal = {\#IEEE\_O\_ACC\#},
- pages = {80218--80245},
- publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
- source = {Crossref},
- title = {From {ChatGPT} to {ThreatGPT:} {Impact} of Generative {AI} in Cybersecurity and Privacy},
- url = {https://doi.org/10.1109/access.2023.3300381},
- volume = {11},
- year = {2023}
+ year = {2020},
+ month = oct,
}
@article{hosseini2017deceiving,
@@ -311,7 +404,7 @@ @article{hosseini2017deceiving
title = {Deceiving google's perspective api built for detecting toxic comments},
url = {https://arxiv.org/abs/1702.08138},
volume = {abs/1702.08138},
- year = {2017}
+ year = {2017},
}
@inproceedings{hsiao2023mavfi,
@@ -326,7 +419,8 @@ @inproceedings{hsiao2023mavfi
source = {Crossref},
title = {{MAVFI:} {An} End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles},
url = {https://doi.org/10.23919/date56975.2023.10137246},
- year = {2023}
+ year = {2023},
+ month = apr,
}
@inproceedings{hutter2009contact,
@@ -341,7 +435,15 @@ @inproceedings{hutter2009contact
source = {Crossref},
title = {Contact-based fault injections and power analysis on {RFID} tags},
url = {https://doi.org/10.1109/ecctd.2009.5275012},
- year = {2009}
+ year = {2009},
+ month = aug,
+}
+
+@article{jin2020towards,
+ author = {Jin, Yilun and Wei, Xiguang and Liu, Yang and Yang, Qiang},
+ title = {Towards utilizing unlabeled data in federated learning: {A} survey and prospective},
+ journal = {arXiv preprint arXiv:2002.11545},
+ year = {2020},
}
@book{joye2012fault,
@@ -355,7 +457,7 @@ @book{joye2012fault
source = {Crossref},
title = {Fault Analysis in Cryptography},
url = {https://doi.org/10.1007/978-3-642-29656-7},
- year = {2012}
+ year = {2012},
}
@article{kairouz2021advances,
@@ -373,20 +475,20 @@ @article{kairouz2021advances
title = {Advances and Open Problems in Federated Learning},
url = {https://doi.org/10.1561/2200000083},
volume = {14},
- year = {2021}
+ year = {2021},
}
@inproceedings{khan2021knowledgeadaptation,
- author = {Mohammad Emtiyaz Khan and Siddharth Swaroop},
+ author = {Khan, Mohammad Emtiyaz and Swaroop, Siddharth},
+ editor = {Ranzato, Marc'Aurelio and Beygelzimer, Alina and Dauphin, Yann N. and Liang, Percy and Vaughan, Jennifer Wortman},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/KhanS21.bib},
booktitle = {Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual},
- editor = {Marc'Aurelio Ranzato and Alina Beygelzimer and Yann N. Dauphin and Percy Liang and Jennifer Wortman Vaughan},
pages = {19757--19770},
timestamp = {Tue, 03 May 2022 01:00:00 +0200},
title = {Knowledge-Adaptation Priors},
url = {https://proceedings.neurips.cc/paper/2021/hash/a4380923dd651c195b1631af7c829187-Abstract.html},
- year = {2021}
+ year = {2021},
}
@inproceedings{kocher1999differential,
@@ -397,67 +499,7 @@ @inproceedings{kocher1999differential
organization = {Springer},
pages = {388--397},
title = {Differential power analysis},
- year = {1999}
-}
-
-@article{Kocher2011Intro,
- author = {Kocher, Paul and Jaffe, Joshua and Jun, Benjamin and Rohatgi, Pankaj},
- date-added = {2023-11-22 16:58:42 -0500},
- date-modified = {2023-11-22 17:00:36 -0500},
- doi = {10.1007/s13389-011-0006-y},
- issn = {2190-8508, 2190-8516},
- journal = {Journal of Cryptographic Engineering},
- number = {1},
- pages = {5--27},
- publisher = {Springer Science and Business Media LLC},
- source = {Crossref},
- title = {Introduction to differential power analysis},
- url = {https://doi.org/10.1007/s13389-011-0006-y},
- volume = {1},
- year = {2011}
-}
-
-@inproceedings{Kocher2018spectre,
- author = {Kocher, Paul and Horn, Jann and Fogh, Anders and Genkin, Daniel and Gruss, Daniel and Haas, Werner and Hamburg, Mike and Lipp, Moritz and Mangard, Stefan and Prescher, Thomas and Schwarz, Michael and Yarom, Yuval},
- booktitle = {2019 IEEE Symposium on Security and Privacy (SP)},
- date-added = {2023-11-22 16:33:35 -0500},
- date-modified = {2023-11-22 16:34:01 -0500},
- doi = {10.1109/sp.2019.00002},
- publisher = {IEEE},
- source = {Crossref},
- title = {Spectre Attacks: {Exploiting} Speculative Execution},
- url = {https://doi.org/10.1109/sp.2019.00002},
- year = {2019}
-}
-
-@article{Li2020Federated,
- author = {Li, Tian and Sahu, Anit Kumar and Talwalkar, Ameet and Smith, Virginia},
- date-added = {2023-11-22 19:15:13 -0500},
- date-modified = {2023-11-22 19:17:19 -0500},
- doi = {10.1109/msp.2020.2975749},
- issn = {1053-5888, 1558-0792},
- journal = {IEEE Signal Process Mag.},
- number = {3},
- pages = {50--60},
- publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
- source = {Crossref},
- title = {Federated Learning: {Challenges,} Methods, and Future Directions},
- url = {https://doi.org/10.1109/msp.2020.2975749},
- volume = {37},
- year = {2020}
-}
-
-@inproceedings{Lipp2018meltdown,
- author = {Kocher, Paul and Horn, Jann and Fogh, Anders and Genkin, Daniel and Gruss, Daniel and Haas, Werner and Hamburg, Mike and Lipp, Moritz and Mangard, Stefan and Prescher, Thomas and Schwarz, Michael and Yarom, Yuval},
- booktitle = {2019 IEEE Symposium on Security and Privacy (SP)},
- date-added = {2023-11-22 16:32:26 -0500},
- date-modified = {2023-11-22 16:33:08 -0500},
- doi = {10.1109/sp.2019.00002},
- publisher = {IEEE},
- source = {Crossref},
- title = {Spectre Attacks: {Exploiting} Speculative Execution},
- url = {https://doi.org/10.1109/sp.2019.00002},
- year = {2019}
+ year = {1999},
}
@article{miller2015remote,
@@ -469,7 +511,7 @@ @article{miller2015remote
pages = {1--91},
title = {Remote exploitation of an unaltered passenger vehicle},
volume = {2015},
- year = {2015}
+ year = {2015},
}
@article{miller2019lessons,
@@ -486,7 +528,8 @@ @article{miller2019lessons
title = {Lessons learned from hacking a car},
url = {https://doi.org/10.1109/mdat.2018.2863106},
volume = {36},
- year = {2019}
+ year = {2019},
+ month = dec,
}
@article{narayanan2006break,
@@ -495,7 +538,7 @@ @article{narayanan2006break
date-modified = {2023-11-22 16:16:59 -0500},
journal = {arXiv preprint cs/0610105},
title = {How to break anonymity of the netflix prize dataset},
- year = {2006}
+ year = {2006},
}
@article{oliynyk2023know,
@@ -513,7 +556,8 @@ @article{oliynyk2023know
title = {I Know What You Trained Last Summer: {A} Survey on Stealing Machine Learning Models and Defences},
url = {https://doi.org/10.1145/3595292},
volume = {55},
- year = {2023}
+ year = {2023},
+ month = jul,
}
@article{oprea2022poisoning,
@@ -528,7 +572,8 @@ @article{oprea2022poisoning
title = {Poisoning Attacks Against Machine Learning: {Can} Machine Learning Be Trustworthy?},
url = {https://doi.org/10.1109/mc.2022.3190787},
volume = {55},
- year = {2022}
+ year = {2022},
+ month = nov,
}
@article{parrish2023adversarial,
@@ -537,37 +582,23 @@ @article{parrish2023adversarial
title = {Adversarial Nibbler: {A} Data-Centric Challenge for Improving the Safety of Text-to-Image Models},
url = {https://arxiv.org/abs/2305.14384},
volume = {abs/2305.14384},
- year = {2023}
+ year = {2023},
}
@inproceedings{ramesh2021zero,
- author = {Aditya Ramesh and Mikhail Pavlov and Gabriel Goh and Scott Gray and Chelsea Voss and Alec Radford and Mark Chen and Ilya Sutskever},
+ author = {Ramesh, Aditya and Pavlov, Mikhail and Goh, Gabriel and Gray, Scott and Voss, Chelsea and Radford, Alec and Chen, Mark and Sutskever, Ilya},
+ editor = {Meila, Marina and Zhang, Tong},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/icml/RameshPGGVRCS21.bib},
- booktitle = {Proceedings of the 38th International Conference on Machine Learning, {ICML} 2021, 18-24 July 2021, Virtual Event},
- editor = {Marina Meila and Tong Zhang},
+ booktitle = {Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event},
pages = {8821--8831},
- publisher = {{PMLR}},
+ publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
timestamp = {Wed, 25 Aug 2021 01:00:00 +0200},
title = {Zero-Shot Text-to-Image Generation},
url = {http://proceedings.mlr.press/v139/ramesh21a.html},
volume = {139},
- year = {2021}
-}
-
-@inproceedings{Rashmi2018Secure,
- author = {R.V., Rashmi and A., Karthikeyan},
- booktitle = {2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA)},
- date-added = {2023-11-22 17:50:16 -0500},
- date-modified = {2023-11-22 17:51:39 -0500},
- doi = {10.1109/iceca.2018.8474730},
- pages = {291--298},
- publisher = {IEEE},
- source = {Crossref},
- title = {Secure boot of Embedded Applications - A Review},
- url = {https://doi.org/10.1109/iceca.2018.8474730},
- year = {2018}
+ year = {2021},
}
@inproceedings{rombach2022highresolution,
@@ -578,7 +609,23 @@ @inproceedings{rombach2022highresolution
source = {Crossref},
title = {High-Resolution Image Synthesis with Latent Diffusion Models},
url = {https://doi.org/10.1109/cvpr52688.2022.01042},
- year = {2022}
+ year = {2022},
+ month = jun,
+}
+
+@article{rosa2021,
+ author = {de Rosa, Gustavo H. and Papa, Jo\~ao P.},
+ journal = {Pattern Recogn.},
+ title = {A survey on text generation using generative adversarial networks},
+ year = {2021},
+ doi = {10.1016/j.patcog.2021.108098},
+ source = {Crossref},
+ url = {https://doi.org/10.1016/j.patcog.2021.108098},
+ volume = {119},
+ publisher = {Elsevier BV},
+ issn = {0031-3203},
+ pages = {108098},
+ month = nov,
}
@article{shan2023prompt,
@@ -587,7 +634,7 @@ @article{shan2023prompt
title = {Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models},
url = {https://arxiv.org/abs/2310.13828},
volume = {abs/2310.13828},
- year = {2023}
+ year = {2023},
}
@inproceedings{skorobogatov2003optical,
@@ -596,7 +643,7 @@ @inproceedings{skorobogatov2003optical
organization = {Springer},
pages = {2--12},
title = {Optical fault induction attacks},
- year = {2003}
+ year = {2003},
}
@inproceedings{skorobogatov2009local,
@@ -609,7 +656,7 @@ @inproceedings{skorobogatov2009local
source = {Crossref},
title = {Local heating attacks on Flash memory devices},
url = {https://doi.org/10.1109/hst.2009.5225028},
- year = {2009}
+ year = {2009},
}
@article{tarun2023deep,
@@ -618,7 +665,7 @@ @article{tarun2023deep
title = {Deep Regression Unlearning},
url = {https://arxiv.org/abs/2210.08196},
volume = {abs/2210.08196},
- year = {2022}
+ year = {2022},
}
@inproceedings{zhao2018fpga,
@@ -633,20 +680,6 @@ @inproceedings{zhao2018fpga
source = {Crossref},
title = {{FPGA}-Based Remote Power Side-Channel Attacks},
url = {https://doi.org/10.1109/sp.2018.00049},
- year = {2018}
+ year = {2018},
+ month = may,
}
-
-@article{rosa2021,
- author = {G. H. de Rosa and J. P. Papa},
- journal = {Pattern Recognition},
- title = {A survey on text generation using generative adversarial networks},
- year = {2021},
- doi = {10.1016/j.patcog.2021.108098}
-}
-
-@article{jin2020towards,
- title={Towards utilizing unlabeled data in federated learning: A survey and prospective},
- author={Jin, Yilun and Wei, Xiguang and Liu, Yang and Yang, Qiang},
- journal={arXiv preprint arXiv:2002.11545},
- year={2020}
-}
\ No newline at end of file
diff --git a/contents/privacy_security/privacy_security.qmd b/contents/privacy_security/privacy_security.qmd
index 6c8bba78..c241a8e0 100644
--- a/contents/privacy_security/privacy_security.qmd
+++ b/contents/privacy_security/privacy_security.qmd
@@ -8,16 +8,16 @@ bibliography: privacy_security.bib
Resources: [Slides](#sec-security-and-privacy-resource), [Labs](#sec-security-and-privacy-resource), [Exercises](#sec-security-and-privacy-resource)
:::
-
+
-Ensuring security and privacy is a critical concern when developing real-world machine learning systems. As machine learning is increasingly applied to sensitive domains like healthcare, finance, and personal data, protecting confidentiality and preventing misuse of data and models becomes imperative. Anyone aiming to build robust and responsible ML systems must have a grasp of potential security and privacy risks such as data leaks, model theft, adversarial attacks, bias, and unintended access to private information. We also need to understand best practices for mitigating these risks. Most importantly, security and privacy cannot be an afterthought and must be proactively addressed throughout the ML system development lifecycle - from data collection and labeling to model training, evaluation, and deployment. Embedding security and privacy considerations into each stage of building, deploying and managing machine learning systems is essential for safely unlocking the benefits of AI.
+Security and privacy are critical when developing real-world machine learning systems. As machine learning is increasingly applied to sensitive domains like healthcare, finance, and personal data, protecting confidentiality and preventing misuse of data and models becomes imperative. Anyone aiming to build robust and responsible ML systems must grasp potential security and privacy risks such as data leaks, model theft, adversarial attacks, bias, and unintended access to private information. We also need to understand best practices for mitigating these risks. Most importantly, security and privacy cannot be an afterthought and must be proactively addressed throughout the ML system development lifecycle - from data collection and labeling to model training, evaluation, and deployment. Embedding security and privacy considerations into each stage of building, deploying, and managing machine learning systems is essential for safely unlocking the benefits of A.I.
::: {.callout-tip}
## Learning Objectives
-* Understand key ML privacy and security risks like data leaks, model theft, adversarial attacks, bias, and unintended data access.
+* Understand key ML privacy and security risks, such as data leaks, model theft, adversarial attacks, bias, and unintended data access.
* Learn from historical hardware and embedded systems security incidents.
@@ -25,9 +25,9 @@ Ensuring security and privacy is a critical concern when developing real-world m
* Recognize hardware security threats to embedded ML spanning hardware bugs, physical attacks, side channels, counterfeit components, etc.
-* Explore embedded ML defenses like trusted execution environments, secure boot, physical unclonable functions, and hardware security modules.
+* Explore embedded ML defenses, such as trusted execution environments, secure boot, physical unclonable functions, and hardware security modules.
-* Discuss privacy issues in handling sensitive user data with embedded ML, including regulations.
+* Discuss privacy issues handling sensitive user data with embedded ML, including regulations.
* Learn privacy-preserving ML techniques like differential privacy, federated learning, homomorphic encryption, and synthetic data generation.
@@ -48,23 +48,23 @@ These events highlighted the growing need to address privacy in ML systems. In t
* Security protects ML systems and data from hacking, theft, and misuse.
-For example, an ML-powered home security camera must secure video feeds against unauthorized access. It also needs privacy protections to ensure only intended users can view the footage. A breach of either security or privacy could expose private user moments.
+For example, an ML-powered home security camera must secure video feeds against unauthorized access and provide privacy protections to ensure only intended users can view the footage. A breach of either security or privacy could expose private user moments.
Embedded ML systems like smart assistants and wearables are ubiquitous and process intimate user data. However, their computational constraints often prevent heavy security protocols. Designers must balance performance needs with rigorous security and privacy standards tailored to embedded hardware limitations.
-This chapter provides essential knowledge for addressing the complex privacy and security landscape of embedded ML. We will explore vulnerabilities and cover various techniques that enhance privacy and security within the resource constraints of embedded systems.
+This chapter provides essential knowledge for addressing the complex privacy and security landscape of embedded ML. We will explore vulnerabilities and cover various techniques that enhance privacy and security within embedded systems' resource constraints.
-We hope you will gain the principles to develop secure, ethical, embedded ML applications by building a holistic understanding of risks and safeguards.
+We hope that by building a holistic understanding of risks and safeguards, you will gain the principles to develop secure, ethical, embedded ML applications.
## Terminology
-In this chapter, we will be talking about security and privacy together, so there are key terms that we need to be clear about.
+In this chapter, we will discuss security and privacy together, so there are key terms that we need to be clear about.
-* **Privacy:** For instance, consider an ML-powered home security camera that identifies and records potential threats. This camera records identifiable information, including faces, of individuals who approach, and potentially enter, this home. Privacy concerns may surround who can access this data.
+* **Privacy:** Consider an ML-powered home security camera that identifies and records potential threats. This camera records identifiable information, including faces, of individuals approaching and potentially entering this home. Privacy concerns may surround who can access this data.
-* **Security:** Consider an ML-powered home security camera that identifies and records potential threats. The security aspect would involve ensuring that these video feeds and recognition models aren't accessible to hackers.
+* **Security:** Consider an ML-powered home security camera that identifies and records potential threats. The security aspect would ensure that hackers cannot access these video feeds and recognition models.
-* **Threat:** Using our home security camera example, a threat could be a hacker trying to gain access to live feeds or stored videos, or using false inputs to trick the system.
+* **Threat:** Using our home security camera example, a threat could be a hacker trying to access live feeds or stored videos or using false inputs to trick the system.
* **Vulnerability:** A common vulnerability might be a poorly secured network through which the camera connects to the internet, which could be exploited to access the data.
@@ -78,7 +78,7 @@ In 2010, something unexpected was found on a computer in Iran - a very complicat
But Stuxnet wasn't designed to steal information or spy on people. Its goal was physical destruction - to sabotage centrifuges at Iran's Natanz nuclear plant! So how did the virus get onto computers at the Natanz plant, which was supposed to be disconnected from the outside world for security? Experts think someone inserted a USB stick containing Stuxnet into the internal Natanz network. This allowed the virus to "jump" from an outside system onto the isolated nuclear control systems and wreak havoc.
-Stuxnet was incredibly advanced malware built by national governments to cross from the digital realm into real-world infrastructure. It specifically targeted important industrial machines, where embedded machine learning is highly applicable, in a way never done before. The virus provided a wake-up call about how sophisticated cyberattacks could now physically destroy equipment and facilities.
+Stuxnet was incredibly advanced malware built by national governments to cross from the digital realm into real-world infrastructure. It specifically targeted important industrial machines, where embedded machine learning is highly applicable in a way never done before. The virus provided a wake-up call about how sophisticated cyberattacks could now physically destroy equipment and facilities.
This breach was significant due to its sophistication; Stuxnet specifically targeted programmable logic controllers (PLCs) used to automate electromechanical processes such as the speed of centrifuges for uranium enrichment. The worm exploited vulnerabilities in the Windows operating system to gain access to the Siemens Step7 software controlling the PLCs. Despite not being a direct attack on ML systems, Stuxnet is relevant for all embedded systems as it showcases the potential for state-level actors to design attacks that bridge the cyber and physical worlds with devastating effects.
@@ -86,39 +86,46 @@ This breach was significant due to its sophistication; Stuxnet specifically targ
The Jeep Cherokee hack was a groundbreaking event demonstrating the risks inherent in increasingly connected automobiles [@miller2019lessons]. In a controlled demonstration, security researchers remotely exploited a vulnerability in the Uconnect entertainment system, which had a cellular connection to the internet. They were able to control the vehicle's engine, transmission, and brakes, alarming the automotive industry into recognizing the severe safety implications of cyber vulnerabilities in vehicles.
+The video below is a short documentary of the attack.
+
{{< video https://www.youtube.com/watch?v=MK0SrxBC1xs&ab_channel=WIRED title="Hackers Remotely Kill a Jeep on a Highway" >}}
While this wasn't an attack on an ML system per se, the reliance of modern vehicles on embedded systems for safety-critical functions has significant parallels to the deployment of ML in embedded systems, underscoring the need for robust security at the hardware level.
### Mirai Botnet
-The Mirai botnet involved the infection of networked devices such as digital cameras and DVR players [@antonakakis2017understanding]. In October 2016, the botnet was used to conduct one of the largest [DDoS](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-attack/) attacks ever, disrupting internet access across the United States. The attack was possible because many devices used default usernames and passwords, which were easily exploited by the Mirai malware to control the devices.
+The Mirai botnet involved the infection of networked devices such as digital cameras and DVR players [@antonakakis2017understanding]. In October 2016, the botnet was used to conduct one of the largest [DDoS](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-attack/) attacks, disrupting internet access across the United States. The attack was possible because many devices used default usernames and passwords, which were easily exploited by the Mirai malware to control the devices.
+
+The following video presentation explains how the Mirai Botnet works.
{{< video https://www.youtube.com/watch?v=1pywzRTJDaY >}}
-Although the devices were not ML-based, the incident is a stark reminder of what can happen when numerous embedded devices with poor security controls are networked together, a situation that is becoming more common with the growth of ML-based IoT devices.
+Although the devices were not ML-based, the incident is a stark reminder of what can happen when numerous embedded devices with poor security controls are networked, which is becoming more common with the growth of ML-based IoT devices.
### Implications
-These historical breaches demonstrate the cascading effects of hardware vulnerabilities in embedded systems. Each incident offers a precedent for understanding the risks and designing better security protocols. For instance, the Mirai botnet highlights the immense destructive potential when threat actors can gain control over networked devices with weak security, a situation becoming increasingly common with ML systems. Many current ML devices function as "edge" devices meant to collect and process data locally before sending it to the cloud. Much like the cameras and DVRs compromised by Mirai, edge ML devices often rely on embedded hardware like ARM processors and run lightweight OS like Linux. Securing the device credentials is critical.
+These historical breaches demonstrate the cascading effects of hardware vulnerabilities in embedded systems. Each incident offers a precedent for understanding the risks and designing better security protocols. For instance, the Mirai botnet highlights the immense destructive potential when threat actors can gain control over networked devices with weak security, a situation becoming increasingly common with ML systems. Many current ML devices function as "edge" devices meant to collect and process data locally before sending it to the cloud. Much like the cameras and DVRs compromised by Mirai, edge ML devices often rely on embedded hardware like ARM processors and run lightweight O.S. like Linux. Securing the device credentials is critical.
Similarly, the Jeep Cherokee hack was a watershed moment for the automotive industry. It exposed serious vulnerabilities in the growing network-connected vehicle systems and their lack of isolation from core drive systems like brakes and steering. In response, auto manufacturers invested heavily in new cybersecurity measures, though gaps likely remain.
Chrysler did a recall to patch the vulnerable Uconnect software, allowing the remote exploit. This included adding network-level protections to prevent unauthorized external access and compartmentalizing in-vehicle systems to limit lateral movement. Additional layers of encryption were added for commands sent over the CAN bus within vehicles.
-The incident also spurred the creation of new cybersecurity standards and best practices. The [Auto-ISAC](https://automotiveisac.com/) was established for automakers to share intelligence, and the NHTSA guided managing risks. New testing and audit procedures were developed to assess vulnerabilities proactively. The aftereffects continue to drive change in the automotive industry as cars become increasingly software-defined.
+The incident also spurred the creation of new cybersecurity standards and best practices. The [Auto-ISAC](https://automotiveisac.com/) was established for automakers to share intelligence, and the NHTSA guided management risks. New testing and audit procedures were developed to assess vulnerabilities proactively. The aftereffects continue to drive change in the automotive industry as cars become increasingly software-defined.
-Unfortunately, in the rush to develop new ML edge devices, manufacturers often overlook security - using default passwords, unencrypted communications, unsecured firmware updates, etc. Any such vulnerabilities could allow attackers to gain access and control devices at scale by infecting them with malware. With a botnet of compromised ML devices, attackers could leverage their aggregated computational power for DDoS attacks on critical infrastructure.
+Unfortunately, manufacturers often overlook security in the rush to develop new ML edge devices - using default passwords, unencrypted communications, unsecured firmware updates, etc. Any such vulnerabilities could allow attackers to gain access and control devices at scale by infecting them with malware. With a botnet of compromised ML devices, attackers could leverage their aggregated computational power for DDoS attacks on critical infrastructure.
-While these events didn't involve machine learning hardware directly, the principles of the attacks carry over to ML systems, which often involve similar embedded devices and network architectures. As ML hardware often operates in continuous interaction with the physical world, securing it against such breaches is paramount. The evolution of security measures in response to these incidents provides valuable insights into protecting current and future ML systems from analogous vulnerabilities.
+While these events didn't directly involve machine learning hardware, the principles of the attacks carry over to ML systems, which often involve similar embedded devices and network architectures. As ML hardware often operates in continuous interaction with the physical world, securing it against such breaches is paramount. The evolution of security measures in response to these incidents provides valuable insights into protecting current and future ML systems from analogous vulnerabilities.
-The distributed nature of ML edge devices means threats can propagate quickly across networks. And if devices are being used for mission-critical purposes like medical devices, industrial controls or self-driving vehicles, the potential physical damage from weaponized ML bots could be severe. Just like Mirai demonstrated the dangerous potential of poorly secured IoT devices, the litmus test for ML hardware security will be how vulnerable or resilient these devices are to worm-like attacks. The stakes are raised as ML spreads to safety-critical domains, putting the onus on manufacturers and system operators to incorporate the lessons from Mirai.
+The distributed nature of ML edge devices means threats can propagate quickly across networks. And if devices are being used for mission-critical purposes like medical devices, industrial controls, or self-driving vehicles, the potential physical damage from weaponized ML bots could be severe. Just like Mirai demonstrated the dangerous potential of poorly secured IoT devices, the litmus test for ML hardware security will be how vulnerable or resilient these devices are to worm-like attacks. The stakes are raised as ML spreads to safety-critical domains, putting the onus on manufacturers and system operators to incorporate the lessons from Mirai.
-The lesson is the importance of designing for security from the outset and having layered defenses. For ML systems, the Jeep case highlights potential blindspots around externally facing software interfaces as well as isolation between subsystems. Manufacturers of ML devices and platforms should assume a similar proactive and comprehensive approach to security rather than leaving it as an afterthought. Rapid response and dissemination of best practices will be key as threats continue evolving.
+The lesson is the importance of designing for security from the outset and having layered defenses. For ML systems, the Jeep case highlights potential blindspots around externally facing software interfaces and isolation between subsystems. Manufacturers of ML devices and platforms should assume a similar proactive and comprehensive approach to security rather than leaving it as an afterthought. Rapid response and dissemination of best practices will be key as threats evolve.
## Security Threats to ML Models
-ML models face security risks that can undermine their integrity, performance, and trustworthiness if not properly addressed. While there are several different threats, the key threats include: 1) model theft, where adversaries steal the proprietary model parameters and the sensitive data they contain; 2) data poisoning, which compromises models through data tampering; and 3) adversarial attacks, which deceive the model to make incorrect or unwanted predictions.
+ML models face security risks that can undermine their integrity, performance, and trustworthiness if not properly addressed. While there are several different threats, the key threats include:
+Model theft, where adversaries steal the proprietary model parameters and the sensitive data they contain.
+Data poisoning, which compromises models through data tampering.
+Adversarial attacks deceive the model to make incorrect or unwanted predictions.
### Model Theft
@@ -126,7 +133,7 @@ Model theft occurs when an attacker gains unauthorized access to a deployed ML m
For instance, consider an ML model developed for personalized recommendations in an e-commerce application. If a competitor steals this model, they gain insights into business analytics, customer preferences, and even trade secrets embedded within the model's data. Attackers could leverage stolen models to craft more effective inputs for model inversion attacks, deducing private details about the model's training data. A cloned e-commerce recommendation model could reveal customer purchase behaviors and demographics.
-To understand model inversion attacks, consider a facial recognition system used to grant access to secured facilities. The system is trained on a dataset of employee photos. An attacker, by observing the model's output to various inputs, could infer features of the original dataset. For example, if the model's confidence level for a particular face is significantly higher for a given set of features, an attacker might deduce that someone with those features is likely in the training dataset.
+To understand model inversion attacks, consider a facial recognition system used to grant access to secured facilities. The system is trained on a dataset of employee photos. An attacker could infer features of the original dataset by observing the model's output to various inputs. For example, suppose the model's confidence level for a particular face is significantly higher for a given set of features. In that case, an attacker might deduce that someone with those features is likely in the training dataset.
The methodology of model inversion typically involves the following steps:
@@ -140,39 +147,39 @@ One historical example of such a vulnerability being explored was the research o
Model theft implies that it could lead to economic losses, undermine competitive advantage, and violate user privacy. There's also the risk of model inversion attacks, where an adversary could input various data into the stolen model to infer sensitive information about the training data.
-Model theft attacks can be divided into two categories based on the desired asset: exact model properties and approximate model behavior.
+Based on the desired asset, model theft attacks can be divided into two categories: exact model properties and approximate model behavior.
##### Stealing Exact Model Properties
-In these attacks, the objective is to extract information about concrete metrics, such as the learned parameters of a network, the fine-tuned hyperparameters, and the model's internal layer architecture [@oliynyk2023know].
+In these attacks, the objective is to extract information about concrete metrics, such as a network's learned parameters, fine-tuned hyperparameters, and the model's internal layer architecture [@oliynyk2023know].
-* **Learned Parameters:** adversaries aim to steal the learned knowledge (weights and biases) of a model in order to replicate it. Parameter theft is generally used in conjunction with other attacks, such as architecture theft, which lacks parameter knowledge.
+* **Learned Parameters:** Adversaries aim to steal a model's learned knowledge (weights and biases) in order to replicate it. Parameter theft is generally used in conjunction with other attacks, such as architecture theft, which lacks parameter knowledge.
-* **Fine-Tuned Hyperparameters:** training is costly, and finding the right configuration of hyperparameters (such as the learning rate and regularization) can be a very long and expensive process.Thus, stealing an optimized model's hyperparameters can allow an adversary to replicate the model without the high training costs.
+* **Fine-Tuned Hyperparameters:** Training is costly, and finding the right configuration of hyperparameters (such as the learning rate and regularization) can be a very long and expensive process. Thus, stealing an optimized model's hyperparameters can allow an adversary to replicate the model without the high training costs.
-* **Model Architecture:** this attack is concerned with the specific design and structure of the model, such as layers, neurons, and connectivity patterns. Aside from the reduction in associated training costs it can provide an attacker, this type of theft is especially dangerous because it concerns core IP theft, which can affect a company's competitive edge. Architecture theft can be achieved by exploiting side-channel attacks (discussed later).
+* **Model Architecture:** This attack concerns the specific design and structure of the model, such as layers, neurons, and connectivity patterns. Aside from reducing associated training costs, it can provide an attacker; this type of theft is especially dangerous because it concerns core I.P. theft, which can affect a company's competitive edge. Architecture theft can be achieved by exploiting side-channel attacks (discussed later).
##### Stealing Approximate Model Behavior
-Instead of focusing on extracting exact numerical values of the model's parameters, these attacks aim at reproducing the model's behavior (predictions and effectiveness), decision-making, and high-level characteristics [@oliynyk2023know]. These techniques aim at achieving similar outcomes while allowing for internal deviations in parameters and architecture. Types of approximate behavior theft include achieving the same level of effectiveness and obtaining prediction consistency.
+Instead of focusing on extracting exact numerical values of the model's parameters, these attacks aim to reproduce the model's behavior (predictions and effectiveness), decision-making, and high-level characteristics [@oliynyk2023know]. These techniques aim to achieve similar outcomes while allowing for internal deviations in parameters and architecture. Types of approximate behavior theft include achieving the same level of effectiveness and obtaining prediction consistency.
-* **Level of Effectiveness:** Rather than focus on the precise parameter values, attackers aim to replicate the model's decision-making capabilities. This is done through understanding the overall behavior of the model. Consider a scenario where an attacker wants to copy the behavior of an image classification model. Through analysis of the model's decision boundaries, the attack tunes their model to reach a level of effectiveness comparable to the original model. This could entail analyzing 1) the confusion matrix to understand the balance of prediction metrics (true positive, true negative, false positive, false negative), and 2)other performance metrics, such as F1 score and precision, to ensure that the two models are comparable.
+* **Level of Effectiveness:** Attackers aim to replicate the model's decision-making capabilities rather than focus on the precise parameter values. This is done through understanding the overall behavior of the model. Consider a scenario where an attacker wants to copy the behavior of an image classification model. By analyzing the model's decision boundaries, the attack tunes its model to reach an effectiveness comparable to the original model. This could entail analyzing 1) the confusion matrix to understand the balance of prediction metrics (true positive, true negative, false positive, false negative) and 2)other performance metrics, such as F1 score and precision, to ensure that the two models are comparable.
-* **Prediction Consistency:** The attacker tries to align their model's prediction patterns with those of the target model. This involves matching prediction outputs (both positive and negative) on the same set of inputs and ensuring distributional consistency across different classes. For instance, consider a natural language processing (NLP) model that generates sentiment analysis for move reviews (labels reviews as positive, neutral, or negative). The attacker will try to fine-tune their model to match the prediction of the original models on the same set of movie reviews. This includes ensuring that the model makes the same mistakes (mispredictions) that the targeted model makes.
+* **Prediction Consistency:** The attacker tries to align their model's prediction patterns with the target model's. This involves matching prediction outputs (both positive and negative) on the same set of inputs and ensuring distributional consistency across different classes. For instance, consider a natural language processing (NLP) model that generates sentiment analysis for move reviews (labels reviews as positive, neutral, or negative). The attacker will try to fine-tune their model to match the prediction of the original models on the same set of movie reviews. This includes ensuring that the model makes the same mistakes (mispredictions) that the targeted model makes.
#### Case Study
In 2018, Tesla filed a [lawsuit](https://storage.courtlistener.com/recap/gov.uscourts.nvd.131251/gov.uscourts.nvd.131251.1.0_1.pdf) against self-driving car startup [Zoox](https://zoox.com/), alleging former employees stole confidential data and trade secrets related to Tesla's autonomous driving assistance system.
-Tesla claimed that several of its former employees took over 10GB of proprietary data including ML models and source code before joining Zoox. This allegedly included one of Tesla's crucial image recognition models used for identifying objects.
+Tesla claimed that several of its former employees took over 10 G.B. of proprietary data, including ML models and source code, before joining Zoox. This allegedly included one of Tesla's crucial image recognition models for identifying objects.
-The theft of this sensitive proprietary model could potentially help Zoox shortcut years of ML development and duplicate Tesla's capabilities. Tesla argued this theft of IP caused major financial and competitive harm. There were also concerns it could allow model inversion attacks to infer private details about Tesla's testing data.
+The theft of this sensitive proprietary model could help Zoox shortcut years of ML development and duplicate Tesla's capabilities. Tesla argued this theft of I.P. caused major financial and competitive harm. There were also concerns it could allow model inversion attacks to infer private details about Tesla's testing data.
-The Zoox employees denied stealing any proprietary information. However, the case highlights the significant risks of model theft - enabling cloning of commercial models, causing economic impacts, and opening the door for further data privacy violations.
+The Zoox employees denied stealing any proprietary information. However, the case highlights the significant risks of model theft—enabling the cloning of commercial models, causing economic impacts, and opening the door for further data privacy violations.
### Data Poisoning
-Data poisoning is an attack where the training data is tampered with, leading to a compromised model [@biggio2012poisoning]. Attackers can modify existing training examples, insert new malicious data points, or influence the data collection process. The poisoned data is labeled in such a way as to skew the model's learned behavior. This can be particularly damaging in applications where ML models make automated decisions based on learned patterns. Beyond training sets, poisoning tests and validation data can allow adversaries to boost reported model performance artificially.
+Data poisoning is an attack where the training data is tampered with, leading to a compromised model [@biggio2012poisoning]. Attackers can modify existing training examples, insert new malicious data points, or influence the data collection process. The poisoned data is labeled in such a way as to skew the model's learned behavior. This can be particularly damaging in applications where ML models make automated decisions based on learned patterns. Beyond training sets, poisoning tests, and validation data can allow adversaries to boost reported model performance artificially.
The process usually involves the following steps:
@@ -184,83 +191,83 @@ The process usually involves the following steps:
The impacts of data poisoning extend beyond just classification errors or accuracy drops. For instance, if incorrect or malicious data is introduced into a traffic sign recognition system's training set, the model may learn to misclassify stop signs as yield signs, which can have dangerous real-world consequences, especially in embedded autonomous systems like autonomous vehicles.
-Data poisoning can degrade the accuracy of a model, force it to make incorrect predictions or cause it to behave unpredictably. In critical applications like healthcare, such alterations can lead to significant trust and safety issues.
+Data poisoning can degrade a model's accuracy, force it to make incorrect predictions or cause it to behave unpredictably. In critical applications like healthcare, such alterations can lead to significant trust and safety issues.
There are six main categories of data poisoning [@oprea2022poisoning]:
-* **Availability Attacks**: these attacks aim to compromise the overall functionality of a model. They cause it to misclassify the majority of testing samples, rendering the model unusable for practical applications. An example is label flipping, where labels of a specific, targeted class are replaced with labels from a different one.
+* **Availability Attacks:** These attacks aim to compromise a model's overall functionality. They cause it to misclassify most testing samples, rendering the model unusable for practical applications. An example is label flipping, where labels of a specific, targeted class are replaced with labels from a different one.
-* **Targeted Attacks:** in contrast to availability attacks, targeted attacks aim to compromise a small number of the testing samples.So the effect is localized to a limited number of classes, while the model maintains the same original level of accuracy on the majority of the classes. The targeted nature of the attack requires the attacker to possess knowledge of the model's classes.It also makes detecting these attacks more challenging.
+* **Targeted Attacks:** In contrast to availability attacks, targeted attacks aim to compromise a small number of the testing samples. So, the effect is localized to a limited number of classes, while the model maintains the same original level of accuracy on the majority of the classes. The targeted nature of the attack requires the attacker to possess knowledge of the model's classes, making detecting these attacks more challenging.
-* **Backdoor Attacks:** in these attacks, an adversary targets specific patterns in the data. The attacker introduces a backdoor(a malicious, hidden trigger or pattern) into the training data.For example, manipulating certain features in structured data or manipulating a pattern of pixels at a fixed position. This causes the model to associate the malicious pattern with specific labels.As a result, when the model encounters test samples that contain the malicious pattern, it makes false predictions.
+* **Backdoor Attacks:** In these attacks, an adversary targets specific patterns in the data. The attacker introduces a backdoor(a malicious, hidden trigger or pattern) into the training data, such as manipulating certain features in structured data or manipulating a pattern of pixels at a fixed position. This causes the model to associate the malicious pattern with specific labels. As a result, when the model encounters test samples that contain a malicious pattern, it makes false predictions.
-* **Subpopulation Attacks:** here attackers selectively choose to compromise a subset of the testing samples, while maintaining accuracy on the rest of the samples. You can think of these attacks as a combination of availability and targeted attacks:performing availability attacks (performance degradation) within the scope of a targeted subset. Although subpopulation attacks may seem very similar to targeted attacks, the two have clear differences:
+* **Subpopulation Attacks:** Attackers selectively choose to compromise a subset of the testing samples while maintaining accuracy on the rest of the samples. You can think of these attacks as a combination of availability and targeted attacks: performing availability attacks (performance degradation) within the scope of a targeted subset. Although subpopulation attacks may seem very similar to targeted attacks, the two have clear differences:
-* **Scope:** while targeted attacks target a selected set of samples,subpopulation attacks target a general subpopulation with similar feature representations. For example, in a targeted attack, an actor inserts manipulated images of a 'speed bump' warning sign(with carefully crafted perturbation or patterns), which causes an autonomous car to fail to recognize such sign and slow down. On the other hand, manipulating all samples of people with a British accent so that a speech recognition model would misclassify aBritish person's speech is an example of a subpopulation attack.
+* **Scope:** While targeted attacks target a selected set of samples, subpopulation attacks target a general subpopulation with similar feature representations. For example, in a targeted attack, an actor inserts manipulated images of a 'speed bump' warning sign(with carefully crafted perturbation or patterns), which causes an autonomous car to fail to recognize such a sign and slow down. On the other hand, manipulating all samples of people with a British accent so that a speech recognition model would misclassify a British person's speech is an example of a subpopulation attack.
-* **Knowledge:** while targeted attacks require a high degree of familiarity with the data, subpopulation attacks require less intimate knowledge in order to be effective.
+* **Knowledge:** While targeted attacks require a high degree of familiarity with the data, subpopulation attacks require less intimate knowledge to be effective.
#### Case Study 1
-In 2017, researchers demonstrated a data poisoning attack against a popular toxicity classification model called Perspective [@hosseini2017deceiving]. This ML model is used to detect toxic comments online.
+In 2017, researchers demonstrated a data poisoning attack against a popular toxicity classification model called Perspective [@hosseini2017deceiving]. This ML model detects toxic comments online.
The researchers added synthetically generated toxic comments with slight misspellings and grammatical errors to the model's training data. This slowly corrupted the model, causing it to misclassify increasing numbers of severely toxic inputs as non-toxic over time.
After retraining on the poisoned data, the model's false negative rate increased from 1.4% to 27% - allowing extremely toxic comments to bypass detection. The researchers warned this stealthy data poisoning could enable the spread of hate speech, harassment, and abuse if deployed against real moderation systems.
-This case highlights how data poisoning can degrade model accuracy and reliability over time. For social media platforms, a poisoning attack that impairs toxicity detection could lead to the proliferation of harmful content and distrust of ML moderation systems. The example demonstrates why securing training data integrity and monitoring for poisoning is critical across application domains.
+This case highlights how data poisoning can degrade model accuracy and reliability. For social media platforms, a poisoning attack that impairs toxicity detection could lead to the proliferation of harmful content and distrust of ML moderation systems. The example demonstrates why securing training data integrity and monitoring for poisoning is critical across application domains.
#### Case Study 2
-Interestingly enough, data poisoning attacks are not always malicious [@shan2023prompt]. Nightshade, a tool developed by a team led by Professor Ben Zhao at the University of Chicago, utilizes data poisoning to help artists protect their art against scraping and copyright violations by generative AI models. Artists can use the tool to make subtle modifications to their images before uploading them online.
+Interestingly enough, data poisoning attacks are not always malicious [@shan2023prompt]. Nightshade, a tool developed by a team led by Professor Ben Zhao at the University of Chicago, utilizes data poisoning to help artists protect their art against scraping and copyright violations by generative A.I. models. Artists can use the tool to modify their images subtly before uploading them online.
-While these changes are indiscernible to the human eye, they can significantly disrupt the performance of generative AI models when incorporated into the training data. Generative models can be manipulated into generating hallucinations and weird images. For example, with only 300 poisoned images, the University of Chicago researchers were able to trick the latest Stable Diffusion model into generating images of dogs that look like cats or images of cows when prompted for cars.
+While these changes are indiscernible to the human eye, they can significantly disrupt the performance of generative A.I. models when incorporated into the training data. Generative models can be manipulated to generate hallucinations and weird images. For example, with only 300 poisoned images, the University of Chicago researchers could trick the latest Stable Diffusion model into generating images of dogs that look like cats or images of cows when prompted for cars.
-As the number of poisoned images on the internet increases, the performance of the models that use scraped data will deteriorate exponentially. First, the poisoned data is hard to detect, and would require a manual elimination process. Second, the "poison" spreads quickly to other labels because generative models rely on connections between words and concepts as they generate images. So a poisoned image of a "car" could spread into generated images associated with words like "truck", "train", "bus", etc.
+As the number of poisoned images on the internet increases, the performance of the models that use scraped data will deteriorate exponentially. First, the poisoned data is hard to detect and requires manual elimination. Second, the "poison" spreads quickly to other labels because generative models rely on connections between words and concepts as they generate images. So a poisoned image of a "car" could spread into generated images associated with words like "truck," "train," "bus," etc.
-On the flip side, this tool can be used maliciously and can affect legitimate applications of the generative models. This goes to show the very challenging and novel nature of machine learning attacks.
+On the other hand, this tool can be used maliciously and can affect legitimate applications of the generative models. This shows the very challenging and novel nature of machine learning attacks.
-@fig-poisoning demonstrates the effects of different levels of data poisoning (50 samples, 100 samples, and 300 samples of poisoned images) on generating images in different categories. Notice how the images start deforming and deviating from the desired category. For example , after 300 poison samples a car prompt generates a cow.
+@fig-poisoning demonstrates the effects of different levels of data poisoning (50 samples, 100 samples, and 300 samples of poisoned images) on generating images in different categories. Notice how the images start deforming and deviating from the desired category. For example, after 300 poison samples, a car prompt generates a cow.
{#fig-poisoning}
### Adversarial Attacks
-Adversarial attacks are methods that aim to trick models into making incorrect predictions by providing it with specially crafted, deceptive inputs (called adversarial examples) [@parrish2023adversarial]. By adding slight perturbations to input data, adversaries can "hack" a model's pattern recognition and deceive it. These are sophisticated techniques where slight, often imperceptible alterations to input data can trick an ML model into making a wrong prediction.
+Adversarial attacks aim to trick models into making incorrect predictions by providing them with specially crafted, deceptive inputs (called adversarial examples) [@parrish2023adversarial]. By adding slight perturbations to input data, adversaries can "hack" a model's pattern recognition and deceive it. These are sophisticated techniques where slight, often imperceptible alterations to input data can trick an ML model into making a wrong prediction.
-In text-to-image models like DALLE [@ramesh2021zero] or Stable Diffusion [@rombach2022highresolution], one can generate prompts that lead to unsafe images. For example, by altering the pixel values of an image, attackers can deceive a facial recognition system into identifying a face as a different person.
+One can generate prompts that lead to unsafe images in text-to-image models like DALLE [@ramesh2021zero] or Stable Diffusion [@rombach2022highresolution]. For example, by altering the pixel values of an image, attackers can deceive a facial recognition system into identifying a face as a different person.
Adversarial attacks exploit the way ML models learn and make decisions during inference. These models work on the principle of recognizing patterns in data. An adversary crafts special inputs with perturbations to mislead the model's pattern recognition---essentially 'hacking' the model's perceptions.
Adversarial attacks fall under different scenarios:
-* **Whitebox Attacks:** the attacker possess full knowledge of the target model's internal workings, including the training data,parameters, and architecture. This comprehensive access creates favorable conditions for an attacker to exploit the model's vulnerabilities. The attacker can take advantage of specific and subtle weaknesses to craft effective adversarial examples.
+* **Whitebox Attacks:** The attacker has full knowledge of the target model's internal workings, including the training data,parameters, and architecture. This comprehensive access creates favorable conditions for exploiting the model's vulnerabilities. The attacker can use specific and subtle weaknesses to craft effective adversarial examples.
-* **Blackbox Attacks:** in contrast to whitebox attacks, in blackbox attacks, the attacker has little to no knowledge of the target model. To carry out the attack, the adversarial actor needs to make careful observations of the model's output behavior.
+* **Blackbox Attacks:** In contrast to whitebox attacks, in blackbox attacks, the attacker has little to no knowledge of the target model. To carry out the attack, the adversarial actor must carefully observe the model's output behavior.
-* **Greybox Attacks:** these fall in between blackbox and whitebox attacks. The attacker has only partial knowledge about the target model's internal design. For example, the attacker could have knowledge about training data but not the architecture or parameters. In the real-world, practical attacks fall under both blackbox and greybox scenarios.
+* **Greybox Attacks:** These fall between blackbox and whitebox attacks. The attacker has only partial knowledge about the target model's internal design. For example, the attacker could have knowledge about training data but not the architecture or parameters. In the real world, practical attacks fall under black black-box box grey-boxes.
-The landscape of machine learning models is both complex and broad, especially given their relatively recent integration into commercial applications. This rapid adoption, while transformative, has brought to light numerous vulnerabilities within these models. Consequently, a diverse array of adversarial attack methods has emerged, each strategically exploiting different aspects of different models. Below, we highlight a subset of these methods, showcasing the multifaceted nature of adversarial attacks on machine learning models:
+The landscape of machine learning models is complex and broad, especially given their relatively recent integration into commercial applications. This rapid adoption, while transformative, has brought to light numerous vulnerabilities within these models. Consequently, various adversarial attack methods have emerged, each strategically exploiting different aspects of different models. Below, we highlight a subset of these methods, showcasing the multifaceted nature of adversarial attacks on machine learning models:
-* **Generative Adversarial Networks (GANs)** are deep learning models that consist of two networks competing against each other: a generator and and a discriminator [@goodfellow2020generative]. The generator tries to synthesize realistic data, while the discriminator evaluates whether they are real or fake. GANs can be used to craft adversarial examples. The generator network is trained to produce inputs that are misclassified by the target model. These GAN-generated images can then be used to attack a target classifier or detection model. The generator and the target model are engaged in a competitive process, with the generator continually improving its ability to create deceptive examples, and the target model enhancing its resistance to such examples. GANs provide a powerful framework for crafting complex and diverse adversarial inputs, illustrating the adaptability of generative models in the adversarial landscape.
+* **Generative Adversarial Networks (GANs)** are deep learning models consisting of two networks competing against each other: a generator and a discriminator [@goodfellow2020generative]. The generator tries to synthesize realistic data while the discriminator evaluates whether they are real or fake. GANs can be used to craft adversarial examples. The generator network is trained to produce inputs that the target model misclassifies. These GAN-generated images can then attack a target classifier or detection model. The generator and the target model are engaged in a competitive process, with the generator continually improving its ability to create deceptive examples and the target model enhancing its resistance to such examples. GANs provide a powerful framework for crafting complex and diverse adversarial inputs, illustrating the adaptability of generative models in the adversarial landscape.
-* **Transfer Learning Adversarial Attacks** exploit the knowledge transferred from a pre-trained model to a target model, enabling the creation of adversarial examples that can deceive both models.These attacks pose a growing concern, particularly when adversaries have knowledge of the feature extractor but lack access to the classification head (the part or layer that is responsible for making the final classifications). Referred to as"headless attacks," these transferable adversarial strategies leverage the expressive capabilities of feature extractors to craft perturbations while being oblivious to the label space or training data. The existence of such attacks underscores the importance of developing robust defenses for transfer learning applications, especially since pre-trained models are commonly used [@ahmed2020headless].
+* **Transfer Learning Adversarial Attacks** exploit the knowledge transferred from a pre-trained model to a target model, creating adversarial examples that can deceive both models. These attacks pose a growing concern, particularly when adversaries have knowledge of the feature extractor but lack access to the classification head (the part or layer responsible for making the final classifications). Referred to as"headless attacks," these transferable adversarial strategies leverage the expressive capabilities of feature extractors to craft perturbations while oblivious to the label space or training data. The existence of such attacks underscores the importance of developing robust defenses for transfer learning applications, especially since pre-trained models are commonly used [@ahmed2020headless].
#### Case Study
In 2017, researchers conducted experiments by placing small black and white stickers on stop signs [@eykholt2018robust]. When viewed by a normal human eye, the stickers did not obscure the sign or prevent interpretability. However, when images of the stickers stop signs were fed into standard traffic sign classification ML models, they were misclassified as speed limit signs over 85% of the time.
-This demonstration showed how simple adversarial stickers could trick ML systems into misreading critical road signs. These attacks could endanger public safety if deployed in the real world, causing autonomous vehicles to misinterpret stop signs as speed limits. Researchers warned this could potentially cause dangerous rolling stops or acceleration into intersections.
+This demonstration showed how simple adversarial stickers could trick ML systems into misreading critical road signs. If deployed in the real world, these attacks could endanger public safety, causing autonomous vehicles to misinterpret stop signs as speed limits. Researchers warned this could potentially cause dangerous rolling stops or acceleration into intersections.
This case study provides a concrete illustration of how adversarial examples exploit how ML models recognize patterns. By subtly manipulating the input data, attackers can induce incorrect predictions and create serious risks for safety-critical applications like self-driving cars. The attack's simplicity shows how even minor changes imperceptible to humans can lead models astray. Developers need robust defenses against such threats.
## Security Threats to ML Hardware
-Discussing the threats to embedded ML hardware security in a structured order is useful for a clear and in-depth understanding of the potential pitfalls for ML systems. We will begin with hardware bugs. We address the issues where intrinsic design flaws in the hardware can be a gateway to exploitation. This forms the fundamental knowledge required to understand the genesis of hardware vulnerabilities. Moving to physical attacks establishes the basic threat model from there, as these are the most overt and direct methods of compromising hardware integrity. Fault-injection attacks naturally extend this discussion, showing how specific manipulations can induce systematic failures.
+Discussing the threats to embedded ML hardware security in a structured order is useful for a clear and in-depth understanding of the potential pitfalls of ML systems. We will begin with hardware bugs. We address the issues where intrinsic design flaws in the hardware can be a gateway to exploitation. This forms the fundamental knowledge required to understand the genesis of hardware vulnerabilities. Moving to physical attacks establishes the basic threat model, as these are the most overt and direct methods of compromising hardware integrity. Fault-injection attacks naturally extend this discussion, showing how specific manipulations can induce systematic failures.
-Advancing to side-channel attacks next will show the increasing complexity, as these rely on exploiting indirect information leakages, requiring a nuanced understanding of hardware operations and environmental interactions. Leaky interfaces will show how external communication channels can become vulnerable, leading to inadvertent data exposures. Counterfeit hardware discussions benefit from prior explorations of hardware integrity and exploitation techniques, as they often compound these issues with additional risks due to their questionable provenance. Finally, supply chain risks encompass all concerns above and frame them within the context of the hardware's journey from production to deployment, highlighting the multifaceted nature of hardware security and the need for vigilance at every stage.
+Advancing to side-channel attacks next will show the increasing complexity, as these rely on exploiting indirect information leakages, requiring a nuanced understanding of hardware operations and environmental interactions. Leaky interfaces will show how external communication channels can become vulnerable, leading to accidental data exposures. Counterfeit hardware discussions benefit from prior explorations of hardware integrity and exploitation techniques, as they often compound these issues with additional risks due to their questionable provenance. Finally, supply chain risks encompass all concerns above and frame them within the context of the hardware's journey from production to deployment, highlighting the multifaceted nature of hardware security and the need for vigilance at every stage.
-Here's an overview table summarizing the topics:
+@tbl-threat_types overview table summarizing the topics:
| Threat Type | Description | Relevance to Embedded ML Hardware Security |
| ----------------------- | -------------------------------------------------------------------------------------------------- | ------------------------------------------------ |
@@ -270,19 +277,21 @@ Here's an overview table summarizing the topics:
| Side-Channel Attacks | Exploitation of leaked information from hardware operation to extract sensitive data. | Indirect attack via environmental observation. |
| Leaky Interfaces | Vulnerabilities arising from interfaces that expose data unintentionally. | Data exposure through communication channels. |
| Counterfeit Hardware | Use of unauthorized hardware components that may have security flaws. | Compounded vulnerability issues. |
-| Supply Chain Risks | Risks introduced through the lifecycle of hardware, from production to deployment. | Cumulative and multifaceted security challenges. |
+| Supply Chain Risks | Risks introduced through the hardware lifecycle, from production to deployment. | Cumulative and multifaceted security challenges. |
+
+: Threat types on hardware security. {#tbl-threat_types}
### Hardware Bugs
Hardware is not immune to the pervasive issue of design flaws or bugs. Attackers can exploit these vulnerabilities to access, manipulate, or extract sensitive data, breaching the confidentiality and integrity that users and services depend on. An example of such vulnerabilities came to light with the discovery of Meltdown and Spectre---two hardware vulnerabilities that exploit critical vulnerabilities in modern processors. These bugs allow attackers to bypass the hardware barrier that separates applications, allowing a malicious program to read the memory of other programs and the operating system.
-Meltdown [@Lipp2018meltdown] and Spectre [@Kocher2018spectre] work by taking advantage of optimizations in modern CPUs that allow them to speculatively execute instructions out of order before validity checks have completed. This reveals data that should be inaccessible, which the attack captures through side channels like caches. The technical complexity demonstrates the difficulty of eliminating vulnerabilities even with extensive validation.
+Meltdown [@Lipp2018meltdown] and Spectre [@Kocher2018spectre] work by taking advantage of optimizations in modern CPUs that allow them to speculatively execute instructions out of order before validity checks have been completed. This reveals data that should be inaccessible, which the attack captures through side channels like caches. The technical complexity demonstrates the difficulty of eliminating vulnerabilities even with extensive validation.
-If an ML system is processing sensitive data, such as personal user information or proprietary business analytics, Meltdown and Spectre represent a real and present danger to data security. Consider the case of an ML accelerator card, which is designed to speed up machine learning processes, such as the ones we discussed in the [AI Hardware](../hw_acceleration/hw_acceleration.qmd) chapter. These accelerators work in tandem with the CPU to handle complex calculations, often related to data analytics, image recognition, and natural language processing. If such an accelerator card has a vulnerability akin to Meltdown or Spectre, it could potentially leak the data it processes. An attacker could exploit this flaw not just to siphon off data but also to gain insights into the ML model's workings, including potentially reverse-engineering the model itself (thus, going back to the issue of [model theft](@sec-model_theft).
+If an ML system is processing sensitive data, such as personal user information or proprietary business analytics, Meltdown and Spectre represent a real and present danger to data security. Consider the case of an ML accelerator card designed to speed up machine learning processes, such as the ones we discussed in the [A.I. Hardware](../hw_acceleration/hw_acceleration.qmd) chapter. These accelerators work with the CPU to handle complex calculations, often related to data analytics, image recognition, and natural language processing. If such an accelerator card has a vulnerability akin to Meltdown or Spectre, it could leak the data it processes. An attacker could exploit this flaw not just to siphon off data but also to gain insights into the ML model's workings, including potentially reverse-engineering the model itself (thus, going back to the issue of [model theft](@sec-model_theft).
-A real-world scenario where this could be devastating would be in the healthcare industry. Here, ML systems routinely process highly sensitive patient data to help diagnose, plan treatment, and forecast outcomes. A bug in the system's hardware could lead to the unauthorized disclosure of personal health information, violating patient privacy and contravening strict regulatory standards like the [Health Insurance Portability and Accountability Act (HIPAA)](https://www.cdc.gov/phlp/publications/topic/hipaa.html)
+A real-world scenario where this could be devastating would be in the healthcare industry. ML systems routinely process highly sensitive patient data to help diagnose, plan treatment, and forecast outcomes. A bug in the system's hardware could lead to the unauthorized disclosure of personal health information, violating patient privacy and contravening strict regulatory standards like the [Health Insurance Portability and Accountability Act (HIPAA)](https://www.cdc.gov/phlp/publications/topic/hipaa.html)
-The [Meltdown and Spectre](https://meltdownattack.com/) vulnerabilities are stark reminders that hardware security is not just about preventing unauthorized physical access, but also about ensuring that the hardware's architecture does not become a conduit for data exposure. Similar hardware design flaws regularly emerge in CPUs, accelerators, memory, buses, and other components. This necessitates ongoing retroactive mitigations and performance tradeoffs in deployed systems. Proactive solutions like confidential computing architectures could mitigate entire classes of vulnerabilities through fundamentally more secure hardware design. Thwarting hardware bugs requires rigor at every design stage, validation, and deployment.
+The [Meltdown and Spectre](https://meltdownattack.com/) vulnerabilities are stark reminders that hardware security is not just about preventing unauthorized physical access but also about ensuring that the hardware's architecture does not become a conduit for data exposure. Similar hardware design flaws regularly emerge in CPUs, accelerators, memory, buses, and other components. This necessitates ongoing retroactive mitigations and performance tradeoffs in deployed systems. Proactive solutions like confidential computing architectures could mitigate entire classes of vulnerabilities through fundamentally more secure hardware design. Thwarting hardware bugs requires rigor at every design stage, validation, and deployment.
### Physical Attacks
@@ -300,7 +309,7 @@ There are several ways that physical tampering can occur in ML hardware:
* **Hardware trojans:** Malicious circuit modifications can introduce trojans that activate under certain inputs. For example, an ML accelerator chip could function normally until a rare trigger case occurs, causing it to accelerate unsafely.
-* **Tampering with memory:** Physically exposing and manipulating memory chips could allow extraction of encrypted ML model parameters.Fault injection techniques can also corrupt model data to degrade accuracy.
+* **Tampering with memory:** Physically exposing and manipulating memory chips could allow the extraction of encrypted ML model parameters. Fault injection techniques can also corrupt model data to degrade accuracy.
* **Introducing backdoors:** Gaining physical access to servers, an adversary could use hardware keyloggers to capture passwords and create backdoor accounts for persistent access. These could then be used to exfiltrate ML training data over time.
@@ -314,11 +323,11 @@ Various physical tampering techniques can be used for fault injection. Low volta
For ML systems, consequences include impaired model accuracy, denial of service, extraction of private training data or model parameters, and reverse engineering of model architectures. Attackers could use fault injection to force misclassifications, disrupt autonomous systems, or steal intellectual property.
-For example, in [@breier2018deeplaser], the authors were able to successfully inject a fault attack into a deep neural network deployed on a microcontroller. They used a laser to heat up specific transistors, forcing them to switch states. In one instance, they used this method to attack a ReLU activation function resulting in the function to always outputing a value of 0, regardless of the input. In the assembly code in @fig-injection, the attack caused the executing program to always skip the `jmp` end instruction on line 6. This means that `HiddenLayerOutput[i]` is always set to 0, overwriting any values written to it on lines 4 and 5. As a result, the targeted neurons are rendered inactive, resulting in misclassifications.
+For example, in [@breier2018deeplaser], the authors successfully injected a fault attack into a deep neural network deployed on a microcontroller. They used a laser to heat specific transistors, forcing them to switch states. In one instance, they used this method to attack a ReLU activation function, resulting in the function always outputting a value of 0, regardless of the input. In the assembly code in @fig-injection, the attack caused the executing program to always skip the `jmp` end instruction on line 6. This means that `HiddenLayerOutput[i]` is always set to 0, overwriting any values written to it on lines 4 and 5. As a result, the targeted neurons are rendered inactive, resulting in misclassifications.
{#fig-injection}
-The strategy for an attacker could be to infer information about the activation functions using side-channel attacks (discussed next). Then the attacker could attempt to target multiple activation function computations by randomly injecting faults into the layers that are as close to the output layer as possible. This increases the likelihood and impact of the attack.
+An attacker's strategy could be to infer information about the activation functions using side-channel attacks (discussed next). Then, the attacker could attempt to target multiple activation function computations by randomly injecting faults into the layers as close to the output layer as possible, increasing the likelihood and impact of the attack.
Embedded devices are particularly vulnerable due to limited physical hardening and resource constraints that restrict robust runtime defenses. Without tamper-resistant packaging, attacker access to system buses and memory enables precise fault strikes. Lightweight embedded ML models also lack redundancy to overcome errors.
@@ -330,23 +339,23 @@ However, balancing robust protections with embedded systems' tight size and powe
### Side-Channel Attacks
-Side-channel attacks are a category of security breach that depends on information gained from the physical implementation of a computer system. Unlike direct attacks on software or network vulnerabilities, side-channel attacks exploit the hardware characteristics of a system. These attacks can be particularly effective against complex machine learning systems, where large amounts of data are processed and a high level of security is expected.
+Side-channel attacks are a category of security breach that depends on information gained from a computer system's physical implementation. Unlike direct attacks on software or network vulnerabilities, side-channel attacks exploit a system's hardware characteristics. These attacks can be particularly effective against complex machine learning systems, where large amounts of data are processed, and a high level of security is expected.
-The fundamental premise of a side-channel attack is that a device's operation can inadvertently leak information. Such leaks can come from various sources, including the electrical power a device consumes [@kocher1999differential], the electromagnetic fields it emits [@gandolfi2001electromagnetic], the time it takes to process certain operations or even the sounds it produces. Each channel can indirectly glimpse the system's internal processes, revealing information that can compromise security.
+The fundamental premise of a side-channel attack is that a device's operation can inadvertently leak information. Such leaks can come from various sources, including the electrical power a device consumes [@kocher1999differential], the electromagnetic fields it emits [@gandolfi2001electromagnetic], the time it takes to process certain operations, or even the sounds it produces. Each channel can indirectly glimpse the system's internal processes, revealing information that can compromise security.
-For instance, consider a machine learning system performing encrypted transactions. Encryption algorithms are supposed to secure data but also require computational work to encrypt and decrypt information. An attacker can analyze the power consumption patterns of the device performing encryption to figure out the cryptographic key. With sophisticated statistical methods, small variations in power usage during the encryption process can be correlated with the data being processed, eventually revealing the key. Some differential analysis attack techniques are Differential Power Analysis (DPA) [@Kocher2011Intro], Differential Electromagnetic Analysis (DEMA), and Correlation Power Analysis (CPA).
+For instance, consider a machine learning system performing encrypted transactions. Encryption algorithms are supposed to secure data but require computational work to encrypt and decrypt information. An attacker can analyze the power consumption patterns of the device performing encryption to figure out the cryptographic key. With sophisticated statistical methods, small variations in power usage during the encryption process can be correlated with the data being processed, eventually revealing the key. Some differential analysis attack techniques are Differential Power Analysis (DPA) [@Kocher2011Intro], Differential Electromagnetic Analysis (DEMA), and Correlation Power Analysis (CPA).
-For example, consider an attacker who is trying to break the AES encryption algorithm using a differential analysis attack. The attacker would first need to collect a large number of power or electromagnetic traces (a trace is a record of consumptions or emissions) of the device while it is performing AES encryption.
+For example, consider an attacker trying to break the AES encryption algorithm using a differential analysis attack. The attacker would first need to collect many power or electromagnetic traces (a trace is a record of consumptions or emissions) of the device while performing AES encryption.
-Once the attacker has collected a sufficient number of traces, they would then use a statistical technique to identify correlations between the traces and the different values of the plaintext (original, unencrypted text) and ciphertext (encrypted text). These correlations would then be used to infer the value of a bit in the AES key, and eventually the entire key. Differential analysis attacks are dangerous because they are low cost, effective, and non-intrusive, which allows attackers to bypass both algorithmic and hardware-level security measures. Compromises by these attacks are also hard to detect because they do not physically modify the device or break the encryption algorithm.
+Once the attacker has collected sufficient traces, they would then use a statistical technique to identify correlations between the traces and the different values of the plaintext (original, unencrypted text) and ciphertext (encrypted text). These correlations would then be used to infer the value of a bit in the AES key and, eventually, the entire key. Differential analysis attacks are dangerous because they are low-cost, effective, and non-intrusive, allowing attackers to bypass algorithmic and hardware-level security measures. Compromises by these attacks are also hard to detect because they do not physically modify the device or break the encryption algorithm.
-Below is a simplified visualization of how analyzing the power consumption patterns of the encryption device can help us extract information about algorithm's operations and, in turn, about the secret data. Say we have a device that takes a 5-byte password as input. We are going to analyze and compare the different voltage patterns that are measured while the encryption device is performing operations on the input to authenticate the password.
+Below is a simplified visualization of how analyzing the power consumption patterns of the encryption device can help us extract information about the algorithm's operations and, in turn, the secret data. Say we have a device that takes a 5-byte password as input. We will analyze and compare the different voltage patterns that are measured while the encryption device performs operations on the input to authenticate the password.
-First, consider the power analysis of the device's operations after entering a correct password in the first picture in @fig-encryption. The dense blue graph is the output of the encryption device's voltage measurement. What matters here is the comparison between the different analysis charts rather than the specific details of what is going on in each scenario.
+First, consider the power analysis of the device's operations after entering a correct password in the first picture in @fig-encryption. The dense blue graph outputs the encryption device's voltage measurement. What matters here is the comparison between the different analysis charts rather than the specific details of what is going on in each scenario.
](images/png/image5.png){#fig-encryption}
-Now, let's look at the power analysis chart when we enter an incorrect password in @fig-encryption2. The first three bytes of the password are correct. As a result, we can see that the voltage patterns are very similar or identical between the two charts, up to and including the fourth byte. After the device processes the fourth byte, it determines that there is a mismatch between the secret key and the attempted input. We notice a change in the pattern at the transition point between the fourth and fifth bytes: the voltage has gone up (the current has gone down) because the device has stopped processing the rest of the input.
+Let's look at the power analysis chart when we enter an incorrect password in @fig-encryption2. The first three bytes of the password are correct. As a result, we can see that the voltage patterns are very similar or identical between the two charts, up to and including the fourth byte. After the device processes the fourth byte, it determines a mismatch between the secret key and the attempted input. We notice a change in the pattern at the transition point between the fourth and fifth bytes: the voltage has gone up (the current has gone down) because the device has stopped processing the rest of the input.
](images/png/image16.png){#fig-encryption2}
@@ -354,9 +363,9 @@ Now, let's look at the power analysis chart when we enter an incorrect password
](images/png/image15.png){#fig-encryption3}
-The example above shows how we can infer information about the encryption process and the secret key itself through analyzing different inputs and try to 'eavesdrop' on the operations that the device is performing on each byte of the input.
+The example above shows how we can infer information about the encryption process and the secret key by analyzing different inputs and trying to 'eavesdrop' on the device's operations on each input byte.
-For additional details, please see the following video:
+For a more detailed explanation, watch the video below.
{{< video title="ECED4406 - 0x501 Power Analysis Attacks" >}}
@@ -364,11 +373,11 @@ Another example is an ML system for speech recognition, which processes voice co
In real-world scenarios, side-channel attacks have been used to extract encryption keys and compromise secure communications. One of the earliest recorded side-channel attacks dates back to the 1960s when British intelligence agency MI5 faced the challenge of deciphering encrypted communications from the Egyptian Embassy in London. Their cipher-breaking attempts were thwarted by the computational limitations of the time until an ingenious observation changed the game.
-MI5 agent Peter Wright proposed using a microphone to capture the subtle acoustic signatures emitted from the embassy's rotor cipher machine during encryption [@Burnet1989Spycatcher]. The distinct mechanical clicks of the rotors as operators configured them daily leaked critical information about the initial settings. This simple side channel of sound enabled MI5 to reduce the complexity of deciphering messages dramatically. This early acoustic leak attack highlights that side-channel attacks are not merely a digital age novelty but a continuation of age-old cryptanalytic principles. The notion that where there is a signal, there is an opportunity for interception remains foundational. From mechanical clicks to electrical fluctuations and beyond, side channels enable adversaries to extract secrets indirectly through careful signal analysis.
+MI5 agent Peter Wright proposed using a microphone to capture the subtle acoustic signatures emitted from the embassy's rotor cipher machine during encryption [@Burnet1989Spycatcher]. The distinct mechanical clicks of the rotors as operators configured them daily leaked critical information about the initial settings. This simple side channel of sound enabled MI5 to dramatically reduce the complexity of deciphering messages. This early acoustic leak attack highlights that side-channel attacks are not merely a digital age novelty but a continuation of age-old cryptanalytic principles. The notion that where there is a signal, there is an opportunity for interception remains foundational. From mechanical clicks to electrical fluctuations and beyond, side channels enable adversaries to extract secrets indirectly through careful signal analysis.
Today, acoustic cryptanalysis has evolved into attacks like keyboard eavesdropping [@Asonov2004Keyboard]. Electrical side channels range from power analysis on cryptographic hardware [@gnad2017voltage] to voltage fluctuations [@zhao2018fpga] on machine learning accelerators. Timing, electromagnetic emission, and even heat footprints can likewise be exploited. New and unexpected side channels often emerge as computing becomes more interconnected and miniaturized.
-Just as MI5's analogue acoustic leak transformed their codebreaking, modern side-channel attacks circumvent traditional boundaries of cyber defense. Understanding the creative spirit and historical persistence of side channel exploits is key knowledge for developers and defenders seeking to secure modern machine learning systems comprehensively against digital and physical threats.
+Just as MI5's analog acoustic leak transformed their codebreaking, modern side-channel attacks circumvent traditional boundaries of cyber defense. Understanding the creative spirit and historical persistence of side channel exploits is key knowledge for developers and defenders seeking to secure modern machine learning systems comprehensively against digital and physical threats.
### Leaky Interfaces
@@ -378,17 +387,17 @@ An interface becomes "leaky" when it exposes more information than it should, of
* **Baby Monitors:** Many WiFi-enabled baby monitors have been found to have unsecured interfaces for remote access. This allowed attackers to gain live audio and video feeds from people's homes, representing a major [privacy violation](https://www.fox19.com/story/25310628/hacked-baby-monitor/).
-* **Pacemakers:** Interface vulnerabilities were discovered in some [pacemakers](https://www.fda.gov/medical-devices/medical-device-recalls/abbott-formally-known-st-jude-medical-recalls-assuritytm-and-enduritytm-pacemakers-potential) that could allow attackers to manipulate cardiac functions if exploited. This presents a potential life-threatening scenario.
+* **Pacemakers:** Interface vulnerabilities were discovered in some [pacemakers](https://www.fda.gov/medical-devices/medical-device-recalls/abbott-formally-known-st-jude-medical-recalls-assuritytm-and-enduritytm-pacemakers-potential) that could allow attackers to manipulate cardiac functions if exploited. This presents a potentially life-threatening scenario.
* **Smart Lightbulbs:** A researcher found he could access unencrypted data from smart lightbulbs via a debug interface, including WiFi credentials, allowing him to gain access to the connected network [@dhanjani2015abusing].
-* **Smart Cars:** The OBD-II diagnostic port has been shown to provide an attack vector into automotive systems if left unsecured.Researchers were able to take control of brakes and other components through it [@miller2015remote].
+* **Smart Cars:** If left unsecured, The OBD-II diagnostic port has been shown to provide an attack vector into automotive systems. Researchers could use it to control brakes and other components [@miller2015remote].
-While the above are not directly connected with ML, consider the example of a smart home system with an embedded ML component that controls home security based on behavior patterns it learns over time. The system includes a maintenance interface accessible via the local network for software updates and system checks. If this interface does not require strong authentication or if the data transmitted through it is not encrypted, an attacker on the same network could potentially gain access to it. They could then eavesdrop on the homeowner's daily routines or reprogram the security settings by manipulating the firmware.
+While the above are not directly connected with ML, consider the example of a smart home system with an embedded ML component that controls home security based on behavior patterns it learns over time. The system includes a maintenance interface accessible via the local network for software updates and system checks. If this interface does not require strong authentication or the data transmitted through it is not encrypted, an attacker on the same network could gain access. They could then eavesdrop on the homeowner's daily routines or reprogram the security settings by manipulating the firmware.
-Such leaks are a privacy issue and a potential entry point for more damaging exploits. The exposure of training data, model parameters, or ML outputs from a leak could help adversaries construct adversarial examples or reverse-engineer models. Access through a leaky interface could also be used to alter an embedded device's firmware, loading it with malicious code that could disable the device, intercept data, or use the device in botnet attacks.
+Such leaks are a privacy issue and a potential entry point for more damaging exploits. The exposure of training data, model parameters, or ML outputs from a leak could help adversaries construct adversarial examples or reverse-engineer models. Access through a leaky interface could also be used to alter an embedded device's firmware, loading it with malicious code that could turn off the device, intercept data, or use it in botnet attacks.
-To mitigate these risks, a multilayered approach is necessary spanning technical controls like authentication, encryption, anomaly detection, policies and processes like interface inventories, access controls, auditing, and secure development practices. Disabling unnecessary interfaces and compartmentalizing risks via a zero-trust model provide additional protection.
+To mitigate these risks, a multi-layered approach is necessary, spanning technical controls like authentication, encryption, anomaly detection, policies and processes like interface inventories, access controls, auditing, and secure development practices. Turning off unnecessary interfaces and compartmentalizing risks via a zero-trust model provide additional protection.
As designers of embedded ML systems, we should assess interfaces early in development and continually monitor them post-deployment as part of an end-to-end security lifecycle. Understanding and securing interfaces is crucial for ensuring the overall security of embedded ML.
@@ -396,37 +405,37 @@ As designers of embedded ML systems, we should assess interfaces early in develo
ML systems are only as reliable as the underlying hardware. In an era where hardware components are global commodities, the rise of counterfeit or cloned hardware presents a significant challenge. Counterfeit hardware encompasses any components that are unauthorized reproductions of original parts. Counterfeit components infiltrate ML systems through complex supply chains that stretch across borders and involve numerous stages from manufacture to delivery.
-A single lapse in the supply chain's integrity can result in the insertion of counterfeit parts designed to imitate the functions and appearance of genuine hardware closely. For instance, a facial recognition system for high-security access control may be compromised if equipped with counterfeit processors. These processors could fail to accurately process and verify biometric data, potentially allowing unauthorized individuals to access restricted areas.
+A single lapse in the supply chain's integrity can result in the insertion of counterfeit parts designed to closely imitate the functions and appearance of genuine hardware. For instance, a facial recognition system for high-security access control may be compromised if equipped with counterfeit processors. These processors could fail to accurately process and verify biometric data, potentially allowing unauthorized individuals to access restricted areas.
The challenge with counterfeit hardware is multifaceted. It undermines the quality and reliability of ML systems, as these components may degrade faster or perform unpredictably due to substandard manufacturing. The security risks are also profound; counterfeit hardware can contain vulnerabilities ripe for exploitation by malicious actors. For example, a cloned network router in an ML data center might include a hidden backdoor, enabling data interception or network intrusion without detection.
Furthermore, counterfeit hardware poses legal and compliance risks. Companies inadvertently utilizing counterfeit parts in their ML systems may face serious legal repercussions, including fines and sanctions for failing to comply with industry regulations and standards. This is particularly true for sectors where compliance with specific safety and privacy regulations is mandatory, such as healthcare and finance.
-The issue of counterfeit hardware is exacerbated by the economic pressures of reducing costs, which can compel businesses to source from lower-cost suppliers without stringent verification processes. This economizing can inadvertently introduce counterfeit parts into otherwise secure systems. Additionally, detecting these counterfeits is inherently difficult since they are created to pass as the original components, often requiring sophisticated equipment and expertise to identify.
+The issue of counterfeit hardware is exacerbated by economic pressures to reduce costs, which can compel businesses to source from lower-cost suppliers without stringent verification processes. This economizing can inadvertently introduce counterfeit parts into otherwise secure systems. Additionally, detecting these counterfeits is inherently difficult since they are created to pass as the original components, often requiring sophisticated equipment and expertise to identify.
-In ML, where decisions are made in real-time and based on complex computations, the consequences of hardware failure are inconvenient and potentially dangerous. Stakeholders in the field of ML need to understand these risks thoroughly. The issues presented by counterfeit hardware necessitate a deep dive into the current challenges facing ML system integrity and emphasize the importance of vigilant, informed management of the hardware life cycle within these advanced systems.
+In ML, where decisions are made in real time and based on complex computations, the consequences of hardware failure are inconvenient and potentially dangerous. Stakeholders in the field of ML need to understand these risks thoroughly. The issues presented by counterfeit hardware necessitate a deep dive into the current challenges facing ML system integrity and emphasize the importance of vigilant, informed management of the hardware life cycle within these advanced systems.
### Supply Chain Risks
-The threat of counterfeit hardware is closely tied to broader supply chain vulnerabilities. Globalized, interconnected supply chains create multiple opportunities for compromised components to infiltrate a product's lifecycle. Supply chains involve numerous entities from design to manufacturing, assembly, distribution, and integration. A lack of transparency and oversight of each partner makes verifying integrity at every step challenging. Lapses anywhere along the chain can allow the insertion of counterfeit parts.
+The threat of counterfeit hardware is closely tied to broader supply chain vulnerabilities. Globalized, interconnected supply chains create multiple opportunities for compromised components to infiltrate a product's lifecycle. Supply chains involve numerous entities, from design to manufacturing, assembly, distribution, and integration. A lack of transparency and oversight of each partner makes verifying integrity at every step challenging. Lapses anywhere along the chain can allow the insertion of counterfeit parts.
For example, a contracted manufacturer may unknowingly receive and incorporate recycled electronic waste containing dangerous counterfeits. An untrustworthy distributor could smuggle in cloned components. Insider threats at any vendor might deliberately mix counterfeits into legitimate shipments.
Once counterfeits enter the supply stream, they move quickly through multiple hands before ending up in ML systems where detection is difficult. Advanced counterfeits like refurbished parts or clones with repackaged externals can masquerade as authentic components, passing visual inspection.
-Thorough technical profiling using micrography, X-ray screening, component forensics, and functional testing is often required to identify fakes. However, such costly analysis is impractical for large-volume procurement.
+To identify fakes, thorough technical profiling using micrography, X-ray screening, component forensics, and functional testing is often required. However, such costly analysis is impractical for large-volume procurement.
-Strategies like supply chain audits, screening suppliers, validating component provenance, and adding tamper-evident protections can help mitigate risks. But ultimately, a zero-trust approach is prudent given global supply chain security challenges. Designing ML systems to utilize redundant checking, fail-safes, and continuous runtime monitoring provides resilience against component compromises.
+Strategies like supply chain audits, screening suppliers, validating component provenance, and adding tamper-evident protections can help mitigate risks. However, given global supply chain security challenges, a zero-trust approach is prudent. Designing ML systems to utilize redundant checking, fail-safes, and continuous runtime monitoring provides resilience against component compromises.
Rigorous validation of hardware sources coupled with fault-tolerant system architectures offers the most robust defense against the pervasive risks of convoluted, opaque global supply chains.
#### Case Study
-In 2018, Bloomberg Businessweek published an alarming [story](https://www.bloomberg.com/news/features/2018-10-04/the-big-hack-how-china-used-a-tiny-chip-to-infiltrate-america-s-top-companies) that got much attention in the tech world. The article claimed that tiny spy chips had been secretly planted on server hardware by Supermicro. Reporters said Chinese state hackers working with Supermicro could sneak these tiny chips onto motherboards during manufacturing. The tiny chips allegedly gave the hackers backdoor access to servers used by over 30 major companies, including Apple and Amazon.
+In 2018, Bloomberg Businessweek published an alarming [story](https://www.bloomberg.com/news/features/2018-10-04/the-big-hack-how-china-used-a-tiny-chip-to-infiltrate-america-s-top-companies) that got much attention in the tech world. The article claimed that Supermicro had secretly planted tiny spy chips on server hardware. Reporters said Chinese state hackers working with Supermicro could sneak these tiny chips onto motherboards during manufacturing. The tiny chips allegedly gave the hackers backdoor access to servers used by over 30 major companies, including Apple and Amazon.
-If true, this would allow hackers to spy on private data or even tamper with systems. But after investigating, Apple and Amazon found no proof such hacked Supermicro hardware existed. Other experts questioned if the Bloomberg article was accurate reporting or not.
+If true, this would allow hackers to spy on private data or even tamper with systems. However, after investigating, Apple and Amazon found no proof that such hacked Supermicro hardware existed. Other experts questioned whether the Bloomberg article was accurate reporting.
-Whether the story is completely true or not is not our concern from a pedagogical viewpoint. However, this incident drew attention to the risks of global supply chains for hardware, especially manufactured in China. When companies outsource and buy hardware components from vendors worldwide, there needs to be more visibility into the process. In this complex global pipeline, there are concerns that counterfeits or tampered hardware could be slipped in somewhere along the way without tech companies realizing it. Companies relying too much on single manufacturers or distributors creates risk. For instance, due to the over reliance on [TSMC](https://www.tsmc.com/english) for semiconductor manufacturing, the US has invested 50 billion dollars into the [CHIPS Act](https://www.whitehouse.gov/briefing-room/statements-releases/2022/08/09/fact-sheet-chips-and-science-act-will-lower-costs-create-jobs-strengthen-supply-chains-and-counter-china/).
+Whether the story is completely true or not is not our concern from a pedagogical viewpoint. However, this incident drew attention to the risks of global supply chains for hardware, especially manufactured in China. When companies outsource and buy hardware components from vendors worldwide, there needs to be more visibility into the process. In this complex global pipeline, there are concerns that counterfeits or tampered hardware could be slipped in somewhere along the way without tech companies realizing it. Companies relying too much on single manufacturers or distributors creates risk. For instance, due to the over-reliance on [TSMC](https://www.tsmc.com/english) for semiconductor manufacturing, the U.S. has invested 50 billion dollars into the [CHIPS Act](https://www.whitehouse.gov/briefing-room/statements-releases/2022/08/09/fact-sheet-chips-and-science-act-will-lower-costs-create-jobs-strengthen-supply-chains-and-counter-china/).
As ML moves into more critical systems, verifying hardware integrity from design through production and delivery is crucial. The reported Supermicro backdoor demonstrated that for ML security, we cannot take global supply chains and manufacturing for granted. We must inspect and validate hardware at every link in the chain.
@@ -446,7 +455,7 @@ For instance, a TEE can protect ML model parameters from being extracted by mali
In ML systems, TEEs can:
-* Securely perform model training and inference, ensuring that the computation results remain confidential.
+* Securely perform model training and inference, ensuring the computation results remain confidential.
* Protect the confidentiality of input data, like biometric information, used for personal identification or sensitive classification tasks.
@@ -468,7 +477,7 @@ The fundamentals of TEEs contain four main parts:
* **Isolated Execution:** Code within a TEE runs in a separate environment from the device's main operating system. This isolation protects the code from unauthorized access by other applications.
-* **Secure Storage:** TEEs can store cryptographic keys,authentication tokens, and sensitive data securely, preventing access by regular applications running outside the TEE.
+* **Secure Storage:** TEEs can securely store cryptographic keys,authentication tokens, and sensitive data, preventing access by regular applications running outside the TEE.
* **Integrity Protection:** TEEs can verify the integrity of code and data, ensuring that they have not been altered before execution or during storage.
@@ -476,24 +485,24 @@ The fundamentals of TEEs contain four main parts:
Here are some examples of TEEs that provide hardware-based security for sensitive applications:
-* **[ARMTrustZone](https://www.arm.com/technologies/trustzone-for-cortex-m):**Creates secure and normal world execution environments isolated using hardware controls. Implemented in many mobile chipsets.
+* **[ARMTrustZone](https://www.arm.com/technologies/trustzone-for-cortex-m):**This technology creates secure and normal world execution environments isolated using hardware controls and implemented in many mobile chipsets.
-* **[IntelSGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html):**Intel's Software Guard Extensions provide an enclave for code execution that protects against certain software attacks,specifically OS layer attacks. Used to safeguard workloads in the cloud.
+* **[IntelSGX](https://www.intel.com/content/www/us/en/architecture-and-technology/software-guard-extensions.html):**Intel's Software Guard Extensions provide an enclave for code execution that protects against certain software attacks, specifically O.S. layer attacks. They are used to safeguard workloads in the cloud.
-* **[Qualcomm Secure ExecutionEnvironment](https://www.qualcomm.com/products/features/mobile-security-solutions):**Hardware sandbox on Qualcomm chipsets for mobile payment and authentication apps.
+* **[Qualcomm Secure Execution Environment](https://www.qualcomm.com/products/features/mobile-security-solutions):**A Hardware sandbox on Qualcomm chipsets for mobile payment and authentication apps.
* **[Apple SecureEnclave](https://support.apple.com/guide/security/secure-enclave-sec59b0b31ff/web):**TEE for biometric data and key management on iPhones and iPads.Facilitates mobile payments.
-@fig-enclave is a diagram demonstrating a secure enclave isolated from the main processor to provide an extra layer of security. The secure enclave has a boot ROM to establish a hardware root of trust, an AES engine for efficient and secure cryptographic operations, and protected memory. The secure enclave has a mechanism to store inromation securely on attached storage seperate from the NAND flash storage used by the application processor and operating system. This design keeps sensitive user data secure even when the Application Processor kernel becomes compromised.
+@fig-enclave is a diagram demonstrating a secure enclave isolated from the main processor to provide an extra layer of security. The secure enclave has a boot ROM to establish a hardware root of trust, an AES engine for efficient and secure cryptographic operations, and protected memory. It also has a mechanism to store information securely on attached storage separate from the NAND flash storage used by the application processor and operating system. This design keeps sensitive user data secure even when the Application Processor kernel becomes compromised.
](images/png/image1.png){#fig-enclave}
-#### Trade-Offs
+#### Tradeoffs
-If TEEs are so good, why don't all systems have TEE enabled by default? The decision to implement a TEE is not taken lightly. There are several reasons why a TEE might not be present in all systems by default. Here are some trade-offs and challenges associated with TEEs:
+If TEEs are so good, why don't all systems have TEE enabled by default? The decision to implement a TEE is not taken lightly. There are several reasons why a TEE might only be present in some systems by default. Here are some tradeoffs and challenges associated with TEEs:
-**Cost:** Implementing TEEs involves additional costs. There are direct costs for the hardware and indirect costs associated with developing and maintaining secure software for TEEs. These costs may not be justifiable for all devices, especially low-margin products.
+**Cost:** Implementing TEEs involves additional costs. There are direct costs for the hardware and indirect costs associated with developing and maintaining secure software for TEEs. These costs may only be justifiable for some devices, especially low-margin products.
**Complexity:** TEEs add complexity to system design and development. Integrating a TEE with existing systems requires a substantial redesign of the hardware and software stack, which can be a barrier, especially for legacy systems.
@@ -507,15 +516,15 @@ If TEEs are so good, why don't all systems have TEE enabled by default? The deci
**Market Demand:** Not all markets or applications require the level of security provided by TEEs. For many consumer applications, the perceived risk may be low enough that manufacturers opt not to include TEEs in their designs.
-**Security Certification and Assurance:** Systems with TEEs may need rigorous security certifications with bodies like [Common Criteria](https://www.commoncriteriaportal.org/ccra/index.cfm) (CC) or the [European Union Agency for Cybersecurity](https://www.enisa.europa.eu/) (ENISA), which can be lengthy and expensive. Some organizations may choose not to implement TEEs to avoid these hurdles.
+**Security Certification and Assurance:** Systems with TEEs may need rigorous security certifications with bodies like [Common Criteria](https://www.commoncriteriaportal.org/ccra/index.cfm) (CC) or the [European Union Agency for Cybersecurity](https://www.enisa.europa.eu/) (ENISA), which can be lengthy and expensive. Some organizations may choose to refrain from implementing TEEs to avoid these hurdles.
-**Limited Resource Devices:** Devices with limited processing power, memory, or storage may not be capable of supporting TEEs without compromising their primary functionality.
+**Limited Resource Devices:** Devices with limited processing power, memory, or storage may only support TEEs without compromising their primary functionality.
### Secure Boot
#### About
-Secure Boot is a security standard that ensures a device boots using only software that is trusted by the Original Equipment Manufacturer (OEM). When the device starts up, the firmware checks the signature of each piece of boot software, including the bootloader, kernel, and base operating system, to ensure it's not tampered with. If the signatures are valid, the device continues to boot. If not, the boot process stops to prevent potential security threats from executing.
+A secure boot is a security standard that ensures a device boots using only software trusted by the original equipment manufacturer (OEM). When the device starts up, the firmware checks the signature of each piece of boot software, including the bootloader, kernel, and base operating system, to ensure it's not tampered with. If the signatures are valid, the device continues to boot. If not, the boot process stops to prevent potential security threats from executing.
#### Benefits
@@ -525,13 +534,13 @@ Secure Boot helps protect embedded ML hardware in several ways:
* **Protecting ML Data:** Ensuring that the data used by ML models, which may include private or sensitive information, is not exposed to tampering or theft during the boot process.
-* **Guarding Model Integrity:** Maintaining the integrity of the ML models themselves, as tampering with the model could lead to incorrect or malicious outcomes.
+* **Guarding Model Integrity:** Maintaining the ML models' integrity is important, as tampering with them could lead to incorrect or malicious outcomes.
* **Secure Model Updates:** Enabling secure updates to ML models and algorithms, ensuring that updates are authenticated and have not been altered.
#### Mechanics
-TEEs benefit from Secure Boot in multiple ways. @fig-secure-boot illustrates a flow diagram of a trusted embedded system. For instance, during initial validation, Secure Boot ensures that the code running inside the TEE is the correct and untampered version approved by the device manufacturer. It can ensure resilience against tampering by verifying the digital signatures of the firmware and other critical components, Secure Boot prevents unauthorized modifications that could undermine the TEE's security properties. Secure Boot establishes a foundation of trust upon which the TEE can securely operate, enabling secure operations such as cryptographic key management, secure processing, and sensitive data handling.
+TEEs benefit from Secure Boot in multiple ways. @fig-secure-boot illustrates a flow diagram of a trusted embedded system. For instance, during initial validation, Secure Boot ensures that the code running inside the TEE is the correct and untampered version approved by the device manufacturer. It can ensure resilience against tampering by verifying the digital signatures of the firmware and other critical components; Secure Boot prevents unauthorized modifications that could undermine the TEE's security properties. Secure Boot establishes a foundation of trust upon which the TEE can securely operate, enabling secure operations such as cryptographic key management, secure processing, and sensitive data handling.
{#fig-secure-boot}
@@ -539,11 +548,11 @@ TEEs benefit from Secure Boot in multiple ways. @fig-secure-boot illustrates a f
Let's take a real-world example. Apple's Face ID technology uses advanced machine learning algorithms to enable [facial recognition](https://support.apple.com/en-us/102381) on iPhones and iPads. It relies on a sophisticated framework of sensors and software to accurately map the geometry of a user's face. For Face ID to function securely and protect user biometric data, the device's operations must be trustworthy from the moment it is powered on, which is where Secure Boot plays a crucial role. Here's how Secure Boot works in conjunction with Face ID:
-**Initial Verification:** When an iPhone is powered on, the Secure Boot process begins in the Secure Enclave, a coprocessor that provides an extra layer of security. The Secure Enclave is responsible for processing fingerprint data for Touch ID and facial recognition data for Face ID. The boot process verifies that Apple signs the Secure Enclave's firmware and has not been tampered with. This step ensures that the firmware used to process biometric data is authentic and safe to execute.
+**Initial Verification:** When an iPhone is powered on, the Secure Boot process begins in the Secure Enclave, a coprocessor providing an extra security layer. The Secure Enclave is responsible for processing fingerprint data for Touch ID and facial recognition data for Face ID. The boot process verifies that Apple has signed the Secure Enclave's firmware and has not been tampered with. This step ensures that the firmware used to process biometric data is authentic and safe.
**Continuous Security Checks:** After the initial power-on self-test and verification by Secure Boot, the Secure Enclave communicates with the device's main processor to continue the secure boot chain. It verifies the digital signatures of the iOS kernel and other critical boot components before allowing the boot process to proceed. This chained trust model prevents unauthorized modifications to the bootloader and operating system, which could compromise the device's security.
-**Face Data Processing:** Once the device has completed its secure boot sequence, the Secure Enclave can interact with the ML algorithms that power Face ID safely. Facial recognition involves projecting and analyzing over 30,000 invisible dots to create a depth map of the user's face and an infrared image. This data is then converted into a mathematical representation compared with the registered face data securely stored in the Secure Enclave.
+**Face Data Processing:** Once the device has completed its secure boot sequence, the Secure Enclave can interact safely with the ML algorithms that power Face ID. Facial recognition involves projecting and analyzing over 30,000 invisible dots to create a depth map of the user's face and an infrared image. This data is then converted into a mathematical representation and compared with the registered face data securely stored in the Secure Enclave.
**Secure Enclave and Data Protection:** The Secure Enclave is designed to protect sensitive data and handle the cryptographic operations that secure it. It ensures that even if the operating system kernel is compromised, the facial data cannot be accessed by unauthorized apps or attackers. Face ID data never leaves the device and is not backed up to iCloud or anywhere else.
@@ -555,9 +564,9 @@ By using Secure Boot with dedicated hardware like the Secure Enclave, Apple can
Implementing Secure Boot poses several challenges that must be addressed to realize its full benefits.
-**Key Management Complexity:** Generating, storing, distributing, rotating, and revoking cryptographic keys in a provably secure manner is extremely challenging, yet vital for maintaining the chain of trust. Any compromise of keys cripples protections. Large enterprises managing multitudes of device keys face particular scale challenges.
+**Key Management Complexity:** Generating, storing, distributing, rotating, and revoking cryptographic keys provably securely is extremely challenging yet vital for maintaining the chain of trust. Any compromise of keys cripples protections. Large enterprises managing multitudes of device keys face particular scale challenges.
-**Performance Overhead:** Checking cryptographic signatures during boot can add 50-100ms or more per component verified. This delay may be prohibitive for time-sensitive or resource-constrained applications. However, performance impacts can be reduced through parallelization and hardware acceleration.
+**Performance Overhead:** Checking cryptographic signatures during Boot can add 50-100ms or more per component verified. This delay may be prohibitive for time-sensitive or resource-constrained applications. However, performance impacts can be reduced through parallelization and hardware acceleration.
**Signing Burden:** Developers must diligently ensure that all software components involved in the boot process - bootloaders, firmware, OS kernel, drivers, applications, etc. are correctly signed by trusted keys. Accommodating third-party code signing remains an issue.
@@ -575,7 +584,7 @@ Adopting Secure Boot requires following security best practices around key manag
A Hardware Security Module (HSM) is a physical device that manages digital keys for strong authentication and provides crypto-processing. These modules are designed to be tamper-resistant and provide a secure environment for performing cryptographic operations. HSMs can come in standalone devices, plug-in cards, or integrated circuits on another device.
-HSMs are crucial for a range of security-sensitive applications because they offer a hardened, secure enclave for the storage of cryptographic keys and execution of cryptographic functions. They are particularly important for ensuring the security of transactions, identity verifications, and data encryption.
+HSMs are crucial for various security-sensitive applications because they offer a hardened, secure enclave for storing cryptographic keys and executing cryptographic functions. They are particularly important for ensuring the security of transactions, identity verifications, and data encryption.
#### Benefits
@@ -587,17 +596,17 @@ HSMs provide several functionalities that are beneficial for the security of ML
**Secure Model Training and Updates:** The training and updating of ML models involve the processing of potentially sensitive data. HSMs ensure that these processes are conducted within a secure cryptographic boundary, protecting against the exposure of training data and unauthorized model updates.
-#### Trade-offs
+#### Tradeoffs
-HSMs involve several trade-offs for embedded ML. These trade-offs are somewhat similar to TEEs, but for the sake of completeness, we will also discuss them here through the lens of HSM.
+HSMs involve several tradeoffs for embedded ML. These tradeoffs are similar to TEEs, but for completeness, we will also discuss them here through the lens of HSM.
-**Cost:** HSMs are specialized devices that can be expensive to procure and implement, which can raise the overall cost of an ML project. This may be a significant factor to consider for embedded systems where cost constraints are often stricter.
+**Cost:** HSMs are specialized devices that can be expensive to procure and implement, raising the overall cost of an ML project. This may be a significant factor for embedded systems, where cost constraints are often stricter.
-**Performance Overhead:** While secure, the cryptographic operations performed by HSMs can introduce latency. Any added delay can be a critical issue in high-performance embedded ML applications where inference needs to happen in real-time, such as in autonomous vehicles or real-time translation devices.
+**Performance Overhead:** While secure, the cryptographic operations performed by HSMs can introduce latency. Any added delay can be critical in high-performance embedded ML applications where inference must happen in real-time, such as in autonomous vehicles or translation devices.
**Physical Space:** Embedded systems are often limited by physical space, and adding an HSM can be challenging in tightly constrained environments. This is especially true for consumer electronics and wearable technology, where size and form factor are key considerations.
-**Power Consumption:** HSMs require power for their operation, which can be a drawback for battery-operated devices that rely on long battery life. The secure processing and cryptographic operations can drain the battery faster, a significant trade-off for mobile or remote embedded ML applications.
+**Power Consumption:** HSMs require power for their operation, which can be a drawback for battery-operated devices with long battery life. The secure processing and cryptographic operations can drain the battery faster, a significant tradeoff for mobile or remote embedded ML applications.
**Complexity in Integration:** Integrating HSMs into existing hardware systems adds complexity. It often requires specialized knowledge to manage the secure communication between the HSM and the system's processor and develop software capable of interfacing with the HSM.
@@ -619,15 +628,15 @@ When stimulated with an input challenge, the PUF circuit produces an output resp
#### Benefits
-PUF key generation avoids the need for external key storage which risks exposure. It also provides a foundation for other hardware security primitives like secure boot. Implementation challenges include managing varying reliability and entropy across different PUFs, sensitivity to environmental conditions, and susceptibility to machine learning modeling attacks. When designed carefully, PUFs enable promising applications in IP protection, trusted computing, and anti-counterfeiting.
+PUF key generation avoids external key storage, which risks exposure. It also provides a foundation for other hardware security primitives like Secure Boot. Implementation challenges include managing varying reliability and entropy across different PUFs, sensitivity to environmental conditions, and susceptibility to machine learning modeling attacks. When designed carefully, PUFs enable promising applications in IP protection, trusted computing, and anti-counterfeiting.
#### Utility
-Machine learning models are rapidly becoming a core part of the functionality for many embedded devices like smartphones, smart home assistants, and autonomous drones. However, securing ML on resource-constrained embedded hardware can be challenging. This is where physical unclonable functions (PUFs) come in uniquely handy. Let's look at some examples of how PUFs can be useful.
+Machine learning models are rapidly becoming a core part of the functionality for many embedded devices, such as smartphones, smart home assistants, and autonomous drones. However, securing ML on resource-constrained embedded hardware can be challenging. This is where physical unclonable functions (PUFs) come in uniquely handy. Let's look at some examples of how PUFs can be useful.
PUFs provide a way to generate unique fingerprints and cryptographic keys tied to the physical characteristics of each chip on the device. Let's take an example. We have a smart camera drone that uses embedded ML to track objects. A PUF integrated into the drone's processor could create a device-specific key to encrypt the ML model before loading it onto the drone. This way, even if an attacker somehow hacks the drone and tries to steal the model, they won't be able to use it on another device!
-The same PUF key could also create a digital watermark embedded in the ML model. If that model ever gets leaked and posted online by someone trying to pirate it, the watermark could help prove it came from your stolen drone and didn't originate from the attacker. Also, imagine the drone camera connects to the cloud to offload some of its ML processing. The PUF can authenticate the camera is legitimate before the cloud will run inference on sensitive video feeds. The cloud could verify that the drone has not been physically tampered with by checking that the PUF responses have not changed.
+The same PUF key could also create a digital watermark embedded in the ML model. If that model ever gets leaked and posted online by someone trying to pirate it, the watermark could help prove it came from your stolen drone and didn't originate from the attacker. Also, imagine the drone camera connects to the cloud to offload some of its ML processing. The PUF can authenticate that the camera is legitimate before the cloud will run inference on sensitive video feeds. The cloud could verify that the drone has not been physically tampered with by checking that the PUF responses have not changed.
PUFs enable all this security through their challenge-response behavior's inherent randomness and hardware binding. Without needing to store keys externally, PUFs are ideal for securing embedded ML with limited resources. Thus, they offer a unique advantage over other mechanisms.
@@ -635,27 +644,27 @@ PUFs enable all this security through their challenge-response behavior's inhere
The working principle behind PUFs, shown in @fig-pfu, involves generating a \"challenge-response" pair, where a specific input (the challenge) to the PUF circuit results in an output (the response) that is determined by the unique physical properties of that circuit. This process can be likened to a fingerprinting mechanism for electronic devices. Devices that utilize ML for processing sensor data can employ PUFs to secure communication between devices and prevent the execution of ML models on counterfeit hardware.
-@fig-pfu illustrates an overview of the PUF basics: a) PUF can be thought of as a unique fingerprint for each piece of hardware; b) an Optical PUF is a special plastic token that is illuminated, creating a unique speckle pattern that is then recorded; c) in an APUF (Arbiter PUF), challenge bits select different paths, and an arbiter decides which one is faster, giving a response of '1' or '0'; d) in an SRAM PUF, the response is determined by the mismatch in the threshold voltage of transistors, where certain conditions lead to a preferred response of '1'. Each of these methods uses specific characteristics of the hardware to create a unique identifier.
+@fig-pfu illustrates an overview of the PUF basics: a) PUF can be thought of as a unique fingerprint for each piece of hardware; b) an Optical PUF is a special plastic token that is illuminated, creating a unique speckle pattern that is then recorded; c) in an APUF (Arbiter PUF), challenge bits select different paths, and a judge decides which one is faster, giving a response of '1' or '0'; d) in an SRAM PUF, the response is determined by the mismatch in the threshold voltage of transistors, where certain conditions lead to a preferred response of '1'. Each of these methods uses specific characteristics of the hardware to create a unique identifier.
{#fig-pfu}
#### Challenges
-There are a few challenges with PUFs. The PUF response can be sensitive to environmental conditions, such as temperature and voltage fluctuations, leading to inconsistent behavior that must be accounted for in the design. Also, since PUFs can potentially generate many unique challenge-response pairs, managing and ensuring the consistency of these pairs across the device's lifetime can be challenging. Last but not least, integrating PUF technology may increase the overall manufacturing cost of a device, although it can save costs in key management over the device's lifecycle.
+There are a few challenges with PUFs. The PUF response can be sensitive to environmental conditions, such as temperature and voltage fluctuations, leading to inconsistent behavior that must be accounted for in the design. Also, since PUFs can generate many unique challenge-response pairs, managing and ensuring the consistency of these pairs across the device's lifetime can be challenging. Last but not least, integrating PUF technology may increase the overall manufacturing cost of a device, although it can save costs in key management over the device's lifecycle.
## Privacy Concerns in Data Handling
-Handling personal and sensitive data securely and ethically is critical as machine learning permeates devices like smartphones, wearables, and smart home appliances. For medical hardware, handling data securely and ethically is further required by law, through the [Health Insurance Portability and Accountability Act](https://aspe.hhs.gov/report/health-insurance-portability-and-accountability-act-1996) (HIPAA). These embedded ML systems pose unique privacy risks given their intimate proximity to users' lives.
+Handling personal and sensitive data securely and ethically is critical as machine learning permeates devices like smartphones, wearables, and smart home appliances. For medical hardware, handling data securely and ethically is further required by law through the [Health Insurance Portability and Accountability Act](https://aspe.hhs.gov/report/health-insurance-portability-and-accountability-act-1996) (HIPAA). These embedded ML systems pose unique privacy risks, given their intimate proximity to users' lives.
### Sensitive Data Types
Embedded ML devices like wearables, smart home assistants, and autonomous vehicles frequently process highly personal data that requires careful handling to maintain user privacy and prevent misuse. Specific examples include medical reports and treatment plans processed by health wearables, private conversations continuously captured by smart home assistants, and detailed driving habits collected by connected cars. Compromise of such sensitive data can lead to serious consequences like identity theft, emotional manipulation, public shaming, and mass surveillance overreach.
-Sensitive data takes many forms - structured records like contact lists and unstructured content like conversational audio and video streams. In medical settings, protected health information (PHI) is collected by doctors throughout every interaction, and is heavily regulated by strict HIPAA guidelines. Even outside of medical settings, sensitive data can still be collected in the form of [Personally Identifiable Information](https://www.dol.gov/general/ppii) (PII), which is defined as "any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means." Examples of PII include email addresses, social security numbers, and phone numbers, among other fields. PII is collected in medical settings, as well as other settings (financial applications, etc) and is heavily regulated by Department of Labor policies.
+Sensitive data takes many forms - structured records like contact lists and unstructured content like conversational audio and video streams. In medical settings, protected health information (PHI) is collected by doctors throughout every interaction and is heavily regulated by strict HIPAA guidelines. Even outside of medical settings, sensitive data can still be collected in the form of [Personally Identifiable Information](https://www.dol.gov/general/ppii) (PII), which is defined as "any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means." Examples of PII include email addresses, social security numbers, and phone numbers, among other fields. PII is collected in medical settings and other settings (financial applications, etc) and is heavily regulated by Department of Labor policies.
-Even derived model outputs could indirectly leak details about individuals. Beyond just personal data, proprietary algorithms and datasets also warrant confidentiality protections. In the Data Engineering section, we covered several of these topics in detail.
+Even derived model outputs could indirectly leak details about individuals. Beyond just personal data, proprietary algorithms and datasets also warrant confidentiality protections. In the Data Engineering section, we covered several topics in detail.
-Techniques like de-identification, aggregation, anonymization, and federation can help transform sensitive data into less risky forms while retaining analytical utility. However, diligent controls around access, encryption, auditing, consent, minimization, and compliance practices are still essential throughout the data lifecycle. Regulations like [GDPR](https://gdpr-info.eu/) categorize different classes of sensitive data and prescribe responsibilities around their ethical handling. Standards like [NIST 800-53](https://csrc.nist.gov/pubs/sp/800/53/r5/upd1/final) provide rigorous security control guidance tailored for confidentiality protection. With growing reliance on embedded ML, understanding sensitive data risks is crucial.
+Techniques like de-identification, aggregation, anonymization, and federation can help transform sensitive data into less risky forms while retaining analytical utility. However, diligent controls around access, encryption, auditing, consent, minimization, and compliance practices are still essential throughout the data lifecycle. Regulations like [GDPR](https://gdpr-info.eu/) categorize different classes of sensitive data and prescribe responsibilities around their ethical handling. Standards like [NIST 800-53](https://csrc.nist.gov/pubs/sp/800/53/r5/upd1/final) provide rigorous security control guidance for confidentiality protection. With growing reliance on embedded ML, understanding sensitive data risks is crucial.
### Applicable Regulations
@@ -663,31 +672,31 @@ Many embedded ML applications handle sensitive user data under HIPAA, GDPR, and
* [HIPAA](}}
Promoting safety requires extensive testing, risk analysis, human oversight, and designing systems that combine multiple weak models to avoid single points of failure. Rigorous safety mechanisms are essential for the responsible deployment of capable AI.
### Accountability and Governance
-When AI systems eventually fail or produce harmful outcomes, there must be mechanisms to address resultant issues, compensate affected parties, and assign responsibility. Both corporate accountability policies and government regulations are indispensable for responsible AI governance. For instance, [Illinois' Artificial Intelligence Video Interview Act](https://www.ilga.gov/legislation/ilcs/ilcs3.asp?ActID@15&ChapterIDh) requires companies to disclose and obtain consent for AI video analysis, promoting accountability.
+When AI systems eventually fail or produce harmful outcomes, mechanisms must exist to address resultant issues, compensate affected parties, and assign responsibility. Both corporate accountability policies and government regulations are indispensable for responsible AI governance. For instance, [Illinois' Artificial Intelligence Video Interview Act](https://www.ilga.gov/legislation/ilcs/ilcs3.asp?ActID@15&ChapterIDh) requires companies to disclose and obtain consent for AI video analysis, promoting accountability.
Without clear accountability, even harms caused unintentionally could go unresolved, furthering public outrage and distrust. Oversight boards, impact assessments, grievance redress processes, and independent audits promote responsible development and deployment.
@@ -117,25 +119,25 @@ The table below summarizes how responsible AI principles manifest differently ac
For cloud-based machine learning, explainability techniques can leverage significant compute resources, enabling complex methods like SHAP values or sampling-based approaches to interpret model behaviors. For example, [Microsoft's InterpretML](https://www.microsoft.com/en-us/research/uploads/prod/2020/05/InterpretML-Whitepaper.pdf) toolkit provides explainability techniques tailored for cloud environments.
-However, edge ML operates on resource-constrained devices, requiring more lightweight explainability methods that can run locally without excessive latency. Techniques like LIME [@ribeiro2016should] approximate model explanations using linear models or decision trees to avoid expensive computations, which makes them ideal for resource-constrained devices. But LIME requires training hundreds to even thousands of models to generate good explanations, which is often infeasible given edge computing constraints. In contrast, saliency-based methods are often much faster in practice, only requiring a single forward pass through the network to estimate feature importance. This greater efficiency makes such methods better suited to edge devices with limited compute resources where low-latency explanations are critical.
+However, edge ML operates on resource-constrained devices, requiring more lightweight explainability methods that can run locally without excessive latency. Techniques like LIME [@ribeiro2016should] approximate model explanations using linear models or decision trees to avoid expensive computations, which makes them ideal for resource-constrained devices. However, LIME requires training hundreds to even thousands of models to generate good explanations, which is often infeasible given edge computing constraints. In contrast, saliency-based methods are often much faster in practice, only requiring a single forward pass through the network to estimate feature importance. This greater efficiency makes such methods better suited to edge devices with limited compute resources where low-latency explanations are critical.
-Embedded systems poses the most significant challenges for explainability, given tiny hardware capabilities. More compact models and limited data make inherent model transparency easier. Explaining decisions may not be feasible on high-size- and power-optimized microcontrollers. [DARPA's Transparent Computing](https://www.darpa.mil/program/transparent-computing) program aims to develop extremely low overhead explainability, especially for TinyML devices like sensors and wearables.
+Given tiny hardware capabilities, embedded systems pose the most significant challenges for explainability. More compact models and limited data make inherent model transparency easier. Explaining decisions may not be feasible on high-size and power-optimized microcontrollers. [DARPA's Transparent Computing](https://www.darpa.mil/program/transparent-computing) program aims to develop extremely low overhead explainability, especially for TinyML devices like sensors and wearables.
### Fairness
For cloud machine learning, vast datasets and computing power enable detecting biases across large heterogeneous populations and mitigating them through techniques like re-weighting data samples. However, biases may emerge from the broad behavioral data used to train cloud models. Amazon's Fairness Flow framework helps assess cloud ML fairness.
-Edge ML relies on limited on-device data, making analyzing biases across diverse groups harder. But edge devices interact closely with individuals, providing an opportunity to adapt locally for fairness. [Google's Federated Learning](https://blog.research.google/2017/04/federated-learning-collaborative.html) distributes model training across devices to incorporate individual differences.
+Edge ML relies on limited on-device data, making analyzing biases across diverse groups harder. However, edge devices interact closely with individuals, providing an opportunity to adapt locally for fairness. [Google's Federated Learning](https://blog.research.google/2017/04/federated-learning-collaborative.html) distributes model training across devices to incorporate individual differences.
TinyML poses unique challenges for fairness with highly dispersed specialized hardware and minimal training data. Bias testing is difficult across diverse devices. Collecting representative data from many devices to mitigate bias has scale and privacy hurdles. [DARPA's Assured Neuro Symbolic Learning and Reasoning (ANSR)](https://www.darpa.mil/news-events/2022-06-03) efforts are geared toward developing fairness techniques given extreme hardware constraints.
### Safety
-For cloud ML, key safety risks include model hacking, data poisoning, and malware disrupting cloud services. Robustness techniques like adversarial training, anomaly detection, and diversified models aim to harden cloud ML against attacks. Redundancy and redundancy can help prevent single points of failure.
+Key safety risks for cloud ML include model hacking, data poisoning, and malware disrupting cloud services. Robustness techniques like adversarial training, anomaly detection, and diversified models aim to harden cloud ML against attacks. Redundancy can help prevent single points of failure.
Edge ML and TinyML interact with the physical world, so reliability and safety validation are critical. Rigorous testing platforms like [Foretellix](https://www.foretellix.com/) synthetically generate edge scenarios to validate safety. TinyML safety is magnified by autonomous devices with limited supervision. TinyML safety often relies on collective coordination - swarms of drones maintain safety through redundancy. Physical control barriers also constrain unsafe TinyML device behaviors.
-In summary, safety is crucial but manifests differently in each domain. Cloud ML guards against hacking, edge ML interacts physically so reliability is key, and TinyML leverages distributed coordination for safety. Understanding the nuances guides appropriate safety techniques.
+In summary, safety is crucial but manifests differently in each domain. Cloud ML guards against hacking, edge ML interacts physically, so reliability is key, and TinyML leverages distributed coordination for safety. Understanding the nuances guides appropriate safety techniques.
### Accountability
@@ -147,11 +149,11 @@ With TinyML, accountability mechanisms must be traced across long, complex suppl
### Governance
-For cloud ML, organizations institute internal governance like ethics boards, audits, and model risk management. But external governance also oversees cloud ML, like regulations on bias and transparency such as the [AI Bill of Rights](https://www.whitehouse.gov/ostp/ai-bill-of-rights/), [General Data Protection Regulation (GDPR)](https://gdpr-info.eu/), and [California Consumer Protection Act (CCPA)](https://oag.ca.gov/privacy/ccpa). Third-party auditing supports cloud ML governance.
+Organizations institute internal governance for cloud ML, such as ethics boards, audits, and model risk management. But external governance also oversees cloud ML, like regulations on bias and transparency such as the [AI Bill of Rights](https://www.whitehouse.gov/ostp/ai-bill-of-rights/), [General Data Protection Regulation (GDPR)](https://gdpr-info.eu/), and [California Consumer Protection Act (CCPA)](https://oag.ca.gov/privacy/ccpa). Third-party auditing supports cloud ML governance.
-Edge ML is more decentralized, requiring responsible self-governance by developers and companies deploying models locally. Industry associations coordinate governance across edge ML vendors. Open software helps align incentives for ethical edge ML.
+Edge ML is more decentralized, requiring responsible self-governance by developers and companies deploying models locally. Industry associations coordinate governance across edge ML vendors, and open software helps align incentives for ethical edge ML.
-With TinyML, extreme decentralization and complexity make external governance infeasible. TinyML relies on protocols and standards for self-governance baked into model design and hardware. Cryptography enables the provable trustworthiness of TinyML devices.
+Extreme decentralization and complexity make external governance infeasible with TinyML. TinyML relies on protocols and standards for self-governance baked into model design and hardware. Cryptography enables the provable trustworthiness of TinyML devices.
### Privacy
@@ -159,7 +161,7 @@ For cloud ML, vast amounts of user data are concentrated in the cloud, creating
Edge ML moves data processing onto user devices, reducing aggregated data collection but increasing potential sensitivity as personal data resides on the device. Apple uses on-device ML and differential privacy to train models while minimizing data sharing. Data anonymization and secure enclaves protect on-device data.
-TinyML distributes data across many resource-constrained devices, making centralized breaches unlikely and challenging for scale anonymization. Data minimization and using edge devices as intermediaries help TinyML privacy.
+TinyML distributes data across many resource-constrained devices, making centralized breaches unlikely and making scale anonymization challenging. Data minimization and using edge devices as intermediaries help TinyML privacy.
So, while cloud ML must protect expansive centralized data, edge ML secures sensitive on-device data, and TinyML aims for minimal distributed data sharing due to constraints. While privacy is vital throughout, techniques must match the environment. Understanding nuances allows for selecting appropriate privacy preservation approaches.
@@ -167,89 +169,89 @@ So, while cloud ML must protect expansive centralized data, edge ML secures sens
### Detecting and Mitigating Bias
-There has been a large body of work demonstrating that machine learning models can exhibit bias, from underperforming for people of a certain identity to making decisions that limit groups' access to important resources [@buolamwini2018genderShades].
+A large body of work has demonstrated that machine learning models can exhibit bias, from underperforming people of a certain identity to making decisions that limit groups' access to important resources [@buolamwini2018genderShades].
-Ensuring fair and equitable treatment for all groups affected by machine learning systems is crucial as these models increasingly impact people's lives in areas like lending, healthcare, and criminal justice. We typically evaluate model fairness by considering "subgroup attributes" - attributes unrelated to the prediction task that capture identities like race, gender, or religion. For example, in a loan default prediction model, subgroups could include race, gender, or religion. When models are trained naively to maximize accuracy, they often ignore subgroup performance. However, this can negatively impact marginalized communities.
+Ensuring fair and equitable treatment for all groups affected by machine learning systems is crucial as these models increasingly impact people's lives in areas like lending, healthcare, and criminal justice. We typically evaluate model fairness by considering "subgroup attributes" unrelated to the prediction task that capture identities like race, gender, or religion. For example, in a loan default prediction model, subgroups could include race, gender, or religion. When models are trained naively to maximize accuracy, they often ignore subgroup performance. However, this can negatively impact marginalized communities.
To illustrate, imagine a model predicting loan repayment where the plusses (+'s) represent repayment and the circles (O's) represent default, as shown in @fig-fairness-example. The optimal accuracy would be correctly classifying all of Group A while misclassifying some of Group B's creditworthy applicants as defaults. If positive classifications allow access loans, Group A would receive many more loans---which would naturally result in a biased outcome.
{#fig-fairness-example}
-Alternatively, correcting the biases against Group B would likely increase "false positives" and reduce accuracy for Group A. Or, we could train separate models focused on maximizing true positives for each group. But this would require explicitly using sensitive attributes like race in the decision process.
+Alternatively, correcting the biases against Group B would likely increase "false positives" and reduce accuracy for Group A. Or, we could train separate models focused on maximizing true positives for each group. However, this would require explicitly using sensitive attributes like race in the decision process.
-As we see, there are inherent tensions around priorities like accuracy versus subgroup fairness, and whether to explicitly account for protected classes. Reasonable people can disagree on the appropriate tradeoffs. And constraints around costs and implementation options further complicate matters. Overall, ensuring the fair and ethical use of machine learning involves navigating these complex challenges.
+As we see, there are inherent tensions around priorities like accuracy versus subgroup fairness and whether to explicitly account for protected classes. Reasonable people can disagree on the appropriate tradeoffs. Constraints around costs and implementation options further complicate matters. Overall, ensuring the fair and ethical use of machine learning involves navigating these complex challenges.
-Thus, fairness literature has proposed three main _fairness metrics_ for quantifying how fair a model performs over a dataset [@hardt2016equality]. Given a model h, a dataset D consisting of (x,y,s) samples, where x is the data features, y is the label, and s is the subgroup attribute, where we assume there are simply two subgroups a and b, we can define the following.
+Thus, the fairness literature has proposed three main _fairness metrics_ for quantifying how fair a model performs over a dataset [@hardt2016equality]. Given a model h and a dataset D consisting of (x,y,s) samples, where x is the data features, y is the label, and s is the subgroup attribute, and we assume there are simply two subgroups a and b, we can define the following.
1. **Demographic Parity** asks how accurate a model is for each subgroup. In other words, P(h(X) = Y S = a) = P(h(X) = Y S = b)
2. **Equalized Odds** asks how precise a model is on positive and negative samples for each subgroup. P(h(X) = y S = a, Y = y) = P(h(X) = y S = b, Y = y)
-3. **Equality of Opportunity** is a special case of equalized odds that asks how precise a model is on positive samples only. This is relevant in cases such as resource allocation where we care about how positive (ie resource allocated) labels are distributed across groups. For example, we care that an equal proportion of loans are given to both men and women. P(h(X) = 1 S = a, Y = 1) = P(h(X) = 1 S = b, Y = 1)
+3. **Equality of Opportunity** is a special case of equalized odds that only asks how precise a model is on positive samples. This is relevant in cases such as resource allocation, where we care about how positive (i.e., resource-allocated) labels are distributed across groups. For example, we care that an equal proportion of loans are given to both men and women. P(h(X) = 1 S = a, Y = 1) = P(h(X) = 1 S = b, Y = 1)
-Note: these definitions often take a narrow view of considering binary comparisons between two subgroups. Another thread of fair machine learning research focusing on _multicalibration_ and _multiaccuracy_ considers the interactions between an arbitrary number of identities, acknowledging the inherent intersectionality of individual identities in the real world [@hebert2018multicalibration].
+Note: These definitions often take a narrow view when considering binary comparisons between two subgroups. Another thread of fair machine learning research focusing on _multicalibration_ and _multiaccuracy_ considers the interactions between an arbitrary number of identities, acknowledging the inherent intersectionality of individual identities in the real world [@hebert2018multicalibration].
#### Context Matters
-Before making any technical decisions in developing an unbiased ML algorithm we need to understand the context surrounding our model. Here are some of the key questions to think about:
+Before making any technical decisions to develop an unbiased ML algorithm, we need to understand the context surrounding our model. Here are some of the key questions to think about:
- Who will this model make decisions for?
- Who is represented in the training data?
-- Who is represented and who is missing at the table of engineers, designers, and managers?
-- What sort of long-lasting impacts could this model have? For example, will it impact the financial security of an individual at a generational scale such as determining college admissions or admitting a loan for a house?
+- Who is represented, and who is missing at the table of engineers, designers, and managers?
+- What sort of long-lasting impacts could this model have? For example, will it impact an individual's financial security at a generational scale, such as determining college admissions or admitting a loan for a house?
- What historical and systematic biases are present in this setting, and are they present in the training data the model will generalize from?
-Understanding the social, ethical and historical background of a system is critical to prevent harm and should inform decisions throughout the model development lifecycle. After understanding the context, there are a wide array of technical decisions one can make to remove bias. First, one must decide what fairness metric is the most appropriate criterion to optimize for. Next, there are generally three main areas where one can intervene to debias an ML system.
+Understanding a system's social, ethical, and historical background is critical to preventing harm and should inform decisions throughout the model development lifecycle. After understanding the context, one can make various technical decisions to remove bias. First, one must decide what fairness metric is the most appropriate criterion for optimizing. Next, there are generally three main areas where one can intervene to debias an ML system.
-First, preprocessing is when one balances a dataset to ensure fair representation, or even increases the weight on certain underrepresented groups to ensure the model performs well on them. Second, in processing attempts to modify the training process of an ML system to ensure it prioritizes fairness. This can be as simple as adding a fairness regularizer [@lowy2021fermi], to training an ensemble of models and sampling from them in a specific manner [@agarwal2018reductions].
+First, preprocessing is when one balances a dataset to ensure fair representation or even increases the weight on certain underrepresented groups to ensure the model performs well. Second, in processing attempts to modify the training process of an ML system to ensure it prioritizes fairness. This can be as simple as adding a fairness regularizer [@lowy2021fermi] to training an ensemble of models and sampling from them in a specific manner [@agarwal2018reductions].
-Finally, post processing debiases a model after the fact, taking a trained model and modifying its predictions in a specific manner to ensure fairness is preserved [@alghamdi2022beyond; @hardt2016equality]. Post processing builds on the preprocessing and in processing steps by providing another opportunity to address bias and fairness issues in the model after it has already been trained.
+Finally, post-processing debases a model after the fact, taking a trained model and modifying its predictions in a specific manner to ensure fairness is preserved [@alghamdi2022beyond; @hardt2016equality]. Post-processing builds on the preprocessing and in-processing steps by providing another opportunity to address bias and fairness issues in the model after it has already been trained.
-The three step process of preprocessing, in processing, and post processing provides a framework for intervening at different stages of model development to mitigate issues around bias and fairness. While preprocessing and in processing focus on data and training, post processing allows for adjustments after the model has been fully trained. Together, these three approaches give multiple opportunities to detect and remove unfair bias.
+The three-step process of preprocessing, in-processing, and post-processing provides a framework for intervening at different stages of model development to mitigate issues around bias and fairness. While preprocessing and in-processing focus on data and training, post-processing allows for adjustments after the model has been fully trained. Together, these three approaches give multiple opportunities to detect and remove unfair bias.
#### Thoughtful Deployment
The breadth of existing fairness definitions and debiasing interventions underscores the need for thoughtful assessment before deploying ML systems. As ML researchers and developers, responsible model development requires proactively educating ourselves on the real-world context, consulting domain experts and end-users, and centering harm prevention.
-Rather than seeing fairness considerations as a box to check, we must deeply engage with the unique social implications and ethical trade offs around each model we build. Every technical choice about datasets, model architectures, evaluation metrics and deployment constraints embeds values. By broadening our perspective beyond narrow technical metrics, carefully evaluating tradeoffs, and listening to impacted voices, we can work to ensure our systems expand opportunity rather than encode bias.
+Rather than seeing fairness considerations as a box to check, we must deeply engage with the unique social implications and ethical tradeoffs around each model we build. Every technical choice about datasets, model architectures, evaluation metrics, and deployment constraints embeds values. By broadening our perspective beyond narrow technical metrics, carefully evaluating tradeoffs, and listening to impacted voices, we can work to ensure our systems expand opportunity rather than encode bias.
-The path forward lies not in an arbitrary debiasing checklist but in a commitment to understanding and upholding our ethical responsibility at each step. This commitment starts with proactively educating ourselves and consulting others, rather than just going through the motions of a fairness checklist. It requires engaging deeply with ethical tradeoffs in our technical choices, evaluating impacts on different groups, and listening to those voices most impacted.
+The path forward lies not in an arbitrary debiasing checklist but in a commitment to understanding and upholding our ethical responsibility at each step. This commitment starts with proactively educating ourselves and consulting others rather than just going through the motions of a fairness checklist. It requires engaging deeply with ethical tradeoffs in our technical choices, evaluating impacts on different groups, and listening to those voices most impacted.
-Ultimately, responsible and ethical AI systems come not from checkbox debiasing, but from upholding our duty to assess harms, broaden perspectives, understand tradeoffs and ensure we provide opportunity for all groups. This ethical responsibility should drive every step.
+Ultimately, responsible and ethical AI systems do not come from checkbox debiasing but from upholding our duty to assess harms, broaden perspectives, understand tradeoffs, and ensure we provide opportunity for all groups. This ethical responsibility should drive every step.
-The connection between the paragraphs is that the first paragraph sets up the need for thoughtful assessment of fairness issues rather than a checkbox approach. The second paragraph then expands on what that thoughtful assessment looks like in practice - engaging with tradeoffs, evaluating impacts on groups, listening to impacted voices. Finally, the last paragraph circles back to the idea of avoiding an "arbitrary debiasing checklist" and instead committing to ethical responsibility through assessment, understanding tradeoffs, and providing opportunity.
+The connection between the paragraphs is that the first paragraph establishes the need for a thoughtful assessment of fairness issues rather than a checkbox approach. The second paragraph then expands on what that thoughtful assessment looks like in practice—engaging with tradeoffs, evaluating impacts on groups, and listening to impacted voices. Finally, the last paragraph refers to avoiding an "arbitrary debiasing checklist" and committing to ethical responsibility through assessment, understanding tradeoffs, and providing opportunity.
### Preserving Privacy
Recent incidents have demonstrated how AI models can memorize sensitive user data in ways that violate privacy. For example, as shown in Figure XXX below, Stable Diffusion's art generations were found to mimic identifiable artists' styles and replicate existing photos, concerning many [@carlini2023extracting]. These risks are amplified with personalized ML systems deployed in intimate environments like homes or wearables.
-Imagine if a smart speaker uses our conversations to improve the quality of service to end users who genuinely want it. Still, others could violate privacy by trying to extract what the speaker "remembers." @fig-diffusion-model-example below shows an example of how diffusion models can memorize and generate individual training examples [@carlini2023extracting].
+Imagine if a smart speaker uses our conversations to improve the quality of service to end users who genuinely want it. Still, others could violate privacy by trying to extract what the speaker "remembers." @fig-diffusion-model-example below shows how diffusion models can memorize and generate individual training examples [@carlini2023extracting].
{#fig-diffusion-model-example}
-Adversaries can take advantage of these memorization capabilities and train models to detect if specific training data influenced a target model. For example, membership inference attacks train a secondary model which learns to detect a change in the target model's outputs when making inference over data it was trained on versus not trained on [@shokri2017membership].
+Adversaries can use these memorization capabilities and train models to detect if specific training data influenced a target model. For example, membership inference attacks train a secondary model that learns to detect a change in the target model's outputs when making inferences over data it was trained on versus not trained on [@shokri2017membership].
-ML devices are especially vulnerable because they are often personalized on user data and are deployed in even more intimate settings such as the home. To combat these privacy issues, private machine learning techniques have evolved to establish safeguards against adversaries, as mentioned in the [Security and Privacy](../privacy_security/privacy_security.qmd) chapter. Methods like differential privacy add mathematical noise during training to obscure individual data points' influence on the model. Popular techniques like DP-SGD [@abadi2016deep] also clip gradients to limit what the model leaks about the data. Still, some argue users should also be able to delete the impact of their data after the fact.
+ML devices are especially vulnerable because they are often personalized on user data and are deployed in even more intimate settings such as the home. Private machine learning techniques have evolved to establish safeguards against adversaries, as mentioned in the [Security and Privacy](../privacy_security/privacy_security.qmd) chapter to combat these privacy issues. Methods like differential privacy add mathematical noise during training to obscure individual data points' influence on the model. Popular techniques like DP-SGD [@abadi2016deep] also clip gradients to limit what the model leaks about the data. Still, users should also be able to delete the impact of their data after the fact.
### Machine Unlearning
-With ML devices personalized to individual users and then deployed to remote edges without connectivity, a challenge arises---how can models responsively "forget" data points after deployment? If a user requests their personal data be removed from a personalized model, the lack of connectivity makes retraining infeasible. Thus, efficient on-device data forgetting is necessary but poses hurdles.
+With ML devices personalized to individual users and then deployed to remote edges without connectivity, a challenge arises---how can models responsively "forget" data points after deployment? If users request their data be removed from a personalized model, the lack of connectivity makes retraining infeasible. Thus, efficient on-device data forgetting is necessary but poses hurdles.
-Initial unlearning approaches faced limitations in this context. Retraining models from scratch on the device to forget data points proves inefficient or even impossible, given the resource constraints. Fully retraining also requires retaining all the original training data on the device, which brings its own security and privacy risks. Common machine unlearning techniques [@bourtoule2021machine] for remote embedded ML systems fail to enable responsive, secure data removal.
+Initial unlearning approaches faced limitations in this context. Given the resource constraints, retrieving models from scratch on the device to forget data points proves inefficient or even impossible. Fully retraining also requires retaining all the original training data on the device, which brings its own security and privacy risks. Common machine unlearning techniques [@bourtoule2021machine] for remote embedded ML systems fail to enable responsive, secure data removal.
However, newer methods show promise in modifying models to approximately forget data [?] without full retraining. While the accuracy loss from avoiding full rebuilds is modest, guaranteeing data privacy should still be the priority when handling sensitive user information ethically. Even slight exposure to private data can violate user trust. As ML systems become deeply personalized, efficiency and privacy must be enabled from the start---not afterthoughts.
-Recent policy discussions which include the [European Union's General Data](https://gdpr-info.eu), [Protection Regulation (GDPR)](https://gdpr-info.eu), the [California Consumer Privacy Act (CCPA)](https://oag.ca.gov/privacy/ccpa), the [Act on the Protection of Personal Information (APPI)](https://www.dataguidance.com/notes/japan-data-protection-overview), and Canada's proposed [Consumer Privacy Protection Act (CPPA)](https://blog.didomi.io/en-us/canada-data-privacy-law), require the deletion of private information. These policies coupled with AI incidents like Stable Diffusion memorizing artist data have underscored the ethical need for users to delete their data from models after training.
+Recent policy discussions which include the [European Union's General Data](https://gdpr-info.eu), [Protection Regulation (GDPR)](https://gdpr-info.eu), the [California Consumer Privacy Act (CCPA)](https://oag.ca.gov/privacy/ccpa), the [Act on the Protection of Personal Information (APPI)](https://www.dataguidance.com/notes/japan-data-protection-overview), and Canada's proposed [Consumer Privacy Protection Act (CPPA)](https://blog.didomi.io/en-us/canada-data-privacy-law), require the deletion of private information. These policies, coupled with AI incidents like Stable Diffusion memorizing artist data, have underscored the ethical need for users to delete their data from models after training.
-The right to remove data arises from privacy concerns around corporations or adversaries misusing sensitive user information. Machine unlearning refers to removing the influence of specific points from an already-trained model. Naively this involves full retraining without the deleted data. However, for ML systems personalized and deployed to remote edges, connectivity constraints often make retraining infeasible. If a smart speaker learns from private home conversations, retaining access to delete that data is important.
+The right to remove data arises from privacy concerns around corporations or adversaries misusing sensitive user information. Machine unlearning refers to removing the influence of specific points from an already-trained model. Naively, this involves full retraining without the deleted data. However, connectivity constraints often make retraining infeasible for ML systems personalized and deployed to remote edges. If a smart speaker learns from private home conversations, retaining access to delete that data is important.
-Although limited, methods are evolving to enable efficient approximations to retraining for unlearning. By modifying models inference-time, they can mimic "forgetting" data without full access to training data. However, most current techniques are restricted to simple models, still have resource costs, and trading some accuracy. Though methods are evolving, enabling efficient data removal and respecting user privacy remains an imperative for responsible TinyML deployment.
+Although limited, methods are evolving to enable efficient approximations of retraining for unlearning. By modifying models' inference time, they can mimic "forgetting" data without full access to training data. However, most current techniques are restricted to simple models, still have resource costs, and trade some accuracy. Though methods are evolving, enabling efficient data removal and respecting user privacy remains imperative for responsible TinyML deployment.
### Adversarial Examples and Robustness
-Machine learning models, especially deep neural networks, have a well-documented Achilles heel: they often break when even tiny perturbations are made to their inputs [@szegedy2013intriguing]. This surprising fragility highlights a major robustness gap that threatens real-world deployment in high-stakes domains. It also opens the door for adversarial attacks designed to deliberately fool models.
+Machine learning models, especially deep neural networks, have a well-documented Achilles heel: they often break when even tiny perturbations are made to their inputs [@szegedy2013intriguing]. This surprising fragility highlights a major robustness gap threatening real-world deployment in high-stakes domains. It also opens the door for adversarial attacks designed to fool models deliberately.
-Machine learning models can exhibit a surprising brittleness - minor input tweaks can cause shocking malfunctions, even in state-of-the-art deep neural networks [@szegedy2013intriguing]. This unpredictability around out-of-sample data underscores gaps in model generalization and robustness. Given the growing ubiquity of ML, it also enables adversarial threats that weaponize models' blindspots.
+Machine learning models can exhibit surprising brittleness—minor input tweaks can cause shocking malfunctions, even in state-of-the-art deep neural networks [@szegedy2013intriguing]. This unpredictability around out-of-sample data underscores gaps in model generalization and robustness. Given the growing ubiquity of ML, it also enables adversarial threats that weaponize models' blindspots.
Deep neural networks demonstrate an almost paradoxical dual nature - human-like proficiency in training distributions coupled with extreme fragility to tiny input perturbations [@szegedy2013intriguing]. This adversarial vulnerability gap highlights gaps in standard ML procedures and threats to real-world reliability. At the same time, it can be exploited: attackers can find model-breaking points humans wouldn't perceive.
@@ -257,67 +259,67 @@ Deep neural networks demonstrate an almost paradoxical dual nature - human-like
](images/png/adversarial_robustness.png){#fig-adversarial-example}
-For instance, past work shows successful attacks that trick models for tasks like NSFW detection [@bhagoji2018practical], ad-blocking [@tramer2019adversarial], and speech recognition [@carlini2016hidden]. While errors in these domains already pose security risks, the problem extends beyond IT security: recently adversarial robustness has been proposed as an additional performance metric by approximating worst-case behavior.
+For instance, past work shows successful attacks that trick models for tasks like NSFW detection [@bhagoji2018practical], ad-blocking [@tramer2019adversarial], and speech recognition [@carlini2016hidden]. While errors in these domains already pose security risks, the problem extends beyond IT security. Recently, adversarial robustness has been proposed as an additional performance metric by approximating worst-case behavior.
-The surprising model fragility highlighted above casts doubt on real-world reliability and opens the door to adversarial manipulation. This growing vulnerability underscores several needs. First, principled robustness evaluations are essential for quantifying model vulnerabilities before deployment. Approximating worst-case behavior surfaces blindspots.
+The surprising model fragility highlighted above casts doubt on real-world reliability and opens the door to adversarial manipulation. This growing vulnerability underscores several needs. First, moral robustness evaluations are essential for quantifying model vulnerabilities before deployment. Approximating worst-case behavior surfaces blindspots.
-Second, effective defenses across domains must be developed to close these robustness gaps. With security on the line, developers cannot ignore the threat of attacks exploiting model weaknesses. Moreover, for safety-critical applications like self-driving vehicles and medical diagnosis, we cannot afford any fragility-induced failures. Lives are at stake.
+Second, effective defenses across domains must be developed to close these robustness gaps. With security on the line, developers cannot ignore the threat of attacks exploiting model weaknesses. Moreover, we cannot afford any fragility-induced failures for safety-critical applications like self-driving vehicles and medical diagnosis. Lives are at stake.
Finally, the research community continues mobilizing rapidly in response. Interest in adversarial machine learning has exploded as attacks reveal the need to bridge the robustness gap between synthetic and real-world data. Conferences now commonly feature defenses for securing and stabilizing models. The community recognizes that model fragility is a critical issue that must be addressed through robustness testing, defense development, and ongoing research. By surfacing blindspots and responding with principled defenses, we can work to ensure reliability and safety for machine learning systems, especially in high-stakes domains.
### Building Interpretable Models
-As models are deployed more frequently in high-stakes settings, practitioners, developers, and downstream end-users, as well as increasing regulation, have highlighted the need for explainability in machine learning. The goal of many interpretability and explainability methods is to provide practitioners with more information about either the overall behavior of models or the behavior given a specific input. This allows users to decide whether or not the output or prediction of a model is trustworthy.
+As models are deployed more frequently in high-stakes settings, practitioners, developers, downstream end-users, and increasing regulation have highlighted the need for explainability in machine learning. The goal of many interpretability and explainability methods is to provide practitioners with more information about the models' overall behavior or the behavior given a specific input. This allows users to decide whether or not a model's output or prediction is trustworthy.
-Such analysis can help developers debug models and improve performance by pointing out biases, spurious correlations, and failure modes of models. In cases where models are able to surpass human performance on a task, interpretability can help users and researchers better understand relationships in their data and patterns that may previously have been unknown.
+Such analysis can help developers debug models and improve performance by pointing out biases, spurious correlations, and failure modes of models. In cases where models can surpass human performance on a task, interpretability can help users and researchers better understand relationships in their data and previously unknown patterns.
-There are many classes of methods in explainability/interpretability, including: post hoc explainability, inherent interpretability, and mechanistic interpretability. These methods aim to make complex machine learning models more understandable and ensure users can trust model predictions, especially in critical settings. By providing transparency into model behavior, explainability techniques are an important tool for developing safe, fair, and reliable AI systems.
+There are many classes of explainability/interpretability methods, including post hoc explainability, inherent interpretability, and mechanistic interpretability. These methods aim to make complex machine learning models more understandable and ensure users can trust model predictions, especially in critical settings. By providing transparency into model behavior, explainability techniques are an important tool for developing safe, fair, and reliable AI systems.
#### Post Hoc Explainability
Post hoc explainability methods typically explain the output behavior of a black-box model on a specific input. Popular methods include counterfactual explanations, feature attribution methods, and concept-based explanations.
-**Counterfactual explanations**, also frequently referred to as algorithmic recourse, take the form of "If X had not occurred, Y would not have occurred" [@wachter2017counterfactual]. For example, consider a person applying for a bank loan whose application is rejected by a model. They may ask their bank for recourse, or how they need to change to be eligible for a loan. A counterfactual explanation would tell them which features they need to change and by how much such that the model's prediction changes.
+**Counterfactual explanations**, also frequently called algorithmic recourse, "If X had not occurred, Y would not have occurred" [@wachter2017counterfactual]. For example, consider a person applying for a bank loan whose application is rejected by a model. They may ask their bank for recourse or how to change to be eligible for a loan. A counterfactual explanation would tell them which features they need to change and by how much such that the model's prediction changes.
-**Feature attribution methods** aim to highlight the input features important or necessary for a particular prediction. For a computer vision model, this would mean highlighting the individual pixels that contributed most to the predicted label of the image. Note that these methods do not explain how those pixels/features impact the prediction, only that they do. Common methods include input gradients, GradCAM [@selvaraju2017grad], SmoothGrad [@smilkov2017smoothgrad], LIME [@ribeiro2016should], and SHAP [@lundberg2017unified].
+**Feature attribution methods** highlight the input features that are important or necessary for a particular prediction. For a computer vision model, this would mean highlighting the individual pixels that contributed most to the predicted label of the image. Note that these methods do not explain how those pixels/features impact the prediction, only that they do. Common methods include input gradients, GradCAM [@selvaraju2017grad], SmoothGrad [@smilkov2017smoothgrad], LIME [@ribeiro2016should], and SHAP [@lundberg2017unified].
By providing examples of changes to input features that would alter a prediction (counterfactuals) or indicating the most influential features for a given prediction (attribution), these post hoc explanation techniques shed light on model behavior for individual inputs. This granular transparency helps users determine whether they can trust and act upon specific model outputs.
-**Concept based explanations** aim to explain model behavior and outputs using a pre-defined set of semantic concepts (e.g. the model recognizes scene class "bedroom" based on the presence of concepts "bed" and "pillow"). Recent work shows that users often prefer these explanations to attribution and example based explanations because they "resemble human reasoning and explanations" [@ramaswamy2023ufo]. Popular concept based explanation methods include TCAV [@kim2018interpretability], Network Dissection [@bau2017network], and interpretable basis decomposition [@zhou2018interpretable].
+**Concept-based explanations** aim to explain model behavior and outputs using a pre-defined set of semantic concepts (e.g., the model recognizes scene class "bedroom" based on the presence of concepts "bed" and "pillow"). Recent work shows that users often prefer these explanations to attribution and example-based explanations because they "resemble human reasoning and explanations" [@ramaswamy2023ufo]. Popular concept-based explanation methods include TCAV [@kim2018interpretability], Network Dissection [@bau2017network], and interpretable basis decomposition [@zhou2018interpretable].
-Note that these methods are extremely sensitive to the size and quality of the concept set, and that there exists a tradeoff between the accuracy and faithfulness of these methods and their interpretability or understandability to humans [@ramaswamy2023overlooked]. By mapping model predictions to human-understandable concepts, however, concept-based explanations can provide transparency into the reasoning behind model outputs.
+Note that these methods are extremely sensitive to the size and quality of the concept set, and there is a tradeoff between their accuracy and faithfulness and their interpretability or understandability to humans [@ramaswamy2023overlooked]. However, by mapping model predictions to human-understandable concepts, concept-based explanations can provide transparency into the reasoning behind model outputs.
#### Inherent Interpretability
Inherently interpretable models are constructed such that their explanations are part of the model architecture and are thus naturally faithful, which sometimes makes them preferable to post-hoc explanations applied to black-box models, especially in high-stakes domains where transparency is imperative [@rudin2019stop]. Often, these models are constrained so that the relationships between input features and predictions are easy for humans to follow (linear models, decision trees, decision sets, k-NN models), or they obey structural knowledge of the domain, such as monotonicity [@gupta2016monotonic], causality, or additivity [@lou2013accurate; @beck1998beyond].
-However, more recent works have relaxed the restrictions on inherently interpretable models, using black-box models for feature extraction and using a simpler inherently interpretable model for classification, allowing for faithful explanations that relate high-level features to prediction. For example, Concept Bottleneck Models [@koh2020concept] predict a concept set c that is passed into a linear classifier, and ProtoPNets [@chen2019looks] dissect inputs into linear combinations of similarities to prototypical parts from the training set.
+However, more recent works have relaxed the restrictions on inherently interpretable models, using black-box models for feature extraction and a simpler inherently interpretable model for classification, allowing for faithful explanations that relate high-level features to prediction. For example, Concept Bottleneck Models [@koh2020concept] predict a concept set c that is passed into a linear classifier. ProtoPNets [@chen2019looks] dissect inputs into linear combinations of similarities to prototypical parts from the training set.
#### Mechanistic Interpretability
-Mechanistic interpretability methods seek to reverse engineer neural networks, often analogized to how one might reverse engineer a compiled binary or how neuroscientists attempt to decode the function of individual neurons and circuits in brains. Most research in mechanistic interpretability views models as a computational graph [@geiger2021causal] and circuits are subgraphs with distinct functionality [@wang2022interpretability]. Current approaches to extracting circuits from neural networks and understanding their functionality rely on human manual inspection of visualizations produced by circuits [@olah2020zoom].
+Mechanistic interpretability methods seek to reverse engineer neural networks, often analogizing them to how one might reverse engineer a compiled binary or how neuroscientists attempt to decode the function of individual neurons and circuits in brains. Most research in mechanistic interpretability views models as a computational graph [@geiger2021causal], and circuits are subgraphs with distinct functionality [@wang2022interpretability]. Current approaches to extracting circuits from neural networks and understanding their functionality rely on human manual inspection of visualizations produced by circuits [@olah2020zoom].
-Alternatively, some approaches build sparse autoencoders that encourage neurons to encode disentangled interpretable features [@bricken2023towards]. This field is much newer than existing areas in explainability and interpretability, and as such most works are generally exploratory rather than solution oriented.
+Alternatively, some approaches build sparse autoencoders that encourage neurons to encode disentangled interpretable features [@bricken2023towards]. This field is much newer than existing areas in explainability and interpretability, and as such, most works are generally exploratory rather than solution-oriented.
-There are many open problems in mechanistic interpretability, including the polysemanticity of neurons and circuits, the inconvenience and subjectivity of human labeling, and the exponential search space for identifying circuits in large models with billions or trillions of neurons.
+There are many problems in mechanistic interpretability, including the polysemanticity of neurons and circuits, the inconvenience and subjectivity of human labeling, and the exponential search space for identifying circuits in large models with billions or trillions of neurons.
#### Challenges and Considerations
-As methods for interpreting and explaining models progress, it is important to note that humans overtrust and misuse interpretability tools [@kaur2020interpreting] and that a user's trust in a model due to an explanation can be independent of the correctness of the explanations [@lakkaraju2020fool]. As such, it is necessary that aside from assessing the faithfulness/correctness of explanations, researchers must also ensure that interpretability methods are developed and deployed with a specific user in mind, and that user studies are performed to evaluate their efficacy and usefulness in practice.
+As methods for interpreting and explaining models progress, it is important to note that humans overtrust and misuse interpretability tools [@kaur2020interpreting] and that a user's trust in a model due to an explanation can be independent of the correctness of the explanations [@lakkaraju2020fool]. As such, it is necessary that aside from assessing the faithfulness/correctness of explanations, researchers must also ensure that interpretability methods are developed and deployed with a specific user in mind and that user studies are performed to evaluate their efficacy and usefulness in practice.
-Furthermore, explanations should be tailored with the expertise of the user in mind, as well as the task they are using the explanation for, and the corresponding minimal amount of information required for the explanation to be useful to prevent information overload.
+Furthermore, explanations should be tailored to the user's expertise, the task they are using the explanation for and the corresponding minimal amount of information required for the explanation to be useful to prevent information overload.
-While interpretability/explainability are popular areas in machine learning research, very few works study their intersection with TinyML and edge computing. Given that a significant application of TinyML is healthcare, which often requires high transparency and interpretability, it is important that existing techniques are tested for scalability and efficiency with respect to edge devices. Many methods rely on extra forward and backward passes, and some even require extensive training of proxy models, all of which would likely be infeasible on microcontrollers that are resource constrained.
+While interpretability/explainability are popular areas in machine learning research, very few works study their intersection with TinyML and edge computing. Given that a significant application of TinyML is healthcare, which often requires high transparency and interpretability, existing techniques must be tested for scalability and efficiency concerning edge devices. Many methods rely on extra forward and backward passes, and some even require extensive training in proxy models, which are infeasible on resource-constrained microcontrollers.
-That being said, explainability methods can be highly useful in the _development_ of models for edge devices, as they can give insights into how input data and models can be compressed and how representations may change post compression. Furthermore, many interpretable models are often smaller than their black-box counterparts, which could have additional benefits in TinyML applications.
+That said, explainability methods can be highly useful in developing models for edge devices, as they can give insights into how input data and models can be compressed and how representations may change post-compression. Furthermore, many interpretable models are often smaller than their black-box counterparts, which could benefit TinyML applications.
### Monitoring Model Performance
-While developers may train models such that they seem adversarially robust, fair, and interpretable before deployment, it is imperative that both the users and the owners of the model continue to monitor the model's performance and trustworthiness during the model's full lifecycle. In practice, data is frequently changing, which can often result in distribution shifts. These distribution shifts can have profound impacts on both the vanilla predictive performance of the model as well as its trustworthiness (fairness, robustness, and interpretability) on real world data.
+While developers may train models that seem adversarially robust, fair, and interpretable before deployment, it is imperative that both the users and the model owners continue to monitor the model's performance and trustworthiness during the model's full lifecycle. Data is frequently changing in practice, which can often result in distribution shifts. These distribution shifts can profoundly impact the model's vanilla predictive performance and its trustworthiness (fairness, robustness, and interpretability) in real-world data.
-Furthermore, definitions of fairness also frequently change with time, such as what society considers a protected attribute, and the expertise of the users asking for explanations may change as well.
+Furthermore, definitions of fairness frequently change with time, such as what society considers a protected attribute, and the expertise of the users asking for explanations may also change.
-To ensure that models keep up to date with such changes in the real world, developers must continually evaluate their model on current and representative data and standards, and update models when necessary.
+To ensure that models keep up to date with such changes in the real world, developers must continually evaluate their models on current and representative data and standards and update models when necessary.
## Implementation Challenges
@@ -339,126 +341,126 @@ Among these are:
### Obtaining Quality and Representative Data
-Responsible AI design must occur at all stages of the pipeline, including data collection such as those things discussed in the [Data Engineering](../data_engineering/data_engineering.qmd) chapter. This begs the question; what does it mean for data to be high-quality and representative? Consider the following scenarios that _hinder_ the representativeness of data:
+As discussed in the [Data Engineering](../data_engineering/data_engineering.qmd) chapter, responsible AI design must occur at all pipeline stages, including data collection. This begs the question: what does it mean for data to be high-quality and representative? Consider the following scenarios that _hinder_ the representativeness of data:
#### Subgroup Imbalance
-This is likely what comes to mind when hearing the phrase "representative data." Subgroup imbalance means that the dataset contains relatively more data from one subgroup than another. This imbalance can negatively affect the downstream ML model, by causing it to overfit to a subgroup of people while having poor performance on another.
+This is likely what comes to mind when hearing "representative data." Subgroup imbalance means the dataset contains relatively more data from one subgroup than another. This imbalance can negatively affect the downstream ML model by causing it to overfit a subgroup of people while performing poorly on another.
One example consequence of subgroup imbalance is racial discrimination in facial recognition technology [@buolamwini2018genderShades]; commercial facial recognition algorithms have up to 34% worse error rates on darker-skinned females than lighter-skinned males.
-Note that data imbalance goes both ways, and subgroups can also be harmfully _overrepresented_ in the dataset. For example, the Allegheny Family Screening Tool (AFST) is used to predict the likelihood that a child will eventually be removed from a home. The AFST produces [disproportionate scores for different subgroups](https://www.aclu.org/the-devil-is-in-the-details-interrogating-values-embedded-in-the-allegheny-family-screening-tool#4-2-the-more-data-the-better), one of the reasons being that it is trained on historically biased data, sourced from juvenile and adult criminal legal systems, public welfare agencies, and behavioral health agencies and programs.
+Note that data imbalance goes both ways, and subgroups can also be harmful _overrepresented_ in the dataset. For example, the Allegheny Family Screening Tool (AFST) predicts the likelihood that a child will eventually be removed from a home. The AFST produces [disproportionate scores for different subgroups](https://www.aclu.org/the-devil-is-in-the-details-interrogating-values-embedded-in-the-allegheny-family-screening-tool#4-2-the-more-data-the-better), one of the reasons being that it is trained on historically biased data, sourced from juvenile and adult criminal legal systems, public welfare agencies, and behavioral health agencies and programs.
#### Quantifying Target Outcomes
-This occurs in applications where the ground-truth label _cannot be measured_ or is _difficult to represent_ in a single quantity. For example, an ML model in a mobile wellness application may want to predict individual stress levels. The true stress labels themselves are impossible to obtain directly, and must be inferred from other biosignals, such as heart rate variability and user's self-reported data. In these situations, noise is built into the data by design, making this a challenging ML task.
+This occurs in applications where the ground-truth label cannot be measured or is difficult to represent in a single quantity. For example, an ML model in a mobile wellness application may want to predict individual stress levels. The true stress labels themselves are impossible to obtain directly and must be inferred from other biosignals, such as heart rate variability and user self-reported data. In these situations, noise is built into the data by design, making this a challenging ML task.
#### Distribution Shift
-Data may no longer be representative of a task if a major external event causes the source of the data to change drastically. The most common way to think about distribution shift is with respect to time; for example, data on consumer shopping habits that was collected pre-covid may no longer be representative of consumer behavior today.
+Data may no longer represent a task if a major external event causes the data source to change drastically. The most common way to think about distribution shifts is with respect to time; for example, data on consumer shopping habits collected pre-covid may no longer be present in consumer behavior today.
-Another form of distribution shift is that caused by transfer. For instance, in applying a triage system that was trained on data from one hospital to another, distribution shift may occur if the two hospitals are very different.#
+The transfer causes another form of distribution shift. For instance, when applying a triage system that was trained on data from one hospital to another, a distribution shift may occur if the two hospitals are very different.#
#### Gathering Data
-A reasonable solution for many of the above problems with non-representative or low-quality data is to collect more; we can collect more data targeting an underrepresented subgroup or collect more data from the target hospital to which our model might be transferred. However, there are also reasons that gathering more data is an inappropriate or infeasible solution for the task at hand.
+A reasonable solution for many of the above problems with non-representative or low-quality data is to collect more; we can collect more data targeting an underrepresented subgroup or from the target hospital to which our model might be transferred. However, for some reasons, gathering more data is an inappropriate or infeasible solution for the task at hand.
-* _Data collection can be harmful._ This is the _paradox of exposure_, the situation in which those that stand to significantly gain from their data being collected are also those that are put at risk by the collection process (@d2023dataFeminism, Chapter 4). For example, collecting more data on non-binary individuals may be important for ensuring fairness of the ML application, but also put them at risk, depending on who is collecting the data and how (whether the data is easily identifiable, contains sensitive content, etc).
+* _Data collection can be harmful._ This is the _paradox of exposure_, the situation in which those who stand to significantly gain from their data being collected are also those who are put at risk by the collection process (@d2023dataFeminism, Chapter 4). For example, collecting more data on non-binary individuals may be important for ensuring the fairness of the ML application, but it also puts them at risk, depending on who is collecting the data and how (whether the data is easily identifiable, contains sensitive content, etc.).
-* _Data collection can be costly._ In some domains, such as in healthcare, obtaining data can be costly in terms of time and money.
+* _Data collection can be costly._ In some domains, such as healthcare, obtaining data can be costly in terms of time and money.
-* _Biased data collection._ For example, Electronic Health Records are a huge data-source for ML driven healthcare applications. Issues of subgroup representation aside, the data itself may be collected in a biased manner. For example, negative language ("nonadherent", "unwilling") is disproportionately used on black patients [@himmelstein2022examination].
+* _Biased data collection._ Electronic Health Records is a huge data source for ML-driven healthcare applications. Issues of subgroup representation aside, the data itself may be collected in a biased manner. For example, negative language ("nonadherent," "unwilling") is disproportionately used on black patients [@himmelstein2022examination].
We conclude with several additional strategies for maintaining data quality: improving understanding of the data, data exploration, and intr. First, fostering a deeper understanding of the data is crucial. This can be achieved through the implementation of standardized labels and measures of data quality, such as in the [Data Nutrition Project](https://datanutrition.org/).
-Directly collaborating with organizations responsible for the data collection can help ensure that the data is interpreted correctly. Second, employing effective tools for data exploration is important. Visualization techniques and statistical analyses can reveal issues with the data. Finally, establishing a feedback loop within the ML pipeline is essential for understanding the real world implications of the data. Metrics, such as fairness measures, allow us to define "data quality" in the context of the downstream application; improving fairness may directly improve the quality of the predictions that the end users receive.
+Collaborating with organizations responsible for collecting data helps ensure the data is interpreted correctly. Second, employing effective tools for data exploration is important. Visualization techniques and statistical analyses can reveal issues with the data. Finally, establishing a feedback loop within the ML pipeline is essential for understanding the real-world implications of the data. Metrics, such as fairness measures, allow us to define "data quality" in the context of the downstream application; improving fairness may directly improve the quality of the predictions that the end users receive.
### Balancing Accuracy and Other Objectives
-Machine learning models are often evaluated on accuracy alone, but this single metric cannot fully capture model performance and tradeoffs for responsible AI systems. Other ethical dimensions like fairness, robustness, interpretability and privacy may compete with pure predictive accuracy during model development. For instance, inherently interpretable models such as small decision trees or linear classifiers with simplified features intentionally trade some accuracy for transparency into the model behavior and predictions. While these simplified models achieve lower accuracy by not capturing all complexity in the dataset, improved interpretability builds trust by enabling direct analysis by human practitioners.
+Machine learning models are often evaluated on accuracy alone, but this single metric cannot fully capture model performance and tradeoffs for responsible AI systems. Other ethical dimensions, such as fairness, robustness, interpretability, and privacy, may compete with pure predictive accuracy during model development. For instance, inherently interpretable models such as small decision trees or linear classifiers with simplified features intentionally trade some accuracy for transparency in the model behavior and predictions. While these simplified models achieve lower accuracy by not capturing all the complexity in the dataset, improved interpretability builds trust by enabling direct analysis by human practitioners.
-Additionally, certain techniques meant to improve adversarial robustness like adversarial training examples or dimensionality reduction can degrade accuracy on clean validation data. In sensitive applications like healthcare, focusing narrowly on state-of-the-art accuracy carries ethical risks if it allows models to rely more on spurious correlations that introduce bias or use opaque reasoning. Therefore, the appropriate performance objectives depend greatly on the sociotechnical context.
+Additionally, certain techniques meant to improve adversarial robustness, such as adversarial training examples or dimensionality reduction, can degrade the accuracy of clean validation data. In sensitive applications like healthcare, focusing narrowly on state-of-the-art accuracy carries ethical risks if it allows models to rely more on spurious correlations that introduce bias or use opaque reasoning. Therefore, the appropriate performance objectives depend greatly on the sociotechnical context.
-Methodologies like [Value Sensitive Design](https://vsdesign.org/) provide frameworks for formally evaluating the priorities of various stakeholders within the real-world deployment system. These elucidate tensions between values like accuracy, interpretability and fairness which can then guide responsible tradeoff decisions. For a medical diagnosis system, achieving the highest accuracy may not be the singular goal - improving transparency to build practitioner trust or reducing bias towards minority groups could justify small losses in accuracy. Analyzing the sociotechnical context is key for setting these objectives.
+Methodologies like [Value Sensitive Design](https://vsdesign.org/) provide frameworks for formally evaluating the priorities of various stakeholders within the real-world deployment system. These elucidate tensions between values like accuracy, interpretation, ility, and fail and redness, which can then guide responsible tradeoff decisions. For a medical diagnosis system, achieving the highest accuracy may not be the singular goal - improving transparency to build practitioner trust or reducing bias towards minority groups could justify small losses in accuracy. Analyzing the sociotechnical context is key for setting these objectives.
-By taking a holistic view, we can responsibly balance accuracy with other ethical objectives for model success. Ongoing monitoring of performance along multiple dimensions is crucial as the system evolves after deployment.
+By taking a holistic view, we can responsibly balance accuracy with other ethical objectives for model success. Ongoing performance monitoring along multiple dimensions is crucial as the system evolves after deployment.
## Ethical Considerations in AI Design
-We must discuss at least some of the many ethical issues at stake in the design and application of AI systems and diverse frameworks for approaching these issues, including those from AI safety, Human-Computer Interaction (HCI), and Science, Technology, and Society (STS).
+We must discuss at least some of the many ethical issues at stake in designing and applying AI systems and diverse frameworks for approaching these issues, including those from AI safety, Human-Computer Interaction (HCI), and Science, Technology, and Society (STS).
### AI Safety and Value Alignment
-In 1960, Norbert Weiner wrote, "'if we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively... we had better be quite sure that the purpose put into the machine is the purpose which we really desire" [@wiener1960some].
+In 1960, Norbert Weiner wrote, "'if we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively... we had better be quite sure that the purpose put into the machine is the purpose which we desire" [@wiener1960some].
-In recent years, as the capabilities of deep learning models have achieved, and sometimes even surpassed human abilities, the issue of how to create AI systems that act in accord with human intentions instead of pursuing unintended or undesirable goals, has become a source of concern [@russell2021human]. Within the field of AI safety, a particular goal concerns "value alignment," or the problem of how to code the "right" purpose into machines [Human-Compatible Artificial Intelligence](https://people.eecs.berkeley.edu/~russell/papers/mi19book-hcai.pdf). Present AI research assumes we know the objectives we want to achieve and "studies the ability to achieve objectives, not the design of those objectives."
+In recent years, as the capabilities of deep learning models have achieved, and sometimes even surpassed, human abilities, the issue of creating AI systems that act in accord with human intentions instead of pursuing unintended or undesirable goals has become a source of concern [@russell2021human]. Within the field of AI safety, a particular goal concerns "value alignment," or the problem of how to code the "right" purpose into machines [Human-Compatible Artificial Intelligence](https://people.eecs.berkeley.edu/~russell/papers/mi19book-hcai.pdf). Present AI research assumes we know the objectives we want to achieve and "studies the ability to achieve objectives, not the design of those objectives."
However, complex real-world deployment contexts make explicitly defining "the right purpose" for machines difficult, requiring frameworks for responsible and ethical goal-setting. Methodologies like [Value Sensitive Design](https://vsdesign.org/) provide formal mechanisms to surface tensions between stakeholder values and priorities.
-By taking a holistic sociotechnical view, we can better ensure intelligent systems pursue objectives that align with broad human intentions rather than maximizing narrow metrics like accuracy alone. Achieving this in practice remains an open and critical research question as AI capabilities continue advancing rapidly.
+By taking a holistic sociotechnical view, we can better ensure intelligent systems pursue objectives that align with broad human intentions rather than maximizing narrow metrics like accuracy alone. Achieving this in practice remains an open and critical research question as AI capabilities advance rapidly.
-The absence of this alignment can lead to a number of AI safety issues, as have been documented in a variety of [deep learning models](https://deepmind.google/discover/blog/specification-gaming-the-flip-side-of-ai-ingenuity/). A common feature of systems that optimize for an objective, is that variables not directly included in the said objective may be set to extreme values to help optimize for that objective, leading to issues that have been characterized as specification gaming, reward hacking, etc. in reinforcement learning (RL).
+The absence of this alignment can lead to several AI safety issues, as have been documented in a variety of [deep learning models](https://deepmind.google/discover/blog/specification-gaming-the-flip-side-of-ai-ingenuity/). A common feature of systems that optimize for an objective is that variables not directly included in the objective may be set to extreme values to help optimize for that objective, leading to issues characterized as specification gaming, reward hacking, etc., in reinforcement learning (RL).
-In recent years, a particularly popular implementation of RL has been models pre-trained using self-supervised learning and fine-tuned using reinforcement learning from human feedback (RLHF) [@christiano2017deep]. Ngo 2022 [@ngo2022alignment] argue that by rewarding models for appearing harmless and ethical, while also maximizing useful outcomes, RLHF could encourage the emergence of three problematic properties: situationally-aware reward hacking where policies exploit human fallibility to gain high reward, misaligned internally-represented goals that generalize beyond the RLHF fine-tuning distribution, and power-seeking strategies.
+In recent years, a particularly popular implementation of RL has been models pre-trained using self-supervised learning and fine-tuned reinforcement learning from human feedback (RLHF) [@christiano2017deep]. Ngo 2022 [@ngo2022alignment] argues that by rewarding models for appearing harmless and ethical while also maximizing useful outcomes, RLHF could encourage the emergence of three problematic properties: situationally aware reward hacking, where policies exploit human fallibility to gain high reward, misaligned internally-represented goals that generalize beyond the RLHF fine-tuning distribution, and power-seeking strategies.
-Similarly, @amodei2016concrete outline six concrete problems for AI safety, including avoiding negative side effects, avoiding reward hacking, scalable oversight for aspects of the objective that are too expensive to be frequently evaluated during training, safe exploration strategies that encourage creativity but while preventing harms, and robustness to distributional shift in unseen testing environments.
+Similarly, @amodei2016concrete outlines six concrete problems for AI safety, including avoiding negative side effects, avoiding reward hacking, scalable oversight for aspects of the objective that are too expensive to be frequently evaluated during training, safe exploration strategies that encourage creativity while preventing harm, and robustness to distributional shift in unseen testing environments.
### Autonomous Systems and Control [and Trust]
-The consequences of autonomous systems that act independently of human oversight, and often outside of human judgment, have been well documented across a number of different industries and use cases. Most recently, the The California Department of Motor Vehicles suspended Cruise's deployment and testing permits for its autonomous vehicles citing ["unreasonable risks to public safety"](https://www.cnbc.com/2023/10/24/california-dmv-suspends-cruises-self-driving-car-permits.html). One such [accident](https://www.cnbc.com/2023/10/17/cruise-under-nhtsa-probe-into-autonomous-driving-pedestrian-injuries.html) occurred when a vehicle struck a pedestrian who stepped into a crosswalk after the stoplight had turned green, and the vehicle was allowed to proceed. In 2018, a pedestrian crossing the street with her bike was killed when a self-driving Uber car, which was operating in autonomous mode, [failed to accurately classify her moving body as an object to be avoided](https://www.bbc.com/news/technology-54175359).
+The consequences of autonomous systems that act independently of human oversight and often outside human judgment have been well documented across several industries and use cases. Most recently, the California Department of Motor Vehicles suspended Cruise's deployment and testing permits for its autonomous vehicles citing ["unreasonable risks to public safety"](https://www.cnbc.com/2023/10/24/california-dmv-suspends-cruises-self-driving-car-permits.html). One such [accident](https://www.cnbc.com/2023/10/17/cruise-under-nhtsa-probe-into-autonomous-driving-pedestrian-injuries.html) occurred when a vehicle struck a pedestrian who stepped into a crosswalk after the stoplight had turned green, and the vehicle was allowed to proceed. In 2018, a pedestrian crossing the street with her bike was killed when a self-driving Uber car, which was operating in autonomous mode, [failed to accurately classify her moving body as an object to be avoided](https://www.bbc.com/news/technology-54175359).
Autonomous systems beyond self-driving vehicles are also susceptible to such issues, with potentially graver consequences, as remotely-powered drones are already [reshaping warfare](https://www.reuters.com/technology/human-machine-teams-driven-by-ai-are-about-reshape-warfare-2023-09-08/). While such incidents bring up important ethical questions regarding [who should be held responsible](https://www.cigionline.org/articles/who-responsible-when-autonomous-systems-fail/) when these systems fail, they also highlight the technical challenges of giving full control of complex, real-world tasks to machines.
-At its core, there is a tension between human and machine autonomy. Engineering and computer science disciplines have tended to focus on machine autonomy. For example, as of 2019, a search for the word "autonomy" in the Digital Library of the Association for Computing Machinery (ACM) reveals that of the top 100 most cited papers, 90% are on machine autonomy [@calvo2020supporting]. In an attempt to build systems for the benefit of humanity, these disciplines have taken without question increasing productivity, efficiency, and automation as primary strategies for benefiting humanity.
+At its core, there is a tension between human and machine autonomy. Engineering and computer science disciplines have tended to focus on machine autonomy. For example, as of 2019, a search for the word "autonomy" in the Digital Library of the Association for Computing Machinery (ACM) reveals that of the top 100 most cited papers, 90% are on machine autonomy [@calvo2020supporting]. In an attempt to build systems for the benefit of humanity, these disciplines have taken, without question, increasing productivity, efficiency, and automation as primary strategies for benefiting humanity.
-These goals put machine automation at the forefront, often at the expense of the human. This approach suffers from inherent challenges, as noted since the early days of AI through the Frame problem and qualification problem, which formalizes the observation that is impossible to specify all the preconditions needed for a real-world action to succeed [@mccarthy1981epistemological].
+These goals put machine automation at the forefront, often at the expense of the human. This approach suffers from inherent challenges, as noted since the early days of AI through the Frame problem and qualification problem, which formalizes the observation that it is impossible to specify all the preconditions needed for a real-world action to succeed [@mccarthy1981epistemological].
-These logical limitations have given rise to mathematical approaches such as Responsibility-sensitive safety (RSS) [@shalev2017formal], which is aimed at breaking down the end goal of an automated driving system (namely safety) into concrete and checkable conditions that can be rigorously formulated in mathematical terms. The goal of RSS is that those safety rules guarantee ADS safety in the rigorous form of mathematical proofs. However, such approaches tend towards using automation to the problems of automation and are susceptible to many of the same issues.
+These logical limitations have given rise to mathematical approaches such as Responsibility-sensitive safety (RSS) [@shalev2017formal], which is aimed at breaking down the end goal of an automated driving system (namely safety) into concrete and checkable conditions that can be rigorously formulated in mathematical terms. The goal of RSS is that those safety rules guarantee ADS safety in the rigorous form of mathematical proof. However, such approaches tend towards using automation to address the problems of automation and are susceptible to many of the same issues.
-Another approach to combating these issues is to turn the focus towards the human-centered design of interactive systems that incorporate human control. Value-sensitive design [@friedman1996value] described three key design factors for a user interface that impact autonomy, including system capability, system complexity, misrepresentation, and fluidity. A more recent model, called METUX (A Model for Motivation, Engagement, and Thriving in the User Experience) leverages insights from Self-determination Theory (SDT) in Psychology to identifies six distinct spheres of technology experience that contribute to the design systems that promote wellbeing and human flourishing [@peters2018designing]. SDT defines autonomy as acting in accordance with one's goals and values, which is distinct from the use of autonomy as simply a synonym for either independence or being in control [@ryan2000self].
+Another approach to combating these issues is to focus on the human-centered design of interactive systems that incorporate human control. Value-sensitive design [@friedman1996value] described three key design factors for a user interface that impact autonomy, including system capability, complexity, misrepresentation, and fluidity. A more recent model, called METUX (A Model for Motivation, Engagement, and Thriving in the User Experience), leverages insights from Self-determination Theory (SDT) in Psychology to identify six distinct spheres of technology experience that contribute to the design systems that promote well-being and human flourishing [@peters2018designing]. SDT defines autonomy as acting by one's goals and values, which is distinct from the use of autonomy as simply a synonym for either independence or being in control [@ryan2000self].
-Calvo 2020 elaborates on METUX and its six "spheres of technology experience" in the context of AI-recommender systems [@calvo2020supporting]. They propose these spheres -- Adoption, Interface, Tasks, Behavior, Life, and Society -- as a way of organizing thinking and evaluation of technology design in order to appropriately capture contradictory and downstream impacts on human autonomy when interacting with AI systems.
+Calvo 2020 elaborates on METUX and its six "spheres of technology experience" in the context of AI-recommender systems [@calvo2020supporting]. They propose these spheres—adoption, Interface, Tasks, Behavior, Life, and Society—as a way of organizing thinking and evaluation of technology design in order to appropriately capture contradictory and downstream impacts on human autonomy when interacting with AI systems.
### Economic Impacts on Jobs, Skills, Wages
-A major concern of the current rise of AI technologies is widespread unemployment. As AI systems' capabilities expand, many fear that these technologies will cause an absolute loss of jobs as they replace current workers and overtake alternative employment roles across industries. However, changing economic landscapes at the hands of automation are not new, and historically, have been found to reflect patterns of *displacement* rather than replacement [@shneiderman2022human]---Chapter 4. In particular, automation usually lowers costs and increases quality, which greatly increases access and demand. The need to serve these growing markets pushes production, which in turn creates new jobs.
+A major concern of the current rise of AI technologies is widespread unemployment. As AI systems' capabilities expand, many fear these technologies will cause an absolute loss of jobs as they replace current workers and overtake alternative employment roles across industries. However, changing economic landscapes at the hands of automation is not new, and historically, have been found to reflect patterns of *displacement* rather than replacement [@shneiderman2022human]---Chapter 4. In particular, automation usually lowers costs and increases quality, greatly increasing access and demand. The need to serve these growing markets pushes production, creating new jobs.
Furthermore, studies have found that attempts to achieve "lights-out" automation -- productive and flexible automation with a minimal number of human workers -- have been unsuccessful. Attempts to do so have led to what the MIT Work of the Future taskforce has termed ["zero-sum automation"](https://hbr.org/2023/03/a-smarter-strategy-for-using-robots), in which process flexibility is sacrificed for increased productivity.
-In contrast, the taskforce propose a "positive-sum automation" approach in which flexibility is increased by designing technology that strategically incorporates humans where they are very much needed: making it easier for line employees to train and debug robots; using a bottom-up approach to identifying what tasks should be automated; and choosing the right metrics for measuring success (see MIT's [Work of the Future](https://workofthefuture-mit-edu.ezp-prod1.hul.harvard.edu/wp-content/uploads/2021/01/2020-Final-Report4.pdf)).
+In contrast, the task force proposes a "positive-sum automation" approach in which flexibility is increased by designing technology that strategically incorporates humans where they are very much needed, making it easier for line employees to train and debug robots, using a bottom-up approach to identifying what tasks should be automated; and choosing the right metrics for measuring success (see MIT's [Work of the Future](https://workofthefuture-mit-edu.ezp-prod1.hul.harvard.edu/wp-content/uploads/2021/01/2020-Final-Report4.pdf)).
-However, the optimism of the high-level outlook does not preclude individual harms, especially to those whose skills and jobs will be rendered obsolete by automation. Public and legislative pressure as well as corporate social responsibility efforts will need to be directed to create policies that share the benefits of automation with workers and result in higher minimum wages and benefits.
+However, the optimism of the high-level outlook does not preclude individual harm, especially to those whose skills and jobs will be rendered obsolete by automation. Public and legislative pressure, as well as corporate social responsibility efforts, will need to be directed at creating policies that share the benefits of automation with workers and result in higher minimum wages and benefits.
### Scientific Communication and AI Literacy
-A 1993 survey of 3000 North American adults' beliefs about the "electronic thinking machine" revealed two primary perspectives of the early computer: the "beneficial tool of man" perspective and the "awesome thinking machine" perspective. The attitudes contributing to the "awesome thinking machine" view in this and other studies, revealed a characterization of computers as "intelligent brains, smarter than people, unlimited, fast, mysterious, and frightening" [@martin1993myth]. These fears highlight an easily overlooked component of responsible AI, especially amidst the rush to commercialize such technologies: scientific communication that accurately communicates the capabilities *and* limitations of these systems, while providing transparency about the limitations of experts' knowledge about these systems.
+A 1993 survey of 3000 North American adults' beliefs about the "electronic thinking machine" revealed two primary perspectives of the early computer: the "beneficial tool of man" perspective and the "awesome thinking machine" perspective. The attitudes contributing to the "awesome thinking machine" view in this and other studies revealed a characterization of computers as "intelligent brains, smarter than people, unlimited, fast, mysterious, and frightening" [@martin1993myth]. These fears highlight an easily overlooked component of responsible AI, especially amidst the rush to commercialize such technologies: scientific communication that accurately communicates the capabilities *and* limitations of these systems while providing transparency about the limitations of experts' knowledge about these systems.
-As AI systems capabilities continue to expand beyond most people's comprehension, there is a natural tendency to assume the kinds of apocalyptic worlds painted by our media. This is in part due to the apparent difficulty of assimilating scientific information, even in technologically advanced cultures, which leads to the products of science being perceived as magic - "understandable only in terms of what it did, not how it worked" [@handlin1965science].
+As AI systems' capabilities expand beyond most people's comprehension, there is a natural tendency to assume the kinds of apocalyptic worlds painted by our media. This is partly due to the apparent difficulty of assimilating scientific information, even in technologically advanced cultures, which leads to the products of science being perceived as magic—"understandable only in terms of what it did, not how it worked" [@handlin1965science].
-While tech companies should be held responsible for limiting grandiose claims and not falling into cycles of hype, research studying scientific communication, especially with respect to (generative) AI, will also be useful in tracking and correcting public understanding of these technologies. An analysis of the Scopus scholarly database found that such research is scarce, with only a handful of papers mentioning both "science communication" and "artificial intelligence" [@schafer2023notorious].
+While tech companies should be held responsible for limiting grandiose claims and not falling into cycles of hype, research studying scientific communication, especially concerning (generative) AI, will also be useful in tracking and correcting public understanding of these technologies. An analysis of the Scopus scholarly database found that such research is scarce, with only a handful of papers mentioning both "science communication" and "artificial intelligence" [@schafer2023notorious].
-Research that exposes the perspectives, frames, and images of the future that are promoted by academic institutions, tech companies, stakeholders, regulators, journalists, NGOs and others will also help to identify potential gaps in AI literacy among adults [@lindgren2023handbook]. Increased focus on AI literacy from all stakeholders will be an important tool in helping people whose skills are rendered obsolete by AI automation [@ng2021ai].
+Research that exposes the perspectives, frames, and images of the future promoted by academic institutions, tech companies, stakeholders, regulators, journalists, NGOs, and others will also help to identify potential gaps in AI literacy among adults [@lindgren2023handbook]. Increased focus on AI literacy from all stakeholders will be important in helping people whose skills are rendered obsolete by AI automation [@ng2021ai].
-*"But even those who never acquire that understanding need assurance that there is a connection between the goals of science and their own welfare, and above all, that the scientist is not a man altogether apart but one who shares some of their own value."* (Handlin, 1965)
+*"But even those who never acquire that understanding need assurance that there is a connection between the goals of science and their welfare, and above all, that the scientist is not a man altogether apart but one who shares some of their value."* (Handlin, 1965)
## Conclusion
-Responsible artificial intelligence is crucial as machine learning systems exert growing influence across sectors like healthcare, employment, finance, and criminal justice. While AI promises immense benefits, thoughtlessly designed models risk perpetrating harm through biases, privacy violations, unintended behaviors, and other pitfalls.
+Responsible artificial intelligence is crucial as machine learning systems exert growing influence across healthcare, employment, finance, and criminal justice sectors. While AI promises immense benefits, thoughtlessly designed models risk perpetrating harm through biases, privacy violations, unintended behaviors, and other pitfalls.
-Upholding principles of fairness, explainability, accountability, safety, and transparency enables developing ethical AI aligned with human values. However, putting these principles into practice involves surmounting complex technical and social challenges around detecting dataset biases, choosing appropriate model tradeoffs, securing quality training data, and more. Frameworks like value-sensitive design provide guidance on balancing accuracy versus other objectives based on stakeholder needs.
+Upholding principles of fairness, explainability, accountability, safety, and transparency enables the development of ethical AI aligned with human values. However, implementing these principles involves surmounting complex technical and social challenges around detecting dataset biases, choosing appropriate model tradeoffs, securing quality training data, and more. Frameworks like value-sensitive design guide balancing accuracy versus other objectives based on stakeholder needs.
-Looking forward, advancing responsible AI necessitates continued research and industry commitment. More standardized benchmarks are required for comparing model biases and robustness. Enabling efficient transparency and user control for edge devices warrants focus as personalized TinyML expands. Revised incentive structures and policies must encourage deliberate, ethical development before reckless deployment. Education around AI literacy and limitations will further responsible public understanding.
+Looking forward, advancing responsible AI necessitates continued research and industry commitment. More standardized benchmarks are required to compare model biases and robustness. As personalized TinyML expands, enabling efficient transparency and user control for edge devices warrants focus. Revised incentive structures and policies must encourage deliberate, ethical development before reckless deployment. Education around AI literacy and its limitations will further contribute to public understanding.
-Responsible methods underscore that while machine learning offers immense potential, thoughtless application risks adverse consequences. Cross-disciplinary collaboration and human-centered design is imperative so AI can promote broad social benefit. The path ahead lies not in an arbitrary checklist but a steadfast commitment at each step to understand and uphold our ethical responsibility. By taking conscientious action, the machine learning community can lead AI toward empowering all people equitably and safely.
+Responsible methods underscore that while machine learning offers immense potential, thoughtless application risks adverse consequences. Cross-disciplinary collaboration and human-centered design are imperative so AI can promote broad social benefit. The path ahead lies not in an arbitrary checklist but in a steadfast commitment to understand and uphold our ethical responsibility at each step. By taking conscientious action, the machine learning community can lead AI toward empowering all people equitably and safely.
## Resources {#sec-responsible-ai-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will be adding new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [What am I building? What is the goal?](https://docs.google.com/presentation/d/1Z9VpUKGOOfUIg6x04aXLVYl-9QoablElOlxhTLkAVno/edit?usp=drive_link&resourcekey=0-Nr9tvJ9KGgaL44O_iJpe4A)
@@ -475,13 +477,13 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
-Coming soon.
+*Coming soon.*
:::
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/robust_ai/images/png/CI_CD_procedure.png b/contents/robust_ai/images/png/CI_CD_procedure.png
new file mode 100644
index 00000000..9e255763
Binary files /dev/null and b/contents/robust_ai/images/png/CI_CD_procedure.png differ
diff --git a/contents/robust_ai/images/png/Reed-Solomon.png b/contents/robust_ai/images/png/Reed-Solomon.png
new file mode 100644
index 00000000..8e2d70f1
Binary files /dev/null and b/contents/robust_ai/images/png/Reed-Solomon.png differ
diff --git a/contents/robust_ai/images/png/ad.png b/contents/robust_ai/images/png/ad.png
new file mode 100644
index 00000000..2b2169d1
Binary files /dev/null and b/contents/robust_ai/images/png/ad.png differ
diff --git a/contents/robust_ai/images/png/adversarial_attack_detection.png b/contents/robust_ai/images/png/adversarial_attack_detection.png
new file mode 100644
index 00000000..63f4971a
Binary files /dev/null and b/contents/robust_ai/images/png/adversarial_attack_detection.png differ
diff --git a/contents/robust_ai/images/png/adversarial_attack_injection.png b/contents/robust_ai/images/png/adversarial_attack_injection.png
new file mode 100644
index 00000000..3d4afda2
Binary files /dev/null and b/contents/robust_ai/images/png/adversarial_attack_injection.png differ
diff --git a/contents/robust_ai/images/png/adversarial_googlenet.png b/contents/robust_ai/images/png/adversarial_googlenet.png
new file mode 100644
index 00000000..1c67f517
Binary files /dev/null and b/contents/robust_ai/images/png/adversarial_googlenet.png differ
diff --git a/contents/robust_ai/images/png/autoencoder.png b/contents/robust_ai/images/png/autoencoder.png
new file mode 100644
index 00000000..ed77bc56
Binary files /dev/null and b/contents/robust_ai/images/png/autoencoder.png differ
diff --git a/contents/robust_ai/images/png/cover_robust_ai.png b/contents/robust_ai/images/png/cover_robust_ai.png
new file mode 100644
index 00000000..58e466a5
Binary files /dev/null and b/contents/robust_ai/images/png/cover_robust_ai.png differ
diff --git a/contents/robust_ai/images/png/data_augmentation.png b/contents/robust_ai/images/png/data_augmentation.png
new file mode 100644
index 00000000..cbc238d0
Binary files /dev/null and b/contents/robust_ai/images/png/data_augmentation.png differ
diff --git a/contents/robust_ai/images/png/dirty_label_example.png b/contents/robust_ai/images/png/dirty_label_example.png
new file mode 100644
index 00000000..88b4a39d
Binary files /dev/null and b/contents/robust_ai/images/png/dirty_label_example.png differ
diff --git a/contents/robust_ai/images/png/distribution_shift.png b/contents/robust_ai/images/png/distribution_shift.png
new file mode 100644
index 00000000..4834ac78
Binary files /dev/null and b/contents/robust_ai/images/png/distribution_shift.png differ
diff --git a/contents/robust_ai/images/png/distribution_shift_example.png b/contents/robust_ai/images/png/distribution_shift_example.png
new file mode 100644
index 00000000..fefbf7de
Binary files /dev/null and b/contents/robust_ai/images/png/distribution_shift_example.png differ
diff --git a/contents/robust_ai/images/png/drift_over_time.png b/contents/robust_ai/images/png/drift_over_time.png
new file mode 100644
index 00000000..d68ca719
Binary files /dev/null and b/contents/robust_ai/images/png/drift_over_time.png differ
diff --git a/contents/robust_ai/images/png/error_masking.png b/contents/robust_ai/images/png/error_masking.png
new file mode 100644
index 00000000..43d843d1
Binary files /dev/null and b/contents/robust_ai/images/png/error_masking.png differ
diff --git a/contents/robust_ai/images/png/gpu_out_of_memory.png b/contents/robust_ai/images/png/gpu_out_of_memory.png
new file mode 100644
index 00000000..aa0dd48b
Binary files /dev/null and b/contents/robust_ai/images/png/gpu_out_of_memory.png differ
diff --git a/contents/robust_ai/images/png/gradient_attack.png b/contents/robust_ai/images/png/gradient_attack.png
new file mode 100644
index 00000000..352c31ac
Binary files /dev/null and b/contents/robust_ai/images/png/gradient_attack.png differ
diff --git a/contents/robust_ai/images/png/graffiti.png b/contents/robust_ai/images/png/graffiti.png
new file mode 100644
index 00000000..84ed032b
Binary files /dev/null and b/contents/robust_ai/images/png/graffiti.png differ
diff --git a/contents/robust_ai/images/png/hardware_errors.png b/contents/robust_ai/images/png/hardware_errors.png
new file mode 100644
index 00000000..d0368796
Binary files /dev/null and b/contents/robust_ai/images/png/hardware_errors.png differ
diff --git a/contents/robust_ai/images/png/hardware_errors_Bolchini.png b/contents/robust_ai/images/png/hardware_errors_Bolchini.png
new file mode 100644
index 00000000..b067f1f9
Binary files /dev/null and b/contents/robust_ai/images/png/hardware_errors_Bolchini.png differ
diff --git a/contents/robust_ai/images/png/heartbeat.png b/contents/robust_ai/images/png/heartbeat.png
new file mode 100644
index 00000000..9ac12f8d
Binary files /dev/null and b/contents/robust_ai/images/png/heartbeat.png differ
diff --git a/contents/robust_ai/images/png/image14.png b/contents/robust_ai/images/png/image14.png
new file mode 100644
index 00000000..15333362
Binary files /dev/null and b/contents/robust_ai/images/png/image14.png differ
diff --git a/contents/robust_ai/images/png/image15.png b/contents/robust_ai/images/png/image15.png
new file mode 100644
index 00000000..f35c56a5
Binary files /dev/null and b/contents/robust_ai/images/png/image15.png differ
diff --git a/contents/robust_ai/images/png/image22.png b/contents/robust_ai/images/png/image22.png
new file mode 100644
index 00000000..93856433
Binary files /dev/null and b/contents/robust_ai/images/png/image22.png differ
diff --git a/contents/robust_ai/images/png/image34.png b/contents/robust_ai/images/png/image34.png
new file mode 100644
index 00000000..078f8e39
Binary files /dev/null and b/contents/robust_ai/images/png/image34.png differ
diff --git a/contents/robust_ai/images/png/intermittent_fault.png b/contents/robust_ai/images/png/intermittent_fault.png
new file mode 100644
index 00000000..4e6ef511
Binary files /dev/null and b/contents/robust_ai/images/png/intermittent_fault.png differ
diff --git a/contents/robust_ai/images/png/intermittent_fault_dram.png b/contents/robust_ai/images/png/intermittent_fault_dram.png
new file mode 100644
index 00000000..89d0bd00
Binary files /dev/null and b/contents/robust_ai/images/png/intermittent_fault_dram.png differ
diff --git a/contents/robust_ai/images/png/mavfi.jpg b/contents/robust_ai/images/png/mavfi.jpg
new file mode 100644
index 00000000..3064a808
Binary files /dev/null and b/contents/robust_ai/images/png/mavfi.jpg differ
diff --git a/contents/robust_ai/images/png/nasa_example.png b/contents/robust_ai/images/png/nasa_example.png
new file mode 100644
index 00000000..123d2477
Binary files /dev/null and b/contents/robust_ai/images/png/nasa_example.png differ
diff --git a/contents/robust_ai/images/png/parity.png b/contents/robust_ai/images/png/parity.png
new file mode 100644
index 00000000..be7a4360
Binary files /dev/null and b/contents/robust_ai/images/png/parity.png differ
diff --git a/contents/robust_ai/images/png/permanent_fault.png b/contents/robust_ai/images/png/permanent_fault.png
new file mode 100644
index 00000000..d500dec8
Binary files /dev/null and b/contents/robust_ai/images/png/permanent_fault.png differ
diff --git a/contents/robust_ai/images/png/phantom_objects.png b/contents/robust_ai/images/png/phantom_objects.png
new file mode 100644
index 00000000..67cbb926
Binary files /dev/null and b/contents/robust_ai/images/png/phantom_objects.png differ
diff --git a/contents/robust_ai/images/png/poisoning_attack_example.png b/contents/robust_ai/images/png/poisoning_attack_example.png
new file mode 100644
index 00000000..101c57b9
Binary files /dev/null and b/contents/robust_ai/images/png/poisoning_attack_example.png differ
diff --git a/contents/robust_ai/images/png/poisoning_example.png b/contents/robust_ai/images/png/poisoning_example.png
new file mode 100644
index 00000000..bee6eba4
Binary files /dev/null and b/contents/robust_ai/images/png/poisoning_example.png differ
diff --git a/contents/robust_ai/images/png/regression_testing.png b/contents/robust_ai/images/png/regression_testing.png
new file mode 100644
index 00000000..bc9d3b15
Binary files /dev/null and b/contents/robust_ai/images/png/regression_testing.png differ
diff --git a/contents/robust_ai/images/png/sdc_example.png b/contents/robust_ai/images/png/sdc_example.png
new file mode 100644
index 00000000..1c8379e3
Binary files /dev/null and b/contents/robust_ai/images/png/sdc_example.png differ
diff --git a/contents/robust_ai/images/png/stuck_fault.png b/contents/robust_ai/images/png/stuck_fault.png
new file mode 100644
index 00000000..80d5edc2
Binary files /dev/null and b/contents/robust_ai/images/png/stuck_fault.png differ
diff --git a/contents/robust_ai/images/png/temporal_evoltion.png b/contents/robust_ai/images/png/temporal_evoltion.png
new file mode 100644
index 00000000..a2b0c351
Binary files /dev/null and b/contents/robust_ai/images/png/temporal_evoltion.png differ
diff --git a/contents/robust_ai/images/png/tesla_dmr.png b/contents/robust_ai/images/png/tesla_dmr.png
new file mode 100644
index 00000000..2e56125e
Binary files /dev/null and b/contents/robust_ai/images/png/tesla_dmr.png differ
diff --git a/contents/robust_ai/images/png/tesla_example.jpg b/contents/robust_ai/images/png/tesla_example.jpg
new file mode 100644
index 00000000..714e3f22
Binary files /dev/null and b/contents/robust_ai/images/png/tesla_example.jpg differ
diff --git a/contents/robust_ai/images/png/transfer_learning.png b/contents/robust_ai/images/png/transfer_learning.png
new file mode 100644
index 00000000..acded529
Binary files /dev/null and b/contents/robust_ai/images/png/transfer_learning.png differ
diff --git a/contents/robust_ai/images/png/transient_fault.png b/contents/robust_ai/images/png/transient_fault.png
new file mode 100644
index 00000000..51860fda
Binary files /dev/null and b/contents/robust_ai/images/png/transient_fault.png differ
diff --git a/contents/robust_ai/images/png/watchdog.png b/contents/robust_ai/images/png/watchdog.png
new file mode 100644
index 00000000..728ec2c9
Binary files /dev/null and b/contents/robust_ai/images/png/watchdog.png differ
diff --git a/contents/robust_ai/robust_ai.bib b/contents/robust_ai/robust_ai.bib
index e69de29b..13a224e8 100644
--- a/contents/robust_ai/robust_ai.bib
+++ b/contents/robust_ai/robust_ai.bib
@@ -0,0 +1,1133 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
+@inproceedings{addepalli2020towards,
+ author = {Addepalli, Sravanti and Vivek, B. S. and Baburaj, Arya and Sriramanan, Gaurang and Venkatesh Babu, R.},
+ title = {Towards Achieving Adversarial Robustness by Enforcing Feature Consistency Across Bit Planes},
+ year = {2020},
+ booktitle = {2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ pages = {1020--1029},
+ doi = {10.1109/cvpr42600.2020.00110},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/cvpr42600.2020.00110},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@article{ahmadilivani2024systematic,
+ author = {Ahmadilivani, Mohammad Hasan and Taheri, Mahdi and Raik, Jaan and Daneshtalab, Masoud and Jenihhin, Maksim},
+ title = {A Systematic Literature Review on Hardware Reliability Assessment Methods for Deep Neural Networks},
+ year = {2024},
+ journal = {ACM Comput. Surv.},
+ publisher = {Association for Computing Machinery (ACM)},
+ volume = {56},
+ number = {6},
+ pages = {1--39},
+ doi = {10.1145/3638242},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3638242},
+ issn = {0360-0300, 1557-7341},
+ month = jan,
+}
+
+@inproceedings{ahmed2020headless,
+ author = {Abdelkader, Ahmed and Curry, Michael J. and Fowl, Liam and Goldstein, Tom and Schwarzschild, Avi and Shu, Manli and Studer, Christoph and Zhu, Chen},
+ title = {Headless Horseman: {Adversarial} Attacks on Transfer Learning Models},
+ year = {2020},
+ booktitle = {ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
+ publisher = {IEEE},
+ pages = {3087--3091},
+ doi = {10.1109/icassp40776.2020.9053181},
+ url = {https://doi.org/10.1109/icassp40776.2020.9053181},
+ bibsource = {dblp computer science bibliography, https://dblp.org},
+ biburl = {https://dblp.org/rec/conf/icassp/AbdelkaderCFGSS20.bib},
+ timestamp = {Thu, 23 Jul 2020 01:00:00 +0200},
+ source = {Crossref},
+ month = may,
+}
+
+@inproceedings{chen2019sc,
+author = {Chen, Zitao and Li, Guanpeng and Pattabiraman, Karthik and DeBardeleben, Nathan},
+title = {BinFI: an efficient fault injector for safety-critical machine learning systems},
+year = {2019},
+isbn = {9781450362290},
+publisher = {Association for Computing Machinery},
+address = {New York, NY, USA},
+url = {https://doi.org/10.1145/3295500.3356177},
+doi = {10.1145/3295500.3356177},
+abstract = {As machine learning (ML) becomes pervasive in high performance computing, ML has found its way into safety-critical domains (e.g., autonomous vehicles). Thus the reliability of ML has grown in importance. Specifically, failures of ML systems can have catastrophic consequences, and can occur due to soft errors, which are increasing in frequency due to system scaling. Therefore, we need to evaluate ML systems in the presence of soft errors.In this work, we propose BinFI, an efficient fault injector (FI) for finding the safety-critical bits in ML applications. We find the widely-used ML computations are often monotonic. Thus we can approximate the error propagation behavior of a ML application as a monotonic function. BinFI uses a binary-search like FI technique to pinpoint the safety-critical bits (also measure the overall resilience). BinFI identifies 99.56\% of safety-critical bits (with 99.63\% precision) in the systems, which significantly outperforms random FI, with much lower costs.},
+booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
+articleno = {69},
+numpages = {23},
+keywords = {machine learning, fault injection, error resilience},
+location = {Denver, Colorado},
+series = {SC '19}
+}
+
+@INPROCEEDINGS{mahmoud2022dsn,
+ author={Mahmoud, Abdulrahman and Tambe, Thierry and Aloui, Tarek and Brooks, David and Wei, Gu-Yeon},
+ booktitle={2022 52nd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
+ title={GoldenEye: A Platform for Evaluating Emerging Numerical Data Formats in DNN Accelerators},
+ year={2022},
+ volume={},
+ number={},
+ pages={206-214},
+ keywords={Deep learning;Analytical models;Metadata;Reliability engineering;Hardware;Numerical models;Open source software;SDC;Data Format;Number Format;DNN Accelerator;Reliability;Functional Simulation;Hardware Software Co Design},
+ doi={10.1109/DSN53405.2022.00031}
+ }
+
+
+@article{arifeen2020approximate,
+ author = {Arifeen, Tooba and Hassan, Abdus Sami and Lee, Jeong-A},
+ title = {Approximate Triple Modular Redundancy: {A} Survey},
+ year = {2020},
+ journal = {\#IEEE\_O\_ACC\#},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {8},
+ pages = {139851--139867},
+ doi = {10.1109/access.2020.3012673},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/access.2020.3012673},
+ issn = {2169-3536},
+}
+
+@article{bai2021recent,
+ author = {Bai, Tao and Luo, Jinqi and Zhao, Jun and Wen, Bihan and Wang, Qian},
+ title = {Recent advances in adversarial training for adversarial robustness},
+ year = {2021},
+ journal = {arXiv preprint arXiv:2102.01356},
+}
+
+@inproceedings{bannon2019computer,
+ author = {Bannon, Pete and Venkataramanan, Ganesh and Sarma, Debjit Das and Talpes, Emil},
+ title = {Computer and Redundancy Solution for the Full Self-Driving Computer},
+ year = {2019},
+ booktitle = {2019 IEEE Hot Chips 31 Symposium (HCS)},
+ pages = {1--22},
+ organization = {IEEE Computer Society},
+ doi = {10.1109/hotchips.2019.8875645},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/hotchips.2019.8875645},
+ publisher = {IEEE},
+ month = aug,
+}
+
+@article{beaton1974fitting,
+ author = {Beaton, Albert E. and Tukey, John W.},
+ title = {The Fitting of Power Series, Meaning Polynomials, Illustrated on Band-Spectroscopic Data},
+ year = {1974},
+ journal = {Technometrics},
+ publisher = {JSTOR},
+ volume = {16},
+ number = {2},
+ pages = {147},
+ doi = {10.2307/1267936},
+ source = {Crossref},
+ url = {https://doi.org/10.2307/1267936},
+ issn = {0040-1706},
+ month = may,
+}
+
+@article{berger2014kolmogorov,
+ author = {Berger, Vance W and Zhou, YanYan},
+ title = {Kolmogorov{\textendash}smirnov test: {Overview}},
+ year = {2014},
+ journal = {Wiley statsref: Statistics reference online},
+ publisher = {Wiley Online Library},
+}
+
+@inproceedings{biggio2012poisoning,
+ author = {Biggio, Battista and Nelson, Blaine and Laskov, Pavel},
+ title = {Poisoning Attacks against Support Vector Machines},
+ year = {2012},
+ booktitle = {Proceedings of the 29th International Conference on Machine Learning, ICML 2012, Edinburgh, Scotland, UK, June 26 - July 1, 2012},
+ publisher = {icml.cc / Omnipress},
+ url = {http://icml.cc/2012/papers/880.pdf},
+ bibsource = {dblp computer science bibliography, https://dblp.org},
+ biburl = {https://dblp.org/rec/conf/icml/BiggioNL12.bib},
+ timestamp = {Wed, 03 Apr 2019 01:00:00 +0200},
+}
+
+@article{binkert2011gem5,
+ author = {Binkert, Nathan and Beckmann, Bradford and Black, Gabriel and Reinhardt, Steven K. and Saidi, Ali and Basu, Arkaprava and Hestness, Joel and Hower, Derek R. and Krishna, Tushar and Sardashti, Somayeh and Sen, Rathijit and Sewell, Korey and Shoaib, Muhammad and Vaish, Nilay and Hill, Mark D. and Wood, David A.},
+ title = {The gem5 simulator},
+ year = {2011},
+ journal = {ACM SIGARCH Computer Architecture News},
+ publisher = {Association for Computing Machinery (ACM)},
+ volume = {39},
+ number = {2},
+ pages = {1--7},
+ doi = {10.1145/2024716.2024718},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/2024716.2024718},
+ issn = {0163-5964},
+ month = may,
+}
+
+@article{bolchini2022fast,
+ author = {Bolchini, Cristiana and Cassano, Luca and Miele, Antonio and Toschi, Alessandro},
+ title = {Fast and Accurate Error Simulation for {CNNs} Against Soft Errors},
+ year = {2023},
+ journal = {IEEE Trans. Comput.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {72},
+ number = {4},
+ pages = {984--997},
+ doi = {10.1109/tc.2022.3184274},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tc.2022.3184274},
+ issn = {0018-9340, 1557-9956, 2326-3814},
+ month = apr,
+}
+
+@article{bushnell2002built,
+ author = {Bushnell, Michael L and Agrawal, Vishwani D},
+ title = {Built-in self-test},
+ year = {2002},
+ journal = {Essentials of electronic testing for digital, memory and mixed-signal VLSI circuits},
+ publisher = {Springer},
+ pages = {489--548},
+}
+
+@inproceedings{carlini2017towards,
+ author = {Carlini, Nicholas and Wagner, David},
+ title = {Towards Evaluating the Robustness of Neural Networks},
+ year = {2017},
+ booktitle = {2017 IEEE Symposium on Security and Privacy (SP)},
+ pages = {39--57},
+ organization = {Ieee},
+ doi = {10.1109/sp.2017.49},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/sp.2017.49},
+ publisher = {IEEE},
+ month = may,
+}
+
+@article{carta2020local,
+ author = {Carta, Salvatore and Podda, Alessandro Sebastian and Recupero, Diego Reforgiato and Saia, Roberto},
+ title = {A Local Feature Engineering Strategy to Improve Network Anomaly Detection},
+ year = {2020},
+ journal = {Future Internet},
+ publisher = {MDPI AG},
+ volume = {12},
+ number = {10},
+ pages = {177},
+ doi = {10.3390/fi12100177},
+ source = {Crossref},
+ url = {https://doi.org/10.3390/fi12100177},
+ issn = {1999-5903},
+ month = oct,
+}
+
+@article{chandola2009anomaly,
+ author = {Chandola, Varun and Banerjee, Arindam and Kumar, Vipin},
+ title = {Anomaly detection},
+ year = {2009},
+ journal = {ACM Comput. Surv.},
+ publisher = {Association for Computing Machinery (ACM)},
+ volume = {41},
+ number = {3},
+ pages = {1--58},
+ doi = {10.1145/1541880.1541882},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/1541880.1541882},
+ subtitle = {A survey},
+ issn = {0360-0300, 1557-7341},
+ month = jul,
+}
+
+@inproceedings{chen2020tensorfi,
+ author = {Chen, Zitao and Narayanan, Niranjhana and Fang, Bo and Li, Guanpeng and Pattabiraman, Karthik and DeBardeleben, Nathan},
+ title = {{TensorFI:} {A} Flexible Fault Injection Framework for {TensorFlow} Applications},
+ year = {2020},
+ booktitle = {2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE)},
+ pages = {426--435},
+ organization = {IEEE},
+ doi = {10.1109/issre5003.2020.00047},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/issre5003.2020.00047},
+ publisher = {IEEE},
+ month = oct,
+}
+
+@inproceedings{constantinescu2008intermittent,
+ author = {Constantinescu, Cristian},
+ title = {Intermittent faults and effects on reliability of integrated circuits},
+ year = {2008},
+ booktitle = {2008 Annual Reliability and Maintainability Symposium},
+ pages = {370--374},
+ organization = {IEEE},
+ doi = {10.1109/rams.2008.4925824},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/rams.2008.4925824},
+ publisher = {IEEE},
+}
+
+@article{dixit2021silent,
+ author = {Vangal, Sriram and Paul, Somnath and Hsu, Steven and Agarwal, Amit and Kumar, Saurabh and Krishnamurthy, Ram and Krishnamurthy, Harish and Tschanz, James and De, Vivek and Kim, Chris H.},
+ title = {Wide-Range Many-Core {SoC} Design in Scaled {CMOS:} {Challenges} and Opportunities},
+ year = {2021},
+ journal = {IEEE Trans. Very Large Scale Integr. VLSI Syst.},
+ doi = {10.1109/tvlsi.2021.3061649},
+ number = {5},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tvlsi.2021.3061649},
+ volume = {29},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ issn = {1063-8210, 1557-9999},
+ pages = {843--856},
+ month = may,
+}
+
+@article{egwutuoha2013survey,
+ author = {Egwutuoha, Ifeanyi P. and Levy, David and Selic, Bran and Chen, Shiping},
+ title = {A survey of fault tolerance mechanisms and checkpoint/restart implementations for high performance computing systems},
+ year = {2013},
+ journal = {The Journal of Supercomputing},
+ publisher = {Springer Science and Business Media LLC},
+ volume = {65},
+ pages = {1302--1326},
+ doi = {10.1007/s11227-013-0884-0},
+ number = {3},
+ source = {Crossref},
+ url = {https://doi.org/10.1007/s11227-013-0884-0},
+ issn = {0920-8542, 1573-0484},
+ month = feb,
+}
+
+@inproceedings{eisenman2022check,
+ author = {Eisenman, Assaf and Matam, Kiran Kumar and Ingram, Steven and Mudigere, Dheevatsa and Krishnamoorthi, Raghuraman and Nair, Krishnakumar and Smelyanskiy, Misha and Annavaram, Murali},
+ title = {Check-N-Run: {A} checkpointing system for training deep learning recommendation models},
+ year = {2022},
+ booktitle = {19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22)},
+ pages = {929--943},
+}
+
+@article{eykholt2018robust,
+ author = {Eykholt, Kevin and Evtimov, Ivan and Fernandes, Earlence and Li, Bo and Rahmati, Amir and Xiao, Chaowei and Prakash, Atul and Kohno, Tadayoshi and Song, Dawn},
+ title = {Robust Physical-World Attacks on Deep Learning Models},
+ year = {2017},
+ journal = {ArXiv preprint},
+ volume = {abs/1707.08945},
+ url = {https://arxiv.org/abs/1707.08945},
+}
+
+@inproceedings{francalanza2017foundation,
+ author = {Francalanza, Adrian and Aceto, Luca and Achilleos, Antonis and Attard, Duncan Paul and Cassar, Ian and Della Monica, Dario and Ing\'olfsd\'ottir, Anna},
+ title = {A foundation for runtime monitoring},
+ year = {2017},
+ booktitle = {International Conference on Runtime Verification},
+ pages = {8--29},
+ organization = {Springer},
+}
+
+@inproceedings{fursov2021adversarial,
+ author = {Fursov, Ivan and Morozov, Matvey and Kaploukhaya, Nina and Kovtun, Elizaveta and Rivera-Castro, Rodrigo and Gusev, Gleb and Babaev, Dmitry and Kireev, Ivan and Zaytsev, Alexey and Burnaev, Evgeny},
+ title = {Adversarial Attacks on Deep Models for Financial Transaction Records},
+ year = {2021},
+ booktitle = {Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery \& Data Mining},
+ pages = {2868--2878},
+ doi = {10.1145/3447548.3467145},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3447548.3467145},
+ publisher = {ACM},
+ month = aug,
+}
+
+@article{goodfellow2020generative,
+ author = {Goodfellow, Ian and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua},
+ title = {Generative adversarial networks},
+ year = {2020},
+ journal = {Commun. ACM},
+ publisher = {Association for Computing Machinery (ACM)},
+ volume = {63},
+ number = {11},
+ pages = {139--144},
+ doi = {10.1145/3422622},
+ issn = {0001-0782, 1557-7317},
+ url = {https://doi.org/10.1145/3422622},
+ source = {Crossref},
+ month = oct,
+}
+
+@inproceedings{grafe2023large,
+ author = {Gr\"afe, Ralf and Sha, Qutub Syed and Geissler, Florian and Paulitsch, Michael},
+ title = {Large-Scale Application of Fault Injection into {PyTorch} Models -an Extension to {PyTorchFI} for Validation Efficiency},
+ year = {2023},
+ booktitle = {2023 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks - Supplemental Volume (DSN-S)},
+ pages = {56--62},
+ organization = {IEEE},
+ doi = {10.1109/dsn-s58398.2023.00025},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dsn-s58398.2023.00025},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@inproceedings{guo2019simple,
+ author = {Guo, Chuan and Gardner, Jacob and You, Yurong and Wilson, Andrew Gordon and Weinberger, Kilian},
+ title = {Simple black-box adversarial attacks},
+ year = {2019},
+ booktitle = {International conference on machine learning},
+ pages = {2484--2493},
+ organization = {PMLR},
+}
+
+@article{hamming1950error,
+ author = {Hamming, R. W.},
+ title = {Error Detecting and Error Correcting Codes},
+ year = {1950},
+ journal = {Bell Syst. Tech. J.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {29},
+ number = {2},
+ pages = {147--160},
+ doi = {10.1002/j.1538-7305.1950.tb00463.x},
+ source = {Crossref},
+ url = {https://doi.org/10.1002/j.1538-7305.1950.tb00463.x},
+ issn = {0005-8580},
+ month = apr,
+}
+
+@inproceedings{he2020fidelity,
+ author = {He, Yi and Balaprakash, Prasanna and Li, Yanjing},
+ title = {{FIdelity:} {Efficient} Resilience Analysis Framework for Deep Learning Accelerators},
+ year = {2020},
+ booktitle = {2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO)},
+ pages = {270--281},
+ organization = {IEEE},
+ doi = {10.1109/micro50266.2020.00033},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/micro50266.2020.00033},
+ publisher = {IEEE},
+ month = oct,
+}
+
+@inproceedings{he2023understanding,
+ author = {He, Yi and Hutton, Mike and Chan, Steven and De Gruijl, Robert and Govindaraju, Rama and Patil, Nishant and Li, Yanjing},
+ title = {Understanding and Mitigating Hardware Failures in Deep Learning Training Systems},
+ year = {2023},
+ booktitle = {Proceedings of the 50th Annual International Symposium on Computer Architecture},
+ pages = {1--16},
+ organization = {IEEE},
+ doi = {10.1145/3579371.3589105},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3579371.3589105},
+ publisher = {ACM},
+ month = jun,
+}
+
+@article{hendrycks2019benchmarking,
+ author = {Hendrycks, Dan and Dietterich, Thomas},
+ title = {Benchmarking neural network robustness to common corruptions and perturbations},
+ year = {2019},
+ journal = {arXiv preprint arXiv:1903.12261},
+}
+
+@inproceedings{hong2019terminal,
+ author = {Hong, Sanghyun and Frigo, Pietro and Kaya, Yi\u{g}itcan and Giuffrida, Cristiano and Dumitras, Tudor},
+ title = {Terminal brain damage: {Exposing} the graceless degradation in deep neural networks under hardware fault attacks},
+ year = {2019},
+ booktitle = {28th USENIX Security Symposium (USENIX Security 19)},
+ pages = {497--514},
+}
+
+@article{hosseini2017deceiving,
+ author = {Hosseini, Hossein and Kannan, Sreeram and Zhang, Baosen and Poovendran, Radha},
+ title = {Deceiving google's perspective api built for detecting toxic comments},
+ year = {2017},
+ journal = {ArXiv preprint},
+ volume = {abs/1702.08138},
+ url = {https://arxiv.org/abs/1702.08138},
+}
+
+@inproceedings{hsiao2023mavfi,
+ author = {Hsiao, Yu-Shun and Wan, Zishen and Jia, Tianyu and Ghosal, Radhika and Mahmoud, Abdulrahman and Raychowdhury, Arijit and Brooks, David and Wei, Gu-Yeon and Reddi, Vijay Janapa},
+ title = {{MAVFI:} {An} End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles},
+ year = {2023},
+ booktitle = {2023 Design, Automation \& Test in Europe Conference \& Exhibition (DATE)},
+ pages = {1--6},
+ organization = {IEEE},
+ doi = {10.23919/date56975.2023.10137246},
+ source = {Crossref},
+ url = {https://doi.org/10.23919/date56975.2023.10137246},
+ publisher = {IEEE},
+ month = apr,
+}
+
+@INPROCEEDINGS{mahmoud2021issre,
+ author={Mahmoud, Abdulrahman and Sastry Hari, Siva Kumar and Fletcher, Christopher W. and Adve, Sarita V. and Sakr, Charbel and Shanbhag, Naresh and Molchanov, Pavlo and Sullivan, Michael B. and Tsai, Timothy and Keckler, Stephen W.},
+ booktitle={2021 IEEE 32nd International Symposium on Software Reliability Engineering (ISSRE)},
+ title={Optimizing Selective Protection for CNN Resilience},
+ year={2021},
+ volume={},
+ number={},
+ pages={127-138},
+ keywords={Runtime;Redundancy;Measurement uncertainty;Graphics processing units;Hardware;Software reliability;Transient analysis;Reliability;Vulnerability;Errors;Silent Data Corruptions (SDC);Software directed;Convolutional Neural Networks (CNNs)},
+ doi={10.1109/ISSRE52982.2021.00025}
+ }
+
+
+@article{hsiao2023silent,
+ author = {Hsiao, Yu-Shun and Wan, Zishen and Jia, Tianyu and Ghosal, Radhika and Mahmoud, Abdulrahman and Raychowdhury, Arijit and Brooks, David and Wei, Gu-Yeon and Reddi, Vijay Janapa},
+ title = {Silent Data Corruption in Robot Operating System: {A} Case for End-to-End System-Level Fault Analysis Using Autonomous {UAVs}},
+ year = {2024},
+ journal = {IEEE Trans. Comput. Aided Des. Integr. Circuits Syst.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ doi = {10.1109/tcad.2023.3332293},
+ number = {4},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tcad.2023.3332293},
+ volume = {43},
+ issn = {0278-0070, 1937-4151},
+ pages = {1037--1050},
+ month = apr,
+}
+
+@inproceedings{jha2019ml,
+ author = {Jha, Saurabh and Banerjee, Subho and Tsai, Timothy and Hari, Siva K. S. and Sullivan, Michael B. and Kalbarczyk, Zbigniew T. and Keckler, Stephen W. and Iyer, Ravishankar K.},
+ title = {{ML}-Based Fault Injection for Autonomous Vehicles: {A} Case for {Bayesian} Fault Injection},
+ year = {2019},
+ booktitle = {2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
+ pages = {112--124},
+ organization = {IEEE},
+ doi = {10.1109/dsn.2019.00025},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dsn.2019.00025},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@inproceedings{kawazoe1997heartbeat,
+ author = {Kawazoe Aguilera, Marcos and Chen, Wei and Toueg, Sam},
+ title = {Heartbeat: {A} timeout-free failure detector for quiescent reliable communication},
+ year = {1997},
+ booktitle = {Distributed Algorithms: 11th International Workshop, WDAG'97 Saarbr\"ucken, Germany, September 24{\textendash}26, 1997 Proceedings 11},
+ pages = {126--140},
+ organization = {Springer},
+}
+
+@inproceedings{kim2015bamboo,
+ author = {Kim, Jungrae and Sullivan, Michael and Erez, Mattan},
+ title = {Bamboo {ECC:} {Strong,} safe, and flexible codes for reliable computer memory},
+ year = {2015},
+ booktitle = {2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA)},
+ pages = {101--112},
+ organization = {IEEE},
+ doi = {10.1109/hpca.2015.7056025},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/hpca.2015.7056025},
+ publisher = {IEEE},
+ month = feb,
+}
+
+@article{kirkpatrick2017overcoming,
+ author = {Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia},
+ title = {Overcoming catastrophic forgetting in neural networks},
+ year = {2017},
+ journal = {Proc. Natl. Acad. Sci.},
+ publisher = {Proceedings of the National Academy of Sciences},
+ volume = {114},
+ number = {13},
+ pages = {3521--3526},
+ doi = {10.1073/pnas.1611835114},
+ source = {Crossref},
+ url = {https://doi.org/10.1073/pnas.1611835114},
+ issn = {0027-8424, 1091-6490},
+ month = mar,
+}
+
+@article{ko2021characterizing,
+ author = {Ko, Yohan},
+ title = {Characterizing System-Level Masking Effects against Soft Errors},
+ year = {2021},
+ journal = {Electronics},
+ publisher = {MDPI AG},
+ volume = {10},
+ number = {18},
+ pages = {2286},
+ doi = {10.3390/electronics10182286},
+ source = {Crossref},
+ url = {https://doi.org/10.3390/electronics10182286},
+ issn = {2079-9292},
+ month = sep,
+}
+
+@article{lee2022design,
+ author = {Lee, Minwoong and Lee, Namho and Gwon, Huijeong and Kim, Jongyeol and Hwang, Younggwan and Cho, Seongik},
+ title = {Design of Radiation-Tolerant High-Speed Signal Processing Circuit for Detecting Prompt Gamma Rays by Nuclear Explosion},
+ year = {2022},
+ journal = {Electronics},
+ publisher = {MDPI AG},
+ volume = {11},
+ number = {18},
+ pages = {2970},
+ doi = {10.3390/electronics11182970},
+ source = {Crossref},
+ url = {https://doi.org/10.3390/electronics11182970},
+ issn = {2079-9292},
+ month = sep,
+}
+
+@inproceedings{li2017understanding,
+ author = {Li, Guanpeng and Hari, Siva Kumar Sastry and Sullivan, Michael and Tsai, Timothy and Pattabiraman, Karthik and Emer, Joel and Keckler, Stephen W.},
+ title = {Understanding error propagation in deep learning neural network {(DNN)} accelerators and applications},
+ year = {2017},
+ booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
+ pages = {1--12},
+ doi = {10.1145/3126908.3126964},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3126908.3126964},
+ publisher = {ACM},
+ month = nov,
+}
+
+@article{li2021survey,
+ author = {Li, Qinbin and Wen, Zeyi and Wu, Zhaomin and Hu, Sixu and Wang, Naibo and Li, Yuan and Liu, Xu and He, Bingsheng},
+ title = {A Survey on Federated Learning Systems: {Vision,} Hype and Reality for Data Privacy and Protection},
+ year = {2023},
+ journal = {IEEE Trans. Knowl. Data Eng.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {35},
+ number = {4},
+ pages = {3347--3366},
+ doi = {10.1109/tkde.2021.3124599},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tkde.2021.3124599},
+ issn = {1041-4347, 1558-2191, 2326-3865},
+ month = apr,
+}
+
+@article{lindholm2019data,
+ author = {Lindholm, Andreas and Zachariah, Dave and Stoica, Petre and Schon, Thomas B.},
+ title = {Data Consistency Approach to Model Validation},
+ year = {2019},
+ journal = {\#IEEE\_O\_ACC\#},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {7},
+ pages = {59788--59796},
+ doi = {10.1109/access.2019.2915109},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/access.2019.2915109},
+ issn = {2169-3536},
+}
+
+@article{lopez2017gradient,
+ author = {Lopez-Paz, David and Ranzato, Marc'Aurelio},
+ title = {Gradient episodic memory for continual learning},
+ year = {2017},
+ journal = {Adv Neural Inf Process Syst},
+ volume = {30},
+}
+
+@article{lowe2020gem5,
+ author = {Lowe-Power, Jason and Ahmad, Abdul Mutaal and Akram, Ayaz and Alian, Mohammad and Amslinger, Rico and Andreozzi, Matteo and Armejach, Adri\`a and Asmussen, Nils and Beckmann, Brad and Bharadwaj, Srikant and others},
+ title = {The gem5 simulator: {Version} 20.0+},
+ year = {2020},
+ journal = {arXiv preprint arXiv:2007.03152},
+}
+
+@inproceedings{ma2024dr,
+ author = {Ma, Dongning and Lin, Fred and Desmaison, Alban and Coburn, Joel and Moore, Daniel and Sankar, Sriram and Jiao, Xun},
+ title = {{Dr.} {DNA:} {Combating} Silent Data Corruptions in Deep Learning using Distribution of Neuron Activations},
+ year = {2024},
+ booktitle = {Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3},
+ pages = {239--252},
+ doi = {10.1145/3620666.3651349},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3620666.3651349},
+ publisher = {ACM},
+ month = apr,
+}
+
+@article{maas2008combining,
+ author = {Maas, Martin and Andersen, David G. and Isard, Michael and Javanmard, Mohammad Mahdi and McKinley, Kathryn S. and Raffel, Colin},
+ title = {Combining Machine Learning and Lifetime-Based Resource Management for Memory Allocation and Beyond},
+ year = {2024},
+ journal = {Commun. ACM},
+ publisher = {Association for Computing Machinery (ACM)},
+ pages = {87--96},
+ doi = {10.1145/3611018},
+ number = {4},
+ source = {Crossref},
+ url = {https://doi.org/10.1145/3611018},
+ volume = {67},
+ issn = {0001-0782, 1557-7317},
+ month = mar,
+}
+
+@article{madry2017towards,
+ author = {Madry, Aleksander and Makelov, Aleksandar and Schmidt, Ludwig and Tsipras, Dimitris and Vladu, Adrian},
+ title = {Towards deep learning models resistant to adversarial attacks},
+ year = {2017},
+ journal = {arXiv preprint arXiv:1706.06083},
+}
+
+@inproceedings{mahmoud2020pytorchfi,
+ author = {Mahmoud, Abdulrahman and Aggarwal, Neeraj and Nobbe, Alex and Vicarte, Jose Rodrigo Sanchez and Adve, Sarita V. and Fletcher, Christopher W. and Frosio, Iuri and Hari, Siva Kumar Sastry},
+ title = {{PyTorchFI:} {A} Runtime Perturbation Tool for {DNNs}},
+ year = {2020},
+ booktitle = {2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W)},
+ pages = {25--31},
+ organization = {IEEE},
+ doi = {10.1109/dsn-w50199.2020.00014},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dsn-w50199.2020.00014},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@article{marulli2022sensitivity,
+ author = {Marulli, Fiammetta and Marrone, Stefano and Verde, Laura},
+ title = {Sensitivity of Machine Learning Approaches to Fake and Untrusted Data in Healthcare Domain},
+ year = {2022},
+ journal = {Journal of Sensor and Actuator Networks},
+ publisher = {MDPI AG},
+ volume = {11},
+ number = {2},
+ pages = {21},
+ doi = {10.3390/jsan11020021},
+ source = {Crossref},
+ url = {https://doi.org/10.3390/jsan11020021},
+ issn = {2224-2708},
+ month = mar,
+}
+
+@inproceedings{mohanram2003partial,
+ author = {Mohanram, K. and Touba, N.A.},
+ title = {Partial error masking to reduce soft error failure rate in logic circuits},
+ year = {2003},
+ booktitle = {Proceedings. 16th IEEE Symposium on Computer Arithmetic},
+ pages = {433--440},
+ organization = {IEEE},
+ doi = {10.1109/dftvs.2003.1250141},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dftvs.2003.1250141},
+ publisher = {IEEE Comput. Soc},
+}
+
+@inproceedings{mukherjee2005soft,
+ author = {Mukherjee, S.S. and Emer, J. and Reinhardt, S.K.},
+ title = {The Soft Error Problem: {An} Architectural Perspective},
+ year = {2005},
+ booktitle = {11th International Symposium on High-Performance Computer Architecture},
+ pages = {243--247},
+ organization = {IEEE},
+ doi = {10.1109/hpca.2005.37},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/hpca.2005.37},
+ publisher = {IEEE},
+}
+
+@article{myllyaho2022misbehaviour,
+ author = {Myllyaho, Lalli and Raatikainen, Mikko and M\"annist\"o, Tomi and Nurminen, Jukka K. and Mikkonen, Tommi},
+ title = {On misbehaviour and fault tolerance in machine learning systems},
+ year = {2022},
+ journal = {J. Syst. Software},
+ publisher = {Elsevier BV},
+ volume = {183},
+ pages = {111096},
+ doi = {10.1016/j.jss.2021.111096},
+ source = {Crossref},
+ url = {https://doi.org/10.1016/j.jss.2021.111096},
+ issn = {0164-1212},
+ month = jan,
+}
+
+@article{oprea2022poisoning,
+ author = {Oprea, Alina and Singhal, Anoop and Vassilev, Apostol},
+ title = {Poisoning Attacks Against Machine Learning: {Can} Machine Learning Be Trustworthy?},
+ year = {2022},
+ journal = {Computer},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {55},
+ number = {11},
+ pages = {94--99},
+ doi = {10.1109/mc.2022.3190787},
+ issn = {0018-9162, 1558-0814},
+ url = {https://doi.org/10.1109/mc.2022.3190787},
+ source = {Crossref},
+ month = nov,
+}
+
+@article{panda2019discretization,
+ author = {Panda, Priyadarshini and Chakraborty, Indranil and Roy, Kaushik},
+ title = {Discretization Based Solutions for Secure Machine Learning Against Adversarial Attacks},
+ year = {2019},
+ journal = {\#IEEE\_O\_ACC\#},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {7},
+ pages = {70157--70168},
+ doi = {10.1109/access.2019.2919463},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/access.2019.2919463},
+ issn = {2169-3536},
+}
+
+@inproceedings{papadimitriou2021demystifying,
+ author = {Papadimitriou, George and Gizopoulos, Dimitris},
+ title = {Demystifying the System Vulnerability Stack: {Transient} Fault Effects Across the Layers},
+ year = {2021},
+ booktitle = {2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA)},
+ pages = {902--915},
+ organization = {IEEE},
+ doi = {10.1109/isca52012.2021.00075},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/isca52012.2021.00075},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@inproceedings{papernot2016distillation,
+ author = {Papernot, Nicolas and McDaniel, Patrick and Wu, Xi and Jha, Somesh and Swami, Ananthram},
+ title = {Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks},
+ year = {2016},
+ booktitle = {2016 IEEE Symposium on Security and Privacy (SP)},
+ pages = {582--597},
+ organization = {IEEE},
+ doi = {10.1109/sp.2016.41},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/sp.2016.41},
+ publisher = {IEEE},
+ month = may,
+}
+
+@article{parrish2023adversarial,
+ author = {Parrish, Alicia and Kirk, Hannah Rose and Quaye, Jessica and Rastogi, Charvi and Bartolo, Max and Inel, Oana and Ciro, Juan and Mosquera, Rafael and Howard, Addison and Cukierski, Will and Sculley, D. and Reddi, Vijay Janapa and Aroyo, Lora},
+ title = {Adversarial Nibbler: {A} Data-Centric Challenge for Improving the Safety of Text-to-Image Models},
+ year = {2023},
+ journal = {ArXiv preprint},
+ volume = {abs/2305.14384},
+ url = {https://arxiv.org/abs/2305.14384},
+}
+
+@article{plank1997tutorial,
+ author = {Plank, James S},
+ title = {A tutorial on {Reed{\textendash}Solomon} coding for fault-tolerance in {RAID}-like systems},
+ year = {1997},
+ journal = {Software: Practice and Experience},
+ publisher = {Wiley Online Library},
+ volume = {27},
+ number = {9},
+ pages = {995--1012},
+}
+
+@inproceedings{pont2002using,
+ author = {Pont, Michael J and Ong, Royan HL},
+ title = {Using watchdog timers to improve the reliability of single-processor embedded systems: {Seven} new patterns and a case study},
+ year = {2002},
+ booktitle = {Proceedings of the First Nordic Conference on Pattern Languages of Programs},
+ pages = {159--200},
+ organization = {Citeseer},
+}
+
+@inproceedings{ramesh2021zero,
+ author = {Ramesh, Aditya and Pavlov, Mikhail and Goh, Gabriel and Gray, Scott and Voss, Chelsea and Radford, Alec and Chen, Mark and Sutskever, Ilya},
+ editor = {Meila, Marina and Zhang, Tong},
+ title = {Zero-Shot Text-to-Image Generation},
+ year = {2021},
+ booktitle = {Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event},
+ publisher = {PMLR},
+ series = {Proceedings of Machine Learning Research},
+ volume = {139},
+ pages = {8821--8831},
+ url = {http://proceedings.mlr.press/v139/ramesh21a.html},
+ bibsource = {dblp computer science bibliography, https://dblp.org},
+ biburl = {https://dblp.org/rec/conf/icml/RameshPGGVRCS21.bib},
+ timestamp = {Wed, 25 Aug 2021 01:00:00 +0200},
+}
+
+@inproceedings{rashid2012intermittent,
+ author = {Rashid, Layali and Pattabiraman, Karthik and Gopalakrishnan, Sathish},
+ title = {Intermittent Hardware Errors Recovery: {Modeling} and Evaluation},
+ year = {2012},
+ booktitle = {2012 Ninth International Conference on Quantitative Evaluation of Systems},
+ pages = {220--229},
+ organization = {IEEE},
+ doi = {10.1109/qest.2012.37},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/qest.2012.37},
+ publisher = {IEEE},
+ month = sep,
+}
+
+@article{rashid2014characterizing,
+ author = {Rashid, Layali and Pattabiraman, Karthik and Gopalakrishnan, Sathish},
+ title = {Characterizing the Impact of Intermittent Hardware Faults on Programs},
+ year = {2015},
+ journal = {IEEE Trans. Reliab.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {64},
+ number = {1},
+ pages = {297--310},
+ doi = {10.1109/tr.2014.2363152},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tr.2014.2363152},
+ issn = {0018-9529, 1558-1721},
+ month = mar,
+}
+
+@inproceedings{reagen2018ares,
+ author = {Reagen, Brandon and Gupta, Udit and Pentecost, Lillian and Whatmough, Paul and Lee, Sae Kyu and Mulholland, Niamh and Brooks, David and Wei, Gu-Yeon},
+ title = {Ares: {A} framework for quantifying the resilience of deep neural networks},
+ year = {2018},
+ booktitle = {2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC)},
+ pages = {1--6},
+ doi = {10.1109/dac.2018.8465834},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dac.2018.8465834},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@inproceedings{reis2005swift,
+ author = {Reis, G.A. and Chang, J. and Vachharajani, N. and Rangan, R. and August, D.I.},
+ title = {{SWIFT:} {Software} Implemented Fault Tolerance},
+ year = {2005},
+ booktitle = {International Symposium on Code Generation and Optimization},
+ pages = {243--254},
+ organization = {IEEE},
+ doi = {10.1109/cgo.2005.34},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/cgo.2005.34},
+ publisher = {IEEE},
+}
+
+@inproceedings{rombach2022highresolution,
+ author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bjorn},
+ title = {High-Resolution Image Synthesis with Latent Diffusion Models},
+ year = {2022},
+ booktitle = {2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ publisher = {IEEE},
+ doi = {10.1109/cvpr52688.2022.01042},
+ url = {https://doi.org/10.1109/cvpr52688.2022.01042},
+ source = {Crossref},
+ month = jun,
+}
+
+@inproceedings{sangchoolie2017one,
+ author = {Sangchoolie, Behrooz and Pattabiraman, Karthik and Karlsson, Johan},
+ title = {One Bit is {(Not)} Enough: {An} Empirical Study of the Impact of Single and Multiple Bit-Flip Errors},
+ year = {2017},
+ booktitle = {2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
+ pages = {97--108},
+ organization = {IEEE},
+ doi = {10.1109/dsn.2017.30},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dsn.2017.30},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@inproceedings{seong2010safer,
+ author = {Seong, Nak Hee and Woo, Dong Hyuk and Srinivasan, Vijayalakshmi and Rivers, Jude A. and Lee, Hsien-Hsin S.},
+ title = {{SAFER:} {Stuck-at-fault} Error Recovery for Memories},
+ year = {2010},
+ booktitle = {2010 43rd Annual IEEE/ACM International Symposium on Microarchitecture},
+ pages = {115--124},
+ organization = {IEEE},
+ doi = {10.1109/micro.2010.46},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/micro.2010.46},
+ publisher = {IEEE},
+ month = dec,
+}
+
+@article{shan2023prompt,
+ author = {Shan, Shawn and Ding, Wenxin and Passananti, Josephine and Zheng, Haitao and Zhao, Ben Y},
+ title = {Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models},
+ year = {2023},
+ journal = {ArXiv preprint},
+ volume = {abs/2310.13828},
+ url = {https://arxiv.org/abs/2310.13828},
+}
+
+@inproceedings{sheaffer2007hardware,
+ author = {Sheaffer, Jeremy W and Luebke, David P and Skadron, Kevin},
+ title = {A hardware redundancy and recovery mechanism for reliable scientific computation on graphics processors},
+ year = {2007},
+ booktitle = {Graphics Hardware},
+ volume = {2007},
+ pages = {55--64},
+ organization = {Citeseer},
+}
+
+@inproceedings{tambe2020algorithm,
+ author = {Tambe, Thierry and Yang, En-Yu and Wan, Zishen and Deng, Yuntian and Janapa Reddi, Vijay and Rush, Alexander and Brooks, David and Wei, Gu-Yeon},
+ title = {Algorithm-Hardware Co-Design of Adaptive Floating-Point Encodings for Resilient Deep Learning Inference},
+ year = {2020},
+ booktitle = {2020 57th ACM/IEEE Design Automation Conference (DAC)},
+ pages = {1--6},
+ organization = {IEEE},
+ doi = {10.1109/dac18072.2020.9218516},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dac18072.2020.9218516},
+ publisher = {IEEE},
+ month = jul,
+}
+
+@inproceedings{tsai2021nvbitfi,
+ author = {Tsai, Timothy and Hari, Siva Kumar Sastry and Sullivan, Michael and Villa, Oreste and Keckler, Stephen W.},
+ title = {{NVBitFI:} {Dynamic} Fault Injection for {GPUs}},
+ year = {2021},
+ booktitle = {2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
+ pages = {284--291},
+ organization = {IEEE},
+ doi = {10.1109/dsn48987.2021.00041},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dsn48987.2021.00041},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@article{tsai2023adversarial,
+ author = {Tsai, Min-Jen and Lin, Ping-Yi and Lee, Ming-En},
+ title = {Adversarial Attacks on Medical Image Classification},
+ year = {2023},
+ journal = {Cancers},
+ publisher = {MDPI AG},
+ volume = {15},
+ number = {17},
+ pages = {4228},
+ doi = {10.3390/cancers15174228},
+ source = {Crossref},
+ url = {https://doi.org/10.3390/cancers15174228},
+ issn = {2072-6694},
+ month = aug,
+}
+
+@article{velazco2010combining,
+ author = {Velazco, Raoul and Foucard, Gilles and Peronnard, Paul},
+ title = {Combining Results of Accelerated Radiation Tests and Fault Injections to Predict the Error Rate of an Application Implemented in {SRAM}-Based {FPGAs}},
+ year = {2010},
+ journal = {IEEE Trans. Nucl. Sci.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {57},
+ number = {6},
+ pages = {3500--3505},
+ doi = {10.1109/tns.2010.2087355},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tns.2010.2087355},
+ issn = {0018-9499},
+ month = dec,
+}
+
+@inproceedings{wan2021analyzing,
+ author = {Wan, Zishen and Anwar, Aqeel and Hsiao, Yu-Shun and Jia, Tianyu and Reddi, Vijay Janapa and Raychowdhury, Arijit},
+ title = {Analyzing and Improving Fault Tolerance of Learning-Based Navigation Systems},
+ year = {2021},
+ booktitle = {2021 58th ACM/IEEE Design Automation Conference (DAC)},
+ pages = {841--846},
+ organization = {IEEE},
+ doi = {10.1109/dac18074.2021.9586116},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dac18074.2021.9586116},
+ publisher = {IEEE},
+ month = dec,
+}
+
+@inproceedings{wan2023vpp,
+ author = {Wan, Zishen and Gan, Yiming and Yu, Bo and Liu, S and Raychowdhury, A and Zhu, Y},
+ title = {Vpp: {The} vulnerability-proportional protection paradigm towards reliable autonomous machines},
+ year = {2023},
+ booktitle = {Proceedings of the 5th International Workshop on Domain Specific System Architecture (DOSSA)},
+ pages = {1--6},
+}
+
+@inproceedings{wilkening2014calculating,
+ author = {Wilkening, Mark and Sridharan, Vilas and Li, Si and Previlon, Fritz and Gurumurthi, Sudhanva and Kaeli, David R.},
+ title = {Calculating Architectural Vulnerability Factors for Spatial Multi-Bit Transient Faults},
+ year = {2014},
+ booktitle = {2014 47th Annual IEEE/ACM International Symposium on Microarchitecture},
+ pages = {293--305},
+ organization = {IEEE},
+ doi = {10.1109/micro.2014.15},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/micro.2014.15},
+ publisher = {IEEE},
+ month = dec,
+}
+
+@article{xu2021grey,
+ author = {Xu, Ying and Zhong, Xu and Yepes, Antonio Jimeno and Lau, Jey Han},
+ title = {{Grey}-box adversarial attack and defence for sentiment classification},
+ year = {2021},
+ journal = {arXiv preprint arXiv:2103.11576},
+}
+
+@article{ye2021thundernna,
+ author = {Ye, Linfeng and Hamidi, Shayan Mohajer},
+ title = {Thundernna: {A} white box adversarial attack},
+ year = {2021},
+ journal = {arXiv preprint arXiv:2111.12305},
+}
+
+@inproceedings{yeh1996triple,
+ author = {Yeh, Y.C.},
+ title = {Triple-triple redundant 777 primary flight computer},
+ year = {1996},
+ booktitle = {1996 IEEE Aerospace Applications Conference. Proceedings},
+ volume = {1},
+ pages = {293--307},
+ organization = {IEEE},
+ doi = {10.1109/aero.1996.495891},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/aero.1996.495891},
+ publisher = {IEEE},
+}
+
+@article{zhang2008distribution,
+ author = {Zhang, Hongyu},
+ title = {On the Distribution of Software Faults},
+ year = {2008},
+ journal = {IEEE Trans. Software Eng.},
+ publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+ volume = {34},
+ number = {2},
+ pages = {301--302},
+ doi = {10.1109/tse.2007.70771},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/tse.2007.70771},
+ issn = {0098-5589},
+ month = mar,
+}
+
+@inproceedings{zhang2018analyzing,
+ author = {Zhang, Jeff Jun and Gu, Tianyu and Basu, Kanad and Garg, Siddharth},
+ title = {Analyzing and mitigating the impact of permanent faults on a systolic array based neural network accelerator},
+ year = {2018},
+ booktitle = {2018 IEEE 36th VLSI Test Symposium (VTS)},
+ pages = {1--6},
+ organization = {IEEE},
+ doi = {10.1109/vts.2018.8368656},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/vts.2018.8368656},
+ publisher = {IEEE},
+ month = apr,
+}
+
+@inproceedings{zhang2018thundervolt,
+ author = {Zhang, Jeff and Rangineni, Kartheek and Ghodsi, Zahra and Garg, Siddharth},
+ title = {{ThUnderVolt:} {Enabling} Aggressive Voltage Underscaling and Timing Error Resilience for Energy Efficient Deep Learning Accelerators},
+ year = {2018},
+ booktitle = {2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC)},
+ pages = {1--6},
+ doi = {10.1109/dac.2018.8465918},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/dac.2018.8465918},
+ publisher = {IEEE},
+ month = jun,
+}
+
+@inproceedings{zhou2018learning,
+ author = {Zhou, Peng and Han, Xintong and Morariu, Vlad I. and Davis, Larry S.},
+ title = {Learning Rich Features for Image Manipulation Detection},
+ year = {2018},
+ booktitle = {2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages = {1053--1061},
+ doi = {10.1109/cvpr.2018.00116},
+ source = {Crossref},
+ url = {https://doi.org/10.1109/cvpr.2018.00116},
+ publisher = {IEEE},
+ month = jun,
+}
diff --git a/contents/robust_ai/robust_ai.qmd b/contents/robust_ai/robust_ai.qmd
index fb4e3c61..0dd8aa9b 100644
--- a/contents/robust_ai/robust_ai.qmd
+++ b/contents/robust_ai/robust_ai.qmd
@@ -1,16 +1,1034 @@
----
+---
bibliography: robust_ai.bib
---
# Robust AI
-**Coming soon!**
+::: {.content-visible when-format="html"}
+Resources: [Slides](#sec-robust-ai-resource), [Labs](#sec-robust-ai-resource), [Exercises](#sec-robust-ai-resource)
+:::
+
+
+
+The development of robust machine learning systems has become increasingly crucial. As these systems are deployed in various critical applications, from autonomous vehicles to healthcare diagnostics, ensuring their resilience to faults and errors is paramount.
+
+Robust AI, in the context of hardware faults, software faults, and errors, plays an important role in maintaining the reliability, safety, and performance of machine learning systems. By addressing the challenges posed by transient, permanent, and intermittent hardware faults [@ahmadilivani2024systematic], as well as bugs, design flaws, and implementation errors in software [@zhang2008distribution], robust AI techniques enable machine learning systems to operate effectively even in adverse conditions.
+
+This chapter explores the fundamental concepts, techniques, and tools for building fault-tolerant and error-resilient machine learning systems. It empowers researchers and practitioners to develop AI solutions that can withstand the complexities and uncertainties of real-world environments.
::: {.callout-tip}
## Learning Objectives
-* coming soon.
+* Understand the importance of robust and resilient AI systems in real-world applications.
+
+* Identify and characterize hardware faults, software faults, and their impact on ML systems.
+
+* Recognize and develop defensive strategies against threats posed by adversarial attacks, data poisoning, and distribution shifts.
+
+* Learn techniques for detecting, mitigating, and designing fault-tolerant ML systems.
+
+* Become familiar with tools and frameworks for studying and enhancing ML system resilience throughout the AI development lifecycle.
+
+:::
+
+## Introduction
+
+Robust AI refers to a system's ability to maintain its performance and reliability in the presence of hardware, software, and errors. A robust machine learning system is designed to be fault-tolerant and error-resilient, capable of operating effectively even under adverse conditions.
+
+As ML systems become increasingly integrated into various aspects of our lives, from cloud-based services to edge devices and embedded systems, the impact of hardware and software faults on their performance and reliability becomes more significant. In the future, as ML systems become more complex and are deployed in even more critical applications, the need for robust and fault-tolerant designs will be paramount.
+
+ML systems are expected to play crucial roles in autonomous vehicles, smart cities, healthcare, and industrial automation domains. In these domains, the consequences of hardware or software faults can be severe, potentially leading to loss of life, economic damage, or environmental harm. To mitigate these risks and ensure the reliable operation of future ML systems, researchers and engineers must focus on developing advanced techniques for fault detection, isolation, and recovery.
+
+This chapter will focus specifically on three main categories of faults and errors that can impact the robustness of ML systems: hardware faults, software faults, and human errors. Hardware faults include transient faults, permanent faults, and intermittent faults that can affect the hardware components of a machine learning system. Software faults encompass bugs, design flaws, and implementation errors in the software components, such as algorithms, libraries, and frameworks. Human errors refer to mistakes or oversights humans make in developing, deploying, or operating a machine-learning system.
+
+The specific challenges and approaches to achieving robustness may vary depending on the scale and constraints of the machine learning system. Large-scale systems, such as those used in cloud computing or data centers, may focus on ensuring fault tolerance and error resilience through redundancy, distributed processing, and advanced error detection and correction techniques. On the other hand, tiny machine learning systems deployed on resource-constrained edge devices or embedded systems face unique challenges due to limited computational power, memory, and energy resources.
+
+Regardless of the scale and constraints, the goal of robust AI remains the same: to ensure that the system can operate reliably and effectively in the presence of faults and errors. The key characteristics of a robust machine learning system include fault tolerance, error resilience, and performance maintenance:
+
+- **Fault Tolerance:** The system can function correctly, even with hardware or software faults. It can detect, isolate, and recover from faults without experiencing a complete failure or significant degradation in performance. Later, we will define the types of faults affecting ML systems.
+
+- **Error Resilience:** The system can handle and recover from errors that may occur during its operation. It can detect and correct errors, preventing them from propagating and causing further damage to the system or its outputs.
+
+- **Performance Maintenance:** A robust machine learning system can maintain performance levels, such as accuracy, speed, and efficiency, even when faced with faults or errors. It can adapt to changing conditions and continue to deliver reliable results.
+
+By understanding and addressing these faults and errors, we can develop machine learning systems that are more robust, reliable, and capable of operating effectively in real-world environments. However, the specific challenges and approaches to achieving robustness may vary depending on the scale and constraints of the machine learning system.
+
+## Real-World Examples
+
+Here are some real-world examples of cases where faults in hardware or software have caused major issues in ML systems across cloud, edge, and embedded environments:
+
+### Cloud
+
+In February 2017, Amazon Web Services (AWS) experienced [a significant outage](https://aws.amazon.com/message/41926/) due to human error during maintenance. An engineer inadvertently entered an incorrect command, causing many servers to be taken offline. This outage disrupted many AWS services, including Amazon's AI-powered assistant, Alexa. As a result, Alexa-powered devices, such as Amazon Echo and third-party products using Alexa Voice Service, could not respond to user requests for several hours. This incident highlights the potential impact of human errors on cloud-based ML systems and the need for robust maintenance procedures and failsafe mechanisms.
+
+In another example [@dixit2021silent], Facebook encountered a silent data corruption issue within its distributed querying infrastructure, as shown in [@fig-sdc-example](#8owvod923jax). Facebook's infrastructure includes a querying system that fetches and executes SQL and SQL-like queries across multiple datasets using frameworks like Presto, Hive, and Spark. One of the applications that utilized this querying infrastructure was a compression application to reduce the footprint of data stores. In this compression application, files were compressed when not being read and decompressed when a read request was made. Before decompression, the file size was checked to ensure it was greater than zero, indicating a valid compressed file with contents.
+
+)](./images/png/sdc_example.png){#fig-sdc-example}
+
+However, in one instance, when the file size was being computed for a valid non-zero-sized file, the decompression algorithm invoked a power function from the Scala library. Unexpectedly, the Scala function returned a zero size value for the file despite having a known non-zero decompressed size. As a result, the decompression was not performed, and the file was not written to the output database. This issue manifested sporadically, with some occurrences of the same file size computation returning the correct non-zero value.
+
+The impact of this silent data corruption was significant, leading to missing files and incorrect data in the output database. The application relying on the decompressed files failed due to the data inconsistencies. In the case study presented in the paper, Facebook's infrastructure, which consists of hundreds of thousands of servers handling billions of requests per day from their massive user base, encountered a silent data corruption issue. The affected system processed user queries, image uploads, and media content, which required fast, reliable, and secure execution.
+
+This case study illustrates how silent data corruption can propagate through multiple layers of an application stack, leading to data loss and application failures in a large-scale distributed system. The intermittent nature of the issue and the lack of explicit error messages made it particularly challenging to diagnose and resolve.
+
+### Edge
+
+Regarding examples of faults and errors in edge ML systems, one area that has gathered significant attention is the domain of self-driving cars. Self-driving vehicles rely heavily on machine learning algorithms for perception, decision-making, and control, making them particularly susceptible to the impact of hardware and software faults. In recent years, several high-profile incidents involving autonomous vehicles have highlighted the challenges and risks associated with deploying these systems in real-world environments.
+
+In May 2016, a fatal accident occurred when a Tesla Model S operating on Autopilot crashed into a white semi-trailer truck crossing the highway. The Autopilot system, which relied on computer vision and machine learning algorithms, failed to recognize the white trailer against a bright sky background. The driver, who was reportedly watching a movie when the crash, did not intervene in time, and the vehicle collided with the trailer at full speed. This incident raised concerns about the limitations of AI-based perception systems and the need for robust failsafe mechanisms in autonomous vehicles. It also highlighted the importance of driver awareness and the need for clear guidelines on using semi-autonomous driving features, as shown in [@fig-tesla-example](#tckwqf2ctxw).
+
+)](./images/png/tesla_example.jpg){#fig-tesla-example}
+
+In March 2018, an Uber self-driving test vehicle struck and killed a pedestrian crossing the street in Tempe, Arizona. The incident was caused by a software flaw in the vehicle's object recognition system, which failed to identify the pedestrians appropriately to avoid them as obstacles. The safety driver, who was supposed to monitor the vehicle's operation and intervene if necessary, was found distracted during the crash. [This incident](https://money.cnn.com/2018/03/19/technology/uber-autonomous-car-fatal-crash/index.html?iid=EL) led to widespread scrutiny of Uber's self-driving program and raised questions about the readiness of autonomous vehicle technology for public roads. It also emphasized the need for rigorous testing, validation, and safety measures in developing and deploying AI-based self-driving systems.
+
+In 2021, Tesla faced increased scrutiny following several accidents involving vehicles operating on Autopilot mode. Some of these accidents were attributed to issues with the Autopilot system's ability to detect and respond to certain road situations, such as stationary emergency vehicles or obstacles in the road. For example, in April 2021, a Tesla Model S crashed into a tree in Texas, killing two passengers. [Initial reports](https://www.cnbc.com/2021/04/18/no-one-was-driving-in-tesla-crash-that-killed-two-men-in-spring-texas-report.html) suggested that no one was in the driver's seat at the time of the crash, raising questions about the use and potential misuse of Autopilot features. These incidents highlight the ongoing challenges in developing robust and reliable autonomous driving systems and the need for clear regulations and consumer education regarding the capabilities and limitations of these technologies.
+
+### Embedded
+
+Embedded systems, which often operate in resource-constrained environments and safety-critical applications, have long faced challenges related to hardware and software faults. As AI and machine learning technologies are increasingly integrated into these systems, the potential for faults and errors takes on new dimensions, with the added complexity of AI algorithms and the critical nature of the applications in which they are deployed.
+
+Let's consider a few examples, starting with outer space exploration. NASA's Mars Polar Lander mission in 1999 suffered [a catastrophic failure](https://spaceref.com/uncategorized/nasa-reveals-probable-cause-of-mars-polar-lander-and-deep-space-2-mission-failures/) due to a software error in the touchdown detection system ([@fig-nasa-example](#e3z8hq3qpwn4)). The spacecraft's onboard software mistakenly interpreted the noise from the deployment of its landing legs as a sign that it had touched down on the Martian surface. As a result, the spacecraft prematurely shut down its engines, causing it to crash into the surface. This incident highlights the critical importance of robust software design and extensive testing in embedded systems, especially those operating in remote and unforgiving environments. As AI capabilities are integrated into future space missions, ensuring these systems' reliability and fault tolerance will be paramount to mission success.
+
+)](./images/png/nasa_example.png){#fig-nasa-example}
+
+Back on earth, in 2015, a Boeing 787 Dreamliner experienced a complete electrical shutdown during a flight due to a software bug in its generator control units. The bug caused the generator control units to enter a failsafe mode, cutting power to the aircraft's electrical systems and forcing an emergency landing. [This incident](https://www.engineering.com/story/vzrxw) underscores the potential for software faults to have severe consequences in complex embedded systems like aircraft. As AI technologies are increasingly applied in aviation, such as in autonomous flight systems and predictive maintenance, ensuring the robustness and reliability of these systems will be critical to passenger safety.
+
+As AI capabilities increasingly integrate into embedded systems, the potential for faults and errors becomes more complex and severe. Imagine a smart [pacemaker](https://www.bbc.com/future/article/20221011-how-space-weather-causes-computer-errors) that has a sudden glitch. A patient could die from that effect. Therefore, AI algorithms, such as those used for perception, decision-making, and control, introduce new sources of potential faults, such as data-related issues, model uncertainties, and unexpected behaviors in edge cases. Moreover, the opaque nature of some AI models can make it challenging to identify and diagnose faults when they occur.
+
+## Hardware Faults
+
+Hardware faults are a significant challenge in computing systems, including traditional and ML systems. These faults occur when physical components, such as processors, memory modules, storage devices, or interconnects, malfunction or behave abnormally. Hardware faults can cause incorrect computations, data corruption, system crashes, or complete system failure, compromising the integrity and trustworthiness of the computations performed by the system [@jha2019ml].
+
+Understanding the taxonomy of hardware faults is essential for anyone working with computing systems, especially in the context of ML systems. ML systems rely on complex hardware architectures and large-scale computations to train and deploy models that learn from data and make intelligent predictions or decisions. However, hardware faults can introduce errors and inconsistencies in the ML pipeline, affecting the trained models' accuracy, robustness, and reliability [@li2017understanding].
+
+Knowing the different types of hardware faults, their mechanisms, and their potential impact on system behavior is crucial for developing effective strategies to detect, mitigate, and recover them. This knowledge is also necessary for designing fault-tolerant computing systems, implementing robust ML algorithms, and ensuring the overall dependability of ML-based applications.
+
+The following sections will explore the three main categories of hardware faults: transient, permanent, and intermittent. We will discuss their definitions, characteristics, causes, mechanisms, and examples of how they manifest in computing systems. We will also cover detection and mitigation techniques specific to each fault type.
+
+- **Transient Faults:** Also known as soft errors, transient faults are temporary and non-recurring. They are often caused by external factors such as cosmic rays, electromagnetic interference, or power fluctuations. A common example of a transient fault is a bit flip, where a single bit in a memory location or register changes its value unexpectedly. Transient faults can lead to incorrect computations or data corruption, but they do not cause permanent damage to the hardware.
+
+- **Permanent Faults:** Permanent faults, also called hard errors, are irreversible and persist over time. They are typically caused by physical defects or wear-out of hardware components. Examples of permanent faults include stuck-at faults, where a bit or signal is permanently set to a specific value (e.g., always 0 or always 1), and device failures, such as a malfunctioning processor or a damaged memory module. Permanent faults can result in complete system failure or significant performance degradation.
+
+- **Intermittent Faults:** Intermittent faults are recurring faults that appear and disappear intermittently. Unstable hardware conditions, such as loose connections, aging components, or manufacturing defects, often cause them. Intermittent faults can be challenging to diagnose and reproduce because they may occur sporadically and under specific conditions. Examples include intermittent short circuits or contact resistance issues. Intermittent faults can lead to unpredictable system behavior and intermittent errors.
+
+By the end of this discussion, readers will have a solid understanding of fault taxonomy and its relevance to traditional computing and ML systems. This foundation will help them make informed decisions when designing, implementing, and deploying fault-tolerant solutions, improving the reliability and trustworthiness of their computing systems and ML applications.
+
+### Transient Faults
+
+#### Definition and Characteristics
+
+Transient faults are characterized by their short duration and non-permanent nature. They typically manifest as single-event upsets (SEUs) or single-event transients (SETs), where a single bit or a group of bits in a memory location or register unexpectedly changes its value [@mukherjee2005soft]. These faults do not persist or leave any lasting impact on the hardware. However, they can still lead to incorrect computations, data corruption, or system misbehavior if not properly handled.
+
+
+
+#### Causes of Transient Faults
+
+Transient faults can be attributed to various external factors. One common cause is cosmic rays, high-energy particles originating from outer space. When these particles strike sensitive areas of the hardware, such as memory cells or transistors, they can induce charge disturbances that alter the stored or transmitted data. This is illustrated in [@fig-transient-fault](#9jd0z5evi3fa). Another cause of transient faults is [electromagnetic interference (EMI)](https://www.trentonsystems.com/en-us/resource-hub/blog/what-is-electromagnetic-interference) from nearby devices or power fluctuations. EMI can couple with the circuits and cause voltage spikes or glitches that temporarily disrupt the normal operation of the hardware.
+
+)](./images/png/transient_fault.png){#fig-transient-fault}
+
+#### Mechanisms of Transient Faults
+
+Transient faults can manifest through different mechanisms depending on the affected hardware component. In memory devices like DRAM or SRAM, transient faults often lead to bit flips, where a single bit changes its value from 0 to 1 or vice versa. This can corrupt the stored data or instructions. In logic circuits, transient faults can cause glitches or voltage spikes propagating through the combinational logic, resulting in incorrect outputs or control signals. Transient faults can also affect communication channels, causing bit errors or packet losses during data transmission.
+
+#### Impact on ML Systems
+
+A common example of a transient fault is a bit flip in the main memory. If an important data structure or critical instruction is stored in the affected memory location, it can lead to incorrect computations or program misbehavior. For instance, a bit flip in the memory storing a loop counter can cause the loop to execute indefinitely or terminate prematurely. Transient faults in control registers or flag bits can alter the flow of program execution, leading to unexpected jumps or incorrect branch decisions. In communication systems, transient faults can corrupt transmitted data packets, resulting in retransmissions or data loss.
+
+In ML systems, transient faults can have significant implications during the training phase [@he2023understanding]. ML training involves iterative computations and updates to model parameters based on large datasets. If a transient fault occurs in the memory storing the model weights or gradients, it can lead to incorrect updates and compromise the convergence and accuracy of the training process.
+
+For example, a bit flip in the weight matrix of a neural network can cause the model to learn incorrect patterns or associations, leading to degraded performance [@wan2021analyzing]. Transient faults in the data pipeline, such as corruption of training samples or labels, can also introduce noise and affect the quality of the learned model.
+
+During the inference phase, transient faults can impact the reliability and trustworthiness of ML predictions. If a transient fault occurs in the memory storing the trained model parameters or in the computation of the inference results, it can lead to incorrect or inconsistent predictions. For instance, a bit flip in the activation values of a neural network can alter the final classification or regression output [@mahmoud2020pytorchfi].
+
+In safety-critical applications, such as autonomous vehicles or medical diagnosis, transient faults during inference can have severe consequences, leading to incorrect decisions or actions [@li2017understanding;@jha2019ml]. Ensuring the resilience of ML systems against transient faults is crucial to maintaining the integrity and reliability of the predictions.
+
+### Permanent Faults
+
+Permanent faults are hardware defects that persist and cause irreversible damage to the affected components. These faults are characterized by their persistent nature and require repair or replacement of the faulty hardware to restore normal system functionality.
+
+#### Definition and Characteristics
+
+Permanent faults are hardware defects that cause persistent and irreversible malfunctions in the affected components. The faulty component remains non-operational until a permanent fault is repaired or replaced. These faults are characterized by their consistent and reproducible nature, meaning that the faulty behavior is observed every time the affected component is used. Permanent faults can impact various hardware components, such as processors, memory modules, storage devices, or interconnects, leading to system crashes, data corruption, or complete system failure.
+
+One notable example of a permanent fault is the [Intel FDIV bug](https://en.wikipedia.org/wiki/Pentium_FDIV_bug), which was discovered in 1994. The FDIV bug was a flaw in certain Intel Pentium processors' floating-point division (FDIV) units. The bug caused incorrect results for specific division operations, leading to inaccurate calculations.
+
+The FDIV bug occurred due to an error in the lookup table used by the division unit. In rare cases, the processor would fetch an incorrect value from the lookup table, resulting in a slightly less precise result than expected. For instance, [@fig-permanent-fault](#djy9mhqllriw) shows a fraction 4195835/3145727 plotted on a Pentium processor with the FDIV permanent fault. The triangular regions are where erroneous calculations occurred. Ideally, all correct values would round to 1.3338, but the erroneous results show 1.3337, indicating a mistake in the 5th digit.
+
+Although the error was small, it could compound over many division operations, leading to significant inaccuracies in mathematical calculations. The impact of the FDIV bug was significant, especially for applications that relied heavily on precise floating-point division, such as scientific simulations, financial calculations, and computer-aided design. The bug led to incorrect results, which could have severe consequences in fields like finance or engineering.
+
+)](./images/png/permanent_fault.png){#fig-permanent-fault}
+
+The Intel FDIV bug is a cautionary tale for the potential impact of permanent faults on ML systems. In the context of ML, permanent faults in hardware components can lead to incorrect computations, affecting the accuracy and reliability of the models. For example, if an ML system relies on a processor with a faulty floating-point unit, similar to the Intel FDIV bug, it could introduce errors in the calculations performed during training or inference.
+
+These errors can propagate through the model, leading to inaccurate predictions or skewed learning. In applications where ML is used for critical tasks, such as autonomous driving, medical diagnosis, or financial forecasting, the consequences of incorrect computations due to permanent faults can be severe.
+
+It is crucial for ML practitioners to be aware of the potential impact of permanent faults and to incorporate fault-tolerant techniques, such as hardware redundancy, error detection and correction mechanisms, and robust algorithm design, to mitigate the risks associated with these faults. Additionally, thorough testing and validation of ML hardware components can help identify and address permanent faults before they impact the system's performance and reliability.
+
+#### Causes of Permanent Faults
+
+Permanent faults can arise from several causes, including manufacturing defects and wear-out mechanisms. [Manufacturing defects](https://www.sciencedirect.com/science/article/pii/B9780128181058000206) are inherent flaws introduced during the fabrication process of hardware components. These defects include improper etching, incorrect doping, or contamination, leading to non-functional or partially functional components.
+
+On the other hand, [wear-out mechanisms](https://semiengineering.com/what-causes-semiconductor-aging/) occur over time as the hardware components are subjected to prolonged use and stress. Factors such as electromigration, oxide breakdown, or thermal stress can cause gradual degradation of the components, eventually leading to permanent failures.
+
+#### Mechanisms of Permanent Faults
+
+Permanent faults can manifest through various mechanisms, depending on the nature and location of the fault. Stuck-at faults [@seong2010safer] are common permanent faults where a signal or memory cell remains fixed at a particular value (either 0 or 1) regardless of the inputs, as illustrated in [@fig-stuck-fault](#ahtmh1s1mxgf).
+
+)](./images/png/stuck_fault.png){#fig-stuck-fault}
+
+Stuck-at faults can occur in logic gates, memory cells, or interconnects, causing incorrect computations or data corruption. Another mechanism is device failures, where a component, such as a transistor or a memory cell, completely ceases to function. This can be due to manufacturing defects or severe wear-out. Bridging faults occur when two or more signal lines are unintentionally connected, causing short circuits or incorrect logic behavior.
+
+#### Impact on ML Systems
+
+Permanent faults can severely affect the behavior and reliability of computing systems. For example, a stuck-at-fault in a processor's arithmetic logic unit (ALU) can cause incorrect computations, leading to erroneous results or system crashes. A permanent fault in a memory module, such as a stuck-at fault in a specific memory cell, can corrupt the stored data, causing data loss or program misbehavior. In storage devices, permanent faults like bad sectors or device failures can result in data inaccessibility or complete loss of stored information. Permanent interconnect faults can disrupt communication channels, causing data corruption or system hangs.
+
+Permanent faults can significantly affect ML systems during the training and inference phases. During training, permanent faults in processing units or memory can lead to incorrect computations, resulting in corrupted or suboptimal models. Faults in storage devices can corrupt the training data or the stored model parameters, leading to data loss or model inconsistencies [@he2023understanding]. During inference, permanent faults can impact the reliability and correctness of ML predictions. Faults in the processing units can produce incorrect results or cause system failures, while faults in memory storing the model parameters can lead to corrupted or outdated models being used for inference [@zhang2018analyzing].
+
+To mitigate the impact of permanent faults in ML systems, fault-tolerant techniques must be employed at both the hardware and software levels. Hardware redundancy, such as duplicating critical components or using error-correcting codes [@kim2015bamboo], can help detect and recover from permanent faults. Software techniques, such as checkpoint and restart mechanisms [@egwutuoha2013survey], can enable the system to recover from permanent faults by returning to a previously saved state. Regular monitoring, testing, and maintenance of ML systems can help identify and replace faulty components before they cause significant disruptions.
+
+Designing ML systems with fault tolerance in mind is crucial to ensure their reliability and robustness in the presence of permanent faults. This may involve incorporating redundancy, error detection and correction mechanisms, and fail-safe strategies into the system architecture. By proactively addressing the challenges posed by permanent faults, ML systems can maintain their integrity, accuracy, and trustworthiness, even in the face of hardware failures.
+
+### Intermittent Faults
+
+Intermittent faults are hardware faults that occur sporadically and unpredictably in a system. An example is illustrated in [@fig-intermittent-fault](#kix.1c0l0udn3cp7), where cracks in the material can introduce increased resistance in circuitry. These faults are particularly challenging to detect and diagnose because they appear and disappear intermittently, making it difficult to reproduce and isolate the root cause. Intermittent faults can lead to system instability, data corruption, and performance degradation.
+
+)](./images/png/intermittent_fault.png){#fig-intermittent-fault}
+
+#### Definition and Characteristics
+
+Intermittent faults are characterized by their sporadic and non-deterministic nature. They occur irregularly and may appear and disappear spontaneously, with varying durations and frequencies. These faults do not consistently manifest every time the affected component is used, making them harder to detect than permanent faults. Intermittent faults can affect various hardware components, including processors, memory modules, storage devices, or interconnects. They can cause transient errors, data corruption, or unexpected system behavior.
+
+Intermittent faults can significantly impact the behavior and reliability of computing systems [@rashid2014characterizing]. For example, an intermittent fault in a processor's control logic can cause irregular program flow, leading to incorrect computations or system hangs. Intermittent faults in memory modules can corrupt data values, resulting in erroneous program execution or data inconsistencies. In storage devices, intermittent faults can cause read/write errors or data loss. Intermittent faults in communication channels can lead to data corruption, packet loss, or intermittent connectivity issues. These faults can cause system crashes, data integrity problems, or performance degradation, depending on the severity and frequency of the intermittent failures.
+
+#### Causes of Intermittent Faults
+
+Intermittent faults can arise from several causes, both internal and external, to the hardware components [@constantinescu2008intermittent]. One common cause is aging and wear-out of the components. As electronic devices age, they become more susceptible to intermittent failures due to degradation mechanisms such as electromigration, oxide breakdown, or solder joint fatigue.
+
+Manufacturing defects or process variations can also introduce intermittent faults, where marginal or borderline components may exhibit sporadic failures under specific conditions, as shown in [@fig-intermittent-fault-dram](#kix.7lswkjecl7ra).
+
+Environmental factors, such as temperature fluctuations, humidity, or vibrations, can trigger intermittent faults by altering the electrical characteristics of the components. Loose or degraded connections, such as those in connectors or printed circuit boards, can cause intermittent faults.
+
+)](./images/png/intermittent_fault_dram.png){#fig-intermittent-fault-dram}
+
+#### Mechanisms of Intermittent Faults
+
+Intermittent faults can manifest through various mechanisms, depending on the underlying cause and the affected component. One mechanism is the intermittent open or short circuit, where a signal path or connection becomes temporarily disrupted or shorted, causing erratic behavior. Another mechanism is the intermittent delay fault [@zhang2018thundervolt], where the timing of signals or propagation delays becomes inconsistent, leading to synchronization issues or incorrect computations. Intermittent faults can manifest as transient bit flips or soft errors in memory cells or registers, causing data corruption or incorrect program execution.
+
+#### Impact on ML Systems
+
+In the context of ML systems, intermittent faults can introduce significant challenges and impact the system's reliability and performance. During the training phase, intermittent faults in processing units or memory can lead to inconsistencies in computations, resulting in incorrect or noisy gradients and weight updates. This can affect the convergence and accuracy of the training process, leading to suboptimal or unstable models. Intermittent data storage or retrieval faults can corrupt the training data, introducing noise or errors that degrade the quality of the learned models [@he2023understanding].
+
+During the inference phase, intermittent faults can impact the reliability and consistency of ML predictions. Faults in the processing units or memory can cause incorrect computations or data corruption, leading to erroneous or inconsistent predictions. Intermittent faults in the data pipeline can introduce noise or errors in the input data, affecting the accuracy and robustness of the predictions. In safety-critical applications, such as autonomous vehicles or medical diagnosis systems, intermittent faults can have severe consequences, leading to incorrect decisions or actions that compromise safety and reliability.
+
+Mitigating the impact of intermittent faults in ML systems requires a multifaceted approach [@rashid2012intermittent]. At the hardware level, techniques such as robust design practices, component selection, and environmental control can help reduce the occurrence of intermittent faults. Redundancy and error correction mechanisms can be employed to detect and recover from intermittent failures. At the software level, runtime monitoring, anomaly detection, and fault-tolerant techniques can be incorporated into the ML pipeline. This may include techniques such as data validation, outlier detection, model ensembling, or runtime model adaptation to handle intermittent faults gracefully.
+
+Designing ML systems resilient to intermittent faults is crucial to ensuring their reliability and robustness. This involves incorporating fault-tolerant techniques, runtime monitoring, and adaptive mechanisms into the system architecture. By proactively addressing the challenges of intermittent faults, ML systems can maintain their accuracy, consistency, and trustworthiness, even in sporadic hardware failures. Regular testing, monitoring, and maintenance of ML systems can help identify and mitigate intermittent faults before they cause significant disruptions or performance degradation.
+
+### Detection and Mitigation
+
+This section explores various fault detection techniques, including hardware-level and software-level approaches, and discusses effective mitigation strategies to enhance the resilience of ML systems. Additionally, we will look into resilient ML system design considerations, present case studies and examples, and highlight future research directions in fault-tolerant ML systems.
+
+#### Fault Detection Techniques
+
+Fault detection techniques are important for identifying and localizing hardware faults in ML systems. These techniques can be broadly categorized into hardware-level and software-level approaches, each offering unique capabilities and advantages.
+
+##### Hardware-level fault detection
+
+Hardware-level fault detection techniques are implemented at the physical level of the system and aim to identify faults in the underlying hardware components. There are several hardware techniques, but broadly, we can bucket these different mechanisms into the following categories.
+
+**Built-in self-test (BIST) mechanisms:** BIST is a powerful technique for detecting faults in hardware components [@bushnell2002built]. It involves incorporating additional hardware circuitry into the system for self-testing and fault detection. BIST can be applied to various components, such as processors, memory modules, or application-specific integrated circuits (ASICs). For example, BIST can be implemented in a processor using scan chains, which are dedicated paths that allow access to internal registers and logic for testing purposes.
+
+During the BIST process, predefined test patterns are applied to the processor's internal circuitry, and the responses are compared against expected values. Any discrepancies indicate the presence of faults. Intel's Xeon processors, for instance, include BIST mechanisms to test the CPU cores, cache memory, and other critical components during system startup.
+
+**Error detection codes:** Error detection codes are widely used to detect data storage and transmission errors [@hamming1950error]. These codes add redundant bits to the original data, allowing the detection of bit errors. Example: Parity checks are a simple form of error detection code shown in [@fig-parity](#kix.2vxlbeehnemj). In a single-bit parity scheme, an extra bit is appended to each data word, making the number of 1s in the word even (even parity) or odd (odd parity).
+
+)](./images/png/parity.png){#fig-parity}
+
+When reading the data, the parity is checked, and if it doesn't match the expected value, an error is detected. More advanced error detection codes, such as cyclic redundancy checks (CRC), calculate a checksum based on the data and append it to the message. The checksum is recalculated at the receiving end and compared with the transmitted checksum to detect errors. Error-correcting code (ECC) memory modules, commonly used in servers and critical systems, employ advanced error detection and correction codes to detect and correct single-bit or multi-bit errors in memory.
+
+**Hardware redundancy and voting mechanisms:** Hardware redundancy involves duplicating critical components and comparing their outputs to detect and mask faults [@sheaffer2007hardware]. Voting mechanisms, such as triple modular redundancy (TMR), employ multiple instances of a component and compare their outputs to identify and mask faulty behavior [@arifeen2020approximate].
+
+In a TMR system, three identical instances of a hardware component, such as a processor or a sensor, perform the same computation in parallel. The outputs of these instances are fed into a voting circuit, which compares the results and selects the majority value as the final output. If one of the instances produces an incorrect result due to a fault, the voting mechanism masks the error and maintains the correct output. TMR is commonly used in aerospace and aviation systems, where high reliability is critical. For instance, the Boeing 777 aircraft employs TMR in its primary flight computer system to ensure the availability and correctness of flight control functions [@yeh1996triple].
+
+Tesla's self-driving computers employ a redundant hardware architecture to ensure the safety and reliability of critical functions, such as perception, decision-making, and vehicle control, as shown in [@fig-tesla-dmr](#kix.nsc1yczcug9r). One key component of this architecture is using dual modular redundancy (DMR) in the car's onboard computer systems.
+
+)](./images/png/tesla_dmr.png){#fig-tesla-dmr}
+
+In Tesla's DMR implementation, two identical hardware units, often called "redundant computers" or "redundant control units," perform the same computations in parallel [@bannon2019computer]. Each unit independently processes sensor data, executes perception and decision-making algorithms, and generates control commands for the vehicle's actuators (e.g., steering, acceleration, and braking).
+
+The outputs of these two redundant units are continuously compared to detect any discrepancies or faults. If the outputs match, the system assumes that both units function correctly, and the control commands are sent to the vehicle's actuators. However, if there is a mismatch between the outputs, the system identifies a potential fault in one of the units and takes appropriate action to ensure safe operation.
+
+The system may employ additional mechanisms to determine which unit is faulty in a mismatch. This can involve using diagnostic algorithms, comparing the outputs with data from other sensors or subsystems, or analyzing the consistency of the outputs over time. Once the faulty unit is identified, the system can isolate it and continue operating using the output from the non-faulty unit.
+
+DMR in Tesla's self-driving computer provides an extra safety and fault tolerance layer. By having two independent units performing the same computations, the system can detect and mitigate faults that may occur in one of the units. This redundancy helps prevent single points of failure and ensures that critical functions remain operational despite hardware faults.
+
+Furthermore, Tesla also incorporates additional redundancy mechanisms beyond DMR. For example, they utilize redundant power supplies, steering and braking systems, and diverse sensor suites (e.g., cameras, radar, and ultrasonic sensors) to provide multiple layers of fault tolerance. These redundancies collectively contribute to the overall safety and reliability of the self-driving system.
+
+It's important to note that while DMR provides fault detection and some level of fault tolerance, TMR may provide a different level of fault masking. In DMR, if both units experience simultaneous faults or the fault affects the comparison mechanism, the system may be unable to identify the fault. Therefore, Tesla's SDCs rely on a combination of DMR and other redundancy mechanisms to achieve a high level of fault tolerance.
+
+The use of DMR in Tesla's self-driving computer highlights the importance of hardware redundancy in safety-critical applications. By employing redundant computing units and comparing their outputs, the system can detect and mitigate faults, enhancing the overall safety and reliability of the self-driving functionality.
+
+**Watchdog timers:** Watchdog timers are hardware components that monitor the execution of critical tasks or processes [@pont2002using]. They are commonly used to detect and recover from software or hardware faults that cause a system to become unresponsive or stuck in an infinite loop. In an embedded system, a watchdog timer can be configured to monitor the execution of the main control loop, as illustrated in [@fig-watchdog](#3l259jcz0lli). The software periodically resets the watchdog timer to indicate that it functions correctly. Suppose the software fails to reset the timer within a specified time limit (timeout period). In that case, the watchdog timer assumes that the system has encountered a fault and triggers a predefined recovery action, such as resetting the system or switching to a backup component. Watchdog timers are widely used in automotive electronics, industrial control systems, and other safety-critical applications to ensure the timely detection and recovery from faults.
+
+)](./images/png/watchdog.png){#fig-watchdog}
+
+##### Software-level fault detection
+
+Software-level fault detection techniques rely on software algorithms and monitoring mechanisms to identify system faults. These techniques can be implemented at various levels of the software stack, including the operating system, middleware, or application level.
+
+**Runtime monitoring and anomaly detection:** Runtime monitoring involves continuously observing the behavior of the system and its components during execution [@francalanza2017foundation]. It helps detect anomalies, errors, or unexpected behavior that may indicate the presence of faults. For example, consider an ML-based image classification system deployed in a self-driving car. Runtime monitoring can be implemented to track the classification model's performance and behavior [@mahmoud2021issre].
+
+Anomaly detection algorithms can be applied to the model's predictions or intermediate layer activations, such as statistical outlier detection or machine learning-based approaches (e.g., One-Class SVM or Autoencoders) [@chandola2009anomaly]. [@fig-ad](#a0u8fu59ui0r) shows example of anomaly detection. Suppose the monitoring system detects a significant deviation from the expected patterns, such as a sudden drop in classification accuracy or out-of-distribution samples. In that case, it can raise an alert indicating a potential fault in the model or the input data pipeline. This early detection allows for timely intervention and fault mitigation strategies to be applied.
+
+)](./images/png/ad.png){#fig-ad}
+
+**Consistency checks and data validation:** Consistency checks and data validation techniques ensure data integrity and correctness at different processing stages in an ML system [@lindholm2019data]. These checks help detect data corruption, inconsistencies, or errors that may propagate and affect the system's behavior. Example: In a distributed ML system where multiple nodes collaborate to train a model, consistency checks can be implemented to validate the integrity of the shared model parameters. Each node can compute a checksum or hash of the model parameters before and after the training iteration, as shown in @fig-ad. Any inconsistencies or data corruption can be detected by comparing the checksums across nodes. Additionally, range checks can be applied to the input data and model outputs to ensure they fall within expected bounds. For instance, if an autonomous vehicle's perception system detects an object with unrealistic dimensions or velocities, it can indicate a fault in the sensor data or the perception algorithms [@wan2023vpp].
+
+**Heartbeat and timeout mechanisms:** Heartbeat mechanisms and timeouts are commonly used to detect faults in distributed systems and ensure the liveness and responsiveness of components [@kawazoe1997heartbeat]. These are quite similar to the watchdog timers found in hardware. For example, in a distributed ML system, where multiple nodes collaborate to perform tasks such as data preprocessing, model training, or inference, heartbeat mechanisms can be implemented to monitor the health and availability of each node. Each node periodically sends a heartbeat message to a central coordinator or its peer nodes, indicating its status and availability. Suppose a node fails to send a heartbeat within a specified timeout period, as shown in [@fig-heartbeat](#ojufkz2g56e). In that case, it is considered faulty, and appropriate actions can be taken, such as redistributing the workload or initiating a failover mechanism. Timeouts can also be used to detect and handle hanging or unresponsive components. For example, if a data loading process exceeds a predefined timeout threshold, it may indicate a fault in the data pipeline, and the system can take corrective measures.
+
+)](./images/png/heartbeat.png){#fig-heartbeat}
+
+
+
+**Software-implemented fault tolerance (SIFT) techniques:** SIFT techniques introduce redundancy and fault detection mechanisms at the software level to enhance the reliability and fault tolerance of the system [@reis2005swift]. Example: N-version programming is a SIFT technique where multiple functionally equivalent software component versions are developed independently by different teams. This can be applied to critical components such as the model inference engine in an ML system. Multiple versions of the inference engine can be executed in parallel, and their outputs can be compared for consistency. It is considered the correct result if most versions produce the same output. If there is a discrepancy, it indicates a potential fault in one or more versions, and appropriate error-handling mechanisms can be triggered. Another example is using software-based error correction codes, such as Reed-Solomon codes [@plank1997tutorial], to detect and correct errors in data storage or transmission, as shown in [@fig-Reed-Solomon](#kjmtegsny44z). These codes add redundancy to the data, enabling detecting and correcting certain errors and enhancing the system's fault tolerance.
+
+)](./images/png/Reed-Solomon.png){#fig-Reed-Solomon}
+
+:::{#exr-ad .callout-exercise collapse="true"}
+
+### Anomaly Detection
+
+In this Colab, play the role of an AI fault detective! You'll build an autoencoder-based anomaly detector to pinpoint errors in heart health data. Learn how to identify malfunctions in ML systems, a vital skill for creating dependable AI. We'll use Keras Tuner to fine-tune your autoencoder for top-notch fault detection. This experience directly links to the Robust AI chapter, demonstrating the importance of fault detection in real-world applications like healthcare and autonomous systems. Get ready to strengthen the reliability of your AI creations!
+
+[](https://colab.research.google.com/drive/1TXaQzsSj2q0E3Ni1uxFDXGpY1SCnu46v?usp=sharing)
+:::
+
+### Summary
+
+@tbl-fault_types provides an extensive comparative analysis of transient, permanent, and intermittent faults. It outlines the primary characteristics or dimensions that distinguish these fault types. Here, we summarize the relevant dimensions we examined and explore the nuances that differentiate transient, permanent, and intermittent faults in greater detail.
+
+| Dimension | Transient Faults | Permanent Faults | Intermittent Faults |
+|-----------|------------------|------------------|---------------------|
+| Duration | Short-lived, temporary | Persistent, remains until repair or replacement | Sporadic, appears and disappears intermittently |
+| Persistence | Disappears after the fault condition passes | Consistently present until addressed | Recurs irregularly, not always present |
+| Causes | External factors (e.g., electromagnetic interference, cosmic rays) | Hardware defects, physical damage, wear-out | Unstable hardware conditions, loose connections, aging components |
+| Manifestation | Bit flips, glitches, temporary data corruption | Stuck-at faults, broken components, complete device failures | Occasional bit flips, intermittent signal issues, sporadic malfunctions |
+| Impact on ML Systems | Introduces temporary errors or noise in computations | Causes consistent errors or failures, affecting reliability | Leads to sporadic and unpredictable errors, challenging to diagnose and mitigate |
+| Detection | Error detection codes, comparison with expected values | Built-in self-tests, error detection codes, consistency checks | Monitoring for anomalies, analyzing error patterns and correlations |
+| Mitigation | Error correction codes, redundancy, checkpoint and restart | Hardware repair or replacement, component redundancy, failover mechanisms | Robust design, environmental control, runtime monitoring, fault-tolerant techniques |
+
+: Comparison of transient, permanent, and intermittent faults. {#tbl-fault_types}
+
+## ML Model Robustness
+
+### Adversarial Attacks
+
+#### Definition and Characteristics
+
+Adversarial attacks aim to trick models into making incorrect predictions by providing them with specially crafted, deceptive inputs (called adversarial examples) [@parrish2023adversarial]. By adding slight perturbations to input data, adversaries can \"hack\" a model's pattern recognition and deceive it. These are sophisticated techniques where slight, often imperceptible alterations to input data can trick an ML model into making a wrong prediction, as shown in [@fig-adversarial-attack-noise-example].
+
+)](./images/png/adversarial_attack_detection.png){#fig-adversarial-attack-noise-example}
+
+One can generate prompts that lead to unsafe images in text-to-image models like DALLE [@ramesh2021zero] or Stable Diffusion [@rombach2022highresolution]. For example, by altering the pixel values of an image, attackers can deceive a facial recognition system into identifying a face as a different person.
+
+Adversarial attacks exploit the way ML models learn and make decisions during inference. These models work on the principle of recognizing patterns in data. An adversary crafts special inputs with perturbations to mislead the model's pattern recognition\-\--essentially 'hacking' the model's perceptions.
+
+Adversarial attacks fall under different scenarios:
+
+* **Whitebox Attacks:** The attacker fully knows the target model's internal workings, including the training data, parameters, and architecture [@ye2021thundernna]. This comprehensive access creates favorable conditions for attackers to exploit the model's vulnerabilities. The attacker can use specific and subtle weaknesses to craft effective adversarial examples.
+
+* **Blackbox Attacks:** In contrast to white-box attacks, black-box attacks involve the attacker having little to no knowledge of the target model [@guo2019simple]. To carry out the attack, the adversarial actor must carefully observe the model's output behavior.
+
+* **Greybox Attacks:** These fall between blackbox and whitebox attacks. The attacker has only partial knowledge about the target model's internal design [@xu2021grey]. For example, the attacker could have knowledge about training data but not the architecture or parameters. In the real world, practical attacks fall under black black-box box grey-boxes.
+
+The landscape of machine learning models is complex and broad, especially given their relatively recent integration into commercial applications. This rapid adoption, while transformative, has brought to light numerous vulnerabilities within these models. Consequently, various adversarial attack methods have emerged, each strategically exploiting different aspects of different models. Below, we highlight a subset of these methods, showcasing the multifaceted nature of adversarial attacks on machine learning models:
+
+* **Generative Adversarial Networks (GANs)** are deep learning models that consist of two networks competing against each other: a generator and a discriminator [@goodfellow2020generative]. The generator tries to synthesize realistic data while the discriminator evaluates whether they are real or fake. GANs can be used to craft adversarial examples. The generator network is trained to produce inputs that the target model misclassifies. These GAN-generated images can then attack a target classifier or detection model. The generator and the target model are engaged in a competitive process, with the generator continually improving its ability to create deceptive examples and the target model enhancing its resistance to such examples. GANs provide a powerful framework for crafting complex and diverse adversarial inputs, illustrating the adaptability of generative models in the adversarial landscape.
+
+* **Transfer Learning Adversarial Attacks** exploit the knowledge transferred from a pre-trained model to a target model, creating adversarial examples that can deceive both models. These attacks pose a growing concern, particularly when adversaries have knowledge of the feature extractor but lack access to the classification head (the part or layer responsible for making the final classifications). Referred to as \"headless attacks,\" these transferable adversarial strategies leverage the expressive capabilities of feature extractors to craft perturbations while being oblivious to the label space or training data. The existence of such attacks underscores the importance of developing robust defenses for transfer learning applications, especially since pre-trained models are commonly used [@ahmed2020headless].
+
+#### Mechanisms of Adversarial Attacks
+
+)](./images/png/gradient_attack.png){#fig-gradient-attack}
+
+**Gradient-based Attacks**
+
+One prominent category of adversarial attacks is gradient-based attacks. These attacks leverage the gradients of the ML model's loss function to craft adversarial examples. The [Fast Gradient Sign Method](https://www.tensorflow.org/tutorials/generative/adversarial_fgsm) (FGSM) is a well-known technique in this category. FGSM perturbs the input data by adding small noise in the gradient direction, aiming to maximize the model's prediction error. FGSM can quickly generate adversarial examples, as shown in [@fig-gradient-attack], by taking a single step in the gradient direction.
+
+Another variant, the Projected Gradient Descent (PGD) attack, extends FGSM by iteratively applying the gradient update step, allowing for more refined and powerful adversarial examples. The Jacobian-based Saliency Map Attack (JSMA) is another gradient-based approach that identifies the most influential input features and perturbs them to create adversarial examples.
+
+**Optimization-based Attacks**
+
+These attacks formulate the generation of adversarial examples as an optimization problem. The Carlini and Wagner (C&W) attack is a prominent example in this category. It aims to find the smallest perturbation that can cause misclassification while maintaining the perceptual similarity to the original input. The C&W attack employs an iterative optimization process to minimize the perturbation while maximizing the model's prediction error.
+
+Another optimization-based approach is the Elastic Net Attack to DNNs (EAD), which incorporates elastic net regularization to generate adversarial examples with sparse perturbations.
+
+**Transfer-based Attacks**
+
+Transfer-based attacks exploit the transferability property of adversarial examples. Transferability refers to the phenomenon where adversarial examples crafted for one ML model can often fool other models, even if they have different architectures or were trained on different datasets. This enables attackers to generate adversarial examples using a surrogate model and then transfer them to the target model without requiring direct access to its parameters or gradients. Transfer-based attacks highlight the generalization of adversarial vulnerabilities across different models and the potential for black-box attacks.
+
+**Physical-world Attacks**
+
+Physical-world attacks bring adversarial examples into the realm of real-world scenarios. These attacks involve creating physical objects or manipulations that can deceive ML models when captured by sensors or cameras. Adversarial patches, for example, are small, carefully designed patches that can be placed on objects to fool object detection or classification models. When attached to real-world objects, these patches can cause models to misclassify or fail to detect the objects accurately. Adversarial objects, such as 3D-printed sculptures or modified road signs, can also be crafted to deceive ML systems in physical environments.
+
+**Summary**
+
+@tbl-attack_types a concise overview of the different categories of adversarial attacks, including gradient-based attacks (FGSM, PGD, JSMA), optimization-based attacks (C&W, EAD), transfer-based attacks, and physical-world attacks (adversarial patches and objects). Each attack is briefly described, highlighting its key characteristics and mechanisms.
+
+| Attack Category | Attack Name | Description |
+|-----------------------|-------------------------------------|-----------------------------------------------------------------------------------------------------------------|
+| Gradient-based | Fast Gradient Sign Method (FGSM) | Perturbs input data by adding small noise in the gradient direction to maximize prediction error. |
+| | Projected Gradient Descent (PGD) | Extends FGSM by iteratively applying the gradient update step for more refined adversarial examples. |
+| | Jacobian-based Saliency Map Attack (JSMA) | Identifies influential input features and perturbs them to create adversarial examples. |
+| Optimization-based | Carlini and Wagner (C&W) Attack | Finds the smallest perturbation that causes misclassification while maintaining perceptual similarity. |
+| | Elastic Net Attack to DNNs (EAD) | Incorporates elastic net regularization to generate adversarial examples with sparse perturbations. |
+| Transfer-based | Transferability-based Attacks | Exploits the transferability of adversarial examples across different models, enabling black-box attacks. |
+| Physical-world | Adversarial Patches | Small, carefully designed patches placed on objects to fool object detection or classification models. |
+| | Adversarial Objects | Physical objects (e.g., 3D-printed sculptures, modified road signs) crafted to deceive ML systems in real-world scenarios. |
+
+: Different attack types on ML models. {#@tbl-attack_types}
+
+The mechanisms of adversarial attacks reveal the intricate interplay between the ML model's decision boundaries, the input data, and the attacker's objectives. By carefully manipulating the input data, attackers can exploit the model's sensitivities and blind spots, leading to incorrect predictions. The success of adversarial attacks highlights the need for a deeper understanding of ML models' robustness and generalization properties.
+
+Defending against adversarial attacks requires a multifaceted approach. Adversarial training is one common defense strategy in which models are trained on adversarial examples to improve robustness. Exposing the model to adversarial examples during training teaches it to classify them correctly and become more resilient to attacks. Defensive distillation, input preprocessing, and ensemble methods are other techniques that can help mitigate the impact of adversarial attacks.
+
+As adversarial machine learning evolves, researchers explore new attack mechanisms and develop more sophisticated defenses. The arms race between attackers and defenders drives the need for constant innovation and vigilance in securing ML systems against adversarial threats. Understanding the mechanisms of adversarial attacks is crucial for developing robust and reliable ML models that can withstand the ever-evolving landscape of adversarial examples.
+
+#### Impact on ML Systems
+
+Adversarial attacks on machine learning systems have emerged as a significant concern in recent years, highlighting the potential vulnerabilities and risks associated with the widespread adoption of ML technologies. These attacks involve carefully crafted perturbations to input data that can deceive or mislead ML models, leading to incorrect predictions or misclassifications, as shown in [@fig-adversarial-googlenet]. The impact of adversarial attacks on ML systems is far-reaching and can have serious consequences in various domains.
+
+One striking example of the impact of adversarial attacks was demonstrated by researchers in 2017. They experimented with small black and white stickers on stop signs [@eykholt2018robust]. To the human eye, these stickers did not obscure the sign or prevent its interpretability. However, when images of the sticker-modified stop signs were fed into standard traffic sign classification ML models, a shocking result emerged. The models misclassified the stop signs as speed limit signs over 85% of the time.
+
+This demonstration shed light on the alarming potential of simple adversarial stickers to trick ML systems into misreading critical road signs. The implications of such attacks in the real world are significant, particularly in the context of autonomous vehicles. If deployed on actual roads, these adversarial stickers could cause self-driving cars to misinterpret stop signs as speed limits, leading to dangerous situations, as shown in [@fig-graffiti]. Researchers warned that this could result in rolling stops or unintended acceleration into intersections, endangering public safety.
+
+)](./images/png/adversarial_googlenet.png){#fig-adversarial-googlenet}
+
+)](./images/png/graffiti.png){#fig-graffiti}
+
+The case study of the adversarial stickers on stop signs provides a concrete illustration of how adversarial examples exploit how ML models recognize patterns. By subtly manipulating the input data in ways that are invisible to humans, attackers can induce incorrect predictions and create serious risks, especially in safety-critical applications like autonomous vehicles. The attack's simplicity highlights the vulnerability of ML models to even minor changes in the input, emphasizing the need for robust defenses against such threats.
+
+The impact of adversarial attacks extends beyond the degradation of model performance. These attacks raise significant security and safety concerns, particularly in domains where ML models are relied upon for critical decision-making. In healthcare applications, adversarial attacks on medical imaging models could lead to misdiagnosis or incorrect treatment recommendations, jeopardizing patient well-being [@tsai2023adversarial]. In financial systems, adversarial attacks could enable fraud or manipulation of trading algorithms, resulting in substantial economic losses.
+
+Moreover, adversarial vulnerabilities undermine the trustworthiness and interpretability of ML models. If carefully crafted perturbations can easily fool models, confidence in their predictions and decisions erodes. Adversarial examples expose the models' reliance on superficial patterns and the inability to capture the true underlying concepts, challenging the reliability of ML systems [@fursov2021adversarial].
+
+Defending against adversarial attacks often requires additional computational resources and can impact the overall system performance. Techniques like adversarial training, where models are trained on adversarial examples to improve robustness, can significantly increase training time and computational requirements [@bai2021recent]. Runtime detection and mitigation mechanisms, such as input preprocessing [@addepalli2020towards] or prediction consistency checks, introduce latency and affect the real-time performance of ML systems.
+
+The presence of adversarial vulnerabilities also complicates the deployment and maintenance of ML systems. System designers and operators must consider the potential for adversarial attacks and incorporate appropriate defenses and monitoring mechanisms. Regular updates and retraining of models become necessary to adapt to new adversarial techniques and maintain system security and performance over time.
+
+The impact of adversarial attacks on ML systems is significant and multifaceted. These attacks expose ML models' vulnerabilities, from degrading model performance and raising security and safety concerns to challenging model trustworthiness and interpretability. Developers and researchers must prioritize the development of robust defenses and countermeasures to mitigate the risks posed by adversarial attacks. By addressing these challenges, we can build more secure, reliable, and trustworthy ML systems that can withstand the ever-evolving landscape of adversarial threats.
+
+:::{#exr-aa .callout-exercise collapse="true"}
+
+### Adversarial Attacks
+
+Get ready to become an AI adversary! In this Colab, you'll become a white-box hacker, learning to craft attacks that deceive image classification models. We'll focus on the Fast Gradient Sign Method (FGSM), where you'll weaponize a model's gradients against it! You'll deliberately distort images with tiny perturbations, observing how they increasingly fool the AI more intensely. This hands-on exercise highlights the importance of building secure AI – a critical skill as AI integrates into cars and healthcare. The Colab directly ties into the Robust AI chapter of your book, moving adversarial attacks from theory into your own hands-on experience.
+
+[](https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/generative/adversarial_fgsm.ipynb#scrollTo=W1L3zJP6pPGD)
+
+Think you can outsmart an AI? In this Colab, learn how to trick image classification models with adversarial attacks. We'll use methods like FGSM to change images and subtly fool the AI. Discover how to design deceptive image patches and witness the surprising vulnerability of these powerful models. This is crucial knowledge for building truly robust AI systems!
+
+[](https://colab.research.google.com/github/phlippe/uvadlc_notebooks/blob/master/docs/tutorial_notebooks/tutorial10/Adversarial_Attacks.ipynb#scrollTo=C5HNmh1-Ka9J)
+:::
+
+### Data Poisoning
+
+#### Definition and Characteristics
+
+Data poisoning is an attack where the training data is tampered with, leading to a compromised model [@biggio2012poisoning], as shown in [@fig-poisoning-example]. Attackers can modify existing training examples, insert new malicious data points, or influence the data collection process. The poisoned data is labeled in such a way as to skew the model's learned behavior. This can be particularly damaging in applications where ML models make automated decisions based on learned patterns. Beyond training sets, poisoning tests, and validation data can allow adversaries to boost reported model performance artificially.
+
+)](./images/png/poisoning_example.png){#fig-poisoning-example}
+
+The process usually involves the following steps:
+
+* **Injection:** The attacker adds incorrect or misleading examples into the training set. These examples are often designed to look normal to cursory inspection but have been carefully crafted to disrupt the learning process.
+
+* **Training:** The ML model trains on this manipulated dataset and develops skewed understandings of the data patterns.
+
+* **Deployment:** Once the model is deployed, the corrupted training leads to flawed decision-making or predictable vulnerabilities the attacker can exploit.
+
+The impact of data poisoning extends beyond classification errors or accuracy drops. In critical applications like healthcare, such alterations can lead to significant trust and safety issues [@marulli2022sensitivity]. Later, we will discuss a few case studies of these issues.
+
+There are six main categories of data poisoning [@oprea2022poisoning]:
+
+* **Availability Attacks:** These attacks aim to compromise the overall functionality of a model. They cause it to misclassify most testing samples, rendering the model unusable for practical applications. An example is label flipping, where labels of a specific, targeted class are replaced with labels from a different one.
+
+* **Targeted Attacks:** In contrast to availability attacks, targeted attacks aim to compromise a small number of the testing samples. So, the effect is localized to a limited number of classes, while the model maintains the same original level of accuracy for the majority of the classes. The targeted nature of the attack requires the attacker to possess knowledge of the model's classes, making detecting these attacks more challenging.
+
+* **Backdoor Attacks:** In these attacks, an adversary targets specific patterns in the data. The attacker introduces a backdoor (a malicious, hidden trigger or pattern) into the training data, such as manipulating certain features in structured data or manipulating a pattern of pixels at a fixed position. This causes the model to associate the malicious pattern with specific labels. As a result, when the model encounters test samples that contain a malicious pattern, it makes false predictions.
+
+* **Subpopulation Attacks:** Attackers selectively choose to compromise a subset of the testing samples while maintaining accuracy on the rest of the samples. You can think of these attacks as a combination of availability and targeted attacks: performing availability attacks (performance degradation) within the scope of a targeted subset. Although subpopulation attacks may seem very similar to targeted attacks, the two have clear differences:
+
+* **Scope:** While targeted attacks target a selected set of samples, subpopulation attacks target a general subpopulation with similar feature representations. For example, in a targeted attack, an actor inserts manipulated images of a 'speed bump' warning sign (with carefully crafted perturbations or patterns), which causes an autonomous car to fail to recognize such a sign and slow down. On the other hand, manipulating all samples of people with a British accent so that a speech recognition model would misclassify a British person's speech is an example of a subpopulation attack.
+
+* **Knowledge:** While targeted attacks require a high degree of familiarity with the data, subpopulation attacks require less intimate knowledge to be effective.
+
+The characteristics of data poisoning include:
+
+**Subtle and hard-to-detect manipulations of training data:** Data poisoning often involves subtle manipulations of the training data that are carefully crafted to be difficult to detect through casual inspection. Attackers employ sophisticated techniques to ensure that the poisoned samples blend seamlessly with the legitimate data, making them easier to identify with thorough analysis. These manipulations can target specific features or attributes of the data, such as altering numerical values, modifying categorical labels, or introducing carefully designed patterns. The goal is to influence the model's learning process while evading detection, allowing the poisoned data to subtly corrupt the model's behavior.
+
+**Can be performed by insiders or external attackers:** Data poisoning attacks can be carried out by various actors, including malicious insiders with access to the training data and external attackers who find ways to influence the data collection or preprocessing pipeline. Insiders pose a significant threat because they often have privileged access and knowledge of the system, enabling them to introduce poisoned data without raising suspicions. On the other hand, external attackers may exploit vulnerabilities in data sourcing, crowdsourcing platforms, or data aggregation processes to inject poisoned samples into the training dataset. This highlights the importance of implementing strong access controls, data governance policies, and monitoring mechanisms to mitigate the risk of insider threats and external attacks.
+
+**Exploits vulnerabilities in data collection and preprocessing:** Data poisoning attacks often exploit vulnerabilities in the machine learning pipeline's data collection and preprocessing stages. Attackers carefully design poisoned samples to evade common data validation techniques, ensuring that the manipulated data still falls within acceptable ranges, follows expected distributions, or maintains consistency with other features. This allows the poisoned data to pass through data preprocessing steps without detection. Furthermore, poisoning attacks can take advantage of weaknesses in data preprocessing, such as inadequate data cleaning, insufficient outlier detection, or lack of integrity checks. Attackers may also exploit the lack of robust data provenance and lineage tracking mechanisms to introduce poisoned data without leaving a traceable trail. Addressing these vulnerabilities requires rigorous data validation, anomaly detection, and data provenance tracking techniques to ensure the integrity and trustworthiness of the training data.
+
+**Disrupts the learning process and skews model behavior:** Data poisoning attacks are designed to disrupt the learning process of machine learning models and skew their behavior towards the attacker's objectives. The poisoned data is typically manipulated with specific goals, such as skewing the model's behavior towards certain classes, introducing backdoors, or degrading overall performance. These manipulations are not random but targeted to achieve the attacker's desired outcomes. By introducing label inconsistencies, where the manipulated samples have labels that do not align with their true nature, poisoning attacks can confuse the model during training and lead to biased or incorrect predictions. The disruption caused by poisoned data can have far-reaching consequences, as the compromised model may make flawed decisions or exhibit unintended behavior when deployed in real-world applications.
+
+**Impacts model performance, fairness, and trustworthiness:** Poisoned data in the training dataset can have severe implications for machine learning models' performance, fairness, and trustworthiness. Poisoned data can degrade the accuracy and performance of the trained model, leading to increased misclassifications or errors in predictions. This can have significant consequences, especially in critical applications where the model's outputs inform important decisions. Moreover, poisoning attacks can introduce biases and fairness issues, causing the model to make discriminatory or unfair decisions for certain subgroups or classes. This undermines machine learning systems' ethical and social responsibilities and can perpetuate or amplify existing biases.
+Furthermore, poisoned data erodes the trustworthiness and reliability of the entire ML system. The model's outputs become questionable and potentially harmful, leading to a loss of confidence in the system's integrity. The impact of poisoned data can propagate throughout the entire ML pipeline, affecting downstream components and decisions that rely on the compromised model. Addressing these concerns requires robust data governance, regular model auditing, and ongoing monitoring to detect and mitigate the effects of data poisoning attacks.
+
+#### Mechanisms of Data Poisoning
+
+Data poisoning attacks can be carried out through various mechanisms, exploiting different ML pipeline vulnerabilities. These mechanisms allow attackers to manipulate the training data and introduce malicious samples that can compromise the model's performance, fairness, or integrity. Understanding these mechanisms is crucial for developing effective defenses against data poisoning and ensuring the robustness of ML systems. Data poisoning mechanisms can be broadly categorized based on the attacker's approach and the stage of the ML pipeline they target. Some common mechanisms include modifying training data labels, altering feature values, injecting carefully crafted malicious samples, exploiting data collection and preprocessing vulnerabilities, manipulating data at the source, poisoning data in online learning scenarios, and collaborating with insiders to manipulate data.
+
+Each of these mechanisms presents unique challenges and requires different mitigation strategies. For example, detecting label manipulation may involve analyzing the distribution of labels and identifying anomalies [@zhou2018learning], while preventing feature manipulation may require secure data preprocessing and anomaly detection techniques [@carta2020local]. Defending against insider threats may involve strict access control policies and monitoring of data access patterns. Moreover, the effectiveness of data poisoning attacks often depends on the attacker's knowledge of the ML system, including the model architecture, training algorithms, and data distribution. Attackers may use adversarial machine learning or data synthesis techniques to craft samples that are more likely to bypass detection and achieve their malicious objectives.
+
+)](./images/png/distribution_shift_example.png){#fig-distribution-shift-example}
+
+**Modifying training data labels:** One of the most straightforward mechanisms of data poisoning is modifying the training data labels. In this approach, the attacker selectively changes the labels of a subset of the training samples to mislead the model's learning process as shown in [@fig-distribution-shift-example]. For example, in a binary classification task, the attacker might flip the labels of some positive samples to negative, or vice versa. By introducing such label noise, the attacker aims to degrade the model's performance or cause it to make incorrect predictions for specific target instances.
+
+**Altering feature values in training data:** Another mechanism of data poisoning involves altering the feature values of the training samples without modifying the labels. The attacker carefully crafts the feature values to introduce specific biases or vulnerabilities into the model. For instance, in an image classification task, the attacker might add imperceptible perturbations to a subset of images, causing the model to learn a particular pattern or association. This type of poisoning can create backdoors or trojans in the trained model, which specific input patterns can trigger.
+
+**Injecting carefully crafted malicious samples:** In this mechanism, the attacker creates malicious samples designed to poison the model. These samples are crafted to have a specific impact on the model's behavior while blending in with the legitimate training data. The attacker might use techniques such as adversarial perturbations or data synthesis to generate poisoned samples that are difficult to detect. The attacker aims to manipulate the model's decision boundaries by injecting these malicious samples into the training data or introducing targeted misclassifications.
+
+**Exploiting data collection and preprocessing vulnerabilities:** Data poisoning attacks can also exploit the data collection and preprocessing pipeline vulnerabilities. If the data collection process is not secure or there are weaknesses in the data preprocessing steps, an attacker can manipulate the data before it reaches the training phase. For example, if data is collected from untrusted sources or issues in data cleaning or aggregation, an attacker can introduce poisoned samples or manipulate the data to their advantage.
+
+**Manipulating data at the source (e.g., sensor data):** In some cases, attackers can manipulate the data at its source, such as sensor data or input devices. By tampering with the sensors or manipulating the environment in which data is collected, attackers can introduce poisoned samples or bias the data distribution. For instance, in a self-driving car scenario, an attacker might manipulate the sensors or the environment to feed misleading information into the training data, compromising the model's ability to make safe and reliable decisions.
+
+)](./images/png/poisoning_attack_example.png){#fig-poisoning-attack-example}
+
+**Poisoning data in online learning scenarios:** Data poisoning attacks can also target ML systems that employ online learning, where the model is continuously updated with new data in real time. In such scenarios, an attacker can gradually inject poisoned samples over time, slowly manipulating the model's behavior. Online learning systems are particularly vulnerable to data poisoning because they adapt to new data without extensive validation, making it easier for attackers to introduce malicious samples, as shown in [@fig-poisoning-attack-example].
+
+**Collaborating with insiders to manipulate data:** Sometimes, data poisoning attacks can involve collaboration with insiders with access to the training data. Malicious insiders, such as employees or data providers, can manipulate the data before it is used to train the model. Insider threats are particularly challenging to detect and prevent, as the attackers have legitimate access to the data and can carefully craft the poisoning strategy to evade detection.
+
+These are the key mechanisms of data poisoning in ML systems. Attackers often employ these mechanisms to make their attacks more effective and harder to detect. The risk of data poisoning attacks grows as ML systems become increasingly complex and rely on larger datasets from diverse sources. Defending against data poisoning requires a multifaceted approach. ML practitioners and system designers must be aware of the various mechanisms of data poisoning and adopt a comprehensive approach to data security and model resilience. This includes secure data collection, robust data validation, and continuous model performance monitoring. Implementing secure data collection and preprocessing practices is crucial to prevent data poisoning at the source. Data validation and anomaly detection techniques can also help identify and mitigate potential poisoning attempts. Monitoring model performance for signs of data poisoning is also essential to detect and respond to attacks promptly.
+
+#### Impact on ML Systems
+
+Data poisoning attacks can severely affect ML systems, compromising their performance, reliability, and trustworthiness. The impact of data poisoning can manifest in various ways, depending on the attacker's objectives and the specific mechanism used. Let's explore each of the potential impacts in detail.
+
+**Degradation of model performance:** One of the primary impacts of data poisoning is the degradation of the model's overall performance. By manipulating the training data, attackers can introduce noise, biases, or inconsistencies that hinder the model's ability to learn accurate patterns and make reliable predictions. This can reduce accuracy, precision, recall, or other performance metrics. The degradation of model performance can have significant consequences, especially in critical applications such as healthcare, finance, or security, where the reliability of predictions is crucial.
+
+**Misclassification of specific targets:** Data poisoning attacks can also be designed to cause the model to misclassify specific target instances. Attackers may introduce carefully crafted poisoned samples similar to the target instances, leading the model to learn incorrect associations. This can result in the model consistently misclassifying the targeted instances, even if it performs well on other inputs. Such targeted misclassification can have severe consequences, such as causing a malware detection system to overlook specific malicious files or leading to the wrong diagnosis in a medical imaging application.
+
+**Backdoors and trojans in trained models:** Data poisoning can introduce backdoors or trojans into the trained model. Backdoors are hidden functionalities that allow attackers to trigger specific behaviors or bypass normal authentication mechanisms. On the other hand, Trojans are malicious components embedded within the model that can activate specific input patterns. By poisoning the training data, attackers can create models that appear to perform normally but contain hidden vulnerabilities that can be exploited later. Backdoors and trojans can compromise the integrity and security of the ML system, allowing attackers to gain unauthorized access, manipulate predictions, or exfiltrate sensitive information.
+
+**Biased or unfair model outcomes:** Data poisoning attacks can introduce biases or unfairness into the model's predictions. By manipulating the training data distribution or injecting samples with specific biases, attackers can cause the model to learn and perpetuate discriminatory patterns. This can lead to unfair treatment of certain groups or individuals based on sensitive attributes such as race, gender, or age. Biased models can have severe societal implications, reinforcing existing inequalities and discriminatory practices. Ensuring fairness and mitigating biases is crucial for building trustworthy and ethical ML systems.
+
+**Increased false positives or false negatives:** Data poisoning can also impact the model's ability to correctly identify positive or negative instances, leading to increased false positives or false negatives. False positives occur when the model incorrectly identifies a negative instance as positive, while false negatives happen when a positive instance is misclassified as negative. The consequences of increased false positives or false negatives can be significant depending on the application. For example, in a fraud detection system, high false positives can lead to unnecessary investigations and customer frustration, while high false negatives can allow fraudulent activities to go undetected.
+
+**Compromised system reliability and trustworthiness:** Data poisoning attacks can undermine ML systems' overall reliability and trustworthiness. When models are trained on poisoned data, their predictions become reliable and trustworthy. This can erode user confidence in the system and lead to a loss of trust in the decisions made by the model. In critical applications where ML systems are relied upon for decision-making, such as autonomous vehicles or medical diagnosis, compromised reliability can have severe consequences, putting lives and property at risk.
+
+Addressing the impact of data poisoning requires a proactive approach to data security, model testing, and monitoring. Organizations must implement robust measures to ensure the integrity and quality of training data, employ techniques to detect and mitigate poisoning attempts, and continuously monitor the performance and behavior of deployed models. Collaboration between ML practitioners, security experts, and domain specialists is essential to develop comprehensive strategies for preventing and responding to data poisoning attacks.
+
+##### Case Study 1
+
+In 2017, researchers demonstrated a data poisoning attack against a popular toxicity classification model called Perspective [@hosseini2017deceiving]. This ML model detects toxic comments online.
+
+The researchers added synthetically generated toxic comments with slight misspellings and grammatical errors to the model's training data. This slowly corrupted the model, causing it to misclassify increasing numbers of severely toxic inputs as non-toxic over time.
+After retraining on the poisoned data, the model's false negative rate increased from 1.4% to 27% - allowing extremely toxic comments to bypass detection. The researchers warned this stealthy data poisoning could enable the spread of hate speech, harassment, and abuse if deployed against real moderation systems.
+
+This case highlights how data poisoning can degrade model accuracy and reliability. For social media platforms, a poisoning attack that impairs toxicity detection could lead to the proliferation of harmful content and distrust of ML moderation systems. The example demonstrates why securing training data integrity and monitoring for poisoning is critical across application domains.
+
+##### Case Study 2
+
+)](./images/png/dirty_label_example.png){#fig-dirty-label-example}
+
+Interestingly enough, data poisoning attacks are not always malicious [@shan2023prompt]. Nightshade, a tool developed by a team led by Professor Ben Zhao at the University of Chicago, utilizes data poisoning to help artists protect their art against scraping and copyright violations by generative AI models. Artists can use the tool to make subtle modifications to their images before uploading them online, as shown in [@fig-dirty-label-example].
+
+While these changes are indiscernible to the human eye, they can significantly disrupt the performance of generative AI models when incorporated into the training data. Generative models can be manipulated to generate hallucinations and weird images. For example, with only 300 poisoned images, the University of Chicago researchers could trick the latest Stable Diffusion model into generating images of dogs that look like cats or images of cows when prompted for cars.
+
+As the number of poisoned images on the internet increases, the performance of the models that use scraped data will deteriorate exponentially. First, the poisoned data is hard to detect and requires manual elimination. Second, the \"poison\" spreads quickly to other labels because generative models rely on connections between words and concepts as they generate images. So a poisoned image of a \"car\" could spread into generated images associated with words like \"truck\," \"train\," \" bus\," etc.
+
+On the other hand, this tool can be used maliciously and can affect legitimate applications of the generative models. This shows the very challenging and novel nature of machine learning attacks.
+
+[@fig-poisoning] demonstrates the effects of different levels of data poisoning (50 samples, 100 samples, and 300 samples of poisoned images) on generating images in different categories. Notice how the images start deforming and deviating from the desired category. For example, after 300 poison samples, a car prompt generates a cow.
+
+{#fig-poisoning}
+
+:::{#exr-pa .callout-exercise collapse="true"}
+
+### Poisoning Attacks
+
+Get ready to explore the dark side of AI security! In this Colab, you'll learn about data poisoning – how bad data can trick AI models into making wrong decisions. We'll focus on a real-world attack against a Support Vector Machine (SVM), observing how the AI's behavior changes under attack. This hands-on exercise will highlight why protecting AI systems is crucial, especially as they become more integrated into our lives. Think like a hacker, understand the vulnerability, and brainstorm how to defend our AI systems!
+
+[](https://colab.research.google.com/github/pralab/secml/blob/HEAD/tutorials/05-Poisoning.ipynb#scrollTo=-8onNPNTOLk2)
:::
+### Distribution Shifts
+
+#### Definition and Characteristics
+
+Distribution shift refers to the phenomenon where the data distribution encountered by an ML model during deployment (inference) differs from the distribution it was trained on, as shown in [@fig-distribution-shift]. This is not so much an attack as it is that the model's robustness will vary over time. In other words, the data's statistical properties, patterns, or underlying assumptions can change between the training and test phases.
+
+)](./images/png/distribution_shift.png){#fig-distribution-shift}
+
+The key characteristics of distribution shift include:
+
+**Domain mismatch:** The input data during inference comes from a different domain or distribution than the training data. When the input data during inference comes from a domain or distribution different from the training data, it can significantly affect the model's performance. This is because the model has learned patterns and relationships specific to the training domain, and when applied to a different domain, those learned patterns may not hold. For example, consider a sentiment analysis model trained on movie reviews. Suppose this model is applied to analyze sentiment in tweets. In that case, it may need help to accurately classify the sentiment because the language, grammar, and context of tweets can differ from movie reviews. This domain mismatch can result in poor performance and unreliable predictions, limiting the model's practical utility.
+
+**Temporal drift:** The data distribution evolves, leading to a gradual or sudden shift in the input characteristics. Temporal drift is important because ML models are often deployed in dynamic environments where the data distribution can change over time. If the model is not updated or adapted to these changes, its performance can gradually degrade. For instance, the patterns and behaviors associated with fraudulent activities may evolve in a fraud detection system as fraudsters adapt their techniques. If the model is not retrained or updated to capture these new patterns, it may fail to detect new types of fraud effectively. Temporal drift can lead to a decline in the model's accuracy and reliability over time, making monitoring and addressing this type of distribution shift crucial.
+
+**Contextual changes:** The ML model's context can vary, resulting in different data distributions based on factors such as location, user behavior, or environmental conditions. Contextual changes matter because ML models are often deployed in various contexts or environments that can have different data distributions. If the model cannot generalize well to these different contexts, its performance may improve. For example, consider a computer vision model trained to recognize objects in a controlled lab environment. When deployed in a real-world setting, factors such as lighting conditions, camera angles, or background clutter can vary significantly, leading to a distribution shift. If the model is robust to these contextual changes, it may be able to accurately recognize objects in the new environment, limiting its practical utility.
+
+**Unrepresentative training data:** The training data may only partially capture the variability and diversity of the real-world data encountered during deployment. Unrepresentative training data can lead to biased or skewed models that perform poorly on real-world data. Suppose the training data needs to capture the variability and diversity of the real-world data adequately. In that case, the model may learn patterns specific to the training set but needs to generalize better to new, unseen data. This can result in poor performance, biased predictions, and limited model applicability. For instance, if a facial recognition model is trained primarily on images of individuals from a specific demographic group, it may struggle to accurately recognize faces from other demographic groups when deployed in a real-world setting. Ensuring that the training data is representative and diverse is crucial for building models that can generalize well to real-world scenarios.
+
+)](./images/png/drift_over_time.png){#fig-drift-over-time}
+
+Distribution shift can manifest in various forms, such as:
+
+**Covariate shift:** The distribution of the input features (covariates) changes while the conditional distribution of the target variable given the input remains the same. Covariate shift matters because it can impact the model's ability to make accurate predictions when the input features (covariates) differ between the training and test data. Even if the relationship between the input features and the target variable remains the same, a change in the distribution of the input features can affect the model's performance. For example, consider a model trained to predict housing prices based on features like square footage, number of bedrooms, and location. Suppose the distribution of these features in the test data significantly differs from the training data (e.g., the test data contains houses with much larger square footage). In that case, the model's predictions may become less accurate. Addressing covariate shifts is important to ensure the model's robustness and reliability when applied to new data.
+
+**Concept drift:** The relationship between the input features and the target variable changes over time, altering the underlying concept the model is trying to learn, as shown in [@fig-drift-over-time]. Concept drift is important because it indicates changes in the fundamental relationship between the input features and the target variable over time. When the underlying concept that the model is trying to learn shifts, its performance can deteriorate if not adapted to the new concept. For instance, in a customer churn prediction model, the factors influencing customer churn may evolve due to market conditions, competitor offerings, or customer preferences. If the model is not updated to capture these changes, its predictions may become less accurate and irrelevant. Detecting and adapting to concept drift is crucial to maintaining the model's effectiveness and alignment with evolving real-world concepts.
+
+**Domain generalization:** The model must generalize to unseen domains or distributions not present during training. Domain generalization is important because it enables ML models to be applied to new, unseen domains without requiring extensive retraining or adaptation. In real-world scenarios, training data that covers all possible domains or distributions that the model may encounter is often infeasible. Domain generalization techniques aim to learn domain-invariant features or models that can generalize well to new domains. For example, consider a model trained to classify images of animals. If the model can learn features invariant to different backgrounds, lighting conditions, or poses, it can generalize well to classify animals in new, unseen environments. Domain generalization is crucial for building models that can be deployed in diverse and evolving real-world settings.
+
+The presence of a distribution shift can significantly impact the performance and reliability of ML models, as the models may need help generalizing well to the new data distribution. Detecting and adapting to distribution shifts is crucial to ensure ML systems' robustness and practical utility in real-world scenarios.
+
+#### Mechanisms of Distribution Shifts
+
+The mechanisms of distribution shift, such as changes in data sources, temporal evolution, domain-specific variations, selection bias, feedback loops, and adversarial manipulations, are important to understand because they help identify the underlying causes of distribution shift. By understanding these mechanisms, practitioners can develop targeted strategies to mitigate their impact and improve the model's robustness. Here are some common mechanisms:
+
+)](./images/png/temporal_evoltion.png){#fig-temporal-evoltion}
+
+**Changes in data sources:** Distribution shifts can occur when the data sources used for training and inference differ. For example, if a model is trained on data from one sensor but deployed on data from another sensor with different characteristics, it can lead to a distribution shift.
+
+**Temporal evolution:** Over time, the underlying data distribution can evolve due to changes in user behavior, market dynamics, or other temporal factors. For instance, in a recommendation system, user preferences may shift over time, leading to a distribution shift in the input data, as shown in [@fig-temporal-evoltion].
+
+**Domain-specific variations:** Different domains or contexts can have distinct data distributions. A model trained on data from one domain may only generalize well to another domain with appropriate adaptation techniques. For example, an image classification model trained on indoor scenes may struggle when applied to outdoor scenes.
+
+**Selection bias:** A Distribution shift can arise from selection bias during data collection or sampling. If the training data does not represent the true population or certain subgroups are over- or underrepresented, this can lead to a mismatch between the training and test distributions.
+
+**Feedback loops:** In some cases, the predictions or actions taken by an ML model can influence future data distribution. For example, in a dynamic pricing system, the prices set by the model can impact customer behavior, leading to a shift in the data distribution over time.
+
+**Adversarial manipulations:** Adversaries can intentionally manipulate the input data to create a distribution shift and deceive the ML model. By introducing carefully crafted perturbations or generating out-of-distribution samples, attackers can exploit the model's vulnerabilities and cause it to make incorrect predictions.
+
+Understanding the mechanisms of distribution shift is important for developing effective strategies to detect and mitigate its impact on ML systems. By identifying the sources and characteristics of the shift, practitioners can design appropriate techniques, such as domain adaptation, transfer learning, or continual learning, to improve the model's robustness and performance under distributional changes.
+
+#### Impact on ML Systems
+
+Distribution shifts can significantly negatively impact the performance and reliability of ML systems. Here are some key ways in which distribution shift can affect ML models:
+
+**Degraded predictive performance:** When the data distribution encountered during inference differs from the training distribution, the model's predictive accuracy can deteriorate. The model may need help generalizing the new data well, leading to increased errors and suboptimal performance.
+
+**Reduced reliability and trustworthiness:** Distribution shift can undermine the reliability and trustworthiness of ML models. If the model's predictions become unreliable or inconsistent due to the shift, users may lose confidence in the system's outputs, leading to potential misuse or disuse of the model.
+
+**Biased predictions:** Distribution shift can introduce biases in the model's predictions. If the training data does not represent the real-world distribution or certain subgroups are underrepresented, the model may make biased predictions that discriminate against certain groups or perpetuate societal biases.
+
+**Increased uncertainty and risk:** Distribution shift introduces additional uncertainty and risk into the ML system. The model's behavior and performance may become less predictable, making it challenging to assess its reliability and suitability for critical applications. This uncertainty can lead to increased operational risks and potential failures.
+
+**Adaptability challenges:** ML models trained on a specific data distribution may need help to adapt to changing environments or new domains. The lack of adaptability can limit the model's usefulness and applicability in dynamic real-world scenarios where the data distribution evolves.
+
+**Maintenance and update difficulties:** Distribution shift can complicate the maintenance and updating of ML models. As the data distribution changes, the model may require frequent retraining or fine-tuning to maintain its performance. This can be time-consuming and resource-intensive, especially if the shift occurs rapidly or continuously.
+
+**Vulnerability to adversarial attacks:** Distribution shift can make ML models more vulnerable to adversarial attacks. Adversaries can exploit the model's sensitivity to distributional changes by crafting adversarial examples outside the training distribution, causing the model to make incorrect predictions or behave unexpectedly.
+
+To mitigate the impact of distribution shifts, it is crucial to develop robust ML systems that detect and adapt to distributional changes. Techniques such as domain adaptation, transfer learning, and continual learning can help improve the model's generalization ability across different distributions. ML model monitoring, testing, and updating are also necessary to ensure their performance and reliability during distribution shifts.
+
+### Detection and Mitigation
+
+#### Adversarial Attacks
+
+As you may recall from above, adversarial attacks pose a significant threat to the robustness and reliability of ML systems. These attacks involve crafting carefully designed inputs, known as adversarial examples, to deceive ML models and cause them to make incorrect predictions. To safeguard ML systems against adversarial attacks, developing effective techniques for detecting and mitigating these threats is crucial.
+
+##### Adversarial Example Detection Techniques
+
+Detecting adversarial examples is the first line of defense against adversarial attacks. Several techniques have been proposed to identify and flag suspicious inputs that may be adversarial.
+
+Statistical methods aim to detect adversarial examples by analyzing the statistical properties of the input data. These methods often compare the input data distribution to a reference distribution, such as the training data distribution or a known benign distribution. Techniques like the [Kolmogorov-Smirnov](https://www.itl.nist.gov/div898/handbook/eda/section3/eda35g.htm) [@berger2014kolmogorov] test or the [Anderson-Darling](https://www.itl.nist.gov/div898/handbook/eda/section3/eda35e.htm) test can be used to measure the discrepancy between the distributions and flag inputs that deviate significantly from the expected distribution.
+
+[Kernel density estimation (KDE)](https://mathisonian.github.io/kde/) is a non-parametric technique used to estimate the probability density function of a dataset. In the context of adversarial example detection, KDE can be used to estimate the density of benign examples in the input space. Adversarial examples often lie in low-density regions and can be detected by comparing their estimated density to a threshold. Inputs with an estimated density below the threshold are flagged as potential adversarial examples.
+
+Another technique is feature squeezing [@panda2019discretization], which reduces the complexity of the input space by applying dimensionality reduction or discretization. The idea behind feature squeezing is that adversarial examples often rely on small, imperceptible perturbations that can be eliminated or reduced through these transformations. Inconsistencies can be detected by comparing the model's predictions on the original input and the squeezed input, indicating the presence of adversarial examples.
+
+Model uncertainty estimation techniques aim to quantify the confidence or uncertainty associated with a model's predictions. Adversarial examples often exploit regions of high uncertainty in the model's decision boundary. By estimating the uncertainty using techniques like Bayesian neural networks, dropout-based uncertainty estimation, or ensemble methods, inputs with high uncertainty can be flagged as potential adversarial examples.
+
+##### Adversarial Defense Strategies
+
+Once adversarial examples are detected, various defense strategies can be employed to mitigate their impact and improve the robustness of ML models.
+
+Adversarial training is a technique that involves augmenting the training data with adversarial examples and retraining the model on this augmented dataset. Exposing the model to adversarial examples during training teaches it to classify them correctly and becomes more robust to adversarial attacks. Adversarial training can be performed using various attack methods, such as the [Fast Gradient Sign Method (FGSM)](https://www.tensorflow.org/tutorials/generative/adversarial_fgsm) or Projected Gradient Descent (PGD) [@madry2017towards].
+
+Defensive distillation [@papernot2016distillation] is a technique that trains a second model (the student model) to mimic the behavior of the original model (the teacher model). The student model is trained on the soft labels produced by the teacher model, which are less sensitive to small perturbations. Using the student model for inference can reduce the impact of adversarial perturbations, as the student model learns to generalize better and is less sensitive to adversarial noise.
+
+Input preprocessing and transformation techniques aim to remove or mitigate the effect of adversarial perturbations before feeding the input to the ML model. These techniques include image denoising, JPEG compression, random resizing, padding, or applying random transformations to the input data. By reducing the impact of adversarial perturbations, these preprocessing steps can help improve the model's robustness to adversarial attacks.
+
+Ensemble methods combine multiple models to make more robust predictions. The ensemble can reduce the impact of adversarial attacks by using a diverse set of models with different architectures, training data, or hyperparameters. Adversarial examples that fool one model may not fool others in the ensemble, leading to more reliable and robust predictions. Model diversification techniques, such as using different preprocessing techniques or feature representations for each model in the ensemble, can further enhance the robustness.
+
+##### Robustness Evaluation and Testing
+
+Conduct thorough evaluation and testing to assess the effectiveness of adversarial defense techniques and measure the robustness of ML models.
+
+Adversarial robustness metrics quantify the model's resilience to adversarial attacks. These metrics can include the model's accuracy on adversarial examples, the average distortion required to fool the model, or the model's performance under different attack strengths. By comparing these metrics across different models or defense techniques, practitioners can assess and compare their robustness levels.
+
+Standardized adversarial attack benchmarks and datasets provide a common ground for evaluating and comparing the robustness of ML models. These benchmarks include datasets with pre-generated adversarial examples and tools and frameworks for generating adversarial attacks. Examples of popular adversarial attack benchmarks include the [MNIST-C](https://github.com/google-research/mnist-c), [CIFAR-10-C](https://paperswithcode.com/dataset/cifar-10c), and ImageNet-C [@hendrycks2019benchmarking] datasets, which contain corrupted or perturbed versions of the original datasets.
+
+Practitioners can develop more robust and resilient ML systems by leveraging these adversarial example detection techniques, defense strategies, and robustness evaluation methods. However, it is important to note that adversarial robustness is an ongoing research area, and no single technique provides complete protection against all types of adversarial attacks. A comprehensive approach that combines multiple defense mechanisms and regular testing is essential to maintain the security and reliability of ML systems in the face of evolving adversarial threats.
+
+#### Data Poisoning
+
+Recall that data poisoning is an attack that targets the integrity of the training data used to build ML models. By manipulating or corrupting the training data, attackers can influence the model's behavior and cause it to make incorrect predictions or perform unintended actions. Detecting and mitigating data poisoning attacks is crucial to ensure the trustworthiness and reliability of ML systems, as shown in [@fig-adversarial-attack-injection].
+
+##### Anomaly Detection Techniques for Identifying Poisoned Data
+
+)](./images/png/adversarial_attack_injection.png){#fig-adversarial-attack-injection}
+
+Statistical outlier detection methods identify data points that deviate significantly from most data. These methods assume that poisoned data instances are likely to be statistical outliers. Techniques such as the [Z-score method](https://ubalt.pressbooks.pub/mathstatsguides/chapter/z-score-basics/), [Tukey's method](https://www.itl.nist.gov/div898/handbook/prc/section4/prc471.htm), or the [Mahalanobis] [distance](https://www.statisticshowto.com/mahalanobis-distance/) can be used to measure the deviation of each data point from the central tendency of the dataset. Data points that exceed a predefined threshold are flagged as potential outliers and considered suspicious for data poisoning.
+
+Clustering-based methods group similar data points together based on their features or attributes. The assumption is that poisoned data instances may form distinct clusters or lie far away from the normal data clusters. By applying clustering algorithms like [K-means](https://www.oreilly.com/library/view/data-algorithms/9781491906170/ch12.html), [DBSCAN](https://www.oreilly.com/library/view/machine-learning-algorithms/9781789347999/50efb27d-abbe-4855-ad81-a5357050161f.xhtml), or [hierarchical clustering](https://www.oreilly.com/library/view/cluster-analysis-5th/9780470978443/chapter04.html), anomalous clusters or data points that do not belong to any cluster can be identified. These anomalous instances are then treated as potentially poisoned data.
+
+)](./images/png/autoencoder.png){#fig-autoencoder}
+
+Autoencoders are neural networks trained to reconstruct the input data from a compressed representation, as shown in [@fig-autoencoder]. They can be used for anomaly detection by learning the normal patterns in the data and identifying instances that deviate from them. During training, the autoencoder is trained on clean, unpoisoned data. At inference time, the reconstruction error for each data point is computed. Data points with high reconstruction errors are considered abnormal and potentially poisoned, as they do not conform to the learned normal patterns.
+
+##### Data Sanitization and Preprocessing Techniques
+
+Data poisoning can be avoided by cleaning data, which involves identifying and removing or correcting noisy, incomplete, or inconsistent data points. Techniques such as data deduplication, missing value imputation, and outlier removal can be applied to improve the quality of the training data. By eliminating or filtering out suspicious or anomalous data points, the impact of poisoned instances can be reduced.
+
+Data validation involves verifying the integrity and consistency of the training data. This can include checking for data type consistency, range validation, and cross-field dependencies. By defining and enforcing data validation rules, anomalous or inconsistent data points indicative of data poisoning can be identified and flagged for further investigation.
+
+Data provenance and lineage tracking involve maintaining a record of data's origin, transformations, and movements throughout the ML pipeline. By documenting the data sources, preprocessing steps, and any modifications made to the data, practitioners can trace anomalies or suspicious patterns back to their origin. This helps identify potential points of data poisoning and facilitates the investigation and mitigation process.
+
+##### Robust Training Techniques
+
+Robust optimization techniques can be used to modify the training objective to minimize the impact of outliers or poisoned instances. This can be achieved by using robust loss functions less sensitive to extreme values, such as the Huber loss or the modified Huber loss. Regularization techniques, such as [L1 or L2 regularization](https://towardsdatascience.com/l1-and-l2-regularization-methods-ce25e7fc831c), can also help in reducing the model's sensitivity to poisoned data by constraining the model's complexity and preventing overfitting.
+
+Robust loss functions are designed to be less sensitive to outliers or noisy data points. Examples include the modified [Huber loss](https://pytorch.org/docs/stable/generated/torch.nn.HuberLoss.html), the Tukey loss [@beaton1974fitting], and the trimmed mean loss. These loss functions down-weight or ignore the contribution of abnormal instances during training, reducing their impact on the model's learning process. Robust objective functions, such as the minimax or distributionally robust objective, aim to optimize the model's performance under worst-case scenarios or in the presence of adversarial perturbations.
+
+Data augmentation techniques involve generating additional training examples by applying random transformations or perturbations to the existing data @fig-data-augmentation. This helps in increasing the diversity and robustness of the training dataset. By introducing controlled variations in the data, the model becomes less sensitive to specific patterns or artifacts that may be present in poisoned instances. Randomization techniques, such as random subsampling or bootstrap aggregating, can also help reduce the impact of poisoned data by training multiple models on different subsets of the data and combining their predictions.
+
+{#fig-data-augmentation}
+
+##### Secure and Trusted Data Sourcing
+
+Implementing the best data collection and curation practices can help mitigate the risk of data poisoning. This includes establishing clear data collection protocols, verifying the authenticity and reliability of data sources, and conducting regular data quality assessments. Sourcing data from trusted and reputable providers and following secure data handling practices can reduce the likelihood of introducing poisoned data into the training pipeline.
+
+Strong data governance and access control mechanisms are essential to prevent unauthorized modifications or tampering with the training data. This involves defining clear roles and responsibilities for data access, implementing access control policies based on the principle of least privilege, and monitoring and logging data access activities. By restricting access to the training data and maintaining an audit trail, potential data poisoning attempts can be detected and investigated.
+
+Detecting and mitigating data poisoning attacks requires a multifaceted approach that combines anomaly detection, data sanitization, robust training techniques, and secure data sourcing practices. By implementing these measures, ML practitioners can enhance the resilience of their models against data poisoning and ensure the integrity and trustworthiness of the training data. However, it is important to note that data poisoning is an active area of research, and new attack vectors and defense mechanisms continue to emerge. Staying informed about the latest developments and adopting a proactive and adaptive approach to data security is crucial for maintaining the robustness of ML systems.
+
+#### Distribution Shifts
+
+##### Detecting and Mitigating Distribution Shifts
+
+Recall that distribution shifts occur when the data distribution encountered by a machine learning (ML) model during deployment differs from the distribution it was trained on. These shifts can significantly impact the model's performance and generalization ability, leading to suboptimal or incorrect predictions. Detecting and mitigating distribution shifts is crucial to ensure the robustness and reliability of ML systems in real-world scenarios.
+
+##### Detection Techniques for Distribution Shifts
+
+Statistical tests can be used to compare the distributions of the training and test data to identify significant differences. Techniques such as the Kolmogorov-Smirnov test or the Anderson-Darling test measure the discrepancy between two distributions and provide a quantitative assessment of the presence of distribution shift. By applying these tests to the input features or the model's predictions, practitioners can detect if there is a statistically significant difference between the training and test distributions.
+
+Divergence metrics quantify the dissimilarity between two probability distributions. Commonly used divergence metrics include the [Kullback-Leibler (KL) divergence](https://towardsdatascience.com/understanding-kl-divergence-f3ddc8dff254) and the [Jensen-Shannon (JS)] [divergence](https://towardsdatascience.com/how-to-understand-and-use-jensen-shannon-divergence-b10e11b03fd6). By calculating the divergence between the training and test data distributions, practitioners can assess the extent of the distribution shift. High divergence values indicate a significant difference between the distributions, suggesting the presence of a distribution shift.
+
+Uncertainty quantification techniques, such as Bayesian neural networks or ensemble methods, can estimate the uncertainty associated with the model's predictions. When a model is applied to data from a different distribution, its predictions may have higher uncertainty. By monitoring the uncertainty levels, practitioners can detect distribution shifts. If the uncertainty consistently exceeds a predetermined threshold for test samples, it suggests that the model is operating outside its trained distribution.
+
+In addition, domain classifiers are trained to distinguish between different domains or distributions. Practitioners can detect distribution shifts by training a classifier to differentiate between the training and test domains. If the domain classifier achieves high accuracy in distinguishing between the two domains, it indicates a significant difference in the underlying distributions. The performance of the domain classifier serves as a measure of the distribution shift.
+
+##### Mitigation Techniques for Distribution Shifts
+
+)](./images/png/transfer_learning.png){#fig-transfer-learning}
+
+Transfer learning leverages knowledge gained from one domain to improve performance in another, as shown in [@fig-transfer-learning]. By using pre-trained models or transferring learned features from a source domain to a target domain, transfer learning can help mitigate the impact of distribution shifts. The pre-trained model can be fine-tuned on a small amount of labeled data from the target domain, allowing it to adapt to the new distribution. Transfer learning is particularly effective when the source and target domains share similar characteristics or when labeled data in the target domain is scarce.
+
+Continual learning, also known as lifelong learning, enables ML models to learn continuously from new data distributions while retaining knowledge from previous distributions. Techniques such as elastic weight consolidation (EWC) [@kirkpatrick2017overcoming] or gradient episodic memory (GEM) [@lopez2017gradient] allow models to adapt to evolving data distributions over time. These techniques aim to balance the plasticity of the model (ability to learn from new data) with the stability of the model (retaining previously learned knowledge). By incrementally updating the model with new data and mitigating catastrophic forgetting, continual learning helps models stay robust to distribution shifts.
+
+Data augmentation techniques, such as those we have seen previously, involve applying transformations or perturbations to the existing training data to increase its diversity and improve the model's robustness to distribution shifts. By introducing variations in the data, such as rotations, translations, scaling, or adding noise, data augmentation helps the model learn invariant features and generalize better to unseen distributions. Data augmentation can be performed during training and inference to enhance the model's ability to handle distribution shifts.
+
+Ensemble methods combine multiple models to make predictions more robust to distribution shifts. By training models on different subsets of the data, using different algorithms, or with different hyperparameters, ensemble methods can capture diverse aspects of the data distribution. When presented with a shifted distribution, the ensemble can leverage the strengths of individual models to make more accurate and stable predictions. Techniques like bagging, boosting, or stacking can create effective ensembles.
+
+Regularly updating models with new data from the target distribution is crucial to mitigate the impact of distribution shifts. As the data distribution evolves, models should be retrained or fine-tuned on the latest available data to adapt to the changing patterns. Monitoring model performance and data characteristics can help detect when an update is necessary. By keeping the models up to date, practitioners can ensure they remain relevant and accurate in the face of distribution shifts.
+
+Evaluating models using robust metrics less sensitive to distribution shifts can provide a more reliable assessment of model performance. Metrics such as the area under the precision-recall curve (AUPRC) or the F1 score are more robust to class imbalance and can better capture the model's performance across different distributions. Additionally, using domain-specific evaluation metrics that align with the desired outcomes in the target domain can provide a more meaningful measure of the model's effectiveness.
+
+Detecting and mitigating distribution shifts is an ongoing process that requires continuous monitoring, adaptation, and improvement. By employing a combination of detection techniques and mitigation strategies, ML practitioners can proactively identify and address distribution shifts, ensuring the robustness and reliability of their models in real-world deployments. It is important to note that distribution shifts can take various forms and may require domain-specific approaches depending on the nature of the data and the application. Staying informed about the latest research and best practices in handling distribution shifts is essential for building resilient ML systems.
+
+## Software Faults
+
+#### Definition and Characteristics
+
+Software faults refer to defects, errors, or bugs in the runtime software frameworks and components that support the execution and deployment of ML models [@myllyaho2022misbehaviour]. These faults can arise from various sources, such as programming mistakes, design flaws, or compatibility issues [@zhang2008distribution], and can have significant implications for ML systems' performance, reliability, and security. Software faults in ML frameworks exhibit several key characteristics:
+
+- **Diversity:** Software faults can manifest in different forms, ranging from simple logic and syntax mistakes to more complex issues like memory leaks, race conditions, and integration problems. The variety of fault types adds to the challenge of detecting and mitigating them effectively.
+
+- **Propagation:** In ML systems, software faults can propagate through the various layers and components of the framework. A fault in one module can trigger a cascade of errors or unexpected behavior in other parts of the system, making it difficult to pinpoint the root cause and assess the full impact of the fault.
+
+- **Intermittency:** Some software faults may exhibit intermittent behavior, occurring sporadically or under specific conditions. These faults can be particularly challenging to reproduce and debug, as they may manifest inconsistently during testing or normal operation.
+
+- **Interaction with ML models:** Software faults in ML frameworks can interact with the trained models in subtle ways. For example, a fault in the data preprocessing pipeline may introduce noise or bias into the model's inputs, leading to degraded performance or incorrect predictions. Similarly, faults in the model serving component may cause inconsistencies between the training and inference environments.
+
+- **Impact on system properties:** Software faults can compromise various desirable properties of ML systems, such as performance, scalability, reliability, and security. Faults may lead to slowdowns, crashes, incorrect outputs, or vulnerabilities that attackers can exploit.
+
+- **Dependency on external factors:** The occurrence and impact of software faults in ML frameworks often depend on external factors, such as the choice of hardware, operating system, libraries, and configurations. Compatibility issues and version mismatches can introduce faults that are difficult to anticipate and mitigate.
+
+Understanding the characteristics of software faults in ML frameworks is crucial for developing effective fault prevention, detection, and mitigation strategies. By recognizing the diversity, propagation, intermittency, and impact of software faults, ML practitioners can design more robust and reliable systems resilient to these issues.
+
+#### Mechanisms of Software Faults in ML Frameworks
+
+Machine learning frameworks, such as TensorFlow, PyTorch, and sci-kit-learn, provide powerful tools and abstractions for building and deploying ML models. However, these frameworks are not immune to software faults that can impact ML systems' performance, reliability, and correctness. Let's explore some of the common software faults that can occur in ML frameworks:
+
+**Memory Leaks and Resource Management Issues:** Improper memory management, such as failing to release memory or close file handles, can lead to memory leaks and resource exhaustion over time. This issue is compounded by inefficient memory usage, where creating unnecessary copies of large tensors or not leveraging memory-efficient data structures can cause excessive memory consumption and degrade system performance. Additionally, failing to manage GPU memory properly can result in out-of-memory errors or suboptimal utilization of GPU resources, further exacerbating the problem as shown in [@fig-gpu-out-of-memory](#nt13lz9kgr7t).
+
+{#fig-gpu-out-of-memory}
+
+**Synchronization and Concurrency Problems:** Incorrect synchronization between threads or processes can lead to race conditions, deadlocks, or inconsistent behavior in multi-threaded or distributed ML systems. This issue is often tied to improper handling of [asynchronous operations](https://odsc.medium.com/optimizing-ml-serving-with-asynchronous-architectures-1071fc1be8e2), such as non-blocking I/O or parallel data loading, which can cause synchronization issues and impact the correctness of the ML pipeline. Moreover, proper coordination and communication between distributed nodes in a cluster can result in consistency or stale data during training or inference, compromising the reliability of the ML system.
+
+**Compatibility Issues:** Mismatches between the versions of ML frameworks, libraries, or dependencies can introduce compatibility problems and runtime errors. Upgrading or changing the versions of underlying libraries without thoroughly testing the impact on the ML system can lead to unexpected behavior or breakages. Furthermore, inconsistencies between the training and deployment environments, such as differences in hardware, operating systems, or package versions, can cause compatibility issues and affect the reproducibility of ML models, making it challenging to ensure consistent performance across different platforms.
+
+**Numerical Instability and Precision Errors:** Inadequate handling of [numerical instabilities](https://pythonnumericalmethods.studentorg.berkeley.edu/notebooks/chapter22.04-Numerical-Error-and-Instability.html), such as division by zero, underflow, or overflow, can lead to incorrect calculations or convergence issues during training. This problem is compounded by insufficient precision or rounding errors, which can accumulate over time and impact the accuracy of the ML models, especially in deep learning architectures with many layers. Moreover, improper scaling or normalization of input data can cause numerical instabilities and affect the convergence and performance of optimization algorithms, resulting in suboptimal or unreliable model performance.
+
+**Inadequate Error Handling and Exception Management:** Proper error handling and exception management can prevent ML systems from crashing or behaving unexpectedly when encountering exceptional conditions or invalid inputs. Failing to catch and handle specific exceptions or relying on generic exception handling can make it difficult to diagnose and recover from errors gracefully, leading to system instability and reduced reliability. Furthermore, incomplete or misleading error messages can hinder the ability to effectively debug and resolve software faults in ML frameworks, prolonging the time required to identify and fix issues.
+
+#### Impact on ML Systems
+
+Software faults in machine learning frameworks can have significant and far-reaching impacts on ML systems' performance, reliability, and security. Let's explore the various ways in which software faults can affect ML systems:
+
+**Performance Degradation and System Slowdowns:** Memory leaks and inefficient resource management can lead to gradual performance degradation over time as the system becomes increasingly memory-constrained and spends more time on garbage collection or memory swapping [@maas2008combining]. This issue is compounded by synchronization issues and concurrency bugs, which can cause delays, reduced throughput, and suboptimal utilization of computational resources, especially in multi-threaded or distributed ML systems. Furthermore, compatibility problems or inefficient code paths can introduce additional overhead and slowdowns, affecting the overall performance of the ML system.
+
+**Incorrect Predictions or Outputs:** Software faults in data preprocessing, feature engineering, or model evaluation can introduce biases, noise, or errors propagating through the ML pipeline and resulting in incorrect predictions or outputs. Over time, numerical instabilities, precision errors, or [rounding issues](https://www.cs.drexel.edu/~popyack/Courses/CSP/Fa17/extras/Rounding/index.html) can accumulate and lead to degraded accuracy or convergence problems in the trained models. Moreover, faults in the model serving or inference components can cause inconsistencies between the expected and actual outputs, leading to incorrect or unreliable predictions in production.
+
+**Reliability and Stability Issues:** Software faults can cause Unparalleled exceptions, crashes, or sudden terminations that can compromise the reliability and stability of ML systems, especially in production environments. Intermittent or sporadic faults can be difficult to reproduce and diagnose, leading to unpredictable behavior and reduced confidence in the ML system's outputs. Additionally, faults in checkpointing, model serialization, or state management can cause data loss or inconsistencies, affecting the reliability and recoverability of the ML system.
+
+**Security Vulnerabilities:** Software faults, such as buffer overflows, injection vulnerabilities, or improper access control, can introduce security risks and expose the ML system to potential attacks or unauthorized access. Adversaries may exploit faults in the preprocessing or feature extraction stages to manipulate the input data and deceive the ML models, leading to incorrect or malicious behavior. Furthermore, inadequate protection of sensitive data, such as user information or confidential model parameters, can lead to data breaches or privacy violations [@li2021survey].
+
+**Difficulty in Reproducing and Debugging:** Software faults can make it challenging to reproduce and debug issues in ML systems, especially when the faults are intermittent or dependent on specific runtime conditions. Incomplete or ambiguous error messages, coupled with the complexity of ML frameworks and models, can prolong the debugging process and hinder the ability to identify and fix the underlying faults. Moreover, inconsistencies between development, testing, and production environments can make reproducing and diagnosing faults in specific contexts difficult.
+
+**Increased Development and Maintenance Costs** Software faults can lead to increased development and maintenance costs, as teams spend more time and resources debugging, fixing, and validating the ML system. The need for extensive testing, monitoring, and fault-tolerant mechanisms to mitigate the impact of software faults can add complexity and overhead to the ML development process. Frequent patches, updates, and bug fixes to address software faults can disrupt the development workflow and require additional effort to ensure the stability and compatibility of the ML system.
+
+Understanding the potential impact of software faults on ML systems is crucial for prioritizing testing efforts, implementing fault-tolerant designs, and establishing effective monitoring and debugging practices. By proactively addressing software faults and their consequences, ML practitioners can build more robust, reliable, and secure ML systems that deliver accurate and trustworthy results.
+
+#### Detection and Mitigation
+
+Detecting and mitigating software faults in machine learning frameworks is essential to ensure ML systems' reliability, performance, and security. Let's explore various techniques and approaches that can be employed to identify and address software faults effectively:
+
+**Thorough Testing and Validation:** Comprehensive unit testing of individual components and modules can verify their correctness and identify potential faults early in development. Integration testing validates the interaction and compatibility between different components of the ML framework, ensuring seamless integration. Systematic testing of edge cases, boundary conditions, and exceptional scenarios helps uncover hidden faults and vulnerabilities. [Continuous testing and regression testing](https://u-tor.com/topic/regression-vs-integration) as shown in [@fig-regression-testing](#gaprh7zcofc9) detect faults introduced by code changes or updates to the ML framework.
+
+)](./images/png/regression_testing.png){#fig-regression-testing}
+
+**Static Code Analysis and Linting:** Utilizing static code analysis tools automatically identifies potential coding issues, such as syntax errors, undefined variables, or security vulnerabilities. Enforcing coding standards and best practices through linting tools maintains code quality and reduces the likelihood of common programming mistakes. Conducting regular code reviews allows manual inspection of the codebase, identification of potential faults, and ensures adherence to coding guidelines and design principles.
+
+**Runtime Monitoring and Logging:** Implementing comprehensive logging mechanisms captures relevant information during runtime, such as input data, model parameters, and system events. Monitoring key performance metrics, resource utilization, and error rates helps detect anomalies, performance bottlenecks, or unexpected behavior. Employing runtime assertion checks and invariants validates assumptions and detects violations of expected conditions during program execution. Utilizing [profiling tools](https://microsoft.github.io/code-with-engineering-playbook/machine-learning/ml-profiling/) identifies performance bottlenecks, memory leaks, or inefficient code paths that may indicate the presence of software faults.
+
+**Fault-Tolerant Design Patterns:** Implementing error handling and exception management mechanisms enables graceful handling and recovery from exceptional conditions or runtime errors. Employing redundancy and failover mechanisms, such as backup systems or redundant computations, ensures the availability and reliability of the ML system in the presence of faults. Designing modular and loosely coupled architectures minimizes the propagation and impact of faults across different components of the ML system. Utilizing checkpointing and recovery mechanisms [@eisenman2022check] allows the system to resume from a known stable state in case of failures or interruptions.
+
+**Regular Updates and Patches:** Staying up to date with the latest versions and patches of the ML frameworks, libraries, and dependencies provides benefits from bug fixes, security updates, and performance improvements. Monitoring release notes, security advisories, and community forums inform practitioners about known issues, vulnerabilities, or compatibility problems in the ML framework. Establishing a systematic process for testing and validating updates and patches before applying them to production systems ensures stability and compatibility.
+
+**Containerization and Isolation:** Leveraging containerization technologies, such as [Docker](https://www.docker.com) or [Kubernetes](https://kubernetes.io), encapsulates ML components and their dependencies in isolated environments. Utilizing containerization ensures consistent and reproducible runtime environments across development, testing, and production stages, reducing the likelihood of compatibility issues or environment-specific faults. Employing isolation techniques, such as virtual environments or sandboxing, prevents faults or vulnerabilities in one component from affecting other parts of the ML system.
+
+**Automated Testing and Continuous Integration/Continuous Deployment (CI/CD):** Implement automated testing frameworks and scripts, execute comprehensive test suites, and catch faults early in development. Integrating automated testing into the CI/CD pipeline, as shown in [@fig-CI-CD-procedure](#f14k3aj3u8av), ensures that code changes are thoroughly tested before being merged or deployed to production. Utilizing continuous monitoring and automated alerting systems detects and notifies developers and operators about potential faults or anomalies in real-time.
+
+)](./images/png/CI_CD_procedure.png){#fig-CI-CD-procedure}
+
+Adopting a proactive and systematic approach to fault detection and mitigation can significantly improve ML systems' robustness, reliability, and maintainability. By investing in comprehensive testing, monitoring, and fault-tolerant design practices, organizations can minimize the impact of software faults and ensure their ML systems' smooth operation in production environments.
+
+:::{#exr-ft .callout-exercise collapse="true"}
+
+### Fault Tolerance
+
+Get ready to become an AI fault-fighting superhero! Software glitches can derail machine learning systems, but in this Colab, you'll learn how to make them resilient. We'll simulate software faults to see how AI can break, then explore techniques to save your ML model's progress, like checkpoints in a game. You'll see how to train your AI to bounce back after a crash, ensuring it stays on track. This is crucial for building reliable, trustworthy AI, especially in critical applications. So gear up because this Colab directly connects with the Robust AI chapter – you'll move from theory to hands-on troubleshooting and build AI systems that can handle the unexpected!
+
+[](https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/guide/migrate/fault_tolerance.ipynb#scrollTo=77z2OchJTk0l)
+:::
+
+## Tools and Frameworks
+
+Given the significance or importance of developing robust AI systems, in recent years, researchers and practitioners have developed a wide range of tools and frameworks to understand how hardware faults manifest and propagate to impact ML systems. These tools and frameworks play a crucial role in evaluating the resilience of ML systems to hardware faults by simulating various fault scenarios and analyzing their impact on the system's performance. This enables designers to identify potential vulnerabilities and develop effective mitigation strategies, ultimately creating more robust and reliable ML systems that can operate safely despite hardware faults. This section provides an overview of widely used fault models in the literature and the tools and frameworks developed to evaluate the impact of such faults on ML systems.
+
+### Fault Models and Error Models
+
+As discussed previously, hardware faults can manifest in various ways, including transient, permanent, and intermittent faults. In addition to the type of fault under study, *how* the fault manifests is also important. For example, does the fault happen in a memory cell or during the computation of a functional unit? Is the impact on a single bit, or does it impact multiple bits? Does the fault propagate all the way and impact the application (causing an error), or does it get masked quickly and is considered benign? All these details impact what is known as the *fault model*, which plays a major role in simulating and measuring what happens to a system when a fault occurs.
+
+To effectively study and understand the impact of hardware faults on ML systems, it is essential to understand the concepts of fault models and error models. A fault model describes how a hardware fault manifests itself in the system, while an error model represents how the fault propagates and affects the system's behavior.
+
+Fault models can be categorized based on various characteristics:
+
+- **Duration:** Transient faults occur briefly and then disappear, while permanent faults persist indefinitely. Intermittent faults occur sporadically and may be difficult to diagnose.
+
+- **Location:** Faults can occur in hardware parts, such as memory cells, functional units, or interconnects.
+
+- **Granularity:** Faults can affect a single bit (e.g., bitflip) or multiple bits (e.g., burst errors) within a hardware component.
+
+On the other hand, error models describe how a fault propagates through the system and manifests as an error. An error may cause the system to deviate from its expected behavior, leading to incorrect results or even system failures. Error models can be defined at different levels of abstraction, from the hardware level (e.g., register-level bitflips) to the software level (e.g., corrupted weights or activations in an ML model).
+
+The fault model (or error model, typically the more applicable terminology in understanding the robustness of an ML system) plays a major role in simulating and measuring what happens to a system when a fault occurs. The chosen model informs the assumptions made about the system being studied. For example, a system focusing on single-bit transient errors [@sangchoolie2017one] would not be well-suited to understand the impact of permanent, multi-bit flip errors [@wilkening2014calculating], as it is designed assuming a different model altogether.
+
+Furthermore, implementing an error model is also an important consideration, particularly regarding where an error is said to occur in the compute stack. For instance, a single-bit flip model at the architectural register level differs from a single-bit flip in the weight of a model at the PyTorch level. Although both target a similar error model, the former would usually be modeled in an architecturally accurate simulator (like gem5 [@ binkert2011gem5]), which captures error propagation compared to the latter, focusing on value propagation through a model.
+
+Recent research has shown that certain characteristics of error models may exhibit similar behaviors across different levels of abstraction [@sangchoolie2017one] [@papadimitriou2021demystifying]. For example, single-bit errors are generally more problematic than multi-bit errors, regardless of whether they are modeled at the hardware or software level. However, other characteristics, such as error masking [@mohanram2003partial] as shown in [@fig-error-masking](#kncu0umx706t), may not always be accurately captured by software-level models, as they can hide underlying system effects. Masking occurs when
+
+![Example of error masking in microarchitectural components [@ko2021characterizing]](./images/png/error_masking.png){#fig-error-masking}
+
+Some tools, such as Fidelity [@he2020fidelity], aim to bridge the gap between hardware-level and software-level error models by mapping patterns between the two levels of abstraction. This allows for more accurate modeling of hardware faults in software-based tools, essential for developing robust and reliable ML systems. Lower-level tools typically represent more accurate error propagation characteristics but must be faster in simulating many errors due to the complex nature of hardware system designs. On the other hand, higher-level tools, such as those implemented in ML frameworks like PyTorch or TensorFlow, which we will discuss soon in the later sections, are often faster and more efficient for evaluating the robustness of ML systems.
+
+In the following subsections, we will discuss various hardware-based and software-based fault injection methods and tools, highlighting their capabilities, limitations, and the fault and error models they support.
+
+### Hardware-based Fault Injection
+
+An error injection tool is a tool that allows the user to implement a particular error model, such as a transient single-bit flip during inference @fig-hardware-errors. Most error injection tools are software-based, as software-level tools are faster for ML robustness studies. However, hardware-based fault injection methods are still important for grounding the higher-level error models, as they are considered the most accurate way to study the impact of faults on ML systems by directly manipulating the hardware to introduce faults. These methods allow researchers to observe the system's behavior under real-world fault conditions. Both software-based and hardware-based error injection tools are described in this section in more detail.
+
+![Hardware errors can occur due to a variety of reasons and at different times and/or locations in a system, which can be explored when studying the impact of hardware-based errors on systems [@ahmadilivani2024systematic]](./images/png/hardware_errors.png){#fig-hardware-errors}
+
+#### Methods
+
+Two of the most common hardware-based fault injection methods are FPGA-based fault injection and radiation or beam testing.
+
+**FPGA-based Fault Injection:** Field-Programmable Gate Arrays (FPGAs) are reconfigurable integrated circuits that can be programmed to implement various hardware designs. In the context of fault injection, FPGAs offer high precision and accuracy, as researchers can target specific bits or sets of bits within the hardware. By modifying the FPGA configuration, faults can be introduced at specific locations and times during the execution of an ML model. FPGA-based fault injection allows for fine-grained control over the fault model, enabling researchers to study the impact of different types of faults, such as single-bit flips or multi-bit errors. This level of control makes FPGA-based fault injection a valuable tool for understanding the resilience of ML systems to hardware faults.
+
+**Radiation or Beam Testing:** Radiation or beam testing [@velazco2010combining] involves exposing the hardware running an ML model to high-energy particles, such as protons or neutrons as illustrated in [@fig-beam-testing](#5a77jp776dxi). These particles can cause bitflips or other types of faults in the hardware, mimicking the effects of real-world radiation-induced faults. Beam testing is widely regarded as a highly accurate method for measuring the error rate induced by particle strikes on a running application. It provides a realistic representation of the faults in real-world environments, particularly in applications exposed to high radiation levels, such as space systems or particle physics experiments. However, unlike FPGA-based fault injection, beam testing could be more precise in targeting specific bits or components within the hardware, as it might be difficult to aim the beam of particles to a particular bit in the hardware. Despite being quite expensive from a research standpoint, beam testing is a well-regarded industry practice for reliability.
+
+
+
+![Radiation test setup for semiconductor components [@lee2022design] (Source: [JD Instrument](https://jdinstruments.net/tester-capabilities-radiation-test/))](./images/png/image14.png){#fig-beam-testing}
+
+#### Limitations
+
+Despite their high accuracy, hardware-based fault injection methods have several limitations that can hinder their widespread adoption:
+
+**Cost:** FPGA-based fault injection and beam testing require specialized hardware and facilities, which can be expensive to set up and maintain. The cost of these methods can be a significant barrier for researchers and organizations with limited resources.
+
+**Scalability:** Hardware-based methods are generally slower and less scalable than software-based methods. Injecting faults and collecting data on hardware can take time, limiting the number of experiments performed within a given timeframe. This can be particularly challenging when studying the resilience of large-scale ML systems or conducting statistical analyses that require many fault injection experiments.
+
+**Flexibility:** Hardware-based methods may not be as flexible as software-based methods in terms of the range of fault models and error models they can support. Modifying the hardware configuration or the experimental setup to accommodate different fault models can be more challenging and time-consuming than software-based methods.
+
+Despite these limitations, hardware-based fault injection methods remain essential tools for validating the accuracy of software-based methods and for studying the impact of faults on ML systems in realistic settings. By combining hardware-based and software-based methods, researchers can gain a more comprehensive understanding of ML systems' resilience to hardware faults and develop effective mitigation strategies.
+
+### Software-based Fault Injection Tools
+
+With the rapid development of ML frameworks in recent years, software-based fault injection tools have gained popularity in studying the resilience of ML systems to hardware faults. These tools simulate the effects of hardware faults by modifying the software representation of the ML model or the underlying computational graph. The rise of ML frameworks such as TensorFlow, PyTorch, and Keras has facilitated the development of fault injection tools that are tightly integrated with these frameworks, making it easier for researchers to conduct fault injection experiments and analyze the results.
+
+##### Advantages and Trade-offs
+
+Software-based fault injection tools offer several advantages over hardware-based methods:
+
+**Speed:** Software-based tools are generally faster than hardware-based methods, as they do not require the modification of physical hardware or the setup of specialized equipment. This allows researchers to conduct more fault injection experiments in a shorter time, enabling more comprehensive analyses of the resilience of ML systems.
+
+**Flexibility:** Software-based tools are more flexible than hardware-based methods in terms of the range of fault and error models they can support. Researchers can easily modify the fault injection tool's software implementation to accommodate different fault models or to target specific components of the ML system.
+
+**Accessibility:** Software-based tools are more accessible than hardware-based methods, as they do not require specialized hardware or facilities. This makes it easier for researchers and practitioners to conduct fault injection experiments and study the resilience of ML systems, even with limited resources.
+
+##### Limitations
+
+Software-based fault injection tools also have some limitations compared to hardware-based methods:
+
+**Accuracy:** Software-based tools may not always capture the full range of effects that hardware faults can have on the system. As these tools operate at a higher level of abstraction, they may need to catch up on some of the low-level hardware interactions and error propagation mechanisms that can impact the behavior of the ML system.
+
+**Fidelity:** Software-based tools may provide a different level of Fidelity than hardware-based methods in terms of representing real-world fault conditions. The accuracy of the results obtained from software-based fault injection experiments may depend on how closely the software model approximates the actual hardware behavior.
+
+)](./images/png/mavfi.jpg){#fig-mavfi}
+
+##### Types of Fault Injection Tools
+
+Software-based fault injection tools can be categorized based on their target frameworks or use cases. Here, we will discuss some of the most popular tools in each category:
+
+Ares [@reagen2018ares], a fault injection tool initially developed for the Keras framework in 2018, emerged as one of the first tools to study the impact of hardware faults on deep neural networks (DNNs) in the context of the rising popularity of ML frameworks in the mid-to-late 2010s. The tool was validated against a DNN accelerator implemented in silicon, demonstrating its effectiveness in modeling hardware faults. Ares provides a comprehensive study on the impact of hardware faults in both weights and activation values, characterizing the effects of single-bit flips and bit-error rates (BER) on hardware structures. Later, the Ares framework was extended to support the PyTorch ecosystem, enabling researchers to investigate hardware faults in a more modern setting and further extending its utility in the field.
+
+{#fig-phantom-objects}
+
+PyTorchFI [@mahmoud2020pytorchfi], a fault injection tool specifically designed for the PyTorch framework, was developed in 2020 in collaboration with Nvidia Research. It enables the injection of faults into the weights, activations, and gradients of PyTorch models, supporting a wide range of fault models. By leveraging the GPU acceleration capabilities of PyTorch, PyTorchFI provides a fast and efficient implementation for conducting fault injection experiments on large-scale ML systems, as shown in [@fig-phantom-objects](#txkz61sj1mj4). The tool's speed and ease of use have led to widespread adoption in the community, resulting in multiple developer-led projects, such as PyTorchALFI by Intel Labs, which focuses on safety in automotive environments. Follow-up PyTorch-centric tools for fault injection include Dr. DNA by Meta [@ma2024dr] (which further facilitates the Pythonic programming model for ease of use), and the GoldenEye framework [@mahmoud2022dsn], which incorporates novel numerical datatypes (such as AdaptivFloat [@tambe2020algorithm] and [BlockFloat](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) in the context of hardware bit flips.
+
+TensorFI [@chen2020tensorfi], or the TensorFlow Fault Injector, is a fault injection tool developed specifically for the TensorFlow framework. Analogous to Ares and PyTorchFI, TensorFI is considered the state-of-the-art tool for ML robustness studies in the TensorFlow ecosystem. It allows researchers to inject faults into the computational graph of TensorFlow models and study their impact on the model's performance, supporting a wide range of fault models. One of the key benefits of TensorFI is its ability to evaluate the resilience of various ML models, not just DNNs. Further advancements, such as BinFi [@chen2019sc], provide a mechanism to speed up error injection experiments by focusing on the \"important\" bits in the system, accelerating the process of ML robustness analysis and prioritizing the critical components of a model.
+
+NVBitFI [@tsai2021nvbitfi], a general-purpose fault injection tool developed by Nvidia for their GPU platforms, operates at a lower level compared to framework-specific tools like Ares, PyTorchFI, and TensorFlow. While these tools focus on various deep learning platforms to implement and perform robustness analysis, NVBitFI targets the underlying hardware assembly code for fault injection. This allows researchers to inject faults into any application running on Nvidia GPUs, making it a versatile tool for studying the resilience of ML systems and other GPU-accelerated applications. By enabling users to inject errors at the architectural level, NVBitFI provides a more general-purpose fault model that is not restricted to just ML models. As Nvidia's GPU systems are commonly used in many ML-based systems, NVBitFI is a valuable tool for comprehensive fault injection analysis across various applications.
+
+###### Domain-specific Examples
+
+Domain-specific fault injection tools have been developed to address various ML application domains' unique challenges and requirements, such as autonomous vehicles and robotics. This section highlights three domain-specific fault injection tools: DriveFI and PyTorchALFI for autonomous vehicles and MAVFI for uncrewed aerial vehicles (UAVs). These tools enable researchers to inject hardware faults into these complex systems' perception, control, and other subsystems, allowing them to study the impact of faults on system performance and safety. The development of these software-based fault injection tools has greatly expanded the capabilities of the ML community to develop more robust and reliable systems that can operate safely and effectively in the presence of hardware faults.
+
+DriveFI [@jha2019ml] is a fault injection tool designed for autonomous vehicles. It enables the injection of hardware faults into the perception and control pipelines of autonomous vehicle systems, allowing researchers to study the impact of these faults on the system's performance and safety. DriveFI has been integrated with industry-standard autonomous driving platforms, such as Nvidia DriveAV and Baidu Apollo, making it a valuable tool for evaluating the resilience of autonomous vehicle systems.
+
+PyTorchALFI [@grafe2023large] is an extension of PyTorchFI developed by Intel Labs for the autonomous vehicle domain. It builds upon PyTorchFI's fault injection capabilities. It adds features specifically tailored for evaluating the resilience of autonomous vehicle systems, such as the ability to inject faults into the camera and LiDAR sensor data.
+
+MAVFI [@hsiao2023mavfi] is a fault injection tool designed for the robotics domain, specifically for uncrewed aerial vehicles (UAVs). MAVFI is built on top of the Robot Operating System (ROS) framework and allows researchers to inject faults into the various components of a UAV system, such as sensors, actuators, and control algorithms. By evaluating the impact of these faults on the UAV's performance and stability, researchers can develop more resilient and fault-tolerant UAV systems.
+
+The development of software-based fault injection tools has greatly expanded the capabilities of researchers and practitioners to study the resilience of ML systems to hardware faults. By leveraging the speed, flexibility, and accessibility of these tools, the ML community can develop more robust and reliable systems that can operate safely and effectively in the presence of hardware faults.
+
+### Bridging the Gap between Hardware and Software Error Models
+![Hardware errors may manifest themselves in different ways at the software level, as classified by Bolchini et al. [@bolchini2022fast]](./images/png/hardware_errors_Bolchini.png){#fig-hardware-errors-bolchini}
+
+While software-based fault injection tools offer many advantages in speed, flexibility, and accessibility, they may not always accurately capture the full range of effects that hardware faults can have on the system. This is because software-based tools operate at a higher level of abstraction than hardware-based methods and may miss some of the low-level hardware interactions and error propagation mechanisms that can impact the behavior of the ML system, as shown in [@fig-hardware-errors-bolchini].
+
+Researchers have developed tools to address this issue by bridging the gap between low-level hardware error models and higher-level software error models. One such tool is Fidelity, designed to map patterns between hardware-level faults and their software-level manifestations.
+
+#### Fidelity: Bridging the Gap
+
+Fidelity [@he2020fidelity] is a tool for accurately modeling hardware faults in software-based fault injection experiments. It achieves this by carefully studying the relationship between hardware-level faults and their impact on the software representation of the ML system.
+
+The key insights behind Fidelity are:
+
+- **Fault Propagation:** Fidelity models how faults propagate through the hardware and manifest as errors in the software-visible state of the system. By understanding these propagation patterns, Fidelity can more accurately simulate the effects of hardware faults in software-based experiments.
+
+Fault Equivalence:** Fidelity identifies equivalent classes of hardware faults that produce similar software-level errors. This allows researchers to design software-based fault models that are representative of the underlying hardware faults without the need to model every possible hardware fault individually.
+
+- **Layered Approach:** Fidelity employs a layered approach to fault modeling, where the effects of hardware faults are propagated through multiple levels of abstraction, from the hardware to the software level. This approach ensures that the software-based fault models are grounded in the actual behavior of the hardware.
+
+By incorporating these insights, Fidelity enables software-based fault injection tools to capture the effects of hardware faults on ML systems accurately. This is particularly important for safety-critical applications, where the system's resilience to hardware faults is paramount.
+
+#### Importance of Capturing True Hardware Behavior
+
+Capturing true hardware behavior in software-based fault injection tools is crucial for several reasons:
+
+- **Accuracy:** By accurately modeling the effects of hardware faults, software-based tools can provide more reliable insights into the resilience of ML systems. This is essential for designing and validating fault-tolerant systems that can operate safely and effectively in the presence of hardware faults.
+
+- **Reproducibility:** When software-based tools accurately capture hardware behavior, fault injection experiments become more reproducible across different platforms and environments. This is important for the scientific study of ML system resilience, as it allows researchers to compare and validate results across different studies and implementations.
+
+- **Efficiency:** Software-based tools that capture true hardware behavior can be more efficient in their fault injection experiments by focusing on the most representative and impactful fault models. This allows researchers to cover a wider range of fault scenarios and system configurations with limited computational resources.
+
+- **Mitigation Strategies:** Understanding how hardware faults manifest at the software level is crucial for developing effective mitigation strategies. By accurately capturing hardware behavior, software-based fault injection tools can help researchers identify the most vulnerable components of the ML system and design targeted hardening techniques to improve resilience.
+
+Tools like Fidelity are vital in advancing the state-of-the-art in ML system resilience research. These tools enable researchers to conduct more accurate, reproducible, and efficient fault injection experiments by bridging the gap between hardware and software error models. As the complexity and criticality of ML systems continue to grow, the importance of capturing true hardware behavior in software-based fault injection tools will only become more apparent.
+
+Ongoing research in this area aims to refine the mapping between hardware and software error models and develop new techniques for efficiently simulating hardware faults in software-based experiments. As these tools mature, they will provide the ML community with increasingly powerful and accessible means to study and improve the resilience of ML systems to hardware faults.
+
+## Conclusion
+
+Developing robust and resilient AI is paramount as machine learning systems become increasingly integrated into safety-critical applications and real-world environments. This chapter has explored the key challenges to AI robustness arising from hardware faults, malicious attacks, distribution shifts, and software bugs.
+
+Some of the key takeaways include the following:
+
+- **Hardware Faults:** Transient, permanent, and intermittent faults in hardware components can corrupt computations and degrade the performance of machine learning models if not properly detected and mitigated. Techniques such as redundancy, error correction, and fault-tolerant designs play a crucial role in building resilient ML systems that can withstand hardware faults.
+
+- **Model Robustness:** Malicious actors can exploit vulnerabilities in ML models through adversarial attacks and data poisoning, aiming to induce targeted misclassifications, skew the model's learned behavior, or compromise the system's integrity and reliability. Also, distribution shifts can occur when the data distribution encountered during deployment differs from those seen during training, leading to performance degradation. Implementing defensive measures, including adversarial training, anomaly detection, robust model architectures, and techniques such as domain adaptation, transfer learning, and continual learning, is essential to safeguard against these challenges and ensure the model's reliability and generalization in dynamic environments.
+
+Software Faults:** Faults in ML frameworks, libraries, and software stacks can propagate errors, degrade performance, and introduce security vulnerabilities. Rigorous testing, runtime monitoring, and adopting fault-tolerant design patterns are essential for building robust software infrastructure supporting reliable ML systems.
+
+As ML systems take on increasingly complex tasks with real-world consequences, prioritizing resilience becomes critical. The tools and frameworks discussed in this chapter, including fault injection techniques, error analysis methods, and robustness evaluation frameworks, provide practitioners with the means to thoroughly test and harden their ML systems against various failure modes and adversarial conditions.
+
+Moving forward, resilience must be a central focus throughout the entire AI development lifecycle, from data collection and model training to deployment and monitoring. By proactively addressing the multifaceted challenges to robustness, we can develop trustworthy, reliable ML systems that can navigate the complexities and uncertainties of real-world environments.
+
+Future research in robust ML should continue to advance techniques for detecting and mitigating faults, attacks, and distributional shifts. Additionally, exploring novel paradigms for developing inherently resilient AI architectures, such as self-healing systems or fail-safe mechanisms, will be crucial in pushing the boundaries of AI robustness. By prioritizing resilience and investing in developing robust AI systems, we can unlock the full potential of machine learning technologies while ensuring their safe, reliable, and responsible deployment in real-world applications. As AI continues to shape our future, building resilient systems that can withstand the challenges of the real world will be a defining factor in the success and societal impact of this transformative technology.
+
+## Resources {#sec-robust-ai-resource .unnumbered}
+
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
+
+:::{.callout-slide collapse="false"}
+# Slides
+
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+
+*Coming soon.*
+
+:::
+
+:::{.callout-exercise collapse="false"}
+# Exercises
+
+To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
+
+* @exr-ad
+
+* @exr-aa
+
+* @exr-pa
+
+* @exr-ft
+:::
+
+:::{.callout-lab collapse="false"}
+# Labs
+
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+
+*Coming soon.*
+
+:::
diff --git a/contents/sustainable_ai/sustainable_ai.bib b/contents/sustainable_ai/sustainable_ai.bib
index ab782546..86145885 100644
--- a/contents/sustainable_ai/sustainable_ai.bib
+++ b/contents/sustainable_ai/sustainable_ai.bib
@@ -1,9 +1,12 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@misc{anthony2020carbontracker,
- author = {Lasse F. Wolff Anthony and Benjamin Kanding and Raghavendra Selvan},
+ author = {Anthony, Lasse F. Wolff and Kanding, Benjamin and Selvan, Raghavendra},
howpublished = {ICML Workshop on Challenges in Deploying and monitoring Machine Learning Systems},
- month = {July},
+ month = jul,
note = {arXiv:2007.03051},
- year = {2020}
+ year = {2020},
}
@book{barroso2019datacenter,
@@ -16,7 +19,7 @@ @book{barroso2019datacenter
subtitle = {Designing Warehouse-Scale Machines},
title = {The Datacenter as a Computer},
url = {https://doi.org/10.1007/978-3-031-01761-2},
- year = {2019}
+ year = {2019},
}
@incollection{bohr2020rise,
@@ -29,36 +32,38 @@ @incollection{bohr2020rise
source = {Crossref},
title = {The rise of artificial intelligence in healthcare applications},
url = {https://doi.org/10.1016/b978-0-12-818438-7.00002-2},
- year = {2020}
+ year = {2020},
}
@inproceedings{bondi2018spot,
- author = {Elizabeth Bondi and Ashish Kapoor and Debadeepta Dey and James Piavis and Shital Shah and Robert Hannaford and Arvind Iyer and Lucas Joppa and Milind Tambe},
+ author = {Bondi, Elizabeth and Kapoor, Ashish and Dey, Debadeepta and Piavis, James and Shah, Shital and Hannaford, Robert and Iyer, Arvind and Joppa, Lucas and Tambe, Milind},
+ editor = {Lang, J\'er\^ome},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/ijcai/BondiKDPSHIJT18.bib},
- booktitle = {Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, {IJCAI} 2018, July 13-19, 2018, Stockholm, Sweden},
+ booktitle = {Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence},
doi = {10.24963/ijcai.2018/847},
- editor = {J{\'{e}}r{\^{o}}me Lang},
pages = {5814--5816},
- publisher = {ijcai.org},
+ publisher = {International Joint Conferences on Artificial Intelligence Organization},
timestamp = {Tue, 20 Aug 2019 01:00:00 +0200},
- title = {Near Real-Time Detection of Poachers from Drones in AirSim},
+ title = {Near Real-Time Detection of Poachers from Drones in {AirSim}},
url = {https://doi.org/10.24963/ijcai.2018/847},
- year = {2018}
+ year = {2018},
+ source = {Crossref},
+ month = jul,
}
@misc{buyya2010energyefficient,
- archiveprefix = {arXiv},
author = {Buyya, Rajkumar and Beloglazov, Anton and Abawajy, Jemal},
+ archiveprefix = {arXiv},
eprint = {1006.0308},
primaryclass = {cs.DC},
title = {Energy-Efficient Management of Data Center Resources for Cloud Computing: {A} Vision, Architectural Elements, and Open Challenges},
- year = {2010}
+ year = {2010},
}
@article{cenci2021ecofriendly,
- abstract = {Abstract Eco-friendliness is becoming an indispensable feature for electrical and electronic equipment to thrive in the competitive market. This comprehensive review is the first to define eco-friendly electronics in its multiple meanings: power saving devices, end-of-life impact attenuators, equipment whose manufacturing uses green processing, electronics that use materials that minimize environmental and health risks, designs that improve lifespan, reparability, etc. More specifically, this review discusses eco-friendly technologies and materials that are being introduced to replace the well-established ones. This is done for all material classes (metals, polymers, ceramics, and composites). Manufacturing, recycling, and final product characteristics are discussed in their various interconnected aspects. Additionally, the concept of consciously planned obsolescence is introduced to address the paradoxical relationship between durability and efficiency. The overall conclusions are that there is an important global trend to make electronics more eco-friendly. However, matching the performance and stability of well-established materials and technologies seems to be the main barrier to achieve it. These new implementations can have detrimental or beneficial net impacts on the environment. Assessing their net outcome is challenging because their impacts are frequently unknown and the current evaluation methods (and tools) are incapable of comprehensively quantifying these impacts and generating reliable verdicts.},
author = {Cenci, Marcelo Pilotto and Scarazzato, Tatiana and Munchen, Daniel Dotto and Dartora, Paula Cristina and Veit, Hugo Marcelo and Bernardes, Andrea Moura and Dias, Pablo R.},
+ abstract = {Abstract Eco-friendliness is becoming an indispensable feature for electrical and electronic equipment to thrive in the competitive market. This comprehensive review is the first to define eco-friendly electronics in its multiple meanings: power saving devices, end-of-life impact attenuators, equipment whose manufacturing uses green processing, electronics that use materials that minimize environmental and health risks, designs that improve lifespan, reparability, etc. More specifically, this review discusses eco-friendly technologies and materials that are being introduced to replace the well-established ones. This is done for all material classes (metals, polymers, ceramics, and composites). Manufacturing, recycling, and final product characteristics are discussed in their various interconnected aspects. Additionally, the concept of consciously planned obsolescence is introduced to address the paradoxical relationship between durability and efficiency. The overall conclusions are that there is an important global trend to make electronics more eco-friendly. However, matching the performance and stability of well-established materials and technologies seems to be the main barrier to achieve it. These new implementations can have detrimental or beneficial net impacts on the environment. Assessing their net outcome is challenging because their impacts are frequently unknown and the current evaluation methods (and tools) are incapable of comprehensively quantifying these impacts and generating reliable verdicts.},
doi = {10.1002/admt.202001263},
issn = {2365-709X, 2365-709X},
journal = {Adv. Mater. Technol.},
@@ -71,14 +76,15 @@ @article{cenci2021ecofriendly
title = {{Eco-Friendly} {Electronics{\textemdash}A} Comprehensive Review},
url = {https://doi.org/10.1002/admt.202001263},
volume = {7},
- year = {2021}
+ year = {2021},
+ month = apr,
}
@inproceedings{challenge2021supply,
author = {Challenge, WEF Net-Zero},
booktitle = {World Economic Forum: Geneva, Switzerland},
title = {The Supply Chain Opportunity},
- year = {2021}
+ year = {2021},
}
@article{chen2006gallium,
@@ -93,7 +99,8 @@ @article{chen2006gallium
title = {Gallium, Indium, and Arsenic Pollution of Groundwater from a Semiconductor Manufacturing Area of {Taiwan}},
url = {https://doi.org/10.1007/s00128-006-1062-3},
volume = {77},
- year = {2006}
+ year = {2006},
+ month = aug,
}
@article{chua1971memristor,
@@ -108,7 +115,7 @@ @article{chua1971memristor
title = {Memristor-The missing circuit element},
url = {https://doi.org/10.1109/tct.1971.1083337},
volume = {18},
- year = {1971}
+ year = {1971},
}
@inproceedings{cooper2011semiconductor,
@@ -121,7 +128,8 @@ @inproceedings{cooper2011semiconductor
source = {Crossref},
title = {A semiconductor company's examination of its water footprint approach},
url = {https://doi.org/10.1109/issst.2011.5936865},
- year = {2011}
+ year = {2011},
+ month = may,
}
@article{cope2009pure,
@@ -130,7 +138,7 @@ @article{cope2009pure
number = {10},
title = {Pure water, semiconductors and the recession},
volume = {10},
- year = {2009}
+ year = {2009},
}
@techreport{davies2011endangered,
@@ -138,14 +146,14 @@ @techreport{davies2011endangered
pages = {50--54},
title = {Endangered elements: {Critical} thinking},
url = {https://www.rsc.org/images/Endangered\%20Elements\%20-\%20Critical\%20Thinking\_tcm18-196054.pdf},
- year = {2011}
+ year = {2011},
}
@techreport{davis2022uptime,
author = {Davis, Jacqueline and Bizo, Daniel and Lawrence, Andy and Rogers, Owen and Smolaks, Max},
institution = {Uptime Institute},
title = {Uptime Institute Global Data Center Survey 2022},
- year = {2022}
+ year = {2022},
}
@article{dayarathna2015data,
@@ -160,12 +168,12 @@ @article{dayarathna2015data
title = {Data Center Energy Consumption Modeling: {A} Survey},
url = {https://doi.org/10.1109/comst.2015.2481183},
volume = {18},
- year = {2016}
+ year = {2016},
}
@article{ebrahimi2014review,
- abstract = {The depletion of the world's limited reservoirs of fossil fuels, the worldwide impact of global warming and the high cost of energy are among the primary issues driving a renewed interest in the capture and reuse of waste energy. A major source of waste energy is being created by data centers through the increasing demand for cloud based connectivity and performance. In fact, recent figures show that data centers are responsible for more than 2\% of the US total electricity usage. Almost half of this power is used for cooling the electronics, creating a significant stream of waste heat. The difficulty associated with recovering and reusing this stream of waste heat is that the heat is of low quality. In this paper, the most promising methods and technologies for recovering data center low-grade waste heat in an effective and economically reasonable way are identified and discussed. A number of currently available and developmental low-grade waste heat recovery techniques including district/plant/water heating, absorption cooling, direct power generation (piezoelectric and thermoelectric), indirect power generation (steam and organic Rankine cycle), biomass co-location, and desalination/clean water are reviewed along with their operational requirements in order to assess the suitability and effectiveness of each technology for data center applications. Based on a comparison between data centers' operational thermodynamic conditions and the operational requirements of the discussed waste heat recovery techniques, absorption cooling and organic Rankine cycle are found to be among the most promising technologies for data center waste heat reuse.},
author = {Ebrahimi, Khosrow and Jones, Gerard F. and Fleischer, Amy S.},
+ abstract = {The depletion of the world's limited reservoirs of fossil fuels, the worldwide impact of global warming and the high cost of energy are among the primary issues driving a renewed interest in the capture and reuse of waste energy. A major source of waste energy is being created by data centers through the increasing demand for cloud based connectivity and performance. In fact, recent figures show that data centers are responsible for more than 2\% of the US total electricity usage. Almost half of this power is used for cooling the electronics, creating a significant stream of waste heat. The difficulty associated with recovering and reusing this stream of waste heat is that the heat is of low quality. In this paper, the most promising methods and technologies for recovering data center low-grade waste heat in an effective and economically reasonable way are identified and discussed. A number of currently available and developmental low-grade waste heat recovery techniques including district/plant/water heating, absorption cooling, direct power generation (piezoelectric and thermoelectric), indirect power generation (steam and organic Rankine cycle), biomass co-location, and desalination/clean water are reviewed along with their operational requirements in order to assess the suitability and effectiveness of each technology for data center applications. Based on a comparison between data centers' operational thermodynamic conditions and the operational requirements of the discussed waste heat recovery techniques, absorption cooling and organic Rankine cycle are found to be among the most promising technologies for data center waste heat reuse.},
doi = {10.1016/j.rser.2013.12.007},
issn = {1364-0321},
journal = {Renewable Sustainable Energy Rev.},
@@ -176,14 +184,15 @@ @article{ebrahimi2014review
title = {A review of data center cooling technology, operating conditions and the corresponding low-grade waste heat recovery opportunities},
url = {https://doi.org/10.1016/j.rser.2013.12.007},
volume = {31},
- year = {2014}
+ year = {2014},
+ month = mar,
}
@book{grossman2007high,
author = {Grossman, Elizabeth},
publisher = {Island press},
title = {High tech trash: {Digital} devices, hidden toxics, and human health},
- year = {2007}
+ year = {2007},
}
@inproceedings{gupta2022,
@@ -196,7 +205,8 @@ @inproceedings{gupta2022
subtitle = {designing sustainable computer systems with an architectural carbon modeling tool},
title = {Act},
url = {https://doi.org/10.1145/3470496.3527408},
- year = {2022}
+ year = {2022},
+ month = jun,
}
@article{henderson2020towards,
@@ -207,7 +217,7 @@ @article{henderson2020towards
publisher = {JMLRORG},
title = {Towards the systematic reporting of the energy and carbon footprints of machine learning},
volume = {21},
- year = {2020}
+ year = {2020},
}
@article{hsu2016accumulation,
@@ -222,12 +232,13 @@ @article{hsu2016accumulation
title = {Accumulation of heavy metals and trace elements in fluvial sediments received effluents from traditional and semiconductor industries},
url = {https://doi.org/10.1038/srep34250},
volume = {6},
- year = {2016}
+ year = {2016},
+ month = sep,
}
@article{irimiavladu2014textquotedblleftgreentextquotedblright,
- abstract = {{\textquotedblleft}Green{\textquotedblright} electronics represents not only a novel scientific term but also an emerging area of research aimed at identifying compounds of natural origin and establishing economically efficient routes for the production of synthetic materials that have applicability in environmentally safe (biodegradable) and/or biocompatible devices. The ultimate goal of this research is to create paths for the production of human- and environmentally friendly electronics in general and the integration of such electronic circuits with living tissue in particular. Researching into the emerging class of {\textquotedblleft}green{\textquotedblright} electronics may help fulfill not only the original promise of organic electronics that is to deliver low-cost and energy efficient materials and devices but also achieve unimaginable functionalities for electronics, for example benign integration into life and environment. This Review will highlight recent research advancements in this emerging group of materials and their integration in unconventional organic electronic devices.},
author = {Irimia-Vladu, Mihai},
+ abstract = {{\textquotedblleft}Green{\textquotedblright} electronics represents not only a novel scientific term but also an emerging area of research aimed at identifying compounds of natural origin and establishing economically efficient routes for the production of synthetic materials that have applicability in environmentally safe (biodegradable) and/or biocompatible devices. The ultimate goal of this research is to create paths for the production of human- and environmentally friendly electronics in general and the integration of such electronic circuits with living tissue in particular. Researching into the emerging class of {\textquotedblleft}green{\textquotedblright} electronics may help fulfill not only the original promise of organic electronics that is to deliver low-cost and energy efficient materials and devices but also achieve unimaginable functionalities for electronics, for example benign integration into life and environment. This Review will highlight recent research advancements in this emerging group of materials and their integration in unconventional organic electronic devices.},
doi = {10.1039/c3cs60235d},
issn = {0306-0012, 1460-4744},
journal = {Chem. Soc. Rev.},
@@ -239,16 +250,16 @@ @article{irimiavladu2014textquotedblleftgreentextquotedblright
title = {{{\textquotedblleft}Green{\textquotedblright}} electronics: {Biodegradable} and biocompatible materials and devices for sustainable future},
url = {https://doi.org/10.1039/c3cs60235d},
volume = {43},
- year = {2014}
+ year = {2014},
}
@article{jaewon2023perseus,
- author = {Jae-Won Chung and Yile Gu and Insu Jang and Luoxi Meng and Nikhil Bansal and Mosharaf Chowdhury},
+ author = {Chung, Jae-Won and Gu, Yile and Jang, Insu and Meng, Luoxi and Bansal, Nikhil and Chowdhury, Mosharaf},
journal = {ArXiv preprint},
- title = {Perseus: Removing Energy Bloat from Large Model Training},
+ title = {Perseus: {Removing} Energy Bloat from Large Model Training},
url = {https://arxiv.org/abs/2312.06902},
volume = {abs/2312.06902},
- year = {2023}
+ year = {2023},
}
@book{jha2014rare,
@@ -260,20 +271,21 @@ @book{jha2014rare
subtitle = {Properties and Applications},
title = {Rare Earth Materials},
url = {https://doi.org/10.1201/b17045},
- year = {2014}
+ year = {2014},
+ month = jun,
}
@inproceedings{jie2023zeus,
+ author = {You, Jie and Chung, Jae-Won and Chowdhury, Mosharaf},
address = {Boston, MA},
- author = {Jie You and Jae-Won Chung and Mosharaf Chowdhury},
booktitle = {20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23)},
isbn = {978-1-939133-33-5},
- month = {April},
+ month = apr,
pages = {119--139},
publisher = {USENIX Association},
- title = {Zeus: Understanding and Optimizing {GPU} Energy Consumption of {DNN} Training},
+ title = {Zeus: {Understanding} and Optimizing {GPU} Energy Consumption of {DNN} Training},
url = {https://www.usenix.org/conference/nsdi23/presentation/you},
- year = {2023}
+ year = {2023},
}
@article{kaplan2020scaling,
@@ -282,7 +294,7 @@ @article{kaplan2020scaling
title = {Scaling Laws for Neural Language Models},
url = {https://arxiv.org/abs/2001.08361},
volume = {abs/2001.08361},
- year = {2020}
+ year = {2020},
}
@article{kim2018chemical,
@@ -297,7 +309,8 @@ @article{kim2018chemical
title = {Chemical use in the semiconductor manufacturing industry},
url = {https://doi.org/10.1080/10773525.2018.1519957},
volume = {24},
- year = {2018}
+ year = {2018},
+ month = oct,
}
@inproceedings{kurth2023fourcastnet,
@@ -309,7 +322,8 @@ @inproceedings{kurth2023fourcastnet
source = {Crossref},
title = {{FourCastNet:} {Accelerating} Global High-Resolution Weather Forecasting Using Adaptive {Fourier} Neural Operators},
url = {https://doi.org/10.1145/3592979.3593412},
- year = {2023}
+ year = {2023},
+ month = jun,
}
@article{lam2023learning,
@@ -317,23 +331,31 @@ @article{lam2023learning
doi = {10.1126/science.adi2336},
issn = {0036-8075, 1095-9203},
journal = {Science},
- pages = {eadi2336},
+ pages = {1416--1421},
publisher = {American Association for the Advancement of Science (AAAS)},
source = {Crossref},
title = {Learning skillful medium-range global weather forecasting},
url = {https://doi.org/10.1126/science.adi2336},
- year = {2023}
+ year = {2023},
+ number = {6677},
+ volume = {382},
+ month = dec,
}
@article{lannelongue2021green,
author = {Lannelongue, Lo{\"\i}c and Grealey, Jason and Inouye, Michael},
- journal = {Advanced science},
+ journal = {Adv. Sci.},
number = {12},
pages = {2100707},
- publisher = {Wiley Online Library},
- title = {Green algorithms: quantifying the carbon footprint of computation},
+ publisher = {Wiley},
+ title = {Green Algorithms: {Quantifying} the Carbon Footprint of Computation},
volume = {8},
- year = {2021}
+ year = {2021},
+ doi = {10.1002/advs.202100707},
+ source = {Crossref},
+ url = {https://doi.org/10.1002/advs.202100707},
+ issn = {2198-3844, 2198-3844},
+ month = may,
}
@article{lecocq2022mitigation,
@@ -347,7 +369,8 @@ @article{lecocq2022mitigation
title = {Examples of shifting development pathways: {Lessons} on how to enable broader, deeper, and faster climate action},
url = {https://doi.org/10.1007/s44168-022-00026-1},
volume = {1},
- year = {2022}
+ year = {2022},
+ month = dec,
}
@article{liu2020energy,
@@ -362,7 +385,8 @@ @article{liu2020energy
title = {Energy consumption and emission mitigation prediction based on data center traffic and {PUE} for global data centers},
url = {https://doi.org/10.1016/j.gloei.2020.07.008},
volume = {3},
- year = {2020}
+ year = {2020},
+ month = jun,
}
@article{maslej2023artificial,
@@ -371,12 +395,12 @@ @article{maslej2023artificial
title = {Artificial intelligence index report 2023},
url = {https://arxiv.org/abs/2310.03715},
volume = {abs/2310.03715},
- year = {2023}
+ year = {2023},
}
@article{maxime2016impact,
- abstract = {This paper studies government subsidies for green technology adoption while considering the manufacturing industry's response. Government subsidies offered directly to consumers impact the supplier's production and pricing decisions. Our analysis expands the current understanding of the price-setting newsvendor model, incorporating the external influence from the government, who is now an additional player in the system. We quantify how demand uncertainty impacts the various players (government, industry, and consumers) when designing policies. We further show that, for convex demand functions, an increase in demand uncertainty leads to higher production quantities and lower prices, resulting in lower profits for the supplier. With this in mind, one could expect consumer surplus to increase with uncertainty. In fact, we show that this is not always the case and that the uncertainty impact on consumer surplus depends on the trade-off between lower prices and the possibility of underserving customers with high valuations. We also show that when policy makers such as governments ignore demand uncertainty when designing consumer subsidies, they can significantly miss the desired adoption target level. From a coordination perspective, we demonstrate that the decentralized decisions are also optimal for a central planner managing jointly the supplier and the government. As a result, subsidies provide a coordination mechanism.},
author = {Cohen, Maxime C. and Lobel, Ruben and Perakis, Georgia},
+ abstract = {This paper studies government subsidies for green technology adoption while considering the manufacturing industry's response. Government subsidies offered directly to consumers impact the supplier's production and pricing decisions. Our analysis expands the current understanding of the price-setting newsvendor model, incorporating the external influence from the government, who is now an additional player in the system. We quantify how demand uncertainty impacts the various players (government, industry, and consumers) when designing policies. We further show that, for convex demand functions, an increase in demand uncertainty leads to higher production quantities and lower prices, resulting in lower profits for the supplier. With this in mind, one could expect consumer surplus to increase with uncertainty. In fact, we show that this is not always the case and that the uncertainty impact on consumer surplus depends on the trade-off between lower prices and the possibility of underserving customers with high valuations. We also show that when policy makers such as governments ignore demand uncertainty when designing consumer subsidies, they can significantly miss the desired adoption target level. From a coordination perspective, we demonstrate that the decentralized decisions are also optimal for a central planner managing jointly the supplier and the government. As a result, subsidies provide a coordination mechanism.},
doi = {10.1287/mnsc.2015.2173},
issn = {0025-1909, 1526-5501},
journal = {Manage. Sci.},
@@ -388,7 +412,8 @@ @article{maxime2016impact
url = {https://doi.org/10.1287/mnsc.2015.2173},
urldate = {2023-12-01},
volume = {62},
- year = {2016}
+ year = {2016},
+ month = may,
}
@article{mills1997overview,
@@ -403,7 +428,8 @@ @article{mills1997overview
title = {An overview of semiconductor photocatalysis},
url = {https://doi.org/10.1016/s1010-6030(97)00118-4},
volume = {108},
- year = {1997}
+ year = {1997},
+ month = jul,
}
@article{monyei2018electrons,
@@ -417,29 +443,28 @@ @article{monyei2018electrons
title = {Electrons have no identity: {Setting} right misrepresentations in Google and Apple{\textquoteright}s clean energy purchasing},
url = {https://doi.org/10.1016/j.erss.2018.06.015},
volume = {46},
- year = {2018}
+ year = {2018},
+ month = dec,
}
@book{nakano2021geopolitics,
author = {Nakano, Jane},
publisher = {JSTOR},
title = {The geopolitics of critical minerals supply chains},
- year = {2021}
+ year = {2021},
}
-@article{patterson2022carbon,
- author = {Patterson, David and Gonzalez, Joseph and Holzle, Urs and Le, Quoc and Liang, Chen and Munguia, Lluis-Miquel and Rothchild, Daniel and So, David R. and Texier, Maud and Dean, Jeff},
- doi = {10.1109/mc.2022.3148714},
- issn = {0018-9162, 1558-0814},
- journal = {Computer},
- number = {7},
- pages = {18--28},
- publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
+@techreport{oecd2023blueprint,
+ author = {Oecd},
+ title = {A blueprint for building national compute capacity for artificial intelligence},
+ year = {2023},
+ number = {350},
+ url = {https://doi.org/10.1787/876367e3-en},
+ doi = {10.1787/876367e3-en},
source = {Crossref},
- title = {The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink},
- url = {https://doi.org/10.1109/mc.2022.3148714},
- volume = {55},
- year = {2022}
+ institution = {Organisation for Economic Co-Operation and Development (OECD)},
+ issn = {2071-6826},
+ month = feb,
}
@article{patterson2022carbon,
@@ -454,7 +479,8 @@ @article{patterson2022carbon
title = {The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink},
url = {https://doi.org/10.1109/mc.2022.3148714},
volume = {55},
- year = {2022}
+ year = {2022},
+ month = jul,
}
@article{phillips2020four,
@@ -462,23 +488,28 @@ @article{phillips2020four
journal = {Gaithersburg, Maryland},
title = {Four principles of explainable artificial intelligence},
volume = {18},
- year = {2020}
+ year = {2020},
}
@article{poff2002aquatic,
author = {LeRoy Poff, N and Brinson, MM and Day, JW},
journal = {Pew Center on Global Climate Change},
title = {Aquatic ecosystems \& Global climate change},
- year = {2002}
+ year = {2002},
}
@inproceedings{prakash2022cfu,
author = {Prakash, Shvetank and Callahan, Tim and Bushagour, Joseph and Banbury, Colby and Green, Alan V. and Warden, Pete and Ansell, Tim and Reddi, Vijay Janapa},
journal = {ArXiv preprint},
title = {{CFU} Playground: {Full-stack} Open-Source Framework for Tiny Machine Learning {(TinyML)} Acceleration on {FPGAs}},
- url = {https://arxiv.org/abs/2201.01863},
+ url = {https://doi.org/10.1109/ispass57527.2023.00024},
volume = {abs/2201.01863},
- year = {2022}
+ year = {2023},
+ doi = {10.1109/ispass57527.2023.00024},
+ source = {Crossref},
+ booktitle = {2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)},
+ publisher = {IEEE},
+ month = apr,
}
@misc{prakash2023tinyml,
@@ -487,7 +518,7 @@ @misc{prakash2023tinyml
title = {Is {TinyML} Sustainable? Assessing the Environmental Impacts of Machine Learning on Microcontrollers},
url = {https://arxiv.org/abs/2301.11899},
volume = {abs/2301.11899},
- year = {2023}
+ year = {2023},
}
@article{schwartz2020green,
@@ -502,7 +533,8 @@ @article{schwartz2020green
title = {Green {AI}},
url = {https://doi.org/10.1145/3381831},
volume = {63},
- year = {2020}
+ year = {2020},
+ month = nov,
}
@inproceedings{schwartz2021deployment,
@@ -515,14 +547,15 @@ @inproceedings{schwartz2021deployment
source = {Crossref},
title = {Deployment of Embedded Edge-{AI} for Wildlife Monitoring in Remote Regions},
url = {https://doi.org/10.1109/icmla52953.2021.00170},
- year = {2021}
+ year = {2021},
+ month = dec,
}
@article{shehabi2016united,
author = {Shehabi, Arman and Smith, Sarah and Sartor, Dale and Brown, Richard and Herrlin, Magnus and Koomey, Jonathan and Masanet, Eric and Horner, Nathaniel and Azevedo, In\^es and Lintner, William},
institution = {Berkeley Laboratory},
title = {United states data center energy usage report},
- year = {2016}
+ year = {2016},
}
@article{siddik2021environmental,
@@ -537,7 +570,8 @@ @article{siddik2021environmental
title = {The environmental footprint of data centers in the United States},
url = {https://doi.org/10.1088/1748-9326/abfba1},
volume = {16},
- year = {2021}
+ year = {2021},
+ month = may,
}
@article{silvestro2022improving,
@@ -552,7 +586,8 @@ @article{silvestro2022improving
title = {Improving biodiversity protection through artificial intelligence},
url = {https://doi.org/10.1038/s41893-022-00851-6},
volume = {5},
- year = {2022}
+ year = {2022},
+ month = mar,
}
@article{singh2022disentangling,
@@ -567,19 +602,21 @@ @article{singh2022disentangling
title = {Disentangling the worldwide web of e-waste and climate change co-benefits},
url = {https://doi.org/10.1016/j.cec.2022.100011},
volume = {1},
- year = {2022}
+ year = {2022},
+ month = dec,
}
@inproceedings{strubell2019energy,
+ author = {Strubell, Emma and Ganesh, Ananya and McCallum, Andrew},
address = {Florence, Italy},
- author = {Strubell, Emma and Ganesh, Ananya and McCallum, Andrew},
booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
- doi = {10.18653/v1/P19-1355},
+ doi = {10.18653/v1/p19-1355},
pages = {3645--3650},
publisher = {Association for Computational Linguistics},
title = {Energy and Policy Considerations for Deep Learning in {NLP}},
- url = {https://aclanthology.org/P19-1355},
- year = {2019}
+ url = {https://doi.org/10.18653/v1/p19-1355},
+ year = {2019},
+ source = {Crossref},
}
@article{sudhakar2023data,
@@ -594,7 +631,8 @@ @article{sudhakar2023data
title = {Data Centers on Wheels: {Emissions} From Computing Onboard Autonomous Vehicles},
url = {https://doi.org/10.1109/mm.2022.3219803},
volume = {43},
- year = {2023}
+ year = {2023},
+ month = jan,
}
@article{thompson2021deep,
@@ -609,7 +647,8 @@ @article{thompson2021deep
title = {Deep Learning's Diminishing Returns: {The} Cost of Improvement is Becoming Unsustainable},
url = {https://doi.org/10.1109/mspec.2021.9563954},
volume = {58},
- year = {2021}
+ year = {2021},
+ month = oct,
}
@article{till2019fish,
@@ -624,12 +663,13 @@ @article{till2019fish
title = {Fish die-offs are concurrent with thermal extremes in north temperate lakes},
url = {https://doi.org/10.1038/s41558-019-0520-y},
volume = {9},
- year = {2019}
+ year = {2019},
+ month = jul,
}
@article{uddin2012energy,
- abstract = {The increasing demand for storage, networking and computation has driven intensification of large complex data centers that run many of today's Internet, financial, commercial and business applications. A data center comprises of many thousands of servers and can use as much energy as small city. Massive amount of computation power is required to drive and run these server farms resulting in many challenging like huge energy consumptions, emission of green house gases, backups and recovery; This paper proposes energy efficiency and low carbon enabler green IT framework for these large and complex server farms to save consumption of electricity and reduce the emission of green house gases to lower the effects of global warming. The framework uses latest energy saving techniques like virtualization, cloud computing and green metrics to achieve greener data centers. It comprises of five phase to properly implement green IT techniques to achieve green data centers. The proposed framework seamlessly divides data center components into different resource pools and then applies green metrics like Power Usage Effectiveness, Data Center Effectiveness and Carbon Emission Calculator to measure performance of individual components so that benchmarking values can be achieved and set as standard to be followed by data centers.},
author = {Uddin, Mueen and Rahman, Azizah Abdul},
+ abstract = {The increasing demand for storage, networking and computation has driven intensification of large complex data centers that run many of today's Internet, financial, commercial and business applications. A data center comprises of many thousands of servers and can use as much energy as small city. Massive amount of computation power is required to drive and run these server farms resulting in many challenging like huge energy consumptions, emission of green house gases, backups and recovery; This paper proposes energy efficiency and low carbon enabler green IT framework for these large and complex server farms to save consumption of electricity and reduce the emission of green house gases to lower the effects of global warming. The framework uses latest energy saving techniques like virtualization, cloud computing and green metrics to achieve greener data centers. It comprises of five phase to properly implement green IT techniques to achieve green data centers. The proposed framework seamlessly divides data center components into different resource pools and then applies green metrics like Power Usage Effectiveness, Data Center Effectiveness and Carbon Emission Calculator to measure performance of individual components so that benchmarking values can be achieved and set as standard to be followed by data centers.},
doi = {10.1016/j.rser.2012.03.014},
issn = {1364-0321},
journal = {Renewable Sustainable Energy Rev.},
@@ -641,7 +681,8 @@ @article{uddin2012energy
title = {Energy efficiency and low carbon enabler green {IT} framework for data centers considering green metrics},
url = {https://doi.org/10.1016/j.rser.2012.03.014},
volume = {16},
- year = {2012}
+ year = {2012},
+ month = aug,
}
@book{un2019circular,
@@ -649,7 +690,7 @@ @book{un2019circular
publisher = {PACE - Platform for Accelerating the Circular Economy},
title = {A New Circular Vision for Electronics, Time for a Global Reboot},
url = {https://www3.weforum.org/docs/WEF\_A\_New\_Circular\_Vision\_for\_Electronics.pdf},
- year = {2019}
+ year = {2019},
}
@article{wald1987semiconductor,
@@ -664,7 +705,8 @@ @article{wald1987semiconductor
title = {Semiconductor manufacturing: {An} introduction to processes and hazards},
url = {https://doi.org/10.1002/ajim.4700110209},
volume = {11},
- year = {1987}
+ year = {1987},
+ month = jan,
}
@article{wu2022sustainable,
@@ -673,7 +715,7 @@ @article{wu2022sustainable
pages = {795--813},
title = {Sustainable ai: {Environmental} implications, challenges and opportunities},
volume = {4},
- year = {2022}
+ year = {2022},
}
@inproceedings{zafrir2019q8bert,
@@ -686,7 +728,8 @@ @inproceedings{zafrir2019q8bert
source = {Crossref},
title = {{Q8BERT:} {Quantized} {8Bit} {BERT}},
url = {https://doi.org/10.1109/emc2-nips53020.2019.00016},
- year = {2019}
+ year = {2019},
+ month = dec,
}
@article{zhang2018review,
@@ -701,14 +744,6 @@ @article{zhang2018review
title = {Review on the research and practice of deep learning and reinforcement learning in smart grids},
url = {https://doi.org/10.17775/cseejpes.2018.00520},
volume = {4},
- year = {2018}
+ year = {2018},
+ month = sep,
}
-
-@article{oecd2023blueprint,
- author = "OECD",
- title = "A blueprint for building national compute capacity for artificial intelligence",
- year = "2023",
- number = "350",
- url = "https://www.oecd-ilibrary.org/content/paper/876367e3-en",
- doi = "https://doi.org/https://doi.org/10.1787/876367e3-en"
-}
\ No newline at end of file
diff --git a/contents/sustainable_ai/sustainable_ai.qmd b/contents/sustainable_ai/sustainable_ai.qmd
index af92a3af..b47a530c 100644
--- a/contents/sustainable_ai/sustainable_ai.qmd
+++ b/contents/sustainable_ai/sustainable_ai.qmd
@@ -8,17 +8,17 @@ bibliography: sustainable_ai.bib
Resources: [Slides](#sec-sustainable-ai-resource), [Labs](#sec-sustainable-ai-resource), [Exercises](#sec-sustainable-ai-resource)
:::
-
+
::: {.callout-tip}
## Learning Objectives
-* Understand the various aspects of AI's environmental impact, including energy consumption, carbon emissions, electronic waste, and biodiversity effects.
+* Understand AI's environmental impact, including energy consumption, carbon emissions, electronic waste, and biodiversity effects.
* Learn about methods and best practices for developing sustainable AI systems
* Appreciate the importance of taking a lifecycle perspective when evaluating and addressing the sustainability of AI systems.
-* Recognize the roles various stakeholders like researchers, corporations, policymakers and end users play in furthering responsible and sustainable AI progress.
-* Learn about specific frameworks, metrics and tools aimed at enabling greener AI development.
+* Recognize the roles various stakeholders, such as researchers, corporations, policymakers, and end users, play in furthering responsible and sustainable AI progress.
+* Learn about specific frameworks, metrics, and tools to enable greener AI development.
* Appreciate real-world case studies like Google's 4M efficiency practices that showcase how organizations are taking tangible steps to improve AI's environmental record
:::
@@ -26,19 +26,19 @@ Resources: [Slides](#sec-sustainable-ai-resource), [Labs](#sec-sustainable-ai-re
## Introduction {#introduction}
-The rapid advancements in artificial intelligence (AI) and machine learning (ML) have led to many beneficial applications and optimizations for performance efficiency. However, the remarkable growth of AI comes with a significant, yet often overlooked cost: its environmental impact. The most recent report released by the IPCC, the international body leading scientific assessments of climate change and its impacts, emphasized the pressing importance of tackling climate change. Without immediate efforts to decrease global $\textrm{CO}_2$ emissions by at least 43 percent before 2030, we exceed global warming of 1.5 degrees celsius [@lecocq2022mitigation]. This could initiate positive feedback loops pushing temperatures even higher. Next to environmental issues, the United Nations recognized [17 Sustainable Development Goals (SDGs)](https://sdgs.un.org/goals), in which AI can play an important role, and vice versa, play an important role in the development of AI systems. As the field continues expanding, considering sustainability is crucial.
+The rapid advancements in artificial intelligence (AI) and machine learning (ML) have led to many beneficial applications and optimizations for performance efficiency. However, the remarkable growth of AI comes with a significant yet often overlooked cost: its environmental impact. The most recent report released by the IPCC, the international body leading scientific assessments of climate change and its impacts, emphasized the pressing importance of tackling climate change. Without immediate efforts to decrease global $\textrm{CO}_2$ emissions by at least 43 percent before 2030, we exceed global warming of 1.5 degrees Celsius [@lecocq2022mitigation]. This could initiate positive feedback loops, pushing temperatures even higher. Next to environmental issues, the United Nations recognized [17 Sustainable Development Goals (SDGs)](https://sdgs.un.org/goals), in which AI can play an important role, and vice versa, play an important role in the development of AI systems. As the field continues expanding, considering sustainability is crucial.
-AI systems, particularly large language models like [GPT-3](https://openai.com/blog/gpt-3-apps/) and computer vision models like [DALL-E 2](https://openai.com/dall-e-2/), require massive amounts of computational resources for training. For example, GPT-3 was estimated to consume 1,300 megawatt-hours of electricity, which is equal to 1,450 average U.S. households in an entire month [@maslej2023artificial], or put another way it consumed enough energy to supply an average U.S. household for 120 years! This immense energy demand stems primarily from power-hungry data centers with servers running intense computations to train these complex neural networks for days or weeks.
+AI systems, particularly large language models like [GPT-3](https://openai.com/blog/gpt-3-apps/) and computer vision models like [DALL-E 2](https://openai.com/dall-e-2/), require massive amounts of computational resources for training. For example, GPT-3 was estimated to consume 1,300 megawatt-hours of electricity, which is equal to 1,450 average US households in an entire month [@maslej2023artificial], or put another way, it consumed enough energy to supply an average US household for 120 years! This immense energy demand stems primarily from power-hungry data centers with servers running intense computations to train these complex neural networks for days or weeks.
-Current estimates indicate that the carbon emissions produced from developing a single sophisticated AI model can equal the emissions over the lifetime of five standard gasoline-powered vehicles [@strubell2019energy]. A significant portion of the electricity presently consumed by data centers is generated from nonrenewable sources such as coal and natural gas, resulting in data centers contributing around [1% of total worldwide carbon emissions](https://www.iea.org/energy-system/buildings/data-centres-and-data-transmission-networks). This is comparable to the emissions from the entire airline sector. This immense carbon footprint demonstrates the pressing need to transition to renewable power sources such as solar and wind to operate AI development.
+Current estimates indicate that the carbon emissions produced from developing a single, sophisticated AI model can equal the emissions over the lifetime of five standard gasoline-powered vehicles [@strubell2019energy]. A significant portion of the electricity presently consumed by data centers is generated from nonrenewable sources such as coal and natural gas, resulting in data centers contributing around [1% of total worldwide carbon emissions](https://www.iea.org/energy-system/buildings/data-centres-and-data-transmission-networks). This is comparable to the emissions from the entire airline sector. This immense carbon footprint demonstrates the pressing need to transition to renewable power sources such as solar and wind to operate AI development.
-Additionally, even small-scale AI systems deployed to edge devices as part of TinyML have environmental impacts that should not be ignored [@prakash2023tinyml]. The specialized hardware required for AI has an environmental toll from natural resource extraction and manufacturing. GPUs, CPUs, and chips like TPUs depend on rare earth metals whose mining and processing generate substantial pollution. The production of these components also has its energy demands. Furthermore, the process of collecting, storing, and preprocessing data used to train both small- and large-scale models comes with environmental costs, which further exacerbates the sustainability implications of ML systems.
+Additionally, even small-scale AI systems deployed to edge devices as part of TinyML have environmental impacts that should not be ignored [@prakash2023tinyml]. The specialized hardware required for AI has an environmental toll from natural resource extraction and manufacturing. GPUs, CPUs, and chips like TPUs depend on rare earth metals whose mining and processing generate substantial pollution. The production of these components also has its energy demands. Furthermore, collecting, storing, and preprocessing data used to train both small- and large-scale models comes with environmental costs, further exacerbating the sustainability implications of ML systems.
-Thus, while AI promises innovative breakthroughs in many fields, sustaining progress requires addressing its sustainability challenges. AI can continue advancing responsibly by optimizing the efficiency of models, exploring alternative specialized hardware and renewable energy sources for data centers, and tracking the overall environmental impact.
+Thus, while AI promises innovative breakthroughs in many fields, sustaining progress requires addressing sustainability challenges. AI can continue advancing responsibly by optimizing models' efficiency, exploring alternative specialized hardware and renewable energy sources for data centers, and tracking its overall environmental impact.
## Social and Ethical Responsibility {#social-and-ethical-responsibility}
-The environmental impact of AI is not just a technical issue but an ethical and social one as well. As AI becomes more integrated into our lives and industries, its sustainability becomes increasingly critical.
+The environmental impact of AI is not just a technical issue but also an ethical and social one. As AI becomes more integrated into our lives and industries, its sustainability becomes increasingly critical.
### Ethical Considerations {#ethical-considerations}
@@ -46,9 +46,9 @@ The scale of AI's environmental footprint raises profound ethical questions abou
There is a clear and present need for us to have open and honest conversations about AI's environmental tradeoffs earlier in the development lifecycle. Researchers should feel empowered to voice concerns if organizational priorities do not align with ethical goals, as in the case of the [open letter to pause giant AI experiments](https://futureoflife.org/open-letter/pause-giant-ai-experiments/).
-Additionally, there is increasing need for AI companies to scrutinize their contributions to climate change and environmental harm. Large tech firms are responsible for the cloud infrastructure, data center energy demands, and resource extraction required to power today's AI. Leadership should assess if organizational values and policies promote sustainability, from hardware manufacturing through model training pipelines.
+Additionally, there is an increasing need for AI companies to scrutinize their contributions to climate change and environmental harm. Large tech firms are responsible for the cloud infrastructure, data center energy demands, and resource extraction required to power today's AI. Leadership should assess whether organizational values and policies promote sustainability, from hardware manufacturing through model training pipelines.
-Furthermore, voluntary self-regulation may not be enough---governments may need to introduce new regulations aimed at sustainable AI standards and practices if we hope to curb the projected energy explosion of ever-larger models. Reported metrics like compute usage, carbon footprint, and efficiency benchmarks could help hold organizations accountable.
+Furthermore, more than voluntary self-regulation may be needed-- -governments may need to introduce new regulations aimed at sustainable AI standards and practices if we hope to curb the projected energy explosion of ever-larger models. Reported metrics like computing usage, carbon footprint, and efficiency benchmarks could hold organizations accountable.
Through ethical principles, company policies, and public rules, AI technologists and corporations have a profound duty to our planet to ensure the responsible and sustainable advancement of technology positioned to transform modern society radically. We owe it to future generations to get this right.
@@ -56,247 +56,247 @@ Through ethical principles, company policies, and public rules, AI technologists
The massive projected expansion of AI raises urgent concerns about its long-term sustainability. As AI software and applications rapidly increase in complexity and usage across industries, demand for computing power and infrastructure will skyrocket exponentially in the coming years.
-To put the scale of projected growth in perspective, the total computing capacity required for training AI models saw an astonishing 350,000x increase from 2012 to 2019 [@schwartz2020green]. Researchers forecast over an order of magnitude growth each year moving forward as personalized AI assistants, autonomous technology, precision medicine tools, and more are developed. Similar trends are estimated for embedded ML systems, with an estimated 2.5 billion AI-enabled edge devices being deployed by 2030.
+To put the scale of projected growth in perspective, the total computing capacity required for training AI models saw an astonishing 350,000x increase from 2012 to 2019 [@schwartz2020green]. Researchers forecast over an order of magnitude growth each year moving forward as personalized AI assistants, autonomous technology, precision medicine tools, and more are developed. Similar trends are estimated for embedded ML systems, with an estimated 2.5 billion AI-enabled edge devices deployed by 2030.
Managing this expansion level requires software and hardware-focused breakthroughs in efficiency and renewable integration from AI engineers and scientists. On the software side, novel techniques in model optimization, distillation, pruning, low-precision numerics, knowledge sharing between systems, and other areas must become widespread best practices to curb energy needs. For example, realizing even a 50% reduced computational demand per capability doubling would have massive compounding on total energy.
-On the hardware infrastructure side, due to increasing costs of data transfer, storage, cooling, and space, continuing today's centralized server farm model at data centers is likely infeasible long-term [@lannelongue2021green]. Exploring alternative decentralized computing options around "edge AI" on local devices or within telco networks can alleviate scaling pressures on power-hungry hyperscale data centers. Likewise, the shift towards carbon-neutral, hybrid renewable energy sources powering leading cloud provider data centers worldwide will be essential.
+On the hardware infrastructure side, due to increasing costs of data transfer, storage, cooling, and space, continuing today's centralized server farm model at data centers is likely infeasible long-term [@lannelongue2021green]. Exploring alternative decentralized computing options around "edge AI" on local devices or within telco networks can alleviate scaling pressures on power-hungry hyper scale data centers. Likewise, the shift towards carbon-neutral, hybrid renewable energy sources powering leading cloud provider data centers worldwide will be essential.
### AI for Environmental Good {#ai-for-environmental-good}
While much focus goes on AI's sustainability challenges, these powerful technologies provide unique solutions to combat climate change and drive environmental progress. For example, ML can continuously optimize smart power grids to improve renewable integration and electricity distribution efficiency across networks [@zhang2018review]. Models can ingest the real-time status of a power grid and weather forecasts to allocate and shift sources responding to supply and demand.
-Fine-tuned neural networks have also proven remarkably effective at next-generation [weather forecasting](https://deepmind.google/discover/blog/graphcast-ai-model-for-faster-and-more-accurate-global-weather-forecasting/) [@lam2023learning] and climate modeling [@kurth2023fourcastnet]. They can rapidly analyze massive volumes of climate data to boost extreme event preparation and resource planning for hurricanes, floods, droughts and more. Climate researchers have achieved state-of-the-art storm path accuracy by combining AI simulations with traditional numerical models.
+Fine-tuned neural networks have also proven remarkably effective at next-generation [weather forecasting](https://deepmind.google/discover/blog/graphcast-ai-model-for-faster-and-more-accurate-global-weather-forecasting/) [@lam2023learning] and climate modeling [@kurth2023fourcastnet]. They can rapidly analyze massive volumes of climate data to boost extreme event preparation and resource planning for hurricanes, floods, droughts, and more. Climate researchers have achieved state-of-the-art storm path accuracy by combining AI simulations with traditional numerical models.
AI also enables better tracking of biodiversity [@silvestro2022improving], wildlife [@schwartz2021deployment], [ecosystems](https://blogs.nvidia.com/blog/conservation-ai-detects-threats-to-endangered-species/#:~:text=The%20Conservation%20AI%20platform%20%E2%80%94%20built,of%20potential%20threats%20via%20email), and illegal deforestation using drones and satellite feeds. Computer vision algorithms can automate species population estimates and habitat health assessments over huge untracked regions. These capabilities provide conservationists with powerful tools for combating poaching [@bondi2018spot], reducing species extinction risks, and understanding ecological shifts.
-Targeted investment into AI applications for environmental sustainability, cross-sector data sharing, and model accessibility can profoundly accelerate solutions to pressing ecological issues. Emphasizing AI for social good steers innovation in cleaner directions, guiding these world-shaping technologies towards ethical and responsible development.
+Targeted investment in AI applications for environmental sustainability, cross-sector data sharing, and model accessibility can profoundly accelerate solutions to pressing ecological issues. Emphasizing AI for social good steers innovation in cleaner directions, guiding these world-shaping technologies towards ethical and responsible development.
### Case Study
-Google's data centers are foundational to powering products like Search, Gmail, and YouTube used by billions daily. However, keeping the vast server farms up and running requires substantial energy, particularly for vital cooling systems. Google continuously strives to enhance efficiency across operations. Yet progress was proving difficult through traditional methods alone considering the complex, custom dynamics involved. This challenge prompted an ML breakthrough yielding potential savings.
+Google's data centers are foundational to powering products like Search, Gmail, and YouTube, which are used by billions daily. However, keeping the vast server farms up and running requires substantial energy, particularly for vital cooling systems. Google continuously strives to enhance efficiency across operations. Yet progress was proving difficult through traditional methods alone, considering the complex, custom dynamics involved. This challenge prompted an ML breakthrough, yielding potential savings.
After over a decade of optimizing data center design, inventing energy-efficient computing hardware, and securing renewable energy sources, [Google brought DeepMind scientists to unlock further advances](https://blog.google/outreach-initiatives/environment/deepmind-ai-reduces-energy-used-for/). The AI experts faced intricate factors surrounding the functioning of industrial cooling apparatuses. Equipment like pumps and chillers interact nonlinearly, while external weather and internal architectural variables also change. Capturing this complexity confounded rigid engineering formulas and human intuition.
-The DeepMind team leveraged Google's extensive historical sensor data detailing temperatures, power draw, and other attributes as training inputs. They built a flexible system based on neural networks to model the relationships and predict optimal configurations, minimizing power usage effectiveness (PUE) [@barroso2019datacenter]; PUE is the standard measurement for gauging how efficiently a data center uses energy-it gives the proportion of total facility power consumed divided by the power directly used for computing operations. When tested live, the AI system delivered remarkable gains beyond prior innovations, lowering cooling energy by 40% for a 15% drop in total PUE, a new site record. The generalizable framework learned cooling dynamics rapidly across shifting conditions that static rules could not match. The breakthrough highlights AI's rising role in transforming modern tech and enabling a sustainable future.
+The DeepMind team leveraged Google's extensive historical sensor data detailing temperatures, power draw, and other attributes as training inputs. They built a flexible system based on neural networks to model the relationships and predict optimal configurations, minimizing power usage effectiveness (PUE) [@barroso2019datacenter]; PUE is the standard measurement for gauging how efficiently a data center uses energy gives the proportion of total facility power consumed divided by the power directly used for computing operations. When tested live, the AI system delivered remarkable gains beyond prior innovations, lowering cooling energy by 40% for a 15% drop in total PUE, a new site record. The generalizable framework learned cooling dynamics rapidly across shifting conditions that static rules could not match. The breakthrough highlights AI's rising role in transforming modern tech and enabling a sustainable future.
## Energy Consumption {#energy-consumption}
### Understanding Energy Needs {#understanding-energy-needs}
-In the rapidly evolving field of AI, understanding the energy needs for training and operating AI models is crucial. With AI entering widespread use in many new fields [@bohr2020rise; @sudhakar2023data], the demand for AI enabled devices and data centers is expected to explode. This understanding helps us grasp why AI, particularly deep learning, is often labeled as energy-intensive.
+Understanding the energy needs for training and operating AI models is crucial in the rapidly evolving field of A.I. With AI entering widespread use in many new fields [@bohr2020rise; @sudhakar2023data], the demand for AI-enabled devices and data centers is expected to explode. This understanding helps us understand why AI, particularly deep learning, is often labeled energy-intensive.
#### Energy Requirements for AI Training {#energy-requirements-for-ai-training}
-The training of complex AI systems like large deep learning models can demand startlingly high levels of computing power--with profound energy implications. Consider OpenAI's state-of-the-art language model GPT-3 as a prime example. This system pushes the frontiers of text generation through algorithms trained on massive datasets, yet the energy GPT-3 consumed for a single training cycle could rival an [entire small town's monthly usage](https://www.washington.edu/news/2023/07/27/how-much-energy-does-chatgpt-use/). In recent years, these generative AI models have gained increasing popularity, leading to an increased number of models being trained. Next to the increased number of models, the number of parameters in these models is likely to increase as well. Research shows that increasing the model size (number of parameters), dataset size, and compute used for training improves performance smoothly with no signs of saturation [@kaplan2020scaling]. See how in @fig-scaling-laws the test loss decreases as each of the 3 aforementioned increases.
+The training of complex AI systems like large deep learning models can demand startlingly high levels of computing power--with profound energy implications. Consider OpenAI's state-of-the-art language model GPT-3 as a prime example. This system pushes the frontiers of text generation through algorithms trained on massive datasets. Yet, the energy GPT-3 consumed for a single training cycle could rival an [entire small town's monthly usage](https://www.washington.edu/news/2023/07/27/how-much-energy-does-chatgpt-use/). In recent years, these generative AI models have gained increasing popularity, leading to more models being trained. Next to the increased number of models, the number of parameters in these models will also increase. Research shows that increasing the model size (number of parameters), dataset size, and compute used for training improves performance smoothly with no signs of saturation [@kaplan2020scaling]. See how, in @fig-scaling-laws, the test loss decreases as each of the 3 increases above.
{#fig-scaling-laws}
-What drives such immense requirements? During training, models like GPT-3 essentially learn their capabilities by continuously processing huge volumes of data to adjust internal parameters. The processing capacity that enables AI's rapid advances also contributes to surging energy usage, especially as datasets and models balloon in size. In fact, GPT-3 highlights a steady trajectory in the field where each leap in AI's sophistication traces back to ever more substantial computational power and resources. Its predecessor GPT-2 required 10x less training compute being only 1.5 billion parameters; a difference now dwarfed by magnitudes as GPT-3 comprises 175 billion parameters. Sustaining this trajectory toward increasingly capable AI therefore raises energy and infrastructure provision challenges ahead.
+What drives such immense requirements? During training, models like GPT-3 learn their capabilities by continuously processing huge volumes of data to adjust internal parameters. The processing capacity enabling AI's rapid advances also contributes to surging energy usage, especially as datasets and models balloon. GPT-3 highlights a steady trajectory in the field where each leap in AI's sophistication traces back to ever more substantial computational power and resources. Its predecessor, GPT-2, required 10x less training to compute only 1.5 billion parameters, a difference now dwarfed by magnitudes as GPT-3 comprises 175 billion parameters. Sustaining this trajectory toward increasingly capable AI raises energy and infrastructure provision challenges ahead.
#### Operational Energy Use {#operational-energy-use}
-The development and training of AI models requires immense amounts of data, computing power, and energy. However, the deployment and operation of those models also incurs significant recurrent resource costs over time. AI systems are now integrated across various industries and applications, and entering daily lives of an increasing demographic. Their cumulative operational energy and infrastructure impacts could eclipse that of the upfront model training.
+Developing and training AI models requires immense data, computing power, and energy. However, the deployment and operation of those models also incur significant recurrent resource costs over time. AI systems are now integrated across various industries and applications and are entering the daily lives of an increasing demographic. Their cumulative operational energy and infrastructure impacts could eclipse the upfront model training.
-This concept is reflected in the demand of training and inference hardware, in datacenters and on the edge. Inference refers to the actual usage of a trained model to make predictions or decisions on real-world data. According to a [recent McKinsey analysis](https://www.mckinsey.com/~/media/McKinsey/Industries/Semiconductors/Our%20Insights/Artificial%20intelligence%20hardware%20New%20opportunities%20for%20semiconductor%20companies/Artificial-intelligence-hardware.ashx), the need for advanced systems to train ever-larger models is rapidly growing. However, inference computations already make up a dominant and increasing portion of total AI workloads, as shown in @fig-mckinsey. Running real-time inference with trained models--whether for image classification, speech recognition, or predictive analytics--invariably demands computing hardware like servers and chips. But even a model handling thousands of facial recognition requests or natural language queries daily is dwarfed by massive platforms like Meta. Where inference on millions of photos and videos shared on social media, the infrastructure energy requirements continue to scale!
+This concept is reflected in the demand for training and inference hardware in data centers and on the edge. Inference refers to using a trained model to make predictions or decisions on real-world data. According to a [recent McKinsey analysis](https://www.mckinsey.com/~/media/McKinsey/Industries/Semiconductors/Our%20Insights/Artificial%20intelligence%20hardware%20New%20opportunities%20for%20semiconductor%20companies/Artificial-intelligence-hardware.ashx), the need for advanced systems to train ever-larger models is rapidly growing. However, inference computations already make up a dominant and increasing portion of total AI workloads, as shown in @fig-mckinsey. Running real-time inference with trained models--whether for image classification, speech recognition, or predictive analytics--invariably demands computing hardware like servers and chips. However, even a model handling thousands of facial recognition requests or natural language queries daily is dwarfed by massive platforms like Meta. Where inference on millions of photos and videos shared on social media, the infrastructure energy requirements continue to scale!
](images/png/mckinsey_analysis.png){#fig-mckinsey}
-Algorithms powering AI-enabled smart assistants, automated warehouses, self-driving vehicles, tailored healthcare, and more have marginal individual energy footprints. However, the projected proliferation of these technologies could add hundreds of millions of endpoints running AI algorithms continually, causing the scale of their collective energy requirements to surge. Current efficiency gains struggle to counterbalance this sheer growth.
+Algorithms powering AI-enabled smart assistants, automated warehouses, self-driving vehicles, tailored healthcare, and more have marginal individual energy footprints. However, the projected proliferation of these technologies could add hundreds of millions of endpoints running AI algorithms continually, causing the scale of their collective energy requirements to surge. Current efficiency gains need help to counterbalance this sheer growth.
-AI is expected to see an [annual growth rate of 37.3% between 2023 and 2030](https://www.forbes.com/advisor/business/ai-statistics/). Yet applying the same growth rate to operational compute could multiply annual AI energy needs up to 1000 times by 2030. So while model optimization tackles one facet, responsible innovation must also consider total lifecycle costs at global deployment scales that were unfathomable just years ago but now pose infrastructure and sustainability challenges ahead.
+AI is expected to see an [annual growth rate of 37.3% between 2023 and 2030](https://www.forbes.com/advisor/business/ai-statistics/). Yet, applying the same growth rate to operational computing could multiply annual AI energy needs up to 1,000 times by 2030. So, while model optimization tackles one facet, responsible innovation must also consider total lifecycle costs at global deployment scales that were unfathomable just years ago but now pose infrastructure and sustainability challenges ahead.
### Data Centers and Their Impact {#data-centers-and-their-impact}
-The impact of data centers on the energy consumption of AI systems is a topic of increasing importance, as the demand for AI services grows. These facilities, while crucial for the advancement and deployment of AI, contribute significantly to its energy footprint.
+As the demand for AI services grows, the impact of data centers on the energy consumption of AI systems is becoming increasingly important. While these facilities are crucial for the advancement and deployment of AI, they contribute significantly to its energy footprint.
#### Scale {#scale}
Data centers are the essential workhorses enabling the recent computational demands of advanced AI systems. For example, leading providers like Meta operate massive data centers spanning up to the [size of multiple football fields](https://tech.facebook.com/engineering/2021/8/eagle-mountain-data-center/), housing hundreds of thousands of high-capacity servers optimized for parallel processing and data throughput.
-These massive facilities provide the infrastructure for training complex neural networks on vast datasets--for instance, based on [leaked information](https://www.semianalysis.com/p/gpt-4-architecture-infrastructure), OpenAI's language model GPT-4 was trained on Azure data centers packing over 25,000 Nvidia A100 GPUs, used continuously for over 90 to 100 days.
+These massive facilities provide the infrastructure for training complex neural networks on vast datasets. For instance, based on [leaked information](https://www.semianalysis.com/p/gpt-4-architecture-infrastructure), OpenAI's language model GPT-4 was trained on Azure data centers packing over 25,000 Nvidia A100 GPUs, used continuously for over 90 to 100 days.
-Additionally, real-time inference for consumer AI applications at scale is only made possible by leveraging the server farms inside data centers. Services like Alexa, Siri and Google Assistant process billions of voice requests per month from users globally by relying on data center computing for low-latency response. Going forward, expanding cutting-edge use cases like self-driving vehicles, precision medicine diagnostics, and accurate climate forecasting models require significant computational resources, obtained by tapping into vast on-demand cloud computing resources from data centers. For some emerging applications like autonomous cars, there are harsh latency and bandwidth constraints. Locating data center-level compute power on the edge rather than the cloud will be necessary.
+Additionally, real-time inference for consumer AI applications at scale is only made possible by leveraging the server farms inside data centers. Services like Alexa, Siri, and Google Assistant process billions of voice requests per month from users globally by relying on data center computing for low-latency response. In the future, expanding cutting-edge use cases like self-driving vehicles, precision medicine diagnostics, and accurate climate forecasting models will require significant computational resources to be obtained by tapping into vast on-demand cloud computing resources from data centers. Some emerging applications, like autonomous cars, have harsh latency and bandwidth constraints. Locating data center-level computing power on the edge rather than the cloud will be necessary.
-MIT research prototypes have shown trucks and cars with on-board hardware performing real-time AI processing of sensor data equivalent to small data centers [@sudhakar2023data]. These innovative "data centers on wheels" demonstrate how vehicles like self-driving trucks may need embedded data center-scale compute on board to achieve millisecond system latency for navigation, though still likely supplemented by wireless 5G connectivity to more powerful cloud data centers.
+MIT research prototypes have shown trucks and cars with onboard hardware performing real-time AI processing of sensor data equivalent to small data centers [@sudhakar2023data]. These innovative "data centers on wheels" demonstrate how vehicles like self-driving trucks may need embedded data center-scale compute on board to achieve millisecond system latency for navigation, though still likely supplemented by wireless 5G connectivity to more powerful cloud data centers.
-The bandwidth, storage, and processing capacities required for enabling this future technology at scale will depend heavily on continuing data center infrastructure advancement alongside AI algorithmic innovations.
+The bandwidth, storage, and processing capacities required to enable this future technology at scale will depend heavily on advancements in data center infrastructure and AI algorithmic innovations.
#### Energy Demand {#energy-demand}
-The energy demand of data centers can roughly be divided into 4 components. Infrastructure, network, storage and servers. In @fig-energydemand, we see that the data infrastructure (which includes aspects such as cooling, lighting and controls) and the servers use the majority of the total energy budget of datacenters in the US [@shehabi2016united]. In this section, we break down the energy demand for the servers and the infrastructure. For the latter, the focus is laid on the cooling systems, as cooling is the dominant factor in energy consumption in the infrastructure.
+The energy demand of data centers can roughly be divided into 4 components—infrastructure, network, storage, and servers. In @fig-energydemand, we see that the data infrastructure (which includes cooling, lighting, and controls) and the servers use most of the total energy budget of data centers in the US [@shehabi2016united]. This section breaks down the energy demand for the servers and the infrastructure. For the latter, the focus is on cooling systems, as cooling is the dominant factor in energy consumption in the infrastructure.
-{#fig-energydemand}
+{#fig-energydemand}
##### Servers {#servers}
-The increase in energy consumption of data centers stems mainly from exponentially growing AI computing requirements. NVIDIA DGX H100 machines that are optimized for deep learning can draw up to [10.2 kW at peak](https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.html). Leading providers operate data centers with hundreds to thousands of these power-hungry DGX nodes networked to train the latest AI models. For example, the supercomputer developed for OpenAI is a single system with more than 285,000 CPU cores, 10,000 GPUs and 400 gigabits per second of network connectivity for each GPU server.
+The increase in energy consumption of data centers stems mainly from exponentially growing AI computing requirements. NVIDIA DGX H100 machines that are optimized for deep learning can draw up to [10.2 kW at peak](https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.html). Leading providers operate data centers with hundreds to thousands of these power-hungry DGX nodes networked to train the latest AI models. For example, the supercomputer developed for OpenAI is a single system with over 285,000 CPU cores, 10,000 GPUs, and 400 gigabits per second of network connectivity for each GPU server.
The intensive computations needed across an entire facility's densely packed fleet and supporting hardware result in data centers drawing tens of megawatts around the clock. Overall, advancing AI algorithms continue to expand data center energy consumption as more DGX nodes get deployed to keep pace with projected growth in demand for AI compute resources over the coming years.
##### Cooling Systems {#cooling-systems}
-To keep the beefy servers fed at peak capacity and cool, data centers require tremendous cooling capacity to counteract the heat produced by densely packed servers, networking equipment, and other hardware running computationally-intensive workloads without pause. With large data centers packing thousands of server racks operating at full tilt, massive industrial-scale cooling towers and chillers are required, using energy amounting to 30-40% of the total data center electricity footprint [@dayarathna2015data]. Consequently, companies are looking for alternative methods of cooling. For example, Microsoft's data center in Ireland leverages a nearby fjord to exchange heat [using over half a million gallons of seawater daily](https://local.microsoft.com/communities/emea/dublin/).
+To keep the beefy servers fed at peak capacity and cool, data centers require tremendous cooling capacity to counteract the heat produced by densely packed servers, networking equipment, and other hardware running computationally intensive workloads without pause. With large data centers packing thousands of server racks operating at full tilt, massive industrial-scale cooling towers and chillers are required, using energy amounting to 30-40% of the total data center electricity footprint [@dayarathna2015data]. Consequently, companies are looking for alternative methods of cooling. For example, Microsoft's data center in Ireland leverages a nearby fjord to exchange heat [using over half a million gallons of seawater daily](https://local.microsoft.com/communities/emea/dublin/).
-Recognizing the importance of energy-efficient cooling, there have been innovations aimed at reducing this energy demand. Techniques like free cooling, which uses outside air or water sources when conditions are favorable, and the use of AI to optimize cooling systems, are examples of how the industry is adapting. These innovations not only reduce energy consumption but also lower operational costs and lessen the environmental footprint. However, exponential increases in AI model complexity continue to demand more servers and acceleration hardware operating at higher utilization, translating to rising heat generation and ever greater energy used solely for cooling purposes.
+Recognizing the importance of energy-efficient cooling, there have been innovations aimed at reducing this energy demand. Techniques like free cooling, which uses outside air or water sources when conditions are favorable, and the use of AI to optimize cooling systems are examples of how the industry adapts. These innovations reduce energy consumption, lower operational costs, and lessen the environmental footprint. However, exponential increases in AI model complexity continue to demand more servers and acceleration hardware operating at higher utilization, translating to rising heat generation and ever greater energy used solely for cooling purposes.
#### The Environmental Impact {#the-environmental-impact}
-The environmental impact of data centers is not only caused by direct energy consumption of the datacenter itself [@siddik2021environmental]. The operation of data centers involves the supply of treated water to the datacenter and the discharge of wastewater from the datacenter. Water and wastewater facilities are major electricity consumers.
+The environmental impact of data centers is not only caused by the direct energy consumption of the data center itself [@siddik2021environmental]. Data center operation involves the supply of treated water to the data center and the discharge of wastewater from the data center. Water and wastewater facilities are major electricity consumers.
-Next to electricity usage, there are many more aspects to the environmental impacts of these data centers. The water usage of the data centers can lead to water scarcity issues, increased water treatment needs and proper wastewater discharge infrastructure. Also raw materials required for construction and network transmission pose considerable impacts on the environment. Finally, components in data centers need to be upgraded and maintained. Where almost 50 percent of servers were refreshed within 3 years of usage, refresh cycles have shown to slow down [@davis2022uptime]. Still, this generates a significant amount of e-waste which can be hard to recycle.
+Next to electricity usage, there are many more aspects to the environmental impacts of these data centers. The water usage of the data centers can lead to water scarcity issues, increased water treatment needs, and proper wastewater discharge infrastructure. Also, raw materials required for construction and network transmission considerably impact environmental t the environment, and components in data centers need to be upgraded and maintained. Where almost 50 percent of servers were refreshed within 3 years of usage, refresh cycles have shown to slow down [@davis2022uptime]. Still, this generates significant e-waste, which can be hard to recycle.
### Energy Optimization {#energy-optimization}
-Ultimately, measuring and understanding the energy consumption of AI facilitate the optimization of energy consumption.
+Ultimately, measuring and understanding the energy consumption of AI facilitates optimizing energy consumption.
One way to reduce the energy consumption of a given amount of computational work is to run it on more energy-efficient hardware.
For instance, TPU chips can be more energy-efficient compared to CPUs when it comes to running large tensor computations for AI, as TPUs can run such computations much faster without drawing significantly more power than CPUs.
-Another way is to build software systems that are aware of energy consumption and application characteristics.
-Good examples are systems works such as Zeus [@jie2023zeus] and Perseus [@jaewon2023perseus], both of which characterize the trade-off between computation time and energy consumption at various levels of an ML training system to achieve energy reduction without end-to-end slowdown.
+Another way is to build software systems aware of energy consumption and application characteristics.
+Good examples are systems works such as Zeus [@jie2023zeus] and Perseus [@jaewon2023perseus], both of which characterize the tradeoff between computation time and energy consumption at various levels of an ML training system to achieve energy reduction without end-to-end slowdown.
In reality, building both energy-efficient hardware and software and combining their benefits should be promising, along with open-source frameworks (e.g., [Zeus](https://ml.energy/zeus)) that facilitate community efforts.
## Carbon Footprint {#carbon-footprint}
-The massive electricity demands of data centers can lead to significant environmental externalities absent an adequate renewable power supply. Many facilities rely heavily on non-renewable energy sources like coal and natural gas. For example, data centers are estimated to produce up to [2% of total global $\textrm{CO}_2$ emissions](https://www.independent.co.uk/climate-change/news/global-warming-data-centres-to-consume-three-times-as-much-energy-in-next-decade-experts-warn-a6830086.html) which is [closing the gap with the airline industry](https://www.computerworld.com/article/3431148/why-data-centres-are-the-new-frontier-in-the-fight-against-climate-change.html). As mentioned in previous sections, the computational demands of AI are set to increase. The emissions of this surge are threefold. First, data centers are projected to increase in size [@liu2020energy]. Secondly, emissions during training are set to increase significantly [@patterson2022carbon]. Thirdly, inference calls to these models are set to increase dramatically as well.
+The massive electricity demands of data centers can lead to significant environmental externalities absent an adequate renewable power supply. Many facilities rely heavily on nonrenewable energy sources like coal and natural gas. For example, data centers are estimated to produce up to [2% of total global $\textrm{CO}_2$ emissions](https://www.independent.co.uk/climate-change/news/global-warming-data-centres-to-consume-three-times-as-much-energy-in-next-decade-experts-warn-a6830086.html) which is [closing the gap with the airline industry](https://www.computerworld.com/article/3431148/why-data-centres-are-the-new-frontier-in-the-fight-against-climate-change.html). As mentioned in previous sections, the computational demands of AI are set to increase. The emissions of this surge are threefold. First, data centers are projected to increase in size [@liu2020energy]. Secondly, emissions during training are set to increase significantly [@patterson2022carbon]. Thirdly, inference calls to these models are set to increase dramatically.
Without action, this exponential demand growth risks ratcheting up the carbon footprint of data centers further to unsustainable levels. Major providers have pledged carbon neutrality and committed funds to secure clean energy, but progress remains incremental compared to overall industry expansion plans. More radical grid decarbonization policies and renewable energy investments may prove essential to counteracting the climate impact of the coming tide of new data centers aimed at supporting the next generation of AI.
### Definition and Significance {#definition-and-significance}
-The concept of a 'carbon footprint' has emerged as a key metric. This term refers to the total amount of greenhouse gasses, particularly carbon dioxide, that are emitted directly or indirectly by an individual, organization, event, or product. These emissions significantly contribute to the greenhouse effect, which in turn accelerates global warming and climate change. The carbon footprint is measured in terms of carbon dioxide equivalents ($\textrm{CO}_2$e), allowing for a comprehensive account that includes various greenhouse gasses and their relative impact on the environment. Examples of this as applied to large-scale ML tasks is shown in @fig-carbonfootprint.
+The concept of a 'carbon footprint' has emerged as a key metric. This term refers to the total amount of greenhouse gasses, particularly carbon dioxide, emitted directly or indirectly by an individual, organization, event, or product. These emissions significantly contribute to the greenhouse effect, accelerating global warming and climate change. The carbon footprint is measured in terms of carbon dioxide equivalents ($\textrm{CO}_2$e), allowing for a comprehensive account that includes various greenhouse gasses and their relative environmental impact. Examples of this as applied to large-scale ML tasks are shown in @fig-carbonfootprint.
{#fig-carbonfootprint}
-The consideration of the carbon footprint is especially important in the field of AI. AI's rapid advancement and integration into various sectors have brought its environmental impact into sharp focus. AI systems, particularly those involving intensive computations like deep learning and large-scale data processing, are known for their substantial energy demands. This energy, often drawn from power grids, may still predominantly rely on fossil fuels, leading to significant greenhouse gas emissions.
+Considering the carbon footprint is especially important in AI AI's rapid advancement and integration into various sectors, bringing its environmental impact into sharp focus. AI systems, particularly those involving intensive computations like deep learning and large-scale data processing, are known for their substantial energy demands. This energy, often drawn from power grids, may still predominantly rely on fossil fuels, leading to significant greenhouse gas emissions.
-Take, for example, the training of large AI models such as GPT-3 or complex neural networks. These processes require immense computational power, typically provided by data centers. The energy consumption associated with operating these centers, particularly for such high-intensity tasks, results in notable greenhouse gas emissions. Studies have highlighted that training a single AI model can generate carbon emissions comparable to that of the lifetime emissions of multiple cars, shedding light on the environmental cost of developing advanced AI technologies [@dayarathna2015data]. @fig-carboncars shows a comparison from lowest to highest carbon footprints, starting with a roundtrip flight between NY and SF, human life average per year, American life average per year, US car including fuel over a lifetime, and a Transformer model with neural architecture search, which has the highest footprint.
+Take, for example, training large AI models such as GPT-3 or complex neural networks. These processes require immense computational power, typically provided by data centers. The energy consumption associated with operating these centers, particularly for high-intensity tasks, results in notable greenhouse gas emissions. Studies have highlighted that training a single AI model can generate carbon emissions comparable to that of the lifetime emissions of multiple cars, shedding light on the environmental cost of developing advanced AI technologies [@dayarathna2015data]. @fig-carboncars shows a comparison from lowest to highest carbon footprints, starting with a roundtrip flight between NY and SF, human life average per year, American life average per year, US car including fuel over a lifetime, and a Transformer model with neural architecture search, which has the highest footprint.
{#fig-carboncars}
-Moreover, the carbon footprint of AI extends beyond the operational phase. The entire lifecycle of AI systems, including the manufacturing of computing hardware, the energy used in data centers for cooling and maintenance, and the disposal of electronic waste, contributes to their overall carbon footprint. Some of which we have discussed earlier and we will discuss the waste aspects later on in this chapter.
+Moreover, AI's carbon footprint extends beyond the operational phase. The entire lifecycle of AI systems, including the manufacturing of computing hardware, the energy used in data centers for cooling and maintenance, and the disposal of electronic waste, contributes to their overall carbon footprint. We have discussed some of these aspects earlier, and we will discuss the waste aspects later in this chapter.
### The Need for Awareness and Action {#the-need-for-awareness-and-action}
Understanding the carbon footprint of AI systems is crucial for several reasons. Primarily, it is a step towards mitigating the impacts of climate change. As AI continues to grow and permeate different aspects of our lives, its contribution to global carbon emissions becomes a significant concern. Awareness of these emissions can inform decisions made by developers, businesses, policymakers, and even ML engineers and scientists like us to ensure a balance between technological innovation and environmental responsibility.
-Furthermore, this understanding stimulates the drive towards 'Green AI' [@schwartz2020green]. This approach focuses on developing AI technologies that are efficient, powerful, and environmentally sustainable. It encourages the exploration of energy-efficient algorithms, the use of renewable energy sources in data centers, and the adoption of practices that reduce the overall environmental impact of AI.
+Furthermore, this understanding stimulates the drive towards 'Green AI' [@schwartz2020green]. This approach focuses on developing AI technologies that are efficient, powerful, and environmentally sustainable. It encourages exploring energy-efficient algorithms, using renewable energy sources in data centers, and adopting practices that reduce A. I'm the overall environmental impact.
In essence, the carbon footprint is an essential consideration in developing and applying AI technologies. As AI evolves and its applications become more widespread, managing its carbon footprint is key to ensuring that this technological progress aligns with the broader environmental sustainability goals.
### Estimating the AI Carbon Footprint {#estimating-the-ai-carbon-footprint}
-In understanding AI's environmental impact, estimating AI systems' carbon footprint is a critical step. This involves analyzing the various elements contributing to emissions throughout the lifecycle of AI technologies and employing specific methodologies to quantify these emissions accurately. Many different methods for quantifying these carbon emissions of ML have been proposed.
+Estimating AI systems' carbon footprint is critical in understanding their environmental impact. This involves analyzing the various elements contributing to emissions throughout AI technologies' lifecycle and employing specific methodologies to quantify these emissions accurately. Many different methods for quantifying ML's carbon emissions have been proposed.
-The carbon footprint of AI encompasses several key elements, each contributing to the overall environmental impact. First, energy is consumed during AI model training and operational phases. The source of this energy heavily influences the carbon emissions. Once trained, these models, depending on their application and scale, continue to consume electricity during operation. Next to energy considerations, the hardware used stresses the environment as well.
+The carbon footprint of AI encompasses several key elements, each contributing to the overall environmental impact. First, energy is consumed during the AI model training and operational phases. The source of this energy heavily influences the carbon emissions. Once trained, these models, depending on their application and scale, continue to consume electricity during operation. Next to energy considerations, the hardware used stresses the environment as well.
-The carbon footprint varies significantly based on the energy sources used. The composition of the sources providing the energy used in the grid varies widely with geographical regions, and even with time in a single day! For example, in the USA, [roughly 60 percent of the total energy supply is still covered by fossil fuels](https://www.eia.gov/tools/faqs/faq.php?id=427&t=3). The remaining 40 percent is roughly equally covered by nuclear and renewable energy sources. These fractions are not constant throughout the day. As the production of renewable energy usually relies on environmental factors, such as solar radiation and pressure fields, they do not provide a constant source of energy.
+The carbon footprint varies significantly based on the energy sources used. The composition of the sources providing the energy used in the grid varies widely depending on geographical region and even time in a single day! For example, in the USA, [roughly 60 percent of the total energy supply is still covered by fossil fuels](https://www.eia.gov/tools/faqs/faq.php?id=427&t=3). Nuclear and renewable energy sources cover the remaining 40 percent. These fractions are not constant throughout the day. As renewable energy production usually relies on environmental factors, such as solar radiation and pressure fields, they do not provide a constant energy source.
-The variability of renewable energy production has been an ongoing challenge in the widespread use of these sources. Looking at @fig-energyprod, which shows data for the European grid, we see that it is not yet possible to produce the required amount of energy throughout the entire day. While solar energy peaks in the middle of the day, wind energy shows two distinct peaks in the mornings and evenings. Currently, to supply the lack of energy during times where renewable energy does not meet requirements, we rely on fossil and coal based energy generation methods.
+The variability of renewable energy production has been an ongoing challenge in the widespread use of these sources. Looking at @fig-energyprod, which shows data for the European grid, we see that it is supposed to be able to produce the required amount of energy throughout the day. While solar energy peaks in the middle of the day, wind energy shows two distinct peaks in the mornings and evenings. Currently, we rely on fossil and coal-based energy generation methods to supply the lack of energy during times when renewable energy does not meet requirements,
-To enable constant use of renewable energy sources, innovation in energy storage solutions is required. Base energy load is currently met with nuclear energy. This constant energy source does not directly emit carbon emissions, but is too slow to accommodate for the variability of renewable energy sources. Tech companies such as Microsoft have shown interest in nuclear energy sources [to power their data centers](https://www.bloomberg.com/news/newsletters/2023-09-29/microsoft-msft-sees-artificial-intelligence-and-nuclear-energy-as-dynamic-duo). As the demand of data centers is more constant than the demand of regular households, nuclear energy could be used as a dominant source of energy.
+Innovation in energy storage solutions is required to enable constant use of renewable energy sources. The base energy load is currently met with nuclear energy. This constant energy source does not directly emit carbon emissions but needs to be faster to accommodate the variability of renewable energy sources. Tech companies such as Microsoft have shown interest in nuclear energy sources [to power their data centers](https://www.bloomberg.com/news/newsletters/2023-09-29/microsoft-msft-sees-artificial-intelligence-and-nuclear-energy-as-dynamic-duo). As the demand of data centers is more constant than the demand of regular households, nuclear energy could be used as a dominant source of energy.
.](images/png/europe_energy_grid.png){#fig-energyprod}
-Additionally, the manufacturing and disposal of AI hardware add to the carbon footprint. The production of specialized computing devices, such as GPUs and CPUs, is an energy- and resource-intensive process. This phase often relies on energy sources that contribute to greenhouse gas emissions. The manufacturing process of the electronics industry has been identified as one of the big eight supply chains, responsible for more than 50 percent of total global emissions [@challenge2021supply]. Furthermore, the end-of-life disposal of this hardware, which can lead to electronic waste, also has environmental implications. As mentioned before, servers currently have a refresh cycle of roughly 3 to 5 years. Of this e-waste, currently [only 17.4 percent is properly collected and recycled.](https://www.genevaenvironmentnetwork.org/resources/updates/the-growing-environmental-risks-of-e-waste/) The carbon emissions of this e-waste has shown an increase of more than 50 percent between 2014 and 2020 [@singh2022disentangling].
+Additionally, the manufacturing and disposal of AI hardware add to the carbon footprint. Producing specialized computing devices, such as GPUs and CPUs, is energy- and resource-intensive. This phase often relies on energy sources that contribute to greenhouse gas emissions. The electronics industry's manufacturing process has been identified as one of the eight big supply chains responsible for more than 50 percent of global emissions [@challenge2021supply]. Furthermore, the end-of-life disposal of this hardware, which can lead to electronic waste, also has environmental implications. As mentioned, servers have a refresh cycle of roughly 3 to 5 years. Of this e-waste, currently [only 17.4 percent is properly collected and recycled.](https://www.genevaenvironmentnetwork.org/resources/updates/the-growing-environmental-risks-of-e-waste/). The carbon emissions of this e-waste has shown an increase of more than 50 percent between 2014 and 2020 [@singh2022disentangling].
-As is clear from the above, a proper Life Cycle Analysis is necessary to portray all relevant aspects of the emissions caused by AI. Another method is carbon accounting, which quantifies the amount of carbon dioxide emissions directly and indirectly associated with AI operations. This measurement is typically in terms of $\textrm{CO}_2$ equivalents, allowing for a standardized way of reporting and assessing emissions.
+As is clear from the above, a proper Life Cycle Analysis is necessary to portray all relevant aspects of the emissions caused by AI. Another method is carbon accounting, which quantifies the amount of carbon dioxide emissions directly and indirectly associated with AI operations. This measurement typically uses $\textrm{CO}_2$ equivalents, allowing for a standardized way of reporting and assessing emissions.
:::{#exr-cf .callout-exercise collapse="true"}
### AI's Carbon Footprint
-Did you know that the cutting-edge AI models you might use have an environmental impact? This exercise will delve into the concept of an AI system's "carbon footprint." You'll learn how the energy demands of data centers, the training of large AI models, and even the manufacturing of hardware contribute to greenhouse gas emissions. We'll discuss why it's crucial to be aware of this impact, and you'll learn methods to estimate the carbon footprint of your own AI projects. Get ready to explore the intersection of AI and environmental sustainability!
+Did you know that the cutting-edge AI models you might use have an environmental impact? This exercise will delve into an AI system's "carbon footprint." You'll learn how data centers' energy demands, large AI models' training, and even hardware manufacturing contribute to greenhouse gas emissions. We'll discuss why it's crucial to be aware of this impact, and you'll learn methods to estimate the carbon footprint of your own AI projects. Get ready to explore the intersection of AI and environmental sustainability!
[](https://colab.research.google.com/drive/1zH7JrUixOAzb0qEexrgnFzBoRvn65nMh#scrollTo=5EunUBwmc9Lm)
:::
## Beyond Carbon Footprint {#beyond-carbon-footprint}
-The current focus on reducing the carbon emissions and energy consumption of AI systems addresses one crucial aspect of sustainability. However, the manufacturing of the semiconductors and hardware that enable AI also carries severe environmental impacts that receive comparatively less public attention. Building and operating a leading-edge semiconductor fabrication plant, or "fab", has substantial resource requirements and polluting byproducts beyond just a large carbon footprint.
+The current focus on reducing AI systems' carbon emissions and energy consumption addresses one crucial aspect of sustainability. However, manufacturing the semiconductors and hardware that enable AI also carries severe environmental impacts that receive comparatively less public attention. Building and operating a leading-edge semiconductor fabrication plant, or "fab," has substantial resource requirements and polluting byproducts beyond a large carbon footprint.
-For example, a state-of-the-art fab producing state of the art chips like in 5nm can require up to [four million gallons of pure water each day](https://wccftech.com/tsmc-using-water-tankers-for-chip-production-as-5nm-plant-faces-rationing/). This water usage approaches what a city of half a million people would require for all needs. Sourcing this consistently places immense strain on local water tables and reservoirs, especially in already water-stressed regions which host many high-tech manufacturing hubs.
+For example, a state-of-the-art fab producing state-of-the-art chips like in 5nm can require up to [four million gallons of pure water each day](https://wccftech.com/tsmc-using-water-tankers-for-chip-production-as-5nm-plant-faces-rationing/). This water usage approaches what a city of half a million people would require for all needs. Sourcing this consistently places immense strain on local water tables and reservoirs, especially in already water-stressed regions that host many high-tech manufacturing hubs.
-Additionally, over 250 unique hazardous chemicals are utilized at various stages of semiconductor production within fabs [@mills1997overview]. These include volatile solvents like sulfuric acid, nitric acid, hydrogen fluoride, along with arsine, phosphine and other highly toxic substances. Preventing discharge of these chemicals requires extensive safety controls and wastewater treatment infrastructure to avoid soil contamination and risks to surrounding communities. Any improper chemical handling or unanticipated spill carries dire consequences.
+Additionally, over 250 unique hazardous chemicals are utilized at various stages of semiconductor production within fabs [@mills1997overview]. These include volatile solvents like sulfuric acid, nitric acid, and hydrogen fluoride, along with arsine, phosphine, and other highly toxic substances. Preventing the discharge of these chemicals requires extensive safety controls and wastewater treatment infrastructure to avoid soil contamination and risks to surrounding communities. Any improper chemical handling or unanticipated spill carries dire consequences.
-Beyond water consumption and chemical risks, fab operation also depends on rare metals sourcing, generates tons of dangerous waste products, and can hamper local biodiversity. This section will analyze these critical but less discussed impacts. With vigilance and investment in safety, the harms from semiconductor manufacturing can be contained while still enabling technological progress. However, ignoring these externalized issues will exacerbate ecological damage and health risks over the long run.
+Beyond water consumption and chemical risks, fab operations also depend on rare metals sourcing, generate tons of dangerous waste products, and can hamper local biodiversity. This section will analyze these critical but less discussed impacts. With vigilance and investment in safety, the harms from semiconductor manufacturing can be contained while still enabling technological progress. However, ignoring these externalized issues will exacerbate ecological damage and health risks over the long run.
### Water Usage and Stress {#water-usage-and-stress}
-Semiconductor fabrication is an incredibly water-intensive process. Based on an article from 2009, a typical 300mm silicon wafer requires 8,328 litres of water in total, of which 5,678 litres is ultrapure water [@cope2009pure]. Today, a typical fab can use up to [four million gallons of pure water](https://wccftech.com/tsmc-arizona-foundry-205-million-approved/). TSMC's latest fab in Arizona is projected to use 8.9 million gallons per day, or nearly 3 percent of the city's current water production, just to operate one facility. To put things in perspective, an by Intel and [Quantis](https://quantis.com/) found that over 97% of their direct water consumption is attributed to semiconductor manufacturing operations within their own fabrication facilities [@cooper2011semiconductor].
+Semiconductor fabrication is an incredibly water-intensive process. Based on an article from 2009, a typical 300mm silicon wafer requires 8,328 liters of water, of which 5,678 liters is ultrapure water [@cope2009pure]. Today, a typical fab can use up to [four million gallons of pure water](https://wccftech.com/tsmc-arizona-foundry-205-million-approved/). To operate one facility, TSMC's latest fab in Arizona is projected to use 8.9 million gallons daily or nearly 3 percent of the city's current water production. To put things in perspective, Intel and [Quantis](https://quantis.com/) found that over 97% of their direct water consumption is attributed to semiconductor manufacturing operations within their fabrication facilities [@cooper2011semiconductor].
-This water is used to flush away contaminants in cleaning steps repeatedly and also acts as a coolant and carrier fluid in thermal oxidation, chemical deposition, and chemical mechanical planarization processes. This approximates the daily water consumption of a city with a population of half a million people during peak summer months.
+This water is repeatedly used to flush away contaminants in cleaning steps and also acts as a coolant and carrier fluid in thermal oxidation, chemical deposition, and chemical mechanical planarization processes. During peak summer months, this approximates the daily water consumption of a city with a population of half a million people.
Despite being located in regions with sufficient water, the intensive usage can severely depress local water tables and drainage basins. For example, the city of Hsinchu in Taiwan suffered [sinking water tables and seawater intrusion](https://wccftech.com/tsmc-using-water-tankers-for-chip-production-as-5nm-plant-faces-rationing/) into aquifers due to excessive pumping to satisfy water supply demands from the Taiwan Semiconductor Manufacturing Company (TSMC) fab. In water-scarce inland areas like Arizona, [massive water inputs are needed](https://www.americanbar.org/groups/environment_energy_resources/publications/wr/a-tale-of-two-shortages/) to support fabs despite already strained reservoirs.
-Besides depletion, water discharge from fabs also risks environmental contamination if not properly treated. While much discharge is recycled within the fab, the purification systems still filter out metals, acids, and other contaminants that can pollute rivers and lakes if not cautiously handled [@prakash2022cfu]. These factors make managing water usage an essential consideration when mitigating wider sustainability impacts.
+Water discharge from fabs risks environmental contamination besides depletion if not properly treated. While much discharge is recycled within the fab, the purification systems still filter out metals, acids, and other contaminants that can pollute rivers and lakes if not cautiously handled [@prakash2022cfu]. These factors make managing water usage essential when mitigating wider sustainability impacts.
### Hazardous Chemicals Usage {#hazardous-chemicals-usage}
Modern semiconductor fabrication involves working with many highly hazardous chemicals under extreme conditions of heat and pressure [@kim2018chemical]. Key chemicals utilized include:
-* **Strong acids:** Hydrofluoric, sulfuric, nitric, and hydrochloric acids rapidly eat through oxides and other surface contaminants but also pose toxicity dangers. Fabs can use thousands of metric tons of these acids annually. Accidental exposure can be fatal for workers.
-* **Solvents:** Key solvents like xylene, methanol, methyl isobutyl ketone (MIBK) handle dissolving photoresists but have adverse health impacts like skin/eye irritation, narcotic effects if mishandled. They also create explosive and air pollution risks.
-* **Toxic gases:** Gas mixtures containing arsine (AsH3), phosphine (PH3), diborane (B2H6), germane (GeH4), etc. are some of the deadliest chemicals used in doping and vapor deposition steps. Minimal exposures can lead to poisoning, tissue damage, and even death without quick treatment.
-* **Chlorinated compounds:** Older chemical mechanical planarization formulations incorporated perchloroethylene, trichloroethylene and other chlorinated solvents since banned due to carcinogenic effects and ozone layer impacts. However, their prior release still threatens surrounding groundwater sources.
+* **Strong acids:** Hydrofluoric, sulfuric, nitric, and hydrochloric acids rapidly eat through oxides and other surface contaminants but also pose toxicity dangers. Fabs can use thousands of metric tons of these acids annually, and accidental exposure can be fatal for workers.
+* **Solvents:** Key solvents like xylene, methanol, and methyl isobutyl ketone (MIBK) handle dissolving photoresists but have adverse health impacts like skin/eye irritation and narcotic effects if mishandled. They also create explosive and air pollution risks.
+* **Toxic gases:** Gas mixtures containing arsine (AsH3), phosphine (PH3), diborane (B2H6), germane (GeH4), etc., are some of the deadliest chemicals used in doping and vapor deposition steps. Minimal exposures can lead to poisoning, tissue damage, and even death without quick treatment.
+* **Chlorinated compounds:** Older chemical mechanical planarization formulations incorporated perchloroethylene, trichloroethylene, and other chlorinated solvents, which have since been banned due to their carcinogenic effects and impacts on the ozone layer. However, their prior release still threatens surrounding groundwater sources.
Strict handling protocols, protective equipment for workers, ventilation, filtrating/scrubbing systems, secondary containment tanks, and specialized disposal mechanisms are vital where these chemicals are used to minimize health, explosion, air, and environmental spill dangers [@wald1987semiconductor]. But human errors and equipment failures still occasionally occur--highlighting why reducing fab chemical intensities is an ongoing sustainability effort.
### Resource Depletion {#resource-depletion}
-While silicon forms the base, there is an almost endless supply of silicon available on Earth. In fact, [silicon is the second most plentiful element found in the Earth's crust](https://en.wikipedia.org/wiki/Abundance_of_elements_in_Earth%27s_crust), accounting for 27.7% of the crust's total mass. Only oxygen exceeds silicon in abundance within the crust. Therefore, silicon is not necessary to consider for resource depletion. However, the various specialty metals and materials that enable the integrated circuit fabrication process and provide specific properties are scarce. Maintaining supplies of these resources is crucial yet threatened by finite availability and geopolitical influences [@nakano2021geopolitics].
+While silicon forms the base, there is an almost endless supply of silicon on Earth. In fact, [silicon is the second most plentiful element found in the Earth's crust](https://en.wikipedia.org/wiki/Abundance_of_elements_in_Earth%27s_crust), accounting for 27.7% of the crust's total mass. Only oxygen exceeds silicon in abundance within the crust. Therefore, silicon is not necessary to consider for resource depletion. However, the various specialty metals and materials that enable the integrated circuit fabrication process and provide specific properties still need to be discovered. Maintaining supplies of these resources is crucial yet threatened by finite availability and geopolitical influences [@nakano2021geopolitics].
-Gallium, indium, and arsenic are vital ingredients in forming ultra-efficient compound semiconductors used in highest speed chips suited for 5G and AI applications [@chen2006gallium]. However, these rare elements have relatively scarce natural deposits that are being depleted. The United States Geological Survey has indium on its list of most critical at-risk commodities--estimated to have less than a 15 year viable global supply at current demand growth [@davies2011endangered].
+Gallium, indium, and arsenic are vital ingredients in forming ultra-efficient compound semiconductors in the highest-speed chips suited for 5G and AI applications [@chen2006gallium]. However, these rare elements have relatively scarce natural deposits that are being depleted. The United States Geological Survey has indium on its list of most critical at-risk commodities, estimated to have less than a 15-year viable global supply at current demand growth [@davies2011endangered].
-Helium is required in huge volumes for next-gen fabs to enable precise wafer cooling during operation. But helium's relative rarity and the fact that once it vents into the atmosphere it quickly escapes Earth makes maintaining helium supplies extremely challenging long-term [@davies2011endangered]. Substantial price increases and supply shocks are already occurring in this thinly-traded market according to the US National Academies.
+Helium is required in huge volumes for next-gen fabs to enable precise wafer cooling during operation. But helium's relative rarity and the fact that once it vents into the atmosphere, it quickly escapes Earth make maintaining helium supplies extremely challenging long-term [@davies2011endangered]. According to the US National Academies, substantial price increases and supply shocks are already occurring in this thinly traded market.
-Other risks include how China controls over 90% of the rare earth elements critical to semiconductor materials production [@jha2014rare]. Any supply chain issues or trade disputes can lead to catastrophic raw material shortages given lack of current alternatives. In conjunction with helium shortages, resolving the limited availability and geographic imbalance in accessing essential ingredients remains a sector priority for sustainability.
+Other risks include China's control over 90% of the rare earth elements critical to semiconductor material production [@jha2014rare]. Any supply chain issues or trade disputes can lead to catastrophic raw material shortages, given the lack of current alternatives. In conjunction with helium shortages, resolving the limited availability and geographic imbalance in accessing essential ingredients remains a sector priority for sustainability.
### Hazardous Waste Generation {#hazardous-waste-generation}
-Semiconductor fabs generate tons of hazardous waste annually as byproducts from the various chemical processes involved [@grossman2007high]. The key waste streams include:
+Semiconductor fabs generate tons of hazardous waste annually as byproducts from the various chemical processes [@grossman2007high]. The key waste streams include:
-* **Gaseous waste:** Fab ventilation systems capture harmful gases like arsine, phosphine, germane and filter them out to avoid worker exposure. But this produces significant quantities of dangerous condensed gas in need of specialized treatment.
-* **VOCs:** Volatile organic compounds like xylene, acetone, methanol are used extensively as photoresist solvents and get evaporated as emissions during baking, etching, and stripping stages. VOCs pose toxicity issues and require scrubbing systems to prevent release.
-* **Spent acids:** Strong acids such as sulfuric acid, hydrofluoric acid, nitric acid get depleted in cleaning and etching steps transforming into a corrosive toxic soup that can dangerously react releasing heat and fumes if mixed.
+* **Gaseous waste:** Fab ventilation systems capture harmful gases like arsine, phosphine, and germane and filter them out to avoid worker exposure. However, this produces significant quantities of dangerous condensed gas that need specialized treatment.
+* **VOCs:** Volatile organic compounds like xylene, acetone, and methanol are used extensively as photoresist solvents and are evaporated as emissions during baking, etching, and stripping. VOCs pose toxicity issues and require scrubbing systems to prevent release.
+* **Spent acids:** Strong acids such as sulfuric acid, hydrofluoric acid, and nitric acid get depleted in cleaning and etching steps, transforming into a corrosive, toxic soup that can dangerously react, releasing heat and fumes if mixed.
* **Sludge:** Water treatment of discharged effluent contains concentrated heavy metals, acid residues, and chemical contaminants. Filter press systems separate this hazardous sludge.
* **Filter cake:** Gaseous filtration systems generate multi-ton sticky cakes of dangerous absorbed compounds requiring containment.
-Without proper handling procedures, storage tanks, packaging materials, and secondary containment--improper disposal of any of these waste streams can lead to dangerous spills, explosions, and environmental release. And the massive volumes mean even well-run fabs produce tons of hazardous waste year after year requiring extensive treatment.
+Without proper handling procedures, storage tanks, packaging materials, and secondary containment, improper disposal of any of these waste streams can lead to dangerous spills, explosions, and environmental releases. The massive volumes mean even well-run fabs produce tons of hazardous waste year after year, requiring extensive treatment.
### Biodiversity Impacts {#biodiversity-impacts}
#### Habitat Disruption and Fragmentation {#habitat-disruption-and-fragmentation}
-Semiconductor fabs require large, contiguous land areas to accommodate cleanrooms, support facilities, chemical storage, waste treatment, and ancillary infrastructure. Developing these vast built-up spaces inevitably dismantles existing habitats, damaging sensitive biomes that may have taken decades to develop. For example, constructing a new fabrication module may level local forest ecosystems relied upon by species like spotted owls and elk for survival. The outright removal of such habitats severely threatens any wildlife populations dependant on those lands.
+Semiconductor fabs require large, contiguous land areas to accommodate cleanrooms, support facilities, chemical storage, waste treatment, and ancillary infrastructure. Developing these vast built-up spaces inevitably dismantles existing habitats, damaging sensitive biomes that may have taken decades to develop. For example, constructing a new fabrication module may level local forest ecosystems that species, like spotted owls and elk, rely upon for survival. The outright removal of such habitats severely threatens wildlife populations dependent on those lands.
-Furthermore, the pipelines, water channels, air and waste exhaust systems, access roads, transmission towers and other support infrastructure fragments the remaining undisturbed habitats. Animals ranging in their daily movements for food, water and spawning can find migration patterns blocked by these physical human barriers bisecting previously natural corridors.
+Furthermore, pipelines, water channels, air and waste exhaust systems, access roads, transmission towers, and other support infrastructure fragment the remaining undisturbed habitats. Animals moving daily for food, water, and spawning can find their migration patterns blocked by these physical human barriers that bisect previously natural corridors.
#### Aquatic Life Disturbances {#aquatic-life-disturbances}
-With semi-conductor fabs consuming millions of gallons of ultra-pure water daily, accessing and discharging such volumes risks altering the suitability of nearby aquatic environments housing fish, water plants, amphibians and other species. If the fab is tapping groundwater tables as its primary supply source, overdrawing at unsustainable rates can deplete lakes or lead to drying of streams as water levels drop [@davies2011endangered].
+With semiconductor fabs consuming millions of gallons of ultra-pure water daily, accessing and discharging such volumes risks altering the suitability of nearby aquatic environments housing fish, water plants, amphibians, and other species. If the fab is tapping groundwater tables as its primary supply source, overdrawing at unsustainable rates can deplete lakes or lead to stream drying as water levels drop [@davies2011endangered].
-Additionally, discharging higher temperature wastewater used for cooling fabrication equipment can shift downstream river conditions through thermal pollution. Temperature changes beyond thresholds which native species evolved for can disrupt reproductive cycles. Warmer water also holds less dissolved oxygen critical to support aquatic plant and animal life [@poff2002aquatic]. Combined with traces of residual contaminants that escape filtration systems, the discharged water can cumulatively transform environments to be far less habitable for sensitive organisms [@till2019fish].
+Also, discharging wastewater at higher temperatures to cool fabrication equipment can shift downstream river conditions through thermal pollution. Temperature changes beyond thresholds that native species evolved for can disrupt reproductive cycles. Warmer water also holds less dissolved oxygen, critical to supporting aquatic plant and animal life [@poff2002aquatic]. Combined with traces of residual contaminants that escape filtration systems, the discharged water can cumulatively transform environments to be far less habitable for sensitive organisms [@till2019fish].
#### Air and Chemical Emissions {#air-and-chemical-emissions}
-While modern semiconductor fabs aim to contain air and chemical discharges through extensive filtration systems, some level of emissions often persist raising risks for nearby flora and fauna. Air pollutants including volatile organic compounds (VOCs), nitrogen oxide compounds (NOxs), and particulate matter from fab operational exhausts as well as power plant fuel emissions can carry downwind.
+While modern semiconductor fabs aim to contain air and chemical discharges through extensive filtration systems, some levels of emissions often persist, raising risks for nearby flora and fauna. Air pollutants can carry downwind, including volatile organic compounds (VOCs), nitrogen oxide compounds (NOx), particulate matter from fab operational exhausts, and power plant fuel emissions.
-As contaminants permeate local soils and water sources, wildlife ingesting affected food and water ingest toxic substances which research shows can hamper cell function, reproduction rates and longevity--slowly poisoning ecosystems [@hsu2016accumulation].
+As contaminants permeate local soils and water sources, wildlife ingesting affected food and water ingest toxic substances, which research shows can hamper cell function, reproduction rates, and longevity--slowly poisoning ecosystems [@hsu2016accumulation].
-Likewise, accidental chemical spills and improper waste handling which releases acids, BODs, and heavy metals into soils can dramatically affect retention and leeching capabilities. Flora such as vulnerable native orchids adapted to nutrient-poor substrates can experience die-offs when contacted by foreign runoff chemicals that alter soil pH and permeability. One analysis found that a single 500 gallon nitric acid spill led to the regional extinction of a rare moss species in the year following when the acidic effluent reached nearby forest habitats. Such contamination events set off chain reactions across the interconnected web of life. Thus strict protocols are essential to avoid hazardous discharge and runoff.
+Likewise, accidental chemical spills and improper waste handling, which release acids, BODs, and heavy metals into soils, can dramatically affect retention and leeching capabilities. Flora, such as vulnerable native orchids adapted to nutrient-poor substrates, can experience die-offs when contacted by foreign runoff chemicals that alter soil pH and permeability. One analysis found that a single 500-gallon nitric acid spill led to the regional extinction of a rare moss species in the year following when the acidic effluent reached nearby forest habitats. Such contamination events set off chain reactions across the interconnected web of life. Thus, strict protocols are essential to avoid hazardous discharge and runoff.
## Life Cycle Analysis {#life-cycle-analysis}
-Understanding the holistic environmental impact of AI systems requires a comprehensive approach that considers the entire life cycle of these technologies. Life Cycle Analysis (LCA) refers to a methodological framework used to quantify the environmental impacts across all stages in the lifespan of a product or system, from raw material extraction to end-of-life disposal. Applying LCA to AI systems can help identify priority areas to target for reducing overall environmental footprints.
+Understanding the holistic environmental impact of AI systems requires a comprehensive approach that considers the entire life cycle of these technologies. Life Cycle Analysis (LCA) refers to a methodological framework used to quantify the environmental impacts across all stages in a product or system's lifespan, from raw material extraction to end-of-life disposal. Applying LCA to AI systems can help identify priority areas to target for reducing overall environmental footprints.
### Stages of an AI System's Life Cycle
The life cycle of an AI system can be divided into four key phases:
-* **Design Phase:** This includes the energy and resources used in the research and development of AI technologies. It encompasses the computational resources used for algorithm development and testing contributing to carbon emissions.
+* **Design Phase:** This includes the energy and resources used in researching and developing AI technologies. It encompasses the computational resources used for algorithm development and testing contributing to carbon emissions.
-* **Manufacture Phase:** This stage involves producing hardware components such as graphics cards, processors, and other computing devices necessary for running AI algorithms. Manufacturing these components often involves significant energy use for material extraction, processing, and greenhouse gas emissions.
+* **Manufacture Phase:** This stage involves producing hardware components such as graphics cards, processors, and other computing devices necessary for running AI algorithms. Manufacturing these components often involves significant energy for material extraction, processing, and greenhouse gas emissions.
* **Use Phase:** The next most energy-intensive phase involves the operational use of AI systems. It includes the electricity consumed in data centers for training and running neural networks and powering end-user applications. This is arguably one of the most carbon-intensive stages.
@@ -306,21 +306,21 @@ The life cycle of an AI system can be divided into four key phases:
**Design and Manufacturing**
-The environmental impact during these beginning-of-life phases includes emissions from energy use and resource depletion from extracting materials for hardware production. At the heart of AI hardware are semiconductors, primarily silicon, used to make the integrated circuits in processors and memory chips. This hardware manufacturing relies on metals like copper for wiring, aluminum for casings, and various plastics and composites for other components. It also uses rare earth metals and specialized alloys--elements like neodymium, terbium, and yttrium, are used in small but vital quantities. For example, the creation of GPUs relies on copper and aluminum. At the same time, chips use rare earth metals--the mining process for which can generate substantial carbon emissions and ecosystem damage.
+The environmental impact during these beginning-of-life phases includes emissions from energy use and resource depletion from extracting materials for hardware production. At the heart of AI hardware are semiconductors, primarily silicon, used to make the integrated circuits in processors and memory chips. This hardware manufacturing relies on metals like copper for wiring, aluminum for casings, and various plastics and composites for other components. It also uses rare earth metals and specialized alloys- elements like neodymium, terbium, and yttrium- used in small but vital quantities. For example, the creation of GPUs relies on copper and aluminum. At the same time, chips use rare earth metals, which is the mining process that can generate substantial carbon emissions and ecosystem damage.
**Use Phase**
-AI computes the majority of emissions in the lifecycle due to continuous high-power consumption, especially for training and running models. This includes direct emissions from electricity usage and indirect emissions from non-renewable grid energy generation. Studies estimate training complex models can have a carbon footprint comparable to the lifetime emissions of up to five cars.
+AI computes the majority of emissions in the lifecycle due to continuous high-power consumption, especially for training and running models. This includes direct and indirect emissions from electricity usage and nonrenewable grid energy generation. Studies estimate training complex models can have a carbon footprint comparable to the lifetime emissions of up to five cars.
**Disposal Phase**
-The impact of the disposal stage includes air and water pollution from toxic materials in devices, challenges associated with complex electronics recycling, and contamination when improperly handled. Harmful compounds from burned e-waste are released into the atmosphere. At the same time, landfill leakage of lead, mercury and other materials poses risks of soil and groundwater contamination if not properly controlled. Implementing effective electronics recycling is crucial.
+The disposal stage impacts include air and water pollution from toxic materials in devices, challenges associated with complex electronics recycling, and contamination when improperly handled. Harmful compounds from burned e-waste are released into the atmosphere. At the same time, landfill leakage of lead, mercury, and other materials poses risks of soil and groundwater contamination if not properly controlled. Implementing effective electronics recycling is crucial.
:::{#exr-mle .callout-exercise collapse="true"}
### Tracking ML Emissions
-In this exercise, you'll delve into the environmental impact of training machine learning models. We'll use a tool called CodeCarbon to track emissions, learn about Life Cycle Analysis (LCA) to understand AI's carbon footprint, and explore strategies to make your ML model development more environmentally friendly. By the end, you'll be equipped to track the carbon emissions of your models and start implementing greener practices in your projects.
+In this exercise, you'll delve into the environmental impact of training machine learning models. We'll use CodeCarbon to track emissions, learn about Life Cycle Analysis (LCA) to understand AI's carbon footprint, and explore strategies to make your ML model development more environmentally friendly. By the end, you'll be equipped to track the carbon emissions of your models and start implementing greener practices in your projects.
[](https://colab.research.google.com/drive/1elYSajW0_qxA_6k-B8w4TGR5ec8vaw5f?usp=drive_link#scrollTo=EFpgp_rIA_TY)
:::
@@ -329,59 +329,59 @@ In this exercise, you'll delve into the environmental impact of training machine
### Lack of Consistency and Standards {#lack-of-consistency-and-standards}
-One major challenge facing life cycle analysis (LCA) for AI systems is the current lack of consistent methodological standards and frameworks. Unlike product categories like building materials that have developed international standards for LCA through ISO 14040, there are no firmly established guidelines tailored to analyzing the environmental footprint of complex information technology like AI.
+One major challenge facing life cycle analysis (LCA) for AI systems is the need for consistent methodological standards and frameworks. Unlike product categories like building materials, which have developed international standards for LCA through ISO 14040, there are no firmly established guidelines for analyzing the environmental footprint of complex information technology like AI.
-This absence of uniformity means researchers make differing assumptions and varying methodological choices. For example, a 2021 study from the University of Massachusetts Amherst [@strubell2019energy] analyzed the life cycle emissions of several natural language processing models but only considered computational resource usage for training and omitted hardware manufacturing impacts. A more comprehensive 2020 study from Stanford University researchers included emissions estimates from the production of relevant servers, processors, and other components, following an ISO-aligned LCA standard for computer hardware. However, these diverging choices in system boundaries and accounting approaches reduce robustness and prevent apples-to-apples comparisons of results.
+This absence of uniformity means researchers make differing assumptions and varying methodological choices. For example, a 2021 study from the University of Massachusetts Amherst [@strubell2019energy] analyzed the life cycle emissions of several natural language processing models but only considered computational resource usage for training and omitted hardware manufacturing impacts. A more comprehensive 2020 study from Stanford University researchers included emissions estimates from producing relevant servers, processors, and other components, following an ISO-aligned LCA standard for computer hardware. However, these diverging choices in system boundaries and accounting approaches reduce robustness and prevent apples-to-apples comparisons of results.
-Having standardized frameworks and protocols tailored to the unique aspects and rapid update cycles of AI systems would provide more coherence. This could better equip researchers and developers to understand environmental hotspots, compare technology options, and accurately track progress on sustainability initiatives across the AI field. Industry groups and international standards bodies like the IEEE or ACM should prioritize addressing this methodological gap.
+Standardized frameworks and protocols tailored to AI systems' unique aspects and rapid update cycles would provide more coherence. This could equip researchers and developers to understand environmental hotspots, compare technology options, and accurately track progress on sustainability initiatives across the AI field. Industry groups and international standards bodies like the IEEE or ACM should prioritize addressing this methodological gap.
### Data Gaps {#data-gaps}
Another key challenge for comprehensive life cycle assessment of AI systems is substantial data gaps, especially regarding upstream supply chain impacts and downstream electronic waste flows. Most existing studies focus narrowly on the learner or usage phase emissions from computational power demands, which misses a significant portion of lifetime emissions [@gupta2022].
-For example, little public data from companies exists quantifying energy use and emissions from manufacturing the specialized hardware components that enable AI--including high-end GPUs, ASIC chips, solid-state drives and more. Researchers often rely on secondary sources or generic industry averages to approximate production impacts. Similarly, there is limited transparency into downstream fate once AI systems are discarded after 4-5 years of usable lifespans on average.
+For example, little public data from companies exists quantifying energy use and emissions from manufacturing the specialized hardware components that enable AI--including high-end GPUs, ASIC chips, solid-state drives, and more. Researchers often rely on secondary sources or generic industry averages to approximate production impacts. Similarly, on average, there is limited transparency into downstream fate once AI systems are discarded after 4-5 years of usable lifespans.
While electronic waste generation levels can be estimated, specifics on hazardous material leakage, recycling rates, and disposal methods for the complex components are hugely uncertain without better corporate documentation or regulatory reporting requirements.
-Even for the usage phase, the lack of fine-grained data on computational resource consumption for training different model types makes reliable per-parameter or per-query emissions calculations difficult. Attempts to create lifecycle inventories estimating average energy needs for key AI tasks exist [@henderson2020towards; @anthony2020carbontracker] but variability across hardware setups, algorithms, and input data uncertainty remains extremely high. Furthermore, real time carbon intensity data, which is critical in accurately tracking operational carbon footprint, is lacking in many geographic locations, thereby rendering existing tools for operational carbon emission mere approximations based on annual average carbon intensity values.
+The need for fine-grained data on computational resource consumption for training different model types makes reliable per-parameter or per-query emissions calculations difficult even for the usage phase. Attempts to create lifecycle inventories estimating average energy needs for key AI tasks exist [@henderson2020towards; @anthony2020carbontracker], but variability across hardware setups, algorithms, and input data uncertainty remains extremely high. Furthermore, real-time carbon intensity data, critical in accurately tracking operational carbon footprint, must be improved in many geographic locations, rendering existing tools for operational carbon emission mere approximations based on annual average carbon intensity values.
The challenge is that tools like [CodeCarbon](https://codecarbon.io/) and [ML $\textrm{CO}_2$](https://mlco2.github.io/impact/#compute) but these are ad hoc approaches at best. Bridging the real data gaps with more rigorous corporate sustainability disclosures and mandated environmental impact reporting will be key for AI's overall climatic impacts to be understood and managed.
### Rapid Pace of Evolution {#rapid-pace-of-evolution}
-The extremely quick evolution of AI systems poses additional challenges when it comes to keeping life cycle assessments up-to-date and accounting for the latest hardware and software advancements. The core algorithms, specialized chips, frameworks, and technical infrastructure underpinning AI have all been advancing at exceptionally fast rates, with new developments rapidly rendering prior systems obsolete.
+The extremely quick evolution of AI systems poses additional challenges in keeping life cycle assessments up-to-date and accounting for the latest hardware and software advancements. The core algorithms, specialized chips, frameworks, and technical infrastructure underpinning AI have all been advancing exceptionally fast, with new developments rapidly rendering prior systems obsolete.
-For example, in the deep learning space, novel neural network architectures that achieve significantly better performance on key benchmarks or new optimized hardware like Google's TPU chips can completely change what an "average" model looks like in less than a year. These swift shifts make one-off LCA studies outdated quickly for accurately tracking emissions from designing, running, or disposing of the latest AI.
+For example, in deep learning, novel neural network architectures that achieve significantly better performance on key benchmarks or new optimized hardware like Google's TPU chips can completely change an "average" model in less than a year. These swift shifts quickly make one-off LCA studies outdated for accurately tracking emissions from designing, running, or disposing of the latest AI.
-However, the resources and access required to continuously update LCAs also poses barriers. Frequently re-doing labor and data intensive life cycle inventories and impact modeling to stay current with AI's state of the art is likely infeasible for many researchers and organizations. But without updated analyses, the environmental hotspots as algorithms and silicon chips continue rapidly evolving could be missed.
+However, the resources and access required to update LCAs continuously need to be improved. Frequently re-doing labor—and data-intensive life cycle inventories and impact modeling to stay current with AI's state-of-the-art is likely infeasible for many researchers and organizations. However, updated analyses could notice environmental hotspots as algorithms and silicon chips continue rapidly evolving.
-This presents a difficulty in balancing dynamic precision through continuous assessment with pragmatic constraints. Some researchers have proposed simplified proxy metrics like tracking hardware generations over time or using representative benchmarks as an oscillating set of goalposts for relative comparisons, though granularity may be sacrificed. Overall, the challenge of rapid change will require innovative methodological solutions to prevent underestimating AI's evolving environmental burdens.
+This presents difficulty in balancing dynamic precision through continuous assessment with pragmatic constraints. Some researchers have proposed simplified proxy metrics like tracking hardware generations over time or using representative benchmarks as an oscillating set of goalposts for relative comparisons, though granularity may be sacrificed. Overall, the challenge of rapid change will require innovative methodological solutions to prevent underestimating AI's evolving environmental burdens.
### Supply Chain Complexity {#supply-chain-complexity}
-Finally, the complex and often opaque supply chains associated with producing the wide array of specialized hardware components that enable AI pose challenges for comprehensive life cycle modeling. State-of-the-art AI relies on leveraging cutting-edge advancements in processing chips, graphics cards, data storage, networking equipment and more. However, tracking emissions and resource use across the tiered networks of globalized suppliers for all these components is extremely difficult.
+Finally, the complex and often opaque supply chains associated with producing the wide array of specialized hardware components that enable AI pose challenges for comprehensive life cycle modeling. State-of-the-art AI relies on cutting-edge advancements in processing chips, graphics cards, data storage, networking equipment, and more. However, tracking emissions and resource use across the tiered networks of globalized suppliers for all these components is extremely difficult.
-For example, NVIDIA graphics processing units dominate much AI computing hardware, but the company relies on over several discrete suppliers across Asia and beyond to produce the GPUs. Many firms at each supplier tier choose not to disclose facility-level environmental data that could enable robust LCAs fully. Gaining end-to-end transparency down multiple levels of suppliers across disparate geographies with varying disclosure protocols and regulations poses barriers, despite being crucial for complete boundary setting. This becomes even more complex when attempting to model emerging hardware accelerators like tensor processing units (TPUs), whose production networks still need to be made public.
+For example, NVIDIA graphics processing units dominate much of the AI computing hardware, but the company relies on several discrete suppliers across Asia and beyond to produce GPUs. Many firms at each supplier tier choose to keep facility-level environmental data private, which could fully enable robust LCAs. Gaining end-to-end transparency down multiple levels of suppliers across disparate geographies with varying disclosure protocols and regulations poses barriers despite being crucial for complete boundary setting. This becomes even more complex when attempting to model emerging hardware accelerators like tensor processing units (TPUs), whose production networks still need to be made public.
-Without willingness from tech giants to require and consolidate environmental impact data disclosure from across their global electronics supply chains, considerable uncertainty will remain around quantifying the full lifecycle footprint of AI hardware enablement. More supply chain visibility coupled with standardized sustainability reporting frameworks specifically addressing AI's complex inputs hold promise for enriching LCAs and prioritizing environmental impact reductions.
+Without tech giants' willingness to require and consolidate environmental impact data disclosure from across their global electronics supply chains, considerable uncertainty will remain around quantifying the full lifecycle footprint of AI hardware enablement. More supply chain visibility coupled with standardized sustainability reporting frameworks specifically addressing AI's complex inputs hold promise for enriching LCAs and prioritizing environmental impact reductions.
## Sustainable Design and Development {#sustainable-design-and-development}
### Sustainability Principles {#sustainability-principles}
-As the impact of AI on the environment becomes increasingly evident, the focus on sustainable design and development in AI is gaining prominence. This involves incorporating sustainability principles into AI design, developing energy-efficient models, and integrating these considerations throughout the AI development pipeline. There is a growing need to consider its sustainability implications and develop principles to guide responsible innovation. Below is a core set of principles. The principles flows from the conceptual foundation, to practical execution, to supporting implementation factors, the principles provide a full cycle perspective on embedding sustainability in AI design and development.
+As the impact of AI on the environment becomes increasingly evident, the focus on sustainable design and development in AI is gaining prominence. This involves incorporating sustainability principles into AI design, developing energy-efficient models, and integrating these considerations throughout the AI development pipeline. There is a growing need to consider its sustainability implications and develop principles to guide responsible innovation. Below is a core set of principles. The principles flow from the conceptual foundation to practical execution to supporting implementation factors; the principles provide a full cycle perspective on embedding sustainability in AI design and development.
**Lifecycle Thinking:** Encouraging designers to consider the entire lifecycle of AI systems, from data collection and preprocessing to model development, training, deployment, and monitoring. The goal is to ensure sustainability is considered at each stage. This includes using energy-efficient hardware, prioritizing renewable energy sources, and planning to reuse or recycle retired models.
**Future Proofing:** Designing AI systems anticipating future needs and changes can enhance sustainability. This may involve making models adaptable via transfer learning and modular architectures. It also includes planning capacity for projected increases in operational scale and data volumes.
-**Efficiency and Minimalism:** This principle focuses on creating AI models that achieve desired results with the least possible resource use. It involves simplifying models and algorithms to reduce computational requirements. Specific techniques include pruning redundant parameters, quantizing and compressing models, and designing efficient model architectures, such as those discussed in the [Optimizations](../optimizations/optimizations.qmd) chapter.
+**Efficiency and Minimalism:** This principle focuses on creating AI models that achieve desired results with the least possible resource use. It involves simplifying models and algorithms to reduce computational requirements. Specific techniques include pruning redundant parameters, quantizing and compressing models, and designing efficient model architectures, such as those discussed in the [Optimizations](../optimizations/optimizations. cmd) chapter.
-**Lifecycle Assessment (LCA) Integration:** Analyzing environmental impacts throughout the development and deployment lifecycles highlights unsustainable practices early on. Teams can then make needed adjustments, instead of discovering issues late when they are more difficult to address. Integrating this analysis into the standard design flow avoids creating legacy sustainability problems.
+**Lifecycle Assessment (LCA) Integration:** Analyzing environmental impacts throughout the development and deployment of lifecycles highlights unsustainable practices early on. Teams can then make adjustments instead of discovering issues late when they are more difficult to address. Integrating this analysis into the standard design flow avoids creating legacy sustainability problems.
-**Incentive Alignment:** Economic and policy incentives should promote and reward sustainable AI development. This may include government grants, corporate initiatives, industry standards, and academic mandates for sustainability. Aligned incentives enable sustainability to become embedded in AI culture.
+**Incentive Alignment:** Economic and policy incentives should promote and reward sustainable AI development. These may include government grants, corporate initiatives, industry standards, and academic mandates for sustainability. Aligned incentives enable sustainability to become embedded in AI culture.
-**Sustainability Metrics and Goals:** Metrics that measure sustainability factors like carbon usage and energy efficiency are important to establish clearly. Establishing clear targets for these metrics provides concrete guidelines for teams to develop responsible AI systems. Tracking performance on metrics over time shows progress towards set sustainability goals.
+**Sustainability Metrics and Goals:** It is important to establish clearly defined Metrics that measure sustainability factors like carbon usage and energy efficiency. Establishing clear targets for these metrics provides concrete guidelines for teams to develop responsible AI systems. Tracking performance on metrics over time shows progress towards set sustainability goals.
**Fairness, Transparency, and Accountability:** Sustainable AI systems should be fair, transparent, and accountable. Models should be unbiased, with transparent development processes and mechanisms for auditing and redressing issues. This builds public trust and enables the identification of unsustainable practices.
@@ -393,46 +393,46 @@ As the impact of AI on the environment becomes increasingly evident, the focus o
Green AI represents a transformative approach to AI that incorporates environmental sustainability as a fundamental principle across the AI system design and lifecycle [@schwartz2020green]. This shift is driven by growing awareness of AI technologies' significant carbon footprint and ecological impact, especially the compute-intensive process of training complex ML models.
-The essence of Green AI lies in its commitment to align AI advancement with sustainability goals around energy efficiency, renewable energy usage, and waste reduction. The introduction of Green AI ideals reflects maturing responsibility across the tech industry towards environmental stewardship and ethical technology practices. It moves beyond technical optimizations towards holistic life cycle assessment on how AI systems affect sustainability metrics. Setting new bars for ecologically conscious AI paves the way for the harmonious coexistence of technological progress and planetary health.
+The essence of Green AI lies in its commitment to align AI advancement with sustainability goals around energy efficiency, renewable energy usage, and waste reduction. The introduction of Green AI ideals reflects maturing responsibility across the tech industry towards environmental stewardship and ethical technology practices. It moves beyond technical optimizations toward holistic life cycle assessment on how AI systems affect sustainability metrics. Setting new bars for ecologically conscious AI paves the way for the harmonious coexistence of technological progress and planetary health.
### Energy Efficient AI Systems {#energy-efficient-ai-systems}
-Energy efficiency in AI systems is a cornerstone of Green AI, aiming to reduce the significant energy demands traditionally associated with AI development and operations. This shift towards energy-conscious AI practices is vital in addressing the environmental concerns raised by the rapidly expanding field of AI. By focusing on energy efficiency, AI systems can become more sustainable, lessening their environmental impact and paving the way for more responsible AI use.
+Energy efficiency in AI systems is a cornerstone of Green AI, aiming to reduce the energy demands traditionally associated with AI development and operations. This shift towards energy-conscious AI practices is vital in addressing the environmental concerns raised by the rapidly expanding field of AI. By focusing on energy efficiency, AI systems can become more sustainable, lessening their environmental impact and paving the way for more responsible AI use.
-As we have discussed earlier, the training and operation of AI models, especially large-scale ones, are known for their high energy consumption stemming from compute-intensive model architecture and reliance on vast amounts of training data. For example, it is estimated that training a large state-of-the-art neural network model can have a carbon footprint of 284 tonnes--equivalent to the lifetime emissions of 5 cars [@strubell2019energy].
+As we discussed earlier, the training and operation of AI models, especially large-scale ones, are known for their high energy consumption, which stems from compute-intensive model architecture and reliance on vast amounts of training data. For example, it is estimated that training a large state-of-the-art neural network model can have a carbon footprint of 284 tonnes—equivalent to the lifetime emissions of 5 cars [@strubell2019energy].
-To tackle the massive energy demands, researchers and developers are actively exploring methods to optimize AI systems for better energy efficiency without losing model accuracy or performance. This includes techniques like the ones we have discussed in the model optimizations, efficient AI and hardware acceleration chapters:
+To tackle the massive energy demands, researchers and developers are actively exploring methods to optimize AI systems for better energy efficiency while maintaining model accuracy and performance. This includes techniques like the ones we have discussed in the model optimizations, efficient AI, and hardware acceleration chapters:
* Knowledge distillation to transfer knowledge from large AI models to miniature versions
* Quantization and pruning approaches that reduce computational and space complexities
* Low-precision numerics--lowering mathematical precision without impacting model quality
* Specialized hardware like TPUs, neuromorphic chips tuned explicitly for efficient AI processing
-One example is Intel's work on Q8BERT---quantizing BERT language model with 8-bit integers, leading to 4x reduction in model size with minimal accuracy loss [@zafrir2019q8bert]. The push for energy-efficient AI is not just a technical endeavor--it has tangible real-world implications. More performant systems lower AI's operational costs and carbon footprint, making it accessible for widespread deployment on mobile and edge devices. It also paves the path toward the democratization of AI and mitigates unfair biases that can emerge from uneven access to computing resources across regions and communities. Pursuing energy-efficient AI is thus crucial for creating an equitable and sustainable future with AI.
+One example is Intel's work on Q8BERT---quantizing the BERT language model with 8-bit integers, leading to a 4x reduction in model size with minimal accuracy loss [@zafrir2019q8bert]. The push for energy-efficient AI is not just a technical endeavor--it has tangible real-world implications. More performant systems lower AI's operational costs and carbon footprint, making it accessible for widespread deployment on mobile and edge devices. It also paves the path toward the democratization of AI and mitigates unfair biases that can emerge from uneven access to computing resources across regions and communities. Pursuing energy-efficient AI is thus crucial for creating an equitable and sustainable future with AI.
### Sustainable AI Infrastructure {#sustainable-ai-infrastructure}
-Sustainable AI infrastructure includes the physical and technological frameworks that support AI systems, focusing on environmental sustainability. This involves designing and operating AI infrastructure in a way that minimizes ecological impact, conserves resources, and reduces carbon emissions. The goal is to create a sustainable ecosystem for AI that aligns with broader environmental objectives.
+Sustainable AI infrastructure includes the physical and technological frameworks that support AI systems, focusing on environmental sustainability. This involves designing and operating AI infrastructure to minimize ecological impact, conserve resources, and reduce carbon emissions. The goal is to create a sustainable ecosystem for AI that aligns with broader environmental objectives.
-Central to sustainable AI infrastructure are green data centers, which are optimized for energy efficiency and often powered by renewable energy sources. These data centers employ advanced cooling technologies [@ebrahimi2014review], energy-efficient server designs [@uddin2012energy], and smart management systems [@buyya2010energyefficient] to reduce power consumption. The shift towards green computing infrastructure also involves adopting energy-efficient hardware, like AI-optimized processors that deliver high performance with lower energy requirements, which we discussed in the [AI Acceleration](../hw_acceleration/hw_acceleration.qmd) chapter. These efforts collectively reduce the carbon footprint of running large-scale AI operations.
+Green data centers are central to sustainable AI infrastructure, optimized for energy efficiency, and often powered by renewable energy sources. These data centers employ advanced cooling technologies [@ebrahimi2014review], energy-efficient server designs [@uddin2012energy], and smart management systems [@buyya2010energyefficient] to reduce power consumption. The shift towards green computing infrastructure also involves adopting energy-efficient hardware, like AI-optimized processors that deliver high performance with lower energy requirements, which we discussed in the [AI. Acceleration](../hw_acceleration/hw_acceleration.qmd) chapter. These efforts collectively reduce the carbon footprint of running large-scale AI operations.
-Integrating renewable energy sources, such as solar, wind, and hydroelectric power, into AI infrastructure is important for environmental sustainability [@chua1971memristor]. Many tech companies and research institutions are [investing in renewable energy projects to power their data centers](https://www.forbes.com/sites/siemens-smart-infrastructure/2023/03/13/how-data-centers-are-driving-the-renewable-energy-transition/?sh=3208c5b54214). This not only helps in making AI operations carbon-neutral but also promotes the wider adoption of clean energy. Using renewable energy sources is a clear statement of commitment to environmental responsibility in the AI industry.
+Integrating renewable energy sources, such as solar, wind, and hydroelectric power, into AI infrastructure is important for environmental sustainability [@chua1971memristor]. Many tech companies and research institutions are [investing in renewable energy projects to power their data centers](https://www.forbes.com/sites/siemens-smart-infrastructure/2023/03/13/how-data-centers-are-driving-the-renewable-energy-transition/?sh=3208c5b54214). This not only helps in making AI operations carbon-neutral but also promotes the wider adoption of clean energy. Using renewable energy sources clearly shows commitment to environmental responsibility in the AI industry.
Sustainability in AI also extends to the materials and hardware used in creating AI systems. This involves choosing environmentally friendly materials, adopting recycling practices, and ensuring responsible electronic waste disposal. Efforts are underway to develop more sustainable hardware components, including energy-efficient chips designed for domain-specific tasks (such as AI accelerators) and environmentally friendly materials in device manufacturing [@cenci2021ecofriendly;@irimiavladu2014textquotedblleftgreentextquotedblright]. The lifecycle of these components is also a focus, with initiatives aimed at extending the lifespan of hardware and promoting recycling and reuse.
-While strides are being made in sustainable AI infrastructure, challenges remain, such as the high costs of green technology and the need for global standards in sustainable practices. Future directions may include more widespread adoption of green energy, further innovations in energy-efficient hardware, and international collaboration on sustainable AI policies. The pursuit of sustainable AI infrastructure is not just a technical endeavor but a holistic approach that encompasses environmental, economic, and social aspects, ensuring that AI advances in harmony with our planet's health.
+While strides are being made in sustainable AI infrastructure, challenges remain, such as the high costs of green technology and the need for global standards in sustainable practices. Future directions include more widespread adoption of green energy, further innovations in energy-efficient hardware, and international collaboration on sustainable AI policies. Pursuing sustainable AI infrastructure is not just a technical endeavor but a holistic approach that encompasses environmental, economic, and social aspects, ensuring that AI advances harmoniously with our planet's health.
### Frameworks and Tools {#frameworks-and-tools}
-To effectively implement Green AI practices, it is essential to have access to the right frameworks and tools. These resources are designed to assist developers and researchers in creating more energy-efficient and environmentally friendly AI systems. They range from software libraries optimized for low-power consumption to platforms that facilitate the development of sustainable AI applications.
+Access to the right frameworks and tools is essential to effectively implementing green AI practices. These resources are designed to assist developers and researchers in creating more energy-efficient and environmentally friendly AI systems. They range from software libraries optimized for low-power consumption to platforms that facilitate the development of sustainable AI applications.
-There are several software libraries and development environments specifically tailored for Green AI. These tools often include features for optimizing AI models to reduce their computational load and, consequently, their energy consumption. For example, libraries in PyTorch and TensorFlow that support model pruning, quantization, and efficient neural network architectures enable developers to build AI systems that require less processing power and energy. Additionally, there are open source communities like the [Green Carbon Foundation](https://github.com/Green-Software-Foundation) creating a centralized carbon intensity metric and building software for carbon-aware computing.
+Several software libraries and development environments are specifically tailored for Green AI. These tools often include features for optimizing AI models to reduce their computational load and, consequently, their energy consumption. For example, libraries in PyTorch and TensorFlow that support model pruning, quantization, and efficient neural network architectures enable developers to build AI systems that require less processing power and energy. Additionally, open-source communities like the [Green Carbon Foundation](https://github.com/Green-Software-Foundation) are creating a centralized carbon intensity metric and building software for carbon-aware computing.
Energy monitoring tools are crucial for Green AI, as they allow developers to measure and analyze the energy consumption of their AI systems. By providing detailed insights into where and how energy is being used, these tools enable developers to make informed decisions about optimizing their models for better energy efficiency. This can involve adjustments in algorithm design, hardware selection, cloud computing software selection, or operational parameters. @fig-azuredashboard is a screenshot of an energy consumption dashboard provided by Microsoft's cloud services platform.
](images/png/azure_dashboard.png){#fig-azuredashboard}
-With the increasing integration of renewable energy sources in AI operations, frameworks that facilitate this process are becoming more important. These frameworks help manage the energy supply from renewable sources like solar or wind power, ensuring that AI systems can operate efficiently with fluctuating energy inputs.
+With the increasing integration of renewable energy sources in AI operations, frameworks facilitating this process are becoming more important. These frameworks help manage the energy supply from renewable sources like solar or wind power, ensuring that AI systems can operate efficiently with fluctuating energy inputs.
Beyond energy efficiency, sustainability assessment tools help evaluate the broader environmental impact of AI systems. These tools can analyze factors like the carbon footprint of AI operations, the lifecycle impact of hardware components [@gupta2022], and the overall sustainability of AI projects [@prakash2022cfu].
@@ -440,239 +440,239 @@ The availability and ongoing development of Green AI frameworks and tools are cr
### Benchmarks and Leaderboards
-Benchmarks and leaderboards are important for driving progress in Green AI by providing standardized ways to measure and compare different methods. Well-designed benchmarks that capture relevant metrics around energy efficiency, carbon emissions, and other sustainability factors enable the community to track advancements in a fair and meaningful way.
+Benchmarks and leaderboards are important for driving progress in Green AI, as they provide standardized ways to measure and compare different methods. Well-designed benchmarks that capture relevant metrics around energy efficiency, carbon emissions, and other sustainability factors enable the community to track advancements fairly and meaningfully.
-There exist extensive benchmarks for tracking AI model performance, such as those extensively discussed in the [Benchmarking](../benchmarking/benchmarking.qmd) chapter, but there is a clear and pressing need for additional standardized benchmarks focused on sustainability metrics like energy efficiency, carbon emissions, and overall ecological impact. Understanding the environmental costs of AI is currently hampered by a lack of transparency and standardized measurement around these factors.
+Extensive benchmarks exist for tracking AI model performance, such as those extensively discussed in the [Benchmarking](../benchmarking/benchmarking. cmd) chapter. Still, a clear and pressing need exists for additional standardized benchmarks focused on sustainability metrics like energy efficiency, carbon emissions, and overall ecological impact. Understanding the environmental costs of AI currently needs to be improved by a lack of transparency and standardized measurement around these factors.
Emerging efforts such as the [ML.ENERGY Leaderboard](https://ml.energy/leaderboard), which provides performance and energy consumption benchmarking results for large language models (LLMs) text generation, assists in enhancing the understanding of the energy cost of GenAI deployment.
-As with any benchmark, it is important that Green AI benchmarks represent realistic usage scenarios and workloads. Benchmarks that focus narrowly on easily gamed metrics may lead to short-term gains but fail to reflect actual production environments where more holistic measures of efficiency and sustainability are needed. The community should continue expanding benchmarks to cover diverse use cases.
+As with any benchmark, Green AI benchmarks must represent realistic usage scenarios and workloads. Benchmarks that focus narrowly on easily gamed metrics may lead to short-term gains but fail to reflect actual production environments where more holistic efficiency and sustainability measures are needed. The community should continue expanding benchmarks to cover diverse use cases.
-Wider adoption of common benchmark suites by industry players will accelerate innovation in Green AI by allowing easier comparison of techniques across organizations. Shared benchmarks lower the barrier for demonstrating the sustainability benefits of new tools and best practices. However, care must be taken around issues like intellectual property, privacy, and commercial sensitivity when designing industry-wide benchmarks. Initiatives to develop open reference datasets for Green AI evaluation may help drive broader participation.
+Wider adoption of common benchmark suites by industry players will accelerate innovation in Green AI by allowing easier comparison of techniques across organizations. Shared benchmarks lower the barrier to demonstrating the sustainability benefits of new tools and best practices. However, when designing industry-wide benchmarks, care must be taken around issues like intellectual property, privacy, and commercial sensitivity. Initiatives to develop open reference datasets for Green AI evaluation may help drive broader participation.
-As methods and infrastructure for Green AI continue maturing, the community also needs to revisit benchmark design to ensure existing suites capture new techniques and scenarios well. Tracking the evolving landscape through regular benchmark updates and reviews will be important to maintain representative comparisons over time. Community efforts for benchmark curation can enable sustainable benchmark suites that stand the test of time. Comprehensive benchmark suites owned by research communities or neutral third parties like [MLCommons](https://mlcommons.org) may encourage wider participation and standardization.
+As methods and infrastructure for Green AI continue maturing, the community must revisit benchmark design to ensure existing suites capture new techniques and scenarios well. Tracking the evolving landscape through regular benchmark updates and reviews will be important to maintain representative comparisons over time. Community efforts for benchmark curation can enable sustainable benchmark suites that stand the test of time. Comprehensive benchmark suites owned by research communities or neutral third parties like [MLCommons](https://mlcommons.org) may encourage wider participation and standardization.
## Case Study: Google's 4Ms {#case-study-google-4ms}
-Over the past decade, AI has rapidly moved from the realm of academic research to large-scale production systems powering numerous Google products and services. As AI models and workloads have grown exponentially in size and computational demands, concerns have emerged about their energy consumption and carbon footprint. Some researchers predicted runaway growth in ML's energy appetite that could outweigh efficiencies gained from improved algorithms and hardware [@thompson2021deep].
+Over the past decade, AI has rapidly moved from academic research to large-scale production systems powering numerous Google products and services. As AI models and workloads have grown exponentially in size and computational demands, concerns have emerged about their energy consumption and carbon footprint. Some researchers predicted runaway growth in ML's energy appetite that could outweigh efficiencies gained from improved algorithms and hardware [@thompson2021deep].
-However, Google's own production data reveals a different story--with AI representing a steady 10-15% of total company energy usage from 2019 to 2021. This case study analyzes how Google applied a systematic approach leveraging four best practices--what they term the "4 Ms" of model efficiency, machine optimization, mechanization through cloud computing, and mapping to green locations to bend the curve on emissions from AI workloads.
+However, Google's production data reveals a different story—AI represents a steady 10-15% of total company energy usage from 2019 to 2021. This case study analyzes how Google applied a systematic approach leveraging four best practices—what they term the "4 Ms" of model efficiency, machine optimization, mechanization through cloud computing, and mapping to green locations—to bend the curve on emissions from AI workloads.
-The scale of Google's AI usage makes it an ideal case study. In 2021 alone, the company was training models like the 1.2 trillion parameter GLam model. Analyzing how the application of AI has been paired with rapid efficiency gains in this environment helps us by providing a logical blueprint for the broader AI field to follow.
+The scale of Google's AI usage makes it an ideal case study. In 2021 alone, the company trained models like the 1.2 trillion-parameter GLam model. Analyzing how the application of AI has been paired with rapid efficiency gains in this environment helps us by providing a logical blueprint for the broader AI field to follow.
-By transparently publishing detailed energy usage statistics, adoption rates of carbon-free clouds and renewables purchases, and more alongside its technical innovations, Google has enabled outside researchers to accurately measure progress. Their study in the ACM CACM [@patterson2022carbon] highlights how the company's multi-pronged approach shows that predictions of runaway AI energy consumption can be overcome through focusing engineering efforts on sustainable development patterns. The pace of improvements also suggests ML's efficiency gains are just getting started.
+By transparently publishing detailed energy usage statistics, adopting rates of carbon-free clouds and renewables purchases, and more, alongside its technical innovations, Google has enabled outside researchers to measure progress accurately. Their study in the ACM CACM [@patterson2022carbon] highlights how the company's multipronged approach shows that runaway AI energy consumption predictions can be overcome by focusing engineering efforts on sustainable development patterns. The pace of improvements also suggests ML's efficiency gains are just starting.
### Google's 4M Best Practices {#google-4m-best-practices}
To curb emissions from their rapidly expanding AI workloads, Google engineers systematically identified four best practice areas--termed the "4 Ms"--where optimizations could compound to reduce the carbon footprint of ML:
-* Model - Selecting efficient AI model architectures can reduce computation by 5-10X with no loss in model quality. Google has focused extensive research on developing sparse models and neural architecture search to create more efficient models like the Evolved Transformer and Primer.
-* Machine - Using hardware optimized for AI over general purpose systems improves performance per watt by 2-5X. Google's Tensor Processing Units (TPUs) led to 5-13X better carbon efficiency versus GPUs not optimized for ML.
-* Mechanization - By leveraging cloud computing systems tailored for high utilization over conventional on-premise data centers, energy costs reduce by 1.4-2X. Google cites its data centers' Power Usage Effectiveness outpacing industry averages.
-* Map - Choosing data center locations with low-carbon electricity reduces gross emissions by another 5-10X. Google provides real-time maps highlighting its renewable energy percentage by facility.
+* Model - Selecting efficient AI model architectures can reduce computation by 5-10X with no loss in model quality. Google has extensively researched developing sparse models and neural architecture search to create more efficient models like the Evolved Transformer and Primer.
+* Machine—Using hardware optimized for AI over general-purpose systems improves performance per watt by 2-5X. Google's Tensor Processing Units (TPUs) led to 5-13X better carbon efficiency versus GPUs not optimized for ML.
+* Mechanization—By leveraging cloud computing systems tailored for high utilization over conventional on-premise data centers, energy costs are reduced by 1.4-2X. Google cites its data center's power usage effectiveness as outpacing industry averages.
+* Map - Choosing data center locations with low-carbon electricity reduces gross emissions by another 5-10X. Google provides real-time maps highlighting the percentage of renewable energy used by its facilities.
-Together, these practices created drastic compound efficiency gains. For example, optimizing the Transformer AI model on TPUs in a sustainable data center location cut energy use by a factor of 83 and lowered $\textrm{CO}_2$ emissions by a factor of 747.
+Together, these practices created drastic compound efficiency gains. For example, optimizing the Transformer AI model on TPUs in a sustainable data center location cut energy use by 83. It lowered $\textrm{CO}_2$ emissions by a factor of 747.
### Significant Results {#significant-results}
-Google's efforts to improve the carbon efficiency of ML have produced measurable gains helping to restrain overall energy appetite, despite exponential growth in AI adoption across products and services. One key datapoint highlighting this progress is that AI workloads have remained a steady 10% to 15% of total company energy use from 2019 to 2021. As AI became integral to ever more Google offerings, overall compute cycles dedicated to AI grew substantially. However, efficiencies on algorithms, specialized hardware, data center design and flexible geography allowed sustainability to keep pace---with AI representing just a fraction of total data center electricity over years of expansion.
+Despite exponential growth in AI adoption across products and services, Google's efforts to improve the carbon efficiency of ML have produced measurable gains, helping to restrain overall energy appetite. One key data point highlighting this progress is that AI workloads have remained a steady 10% to 15% of total company energy use from 2019 to 2021. As AI became integral to more Google offerings, overall compute cycles dedicated to AI grew substantially. However, efficiencies in algorithms, specialized hardware, data center design, and flexible geography allowed sustainability to keep pace---with AI representing just a fraction of total data center electricity over years of expansion.
-Other case studies further underscore how an engineering focus on sustainable AI development patterns enabled rapid quality improvements in lockstep with environmental gains. For example, the natural language processing model GPT-3 was viewed as state-of-the-art in mid-2020. Yet its successor GLaM improved accuracy while cutting training compute needs and using cleaner data center energy--cutting CO2 emissions by a factor of 14 in just 18 months of model evolution.
+Other case studies underscore how an engineering focus on sustainable AI development patterns enabled rapid quality improvements in lockstep with environmental gains. For example, the natural language processing model GPT-3 was viewed as state-of-the-art in mid-2020. Yet its successor GLaM improved accuracy while cutting training compute needs and using cleaner data center energy--cutting CO2 emissions by a factor of 14 in just 18 months of model evolution.
-Similarly, Google found past published speculation missing the mark on ML's energy appetite by factors of 100 to 100,000X due to lacking real-world metrics. By transparently tracking optimization impact, Google hoped to motivate efficiency while preventing overestimated extrapolations about ML's environmental toll.
+Similarly, Google found past published speculation missing the mark on ML's energy appetite by factors of 100 to 100,000X due to a lack of real-world metrics. By transparently tracking optimization impact, Google hoped to motivate efficiency while preventing overestimated extrapolations about ML's environmental toll.
-Together these data-driven case studies show how companies like Google are steering AI advancements toward sustainable trajectories and driving efficiency improvements to outpace adoption growth. And with further efforts around lifecycle analysis, inference optimization, and renewable expansion, companies can aim to accelerate progress---giving evidence that ML's clean potential is only just being unlocked by current gains.
+These data-driven case studies show how companies like Google are steering AI advancements toward sustainable trajectories and improving efficiency to outpace adoption growth. With further efforts around lifecycle analysis, inference optimization, and renewable expansion, companies can aim to accelerate progress, giving evidence that ML's clean potential is only just being unlocked by current gains.
### Further Improvements {#further-improvements}
While Google has made measurable progress in restraining the carbon footprint of its AI operations, the company recognizes further efficiency gains will be vital for responsible innovation given the technology's ongoing expansion.
-One area of focus is showing how advances often incorrectly viewed as increasing unsustainable computing---like neural architecture search (NAS) to find optimized models---actually spur downstream savings outweighing their upfront costs. Despite expending more energy for model discovery rather than hand-engineering, NAS cuts lifetime emissions by producing efficient designs callable across countless applications.
+One area of focus is showing how advances are often incorrectly viewed as increasing unsustainable computing---like neural architecture search (NAS) to find optimized models--- spur downstream savings, outweighing their upfront costs. Despite expending more energy on model discovery rather than hand-engineering, NAS cuts lifetime emissions by producing efficient designs callable across countless applications.
-Additionally, analysis reveals focusing sustainability efforts on data center and server-side optimization makes sense given the dominant energy draw versus consumer devices. Though Google aims to shrink inference impacts across processors like mobile phones, priority rests on improving training cycles and data center renewables procurement for maximal effect.
+Additionally, the analysis reveals that focusing sustainability efforts on data center and server-side optimization makes sense, given the dominant energy draw versus consumer devices. Though Google aims to shrink inference impacts across processors like mobile phones, priority rests on improving training cycles and data center renewables procurement for maximal effect.
-To that end, Google's progress in pooling compute in efficiently designed cloud facilities highlights the value of scale and centralization. As more workloads shift away from inefficient on-premise servers, internet giants' prioritization of renewable energy---with Google and Facebook matched 100% by renewables since 2017 and 2020 respectively---unlocks compounding emissions cuts.
+To that end, Google's progress in pooling computing inefficiently designed cloud facilities highlights the value of scale and centralization. As more workloads shift away from inefficient on-premise servers, internet giants' prioritization of renewable energy—with Google and Facebook matched 100% by renewables since 2017 and 2020, respectively—unlocks compounding emissions cuts.
-Together these efforts emphasize that while no resting on laurels is possible, Google's multipronged approach shows AI efficiency improvements are only accelerating. Cross-domain initiatives around lifecycle assessment, carbon-conscious development patterns, transparency, and matching rising AI demand with clean electricity supply pave a path toward bending the curve further as adoption grows. The company's results compel the broader field towards replicating these integrated sustainability pursuits.
+Together, these efforts emphasize that while no resting on laurels is possible, Google's multipronged approach shows that AI efficiency improvements are only accelerating. Cross-domain initiatives around lifecycle assessment, carbon-conscious development patterns, transparency, and matching rising AI demand with clean electricity supply pave a path toward bending the curve further as adoption grows. The company's results compel the broader field towards replicating these integrated sustainability pursuits.
## Embedded AI - Internet of Trash {#embedded-ai-internet-of-trash}
While much attention has focused on making the immense data centers powering AI more sustainable, an equally pressing concern is the movement of AI capabilities into smart edge devices and endpoints. Edge/embedded AI allows near real-time responsiveness without connectivity dependencies. It also reduces transmission bandwidth needs. However, the increase of tiny devices leads to other risks.
-Tiny computers, microcontrollers, and custom ASICs powering edge intelligence face size, cost and power limitations that rule out high-end GPUs used in data centers. Instead, they require optimized algorithms and extremely compact, energy-efficient circuitry to run smoothly. But engineering for these microscopic form factors opens up risks around planned obsolescence, disposability, and waste. @fig-iot-devices shows that the number of IoT devices is projected to [reach 30 billion connected devices by 2030](https://www.statista.com/statistics/1183457/iot-connected-devices-worldwide/).
+Tiny computers, microcontrollers, and custom ASICs powering edge intelligence face size, cost, and power limitations that rule out high-end GPUs used in data centers. Instead, they require optimized algorithms and extremely compact, energy-efficient circuitry to run smoothly. However, engineering for these microscopic form factors opens up risks around planned obsolescence, disposability, and waste. @fig-iot-devices shows that the number of IoT devices is projected to [reach 30 billion connected devices by 2030](https://www.statista.com/statistics/1183457/iot-connected-devices-worldwide/).
](images/png/statista_chip_growth.png){#fig-iot-devices}
-End-of-life handling of internet-connected gadgets embedded with sensors and AI remains an often overlooked issue during design, though these products permeate consumer goods, vehicles, public infrastructure, industrial equipment and more.
+End-of-life handling of internet-connected gadgets embedded with sensors and AI remains an often overlooked issue during design. However, these products permeate consumer goods, vehicles, public infrastructure, industrial equipment, and more.
#### E-waste {#e-waste}
-Electronic waste, or e-waste, refers to discarded electrical equipment and components that enter the waste stream. This includes devices that have to be plugged in, have a battery, or electrical circuitry. With the rising adoption of internet-connected smart devices and sensors, e-waste volumes are rapidly increasing each year. These proliferating gadgets contain toxic heavy metals like lead, mercury, and cadmium that become environmental and health hazards when improperly disposed.
+Electronic waste, or e-waste, refers to discarded electrical equipment and components that enter the waste stream. This includes devices that have to be plugged in, have a battery, or electrical circuitry. With the rising adoption of internet-connected smart devices and sensors, e-waste volumes rapidly increase yearly. These proliferating gadgets contain toxic heavy metals like lead, mercury, and cadmium that become environmental and health hazards when improperly disposed of.
-The amount of electronic waste being produced is growing at an alarming rate. Today, [we already produce 50 million tons per year](https://www.unep.org/news-and-stories/press-release/un-report-time-seize-opportunity-tackle-challenge-e-waste). By 2030, that figure is projected to jump to a staggering 75 million tons as consumer electronics consumption continues to accelerate. Global e-waste production is on track to reach 120 million tonnes per year by 2050 [@un2019circular]. From smartphones and tablets to internet-connected devices and home appliances, the soaring production and short lifecycles of our gadgets is fueling this crisis.
+The amount of electronic waste being produced is growing at an alarming rate. Today, [we already produce 50 million tons per year](https://www.unep.org/news-and-stories/press-release/un-report-time-seize-opportunity-tackle-challenge-e-waste). By 2030, that figure is projected to jump to a staggering 75 million tons as consumer electronics consumption continues to accelerate. Global e-waste production will reach 120 million tonnes annually by 2050 [@un2019circular]. The soaring production and short lifecycles of our gadgets fuel this crisis, from smartphones and tablets to internet-connected devices and home appliances.
-Developing nations are being hit the hardest as they lack the infrastructure to safely process obsolete electronics. In 2019, formal e-waste recycling rates in poorer countries ranged from just 13% to 23%. The remainder ends up illegally dumped, burned, or crudely dismantled--releasing toxic materials into the environment and harming workers as well as local communities. Clearly more needs to be done to build global capacity for ethical and sustainable e-waste management or we risk irreversible damage.
+Developing nations are being hit the hardest as they need more infrastructure to process obsolete electronics safely. In 2019, formal e-waste recycling rates in poorer countries ranged from 13% to 23%. The remainder ends up illegally dumped, burned, or crudely dismantled, releasing toxic materials into the environment and harming workers and local communities. Clearly, more needs to be done to build global capacity for ethical and sustainable e-waste management, or we risk irreversible damage.
-The danger is that crude handling of electronics to strip valuables exposes marginalized workers and communities to noxious burnt plastics/metals. Lead poisoning poses especially high risks to child development if ingested or inhaled. Overall, only about 20% of e-waste produced was collected using environmentally sound methods according to UN estimates [@un2019circular]. So solutions for responsible lifecycle management are urgently required to contain the unsafe disposal as volume soars higher.
+The danger is that crude handling of electronics to strip valuables exposes marginalized workers and communities to noxious burnt plastics/metals. Lead poisoning poses especially high risks to child development if ingested or inhaled. Overall, only about 20% of e-waste produced was collected using environmentally sound methods, according to UN estimates [@un2019circular]. So solutions for responsible lifecycle management are urgently required to contain the unsafe disposal as volume soars higher.
#### Disposable Electronics {#disposable-electronics}
-Rapidly falling costs of microcontrollers, tiny rechargeable batteries, and compact communication hardware has enabled embedding intelligent sensor systems throughout everyday consumer goods. These internet-of-things (IoT) devices monitor product conditions, user interactions, and environment factors in order to enable real-time responsiveness, personalization, and data-driven business decisions in the evolving connected marketplace.
+The rapidly falling costs of microcontrollers, tiny rechargeable batteries, and compact communication hardware have enabled the embedding of intelligent sensor systems throughout everyday consumer goods. These internet-of-things (IoT) devices monitor product conditions, user interactions, and environmental factors to enable real-time responsiveness, personalization, and data-driven business decisions in the evolving connected marketplace.
-However, these embedded electronics face little oversight or planning around sustainably handling their eventual disposal once the often plastic-encased products get thrown out following brief lifetimes. IoT sensors now commonly reside in single-use items like water bottles, food packaging, prescription bottles, and cosmetic containers that overwhelmingly enter landfill waste streams after a few weeks to months of consumer use.
+However, these embedded electronics face little oversight or planning around sustainably handling their eventual disposal once the often plastic-encased products are discarded after brief lifetimes. IoT sensors now commonly reside in single-use items like water bottles, food packaging, prescription bottles, and cosmetic containers that overwhelmingly enter landfill waste streams after a few weeks to months of consumer use.
-The problem accelerates as more manufacturers rush to integrate mobile chips, power sources, Bluetooth modules and other modern silicon ICs costing under US$1 into various merchandise without protocols for recycling, replacing batteries or component reusability. Despite their small individual size, collectively the volumes of these devices and lifetime waste burden loom large. Unlike regulating larger electronics, few policy constraints currently exist around materials requirements or toxicity in tiny disposable gadgets.
+The problem accelerates as more manufacturers rush to integrate mobile chips, power sources, Bluetooth modules, and other modern silicon ICs, costing under US$1, into various merchandise without protocols for recycling, replacing batteries, or component reusability. Despite their small individual size, the volumes of these devices and lifetime waste burden loom large. Unlike regulating larger electronics, few policy constraints exist around materials requirements or toxicity in tiny disposable gadgets.
While offering convenience when working, the unsustainable combination of difficult retrievability and limited safe breakdown mechanisms causes disposable connected devices to contribute outsized shares of future e-waste volumes needing urgent attention.
#### Planned Obsolescence {#planned-obsolescence}
-Planned obsolescence refers to the intentional design strategy of manufacturing products with artificially limited lifetimes that quickly become non-functional or outdated. This spurs faster replacement purchase cycles as consumers find devices no longer meeting needs within a few years. However, electronics designed for premature obsolescence contribute to unsustainable e-waste volumes.
+Planned obsolescence refers to the intentional design strategy of manufacturing products with artificially limited lifetimes that quickly become non-functional or outdated. This spurs faster replacement purchase cycles as consumers find devices no longer meet their needs within a few years. However, electronics designed for premature obsolescence contribute to unsustainable e-waste volumes.
-For example, gluing smartphone batteries and components together hinders repairability compared to using modular, accessible assemblies. Or rolling out software updates that deliberately slow system performance creates a perception worth upgrading devices produced only several years earlier.
+For example, gluing smartphone batteries and components together hinders repairability compared to modular, accessible assemblies. Rolling out software updates that deliberately slow system performance creates a perception that upgrading devices produced only several years earlier is worth it.
-Likewise, fashionable introductions of new product generations with minor but exclusive feature additions makes prior versions rapidly seem dated. These tactics compel buying new gadgets ([e.g. Iphones](https://www.cnbc.com/2020/12/08/the-psychology-of-new-iphone-releases-apple-marketing.html)) long before operational endpoints. When multiplied across fast-paced electronics categories, the result is billions of barely worn items being discarded annually.
+Likewise, fashionable introductions of new product generations with minor but exclusive feature additions make prior versions rapidly seem dated. These tactics compel buying new gadgets ([e.g., iPhones](https://www.cnbc.com/2020/12/08/the-psychology-of-new-iphone-releases-apple-marketing.html)) long before operational endpoints. When multiplied across fast-paced electronics categories, billions of barely worn items are discarded annually.
-Planned obsolescence thus intensifies resource utilization and waste creation in making products with no intention for long lifetimes. This contradicts sustainability principles around durability, reuse and material conservation. While stimulating continuous sales and gains for manufacturers in the short term, the strategy externalizes environmental costs and toxins onto communities lacking proper e-waste processing infrastructure.
+Planned obsolescence thus intensifies resource utilization and waste creation in making products with no intention for long lifetimes. This contradicts sustainability principles around durability, reuse, and material conservation. While stimulating continuous sales and gains for manufacturers in the short term, the strategy externalizes environmental costs and toxins onto communities lacking proper e-waste processing infrastructure.
-Policy and consumer action is crucial to counter gadget designs that are needlessly disposable by default. Companies should also invest in product stewardship programs supporting responsible reuse and reclamation.
+Policy and consumer action are crucial to counter gadget designs that are needlessly disposable by default. Companies should also invest in product stewardship programs supporting responsible reuse and reclamation.
-Consider the real world example. [Apple has faced scrutiny](https://undergradlawreview.blog.fordham.edu/consumer-protection/the-product-ecosystem-and-planned-obsolescence-apples-threats-to-consumer-rights/) over the years for allegedly engaging in planned obsolescence to encourage customers to buy new iPhone models. The company was allegedly designing its phones so that performance degrades over time or existing features become incompatible with new operating systems, which critics argue is meant to spur more rapid upgrade cycles. In 2020, Apple paid a 25 million Euros in fine to settle a case in France where regulators found the company guilty of intentionally slowing down older iPhones without clearly informing customers via iOS updates.
+Consider the real-world example. [Apple has faced scrutiny](https://undergradlawreview.blog.fordham.edu/consumer-protection/the-product-ecosystem-and-planned-obsolescence-apples-threats-to-consumer-rights/) over the years for allegedly engaging in planned obsolescence to encourage customers to buy new iPhone models. The company allegedly designed its phones so that performance degrades over time or existing features become incompatible with new operating systems, which critics argue is meant to spur more rapid upgrade cycles. In 2020, Apple paid a 25 million Euros fine to settle a case in France where regulators found the company guilty of intentionally slowing down older iPhones without clearly informing customers via iOS updates.
-By failing to be transparent about power management changes that reduced device performance, Apple participated in deceptive activities that reduced product lifespan to drive sales. The company claimed it was done to "smooth out" peaks that could cause older batteries to shut down suddenly. But this is an example that clearly highlights the legal risks around employing planned obsolescence and not properly disclosing when functionality changes impact device usability over time--even leading brands like Apple can run into trouble if perceived to be intentionally shortening product life cycles.
+By failing to be transparent about power management changes that reduced device performance, Apple participated in deceptive activities that reduced product lifespan to drive sales. The company claimed it was done to "smooth out" peaks that could suddenly cause older batteries to shut down. However, this example highlights the legal risks around employing planned obsolescence and not properly disclosing when functionality changes impact device usability over time- even leading brands like Apple can run into trouble if perceived as intentionally shortening product life cycles.
## Policy and Regulatory Considerations {#policy-and-regulatory-considerations}
### Measurement and Reporting Mandates {#measurement-and-reporting-mandates}
-One policy mechanism with increasing relevance for AI systems is measurement and reporting requirements regarding energy consumption and carbon emissions. Mandated metering, auditing, disclosures, and more rigorous methodologies aligned to sustainability metrics can help address information gaps hindering efficiency optimizations.
+One policy mechanism that is increasingly relevant for AI systems is measurement and reporting requirements regarding energy consumption and carbon emissions. Mandated metering, auditing, disclosures, and more rigorous methodologies aligned to sustainability metrics can help address information gaps hindering efficiency optimizations.
-On the simple end, national or regional policies may require companies above a certain size utilizing AI in their products or backend systems to report energy consumption or emissions associated with major AI workloads. Organizations like the Partnership on AI, IEEE, and NIST could help shape standardized methodologies. More complex proposals involve defining consistent ways to measure computational complexity, data center PUE, carbon intensity of energy supply, and efficiencies gained through AI-specific hardware.
+Simultaneously, national or regional policies require companies above a certain size to utilize AI in their products or backend systems to report energy consumption or emissions associated with major AI workloads. Organizations like the Partnership on AI, IEEE, and NIST could help shape standardized methodologies. More complex proposals involve defining consistent ways to measure computational complexity, data center PUE, carbon intensity of energy supply, and efficiencies gained through AI-specific hardware.
-Reporting obligations for public sector users procuring AI services--such as through proposed legislation in Europe--could also increase transparency. However, regulators must balance the additional measurement burden such mandates place on organizations versus ongoing carbon reductions from ingraining sustainability-conscious development patterns.
+Reporting obligations for public sector users procuring AI services—such as through proposed legislation in Europe—could also increase transparency. However, regulators must balance the additional measurement burden such mandates place on organizations against ongoing carbon reductions from ingraining sustainability-conscious development patterns.
-To be most constructive, any measurement and reporting policies should focus on enabling continuous refinement rather than simplistic restrictions or caps. As AI advancements unfold rapidly, nimble governance guardrails that embed sustainability considerations into normal evaluation metrics can motivate positive change. But overprescription risks constraining innovation if requirements grow outdated. By combining flexibility with appropriate transparency guardrails, AI efficiency policy aims to accelerate progress industry-wide.
+To be most constructive, any measurement and reporting policies should focus on enabling continuous refinement rather than simplistic restrictions or caps. As AI advancements unfold rapidly, nimble governance guardrails that embed sustainability considerations into normal evaluation metrics can motivate positive change. However, overprescription risks constraining innovation if requirements grow outdated. AI efficiency policy aims to accelerate progress industry-wide by combining flexibility with appropriate transparency guardrails.
### Restriction Mechanisms {#restriction-mechanisms}
In addition to reporting mandates, policymakers have several restriction mechanisms that could directly shape how AI systems are developed and deployed to curb emissions:
-Caps on Computing Emissions: The [European Commission's proposed AI Act](https://digital-strategy.ec.europa.eu/en/policies/european-approach-artificial-intelligence) takes a horizontal approach that could allow setting economy-wide caps on the volume of computing power available for training AI models. Similar to emissions trading systems, caps aim to indirectly disincentivize extensive computing over sustainability. However, model quality could suffer absent pathways for procuring additional capacity.
+Caps on Computing Emissions: The [European Commission's proposed AI Act](https://digital-strategy.ec.europa.eu/en/policies/european-approach-artificial-intelligence) takes a horizontal approach that could allow setting economy-wide caps on the volume of computing power available for training AI models. Like emissions trading systems, caps aim to disincentivize extensive computing over sustainability indirectly. However, model quality could be improved to provide more pathways for procuring additional capacity.
-Conditioning Access to Public Resources: Some experts have proposed incentives like only allowing access to public datasets or computing power for developing fundamentally efficient models rather than extravagant architectures. For example, the [MLCommons benchmarking consortium](https://mlcommons.org/) founded by major tech firms could formally integrate efficiency into its standardized leaderboard metrics. However, conditioned access risks limiting innovation.
+Conditioning Access to Public Resources: Some experts have proposed incentives like only allowing access to public datasets or computing power for developing fundamentally efficient models rather than extravagant architectures. For example, the [MLCommons benchmarking consortium](https://mlcommons.org/) founded by major tech firms could formally integrate efficiency into its standardized leaderboard metrics—however, conditioned access risks limiting innovation.
-Financial Mechanisms: Analogous to carbon taxes on polluting industries, fees applied per unit of AI-related compute consumption could discourage unnecessary model scaling while funding efficiency innovations. Tax credits could alternatively reward organizations pioneering more accurate but compact AI techniques. But financial tools require careful calibration between revenue generation, fairness, and not over-penalizing productive uses of AI.
+Financial Mechanisms: Analogous to carbon taxes on polluting industries, fees applied per unit of AI-related compute consumption could discourage unnecessary model scaling while funding efficiency innovations. Tax credits could alternatively reward organizations pioneering more accurate but compact AI techniques. However, financial tools require careful calibration between revenue generation and fairness and not over-penalizing productive uses of AI.
Technology Bans: If measurement consistently pinned extreme emissions on specific applications of AI without paths for remediation, outright bans present a tool of last resort for policymakers. However, given AI's dual use, defining harmful versus beneficial deployments proves complex, necessitating holistic impact assessment before concluding no redeeming value exists. Banning promising technologies risks unintended consequences and requires caution.
### Government Incentives {#government-incentives}
-It is a common practice for governments to provide tax or other incentives to consumers or businesses when contributing to more sustainable practices in technology. Such incentives already exist in the US for [adopting solar panels](https://www.irs.gov/credits-deductions/residential-clean-energy-credit) or [energy efficient buildings](https://www.energy.gov/eere/buildings/179d-commercial-buildings-energy-efficiency-tax-deduction). To the best of our knowledge, no such tax incentives exist for AI specific development practices yet.
+It is a common practice for governments to provide tax or other incentives to consumers or businesses when contributing to more sustainable technological practices. Such incentives already exist in the US for [adopting solar panels](https://www.irs.gov/credits-deductions/residential-clean-energy-credit) or [energy-efficient buildings](https://www.energy.gov/eere/buildings/179d-commercial-buildings-energy-efficiency-tax-deduction). To the best of our knowledge, no such tax incentives exist for AI-specific development practices yet.
-Another potential incentive program that is beginning to be explored is the use of government grants to fund Green AI projects. For example, in Spain, [300 million euros have been allocated](https://www.state.gov/artificial-intelligence-for-accelerating-progress-on-the-sustainable-development-goals-addressing-societys-greatest-challenges/) to specifically fund projects in AI and sustainability. Government incentives are a promising avenue to encourage sustainable practices in business and consumer behavior, but they require careful thought into how those incentives will fit into market demands [@maxime2016impact].
+Another potential incentive program that is beginning to be explored is using government grants to fund Green AI projects. For example, in Spain, [300 million euros have been allocated](https://www.state.gov/artificial-intelligence-for-accelerating-progress-on-the-sustainable-development-goals-addressing-societys-greatest-challenges/) to specifically fund projects in AI and sustainability. Government incentives are a promising avenue to encourage sustainable business and consumer behavior practices, but careful thought is required to determine how those incentives will fit into market demands [@maxime2016impact].
### Self-Regulation {#self-regulation}
Complimentary to potential government action, voluntary self-governance mechanisms allow the AI community to pursue sustainability ends without top-down intervention:
-Renewables Commitments: Large AI practitioners like Google, Microsoft, Amazon and Facebook have pledged to procure enough renewable electricity to match 100% of their energy demands. These commitments unlock compounding emissions cuts as compute scales up. Formalizing such programs incentivizes green data center regions. However, there are critiques to whether these pledges are enough [@monyei2018electrons].
+Renewables Commitments: Large AI practitioners like Google, Microsoft, Amazon, and Facebook have pledged to procure enough renewable electricity to match 100% of their energy demands. These commitments unlock compounding emissions cuts as compute scales up. Formalizing such programs incentivizes green data center regions. However, there are critiques on whether these pledges are enough [@monyei2018electrons].
Internal Carbon Prices: Some organizations utilize shadow prices on carbon emissions to represent environmental costs in capital allocation decisions between AI projects. If modeled effectively, theoretical charges on development carbon footprints steer funding toward efficient innovations rather than solely accuracy gains.
-Efficiency Development Checklists: Groups like the AI Sustainability Coalition suggest voluntary checklist templates highlighting model design choices, hardware configurations, and other factors architects can tune per application to restrain emissions. By ingraining sustainability as a primary success metric alongside accuracy and cost, organizations can drive change.
+Efficiency Development Checklists: Groups like the AI Sustainability Coalition suggest voluntary checklist templates highlighting model design choices, hardware configurations, and other factors architects can tune per application to restrain emissions. Organizations can drive change by ingraining sustainability as a primary success metric alongside accuracy and cost.
Independent Auditing: Even absent public disclosure mandates, firms specializing in technology sustainability audits help AI developers identify waste, create efficiency roadmaps, and benchmark progress via impartial reviews. Structuring such audits into internal governance procedures or the procurement process expands accountability.
### Global Considerations {#global-considerations}
-While measurement, restrictions, incentives, and self-regulation all represent potential policy mechanisms for furthering AI sustainability, fragmentation across national regimes risks unintended consequences. As with other technology policy domains, divergence between regions must be carefully managed.
+While measurement, restrictions, incentives, and self-regulation represent potential policy mechanisms for furthering AI sustainability, fragmentation across national regimes risks unintended consequences. As with other technology policy domains, divergence between regions must be carefully managed.
-For example, OpenAI barred access to its viral ChatGPT chatbot for European users over data privacy concerns in the region. This came after the EU's proposed AI Act signaled a precautionary approach allowing the EC to ban certain AI uses deemed high-risk, enforcing transparency rules that create uncertainty for release of brand new models. However, it would be wise to caution regulator action as it could inadvertently limit European innovation if regimes with lighter touch regulation attract more private sector AI research spending and talent. Finding common ground is key.
+For example, due to regional data privacy concerns, OpenAI barred European users from accessing its viral ChatGPT chatbot. This came after the EU's proposed AI Act signaled a precautionary approach, allowing the EC to ban certain high-risk AI uses and enforcing transparency rules that create uncertainty for releasing brand new models. However, it would be wise to caution against regulator action as it could inadvertently limit European innovation if regimes with lighter-touch regulation attract more private-sector AI research spending and talent. Finding common ground is key.
-The OECD principles on AI and the United Nations frameworks underscore universally agreed tenets all national policies should uphold: transparency, accountability, bias mitigation, and more. Constructively embedding sustainability as a core principle for responsible AI within such international guidance can motivate unified action without sacrificing flexibility across divergent legal systems. Avoiding race-to-the-bottom dynamics hinges on enlightened multilateral cooperation.
+The OECD principles on AI and the United Nations frameworks underscore universally agreed-upon tenets all national policies should uphold: transparency, accountability, bias mitigation, and more. Constructively embedding sustainability as a core principle for responsible AI within international guidance can motivate unified action without sacrificing flexibility across divergent legal systems. Avoiding race-to-the-bottom dynamics hinges on enlightened multilateral cooperation.
## Public Perception and Engagement {#public-perception-and-engagement}
-As societal attention and policy efforts aimed at environmental sustainability ramp up worldwide, there is growing enthusiasm around leveraging AI to help address ecological challenges. However, public understanding and attitudes towards the role of AI systems in sustainability contexts remain mixed and clouded by misconceptions. On one hand, people hope advanced algorithms can provide new solutions for green energy, responsible consumption, decarbonization pathways and ecosystem preservation. But on the other, fears regarding risks of uncontrolled AI also seep into the environmental domain and undermine constructive discourse. Furthermore, lack of public awareness on key issues like transparency in development of sustainability-focused AI tools as well as potential biases in data or modeling also threaten to limit inclusive participation and degrade public trust.
+As societal attention and policy efforts aimed at environmental sustainability ramp up worldwide, there is growing enthusiasm for leveraging AI to help address ecological challenges. However, public understanding and attitudes toward the role of AI systems in sustainability contexts still need to be clarified and clouded by misconceptions. On the one hand, people hope advanced algorithms can provide new solutions for green energy, responsible consumption, decarbonization pathways, and ecosystem preservation. On the other, fears regarding the risks of uncontrolled AI also seep into the environmental domain and undermine constructive discourse. Furthermore, a lack of public awareness on key issues like transparency in developing sustainability-focused AI tools and potential biases in data or modeling also threaten to limit inclusive participation and degrade public trust.
-Tackling complex, interdisciplinary priorities like environmental sustainability requires informed, nuanced public engagement along with responsible advances in AI innovation itself. The path forward demands careful, equitable collaborative efforts between experts in fields like ML, climate science, environmental policy, social science and communication. Mapping the landscape of public perceptions, identifying pitfalls, and charting strategies to cultivate understandable, accessible and trustworthy AI systems targeting shared ecological priorities will prove essential to realizing sustainability goals. This complex terrain warrants deep examination into the sociotechnical dynamics involved.
+Tackling complex, interdisciplinary priorities like environmental sustainability requires informed, nuanced public engagement and responsible advances in AI innovation. The path forward demands careful, equitable collaborative efforts between experts in ML, climate science, environmental policy, social science, and communication. Mapping the landscape of public perceptions, identifying pitfalls, and charting strategies to cultivate understandable, accessible, and trustworthy AI systems targeting shared ecological priorities will prove essential to realizing sustainability goals. This complex terrain warrants a deep examination of the sociotechnical dynamics involved.
### AI Awareness {#ai-awareness}
-In May 2022, [Pew Research Center polled 5,101 U.S. adults](https://www.pewresearch.org/internet/2023/08/17/what-americans-know-about-ai-cybersecurity-and-big-tech/) finding 60% had heard or read "a little" about AI while 27% heard "a lot"--indicating decent broad recognition, but likely limited comprehension about details or applications. However, among those with some AI familiarity, concerns emerge regarding risks of personal data misuse according to agreed terms. Still 62% felt AI could potentially ease modern life if applied responsibly. Yet specific understanding of sustainability contexts remains lacking.
+In May 2022, [the Pew Research Center polled 5,101 US adults](https://www.pewresearch.org/internet/2023/08/17/what-americans-know-about-ai-cybersecurity-and-big-tech/), finding 60% had heard or read "a little" about AI while 27% heard "a lot"--indicating decent broad recognition, but likely limited comprehension about details or applications. However, among those with some AI familiarity, concerns emerge regarding risks of personal data misuse according to agreed terms. Still, 62% felt AI could ease modern life if applied responsibly. Yet, a specific understanding of sustainability contexts still needs to be improved.
-Studies attempting to categorize online discourse sentiments find a nearly even split between optimism and caution regarding deployment of AI for sustainability goals. Factors driving positivity include hopes around better forecasting of ecological shifts using ML models. Negativity arises from lack of confidence in self-supervised algorithms avoiding unintended consequences due to unpredictable human impacts on complex natural systems during training.
+Studies attempting to categorize online discourse sentiments find a nearly even split between optimism and caution regarding deploying AI for sustainability goals. Factors driving positivity include hopes around better forecasting of ecological shifts using ML models. Negativity arises from a lack of confidence in self-supervised algorithms avoiding unintended consequences due to unpredictable human impacts on complex natural systems during training.
-The most prevalent public belief remains that while AI does harbor potential for accelerating solutions on issues like emission reductions and wildlife protections, inadequate safeguarding around data biases, ethical blindspots and privacy considerations pose underappreciated risks if pursued carelessly, especially at scale. This leads to hesitancy around unconditional support without evidence of deliberate, democratically guided development.
+The most prevalent public belief remains that while AI does harbor the potential for accelerating solutions on issues like emission reductions and wildlife protections, inadequate safeguarding around data biases, ethical blindspots, and privacy considerations could be more appreciated risks if pursued carelessly, especially at scale. This leads to hesitancy around unconditional support without evidence of deliberate, democratically guided development.
### Messaging {#messaging}
-[Optimistic efforts](https://www.climatechange.ai/) are highlighting AI's sustainability promise emphasize potential for advanced ML to radically accelerate decarbonization effects from smart grids, personalized carbon tracking apps, automated building efficiency optimizations, and predictive analytics guiding targeted conservation efforts. More comprehensive real-time modeling of complex climate and ecological shifts using self-improving algorithms offers hope for mitigating biodiversity losses and averting worst case scenarios.
+[Optimistic efforts](https://www.climatechange.ai/) are highlighting AI's sustainability promise and emphasize the potential for advanced ML to radically accelerate decarbonization effects from smart grids, personalized carbon tracking apps, automated building efficiency optimizations, and predictive analytics guiding targeted conservation efforts. More comprehensive real-time modeling of complex climate and ecological shifts using self-improving algorithms offers hope for mitigating biodiversity losses and averting worst-case scenarios.
-However, [cautionary perspectives](https://time.com/6266923/ai-eliezer-yudkowsky-open-letter-not-enough/), such as the [Asilomar AI Principles](https://futureoflife.org/open-letter/ai-principles/), question whether AI itself could exacerbate sustainability challenges if improperly constrained. Rising energy demands of large scale computing systems and increasingly massive neural network model training conflicts with clean energy ambitions. Lack of diversity in data inputs or priorities of developers might inadvertently downplay urgent environmental justice considerations. Near term skeptical public engagement likely hinges on lack of perceivable safeguards against uncontrolled AI systems that are running amok on core ecological processes before our eyes.
+However, [cautionary perspectives](https://time.com/6266923/ai-eliezer-yudkowsky-open-letter-not-enough/), such as the [Asilomar AI Principles](https://futureoflife.org/open-letter/ai-principles/), question whether AI itself could exacerbate sustainability challenges if improperly constrained. The rising energy demands of large-scale computing systems and the increasingly massive neural network model training conflict with clean energy ambitions. Lack of diversity in data inputs or developers' priorities may downplay urgent environmental justice considerations. Near-term skeptical public engagement likely hinges on a need for perceivable safeguards against uncontrolled AI systems running amok on core ecological processes.
-In essence, polarized framings either promote AI as an indispensable tool for sustainability problem-solving--if compassionately directed toward people and planet--or present AI as an amplifier of existing harms insidiously dominating hidden facets of natural systems central to all life. Overcoming such impasses demands balancing honest trade-off discussions with shared visions for equitable, democratically governed technological progress targeting restoration.
+In essence, polarized framings either promote AI as an indispensable tool for sustainability problem-solving--if compassionately directed toward people and the planet--or present AI as an amplifier of existing harms insidiously dominating hidden facets of natural systems central to all life. Overcoming such impasses demands balancing honest trade-off discussions with shared visions for equitable, democratically governed technological progress targeting restoration.
### Equitable Participation {#equitable-participation}
-Ensuring equitable participation and access should form a cornerstone of any sustainability initiative with potential for major societal impacts. This principle applies equally to AI systems targeting environmental goals. However, commonly excluded voices like frontline, rural or indigenous communities and future generations not present to consent could suffer disproportionate consequences from technology transformations. For instance, the [Partnership on AI](https://partnershiponai.org) has launched events expressly targeting input from marginalized communities on deploying AI responsibly.
+Ensuring equitable participation and access should form a cornerstone of any sustainability initiative with the potential for major societal impacts. This principle applies equally to AI systems targeting environmental goals. However, commonly excluded voices like frontline, rural, or indigenous communities and future generations not present to consent could suffer disproportionate consequences from technology transformations. For instance, the [Partnership on AI](https://partnershiponai.org) has launched events expressly targeting input from marginalized communities on deploying AI responsibly.
-Ensuring equitable access and participation should form a cornerstone of any sustainability initiative with potential for major societal impacts be it AI or otherwise. However, inclusive engagement on environmental AI relies partly on availability and understanding of fundamental computing resources. As the recent [OECD](https://www.oecd.org/) report on [National AI Compute Capacity](https://www.oecd.org/economy/a-blueprint-for-building-national-compute-capacity-for-artificial-intelligence-876367e3-en.htm) highlights [@oecd2023blueprint], many countries currently lack data or strategic plans mapping needs for the infrastructure required to fuel AI systems. This policy blind-spot could constrain economic goals and exacerbate barriers to entry for marginalized populations. Their blueprint urges developing national AI compute capacity strategies along dimensions of capacity, accessibility, innovation pipelines and resilience to anchor innovation. Otherwise inadequacies in underlying data storage, model development platforms or specialized hardware could inadvertently concentrate AI progress in the hands of select groups. Therefore, planning for balanced expansion of fundamental AI computing resources via policy initiatives ties directly to hopes for democratized sustainability problem-solving using equitable and transparent ML tools.
+Ensuring equitable access and participation should form a cornerstone of any sustainability initiative with the potential for major societal impacts, whether AI or otherwise. However, inclusive engagement in environmental AI relies partly on the availability and understanding of fundamental computing resources. As the recent [OECD](https://www.oecd.org/) report on [National AI Compute Capacity](https://www.oecd.org/economy/a-blueprint-for-building-national-compute-capacity-for-artificial-intelligence-876367e3-en.htm) highlights [@oecd2023blueprint], many countries currently lack data or strategic plans mapping needs for the infrastructure required to fuel AI systems. This policy blindspot could constrain economic goals and exacerbate barriers to entry for marginalized populations. Their blueprint urges developing national AI compute capacity strategies along dimensions of capacity, accessibility, innovation pipelines, and resilience to anchor innovation. The underlying data storage needs to be improved, and model development platforms or specialized hardware could inadvertently concentrate AI progress in the hands of select groups. Therefore, planning for a balanced expansion of fundamental AI computing resources via policy initiatives ties directly to hopes for democratized sustainability problem-solving using equitable and transparent ML tools.
-The key idea is that equitable participation in AI systems targeting environmental challenges relies in part on getting the underlying computing capacity and infrastructure right, which requires proactive policy planning from a national perspective.
+The key idea is that equitable participation in AI systems targeting environmental challenges relies in part on ensuring the underlying computing capacity and infrastructure are correct, which requires proactive policy planning from a national perspective.
### Transparency {#transparency}
-As public sector agencies and private companies alike rush towards adopting AI tools to help tackle pressing environmental challenges, calls for transparency around the development and functionality of these systems has began to amplify. Explainable and interpretable ML features grow more crucial for building trust in emerging models aiming to guide consequential sustainability policies. Initiatives like the [Montreal Carbon Pledge](https://unfccc.int/news/montreal-carbon-pledge) brought tech leaders together to commit to publishing impact assessments before launching environmental systems, as pledged below:
+As public sector agencies and private companies alike rush towards adopting AI tools to help tackle pressing environmental challenges, calls for transparency around these systems' development and functionality have begun to amplify. Explainable and interpretable ML features grow more crucial for building trust in emerging models aiming to guide consequential sustainability policies. Initiatives like the [Montreal Carbon Pledge](https://unfccc.int/news/montreal-carbon-pledge) brought tech leaders together to commit to publishing impact assessments before launching environmental systems, as pledged below:
-*"As institutional investors, we have a duty to act in the best long-term interests of our beneficiaries. In this fiduciary role, we believe that there are long-term investment risks associated with greenhouse gas emissions, climate change and carbon regulation.
+*"As institutional investors, we must act in the best long-term interests of our beneficiaries. In this fiduciary role, long-term investment risks are associated with greenhouse gas emissions, climate change, and carbon regulation.
-In order to better understand, quantify and manage the carbon and climate change related impacts, risks and opportunities in our investments, it is integral to measure our carbon footprint. Therefore, we commit, as a first step, to measure and disclose the carbon footprint of our investments annually with the aim of using this information to develop an engagement strategy and/or identify and set carbon footprint reduction targets."*
+Measuring our carbon footprint is integral to understanding better, quantifying, and managing the carbon and climate change-related impacts, risks, and opportunities in our investments. Therefore, as a first step, we commit to measuring and disclosing the carbon footprint of our investments annually to use this information to develop an engagement strategy and identify and set carbon footprint reduction targets."*
-We need a similar pledge for AI sustainability and responsibility. Widespread acceptance and impact of AI sustainability solutions will partly on deliberate communication of validation schemes, metrics, and layers of human judgment applied before live deployment. Efforts like [NIST's Principles for Explainable AI](https://oecd.ai/en/dashboards/policy-initiatives/http:%2F%2Faipo.oecd.org%2F2021-data-policyInitiatives-26746) can be helpful for fostering transparency into AI systems. The National Institute of Standards and Technology (NIST) has published an influential set of guidelines dubbed the Principles for Explainable AI [@phillips2020four]. This framework articulates best practices for designing, evaluating and deploying responsible AI systems with transparent and interpretable features that build critical user understanding and trust.
+We need a similar pledge for AI sustainability and responsibility. Widespread acceptance and impact of AI sustainability solutions will partly be on deliberate communication of validation schemes, metrics, and layers of human judgment applied before live deployment. Efforts like [NIST's Principles for Explainable AI](https://oecd.ai/en/dashboards/policy-initiatives/http:%2F%2Faipo.oecd.org%2F2021-data-policyInitiatives-26746) can help foster transparency into AI systems. The National Institute of Standards and Technology (NIST) has published an influential set of guidelines dubbed the Principles for Explainable AI [@phillips2020four]. This framework articulates best practices for designing, evaluating, and deploying responsible AI systems with transparent and interpretable features that build critical user understanding and trust.
-It delineates four core principles: Firstly, AI systems should provide contextually relevant explanations justifying the reasoning behind their outputs to appropriate stakeholders. Secondly, these AI explanations must communicate information in a truly meaningful way for their target audience's appropriate comprehension level. Next, there is the accuracy principle which dictates explanations should faithfully reflect the actual process and logic informing an AI model's internal mechanics for generating given outputs or recommendations based on inputs. Finally, a knowledge limits principle compels explanations to clarify an AI model's boundaries in capturing the full breadth of real-world complexity, variance and uncertainties within a problem space.
+It delineates four core principles: Firstly, AI systems should provide contextually relevant explanations justifying the reasoning behind their outputs to appropriate stakeholders. Secondly, these AI explanations must communicate information meaningfully for their target audience's appropriate comprehension level. Next is the accuracy principle, which dictates that explanations should faithfully reflect the actual process and logic informing an AI model's internal mechanics for generating given outputs or recommendations based on inputs. Finally, a knowledge limits principle compels explanations to clarify an AI model's boundaries in capturing the full breadth of real-world complexity, variance, and uncertainties within a problem space.
-Altogether, these NIST principles offer AI practitioners and adopters guidance on key transparency considerations vital for developing accessible solutions that prioritize user autonomy and trust rather than simply maximizing predictive accuracy metrics alone. As AI rapidly advances across sensitive social contexts like healthcare, finance, employment and beyond, such human centered design guidelines will continue growing in importance for anchoring innovation to public interests.
+Altogether, these NIST principles offer AI practitioners and adopters guidance on key transparency considerations vital for developing accessible solutions prioritizing user autonomy and trust rather than simply maximizing predictive accuracy metrics alone. As AI rapidly advances across sensitive social contexts like healthcare, finance, employment, and beyond, such human-centered design guidelines will continue growing in importance for anchoring innovation to public interests.
-This applies equally to the environmental ability domain. Overall, responsible and democratically guided AI innovation targeting shared ecological priorities depends on maintaining public vigilance, understanding, and oversight over otherwise opaque systems taking prominent roles in societal decisions. Prioritizing explainable algorithm designs and radical transparency practices per global standards can help sustain collective confidence that these tools improve rather than imperil hopes for AI driven future.
+This applies equally to the domain of environmental ability. Responsible and democratically guided AI innovation targeting shared ecological priorities depends on maintaining public vigilance, understanding, and oversight over otherwise opaque systems taking prominent roles in societal decisions. Prioritizing explainable algorithm designs and radical transparency practices per global standards can help sustain collective confidence that these tools improve rather than imperil hopes for a driven future.
## Future Directions and Challenges {#future-directions-and-challenges}
-As we look towards the future, the role of AI in environmental sustainability is poised to grow even more significant. The potential of AI to drive advancements in renewable energy, climate modeling, conservation efforts, and more is immense. However, it is a two-sided coin, as we need to overcome several challenges and direct our efforts towards sustainable and responsible AI development.
+As we look towards the future, the role of AI in environmental sustainability is poised to grow even more significant. AI's potential to drive advancements in renewable energy, climate modeling, conservation efforts, and more is immense. However, it is a two-sided coin, as we need to overcome several challenges and direct our efforts towards sustainable and responsible AI development.
### Future Directions {#future-directions}
-One of the key future directions is the development of more energy-efficient AI models and algorithms. This involves ongoing research and innovation in areas like model pruning, quantization, and the use of low-precision numerics, and developing the hardware to enable full profitability of these innovations. Even further, we look at alternative computing paradigms which do not rely on von-Neumann architectures. More on this topic can be found in the hardware acceleration chapter. The goal is to create AI systems that deliver high performance while minimizing energy consumption and carbon emissions.
+One key future direction is the development of more energy-efficient AI models and algorithms. This involves ongoing research and innovation in areas like model pruning, quantization, and the use of low-precision numerics, as well as developing the hardware to enable full profitability of these innovations. Even further, we look at alternative computing paradigms that do not rely on von-Neumann architectures. More on this topic can be found in the hardware acceleration chapter. The goal is to create AI systems that deliver high performance while minimizing energy consumption and carbon emissions.
Another important direction is the integration of renewable energy sources into AI infrastructure. As data centers continue to be major contributors to AI's carbon footprint, transitioning to renewable energy sources like solar and wind is crucial. Developments in long-term, sustainable energy storage, such as [Ambri](https://ambri.com/), an MIT spinoff, could enable this transition. This requires significant investment and collaboration between tech companies, energy providers, and policymakers.
### Challenges {#challenges}
-Despite these promising directions, several challenges need to be addressed. One of the major challenges is the lack of consistent standards and methodologies for measuring and reporting the environmental impact of AI. It is essential that the complexity of life cycles of both AI models and system hardware are captured by these methods. Next, efficient and environmentally-sustainable AI infrastructure and system hardware is needed. This consists of three components. Aimed at maximizing the utilization of accelerator and system resources, prolonging the lifetime of AI infrastructure, and designing systems hardware with environmental impact in mind.
+Despite these promising directions, several challenges need to be addressed. One of the major challenges is the need for consistent standards and methodologies for measuring and reporting the environmental impact of AI. These methods must capture the complexity of the life cycles of AI models and system hardware. Next, efficient and environmentally sustainable AI infrastructure and system hardware are needed. This consists of three components. It aims to maximize the utilization of accelerator and system resources, prolong the lifetime of AI infrastructure, and design systems hardware with environmental impact in mind.
-On the software side, we should make a trade-off between experimentation and the subsequent training cost. Techniques such as neural architecture search and hyperparameter optimization can be used for design space exploration. However, these are often very resource-intensive. Efficient experimentation can reduce the environmental footprint overhead significantly. Next, methods to reduce wasted training efforts should be explored.
+On the software side, we should trade off experimentation and the subsequent training cost. Techniques such as neural architecture search and hyperparameter optimization can be used for design space exploration. However, these are often very resource-intensive. Efficient experimentation can significantly reduce the environmental footprint overhead. Next, methods to reduce wasted training efforts should be explored.
-To improve model quality, we often scale the dataset. However, the increased system resources required for data storage and ingestion caused by this scaling has a significant environmental impact [@wu2022sustainable]. A thorough understanding of the rate at which data loses its predictive value and devising data sampling strategies is important.
+To improve model quality, we often scale the dataset. However, the increased system resources required for data storage and ingestion caused by this scaling have a significant environmental impact [@wu2022sustainable]. A thorough understanding of the rate at which data loses its predictive value and devising data sampling strategies is important.
-Data gaps also pose a significant challenge. Without companies and governments openly sharing detailed and accurate data on energy consumption, carbon emissions, and other environmental impacts, it is difficult to develop effective strategies for sustainable AI.
+Data gaps also pose a significant challenge. Without companies and governments openly sharing detailed and accurate data on energy consumption, carbon emissions, and other environmental impacts, it isn't easy to develop effective strategies for sustainable AI.
-Finally, the fast pace of AI development requires an agile approach to the policy imposed on these systems. The policy should ensure sustainable development without constraining innovation. This requires experts in all domains of AI, environmental sciences, energy and policy to work together to achieve a sustainable future.
+Finally, the fast pace of AI development requires an agile approach to the policy imposed on these systems. The policy should ensure sustainable development without constraining innovation. This requires experts in all domains of AI, environmental sciences, energy, and policy to work together to achieve a sustainable future.
## Conclusion {#conclusion}
-As AI continues rapidly expanding across industries and society, we must address sustainability considerations. AI promises breakthrough innovations, yet its environmental footprint threatens its widespread growth. This chapter analyzes multiple facets, from energy and emissions to waste and biodiversity impacts, that AI/ML developers must weigh when creating responsible AI systems.
+We must address sustainability considerations as AI rapidly expands across industries and society. AI promises breakthrough innovations, yet its environmental footprint threatens its widespread growth. This chapter analyzes multiple facets, from energy and emissions to waste and biodiversity impacts, that AI/ML developers must weigh when creating responsible AI systems.
-Fundamentally, we require elevating sustainability as a primary design priority rather than an afterthought. Techniques like energy-efficient models, renewable-powered data centers, and hardware recycling programs offer solutions, but holistic commitment remains vital. We need standards around transparency, carbon accounting, and supply chain disclosures to supplement technical gains. Still, examples like Google's 4M efficiency practices containing ML energy use highlight that with concerted effort, we can advance AI in lockstep with environmental objectives. We achieve this harmonious balance by having researchers, corporations, regulators and users collaborate across domains. The aim is not perfect solutions but rather continuous improvement as we integrate AI across new sectors.
+Fundamentally, we require elevating sustainability as a primary design priority rather than an afterthought. Techniques like energy-efficient models, renewable-powered data centers, and hardware recycling programs offer solutions, but the holistic commitment remains vital. We need standards around transparency, carbon accounting, and supply chain disclosures to supplement technical gains. Still, examples like Google's 4M efficiency practices containing ML energy use highlight that we can advance AI in lockstep with environmental objectives with concerted effort. We achieve this harmonious balance by having researchers, corporations, regulators, and users collaborate across domains. The aim is not perfect solutions but continuous improvement as we integrate AI across new sectors.
## Resources {#sec-sustainable-ai-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Transparency and Sustainability.](https://docs.google.com/presentation/d/1wGKWV-speisH6V-g-u_w8xFwEjZjqp7u2YXs27flmiM/edit#slide=id.ge93ee14fb9_0_0)
@@ -685,6 +685,8 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
:::{.callout-exercise collapse="false"}
# Exercises
+To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
+
- @exr-cf
- @exr-mle
@@ -693,7 +695,7 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/toc.qmd b/contents/toc.qmd
index 9bb23e00..eb1ca0e2 100644
--- a/contents/toc.qmd
+++ b/contents/toc.qmd
@@ -56,21 +56,21 @@ Here's a closer look at what each chapter covers:
To get the most out of this book, consider the following structured approach:
-1. **Basic Knowledge (Chapters 1-4)**: Start by building a strong foundation with the initial chapters, which provide an introduction to embedded AI and cover core topics like embedded systems and deep learning.
+1. **Basic Knowledge (Chapters 1-4):** Start by building a strong foundation with the initial chapters, which provide an introduction to embedded AI and cover core topics like embedded systems and deep learning.
-2. **Development Process (Chapters 5-10)**: With that foundation, move on to the chapters focused on practical aspects of the AI model building process like workflows, data engineering, training, optimizations and frameworks.
+2. **Development Process (Chapters 5-10):** With that foundation, move on to the chapters focused on practical aspects of the AI model building process like workflows, data engineering, training, optimizations and frameworks.
-3. **Deployment and Monitoring (Chapters 11-14)**: These chapters offer insights into effectively deploying AI on devices and monitoring the operationalization through methods like benchmarking and on-device learning.
+3. **Deployment and Monitoring (Chapters 11-14):** These chapters offer insights into effectively deploying AI on devices and monitoring the operationalization through methods like benchmarking and on-device learning.
-4. **Responsible and Emerging AI (Chapters 15-18)**: Critically examine topics like ethics, security, sustainability and cutting edge techniques in AI as you conclude the learning journey.
+4. **Responsible and Emerging AI (Chapters 15-18):** Critically examine topics like ethics, security, sustainability and cutting edge techniques in AI as you conclude the learning journey.
-5. **Interconnected Learning**: While designed for progressive learning, feel free to navigate chapters based on your interests and needs.
+5. **Interconnected Learning:** While designed for progressive learning, feel free to navigate chapters based on your interests and needs.
-6. **Practical Applications**: Relate theory to real-world applications by engaging with case studies and hands-on exercises throughout.
+6. **Practical Applications:** Relate theory to real-world applications by engaging with case studies and hands-on exercises throughout.
-7. **Discussion and Networking**: Participate in forums and groups to debate concepts and share insights.
+7. **Discussion and Networking:** Participate in forums and groups to debate concepts and share insights.
-8. **Revisit and Reflect**: Revisiting chapters can reinforce learnings and offer new perspectives on concepts.
+8. **Revisit and Reflect:** Revisiting chapters can reinforce learnings and offer new perspectives on concepts.
By adopting this structured yet flexible approach, you're setting the stage for a fulfilling and enriching learning experience.
diff --git a/contents/training/training.bib b/contents/training/training.bib
index d5591dee..bf0ef6cf 100644
--- a/contents/training/training.bib
+++ b/contents/training/training.bib
@@ -1,3 +1,6 @@
+%comment{This file was created with betterbib v5.0.11.}
+
+
@article{dahl2023benchmarking,
author = {Dahl, George E and Schneider, Frank and Nado, Zachary and Agarwal, Naman and Sastry, Chandramouli Shama and Hennig, Philipp and Medapati, Sourabh and Eschenhagen, Runa and Kasimbeg, Priya and Suo, Daniel and others},
doi = {10.1212/nxi.0000000000001086},
@@ -9,19 +12,20 @@ @article{dahl2023benchmarking
title = {{CSF} Findings in Acute {NMDAR} and {LGI1} {Antibody{\textendash}Associated} Autoimmune Encephalitis},
url = {https://doi.org/10.1212/nxi.0000000000001086},
volume = {8},
- year = {2021}
+ year = {2021},
+ month = nov,
}
@inproceedings{diederik2015adam,
- author = {Diederik P. Kingma and Jimmy Ba},
+ author = {Kingma, Diederik P. and Ba, Jimmy},
+ editor = {Bengio, Yoshua and LeCun, Yann},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/journals/corr/KingmaB14.bib},
- booktitle = {3rd International Conference on Learning Representations, {ICLR} 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings},
- editor = {Yoshua Bengio and Yann LeCun},
+ booktitle = {3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings},
timestamp = {Thu, 25 Jul 2019 01:00:00 +0200},
title = {Adam: {A} Method for Stochastic Optimization},
url = {http://arxiv.org/abs/1412.6980},
- year = {2015}
+ year = {2015},
}
@inproceedings{glorot2010understanding,
@@ -29,7 +33,7 @@ @inproceedings{glorot2010understanding
booktitle = {Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics},
title = {Understanding the difficulty of training deep feedforward neural networks},
url = {https://proceedings.mlr.press/v9/glorot10a.html},
- year = {2010}
+ year = {2010},
}
@misc{hinton2017overview,
@@ -37,48 +41,50 @@ @misc{hinton2017overview
howpublished = {University Lecture},
institution = {University of Toronto},
title = {Overview of Minibatch Gradient Descent},
- year = {2017}
+ year = {2017},
}
@inproceedings{jasper2012practical,
- author = {Jasper Snoek and Hugo Larochelle and Ryan P. Adams},
+ author = {Snoek, Jasper and Larochelle, Hugo and Adams, Ryan P.},
+ editor = {Bartlett, Peter L. and Pereira, Fernando C. N. and Burges, Christopher J. C. and Bottou, L\'eon and Weinberger, Kilian Q.},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/nips/SnoekLA12.bib},
booktitle = {Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States},
- editor = {Peter L. Bartlett and Fernando C. N. Pereira and Christopher J. C. Burges and L{\'{e}}on Bottou and Kilian Q. Weinberger},
pages = {2960--2968},
timestamp = {Thu, 21 Jan 2021 00:00:00 +0100},
- title = {Practical Bayesian Optimization of Machine Learning Algorithms},
+ title = {Practical {Bayesian} Optimization of Machine Learning Algorithms},
url = {https://proceedings.neurips.cc/paper/2012/hash/05311655a15b75fab86956663e1819cd-Abstract.html},
- year = {2012}
+ year = {2012},
}
@inproceedings{john2010adaptive,
- author = {John C. Duchi and Elad Hazan and Yoram Singer},
+ author = {Duchi, John C. and Hazan, Elad and Singer, Yoram},
+ editor = {Kalai, Adam Tauman and Mohri, Mehryar},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/colt/DuchiHS10.bib},
- booktitle = {{COLT} 2010 - The 23rd Conference on Learning Theory, Haifa, Israel, June 27-29, 2010},
- editor = {Adam Tauman Kalai and Mehryar Mohri},
+ booktitle = {COLT 2010 - The 23rd Conference on Learning Theory, Haifa, Israel, June 27-29, 2010},
pages = {257--269},
publisher = {Omnipress},
timestamp = {Tue, 19 Feb 2013 00:00:00 +0100},
title = {Adaptive Subgradient Methods for Online Learning and Stochastic Optimization},
url = {http://colt2010.haifa.il.ibm.com/papers/COLT2010proceedings.pdf\#page=265},
- year = {2010}
+ year = {2010},
}
@inproceedings{kaiming2015delving,
- author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
+ author = {He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/iccv/HeZRS15.bib},
- booktitle = {2015 {IEEE} International Conference on Computer Vision, {ICCV} 2015, Santiago, Chile, December 7-13, 2015},
- doi = {10.1109/ICCV.2015.123},
+ booktitle = {2015 IEEE International Conference on Computer Vision (ICCV)},
+ doi = {10.1109/iccv.2015.123},
pages = {1026--1034},
- publisher = {{IEEE} Computer Society},
+ publisher = {IEEE},
timestamp = {Wed, 17 Apr 2019 01:00:00 +0200},
- title = {Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification},
- url = {https://doi.org/10.1109/ICCV.2015.123},
- year = {2015}
+ title = {Delving Deep into Rectifiers: {Surpassing} Human-Level Performance on {ImageNet} Classification},
+ url = {https://doi.org/10.1109/iccv.2015.123},
+ year = {2015},
+ source = {Crossref},
+ month = dec,
}
@article{robbins1951stochastic,
@@ -93,7 +99,8 @@ @article{robbins1951stochastic
title = {A Stochastic Approximation Method},
url = {https://doi.org/10.1214/aoms/1177729586},
volume = {22},
- year = {1951}
+ year = {1951},
+ month = sep,
}
@article{ruder2016overview,
@@ -102,7 +109,7 @@ @article{ruder2016overview
title = {An overview of gradient descent optimization algorithms},
url = {https://arxiv.org/abs/1609.04747},
volume = {abs/1609.04747},
- year = {2016}
+ year = {2016},
}
@article{srivastava2014dropout,
@@ -110,39 +117,39 @@ @article{srivastava2014dropout
journal = {J. Mach. Learn. Res.},
title = {Dropout: {A} Simple Way to Prevent Neural Networks from Overfitting},
url = {http://jmlr.org/papers/v15/srivastava14a.html},
- year = {2014}
+ year = {2014},
}
@misc{torsten2021sparsity,
+ author = {Hoefler, Torsten and Alistarh, Dan and Ben-Nun, Tal and Dryden, Nikoli and Peste, Alexandra},
archiveprefix = {arXiv},
- author = {Torsten Hoefler and Dan Alistarh and Tal Ben-Nun and Nikoli Dryden and Alexandra Peste},
eprint = {2102.00554},
primaryclass = {cs.LG},
- title = {Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks},
- year = {2021}
+ title = {Sparsity in Deep Learning: {Pruning} and growth for efficient inference and training in neural networks},
+ year = {2021},
}
@misc{yang2018imagenet,
+ author = {You, Yang and Zhang, Zhao and Hsieh, Cho-Jui and Demmel, James and Keutzer, Kurt},
archiveprefix = {arXiv},
- author = {Yang You and Zhao Zhang and Cho-Jui Hsieh and James Demmel and Kurt Keutzer},
eprint = {1709.05011},
primaryclass = {cs.CV},
- title = {ImageNet Training in Minutes},
- year = {2018}
+ title = {{ImageNet} Training in Minutes},
+ year = {2018},
}
@misc{you2018imagenet,
- archiveprefix = {arXiv},
author = {You, Yang and Zhang, Zhao and Hsieh, Cho-Jui and Demmel, James and Keutzer, Kurt},
+ archiveprefix = {arXiv},
eprint = {1709.05011},
primaryclass = {cs.CV},
title = {{ImageNet} Training in Minutes},
- year = {2018}
+ year = {2018},
}
@misc{zeiler2012reinforcement,
- archiveprefix = {arXiv},
author = {Zeiler, Matthew D.},
+ archiveprefix = {arXiv},
doi = {10.1002/9781118266502.ch6},
eprint = {1212.5701},
isbn = {9780470919996, 9781118266502},
@@ -152,12 +159,13 @@ @misc{zeiler2012reinforcement
source = {Crossref},
title = {Reinforcement and Systemic Machine Learning for Decision Making},
url = {https://doi.org/10.1002/9781118266502.ch6},
- year = {2012}
+ year = {2012},
+ month = jul,
}
@misc{zoph2023cybernetical,
- archiveprefix = {arXiv},
author = {Zoph, Barret and Le, Quoc V.},
+ archiveprefix = {arXiv},
doi = {10.1002/9781394217519.ch17},
eprint = {1611.01578},
isbn = {9781394217489, 9781394217519},
@@ -167,5 +175,6 @@ @misc{zoph2023cybernetical
source = {Crossref},
title = {Cybernetical Intelligence},
url = {https://doi.org/10.1002/9781394217519.ch17},
- year = {2023}
+ year = {2023},
+ month = oct,
}
diff --git a/contents/training/training.qmd b/contents/training/training.qmd
index d0ae3e36..648e4ead 100644
--- a/contents/training/training.qmd
+++ b/contents/training/training.qmd
@@ -10,7 +10,7 @@ Resources: [Slides](#sec-ai-training-resource), [Labs](#sec-ai-training-resource

-The process of training is central to developing accurate and useful AI systems using machine learning techniques. At a high level, training involves feeding data into machine learning algorithms so they can learn patterns and make predictions. However, effectively training models requires tackling a variety of challenges around data, algorithms, optimization of model parameters, and enabling generalization. In this chapter, we will dive into the nuances and considerations around training machine learning models.
+Training is central to developing accurate and useful AI systems using machine learning techniques. At a high level, training involves feeding data into machine learning algorithms so they can learn patterns and make predictions. However, effectively training models requires tackling various challenges around data, algorithms, optimization of model parameters, and enabling generalization. This chapter will explore the nuances and considerations around training machine learning models.
::: {.callout-tip}
@@ -22,7 +22,7 @@ The process of training is central to developing accurate and useful AI systems
* Learn various optimization algorithms like stochastic gradient descent and adaptations like momentum and Adam that accelerate training.
-* Understand techniques for hyperparameter tuning and regularization to improve model generalization through reducing overfitting.
+* Understand hyperparameter tuning and regularization techniques to improve model generalization by reducing overfitting.
* Learn proper weight initialization strategies matched to model architectures and activation choices that accelerate convergence.
@@ -37,17 +37,17 @@ The process of training is central to developing accurate and useful AI systems
## Introduction
-Training is a critical process for developing accurate and useful AI systems using machine learning. The goal of training is to create a machine learning model that can generalize to new, unseen data, rather than memorizing the training examples. This is done by feeding **training data** into algorithms that learn patterns from these examples by adjusting internal parameters.
+Training is critical for developing accurate and useful AI systems using machine learning. The training aims to create a machine learning model that can generalize to new, unseen data rather than memorizing the training examples. This is done by feeding **training data** into algorithms that learn patterns from these examples by adjusting internal parameters.
-The algorithms minimize a **loss function**, which compares their predictions on the training data to the known labels or solutions, guiding the learning. Effective training often requires high-quality, representative training data sets that are large enough to capture variability in the real-world use cases.
+The algorithms minimize a **loss function**, which compares their predictions on the training data to the known labels or solutions, guiding the learning. Effective training often requires high-quality, representative data sets large enough to capture variability in real-world use cases.
-It also requires choosing an **algorithm** suited to the task, whether that be a neural network for computer vision, a reinforcement learning algorithm for robotic control, or a tree-based method for categorical prediction. Careful tuning is needed for the model structure, such as neural network depth and width, and learning parameters like step size and regularization strength.
+It also requires choosing an **algorithm** suited to the task, whether a neural network for computer vision, a reinforcement learning algorithm for robotic control, or a tree-based method for categorical prediction. Careful tuning is needed for the model structure, such as neural network depth and width, and learning parameters like step size and regularization strength.
-Techniques to prevent **overfitting** like regularization penalties and validation with held-out data are also important. Overfitting can occur when a model fits the training data too closely, failing to generalize to new data. This can happen if the model is too complex or trained for too long.
+Techniques to prevent **overfitting** like regularization penalties and validation with held-out data, are also important. Overfitting can occur when a model fits the training data too closely, failing to generalize to new data. This can happen if the model is too complex or trained too long.
-To avoid overfitting **regularization** techniques can help constrain the model. One regularization method is adding a penalty term to the loss function that discourages complexity, like the L2 norm of the weights. This penalizes large parameter values. Another technique is dropout, where a percentage of neurons are randomly set to zero during training. This reduces co-adaptation of neurons.
+To avoid overfitting, **regularization** techniques can help constrain the model. One regularization method is adding a penalty term to the loss function that discourages complexity, like the L2 norm of the weights. This penalizes large parameter values. Another technique is dropout, where a percentage of neurons is randomly set to zero during training. This reduces neuron co-adaptation.
-**Validation** methods also help detect and avoid overfitting. Part of the training data is held out from the training loop as a validation set. The model is evaluated on this data. If validation error increases while training error decreases, overfitting is occurring. The training can then be stopped early or regularized more strongly. Careful use of regularization and validation enables models to train to maximum capability without overfitting the training data.
+**Validation** methods also help detect and avoid overfitting. Part of the training data is held out from the training loop as a validation set. The model is evaluated on this data. If validation error increases while training error decreases, overfitting occurs. The training can then be stopped early or regularized more strongly. Regularization and validation enable models to train to maximum capability without overfitting the training data.
Training takes significant **computing resources**, especially for deep neural networks used in computer vision, natural language processing, and other areas. These networks have millions of adjustable weights that must be tuned through extensive training. Hardware improvements and distributed training techniques have enabled training ever larger neural nets that can achieve human-level performance on some tasks.
@@ -56,20 +56,20 @@ In summary, some key points about training:
* **Data is crucial:** Machine learning models learn from examples in training data. More high-quality, representative data leads to better model performance. Data needs to be processed and formatted for training.
* **Algorithms learn from data:** Different algorithms (neural networks, decision trees, etc.) have different approaches to finding patterns in data. Choosing the right algorithm for the task is important.
* **Training refines model parameters:** Model training adjusts internal parameters to find patterns in data. Advanced models like neural networks have many adjustable weights. Training iteratively adjusts weights to minimize a loss function.
-* **Generalization is the goal:** A model that overfits to the training data will not generalize well. Regularization techniques (dropout, early stopping, etc.) reduce overfitting. Validation data is used to evaluate generalization.
+* **Generalization is the goal:** A model that overfits the training data will not generalize well. Regularization techniques (dropout, early stopping, etc.) reduce overfitting. Validation data is used to evaluate generalization.
* **Training takes compute resources:** Training complex models requires significant processing power and time. Hardware improvements and distributed training across GPUs/TPUs have enabled advances.
We will walk you through these details in the rest of the sections. Understanding how to effectively leverage data, algorithms, parameter optimization, and generalization through thorough training is essential for developing capable, deployable AI systems that work robustly in the real world.
## Mathematics of Neural Networks
-Deep learning has revolutionized the fields of machine learning and artificial intelligence, enabling computers to learn complex patterns and make intelligent decisions. At the heart of the deep learning revolution is the neural network, which, as discussed in section 3 "Deep Learning Primer", is a cornerstone in some of these advancements.
+Deep learning has revolutionized machine learning and artificial intelligence, enabling computers to learn complex patterns and make intelligent decisions. The neural network is at the heart of the deep learning revolution, and as discussed in section 3, "Deep Learning Primer," it is a cornerstone in some of these advancements.
-Neural networks are made up of simple functions layered on top of each other. Each **layer** takes in some data, performs some computation, and passes it to the next layer. These layers learn progressively high level features that are useful for the task the network is trained to perform. For example, in a network trained for image recognition, the input layer may take in pixel values, while the next layers may detect simple shapes like edges, then the layers after that may detect more complex shapes like noses or eyes, and so on. The final output layer classifies the image as a whole.
+Neural networks are made up of simple functions layered on each other. Each **layer** takes in some data, performs some computation, and passes it to the next layer. These layers learn progressively high-level features useful for the tasks the network is trained to perform. For example, in a network trained for image recognition, the input layer may take in pixel values, while the next layers may detect simple shapes like edges. The layers after that may detect more complex shapes like noses, eyes, etc. The final output layer classifies the image as a whole.
-The network in a neural network refers to how these layers are connected. Each layer's output is considered as a single neuron, and is connected to many other neurons in the layers preceding it, forming a "network". The way these neurons interact with each other is determined by the weights between them, which model synaptic strengths similar to that of a brain's neuron. The neural network is trained by adjusting these weights. Concretely, the weights are initially set randomly, then an input is fed in and the output is compared to the desired result, and finally the weights are then tweaked to make the network better. This process is repeated until the network reliably minimizes the loss, indicating it has learned the patterns in the data.
+The network in a neural network refers to how these layers are connected. Each layer's output is considered a single neuron and is connected to many other neurons in the layers preceding it, forming a "network." The way these neurons interact is determined by the weights between them, which model synaptic strengths similar to that of a brain's neuron. The neural network is trained by adjusting these weights. Concretely, the weights are initially set randomly, then input is fed in, the output is compared to the desired result, and finally, the weights are tweaked to improve the network. This process is repeated until the network reliably minimizes the loss, indicating it has learned the patterns in the data.
-How is this process defined mathematically? Formally, neural networks are mathematical models that consist of alternating **linear** and **nonlinear** operations, parameterized by a set of learnable **weights** that are trained to minimize some **loss** function. This loss function is a measure of how good our model is with respect to fitting our training data, and it produces a numerical value when evaluated on our model against the training data. Training neural networks involve repeatedly evaluating the loss function on many different datapoints to get a measure of how good our model is, then continuously tweaking the weights of our model using backpropagation so that the loss decreases, which ultimately optimizes the model to fit our data.
+How is this process defined mathematically? Formally, neural networks are mathematical models that consist of alternating **linear** and **nonlinear** operations, parameterized by a set of learnable **weights** that are trained to minimize some **loss** function. This loss function measures how good our model is concerning fitting our training data, and it produces a numerical value when evaluated on our model against the training data. Training neural networks involves repeatedly evaluating the loss function on many different data points to measure how good our model is, then continuously tweaking the weights of our model using backpropagation so that the loss decreases, ultimately optimizing the model to fit our data.
### Neural Network Notation
@@ -84,47 +84,47 @@ A_i = F_i(L_{i})
$$
:::{.callout-note}
-Why are the nonlinear operations necessary? If we only had linear layers the entire network is equivalent to just a single linear layer consisting of the product of the linear operators. Hence, the nonlinear functions play a key role in the power of neural networks as they enhance the neural network's ability to fit functions.
+Why are the nonlinear operations necessary? If we only had linear layers, the entire network would be equivalent to a single linear layer consisting of the product of the linear operators. Hence, the nonlinear functions play a key role in the power of neural networks as they enhance the neural network's ability to fit functions.
:::
:::{.callout-note}
-Convolutions are also linear operators, and can be cast as a matrix multiplication.
+Convolutions are also linear operators and can be cast as a matrix multiplication.
:::

-where $A_{0}$ is a vector input to the neural network (i.e: an image that we want the neural network to classify, or some other data that the neural network operates on), $A_{n}$ (where $n$ is the number of layers of the network) is the vector output of the neural network (i.e: a vector of size 10 in the case of classifying pictures of handwritten digits), $W_i$s are the weights of the neural network that are tweaked at training time to fit our data, and $F_{i}$ is that layer's nonlinear activation function (i.e: ReLU, softmax, etc). As defined, the intermediate output of the neural network is a vector of real-valued numbers with dimensions:
+Where $A_{0}$ is a vector input to the neural network (i.e., an image that we want the neural network to classify or some other data that the neural network operates on), $A_{n}$ (where $n$ is the number of layers of the network) is the vector output of the neural network (i.e., a vector of size 10 in the case of classifying pictures of handwritten digits), $W_i$s are the weights of the neural network that are tweaked at training time to fit our data, and $F_{i}$ is that layer's nonlinear activation function (i.e., ReLU, softmax, etc.). As defined, the intermediate output of the neural network is a vector of real-valued numbers with dimensions:
$$
L_i, A_i \in \mathbb{R}^{d_{i}}
$$
-where $d_{i}$ is the number of neurons at layer $i$; in the case of the first layer $i=0$, $d_{i}$ is the dimension of the input data, and in the last layer $i=n$, $d_{n}$ is the dimension of the output label, and anything in between can be set arbitrarily and may be viewed as the **architecture** of the neural network (i.e: dimensionality of the intermediate layers). The weights, which determine how each layer of the neural network interacts with each other, therefore are matrices of real numbers with shape
+Where $d_{i}$ is the number of neurons at layer $i$; in the case of the first layer $i=0$, $d_{i}$ is the dimension of the input data, and in the last layer $i=n$, $d_{n}$ is the dimension of the output label. Anything in between can be set arbitrarily and may be viewed as the **architecture** of the neural network (i.e., the dimensionality of the intermediate layers). The weights, which determine how each layer of the neural network interacts with each other, are matrices of real numbers with shape.
$$
W_i \in \mathbb{R}^{d_{i} \times d_{i-1}}
$$
-Our neural network, as defined, performs a sequence of linear and nonlinear operations on the input data ($L_{0}$), to optain predictions ($L_{n}$) which hopefully is a good answer to what we want the neural network to do on the input (i.e: classify if the input image is a cat or not). Our neural network may then be represented succinctly as a function $N$ which takes in an input $x \in \mathbb{R}^{d_0}$ parameterized by $W_1, ..., W_n$:
+Our neural network, as defined, performs a sequence of linear and nonlinear operations on the input data ($L_{0}$) to obtain predictions ($L_{n}$), which hopefully is a good answer to what we want the neural network to do on the input (i.e., classify if the input image is a cat or not). Our neural network may then be represented succinctly as a function $N$ which takes in an input $x \in \mathbb{R}^{d_0}$ parameterized by $W_1, ..., W_n$:
$$
N(x; W_1, ... W_n) = \text{Let } A_0 = x, \text{ then output } A_n
$$
-Next we will see how to evaluate this neural network against training data by introducing a loss function.
+Next, we will see how to evaluate this neural network against training data by introducing a loss function.
### Loss Function as a Measure of Goodness of Fit against Training Data
-After defining our neural network, we are given some training data, which is a set of points ${(x_j, y_j)}$ for $j=1..M$, and we want to evaluate how good our neural network is on fitting this data. To do this, we introduce a **loss function**, which is a function that takes the output of the neural network on a particular datapoint ($N(x_j; W_1, ..., W_n)$), and compares it against the "label" of that particular datapoint (the corresponding $y_j$), and outputs a single numerical scalar (i.e: one real number) that represents how "good" the neural network fit that particular data point; the final measure of how good the neural network is on the entire dataset is therefore just the average of the losses across all datapoints.
+After defining our neural network, we are given some training data, which is a set of points ${(x_j, y_j)}$ for $j=1..M$, and we want to evaluate how good our neural network is at fitting this data. To do this, we introduce a **loss function**, which is a function that takes the output of the neural network on a particular datapoint ($N(x_j; W_1, ..., W_n)$) and compares it against the "label" of that particular datapoint (the corresponding $y_j$), and outputs a single numerical scalar (i.e., one real number) that represents how "good" the neural network fit that particular data point; the final measure of how good the neural network is on the entire dataset is therefore just the average of the losses across all data points.
-There are many different types of loss functions, for example, in the case of image classification, we might use the cross-entropy loss function, which tells us how good two vectors that represent classification predictions compare (i.e: if our prediction predicts that an image is more likely a dog, but the label says it is a cat, it will return a high "loss" indicating a bad fit).
+There are many different types of loss functions; for example, in the case of image classification, we might use the cross-entropy loss function, which tells us how well two vectors representing classification predictions compare (i.e., if our prediction predicts that an image is more likely a dog, but the label says it is a cat, it will return a high "loss," indicating a bad fit).
-Mathematically, this loss function is a function which takes in two real-valued vectors of the shape of the label, and outputs a single numerical scalar
+Mathematically, this loss function is a function that takes in two real-valued vectors of the shape of the label and outputs a single numerical scalar.
$$
L: \mathbb{R}^{d_{n}} \times \mathbb{R}^{d_{n}} \longrightarrow \mathbb{R}
$$
-and the loss across the entire dataset can be written as the average loss across all datapoints in the training data
+The loss across the entire dataset can be written as the average loss across all data points in the training data.
> Loss Function for Optimizing Neural Network Model on a Dataset
$$
@@ -133,7 +133,7 @@ $$
### Training Neural Networks with Gradient Descent
-Now that we have a measure of how good our network fits the training data, we can optimize the weights of the neural network to minimize this loss. At a high level, we tweak the parameters of the real-valued matrices $W_i$s so that the loss function $L_{full}$ is minimized. Overall, our mathematical objective is
+Now that we can measure how well our network fits the training data, we can optimize the neural network weights to minimize this loss. At a high level, we tweak the parameters of the real-valued matrices $W_i$s to minimize the loss function $L_{full}$. Overall, our mathematical objective is
> Neural Network Training Objective
$$
@@ -143,7 +143,7 @@ $$
= min_{W_1, ..., W_n} \frac{1}{M} \sum_{j=1}^{M} L(N(x_j; W_1,...W_n), y_j)
$$
-So how do we optimize this objective? Recall from calculus that minimizing a function can be done by taking the derivative of the function with respect to the input parameters and tweaking the parameters in the direction of the gradient. This technique is called **gradient descent** and concretely involves calculating the derivative of the loss function $L_{full}$ with respect to $W_1, ..., W_n$ to obtain a gradient for these parameters to take a step in, then updating these parameters in the direction of the gradient. Thus, we can train our neural network using gradient descent which repeatedly applies the update rule
+So, how do we optimize this objective? Recall from calculus that minimizing a function can be done by taking the function's derivative concerning the input parameters and tweaking the parameters in the gradient direction. This technique is called **gradient descent** and concretely involves calculating the derivative of the loss function $L_{full}$ concerning $W_1, ..., W_n$ to obtain a gradient for these parameters to take a step in, then updating these parameters in the direction of the gradient. Thus, we can train our neural network using gradient descent, which repeatedly applies the update rule.
> Gradient Descent Update Rule
$$
@@ -151,18 +151,18 @@ W_i := W_i - \lambda \frac{\partial L_{full}}{\partial W_i} \mbox{ for } i=1..n
$$
:::{.callout-note}
-In practice, the gradient is computed over a minibatch of datapoints, to improve computational efficiency. This is called stochastic gradient descent or batch gradient descent.
+In practice, the gradient is computed over a minibatch of data points to improve computational efficiency. This is called stochastic gradient descent or batch gradient descent.
:::
-where $\lambda$ is the stepsize or learning rate of our tweaks. In training our neural network, we repeatedly perform the step above until convergence, or when the loss no longer decreases. This prior approach is known as full gradient descent since we are computing the derivative with respect to the entire training data, and only then taking a single gradient step; a more efficient approach is to calculate the gradient with respect to just a random batch of datapoints and then taking a step, a process known as batch gradient descent or stochastic gradient descent [@robbins1951stochastic], which is more efficient since now we are taking many more steps per pass of the entire training data. Next we will cover the mathematics behind computing the gradient of the loss function with respect to the $W_i$s, a process known as backpropagation.
+Where $\lambda$ is the stepsize or learning rate of our tweaks, in training our neural network, we repeatedly perform the step above until convergence or when the loss no longer decreases. This prior approach is known as full gradient descent since we are computing the derivative concerning the entire training data and only then taking a single gradient step; a more efficient approach is to calculate the gradient concerning just a random batch of data points and then taking a step, a process known as batch gradient descent or stochastic gradient descent [@robbins1951stochastic], which is more efficient since now we are taking many more steps per pass of the entire training data. Next, we will cover the mathematics behind computing the gradient of the loss function concerning the $W_i$s, a process known as backpropagation.
-
+
### Backpropagation
-Training neural networks involve repeated applications of the gradient descent algorithm, which involves computing the derivative of the loss function with respect to the $W_i$s. How do we compute the derivative of the loss with respect to the $W_i$s given that the $W_i$s are nested functions of each other in a deep neural network? The trick is to leverage the **chain rule**: we can compute the derivative of the loss with respect to the $W_i$s by repeatedly applying the chain rule, in a complete process known as backpropagation. Specifically, we can calculate the gradients by computing the derivative of the loss with respect to the outputs of the last layer, then progressively use this to compute the derivative of the loss with respect to each prior layer, all the way to the input layer. This process starts from the end of the network (the layer closest to the output) and progresses backwards, and hence gets its name backpropagation.
+Training neural networks involve repeated applications of the gradient descent algorithm, which involves computing the derivative of the loss function with respect to the $W_i$s. How do we compute the loss derivative concerning the $W_i$s, given that the $W_i$s are nested functions of each other in a deep neural network? The trick is to leverage the **chain rule:** we can compute the derivative of the loss concerning the $W_i$s by repeatedly applying the chain rule in a complete process known as backpropagation. Specifically, we can calculate the gradients by computing the derivative of the loss concerning the outputs of the last layer, then progressively use this to compute the derivative of the loss concerning each prior layer to the input layer. This process starts from the end of the network (the layer closest to the output) and progresses backwards, and hence gets its name backpropagation.
-Let's break this down. We can compute the derivative of the loss with respect to the _the outputs of each layer of the neural network_ by using repeated applications of the chain rule
+Let's break this down. We can compute the derivative of the loss concerning the _outputs of each layer of the neural network_ by using repeated applications of the chain rule.
$$
\frac{\partial L_{full}}{\partial L_{n}} = \frac{\partial A_{n}}{\partial L_{n}} \frac{\partial L_{full}}{\partial A_{n}}
@@ -179,21 +179,21 @@ $$
$$
:::{.callout-note}
-In what order should we perform this computation? It is preferrable from a computational perspective to perform the calculations from the end to the front
-(i.e: first compute $\frac{\partial L_{full}}{\partial A_{n}}$ then the prior terms, rather than start in the middle) since this avoids materializing and computing large jacobians. This is because $\frac{\partial L_{full}}{\partial A_{n}}$ is a vector, hence any matrix operation that includes this term has an output that is squished to be a vector. Thus performing the computation from the end avoids large matrix-matrix multiplications by ensuring that the intermediate products are vectors.
+In what order should we perform this computation? From a computational perspective, performing the calculations from the end to the front is preferable.
+(i.e: first compute $\frac{\partial L_{full}}{\partial A_{n}}$ then the prior terms, rather than start in the middle) since this avoids materializing and computing large jacobians. This is because $\ \frac {\partial L_{full}}{\partial A_{n}}$ is a vector; hence, any matrix operation that includes this term has an output that is squished to be a vector. Thus, performing the computation from the end avoids large matrix-matrix multiplications by ensuring that the intermediate products are vectors.
:::
:::{.callout-note}
In our notation, we assume the intermediate activations $A_{i}$ are _column_ vectors, rather than _row_ vectors, hence the chain rule is $\frac{\partial L}{\partial L_{i}} = \frac{\partial L_{i+1}}{\partial L_{i}} ... \frac{\partial L}{\partial L_{n}}$ rather than $\frac{\partial L}{\partial L_{i}} = \frac{\partial L}{\partial L_{n}} ... \frac{\partial L_{i+1}}{\partial L_{i}}$
:::
-After computing the derivative of the loss with respect to the _output of each layer_, we can easily obtain the derivative of the loss with respect to the _parameters_, again using the chain rule:
+After computing the derivative of the loss concerning the _output of each layer_, we can easily obtain the derivative of the loss concerning the _parameters_, again using the chain rule:
$$
\frac{\partial L_{full}}{W_{i}} = \frac{\partial L_{i}}{\partial W_{i}} \frac{\partial L_{full}}{\partial L_{i}}
$$
-And this is ultimately how the derivatives of the layers' weights are computed using backpropagation! What does this concretely look like in a specific example? Below we walk through a specific example on a simple 2 layer neural network, on a regression task using a MSE loss function, with 100-dimensional inputs and a 30-dimensional hidden layer:
+And this is ultimately how the derivatives of the layers' weights are computed using backpropagation! What does this concretely look like in a specific example? Below, we walk through a specific example of a simple 2-layer neural network on a regression task using an MSE loss function with 100-dimensional inputs and a 30-dimensional hidden layer:
> Example of Backpropagation\
Suppose we have a two-layer neural network
@@ -212,7 +212,7 @@ $$
$$
NN(x) = \mbox{Let } A_{0} = x \mbox{ then output } A_2
$$
-where $W_1 \in \mathbb{R}^{30 \times 100}$ and $W_2 \in \mathbb{R}^{1 \times 30}$. Furthermore suppose we use the MSE loss function:
+where $W_1 \in \mathbb{R}^{30 \times 100}$ and $W_2 \in \mathbb{R}^{1 \times 30}$. Furthermore, suppose we use the MSE loss function:
$$
L(x, y) = (x-y)^2
$$
@@ -252,24 +252,24 @@ $$
$$
::: {.callout-tip}
-Double check your work by making sure that the shapes are correct!
+Double-check your work by making sure that the shapes are correct!
-* All hadamard products ($\odot$) should operate on tensors of the same shape
-* All matrix multiplications should operate on matrices that share a common dimension (i.e: m by n, n by k)
-* All gradients with respect to the weights should have the same shape as the weight matrices themselves
+* All Hadamard products ($\odot$) should operate on tensors of the same shape
+* All matrix multiplications should operate on matrices that share a common dimension (i.e., m by n, n by k)
+* All gradients concerning the weights should have the same shape as the weight matrices themselves
:::
-The entire backpropagation process can be complex, especially for networks that are very deep. Fortunately, machine learning frameworks like PyTorch support automatic differentiation, which performs backpropagation for us. In these machine learning frameworks we simply need to specify the forward pass, and the derivatives will be automatically computed for us. Nevertheless, it is beneficial to understand the theoretical process that is happening under the hood in these machine-learning frameworks.
+The entire backpropagation process can be complex, especially for very deep networks. Fortunately, machine learning frameworks like PyTorch support automatic differentiation, which performs backpropagation for us. In these frameworks, we simply need to specify the forward pass, and the derivatives will be automatically computed for us. Nevertheless, it is beneficial to understand the theoretical process that is happening under the hood in these machine-learning frameworks.
:::{.callout-note}
-As seen above, intermediate activations $A_i$ are re-used in backpropagation. To improve performance, these activations are cached from the forward pass to avoid recomputing them. However, this means that activations must be kept in memory between the forward and backward passes, leading to higher memory usage. If the network and batchsize is large, this may lead to memory issues. Similarly, the derivatives with respect to each layer's outputs are cached to avoid recomputation.
+As seen above, intermediate activations $A_i$ are reused in backpropagation. To improve performance, these activations are cached from the forward pass to avoid being recomputed. However, activations must be kept in memory between the forward and backward passes, leading to higher memory usage. If the network and batch size are large, this may lead to memory issues. Similarly, the derivatives with respect to each layer's outputs are cached to avoid recomputation.
:::
:::{#exr-nn .callout-exercise collapse="true"}
### Neural Networks with Backpropagation and Gradient Descent
-Unlock the math behind powerful neural networks! Deep learning might seem like magic, but it's rooted in mathematical principles. In this chapter, you've broken down neural network notation, loss functions, and the powerful technique of backpropagation. Now, get ready to put this theory into action with these Colab notebooks. Dive into the heart of how neural networks learn. You'll see the math behind backpropagation and gradient descent in action, updating those weights step-by-step.
+Unlock the math behind powerful neural networks! Deep learning might seem like magic, but it's rooted in mathematical principles. In this chapter, you've broken down neural network notation, loss functions, and the powerful technique of backpropagation. Now, prepare to implement this theory with these Colab notebooks. Dive into the heart of how neural networks learn. You'll see the math behind backpropagation and gradient descent, updating those weights step-by-step.
[](https://colab.research.google.com/github/jigsawlabs-student/pytorch-intro-curriculum/blob/main/5-training-mathematically/20-backpropagation-and-gradient-descent.ipynb)
@@ -277,17 +277,17 @@ Unlock the math behind powerful neural networks! Deep learning might seem like m
## Differentiable Computation Graphs
-In general, stochastic gradient descent using backpropagation can be performed on any computational graph that a user may define, provided that the operations of the computation are differentiable. As such, generic deep learning libraries like PyTorch and Tensorflow allow users to specify their computational process (i.e: neural networks) as a computational graph. Backpropagation is automatically performed via automatic differentiation when performing stochast gradient descent on these computational graphs. Framing AI training as an optimization problem on differentiable computation graphs is a general way to understand what is happening under the hood with deep learning systems.
+In general, stochastic gradient descent using backpropagation can be performed on any computational graph that a user may define, provided that the operations of the computation are differentiable. As such, generic deep learning libraries like PyTorch and Tensorflow allow users to specify their computational process (i.e., neural networks) as a computational graph. Backpropagation is automatically performed via automatic differentiation when stochastic gradient descent is performed on these computational graphs. Framing AI training as an optimization problem on differentiable computation graphs is a general way to understand what is happening under the hood with deep learning systems.
{width=70%}
## Training Data
-To enable effective training of neural networks, the available data must be split into training, validation, and test sets. The training set is used to train the model parameters. The validation set evaluates the model during training to tune hyperparameters and prevent overfitting. The test set provides an unbiased final evaluation of the trained model's performance.
+To enable effective neural network training, the available data must be split into training, validation, and test sets. The training set is used to train the model parameters. The validation set evaluates the model during training to tune hyperparameters and prevent overfitting. The test set provides an unbiased final evaluation of the trained model's performance.
-Maintaining clear splits between train, validation, and test sets with representative data in each is crucial to properly training, tuning, and evaluating models to achieve the best real-world performance. To this end, we will learn about the common pitfalls or mistakes that people make in creating these data splits.
+Maintaining clear splits between train, validation, and test sets with representative data is crucial to properly training, tuning, and evaluating models to achieve the best real-world performance. To this end, we will learn about the common pitfalls or mistakes people make when creating these data splits.
-Here is a summary table for training, validation, and test data splits:
+@tbl-training_splits compares the differences between training, validation, and test data splits:
| Data Split | Purpose | Typical Size |
|-|-|-|
@@ -295,21 +295,25 @@ Here is a summary table for training, validation, and test data splits:
| Validation Set | Evaluate model during training to tune hyperparameters and prevent overfitting | ∼20% of total data |
| Test Set | Provide unbiased evaluation of final trained model | ∼20% of total data |
+: Comparing training, validation, and test data splits. {#tbl-training_splits}
+
### Dataset Splits
#### Training Set
-The training set is used to actually train the model. It is the largest subset consisting of typically 60-80% of the total data. The model sees and learns from the training data in order to make predictions. A sufficiently large and representative training set is required for the model to effectively learn the underlying patterns.
+The training set is used to train the model. It is the largest subset, typically 60-80% of the total data. The model sees and learns from the training data to make predictions. A sufficiently large and representative training set is required for the model to learn the underlying patterns effectively.
#### Validation Set
-The validation set is used to evaluate the model during training, usually after each epoch. Typically 20% of the data is allocated for the validation set. The model does not learn or update its parameters based on the validation data. It is used to tune hyperparameters and make other tweaks to improve training. Monitoring metrics like loss and accuracy on the validation set prevents overfitting on just the training data.
+The validation set evaluates the model during training, usually after each epoch. Typically, 20% of the data is allocated for the validation set. The model does not learn or update its parameters based on the validation data. It is used to tune hyperparameters and make other tweaks to improve training. Monitoring metrics like loss and accuracy on the validation set prevents overfitting on just the training data.
#### Test Set
-The test set acts as a completely unseen dataset that the model did not see during training. It is used to provide an unbiased evaluation of the final trained model. Typically 20% of the data is reserved for testing. Maintaining a hold-out test set is vital for obtaining an accurate estimate of how the trained model would perform on real world unseen data. Data leakage from the test set must be avoided at all costs.
+The test set acts as a completely unseen dataset that the model did not see during training. It is used to provide an unbiased evaluation of the final trained model. Typically, 20% of the data is reserved for testing. Maintaining a hold-out test set is vital for obtaining an accurate estimate of how the trained model would perform on real-world unseen data. Data leakage from the test set must be avoided at all costs.
+
+The relative proportions of the training, validation, and test sets can vary based on data size and application. However, following the general guidelines for a 60/20/20 split is a good starting point. Careful data splitting ensures models are properly trained, tuned, and evaluated to achieve the best performance.
-The relative proportions of the training, validation and test sets can vary based on data size and application. But following the general guideline of a 60/20/20 split is a good starting point. Careful splitting of data ensures models are properly trained, tuned and evaluated to achieve the best performance.
+The video below explains how to properly split the dataset into training, validation, and testing sets, ensuring an optimal training process.
{{< video https://www.youtube.com/watch?v=1waHlpKiNyY >}}
@@ -319,167 +323,169 @@ The relative proportions of the training, validation and test sets can vary base
Allocating too little data to the training set is a common mistake when splitting data that can severely impact model performance. If the training set is too small, the model will not have enough samples to effectively learn the true underlying patterns in the data. This leads to high variance and causes the model to fail to generalize well to new data.
-For example, if you are training an image classification model to recognize handwritten digits, providing only 10 or 20 images per digit class would be completely inadequate. The model would struggle to capture the wide variances in writing styles, rotations, stroke widths and other variations with so few examples.
+For example, if you train an image classification model to recognize handwritten digits, providing only 10 or 20 images per digit class would be completely inadequate. The model would need more examples to capture the wide variances in writing styles, rotations, stroke widths, and other variations.
-As a rule of thumb, the training set size should be at least in the hundreds or thousands of examples for most machine learning algorithms to work effectively. For deep neural networks, especially those using convolutional layers, the training set often needs to be in the tens or hundreds of thousands due to the large number of parameters.
+As a rule of thumb, the training set size should be at least hundreds or thousands of examples for most machine learning algorithms to work effectively. Due to the large number of parameters, the training set often needs to be in the tens or hundreds of thousands for deep neural networks, especially those using convolutional layers.
-Insufficient training data typically manifests in symptoms like high error rates on validation/test sets, low model accuracy, high variance, and overfitting on the small training set samples. Collecting more quality training data is the solution. Data augmentation techniques can also help virtually increase training data size for images, audio etc.
+Insufficient training data typically manifests in symptoms like high error rates on validation/test sets, low model accuracy, high variance, and overfitting on small training set samples. Collecting more quality training data is the solution. Data augmentation techniques can also help virtually increase the size of training data for images, audio, etc.
-Carefully factoring in the model complexity and problem difficulty when allocating training samples is important to ensure sufficient data is available for the model to learn successfully. Following guidelines on minimum training set sizes for different algorithms is also recommended. Insufficient training data is a fundamental issue that will undermine the overall success of any machine learning application.
+Carefully factoring in the model complexity and problem difficulty when allocating training samples is important to ensure sufficient data is available for the model to learn successfully. Following guidelines on minimum training set sizes for different algorithms is also recommended. More training data is needed to maintain the overall success of any machine learning application.

-On the flip side, if the model is not trained enough on the data, the model may underfit the data fail to learn the salient aspsects of the task at hand.
+On the flip side, if the model is not trained enough on the data, it may underfit the data and fail to learn the salient aspects of the task at hand.

+The video below provides an overview of bias and variance and the relationship between the two concepts and model accuracy.
+
{{< video https://www.youtube.com/watch?v=SjQyLhQIXSM >}}
#### Data Leakage Between Sets
Data leakage refers to the unintentional transfer of information between the training, validation, and test sets. This violates the fundamental assumption that the splits are completely separated. Data leakage leads to seriously compromised evaluation results and inflated performance metrics.
-A common way data leakage can occur is if some samples from the test set inadvertently get included in the training data. Now when evaluating on the test set, the model has already seen some of the data which gives overly optimistic scores. For example, if 2% of the test data leaks into the training set of a binary classifier, it can result in a accuracy boost of up to 20%!
+A common way data leakage occurs is if some samples from the test set are inadvertently included in the training data. When evaluating the t-set, the model has already seen some of the data, which gives overly optimistic scores. For example, if 2% of the test data leaks into the training set of a binary classifier, it can result in an accuracy boost of up to 20%!
-More subtle forms of leakage can happen if the data splits are not done carefully. If the splits are not properly randomized and shuffled, samples close to each other in the dataset may end up across different splits. This creates information bleed through based on proximity in the dataset. Time series data is especially vulnerable unless special cross validation techniques are used.
+If the data splits are not done carefully, more subtle forms of leakage can happen. If the splits are not properly randomized and shuffled, samples close to each other in the dataset may end up across different splits. This creates information bleed through based on proximity in the dataset. Time series data is especially vulnerable unless special cross-validation techniques are used.
-Preventing data leakage requires creating solid separation between splits - no sample should exist in more than one split. Shuffling and randomized splitting help create robust divisions. Cross validation techniques can be used for more rigorous evaluation. Detecting leakage is difficult buttelltale signs include models doing way better on test vs. validation data.
+Preventing data leakage requires creating solid separation between splits—no sample should exist in more than one split. Shuffling and randomized splitting help create robust divisions. Cross-validation techniques can be used for more rigorous evaluation. Detecting leakage is difficult, but telltale signs include models doing way better on test vs. validation data.
-Data leakage severely compromises the validity of evaluation because the model has already partially seen the test data. No amount of tuning or complex architectures can substitute for clean data splits. It is better to be conservative and create complete separation between splits to avoid this fundamental mistake in machine learning pipelines.
+Data leakage severely compromises the validity of the evaluation because the model has already partially seen the test data. No amount of tuning or complex architectures can substitute for clean data splits. It is better to be conservative and create complete separation between splits to avoid this fundamental mistake in machine learning pipelines.
#### Small or Unrepresentative Validation Set
-The validation set is used to evaluate models during training and for hyperparameter tuning. If the validation set is too small or not representative of the real data distribution, it will not provide reliable or stable evaluations during training. This makes model selection and tuning more difficult.
+The validation set evaluates models during training and for hyperparameter tuning. It must be bigger and representative of the real data distribution to provide reliable and stable evaluations during training, making model selection and tuning more difficult.
-For example, if the validation set only contains 100 samples, metrics calculated on it will have high variance. The accuracy may fluctuate up to 5-10% between epochs just due to noise. This makes it difficult to know if a drop in validation accuracy is due to overfitting or natural variance. With a larger validation set of say 1000 samples, the metrics will be much more stable.
+For example, if the validation set only contains 100 samples, the metrics calculated will have a high variance. Due to noise, the accuracy may fluctuate up to 5-10% between epochs. This makes it difficult to know if a drop in validation accuracy is due to overfitting or natural variance. With a larger validation set, say 1000 samples, the metrics will be much more stable.
-Additionally, if the validation set is not representative, perhaps missing certain subclasses, the estimated skill of the model may be inflated. This could lead to poor choices of hyperparameters or stopping training prematurely. Models selected based on such biased validation sets do not generalize well to real data.
+Additionally, if the validation set is not representative, perhaps missing certain subclasses, the estimated skill of the model may be inflated. This could lead to poor hyperparameter choices or premature training stops. Models selected based on such biased validation sets do not generalize well to real data.
-A good rule of thumb is the validation set size should be at least several hundred samples, and up to 10-20% size of the training set. The splits should also be stratified, especially if working with imbalanced datasets. A larger validation set that well represents the original data characteristics is essential for proper model selection and tuning.
+A good rule of thumb is that the validation set size should be at least several hundred samples and up to 10-20% of the training set. The splits should also be stratified, especially if working with imbalanced datasets. A larger validation set representing the original data characteristics is essential for proper model selection and tuning.
-Care should be taken that the validation set is also not too large, leaving insufficient samples for training. Overall, the validation set is a critical piece of the data splitting process and care should be taken to avoid the pitfalls of small, inadequate samples that negatively impact model development.
+The validation set should also be manageable, leaving insufficient samples for training. Overall, the validation set is a critical piece of the data-splitting process, and care should be taken to avoid the pitfalls of small, inadequate samples that negatively impact model development.
#### Reusing the Test Set Multiple Times
-The test set is designed to provide an unbiased evaluation of the fully-trained model only once at the end of the model development process. Reusing the test set multiple times during development for model evaluation, hyperparameter tuning, model selection etc. can result in overfitting on the test data.
+The test set is designed to provide an unbiased evaluation of the fully trained model only once at the end of the model development process. Reusing the test set multiple times during development for model evaluation, hyperparameter tuning, model selection, etc., can result in overfitting on the test data.
-If the test set is reused as part of the validation process, the model may start to see and learn from the test samples. This coupled with intentionally or unintentionally optimizing model performance on the test set can artificially inflate metrics like accuracy.
+If the test set is reused as part of the validation process, the model may start to see and learn from the test samples. This, coupled with intentionally or unintentionally optimizing model performance on the test set, can artificially inflate metrics like accuracy.
-For example, if the test set is used repeatedly for model selection out of 5 architectures, the model may achieve 99% test accuracy just by memorizing the samples rather than learning generalizable patterns. However, deployed in the real world, the accuracy could drop to 60% on new data.
+For example, suppose the test set is used repeatedly for model selection out of 5 architectures. In that case, the model may achieve 99% test accuracy by memorizing the samples rather than learning generalizable patterns. However, when deployed in the real world, the accuracy of new data could drop by 60%.
-Best practice is to interact with the test set only once at the very end to report unbiased metrics on how the final tuned model would perform in the real world. The validation set should be used for all parameter tuning, model selection, early stopping etc. while developing the model.
+The best practice is to interact with the test set only once at the end to report unbiased metrics on how the final tuned model would perform in the real world. While developing the model, the validation set should be used for all parameter tuning, model selection, early stopping, etc.
-Maintaining the complete separation of training/validation from the test set is essential to obtain accurate estimates of model performance. Even minor deviations from single use of the test set could positively bias results and metrics, providing an overly optimistic view of real world efficacy.
+Maintaining the complete separation of training/validation from the test set is essential to obtain accurate estimates of model performance. Even minor deviations from a single use of the test set could positively bias results and metrics, providing an overly optimistic view of real-world efficacy.
#### Same Data Splits Across Experiments
-When comparing different machine learning models or experimenting with various architectures and hyperparameters, using the same data splits for training, validation and testing across the different experiments can introduce bias and invalidate the comparisons.
+When comparing different machine learning models or experimenting with various architectures and hyperparameters, using the same data splits for training, validation, and testing across the different experiments can introduce bias and invalidate the comparisons.
-If the same splits are reused, the evaluation results may be overly correlated and not provide an accurate measure of which model performs better. For example, a certain random split of the data may happen to favor model A over model B irrespective of the algorithms. Reusing this split will then be biased towards model A.
+If the same splits are reused, the evaluation results may be more balanced and accurately measure which model performs better. For example, a certain random data split may favor model A over model B irrespective of the algorithms. Reusing this split will then bias towards model A.
Instead, the data splits should be randomized or shuffled for each experimental iteration. This ensures that randomness in the sampling of the splits does not confer an unfair advantage to any model.
-With different splits per experiment, the evaluation becomes more robust. Each model is tested on a wide range of test sets drawn randomly from the overall population. This smoothens out variation and removes correlation between results.
+With different splits per experiment, the evaluation becomes more robust. Each model is tested on a wide range of test sets drawn randomly from the overall population, smoothing out variation and removing correlation between results.
-Proper practice is to set a random seed before splitting the data for each experiment. Splitting should be carried out after any shuffling/resampling as part of the experimental pipeline. Carrying out comparisons on the same splits violates the i.i.d (independent and identically distributed) assumption required for statistical validity.
+Proper practice is to set a random seed before splitting the data for each experiment. Splitting should occur after shuffling/resampling as part of the experimental pipeline. Carrying out comparisons on the same splits violates the i.i.d (independent and identically distributed) assumption required for statistical validity.
-Unique splits are essential for fair model comparisons. Though more compute intensive, randomized allocation per experiment removes sampling bias and enables valid benchmarking. This highlights the true differences in model performance irrespective of a particular split's characteristics.
+Unique splits are essential for fair model comparisons. Though more compute-intensive, randomized allocation per experiment removes sampling bias and enables valid benchmarking. This highlights the true differences in model performance irrespective of a particular split's characteristics.
#### Information Leakage Between Sets
-Information leakage between the training, validation and test sets occurs when information from one set inadvertently bleeds into another set. This could happen due to flaws in the data splitting process and violates the assumption that the sets are mutually exclusive.
+Information leakage between the training, validation, and test sets occurs when information from one set inadvertently bleeds into another. This could happen due to flaws in the data-splitting process, which violates the assumption that the sets are mutually exclusive.
For example, consider a dataset sorted chronologically. If a simple random split is performed, samples close to each other in the dataset may end up in different splits. Models could then learn from 'future' data if test samples are leaked into the training set.
-Similarly, if the splits are not properly shuffled, distribution biases may persist across sets. The training set may not contain certain outliers that end up in the test set only, compromising generalization. Issues like class imbalance may also get amplified if splitting is not stratified.
+Similarly, distribution biases may persist across sets if the splits are not properly shuffled. The training set may contain more than certain outliers in the test set, compromising generalization. Issues like class imbalance may also get amplified if splitting is not stratified.
-Another case is when datasets have linked samples that are inherently connected, such as graphs, networks or time series data. Naive splitting may isolate connected nodes or time steps into different sets. Models can make invalid assumptions based on partial information.
+Another case is when datasets have linked, inherently connected samples, such as graphs, networks, or time series data. Naive splitting may isolate connected nodes or time steps into different sets. Models can make invalid assumptions based on partial information.
-Preventing information leakage requires awareness of the structure of the dataset and relationships between samples. Shuffling, stratification and grouped splitting of related samples can help mitigate leakage. Proper cross validation procedures should be followed, being mindful of temporal or sample proximity.
+Preventing information leakage requires awareness of the dataset's structure and relationships between samples. Shuffling, stratification, and grouped splitting of related samples can help mitigate leakage. Proper cross-validation procedures should be followed, mindful of temporal or sample proximity.
Subtle leakage of information between sets undermines model evaluation and training. It creates misleading results on model effectiveness. Data splitting procedures should account for sample relationships and distribution differences to ensure mutual exclusivity between sets.
#### Failing to Stratify Splits
-When splitting data into training, validation and test sets, failing to stratify the splits can result in uneven representation of the target classes across the splits and introduce sampling bias. This is especially problematic for imbalanced datasets.
+When splitting data into training, validation, and test sets, failing to stratify the splits can result in an uneven representation of the target classes across the splits and introduce sampling bias. This is especially problematic for imbalanced datasets.
Stratified splitting involves sampling data points such that the proportion of output classes is approximately preserved in each split. For example, if performing a 70/30 train-test split on a dataset with 60% negative and 40% positive samples, stratification ensures ~60% negative and ~40% positive examples in both training and test sets.
-Without stratification, due to random chance, the training split could end up with 70% positive while test has 30% positive samples. The model trained on this skewed training distribution will not generalize well. Class imbalance also compromises model metrics like accuracy.
+Without stratification, random chance could result in the training split having 70% positive samples while the test has 30% positive samples. The model trained on this skewed training distribution will not generalize well. Class imbalance also compromises model metrics like accuracy.
-Stratification works best when done using the labels though proxies like clustering can be used for unsupervised learning. It becomes essential for highly skewed datasets with rare classes that could easily get omitted from splits.
+Stratification works best when done using labels, though proxies like clustering can be used for unsupervised learning. It becomes essential for highly skewed datasets with rare classes that could easily be omitted from splits.
-Libraries like Scikit-Learn have stratified splitting methods inbuilt. Failing to use them could inadvertently introduce sampling bias and hurt model performance on minority groups. The overall class balance should be examined after performing the splits to ensure even representation across the splits.
+Libraries like Scikit-Learn have stratified splitting methods built into them. Failing to use them could inadvertently introduce sampling bias and hurt model performance on minority groups. After performing the splits, the overall class balance should be examined to ensure even representation across the splits.
-Stratification provides a balanced dataset for both model training and evaluation. Though simple random splitting is easy, being mindful of stratification needs, especially for real-world imbalanced data, results in more robust model development and evaluation.
+Stratification provides a balanced dataset for both model training and evaluation. Though simple random splitting is easy, mindful of stratification needs, especially for real-world imbalanced data, results in more robust model development and evaluation.
#### Ignoring Time Series Dependencies
Time series data has an inherent temporal structure with observations depending on past context. Naively splitting time series data into train and test sets without accounting for this dependency leads to data leakage and lookahead bias.
-For example, simply splitting a time series into the first 70% training and last 30% as test data will contaminate the training data with future data points. The model can use this information to "peek" ahead during training.
+For example, simply splitting a time series into the first 70% of training and the last 30% as test data will contaminate the training data with future data points. The model can use this information to "peek" ahead during training.
-This results in overly optimistic evaluation of the model's performance. The model may appear to forecast the future accurately but has actually implicitly learned based on future data. This does not translate to real world performance.
+This results in an overly optimistic evaluation of the model's performance. The model may appear to forecast the future accurately but has actually implicitly learned based on future data, which does not translate to real-world performance.
-Proper time series cross validation techniques should be used to preserve order and dependency, such as forward chaining. The test set should only contain data points from a future time window that the model did not get exposed to for training.
+Proper time series cross-validation techniques, such as forward chaining, should be used to preserve order and dependency. The test set should only contain data points from a future time window that the model was not exposed to for training.
-Failing to account for temporal relationships leads to invalid assumptions of causality. The model may also not learn how to extrapolate forecasts further into the future if the training data contains future points.
+Failing to account for temporal relationships leads to invalid causality assumptions. If the training data contains future points, the model may also need to learn how to extrapolate forecasts further.
-Maintaining the temporal flow of events and avoiding lookahead bias is key for properly training and testing time series models to ensure they can truly predict future patterns and not just memorize past training data.
+Maintaining the temporal flow of events and avoiding lookahead bias is key to properly training and testing time series models. This ensures they can truly predict future patterns and not just memorize past training data.
#### No Unseen Data for Final Evaluation
-A common mistake when splitting data is failing to keep aside some portion of the data just for final evaluation of the completed model. All of the data is used for training, validation and test sets during development.
+A common mistake when splitting data is failing to set aside some portion of the data just for the final evaluation of the completed model. All of the data is used for training, validation, and test sets during development.
-This leaves no unseen data to get an unbiased estimate of how the final tuned model would perform in the real world. The metrics on the test set used during development may not fully reflect actual model skill.
+This leaves no unseen data to get an unbiased estimate of how the final tuned model would perform in the real world. The metrics on the test set used during development may only partially reflect actual model skills.
-For example, choices like early stopping and hyperparameter tuning are often optimized based on performance on the test set. This couples the model to the test data. An unseen dataset is needed to break this coupling and get true real-world metrics.
+For example, choices like early stopping and hyperparameter tuning are often optimized based on test set performance. This couples the model to the test data. An unseen dataset is needed to break this coupling and get true real-world metrics.
-Best practice is to reserve a portion like 20-30% of the full dataset solely for final model evaluation. This data should not be used for any validation, tuning or model selection during development.
+Best practice is to reserve a portion, such as 20-30% of the full dataset, solely for final model evaluation. This data should not be used for validation, tuning, or model selection during development.
-Saving some unseen data allows evaluating the completely trained model as a black box on real-world like data. This provides reliable metrics to decide if the model is truly ready for production deployment.
+Saving some unseen data allows for evaluating the completely trained model as a black box on real-world data. This provides reliable metrics to decide whether the model is ready for production deployment.
-Failing to keep an unseen hold-out set for final validation risks optimistically biasing results and overlooking potential failures before model release. Having some fresh data provides a final sanity check on real-world efficacy.
+Failing to keep an unseen hold-out set for final validation risks optimizing results and overlooking potential failures before model release. Having some fresh data provides a final sanity check on real-world efficacy.
#### Overoptimizing on the Validation Set
-The validation set is meant to guide the model training process, not serve as additional training data. Overoptimizing on the validation set to maximize performance metrics treats it more like a secondary training set and leads to inflated metrics and poor generalization.
+The validation set is meant to guide the model training process, not serve as additional training data. Overoptimizing the validation set to maximize performance metrics treats it more like a secondary training set, leading to inflated metrics and poor generalization.
For example, techniques like extensively tuning hyperparameters or adding data augmentations targeted to boost validation accuracy can cause the model to fit too closely to the validation data. The model may achieve 99% validation accuracy but only 55% test accuracy.
-Similarly, reusing the validation set for early stopping can also optimize the model specifically for that data. Stopping at the best validation performance overfits to noise and fluctuations caused by the small validation size.
+Similarly, reusing the validation set for early stopping can also optimize the model specifically for that data. Stopping at the best validation performance overfits noise and fluctuations caused by the small validation size.
-The validation set serves as a proxy to tune and select models. But the end goal remains maximizing performance on real-world data, not the validation set. Minimizing the loss or error on validation data does not automatically translate to good generalization.
+The validation set serves as a proxy to tune and select models. However, the goal remains maximizing real-world data performance, not the validation set. Minimizing the loss or error on validation data does not automatically translate to good generalization.
-A good approach is to keep the validation set use minimal - hyperparameters can be tuned coarsely first on training data for example. The validation set guides the training, but should not influence or alter the model itself. It is a diagnostic, not an optimization tool.
+A good approach is to keep the use of the validation set minimal—hyperparameters can be tuned coarsely first on training data, for example. The validation set guides the training but should not influence or alter the model itself. It is a diagnostic, not an optimization tool.
-Care should be taken to not overfit when assessing performance on the validation set. Tradeoffs are needed to build models that perform well on the overall population, not overly tuned to the validation samples.
+When assessing performance on the validation set, care should be taken not to overfit. Tradeoffs are needed to build models that perform well on the overall population and are not overly tuned to the validation samples.
## Optimization Algorithms
-Stochastic gradient descent (SGD) is a simple yet powerful optimization algorithm commonly used to train machine learning models. SGD works by estimating the gradient of the loss function with respect to the model parameters using a single training example, and then updating the parameters in the direction that reduces the loss.
+Stochastic gradient descent (SGD) is a simple yet powerful optimization algorithm for training machine learning models. It works by estimating the gradient of the loss function concerning the model parameters using a single training example and then updating the parameters in the direction that reduces the loss.
-While conceptually straightforward, SGD suffers from a few shortcomings. First, choosing a proper learning rate can be difficult - too small and progress is very slow, too large and parameters may oscillate and fail to converge. Second, SGD treats all parameters equally and independently, which may not be ideal in all cases. Finally, vanilla SGD uses only first order gradient information which results in slow progress on ill-conditioned problems.
+While conceptually straightforward, SGD needs a few areas for improvement. First, choosing a proper learning rate can be difficult—too small, and progress is very slow; too large, and parameters may oscillate and fail to converge. Second, SGD treats all parameters equally and independently, which may not be ideal in all cases. Finally, vanilla SGD uses only first-order gradient information, which results in slow progress on ill-conditioned problems.
### Optimizations
-Over the years, various optimizations have been proposed to accelerate and improve upon vanilla SGD. @ruder2016overview gives an excellent overview of the different optimizers. Briefly, several commonly used SGD optimization techniques include:
+Over the years, various optimizations have been proposed to accelerate and improve vanilla SGD. @ruder2016overview gives an excellent overview of the different optimizers. Briefly, several commonly used SGD optimization techniques include:
**Momentum:** Accumulates a velocity vector in directions of persistent gradient across iterations. This helps accelerate progress by dampening oscillations and maintains progress in consistent directions.
-**Nesterov Accelerated Gradient (NAG):** A variant of momentum that computes gradients at the "look ahead" position rather than the current parameter position. This anticipatory update prevents overshooting while the momentum maintains the accelerated progress.
+**Nesterov Accelerated Gradient (NAG):** A variant of momentum that computes gradients at the "look ahead" rather than the current parameter position. This anticipatory update prevents overshooting while the momentum maintains the accelerated progress.
**RMSProp:** Divides the learning rate by an exponentially decaying average of squared gradients. This has a similar normalizing effect as Adagrad but does not accumulate the gradients over time, avoiding a rapid decay of learning rates [@hinton2017overview].
-**Adagrad:** An adaptive learning rate algorithm that maintains a per-parameter learning rate that is scaled down proportionate to the historical sum of gradients on each parameter. This helps eliminate the need to manually tune learning rates [@john2010adaptive].
+**Adagrad:** An adaptive learning rate algorithm that maintains a per-parameter learning rate scaled down proportionate to each parameter's historical sum of gradients. This helps eliminate the need to tune learning rates [@john2010adaptive] manually.
-**Adadelta:** A modification to Adagrad which restricts the window of accumulated past gradients thus reducing the aggressive decay of learning rates [@zeiler2012reinforcement].
+**Adadelta:** A modification to Adagrad restricts the window of accumulated past gradients, thus reducing the aggressive decay of learning rates [@zeiler2012reinforcement].
-**Adam:** - Combination of momentum and rmsprop where rmsprop modifies the learning rate based on average of recent magnitudes of gradients. Displays very fast initial progress and automatically tunes step sizes [@diederik2015adam].
+**Adam:** - Combination of momentum and rmsprop where rmsprop modifies the learning rate based on the average of recent magnitudes of gradients. Displays very fast initial progress and automatically tunes step sizes [@diederik2015adam].
-Of these methods, Adam is widely considered the go-to optimization algorithm for many deep learning tasks, consistently outperforming vanilla SGD in terms of both training speed and performance. Other optimizers may be better suited in some cases, particularly for simpler models.
+Of these methods, Adam has widely considered the go-to optimization algorithm for many deep-learning tasks. It consistently outperforms vanilla SGD in terms of training speed and performance. Other optimizers may be better suited in some cases, particularly for simpler models.
-### Trade-offs
+### Tradeoffs
Here is a pros and cons table for some of the main optimization algorithms for neural network training:
@@ -487,7 +493,7 @@ Here is a pros and cons table for some of the main optimization algorithms for n
|-|-|-|
| Momentum | Faster convergence due to acceleration along gradients Less oscillation than vanilla SGD | Requires tuning of momentum parameter |
| Nesterov Accelerated Gradient (NAG) | Faster than standard momentum in some cases Anticipatory updates prevent overshooting | More complex to understand intuitively |
-| Adagrad | Eliminates need to manually tune learning rates Performs well on sparse gradients | Learning rate may decay too quickly on dense gradients |
+| Adagrad | Eliminates need to tune learning rates manually Performs well on sparse gradients | Learning rate may decay too quickly on dense gradients |
| Adadelta | Less aggressive learning rate decay than Adagrad | Still sensitive to initial learning rate value |
| RMSProp | Automatically adjusts learning rates Works well in practice | No major downsides |
| Adam | Combination of momentum and adaptive learning rates Efficient and fast convergence | Slightly worse generalization performance in some cases |
@@ -495,90 +501,90 @@ Here is a pros and cons table for some of the main optimization algorithms for n
### Benchmarking Algorithms
-No single method is best for all problem types. This means we need a comprehensive benchmarking to identify the most effective optimizer for specific datasets and models. The performance of algorithms like Adam, RMSProp, and Momentum varies due to factors such as batch size, learning rate schedules, model architecture, data distribution, and regularization. These variations underline the importance of evaluating each optimizer under diverse conditions.
+No single method is best for all problem types. This means we need comprehensive benchmarking to identify the most effective optimizer for specific datasets and models. The performance of algorithms like Adam, RMSProp, and Momentum varies due to batch size, learning rate schedules, model architecture, data distribution, and regularization. These variations underline the importance of evaluating each optimizer under diverse conditions.
-Take Adam, for example, which often excels in computer vision tasks, in contrast to RMSProp that may show better generalization in certain natural language processing tasks. Momentum's strength lies in its acceleration in scenarios with consistent gradient directions, whereas Adagrad's adaptive learning rates are more suited for sparse gradient problems.
+Take Adam, for example, who often excels in computer vision tasks, unlike RMSProp, who may show better generalization in certain natural language processing tasks. Momentum's strength lies in its acceleration in scenarios with consistent gradient directions, whereas Adagrad's adaptive learning rates are more suited for sparse gradient problems.
-This wide array of interactions among different optimizers demonstrates the challenge in declaring a single, universally superior algorithm. Each optimizer has unique strengths, making it crucial to empirically evaluate a range of methods to discover their optimal application conditions.
+This wide array of interactions among optimizers demonstrates the challenge of declaring a single, universally superior algorithm. Each optimizer has unique strengths, making it crucial to evaluate various methods to discover their optimal application conditions empirically.
-A comprehensive benchmarking approach should assess not just the speed of convergence but also factors like generalization error, stability, hyperparameter sensitivity, and computational efficiency, among others. This entails monitoring training and validation learning curves across multiple runs and comparing optimizers on a variety of datasets and models to understand their strengths and weaknesses.
+A comprehensive benchmarking approach should assess the speed of convergence and factors like generalization error, stability, hyperparameter sensitivity, and computational efficiency, among others. This entails monitoring training and validation learning curves across multiple runs and comparing optimizers on various datasets and models to understand their strengths and weaknesses.
-AlgoPerf, introduced by @dahl2023benchmarking, addresses the need for a robust benchmarking system. This platform evaluates optimizer performance using criteria such as training loss curves, generalization error, sensitivity to hyperparameters, and computational efficiency. AlgoPerf tests various optimization methods, including Adam, LAMB, and Adafactor, across different model types like CNNs and RNNs/LSTMs on established datasets. It utilizes containerization and automatic metric collection to minimize inconsistencies and allows for controlled experiments across thousands of configurations, providing a reliable basis for comparing different optimizers.
+AlgoPerf, introduced by @dahl2023benchmarking, addresses the need for a robust benchmarking system. This platform evaluates optimizer performance using criteria such as training loss curves, generalization error, sensitivity to hyperparameters, and computational efficiency. AlgoPerf tests various optimization methods, including Adam, LAMB, and Adafactor, across different model types like CNNs and RNNs/LSTMs on established datasets. It utilizes containerization and automatic metric collection to minimize inconsistencies and allows for controlled experiments across thousands of configurations, providing a reliable basis for comparing optimizers.
-The insights gained from AlgoPerf and similar benchmarks are invaluable for guiding the optimal choice or tuning of optimizers. By enabling reproducible evaluations, these benchmarks contribute to a deeper understanding of each optimizer's performance, paving the way for future innovations and accelerated progress in the field.
+The insights gained from AlgoPerf and similar benchmarks are invaluable for guiding optimizers' optimal choice or tuning. By enabling reproducible evaluations, these benchmarks contribute to a deeper understanding of each optimizer's performance, paving the way for future innovations and accelerated progress in the field.
## Hyperparameter Tuning
-Hyperparameters are important settings in machine learning models that have a large impact on how well your models ultimately perform. Unlike other model parameters that are learned during training, hyperparameters are specified by the data scientists or machine learning engineers prior to training the model.
+Hyperparameters are important settings in machine learning models that greatly impact how well your models ultimately perform. Unlike other model parameters that are learned during training, hyperparameters are specified by the data scientists or machine learning engineers before training the model.
-Choosing the right hyperparameter values is crucial for enabling your models to effectively learn patterns from data. Some examples of key hyperparameters across ML algorithms include:
+Choosing the right hyperparameter values enables your models to learn patterns from data effectively. Some examples of key hyperparameters across ML algorithms include:
* **Neural networks:** Learning rate, batch size, number of hidden units, activation functions
* **Support vector machines:** Regularization strength, kernel type and parameters
* **Random forests:** Number of trees, tree depth
* **K-means:** Number of clusters
-The problem is that there are no reliable rules-of-thumb for choosing optimal hyperparameter configurations - you typically have to try out different values and evaluate performance. This process is called hyperparameter tuning.
+The problem is that there are no reliable rules of thumb for choosing optimal hyperparameter configurations—you typically have to try out different values and evaluate performance. This process is called hyperparameter tuning.
-In the early years of modern deep learning, researchers were still grappling with unstable and slow convergence issues. Common pain points included training losses fluctuating wildly, gradients exploding or vanishing, and extensive trial-and-error needed to train networks reliably. As a result, an early focal point was using hyperparameters to control model optimization. For instance, seminal techniques like batch normalization allowed much faster model convergence by tuning aspects of internal covariate shift. Adaptive learning rate methods also mitigated the need for extensive manual schedules. These addressed optimization issues during training like uncontrolled gradient divergence. Carefully adapted learning rates are also the primary control factor even today for achieving rapid and stable convegence.
+In the early years of modern deep learning, researchers were still grappling with unstable and slow convergence issues. Common pain points included training losses fluctuating wildly, gradients exploding or vanishing, and extensive trial-and-error needed to train networks reliably. As a result, an early focal point was using hyperparameters to control model optimization. For instance, seminal techniques like batch normalization allowed faster model convergence by tuning aspects of internal covariate shift. Adaptive learning rate methods also mitigated the need for extensive manual schedules. These addressed optimization issues during training, such as uncontrolled gradient divergence. Carefully adapted learning rates are also the primary control factor for achieving rapid and stable convergence even today.
-As computational capacity expanded exponentially in subsequent years, much larger models could be trained without falling prey to pure numerical optimization issues. The focus shifted towards generalization - though efficient convergence was a core prerequisite. State-of-the-art techniques like Transformers brought in parameters in billions. At such sizes, hyperparameters around capacity, regularization, ensembling etc. took center stage for tuning rather than only raw convergence metrics.
+As computational capacity expanded exponentially in subsequent years, much larger models could be trained without falling prey to pure numerical optimization issues. The focus shifted towards generalization - though efficient convergence was a core prerequisite. State-of-the-art techniques like Transformers brought in parameters in billions. At such sizes, hyperparameters around capacity, regularization, ensembling, etc., took center stage for tuning rather than only raw convergence metrics.
-The lesson is that understanding acceleration and stability of the optimization process itself constitutes the groundwork. Even today initialization schemes, batch sizes, weight decays and other training hyperparameters remain indispensable. Mastering fast and flawless convergence allows practitioners to expand focus on emerging needs around tuning for metrics like accuracy, robustness and efficiency at scale.
+The lesson is that understanding the acceleration and stability of the optimization process itself constitutes the groundwork. Initialization schemes, batch sizes, weight decays, and other training hyperparameters remain indispensable today. Mastering fast and flawless convergence allows practitioners to expand their focus on emerging needs around tuning for metrics like accuracy, robustness, and efficiency at scale.
### Search Algorithms
-When it comes to the critical process of hyperparameter tuning, there are several sophisticated algorithms machine learning practitioners rely on to systematically search through the vast space of possible model configurations. Some of the most prominent hyperparameter search algorithms include:
+When it comes to the critical process of hyperparameter tuning, there are several sophisticated algorithms that machine learning practitioners rely on to search through the vast space of possible model configurations systematically. Some of the most prominent hyperparameter search algorithms include:
-* **Grid Search:** The most basic search method, where you manually define a grid of values to check for each hyperparameter. For example, checking learning rates = [0.01, 0.1, 1] and batch sizes = [32, 64, 128]. The key advantage is simplicity, but exploring all combinations leads to exponential search space explosion. Best for fine-tuning a few params.
+* **Grid Search:** The most basic search method, where you manually define a grid of values to check for each hyperparameter. For example, checking learning rates = [0.01, 0.1, 1] and batch sizes = [32, 64, 128]. The key advantage is simplicity, but exploring all combinations leads to exponential search space explosion. Best for fine-tuning a few parameters.
-* **Random Search:** Instead of a grid, you define a random distribution per hyperparameter to sample values from during search. It is more efficient at searching a vast hyperparameter space. However, still somewhat arbitrary compared to more adaptive methods.
+* **Random Search:** Instead of a grid, you define a random distribution per hyperparameter to sample values from during the search. This method is more efficient at searching a vast hyperparameter space. However, it is still somewhat arbitrary compared to more adaptive methods.
-* **Bayesian Optimization:** An advanced probabilistic approach for adaptive exploration based on a surrogate function to model performance over iterations. It is very sample efficient - finds highly optimized hyperparameters in fewer evaluation steps. Requires more investment in setup [@jasper2012practical].
+* **Bayesian Optimization:** This is an advanced probabilistic approach for adaptive exploration based on a surrogate function to model performance over iterations. It is simple and efficient—it finds highly optimized hyperparameters in fewer evaluation steps. However, it requires more investment in setup [@jasper2012practical].
-* **Evolutionary Algorithms:** Mimic natural selection principles - generate populations of hyperparameter combinations, evolve them over time based on performance. These algorithms offer robust search capabilities better suited for complex response surfaces. But many iterations required for reasonable convergence.
+* **Evolutionary Algorithms:** These algorithms Mimic natural selection principles. They generate populations of hyperparameter combinations and evolve them over time-based on performance. These algorithms offer robust search capabilities better suited for complex response surfaces. However, many iterations are required for reasonable convergence.
-* **Neural Architecture Search:** An approach to designing well-performing architectures for neural networks. Traditionally, NAS approaches use some form of reinforcement learning to propose neural network architectures which are then repeatedly evaluated [@zoph2023cybernetical].
+* **Neural Architecture Search:** An approach to designing well-performing architectures for neural networks. Traditionally, NAS approaches use some form of reinforcement learning to propose neural network architectures, which are then repeatedly evaluated [@zoph2023cybernetical].
### System Implications
-Hyperparameter tuning can significantly impact time to convergence during model training, directly affecting overall runtime. Selecting the right values for key training hyperparameters is crucial for efficient model convergence. For example, the learning rate hyperparameter controls the step size during gradient descent optimization. Setting a properly tuned learning rate schedule ensures the optimization algorithm converges quickly towards a good minimum. Too small a learning rate leads to painfully slow convergence, while too large a value causes the losses to fluctuate wildly. Proper tuning ensures rapid movement towards optimal weights and biases.
+Hyperparameter tuning can significantly impact time to convergence during model training, directly affecting overall runtime. The right values for key training hyperparameters are crucial for efficient model convergence. For example, the hyperparameter's learning rate controls the step size during gradient descent optimization. Setting a properly tuned learning rate schedule ensures the optimization algorithm converges quickly towards a good minimum. Too small a learning rate leads to painfully slow convergence, while too large a value causes the losses to fluctuate wildly. Proper tuning ensures rapid movement towards optimal weights and biases.
-Similarly, batch size for stochastic gradient descent impacts convergence stability. The right batch size smooths out fluctuations in parameter updates to approach the minimum faster. Insufficient batch sizes cause noisy convergence, while large batch sizes fail to generalize and also slow down convergence due to less frequent parameter updates. Tuning hyperparameters for faster convergence and reduced training duration has direct implications on cost and resource requirements for scaling machine learning systems:
+Similarly, the batch size for stochastic gradient descent impacts convergence stability. The right batch size smooths out fluctuations in parameter updates to approach the minimum faster. More batch sizes are needed to avoid noisy convergence, while large batch sizes fail to generalize and slow down convergence due to less frequent parameter updates. Tuning hyperparameters for faster convergence and reduced training duration has direct implications on cost and resource requirements for scaling machine learning systems:
-* **Lower computatioanal costs:** Shorter time to convergence means lower computational costs for training models. ML training often leverages large cloud compute instances like GPU and TPU clusters that incur heavy charges per hour. Minimizing training time directly brings down this resource rental cost that tends to dominate ML budgets for organizations. Quicker iteration also lets data scientists experiment more freely within the same budget.
+* **Lower computational costs:** Shorter time to convergence means lower computational costs for training models. ML training often leverages large cloud computing instances like GPU and TPU clusters that incur heavy hourly charges. Minimizing training time directly reduces this resource rental cost, which tends to dominate ML budgets for organizations. Quicker iteration also lets data scientists experiment more freely within the same budget.
-* **Reduced training time:** Reduced training time unlocks opportunities to train more models using the same computational budget. Optimized hyperparameters stretch available resources further allowing businesses to develop and experiment with more models under resource constraints to maximize performance.
+* **Reduced training time:** Reduced training time unlocks opportunities to train more models using the same computational budget. Optimized hyperparameters stretch available resources further, allowing businesses to develop and experiment with more models under resource constraints to maximize performance.
-* **Resource efficiency:** Quicker training allows allocating smaller compute instances in cloud since models require access to the resources for a shorter duration. For example, a 1-hour training job allows using less powerful GPU instances compared to multi-hour training requiring sustained compute access over longer intervals. This achieves cost savings especially for large workloads.
+* **Resource efficiency:** Quicker training allows allocating smaller compute instances in the cloud since models require access to the resources for a shorter duration. For example, a one-hour training job allows using less powerful GPU instances compared to multi-hour training, which requires sustained compute access over longer intervals. This achieves cost savings, especially for large workloads.
-There are other benefits as well. For instance, faster convergence reduces pressure on ML engineering teams around provisioning training resources. Simple model retraining routines can use lower powered resources as opposed to requesting for access to high priority queues for constrained production-grade GPU clusters. This frees up deployment resources for other applications.
+There are other benefits as well. For instance, faster convergence reduces pressure on ML engineering teams regarding provisioning training resources. Simple model retraining routines can use lower-powered resources instead of requesting access to high-priority queues for constrained production-grade GPU clusters, freeing up deployment resources for other applications.
### Auto Tuners
-There are a wide array of commercial offerings to help with hyperparameter tuning given how important it is. We will briefly touch on two examples focused on optimization for machine learning models targeting microcontrollers and another focused on cloud-scale ML.
+Given its importance, there is a wide array of commercial offerings to help with hyperparameter tuning. We will briefly touch on two examples: one focused on optimization for machine learning models targeting microcontrollers and another on cloud-scale ML.
#### BigML
-There are several commercial auto tuning platforms available to deal with this problem. One such solution is Google's Vertex AI Cloud, which has extensive integrated support for state-of-the-art tuning techniques.
+Several commercial auto-tuning platforms are available to address this problem. One solution is Google's Vertex AI Cloud, which has extensive integrated support for state-of-the-art tuning techniques.
-One of the most salient capabilities offered by Google's Vertex AI managed machine learning platform is efficient, integrated hyperparameter tuning for model development. Successfully training performant ML models requires identifying optimal configurations for a set of external hyperparameters that dictate model behavior - which poses a challenging high-dimensional search problem. Vertex AI aims to simplify this through Automated Machine Learning (AutoML) tooling.
+One of the most salient capabilities of Google's Vertex AI-managed machine learning platform is efficient, integrated hyperparameter tuning for model development. Successfully training performant ML models requires identifying optimal configurations for a set of external hyperparameters that dictate model behavior, posing a challenging high-dimensional search problem. Vertex AI aims to simplify this through Automated Machine Learning (AutoML) tooling.
-Specifically, data scientists can leverage Vertex AI's hyperparameter tuning engines by providing a labeled dataset and choosing a model type such as Neural Network or Random Forest classifier. Vertex launches a Hyperparameter Search job transparently on the backend, fully handling resource provisioning, model training, metric tracking and result analysis automatically using advanced optimization algorithms.
+Specifically, data scientists can leverage Vertex AI's hyperparameter tuning engines by providing a labeled dataset and choosing a model type such as a Neural Network or Random Forest classifier. Vertex launches a Hyperparameter Search job transparently on the backend, fully handling resource provisioning, model training, metric tracking, and result analysis automatically using advanced optimization algorithms.
-Under the hood, Vertex AutoML employs a wide array of different search strategies to intelligently explore the most promising hyperparameter configurations based on previous evaluation results. Compared to standard Grid Search or Random Search methods, Bayesian Optimization offers superior sample efficiency requiring fewer training iterations to arrive at optimized model quality. For more complex neural architecture search spaces, Vertex AutoML utilizes Population Based Training approaches which evolve candidate solutions over time analogous to natural selection principles.
+Under the hood, Vertex AutoML employs various search strategies to intelligently explore the most promising hyperparameter configurations based on previous evaluation results. Compared to standard Grid Search or Random Search methods, Bayesian Optimization offers superior sample efficiency, requiring fewer training iterations to arrive at optimized model quality. For more complex neural architecture search spaces, Vertex AutoML utilizes Population-Based Training approaches, which evolve candidate solutions over time analogous to natural selection principles.
-Vertex AI aims to democratize state-of-the-art hyperparameter search techniques at cloud scale for all ML developers, abstracting away the underlying orchestration and execution complexity. Users focus solely on their dataset, model requirements and accuracy goals while Vertex manages the tuning cycle, resource allocation, model training, accuracy tracking and artifact storage under the hood. The end result is getting deployment-ready, optimized ML models faster for the target problem.
+Vertex AI aims to democratize state-of-the-art hyperparameter search techniques at the cloud scale for all ML developers, abstracting away the underlying orchestration and execution complexity. Users focus solely on their dataset, model requirements, and accuracy goals, while Vertex manages the tuning cycle, resource allocation, model training, accuracy tracking, and artifact storage under the hood. The result is getting deployment-ready, optimized ML models faster for the target problem.
#### TinyML
-Edge Impulse's Efficient On-device Neural Network Tuner (EON Tuner) is an automated hyperparameter optimization tool designed specifically for developing machine learning models for microcontrollers. The EON Tuner streamlines the model development process by automatically finding the best neural network configuration for efficient and accurate deployment on resource-constrained devices.
+Edge Impulse's Efficient On-device Neural Network Tuner (EON Tuner) is an automated hyperparameter optimization tool designed to develop microcontroller machine learning models. It streamlines the model development process by automatically finding the best neural network configuration for efficient and accurate deployment on resource-constrained devices.
-The key functionality of the EON Tuner is as follows. First, developers define the model hyperparameters, such as number of layers, nodes per layer, activation functions, and learning rate annealing schedule. These parameters constitute the search space that will be optimized. Next, the target microcontroller platform is selected, providing embedded hardware constraints. The user can also specify optimization objectives, such as minimizing memory footprint, lowering latency, reducing power consumption or maximizing accuracy.
+The key functionality of the EON Tuner is as follows. First, developers define the model hyperparameters, such as number of layers, nodes per layer, activation functions, and learning rate annealing schedule. These parameters constitute the search space that will be optimized. Next, the target microcontroller platform is selected, providing embedded hardware constraints. The user can also specify optimization objectives, such as minimizing memory footprint, lowering latency, reducing power consumption, or maximizing accuracy.
-With the search space and optimization goals defined, the EON Tuner leverages Bayesian hyperparameter optimization to intelligently explore possible configurations. Each prospective configuration is automatically implemented as a full model specification, trained and evaluated for quality metrics. The continual process balances exploration and exploitation to arrive at optimized settings tailored to the developer's chosen chip architecture and performance requirements.
+With the defined search space and optimization goals, the EON Tuner leverages Bayesian hyperparameter optimization to explore possible configurations intelligently. Each prospective configuration is automatically implemented as a full model specification, trained, and evaluated for quality metrics. The continual process balances exploration and exploitation to arrive at optimized settings tailored to the developer's chosen chip architecture and performance requirements.
-By automatically tuning models for embedded deployment, the EON Tuner frees machine learning engineers from the demandingly iterative process of hand-tuning models. The tool integrates seamlessly into the Edge Impulse workflow for taking models from concept to efficiently optimized implementations on microcontrollers. The expertise encapsulated in EON Tuner regarding ML model optimization for microcontrollers ensures beginner and experienced developers alike can rapidly iterate to models fitting their project needs.
+The EON Tuner frees machine learning engineers from the demandingly iterative process of hand-tuning models by automatically tuning models for embedded deployment. The tool integrates seamlessly into the Edge Impulse workflow, taking models from concept to efficiently optimized implementations on microcontrollers. The expertise encapsulated in EON Tuner regarding ML model optimization for microcontrollers ensures beginner and experienced developers alike can rapidly iterate to models fitting their project needs.
:::{#exr-hpt .callout-exercise collapse="true"}
@@ -590,17 +596,19 @@ Get ready to unlock the secrets of hyperparameter tuning and take your PyTorch m
:::
+The video below explains the systematic organization of the hyperparameter tuning process.
+
{{< video https://www.youtube.com/watch?v=AXDByU3D1hA&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=24 >}}
## Regularization
-Regularization is a critical technique for improving the performance and generalizability of machine learning models in applied settings. It refers to mathematically constraining or penalizing model complexity to avoid overfitting the training data. Without regularization, complex ML models are prone to overfitting to the dataset and memorize peculiarities and noise in the training set, rather than learning meaningful patterns. They may achieve high training accuracy, but perform poorly when evaluating new unseen inputs.
+Regularization is a critical technique for improving the performance and generalizability of machine learning models in applied settings. It refers to mathematically constraining or penalizing model complexity to avoid overfitting the training data. Without regularization, complex ML models are prone to overfitting the dataset and memorizing peculiarities and noise in the training set rather than learning meaningful patterns. They may achieve high training accuracy but perform poorly when evaluating new unseen inputs.
Regularization helps address this problem by placing constraints that favor simpler, more generalizable models that don't latch onto sampling errors. Techniques like L1/L2 regularization directly penalize large parameter values during training, forcing the model to use the smallest parameters that can adequately explain the signal. Early stopping rules halt training when validation set performance stops improving - before the model starts overfitting.
Appropriate regularization is crucial when deploying models to new user populations and environments where distribution shifts are likely. For example, an irregularized fraud detection model trained at a bank may work initially but accrue technical debt over time as new fraud patterns emerge.
-Regularizing complex neural networks also allows computational advantages - smaller models require less data augmentation, compute power, and data storage. Regularization allows more efficient AI systems, where accuracy, robustness, and resource management are balanced thoughtfully against training set limitations.
+Regularizing complex neural networks also offers computational advantages—smaller models require less data augmentation, compute power, and data storage. Regularization also allows for more efficient AI systems, where accuracy, robustness, and resource management are thoughtfully balanced against training set limitations.
Several powerful regularization techniques are commonly used to improve model generalization. Architecting the optimal strategy requires understanding how each method affects model learning and complexity.
@@ -608,7 +616,7 @@ Several powerful regularization techniques are commonly used to improve model ge
Two of the most widely used regularization forms are L1 and L2 regularization. Both penalize model complexity by adding an extra term to the cost function optimized during training. This term grows larger as model parameters increase.
-L2 regularization, also known as ridge regression, adds the sum of squared magnitudes of all parameters, multiplied by a coefficient α. This quadratic penalty curtails extreme parameter values more aggressively than L1 techniques. Implementation requires only changing the cost function and tuning α.
+L2 regularization, also known as ridge regression, adds the sum of squared magnitudes of all parameters multiplied by a coefficient α. This quadratic penalty curtails extreme parameter values more aggressively than L1 techniques. Implementation requires only changing the cost function and tuning α.
$$R_{L2}(\Theta) = \alpha \sum_{i=1}^{n}\theta_{i}^2$$
@@ -629,7 +637,7 @@ Where:
* $L(\theta)$ - The original unregularized cost function
* $J(\theta)$ - The new regularized cost function
-Both L1 and L2 regularization penalize large weights in the neural network, however, the key difference between L1 and L2 regularization is that L2 regularization penalizes the squares of the parameters rather than the absolute values. This key difference has considerable impact on the resulting regularized weights. L1 regularization, also known as lasso regression, utilizes the absolute sum of magnitudes, rather than the square, multiplied by α. Penalizing the absolute value of weights induces sparsity, since the gradient of the errors extrapolates linearly as the weight terms tend towards zero; this is unlike penalizing the squared value of the weights where the penalty reduces as the weights tend towards 0. By inducing sparsity in the parameter vector, L1 regularization automatically performs feature selection, setting the weights of irrelevant features to zero. Unlike L2 regularization, L1 regularization leads to sparsity as weights are set to 0; in L2 regularization weights are set to a value very close to 0 but generally never reach exact 0. The fact that L1 regularization encourages sparsity has been used in some works to train sparse networks that may be more hardware efficient [@torsten2021sparsity].
+Both L1 and L2 regularization penalize large weights in the neural network. However, the key difference between L1 and L2 regularization is that L2 regularization penalizes the squares of the parameters rather than the absolute values. This key difference has a considerable impact on the resulting regularized weights. L1 regularization, or lasso regression, utilizes the absolute sum of magnitudes rather than the square multiplied by α. Penalizing the absolute value of weights induces sparsity since the gradient of the errors extrapolates linearly as the weight terms tend towards zero; this is unlike penalizing the squared value of the weights, where the penalty reduces as the weights tend towards 0. By inducing sparsity in the parameter vector, L1 regularization automatically performs feature selection, setting the weights of irrelevant features to zero. Unlike L2 regularization, L1 regularization leads to sparsity as weights are set to 0; in L2 regularization, weights are set to a value very close to 0 but generally never reach exact 0. L1 regularization encourages sparsity and has been used in some works to train sparse networks that may be more hardware efficient [@torsten2021sparsity].
$$R_{L1}(\Theta) = \alpha \sum_{i=1}^{n}||\theta_{i}||$$
@@ -652,15 +660,17 @@ Where:
The choice between L1 and L2 depends on the expected model complexity and whether intrinsic feature selection is needed. Both require iterative tuning across a validation set to select the optimal α hyperparameter.
+The two videos below explain how regularization works and can help reduce model overfitting to improve performance.
+
{{< video https://www.youtube.com/watch?v=6g0t3Phly2M&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=4 >}}
{{< video https://www.youtube.com/watch?v=NyG-7nRpsW8&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=5 >}}
### Dropout
-Another widely adopted regularization method is dropout [@srivastava2014dropout]. During training, dropout randomly sets a fraction $p$ of node outputs or hidden activations to zero. This encourages greater distribribution of information across more nodes, rather than reliance on a small number of nodes. Come prediction time, the full neural network is used, with intermediate activations scaled by $p$ to maintain output magnitudes. GPU optimizations make implementing dropout efficiently straightforward via frameworks like PyTorch and TensorFlow.
+Another widely adopted regularization method is dropout [@srivastava2014dropout]. During training, dropout randomly sets a fraction $p$ of node outputs or hidden activations to zero. This encourages greater information distribution across more nodes rather than reliance on a small number of nodes. Come prediction time; the full neural network is used, with intermediate activations scaled by $p$ to maintain output magnitudes. GPU optimizations make implementing dropout efficiently straightforward via frameworks like PyTorch and TensorFlow.
-Let's be a bit more pendantic. During training with dropout, each node's output $a_i$ is passed through a dropout mask $r_i$ before being used by the next layer:
+Let's be more pedantic. During training with dropout, each node's output $a_i$ is passed through a dropout mask $r_i$ before being used by the next layer:
$$ ã_i = r_i \odot a_i $$
@@ -671,9 +681,9 @@ Where:
* $r_i$ - independent Bernoulli random variable with probability $p$ of being 1
* $\odot$ - elementwise multiplication
-This dropout mask $r_i$ randomly sets a fraction $1-p$ of activations to 0 during training, forcing the network to redundant representations.
+This dropout mask $r_i$ randomly sets a fraction $1-p$ of activations to 0 during training, forcing the network to make redundant representations.
-At test time, the dropout mask is removed and the activations are rescaled by $p$ to maintain expected output magnitudes:
+At test time, the dropout mask is removed, and the activations are rescaled by $p$ to maintain expected output magnitudes:
$$ a_i^{test} = p a_i$$
@@ -684,48 +694,52 @@ Where:
The key hyperparameter is $p$, the fraction of nodes dropped, often set between 0.2 and 0.5. Larger networks tend to benefit from more dropout, while small networks risk underfitting if too many nodes are cut out. Trial and error combined with monitoring validation performance helps tune the dropout level.
+The following video discusses the intuition behind the dropout regularization technique and how it works.
+
{{< video https://www.youtube.com/watch?v=ARq74QuavAo&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=7 >}}
### Early Stopping
-The intuition behind early stopping involves tracking model performance on a held-out validation set across training epochs. At first, increases in training set fitness accompany gains in validation accuracy as the model picks up generalizable patterns. After some point however, the model starts overfitting - latching onto peculiarities and noise in the training data that don't apply more broadly. The validation performance peaks and then degrades if training continues. Early stopping rules halt training at this peak to prevent overfitting. This technique demonstrates how ML pipelines must monitor system feedback, not just blindly maximize performance on a static training set. The system's state evolves, and the optimal endpoints change.
+The intuition behind early stopping involves tracking model performance on a held-out validation set across training epochs. At first, increases in training set fitness accompany gains in validation accuracy as the model picks up generalizable patterns. After some point, however, the model starts overfitting - latching onto peculiarities and noise in the training data that don't apply more broadly. The validation performance peaks and then degrades if training continues. Early stopping rules halt training at this peak to prevent overfitting. This technique demonstrates how ML pipelines must monitor system feedback, not just unquestioningly maximize performance on a static training set. The system's state evolves, and the optimal endpoints change.
-Formal early stopping methods therefore require monitoring a metric like validation accuracy or loss after each epoch. Common curves exhibit rapid initial gains that taper off, eventually plateauing and decreasing slightly as overfitting occurs. The optimal stopping point is often between 5-15 epochs past the peak depending on patience thresholds. Tracking multiple metrics can improve signal since variance exists between measures.
+Therefore, formal early stopping methods require monitoring a metric like validation accuracy or loss after each epoch. Common curves exhibit rapid initial gains that taper off, eventually plateauing and decreasing slightly as overfitting occurs. The optimal stopping point is often between 5 and 15 epochs past the peak, depending on patient thresholds. Tracking multiple metrics can improve signal since variance exists between measures.
-Simple early stopping rules stop immediately at the first post-peak degradation. More robust methods introduce a patience parameter - the number of degrading epochs permitted before stopping. This avoids prematurely halting training due to transient fluctuations. Typical patience windows range from 50-200 validation batches. Wider windows incur risk of overfit. Formal tuning strategies can determine optimal patience.
+Simple, early-stopping rules stop immediately at the first post-peak degradation. More robust methods introduce a patience parameter—the number of degrading epochs permitted before stopping. This avoids prematurely halting training due to transient fluctuations. Typical patience windows range from 50 to 200 validation batches. Wider windows incur the risk of overfitting. Formal tuning strategies can determine optimal patience.
:::{#exr-r .callout-exercise collapse="true"}
### Regularization
-Battling Overfitting: Unlock the secrets of Regularization! Overfitting is like your model memorizing the answers to a practice test, then failing the real exam. Regularization techniques are the study guides that help your model generalize and ace new challenges. In this Colab notebook, you'll learn how to tune regularization parameters for optimal results using L1 & L2 regularization, dropout and early stopping.
+Battling Overfitting: Unlock the Secrets of Regularization! Overfitting is like your model memorizing the answers to a practice test, then failing the real exam. Regularization techniques are the study guides that help your model generalize and ace new challenges. In this Colab notebook, you'll learn how to tune regularization parameters for optimal results using L1 & L2 regularization, dropout, and early stopping.
[](https://colab.research.google.com/github/dphi-official/Deep_Learning_Bootcamp/blob/master/Optimization_Techniques/Regularization_and_Dropout.ipynb)
:::
+The following video covers a few other regularization methods that can reduce model overfitting.
+
{{< video https://www.youtube.com/watch?v=BOCLq2gpcGU&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=8 >}}
## Weight Initialization
-Proper initialization of the weights in a neural network prior to training is a vital step that directly impacts model performance. Randomly initializing weights to very large or small values can lead to problems like vanishing/exploding gradients, slow convergence of training, or getting trapped in poor local minima. Proper weight initialization not only accelerates model convergence during training, but also carries implications for system performance at inference time in production environments. Some key aspects include:
+Proper Initializing the weights in a neural network before training is a vital step directly impacting model performance. Randomly initializing weights to very large or small values can lead to problems like vanishing/exploding gradients, slow convergence of training, or getting trapped in poor local minima. Proper weight initialization accelerates model convergence during training and carries implications for system performance at inference time in production environments. Some key aspects include:
-* **Faster Time-to-Accuracy:** Carefully tuned initialization leading to faster convergence results in models reaching target accuracy milestones earlier in the training cycle. For instance, Xavier init could reduce time-to-accuracy by 20% versus bad random init. As training is typically the most time and compute-intensive phase, this directly enhances ML system velocity and productivity.
+* **Faster Time-to-Accuracy:** Carefully tuned Initialization leads to faster convergence, which results in models reaching target accuracy milestones earlier in the training cycle. For instance, Xavier init could reduce time-to-accuracy by 20% versus bad random init. As training is typically the most time- and compute-intensive phase, this directly enhances ML system velocity and productivity.
-* **Model Iteration Cycle Efficiency:** If models train faster, the overall turnaround time for experimentation, evaluation, and model design iterations also decreases significantly. Systems have more flexibility to explore architectures, data pipelines etc within given timeframes.
+* **Model Iteration Cycle Efficiency:** If models train faster, the overall turnaround time for experimentation, evaluation, and model design iterations decreases significantly. Systems have more flexibility to explore architectures, data pipelines, etc, within given timeframes.
-* **Impact on Necessary Training Epochs:** The training process runs for multiple epochs - with each full pass through the data being an epoch. Good initialization can reduce the epochs required to converge the loss and accuracy curves on the training set by 10-30% in some cases. This means tangible resource and infrastructure cost savings.
+* **Impact on Necessary Training Epochs:** The training process runs for multiple epochs - with each full pass through the data being an epoch. Good Initialization can reduce the epochs required to converge the loss and accuracy curves on the training set by 10-30%. This means tangible resource and infrastructure cost savings.
-* **Effect on Training Hyperparameters:** Weight initialization parameters interacts strongly with certain regularization hyperparameters that govern the training dynamics - like learning rate schedules and dropout probabilities. Finding the right combination of settings is non-trivial. Appropriate initialization smoothens this search.
+* **Effect on Training Hyperparameters:** Weight initialization parameters interact strongly with certain regularization hyperparameters that govern the training dynamics, like learning rate schedules and dropout probabilities. Finding the right combination of settings is non-trivial. Appropriate Initialization smoothens this search.
-Weight initialization has cascading benefits for machine learning engineering efficiency as well as minimized system resource overhead. It is an easily overlooked tactic that every practitioner should master. The choice of which weight initialization technique to use depends on factors like model architecture (number of layers, connectivity pattern etc.), activation functions, and the specific problem being solved. Over the years, researchers have developed and empirically verified different initialization strategies targeted to common neural network architectures, which we will discuss here.
+Weight initialization has cascading benefits for machine learning engineering efficiency and minimized system resource overhead. It is an easily overlooked tactic that every practitioner should master. The choice of which weight initialization technique to use depends on factors like model architecture (number of layers, connectivity pattern, etc.), activation functions, and the specific problem being solved. Over the years, researchers have developed and empirically verified different initialization strategies targeted to common neural network architectures, which we will discuss here.
### Uniform and Normal Initialization
-When randomly initializing weights, two standard probability distributions are commonly used - uniform and Gaussian (normal). The uniform distribution sets equal probability of the initial weight parameters falling anywhere within set minimum and maximum bounds. For example, the bounds could be -1 and 1, leading to a uniform spread of weights between these limits. The Gaussian distribution on the other hand concentrates probability around a mean value, following the shape of a bell curve. Most of the weight values will cluster in the region of the specified mean, with fewer samples towards the extreme ends. The standard deviation (std dev) parameter controls the spread around the mean.
+When randomly initializing weights, two standard probability distributions are commonly used - uniform and Gaussian (normal). The uniform distribution sets an equal probability of the initial weight parameters falling anywhere within set minimum and maximum bounds. For example, the bounds could be -1 and 1, leading to a uniform spread of weights between these limits. The Gaussian distribution, on the other hand, concentrates probability around a mean value, following the shape of a bell curve. Most weight values will cluster in the region of the specified mean, with fewer samples towards the extreme ends. The standard deviation (std dev) parameter controls the spread around the mean.
-The choice between uniform or normal initialization depends on the network architecture and activation functions. For shallow networks, a normal distribution with relatively small std dev (e.g. 0.01) is recommended. The bell curve prevents very large weight values that could trigger training instability in small networks. For deeper networks, a normal distribution with higher std dev (say 0.5 or above) or uniform distribution may be preferred to account for vanishing gradient issues over many layers. The larger spread drives greater differentiation between neuron behaviors. Fine-tuning the initialization distribution parameters is crucial for stable and speedy model convergence. Monitoring training loss trends can diagnose issues for tweaking the parameters iteratively.
+The choice between uniform or normal Initialization depends on the network architecture and activation functions. For shallow networks, a normal distribution with a relatively small std dev (e.g., 0.01) is recommended. The bell curve prevents large weight values that could trigger training instability in small networks. For deeper networks, a normal distribution with higher std dev (say 0.5 or above) or uniform distribution may be preferred to account for vanishing gradient issues over many layers. The larger spread drives greater differentiation between neuron behaviors. Fine-tuning the initialization distribution parameters is crucial for stable and speedy model convergence. Monitoring training loss trends can diagnose issues for tweaking the parameters iteratively.
### Xavier/Glorot Initialization
@@ -737,41 +751,43 @@ Sampling the initial weights from a uniform or normal distribution centered at 0
### He Initialization
-Proposed by @kaiming2015delving this initialization is tailored for ReLU (Rectified Linear Unit) activation functions. ReLUs introduce the dying neuron problem where units get stuck outputting all 0s if they receive strong negative inputs initially. This slows and hinders training.
+As proposed by @kaiming2015delving, this Initialization is tailored to ReLU (Rectified Linear Unit) activation functions. ReLUs introduce the dying neuron problem where units get stuck outputting all 0s if they receive strong negative inputs initially. This slows and hinders training.
-He init overcomes this by sampling weights from a distribution with variance set based only on the number of inputs per layer, disregarding the outputs. This keeps the incoming signals small enough to activate the ReLUs into their linear regime from the beginning, avoiding dead units. For a layer with 1024 inputs, the formula variance = 2/1024 = 0.002 keeps most weights concentrated closely around 0.
+He overcomes this by sampling weights from a distribution with a variance set based only on the number of inputs per layer, disregarding the outputs. This keeps the incoming signals small enough to activate the ReLUs into their linear regime from the beginning, avoiding dead units. For a layer with 1024 inputs, the formula variance = 2/1024 = 0.002 keeps most weights concentrated closely around 0.
-This specialized initialization allows ReLU networks to converge efficiently right from the start. The choice between Xavier and He init must match the intended network activation function.
+This specialized Initialization allows ReLU networks to converge efficiently right from the start. The choice between Xavier and He must match the intended network activation function.
:::{#exr-wi .callout-exercise collapse="true"}
### Weight Initialization
-Get your neural network off to a strong start with weight initialization! How you set those initial weights can make or break your model's training. Think of it like tuning the instruments in an orchestra before the concert. In this Colab notebook, you'll learn that the right initialization strategy can save you time, improve model performance, and make your deep learning journey a whole lot smoother.
+Get your neural network off to a strong start with weight initialization! How you set those initial weights can make or break your model's training. Think of it like tuning the instruments in an orchestra before the concert. In this Colab notebook, you'll learn that the right initialization strategy can save time, improve model performance, and make your deep-learning journey much smoother.
[](https://colab.research.google.com/github/csaybar/DLcoursera/blob/master/Improving%20Deep%20Neural%20Networks%20Hyperparameter%20tuning%2C%20Regularization%20and%20Optimization/week5/Initialization/Initialization.ipynb)
:::
+The video below emphasizes the importance of deliberately selecting initial weight values over random choices.
+
{{< video https://www.youtube.com/watch?v=s2coXdufOzE&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=11 >}}
## Activation Functions
-Activation functions play a crucial role in neural networks - they introduce non-linear behaviors that allow neural nets to model complex patterns. Element-wise activation functions are applied to the weighted sums coming into each neuron in the network. Without activation functions, neural nets would be reduced to just linear regression models.
+Activation functions play a crucial role in neural networks. They introduce nonlinear behaviors that allow neural nets to model complex patterns. Element-wise activation functions are applied to the weighted sums coming into each neuron in the network. Without activation functions, neural nets would be reduced to linear regression models.
Ideally, activation functions possess certain desirable qualities:
-* **Non-linear:** They enable modeling complex relationships through nonlinear transformations of the input sum.
+* **Nonlinear:** They enable modeling complex relationships through nonlinear transformations of the input sum.
* **Differentiable:** They must have well-defined first derivatives to enable backpropagation and gradient-based optimization during training.
-* **Range-bounding:** They constrain the output signal preventing explosion. For example, sigmoid squashes inputs to (0,1).
+* **Range-bounding:** They constrain the output signal, preventing an explosion. For example, sigmoid squashes inputs to (0,1).
Additionally, properties like computational efficiency, monotonicity, and smoothness make some activations better suited over others based on network architecture and problem complexity.
-We will briefly survey some of the most widely adopted activation functions along with their strengths and limitations. We also provide guidelines for selecting appropriate functions matched to ML system constraints and use case needs.
+We will briefly survey some of the most widely adopted activation functions and their strengths and limitations. We will also provide guidelines for selecting appropriate functions matched to ML system constraints and use case needs.
### Sigmoid
-The sigmoid activation applies a squashingle S-shaped curve that tightly binds the output between 0 and 1. It has the mathematical form:
+The sigmoid activation applies a squashing S-shaped curve tightly binding the output between 0 and 1. It has the mathematical form:
$$ sigmoid(x) = \frac{1}{1+e^{-x}} $$
@@ -779,23 +795,23 @@ The exponentiation transform allows the function to smoothly transition from nea
Pros:
-Smooth gradient always available for backprop
+A smooth gradient is always available for a backdrop
Output bounded preventing "exploding"
Simple formula
Cons:
-Tendency to saturate at extremes killing gradients ("vanishing")
+Tendency to saturate at extremes, killing gradients ("vanishing")
Not zero-centered - outputs not symmetrically distributed
### Tanh
-Tanh or hyperbolic tangent also assumes an S-shape but is zero-centered meaning the output average value sits at 0.
+Tanh or hyperbolic tangent also assumes an S-shape but is zero-centered, meaning the average output value is 0.
$$ tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $$
-The numerator/denominator transform shifts the range from (0,1) in sigmoid to (-1, 1) in tanh.
+The numerator/denominator transform shifts the range from (0,1) in Sigmoid to (-1, 1) in tanh.
-Most of the pros/cons are shared with sigmoid, but tanh avoids some output saturation issues by being centered. However, it still suffers from vanishing gradients with many layers.
+Most pros/cons are shared with Sigmoid, but Tanh avoids some output saturation issues by being centered. However, it still suffers from vanishing gradients with many layers.
### ReLU
@@ -809,7 +825,7 @@ It leaves all positive inputs unchanged while clipping all negative values to 0.
### Softmax
-The softmax activation function is generally used as the last layer for classification tasks to normalize the activation value vector so that its elements sum to 1. This is useful for classification tasks where we want to learn to predict class specific probabilities of a particular input, in which case the cumulative probability across classes sum to 1. The softmax activation function is defined as
+The softmax activation function is generally used as the last layer for classification tasks to normalize the activation value vector so that its elements sum to 1. This is useful for classification tasks where we want to learn to predict class-specific probabilities of a particular input, in which case the cumulative probability across classes is equal to 1. The softmax activation function is defined as
$$\sigma(z_i) = \frac{e^{z_{i}}}{\sum_{j=1}^K e^{z_{j}}} \ \ \ for\ i=1,2,\dots,K$$
@@ -819,16 +835,16 @@ Here are the summarizing pros and cons of these various standard activation func
| Activation Function | Pros | Cons |
|:-|:-|:-|
-| Sigmoid | Smooth gradient for backprop
Output bounded between 0 and 1 | Saturation kills gradients
Not zero-centered |
+| Sigmoid | Smooth gradient for backdrop
Output bounded between 0 and 1 | Saturation kills gradients
Not zero-centered |
| Tanh | Smoother gradient than sigmoid
Zero-centered output [-1, 1] | Still suffers vanishing gradient issue |
| ReLU | Computationally efficient
Introduces sparsity
Avoids vanishing gradients | "Dying ReLU" units
Not bounded |
-| Softmax | Used for last layer to normalize vector outputs to be a probability distribution; typically used for classification tasks | - |
+| Softmax | Used for the last layer to normalize vector outputs to be a probability distribution; typically used for classification tasks | - |
:::{#exr-af .callout-exercise collapse="true"}
### Activation Functions
-Unlock the power of activation functions! These little mathematical workhorses are what make neural networks so incredibly flexible. In this Colab notebook, you'll go hands-on with functions like the sigmoid, tanh, and the superstar ReLU. See how they transform inputs and learn which ones work best in different situations. It's the key to building neural networks that can tackle complex problems!
+Unlock the power of activation functions! These little mathematical workhorses are what make neural networks so incredibly flexible. In this Colab notebook, you'll go hands-on with functions like the Sigmoid, tanh, and the superstar ReLU. See how they transform inputs and learn which works best in different situations. It's the key to building neural networks that can tackle complex problems!
[](https://colab.research.google.com/github/jfogarty/machine-learning-intro-workshop/blob/master/notebooks/nn_activation_functions.ipynb)
@@ -836,45 +852,45 @@ Unlock the power of activation functions! These little mathematical workhorses a
## System Bottlenecks
-As introduced earlier, neural networks are comprised of linear operations (matrix multiplications) interleaved with element-wise nonlinear activation functions. The most computationally expensive portion of neural networks is the linear transformations, specifically the matrix multiplications between each layer. These linear layers map the activations from the previous layer to a higher dimensional space that serves as inputs to the next layer's activation function.
+As introduced earlier, neural networks comprise linear operations (matrix multiplications) interleaved with element-wise nonlinear activation functions. The most computationally expensive portion of neural networks is the linear transformations, specifically the matrix multiplications between each layer. These linear layers map the activations from the previous layer to a higher dimensional space that serves as inputs to the next layer's activation function.
### Runtime Complexity of Matrix Multiplication
#### Layer Multiplications vs. Activations
-The bulk of computation in neural networks arises from the matrix multiplications between layers. Consider a neural network layer with an input dimension of $M$ = 500 and output dimension of $N$ = 1000, the matrix multiplication requires $O(N \cdot M) = O(1000 \cdot 500) = 500,000$ multiply-accumulate (MAC) operations between those layers.
+The bulk of computation in neural networks arises from the matrix multiplications between layers. Consider a neural network layer with an input dimension of $M$ = 500 and output dimension of $N$ = 1000; the matrix multiplication requires $O(N \cdot M) = O(1000 \cdot 500) = 500,000$ multiply-accumulate (MAC) operations between those layers.
-Contrast this with the preceding layer which had $M$ = 300 inputs, requiring $O(500 \cdot 300) = 150,000$ ops. We can see how the computations scale exponentially as the layer widths increase, with the total computations across $L$ layers being $\sum_{l=1}^{L-1} O\big(N^{(l)} \cdot M^{(l-1)}\big)$.
+Contrast this with the preceding layer, which had $M$ = 300 inputs, requiring $O(500 \cdot 300) = 150,000$ ops. We can see how the computations scale exponentially as the layer widths increase, with the total computations across $L$ layers being $\sum_{l=1}^{L-1} O\big(N^{(l)} \cdot M^{(l-1)}\big)$.
-Now comparing the matrix multiplication to the activation function which requires only $O(N) = 1000$ element-wise nonlinearities for $N = 1000$ outputs, we can clearly see the linear transformations dominating the activations computationally.
+Now, comparing the matrix multiplication to the activation function, which requires only $O(N) = 1000$ element-wise nonlinearities for $N = 1000$ outputs, we can see the linear transformations dominating the activations computationally.
-These large matrix multiplications directly impact hardware choices, inference latency, and power constraints for real-world neural network applications. For example, a typical DNN layer may require 500,000 multiply-accumulates vs. only 1000 nonlinear activations, demonstrating a 500x increase in mathematical operations.
+These large matrix multiplications impact hardware choices, inference latency, and power constraints for real-world neural network applications. For example, a typical DNN layer may require 500,000 multiply-accumulates vs. only 1000 nonlinear activations, demonstrating a 500x increase in mathematical operations.
-When training neural networks, we typically use mini-batch gradient descent, operating on small batches of data at a time. Considering a batch size of $B$ training examples, the input to the matrix multiplication becomes a $M \times B$ matrix, while the output is an $N \times B$ matrix.
+When training neural networks, we typically use mini-batch gradient descent, operating on small batches of data simultaneously. Considering a batch size of $B$ training examples, the input to the matrix multiplication becomes a $M \times B$ matrix, while the output is an $N \times B$ matrix.
#### Mini-batch
-In training neural networks, we need to repeatedly estimate the gradient of the loss function with respect to the network parameters (i.e. weights and biases). This gradient indicates which direction the parameters should be updated in order to minimize the loss. As introduced previously, use perform updates over a batch of datapoints every update, also known as stochastic gradient descent, or mini-batch gradient descent.
+In training neural networks, we need to repeatedly estimate the gradient of the loss function with respect to the network parameters (i.e., weights, and biases). This gradient indicates which direction the parameters should be updated in to minimize the loss. As introduced previously, we perform updates over a batch of data points every update, also known as stochastic gradient descent or mini-batch gradient descent.
-The most straightforward approach is to estimate the gradient based on a single training example, compute the parameter update, lather, rinse, and repeat for the next example. However, this involves very small and frequent parameter updates that can be computationally inefficient, and may additionally be inaccurate in terms of convergence due to the stochasticity of using just a single datapoint for a model update.
+The most straightforward approach is to estimate the gradient based on a single training example, compute the parameter update, lather, rinse, and repeat for the next example. However, this involves very small and frequent parameter updates that can be computationally inefficient and may need to be more accurate in terms of convergence due to the stochasticity of using just a single data point for a model update.
-Instead, mini-batch gradient descent strikes a balance between convergence stability and computational efficiency. Rather than compute the gradient on single examples, we estimate the gradient based on small "mini-batches" of data - usually between 8 to 256 examples in practice.
+Instead, mini-batch gradient descent balances convergence stability and computational efficiency. Rather than computing the gradient on single examples, we estimate the gradient based on small "mini-batches" of data—usually between 8 and 256 examples in practice.
-This provides a noisy but consistent gradient estimate that leads to more stable convergence. Additionally, the parameter update only needs to be performed once per mini-batch rather than once per example, reducing computational overhead.
+This provides a noisy but consistent gradient estimate that leads to more stable convergence. Additionally, the parameter update must only be performed once per mini-batch rather than once per example, reducing computational overhead.
-By tuning the mini-batch size, we can control the tradeoff between the smoothness of the estimate (larger batches are generally better) and the frequency of updates (smaller batches allow more frequent updates). Mini-batch sizes are usually powers of 2 so they can leverage parallelism across GPU cores efficiently.
+By tuning the mini-batch size, we can control the tradeoff between the smoothness of the estimate (larger batches are generally better) and the frequency of updates (smaller batches allow more frequent updates). Mini-batch sizes are usually powers of 2, so they can efficiently leverage parallelism across GPU cores.
-So the total computation is performing an $N \times M$ by $M \times B$ matrix multiplication, yielding $O(N \cdot M \cdot B)$ floating point operations. As a numerical example, with $N=1000$ hidden units, $M=500$ input units, and a batch size $B=64$, this equates to 1000 x 500 x 64 = 32 million multiply-accumulates per training iteration!
+So, the total computation performs an $N \times M$ by $M \times B$ matrix multiplication, yielding $O(N \cdot M \cdot B)$ floating point operations. As a numerical example, $N=1000$ hidden units, $M=500$ input units, and a batch size $B=64$ equates to 1000 x 500 x 64 = 32 million multiply-accumulates per training iteration!
In contrast, the activation functions are applied element-wise to the $N \times B$ output matrix, requiring only $O(N \cdot B)$ computations. For $N=1000$ and $B=64$, that is just 64,000 nonlinearities - 500X less work than the matrix multiplication.
As we increase the batch size to fully leverage parallel hardware like GPUs, the discrepancy between matrix multiplication and activation function cost grows even larger. This reveals how optimizing the linear algebra operations offers tremendous efficiency gains.
-Therefore, when analyzing where and how neural networks spend computation, matrix multiplication clearly plays a central role. For example, matrix multiplications often account for over 90% of both inference latency and training time in common convolutional and recurrent neural networks.
+Therefore, matrix multiplication is central in analyzing where and how neural networks spend computation. For example, matrix multiplications often account for over 90% of inference latency and training time in common convolutional and recurrent neural networks.
#### Optimizing Matrix Multiplication
-A number of techniques enhance the efficiency of general dense/sparse matrix-matrix and matrix-vector operations to directly improve overall efficiency. Some key methods include:
+Several techniques enhance the efficiency of general dense/sparse matrix-matrix and matrix-vector operations to improve overall efficiency. Some key methods include:
* Leveraging optimized math libraries like [cuBLAS](https://developer.nvidia.com/cublas) for GPU acceleration
* Enabling lower precision formats like FP16 or INT8 where accuracy permits
@@ -882,113 +898,113 @@ A number of techniques enhance the efficiency of general dense/sparse matrix-mat
* Sparsity-aware computations and data storage formats to exploit zero parameters
* Approximating matrix multiplications with algorithms like Fast Fourier Transforms
* Model architecture design to reduce layer widths and activations
-* Quantization, pruning, distillation and other compression techniques
+* Quantization, pruning, distillation, and other compression techniques
* Parallelization of computation across available hardware
* Caching/pre-computing results where possible to reduce redundant operations
-The potential optimization techniques are vast given the outsized portion of time models spend in matrix and vector math. Even incremental improvements would directly speed up runtimes and lower energy usage. Finding new ways to enhance these linear algebra primitives continues to be an active area of research aligned with the future demands of machine learning. We will discuss these in detail in the [Optimizations](../optimizations/optimizations.qmd) and [AI Acceleration](../hw_acceleration/hw_acceleration.qmd) chapters.
+The potential optimization techniques are vast, given the outsized portion of time models spend in matrix and vector math. Even incremental improvements speed up runtimes and lower energy usage. Finding new ways to enhance these linear algebra primitives remains an active area of research aligned with the future demands of machine learning. We will discuss these in detail in the [Optimizations](../optimizations/optimizations.qmd) and [AI Acceleration](../hw_acceleration/hw_acceleration.qmd) chapters.
-### Compute vs Memory Bottleneck
+### Compute vs. Memory Bottleneck
-At this point, it should be clear that the core mathematical operation underpinning neural networks is the matrix-matrix multiplication. Both training and inference for neural networks heavily utilize these matrix multiply operations. Analysis shows that over 90% of computational requirements in state-of-the-art neural networks arise from matrix multiplications. Consequently, the performance of matrix multiplication has an enormous influence on overall model training or inference time.
+At this point, matrix-matrix multiplication is the core mathematical operation underpinning neural networks. Both training and inference for neural networks heavily utilize these matrix multiply operations. Analysis shows that over 90% of computational requirements in state-of-the-art neural networks arise from matrix multiplications. Consequently, the performance of matrix multiplication has an enormous influence on overall model training or inference time.
#### Training versus Inference
-While both training and inference rely heavily on matrix multiplication performance, their precise computational profiles differ. Specifically, neural network inference tends to be more compute-bound compared to training for an equivalent batch size. The key difference lies in the backpropagation pass which is only required during training. Backpropagation involves a sequence matrix multiply operations to calculate gradients with respect to activations across each network layer. Critically though, no additional memory bandwidth is needed here - the inputs, outputs, and gradients are read/written from cache or registers.
+While training and inference rely heavily on matrix multiplication performance, their precise computational profiles differ. Specifically, neural network inference tends to be more compute-bound than training for an equivalent batch size. The key difference lies in the backpropagation pass, which is only required during training. Backpropagation involves a sequence of matrix multiply operations to calculate gradients with respect to activations across each network layer. Critically, though, no additional memory bandwidth is needed here—the inputs, outputs, and gradients are read/written from cache or registers.
-As a result, training exhibits lower arithmetic intensities, with gradient calculations bounded by memory access instead of FLOPs. In contrast, neural network inference is dominated by the forward propagation which corresponds to a series of matrix-matrix multiplies. With no memory-intensive gradient retrospecting, larger batch sizes readily push inference into being extremely compute-bound. This is exhibited by the high measured arithmetic intensities. Note that for some inference applications, response times may be a critical requirement, which might force the application-provider to use a smaller batch size to meet these response-time requirements, thereby reducing hardware efficiency; hence in these cases inference may see lower hardware utilization.
+As a result, training exhibits lower arithmetic intensities, with gradient calculations bounded by memory access instead of FLOPs. In contrast, the forward propagation dominates neural network inference, which corresponds to a series of matrix-matrix multiplies. With no memory-intensive gradient retrospecting, larger batch sizes readily push inference into being extremely compute-bound. The high measured arithmetic intensities exhibit this. Response times may be critical for some inference applications, forcing the application provider to use a smaller batch size to meet these response-time requirements, thereby reducing hardware efficiency; hence, inferences may see lower hardware utilization.
-The implications are that hardware provisioning and bandwidth vs FLOP tradeoffs differ based on whether a system targets training or inference. High-throughput low-latency servers for inference should emphasize computational power instead of memory while training clusters require a more balanced architecture.
+The implications are that hardware provisioning and bandwidth vs. FLOP tradeoffs differ depending on whether a system targets training or inference. High-throughput, low-latency servers for inference should emphasize computational power instead of memory, while training clusters require a more balanced architecture.
-However, matrix multiplication exhibits an interesting tension - it can either be bound by the memory bandwidth or arithmetic throughput capabilities of the underlying hardware. The system's ability to fetch and supply matrix data versus its ability to perform computational operations determines this direction.
+However, matrix multiplication exhibits an interesting tension - the underlying hardware's memory bandwidth or arithmetic throughput capabilities can bind it. The system's ability to fetch and supply matrix data versus its ability to perform computational operations determines this direction.
-This phenomenon has profound impacts; hardware must be designed judiciously and software optimizations need to keep this in mind. Optimizing and balancing compute versus memory to alleviate this underlying matrix multiplication bottleneck is crucial for both efficient model training as well as deployment.
+This phenomenon has profound impacts; hardware must be designed judiciously, and software optimizations must be considered. Optimizing and balancing compute versus memory to alleviate this underlying matrix multiplication bottleneck is crucial for efficient model training and deployment.
-Finally, the batch size used may impact convergence rates during neural network training, which is another important consideration. For example, there is generally diminishing returns in benefits to convergence with extremely large batch sizes (i.e: > 16384), and hence while extremely large batch sizes may be increasingly beneficial from a hardware/arithmetic intensity perspective, using such large batches may not translate to faster convergence vs wall-clock time due to their diminishing benefits to convergence. These tradeoffs are part of the design decisions core to systems for machine-learning type of research.
+Finally, batch size may impact convergence rates during neural network training, another important consideration. For example, there are generally diminishing returns in benefits to convergence with extremely large batch sizes (i.e.,> 16384). In contrast, extremely large batch sizes may be increasingly beneficial from a hardware/arithmetic intensity perspective; using such large batches may not translate to faster convergence vs wall-clock time due to their diminishing benefits to convergence. These tradeoffs are part of the design decisions core to systems for the machine-learning type of research.
#### Batch Size
-The batch size used during neural network training and inference has a significant impact on whether matrix multiplication poses more of a computational or memory bottleneck. Concretely, the batch size refers to the number of samples that are propagated through the network together in one forward/backward pass. In terms of matrix multiplication, this equates to larger matrix sizes.
+The batch size used during neural network training and inference significantly impacts whether matrix multiplication poses more of a computational or memory bottleneck. Concretely, the batch size refers to the number of samples propagated through the network together in one forward/backward pass. Matrix multiplication equates to larger matrix sizes.
Specifically, let's look at the arithmetic intensity of matrix multiplication during neural network training. This measures the ratio between computational operations and memory transfers. The matrix multiply of two matrices of size $N \times M$ and $M \times B$ requires $N \times M \times B$ multiply-accumulate operations, but only transfers of $N \times M + M \times B$ matrix elements.
-As we increase the batch size $B$, the number of arithmetic operations grows much faster than the memory transfers. For example, with a batch size of 1, we need $N \times M$ operations and $N + M$ transfers, giving an arithmetic intensity ratio of around $\frac{N \times M}{N+M}$. But with a large batch size of 128, the intensity ratio becomes $\frac{128 \times N \times M}{N \times M + M \times 128} \approx 128$. Using a larger batch size shifts the overall computation from being more memory-bounded to being more compute-bounded. In practice, AI training uses large batch sizes and is generally limited by peak arithmetic computational performance, i.e: Application 3 in @fig-roofline.
+As we increase the batch size $B$, the number of arithmetic operations grows faster than the memory transfers. For example, with a batch size of 1, we need $N \times M$ operations and $N + M$ transfers, giving an arithmetic intensity ratio of around $\frac{N \times M}{N+M}$. But with a large batch size of 128, the intensity ratio becomes $\frac{128 \times N \times M}{N \times M + M \times 128} \approx 128$. Using a larger batch size shifts the overall computation from memory-bounded to more compute-bounded. AI training uses large batch sizes and is generally limited by peak arithmetic computational performance, i.e., Application 3 in @fig-roofline.
-Therefore, batched matrix multiplication is far more computationally intensive than memory access bound. This has implications on hardware design as well as software optimizations, which we will cover next. The key insight is that by tuning the batch size, we can significantly alter the computational profile and bottlenecks posed by neural network training and inference.
+Therefore, batched matrix multiplication is far more computationally intensive than memory access bound. This has implications for hardware design and software optimizations, which we will cover next. The key insight is that we can significantly alter the computational profile and bottlenecks posed by neural network training and inference by tuning the batch size.
{#fig-roofline}
#### Hardware Characteristics
-Modern hardware like CPUs and GPUs are highly optimized for computational throughput as opposed to memory bandwidth. For example, high-end H100 Tensor Core GPUs can deliver over 60 TFLOPS of double-precision performance but only provide up to 3 TB/s of memory bandwidth. This means there is almost a 20x imbalance between arithmetic units and memory access. Consequently, for hardware like GPU accelerators, neural network training workloads need to be made as computationally intensive as possible in order to fully utilize the available resources.
+Modern hardware like CPUs and GPUs is highly optimized for computational throughput rather than memory bandwidth. For example, high-end H100 Tensor Core GPUs can deliver over 60 TFLOPS of double-precision performance but only provide up to 3 TB/s of memory bandwidth. This means there is almost a 20x imbalance between arithmetic units and memory access; consequently, for hardware like GPU accelerators, neural network training workloads must be made as computationally intensive as possible to utilize the available resources fully.
-This further motivates the need for using large batch sizes during training. When using a small batch, the matrix multiplication is bounded by memory bandwidth, underutilizing the abundant compute resources. However, with sufficiently large batches, we can shift the bottleneck more towards computation and attain much higher arithmetic intensity. For instance, batches of 256 or 512 samples may be needed to saturate a high-end GPU. The downside is that larger batches provide less frequent parameter updates, which can impact convergence. Still, the parameter serves as an important tuning knob to balance memory vs compute limitations.
+This further motivates the need for using large batch sizes during training. When using a small batch, the matrix multiplication is bounded by memory bandwidth, underutilizing the abundant compute resources. However, we can shift the bottleneck towards computation and attain much higher arithmetic intensity with sufficiently large batches. For instance, batches of 256 or 512 samples may be needed to saturate a high-end GPU. The downside is that larger batches provide less frequent parameter updates, which can impact convergence. Still, the parameter serves as an important tuning knob to balance memory vs compute limitations.
-Therefore, given the imbalanced compute-memory architectures of modern hardware, employing large batch sizes is essential to alleviate bottlenecks and maximize throughput. The subsequent software and algorithms also need to accommodate such batch sizes, as mentioned, since larger batch sizes may have diminishing returns towards the convergence of the network. Using very small batch sizes may lead to suboptimal hardware utilization, ultimately limiting training efficiency. Scaling up to large batch sizes is a topic of research and has been explored in various works that aim to do large scale training [@yang2018imagenet].
+Therefore, given the imbalanced compute-memory architectures of modern hardware, employing large batch sizes is essential to alleviate bottlenecks and maximize throughput. As mentioned, the subsequent software and algorithms also need to accommodate such batch sizes since larger batch sizes may have diminishing returns toward the network's convergence. Using very small batch sizes may lead to suboptimal hardware utilization, ultimately limiting training efficiency. Scaling up to large batch sizes is a research topic explored in various works that aim to do large-scale training [@yang2018imagenet].
#### Model Architectures
-The underlying neural network architecture also affects whether matrix multiplication poses more of a computational or memory bottleneck during execution. Transformers and MLPs tend to be much more compute-bound compared to CNN convolutional neural networks. This stems from the types of matrix multiplication operations involved in each model. Transformers rely on self-attention - multiplying large activation matrices by massive parameter matrices to relate elements. MLPs stack fully-connected layers also requiring large matrix multiplies.
+The underlying neural network architecture also affects whether matrix multiplication poses more of a computational or memory bottleneck during execution. Transformers and MLPs are much more compute-bound than CNN convolutional neural networks. This stems from the types of matrix multiplication operations involved in each model. Transformers rely on self-attention, multiplying large activation matrices by massive parameter matrices to relate elements. MLPs stack fully connected layers, also requiring large matrix multiplies.
-In contrast, the convolutional layers in CNNs have a sliding window that reuses activations and parameters across the input. This means fewer unique matrix operations are needed. However, the convolutions require repeatedly accessing small parts of the input and moving partial sums to populate each window. Even though the arithmetic operations in convolutions are intense, this data movement and buffer manipulation imposes huge memory access overheads. Additionally, CNNs comprise several layered stages so intermediate outputs need to be materialized to memory frequently.
+In contrast, the convolutional layers in CNNs have a sliding window that reuses activations and parameters across the input, which means fewer unique matrix operations are needed. However, the convolutions require repeatedly accessing small input parts and moving partial sums to populate each window. Even though the arithmetic operations in convolutions are intense, this data movement and buffer manipulation impose huge memory access overheads. CNNs comprise several layered stages, so intermediate outputs must frequently materialize in memory.
-As a result, CNN training tends to be more memory bandwidth bound relative to arithmetic bound compared to Transformers and MLPs. Therefore, the matrix multiplication profile and in turn the bottleneck posed varies significantly based on model choice. Hardware and systems need to be designed with appropriate compute-memory bandwidth balance depending on target model deployment. Models relying more on attention and MLP layers require higher arithmetic throughput compared to CNNs which necessitate high memory bandwidth.
+As a result, CNN training tends to be more memory bandwidth bound relative to arithmetic bound compared to Transformers and MLPs. Therefore, the matrix multiplication profile, and in turn, the bottleneck posed, varies significantly based on model choice. Hardware and systems need to be designed with appropriate compute-memory bandwidth balance depending on target model deployment. Models relying more on attention and MLP layers require higher arithmetic throughput compared to CNNs, which necessitates high memory bandwidth.
## Training Parallelization
Training neural networks entails intensive computational and memory demands. The backpropagation algorithm for calculating gradients and updating weights consists of repeated matrix multiplications and arithmetic operations over the entire dataset. For example, one pass of backpropagation scales in time complexity with $O(num\_parameters \times batch\_size \times sequence\_length)$.
-As model size increases in terms of parameters and layers, the computational requirements grow rapidly. Moreover, the algorithm requires storing activation outputs and model parameters for the backward pass, which also grows with model size.
+The computational requirements grow rapidly as model size increases in parameters and layers. Moreover, the algorithm requires storing activation outputs and model parameters for the backward pass, which grows with model size.
-The memory footprint becomes prohibitive for larger models to fit and train on a single accelerator device like a GPU. Therefore, we need to parallelize model training across multiple devices in order to provide sufficient compute and memory to train state-of-the-art neural networks.
+Larger models cannot fit and train on a single accelerator device like a GPU, and the memory footprint becomes prohibitive. Therefore, we need to parallelize model training across multiple devices to provide sufficient compute and memory to train state-of-the-art neural networks.
-As shown in @fig-training-parallelism, the two main approaches are _data parallelism_, which replicates the model across devices while splitting the input data batch-wise, and _model parallelism_, which partitions the model architecture itself across different devices. By training in parallel, we can leverage greater aggregate compute and memory resources to overcome system limitations and accelerate deep learning workloads.
+As shown in @fig-training-parallelism, the two main approaches are data parallelism, which replicates the model across devices while splitting the input data batch-wise, and model parallelism, which partitions the model architecture itself across different devices. By training in parallel, we can leverage greater aggregate compute and memory resources to overcome system limitations and accelerate deep learning workloads.
{#fig-training-parallelism}
### Data Parallel
-Data parallelization is a common approach to parallelize machine learning training across multiple processing units, such as GPUs or distributed computing resources. In data parallelism, the training dataset is divided into batches, and each batch is processed by a separate processing unit. The model parameters are then updated based on the gradients computed from the processing of each batch. Here's a step-by-step description of data parallel parallelization for ML training:
+Data parallelization is a common approach to parallelize machine learning training across multiple processing units, such as GPUs or distributed computing resources. The training dataset is divided into batches in data parallelism, and a separate processing unit processes each batch. The model parameters are then updated based on the gradients computed from the processing of each batch. Here's a step-by-step description of data parallel parallelization for ML training:
-1. **Dividing the Dataset:** The entire training dataset is divided into smaller batches. Each batch contains a subset of the training examples.
+1. **Dividing the Dataset:** The training dataset is divided into smaller batches, each containing a subset of the training examples.
-2. **Replicating the Model:** The neural network model is replicated across all processing units. Each processing unit has its copy of the model.
+2. **Replicating the Model:** The neural network model is replicated across all processing units, and each processing unit has its copy of the model.
-3. **Parallel Computation:** Each processing unit takes a different batch and computes the forward and backward passes independently. During the forward pass, the model makes predictions on the input data. During the backward pass, gradients are computed for the model parameters using the loss function.
+3. **Parallel Computation:** Each processing unit takes a different batch and independently computes the forward and backward passes. During the forward pass, the model makes predictions on the input data. The loss function calculates gradients for the model parameters during the backward pass.
4. **Gradient Aggregation:** After processing their respective batches, the gradients from each processing unit are aggregated. Common aggregation methods include summation or averaging of the gradients.
-5. **Parameter Update:** The aggregated gradients are used to update the model parameters. The update can be performed using optimization algorithms like SGD or variants like Adam.
+5. **Parameter Update:** The aggregated gradients update the model parameters. The update can be performed using optimization algorithms like SGD or variants like Adam.
-6. **Synchronization:** All processing units synchronize their model parameters after the update. This ensures that each processing unit has the latest version of the model.
+6. **Synchronization:** After the update, all processing units synchronize their model parameters, ensuring that each has the latest version of the model.
-The prior steps are repeated for a certain number of iterations or until convergence.
+The prior steps are repeated for several iterations or until convergence.
-Let's take a specific example. Let's say for instance we have 256 batch size and 8 GPUs, each GPU will get a micro-batch of 32 samples. Their forward and backward passes compute losses and gradients only based on the local 32 samples. The gradients get aggregated across devices either with a parameter server or collective communications library to get the effective gradient for the global batch. Weight updates happen independently on each GPU according to these gradients. After a configured number of iterations, updated weights synchronize and equalize across devices before continuing for the next iterations.
+Let's take a specific example. We have 256 batch sizes and 8 GPUs; each GPU will get a micro-batch of 32 samples. Their forward and backward passes compute losses and gradients only based on the local 32 samples. The gradients get aggregated across devices with a parameter server or collective communications library to get the effective gradient for the global batch. Weight updates happen independently on each GPU according to these gradients. After a configured number of iterations, updated weights synchronize and equalize across devices before continuing to the next iterations.
-Data parallelism is effective when the model is large, and the dataset is substantial, as it allows for parallel processing of different parts of the data. It is widely used in deep learning frameworks and libraries that support distributed training, such as TensorFlow and PyTorch. However, care must be taken to handle issues like communication overhead, load balancing, and synchronization to ensure efficient parallelization.
+Data parallelism is effective when the model is large, and the dataset is substantial, as it allows for parallel processing of different parts of the data. It is widely used in deep learning frameworks and libraries that support distributed training, such as TensorFlow and PyTorch. However, to ensure efficient parallelization, care must be taken to handle issues like communication overhead, load balancing, and synchronization.
### Model Parallel
-Model parallelism refers to distributing the neural network model itself across multiple devices, rather than replicating the full model like data parallelism. This is particularly useful when a model is too large to fit into the memory of a single GPU or accelerator device. While this might not be specifically applicable for embedded or TinyML use cases as most of the models are relatively small(er), it is still useful to know.
+Model parallelism refers to distributing the neural network model across multiple devices rather than replicating the full model like data parallelism. This is particularly useful when a model is too large to fit into the memory of a single GPU or accelerator device. While this might not be specifically applicable for embedded or TinyML use cases as most models are relatively small(er), it is still useful to know.
In model parallel training, different parts or layers of the model are assigned to separate devices. The input activations and intermediate outputs get partitioned and passed between these devices during the forward and backward passes to coordinate gradient computations across model partitions.
-By splitting the model architecture across multiple devices, the memory footprint and computational operations distribute across the devices instead of concentrating on one. This enables training very large models with billions of parameters that otherwise exceed capacity of a single device. There are several main ways in which we can do partitioning:
+The memory footprint and computational operations are distributed by splitting the model architecture across multiple devices instead of concentrating on one. This enables training very large models with billions of parameters that otherwise exceed the capacity of a single device. There are several main ways in which we can do partitioning:
-* **Layer-wise parallelism:** Consecutive layers are distributed onto different devices. For example, device 1 contains layers 1-3, device 2 contains layers 4-6. The output activations from layer 3 would be transferred to device 2 to start the next layers for the forward pass computations.
+* **Layer-wise parallelism:** Consecutive layers are distributed onto different devices. For example, device 1 contains layers 1-3; device 2 contains layers 4-6. The output activations from layer 3 would be transferred to device 2 to start the next layers for the forward pass computations.
-* **Filter-wise parallelism:** In convolutional layers, output filters can be split up among devices. Each device computes activation outputs for a subset of filters, which get concatenated before propagating further.
+* **Filter-wise parallelism:** In convolutional layers, output filters can be split among devices. Each device computes activation outputs for a subset of filters, which get concatenated before propagating further.
* **Spatial parallelism:** The input images get divided spatially, so each device processes over a certain region like the top-left quarter of images. The output regions then combine to form the full output.
-Additionally, hybrid combinations can split model both layer-wise and data batch-wise. The appropriate type of model parallelism to use depends on the specific neural architecture constraints and hardware setup. Optimizing the partitioning and communication for the model topology is key to minimizing overhead.
+Additionally, hybrid combinations can split the model layer-wise and data batch-wise. The appropriate type of model parallelism depends on the specific neural architecture constraints and hardware setup. Optimizing the partitioning and communication for the model topology is key to minimizing overhead.
-However, as the model parts run on physically separate devices, they must communicate and synchronize their parameters during each training step. The backward pass needs to ensure gradient updates propagate across the model partitions accurately. Hence, coordination and high-speed interconnect between devices is crucial for optimizing performance of model parallel training. Careful partitioning and communication protocols are required to minimize transfer overhead.
+However, as the model parts run on physically separate devices, they must communicate and synchronize their parameters during each training step. The backward pass must ensure gradient updates propagate accurately across the model partitions. Hence, coordination and high-speed interconnecting between devices are crucial for optimizing the performance of model parallel training. Careful partitioning and communication protocols are required to minimize transfer overhead.
### Comparison
-To summarize, here are some key characteristics to compare data parallelism and model parallelism in a summary table:
+To summarize, @tbl-parallelism demonstrates some of the key characteristics for comparing data parallelism and model parallelism:
| Characteristic | Data Parallelism | Model Parallelism |
|-|-----------------|-------------------|
@@ -1002,26 +1018,24 @@ To summarize, here are some key characteristics to compare data parallelism and
| Code Complexity | Minimal changes | More significant model surgery |
| Popular Libraries | Horovod, PyTorch Distributed | Mesh TensorFlow |
-I included the high-level definition/objective, way it scales, main hardware assumptions and constraints, types of techniques (where applicable), overall implementation complexity, and some examples of associated libraries.
-
-Let me know if you would like me to explain or expand on any part of this comparison summary! Open to adding other characteristics as well.
+: Comparing data parallelism and model parallelism. {#tbl-parallelism}
## Conclusion
In this chapter, we have covered the core foundations that enable effective training of artificial intelligence models. We explored the mathematical concepts like loss functions, backpropagation, and gradient descent that make neural network optimization possible. We also discussed practical techniques around leveraging training data, regularization, hyperparameter tuning, weight initialization, and distributed parallelization strategies that improve convergence, generalization, and scalability.
-These methodologies form the bedrock through which the success of deep learning has been attained over the past decade. Mastering these fundamentals equips practitioners to architect systems and refine models tailored to their problem context. However, as models and datasets grow exponentially in size, training systems will need to optimize across metrics like time, cost, and carbon footprint. Hardware scaling through warehouse-scales enables massive computational throughput - but optimizations around efficiency and specialization will be key. Software techniques like compression and sparsity exploitation can augment hardware gains. We will discuss several of these in the coming chapters.
+These methodologies form the bedrock through which the success of deep learning has been attained over the past decade. Mastering these fundamentals equips practitioners to architect systems and refine models tailored to their problem context. However, as models and datasets grow exponentially, training systems must optimize across metrics like time, cost, and carbon footprint. Hardware scaling through warehouse scales enables massive computational throughput - but optimizations around efficiency and specialization will be key. Software techniques like compression and sparsity exploitation can augment hardware gains. We will discuss several of these in the coming chapters.
-Overall, the fundamentals covered in this chapter equip practitioners to build, refine and deploy models. However, interdisciplinary skills spanning theory, systems, and hardware will differentiate experts who can lift AI to the next level in the sustainable and responsible manner that society requires. Understanding efficiency alongside accuracy constitutes the balanced engineering approach needed to train intelligent systems that integrate smoothly across a breadth of real-world contexts.
+Overall, the fundamentals covered in this chapter equip practitioners to build, refine, and deploy models. However, interdisciplinary skills spanning theory, systems, and hardware will differentiate experts who can lift AI to the next level sustainably and responsibly that society requires. Understanding efficiency alongside accuracy constitutes the balanced engineering approach needed to train intelligent systems that integrate smoothly across many real-world contexts.
## Resources {#sec-ai-training-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will be adding new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [Thinking About Loss.](https://docs.google.com/presentation/d/1X92JqVkUY7k6yJXQcT2u83dpdrx5UzGFAJkkDMDfKe0/edit#slide=id.g94db9f9f78_0_2)
@@ -1029,7 +1043,7 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
* [Training, Validation, and Test Data.](https://docs.google.com/presentation/d/1G56D0-qG9YWnzQQeje9LMpcLSotMgBCiMyfj53yz7lY/edit?usp=drive_link)
-* Continouos Training:
+* Continuous Training:
* [Retraining Trigger.](https://docs.google.com/presentation/d/1jtkcAnFot3VoY6dm8wARtIRPhM1Cfoe8S_8lMMox2To/edit?usp=drive_link)
* [Data Processing Overview.](https://docs.google.com/presentation/d/1vW4jFv5mqpLo2_G2JXQrKLPMNoWoOvSXhFYotUbg3B0/edit?usp=drive_link)
@@ -1070,7 +1084,7 @@ To reinforce the concepts covered in this chapter, we have curated a set of exer
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/contents/workflow/workflow.bib b/contents/workflow/workflow.bib
index e69de29b..00614696 100644
--- a/contents/workflow/workflow.bib
+++ b/contents/workflow/workflow.bib
@@ -0,0 +1,2 @@
+%comment{This file was created with betterbib v5.0.11.}
+
diff --git a/contents/workflow/workflow.qmd b/contents/workflow/workflow.qmd
index 57403301..a263d3ef 100644
--- a/contents/workflow/workflow.qmd
+++ b/contents/workflow/workflow.qmd
@@ -8,26 +8,26 @@ bibliography: workflow.bib
Resources: [Slides](#sec-ai-workflow-resource), [Labs](#sec-ai-workflow-resource), [Exercises](#sec-ai-workflow-resource)
:::
-
+
-In this chapter, we'll explore the machine learning (ML) workflow, setting the stage for subsequent chapters that delve into the specifics. To ensure we don't lose sight of the bigger picture, this chapter offers a high-level overview of the steps involved in the ML workflow.
+In this chapter, we'll explore the machine learning (ML) workflow, setting the stage for subsequent chapters that delve into the specifics. To ensure we see the bigger picture, this chapter offers a high-level overview of the steps involved in the ML workflow.
-The ML workflow is a structured approach that guides professionals and researchers through the process of developing, deploying, and maintaining ML models. This workflow is generally divided into several crucial stages, each contributing to the effective development of intelligent systems.
+The ML workflow is a structured approach that guides professionals and researchers through developing, deploying, and maintaining ML models. This workflow is generally divided into several crucial stages, each contributing to the effective development of intelligent systems.
::: {.callout-tip}
## Learning Objectives
-* Understand the ML workflow and gain insights into the structured approach and stages involved in developing, deploying, and maintaining machine learning models.
+* Understand the ML workflow and gain insights into the structured approach and stages of developing, deploying, and maintaining machine learning models.
* Learn about the unique challenges and distinctions between workflows for Traditional machine learning and embedded AI.
-* Appreciate the various roles involved in ML projects and understand their respective responsibilities and significance.
+* Appreciate the roles in ML projects and understand their responsibilities and significance.
-* Understanding the importance, applications, and the considerations for implementing ML models in resource-constrained environments.
+* Understanding the importance, applications, and considerations for implementing ML models in resource-constrained environments.
-* Gain awareness about the ethical and legal aspects that need to be considered and adhered to in ML and embedded AI projects.
+* Gain awareness about the ethical and legal aspects that must be considered and adhered to in ML and embedded AI projects.
* Establish a basic understanding of ML workflows and roles to be well-prepared for deeper exploration in the following chapters.
@@ -38,53 +38,53 @@ The ML workflow is a structured approach that guides professionals and researche
{#fig-ml-life-cycle}
-Developing a successful machine learning model requires a systematic workflow. This end-to-end process enables you to build, deploy and maintain models effectively. As shown in @fig-ml-life-cycle, It typically involves the following key steps:
+Developing a successful machine learning model requires a systematic workflow. This end-to-end process enables you to build, deploy, and maintain models effectively. As shown in @fig-ml-life-cycle, It typically involves the following key steps:
-1. **Problem Definition** - Start by clearly articulating the specific problem you want to solve. This focuses your efforts during data collection and model building.
-2. **Data Collection to Preparation** - Gather relevant, high-quality training data that captures all aspects of the problem. Clean and preprocess the data to get it ready for modeling.
-3. **Model Selection and Training** - Choose a machine learning algorithm suited to your problem type and data. Consider pros and cons of different approaches. Feed the prepared data into the model to train it. Training time varies based on data size and model complexity.
-4. **Model Evaluation** - Test the trained model on new unseen data to measure its predictive accuracy. Identify any limitations.
-6. **Model Deployment** - Integrate the validated model into applications or systems to start operationalization.
-7. **Monitor and Maintain** - Track model performance in production. Retrain periodically on new data to keep it current.
+1. **Problem Definition** - Start by clearly articulating the specific problem you want to solve. This focuses on your efforts during data collection and model building.
+2. **Data Collection to Preparation:** Gather relevant, high-quality training data that captures all aspects of the problem. Clean and preprocess the data to prepare it for modeling.
+3. **Model Selection and Training:** Choose a machine learning algorithm suited to your problem type and data. Consider the pros and cons of different approaches. Feed the prepared data into the model to train it. Training time varies based on data size and model complexity.
+4. **Model Evaluation:** Test the trained model on new unseen data to measure its predictive accuracy. Identify any limitations.
+6. **Model Deployment:** Integrate the validated model into applications or systems to start operationalization.
+7. **Monitor and Maintain:** Track model performance in production. Retrain periodically on new data to keep it current.
-Following this structured **ML workflow** helps guide you through the key phases of development. It ensures you build effective and robust models that are ready for real-world deployment. The end result is higher quality models that solve your business needs.
+Following this structured ML workflow helps guide you through the key phases of development. It ensures you build effective and robust models ready for real-world deployment, resulting in higher-quality models that solve your business needs.
The ML workflow is iterative, requiring ongoing monitoring and potential adjustments. Additional considerations include:
-* **Version Control**: Keep track of code and data changes to reproduce results and revert to earlier versions if needed.
-* **Documentation**: Maintain detailed documentation to allow for workflow understanding and reproduction.
-* **Testing**: Rigorously test the workflow to ensure its functionality.
-* **Security**: Safeguard your workflow and data, particularly when deploying models in production settings.
+* **Version Control:** Track code and data changes to reproduce results and revert to earlier versions if needed.
+* **Documentation:** Maintain detailed documentation for workflow understanding and reproduction.
+* **Testing:** Rigorously test the workflow to ensure its functionality.
+* **Security:** Safeguard your workflow and data when deploying models in production settings.
## Traditional vs. Embedded AI
-The ML workflow serves as a universal guide, applicable across various platforms including cloud-based solutions, edge computing, and TinyML. However, the workflow for Embedded AI introduces unique complexities and challenges, which not only make it a captivating domain but also pave the way for remarkable innovations.
+The ML workflow is a universal guide applicable across various platforms, including cloud-based solutions, edge computing, and TinyML. However, the workflow for Embedded AI introduces unique complexities and challenges, making it a captivating domain and paving the way for remarkable innovations.
### Resource Optimization
-* **Traditional ML Workflow**: Prioritizes model accuracy and performance, often leveraging abundant computational resources in cloud or data center environments.
-* **Embedded AI Workflow**: Requires careful planning to optimize model size and computational demands, given the resource constraints of embedded systems. Techniques like model quantization and pruning are crucial.
+* **Traditional ML Workflow:** This workflow prioritizes model accuracy and performance, often leveraging abundant computational resources in cloud or data center environments.
+* **Embedded AI Workflow:** Given embedded systems' resource constraints, this workflow requires careful planning to optimize model size and computational demands. Techniques like model quantization and pruning are crucial.
### Real-time Processing
-* **Traditional ML Workflow**: Less emphasis on real-time processing, often relying on batch data processing.
-* **Embedded AI Workflow**: Prioritizes real-time data processing, making low latency and quick execution essential, especially in applications like autonomous vehicles and industrial automation.
+* **Traditional ML Workflow:** Less emphasis on real-time processing, often relying on batch data processing.
+* **Embedded AI Workflow:** Prioritizes real-time data processing, making low latency and quick execution essential, especially in applications like autonomous vehicles and industrial automation.
### Data Management and Privacy
-* **Traditional ML Workflow**: Processes data in centralized locations, often necessitating extensive data transfer and focusing on data security during transit and storage.
-* **Embedded AI Workflow**: Leverages edge computing to process data closer to its source, reducing data transmission and enhancing privacy through data localization.
+* **Traditional ML Workflow:** Processes data in centralized locations, often necessitating extensive data transfer and focusing on data security during transit and storage.
+* **Embedded AI Workflow:** This workflow leverages edge computing to process data closer to its source, reducing data transmission and enhancing privacy through data localization.
### Hardware-Software Integration
-* **Traditional ML Workflow**: Typically operates on general-purpose hardware, with software development occurring somewhat independently.
-* **Embedded AI Workflow**: Involves a more integrated approach to hardware and software development, often incorporating custom chips or hardware accelerators to achieve optimal performance.
+* **Traditional ML Workflow:** Typically operates on general-purpose hardware, with software development occurring independently.
+* **Embedded AI Workflow:** This workflow involves a more integrated approach to hardware and software development, often incorporating custom chips or hardware accelerators to achieve optimal performance.
## Roles & Responsibilities
-Creating an ML solution, especially for embedded AI, is a multidisciplinary effort involving various specialists.
+Creating an ML solution, especially for embedded AI, is a multidisciplinary effort involving various specialists.
-Here's a rundown of the typical roles involved:
+@tbl-mlops_roles shows a rundown of the typical roles involved:
| Role | Responsibilities |
|--------------------------------|----------------------------------------------------------------------------------------------------|
@@ -102,16 +102,18 @@ Here's a rundown of the typical roles involved:
| Operations and Maintenance Personnel | Monitor and maintain the deployed system. |
| Security Specialists | Ensure system security. |
-Understanding these roles is crucial for the successful completion of an ML project. As we proceed through the upcoming chapters, we'll delve into each role's essence and expertise, fostering a comprehensive understanding of the complexities involved in embedded AI projects. This holistic view not only facilitates seamless collaboration but also nurtures an environment ripe for innovation and breakthroughs.
+: Roles and responsibilities of people involved in MLOps. {#tbl-mlops_roles}
+
+Understanding these roles is crucial for completing an ML project. As we proceed through the upcoming chapters, we'll delve into each role's essence and expertise, fostering a comprehensive understanding of the complexities involved in embedded AI projects. This holistic view facilitates seamless collaboration and nurtures an environment ripe for innovation and breakthroughs.
## Resources {#sec-ai-workflow-resource .unnumbered}
-Here is a curated list of resources to support both students and instructors in their learning and teaching journey. We are continuously working on expanding this collection and will be adding new exercises in the near future.
+Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
:::{.callout-slide collapse="false"}
# Slides
-These slides serve as a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage both students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
+These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to enhance their understanding and facilitate effective knowledge transfer.
* [ML Workflow.](https://docs.google.com/presentation/d/1rWXLegepZjpJHonYLKcOJYfOIunmOBnrg0SGhy1pZ_I/edit)
@@ -124,14 +126,14 @@ These slides serve as a valuable tool for instructors to deliver lectures and fo
To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
-Coming soon.
+*Coming soon.*
:::
:::{.callout-lab collapse="false"}
# Labs
-In addition to exercises, we also offer a series of hands-on labs that allow students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
+In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
-Coming soon.
+*Coming soon.*
:::
diff --git a/cover-image-transparent.png b/cover-image-transparent.png
new file mode 100644
index 00000000..153f7213
Binary files /dev/null and b/cover-image-transparent.png differ
diff --git a/cover-image-white.png b/cover-image-white.png
new file mode 100644
index 00000000..8034c820
Binary files /dev/null and b/cover-image-white.png differ