diff --git a/images/modeloptimization_color_mappings.jpeg b/images/modeloptimization_color_mappings.jpeg
new file mode 100644
index 000000000..0531a9d8c
Binary files /dev/null and b/images/modeloptimization_color_mappings.jpeg differ
diff --git a/images/modeloptimization_onnx.jpg b/images/modeloptimization_onnx.jpg
new file mode 100644
index 000000000..e5218a9c3
Binary files /dev/null and b/images/modeloptimization_onnx.jpg differ
diff --git a/images/modeloptimization_quant_hist.png b/images/modeloptimization_quant_hist.png
new file mode 100644
index 000000000..a9cdff8e1
Binary files /dev/null and b/images/modeloptimization_quant_hist.png differ
diff --git a/optimizations.qmd b/optimizations.qmd
index 42a258d0a..cb38f24f1 100644
--- a/optimizations.qmd
+++ b/optimizations.qmd
@@ -17,7 +17,7 @@ Going one level lower, in @sec-model_ops_numerics, we study the role of numerica
Finally, as we go lower closer to the hardware, in @sec-model_ops_hw, we will navigate through the landscape of hardware-software co-design, exploring how models can be optimized by tailoring them to the specific characteristics and capabilities of the target hardware. We will discuss how models can be adapted to exploit the available hardware resources effectively.
-
+{width=50%}
## Efficient Model Representation {#sec-model_ops_representation}
@@ -130,11 +130,11 @@ The following compact table provides a concise comparison between structured and
Pruning has evolved from a purely post-training technique that came at the cost of some accuracy, to a powerful meta-learning approach applied during training to reduce model complexity. This advancement in turn improves compute, memory, and latency efficiency at both training and inference.
-A breakthrough finding that catalyzed this evolution was the [lottery ticket hypothesis](https://arxiv.org/abs/1803.03635) empirically discovered by Jonathan Frankle and Michael Carbin. Their work states that within dense neural networks, there exist sparse subnetworks, referred to as "winning tickets," that can match or even exceed the performance of the original model when trained in isolation. Specifically, these winning tickets, when initialized using the same weights as the original network, can achieve similarly high training convergence and accuracy on a given task. It is worthwhile pointing out that they empirically discovered the lottery ticket hypothesis, which was later formalized.
+A breakthrough finding that catalyzed this evolution was the [lottery ticket hypothesis](https://arxiv.org/abs/1803.03635) by @frankle_lottery_2019. They empirically discovered by Jonathan Frankle and Michael Carbin. Their work states that within dense neural networks, there exist sparse subnetworks, referred to as "winning tickets," that can match or even exceed the performance of the original model when trained in isolation. Specifically, these winning tickets, when initialized using the same weights as the original network, can achieve similarly high training convergence and accuracy on a given task. It is worthwhile pointing out that they empirically discovered the lottery ticket hypothesis, which was later formalized.
-More formally, the lottery ticket hypothesis is a concept in deep learning that suggests that within a neural network, there exist sparse subnetworks (or "winning tickets") that, when initialized with the right weights, are capable of achieving high training convergence and inference performance on a given task. The intuition behind this hypothesis is that, during the training process of a neural network, many neurons and connections become redundant or unimportant, particularly with the inclusion of training techniques encouraging redundancy like dropout. Identifying, pruning out, and initializing these "winning tickets'' allows for faster training and more efficient models, as they contain the essential model decision information for the task. Furthermore, as generally known with the bias-variance tradeoff theory, these tickets suffer less from overparameterization and thus generalize better rather than overfitting to the task. 
+More formally, the lottery ticket hypothesis is a concept in deep learning that suggests that within a neural network, there exist sparse subnetworks (or "winning tickets") that, when initialized with the right weights, are capable of achieving high training convergence and inference performance on a given task. The intuition behind this hypothesis is that, during the training process of a neural network, many neurons and connections become redundant or unimportant, particularly with the inclusion of training techniques encouraging redundancy like dropout. Identifying, pruning out, and initializing these "winning tickets'' allows for faster training and more efficient models, as they contain the essential model decision information for the task. Furthermore, as generally known with the bias-variance tradeoff theory, these tickets suffer less from overparameterization and thus generalize better rather than overfitting to the task.
-
+
#### Challenges & Limitations
@@ -174,7 +174,7 @@ Model compression techniques are crucial for deploying deep learning models on r
#### Knowledge Distillation {#sec-kd}
-One popular technique is knowledge distillation (KD), which transfers knowledge from a large, complex "teacher" model to a smaller "student" model. The key idea is to train the student model to mimic the teacher's outputs.The concept of KD was first popularized by the work of Geoffrey Hinton, Oriol Vinyals, and Jeff Dean in their paper ["Distilling the Knowledge in a Neural Network" (2015)](https://arxiv.org/abs/1503.02531).
+One popular technique is knowledge distillation (KD), which transfers knowledge from a large, complex "teacher" model to a smaller "student" model. The key idea is to train the student model to mimic the teacher's outputs. The concept of KD was first popularized by @hinton2015distilling.
##### Overview and Benefits
@@ -206,7 +206,7 @@ One of the seminal works in the realm of matrix factorization, particularly in t
The main advantage of low-rank matrix factorization lies in its ability to reduce data dimensionality as shown in the image below where there are fewer parameters to store, making it computationally more efficient and reducing storage requirements at the cost of some additional compute. This can lead to faster computations and more compact data representations, which is especially valuable when dealing with large datasets. Additionally, it may aid in noise reduction and can reveal underlying patterns and relationships in the data.
-
+
##### Challenges
@@ -242,11 +242,19 @@ One edge friendly architecture design is depthwise separable convolutions. Commo
#### Example Model Architectures
-In this vein, a number of recent architectures have been, from inception, specifically designed for maximizing accuracy on an edge deployment, notably SqueezeNet, MobileNet, and EfficientNet. [SqueezeNet]([https://arxiv.org/abs/1602.07360](https://arxiv.org/abs/1602.07360)), for instance, utilizes a compact architecture with 1x1 convolutions and fire modules to minimize the number of parameters while maintaining strong accuracy. [MobileNet]([https://arxiv.org/abs/1704.04861](https://arxiv.org/abs/1704.04861)), on the other hand, employs the aforementioned depthwise separable convolutions to reduce both computation and model size. [EfficientNet]([https://arxiv.org/abs/1905.11946](https://arxiv.org/abs/1905.11946)) takes a different approach by optimizing network scaling (i.e. varying the depth, width and resolution of a network) and compound scaling, a more nuanced variation network scaling, to achieve superior performance with fewer parameters. These models are essential in the context of edge computing where limited processing power and memory require lightweight yet effective models that can efficiently perform tasks such as image recognition, object detection, and more. Their design principles showcase the importance of intentionally tailored model architecture for edge computing, where performance and efficiency must fit within constraints.
+In this vein, a number of recent architectures have been, from inception, specifically designed for maximizing accuracy on an edge deployment, notably SqueezeNet, MobileNet, and EfficientNet.
+
+* [SqueezeNet]([https://arxiv.org/abs/1602.07360](https://arxiv.org/abs/1602.07360)) by @iandola2016squeezenet for instance, utilizes a compact architecture with 1x1 convolutions and fire modules to minimize the number of parameters while maintaining strong accuracy.
+
+* [MobileNet]([https://arxiv.org/abs/1704.04861](https://arxiv.org/abs/1704.04861)) by @howard2017mobilenets, on the other hand, employs the aforementioned depthwise separable convolutions to reduce both computation and model size.
+
+* [EfficientNet]([https://arxiv.org/abs/1905.11946](https://arxiv.org/abs/1905.11946)) by @tan2020efficientnet takes a different approach by optimizing network scaling (i.e. varying the depth, width and resolution of a network) and compound scaling, a more nuanced variation network scaling, to achieve superior performance with fewer parameters.
+
+These models are essential in the context of edge computing where limited processing power and memory require lightweight yet effective models that can efficiently perform tasks such as image recognition, object detection, and more. Their design principles showcase the importance of intentionally tailored model architecture for edge computing, where performance and efficiency must fit within constraints.
#### Streamlining Model Architecture Search
-Finally, systematized pipelines for searching for performant edge-compatible model architectures are possible through frameworks like [TinyNAS](https://arxiv.org/abs/2007.10319) and [MorphNet]([https://arxiv.org/abs/1711.06798](https://arxiv.org/abs/1711.06798)).
+Finally, systematized pipelines for searching for performant edge-compatible model architectures are possible through frameworks like [TinyNAS](https://arxiv.org/abs/2007.10319) by @lin2020mcunet and [MorphNet]([https://arxiv.org/abs/1711.06798](https://arxiv.org/abs/1711.06798)) by @gordon2018morphnet.
TinyNAS is an innovative neural architecture search framework introduced in the MCUNet paper, designed to efficiently discover lightweight neural network architectures for edge devices with limited computational resources. Leveraging reinforcement learning and a compact search space of micro neural modules, TinyNAS optimizes for both accuracy and latency, enabling the deployment of deep learning models on microcontrollers, IoT devices, and other resource-constrained platforms. Specifically, TinyNAS, in conjunction with a network optimizer TinyEngine, generates different search spaces by scaling the input resolution and the model width of a model, then collects the computation FLOPs distribution of satisfying networks within the search space to evaluate its priority. TinyNAS relies on the assumption that a search space that accommodates higher FLOPs under memory constraint can produce higher accuracy models, something that the authors verified in practice in their work. In empirical performance, TinyEngine reduced the peak memory usage of models by around 3.4 times and accelerated inference by 1.7 to 3.3 times compared to [TFLite]([https://www.tensorflow.org/lite](https://www.tensorflow.org/lite)) and [CMSIS-NN]([https://www.keil.com/pack/doc/CMSIS/NN/html/index.html](https://www.keil.com/pack/doc/CMSIS/NN/html/index.html))..
@@ -265,7 +273,7 @@ The imperative for efficient numerics representation arises, particularly as eff
Beyond minimizing memory demands, the tremendous potential of efficient numerics representation lies in but is not limited to these fundamental ways. By diminishing computational intensity, efficient numerics can thereby amplify computational speed, allowing more complex models to compute on low-powered devices. Reducing the bit precision of weights and activations on heavily over-parameterized models enables condensation of model size for edge devices without significantly harming the model's predictive accuracy. With the omnipresence of neural networks in models, efficient numerics has a unique advantage in leveraging the layered structure of NNs to vary numeric precision across layers, minimizing precision in resistant layers while preserving higher precision in sensitive layers.
-In this segment, we'll delve into how practitioners can harness the principles of hardware-software co-design at the lowest levels of a model to facilitate compatibility with edge devices. Kicking off with an introduction to the numerics, we will examine its implications for device memory and computational complexity. Subsequently, we will embark on a discussion regarding the trade-offs entailed in adopting this strategy, followed by a deep dive into a paramount method of efficient numerics: quantization.
+In this section, we will dive into how practitioners can harness the principles of hardware-software co-design at the lowest levels of a model to facilitate compatibility with edge devices. Kicking off with an introduction to the numerics, we will examine its implications for device memory and computational complexity. Subsequently, we will embark on a discussion regarding the trade-offs entailed in adopting this strategy, followed by a deep dive into a paramount method of efficient numerics: quantization.
### The Basics
@@ -295,14 +303,15 @@ Precision, delineating the exactness with which a number is represented, bifurca
**Integer:** Integer representations are made using 8, 4, and 2 bits. They are often used during the inference phase of neural networks, where the weights and activations of the model are quantized to these lower precisions. Integer representations are deterministic and offer significant speed and memory advantages over floating-point representations. For many inference tasks, especially on edge devices, the slight loss in accuracy due to quantization is often acceptable given the efficiency gains. An extreme form of integer numerics is for binary neural networks (BNNs), where weights and activations are constrained to one of two values: either +1 or -1.
-| **Precision** | **Pros** | **Cons** |
-|------------|--------------------------------------------------|--------------------------------------------------|
-| **FP32** (Floating Point 32-bit) | - Standard precision used in most deep learning frameworks.
- High accuracy due to ample representational capacity.
- Well-suited for training. | - High memory usage.
- Slower inference times compared to quantized models.
- Higher energy consumption. |
-| **FP16** (Floating Point 16-bit) | - Reduces memory usage compared to FP32.
- Speeds up computations on hardware that supports FP16.
- Often used in mixed-precision training to balance speed and accuracy. | - Lower representational capacity compared to FP32.
- Risk of numerical instability in some models or layers. |
-| **INT8** (8-bit Integer) | - Significantly reduced memory footprint compared to floating-point representations.
- Faster inference if hardware supports INT8 computations.
- Suitable for many post-training quantization scenarios. | - Quantization can lead to some accuracy loss.
- Requires careful calibration during quantization to minimize accuracy degradation. |
-| **INT4** (4-bit Integer) | - Even lower memory usage than INT8.
- Further speed-up potential for inference. | - Higher risk of accuracy loss compared to INT8.
- Calibration during quantization becomes more critical. |
-| **Binary** | - Minimal memory footprint (only 1 bit per parameter).
- Extremely fast inference due to bitwise operations.
- Power efficient. | - Significant accuracy drop for many tasks.
- Complex training dynamics due to extreme quantization. |
-| **Ternary** | - Low memory usage but slightly more than binary.
- Offers a middle ground between representation and efficiency. | - Accuracy might still be lower than higher precision models.
- Training dynamics can be complex. |
+| **Precision** | **Pros** | **Cons** |
+|---------------------------------------|------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------|
+| **FP32** (Floating Point 32-bit) | • Standard precision used in most deep learning frameworks.
• High accuracy due to ample representational capacity.
• Well-suited for training. | • High memory usage.
• Slower inference times compared to quantized models.
• Higher energy consumption. |
+| **FP16** (Floating Point 16-bit) | • Reduces memory usage compared to FP32.
• Speeds up computations on hardware that supports FP16.
• Often used in mixed-precision training to balance speed and accuracy. | • Lower representational capacity compared to FP32.
• Risk of numerical instability in some models or layers. |
+| **INT8** (8-bit Integer) | • Significantly reduced memory footprint compared to floating-point representations.
• Faster inference if hardware supports INT8 computations.
• Suitable for many post-training quantization scenarios. | • Quantization can lead to some accuracy loss.
• Requires careful calibration during quantization to minimize accuracy degradation. |
+| **INT4** (4-bit Integer) | • Even lower memory usage than INT8.
• Further speed-up potential for inference. | • Higher risk of accuracy loss compared to INT8.
• Calibration during quantization becomes more critical. |
+| **Binary** | • Minimal memory footprint (only 1 bit per parameter).
• Extremely fast inference due to bitwise operations.
• Power efficient. | • Significant accuracy drop for many tasks.
• Complex training dynamics due to extreme quantization. |
+| **Ternary** | • Low memory usage but slightly more than binary.
• Offers a middle ground between representation and efficiency. | • Accuracy might still be lower than higher precision models.
• Training dynamics can be complex. |
+
#### Numeric Encoding and Storage
@@ -463,7 +472,7 @@ As discussed, some precision in the real value is lost by quantization. In this
Non-uniform quantization, on the other hand, does not maintain a consistent interval between quantized values. This approach might be used to allocate more possible discrete values in regions where the parameter values are more densely populated, thereby preserving more detail where it is most needed. For instance, in bell-shaped distributions of weights with long tails, a set of weights in a model predominantly lies within a certain range; thus, more quantization levels might be allocated to that range to preserve finer details, enabling us to better capture information. However, one major weakness of non-uniform quantization is that it requires dequantization before higher precision computations due to its non-uniformity, restricting its ability to accelerate computation compared to uniform quantization.
-Typically, a rule-based non-uniform quantization uses a logarithmic distribution of exponentially increasing steps and levels as opposed to linearly. Another popular branch lies in binary-code-based quantization where real number vectors are quantized into binary vectors with a scaling factor. Notably, there is no closed form solution for minimizing errors between the real value and non-uniformly quantized value, so most quantizations in this field rely on heuristic solutions. For instance, [recent work](https://arxiv.org/abs/1802.00150) formulates non-uniform quantization as an optimization problem where the quantization steps/levels in quantizer Q are adjusted to minimize the difference between the original tensor and quantized counterpart.
+Typically, a rule-based non-uniform quantization uses a logarithmic distribution of exponentially increasing steps and levels as opposed to linearly. Another popular branch lies in binary-code-based quantization where real number vectors are quantized into binary vectors with a scaling factor. Notably, there is no closed form solution for minimizing errors between the real value and non-uniformly quantized value, so most quantizations in this field rely on heuristic solutions. For instance, [recent work](https://arxiv.org/abs/1802.00150) by @xu2018alternating formulates non-uniform quantization as an optimization problem where the quantization steps/levels in quantizer Q are adjusted to minimize the difference between the original tensor and quantized counterpart.
$$
\min_Q ||Q(r)-r||^2
@@ -621,32 +630,30 @@ Efficient hardware implementation transcends the selection of suitable component
### Hardware-Aware Neural Architecture Search
-Focusing only on the accuracy when performing Neural Architecture Search leads to models that are exponentially complex and require increasing memory and compute. This has lead to hardware constraints limiting the exploitation of the deep learning models at their full potential. Manually designing the architecture of the model is even harder when considering the hardware variety and limitations. This has lead to the creation of Hardware-aware Neural Architecture Search that incorporate the hardware contractions into their search and optimize the search space for a specific hardware and accuracy. HW-NAS can be catogrized based how it optimizes for hardware. We will briefly explore these categories and leave links to related papers for the interested reader.
+Focusing only on the accuracy when performing Neural Architecture Search leads to models that are exponentially complex and require increasing memory and compute. This has lead to hardware constraints limiting the exploitation of the deep learning models at their full potential. Manually designing the architecture of the model is even harder when considering the hardware variety and limitations. This has lead to the creation of Hardware-aware Neural Architecture Search that incorporate the hardware contractions into their search and optimize the search space for a specific hardware and accuracy. HW-NAS can be categorized based how it optimizes for hardware. We will briefly explore these categories and leave links to related papers for the interested reader.
-](images/modeloptimization_HW-NAS.png)
+))](images/modeloptimization_HW-NAS.png)
#### Single Target, Fixed Platfrom Configuration
-The goal here is to find the best architecture in terms of accuracy and hardware efficiency for one fixed target hardware. For a specific hardware, the Arduino Nicla Vision for example, this category of HW-NAS will look for the architecture that optimizes accuracy, latency, energy consumption, …
-
-Two approaches fall under this category
+The goal here is to find the best architecture in terms of accuracy and hardware efficiency for one fixed target hardware. For a specific hardware, the Arduino Nicla Vision for example, this category of HW-NAS will look for the architecture that optimizes accuracy, latency, energy consumption, etc.
##### Hardware-aware Search Strategy
-Here, the search is a multi-objective optimization problem, where both the accuracy and hardware cost guide the searching algorithm to find the most efficient architecture. [1](https://openaccess.thecvf.com/content_CVPR_2019/html/Tan_MnasNet_Platform-Aware_Neural_Architecture_Search_for_Mobile_CVPR_2019_paper.html)[2](https://arxiv.org/abs/1812.00332)[3](https://arxiv.org/abs/1812.03443)
+Here, the search is a multi-objective optimization problem, where both the accuracy and hardware cost guide the searching algorithm to find the most efficient architecture [@tan2019mnasnet; @cai2018proxylessnas; @wu2019fbnet].
##### Hardware-aware Search Space
-Here, the search space is restricted to the architectures that perform well on the specific hardware. This can be achieved by either measuring the operators (Conv operator, Pool operator, …) performance, or define a set of rules that limit the search space. [1](https://openaccess.thecvf.com/content_CVPRW_2020/html/w40/Zhang_Fast_Hardware-Aware_Neural_Architecture_Search_CVPRW_2020_paper.html)
+Here, the search space is restricted to the architectures that perform well on the specific hardware. This can be achieved by either measuring the operators (Conv operator, Pool operator, …) performance, or define a set of rules that limit the search space. (Zhang et al. ([2020](https://openaccess.thecvf.com/content_CVPRW_2020/html/w40/Zhang_Fast_Hardware-Aware_Neural_Architecture_Search_CVPRW_2020_paper.html)))
#### Single Target, Multiple Platform Configurations
-Some hardwares may have different configurations. For example, FPGAs have Configurable Logic Blocks (CLBs) that can be configured by the firmware. This method allows for the HW-NAS to explore different configurations. [1](https://arxiv.org/abs/1901.11211)[2](https://arxiv.org/abs/2002.04116)
+Some hardwares may have different configurations. For example, FPGAs have Configurable Logic Blocks (CLBs) that can be configured by the firmware. This method allows for the HW-NAS to explore different configurations. (Jiang et al. ([2019](https://arxiv.org/abs/1901.11211)))(Yang et al. ([2020](https://arxiv.org/abs/2002.04116)))
#### Multiple Targets
-This category aims at optimizing a single model for multiple hardwares. This can be helpful for mobile devices development as it can optimize to different phones models. [1](https://arxiv.org/abs/2008.08178)[2](https://ieeexplore.ieee.org/document/9102721)
+This category aims at optimizing a single model for multiple hardwares. This can be helpful for mobile devices development as it can optimize to different phones models. (Chu et al. ([2020](https://arxiv.org/abs/2008.08178)))(Jiang et al. ([2020](https://ieeexplore.ieee.org/document/9102721)))
#### Examples of Hardware-Aware Neural Architecture Search
@@ -656,13 +663,14 @@ TinyNAS adopts a two stage approach to finding an optimal architecture for model
First, TinyNAS generate multiple search spaces by varying the input resolution of the model, and the number of channels of the layers of the model. Then, TinyNAS chooses a search space based on the FLOPs (Floating Point Operations Per Second) of each search space
-Then, TinyNAS performs a search operation on the chosen space to find the optimal architecture for the specific constraints of the microcontroller. [1](https://arxiv.org/abs/2007.10319)
+Then, TinyNAS performs a search operation on the chosen space to find the optimal architecture for the specific constraints of the microcontroller. (Han et al. ([2020](https://arxiv.org/abs/2007.10319)))
+
+))](images/modeloptimization_TinyNAS.png)
-](images/modeloptimization_TinyNAS.png)
#### Topology-Aware NAS
-Focuses on creating and optimizing a search space that aligns with the hardware topology of the device. [1](https://arxiv.org/pdf/1911.09251.pdf)
+Focuses on creating and optimizing a search space that aligns with the hardware topology of the device. (Zhang et al. ([2019](https://arxiv.org/pdf/1911.09251.pdf)))
### Challenges of Hardware-Aware Neural Architecture Search
@@ -690,51 +698,52 @@ Similarly to blocking, tiling divides data and computation into chunks, but exte
##### Optimized Kernel Libraries
-This comprises developing optimized kernels that take full advantage of a specific hardware. One example is the CMSIS-NN library, which is a collection of efficient neural network kernels developed to optimize the performance and minimize the memory footprint of models on Arm Cortex-M processors, which are common on IoT edge devices. The kernel leverage multiple hardware capabilities of Cortex-M processors like Single Instruction Multple Data (SIMD), Floating Point Units (FPUs) and M-Profile Vector Extensions (MVE). These optimization make common operations like matrix multiplications more efficient, boosting the performance of model operations on Cortex-M processors. [1](https://arxiv.org/abs/1801.06601#:~:text=This%20paper%20presents%20CMSIS,for%20intelligent%20IoT%20edge%20devices)
+This comprises developing optimized kernels that take full advantage of a specific hardware. One example is the CMSIS-NN library, which is a collection of efficient neural network kernels developed to optimize the performance and minimize the memory footprint of models on Arm Cortex-M processors, which are common on IoT edge devices. The kernel leverage multiple hardware capabilities of Cortex-M processors like Single Instruction Multple Data (SIMD), Floating Point Units (FPUs) and M-Profile Vector Extensions (MVE). These optimization make common operations like matrix multiplications more efficient, boosting the performance of model operations on Cortex-M processors. (Lai et al. ([2018](https://arxiv.org/abs/1801.06601#:~:text=This%20paper%20presents%20CMSIS,for%20intelligent%20IoT%20edge%20devices)))
### Compute-in-Memory (CiM)
-This is one example of Algorithm-Hardware Co-design. CiM is a computing paradigm that performs computation within memory. Therefore, CiM architectures allow for operations to be performed directly on the stored data, without the need to shuttle data back and forth between separate processing and memory units. This design paradigm is particularly beneficial in scenarios where data movement is a primary source of energy consumption and latency, such as in TinyML applications on edge devices. Through algorithm-hardware co-design, the algorithms can be optimized to leverage the unique characteristics of CiM architectures, and conversely, the CiM hardware can be customized or configured to better support the computational requirements and characteristics of the algorithms. This is achieved by using the analog properties of memory cells, such as addition and multiplication in DRAM. [1](https://arxiv.org/abs/2111.06503)
+This is one example of Algorithm-Hardware Co-design. CiM is a computing paradigm that performs computation within memory. Therefore, CiM architectures allow for operations to be performed directly on the stored data, without the need to shuttle data back and forth between separate processing and memory units. This design paradigm is particularly beneficial in scenarios where data movement is a primary source of energy consumption and latency, such as in TinyML applications on edge devices. Through algorithm-hardware co-design, the algorithms can be optimized to leverage the unique characteristics of CiM architectures, and conversely, the CiM hardware can be customized or configured to better support the computational requirements and characteristics of the algorithms. This is achieved by using the analog properties of memory cells, such as addition and multiplication in DRAM. (Zhou et al. ([2021](https://arxiv.org/abs/2111.06503)))
](images/modeloptimization_CiM.png)
-## Memory Access Optimization
+### Memory Access Optimization
Different devices may have different memory hierarchies. Optimizing for the specific memory hierarchy in the specific hardware can lead to great performance improvements by reducing the costly operations of reading and writing to memory. Dataflow optimization can be achieved by optimizing for reusing data within a single layer and across multiple layers. This dataflow optimization can be tailored to the specific memory hierarchy of the hardware, which can lead to greater benefits than general optimizations for different hardwares.
### Leveraging Sparsity
-Pruning is a fundamental approach to compress models to make them compatible with resource constrained devices. This results in sparse models where a lot of weights are 0's. Therefore, leveraging this sparsity can lead to significant improvements in performance. Tools were created to achieve exactly this. RAMAN, is a sparseTinyML accelerator designed for inference on edge devices. RAMAN overlap input and output activations on the same memory space, reducing storage requirements by up to 50%. [1](https://ar5iv.labs.arxiv.org/html/2306.06493)
+Pruning is a fundamental approach to compress models to make them compatible with resource constrained devices. This results in sparse models where a lot of weights are 0's. Therefore, leveraging this sparsity can lead to significant improvements in performance. Tools were created to achieve exactly this. RAMAN, is a sparseTinyML accelerator designed for inference on edge devices. RAMAN overlap input and output activations on the same memory space, reducing storage requirements by up to 50%. (Krishna et al. ([2023](https://ar5iv.labs.arxiv.org/html/2306.06493)))
+
+))](images/modeloptimization_sparsity.png)
-](images/modeloptimization_sparsity.png)
### Optimization Frameworks
Optimization Frameworks have been introduced to exploit the specific capabilities of the hardware to accelerate the software. One example of such a framework is hls4ml. This open-source software-hardware co-design workflow aids in interpreting and translating machine learning algorithms for implementation with both FPGA and ASIC technologies, enhancing their. Features such as network optimization, new Python APIs, quantization-aware pruning, and end-to-end FPGA workflows are embedded into the hls4ml framework, leveraging parallel processing units, memory hierarchies, and specialized instruction sets to optimize models for edge hardware. Moreover, hls4ml is capable of translating machine learning algorithms directly into FPGA firmware.
-](images/modeloptimization_hls4ml.png)
+))](images/modeloptimization_hls4ml.png)
-One other framework for FPGAs that focuses on a holistic approach is CFU Playground [1](https://arxiv.org/abs/2201.01863)
+One other framework for FPGAs that focuses on a holistic approach is CFU Playground (Prakash et al. ([2022](https://arxiv.org/abs/2201.01863)))
### Hardware Built Around Software
-In a contrasting approach, hardware can be custom-designed around software requirements to optimize the performance for a specific application. This paradigm creates specialized hardware to better adapt to the specifics of the software, thus reducing computational overhead and improving operational efficiency. One example of this approach is a voice-recognition application by [1](https://www.mdpi.com/2076-3417/11/22/11073). The paper proposes a structure wherein preprocessing operations, traditionally handled by software, are allocated to custom-designed hardware. This technique was achieved by introducing resistor–transistor logic to an inter-integrated circuit sound module for windowing and audio raw data acquisition in the voice-recognition application. Consequently, this offloading of preprocessing operations led to a reduction in computational load on the software, showcasing a practical application of building hardware around software to enhance the efficiency and performance. [1](https://www.mdpi.com/2076-3417/11/22/11073)
+In a contrasting approach, hardware can be custom-designed around software requirements to optimize the performance for a specific application. This paradigm creates specialized hardware to better adapt to the specifics of the software, thus reducing computational overhead and improving operational efficiency. One example of this approach is a voice-recognition application by (Kwon et al. ([2021](https://www.mdpi.com/2076-3417/11/22/11073))). The paper proposes a structure wherein preprocessing operations, traditionally handled by software, are allocated to custom-designed hardware. This technique was achieved by introducing resistor–transistor logic to an inter-integrated circuit sound module for windowing and audio raw data acquisition in the voice-recognition application. Consequently, this offloading of preprocessing operations led to a reduction in computational load on the software, showcasing a practical application of building hardware around software to enhance the efficiency and performance.
-](images/modeloptimization_preprocessor.png)
+))](images/modeloptimization_preprocessor.png)
### SplitNets
-SplitNets were introduced in the context of Head-Mounted systems. They distribute the Deep Neural Networks (DNNs) workload among camera sensors and an aggregator. This is particularly compelling the in context of TinyML. The SplitNet framework is a split-aware NAS to find the optimal neural network architecture to achieve good accuracy, split the model among the sensors and the aggregator, and minimize the communication between the sensors and the aggregator. Minimal communication is important in TinyML where memory is highly constrained, this way the sensors conduct some of the processing on their chips and then they send only the necessary information to the aggregator. When testing on ImageNet, SplitNets were able to reduce the latency by one order of magnitude on head-mounted devices. This can be helpful when the sensor has it's own chip. [1](https://arxiv.org/pdf/2204.04705.pdf)
+SplitNets were introduced in the context of Head-Mounted systems. They distribute the Deep Neural Networks (DNNs) workload among camera sensors and an aggregator. This is particularly compelling the in context of TinyML. The SplitNet framework is a split-aware NAS to find the optimal neural network architecture to achieve good accuracy, split the model among the sensors and the aggregator, and minimize the communication between the sensors and the aggregator. Minimal communication is important in TinyML where memory is highly constrained, this way the sensors conduct some of the processing on their chips and then they send only the necessary information to the aggregator. When testing on ImageNet, SplitNets were able to reduce the latency by one order of magnitude on head-mounted devices. This can be helpful when the sensor has its own chip. (Dong et al. ([2022](https://arxiv.org/pdf/2204.04705.pdf)))
-](images/modeloptimization_SplitNets.png)
+))](images/modeloptimization_SplitNets.png)
### Hardware Specific Data Augmentation
Each edge device may possess unique sensor characteristics, leading to specific noise patterns that can impact model performance. One example is audio data, where variations stemming from the choice of microphone are prevalent. Applications such as Keyword Spotting can experience substantial enhancements by incorporating data recorded from devices similar to those intended for deployment. Fine-tuning of existing models can be employed to adapt the data precisely to the sensor's distinctive characteristics.
-### Software and Framework Support
+## Software and Framework Support
While all of the aforementioned techniques like [pruning](#sec-pruning), [quantization](#sec-quant), and efficient numerics are well-known, they would remain impractical and inaccessible without extensive software support. For example, directly quantizing weights and activations in a model would require manually modifying the model definition and inserting quantization operations throughout. Similarly, directly pruning model weights requires manipulating weight tensors. Such tedious approaches become infeasible at scale.
@@ -760,7 +769,7 @@ Automated optimization tools provided by frameworks can analyze models and autom
- [Pruning](https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras) - Automatically removes unnecessary connections in a model based on analysis of weight importance. Can prune entire filters in convolutional layers or attention heads in transformers. Handles iterative re-training to recover any accuracy loss.
- [GraphOptimizer](https://www.tensorflow.org/guide/graph_optimization) - Applies graph optimizations like operator fusion to consolidate operations and reduce execution latency, especially for inference.
-
+
These automated modules only require the user to provide the original floating point model, and handle the end-to-end optimization pipeline including any re-training to regain accuracy. Other frameworks like PyTorch also offer increasing automation support, for example through torch.quantization.quantize\_dynamic. Automated optimization makes efficient ML accessible to practitioners without optimization expertise.
@@ -773,7 +782,7 @@ Quantization: For example, TensorRT and TensorFlow Lite both support quantizatio
Kernel Optimization: For instance, TensorRT does auto-tuning to optimize CUDA kernels based on the GPU architecture for each layer in the model graph. This extracts maximum throughput.
Operator Fusion: TensorFlow XLA does aggressive fusion to create optimized binary for TPUs. On mobile, frameworks like NCNN also support fused operators.
-
+`
Hardware-Specific Code: Libraries are used to generate optimized binary code specialized for the target hardware. For example, [TensorRT](https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html) uses Nvidia CUDA/cuDNN libraries which are hand-tuned for each GPU architecture. This hardware-specific coding is key for performance. On tinyML devices, this can mean assembly code optimized for a Cortex M4 CPU for example. Vendors provide CMSIS-NN and other libraries.
Data Layout Optimizations - We can efficiently leverage memory hierarchy of hardware like cache and registers through techniques like tensor/weight rearrangement, tiling, and reuse. For example, TensorFlow XLA optimizes buffer layouts to maximize TPU utilization. This helps any memory constrained systems.
@@ -788,13 +797,13 @@ Implementing model optimization techniques without visibility into the effects o
##### Sparsity (ADD SOME LINKS INTO HERE)
-For example, consider sparsity optimizations. Sparsity visualization tools can provide critical insights into pruned models by mapping out exactly which weights have been removed. For example, sparsity heat maps can use color gradients to indicate the percentage of weights pruned in each layer of a neural network. Layers with higher percentages pruned appear darker. This identifies which layers have been simplified the most by pruning.
+For example, consider sparsity optimizations. Sparsity visualization tools can provide critical insights into pruned models by mapping out exactly which weights have been removed. For example, sparsity heat maps can use color gradients to indicate the percentage of weights pruned in each layer of a neural network. Layers with higher percentages pruned appear darker. This identifies which layers have been simplified the most by pruning. (Souza ([2020](https://www.numenta.com/blog/2020/10/30/case-for-sparsity-in-neural-networks-part-2-dynamic-sparsity/)))
-[Figure: maybe consider including an example from Wolfram]
+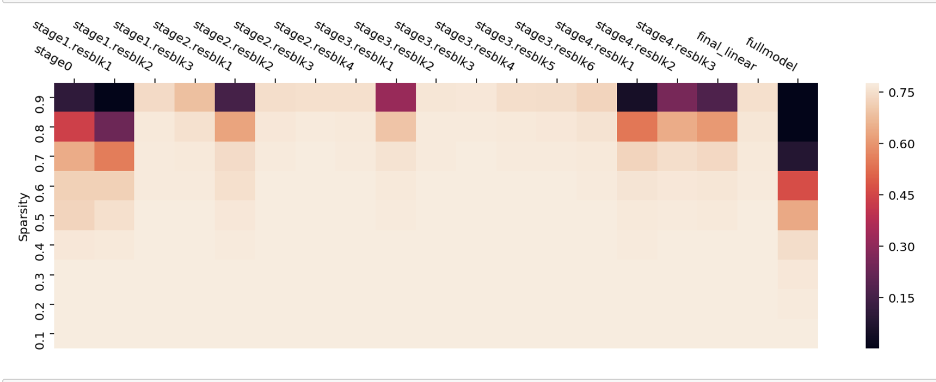
Trend plots can also track sparsity over successive pruning rounds - they may show initial rapid pruning followed by more gradual incremental increases. Tracking the current global sparsity along with statistics like average, minimum, and maximum sparsity per-layer in tables or plots provides an overview of the model composition. For a sample convolutional network, these tools could reveal that the first convolution layer is pruned 20% while the final classifier layer is pruned 70% given its redundancy. The global model sparsity may increase from 10% after initial pruning to 40% after five rounds.
-[Figure: Line graph with one line per layer, showing sparsity % over multiple pruning rounds or something to that effet]
+))](images/modeloptimization_sparsity.png)
By making sparsity data visually accessible, practitioners can better understand exactly how their model is being optimized and which areas are being impacted. The visibility enables them to fine-tune and control the pruning process for a given architecture.
@@ -804,11 +813,11 @@ Sparsity visualization turns pruning into a transparent technique instead of a b
Converting models to lower numeric precisions through quantization introduces errors that can impact model accuracy if not properly tracked and addressed. Visualizing quantization error distributions provides valuable insights into the effects of reduced precision numerics applied to different parts of a model. For this, histograms of the quantization errors for weights and activations can be generated. These histograms can reveal the shape of the error distribution - whether they resemble a Gaussian distribution or contain significant outliers and spikes. Large outliers may indicate issues with particular layers handling the quantization. Comparing the histograms across layers highlights any problem areas standing out with abnormally high errors.
-[Figure: include the example of the histograms, this stuff exists in papers]
+))](images/modeloptimization_quant_hist.png)
-Activation visualizations are also important to detect overflow issues. By color mapping the activations before and after quantization, any values pushed outside the intended ranges become visible. This reveals saturation and truncation issues that could skew the information flowing through the model. Detecting these errors allows recalibrating activations to prevent loss of information.
+Activation visualizations are also important to detect overflow issues. By color mapping the activations before and after quantization, any values pushed outside the intended ranges become visible. This reveals saturation and truncation issues that could skew the information flowing through the model. Detecting these errors allows recalibrating activations to prevent loss of information. (Mandal ([2022](https://medium.com/exemplifyml-ai/visualizing-neural-network-activation-a27caa451ff)))
-[Figure: include a color mapping example]
+
Other techniques, such as tracking the overall mean square quantization error at each step of the quantization-aware training process identifies fluctuations and divergences. Sudden spikes in the tracking plot may indicate points where quantization is disrupting the model training. Monitoring this metric builds intuition on model behavior under quantization. Together these techniques turn quantization into a transparent process. The empirical insights enable practitioners to properly assess quantization effects. They pinpoint areas of the model architecture or training process to recalibrate based on observed quantization issues. This helps achieve numerically stable and accurate quantized models.
@@ -824,7 +833,7 @@ TensorFlow Lite - TensorFlow's platform to convert models to a lightweight forma
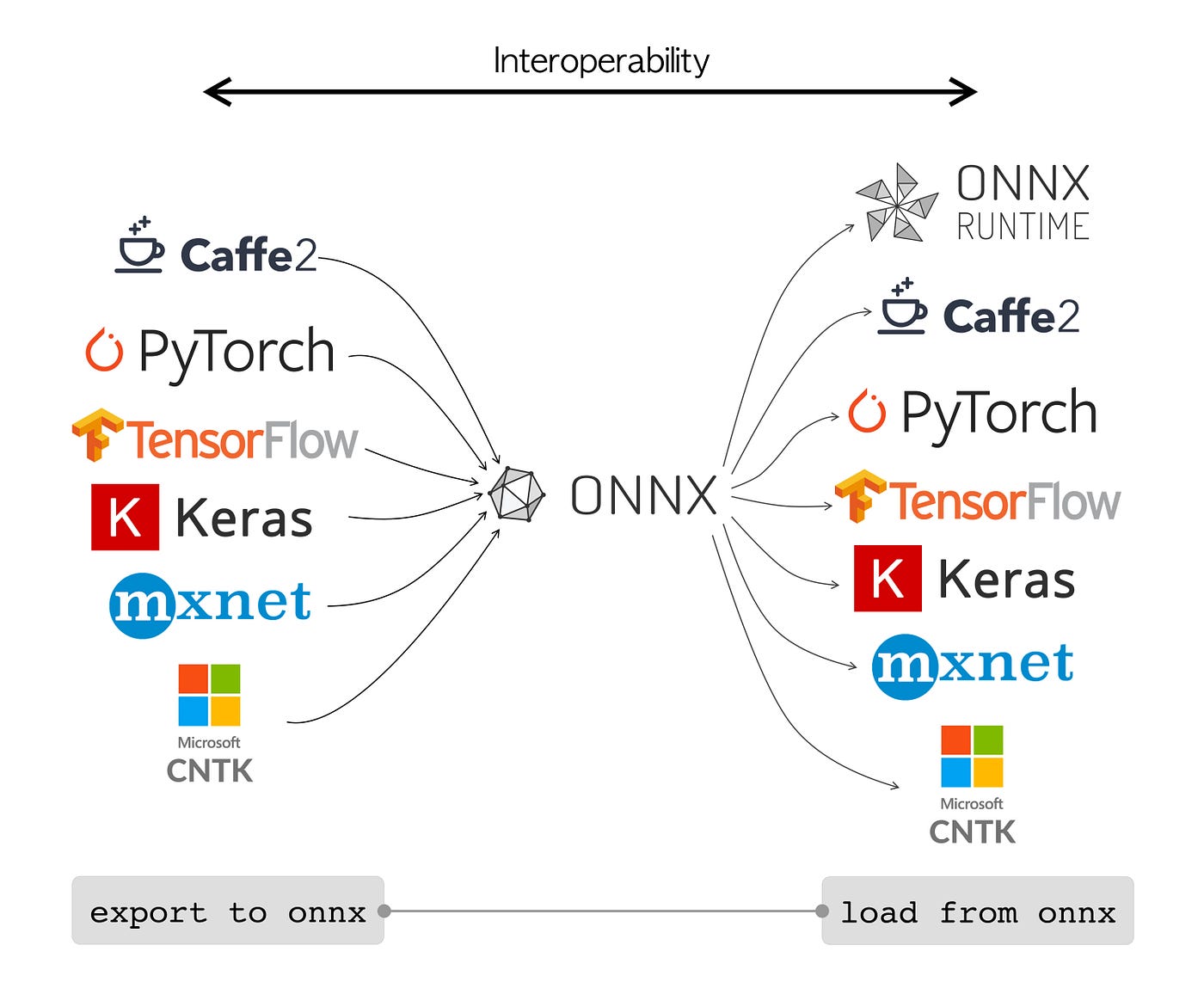
ONNX Runtime - Performs model conversion and inference for models in the open ONNX model format. Provides optimized kernels, supports hardware accelerators like GPUs, and cross-platform deployment from cloud to edge. Allows framework-agnostic deployment.
-[add figure of ONNX being an interoperable framework]
+
PyTorch Mobile - Enables PyTorch models to be run on iOS and Android by converting to mobile-optimized representations. Provides efficient mobile implementations of ops like convolution and special functions optimized for mobile hardware.
diff --git a/references.bib b/references.bib
index 1d13cb500..83991aa9e 100644
--- a/references.bib
+++ b/references.bib
@@ -14,6 +14,98 @@ @article{banbury2020benchmarking
year={2020}
}
+@misc{hinton2015distilling,
+ title={Distilling the Knowledge in a Neural Network},
+ author={Geoffrey Hinton and Oriol Vinyals and Jeff Dean},
+ year={2015},
+ eprint={1503.02531},
+ archivePrefix={arXiv},
+ primaryClass={stat.ML}
+}
+
+@inproceedings{gordon2018morphnet,
+ title={Morphnet: Fast \& simple resource-constrained structure learning of deep networks},
+ author={Gordon, Ariel and Eban, Elad and Nachum, Ofir and Chen, Bo and Wu, Hao and Yang, Tien-Ju and Choi, Edward},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={1586--1595},
+ year={2018}
+}
+
+
+@article{lin2020mcunet,
+ title={Mcunet: Tiny deep learning on iot devices},
+ author={Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Gan, Chuang and Han, Song and others},
+ journal={Advances in Neural Information Processing Systems},
+ volume={33},
+ pages={11711--11722},
+ year={2020}
+}
+
+@inproceedings{tan2019mnasnet,
+ title={Mnasnet: Platform-aware neural architecture search for mobile},
+ author={Tan, Mingxing and Chen, Bo and Pang, Ruoming and Vasudevan, Vijay and Sandler, Mark and Howard, Andrew and Le, Quoc V},
+ booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
+ pages={2820--2828},
+ year={2019}
+}
+
+@article{cai2018proxylessnas,
+ title={Proxylessnas: Direct neural architecture search on target task and hardware},
+ author={Cai, Han and Zhu, Ligeng and Han, Song},
+ journal={arXiv preprint arXiv:1812.00332},
+ year={2018}
+}
+
+@inproceedings{wu2019fbnet,
+ title={Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search},
+ author={Wu, Bichen and Dai, Xiaoliang and Zhang, Peizhao and Wang, Yanghan and Sun, Fei and Wu, Yiming and Tian, Yuandong and Vajda, Peter and Jia, Yangqing and Keutzer, Kurt},
+ booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
+ pages={10734--10742},
+ year={2019}
+}
+
+
+@article{xu2018alternating,
+ title={Alternating multi-bit quantization for recurrent neural networks},
+ author={Xu, Chen and Yao, Jianqiang and Lin, Zhouchen and Ou, Wenwu and Cao, Yuanbin and Wang, Zhirong and Zha, Hongbin},
+ journal={arXiv preprint arXiv:1802.00150},
+ year={2018}
+}
+
+@article{krishnamoorthi2018quantizing,
+ title={Quantizing deep convolutional networks for efficient inference: A whitepaper},
+ author={Krishnamoorthi, Raghuraman},
+ journal={arXiv preprint arXiv:1806.08342},
+ year={2018}
+}
+
+
+@article{iandola2016squeezenet,
+ title={SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size},
+ author={Iandola, Forrest N and Han, Song and Moskewicz, Matthew W and Ashraf, Khalid and Dally, William J and Keutzer, Kurt},
+ journal={arXiv preprint arXiv:1602.07360},
+ year={2016}
+}
+
+
+@misc{tan2020efficientnet,
+ title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
+ author={Mingxing Tan and Quoc V. Le},
+ year={2020},
+ eprint={1905.11946},
+ archivePrefix={arXiv},
+ primaryClass={cs.LG}
+}
+
+@misc{howard2017mobilenets,
+ title={MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications},
+ author={Andrew G. Howard and Menglong Zhu and Bo Chen and Dmitry Kalenichenko and Weijun Wang and Tobias Weyand and Marco Andreetto and Hartwig Adam},
+ year={2017},
+ eprint={1704.04861},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+
@inproceedings{hendrycks2021natural,
title={Natural adversarial examples},
author={Hendrycks, Dan and Zhao, Kevin and Basart, Steven and Steinhardt, Jacob and Song, Dawn},