diff --git a/.github/workflows/build_documentation.yml b/.github/workflows/build_documentation.yml
index c74f96b..42a6672 100644
--- a/.github/workflows/build_documentation.yml
+++ b/.github/workflows/build_documentation.yml
@@ -14,6 +14,6 @@ jobs:
package_name: audio-course
path_to_docs: audio-transformers-course/chapters/
additional_args: --not_python_module
- languages: en bn ko es zh-CN ru fr tr
+ languages: en bn ko es zh-CN ru fr tr pt-BR
secrets:
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
diff --git a/.github/workflows/build_pr_documentation.yml b/.github/workflows/build_pr_documentation.yml
index 2e17e8a..7ba08d1 100644
--- a/.github/workflows/build_pr_documentation.yml
+++ b/.github/workflows/build_pr_documentation.yml
@@ -17,4 +17,4 @@ jobs:
package_name: audio-course
path_to_docs: audio-transformers-course/chapters/
additional_args: --not_python_module
- languages: en bn ko es zh-CN ru fr tr
+ languages: en bn ko es zh-CN ru fr tr pt-BR
diff --git a/chapters/pt-BR/_toctree.yml b/chapters/pt-BR/_toctree.yml
new file mode 100644
index 0000000..42d30dc
--- /dev/null
+++ b/chapters/pt-BR/_toctree.yml
@@ -0,0 +1,26 @@
+- title: Unidade 0. Bem vindo ao Curso!
+ sections:
+ - local: chapter0/introduction
+ title: O que esperar deste curso
+ - local: chapter0/get_ready
+ title: Prepare-se
+ - local: chapter0/community
+ title: Junte-se à comunidade
+
+- title: Unidade 1. Trabalhando com dados de áudio
+ sections:
+ - local: chapter1/introduction
+ title: O que você vai aprender
+ - local: chapter1/audio_data
+ title: Introdução aos dados de áudio
+ - local: chapter1/load_and_explore
+ title: Carregue e explore um dataset de áudio
+ - local: chapter1/preprocessing
+ title: Pré-processamento do dados de áudio
+ - local: chapter1/streaming
+ title: Streaming de dados de áudio
+ - local: chapter1/quiz
+ title: Quiz
+ quiz: 1
+ - local: chapter1/supplemental_reading
+ title: Leitura e material adicional
\ No newline at end of file
diff --git a/chapters/pt-BR/chapter0/community.mdx b/chapters/pt-BR/chapter0/community.mdx
new file mode 100644
index 0000000..7ddfd42
--- /dev/null
+++ b/chapters/pt-BR/chapter0/community.mdx
@@ -0,0 +1,34 @@
+# Junte-se à comunidade!
+
+Convidamos você a [se juntar à nossa comunidade vibrante e solidária no Discord](http://hf.co/join/discord). Você terá a oportunidade de conhecer
+alunos com interesses semelhantes, trocar ideias e receber feedback valioso sobre seus exercícios práticos. Você pode fazer perguntas,
+compartilhar materiais e colaborar com outros.
+
+Nossa equipe também está ativa no Discord e está disponível para fornecer suporte e orientação quando você precisar.
+Juntar-se à nossa comunidade é uma excelente maneira de se manter motivado, engajado e conectado, e estamos ansiosos para
+ver você lá!
+
+## O que é Discord?
+
+Discord é uma plataforma de bate-papo gratuita. Se você já usou o Slack, vai achar bastante semelhante. O servidor do Discord do Hugging Face
+é o lar de uma comunidade próspera de 18.000 especialistas em IA, alunos e entusiastas dos quais você pode fazer parte.
+
+## Navegando pelo Discord
+
+Uma vez que você se inscreveu em nosso servidor do Discord, você precisará escolher os tópicos de seu interesse clicando em `#role-assignment`
+à esquerda. Você pode escolher quantas categorias diferentes quiser. Para se juntar a outros alunos deste curso, certifique-se de
+clicar em "ML for Audio" (#ml-4-audio).
+Explore os canais e compartilhe algumas coisas sobre você no canal `#introduce-yourself`.
+
+## Canais do curso de áudio
+
+Há muitos canais focados em vários tópicos em nosso servidor do Discord. Você encontrará pessoas discutindo artigos, organizando
+eventos, compartilhando seus projetos e ideias, fazendo brainstorming e muito mais.
+
+Como um aluno do curso de áudio, você pode achar o seguinte conjunto de canais particularmente relevante:
+
+* `#audio-announcements`: atualizações sobre o curso, notícias do Hugging Face relacionadas a tudo sobre áudio, anúncios de eventos e mais.
+* `#audio-study-group`: um lugar para trocar ideias, fazer perguntas sobre o curso e iniciar discussões.
+* `#audio-discuss`: um lugar geral para ter discussões sobre coisas relacionadas ao áudio.
+
+Além de se juntar ao `#audio-study-group`, sinta-se livre para criar seu próprio grupo de estudos, aprender juntos é sempre mais fácil!
diff --git a/chapters/pt-BR/chapter0/get_ready.mdx b/chapters/pt-BR/chapter0/get_ready.mdx
new file mode 100644
index 0000000..243a217
--- /dev/null
+++ b/chapters/pt-BR/chapter0/get_ready.mdx
@@ -0,0 +1,39 @@
+# Prepare-se para iniciar o curso
+
+Esperamos que você esteja animado para começar o curso, e projetamos esta página para garantir que você tenha tudo o que precisa para vir com tudo!
+
+## Passo 1. Inscreva-se
+
+Para ficar por dentro de todas as atualizações e eventos sociais especiais, inscreva-se no curso.
+
+[👉 INSCREVA-SE](http://eepurl.com/insvcI)
+
+## Passo 2. Crie uma conta no Hugging Face
+
+Se você ainda não tem uma, crie uma conta no Hugging Face (é grátis). Você precisará dela para completar tarefas práticas, receber seu certificado de conclusão, explorar modelos pré-treinados, acessar datasets e muito mais.
+
+[👉 CRIE UMA CONTA NO HUGGING FACE](https://huggingface.co/join)
+
+## Passo 3. Revise os fundamentos (se necessário)
+
+Presumimos que você esteja familiarizado com os conceitos básicos de deep learning e o uso de transformers. Se você precisar revisar seu entendimento sobre transformers, veja o nosso [Curso de NLP](https://huggingface.co/course/chapter1/1).
+
+## Passo 4. Verifique sua configuração
+
+Para acompanhar os materiais do curso, você precisará de:
+- Um computador com conexão à internet
+- [Google Colab](https://colab.research.google.com) para os exercícios práticos. A versão gratuita é suficiente. Se você nunca usou o Google Colab antes, confira este [caderno de introdução oficial](https://colab.research.google.com/notebooks/intro.ipynb?hl=pt-BR).
+
+
+
+Como alternativa à versão gratuita do Google Colab, você pode usar seu próprio ambiente local ou o Kaggle. O Kaggle Notebooks oferece um número fixo de horas de GPU e têm funcionalidades semelhantes ao Google Colab, no entanto, existem diferenças quando se trata de compartilhar seus modelos no 🤗 Hub (para completar tarefas, por exemplo). Se você decidir usar o Kaggle como sua ferramenta de escolha, confira o [notebook de exemplo do Kaggle](https://www.kaggle.com/code/michaelshekasta/test-notebook) criado por [@michaelshekasta](https://github.com/michaelshekasta). Este notebook demonstra como você pode treinar e compartilhar seu modelo treinado no 🤗 Hub.
+
+
+
+## Passo 5. Junte-se à comunidade
+
+Inscreva-se em nosso Discord, o lugar onde você pode trocar ideias com seus colegas de classe e entrar em contato conosco (a equipe do Hugging Face).
+
+[👉 JUNTE-SE À COMUNIDADE NO DISCORD](http://hf.co/join/discord)
+
+Para saber mais sobre nossa comunidade no Discord e como aproveitar ao máximo, confira a [próxima página](community).
diff --git a/chapters/pt-BR/chapter0/introduction.mdx b/chapters/pt-BR/chapter0/introduction.mdx
new file mode 100644
index 0000000..8b51267
--- /dev/null
+++ b/chapters/pt-BR/chapter0/introduction.mdx
@@ -0,0 +1,86 @@
+# Bem vindo ao curso de Áudio do Hugging Face!
+
+Caro aluno,
+
+Bem vindo a este curso sobre o uso de transformers para áudio. Cada vez mais os transformers se provam como uma das arquiteturas deep learning mais poderosas e versáteis, capaz de alcançar resultados de ponta em uma variedade de tarefas, incluindo o processamento de linguagem natural, visão computacional, e mais recentemente, processamento de áudio.
+
+Neste curso, nós iremos explorar como os transformers podem ser usados em dados de áudio. Você aprenderá como usá-los para lidar com uma série de tarefas relacionadas ao áudio. Se você está interessado em reconhecimento de fala, classificação de áudio, ou geração de fala a partir do texto, os transformers e este curso vão atender as suas necessidades.
+
+Para te dar um gostinho do que esses modelos podem fazer, diga algumas palavras na demo abaixo e veja o modelo transcrevê-las em tempo real!
+
+
+
+Através do curso, você entenderá detalhes do trabalho com dados de áudio, aprenderá sobre as diferentes arquiteturas de transformers e irá treinar seu próprio transformer de áudio aproveitando poderosos modelos pré-treinados.
+
+Este curso é voltado para estudantes com algum conhecimento prévio em deep learning e transformers. Nenhuma expertise em processamento de áudio é necessária. Se você precisa revisar seu conhecimento de transformers, dê uma olhada no nosso [curso de NLP](https://huggingface.co/course/chapter1/1) que aborda em detalhes os conceitos básicos de transformers.
+
+## Conheça a equipe do curso
+
+**Sanchit Gandhi, Engenheiro de Pesquisa em Machine Learning no Hugging Face**
+
+Olá! Me chamo Sanchit e sou o engenheiro de pesquisa em machine learning para áudio no time de open-source do Hugging Face 🤗. Meu foco principal é o reconhecimento e a tradução automáticos de fala, com o objetivo atual de tornar os modelos de fala mais rápidos, leves e fáceis de usar!
+
+**Matthijs Hollemans, Engenheiro de Machine Learning no Hugging Face**
+
+Me chamo Matthijs, e sou o engenheiro de machine learning para áudio no time de open source do Hugging Face. Eu também sou o autor do livro sobre como escrever um sintetizador de som e crio plugins de áudio no meu tempo livre.
+
+**Maria Khalusova, Cursos & Documentação no Hugging Face**
+
+Eu sou Maria e crio conteúdo educacional e documentação para fazer os Transformers e outras ferramentas open source ainda mais acessíveis. Eu simplifico conceitos técnicos complexos e ajudo as pessoas a iniciarem em tecnologias de ponta.
+
+**Vaibhav Srivastav, ML Developer Advocate Engineer no Hugging Face**
+
+Me chamo Vaibhav (VB) e sou o Engenheiro Developer Advocate para áudio no time de open source do Hugging Face. Eu estudo soluções de Texto para Fala de baixo recurso e ajudo a levar pesquisas estado da arte em fala para o grande público.
+
+## Estrutura do Curso
+
+O curso está estruturado em várias unidades que abordam diversos tópicos em detalhes:
+
+* [Unidade 1](https://huggingface.co/learn/audio-course/chapter1): aprenda sobre detalhes do trabalho com dados de áudio, incluindo técnicas de processamento de áudio e preparação de dados.
+* [Unidade 2](https://huggingface.co/learn/audio-course/chapter2): conheça aplicações de áudio e aprenda como usar 🤗 Transformers pipelines para diferentes tarefas, como classificação de áudio e reconhecimento de fala.
+* [Unidade 3](https://huggingface.co/learn/audio-course/chapter3): explore arquiteturas de transformers de áudio, aprenda como eles se diferem e para quais tarefas são mais adequados
+* [Unidade 4](https://huggingface.co/learn/audio-course/chapter4): aprenda como fazer seu próprio classificador de gênero musical
+* [Unidade 5](https://huggingface.co/learn/audio-course/chapter5): mergulhe no reconhecimento de fala e construa um modelo que faça transcrição de reuniões gravadas
+* [Unidade 6](https://huggingface.co/learn/audio-course/chapter6): aprenda como gerar fala a partir do texto
+* [Unidade 7](https://huggingface.co/learn/audio-course/chapter7): aprenda como construir aplicações do mundo real com transformers
+
+Cada unidade inclui uma parte teórica, onde você irá compreender os conceitos e as técnicas. Ao longo do curso, nós vamos fornecer questionários para te ajudar a testar seu conhecimento e reforçar seu aprendizado. Alguns capítulos incluem exercícios práticos, onde você terá a oportunidade de testar o que você aprendeu.
+
+No final do curso, você terá uma base sólida sobre o uso de transformers para os dados de áudio e está pronto para aplicar essas técnicas em uma varidade de tarefas relacionadas à áudio.
+
+Este curso será lançado em vários blocos consecutivos respeitando o seguinte agendamento:
+
+| Unidades |Data de Publicação |
+|-------------------------------|-------------------|
+| Unidade 0, 1 e 2 | 14 de Junho 2023 |
+| Unidade 3 e 4 | 21 de Junho 2023 |
+| Unidade 5 | 28 de Junho 2023 |
+| Unidade 6 | 5 de Julho 2023 |
+| Unidade 7 e 8 | 12 de Julho 2023 |
+
+## Trilhas de aprendizado e certificação
+
+Não existe um jeito certo ou errado de fazer este curso. Todos os materiais nesse curso são 100% gratuitos, públicos e open source.
+Você pode fazer o curso no seu próprio ritmo, contudo, nós recomendamos ir na ordem numérica das unidades.
+
+Se você quiser obter um certificado ao completar o curso, nós oferecemos duas opções:
+
+| Tipo Certificado | Requisitos |
+|---|--------------------------------------------------------------------|
+| Certificado de conclusão | Complete 80% dos exercícios práticos conforme as instruções |
+| Certificado de honras | Complete 100% dos exercícios práticos conforme as instruções |
+
+Cada exercício determina seus critérios de conclusão. Quando você concluir exercícios suficiente para se qualificar para algum dos certificados, vá a última unidade para aprender como você pode obtê-lo. Bons estudos!
+
+## Inscreva-se no curso
+
+As unidades deste curso serão lançadas gradualmente ao longo de algumas semanas. Encorajamos você a se inscrever nas atualizações, assim você fica sabendo das unidades assim que elas forem lançadas. Ao se inscrever nas atualizações do curso, o estudante também ficará sabendo em primeira mão, sobre eventos sociais que nós planejamos realizar.
+
+[INSCREVA-SE](http://eepurl.com/insvcI)
+
+Aproveite o curso!
\ No newline at end of file
diff --git a/chapters/pt-BR/chapter1/audio_data.mdx b/chapters/pt-BR/chapter1/audio_data.mdx
new file mode 100644
index 0000000..609f439
--- /dev/null
+++ b/chapters/pt-BR/chapter1/audio_data.mdx
@@ -0,0 +1,214 @@
+# Introdução a dados de áudio
+
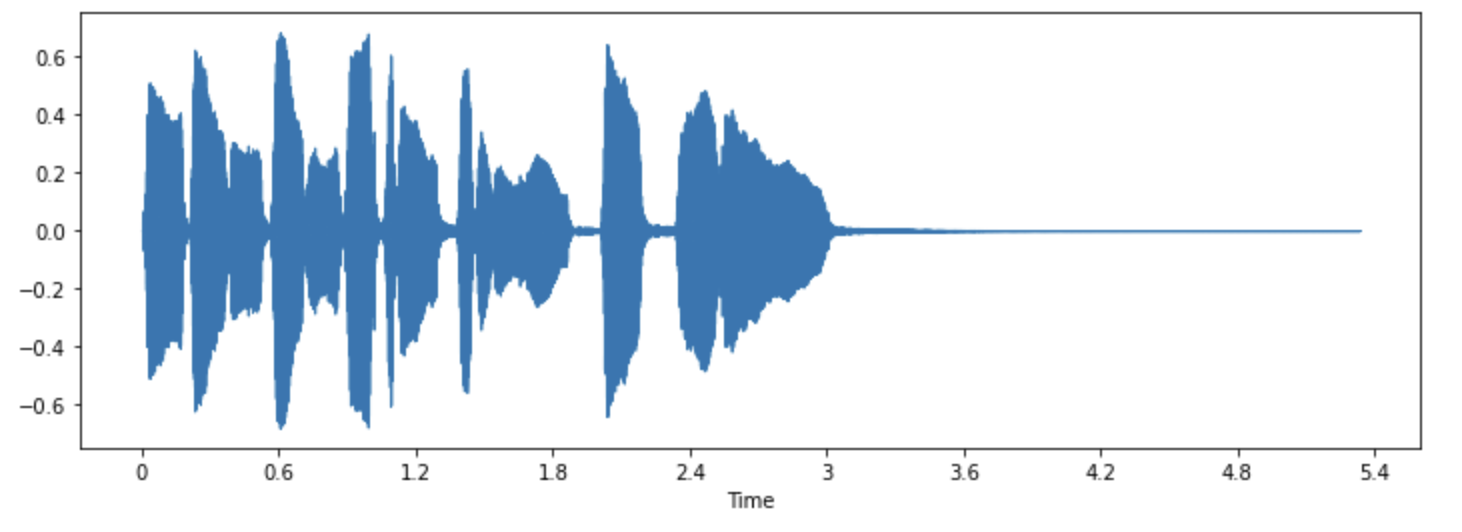
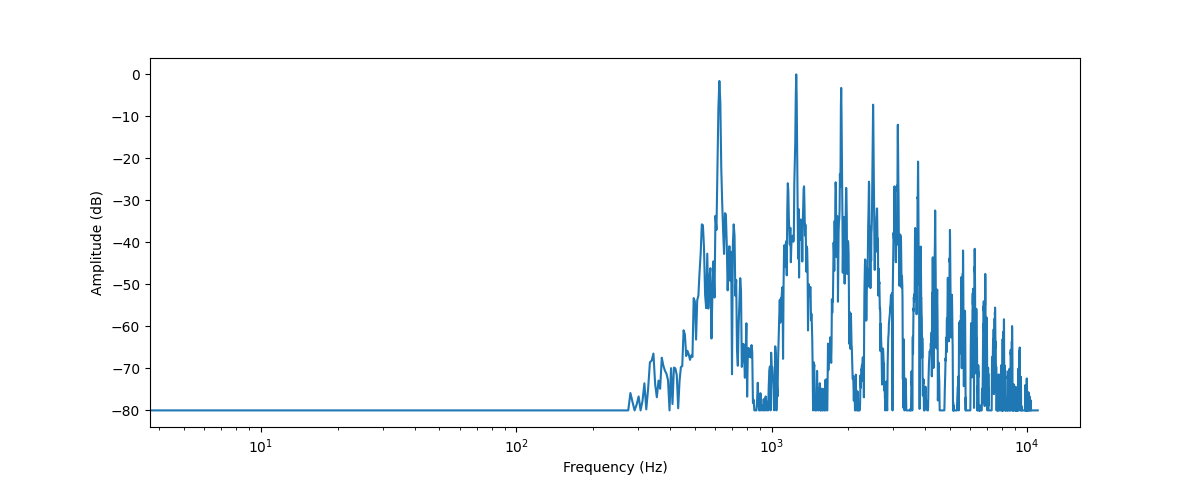
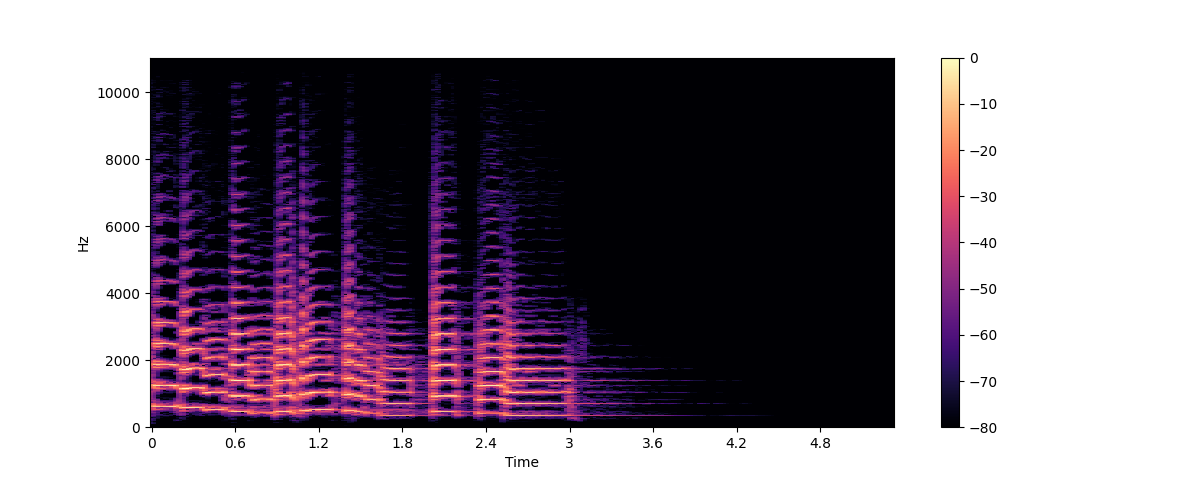
+Por natureza, uma onda sonora é um sinal contínuo, o que significa que contém um número infinito de valores de sinal em um determinado tempo. Isso traz problemas para dispositivos digitais que esperam arrays finitos. Para ser processada, armazenada e transmitida por dispositivos digitais, a onda sonora contínua precisa ser convertida em uma série de valores discretos, conhecidos como representação digital.
+
+Se você olhar para qualquer dataset de áudio, encontrará arquivos digitais com trechos de som, como narração de texto ou música. Você pode encontrar diferentes formatos de arquivo, como `.wav` (Waveform Audio File), `.flac` (Free Lossless Audio Codec) e `.mp3` (MPEG-1 Audio Layer 3). Esses formatos diferem principalmente na forma como comprimem a representação digital do sinal de áudio.
+
+Vamos dar uma olhada em como saímos de um sinal contínuo para essa representação. O sinal analógico é primeiro capturado por um microfone, que converte as ondas sonoras em um sinal elétrico. O sinal elétrico é então digitalizado por um Conversor Analógico-Digital para obter a representação digital por meio da amostragem.
+
+## Amostragem e taxa de amostragem
+
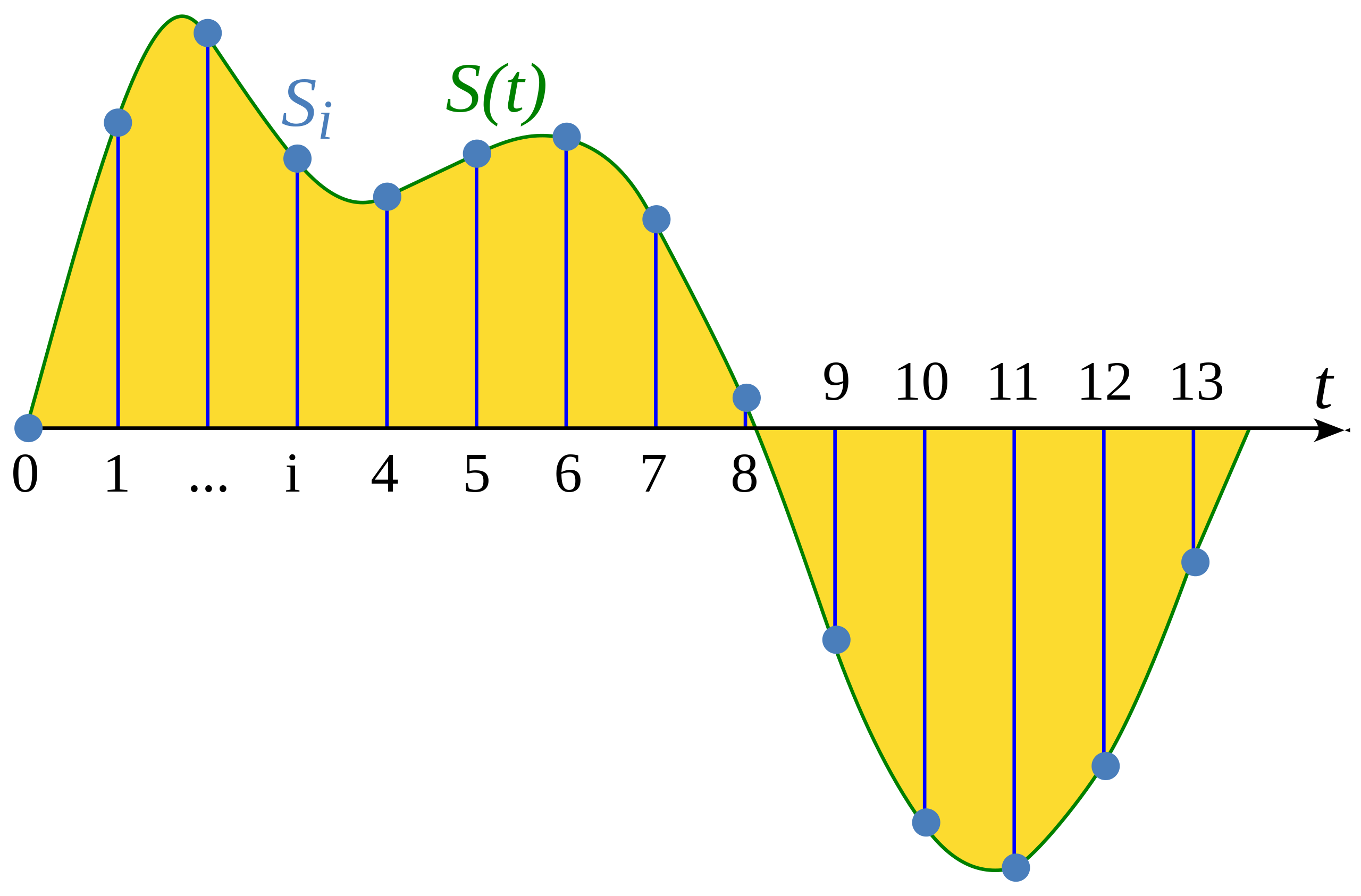
+Amostragem (sampling) é o processo de medir o valor de um sinal contínuo em etapas (amostras) que possuem o mesmo tempo. A forma da onda que foi amostrada é _discreta_, pois contém um número finito dos valores do sinal em intervalos uniformes.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+