diff --git a/chapters/th/_toctree.yml b/chapters/th/_toctree.yml
index 7638d0516..39b7a199d 100644
--- a/chapters/th/_toctree.yml
+++ b/chapters/th/_toctree.yml
@@ -11,4 +11,20 @@
- title: 3. การ fine-tune โมเดลที่ผ่านการเทรนมาแล้ว (pretrained model)
sections:
- local: chapter3/1
- title: บทนำ
\ No newline at end of file
+ title: บทนำ
+
+- title: 4. การแบ่งปันโมเดลและ tokenizers
+ sections:
+ - local: chapter4/1
+ title: The Hugging Face Hub
+ - local: chapter4/2
+ title: การใช้งานโมเดลที่ผ่านการเทรนมาแล้ว (pretrained models)
+ - local: chapter4/3
+ title: การแบ่งปันโมเดลที่ผ่านการเทรนมาแล้ว (pretrained models)
+ - local: chapter4/4
+ title: การสร้างการ์ดโมเดล (model card)
+ - local: chapter4/5
+ title: จบพาร์ทที่ 1!
+ - local: chapter4/6
+ title: คำถามท้ายบท
+ quiz: 4
\ No newline at end of file
diff --git a/chapters/th/chapter4/1.mdx b/chapters/th/chapter4/1.mdx
new file mode 100644
index 000000000..c4a18cd1e
--- /dev/null
+++ b/chapters/th/chapter4/1.mdx
@@ -0,0 +1,17 @@
+# The Hugging Face Hub
+
+[Hugging Face Hub](https://huggingface.co/) –- เว็บไซต์หลักของเรา –- เป็นแพลตฟอร์มกลางที่ทุกคนสามารถค้นหาโมเดลและชุดข้อมูลที่ล้ำสมัยที่สุด (state-of-the-art) และสามารถนำไปใช้งาน รวมถึงมีส่วนร่วมได้ เรามีโมเดลที่เปิดให้ใช้ได้อย่างเป็นสาธารณะที่หลากหลายมากกว่า 10,000 โมเดลให้เลือกใช้ ซึ่งในบทนี้เราจะมาเจาะลึกลงในเรื่องของโมเดล และเราจะพูดถึงชุดข้อมูลในบทที่ 5
+
+โมเดลใน hub ของเราไม่ได้มีแค่ 🤗 Transformers หรือ NLP เท่านั้น ยังมีโมเดลจาก [Flair](https://github.com/flairNLP/flair) และ [AllenNLP](https://github.com/allenai/allennlp) สำหรับงาน NLP, [Asteroid](https://github.com/asteroid-team/asteroid) และ [pyannote](https://github.com/pyannote/pyannote-audio) สำหรับงานเสียง และ [timm](https://github.com/rwightman/pytorch-image-models) สำหรับงานภาพ และอื่นๆอีกมากมาย
+
+โมเดลเหล่านี้ถูกเก็บไว้ในรูปแบบของ Git repository ซึ่งนั่นสามารถทำให้เกิดการกำหนดเวอร์ชั่น (versioning) และการทำซ้ำได้ (reproducibility) การแบ่งปันโมเดลบน hub นั้นหมายถึงการปล่อยโมเดลสู่ชุมชน และทำให้ผู้คนสามารถเข้าถึงโมเดลได้อย่างง่ายดาย รวมถึงช่วยกำจัดความจำเป็นในการเทรนโมเดลด้วยตัวเอง และทำให้สามารถแบ่งปันและใช้งานได้ง่ายอีกด้วย
+
+มากไปกว่านั้นการแบ่งปันโมเดลบน hub ยังเป็นการปล่อย (deploy) API สำหรับใช้โมเดลนั้นในการทำนายผลด้วย ซึ่งทุกคนสามารถนำไปทดสอบใช้งานกับข้อมูลอินพุตที่กำหนดได้เอง (custom inputs) และใช้คู่กับเครื่องมือที่เหมาะสมได้โดยตรงจากหน้าเว็บไซต์ของโมเดลนั้นโดยไม่มีค่าใช้จ่าย
+
+ส่วนที่ดีที่สุดคือ การแบ่งปันและใช้โมเดลสาธารณะบน hub นั้นไม่มีค่าใช้จ่ายโดยสิ้นเชิง! ซึ่งเรามี [แผนแบบจ่าย](https://huggingface.co/pricing) ถ้าหากคุณต้องการจะแบ่งปันโมเดลอย่างเป็นส่วนตัว
+
+วีดีโอข้างล่างนี้แสดงวิธีการนำทางไปหน้าต่างๆใน hub
+
+
+
+ในส่วนนี้คุณจำเป็นที่จะต้องมีบัญชี huggingface.co เพื่อที่จะทำตาม เพราะเราจะมีการสร้างและจัดการ repositories บน Hugging Face Hub: [สร้างบัญชี](https://huggingface.co/join)
diff --git a/chapters/th/chapter4/2.mdx b/chapters/th/chapter4/2.mdx
new file mode 100644
index 000000000..22972bd41
--- /dev/null
+++ b/chapters/th/chapter4/2.mdx
@@ -0,0 +1,96 @@
+
+
+# การใช้งานโมเดลที่ผ่านการเทรนมาแล้ว (pretrained models)
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Model Hub ทำให้การเลือกใช้โมเดลที่เหมาะสมเป็นเรื่องง่ายขนาดที่ว่า การใช้งานมันคู่กับ library ปลายน้ำสามารถเสร็จได้ในการใช้โค้ดเพียงไม่กี่บรรทัดเท่านั้น มาดูวิธีใช้โมเดลพวกนี้และการให้ความช่วยเหลือกับชุมชนกันดีกว่า
+
+สมมุติว่าเรากำลังมองหาโมเดลภาษาฝรั่งเศสที่สามารถเติมคำที่หายไปได้ (mask filling)
+
+
+

+
+

+
+

+
+

+
+
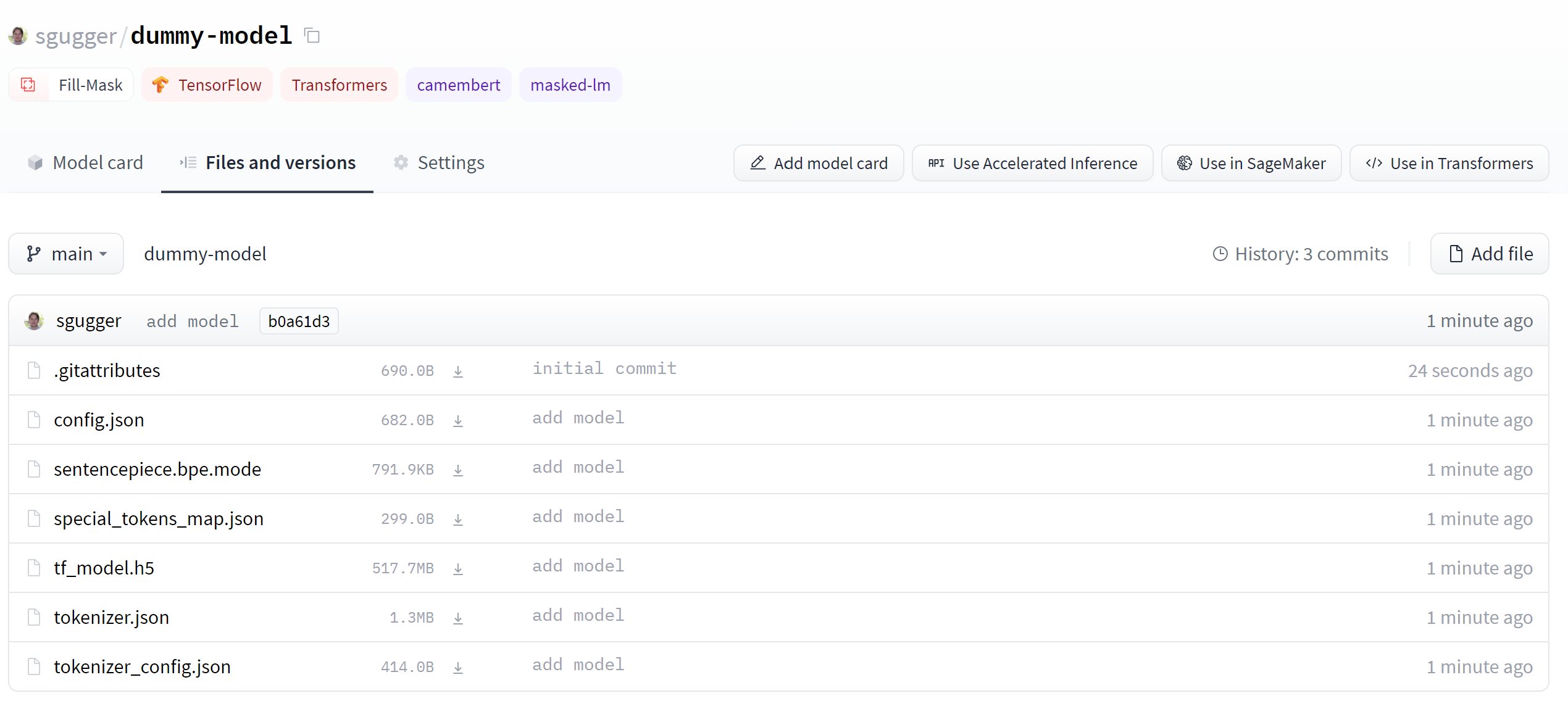
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
push_to_hub และใช้มันในการดันพวกมันขึ้นไปยัง repo ที่กำหนดได้ มีอะไรอีกที่คุณสามารถแบ่งปันได้?",
+ correct: true
+ },
+ {
+ text: "model",
+ explain: "ถูกต้องแล้ว! โมเดลทั้งหมดมีคำสั่ง push_to_hub และใช้มันในการดันพวกมันและไฟล์กำหนดค่าของพวกมันขึ้นไปยัง repo ที่กำหนดได้ แต่นั่นก็ไม่ใช่ทั้งหมดที่คุณแบ่งปันได้",
+ correct: true
+ },
+ {
+ text: "Trainer",
+ explain: "ถูกต้อง — Trainer ก็มีคำสั่ง push_to_hub และใช้มันในการอัพโหลดโมเดล, ไฟล์กำหนดค่า, tokenizer และดราฟของการ์ดโมเดลไปยัง repo ที่กำหนดได้ ลองตอบข้ออื่นดู!",
+ correct: true
+ }
+ ]}
+/>
+{:else}
+push_to_hub และใช้มันในการดันไฟล์ทั้งหมดของ tokenizer (คำศัพท์ (vocabulary), สถาปัตยกรรมของ tokenizer และอื่นๆ) ไปยัง repo ที่กำหนดได้ แต่นี่ก็ไม่ใช่คำตอบที่ถูกเพียงข้อเดียว!",
+ correct: true
+ },
+ {
+ text: "model configuration",
+ explain: "ถูกต้องแล้ว! ไฟล์สำหรับกำหนดค่าของโมเดล (model configurations) ทั้งหมดมีคำสั่ง push_to_hub และใช้มันในการดันพวกมันขึ้นไปยัง repo ที่กำหนดได้ มีอะไรอีกที่คุณสามารถแบ่งปันได้?",
+ correct: true
+ },
+ {
+ text: "model",
+ explain: "ถูกต้องแล้ว! โมเดลทั้งหมดมีคำสั่ง push_to_hub และใช้มันในการดันพวกมันและไฟล์กำหนดค่าของพวกมันขึ้นไปยัง repo ที่กำหนดได้ แต่นั่นก็ไม่ใช่ทั้งหมดที่คุณแบ่งปันได้",
+ correct: true
+ },
+ {
+ text: "ทั้งหมดที่กล่าวมารวมกับ callback ที่อุทิศให้",
+ explain: "ถูกต้อง — โดยปกติ PushToHubCallback จะส่งวัตถุทั้งหมดเหล่านั้นไปยัง repo ระหว่างการเทรน",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### 6. อะไรคือขั้นตอนแรกในการใช้คำสั่ง `push_to_hub()` หรือเครื่องมือ CLI?
+
+
+
+### 7. คุณกำลังใช้งานโมเดลและ tokenizer อยู่ — คุณจะสามารถอัพโหลดพวกมันขึ้นไปบน Hub ได้อย่างไร?
+
+huggingface_hub utility",
+ explain: "โมเดลและ tokenizers ถ้ารับประโยชน์จาก huggingface_hub utilities อยู่แล้ว: ไม่จำเป็นจะต้องมีการคลุมเพิ่ม!"
+ },
+ {
+ text: "โดยการบันทึกพวกมันลงบนเครื่องและเรียกใช้คำสั่ง transformers-cli upload-model",
+ explain: "ไม่มีคำสั่ง upload-model นี้อยู่"
+ }
+ ]}
+/>
+
+### 8. มีการดำเนินการ git (git operations) ใดบ้างที่คุณสามารถทำได้กับคลาส `Repository`?
+
+git_commit() มีไว้สำหรับสิ่งนี้",
+ correct: true
+ },
+ {
+ text: "pull",
+ explain: "นั่นคือวัตถุประสงค์ของคำสั่ง git_pull()",
+ correct: true
+ },
+ {
+ text: "push",
+ explain: "คำสั่ง git_push() มีไว้ทำสิ่งนี้",
+ correct: true
+ },
+ {
+ text: "merge",
+ explain: "ไม่ การดำเนินการนี้ไม่สามารถทำได้กับ API นี้"
+ }
+ ]}
+/>