Add all 2024 conference sessions to your calendar. You can add this address to your online calendaring system if you want to receive updates dynamically.
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
VIS Full Papers
Look, Learn, Language Models
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Nicole Sultanum
6 presentations in this session. See more »
VIS Full Papers
Where the Networks Are
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Oliver Deussen
6 presentations in this session. See more »
VIS Full Papers
Human and Machine Visualization Literacy
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Bum Chul Kwon
6 presentations in this session. See more »
VIS Full Papers
Flow, Topology, and Uncertainty
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Bei Wang
6 presentations in this session. See more »
2024-10-18T14:15:00Z – 2024-10-18T15:00:00Z
Conference Events
Test of Time Awards
2024-10-18T14:15:00Z – 2024-10-18T15:00:00Z
Chair: Ross Maciejewski
1 presentations in this session. See more »
2024-10-18T15:00:00Z – 2024-10-18T16:30:00Z
Conference Events
IEEE VIS Capstone and Closing
2024-10-18T15:00:00Z – 2024-10-18T16:30:00Z
Chair: Paul Rosen, Kristi Potter, Remco Chang
3 presentations in this session. See more »
2024-10-15T12:30:00Z – 2024-10-15T13:45:00Z
Conference Events
Opening Session
2024-10-15T12:30:00Z – 2024-10-15T13:45:00Z
Chair: Paul Rosen, Kristi Potter, Remco Chang
2 presentations in this session. See more »
2024-10-15T14:15:00Z – 2024-10-15T15:45:00Z
VIS Short Papers
VGTC Awards & Best Short Papers
2024-10-15T14:15:00Z – 2024-10-15T15:45:00Z
Chair: Chaoli Wang
4 presentations in this session. See more »
2024-10-15T15:35:00Z – 2024-10-15T16:00:00Z
Conference Events
VIS Governance
2024-10-15T15:35:00Z – 2024-10-15T16:00:00Z
Chair: Petra Isenberg, Jean-Daniel Fekete
2 presentations in this session. See more »
2024-10-15T16:00:00Z – 2024-10-15T17:30:00Z
VIS Full Papers
Best Full Papers
2024-10-15T16:00:00Z – 2024-10-15T17:30:00Z
Chair: Claudio Silva
6 presentations in this session. See more »
2024-10-15T18:00:00Z – 2024-10-15T19:00:00Z
VIS Arts Program
VISAP Keynote: The Golden Age of Visualization Dissensus
2024-10-15T18:00:00Z – 2024-10-15T19:00:00Z
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner, Alberto Cairo
0 presentations in this session. See more »
2024-10-15T19:00:00Z – 2024-10-15T21:00:00Z
Conference Events
Posters
2024-10-15T19:00:00Z – 2024-10-15T21:00:00Z
0 presentations in this session. See more »
VIS Arts Program
VISAP Artist Talks
2024-10-15T19:00:00Z – 2024-10-15T21:00:00Z
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
16 presentations in this session. See more »
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
VIS Full Papers
Visualization Recommendation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Johannes Knittel
6 presentations in this session. See more »
VIS Full Papers
Model-checking and Validation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Michael Correll
6 presentations in this session. See more »
VIS Full Papers
Embeddings and Document Spatialization
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Alex Endert
6 presentations in this session. See more »
VIS Short Papers
Short Papers: Perception and Representation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Anjana Arunkumar
8 presentations in this session. See more »
VIS Panels
Panel: Human-Centered Computing Research in South America: Status Quo, Opportunities, and Challenges
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Chaoli Wang
0 presentations in this session. See more »
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
VIS Full Papers
Applications: Sports. Games, and Finance
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Marc Streit
6 presentations in this session. See more »
VIS Full Papers
Visual Design: Sketching and Labeling
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Jonathan C. Roberts
6 presentations in this session. See more »
VIS Full Papers
Topological Data Analysis
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Ingrid Hotz
6 presentations in this session. See more »
VIS Short Papers
Short Papers: Text and Multimedia
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Min Lu
8 presentations in this session. See more »
VIS Panels
Panel: (Yet Another) Evaluation Needed? A Panel Discussion on Evaluation Trends in Visualization
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Ghulam Jilani Quadri, Danielle Albers Szafir, Arran Zeyu Wang, Hyeon Jeon
0 presentations in this session. See more »
VIS Arts Program
VISAP Pictorials
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
8 presentations in this session. See more »
2024-10-17T15:30:00Z – 2024-10-17T16:00:00Z
Conference Events
IEEE VIS 2025 Kickoff
2024-10-17T15:30:00Z – 2024-10-17T16:00:00Z
Chair: Johanna Schmidt, Kresimir Matković, Barbora Kozlíková, Eduard Gröller
1 presentations in this session. See more »
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
VIS Full Papers
Once Upon a Visualization
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Marti Hearst
6 presentations in this session. See more »
VIS Full Papers
Visualization Design Methods
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Miriah Meyer
6 presentations in this session. See more »
VIS Full Papers
The Toolboxes of Visualization
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Dominik Moritz
6 presentations in this session. See more »
VIS Short Papers
Short Papers: Analytics and Applications
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Anna Vilanova
8 presentations in this session. See more »
CG&A Invited Partnership Presentations
CG&A: Systems, Theory, and Evaluations
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Francesca Samsel
6 presentations in this session. See more »
VIS Panels
Panel: Vogue or Visionary? Current Challenges and Future Opportunities in Situated Visualizations
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Michelle A. Borkin, Melanie Tory
0 presentations in this session. See more »
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
VIS Full Papers
Journalism and Public Policy
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Sungahn Ko
6 presentations in this session. See more »
VIS Full Papers
Applications: Industry, Computing, and Medicine
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Joern Kohlhammer
6 presentations in this session. See more »
VIS Full Papers
Accessibility and Touch
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Narges Mahyar
6 presentations in this session. See more »
VIS Full Papers
Motion and Animated Notions
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Catherine d'Ignazio
6 presentations in this session. See more »
VIS Short Papers
Short Papers: AI and LLM
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Cindy Xiong Bearfield
8 presentations in this session. See more »
VIS Panels
Panel: Dear Younger Me: A Dialog About Professional Development Beyond The Initial Career Phases
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Robert M Kirby, Michael Gleicher
0 presentations in this session. See more »
2024-10-16T12:30:00Z – 2024-10-16T13:30:00Z
VIS Full Papers
Virtual: VIS from around the world
2024-10-16T12:30:00Z – 2024-10-16T13:30:00Z
Chair: Mahmood Jasim
6 presentations in this session. See more »
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
VIS Full Papers
Text, Annotation, and Metaphor
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Melanie Tory
6 presentations in this session. See more »
VIS Full Papers
Immersive Visualization and Visual Analytics
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Lingyun Yu
6 presentations in this session. See more »
VIS Full Papers
Machine Learning for Visualization
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Joshua Levine
6 presentations in this session. See more »
VIS Short Papers
Short Papers: Graph, Hierarchy and Multidimensional
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Alfie Abdul-Rahman
8 presentations in this session. See more »
VIS Panels
Panel: What Do Visualization Art Projects Bring to the VIS Community?
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Xinhuan Shu, Yifang Wang, Junxiu Tang
0 presentations in this session. See more »
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
VIS Full Papers
Biological Data Visualization
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Nils Gehlenborg
6 presentations in this session. See more »
VIS Full Papers
Judgment and Decision-making
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Wenwen Dou
6 presentations in this session. See more »
VIS Full Papers
Time and Sequences
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Silvia Miksch
6 presentations in this session. See more »
VIS Full Papers
Dimensionality Reduction
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Jian Zhao
6 presentations in this session. See more »
VIS Full Papers
Urban Planning, Construction, and Disaster Management
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Siming Chen
6 presentations in this session. See more »
VIS Arts Program
VISAP Papers
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
6 presentations in this session. See more »
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
VIS Full Papers
Natural Language and Multimodal Interaction
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Ana Crisan
6 presentations in this session. See more »
VIS Full Papers
Collaboration and Communication
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Vidya Setlur
6 presentations in this session. See more »
VIS Full Papers
Perception and Cognition
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Bernhard Preim
6 presentations in this session. See more »
VIS Short Papers
Short Papers: Scientific and Immersive Visualization
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Bei Wang
8 presentations in this session. See more »
CG&A Invited Partnership Presentations
CG&A: Analytics and Applications
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Bruce Campbell
6 presentations in this session. See more »
VIS Panels
Panel: 20 Years of Visual Analytics
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: David Ebert, Wolfgang Jentner, Ross Maciejewski, Jieqiong Zhao
0 presentations in this session. See more »
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
VIS Full Papers
Designing Palettes and Encodings
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Khairi Rheda
6 presentations in this session. See more »
VIS Full Papers
Of Nodes and Networks
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Carolina Nobre
6 presentations in this session. See more »
VIS Full Papers
Scripts, Notebooks, and Provenance
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Alex Lex
6 presentations in this session. See more »
VIS Short Papers
Short Papers: System design
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Chris Bryan
8 presentations in this session. See more »
VIS Panels
Panel: Past, Present, and Future of Data Storytelling
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Haotian Li, Yun Wang, Benjamin Bach, Sheelagh Carpendale, Fanny Chevalier, Nathalie Riche
0 presentations in this session. See more »
Application Spotlights
Application Spotlight: Visualization within the Department of Energy
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Ana Crisan, Menna El-Assady
0 presentations in this session. See more »
2024-10-16T19:00:00Z – 2024-10-16T19:30:00Z
Conference Events
IEEE VIS Town Hall
2024-10-16T19:00:00Z – 2024-10-16T19:30:00Z
Chair: Ross Maciejewski
0 presentations in this session. See more »
2024-10-16T19:30:00Z – 2024-10-16T20:30:00Z
VIS Panels
Panel: VIS Conference Futures: Community Opinions on Recent Experiences, Challenges, and Opportunities for Hybrid Event Formats
2024-10-16T19:30:00Z – 2024-10-16T20:30:00Z
Chair: Matthew Brehmer, Narges Mahyar
0 presentations in this session. See more »
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
VAST Challenge
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: R. Jordan Crouser, Steve Gomez, Jereme Haack
13 presentations in this session. See more »
VISxAI: 7th Workshop on Visualization for AI Explainability
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Alex Bäuerle, Angie Boggust, Fred Hohman
12 presentations in this session. See more »
1st Workshop on Accessible Data Visualization
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Brianna Wimer, Laura South
7 presentations in this session. See more »
First-Person Visualizations for Outdoor Physical Activities: Challenges and Opportunities
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Charles Perin, Tica Lin, Lijie Yao, Yalong Yang, Maxime Cordeil, Wesley Willett
0 presentations in this session. See more »
EduVis: Workshop on Visualization Education, Literacy, and Activities
EduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 1)
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach
3 presentations in this session. See more »
Visualization Analysis and Design
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Tamara Munzner
0 presentations in this session. See more »
Developing Immersive and Collaborative Visualizations with Web-Technologies
Developing Immersive and Collaborative Visualizations with Web Technologies
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: David Saffo
0 presentations in this session. See more »
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
VDS: Visualization in Data Science Symposium
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Ana Crisan, Dylan Cashman
6 presentations in this session. See more »
LDAV: 13th IEEE Symposium on Large Data Analysis and Visualization
LDAV: 14th IEEE Symposium on Large Data Analysis and Visualization
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Silvio Rizzi, Gunther Weber, Guido Reina, Ken Moreland
6 presentations in this session. See more »
Bio+MedVis Challenges
Bio+Med+Vis Workshop
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Barbora Kozlikova, Nils Gehlenborg, Laura Garrison, Eric Mörth, Morgan Turner, Simon Warchol
6 presentations in this session. See more »
Workshop on Data Storytelling in an Era of Generative AI
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Xingyu Lan, Leni Yang, Zezhong Wang, Yun Wang, Danqing Shi, Sheelagh Carpendale
4 presentations in this session. See more »
EduVis: Workshop on Visualization Education, Literacy, and Activities
EduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 2)
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Jillian Aurisano, Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
Generating Color Schemes for your Data Visualizations
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Theresa-Marie Rhyne
0 presentations in this session. See more »
Running Online User Studies with the reVISit Framework
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Jack Wilburn
0 presentations in this session. See more »
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
VisInPractice
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Arjun Srinivasan, Ayan Biswas
0 presentations in this session. See more »
SciVis Contest
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Karen Bemis, Tim Gerrits
0 presentations in this session. See more »
BELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization
BELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization (Session 1)
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Anastasia Bezerianos, Michael Correll, Kyle Hall, Jürgen Bernard, Dan Keefe, Mai Elshehaly, Mahsan Nourani
6 presentations in this session. See more »
Progressive Data Analysis and Visualization (PDAV) Workshop.
Progressive Data Analysis and Visualization (PDAV) Workshop
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Alex Ulmer, Jaemin Jo, Michael Sedlmair, Jean-Daniel Fekete
3 presentations in this session. See more »
Uncertainty Visualization: Applications, Techniques, Software, and Decision Frameworks
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Tushar M. Athawale, Chris R. Johnson, Kristi Potter, Paul Rosen, David Pugmire
12 presentations in this session. See more »
Visualization for Climate Action and Sustainability
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Benjamin Bach, Fanny Chevalier, Helen-Nicole Kostis, Mark SubbaRao, Yvonne Jansen, Robert Soden
13 presentations in this session. See more »
LLM4Vis: Large Language Models for Information Visualization
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Enamul Hoque
0 presentations in this session. See more »
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
TopoInVis: Workshop on Topological Data Analysis and Visualization
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Federico Iuricich, Yue Zhang
6 presentations in this session. See more »
BELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization
BELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization (Sesssion 2)
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Anastasia Bezerianos, Michael Correll, Kyle Hall, Jürgen Bernard, Dan Keefe, Mai Elshehaly, Mahsan Nourani
11 presentations in this session. See more »
NLVIZ Workshop: Exploring Research Opportunities for Natural Language, Text, and Data Visualization
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Vidya Setlur, Arjun Srinivasan
11 presentations in this session. See more »
EnergyVis 2024: 4th Workshop on Energy Data Visualization
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Kenny Gruchalla, Anjana Arunkumar, Sarah Goodwin, Arnaud Prouzeau, Lyn Bartram
11 presentations in this session. See more »
VISions of the Future: Workshop on Sustainable Practices within Visualization and Physicalisation
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Georgia Panagiotidou, Luiz Morais, Sarah Hayes, Derya Akbaba, Tatiana Losev, Andrew McNutt
5 presentations in this session. See more »
Enabling Scientific Discovery: A Tutorial for Harnessing the Power of the National Science Data Fabric for Large-Scale Data Analysis
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Amy Gooch
0 presentations in this session. See more »
Preparing, Conducting, and Analyzing Participatory Design Sessions for Information Visualizations
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
Chair: Adriana Arcia
0 presentations in this session. See more »
- associated
VAST Challenge
Bayshore II
Chair: R. Jordan Crouser, Steve Gomez, Jereme Haack
13 presentations in this session. See more »
workshopVISxAI: 7th Workshop on Visualization for AI Explainability
Bayshore I
Chair: Alex Bäuerle, Angie Boggust, Fred Hohman
12 presentations in this session. See more »
workshop1st Workshop on Accessible Data Visualization
Bayshore V
Chair: Brianna Wimer, Laura South
7 presentations in this session. See more »
workshopFirst-Person Visualizations for Outdoor Physical Activities: Challenges and Opportunities
Bayshore VII
Chair: Charles Perin, Tica Lin, Lijie Yao, Yalong Yang, Maxime Cordeil, Wesley Willett
0 presentations in this session. See more »
workshopEduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 1)
Esplanade Suites I + II + III
Chair: Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach
3 presentations in this session. See more »
tutorialVisualization Analysis and Design
Bayshore VI
Chair: Tamara Munzner
0 presentations in this session. See more »
tutorialDeveloping Immersive and Collaborative Visualizations with Web Technologies
Bayshore III
Chair: David Saffo
0 presentations in this session. See more »
- associated
VDS: Visualization in Data Science Symposium
Bayshore I
Chair: Ana Crisan, Dylan Cashman
6 presentations in this session. See more »
associatedLDAV: 14th IEEE Symposium on Large Data Analysis and Visualization
Bayshore II
Chair: Silvio Rizzi, Gunther Weber, Guido Reina, Ken Moreland
6 presentations in this session. See more »
associatedBio+Med+Vis Workshop
Bayshore V
Chair: Barbora Kozlikova, Nils Gehlenborg, Laura Garrison, Eric Mörth, Morgan Turner, Simon Warchol
6 presentations in this session. See more »
workshopWorkshop on Data Storytelling in an Era of Generative AI
Bayshore VII
Chair: Xingyu Lan, Leni Yang, Zezhong Wang, Yun Wang, Danqing Shi, Sheelagh Carpendale
4 presentations in this session. See more »
workshopEduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 2)
Esplanade Suites I + II + III
Chair: Jillian Aurisano, Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
tutorialGenerating Color Schemes for your Data Visualizations
Bayshore VI
Chair: Theresa-Marie Rhyne
0 presentations in this session. See more »
tutorialRunning Online User Studies with the reVISit Framework
Bayshore III
Chair: Jack Wilburn
0 presentations in this session. See more »
- associated
VisInPractice
Bayshore III
Chair: Arjun Srinivasan, Ayan Biswas
0 presentations in this session. See more »
associatedSciVis Contest
Bayshore V
Chair: Karen Bemis, Tim Gerrits
0 presentations in this session. See more »
workshopBELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization (Session 1)
Bayshore I
Chair: Anastasia Bezerianos, Michael Correll, Kyle Hall, Jürgen Bernard, Dan Keefe, Mai Elshehaly, Mahsan Nourani
6 presentations in this session. See more »
workshopProgressive Data Analysis and Visualization (PDAV) Workshop
Bayshore VII
Chair: Alex Ulmer, Jaemin Jo, Michael Sedlmair, Jean-Daniel Fekete
3 presentations in this session. See more »
workshopUncertainty Visualization: Applications, Techniques, Software, and Decision Frameworks
Bayshore VI
Chair: Tushar M. Athawale, Chris R. Johnson, Kristi Potter, Paul Rosen, David Pugmire
12 presentations in this session. See more »
workshopVisualization for Climate Action and Sustainability
Esplanade Suites I + II + III
Chair: Benjamin Bach, Fanny Chevalier, Helen-Nicole Kostis, Mark SubbaRao, Yvonne Jansen, Robert Soden
13 presentations in this session. See more »
tutorialLLM4Vis: Large Language Models for Information Visualization
Bayshore II
Chair: Enamul Hoque
0 presentations in this session. See more »
- workshop
TopoInVis: Workshop on Topological Data Analysis and Visualization
Bayshore III
Chair: Federico Iuricich, Yue Zhang
6 presentations in this session. See more »
workshopBELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization (Sesssion 2)
Bayshore I
Chair: Anastasia Bezerianos, Michael Correll, Kyle Hall, Jürgen Bernard, Dan Keefe, Mai Elshehaly, Mahsan Nourani
11 presentations in this session. See more »
workshopNLVIZ Workshop: Exploring Research Opportunities for Natural Language, Text, and Data Visualization
Bayshore II
Chair: Vidya Setlur, Arjun Srinivasan
11 presentations in this session. See more »
workshopEnergyVis 2024: 4th Workshop on Energy Data Visualization
Bayshore VI
Chair: Kenny Gruchalla, Anjana Arunkumar, Sarah Goodwin, Arnaud Prouzeau, Lyn Bartram
11 presentations in this session. See more »
workshopVISions of the Future: Workshop on Sustainable Practices within Visualization and Physicalisation
Esplanade Suites I + II + III
Chair: Georgia Panagiotidou, Luiz Morais, Sarah Hayes, Derya Akbaba, Tatiana Losev, Andrew McNutt
5 presentations in this session. See more »
tutorialEnabling Scientific Discovery: A Tutorial for Harnessing the Power of the National Science Data Fabric for Large-Scale Data Analysis
Bayshore V
Chair: Amy Gooch
0 presentations in this session. See more »
tutorialPreparing, Conducting, and Analyzing Participatory Design Sessions for Information Visualizations
Bayshore VII
Chair: Adriana Arcia
0 presentations in this session. See more »
- vis
Opening Session
Bayshore I + II + III
Chair: Paul Rosen, Kristi Potter, Remco Chang
2 presentations in this session. See more »
- short
VGTC Awards & Best Short Papers
Bayshore I + II + III
Chair: Chaoli Wang
4 presentations in this session. See more »
- vis
VIS Governance
None
Chair: Petra Isenberg, Jean-Daniel Fekete
2 presentations in this session. See more »
- full
Best Full Papers
Bayshore I + II + III
Chair: Claudio Silva
6 presentations in this session. See more »
- visap
VISAP Keynote: The Golden Age of Visualization Dissensus
Bayshore I + II + III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner, Alberto Cairo
0 presentations in this session. See more »
- visap
VISAP Artist Talks
Bayshore III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
16 presentations in this session. See more »
- full
Virtual: VIS from around the world
Palma Ceia I
Chair: Mahmood Jasim
6 presentations in this session. See more »
- full
Text, Annotation, and Metaphor
Bayshore V
Chair: Melanie Tory
6 presentations in this session. See more »
fullImmersive Visualization and Visual Analytics
Bayshore II
Chair: Lingyun Yu
6 presentations in this session. See more »
fullMachine Learning for Visualization
Bayshore I
Chair: Joshua Levine
6 presentations in this session. See more »
shortShort Papers: Graph, Hierarchy and Multidimensional
Bayshore VI
Chair: Alfie Abdul-Rahman
8 presentations in this session. See more »
panelPanel: What Do Visualization Art Projects Bring to the VIS Community?
Bayshore VII
Chair: Xinhuan Shu, Yifang Wang, Junxiu Tang
0 presentations in this session. See more »
- full
Biological Data Visualization
Bayshore I
Chair: Nils Gehlenborg
6 presentations in this session. See more »
fullJudgment and Decision-making
Bayshore II
Chair: Wenwen Dou
6 presentations in this session. See more »
fullTime and Sequences
Bayshore VI
Chair: Silvia Miksch
6 presentations in this session. See more »
fullDimensionality Reduction
Bayshore V
Chair: Jian Zhao
6 presentations in this session. See more »
fullUrban Planning, Construction, and Disaster Management
Bayshore VII
Chair: Siming Chen
6 presentations in this session. See more »
visapVISAP Papers
Bayshore III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
6 presentations in this session. See more »
- full
Natural Language and Multimodal Interaction
Bayshore I
Chair: Ana Crisan
6 presentations in this session. See more »
fullCollaboration and Communication
Bayshore V
Chair: Vidya Setlur
6 presentations in this session. See more »
fullPerception and Cognition
Bayshore II
Chair: Bernhard Preim
6 presentations in this session. See more »
shortShort Papers: Scientific and Immersive Visualization
Bayshore VI
Chair: Bei Wang
8 presentations in this session. See more »
invitedCG&A: Analytics and Applications
Bayshore III
Chair: Bruce Campbell
6 presentations in this session. See more »
panelPanel: 20 Years of Visual Analytics
Bayshore VII
Chair: David Ebert, Wolfgang Jentner, Ross Maciejewski, Jieqiong Zhao
0 presentations in this session. See more »
- full
Designing Palettes and Encodings
Bayshore II
Chair: Khairi Rheda
6 presentations in this session. See more »
fullOf Nodes and Networks
Bayshore I
Chair: Carolina Nobre
6 presentations in this session. See more »
fullScripts, Notebooks, and Provenance
Bayshore V
Chair: Alex Lex
6 presentations in this session. See more »
shortShort Papers: System design
Bayshore VI
Chair: Chris Bryan
8 presentations in this session. See more »
panelPanel: Past, Present, and Future of Data Storytelling
Bayshore VII
Chair: Haotian Li, Yun Wang, Benjamin Bach, Sheelagh Carpendale, Fanny Chevalier, Nathalie Riche
0 presentations in this session. See more »
applicationApplication Spotlight: Visualization within the Department of Energy
Bayshore III
Chair: Ana Crisan, Menna El-Assady
0 presentations in this session. See more »
- vis
IEEE VIS Town Hall
Bayshore I + II + III
Chair: Ross Maciejewski
0 presentations in this session. See more »
- panel
Panel: VIS Conference Futures: Community Opinions on Recent Experiences, Challenges, and Opportunities for Hybrid Event Formats
Bayshore VII
Chair: Matthew Brehmer, Narges Mahyar
0 presentations in this session. See more »
- full
Visualization Recommendation
Bayshore II
Chair: Johannes Knittel
6 presentations in this session. See more »
fullModel-checking and Validation
Bayshore V
Chair: Michael Correll
6 presentations in this session. See more »
fullEmbeddings and Document Spatialization
Bayshore I
Chair: Alex Endert
6 presentations in this session. See more »
shortShort Papers: Perception and Representation
Bayshore VI
Chair: Anjana Arunkumar
8 presentations in this session. See more »
panelPanel: Human-Centered Computing Research in South America: Status Quo, Opportunities, and Challenges
Bayshore VII
Chair: Chaoli Wang
0 presentations in this session. See more »
- full
Applications: Sports. Games, and Finance
Bayshore V
Chair: Marc Streit
6 presentations in this session. See more »
fullVisual Design: Sketching and Labeling
Bayshore II
Chair: Jonathan C. Roberts
6 presentations in this session. See more »
fullTopological Data Analysis
Bayshore I
Chair: Ingrid Hotz
6 presentations in this session. See more »
shortShort Papers: Text and Multimedia
Bayshore VI
Chair: Min Lu
8 presentations in this session. See more »
panelPanel: (Yet Another) Evaluation Needed? A Panel Discussion on Evaluation Trends in Visualization
Bayshore VII
Chair: Ghulam Jilani Quadri, Danielle Albers Szafir, Arran Zeyu Wang, Hyeon Jeon
0 presentations in this session. See more »
visapVISAP Pictorials
Bayshore III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
8 presentations in this session. See more »
- vis
IEEE VIS 2025 Kickoff
Bayshore I + II + III
Chair: Johanna Schmidt, Kresimir Matković, Barbora Kozlíková, Eduard Gröller
1 presentations in this session. See more »
- full
Once Upon a Visualization
Bayshore V
Chair: Marti Hearst
6 presentations in this session. See more »
fullVisualization Design Methods
Bayshore II
Chair: Miriah Meyer
6 presentations in this session. See more »
fullThe Toolboxes of Visualization
Bayshore I
Chair: Dominik Moritz
6 presentations in this session. See more »
shortShort Papers: Analytics and Applications
Bayshore VI
Chair: Anna Vilanova
8 presentations in this session. See more »
invitedCG&A: Systems, Theory, and Evaluations
Bayshore III
Chair: Francesca Samsel
6 presentations in this session. See more »
panelPanel: Vogue or Visionary? Current Challenges and Future Opportunities in Situated Visualizations
Bayshore VII
Chair: Michelle A. Borkin, Melanie Tory
0 presentations in this session. See more »
- full
Journalism and Public Policy
Bayshore II
Chair: Sungahn Ko
6 presentations in this session. See more »
fullApplications: Industry, Computing, and Medicine
Bayshore V
Chair: Joern Kohlhammer
6 presentations in this session. See more »
fullAccessibility and Touch
Bayshore I
Chair: Narges Mahyar
6 presentations in this session. See more »
fullMotion and Animated Notions
Bayshore III
Chair: Catherine d'Ignazio
6 presentations in this session. See more »
shortShort Papers: AI and LLM
Bayshore VI
Chair: Cindy Xiong Bearfield
8 presentations in this session. See more »
panelPanel: Dear Younger Me: A Dialog About Professional Development Beyond The Initial Career Phases
Bayshore VII
Chair: Robert M Kirby, Michael Gleicher
0 presentations in this session. See more »
- full
Look, Learn, Language Models
Bayshore V
Chair: Nicole Sultanum
6 presentations in this session. See more »
fullWhere the Networks Are
Bayshore VII
Chair: Oliver Deussen
6 presentations in this session. See more »
fullHuman and Machine Visualization Literacy
Bayshore I + II + III
Chair: Bum Chul Kwon
6 presentations in this session. See more »
fullFlow, Topology, and Uncertainty
Bayshore VI
Chair: Bei Wang
6 presentations in this session. See more »
- vis
Test of Time Awards
Bayshore I
Chair: Ross Maciejewski
1 presentations in this session. See more »
- vis
IEEE VIS Capstone and Closing
Bayshore I + II + III
Chair: Paul Rosen, Kristi Potter, Remco Chang
3 presentations in this session. See more »
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
2024-10-15T12:30:00Z – 2024-10-15T13:45:00Z
2024-10-15T14:15:00Z – 2024-10-15T15:45:00Z
2024-10-15T15:35:00Z – 2024-10-15T16:00:00Z
2024-10-15T16:00:00Z – 2024-10-15T17:30:00Z
2024-10-15T18:00:00Z – 2024-10-15T19:00:00Z
2024-10-15T19:00:00Z – 2024-10-15T21:00:00Z
2024-10-16T12:30:00Z – 2024-10-16T13:30:00Z
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
2024-10-16T19:00:00Z – 2024-10-16T19:30:00Z
2024-10-16T19:30:00Z – 2024-10-16T20:30:00Z
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
2024-10-17T15:30:00Z – 2024-10-17T16:00:00Z
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
2024-10-18T14:15:00Z – 2024-10-18T15:00:00Z
2024-10-18T15:00:00Z – 2024-10-18T16:30:00Z
- associated
VAST Challenge
Bayshore II
Chair: R. Jordan Crouser, Steve Gomez, Jereme Haack
10 presentations in this session. See more »
workshopVISxAI: 7th Workshop on Visualization for AI Explainability
Bayshore I
Chair: Alex Bäuerle, Angie Boggust, Fred Hohman
12 presentations in this session. See more »
workshop1st Workshop on Accessible Data Visualization
Bayshore V
Chair: Brianna Wimer, Laura South
7 presentations in this session. See more »
workshopFirst-Person Visualizations for Outdoor Physical Activities: Challenges and Opportunities
Bayshore VII
Chair: Charles Perin, Tica Lin, Lijie Yao, Yalong Yang, Maxime Cordeil, Wesley Willett
0 presentations in this session. See more »
workshopEduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 1)
Esplanade Suites I + II + III
Chair: Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
tutorialVisualization Analysis and Design
Bayshore VI
Chair: Tamara Munzner
0 presentations in this session. See more »
tutorialDeveloping Immersive and Collaborative Visualizations with Web Technologies
Bayshore III
Chair: David Saffo
0 presentations in this session. See more »
- associated
VDS: Visualization in Data Science Symposium
Bayshore I
Chair: Ana Crisan, Dylan Cashman, Saugat Pandey, Alvitta Ottley, John E Wenskovitch
6 presentations in this session. See more »
associatedLDAV: 14th IEEE Symposium on Large Data Analysis and Visualization
Bayshore II
Chair: Silvio Rizzi, Gunther Weber, Guido Reina, Ken Moreland
6 presentations in this session. See more »
associatedBio+Med+Vis Workshop
Bayshore V
Chair: Barbora Kozlikova, Nils Gehlenborg, Laura Garrison, Eric Mörth, Morgan Turner, Simon Warchol
6 presentations in this session. See more »
workshopWorkshop on Data Storytelling in an Era of Generative AI
Bayshore VII
Chair: Xingyu Lan, Leni Yang, Zezhong Wang, Yun Wang, Danqing Shi, Sheelagh Carpendale
4 presentations in this session. See more »
workshopEduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 2)
Esplanade Suites I + II + III
Chair: Jillian Aurisano, Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
tutorialGenerating Color Schemes for your Data Visualizations
Bayshore VI
Chair: Theresa-Marie Rhyne
0 presentations in this session. See more »
tutorialRunning Online User Studies with the reVISit Framework
Bayshore III
Chair: Jack Wilburn
0 presentations in this session. See more »
- associated
VisInPractice
Bayshore III
Chair: Arjun Srinivasan, Ayan Biswas
0 presentations in this session. See more »
associatedSciVis Contest
Bayshore V
Chair: Karen Bemis, Tim Gerrits
3 presentations in this session. See more »
workshopBELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization (Session 1)
Bayshore I
Chair: Anastasia Bezerianos, Michael Correll, Kyle Hall, Jürgen Bernard, Dan Keefe, Mai Elshehaly, Mahsan Nourani
6 presentations in this session. See more »
workshopProgressive Data Analysis and Visualization (PDAV) Workshop
Bayshore VII
Chair: Alex Ulmer, Jaemin Jo, Michael Sedlmair, Jean-Daniel Fekete
3 presentations in this session. See more »
workshopUncertainty Visualization: Applications, Techniques, Software, and Decision Frameworks
Bayshore VI
Chair: Tushar M. Athawale, Chris R. Johnson, Kristi Potter, Paul Rosen, David Pugmire
12 presentations in this session. See more »
workshopVisualization for Climate Action and Sustainability
Esplanade Suites I + II + III
Chair: Benjamin Bach, Fanny Chevalier, Helen-Nicole Kostis, Mark SubbaRao, Yvonne Jansen, Robert Soden
13 presentations in this session. See more »
tutorialLLM4Vis: Large Language Models for Information Visualization
Bayshore II
Chair: Enamul Hoque
0 presentations in this session. See more »
- workshop
TopoInVis: Workshop on Topological Data Analysis and Visualization
Bayshore III
Chair: Federico Iuricich, Yue Zhang
6 presentations in this session. See more »
workshopBELIV: evaluation and BEyond - methodoLogIcal approaches for Visualization (Sesssion 2)
Bayshore I
Chair: Anastasia Bezerianos, Michael Correll, Kyle Hall, Jürgen Bernard, Dan Keefe, Mai Elshehaly, Mahsan Nourani
11 presentations in this session. See more »
workshopNLVIZ Workshop: Exploring Research Opportunities for Natural Language, Text, and Data Visualization
Bayshore II
Chair: Vidya Setlur, Arjun Srinivasan
11 presentations in this session. See more »
workshopEnergyVis 2024: 4th Workshop on Energy Data Visualization
Bayshore VI
Chair: Kenny Gruchalla, Anjana Arunkumar, Sarah Goodwin, Arnaud Prouzeau, Lyn Bartram
11 presentations in this session. See more »
workshopVISions of the Future: Workshop on Sustainable Practices within Visualization and Physicalisation
Esplanade Suites I + II + III
Chair: Georgia Panagiotidou, Luiz Morais, Sarah Hayes, Derya Akbaba, Tatiana Losev, Andrew McNutt
5 presentations in this session. See more »
tutorialEnabling Scientific Discovery: A Tutorial for Harnessing the Power of the National Science Data Fabric for Large-Scale Data Analysis
Bayshore V
Chair: Amy Gooch
0 presentations in this session. See more »
tutorialPreparing, Conducting, and Analyzing Participatory Design Sessions for Information Visualizations
Bayshore VII
Chair: Adriana Arcia
0 presentations in this session. See more »
- vis
Opening Session
Bayshore I + II + III
Chair: Paul Rosen, Kristi Potter, Remco Chang
2 presentations in this session. See more »
- short
VGTC Awards & Best Short Papers
Bayshore I + II + III
Chair: Chaoli Wang
4 presentations in this session. See more »
- vis
VIS Governance
None
Chair: Petra Isenberg, Jean-Daniel Fekete
2 presentations in this session. See more »
- full
Best Full Papers
Bayshore I + II + III
Chair: Claudio Silva
6 presentations in this session. See more »
- visap
VISAP Keynote: The Golden Age of Visualization Dissensus
Bayshore I + II + III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner, Alberto Cairo
0 presentations in this session. See more »
- visap
VISAP Artist Talks
Bayshore III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
16 presentations in this session. See more »
- full
Virtual: VIS from around the world
Palma Ceia I
Chair: Mahmood Jasim
6 presentations in this session. See more »
- full
Text, Annotation, and Metaphor
Bayshore V
Chair: Melanie Tory
6 presentations in this session. See more »
fullImmersive Visualization and Visual Analytics
Bayshore II
Chair: Lingyun Yu
6 presentations in this session. See more »
fullMachine Learning for Visualization
Bayshore I
Chair: Joshua Levine
6 presentations in this session. See more »
shortShort Papers: Graph, Hierarchy and Multidimensional
Bayshore VI
Chair: Alfie Abdul-Rahman
8 presentations in this session. See more »
panelPanel: What Do Visualization Art Projects Bring to the VIS Community?
Bayshore VII
Chair: Xinhuan Shu, Yifang Wang, Junxiu Tang
0 presentations in this session. See more »
- full
Biological Data Visualization
Bayshore I
Chair: Nils Gehlenborg
6 presentations in this session. See more »
fullJudgment and Decision-making
Bayshore II
Chair: Wenwen Dou
6 presentations in this session. See more »
fullTime and Sequences
Bayshore VI
Chair: Silvia Miksch
6 presentations in this session. See more »
fullDimensionality Reduction
Bayshore V
Chair: Jian Zhao
6 presentations in this session. See more »
fullUrban Planning, Construction, and Disaster Management
Bayshore VII
Chair: Siming Chen
6 presentations in this session. See more »
visapVISAP Papers
Bayshore III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
6 presentations in this session. See more »
- full
Natural Language and Multimodal Interaction
Bayshore I
Chair: Ana Crisan
6 presentations in this session. See more »
fullCollaboration and Communication
Bayshore V
Chair: Vidya Setlur
6 presentations in this session. See more »
fullPerception and Cognition
Bayshore II
Chair: Tamara Munzner
6 presentations in this session. See more »
shortShort Papers: Scientific and Immersive Visualization
Bayshore VI
Chair: Bei Wang
8 presentations in this session. See more »
invitedCG&A: Analytics and Applications
Bayshore III
Chair: Bruce Campbell
6 presentations in this session. See more »
panelPanel: 20 Years of Visual Analytics
Bayshore VII
Chair: David Ebert, Wolfgang Jentner, Ross Maciejewski, Jieqiong Zhao
0 presentations in this session. See more »
- full
Designing Palettes and Encodings
Bayshore II
Chair: Khairi Rheda
6 presentations in this session. See more »
fullOf Nodes and Networks
Bayshore I
Chair: Carolina Nobre
6 presentations in this session. See more »
fullScripts, Notebooks, and Provenance
Bayshore V
Chair: Alex Lex
6 presentations in this session. See more »
shortShort Papers: System design
Bayshore VI
Chair: Chris Bryan
8 presentations in this session. See more »
panelPanel: Past, Present, and Future of Data Storytelling
Bayshore VII
Chair: Haotian Li, Yun Wang, Benjamin Bach, Sheelagh Carpendale, Fanny Chevalier, Nathalie Riche
0 presentations in this session. See more »
applicationApplication Spotlight: Visualization within the Department of Energy
Bayshore III
Chair: Ana Crisan, Menna El-Assady
0 presentations in this session. See more »
- vis
IEEE VIS Town Hall
Bayshore I + II + III
Chair: Ross Maciejewski
0 presentations in this session. See more »
- panel
Panel: VIS Conference Futures: Community Opinions on Recent Experiences, Challenges, and Opportunities for Hybrid Event Formats
Bayshore VII
Chair: Matthew Brehmer, Narges Mahyar
0 presentations in this session. See more »
- full
Visualization Recommendation
Bayshore II
Chair: Johannes Knittel
6 presentations in this session. See more »
fullModel-checking and Validation
Bayshore V
Chair: Michael Correll
6 presentations in this session. See more »
fullEmbeddings and Document Spatialization
Bayshore I
Chair: Alex Endert
6 presentations in this session. See more »
shortShort Papers: Perception and Representation
Bayshore VI
Chair: Anjana Arunkumar
8 presentations in this session. See more »
panelPanel: Human-Centered Computing Research in South America: Status Quo, Opportunities, and Challenges
Bayshore VII
Chair: Chaoli Wang
0 presentations in this session. See more »
- full
Applications: Sports. Games, and Finance
Bayshore V
Chair: Marc Streit
6 presentations in this session. See more »
fullVisual Design: Sketching and Labeling
Bayshore II
Chair: Jonathan C. Roberts
6 presentations in this session. See more »
fullTopological Data Analysis
Bayshore I
Chair: Ingrid Hotz
6 presentations in this session. See more »
shortShort Papers: Text and Multimedia
Bayshore VI
Chair: Min Lu
8 presentations in this session. See more »
panelPanel: (Yet Another) Evaluation Needed? A Panel Discussion on Evaluation Trends in Visualization
Bayshore VII
Chair: Ghulam Jilani Quadri, Danielle Albers Szafir, Arran Zeyu Wang, Hyeon Jeon
0 presentations in this session. See more »
visapVISAP Pictorials
Bayshore III
Chair: Pedro Cruz, Rewa Wright, Rebecca Ruige Xu, Lori Jacques, Santiago Echeverry, Kate Terrado, Todd Linkner
8 presentations in this session. See more »
- vis
IEEE VIS 2025 Kickoff
Bayshore I + II + III
Chair: Johanna Schmidt, Kresimir Matković, Barbora Kozlíková, Eduard Gröller
1 presentations in this session. See more »
- full
Once Upon a Visualization
Bayshore V
Chair: Marti Hearst
6 presentations in this session. See more »
fullVisualization Design Methods
Bayshore II
Chair: Miriah Meyer
6 presentations in this session. See more »
fullThe Toolboxes of Visualization
Bayshore I
Chair: Dominik Moritz
6 presentations in this session. See more »
shortShort Papers: Analytics and Applications
Bayshore VI
Chair: Anna Vilanova
8 presentations in this session. See more »
invitedCG&A: Systems, Theory, and Evaluations
Bayshore III
Chair: Francesca Samsel
6 presentations in this session. See more »
panelPanel: Vogue or Visionary? Current Challenges and Future Opportunities in Situated Visualizations
Bayshore VII
Chair: Michelle A. Borkin, Melanie Tory
0 presentations in this session. See more »
- full
Journalism and Public Policy
Bayshore II
Chair: Sungahn Ko
6 presentations in this session. See more »
fullApplications: Industry, Computing, and Medicine
Bayshore V
Chair: Joern Kohlhammer
6 presentations in this session. See more »
fullAccessibility and Touch
Bayshore I
Chair: Narges Mahyar
6 presentations in this session. See more »
fullMotion and Animated Notions
Bayshore III
Chair: Catherine d'Ignazio
6 presentations in this session. See more »
shortShort Papers: AI and LLM
Bayshore VI
Chair: Cindy Xiong Bearfield
8 presentations in this session. See more »
panelPanel: Dear Younger Me: A Dialog About Professional Development Beyond The Initial Career Phases
Bayshore VII
Chair: Robert M Kirby, Michael Gleicher
0 presentations in this session. See more »
- full
Look, Learn, Language Models
Bayshore V
Chair: Nicole Sultanum
6 presentations in this session. See more »
fullWhere the Networks Are
Bayshore VII
Chair: Oliver Deussen
6 presentations in this session. See more »
fullHuman and Machine Visualization Literacy
Bayshore I + II + III
Chair: Bum Chul Kwon
6 presentations in this session. See more »
fullFlow, Topology, and Uncertainty
Bayshore VI
Chair: Bei Wang
6 presentations in this session. See more »
- vis
Test of Time Awards
Bayshore I
Chair: Ross Maciejewski
1 presentations in this session. See more »
- vis
IEEE VIS Capstone and Closing
Bayshore I + II + III
Chair: Paul Rosen, Kristi Potter, Remco Chang
3 presentations in this session. See more »
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
2024-10-14T16:00:00Z – 2024-10-14T19:00:00Z
2024-10-15T12:30:00Z – 2024-10-15T13:45:00Z
2024-10-15T14:15:00Z – 2024-10-15T15:45:00Z
2024-10-15T15:35:00Z – 2024-10-15T16:00:00Z
2024-10-15T16:00:00Z – 2024-10-15T17:30:00Z
2024-10-15T18:00:00Z – 2024-10-15T19:00:00Z
2024-10-15T19:00:00Z – 2024-10-15T21:00:00Z
2024-10-16T12:30:00Z – 2024-10-16T13:30:00Z
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
2024-10-16T19:00:00Z – 2024-10-16T19:30:00Z
2024-10-16T19:30:00Z – 2024-10-16T20:30:00Z
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
2024-10-17T15:30:00Z – 2024-10-17T16:00:00Z
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
2024-10-18T14:15:00Z – 2024-10-18T15:00:00Z
2024-10-18T15:00:00Z – 2024-10-18T16:30:00Z
SciVis Contest
https://ieeevis.org/year/2024/program/event_a-scivis-contest.html
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Add all of this event's sessions to your calendar.
SciVis Contest
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Karen Bemis, Tim Gerrits
0 presentations in this session. See more »
SciVis Contest
https://ieeevis.org/year/2024/program/event_a-scivis-contest.html
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Add all of this event's sessions to your calendar.
SciVis Contest
2024-10-14T12:30:00Z – 2024-10-14T15:30:00Z
Chair: Karen Bemis, Tim Gerrits
3 presentations in this session. See more »
VAST Challenge
https://ieeevis.org/year/2024/program/event_a-vast-challenge.html
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Add all of this event's sessions to your calendar.
VAST Challenge
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: R. Jordan Crouser, Steve Gomez, Jereme Haack
13 presentations in this session. See more »
VAST Challenge
https://ieeevis.org/year/2024/program/event_a-vast-challenge.html
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Add all of this event's sessions to your calendar.
VAST Challenge
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: R. Jordan Crouser, Steve Gomez, Jereme Haack
10 presentations in this session. See more »
VDS: Visualization in Data Science Symposium
https://ieeevis.org/year/2024/program/event_s-vds.html
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Add all of this event's sessions to your calendar.
VDS: Visualization in Data Science Symposium
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Ana Crisan, Dylan Cashman
6 presentations in this session. See more »
VDS: Visualization in Data Science Symposium
https://ieeevis.org/year/2024/program/event_s-vds.html
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Add all of this event's sessions to your calendar.
VDS: Visualization in Data Science Symposium
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Ana Crisan, Dylan Cashman, Saugat Pandey, Alvitta Ottley, John E Wenskovitch
6 presentations in this session. See more »
VIS Full Papers
https://ieeevis.org/year/2024/program/event_v-full.html
2024-10-15T16:00:00Z – 2024-10-16T13:30:00Z
Add all of this event's sessions to your calendar.
Best Full Papers
2024-10-15T16:00:00Z – 2024-10-15T17:30:00Z
Chair: Claudio Silva
6 presentations in this session. See more »
Applications: Sports. Games, and Finance
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Marc Streit
6 presentations in this session. See more »
Designing Palettes and Encodings
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Khairi Rheda
6 presentations in this session. See more »
Text, Annotation, and Metaphor
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Melanie Tory
6 presentations in this session. See more »
Journalism and Public Policy
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Sungahn Ko
6 presentations in this session. See more »
Natural Language and Multimodal Interaction
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Ana Crisan
6 presentations in this session. See more »
Look, Learn, Language Models
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Nicole Sultanum
6 presentations in this session. See more »
Biological Data Visualization
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Nils Gehlenborg
6 presentations in this session. See more »
Immersive Visualization and Visual Analytics
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Lingyun Yu
6 presentations in this session. See more »
Machine Learning for Visualization
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Joshua Levine
6 presentations in this session. See more »
Where the Networks Are
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Oliver Deussen
6 presentations in this session. See more »
Visualization Recommendation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Johannes Knittel
6 presentations in this session. See more »
Applications: Industry, Computing, and Medicine
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Joern Kohlhammer
6 presentations in this session. See more »
Judgment and Decision-making
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Wenwen Dou
6 presentations in this session. See more »
Model-checking and Validation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Michael Correll
6 presentations in this session. See more »
Time and Sequences
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Silvia Miksch
6 presentations in this session. See more »
Accessibility and Touch
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Narges Mahyar
6 presentations in this session. See more »
Collaboration and Communication
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Vidya Setlur
6 presentations in this session. See more »
Once Upon a Visualization
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Marti Hearst
6 presentations in this session. See more »
Perception and Cognition
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Bernhard Preim
6 presentations in this session. See more »
Of Nodes and Networks
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Carolina Nobre
6 presentations in this session. See more »
Human and Machine Visualization Literacy
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Bum Chul Kwon
6 presentations in this session. See more »
Visualization Design Methods
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Miriah Meyer
6 presentations in this session. See more »
Flow, Topology, and Uncertainty
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Bei Wang
6 presentations in this session. See more »
Scripts, Notebooks, and Provenance
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Alex Lex
6 presentations in this session. See more »
Visual Design: Sketching and Labeling
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Jonathan C. Roberts
6 presentations in this session. See more »
The Toolboxes of Visualization
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Dominik Moritz
6 presentations in this session. See more »
Topological Data Analysis
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Ingrid Hotz
6 presentations in this session. See more »
Motion and Animated Notions
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Catherine d'Ignazio
6 presentations in this session. See more »
Dimensionality Reduction
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Jian Zhao
6 presentations in this session. See more »
Urban Planning, Construction, and Disaster Management
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Siming Chen
6 presentations in this session. See more »
Embeddings and Document Spatialization
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Alex Endert
6 presentations in this session. See more »
Virtual: VIS from around the world
2024-10-16T12:30:00Z – 2024-10-16T13:30:00Z
Chair: Mahmood Jasim
6 presentations in this session. See more »
VIS Full Papers
https://ieeevis.org/year/2024/program/event_v-full.html
2024-10-15T16:00:00Z – 2024-10-16T13:30:00Z
Add all of this event's sessions to your calendar.
Best Full Papers
2024-10-15T16:00:00Z – 2024-10-15T17:30:00Z
Chair: Claudio Silva
6 presentations in this session. See more »
Applications: Sports. Games, and Finance
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Marc Streit
6 presentations in this session. See more »
Designing Palettes and Encodings
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Khairi Rheda
6 presentations in this session. See more »
Text, Annotation, and Metaphor
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Melanie Tory
6 presentations in this session. See more »
Journalism and Public Policy
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Sungahn Ko
6 presentations in this session. See more »
Natural Language and Multimodal Interaction
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Ana Crisan
6 presentations in this session. See more »
Look, Learn, Language Models
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Nicole Sultanum
6 presentations in this session. See more »
Biological Data Visualization
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Nils Gehlenborg
6 presentations in this session. See more »
Immersive Visualization and Visual Analytics
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Lingyun Yu
6 presentations in this session. See more »
Machine Learning for Visualization
2024-10-16T12:30:00Z – 2024-10-16T13:45:00Z
Chair: Joshua Levine
6 presentations in this session. See more »
Where the Networks Are
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Oliver Deussen
6 presentations in this session. See more »
Visualization Recommendation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Johannes Knittel
6 presentations in this session. See more »
Applications: Industry, Computing, and Medicine
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Joern Kohlhammer
6 presentations in this session. See more »
Judgment and Decision-making
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Wenwen Dou
6 presentations in this session. See more »
Model-checking and Validation
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Michael Correll
6 presentations in this session. See more »
Time and Sequences
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Silvia Miksch
6 presentations in this session. See more »
Accessibility and Touch
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Narges Mahyar
6 presentations in this session. See more »
Collaboration and Communication
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Vidya Setlur
6 presentations in this session. See more »
Once Upon a Visualization
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Marti Hearst
6 presentations in this session. See more »
Perception and Cognition
2024-10-16T16:00:00Z – 2024-10-16T17:15:00Z
Chair: Tamara Munzner
6 presentations in this session. See more »
Of Nodes and Networks
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Carolina Nobre
6 presentations in this session. See more »
Human and Machine Visualization Literacy
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Bum Chul Kwon
6 presentations in this session. See more »
Visualization Design Methods
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Miriah Meyer
6 presentations in this session. See more »
Flow, Topology, and Uncertainty
2024-10-18T12:30:00Z – 2024-10-18T13:45:00Z
Chair: Bei Wang
6 presentations in this session. See more »
Scripts, Notebooks, and Provenance
2024-10-16T17:45:00Z – 2024-10-16T19:00:00Z
Chair: Alex Lex
6 presentations in this session. See more »
Visual Design: Sketching and Labeling
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Jonathan C. Roberts
6 presentations in this session. See more »
The Toolboxes of Visualization
2024-10-17T16:00:00Z – 2024-10-17T17:15:00Z
Chair: Dominik Moritz
6 presentations in this session. See more »
Topological Data Analysis
2024-10-17T14:15:00Z – 2024-10-17T15:30:00Z
Chair: Ingrid Hotz
6 presentations in this session. See more »
Motion and Animated Notions
2024-10-17T17:45:00Z – 2024-10-17T19:00:00Z
Chair: Catherine d'Ignazio
6 presentations in this session. See more »
Dimensionality Reduction
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Jian Zhao
6 presentations in this session. See more »
Urban Planning, Construction, and Disaster Management
2024-10-16T14:15:00Z – 2024-10-16T15:30:00Z
Chair: Siming Chen
6 presentations in this session. See more »
Embeddings and Document Spatialization
2024-10-17T12:30:00Z – 2024-10-17T13:45:00Z
Chair: Alex Endert
6 presentations in this session. See more »
Virtual: VIS from around the world
2024-10-16T12:30:00Z – 2024-10-16T13:30:00Z
Chair: Mahmood Jasim
6 presentations in this session. See more »
EduVis: Workshop on Visualization Education, Literacy, and Activities
https://ieeevis.org/year/2024/program/event_w-eduvis.html
2024-10-13T12:30:00Z – 2024-10-13T19:00:00Z
Add all of this event's sessions to your calendar.
EduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 1)
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach
3 presentations in this session. See more »
EduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 2)
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Jillian Aurisano, Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
EduVis: Workshop on Visualization Education, Literacy, and Activities
https://ieeevis.org/year/2024/program/event_w-eduvis.html
2024-10-13T12:30:00Z – 2024-10-13T19:00:00Z
Add all of this event's sessions to your calendar.
EduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 1)
2024-10-13T12:30:00Z – 2024-10-13T15:30:00Z
Chair: Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
EduVis: 2nd IEEE VIS Workshop on Visualization Education, Literacy, and Activities (Session 2)
2024-10-13T16:00:00Z – 2024-10-13T19:00:00Z
Chair: Jillian Aurisano, Fateme Rajabiyazdi, Mandy Keck, Lonni Besancon, Alon Friedman, Benjamin Bach, Jonathan Roberts, Christina Stoiber, Magdalena Boucher, Lily Ge
3 presentations in this session. See more »
PlumeViz: Interactive Exploration for Multi-Facet Features of Hydrothermal Plumes in Sonar Images
Yiming Shao -
Chengming Liu -
Zhiyuan Meng -
Shufan Qian -
Peng Jiang -
Yunhai Wang -
Dr. Qiong Zeng -
Room: Bayshore V
2024-10-14T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-14T12:30:00Z
Abstract
Visualization of Sonar Imaging for Hydrothermal Systems
Ngan V. T. Nguyen -
Minh N. A. Tran -
Si Chi Hoang -
Vuong Tran Thien -
Nguyen Tran Nguyen Thanh -
Ngo Ly -
Phuc Thien Nguyen -
Sinh Huy Gip -
Sang Thanh Ngo -
Nguyễn Thái Hòa -
Room: Bayshore V
2024-10-14T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-14T12:30:00Z
Abstract
Topology Based Visualization of Hydrothermal Plumes
Adhitya Kamakshidasan -
Harikrishnan Pattathil -
Room: Bayshore V
2024-10-14T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-14T12:30:00Z
Abstract
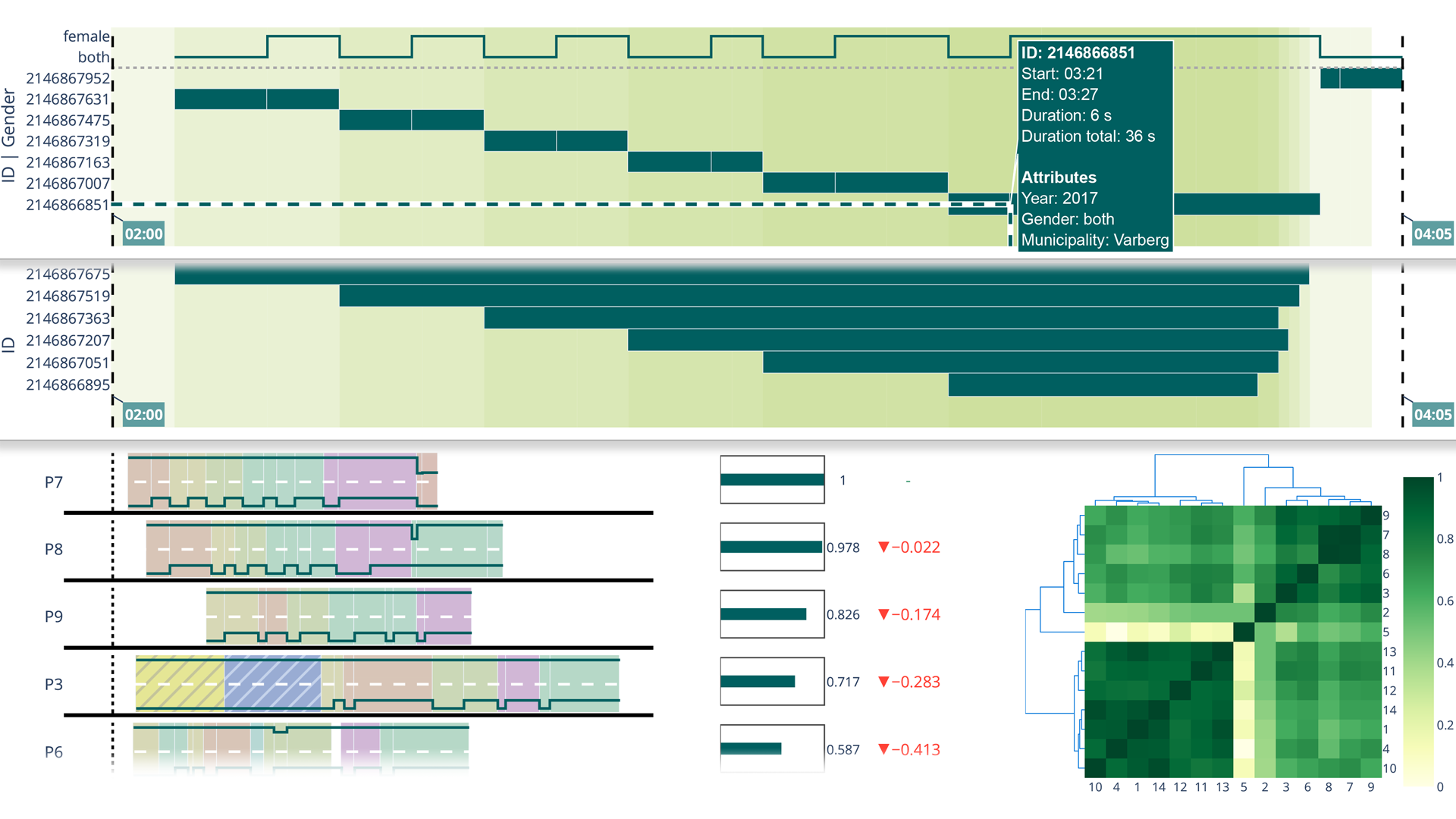
Revealing Interaction Dynamics: Multi-Level Visual Exploration of User Strategies with an Interactive Digital Environment
Peilin Yu - Linköping University, Norrköping, Sweden
Aida Nordman - Linköping University, Norrköping, Sweden
Marta M. Koc-Januchta - Linköping University, Norrköping, Sweden
Konrad J Schönborn - Linköping University, Norrköping, Sweden. Linköping University, Norrköping, Sweden
Lonni Besançon - Linköping University, Norrköping, Sweden
Katerina Vrotsou - Linköping University, Norrköping, Sweden
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore VI
2024-10-16T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:15:00Z
Fast forward
Keywords
Visual analytics, Visualization systems and tools, Interaction logs, Visualization techniques, Visual learning
Abstract
We present a visual analytics approach for multi-level visual exploration of users' interaction strategies in an interactive digital environment. The use of interactive touchscreen exhibits in informal learning environments, such as museums and science centers, often incorporate frameworks that classify learning processes, such as Bloom’s taxonomy, to achieve better user engagement and knowledge transfer. To analyze user behavior within these digital environments, interaction logs are recorded to capture diverse exploration strategies. However, analysis of such logs is challenging, especially in terms of coupling interactions and cognitive learning processes, and existing work within learning and educational contexts remains limited. To address these gaps, we develop a visual analytics approach for analyzing interaction logs that supports exploration at the individual user level and multi-user comparison. The approach utilizes algorithmic methods to identify similarities in users' interactions and reveal their exploration strategies. We motivate and illustrate our approach through an application scenario, using event sequences derived from interaction log data in an experimental study conducted with science center visitors from diverse backgrounds and demographics. The study involves 14 users completing tasks of increasing complexity, designed to stimulate different levels of cognitive learning processes. We implement our approach in an interactive visual analytics prototype system, named VISID, and together with domain experts, discover a set of task-solving exploration strategies, such as "cascading" and "nested-loop", which reflect different levels of learning processes from Bloom's taxonomy. Finally, we discuss the generalizability and scalability of the presented system and the need for further research with data acquired in the wild.
Revealing Interaction Dynamics: Multi-Level Visual Exploration of User Strategies with an Interactive Digital Environment
Peilin Yu - Linköping University, Norrköping, Sweden
Aida Nordman - Linköping University, Norrköping, Sweden
Marta M. Koc-Januchta - Linköping University, Norrköping, Sweden
Konrad J Schönborn - Linköping University, Norrköping, Sweden. Linköping University, Norrköping, Sweden
Lonni Besançon - Linköping University, Norrköping, Sweden
Katerina Vrotsou - Linköping University, Norrköping, Sweden
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore VI
2024-10-16T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:15:00Z
Fast forward
Keywords
Visual analytics, Visualization systems and tools, Interaction logs, Visualization techniques, Visual learning
Abstract
We present a visual analytics approach for multi-level visual exploration of users' interaction strategies in an interactive digital environment. The use of interactive touchscreen exhibits in informal learning environments, such as museums and science centers, often incorporate frameworks that classify learning processes, such as Bloom’s taxonomy, to achieve better user engagement and knowledge transfer. To analyze user behavior within these digital environments, interaction logs are recorded to capture diverse exploration strategies. However, analysis of such logs is challenging, especially in terms of coupling interactions and cognitive learning processes, and existing work within learning and educational contexts remains limited. To address these gaps, we develop a visual analytics approach for analyzing interaction logs that supports exploration at the individual user level and multi-user comparison. The approach utilizes algorithmic methods to identify similarities in users' interactions and reveal their exploration strategies. We motivate and illustrate our approach through an application scenario, using event sequences derived from interaction log data in an experimental study conducted with science center visitors from diverse backgrounds and demographics. The study involves 14 users completing tasks of increasing complexity, designed to stimulate different levels of cognitive learning processes. We implement our approach in an interactive visual analytics prototype system, named VISID, and together with domain experts, discover a set of task-solving exploration strategies, such as "cascading" and "nested-loop", which reflect different levels of learning processes from Bloom's taxonomy. Finally, we discuss the generalizability and scalability of the presented system and the need for further research with data acquired in the wild.
Team-Scouter: Simulative Visual Analytics of Soccer Player Scouting
Anqi Cao - Zhejiang University, Hangzhou, China
Xiao Xie - Zhejiang University, Hangzhou, China
Runjin Zhang - Zhejiang University, Hangzhou, China
Yuxin Tian - Zhejiang University, Hangzhou, China
Mu Fan - Zhejiang University, Hangzhou, China
Hui Zhang - Zhejiang University, Hangzhou, China
Yingcai Wu - Zhejiang University, Hangzhou, China
Download camera-ready PDF
Room: Bayshore V
2024-10-17T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:15:00Z

Fast forward
Keywords
Soccer Visualization, Player Scouting, Design Study
Abstract
In soccer, player scouting aims to find players suitable for a team to increase the winning chance in future matches. To scout suitable players, coaches and analysts need to consider whether the players will perform well in a new team, which is hard to learn directly from their historical performances. Match simulation methods have been introduced to scout players by estimating their expected contributions to a new team. However, they usually focus on the simulation of match results and hardly support interactive analysis to navigate potential target players and compare them in fine-grained simulated behaviors. In this work, we propose a visual analytics method to assist soccer player scouting based on match simulation. We construct a two-level match simulation framework for estimating both match results and player behaviors when a player comes to a new team. Based on the framework, we develop a visual analytics system, Team-Scouter, to facilitate the simulative-based soccer player scouting process through player navigation, comparison, and investigation. With our system, coaches and analysts can find potential players suitable for the team and compare them on historical and expected performances. For an in-depth investigation of the players' expected performances, the system provides a visual comparison between the simulated behaviors of the player and the actual ones. The usefulness and effectiveness of the system are demonstrated by two case studies on a real-world dataset and an expert interview.
Team-Scouter: Simulative Visual Analytics of Soccer Player Scouting
Anqi Cao - Zhejiang University, Hangzhou, China
Xiao Xie - Zhejiang University, Hangzhou, China
Runjin Zhang - Zhejiang University, Hangzhou, China
Yuxin Tian - Zhejiang University, Hangzhou, China
Mu Fan - Zhejiang University, Hangzhou, China
Hui Zhang - Zhejiang University, Hangzhou, China
Yingcai Wu - Zhejiang University, Hangzhou, China
Download camera-ready PDF
Room: Bayshore V
2024-10-17T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:15:00Z
Fast forward
Keywords
Soccer Visualization, Player Scouting, Design Study
Abstract
In soccer, player scouting aims to find players suitable for a team to increase the winning chance in future matches. To scout suitable players, coaches and analysts need to consider whether the players will perform well in a new team, which is hard to learn directly from their historical performances. Match simulation methods have been introduced to scout players by estimating their expected contributions to a new team. However, they usually focus on the simulation of match results and hardly support interactive analysis to navigate potential target players and compare them in fine-grained simulated behaviors. In this work, we propose a visual analytics method to assist soccer player scouting based on match simulation. We construct a two-level match simulation framework for estimating both match results and player behaviors when a player comes to a new team. Based on the framework, we develop a visual analytics system, Team-Scouter, to facilitate the simulative-based soccer player scouting process through player navigation, comparison, and investigation. With our system, coaches and analysts can find potential players suitable for the team and compare them on historical and expected performances. For an in-depth investigation of the players' expected performances, the system provides a visual comparison between the simulated behaviors of the player and the actual ones. The usefulness and effectiveness of the system are demonstrated by two case studies on a real-world dataset and an expert interview.
Visualizing Temporal Topic Embeddings with a Compass
Daniel Palamarchuk - Virginia Tech, Blacksburg, United States
Lemara Williams - Virginia Polytechnic Institute of Technology , Blacksburg, United States
Brian Mayer - Virginia Tech, Blacksburg, United States
Thomas Danielson - Savannah River National Laboratory, Aiken, United States
Rebecca Faust - Tulane University, New Orleans, United States
Larry M Deschaine PhD - Savannah River National Laboratory, Aiken, United States
Chris North - Virginia Tech, Blacksburg, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-17T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T12:30:00Z
Fast forward
Keywords
High dimensional data, Dynamic topic modeling, Cluster analysis
Abstract
Dynamic topic modeling is useful at discovering the development and change in latent topics over time. However, present methodology relies on algorithms that separate document and word representations. This prevents the creation of a meaningful embedding space where changes in word usage and documents can be directly analyzed in a temporal context. This paper proposes an expansion of the compass-aligned temporal Word2Vec methodology into dynamic topic modeling. Such a method allows for the direct comparison of word and document embeddings across time in dynamic topics. This enables the creation of visualizations that incorporate temporal word embeddings within the context of documents into topic visualizations. In experiments against the current state-of-the-art, our proposed method demonstrates overall competitive performance in topic relevancy and diversity across temporal datasets of varying size. Simultaneously, it provides insightful visualizations focused on temporal word embeddings while maintaining the insights provided by global topic evolution, advancing our understanding of how topics evolve over time.
Visualizing Temporal Topic Embeddings with a Compass
Daniel Palamarchuk - Virginia Tech, Blacksburg, United States
Lemara Williams - Virginia Polytechnic Institute of Technology , Blacksburg, United States
Brian Mayer - Virginia Tech, Blacksburg, United States
Thomas Danielson - Savannah River National Laboratory, Aiken, United States
Rebecca Faust - Tulane University, New Orleans, United States
Larry M Deschaine PhD - Savannah River National Laboratory, Aiken, United States
Chris North - Virginia Tech, Blacksburg, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-17T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T12:30:00Z
Fast forward
Keywords
High dimensional data, Dynamic topic modeling, Cluster analysis
Abstract
Dynamic topic modeling is useful at discovering the development and change in latent topics over time. However, present methodology relies on algorithms that separate document and word representations. This prevents the creation of a meaningful embedding space where changes in word usage and documents can be directly analyzed in a temporal context. This paper proposes an expansion of the compass-aligned temporal Word2Vec methodology into dynamic topic modeling. Such a method allows for the direct comparison of word and document embeddings across time in dynamic topics. This enables the creation of visualizations that incorporate temporal word embeddings within the context of documents into topic visualizations. In experiments against the current state-of-the-art, our proposed method demonstrates overall competitive performance in topic relevancy and diversity across temporal datasets of varying size. Simultaneously, it provides insightful visualizations focused on temporal word embeddings while maintaining the insights provided by global topic evolution, advancing our understanding of how topics evolve over time.
Blowing Seeds Across Gardens: Visualizing Implicit Propagation of Cross-Platform Social Media Posts
Jianing Yin - Zhejiang University, Hangzhou, China
Hanze Jia - Zhejiang University, Hangzhou, China
Buwei Zhou - Zhejiang University, Hangzhou, China
Tan Tang - Zhejiang University, Hangzhou, China
Lu Ying - Zhejiang University, Hangzhou, China
Shuainan Ye - Zhejiang University, Hangzhou, China
Tai-Quan Peng - Michigan State University, East Lansing, United States
Yingcai Wu - Zhejiang University, Hangzhou, China
Download camera-ready PDF
Room: Bayshore III
2024-10-17T18:33:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:33:00Z
Fast forward
Keywords
Propagation analysis, social media visualization, cross-platform propagation, metaphor design
Abstract
Propagation analysis refers to studying how information spreads on social media, a pivotal endeavor for understanding social sentiment and public opinions. Numerous studies contribute to visualizing information spread, but few have considered the implicit and complex diffusion patterns among multiple platforms. To bridge the gap, we summarize cross-platform diffusion patterns with experts and identify significant factors that dissect the mechanisms of cross-platform information spread. Based on that, we propose an information diffusion model that estimates the likelihood of a topic/post spreading among different social media platforms. Moreover, we propose a novel visual metaphor that encapsulates cross-platform propagation in a manner analogous to the spread of seeds across gardens. Specifically, we visualize platforms, posts, implicit cross-platform routes, and salient instances as elements of a virtual ecosystem — gardens, flowers, winds, and seeds, respectively. We further develop a visual analytic system, namely BloomWind, that enables users to quickly identify the cross-platform diffusion patterns and investigate the relevant social media posts. Ultimately, we demonstrate the usage of BloomWind through two case studies and validate its effectiveness using expert interviews.
Blowing Seeds Across Gardens: Visualizing Implicit Propagation of Cross-Platform Social Media Posts
Jianing Yin - Zhejiang University, Hangzhou, China
Hanze Jia - Zhejiang University, Hangzhou, China
Buwei Zhou - Zhejiang University, Hangzhou, China
Tan Tang - Zhejiang University, Hangzhou, China
Lu Ying - Zhejiang University, Hangzhou, China
Shuainan Ye - Zhejiang University, Hangzhou, China
Tai-Quan Peng - Michigan State University, East Lansing, United States
Yingcai Wu - Zhejiang University, Hangzhou, China
Download camera-ready PDF
Room: Bayshore III
2024-10-17T18:33:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:33:00Z
Fast forward
Keywords
Propagation analysis, social media visualization, cross-platform propagation, metaphor design
Abstract
Propagation analysis refers to studying how information spreads on social media, a pivotal endeavor for understanding social sentiment and public opinions. Numerous studies contribute to visualizing information spread, but few have considered the implicit and complex diffusion patterns among multiple platforms. To bridge the gap, we summarize cross-platform diffusion patterns with experts and identify significant factors that dissect the mechanisms of cross-platform information spread. Based on that, we propose an information diffusion model that estimates the likelihood of a topic/post spreading among different social media platforms. Moreover, we propose a novel visual metaphor that encapsulates cross-platform propagation in a manner analogous to the spread of seeds across gardens. Specifically, we visualize platforms, posts, implicit cross-platform routes, and salient instances as elements of a virtual ecosystem — gardens, flowers, winds, and seeds, respectively. We further develop a visual analytic system, namely BloomWind, that enables users to quickly identify the cross-platform diffusion patterns and investigate the relevant social media posts. Ultimately, we demonstrate the usage of BloomWind through two case studies and validate its effectiveness using expert interviews.
DITTO: A Visual Digital Twin for Interventions and Temporal Treatment Outcomes in Head and Neck Cancer
Andrew Wentzel - University of Illinois at Chicago, Chicago, United States
Serageldin Attia - University of Houston, Houston, United States
Xinhua Zhang - University of Illinois Chicago, Chicago, United States
Guadalupe Canahuate - University of Iowa, Iowa City, United States
Clifton David Fuller - University of Texas, Houston, United States
G. Elisabeta Marai - University of Illinois at Chicago, Chicago, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T18:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:45:00Z
Fast forward
Keywords
Medicine; Machine Learning; Application Domains; High Dimensional data; Spatial Data; Activity Centered Design
Abstract
Digital twin models are of high interest to Head and Neck Cancer (HNC) oncologists, who have to navigate a series of complex treatment decisions that weigh the efficacy of tumor control against toxicity and mortality risks. Evaluating individual risk profiles necessitates a deeper understanding of the interplay between different factors such as patient health, spatial tumor location and spread, and risk of subsequent toxicities that can not be adequately captured through simple heuristics. To support clinicians in better understanding tradeoffs when deciding on treatment courses, we developed DITTO, a digital-twin and visual computing system that allows clinicians to analyze detailed risk profiles for each patient, and decide on a treatment plan. DITTO relies on a sequential Deep Reinforcement Learning digital twin (DT) to deliver personalized risk of both long-term and short-term disease outcome and toxicity risk for HNC patients. Based on a participatory collaborative design alongside oncologists, we also implement several visual explainability methods to promote clinical trust and encourage healthy skepticism when using our system. We evaluate the efficacy of DITTO through quantitative evaluation of performance and case studies with qualitative feedback. Finally, we discuss design lessons for developing clinical visual XAI applications for clinical end users.
DITTO: A Visual Digital Twin for Interventions and Temporal Treatment Outcomes in Head and Neck Cancer
Andrew Wentzel - University of Illinois at Chicago, Chicago, United States
Serageldin Attia - University of Houston, Houston, United States
Xinhua Zhang - University of Illinois Chicago, Chicago, United States
Guadalupe Canahuate - University of Iowa, Iowa City, United States
Clifton David Fuller - University of Texas, Houston, United States
G. Elisabeta Marai - University of Illinois at Chicago, Chicago, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T18:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:45:00Z
Fast forward
Keywords
Medicine; Machine Learning; Application Domains; High Dimensional data; Spatial Data; Activity Centered Design
Abstract
Digital twin models are of high interest to Head and Neck Cancer (HNC) oncologists, who have to navigate a series of complex treatment decisions that weigh the efficacy of tumor control against toxicity and mortality risks. Evaluating individual risk profiles necessitates a deeper understanding of the interplay between different factors such as patient health, spatial tumor location and spread, and risk of subsequent toxicities that can not be adequately captured through simple heuristics. To support clinicians in better understanding tradeoffs when deciding on treatment courses, we developed DITTO, a digital-twin and visual computing system that allows clinicians to analyze detailed risk profiles for each patient, and decide on a treatment plan. DITTO relies on a sequential Deep Reinforcement Learning digital twin (DT) to deliver personalized risk of both long-term and short-term disease outcome and toxicity risk for HNC patients. Based on a participatory collaborative design alongside oncologists, we also implement several visual explainability methods to promote clinical trust and encourage healthy skepticism when using our system. We evaluate the efficacy of DITTO through quantitative evaluation of performance and case studies with qualitative feedback. Finally, we discuss design lessons for developing clinical visual XAI applications for clinical end users.
Honorable Mention
From Instruction to Insight: Exploring the Semantic and Functional Roles of Text in Interactive Dashboards
Nicole Sultanum - Tableau Research, Seattle, United States
Vidya Setlur - Tableau Research, Palo Alto, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T13:06:00Z

Fast forward
Keywords
Text, dashboards, semantic levels, metadata, interactivity, instruction, description, takeaways, conversational heuristics
Abstract
There is increased interest in understanding the interplay between text and visuals in the field of data visualization. However, this attention has predominantly been on the use of text in standalone visualizations (such as text annotation overlays) or augmenting text stories supported by a series of independent views. In this paper, we shift from the traditional focus on single-chart annotations to characterize the nuanced but crucial communication role of text in the complex environment of interactive dashboards. Through a survey and analysis of 190 dashboards in the wild, plus 13 expert interview sessions with experienced dashboard authors, we highlight the distinctive nature of text as an integral component of the dashboard experience, while delving into the categories, semantic levels, and functional roles of text, and exploring how these text elements are coalesced by dashboard authors to guide and inform dashboard users. Our contributions are threefold. First, we distill qualitative and quantitative findings from our studies to characterize current practices of text use in dashboards, including a categorization of text-based components and design patterns. Second, we leverage current practices and existing literature to propose, discuss, and validate recommended practices for text in dashboards, embodied as a set of 12 heuristics that underscore the semantic and functional role of text in offering navigational cues, contextualizing data insights, supporting reading order, among other concerns. Third, we reflect on our findings to identify gaps and propose opportunities for data visualization researchers to push the boundaries on text usage for dashboards, from authoring support and interactivity to text generation and content personalization. Our research underscores the significance of elevating text as a first-class citizen in data visualization, and the need to support the inclusion of textual components and their interactive affordances in dashboard design.
Honorable Mention
From Instruction to Insight: Exploring the Semantic and Functional Roles of Text in Interactive Dashboards
Nicole Sultanum - Tableau Research, Seattle, United States
Vidya Setlur - Tableau Research, Palo Alto, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T13:06:00Z
Fast forward
Keywords
Text, dashboards, semantic levels, metadata, interactivity, instruction, description, takeaways, conversational heuristics
Abstract
There is increased interest in understanding the interplay between text and visuals in the field of data visualization. However, this attention has predominantly been on the use of text in standalone visualizations (such as text annotation overlays) or augmenting text stories supported by a series of independent views. In this paper, we shift from the traditional focus on single-chart annotations to characterize the nuanced but crucial communication role of text in the complex environment of interactive dashboards. Through a survey and analysis of 190 dashboards in the wild, plus 13 expert interview sessions with experienced dashboard authors, we highlight the distinctive nature of text as an integral component of the dashboard experience, while delving into the categories, semantic levels, and functional roles of text, and exploring how these text elements are coalesced by dashboard authors to guide and inform dashboard users. Our contributions are threefold. First, we distill qualitative and quantitative findings from our studies to characterize current practices of text use in dashboards, including a categorization of text-based components and design patterns. Second, we leverage current practices and existing literature to propose, discuss, and validate recommended practices for text in dashboards, embodied as a set of 12 heuristics that underscore the semantic and functional role of text in offering navigational cues, contextualizing data insights, supporting reading order, among other concerns. Third, we reflect on our findings to identify gaps and propose opportunities for data visualization researchers to push the boundaries on text usage for dashboards, from authoring support and interactivity to text generation and content personalization. Our research underscores the significance of elevating text as a first-class citizen in data visualization, and the need to support the inclusion of textual components and their interactive affordances in dashboard design.
DeLVE into Earth’s Past: A Visualization-Based Exhibit Deployed Across Multiple Museum Contexts
Mara Solen - The University of British Columbia, Vancouver, Canada
Nigar Sultana - University of British Columbia , Vancouver, Canada
Laura A. Lukes - University of British Columbia, Vancouver, Canada
Tamara Munzner - University of British Columbia, Vancouver, Canada
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T16:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:00:00Z

Fast forward
Keywords
Visualization, design study, museum, deep time.
Abstract
While previous work has found success in deploying visualizations as museum exhibits, it has not investigated whether museum context impacts visitor behaviour with these exhibits. We present an interactive Deep-time Literacy Visualization Exhibit (DeLVE) to help museum visitors understand deep time (lengths of extremely long geological processes) by improving proportional reasoning skills through comparison of different time periods. DeLVE uses a new visualization idiom, Connected Multi-Tier Ranges, to visualize curated datasets of past events across multiple scales of time, relating extreme scales with concrete scales that have more familiar magnitudes and units. Museum staff at three separate museums approved the deployment of DeLVE as a digital kiosk, and devoted time to curating a unique dataset in each of them. We collect data from two sources, an observational study and system trace logs. We discuss the importance of context: similar museum exhibits in different contexts were received very differently by visitors. We additionally discuss differences in our process from Sedlmair et al.'s design study methodology which is focused on design studies triggered by connection with collaborators rather than the discovery of a concept to communicate. Supplemental materials are available at: https://osf.io/z53dq/
DeLVE into Earth’s Past: A Visualization-Based Exhibit Deployed Across Multiple Museum Contexts
Mara Solen - The University of British Columbia, Vancouver, Canada
Nigar Sultana - University of British Columbia , Vancouver, Canada
Laura A. Lukes - University of British Columbia, Vancouver, Canada
Tamara Munzner - University of British Columbia, Vancouver, Canada
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T16:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:00:00Z
Fast forward
Keywords
Visualization, design study, museum, deep time.
Abstract
While previous work has found success in deploying visualizations as museum exhibits, it has not investigated whether museum context impacts visitor behaviour with these exhibits. We present an interactive Deep-time Literacy Visualization Exhibit (DeLVE) to help museum visitors understand deep time (lengths of extremely long geological processes) by improving proportional reasoning skills through comparison of different time periods. DeLVE uses a new visualization idiom, Connected Multi-Tier Ranges, to visualize curated datasets of past events across multiple scales of time, relating extreme scales with concrete scales that have more familiar magnitudes and units. Museum staff at three separate museums approved the deployment of DeLVE as a digital kiosk, and devoted time to curating a unique dataset in each of them. We collect data from two sources, an observational study and system trace logs. We discuss the importance of context: similar museum exhibits in different contexts were received very differently by visitors. We additionally discuss differences in our process from Sedlmair et al.'s design study methodology which is focused on design studies triggered by connection with collaborators rather than the discovery of a concept to communicate. Supplemental materials are available at: https://osf.io/z53dq/
Honorable Mention
AdversaFlow: Visual Red Teaming for Large Language Models with Multi-Level Adversarial Flow
Dazhen Deng - Zhejiang University, Ningbo, China
Chuhan Zhang - Zhejiang University, Hangzhou, China
Huawei Zheng - Zhejiang University, Hangzhou, China
Yuwen Pu - Zhejiang University, Hangzhou, China
Shouling Ji - Zhejiang University, Hangzhou, China
Yingcai Wu - Zhejiang University, Hangzhou, China
Screen-reader Accessible PDF
Download camera-ready PDF
Room: Bayshore V
2024-10-18T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:30:00Z
Fast forward
Keywords
Visual Analytics for Machine Learning, Artificial Intelligence Security, Large Language Models, Text Visualization
Abstract
Large Language Models (LLMs) are powerful but also raise significant security concerns, particularly regarding the harm they can cause, such as generating fake news that manipulates public opinion on social media and providing responses to unethical activities. Traditional red teaming approaches for identifying AI vulnerabilities rely on manual prompt construction and expertise. This paper introduces AdversaFlow, a novel visual analytics system designed to enhance LLM security against adversarial attacks through human-AI collaboration. AdversaFlow involves adversarial training between a target model and a red model, featuring unique multi-level adversarial flow and fluctuation path visualizations. These features provide insights into adversarial dynamics and LLM robustness, enabling experts to identify and mitigate vulnerabilities effectively. We present quantitative evaluations and case studies validating our system's utility and offering insights for future AI security solutions. Our method can enhance LLM security, supporting downstream scenarios like social media regulation by enabling more effective detection, monitoring, and mitigation of harmful content and behaviors.
Honorable Mention
AdversaFlow: Visual Red Teaming for Large Language Models with Multi-Level Adversarial Flow
Dazhen Deng - Zhejiang University, Ningbo, China
Chuhan Zhang - Zhejiang University, Hangzhou, China
Huawei Zheng - Zhejiang University, Hangzhou, China
Yuwen Pu - Zhejiang University, Hangzhou, China
Shouling Ji - Zhejiang University, Hangzhou, China
Yingcai Wu - Zhejiang University, Hangzhou, China
Screen-reader Accessible PDF
Download camera-ready PDF
Room: Bayshore V
2024-10-18T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:30:00Z
Fast forward
Keywords
Visual Analytics for Machine Learning, Artificial Intelligence Security, Large Language Models, Text Visualization
Abstract
Large Language Models (LLMs) are powerful but also raise significant security concerns, particularly regarding the harm they can cause, such as generating fake news that manipulates public opinion on social media and providing responses to unethical activities. Traditional red teaming approaches for identifying AI vulnerabilities rely on manual prompt construction and expertise. This paper introduces AdversaFlow, a novel visual analytics system designed to enhance LLM security against adversarial attacks through human-AI collaboration. AdversaFlow involves adversarial training between a target model and a red model, featuring unique multi-level adversarial flow and fluctuation path visualizations. These features provide insights into adversarial dynamics and LLM robustness, enabling experts to identify and mitigate vulnerabilities effectively. We present quantitative evaluations and case studies validating our system's utility and offering insights for future AI security solutions. Our method can enhance LLM security, supporting downstream scenarios like social media regulation by enabling more effective detection, monitoring, and mitigation of harmful content and behaviors.
Best Paper Award
Entanglements for Visualization: Changing Research Outcomes through Feminist Theory
Derya Akbaba - Linköping University, Norrköping, Sweden
Lauren Klein - Emory University, Atlanta, United States
Miriah Meyer - Linköping University, Nörrkoping, Sweden
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-15T16:10:00Z GMT-0600 Change your timezone on the schedule page
2024-10-15T16:10:00Z

Fast forward
Keywords
Epistemology, feminism, entanglement, theory
Abstract
A growing body of work draws on feminist thinking to challenge assumptions about how people engage with and use visualizations. This work draws on feminist values, driving design and research guidelines that account for the influences of power and neglect. This prior work is largely prescriptive, however, forgoing articulation of how feminist theories of knowledge — or feminist epistemology — can alter research design and outcomes. At the core of our work is an engagement with feminist epistemology, drawing attention to how a new framework for how we know what we know enabled us to overcome intellectual tensions in our research. Specifically, we focus on the theoretical concept of entanglement, central to recent feminist scholarship, and contribute: a history of entanglement in the broader scope of feminist theory; an articulation of the main points of entanglement theory for a visualization context; and a case study of research outcomes as evidence of the potential of feminist epistemology to impact visualization research. This work answers a call in the community to embrace a broader set of theoretical and epistemic foundations and provides a starting point for bringing feminist theories into visualization research.
Best Paper Award
Entanglements for Visualization: Changing Research Outcomes through Feminist Theory
Derya Akbaba - Linköping University, Norrköping, Sweden
Lauren Klein - Emory University, Atlanta, United States
Miriah Meyer - Linköping University, Nörrkoping, Sweden
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-15T16:10:00Z GMT-0600 Change your timezone on the schedule page
2024-10-15T16:10:00Z
Fast forward
Keywords
Epistemology, feminism, entanglement, theory
Abstract
A growing body of work draws on feminist thinking to challenge assumptions about how people engage with and use visualizations. This work draws on feminist values, driving design and research guidelines that account for the influences of power and neglect. This prior work is largely prescriptive, however, forgoing articulation of how feminist theories of knowledge — or feminist epistemology — can alter research design and outcomes. At the core of our work is an engagement with feminist epistemology, drawing attention to how a new framework for how we know what we know enabled us to overcome intellectual tensions in our research. Specifically, we focus on the theoretical concept of entanglement, central to recent feminist scholarship, and contribute: a history of entanglement in the broader scope of feminist theory; an articulation of the main points of entanglement theory for a visualization context; and a case study of research outcomes as evidence of the potential of feminist epistemology to impact visualization research. This work answers a call in the community to embrace a broader set of theoretical and epistemic foundations and provides a starting point for bringing feminist theories into visualization research.
Fine-Tuned Large Language Model for Visualization System: A Study on Self-Regulated Learning in Education
Lin Gao - Fudan University, Shanghai, China
Jing Lu - Fudan University, ShangHai, China
Zekai Shao - Fudan University, Shanghai, China
Ziyue Lin - Fudan University, Shanghai, China
Shengbin Yue - Fudan unversity, ShangHai, China
Chiokit Ieong - Fudan University, Shanghai, China
Yi Sun - Fudan University, Shanghai, China
Rory Zauner - University of Vienna, Vienna, Austria
Zhongyu Wei - Fudan University, Shanghai, China
Siming Chen - Fudan University, Shanghai, China
Download preprint PDF
Download camera-ready PDF
Room: Bayshore V
2024-10-18T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:54:00Z

Fast forward
Keywords
Fine-tuned large language model, visualization system, self-regulated learning, intelligent tutorial system
Abstract
Large Language Models (LLMs) have shown great potential in intelligent visualization systems, especially for domain-specific applications. Integrating LLMs into visualization systems presents challenges, and we categorize these challenges into three alignments: domain problems with LLMs, visualization with LLMs, and interaction with LLMs. To achieve these alignments, we propose a framework and outline a workflow to guide the application of fine-tuned LLMs to enhance visual interactions for domain-specific tasks. These alignment challenges are critical in education because of the need for an intelligent visualization system to support beginners' self-regulated learning. Therefore, we apply the framework to education and introduce Tailor-Mind, an interactive visualization system designed to facilitate self-regulated learning for artificial intelligence beginners. Drawing on insights from a preliminary study, we identify self-regulated learning tasks and fine-tuning objectives to guide visualization design and tuning data construction. Our focus on aligning visualization with fine-tuned LLM makes Tailor-Mind more like a personalized tutor. Tailor-Mind also supports interactive recommendations to help beginners better achieve their learning goals. Model performance evaluations and user studies confirm that Tailor-Mind improves the self-regulated learning experience, effectively validating the proposed framework.
Fine-Tuned Large Language Model for Visualization System: A Study on Self-Regulated Learning in Education
Lin Gao - Fudan University, Shanghai, China
Jing Lu - Fudan University, ShangHai, China
Zekai Shao - Fudan University, Shanghai, China
Ziyue Lin - Fudan University, Shanghai, China
Shengbin Yue - Fudan unversity, ShangHai, China
Chiokit Ieong - Fudan University, Shanghai, China
Yi Sun - Fudan University, Shanghai, China
Rory Zauner - University of Vienna, Vienna, Austria
Zhongyu Wei - Fudan University, Shanghai, China
Siming Chen - Fudan University, Shanghai, China
Download preprint PDF
Download camera-ready PDF
Room: Bayshore V
2024-10-18T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:54:00Z
Fast forward
Keywords
Fine-tuned large language model, visualization system, self-regulated learning, intelligent tutorial system
Abstract
Large Language Models (LLMs) have shown great potential in intelligent visualization systems, especially for domain-specific applications. Integrating LLMs into visualization systems presents challenges, and we categorize these challenges into three alignments: domain problems with LLMs, visualization with LLMs, and interaction with LLMs. To achieve these alignments, we propose a framework and outline a workflow to guide the application of fine-tuned LLMs to enhance visual interactions for domain-specific tasks. These alignment challenges are critical in education because of the need for an intelligent visualization system to support beginners' self-regulated learning. Therefore, we apply the framework to education and introduce Tailor-Mind, an interactive visualization system designed to facilitate self-regulated learning for artificial intelligence beginners. Drawing on insights from a preliminary study, we identify self-regulated learning tasks and fine-tuning objectives to guide visualization design and tuning data construction. Our focus on aligning visualization with fine-tuned LLM makes Tailor-Mind more like a personalized tutor. Tailor-Mind also supports interactive recommendations to help beginners better achieve their learning goals. Model performance evaluations and user studies confirm that Tailor-Mind improves the self-regulated learning experience, effectively validating the proposed framework.
Smartboard: Visual Exploration of Team Tactics with LLM Agent
Ziao Liu - Zhejiang University, Hangzhou, China
Xiao Xie - Zhejiang University, Hangzhou, China
Moqi He - Zhejiang University, Hangzhou, China
Wenshuo Zhao - Zhejiang University, Hangzhou, China
Yihong Wu - Zhejiang University, Hangzhou, China
Liqi Cheng - Zhejiang University, Hangzhou, China
Hui Zhang - Zhejiang University, Hangzhou, China
Yingcai Wu - Zhejiang University, Hangzhou, China
Download camera-ready PDF
Room: Bayshore V
2024-10-17T14:39:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:39:00Z
Fast forward
Keywords
Sports visualization, tactic board, tactical analysis
Abstract
Tactics play an important role in team sports by guiding how players interact on the field. Both sports fans and experts have a demand for analyzing sports tactics. Existing approaches allow users to visually perceive the multivariate tactical effects. However, these approaches require users to experience a complex reasoning process to connect the multiple interactions within each tactic to the final tactical effect. In this work, we collaborate with basketball experts and propose a progressive approach to help users gain a deeper understanding of how each tactic works and customize tactics on demand. Users can progressively sketch on a tactic board, and a coach agent will simulate the possible actions in each step and present the simulation to users with facet visualizations. We develop an extensible framework that integrates large language models (LLMs) and visualizations to help users communicate with the coach agent with multimodal inputs. Based on the framework, we design and develop Smartboard, an agent-based interactive visualization system for fine-grained tactical analysis, especially for play design. Smartboard provides users with a structured process of setup, simulation, and evolution, allowing for iterative exploration of tactics based on specific personalized scenarios. We conduct case studies based on real-world basketball datasets to demonstrate the effectiveness and usefulness of our system.
Smartboard: Visual Exploration of Team Tactics with LLM Agent
Ziao Liu - Zhejiang University, Hangzhou, China
Xiao Xie - Zhejiang University, Hangzhou, China
Moqi He - Zhejiang University, Hangzhou, China
Wenshuo Zhao - Zhejiang University, Hangzhou, China
Yihong Wu - Zhejiang University, Hangzhou, China
Liqi Cheng - Zhejiang University, Hangzhou, China
Hui Zhang - Zhejiang University, Hangzhou, China
Yingcai Wu - Zhejiang University, Hangzhou, China
Download camera-ready PDF
Room: Bayshore V
2024-10-17T14:39:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:39:00Z
Fast forward
Keywords
Sports visualization, tactic board, tactical analysis
Abstract
Tactics play an important role in team sports by guiding how players interact on the field. Both sports fans and experts have a demand for analyzing sports tactics. Existing approaches allow users to visually perceive the multivariate tactical effects. However, these approaches require users to experience a complex reasoning process to connect the multiple interactions within each tactic to the final tactical effect. In this work, we collaborate with basketball experts and propose a progressive approach to help users gain a deeper understanding of how each tactic works and customize tactics on demand. Users can progressively sketch on a tactic board, and a coach agent will simulate the possible actions in each step and present the simulation to users with facet visualizations. We develop an extensible framework that integrates large language models (LLMs) and visualizations to help users communicate with the coach agent with multimodal inputs. Based on the framework, we design and develop Smartboard, an agent-based interactive visualization system for fine-grained tactical analysis, especially for play design. Smartboard provides users with a structured process of setup, simulation, and evolution, allowing for iterative exploration of tactics based on specific personalized scenarios. We conduct case studies based on real-world basketball datasets to demonstrate the effectiveness and usefulness of our system.
Causal Priors and Their Influence on Judgements of Causality in Visualized Data
Arran Zeyu Wang - University of North Carolina-Chapel Hill, Chapel Hill, United States
David Borland - UNC-Chapel Hill, Chapel Hill, United States
Tabitha C. Peck - Davidson College, Davidson, United States
Wenyuan Wang - University of North Carolina, Chapel Hill, United States
David Gotz - University of North Carolina, Chapel Hill, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T14:51:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:51:00Z
Fast forward
Keywords
Causal inference, Perception and cognition, Causal prior, Association, Causality, Visualization
Abstract
``Correlation does not imply causation'' is a famous mantra in statistical and visual analysis. However, consumers of visualizations often draw causal conclusions when only correlations between variables are shown. In this paper, we investigate factors that contribute to causal relationships users perceive in visualizations. We collected a corpus of concept pairs from variables in widely used datasets and created visualizations that depict varying correlative associations using three typical statistical chart types. We conducted two MTurk studies on (1) preconceived notions on causal relations without charts, and (2) perceived causal relations with charts, for each concept pair. Our results indicate that people make assumptions about causal relationships between pairs of concepts even without seeing any visualized data. Moreover, our results suggest that these assumptions constitute causal priors that, in combination with visualized association, impact how data visualizations are interpreted. The results also suggest that causal priors may lead to over- or under-estimation in perceived causal relations in different circumstances, and that those priors can also impact users' confidence in their causal assessments. In addition, our results align with prior work, indicating that chart type may also affect causal inference. Using data from the studies, we develop a model to capture the interaction between causal priors and visualized associations as they combine to impact a user's perceived causal relations. In addition to reporting the study results and analyses, we provide an open dataset of causal priors for 56 specific concept pairs that can serve as a potential benchmark for future studies. We also suggest remaining challenges and heuristic-based guidelines to help designers improve visualization design choices to better support visual causal inference.
Causal Priors and Their Influence on Judgements of Causality in Visualized Data
Arran Zeyu Wang - University of North Carolina-Chapel Hill, Chapel Hill, United States
David Borland - UNC-Chapel Hill, Chapel Hill, United States
Tabitha C. Peck - Davidson College, Davidson, United States
Wenyuan Wang - University of North Carolina, Chapel Hill, United States
David Gotz - University of North Carolina, Chapel Hill, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T14:51:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:51:00Z
Fast forward
Keywords
Causal inference, Perception and cognition, Causal prior, Association, Causality, Visualization
Abstract
``Correlation does not imply causation'' is a famous mantra in statistical and visual analysis. However, consumers of visualizations often draw causal conclusions when only correlations between variables are shown. In this paper, we investigate factors that contribute to causal relationships users perceive in visualizations. We collected a corpus of concept pairs from variables in widely used datasets and created visualizations that depict varying correlative associations using three typical statistical chart types. We conducted two MTurk studies on (1) preconceived notions on causal relations without charts, and (2) perceived causal relations with charts, for each concept pair. Our results indicate that people make assumptions about causal relationships between pairs of concepts even without seeing any visualized data. Moreover, our results suggest that these assumptions constitute causal priors that, in combination with visualized association, impact how data visualizations are interpreted. The results also suggest that causal priors may lead to over- or under-estimation in perceived causal relations in different circumstances, and that those priors can also impact users' confidence in their causal assessments. In addition, our results align with prior work, indicating that chart type may also affect causal inference. Using data from the studies, we develop a model to capture the interaction between causal priors and visualized associations as they combine to impact a user's perceived causal relations. In addition to reporting the study results and analyses, we provide an open dataset of causal priors for 56 specific concept pairs that can serve as a potential benchmark for future studies. We also suggest remaining challenges and heuristic-based guidelines to help designers improve visualization design choices to better support visual causal inference.
PhenoFlow: A Human-LLM Driven Visual Analytics System for Exploring Large and Complex Stroke Datasets
Jaeyoung Kim - Seoul National University, Seoul, Korea, Republic of
Sihyeon Lee - Seoul National University, Seoul, Korea, Republic of
Hyeon Jeon - Seoul National University, Seoul, Korea, Republic of
Keon-Joo Lee - Korea University Guro Hospital, Seoul, Korea, Republic of
Bohyoung Kim - Hankuk University of Foreign Studies, Yongin-si, Korea, Republic of
HEE JOON - Seoul National University Bundang Hospital, Seongnam, Korea, Republic of
Jinwook Seo - Seoul National University, Seoul, Korea, Republic of
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-16T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:12:00Z

Fast forward
Keywords
Stroke, Irregularly spaced time-series data, Multi-dimensional data, Cohort analysis, Large language models
Abstract
Acute stroke demands prompt diagnosis and treatment to achieve optimal patient outcomes. However, the intricate and irregular nature of clinical data associated with acute stroke, particularly blood pressure (BP) measurements, presents substantial obstacles to effective visual analytics and decision-making. Through a year-long collaboration with experienced neurologists, we developed PhenoFlow, a visual analytics system that leverages the collaboration between human and Large Language Models (LLMs) to analyze the extensive and complex data of acute ischemic stroke patients. PhenoFlow pioneers an innovative workflow, where the LLM serves as a data wrangler while neurologists explore and supervise the output using visualizations and natural language interactions. This approach enables neurologists to focus more on decision-making with reduced cognitive load. To protect sensitive patient information, PhenoFlow only utilizes metadata to make inferences and synthesize executable codes, without accessing raw patient data. This ensures that the results are both reproducible and interpretable while maintaining patient privacy. The system incorporates a slice-and-wrap design that employs temporal folding to create an overlaid circular visualization. Combined with a linear bar graph, this design aids in exploring meaningful patterns within irregularly measured BP data. Through case studies, PhenoFlow has demonstrated its capability to support iterative analysis of extensive clinical datasets, reducing cognitive load and enabling neurologists to make well-informed decisions. Grounded in long-term collaboration with domain experts, our research demonstrates the potential of utilizing LLMs to tackle current challenges in data-driven clinical decision-making for acute ischemic stroke patients.
PhenoFlow: A Human-LLM Driven Visual Analytics System for Exploring Large and Complex Stroke Datasets
Jaeyoung Kim - Seoul National University, Seoul, Korea, Republic of
Sihyeon Lee - Seoul National University, Seoul, Korea, Republic of
Hyeon Jeon - Seoul National University, Seoul, Korea, Republic of
Keon-Joo Lee - Korea University Guro Hospital, Seoul, Korea, Republic of
Bohyoung Kim - Hankuk University of Foreign Studies, Yongin-si, Korea, Republic of
HEE JOON - Seoul National University Bundang Hospital, Seongnam, Korea, Republic of
Jinwook Seo - Seoul National University, Seoul, Korea, Republic of
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-16T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:12:00Z
Fast forward
Keywords
Stroke, Irregularly spaced time-series data, Multi-dimensional data, Cohort analysis, Large language models
Abstract
Acute stroke demands prompt diagnosis and treatment to achieve optimal patient outcomes. However, the intricate and irregular nature of clinical data associated with acute stroke, particularly blood pressure (BP) measurements, presents substantial obstacles to effective visual analytics and decision-making. Through a year-long collaboration with experienced neurologists, we developed PhenoFlow, a visual analytics system that leverages the collaboration between human and Large Language Models (LLMs) to analyze the extensive and complex data of acute ischemic stroke patients. PhenoFlow pioneers an innovative workflow, where the LLM serves as a data wrangler while neurologists explore and supervise the output using visualizations and natural language interactions. This approach enables neurologists to focus more on decision-making with reduced cognitive load. To protect sensitive patient information, PhenoFlow only utilizes metadata to make inferences and synthesize executable codes, without accessing raw patient data. This ensures that the results are both reproducible and interpretable while maintaining patient privacy. The system incorporates a slice-and-wrap design that employs temporal folding to create an overlaid circular visualization. Combined with a linear bar graph, this design aids in exploring meaningful patterns within irregularly measured BP data. Through case studies, PhenoFlow has demonstrated its capability to support iterative analysis of extensive clinical datasets, reducing cognitive load and enabling neurologists to make well-informed decisions. Grounded in long-term collaboration with domain experts, our research demonstrates the potential of utilizing LLMs to tackle current challenges in data-driven clinical decision-making for acute ischemic stroke patients.
PUREsuggest: Citation-based Literature Search and Visual Exploration with Keyword-controlled Rankings
Fabian Beck - University of Bamberg, Bamberg, Germany
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-17T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:18:00Z

Fast forward
Keywords
Scientific literature search, citation network visualization, visual recommender system.
Abstract
Citations allow quickly identifying related research. If multiple publications are selected as seeds, specific suggestions for related literature can be made based on the number of incoming and outgoing citation links to this selection. Interactively adding recommended publications to the selection refines the next suggestion and incrementally builds a relevant collection of publications. Following this approach, the paper presents a search and foraging approach, PUREsuggest, which combines citation-based suggestions with augmented visualizations of the citation network. The focus and novelty of the approach is, first, the transparency of how the rankings are explained visually and, second, that the process can be steered through user-defined keywords, which reflect topics of interests. The system can be used to build new literature collections, to update and assess existing ones, as well as to use the collected literature for identifying relevant experts in the field. We evaluated the recommendation approach through simulated sessions and performed a user study investigating search strategies and usage patterns supported by the interface.
PUREsuggest: Citation-based Literature Search and Visual Exploration with Keyword-controlled Rankings
Fabian Beck - University of Bamberg, Bamberg, Germany
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-17T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:18:00Z
Fast forward
Keywords
Scientific literature search, citation network visualization, visual recommender system.
Abstract
Citations allow quickly identifying related research. If multiple publications are selected as seeds, specific suggestions for related literature can be made based on the number of incoming and outgoing citation links to this selection. Interactively adding recommended publications to the selection refines the next suggestion and incrementally builds a relevant collection of publications. Following this approach, the paper presents a search and foraging approach, PUREsuggest, which combines citation-based suggestions with augmented visualizations of the citation network. The focus and novelty of the approach is, first, the transparency of how the rankings are explained visually and, second, that the process can be steered through user-defined keywords, which reflect topics of interests. The system can be used to build new literature collections, to update and assess existing ones, as well as to use the collected literature for identifying relevant experts in the field. We evaluated the recommendation approach through simulated sessions and performed a user study investigating search strategies and usage patterns supported by the interface.
Honorable Mention
Touching the Ground: Evaluating the Effectiveness of Data Physicalizations for Spatial Data Analysis Tasks
Bridger Herman - University of Minnesota, Minneapolis, United States
Cullen D. Jackson - Beth Israel Deaconess Medical Center, Boston, United States
Daniel F. Keefe - University of Minnesota, Minneapolis, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-17T18:21:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:21:00Z

Fast forward
Keywords
Data physicalization, virtual reality, evaluation.
Abstract
Abstract—Inspired by recent advances in digital fabrication, artists and scientists have demonstrated that physical data encodings (i.e., data physicalizations) can increase engagement with data, foster collaboration, and in some cases, improve data legibility and analysis relative to digital alternatives. However, prior empirical studies have only investigated abstract data encoded in physical form (e.g., laser cut bar charts) and not continuously sampled spatial data fields relevant to climate and medical science (e.g., heights, temperatures, densities, and velocities sampled on a spatial grid). This paper presents the design and results of the first study to characterize human performance in 3D spatial data analysis tasks across analogous physical and digital visualizations. Participants analyzed continuous spatial elevation data with three visualization modalities: (1) 2D digital visualization; (2) perspective-tracked, stereoscopic "fishtank" virtual reality; and (3) 3D printed data physicalization. Their tasks included tracing paths downhill, looking up spatial locations and comparing their relative heights, and identifying and reporting the minimum and maximum heights within certain spatial regions. As hypothesized, in most cases, participants performed the tasks just as well or better in the physical modality (based on time and error metrics). Additional results include an analysis of open-ended feedback from participants and discussion of implications for further research on the value of data physicalization. All data and supplemental materials are available at https://osf.io/7xdq4/.
Honorable Mention
Touching the Ground: Evaluating the Effectiveness of Data Physicalizations for Spatial Data Analysis Tasks
Bridger Herman - University of Minnesota, Minneapolis, United States
Cullen D. Jackson - Beth Israel Deaconess Medical Center, Boston, United States
Daniel F. Keefe - University of Minnesota, Minneapolis, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-17T18:21:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:21:00Z
Fast forward
Keywords
Data physicalization, virtual reality, evaluation.
Abstract
Abstract—Inspired by recent advances in digital fabrication, artists and scientists have demonstrated that physical data encodings (i.e., data physicalizations) can increase engagement with data, foster collaboration, and in some cases, improve data legibility and analysis relative to digital alternatives. However, prior empirical studies have only investigated abstract data encoded in physical form (e.g., laser cut bar charts) and not continuously sampled spatial data fields relevant to climate and medical science (e.g., heights, temperatures, densities, and velocities sampled on a spatial grid). This paper presents the design and results of the first study to characterize human performance in 3D spatial data analysis tasks across analogous physical and digital visualizations. Participants analyzed continuous spatial elevation data with three visualization modalities: (1) 2D digital visualization; (2) perspective-tracked, stereoscopic "fishtank" virtual reality; and (3) 3D printed data physicalization. Their tasks included tracing paths downhill, looking up spatial locations and comparing their relative heights, and identifying and reporting the minimum and maximum heights within certain spatial regions. As hypothesized, in most cases, participants performed the tasks just as well or better in the physical modality (based on time and error metrics). Additional results include an analysis of open-ended feedback from participants and discussion of implications for further research on the value of data physicalization. All data and supplemental materials are available at https://osf.io/7xdq4/.
"It's a Good Idea to Put It Into Words": Writing 'Rudders' in the Initial Stages of Visualization Design
Chase Stokes - UC Berkeley, Berkeley, United States
Clara Hu - Self, Berkeley, United States
Marti Hearst - UC Berkeley, Berkeley, United States
Download preprint PDF
Download camera-ready PDF
Room: Bayshore II
2024-10-17T16:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:00:00Z

Fast forward
Keywords
Visualization, design, language, text
Abstract
Written language is a useful tool for non-visual creative activities like composing essays and planning searches. This paper investigates the integration of written language into the visualization design process. We create the idea of a 'writing rudder,' which acts as a guiding force or strategy for the designer. Via an interview study of 24 working visualization designers, we first established that only a minority of participants systematically use writingto aid in design. A second study with 15 visualization designers examined four different variants of written rudders: asking questions, stating conclusions, composing a narrative, and writing titles. Overall, participants had a positive reaction; designers recognized the benefits of explicitly writing down components of the design and indicated that they would use this approach in future design work.More specifically, two approaches - writing questions and writing conclusions/takeaways - were seen as beneficial across the design process, while writing narratives showed promise mainly for the creation stage. Although concerns around potential bias during data exploration were raised, participants also discussed strategies to mitigate such concerns. This paper contributes to a deeper understanding of the interplay between language and visualization, and proposes a straightforward, lightweight addition to the visualization design process.
"It's a Good Idea to Put It Into Words": Writing 'Rudders' in the Initial Stages of Visualization Design
Chase Stokes - UC Berkeley, Berkeley, United States
Clara Hu - Self, Berkeley, United States
Marti Hearst - UC Berkeley, Berkeley, United States
Download preprint PDF
Download camera-ready PDF
Room: Bayshore II
2024-10-17T16:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:00:00Z
Fast forward
Keywords
Visualization, design, language, text
Abstract
Written language is a useful tool for non-visual creative activities like composing essays and planning searches. This paper investigates the integration of written language into the visualization design process. We create the idea of a 'writing rudder,' which acts as a guiding force or strategy for the designer. Via an interview study of 24 working visualization designers, we first established that only a minority of participants systematically use writingto aid in design. A second study with 15 visualization designers examined four different variants of written rudders: asking questions, stating conclusions, composing a narrative, and writing titles. Overall, participants had a positive reaction; designers recognized the benefits of explicitly writing down components of the design and indicated that they would use this approach in future design work.More specifically, two approaches - writing questions and writing conclusions/takeaways - were seen as beneficial across the design process, while writing narratives showed promise mainly for the creation stage. Although concerns around potential bias during data exploration were raised, participants also discussed strategies to mitigate such concerns. This paper contributes to a deeper understanding of the interplay between language and visualization, and proposes a straightforward, lightweight addition to the visualization design process.
Compress and Compare: Interactively Evaluating Efficiency and Behavior Across ML Model Compression Experiments
Angie Boggust - Massachusetts Institute of Technology, Cambridge, United States
Venkatesh Sivaraman - Carnegie Mellon University, Pittsburgh, United States
Yannick Assogba - Apple, Cambridge, United States
Donghao Ren - Apple, Seattle, United States
Dominik Moritz - Apple, Pittsburgh, United States
Fred Hohman - Apple, Seattle, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:18:00Z
Fast forward
Keywords
Efficient machine learning, model compression, visual analytics, model comparison
Abstract
To deploy machine learning models on-device, practitioners use compression algorithms to shrink and speed up models while maintaining their high-quality output. A critical aspect of compression in practice is model comparison, including tracking many compression experiments, identifying subtle changes in model behavior, and negotiating complex accuracy-efficiency trade-offs. However, existing compression tools poorly support comparison, leading to tedious and, sometimes, incomplete analyses spread across disjoint tools. To support real-world comparative workflows, we develop an interactive visual system called Compress and Compare. Within a single interface, Compress and Compare surfaces promising compression strategies by visualizing provenance relationships between compressed models and reveals compression-induced behavior changes by comparing models’ predictions, weights, and activations. We demonstrate how Compress and Compare supports common compression analysis tasks through two case studies, debugging failed compression on generative language models and identifying compression artifacts in image classification models. We further evaluate Compress and Compare in a user study with eight compression experts, illustrating its potential to provide structure to compression workflows, help practitioners build intuition about compression, and encourage thorough analysis of compression’s effect on model behavior. Through these evaluations, we identify compression-specific challenges that future visual analytics tools should consider and Compress and Compare visualizations that may generalize to broader model comparison tasks.
Compress and Compare: Interactively Evaluating Efficiency and Behavior Across ML Model Compression Experiments
Angie Boggust - Massachusetts Institute of Technology, Cambridge, United States
Venkatesh Sivaraman - Carnegie Mellon University, Pittsburgh, United States
Yannick Assogba - Apple, Cambridge, United States
Donghao Ren - Apple, Seattle, United States
Dominik Moritz - Apple, Pittsburgh, United States
Fred Hohman - Apple, Seattle, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:18:00Z
Fast forward
Keywords
Efficient machine learning, model compression, visual analytics, model comparison
Abstract
To deploy machine learning models on-device, practitioners use compression algorithms to shrink and speed up models while maintaining their high-quality output. A critical aspect of compression in practice is model comparison, including tracking many compression experiments, identifying subtle changes in model behavior, and negotiating complex accuracy-efficiency trade-offs. However, existing compression tools poorly support comparison, leading to tedious and, sometimes, incomplete analyses spread across disjoint tools. To support real-world comparative workflows, we develop an interactive visual system called Compress and Compare. Within a single interface, Compress and Compare surfaces promising compression strategies by visualizing provenance relationships between compressed models and reveals compression-induced behavior changes by comparing models’ predictions, weights, and activations. We demonstrate how Compress and Compare supports common compression analysis tasks through two case studies, debugging failed compression on generative language models and identifying compression artifacts in image classification models. We further evaluate Compress and Compare in a user study with eight compression experts, illustrating its potential to provide structure to compression workflows, help practitioners build intuition about compression, and encourage thorough analysis of compression’s effect on model behavior. Through these evaluations, we identify compression-specific challenges that future visual analytics tools should consider and Compress and Compare visualizations that may generalize to broader model comparison tasks.
An Empirical Evaluation of the GPT-4 Multimodal Language Model on Visualization Literacy Tasks
Alexander Bendeck - Georgia Institute of Technology, Atlanta, United States
John Stasko - Georgia Institute of Technology, Atlanta, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:18:00Z

Fast forward
Keywords
Visualization Literacy, Large Language Models, Natural Language
Abstract
Large Language Models (LLMs) like GPT-4 which support multimodal input (i.e., prompts containing images in addition to text) have immense potential to advance visualization research. However, many questions exist about the visual capabilities of such models, including how well they can read and interpret visually represented data. In our work, we address this question by evaluating the GPT-4 multimodal LLM using a suite of task sets meant to assess the model's visualization literacy. The task sets are based on existing work in the visualization community addressing both automated chart question answering and human visualization literacy across multiple settings. Our assessment finds that GPT-4 can perform tasks such as recognizing trends and extreme values, and also demonstrates some understanding of visualization design best-practices. By contrast, GPT-4 struggles with simple value retrieval when not provided with the original dataset, lacks the ability to reliably distinguish between colors in charts, and occasionally suffers from hallucination and inconsistency. We conclude by reflecting on the model's strengths and weaknesses as well as the potential utility of models like GPT-4 for future visualization research. We also release all code, stimuli, and results for the task sets at the following link: https://doi.org/10.17605/OSF.IO/F39J6
An Empirical Evaluation of the GPT-4 Multimodal Language Model on Visualization Literacy Tasks
Alexander Bendeck - Georgia Institute of Technology, Atlanta, United States
John Stasko - Georgia Institute of Technology, Atlanta, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:18:00Z
Fast forward
Keywords
Visualization Literacy, Large Language Models, Natural Language
Abstract
Large Language Models (LLMs) like GPT-4 which support multimodal input (i.e., prompts containing images in addition to text) have immense potential to advance visualization research. However, many questions exist about the visual capabilities of such models, including how well they can read and interpret visually represented data. In our work, we address this question by evaluating the GPT-4 multimodal LLM using a suite of task sets meant to assess the model's visualization literacy. The task sets are based on existing work in the visualization community addressing both automated chart question answering and human visualization literacy across multiple settings. Our assessment finds that GPT-4 can perform tasks such as recognizing trends and extreme values, and also demonstrates some understanding of visualization design best-practices. By contrast, GPT-4 struggles with simple value retrieval when not provided with the original dataset, lacks the ability to reliably distinguish between colors in charts, and occasionally suffers from hallucination and inconsistency. We conclude by reflecting on the model's strengths and weaknesses as well as the potential utility of models like GPT-4 for future visualization research. We also release all code, stimuli, and results for the task sets at the following link: https://doi.org/10.17605/OSF.IO/F39J6
CompositingVis: Exploring Interaction for Creating Composite Visualizations in Immersive Environments
Qian Zhu - The Hong Kong University of Science and Technology, Hong Kong, China. The Hong Kong University of Science and Technology, Hong Kong, China
Tao Lu - Georgia Institute of Technology, Atlanta, United States. Georgia Institute of Technology, Atlanta, United States
Shunan Guo - Adobe Research, San Jose, United States. Adobe Research, San Jose, United States
Xiaojuan Ma - Hong Kong University of Science and Technology, Hong Kong, Hong Kong. Hong Kong University of Science and Technology, Hong Kong, Hong Kong
Yalong Yang - Georgia Institute of Technology, Atlanta, United States. Georgia Institute of Technology, Atlanta, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Room: Bayshore II
2024-10-16T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:30:00Z

Fast forward
Keywords
Composite Visualization, Immersive Analytics, Embodied Interaction
Abstract
Composite visualization represents a widely embraced design that combines multiple visual representations to create an integrated view.However, the traditional approach of creating composite visualizations in immersive environments typically occurs asynchronously outside of the immersive space and is carried out by experienced experts.In this work, we aim to empower users to participate in the creation of composite visualization within immersive environments through embodied interactions.This could provide a flexible and fluid experience with immersive visualization and has the potential to facilitate understanding of the relationship between visualization views. We begin with developing a design space of embodied interactions to create various types of composite visualizations with the consideration of data relationships. Drawing inspiration from people's natural experience of manipulating physical objects, we design interactions based on the combination of 3D manipulations in immersive environments. Building upon the design space, we present a series of case studies showcasing the interaction to create different kinds of composite visualizations in virtual reality.Subsequently, we conduct a user study to evaluate the usability of the derived interaction techniques and user experience of creating composite visualizations through embodied interactions.We find that empowering users to participate in composite visualizations through embodied interactions enables them to flexibly leverage different visualization views for understanding and communicating the relationships between different views, which underscores the potential of several future application scenarios.
CompositingVis: Exploring Interaction for Creating Composite Visualizations in Immersive Environments
Qian Zhu - The Hong Kong University of Science and Technology, Hong Kong, China. The Hong Kong University of Science and Technology, Hong Kong, China
Tao Lu - Georgia Institute of Technology, Atlanta, United States. Georgia Institute of Technology, Atlanta, United States
Shunan Guo - Adobe Research, San Jose, United States. Adobe Research, San Jose, United States
Xiaojuan Ma - Hong Kong University of Science and Technology, Hong Kong, Hong Kong. Hong Kong University of Science and Technology, Hong Kong, Hong Kong
Yalong Yang - Georgia Institute of Technology, Atlanta, United States. Georgia Institute of Technology, Atlanta, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Room: Bayshore II
2024-10-16T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:30:00Z
Fast forward
Keywords
Composite Visualization, Immersive Analytics, Embodied Interaction
Abstract
Composite visualization represents a widely embraced design that combines multiple visual representations to create an integrated view.However, the traditional approach of creating composite visualizations in immersive environments typically occurs asynchronously outside of the immersive space and is carried out by experienced experts.In this work, we aim to empower users to participate in the creation of composite visualization within immersive environments through embodied interactions.This could provide a flexible and fluid experience with immersive visualization and has the potential to facilitate understanding of the relationship between visualization views. We begin with developing a design space of embodied interactions to create various types of composite visualizations with the consideration of data relationships. Drawing inspiration from people's natural experience of manipulating physical objects, we design interactions based on the combination of 3D manipulations in immersive environments. Building upon the design space, we present a series of case studies showcasing the interaction to create different kinds of composite visualizations in virtual reality.Subsequently, we conduct a user study to evaluate the usability of the derived interaction techniques and user experience of creating composite visualizations through embodied interactions.We find that empowering users to participate in composite visualizations through embodied interactions enables them to flexibly leverage different visualization views for understanding and communicating the relationships between different views, which underscores the potential of several future application scenarios.
SimpleSets: Capturing Categorical Point Patterns with Simple Shapes
Steven van den Broek - TU Eindhoven, Eindhoven, Netherlands
Wouter Meulemans - TU Eindhoven, Eindhoven, Netherlands
Bettina Speckmann - TU Eindhoven, Eindhoven, Netherlands
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore VII
2024-10-16T15:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T15:15:00Z
Fast forward
Keywords
Set visualization, geographic visualization, algorithms
Abstract
Points of interest on a map such as restaurants, hotels, or subway stations, give rise to categorical point data: data that have a fixed location and one or more categorical attributes. Consequently, recent years have seen various set visualization approaches that visually connect points of the same category to support users in understanding the spatial distribution of categories. Existing methods use complex and often highly irregular shapes to connect points of the same category, leading to high cognitive load for the user. In this paper we introduce SimpleSets, which uses simple shapes to enclose categorical point patterns, thereby providing a clean overview of the data distribution. SimpleSets is designed to visualize sets of points with a single categorical attribute; as a result, the point patterns enclosed by SimpleSets form a partition of the data. We give formal definitions of point patterns that correspond to simple shapes and describe an algorithm that partitions categorical points into few such patterns. Our second contribution is a rendering algorithm that transforms a given partition into a clean set of shapes resulting in an aesthetically pleasing set visualization. Our algorithm pays particular attention to resolving intersections between nearby shapes in a consistent manner. We compare SimpleSets to the state-of-the-art set visualizations using standard datasets from the literature.
SimpleSets: Capturing Categorical Point Patterns with Simple Shapes
Steven van den Broek - TU Eindhoven, Eindhoven, Netherlands
Wouter Meulemans - TU Eindhoven, Eindhoven, Netherlands
Bettina Speckmann - TU Eindhoven, Eindhoven, Netherlands
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore VII
2024-10-16T15:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T15:15:00Z
Fast forward
Keywords
Set visualization, geographic visualization, algorithms
Abstract
Points of interest on a map such as restaurants, hotels, or subway stations, give rise to categorical point data: data that have a fixed location and one or more categorical attributes. Consequently, recent years have seen various set visualization approaches that visually connect points of the same category to support users in understanding the spatial distribution of categories. Existing methods use complex and often highly irregular shapes to connect points of the same category, leading to high cognitive load for the user. In this paper we introduce SimpleSets, which uses simple shapes to enclose categorical point patterns, thereby providing a clean overview of the data distribution. SimpleSets is designed to visualize sets of points with a single categorical attribute; as a result, the point patterns enclosed by SimpleSets form a partition of the data. We give formal definitions of point patterns that correspond to simple shapes and describe an algorithm that partitions categorical points into few such patterns. Our second contribution is a rendering algorithm that transforms a given partition into a clean set of shapes resulting in an aesthetically pleasing set visualization. Our algorithm pays particular attention to resolving intersections between nearby shapes in a consistent manner. We compare SimpleSets to the state-of-the-art set visualizations using standard datasets from the literature.
Charting EDA: How Visualizations and Interactions Shape Analysis in Computational Notebooks.
Dylan Wootton - MIT, Cambridge, United States
Amy Rae Fox - MIT, Cambridge, United States
Evan Peck - University of Colorado Boulder, Boulder, United States
Arvind Satyanarayan - MIT, Cambridge, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T17:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:45:00Z
Keywords
Interaction Design, Methodologies, HumanQual, HumanQuant.
Abstract
Interactive visualizations are powerful tools for Exploratory Data Analysis (EDA), but how do they affect the observations analysts make about their data? We conducted a qualitative experiment with 13 professional data scientists analyzing two datasets with Jupyter notebooks, collecting a rich dataset of interaction traces and think-aloud utterances. By qualitatively coding participant utterances, we introduce a formalism that describes EDA as a sequence of analysis states, where each state is comprised of either a representation an analyst constructs (e.g., the output of a data frame, an interactive visualization, etc.) or an observation the analyst makes (e.g., about missing data, the relationship between variables, etc.). By applying our formalism to our dataset, we identify that interactive visualizations, on average, lead to earlier and more complex insights about relationships between dataset attributes compared to static visualizations. Moreover, by calculating metrics such as revisit count and representational diversity, we uncover that some representations serve more as "planning aids" during EDA rather than tools strictly for hypothesis-answering. We show how these measures help identify other patterns of analysis behavior, such as the "80-20 rule", where a small subset of representations drove the majority of observations. Based on these findings, we offer design guidelines for interactive exploratory analysis tooling and reflect on future directions for studying the role that visualizations play in EDA.
Charting EDA: How Visualizations and Interactions Shape Analysis in Computational Notebooks.
Dylan Wootton - MIT, Cambridge, United States
Amy Rae Fox - MIT, Cambridge, United States
Evan Peck - University of Colorado Boulder, Boulder, United States
Arvind Satyanarayan - MIT, Cambridge, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T17:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:45:00Z
Fast forward
Keywords
Interaction Design, Methodologies, HumanQual, HumanQuant.
Abstract
Interactive visualizations are powerful tools for Exploratory Data Analysis (EDA), but how do they affect the observations analysts make about their data? We conducted a qualitative experiment with 13 professional data scientists analyzing two datasets with Jupyter notebooks, collecting a rich dataset of interaction traces and think-aloud utterances. By qualitatively coding participant utterances, we introduce a formalism that describes EDA as a sequence of analysis states, where each state is comprised of either a representation an analyst constructs (e.g., the output of a data frame, an interactive visualization, etc.) or an observation the analyst makes (e.g., about missing data, the relationship between variables, etc.). By applying our formalism to our dataset, we identify that interactive visualizations, on average, lead to earlier and more complex insights about relationships between dataset attributes compared to static visualizations. Moreover, by calculating metrics such as revisit count and representational diversity, we uncover that some representations serve more as "planning aids" during EDA rather than tools strictly for hypothesis-answering. We show how these measures help identify other patterns of analysis behavior, such as the "80-20 rule", where a small subset of representations drove the majority of observations. Based on these findings, we offer design guidelines for interactive exploratory analysis tooling and reflect on future directions for studying the role that visualizations play in EDA.
ParetoTracker: Understanding Population Dynamics in Multi-objective Evolutionary Algorithms through Visual Analytics
Zherui Zhang - Southern University of Science and Technology, Shenzhen, China
Fan Yang - Southern University of Science and Technology, Shenzhen, China
Ran Cheng - Southern University of Science and Technology, Shenzhen, China
Yuxin Ma - Southern University of Science and Technology, Shenzhen, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T13:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:30:00Z

Fast forward
Keywords
Visual analytics, multi-objective evolutionary algorithms, evolutionary computation
Abstract
Multi-objective evolutionary algorithms (MOEAs) have emerged as powerful tools for solving complex optimization problems characterized by multiple, often conflicting, objectives. While advancements have been made in computational efficiency as well as diversity and convergence of solutions, a critical challenge persists: the internal evolutionary mechanisms are opaque to human users. Drawing upon the successes of explainable AI in explaining complex algorithms and models, we argue that the need to understand the underlying evolutionary operators and population dynamics within MOEAs aligns well with a visual analytics paradigm. This paper introduces ParetoTracker, a visual analytics framework designed to support the comprehension and inspection of population dynamics in the evolutionary processes of MOEAs. Informed by preliminary literature review and expert interviews, the framework establishes a multi-level analysis scheme, which caters to user engagement and exploration ranging from examining overall trends in performance metrics to conducting fine-grained inspections of evolutionary operations. In contrast to conventional practices that require manual plotting of solutions for each generation, ParetoTracker facilitates the examination of temporal trends and dynamics across consecutive generations in an integrated visual interface. The effectiveness of the framework is demonstrated through case studies and expert interviews focused on widely adopted benchmark optimization problems.
ParetoTracker: Understanding Population Dynamics in Multi-objective Evolutionary Algorithms through Visual Analytics
Zherui Zhang - Southern University of Science and Technology, Shenzhen, China
Fan Yang - Southern University of Science and Technology, Shenzhen, China
Ran Cheng - Southern University of Science and Technology, Shenzhen, China
Yuxin Ma - Southern University of Science and Technology, Shenzhen, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T13:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:30:00Z
Fast forward
Keywords
Visual analytics, multi-objective evolutionary algorithms, evolutionary computation
Abstract
Multi-objective evolutionary algorithms (MOEAs) have emerged as powerful tools for solving complex optimization problems characterized by multiple, often conflicting, objectives. While advancements have been made in computational efficiency as well as diversity and convergence of solutions, a critical challenge persists: the internal evolutionary mechanisms are opaque to human users. Drawing upon the successes of explainable AI in explaining complex algorithms and models, we argue that the need to understand the underlying evolutionary operators and population dynamics within MOEAs aligns well with a visual analytics paradigm. This paper introduces ParetoTracker, a visual analytics framework designed to support the comprehension and inspection of population dynamics in the evolutionary processes of MOEAs. Informed by preliminary literature review and expert interviews, the framework establishes a multi-level analysis scheme, which caters to user engagement and exploration ranging from examining overall trends in performance metrics to conducting fine-grained inspections of evolutionary operations. In contrast to conventional practices that require manual plotting of solutions for each generation, ParetoTracker facilitates the examination of temporal trends and dynamics across consecutive generations in an integrated visual interface. The effectiveness of the framework is demonstrated through case studies and expert interviews focused on widely adopted benchmark optimization problems.
Does This Have a Particular Meaning?: Interactive Pattern Explanation for Network Visualizations
Xinhuan Shu - Newcastle University, Newcastle Upon Tyne, United Kingdom. University of Edinburgh, Edinburgh, United Kingdom
Alexis Pister - University of Edinburgh, Edinburgh, United Kingdom
Junxiu Tang - Zhejiang University, Hangzhou, China
Fanny Chevalier - University of Toronto, Toronto, Canada
Benjamin Bach - Inria, Bordeaux, France. University of Edinburgh, Edinburgh, United Kingdom
Download preprint PDF
Download camera-ready PDF
Room: Bayshore VII
2024-10-18T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:54:00Z

Fast forward
Keywords
Visualization education, network visualization
Abstract
This paper presents an interactive technique to explain visual patterns in network visualizations to analysts who do not understand these visualizations and who are learning to read them. Learning a visualization requires mastering its visual grammar and decoding information presented through visual marks, graphical encodings, and spatial configurations. To help people learn network visualization designs and extract meaningful information, we introduce the concept of interactive pattern explanation that allows viewers to select an arbitrary area in a visualization, then automatically mines the underlying data patterns, and explains both visual and data patterns present in the viewer’s selection. In a qualitative and a quantitative user study with a total of 32 participants, we compare interactive pattern explanations to textual-only and visual-only (cheatsheets) explanations. Our results show that interactive explanations increase learning of i) unfamiliar visualizations, ii) patterns in network science, and iii) the respective network terminology.
Does This Have a Particular Meaning?: Interactive Pattern Explanation for Network Visualizations
Xinhuan Shu - Newcastle University, Newcastle Upon Tyne, United Kingdom. University of Edinburgh, Edinburgh, United Kingdom
Alexis Pister - University of Edinburgh, Edinburgh, United Kingdom
Junxiu Tang - Zhejiang University, Hangzhou, China
Fanny Chevalier - University of Toronto, Toronto, Canada
Benjamin Bach - Inria, Bordeaux, France. University of Edinburgh, Edinburgh, United Kingdom
Download preprint PDF
Download camera-ready PDF
Room: Bayshore VII
2024-10-18T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:54:00Z
Fast forward
Keywords
Visualization education, network visualization
Abstract
This paper presents an interactive technique to explain visual patterns in network visualizations to analysts who do not understand these visualizations and who are learning to read them. Learning a visualization requires mastering its visual grammar and decoding information presented through visual marks, graphical encodings, and spatial configurations. To help people learn network visualization designs and extract meaningful information, we introduce the concept of interactive pattern explanation that allows viewers to select an arbitrary area in a visualization, then automatically mines the underlying data patterns, and explains both visual and data patterns present in the viewer’s selection. In a qualitative and a quantitative user study with a total of 32 participants, we compare interactive pattern explanations to textual-only and visual-only (cheatsheets) explanations. Our results show that interactive explanations increase learning of i) unfamiliar visualizations, ii) patterns in network science, and iii) the respective network terminology.
Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
Xingchen Zeng - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
Haichuan Lin - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
Yilin Ye - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
Wei Zeng - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China. The Hong Kong University of Science and Technology, Hong Kong SAR, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-18T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:06:00Z

Fast forward
Keywords
Chart-question answering, multimodal large language models, benchmark
Abstract
Emerging multimodal large language models (MLLMs) exhibit great potential for chart question answering (CQA). Recent efforts primarily focus on scaling up training datasets (i.e., charts, data tables, and question-answer (QA) pairs) through data collection and synthesis. However, our empirical study on existing MLLMs and CQA datasets reveals notable gaps. First, current data collection and synthesis focus on data volume and lack consideration of fine-grained visual encodings and QA tasks, resulting in unbalanced data distribution divergent from practical CQA scenarios. Second, existing work follows the training recipe of the base MLLMs initially designed for natural images, under-exploring the adaptation to unique chart characteristics, such as rich text elements. To fill the gap, we propose a visualization-referenced instruction tuning approach to guide the training dataset enhancement and model development. Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. Experimental results validate the effectiveness of our approach. Even with fewer training examples, our model consistently outperforms state-of-the-art CQA models on established benchmarks. We also contribute a dataset split as a benchmark for future research. Source codes and datasets of this paper are available at https://github.com/zengxingchen/ChartQA-MLLM.
Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
Xingchen Zeng - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
Haichuan Lin - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
Yilin Ye - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
Wei Zeng - The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China. The Hong Kong University of Science and Technology, Hong Kong SAR, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-18T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:06:00Z
Fast forward
Keywords
Chart-question answering, multimodal large language models, benchmark
Abstract
Emerging multimodal large language models (MLLMs) exhibit great potential for chart question answering (CQA). Recent efforts primarily focus on scaling up training datasets (i.e., charts, data tables, and question-answer (QA) pairs) through data collection and synthesis. However, our empirical study on existing MLLMs and CQA datasets reveals notable gaps. First, current data collection and synthesis focus on data volume and lack consideration of fine-grained visual encodings and QA tasks, resulting in unbalanced data distribution divergent from practical CQA scenarios. Second, existing work follows the training recipe of the base MLLMs initially designed for natural images, under-exploring the adaptation to unique chart characteristics, such as rich text elements. To fill the gap, we propose a visualization-referenced instruction tuning approach to guide the training dataset enhancement and model development. Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. Experimental results validate the effectiveness of our approach. Even with fewer training examples, our model consistently outperforms state-of-the-art CQA models on established benchmarks. We also contribute a dataset split as a benchmark for future research. Source codes and datasets of this paper are available at https://github.com/zengxingchen/ChartQA-MLLM.
Unmasking Dunning-Kruger Effect in Visual Reasoning and Visual Data Analysis
Mengyu Chen - Emory University, Atlanta, United States
Yijun Liu - Emory University, Atlanta, United States
Emily Wall - Emory University, Atlanta, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T14:27:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:27:00Z

Fast forward
Keywords
Cognitive Bias, Dunning Kruger Effect, Metacognition, Personality Traits, Interactions, Visual Reasoning
Abstract
The Dunning-Kruger Effect (DKE) is a metacognitive phenomenon where low-skilled individuals tend to overestimate their competence while high-skilled individuals tend to underestimate their competence. This effect has been observed in a number of domains including humor, grammar, and logic. In this paper, we explore if and how DKE manifests in visual reasoning and judgment tasks. Across two online user studies involving (1) a sliding puzzle game and (2) a scatterplot-based categorization task, we demonstrate that individuals are susceptible to DKE in visual reasoning and judgment tasks: those who performed best underestimated their performance, while bottom performers overestimated their performance. In addition, we contribute novel analyses that correlate susceptibility of DKE with personality traits and user interactions. Our findings pave the way for novel modes of bias detection via interaction patterns and establish promising directions towards interventions tailored to an individual’s personality traits. All materials and analyses are in supplemental materials: https://github.com/CAV-Lab/DKE_supplemental.git.
Unmasking Dunning-Kruger Effect in Visual Reasoning and Visual Data Analysis
Mengyu Chen - Emory University, Atlanta, United States
Yijun Liu - Emory University, Atlanta, United States
Emily Wall - Emory University, Atlanta, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T14:27:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:27:00Z
Fast forward
Keywords
Cognitive Bias, Dunning Kruger Effect, Metacognition, Personality Traits, Interactions, Visual Reasoning
Abstract
The Dunning-Kruger Effect (DKE) is a metacognitive phenomenon where low-skilled individuals tend to overestimate their competence while high-skilled individuals tend to underestimate their competence. This effect has been observed in a number of domains including humor, grammar, and logic. In this paper, we explore if and how DKE manifests in visual reasoning and judgment tasks. Across two online user studies involving (1) a sliding puzzle game and (2) a scatterplot-based categorization task, we demonstrate that individuals are susceptible to DKE in visual reasoning and judgment tasks: those who performed best underestimated their performance, while bottom performers overestimated their performance. In addition, we contribute novel analyses that correlate susceptibility of DKE with personality traits and user interactions. Our findings pave the way for novel modes of bias detection via interaction patterns and establish promising directions towards interventions tailored to an individual’s personality traits. All materials and analyses are in supplemental materials: https://github.com/CAV-Lab/DKE_supplemental.git.
ProvenanceWidgets: A Library of UI Control Elements to Track and Dynamically Overlay Analytic Provenance
Arpit Narechania - Georgia Institute of Technology, Atlanta, United States
Kaustubh Odak - Georgia Institute of Technology, Atlanta, United States
Mennatallah El-Assady - ETH Zürich, Zürich, Switzerland
Alex Endert - Georgia Institute of Technology, Atlanta, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T18:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T18:45:00Z

Fast forward
Keywords
Provenance, Analytic provenance, Visualization, UI controls, GUI elements, JavaScript library.
Abstract
We present ProvenanceWidgets, a Javascript library of UI control elements such as radio buttons, checkboxes, and dropdowns to track and dynamically overlay a user's analytic provenance. These in situ overlays not only save screen space but also minimize the amount of time and effort needed to access the same information from elsewhere in the UI. In this paper, we discuss how we design modular UI control elements to track how often and how recently a user interacts with them and design visual overlays showing an aggregated summary as well as a detailed temporal history. We demonstrate the capability of ProvenanceWidgets by recreating three prior widget libraries: (1) Scented Widgets, (2) Phosphor objects, and (3) Dynamic Query Widgets. We also evaluated its expressiveness and conducted case studies with visualization developers to evaluate its effectiveness. We find that ProvenanceWidgets enables developers to implement custom provenance-tracking applications effectively. ProvenanceWidgets is available as open-source software at https://github.com/ProvenanceWidgets to help application developers build custom provenance-based systems.
ProvenanceWidgets: A Library of UI Control Elements to Track and Dynamically Overlay Analytic Provenance
Arpit Narechania - Georgia Institute of Technology, Atlanta, United States
Kaustubh Odak - Georgia Institute of Technology, Atlanta, United States
Mennatallah El-Assady - ETH Zürich, Zürich, Switzerland
Alex Endert - Georgia Institute of Technology, Atlanta, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T18:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T18:45:00Z
Fast forward
Keywords
Provenance, Analytic provenance, Visualization, UI controls, GUI elements, JavaScript library.
Abstract
We present ProvenanceWidgets, a Javascript library of UI control elements such as radio buttons, checkboxes, and dropdowns to track and dynamically overlay a user's analytic provenance. These in situ overlays not only save screen space but also minimize the amount of time and effort needed to access the same information from elsewhere in the UI. In this paper, we discuss how we design modular UI control elements to track how often and how recently a user interacts with them and design visual overlays showing an aggregated summary as well as a detailed temporal history. We demonstrate the capability of ProvenanceWidgets by recreating three prior widget libraries: (1) Scented Widgets, (2) Phosphor objects, and (3) Dynamic Query Widgets. We also evaluated its expressiveness and conducted case studies with visualization developers to evaluate its effectiveness. We find that ProvenanceWidgets enables developers to implement custom provenance-tracking applications effectively. ProvenanceWidgets is available as open-source software at https://github.com/ProvenanceWidgets to help application developers build custom provenance-based systems.
Improved Visual Saliency of Graph Clusters with Orderable Node-Link Layouts
Nora Al-Naami - Luxembourg Institute of Science and Technology, Esch-sur-Alzette, Luxembourg
Nicolas Medoc - Luxembourg Institute of Science and Technology, Belvaux, Luxembourg
Matteo Magnani - Uppsala University, Uppsala, Sweden
Mohammad Ghoniem - Luxembourg Institute of Science and Technology, Belvaux, Luxembourg
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-16T17:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:45:00Z

Fast forward
Keywords
network visualization, arc diagrams, radial diagrams, cluster perception, graph seriation
Abstract
Graphs are often used to model relationships between entities. The identification and visualization of clusters in graphs enable insight discovery in many application areas, such as life sciences and social sciences. Force-directed graph layouts promote the visual saliency of clusters, as they bring adjacent nodes closer together, and push non-adjacent nodes apart. At the same time, matrices can effectively show clusters when a suitable row/column ordering is applied, but are less appealing to untrained users not providing an intuitive node-link metaphor. It is thus worth exploring layouts combining the strengths of the node-link metaphor and node ordering. In this work, we study the impact of node ordering on the visual saliency of clusters in orderable node-link diagrams, namely radial diagrams, arc diagrams and symmetric arc diagrams. Through a crowdsourced controlled experiment, we show that users can count clusters consistently more accurately, and to a large extent faster, with orderable node-link diagrams than with three state-of-the art force-directed layout algorithms, i.e., `Linlog', `Backbone' and `sfdp'. The measured advantage is greater in case of low cluster separability and/or low compactness. A free copy of this paper and all supplemental materials are available at https://osf.io/kc3dg/.
Improved Visual Saliency of Graph Clusters with Orderable Node-Link Layouts
Nora Al-Naami - Luxembourg Institute of Science and Technology, Esch-sur-Alzette, Luxembourg
Nicolas Medoc - Luxembourg Institute of Science and Technology, Belvaux, Luxembourg
Matteo Magnani - Uppsala University, Uppsala, Sweden
Mohammad Ghoniem - Luxembourg Institute of Science and Technology, Belvaux, Luxembourg
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I
2024-10-16T17:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:45:00Z
Fast forward
Keywords
network visualization, arc diagrams, radial diagrams, cluster perception, graph seriation
Abstract
Graphs are often used to model relationships between entities. The identification and visualization of clusters in graphs enable insight discovery in many application areas, such as life sciences and social sciences. Force-directed graph layouts promote the visual saliency of clusters, as they bring adjacent nodes closer together, and push non-adjacent nodes apart. At the same time, matrices can effectively show clusters when a suitable row/column ordering is applied, but are less appealing to untrained users not providing an intuitive node-link metaphor. It is thus worth exploring layouts combining the strengths of the node-link metaphor and node ordering. In this work, we study the impact of node ordering on the visual saliency of clusters in orderable node-link diagrams, namely radial diagrams, arc diagrams and symmetric arc diagrams. Through a crowdsourced controlled experiment, we show that users can count clusters consistently more accurately, and to a large extent faster, with orderable node-link diagrams than with three state-of-the art force-directed layout algorithms, i.e., `Linlog', `Backbone' and `sfdp'. The measured advantage is greater in case of low cluster separability and/or low compactness. A free copy of this paper and all supplemental materials are available at https://osf.io/kc3dg/.
Graph Transformer for Label Placement
Jingwei Qu - Southwest University, Beibei, China
Pingshun Zhang - Southwest University, Chongqing, China
Enyu Che - Southwest University, Beibei, China
Yinan Chen - COLLEGE OF COMPUTER AND INFORMATION SCIENCE, SOUTHWEST UNIVERSITY SCHOOL OF SOFTWAREC, Chongqin, China
Haibin Ling - Stony Brook University, New York, United States
Download camera-ready PDF
Room: Bayshore II
2024-10-17T15:03:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T15:03:00Z

Fast forward
Keywords
Label placement, Graph neural network, Transformer
Abstract
Placing text labels is a common way to explain key elements in a given scene. Given a graphic input and original label information, how to place labels to meet both geometric and aesthetic requirements is an open challenging problem. Geometry-wise, traditional rule-driven solutions struggle to capture the complex interactions between labels, let alone consider graphical/appearance content. In terms of aesthetics, training/evaluation data ideally require nontrivial effort and expertise in design, thus resulting in a lack of decent datasets for learning-based methods. To address the above challenges, we formulate the task with a graph representation, where nodes correspond to labels and edges to interactions between labels, and treat label placement as a node position prediction problem. With this novel representation, we design a Label Placement Graph Transformer (LPGT) to predict label positions. Specifically, edge-level attention, conditioned on node representations, is introduced to reveal potential relationships between labels. To integrate graphic/image information, we design a feature aligning strategy that extracts deep features for nodes and edges efficiently. Next, to address the dataset issue, we collect commercial illustrations with professionally designed label layouts from household appliance manuals, and annotate them with useful information to create a novel dataset named the Appliance Manual Illustration Labels (AMIL) dataset. In the thorough evaluation on AMIL, our LPGT solution achieves promising label placement performance compared with popular baselines. Our algorithm is available at https://github.com/JingweiQu/LPGT.
Graph Transformer for Label Placement
Jingwei Qu - Southwest University, Beibei, China
Pingshun Zhang - Southwest University, Chongqing, China
Enyu Che - Southwest University, Beibei, China
Yinan Chen - COLLEGE OF COMPUTER AND INFORMATION SCIENCE, SOUTHWEST UNIVERSITY SCHOOL OF SOFTWAREC, Chongqin, China
Haibin Ling - Stony Brook University, New York, United States
Download camera-ready PDF
Room: Bayshore II
2024-10-17T15:03:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T15:03:00Z
Fast forward
Keywords
Label placement, Graph neural network, Transformer
Abstract
Placing text labels is a common way to explain key elements in a given scene. Given a graphic input and original label information, how to place labels to meet both geometric and aesthetic requirements is an open challenging problem. Geometry-wise, traditional rule-driven solutions struggle to capture the complex interactions between labels, let alone consider graphical/appearance content. In terms of aesthetics, training/evaluation data ideally require nontrivial effort and expertise in design, thus resulting in a lack of decent datasets for learning-based methods. To address the above challenges, we formulate the task with a graph representation, where nodes correspond to labels and edges to interactions between labels, and treat label placement as a node position prediction problem. With this novel representation, we design a Label Placement Graph Transformer (LPGT) to predict label positions. Specifically, edge-level attention, conditioned on node representations, is introduced to reveal potential relationships between labels. To integrate graphic/image information, we design a feature aligning strategy that extracts deep features for nodes and edges efficiently. Next, to address the dataset issue, we collect commercial illustrations with professionally designed label layouts from household appliance manuals, and annotate them with useful information to create a novel dataset named the Appliance Manual Illustration Labels (AMIL) dataset. In the thorough evaluation on AMIL, our LPGT solution achieves promising label placement performance compared with popular baselines. Our algorithm is available at https://github.com/JingweiQu/LPGT.
Best Paper Award
Aardvark: Composite Visualizations of Trees, Time-Series, and Images
Devin Lange - University of Utah, Salt Lake City, United States
Robert L Judson-Torres - University of Utah, Salt Lake City, United States
Thomas A Zangle - University of Utah, Salt Lake City, United States
Alexander Lex - University of Utah, Salt Lake City, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-15T16:25:00Z GMT-0600 Change your timezone on the schedule page
2024-10-15T16:25:00Z
Fast forward
Keywords
Visualization, Cell Microscopy, View Composition
Abstract
How do cancer cells grow, divide, proliferate, and die? How do drugs influence these processes? These are difficult questions that we can attempt to answer with a combination of time-series microscopy experiments, classification algorithms, and data visualization.However, collecting this type of data and applying algorithms to segment and track cells and construct lineages of proliferation is error-prone; and identifying the errors can be challenging since it often requires cross-checking multiple data types. Similarly, analyzing and communicating the results necessitates synthesizing different data types into a single narrative. State-of-the-art visualization methods for such data use independent line charts, tree diagrams, and images in separate views. However, this spatial separation requires the viewer of these charts to combine the relevant pieces of data in memory. To simplify this challenging task, we describe design principles for weaving cell images, time-series data, and tree data into a cohesive visualization. Our design principles are based on choosing a primary data type that drives the layout and integrates the other data types into that layout. We then introduce Aardvark, a system that uses these principles to implement novel visualization techniques. Based on Aardvark, we demonstrate the utility of each of these approaches for discovery, communication, and data debugging in a series of case studies.
Best Paper Award
Aardvark: Composite Visualizations of Trees, Time-Series, and Images
Devin Lange - University of Utah, Salt Lake City, United States
Robert L Judson-Torres - University of Utah, Salt Lake City, United States
Thomas A Zangle - University of Utah, Salt Lake City, United States
Alexander Lex - University of Utah, Salt Lake City, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-15T16:25:00Z GMT-0600 Change your timezone on the schedule page
2024-10-15T16:25:00Z
Fast forward
Keywords
Visualization, Cell Microscopy, View Composition
Abstract
How do cancer cells grow, divide, proliferate, and die? How do drugs influence these processes? These are difficult questions that we can attempt to answer with a combination of time-series microscopy experiments, classification algorithms, and data visualization.However, collecting this type of data and applying algorithms to segment and track cells and construct lineages of proliferation is error-prone; and identifying the errors can be challenging since it often requires cross-checking multiple data types. Similarly, analyzing and communicating the results necessitates synthesizing different data types into a single narrative. State-of-the-art visualization methods for such data use independent line charts, tree diagrams, and images in separate views. However, this spatial separation requires the viewer of these charts to combine the relevant pieces of data in memory. To simplify this challenging task, we describe design principles for weaving cell images, time-series data, and tree data into a cohesive visualization. Our design principles are based on choosing a primary data type that drives the layout and integrates the other data types into that layout. We then introduce Aardvark, a system that uses these principles to implement novel visualization techniques. Based on Aardvark, we demonstrate the utility of each of these approaches for discovery, communication, and data debugging in a series of case studies.
Loops: Leveraging Provenance and Visualization to Support Exploratory Data Analysis in Notebooks
Klaus Eckelt - Johannes Kepler University Linz, Linz, Austria
Kiran Gadhave - University of Utah, Salt Lake City, United States
Alexander Lex - University of Utah, Salt Lake City, United States
Marc Streit - Johannes Kepler University Linz, Linz, Austria
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T18:09:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T18:09:00Z
Fast forward
Keywords
Comparative visualization, computational notebooks, provenance, data science
Abstract
Exploratory data science is an iterative process of obtaining, cleaning, profiling, analyzing, and interpreting data. This cyclical way of working creates challenges within the linear structure of computational notebooks, leading to issues with code quality, recall, and reproducibility. To remedy this, we present Loops, a set of visual support techniques for iterative and exploratory data analysis in computational notebooks. Loops leverages provenance information to visualize the impact of changes made within a notebook. In visualizations of the notebook provenance, we trace the evolution of the notebook over time and highlight differences between versions. Loops visualizes the provenance of code, markdown, tables, visualizations, and images and their respective differences. Analysts can explore these differences in detail in a separate view. Loops not only makes the analysis process transparent but also supports analysts in their data science work by showing the effects of changes and facilitating comparison of multiple versions. We demonstrate our approach's utility and potential impact in two use cases and feedback from notebook users from various backgrounds. This paper and all supplemental materials are available at https://osf.io/79eyn.
Loops: Leveraging Provenance and Visualization to Support Exploratory Data Analysis in Notebooks
Klaus Eckelt - Johannes Kepler University Linz, Linz, Austria
Kiran Gadhave - University of Utah, Salt Lake City, United States
Alexander Lex - University of Utah, Salt Lake City, United States
Marc Streit - Johannes Kepler University Linz, Linz, Austria
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T18:09:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T18:09:00Z
Fast forward
Keywords
Comparative visualization, computational notebooks, provenance, data science
Abstract
Exploratory data science is an iterative process of obtaining, cleaning, profiling, analyzing, and interpreting data. This cyclical way of working creates challenges within the linear structure of computational notebooks, leading to issues with code quality, recall, and reproducibility. To remedy this, we present Loops, a set of visual support techniques for iterative and exploratory data analysis in computational notebooks. Loops leverages provenance information to visualize the impact of changes made within a notebook. In visualizations of the notebook provenance, we trace the evolution of the notebook over time and highlight differences between versions. Loops visualizes the provenance of code, markdown, tables, visualizations, and images and their respective differences. Analysts can explore these differences in detail in a separate view. Loops not only makes the analysis process transparent but also supports analysts in their data science work by showing the effects of changes and facilitating comparison of multiple versions. We demonstrate our approach's utility and potential impact in two use cases and feedback from notebook users from various backgrounds. This paper and all supplemental materials are available at https://osf.io/79eyn.
Trust Your Gut: Comparing Human and Machine Inference from Noisy Visualizations
Ratanond Koonchanok - Indiana University, Indianapolis, United States
Michael E. Papka - Argonne National Laboratory, Lemont, United States. University of Illinois Chicago, Chicago, United States
Khairi Reda - Indiana University, Indianapolis, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T14:39:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:39:00Z

Fast forward
Keywords
Visual inference, statistical rationality, human-machine collaboration
Abstract
People commonly utilize visualizations not only to examine a given dataset, but also to draw generalizable conclusions about the underlying models or phenomena. Prior research has compared human visual inference to that of an optimal Bayesian agent, with deviations from rational analysis viewed as problematic. However, human reliance on non-normative heuristics may prove advantageous in certain circumstances. We investigate scenarios where human intuition might surpass idealized statistical rationality. In two experiments, we examine individuals’ accuracy in characterizing the parameters of known data-generating models from bivariate visualizations. Our findings indicate that, although participants generally exhibited lower accuracy compared to statistical models, they frequently outperformed Bayesian agents, particularly when faced with extreme samples. Participants appeared to rely on their internal models to filter out noisy visualizations, thus improving their resilience against spurious data. However, participants displayed overconfidence and struggled with uncertainty estimation. They also exhibited higher variance than statistical machines. Our findings suggest that analyst gut reactions to visualizations may provide an advantage, even when departing from rationality. These results carry implications for designing visual analytics tools, offering new perspectives on how to integrate statistical models and analyst intuition for improved inference and decision-making. The data and materials for this paper are available at https://osf.io/qmfv6
Trust Your Gut: Comparing Human and Machine Inference from Noisy Visualizations
Ratanond Koonchanok - Indiana University, Indianapolis, United States
Michael E. Papka - Argonne National Laboratory, Lemont, United States. University of Illinois Chicago, Chicago, United States
Khairi Reda - Indiana University, Indianapolis, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T14:39:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:39:00Z
Fast forward
Keywords
Visual inference, statistical rationality, human-machine collaboration
Abstract
People commonly utilize visualizations not only to examine a given dataset, but also to draw generalizable conclusions about the underlying models or phenomena. Prior research has compared human visual inference to that of an optimal Bayesian agent, with deviations from rational analysis viewed as problematic. However, human reliance on non-normative heuristics may prove advantageous in certain circumstances. We investigate scenarios where human intuition might surpass idealized statistical rationality. In two experiments, we examine individuals’ accuracy in characterizing the parameters of known data-generating models from bivariate visualizations. Our findings indicate that, although participants generally exhibited lower accuracy compared to statistical models, they frequently outperformed Bayesian agents, particularly when faced with extreme samples. Participants appeared to rely on their internal models to filter out noisy visualizations, thus improving their resilience against spurious data. However, participants displayed overconfidence and struggled with uncertainty estimation. They also exhibited higher variance than statistical machines. Our findings suggest that analyst gut reactions to visualizations may provide an advantage, even when departing from rationality. These results carry implications for designing visual analytics tools, offering new perspectives on how to integrate statistical models and analyst intuition for improved inference and decision-making. The data and materials for this paper are available at https://osf.io/qmfv6
Honorable Mention
Beyond Correlation: Incorporating Counterfactual Guidance to Better Support Exploratory Visual Analysis
Arran Zeyu Wang - University of North Carolina-Chapel Hill, Chapel Hill, United States
David Borland - UNC-Chapel Hill, Chapel Hill, United States
David Gotz - University of North Carolina, Chapel Hill, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T12:30:00Z
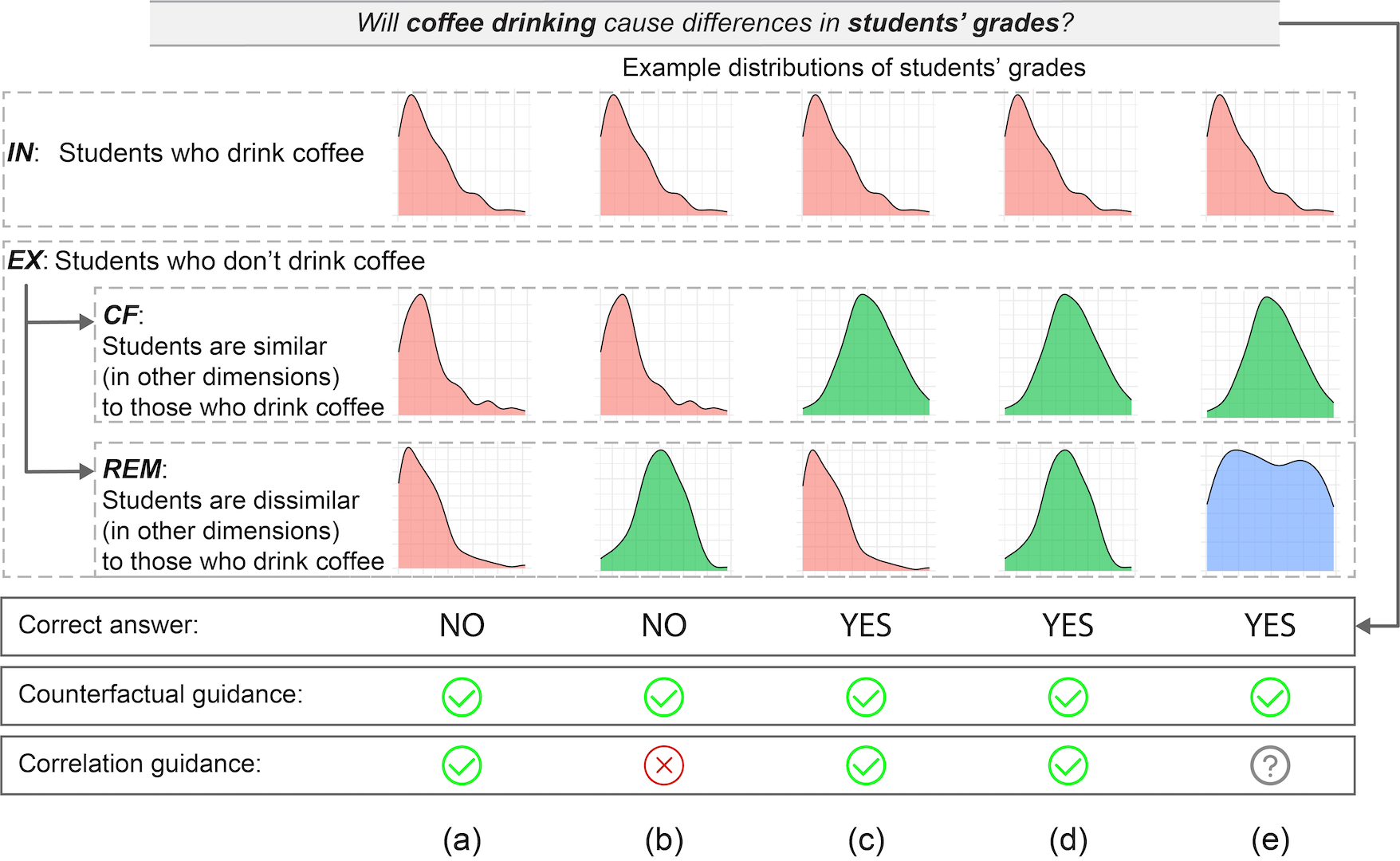
Fast forward
Keywords
Counterfactual, Guidance, Exploratory visual analysis, Visual causal inference, Correlation
Abstract
Providing effective guidance for users has long been an important and challenging task for efficient exploratory visual analytics, especially when selecting variables for visualization in high-dimensional datasets. Correlation is the most widely applied metric for guidance in statistical and analytical tools, however a reliance on correlation may lead users towards false positives when interpreting causal relations in the data. In this work, inspired by prior insights on the benefits of counterfactual visualization in supporting visual causal inference, we propose a novel, simple, and efficient counterfactual guidance method to enhance causal inference performance in guided exploratory analytics based on insights and concerns gathered from expert interviews. Our technique aims to capitalize on the benefits of counterfactual approaches while reducing their complexity for users. We integrated counterfactual guidance into an exploratory visual analytics system, and using a synthetically generated ground-truth causal dataset, conducted a comparative user study and evaluated to what extent counterfactual guidance can help lead users to more precise visual causal inferences. The results suggest that counterfactual guidance improved visual causal inference performance, and also led to different exploratory behaviors compared to correlation-based guidance. Based on these findings, we offer future directions and challenges for incorporating counterfactual guidance to better support exploratory visual analytics.
Honorable Mention
Beyond Correlation: Incorporating Counterfactual Guidance to Better Support Exploratory Visual Analysis
Arran Zeyu Wang - University of North Carolina-Chapel Hill, Chapel Hill, United States
David Borland - UNC-Chapel Hill, Chapel Hill, United States
David Gotz - University of North Carolina, Chapel Hill, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T12:30:00Z
Fast forward
Keywords
Counterfactual, Guidance, Exploratory visual analysis, Visual causal inference, Correlation
Abstract
Providing effective guidance for users has long been an important and challenging task for efficient exploratory visual analytics, especially when selecting variables for visualization in high-dimensional datasets. Correlation is the most widely applied metric for guidance in statistical and analytical tools, however a reliance on correlation may lead users towards false positives when interpreting causal relations in the data. In this work, inspired by prior insights on the benefits of counterfactual visualization in supporting visual causal inference, we propose a novel, simple, and efficient counterfactual guidance method to enhance causal inference performance in guided exploratory analytics based on insights and concerns gathered from expert interviews. Our technique aims to capitalize on the benefits of counterfactual approaches while reducing their complexity for users. We integrated counterfactual guidance into an exploratory visual analytics system, and using a synthetically generated ground-truth causal dataset, conducted a comparative user study and evaluated to what extent counterfactual guidance can help lead users to more precise visual causal inferences. The results suggest that counterfactual guidance improved visual causal inference performance, and also led to different exploratory behaviors compared to correlation-based guidance. Based on these findings, we offer future directions and challenges for incorporating counterfactual guidance to better support exploratory visual analytics.
UnDRground Tubes: Exploring Spatial Data With Multidimensional Projections and Set Visualization
Nikolaus Piccolotto - TU Wien, Vienna, Austria
Markus Wallinger - TU Wien, Vienna, Austria
Silvia Miksch - Institute of Visual Computing and Human-Centered Technology, Vienna, Austria
Markus Bögl - TU Wien, Vienna, Austria
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:15:00Z

Fast forward
Keywords
Geographical data, multivariate data, set visualization, visual cluster analysis.
Abstract
In various scientific and industrial domains, analyzing multivariate spatial data, i.e., vectors associated with spatial locations, is common practice. To analyze those datasets, analysts may turn to methods such as Spatial Blind Source Separation (SBSS). Designed explicitly for spatial data analysis, SBSS finds latent components in the dataset and is superior to popular non-spatial methods, like PCA. However, when analysts try different tuning parameter settings, the amount of latent components complicates analytical tasks. Based on our years-long collaboration with SBSS researchers, we propose a visualization approach to tackle this challenge. The main component is UnDRground Tubes (UT), a general-purpose idiom combining ideas from set visualization and multidimensional projections. We describe the UT visualization pipeline and integrate UT into an interactive multiple-view system. We demonstrate its effectiveness through interviews with SBSS experts, a qualitative evaluation with visualization experts, and computational experiments. SBSS experts were excited about our approach. They saw many benefits for their work and potential applications for geostatistical data analysis more generally. UT was also well received by visualization experts. Our benchmarks show that UT projections and its heuristics are appropriate.
UnDRground Tubes: Exploring Spatial Data With Multidimensional Projections and Set Visualization
Nikolaus Piccolotto - TU Wien, Vienna, Austria
Markus Wallinger - TU Wien, Vienna, Austria
Silvia Miksch - Institute of Visual Computing and Human-Centered Technology, Vienna, Austria
Markus Bögl - TU Wien, Vienna, Austria
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:15:00Z
Fast forward
Keywords
Geographical data, multivariate data, set visualization, visual cluster analysis.
Abstract
In various scientific and industrial domains, analyzing multivariate spatial data, i.e., vectors associated with spatial locations, is common practice. To analyze those datasets, analysts may turn to methods such as Spatial Blind Source Separation (SBSS). Designed explicitly for spatial data analysis, SBSS finds latent components in the dataset and is superior to popular non-spatial methods, like PCA. However, when analysts try different tuning parameter settings, the amount of latent components complicates analytical tasks. Based on our years-long collaboration with SBSS researchers, we propose a visualization approach to tackle this challenge. The main component is UnDRground Tubes (UT), a general-purpose idiom combining ideas from set visualization and multidimensional projections. We describe the UT visualization pipeline and integrate UT into an interactive multiple-view system. We demonstrate its effectiveness through interviews with SBSS experts, a qualitative evaluation with visualization experts, and computational experiments. SBSS experts were excited about our approach. They saw many benefits for their work and potential applications for geostatistical data analysis more generally. UT was also well received by visualization experts. Our benchmarks show that UT projections and its heuristics are appropriate.
Honorable Mention
PREVis: Perceived Readability Evaluation for Visualizations
Anne-Flore Cabouat - LISN, Université Paris Saclay, CNRS, Orsay, France. Aviz, Inria, Saclay, France
Tingying He - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Petra Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Tobias Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:54:00Z

Fast forward
Keywords
Visualization, readability, validated instrument, perception, user experiments, empirical methods, methodology
Abstract
We developed and validated an instrument to measure the perceived readability in data visualization: PREVis. Researchers and practitioners can easily use this instrument as part of their evaluations to compare the perceived readability of different visual data representations. Our instrument can complement results from controlled experiments on user task performance or provide additional data during in-depth qualitative work such as design iterations when developing a new technique. Although readability is recognized as an essential quality of data visualizations, so far there has not been a unified definition of the construct in the context of visual representations. As a result, researchers often lack guidance for determining how to ask people to rate their perceived readability of a visualization. To address this issue, we engaged in a rigorous process to develop the first validated instrument targeted at the subjective readability of visual data representations. Our final instrument consists of 11 items across 4 dimensions: understandability, layout clarity, readability of data values, and readability of data patterns. We provide the questionnaire as a document with implementation guidelines on osf.io/9cg8j. Beyond this instrument, we contribute a discussion of how researchers have previously assessed visualization readability, and an analysis of the factors underlying perceived readability in visual data representations.
Honorable Mention
PREVis: Perceived Readability Evaluation for Visualizations
Anne-Flore Cabouat - LISN, Université Paris Saclay, CNRS, Orsay, France. Aviz, Inria, Saclay, France
Tingying He - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Petra Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Tobias Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:54:00Z
Fast forward
Keywords
Visualization, readability, validated instrument, perception, user experiments, empirical methods, methodology
Abstract
We developed and validated an instrument to measure the perceived readability in data visualization: PREVis. Researchers and practitioners can easily use this instrument as part of their evaluations to compare the perceived readability of different visual data representations. Our instrument can complement results from controlled experiments on user task performance or provide additional data during in-depth qualitative work such as design iterations when developing a new technique. Although readability is recognized as an essential quality of data visualizations, so far there has not been a unified definition of the construct in the context of visual representations. As a result, researchers often lack guidance for determining how to ask people to rate their perceived readability of a visualization. To address this issue, we engaged in a rigorous process to develop the first validated instrument targeted at the subjective readability of visual data representations. Our final instrument consists of 11 items across 4 dimensions: understandability, layout clarity, readability of data values, and readability of data patterns. We provide the questionnaire as a document with implementation guidelines on osf.io/9cg8j. Beyond this instrument, we contribute a discussion of how researchers have previously assessed visualization readability, and an analysis of the factors underlying perceived readability in visual data representations.
Uncertainty Visualization of Critical Points of 2D Scalar Fields for Parametric and Nonparametric Probabilistic Models
Tushar M. Athawale - Oak Ridge National Laboratory, Oak Ridge, United States
Zhe Wang - Oak Ridge National Laboratory, Oak Ridge, United States
David Pugmire - Oak Ridge National Laboratory, Oak Ridge, United States
Kenneth Moreland - Oak Ridge National Laboratory, Oak Ridge, United States
Qian Gong - Oak Ridge National Laboratory, Oak Ridge, United States
Scott Klasky - Oak Ridge National Laboratory, Oak Ridge, United States
Chris R. Johnson - University of Utah, Salt Lake City, United States
Paul Rosen - University of Utah, Salt Lake City, United States
Download preprint PDF
Download camera-ready PDF
Room: Bayshore VI
2024-10-18T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:06:00Z
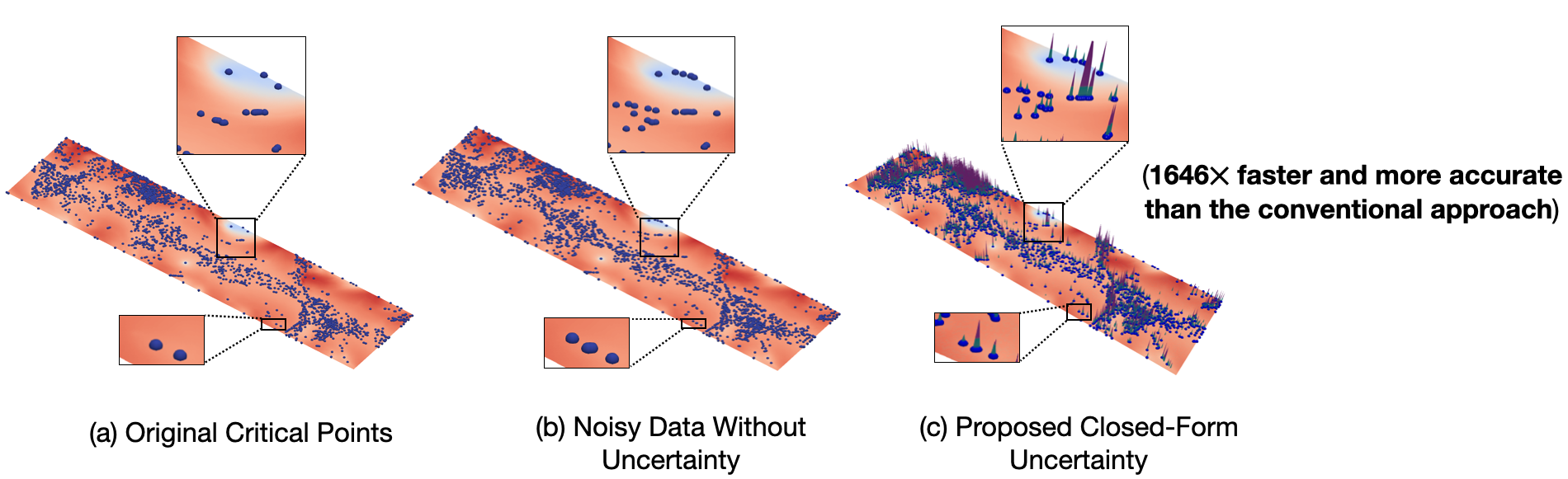
Fast forward
Keywords
Topology, uncertainty, critical points, probabilistic analysis
Abstract
This paper presents a novel end-to-end framework for closed-form computation and visualization of critical point uncertainty in 2D uncertain scalar fields. Critical points are fundamental topological descriptors used in the visualization and analysis of scalar fields. The uncertainty inherent in data (e.g., observational and experimental data, approximations in simulations, and compression), however, creates uncertainty regarding critical point positions. Uncertainty in critical point positions, therefore, cannot be ignored, given their impact on downstream data analysis tasks. In this work, we study uncertainty in critical points as a function of uncertainty in data modeled with probability distributions. Although Monte Carlo (MC) sampling techniques have been used in prior studies to quantify critical point uncertainty, they are often expensive and are infrequently used in production-quality visualization software. We, therefore, propose a new end-to-end framework to address these challenges that comprises a threefold contribution. First, we derive the critical point uncertainty in closed form, which is more accurate and efficient than the conventional MC sampling methods. Specifically, we provide the closed-form and semianalytical (a mix of closed-form and MC methods) solutions for parametric (e.g., uniform, Epanechnikov) and nonparametric models (e.g., histograms) with finite support. Second, we accelerate critical point probability computations using a parallel implementation with the VTK-m library, which is platform portable. Finally, we demonstrate the integration of our implementation with the ParaView software system to demonstrate near-real-time results for real datasets.
Uncertainty Visualization of Critical Points of 2D Scalar Fields for Parametric and Nonparametric Probabilistic Models
Tushar M. Athawale - Oak Ridge National Laboratory, Oak Ridge, United States
Zhe Wang - Oak Ridge National Laboratory, Oak Ridge, United States
David Pugmire - Oak Ridge National Laboratory, Oak Ridge, United States
Kenneth Moreland - Oak Ridge National Laboratory, Oak Ridge, United States
Qian Gong - Oak Ridge National Laboratory, Oak Ridge, United States
Scott Klasky - Oak Ridge National Laboratory, Oak Ridge, United States
Chris R. Johnson - University of Utah, Salt Lake City, United States
Paul Rosen - University of Utah, Salt Lake City, United States
Download preprint PDF
Download camera-ready PDF
Room: Bayshore VI
2024-10-18T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:06:00Z
Fast forward
Keywords
Topology, uncertainty, critical points, probabilistic analysis
Abstract
This paper presents a novel end-to-end framework for closed-form computation and visualization of critical point uncertainty in 2D uncertain scalar fields. Critical points are fundamental topological descriptors used in the visualization and analysis of scalar fields. The uncertainty inherent in data (e.g., observational and experimental data, approximations in simulations, and compression), however, creates uncertainty regarding critical point positions. Uncertainty in critical point positions, therefore, cannot be ignored, given their impact on downstream data analysis tasks. In this work, we study uncertainty in critical points as a function of uncertainty in data modeled with probability distributions. Although Monte Carlo (MC) sampling techniques have been used in prior studies to quantify critical point uncertainty, they are often expensive and are infrequently used in production-quality visualization software. We, therefore, propose a new end-to-end framework to address these challenges that comprises a threefold contribution. First, we derive the critical point uncertainty in closed form, which is more accurate and efficient than the conventional MC sampling methods. Specifically, we provide the closed-form and semianalytical (a mix of closed-form and MC methods) solutions for parametric (e.g., uniform, Epanechnikov) and nonparametric models (e.g., histograms) with finite support. Second, we accelerate critical point probability computations using a parallel implementation with the VTK-m library, which is platform portable. Finally, we demonstrate the integration of our implementation with the ParaView software system to demonstrate near-real-time results for real datasets.
What Can Interactive Visualization do for Participatory Budgeting in Chicago?
Alex Kale - University of Chicago, Chicago, United States
Danni Liu - University of Chicago, Chicago, United States
Maria Gabriela Ayala - University of Chicago, Chicago, United States
Harper Schwab - University of Chicago, Chicago, United States
Andrew M McNutt - University of Washington, Seattle, United States. University of Utah, Salt Lake City, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T18:09:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:09:00Z

Fast forward
Keywords
Visualization, Preference elicitation, Digital democracy
Abstract
Participatory budgeting (PB) is a democratic approach to allocating municipal spending that has been adopted in many places in recent years, including in Chicago. Current PB voting resembles a ballot where residents are asked which municipal projects, such as school improvements and road repairs, to fund with a limited budget. In this work, we ask how interactive visualization can benefit PB by conducting a design probe-based interview study (N=13) with policy workers and academics with expertise in PB, urban planning, and civic HCI. Our probe explores how graphical elicitation of voter preferences and a dashboard of voting statistics can be incorporated into a realistic PB tool. Through qualitative analysis, we find that visualization creates opportunities for city government to set expectations about budget constraints while also granting their constituents greater freedom to articulate a wider range of preferences. However, using visualization to provide transparency about PB requires efforts to mitigate potential access barriers and mistrust. We call for more visualization professionals to help build civic capacity by working in and studying political systems.
What Can Interactive Visualization do for Participatory Budgeting in Chicago?
Alex Kale - University of Chicago, Chicago, United States
Danni Liu - University of Chicago, Chicago, United States
Maria Gabriela Ayala - University of Chicago, Chicago, United States
Harper Schwab - University of Chicago, Chicago, United States
Andrew M McNutt - University of Washington, Seattle, United States. University of Utah, Salt Lake City, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T18:09:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T18:09:00Z
Fast forward
Keywords
Visualization, Preference elicitation, Digital democracy
Abstract
Participatory budgeting (PB) is a democratic approach to allocating municipal spending that has been adopted in many places in recent years, including in Chicago. Current PB voting resembles a ballot where residents are asked which municipal projects, such as school improvements and road repairs, to fund with a limited budget. In this work, we ask how interactive visualization can benefit PB by conducting a design probe-based interview study (N=13) with policy workers and academics with expertise in PB, urban planning, and civic HCI. Our probe explores how graphical elicitation of voter preferences and a dashboard of voting statistics can be incorporated into a realistic PB tool. Through qualitative analysis, we find that visualization creates opportunities for city government to set expectations about budget constraints while also granting their constituents greater freedom to articulate a wider range of preferences. However, using visualization to provide transparency about PB requires efforts to mitigate potential access barriers and mistrust. We call for more visualization professionals to help build civic capacity by working in and studying political systems.
The Effect of Visual Aids on Reading Numeric Data Tables
YongFeng Ji - University of Victoria, Victoria, Canada
Charles Perin - University of Victoria, Victoria, Canada
Miguel A Nacenta - University of Victoria, Victoria, Canada
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:12:00Z

Fast forward
Keywords
Data Table, Visual Encoding, Visual Aid, Gaze Analysis, Zebra, Data Bars, Tabular Representations.
Abstract
Data tables are one of the most common ways in which people encounter data. Although mostly built with text and numbers, data tables have a spatial layout and often exhibit visual elements meant to facilitate their reading. Surprisingly, there is an empirical knowledge gap on how people read tables and how different visual aids affect people's reading of tables. In this work, we seek to address this vacuum through a controlled study. We asked participants to repeatedly perform four different tasks with four table representation conditions (plain tables, tables with zebra striping, tables with cell background color encoding cell value, and tables with in-cell bars with lengths encoding cell value). We analyzed completion time, error rate, gaze-tracking data, mouse movement and participant preferences. We found that color and bar encodings help for finding maximum values. For a more complex task (comparison of proportional differences) color and bar helped less than zebra striping. We also characterize typical human behavior for the four tasks. These findings inform the design of tables and research directions for improving presentation of data in tabular form.
The Effect of Visual Aids on Reading Numeric Data Tables
YongFeng Ji - University of Victoria, Victoria, Canada
Charles Perin - University of Victoria, Victoria, Canada
Miguel A Nacenta - University of Victoria, Victoria, Canada
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:12:00Z
Fast forward
Keywords
Data Table, Visual Encoding, Visual Aid, Gaze Analysis, Zebra, Data Bars, Tabular Representations.
Abstract
Data tables are one of the most common ways in which people encounter data. Although mostly built with text and numbers, data tables have a spatial layout and often exhibit visual elements meant to facilitate their reading. Surprisingly, there is an empirical knowledge gap on how people read tables and how different visual aids affect people's reading of tables. In this work, we seek to address this vacuum through a controlled study. We asked participants to repeatedly perform four different tasks with four table representation conditions (plain tables, tables with zebra striping, tables with cell background color encoding cell value, and tables with in-cell bars with lengths encoding cell value). We analyzed completion time, error rate, gaze-tracking data, mouse movement and participant preferences. We found that color and bar encodings help for finding maximum values. For a more complex task (comparison of proportional differences) color and bar helped less than zebra striping. We also characterize typical human behavior for the four tasks. These findings inform the design of tables and research directions for improving presentation of data in tabular form.
Mixing Linters with GUIs: A Color Palette Design Probe
Andrew M McNutt - University of Washington, Seattle, United States. University of Utah, Salt Lake City, United States
Maureen Stone - University of Washington, Seattle, United States
Jeffrey Heer - University of Washington, Seattle, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T17:57:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:57:00Z
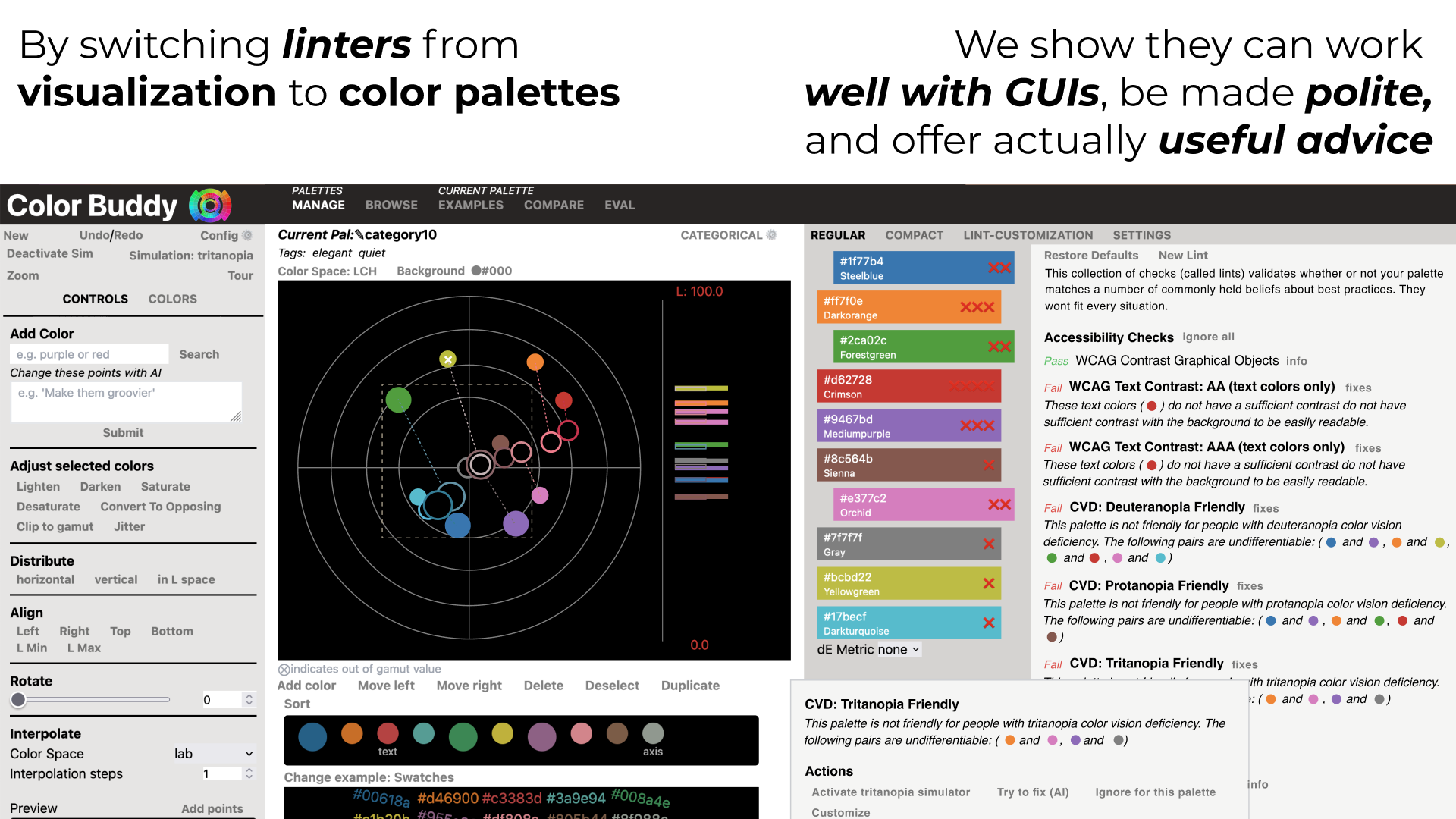
Fast forward
Keywords
Linters, Color Palette Design, Design Probe, Reflection
Abstract
Visualization linters are end-user facing evaluators that automatically identify potential chart issues. These spell-checker like systems offer a blend of interpretability and customization that is not found in other forms of automated assistance. However, existing linters do not model context and have primarily targeted users who do not need assistance, resulting in obvious---even annoying---advice. We investigate these issues within the domain of color palette design, which serves as a microcosm of visualization design concerns. We contribute a GUI-based color palette linter as a design probe that covers perception, accessibility, context, and other design criteria, and use it to explore visual explanations, integrated fixes, and user defined linting rules. Through a formative interview study and theory-driven analysis, we find that linters can be meaningfully integrated into graphical contextsthereby addressing many of their core issues.We discuss implications for integrating linters into visualization tools, developing improved assertion languages, and supporting end-user tunable advice---all laying the groundwork for more effective visualization linters in any context.
Mixing Linters with GUIs: A Color Palette Design Probe
Andrew M McNutt - University of Washington, Seattle, United States. University of Utah, Salt Lake City, United States
Maureen Stone - University of Washington, Seattle, United States
Jeffrey Heer - University of Washington, Seattle, United States
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T17:57:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:57:00Z
Fast forward
Keywords
Linters, Color Palette Design, Design Probe, Reflection
Abstract
Visualization linters are end-user facing evaluators that automatically identify potential chart issues. These spell-checker like systems offer a blend of interpretability and customization that is not found in other forms of automated assistance. However, existing linters do not model context and have primarily targeted users who do not need assistance, resulting in obvious---even annoying---advice. We investigate these issues within the domain of color palette design, which serves as a microcosm of visualization design concerns. We contribute a GUI-based color palette linter as a design probe that covers perception, accessibility, context, and other design criteria, and use it to explore visual explanations, integrated fixes, and user defined linting rules. Through a formative interview study and theory-driven analysis, we find that linters can be meaningfully integrated into graphical contextsthereby addressing many of their core issues.We discuss implications for integrating linters into visualization tools, developing improved assertion languages, and supporting end-user tunable advice---all laying the groundwork for more effective visualization linters in any context.
Quantifying Emotional Responses to Immutable Data Characteristics and Designer Choices in Data Visualizations
Carter Blair - University of Waterloo, Waterloo, Canada. University of Victoria, Victoria, Canada
Xiyao Wang - University of Victoria, Victoira, Canada. Delft University of Technology, Delft, Netherlands
Charles Perin - University of Victoria, Victoria, Canada
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T16:24:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:24:00Z
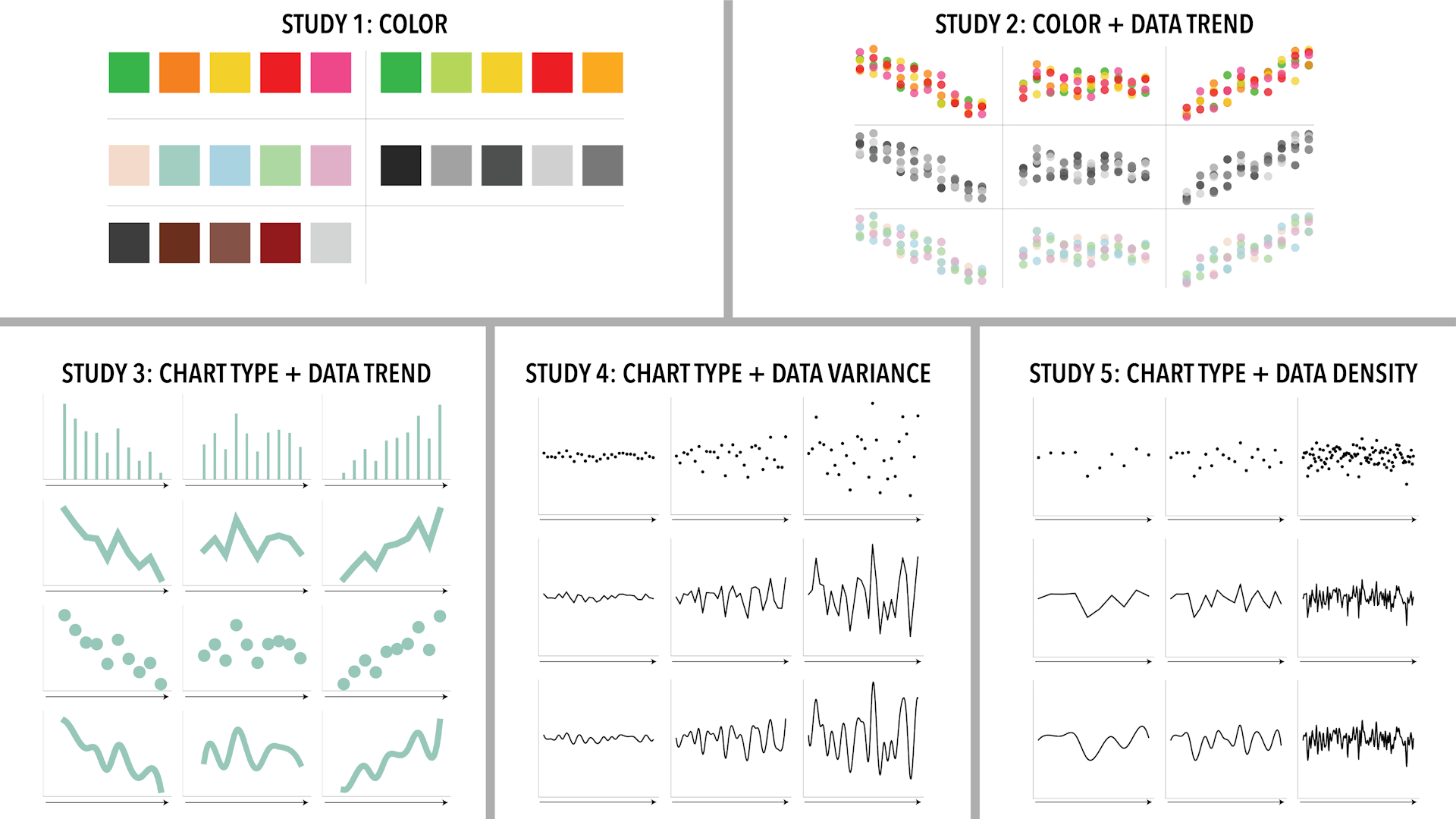
Fast forward
Keywords
Affect, Data Visualization, Emotion, Quantitative Study
Abstract
Emotion is an important factor to consider when designing visualizations as it can impact the amount of trust viewers place in a visualization, how well they can retrieve information and understand the underlying data, and how much they engage with or connect to a visualization. We conducted five crowdsourced experiments to quantify the effects of color, chart type, data trend, data variability and data density on emotion (measured through self-reported arousal and valence). Results from our experiments show that there are multiple design elements which influence the emotion induced by a visualization and, more surprisingly, that certain data characteristics influence the emotion of viewers even when the data has no meaning. In light of these findings, we offer guidelines on how to use color, scale, and chart type to counterbalance and emphasize the emotional impact of immutable data characteristics.
Quantifying Emotional Responses to Immutable Data Characteristics and Designer Choices in Data Visualizations
Carter Blair - University of Waterloo, Waterloo, Canada. University of Victoria, Victoria, Canada
Xiyao Wang - University of Victoria, Victoira, Canada. Delft University of Technology, Delft, Netherlands
Charles Perin - University of Victoria, Victoria, Canada
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-16T16:24:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:24:00Z
Fast forward
Keywords
Affect, Data Visualization, Emotion, Quantitative Study
Abstract
Emotion is an important factor to consider when designing visualizations as it can impact the amount of trust viewers place in a visualization, how well they can retrieve information and understand the underlying data, and how much they engage with or connect to a visualization. We conducted five crowdsourced experiments to quantify the effects of color, chart type, data trend, data variability and data density on emotion (measured through self-reported arousal and valence). Results from our experiments show that there are multiple design elements which influence the emotion induced by a visualization and, more surprisingly, that certain data characteristics influence the emotion of viewers even when the data has no meaning. In light of these findings, we offer guidelines on how to use color, scale, and chart type to counterbalance and emphasize the emotional impact of immutable data characteristics.
A Qualitative Analysis of Common Practices in Annotations: A Taxonomy and Design Space
Md Dilshadur Rahman - University of Utah, Salt Lake City, United States. University of Utah, Salt Lake City, United States
Ghulam Jilani Quadri - University of Oklahoma, Norman, United States. University of Oklahoma, Norman, United States
Bhavana Doppalapudi - University of South Florida , Tampa, United States. University of South Florida , Tampa, United States
Danielle Albers Szafir - University of North Carolina-Chapel Hill, Chapel Hill, United States. University of North Carolina-Chapel Hill, Chapel Hill, United States
Paul Rosen - University of Utah, Salt Lake City, United States. University of Utah, Salt Lake City, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T12:42:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:42:00Z
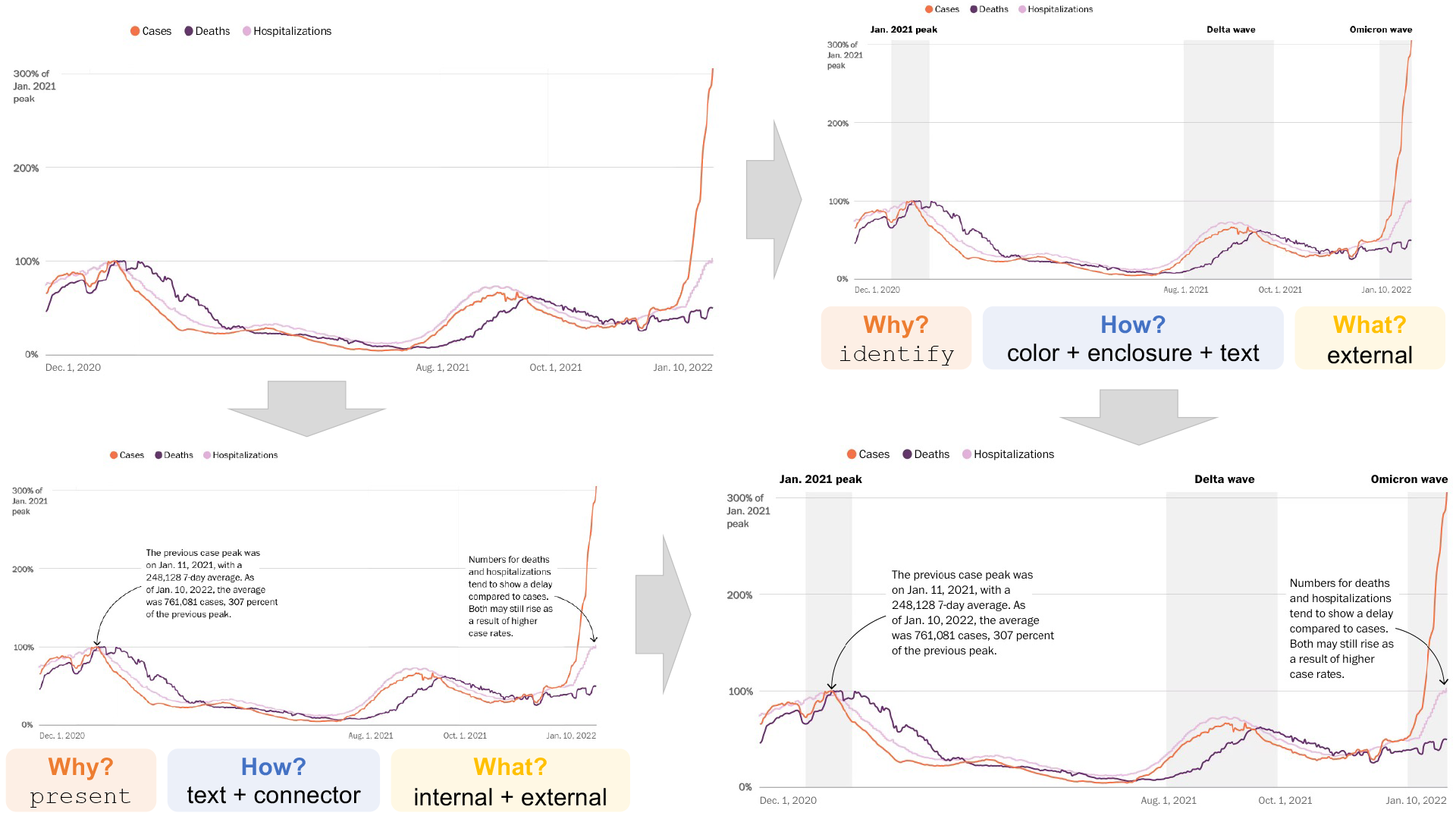
Fast forward
Keywords
Annotations, visualizations, qualitative study, design space, taxonomy
Abstract
Annotations play a vital role in highlighting critical aspects of visualizations, aiding in data externalization and exploration, collaborative sensemaking, and visual storytelling. However, despite their widespread use, we identified a lack of a design space for common practices for annotations. In this paper, we evaluated over 1,800 static annotated charts to understand how people annotate visualizations in practice. Through qualitative coding of these diverse real-world annotated charts, we explored three primary aspects of annotation usage patterns: analytic purposes for chart annotations (e.g., present, identify, summarize, or compare data features), mechanisms for chart annotations (e.g., types and combinations of annotations used, frequency of different annotation types across chart types, etc.), and the data source used to generate the annotations. We then synthesized our findings into a design space of annotations, highlighting key design choices for chart annotations. We presented three case studies illustrating our design space as a practical framework for chart annotations to enhance the communication of visualization insights. All supplemental materials are available at \url{https://shorturl.at/bAGM1}.
A Qualitative Analysis of Common Practices in Annotations: A Taxonomy and Design Space
Md Dilshadur Rahman - University of Utah, Salt Lake City, United States. University of Utah, Salt Lake City, United States
Ghulam Jilani Quadri - University of Oklahoma, Norman, United States. University of Oklahoma, Norman, United States
Bhavana Doppalapudi - University of South Florida , Tampa, United States. University of South Florida , Tampa, United States
Danielle Albers Szafir - University of North Carolina-Chapel Hill, Chapel Hill, United States. University of North Carolina-Chapel Hill, Chapel Hill, United States
Paul Rosen - University of Utah, Salt Lake City, United States. University of Utah, Salt Lake City, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T12:42:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:42:00Z
Fast forward
Keywords
Annotations, visualizations, qualitative study, design space, taxonomy
Abstract
Annotations play a vital role in highlighting critical aspects of visualizations, aiding in data externalization and exploration, collaborative sensemaking, and visual storytelling. However, despite their widespread use, we identified a lack of a design space for common practices for annotations. In this paper, we evaluated over 1,800 static annotated charts to understand how people annotate visualizations in practice. Through qualitative coding of these diverse real-world annotated charts, we explored three primary aspects of annotation usage patterns: analytic purposes for chart annotations (e.g., present, identify, summarize, or compare data features), mechanisms for chart annotations (e.g., types and combinations of annotations used, frequency of different annotation types across chart types, etc.), and the data source used to generate the annotations. We then synthesized our findings into a design space of annotations, highlighting key design choices for chart annotations. We presented three case studies illustrating our design space as a practical framework for chart annotations to enhance the communication of visualization insights. All supplemental materials are available at \url{https://shorturl.at/bAGM1}.
Honorable Mention
Talk to the Wall: The Role of Speech Interaction in Collaborative Visual Analytics
Gabriela Molina León - University of Bremen, Bremen, Germany. University of Bremen, Bremen, Germany
Anastasia Bezerianos - LISN, Université Paris-Saclay, CNRS, INRIA, Orsay, France
Olivier Gladin - Inria, Palaiseau, France
Petra Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T17:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:00:00Z

Fast forward
Keywords
Speech interaction, wall display, collaborative sensemaking, multimodal interaction, collaboration styles
Abstract
We present the results of an exploratory study on how pairs interact with speech commands and touch gestures on a wall-sized display during a collaborative sensemaking task. Previous work has shown that speech commands, alone or in combination with other input modalities, can support visual data exploration by individuals. However, it is still unknown whether and how speech commands can be used in collaboration, and for what tasks. To answer these questions, we developed a functioning prototype that we used as a technology probe. We conducted an in-depth exploratory study with 10 participant pairs to analyze their interaction choices, the interplay between the input modalities, and their collaboration. While touch was the most used modality, we found that participants preferred speech commands for global operations, used them for distant interaction, and that speech interaction contributed to the awareness of the partner’s actions. Furthermore, the likelihood of using speech commands during collaboration was related to the personality trait of agreeableness. Regarding collaboration styles, participants interacted with speech equally often whether they were in loosely or closely coupled collaboration. While the partners stood closer to each other during close collaboration, they did not distance themselves to use speech commands. From our findings, we derive and contribute a set of design considerations for collaborative and multimodal interactive data analysis systems. All supplemental materials are available at https://osf.io/8gpv2.
Honorable Mention
Talk to the Wall: The Role of Speech Interaction in Collaborative Visual Analytics
Gabriela Molina León - University of Bremen, Bremen, Germany. University of Bremen, Bremen, Germany
Anastasia Bezerianos - LISN, Université Paris-Saclay, CNRS, INRIA, Orsay, France
Olivier Gladin - Inria, Palaiseau, France
Petra Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T17:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T17:00:00Z
Fast forward
Keywords
Speech interaction, wall display, collaborative sensemaking, multimodal interaction, collaboration styles
Abstract
We present the results of an exploratory study on how pairs interact with speech commands and touch gestures on a wall-sized display during a collaborative sensemaking task. Previous work has shown that speech commands, alone or in combination with other input modalities, can support visual data exploration by individuals. However, it is still unknown whether and how speech commands can be used in collaboration, and for what tasks. To answer these questions, we developed a functioning prototype that we used as a technology probe. We conducted an in-depth exploratory study with 10 participant pairs to analyze their interaction choices, the interplay between the input modalities, and their collaboration. While touch was the most used modality, we found that participants preferred speech commands for global operations, used them for distant interaction, and that speech interaction contributed to the awareness of the partner’s actions. Furthermore, the likelihood of using speech commands during collaboration was related to the personality trait of agreeableness. Regarding collaboration styles, participants interacted with speech equally often whether they were in loosely or closely coupled collaboration. While the partners stood closer to each other during close collaboration, they did not distance themselves to use speech commands. From our findings, we derive and contribute a set of design considerations for collaborative and multimodal interactive data analysis systems. All supplemental materials are available at https://osf.io/8gpv2.
BEMTrace: Visualization-driven approach for deriving Building Energy Models from BIM
Andreas Walch - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Attila Szabo - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Harald Steinlechner - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Thomas Ortner - Independent Researcher, Vienna, Austria
Eduard Gröller - Institute of Visual Computing . Human-Centered Technology, Vienna, Austria
Johanna Schmidt - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Room: Bayshore VII
2024-10-16T14:27:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:27:00Z
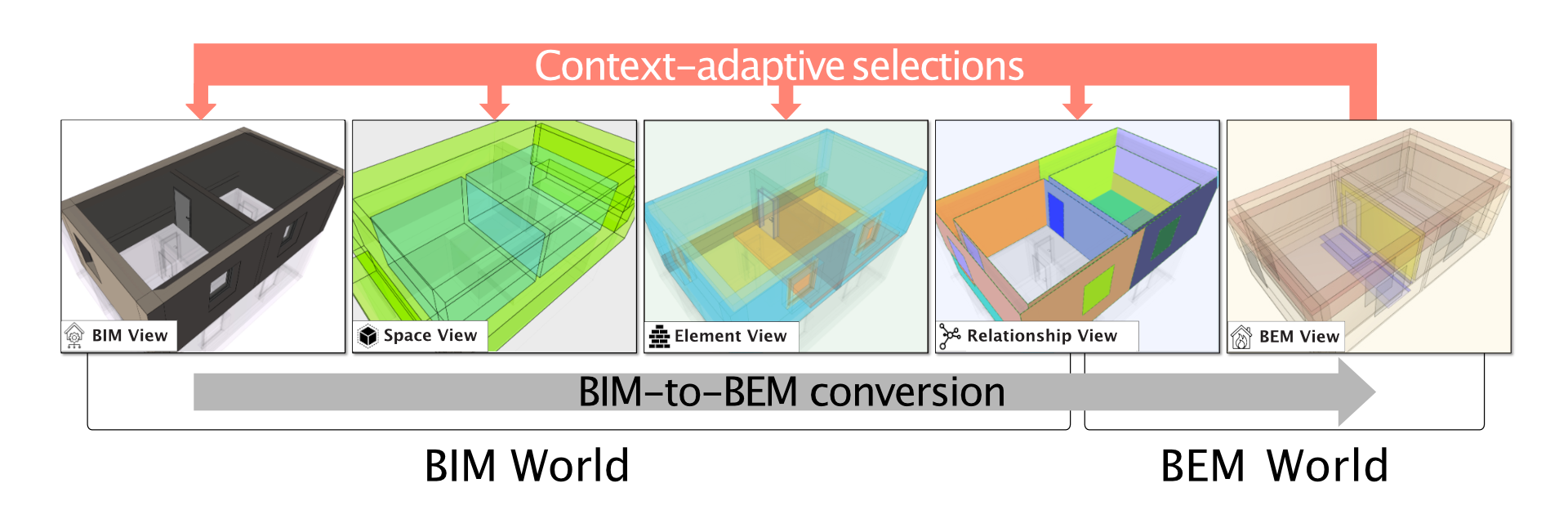
Fast forward
Keywords
BIM, BEM, BIM-to-BEM, 3D Data Wrangling, 3D selections, Visualization for trust building
Abstract
Building Information Modeling (BIM) describes a central data pool covering the entire life cycle of a construction project. Similarly, Building Energy Modeling (BEM) describes the process of using a 3D representation of a building as a basis for thermal simulations to assess the building’s energy performance. This paper explores the intersection of BIM and BEM, focusing on the challenges and methodologies in converting BIM data into BEM representations for energy performance analysis. BEMTrace integrates 3D data wrangling techniques with visualization methodologies to enhance the accuracy and traceability of the BIM-to-BEM conversion process. Through parsing, error detection, and algorithmic correction of BIM data, our methods generate valid BEM models suitable for energy simulation. Visualization techniques provide transparent insights into the conversion process, aiding error identification, validation, and user comprehension. We introduce context-adaptive selections to facilitate user interaction and to show that the BEMTrace workflow helps users understand complex 3D data wrangling processes.
BEMTrace: Visualization-driven approach for deriving Building Energy Models from BIM
Andreas Walch - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Attila Szabo - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Harald Steinlechner - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Thomas Ortner - Independent Researcher, Vienna, Austria
Eduard Gröller - Institute of Visual Computing . Human-Centered Technology, Vienna, Austria
Johanna Schmidt - VRVis Zentrum für Virtual Reality und Visualisierung Forschungs-GmbH, Vienna, Austria
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Room: Bayshore VII
2024-10-16T14:27:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T14:27:00Z
Fast forward
Keywords
BIM, BEM, BIM-to-BEM, 3D Data Wrangling, 3D selections, Visualization for trust building
Abstract
Building Information Modeling (BIM) describes a central data pool covering the entire life cycle of a construction project. Similarly, Building Energy Modeling (BEM) describes the process of using a 3D representation of a building as a basis for thermal simulations to assess the building’s energy performance. This paper explores the intersection of BIM and BEM, focusing on the challenges and methodologies in converting BIM data into BEM representations for energy performance analysis. BEMTrace integrates 3D data wrangling techniques with visualization methodologies to enhance the accuracy and traceability of the BIM-to-BEM conversion process. Through parsing, error detection, and algorithmic correction of BIM data, our methods generate valid BEM models suitable for energy simulation. Visualization techniques provide transparent insights into the conversion process, aiding error identification, validation, and user comprehension. We introduce context-adaptive selections to facilitate user interaction and to show that the BEMTrace workflow helps users understand complex 3D data wrangling processes.
VMC: A Grammar for Visualizing Statistical Model Checks
Ziyang Guo - Northwestern University, Evanston, United States
Alex Kale - University of Chicago, Chicago, United States
Matthew Kay - Northwestern University, Chicago, United States
Jessica Hullman - Northwestern University, Evanston, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T12:54:00Z
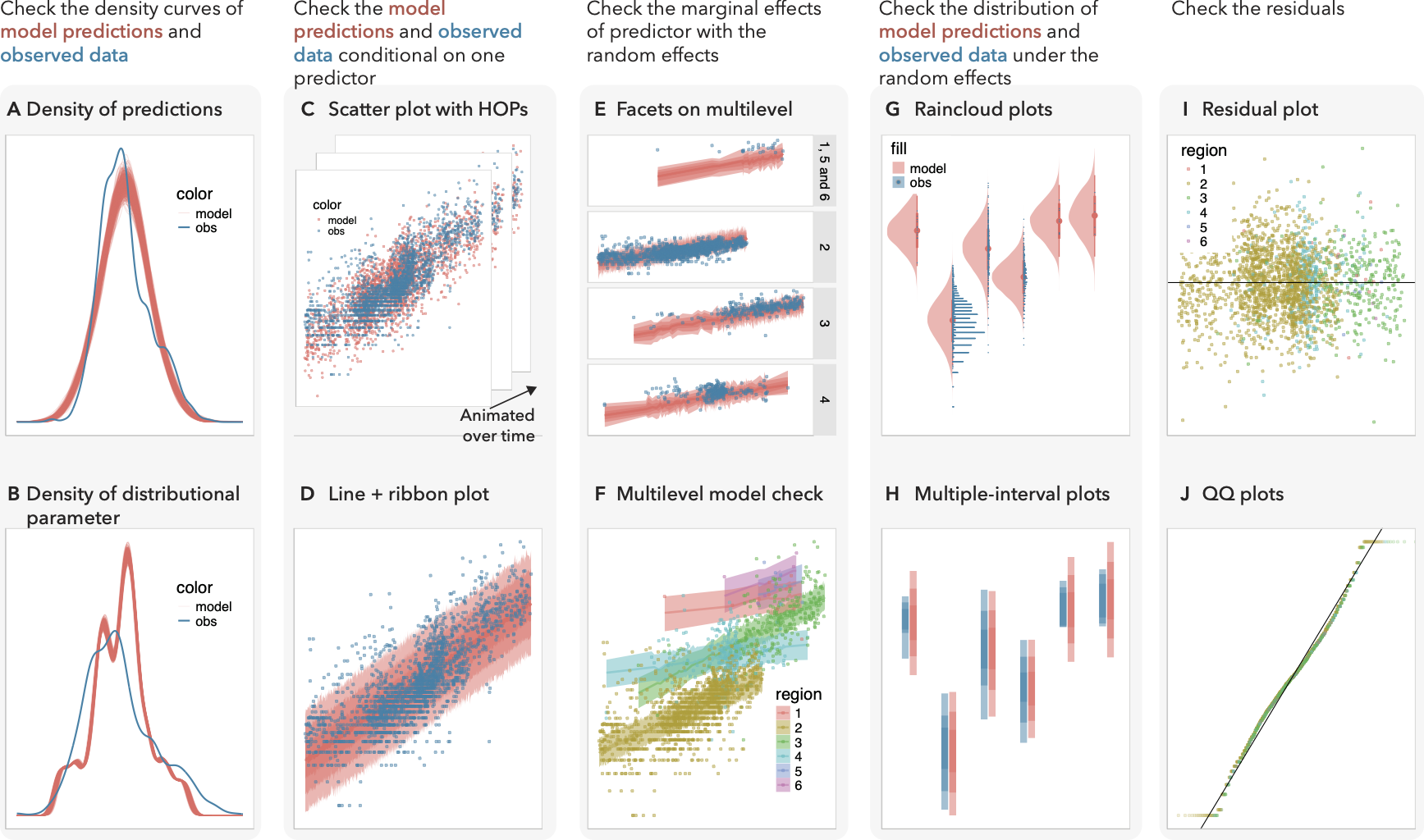
Fast forward
Keywords
Model checking and evaluation; Uncertainty visualization; Grammar of Graphics
Abstract
Visualizations play a critical role in validating and improving statistical models. However, the design space of model check visualizations is not well understood, making it difficult for authors to explore and specify effective graphical model checks. VMC defines a model check visualization using four components: (1) samples of distributions of checkable quantities generated from the model,including predictive distributions for new data and distributions of model parameters; (2) transformations on observed data to facilitate comparison; (3) visual representations of distributions; and (4) layouts to facilitate comparing model samples and observed data. We contribute an implementation of VMC as an R package. We validate VMC by reproducing a set of canonical model check examples, and show how using VMC to generate model checks reduces the edit distance between visualizations relative to existing visualization toolkits. The findings of an interview study with three expert modelers who used VMC highlight challenges and opportunities for encouraging exploration of correct, effective model check visualizations.
VMC: A Grammar for Visualizing Statistical Model Checks
Ziyang Guo - Northwestern University, Evanston, United States
Alex Kale - University of Chicago, Chicago, United States
Matthew Kay - Northwestern University, Chicago, United States
Jessica Hullman - Northwestern University, Evanston, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-17T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T12:54:00Z
Fast forward
Keywords
Model checking and evaluation; Uncertainty visualization; Grammar of Graphics
Abstract
Visualizations play a critical role in validating and improving statistical models. However, the design space of model check visualizations is not well understood, making it difficult for authors to explore and specify effective graphical model checks. VMC defines a model check visualization using four components: (1) samples of distributions of checkable quantities generated from the model,including predictive distributions for new data and distributions of model parameters; (2) transformations on observed data to facilitate comparison; (3) visual representations of distributions; and (4) layouts to facilitate comparing model samples and observed data. We contribute an implementation of VMC as an R package. We validate VMC by reproducing a set of canonical model check examples, and show how using VMC to generate model checks reduces the edit distance between visualizations relative to existing visualization toolkits. The findings of an interview study with three expert modelers who used VMC highlight challenges and opportunities for encouraging exploration of correct, effective model check visualizations.
The Language of Infographics: Toward Understanding Conceptual Metaphor Use in Scientific Storytelling
Hana Pokojná - Masaryk University, Brno, Czech Republic
Tobias Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Stefan Bruckner - University of Rostock, Rostock, Germany
Barbora Kozlikova - Masaryk University, Brno, Czech Republic
Laura Garrison - University of Bergen, Bergen, Norway. Haukeland University Hospital, University of Bergen, Bergen, Norway
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:54:00Z
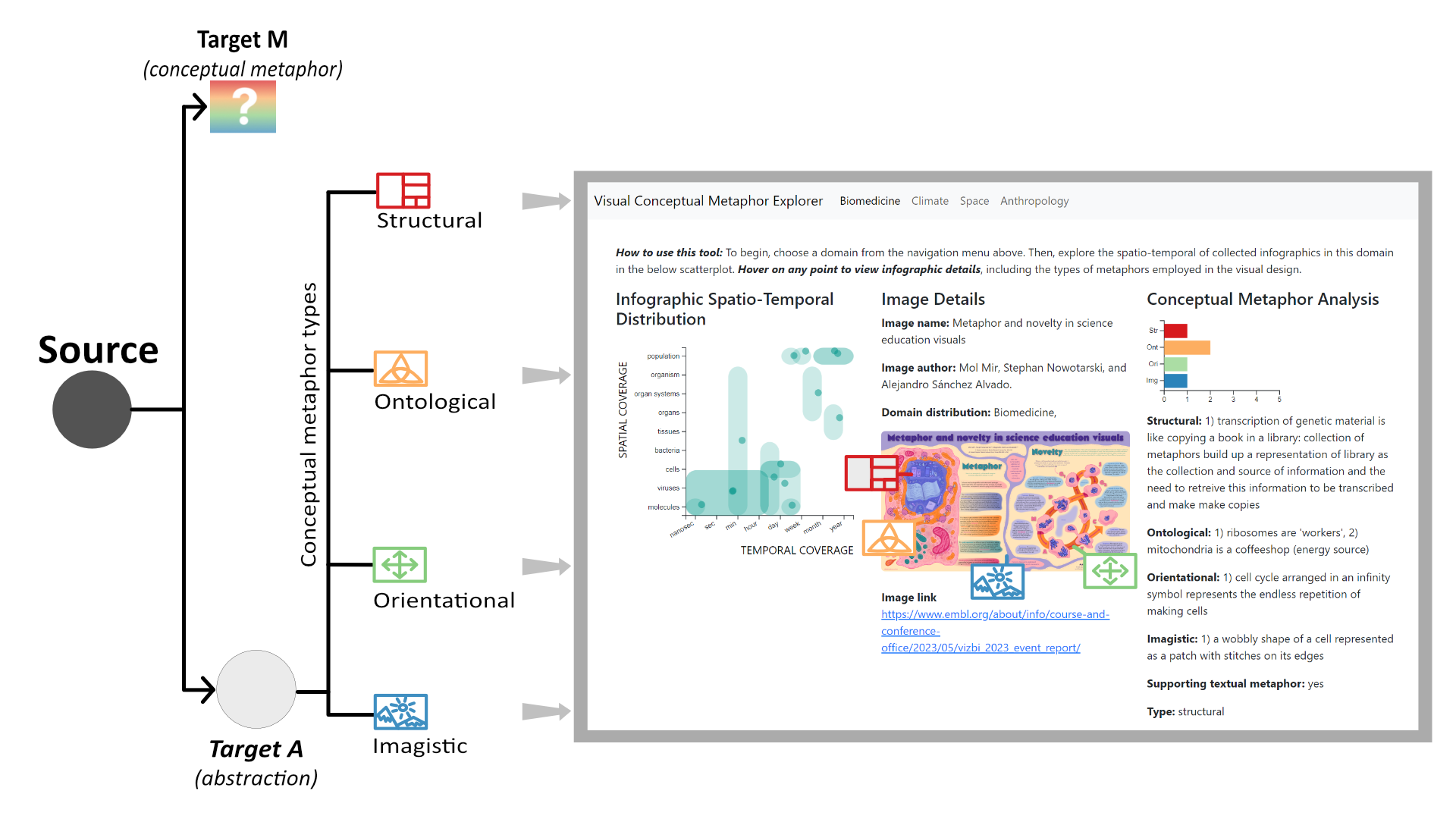
Fast forward
Keywords
Visualization, visual metaphors, science communication, conceptual metaphors, visual communication
Abstract
We apply an approach from cognitive linguistics by mapping Conceptual Metaphor Theory (CMT) to the visualization domain to address patterns of visual conceptual metaphors that are often used in science infographics. Metaphors play an essential part in visual communication and are frequently employed to explain complex concepts. However, their use is often based on intuition, rather than following a formal process. At present, we lack tools and language for understanding and describing metaphor use in visualization to the extent where taxonomy and grammar could guide the creation of visual components, e.g., infographics. Our classification of the visual conceptual mappings within scientific representations is based on the breakdown of visual components in existing scientific infographics. We demonstrate the development of this mapping through a detailed analysis of data collected from four domains (biomedicine, climate, space, and anthropology) that represent a diverse range of visual conceptual metaphors used in the visual communication of science. This work allows us to identify patterns of visual conceptual metaphor use within the domains, resolve ambiguities about why specific conceptual metaphors are used, and develop a better overall understanding of visual metaphor use in scientific infographics. Our analysis shows that ontological and orientational conceptual metaphors are the most widely applied to translate complex scientific concepts. To support our findings we developed a visual exploratory tool based on the collected database that places the individual infographics on a spatio-temporal scale and illustrates the breakdown of visual conceptual metaphors.
The Language of Infographics: Toward Understanding Conceptual Metaphor Use in Scientific Storytelling
Hana Pokojná - Masaryk University, Brno, Czech Republic
Tobias Isenberg - Université Paris-Saclay, CNRS, Orsay, France. Inria, Saclay, France
Stefan Bruckner - University of Rostock, Rostock, Germany
Barbora Kozlikova - Masaryk University, Brno, Czech Republic
Laura Garrison - University of Bergen, Bergen, Norway. Haukeland University Hospital, University of Bergen, Bergen, Norway
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:54:00Z
Fast forward
Keywords
Visualization, visual metaphors, science communication, conceptual metaphors, visual communication
Abstract
We apply an approach from cognitive linguistics by mapping Conceptual Metaphor Theory (CMT) to the visualization domain to address patterns of visual conceptual metaphors that are often used in science infographics. Metaphors play an essential part in visual communication and are frequently employed to explain complex concepts. However, their use is often based on intuition, rather than following a formal process. At present, we lack tools and language for understanding and describing metaphor use in visualization to the extent where taxonomy and grammar could guide the creation of visual components, e.g., infographics. Our classification of the visual conceptual mappings within scientific representations is based on the breakdown of visual components in existing scientific infographics. We demonstrate the development of this mapping through a detailed analysis of data collected from four domains (biomedicine, climate, space, and anthropology) that represent a diverse range of visual conceptual metaphors used in the visual communication of science. This work allows us to identify patterns of visual conceptual metaphor use within the domains, resolve ambiguities about why specific conceptual metaphors are used, and develop a better overall understanding of visual metaphor use in scientific infographics. Our analysis shows that ontological and orientational conceptual metaphors are the most widely applied to translate complex scientific concepts. To support our findings we developed a visual exploratory tool based on the collected database that places the individual infographics on a spatio-temporal scale and illustrates the breakdown of visual conceptual metaphors.
How Good (Or Bad) Are LLMs in Detecting Misleading Visualizations
Leo Yu-Ho Lo - The Hong Kong University of Science and Technology, Hong Kong, China
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T13:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:30:00Z

Fast forward
Keywords
Deceptive Visualization, Large Language Models, Prompt Engineering
Abstract
In this study, we address the growing issue of misleading charts, a prevalent problem that undermines the integrity of information dissemination. Misleading charts can distort the viewer’s perception of data, leading to misinterpretations and decisions based on false information. The development of effective automatic detection methods for misleading charts is an urgent field of research. The recent advancement of multimodal Large Language Models (LLMs) has introduced a promising direction for addressing this challenge. We explored the capabilities of these models in analyzing complex charts and assessing the impact of different prompting strategies on the models’ analyses. We utilized a dataset of misleading charts collected from the internet by prior research and crafted nine distinct prompts, ranging from simple to complex, to test the ability of four different multimodal LLMs in detecting over 21 different chart issues. Through three experiments–from initial exploration to detailed analysis–we progressively gained insights into how to effectively prompt LLMs to identify misleading charts and developed strategies to address the scalability challenges encountered as we expanded our detection range from the initial five issues to 21 issues in the final experiment. Our findings reveal that multimodal LLMs possess a strong capability for chart comprehension and critical thinking in data interpretation. There is significant potential in employing multimodal LLMs to counter misleading information by supporting critical thinking and enhancing visualization literacy. This study demonstrates the applicability of LLMs in addressing the pressing concern of misleading charts.
How Good (Or Bad) Are LLMs in Detecting Misleading Visualizations
Leo Yu-Ho Lo - The Hong Kong University of Science and Technology, Hong Kong, China
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T13:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:30:00Z
Fast forward
Keywords
Deceptive Visualization, Large Language Models, Prompt Engineering
Abstract
In this study, we address the growing issue of misleading charts, a prevalent problem that undermines the integrity of information dissemination. Misleading charts can distort the viewer’s perception of data, leading to misinterpretations and decisions based on false information. The development of effective automatic detection methods for misleading charts is an urgent field of research. The recent advancement of multimodal Large Language Models (LLMs) has introduced a promising direction for addressing this challenge. We explored the capabilities of these models in analyzing complex charts and assessing the impact of different prompting strategies on the models’ analyses. We utilized a dataset of misleading charts collected from the internet by prior research and crafted nine distinct prompts, ranging from simple to complex, to test the ability of four different multimodal LLMs in detecting over 21 different chart issues. Through three experiments–from initial exploration to detailed analysis–we progressively gained insights into how to effectively prompt LLMs to identify misleading charts and developed strategies to address the scalability challenges encountered as we expanded our detection range from the initial five issues to 21 issues in the final experiment. Our findings reveal that multimodal LLMs possess a strong capability for chart comprehension and critical thinking in data interpretation. There is significant potential in employing multimodal LLMs to counter misleading information by supporting critical thinking and enhancing visualization literacy. This study demonstrates the applicability of LLMs in addressing the pressing concern of misleading charts.
Motion-Based Visual Encoding Can Improve Performance on Perceptual Tasks with Dynamic Time Series
Songwen Hu - Georgia Institute of Technology, Atlanta, United States
Ouxun Jiang - Northwestern University, Evanston, United States
Jeffrey Riedmiller - Dolby Laboratories Inc., San Francisco, United States
Cindy Xiong Bearfield - Georgia Tech, Atlanta, United States. University of Massachusetts Amherst, Amherst, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore III
2024-10-17T17:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T17:45:00Z
Fast forward
Keywords
Animation, Dynamic Displays, Perception, Motion, Analytic Tasks
Abstract
Dynamic data visualizations can convey large amounts of information over time, such as using motion to depict changes in data values for multiple entities. Such dynamic displays put a demand on our visual processing capacities, yet our perception of motion is limited. Several techniques have been shown to improve the processing of dynamic displays. Staging the animation to sequentially show steps in a transition and tracing object movement by displaying trajectory histories can improve processing by reducing the cognitive load. In this paper, We examine the effectiveness of staging and tracing in dynamic displays. We showed participants animated line charts depicting the movements of lines and asked them to identify the line with the highest mean and variance. We manipulated the animation to display the lines with or without staging, tracing and history, and compared the results to a static chart as a control. Results showed that tracing and staging are preferred by participants, and improve their performance in mean and variance tasks respectively. They also preferred display time 3 times shorter when staging is used. Also, encoding animation speed with mean and variance in congruent tasks is associated with higher accuracy. These findings help inform real-world best practices for building dynamic displays. The supplementary materials can be found at https://osf.io/8c95v/
Motion-Based Visual Encoding Can Improve Performance on Perceptual Tasks with Dynamic Time Series
Songwen Hu - Georgia Institute of Technology, Atlanta, United States
Ouxun Jiang - Northwestern University, Evanston, United States
Jeffrey Riedmiller - Dolby Laboratories Inc., San Francisco, United States
Cindy Xiong Bearfield - Georgia Tech, Atlanta, United States. University of Massachusetts Amherst, Amherst, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore III
2024-10-17T17:45:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T17:45:00Z
Fast forward
Keywords
Animation, Dynamic Displays, Perception, Motion, Analytic Tasks
Abstract
Dynamic data visualizations can convey large amounts of information over time, such as using motion to depict changes in data values for multiple entities. Such dynamic displays put a demand on our visual processing capacities, yet our perception of motion is limited. Several techniques have been shown to improve the processing of dynamic displays. Staging the animation to sequentially show steps in a transition and tracing object movement by displaying trajectory histories can improve processing by reducing the cognitive load. In this paper, We examine the effectiveness of staging and tracing in dynamic displays. We showed participants animated line charts depicting the movements of lines and asked them to identify the line with the highest mean and variance. We manipulated the animation to display the lines with or without staging, tracing and history, and compared the results to a static chart as a control. Results showed that tracing and staging are preferred by participants, and improve their performance in mean and variance tasks respectively. They also preferred display time 3 times shorter when staging is used. Also, encoding animation speed with mean and variance in congruent tasks is associated with higher accuracy. These findings help inform real-world best practices for building dynamic displays. The supplementary materials can be found at https://osf.io/8c95v/
LLM Comparator: Interactive Analysis of Side-by-Side Evaluation of Large Language Models
Minsuk Kahng - Google, Atlanta, United States
Ian Tenney - Google Research, Seattle, United States
Mahima Pushkarna - Google Research, Cambridge, United States
Michael Xieyang Liu - Google Research, Pittsburgh, United States
James Wexler - Google Research, Cambridge, United States
Emily Reif - Google, Cambridge, United States
Krystal Kallarackal - Google Research, Mountain View, United States
Minsuk Chang - Google Research, Seattle, United States
Michael Terry - Google, Cambridge, United States
Lucas Dixon - Google, Paris, France
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-18T12:42:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:42:00Z
Fast forward
Keywords
Visual analytics, large language models, model evaluation, responsible AI, machine learning interpretability.
Abstract
Evaluating large language models (LLMs) presents unique challenges. While automatic side-by-side evaluation, also known as LLM-as-a-judge, has become a promising solution, model developers and researchers face difficulties with scalability and interpretability when analyzing these evaluation outcomes. To address these challenges, we introduce LLM Comparator, a new visual analytics tool designed for side-by-side evaluations of LLMs. This tool provides analytical workflows that help users understand when and why one LLM outperforms or underperforms another, and how their responses differ. Through close collaboration with practitioners developing LLMs at Google, we have iteratively designed, developed, and refined the tool. Qualitative feedback from these users highlights that the tool facilitates in-depth analysis of individual examples while enabling users to visually overview and flexibly slice data. This empowers users to identify undesirable patterns, formulate hypotheses about model behavior, and gain insights for model improvement. LLM Comparator has been integrated into Google's LLM evaluation platforms and open-sourced.
LLM Comparator: Interactive Analysis of Side-by-Side Evaluation of Large Language Models
Minsuk Kahng - Google, Atlanta, United States
Ian Tenney - Google Research, Seattle, United States
Mahima Pushkarna - Google Research, Cambridge, United States
Michael Xieyang Liu - Google Research, Pittsburgh, United States
James Wexler - Google Research, Cambridge, United States
Emily Reif - Google, Cambridge, United States
Krystal Kallarackal - Google Research, Mountain View, United States
Minsuk Chang - Google Research, Seattle, United States
Michael Terry - Google, Cambridge, United States
Lucas Dixon - Google, Paris, France
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-18T12:42:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T12:42:00Z
Fast forward
Keywords
Visual analytics, large language models, model evaluation, responsible AI, machine learning interpretability.
Abstract
Evaluating large language models (LLMs) presents unique challenges. While automatic side-by-side evaluation, also known as LLM-as-a-judge, has become a promising solution, model developers and researchers face difficulties with scalability and interpretability when analyzing these evaluation outcomes. To address these challenges, we introduce LLM Comparator, a new visual analytics tool designed for side-by-side evaluations of LLMs. This tool provides analytical workflows that help users understand when and why one LLM outperforms or underperforms another, and how their responses differ. Through close collaboration with practitioners developing LLMs at Google, we have iteratively designed, developed, and refined the tool. Qualitative feedback from these users highlights that the tool facilitates in-depth analysis of individual examples while enabling users to visually overview and flexibly slice data. This empowers users to identify undesirable patterns, formulate hypotheses about model behavior, and gain insights for model improvement. LLM Comparator has been integrated into Google's LLM evaluation platforms and open-sourced.
StuGPTViz: A Visual Analytics Approach to Understand Student-ChatGPT Interactions
Zixin Chen - The Hong Kong University of Science and Technology, Hong Kong, China
Jiachen Wang - The Hong Kong University of Science and Technology, Sai Kung, China
Meng Xia - Texas A. M University, College Station, United States
Kento Shigyo - The Hong Kong University of Science and Technology, Kowloon, Hong Kong
Dingdong Liu - The Hong Kong University of Science and Technology, Hong Kong, China
Rong Zhang - Hong Kong University of Science and Technology, Hong Kong, Hong Kong
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T16:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:00:00Z

Fast forward
Keywords
Visual analytics for education, ChatGPT for education, student-ChatGPT interaction
Abstract
The integration of Large Language Models (LLMs), especially ChatGPT, into education is poised to revolutionize students’ learning experiences by introducing innovative conversational learning methodologies. To empower students to fully leverage the capabilities of ChatGPT in educational scenarios, understanding students’ interaction patterns with ChatGPT is crucial for instructors. However, this endeavor is challenging due to the absence of datasets focused on student-ChatGPT conversations and the complexities in identifying and analyzing the evolutional interaction patterns within conversations. To address these challenges, we collected conversational data from 48 students interacting with ChatGPT in a master’s level data visualization course over one semester. We then developed a coding scheme, grounded in the literature on cognitive levels and thematic analysis, to categorize students’ interaction patterns with ChatGPT. Furthermore, we present a visual analytics system, StuGPTViz, that tracks and compares temporal patterns in student prompts and the quality of ChatGPT’s responses at multiple scales, revealing significant pedagogical insights for instructors. We validated the system’s effectiveness through expert interviews with six data visualization instructors and three case studies. The results confirmed StuGPTViz’s capacity to enhance educators’ insights into the pedagogical value of ChatGPT. We also discussed the potential research opportunities of applying visual analytics in education and developing AI-driven personalized learning solutions.
StuGPTViz: A Visual Analytics Approach to Understand Student-ChatGPT Interactions
Zixin Chen - The Hong Kong University of Science and Technology, Hong Kong, China
Jiachen Wang - The Hong Kong University of Science and Technology, Sai Kung, China
Meng Xia - Texas A. M University, College Station, United States
Kento Shigyo - The Hong Kong University of Science and Technology, Kowloon, Hong Kong
Dingdong Liu - The Hong Kong University of Science and Technology, Hong Kong, China
Rong Zhang - Hong Kong University of Science and Technology, Hong Kong, Hong Kong
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T16:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:00:00Z
Fast forward
Keywords
Visual analytics for education, ChatGPT for education, student-ChatGPT interaction
Abstract
The integration of Large Language Models (LLMs), especially ChatGPT, into education is poised to revolutionize students’ learning experiences by introducing innovative conversational learning methodologies. To empower students to fully leverage the capabilities of ChatGPT in educational scenarios, understanding students’ interaction patterns with ChatGPT is crucial for instructors. However, this endeavor is challenging due to the absence of datasets focused on student-ChatGPT conversations and the complexities in identifying and analyzing the evolutional interaction patterns within conversations. To address these challenges, we collected conversational data from 48 students interacting with ChatGPT in a master’s level data visualization course over one semester. We then developed a coding scheme, grounded in the literature on cognitive levels and thematic analysis, to categorize students’ interaction patterns with ChatGPT. Furthermore, we present a visual analytics system, StuGPTViz, that tracks and compares temporal patterns in student prompts and the quality of ChatGPT’s responses at multiple scales, revealing significant pedagogical insights for instructors. We validated the system’s effectiveness through expert interviews with six data visualization instructors and three case studies. The results confirmed StuGPTViz’s capacity to enhance educators’ insights into the pedagogical value of ChatGPT. We also discussed the potential research opportunities of applying visual analytics in education and developing AI-driven personalized learning solutions.
Best Paper Award
VisEval: A Benchmark for Data Visualization in the Era of Large Language Models
Nan Chen - Microsoft Research, Shanghai, China
Yuge Zhang - Microsoft Research, Shanghai, China
Jiahang Xu - Microsoft Research, Shanghai, China
Kan Ren - ShanghaiTech University, Shanghai, China
Yuqing Yang - Microsoft Research, Shanghai, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-15T16:40:00Z GMT-0600 Change your timezone on the schedule page
2024-10-15T16:40:00Z
Fast forward
Keywords
Visualization evaluation, automatic visualization, large language models, benchmark
Abstract
Translating natural language to visualization (NL2VIS) has shown great promise for visual data analysis, but it remains a challenging task that requires multiple low-level implementations, such as natural language processing and visualization design. Recent advancements in pre-trained large language models (LLMs) are opening new avenues for generating visualizations from natural language. However, the lack of a comprehensive and reliable benchmark hinders our understanding of LLMs’ capabilities in visualization generation. In this paper, we address this gap by proposing a new NL2VIS benchmark called VisEval. Firstly, we introduce a high-quality and large-scale dataset. This dataset includes 2,524 representative queries covering 146 databases, paired with accurately labeled ground truths. Secondly, we advocate for a comprehensive automated evaluation methodology covering multiple dimensions, including validity, legality, and readability. By systematically scanning for potential issues with a number of heterogeneous checkers, VisEval provides reliable and trustworthy evaluation outcomes. We run VisEval on a series of state-of-the-art LLMs. Our evaluation reveals prevalent challenges and delivers essential insights for future advancements.
Best Paper Award
VisEval: A Benchmark for Data Visualization in the Era of Large Language Models
Nan Chen - Microsoft Research, Shanghai, China
Yuge Zhang - Microsoft Research, Shanghai, China
Jiahang Xu - Microsoft Research, Shanghai, China
Kan Ren - ShanghaiTech University, Shanghai, China
Yuqing Yang - Microsoft Research, Shanghai, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-15T16:40:00Z GMT-0600 Change your timezone on the schedule page
2024-10-15T16:40:00Z
Fast forward
Keywords
Visualization evaluation, automatic visualization, large language models, benchmark
Abstract
Translating natural language to visualization (NL2VIS) has shown great promise for visual data analysis, but it remains a challenging task that requires multiple low-level implementations, such as natural language processing and visualization design. Recent advancements in pre-trained large language models (LLMs) are opening new avenues for generating visualizations from natural language. However, the lack of a comprehensive and reliable benchmark hinders our understanding of LLMs’ capabilities in visualization generation. In this paper, we address this gap by proposing a new NL2VIS benchmark called VisEval. Firstly, we introduce a high-quality and large-scale dataset. This dataset includes 2,524 representative queries covering 146 databases, paired with accurately labeled ground truths. Secondly, we advocate for a comprehensive automated evaluation methodology covering multiple dimensions, including validity, legality, and readability. By systematically scanning for potential issues with a number of heterogeneous checkers, VisEval provides reliable and trustworthy evaluation outcomes. We run VisEval on a series of state-of-the-art LLMs. Our evaluation reveals prevalent challenges and delivers essential insights for future advancements.
Telling Data Stories with the Hero’s Journey: Design Guidance for Creating Data Videos
Zheng Wei - The Hong Kong University of Science and Technology, Hong Kong, Hong Kong
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Xian Xu - The Hong Kong University of Science and Technology, Hong Kong, China
Download camera-ready PDF
Room: Bayshore V
2024-10-17T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:12:00Z

Fast forward
Keywords
The Hero's Journey, Narrative Structure, Narrative Visualization, Data Visualization, Data Videos
Abstract
Data videos increasingly becoming a popular data storytelling form represented by visual and audio integration. In recent years, more and more researchers have explored many narrative structures for effective and attractive data storytelling. Meanwhile, the Hero's Journey provides a classic narrative framework specific to the Hero's story that has been adopted by various mediums. There are continuous discussions about applying Hero's Journey to data stories. However, so far, little systematic and practical guidance on how to create a data video for a specific story type like the Hero's Journey, as well as how to manipulate its sound and visual designs simultaneously. To fulfill this gap, we first identified 48 data videos aligned with the Hero's Journey as the common storytelling from 109 high-quality data videos. Then, we examined how existing practices apply Hero's Journey for creating data videos. We coded the 48 data videos in terms of the narrative stages, sound design, and visual design according to the Hero's Journey structure. Based on our findings, we proposed a design space to provide practical guidance on the narrative, visual, and sound custom design for different narrative segments of the hero's journey (i.e., Departure, Initiation, Return) through data video creation. To validate our proposed design space, we conducted a user study where 20 participants were invited to design data videos with and without our design space guidance, which was evaluated by two experts. Results show that our design space provides useful and practical guidance for data storytellers effectively creating data videos with the Hero's Journey.
Telling Data Stories with the Hero’s Journey: Design Guidance for Creating Data Videos
Zheng Wei - The Hong Kong University of Science and Technology, Hong Kong, Hong Kong
Huamin Qu - The Hong Kong University of Science and Technology, Hong Kong, China
Xian Xu - The Hong Kong University of Science and Technology, Hong Kong, China
Download camera-ready PDF
Room: Bayshore V
2024-10-17T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:12:00Z
Fast forward
Keywords
The Hero's Journey, Narrative Structure, Narrative Visualization, Data Visualization, Data Videos
Abstract
Data videos increasingly becoming a popular data storytelling form represented by visual and audio integration. In recent years, more and more researchers have explored many narrative structures for effective and attractive data storytelling. Meanwhile, the Hero's Journey provides a classic narrative framework specific to the Hero's story that has been adopted by various mediums. There are continuous discussions about applying Hero's Journey to data stories. However, so far, little systematic and practical guidance on how to create a data video for a specific story type like the Hero's Journey, as well as how to manipulate its sound and visual designs simultaneously. To fulfill this gap, we first identified 48 data videos aligned with the Hero's Journey as the common storytelling from 109 high-quality data videos. Then, we examined how existing practices apply Hero's Journey for creating data videos. We coded the 48 data videos in terms of the narrative stages, sound design, and visual design according to the Hero's Journey structure. Based on our findings, we proposed a design space to provide practical guidance on the narrative, visual, and sound custom design for different narrative segments of the hero's journey (i.e., Departure, Initiation, Return) through data video creation. To validate our proposed design space, we conducted a user study where 20 participants were invited to design data videos with and without our design space guidance, which was evaluated by two experts. Results show that our design space provides useful and practical guidance for data storytellers effectively creating data videos with the Hero's Journey.
Understanding Visualization Authoring Techniques for Genomics Data in the Context of Personas and Tasks
Astrid van den Brandt - Eindhoven University of Technology, Eindhoven, Netherlands
Sehi L'Yi - Harvard Medical School, Boston, United States
Huyen N. Nguyen - Harvard Medical School, Boston, United States
Anna Vilanova - Eindhoven University of Technology, Eindhoven, Netherlands
Nils Gehlenborg - Harvard Medical School, Boston, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T17:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T17:00:00Z
Fast forward
Keywords
User interviews, visual probes, visualization authoring, genomics data visualization
Abstract
Genomics experts rely on visualization to extract and share insights from complex and large-scale datasets. Beyond off-the-shelf tools for data exploration, there is an increasing need for platforms that aid experts in authoring customized visualizations for both exploration and communication of insights. A variety of interactive techniques have been proposed for authoring data visualizations, such as template editing, shelf configuration, natural language input, and code editors. However, it remains unclear how genomics experts create visualizations and which techniques best support their visualization tasks and needs. To address this gap, we conducted two user studies with genomics researchers: (1) semi-structured interviews (n=20) to identify the tasks, user contexts, and current visualization authoring techniques and (2) an exploratory study (n=13) using visual probes to elicit users’ intents and desired techniques when creating visualizations. Our contributions include (1) a characterization of how visualization authoring is currently utilized in genomics visualization, identifying limitations and benefits in light of common criteria for authoring tools, and (2) generalizable design implications for genomics visualization authoring tools based on our findings on task- and user-specific usefulness of authoring techniques. All supplemental materials are available at https://osf.io/bdj4v/.
Understanding Visualization Authoring Techniques for Genomics Data in the Context of Personas and Tasks
Astrid van den Brandt - Eindhoven University of Technology, Eindhoven, Netherlands
Sehi L'Yi - Harvard Medical School, Boston, United States
Huyen N. Nguyen - Harvard Medical School, Boston, United States
Anna Vilanova - Eindhoven University of Technology, Eindhoven, Netherlands
Nils Gehlenborg - Harvard Medical School, Boston, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T17:00:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T17:00:00Z
Fast forward
Keywords
User interviews, visual probes, visualization authoring, genomics data visualization
Abstract
Genomics experts rely on visualization to extract and share insights from complex and large-scale datasets. Beyond off-the-shelf tools for data exploration, there is an increasing need for platforms that aid experts in authoring customized visualizations for both exploration and communication of insights. A variety of interactive techniques have been proposed for authoring data visualizations, such as template editing, shelf configuration, natural language input, and code editors. However, it remains unclear how genomics experts create visualizations and which techniques best support their visualization tasks and needs. To address this gap, we conducted two user studies with genomics researchers: (1) semi-structured interviews (n=20) to identify the tasks, user contexts, and current visualization authoring techniques and (2) an exploratory study (n=13) using visual probes to elicit users’ intents and desired techniques when creating visualizations. Our contributions include (1) a characterization of how visualization authoring is currently utilized in genomics visualization, identifying limitations and benefits in light of common criteria for authoring tools, and (2) generalizable design implications for genomics visualization authoring tools based on our findings on task- and user-specific usefulness of authoring techniques. All supplemental materials are available at https://osf.io/bdj4v/.
Sportify: Question Answering with Embedded Visualizations and Personified Narratives for Sports Video
Chunggi Lee - Harvard University, Allston, United States
Tica Lin - Harvard University, Cambridge, United States
Hanspeter Pfister - Harvard University, Cambridge, United States
Chen Zhu-Tian - University of Minnesota-Twin Cities, Minneapolis, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Room: Bayshore V
2024-10-17T14:27:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:27:00Z

Fast forward
Keywords
Embedded Visualization, Narrative and storytelling, Basketball tactic, Question-answering (QA) system
Abstract
As basketball’s popularity surges, fans often find themselves confused and overwhelmed by the rapid game pace and complexity. Basketball tactics, involving a complex series of actions, require substantial knowledge to be fully understood. This complexity leads to a need for additional information and explanation, which can distract fans from the game. To tackle these challenges, we present Sportify, a Visual Question Answering system that integrates narratives and embedded visualization for demystifying basketball tactical questions, aiding fans in understanding various game aspects. We propose three novel action visualizations (i.e., Pass, Cut, and Screen) to demonstrate critical action sequences. To explain the reasoning and logic behind players’ actions, we leverage a large-language model (LLM) to generate narratives. We adopt a storytelling approach for complex scenarios from both first and third-person perspectives, integrating action visualizations. We evaluated Sportify with basketball fans to investigate its impact on understanding of tactics, and how different personal perspectives of narratives impact the understanding of complex tactic with action visualizations. Our evaluation with basketball fans demonstrates Sportify’s capability to deepen tactical insights and amplify the viewing experience. Furthermore, third-person narration assists people in getting in-depth game explanations while first-person narration enhances fans’ game engagement.
Sportify: Question Answering with Embedded Visualizations and Personified Narratives for Sports Video
Chunggi Lee - Harvard University, Allston, United States
Tica Lin - Harvard University, Cambridge, United States
Hanspeter Pfister - Harvard University, Cambridge, United States
Chen Zhu-Tian - University of Minnesota-Twin Cities, Minneapolis, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Room: Bayshore V
2024-10-17T14:27:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:27:00Z
Fast forward
Keywords
Embedded Visualization, Narrative and storytelling, Basketball tactic, Question-answering (QA) system
Abstract
As basketball’s popularity surges, fans often find themselves confused and overwhelmed by the rapid game pace and complexity. Basketball tactics, involving a complex series of actions, require substantial knowledge to be fully understood. This complexity leads to a need for additional information and explanation, which can distract fans from the game. To tackle these challenges, we present Sportify, a Visual Question Answering system that integrates narratives and embedded visualization for demystifying basketball tactical questions, aiding fans in understanding various game aspects. We propose three novel action visualizations (i.e., Pass, Cut, and Screen) to demonstrate critical action sequences. To explain the reasoning and logic behind players’ actions, we leverage a large-language model (LLM) to generate narratives. We adopt a storytelling approach for complex scenarios from both first and third-person perspectives, integrating action visualizations. We evaluated Sportify with basketball fans to investigate its impact on understanding of tactics, and how different personal perspectives of narratives impact the understanding of complex tactic with action visualizations. Our evaluation with basketball fans demonstrates Sportify’s capability to deepen tactical insights and amplify the viewing experience. Furthermore, third-person narration assists people in getting in-depth game explanations while first-person narration enhances fans’ game engagement.
FPCS: Feature Preserving Compensated Sampling of Streaming Time Series Data
Hongyan Li - China Nanhu Academy of Electronics and Information Technology(CNAEIT), JiaXing, China
Bo Yang - China Nanhu Academy of Electronics and Information Technology(CNAEIT), JiaXing, China
Yansong Chua - China Nanhu Academy of Electronics and Information Technology, Jiaxing, China
Download camera-ready PDF
Room: Palma Ceia I
2024-10-16T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:30:00Z
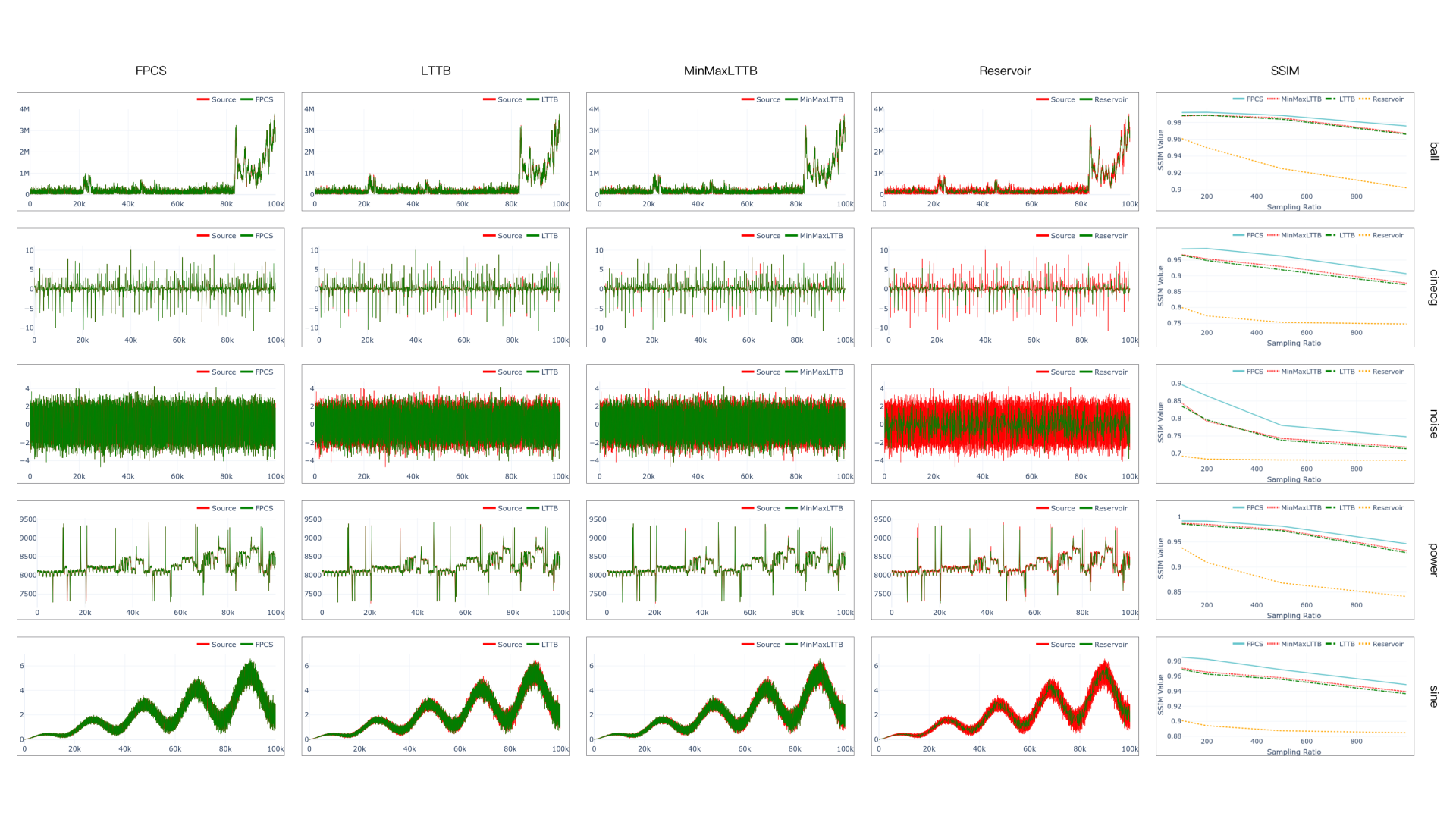
Fast forward
Keywords
Data visualization, Massive, Streaming, Time series, Line charts, Sampling, Feature, Compensating
Abstract
Data visualization aids in making data analysis more intuitive and in-depth, with widespread applications in fields such as biology, finance, and medicine. For massive and continuously growing streaming time series data, these data are typically visualized in the form of line charts, but the data transmission puts significant pressure on the network, leading to visualization lag or even failure to render completely. This paper proposes a universal sampling algorithm FPCS, which retains feature points from continuously received streaming time series data, compensates for the frequent fluctuating feature points, and aims to achieve efficient visualization. This algorithm bridges the gap in sampling for streaming time series data. The algorithm has several advantages: (1) It optimizes the sampling results by compensating for fewer feature points, retaining the visualization features of the original data very well, ensuring high-quality sampled data; (2) The execution time is the shortest compared to similar existing algorithms; (3) It has an almost negligible space overhead; (4) The data sampling process does not depend on the overall data; (5) This algorithm can be applied to infinite streaming data and finite static data.
FPCS: Feature Preserving Compensated Sampling of Streaming Time Series Data
Hongyan Li - China Nanhu Academy of Electronics and Information Technology(CNAEIT), JiaXing, China
Bo Yang - China Nanhu Academy of Electronics and Information Technology(CNAEIT), JiaXing, China
Yansong Chua - China Nanhu Academy of Electronics and Information Technology, Jiaxing, China
Download camera-ready PDF
Room: Palma Ceia I
2024-10-16T12:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:30:00Z
Fast forward
Keywords
Data visualization, Massive, Streaming, Time series, Line charts, Sampling, Feature, Compensating
Abstract
Data visualization aids in making data analysis more intuitive and in-depth, with widespread applications in fields such as biology, finance, and medicine. For massive and continuously growing streaming time series data, these data are typically visualized in the form of line charts, but the data transmission puts significant pressure on the network, leading to visualization lag or even failure to render completely. This paper proposes a universal sampling algorithm FPCS, which retains feature points from continuously received streaming time series data, compensates for the frequent fluctuating feature points, and aims to achieve efficient visualization. This algorithm bridges the gap in sampling for streaming time series data. The algorithm has several advantages: (1) It optimizes the sampling results by compensating for fewer feature points, retaining the visualization features of the original data very well, ensuring high-quality sampled data; (2) The execution time is the shortest compared to similar existing algorithms; (3) It has an almost negligible space overhead; (4) The data sampling process does not depend on the overall data; (5) This algorithm can be applied to infinite streaming data and finite static data.
SLInterpreter: An Exploratory and Iterative Human-AI Collaborative System for GNN-based Synthetic Lethal Prediction
Haoran Jiang - Shanghaitech University, Shanghai, China
Shaohan Shi - ShanghaiTech University, Shanghai, China
Shuhao Zhang - ShanghaiTech University, Shanghai, China
Jie Zheng - ShanghaiTech University, Shanghai, China
Quan Li - ShanghaiTech University, Shanghai, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:12:00Z

Fast forward
Keywords
Synthetic Lethality, Model Interpretability, Visual Analytics, Iterative Human-AI Collaboration.
Abstract
Synthetic Lethal (SL) relationships, though rare among the vast array of gene combinations, hold substantial promise for targeted cancer therapy. Despite advancements in AI model accuracy, there is still a significant need among domain experts for interpretive paths and mechanism explorations that align better with domain-specific knowledge, particularly due to the high costs of experimentation. To address this gap, we propose an iterative Human-AI collaborative framework with two key components: 1) Human-Engaged Knowledge Graph Refinement based on Metapath Strategies, which leverages insights from interpretive paths and domain expertise to refine the knowledge graph through metapath strategies with appropriate granularity. 2) Cross-Granularity SL Interpretation Enhancement and Mechanism Analysis, which aids experts in organizing and comparing predictions and interpretive paths across different granularities, uncovering new SL relationships, enhancing result interpretation, and elucidating potential mechanisms inferred by Graph Neural Network (GNN) models. These components cyclically optimize model predictions and mechanism explorations, enhancing expert involvement and intervention to build trust. Facilitated by SLInterpreter, this framework ensures that newly generated interpretive paths increasingly align with domain knowledge and adhere more closely to real-world biological principles through iterative Human-AI collaboration. We evaluate the framework’s efficacy through a case study and expert interviews.
SLInterpreter: An Exploratory and Iterative Human-AI Collaborative System for GNN-based Synthetic Lethal Prediction
Haoran Jiang - Shanghaitech University, Shanghai, China
Shaohan Shi - ShanghaiTech University, Shanghai, China
Shuhao Zhang - ShanghaiTech University, Shanghai, China
Jie Zheng - ShanghaiTech University, Shanghai, China
Quan Li - ShanghaiTech University, Shanghai, China
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore V
2024-10-16T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T16:12:00Z
Fast forward
Keywords
Synthetic Lethality, Model Interpretability, Visual Analytics, Iterative Human-AI Collaboration.
Abstract
Synthetic Lethal (SL) relationships, though rare among the vast array of gene combinations, hold substantial promise for targeted cancer therapy. Despite advancements in AI model accuracy, there is still a significant need among domain experts for interpretive paths and mechanism explorations that align better with domain-specific knowledge, particularly due to the high costs of experimentation. To address this gap, we propose an iterative Human-AI collaborative framework with two key components: 1) Human-Engaged Knowledge Graph Refinement based on Metapath Strategies, which leverages insights from interpretive paths and domain expertise to refine the knowledge graph through metapath strategies with appropriate granularity. 2) Cross-Granularity SL Interpretation Enhancement and Mechanism Analysis, which aids experts in organizing and comparing predictions and interpretive paths across different granularities, uncovering new SL relationships, enhancing result interpretation, and elucidating potential mechanisms inferred by Graph Neural Network (GNN) models. These components cyclically optimize model predictions and mechanism explorations, enhancing expert involvement and intervention to build trust. Facilitated by SLInterpreter, this framework ensures that newly generated interpretive paths increasingly align with domain knowledge and adhere more closely to real-world biological principles through iterative Human-AI collaboration. We evaluate the framework’s efficacy through a case study and expert interviews.
StyleRF-VolVis: Style Transfer of Neural Radiance Fields for Expressive Volume Visualization
Kaiyuan Tang - University of Notre Dame, Notre Dame, United States
Chaoli Wang - University of Notre Dame, Notre Dame, United States
Download preprint PDF
Download camera-ready PDF
Room: Bayshore I
2024-10-16T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:54:00Z
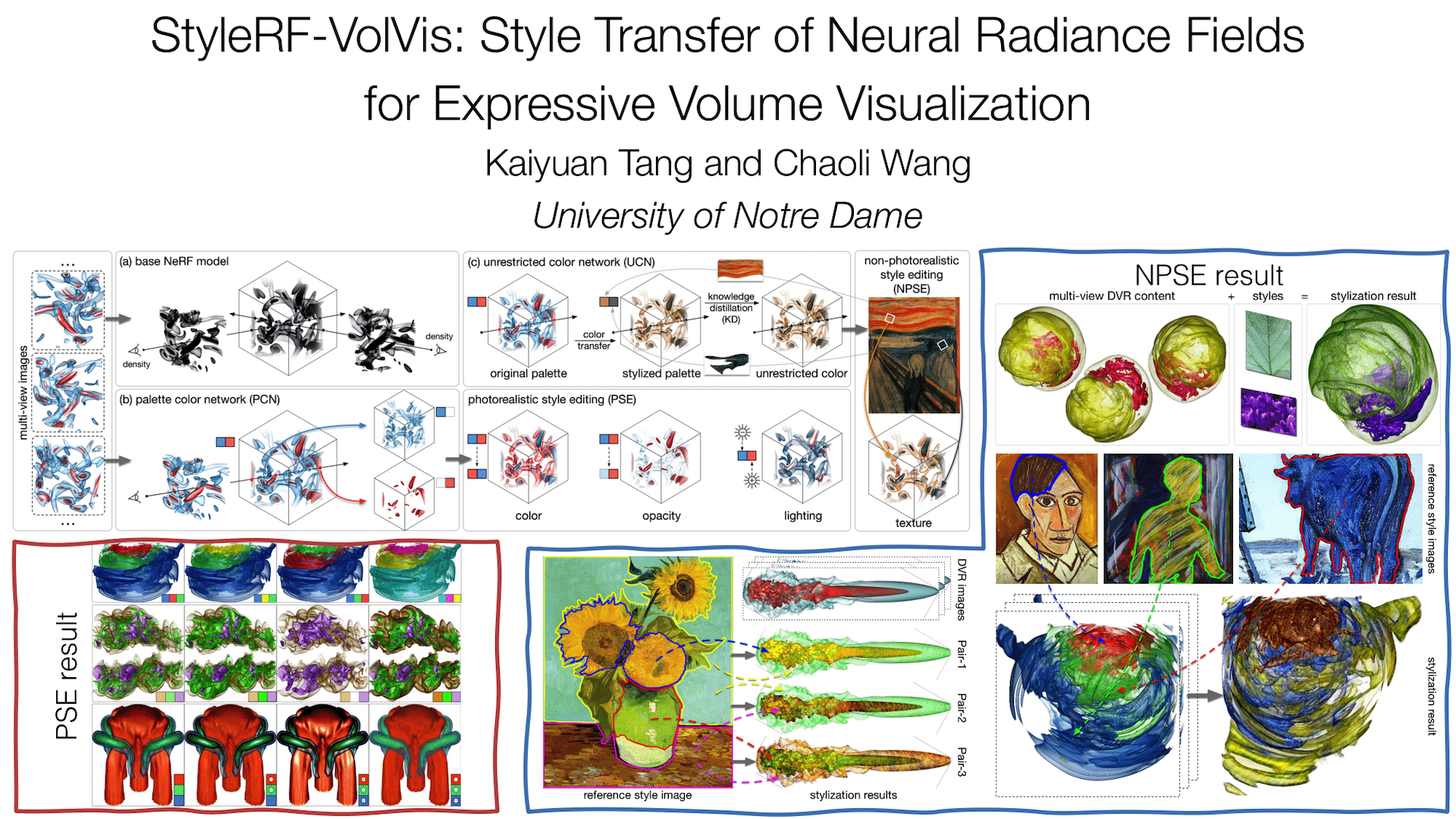
Fast forward
Keywords
Style transfer, neural radiance field, knowledge distillation, volume visualization
Abstract
In volume visualization, visualization synthesis has attracted much attention due to its ability to generate novel visualizations without following the conventional rendering pipeline. However, existing solutions based on generative adversarial networks often require many training images and take significant training time. Still, issues such as low quality, consistency, and flexibility persist. This paper introduces StyleRF-VolVis, an innovative style transfer framework for expressive volume visualization (VolVis) via neural radiance field (NeRF). The expressiveness of StyleRF-VolVis is upheld by its ability to accurately separate the underlying scene geometry (i.e., content) and color appearance (i.e., style), conveniently modify color, opacity, and lighting of the original rendering while maintaining visual content consistency across the views, and effectively transfer arbitrary styles from reference images to the reconstructed 3D scene. To achieve these, we design a base NeRF model for scene geometry extraction, a palette color network to classify regions of the radiance field for photorealistic editing, and an unrestricted color network to lift the color palette constraint via knowledge distillation for non-photorealistic editing. We demonstrate the superior quality, consistency, and flexibility of StyleRF-VolVis by experimenting with various volume rendering scenes and reference images and comparing StyleRF-VolVis against other image-based (AdaIN), video-based (ReReVST), and NeRF-based (ARF and SNeRF) style rendering solutions.
StyleRF-VolVis: Style Transfer of Neural Radiance Fields for Expressive Volume Visualization
Kaiyuan Tang - University of Notre Dame, Notre Dame, United States
Chaoli Wang - University of Notre Dame, Notre Dame, United States
Download preprint PDF
Download camera-ready PDF
Room: Bayshore I
2024-10-16T12:54:00Z GMT-0600 Change your timezone on the schedule page
2024-10-16T12:54:00Z
Fast forward
Keywords
Style transfer, neural radiance field, knowledge distillation, volume visualization
Abstract
In volume visualization, visualization synthesis has attracted much attention due to its ability to generate novel visualizations without following the conventional rendering pipeline. However, existing solutions based on generative adversarial networks often require many training images and take significant training time. Still, issues such as low quality, consistency, and flexibility persist. This paper introduces StyleRF-VolVis, an innovative style transfer framework for expressive volume visualization (VolVis) via neural radiance field (NeRF). The expressiveness of StyleRF-VolVis is upheld by its ability to accurately separate the underlying scene geometry (i.e., content) and color appearance (i.e., style), conveniently modify color, opacity, and lighting of the original rendering while maintaining visual content consistency across the views, and effectively transfer arbitrary styles from reference images to the reconstructed 3D scene. To achieve these, we design a base NeRF model for scene geometry extraction, a palette color network to classify regions of the radiance field for photorealistic editing, and an unrestricted color network to lift the color palette constraint via knowledge distillation for non-photorealistic editing. We demonstrate the superior quality, consistency, and flexibility of StyleRF-VolVis by experimenting with various volume rendering scenes and reference images and comparing StyleRF-VolVis against other image-based (AdaIN), video-based (ReReVST), and NeRF-based (ARF and SNeRF) style rendering solutions.
Practices and Strategies in Responsive Thematic Map Design: A Report from Design Workshops with Experts
Sarah Schöttler - University of Edinburgh, Edinburgh, United Kingdom
Uta Hinrichs - University of Edinburgh, Edinburgh, United Kingdom
Benjamin Bach - Inria, Bordeaux, France. University of Edinburgh, Edinburgh, United Kingdom
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T16:24:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:24:00Z

Fast forward
Keywords
information visualization, responsive visualization, thematic map design
Abstract
This paper discusses challenges and design strategies in responsive design for thematic maps in information visualization. Thematic maps pose a number of unique challenges for responsiveness, such as inflexible aspect ratios that do not easily adapt to varying screen dimensions, or densely clustered visual elements in urban areas becoming illegible at smaller scales. However, design guidance on how to best address these issues is currently lacking. We conducted design sessions with eight professional designers and developers of web-based thematic maps for information visualization. Participants were asked to redesign a given map for various screen sizes and aspect ratios and to describe their reasoning for when and how they adapted the design. We report general observations of practitioners’ motivations, decision-making processes, and personal design frameworks. We then derive seven challenges commonly encountered in responsive maps, and 17 strategies to address them, such as repositioning elements, segmenting the map, or using alternative visualizations. We compile these challenges and strategies into an illustrated cheat sheet targeted at anyone designing or learning to design responsive maps. The cheat sheet is available online: responsive-vis.github.io/map-cheat-sheet.
Practices and Strategies in Responsive Thematic Map Design: A Report from Design Workshops with Experts
Sarah Schöttler - University of Edinburgh, Edinburgh, United Kingdom
Uta Hinrichs - University of Edinburgh, Edinburgh, United Kingdom
Benjamin Bach - Inria, Bordeaux, France. University of Edinburgh, Edinburgh, United Kingdom
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T16:24:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:24:00Z
Fast forward
Keywords
information visualization, responsive visualization, thematic map design
Abstract
This paper discusses challenges and design strategies in responsive design for thematic maps in information visualization. Thematic maps pose a number of unique challenges for responsiveness, such as inflexible aspect ratios that do not easily adapt to varying screen dimensions, or densely clustered visual elements in urban areas becoming illegible at smaller scales. However, design guidance on how to best address these issues is currently lacking. We conducted design sessions with eight professional designers and developers of web-based thematic maps for information visualization. Participants were asked to redesign a given map for various screen sizes and aspect ratios and to describe their reasoning for when and how they adapted the design. We report general observations of practitioners’ motivations, decision-making processes, and personal design frameworks. We then derive seven challenges commonly encountered in responsive maps, and 17 strategies to address them, such as repositioning elements, segmenting the map, or using alternative visualizations. We compile these challenges and strategies into an illustrated cheat sheet targeted at anyone designing or learning to design responsive maps. The cheat sheet is available online: responsive-vis.github.io/map-cheat-sheet.
Discursive Patinas: Anchoring Discussions in Data Visualizations
Tobias Kauer - University of Edinburgh, Edinburgh, United Kingdom. Potsdam University of Applied Sciences, Potsdam, Germany
Derya Akbaba - Linköping University, Norrköping, Sweden
Marian Dörk - University of Applied Sciences Potsdam, Potsdam, Germany
Benjamin Bach - Inria, Bordeaux, France. University of Edinburgh, Edinburgh, United Kingdom
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Room: Bayshore II
2024-10-17T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:15:00Z
Fast forward
Keywords
Data Visualization, Discussion, Annotation
Abstract
This paper presents discursive patinas, a technique to visualize discussions onto data visualizations, inspired by how people leave traces in the physical world. While data visualizations are widely discussed in online communities and social media, comments tend to be displayed separately from the visualization and we lack ways to relate these discussions back to the content of the visualization, e.g., to situate comments, explain visual patterns, or question assumptions. In our visualization annotation interface, users can designate areas within the visualization. Discursive patinas are made of overlaid visual marks (anchors), attached to textual comments with category labels, likes, and replies. By coloring and styling the anchors, a meta visualization emerges, showing what and where people comment and annotate the visualization. These patinas show regions of heavy discussions, recent commenting activity, and the distribution of questions, suggestions, or personal stories. We ran workshops with 90 students, domain experts, and visualization researchers to study how people use anchors to discuss visualizations and how patinas influence people's understanding of the discussion. Our results show that discursive patinas improve the ability to navigate discussions and guide people to comments that help understand, contextualize, or scrutinize the visualization. We discuss the potential of anchors and patinas to support discursive engagements, including critical readings of visualizations, design feedback, and feminist approaches to data visualization.
Discursive Patinas: Anchoring Discussions in Data Visualizations
Tobias Kauer - University of Edinburgh, Edinburgh, United Kingdom. Potsdam University of Applied Sciences, Potsdam, Germany
Derya Akbaba - Linköping University, Norrköping, Sweden
Marian Dörk - University of Applied Sciences Potsdam, Potsdam, Germany
Benjamin Bach - Inria, Bordeaux, France. University of Edinburgh, Edinburgh, United Kingdom
Screen-reader Accessible PDF
Download preprint PDF
Download camera-ready PDF
Room: Bayshore II
2024-10-17T14:15:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T14:15:00Z
Fast forward
Keywords
Data Visualization, Discussion, Annotation
Abstract
This paper presents discursive patinas, a technique to visualize discussions onto data visualizations, inspired by how people leave traces in the physical world. While data visualizations are widely discussed in online communities and social media, comments tend to be displayed separately from the visualization and we lack ways to relate these discussions back to the content of the visualization, e.g., to situate comments, explain visual patterns, or question assumptions. In our visualization annotation interface, users can designate areas within the visualization. Discursive patinas are made of overlaid visual marks (anchors), attached to textual comments with category labels, likes, and replies. By coloring and styling the anchors, a meta visualization emerges, showing what and where people comment and annotate the visualization. These patinas show regions of heavy discussions, recent commenting activity, and the distribution of questions, suggestions, or personal stories. We ran workshops with 90 students, domain experts, and visualization researchers to study how people use anchors to discuss visualizations and how patinas influence people's understanding of the discussion. Our results show that discursive patinas improve the ability to navigate discussions and guide people to comments that help understand, contextualize, or scrutinize the visualization. We discuss the potential of anchors and patinas to support discursive engagements, including critical readings of visualizations, design feedback, and feminist approaches to data visualization.
D-Tour: Semi-Automatic Generation of Interactive Guided Tours for Visualization Dashboard Onboarding
Vaishali Dhanoa - Pro2Future GmbH, Linz, Austria. Johannes Kepler University, Linz, Austria
Andreas Hinterreiter - Johannes Kepler University, Linz, Austria
Vanessa Fediuk - Johannes Kepler University, Linz, Austria
Niklas Elmqvist - Aarhus University, Aarhus, Denmark
Eduard Gröller - Institute of Visual Computing . Human-Centered Technology, Vienna, Austria
Marc Streit - Johannes Kepler University Linz, Linz, Austria
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:18:00Z

Fast forward
Keywords
Dashboards, onboarding, storytelling, tutorial, interactive tours, open-world games
Abstract
Onboarding a user to a visualization dashboard entails explaining its various components, including the chart types used, the data loaded, and the interactions available. Authoring such an onboarding experience is time-consuming and requires significant knowledge and little guidance on how best to complete this task. Depending on their levels of expertise, end users being onboarded to a new dashboard can be either confused and overwhelmed or disinterested and disengaged. We propose interactive dashboard tours (D-Tours) as semi-automated onboarding experiences that preserve the agency of users with various levels of expertise to keep them interested and engaged. Our interactive tours concept draws from open-world game design to give the user freedom in choosing their path through onboarding. We have implemented the concept in a tool called D-TOUR PROTOTYPE, which allows authors to craft custom interactive dashboard tours from scratch or using automatic templates. Automatically generated tours can still be customized to use different media (e.g., video, audio, and highlighting) or new narratives to produce an onboarding experience tailored to an individual user. We demonstrate the usefulness of interactive dashboard tours through use cases and expert interviews. Our evaluation shows that authors found the automation in the D-Tour Prototype helpful and time-saving, and users found the created tours engaging and intuitive. This paper and all supplemental materials are available at https://osf.io/6fbjp/.
D-Tour: Semi-Automatic Generation of Interactive Guided Tours for Visualization Dashboard Onboarding
Vaishali Dhanoa - Pro2Future GmbH, Linz, Austria. Johannes Kepler University, Linz, Austria
Andreas Hinterreiter - Johannes Kepler University, Linz, Austria
Vanessa Fediuk - Johannes Kepler University, Linz, Austria
Niklas Elmqvist - Aarhus University, Aarhus, Denmark
Eduard Gröller - Institute of Visual Computing . Human-Centered Technology, Vienna, Austria
Marc Streit - Johannes Kepler University Linz, Linz, Austria
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T13:18:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:18:00Z
Fast forward
Keywords
Dashboards, onboarding, storytelling, tutorial, interactive tours, open-world games
Abstract
Onboarding a user to a visualization dashboard entails explaining its various components, including the chart types used, the data loaded, and the interactions available. Authoring such an onboarding experience is time-consuming and requires significant knowledge and little guidance on how best to complete this task. Depending on their levels of expertise, end users being onboarded to a new dashboard can be either confused and overwhelmed or disinterested and disengaged. We propose interactive dashboard tours (D-Tours) as semi-automated onboarding experiences that preserve the agency of users with various levels of expertise to keep them interested and engaged. Our interactive tours concept draws from open-world game design to give the user freedom in choosing their path through onboarding. We have implemented the concept in a tool called D-TOUR PROTOTYPE, which allows authors to craft custom interactive dashboard tours from scratch or using automatic templates. Automatically generated tours can still be customized to use different media (e.g., video, audio, and highlighting) or new narratives to produce an onboarding experience tailored to an individual user. We demonstrate the usefulness of interactive dashboard tours through use cases and expert interviews. Our evaluation shows that authors found the automation in the D-Tour Prototype helpful and time-saving, and users found the created tours engaging and intuitive. This paper and all supplemental materials are available at https://osf.io/6fbjp/.
Unveiling How Examples Shape Data Visualization Design Outcomes
Hannah K. Bako - University of Maryland, College Park, United States
Xinyi Liu - The University of Texas at Austin, Austin, United States
Grace Ko - University of Maryland, College Park, United States
Hyemi Song - Human Data Interaction Lab, College Park, United States
Leilani Battle - University of Washington, Seattle, United States
Zhicheng Liu - University of Maryland, College Park, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:12:00Z

Fast forward
Keywords
data visualization, design, examples
Abstract
Visualization designers (e.g., journalists or data analysts) often rely on examples to explore the space of possible designs, yet we have little insight into how examples shape data visualization design outcomes. While the effects of examples have been studied in other disciplines, such as web design or engineering, the results are not readily applicable to visualization due to inconsistencies in findings and challenges unique to visualization design. Towards bridging this gap, we conduct an exploratory experiment involving 32 data visualization designers focusing on the influence of five factors (timing, quantity, diversity, data topic similarity, and data schema similarity) on objectively measurable design outcomes (e.g., numbers of designs and idea transfers). Our quantitative analysis shows that when examples are introduced after initial brainstorming, designers curate examples with topics less similar to the dataset they are working on and produce more designs with a high variation in visualization components. Also, designers copy more ideas from examples with higher data schema similarities. Our qualitative analysis of participants’ thought processes provides insights into why designers incorporate examples into their designs, revealing potential factors that have not been previously investigated. Finally, we discuss how our results inform how designers may use examples during design ideation as well as future research on quantifying designs and supporting example-based visualization design. All supplemental materials are available in our OSF repo.
Unveiling How Examples Shape Data Visualization Design Outcomes
Hannah K. Bako - University of Maryland, College Park, United States
Xinyi Liu - The University of Texas at Austin, Austin, United States
Grace Ko - University of Maryland, College Park, United States
Hyemi Song - Human Data Interaction Lab, College Park, United States
Leilani Battle - University of Washington, Seattle, United States
Zhicheng Liu - University of Maryland, College Park, United States
Screen-reader Accessible PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T16:12:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T16:12:00Z
Fast forward
Keywords
data visualization, design, examples
Abstract
Visualization designers (e.g., journalists or data analysts) often rely on examples to explore the space of possible designs, yet we have little insight into how examples shape data visualization design outcomes. While the effects of examples have been studied in other disciplines, such as web design or engineering, the results are not readily applicable to visualization due to inconsistencies in findings and challenges unique to visualization design. Towards bridging this gap, we conduct an exploratory experiment involving 32 data visualization designers focusing on the influence of five factors (timing, quantity, diversity, data topic similarity, and data schema similarity) on objectively measurable design outcomes (e.g., numbers of designs and idea transfers). Our quantitative analysis shows that when examples are introduced after initial brainstorming, designers curate examples with topics less similar to the dataset they are working on and produce more designs with a high variation in visualization components. Also, designers copy more ideas from examples with higher data schema similarities. Our qualitative analysis of participants’ thought processes provides insights into why designers incorporate examples into their designs, revealing potential factors that have not been previously investigated. Finally, we discuss how our results inform how designers may use examples during design ideation as well as future research on quantifying designs and supporting example-based visualization design. All supplemental materials are available in our OSF repo.
Honorable Mention
Manipulable Semantic Components: a Computational Representation of Data Visualization Scenes
Zhicheng Liu - University of Maryland, College Park, United States
Chen Chen - University of Maryland, College Park, United States
John Hooker - University of Maryland, College Park, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T13:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:30:00Z
Fast forward
Keywords
data visualization, scene abstraction, visualization model
Abstract
Various data visualization applications such as reverse engineering and interactive authoring require a vocabulary that describes the structure of visualization scenes and the procedure to manipulate them. A few scene abstractions have been proposed, but they are restricted to specific applications for a limited set of visualization types. A unified and expressive model of data visualization scenes for different applications has been missing. To fill this gap, we present Manipulable Semantic Components (MSC), a computational representation of data visualization scenes, to support applications in scene understanding and augmentation. MSC consists of two parts: a unified object model describing the structure of a visualization scene in terms of semantic components, and a set of operations to generate and modify the scene components. We demonstrate the benefits of MSC in three applications: visualization authoring, visualization deconstruction and reuse, and animation specification.
Honorable Mention
Manipulable Semantic Components: a Computational Representation of Data Visualization Scenes
Zhicheng Liu - University of Maryland, College Park, United States
Chen Chen - University of Maryland, College Park, United States
John Hooker - University of Maryland, College Park, United States
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore II
2024-10-17T13:30:00Z GMT-0600 Change your timezone on the schedule page
2024-10-17T13:30:00Z
Fast forward
Keywords
data visualization, scene abstraction, visualization model
Abstract
Various data visualization applications such as reverse engineering and interactive authoring require a vocabulary that describes the structure of visualization scenes and the procedure to manipulate them. A few scene abstractions have been proposed, but they are restricted to specific applications for a limited set of visualization types. A unified and expressive model of data visualization scenes for different applications has been missing. To fill this gap, we present Manipulable Semantic Components (MSC), a computational representation of data visualization scenes, to support applications in scene understanding and augmentation. MSC consists of two parts: a unified object model describing the structure of a visualization scene in terms of semantic components, and a set of operations to generate and modify the scene components. We demonstrate the benefits of MSC in three applications: visualization authoring, visualization deconstruction and reuse, and animation specification.
Promises and Pitfalls: Using Large Language Models to Generate Visualization Items
Yuan Cui - Northwestern University, Evanston, United States
Lily W. Ge - Northwestern University, Evanston, United States
Yiren Ding - Worcester Polytechnic Institute, Worcester, United States
Lane Harrison - Worcester Polytechnic Institute, Worcester, United States
Fumeng Yang - Northwestern University, Evanston, United States
Matthew Kay - Northwestern University, Chicago, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:06:00Z
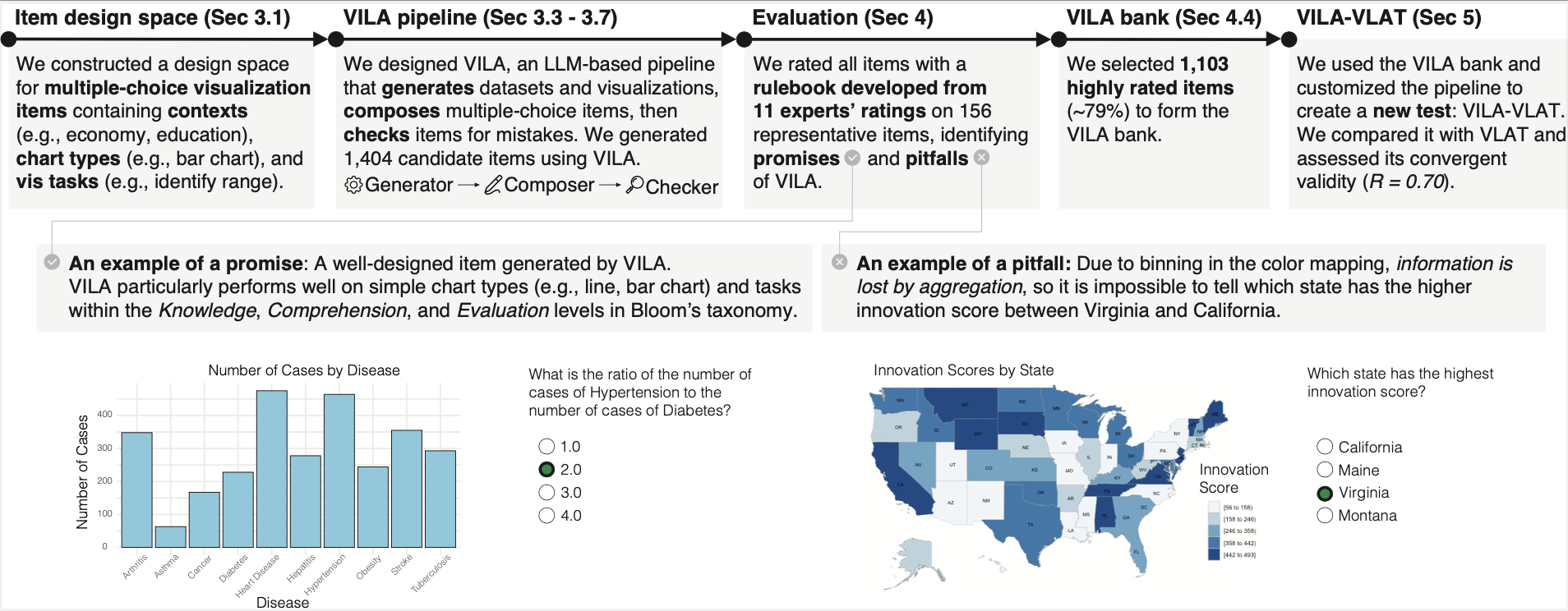
Fast forward
Keywords
Visualization Items, Large Language Models, Visualization Literacy Assessment
Abstract
Visualization items—factual questions about visualizations that ask viewers to accomplish visualization tasks—are regularly used in the field of information visualization as educational and evaluative materials. For example, researchers of visualization literacy require large, diverse banks of items to conduct studies where the same skill is measured repeatedly on the same participants. Yet, generating a large number of high-quality, diverse items requires significant time and expertise. To address the critical need for a large number of diverse visualization items in education and research, this paper investigates the potential for large language models (LLMs) to automate the generation of multiple-choice visualization items. Through an iterative design process, we develop the VILA (Visualization Items Generated by Large LAnguage Models) pipeline, for efficiently generating visualization items that measure people’s ability to accomplish visualization tasks. We use the VILA pipeline to generate 1,404 candidate items across 12 chart types and 13 visualization tasks. In collaboration with 11 visualization experts, we develop an evaluation rulebook which we then use to rate the quality of all candidate items. The result is the VILA bank of ∼1,100 items. From this evaluation, we also identify and classify current limitations of the VILA pipeline, and discuss the role of human oversight in ensuring quality. In addition, we demonstrate an application of our work by creating a visualization literacy test, VILA-VLAT, which measures people’s ability to complete a diverse set of tasks on various types of visualizations; comparing it to the existing VLAT, VILA-VLAT shows moderate to high convergent validity (R = 0.70). Lastly, we discuss the application areas of the VILA pipeline and the VILA bank and provide practical recommendations for their use. All supplemental materials are available at https://osf.io/ysrhq/.
Promises and Pitfalls: Using Large Language Models to Generate Visualization Items
Yuan Cui - Northwestern University, Evanston, United States
Lily W. Ge - Northwestern University, Evanston, United States
Yiren Ding - Worcester Polytechnic Institute, Worcester, United States
Lane Harrison - Worcester Polytechnic Institute, Worcester, United States
Fumeng Yang - Northwestern University, Evanston, United States
Matthew Kay - Northwestern University, Chicago, United States
Download preprint PDF
Download camera-ready PDF
Download Supplemental Material
Room: Bayshore I + II + III
2024-10-18T13:06:00Z GMT-0600 Change your timezone on the schedule page
2024-10-18T13:06:00Z
Fast forward
Keywords
Visualization Items, Large Language Models, Visualization Literacy Assessment
Abstract
Visualization items—factual questions about visualizations that ask viewers to accomplish visualization tasks—are regularly used in the field of information visualization as educational and evaluative materials. For example, researchers of visualization literacy require large, diverse banks of items to conduct studies where the same skill is measured repeatedly on the same participants. Yet, generating a large number of high-quality, diverse items requires significant time and expertise. To address the critical need for a large number of diverse visualization items in education and research, this paper investigates the potential for large language models (LLMs) to automate the generation of multiple-choice visualization items. Through an iterative design process, we develop the VILA (Visualization Items Generated by Large LAnguage Models) pipeline, for efficiently generating visualization items that measure people’s ability to accomplish visualization tasks. We use the VILA pipeline to generate 1,404 candidate items across 12 chart types and 13 visualization tasks. In collaboration with 11 visualization experts, we develop an evaluation rulebook which we then use to rate the quality of all candidate items. The result is the VILA bank of ∼1,100 items. From this evaluation, we also identify and classify current limitations of the VILA pipeline, and discuss the role of human oversight in ensuring quality. In addition, we demonstrate an application of our work by creating a visualization literacy test, VILA-VLAT, which measures people’s ability to complete a diverse set of tasks on various types of visualizations; comparing it to the existing VLAT, VILA-VLAT shows moderate to high convergent validity (R = 0.70). Lastly, we discuss the application areas of the VILA pipeline and the VILA bank and provide practical recommendations for their use. All supplemental materials are available at https://osf.io/ysrhq/.