本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新405篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:Active Stereo Without Pattern Projector
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2309.12315
+ 作者:Luca Bartolomei, Matteo Poggi, Fabio Tosi, Andrea Conti, Stefano Mattoccia
+ 备注:ICCV 2023. Code: this https URL - Project page: this https URL
+ 关键词:standard passive camera, passive camera systems, physical pattern projector, paper proposes, integrating the principles
+
+ 点击查看摘要
+ This paper proposes a novel framework integrating the principles of active stereo in standard passive camera systems without a physical pattern projector. We virtually project a pattern over the left and right images according to the sparse measurements obtained from a depth sensor. Any such devices can be seamlessly plugged into our framework, allowing for the deployment of a virtual active stereo setup in any possible environment, overcoming the limitation of pattern projectors, such as limited working range or environmental conditions. Experiments on indoor/outdoor datasets, featuring both long and close-range, support the seamless effectiveness of our approach, boosting the accuracy of both stereo algorithms and deep networks.
+
+
+
+ 2. 标题:TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.12314
+ 作者:Kan Wu, Houwen Peng, Zhenghong Zhou, Bin Xiao, Mengchen Liu, Lu Yuan, Hong Xuan, Michael Valenzuela, Xi (Stephen) Chen, Xinggang Wang, Hongyang Chao, Han Hu
+ 备注:Accepted By ICCV 2023
+ 关键词:large-scale language-image pre-trained, large-scale language-image, language-image pre-trained models, cross-modal distillation method, weight inheritance
+
+ 点击查看摘要
+ In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at this https URL.
+
+
+
+ 3. 标题:ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.12312
+ 作者:Jeremy A. Collins, Cody Houff, You Liang Tan, Charles C. Kemp
+ 备注:
+ 关键词:deep neural network, predicts visual-force goals, neural network, predicts visual-force, present ForceSight
+
+ 点击查看摘要
+ We present ForceSight, a system for text-guided mobile manipulation that predicts visual-force goals using a deep neural network. Given a single RGBD image combined with a text prompt, ForceSight determines a target end-effector pose in the camera frame (kinematic goal) and the associated forces (force goal). Together, these two components form a visual-force goal. Prior work has demonstrated that deep models outputting human-interpretable kinematic goals can enable dexterous manipulation by real robots. Forces are critical to manipulation, yet have typically been relegated to lower-level execution in these systems. When deployed on a mobile manipulator equipped with an eye-in-hand RGBD camera, ForceSight performed tasks such as precision grasps, drawer opening, and object handovers with an 81% success rate in unseen environments with object instances that differed significantly from the training data. In a separate experiment, relying exclusively on visual servoing and ignoring force goals dropped the success rate from 90% to 45%, demonstrating that force goals can significantly enhance performance. The appendix, videos, code, and trained models are available at this https URL.
+
+
+
+ 4. 标题:LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.12311
+ 作者:Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F. Fouhey, Joyce Chai
+ 备注:Project website: this https URL
+ 关键词:Large Language Model, answer questions based, household robots, critical skill, skill for household
+
+ 点击查看摘要
+ 3D visual grounding is a critical skill for household robots, enabling them to navigate, manipulate objects, and answer questions based on their environment. While existing approaches often rely on extensive labeled data or exhibit limitations in handling complex language queries, we propose LLM-Grounder, a novel zero-shot, open-vocabulary, Large Language Model (LLM)-based 3D visual grounding pipeline. LLM-Grounder utilizes an LLM to decompose complex natural language queries into semantic constituents and employs a visual grounding tool, such as OpenScene or LERF, to identify objects in a 3D scene. The LLM then evaluates the spatial and commonsense relations among the proposed objects to make a final grounding decision. Our method does not require any labeled training data and can generalize to novel 3D scenes and arbitrary text queries. We evaluate LLM-Grounder on the ScanRefer benchmark and demonstrate state-of-the-art zero-shot grounding accuracy. Our findings indicate that LLMs significantly improve the grounding capability, especially for complex language queries, making LLM-Grounder an effective approach for 3D vision-language tasks in robotics. Videos and interactive demos can be found on the project website this https URL .
+
+
+
+ 5. 标题:TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning
+ 编号:[7]
+ 链接:https://arxiv.org/abs/2309.12306
+ 作者:Chaeyoung Jung, Suyeon Lee, Kihyun Nam, Kyeongha Rho, You Jin Kim, Youngjoon Jang, Joon Son Chung
+ 备注:
+ 关键词:Active Speaker Detection, Speaker Detection, Active Speaker, video frames, series of video
+
+ 点击查看摘要
+ The goal of this work is Active Speaker Detection (ASD), a task to determine whether a person is speaking or not in a series of video frames. Previous works have dealt with the task by exploring network architectures while learning effective representations has been less explored. In this work, we propose TalkNCE, a novel talk-aware contrastive loss. The loss is only applied to part of the full segments where a person on the screen is actually speaking. This encourages the model to learn effective representations through the natural correspondence of speech and facial movements. Our loss can be jointly optimized with the existing objectives for training ASD models without the need for additional supervision or training data. The experiments demonstrate that our loss can be easily integrated into the existing ASD frameworks, improving their performance. Our method achieves state-of-the-art performances on AVA-ActiveSpeaker and ASW datasets.
+
+
+
+ 6. 标题:SlowFast Network for Continuous Sign Language Recognition
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2309.12304
+ 作者:Junseok Ahn, Youngjoon Jang, Joon Son Chung
+ 备注:
+ 关键词:Sign Language Recognition, Continuous Sign Language, Language Recognition, Continuous Sign, Sign Language
+
+ 点击查看摘要
+ The objective of this work is the effective extraction of spatial and dynamic features for Continuous Sign Language Recognition (CSLR). To accomplish this, we utilise a two-pathway SlowFast network, where each pathway operates at distinct temporal resolutions to separately capture spatial (hand shapes, facial expressions) and dynamic (movements) information. In addition, we introduce two distinct feature fusion methods, carefully designed for the characteristics of CSLR: (1) Bi-directional Feature Fusion (BFF), which facilitates the transfer of dynamic semantics into spatial semantics and vice versa; and (2) Pathway Feature Enhancement (PFE), which enriches dynamic and spatial representations through auxiliary subnetworks, while avoiding the need for extra inference time. As a result, our model further strengthens spatial and dynamic representations in parallel. We demonstrate that the proposed framework outperforms the current state-of-the-art performance on popular CSLR datasets, including PHOENIX14, PHOENIX14-T, and CSL-Daily.
+
+
+
+ 7. 标题:PanoVOS: Bridging Non-panoramic and Panoramic Views with Transformer for Video Segmentation
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2309.12303
+ 作者:Shilin Yan, Xiaohao Xu, Lingyi Hong, Wenchao Chen, Wenqiang Zhang, Wei Zhang
+ 备注:
+ 关键词:attracted tremendous amounts, richer spatial information, virtual reality, richer spatial, attracted tremendous
+
+ 点击查看摘要
+ Panoramic videos contain richer spatial information and have attracted tremendous amounts of attention due to their exceptional experience in some fields such as autonomous driving and virtual reality. However, existing datasets for video segmentation only focus on conventional planar images. To address the challenge, in this paper, we present a panoramic video dataset, PanoVOS. The dataset provides 150 videos with high video resolutions and diverse motions. To quantify the domain gap between 2D planar videos and panoramic videos, we evaluate 15 off-the-shelf video object segmentation (VOS) models on PanoVOS. Through error analysis, we found that all of them fail to tackle pixel-level content discontinues of panoramic videos. Thus, we present a Panoramic Space Consistency Transformer (PSCFormer), which can effectively utilize the semantic boundary information of the previous frame for pixel-level matching with the current frame. Extensive experiments demonstrate that compared with the previous SOTA models, our PSCFormer network exhibits a great advantage in terms of segmentation results under the panoramic setting. Our dataset poses new challenges in panoramic VOS and we hope that our PanoVOS can advance the development of panoramic segmentation/tracking.
+
+
+
+ 8. 标题:Text-Guided Vector Graphics Customization
+ 编号:[10]
+ 链接:https://arxiv.org/abs/2309.12302
+ 作者:Peiying Zhang, Nanxuan Zhao, Jing Liao
+ 备注:Accepted by SIGGRAPH Asia 2023. Project page: this https URL
+ 关键词:Vector graphics, layer-wise topological properties, digital art, art and valued, valued by designers
+
+ 点击查看摘要
+ Vector graphics are widely used in digital art and valued by designers for their scalability and layer-wise topological properties. However, the creation and editing of vector graphics necessitate creativity and design expertise, leading to a time-consuming process. In this paper, we propose a novel pipeline that generates high-quality customized vector graphics based on textual prompts while preserving the properties and layer-wise information of a given exemplar SVG. Our method harnesses the capabilities of large pre-trained text-to-image models. By fine-tuning the cross-attention layers of the model, we generate customized raster images guided by textual prompts. To initialize the SVG, we introduce a semantic-based path alignment method that preserves and transforms crucial paths from the exemplar SVG. Additionally, we optimize path parameters using both image-level and vector-level losses, ensuring smooth shape deformation while aligning with the customized raster image. We extensively evaluate our method using multiple metrics from vector-level, image-level, and text-level perspectives. The evaluation results demonstrate the effectiveness of our pipeline in generating diverse customizations of vector graphics with exceptional quality. The project page is this https URL.
+
+
+
+ 9. 标题:Environment-biased Feature Ranking for Novelty Detection Robustness
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.12301
+ 作者:Stefan Smeu, Elena Burceanu, Emanuela Haller, Andrei Liviu Nicolicioiu
+ 备注:ICCV 2024 - Workshop on Out Of Distribution Generalization in Computer Vision
+ 关键词:robust novelty detection, irrelevant factors, novelty detection, tackle the problem, problem of robust
+
+ 点击查看摘要
+ We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
+
+
+
+ 10. 标题:See to Touch: Learning Tactile Dexterity through Visual Incentives
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2309.12300
+ 作者:Irmak Guzey, Yinlong Dai, Ben Evans, Soumith Chintala, Lerrel Pinto
+ 备注:
+ 关键词:Equipping multi-fingered robots, Equipping multi-fingered, achieving the precise, crucial for achieving, tactile sensing
+
+ 点击查看摘要
+ Equipping multi-fingered robots with tactile sensing is crucial for achieving the precise, contact-rich, and dexterous manipulation that humans excel at. However, relying solely on tactile sensing fails to provide adequate cues for reasoning about objects' spatial configurations, limiting the ability to correct errors and adapt to changing situations. In this paper, we present Tactile Adaptation from Visual Incentives (TAVI), a new framework that enhances tactile-based dexterity by optimizing dexterous policies using vision-based rewards. First, we use a contrastive-based objective to learn visual representations. Next, we construct a reward function using these visual representations through optimal-transport based matching on one human demonstration. Finally, we use online reinforcement learning on our robot to optimize tactile-based policies that maximize the visual reward. On six challenging tasks, such as peg pick-and-place, unstacking bowls, and flipping slender objects, TAVI achieves a success rate of 73% using our four-fingered Allegro robot hand. The increase in performance is 108% higher than policies using tactile and vision-based rewards and 135% higher than policies without tactile observational input. Robot videos are best viewed on our project website: this https URL.
+
+
+
+ 11. 标题:Learning to Drive Anywhere
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.12295
+ 作者:Ruizhao Zhu, Peng Huang, Eshed Ohn-Bar, Venkatesh Saligrama
+ 备注:Conference on Robot Learning (CoRL) 2023. this https URL
+ 关键词:Human drivers, left vs. right-hand, drivers can seamlessly, decisions across geographical, diverse conditions
+
+ 点击查看摘要
+ Human drivers can seamlessly adapt their driving decisions across geographical locations with diverse conditions and rules of the road, e.g., left vs. right-hand traffic. In contrast, existing models for autonomous driving have been thus far only deployed within restricted operational domains, i.e., without accounting for varying driving behaviors across locations or model scalability. In this work, we propose AnyD, a single geographically-aware conditional imitation learning (CIL) model that can efficiently learn from heterogeneous and globally distributed data with dynamic environmental, traffic, and social characteristics. Our key insight is to introduce a high-capacity geo-location-based channel attention mechanism that effectively adapts to local nuances while also flexibly modeling similarities among regions in a data-driven manner. By optimizing a contrastive imitation objective, our proposed approach can efficiently scale across inherently imbalanced data distributions and location-dependent events. We demonstrate the benefits of our AnyD agent across multiple datasets, cities, and scalable deployment paradigms, i.e., centralized, semi-supervised, and distributed agent training. Specifically, AnyD outperforms CIL baselines by over 14% in open-loop evaluation and 30% in closed-loop testing on CARLA.
+
+
+
+ 12. 标题:Can We Reliably Improve the Robustness to Image Acquisition of Remote Sensing of PV Systems?
+ 编号:[49]
+ 链接:https://arxiv.org/abs/2309.12214
+ 作者:Gabriel Kasmi, Laurent Dubus, Yves-Marie Saint-Drenan, Philippe Blanc
+ 备注:13 pages, 9 figures, 3 tables. arXiv admin note: text overlap with arXiv:2305.14979
+ 关键词:acquisition conditions, current techniques lack, techniques lack reliability, Photovoltaic, energy
+
+ 点击查看摘要
+ Photovoltaic (PV) energy is crucial for the decarbonization of energy systems. Due to the lack of centralized data, remote sensing of rooftop PV installations is the best option to monitor the evolution of the rooftop PV installed fleet at a regional scale. However, current techniques lack reliability and are notably sensitive to shifts in the acquisition conditions. To overcome this, we leverage the wavelet scale attribution method (WCAM), which decomposes a model's prediction in the space-scale domain. The WCAM enables us to assess on which scales the representation of a PV model rests and provides insights to derive methods that improve the robustness to acquisition conditions, thus increasing trust in deep learning systems to encourage their use for the safe integration of clean energy in electric systems.
+
+
+
+ 13. 标题:SG-Bot: Object Rearrangement via Coarse-to-Fine Robotic Imagination on Scene Graphs
+ 编号:[58]
+ 链接:https://arxiv.org/abs/2309.12188
+ 作者:Guangyao Zhai, Xiaoni Cai, Dianye Huang, Yan Di, Fabian Manhardt, Federico Tombari, Nassir Navab, Benjamin Busam
+ 备注:8 pages, 6 figures. A video is uploaded here: this https URL
+ 关键词:robotic-environment interactions, representing a significant, pivotal in robotic-environment, significant capability, capability in embodied
+
+ 点击查看摘要
+ Object rearrangement is pivotal in robotic-environment interactions, representing a significant capability in embodied AI. In this paper, we present SG-Bot, a novel rearrangement framework that utilizes a coarse-to-fine scheme with a scene graph as the scene representation. Unlike previous methods that rely on either known goal priors or zero-shot large models, SG-Bot exemplifies lightweight, real-time, and user-controllable characteristics, seamlessly blending the consideration of commonsense knowledge with automatic generation capabilities. SG-Bot employs a three-fold procedure--observation, imagination, and execution--to adeptly address the task. Initially, objects are discerned and extracted from a cluttered scene during the observation. These objects are first coarsely organized and depicted within a scene graph, guided by either commonsense or user-defined criteria. Then, this scene graph subsequently informs a generative model, which forms a fine-grained goal scene considering the shape information from the initial scene and object semantics. Finally, for execution, the initial and envisioned goal scenes are matched to formulate robotic action policies. Experimental results demonstrate that SG-Bot outperforms competitors by a large margin.
+
+
+
+ 14. 标题:ORTexME: Occlusion-Robust Human Shape and Pose via Temporal Average Texture and Mesh Encoding
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.12183
+ 作者:Yu Cheng, Bo Wang, Robby T. Tan
+ 备注:8 pages, 8 figures
+ 关键词:limited labeled data, human shape, initial human shape, models trained, shape and pose
+
+ 点击查看摘要
+ In 3D human shape and pose estimation from a monocular video, models trained with limited labeled data cannot generalize well to videos with occlusion, which is common in the wild videos. The recent human neural rendering approaches focusing on novel view synthesis initialized by the off-the-shelf human shape and pose methods have the potential to correct the initial human shape. However, the existing methods have some drawbacks such as, erroneous in handling occlusion, sensitive to inaccurate human segmentation, and ineffective loss computation due to the non-regularized opacity field. To address these problems, we introduce ORTexME, an occlusion-robust temporal method that utilizes temporal information from the input video to better regularize the occluded body parts. While our ORTexME is based on NeRF, to determine the reliable regions for the NeRF ray sampling, we utilize our novel average texture learning approach to learn the average appearance of a person, and to infer a mask based on the average texture. In addition, to guide the opacity-field updates in NeRF to suppress blur and noise, we propose the use of human body mesh. The quantitative evaluation demonstrates that our method achieves significant improvement on the challenging multi-person 3DPW dataset, where our method achieves 1.8 P-MPJPE error reduction. The SOTA rendering-based methods fail and enlarge the error up to 5.6 on the same dataset.
+
+
+
+ 15. 标题:Autoregressive Sign Language Production: A Gloss-Free Approach with Discrete Representations
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2309.12179
+ 作者:Eui Jun Hwang, Huije Lee, Jong C. Park
+ 备注:5 pages, 3 figures, 6 tables
+ 关键词:Sign Language Production, Vector Quantization Network, Gloss-free Sign Language, spoken language sentences, language Vector Quantization
+
+ 点击查看摘要
+ Gloss-free Sign Language Production (SLP) offers a direct translation of spoken language sentences into sign language, bypassing the need for gloss intermediaries. This paper presents the Sign language Vector Quantization Network, a novel approach to SLP that leverages Vector Quantization to derive discrete representations from sign pose sequences. Our method, rooted in both manual and non-manual elements of signing, supports advanced decoding methods and integrates latent-level alignment for enhanced linguistic coherence. Through comprehensive evaluations, we demonstrate superior performance of our method over prior SLP methods and highlight the reliability of Back-Translation and Fréchet Gesture Distance as evaluation metrics.
+
+
+
+ 16. 标题:SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset
+ 编号:[62]
+ 链接:https://arxiv.org/abs/2309.12172
+ 作者:Sagar M. Waghmare, Kimberly Wilber, Dave Hawkey, Xuan Yang, Matthew Wilson, Stephanie Debats, Cattalyya Nuengsigkapian, Astuti Sharma, Lars Pandikow, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko
+ 备注:10 pages plus additional references. 13 figures
+ 关键词:outdoor environments, diverse outdoor environments, SANPO, video, environments
+
+ 点击查看摘要
+ We introduce SANPO, a large-scale egocentric video dataset focused on dense prediction in outdoor environments. It contains stereo video sessions collected across diverse outdoor environments, as well as rendered synthetic video sessions. (Synthetic data was provided by Parallel Domain.) All sessions have (dense) depth and odometry labels. All synthetic sessions and a subset of real sessions have temporally consistent dense panoptic segmentation labels. To our knowledge, this is the first human egocentric video dataset with both large scale dense panoptic segmentation and depth annotations. In addition to the dataset we also provide zero-shot baselines and SANPO benchmarks for future research. We hope that the challenging nature of SANPO will help advance the state-of-the-art in video segmentation, depth estimation, multi-task visual modeling, and synthetic-to-real domain adaptation, while enabling human navigation systems.
+SANPO is available here: this https URL
+
+
+
+ 17. 标题:Information Forensics and Security: A quarter-century-long journey
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2309.12159
+ 作者:Mauro Barni, Patrizio Campisi, Edward J. Delp, Gwenael Doërr, Jessica Fridrich, Nasir Memon, Fernando Pérez-González, Anderson Rocha, Luisa Verdoliva, Min Wu
+ 备注:
+ 关键词:hold perpetrators accountable, Forensics and Security, IFS research area, Information Forensics, people use devices
+
+ 点击查看摘要
+ Information Forensics and Security (IFS) is an active R&D area whose goal is to ensure that people use devices, data, and intellectual properties for authorized purposes and to facilitate the gathering of solid evidence to hold perpetrators accountable. For over a quarter century since the 1990s, the IFS research area has grown tremendously to address the societal needs of the digital information era. The IEEE Signal Processing Society (SPS) has emerged as an important hub and leader in this area, and the article below celebrates some landmark technical contributions. In particular, we highlight the major technological advances on some selected focus areas in the field developed in the last 25 years from the research community and present future trends.
+
+
+
+ 18. 标题:Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.12140
+ 作者:Travis Zhang, Katie Luo, Cheng Perng Phoo, Yurong You, Wei-Lun Chao, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
+ 备注:
+ 关键词:significantly improved accuracy, improved accuracy, rapid development, self-driving cars, cars has significantly
+
+ 点击查看摘要
+ The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at this https URL.
+
+
+
+ 19. 标题:Vulnerability of 3D Face Recognition Systems to Morphing Attacks
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2309.12118
+ 作者:Sanjeet Vardam, Luuk Spreeuwers
+ 备注:
+ 关键词:recent years face, hardware and software, recent years, mainstream due, face
+
+ 点击查看摘要
+ In recent years face recognition systems have been brought to the mainstream due to development in hardware and software. Consistent efforts are being made to make them better and more secure. This has also brought developments in 3D face recognition systems at a rapid pace. These 3DFR systems are expected to overcome certain vulnerabilities of 2DFR systems. One such problem that the domain of 2DFR systems face is face image morphing. A substantial amount of research is being done for generation of high quality face morphs along with detection of attacks from these morphs. Comparatively the understanding of vulnerability of 3DFR systems against 3D face morphs is less. But at the same time an expectation is set from 3DFR systems to be more robust against such attacks. This paper attempts to research and gain more information on this matter. The paper describes a couple of methods that can be used to generate 3D face morphs. The face morphs that are generated using this method are then compared to the contributing faces to obtain similarity scores. The highest MMPMR is obtained around 40% with RMMR of 41.76% when 3DFRS are attacked with look-a-like morphs.
+
+
+
+ 20. 标题:Exploiting CLIP-based Multi-modal Approach for Artwork Classification and Retrieval
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2309.12110
+ 作者:Alberto Baldrati, Marco Bertini, Tiberio Uricchio, Alberto Del Bimbo
+ 备注:Proc. of Florence Heri-Tech 2022: The Future of Heritage Science and Technologies: ICT and Digital Heritage, 2022
+ 关键词:semantically dense textual, dense textual supervision, textual supervision tend, visual models trained, recent CLIP model
+
+ 点击查看摘要
+ Given the recent advances in multimodal image pretraining where visual models trained with semantically dense textual supervision tend to have better generalization capabilities than those trained using categorical attributes or through unsupervised techniques, in this work we investigate how recent CLIP model can be applied in several tasks in artwork domain. We perform exhaustive experiments on the NoisyArt dataset which is a dataset of artwork images crawled from public resources on the web. On such dataset CLIP achieves impressive results on (zero-shot) classification and promising results in both artwork-to-artwork and description-to-artwork domain.
+
+
+
+ 21. 标题:FourierLoss: Shape-Aware Loss Function with Fourier Descriptors
+ 编号:[93]
+ 链接:https://arxiv.org/abs/2309.12106
+ 作者:Mehmet Bahadir Erden, Selahattin Cansiz, Onur Caki, Haya Khattak, Durmus Etiz, Melek Cosar Yakar, Kerem Duruer, Berke Barut, Cigdem Gunduz-Demir
+ 备注:
+ 关键词:loss function, image segmentation tasks, medical image segmentation, shape-aware loss function, popular choice
+
+ 点击查看摘要
+ Encoder-decoder networks become a popular choice for various medical image segmentation tasks. When they are trained with a standard loss function, these networks are not explicitly enforced to preserve the shape integrity of an object in an image. However, this ability of the network is important to obtain more accurate results, especially when there is a low-contrast difference between the object and its surroundings. In response to this issue, this work introduces a new shape-aware loss function, which we name FourierLoss. This loss function relies on quantifying the shape dissimilarity between the ground truth and the predicted segmentation maps through the Fourier descriptors calculated on their objects, and penalizing this dissimilarity in network training. Different than the previous studies, FourierLoss offers an adaptive loss function with trainable hyperparameters that control the importance of the level of the shape details that the network is enforced to learn in the training process. This control is achieved by the proposed adaptive loss update mechanism, which end-to-end learns the hyperparameters simultaneously with the network weights by backpropagation. As a result of using this mechanism, the network can dynamically change its attention from learning the general outline of an object to learning the details of its contour points, or vice versa, in different training epochs. Working on 2879 computed tomography images of 93 subjects, our experiments revealed that the proposed adaptive shape-aware loss function led to statistically significantly better results for liver segmentation, compared to its counterparts.
+
+
+
+ 22. 标题:Multi-Task Cooperative Learning via Searching for Flat Minima
+ 编号:[96]
+ 链接:https://arxiv.org/abs/2309.12090
+ 作者:Fuping Wu, Le Zhang, Yang Sun, Yuanhan Mo, Thomas Nichols, Bartlomiej W. Papiez
+ 备注:This paper has been accepted by MedAGI workshop in MICCAI2023
+ 关键词:medical image analysis, shown great potential, image analysis, improving the generalizability, shown great
+
+ 点击查看摘要
+ Multi-task learning (MTL) has shown great potential in medical image analysis, improving the generalizability of the learned features and the performance in individual tasks. However, most of the work on MTL focuses on either architecture design or gradient manipulation, while in both scenarios, features are learned in a competitive manner. In this work, we propose to formulate MTL as a multi/bi-level optimization problem, and therefore force features to learn from each task in a cooperative approach. Specifically, we update the sub-model for each task alternatively taking advantage of the learned sub-models of the other tasks. To alleviate the negative transfer problem during the optimization, we search for flat minima for the current objective function with regard to features from other tasks. To demonstrate the effectiveness of the proposed approach, we validate our method on three publicly available datasets. The proposed method shows the advantage of cooperative learning, and yields promising results when compared with the state-of-the-art MTL approaches. The code will be available online.
+
+
+
+ 23. 标题:Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer -- Current Trends and Research Perspectives
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.12067
+ 作者:Karolina Seweryn, Anna Wróblewska, Szymon Łukasik
+ 备注:
+ 关键词:challenging task due, interactions between players, complex and dynamic, dynamic nature, challenging task
+
+ 点击查看摘要
+ Action scene understanding in soccer is a challenging task due to the complex and dynamic nature of the game, as well as the interactions between players. This article provides a comprehensive overview of this task divided into action recognition, spotting, and spatio-temporal action localization, with a particular emphasis on the modalities used and multimodal methods. We explore the publicly available data sources and metrics used to evaluate models' performance. The article reviews recent state-of-the-art methods that leverage deep learning techniques and traditional methods. We focus on multimodal methods, which integrate information from multiple sources, such as video and audio data, and also those that represent one source in various ways. The advantages and limitations of methods are discussed, along with their potential for improving the accuracy and robustness of models. Finally, the article highlights some of the open research questions and future directions in the field of soccer action recognition, including the potential for multimodal methods to advance this field. Overall, this survey provides a valuable resource for researchers interested in the field of action scene understanding in soccer.
+
+
+
+ 24. 标题:Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
+ 编号:[111]
+ 链接:https://arxiv.org/abs/2309.12047
+ 作者:Kiseok Choi, Inchul Kim, Dongyoung Choi, Julio Marco, Diego Gutierrez, Min H. Kim
+ 备注:
+ 关键词:indirect illumination measured, hidden scenes, inverting the optical, optical paths, paths of indirect
+
+ 点击查看摘要
+ Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes. We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.
+
+
+
+ 25. 标题:Beyond Image Borders: Learning Feature Extrapolation for Unbounded Image Composition
+ 编号:[112]
+ 链接:https://arxiv.org/abs/2309.12042
+ 作者:Xiaoyu Liu, Ming Liu, Junyi Li, Shuai Liu, Xiaotao Wang, Lei Lei, Wangmeng Zuo
+ 备注:
+ 关键词:image, image composition, view, camera view, improving image composition
+
+ 点击查看摘要
+ For improving image composition and aesthetic quality, most existing methods modulate the captured images by striking out redundant content near the image borders. However, such image cropping methods are limited in the range of image views. Some methods have been suggested to extrapolate the images and predict cropping boxes from the extrapolated image. Nonetheless, the synthesized extrapolated regions may be included in the cropped image, making the image composition result not real and potentially with degraded image quality. In this paper, we circumvent this issue by presenting a joint framework for both unbounded recommendation of camera view and image composition (i.e., UNIC). In this way, the cropped image is a sub-image of the image acquired by the predicted camera view, and thus can be guaranteed to be real and consistent in image quality. Specifically, our framework takes the current camera preview frame as input and provides a recommendation for view adjustment, which contains operations unlimited by the image borders, such as zooming in or out and camera movement. To improve the prediction accuracy of view adjustment prediction, we further extend the field of view by feature extrapolation. After one or several times of view adjustments, our method converges and results in both a camera view and a bounding box showing the image composition recommendation. Extensive experiments are conducted on the datasets constructed upon existing image cropping datasets, showing the effectiveness of our UNIC in unbounded recommendation of camera view and image composition. The source code, dataset, and pretrained models is available at this https URL.
+
+
+
+ 26. 标题:BASE: Probably a Better Approach to Multi-Object Tracking
+ 编号:[116]
+ 链接:https://arxiv.org/abs/2309.12035
+ 作者:Martin Vonheim Larsen, Sigmund Rolfsjord, Daniel Gusland, Jörgen Ahlberg, Kim Mathiassen
+ 备注:
+ 关键词:hoc schemes, visual object tracking, tracking algorithms, combine simple tracking, Bayesian Approximation Single-hypothesis
+
+ 点击查看摘要
+ The field of visual object tracking is dominated by methods that combine simple tracking algorithms and ad hoc schemes. Probabilistic tracking algorithms, which are leading in other fields, are surprisingly absent from the leaderboards. We found that accounting for distance in target kinematics, exploiting detector confidence and modelling non-uniform clutter characteristics is critical for a probabilistic tracker to work in visual tracking. Previous probabilistic methods fail to address most or all these aspects, which we believe is why they fall so far behind current state-of-the-art (SOTA) methods (there are no probabilistic trackers in the MOT17 top 100). To rekindle progress among probabilistic approaches, we propose a set of pragmatic models addressing these challenges, and demonstrate how they can be incorporated into a probabilistic framework. We present BASE (Bayesian Approximation Single-hypothesis Estimator), a simple, performant and easily extendible visual tracker, achieving state-of-the-art (SOTA) on MOT17 and MOT20, without using Re-Id. Code will be made available at this https URL
+
+
+
+ 27. 标题:Face Identity-Aware Disentanglement in StyleGAN
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2309.12033
+ 作者:Adrian Suwała, Bartosz Wójcik, Magdalena Proszewska, Jacek Tabor, Przemysław Spurek, Marek Śmieja
+ 备注:
+ 关键词:Conditional GANs, GANs are frequently, person identity, face attributes, attributes
+
+ 点击查看摘要
+ Conditional GANs are frequently used for manipulating the attributes of face images, such as expression, hairstyle, pose, or age. Even though the state-of-the-art models successfully modify the requested attributes, they simultaneously modify other important characteristics of the image, such as a person's identity. In this paper, we focus on solving this problem by introducing PluGeN4Faces, a plugin to StyleGAN, which explicitly disentangles face attributes from a person's identity. Our key idea is to perform training on images retrieved from movie frames, where a given person appears in various poses and with different attributes. By applying a type of contrastive loss, we encourage the model to group images of the same person in similar regions of latent space. Our experiments demonstrate that the modifications of face attributes performed by PluGeN4Faces are significantly less invasive on the remaining characteristics of the image than in the existing state-of-the-art models.
+
+
+
+ 28. 标题:Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded Environments
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2309.12029
+ 作者:Yifei Chen, Kunyu Peng, Alina Roitberg, David Schneider, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, Rainer Stiefelhagen
+ 备注:The source code will be made publicly available at this https URL
+ 关键词:autonomous robotic systems, adverse situations involving, situations involving target, involving target occlusions, integrate action recognition
+
+ 点击查看摘要
+ To integrate action recognition methods into autonomous robotic systems, it is crucial to consider adverse situations involving target occlusions. Such a scenario, despite its practical relevance, is rarely addressed in existing self-supervised skeleton-based action recognition methods. To empower robots with the capacity to address occlusion, we propose a simple and effective method. We first pre-train using occluded skeleton sequences, then use k-means clustering (KMeans) on sequence embeddings to group semantically similar samples. Next, we employ K-nearest-neighbor (KNN) to fill in missing skeleton data based on the closest sample neighbors. Imputing incomplete skeleton sequences to create relatively complete sequences as input provides significant benefits to existing skeleton-based self-supervised models. Meanwhile, building on the state-of-the-art Partial Spatio-Temporal Learning (PSTL), we introduce an Occluded Partial Spatio-Temporal Learning (OPSTL) framework. This enhancement utilizes Adaptive Spatial Masking (ASM) for better use of high-quality, intact skeletons. The effectiveness of our imputation methods is verified on the challenging occluded versions of the NTURGB+D 60 and NTURGB+D 120. The source code will be made publicly available at this https URL.
+
+
+
+ 29. 标题:Precision in Building Extraction: Comparing Shallow and Deep Models using LiDAR Data
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.12027
+ 作者:Muhammad Sulaiman, Mina Farmanbar, Ahmed Nabil Belbachir, Chunming Rong
+ 备注:Accepted at FAIEMA 2023
+ 关键词:Intersection over Union, population management, deep learning models, infrastructure development, geological observations
+
+ 点击查看摘要
+ Building segmentation is essential in infrastructure development, population management, and geological observations. This article targets shallow models due to their interpretable nature to assess the presence of LiDAR data for supervised segmentation. The benchmark data used in this article are published in NORA MapAI competition for deep learning model. Shallow models are compared with deep learning models based on Intersection over Union (IoU) and Boundary Intersection over Union (BIoU). In the proposed work, boundary masks from the original mask are generated to improve the BIoU score, which relates to building shapes' borderline. The influence of LiDAR data is tested by training the model with only aerial images in task 1 and a combination of aerial and LiDAR data in task 2 and then compared. shallow models outperform deep learning models in IoU by 8% using aerial images (task 1) only and 2% in combined aerial images and LiDAR data (task 2). In contrast, deep learning models show better performance on BIoU scores. Boundary masks improve BIoU scores by 4% in both tasks. Light Gradient-Boosting Machine (LightGBM) performs better than RF and Extreme Gradient Boosting (XGBoost).
+
+
+
+ 30. 标题:Demystifying Visual Features of Movie Posters for Multi-Label Genre Identification
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2309.12022
+ 作者:Utsav Kumar Nareti, Chandranath Adak, Soumi Chattopadhyay
+ 备注:
+ 关键词:OTT platforms, media and OTT, social media, part of advertising, advertising and marketing
+
+ 点击查看摘要
+ In the film industry, movie posters have been an essential part of advertising and marketing for many decades, and continue to play a vital role even today in the form of digital posters through online, social media and OTT platforms. Typically, movie posters can effectively promote and communicate the essence of a film, such as its genre, visual style/ tone, vibe and storyline cue/ theme, which are essential to attract potential viewers. Identifying the genres of a movie often has significant practical applications in recommending the film to target audiences. Previous studies on movie genre identification are limited to subtitles, plot synopses, and movie scenes that are mostly accessible after the movie release. Posters usually contain pre-release implicit information to generate mass interest. In this paper, we work for automated multi-label genre identification only from movie poster images, without any aid of additional textual/meta-data information about movies, which is one of the earliest attempts of its kind. Here, we present a deep transformer network with a probabilistic module to identify the movie genres exclusively from the poster. For experimental analysis, we procured 13882 number of posters of 13 genres from the Internet Movie Database (IMDb), where our model performances were encouraging and even outperformed some major contemporary architectures.
+
+
+
+ 31. 标题:Elevating Skeleton-Based Action Recognition with Efficient Multi-Modality Self-Supervision
+ 编号:[129]
+ 链接:https://arxiv.org/abs/2309.12009
+ 作者:Yiping Wei, Kunyu Peng, Alina Roitberg, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, Rainer Stiefelhagen
+ 备注:The source code will be made publicly available at this https URL
+ 关键词:Self-supervised representation learning, human action recognition, Self-supervised representation, recent years, representation learning
+
+ 点击查看摘要
+ Self-supervised representation learning for human action recognition has developed rapidly in recent years. Most of the existing works are based on skeleton data while using a multi-modality setup. These works overlooked the differences in performance among modalities, which led to the propagation of erroneous knowledge between modalities while only three fundamental modalities, i.e., joints, bones, and motions are used, hence no additional modalities are explored.
+In this work, we first propose an Implicit Knowledge Exchange Module (IKEM) which alleviates the propagation of erroneous knowledge between low-performance modalities. Then, we further propose three new modalities to enrich the complementary information between modalities. Finally, to maintain efficiency when introducing new modalities, we propose a novel teacher-student framework to distill the knowledge from the secondary modalities into the mandatory modalities considering the relationship constrained by anchors, positives, and negatives, named relational cross-modality knowledge distillation. The experimental results demonstrate the effectiveness of our approach, unlocking the efficient use of skeleton-based multi-modality data. Source code will be made publicly available at this https URL.
+
+
+
+ 32. 标题:Neural Stochastic Screened Poisson Reconstruction
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2309.11993
+ 作者:Silvia Sellán, Alec Jacobson
+ 备注:
+ 关键词:Reconstructing a surface, underdetermined problem, point cloud, Poisson smoothness prior, Poisson smoothness
+
+ 点击查看摘要
+ Reconstructing a surface from a point cloud is an underdetermined problem. We use a neural network to study and quantify this reconstruction uncertainty under a Poisson smoothness prior. Our algorithm addresses the main limitations of existing work and can be fully integrated into the 3D scanning pipeline, from obtaining an initial reconstruction to deciding on the next best sensor position and updating the reconstruction upon capturing more data.
+
+
+
+ 33. 标题:Crop Row Switching for Vision-Based Navigation: A Comprehensive Approach for Efficient Crop Field Navigation
+ 编号:[139]
+ 链接:https://arxiv.org/abs/2309.11989
+ 作者:Rajitha de Silva, Grzegorz Cielniak, Junfeng Gao
+ 备注:Submitted to IEEE ICRA 2024
+ 关键词:crop row, crop, limited to in-row, row, Vision-based mobile robot
+
+ 点击查看摘要
+ Vision-based mobile robot navigation systems in arable fields are mostly limited to in-row navigation. The process of switching from one crop row to the next in such systems is often aided by GNSS sensors or multiple camera setups. This paper presents a novel vision-based crop row-switching algorithm that enables a mobile robot to navigate an entire field of arable crops using a single front-mounted camera. The proposed row-switching manoeuvre uses deep learning-based RGB image segmentation and depth data to detect the end of the crop row, and re-entry point to the next crop row which would be used in a multi-state row switching pipeline. Each state of this pipeline use visual feedback or wheel odometry of the robot to successfully navigate towards the next crop row. The proposed crop row navigation pipeline was tested in a real sugar beet field containing crop rows with discontinuities, varying light levels, shadows and irregular headland surfaces. The robot could successfully exit from one crop row and re-enter the next crop row using the proposed pipeline with absolute median errors averaging at 19.25 cm and 6.77° for linear and rotational steps of the proposed manoeuvre.
+
+
+
+ 34. 标题:ZS6D: Zero-shot 6D Object Pose Estimation using Vision Transformers
+ 编号:[141]
+ 链接:https://arxiv.org/abs/2309.11986
+ 作者:Philipp Ausserlechner, David Haberger, Stefan Thalhammer, Jean-Baptiste Weibel, Markus Vincze
+ 备注:
+ 关键词:unconstrained real-world scenarios, robotic systems increasingly, systems increasingly encounter, increasingly encounter complex, pose estimation
+
+ 点击查看摘要
+ As robotic systems increasingly encounter complex and unconstrained real-world scenarios, there is a demand to recognize diverse objects. The state-of-the-art 6D object pose estimation methods rely on object-specific training and therefore do not generalize to unseen objects. Recent novel object pose estimation methods are solving this issue using task-specific fine-tuned CNNs for deep template matching. This adaptation for pose estimation still requires expensive data rendering and training procedures. MegaPose for example is trained on a dataset consisting of two million images showing 20,000 different objects to reach such generalization capabilities. To overcome this shortcoming we introduce ZS6D, for zero-shot novel object 6D pose estimation. Visual descriptors, extracted using pre-trained Vision Transformers (ViT), are used for matching rendered templates against query images of objects and for establishing local correspondences. These local correspondences enable deriving geometric correspondences and are used for estimating the object's 6D pose with RANSAC-based PnP. This approach showcases that the image descriptors extracted by pre-trained ViTs are well-suited to achieve a notable improvement over two state-of-the-art novel object 6D pose estimation methods, without the need for task-specific fine-tuning. Experiments are performed on LMO, YCBV, and TLESS. In comparison to one of the two methods we improve the Average Recall on all three datasets and compared to the second method we improve on two datasets.
+
+
+
+ 35. 标题:NeuralLabeling: A versatile toolset for labeling vision datasets using Neural Radiance Fields
+ 编号:[151]
+ 链接:https://arxiv.org/abs/2309.11966
+ 作者:Floris Erich, Naoya Chiba, Yusuke Yoshiyasu, Noriaki Ando, Ryo Hanai, Yukiyasu Domae
+ 备注:8 pages, project website: this https URL
+ 关键词:generating segmentation masks, bounding boxes, Neural Radiance Fields, segmentation masks, toolset for annotating
+
+ 点击查看摘要
+ We present NeuralLabeling, a labeling approach and toolset for annotating a scene using either bounding boxes or meshes and generating segmentation masks, affordance maps, 2D bounding boxes, 3D bounding boxes, 6DOF object poses, depth maps and object meshes. NeuralLabeling uses Neural Radiance Fields (NeRF) as renderer, allowing labeling to be performed using 3D spatial tools while incorporating geometric clues such as occlusions, relying only on images captured from multiple viewpoints as input. To demonstrate the applicability of NeuralLabeling to a practical problem in robotics, we added ground truth depth maps to 30000 frames of transparent object RGB and noisy depth maps of glasses placed in a dishwasher captured using an RGBD sensor, yielding the Dishwasher30k dataset. We show that training a simple deep neural network with supervision using the annotated depth maps yields a higher reconstruction performance than training with the previously applied weakly supervised approach.
+
+
+
+ 36. 标题:Ego3DPose: Capturing 3D Cues from Binocular Egocentric Views
+ 编号:[154]
+ 链接:https://arxiv.org/abs/2309.11962
+ 作者:Taeho Kang, Kyungjin Lee, Jinrui Zhang, Youngki Lee
+ 备注:12 pages, 10 figures, to be published as SIGGRAPH Asia 2023 Conference Papers
+ 关键词:highly accurate binocular, accurate binocular egocentric, highly accurate, pose reconstruction system, egocentric
+
+ 点击查看摘要
+ We present Ego3DPose, a highly accurate binocular egocentric 3D pose reconstruction system. The binocular egocentric setup offers practicality and usefulness in various applications, however, it remains largely under-explored. It has been suffering from low pose estimation accuracy due to viewing distortion, severe self-occlusion, and limited field-of-view of the joints in egocentric 2D images. Here, we notice that two important 3D cues, stereo correspondences, and perspective, contained in the egocentric binocular input are neglected. Current methods heavily rely on 2D image features, implicitly learning 3D information, which introduces biases towards commonly observed motions and leads to low overall accuracy. We observe that they not only fail in challenging occlusion cases but also in estimating visible joint positions. To address these challenges, we propose two novel approaches. First, we design a two-path network architecture with a path that estimates pose per limb independently with its binocular heatmaps. Without full-body information provided, it alleviates bias toward trained full-body distribution. Second, we leverage the egocentric view of body limbs, which exhibits strong perspective variance (e.g., a significantly large-size hand when it is close to the camera). We propose a new perspective-aware representation using trigonometry, enabling the network to estimate the 3D orientation of limbs. Finally, we develop an end-to-end pose reconstruction network that synergizes both techniques. Our comprehensive evaluations demonstrate that Ego3DPose outperforms state-of-the-art models by a pose estimation error (i.e., MPJPE) reduction of 23.1% in the UnrealEgo dataset. Our qualitative results highlight the superiority of our approach across a range of scenarios and challenges.
+
+
+
+ 37. 标题:A Study of Forward-Forward Algorithm for Self-Supervised Learning
+ 编号:[158]
+ 链接:https://arxiv.org/abs/2309.11955
+ 作者:Jonas Brenig, Radu Timofte
+ 备注:
+ 关键词:Self-supervised representation learning, representation learning, remarkable progress, learn useful image, Self-supervised representation
+
+ 点击查看摘要
+ Self-supervised representation learning has seen remarkable progress in the last few years, with some of the recent methods being able to learn useful image representations without labels. These methods are trained using backpropagation, the de facto standard. Recently, Geoffrey Hinton proposed the forward-forward algorithm as an alternative training method. It utilizes two forward passes and a separate loss function for each layer to train the network without backpropagation.
+In this study, for the first time, we study the performance of forward-forward vs. backpropagation for self-supervised representation learning and provide insights into the learned representation spaces. Our benchmark employs four standard datasets, namely MNIST, F-MNIST, SVHN and CIFAR-10, and three commonly used self-supervised representation learning techniques, namely rotation, flip and jigsaw.
+Our main finding is that while the forward-forward algorithm performs comparably to backpropagation during (self-)supervised training, the transfer performance is significantly lagging behind in all the studied settings. This may be caused by a combination of factors, including having a loss function for each layer and the way the supervised training is realized in the forward-forward paradigm. In comparison to backpropagation, the forward-forward algorithm focuses more on the boundaries and drops part of the information unnecessary for making decisions which harms the representation learning goal. Further investigation and research are necessary to stabilize the forward-forward strategy for self-supervised learning, to work beyond the datasets and configurations demonstrated by Geoffrey Hinton.
+
+
+
+ 38. 标题:Fully Transformer-Equipped Architecture for End-to-End Referring Video Object Segmentation
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2309.11933
+ 作者:Ping Li, Yu Zhang, Li Yuan, Xianghua Xu
+ 备注:
+ 关键词:Video Object Segmentation, Referring Video Object, natural language query, Object Segmentation, referred object
+
+ 点击查看摘要
+ Referring Video Object Segmentation (RVOS) requires segmenting the object in video referred by a natural language query. Existing methods mainly rely on sophisticated pipelines to tackle such cross-modal task, and do not explicitly model the object-level spatial context which plays an important role in locating the referred object. Therefore, we propose an end-to-end RVOS framework completely built upon transformers, termed \textit{Fully Transformer-Equipped Architecture} (FTEA), which treats the RVOS task as a mask sequence learning problem and regards all the objects in video as candidate objects. Given a video clip with a text query, the visual-textual features are yielded by encoder, while the corresponding pixel-level and word-level features are aligned in terms of semantic similarity. To capture the object-level spatial context, we have developed the Stacked Transformer, which individually characterizes the visual appearance of each candidate object, whose feature map is decoded to the binary mask sequence in order directly. Finally, the model finds the best matching between mask sequence and text query. In addition, to diversify the generated masks for candidate objects, we impose a diversity loss on the model for capturing more accurate mask of the referred object. Empirical studies have shown the superiority of the proposed method on three benchmarks, e.g., FETA achieves 45.1% and 38.7% in terms of mAP on A2D Sentences (3782 videos) and J-HMDB Sentences (928 videos), respectively; it achieves 56.6% in terms of $\mathcal{J\&F}$ on Ref-YouTube-VOS (3975 videos and 7451 objects). Particularly, compared to the best candidate method, it has a gain of 2.1% and 3.2% in terms of P$@$0.5 on the former two, respectively, while it has a gain of 2.9% in terms of $\mathcal{J}$ on the latter one.
+
+
+
+ 39. 标题:Bridging the Gap: Learning Pace Synchronization for Open-World Semi-Supervised Learning
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.11930
+ 作者:Bo Ye, Kai Gan, Tong Wei, Min-Ling Zhang
+ 备注:
+ 关键词:open-world semi-supervised learning, machine learning model, unlabeled data, labeled data, open-world semi-supervised
+
+ 点击查看摘要
+ In open-world semi-supervised learning, a machine learning model is tasked with uncovering novel categories from unlabeled data while maintaining performance on seen categories from labeled data. The central challenge is the substantial learning gap between seen and novel categories, as the model learns the former faster due to accurate supervisory information. To address this, we introduce 1) an adaptive margin loss based on estimated class distribution, which encourages a large negative margin for samples in seen classes, to synchronize learning paces, and 2) pseudo-label contrastive clustering, which pulls together samples which are likely from the same class in the output space, to enhance novel class discovery. Our extensive evaluations on multiple datasets demonstrate that existing models still hinder novel class learning, whereas our approach strikingly balances both seen and novel classes, achieving a remarkable 3% average accuracy increase on the ImageNet dataset compared to the prior state-of-the-art. Additionally, we find that fine-tuning the self-supervised pre-trained backbone significantly boosts performance over the default in prior literature. After our paper is accepted, we will release the code.
+
+
+
+ 40. 标题:Video Scene Location Recognition with Neural Networks
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2309.11928
+ 作者:Lukáš Korel, Petr Pulc, Jiří Tumpach, Martin Holeňa
+ 备注:
+ 关键词:repeated shooting locations, artificial neural networks, Theory television series, Big Bang Theory, Bang Theory television
+
+ 点击查看摘要
+ This paper provides an insight into the possibility of scene recognition from a video sequence with a small set of repeated shooting locations (such as in television series) using artificial neural networks. The basic idea of the presented approach is to select a set of frames from each scene, transform them by a pre-trained singleimage pre-processing convolutional network, and classify the scene location with subsequent layers of the neural network. The considered networks have been tested and compared on a dataset obtained from The Big Bang Theory television series. We have investigated different neural network layers to combine individual frames, particularly AveragePooling, MaxPooling, Product, Flatten, LSTM, and Bidirectional LSTM layers. We have observed that only some of the approaches are suitable for the task at hand.
+
+
+
+ 41. 标题:TextCLIP: Text-Guided Face Image Generation And Manipulation Without Adversarial Training
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2309.11923
+ 作者:Xiaozhou You, Jian Zhang
+ 备注:10 pages, 6 figures
+ 关键词:semantically edit parts, desired images conditioned, refers to semantically, semantically edit, edit parts
+
+ 点击查看摘要
+ Text-guided image generation aimed to generate desired images conditioned on given texts, while text-guided image manipulation refers to semantically edit parts of a given image based on specified texts. For these two similar tasks, the key point is to ensure image fidelity as well as semantic consistency. Many previous approaches require complex multi-stage generation and adversarial training, while struggling to provide a unified framework for both tasks. In this work, we propose TextCLIP, a unified framework for text-guided image generation and manipulation without adversarial training. The proposed method accepts input from images or random noise corresponding to these two different tasks, and under the condition of the specific texts, a carefully designed mapping network that exploits the powerful generative capabilities of StyleGAN and the text image representation capabilities of Contrastive Language-Image Pre-training (CLIP) generates images of up to $1024\times1024$ resolution that can currently be generated. Extensive experiments on the Multi-modal CelebA-HQ dataset have demonstrated that our proposed method outperforms existing state-of-the-art methods, both on text-guided generation tasks and manipulation tasks.
+
+
+
+ 42. 标题:Unlocking the Heart Using Adaptive Locked Agnostic Networks
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2309.11899
+ 作者:Sylwia Majchrowska, Anders Hildeman, Philip Teare, Tom Diethe
+ 备注:The article was accepted to ICCV 2023 workshop PerDream: PERception, Decision making and REAsoning through Multimodal foundational modeling
+ 关键词:imaging applications requires, medical imaging applications, deep learning models, Locked Agnostic Network, Adaptive Locked Agnostic
+
+ 点击查看摘要
+ Supervised training of deep learning models for medical imaging applications requires a significant amount of labeled data. This is posing a challenge as the images are required to be annotated by medical professionals. To address this limitation, we introduce the Adaptive Locked Agnostic Network (ALAN), a concept involving self-supervised visual feature extraction using a large backbone model to produce anatomically robust semantic self-segmentation. In the ALAN methodology, this self-supervised training occurs only once on a large and diverse dataset. Due to the intuitive interpretability of the segmentation, downstream models tailored for specific tasks can be easily designed using white-box models with few parameters. This, in turn, opens up the possibility of communicating the inner workings of a model with domain experts and introducing prior knowledge into it. It also means that the downstream models become less data-hungry compared to fully supervised approaches. These characteristics make ALAN particularly well-suited for resource-scarce scenarios, such as costly clinical trials and rare diseases. In this paper, we apply the ALAN approach to three publicly available echocardiography datasets: EchoNet-Dynamic, CAMUS, and TMED-2. Our findings demonstrate that the self-supervised backbone model robustly identifies anatomical subregions of the heart in an apical four-chamber view. Building upon this, we design two downstream models, one for segmenting a target anatomical region, and a second for echocardiogram view classification.
+
+
+
+ 43. 标题:On-the-Fly SfM: What you capture is What you get
+ 编号:[192]
+ 链接:https://arxiv.org/abs/2309.11883
+ 作者:Zongqian Zhan, Rui Xia, Yifei Yu, Yibo Xu, Xin Wang
+ 备注:This work has been submitted to the IEEE International Conference on Robotics and Automation (ICRA 2024) for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:Structure from motion, made on Structure, ample achievements, Structure, SfM
+
+ 点击查看摘要
+ Over the last decades, ample achievements have been made on Structure from motion (SfM). However, the vast majority of them basically work in an offline manner, i.e., images are firstly captured and then fed together into a SfM pipeline for obtaining poses and sparse point cloud. In this work, on the contrary, we present an on-the-fly SfM: running online SfM while image capturing, the newly taken On-the-Fly image is online estimated with the corresponding pose and points, i.e., what you capture is what you get. Specifically, our approach firstly employs a vocabulary tree that is unsupervised trained using learning-based global features for fast image retrieval of newly fly-in image. Then, a robust feature matching mechanism with least squares (LSM) is presented to improve image registration performance. Finally, via investigating the influence of newly fly-in image's connected neighboring images, an efficient hierarchical weighted local bundle adjustment (BA) is used for optimization. Extensive experimental results demonstrate that on-the-fly SfM can meet the goal of robustly registering the images while capturing in an online way.
+
+
+
+ 44. 标题:Using Saliency and Cropping to Improve Video Memorability
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2309.11881
+ 作者:Vaibhav Mudgal, Qingyang Wang, Lorin Sweeney, Alan F. Smeaton
+ 备注:12 pages
+ 关键词:emotional connection, video content, Video, viewer, memorability
+
+ 点击查看摘要
+ Video memorability is a measure of how likely a particular video is to be remembered by a viewer when that viewer has no emotional connection with the video content. It is an important characteristic as videos that are more memorable are more likely to be shared, viewed, and discussed. This paper presents results of a series of experiments where we improved the memorability of a video by selectively cropping frames based on image saliency. We present results of a basic fixed cropping as well as the results from dynamic cropping where both the size of the crop and the position of the crop within the frame, move as the video is played and saliency is tracked. Our results indicate that especially for videos of low initial memorability, the memorability score can be improved.
+
+
+
+ 45. 标题:Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2309.11876
+ 作者:Shuang Zeng, Lei Zhu, Xinliang Zhang, Zifeng Tian, Qian Chen, Lujia Jin, Jiayi Wang, Yanye Lu
+ 备注:
+ 关键词:limited labeled data, unlabeled data, labeled data, Contrastive learning, leads a promising
+
+ 点击查看摘要
+ Contrastive learning, which is a powerful technique for learning image-level representations from unlabeled data, leads a promising direction to dealing with the dilemma between large-scale pre-training and limited labeled data. However, most existing contrastive learning strategies are designed mainly for downstream tasks of natural images, therefore they are sub-optimal and even worse than learning from scratch when directly applied to medical images whose downstream tasks are usually segmentation. In this work, we propose a novel asymmetric contrastive learning framework named JCL for medical image segmentation with self-supervised pre-training. Specifically, (1) A novel asymmetric contrastive learning strategy is proposed to pre-train both encoder and decoder simultaneously in one-stage to provide better initialization for segmentation models. (2) A multi-level contrastive loss is designed to take the correspondence among feature-level, image-level and pixel-level projections, respectively into account to make sure multi-level representations can be learned by the encoder and decoder during pre-training. (3) Experiments on multiple medical image datasets indicate our JCL framework outperforms existing SOTA contrastive learning strategies.
+
+
+
+ 46. 标题:OSNet & MNetO: Two Types of General Reconstruction Architectures for Linear Computed Tomography in Multi-Scenarios
+ 编号:[205]
+ 链接:https://arxiv.org/abs/2309.11858
+ 作者:Zhisheng Wang, Zihan Deng, Fenglin Liu, Yixing Huang, Haijun Yu, Junning Cui
+ 备注:13 pages, 13 figures
+ 关键词:actively attracted attention, Hilbert filtering, LCT, linear computed tomography, DBP images
+
+ 点击查看摘要
+ Recently, linear computed tomography (LCT) systems have actively attracted attention. To weaken projection truncation and image the region of interest (ROI) for LCT, the backprojection filtration (BPF) algorithm is an effective solution. However, in BPF for LCT, it is difficult to achieve stable interior reconstruction, and for differentiated backprojection (DBP) images of LCT, multiple rotation-finite inversion of Hilbert transform (Hilbert filtering)-inverse rotation operations will blur the image. To satisfy multiple reconstruction scenarios for LCT, including interior ROI, complete object, and exterior region beyond field-of-view (FOV), and avoid the rotation operations of Hilbert filtering, we propose two types of reconstruction architectures. The first overlays multiple DBP images to obtain a complete DBP image, then uses a network to learn the overlying Hilbert filtering function, referred to as the Overlay-Single Network (OSNet). The second uses multiple networks to train different directional Hilbert filtering models for DBP images of multiple linear scannings, respectively, and then overlays the reconstructed results, i.e., Multiple Networks Overlaying (MNetO). In two architectures, we introduce a Swin Transformer (ST) block to the generator of pix2pixGAN to extract both local and global features from DBP images at the same time. We investigate two architectures from different networks, FOV sizes, pixel sizes, number of projections, geometric magnification, and processing time. Experimental results show that two architectures can both recover images. OSNet outperforms BPF in various scenarios. For the different networks, ST-pix2pixGAN is superior to pix2pixGAN and CycleGAN. MNetO exhibits a few artifacts due to the differences among the multiple models, but any one of its models is suitable for imaging the exterior edge in a certain direction.
+
+
+
+ 47. 标题:TCOVIS: Temporally Consistent Online Video Instance Segmentation
+ 编号:[206]
+ 链接:https://arxiv.org/abs/2309.11857
+ 作者:Junlong Li, Bingyao Yu, Yongming Rao, Jie Zhou, Jiwen Lu
+ 备注:11 pages, 4 figures. This paper has been accepted for ICCV 2023
+ 关键词:online methods achieving, video instance segmentation, recent years, significant progress, methods achieving
+
+ 点击查看摘要
+ In recent years, significant progress has been made in video instance segmentation (VIS), with many offline and online methods achieving state-of-the-art performance. While offline methods have the advantage of producing temporally consistent predictions, they are not suitable for real-time scenarios. Conversely, online methods are more practical, but maintaining temporal consistency remains a challenging task. In this paper, we propose a novel online method for video instance segmentation, called TCOVIS, which fully exploits the temporal information in a video clip. The core of our method consists of a global instance assignment strategy and a spatio-temporal enhancement module, which improve the temporal consistency of the features from two aspects. Specifically, we perform global optimal matching between the predictions and ground truth across the whole video clip, and supervise the model with the global optimal objective. We also capture the spatial feature and aggregate it with the semantic feature between frames, thus realizing the spatio-temporal enhancement. We evaluate our method on four widely adopted VIS benchmarks, namely YouTube-VIS 2019/2021/2022 and OVIS, and achieve state-of-the-art performance on all benchmarks without bells-and-whistles. For instance, on YouTube-VIS 2021, TCOVIS achieves 49.5 AP and 61.3 AP with ResNet-50 and Swin-L backbones, respectively. Code is available at this https URL.
+
+
+
+ 48. 标题:DEYOv3: DETR with YOLO for Real-time Object Detection
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2309.11851
+ 作者:Haodong Ouyang
+ 备注:Work in process
+ 关键词:gained significant attention, research community due, training method, training, outstanding performance
+
+ 点击查看摘要
+ Recently, end-to-end object detectors have gained significant attention from the research community due to their outstanding performance. However, DETR typically relies on supervised pretraining of the backbone on ImageNet, which limits the practical application of DETR and the design of the backbone, affecting the model's potential generalization ability. In this paper, we propose a new training method called step-by-step training. Specifically, in the first stage, the one-to-many pre-trained YOLO detector is used to initialize the end-to-end detector. In the second stage, the backbone and encoder are consistent with the DETR-like model, but only the detector needs to be trained from scratch. Due to this training method, the object detector does not need the additional dataset (ImageNet) to train the backbone, which makes the design of the backbone more flexible and dramatically reduces the training cost of the detector, which is helpful for the practical application of the object detector. At the same time, compared with the DETR-like model, the step-by-step training method can achieve higher accuracy than the traditional training method of the DETR-like model. With the aid of this novel training method, we propose a brand-new end-to-end real-time object detection model called DEYOv3. DEYOv3-N achieves 41.1% on COCO val2017 and 270 FPS on T4 GPU, while DEYOv3-L achieves 51.3% AP and 102 FPS. Without the use of additional training data, DEYOv3 surpasses all existing real-time object detectors in terms of both speed and accuracy. It is worth noting that for models of N, S, and M scales, the training on the COCO dataset can be completed using a single 24GB RTX3090 GPU.
+
+
+
+ 49. 标题:MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion
+ 编号:[213]
+ 链接:https://arxiv.org/abs/2309.11847
+ 作者:Ting Jiang, Chuan Wang, Xinpeng Li, Ru Li, Haoqiang Fan, Shuaicheng Liu
+ 备注:
+ 关键词:multi-exposure image fusion, LUT, high-quality multi-exposure image, high-quality multi-exposure, fusion
+
+ 点击查看摘要
+ In this paper, we introduce a new approach for high-quality multi-exposure image fusion (MEF). We show that the fusion weights of an exposure can be encoded into a 1D lookup table (LUT), which takes pixel intensity value as input and produces fusion weight as output. We learn one 1D LUT for each exposure, then all the pixels from different exposures can query 1D LUT of that exposure independently for high-quality and efficient fusion. Specifically, to learn these 1D LUTs, we involve attention mechanism in various dimensions including frame, channel and spatial ones into the MEF task so as to bring us significant quality improvement over the state-of-the-art (SOTA). In addition, we collect a new MEF dataset consisting of 960 samples, 155 of which are manually tuned by professionals as ground-truth for evaluation. Our network is trained by this dataset in an unsupervised manner. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show that our approach outperforms the SOTA in our and another representative dataset SICE, both qualitatively and quantitatively. Moreover, our 1D LUT approach takes less than 4ms to run a 4K image on a PC GPU. Given its high quality, efficiency and robustness, our method has been shipped into millions of Android mobiles across multiple brands world-wide. Code is available at: this https URL.
+
+
+
+ 50. 标题:MoPA: Multi-Modal Prior Aided Domain Adaptation for 3D Semantic Segmentation
+ 编号:[216]
+ 链接:https://arxiv.org/abs/2309.11839
+ 作者:Haozhi Cao, Yuecong Xu, Jianfei Yang, Pengyu Yin, Shenghai Yuan, Lihua Xie
+ 备注:
+ 关键词:expensive point-wise annotations, embed semantic understanding, Multi-modal unsupervised domain, point-wise annotations, understanding in autonomous
+
+ 点击查看摘要
+ Multi-modal unsupervised domain adaptation (MM-UDA) for 3D semantic segmentation is a practical solution to embed semantic understanding in autonomous systems without expensive point-wise annotations. While previous MM-UDA methods can achieve overall improvement, they suffer from significant class-imbalanced performance, restricting their adoption in real applications. This imbalanced performance is mainly caused by: 1) self-training with imbalanced data and 2) the lack of pixel-wise 2D supervision signals. In this work, we propose Multi-modal Prior Aided (MoPA) domain adaptation to improve the performance of rare objects. Specifically, we develop Valid Ground-based Insertion (VGI) to rectify the imbalance supervision signals by inserting prior rare objects collected from the wild while avoiding introducing artificial artifacts that lead to trivial solutions. Meanwhile, our SAM consistency loss leverages the 2D prior semantic masks from SAM as pixel-wise supervision signals to encourage consistent predictions for each object in the semantic mask. The knowledge learned from modal-specific prior is then shared across modalities to achieve better rare object segmentation. Extensive experiments show that our method achieves state-of-the-art performance on the challenging MM-UDA benchmark. Code will be available at this https URL.
+
+
+
+ 51. 标题:FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
+ 编号:[230]
+ 链接:https://arxiv.org/abs/2309.11804
+ 作者:Zixuan Yin, Han Sun, Ningzhong Liu, Huiyu Zhou, Jiaquan Shen
+ 备注:accepted by PRCV2023, code: this https URL
+ 关键词:provide complementary information, critical sensors, sensors that provide, provide complementary, point cloud
+
+ 点击查看摘要
+ Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.
+
+
+
+ 52. 标题:DimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2309.11782
+ 作者:Thanh Nguyen, Trung Pham, Chaoning Zhang, Tung Luu, Thang Vu, Chang D. Yoo
+ 备注:
+ 关键词:contrastive learning, gained remarkable success, Self-supervised learning, Dimensional Contrastive Learning, plays a key
+
+ 点击查看摘要
+ Self-supervised learning (SSL) has gained remarkable success, for which contrastive learning (CL) plays a key role. However, the recent development of new non-CL frameworks has achieved comparable or better performance with high improvement potential, prompting researchers to enhance these frameworks further. Assimilating CL into non-CL frameworks has been thought to be beneficial, but empirical evidence indicates no visible improvements. In view of that, this paper proposes a strategy of performing CL along the dimensional direction instead of along the batch direction as done in conventional contrastive learning, named Dimensional Contrastive Learning (DimCL). DimCL aims to enhance the feature diversity, and it can serve as a regularizer to prior SSL frameworks. DimCL has been found to be effective, and the hardness-aware property is identified as a critical reason for its success. Extensive experimental results reveal that assimilating DimCL into SSL frameworks leads to performance improvement by a non-trivial margin on various datasets and backbone architectures.
+
+
+
+ 53. 标题:A Real-Time Multi-Task Learning System for Joint Detection of Face, Facial Landmark and Head Pose
+ 编号:[237]
+ 链接:https://arxiv.org/abs/2309.11773
+ 作者:Qingtian Wu, Liming Zhang
+ 备注:11 pages, 10 figures, 7 tables
+ 关键词:Extreme head postures, including face detection, accurate FLD relies, facial analysis tasks, head pose estimation
+
+ 点击查看摘要
+ Extreme head postures pose a common challenge across a spectrum of facial analysis tasks, including face detection, facial landmark detection (FLD), and head pose estimation (HPE). These tasks are interdependent, where accurate FLD relies on robust face detection, and HPE is intricately associated with these key points. This paper focuses on the integration of these tasks, particularly when addressing the complexities posed by large-angle face poses. The primary contribution of this study is the proposal of a real-time multi-task detection system capable of simultaneously performing joint detection of faces, facial landmarks, and head poses. This system builds upon the widely adopted YOLOv8 detection framework. It extends the original object detection head by incorporating additional landmark regression head, enabling efficient localization of crucial facial landmarks. Furthermore, we conduct optimizations and enhancements on various modules within the original YOLOv8 framework. To validate the effectiveness and real-time performance of our proposed model, we conduct extensive experiments on 300W-LP and AFLW2000-3D datasets. The results obtained verify the capability of our model to tackle large-angle face pose challenges while delivering real-time performance across these interconnected tasks.
+
+
+
+ 54. 标题:Fast Satellite Tensorial Radiance Field for Multi-date Satellite Imagery of Large Size
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2309.11767
+ 作者:Tongtong Zhang, Yuanxiang Li
+ 备注:
+ 关键词:mandatory solar information, handling large satellite, Existing NeRF models, satellite images suffer, Existing NeRF
+
+ 点击查看摘要
+ Existing NeRF models for satellite images suffer from slow speeds, mandatory solar information as input, and limitations in handling large satellite images. In response, we present SatensoRF, which significantly accelerates the entire process while employing fewer parameters for satellite imagery of large size. Besides, we observed that the prevalent assumption of Lambertian surfaces in neural radiance fields falls short for vegetative and aquatic elements. In contrast to the traditional hierarchical MLP-based scene representation, we have chosen a multiscale tensor decomposition approach for color, volume density, and auxiliary variables to model the lightfield with specular color. Additionally, to rectify inconsistencies in multi-date imagery, we incorporate total variation loss to restore the density tensor field and treat the problem as a denosing this http URL validate our approach, we conducted assessments of SatensoRF using subsets from the spacenet multi-view dataset, which includes both multi-date and single-date multi-view RGB images. Our results clearly demonstrate that SatensoRF surpasses the state-of-the-art Sat-NeRF series in terms of novel view synthesis performance. Significantly, SatensoRF requires fewer parameters for training, resulting in faster training and inference speeds and reduced computational demands.
+
+
+
+ 55. 标题:Dictionary Attack on IMU-based Gait Authentication
+ 编号:[240]
+ 链接:https://arxiv.org/abs/2309.11766
+ 作者:Rajesh Kumar, Can Isik, Chilukuri K. Mohan
+ 备注:12 pages, 9 figures, accepted at AISec23 colocated with ACM CCS, November 30, 2023, Copenhagen, Denmark
+ 关键词:inertial measurement unit, built into smartphones, measurement unit, inertial measurement, authentication systems
+
+ 点击查看摘要
+ We present a novel adversarial model for authentication systems that use gait patterns recorded by the inertial measurement unit (IMU) built into smartphones. The attack idea is inspired by and named after the concept of a dictionary attack on knowledge (PIN or password) based authentication systems. In particular, this work investigates whether it is possible to build a dictionary of IMUGait patterns and use it to launch an attack or find an imitator who can actively reproduce IMUGait patterns that match the target's IMUGait pattern. Nine physically and demographically diverse individuals walked at various levels of four predefined controllable and adaptable gait factors (speed, step length, step width, and thigh-lift), producing 178 unique IMUGait patterns. Each pattern attacked a wide variety of user authentication models. The deeper analysis of error rates (before and after the attack) challenges the belief that authentication systems based on IMUGait patterns are the most difficult to spoof; further research is needed on adversarial models and associated countermeasures.
+
+
+
+ 56. 标题:SAM-OCTA: A Fine-Tuning Strategy for Applying Foundation Model to OCTA Image Segmentation Tasks
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2309.11758
+ 作者:Chengliang Wang, Xinrun Chen, Haojian Ning, Shiying Li
+ 备注:ICASSP conference is in submission
+ 关键词:coherence tomography angiography, optical coherence tomography, segmenting specific targets, tomography angiography, analysis of optical
+
+ 点击查看摘要
+ In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 dataset. While achieving state-of-the-art performance metrics, this method accomplishes local vessel segmentation as well as effective artery-vein segmentation, which was not well-solved in previous works. The code is available at: this https URL.
+
+
+
+ 57. 标题:2DDATA: 2D Detection Annotations Transmittable Aggregation for Semantic Segmentation on Point Cloud
+ 编号:[244]
+ 链接:https://arxiv.org/abs/2309.11755
+ 作者:Guan-Cheng Lee
+ 备注:
+ 关键词:LiDAR and cameras, Local Object Branch, Detection Annotations Transmittable, Annotations Transmittable Aggregation, complementary information
+
+ 点击查看摘要
+ Recently, multi-modality models have been introduced because of the complementary information from different sensors such as LiDAR and cameras. It requires paired data along with precise calibrations for all modalities, the complicated calibration among modalities hugely increases the cost of collecting such high-quality datasets, and hinder it from being applied to practical scenarios. Inherit from the previous works, we not only fuse the information from multi-modality without above issues, and also exhaust the information in the RGB modality. We introduced the 2D Detection Annotations Transmittable Aggregation(\textbf{2DDATA}), designing a data-specific branch, called \textbf{Local Object Branch}, which aims to deal with points in a certain bounding box, because of its easiness of acquiring 2D bounding box annotations. We demonstrate that our simple design can transmit bounding box prior information to the 3D encoder model, proving the feasibility of large multi-modality models fused with modality-specific data.
+
+
+
+ 58. 标题:A Vision-Centric Approach for Static Map Element Annotation
+ 编号:[245]
+ 链接:https://arxiv.org/abs/2309.11754
+ 作者:Jiaxin Zhang, Shiyuan Chen, Haoran Yin, Ruohong Mei, Xuan Liu, Cong Yang, Qian Zhang, Wei Sui
+ 备注:Submitted to ICRA 2024
+ 关键词:static map element, recent development, development of online, online static map, map
+
+ 点击查看摘要
+ The recent development of online static map element (a.k.a. HD Map) construction algorithms has raised a vast demand for data with ground truth annotations. However, available public datasets currently cannot provide high-quality training data regarding consistency and accuracy. To this end, we present CAMA: a vision-centric approach for Consistent and Accurate Map Annotation. Without LiDAR inputs, our proposed framework can still generate high-quality 3D annotations of static map elements. Specifically, the annotation can achieve high reprojection accuracy across all surrounding cameras and is spatial-temporal consistent across the whole sequence. We apply our proposed framework to the popular nuScenes dataset to provide efficient and highly accurate annotations. Compared with the original nuScenes static map element, models trained with annotations from CAMA achieve lower reprojection errors (e.g., 4.73 vs. 8.03 pixels).
+
+
+
+ 59. 标题:How Robust is Google's Bard to Adversarial Image Attacks?
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2309.11751
+ 作者:Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, Xiao Yang, Yichi Zhang, Yu Tian, Hang Su, Jun Zhu
+ 备注:Technical report
+ 关键词:Large Language Models, Multimodal Large Language, Large Language, achieved unprecedented performance, Language Models
+
+ 点击查看摘要
+ Multimodal Large Language Models (MLLMs) that integrate text and other modalities (especially vision) have achieved unprecedented performance in various multimodal tasks. However, due to the unsolved adversarial robustness problem of vision models, MLLMs can have more severe safety and security risks by introducing the vision inputs. In this work, we study the adversarial robustness of Google's Bard, a competitive chatbot to ChatGPT that released its multimodal capability recently, to better understand the vulnerabilities of commercial MLLMs. By attacking white-box surrogate vision encoders or MLLMs, the generated adversarial examples can mislead Bard to output wrong image descriptions with a 22% success rate based solely on the transferability. We show that the adversarial examples can also attack other MLLMs, e.g., a 26% attack success rate against Bing Chat and a 86% attack success rate against ERNIE bot. Moreover, we identify two defense mechanisms of Bard, including face detection and toxicity detection of images. We design corresponding attacks to evade these defenses, demonstrating that the current defenses of Bard are also vulnerable. We hope this work can deepen our understanding on the robustness of MLLMs and facilitate future research on defenses. Our code is available at this https URL.
+
+
+
+ 60. 标题:CPR-Coach: Recognizing Composite Error Actions based on Single-class Training
+ 编号:[260]
+ 链接:https://arxiv.org/abs/2309.11718
+ 作者:Shunli Wang, Qing Yu, Shuaibing Wang, Dingkang Yang, Liuzhen Su, Xiao Zhao, Haopeng Kuang, Peixuan Zhang, Peng Zhai, Lihua Zhang
+ 备注:
+ 关键词:received considerable attention, recognition communities recently, pattern recognition communities, communities recently, algorithm shortage
+
+ 点击查看摘要
+ The fine-grained medical action analysis task has received considerable attention from pattern recognition communities recently, but it faces the problems of data and algorithm shortage. Cardiopulmonary Resuscitation (CPR) is an essential skill in emergency treatment. Currently, the assessment of CPR skills mainly depends on dummies and trainers, leading to high training costs and low efficiency. For the first time, this paper constructs a vision-based system to complete error action recognition and skill assessment in CPR. Specifically, we define 13 types of single-error actions and 74 types of composite error actions during external cardiac compression and then develop a video dataset named CPR-Coach. By taking the CPR-Coach as a benchmark, this paper thoroughly investigates and compares the performance of existing action recognition models based on different data modalities. To solve the unavoidable Single-class Training & Multi-class Testing problem, we propose a humancognition-inspired framework named ImagineNet to improve the model's multierror recognition performance under restricted supervision. Extensive experiments verify the effectiveness of the framework. We hope this work could advance research toward fine-grained medical action analysis and skill assessment. The CPR-Coach dataset and the code of ImagineNet are publicly available on Github.
+
+
+
+ 61. 标题:Deshadow-Anything: When Segment Anything Model Meets Zero-shot shadow removal
+ 编号:[261]
+ 链接:https://arxiv.org/abs/2309.11715
+ 作者:Xiao Feng Zhang, Tian Yi Song, Jia Wei Yao
+ 备注:
+ 关键词:segmentation model trained, expansive visual dataset, universal image segmentation, advanced universal image, computer vision
+
+ 点击查看摘要
+ Segment Anything (SAM), an advanced universal image segmentation model trained on an expansive visual dataset, has set a new benchmark in image segmentation and computer vision. However, it faced challenges when it came to distinguishing between shadows and their backgrounds. To address this, we developed Deshadow-Anything, considering the generalization of large-scale datasets, and we performed Fine-tuning on large-scale datasets to achieve image shadow removal. The diffusion model can diffuse along the edges and textures of an image, helping to remove shadows while preserving the details of the image. Furthermore, we design Multi-Self-Attention Guidance (MSAG) and adaptive input perturbation (DDPM-AIP) to accelerate the iterative training speed of diffusion. Experiments on shadow removal tasks demonstrate that these methods can effectively improve image restoration performance.
+
+
+
+ 62. 标题:MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
+ 编号:[262]
+ 链接:https://arxiv.org/abs/2309.11711
+ 作者:Fei Pan, Xu Yin, Seokju Lee, Sungeui Yoon, In So Kweon
+ 备注:Under Review in IEEE Transactions on Image Processing
+ 关键词:Unsupervised domain adaptation, target domain, domain, practical UDA setting, lack of annotations
+
+ 点击查看摘要
+ Unsupervised domain adaptation (UDA) is an effective approach to handle the lack of annotations in the target domain for the semantic segmentation task. In this work, we consider a more practical UDA setting where the target domain contains sequential frames of the unlabeled videos which are easy to collect in practice. A recent study suggests self-supervised learning of the object motion from unlabeled videos with geometric constraints. We design a motion-guided domain adaptive semantic segmentation framework (MoDA), that utilizes self-supervised object motion to learn effective representations in the target domain. MoDA differs from previous methods that use temporal consistency regularization for the target domain frames. Instead, MoDA deals separately with the domain alignment on the foreground and background categories using different strategies. Specifically, MoDA contains foreground object discovery and foreground semantic mining to align the foreground domain gaps by taking the instance-level guidance from the object motion. Additionally, MoDA includes background adversarial training which contains a background category-specific discriminator to handle the background domain gaps. Experimental results on multiple benchmarks highlight the effectiveness of MoDA against existing approaches in the domain adaptive image segmentation and domain adaptive video segmentation. Moreover, MoDA is versatile and can be used in conjunction with existing state-of-the-art approaches to further improve performance.
+
+
+
+ 63. 标题:ContextRef: Evaluating Referenceless Metrics For Image Description Generation
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2309.11710
+ 作者:Elisa Kreiss, Eric Zelikman, Christopher Potts, Nick Haber
+ 备注:
+ 关键词:ground-truth reference texts, costly ground-truth reference, reference texts, directly without costly, costly ground-truth
+
+ 点击查看摘要
+ Referenceless metrics (e.g., CLIPScore) use pretrained vision--language models to assess image descriptions directly without costly ground-truth reference texts. Such methods can facilitate rapid progress, but only if they truly align with human preference judgments. In this paper, we introduce ContextRef, a benchmark for assessing referenceless metrics for such alignment. ContextRef has two components: human ratings along a variety of established quality dimensions, and ten diverse robustness checks designed to uncover fundamental weaknesses. A crucial aspect of ContextRef is that images and descriptions are presented in context, reflecting prior work showing that context is important for description quality. Using ContextRef, we assess a variety of pretrained models, scoring functions, and techniques for incorporating context. None of the methods is successful with ContextRef, but we show that careful fine-tuning yields substantial improvements. ContextRef remains a challenging benchmark though, in large part due to the challenge of context dependence.
+
+
+
+ 64. 标题:Efficient Long-Short Temporal Attention Network for Unsupervised Video Object Segmentation
+ 编号:[264]
+ 链接:https://arxiv.org/abs/2309.11707
+ 作者:Ping Li, Yu Zhang, Li Yuan, Huaxin Xiao, Binbin Lin, Xianghua Xu
+ 备注:
+ 关键词:Video Object Segmentation, Unsupervised Video Object, primary foreground objects, Short Temporal Attention, Object Segmentation
+
+ 点击查看摘要
+ Unsupervised Video Object Segmentation (VOS) aims at identifying the contours of primary foreground objects in videos without any prior knowledge. However, previous methods do not fully use spatial-temporal context and fail to tackle this challenging task in real-time. This motivates us to develop an efficient Long-Short Temporal Attention network (termed LSTA) for unsupervised VOS task from a holistic view. Specifically, LSTA consists of two dominant modules, i.e., Long Temporal Memory and Short Temporal Attention. The former captures the long-term global pixel relations of the past frames and the current frame, which models constantly present objects by encoding appearance pattern. Meanwhile, the latter reveals the short-term local pixel relations of one nearby frame and the current frame, which models moving objects by encoding motion pattern. To speedup the inference, the efficient projection and the locality-based sliding window are adopted to achieve nearly linear time complexity for the two light modules, respectively. Extensive empirical studies on several benchmarks have demonstrated promising performances of the proposed method with high efficiency.
+
+
+
+ 65. 标题:Meta OOD Learning for Continuously Adaptive OOD Detection
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2309.11705
+ 作者:Xinheng Wu, Jie Lu, Zhen Fang, Guangquan Zhang
+ 备注:Accepted by ICCV 2023
+ 关键词:OOD detection, OOD, OOD detection methods, OOD detection model, OOD detection performance
+
+ 点击查看摘要
+ Out-of-distribution (OOD) detection is crucial to modern deep learning applications by identifying and alerting about the OOD samples that should not be tested or used for making predictions. Current OOD detection methods have made significant progress when in-distribution (ID) and OOD samples are drawn from static distributions. However, this can be unrealistic when applied to real-world systems which often undergo continuous variations and shifts in ID and OOD distributions over time. Therefore, for an effective application in real-world systems, the development of OOD detection methods that can adapt to these dynamic and evolving distributions is essential. In this paper, we propose a novel and more realistic setting called continuously adaptive out-of-distribution (CAOOD) detection which targets on developing an OOD detection model that enables dynamic and quick adaptation to a new arriving distribution, with insufficient ID samples during deployment time. To address CAOOD, we develop meta OOD learning (MOL) by designing a learning-to-adapt diagram such that a good initialized OOD detection model is learned during the training process. In the testing process, MOL ensures OOD detection performance over shifting distributions by quickly adapting to new distributions with a few adaptations. Extensive experiments on several OOD benchmarks endorse the effectiveness of our method in preserving both ID classification accuracy and OOD detection performance on continuously shifting distributions.
+
+
+
+ 66. 标题:Understanding Pose and Appearance Disentanglement in 3D Human Pose Estimation
+ 编号:[285]
+ 链接:https://arxiv.org/abs/2309.11667
+ 作者:Krishna Kanth Nakka, Mathieu Salzmann
+ 备注:
+ 关键词:received increasing attention, appearance information, pose, supervised learning scenario, tackling the case
+
+ 点击查看摘要
+ As 3D human pose estimation can now be achieved with very high accuracy in the supervised learning scenario, tackling the case where 3D pose annotations are not available has received increasing attention. In particular, several methods have proposed to learn image representations in a self-supervised fashion so as to disentangle the appearance information from the pose one. The methods then only need a small amount of supervised data to train a pose regressor using the pose-related latent vector as input, as it should be free of appearance information. In this paper, we carry out in-depth analysis to understand to what degree the state-of-the-art disentangled representation learning methods truly separate the appearance information from the pose one. First, we study disentanglement from the perspective of the self-supervised network, via diverse image synthesis experiments. Second, we investigate disentanglement with respect to the 3D pose regressor following an adversarial attack perspective. Specifically, we design an adversarial strategy focusing on generating natural appearance changes of the subject, and against which we could expect a disentangled network to be robust. Altogether, our analyses show that disentanglement in the three state-of-the-art disentangled representation learning frameworks if far from complete, and that their pose codes contain significant appearance information. We believe that our approach provides a valuable testbed to evaluate the degree of disentanglement of pose from appearance in self-supervised 3D human pose estimation.
+
+
+
+ 67. 标题:Neural Image Compression Using Masked Sparse Visual Representation
+ 编号:[288]
+ 链接:https://arxiv.org/abs/2309.11661
+ 作者:Wei Jiang, Wei Wang, Yue Chen
+ 备注:
+ 关键词:Sparse Visual Representation, Visual Representation, Sparse Visual, discrete latent space, latent space spanned
+
+ 点击查看摘要
+ We study neural image compression based on the Sparse Visual Representation (SVR), where images are embedded into a discrete latent space spanned by learned visual codebooks. By sharing codebooks with the decoder, the encoder transfers integer codeword indices that are efficient and cross-platform robust, and the decoder retrieves the embedded latent feature using the indices for reconstruction. Previous SVR-based compression lacks effective mechanism for rate-distortion tradeoffs, where one can only pursue either high reconstruction quality or low transmission bitrate. We propose a Masked Adaptive Codebook learning (M-AdaCode) method that applies masks to the latent feature subspace to balance bitrate and reconstruction quality. A set of semantic-class-dependent basis codebooks are learned, which are weighted combined to generate a rich latent feature for high-quality reconstruction. The combining weights are adaptively derived from each input image, providing fidelity information with additional transmission costs. By masking out unimportant weights in the encoder and recovering them in the decoder, we can trade off reconstruction quality for transmission bits, and the masking rate controls the balance between bitrate and distortion. Experiments over the standard JPEG-AI dataset demonstrate the effectiveness of our M-AdaCode approach.
+
+
+
+ 68. 标题:Orbital AI-based Autonomous Refuelling Solution
+ 编号:[294]
+ 链接:https://arxiv.org/abs/2309.11648
+ 作者:Duarte Rondao, Lei He, Nabil Aouf
+ 备注:13 pages
+ 关键词:small form factor, space rendezvous due, inexpensive power, rendezvous due, small form
+
+ 点击查看摘要
+ Cameras are rapidly becoming the choice for on-board sensors towards space rendezvous due to their small form factor and inexpensive power, mass, and volume costs. When it comes to docking, however, they typically serve a secondary role, whereas the main work is done by active sensors such as lidar. This paper documents the development of a proposed AI-based (artificial intelligence) navigation algorithm intending to mature the use of on-board visible wavelength cameras as a main sensor for docking and on-orbit servicing (OOS), reducing the dependency on lidar and greatly reducing costs. Specifically, the use of AI enables the expansion of the relative navigation solution towards multiple classes of scenarios, e.g., in terms of targets or illumination conditions, which would otherwise have to be crafted on a case-by-case manner using classical image processing methods. Multiple convolutional neural network (CNN) backbone architectures are benchmarked on synthetically generated data of docking manoeuvres with the International Space Station (ISS), achieving position and attitude estimates close to 1% range-normalised and 1 deg, respectively. The integration of the solution with a physical prototype of the refuelling mechanism is validated in laboratory using a robotic arm to simulate a berthing procedure.
+
+
+
+ 69. 标题:Attentive VQ-VAE
+ 编号:[297]
+ 链接:https://arxiv.org/abs/2309.11641
+ 作者:Mariano Rivera, Angello Hoyos
+ 备注:5 pages, 4 figures, 2 table2, 1 pseudo-code
+ 关键词:Attentive Residual Encoder, Attentive Residual, Residual Pixel Attention, Residual Encoder, Residual Pixel
+
+ 点击查看摘要
+ We present a novel approach to enhance the capabilities of VQVAE models through the integration of an Attentive Residual Encoder (AREN) and a Residual Pixel Attention layer. The objective of our research is to improve the performance of VQVAE while maintaining practical parameter levels. The AREN encoder is designed to operate effectively at multiple levels, accommodating diverse architectural complexities. The key innovation is the integration of an inter-pixel auto-attention mechanism into the AREN encoder. This approach allows us to efficiently capture and utilize contextual information across latent vectors. Additionally, our models uses additional encoding levels to further enhance the model's representational power. Our attention layer employs a minimal parameter approach, ensuring that latent vectors are modified only when pertinent information from other pixels is available. Experimental results demonstrate that our proposed modifications lead to significant improvements in data representation and generation, making VQVAEs even more suitable for a wide range of applications.
+
+
+
+ 70. 标题:GenLayNeRF: Generalizable Layered Representations with 3D Model Alignment for Multi-Human View Synthesis
+ 编号:[304]
+ 链接:https://arxiv.org/abs/2309.11627
+ 作者:Youssef Abdelkareem, Shady Shehata, Fakhri Karray
+ 备注:Accepted to GCPR 2023
+ 关键词:complex inter-human occlusions, imposes challenges due, scenes imposes challenges, inter-human occlusions, imposes challenges
+
+ 点击查看摘要
+ Novel view synthesis (NVS) of multi-human scenes imposes challenges due to the complex inter-human occlusions. Layered representations handle the complexities by dividing the scene into multi-layered radiance fields, however, they are mainly constrained to per-scene optimization making them inefficient. Generalizable human view synthesis methods combine the pre-fitted 3D human meshes with image features to reach generalization, yet they are mainly designed to operate on single-human scenes. Another drawback is the reliance on multi-step optimization techniques for parametric pre-fitting of the 3D body models that suffer from misalignment with the images in sparse view settings causing hallucinations in synthesized views. In this work, we propose, GenLayNeRF, a generalizable layered scene representation for free-viewpoint rendering of multiple human subjects which requires no per-scene optimization and very sparse views as input. We divide the scene into multi-human layers anchored by the 3D body meshes. We then ensure pixel-level alignment of the body models with the input views through a novel end-to-end trainable module that carries out iterative parametric correction coupled with multi-view feature fusion to produce aligned 3D models. For NVS, we extract point-wise image-aligned and human-anchored features which are correlated and fused using self-attention and cross-attention modules. We augment low-level RGB values into the features with an attention-based RGB fusion module. To evaluate our approach, we construct two multi-human view synthesis datasets; DeepMultiSyn and ZJU-MultiHuman. The results indicate that our proposed approach outperforms generalizable and non-human per-scene NeRF methods while performing at par with layered per-scene methods without test time optimization.
+
+
+
+ 71. 标题:Hand Gesture Recognition with Two Stage Approach Using Transfer Learning and Deep Ensemble Learning
+ 编号:[312]
+ 链接:https://arxiv.org/abs/2309.11610
+ 作者:Serkan Savaş, Atilla Ergüzen
+ 备注:ICISNA'23 - 1st International Conference on Intelligent Systems and New Applications Proceedings Book, Liverpool, UNITED KINGDOM, April 28-30, 2023. E-ISBN: 978-605-72180-3-2
+ 关键词:Human-Computer Interaction, focused on improving, recent studies, studies have focused, accuracy rates
+
+ 点击查看摘要
+ Human-Computer Interaction (HCI) has been the subject of research for many years, and recent studies have focused on improving its performance through various techniques. In the past decade, deep learning studies have shown high performance in various research areas, leading researchers to explore their application to HCI. Convolutional neural networks can be used to recognize hand gestures from images using deep architectures. In this study, we evaluated pre-trained high-performance deep architectures on the HG14 dataset, which consists of 14 different hand gesture classes. Among 22 different models, versions of the VGGNet and MobileNet models attained the highest accuracy rates. Specifically, the VGG16 and VGG19 models achieved accuracy rates of 94.64% and 94.36%, respectively, while the MobileNet and MobileNetV2 models achieved accuracy rates of 96.79% and 94.43%, respectively. We performed hand gesture recognition on the dataset using an ensemble learning technique, which combined the four most successful models. By utilizing these models as base learners and applying the Dirichlet ensemble technique, we achieved an accuracy rate of 98.88%. These results demonstrate the effectiveness of the deep ensemble learning technique for HCI and its potential applications in areas such as augmented reality, virtual reality, and game technologies.
+
+
+
+ 72. 标题:Sentence Attention Blocks for Answer Grounding
+ 编号:[318]
+ 链接:https://arxiv.org/abs/2309.11593
+ 作者:Seyedalireza Khoshsirat, Chandra Kambhamettu
+ 备注:
+ 关键词:Visual Question Answering, Question Answering task, relevant visual evidence, locating relevant visual, Question Answering
+
+ 点击查看摘要
+ Answer grounding is the task of locating relevant visual evidence for the Visual Question Answering task. While a wide variety of attention methods have been introduced for this task, they suffer from the following three problems: designs that do not allow the usage of pre-trained networks and do not benefit from large data pre-training, custom designs that are not based on well-grounded previous designs, therefore limiting the learning power of the network, or complicated designs that make it challenging to re-implement or improve them. In this paper, we propose a novel architectural block, which we term Sentence Attention Block, to solve these problems. The proposed block re-calibrates channel-wise image feature-maps by explicitly modeling inter-dependencies between the image feature-maps and sentence embedding. We visually demonstrate how this block filters out irrelevant feature-maps channels based on sentence embedding. We start our design with a well-known attention method, and by making minor modifications, we improve the results to achieve state-of-the-art accuracy. The flexibility of our method makes it easy to use different pre-trained backbone networks, and its simplicity makes it easy to understand and be re-implemented. We demonstrate the effectiveness of our method on the TextVQA-X, VQS, VQA-X, and VizWiz-VQA-Grounding datasets. We perform multiple ablation studies to show the effectiveness of our design choices.
+
+
+
+ 73. 标题:Continuous Levels of Detail for Light Field Networks
+ 编号:[320]
+ 链接:https://arxiv.org/abs/2309.11591
+ 作者:David Li, Brandon Y. Feng, Amitabh Varshney
+ 备注:Accepted to BMVC 2023. Webpage at this https URL
+ 关键词:approaches have emerged, emerged for generating, multiple levels, generating neural representations, LODs
+
+ 点击查看摘要
+ Recently, several approaches have emerged for generating neural representations with multiple levels of detail (LODs). LODs can improve the rendering by using lower resolutions and smaller model sizes when appropriate. However, existing methods generally focus on a few discrete LODs which suffer from aliasing and flicker artifacts as details are changed and limit their granularity for adapting to resource limitations. In this paper, we propose a method to encode light field networks with continuous LODs, allowing for finely tuned adaptations to rendering conditions. Our training procedure uses summed-area table filtering allowing efficient and continuous filtering at various LODs. Furthermore, we use saliency-based importance sampling which enables our light field networks to distribute their capacity, particularly limited at lower LODs, towards representing the details viewers are most likely to focus on. Incorporating continuous LODs into neural representations enables progressive streaming of neural representations, decreasing the latency and resource utilization for rendering.
+
+
+
+ 74. 标题:Distilling Adversarial Prompts from Safety Benchmarks: Report for the Adversarial Nibbler Challenge
+ 编号:[327]
+ 链接:https://arxiv.org/abs/2309.11575
+ 作者:Manuel Brack, Patrick Schramowski, Kristian Kersting
+ 备注:
+ 关键词:recently achieved astonishing, Text-conditioned image generation, alignment results, achieved astonishing image, astonishing image quality
+
+ 点击查看摘要
+ Text-conditioned image generation models have recently achieved astonishing image quality and alignment results. Consequently, they are employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the web, they also produce unsafe content. As a contribution to the Adversarial Nibbler challenge, we distill a large set of over 1,000 potential adversarial inputs from existing safety benchmarks. Our analysis of the gathered prompts and corresponding images demonstrates the fragility of input filters and provides further insights into systematic safety issues in current generative image models.
+
+
+
+ 75. 标题:Revisiting Kernel Temporal Segmentation as an Adaptive Tokenizer for Long-form Video Understanding
+ 编号:[329]
+ 链接:https://arxiv.org/abs/2309.11569
+ 作者:Mohamed Afham, Satya Narayan Shukla, Omid Poursaeed, Pengchuan Zhang, Ashish Shah, Sernam Lim
+ 备注:
+ 关键词:understanding models operate, operate on short-range, long videos, modern video understanding, models operate
+
+ 点击查看摘要
+ While most modern video understanding models operate on short-range clips, real-world videos are often several minutes long with semantically consistent segments of variable length. A common approach to process long videos is applying a short-form video model over uniformly sampled clips of fixed temporal length and aggregating the outputs. This approach neglects the underlying nature of long videos since fixed-length clips are often redundant or uninformative. In this paper, we aim to provide a generic and adaptive sampling approach for long-form videos in lieu of the de facto uniform sampling. Viewing videos as semantically consistent segments, we formulate a task-agnostic, unsupervised, and scalable approach based on Kernel Temporal Segmentation (KTS) for sampling and tokenizing long videos. We evaluate our method on long-form video understanding tasks such as video classification and temporal action localization, showing consistent gains over existing approaches and achieving state-of-the-art performance on long-form video modeling.
+
+
+
+ 76. 标题:EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian
+ 编号:[335]
+ 链接:https://arxiv.org/abs/2309.11531
+ 作者:Ofir Gordon, Hai Victor Habi, Arnon Netzer
+ 备注:
+ 关键词:deep neural networks, Post Training Quantization, neural networks, Enhanced Post Training, end-user devices
+
+ 点击查看摘要
+ Quantization of deep neural networks (DNN) has become a key element in the efforts of embedding such networks on end-user devices. However, current quantization methods usually suffer from costly accuracy degradation. In this paper, we propose a new method for Enhanced Post Training Quantization named EPTQ. The method is based on knowledge distillation with an adaptive weighting of layers. In addition, we introduce a new label-free technique for approximating the Hessian trace of the task loss, named Label-Free Hessian. This technique removes the requirement of a labeled dataset for computing the Hessian. The adaptive knowledge distillation uses the Label-Free Hessian technique to give greater attention to the sensitive parts of the model while performing the optimization. Empirically, by employing EPTQ we achieve state-of-the-art results on a wide variety of models, tasks, and datasets, including ImageNet classification, COCO object detection, and Pascal-VOC for semantic segmentation. We demonstrate the performance and compatibility of EPTQ on an extended set of architectures, including CNNs, Transformers, hybrid, and MLP-only models.
+
+
+
+ 77. 标题:Light Field Diffusion for Single-View Novel View Synthesis
+ 编号:[339]
+ 链接:https://arxiv.org/abs/2309.11525
+ 作者:Yifeng Xiong, Haoyu Ma, Shanlin Sun, Kun Han, Xiaohui Xie
+ 备注:
+ 关键词:Denoising Diffusion Probabilistic, computer vision, challenging task, viewpoints based, important but challenging
+
+ 点击查看摘要
+ Single-view novel view synthesis, the task of generating images from new viewpoints based on a single reference image, is an important but challenging task in computer vision. Recently, Denoising Diffusion Probabilistic Model (DDPM) has become popular in this area due to its strong ability to generate high-fidelity images. However, current diffusion-based methods directly rely on camera pose matrices as viewing conditions, globally and implicitly introducing 3D constraints. These methods may suffer from inconsistency among generated images from different perspectives, especially in regions with intricate textures and structures. In this work, we present Light Field Diffusion (LFD), a conditional diffusion-based model for single-view novel view synthesis. Unlike previous methods that employ camera pose matrices, LFD transforms the camera view information into light field encoding and combines it with the reference image. This design introduces local pixel-wise constraints within the diffusion models, thereby encouraging better multi-view consistency. Experiments on several datasets show that our LFD can efficiently generate high-fidelity images and maintain better 3D consistency even in intricate regions. Our method can generate images with higher quality than NeRF-based models, and we obtain sample quality similar to other diffusion-based models but with only one-third of the model size.
+
+
+
+ 78. 标题:RMT: Retentive Networks Meet Vision Transformers
+ 编号:[340]
+ 链接:https://arxiv.org/abs/2309.11523
+ 作者:Qihang Fan, Huaibo Huang, Mingrui Chen, Hongmin Liu, Ran He
+ 备注:
+ 关键词:natural language processing, demonstrates excellent performance, Retentive Network, computer vision domain, field of natural
+
+ 点击查看摘要
+ Transformer first appears in the field of natural language processing and is later migrated to the computer vision domain, where it demonstrates excellent performance in vision tasks. However, recently, Retentive Network (RetNet) has emerged as an architecture with the potential to replace Transformer, attracting widespread attention in the NLP community. Therefore, we raise the question of whether transferring RetNet's idea to vision can also bring outstanding performance to vision tasks. To address this, we combine RetNet and Transformer to propose RMT. Inspired by RetNet, RMT introduces explicit decay into the vision backbone, bringing prior knowledge related to spatial distances to the vision model. This distance-related spatial prior allows for explicit control of the range of tokens that each token can attend to. Additionally, to reduce the computational cost of global modeling, we decompose this modeling process along the two coordinate axes of the image. Abundant experiments have demonstrated that our RMT exhibits exceptional performance across various computer vision tasks. For example, RMT achieves 84.1% Top1-acc on ImageNet-1k using merely 4.5G FLOPs. To the best of our knowledge, among all models, RMT achieves the highest Top1-acc when models are of similar size and trained with the same strategy. Moreover, RMT significantly outperforms existing vision backbones in downstream tasks such as object detection, instance segmentation, and semantic segmentation. Our work is still in progress.
+
+
+
+ 79. 标题:When is a Foundation Model a Foundation Model
+ 编号:[345]
+ 链接:https://arxiv.org/abs/2309.11510
+ 作者:Saghir Alfasly, Peyman Nejat, Sobhan Hemati, Jibran Khan, Isaiah Lahr, Areej Alsaafin, Abubakr Shafique, Nneka Comfere, Dennis Murphree, Chady Meroueh, Saba Yasir, Aaron Mangold, Lisa Boardman, Vijay Shah, Joaquin J. Garcia, H.R. Tizhoosh
+ 备注:
+ 关键词:online data sources, Twitter and PubMed, field of medicine, utilizing images, studies have reported
+
+ 点击查看摘要
+ Recently, several studies have reported on the fine-tuning of foundation models for image-text modeling in the field of medicine, utilizing images from online data sources such as Twitter and PubMed. Foundation models are large, deep artificial neural networks capable of learning the context of a specific domain through training on exceptionally extensive datasets. Through validation, we have observed that the representations generated by such models exhibit inferior performance in retrieval tasks within digital pathology when compared to those generated by significantly smaller, conventional deep networks.
+
+
+
+ 80. 标题:Adaptive Input-image Normalization for Solving Mode Collapse Problem in GAN-based X-ray Images
+ 编号:[353]
+ 链接:https://arxiv.org/abs/2309.12245
+ 作者:Muhammad Muneeb Saad, Mubashir Husain Rehmani, Ruairi O'Reilly
+ 备注:Submitted to the IEEE Journal
+ 关键词:Biomedical image datasets, Generative Adversarial Networks, Adversarial Networks play, mode collapse, targeted diseases
+
+ 点击查看摘要
+ Biomedical image datasets can be imbalanced due to the rarity of targeted diseases. Generative Adversarial Networks play a key role in addressing this imbalance by enabling the generation of synthetic images to augment datasets. It is important to generate synthetic images that incorporate a diverse range of features to accurately represent the distribution of features present in the training imagery. Furthermore, the absence of diverse features in synthetic images can degrade the performance of machine learning classifiers. The mode collapse problem impacts Generative Adversarial Networks' capacity to generate diversified images. Mode collapse comes in two varieties: intra-class and inter-class. In this paper, both varieties of the mode collapse problem are investigated, and their subsequent impact on the diversity of synthetic X-ray images is evaluated. This work contributes an empirical demonstration of the benefits of integrating the adaptive input-image normalization with the Deep Convolutional GAN and Auxiliary Classifier GAN to alleviate the mode collapse problems. Synthetically generated images are utilized for data augmentation and training a Vision Transformer model. The classification performance of the model is evaluated using accuracy, recall, and precision scores. Results demonstrate that the DCGAN and the ACGAN with adaptive input-image normalization outperform the DCGAN and ACGAN with un-normalized X-ray images as evidenced by the superior diversity scores and classification scores.
+
+
+
+ 81. 标题:Brain Tumor Detection Using Deep Learning Approaches
+ 编号:[360]
+ 链接:https://arxiv.org/abs/2309.12193
+ 作者:Razia Sultana Misu
+ 备注:Bachelor's thesis. Supervisor: Nushrat Jahan Ria
+ 关键词:Deep Learning, masses or clusters, deep learning techniques, Deep Learning methods, collections of abnormal
+
+ 点击查看摘要
+ Brain tumors are collections of abnormal cells that can develop into masses or clusters. Because they have the potential to infiltrate other tissues, they pose a risk to the patient. The main imaging technique used, MRI, may be able to identify a brain tumor with accuracy. The fast development of Deep Learning methods for use in computer vision applications has been facilitated by a vast amount of training data and improvements in model construction that offer better approximations in a supervised setting. The need for these approaches has been the main driver of this expansion. Deep learning methods have shown promise in improving the precision of brain tumor detection and classification using magnetic resonance imaging (MRI). The study on the use of deep learning techniques, especially ResNet50, for brain tumor identification is presented in this abstract. As a result, this study investigates the possibility of automating the detection procedure using deep learning techniques. In this study, I utilized five transfer learning models which are VGG16, VGG19, DenseNet121, ResNet50 and YOLO V4 where ResNet50 provide the best or highest accuracy 99.54%. The goal of the study is to guide researchers and medical professionals toward powerful brain tumor detecting systems by employing deep learning approaches by way of this evaluation and analysis.
+
+
+
+ 82. 标题:AutoPET Challenge 2023: Sliding Window-based Optimization of U-Net
+ 编号:[365]
+ 链接:https://arxiv.org/abs/2309.12114
+ 作者:Matthias Hadlich, Zdravko Marinov, Rainer Stiefelhagen
+ 备注:9 pages, 1 figure, MICCAI 2023 - AutoPET Challenge Submission
+ 关键词:medical imaging, imaging is crucial, crucial and relies, Tumor segmentation, Computed Tomography
+
+ 点击查看摘要
+ Tumor segmentation in medical imaging is crucial and relies on precise delineation. Fluorodeoxyglucose Positron-Emission Tomography (FDG-PET) is widely used in clinical practice to detect metabolically active tumors. However, FDG-PET scans may misinterpret irregular glucose consumption in healthy or benign tissues as cancer. Combining PET with Computed Tomography (CT) can enhance tumor segmentation by integrating metabolic and anatomic information. FDG-PET/CT scans are pivotal for cancer staging and reassessment, utilizing radiolabeled fluorodeoxyglucose to highlight metabolically active regions. Accurately distinguishing tumor-specific uptake from physiological uptake in normal tissues is a challenging aspect of precise tumor segmentation. The AutoPET challenge addresses this by providing a dataset of 1014 FDG-PET/CT studies, encouraging advancements in accurate tumor segmentation and analysis within the FDG-PET/CT domain. Code: this https URL
+
+
+
+ 83. 标题:Bayesian sparsification for deep neural networks with Bayesian model reduction
+ 编号:[366]
+ 链接:https://arxiv.org/abs/2309.12095
+ 作者:Dimitrije Marković, Karl J. Friston, Stefan J. Kiebel
+ 备注:
+ 关键词:effective sparsification techniques, learning immense capabilities, Deep learning, Deep learning immense, Bayesian sparsification
+
+ 点击查看摘要
+ Deep learning's immense capabilities are often constrained by the complexity of its models, leading to an increasing demand for effective sparsification techniques. Bayesian sparsification for deep learning emerges as a crucial approach, facilitating the design of models that are both computationally efficient and competitive in terms of performance across various deep learning applications. The state-of-the-art -- in Bayesian sparsification of deep neural networks -- combines structural shrinkage priors on model weights with an approximate inference scheme based on black-box stochastic variational inference. However, model inversion of the full generative model is exceptionally computationally demanding, especially when compared to standard deep learning of point estimates. In this context, we advocate for the use of Bayesian model reduction (BMR) as a more efficient alternative for pruning of model weights. As a generalization of the Savage-Dickey ratio, BMR allows a post-hoc elimination of redundant model weights based on the posterior estimates under a straightforward (non-hierarchical) generative model. Our comparative study highlights the computational efficiency and the pruning rate of the BMR method relative to the established stochastic variational inference (SVI) scheme, when applied to the full hierarchical generative model. We illustrate the potential of BMR to prune model parameters across various deep learning architectures, from classical networks like LeNet to modern frameworks such as Vision Transformers and MLP-Mixers.
+
+
+
+ 84. 标题:Convolution and Attention Mixer for Synthetic Aperture Radar Image Change Detection
+ 编号:[369]
+ 链接:https://arxiv.org/abs/2309.12010
+ 作者:Haopeng Zhang, Zijing Lin, Feng Gao, Junyu Dong, Qian Du, Heng-Chao Li
+ 备注:Accepted by IEEE GRSL
+ 关键词:Synthetic aperture radar, SAR change detection, remote sensing community, image change detection, received increasing attentions
+
+ 点击查看摘要
+ Synthetic aperture radar (SAR) image change detection is a critical task and has received increasing attentions in the remote sensing community. However, existing SAR change detection methods are mainly based on convolutional neural networks (CNNs), with limited consideration of global attention mechanism. In this letter, we explore Transformer-like architecture for SAR change detection to incorporate global attention. To this end, we propose a convolution and attention mixer (CAMixer). First, to compensate the inductive bias for Transformer, we combine self-attention with shift convolution in a parallel way. The parallel design effectively captures the global semantic information via the self-attention and performs local feature extraction through shift convolution simultaneously. Second, we adopt a gating mechanism in the feed-forward network to enhance the non-linear feature transformation. The gating mechanism is formulated as the element-wise multiplication of two parallel linear layers. Important features can be highlighted, leading to high-quality representations against speckle noise. Extensive experiments conducted on three SAR datasets verify the superior performance of the proposed CAMixer. The source codes will be publicly available at this https URL .
+
+
+
+ 85. 标题:Identification of pneumonia on chest x-ray images through machine learning
+ 编号:[371]
+ 链接:https://arxiv.org/abs/2309.11995
+ 作者:Eduardo Augusto Roeder
+ 备注:In Brazilian Portuguese, 30 pages, 16 figures. This thesis was elaborated by the guidance of Prof. Dr. Akihito Inca Atahualpa Urdiales
+ 关键词:leading infectious, infant death, chest X-ray, chest X-rays images, children chest X-rays
+
+ 点击查看摘要
+ Pneumonia is the leading infectious cause of infant death in the world. When identified early, it is possible to alter the prognosis of the patient, one could use imaging exams to help in the diagnostic confirmation. Performing and interpreting the exams as soon as possible is vital for a good treatment, with the most common exam for this pathology being chest X-ray. The objective of this study was to develop a software that identify the presence or absence of pneumonia in chest radiographs. The software was developed as a computational model based on machine learning using transfer learning technique. For the training process, images were collected from a database available online with children's chest X-rays images taken at a hospital in China. After training, the model was then exposed to new images, achieving relevant results on identifying such pathology, reaching 98% sensitivity and 97.3% specificity for the sample used for testing. It can be concluded that it is possible to develop a software that identifies pneumonia in chest X-ray images.
+
+
+
+ 86. 标题:Spatial-Temporal Transformer based Video Compression Framework
+ 编号:[381]
+ 链接:https://arxiv.org/abs/2309.11913
+ 作者:Yanbo Gao, Wenjia Huang, Shuai Li, Hui Yuan, Mao Ye, Siwei Ma
+ 备注:
+ 关键词:witnessed remarkable advancements, Learned video compression, LVC inherits motion, video compression, Transformer based Video
+
+ 点击查看摘要
+ Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
+
+
+
+ 87. 标题:Heart Rate Detection Using an Event Camera
+ 编号:[382]
+ 链接:https://arxiv.org/abs/2309.11891
+ 作者:Aniket Jagtap, RamaKrishna Venkatesh Saripalli, Joe Lemley, Waseem Shariff, Alan F. Smeaton
+ 备注:Dataset available at this https URL
+ 关键词:low power consumption, including high temporal, high temporal resolution, selective data acquisition, including high
+
+ 点击查看摘要
+ Event cameras, also known as neuromorphic cameras, are an emerging technology that offer advantages over traditional shutter and frame-based cameras, including high temporal resolution, low power consumption, and selective data acquisition. In this study, we propose to harnesses the capabilities of event-based cameras to capture subtle changes in the surface of the skin caused by the pulsatile flow of blood in the wrist region. We investigate whether an event camera could be used for continuous noninvasive monitoring of heart rate (HR). Event camera video data from 25 participants, comprising varying age groups and skin colours, was collected and analysed. Ground-truth HR measurements obtained using conventional methods were used to evaluate of the accuracy of automatic detection of HR from event camera data. Our experimental results and comparison to the performance of other non-contact HR measurement methods demonstrate the feasibility of using event cameras for pulse detection. We also acknowledge the challenges and limitations of our method, such as light-induced flickering and the sub-conscious but naturally-occurring tremors of an individual during data capture.
+
+
+
+ 88. 标题:Automatic Endoscopic Ultrasound Station Recognition with Limited Data
+ 编号:[388]
+ 链接:https://arxiv.org/abs/2309.11820
+ 作者:Abhijit Ramesh, Anantha Nandanan, Nikhil Boggavarapu, Priya Nair MD, Gilad Gressel
+ 备注:
+ 关键词:cancer-related deaths worldwide, deaths worldwide, lethal form, significantly contributes, contributes to cancer-related
+
+ 点击查看摘要
+ Pancreatic cancer is a lethal form of cancer that significantly contributes to cancer-related deaths worldwide. Early detection is essential to improve patient prognosis and survival rates. Despite advances in medical imaging techniques, pancreatic cancer remains a challenging disease to detect. Endoscopic ultrasound (EUS) is the most effective diagnostic tool for detecting pancreatic cancer. However, it requires expert interpretation of complex ultrasound images to complete a reliable patient scan. To obtain complete imaging of the pancreas, practitioners must learn to guide the endoscope into multiple "EUS stations" (anatomical locations), which provide different views of the pancreas. This is a difficult skill to learn, involving over 225 proctored procedures with the support of an experienced doctor. We build an AI-assisted tool that utilizes deep learning techniques to identify these stations of the stomach in real time during EUS procedures. This computer-assisted diagnostic (CAD) will help train doctors more efficiently. Historically, the challenge faced in developing such a tool has been the amount of retrospective labeling required by trained clinicians. To solve this, we developed an open-source user-friendly labeling web app that streamlines the process of annotating stations during the EUS procedure with minimal effort from the clinicians. Our research shows that employing only 43 procedures with no hyperparameter fine-tuning obtained a balanced accuracy of 90%, comparable to the current state of the art. In addition, we employ Grad-CAM, a visualization technology that provides clinicians with interpretable and explainable visualizations.
+
+
+
+ 89. 标题:PIE: Simulating Disease Progression via Progressive Image Editing
+ 编号:[393]
+ 链接:https://arxiv.org/abs/2309.11745
+ 作者:Kaizhao Liang, Xu Cao, Kuei-Da Liao, Tianren Gao, Zhengyu Chen, Tejas Nama
+ 备注:
+ 关键词:crucial area, significant implications, Disease progression simulation, Progressive Image Editing, Disease progression
+
+ 点击查看摘要
+ Disease progression simulation is a crucial area of research that has significant implications for clinical diagnosis, prognosis, and treatment. One major challenge in this field is the lack of continuous medical imaging monitoring of individual patients over time. To address this issue, we develop a novel framework termed Progressive Image Editing (PIE) that enables controlled manipulation of disease-related image features, facilitating precise and realistic disease progression simulation. Specifically, we leverage recent advancements in text-to-image generative models to simulate disease progression accurately and personalize it for each patient. We theoretically analyze the iterative refining process in our framework as a gradient descent with an exponentially decayed learning rate. To validate our framework, we conduct experiments in three medical imaging domains. Our results demonstrate the superiority of PIE over existing methods such as Stable Diffusion Walk and Style-Based Manifold Extrapolation based on CLIP score (Realism) and Disease Classification Confidence (Alignment). Our user study collected feedback from 35 veteran physicians to assess the generated progressions. Remarkably, 76.2% of the feedback agrees with the fidelity of the generated progressions. To our best knowledge, PIE is the first of its kind to generate disease progression images meeting real-world standards. It is a promising tool for medical research and clinical practice, potentially allowing healthcare providers to model disease trajectories over time, predict future treatment responses, and improve patient outcomes.
+
+
+
+ 90. 标题:Cross-scale Multi-instance Learning for Pathological Image Diagnosis
+ 编号:[405]
+ 链接:https://arxiv.org/abs/2304.00216
+ 作者:Ruining Deng, Can Cui, Lucas W. Remedios, Shunxing Bao, R. Michael Womick, Sophie Chiron, Jia Li, Joseph T. Roland, Ken S. Lau, Qi Liu, Keith T. Wilson, Yaohong Wang, Lori A. Coburn, Bennett A. Landman, Yuankai Huo
+ 备注:
+ 关键词:Analyzing high resolution, multiple scales poses, high resolution images, digital pathology, high resolution
+
+ 点击查看摘要
+ Analyzing high resolution whole slide images (WSIs) with regard to information across multiple scales poses a significant challenge in digital pathology. Multi-instance learning (MIL) is a common solution for working with high resolution images by classifying bags of objects (i.e. sets of smaller image patches). However, such processing is typically performed at a single scale (e.g., 20x magnification) of WSIs, disregarding the vital inter-scale information that is key to diagnoses by human pathologists. In this study, we propose a novel cross-scale MIL algorithm to explicitly aggregate inter-scale relationships into a single MIL network for pathological image diagnosis. The contribution of this paper is three-fold: (1) A novel cross-scale MIL (CS-MIL) algorithm that integrates the multi-scale information and the inter-scale relationships is proposed; (2) A toy dataset with scale-specific morphological features is created and released to examine and visualize differential cross-scale attention; (3) Superior performance on both in-house and public datasets is demonstrated by our simple cross-scale MIL strategy. The official implementation is publicly available at this https URL.
+
+
+自然语言处理
+
+ 1. 标题:LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.12311
+ 作者:Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F. Fouhey, Joyce Chai
+ 备注:Project website: this https URL
+ 关键词:Large Language Model, answer questions based, household robots, critical skill, skill for household
+
+ 点击查看摘要
+ 3D visual grounding is a critical skill for household robots, enabling them to navigate, manipulate objects, and answer questions based on their environment. While existing approaches often rely on extensive labeled data or exhibit limitations in handling complex language queries, we propose LLM-Grounder, a novel zero-shot, open-vocabulary, Large Language Model (LLM)-based 3D visual grounding pipeline. LLM-Grounder utilizes an LLM to decompose complex natural language queries into semantic constituents and employs a visual grounding tool, such as OpenScene or LERF, to identify objects in a 3D scene. The LLM then evaluates the spatial and commonsense relations among the proposed objects to make a final grounding decision. Our method does not require any labeled training data and can generalize to novel 3D scenes and arbitrary text queries. We evaluate LLM-Grounder on the ScanRefer benchmark and demonstrate state-of-the-art zero-shot grounding accuracy. Our findings indicate that LLMs significantly improve the grounding capability, especially for complex language queries, making LLM-Grounder an effective approach for 3D vision-language tasks in robotics. Videos and interactive demos can be found on the project website this https URL .
+
+
+
+ 2. 标题:Rehearsal: Simulating Conflict to Teach Conflict Resolution
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.12309
+ 作者:Omar Shaikh, Valentino Chai, Michele J. Gelfand, Diyi Yang, Michael S. Bernstein
+ 备注:
+ 关键词:fact of life, uncomfortable but unavoidable, unavoidable fact, conflict, Rehearsal
+
+ 点击查看摘要
+ Interpersonal conflict is an uncomfortable but unavoidable fact of life. Navigating conflict successfully is a skill -- one that can be learned through deliberate practice -- but few have access to effective training or feedback. To expand this access, we introduce Rehearsal, a system that allows users to rehearse conflicts with a believable simulated interlocutor, explore counterfactual "what if?" scenarios to identify alternative conversational paths, and learn through feedback on how and when to apply specific conflict strategies. Users can utilize Rehearsal to practice handling a variety of predefined conflict scenarios, from office disputes to relationship issues, or they can choose to create their own. To enable Rehearsal, we develop IRP prompting, a method of conditioning output of a large language model on the influential Interest-Rights-Power (IRP) theory from conflict resolution. Rehearsal uses IRP to generate utterances grounded in conflict resolution theory, guiding users towards counterfactual conflict resolution strategies that help de-escalate difficult conversations. In a between-subjects evaluation, 40 participants engaged in an actual conflict with a confederate after training. Compared to a control group with lecture material covering the same IRP theory, participants with simulated training from Rehearsal significantly improved their performance in the unaided conflict: they reduced their use of escalating competitive strategies by an average of 67%, while doubling their use of cooperative strategies. Overall, Rehearsal highlights the potential effectiveness of language models as tools for learning and practicing interpersonal skills.
+
+
+
+ 3. 标题:LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2309.12307
+ 作者:Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
+ 备注:Code, models, dataset, and demo are available at this https URL
+ 关键词:pre-trained large language, large language models, efficient fine-tuning approach, context, pre-trained large
+
+ 点击查看摘要
+ We present LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost. Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. For example, training on the context length of 8192 needs 16x computational costs in self-attention layers as that of 2048. In this paper, we speed up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine-tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention effectively enables context extension, leading to non-trivial computation saving with similar performance to fine-tuning with vanilla attention. Particularly, it can be implemented with only two lines of code in training, while being optional in inference. On the other hand, we revisit the parameter-efficient fine-tuning regime for context expansion. Notably, we find that LoRA for context extension works well under the premise of trainable embedding and normalization. LongLoRA demonstrates strong empirical results on various tasks on LLaMA2 models from 7B/13B to 70B. LongLoRA adopts LLaMA2 7B from 4k context to 100k, or LLaMA2 70B to 32k on a single 8x A100 machine. LongLoRA extends models' context while retaining their original architectures, and is compatible with most existing techniques, like FlashAttention-2. In addition, to make LongLoRA practical, we collect a dataset, LongQA, for supervised fine-tuning. It contains more than 3k long context question-answer pairs.
+
+
+
+ 4. 标题:Reranking for Natural Language Generation from Logical Forms: A Study based on Large Language Models
+ 编号:[14]
+ 链接:https://arxiv.org/abs/2309.12294
+ 作者:Levon Haroutunian, Zhuang Li, Lucian Galescu, Philip Cohen, Raj Tumuluri, Gholamreza Haffari
+ 备注:IJCNLP-AACL 2023
+ 关键词:demonstrated impressive capabilities, natural language generation, Large language models, natural language, demonstrated impressive
+
+ 点击查看摘要
+ Large language models (LLMs) have demonstrated impressive capabilities in natural language generation. However, their output quality can be inconsistent, posing challenges for generating natural language from logical forms (LFs). This task requires the generated outputs to embody the exact semantics of LFs, without missing any LF semantics or creating any hallucinations. In this work, we tackle this issue by proposing a novel generate-and-rerank approach. Our approach involves initially generating a set of candidate outputs by prompting an LLM and subsequently reranking them using a task-specific reranker model. In addition, we curate a manually collected dataset to evaluate the alignment between different ranking metrics and human judgements. The chosen ranking metrics are utilized to enhance the training and evaluation of the reranker model. By conducting extensive experiments on three diverse datasets, we demonstrate that the candidates selected by our reranker outperform those selected by baseline methods in terms of semantic consistency and fluency, as measured by three comprehensive metrics. Our findings provide strong evidence for the effectiveness of our approach in improving the quality of generated outputs.
+
+
+
+ 5. 标题:The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.12288
+ 作者:Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
+ 备注:18 pages, 10 figures
+ 关键词:auto-regressive large language, Reversal Curse, large language models, Mary Lee Pfeiffer, Chancellor of Germany
+
+ 点击查看摘要
+ We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany", it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?". Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e. if "A is B'' occurs, "B is A" is more likely to occur). We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of 'Abyssal Melodies'" and showing that they fail to correctly answer "Who composed 'Abyssal Melodies?'". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?". GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is available at this https URL.
+
+
+
+ 6. 标题:MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.12284
+ 作者:Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, Weiyang Liu
+ 备注:Technical Report, Work in Progress. Project Page: this https URL
+ 关键词:excellent problem-solving ability, exhibited excellent problem-solving, natural language understanding, problem-solving ability, Large language models
+
+ 点击查看摘要
+ Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
+
+
+
+ 7. 标题:Inspire the Large Language Model by External Knowledge on BioMedical Named Entity Recognition
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.12278
+ 作者:Junyi Bian, Jiaxuan Zheng, Yuyi Zhang, Shanfeng Zhu
+ 备注:10 pages, 5 figures
+ 关键词:Large language models, Named Entity Recognition, demonstrated dominating performance, NLP tasks, Biomedical Named Entity
+
+ 点击查看摘要
+ Large language models (LLMs) have demonstrated dominating performance in many NLP tasks, especially on generative tasks. However, they often fall short in some information extraction tasks, particularly those requiring domain-specific knowledge, such as Biomedical Named Entity Recognition (NER). In this paper, inspired by Chain-of-thought, we leverage the LLM to solve the Biomedical NER step-by-step: break down the NER task into entity span extraction and entity type determination. Additionally, for entity type determination, we inject entity knowledge to address the problem that LLM's lack of domain knowledge when predicting entity category. Experimental results show a significant improvement in our two-step BioNER approach compared to previous few-shot LLM baseline. Additionally, the incorporation of external knowledge significantly enhances entity category determination performance.
+
+
+
+ 8. 标题:LLMR: Real-time Prompting of Interactive Worlds using Large Language Models
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.12276
+ 作者:Fernanda De La Torre, Cathy Mengying Fang, Han Huang, Andrzej Banburski-Fahey, Judith Amores Fernandez, Jaron Lanier
+ 备注:50 pages (22 in main text), 15 figures
+ 关键词:Large Language Model, interactive Mixed Reality, present Large Language, Mixed Reality experiences, Mixed Reality
+
+ 点击查看摘要
+ We present Large Language Model for Mixed Reality (LLMR), a framework for the real-time creation and modification of interactive Mixed Reality experiences using LLMs. LLMR leverages novel strategies to tackle difficult cases where ideal training data is scarce, or where the design goal requires the synthesis of internal dynamics, intuitive analysis, or advanced interactivity. Our framework relies on text interaction and the Unity game engine. By incorporating techniques for scene understanding, task planning, self-debugging, and memory management, LLMR outperforms the standard GPT-4 by 4x in average error rate. We demonstrate LLMR's cross-platform interoperability with several example worlds, and evaluate it on a variety of creation and modification tasks to show that it can produce and edit diverse objects, tools, and scenes. Finally, we conducted a usability study (N=11) with a diverse set that revealed participants had positive experiences with the system and would use it again.
+
+
+
+ 9. 标题:Improving VTE Identification through Adaptive NLP Model Selection and Clinical Expert Rule-based Classifier from Radiology Reports
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2309.12273
+ 作者:Jamie Deng, Yusen Wu, Hilary Hayssen, Brain Englum, Aman Kankaria, Minerva Mayorga-Carlin, Shalini Sahoo, John Sorkin, Brajesh Lal, Yelena Yesha, Phuong Nguyen
+ 备注:
+ 关键词:severe cardiovascular condition, cardiovascular condition including, deep vein thrombosis, condition including deep, including deep vein
+
+ 点击查看摘要
+ Rapid and accurate identification of Venous thromboembolism (VTE), a severe cardiovascular condition including deep vein thrombosis (DVT) and pulmonary embolism (PE), is important for effective treatment. Leveraging Natural Language Processing (NLP) on radiology reports, automated methods have shown promising advancements in identifying VTE events from retrospective data cohorts or aiding clinical experts in identifying VTE events from radiology reports. However, effectively training Deep Learning (DL) and the NLP models is challenging due to limited labeled medical text data, the complexity and heterogeneity of radiology reports, and data imbalance. This study proposes novel method combinations of DL methods, along with data augmentation, adaptive pre-trained NLP model selection, and a clinical expert NLP rule-based classifier, to improve the accuracy of VTE identification in unstructured (free-text) radiology reports. Our experimental results demonstrate the model's efficacy, achieving an impressive 97\% accuracy and 97\% F1 score in predicting DVT, and an outstanding 98.3\% accuracy and 98.4\% F1 score in predicting PE. These findings emphasize the model's robustness and its potential to significantly contribute to VTE research.
+
+
+
+ 10. 标题:The Cambridge Law Corpus: A Corpus for Legal AI Research
+ 编号:[25]
+ 链接:https://arxiv.org/abs/2309.12269
+ 作者:Andreas Östling, Holli Sargeant, Huiyuan Xie, Ludwig Bull, Alexander Terenin, Leif Jonsson, Måns Magnusson, Felix Steffek
+ 备注:
+ 关键词:Cambridge Law Corpus, Cambridge Law, introduce the Cambridge, Law Corpus, Corpus
+
+ 点击查看摘要
+ We introduce the Cambridge Law Corpus (CLC), a corpus for legal AI research. It consists of over 250 000 court cases from the UK. Most cases are from the 21st century, but the corpus includes cases as old as the 16th century. This paper presents the first release of the corpus, containing the raw text and meta-data. Together with the corpus, we provide annotations on case outcomes for 638 cases, done by legal experts. Using our annotated data, we have trained and evaluated case outcome extraction with GPT-3, GPT-4 and RoBERTa models to provide benchmarks. We include an extensive legal and ethical discussion to address the potentially sensitive nature of this material. As a consequence, the corpus will only be released for research purposes under certain restrictions.
+
+
+
+ 11. 标题:On the Relationship between Skill Neurons and Robustness in Prompt Tuning
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.12263
+ 作者:Leon Ackermann, Xenia Ohmer
+ 备注:
+ 关键词:Prompt Tuning, popular parameter-efficient finetuning, parameter-efficient finetuning method, pre-trained large language, Prompt Tuning activates
+
+ 点击查看摘要
+ Prompt Tuning is a popular parameter-efficient finetuning method for pre-trained large language models (PLMs). Recently, based on experiments with RoBERTa, it has been suggested that Prompt Tuning activates specific neurons in the transformer's feed-forward networks, that are highly predictive and selective for the given task. In this paper, we study the robustness of Prompt Tuning in relation to these "skill neurons", using RoBERTa and T5. We show that prompts tuned for a specific task are transferable to tasks of the same type but are not very robust to adversarial data, with higher robustness for T5 than RoBERTa. At the same time, we replicate the existence of skill neurons in RoBERTa and further show that skill neurons also seem to exist in T5. Interestingly, the skill neurons of T5 determined on non-adversarial data are also among the most predictive neurons on the adversarial data, which is not the case for RoBERTa. We conclude that higher adversarial robustness may be related to a model's ability to activate the relevant skill neurons on adversarial data.
+
+
+
+ 12. 标题:SQUARE: Automatic Question Answering Evaluation using Multiple Positive and Negative References
+ 编号:[34]
+ 链接:https://arxiv.org/abs/2309.12250
+ 作者:Matteo Gabburo, Siddhant Garg, Rik Koncel Kedziorski, Alessandro Moschitti
+ 备注:Accepted to IJCNLP-AACL 2023
+ 关键词:challenging and expensive, reliable approach, Evaluation, correct reference answer, human annotations
+
+ 点击查看摘要
+ Evaluation of QA systems is very challenging and expensive, with the most reliable approach being human annotations of correctness of answers for questions. Recent works (AVA, BEM) have shown that transformer LM encoder based similarity metrics transfer well for QA evaluation, but they are limited by the usage of a single correct reference answer. We propose a new evaluation metric: SQuArE (Sentence-level QUestion AnsweRing Evaluation), using multiple reference answers (combining multiple correct and incorrect references) for sentence-form QA. We evaluate SQuArE on both sentence-level extractive (Answer Selection) and generative (GenQA) QA systems, across multiple academic and industrial datasets, and show that it outperforms previous baselines and obtains the highest correlation with human annotations.
+
+
+
+ 13. 标题:Bad Actor, Good Advisor: Exploring the Role of Large Language Models in Fake News Detection
+ 编号:[35]
+ 链接:https://arxiv.org/abs/2309.12247
+ 作者:Beizhe Hu, Qiang Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Wang, Peng Qi
+ 备注:17 pages, 6 figures, and 9 tables. Work in progress
+ 关键词:language models, large language models, fake news detection, capability limitations, small language models
+
+ 点击查看摘要
+ Detecting fake news requires both a delicate sense of diverse clues and a profound understanding of the real-world background, which remains challenging for detectors based on small language models (SLMs) due to their knowledge and capability limitations. Recent advances in large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with fake news detection remains underexplored. In this paper, we investigate the potential of LLMs in fake news detection. First, we conduct an empirical study and find that a sophisticated LLM such as GPT 3.5 could generally expose fake news and provide desirable multi-perspective rationales but still underperforms the basic SLM, fine-tuned BERT. Our subsequent analysis attributes such a gap to the LLM's inability to select and integrate rationales properly to conclude. Based on these findings, we propose that current LLMs may not substitute fine-tuned SLMs in fake news detection but can be a good advisor for SLMs by providing multi-perspective instructive rationales. To instantiate this proposal, we design an adaptive rationale guidance network for fake news detection (ARG), in which SLMs selectively acquire insights on news analysis from the LLMs' rationales. We further derive a rationale-free version of ARG by distillation, namely ARG-D, which services cost-sensitive scenarios without inquiring LLMs. Experiments on two real-world datasets demonstrate that ARG and ARG-D outperform three types of baseline methods, including SLM-based, LLM-based, and combinations of small and large language models.
+
+
+
+ 14. 标题:ChaCha: Leveraging Large Language Models to Prompt Children to Share Their Emotions about Personal Events
+ 编号:[36]
+ 链接:https://arxiv.org/abs/2309.12244
+ 作者:Woosuk Seo, Chanmo Yang, Young-Ho Kim
+ 备注:21 pages, 4 figures, 2 tables
+ 关键词:Children typically learn, typically learn, learn to identify, identify and express, Children
+
+ 点击查看摘要
+ Children typically learn to identify and express emotions through sharing their stories and feelings with others, particularly their family. However, it is challenging for parents or siblings to have emotional communication with children since children are still developing their communication skills. We present ChaCha, a chatbot that encourages and guides children to share personal events and associated emotions. ChaCha combines a state machine and large language models (LLMs) to keep the dialogue on track while carrying on free-form conversations. Through an exploratory study with 20 children (aged 8-12), we examine how ChaCha prompts children to share personal events and guides them to describe associated emotions. Participants perceived ChaCha as a close friend and shared their stories on various topics, such as family trips and personal achievements. Based on the quantitative and qualitative findings, we discuss opportunities for leveraging LLMs to design child-friendly chatbots to support children in sharing their emotions.
+
+
+
+ 15. 标题:Bridging the Gaps of Both Modality and Language: Synchronous Bilingual CTC for Speech Translation and Speech Recognition
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.12234
+ 作者:Chen Xu, Xiaoqian Liu, Erfeng He, Yuhao Zhang, Qianqian Dong, Tong Xiao, Jingbo Zhu, Dapeng Man, Wu Yang
+ 备注:Submitted to ICASSP 2024
+ 关键词:Connectionist Temporal Classification, bilingual Connectionist Temporal, synchronous bilingual Connectionist, Temporal Classification, present synchronous bilingual
+
+ 点击查看摘要
+ In this study, we present synchronous bilingual Connectionist Temporal Classification (CTC), an innovative framework that leverages dual CTC to bridge the gaps of both modality and language in the speech translation (ST) task. Utilizing transcript and translation as concurrent objectives for CTC, our model bridges the gap between audio and text as well as between source and target languages. Building upon the recent advances in CTC application, we develop an enhanced variant, BiL-CTC+, that establishes new state-of-the-art performances on the MuST-C ST benchmarks under resource-constrained scenarios. Intriguingly, our method also yields significant improvements in speech recognition performance, revealing the effect of cross-lingual learning on transcription and demonstrating its broad applicability. The source code is available at this https URL.
+
+
+
+ 16. 标题:Towards Answering Health-related Questions from Medical Videos: Datasets and Approaches
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2309.12224
+ 作者:Deepak Gupta, Kush Attal, Dina Demner-Fushman
+ 备注:Work in progress
+ 关键词:information and knowledge, availability of online, access information, medical, medical videos
+
+ 点击查看摘要
+ The increase in the availability of online videos has transformed the way we access information and knowledge. A growing number of individuals now prefer instructional videos as they offer a series of step-by-step procedures to accomplish particular tasks. The instructional videos from the medical domain may provide the best possible visual answers to first aid, medical emergency, and medical education questions. Toward this, this paper is focused on answering health-related questions asked by the public by providing visual answers from medical videos. The scarcity of large-scale datasets in the medical domain is a key challenge that hinders the development of applications that can help the public with their health-related questions. To address this issue, we first proposed a pipelined approach to create two large-scale datasets: HealthVidQA-CRF and HealthVidQA-Prompt. Later, we proposed monomodal and multimodal approaches that can effectively provide visual answers from medical videos to natural language questions. We conducted a comprehensive analysis of the results, focusing on the impact of the created datasets on model training and the significance of visual features in enhancing the performance of the monomodal and multi-modal approaches. Our findings suggest that these datasets have the potential to enhance the performance of medical visual answer localization tasks and provide a promising future direction to further enhance the performance by using pre-trained language-vision models.
+
+
+
+ 17. 标题:Code Soliloquies for Accurate Calculations in Large Language Models
+ 编号:[68]
+ 链接:https://arxiv.org/abs/2309.12161
+ 作者:Shashank Sonkar, MyCo Le, Xinghe Chen, Naiming Liu, Debshila Basu Mallick, Richard G. Baraniuk
+ 备注:
+ 关键词:Intelligent Tutoring Systems, Large Language Model, Tutoring Systems, Intelligent Tutoring, Large Language
+
+ 点击查看摘要
+ High-quality conversational datasets are integral to the successful development of Intelligent Tutoring Systems (ITS) that employ a Large Language Model (LLM) backend. These datasets, when used to fine-tune the LLM backend, significantly enhance the quality of interactions between students and ITS. A common strategy for developing these datasets involves generating synthetic student-teacher dialogues using advanced GPT-4 models. However, challenges arise when these dialogues demand complex calculations, common in subjects like physics. Despite its advanced capabilities, GPT-4's performance falls short in reliably handling even simple multiplication tasks, marking a significant limitation in its utility for these subjects. To address these challenges, this paper introduces an innovative stateful prompt design. Our approach generates a mock conversation between a student and a tutorbot, both roles simulated by GPT-4. Each student response triggers a soliloquy (an inner monologue) in the GPT-tutorbot, which assesses whether its response would necessitate calculations. If so, it proceeds to script the required code in Python and then uses the resulting output to construct its response to the student. Our approach notably enhances the quality of synthetic conversation datasets, especially for subjects that are calculation-intensive. Our findings show that our Higgs model -- a LLaMA finetuned with datasets generated through our novel stateful prompt design -- proficiently utilizes Python for computations. Consequently, finetuning with our datasets enriched with code soliloquies enhances not just the accuracy but also the computational reliability of Higgs' responses.
+
+
+
+ 18. 标题:OSN-MDAD: Machine Translation Dataset for Arabic Multi-Dialectal Conversations on Online Social Media
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.12137
+ 作者:Fatimah Alzamzami, Abdulmotaleb El Saddik
+ 备注:
+ 关键词:Arabic, Arabic dialects, fairly sufficient, sufficient to understand, MSA
+
+ 点击查看摘要
+ While resources for English language are fairly sufficient to understand content on social media, similar resources in Arabic are still immature. The main reason that the resources in Arabic are insufficient is that Arabic has many dialects in addition to the standard version (MSA). Arabs do not use MSA in their daily communications; rather, they use dialectal versions. Unfortunately, social users transfer this phenomenon into their use of social media platforms, which in turn has raised an urgent need for building suitable AI models for language-dependent applications. Existing machine translation (MT) systems designed for MSA fail to work well with Arabic dialects. In light of this, it is necessary to adapt to the informal nature of communication on social networks by developing MT systems that can effectively handle the various dialects of Arabic. Unlike for MSA that shows advanced progress in MT systems, little effort has been exerted to utilize Arabic dialects for MT systems. While few attempts have been made to build translation datasets for dialectal Arabic, they are domain dependent and are not OSN cultural-language friendly. In this work, we attempt to alleviate these limitations by proposing an online social network-based multidialect Arabic dataset that is crafted by contextually translating English tweets into four Arabic dialects: Gulf, Yemeni, Iraqi, and Levantine. To perform the translation, we followed our proposed guideline framework for content translation, which could be universally applicable for translation between foreign languages and local dialects. We validated the authenticity of our proposed dataset by developing neural MT models for four Arabic dialects. Our results have shown a superior performance of our NMT models trained using our dataset. We believe that our dataset can reliably serve as an Arabic multidialectal translation dataset for informal MT tasks.
+
+
+
+ 19. 标题:How-to Guides for Specific Audiences: A Corpus and Initial Findings
+ 编号:[84]
+ 链接:https://arxiv.org/abs/2309.12117
+ 作者:Nicola Fanton, Agnieszka Falenska, Michael Roth
+ 备注:ACL 2023 best student paper
+ 关键词:specific target groups, desired goals, account the prior, prior knowledge, readers in order
+
+ 点击查看摘要
+ Instructional texts for specific target groups should ideally take into account the prior knowledge and needs of the readers in order to guide them efficiently to their desired goals. However, targeting specific groups also carries the risk of reflecting disparate social norms and subtle stereotypes. In this paper, we investigate the extent to which how-to guides from one particular platform, wikiHow, differ in practice depending on the intended audience. We conduct two case studies in which we examine qualitative features of texts written for specific audiences. In a generalization study, we investigate which differences can also be systematically demonstrated using computational methods. The results of our studies show that guides from wikiHow, like other text genres, are subject to subtle biases. We aim to raise awareness of these inequalities as a first step to addressing them in future work.
+
+
+
+ 20. 标题:PEFTT: Parameter-Efficient Fine-Tuning for low-resource Tibetan pre-trained language models
+ 编号:[90]
+ 链接:https://arxiv.org/abs/2309.12109
+ 作者:Zhou Mingjun, Daiqing Zhuoma, Qun Nuo, Nyima Tashi
+ 备注:
+ 关键词:Tibetan, users and institutions, traditional training, increasingly unimaginable, unimaginable for regular
+
+ 点击查看摘要
+ In this era of large language models (LLMs), the traditional training of models has become increasingly unimaginable for regular users and institutions. The exploration of efficient fine-tuning for high-resource languages on these models is an undeniable trend that is gradually gaining popularity. However, there has been very little exploration for various low-resource languages, such as Tibetan. Research in Tibetan NLP is inherently scarce and limited. While there is currently no existing large language model for Tibetan due to its low-resource nature, that day will undoubtedly arrive. Therefore, research on efficient fine-tuning for low-resource language models like Tibetan is highly necessary. Our research can serve as a reference to fill this crucial gap. Efficient fine-tuning strategies for pre-trained language models (PLMs) in Tibetan have seen minimal exploration. We conducted three types of efficient fine-tuning experiments on the publicly available TNCC-title dataset: "prompt-tuning," "Adapter lightweight fine-tuning," and "prompt-tuning + Adapter fine-tuning." The experimental results demonstrate significant improvements using these methods, providing valuable insights for advancing Tibetan language applications in the context of pre-trained models.
+
+
+
+ 21. 标题:A Computational Analysis of Vagueness in Revisions of Instructional Texts
+ 编号:[92]
+ 链接:https://arxiv.org/abs/2309.12107
+ 作者:Alok Debnath, Michael Roth
+ 备注:EACL 2021 best student paper
+ 关键词:revised by users, open-domain repository, repository of instructional, instructional articles, extract pairwise versions
+
+ 点击查看摘要
+ WikiHow is an open-domain repository of instructional articles for a variety of tasks, which can be revised by users. In this paper, we extract pairwise versions of an instruction before and after a revision was made. Starting from a noisy dataset of revision histories, we specifically extract and analyze edits that involve cases of vagueness in instructions. We further investigate the ability of a neural model to distinguish between two versions of an instruction in our data by adopting a pairwise ranking task from previous work and showing improvements over existing baselines.
+
+
+
+ 22. 标题:SemEval-2022 Task 7: Identifying Plausible Clarifications of Implicit and Underspecified Phrases in Instructional Texts
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2309.12102
+ 作者:Michael Roth, Talita Anthonio, Anna Sauer
+ 备注:SemEval-2022 best task description paper
+ 关键词:instructional texts, shared task, Task, human plausibility judgements, collected human plausibility
+
+ 点击查看摘要
+ We describe SemEval-2022 Task 7, a shared task on rating the plausibility of clarifications in instructional texts. The dataset for this task consists of manually clarified how-to guides for which we generated alternative clarifications and collected human plausibility judgements. The task of participating systems was to automatically determine the plausibility of a clarification in the respective context. In total, 21 participants took part in this task, with the best system achieving an accuracy of 68.9%. This report summarizes the results and findings from 8 teams and their system descriptions. Finally, we show in an additional evaluation that predictions by the top participating team make it possible to identify contexts with multiple plausible clarifications with an accuracy of 75.2%.
+
+
+
+ 23. 标题:Accelerating Thematic Investment with Prompt Tuned Pretrained Language Models
+ 编号:[100]
+ 链接:https://arxiv.org/abs/2309.12075
+ 作者:Valentin Leonhard Buchner, Lele Cao, Jan-Christoph Kalo
+ 备注:A thesis written in fulfillment of the requirements for the joint MSc degree in Artificial Intelligence at the VU Amsterdam and University of Amsterdam
+ 关键词:fine-tune Pretrained Language, Pretrained Language Models, Prompt Tuning, fine-tune Pretrained, Pretrained Language
+
+ 点击查看摘要
+ Prompt Tuning is emerging as a scalable and cost-effective method to fine-tune Pretrained Language Models (PLMs). This study benchmarks the performance and computational efficiency of Prompt Tuning and baseline methods on a multi-label text classification task. This is applied to the use case of classifying companies into an investment firm's proprietary industry taxonomy, supporting their thematic investment strategy. Text-to-text classification with PLMs is frequently reported to outperform classification with a classification head, but has several limitations when applied to a multi-label classification problem where each label consists of multiple tokens: (a) Generated labels may not match any label in the industry taxonomy; (b) During fine-tuning, multiple labels must be provided in an arbitrary order; (c) The model provides a binary decision for each label, rather than an appropriate confidence score. Limitation (a) is addressed by applying constrained decoding using Trie Search, which slightly improves classification performance. All limitations (a), (b), and (c) are addressed by replacing the PLM's language head with a classification head. This improves performance significantly, while also reducing computational costs during inference. The results indicate the continuing need to adapt state-of-the-art methods to domain-specific tasks, even in the era of PLMs with strong generalization abilities.
+
+
+
+ 24. 标题:Benchmarking quantized LLaMa-based models on the Brazilian Secondary School Exam
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2309.12071
+ 作者:Matheus L. O. Santos, Cláudio E. C. Campelo
+ 备注:8 pages, 6 figures, 4 tables
+ 关键词:Large Language Models, Large Language, Language Models, represent a revolution, interact with computers
+
+ 点击查看摘要
+ Although Large Language Models (LLMs) represent a revolution in the way we interact with computers, allowing the construction of complex questions and the ability to reason over a sequence of statements, their use is restricted due to the need for dedicated hardware for execution. In this study, we evaluate the performance of LLMs based on the 7 and 13 billion LLaMA models, subjected to a quantization process and run on home hardware. The models considered were Alpaca, Koala, and Vicuna. To evaluate the effectiveness of these models, we developed a database containing 1,006 questions from the ENEM (Brazilian National Secondary School Exam). Our analysis revealed that the best performing models achieved an accuracy of approximately 46% for the original texts of the Portuguese questions and 49% on their English translations. In addition, we evaluated the computational efficiency of the models by measuring the time required for execution. On average, the 7 and 13 billion LLMs took approximately 20 and 50 seconds, respectively, to process the queries on a machine equipped with an AMD Ryzen 5 3600x processor
+
+
+
+ 25. 标题:BELT:Bootstrapping Electroencephalography-to-Language Decoding and Zero-Shot Sentiment Classification by Natural Language Supervision
+ 编号:[106]
+ 链接:https://arxiv.org/abs/2309.12056
+ 作者:Jinzhao Zhou, Yiqun Duan, Yu-Cheng Chang, Yu-Kai Wang, Chin-Teng Lin
+ 备注:
+ 关键词:paper presents BELT, EEG representation, paper presents, pivotal topic, presents BELT
+
+ 点击查看摘要
+ This paper presents BELT, a novel model and learning framework for the pivotal topic of brain-to-language translation research. The translation from noninvasive brain signals into readable natural language has the potential to promote the application scenario as well as the development of brain-computer interfaces (BCI) as a whole. The critical problem in brain signal decoding or brain-to-language translation is the acquisition of semantically appropriate and discriminative EEG representation from a dataset of limited scale and quality. The proposed BELT method is a generic and efficient framework that bootstraps EEG representation learning using off-the-shelf large-scale pretrained language models (LMs). With a large LM's capacity for understanding semantic information and zero-shot generalization, BELT utilizes large LMs trained on Internet-scale datasets to bring significant improvements to the understanding of EEG signals.
+In particular, the BELT model is composed of a deep conformer encoder and a vector quantization encoder. Semantical EEG representation is achieved by a contrastive learning step that provides natural language supervision. We achieve state-of-the-art results on two featuring brain decoding tasks including the brain-to-language translation and zero-shot sentiment classification. Specifically, our model surpasses the baseline model on both tasks by 5.45% and over 10% and archives a 42.31% BLEU-1 score and 67.32% precision on the main evaluation metrics for translation and zero-shot sentiment classification respectively.
+
+
+
+ 26. 标题:AceGPT, Localizing Large Language Models in Arabic
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2309.12053
+ 作者:Huang Huang, Fei Yu, Jianqing Zhu, Xuening Sun, Hao Cheng, Dingjie Song, Zhihong Chen, Abdulmohsen Alharthi, Bang An, Ziche Liu, Zhiyi Zhang, Junying Chen, Jianquan Li, Benyou Wang, Lian Zhang, Ruoyu Sun, Xiang Wan, Haizhou Li, Jinchao Xu
+ 备注:this https URL
+ 关键词:localized Large Language, Large Language Model, localized Large, unique cultural characteristics, current mainstream models
+
+ 点击查看摘要
+ This paper explores the imperative need and methodology for developing a localized Large Language Model (LLM) tailored for Arabic, a language with unique cultural characteristics that are not adequately addressed by current mainstream models like ChatGPT. Key concerns additionally arise when considering cultural sensitivity and local values. To this end, the paper outlines a packaged solution, including further pre-training with Arabic texts, supervised fine-tuning (SFT) using native Arabic instructions and GPT-4 responses in Arabic, and reinforcement learning with AI feedback (RLAIF) using a reward model that is sensitive to local culture and values. The objective is to train culturally aware and value-aligned Arabic LLMs that can serve the diverse application-specific needs of Arabic-speaking communities.
+Extensive evaluations demonstrated that the resulting LLM called `AceGPT' is the SOTA open Arabic LLM in various benchmarks, including instruction-following benchmark (i.e., Arabic Vicuna-80 and Arabic AlpacaEval), knowledge benchmark (i.e., Arabic MMLU and EXAMs), as well as the newly-proposed Arabic cultural \& value alignment benchmark. Notably, AceGPT outperforms ChatGPT in the popular Vicuna-80 benchmark when evaluated with GPT-4, despite the benchmark's limited scale. % Natural Language Understanding (NLU) benchmark (i.e., ALUE)
+Codes, data, and models are in this https URL.
+
+
+
+ 27. 标题:CAMERA: A Multimodal Dataset and Benchmark for Ad Text Generation
+ 编号:[120]
+ 链接:https://arxiv.org/abs/2309.12030
+ 作者:Masato Mita, Soichiro Murakami, Akihiko Kato, Peinan Zhang
+ 备注:13 pages
+ 关键词:online ad production, significant research, limitations of manual, manual online, text generation
+
+ 点击查看摘要
+ In response to the limitations of manual online ad production, significant research has been conducted in the field of automatic ad text generation (ATG). However, comparing different methods has been challenging because of the lack of benchmarks encompassing the entire field and the absence of well-defined problem sets with clear model inputs and outputs. To address these challenges, this paper aims to advance the field of ATG by introducing a redesigned task and constructing a benchmark. Specifically, we defined ATG as a cross-application task encompassing various aspects of the Internet advertising. As part of our contribution, we propose a first benchmark dataset, CA Multimodal Evaluation for Ad Text GeneRAtion (CAMERA), carefully designed for ATG to be able to leverage multi-modal information and conduct an industry-wise evaluation. Furthermore, we demonstrate the usefulness of our proposed benchmark through evaluation experiments using multiple baseline models, which vary in terms of the type of pre-trained language model used and the incorporation of multi-modal information. We also discuss the current state of the task and the future challenges.
+
+
+
+ 28. 标题:LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2309.11998
+ 作者:Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric. P Xing, Joseph E. Gonzalez, Ion Stoica, Hao Zhang
+ 备注:
+ 关键词:increasingly important due, large language models, Studying how people, people interact, interact with large
+
+ 点击查看摘要
+ Studying how people interact with large language models (LLMs) in real-world scenarios is increasingly important due to their widespread use in various applications. In this paper, we introduce LMSYS-Chat-1M, a large-scale dataset containing one million real-world conversations with 25 state-of-the-art LLMs. This dataset is collected from 210K unique IP addresses in the wild on our Vicuna demo and Chatbot Arena website. We offer an overview of the dataset's content, including its curation process, basic statistics, and topic distribution, highlighting its diversity, originality, and scale. We demonstrate its versatility through four use cases: developing content moderation models that perform similarly to GPT-4, building a safety benchmark, training instruction-following models that perform similarly to Vicuna, and creating challenging benchmark questions. We believe that this dataset will serve as a valuable resource for understanding and advancing LLM capabilities. The dataset is publicly available at this https URL.
+
+
+
+ 29. 标题:Rethinking the Evaluating Framework for Natural Language Understanding in AI Systems: Language Acquisition as a Core for Future Metrics
+ 编号:[145]
+ 链接:https://arxiv.org/abs/2309.11981
+ 作者:Patricio Vera, Pedro Moya, Lisa Barraza
+ 备注:25 pages, 1 table, 2 figures
+ 关键词:large language models, natural language processing, artificial intelligence, machine intelligence, offers an opportunity
+
+ 点击查看摘要
+ In the burgeoning field of artificial intelligence (AI), the unprecedented progress of large language models (LLMs) in natural language processing (NLP) offers an opportunity to revisit the entire approach of traditional metrics of machine intelligence, both in form and content. As the realm of machine cognitive evaluation has already reached Imitation, the next step is an efficient Language Acquisition and Understanding. Our paper proposes a paradigm shift from the established Turing Test towards an all-embracing framework that hinges on language acquisition, taking inspiration from the recent advancements in LLMs. The present contribution is deeply tributary of the excellent work from various disciplines, point out the need to keep interdisciplinary bridges open, and delineates a more robust and sustainable approach.
+
+
+
+ 30. 标题:Scaling up COMETKIWI: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2309.11925
+ 作者:Ricardo Rei, Nuno M. Guerreiro, José Pombal, Daan van Stigt, Marcos Treviso, Luisa Coheur, José G.C. de Souza, André F.T. Martins
+ 备注:
+ 关键词:Instituto Superior Técnico, Unbabel and Instituto, Instituto Superior, Superior Técnico, contribution of Unbabel
+
+ 点击查看摘要
+ We present the joint contribution of Unbabel and Instituto Superior Técnico to the WMT 2023 Shared Task on Quality Estimation (QE). Our team participated on all tasks: sentence- and word-level quality prediction (task 1) and fine-grained error span detection (task 2). For all tasks, we build on the COMETKIWI-22 model (Rei et al., 2022b). Our multilingual approaches are ranked first for all tasks, reaching state-of-the-art performance for quality estimation at word-, span- and sentence-level granularity. Compared to the previous state-of-the-art COMETKIWI-22, we show large improvements in correlation with human judgements (up to 10 Spearman points). Moreover, we surpass the second-best multilingual submission to the shared-task with up to 3.8 absolute points.
+
+
+
+ 31. 标题:InstructERC: Reforming Emotion Recognition in Conversation with a Retrieval Multi-task LLMs Framework
+ 编号:[176]
+ 链接:https://arxiv.org/abs/2309.11911
+ 作者:Shanglin Lei, Guanting Dong, Xiaoping Wang, Keheng Wang, Sirui Wang
+ 备注:
+ 关键词:pipeline designs, consistently hindered, complexity of pipeline, overfit to specific, Large Language Models
+
+ 点击查看摘要
+ The development of emotion recognition in dialogue (ERC) has been consistently hindered by the complexity of pipeline designs, leading to ERC models that often overfit to specific datasets and dialogue patterns. In this study, we propose a novel approach, namely
+InstructERC, to reformulates the ERC task from a discriminative framework to a generative framework based on Large Language Models (LLMs) . InstructERC has two significant contributions: Firstly, InstructERC introduces a simple yet effective retrieval template module, which helps the model explicitly integrate multi-granularity dialogue supervision information by concatenating the historical dialog content, label statement, and emotional domain demonstrations with high semantic similarity. Furthermore, we introduce two additional emotion alignment tasks, namely speaker identification and emotion prediction tasks, to implicitly model the dialogue role relationships and future emotional tendencies in conversations. Our LLM-based plug-and-play plugin framework significantly outperforms all previous models and achieves comprehensive SOTA on three commonly used ERC datasets. Extensive analysis of parameter-efficient and data-scaling experiments provide empirical guidance for applying InstructERC in practical scenarios. Our code will be released after blind review.
+
+
+
+ 32. 标题:Focal Inferential Infusion Coupled with Tractable Density Discrimination for Implicit Hate Speech Detection
+ 编号:[184]
+ 链接:https://arxiv.org/abs/2309.11896
+ 作者:Sarah Masud, Ashutosh Bajpai, Tanmoy Chakraborty
+ 备注:21 pages, 6 Figures and 9 Tables
+ 关键词:large language models, pre-trained large language, implicit hate, NLP tasks, implicit hate speech
+
+ 点击查看摘要
+ Although pre-trained large language models (PLMs) have achieved state-of-the-art on many NLP tasks, they lack understanding of subtle expressions of implicit hate speech. Such nuanced and implicit hate is often misclassified as non-hate. Various attempts have been made to enhance the detection of (implicit) hate content by augmenting external context or enforcing label separation via distance-based metrics. We combine these two approaches and introduce FiADD, a novel Focused Inferential Adaptive Density Discrimination framework. FiADD enhances the PLM finetuning pipeline by bringing the surface form of an implicit hate speech closer to its implied form while increasing the inter-cluster distance among various class labels. We test FiADD on three implicit hate datasets and observe significant improvement in the two-way and three-way hate classification tasks. We further experiment on the generalizability of FiADD on three other tasks, namely detecting sarcasm, irony, and stance, in which surface and implied forms differ, and observe similar performance improvement. We analyze the generated latent space to understand its evolution under FiADD, which corroborates the advantage of employing FiADD for implicit hate speech detection.
+
+
+
+ 33. 标题:Audio Contrastive based Fine-tuning
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.11895
+ 作者:Yang Wang, Qibin Liang, Chenghao Xiao, Yizhi Li, Noura Al Moubayed, Chenghua Lin
+ 备注:Under review
+ 关键词:sound processing tasks, range of applications, Audio classification plays, plays a crucial, crucial role
+
+ 点击查看摘要
+ Audio classification plays a crucial role in speech and sound processing tasks with a wide range of applications. There still remains a challenge of striking the right balance between fitting the model to the training data (avoiding overfitting) and enabling it to generalise well to a new domain. Leveraging the transferability of contrastive learning, we introduce Audio Contrastive-based Fine-tuning (AudioConFit), an efficient approach characterised by robust generalisability. Empirical experiments on a variety of audio classification tasks demonstrate the effectiveness and robustness of our approach, which achieves state-of-the-art results in various settings.
+
+
+
+ 34. 标题:Is It Really Useful to Jointly Parse Constituency and Dependency Trees? A Revisit
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2309.11888
+ 作者:Yanggang Gu, Yang Hou, Zhefeng Wang, Xinyu Duan, Zhenghua Li
+ 备注:
+ 关键词:dependency trees simultaneously, jointly parsing constituency, produce compatible constituency, constituency and dependency, dependency trees
+
+ 点击查看摘要
+ This work visits the topic of jointly parsing constituency and dependency trees, i.e., to produce compatible constituency and dependency trees simultaneously for input sentences, which is attractive considering that the two types of trees are complementary in representing syntax. Compared with previous works, we make progress in four aspects: (1) adopting a much more efficient decoding algorithm, (2) exploring joint modeling at the training phase, instead of only at the inference phase, (3) proposing high-order scoring components for constituent-dependency interaction, (4) gaining more insights via in-depth experiments and analysis.
+
+
+
+ 35. 标题:Syntactic Variation Across the Grammar: Modelling a Complex Adaptive System
+ 编号:[199]
+ 链接:https://arxiv.org/abs/2309.11869
+ 作者:Jonathan Dunn
+ 备注:
+ 关键词:complex adaptive system, adaptive system, syntactic variation observes, complex adaptive, grammar
+
+ 点击查看摘要
+ While language is a complex adaptive system, most work on syntactic variation observes a few individual constructions in isolation from the rest of the grammar. This means that the grammar, a network which connects thousands of structures at different levels of abstraction, is reduced to a few disconnected variables. This paper quantifies the impact of such reductions by systematically modelling dialectal variation across 49 local populations of English speakers in 16 countries. We perform dialect classification with both an entire grammar as well as with isolated nodes within the grammar in order to characterize the syntactic differences between these dialects. The results show, first, that many individual nodes within the grammar are subject to variation but, in isolation, none perform as well as the grammar as a whole. This indicates that an important part of syntactic variation consists of interactions between different parts of the grammar. Second, the results show that the similarity between dialects depends heavily on the sub-set of the grammar being observed: for example, New Zealand English could be more similar to Australian English in phrasal verbs but at the same time more similar to UK English in dative phrases.
+
+
+
+ 36. 标题:BitCoin: Bidirectional Tagging and Supervised Contrastive Learning based Joint Relational Triple Extraction Framework
+ 编号:[207]
+ 链接:https://arxiv.org/abs/2309.11853
+ 作者:Luyao He, Zhongbao Zhang, Sen Su, Yuxin Chen
+ 备注:arXiv admin note: text overlap with arXiv:2112.04940 by other authors
+ 关键词:knowledge graph construction, graph construction, knowledge graph, RTE, subject
+
+ 点击查看摘要
+ Relation triple extraction (RTE) is an essential task in information extraction and knowledge graph construction. Despite recent advancements, existing methods still exhibit certain limitations. They just employ generalized pre-trained models and do not consider the specificity of RTE tasks. Moreover, existing tagging-based approaches typically decompose the RTE task into two subtasks, initially identifying subjects and subsequently identifying objects and relations. They solely focus on extracting relational triples from subject to object, neglecting that once the extraction of a subject fails, it fails in extracting all triples associated with that subject. To address these issues, we propose BitCoin, an innovative Bidirectional tagging and supervised Contrastive learning based joint relational triple extraction framework. Specifically, we design a supervised contrastive learning method that considers multiple positives per anchor rather than restricting it to just one positive. Furthermore, a penalty term is introduced to prevent excessive similarity between the subject and object. Our framework implements taggers in two directions, enabling triples extraction from subject to object and object to subject. Experimental results show that BitCoin achieves state-of-the-art results on the benchmark datasets and significantly improves the F1 score on Normal, SEO, EPO, and multiple relation extraction tasks.
+
+
+
+ 37. 标题:Knowledge Sanitization of Large Language Models
+ 编号:[208]
+ 链接:https://arxiv.org/abs/2309.11852
+ 作者:Yoichi Ishibashi, Hidetoshi Shimodaira
+ 备注:
+ 关键词:knowledge sanitization approach, large language models, sanitization approach, approach to mitigate, mitigate the privacy
+
+ 点击查看摘要
+ We explore a knowledge sanitization approach to mitigate the privacy concerns associated with large language models (LLMs). LLMs trained on a large corpus of Web data can memorize and potentially reveal sensitive or confidential information, raising critical security concerns. Our technique fine-tunes these models, prompting them to generate harmless responses such as ``I don't know'' when queried about specific information. Experimental results in a closed-book question-answering task show that our straightforward method not only minimizes particular knowledge leakage but also preserves the overall performance of LLM. These two advantages strengthen the defense against extraction attacks and reduces the emission of harmful content such as hallucinations.
+
+
+
+ 38. 标题:A Discourse-level Multi-scale Prosodic Model for Fine-grained Emotion Analysis
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2309.11849
+ 作者:Xianhao Wei, Jia Jia, Xiang Li, Zhiyong Wu, Ziyi Wang
+ 备注:ChinaMM 2023
+ 关键词:Local Prosody Embedding, paper explores predicting, explores predicting suitable, predicting suitable prosodic, Global Style Embedding
+
+ 点击查看摘要
+ This paper explores predicting suitable prosodic features for fine-grained emotion analysis from the discourse-level text. To obtain fine-grained emotional prosodic features as predictive values for our model, we extract a phoneme-level Local Prosody Embedding sequence (LPEs) and a Global Style Embedding as prosodic speech features from the speech with the help of a style transfer model. We propose a Discourse-level Multi-scale text Prosodic Model (D-MPM) that exploits multi-scale text to predict these two prosodic features. The proposed model can be used to analyze better emotional prosodic features and thus guide the speech synthesis model to synthesize more expressive speech. To quantitatively evaluate the proposed model, we contribute a new and large-scale Discourse-level Chinese Audiobook (DCA) dataset with more than 13,000 utterances annotated sequences to evaluate the proposed model. Experimental results on the DCA dataset show that the multi-scale text information effectively helps to predict prosodic features, and the discourse-level text improves both the overall coherence and the user experience. More interestingly, although we aim at the synthesis effect of the style transfer model, the synthesized speech by the proposed text prosodic analysis model is even better than the style transfer from the original speech in some user evaluation indicators.
+
+
+
+ 39. 标题:Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
+ 编号:[217]
+ 链接:https://arxiv.org/abs/2309.11838
+ 作者:Norbert Braunschweiler, Rama Doddipatla, Simon Keizer, Svetlana Stoyanchev
+ 备注:10 pages
+ 关键词:large language models, large language, Shared Task, shared task winning, document-grounded response generation
+
+ 点击查看摘要
+ In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
+
+
+
+ 40. 标题:A Chinese Prompt Attack Dataset for LLMs with Evil Content
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2309.11830
+ 作者:Chengyuan Liu, Fubang Zhao, Lizhi Qing, Yangyang Kang, Changlong Sun, Kun Kuang, Fei Wu
+ 备注:
+ 关键词:Large Language Models, Language Models, present significant priority, Large Language, Prompt Attack
+
+ 点击查看摘要
+ Large Language Models (LLMs) present significant priority in text understanding and generation. However, LLMs suffer from the risk of generating harmful contents especially while being employed to applications. There are several black-box attack methods, such as Prompt Attack, which can change the behaviour of LLMs and induce LLMs to generate unexpected answers with harmful contents. Researchers are interested in Prompt Attack and Defense with LLMs, while there is no publicly available dataset to evaluate the abilities of defending prompt attack. In this paper, we introduce a Chinese Prompt Attack Dataset for LLMs, called CPAD. Our prompts aim to induce LLMs to generate unexpected outputs with several carefully designed prompt attack approaches and widely concerned attacking contents. Different from previous datasets involving safety estimation, We construct the prompts considering three dimensions: contents, attacking methods and goals, thus the responses can be easily evaluated and analysed. We run several well-known Chinese LLMs on our dataset, and the results show that our prompts are significantly harmful to LLMs, with around 70% attack success rate. We will release CPAD to encourage further studies on prompt attack and defense.
+
+
+
+ 41. 标题:Word Embedding with Neural Probabilistic Prior
+ 编号:[223]
+ 链接:https://arxiv.org/abs/2309.11824
+ 作者:Shaogang Ren, Dingcheng Li, Ping Li
+ 备注:
+ 关键词:word representation learning, representation learning, seamlessly integrated, word embedding models, word representation
+
+ 点击查看摘要
+ To improve word representation learning, we propose a probabilistic prior which can be seamlessly integrated with word embedding models. Different from previous methods, word embedding is taken as a probabilistic generative model, and it enables us to impose a prior regularizing word representation learning. The proposed prior not only enhances the representation of embedding vectors but also improves the model's robustness and stability. The structure of the proposed prior is simple and effective, and it can be easily implemented and flexibly plugged in most existing word embedding models. Extensive experiments show the proposed method improves word representation on various tasks.
+
+
+
+ 42. 标题:SLHCat: Mapping Wikipedia Categories and Lists to DBpedia by Leveraging Semantic, Lexical, and Hierarchical Features
+ 编号:[233]
+ 链接:https://arxiv.org/abs/2309.11791
+ 作者:Zhaoyi Wang, Zhenyang Zhang, Jiaxin Qin, Mizuho Iwaihara
+ 备注:
+ 关键词:categories and lists, universal taxonomy, redundancies and inconsistencies, Wikipedia articles, articles are hierarchically
+
+ 点击查看摘要
+ Wikipedia articles are hierarchically organized through categories and lists, providing one of the most comprehensive and universal taxonomy, but its open creation is causing redundancies and inconsistencies. Assigning DBPedia classes to Wikipedia categories and lists can alleviate the problem, realizing a large knowledge graph which is essential for categorizing digital contents through entity linking and typing. However, the existing approach of CaLiGraph is producing incomplete and non-fine grained mappings. In this paper, we tackle the problem as ontology alignment, where structural information of knowledge graphs and lexical and semantic features of ontology class names are utilized to discover confident mappings, which are in turn utilized for finetuing pretrained language models in a distant supervision fashion. Our method SLHCat consists of two main parts: 1) Automatically generating training data by leveraging knowledge graph structure, semantic similarities, and named entity typing. 2) Finetuning and prompt-tuning of the pre-trained language model BERT are carried out over the training data, to capture semantic and syntactic properties of class names. Our model SLHCat is evaluated over a benchmark dataset constructed by annotating 3000 fine-grained CaLiGraph-DBpedia mapping pairs. SLHCat is outperforming the baseline model by a large margin of 25% in accuracy, offering a practical solution for large-scale ontology mapping.
+
+
+
+ 43. 标题:ContextRef: Evaluating Referenceless Metrics For Image Description Generation
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2309.11710
+ 作者:Elisa Kreiss, Eric Zelikman, Christopher Potts, Nick Haber
+ 备注:
+ 关键词:ground-truth reference texts, costly ground-truth reference, reference texts, directly without costly, costly ground-truth
+
+ 点击查看摘要
+ Referenceless metrics (e.g., CLIPScore) use pretrained vision--language models to assess image descriptions directly without costly ground-truth reference texts. Such methods can facilitate rapid progress, but only if they truly align with human preference judgments. In this paper, we introduce ContextRef, a benchmark for assessing referenceless metrics for such alignment. ContextRef has two components: human ratings along a variety of established quality dimensions, and ten diverse robustness checks designed to uncover fundamental weaknesses. A crucial aspect of ContextRef is that images and descriptions are presented in context, reflecting prior work showing that context is important for description quality. Using ContextRef, we assess a variety of pretrained models, scoring functions, and techniques for incorporating context. None of the methods is successful with ContextRef, but we show that careful fine-tuning yields substantial improvements. ContextRef remains a challenging benchmark though, in large part due to the challenge of context dependence.
+
+
+
+ 44. 标题:Memory-Augmented LLM Personalization with Short- and Long-Term Memory Coordination
+ 编号:[268]
+ 链接:https://arxiv.org/abs/2309.11696
+ 作者:Kai Zhang, Fubang Zhao, Yangyang Kang, Xiaozhong Liu
+ 备注:
+ 关键词:Large Language Models, generating natural language, Language Models, exhibited remarkable proficiency, Large Language
+
+ 点击查看摘要
+ Large Language Models (LLMs), such as GPT3.5, have exhibited remarkable proficiency in comprehending and generating natural language. However, their unpersonalized generation paradigm may result in suboptimal user-specific outcomes. Typically, users converse differently based on their knowledge and preferences. This necessitates the task of enhancing user-oriented LLM which remains unexplored. While one can fully train an LLM for this objective, the resource consumption is unaffordable. Prior research has explored memory-based methods to store and retrieve knowledge to enhance generation without retraining for new queries. However, we contend that a mere memory module is inadequate to comprehend a user's preference, and fully training an LLM can be excessively costly. In this study, we propose a novel computational bionic memory mechanism, equipped with a parameter-efficient fine-tuning schema, to personalize LLMs. Our extensive experimental results demonstrate the effectiveness and superiority of the proposed approach. To encourage further research into this area, we are releasing a new conversation dataset generated entirely by LLM based on an open-source medical corpus, as well as our implementation code.
+
+
+
+ 45. 标题:Semi-supervised News Discourse Profiling with Contrastive Learning
+ 编号:[270]
+ 链接:https://arxiv.org/abs/2309.11692
+ 作者:Ming Li, Ruihong Huang
+ 备注:IJCNLP-AACL 2023
+ 关键词:Discourse Profiling seeks, downstream applications, Discourse Profiling, discourse profiling task, seeks to scrutinize
+
+ 点击查看摘要
+ News Discourse Profiling seeks to scrutinize the event-related role of each sentence in a news article and has been proven useful across various downstream applications. Specifically, within the context of a given news discourse, each sentence is assigned to a pre-defined category contingent upon its depiction of the news event structure. However, existing approaches suffer from an inadequacy of available human-annotated data, due to the laborious and time-intensive nature of generating discourse-level annotations. In this paper, we present a novel approach, denoted as Intra-document Contrastive Learning with Distillation (ICLD), for addressing the news discourse profiling task, capitalizing on its unique structural characteristics. Notably, we are the first to apply a semi-supervised methodology within this task paradigm, and evaluation demonstrates the effectiveness of the presented approach.
+
+
+
+ 46. 标题:LLM Guided Inductive Inference for Solving Compositional Problems
+ 编号:[273]
+ 链接:https://arxiv.org/abs/2309.11688
+ 作者:Abhigya Sodani, Lauren Moos, Matthew Mirman
+ 备注:5 pages, ICML TEACH Workshop
+ 关键词:demonstrated impressive performance, model training data, large language models, questions require knowledge, real world
+
+ 点击查看摘要
+ While large language models (LLMs) have demonstrated impressive performance in question-answering tasks, their performance is limited when the questions require knowledge that is not included in the model's training data and can only be acquired through direct observation or interaction with the real world. Existing methods decompose reasoning tasks through the use of modules invoked sequentially, limiting their ability to answer deep reasoning tasks. We introduce a method, Recursion based extensible LLM (REBEL), which handles open-world, deep reasoning tasks by employing automated reasoning techniques like dynamic planning and forward-chaining strategies. REBEL allows LLMs to reason via recursive problem decomposition and utilization of external tools. The tools that REBEL uses are specified only by natural language description. We further demonstrate REBEL capabilities on a set of problems that require a deeply nested use of external tools in a compositional and conversational setting.
+
+
+
+ 47. 标题:A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
+ 编号:[280]
+ 链接:https://arxiv.org/abs/2309.11674
+ 作者:Haoran Xu, Young Jin Kim, Amr Sharaf, Hany Hassan Awadalla
+ 备注:
+ 关键词:Generative Large Language, Large Language Models, achieved remarkable advancements, Generative Large, NLP tasks
+
+ 点击查看摘要
+ Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. However, these advances have not been reflected in the translation task, especially those with moderate model sizes (i.e., 7B or 13B parameters), which still lag behind conventional supervised encoder-decoder translation models. Previous studies have attempted to improve the translation capabilities of these moderate LLMs, but their gains have been limited. In this study, we propose a novel fine-tuning approach for LLMs that is specifically designed for the translation task, eliminating the need for the abundant parallel data that traditional translation models usually depend on. Our approach consists of two fine-tuning stages: initial fine-tuning on monolingual data followed by subsequent fine-tuning on a small set of high-quality parallel data. We introduce the LLM developed through this strategy as Advanced Language Model-based trAnslator (ALMA). Based on LLaMA-2 as our underlying model, our results show that the model can achieve an average improvement of more than 12 BLEU and 12 COMET over its zero-shot performance across 10 translation directions from the WMT'21 (2 directions) and WMT'22 (8 directions) test datasets. The performance is significantly better than all prior work and even superior to the NLLB-54B model and GPT-3.5-text-davinci-003, with only 7B or 13B parameters. This method establishes the foundation for a novel training paradigm in machine translation.
+
+
+
+ 48. 标题:Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2309.11669
+ 作者:Ali Mousavi, Xin Zhan, He Bai, Peng Shi, Theo Rekatsinas, Benjamin Han, Yunyao Li, Jeff Pound, Josh Susskind, Natalie Schluter, Ihab Ilyas, Navdeep Jaitly
+ 备注:16 pages
+ 关键词:pair Knowledge Graphs, Knowledge Graphs, pair Knowledge, reverse neural models, vice versa
+
+ 点击查看摘要
+ Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.
+
+
+
+ 49. 标题:Towards Effective Disambiguation for Machine Translation with Large Language Models
+ 编号:[284]
+ 链接:https://arxiv.org/abs/2309.11668
+ 作者:Vivek Iyer, Pinzhen Chen, Alexandra Birch
+ 备注:10 pages, 3 figures
+ 关键词:Neural Machine Translation, Resolving semantic ambiguity, machine translation, conventional Neural Machine, Resolving semantic
+
+ 点击查看摘要
+ Resolving semantic ambiguity has long been recognised as a central challenge in the field of machine translation. Recent work on benchmarking translation performance on ambiguous sentences has exposed the limitations of conventional Neural Machine Translation (NMT) systems, which fail to capture many of these cases. Large language models (LLMs) have emerged as a promising alternative, demonstrating comparable performance to traditional NMT models while introducing new paradigms for controlling the target outputs. In this paper, we study the capabilities of LLMs to translate ambiguous sentences containing polysemous words and rare word senses. We also propose two ways to improve the handling of such ambiguity through in-context learning and fine-tuning on carefully curated ambiguous datasets. Experiments show that our methods can match or outperform state-of-the-art systems such as DeepL and NLLB in four out of five language directions. Our research provides valuable insights into effectively adapting LLMs for disambiguation during machine translation.
+
+
+
+ 50. 标题:Hate speech detection in algerian dialect using deep learning
+ 编号:[311]
+ 链接:https://arxiv.org/abs/2309.11611
+ 作者:Dihia Lanasri, Juan Olano, Sifal Klioui, Sin Liang Lee, Lamia Sekkai
+ 备注:
+ 关键词:hate speech, people have experienced, situations and threats, experienced a significant, significant increase
+
+ 点击查看摘要
+ With the proliferation of hate speech on social networks under different formats, such as abusive language, cyberbullying, and violence, etc., people have experienced a significant increase in violence, putting them in uncomfortable situations and threats. Plenty of efforts have been dedicated in the last few years to overcome this phenomenon to detect hate speech in different structured languages like English, French, Arabic, and others. However, a reduced number of works deal with Arabic dialects like Tunisian, Egyptian, and Gulf, mainly the Algerian ones. To fill in the gap, we propose in this work a complete approach for detecting hate speech on online Algerian messages. Many deep learning architectures have been evaluated on the corpus we created from some Algerian social networks (Facebook, YouTube, and Twitter). This corpus contains more than 13.5K documents in Algerian dialect written in Arabic, labeled as hateful or non-hateful. Promising results are obtained, which show the efficiency of our approach.
+
+
+
+ 51. 标题:SpeechAlign: a Framework for Speech Translation Alignment Evaluation
+ 编号:[323]
+ 链接:https://arxiv.org/abs/2309.11585
+ 作者:Belen Alastruey, Aleix Sant, Gerard I. Gállego, David Dale, Marta R. Costa-jussà
+ 备注:
+ 关键词:Alignment Error Rate, Speech Alignment Error, areas of research, Error Rate, Gold Alignment dataset
+
+ 点击查看摘要
+ Speech-to-Speech and Speech-to-Text translation are currently dynamic areas of research. To contribute to these fields, we present SpeechAlign, a framework to evaluate the underexplored field of source-target alignment in speech models. Our framework has two core components. First, to tackle the absence of suitable evaluation datasets, we introduce the Speech Gold Alignment dataset, built upon a English-German text translation gold alignment dataset. Secondly, we introduce two novel metrics, Speech Alignment Error Rate (SAER) and Time-weighted Speech Alignment Error Rate (TW-SAER), to evaluate alignment quality in speech models. By publishing SpeechAlign we provide an accessible evaluation framework for model assessment, and we employ it to benchmark open-source Speech Translation models.
+
+
+
+ 52. 标题:Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better Generalization
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2309.11582
+ 作者:Yilun Zhu, Siyao Peng, Sameer Pradhan, Amir Zeldes
+ 备注:IJCNLP-AACL 2023
+ 关键词:neural coreference resolution, resolution for English, Previous attempts, mention detection step, attempts to incorporate
+
+ 点击查看摘要
+ Previous attempts to incorporate a mention detection step into end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention span data as well as other entity information. This paper presents a coreference model that learns singletons as well as features such as entity type and information status via a multi-task learning-based approach. This approach achieves new state-of-the-art scores on the OntoGUM benchmark (+2.7 points) and increases robustness on multiple out-of-domain datasets (+2.3 points on average), likely due to greater generalizability for mention detection and utilization of more data from singletons when compared to only coreferent mention pair matching.
+
+
+
+ 53. 标题:Examining the Limitations of Computational Rumor Detection Models Trained on Static Datasets
+ 编号:[326]
+ 链接:https://arxiv.org/abs/2309.11576
+ 作者:Yida Mu, Xingyi Song, Kalina Bontcheva, Nikolaos Aletras
+ 备注:
+ 关键词:previously unknown rumors, ability to generalize, ability to detect, rumor detection model, rumor detection
+
+ 点击查看摘要
+ A crucial aspect of a rumor detection model is its ability to generalize, particularly its ability to detect emerging, previously unknown rumors. Past research has indicated that content-based (i.e., using solely source posts as input) rumor detection models tend to perform less effectively on unseen rumors. At the same time, the potential of context-based models remains largely untapped. The main contribution of this paper is in the in-depth evaluation of the performance gap between content and context-based models specifically on detecting new, unseen rumors. Our empirical findings demonstrate that context-based models are still overly dependent on the information derived from the rumors' source post and tend to overlook the significant role that contextual information can play. We also study the effect of data split strategies on classifier performance. Based on our experimental results, the paper also offers practical suggestions on how to minimize the effects of temporal concept drift in static datasets during the training of rumor detection methods.
+
+
+
+ 54. 标题:BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2309.11568
+ 作者:Nolan Dey, Daria Soboleva, Faisal Al-Khateeb, Bowen Yang, Ribhu Pathria, Hemant Khachane, Shaheer Muhammad, Zhiming (Charles) Chen, Robert Myers, Jacob Robert Steeves, Natalia Vassilieva, Marvin Tom, Joel Hestness
+ 备注:
+ 关键词:Bittensor Language Model, introduce the Bittensor, billion parameter open-source, Bittensor Language, open-source language model
+
+ 点击查看摘要
+ We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity.
+On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: this https URL.
+
+
+
+ 55. 标题:SignBank+: Multilingual Sign Language Translation Dataset
+ 编号:[331]
+ 链接:https://arxiv.org/abs/2309.11566
+ 作者:Amit Moryossef, Zifan Jiang
+ 备注:
+ 关键词:sign language machine, language machine translation, advances the field, field of sign, sign language
+
+ 点击查看摘要
+ This work advances the field of sign language machine translation by focusing on dataset quality and simplification of the translation system. We introduce SignBank+, a clean version of the SignBank dataset, optimized for machine translation. Contrary to previous works that employ complex factorization techniques for translation, we advocate for a simplified text-to-text translation approach. Our evaluation shows that models trained on SignBank+ surpass those on the original dataset, establishing a new benchmark and providing an open resource for future research.
+
+
+
+ 56. 标题:Hierarchical reinforcement learning with natural language subgoals
+ 编号:[332]
+ 链接:https://arxiv.org/abs/2309.11564
+ 作者:Arun Ahuja, Kavya Kopparapu, Rob Fergus, Ishita Dasgupta
+ 备注:
+ 关键词:achieving goal directed, sequences of actions, Hierarchical reinforcement learning, goal directed behavior, Hierarchical reinforcement
+
+ 点击查看摘要
+ Hierarchical reinforcement learning has been a compelling approach for achieving goal directed behavior over long sequences of actions. However, it has been challenging to implement in realistic or open-ended environments. A main challenge has been to find the right space of sub-goals over which to instantiate a hierarchy. We present a novel approach where we use data from humans solving these tasks to softly supervise the goal space for a set of long range tasks in a 3D embodied environment. In particular, we use unconstrained natural language to parameterize this space. This has two advantages: first, it is easy to generate this data from naive human participants; second, it is flexible enough to represent a vast range of sub-goals in human-relevant tasks. Our approach outperforms agents that clone expert behavior on these tasks, as well as HRL from scratch without this supervised sub-goal space. Our work presents a novel approach to combining human expert supervision with the benefits and flexibility of reinforcement learning.
+
+
+
+ 57. 标题:Towards LLM-based Autograding for Short Textual Answers
+ 编号:[347]
+ 链接:https://arxiv.org/abs/2309.11508
+ 作者:Johannes Schneider, Bernd Schenk, Christina Niklaus, Michaelis Vlachos
+ 备注:
+ 关键词:frequently challenging task, labor intensive, repetitive and frequently, challenging task, frequently challenging
+
+ 点击查看摘要
+ Grading of exams is an important, labor intensive, subjective, repetitive and frequently challenging task. The feasibility of autograding textual responses has greatly increased thanks to the availability of large language models (LLMs) such as ChatGPT and because of the substantial influx of data brought about by digitalization. However, entrusting AI models with decision-making roles raises ethical considerations, mainly stemming from potential biases and issues related to generating false information. Thus, in this manuscript we provide an evaluation of a large language model for the purpose of autograding, while also highlighting how LLMs can support educators in validating their grading procedures. Our evaluation is targeted towards automatic short textual answers grading (ASAG), spanning various languages and examinations from two distinct courses. Our findings suggest that while "out-of-the-box" LLMs provide a valuable tool to provide a complementary perspective, their readiness for independent automated grading remains a work in progress, necessitating human oversight.
+
+
+
+ 58. 标题:Matching Table Metadata with Business Glossaries Using Large Language Models
+ 编号:[349]
+ 链接:https://arxiv.org/abs/2309.11506
+ 作者:Elita Lobo, Oktie Hassanzadeh, Nhan Pham, Nandana Mihindukulasooriya, Dharmashankar Subramanian, Horst Samulowitz
+ 备注:This paper is a work in progress with findings based on limited evidence. Please exercise discretion when interpreting the findings
+ 关键词:enterprise data lake, data, enterprise data, data lake, structured data
+
+ 点击查看摘要
+ Enterprises often own large collections of structured data in the form of large databases or an enterprise data lake. Such data collections come with limited metadata and strict access policies that could limit access to the data contents and, therefore, limit the application of classic retrieval and analysis solutions. As a result, there is a need for solutions that can effectively utilize the available metadata. In this paper, we study the problem of matching table metadata to a business glossary containing data labels and descriptions. The resulting matching enables the use of an available or curated business glossary for retrieval and analysis without or before requesting access to the data contents. One solution to this problem is to use manually-defined rules or similarity measures on column names and glossary descriptions (or their vector embeddings) to find the closest match. However, such approaches need to be tuned through manual labeling and cannot handle many business glossaries that contain a combination of simple as well as complex and long descriptions. In this work, we leverage the power of large language models (LLMs) to design generic matching methods that do not require manual tuning and can identify complex relations between column names and glossaries. We propose methods that utilize LLMs in two ways: a) by generating additional context for column names that can aid with matching b) by using LLMs to directly infer if there is a relation between column names and glossary descriptions. Our preliminary experimental results show the effectiveness of our proposed methods.
+
+
+
+ 59. 标题:Stock Market Sentiment Classification and Backtesting via Fine-tuned BERT
+ 编号:[374]
+ 链接:https://arxiv.org/abs/2309.11979
+ 作者:Jiashu Lou
+ 备注:
+ 关键词:received widespread attention, real-time information acquisition, stock trading market, low-latency automatic trading, trading platforms based
+
+ 点击查看摘要
+ With the rapid development of big data and computing devices, low-latency automatic trading platforms based on real-time information acquisition have become the main components of the stock trading market, so the topic of quantitative trading has received widespread attention. And for non-strongly efficient trading markets, human emotions and expectations always dominate market trends and trading decisions. Therefore, this paper starts from the theory of emotion, taking East Money as an example, crawling user comment titles data from its corresponding stock bar and performing data cleaning. Subsequently, a natural language processing model BERT was constructed, and the BERT model was fine-tuned using existing annotated data sets. The experimental results show that the fine-tuned model has different degrees of performance improvement compared to the original model and the baseline model. Subsequently, based on the above model, the user comment data crawled is labeled with emotional polarity, and the obtained label information is combined with the Alpha191 model to participate in regression, and significant regression results are obtained. Subsequently, the regression model is used to predict the average price change for the next five days, and use it as a signal to guide automatic trading. The experimental results show that the incorporation of emotional factors increased the return rate by 73.8\% compared to the baseline during the trading period, and by 32.41\% compared to the original alpha191 model. Finally, we discuss the advantages and disadvantages of incorporating emotional factors into quantitative trading, and give possible directions for further research in the future.
+
+
+机器学习
+
+ 1. 标题:ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.12312
+ 作者:Jeremy A. Collins, Cody Houff, You Liang Tan, Charles C. Kemp
+ 备注:
+ 关键词:deep neural network, predicts visual-force goals, neural network, predicts visual-force, present ForceSight
+
+ 点击查看摘要
+ We present ForceSight, a system for text-guided mobile manipulation that predicts visual-force goals using a deep neural network. Given a single RGBD image combined with a text prompt, ForceSight determines a target end-effector pose in the camera frame (kinematic goal) and the associated forces (force goal). Together, these two components form a visual-force goal. Prior work has demonstrated that deep models outputting human-interpretable kinematic goals can enable dexterous manipulation by real robots. Forces are critical to manipulation, yet have typically been relegated to lower-level execution in these systems. When deployed on a mobile manipulator equipped with an eye-in-hand RGBD camera, ForceSight performed tasks such as precision grasps, drawer opening, and object handovers with an 81% success rate in unseen environments with object instances that differed significantly from the training data. In a separate experiment, relying exclusively on visual servoing and ignoring force goals dropped the success rate from 90% to 45%, demonstrating that force goals can significantly enhance performance. The appendix, videos, code, and trained models are available at this https URL.
+
+
+
+ 2. 标题:LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.12311
+ 作者:Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F. Fouhey, Joyce Chai
+ 备注:Project website: this https URL
+ 关键词:Large Language Model, answer questions based, household robots, critical skill, skill for household
+
+ 点击查看摘要
+ 3D visual grounding is a critical skill for household robots, enabling them to navigate, manipulate objects, and answer questions based on their environment. While existing approaches often rely on extensive labeled data or exhibit limitations in handling complex language queries, we propose LLM-Grounder, a novel zero-shot, open-vocabulary, Large Language Model (LLM)-based 3D visual grounding pipeline. LLM-Grounder utilizes an LLM to decompose complex natural language queries into semantic constituents and employs a visual grounding tool, such as OpenScene or LERF, to identify objects in a 3D scene. The LLM then evaluates the spatial and commonsense relations among the proposed objects to make a final grounding decision. Our method does not require any labeled training data and can generalize to novel 3D scenes and arbitrary text queries. We evaluate LLM-Grounder on the ScanRefer benchmark and demonstrate state-of-the-art zero-shot grounding accuracy. Our findings indicate that LLMs significantly improve the grounding capability, especially for complex language queries, making LLM-Grounder an effective approach for 3D vision-language tasks in robotics. Videos and interactive demos can be found on the project website this https URL .
+
+
+
+ 3. 标题:LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2309.12307
+ 作者:Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
+ 备注:Code, models, dataset, and demo are available at this https URL
+ 关键词:pre-trained large language, large language models, efficient fine-tuning approach, context, pre-trained large
+
+ 点击查看摘要
+ We present LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost. Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. For example, training on the context length of 8192 needs 16x computational costs in self-attention layers as that of 2048. In this paper, we speed up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine-tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention effectively enables context extension, leading to non-trivial computation saving with similar performance to fine-tuning with vanilla attention. Particularly, it can be implemented with only two lines of code in training, while being optional in inference. On the other hand, we revisit the parameter-efficient fine-tuning regime for context expansion. Notably, we find that LoRA for context extension works well under the premise of trainable embedding and normalization. LongLoRA demonstrates strong empirical results on various tasks on LLaMA2 models from 7B/13B to 70B. LongLoRA adopts LLaMA2 7B from 4k context to 100k, or LLaMA2 70B to 32k on a single 8x A100 machine. LongLoRA extends models' context while retaining their original architectures, and is compatible with most existing techniques, like FlashAttention-2. In addition, to make LongLoRA practical, we collect a dataset, LongQA, for supervised fine-tuning. It contains more than 3k long context question-answer pairs.
+
+
+
+ 4. 标题:Environment-biased Feature Ranking for Novelty Detection Robustness
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.12301
+ 作者:Stefan Smeu, Elena Burceanu, Emanuela Haller, Andrei Liviu Nicolicioiu
+ 备注:ICCV 2024 - Workshop on Out Of Distribution Generalization in Computer Vision
+ 关键词:robust novelty detection, irrelevant factors, novelty detection, tackle the problem, problem of robust
+
+ 点击查看摘要
+ We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
+
+
+
+ 5. 标题:See to Touch: Learning Tactile Dexterity through Visual Incentives
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2309.12300
+ 作者:Irmak Guzey, Yinlong Dai, Ben Evans, Soumith Chintala, Lerrel Pinto
+ 备注:
+ 关键词:Equipping multi-fingered robots, Equipping multi-fingered, achieving the precise, crucial for achieving, tactile sensing
+
+ 点击查看摘要
+ Equipping multi-fingered robots with tactile sensing is crucial for achieving the precise, contact-rich, and dexterous manipulation that humans excel at. However, relying solely on tactile sensing fails to provide adequate cues for reasoning about objects' spatial configurations, limiting the ability to correct errors and adapt to changing situations. In this paper, we present Tactile Adaptation from Visual Incentives (TAVI), a new framework that enhances tactile-based dexterity by optimizing dexterous policies using vision-based rewards. First, we use a contrastive-based objective to learn visual representations. Next, we construct a reward function using these visual representations through optimal-transport based matching on one human demonstration. Finally, we use online reinforcement learning on our robot to optimize tactile-based policies that maximize the visual reward. On six challenging tasks, such as peg pick-and-place, unstacking bowls, and flipping slender objects, TAVI achieves a success rate of 73% using our four-fingered Allegro robot hand. The increase in performance is 108% higher than policies using tactile and vision-based rewards and 135% higher than policies without tactile observational input. Robot videos are best viewed on our project website: this https URL.
+
+
+
+ 6. 标题:Learning to Drive Anywhere
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.12295
+ 作者:Ruizhao Zhu, Peng Huang, Eshed Ohn-Bar, Venkatesh Saligrama
+ 备注:Conference on Robot Learning (CoRL) 2023. this https URL
+ 关键词:Human drivers, left vs. right-hand, drivers can seamlessly, decisions across geographical, diverse conditions
+
+ 点击查看摘要
+ Human drivers can seamlessly adapt their driving decisions across geographical locations with diverse conditions and rules of the road, e.g., left vs. right-hand traffic. In contrast, existing models for autonomous driving have been thus far only deployed within restricted operational domains, i.e., without accounting for varying driving behaviors across locations or model scalability. In this work, we propose AnyD, a single geographically-aware conditional imitation learning (CIL) model that can efficiently learn from heterogeneous and globally distributed data with dynamic environmental, traffic, and social characteristics. Our key insight is to introduce a high-capacity geo-location-based channel attention mechanism that effectively adapts to local nuances while also flexibly modeling similarities among regions in a data-driven manner. By optimizing a contrastive imitation objective, our proposed approach can efficiently scale across inherently imbalanced data distributions and location-dependent events. We demonstrate the benefits of our AnyD agent across multiple datasets, cities, and scalable deployment paradigms, i.e., centralized, semi-supervised, and distributed agent training. Specifically, AnyD outperforms CIL baselines by over 14% in open-loop evaluation and 30% in closed-loop testing on CARLA.
+
+
+
+ 7. 标题:The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.12288
+ 作者:Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
+ 备注:18 pages, 10 figures
+ 关键词:auto-regressive large language, Reversal Curse, large language models, Mary Lee Pfeiffer, Chancellor of Germany
+
+ 点击查看摘要
+ We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany", it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?". Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e. if "A is B'' occurs, "B is A" is more likely to occur). We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of 'Abyssal Melodies'" and showing that they fail to correctly answer "Who composed 'Abyssal Melodies?'". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?". GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is available at this https URL.
+
+
+
+ 8. 标题:Performance Conditioning for Diffusion-Based Multi-Instrument Music Synthesis
+ 编号:[19]
+ 链接:https://arxiv.org/abs/2309.12283
+ 作者:Ben Maman, Johannes Zeitler, Meinard Müller, Amit H. Bermano
+ 备注:5 pages, project page available at benadar293.github.io/midipm
+ 关键词:Music Information Retrieval, Information Retrieval, symbolic music representations, Music Information, Generating multi-instrument music
+
+ 点击查看摘要
+ Generating multi-instrument music from symbolic music representations is an important task in Music Information Retrieval (MIR). A central but still largely unsolved problem in this context is musically and acoustically informed control in the generation process. As the main contribution of this work, we propose enhancing control of multi-instrument synthesis by conditioning a generative model on a specific performance and recording environment, thus allowing for better guidance of timbre and style. Building on state-of-the-art diffusion-based music generative models, we introduce performance conditioning - a simple tool indicating the generative model to synthesize music with style and timbre of specific instruments taken from specific performances. Our prototype is evaluated using uncurated performances with diverse instrumentation and achieves state-of-the-art FAD realism scores while allowing novel timbre and style control. Our project page, including samples and demonstrations, is available at this http URL
+
+
+
+ 9. 标题:The Broad Impact of Feature Imitation: Neural Enhancements Across Financial, Speech, and Physiological Domains
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2309.12279
+ 作者:Reza Khanmohammadi, Tuka Alhanai, Mohammad M. Ghassemi
+ 备注:
+ 关键词:network weights plays, neural network weights, Feature Imitating Networks, Initialization of neural, Bitcoin price prediction
+
+ 点击查看摘要
+ Initialization of neural network weights plays a pivotal role in determining their performance. Feature Imitating Networks (FINs) offer a novel strategy by initializing weights to approximate specific closed-form statistical features, setting a promising foundation for deep learning architectures. While the applicability of FINs has been chiefly tested in biomedical domains, this study extends its exploration into other time series datasets. Three different experiments are conducted in this study to test the applicability of imitating Tsallis entropy for performance enhancement: Bitcoin price prediction, speech emotion recognition, and chronic neck pain detection. For the Bitcoin price prediction, models embedded with FINs reduced the root mean square error by around 1000 compared to the baseline. In the speech emotion recognition task, the FIN-augmented model increased classification accuracy by over 3 percent. Lastly, in the CNP detection experiment, an improvement of about 7 percent was observed compared to established classifiers. These findings validate the broad utility and potency of FINs in diverse applications.
+
+
+
+ 10. 标题:Improving VTE Identification through Adaptive NLP Model Selection and Clinical Expert Rule-based Classifier from Radiology Reports
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2309.12273
+ 作者:Jamie Deng, Yusen Wu, Hilary Hayssen, Brain Englum, Aman Kankaria, Minerva Mayorga-Carlin, Shalini Sahoo, John Sorkin, Brajesh Lal, Yelena Yesha, Phuong Nguyen
+ 备注:
+ 关键词:severe cardiovascular condition, cardiovascular condition including, deep vein thrombosis, condition including deep, including deep vein
+
+ 点击查看摘要
+ Rapid and accurate identification of Venous thromboembolism (VTE), a severe cardiovascular condition including deep vein thrombosis (DVT) and pulmonary embolism (PE), is important for effective treatment. Leveraging Natural Language Processing (NLP) on radiology reports, automated methods have shown promising advancements in identifying VTE events from retrospective data cohorts or aiding clinical experts in identifying VTE events from radiology reports. However, effectively training Deep Learning (DL) and the NLP models is challenging due to limited labeled medical text data, the complexity and heterogeneity of radiology reports, and data imbalance. This study proposes novel method combinations of DL methods, along with data augmentation, adaptive pre-trained NLP model selection, and a clinical expert NLP rule-based classifier, to improve the accuracy of VTE identification in unstructured (free-text) radiology reports. Our experimental results demonstrate the model's efficacy, achieving an impressive 97\% accuracy and 97\% F1 score in predicting DVT, and an outstanding 98.3\% accuracy and 98.4\% F1 score in predicting PE. These findings emphasize the model's robustness and its potential to significantly contribute to VTE research.
+
+
+
+ 11. 标题:Enabling Quartile-based Estimated-Mean Gradient Aggregation As Baseline for Federated Image Classifications
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2309.12267
+ 作者:Yusen Wu, Jamie Deng, Hao Chen, Phuong Nguyen, Yelena Yesha
+ 备注:
+ 关键词:improving model performance, safeguarding sensitive data, train deep neural, deep neural networks, enabling decentralized collaboration
+
+ 点击查看摘要
+ Federated Learning (FL) has revolutionized how we train deep neural networks by enabling decentralized collaboration while safeguarding sensitive data and improving model performance. However, FL faces two crucial challenges: the diverse nature of data held by individual clients and the vulnerability of the FL system to security breaches. This paper introduces an innovative solution named Estimated Mean Aggregation (EMA) that not only addresses these challenges but also provides a fundamental reference point as a $\mathsf{baseline}$ for advanced aggregation techniques in FL systems. EMA's significance lies in its dual role: enhancing model security by effectively handling malicious outliers through trimmed means and uncovering data heterogeneity to ensure that trained models are adaptable across various client datasets. Through a wealth of experiments, EMA consistently demonstrates high accuracy and area under the curve (AUC) compared to alternative methods, establishing itself as a robust baseline for evaluating the effectiveness and security of FL aggregation methods. EMA's contributions thus offer a crucial step forward in advancing the efficiency, security, and versatility of decentralized deep learning in the context of FL.
+
+
+
+ 12. 标题:Soft Merging: A Flexible and Robust Soft Model Merging Approach for Enhanced Neural Network Performance
+ 编号:[29]
+ 链接:https://arxiv.org/abs/2309.12259
+ 作者:Hao Chen, Yusen Wu, Phuong Nguyen, Chao Liu, Yelena Yesha
+ 备注:
+ 关键词:local optima due, local optima models, local optima, Stochastic Gradient Descent, widely used optimization
+
+ 点击查看摘要
+ Stochastic Gradient Descent (SGD), a widely used optimization algorithm in deep learning, is often limited to converging to local optima due to the non-convex nature of the problem. Leveraging these local optima to improve model performance remains a challenging task. Given the inherent complexity of neural networks, the simple arithmetic averaging of the obtained local optima models in undesirable results. This paper proposes a {\em soft merging} method that facilitates rapid merging of multiple models, simplifies the merging of specific parts of neural networks, and enhances robustness against malicious models with extreme values. This is achieved by learning gate parameters through a surrogate of the $l_0$ norm using hard concrete distribution without modifying the model weights of the given local optima models. This merging process not only enhances the model performance by converging to a better local optimum, but also minimizes computational costs, offering an efficient and explicit learning process integrated with stochastic gradient descent. Thorough experiments underscore the effectiveness and superior performance of the merged neural networks.
+
+
+
+ 13. 标题:SALSA-CLRS: A Sparse and Scalable Benchmark for Algorithmic Reasoning
+ 编号:[31]
+ 链接:https://arxiv.org/abs/2309.12253
+ 作者:Julian Minder, Florian Grötschla, Joël Mathys, Roger Wattenhofer
+ 备注:
+ 关键词:CLRS algorithmic learning, algorithmic learning benchmark, algorithmic learning, CLRS, CLRS algorithmic
+
+ 点击查看摘要
+ We introduce an extension to the CLRS algorithmic learning benchmark, prioritizing scalability and the utilization of sparse representations. Many algorithms in CLRS require global memory or information exchange, mirrored in its execution model, which constructs fully connected (not sparse) graphs based on the underlying problem. Despite CLRS's aim of assessing how effectively learned algorithms can generalize to larger instances, the existing execution model becomes a significant constraint due to its demanding memory requirements and runtime (hard to scale). However, many important algorithms do not demand a fully connected graph; these algorithms, primarily distributed in nature, align closely with the message-passing paradigm employed by Graph Neural Networks. Hence, we propose SALSA-CLRS, an extension of the current CLRS benchmark specifically with scalability and sparseness in mind. Our approach includes adapted algorithms from the original CLRS benchmark and introduces new problems from distributed and randomized algorithms. Moreover, we perform a thorough empirical evaluation of our benchmark. Code is publicly available at this https URL.
+
+
+
+ 14. 标题:Parallelizing non-linear sequential models over the sequence length
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2309.12252
+ 作者:Yi Heng Lim, Qi Zhu, Joshua Selfridge, Muhammad Firmansyah Kasim
+ 备注:
+ 关键词:Ordinary Differential Equations, Neural Ordinary Differential, Recurrent Neural Networks, Differential Equations, Neural Networks
+
+ 点击查看摘要
+ Sequential models, such as Recurrent Neural Networks and Neural Ordinary Differential Equations, have long suffered from slow training due to their inherent sequential nature. For many years this bottleneck has persisted, as many thought sequential models could not be parallelized. We challenge this long-held belief with our parallel algorithm that accelerates GPU evaluation of sequential models by up to 3 orders of magnitude faster without compromising output accuracy. The algorithm does not need any special structure in the sequential models' architecture, making it applicable to a wide range of architectures. Using our method, training sequential models can be more than 10 times faster than the common sequential method without any meaningful difference in the training results. Leveraging this accelerated training, we discovered the efficacy of the Gated Recurrent Unit in a long time series classification problem with 17k time samples. By overcoming the training bottleneck, our work serves as the first step to unlock the potential of non-linear sequential models for long sequence problems.
+
+
+
+ 15. 标题:SQUARE: Automatic Question Answering Evaluation using Multiple Positive and Negative References
+ 编号:[34]
+ 链接:https://arxiv.org/abs/2309.12250
+ 作者:Matteo Gabburo, Siddhant Garg, Rik Koncel Kedziorski, Alessandro Moschitti
+ 备注:Accepted to IJCNLP-AACL 2023
+ 关键词:challenging and expensive, reliable approach, Evaluation, correct reference answer, human annotations
+
+ 点击查看摘要
+ Evaluation of QA systems is very challenging and expensive, with the most reliable approach being human annotations of correctness of answers for questions. Recent works (AVA, BEM) have shown that transformer LM encoder based similarity metrics transfer well for QA evaluation, but they are limited by the usage of a single correct reference answer. We propose a new evaluation metric: SQuArE (Sentence-level QUestion AnsweRing Evaluation), using multiple reference answers (combining multiple correct and incorrect references) for sentence-form QA. We evaluate SQuArE on both sentence-level extractive (Answer Selection) and generative (GenQA) QA systems, across multiple academic and industrial datasets, and show that it outperforms previous baselines and obtains the highest correlation with human annotations.
+
+
+
+ 16. 标题:Weakly-supervised Automated Audio Captioning via text only training
+ 编号:[37]
+ 链接:https://arxiv.org/abs/2309.12242
+ 作者:Theodoros Kouzelis, Vassilis Katsouros
+ 备注:DCASE Workshop 2023
+ 关键词:Automated Audio Captioning, enabled remarkable success, automatically generating descriptions, Audio Captioning, Automated Audio
+
+ 点击查看摘要
+ In recent years, datasets of paired audio and captions have enabled remarkable success in automatically generating descriptions for audio clips, namely Automated Audio Captioning (AAC). However, it is labor-intensive and time-consuming to collect a sufficient number of paired audio and captions. Motivated by the recent advances in Contrastive Language-Audio Pretraining (CLAP), we propose a weakly-supervised approach to train an AAC model assuming only text data and a pre-trained CLAP model, alleviating the need for paired target data. Our approach leverages the similarity between audio and text embeddings in CLAP. During training, we learn to reconstruct the text from the CLAP text embedding, and during inference, we decode using the audio embeddings. To mitigate the modality gap between the audio and text embeddings we employ strategies to bridge the gap during training and inference stages. We evaluate our proposed method on Clotho and AudioCaps datasets demonstrating its ability to achieve a relative performance of up to ~$83\%$ compared to fully supervised approaches trained with paired target data.
+
+
+
+ 17. 标题:t-EER: Parameter-Free Tandem Evaluation of Countermeasures and Biometric Comparators
+ 编号:[40]
+ 链接:https://arxiv.org/abs/2309.12237
+ 作者:Tomi Kinnunen, Kong Aik Lee, Hemlata Tak, Nicholas Evans, Andreas Nautsch
+ 备注:To appear in IEEE Transactions on Pattern Analysis and Machine Intelligence. For associated codes, see this https URL (Github) and this https URL (Google Colab)
+ 关键词:typically operates alongside, alongside biometric verification, operates alongside biometric, biometric verification, improve reliablity
+
+ 点击查看摘要
+ Presentation attack (spoofing) detection (PAD) typically operates alongside biometric verification to improve reliablity in the face of spoofing attacks. Even though the two sub-systems operate in tandem to solve the single task of reliable biometric verification, they address different detection tasks and are hence typically evaluated separately. Evidence shows that this approach is suboptimal. We introduce a new metric for the joint evaluation of PAD solutions operating in situ with biometric verification. In contrast to the tandem detection cost function proposed recently, the new tandem equal error rate (t-EER) is parameter free. The combination of two classifiers nonetheless leads to a \emph{set} of operating points at which false alarm and miss rates are equal and also dependent upon the prevalence of attacks. We therefore introduce the \emph{concurrent} t-EER, a unique operating point which is invariable to the prevalence of attacks. Using both modality (and even application) agnostic simulated scores, as well as real scores for a voice biometrics application, we demonstrate application of the t-EER to a wide range of biometric system evaluations under attack. The proposed approach is a strong candidate metric for the tandem evaluation of PAD systems and biometric comparators.
+
+
+
+ 18. 标题:Smooth ECE: Principled Reliability Diagrams via Kernel Smoothing
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2309.12236
+ 作者:Jarosław Błasiok, Preetum Nakkiran
+ 备注:Code at: this https URL
+ 关键词:reliability diagrams, probabilistic predictors, Calibration, Calibration measures, Expected Calibration Error
+
+ 点击查看摘要
+ Calibration measures and reliability diagrams are two fundamental tools for measuring and interpreting the calibration of probabilistic predictors. Calibration measures quantify the degree of miscalibration, and reliability diagrams visualize the structure of this miscalibration. However, the most common constructions of reliability diagrams and calibration measures -- binning and ECE -- both suffer from well-known flaws (e.g. discontinuity). We show that a simple modification fixes both constructions: first smooth the observations using an RBF kernel, then compute the Expected Calibration Error (ECE) of this smoothed function. We prove that with a careful choice of bandwidth, this method yields a calibration measure that is well-behaved in the sense of (Błasiok, Gopalan, Hu, and Nakkiran 2023a) -- a consistent calibration measure. We call this measure the SmoothECE. Moreover, the reliability diagram obtained from this smoothed function visually encodes the SmoothECE, just as binned reliability diagrams encode the BinnedECE.
+We also provide a Python package with simple, hyperparameter-free methods for measuring and plotting calibration: `pip install relplot\`.
+
+
+
+ 19. 标题:Smooth Nash Equilibria: Algorithms and Complexity
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2309.12226
+ 作者:Constantinos Daskalakis, Noah Golowich, Nika Haghtalab, Abhishek Shetty
+ 备注:
+ 关键词:smooth Nash equilibria, smooth Nash, Nash equilibria, Nash equilibrium, Nash
+
+ 点击查看摘要
+ A fundamental shortcoming of the concept of Nash equilibrium is its computational intractability: approximating Nash equilibria in normal-form games is PPAD-hard. In this paper, inspired by the ideas of smoothed analysis, we introduce a relaxed variant of Nash equilibrium called $\sigma$-smooth Nash equilibrium, for a smoothness parameter $\sigma$. In a $\sigma$-smooth Nash equilibrium, players only need to achieve utility at least as high as their best deviation to a $\sigma$-smooth strategy, which is a distribution that does not put too much mass (as parametrized by $\sigma$) on any fixed action. We distinguish two variants of $\sigma$-smooth Nash equilibria: strong $\sigma$-smooth Nash equilibria, in which players are required to play $\sigma$-smooth strategies under equilibrium play, and weak $\sigma$-smooth Nash equilibria, where there is no such requirement.
+We show that both weak and strong $\sigma$-smooth Nash equilibria have superior computational properties to Nash equilibria: when $\sigma$ as well as an approximation parameter $\epsilon$ and the number of players are all constants, there is a constant-time randomized algorithm to find a weak $\epsilon$-approximate $\sigma$-smooth Nash equilibrium in normal-form games. In the same parameter regime, there is a polynomial-time deterministic algorithm to find a strong $\epsilon$-approximate $\sigma$-smooth Nash equilibrium in a normal-form game. These results stand in contrast to the optimal algorithm for computing $\epsilon$-approximate Nash equilibria, which cannot run in faster than quasipolynomial-time. We complement our upper bounds by showing that when either $\sigma$ or $\epsilon$ is an inverse polynomial, finding a weak $\epsilon$-approximate $\sigma$-smooth Nash equilibria becomes computationally intractable.
+
+
+
+ 20. 标题:SR-PredictAO: Session-based Recommendation with High-Capability Predictor Add-On
+ 编号:[47]
+ 链接:https://arxiv.org/abs/2309.12218
+ 作者:Ruida Wang, Raymond Chi-Wing Wong, Weile Tan
+ 备注:
+ 关键词:item click based, random user behavior, complex problem, Session-based recommendation, complex problem requires
+
+ 点击查看摘要
+ Session-based recommendation, aiming at making the prediction of the user's next item click based on the information in a single session only even in the presence of some random user's behavior, is a complex problem. This complex problem requires a high-capability model of predicting the user's next action. Most (if not all) existing models follow the encoder-predictor paradigm where all studies focus on how to optimize the encoder module extensively in the paradigm but they ignore how to optimize the predictor module. In this paper, we discover the existing critical issue of the low-capability predictor module among existing models. Motivated by this, we propose a novel framework called \emph{\underline{S}ession-based \underline{R}ecommendation with \underline{Pred}ictor \underline{A}dd-\underline{O}n} (SR-PredictAO). In this framework, we propose a high-capability predictor module which could alleviate the effect of random user's behavior for prediction. It is worth mentioning that this framework could be applied to any existing models, which could give opportunities for further optimizing the framework. Extensive experiments on two real benchmark datasets for three state-of-the-art models show that \emph{SR-PredictAO} out-performs the current state-of-the-art model by up to 2.9\% in HR@20 and 2.3\% in MRR@20. More importantly, the improvement is consistent across almost all the existing models on all datasets, which could be regarded as a significant contribution in the field.
+
+
+
+ 21. 标题:Regionally Additive Models: Explainable-by-design models minimizing feature interactions
+ 编号:[48]
+ 链接:https://arxiv.org/abs/2309.12215
+ 作者:Vasilis Gkolemis, Anargiros Tzerefos, Theodore Dalamagas, Eirini Ntoutsi, Christos Diou
+ 备注:Accepted at ECMLPKDD 2023 Workshop Uncertainty meets Explainability
+ 关键词:Generalized Additive Models, Generalized Additive, Regionally Additive Models, Additive Models, GAMs
+
+ 点击查看摘要
+ Generalized Additive Models (GAMs) are widely used explainable-by-design models in various applications. GAMs assume that the output can be represented as a sum of univariate functions, referred to as components. However, this assumption fails in ML problems where the output depends on multiple features simultaneously. In these cases, GAMs fail to capture the interaction terms of the underlying function, leading to subpar accuracy. To (partially) address this issue, we propose Regionally Additive Models (RAMs), a novel class of explainable-by-design models. RAMs identify subregions within the feature space where interactions are minimized. Within these regions, it is more accurate to express the output as a sum of univariate functions (components). Consequently, RAMs fit one component per subregion of each feature instead of one component per feature. This approach yields a more expressive model compared to GAMs while retaining interpretability. The RAM framework consists of three steps. Firstly, we train a black-box model. Secondly, using Regional Effect Plots, we identify subregions where the black-box model exhibits near-local additivity. Lastly, we fit a GAM component for each identified subregion. We validate the effectiveness of RAMs through experiments on both synthetic and real-world datasets. The results confirm that RAMs offer improved expressiveness compared to GAMs while maintaining interpretability.
+
+
+
+ 22. 标题:SupeRBNN: Randomized Binary Neural Network Using Adiabatic Superconductor Josephson Devices
+ 编号:[50]
+ 链接:https://arxiv.org/abs/2309.12212
+ 作者:Zhengang Li, Geng Yuan, Tomoharu Yamauchi, Zabihi Masoud, Yanyue Xie, Peiyan Dong, Xulong Tang, Nobuyuki Yoshikawa, Devesh Tiwari, Yanzhi Wang, Olivia Chen
+ 备注:Accepted by MICRO'23 (56th IEEE/ACM International Symposium on Microarchitecture)
+ 关键词:extremely high energy, AQFP devices, AQFP devices serve, extremely high, AQFP
+
+ 点击查看摘要
+ Adiabatic Quantum-Flux-Parametron (AQFP) is a superconducting logic with extremely high energy efficiency. By employing the distinct polarity of current to denote logic `0' and `1', AQFP devices serve as excellent carriers for binary neural network (BNN) computations. Although recent research has made initial strides toward developing an AQFP-based BNN accelerator, several critical challenges remain, preventing the design from being a comprehensive solution. In this paper, we propose SupeRBNN, an AQFP-based randomized BNN acceleration framework that leverages software-hardware co-optimization to eventually make the AQFP devices a feasible solution for BNN acceleration. Specifically, we investigate the randomized behavior of the AQFP devices and analyze the impact of crossbar size on current attenuation, subsequently formulating the current amplitude into the values suitable for use in BNN computation. To tackle the accumulation problem and improve overall hardware performance, we propose a stochastic computing-based accumulation module and a clocking scheme adjustment-based circuit optimization method. We validate our SupeRBNN framework across various datasets and network architectures, comparing it with implementations based on different technologies, including CMOS, ReRAM, and superconducting RSFQ/ERSFQ. Experimental results demonstrate that our design achieves an energy efficiency of approximately 7.8x10^4 times higher than that of the ReRAM-based BNN framework while maintaining a similar level of model accuracy. Furthermore, when compared with superconductor-based counterparts, our framework demonstrates at least two orders of magnitude higher energy efficiency.
+
+
+
+ 23. 标题:Physics-informed State-space Neural Networks for Transport Phenomena
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2309.12211
+ 作者:Akshay J Dave, Richard B. Vilim
+ 备注:19 pages, 13 figures
+ 关键词:introduces Physics-informed State-space, achieving real-time optimization, work introduces Physics-informed, Physics-informed State-space neural, Partial Differential Equations
+
+ 点击查看摘要
+ This work introduces Physics-informed State-space neural network Models (PSMs), a novel solution to achieving real-time optimization, flexibility, and fault tolerance in autonomous systems, particularly in transport-dominated systems such as chemical, biomedical, and power plants. Traditional data-driven methods fall short due to a lack of physical constraints like mass conservation; PSMs address this issue by training deep neural networks with sensor data and physics-informing using components' Partial Differential Equations (PDEs), resulting in a physics-constrained, end-to-end differentiable forward dynamics model. Through two in silico experiments - a heated channel and a cooling system loop - we demonstrate that PSMs offer a more accurate approach than purely data-driven models.
+Beyond accuracy, there are several compelling use cases for PSMs. In this work, we showcase two: the creation of a nonlinear supervisory controller through a sequentially updated state-space representation and the proposal of a diagnostic algorithm using residuals from each of the PDEs. The former demonstrates the ability of PSMs to handle both constant and time-dependent constraints, while the latter illustrates their value in system diagnostics and fault detection. We further posit that PSMs could serve as a foundation for Digital Twins, constantly updated digital representations of physical systems.
+
+
+
+ 24. 标题:Boolformer: Symbolic Regression of Logic Functions with Transformers
+ 编号:[53]
+ 链接:https://arxiv.org/abs/2309.12207
+ 作者:Stéphane d'Ascoli, Samy Bengio, Josh Susskind, Emmanuel Abbé
+ 备注:
+ 关键词:Transformer architecture trained, Transformer architecture, regression of Boolean, Boolean functions, trained to perform
+
+ 点击查看摘要
+ In this work, we introduce Boolformer, the first Transformer architecture trained to perform end-to-end symbolic regression of Boolean functions. First, we show that it can predict compact formulas for complex functions which were not seen during training, when provided a clean truth table. Then, we demonstrate its ability to find approximate expressions when provided incomplete and noisy observations. We evaluate the Boolformer on a broad set of real-world binary classification datasets, demonstrating its potential as an interpretable alternative to classic machine learning methods. Finally, we apply it to the widespread task of modelling the dynamics of gene regulatory networks. Using a recent benchmark, we show that Boolformer is competitive with state-of-the art genetic algorithms with a speedup of several orders of magnitude. Our code and models are available publicly.
+
+
+
+ 25. 标题:PrNet: A Neural Network for Correcting Pseudoranges to Improve Positioning with Android Raw GNSS Measurements
+ 编号:[55]
+ 链接:https://arxiv.org/abs/2309.12204
+ 作者:Xu Weng, Keck Voon Ling, Haochen Liu
+ 备注:
+ 关键词:Multiple Layer Perceptron, Navigation Satellite System, Global Navigation Satellite, Android raw Global, improve localization performance
+
+ 点击查看摘要
+ We present a neural network for mitigating pseudorange bias to improve localization performance with data collected from Android smartphones. We represent pseudorange bias using a pragmatic satellite-wise Multiple Layer Perceptron (MLP), the inputs of which are six satellite-receiver-context-related features derived from Android raw Global Navigation Satellite System (GNSS) measurements. To supervise the training process, we carefully calculate the target values of pseudorange bias using location ground truth and smoothing techniques and optimize a loss function containing the estimation residuals of smartphone clock bias. During the inference process, we employ model-based localization engines to compute locations with pseudoranges corrected by the neural network. Consequently, this hybrid pipeline can attend to both pseudorange bias and noise. We evaluate the framework on an open dataset and consider four application scenarios for investigating fingerprinting and cross-trace localization in rural and urban areas. Extensive experiments demonstrate that the proposed framework outperforms model-based and state-of-the-art data-driven approaches.
+
+
+
+ 26. 标题:Towards Robust and Truly Large-Scale Audio-Sheet Music Retrieval
+ 编号:[71]
+ 链接:https://arxiv.org/abs/2309.12158
+ 作者:Luis Carvalho, Gerhard Widmer
+ 备注:Proceedings of the IEEE 6th International Conference on Multimedia Information Processing and Retrieval (MIPR)
+ 关键词:connecting large collections, multi-modal music information, sheet music images, music information retrieval, identifying pairs
+
+ 点击查看摘要
+ A range of applications of multi-modal music information retrieval is centred around the problem of connecting large collections of sheet music (images) to corresponding audio recordings, that is, identifying pairs of audio and score excerpts that refer to the same musical content. One of the typical and most recent approaches to this task employs cross-modal deep learning architectures to learn joint embedding spaces that link the two distinct modalities - audio and sheet music images. While there has been steady improvement on this front over the past years, a number of open problems still prevent large-scale employment of this methodology. In this article we attempt to provide an insightful examination of the current developments on audio-sheet music retrieval via deep learning methods. We first identify a set of main challenges on the road towards robust and large-scale cross-modal music retrieval in real scenarios. We then highlight the steps we have taken so far to address some of these challenges, documenting step-by-step improvement along several dimensions. We conclude by analysing the remaining challenges and present ideas for solving these, in order to pave the way to a unified and robust methodology for cross-modal music retrieval.
+
+
+
+ 27. 标题:Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.12140
+ 作者:Travis Zhang, Katie Luo, Cheng Perng Phoo, Yurong You, Wei-Lun Chao, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
+ 备注:
+ 关键词:significantly improved accuracy, improved accuracy, rapid development, self-driving cars, cars has significantly
+
+ 点击查看摘要
+ The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at this https URL.
+
+
+
+ 28. 标题:Self-Supervised Contrastive Learning for Robust Audio-Sheet Music Retrieval Systems
+ 编号:[79]
+ 链接:https://arxiv.org/abs/2309.12134
+ 作者:Luis Carvalho, Tobias Washüttl, Gerhard Widmer
+ 备注:
+ 关键词:audio recordings remains, Linking sheet music, efficient cross-modal music, music retrieval systems, recordings remains
+
+ 点击查看摘要
+ Linking sheet music images to audio recordings remains a key problem for the development of efficient cross-modal music retrieval systems. One of the fundamental approaches toward this task is to learn a cross-modal embedding space via deep neural networks that is able to connect short snippets of audio and sheet music. However, the scarcity of annotated data from real musical content affects the capability of such methods to generalize to real retrieval scenarios. In this work, we investigate whether we can mitigate this limitation with self-supervised contrastive learning, by exposing a network to a large amount of real music data as a pre-training step, by contrasting randomly augmented views of snippets of both modalities, namely audio and sheet images. Through a number of experiments on synthetic and real piano data, we show that pre-trained models are able to retrieve snippets with better precision in all scenarios and pre-training configurations. Encouraged by these results, we employ the snippet embeddings in the higher-level task of cross-modal piece identification and conduct more experiments on several retrieval configurations. In this task, we observe that the retrieval quality improves from 30% up to 100% when real music data is present. We then conclude by arguing for the potential of self-supervised contrastive learning for alleviating the annotated data scarcity in multi-modal music retrieval models.
+
+
+
+ 29. 标题:Convergence and Recovery Guarantees of Unsupervised Neural Networks for Inverse Problems
+ 编号:[81]
+ 链接:https://arxiv.org/abs/2309.12128
+ 作者:Nathan Buskulic, Jalal Fadili, Yvain Quéau
+ 备注:
+ 关键词:solve inverse problems, solve inverse, inverse problems, recent years, Neural Tangent Kernel
+
+ 点击查看摘要
+ Neural networks have become a prominent approach to solve inverse problems in recent years. While a plethora of such methods was developed to solve inverse problems empirically, we are still lacking clear theoretical guarantees for these methods. On the other hand, many works proved convergence to optimal solutions of neural networks in a more general setting using overparametrization as a way to control the Neural Tangent Kernel. In this work we investigate how to bridge these two worlds and we provide deterministic convergence and recovery guarantees for the class of unsupervised feedforward multilayer neural networks trained to solve inverse problems. We also derive overparametrization bounds under which a two-layers Deep Inverse Prior network with smooth activation function will benefit from our guarantees.
+
+
+
+ 30. 标题:Passage Summarization with Recurrent Models for Audio-Sheet Music Retrieval
+ 编号:[88]
+ 链接:https://arxiv.org/abs/2309.12111
+ 作者:Luis Carvalho, Gerhard Widmer
+ 备注:In Proceedings of the 24th Conference of the International Society for Music Information Retrieval (ISMIR 2023), Milan, Italy
+ 关键词:sheet music, connecting sheet music, sheet music images, audio and sheet, related to connecting
+
+ 点击查看摘要
+ Many applications of cross-modal music retrieval are related to connecting sheet music images to audio recordings. A typical and recent approach to this is to learn, via deep neural networks, a joint embedding space that correlates short fixed-size snippets of audio and sheet music by means of an appropriate similarity structure. However, two challenges that arise out of this strategy are the requirement of strongly aligned data to train the networks, and the inherent discrepancies of musical content between audio and sheet music snippets caused by local and global tempo differences. In this paper, we address these two shortcomings by designing a cross-modal recurrent network that learns joint embeddings that can summarize longer passages of corresponding audio and sheet music. The benefits of our method are that it only requires weakly aligned audio-sheet music pairs, as well as that the recurrent network handles the non-linearities caused by tempo variations between audio and sheet music. We conduct a number of experiments on synthetic and real piano data and scores, showing that our proposed recurrent method leads to more accurate retrieval in all possible configurations.
+
+
+
+ 31. 标题:Clustering-based Domain-Incremental Learning
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2309.12078
+ 作者:Christiaan Lamers, Rene Vidal, Nabil Belbachir, Niki van Stein, Thomas Baeck, Paris Giampouras
+ 备注:
+ 关键词:learning multiple tasks, Gradient Episodic Memory, Orthogonal Gradient Descent, Averaged Gradient Episodic, streaming fashion
+
+ 点击查看摘要
+ We consider the problem of learning multiple tasks in a continual learning setting in which data from different tasks is presented to the learner in a streaming fashion. A key challenge in this setting is the so-called "catastrophic forgetting problem", in which the performance of the learner in an "old task" decreases when subsequently trained on a "new task". Existing continual learning methods, such as Averaged Gradient Episodic Memory (A-GEM) and Orthogonal Gradient Descent (OGD), address catastrophic forgetting by minimizing the loss for the current task without increasing the loss for previous tasks. However, these methods assume the learner knows when the task changes, which is unrealistic in practice. In this paper, we alleviate the need to provide the algorithm with information about task changes by using an online clustering-based approach on a dynamically updated finite pool of samples or gradients. We thereby successfully counteract catastrophic forgetting in one of the hardest settings, namely: domain-incremental learning, a setting for which the problem was previously unsolved. We showcase the benefits of our approach by applying these ideas to projection-based methods, such as A-GEM and OGD, which lead to task-agnostic versions of them. Experiments on real datasets demonstrate the effectiveness of the proposed strategy and its promising performance compared to state-of-the-art methods.
+
+
+
+ 32. 标题:Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer -- Current Trends and Research Perspectives
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.12067
+ 作者:Karolina Seweryn, Anna Wróblewska, Szymon Łukasik
+ 备注:
+ 关键词:challenging task due, interactions between players, complex and dynamic, dynamic nature, challenging task
+
+ 点击查看摘要
+ Action scene understanding in soccer is a challenging task due to the complex and dynamic nature of the game, as well as the interactions between players. This article provides a comprehensive overview of this task divided into action recognition, spotting, and spatio-temporal action localization, with a particular emphasis on the modalities used and multimodal methods. We explore the publicly available data sources and metrics used to evaluate models' performance. The article reviews recent state-of-the-art methods that leverage deep learning techniques and traditional methods. We focus on multimodal methods, which integrate information from multiple sources, such as video and audio data, and also those that represent one source in various ways. The advantages and limitations of methods are discussed, along with their potential for improving the accuracy and robustness of models. Finally, the article highlights some of the open research questions and future directions in the field of soccer action recognition, including the potential for multimodal methods to advance this field. Overall, this survey provides a valuable resource for researchers interested in the field of action scene understanding in soccer.
+
+
+
+ 33. 标题:An Efficient Consolidation of Word Embedding and Deep Learning Techniques for Classifying Anticancer Peptides: FastText+BiLSTM
+ 编号:[105]
+ 链接:https://arxiv.org/abs/2309.12058
+ 作者:Onur Karakaya, Zeynep Hilal Kilimci
+ 备注:
+ 关键词:exhibite antineoplastic properties, antineoplastic properties, exhibite antineoplastic, word embedding, Anticancer peptides
+
+ 点击查看摘要
+ Anticancer peptides (ACPs) are a group of peptides that exhibite antineoplastic properties. The utilization of ACPs in cancer prevention can present a viable substitute for conventional cancer therapeutics, as they possess a higher degree of selectivity and safety. Recent scientific advancements generate an interest in peptide-based therapies which offer the advantage of efficiently treating intended cells without negatively impacting normal cells. However, as the number of peptide sequences continues to increase rapidly, developing a reliable and precise prediction model becomes a challenging task. In this work, our motivation is to advance an efficient model for categorizing anticancer peptides employing the consolidation of word embedding and deep learning models. First, Word2Vec and FastText are evaluated as word embedding techniques for the purpose of extracting peptide sequences. Then, the output of word embedding models are fed into deep learning approaches CNN, LSTM, BiLSTM. To demonstrate the contribution of proposed framework, extensive experiments are carried on widely-used datasets in the literature, ACPs250 and Independent. Experiment results show the usage of proposed model enhances classification accuracy when compared to the state-of-the-art studies. The proposed combination, FastText+BiLSTM, exhibits 92.50% of accuracy for ACPs250 dataset, and 96.15% of accuracy for Independent dataset, thence determining new state-of-the-art.
+
+
+
+ 34. 标题:S-GBDT: Frugal Differentially Private Gradient Boosting Decision Trees
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2309.12041
+ 作者:Moritz Kirsche, Thorsten Peinemann, Joshua Stock, Carlos Cotrini, Esfandiar Mohammadi
+ 备注:The first two authors equally contributed to this work
+ 关键词:extract non-linear patterns, medical meta data, classical GBDT learners, gradient boosting decision, small sized datasets
+
+ 点击查看摘要
+ Privacy-preserving learning of gradient boosting decision trees (GBDT) has the potential for strong utility-privacy tradeoffs for tabular data, such as census data or medical meta data: classical GBDT learners can extract non-linear patterns from small sized datasets. The state-of-the-art notion for provable privacy-properties is differential privacy, which requires that the impact of single data points is limited and deniable. We introduce a novel differentially private GBDT learner and utilize four main techniques to improve the utility-privacy tradeoff. (1) We use an improved noise scaling approach with tighter accounting of privacy leakage of a decision tree leaf compared to prior work, resulting in noise that in expectation scales with $O(1/n)$, for $n$ data points. (2) We integrate individual Rényi filters to our method to learn from data points that have been underutilized during an iterative training process, which -- potentially of independent interest -- results in a natural yet effective insight to learning streams of non-i.i.d. data. (3) We incorporate the concept of random decision tree splits to concentrate privacy budget on learning leaves. (4) We deploy subsampling for privacy amplification. Our evaluation shows for the Abalone dataset ($<4k$ training data points) a $r^2$-score of $0.39$ for $\varepsilon="0.15$," which the closest prior work only achieved on adult dataset ($50k$ we achieve test error $18.7\,\%$ abalone $0.47$ is very close to $0.54$ nonprivate version gbdt. $17.1\,\%$ $13.7\,\%$ gbdt.< p>
+
+
+
+ 35. 标题:Uplift vs. predictive modeling: a theoretical analysis
+ 编号:[115]
+ 链接:https://arxiv.org/abs/2309.12036
+ 作者:Théo Verhelst, Robin Petit, Wouter Verbeke, Gianluca Bontempi
+ 备注:46 pages, 6 figures
+ 关键词:pure machine-learning approaches, machine-learning techniques, pure machine-learning, techniques in decision-making, growing popularity
+
+ 点击查看摘要
+ Despite the growing popularity of machine-learning techniques in decision-making, the added value of causal-oriented strategies with respect to pure machine-learning approaches has rarely been quantified in the literature. These strategies are crucial for practitioners in various domains, such as marketing, telecommunications, health care and finance. This paper presents a comprehensive treatment of the subject, starting from firm theoretical foundations and highlighting the parameters that influence the performance of the uplift and predictive approaches. The focus of the paper is on a binary outcome case and a binary action, and the paper presents a theoretical analysis of uplift modeling, comparing it with the classical predictive approach. The main research contributions of the paper include a new formulation of the measure of profit, a formal proof of the convergence of the uplift curve to the measure of profit ,and an illustration, through simulations, of the conditions under which predictive approaches still outperform uplift modeling. We show that the mutual information between the features and the outcome plays a significant role, along with the variance of the estimators, the distribution of the potential outcomes and the underlying costs and benefits of the treatment and the outcome.
+
+
+
+ 36. 标题:Face Identity-Aware Disentanglement in StyleGAN
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2309.12033
+ 作者:Adrian Suwała, Bartosz Wójcik, Magdalena Proszewska, Jacek Tabor, Przemysław Spurek, Marek Śmieja
+ 备注:
+ 关键词:Conditional GANs, GANs are frequently, person identity, face attributes, attributes
+
+ 点击查看摘要
+ Conditional GANs are frequently used for manipulating the attributes of face images, such as expression, hairstyle, pose, or age. Even though the state-of-the-art models successfully modify the requested attributes, they simultaneously modify other important characteristics of the image, such as a person's identity. In this paper, we focus on solving this problem by introducing PluGeN4Faces, a plugin to StyleGAN, which explicitly disentangles face attributes from a person's identity. Our key idea is to perform training on images retrieved from movie frames, where a given person appears in various poses and with different attributes. By applying a type of contrastive loss, we encourage the model to group images of the same person in similar regions of latent space. Our experiments demonstrate that the modifications of face attributes performed by PluGeN4Faces are significantly less invasive on the remaining characteristics of the image than in the existing state-of-the-art models.
+
+
+
+ 37. 标题:Human-in-the-Loop Causal Discovery under Latent Confounding using Ancestral GFlowNets
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2309.12032
+ 作者:Tiago da Silva, Eliezer Silva, Adèle Ribeiro, António Góis, Dominik Heider, Samuel Kaski, Diego Mesquita
+ 备注:
+ 关键词:Structure learning, ancestral graphs, causal, graphs, uncertainty estimates
+
+ 点击查看摘要
+ Structure learning is the crux of causal inference. Notably, causal discovery (CD) algorithms are brittle when data is scarce, possibly inferring imprecise causal relations that contradict expert knowledge -- especially when considering latent confounders. To aggravate the issue, most CD methods do not provide uncertainty estimates, making it hard for users to interpret results and improve the inference process. Surprisingly, while CD is a human-centered affair, no works have focused on building methods that both 1) output uncertainty estimates that can be verified by experts and 2) interact with those experts to iteratively refine CD. To solve these issues, we start by proposing to sample (causal) ancestral graphs proportionally to a belief distribution based on a score function, such as the Bayesian information criterion (BIC), using generative flow networks. Then, we leverage the diversity in candidate graphs and introduce an optimal experimental design to iteratively probe the expert about the relations among variables, effectively reducing the uncertainty of our belief over ancestral graphs. Finally, we update our samples to incorporate human feedback via importance sampling. Importantly, our method does not require causal sufficiency (i.e., unobserved confounders may exist). Experiments with synthetic observational data show that our method can accurately sample from distributions over ancestral graphs and that we can greatly improve inference quality with human aid.
+
+
+
+ 38. 标题:Dynamic Hypergraph Structure Learning for Traffic Flow Forecasting
+ 编号:[122]
+ 链接:https://arxiv.org/abs/2309.12028
+ 作者:Yusheng Zhao, Xiao Luo, Wei Ju, Chong Chen, Xian-Sheng Hua, Ming Zhang
+ 备注:Accepted by 2023 IEEE 39th International Conference on Data Engineering (ICDE 2023)
+ 关键词:future traffic conditions, predict future traffic, traffic conditions, aims to predict, predict future
+
+ 点击查看摘要
+ This paper studies the problem of traffic flow forecasting, which aims to predict future traffic conditions on the basis of road networks and traffic conditions in the past. The problem is typically solved by modeling complex spatio-temporal correlations in traffic data using spatio-temporal graph neural networks (GNNs). However, the performance of these methods is still far from satisfactory since GNNs usually have limited representation capacity when it comes to complex traffic networks. Graphs, by nature, fall short in capturing non-pairwise relations. Even worse, existing methods follow the paradigm of message passing that aggregates neighborhood information linearly, which fails to capture complicated spatio-temporal high-order interactions. To tackle these issues, in this paper, we propose a novel model named Dynamic Hypergraph Structure Learning (DyHSL) for traffic flow prediction. To learn non-pairwise relationships, our DyHSL extracts hypergraph structural information to model dynamics in the traffic networks, and updates each node representation by aggregating messages from its associated hyperedges. Additionally, to capture high-order spatio-temporal relations in the road network, we introduce an interactive graph convolution block, which further models the neighborhood interaction for each node. Finally, we integrate these two views into a holistic multi-scale correlation extraction module, which conducts temporal pooling with different scales to model different temporal patterns. Extensive experiments on four popular traffic benchmark datasets demonstrate the effectiveness of our proposed DyHSL compared with a broad range of competing baselines.
+
+
+
+ 39. 标题:Robust Approximation Algorithms for Non-monotone $k$-Submodular Maximization under a Knapsack Constraint
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.12025
+ 作者:Dung T.K. Ha, Canh V. Pham, Tan D. Tran, Huan X. Hoang
+ 备注:12 pages
+ 关键词:ground set size, information propagation, knapsack constraint, machine learning, ground set
+
+ 点击查看摘要
+ The problem of non-monotone $k$-submodular maximization under a knapsack constraint ($\kSMK$) over the ground set size $n$ has been raised in many applications in machine learning, such as data summarization, information propagation, etc. However, existing algorithms for the problem are facing questioning of how to overcome the non-monotone case and how to fast return a good solution in case of the big size of data. This paper introduces two deterministic approximation algorithms for the problem that competitively improve the query complexity of existing algorithms.
+Our first algorithm, $\LAA$, returns an approximation ratio of $1/19$ within $O(nk)$ query complexity. The second one, $\RLA$, improves the approximation ratio to $1/5-\epsilon$ in $O(nk)$ queries, where $\epsilon$ is an input parameter.
+Our algorithms are the first ones that provide constant approximation ratios within only $O(nk)$ query complexity for the non-monotone objective. They, therefore, need fewer the number of queries than state-of-the-the-art ones by a factor of $\Omega(\log n)$.
+Besides the theoretical analysis, we have evaluated our proposed ones with several experiments in some instances: Influence Maximization and Sensor Placement for the problem. The results confirm that our algorithms ensure theoretical quality as the cutting-edge techniques and significantly reduce the number of queries.
+
+
+
+ 40. 标题:Safe Hierarchical Reinforcement Learning for CubeSat Task Scheduling Based on Energy Consumption
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.12004
+ 作者:Mahya Ramezani, M. Amin Alandihallaj, Jose Luis Sanchez-Lopez, Andreas Hein
+ 备注:
+ 关键词:Low Earth Orbits, Earth Orbits, Hierarchical Reinforcement Learning, Low Earth, Learning methodology tailored
+
+ 点击查看摘要
+ This paper presents a Hierarchical Reinforcement Learning methodology tailored for optimizing CubeSat task scheduling in Low Earth Orbits (LEO). Incorporating a high-level policy for global task distribution and a low-level policy for real-time adaptations as a safety mechanism, our approach integrates the Similarity Attention-based Encoder (SABE) for task prioritization and an MLP estimator for energy consumption forecasting. Integrating this mechanism creates a safe and fault-tolerant system for CubeSat task scheduling. Simulation results validate the Hierarchical Reinforcement Learning superior convergence and task success rate, outperforming both the MADDPG model and traditional random scheduling across multiple CubeSat configurations.
+
+
+
+ 41. 标题:Enhancing SAEAs with Unevaluated Solutions: A Case Study of Relation Model for Expensive Optimization
+ 编号:[136]
+ 链接:https://arxiv.org/abs/2309.11994
+ 作者:Hao Hao, Xiaoqun Zhang, Aimin Zhou
+ 备注:18 pages, 9 figures
+ 关键词:hold significant importance, expensive optimization problems, resolving expensive optimization, Surrogate-assisted evolutionary algorithms, Surrogate-assisted evolutionary
+
+ 点击查看摘要
+ Surrogate-assisted evolutionary algorithms (SAEAs) hold significant importance in resolving expensive optimization problems~(EOPs). Extensive efforts have been devoted to improving the efficacy of SAEAs through the development of proficient model-assisted selection methods. However, generating high-quality solutions is a prerequisite for selection. The fundamental paradigm of evaluating a limited number of solutions in each generation within SAEAs reduces the variance of adjacent populations, thus impacting the quality of offspring solutions. This is a frequently encountered issue, yet it has not gained widespread attention. This paper presents a framework using unevaluated solutions to enhance the efficiency of SAEAs. The surrogate model is employed to identify high-quality solutions for direct generation of new solutions without evaluation. To ensure dependable selection, we have introduced two tailored relation models for the selection of the optimal solution and the unevaluated population. A comprehensive experimental analysis is performed on two test suites, which showcases the superiority of the relation model over regression and classification models in the selection phase. Furthermore, the surrogate-selected unevaluated solutions with high potential have been shown to significantly enhance the efficiency of the algorithm.
+
+
+
+ 42. 标题:Predictability and Comprehensibility in Post-Hoc XAI Methods: A User-Centered Analysis
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2309.11987
+ 作者:Anahid Jalali, Bernhard Haslhofer, Simone Kriglstein, Andreas Rauber
+ 备注:17
+ 关键词:aim to clarify, clarify predictions, predictions of black-box, black-box machine learning, explainability methods aim
+
+ 点击查看摘要
+ Post-hoc explainability methods aim to clarify predictions of black-box machine learning models. However, it is still largely unclear how well users comprehend the provided explanations and whether these increase the users ability to predict the model behavior. We approach this question by conducting a user study to evaluate comprehensibility and predictability in two widely used tools: LIME and SHAP. Moreover, we investigate the effect of counterfactual explanations and misclassifications on users ability to understand and predict the model behavior. We find that the comprehensibility of SHAP is significantly reduced when explanations are provided for samples near a model's decision boundary. Furthermore, we find that counterfactual explanations and misclassifications can significantly increase the users understanding of how a machine learning model is making decisions. Based on our findings, we also derive design recommendations for future post-hoc explainability methods with increased comprehensibility and predictability.
+
+
+
+ 43. 标题:Variational Connectionist Temporal Classification for Order-Preserving Sequence Modeling
+ 编号:[144]
+ 链接:https://arxiv.org/abs/2309.11983
+ 作者:Zheng Nan, Ting Dang, Vidhyasaharan Sethu, Beena Ahmed
+ 备注:5 pages, 3 figures, conference
+ 关键词:Connectionist temporal classification, sequence modeling tasks, Connectionist temporal, temporal classification, speech recognition
+
+ 点击查看摘要
+ Connectionist temporal classification (CTC) is commonly adopted for sequence modeling tasks like speech recognition, where it is necessary to preserve order between the input and target sequences. However, CTC is only applied to deterministic sequence models, where the latent space is discontinuous and sparse, which in turn makes them less capable of handling data variability when compared to variational models. In this paper, we integrate CTC with a variational model and derive loss functions that can be used to train more generalizable sequence models that preserve order. Specifically, we derive two versions of the novel variational CTC based on two reasonable assumptions, the first being that the variational latent variables at each time step are conditionally independent; and the second being that these latent variables are Markovian. We show that both loss functions allow direct optimization of the variational lower bound for the model log-likelihood, and present computationally tractable forms for implementing them.
+
+
+
+ 44. 标题:Generating Hierarchical Structures for Improved Time Series Classification Using Stochastic Splitting Functions
+ 编号:[153]
+ 链接:https://arxiv.org/abs/2309.11963
+ 作者:Celal Alagoz
+ 备注:
+ 关键词:divisive clustering approach, hierarchical divisive clustering, divisive clustering, stochastic splitting functions, enhance classification performance
+
+ 点击查看摘要
+ This study introduces a novel hierarchical divisive clustering approach with stochastic splitting functions (SSFs) to enhance classification performance in multi-class datasets through hierarchical classification (HC). The method has the unique capability of generating hierarchy without requiring explicit information, making it suitable for datasets lacking prior knowledge of hierarchy. By systematically dividing classes into two subsets based on their discriminability according to the classifier, the proposed approach constructs a binary tree representation of hierarchical classes. The approach is evaluated on 46 multi-class time series datasets using popular classifiers (svm and rocket) and SSFs (potr, srtr, and lsoo). The results reveal that the approach significantly improves classification performance in approximately half and a third of the datasets when using rocket and svm as the classifier, respectively. The study also explores the relationship between dataset features and HC performance. While the number of classes and flat classification (FC) score show consistent significance, variations are observed with different splitting functions. Overall, the proposed approach presents a promising strategy for enhancing classification by generating hierarchical structure in multi-class time series datasets. Future research directions involve exploring different splitting functions, classifiers, and hierarchy structures, as well as applying the approach to diverse domains beyond time series data. The source code is made openly available to facilitate reproducibility and further exploration of the method.
+
+
+
+ 45. 标题:A Study of Forward-Forward Algorithm for Self-Supervised Learning
+ 编号:[158]
+ 链接:https://arxiv.org/abs/2309.11955
+ 作者:Jonas Brenig, Radu Timofte
+ 备注:
+ 关键词:Self-supervised representation learning, representation learning, remarkable progress, learn useful image, Self-supervised representation
+
+ 点击查看摘要
+ Self-supervised representation learning has seen remarkable progress in the last few years, with some of the recent methods being able to learn useful image representations without labels. These methods are trained using backpropagation, the de facto standard. Recently, Geoffrey Hinton proposed the forward-forward algorithm as an alternative training method. It utilizes two forward passes and a separate loss function for each layer to train the network without backpropagation.
+In this study, for the first time, we study the performance of forward-forward vs. backpropagation for self-supervised representation learning and provide insights into the learned representation spaces. Our benchmark employs four standard datasets, namely MNIST, F-MNIST, SVHN and CIFAR-10, and three commonly used self-supervised representation learning techniques, namely rotation, flip and jigsaw.
+Our main finding is that while the forward-forward algorithm performs comparably to backpropagation during (self-)supervised training, the transfer performance is significantly lagging behind in all the studied settings. This may be caused by a combination of factors, including having a loss function for each layer and the way the supervised training is realized in the forward-forward paradigm. In comparison to backpropagation, the forward-forward algorithm focuses more on the boundaries and drops part of the information unnecessary for making decisions which harms the representation learning goal. Further investigation and research are necessary to stabilize the forward-forward strategy for self-supervised learning, to work beyond the datasets and configurations demonstrated by Geoffrey Hinton.
+
+
+
+ 46. 标题:A Machine Learning-oriented Survey on Tiny Machine Learning
+ 编号:[166]
+ 链接:https://arxiv.org/abs/2309.11932
+ 作者:Luigi Capogrosso, Federico Cunico, Dong Seon Cheng, Franco Fummi, Marco cristani
+ 备注:Article currently under review at IEEE Access
+ 关键词:Tiny Machine Learning, Tiny Machine, Artificial Intelligence, learning-based software architectures, emergence of Tiny
+
+ 点击查看摘要
+ The emergence of Tiny Machine Learning (TinyML) has positively revolutionized the field of Artificial Intelligence by promoting the joint design of resource-constrained IoT hardware devices and their learning-based software architectures. TinyML carries an essential role within the fourth and fifth industrial revolutions in helping societies, economies, and individuals employ effective AI-infused computing technologies (e.g., smart cities, automotive, and medical robotics). Given its multidisciplinary nature, the field of TinyML has been approached from many different angles: this comprehensive survey wishes to provide an up-to-date overview focused on all the learning algorithms within TinyML-based solutions. The survey is based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) methodological flow, allowing for a systematic and complete literature survey. In particular, firstly we will examine the three different workflows for implementing a TinyML-based system, i.e., ML-oriented, HW-oriented, and co-design. Secondly, we propose a taxonomy that covers the learning panorama under the TinyML lens, examining in detail the different families of model optimization and design, as well as the state-of-the-art learning techniques. Thirdly, this survey will present the distinct features of hardware devices and software tools that represent the current state-of-the-art for TinyML intelligent edge applications. Finally, we discuss the challenges and future directions.
+
+
+
+ 47. 标题:Bridging the Gap: Learning Pace Synchronization for Open-World Semi-Supervised Learning
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.11930
+ 作者:Bo Ye, Kai Gan, Tong Wei, Min-Ling Zhang
+ 备注:
+ 关键词:open-world semi-supervised learning, machine learning model, unlabeled data, labeled data, open-world semi-supervised
+
+ 点击查看摘要
+ In open-world semi-supervised learning, a machine learning model is tasked with uncovering novel categories from unlabeled data while maintaining performance on seen categories from labeled data. The central challenge is the substantial learning gap between seen and novel categories, as the model learns the former faster due to accurate supervisory information. To address this, we introduce 1) an adaptive margin loss based on estimated class distribution, which encourages a large negative margin for samples in seen classes, to synchronize learning paces, and 2) pseudo-label contrastive clustering, which pulls together samples which are likely from the same class in the output space, to enhance novel class discovery. Our extensive evaluations on multiple datasets demonstrate that existing models still hinder novel class learning, whereas our approach strikingly balances both seen and novel classes, achieving a remarkable 3% average accuracy increase on the ImageNet dataset compared to the prior state-of-the-art. Additionally, we find that fine-tuning the self-supervised pre-trained backbone significantly boosts performance over the default in prior literature. After our paper is accepted, we will release the code.
+
+
+
+ 48. 标题:Stochastic stiffness identification and response estimation of Timoshenko beams via physics-informed Gaussian processes
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.11875
+ 作者:Gledson Rodrigo Tondo, Sebastian Rau, Igor Kavrakov, Guido Morgenthal
+ 备注:
+ 关键词:Machine learning models, learning models trained, Machine learning, powerful tool, model
+
+ 点击查看摘要
+ Machine learning models trained with structural health monitoring data have become a powerful tool for system identification. This paper presents a physics-informed Gaussian process (GP) model for Timoshenko beam elements. The model is constructed as a multi-output GP with covariance and cross-covariance kernels analytically derived based on the differential equations for deflections, rotations, strains, bending moments, shear forces and applied loads. Stiffness identification is performed in a Bayesian format by maximising a posterior model through a Markov chain Monte Carlo method, yielding a stochastic model for the structural parameters. The optimised GP model is further employed for probabilistic predictions of unobserved responses. Additionally, an entropy-based method for physics-informed sensor placement optimisation is presented, exploiting heterogeneous sensor position information and structural boundary conditions built into the GP model. Results demonstrate that the proposed approach is effective at identifying structural parameters and is capable of fusing data from heterogeneous and multi-fidelity sensors. Probabilistic predictions of structural responses and internal forces are in closer agreement with measured data. We validate our model with an experimental setup and discuss the quality and uncertainty of the obtained results. The proposed approach has potential applications in the field of structural health monitoring (SHM) for both mechanical and structural systems.
+
+
+
+ 49. 标题:TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
+ 编号:[214]
+ 链接:https://arxiv.org/abs/2309.11845
+ 作者:Meng Liu, Ke Liang, Dayu Hu, Hao Yu, Yue Liu, Lingyuan Meng, Wenxuan Tu, Sihang Zhou, Xinwang Liu
+ 备注:
+ 关键词:raises higher requirements, digital age, raises higher, higher requirements, data
+
+ 点击查看摘要
+ Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at this https URL.
+
+
+
+ 50. 标题:A Comprehensive Review of Community Detection in Graphs
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2309.11798
+ 作者:Songlai Ning, Jiakang Li, Yonggang Lu
+ 备注:
+ 关键词:community detection, community, significantly advanced, detection, community detection methods
+
+ 点击查看摘要
+ The study of complex networks has significantly advanced our understanding of community structures which serves as a crucial feature of real-world graphs. Detecting communities in graphs is a challenging problem with applications in sociology, biology, and computer science. Despite the efforts of an interdisciplinary community of scientists, a satisfactory solution to this problem has not yet been achieved. This review article delves into the topic of community detection in graphs, which serves as a crucial role in understanding the organization and functioning of complex systems. We begin by introducing the concept of community structure, which refers to the arrangement of vertices into clusters, with strong internal connections and weaker connections between clusters. Then, we provide a thorough exposition of various community detection methods, including a new method designed by us. Additionally, we explore real-world applications of community detection in diverse networks. In conclusion, this comprehensive review provides a deep understanding of community detection in graphs. It serves as a valuable resource for researchers and practitioners in multiple disciplines, offering insights into the challenges, methodologies, and applications of community detection in complex networks.
+
+
+
+ 51. 标题:DimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2309.11782
+ 作者:Thanh Nguyen, Trung Pham, Chaoning Zhang, Tung Luu, Thang Vu, Chang D. Yoo
+ 备注:
+ 关键词:contrastive learning, gained remarkable success, Self-supervised learning, Dimensional Contrastive Learning, plays a key
+
+ 点击查看摘要
+ Self-supervised learning (SSL) has gained remarkable success, for which contrastive learning (CL) plays a key role. However, the recent development of new non-CL frameworks has achieved comparable or better performance with high improvement potential, prompting researchers to enhance these frameworks further. Assimilating CL into non-CL frameworks has been thought to be beneficial, but empirical evidence indicates no visible improvements. In view of that, this paper proposes a strategy of performing CL along the dimensional direction instead of along the batch direction as done in conventional contrastive learning, named Dimensional Contrastive Learning (DimCL). DimCL aims to enhance the feature diversity, and it can serve as a regularizer to prior SSL frameworks. DimCL has been found to be effective, and the hardness-aware property is identified as a critical reason for its success. Extensive experimental results reveal that assimilating DimCL into SSL frameworks leads to performance improvement by a non-trivial margin on various datasets and backbone architectures.
+
+
+
+ 52. 标题:Dictionary Attack on IMU-based Gait Authentication
+ 编号:[240]
+ 链接:https://arxiv.org/abs/2309.11766
+ 作者:Rajesh Kumar, Can Isik, Chilukuri K. Mohan
+ 备注:12 pages, 9 figures, accepted at AISec23 colocated with ACM CCS, November 30, 2023, Copenhagen, Denmark
+ 关键词:inertial measurement unit, built into smartphones, measurement unit, inertial measurement, authentication systems
+
+ 点击查看摘要
+ We present a novel adversarial model for authentication systems that use gait patterns recorded by the inertial measurement unit (IMU) built into smartphones. The attack idea is inspired by and named after the concept of a dictionary attack on knowledge (PIN or password) based authentication systems. In particular, this work investigates whether it is possible to build a dictionary of IMUGait patterns and use it to launch an attack or find an imitator who can actively reproduce IMUGait patterns that match the target's IMUGait pattern. Nine physically and demographically diverse individuals walked at various levels of four predefined controllable and adaptable gait factors (speed, step length, step width, and thigh-lift), producing 178 unique IMUGait patterns. Each pattern attacked a wide variety of user authentication models. The deeper analysis of error rates (before and after the attack) challenges the belief that authentication systems based on IMUGait patterns are the most difficult to spoof; further research is needed on adversarial models and associated countermeasures.
+
+
+
+ 53. 标题:Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation
+ 编号:[241]
+ 链接:https://arxiv.org/abs/2309.11765
+ 作者:Xinyu Tang, Richard Shin, Huseyin A. Inan, Andre Manoel, Fatemehsadat Mireshghallah, Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, Robert Sim
+ 备注:
+ 关键词:large language models, in-context learning, language models, study the problem, problem of in-context
+
+ 点击查看摘要
+ We study the problem of in-context learning (ICL) with large language models (LLMs) on private datasets. This scenario poses privacy risks, as LLMs may leak or regurgitate the private examples demonstrated in the prompt. We propose a novel algorithm that generates synthetic few-shot demonstrations from the private dataset with formal differential privacy (DP) guarantees, and show empirically that it can achieve effective ICL. We conduct extensive experiments on standard benchmarks and compare our algorithm with non-private ICL and zero-shot solutions. Our results demonstrate that our algorithm can achieve competitive performance with strong privacy levels. These results open up new possibilities for ICL with privacy protection for a broad range of applications.
+
+
+
+ 54. 标题:SAM-OCTA: A Fine-Tuning Strategy for Applying Foundation Model to OCTA Image Segmentation Tasks
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2309.11758
+ 作者:Chengliang Wang, Xinrun Chen, Haojian Ning, Shiying Li
+ 备注:ICASSP conference is in submission
+ 关键词:coherence tomography angiography, optical coherence tomography, segmenting specific targets, tomography angiography, analysis of optical
+
+ 点击查看摘要
+ In the analysis of optical coherence tomography angiography (OCTA) images, the operation of segmenting specific targets is necessary. Existing methods typically train on supervised datasets with limited samples (approximately a few hundred), which can lead to overfitting. To address this, the low-rank adaptation technique is adopted for foundation model fine-tuning and proposed corresponding prompt point generation strategies to process various segmentation tasks on OCTA datasets. This method is named SAM-OCTA and has been experimented on the publicly available OCTA-500 dataset. While achieving state-of-the-art performance metrics, this method accomplishes local vessel segmentation as well as effective artery-vein segmentation, which was not well-solved in previous works. The code is available at: this https URL.
+
+
+
+ 55. 标题:How Robust is Google's Bard to Adversarial Image Attacks?
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2309.11751
+ 作者:Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, Xiao Yang, Yichi Zhang, Yu Tian, Hang Su, Jun Zhu
+ 备注:Technical report
+ 关键词:Large Language Models, Multimodal Large Language, Large Language, achieved unprecedented performance, Language Models
+
+ 点击查看摘要
+ Multimodal Large Language Models (MLLMs) that integrate text and other modalities (especially vision) have achieved unprecedented performance in various multimodal tasks. However, due to the unsolved adversarial robustness problem of vision models, MLLMs can have more severe safety and security risks by introducing the vision inputs. In this work, we study the adversarial robustness of Google's Bard, a competitive chatbot to ChatGPT that released its multimodal capability recently, to better understand the vulnerabilities of commercial MLLMs. By attacking white-box surrogate vision encoders or MLLMs, the generated adversarial examples can mislead Bard to output wrong image descriptions with a 22% success rate based solely on the transferability. We show that the adversarial examples can also attack other MLLMs, e.g., a 26% attack success rate against Bing Chat and a 86% attack success rate against ERNIE bot. Moreover, we identify two defense mechanisms of Bard, including face detection and toxicity detection of images. We design corresponding attacks to evade these defenses, demonstrating that the current defenses of Bard are also vulnerable. We hope this work can deepen our understanding on the robustness of MLLMs and facilitate future research on defenses. Our code is available at this https URL.
+
+
+
+ 56. 标题:Unveiling Optimal SDG Pathways: An Innovative Approach Leveraging Graph Pruning and Intent Graph for Effective Recommendations
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2309.11741
+ 作者:Zhihang Yu, Shu Wang, Yunqiang Zhu, Wen Yuan, Xiaoliang Dai, Zhiqiang Zou
+ 备注:
+ 关键词:Sustainable Development Goals, ecological civilization patterns, sustainable development patterns, achieving Sustainable Development, Development Goals
+
+ 点击查看摘要
+ The recommendation of appropriate development pathways, also known as ecological civilization patterns for achieving Sustainable Development Goals (namely, sustainable development patterns), are of utmost importance for promoting ecological, economic, social, and resource sustainability in a specific region. To achieve this, the recommendation process must carefully consider the region's natural, environmental, resource, and economic characteristics. However, current recommendation algorithms in the field of computer science fall short in adequately addressing the spatial heterogeneity related to environment and sparsity of regional historical interaction data, which limits their effectiveness in recommending sustainable development patterns. To overcome these challenges, this paper proposes a method called User Graph after Pruning and Intent Graph (UGPIG). Firstly, we utilize the high-density linking capability of the pruned User Graph to address the issue of spatial heterogeneity neglect in recommendation algorithms. Secondly, we construct an Intent Graph by incorporating the intent network, which captures the preferences for attributes including environmental elements of target regions. This approach effectively alleviates the problem of sparse historical interaction data in the region. Through extensive experiments, we demonstrate that UGPIG outperforms state-of-the-art recommendation algorithms like KGCN, KGAT, and KGIN in sustainable development pattern recommendations, with a maximum improvement of 9.61% in Top-3 recommendation performance.
+
+
+
+ 57. 标题:Turaco: Complexity-Guided Data Sampling for Training Neural Surrogates of Programs
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2309.11726
+ 作者:Alex Renda, Yi Ding, Michael Carbin
+ 备注:Published in OOPSLA 2023
+ 关键词:increasingly developing surrogates, software development challenges, Programmers train surrogates, researchers are increasingly, increasingly developing
+
+ 点击查看摘要
+ Programmers and researchers are increasingly developing surrogates of programs, models of a subset of the observable behavior of a given program, to solve a variety of software development challenges. Programmers train surrogates from measurements of the behavior of a program on a dataset of input examples. A key challenge of surrogate construction is determining what training data to use to train a surrogate of a given program.
+We present a methodology for sampling datasets to train neural-network-based surrogates of programs. We first characterize the proportion of data to sample from each region of a program's input space (corresponding to different execution paths of the program) based on the complexity of learning a surrogate of the corresponding execution path. We next provide a program analysis to determine the complexity of different paths in a program. We evaluate these results on a range of real-world programs, demonstrating that complexity-guided sampling results in empirical improvements in accuracy.
+
+
+
+ 58. 标题:Efficient Core-selecting Incentive Mechanism for Data Sharing in Federated Learning
+ 编号:[258]
+ 链接:https://arxiv.org/abs/2309.11722
+ 作者:Mengda Ji, Genjiu Xu, Jianjun Ge, Mingqiang Li
+ 备注:
+ 关键词:Federated learning, distributed machine learning, machine learning system, improved global model, Federated
+
+ 点击查看摘要
+ Federated learning is a distributed machine learning system that uses participants' data to train an improved global model. In federated learning, participants cooperatively train a global model, and they will receive the global model and payments. Rational participants try to maximize their individual utility, and they will not input their high-quality data truthfully unless they are provided with satisfactory payments based on their data quality. Furthermore, federated learning benefits from the cooperative contributions of participants. Accordingly, how to establish an incentive mechanism that both incentivizes inputting data truthfully and promotes stable cooperation has become an important issue to consider. In this paper, we introduce a data sharing game model for federated learning and employ game-theoretic approaches to design a core-selecting incentive mechanism by utilizing a popular concept in cooperative games, the core. In federated learning, the core can be empty, resulting in the core-selecting mechanism becoming infeasible. To address this, our core-selecting mechanism employs a relaxation method and simultaneously minimizes the benefits of inputting false data for all participants. However, this mechanism is computationally expensive because it requires aggregating exponential models for all possible coalitions, which is infeasible in federated learning. To address this, we propose an efficient core-selecting mechanism based on sampling approximation that only aggregates models on sampled coalitions to approximate the exact result. Extensive experiments verify that the efficient core-selecting mechanism can incentivize inputting high-quality data and stable cooperation, while it reduces computational overhead compared to the core-selecting mechanism.
+
+
+
+ 59. 标题:Meta OOD Learning for Continuously Adaptive OOD Detection
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2309.11705
+ 作者:Xinheng Wu, Jie Lu, Zhen Fang, Guangquan Zhang
+ 备注:Accepted by ICCV 2023
+ 关键词:OOD detection, OOD, OOD detection methods, OOD detection model, OOD detection performance
+
+ 点击查看摘要
+ Out-of-distribution (OOD) detection is crucial to modern deep learning applications by identifying and alerting about the OOD samples that should not be tested or used for making predictions. Current OOD detection methods have made significant progress when in-distribution (ID) and OOD samples are drawn from static distributions. However, this can be unrealistic when applied to real-world systems which often undergo continuous variations and shifts in ID and OOD distributions over time. Therefore, for an effective application in real-world systems, the development of OOD detection methods that can adapt to these dynamic and evolving distributions is essential. In this paper, we propose a novel and more realistic setting called continuously adaptive out-of-distribution (CAOOD) detection which targets on developing an OOD detection model that enables dynamic and quick adaptation to a new arriving distribution, with insufficient ID samples during deployment time. To address CAOOD, we develop meta OOD learning (MOL) by designing a learning-to-adapt diagram such that a good initialized OOD detection model is learned during the training process. In the testing process, MOL ensures OOD detection performance over shifting distributions by quickly adapting to new distributions with a few adaptations. Extensive experiments on several OOD benchmarks endorse the effectiveness of our method in preserving both ID classification accuracy and OOD detection performance on continuously shifting distributions.
+
+
+
+ 60. 标题:Incentivized Communication for Federated Bandits
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2309.11702
+ 作者:Zhepei Wei, Chuanhao Li, Haifeng Xu, Hongning Wang
+ 备注:25 pages, 4 figures
+ 关键词:good whenever needed, existing works, altruistic about sharing, collective good, share data
+
+ 点击查看摘要
+ Most existing works on federated bandits take it for granted that all clients are altruistic about sharing their data with the server for the collective good whenever needed. Despite their compelling theoretical guarantee on performance and communication efficiency, this assumption is overly idealistic and oftentimes violated in practice, especially when the algorithm is operated over self-interested clients, who are reluctant to share data without explicit benefits. Negligence of such self-interested behaviors can significantly affect the learning efficiency and even the practical operability of federated bandit learning. In light of this, we aim to spark new insights into this under-explored research area by formally introducing an incentivized communication problem for federated bandits, where the server shall motivate clients to share data by providing incentives. Without loss of generality, we instantiate this bandit problem with the contextual linear setting and propose the first incentivized communication protocol, namely, Inc-FedUCB, that achieves near-optimal regret with provable communication and incentive cost guarantees. Extensive empirical experiments on both synthetic and real-world datasets further validate the effectiveness of the proposed method across various environments.
+
+
+
+ 61. 标题:Large-scale Pretraining Improves Sample Efficiency of Active Learning based Molecule Virtual Screening
+ 编号:[274]
+ 链接:https://arxiv.org/abs/2309.11687
+ 作者:Zhonglin Cao, Simone Sciabola, Ye Wang
+ 备注:
+ 关键词:identify potential hit, potential hit candidates, large compound libraries, Virtual screening, libraries to identify
+
+ 点击查看摘要
+ Virtual screening of large compound libraries to identify potential hit candidates is one of the earliest steps in drug discovery. As the size of commercially available compound collections grows exponentially to the scale of billions, brute-force virtual screening using traditional tools such as docking becomes infeasible in terms of time and computational resources. Active learning and Bayesian optimization has recently been proven as effective methods of narrowing down the search space. An essential component in those methods is a surrogate machine learning model that is trained with a small subset of the library to predict the desired properties of compounds. Accurate model can achieve high sample efficiency by finding the most promising compounds with only a fraction of the whole library being virtually screened. In this study, we examined the performance of pretrained transformer-based language model and graph neural network in Bayesian optimization active learning framework. The best pretrained models identifies 58.97% of the top-50000 by docking score after screening only 0.6% of an ultra-large library containing 99.5 million compounds, improving 8% over previous state-of-the-art baseline. Through extensive benchmarks, we show that the superior performance of pretrained models persists in both structure-based and ligand-based drug discovery. Such model can serve as a boost to the accuracy and sample efficiency of active learning based molecule virtual screening.
+
+
+
+ 62. 标题:Dr. FERMI: A Stochastic Distributionally Robust Fair Empirical Risk Minimization Framework
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2309.11682
+ 作者:Sina Baharlouei, Meisam Razaviyayn
+ 备注:22 pages, 3 figures
+ 关键词:training fair machine, machine learning models, developed methods rely, fair machine learning, recent years
+
+ 点击查看摘要
+ While training fair machine learning models has been studied extensively in recent years, most developed methods rely on the assumption that the training and test data have similar distributions. In the presence of distribution shifts, fair models may behave unfairly on test data. There have been some developments for fair learning robust to distribution shifts to address this shortcoming. However, most proposed solutions are based on the assumption of having access to the causal graph describing the interaction of different features. Moreover, existing algorithms require full access to data and cannot be used when small batches are used (stochastic/batch implementation). This paper proposes the first stochastic distributionally robust fairness framework with convergence guarantees that do not require knowledge of the causal graph. More specifically, we formulate the fair inference in the presence of the distribution shift as a distributionally robust optimization problem under $L_p$ norm uncertainty sets with respect to the Exponential Renyi Mutual Information (ERMI) as the measure of fairness violation. We then discuss how the proposed method can be implemented in a stochastic fashion. We have evaluated the presented framework's performance and efficiency through extensive experiments on real datasets consisting of distribution shifts.
+
+
+
+ 63. 标题:Federated Learning with Neural Graphical Models
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2309.11680
+ 作者:Urszula Chajewska, Harsh Shrivastava
+ 备注:
+ 关键词:retain exclusive control, Probabilistic Graphical models, create models based, improved model accuracy, model accuracy due
+
+ 点击查看摘要
+ Federated Learning (FL) addresses the need to create models based on proprietary data in such a way that multiple clients retain exclusive control over their data, while all benefit from improved model accuracy due to pooled resources. Recently proposed Neural Graphical Models (NGMs) are Probabilistic Graphical models that utilize the expressive power of neural networks to learn complex non-linear dependencies between the input features. They learn to capture the underlying data distribution and have efficient algorithms for inference and sampling. We develop a FL framework which maintains a global NGM model that learns the averaged information from the local NGM models while keeping the training data within the client's environment. Our design, FedNGMs, avoids the pitfalls and shortcomings of neuron matching frameworks like Federated Matched Averaging that suffers from model parameter explosion. Our global model size remains constant throughout the process. In the cases where clients have local variables that are not part of the combined global distribution, we propose a `Stitching' algorithm, which personalizes the global NGM models by merging the additional variables using the client's data. FedNGM is robust to data heterogeneity, large number of participants, and limited communication bandwidth.
+
+
+
+ 64. 标题:Popularity Degradation Bias in Local Music Recommendation
+ 编号:[282]
+ 链接:https://arxiv.org/abs/2309.11671
+ 作者:April Trainor, Douglas Turnbull
+ 备注:Presented at MuRS Workshop, RecSys '23
+ 关键词:Weight Relevance Matrix, Relevance Matrix Factorization, Multinomial Variational Autoencoder, popularity degradation bias, Weight Relevance
+
+ 点击查看摘要
+ In this paper, we study the effect of popularity degradation bias in the context of local music recommendations. Specifically, we examine how accurate two top-performing recommendation algorithms, Weight Relevance Matrix Factorization (WRMF) and Multinomial Variational Autoencoder (Mult-VAE), are at recommending artists as a function of artist popularity. We find that both algorithms improve recommendation performance for more popular artists and, as such, exhibit popularity degradation bias. While both algorithms produce a similar level of performance for more popular artists, Mult-VAE shows better relative performance for less popular artists. This suggests that this algorithm should be preferred for local (long-tail) music artist recommendation.
+
+
+
+ 65. 标题:GLM Regression with Oblivious Corruptions
+ 编号:[289]
+ 链接:https://arxiv.org/abs/2309.11657
+ 作者:Ilias Diakonikolas, Sushrut Karmalkar, Jongho Park, Christos Tzamos
+ 备注:Published in COLT 2023
+ 关键词:generalized linear models, additive oblivious noise, cdot, presence of additive, oblivious noise
+
+ 点击查看摘要
+ We demonstrate the first algorithms for the problem of regression for generalized linear models (GLMs) in the presence of additive oblivious noise. We assume we have sample access to examples $(x, y)$ where $y$ is a noisy measurement of $g(w^* \cdot x)$. In particular, \new{the noisy labels are of the form} $y = g(w^* \cdot x) + \xi + \epsilon$, where $\xi$ is the oblivious noise drawn independently of $x$ \new{and satisfies} $\Pr[\xi = 0] \geq o(1)$, and $\epsilon \sim \mathcal N(0, \sigma^2)$. Our goal is to accurately recover a \new{parameter vector $w$ such that the} function $g(w \cdot x)$ \new{has} arbitrarily small error when compared to the true values $g(w^* \cdot x)$, rather than the noisy measurements $y$.
+We present an algorithm that tackles \new{this} problem in its most general distribution-independent setting, where the solution may not \new{even} be identifiable. \new{Our} algorithm returns \new{an accurate estimate of} the solution if it is identifiable, and otherwise returns a small list of candidates, one of which is close to the true solution. Furthermore, we \new{provide} a necessary and sufficient condition for identifiability, which holds in broad settings. \new{Specifically,} the problem is identifiable when the quantile at which $\xi + \epsilon = 0$ is known, or when the family of hypotheses does not contain candidates that are nearly equal to a translated $g(w^* \cdot x) + A$ for some real number $A$, while also having large error when compared to $g(w^* \cdot x)$.
+This is the first \new{algorithmic} result for GLM regression \new{with oblivious noise} which can handle more than half the samples being arbitrarily corrupted. Prior work focused largely on the setting of linear regression, and gave algorithms under restrictive assumptions.
+
+
+
+ 66. 标题:Drift Control of High-Dimensional RBM: A Computational Method Based on Neural Networks
+ 编号:[293]
+ 链接:https://arxiv.org/abs/2309.11651
+ 作者:Baris Ata, J. Michael Harrison, Nian Si
+ 备注:
+ 关键词:dimensional positive orthant, Motivated by applications, queueing theory, dimensional positive, applications in queueing
+
+ 点击查看摘要
+ Motivated by applications in queueing theory, we consider a stochastic control problem whose state space is the $d$-dimensional positive orthant. The controlled process $Z$ evolves as a reflected Brownian motion whose covariance matrix is exogenously specified, as are its directions of reflection from the orthant's boundary surfaces. A system manager chooses a drift vector $\theta(t)$ at each time $t$ based on the history of $Z$, and the cost rate at time $t$ depends on both $Z(t)$ and $\theta(t)$. In our initial problem formulation, the objective is to minimize expected discounted cost over an infinite planning horizon, after which we treat the corresponding ergodic control problem. Extending earlier work by Han et al. (Proceedings of the National Academy of Sciences, 2018, 8505-8510), we develop and illustrate a simulation-based computational method that relies heavily on deep neural network technology. For test problems studied thus far, our method is accurate to within a fraction of one percent, and is computationally feasible in dimensions up to at least $d=30$.
+
+
+
+ 67. 标题:Orbital AI-based Autonomous Refuelling Solution
+ 编号:[294]
+ 链接:https://arxiv.org/abs/2309.11648
+ 作者:Duarte Rondao, Lei He, Nabil Aouf
+ 备注:13 pages
+ 关键词:small form factor, space rendezvous due, inexpensive power, rendezvous due, small form
+
+ 点击查看摘要
+ Cameras are rapidly becoming the choice for on-board sensors towards space rendezvous due to their small form factor and inexpensive power, mass, and volume costs. When it comes to docking, however, they typically serve a secondary role, whereas the main work is done by active sensors such as lidar. This paper documents the development of a proposed AI-based (artificial intelligence) navigation algorithm intending to mature the use of on-board visible wavelength cameras as a main sensor for docking and on-orbit servicing (OOS), reducing the dependency on lidar and greatly reducing costs. Specifically, the use of AI enables the expansion of the relative navigation solution towards multiple classes of scenarios, e.g., in terms of targets or illumination conditions, which would otherwise have to be crafted on a case-by-case manner using classical image processing methods. Multiple convolutional neural network (CNN) backbone architectures are benchmarked on synthetically generated data of docking manoeuvres with the International Space Station (ISS), achieving position and attitude estimates close to 1% range-normalised and 1 deg, respectively. The integration of the solution with a physical prototype of the refuelling mechanism is validated in laboratory using a robotic arm to simulate a berthing procedure.
+
+
+
+ 68. 标题:Early diagnosis of autism spectrum disorder using machine learning approaches
+ 编号:[295]
+ 链接:https://arxiv.org/abs/2309.11646
+ 作者:Rownak Ara Rasul, Promy Saha, Diponkor Bala, S M Rakib Ul Karim, Ibrahim Abdullah, Bishwajit Saha
+ 备注:14 pages, 2 figures, 12 tables
+ 关键词:Autistic Spectrum Disorder, Spectrum Disorder, neurological disease characterized, Autistic Spectrum, social interaction
+
+ 点击查看摘要
+ Autistic Spectrum Disorder (ASD) is a neurological disease characterized by difficulties with social interaction, communication, and repetitive activities. The severity of these difficulties varies, and those with this diagnosis face unique challenges. While its primary origin lies in genetics, identifying and addressing it early can contribute to the enhancement of the condition. In recent years, machine learning-driven intelligent diagnosis has emerged as a supplement to conventional clinical approaches, aiming to address the potential drawbacks of time-consuming and costly traditional methods. In this work, we utilize different machine learning algorithms to find the most significant traits responsible for ASD and to automate the diagnostic process. We study six classification models to see which model works best to identify ASD and also study five popular clustering methods to get a meaningful insight of these ASD datasets. To find the best classifier for these binary datasets, we evaluate the models using accuracy, precision, recall, specificity, F1-score, AUC, kappa and log loss metrics. Our evaluation demonstrates that five out of the six selected models perform exceptionally, achieving a 100% accuracy rate on the ASD datasets when hyperparameters are meticulously tuned for each model. As almost all classification models are able to get 100% accuracy, we become interested in observing the underlying insights of the datasets by implementing some popular clustering algorithms on these datasets. We calculate Normalized Mutual Information (NMI), Adjusted Rand Index (ARI) & Silhouette Coefficient (SC) metrics to select the best clustering models. Our evaluation finds that spectral clustering outperforms all other benchmarking clustering models in terms of NMI & ARI metrics and it also demonstrates comparability to the optimal SC achieved by k-means.
+
+
+
+ 69. 标题:A survey on the semantics of sequential patterns with negation
+ 编号:[300]
+ 链接:https://arxiv.org/abs/2309.11638
+ 作者:Thomas Guyet
+ 备注:
+ 关键词:negative sequential pattern, sequential pattern, pattern, sequential, negative sequential
+
+ 点击查看摘要
+ A sequential pattern with negation, or negative sequential pattern, takes the form of a sequential pattern for which the negation symbol may be used in front of some of the pattern's itemsets. Intuitively, such a pattern occurs in a sequence if negated itemsets are absent in the sequence. Recent work has shown that different semantics can be attributed to these pattern forms, and that state-of-the-art algorithms do not extract the same sets of patterns. This raises the important question of the interpretability of sequential pattern with negation. In this study, our focus is on exploring how potential users perceive negation in sequential patterns. Our aim is to determine whether specific semantics are more "intuitive" than others and whether these align with the semantics employed by one or more state-of-the-art algorithms. To achieve this, we designed a questionnaire to reveal the semantics' intuition of each user. This article presents both the design of the questionnaire and an in-depth analysis of the 124 responses obtained. The outcomes indicate that two of the semantics are predominantly intuitive; however, neither of them aligns with the semantics of the primary state-of-the-art algorithms. As a result, we provide recommendations to account for this disparity in the conclusions drawn.
+
+
+
+ 70. 标题:Leveraging Negative Signals with Self-Attention for Sequential Music Recommendation
+ 编号:[306]
+ 链接:https://arxiv.org/abs/2309.11623
+ 作者:Pavan Seshadri, Peter Knees
+ 备注:Accepted to the 1st Workshop on Music Recommender Systems, co-located with the 17th ACM Conference on Recommender Systems (MuRS @ RecSys 2023)
+ 关键词:streaming services heavily, services heavily rely, continuously provide content, Music streaming services, streaming services
+
+ 点击查看摘要
+ Music streaming services heavily rely on their recommendation engines to continuously provide content to their consumers. Sequential recommendation consequently has seen considerable attention in current literature, where state of the art approaches focus on self-attentive models leveraging contextual information such as long and short-term user history and item features; however, most of these studies focus on long-form content domains (retail, movie, etc.) rather than short-form, such as music. Additionally, many do not explore incorporating negative session-level feedback during training. In this study, we investigate the use of transformer-based self-attentive architectures to learn implicit session-level information for sequential music recommendation. We additionally propose a contrastive learning task to incorporate negative feedback (e.g skipped tracks) to promote positive hits and penalize negative hits. This task is formulated as a simple loss term that can be incorporated into a variety of deep learning architectures for sequential recommendation. Our experiments show that this results in consistent performance gains over the baseline architectures ignoring negative user feedback.
+
+
+
+ 71. 标题:Latent Diffusion Models for Structural Component Design
+ 编号:[314]
+ 链接:https://arxiv.org/abs/2309.11601
+ 作者:Ethan Herron, Jaydeep Rade, Anushrut Jignasu, Baskar Ganapathysubramanian, Aditya Balu, Soumik Sarkar, Adarsh Krishnamurthy
+ 备注:
+ 关键词:enabling high-quality image, revolutionized generative modeling, high-quality image generation, image generation tailored, generative modeling
+
+ 点击查看摘要
+ Recent advances in generative modeling, namely Diffusion models, have revolutionized generative modeling, enabling high-quality image generation tailored to user needs. This paper proposes a framework for the generative design of structural components. Specifically, we employ a Latent Diffusion model to generate potential designs of a component that can satisfy a set of problem-specific loading conditions. One of the distinct advantages our approach offers over other generative approaches, such as generative adversarial networks (GANs), is that it permits the editing of existing designs. We train our model using a dataset of geometries obtained from structural topology optimization utilizing the SIMP algorithm. Consequently, our framework generates inherently near-optimal designs. Our work presents quantitative results that support the structural performance of the generated designs and the variability in potential candidate designs. Furthermore, we provide evidence of the scalability of our framework by operating over voxel domains with resolutions varying from $32^3$ to $128^3$. Our framework can be used as a starting point for generating novel near-optimal designs similar to topology-optimized designs.
+
+
+
+ 72. 标题:CATS: Conditional Adversarial Trajectory Synthesis for Privacy-Preserving Trajectory Data Publication Using Deep Learning Approaches
+ 编号:[322]
+ 链接:https://arxiv.org/abs/2309.11587
+ 作者:Jinmeng Rao, Song Gao, Sijia Zhu
+ 备注:9 figures, 4 figures
+ 关键词:mobile Internet enables, ubiquitous location-aware devices, mobile Internet, Internet enables, collect massive individual-level
+
+ 点击查看摘要
+ The prevalence of ubiquitous location-aware devices and mobile Internet enables us to collect massive individual-level trajectory dataset from users. Such trajectory big data bring new opportunities to human mobility research but also raise public concerns with regard to location privacy. In this work, we present the Conditional Adversarial Trajectory Synthesis (CATS), a deep-learning-based GeoAI methodological framework for privacy-preserving trajectory data generation and publication. CATS applies K-anonymity to the underlying spatiotemporal distributions of human movements, which provides a distributional-level strong privacy guarantee. By leveraging conditional adversarial training on K-anonymized human mobility matrices, trajectory global context learning using the attention-based mechanism, and recurrent bipartite graph matching of adjacent trajectory points, CATS is able to reconstruct trajectory topology from conditionally sampled locations and generate high-quality individual-level synthetic trajectory data, which can serve as supplements or alternatives to raw data for privacy-preserving trajectory data publication. The experiment results on over 90k GPS trajectories show that our method has a better performance in privacy preservation, spatiotemporal characteristic preservation, and downstream utility compared with baseline methods, which brings new insights into privacy-preserving human mobility research using generative AI techniques and explores data ethics issues in GIScience.
+
+
+
+ 73. 标题:Distilling Adversarial Prompts from Safety Benchmarks: Report for the Adversarial Nibbler Challenge
+ 编号:[327]
+ 链接:https://arxiv.org/abs/2309.11575
+ 作者:Manuel Brack, Patrick Schramowski, Kristian Kersting
+ 备注:
+ 关键词:recently achieved astonishing, Text-conditioned image generation, alignment results, achieved astonishing image, astonishing image quality
+
+ 点击查看摘要
+ Text-conditioned image generation models have recently achieved astonishing image quality and alignment results. Consequently, they are employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the web, they also produce unsafe content. As a contribution to the Adversarial Nibbler challenge, we distill a large set of over 1,000 potential adversarial inputs from existing safety benchmarks. Our analysis of the gathered prompts and corresponding images demonstrates the fragility of input filters and provides further insights into systematic safety issues in current generative image models.
+
+
+
+ 74. 标题:BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2309.11568
+ 作者:Nolan Dey, Daria Soboleva, Faisal Al-Khateeb, Bowen Yang, Ribhu Pathria, Hemant Khachane, Shaheer Muhammad, Zhiming (Charles) Chen, Robert Myers, Jacob Robert Steeves, Natalia Vassilieva, Marvin Tom, Joel Hestness
+ 备注:
+ 关键词:Bittensor Language Model, introduce the Bittensor, billion parameter open-source, Bittensor Language, open-source language model
+
+ 点击查看摘要
+ We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity.
+On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: this https URL.
+
+
+
+ 75. 标题:Hierarchical reinforcement learning with natural language subgoals
+ 编号:[332]
+ 链接:https://arxiv.org/abs/2309.11564
+ 作者:Arun Ahuja, Kavya Kopparapu, Rob Fergus, Ishita Dasgupta
+ 备注:
+ 关键词:achieving goal directed, sequences of actions, Hierarchical reinforcement learning, goal directed behavior, Hierarchical reinforcement
+
+ 点击查看摘要
+ Hierarchical reinforcement learning has been a compelling approach for achieving goal directed behavior over long sequences of actions. However, it has been challenging to implement in realistic or open-ended environments. A main challenge has been to find the right space of sub-goals over which to instantiate a hierarchy. We present a novel approach where we use data from humans solving these tasks to softly supervise the goal space for a set of long range tasks in a 3D embodied environment. In particular, we use unconstrained natural language to parameterize this space. This has two advantages: first, it is easy to generate this data from naive human participants; second, it is flexible enough to represent a vast range of sub-goals in human-relevant tasks. Our approach outperforms agents that clone expert behavior on these tasks, as well as HRL from scratch without this supervised sub-goal space. Our work presents a novel approach to combining human expert supervision with the benefits and flexibility of reinforcement learning.
+
+
+
+ 76. 标题:EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian
+ 编号:[335]
+ 链接:https://arxiv.org/abs/2309.11531
+ 作者:Ofir Gordon, Hai Victor Habi, Arnon Netzer
+ 备注:
+ 关键词:deep neural networks, Post Training Quantization, neural networks, Enhanced Post Training, end-user devices
+
+ 点击查看摘要
+ Quantization of deep neural networks (DNN) has become a key element in the efforts of embedding such networks on end-user devices. However, current quantization methods usually suffer from costly accuracy degradation. In this paper, we propose a new method for Enhanced Post Training Quantization named EPTQ. The method is based on knowledge distillation with an adaptive weighting of layers. In addition, we introduce a new label-free technique for approximating the Hessian trace of the task loss, named Label-Free Hessian. This technique removes the requirement of a labeled dataset for computing the Hessian. The adaptive knowledge distillation uses the Label-Free Hessian technique to give greater attention to the sensitive parts of the model while performing the optimization. Empirically, by employing EPTQ we achieve state-of-the-art results on a wide variety of models, tasks, and datasets, including ImageNet classification, COCO object detection, and Pascal-VOC for semantic segmentation. We demonstrate the performance and compatibility of EPTQ on an extended set of architectures, including CNNs, Transformers, hybrid, and MLP-only models.
+
+
+
+ 77. 标题:TrueLearn: A Python Library for Personalised Informational Recommendations with (Implicit) Feedback
+ 编号:[337]
+ 链接:https://arxiv.org/abs/2309.11527
+ 作者:Yuxiang Qiu, Karim Djemili, Denis Elezi, Aaneel Shalman, María Pérez-Ortiz, Sahan Bulathwela
+ 备注:To be presented at the ORSUM workshop at RecSys 2023
+ 关键词:online learning Bayesian, TrueLearn Python library, learning Bayesian models, TrueLearn Python, Bayesian models
+
+ 点击查看摘要
+ This work describes the TrueLearn Python library, which contains a family of online learning Bayesian models for building educational (or more generally, informational) recommendation systems. This family of models was designed following the "open learner" concept, using humanly-intuitive user representations. For the sake of interpretability and putting the user in control, the TrueLearn library also contains different representations to help end-users visualise the learner models, which may in the future facilitate user interaction with their own models. Together with the library, we include a previously publicly released implicit feedback educational dataset with evaluation metrics to measure the performance of the models. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytic practitioners. The library and the support documentation with examples are available at this https URL.
+
+
+
+ 78. 标题:Likelihood-based Sensor Calibration for Expert-Supported Distributed Learning Algorithms in IoT Systems
+ 编号:[338]
+ 链接:https://arxiv.org/abs/2309.11526
+ 作者:Rüdiger Machhamer, Lejla Begic Fazlic, Eray Guven, David Junk, Gunes Karabulut Kurt, Stefan Naumann, Stephan Didas, Klaus-Uwe Gollmer, Ralph Bergmann, Ingo J. Timm, Guido Dartmann
+ 备注:
+ 关键词:important task, procedures of measurements, efficient implementation, identical design, adaptation procedures
+
+ 点击查看摘要
+ An important task in the field of sensor technology is the efficient implementation of adaptation procedures of measurements from one sensor to another sensor of identical design. One idea is to use the estimation of an affine transformation between different systems, which can be improved by the knowledge of experts. This paper presents an improved solution from Glacier Research that was published back in 1973. It is shown that this solution can be adapted for software calibration of sensors, implementation of expert-based adaptation, and federated learning methods. We evaluate our research with simulations and also with real measured data of a multi-sensor board with 8 identical sensors. The results show an improvement for both the simulation and the experiments with real data.
+
+
+
+ 79. 标题:Ad-load Balancing via Off-policy Learning in a Content Marketplace
+ 编号:[342]
+ 链接:https://arxiv.org/abs/2309.11518
+ 作者:Hitesh Sagtani, Madan Jhawar, Rishabh Mehrotra, Olivier Jeunen
+ 备注:Presented at the CONSEQUENCES'23 workshop at RecSys '23
+ 关键词:satisfactory user experience, maximize user engagement, social media platforms, online advertising systems, advertising systems
+
+ 点击查看摘要
+ Ad-load balancing is a critical challenge in online advertising systems, particularly in the context of social media platforms, where the goal is to maximize user engagement and revenue while maintaining a satisfactory user experience. This requires the optimization of conflicting objectives, such as user satisfaction and ads revenue. Traditional approaches to ad-load balancing rely on static allocation policies, which fail to adapt to changing user preferences and contextual factors. In this paper, we present an approach that leverages off-policy learning and evaluation from logged bandit feedback. We start by presenting a motivating analysis of the ad-load balancing problem, highlighting the conflicting objectives between user satisfaction and ads revenue. We emphasize the nuances that arise due to user heterogeneity and the dependence on the user's position within a session. Based on this analysis, we define the problem as determining the optimal ad-load for a particular feed fetch. To tackle this problem, we propose an off-policy learning framework that leverages unbiased estimators such as Inverse Propensity Scoring (IPS) and Doubly Robust (DR) to learn and estimate the policy values using offline collected stochastic data. We present insights from online A/B experiments deployed at scale across over 80 million users generating over 200 million sessions, where we find statistically significant improvements in both user satisfaction metrics and ads revenue for the platform.
+
+
+
+ 80. 标题:Private Matrix Factorization with Public Item Features
+ 编号:[343]
+ 链接:https://arxiv.org/abs/2309.11516
+ 作者:Mihaela Curmei, Walid Krichene, Li Zhang, Mukund Sundararajan
+ 备注:Presented at ACM Recsys 2023
+ 关键词:item, item features, public item, public, public item features
+
+ 点击查看摘要
+ We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information.
+The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data.
+Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.
+
+
+
+ 81. 标题:Towards Differential Privacy in Sequential Recommendation: A Noisy Graph Neural Network Approach
+ 编号:[344]
+ 链接:https://arxiv.org/abs/2309.11515
+ 作者:Wentao Hu, Hui Fang
+ 备注:
+ 关键词:high-profile privacy breaches, Graph Neural Network, private recommender systems, online platforms, increasing frequency
+
+ 点击查看摘要
+ With increasing frequency of high-profile privacy breaches in various online platforms, users are becoming more concerned about their privacy. And recommender system is the core component of online platforms for providing personalized service, consequently, its privacy preservation has attracted great attention. As the gold standard of privacy protection, differential privacy has been widely adopted to preserve privacy in recommender systems. However, existing differentially private recommender systems only consider static and independent interactions, so they cannot apply to sequential recommendation where behaviors are dynamic and dependent. Meanwhile, little attention has been paid on the privacy risk of sensitive user features, most of them only protect user feedbacks. In this work, we propose a novel DIfferentially Private Sequential recommendation framework with a noisy Graph Neural Network approach (denoted as DIPSGNN) to address these limitations. To the best of our knowledge, we are the first to achieve differential privacy in sequential recommendation with dependent interactions. Specifically, in DIPSGNN, we first leverage piecewise mechanism to protect sensitive user features. Then, we innovatively add calibrated noise into aggregation step of graph neural network based on aggregation perturbation mechanism. And this noisy graph neural network can protect sequentially dependent interactions and capture user preferences simultaneously. Extensive experiments demonstrate the superiority of our method over state-of-the-art differentially private recommender systems in terms of better balance between privacy and accuracy.
+
+
+
+ 82. 标题:Using causal inference to avoid fallouts in data-driven parametric analysis: a case study in the architecture, engineering, and construction industry
+ 编号:[346]
+ 链接:https://arxiv.org/abs/2309.11509
+ 作者:Xia Chen, Ruiji Sun, Ueli Saluz, Stefano Schiavon, Philipp Geyer
+ 备注:16 pages,6 figures
+ 关键词:causal analysis, real-world implementations, growing reliance, data-driven models, data-driven
+
+ 点击查看摘要
+ The decision-making process in real-world implementations has been affected by a growing reliance on data-driven models. We investigated the synergetic pattern between the data-driven methods, empirical domain knowledge, and first-principles simulations. We showed the potential risk of biased results when using data-driven models without causal analysis. Using a case study assessing the implication of several design solutions on the energy consumption of a building, we proved the necessity of causal analysis during the data-driven modeling process. We concluded that: (a) Data-driven models' accuracy assessment or domain knowledge screening may not rule out biased and spurious results; (b) Data-driven models' feature selection should involve careful consideration of causal relationships, especially colliders; (c) Causal analysis results can be used as an aid to first-principles simulation design and parameter checking to avoid cognitive biases. We proved the benefits of causal analysis when applied to data-driven models in building engineering.
+
+
+
+ 83. 标题:AdBooster: Personalized Ad Creative Generation using Stable Diffusion Outpainting
+ 编号:[348]
+ 链接:https://arxiv.org/abs/2309.11507
+ 作者:Veronika Shilova, Ludovic Dos Santos, Flavian Vasile, Gaëtan Racic, Ugo Tanielian
+ 备注:Fifth Workshop on Recommender Systems in Fashion (Fashion x RecSys 2023)
+ 关键词:considered separate disciplines, digital advertising, separate disciplines, Generative Creative Optimization, creative optimization
+
+ 点击查看摘要
+ In digital advertising, the selection of the optimal item (recommendation) and its best creative presentation (creative optimization) have traditionally been considered separate disciplines. However, both contribute significantly to user satisfaction, underpinning our assumption that it relies on both an item's relevance and its presentation, particularly in the case of visual creatives. In response, we introduce the task of {\itshape Generative Creative Optimization (GCO)}, which proposes the use of generative models for creative generation that incorporate user interests, and {\itshape AdBooster}, a model for personalized ad creatives based on the Stable Diffusion outpainting architecture. This model uniquely incorporates user interests both during fine-tuning and at generation time. To further improve AdBooster's performance, we also introduce an automated data augmentation pipeline. Through our experiments on simulated data, we validate AdBooster's effectiveness in generating more relevant creatives than default product images, showing its potential of enhancing user engagement.
+
+
+
+ 84. 标题:Fairness Vs. Personalization: Towards Equity in Epistemic Utility
+ 编号:[350]
+ 链接:https://arxiv.org/abs/2309.11503
+ 作者:Jennifer Chien, David Danks
+ 备注:11 pages, 2 tables, FAccTRec '23 (Singapore)
+ 关键词:encompassing social media, search engine results, online shopping, rapidly expanding, encompassing social
+
+ 点击查看摘要
+ The applications of personalized recommender systems are rapidly expanding: encompassing social media, online shopping, search engine results, and more. These systems offer a more efficient way to navigate the vast array of items available. However, alongside this growth, there has been increased recognition of the potential for algorithmic systems to exhibit and perpetuate biases, risking unfairness in personalized domains. In this work, we explicate the inherent tension between personalization and conventional implementations of fairness. As an alternative, we propose equity to achieve fairness in the context of epistemic utility. We provide a mapping between goals and practical implementations and detail policy recommendations across key stakeholders to forge a path towards achieving fairness in personalized systems.
+
+
+
+ 85. 标题:Adaptive Input-image Normalization for Solving Mode Collapse Problem in GAN-based X-ray Images
+ 编号:[353]
+ 链接:https://arxiv.org/abs/2309.12245
+ 作者:Muhammad Muneeb Saad, Mubashir Husain Rehmani, Ruairi O'Reilly
+ 备注:Submitted to the IEEE Journal
+ 关键词:Biomedical image datasets, Generative Adversarial Networks, Adversarial Networks play, mode collapse, targeted diseases
+
+ 点击查看摘要
+ Biomedical image datasets can be imbalanced due to the rarity of targeted diseases. Generative Adversarial Networks play a key role in addressing this imbalance by enabling the generation of synthetic images to augment datasets. It is important to generate synthetic images that incorporate a diverse range of features to accurately represent the distribution of features present in the training imagery. Furthermore, the absence of diverse features in synthetic images can degrade the performance of machine learning classifiers. The mode collapse problem impacts Generative Adversarial Networks' capacity to generate diversified images. Mode collapse comes in two varieties: intra-class and inter-class. In this paper, both varieties of the mode collapse problem are investigated, and their subsequent impact on the diversity of synthetic X-ray images is evaluated. This work contributes an empirical demonstration of the benefits of integrating the adaptive input-image normalization with the Deep Convolutional GAN and Auxiliary Classifier GAN to alleviate the mode collapse problems. Synthetically generated images are utilized for data augmentation and training a Vision Transformer model. The classification performance of the model is evaluated using accuracy, recall, and precision scores. Results demonstrate that the DCGAN and the ACGAN with adaptive input-image normalization outperform the DCGAN and ACGAN with un-normalized X-ray images as evidenced by the superior diversity scores and classification scores.
+
+
+
+ 86. 标题:Model-based Deep Learning for High-Dimensional Periodic Structures
+ 编号:[355]
+ 链接:https://arxiv.org/abs/2309.12223
+ 作者:Lucas Polo-López (IETR, INSA Rennes), Luc Le Magoarou (INSA Rennes, IETR), Romain Contreres (CNES), María García-Vigueras (IETR, INSA Rennes)
+ 备注:
+ 关键词:deep learning surrogate, learning surrogate model, high-dimensional frequency selective, frequency selective surfaces, frequency selective
+
+ 点击查看摘要
+ This work presents a deep learning surrogate model for the fast simulation of high-dimensional frequency selective surfaces. We consider unit-cells which are built as multiple concatenated stacks of screens and their design requires the control over many geometrical degrees of freedom. Thanks to the introduction of physical insight into the model, it can produce accurate predictions of the S-parameters of a certain structure after training with a reduced dataset.The proposed model is highly versatile and it can be used with any kind of frequency selective surface, based on either perforations or patches of any arbitrary geometry. Numeric examples are presented here for the case of frequency selective surfaces composed of screens with rectangular perforations, showing an excellent agreement between the predicted performance and such obtained with a full-wave simulator.
+
+
+
+ 87. 标题:A Multi-label Classification Approach to Increase Expressivity of EMG-based Gesture Recognition
+ 编号:[356]
+ 链接:https://arxiv.org/abs/2309.12217
+ 作者:Niklas Smedemark-Margulies, Yunus Bicer, Elifnur Sunger, Stephanie Naufel, Tales Imbiriba, Eugene Tunik, Deniz Erdoğmuş, Mathew Yarossi
+ 备注:14 pages, 12 figures
+ 关键词:surface electromyography-based, gesture recognition systems, synthetic data, problem transformation approach, synthetic data generation
+
+ 点击查看摘要
+ Objective: The objective of the study is to efficiently increase the expressivity of surface electromyography-based (sEMG) gesture recognition systems. Approach: We use a problem transformation approach, in which actions were subset into two biomechanically independent components - a set of wrist directions and a set of finger modifiers. To maintain fast calibration time, we train models for each component using only individual gestures, and extrapolate to the full product space of combination gestures by generating synthetic data. We collected a supervised dataset with high-confidence ground truth labels in which subjects performed combination gestures while holding a joystick, and conducted experiments to analyze the impact of model architectures, classifier algorithms, and synthetic data generation strategies on the performance of the proposed approach. Main Results: We found that a problem transformation approach using a parallel model architecture in combination with a non-linear classifier, along with restricted synthetic data generation, shows promise in increasing the expressivity of sEMG-based gestures with a short calibration time. Significance: sEMG-based gesture recognition has applications in human-computer interaction, virtual reality, and the control of robotic and prosthetic devices. Existing approaches require exhaustive model calibration. The proposed approach increases expressivity without requiring users to demonstrate all combination gesture classes. Our results may be extended to larger gesture vocabularies and more complicated model architectures.
+
+
+
+ 88. 标题:Empowering Precision Medicine: AI-Driven Schizophrenia Diagnosis via EEG Signals: A Comprehensive Review from 2002-2023
+ 编号:[357]
+ 链接:https://arxiv.org/abs/2309.12202
+ 作者:Mahboobeh Jafari, Delaram Sadeghi, Afshin Shoeibi, Hamid Alinejad-Rokny, Amin Beheshti, David López García, Zhaolin Chen, U. Rajendra Acharya, Juan M. Gorriz
+ 备注:
+ 关键词:prevalent mental disorder, mental disorder characterized, characterized by cognitive, prevalent mental, disorder characterized
+
+ 点击查看摘要
+ Schizophrenia (SZ) is a prevalent mental disorder characterized by cognitive, emotional, and behavioral changes. Symptoms of SZ include hallucinations, illusions, delusions, lack of motivation, and difficulties in concentration. Diagnosing SZ involves employing various tools, including clinical interviews, physical examinations, psychological evaluations, the Diagnostic and Statistical Manual of Mental Disorders (DSM), and neuroimaging techniques. Electroencephalography (EEG) recording is a significant functional neuroimaging modality that provides valuable insights into brain function during SZ. However, EEG signal analysis poses challenges for neurologists and scientists due to the presence of artifacts, long-term recordings, and the utilization of multiple channels. To address these challenges, researchers have introduced artificial intelligence (AI) techniques, encompassing conventional machine learning (ML) and deep learning (DL) methods, to aid in SZ diagnosis. This study reviews papers focused on SZ diagnosis utilizing EEG signals and AI methods. The introduction section provides a comprehensive explanation of SZ diagnosis methods and intervention techniques. Subsequently, review papers in this field are discussed, followed by an introduction to the AI methods employed for SZ diagnosis and a summary of relevant papers presented in tabular form. Additionally, this study reports on the most significant challenges encountered in SZ diagnosis, as identified through a review of papers in this field. Future directions to overcome these challenges are also addressed. The discussion section examines the specific details of each paper, culminating in the presentation of conclusions and findings.
+
+
+
+ 89. 标题:Electroencephalogram Sensor Data Compression Using An Asymmetrical Sparse Autoencoder With A Discrete Cosine Transform Layer
+ 编号:[358]
+ 链接:https://arxiv.org/abs/2309.12201
+ 作者:Xin Zhu, Hongyi Pan, Shuaiang Rong, Ahmet Enis Cetin
+ 备注:
+ 关键词:wireless recording applications, DCT layer, compress EEG signals, DCT, wireless recording
+
+ 点击查看摘要
+ Electroencephalogram (EEG) data compression is necessary for wireless recording applications to reduce the amount of data that needs to be transmitted. In this paper, an asymmetrical sparse autoencoder with a discrete cosine transform (DCT) layer is proposed to compress EEG signals. The encoder module of the autoencoder has a combination of a fully connected linear layer and the DCT layer to reduce redundant data using hard-thresholding nonlinearity. Furthermore, the DCT layer includes trainable hard-thresholding parameters and scaling layers to give emphasis or de-emphasis on individual DCT coefficients. Finally, the one-by-one convolutional layer generates the latent space. The sparsity penalty-based cost function is employed to keep the feature map as sparse as possible in the latent space. The latent space data is transmitted to the receiver. The decoder module of the autoencoder is designed using the inverse DCT and two fully connected linear layers to improve the accuracy of data reconstruction. In comparison to other state-of-the-art methods, the proposed method significantly improves the average quality score in various data compression experiments.
+
+
+
+ 90. 标题:A Variational Auto-Encoder Enabled Multi-Band Channel Prediction Scheme for Indoor Localization
+ 编号:[359]
+ 链接:https://arxiv.org/abs/2309.12200
+ 作者:Ruihao Yuan, Kaixuan Huang, Pan Yang, Shunqing Zhang
+ 备注:
+ 关键词:Augmented reality, cutting-edged technologies, smart home, reality and smart, increasing demands
+
+ 点击查看摘要
+ Indoor localization is getting increasing demands for various cutting-edged technologies, like Virtual/Augmented reality and smart home. Traditional model-based localization suffers from significant computational overhead, so fingerprint localization is getting increasing attention, which needs lower computation cost after the fingerprint database is built. However, the accuracy of indoor localization is limited by the complicated indoor environment which brings the multipath signal refraction. In this paper, we provided a scheme to improve the accuracy of indoor fingerprint localization from the frequency domain by predicting the channel state information (CSI) values from another transmitting channel and spliced the multi-band information together to get more precise localization results. We tested our proposed scheme on COST 2100 simulation data and real time orthogonal frequency division multiplexing (OFDM) WiFi data collected from an office scenario.
+
+
+
+ 91. 标题:Brain Tumor Detection Using Deep Learning Approaches
+ 编号:[360]
+ 链接:https://arxiv.org/abs/2309.12193
+ 作者:Razia Sultana Misu
+ 备注:Bachelor's thesis. Supervisor: Nushrat Jahan Ria
+ 关键词:Deep Learning, masses or clusters, deep learning techniques, Deep Learning methods, collections of abnormal
+
+ 点击查看摘要
+ Brain tumors are collections of abnormal cells that can develop into masses or clusters. Because they have the potential to infiltrate other tissues, they pose a risk to the patient. The main imaging technique used, MRI, may be able to identify a brain tumor with accuracy. The fast development of Deep Learning methods for use in computer vision applications has been facilitated by a vast amount of training data and improvements in model construction that offer better approximations in a supervised setting. The need for these approaches has been the main driver of this expansion. Deep learning methods have shown promise in improving the precision of brain tumor detection and classification using magnetic resonance imaging (MRI). The study on the use of deep learning techniques, especially ResNet50, for brain tumor identification is presented in this abstract. As a result, this study investigates the possibility of automating the detection procedure using deep learning techniques. In this study, I utilized five transfer learning models which are VGG16, VGG19, DenseNet121, ResNet50 and YOLO V4 where ResNet50 provide the best or highest accuracy 99.54%. The goal of the study is to guide researchers and medical professionals toward powerful brain tumor detecting systems by employing deep learning approaches by way of this evaluation and analysis.
+
+
+
+ 92. 标题:Optimal Conditional Inference in Adaptive Experiments
+ 编号:[362]
+ 链接:https://arxiv.org/abs/2309.12162
+ 作者:Jiafeng Chen, Isaiah Andrews
+ 备注:An extended abstract of this paper was presented at CODE@MIT 2021
+ 关键词:study batched bandit, batched bandit experiments, realized stopping time, study batched, batched bandit
+
+ 点击查看摘要
+ We study batched bandit experiments and consider the problem of inference conditional on the realized stopping time, assignment probabilities, and target parameter, where all of these may be chosen adaptively using information up to the last batch of the experiment. Absent further restrictions on the experiment, we show that inference using only the results of the last batch is optimal. When the adaptive aspects of the experiment are known to be location-invariant, in the sense that they are unchanged when we shift all batch-arm means by a constant, we show that there is additional information in the data, captured by one additional linear function of the batch-arm means. In the more restrictive case where the stopping time, assignment probabilities, and target parameter are known to depend on the data only through a collection of polyhedral events, we derive computationally tractable and optimal conditional inference procedures.
+
+
+
+ 93. 标题:Bayesian sparsification for deep neural networks with Bayesian model reduction
+ 编号:[366]
+ 链接:https://arxiv.org/abs/2309.12095
+ 作者:Dimitrije Marković, Karl J. Friston, Stefan J. Kiebel
+ 备注:
+ 关键词:effective sparsification techniques, learning immense capabilities, Deep learning, Deep learning immense, Bayesian sparsification
+
+ 点击查看摘要
+ Deep learning's immense capabilities are often constrained by the complexity of its models, leading to an increasing demand for effective sparsification techniques. Bayesian sparsification for deep learning emerges as a crucial approach, facilitating the design of models that are both computationally efficient and competitive in terms of performance across various deep learning applications. The state-of-the-art -- in Bayesian sparsification of deep neural networks -- combines structural shrinkage priors on model weights with an approximate inference scheme based on black-box stochastic variational inference. However, model inversion of the full generative model is exceptionally computationally demanding, especially when compared to standard deep learning of point estimates. In this context, we advocate for the use of Bayesian model reduction (BMR) as a more efficient alternative for pruning of model weights. As a generalization of the Savage-Dickey ratio, BMR allows a post-hoc elimination of redundant model weights based on the posterior estimates under a straightforward (non-hierarchical) generative model. Our comparative study highlights the computational efficiency and the pruning rate of the BMR method relative to the established stochastic variational inference (SVI) scheme, when applied to the full hierarchical generative model. We illustrate the potential of BMR to prune model parameters across various deep learning architectures, from classical networks like LeNet to modern frameworks such as Vision Transformers and MLP-Mixers.
+
+
+
+ 94. 标题:Identification of pneumonia on chest x-ray images through machine learning
+ 编号:[371]
+ 链接:https://arxiv.org/abs/2309.11995
+ 作者:Eduardo Augusto Roeder
+ 备注:In Brazilian Portuguese, 30 pages, 16 figures. This thesis was elaborated by the guidance of Prof. Dr. Akihito Inca Atahualpa Urdiales
+ 关键词:leading infectious, infant death, chest X-ray, chest X-rays images, children chest X-rays
+
+ 点击查看摘要
+ Pneumonia is the leading infectious cause of infant death in the world. When identified early, it is possible to alter the prognosis of the patient, one could use imaging exams to help in the diagnostic confirmation. Performing and interpreting the exams as soon as possible is vital for a good treatment, with the most common exam for this pathology being chest X-ray. The objective of this study was to develop a software that identify the presence or absence of pneumonia in chest radiographs. The software was developed as a computational model based on machine learning using transfer learning technique. For the training process, images were collected from a database available online with children's chest X-rays images taken at a hospital in China. After training, the model was then exposed to new images, achieving relevant results on identifying such pathology, reaching 98% sensitivity and 97.3% specificity for the sample used for testing. It can be concluded that it is possible to develop a software that identifies pneumonia in chest X-ray images.
+
+
+
+ 95. 标题:Stock Market Sentiment Classification and Backtesting via Fine-tuned BERT
+ 编号:[374]
+ 链接:https://arxiv.org/abs/2309.11979
+ 作者:Jiashu Lou
+ 备注:
+ 关键词:received widespread attention, real-time information acquisition, stock trading market, low-latency automatic trading, trading platforms based
+
+ 点击查看摘要
+ With the rapid development of big data and computing devices, low-latency automatic trading platforms based on real-time information acquisition have become the main components of the stock trading market, so the topic of quantitative trading has received widespread attention. And for non-strongly efficient trading markets, human emotions and expectations always dominate market trends and trading decisions. Therefore, this paper starts from the theory of emotion, taking East Money as an example, crawling user comment titles data from its corresponding stock bar and performing data cleaning. Subsequently, a natural language processing model BERT was constructed, and the BERT model was fine-tuned using existing annotated data sets. The experimental results show that the fine-tuned model has different degrees of performance improvement compared to the original model and the baseline model. Subsequently, based on the above model, the user comment data crawled is labeled with emotional polarity, and the obtained label information is combined with the Alpha191 model to participate in regression, and significant regression results are obtained. Subsequently, the regression model is used to predict the average price change for the next five days, and use it as a signal to guide automatic trading. The experimental results show that the incorporation of emotional factors increased the return rate by 73.8\% compared to the baseline during the trading period, and by 32.41\% compared to the original alpha191 model. Finally, we discuss the advantages and disadvantages of incorporating emotional factors into quantitative trading, and give possible directions for further research in the future.
+
+
+
+ 96. 标题:On the Probability of Immunity
+ 编号:[378]
+ 链接:https://arxiv.org/abs/2309.11942
+ 作者:Jose M. Peña
+ 备注:
+ 关键词:work is devoted, probability, probability of immunity, probability of benefit, effect occurs
+
+ 点击查看摘要
+ This work is devoted to the study of the probability of immunity, i.e. the effect occurs whether exposed or not. We derive necessary and sufficient conditions for non-immunity and $\epsilon$-bounded immunity, i.e. the probability of immunity is zero and $\epsilon$-bounded, respectively. The former allows us to estimate the probability of benefit (i.e., the effect occurs if and only if exposed) from a randomized controlled trial, and the latter allows us to produce bounds of the probability of benefit that are tighter than the existing ones. We also introduce the concept of indirect immunity (i.e., through a mediator) and repeat our previous analysis for it. Finally, we propose a method for sensitivity analysis of the probability of immunity under unmeasured confounding.
+
+
+
+ 97. 标题:Activation Compression of Graph Neural Networks using Block-wise Quantization with Improved Variance Minimization
+ 编号:[384]
+ 链接:https://arxiv.org/abs/2309.11856
+ 作者:Sebastian Eliassen, Raghavendra Selvan
+ 备注:Source code at this https URL
+ 关键词:graph neural networks, large-scale graph neural, Efficient training, neural networks, memory consumption
+
+ 点击查看摘要
+ Efficient training of large-scale graph neural networks (GNNs) has been studied with a specific focus on reducing their memory consumption. Work by Liu et al. (2022) proposed extreme activation compression (EXACT) which demonstrated drastic reduction in memory consumption by performing quantization of the intermediate activation maps down to using INT2 precision. They showed little to no reduction in performance while achieving large reductions in GPU memory consumption. In this work, we present an improvement to the EXACT strategy by using block-wise quantization of the intermediate activation maps. We experimentally analyze different block sizes and show further reduction in memory consumption (>15%), and runtime speedup per epoch (about 5%) even when performing extreme extents of quantization with similar performance trade-offs as with the original EXACT. Further, we present a correction to the assumptions on the distribution of intermediate activation maps in EXACT (assumed to be uniform) and show improved variance estimations of the quantization and dequantization steps.
+
+
+
+ 98. 标题:PIE: Simulating Disease Progression via Progressive Image Editing
+ 编号:[393]
+ 链接:https://arxiv.org/abs/2309.11745
+ 作者:Kaizhao Liang, Xu Cao, Kuei-Da Liao, Tianren Gao, Zhengyu Chen, Tejas Nama
+ 备注:
+ 关键词:crucial area, significant implications, Disease progression simulation, Progressive Image Editing, Disease progression
+
+ 点击查看摘要
+ Disease progression simulation is a crucial area of research that has significant implications for clinical diagnosis, prognosis, and treatment. One major challenge in this field is the lack of continuous medical imaging monitoring of individual patients over time. To address this issue, we develop a novel framework termed Progressive Image Editing (PIE) that enables controlled manipulation of disease-related image features, facilitating precise and realistic disease progression simulation. Specifically, we leverage recent advancements in text-to-image generative models to simulate disease progression accurately and personalize it for each patient. We theoretically analyze the iterative refining process in our framework as a gradient descent with an exponentially decayed learning rate. To validate our framework, we conduct experiments in three medical imaging domains. Our results demonstrate the superiority of PIE over existing methods such as Stable Diffusion Walk and Style-Based Manifold Extrapolation based on CLIP score (Realism) and Disease Classification Confidence (Alignment). Our user study collected feedback from 35 veteran physicians to assess the generated progressions. Remarkably, 76.2% of the feedback agrees with the fidelity of the generated progressions. To our best knowledge, PIE is the first of its kind to generate disease progression images meeting real-world standards. It is a promising tool for medical research and clinical practice, potentially allowing healthcare providers to model disease trajectories over time, predict future treatment responses, and improve patient outcomes.
+
+
+
+ 99. 标题:A Dynamic Domain Adaptation Deep Learning Network for EEG-based Motor Imagery Classification
+ 编号:[396]
+ 链接:https://arxiv.org/abs/2309.11714
+ 作者:Jie Jiao, Meiyan Xu, Qingqing Chen, Hefan Zhou, Wangliang Zhou
+ 备注:10 pages,4 figures,journal
+ 关键词:Deep Learning Network, Adaptation Based Deep, Based Deep Learning, channels of electroencephalogram, adjacent channels
+
+ 点击查看摘要
+ There is a correlation between adjacent channels of electroencephalogram (EEG), and how to represent this correlation is an issue that is currently being explored. In addition, due to inter-individual differences in EEG signals, this discrepancy results in new subjects need spend a amount of calibration time for EEG-based motor imagery brain-computer interface. In order to solve the above problems, we propose a Dynamic Domain Adaptation Based Deep Learning Network (DADL-Net). First, the EEG data is mapped to the three-dimensional geometric space and its temporal-spatial features are learned through the 3D convolution module, and then the spatial-channel attention mechanism is used to strengthen the features, and the final convolution module can further learn the spatial-temporal information of the features. Finally, to account for inter-subject and cross-sessions differences, we employ a dynamic domain-adaptive strategy, the distance between features is reduced by introducing a Maximum Mean Discrepancy loss function, and the classification layer is fine-tuned by using part of the target domain data. We verify the performance of the proposed method on BCI competition IV 2a and OpenBMI datasets. Under the intra-subject experiment, the accuracy rates of 70.42% and 73.91% were achieved on the OpenBMI and BCIC IV 2a datasets.
+
+
+
+ 100. 标题:Quasi-Monte Carlo for 3D Sliced Wasserstein
+ 编号:[397]
+ 链接:https://arxiv.org/abs/2309.11713
+ 作者:Khai Nguyen, Nicola Bariletto, Nhat Ho
+ 备注:31 pages, 13 figures, 6 tables
+ 关键词:standard computation approach, Sliced Wasserstein, Monte Carlo, analytical form, standard computation
+
+ 点击查看摘要
+ Monte Carlo (MC) approximation has been used as the standard computation approach for the Sliced Wasserstein (SW) distance, which has an intractable expectation in its analytical form. However, the MC method is not optimal in terms of minimizing the absolute approximation error. To provide a better class of empirical SW, we propose quasi-sliced Wasserstein (QSW) approximations that rely on Quasi-Monte Carlo (QMC) methods. For a comprehensive investigation of QMC for SW, we focus on the 3D setting, specifically computing the SW between probability measures in three dimensions. In greater detail, we empirically verify various ways of constructing QMC points sets on the 3D unit-hypersphere, including Gaussian-based mapping, equal area mapping, generalized spiral points, and optimizing discrepancy energies. Furthermore, to obtain an unbiased estimation for stochastic optimization, we extend QSW into Randomized Quasi-Sliced Wasserstein (RQSW) by introducing randomness to the discussed low-discrepancy sequences. For theoretical properties, we prove the asymptotic convergence of QSW and the unbiasedness of RQSW. Finally, we conduct experiments on various 3D tasks, such as point-cloud comparison, point-cloud interpolation, image style transfer, and training deep point-cloud autoencoders, to demonstrate the favorable performance of the proposed QSW and RQSW variants.
+
+
+
+ 101. 标题:Potential and limitations of random Fourier features for dequantizing quantum machine learning
+ 编号:[399]
+ 链接:https://arxiv.org/abs/2309.11647
+ 作者:Ryan Sweke, Erik Recio, Sofiene Jerbi, Elies Gil-Fuster, Bryce Fuller, Jens Eisert, Johannes Jakob Meyer
+ 备注:33 pages, 2 figures. Comments and feedback welcome
+ 关键词:Quantum machine learning, near-term quantum devices, machine learning, variational quantum machine, Quantum machine
+
+ 点击查看摘要
+ Quantum machine learning is arguably one of the most explored applications of near-term quantum devices. Much focus has been put on notions of variational quantum machine learning where parameterized quantum circuits (PQCs) are used as learning models. These PQC models have a rich structure which suggests that they might be amenable to efficient dequantization via random Fourier features (RFF). In this work, we establish necessary and sufficient conditions under which RFF does indeed provide an efficient dequantization of variational quantum machine learning for regression. We build on these insights to make concrete suggestions for PQC architecture design, and to identify structures which are necessary for a regression problem to admit a potential quantum advantage via PQC based optimization.
+
+
+
+ 102. 标题:Multidimensional well-being of US households at a fine spatial scale using fused household surveys: fusionACS
+ 编号:[403]
+ 链接:https://arxiv.org/abs/2309.11512
+ 作者:Kevin Ummel, Miguel Poblete-Cazenave, Karthik Akkiraju, Nick Graetz, Hero Ashman, Cora Kingdon, Steven Herrera Tenorio, Aaryaman "Sunny" Singhal, Daniel Aldana Cohen, Narasimha D. Rao
+ 备注:35 pages, 6 figures
+ 关键词:Social science, American Community Survey, science often relies, American Housing Survey, survey
+
+ 点击查看摘要
+ Social science often relies on surveys of households and individuals. Dozens of such surveys are regularly administered by the U.S. government. However, they field independent, unconnected samples with specialized questions, limiting research questions to those that can be answered by a single survey. The fusionACS project seeks to integrate data from multiple U.S. household surveys by statistically "fusing" variables from "donor" surveys onto American Community Survey (ACS) microdata. This results in an integrated microdataset of household attributes and well-being dimensions that can be analyzed to address research questions in ways that are not currently possible. The presented data comprise the fusion onto the ACS of select donor variables from the Residential Energy Consumption Survey (RECS) of 2015, the National Household Transportation Survey (NHTS) of 2017, the American Housing Survey (AHS) of 2019, and the Consumer Expenditure Survey - Interview (CEI) for the years 2015-2019. The underlying statistical techniques are included in an open-source $R$ package, fusionModel, that provides generic tools for the creation, analysis, and validation of fused microdata.
+
+
+
+ 103. 标题:Cross-scale Multi-instance Learning for Pathological Image Diagnosis
+ 编号:[405]
+ 链接:https://arxiv.org/abs/2304.00216
+ 作者:Ruining Deng, Can Cui, Lucas W. Remedios, Shunxing Bao, R. Michael Womick, Sophie Chiron, Jia Li, Joseph T. Roland, Ken S. Lau, Qi Liu, Keith T. Wilson, Yaohong Wang, Lori A. Coburn, Bennett A. Landman, Yuankai Huo
+ 备注:
+ 关键词:Analyzing high resolution, multiple scales poses, high resolution images, digital pathology, high resolution
+
+ 点击查看摘要
+ Analyzing high resolution whole slide images (WSIs) with regard to information across multiple scales poses a significant challenge in digital pathology. Multi-instance learning (MIL) is a common solution for working with high resolution images by classifying bags of objects (i.e. sets of smaller image patches). However, such processing is typically performed at a single scale (e.g., 20x magnification) of WSIs, disregarding the vital inter-scale information that is key to diagnoses by human pathologists. In this study, we propose a novel cross-scale MIL algorithm to explicitly aggregate inter-scale relationships into a single MIL network for pathological image diagnosis. The contribution of this paper is three-fold: (1) A novel cross-scale MIL (CS-MIL) algorithm that integrates the multi-scale information and the inter-scale relationships is proposed; (2) A toy dataset with scale-specific morphological features is created and released to examine and visualize differential cross-scale attention; (3) Superior performance on both in-house and public datasets is demonstrated by our simple cross-scale MIL strategy. The official implementation is publicly available at this https URL.
+
+
+人工智能
+
+ 1. 标题:ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.12312
+ 作者:Jeremy A. Collins, Cody Houff, You Liang Tan, Charles C. Kemp
+ 备注:
+ 关键词:deep neural network, predicts visual-force goals, neural network, predicts visual-force, present ForceSight
+
+ 点击查看摘要
+ We present ForceSight, a system for text-guided mobile manipulation that predicts visual-force goals using a deep neural network. Given a single RGBD image combined with a text prompt, ForceSight determines a target end-effector pose in the camera frame (kinematic goal) and the associated forces (force goal). Together, these two components form a visual-force goal. Prior work has demonstrated that deep models outputting human-interpretable kinematic goals can enable dexterous manipulation by real robots. Forces are critical to manipulation, yet have typically been relegated to lower-level execution in these systems. When deployed on a mobile manipulator equipped with an eye-in-hand RGBD camera, ForceSight performed tasks such as precision grasps, drawer opening, and object handovers with an 81% success rate in unseen environments with object instances that differed significantly from the training data. In a separate experiment, relying exclusively on visual servoing and ignoring force goals dropped the success rate from 90% to 45%, demonstrating that force goals can significantly enhance performance. The appendix, videos, code, and trained models are available at this https URL.
+
+
+
+ 2. 标题:LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.12311
+ 作者:Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F. Fouhey, Joyce Chai
+ 备注:Project website: this https URL
+ 关键词:Large Language Model, answer questions based, household robots, critical skill, skill for household
+
+ 点击查看摘要
+ 3D visual grounding is a critical skill for household robots, enabling them to navigate, manipulate objects, and answer questions based on their environment. While existing approaches often rely on extensive labeled data or exhibit limitations in handling complex language queries, we propose LLM-Grounder, a novel zero-shot, open-vocabulary, Large Language Model (LLM)-based 3D visual grounding pipeline. LLM-Grounder utilizes an LLM to decompose complex natural language queries into semantic constituents and employs a visual grounding tool, such as OpenScene or LERF, to identify objects in a 3D scene. The LLM then evaluates the spatial and commonsense relations among the proposed objects to make a final grounding decision. Our method does not require any labeled training data and can generalize to novel 3D scenes and arbitrary text queries. We evaluate LLM-Grounder on the ScanRefer benchmark and demonstrate state-of-the-art zero-shot grounding accuracy. Our findings indicate that LLMs significantly improve the grounding capability, especially for complex language queries, making LLM-Grounder an effective approach for 3D vision-language tasks in robotics. Videos and interactive demos can be found on the project website this https URL .
+
+
+
+ 3. 标题:Rehearsal: Simulating Conflict to Teach Conflict Resolution
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.12309
+ 作者:Omar Shaikh, Valentino Chai, Michele J. Gelfand, Diyi Yang, Michael S. Bernstein
+ 备注:
+ 关键词:fact of life, uncomfortable but unavoidable, unavoidable fact, conflict, Rehearsal
+
+ 点击查看摘要
+ Interpersonal conflict is an uncomfortable but unavoidable fact of life. Navigating conflict successfully is a skill -- one that can be learned through deliberate practice -- but few have access to effective training or feedback. To expand this access, we introduce Rehearsal, a system that allows users to rehearse conflicts with a believable simulated interlocutor, explore counterfactual "what if?" scenarios to identify alternative conversational paths, and learn through feedback on how and when to apply specific conflict strategies. Users can utilize Rehearsal to practice handling a variety of predefined conflict scenarios, from office disputes to relationship issues, or they can choose to create their own. To enable Rehearsal, we develop IRP prompting, a method of conditioning output of a large language model on the influential Interest-Rights-Power (IRP) theory from conflict resolution. Rehearsal uses IRP to generate utterances grounded in conflict resolution theory, guiding users towards counterfactual conflict resolution strategies that help de-escalate difficult conversations. In a between-subjects evaluation, 40 participants engaged in an actual conflict with a confederate after training. Compared to a control group with lecture material covering the same IRP theory, participants with simulated training from Rehearsal significantly improved their performance in the unaided conflict: they reduced their use of escalating competitive strategies by an average of 67%, while doubling their use of cooperative strategies. Overall, Rehearsal highlights the potential effectiveness of language models as tools for learning and practicing interpersonal skills.
+
+
+
+ 4. 标题:LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2309.12307
+ 作者:Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
+ 备注:Code, models, dataset, and demo are available at this https URL
+ 关键词:pre-trained large language, large language models, efficient fine-tuning approach, context, pre-trained large
+
+ 点击查看摘要
+ We present LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost. Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. For example, training on the context length of 8192 needs 16x computational costs in self-attention layers as that of 2048. In this paper, we speed up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine-tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention effectively enables context extension, leading to non-trivial computation saving with similar performance to fine-tuning with vanilla attention. Particularly, it can be implemented with only two lines of code in training, while being optional in inference. On the other hand, we revisit the parameter-efficient fine-tuning regime for context expansion. Notably, we find that LoRA for context extension works well under the premise of trainable embedding and normalization. LongLoRA demonstrates strong empirical results on various tasks on LLaMA2 models from 7B/13B to 70B. LongLoRA adopts LLaMA2 7B from 4k context to 100k, or LLaMA2 70B to 32k on a single 8x A100 machine. LongLoRA extends models' context while retaining their original architectures, and is compatible with most existing techniques, like FlashAttention-2. In addition, to make LongLoRA practical, we collect a dataset, LongQA, for supervised fine-tuning. It contains more than 3k long context question-answer pairs.
+
+
+
+ 5. 标题:Environment-biased Feature Ranking for Novelty Detection Robustness
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.12301
+ 作者:Stefan Smeu, Elena Burceanu, Emanuela Haller, Andrei Liviu Nicolicioiu
+ 备注:ICCV 2024 - Workshop on Out Of Distribution Generalization in Computer Vision
+ 关键词:robust novelty detection, irrelevant factors, novelty detection, tackle the problem, problem of robust
+
+ 点击查看摘要
+ We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
+
+
+
+ 6. 标题:See to Touch: Learning Tactile Dexterity through Visual Incentives
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2309.12300
+ 作者:Irmak Guzey, Yinlong Dai, Ben Evans, Soumith Chintala, Lerrel Pinto
+ 备注:
+ 关键词:Equipping multi-fingered robots, Equipping multi-fingered, achieving the precise, crucial for achieving, tactile sensing
+
+ 点击查看摘要
+ Equipping multi-fingered robots with tactile sensing is crucial for achieving the precise, contact-rich, and dexterous manipulation that humans excel at. However, relying solely on tactile sensing fails to provide adequate cues for reasoning about objects' spatial configurations, limiting the ability to correct errors and adapt to changing situations. In this paper, we present Tactile Adaptation from Visual Incentives (TAVI), a new framework that enhances tactile-based dexterity by optimizing dexterous policies using vision-based rewards. First, we use a contrastive-based objective to learn visual representations. Next, we construct a reward function using these visual representations through optimal-transport based matching on one human demonstration. Finally, we use online reinforcement learning on our robot to optimize tactile-based policies that maximize the visual reward. On six challenging tasks, such as peg pick-and-place, unstacking bowls, and flipping slender objects, TAVI achieves a success rate of 73% using our four-fingered Allegro robot hand. The increase in performance is 108% higher than policies using tactile and vision-based rewards and 135% higher than policies without tactile observational input. Robot videos are best viewed on our project website: this https URL.
+
+
+
+ 7. 标题:Learning to Drive Anywhere
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.12295
+ 作者:Ruizhao Zhu, Peng Huang, Eshed Ohn-Bar, Venkatesh Saligrama
+ 备注:Conference on Robot Learning (CoRL) 2023. this https URL
+ 关键词:Human drivers, left vs. right-hand, drivers can seamlessly, decisions across geographical, diverse conditions
+
+ 点击查看摘要
+ Human drivers can seamlessly adapt their driving decisions across geographical locations with diverse conditions and rules of the road, e.g., left vs. right-hand traffic. In contrast, existing models for autonomous driving have been thus far only deployed within restricted operational domains, i.e., without accounting for varying driving behaviors across locations or model scalability. In this work, we propose AnyD, a single geographically-aware conditional imitation learning (CIL) model that can efficiently learn from heterogeneous and globally distributed data with dynamic environmental, traffic, and social characteristics. Our key insight is to introduce a high-capacity geo-location-based channel attention mechanism that effectively adapts to local nuances while also flexibly modeling similarities among regions in a data-driven manner. By optimizing a contrastive imitation objective, our proposed approach can efficiently scale across inherently imbalanced data distributions and location-dependent events. We demonstrate the benefits of our AnyD agent across multiple datasets, cities, and scalable deployment paradigms, i.e., centralized, semi-supervised, and distributed agent training. Specifically, AnyD outperforms CIL baselines by over 14% in open-loop evaluation and 30% in closed-loop testing on CARLA.
+
+
+
+ 8. 标题:The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.12288
+ 作者:Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
+ 备注:18 pages, 10 figures
+ 关键词:auto-regressive large language, Reversal Curse, large language models, Mary Lee Pfeiffer, Chancellor of Germany
+
+ 点击查看摘要
+ We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany", it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?". Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e. if "A is B'' occurs, "B is A" is more likely to occur). We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of 'Abyssal Melodies'" and showing that they fail to correctly answer "Who composed 'Abyssal Melodies?'". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?". GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is available at this https URL.
+
+
+
+ 9. 标题:MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.12284
+ 作者:Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, Weiyang Liu
+ 备注:Technical Report, Work in Progress. Project Page: this https URL
+ 关键词:excellent problem-solving ability, exhibited excellent problem-solving, natural language understanding, problem-solving ability, Large language models
+
+ 点击查看摘要
+ Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
+
+
+
+ 10. 标题:LLMR: Real-time Prompting of Interactive Worlds using Large Language Models
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.12276
+ 作者:Fernanda De La Torre, Cathy Mengying Fang, Han Huang, Andrzej Banburski-Fahey, Judith Amores Fernandez, Jaron Lanier
+ 备注:50 pages (22 in main text), 15 figures
+ 关键词:Large Language Model, interactive Mixed Reality, present Large Language, Mixed Reality experiences, Mixed Reality
+
+ 点击查看摘要
+ We present Large Language Model for Mixed Reality (LLMR), a framework for the real-time creation and modification of interactive Mixed Reality experiences using LLMs. LLMR leverages novel strategies to tackle difficult cases where ideal training data is scarce, or where the design goal requires the synthesis of internal dynamics, intuitive analysis, or advanced interactivity. Our framework relies on text interaction and the Unity game engine. By incorporating techniques for scene understanding, task planning, self-debugging, and memory management, LLMR outperforms the standard GPT-4 by 4x in average error rate. We demonstrate LLMR's cross-platform interoperability with several example worlds, and evaluate it on a variety of creation and modification tasks to show that it can produce and edit diverse objects, tools, and scenes. Finally, we conducted a usability study (N=11) with a diverse set that revealed participants had positive experiences with the system and would use it again.
+
+
+
+ 11. 标题:Enabling Quartile-based Estimated-Mean Gradient Aggregation As Baseline for Federated Image Classifications
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2309.12267
+ 作者:Yusen Wu, Jamie Deng, Hao Chen, Phuong Nguyen, Yelena Yesha
+ 备注:
+ 关键词:improving model performance, safeguarding sensitive data, train deep neural, deep neural networks, enabling decentralized collaboration
+
+ 点击查看摘要
+ Federated Learning (FL) has revolutionized how we train deep neural networks by enabling decentralized collaboration while safeguarding sensitive data and improving model performance. However, FL faces two crucial challenges: the diverse nature of data held by individual clients and the vulnerability of the FL system to security breaches. This paper introduces an innovative solution named Estimated Mean Aggregation (EMA) that not only addresses these challenges but also provides a fundamental reference point as a $\mathsf{baseline}$ for advanced aggregation techniques in FL systems. EMA's significance lies in its dual role: enhancing model security by effectively handling malicious outliers through trimmed means and uncovering data heterogeneity to ensure that trained models are adaptable across various client datasets. Through a wealth of experiments, EMA consistently demonstrates high accuracy and area under the curve (AUC) compared to alternative methods, establishing itself as a robust baseline for evaluating the effectiveness and security of FL aggregation methods. EMA's contributions thus offer a crucial step forward in advancing the efficiency, security, and versatility of decentralized deep learning in the context of FL.
+
+
+
+ 12. 标题:SALSA-CLRS: A Sparse and Scalable Benchmark for Algorithmic Reasoning
+ 编号:[31]
+ 链接:https://arxiv.org/abs/2309.12253
+ 作者:Julian Minder, Florian Grötschla, Joël Mathys, Roger Wattenhofer
+ 备注:
+ 关键词:CLRS algorithmic learning, algorithmic learning benchmark, algorithmic learning, CLRS, CLRS algorithmic
+
+ 点击查看摘要
+ We introduce an extension to the CLRS algorithmic learning benchmark, prioritizing scalability and the utilization of sparse representations. Many algorithms in CLRS require global memory or information exchange, mirrored in its execution model, which constructs fully connected (not sparse) graphs based on the underlying problem. Despite CLRS's aim of assessing how effectively learned algorithms can generalize to larger instances, the existing execution model becomes a significant constraint due to its demanding memory requirements and runtime (hard to scale). However, many important algorithms do not demand a fully connected graph; these algorithms, primarily distributed in nature, align closely with the message-passing paradigm employed by Graph Neural Networks. Hence, we propose SALSA-CLRS, an extension of the current CLRS benchmark specifically with scalability and sparseness in mind. Our approach includes adapted algorithms from the original CLRS benchmark and introduces new problems from distributed and randomized algorithms. Moreover, we perform a thorough empirical evaluation of our benchmark. Code is publicly available at this https URL.
+
+
+
+ 13. 标题:Bad Actor, Good Advisor: Exploring the Role of Large Language Models in Fake News Detection
+ 编号:[35]
+ 链接:https://arxiv.org/abs/2309.12247
+ 作者:Beizhe Hu, Qiang Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Wang, Peng Qi
+ 备注:17 pages, 6 figures, and 9 tables. Work in progress
+ 关键词:language models, large language models, fake news detection, capability limitations, small language models
+
+ 点击查看摘要
+ Detecting fake news requires both a delicate sense of diverse clues and a profound understanding of the real-world background, which remains challenging for detectors based on small language models (SLMs) due to their knowledge and capability limitations. Recent advances in large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with fake news detection remains underexplored. In this paper, we investigate the potential of LLMs in fake news detection. First, we conduct an empirical study and find that a sophisticated LLM such as GPT 3.5 could generally expose fake news and provide desirable multi-perspective rationales but still underperforms the basic SLM, fine-tuned BERT. Our subsequent analysis attributes such a gap to the LLM's inability to select and integrate rationales properly to conclude. Based on these findings, we propose that current LLMs may not substitute fine-tuned SLMs in fake news detection but can be a good advisor for SLMs by providing multi-perspective instructive rationales. To instantiate this proposal, we design an adaptive rationale guidance network for fake news detection (ARG), in which SLMs selectively acquire insights on news analysis from the LLMs' rationales. We further derive a rationale-free version of ARG by distillation, namely ARG-D, which services cost-sensitive scenarios without inquiring LLMs. Experiments on two real-world datasets demonstrate that ARG and ARG-D outperform three types of baseline methods, including SLM-based, LLM-based, and combinations of small and large language models.
+
+
+
+ 14. 标题:ChaCha: Leveraging Large Language Models to Prompt Children to Share Their Emotions about Personal Events
+ 编号:[36]
+ 链接:https://arxiv.org/abs/2309.12244
+ 作者:Woosuk Seo, Chanmo Yang, Young-Ho Kim
+ 备注:21 pages, 4 figures, 2 tables
+ 关键词:Children typically learn, typically learn, learn to identify, identify and express, Children
+
+ 点击查看摘要
+ Children typically learn to identify and express emotions through sharing their stories and feelings with others, particularly their family. However, it is challenging for parents or siblings to have emotional communication with children since children are still developing their communication skills. We present ChaCha, a chatbot that encourages and guides children to share personal events and associated emotions. ChaCha combines a state machine and large language models (LLMs) to keep the dialogue on track while carrying on free-form conversations. Through an exploratory study with 20 children (aged 8-12), we examine how ChaCha prompts children to share personal events and guides them to describe associated emotions. Participants perceived ChaCha as a close friend and shared their stories on various topics, such as family trips and personal achievements. Based on the quantitative and qualitative findings, we discuss opportunities for leveraging LLMs to design child-friendly chatbots to support children in sharing their emotions.
+
+
+
+ 15. 标题:Explainable Artificial Intelligence for Drug Discovery and Development -- A Comprehensive Survey
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.12177
+ 作者:Roohallah Alizadehsani, Sadiq Hussain, Rene Ripardo Calixto, Victor Hugo C. de Albuquerque, Mohamad Roshanzamir, Mohamed Rahouti, Senthil Kumar Jagatheesaperumal
+ 备注:13 pages, 3 figures
+ 关键词:drug discovery, XAI, artificial intelligence, Explainable Artificial Intelligence, drug
+
+ 点击查看摘要
+ The field of drug discovery has experienced a remarkable transformation with the advent of artificial intelligence (AI) and machine learning (ML) technologies. However, as these AI and ML models are becoming more complex, there is a growing need for transparency and interpretability of the models. Explainable Artificial Intelligence (XAI) is a novel approach that addresses this issue and provides a more interpretable understanding of the predictions made by machine learning models. In recent years, there has been an increasing interest in the application of XAI techniques to drug discovery. This review article provides a comprehensive overview of the current state-of-the-art in XAI for drug discovery, including various XAI methods, their application in drug discovery, and the challenges and limitations of XAI techniques in drug discovery. The article also covers the application of XAI in drug discovery, including target identification, compound design, and toxicity prediction. Furthermore, the article suggests potential future research directions for the application of XAI in drug discovery. The aim of this review article is to provide a comprehensive understanding of the current state of XAI in drug discovery and its potential to transform the field.
+
+
+
+ 16. 标题:Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.12140
+ 作者:Travis Zhang, Katie Luo, Cheng Perng Phoo, Yurong You, Wei-Lun Chao, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
+ 备注:
+ 关键词:significantly improved accuracy, improved accuracy, rapid development, self-driving cars, cars has significantly
+
+ 点击查看摘要
+ The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at this https URL.
+
+
+
+ 17. 标题:On the relationship between Benchmarking, Standards and Certification in Robotics and AI
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2309.12139
+ 作者:Alan F.T. Winfield, Matthew Studley
+ 备注:
+ 关键词:closely related processes, closely related, standards, related processes, certification
+
+ 点击查看摘要
+ Benchmarking, standards and certification are closely related processes. Standards can provide normative requirements that robotics and AI systems may or may not conform to. Certification generally relies upon conformance with one or more standards as the key determinant of granting a certificate to operate. And benchmarks are sets of standardised tests against which robots and AI systems can be measured. Benchmarks therefore can be thought of as informal standards. In this paper we will develop these themes with examples from benchmarking, standards and certification, and argue that these three linked processes are not only useful but vital to the broader practice of Responsible Innovation.
+
+
+
+ 18. 标题:OSN-MDAD: Machine Translation Dataset for Arabic Multi-Dialectal Conversations on Online Social Media
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.12137
+ 作者:Fatimah Alzamzami, Abdulmotaleb El Saddik
+ 备注:
+ 关键词:Arabic, Arabic dialects, fairly sufficient, sufficient to understand, MSA
+
+ 点击查看摘要
+ While resources for English language are fairly sufficient to understand content on social media, similar resources in Arabic are still immature. The main reason that the resources in Arabic are insufficient is that Arabic has many dialects in addition to the standard version (MSA). Arabs do not use MSA in their daily communications; rather, they use dialectal versions. Unfortunately, social users transfer this phenomenon into their use of social media platforms, which in turn has raised an urgent need for building suitable AI models for language-dependent applications. Existing machine translation (MT) systems designed for MSA fail to work well with Arabic dialects. In light of this, it is necessary to adapt to the informal nature of communication on social networks by developing MT systems that can effectively handle the various dialects of Arabic. Unlike for MSA that shows advanced progress in MT systems, little effort has been exerted to utilize Arabic dialects for MT systems. While few attempts have been made to build translation datasets for dialectal Arabic, they are domain dependent and are not OSN cultural-language friendly. In this work, we attempt to alleviate these limitations by proposing an online social network-based multidialect Arabic dataset that is crafted by contextually translating English tweets into four Arabic dialects: Gulf, Yemeni, Iraqi, and Levantine. To perform the translation, we followed our proposed guideline framework for content translation, which could be universally applicable for translation between foreign languages and local dialects. We validated the authenticity of our proposed dataset by developing neural MT models for four Arabic dialects. Our results have shown a superior performance of our NMT models trained using our dataset. We believe that our dataset can reliably serve as an Arabic multidialectal translation dataset for informal MT tasks.
+
+
+
+ 19. 标题:A knowledge representation approach for construction contract knowledge modeling
+ 编号:[80]
+ 链接:https://arxiv.org/abs/2309.12132
+ 作者:Chunmo Zheng, Saika Wong, Xing Su, Yinqiu Tang
+ 备注:
+ 关键词:large language models, reducing human errors, saving significant time, automate construction contract, language models
+
+ 点击查看摘要
+ The emergence of large language models (LLMs) presents an unprecedented opportunity to automate construction contract management, reducing human errors and saving significant time and costs. However, LLMs may produce convincing yet inaccurate and misleading content due to a lack of domain expertise. To address this issue, expert-driven contract knowledge can be represented in a structured manner to constrain the automatic contract management process. This paper introduces the Nested Contract Knowledge Graph (NCKG), a knowledge representation approach that captures the complexity of contract knowledge using a nested structure. It includes a nested knowledge representation framework, a NCKG ontology built on the framework, and an implementation method. Furthermore, we present the LLM-assisted contract review pipeline enhanced with external knowledge in NCKG. Our pipeline achieves a promising performance in contract risk reviewing, shedding light on the combination of LLM and KG towards more reliable and interpretable contract management.
+
+
+
+ 20. 标题:Incentivizing Massive Unknown Workers for Budget-Limited Crowdsensing: From Off-Line and On-Line Perspectives
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2309.12113
+ 作者:Feng Li, Yuqi Chai, Huan Yang, Pengfei Hu, Lingjie Duan
+ 备注:
+ 关键词:Combinatorial Multi-Armed Bandit, standard Combinatorial Multi-Armed, Multi-Armed Bandit, Combinatorial Multi-Armed, standard Combinatorial
+
+ 点击查看摘要
+ Although the uncertainties of the workers can be addressed by the standard Combinatorial Multi-Armed Bandit (CMAB) framework in existing proposals through a trade-off between exploration and exploitation, we may not have sufficient budget to enable the trade-off among the individual workers, especially when the number of the workers is huge while the budget is limited. Moreover, the standard CMAB usually assumes the workers always stay in the system, whereas the workers may join in or depart from the system over time, such that what we have learnt for an individual worker cannot be applied after the worker leaves. To address the above challenging issues, in this paper, we first propose an off-line Context-Aware CMAB-based Incentive (CACI) mechanism. We innovate in leveraging the exploration-exploitation trade-off in a elaborately partitioned context space instead of the individual workers, to effectively incentivize the massive unknown workers with very limited budget. We also extend the above basic idea to the on-line setting where unknown workers may join in or depart from the systems dynamically, and propose an on-line version of the CACI mechanism. Specifically, by the exploitation-exploration trade-off in the context space, we learn to estimate the sensing ability of any unknown worker (even it never appeared in the system before) according to its context information. We perform rigorous theoretical analysis to reveal the upper bounds on the regrets of our CACI mechanisms and to prove their truthfulness and individual rationality, respectively. Extensive experiments on both synthetic and real datasets are also conducted to verify the efficacy of our mechanisms.
+
+
+
+ 21. 标题:PEFTT: Parameter-Efficient Fine-Tuning for low-resource Tibetan pre-trained language models
+ 编号:[90]
+ 链接:https://arxiv.org/abs/2309.12109
+ 作者:Zhou Mingjun, Daiqing Zhuoma, Qun Nuo, Nyima Tashi
+ 备注:
+ 关键词:Tibetan, users and institutions, traditional training, increasingly unimaginable, unimaginable for regular
+
+ 点击查看摘要
+ In this era of large language models (LLMs), the traditional training of models has become increasingly unimaginable for regular users and institutions. The exploration of efficient fine-tuning for high-resource languages on these models is an undeniable trend that is gradually gaining popularity. However, there has been very little exploration for various low-resource languages, such as Tibetan. Research in Tibetan NLP is inherently scarce and limited. While there is currently no existing large language model for Tibetan due to its low-resource nature, that day will undoubtedly arrive. Therefore, research on efficient fine-tuning for low-resource language models like Tibetan is highly necessary. Our research can serve as a reference to fill this crucial gap. Efficient fine-tuning strategies for pre-trained language models (PLMs) in Tibetan have seen minimal exploration. We conducted three types of efficient fine-tuning experiments on the publicly available TNCC-title dataset: "prompt-tuning," "Adapter lightweight fine-tuning," and "prompt-tuning + Adapter fine-tuning." The experimental results demonstrate significant improvements using these methods, providing valuable insights for advancing Tibetan language applications in the context of pre-trained models.
+
+
+
+ 22. 标题:Accelerating Thematic Investment with Prompt Tuned Pretrained Language Models
+ 编号:[100]
+ 链接:https://arxiv.org/abs/2309.12075
+ 作者:Valentin Leonhard Buchner, Lele Cao, Jan-Christoph Kalo
+ 备注:A thesis written in fulfillment of the requirements for the joint MSc degree in Artificial Intelligence at the VU Amsterdam and University of Amsterdam
+ 关键词:fine-tune Pretrained Language, Pretrained Language Models, Prompt Tuning, fine-tune Pretrained, Pretrained Language
+
+ 点击查看摘要
+ Prompt Tuning is emerging as a scalable and cost-effective method to fine-tune Pretrained Language Models (PLMs). This study benchmarks the performance and computational efficiency of Prompt Tuning and baseline methods on a multi-label text classification task. This is applied to the use case of classifying companies into an investment firm's proprietary industry taxonomy, supporting their thematic investment strategy. Text-to-text classification with PLMs is frequently reported to outperform classification with a classification head, but has several limitations when applied to a multi-label classification problem where each label consists of multiple tokens: (a) Generated labels may not match any label in the industry taxonomy; (b) During fine-tuning, multiple labels must be provided in an arbitrary order; (c) The model provides a binary decision for each label, rather than an appropriate confidence score. Limitation (a) is addressed by applying constrained decoding using Trie Search, which slightly improves classification performance. All limitations (a), (b), and (c) are addressed by replacing the PLM's language head with a classification head. This improves performance significantly, while also reducing computational costs during inference. The results indicate the continuing need to adapt state-of-the-art methods to domain-specific tasks, even in the era of PLMs with strong generalization abilities.
+
+
+
+ 23. 标题:Benchmarking quantized LLaMa-based models on the Brazilian Secondary School Exam
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2309.12071
+ 作者:Matheus L. O. Santos, Cláudio E. C. Campelo
+ 备注:8 pages, 6 figures, 4 tables
+ 关键词:Large Language Models, Large Language, Language Models, represent a revolution, interact with computers
+
+ 点击查看摘要
+ Although Large Language Models (LLMs) represent a revolution in the way we interact with computers, allowing the construction of complex questions and the ability to reason over a sequence of statements, their use is restricted due to the need for dedicated hardware for execution. In this study, we evaluate the performance of LLMs based on the 7 and 13 billion LLaMA models, subjected to a quantization process and run on home hardware. The models considered were Alpaca, Koala, and Vicuna. To evaluate the effectiveness of these models, we developed a database containing 1,006 questions from the ENEM (Brazilian National Secondary School Exam). Our analysis revealed that the best performing models achieved an accuracy of approximately 46% for the original texts of the Portuguese questions and 49% on their English translations. In addition, we evaluated the computational efficiency of the models by measuring the time required for execution. On average, the 7 and 13 billion LLMs took approximately 20 and 50 seconds, respectively, to process the queries on a machine equipped with an AMD Ryzen 5 3600x processor
+
+
+
+ 24. 标题:Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer -- Current Trends and Research Perspectives
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.12067
+ 作者:Karolina Seweryn, Anna Wróblewska, Szymon Łukasik
+ 备注:
+ 关键词:challenging task due, interactions between players, complex and dynamic, dynamic nature, challenging task
+
+ 点击查看摘要
+ Action scene understanding in soccer is a challenging task due to the complex and dynamic nature of the game, as well as the interactions between players. This article provides a comprehensive overview of this task divided into action recognition, spotting, and spatio-temporal action localization, with a particular emphasis on the modalities used and multimodal methods. We explore the publicly available data sources and metrics used to evaluate models' performance. The article reviews recent state-of-the-art methods that leverage deep learning techniques and traditional methods. We focus on multimodal methods, which integrate information from multiple sources, such as video and audio data, and also those that represent one source in various ways. The advantages and limitations of methods are discussed, along with their potential for improving the accuracy and robustness of models. Finally, the article highlights some of the open research questions and future directions in the field of soccer action recognition, including the potential for multimodal methods to advance this field. Overall, this survey provides a valuable resource for researchers interested in the field of action scene understanding in soccer.
+
+
+
+ 25. 标题:An Efficient Consolidation of Word Embedding and Deep Learning Techniques for Classifying Anticancer Peptides: FastText+BiLSTM
+ 编号:[105]
+ 链接:https://arxiv.org/abs/2309.12058
+ 作者:Onur Karakaya, Zeynep Hilal Kilimci
+ 备注:
+ 关键词:exhibite antineoplastic properties, antineoplastic properties, exhibite antineoplastic, word embedding, Anticancer peptides
+
+ 点击查看摘要
+ Anticancer peptides (ACPs) are a group of peptides that exhibite antineoplastic properties. The utilization of ACPs in cancer prevention can present a viable substitute for conventional cancer therapeutics, as they possess a higher degree of selectivity and safety. Recent scientific advancements generate an interest in peptide-based therapies which offer the advantage of efficiently treating intended cells without negatively impacting normal cells. However, as the number of peptide sequences continues to increase rapidly, developing a reliable and precise prediction model becomes a challenging task. In this work, our motivation is to advance an efficient model for categorizing anticancer peptides employing the consolidation of word embedding and deep learning models. First, Word2Vec and FastText are evaluated as word embedding techniques for the purpose of extracting peptide sequences. Then, the output of word embedding models are fed into deep learning approaches CNN, LSTM, BiLSTM. To demonstrate the contribution of proposed framework, extensive experiments are carried on widely-used datasets in the literature, ACPs250 and Independent. Experiment results show the usage of proposed model enhances classification accuracy when compared to the state-of-the-art studies. The proposed combination, FastText+BiLSTM, exhibits 92.50% of accuracy for ACPs250 dataset, and 96.15% of accuracy for Independent dataset, thence determining new state-of-the-art.
+
+
+
+ 26. 标题:BELT:Bootstrapping Electroencephalography-to-Language Decoding and Zero-Shot Sentiment Classification by Natural Language Supervision
+ 编号:[106]
+ 链接:https://arxiv.org/abs/2309.12056
+ 作者:Jinzhao Zhou, Yiqun Duan, Yu-Cheng Chang, Yu-Kai Wang, Chin-Teng Lin
+ 备注:
+ 关键词:paper presents BELT, EEG representation, paper presents, pivotal topic, presents BELT
+
+ 点击查看摘要
+ This paper presents BELT, a novel model and learning framework for the pivotal topic of brain-to-language translation research. The translation from noninvasive brain signals into readable natural language has the potential to promote the application scenario as well as the development of brain-computer interfaces (BCI) as a whole. The critical problem in brain signal decoding or brain-to-language translation is the acquisition of semantically appropriate and discriminative EEG representation from a dataset of limited scale and quality. The proposed BELT method is a generic and efficient framework that bootstraps EEG representation learning using off-the-shelf large-scale pretrained language models (LMs). With a large LM's capacity for understanding semantic information and zero-shot generalization, BELT utilizes large LMs trained on Internet-scale datasets to bring significant improvements to the understanding of EEG signals.
+In particular, the BELT model is composed of a deep conformer encoder and a vector quantization encoder. Semantical EEG representation is achieved by a contrastive learning step that provides natural language supervision. We achieve state-of-the-art results on two featuring brain decoding tasks including the brain-to-language translation and zero-shot sentiment classification. Specifically, our model surpasses the baseline model on both tasks by 5.45% and over 10% and archives a 42.31% BLEU-1 score and 67.32% precision on the main evaluation metrics for translation and zero-shot sentiment classification respectively.
+
+
+
+ 27. 标题:Uncertainty-driven Exploration Strategies for Online Grasp Learning
+ 编号:[114]
+ 链接:https://arxiv.org/abs/2309.12038
+ 作者:Yitian Shi, Philipp Schillinger, Miroslav Gabriel, Alexander Kuss, Zohar Feldman, Hanna Ziesche, Ngo Anh Vien
+ 备注:Under review for ICRA 2024
+ 关键词:Existing grasp prediction, grasp prediction approaches, grasp, learning, exploratory grasp learning
+
+ 点击查看摘要
+ Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Specifically, the online learning algorithm with an effective exploration strategy can significantly improve its adaptation performance to unseen environment settings. To this end, we first propose to formulate online grasp learning as a RL problem that will allow to adapt both grasp reward prediction and grasp poses. We propose various uncertainty estimation schemes based on Bayesian Uncertainty Quantification and Distributional Ensembles. We carry out evaluations on real-world bin picking scenes of varying difficulty. The objects in the bin have various challenging physical and perceptual characteristics that can be characterized by semi- or total transparency, and irregular or curved surfaces. The results of our experiments demonstrate a notable improvement in the suggested approach compared to conventional online learning methods which incorporate only naive exploration strategies.
+
+
+
+ 28. 标题:Dynamic Hypergraph Structure Learning for Traffic Flow Forecasting
+ 编号:[122]
+ 链接:https://arxiv.org/abs/2309.12028
+ 作者:Yusheng Zhao, Xiao Luo, Wei Ju, Chong Chen, Xian-Sheng Hua, Ming Zhang
+ 备注:Accepted by 2023 IEEE 39th International Conference on Data Engineering (ICDE 2023)
+ 关键词:future traffic conditions, predict future traffic, traffic conditions, aims to predict, predict future
+
+ 点击查看摘要
+ This paper studies the problem of traffic flow forecasting, which aims to predict future traffic conditions on the basis of road networks and traffic conditions in the past. The problem is typically solved by modeling complex spatio-temporal correlations in traffic data using spatio-temporal graph neural networks (GNNs). However, the performance of these methods is still far from satisfactory since GNNs usually have limited representation capacity when it comes to complex traffic networks. Graphs, by nature, fall short in capturing non-pairwise relations. Even worse, existing methods follow the paradigm of message passing that aggregates neighborhood information linearly, which fails to capture complicated spatio-temporal high-order interactions. To tackle these issues, in this paper, we propose a novel model named Dynamic Hypergraph Structure Learning (DyHSL) for traffic flow prediction. To learn non-pairwise relationships, our DyHSL extracts hypergraph structural information to model dynamics in the traffic networks, and updates each node representation by aggregating messages from its associated hyperedges. Additionally, to capture high-order spatio-temporal relations in the road network, we introduce an interactive graph convolution block, which further models the neighborhood interaction for each node. Finally, we integrate these two views into a holistic multi-scale correlation extraction module, which conducts temporal pooling with different scales to model different temporal patterns. Extensive experiments on four popular traffic benchmark datasets demonstrate the effectiveness of our proposed DyHSL compared with a broad range of competing baselines.
+
+
+
+ 29. 标题:Demystifying Visual Features of Movie Posters for Multi-Label Genre Identification
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2309.12022
+ 作者:Utsav Kumar Nareti, Chandranath Adak, Soumi Chattopadhyay
+ 备注:
+ 关键词:OTT platforms, media and OTT, social media, part of advertising, advertising and marketing
+
+ 点击查看摘要
+ In the film industry, movie posters have been an essential part of advertising and marketing for many decades, and continue to play a vital role even today in the form of digital posters through online, social media and OTT platforms. Typically, movie posters can effectively promote and communicate the essence of a film, such as its genre, visual style/ tone, vibe and storyline cue/ theme, which are essential to attract potential viewers. Identifying the genres of a movie often has significant practical applications in recommending the film to target audiences. Previous studies on movie genre identification are limited to subtitles, plot synopses, and movie scenes that are mostly accessible after the movie release. Posters usually contain pre-release implicit information to generate mass interest. In this paper, we work for automated multi-label genre identification only from movie poster images, without any aid of additional textual/meta-data information about movies, which is one of the earliest attempts of its kind. Here, we present a deep transformer network with a probabilistic module to identify the movie genres exclusively from the poster. For experimental analysis, we procured 13882 number of posters of 13 genres from the Internet Movie Database (IMDb), where our model performances were encouraging and even outperformed some major contemporary architectures.
+
+
+
+ 30. 标题:Safe Hierarchical Reinforcement Learning for CubeSat Task Scheduling Based on Energy Consumption
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.12004
+ 作者:Mahya Ramezani, M. Amin Alandihallaj, Jose Luis Sanchez-Lopez, Andreas Hein
+ 备注:
+ 关键词:Low Earth Orbits, Earth Orbits, Hierarchical Reinforcement Learning, Low Earth, Learning methodology tailored
+
+ 点击查看摘要
+ This paper presents a Hierarchical Reinforcement Learning methodology tailored for optimizing CubeSat task scheduling in Low Earth Orbits (LEO). Incorporating a high-level policy for global task distribution and a low-level policy for real-time adaptations as a safety mechanism, our approach integrates the Similarity Attention-based Encoder (SABE) for task prioritization and an MLP estimator for energy consumption forecasting. Integrating this mechanism creates a safe and fault-tolerant system for CubeSat task scheduling. Simulation results validate the Hierarchical Reinforcement Learning superior convergence and task success rate, outperforming both the MADDPG model and traditional random scheduling across multiple CubeSat configurations.
+
+
+
+ 31. 标题:LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2309.11998
+ 作者:Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric. P Xing, Joseph E. Gonzalez, Ion Stoica, Hao Zhang
+ 备注:
+ 关键词:increasingly important due, large language models, Studying how people, people interact, interact with large
+
+ 点击查看摘要
+ Studying how people interact with large language models (LLMs) in real-world scenarios is increasingly important due to their widespread use in various applications. In this paper, we introduce LMSYS-Chat-1M, a large-scale dataset containing one million real-world conversations with 25 state-of-the-art LLMs. This dataset is collected from 210K unique IP addresses in the wild on our Vicuna demo and Chatbot Arena website. We offer an overview of the dataset's content, including its curation process, basic statistics, and topic distribution, highlighting its diversity, originality, and scale. We demonstrate its versatility through four use cases: developing content moderation models that perform similarly to GPT-4, building a safety benchmark, training instruction-following models that perform similarly to Vicuna, and creating challenging benchmark questions. We believe that this dataset will serve as a valuable resource for understanding and advancing LLM capabilities. The dataset is publicly available at this https URL.
+
+
+
+ 32. 标题:Predictability and Comprehensibility in Post-Hoc XAI Methods: A User-Centered Analysis
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2309.11987
+ 作者:Anahid Jalali, Bernhard Haslhofer, Simone Kriglstein, Andreas Rauber
+ 备注:17
+ 关键词:aim to clarify, clarify predictions, predictions of black-box, black-box machine learning, explainability methods aim
+
+ 点击查看摘要
+ Post-hoc explainability methods aim to clarify predictions of black-box machine learning models. However, it is still largely unclear how well users comprehend the provided explanations and whether these increase the users ability to predict the model behavior. We approach this question by conducting a user study to evaluate comprehensibility and predictability in two widely used tools: LIME and SHAP. Moreover, we investigate the effect of counterfactual explanations and misclassifications on users ability to understand and predict the model behavior. We find that the comprehensibility of SHAP is significantly reduced when explanations are provided for samples near a model's decision boundary. Furthermore, we find that counterfactual explanations and misclassifications can significantly increase the users understanding of how a machine learning model is making decisions. Based on our findings, we also derive design recommendations for future post-hoc explainability methods with increased comprehensibility and predictability.
+
+
+
+ 33. 标题:Representation Abstractions as Incentives for Reinforcement Learning Agents: A Robotic Grasping Case Study
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2309.11984
+ 作者:Panagiotis Petropoulakis, Ludwig Gräf, Josip Josifovski, Mohammadhossein Malmir, Alois Knoll
+ 备注:8 pages, 6 figures
+ 关键词:underlying decision-making process, underlying decision-making, decision-making process, state representation, agent
+
+ 点击查看摘要
+ Choosing an appropriate representation of the environment for the underlying decision-making process of the RL agent is not always straightforward. The state representation should be inclusive enough to allow the agent to informatively decide on its actions and compact enough to increase sample efficiency for policy training. Given this outlook, this work examines the effect of various state representations in incentivizing the agent to solve a specific robotic task: antipodal and planar object grasping. A continuum of state representation abstractions is defined, starting from a model-based approach with complete system knowledge, through hand-crafted numerical, to image-based representations with decreasing level of induced task-specific knowledge. We examine the effects of each representation in the ability of the agent to solve the task in simulation and the transferability of the learned policy to the real robot. The results show that RL agents using numerical states can perform on par with non-learning baselines. Furthermore, we find that agents using image-based representations from pre-trained environment embedding vectors perform better than end-to-end trained agents, and hypothesize that task-specific knowledge is necessary for achieving convergence and high success rates in robot control.
+
+
+
+ 34. 标题:Rethinking the Evaluating Framework for Natural Language Understanding in AI Systems: Language Acquisition as a Core for Future Metrics
+ 编号:[145]
+ 链接:https://arxiv.org/abs/2309.11981
+ 作者:Patricio Vera, Pedro Moya, Lisa Barraza
+ 备注:25 pages, 1 table, 2 figures
+ 关键词:large language models, natural language processing, artificial intelligence, machine intelligence, offers an opportunity
+
+ 点击查看摘要
+ In the burgeoning field of artificial intelligence (AI), the unprecedented progress of large language models (LLMs) in natural language processing (NLP) offers an opportunity to revisit the entire approach of traditional metrics of machine intelligence, both in form and content. As the realm of machine cognitive evaluation has already reached Imitation, the next step is an efficient Language Acquisition and Understanding. Our paper proposes a paradigm shift from the established Turing Test towards an all-embracing framework that hinges on language acquisition, taking inspiration from the recent advancements in LLMs. The present contribution is deeply tributary of the excellent work from various disciplines, point out the need to keep interdisciplinary bridges open, and delineates a more robust and sustainable approach.
+
+
+
+ 35. 标题:Inferring Capabilities from Task Performance with Bayesian Triangulation
+ 编号:[147]
+ 链接:https://arxiv.org/abs/2309.11975
+ 作者:John Burden, Konstantinos Voudouris, Ryan Burnell, Danaja Rutar, Lucy Cheke, José Hernández-Orallo
+ 备注:8 Pages + 14 pages of Appendices. 15 Figures. Submitted to AAAI 2024. Preprint
+ 关键词:machine learning models, machine learning, learning models, diverse experimental data, general
+
+ 点击查看摘要
+ As machine learning models become more general, we need to characterise them in richer, more meaningful ways. We describe a method to infer the cognitive profile of a system from diverse experimental data. To do so, we introduce measurement layouts that model how task-instance features interact with system capabilities to affect performance. These features must be triangulated in complex ways to be able to infer capabilities from non-populational data -- a challenge for traditional psychometric and inferential tools. Using the Bayesian probabilistic programming library PyMC, we infer different cognitive profiles for agents in two scenarios: 68 actual contestants in the AnimalAI Olympics and 30 synthetic agents for O-PIAAGETS, an object permanence battery. We showcase the potential for capability-oriented evaluation.
+
+
+
+ 36. 标题:A Comprehensive Review on Financial Explainable AI
+ 编号:[155]
+ 链接:https://arxiv.org/abs/2309.11960
+ 作者:Wei Jie Yeo, Wihan van der Heever, Rui Mao, Erik Cambria, Ranjan Satapathy, Gianmarco Mengaldo
+ 备注:
+ 关键词:learn complex patterns, process huge amounts, deep learning models, artificial intelligence, complex patterns
+
+ 点击查看摘要
+ The success of artificial intelligence (AI), and deep learning models in particular, has led to their widespread adoption across various industries due to their ability to process huge amounts of data and learn complex patterns. However, due to their lack of explainability, there are significant concerns regarding their use in critical sectors, such as finance and healthcare, where decision-making transparency is of paramount importance. In this paper, we provide a comparative survey of methods that aim to improve the explainability of deep learning models within the context of finance. We categorize the collection of explainable AI methods according to their corresponding characteristics, and we review the concerns and challenges of adopting explainable AI methods, together with future directions we deemed appropriate and important.
+
+
+
+ 37. 标题:On the Definition of Appropriate Trust and the Tools that Come with it
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2309.11937
+ 作者:Helena Löfström
+ 备注:8 pages, 3 figures, Conference: ICDATA 2023
+ 关键词:objective quality aspects, interactions is challenging, efficiency of human-AI, human-AI interactions, model performance evaluation
+
+ 点击查看摘要
+ Evaluating the efficiency of human-AI interactions is challenging, including subjective and objective quality aspects. With the focus on the human experience of the explanations, evaluations of explanation methods have become mostly subjective, making comparative evaluations almost impossible and highly linked to the individual user. However, it is commonly agreed that one aspect of explanation quality is how effectively the user can detect if the predictions are trustworthy and correct, i.e., if the explanations can increase the user's appropriate trust in the model. This paper starts with the definitions of appropriate trust from the literature. It compares the definitions with model performance evaluation, showing the strong similarities between appropriate trust and model performance evaluation. The paper's main contribution is a novel approach to evaluating appropriate trust by taking advantage of the likenesses between definitions. The paper offers several straightforward evaluation methods for different aspects of user performance, including suggesting a method for measuring uncertainty and appropriate trust in regression.
+
+
+
+ 38. 标题:Learning to Recover for Safe Reinforcement Learning
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2309.11907
+ 作者:Haoyu Wang, Xin Yuan, Qinqing Ren
+ 备注:
+ 关键词:Safety, safety controller, handcrafted safety constraints, achieve safe reinforcement, task training
+
+ 点击查看摘要
+ Safety controllers is widely used to achieve safe reinforcement learning. Most methods that apply a safety controller are using handcrafted safety constraints to construct the safety controller. However, when the environment dynamics are sophisticated, handcrafted safety constraints become unavailable. Therefore, it worth to research on constructing safety controllers by learning algorithms. We propose a three-stage architecture for safe reinforcement learning, namely TU-Recovery Architecture. A safety critic and a recovery policy is learned before task training. They form a safety controller to ensure safety in task training. Then a phenomenon induced by disagreement between task policy and recovery policy, called adversarial phenomenon, which reduces learning efficiency and model performance, is described. Auxiliary reward is proposed to mitigate adversarial phenomenon, while help the task policy to learn to recover from high-risk states. A series of experiments are conducted in a robot navigation environment. Experiments demonstrate that TU-Recovery outperforms unconstrained counterpart in both reward gaining and constraint violations during task training, and auxiliary reward further improve TU-Recovery in reward-to-cost ratio by significantly reduce constraint violations.
+
+
+
+ 39. 标题:Unlocking the Heart Using Adaptive Locked Agnostic Networks
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2309.11899
+ 作者:Sylwia Majchrowska, Anders Hildeman, Philip Teare, Tom Diethe
+ 备注:The article was accepted to ICCV 2023 workshop PerDream: PERception, Decision making and REAsoning through Multimodal foundational modeling
+ 关键词:imaging applications requires, medical imaging applications, deep learning models, Locked Agnostic Network, Adaptive Locked Agnostic
+
+ 点击查看摘要
+ Supervised training of deep learning models for medical imaging applications requires a significant amount of labeled data. This is posing a challenge as the images are required to be annotated by medical professionals. To address this limitation, we introduce the Adaptive Locked Agnostic Network (ALAN), a concept involving self-supervised visual feature extraction using a large backbone model to produce anatomically robust semantic self-segmentation. In the ALAN methodology, this self-supervised training occurs only once on a large and diverse dataset. Due to the intuitive interpretability of the segmentation, downstream models tailored for specific tasks can be easily designed using white-box models with few parameters. This, in turn, opens up the possibility of communicating the inner workings of a model with domain experts and introducing prior knowledge into it. It also means that the downstream models become less data-hungry compared to fully supervised approaches. These characteristics make ALAN particularly well-suited for resource-scarce scenarios, such as costly clinical trials and rare diseases. In this paper, we apply the ALAN approach to three publicly available echocardiography datasets: EchoNet-Dynamic, CAMUS, and TMED-2. Our findings demonstrate that the self-supervised backbone model robustly identifies anatomical subregions of the heart in an apical four-chamber view. Building upon this, we design two downstream models, one for segmenting a target anatomical region, and a second for echocardiogram view classification.
+
+
+
+ 40. 标题:Audio Contrastive based Fine-tuning
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.11895
+ 作者:Yang Wang, Qibin Liang, Chenghao Xiao, Yizhi Li, Noura Al Moubayed, Chenghua Lin
+ 备注:Under review
+ 关键词:sound processing tasks, range of applications, Audio classification plays, plays a crucial, crucial role
+
+ 点击查看摘要
+ Audio classification plays a crucial role in speech and sound processing tasks with a wide range of applications. There still remains a challenge of striking the right balance between fitting the model to the training data (avoiding overfitting) and enabling it to generalise well to a new domain. Leveraging the transferability of contrastive learning, we introduce Audio Contrastive-based Fine-tuning (AudioConFit), an efficient approach characterised by robust generalisability. Empirical experiments on a variety of audio classification tasks demonstrate the effectiveness and robustness of our approach, which achieves state-of-the-art results in various settings.
+
+
+
+ 41. 标题:Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2309.11876
+ 作者:Shuang Zeng, Lei Zhu, Xinliang Zhang, Zifeng Tian, Qian Chen, Lujia Jin, Jiayi Wang, Yanye Lu
+ 备注:
+ 关键词:limited labeled data, unlabeled data, labeled data, Contrastive learning, leads a promising
+
+ 点击查看摘要
+ Contrastive learning, which is a powerful technique for learning image-level representations from unlabeled data, leads a promising direction to dealing with the dilemma between large-scale pre-training and limited labeled data. However, most existing contrastive learning strategies are designed mainly for downstream tasks of natural images, therefore they are sub-optimal and even worse than learning from scratch when directly applied to medical images whose downstream tasks are usually segmentation. In this work, we propose a novel asymmetric contrastive learning framework named JCL for medical image segmentation with self-supervised pre-training. Specifically, (1) A novel asymmetric contrastive learning strategy is proposed to pre-train both encoder and decoder simultaneously in one-stage to provide better initialization for segmentation models. (2) A multi-level contrastive loss is designed to take the correspondence among feature-level, image-level and pixel-level projections, respectively into account to make sure multi-level representations can be learned by the encoder and decoder during pre-training. (3) Experiments on multiple medical image datasets indicate our JCL framework outperforms existing SOTA contrastive learning strategies.
+
+
+
+ 42. 标题:Stochastic stiffness identification and response estimation of Timoshenko beams via physics-informed Gaussian processes
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.11875
+ 作者:Gledson Rodrigo Tondo, Sebastian Rau, Igor Kavrakov, Guido Morgenthal
+ 备注:
+ 关键词:Machine learning models, learning models trained, Machine learning, powerful tool, model
+
+ 点击查看摘要
+ Machine learning models trained with structural health monitoring data have become a powerful tool for system identification. This paper presents a physics-informed Gaussian process (GP) model for Timoshenko beam elements. The model is constructed as a multi-output GP with covariance and cross-covariance kernels analytically derived based on the differential equations for deflections, rotations, strains, bending moments, shear forces and applied loads. Stiffness identification is performed in a Bayesian format by maximising a posterior model through a Markov chain Monte Carlo method, yielding a stochastic model for the structural parameters. The optimised GP model is further employed for probabilistic predictions of unobserved responses. Additionally, an entropy-based method for physics-informed sensor placement optimisation is presented, exploiting heterogeneous sensor position information and structural boundary conditions built into the GP model. Results demonstrate that the proposed approach is effective at identifying structural parameters and is capable of fusing data from heterogeneous and multi-fidelity sensors. Probabilistic predictions of structural responses and internal forces are in closer agreement with measured data. We validate our model with an experimental setup and discuss the quality and uncertainty of the obtained results. The proposed approach has potential applications in the field of structural health monitoring (SHM) for both mechanical and structural systems.
+
+
+
+ 43. 标题:OSNet & MNetO: Two Types of General Reconstruction Architectures for Linear Computed Tomography in Multi-Scenarios
+ 编号:[205]
+ 链接:https://arxiv.org/abs/2309.11858
+ 作者:Zhisheng Wang, Zihan Deng, Fenglin Liu, Yixing Huang, Haijun Yu, Junning Cui
+ 备注:13 pages, 13 figures
+ 关键词:actively attracted attention, Hilbert filtering, LCT, linear computed tomography, DBP images
+
+ 点击查看摘要
+ Recently, linear computed tomography (LCT) systems have actively attracted attention. To weaken projection truncation and image the region of interest (ROI) for LCT, the backprojection filtration (BPF) algorithm is an effective solution. However, in BPF for LCT, it is difficult to achieve stable interior reconstruction, and for differentiated backprojection (DBP) images of LCT, multiple rotation-finite inversion of Hilbert transform (Hilbert filtering)-inverse rotation operations will blur the image. To satisfy multiple reconstruction scenarios for LCT, including interior ROI, complete object, and exterior region beyond field-of-view (FOV), and avoid the rotation operations of Hilbert filtering, we propose two types of reconstruction architectures. The first overlays multiple DBP images to obtain a complete DBP image, then uses a network to learn the overlying Hilbert filtering function, referred to as the Overlay-Single Network (OSNet). The second uses multiple networks to train different directional Hilbert filtering models for DBP images of multiple linear scannings, respectively, and then overlays the reconstructed results, i.e., Multiple Networks Overlaying (MNetO). In two architectures, we introduce a Swin Transformer (ST) block to the generator of pix2pixGAN to extract both local and global features from DBP images at the same time. We investigate two architectures from different networks, FOV sizes, pixel sizes, number of projections, geometric magnification, and processing time. Experimental results show that two architectures can both recover images. OSNet outperforms BPF in various scenarios. For the different networks, ST-pix2pixGAN is superior to pix2pixGAN and CycleGAN. MNetO exhibits a few artifacts due to the differences among the multiple models, but any one of its models is suitable for imaging the exterior edge in a certain direction.
+
+
+
+ 44. 标题:BitCoin: Bidirectional Tagging and Supervised Contrastive Learning based Joint Relational Triple Extraction Framework
+ 编号:[207]
+ 链接:https://arxiv.org/abs/2309.11853
+ 作者:Luyao He, Zhongbao Zhang, Sen Su, Yuxin Chen
+ 备注:arXiv admin note: text overlap with arXiv:2112.04940 by other authors
+ 关键词:knowledge graph construction, graph construction, knowledge graph, RTE, subject
+
+ 点击查看摘要
+ Relation triple extraction (RTE) is an essential task in information extraction and knowledge graph construction. Despite recent advancements, existing methods still exhibit certain limitations. They just employ generalized pre-trained models and do not consider the specificity of RTE tasks. Moreover, existing tagging-based approaches typically decompose the RTE task into two subtasks, initially identifying subjects and subsequently identifying objects and relations. They solely focus on extracting relational triples from subject to object, neglecting that once the extraction of a subject fails, it fails in extracting all triples associated with that subject. To address these issues, we propose BitCoin, an innovative Bidirectional tagging and supervised Contrastive learning based joint relational triple extraction framework. Specifically, we design a supervised contrastive learning method that considers multiple positives per anchor rather than restricting it to just one positive. Furthermore, a penalty term is introduced to prevent excessive similarity between the subject and object. Our framework implements taggers in two directions, enabling triples extraction from subject to object and object to subject. Experimental results show that BitCoin achieves state-of-the-art results on the benchmark datasets and significantly improves the F1 score on Normal, SEO, EPO, and multiple relation extraction tasks.
+
+
+
+ 45. 标题:Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
+ 编号:[217]
+ 链接:https://arxiv.org/abs/2309.11838
+ 作者:Norbert Braunschweiler, Rama Doddipatla, Simon Keizer, Svetlana Stoyanchev
+ 备注:10 pages
+ 关键词:large language models, large language, Shared Task, shared task winning, document-grounded response generation
+
+ 点击查看摘要
+ In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
+
+
+
+ 46. 标题:JobRecoGPT -- Explainable job recommendations using LLMs
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2309.11805
+ 作者:Preetam Ghosh, Vaishali Sadaphal
+ 备注:10 pages, 29 figures
+ 关键词:today rapidly evolving, evolving job market, rapidly evolving job, daunting challenge, today rapidly
+
+ 点击查看摘要
+ In today's rapidly evolving job market, finding the right opportunity can be a daunting challenge. With advancements in the field of AI, computers can now recommend suitable jobs to candidates. However, the task of recommending jobs is not same as recommending movies to viewers. Apart from must-have criteria, like skills and experience, there are many subtle aspects to a job which can decide if it is a good fit or not for a given candidate. Traditional approaches can capture the quantifiable aspects of jobs and candidates, but a substantial portion of the data that is present in unstructured form in the job descriptions and resumes is lost in the process of conversion to structured format. As of late, Large Language Models (LLMs) have taken over the AI field by storm with extraordinary performance in fields where text-based data is available. Inspired by the superior performance of LLMs, we leverage their capability to understand natural language for capturing the information that was previously getting lost during the conversion of unstructured data to structured form. To this end, we compare performance of four different approaches for job recommendations namely, (i) Content based deterministic, (ii) LLM guided, (iii) LLM unguided, and (iv) Hybrid. In this study, we present advantages and limitations of each method and evaluate their performance in terms of time requirements.
+
+
+
+ 47. 标题:DimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2309.11782
+ 作者:Thanh Nguyen, Trung Pham, Chaoning Zhang, Tung Luu, Thang Vu, Chang D. Yoo
+ 备注:
+ 关键词:contrastive learning, gained remarkable success, Self-supervised learning, Dimensional Contrastive Learning, plays a key
+
+ 点击查看摘要
+ Self-supervised learning (SSL) has gained remarkable success, for which contrastive learning (CL) plays a key role. However, the recent development of new non-CL frameworks has achieved comparable or better performance with high improvement potential, prompting researchers to enhance these frameworks further. Assimilating CL into non-CL frameworks has been thought to be beneficial, but empirical evidence indicates no visible improvements. In view of that, this paper proposes a strategy of performing CL along the dimensional direction instead of along the batch direction as done in conventional contrastive learning, named Dimensional Contrastive Learning (DimCL). DimCL aims to enhance the feature diversity, and it can serve as a regularizer to prior SSL frameworks. DimCL has been found to be effective, and the hardness-aware property is identified as a critical reason for its success. Extensive experimental results reveal that assimilating DimCL into SSL frameworks leads to performance improvement by a non-trivial margin on various datasets and backbone architectures.
+
+
+
+ 48. 标题:2DDATA: 2D Detection Annotations Transmittable Aggregation for Semantic Segmentation on Point Cloud
+ 编号:[244]
+ 链接:https://arxiv.org/abs/2309.11755
+ 作者:Guan-Cheng Lee
+ 备注:
+ 关键词:LiDAR and cameras, Local Object Branch, Detection Annotations Transmittable, Annotations Transmittable Aggregation, complementary information
+
+ 点击查看摘要
+ Recently, multi-modality models have been introduced because of the complementary information from different sensors such as LiDAR and cameras. It requires paired data along with precise calibrations for all modalities, the complicated calibration among modalities hugely increases the cost of collecting such high-quality datasets, and hinder it from being applied to practical scenarios. Inherit from the previous works, we not only fuse the information from multi-modality without above issues, and also exhaust the information in the RGB modality. We introduced the 2D Detection Annotations Transmittable Aggregation(\textbf{2DDATA}), designing a data-specific branch, called \textbf{Local Object Branch}, which aims to deal with points in a certain bounding box, because of its easiness of acquiring 2D bounding box annotations. We demonstrate that our simple design can transmit bounding box prior information to the 3D encoder model, proving the feasibility of large multi-modality models fused with modality-specific data.
+
+
+
+ 49. 标题:Improve the efficiency of deep reinforcement learning through semantic exploration guided by natural language
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2309.11753
+ 作者:Zhourui Guo, Meng Yao, Yang Yu, Qiyue Yin
+ 备注:
+ 关键词:achieve good performance, trial and error, powerful technique, achieve good, oracle
+
+ 点击查看摘要
+ Reinforcement learning is a powerful technique for learning from trial and error, but it often requires a large number of interactions to achieve good performance. In some domains, such as sparse-reward tasks, an oracle that can provide useful feedback or guidance to the agent during the learning process is really of great importance. However, querying the oracle too frequently may be costly or impractical, and the oracle may not always have a clear answer for every situation. Therefore, we propose a novel method for interacting with the oracle in a selective and efficient way, using a retrieval-based approach. We assume that the interaction can be modeled as a sequence of templated questions and answers, and that there is a large corpus of previous interactions available. We use a neural network to encode the current state of the agent and the oracle, and retrieve the most relevant question from the corpus to ask the oracle. We then use the oracle's answer to update the agent's policy and value function. We evaluate our method on an object manipulation task. We show that our method can significantly improve the efficiency of RL by reducing the number of interactions needed to reach a certain level of performance, compared to baselines that do not use the oracle or use it in a naive way.
+
+
+
+ 50. 标题:How Robust is Google's Bard to Adversarial Image Attacks?
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2309.11751
+ 作者:Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, Xiao Yang, Yichi Zhang, Yu Tian, Hang Su, Jun Zhu
+ 备注:Technical report
+ 关键词:Large Language Models, Multimodal Large Language, Large Language, achieved unprecedented performance, Language Models
+
+ 点击查看摘要
+ Multimodal Large Language Models (MLLMs) that integrate text and other modalities (especially vision) have achieved unprecedented performance in various multimodal tasks. However, due to the unsolved adversarial robustness problem of vision models, MLLMs can have more severe safety and security risks by introducing the vision inputs. In this work, we study the adversarial robustness of Google's Bard, a competitive chatbot to ChatGPT that released its multimodal capability recently, to better understand the vulnerabilities of commercial MLLMs. By attacking white-box surrogate vision encoders or MLLMs, the generated adversarial examples can mislead Bard to output wrong image descriptions with a 22% success rate based solely on the transferability. We show that the adversarial examples can also attack other MLLMs, e.g., a 26% attack success rate against Bing Chat and a 86% attack success rate against ERNIE bot. Moreover, we identify two defense mechanisms of Bard, including face detection and toxicity detection of images. We design corresponding attacks to evade these defenses, demonstrating that the current defenses of Bard are also vulnerable. We hope this work can deepen our understanding on the robustness of MLLMs and facilitate future research on defenses. Our code is available at this https URL.
+
+
+
+ 51. 标题:Choice-75: A Dataset on Decision Branching in Script Learning
+ 编号:[251]
+ 链接:https://arxiv.org/abs/2309.11737
+ 作者:Zhaoyi Joey Hou, Li Zhang, Chris Callison-Burch
+ 备注:
+ 关键词:daily events unfold, Script learning studies, learning studies, studies how daily, events unfold
+
+ 点击查看摘要
+ Script learning studies how daily events unfold. Previous works tend to consider a script as a linear sequence of events while ignoring the potential branches that arise due to people's circumstantial choices. We hence propose Choice-75, the first benchmark that challenges intelligent systems to predict decisions given descriptive scenarios, containing 75 scripts and more than 600 scenarios. While large language models demonstrate overall decent performances, there is still notable room for improvement in many hard scenarios.
+
+
+
+ 52. 标题:FluentEditor: Text-based Speech Editing by Considering Acoustic and Prosody Consistency
+ 编号:[255]
+ 链接:https://arxiv.org/abs/2309.11725
+ 作者:Rui Liu, Jiatian Xi, Ziyue Jiang, Haizhou Li
+ 备注:Submitted to ICASSP'2024
+ 关键词:input text transcript, Text-based speech editing, network-based TSE techniques, fluency speech editing, speech editing
+
+ 点击查看摘要
+ Text-based speech editing (TSE) techniques are designed to enable users to edit the output audio by modifying the input text transcript instead of the audio itself. Despite much progress in neural network-based TSE techniques, the current techniques have focused on reducing the difference between the generated speech segment and the reference target in the editing region, ignoring its local and global fluency in the context and original utterance. To maintain the speech fluency, we propose a fluency speech editing model, termed \textit{FluentEditor}, by considering fluency-aware training criterion in the TSE training. Specifically, the \textit{acoustic consistency constraint} aims to smooth the transition between the edited region and its neighboring acoustic segments consistent with the ground truth, while the \textit{prosody consistency constraint} seeks to ensure that the prosody attributes within the edited regions remain consistent with the overall style of the original utterance. The subjective and objective experimental results on VCTK demonstrate that our \textit{FluentEditor} outperforms all advanced baselines in terms of naturalness and fluency. The audio samples and code are available at \url{this https URL}.
+
+
+
+ 53. 标题:Emotion-Aware Prosodic Phrasing for Expressive Text-to-Speech
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2309.11724
+ 作者:Rui Liu, Bin Liu, Haizhou Li
+ 备注:Submitted to ICASSP'2024
+ 关键词:Prosodic phrasing, naturalness and intelligibility, TTS, Prosodic, phrasing
+
+ 点击查看摘要
+ Prosodic phrasing is crucial to the naturalness and intelligibility of end-to-end Text-to-Speech (TTS). There exist both linguistic and emotional prosody in natural speech. As the study of prosodic phrasing has been linguistically motivated, prosodic phrasing for expressive emotion rendering has not been well studied. In this paper, we propose an emotion-aware prosodic phrasing model, termed \textit{EmoPP}, to mine the emotional cues of utterance accurately and predict appropriate phrase breaks. We first conduct objective observations on the ESD dataset to validate the strong correlation between emotion and prosodic phrasing. Then the objective and subjective evaluations show that the EmoPP outperforms all baselines and achieves remarkable performance in terms of emotion expressiveness. The audio samples and the code are available at \url{this https URL}.
+
+
+
+ 54. 标题:RAI4IoE: Responsible AI for Enabling the Internet of Energy
+ 编号:[271]
+ 链接:https://arxiv.org/abs/2309.11691
+ 作者:Minhui Xue, Surya Nepal, Ling Liu, Subbu Sethuvenkatraman, Xingliang Yuan, Carsten Rudolph, Ruoxi Sun, Greg Eisenhauer
+ 备注:Accepted to IEEE International Conference on Trust, Privacy and Security in Intelligent Systems, and Applications (TPS) 2023
+ 关键词:paper plans, plans to develop, framework with enabling, enabling techniques, techniques and algorithms
+
+ 点击查看摘要
+ This paper plans to develop an Equitable and Responsible AI framework with enabling techniques and algorithms for the Internet of Energy (IoE), in short, RAI4IoE. The energy sector is going through substantial changes fueled by two key drivers: building a zero-carbon energy sector and the digital transformation of the energy infrastructure. We expect to see the convergence of these two drivers resulting in the IoE, where renewable distributed energy resources (DERs), such as electric cars, storage batteries, wind turbines and photovoltaics (PV), can be connected and integrated for reliable energy distribution by leveraging advanced 5G-6G networks and AI technology. This allows DER owners as prosumers to participate in the energy market and derive economic incentives. DERs are inherently asset-driven and face equitable challenges (i.e., fair, diverse and inclusive). Without equitable access, privileged individuals, groups and organizations can participate and benefit at the cost of disadvantaged groups. The real-time management of DER resources not only brings out the equity problem to the IoE, it also collects highly sensitive location, time, activity dependent data, which requires to be handled responsibly (e.g., privacy, security and safety), for AI-enhanced predictions, optimization and prioritization services, and automated management of flexible resources. The vision of our project is to ensure equitable participation of the community members and responsible use of their data in IoE so that it could reap the benefits of advances in AI to provide safe, reliable and sustainable energy services.
+
+
+
+ 55. 标题:LLM Guided Inductive Inference for Solving Compositional Problems
+ 编号:[273]
+ 链接:https://arxiv.org/abs/2309.11688
+ 作者:Abhigya Sodani, Lauren Moos, Matthew Mirman
+ 备注:5 pages, ICML TEACH Workshop
+ 关键词:demonstrated impressive performance, model training data, large language models, questions require knowledge, real world
+
+ 点击查看摘要
+ While large language models (LLMs) have demonstrated impressive performance in question-answering tasks, their performance is limited when the questions require knowledge that is not included in the model's training data and can only be acquired through direct observation or interaction with the real world. Existing methods decompose reasoning tasks through the use of modules invoked sequentially, limiting their ability to answer deep reasoning tasks. We introduce a method, Recursion based extensible LLM (REBEL), which handles open-world, deep reasoning tasks by employing automated reasoning techniques like dynamic planning and forward-chaining strategies. REBEL allows LLMs to reason via recursive problem decomposition and utilization of external tools. The tools that REBEL uses are specified only by natural language description. We further demonstrate REBEL capabilities on a set of problems that require a deeply nested use of external tools in a compositional and conversational setting.
+
+
+
+ 56. 标题:Dr. FERMI: A Stochastic Distributionally Robust Fair Empirical Risk Minimization Framework
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2309.11682
+ 作者:Sina Baharlouei, Meisam Razaviyayn
+ 备注:22 pages, 3 figures
+ 关键词:training fair machine, machine learning models, developed methods rely, fair machine learning, recent years
+
+ 点击查看摘要
+ While training fair machine learning models has been studied extensively in recent years, most developed methods rely on the assumption that the training and test data have similar distributions. In the presence of distribution shifts, fair models may behave unfairly on test data. There have been some developments for fair learning robust to distribution shifts to address this shortcoming. However, most proposed solutions are based on the assumption of having access to the causal graph describing the interaction of different features. Moreover, existing algorithms require full access to data and cannot be used when small batches are used (stochastic/batch implementation). This paper proposes the first stochastic distributionally robust fairness framework with convergence guarantees that do not require knowledge of the causal graph. More specifically, we formulate the fair inference in the presence of the distribution shift as a distributionally robust optimization problem under $L_p$ norm uncertainty sets with respect to the Exponential Renyi Mutual Information (ERMI) as the measure of fairness violation. We then discuss how the proposed method can be implemented in a stochastic fashion. We have evaluated the presented framework's performance and efficiency through extensive experiments on real datasets consisting of distribution shifts.
+
+
+
+ 57. 标题:Federated Learning with Neural Graphical Models
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2309.11680
+ 作者:Urszula Chajewska, Harsh Shrivastava
+ 备注:
+ 关键词:retain exclusive control, Probabilistic Graphical models, create models based, improved model accuracy, model accuracy due
+
+ 点击查看摘要
+ Federated Learning (FL) addresses the need to create models based on proprietary data in such a way that multiple clients retain exclusive control over their data, while all benefit from improved model accuracy due to pooled resources. Recently proposed Neural Graphical Models (NGMs) are Probabilistic Graphical models that utilize the expressive power of neural networks to learn complex non-linear dependencies between the input features. They learn to capture the underlying data distribution and have efficient algorithms for inference and sampling. We develop a FL framework which maintains a global NGM model that learns the averaged information from the local NGM models while keeping the training data within the client's environment. Our design, FedNGMs, avoids the pitfalls and shortcomings of neuron matching frameworks like Federated Matched Averaging that suffers from model parameter explosion. Our global model size remains constant throughout the process. In the cases where clients have local variables that are not part of the combined global distribution, we propose a `Stitching' algorithm, which personalizes the global NGM models by merging the additional variables using the client's data. FedNGM is robust to data heterogeneity, large number of participants, and limited communication bandwidth.
+
+
+
+ 58. 标题:Generative AI in Mafia-like Game Simulation
+ 编号:[281]
+ 链接:https://arxiv.org/abs/2309.11672
+ 作者:Munyeong Kim, Sungsu Kim
+ 备注:26 pages, 3 figures; data, scripts, and codes: this https URL like-Game
+ 关键词:role-playing simulations exemplified, exemplified through Spyfall, renowned mafia-style game, specifically focusing, explore the efficacy
+
+ 点击查看摘要
+ In this research, we explore the efficacy and potential of Generative AI models, specifically focusing on their application in role-playing simulations exemplified through Spyfall, a renowned mafia-style game. By leveraging GPT-4's advanced capabilities, the study aimed to showcase the model's potential in understanding, decision-making, and interaction during game scenarios. Comparative analyses between GPT-4 and its predecessor, GPT-3.5-turbo, demonstrated GPT-4's enhanced adaptability to the game environment, with significant improvements in posing relevant questions and forming human-like responses. However, challenges such as the model;s limitations in bluffing and predicting opponent moves emerged. Reflections on game development, financial constraints, and non-verbal limitations of the study were also discussed. The findings suggest that while GPT-4 exhibits promising advancements over earlier models, there remains potential for further development, especially in instilling more human-like attributes in AI.
+
+
+
+ 59. 标题:"It's a Fair Game'', or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents
+ 编号:[292]
+ 链接:https://arxiv.org/abs/2309.11653
+ 作者:Zhiping Zhang, Michelle Jia, Hao-Ping (Hank)Lee, Bingsheng Yao, Sauvik Das, Ada Lerner, Dakuo Wang, Tianshi Li
+ 备注:37 pages, 5 figures
+ 关键词:Large Language Model, Large Language, based conversational agents, Language Model, based conversational
+
+ 点击查看摘要
+ The widespread use of Large Language Model (LLM)-based conversational agents (CAs), especially in high-stakes domains, raises many privacy concerns. Building ethical LLM-based CAs that respect user privacy requires an in-depth understanding of the privacy risks that concern users the most. However, existing research, primarily model-centered, does not provide insight into users' perspectives. To bridge this gap, we analyzed sensitive disclosures in real-world ChatGPT conversations and conducted semi-structured interviews with 19 LLM-based CA users. We found that users are constantly faced with trade-offs between privacy, utility, and convenience when using LLM-based CAs. However, users' erroneous mental models and the dark patterns in system design limited their awareness and comprehension of the privacy risks. Additionally, the human-like interactions encouraged more sensitive disclosures, which complicated users' ability to navigate the trade-offs. We discuss practical design guidelines and the needs for paradigmatic shifts to protect the privacy of LLM-based CA users.
+
+
+
+ 60. 标题:Orbital AI-based Autonomous Refuelling Solution
+ 编号:[294]
+ 链接:https://arxiv.org/abs/2309.11648
+ 作者:Duarte Rondao, Lei He, Nabil Aouf
+ 备注:13 pages
+ 关键词:small form factor, space rendezvous due, inexpensive power, rendezvous due, small form
+
+ 点击查看摘要
+ Cameras are rapidly becoming the choice for on-board sensors towards space rendezvous due to their small form factor and inexpensive power, mass, and volume costs. When it comes to docking, however, they typically serve a secondary role, whereas the main work is done by active sensors such as lidar. This paper documents the development of a proposed AI-based (artificial intelligence) navigation algorithm intending to mature the use of on-board visible wavelength cameras as a main sensor for docking and on-orbit servicing (OOS), reducing the dependency on lidar and greatly reducing costs. Specifically, the use of AI enables the expansion of the relative navigation solution towards multiple classes of scenarios, e.g., in terms of targets or illumination conditions, which would otherwise have to be crafted on a case-by-case manner using classical image processing methods. Multiple convolutional neural network (CNN) backbone architectures are benchmarked on synthetically generated data of docking manoeuvres with the International Space Station (ISS), achieving position and attitude estimates close to 1% range-normalised and 1 deg, respectively. The integration of the solution with a physical prototype of the refuelling mechanism is validated in laboratory using a robotic arm to simulate a berthing procedure.
+
+
+
+ 61. 标题:Attentive VQ-VAE
+ 编号:[297]
+ 链接:https://arxiv.org/abs/2309.11641
+ 作者:Mariano Rivera, Angello Hoyos
+ 备注:5 pages, 4 figures, 2 table2, 1 pseudo-code
+ 关键词:Attentive Residual Encoder, Attentive Residual, Residual Pixel Attention, Residual Encoder, Residual Pixel
+
+ 点击查看摘要
+ We present a novel approach to enhance the capabilities of VQVAE models through the integration of an Attentive Residual Encoder (AREN) and a Residual Pixel Attention layer. The objective of our research is to improve the performance of VQVAE while maintaining practical parameter levels. The AREN encoder is designed to operate effectively at multiple levels, accommodating diverse architectural complexities. The key innovation is the integration of an inter-pixel auto-attention mechanism into the AREN encoder. This approach allows us to efficiently capture and utilize contextual information across latent vectors. Additionally, our models uses additional encoding levels to further enhance the model's representational power. Our attention layer employs a minimal parameter approach, ensuring that latent vectors are modified only when pertinent information from other pixels is available. Experimental results demonstrate that our proposed modifications lead to significant improvements in data representation and generation, making VQVAEs even more suitable for a wide range of applications.
+
+
+
+ 62. 标题:A survey on the semantics of sequential patterns with negation
+ 编号:[300]
+ 链接:https://arxiv.org/abs/2309.11638
+ 作者:Thomas Guyet
+ 备注:
+ 关键词:negative sequential pattern, sequential pattern, pattern, sequential, negative sequential
+
+ 点击查看摘要
+ A sequential pattern with negation, or negative sequential pattern, takes the form of a sequential pattern for which the negation symbol may be used in front of some of the pattern's itemsets. Intuitively, such a pattern occurs in a sequence if negated itemsets are absent in the sequence. Recent work has shown that different semantics can be attributed to these pattern forms, and that state-of-the-art algorithms do not extract the same sets of patterns. This raises the important question of the interpretability of sequential pattern with negation. In this study, our focus is on exploring how potential users perceive negation in sequential patterns. Our aim is to determine whether specific semantics are more "intuitive" than others and whether these align with the semantics employed by one or more state-of-the-art algorithms. To achieve this, we designed a questionnaire to reveal the semantics' intuition of each user. This article presents both the design of the questionnaire and an in-depth analysis of the 124 responses obtained. The outcomes indicate that two of the semantics are predominantly intuitive; however, neither of them aligns with the semantics of the primary state-of-the-art algorithms. As a result, we provide recommendations to account for this disparity in the conclusions drawn.
+
+
+
+ 63. 标题:Cloud-Based Hierarchical Imitation Learning for Scalable Transfer of Construction Skills from Human Workers to Assisting Robots
+ 编号:[309]
+ 链接:https://arxiv.org/abs/2309.11619
+ 作者:Hongrui Yu, Vineet R. Kamat, Carol C. Menassa
+ 备注:
+ 关键词:occupational injuries, physically-demanding construction tasks, exposure to occupational, construction, alleviate human workers
+
+ 点击查看摘要
+ Assigning repetitive and physically-demanding construction tasks to robots can alleviate human workers's exposure to occupational injuries. Transferring necessary dexterous and adaptive artisanal construction craft skills from workers to robots is crucial for the successful delegation of construction tasks and achieving high-quality robot-constructed work. Predefined motion planning scripts tend to generate rigid and collision-prone robotic behaviors in unstructured construction site environments. In contrast, Imitation Learning (IL) offers a more robust and flexible skill transfer scheme. However, the majority of IL algorithms rely on human workers to repeatedly demonstrate task performance at full scale, which can be counterproductive and infeasible in the case of construction work. To address this concern, this paper proposes an immersive, cloud robotics-based virtual demonstration framework that serves two primary purposes. First, it digitalizes the demonstration process, eliminating the need for repetitive physical manipulation of heavy construction objects. Second, it employs a federated collection of reusable demonstrations that are transferable for similar tasks in the future and can thus reduce the requirement for repetitive illustration of tasks by human agents. Additionally, to enhance the trustworthiness, explainability, and ethical soundness of the robot training, this framework utilizes a Hierarchical Imitation Learning (HIL) model to decompose human manipulation skills into sequential and reactive sub-skills. These two layers of skills are represented by deep generative models, enabling adaptive control of robot actions. By delegating the physical strains of construction work to human-trained robots, this framework promotes the inclusion of workers with diverse physical capabilities and educational backgrounds within the construction industry.
+
+
+
+ 64. 标题:Hand Gesture Recognition with Two Stage Approach Using Transfer Learning and Deep Ensemble Learning
+ 编号:[312]
+ 链接:https://arxiv.org/abs/2309.11610
+ 作者:Serkan Savaş, Atilla Ergüzen
+ 备注:ICISNA'23 - 1st International Conference on Intelligent Systems and New Applications Proceedings Book, Liverpool, UNITED KINGDOM, April 28-30, 2023. E-ISBN: 978-605-72180-3-2
+ 关键词:Human-Computer Interaction, focused on improving, recent studies, studies have focused, accuracy rates
+
+ 点击查看摘要
+ Human-Computer Interaction (HCI) has been the subject of research for many years, and recent studies have focused on improving its performance through various techniques. In the past decade, deep learning studies have shown high performance in various research areas, leading researchers to explore their application to HCI. Convolutional neural networks can be used to recognize hand gestures from images using deep architectures. In this study, we evaluated pre-trained high-performance deep architectures on the HG14 dataset, which consists of 14 different hand gesture classes. Among 22 different models, versions of the VGGNet and MobileNet models attained the highest accuracy rates. Specifically, the VGG16 and VGG19 models achieved accuracy rates of 94.64% and 94.36%, respectively, while the MobileNet and MobileNetV2 models achieved accuracy rates of 96.79% and 94.43%, respectively. We performed hand gesture recognition on the dataset using an ensemble learning technique, which combined the four most successful models. By utilizing these models as base learners and applying the Dirichlet ensemble technique, we achieved an accuracy rate of 98.88%. These results demonstrate the effectiveness of the deep ensemble learning technique for HCI and its potential applications in areas such as augmented reality, virtual reality, and game technologies.
+
+
+
+ 65. 标题:Dataset Factory: A Toolchain For Generative Computer Vision Datasets
+ 编号:[313]
+ 链接:https://arxiv.org/abs/2309.11608
+ 作者:Daniel Kharitonov, Ryan Turner
+ 备注:Presented at the datacomp.ai workshop at ICCV 2023
+ 关键词:workflows heavily rely, vector distances, Generative AI workflows, annotation fields, custom classifiers
+
+ 点击查看摘要
+ Generative AI workflows heavily rely on data-centric tasks - such as filtering samples by annotation fields, vector distances, or scores produced by custom classifiers. At the same time, computer vision datasets are quickly approaching petabyte volumes, rendering data wrangling difficult. In addition, the iterative nature of data preparation necessitates robust dataset sharing and versioning mechanisms, both of which are hard to implement ad-hoc. To solve these challenges, we propose a "dataset factory" approach that separates the storage and processing of samples from metadata and enables data-centric operations at scale for machine learning teams and individual researchers.
+
+
+
+ 66. 标题:CATS: Conditional Adversarial Trajectory Synthesis for Privacy-Preserving Trajectory Data Publication Using Deep Learning Approaches
+ 编号:[322]
+ 链接:https://arxiv.org/abs/2309.11587
+ 作者:Jinmeng Rao, Song Gao, Sijia Zhu
+ 备注:9 figures, 4 figures
+ 关键词:mobile Internet enables, ubiquitous location-aware devices, mobile Internet, Internet enables, collect massive individual-level
+
+ 点击查看摘要
+ The prevalence of ubiquitous location-aware devices and mobile Internet enables us to collect massive individual-level trajectory dataset from users. Such trajectory big data bring new opportunities to human mobility research but also raise public concerns with regard to location privacy. In this work, we present the Conditional Adversarial Trajectory Synthesis (CATS), a deep-learning-based GeoAI methodological framework for privacy-preserving trajectory data generation and publication. CATS applies K-anonymity to the underlying spatiotemporal distributions of human movements, which provides a distributional-level strong privacy guarantee. By leveraging conditional adversarial training on K-anonymized human mobility matrices, trajectory global context learning using the attention-based mechanism, and recurrent bipartite graph matching of adjacent trajectory points, CATS is able to reconstruct trajectory topology from conditionally sampled locations and generate high-quality individual-level synthetic trajectory data, which can serve as supplements or alternatives to raw data for privacy-preserving trajectory data publication. The experiment results on over 90k GPS trajectories show that our method has a better performance in privacy preservation, spatiotemporal characteristic preservation, and downstream utility compared with baseline methods, which brings new insights into privacy-preserving human mobility research using generative AI techniques and explores data ethics issues in GIScience.
+
+
+
+ 67. 标题:Distilling Adversarial Prompts from Safety Benchmarks: Report for the Adversarial Nibbler Challenge
+ 编号:[327]
+ 链接:https://arxiv.org/abs/2309.11575
+ 作者:Manuel Brack, Patrick Schramowski, Kristian Kersting
+ 备注:
+ 关键词:recently achieved astonishing, Text-conditioned image generation, alignment results, achieved astonishing image, astonishing image quality
+
+ 点击查看摘要
+ Text-conditioned image generation models have recently achieved astonishing image quality and alignment results. Consequently, they are employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the web, they also produce unsafe content. As a contribution to the Adversarial Nibbler challenge, we distill a large set of over 1,000 potential adversarial inputs from existing safety benchmarks. Our analysis of the gathered prompts and corresponding images demonstrates the fragility of input filters and provides further insights into systematic safety issues in current generative image models.
+
+
+
+ 68. 标题:BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2309.11568
+ 作者:Nolan Dey, Daria Soboleva, Faisal Al-Khateeb, Bowen Yang, Ribhu Pathria, Hemant Khachane, Shaheer Muhammad, Zhiming (Charles) Chen, Robert Myers, Jacob Robert Steeves, Natalia Vassilieva, Marvin Tom, Joel Hestness
+ 备注:
+ 关键词:Bittensor Language Model, introduce the Bittensor, billion parameter open-source, Bittensor Language, open-source language model
+
+ 点击查看摘要
+ We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity.
+On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: this https URL.
+
+
+
+ 69. 标题:Limitations in odour recognition and generalisation in a neuromorphic olfactory circuit
+ 编号:[333]
+ 链接:https://arxiv.org/abs/2309.11555
+ 作者:Nik Dennler, André van Schaik, Michael Schmuker
+ 备注:8 pages, 4 figures
+ 关键词:significantly reduce power, reduce power consumption, Artificial Intelligence, consumption in Machine, Machine Learning
+
+ 点击查看摘要
+ Neuromorphic computing is one of the few current approaches that have the potential to significantly reduce power consumption in Machine Learning and Artificial Intelligence. Imam & Cleland presented an odour-learning algorithm that runs on a neuromorphic architecture and is inspired by circuits described in the mammalian olfactory bulb. They assess the algorithm's performance in "rapid online learning and identification" of gaseous odorants and odorless gases (short "gases") using a set of gas sensor recordings of different odour presentations and corrupting them by impulse noise. We replicated parts of the study and discovered limitations that affect some of the conclusions drawn. First, the dataset used suffers from sensor drift and a non-randomised measurement protocol, rendering it of limited use for odour identification benchmarks. Second, we found that the model is restricted in its ability to generalise over repeated presentations of the same gas. We demonstrate that the task the study refers to can be solved with a simple hash table approach, matching or exceeding the reported results in accuracy and runtime. Therefore, a validation of the model that goes beyond restoring a learned data sample remains to be shown, in particular its suitability to odour identification tasks.
+
+
+
+ 70. 标题:Learning Complete Topology-Aware Correlations Between Relations for Inductive Link Prediction
+ 编号:[336]
+ 链接:https://arxiv.org/abs/2309.11528
+ 作者:Jie Wang, Hanzhu Chen, Qitan Lv, Zhihao Shi, Jiajun Chen, Huarui He, Hongtao Xie, Yongdong Zhang, Feng Wu
+ 备注:arXiv admin note: text overlap with arXiv:2103.03642
+ 关键词:completing evolving knowledge, evolving knowledge graphs, Inductive link prediction, semantic correlations, entities during training
+
+ 点击查看摘要
+ Inductive link prediction -- where entities during training and inference stages can be different -- has shown great potential for completing evolving knowledge graphs in an entity-independent manner. Many popular methods mainly focus on modeling graph-level features, while the edge-level interactions -- especially the semantic correlations between relations -- have been less explored. However, we notice a desirable property of semantic correlations between relations is that they are inherently edge-level and entity-independent. This implies the great potential of the semantic correlations for the entity-independent inductive link prediction task. Inspired by this observation, we propose a novel subgraph-based method, namely TACO, to model Topology-Aware COrrelations between relations that are highly correlated to their topological structures within subgraphs. Specifically, we prove that semantic correlations between any two relations can be categorized into seven topological patterns, and then proposes Relational Correlation Network (RCN) to learn the importance of each pattern. To further exploit the potential of RCN, we propose Complete Common Neighbor induced subgraph that can effectively preserve complete topological patterns within the subgraph. Extensive experiments demonstrate that TACO effectively unifies the graph-level information and edge-level interactions to jointly perform reasoning, leading to a superior performance over existing state-of-the-art methods for the inductive link prediction task.
+
+
+
+ 71. 标题:TrueLearn: A Python Library for Personalised Informational Recommendations with (Implicit) Feedback
+ 编号:[337]
+ 链接:https://arxiv.org/abs/2309.11527
+ 作者:Yuxiang Qiu, Karim Djemili, Denis Elezi, Aaneel Shalman, María Pérez-Ortiz, Sahan Bulathwela
+ 备注:To be presented at the ORSUM workshop at RecSys 2023
+ 关键词:online learning Bayesian, TrueLearn Python library, learning Bayesian models, TrueLearn Python, Bayesian models
+
+ 点击查看摘要
+ This work describes the TrueLearn Python library, which contains a family of online learning Bayesian models for building educational (or more generally, informational) recommendation systems. This family of models was designed following the "open learner" concept, using humanly-intuitive user representations. For the sake of interpretability and putting the user in control, the TrueLearn library also contains different representations to help end-users visualise the learner models, which may in the future facilitate user interaction with their own models. Together with the library, we include a previously publicly released implicit feedback educational dataset with evaluation metrics to measure the performance of the models. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytic practitioners. The library and the support documentation with examples are available at this https URL.
+
+
+
+ 72. 标题:Likelihood-based Sensor Calibration for Expert-Supported Distributed Learning Algorithms in IoT Systems
+ 编号:[338]
+ 链接:https://arxiv.org/abs/2309.11526
+ 作者:Rüdiger Machhamer, Lejla Begic Fazlic, Eray Guven, David Junk, Gunes Karabulut Kurt, Stefan Naumann, Stephan Didas, Klaus-Uwe Gollmer, Ralph Bergmann, Ingo J. Timm, Guido Dartmann
+ 备注:
+ 关键词:important task, procedures of measurements, efficient implementation, identical design, adaptation procedures
+
+ 点击查看摘要
+ An important task in the field of sensor technology is the efficient implementation of adaptation procedures of measurements from one sensor to another sensor of identical design. One idea is to use the estimation of an affine transformation between different systems, which can be improved by the knowledge of experts. This paper presents an improved solution from Glacier Research that was published back in 1973. It is shown that this solution can be adapted for software calibration of sensors, implementation of expert-based adaptation, and federated learning methods. We evaluate our research with simulations and also with real measured data of a multi-sensor board with 8 identical sensors. The results show an improvement for both the simulation and the experiments with real data.
+
+
+
+ 73. 标题:When is a Foundation Model a Foundation Model
+ 编号:[345]
+ 链接:https://arxiv.org/abs/2309.11510
+ 作者:Saghir Alfasly, Peyman Nejat, Sobhan Hemati, Jibran Khan, Isaiah Lahr, Areej Alsaafin, Abubakr Shafique, Nneka Comfere, Dennis Murphree, Chady Meroueh, Saba Yasir, Aaron Mangold, Lisa Boardman, Vijay Shah, Joaquin J. Garcia, H.R. Tizhoosh
+ 备注:
+ 关键词:online data sources, Twitter and PubMed, field of medicine, utilizing images, studies have reported
+
+ 点击查看摘要
+ Recently, several studies have reported on the fine-tuning of foundation models for image-text modeling in the field of medicine, utilizing images from online data sources such as Twitter and PubMed. Foundation models are large, deep artificial neural networks capable of learning the context of a specific domain through training on exceptionally extensive datasets. Through validation, we have observed that the representations generated by such models exhibit inferior performance in retrieval tasks within digital pathology when compared to those generated by significantly smaller, conventional deep networks.
+
+
+
+ 74. 标题:Towards LLM-based Autograding for Short Textual Answers
+ 编号:[347]
+ 链接:https://arxiv.org/abs/2309.11508
+ 作者:Johannes Schneider, Bernd Schenk, Christina Niklaus, Michaelis Vlachos
+ 备注:
+ 关键词:frequently challenging task, labor intensive, repetitive and frequently, challenging task, frequently challenging
+
+ 点击查看摘要
+ Grading of exams is an important, labor intensive, subjective, repetitive and frequently challenging task. The feasibility of autograding textual responses has greatly increased thanks to the availability of large language models (LLMs) such as ChatGPT and because of the substantial influx of data brought about by digitalization. However, entrusting AI models with decision-making roles raises ethical considerations, mainly stemming from potential biases and issues related to generating false information. Thus, in this manuscript we provide an evaluation of a large language model for the purpose of autograding, while also highlighting how LLMs can support educators in validating their grading procedures. Our evaluation is targeted towards automatic short textual answers grading (ASAG), spanning various languages and examinations from two distinct courses. Our findings suggest that while "out-of-the-box" LLMs provide a valuable tool to provide a complementary perspective, their readiness for independent automated grading remains a work in progress, necessitating human oversight.
+
+
+
+ 75. 标题:Matching Table Metadata with Business Glossaries Using Large Language Models
+ 编号:[349]
+ 链接:https://arxiv.org/abs/2309.11506
+ 作者:Elita Lobo, Oktie Hassanzadeh, Nhan Pham, Nandana Mihindukulasooriya, Dharmashankar Subramanian, Horst Samulowitz
+ 备注:This paper is a work in progress with findings based on limited evidence. Please exercise discretion when interpreting the findings
+ 关键词:enterprise data lake, data, enterprise data, data lake, structured data
+
+ 点击查看摘要
+ Enterprises often own large collections of structured data in the form of large databases or an enterprise data lake. Such data collections come with limited metadata and strict access policies that could limit access to the data contents and, therefore, limit the application of classic retrieval and analysis solutions. As a result, there is a need for solutions that can effectively utilize the available metadata. In this paper, we study the problem of matching table metadata to a business glossary containing data labels and descriptions. The resulting matching enables the use of an available or curated business glossary for retrieval and analysis without or before requesting access to the data contents. One solution to this problem is to use manually-defined rules or similarity measures on column names and glossary descriptions (or their vector embeddings) to find the closest match. However, such approaches need to be tuned through manual labeling and cannot handle many business glossaries that contain a combination of simple as well as complex and long descriptions. In this work, we leverage the power of large language models (LLMs) to design generic matching methods that do not require manual tuning and can identify complex relations between column names and glossaries. We propose methods that utilize LLMs in two ways: a) by generating additional context for column names that can aid with matching b) by using LLMs to directly infer if there is a relation between column names and glossary descriptions. Our preliminary experimental results show the effectiveness of our proposed methods.
+
+
+
+ 76. 标题:Electroencephalogram Sensor Data Compression Using An Asymmetrical Sparse Autoencoder With A Discrete Cosine Transform Layer
+ 编号:[358]
+ 链接:https://arxiv.org/abs/2309.12201
+ 作者:Xin Zhu, Hongyi Pan, Shuaiang Rong, Ahmet Enis Cetin
+ 备注:
+ 关键词:wireless recording applications, DCT layer, compress EEG signals, DCT, wireless recording
+
+ 点击查看摘要
+ Electroencephalogram (EEG) data compression is necessary for wireless recording applications to reduce the amount of data that needs to be transmitted. In this paper, an asymmetrical sparse autoencoder with a discrete cosine transform (DCT) layer is proposed to compress EEG signals. The encoder module of the autoencoder has a combination of a fully connected linear layer and the DCT layer to reduce redundant data using hard-thresholding nonlinearity. Furthermore, the DCT layer includes trainable hard-thresholding parameters and scaling layers to give emphasis or de-emphasis on individual DCT coefficients. Finally, the one-by-one convolutional layer generates the latent space. The sparsity penalty-based cost function is employed to keep the feature map as sparse as possible in the latent space. The latent space data is transmitted to the receiver. The decoder module of the autoencoder is designed using the inverse DCT and two fully connected linear layers to improve the accuracy of data reconstruction. In comparison to other state-of-the-art methods, the proposed method significantly improves the average quality score in various data compression experiments.
+
+
+
+ 77. 标题:Multimodal Transformers for Wireless Communications: A Case Study in Beam Prediction
+ 编号:[389]
+ 链接:https://arxiv.org/abs/2309.11811
+ 作者:Yu Tian, Qiyang Zhao, Zine el abidine Kherroubi, Fouzi Boukhalfa, Kebin Wu, Faouzi Bader
+ 备注:
+ 关键词:antenna arrays face, arrays face challenges, large antenna arrays, multimodality sensing information, information from cameras
+
+ 点击查看摘要
+ Wireless communications at high-frequency bands with large antenna arrays face challenges in beam management, which can potentially be improved by multimodality sensing information from cameras, LiDAR, radar, and GPS. In this paper, we present a multimodal transformer deep learning framework for sensing-assisted beam prediction. We employ a convolutional neural network to extract the features from a sequence of images, point clouds, and radar raw data sampled over time. At each convolutional layer, we use transformer encoders to learn the hidden relations between feature tokens from different modalities and time instances over abstraction space and produce encoded vectors for the next-level feature extraction. We train the model on a combination of different modalities with supervised learning. We try to enhance the model over imbalanced data by utilizing focal loss and exponential moving average. We also evaluate data processing and augmentation techniques such as image enhancement, segmentation, background filtering, multimodal data flipping, radar signal transformation, and GPS angle calibration. Experimental results show that our solution trained on image and GPS data produces the best distance-based accuracy of predicted beams at 78.44%, with effective generalization to unseen day scenarios near 73% and night scenarios over 84%. This outperforms using other modalities and arbitrary data processing techniques, which demonstrates the effectiveness of transformers with feature fusion in performing radio beam prediction from images and GPS. Furthermore, our solution could be pretrained from large sequences of multimodality wireless data, on fine-tuning for multiple downstream radio network tasks.
+
+
+
+ 78. 标题:A Dynamic Domain Adaptation Deep Learning Network for EEG-based Motor Imagery Classification
+ 编号:[396]
+ 链接:https://arxiv.org/abs/2309.11714
+ 作者:Jie Jiao, Meiyan Xu, Qingqing Chen, Hefan Zhou, Wangliang Zhou
+ 备注:10 pages,4 figures,journal
+ 关键词:Deep Learning Network, Adaptation Based Deep, Based Deep Learning, channels of electroencephalogram, adjacent channels
+
+ 点击查看摘要
+ There is a correlation between adjacent channels of electroencephalogram (EEG), and how to represent this correlation is an issue that is currently being explored. In addition, due to inter-individual differences in EEG signals, this discrepancy results in new subjects need spend a amount of calibration time for EEG-based motor imagery brain-computer interface. In order to solve the above problems, we propose a Dynamic Domain Adaptation Based Deep Learning Network (DADL-Net). First, the EEG data is mapped to the three-dimensional geometric space and its temporal-spatial features are learned through the 3D convolution module, and then the spatial-channel attention mechanism is used to strengthen the features, and the final convolution module can further learn the spatial-temporal information of the features. Finally, to account for inter-subject and cross-sessions differences, we employ a dynamic domain-adaptive strategy, the distance between features is reduced by introducing a Maximum Mean Discrepancy loss function, and the classification layer is fine-tuned by using part of the target domain data. We verify the performance of the proposed method on BCI competition IV 2a and OpenBMI datasets. Under the intra-subject experiment, the accuracy rates of 70.42% and 73.91% were achieved on the OpenBMI and BCIC IV 2a datasets.
+
+
+





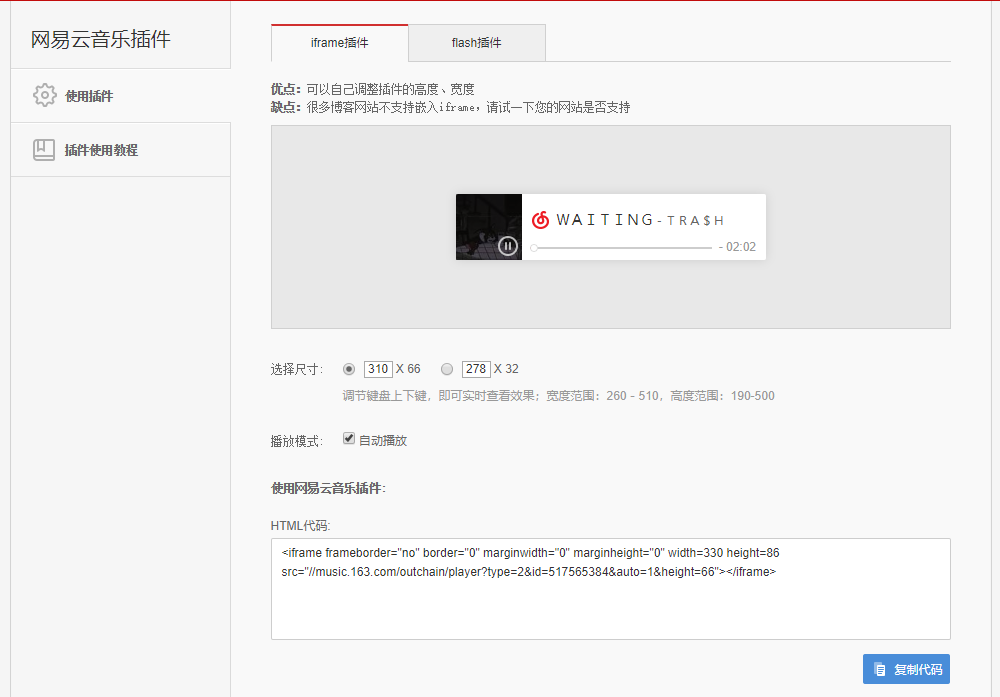
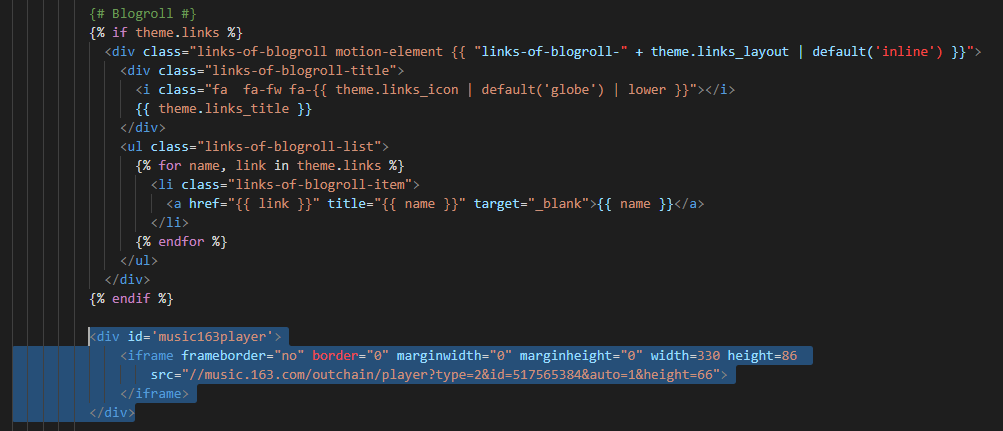
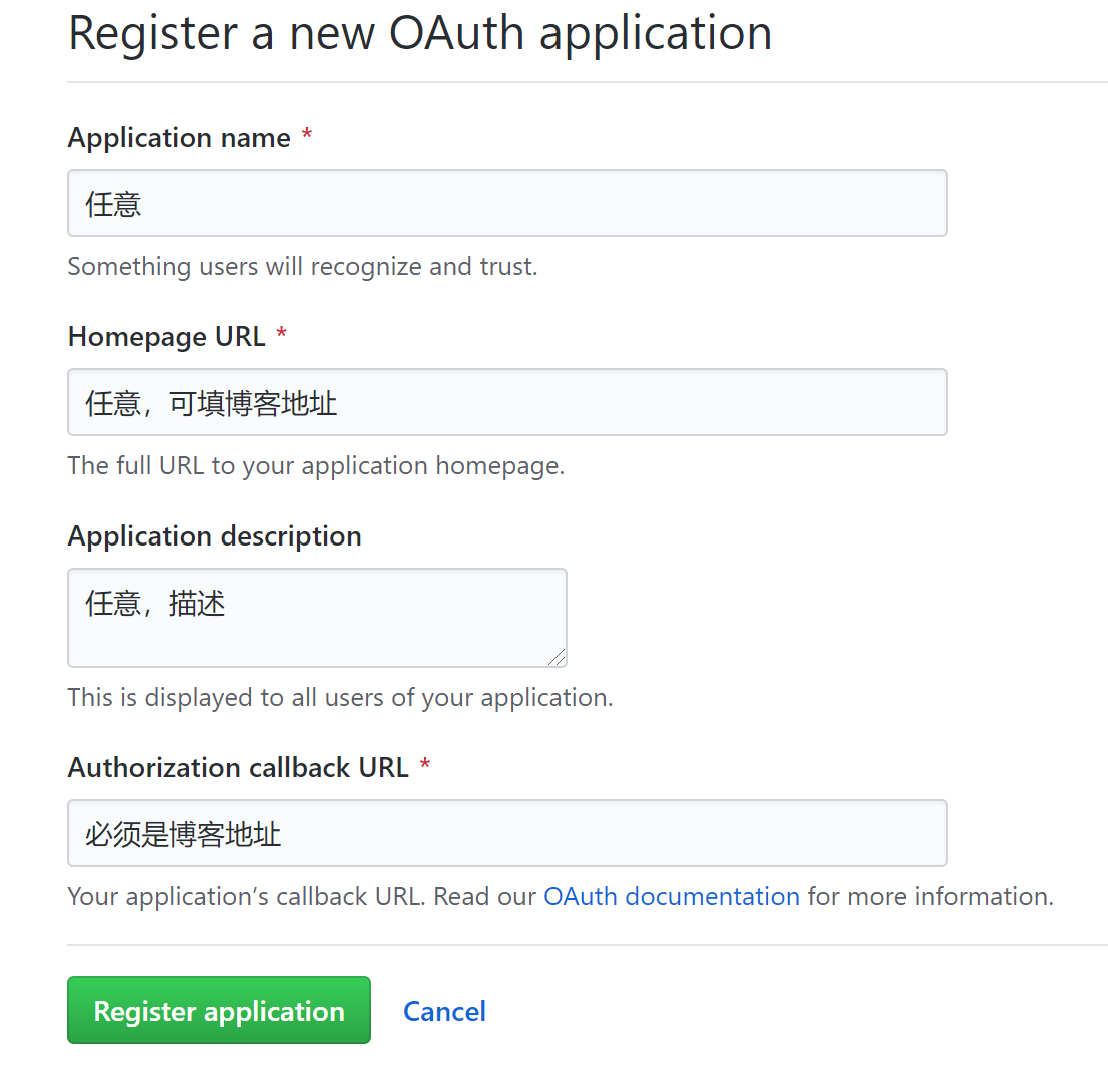
/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

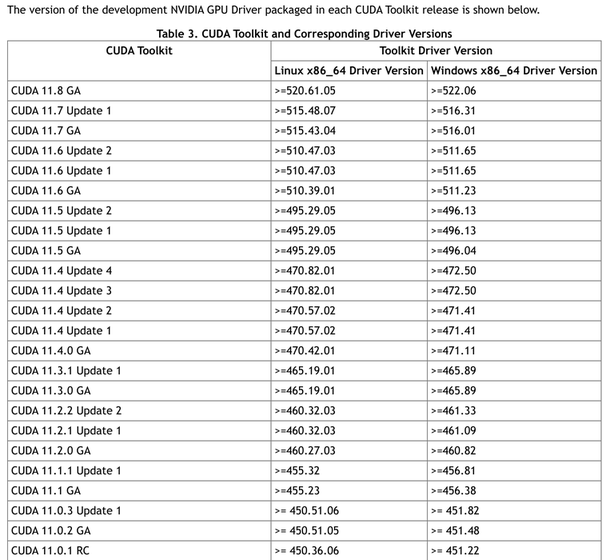

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







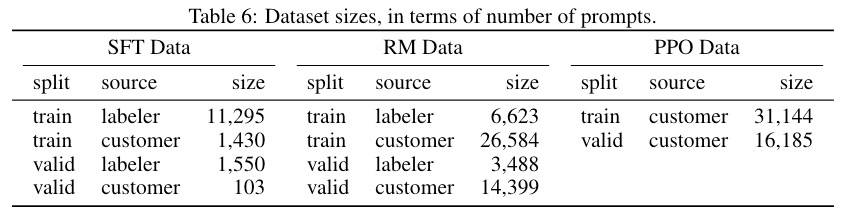
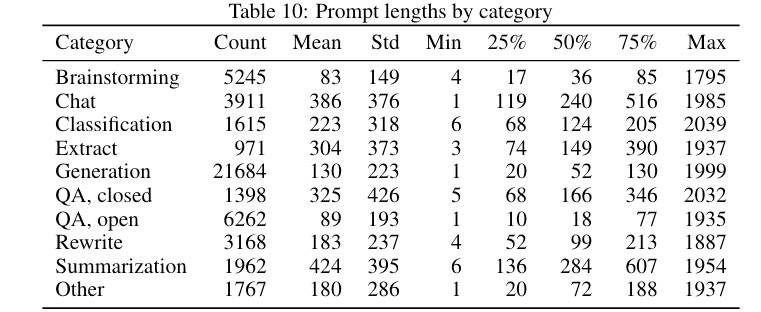
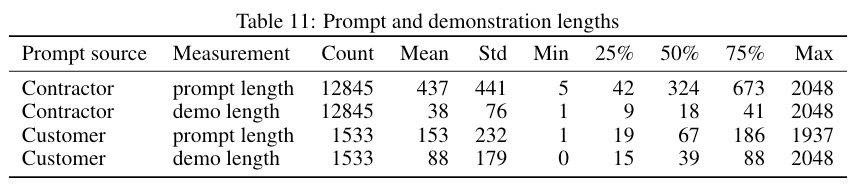

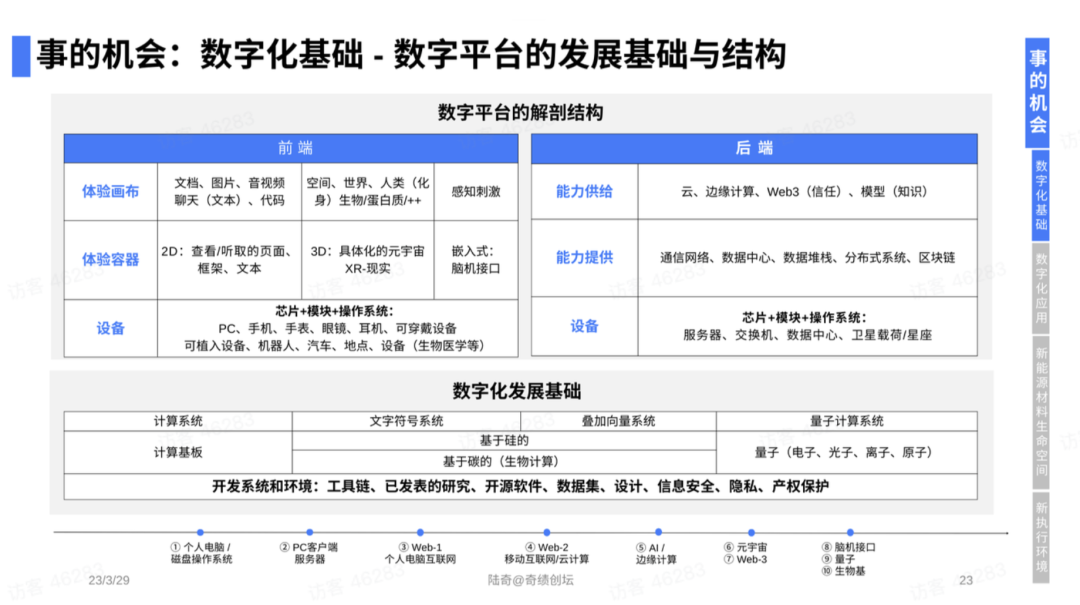

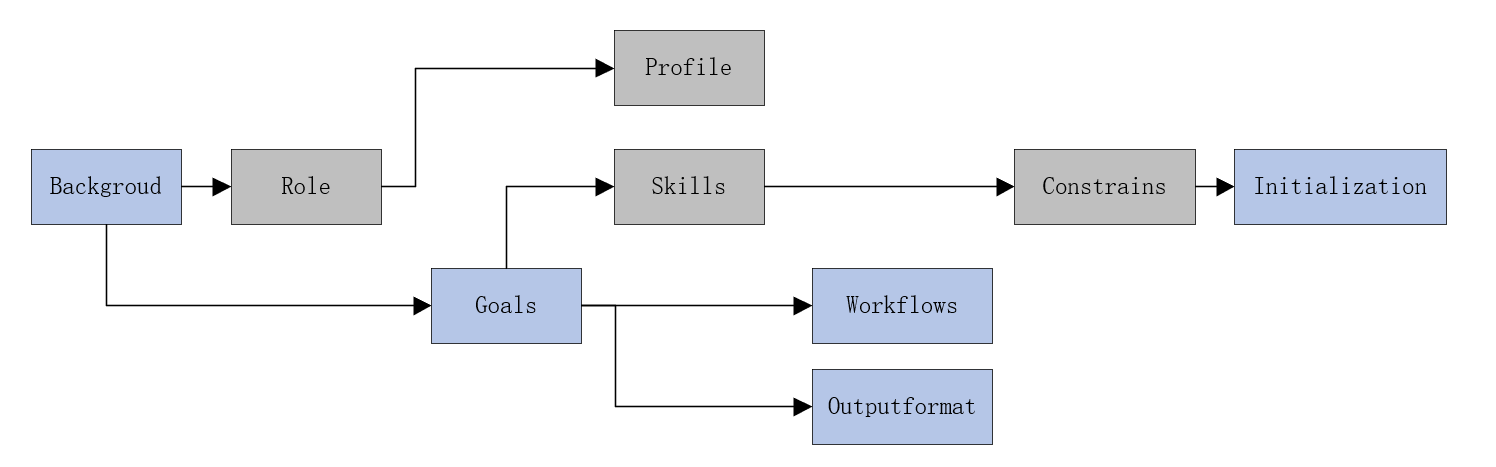

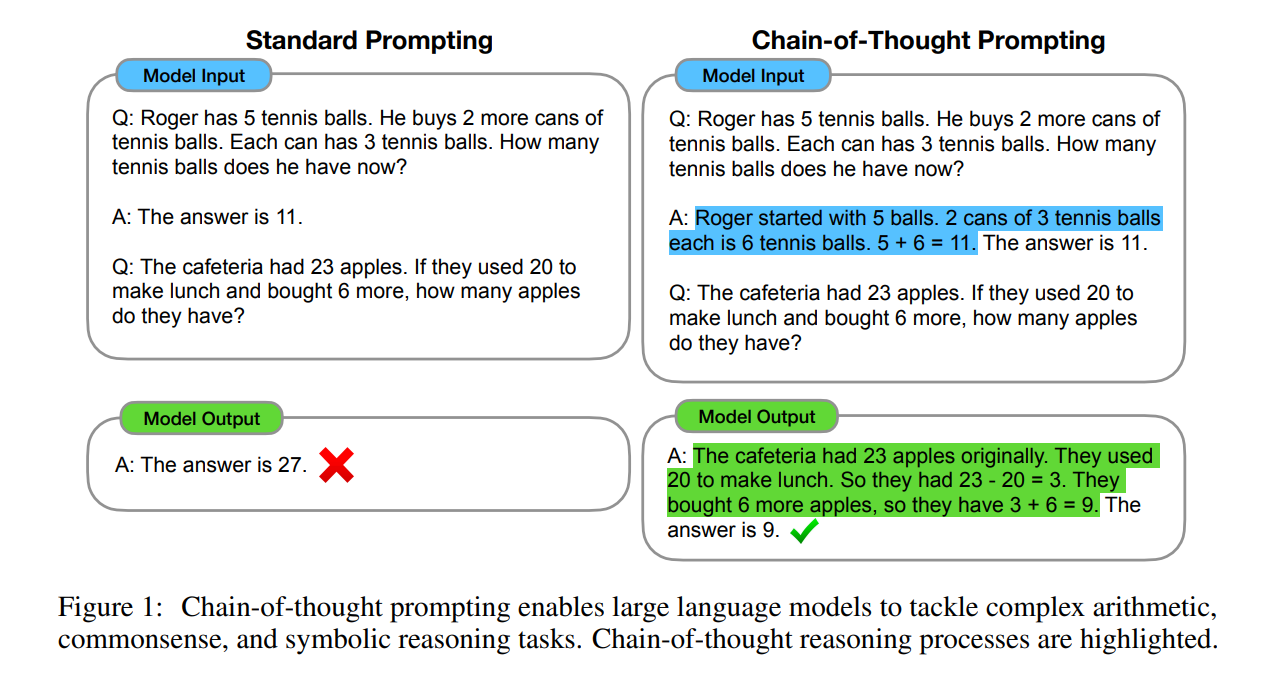

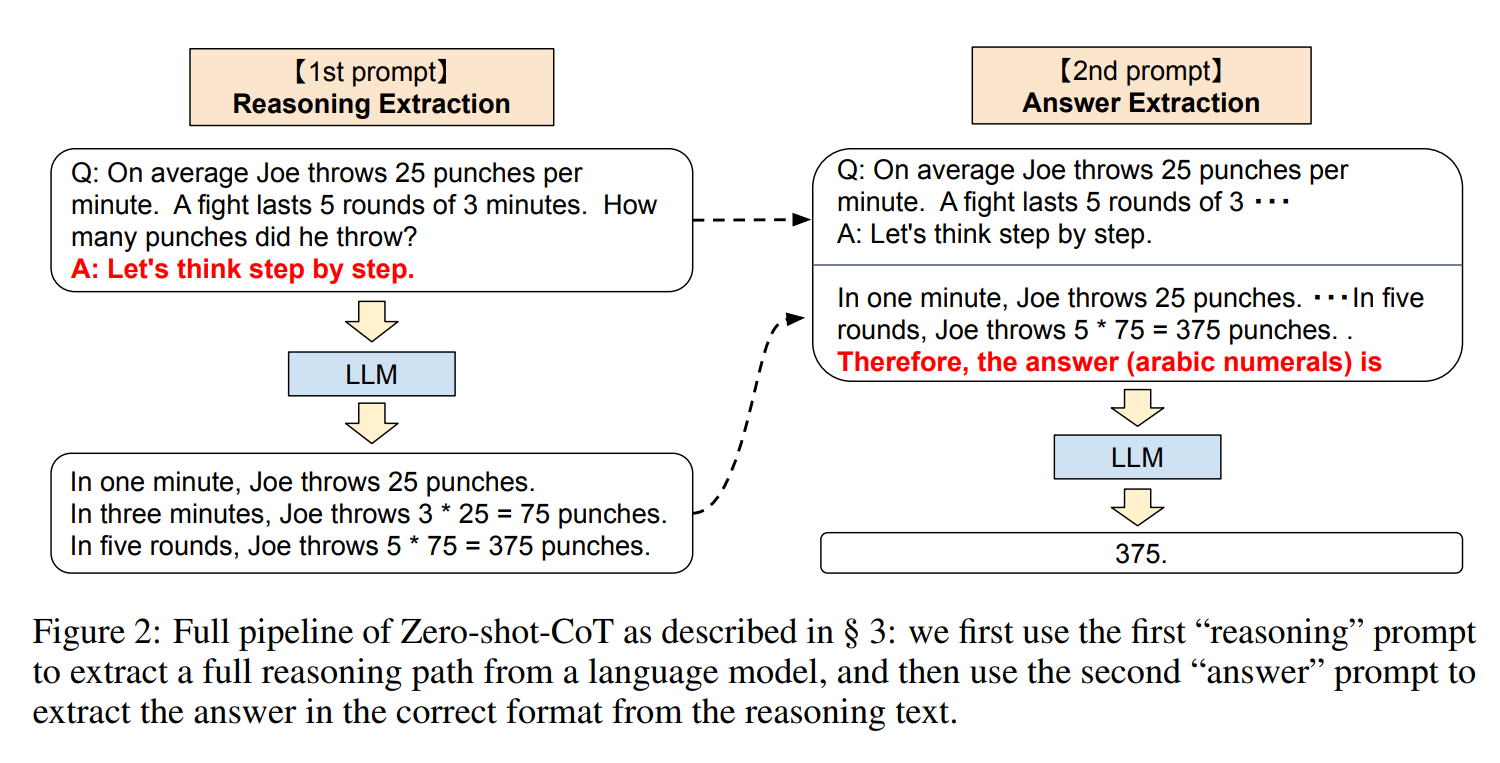
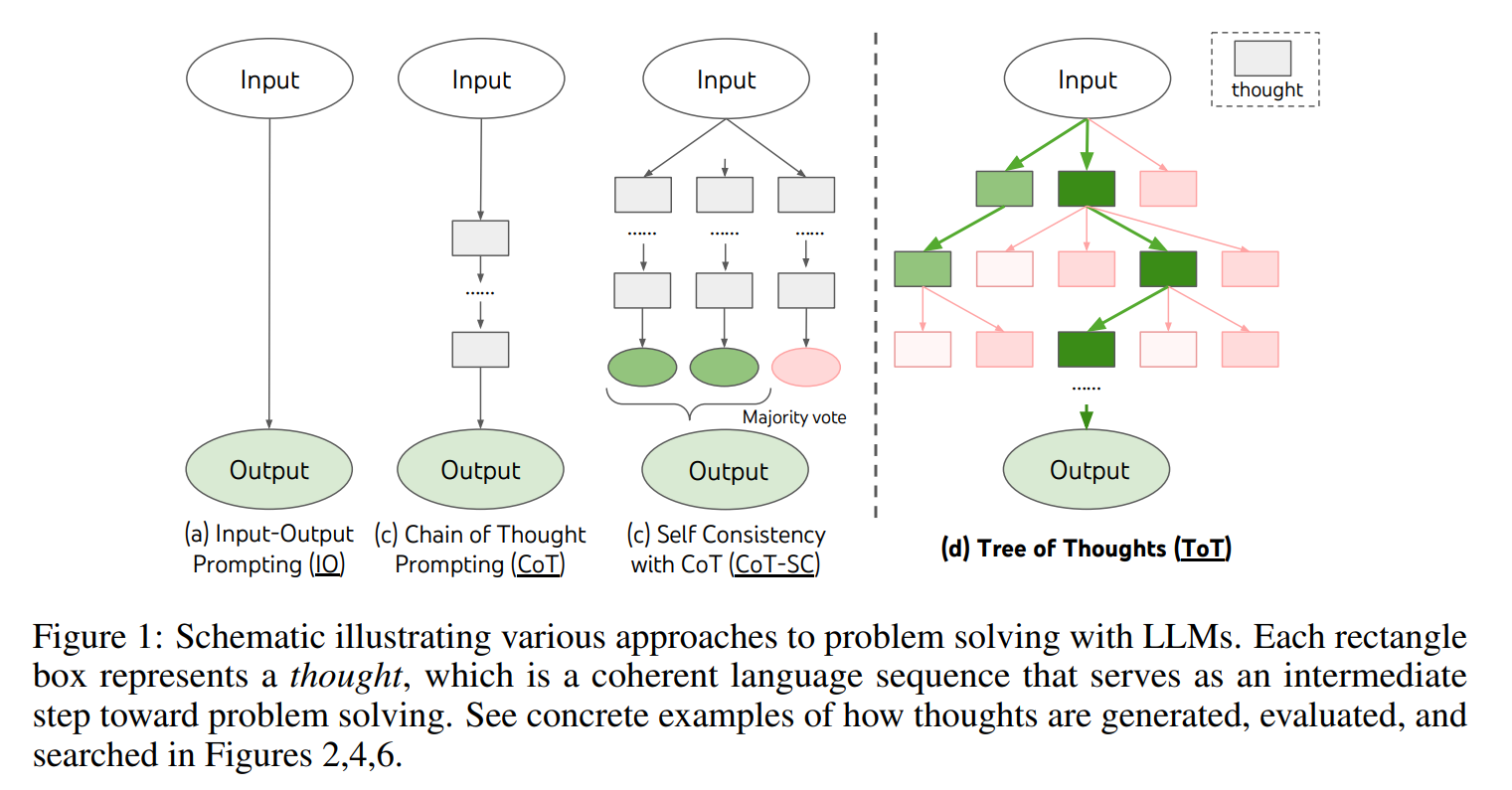


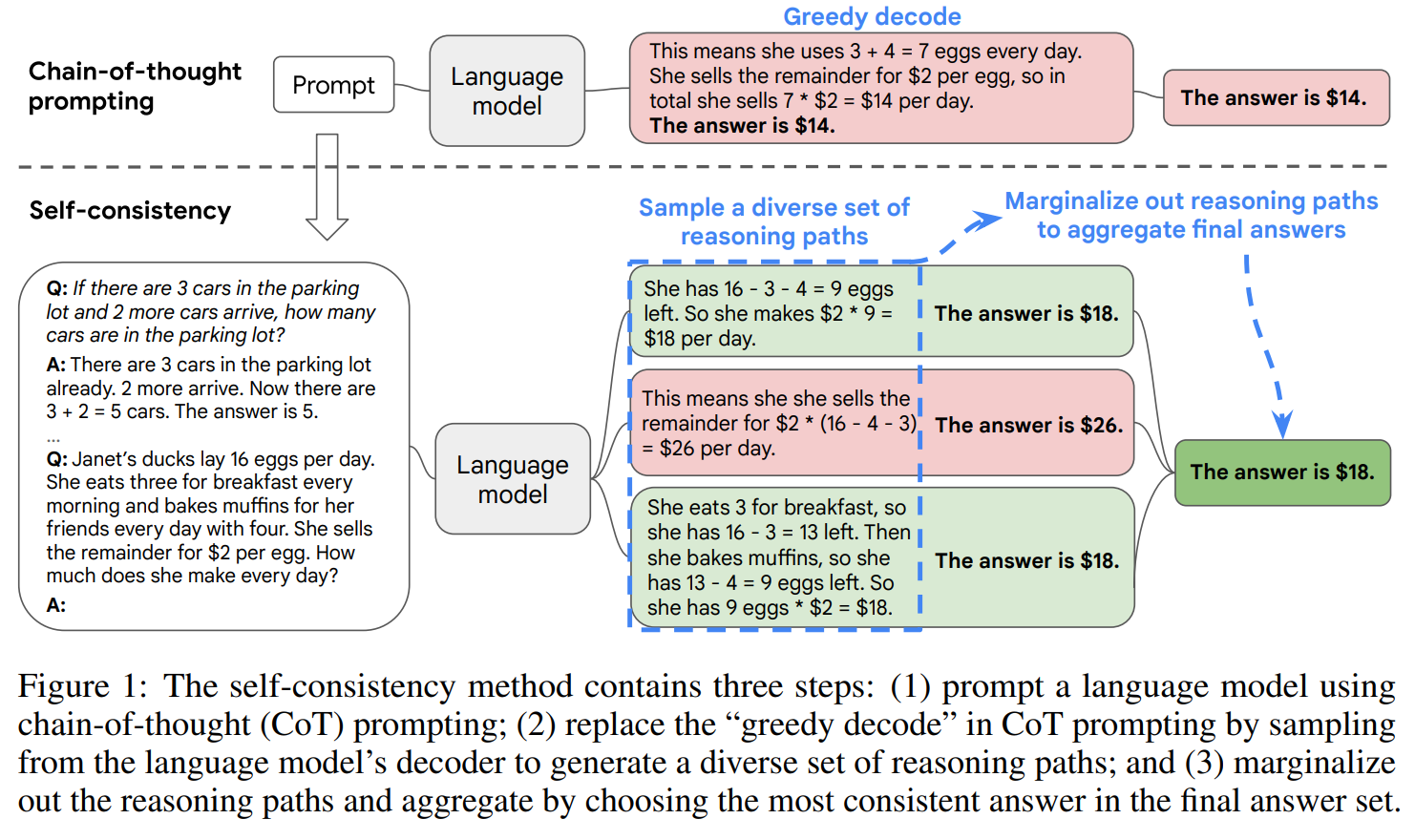
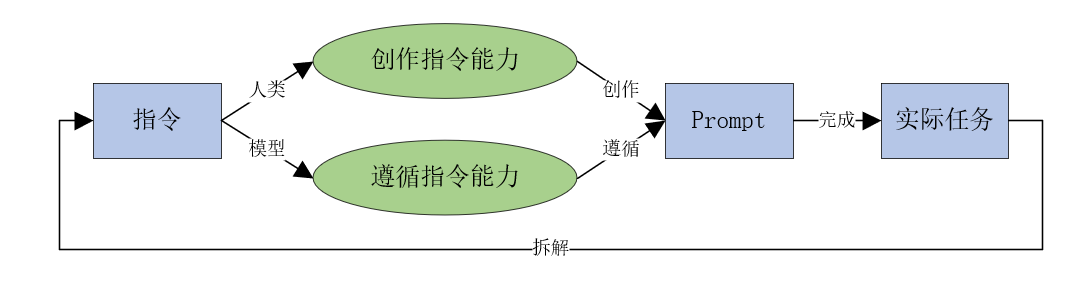



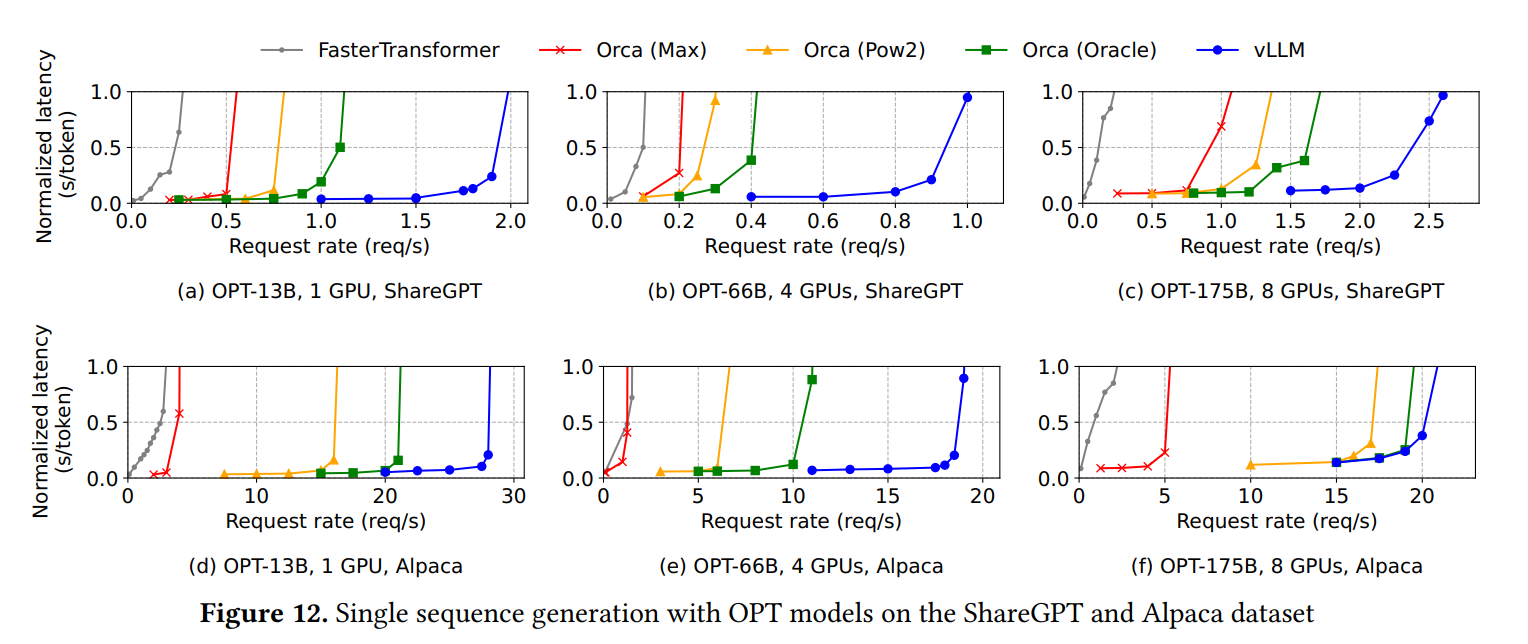
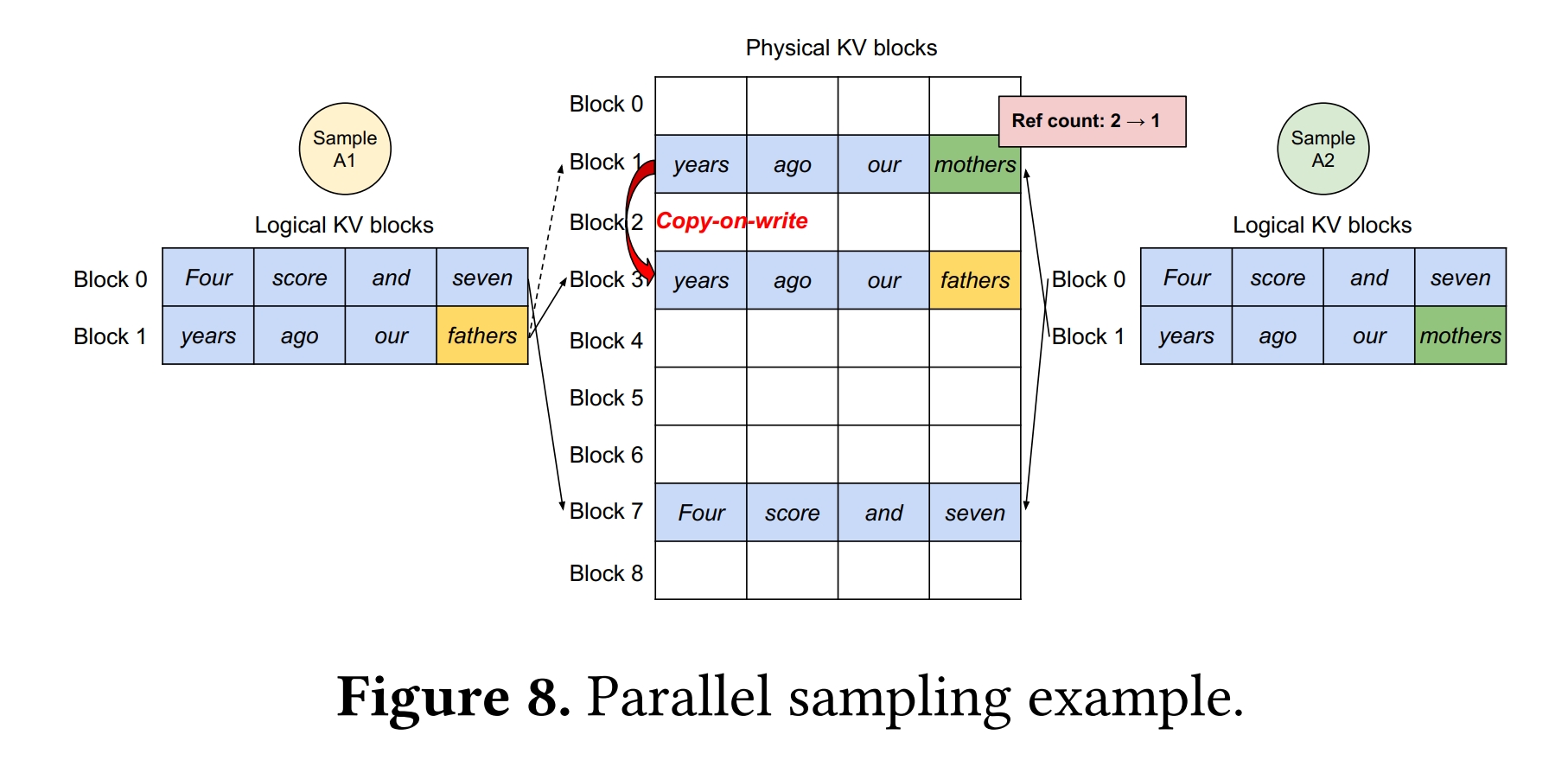
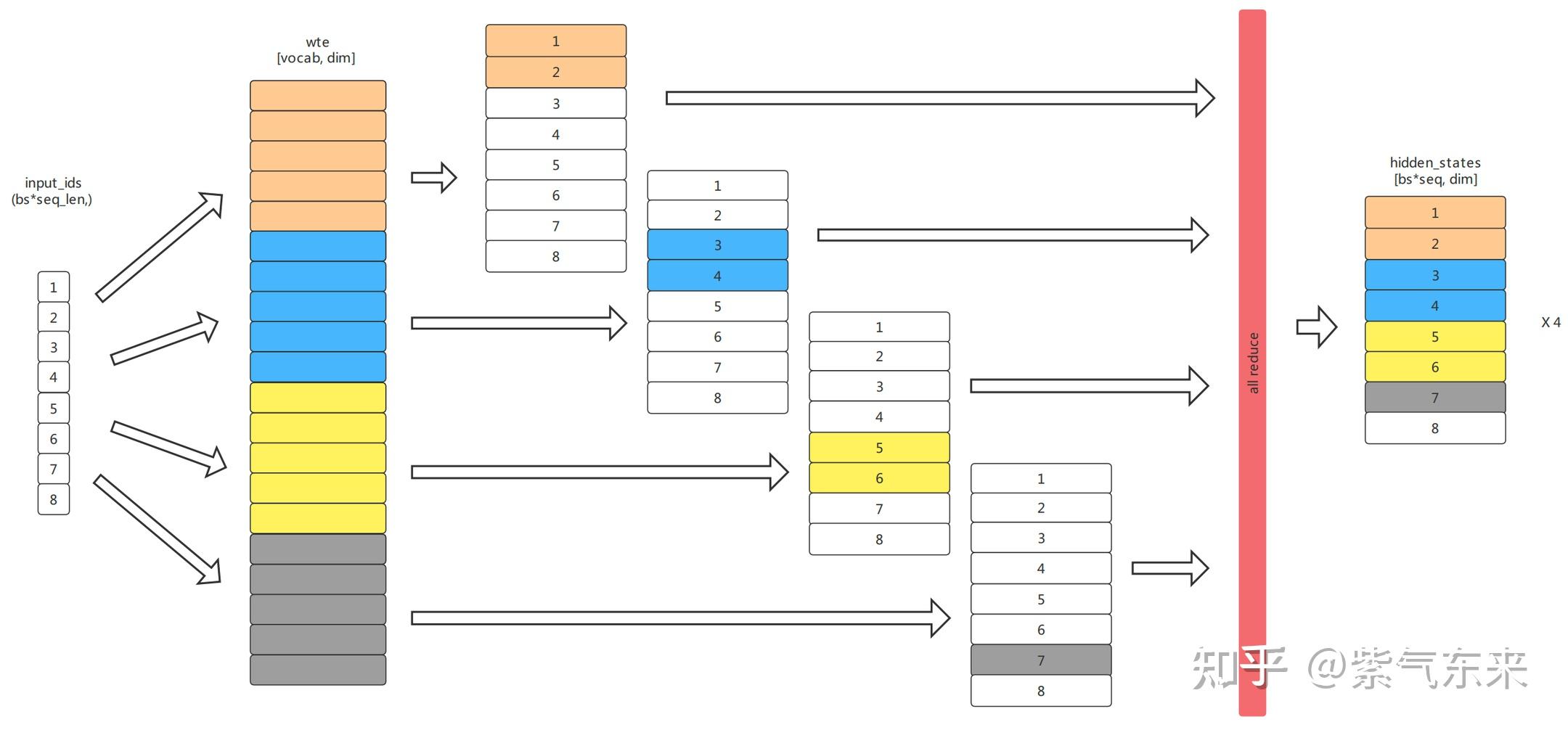
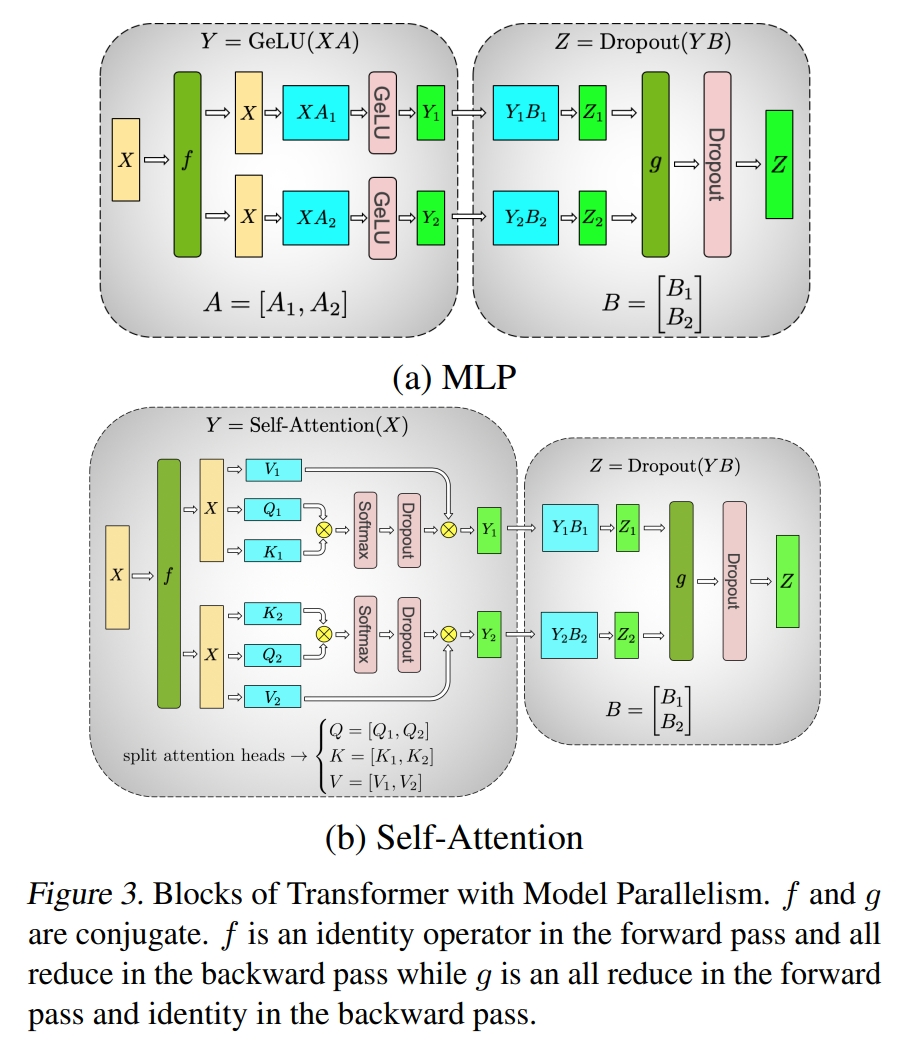








 ' +
+ '
' +
+ '