本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新314篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:Alice Benchmarks: Connecting Real World Object Re-Identification with the Synthetic
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2310.04416
+ 作者:Xiaoxiao Sun, Yue Yao, Shengjin Wang, Hongdong Li, Liang Zheng
+ 备注:9 pages, 4 figures, 4 tables
+ 关键词:cheaply acquire large-scale, Alice benchmarks, privacy concerns, synthetic data, cheaply acquire
+
+ 点击查看摘要
+ For object re-identification (re-ID), learning from synthetic data has become a promising strategy to cheaply acquire large-scale annotated datasets and effective models, with few privacy concerns. Many interesting research problems arise from this strategy, e.g., how to reduce the domain gap between synthetic source and real-world target. To facilitate developing more new approaches in learning from synthetic data, we introduce the Alice benchmarks, large-scale datasets providing benchmarks as well as evaluation protocols to the research community. Within the Alice benchmarks, two object re-ID tasks are offered: person and vehicle re-ID. We collected and annotated two challenging real-world target datasets: AlicePerson and AliceVehicle, captured under various illuminations, image resolutions, etc. As an important feature of our real target, the clusterability of its training set is not manually guaranteed to make it closer to a real domain adaptation test scenario. Correspondingly, we reuse existing PersonX and VehicleX as synthetic source domains. The primary goal is to train models from synthetic data that can work effectively in the real world. In this paper, we detail the settings of Alice benchmarks, provide an analysis of existing commonly-used domain adaptation methods, and discuss some interesting future directions. An online server will be set up for the community to evaluate methods conveniently and fairly.
+
+
+
+ 2. 标题:CIFAR-10-Warehouse: Broad and More Realistic Testbeds in Model Generalization Analysis
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2310.04414
+ 作者:Xiaoxiao Sun, Xingjian Leng, Zijian Wang, Yang Yang, Zi Huang, Liang Zheng
+ 备注:9 pages, 5 figures, 3 tables
+ 关键词:machine learning community, critical research problem, Analyzing model performance, learning community, critical research
+
+ 点击查看摘要
+ Analyzing model performance in various unseen environments is a critical research problem in the machine learning community. To study this problem, it is important to construct a testbed with out-of-distribution test sets that have broad coverage of environmental discrepancies. However, existing testbeds typically either have a small number of domains or are synthesized by image corruptions, hindering algorithm design that demonstrates real-world effectiveness. In this paper, we introduce CIFAR-10-Warehouse, consisting of 180 datasets collected by prompting image search engines and diffusion models in various ways. Generally sized between 300 and 8,000 images, the datasets contain natural images, cartoons, certain colors, or objects that do not naturally appear. With CIFAR-10-W, we aim to enhance the evaluation and deepen the understanding of two generalization tasks: domain generalization and model accuracy prediction in various out-of-distribution environments. We conduct extensive benchmarking and comparison experiments and show that CIFAR-10-W offers new and interesting insights inherent to these tasks. We also discuss other fields that would benefit from CIFAR-10-W.
+
+
+
+ 3. 标题:FedConv: Enhancing Convolutional Neural Networks for Handling Data Heterogeneity in Federated Learning
+ 编号:[7]
+ 链接:https://arxiv.org/abs/2310.04412
+ 作者:Peiran Xu, Zeyu Wang, Jieru Mei, Liangqiong Qu, Alan Yuille, Cihang Xie, Yuyin Zhou
+ 备注:9 pages, 6 figures. Equal contribution by P. Xu and Z. Wang
+ 关键词:Convolutional Neural Networks, Federated learning, machine learning, outperforms Convolutional Neural, emerging paradigm
+
+ 点击查看摘要
+ Federated learning (FL) is an emerging paradigm in machine learning, where a shared model is collaboratively learned using data from multiple devices to mitigate the risk of data leakage. While recent studies posit that Vision Transformer (ViT) outperforms Convolutional Neural Networks (CNNs) in addressing data heterogeneity in FL, the specific architectural components that underpin this advantage have yet to be elucidated. In this paper, we systematically investigate the impact of different architectural elements, such as activation functions and normalization layers, on the performance within heterogeneous FL. Through rigorous empirical analyses, we are able to offer the first-of-its-kind general guidance on micro-architecture design principles for heterogeneous FL.
+Intriguingly, our findings indicate that with strategic architectural modifications, pure CNNs can achieve a level of robustness that either matches or even exceeds that of ViTs when handling heterogeneous data clients in FL. Additionally, our approach is compatible with existing FL techniques and delivers state-of-the-art solutions across a broad spectrum of FL benchmarks. The code is publicly available at this https URL
+
+
+
+ 4. 标题:Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2310.04406
+ 作者:Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, Yu-Xiong Wang
+ 备注:Website and code can be found at this https URL
+ 关键词:large language models, demonstrated impressive performance, simple acting processes, Language Agent Tree, Agent Tree Search
+
+ 点击查看摘要
+ While large language models (LLMs) have demonstrated impressive performance on a range of decision-making tasks, they rely on simple acting processes and fall short of broad deployment as autonomous agents. We introduce LATS (Language Agent Tree Search), a general framework that synergizes the capabilities of LLMs in planning, acting, and reasoning. Drawing inspiration from Monte Carlo tree search in model-based reinforcement learning, LATS employs LLMs as agents, value functions, and optimizers, repurposing their latent strengths for enhanced decision-making. What is crucial in this method is the use of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that moves beyond the limitations of existing techniques. Our experimental evaluation across diverse domains, such as programming, HotPotQA, and WebShop, illustrates the applicability of LATS for both reasoning and acting. In particular, LATS achieves 94.4\% for programming on HumanEval with GPT-4 and an average score of 75.9 for web browsing on WebShop with GPT-3.5, demonstrating the effectiveness and generality of our method.
+
+
+
+ 5. 标题:Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2310.04378
+ 作者:Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao
+ 备注:
+ 关键词:achieved remarkable results, Latent Consistency Models, Consistency Models, synthesizing high-resolution images, Diffusion models
+
+ 点击查看摘要
+ Latent Diffusion models (LDMs) have achieved remarkable results in synthesizing high-resolution images. However, the iterative sampling process is computationally intensive and leads to slow generation. Inspired by Consistency Models (song et al.), we propose Latent Consistency Models (LCMs), enabling swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion (rombach et al). Viewing the guided reverse diffusion process as solving an augmented probability flow ODE (PF-ODE), LCMs are designed to directly predict the solution of such ODE in latent space, mitigating the need for numerous iterations and allowing rapid, high-fidelity sampling. Efficiently distilled from pre-trained classifier-free guided diffusion models, a high-quality 768 x 768 2~4-step LCM takes only 32 A100 GPU hours for training. Furthermore, we introduce Latent Consistency Fine-tuning (LCF), a novel method that is tailored for fine-tuning LCMs on customized image datasets. Evaluation on the LAION-5B-Aesthetics dataset demonstrates that LCMs achieve state-of-the-art text-to-image generation performance with few-step inference. Project Page: this https URL
+
+
+
+ 6. 标题:SwimXYZ: A large-scale dataset of synthetic swimming motions and videos
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2310.04360
+ 作者:Fiche Guénolé, Sevestre Vincent, Gonzalez-Barral Camila, Leglaive Simon, Séguier Renaud
+ 备注:ACM MIG 2023
+ 关键词:increasingly important role, real competitive advantage, Technologies play, play an increasingly, increasingly important
+
+ 点击查看摘要
+ Technologies play an increasingly important role in sports and become a real competitive advantage for the athletes who benefit from it. Among them, the use of motion capture is developing in various sports to optimize sporting gestures. Unfortunately, traditional motion capture systems are expensive and constraining. Recently developed computer vision-based approaches also struggle in certain sports, like swimming, due to the aquatic environment. One of the reasons for the gap in performance is the lack of labeled datasets with swimming videos. In an attempt to address this issue, we introduce SwimXYZ, a synthetic dataset of swimming motions and videos. SwimXYZ contains 3.4 million frames annotated with ground truth 2D and 3D joints, as well as 240 sequences of swimming motions in the SMPL parameters format. In addition to making this dataset publicly available, we present use cases for SwimXYZ in swimming stroke clustering and 2D pose estimation.
+
+
+
+ 7. 标题:Distributed Deep Joint Source-Channel Coding with Decoder-Only Side Information
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2310.04311
+ 作者:Selim F. Yilmaz, Ezgi Ozyilkan, Deniz Gunduz, Elza Erkip
+ 备注:7 pages, 4 figures
+ 关键词:low-latency image transmission, noisy wireless channel, correlated side information, Wyner-Ziv scenario, low-latency image
+
+ 点击查看摘要
+ We consider low-latency image transmission over a noisy wireless channel when correlated side information is present only at the receiver side (the Wyner-Ziv scenario). In particular, we are interested in developing practical schemes using a data-driven joint source-channel coding (JSCC) approach, which has been previously shown to outperform conventional separation-based approaches in the practical finite blocklength regimes, and to provide graceful degradation with channel quality. We propose a novel neural network architecture that incorporates the decoder-only side information at multiple stages at the receiver side. Our results demonstrate that the proposed method succeeds in integrating the side information, yielding improved performance at all channel noise levels in terms of the various distortion criteria considered here, especially at low channel signal-to-noise ratios (SNRs) and small bandwidth ratios (BRs). We also provide the source code of the proposed method to enable further research and reproducibility of the results.
+
+
+
+ 8. 标题:Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2310.04306
+ 作者:Qing Zhu, Qirong Mao, Jialin Zhang, Xiaohua Huang, Wenming Zheng
+ 备注:11 pages,3 figures
+ 关键词:human behavior analysis, Group-level emotion recognition, behavior analysis, aiming to recognize, inseparable part
+
+ 点击查看摘要
+ Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
+
+
+
+ 9. 标题:Graph learning in robotics: a survey
+ 编号:[50]
+ 链接:https://arxiv.org/abs/2310.04294
+ 作者:Francesca Pistilli, Giuseppe Averta
+ 备注:
+ 关键词:complex non-euclidean data, Deep neural networks, non-euclidean data, powerful tool, complex non-euclidean
+
+ 点击查看摘要
+ Deep neural networks for graphs have emerged as a powerful tool for learning on complex non-euclidean data, which is becoming increasingly common for a variety of different applications. Yet, although their potential has been widely recognised in the machine learning community, graph learning is largely unexplored for downstream tasks such as robotics applications. To fully unlock their potential, hence, we propose a review of graph neural architectures from a robotics perspective. The paper covers the fundamentals of graph-based models, including their architecture, training procedures, and applications. It also discusses recent advancements and challenges that arise in applied settings, related for example to the integration of perception, decision-making, and control. Finally, the paper provides an extensive review of various robotic applications that benefit from learning on graph structures, such as bodies and contacts modelling, robotic manipulation, action recognition, fleet motion planning, and many more. This survey aims to provide readers with a thorough understanding of the capabilities and limitations of graph neural architectures in robotics, and to highlight potential avenues for future research.
+
+
+
+ 10. 标题:Assessing Robustness via Score-Based Adversarial Image Generation
+ 编号:[56]
+ 链接:https://arxiv.org/abs/2310.04285
+ 作者:Marcel Kollovieh, Lukas Gosch, Yan Scholten, Marten Lienen, Stephan Günnemann
+ 备注:
+ 关键词:norm constraints, ell, adversarial, norm, constraints
+
+ 点击查看摘要
+ Most adversarial attacks and defenses focus on perturbations within small $\ell_p$-norm constraints. However, $\ell_p$ threat models cannot capture all relevant semantic-preserving perturbations, and hence, the scope of robustness evaluations is limited. In this work, we introduce Score-Based Adversarial Generation (ScoreAG), a novel framework that leverages the advancements in score-based generative models to generate adversarial examples beyond $\ell_p$-norm constraints, so-called unrestricted adversarial examples, overcoming their limitations. Unlike traditional methods, ScoreAG maintains the core semantics of images while generating realistic adversarial examples, either by transforming existing images or synthesizing new ones entirely from scratch. We further exploit the generative capability of ScoreAG to purify images, empirically enhancing the robustness of classifiers. Our extensive empirical evaluation demonstrates that ScoreAG matches the performance of state-of-the-art attacks and defenses across multiple benchmarks. This work highlights the importance of investigating adversarial examples bounded by semantics rather than $\ell_p$-norm constraints. ScoreAG represents an important step towards more encompassing robustness assessments.
+
+
+
+ 11. 标题:Compositional Servoing by Recombining Demonstrations
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2310.04271
+ 作者:Max Argus, Abhijeet Nayak, Martin Büchner, Silvio Galesso, Abhinav Valada, Thomas Brox
+ 备注:this http URL
+ 关键词:Learning-based manipulation policies, task transfer capabilities, weak task transfer, Learning-based manipulation, manipulation policies
+
+ 点击查看摘要
+ Learning-based manipulation policies from image inputs often show weak task transfer capabilities. In contrast, visual servoing methods allow efficient task transfer in high-precision scenarios while requiring only a few demonstrations. In this work, we present a framework that formulates the visual servoing task as graph traversal. Our method not only extends the robustness of visual servoing, but also enables multitask capability based on a few task-specific demonstrations. We construct demonstration graphs by splitting existing demonstrations and recombining them. In order to traverse the demonstration graph in the inference case, we utilize a similarity function that helps select the best demonstration for a specific task. This enables us to compute the shortest path through the graph. Ultimately, we show that recombining demonstrations leads to higher task-respective success. We present extensive simulation and real-world experimental results that demonstrate the efficacy of our approach.
+
+
+
+ 12. 标题:Collaborative Camouflaged Object Detection: A Large-Scale Dataset and Benchmark
+ 编号:[69]
+ 链接:https://arxiv.org/abs/2310.04253
+ 作者:Cong Zhang, Hongbo Bi, Tian-Zhu Xiang, Ranwan Wu, Jinghui Tong, Xiufang Wang
+ 备注:Accepted by IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
+ 关键词:simultaneously detect camouflaged, task called collaborative, detect camouflaged objects, camouflaged object detection, called collaborative camouflaged
+
+ 点击查看摘要
+ In this paper, we provide a comprehensive study on a new task called collaborative camouflaged object detection (CoCOD), which aims to simultaneously detect camouflaged objects with the same properties from a group of relevant images. To this end, we meticulously construct the first large-scale dataset, termed CoCOD8K, which consists of 8,528 high-quality and elaborately selected images with object mask annotations, covering 5 superclasses and 70 subclasses. The dataset spans a wide range of natural and artificial camouflage scenes with diverse object appearances and backgrounds, making it a very challenging dataset for CoCOD. Besides, we propose the first baseline model for CoCOD, named bilateral-branch network (BBNet), which explores and aggregates co-camouflaged cues within a single image and between images within a group, respectively, for accurate camouflaged object detection in given images. This is implemented by an inter-image collaborative feature exploration (CFE) module, an intra-image object feature search (OFS) module, and a local-global refinement (LGR) module. We benchmark 18 state-of-the-art models, including 12 COD algorithms and 6 CoSOD algorithms, on the proposed CoCOD8K dataset under 5 widely used evaluation metrics. Extensive experiments demonstrate the effectiveness of the proposed method and the significantly superior performance compared to other competitors. We hope that our proposed dataset and model will boost growth in the COD community. The dataset, model, and results will be available at: this https URL.
+
+
+
+ 13. 标题:Semantic segmentation of longitudinal thermal images for identification of hot and cool spots in urban areas
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2310.04247
+ 作者:Vasantha Ramani, Pandarasamy Arjunan, Kameshwar Poolla, Clayton Miller
+ 备注:14 pages, 13 figures
+ 关键词:spatially rich thermal, rich thermal images, thermal images collected, thermal images, thermal image dataset
+
+ 点击查看摘要
+ This work presents the analysis of semantically segmented, longitudinally, and spatially rich thermal images collected at the neighborhood scale to identify hot and cool spots in urban areas. An infrared observatory was operated over a few months to collect thermal images of different types of buildings on the educational campus of the National University of Singapore. A subset of the thermal image dataset was used to train state-of-the-art deep learning models to segment various urban features such as buildings, vegetation, sky, and roads. It was observed that the U-Net segmentation model with `resnet34' CNN backbone has the highest mIoU score of 0.99 on the test dataset, compared to other models such as DeepLabV3, DeeplabV3+, FPN, and PSPnet. The masks generated using the segmentation models were then used to extract the temperature from thermal images and correct for differences in the emissivity of various urban features. Further, various statistical measure of the temperature extracted using the predicted segmentation masks is shown to closely match the temperature extracted using the ground truth masks. Finally, the masks were used to identify hot and cool spots in the urban feature at various instances of time. This forms one of the very few studies demonstrating the automated analysis of thermal images, which can be of potential use to urban planners for devising mitigation strategies for reducing the urban heat island (UHI) effect, improving building energy efficiency, and maximizing outdoor thermal comfort.
+
+
+
+ 14. 标题:Enhancing the Authenticity of Rendered Portraits with Identity-Consistent Transfer Learning
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2310.04194
+ 作者:Luyuan Wang, Yiqian Wu, Yongliang Yang, Chen Liu, Xiaogang Jin
+ 备注:10 pages, 8 figures, 2 tables
+ 关键词:creating high-quality photo-realistic, high-quality photo-realistic virtual, uncanny valley effect, computer graphics, creating high-quality
+
+ 点击查看摘要
+ Despite rapid advances in computer graphics, creating high-quality photo-realistic virtual portraits is prohibitively expensive. Furthermore, the well-know ''uncanny valley'' effect in rendered portraits has a significant impact on the user experience, especially when the depiction closely resembles a human likeness, where any minor artifacts can evoke feelings of eeriness and repulsiveness. In this paper, we present a novel photo-realistic portrait generation framework that can effectively mitigate the ''uncanny valley'' effect and improve the overall authenticity of rendered portraits. Our key idea is to employ transfer learning to learn an identity-consistent mapping from the latent space of rendered portraits to that of real portraits. During the inference stage, the input portrait of an avatar can be directly transferred to a realistic portrait by changing its appearance style while maintaining the facial identity. To this end, we collect a new dataset, Daz-Rendered-Faces-HQ (DRFHQ), that is specifically designed for rendering-style portraits. We leverage this dataset to fine-tune the StyleGAN2 generator, using our carefully crafted framework, which helps to preserve the geometric and color features relevant to facial identity. We evaluate our framework using portraits with diverse gender, age, and race variations. Qualitative and quantitative evaluations and ablation studies show the advantages of our method compared to state-of-the-art approaches.
+
+
+
+ 15. 标题:Bridging the Gap between Human Motion and Action Semantics via Kinematic Phrases
+ 编号:[92]
+ 链接:https://arxiv.org/abs/2310.04189
+ 作者:Xinpeng Liu, Yong-Lu Li, Ailing Zeng, Zizheng Zhou, Yang You, Cewu Lu
+ 备注:
+ 关键词:action semantics, abstract action semantic, semantics, motion, action
+
+ 点击查看摘要
+ The goal of motion understanding is to establish a reliable mapping between motion and action semantics, while it is a challenging many-to-many problem. An abstract action semantic (i.e., walk forwards) could be conveyed by perceptually diverse motions (walk with arms up or swinging), while a motion could carry different semantics w.r.t. its context and intention. This makes an elegant mapping between them difficult. Previous attempts adopted direct-mapping paradigms with limited reliability. Also, current automatic metrics fail to provide reliable assessments of the consistency between motions and action semantics. We identify the source of these problems as the significant gap between the two modalities. To alleviate this gap, we propose Kinematic Phrases (KP) that take the objective kinematic facts of human motion with proper abstraction, interpretability, and generality characteristics. Based on KP as a mediator, we can unify a motion knowledge base and build a motion understanding system. Meanwhile, KP can be automatically converted from motions and to text descriptions with no subjective bias, inspiring Kinematic Prompt Generation (KPG) as a novel automatic motion generation benchmark. In extensive experiments, our approach shows superiority over other methods. Our code and data would be made publicly available at this https URL.
+
+
+
+ 16. 标题:DiffPrompter: Differentiable Implicit Visual Prompts for Semantic-Segmentation in Adverse Conditions
+ 编号:[96]
+ 链接:https://arxiv.org/abs/2310.04181
+ 作者:Sanket Kalwar, Mihir Ungarala, Shruti Jain, Aaron Monis, Krishna Reddy Konda, Sourav Garg, K Madhava Krishna
+ 备注:
+ 关键词:autonomous driving systems, driving systems, autonomous driving, Semantic segmentation, adverse weather
+
+ 点击查看摘要
+ Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios. We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed $\nabla$HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios. Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach. Project page at this https URL.
+
+
+
+ 17. 标题:Degradation-Aware Self-Attention Based Transformer for Blind Image Super-Resolution
+ 编号:[97]
+ 链接:https://arxiv.org/abs/2310.04180
+ 作者:Qingguo Liu, Pan Gao, Kang Han, Ningzhong Liu, Wei Xiang
+ 备注:12 pages
+ 关键词:restoration outcomes due, impressive image restoration, image restoration outcomes, model remote dependencies, Transformer-based methods
+
+ 点击查看摘要
+ Compared to CNN-based methods, Transformer-based methods achieve impressive image restoration outcomes due to their abilities to model remote dependencies. However, how to apply Transformer-based methods to the field of blind super-resolution (SR) and further make an SR network adaptive to degradation information is still an open problem. In this paper, we propose a new degradation-aware self-attention-based Transformer model, where we incorporate contrastive learning into the Transformer network for learning the degradation representations of input images with unknown noise. In particular, we integrate both CNN and Transformer components into the SR network, where we first use the CNN modulated by the degradation information to extract local features, and then employ the degradation-aware Transformer to extract global semantic features. We apply our proposed model to several popular large-scale benchmark datasets for testing, and achieve the state-of-the-art performance compared to existing methods. In particular, our method yields a PSNR of 32.43 dB on the Urban100 dataset at $\times$2 scale, 0.94 dB higher than DASR, and 26.62 dB on the Urban100 dataset at $\times$4 scale, 0.26 dB improvement over KDSR, setting a new benchmark in this area. Source code is available at: this https URL.
+
+
+
+ 18. 标题:Entropic Score metric: Decoupling Topology and Size in Training-free NAS
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2310.04179
+ 作者:Niccolò Cavagnero, Luca Robbiano, Francesca Pistilli, Barbara Caputo, Giuseppe Averta
+ 备注:10 pages, 3 figures
+ 关键词:resource-constrained scenarios typical, Neural Architecture Search, daunting task, Neural Networks design, resource-constrained scenarios
+
+ 点击查看摘要
+ Neural Networks design is a complex and often daunting task, particularly for resource-constrained scenarios typical of mobile-sized models. Neural Architecture Search is a promising approach to automate this process, but existing competitive methods require large training time and computational resources to generate accurate models. To overcome these limits, this paper contributes with: i) a novel training-free metric, named Entropic Score, to estimate model expressivity through the aggregated element-wise entropy of its activations; ii) a cyclic search algorithm to separately yet synergistically search model size and topology. Entropic Score shows remarkable ability in searching for the topology of the network, and a proper combination with LogSynflow, to search for model size, yields superior capability to completely design high-performance Hybrid Transformers for edge applications in less than 1 GPU hour, resulting in the fastest and most accurate NAS method for ImageNet classification.
+
+
+
+ 19. 标题:Improving Neural Radiance Field using Near-Surface Sampling with Point Cloud Generation
+ 编号:[106]
+ 链接:https://arxiv.org/abs/2310.04152
+ 作者:Hye Bin Yoo, Hyun Min Han, Sung Soo Hwang, Il Yong Chun
+ 备注:13 figures, 2 tables
+ 关键词:Neural radiance field, emerging view synthesis, Neural radiance, radiance field, color probabilities
+
+ 点击查看摘要
+ Neural radiance field (NeRF) is an emerging view synthesis method that samples points in a three-dimensional (3D) space and estimates their existence and color probabilities. The disadvantage of NeRF is that it requires a long training time since it samples many 3D points. In addition, if one samples points from occluded regions or in the space where an object is unlikely to exist, the rendering quality of NeRF can be degraded. These issues can be solved by estimating the geometry of 3D scene. This paper proposes a near-surface sampling framework to improve the rendering quality of NeRF. To this end, the proposed method estimates the surface of a 3D object using depth images of the training set and sampling is performed around there only. To obtain depth information on a novel view, the paper proposes a 3D point cloud generation method and a simple refining method for projected depth from a point cloud. Experimental results show that the proposed near-surface sampling NeRF framework can significantly improve the rendering quality, compared to the original NeRF and a state-of-the-art depth-based NeRF method. In addition, one can significantly accelerate the training time of a NeRF model with the proposed near-surface sampling framework.
+
+
+
+ 20. 标题:Self-Supervised Neuron Segmentation with Multi-Agent Reinforcement Learning
+ 编号:[107]
+ 链接:https://arxiv.org/abs/2310.04148
+ 作者:Yinda Chen, Wei Huang, Shenglong Zhou, Qi Chen, Zhiwei Xiong
+ 备注:IJCAI 23 main track paper
+ 关键词:scale electron microscopy, large scale electron, existing supervised neuron, supervised neuron segmentation, accurate annotations
+
+ 点击查看摘要
+ The performance of existing supervised neuron segmentation methods is highly dependent on the number of accurate annotations, especially when applied to large scale electron microscopy (EM) data. By extracting semantic information from unlabeled data, self-supervised methods can improve the performance of downstream tasks, among which the mask image model (MIM) has been widely used due to its simplicity and effectiveness in recovering original information from masked images. However, due to the high degree of structural locality in EM images, as well as the existence of considerable noise, many voxels contain little discriminative information, making MIM pretraining inefficient on the neuron segmentation task. To overcome this challenge, we propose a decision-based MIM that utilizes reinforcement learning (RL) to automatically search for optimal image masking ratio and masking strategy. Due to the vast exploration space, using single-agent RL for voxel prediction is impractical. Therefore, we treat each input patch as an agent with a shared behavior policy, allowing for multi-agent collaboration. Furthermore, this multi-agent model can capture dependencies between voxels, which is beneficial for the downstream segmentation task. Experiments conducted on representative EM datasets demonstrate that our approach has a significant advantage over alternative self-supervised methods on the task of neuron segmentation. Code is available at \url{this https URL}.
+
+
+
+ 21. 标题:TiC: Exploring Vision Transformer in Convolution
+ 编号:[110]
+ 链接:https://arxiv.org/abs/2310.04134
+ 作者:Song Zhang, Qingzhong Wang, Jiang Bian, Haoyi Xiong
+ 备注:
+ 关键词:arbitrary resolution images, phonemically surging, architecture and configuration, positional encoding, limiting their flexibility
+
+ 点击查看摘要
+ While models derived from Vision Transformers (ViTs) have been phonemically surging, pre-trained models cannot seamlessly adapt to arbitrary resolution images without altering the architecture and configuration, such as sampling the positional encoding, limiting their flexibility for various vision tasks. For instance, the Segment Anything Model (SAM) based on ViT-Huge requires all input images to be resized to 1024$\times$1024. To overcome this limitation, we propose the Multi-Head Self-Attention Convolution (MSA-Conv) that incorporates Self-Attention within generalized convolutions, including standard, dilated, and depthwise ones. Enabling transformers to handle images of varying sizes without retraining or rescaling, the use of MSA-Conv further reduces computational costs compared to global attention in ViT, which grows costly as image size increases. Later, we present the Vision Transformer in Convolution (TiC) as a proof of concept for image classification with MSA-Conv, where two capacity enhancing strategies, namely Multi-Directional Cyclic Shifted Mechanism and Inter-Pooling Mechanism, have been proposed, through establishing long-distance connections between tokens and enlarging the effective receptive field. Extensive experiments have been carried out to validate the overall effectiveness of TiC. Additionally, ablation studies confirm the performance improvement made by MSA-Conv and the two capacity enhancing strategies separately. Note that our proposal aims at studying an alternative to the global attention used in ViT, while MSA-Conv meets our goal by making TiC comparable to state-of-the-art on ImageNet-1K. Code will be released at this https URL.
+
+
+
+ 22. 标题:VI-Diff: Unpaired Visible-Infrared Translation Diffusion Model for Single Modality Labeled Visible-Infrared Person Re-identification
+ 编号:[116]
+ 链接:https://arxiv.org/abs/2310.04122
+ 作者:Han Huang, Yan Huang, Liang Wang
+ 备注:11 pages, 7 figures
+ 关键词:real-world scenarios poses, significant challenge due, cross-modality data annotation, Visible-Infrared person re-identification, real-world scenarios
+
+ 点击查看摘要
+ Visible-Infrared person re-identification (VI-ReID) in real-world scenarios poses a significant challenge due to the high cost of cross-modality data annotation. Different sensing cameras, such as RGB/IR cameras for good/poor lighting conditions, make it costly and error-prone to identify the same person across modalities. To overcome this, we explore the use of single-modality labeled data for the VI-ReID task, which is more cost-effective and practical. By labeling pedestrians in only one modality (e.g., visible images) and retrieving in another modality (e.g., infrared images), we aim to create a training set containing both originally labeled and modality-translated data using unpaired image-to-image translation techniques. In this paper, we propose VI-Diff, a diffusion model that effectively addresses the task of Visible-Infrared person image translation. Through comprehensive experiments, we demonstrate that VI-Diff outperforms existing diffusion and GAN models, making it a promising solution for VI-ReID with single-modality labeled data. Our approach can be a promising solution to the VI-ReID task with single-modality labeled data and serves as a good starting point for future study. Code will be available.
+
+
+
+ 23. 标题:Dense Random Texture Detection using Beta Distribution Statistics
+ 编号:[120]
+ 链接:https://arxiv.org/abs/2310.04111
+ 作者:Soeren Molander
+ 备注:
+ 关键词:detecting dense random, dense random texture, note describes, detecting dense, dense random
+
+ 点击查看摘要
+ This note describes a method for detecting dense random texture using fully connected points sampled on image edges. An edge image is randomly sampled with points, the standard L2 distance is calculated between all connected points in a neighbourhood. For each point, a check is made if the point intersects with an image edge. If this is the case, a unity value is added to the distance, otherwise zero. From this an edge excess index is calculated for the fully connected edge graph in the range [1.0..2.0], where 1.0 indicate no edges. The ratio can be interpreted as a sampled Bernoulli process with unknown probability. The Bayesian posterior estimate of the probability can be associated with its conjugate prior which is a Beta($\alpha$, $\beta$) distribution, with hyper parameters $\alpha$ and $\beta$ related to the number of edge crossings. Low values of $\beta$ indicate a texture rich area, higher values less rich. The method has been applied to real-time SLAM-based moving object detection, where points are confined to tracked boxes (rois).
+
+
+
+ 24. 标题:Automated 3D Segmentation of Kidneys and Tumors in MICCAI KiTS 2023 Challenge
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2310.04110
+ 作者:Andriy Myronenko, Dong Yang, Yufan He, Daguang Xu
+ 备注:MICCAI 2023, KITS 2023 challenge 1st place
+ 关键词:Kidney Tumor Segmentation, Kidney Tumor, Tumor Segmentation Challenge, Tumor Segmentation, offers a platform
+
+ 点击查看摘要
+ Kidney and Kidney Tumor Segmentation Challenge (KiTS) 2023 offers a platform for researchers to compare their solutions to segmentation from 3D CT. In this work, we describe our submission to the challenge using automated segmentation of Auto3DSeg available in MONAI. Our solution achieves the average dice of 0.835 and surface dice of 0.723, which ranks first and wins the KiTS 2023 challenge.
+
+
+
+ 25. 标题:ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2310.04099
+ 作者:Yifan Xu, Pourya Shamsolmoali, Jie Yang
+ 备注:
+ 关键词:including robot navigation, highly challenging task, range of applications, including robot, self-driving vehicles
+
+ 点击查看摘要
+ Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.
+
+
+
+ 26. 标题:End-to-End Chess Recognition
+ 编号:[129]
+ 链接:https://arxiv.org/abs/2310.04086
+ 作者:Athanasios Masouris, Jan van Gemert
+ 备注:9 pages
+ 关键词:Chess recognition refers, chess pieces configuration, Chess recognition, Chess, Chess Recognition Dataset
+
+ 点击查看摘要
+ Chess recognition refers to the task of identifying the chess pieces configuration from a chessboard image. Contrary to the predominant approach that aims to solve this task through the pipeline of chessboard detection, square localization, and piece classification, we rely on the power of deep learning models and introduce two novel methodologies to circumvent this pipeline and directly predict the chessboard configuration from the entire image. In doing so, we avoid the inherent error accumulation of the sequential approaches and the need for intermediate annotations. Furthermore, we introduce a new dataset, Chess Recognition Dataset (ChessReD), specifically designed for chess recognition that consists of 10,800 images and their corresponding annotations. In contrast to existing synthetic datasets with limited angles, this dataset comprises a diverse collection of real images of chess formations captured from various angles using smartphone cameras; a sensor choice made to ensure real-world applicability. We use this dataset to both train our model and evaluate and compare its performance to that of the current state-of-the-art. Our approach in chess recognition on this new benchmark dataset outperforms related approaches, achieving a board recognition accuracy of 15.26% ($\approx$7x better than the current state-of-the-art).
+
+
+
+ 27. 标题:A Deeply Supervised Semantic Segmentation Method Based on GAN
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2310.04081
+ 作者:Wei Zhao, Qiyu Wei, Zeng Zeng
+ 备注:6 pages, 2 figures, ITSC conference
+ 关键词:witnessed rapid advancements, Semantic segmentation, recent years, rapid advancements, semantic segmentation model
+
+ 点击查看摘要
+ In recent years, the field of intelligent transportation has witnessed rapid advancements, driven by the increasing demand for automation and efficiency in transportation systems. Traffic safety, one of the tasks integral to intelligent transport systems, requires accurately identifying and locating various road elements, such as road cracks, lanes, and traffic signs. Semantic segmentation plays a pivotal role in achieving this task, as it enables the partition of images into meaningful regions with accurate boundaries. In this study, we propose an improved semantic segmentation model that combines the strengths of adversarial learning with state-of-the-art semantic segmentation techniques. The proposed model integrates a generative adversarial network (GAN) framework into the traditional semantic segmentation model, enhancing the model's performance in capturing complex and subtle features in transportation images. The effectiveness of our approach is demonstrated by a significant boost in performance on the road crack dataset compared to the existing methods, \textit{i.e.,} SEGAN. This improvement can be attributed to the synergistic effect of adversarial learning and semantic segmentation, which leads to a more refined and accurate representation of road structures and conditions. The enhanced model not only contributes to better detection of road cracks but also to a wide range of applications in intelligent transportation, such as traffic sign recognition, vehicle detection, and lane segmentation.
+
+
+
+ 28. 标题:In the Blink of an Eye: Event-based Emotion Recognition
+ 编号:[145]
+ 链接:https://arxiv.org/abs/2310.04043
+ 作者:Haiwei Zhang, Jiqing Zhang, Bo Dong, Pieter Peers, Wenwei Wu, Xiaopeng Wei, Felix Heide, Xin Yang
+ 备注:
+ 关键词:introduce a wearable, partial observations, wearable single-eye emotion, Spiking Eye Emotion, Eye Emotion Network
+
+ 点击查看摘要
+ We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network.
+
+
+
+ 29. 标题:Excision and Recovery: Enhancing Surface Anomaly Detection with Attention-based Single Deterministic Masking
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2310.04010
+ 作者:YeongHyeon Park, Sungho Kang, Myung Jin Kim, Yeonho Lee, Juneho Yi
+ 备注:5 pages, 3 figures, 4 tables
+ 关键词:quantity imbalance problem, scarce abnormal data, Anomaly detection, essential yet challenging, challenging task
+
+ 点击查看摘要
+ Anomaly detection (AD) in surface inspection is an essential yet challenging task in manufacturing due to the quantity imbalance problem of scarce abnormal data. To overcome the above, a reconstruction encoder-decoder (ED) such as autoencoder or U-Net which is trained with only anomaly-free samples is widely adopted, in the hope that unseen abnormals should yield a larger reconstruction error than normal. Over the past years, researches on self-supervised reconstruction-by-inpainting have been reported. They mask out suspected defective regions for inpainting in order to make them invisible to the reconstruction ED to deliberately cause inaccurate reconstruction for abnormals. However, their limitation is multiple random masking to cover the whole input image due to defective regions not being known in advance. We propose a novel reconstruction-by-inpainting method dubbed Excision and Recovery (EAR) that features single deterministic masking. For this, we exploit a pre-trained spatial attention model to predict potential suspected defective regions that should be masked out. We also employ a variant of U-Net as our ED to further limit the reconstruction ability of the U-Net model for abnormals, in which skip connections of different layers can be selectively disabled. In the training phase, all the skip connections are switched on to fully take the benefits from the U-Net architecture. In contrast, for inferencing, we only keep deeper skip connections with shallower connections off. We validate the effectiveness of EAR using an MNIST pre-trained attention for a commonly used surface AD dataset, KolektorSDD2. The experimental results show that EAR achieves both better AD performance and higher throughput than state-of-the-art methods. We expect that the proposed EAR model can be widely adopted as training and inference strategies for AD purposes.
+
+
+
+ 30. 标题:Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2310.03986
+ 作者:Md Kaykobad Reza, Ashley Prater-Bennette, M. Salman Asif
+ 备注:18 pages, 3 figures, 11 tables
+ 关键词:seeks to utilize, sources to improve, missing modalities, Multimodal, modalities
+
+ 点击查看摘要
+ Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
+
+
+
+ 31. 标题:CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
+ 编号:[172]
+ 链接:https://arxiv.org/abs/2310.03981
+ 作者:Weibin Liao, Xuhong Li, Qingzhong Wang, Yanwu Xu, Zhaozheng Yin, Haoyi Xiong
+ 备注:
+ 关键词:massive fine-annotated cell, cell, cell segmentation, pre-training DNN models, bounding boxes
+
+ 点击查看摘要
+ While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.
+
+
+
+ 32. 标题:Sub-token ViT Embedding via Stochastic Resonance Transformers
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2310.03967
+ 作者:Dong Lao, Yangchao Wu, Tian Yu Liu, Alex Wong, Stefano Soatto
+ 备注:
+ 关键词:Vision Transformers, Stochastic Resonance Transformer, tokenization step inherent, discover the presence, arise due
+
+ 点击查看摘要
+ We discover the presence of quantization artifacts in Vision Transformers (ViTs), which arise due to the image tokenization step inherent in these architectures. These artifacts result in coarsely quantized features, which negatively impact performance, especially on downstream dense prediction tasks. We present a zero-shot method to improve how pre-trained ViTs handle spatial quantization. In particular, we propose to ensemble the features obtained from perturbing input images via sub-token spatial translations, inspired by Stochastic Resonance, a method traditionally applied to climate dynamics and signal processing. We term our method ``Stochastic Resonance Transformer" (SRT), which we show can effectively super-resolve features of pre-trained ViTs, capturing more of the local fine-grained structures that might otherwise be neglected as a result of tokenization. SRT can be applied at any layer, on any task, and does not require any fine-tuning. The advantage of the former is evident when applied to monocular depth prediction, where we show that ensembling model outputs are detrimental while applying SRT on intermediate ViT features outperforms the baseline models by an average of 4.7% and 14.9% on the RMSE and RMSE-log metrics across three different architectures. When applied to semi-supervised video object segmentation, SRT also improves over the baseline models uniformly across all metrics, and by an average of 2.4% in F&J score. We further show that these quantization artifacts can be attenuated to some extent via self-distillation. On the unsupervised salient region segmentation, SRT improves upon the base model by an average of 2.1% on the maxF metric. Finally, despite operating purely on pixel-level features, SRT generalizes to non-dense prediction tasks such as image retrieval and object discovery, yielding consistent improvements of up to 2.6% and 1.0% respectively.
+
+
+
+ 33. 标题:Towards Increasing the Robustness of Predictive Steering-Control Autonomous Navigation Systems Against Dash Cam Image Angle Perturbations Due to Pothole Encounters
+ 编号:[184]
+ 链接:https://arxiv.org/abs/2310.03959
+ 作者:Shivam Aarya (Johns Hopkins University)
+ 备注:7 pages, 6 figures
+ 关键词:Vehicle manufacturers, manufacturers are racing, racing to create, create autonomous navigation, steering
+
+ 点击查看摘要
+ Vehicle manufacturers are racing to create autonomous navigation and steering control algorithms for their vehicles. These software are made to handle various real-life scenarios such as obstacle avoidance and lane maneuvering. There is some ongoing research to incorporate pothole avoidance into these autonomous systems. However, there is very little research on the effect of hitting a pothole on the autonomous navigation software that uses cameras to make driving decisions. Perturbations in the camera angle when hitting a pothole can cause errors in the predicted steering angle. In this paper, we present a new model to compensate for such angle perturbations and reduce any errors in steering control prediction algorithms. We evaluate our model on perturbations of publicly available datasets and show our model can reduce the errors in the estimated steering angle from perturbed images to 2.3%, making autonomous steering control robust against the dash cam image angle perturbations induced when one wheel of a car goes over a pothole.
+
+
+
+ 34. 标题:Understanding prompt engineering may not require rethinking generalization
+ 编号:[186]
+ 链接:https://arxiv.org/abs/2310.03957
+ 作者:Victor Akinwande, Yiding Jiang, Dylan Sam, J. Zico Kolter
+ 备注:
+ 关键词:explicit training process, achieved impressive performance, prompted vision-language models, learning in prompted, prompted vision-language
+
+ 点击查看摘要
+ Zero-shot learning in prompted vision-language models, the practice of crafting prompts to build classifiers without an explicit training process, has achieved impressive performance in many settings. This success presents a seemingly surprising observation: these methods suffer relatively little from overfitting, i.e., when a prompt is manually engineered to achieve low error on a given training set (thus rendering the method no longer actually zero-shot), the approach still performs well on held-out test data. In this paper, we show that we can explain such performance well via recourse to classical PAC-Bayes bounds. Specifically, we show that the discrete nature of prompts, combined with a PAC-Bayes prior given by a language model, results in generalization bounds that are remarkably tight by the standards of the literature: for instance, the generalization bound of an ImageNet classifier is often within a few percentage points of the true test error. We demonstrate empirically that this holds for existing handcrafted prompts and prompts generated through simple greedy search. Furthermore, the resulting bound is well-suited for model selection: the models with the best bound typically also have the best test performance. This work thus provides a possible justification for the widespread practice of prompt engineering, even if it seems that such methods could potentially overfit the training data.
+
+
+
+ 35. 标题:Gradient Descent Provably Solves Nonlinear Tomographic Reconstruction
+ 编号:[187]
+ 链接:https://arxiv.org/abs/2310.03956
+ 作者:Sara Fridovich-Keil, Fabrizio Valdivia, Gordon Wetzstein, Benjamin Recht, Mahdi Soltanolkotabi
+ 备注:
+ 关键词:exponential nonlinearity based, linear Radon transform, Beer-Lambert Law, Radon transform, computed tomography
+
+ 点击查看摘要
+ In computed tomography (CT), the forward model consists of a linear Radon transform followed by an exponential nonlinearity based on the attenuation of light according to the Beer-Lambert Law. Conventional reconstruction often involves inverting this nonlinearity as a preprocessing step and then solving a convex inverse problem. However, this nonlinear measurement preprocessing required to use the Radon transform is poorly conditioned in the vicinity of high-density materials, such as metal. This preprocessing makes CT reconstruction methods numerically sensitive and susceptible to artifacts near high-density regions. In this paper, we study a technique where the signal is directly reconstructed from raw measurements through the nonlinear forward model. Though this optimization is nonconvex, we show that gradient descent provably converges to the global optimum at a geometric rate, perfectly reconstructing the underlying signal with a near minimal number of random measurements. We also prove similar results in the under-determined setting where the number of measurements is significantly smaller than the dimension of the signal. This is achieved by enforcing prior structural information about the signal through constraints on the optimization variables. We illustrate the benefits of direct nonlinear CT reconstruction with cone-beam CT experiments on synthetic and real 3D volumes. We show that this approach reduces metal artifacts compared to a commercial reconstruction of a human skull with metal dental crowns.
+
+
+
+ 36. 标题:ILSH: The Imperial Light-Stage Head Dataset for Human Head View Synthesis
+ 编号:[189]
+ 链接:https://arxiv.org/abs/2310.03952
+ 作者:Jiali Zheng, Youngkyoon Jang, Athanasios Papaioannou, Christos Kampouris, Rolandos Alexandros Potamias, Foivos Paraperas Papantoniou, Efstathios Galanakis, Ales Leonardis, Stefanos Zafeiriou
+ 备注:ICCV 2023 Workshop, 9 pages, 6 figures
+ 关键词:Imperial Light-Stage Head, introduces the Imperial, Imperial Light-Stage, ILSH dataset, human head dataset
+
+ 点击查看摘要
+ This paper introduces the Imperial Light-Stage Head (ILSH) dataset, a novel light-stage-captured human head dataset designed to support view synthesis academic challenges for human heads. The ILSH dataset is intended to facilitate diverse approaches, such as scene-specific or generic neural rendering, multiple-view geometry, 3D vision, and computer graphics, to further advance the development of photo-realistic human avatars. This paper details the setup of a light-stage specifically designed to capture high-resolution (4K) human head images and describes the process of addressing challenges (preprocessing, ethical issues) in collecting high-quality data. In addition to the data collection, we address the split of the dataset into train, validation, and test sets. Our goal is to design and support a fair view synthesis challenge task for this novel dataset, such that a similar level of performance can be maintained and expected when using the test set, as when using the validation set. The ILSH dataset consists of 52 subjects captured using 24 cameras with all 82 lighting sources turned on, resulting in a total of 1,248 close-up head images, border masks, and camera pose pairs.
+
+
+
+ 37. 标题:Hard View Selection for Contrastive Learning
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2310.03940
+ 作者:Fabio Ferreira, Ivo Rapant, Frank Hutter
+ 备注:
+ 关键词:Contrastive Learning, good data augmentation, data augmentation pipeline, image augmentation pipeline, augmentation pipeline
+
+ 点击查看摘要
+ Many Contrastive Learning (CL) methods train their models to be invariant to different "views" of an image input for which a good data augmentation pipeline is crucial. While considerable efforts were directed towards improving pre-text tasks, architectures, or robustness (e.g., Siamese networks or teacher-softmax centering), the majority of these methods remain strongly reliant on the random sampling of operations within the image augmentation pipeline, such as the random resized crop or color distortion operation. In this paper, we argue that the role of the view generation and its effect on performance has so far received insufficient attention. To address this, we propose an easy, learning-free, yet powerful Hard View Selection (HVS) strategy designed to extend the random view generation to expose the pretrained model to harder samples during CL training. It encompasses the following iterative steps: 1) randomly sample multiple views and create pairs of two views, 2) run forward passes for each view pair on the currently trained model, 3) adversarially select the pair yielding the worst loss, and 4) run the backward pass with the selected pair. In our empirical analysis we show that under the hood, HVS increases task difficulty by controlling the Intersection over Union of views during pretraining. With only 300-epoch pretraining, HVS is able to closely rival the 800-epoch DINO baseline which remains very favorable even when factoring in the slowdown induced by the additional forwards of HVS. Additionally, HVS consistently achieves accuracy improvements on ImageNet between 0.55% and 1.9% on linear evaluation and similar improvements on transfer tasks across multiple CL methods, such as DINO, SimSiam, and SimCLR.
+
+
+
+ 38. 标题:Diffusion Models as Masked Audio-Video Learners
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2310.03937
+ 作者:Elvis Nunez, Yanzi Jin, Mohammad Rastegari, Sachin Mehta, Maxwell Horton
+ 备注:
+ 关键词:richer audio-visual representations, learn richer audio-visual, past several years, audio-visual representations, visual signals
+
+ 点击查看摘要
+ Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly reconstruct audio spectrograms and video frames by fusing information from both modalities. In this paper, we study the potential synergy between diffusion models and MAViL, seeking to derive mutual benefits from these two frameworks. The incorporation of diffusion into MAViL, combined with various training efficiency methodologies that include the utilization of a masking ratio curriculum and adaptive batch sizing, results in a notable 32% reduction in pre-training Floating-Point Operations (FLOPS) and an 18% decrease in pre-training wall clock time. Crucially, this enhanced efficiency does not compromise the model's performance in downstream audio-classification tasks when compared to MAViL's performance.
+
+
+
+ 39. 标题:Open-Fusion: Real-time Open-Vocabulary 3D Mapping and Queryable Scene Representation
+ 编号:[201]
+ 链接:https://arxiv.org/abs/2310.03923
+ 作者:Kashu Yamazaki, Taisei Hanyu, Khoa Vo, Thang Pham, Minh Tran, Gianfranco Doretto, Anh Nguyen, Ngan Le
+ 备注:
+ 关键词:pivotal in robotics, Signed Distance Function, Truncated Signed Distance, environmental mapping, Distance Function
+
+ 点击查看摘要
+ Precise 3D environmental mapping is pivotal in robotics. Existing methods often rely on predefined concepts during training or are time-intensive when generating semantic maps. This paper presents Open-Fusion, a groundbreaking approach for real-time open-vocabulary 3D mapping and queryable scene representation using RGB-D data. Open-Fusion harnesses the power of a pre-trained vision-language foundation model (VLFM) for open-set semantic comprehension and employs the Truncated Signed Distance Function (TSDF) for swift 3D scene reconstruction. By leveraging the VLFM, we extract region-based embeddings and their associated confidence maps. These are then integrated with 3D knowledge from TSDF using an enhanced Hungarian-based feature-matching mechanism. Notably, Open-Fusion delivers outstanding annotation-free 3D segmentation for open-vocabulary without necessitating additional 3D training. Benchmark tests on the ScanNet dataset against leading zero-shot methods highlight Open-Fusion's superiority. Furthermore, it seamlessly combines the strengths of region-based VLFM and TSDF, facilitating real-time 3D scene comprehension that includes object concepts and open-world semantics. We encourage the readers to view the demos on our project page: this https URL
+
+
+
+ 40. 标题:Coloring Deep CNN Layers with Activation Hue Loss
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2310.03911
+ 作者:Louis-François Bouchard, Mohsen Ben Lazreg, Matthew Toews
+ 备注:
+ 关键词:deep convolutional neural, convolutional neural network, effective learning, regularizing models, RGB intensity space
+
+ 点击查看摘要
+ This paper proposes a novel hue-like angular parameter to model the structure of deep convolutional neural network (CNN) activation space, referred to as the {\em activation hue}, for the purpose of regularizing models for more effective learning. The activation hue generalizes the notion of color hue angle in standard 3-channel RGB intensity space to $N$-channel activation space. A series of observations based on nearest neighbor indexing of activation vectors with pre-trained networks indicate that class-informative activations are concentrated about an angle $\theta$ in both the $(x,y)$ image plane and in multi-channel activation space. A regularization term in the form of hue-like angular $\theta$ labels is proposed to complement standard one-hot loss. Training from scratch using combined one-hot + activation hue loss improves classification performance modestly for a wide variety of classification tasks, including ImageNet.
+
+
+
+ 41. 标题:TWICE Dataset: Digital Twin of Test Scenarios in a Controlled Environment
+ 编号:[217]
+ 链接:https://arxiv.org/abs/2310.03895
+ 作者:Leonardo Novicki Neto, Fabio Reway, Yuri Poledna, Maikol Funk Drechsler, Eduardo Parente Ribeiro, Werner Huber, Christian Icking
+ 备注:8 pages, 13 figures, submitted to IEEE Sensors Journal
+ 关键词:adverse weather remains, adverse weather conditions, Ensuring the safe, significant challenge, adverse weather
+
+ 点击查看摘要
+ Ensuring the safe and reliable operation of autonomous vehicles under adverse weather remains a significant challenge. To address this, we have developed a comprehensive dataset composed of sensor data acquired in a real test track and reproduced in the laboratory for the same test scenarios. The provided dataset includes camera, radar, LiDAR, inertial measurement unit (IMU), and GPS data recorded under adverse weather conditions (rainy, night-time, and snowy conditions). We recorded test scenarios using objects of interest such as car, cyclist, truck and pedestrian -- some of which are inspired by EURONCAP (European New Car Assessment Programme). The sensor data generated in the laboratory is acquired by the execution of simulation-based tests in hardware-in-the-loop environment with the digital twin of each real test scenario. The dataset contains more than 2 hours of recording, which totals more than 280GB of data. Therefore, it is a valuable resource for researchers in the field of autonomous vehicles to test and improve their algorithms in adverse weather conditions, as well as explore the simulation-to-reality gap. The dataset is available for download at: this https URL
+
+
+
+ 42. 标题:Characterizing the Features of Mitotic Figures Using a Conditional Diffusion Probabilistic Model
+ 编号:[218]
+ 链接:https://arxiv.org/abs/2310.03893
+ 作者:Cagla Deniz Bahadir, Benjamin Liechty, David J. Pisapia, Mert R. Sabuncu
+ 备注:Accepted for Deep Generative Models Workshop at Medical Image Computing and Computer Assisted Intervention (MICCAI) 2023
+ 关键词:gold-standard independent ground-truth, clinically significant task, gold-standard independent, independent ground-truth, Mitotic figure detection
+
+ 点击查看摘要
+ Mitotic figure detection in histology images is a hard-to-define, yet clinically significant task, where labels are generated with pathologist interpretations and where there is no ``gold-standard'' independent ground-truth. However, it is well-established that these interpretation based labels are often unreliable, in part, due to differences in expertise levels and human subjectivity. In this paper, our goal is to shed light on the inherent uncertainty of mitosis labels and characterize the mitotic figure classification task in a human interpretable manner. We train a probabilistic diffusion model to synthesize patches of cell nuclei for a given mitosis label condition. Using this model, we can then generate a sequence of synthetic images that correspond to the same nucleus transitioning into the mitotic state. This allows us to identify different image features associated with mitosis, such as cytoplasm granularity, nuclear density, nuclear irregularity and high contrast between the nucleus and the cell body. Our approach offers a new tool for pathologists to interpret and communicate the features driving the decision to recognize a mitotic figure.
+
+
+
+ 43. 标题:Accelerated Neural Network Training with Rooted Logistic Objectives
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2310.03890
+ 作者:Zhu Wang, Praveen Raj Veluswami, Harsh Mishra, Sathya N. Ravi
+ 备注:
+ 关键词:real world scenarios, cross entropy based, real world, world scenarios, scenarios are trained
+
+ 点击查看摘要
+ Many neural networks deployed in the real world scenarios are trained using cross entropy based loss functions. From the optimization perspective, it is known that the behavior of first order methods such as gradient descent crucially depend on the separability of datasets. In fact, even in the most simplest case of binary classification, the rate of convergence depends on two factors: (1) condition number of data matrix, and (2) separability of the dataset. With no further pre-processing techniques such as over-parametrization, data augmentation etc., separability is an intrinsic quantity of the data distribution under consideration. We focus on the landscape design of the logistic function and derive a novel sequence of {\em strictly} convex functions that are at least as strict as logistic loss. The minimizers of these functions coincide with those of the minimum norm solution wherever possible. The strict convexity of the derived function can be extended to finetune state-of-the-art models and applications. In empirical experimental analysis, we apply our proposed rooted logistic objective to multiple deep models, e.g., fully-connected neural networks and transformers, on various of classification benchmarks. Our results illustrate that training with rooted loss function is converged faster and gains performance improvements. Furthermore, we illustrate applications of our novel rooted loss function in generative modeling based downstream applications, such as finetuning StyleGAN model with the rooted loss. The code implementing our losses and models can be found here for open source software development purposes: https://anonymous.4open.science/r/rooted_loss.
+
+
+
+ 44. 标题:Consistency Regularization Improves Placenta Segmentation in Fetal EPI MRI Time Series
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2310.03870
+ 作者:Yingcheng Liu, Neerav Karani, Neel Dey, S. Mazdak Abulnaga, Junshen Xu, P. Ellen Grant, Esra Abaci Turk, Polina Golland
+ 备注:
+ 关键词:fetal EPI MRI, EPI MRI time, EPI MRI, EPI MRI holds, fetal EPI
+
+ 点击查看摘要
+ The placenta plays a crucial role in fetal development. Automated 3D placenta segmentation from fetal EPI MRI holds promise for advancing prenatal care. This paper proposes an effective semi-supervised learning method for improving placenta segmentation in fetal EPI MRI time series. We employ consistency regularization loss that promotes consistency under spatial transformation of the same image and temporal consistency across nearby images in a time series. The experimental results show that the method improves the overall segmentation accuracy and provides better performance for outliers and hard samples. The evaluation also indicates that our method improves the temporal coherency of the prediction, which could lead to more accurate computation of temporal placental biomarkers. This work contributes to the study of the placenta and prenatal clinical decision-making. Code is available at this https URL.
+
+
+
+ 45. 标题:OpenIncrement: A Unified Framework for Open Set Recognition and Deep Class-Incremental Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2310.03848
+ 作者:Jiawen Xu, Claas Grohnfeldt, Odej Kao
+ 备注:
+ 关键词:neural network retraining, network retraining, pre-identified for neural, neural network, open set
+
+ 点击查看摘要
+ In most works on deep incremental learning research, it is assumed that novel samples are pre-identified for neural network retraining. However, practical deep classifiers often misidentify these samples, leading to erroneous predictions. Such misclassifications can degrade model performance. Techniques like open set recognition offer a means to detect these novel samples, representing a significant area in the machine learning domain.
+In this paper, we introduce a deep class-incremental learning framework integrated with open set recognition. Our approach refines class-incrementally learned features to adapt them for distance-based open set recognition. Experimental results validate that our method outperforms state-of-the-art incremental learning techniques and exhibits superior performance in open set recognition compared to baseline methods.
+
+
+
+ 46. 标题:Less is More: On the Feature Redundancy of Pretrained Models When Transferring to Few-shot Tasks
+ 编号:[237]
+ 链接:https://arxiv.org/abs/2310.03843
+ 作者:Xu Luo, Difan Zou, Lianli Gao, Zenglin Xu, Jingkuan Song
+ 备注:
+ 关键词:frozen features extracted, conducting linear probing, easy as conducting, classifier upon frozen, pretrained
+
+ 点击查看摘要
+ Transferring a pretrained model to a downstream task can be as easy as conducting linear probing with target data, that is, training a linear classifier upon frozen features extracted from the pretrained model. As there may exist significant gaps between pretraining and downstream datasets, one may ask whether all dimensions of the pretrained features are useful for a given downstream task. We show that, for linear probing, the pretrained features can be extremely redundant when the downstream data is scarce, or few-shot. For some cases such as 5-way 1-shot tasks, using only 1\% of the most important feature dimensions is able to recover the performance achieved by using the full representation. Interestingly, most dimensions are redundant only under few-shot settings and gradually become useful when the number of shots increases, suggesting that feature redundancy may be the key to characterizing the "few-shot" nature of few-shot transfer problems. We give a theoretical understanding of this phenomenon and show how dimensions with high variance and small distance between class centroids can serve as confounding factors that severely disturb classification results under few-shot settings. As an attempt at solving this problem, we find that the redundant features are difficult to identify accurately with a small number of training samples, but we can instead adjust feature magnitude with a soft mask based on estimated feature importance. We show that this method can generally improve few-shot transfer performance across various pretrained models and downstream datasets.
+
+
+
+ 47. 标题:Integrating Audio-Visual Features for Multimodal Deepfake Detection
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2310.03827
+ 作者:Sneha Muppalla, Shan Jia, Siwei Lyu
+ 备注:
+ 关键词:digitally modified, AI-generated media, image or video, detection, deepfake
+
+ 点击查看摘要
+ Deepfakes are AI-generated media in which an image or video has been digitally modified. The advancements made in deepfake technology have led to privacy and security issues. Most deepfake detection techniques rely on the detection of a single modality. Existing methods for audio-visual detection do not always surpass that of the analysis based on single modalities. Therefore, this paper proposes an audio-visual-based method for deepfake detection, which integrates fine-grained deepfake identification with binary classification. We categorize the samples into four types by combining labels specific to each single modality. This method enhances the detection under intra-domain and cross-domain testing.
+
+
+
+ 48. 标题:WLST: Weak Labels Guided Self-training for Weakly-supervised Domain Adaptation on 3D Object Detection
+ 编号:[248]
+ 链接:https://arxiv.org/abs/2310.03821
+ 作者:Tsung-Lin Tsou, Tsung-Han Wu, Winston H. Hsu
+ 备注:
+ 关键词:unsupervised domain adaptation, domain adaptation, weakly-supervised domain adaptation, work is dedicated, dedicated to unsupervised
+
+ 点击查看摘要
+ In the field of domain adaptation (DA) on 3D object detection, most of the work is dedicated to unsupervised domain adaptation (UDA). Yet, without any target annotations, the performance gap between the UDA approaches and the fully-supervised approach is still noticeable, which is impractical for real-world applications. On the other hand, weakly-supervised domain adaptation (WDA) is an underexplored yet practical task that only requires few labeling effort on the target domain. To improve the DA performance in a cost-effective way, we propose a general weak labels guided self-training framework, WLST, designed for WDA on 3D object detection. By incorporating autolabeler, which can generate 3D pseudo labels from 2D bounding boxes, into the existing self-training pipeline, our method is able to generate more robust and consistent pseudo labels that would benefit the training process on the target domain. Extensive experiments demonstrate the effectiveness, robustness, and detector-agnosticism of our WLST framework. Notably, it outperforms previous state-of-the-art methods on all evaluation tasks.
+
+
+
+ 49. 标题:Functional data learning using convolutional neural networks
+ 编号:[259]
+ 链接:https://arxiv.org/abs/2310.03773
+ 作者:Jose Galarza, Tamer Oraby
+ 备注:38 pages, 23 figures
+ 关键词:convolutional neural networks, functional data, convolutional neural, functional, neural networks
+
+ 点击查看摘要
+ In this paper, we show how convolutional neural networks (CNN) can be used in regression and classification learning problems of noisy and non-noisy functional data. The main idea is to transform the functional data into a 28 by 28 image. We use a specific but typical architecture of a convolutional neural network to perform all the regression exercises of parameter estimation and functional form classification. First, we use some functional case studies of functional data with and without random noise to showcase the strength of the new method. In particular, we use it to estimate exponential growth and decay rates, the bandwidths of sine and cosine functions, and the magnitudes and widths of curve peaks. We also use it to classify the monotonicity and curvatures of functional data, algebraic versus exponential growth, and the number of peaks of functional data. Second, we apply the same convolutional neural networks to Lyapunov exponent estimation in noisy and non-noisy chaotic data, in estimating rates of disease transmission from epidemic curves, and in detecting the similarity of drug dissolution profiles. Finally, we apply the method to real-life data to detect Parkinson's disease patients in a classification problem. The method, although simple, shows high accuracy and is promising for future use in engineering and medical applications.
+
+
+
+ 50. 标题:Convergent ADMM Plug and Play PET Image Reconstruction
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2310.04299
+ 作者:Florent Sureau, Mahdi Latreche, Marion Savanier, Claude Comtat
+ 备注:
+ 关键词:learnt Deep Neural, Deep Neural Network, Neural Network operator, hybrid PET reconstruction, investigate hybrid PET
+
+ 点击查看摘要
+ In this work, we investigate hybrid PET reconstruction algorithms based on coupling a model-based variational reconstruction and the application of a separately learnt Deep Neural Network operator (DNN) in an ADMM Plug and Play framework. Following recent results in optimization, fixed point convergence of the scheme can be achieved by enforcing an additional constraint on network parameters during learning. We propose such an ADMM algorithm and show in a realistic [18F]-FDG synthetic brain exam that the proposed scheme indeed lead experimentally to convergence to a meaningful fixed point. When the proposed constraint is not enforced during learning of the DNN, the proposed ADMM algorithm was observed experimentally not to converge.
+
+
+
+ 51. 标题:Whole Slide Multiple Instance Learning for Predicting Axillary Lymph Node Metastasis
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2310.04187
+ 作者:Glejdis Shkëmbi, Johanna P. Müller, Zhe Li, Katharina Breininger, Peter Schüffler, Bernhard Kainz
+ 备注:Accepted for MICCAI DEMI Workshop 2023
+ 关键词:women health globally, axillary lymph node, Breast cancer, health globally, lymph node
+
+ 点击查看摘要
+ Breast cancer is a major concern for women's health globally, with axillary lymph node (ALN) metastasis identification being critical for prognosis evaluation and treatment guidance. This paper presents a deep learning (DL) classification pipeline for quantifying clinical information from digital core-needle biopsy (CNB) images, with one step less than existing methods. A publicly available dataset of 1058 patients was used to evaluate the performance of different baseline state-of-the-art (SOTA) DL models in classifying ALN metastatic status based on CNB images. An extensive ablation study of various data augmentation techniques was also conducted. Finally, the manual tumor segmentation and annotation step performed by the pathologists was assessed.
+
+
+
+ 52. 标题:Aorta Segmentation from 3D CT in MICCAI SEG.A. 2023 Challenge
+ 编号:[286]
+ 链接:https://arxiv.org/abs/2310.04114
+ 作者:Andriy Myronenko, Dong Yang, Yufan He, Daguang Xu
+ 备注:MICCAI 2023, SEG.A. 2023 challenge 1st place
+ 关键词:main blood supply, main blood, blood supply, Aorta, early aortic disease
+
+ 点击查看摘要
+ Aorta provides the main blood supply of the body. Screening of aorta with imaging helps for early aortic disease detection and monitoring. In this work, we describe our solution to the Segmentation of the Aorta (SEG.A.231) from 3D CT challenge. We use automated segmentation method Auto3DSeg available in MONAI. Our solution achieves an average Dice score of 0.920 and 95th percentile of the Hausdorff Distance (HD95) of 6.013, which ranks first and wins the SEG.A. 2023 challenge.
+
+
+
+ 53. 标题:FNOSeg3D: Resolution-Robust 3D Image Segmentation with Fourier Neural Operator
+ 编号:[296]
+ 链接:https://arxiv.org/abs/2310.03872
+ 作者:Ken C. L. Wong, Hongzhi Wang, Tanveer Syeda-Mahmood
+ 备注:This paper was accepted by the IEEE International Symposium on Biomedical Imaging (ISBI) 2023
+ 关键词:medical image segmentation, computational complexity, common remedy, training image resolution, downsampled images
+
+ 点击查看摘要
+ Due to the computational complexity of 3D medical image segmentation, training with downsampled images is a common remedy for out-of-memory errors in deep learning. Nevertheless, as standard spatial convolution is sensitive to variations in image resolution, the accuracy of a convolutional neural network trained with downsampled images can be suboptimal when applied on the original resolution. To address this limitation, we introduce FNOSeg3D, a 3D segmentation model robust to training image resolution based on the Fourier neural operator (FNO). The FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We improve the FNO by reducing its parameter requirement and enhancing its learning capability through residual connections and deep supervision, and these result in our FNOSeg3D model which is parameter efficient and resolution robust. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
+
+
+
+ 54. 标题:Enhancing Healthcare with EOG: A Novel Approach to Sleep Stage Classification
+ 编号:[305]
+ 链接:https://arxiv.org/abs/2310.03757
+ 作者:Suvadeep Maiti, Shivam Kumar Sharma, Raju S. Bapi
+ 备注:
+ 关键词:EEG data acquisition, addressing the discomfort, data acquisition, raw EOG signal, introduce an innovative
+
+ 点击查看摘要
+ We introduce an innovative approach to automated sleep stage classification using EOG signals, addressing the discomfort and impracticality associated with EEG data acquisition. In addition, it is important to note that this approach is untapped in the field, highlighting its potential for novel insights and contributions. Our proposed SE-Resnet-Transformer model provides an accurate classification of five distinct sleep stages from raw EOG signal. Extensive validation on publically available databases (SleepEDF-20, SleepEDF-78, and SHHS) reveals noteworthy performance, with macro-F1 scores of 74.72, 70.63, and 69.26, respectively. Our model excels in identifying REM sleep, a crucial aspect of sleep disorder investigations. We also provide insight into the internal mechanisms of our model using techniques such as 1D-GradCAM and t-SNE plots. Our method improves the accessibility of sleep stage classification while decreasing the need for EEG modalities. This development will have promising implications for healthcare and the incorporation of wearable technology into sleep studies, thereby advancing the field's potential for enhanced diagnostics and patient comfort.
+
+
+自然语言处理
+
+ 1. 标题:RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2310.04408
+ 作者:Fangyuan Xu, Weijia Shi, Eunsol Choi
+ 备注:
+ 关键词:retrieved documents, inference time improves, documents, wide range, inference time
+
+ 点击查看摘要
+ Retrieving documents and prepending them in-context at inference time improves performance of language model (LMs) on a wide range of tasks. However, these documents, often spanning hundreds of words, make inference substantially more expensive. We propose compressing the retrieved documents into textual summaries prior to in-context integration. This not only reduces the computational costs but also relieves the burden of LMs to identify relevant information in long retrieved documents. We present two compressors -- an extractive compressor which selects useful sentences from retrieved documents and an abstractive compressor which generates summaries by synthesizing information from multiple documents. Both compressors are trained to improve LMs' performance on end tasks when the generated summaries are prepended to the LMs' input, while keeping the summary concise.If the retrieved documents are irrelevant to the input or offer no additional information to LM, our compressor can return an empty string, implementing selective augmentation.We evaluate our approach on language modeling task and open domain question answering task. We achieve a compression rate of as low as 6% with minimal loss in performance for both tasks, significantly outperforming the off-the-shelf summarization models. We show that our compressors trained for one LM can transfer to other LMs on the language modeling task and provide summaries largely faithful to the retrieved documents.
+
+
+
+ 2. 标题:Policy-Gradient Training of Language Models for Ranking
+ 编号:[10]
+ 链接:https://arxiv.org/abs/2310.04407
+ 作者:Ge Gao, Jonathan D. Chang, Claire Cardie, Kianté Brantley, Thorsten Joachim
+ 备注:
+ 关键词:incorporating factual knowledge, chat-based web search, Text retrieval plays, language processing pipelines, ranging from chat-based
+
+ 点击查看摘要
+ Text retrieval plays a crucial role in incorporating factual knowledge for decision making into language processing pipelines, ranging from chat-based web search to question answering systems. Current state-of-the-art text retrieval models leverage pre-trained large language models (LLMs) to achieve competitive performance, but training LLM-based retrievers via typical contrastive losses requires intricate heuristics, including selecting hard negatives and using additional supervision as learning signals. This reliance on heuristics stems from the fact that the contrastive loss itself is heuristic and does not directly optimize the downstream metrics of decision quality at the end of the processing pipeline. To address this issue, we introduce Neural PG-RANK, a novel training algorithm that learns to rank by instantiating a LLM as a Plackett-Luce ranking policy. Neural PG-RANK provides a principled method for end-to-end training of retrieval models as part of larger decision systems via policy gradient, with little reliance on complex heuristics, and it effectively unifies the training objective with downstream decision-making quality. We conduct extensive experiments on various text retrieval benchmarks. The results demonstrate that when the training objective aligns with the evaluation setup, Neural PG-RANK yields remarkable in-domain performance improvement, with substantial out-of-domain generalization to some critical datasets employed in downstream question answering tasks.
+
+
+
+ 3. 标题:Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2310.04406
+ 作者:Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, Yu-Xiong Wang
+ 备注:Website and code can be found at this https URL
+ 关键词:large language models, demonstrated impressive performance, simple acting processes, Language Agent Tree, Agent Tree Search
+
+ 点击查看摘要
+ While large language models (LLMs) have demonstrated impressive performance on a range of decision-making tasks, they rely on simple acting processes and fall short of broad deployment as autonomous agents. We introduce LATS (Language Agent Tree Search), a general framework that synergizes the capabilities of LLMs in planning, acting, and reasoning. Drawing inspiration from Monte Carlo tree search in model-based reinforcement learning, LATS employs LLMs as agents, value functions, and optimizers, repurposing their latent strengths for enhanced decision-making. What is crucial in this method is the use of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that moves beyond the limitations of existing techniques. Our experimental evaluation across diverse domains, such as programming, HotPotQA, and WebShop, illustrates the applicability of LATS for both reasoning and acting. In particular, LATS achieves 94.4\% for programming on HumanEval with GPT-4 and an average score of 75.9 for web browsing on WebShop with GPT-3.5, demonstrating the effectiveness and generality of our method.
+
+
+
+ 4. 标题:Improving Stability in Simultaneous Speech Translation: A Revision-Controllable Decoding Approach
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2310.04399
+ 作者:Junkun Chen, Jian Xue, Peidong Wang, Jing Pan, Jinyu Li
+ 备注:accepted by ASRU 2023
+ 关键词:real-time crosslingual communication, crosslingual communication, serves a critical, critical role, role in real-time
+
+ 点击查看摘要
+ Simultaneous Speech-to-Text translation serves a critical role in real-time crosslingual communication. Despite the advancements in recent years, challenges remain in achieving stability in the translation process, a concern primarily manifested in the flickering of partial results. In this paper, we propose a novel revision-controllable method designed to address this issue. Our method introduces an allowed revision window within the beam search pruning process to screen out candidate translations likely to cause extensive revisions, leading to a substantial reduction in flickering and, crucially, providing the capability to completely eliminate flickering. The experiments demonstrate the proposed method can significantly improve the decoding stability without compromising substantially on the translation quality.
+
+
+
+ 5. 标题:Hermes: Unlocking Security Analysis of Cellular Network Protocols by Synthesizing Finite State Machines from Natural Language Specifications
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2310.04381
+ 作者:Abdullah Al Ishtiaq, Sarkar Snigdha Sarathi Das, Syed Md Mukit Rashid, Ali Ranjbar, Kai Tu, Tianwei Wu, Zhezheng Song, Weixuan Wang, Mujtahid Akon, Rui Zhang, Syed Rafiul Hussain
+ 备注:Accepted at USENIX Security 24
+ 关键词:natural language cellular, framework to automatically, representations from natural, automatically generate formal, generate formal representations
+
+ 点击查看摘要
+ In this paper, we present Hermes, an end-to-end framework to automatically generate formal representations from natural language cellular specifications. We first develop a neural constituency parser, NEUTREX, to process transition-relevant texts and extract transition components (i.e., states, conditions, and actions). We also design a domain-specific language to translate these transition components to logical formulas by leveraging dependency parse trees. Finally, we compile these logical formulas to generate transitions and create the formal model as finite state machines. To demonstrate the effectiveness of Hermes, we evaluate it on 4G NAS, 5G NAS, and 5G RRC specifications and obtain an overall accuracy of 81-87%, which is a substantial improvement over the state-of-the-art. Our security analysis of the extracted models uncovers 3 new vulnerabilities and identifies 19 previous attacks in 4G and 5G specifications, and 7 deviations in commercial 4G basebands.
+
+
+
+ 6. 标题:Amortizing intractable inference in large language models
+ 编号:[25]
+ 链接:https://arxiv.org/abs/2310.04363
+ 作者:Edward J. Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, Nikolay Malkin
+ 备注:23 pages; code: this https URL
+ 关键词:large language models, Autoregressive large language, next-token conditional distributions, language models, large language
+
+ 点击查看摘要
+ Autoregressive large language models (LLMs) compress knowledge from their training data through next-token conditional distributions. This limits tractable querying of this knowledge to start-to-end autoregressive sampling. However, many tasks of interest -- including sequence continuation, infilling, and other forms of constrained generation -- involve sampling from intractable posterior distributions. We address this limitation by using amortized Bayesian inference to sample from these intractable posteriors. Such amortization is algorithmically achieved by fine-tuning LLMs via diversity-seeking reinforcement learning algorithms: generative flow networks (GFlowNets). We empirically demonstrate that this distribution-matching paradigm of LLM fine-tuning can serve as an effective alternative to maximum-likelihood training and reward-maximizing policy optimization. As an important application, we interpret chain-of-thought reasoning as a latent variable modeling problem and demonstrate that our approach enables data-efficient adaptation of LLMs to tasks that require multi-step rationalization and tool use.
+
+
+
+ 7. 标题:Transferring speech-generic and depression-specific knowledge for Alzheimer's disease detection
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2310.04358
+ 作者:Ziyun Cui, Wen Wu, Wei-Qiang Zhang, Ji Wu, Chao Zhang
+ 备注:8 pages, 4 figures. Accepted by ASRU 2023
+ 关键词:attracted increasing attention, Alzheimer disease, training data remains, attracted increasing, increasing attention
+
+ 点击查看摘要
+ The detection of Alzheimer's disease (AD) from spontaneous speech has attracted increasing attention while the sparsity of training data remains an important issue. This paper handles the issue by knowledge transfer, specifically from both speech-generic and depression-specific knowledge. The paper first studies sequential knowledge transfer from generic foundation models pretrained on large amounts of speech and text data. A block-wise analysis is performed for AD diagnosis based on the representations extracted from different intermediate blocks of different foundation models. Apart from the knowledge from speech-generic representations, this paper also proposes to simultaneously transfer the knowledge from a speech depression detection task based on the high comorbidity rates of depression and AD. A parallel knowledge transfer framework is studied that jointly learns the information shared between these two tasks. Experimental results show that the proposed method improves AD and depression detection, and produces a state-of-the-art F1 score of 0.928 for AD diagnosis on the commonly used ADReSSo dataset.
+
+
+
+ 8. 标题:Large-Scale Korean Text Dataset for Classifying Biased Speech in Real-World Online Services
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2310.04313
+ 作者:Dasol Choi, Jooyoung Song, Eunsun Lee, Jinwoo Seo, Heejune Park, Dongbin Na
+ 备注:13 pages
+ 关键词:increasingly evident, sentiment analysis, South Korean SNS, online services, advanced text classification
+
+ 点击查看摘要
+ With the growth of online services, the need for advanced text classification algorithms, such as sentiment analysis and biased text detection, has become increasingly evident. The anonymous nature of online services often leads to the presence of biased and harmful language, posing challenges to maintaining the health of online communities. This phenomenon is especially relevant in South Korea, where large-scale hate speech detection algorithms have not yet been broadly explored. In this paper, we introduce a new comprehensive, large-scale dataset collected from a well-known South Korean SNS platform. Our proposed dataset provides annotations including (1) Preferences, (2) Profanities, and (3) Nine types of Bias for the text samples, enabling multi-task learning for simultaneous classification of user-generated texts. Leveraging state-of-the-art BERT-based language models, our approach surpasses human-level accuracy across diverse classification tasks, as measured by various metrics. Beyond academic contributions, our work can provide practical solutions for real-world hate speech and bias mitigation, contributing directly to the improvement of online community health. Our work provides a robust foundation for future research aiming to improve the quality of online discourse and foster societal well-being. All source codes and datasets are publicly accessible at this https URL.
+
+
+
+ 9. 标题:A Comprehensive Evaluation of Large Language Models on Benchmark Biomedical Text Processing Tasks
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2310.04270
+ 作者:Israt Jahan, Md Tahmid Rahman Laskar, Chun Peng, Jimmy Huang
+ 备注:arXiv admin note: substantial text overlap with arXiv:2306.04504
+ 关键词:Large Language Models, demonstrated impressive capability, Language Models, Large Language, biomedical
+
+ 点击查看摘要
+ Recently, Large Language Models (LLM) have demonstrated impressive capability to solve a wide range of tasks. However, despite their success across various tasks, no prior work has investigated their capability in the biomedical domain yet. To this end, this paper aims to evaluate the performance of LLMs on benchmark biomedical tasks. For this purpose, we conduct a comprehensive evaluation of 4 popular LLMs in 6 diverse biomedical tasks across 26 datasets. To the best of our knowledge, this is the first work that conducts an extensive evaluation and comparison of various LLMs in the biomedical domain. Interestingly, we find based on our evaluation that in biomedical datasets that have smaller training sets, zero-shot LLMs even outperform the current state-of-the-art fine-tuned biomedical models. This suggests that pretraining on large text corpora makes LLMs quite specialized even in the biomedical domain. We also find that not a single LLM can outperform other LLMs in all tasks, with the performance of different LLMs may vary depending on the task. While their performance is still quite poor in comparison to the biomedical models that were fine-tuned on large training sets, our findings demonstrate that LLMs have the potential to be a valuable tool for various biomedical tasks that lack large annotated data.
+
+
+
+ 10. 标题:Written and spoken corpus of real and fake social media postings about COVID-19
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2310.04237
+ 作者:Ng Bee Chin, Ng Zhi Ee Nicole, Kyla Kwan, Lee Yong Han Dylann, Liu Fang, Xu Hong
+ 备注:9 pages, 3 tables
+ 关键词:data, fake, study, study investigates, real
+
+ 点击查看摘要
+ This study investigates the linguistic traits of fake news and real news. There are two parts to this study: text data and speech data. The text data for this study consisted of 6420 COVID-19 related tweets re-filtered from Patwa et al. (2021). After cleaning, the dataset contained 3049 tweets, with 2161 labeled as 'real' and 888 as 'fake'. The speech data for this study was collected from TikTok, focusing on COVID-19 related videos. Research assistants fact-checked each video's content using credible sources and labeled them as 'Real', 'Fake', or 'Questionable', resulting in a dataset of 91 real entries and 109 fake entries from 200 TikTok videos with a total word count of 53,710 words. The data was analysed using the Linguistic Inquiry and Word Count (LIWC) software to detect patterns in linguistic data. The results indicate a set of linguistic features that distinguish fake news from real news in both written and speech data. This offers valuable insights into the role of language in shaping trust, social media interactions, and the propagation of fake news.
+
+
+
+ 11. 标题:Keyword Augmented Retrieval: Novel framework for Information Retrieval integrated with speech interface
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2310.04205
+ 作者:Anupam Purwar, Rahul Sundar
+ 备注:
+ 关键词:low cost manner, knowledge retrieval automation, Language models, quick and low, manner without hallucinations
+
+ 点击查看摘要
+ Retrieving answers in a quick and low cost manner without hallucinations from a combination of structured and unstructured data using Language models is a major hurdle which prevents employment of Language models in knowledge retrieval automation. This becomes accentuated when one wants to integrate a speech interface. Besides, for commercial search and chatbot applications, complete reliance on commercial large language models (LLMs) like GPT 3.5 etc. can be very costly. In this work, authors have addressed this problem by first developing a keyword based search framework which augments discovery of the context to be provided to the large language model. The keywords in turn are generated by LLM and cached for comparison with keywords generated by LLM against the query raised. This significantly reduces time and cost to find the context within documents. Once the context is set, LLM uses that to provide answers based on a prompt tailored for Q&A. This research work demonstrates that use of keywords in context identification reduces the overall inference time and cost of information retrieval. Given this reduction in inference time and cost with the keyword augmented retrieval framework, a speech based interface for user input and response readout was integrated. This allowed a seamless interaction with the language model.
+
+
+
+ 12. 标题:mlirSynth: Automatic, Retargetable Program Raising in Multi-Level IR using Program Synthesis
+ 编号:[88]
+ 链接:https://arxiv.org/abs/2310.04196
+ 作者:Alexander Brauckmann, Elizabeth Polgreen, Tobias Grosser, Michael F. P. O'Boyle
+ 备注:
+ 关键词:emerging compiler infrastructure, lower-level general purpose, general purpose languages, MLIR high-performance compilation, MLIR dialects
+
+ 点击查看摘要
+ MLIR is an emerging compiler infrastructure for modern hardware, but existing programs cannot take advantage of MLIR's high-performance compilation if they are described in lower-level general purpose languages. Consequently, to avoid programs needing to be rewritten manually, this has led to efforts to automatically raise lower-level to higher-level dialects in MLIR. However, current methods rely on manually-defined raising rules, which limit their applicability and make them challenging to maintain as MLIR dialects evolve.
+We present mlirSynth -- a novel approach which translates programs from lower-level MLIR dialects to high-level ones without manually defined rules. Instead, it uses available dialect definitions to construct a program space and searches it effectively using type constraints and equivalences. We demonstrate its effectiveness \revi{by raising C programs} to two distinct high-level MLIR dialects, which enables us to use existing high-level dialect specific compilation flows. On Polybench, we show a greater coverage than previous approaches, resulting in geomean speedups of 2.5x (Intel) and 3.4x (AMD) over state-of-the-art compilation flows for the C programming language. mlirSynth also enables retargetability to domain-specific accelerators, resulting in a geomean speedup of 21.6x on a TPU.
+
+
+
+ 13. 标题:Automatic Aspect Extraction from Scientific Texts
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2310.04074
+ 作者:Anna Marshalova, Elena Bruches, Tatiana Batura
+ 备注:
+ 关键词:scientific literature review, key insights, main points, important information, literature review
+
+ 点击查看摘要
+ Being able to extract from scientific papers their main points, key insights, and other important information, referred to here as aspects, might facilitate the process of conducting a scientific literature review. Therefore, the aim of our research is to create a tool for automatic aspect extraction from Russian-language scientific texts of any domain. In this paper, we present a cross-domain dataset of scientific texts in Russian, annotated with such aspects as Task, Contribution, Method, and Conclusion, as well as a baseline algorithm for aspect extraction, based on the multilingual BERT model fine-tuned on our data. We show that there are some differences in aspect representation in different domains, but even though our model was trained on a limited number of scientific domains, it is still able to generalize to new domains, as was proved by cross-domain experiments. The code and the dataset are available at \url{this https URL}.
+
+
+
+ 14. 标题:How to Capture Higher-order Correlations? Generalizing Matrix Softmax Attention to Kronecker Computation
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2310.04064
+ 作者:Josh Alman, Zhao Song
+ 备注:
+ 关键词:transformer attention scheme, classical transformer attention, exp, top, size matrices
+
+ 点击查看摘要
+ In the classical transformer attention scheme, we are given three $n \times d$ size matrices $Q, K, V$ (the query, key, and value tokens), and the goal is to compute a new $n \times d$ size matrix $D^{-1} \exp(QK^\top) V$ where $D = \mathrm{diag}( \exp(QK^\top) {\bf 1}_n )$. In this work, we study a generalization of attention which captures triple-wise correlations. This generalization is able to solve problems about detecting triple-wise connections that were shown to be impossible for transformers. The potential downside of this generalization is that it appears as though computations are even more difficult, since the straightforward algorithm requires cubic time in $n$. However, we show that in the bounded-entry setting (which arises in practice, and which is well-studied in both theory and practice), there is actually a near-linear time algorithm. More precisely, we show that bounded entries are both necessary and sufficient for quickly performing generalized computations:
+$\bullet$ On the positive side, if all entries of the input matrices are bounded above by $o(\sqrt[3]{\log n})$ then we show how to approximate the ``tensor-type'' attention matrix in $n^{1+o(1)}$ time.
+$\bullet$ On the negative side, we show that if the entries of the input matrices may be as large as $\Omega(\sqrt[3]{\log n})$, then there is no algorithm that runs faster than $n^{3-o(1)}$ (assuming the Strong Exponential Time Hypothesis from fine-grained complexity theory).
+We also show that our construction, algorithms, and lower bounds naturally generalize to higher-order tensors and correlations. Interestingly, the higher the order of the tensors, the lower the bound on the entries needs to be for an efficient algorithm. Our results thus yield a natural tradeoff between the boundedness of the entries, and order of the tensor one may use for more expressive, efficient attention computation.
+
+
+
+ 15. 标题:Analysis of the Reasoning with Redundant Information Provided Ability of Large Language Models
+ 编号:[148]
+ 链接:https://arxiv.org/abs/2310.04039
+ 作者:Wenbei Xie
+ 备注:
+ 关键词:Artificial General Intelligence, achieving Artificial General, Large Language Models, natural language processing, General Intelligence
+
+ 点击查看摘要
+ Recent advancements in Large Language Models (LLMs) have demonstrated impressive capabilities across a range of natural language processing tasks, especially in reasoning, a cornerstone for achieving Artificial General Intelligence (AGI). However, commonly used benchmarks may not fully encapsulate the inferential abilities of these models in real-world scenarios. To address this gap, a new form of Question-Answering (QA) task, termed Reasoning with Redundant Information Provided (RRIP), is introduced. The study designed a modified version of the grade school math 8K (GSM-8K) dataset which has several variants focusing on different attributes of redundant information. This investigation evaluates two popular LLMs, LlaMA2-13B-chat and generative pre-trained transformer 3.5 (GPT-3.5), contrasting their performance on traditional QA tasks against the RRIP tasks. Findings indicate that while these models achieved moderate success on standard QA benchmarks, their performance notably declines when assessed on RRIP tasks. The study not only highlights the limitations of current LLMs in handling redundant information but also suggests that future training of these models should focus on incorporating redundant information into the training data to increase the performance on RRIP tasks.
+
+
+
+ 16. 标题:Enhancing Financial Sentiment Analysis via Retrieval Augmented Large Language Models
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2310.04027
+ 作者:Boyu Zhang, Hongyang Yang, Tianyu Zhou, Ali Babar, Xiao-Yang Liu
+ 备注:ACM International Conference on AI in Finance (ICAIF) 2023
+ 关键词:Large Language Models, investment decision-making, Financial sentiment analysis, critical for valuation, valuation and investment
+
+ 点击查看摘要
+ Financial sentiment analysis is critical for valuation and investment decision-making. Traditional NLP models, however, are limited by their parameter size and the scope of their training datasets, which hampers their generalization capabilities and effectiveness in this field. Recently, Large Language Models (LLMs) pre-trained on extensive corpora have demonstrated superior performance across various NLP tasks due to their commendable zero-shot abilities. Yet, directly applying LLMs to financial sentiment analysis presents challenges: The discrepancy between the pre-training objective of LLMs and predicting the sentiment label can compromise their predictive performance. Furthermore, the succinct nature of financial news, often devoid of sufficient context, can significantly diminish the reliability of LLMs' sentiment analysis. To address these challenges, we introduce a retrieval-augmented LLMs framework for financial sentiment analysis. This framework includes an instruction-tuned LLMs module, which ensures LLMs behave as predictors of sentiment labels, and a retrieval-augmentation module which retrieves additional context from reliable external sources. Benchmarked against traditional models and LLMs like ChatGPT and LLaMA, our approach achieves 15\% to 48\% performance gain in accuracy and F1 score.
+
+
+
+ 17. 标题:SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation
+ 编号:[167]
+ 链接:https://arxiv.org/abs/2310.03991
+ 作者:Abe Bohan Hou, Jingyu Zhang, Tianxing He, Yichen Wang, Yung-Sung Chuang, Hongwei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, Yulia Tsvetkov
+ 备注:
+ 关键词:semantic watermarking algorithm, sentence-level semantic watermarking, watermarking algorithm based, Existing watermarking algorithms, token-level design
+
+ 点击查看摘要
+ Existing watermarking algorithms are vulnerable to paraphrase attacks because of their token-level design. To address this issue, we propose SemStamp, a robust sentence-level semantic watermarking algorithm based on locality-sensitive hashing (LSH), which partitions the semantic space of sentences. The algorithm encodes and LSH-hashes a candidate sentence generated by an LLM, and conducts sentence-level rejection sampling until the sampled sentence falls in watermarked partitions in the semantic embedding space. A margin-based constraint is used to enhance its robustness. To show the advantages of our algorithm, we propose a "bigram" paraphrase attack using the paraphrase that has the fewest bigram overlaps with the original sentence. This attack is shown to be effective against the existing token-level watermarking method. Experimental results show that our novel semantic watermark algorithm is not only more robust than the previous state-of-the-art method on both common and bigram paraphrase attacks, but also is better at preserving the quality of generation.
+
+
+
+ 18. 标题:Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2310.03985
+ 作者:Zih-Jyun Lin, Yi-Ju Chen, Po-Chih Kuo, Likai Huang, Chaur-Jong Hu, Cheng-Yu Chen
+ 备注:submitted to IEEE ICASSP 2024
+ 关键词:Dementia diagnosis requires, testing methods, complex and time-consuming, diagnosis requires, requires a series
+
+ 点击查看摘要
+ Dementia diagnosis requires a series of different testing methods, which is complex and time-consuming. Early detection of dementia is crucial as it can prevent further deterioration of the condition. This paper utilizes a speech recognition model to construct a dementia assessment system tailored for Mandarin speakers during the picture description task. By training an attention-based speech recognition model on voice data closely resembling real-world scenarios, we have significantly enhanced the model's recognition capabilities. Subsequently, we extracted the encoder from the speech recognition model and added a linear layer for dementia assessment. We collected Mandarin speech data from 99 subjects and acquired their clinical assessments from a local hospital. We achieved an accuracy of 92.04% in Alzheimer's disease detection and a mean absolute error of 9% in clinical dementia rating score prediction.
+
+
+
+ 19. 标题:HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
+ 编号:[175]
+ 链接:https://arxiv.org/abs/2310.03975
+ 作者:Takashi Maekaku, Jiatong Shi, Xuankai Chang, Yuya Fujita, Shinji Watanabe
+ 备注:Submitted to IEEE ICASSP 2024
+ 关键词:usefulness of self-supervised, self-supervised representation learning, SSRL, semantic, self-supervised representation
+
+ 点击查看摘要
+ Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
+
+
+
+ 20. 标题:Quantized Transformer Language Model Implementations on Edge Devices
+ 编号:[176]
+ 链接:https://arxiv.org/abs/2310.03971
+ 作者:Mohammad Wali Ur Rahman, Murad Mehrab Abrar, Hunter Gibbons Copening, Salim Hariri, Sicong Shao, Pratik Satam, Soheil Salehi
+ 备注:Accepted for publication on 22nd International Conference of Machine Learning and Applications, ICMLA 2023
+ 关键词:Bidirectional Encoder Representations, Natural Language Processing, downstream NLP task, Representations from Transformers, Bidirectional Encoder
+
+ 点击查看摘要
+ Large-scale transformer-based models like the Bidirectional Encoder Representations from Transformers (BERT) are widely used for Natural Language Processing (NLP) applications, wherein these models are initially pre-trained with a large corpus with millions of parameters and then fine-tuned for a downstream NLP task. One of the major limitations of these large-scale models is that they cannot be deployed on resource-constrained devices due to their large model size and increased inference latency. In order to overcome these limitations, such large-scale models can be converted to an optimized FlatBuffer format, tailored for deployment on resource-constrained edge devices. Herein, we evaluate the performance of such FlatBuffer transformed MobileBERT models on three different edge devices, fine-tuned for Reputation analysis of English language tweets in the RepLab 2013 dataset. In addition, this study encompassed an evaluation of the deployed models, wherein their latency, performance, and resource efficiency were meticulously assessed. Our experiment results show that, compared to the original BERT large model, the converted and quantized MobileBERT models have 160$\times$ smaller footprints for a 4.1% drop in accuracy while analyzing at least one tweet per second on edge devices. Furthermore, our study highlights the privacy-preserving aspect of TinyML systems as all data is processed locally within a serverless environment.
+
+
+
+ 21. 标题:Thought Propagation: An Analogical Approach to Complex Reasoning with Large Language Models
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2310.03965
+ 作者:Junchi Yu, Ran He, Rex Ying
+ 备注:
+ 关键词:Large Language Models, Language Models, achieved remarkable success, Large Language, analogous problems
+
+ 点击查看摘要
+ Large Language Models (LLMs) have achieved remarkable success in reasoning tasks with the development of prompting methods. However, existing prompting approaches cannot reuse insights of solving similar problems and suffer from accumulated errors in multi-step reasoning, since they prompt LLMs to reason \textit{from scratch}. To address these issues, we propose \textbf{\textit{Thought Propagation} (TP)}, which explores the analogous problems and leverages their solutions to enhance the complex reasoning ability of LLMs. These analogous problems are related to the input one, with reusable solutions and problem-solving strategies. Thus, it is promising to propagate insights of solving previous analogous problems to inspire new problem-solving. To achieve this, TP first prompts LLMs to propose and solve a set of analogous problems that are related to the input one. Then, TP reuses the results of analogous problems to directly yield a new solution or derive a knowledge-intensive plan for execution to amend the initial solution obtained from scratch. TP is compatible with existing prompting approaches, allowing plug-and-play generalization and enhancement in a wide range of tasks without much labor in task-specific prompt engineering. Experiments across three challenging tasks demonstrate TP enjoys a substantial improvement over the baselines by an average of 12\% absolute increase in finding the optimal solutions in Shortest-path Reasoning, 13\% improvement of human preference in Creative Writing, and 15\% enhancement in the task completion rate of LLM-Agent Planning.
+
+
+
+ 22. 标题:Chain of Natural Language Inference for Reducing Large Language Model Ungrounded Hallucinations
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2310.03951
+ 作者:Deren Lei, Yaxi Li, Mengya (Mia)Hu, Mingyu Wang, Vincent Yun, Emily Ching, Eslam Kamal
+ 备注:The source code is available at this https URL
+ 关键词:Large language models, fluent natural language, generate fluent natural, relevant documents, documents as background
+
+ 点击查看摘要
+ Large language models (LLMs) can generate fluent natural language texts when given relevant documents as background context. This ability has attracted considerable interest in developing industry applications of LLMs. However, LLMs are prone to generate hallucinations that are not supported by the provided sources. In this paper, we propose a hierarchical framework to detect and mitigate such ungrounded hallucination. Our framework uses Chain of Natural Language Inference (CoNLI) for hallucination detection and hallucination reduction via post-editing. Our approach achieves state-of-the-art performance on hallucination detection and enhances text quality through rewrite, using LLMs without any fine-tuning or domain-specific prompt engineering. We show that this simple plug-and-play framework can serve as an effective choice for hallucination detection and reduction, achieving competitive performance across various contexts.
+
+
+
+ 23. 标题:Exploring the evolution of research topics during the COVID-19 pandemic
+ 编号:[198]
+ 链接:https://arxiv.org/abs/2310.03928
+ 作者:Francesco Invernici, Anna Bernasconi, Stefano Ceri
+ 备注:16 pages, 6 figures, 1 table
+ 关键词:Open Research Dataset, pandemic has changed, variety of domains, overwhelming production, research agendas
+
+ 点击查看摘要
+ The COVID-19 pandemic has changed the research agendas of most scientific communities, resulting in an overwhelming production of research articles in a variety of domains, including medicine, virology, epidemiology, economy, psychology, and so on. Several open-access corpora and literature hubs were established; among them, the COVID-19 Open Research Dataset (CORD-19) has systematically gathered scientific contributions for 2.5 years, by collecting and indexing over one million articles. Here, we present the CORD-19 Topic Visualizer (CORToViz), a method and associated visualization tool for inspecting the CORD-19 textual corpus of scientific abstracts. Our method is based upon a careful selection of up-to-date technologies (including large language models), resulting in an architecture for clustering articles along orthogonal dimensions and extraction techniques for temporal topic mining. Topic inspection is supported by an interactive dashboard, providing fast, one-click visualization of topic contents as word clouds and topic trends as time series, equipped with easy-to-drive statistical testing for analyzing the significance of topic emergence along arbitrarily selected time windows. The processes of data preparation and results visualization are completely general and virtually applicable to any corpus of textual documents - thus suited for effective adaptation to other contexts.
+
+
+
+ 24. 标题:Evaluating Multi-Agent Coordination Abilities in Large Language Models
+ 编号:[212]
+ 链接:https://arxiv.org/abs/2310.03903
+ 作者:Saaket Agashe, Yue Fan, Xin Eric Wang
+ 备注:
+ 关键词:enabling effective collaboration, develop agents proficient, Large Language Models, enabling effective, pivotal aim
+
+ 点击查看摘要
+ A pivotal aim in contemporary AI research is to develop agents proficient in multi-agent coordination, enabling effective collaboration with both humans and other systems. Large Language Models (LLMs), with their notable ability to understand, generate, and interpret language in a human-like manner, stand out as promising candidates for the development of such agents. In this study, we build and assess the effectiveness of agents crafted using LLMs in various coordination scenarios. We introduce the LLM-Coordination (LLM-Co) Framework, specifically designed to enable LLMs to play coordination games. With the LLM-Co framework, we conduct our evaluation with three game environments and organize the evaluation into five aspects: Theory of Mind, Situated Reasoning, Sustained Coordination, Robustness to Partners, and Explicit Assistance. First, the evaluation of the Theory of Mind and Situated Reasoning reveals the capabilities of LLM to infer the partner's intention and reason actions accordingly. Then, the evaluation around Sustained Coordination and Robustness to Partners further showcases the ability of LLMs to coordinate with an unknown partner in complex long-horizon tasks, outperforming Reinforcement Learning baselines. Lastly, to test Explicit Assistance, which refers to the ability of an agent to offer help proactively, we introduce two novel layouts into the Overcooked-AI benchmark, examining if agents can prioritize helping their partners, sacrificing time that could have been spent on their tasks. This research underscores the promising capabilities of LLMs in sophisticated coordination environments and reveals the potential of LLMs in building strong real-world agents for multi-agent coordination.
+
+
+
+ 25. 标题:Trustworthy Formal Natural Language Specifications
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2310.03885
+ 作者:Colin S. Gordon, Sergey Matskevich
+ 备注:arXiv admin note: substantial text overlap with arXiv:2205.07811
+ 关键词:computer programs carefully, programs carefully constructed, Interactive proof assistants, proof assistants, computer programs
+
+ 点击查看摘要
+ Interactive proof assistants are computer programs carefully constructed to check a human-designed proof of a mathematical claim with high confidence in the implementation. However, this only validates truth of a formal claim, which may have been mistranslated from a claim made in natural language. This is especially problematic when using proof assistants to formally verify the correctness of software with respect to a natural language specification. The translation from informal to formal remains a challenging, time-consuming process that is difficult to audit for correctness.
+This paper shows that it is possible to build support for specifications written in expressive subsets of natural language, within existing proof assistants, consistent with the principles used to establish trust and auditability in proof assistants themselves. We implement a means to provide specifications in a modularly extensible formal subset of English, and have them automatically translated into formal claims, entirely within the Lean proof assistant. Our approach is extensible (placing no permanent restrictions on grammatical structure), modular (allowing information about new words to be distributed alongside libraries), and produces proof certificates explaining how each word was interpreted and how the sentence's structure was used to compute the meaning.
+We apply our prototype to the translation of various English descriptions of formal specifications from a popular textbook into Lean formalizations; all can be translated correctly with a modest lexicon with only minor modifications related to lexicon size.
+
+
+
+ 26. 标题:Automatic and Human-AI Interactive Text Generation
+ 编号:[227]
+ 链接:https://arxiv.org/abs/2310.03878
+ 作者:Yao Dou, Philippe Laban, Claire Gardent, Wei Xu
+ 备注:To appear at ACL 2024, Tutorial
+ 关键词:natural language generation, specific criteria, readability or linguistic, largely retaining, retaining the original
+
+ 点击查看摘要
+ In this tutorial, we focus on text-to-text generation, a class of natural language generation (NLG) tasks, that takes a piece of text as input and then generates a revision that is improved according to some specific criteria (e.g., readability or linguistic styles), while largely retaining the original meaning and the length of the text. This includes many useful applications, such as text simplification, paraphrase generation, style transfer, etc. In contrast to text summarization and open-ended text completion (e.g., story), the text-to-text generation tasks we discuss in this tutorial are more constrained in terms of semantic consistency and targeted language styles. This level of control makes these tasks ideal testbeds for studying the ability of models to generate text that is both semantically adequate and stylistically appropriate. Moreover, these tasks are interesting from a technical standpoint, as they require complex combinations of lexical and syntactical transformations, stylistic control, and adherence to factual knowledge, -- all at once. With a special focus on text simplification and revision, this tutorial aims to provide an overview of the state-of-the-art natural language generation research from four major aspects -- Data, Models, Human-AI Collaboration, and Evaluation -- and to discuss and showcase a few significant and recent advances: (1) the use of non-retrogressive approaches; (2) the shift from fine-tuning to prompting with large language models; (3) the development of new learnable metric and fine-grained human evaluation framework; (4) a growing body of studies and datasets on non-English languages; (5) the rise of HCI+NLP+Accessibility interdisciplinary research to create real-world writing assistant systems.
+
+
+
+ 27. 标题:Contextualized Structural Self-supervised Learning for Ontology Matching
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2310.03840
+ 作者:Zhu Wang
+ 备注:
+ 关键词:Ontology matching, entails the identification, identification of semantic, semantic relationships, critical step
+
+ 点击查看摘要
+ Ontology matching (OM) entails the identification of semantic relationships between concepts within two or more knowledge graphs (KGs) and serves as a critical step in integrating KGs from various sources. Recent advancements in deep OM models have harnessed the power of transformer-based language models and the advantages of knowledge graph embedding. Nevertheless, these OM models still face persistent challenges, such as a lack of reference alignments, runtime latency, and unexplored different graph structures within an end-to-end framework. In this study, we introduce a novel self-supervised learning OM framework with input ontologies, called LaKERMap. This framework capitalizes on the contextual and structural information of concepts by integrating implicit knowledge into transformers. Specifically, we aim to capture multiple structural contexts, encompassing both local and global interactions, by employing distinct training objectives. To assess our methods, we utilize the Bio-ML datasets and tasks. The findings from our innovative approach reveal that LaKERMap surpasses state-of-the-art systems in terms of alignment quality and inference time. Our models and codes are available here: this https URL.
+
+
+
+ 28. 标题:HandMeThat: Human-Robot Communication in Physical and Social Environments
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2310.03779
+ 作者:Yanming Wan, Jiayuan Mao, Joshua B. Tenenbaum
+ 备注:NeurIPS 2022 (Dataset and Benchmark Track). First two authors contributed equally. Project page: this http URL
+ 关键词:holistic evaluation, instruction understanding, introduce HandMeThat, physical and social, HandMeThat
+
+ 点击查看摘要
+ We introduce HandMeThat, a benchmark for a holistic evaluation of instruction understanding and following in physical and social environments. While previous datasets primarily focused on language grounding and planning, HandMeThat considers the resolution of human instructions with ambiguities based on the physical (object states and relations) and social (human actions and goals) information. HandMeThat contains 10,000 episodes of human-robot interactions. In each episode, the robot first observes a trajectory of human actions towards her internal goal. Next, the robot receives a human instruction and should take actions to accomplish the subgoal set through the instruction. In this paper, we present a textual interface for our benchmark, where the robot interacts with a virtual environment through textual commands. We evaluate several baseline models on HandMeThat, and show that both offline and online reinforcement learning algorithms perform poorly on HandMeThat, suggesting significant room for future work on physical and social human-robot communications and interactions.
+
+
+
+ 29. 标题:PrIeD-KIE: Towards Privacy Preserved Document Key Information Extraction
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2310.03777
+ 作者:Saifullah Saifullah (1 and 2), Stefan Agne (2 and 3), Andreas Dengel (1 and 2), Sheraz Ahmed (2 and 3) ((1) Department of Computer Science, University of Kaiserslautern-Landau, Kaiserslautern, Rhineland-Palatinate, Germany, (2) German Research Center for Artificial Intelligence, DFKI GmbH, Kaiserslautern, Rhineland-Palatinate, Germany, (3) DeepReader GmbH, Kaiserlautern, Germany)
+ 备注:
+ 关键词:Key Information Extraction, private Key Information, Information Extraction, developing private Key, Key Information
+
+ 点击查看摘要
+ In this paper, we introduce strategies for developing private Key Information Extraction (KIE) systems by leveraging large pretrained document foundation models in conjunction with differential privacy (DP), federated learning (FL), and Differentially Private Federated Learning (DP-FL). Through extensive experimentation on six benchmark datasets (FUNSD, CORD, SROIE, WildReceipts, XFUND, and DOCILE), we demonstrate that large document foundation models can be effectively fine-tuned for the KIE task under private settings to achieve adequate performance while maintaining strong privacy guarantees. Moreover, by thoroughly analyzing the impact of various training and model parameters on model performance, we propose simple yet effective guidelines for achieving an optimal privacy-utility trade-off for the KIE task under global DP. Finally, we introduce FeAm-DP, a novel DP-FL algorithm that enables efficiently upscaling global DP from a standalone context to a multi-client federated environment. We conduct a comprehensive evaluation of the algorithm across various client and privacy settings, and demonstrate its capability to achieve comparable performance and privacy guarantees to standalone DP, even when accommodating an increasing number of participating clients. Overall, our study offers valuable insights into the development of private KIE systems, and highlights the potential of document foundation models for privacy-preserved Document AI applications. To the best of authors' knowledge, this is the first work that explores privacy preserved document KIE using document foundation models.
+
+
+
+ 30. 标题:Investigating Alternative Feature Extraction Pipelines For Clinical Note Phenotyping
+ 编号:[260]
+ 链接:https://arxiv.org/abs/2310.03772
+ 作者:Neil Daniel
+ 备注:11 pages, 0 figures, 1 table
+ 关键词:detailed patient observations, clinical notes, consist of detailed, clinical, medical
+
+ 点击查看摘要
+ A common practice in the medical industry is the use of clinical notes, which consist of detailed patient observations. However, electronic health record systems frequently do not contain these observations in a structured format, rendering patient information challenging to assess and evaluate automatically. Using computational systems for the extraction of medical attributes offers many applications, including longitudinal analysis of patients, risk assessment, and hospital evaluation. Recent work has constructed successful methods for phenotyping: extracting medical attributes from clinical notes. BERT-based models can be used to transform clinical notes into a series of representations, which are then condensed into a single document representation based on their CLS embeddings and passed into an LSTM (Mulyar et al., 2020). Though this pipeline yields a considerable performance improvement over previous results, it requires extensive convergence time. This method also does not allow for predicting attributes not yet identified in clinical notes.
+Considering the wide variety of medical attributes that may be present in a clinical note, we propose an alternative pipeline utilizing ScispaCy (Neumann et al., 2019) for the extraction of common diseases. We then train various supervised learning models to associate the presence of these conditions with patient attributes. Finally, we replicate a ClinicalBERT (Alsentzer et al., 2019) and LSTM-based approach for purposes of comparison. We find that alternative methods moderately underperform the replicated LSTM approach. Yet, considering a complex tradeoff between accuracy and runtime, in addition to the fact that the alternative approach also allows for the detection of medical conditions that are not already present in a clinical note, its usage may be considered as a supplement to established methods.
+
+
+
+ 31. 标题:Benchmarking a foundation LLM on its ability to re-label structure names in accordance with the AAPM TG-263 report
+ 编号:[295]
+ 链接:https://arxiv.org/abs/2310.03874
+ 作者:Jason Holmes, Lian Zhang, Yuzhen Ding, Hongying Feng, Zhengliang Liu, Tianming Liu, William W. Wong, Sujay A. Vora, Jonathan B. Ashman, Wei Liu
+ 备注:20 pages, 5 figures, 1 table
+ 关键词:Task Group, American Association, Association of Physicists, large language models, Physicists in Medicine
+
+ 点击查看摘要
+ Purpose: To introduce the concept of using large language models (LLMs) to re-label structure names in accordance with the American Association of Physicists in Medicine (AAPM) Task Group (TG)-263 standard, and to establish a benchmark for future studies to reference.
+Methods and Materials: The Generative Pre-trained Transformer (GPT)-4 application programming interface (API) was implemented as a Digital Imaging and Communications in Medicine (DICOM) storage server, which upon receiving a structure set DICOM file, prompts GPT-4 to re-label the structure names of both target volumes and normal tissues according to the AAPM TG-263. Three disease sites, prostate, head and neck, and thorax were selected for evaluation. For each disease site category, 150 patients were randomly selected for manually tuning the instructions prompt (in batches of 50) and 50 patients were randomly selected for evaluation. Structure names that were considered were those that were most likely to be relevant for studies utilizing structure contours for many patients.
+Results: The overall re-labeling accuracy of both target volumes and normal tissues for prostate, head and neck, and thorax cases was 96.0%, 98.5%, and 96.9% respectively. Re-labeling of target volumes was less accurate on average except for prostate - 100%, 93.1%, and 91.1% respectively.
+Conclusions: Given the accuracy of GPT-4 in re-labeling structure names of both target volumes and normal tissues as presented in this work, LLMs are poised to be the preferred method for standardizing structure names in radiation oncology, especially considering the rapid advancements in LLM capabilities that are likely to continue.
+
+
+机器学习
+
+ 1. 标题:BrainSCUBA: Fine-Grained Natural Language Captions of Visual Cortex Selectivity
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2310.04420
+ 作者:Andrew F. Luo, Margaret M. Henderson, Michael J. Tarr, Leila Wehbe
+ 备注:
+ 关键词:focus in neuroscience, higher visual cortex, organization of higher, central focus, visual cortex
+
+ 点击查看摘要
+ Understanding the functional organization of higher visual cortex is a central focus in neuroscience. Past studies have primarily mapped the visual and semantic selectivity of neural populations using hand-selected stimuli, which may potentially bias results towards pre-existing hypotheses of visual cortex functionality. Moving beyond conventional approaches, we introduce a data-driven method that generates natural language descriptions for images predicted to maximally activate individual voxels of interest. Our method -- Semantic Captioning Using Brain Alignments ("BrainSCUBA") -- builds upon the rich embedding space learned by a contrastive vision-language model and utilizes a pre-trained large language model to generate interpretable captions. We validate our method through fine-grained voxel-level captioning across higher-order visual regions. We further perform text-conditioned image synthesis with the captions, and show that our images are semantically coherent and yield high predicted activations. Finally, to demonstrate how our method enables scientific discovery, we perform exploratory investigations on the distribution of "person" representations in the brain, and discover fine-grained semantic selectivity in body-selective areas. Unlike earlier studies that decode text, our method derives voxel-wise captions of semantic selectivity. Our results show that BrainSCUBA is a promising means for understanding functional preferences in the brain, and provides motivation for further hypothesis-driven investigation of visual cortex.
+
+
+
+ 2. 标题:Functional Interpolation for Relative Positions Improves Long Context Transformers
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2310.04418
+ 作者:Shanda Li, Chong You, Guru Guruganesh, Joshua Ainslie, Santiago Ontanon, Manzil Zaheer, Sumit Sanghai, Yiming Yang, Sanjiv Kumar, Srinadh Bhojanapalli
+ 备注:
+ 关键词:important challenge, challenge in extending, Preventing the performance, performance decay, input sequence lengths
+
+ 点击查看摘要
+ Preventing the performance decay of Transformers on inputs longer than those used for training has been an important challenge in extending the context length of these models. Though the Transformer architecture has fundamentally no limits on the input sequence lengths it can process, the choice of position encoding used during training can limit the performance of these models on longer inputs. We propose a novel functional relative position encoding with progressive interpolation, FIRE, to improve Transformer generalization to longer contexts. We theoretically prove that this can represent some of the popular relative position encodings, such as T5's RPE, Alibi, and Kerple. We next empirically show that FIRE models have better generalization to longer contexts on both zero-shot language modeling and long text benchmarks.
+
+
+
+ 3. 标题:Why Do We Need Weight Decay in Modern Deep Learning?
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2310.04415
+ 作者:Maksym Andriushchenko, Francesco D'Angelo, Aditya Varre, Nicolas Flammarion
+ 备注:
+ 关键词:Weight decay, broadly used technique, including large language, Weight, decay
+
+ 点击查看摘要
+ Weight decay is a broadly used technique for training state-of-the-art deep networks, including large language models. Despite its widespread usage, its role remains poorly understood. In this work, we highlight that the role of weight decay in modern deep learning is different from its regularization effect studied in classical learning theory. For overparameterized deep networks, we show how weight decay modifies the optimization dynamics enhancing the ever-present implicit regularization of SGD via the loss stabilization mechanism. In contrast, for underparameterized large language models trained with nearly online SGD, we describe how weight decay balances the bias-variance tradeoff in stochastic optimization leading to lower training loss. Moreover, we show that weight decay also prevents sudden loss divergences for bfloat16 mixed-precision training which is a crucial tool for LLM training. Overall, we present a unifying perspective from ResNets on vision tasks to LLMs: weight decay is never useful as an explicit regularizer but instead changes the training dynamics in a desirable way. Our code is available at this https URL.
+
+
+
+ 4. 标题:Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2310.04413
+ 作者:Zhang-Wei Hong, Aviral Kumar, Sathwik Karnik, Abhishek Bhandwaldar, Akash Srivastava, Joni Pajarinen, Romain Laroche, Abhishek Gupta, Pulkit Agrawal
+ 备注:Accepted NeurIPS 2023
+ 关键词:learning decision-making policies, collecting additional data, decision-making policies, policies using existing, collecting additional
+
+ 点击查看摘要
+ Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at this https URL.
+
+
+
+ 5. 标题:Understanding, Predicting and Better Resolving Q-Value Divergence in Offline-RL
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2310.04411
+ 作者:Yang Yue, Rui Lu, Bingyi Kang, Shiji Song, Gao Huang
+ 备注:31 pages, 20 figures
+ 关键词:real dynamics, access to real, Q-value estimation divergence, Q-value estimation, prominent issue
+
+ 点击查看摘要
+ The divergence of the Q-value estimation has been a prominent issue in offline RL, where the agent has no access to real dynamics. Traditional beliefs attribute this instability to querying out-of-distribution actions when bootstrapping value targets. Though this issue can be alleviated with policy constraints or conservative Q estimation, a theoretical understanding of the underlying mechanism causing the divergence has been absent. In this work, we aim to thoroughly comprehend this mechanism and attain an improved solution. We first identify a fundamental pattern, self-excitation, as the primary cause of Q-value estimation divergence in offline RL. Then, we propose a novel Self-Excite Eigenvalue Measure (SEEM) metric based on Neural Tangent Kernel (NTK) to measure the evolving property of Q-network at training, which provides an intriguing explanation of the emergence of divergence. For the first time, our theory can reliably decide whether the training will diverge at an early stage, and even predict the order of the growth for the estimated Q-value, the model's norm, and the crashing step when an SGD optimizer is used. The experiments demonstrate perfect alignment with this theoretic analysis. Building on our insights, we propose to resolve divergence from a novel perspective, namely improving the model's architecture for better extrapolating behavior. Through extensive empirical studies, we identify LayerNorm as a good solution to effectively avoid divergence without introducing detrimental bias, leading to superior performance. Experimental results prove that it can still work in some most challenging settings, i.e. using only 1 transitions of the dataset, where all previous methods fail. Moreover, it can be easily plugged into modern offline RL methods and achieve SOTA results on many challenging tasks. We also give unique insights into its effectiveness.
+
+
+
+ 6. 标题:Policy-Gradient Training of Language Models for Ranking
+ 编号:[10]
+ 链接:https://arxiv.org/abs/2310.04407
+ 作者:Ge Gao, Jonathan D. Chang, Claire Cardie, Kianté Brantley, Thorsten Joachim
+ 备注:
+ 关键词:incorporating factual knowledge, chat-based web search, Text retrieval plays, language processing pipelines, ranging from chat-based
+
+ 点击查看摘要
+ Text retrieval plays a crucial role in incorporating factual knowledge for decision making into language processing pipelines, ranging from chat-based web search to question answering systems. Current state-of-the-art text retrieval models leverage pre-trained large language models (LLMs) to achieve competitive performance, but training LLM-based retrievers via typical contrastive losses requires intricate heuristics, including selecting hard negatives and using additional supervision as learning signals. This reliance on heuristics stems from the fact that the contrastive loss itself is heuristic and does not directly optimize the downstream metrics of decision quality at the end of the processing pipeline. To address this issue, we introduce Neural PG-RANK, a novel training algorithm that learns to rank by instantiating a LLM as a Plackett-Luce ranking policy. Neural PG-RANK provides a principled method for end-to-end training of retrieval models as part of larger decision systems via policy gradient, with little reliance on complex heuristics, and it effectively unifies the training objective with downstream decision-making quality. We conduct extensive experiments on various text retrieval benchmarks. The results demonstrate that when the training objective aligns with the evaluation setup, Neural PG-RANK yields remarkable in-domain performance improvement, with substantial out-of-domain generalization to some critical datasets employed in downstream question answering tasks.
+
+
+
+ 7. 标题:Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2310.04406
+ 作者:Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, Yu-Xiong Wang
+ 备注:Website and code can be found at this https URL
+ 关键词:large language models, demonstrated impressive performance, simple acting processes, Language Agent Tree, Agent Tree Search
+
+ 点击查看摘要
+ While large language models (LLMs) have demonstrated impressive performance on a range of decision-making tasks, they rely on simple acting processes and fall short of broad deployment as autonomous agents. We introduce LATS (Language Agent Tree Search), a general framework that synergizes the capabilities of LLMs in planning, acting, and reasoning. Drawing inspiration from Monte Carlo tree search in model-based reinforcement learning, LATS employs LLMs as agents, value functions, and optimizers, repurposing their latent strengths for enhanced decision-making. What is crucial in this method is the use of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that moves beyond the limitations of existing techniques. Our experimental evaluation across diverse domains, such as programming, HotPotQA, and WebShop, illustrates the applicability of LATS for both reasoning and acting. In particular, LATS achieves 94.4\% for programming on HumanEval with GPT-4 and an average score of 75.9 for web browsing on WebShop with GPT-3.5, demonstrating the effectiveness and generality of our method.
+
+
+
+ 8. 标题:On the Embedding Collapse when Scaling up Recommendation Models
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2310.04400
+ 作者:Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, Mingsheng Long
+ 备注:
+ 关键词:leverage vast amounts, deep foundation models, developing large recommendation, large recommendation models, recommendation models
+
+ 点击查看摘要
+ Recent advances in deep foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. However, we experiment to scale up existing recommendation models and observe that the enlarged models do not improve satisfactorily. In this context, we investigate the embedding layers of enlarged models and identify a phenomenon of embedding collapse, which ultimately hinders scalability, wherein the embedding matrix tends to reside in a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate that the feature interaction module specific to recommendation models has a two-sided effect. On the one hand, the interaction restricts embedding learning when interacting with collapsed embeddings, exacerbating the collapse issue. On the other hand, feature interaction is crucial in mitigating the fitting of spurious features, thereby improving scalability. Based on this analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to capture diverse patterns and reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability for various recommendation models.
+
+
+
+ 9. 标题:Leveraging Self-Consistency for Data-Efficient Amortized Bayesian Inference
+ 编号:[14]
+ 链接:https://arxiv.org/abs/2310.04395
+ 作者:Marvin Schmitt, Daniel Habermann, Paul-Christian Bürkner, Ullrich Köthe, Stefan T. Radev
+ 备注:
+ 关键词:amortized Bayesian inference, leveraging universal symmetries, Bayesian inference, amortized Bayesian, probabilistic joint model
+
+ 点击查看摘要
+ We propose a method to improve the efficiency and accuracy of amortized Bayesian inference (ABI) by leveraging universal symmetries in the probabilistic joint model $p(\theta, y)$ of parameters $\theta$ and data $y$. In a nutshell, we invert Bayes' theorem and estimate the marginal likelihood based on approximate representations of the joint model. Upon perfect approximation, the marginal likelihood is constant across all parameter values by definition. However, approximation error leads to undesirable variance in the marginal likelihood estimates across different parameter values. We formulate violations of this symmetry as a loss function to accelerate the learning dynamics of conditional neural density estimators. We apply our method to a bimodal toy problem with an explicit likelihood (likelihood-based) and a realistic model with an implicit likelihood (simulation-based).
+
+
+
+ 10. 标题:Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2310.04378
+ 作者:Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao
+ 备注:
+ 关键词:achieved remarkable results, Latent Consistency Models, Consistency Models, synthesizing high-resolution images, Diffusion models
+
+ 点击查看摘要
+ Latent Diffusion models (LDMs) have achieved remarkable results in synthesizing high-resolution images. However, the iterative sampling process is computationally intensive and leads to slow generation. Inspired by Consistency Models (song et al.), we propose Latent Consistency Models (LCMs), enabling swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion (rombach et al). Viewing the guided reverse diffusion process as solving an augmented probability flow ODE (PF-ODE), LCMs are designed to directly predict the solution of such ODE in latent space, mitigating the need for numerous iterations and allowing rapid, high-fidelity sampling. Efficiently distilled from pre-trained classifier-free guided diffusion models, a high-quality 768 x 768 2~4-step LCM takes only 32 A100 GPU hours for training. Furthermore, we introduce Latent Consistency Fine-tuning (LCF), a novel method that is tailored for fine-tuning LCMs on customized image datasets. Evaluation on the LAION-5B-Aesthetics dataset demonstrates that LCMs achieve state-of-the-art text-to-image generation performance with few-step inference. Project Page: this https URL
+
+
+
+ 11. 标题:Confronting Reward Model Overoptimization with Constrained RLHF
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2310.04373
+ 作者:Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, Stephen McAleer
+ 备注:
+ 关键词:Large language models, typically aligned, reward models, human preferences, simpler reward models
+
+ 点击查看摘要
+ Large language models are typically aligned with human preferences by optimizing $\textit{reward models}$ (RMs) fitted to human feedback. However, human preferences are multi-faceted, and it is increasingly common to derive reward from a composition of simpler reward models which each capture a different aspect of language quality. This itself presents a challenge, as it is difficult to appropriately weight these component RMs when combining them. Compounding this difficulty, because any RM is only a proxy for human evaluation, this process is vulnerable to $\textit{overoptimization}$, wherein past a certain point, accumulating higher reward is associated with worse human ratings. In this paper, we perform, to our knowledge, the first study on overoptimization in composite RMs, showing that correlation between component RMs has a significant effect on the locations of these points. We then introduce an approach to solve this issue using constrained reinforcement learning as a means of preventing the agent from exceeding each RM's threshold of usefulness. Our method addresses the problem of weighting component RMs by learning dynamic weights, naturally given by the Lagrange multipliers. As a result, each RM stays within the range at which it is an effective proxy, improving evaluation performance. Finally, we introduce an adaptive method using gradient-free optimization to identify and optimize towards these points during a single run.
+
+
+
+ 12. 标题:MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2310.04369
+ 作者:Weiming Xu, Zhouxuan Chen, Zhili Tan, Shubo Lv, Runduo Han, Wenjiang Zhou, Weifeng Zhao, Lei Xie
+ 备注:
+ 关键词:typical neural speech, approach mainly handles, voice enhancement scenarios, handles speech, singing voice enhancement
+
+ 点击查看摘要
+ A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
+
+
+
+ 13. 标题:Amortizing intractable inference in large language models
+ 编号:[25]
+ 链接:https://arxiv.org/abs/2310.04363
+ 作者:Edward J. Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, Nikolay Malkin
+ 备注:23 pages; code: this https URL
+ 关键词:large language models, Autoregressive large language, next-token conditional distributions, language models, large language
+
+ 点击查看摘要
+ Autoregressive large language models (LLMs) compress knowledge from their training data through next-token conditional distributions. This limits tractable querying of this knowledge to start-to-end autoregressive sampling. However, many tasks of interest -- including sequence continuation, infilling, and other forms of constrained generation -- involve sampling from intractable posterior distributions. We address this limitation by using amortized Bayesian inference to sample from these intractable posteriors. Such amortization is algorithmically achieved by fine-tuning LLMs via diversity-seeking reinforcement learning algorithms: generative flow networks (GFlowNets). We empirically demonstrate that this distribution-matching paradigm of LLM fine-tuning can serve as an effective alternative to maximum-likelihood training and reward-maximizing policy optimization. As an important application, we interpret chain-of-thought reasoning as a latent variable modeling problem and demonstrate that our approach enables data-efficient adaptation of LLMs to tasks that require multi-step rationalization and tool use.
+
+
+
+ 14. 标题:Exploiting Transformer Activation Sparsity with Dynamic Inference
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2310.04361
+ 作者:Mikołaj Piórczyński, Filip Szatkowski, Klaudia Bałazy, Bartosz Wójcik
+ 备注:
+ 关键词:high computational requirements, face practical limitations, practical limitations due, Dynamic Sparsified Transformer, Sparsified Transformer Inference
+
+ 点击查看摘要
+ Transformer models, despite their impressive performance, often face practical limitations due to their high computational requirements. At the same time, previous studies have revealed significant activation sparsity in these models, indicating the presence of redundant computations. In this paper, we propose Dynamic Sparsified Transformer Inference (DSTI), a method that radically reduces the inference cost of Transformer models by enforcing activation sparsity and subsequently transforming a dense model into its sparse Mixture of Experts (MoE) version. We demonstrate that it is possible to train small gating networks that successfully predict the relative contribution of each expert during inference. Furthermore, we introduce a mechanism that dynamically determines the number of executed experts individually for each token. DSTI can be applied to any Transformer-based architecture and has negligible impact on the accuracy. For the BERT-base classification model, we reduce inference cost by almost 60%.
+
+
+
+ 15. 标题:A Language-Agent Approach to Formal Theorem-Proving
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2310.04353
+ 作者:Amitayush Thakur, Yeming Wen, Swarat Chaudhuri
+ 备注:
+ 关键词:large language model, Language agents, large language, capable of in-context, in-context learning
+
+ 点击查看摘要
+ Language agents, which use a large language model (LLM) capable of in-context learning to interact with an external environment, have recently emerged as a promising approach to control tasks. We present the first language-agent approach to formal theorem-proving. Our method, COPRA, uses a high-capacity, black-box LLM (GPT-4) as part of a policy for a stateful backtracking search. During the search, the policy can select proof tactics and retrieve lemmas and definitions from an external database. Each selected tactic is executed in the underlying proof framework, and the execution feedback is used to build the prompt for the next policy invocation. The search also tracks selected information from its history and uses it to reduce hallucinations and unnecessary LLM queries.
+We evaluate COPRA on the miniF2F benchmark for Lean and a set of Coq tasks from the Compcert project. On these benchmarks, COPRA is significantly better than one-shot invocations of GPT-4, as well as state-of-the-art models fine-tuned on proof data, at finding correct proofs quickly.
+
+
+
+ 16. 标题:Learning to Grasp: from Somewhere to Anywhere
+ 编号:[31]
+ 链接:https://arxiv.org/abs/2310.04349
+ 作者:François Hélénon, Johann Huber, Faïz Ben Amar, Stéphane Doncieux
+ 备注:
+ 关键词:data-driven techniques play, partially solved, multidisciplinary problem, increasing role, problem where data-driven
+
+ 点击查看摘要
+ Robotic grasping is still a partially solved, multidisciplinary problem where data-driven techniques play an increasing role. The sparse nature of rewards make the automatic generation of grasping datasets challenging, especially for unconventional morphologies or highly actuated end-effectors. Most approaches for obtaining large-scale datasets rely on numerous human-provided demonstrations or heavily engineered solutions that do not scale well. Recent advances in Quality-Diversity (QD) methods have investigated how to learn object grasping at a specific pose with different robot morphologies. The present work introduces a pipeline for adapting QD-generated trajectories to new object poses. Using an RGB-D data stream, the vision pipeline first detects the targeted object, predicts its 6-DOF pose, and finally tracks it. An automatically generated reach-and-grasp trajectory can then be adapted by projecting it relatively to the object frame. Hundreds of trajectories have been deployed into the real world on several objects and with different robotic setups: a Franka Research 3 with a parallel gripper and a UR5 with a dexterous SIH Schunk hand. The transfer ratio obtained when applying transformation to the object pose matches the one obtained when the object pose matches the simulation, demonstrating the efficiency of the proposed approach.
+
+
+
+ 17. 标题:Functional Geometry Guided Protein Sequence and Backbone Structure Co-Design
+ 编号:[33]
+ 链接:https://arxiv.org/abs/2310.04343
+ 作者:Zhenqiao Song, Yunlong Zhao, Wenxian Shi, Yang Yang, Lei Li
+ 备注:
+ 关键词:living organisms, macromolecules responsible, responsible for essential, protein sequence, essential functions
+
+ 点击查看摘要
+ Proteins are macromolecules responsible for essential functions in almost all living organisms. Designing reasonable proteins with desired functions is crucial. A protein's sequence and structure are strongly correlated and they together determine its function. In this paper, we propose NAEPro, a model to jointly design Protein sequence and structure based on automatically detected functional sites. NAEPro is powered by an interleaving network of attention and equivariant layers, which can capture global correlation in a whole sequence and local influence from nearest amino acids in three dimensional (3D) space. Such an architecture facilitates effective yet economic message passing at two levels. We evaluate our model and several strong baselines on two protein datasets, $\beta$-lactamase and myoglobin. Experimental results show that our model consistently achieves the highest amino acid recovery rate, TM-score, and the lowest RMSD among all competitors. These findings prove the capability of our model to design protein sequences and structures that closely resemble their natural counterparts. Furthermore, in-depth analysis further confirms our model's ability to generate highly effective proteins capable of binding to their target metallocofactors. We provide code, data and models in Github.
+
+
+
+ 18. 标题:Saliency-Guided Hidden Associative Replay for Continual Learning
+ 编号:[35]
+ 链接:https://arxiv.org/abs/2310.04334
+ 作者:Guangji Bai, Qilong Zhao, Xiaoyang Jiang, Yifei Zhang, Liang Zhao
+ 备注:Preprint. Do not distribute
+ 关键词:training neural networks, focusing on training, burgeoning domain, domain in next-generation, training neural
+
+ 点击查看摘要
+ Continual Learning is a burgeoning domain in next-generation AI, focusing on training neural networks over a sequence of tasks akin to human learning. While CL provides an edge over traditional supervised learning, its central challenge remains to counteract catastrophic forgetting and ensure the retention of prior tasks during subsequent learning. Amongst various strategies to tackle this, replay based methods have emerged as preeminent, echoing biological memory mechanisms. However, these methods are memory intensive, often preserving entire data samples, an approach inconsistent with humans selective memory retention of salient experiences. While some recent works have explored the storage of only significant portions of data in episodic memory, the inherent nature of partial data necessitates innovative retrieval mechanisms. Current solutions, like inpainting, approximate full data reconstruction from partial cues, a method that diverges from genuine human memory processes. Addressing these nuances, this paper presents the Saliency Guided Hidden Associative Replay for Continual Learning. This novel framework synergizes associative memory with replay-based strategies. SHARC primarily archives salient data segments via sparse memory encoding. Importantly, by harnessing associative memory paradigms, it introduces a content focused memory retrieval mechanism, promising swift and near-perfect recall, bringing CL a step closer to authentic human memory processes. Extensive experimental results demonstrate the effectiveness of our proposed method for various continual learning tasks.
+
+
+
+ 19. 标题:Robust Losses for Decision-Focused Learning
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2310.04328
+ 作者:Noah Schutte, Krzysztof Postek, Neil Yorke-Smith
+ 备注:13 pages, 3 figures
+ 关键词:make discrete decisions, empirical regret, uncertain parameters, regret, discrete decisions
+
+ 点击查看摘要
+ Optimization models used to make discrete decisions often contain uncertain parameters that are context-dependent and are estimated through prediction. To account for the quality of the decision made based on the prediction, decision-focused learning (end-to-end predict-then-optimize) aims at training the predictive model to minimize regret, i.e., the loss incurred by making a suboptimal decision. Despite the challenge of this loss function being possibly non-convex and in general non-differentiable, effective gradient-based learning approaches have been proposed to minimize the expected loss, using the empirical loss as a surrogate. However, empirical regret can be an ineffective surrogate because the uncertainty in the optimization model makes the empirical regret unequal to the expected regret in expectation. To illustrate the impact of this inequality, we evaluate the effect of aleatoric and epistemic uncertainty on the accuracy of empirical regret as a surrogate. Next, we propose three robust loss functions that more closely approximate expected regret. Experimental results show that training two state-of-the-art decision-focused learning approaches using robust regret losses improves test-sample empirical regret in general while keeping computational time equivalent relative to the number of training epochs.
+
+
+
+ 20. 标题:Program Synthesis with Best-First Bottom-Up Search
+ 编号:[40]
+ 链接:https://arxiv.org/abs/2310.04327
+ 作者:Saqib Ameen, Levi H. S. Lelis
+ 备注:Published at the Journal of Artificial Intelligence Research (JAIR)
+ 关键词:Bee Search, search, cost-guided BUS algorithms, cost-guided BUS, BUS algorithms suffer
+
+ 点击查看摘要
+ Cost-guided bottom-up search (BUS) algorithms use a cost function to guide the search to solve program synthesis tasks. In this paper, we show that current state-of-the-art cost-guided BUS algorithms suffer from a common problem: they can lose useful information given by the model and fail to perform the search in a best-first order according to a cost function. We introduce a novel best-first bottom-up search algorithm, which we call Bee Search, that does not suffer information loss and is able to perform cost-guided bottom-up synthesis in a best-first manner. Importantly, Bee Search performs best-first search with respect to the generation of programs, i.e., it does not even create in memory programs that are more expensive than the solution program. It attains best-first ordering with respect to generation by performing a search in an abstract space of program costs. We also introduce a new cost function that better uses the information provided by an existing cost model. Empirical results on string manipulation and bit-vector tasks show that Bee Search can outperform existing cost-guided BUS approaches when employing more complex domain-specific languages (DSLs); Bee Search and previous approaches perform equally well with simpler DSLs. Furthermore, our new cost function with Bee Search outperforms previous cost functions on string manipulation tasks.
+
+
+
+ 21. 标题:Adjustable Robust Reinforcement Learning for Online 3D Bin Packing
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2310.04323
+ 作者:Yuxin Pan, Yize Chen, Fangzhen Lin
+ 备注:Accepted to NeurIPS2023
+ 关键词:Designing effective policies, stringent physical constraints, incoming box sequences, bin packing problem, box sequence distribution
+
+ 点击查看摘要
+ Designing effective policies for the online 3D bin packing problem (3D-BPP) has been a long-standing challenge, primarily due to the unpredictable nature of incoming box sequences and stringent physical constraints. While current deep reinforcement learning (DRL) methods for online 3D-BPP have shown promising results in optimizing average performance over an underlying box sequence distribution, they often fail in real-world settings where some worst-case scenarios can materialize. Standard robust DRL algorithms tend to overly prioritize optimizing the worst-case performance at the expense of performance under normal problem instance distribution. To address these issues, we first introduce a permutation-based attacker to investigate the practical robustness of both DRL-based and heuristic methods proposed for solving online 3D-BPP. Then, we propose an adjustable robust reinforcement learning (AR2L) framework that allows efficient adjustment of robustness weights to achieve the desired balance of the policy's performance in average and worst-case environments. Specifically, we formulate the objective function as a weighted sum of expected and worst-case returns, and derive the lower performance bound by relating to the return under a mixture dynamics. To realize this lower bound, we adopt an iterative procedure that searches for the associated mixture dynamics and improves the corresponding policy. We integrate this procedure into two popular robust adversarial algorithms to develop the exact and approximate AR2L algorithms. Experiments demonstrate that AR2L is versatile in the sense that it improves policy robustness while maintaining an acceptable level of performance for the nominal case.
+
+
+
+ 22. 标题:Latent Graph Inference with Limited Supervision
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2310.04314
+ 作者:Jianglin Lu, Yi Xu, Huan Wang, Yue Bai, Yun Fu
+ 备注:
+ 关键词:Latent graph inference, underlying graph structure, aims to jointly, data features, jointly learn
+
+ 点击查看摘要
+ Latent graph inference (LGI) aims to jointly learn the underlying graph structure and node representations from data features. However, existing LGI methods commonly suffer from the issue of supervision starvation, where massive edge weights are learned without semantic supervision and do not contribute to the training loss. Consequently, these supervision-starved weights, which may determine the predictions of testing samples, cannot be semantically optimal, resulting in poor generalization. In this paper, we observe that this issue is actually caused by the graph sparsification operation, which severely destroys the important connections established between pivotal nodes and labeled ones. To address this, we propose to restore the corrupted affinities and replenish the missed supervision for better LGI. The key challenge then lies in identifying the critical nodes and recovering the corrupted affinities. We begin by defining the pivotal nodes as $k$-hop starved nodes, which can be identified based on a given adjacency matrix. Considering the high computational burden, we further present a more efficient alternative inspired by CUR matrix decomposition. Subsequently, we eliminate the starved nodes by reconstructing the destroyed connections. Extensive experiments on representative benchmarks demonstrate that reducing the starved nodes consistently improves the performance of state-of-the-art LGI methods, especially under extremely limited supervision (6.12% improvement on Pubmed with a labeling rate of only 0.3%).
+
+
+
+ 23. 标题:Distributed Deep Joint Source-Channel Coding with Decoder-Only Side Information
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2310.04311
+ 作者:Selim F. Yilmaz, Ezgi Ozyilkan, Deniz Gunduz, Elza Erkip
+ 备注:7 pages, 4 figures
+ 关键词:low-latency image transmission, noisy wireless channel, correlated side information, Wyner-Ziv scenario, low-latency image
+
+ 点击查看摘要
+ We consider low-latency image transmission over a noisy wireless channel when correlated side information is present only at the receiver side (the Wyner-Ziv scenario). In particular, we are interested in developing practical schemes using a data-driven joint source-channel coding (JSCC) approach, which has been previously shown to outperform conventional separation-based approaches in the practical finite blocklength regimes, and to provide graceful degradation with channel quality. We propose a novel neural network architecture that incorporates the decoder-only side information at multiple stages at the receiver side. Our results demonstrate that the proposed method succeeds in integrating the side information, yielding improved performance at all channel noise levels in terms of the various distortion criteria considered here, especially at low channel signal-to-noise ratios (SNRs) and small bandwidth ratios (BRs). We also provide the source code of the proposed method to enable further research and reproducibility of the results.
+
+
+
+ 24. 标题:Identifying Representations for Intervention Extrapolation
+ 编号:[49]
+ 链接:https://arxiv.org/abs/2310.04295
+ 作者:Sorawit Saengkyongam, Elan Rosenfeld, Pradeep Ravikumar, Niklas Pfister, Jonas Peters
+ 备注:
+ 关键词:generalizability or robustness, intervention extrapolation, improve the current, paradigm in terms, terms of generalizability
+
+ 点击查看摘要
+ The premise of identifiable and causal representation learning is to improve the current representation learning paradigm in terms of generalizability or robustness. Despite recent progress in questions of identifiability, more theoretical results demonstrating concrete advantages of these methods for downstream tasks are needed. In this paper, we consider the task of intervention extrapolation: predicting how interventions affect an outcome, even when those interventions are not observed at training time, and show that identifiable representations can provide an effective solution to this task even if the interventions affect the outcome non-linearly. Our setup includes an outcome Y, observed features X, which are generated as a non-linear transformation of latent features Z, and exogenous action variables A, which influence Z. The objective of intervention extrapolation is to predict how interventions on A that lie outside the training support of A affect Y. Here, extrapolation becomes possible if the effect of A on Z is linear and the residual when regressing Z on A has full support. As Z is latent, we combine the task of intervention extrapolation with identifiable representation learning, which we call Rep4Ex: we aim to map the observed features X into a subspace that allows for non-linear extrapolation in A. We show using Wiener's Tauberian theorem that the hidden representation is identifiable up to an affine transformation in Z-space, which is sufficient for intervention extrapolation. The identifiability is characterized by a novel constraint describing the linearity assumption of A on Z. Based on this insight, we propose a method that enforces the linear invariance constraint and can be combined with any type of autoencoder. We validate our theoretical findings through synthetic experiments and show that our approach succeeds in predicting the effects of unseen interventions.
+
+
+
+ 25. 标题:Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2310.04292
+ 作者:Dominique Beaini, Shenyang Huang, Joao Alex Cunha, Gabriela Moisescu-Pareja, Oleksandr Dymov, Samuel Maddrell-Mander, Callum McLean, Frederik Wenkel, Luis Müller, Jama Hussein Mohamud, Ali Parviz, Michael Craig, Michał Koziarski, Jiarui Lu, Zhaocheng Zhu, Cristian Gabellini, Kerstin Klaser, Josef Dean, Cas Wognum, Maciej Sypetkowski, Guillaume Rabusseau, Reihaneh Rabbany, Jian Tang, Christopher Morris, Mirco Ravanelli, Guy Wolf, Prudencio Tossou, Hadrien Mary, Therence Bois, Andrew Fitzgibbon, Błażej Banaszewski, Chad Martin, Dominic Masters
+ 备注:
+ 关键词:enabled significant advancements, pre-trained foundation models, multiple fields, enabled significant, significant advancements
+
+ 点击查看摘要
+ Recently, pre-trained foundation models have enabled significant advancements in multiple fields. In molecular machine learning, however, where datasets are often hand-curated, and hence typically small, the lack of datasets with labeled features, and codebases to manage those datasets, has hindered the development of foundation models. In this work, we present seven novel datasets categorized by size into three distinct categories: ToyMix, LargeMix and UltraLarge. These datasets push the boundaries in both the scale and the diversity of supervised labels for molecular learning. They cover nearly 100 million molecules and over 3000 sparsely defined tasks, totaling more than 13 billion individual labels of both quantum and biological nature. In comparison, our datasets contain 300 times more data points than the widely used OGB-LSC PCQM4Mv2 dataset, and 13 times more than the quantum-only QM1B dataset. In addition, to support the development of foundational models based on our proposed datasets, we present the Graphium graph machine learning library which simplifies the process of building and training molecular machine learning models for multi-task and multi-level molecular datasets. Finally, we present a range of baseline results as a starting point of multi-task and multi-level training on these datasets. Empirically, we observe that performance on low-resource biological datasets show improvement by also training on large amounts of quantum data. This indicates that there may be potential in multi-task and multi-level training of a foundation model and fine-tuning it to resource-constrained downstream tasks.
+
+
+
+ 26. 标题:Assessing Robustness via Score-Based Adversarial Image Generation
+ 编号:[56]
+ 链接:https://arxiv.org/abs/2310.04285
+ 作者:Marcel Kollovieh, Lukas Gosch, Yan Scholten, Marten Lienen, Stephan Günnemann
+ 备注:
+ 关键词:norm constraints, ell, adversarial, norm, constraints
+
+ 点击查看摘要
+ Most adversarial attacks and defenses focus on perturbations within small $\ell_p$-norm constraints. However, $\ell_p$ threat models cannot capture all relevant semantic-preserving perturbations, and hence, the scope of robustness evaluations is limited. In this work, we introduce Score-Based Adversarial Generation (ScoreAG), a novel framework that leverages the advancements in score-based generative models to generate adversarial examples beyond $\ell_p$-norm constraints, so-called unrestricted adversarial examples, overcoming their limitations. Unlike traditional methods, ScoreAG maintains the core semantics of images while generating realistic adversarial examples, either by transforming existing images or synthesizing new ones entirely from scratch. We further exploit the generative capability of ScoreAG to purify images, empirically enhancing the robustness of classifiers. Our extensive empirical evaluation demonstrates that ScoreAG matches the performance of state-of-the-art attacks and defenses across multiple benchmarks. This work highlights the importance of investigating adversarial examples bounded by semantics rather than $\ell_p$-norm constraints. ScoreAG represents an important step towards more encompassing robustness assessments.
+
+
+
+ 27. 标题:On the Error-Propagation of Inexact Deflation for Principal Component Analysis
+ 编号:[58]
+ 链接:https://arxiv.org/abs/2310.04283
+ 作者:Fangshuo Liao, Junhyung Lyle Kim, Cruz Barnum, Anastasios Kyrillidis
+ 备注:
+ 关键词:principal components, Principal Component Analysis, individual principal components, estimating principal components, principal component estimations
+
+ 点击查看摘要
+ Principal Component Analysis (PCA) is a popular tool in data analysis, especially when the data is high-dimensional. PCA aims to find subspaces, spanned by the so-called \textit{principal components}, that best explain the variance in the dataset. The deflation method is a popular meta-algorithm -- used to discover such subspaces -- that sequentially finds individual principal components, starting from the most important one and working its way towards the less important ones. However, due to its sequential nature, the numerical error introduced by not estimating principal components exactly -- e.g., due to numerical approximations through this process -- propagates, as deflation proceeds. To the best of our knowledge, this is the first work that mathematically characterizes the error propagation of the inexact deflation method, and this is the key contribution of this paper. We provide two main results: $i)$ when the sub-routine for finding the leading eigenvector is generic, and $ii)$ when power iteration is used as the sub-routine. In the latter case, the additional directional information from power iteration allows us to obtain a tighter error bound than the analysis of the sub-routine agnostic case. As an outcome, we provide explicit characterization on how the error progresses and affects subsequent principal component estimations for this fundamental problem.
+
+
+
+ 28. 标题:C(NN)FD -- deep learning predictions of tip clearance variations on multi-stage axial compressors aerodynamic performance
+ 编号:[65]
+ 链接:https://arxiv.org/abs/2310.04264
+ 作者:Giuseppe Bruni, Sepehr Maleki, Senthil K. Krishnababu
+ 备注:arXiv admin note: text overlap with arXiv:2306.05889
+ 关键词:Computational Fluid Dynamics, Computational Fluid, Fluid Dynamics, limited industrial relevance, deep learning methods
+
+ 点击查看摘要
+ Application of deep learning methods to physical simulations such as CFD (Computational Fluid Dynamics), have been so far of limited industrial relevance. This paper demonstrates the development and application of a deep learning framework for real-time predictions of the impact of tip clearance variations on the aerodynamic performance of multi-stage axial compressors in gas turbines. The proposed C(NN)FD architecture is proven to be scalable to industrial applications, and achieves in real-time accuracy comparable to the CFD benchmark. The deployed model, is readily integrated within the manufacturing and build process of gas turbines, thus providing the opportunity to analytically assess the impact on performance and potentially reduce requirements for expensive physical tests.
+
+
+
+ 29. 标题:Comparing Auxiliary Tasks for Learning Representations for Reinforcement Learning
+ 编号:[73]
+ 链接:https://arxiv.org/abs/2310.04241
+ 作者:Moritz Lange, Noah Krystiniak, Raphael C. Engelhardt, Wolfgang Konen, Laurenz Wiskott
+ 备注:
+ 关键词:gained steady popularity, gained steady, steady popularity, popularity in reinforcement, potential to improve
+
+ 点击查看摘要
+ Learning state representations has gained steady popularity in reinforcement learning (RL) due to its potential to improve both sample efficiency and returns on many environments. A straightforward and efficient method is to generate representations with a distinct neural network trained on an auxiliary task, i.e. a task that differs from the actual RL task. While a whole range of such auxiliary tasks has been proposed in the literature, a comparison on typical continuous control benchmark environments is computationally expensive and has, to the best of our knowledge, not been performed before. This paper presents such a comparison of common auxiliary tasks, based on hundreds of agents trained with state-of-the-art off-policy RL algorithms. We compare possible improvements in both sample efficiency and returns for environments ranging from simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks is beneficial for environments of higher dimension and complexity, and that learning environment dynamics is preferable to predicting rewards. We believe these insights will enable other researchers to make more informed decisions on how to utilize representation learning for their specific problem.
+
+
+
+ 30. 标题:Bringing Quantum Algorithms to Automated Machine Learning: A Systematic Review of AutoML Frameworks Regarding Extensibility for QML Algorithms
+ 编号:[75]
+ 链接:https://arxiv.org/abs/2310.04238
+ 作者:Dennis Klau, Marc Zöller, Christian Tutschku
+ 备注:Whitepaper
+ 关键词:Quantum Machine Learning, incorporating Quantum Machine, automated solving approach, Automated Quantum Machine, Machine Learning
+
+ 点击查看摘要
+ This work describes the selection approach and analysis of existing AutoML frameworks regarding their capability of a) incorporating Quantum Machine Learning (QML) algorithms into this automated solving approach of the AutoML framing and b) solving a set of industrial use-cases with different ML problem types by benchmarking their most important characteristics. For that, available open-source tools are condensed into a market overview and suitable frameworks are systematically selected on a multi-phase, multi-criteria approach. This is done by considering software selection approaches, as well as in terms of the technical perspective of AutoML. The requirements for the framework selection are divided into hard and soft criteria regarding their software and ML attributes. Additionally, a classification of AutoML frameworks is made into high- and low-level types, inspired by the findings of. Finally, we select Ray and AutoGluon as the suitable low- and high-level frameworks respectively, as they fulfil all requirements sufficiently and received the best evaluation feedback during the use-case study. Based on those findings, we build an extended Automated Quantum Machine Learning (AutoQML) framework with QC-specific pipeline steps and decision characteristics for hardware and software constraints.
+
+
+
+ 31. 标题:A Fixed-Parameter Tractable Algorithm for Counting Markov Equivalence Classes with the same Skeleton
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2310.04218
+ 作者:Vidya Sagar Sharma
+ 备注:75 pages, 2 Figures
+ 关键词:Bayesian networks, random variables, Markov equivalent DAGs, Causal DAGs, encoding conditional dependencies
+
+ 点击查看摘要
+ Causal DAGs (also known as Bayesian networks) are a popular tool for encoding conditional dependencies between random variables. In a causal DAG, the random variables are modeled as vertices in the DAG, and it is stipulated that every random variable is independent of its ancestors conditioned on its parents. It is possible, however, for two different causal DAGs on the same set of random variables to encode exactly the same set of conditional dependencies. Such causal DAGs are said to be Markov equivalent, and equivalence classes of Markov equivalent DAGs are known as Markov Equivalent Classes (MECs). Beautiful combinatorial characterizations of MECs have been developed in the past few decades, and it is known, in particular that all DAGs in the same MEC must have the same ''skeleton'' (underlying undirected graph) and v-structures (induced subgraph of the form $a\rightarrow b \leftarrow c$).
+These combinatorial characterizations also suggest several natural algorithmic questions. One of these is: given an undirected graph $G$ as input, how many distinct Markov equivalence classes have the skeleton $G$? Much work has been devoted in the last few years to this and other closely related problems. However, to the best of our knowledge, a polynomial time algorithm for the problem remains unknown.
+In this paper, we make progress towards this goal by giving a fixed parameter tractable algorithm for the above problem, with the parameters being the treewidth and the maximum degree of the input graph $G$. The main technical ingredient in our work is a construction we refer to as shadow, which lets us create a "local description'' of long-range constraints imposed by the combinatorial characterizations of MECs.
+
+
+
+ 32. 标题:Cost-Effective Retraining of Machine Learning Models
+ 编号:[84]
+ 链接:https://arxiv.org/abs/2310.04216
+ 作者:Ananth Mahadevan, Michael Mathioudakis
+ 备注:
+ 关键词:machine learning, order to maintain, model, Cara, important to retrain
+
+ 点击查看摘要
+ It is important to retrain a machine learning (ML) model in order to maintain its performance as the data changes over time. However, this can be costly as it usually requires processing the entire dataset again. This creates a trade-off between retraining too frequently, which leads to unnecessary computing costs, and not retraining often enough, which results in stale and inaccurate ML models. To address this challenge, we propose ML systems that make automated and cost-effective decisions about when to retrain an ML model. We aim to optimize the trade-off by considering the costs associated with each decision. Our research focuses on determining whether to retrain or keep an existing ML model based on various factors, including the data, the model, and the predictive queries answered by the model. Our main contribution is a Cost-Aware Retraining Algorithm called Cara, which optimizes the trade-off over streams of data and queries. To evaluate the performance of Cara, we analyzed synthetic datasets and demonstrated that Cara can adapt to different data drifts and retraining costs while performing similarly to an optimal retrospective algorithm. We also conducted experiments with real-world datasets and showed that Cara achieves better accuracy than drift detection baselines while making fewer retraining decisions, ultimately resulting in lower total costs.
+
+
+
+ 33. 标题:Non-Redundant Graph Neural Networks with Improved Expressiveness
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2310.04190
+ 作者:Franka Bause, Samir Moustafa, Johannes Langguth, Wilfried N. Gansterer, Nils M. Kriege
+ 备注:
+ 关键词:Message passing, neural networks iteratively, Message, networks iteratively compute, passing
+
+ 点击查看摘要
+ Message passing graph neural networks iteratively compute node embeddings by aggregating messages from all neighbors. This procedure can be viewed as a neural variant of the Weisfeiler-Leman method, which limits their expressive power. Moreover, oversmoothing and oversquashing restrict the number of layers these networks can effectively utilize. The repeated exchange and encoding of identical information in message passing amplifies oversquashing. We propose a novel aggregation scheme based on neighborhood trees, which allows for controlling the redundancy by pruning branches of the unfolding trees underlying standard message passing. We prove that reducing redundancy improves expressivity and experimentally show that it alleviates oversquashing. We investigate the interaction between redundancy in message passing and redundancy in computation and propose a compact representation of neighborhood trees, from which we compute node and graph embeddings via a neural tree canonization technique. Our method is provably more expressive than the Weisfeiler-Leman method, less susceptible to oversquashing than message passing neural networks, and provides high classification accuracy on widely-used benchmark datasets.
+
+
+
+ 34. 标题:Entropic Score metric: Decoupling Topology and Size in Training-free NAS
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2310.04179
+ 作者:Niccolò Cavagnero, Luca Robbiano, Francesca Pistilli, Barbara Caputo, Giuseppe Averta
+ 备注:10 pages, 3 figures
+ 关键词:resource-constrained scenarios typical, Neural Architecture Search, daunting task, Neural Networks design, resource-constrained scenarios
+
+ 点击查看摘要
+ Neural Networks design is a complex and often daunting task, particularly for resource-constrained scenarios typical of mobile-sized models. Neural Architecture Search is a promising approach to automate this process, but existing competitive methods require large training time and computational resources to generate accurate models. To overcome these limits, this paper contributes with: i) a novel training-free metric, named Entropic Score, to estimate model expressivity through the aggregated element-wise entropy of its activations; ii) a cyclic search algorithm to separately yet synergistically search model size and topology. Entropic Score shows remarkable ability in searching for the topology of the network, and a proper combination with LogSynflow, to search for model size, yields superior capability to completely design high-performance Hybrid Transformers for edge applications in less than 1 GPU hour, resulting in the fastest and most accurate NAS method for ImageNet classification.
+
+
+
+ 35. 标题:Introducing the Attribution Stability Indicator: a Measure for Time Series XAI Attributions
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2310.04178
+ 作者:Udo Schlegel, Daniel A. Keim
+ 备注:16 pages, 6 figures, ECML-PKDD Workshop XAI-TS: Explainable AI for Time Series: Advances and Applications
+ 关键词:provide interpretable insights, time series data, time series, Attribution Stability Indicator, weather forecasting
+
+ 点击查看摘要
+ Given the increasing amount and general complexity of time series data in domains such as finance, weather forecasting, and healthcare, there is a growing need for state-of-the-art performance models that can provide interpretable insights into underlying patterns and relationships. Attribution techniques enable the extraction of explanations from time series models to gain insights but are hard to evaluate for their robustness and trustworthiness. We propose the Attribution Stability Indicator (ASI), a measure to incorporate robustness and trustworthiness as properties of attribution techniques for time series into account. We extend a perturbation analysis with correlations of the original time series to the perturbed instance and the attributions to include wanted properties in the measure. We demonstrate the wanted properties based on an analysis of the attributions in a dimension-reduced space and the ASI scores distribution over three whole time series classification datasets.
+
+
+
+ 36. 标题:Dynamic Relation-Attentive Graph Neural Networks for Fraud Detection
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2310.04171
+ 作者:Heehyeon Kim, Jinhyeok Choi, Joyce Jiyoung Whang
+ 备注:5 pages, 3 figures, 3 tables. 23rd IEEE International Conference on Data Mining Workshops (ICDMW)
+ 关键词:leaving fake reviews, making abnormal transactions, discover fraudsters deceiving, leaving fake, abnormal transactions
+
+ 点击查看摘要
+ Fraud detection aims to discover fraudsters deceiving other users by, for example, leaving fake reviews or making abnormal transactions. Graph-based fraud detection methods consider this task as a classification problem with two classes: frauds or normal. We address this problem using Graph Neural Networks (GNNs) by proposing a dynamic relation-attentive aggregation mechanism. Based on the observation that many real-world graphs include different types of relations, we propose to learn a node representation per relation and aggregate the node representations using a learnable attention function that assigns a different attention coefficient to each relation. Furthermore, we combine the node representations from different layers to consider both the local and global structures of a target node, which is beneficial to improving the performance of fraud detection on graphs with heterophily. By employing dynamic graph attention in all the aggregation processes, our method adaptively computes the attention coefficients for each node. Experimental results show that our method, DRAG, outperforms state-of-the-art fraud detection methods on real-world benchmark datasets.
+
+
+
+ 37. 标题:Amortized Network Intervention to Steer the Excitatory Point Processes
+ 编号:[103]
+ 链接:https://arxiv.org/abs/2310.04159
+ 作者:Zitao Song, Wendi Ren, Shuang Li
+ 备注:
+ 关键词:excitatory point processes, guiding excitatory point, large-scale network intervention, Model Predictive Control, traffic congestion control
+
+ 点击查看摘要
+ We tackle the challenge of large-scale network intervention for guiding excitatory point processes, such as infectious disease spread or traffic congestion control. Our model-based reinforcement learning utilizes neural ODEs to capture how the networked excitatory point processes will evolve subject to the time-varying changes in network topology. Our approach incorporates Gradient-Descent based Model Predictive Control (GD-MPC), offering policy flexibility to accommodate prior knowledge and constraints. To address the intricacies of planning and overcome the high dimensionality inherent to such decision-making problems, we design an Amortize Network Interventions (ANI) framework, allowing for the pooling of optimal policies from history and other contexts, while ensuring a permutation equivalent property. This property enables efficient knowledge transfer and sharing across diverse contexts. Our approach has broad applications, from curbing infectious disease spread to reducing carbon emissions through traffic light optimization, and thus has the potential to address critical societal and environmental challenges.
+
+
+
+ 38. 标题:From Zero to Hero: Detecting Leaked Data through Synthetic Data Injection and Model Querying
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2310.04145
+ 作者:Biao Wu, Qiang Huang, Anthony K. H. Tung
+ 备注:13 pages, 11 figures, and 4 tables
+ 关键词:Intellectual Property, machine learning applications, learning applications continue, success heavily relies, Safeguarding the Intellectual
+
+ 点击查看摘要
+ Safeguarding the Intellectual Property (IP) of data has become critically important as machine learning applications continue to proliferate, and their success heavily relies on the quality of training data. While various mechanisms exist to secure data during storage, transmission, and consumption, fewer studies have been developed to detect whether they are already leaked for model training without authorization. This issue is particularly challenging due to the absence of information and control over the training process conducted by potential attackers.
+In this paper, we concentrate on the domain of tabular data and introduce a novel methodology, Local Distribution Shifting Synthesis (\textsc{LDSS}), to detect leaked data that are used to train classification models. The core concept behind \textsc{LDSS} involves injecting a small volume of synthetic data--characterized by local shifts in class distribution--into the owner's dataset. This enables the effective identification of models trained on leaked data through model querying alone, as the synthetic data injection results in a pronounced disparity in the predictions of models trained on leaked and modified datasets. \textsc{LDSS} is \emph{model-oblivious} and hence compatible with a diverse range of classification models, such as Naive Bayes, Decision Tree, and Random Forest. We have conducted extensive experiments on seven types of classification models across five real-world datasets. The comprehensive results affirm the reliability, robustness, fidelity, security, and efficiency of \textsc{LDSS}.
+
+
+
+ 39. 标题:Routing Arena: A Benchmark Suite for Neural Routing Solvers
+ 编号:[109]
+ 链接:https://arxiv.org/abs/2310.04140
+ 作者:Daniela Thyssens, Tim Dernedde, Jonas K. Falkner, Lars Schmidt-Thieme
+ 备注:
+ 关键词:Neural Combinatorial Optimization, Combinatorial Optimization, Operations Research, Operations Research solvers, proposed Machine Learning
+
+ 点击查看摘要
+ Neural Combinatorial Optimization has been researched actively in the last eight years. Even though many of the proposed Machine Learning based approaches are compared on the same datasets, the evaluation protocol exhibits essential flaws and the selection of baselines often neglects State-of-the-Art Operations Research approaches. To improve on both of these shortcomings, we propose the Routing Arena, a benchmark suite for Routing Problems that provides a seamless integration of consistent evaluation and the provision of baselines and benchmarks prevalent in the Machine Learning- and Operations Research field. The proposed evaluation protocol considers the two most important evaluation cases for different applications: First, the solution quality for an a priori fixed time budget and secondly the anytime performance of the respective methods. By setting the solution trajectory in perspective to a Best Known Solution and a Base Solver's solutions trajectory, we furthermore propose the Weighted Relative Average Performance (WRAP), a novel evaluation metric that quantifies the often claimed runtime efficiency of Neural Routing Solvers. A comprehensive first experimental evaluation demonstrates that the most recent Operations Research solvers generate state-of-the-art results in terms of solution quality and runtime efficiency when it comes to the vehicle routing problem. Nevertheless, some findings highlight the advantages of neural approaches and motivate a shift in how neural solvers should be conceptualized.
+
+
+
+ 40. 标题:Reinforcement Learning with Fast and Forgetful Memory
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2310.04128
+ 作者:Steven Morad, Ryan Kortvelesy, Stephan Liwicki, Amanda Prorok
+ 备注:
+ 关键词:inherently partially observable, Reinforcement Learning, real world tasks, Supervised Learning, partially observable
+
+ 点击查看摘要
+ Nearly all real world tasks are inherently partially observable, necessitating the use of memory in Reinforcement Learning (RL). Most model-free approaches summarize the trajectory into a latent Markov state using memory models borrowed from Supervised Learning (SL), even though RL tends to exhibit different training and efficiency characteristics. Addressing this discrepancy, we introduce Fast and Forgetful Memory, an algorithm-agnostic memory model designed specifically for RL. Our approach constrains the model search space via strong structural priors inspired by computational psychology. It is a drop-in replacement for recurrent neural networks (RNNs) in recurrent RL algorithms, achieving greater reward than RNNs across various recurrent benchmarks and algorithms without changing any hyperparameters. Moreover, Fast and Forgetful Memory exhibits training speeds two orders of magnitude faster than RNNs, attributed to its logarithmic time and linear space complexity. Our implementation is available at this https URL.
+
+
+
+ 41. 标题:Beyond Myopia: Learning from Positive and Unlabeled Data through Holistic Predictive Trends
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2310.04078
+ 作者:Xinrui Wang, Wenhai Wan, Chuanxin Geng, Shaoyuan LI, Songcan Chen
+ 备注:25 pages
+ 关键词:Learning binary classifiers, Learning binary, binary classifiers, PUL, verifying negative
+
+ 点击查看摘要
+ Learning binary classifiers from positive and unlabeled data (PUL) is vital in many real-world applications, especially when verifying negative examples is difficult. Despite the impressive empirical performance of recent PUL methods, challenges like accumulated errors and increased estimation bias persist due to the absence of negative labels. In this paper, we unveil an intriguing yet long-overlooked observation in PUL: \textit{resampling the positive data in each training iteration to ensure a balanced distribution between positive and unlabeled examples results in strong early-stage performance. Furthermore, predictive trends for positive and negative classes display distinctly different patterns.} Specifically, the scores (output probability) of unlabeled negative examples consistently decrease, while those of unlabeled positive examples show largely chaotic trends. Instead of focusing on classification within individual time frames, we innovatively adopt a holistic approach, interpreting the scores of each example as a temporal point process (TPP). This reformulates the core problem of PUL as recognizing trends in these scores. We then propose a novel TPP-inspired measure for trend detection and prove its asymptotic unbiasedness in predicting changes. Notably, our method accomplishes PUL without requiring additional parameter tuning or prior assumptions, offering an alternative perspective for tackling this problem. Extensive experiments verify the superiority of our method, particularly in a highly imbalanced real-world setting, where it achieves improvements of up to $11.3\%$ in key metrics. The code is available at \href{this https URL}{this https URL}.
+
+
+
+ 42. 标题:Automatic Aspect Extraction from Scientific Texts
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2310.04074
+ 作者:Anna Marshalova, Elena Bruches, Tatiana Batura
+ 备注:
+ 关键词:scientific literature review, key insights, main points, important information, literature review
+
+ 点击查看摘要
+ Being able to extract from scientific papers their main points, key insights, and other important information, referred to here as aspects, might facilitate the process of conducting a scientific literature review. Therefore, the aim of our research is to create a tool for automatic aspect extraction from Russian-language scientific texts of any domain. In this paper, we present a cross-domain dataset of scientific texts in Russian, annotated with such aspects as Task, Contribution, Method, and Conclusion, as well as a baseline algorithm for aspect extraction, based on the multilingual BERT model fine-tuned on our data. We show that there are some differences in aspect representation in different domains, but even though our model was trained on a limited number of scientific domains, it is still able to generalize to new domains, as was proved by cross-domain experiments. The code and the dataset are available at \url{this https URL}.
+
+
+
+ 43. 标题:How to Capture Higher-order Correlations? Generalizing Matrix Softmax Attention to Kronecker Computation
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2310.04064
+ 作者:Josh Alman, Zhao Song
+ 备注:
+ 关键词:transformer attention scheme, classical transformer attention, exp, top, size matrices
+
+ 点击查看摘要
+ In the classical transformer attention scheme, we are given three $n \times d$ size matrices $Q, K, V$ (the query, key, and value tokens), and the goal is to compute a new $n \times d$ size matrix $D^{-1} \exp(QK^\top) V$ where $D = \mathrm{diag}( \exp(QK^\top) {\bf 1}_n )$. In this work, we study a generalization of attention which captures triple-wise correlations. This generalization is able to solve problems about detecting triple-wise connections that were shown to be impossible for transformers. The potential downside of this generalization is that it appears as though computations are even more difficult, since the straightforward algorithm requires cubic time in $n$. However, we show that in the bounded-entry setting (which arises in practice, and which is well-studied in both theory and practice), there is actually a near-linear time algorithm. More precisely, we show that bounded entries are both necessary and sufficient for quickly performing generalized computations:
+$\bullet$ On the positive side, if all entries of the input matrices are bounded above by $o(\sqrt[3]{\log n})$ then we show how to approximate the ``tensor-type'' attention matrix in $n^{1+o(1)}$ time.
+$\bullet$ On the negative side, we show that if the entries of the input matrices may be as large as $\Omega(\sqrt[3]{\log n})$, then there is no algorithm that runs faster than $n^{3-o(1)}$ (assuming the Strong Exponential Time Hypothesis from fine-grained complexity theory).
+We also show that our construction, algorithms, and lower bounds naturally generalize to higher-order tensors and correlations. Interestingly, the higher the order of the tensors, the lower the bound on the entries needs to be for an efficient algorithm. Our results thus yield a natural tradeoff between the boundedness of the entries, and order of the tensor one may use for more expressive, efficient attention computation.
+
+
+
+ 44. 标题:DEFT: A new distance-based feature set for keystroke dynamics
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2310.04059
+ 作者:Nuwan Kaluarachchi, Sevvandi Kandanaarachchi, Kristen Moore, Arathi Arakala
+ 备注:12 pages, 5 figures, 3 tables, conference paper
+ 关键词:behavioural biometric utilised, identification and authentication, Distance Enhanced Flight, Enhanced Flight Time, behavioural biometric
+
+ 点击查看摘要
+ Keystroke dynamics is a behavioural biometric utilised for user identification and authentication. We propose a new set of features based on the distance between keys on the keyboard, a concept that has not been considered before in keystroke dynamics. We combine flight times, a popular metric, with the distance between keys on the keyboard and call them as Distance Enhanced Flight Time features (DEFT). This novel approach provides comprehensive insights into a person's typing behaviour, surpassing typing velocity alone. We build a DEFT model by combining DEFT features with other previously used keystroke dynamic features. The DEFT model is designed to be device-agnostic, allowing us to evaluate its effectiveness across three commonly used devices: desktop, mobile, and tablet. The DEFT model outperforms the existing state-of-the-art methods when we evaluate its effectiveness across two datasets. We obtain accuracy rates exceeding 99% and equal error rates below 10% on all three devices.
+
+
+
+ 45. 标题:AUTOPARLLM: GNN-Guided Automatic Code Parallelization using Large Language Models
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2310.04047
+ 作者:Quazi Ishtiaque Mahmud, Ali TehraniJamsaz, Hung D Phan, Nesreen K. Ahmed, Ali Jannesari
+ 备注:10 pages
+ 关键词:sequentially written programs, NAS Parallel Benchmark, Parallelizing sequentially written, sequentially written, parallel
+
+ 点击查看摘要
+ Parallelizing sequentially written programs is a challenging task. Even experienced developers need to spend considerable time finding parallelism opportunities and then actually writing parallel versions of sequentially written programs. To address this issue, we present AUTOPARLLM, a framework for automatically discovering parallelism and generating the parallel version of the sequentially written program. Our framework consists of two major components: i) a heterogeneous Graph Neural Network (GNN) based parallelism discovery and parallel pattern detection module, and ii) an LLM-based code generator to generate the parallel counterpart of the sequential programs. We use the GNN to learn the flow-aware characteristics of the programs to identify parallel regions in sequential programs and then construct an enhanced prompt using the GNN's results for the LLM-based generator to finally produce the parallel counterparts of the sequential programs. We evaluate AUTOPARLLM on 11 applications of 2 well-known benchmark suites: NAS Parallel Benchmark and Rodinia Benchmark. Our results show that AUTOPARLLM is indeed effective in improving the state-of-the-art LLM-based models for the task of parallel code generation in terms of multiple code generation metrics. AUTOPARLLM also improves the average runtime of the parallel code generated by the state-of-the-art LLMs by as high as 3.4% and 2.9% for the NAS Parallel Benchmark and Rodinia Benchmark respectively. Additionally, to overcome the issue that well-known metrics for translation evaluation have not been optimized to evaluate the quality of the generated parallel code, we propose OMPScore for evaluating the quality of the generated code. We show that OMPScore exhibits a better correlation with human judgment than existing metrics, measured by up to 75% improvement of Spearman correlation.
+
+
+
+ 46. 标题:Observation-Guided Diffusion Probabilistic Models
+ 编号:[147]
+ 链接:https://arxiv.org/abs/2310.04041
+ 作者:Junoh Kang, Jinyoung Choi, Sungik Choi, Bohyung Han
+ 备注:
+ 关键词:model called observation-guided, called observation-guided diffusion, observation-guided diffusion probabilistic, diffusion probabilistic model, diffusion model called
+
+ 点击查看摘要
+ We propose a novel diffusion model called observation-guided diffusion probabilistic model (OGDM), which effectively addresses the trade-off between quality control and fast sampling. Our approach reestablishes the training objective by integrating the guidance of the observation process with the Markov chain in a principled way. This is achieved by introducing an additional loss term derived from the observation based on the conditional discriminator on noise level, which employs Bernoulli distribution indicating whether its input lies on the (noisy) real manifold or not. This strategy allows us to optimize the more accurate negative log-likelihood induced in the inference stage especially when the number of function evaluations is limited. The proposed training method is also advantageous even when incorporated only into the fine-tuning process, and it is compatible with various fast inference strategies since our method yields better denoising networks using the exactly same inference procedure without incurring extra computational cost. We demonstrate the effectiveness of the proposed training algorithm using diverse inference methods on strong diffusion model baselines.
+
+
+
+ 47. 标题:Joint Projection Learning and Tensor Decomposition Based Incomplete Multi-view Clustering
+ 编号:[149]
+ 链接:https://arxiv.org/abs/2310.04038
+ 作者:Wei Lv, Chao Zhang, Huaxiong Li, Xiuyi Jia, Chunlin Chen
+ 备注:IEEE Transactions on Neural Networks and Learning Systems, 2023
+ 关键词:received increasing attention, Incomplete multi-view clustering, original incomplete multi-view, Incomplete multi-view, incomplete multi-view data
+
+ 点击查看摘要
+ Incomplete multi-view clustering (IMVC) has received increasing attention since it is often that some views of samples are incomplete in reality. Most existing methods learn similarity subgraphs from original incomplete multi-view data and seek complete graphs by exploring the incomplete subgraphs of each view for spectral clustering. However, the graphs constructed on the original high-dimensional data may be suboptimal due to feature redundancy and noise. Besides, previous methods generally ignored the graph noise caused by the inter-class and intra-class structure variation during the transformation of incomplete graphs and complete graphs. To address these problems, we propose a novel Joint Projection Learning and Tensor Decomposition Based method (JPLTD) for IMVC. Specifically, to alleviate the influence of redundant features and noise in high-dimensional data, JPLTD introduces an orthogonal projection matrix to project the high-dimensional features into a lower-dimensional space for compact feature learning.Meanwhile, based on the lower-dimensional space, the similarity graphs corresponding to instances of different views are learned, and JPLTD stacks these graphs into a third-order low-rank tensor to explore the high-order correlations across different views. We further consider the graph noise of projected data caused by missing samples and use a tensor-decomposition based graph filter for robust clustering.JPLTD decomposes the original tensor into an intrinsic tensor and a sparse tensor. The intrinsic tensor models the true data similarities. An effective optimization algorithm is adopted to solve the JPLTD model. Comprehensive experiments on several benchmark datasets demonstrate that JPLTD outperforms the state-of-the-art methods. The code of JPLTD is available at this https URL.
+
+
+
+ 48. 标题:Genetic prediction of quantitative traits: a machine learner's guide focused on height
+ 编号:[151]
+ 链接:https://arxiv.org/abs/2310.04028
+ 作者:Lucie Bourguignon, Caroline Weis, Catherine R. Jutzeler, Michael Adamer
+ 备注:
+ 关键词:machine learning community, Machine learning, protein folding, celebrating many successes, application to biological
+
+ 点击查看摘要
+ Machine learning and deep learning have been celebrating many successes in the application to biological problems, especially in the domain of protein folding. Another equally complex and important question has received relatively little attention by the machine learning community, namely the one of prediction of complex traits from genetics. Tackling this problem requires in-depth knowledge of the related genetics literature and awareness of various subtleties associated with genetic data. In this guide, we provide an overview for the machine learning community on current state of the art models and associated subtleties which need to be taken into consideration when developing new models for phenotype prediction. We use height as an example of a continuous-valued phenotype and provide an introduction to benchmark datasets, confounders, feature selection, and common metrics.
+
+
+
+ 49. 标题:PGraphDTA: Improving Drug Target Interaction Prediction using Protein Language Models and Contact Maps
+ 编号:[156]
+ 链接:https://arxiv.org/abs/2310.04017
+ 作者:Rakesh Bal, Yijia Xiao, Wei Wang
+ 备注:11 pages, 5 figures, 4 tables
+ 关键词:involves substantial costs, time investment, Developing and discovering, substantial costs, safety concerns
+
+ 点击查看摘要
+ Developing and discovering new drugs is a complex and resource-intensive endeavor that often involves substantial costs, time investment, and safety concerns. A key aspect of drug discovery involves identifying novel drug-target (DT) interactions. Existing computational methods for predicting DT interactions have primarily focused on binary classification tasks, aiming to determine whether a DT pair interacts or not. However, protein-ligand interactions exhibit a continuum of binding strengths, known as binding affinity, presenting a persistent challenge for accurate prediction. In this study, we investigate various techniques employed in Drug Target Interaction (DTI) prediction and propose novel enhancements to enhance their performance. Our approaches include the integration of Protein Language Models (PLMs) and the incorporation of Contact Map information as an inductive bias within current models. Through extensive experimentation, we demonstrate that our proposed approaches outperform the baseline models considered in this study, presenting a compelling case for further development in this direction. We anticipate that the insights gained from this work will significantly narrow the search space for potential drugs targeting specific proteins, thereby accelerating drug discovery. Code and data for PGraphDTA are available at https://anonymous.4open.science/r/PGraphDTA.
+
+
+
+ 50. 标题:Learning via Look-Alike Clustering: A Precise Analysis of Model Generalization
+ 编号:[157]
+ 链接:https://arxiv.org/abs/2310.04015
+ 作者:Adel Javanmard, Vahab Mirrokni
+ 备注:accepted at the Conference on Neural Information Processing Systems (NeurIPS 2023)
+ 关键词:personalized recommendations systems, ensuring user data, user data protection, data protection remains, recommendations systems
+
+ 点击查看摘要
+ While personalized recommendations systems have become increasingly popular, ensuring user data protection remains a paramount concern in the development of these learning systems. A common approach to enhancing privacy involves training models using anonymous data rather than individual data. In this paper, we explore a natural technique called \emph{look-alike clustering}, which involves replacing sensitive features of individuals with the cluster's average values. We provide a precise analysis of how training models using anonymous cluster centers affects their generalization capabilities. We focus on an asymptotic regime where the size of the training set grows in proportion to the features dimension. Our analysis is based on the Convex Gaussian Minimax Theorem (CGMT) and allows us to theoretically understand the role of different model components on the generalization error. In addition, we demonstrate that in certain high-dimensional regimes, training over anonymous cluster centers acts as a regularization and improves generalization error of the trained models. Finally, we corroborate our asymptotic theory with finite-sample numerical experiments where we observe a perfect match when the sample size is only of order of a few hundreds.
+
+
+
+ 51. 标题:The Role of Federated Learning in a Wireless World with Foundation Models
+ 编号:[162]
+ 链接:https://arxiv.org/abs/2310.04003
+ 作者:Zihan Chen, Howard H. Yang, Y. C. Tay, Kai Fong Ernest Chong, Tony Q. S. Quek
+ 备注:8 pages, 5 figures, 1 table
+ 关键词:general-purpose artificial intelligence, enabled multiple brand-new, multiple brand-new generative, recently enabled multiple, Foundation models
+
+ 点击查看摘要
+ Foundation models (FMs) are general-purpose artificial intelligence (AI) models that have recently enabled multiple brand-new generative AI applications. The rapid advances in FMs serve as an important contextual backdrop for the vision of next-generation wireless networks, where federated learning (FL) is a key enabler of distributed network intelligence. Currently, the exploration of the interplay between FMs and FL is still in its nascent stage. Naturally, FMs are capable of boosting the performance of FL, and FL could also leverage decentralized data and computing resources to assist in the training of FMs. However, the exceptionally high requirements that FMs have for computing resources, storage, and communication overhead would pose critical challenges to FL-enabled wireless networks. In this article, we explore the extent to which FMs are suitable for FL over wireless networks, including a broad overview of research challenges and opportunities. In particular, we discuss multiple new paradigms for realizing future intelligent networks that integrate FMs and FL. We also consolidate several broad research directions associated with these paradigms.
+
+
+
+ 52. 标题:Runtime Monitoring DNN-Based Perception
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2310.03999
+ 作者:Chih-Hong Cheng, Michael Luttenberger, Rongjie Yan
+ 备注:
+ 关键词:Deep neural networks, complex perception systems, realizing complex perception, Deep neural, neural networks
+
+ 点击查看摘要
+ Deep neural networks (DNNs) are instrumental in realizing complex perception systems. As many of these applications are safety-critical by design, engineering rigor is required to ensure that the functional insufficiency of the DNN-based perception is not the source of harm. In addition to conventional static verification and testing techniques employed during the design phase, there is a need for runtime verification techniques that can detect critical events, diagnose issues, and even enforce requirements. This tutorial aims to provide readers with a glimpse of techniques proposed in the literature. We start with classical methods proposed in the machine learning community, then highlight a few techniques proposed by the formal methods community. While we surely can observe similarities in the design of monitors, how the decision boundaries are created vary between the two communities. We conclude by highlighting the need to rigorously design monitors, where data availability outside the operational domain plays an important role.
+
+
+
+ 53. 标题:Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2310.03986
+ 作者:Md Kaykobad Reza, Ashley Prater-Bennette, M. Salman Asif
+ 备注:18 pages, 3 figures, 11 tables
+ 关键词:seeks to utilize, sources to improve, missing modalities, Multimodal, modalities
+
+ 点击查看摘要
+ Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
+
+
+
+ 54. 标题:Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2310.03985
+ 作者:Zih-Jyun Lin, Yi-Ju Chen, Po-Chih Kuo, Likai Huang, Chaur-Jong Hu, Cheng-Yu Chen
+ 备注:submitted to IEEE ICASSP 2024
+ 关键词:Dementia diagnosis requires, testing methods, complex and time-consuming, diagnosis requires, requires a series
+
+ 点击查看摘要
+ Dementia diagnosis requires a series of different testing methods, which is complex and time-consuming. Early detection of dementia is crucial as it can prevent further deterioration of the condition. This paper utilizes a speech recognition model to construct a dementia assessment system tailored for Mandarin speakers during the picture description task. By training an attention-based speech recognition model on voice data closely resembling real-world scenarios, we have significantly enhanced the model's recognition capabilities. Subsequently, we extracted the encoder from the speech recognition model and added a linear layer for dementia assessment. We collected Mandarin speech data from 99 subjects and acquired their clinical assessments from a local hospital. We achieved an accuracy of 92.04% in Alzheimer's disease detection and a mean absolute error of 9% in clinical dementia rating score prediction.
+
+
+
+ 55. 标题:AdaRec: Adaptive Sequential Recommendation for Reinforcing Long-term User Engagement
+ 编号:[170]
+ 链接:https://arxiv.org/abs/2310.03984
+ 作者:Zhenghai Xue, Qingpeng Cai, Tianyou Zuo, Bin Yang, Lantao Hu, Peng Jiang, Kun Gai, Bo An
+ 备注:Preprint. Under Review
+ 关键词:Reinforcement Learning, paid to Reinforcement, Markov Decision Process, sequential recommendation tasks, Growing attention
+
+ 点击查看摘要
+ Growing attention has been paid to Reinforcement Learning (RL) algorithms when optimizing long-term user engagement in sequential recommendation tasks. One challenge in large-scale online recommendation systems is the constant and complicated changes in users' behavior patterns, such as interaction rates and retention tendencies. When formulated as a Markov Decision Process (MDP), the dynamics and reward functions of the recommendation system are continuously affected by these changes. Existing RL algorithms for recommendation systems will suffer from distribution shift and struggle to adapt in such an MDP. In this paper, we introduce a novel paradigm called Adaptive Sequential Recommendation (AdaRec) to address this issue. AdaRec proposes a new distance-based representation loss to extract latent information from users' interaction trajectories. Such information reflects how RL policy fits to current user behavior patterns, and helps the policy to identify subtle changes in the recommendation system. To make rapid adaptation to these changes, AdaRec encourages exploration with the idea of optimism under uncertainty. The exploration is further guarded by zero-order action optimization to ensure stable recommendation quality in complicated environments. We conduct extensive empirical analyses in both simulator-based and live sequential recommendation tasks, where AdaRec exhibits superior long-term performance compared to all baseline algorithms.
+
+
+
+ 56. 标题:CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
+ 编号:[172]
+ 链接:https://arxiv.org/abs/2310.03981
+ 作者:Weibin Liao, Xuhong Li, Qingzhong Wang, Yanwu Xu, Zhaozheng Yin, Haoyi Xiong
+ 备注:
+ 关键词:massive fine-annotated cell, cell, cell segmentation, pre-training DNN models, bounding boxes
+
+ 点击查看摘要
+ While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.
+
+
+
+ 57. 标题:Perfect Alignment May be Poisonous to Graph Contrastive Learning
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2310.03977
+ 作者:Jingyu Liu, Huayi Tang, Yong Liu
+ 备注:
+ 关键词:Contrastive Learning, learn node representations, aims to learn, representations by aligning, Learning
+
+ 点击查看摘要
+ Graph Contrastive Learning (GCL) aims to learn node representations by aligning positive pairs and separating negative ones. However, limited research has been conducted on the inner law behind specific augmentations used in graph-based learning. What kind of augmentation will help downstream performance, how does contrastive learning actually influence downstream tasks, and why the magnitude of augmentation matters? This paper seeks to address these questions by establishing a connection between augmentation and downstream performance, as well as by investigating the generalization of contrastive learning. Our findings reveal that GCL contributes to downstream tasks mainly by separating different classes rather than gathering nodes of the same class. So perfect alignment and augmentation overlap which draw all intra-class samples the same can not explain the success of contrastive learning. Then in order to comprehend how augmentation aids the contrastive learning process, we conduct further investigations into its generalization, finding that perfect alignment that draw positive pair the same could help contrastive loss but is poisonous to generalization, on the contrary, imperfect alignment enhances the model's generalization ability. We analyse the result by information theory and graph spectrum theory respectively, and propose two simple but effective methods to verify the theories. The two methods could be easily applied to various GCL algorithms and extensive experiments are conducted to prove its effectiveness.
+
+
+
+ 58. 标题:Ultimate limit on learning non-Markovian behavior: Fisher information rate and excess information
+ 编号:[179]
+ 链接:https://arxiv.org/abs/2310.03968
+ 作者:Paul M. Riechers
+ 备注:
+ 关键词:learning unknown parameters, information rate, Fisher information rate, address the fundamental, fundamental limits
+
+ 点击查看摘要
+ We address the fundamental limits of learning unknown parameters of any stochastic process from time-series data, and discover exact closed-form expressions for how optimal inference scales with observation length. Given a parametrized class of candidate models, the Fisher information of observed sequence probabilities lower-bounds the variance in model estimation from finite data. As sequence-length increases, the minimal variance scales as the square inverse of the length -- with constant coefficient given by the information rate. We discover a simple closed-form expression for this information rate, even in the case of infinite Markov order. We furthermore obtain the exact analytic lower bound on model variance from the observation-induced metadynamic among belief states. We discover ephemeral, exponential, and more general modes of convergence to the asymptotic information rate. Surprisingly, this myopic information rate converges to the asymptotic Fisher information rate with exactly the same relaxation timescales that appear in the myopic entropy rate as it converges to the Shannon entropy rate for the process. We illustrate these results with a sequence of examples that highlight qualitatively distinct features of stochastic processes that shape optimal learning.
+
+
+
+ 59. 标题:A Learnable Counter-condition Analysis Framework for Functional Connectivity-based Neurological Disorder Diagnosis
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2310.03964
+ 作者:Eunsong Kang, Da-woon Heo, Jiwon Lee, Heung-Il Suk
+ 备注:
+ 关键词:deep learning-based models, widely utilized deep, utilized deep learning-based, conducted post-hoc analyses, discover disease-related biomarkers
+
+ 点击查看摘要
+ To understand the biological characteristics of neurological disorders with functional connectivity (FC), recent studies have widely utilized deep learning-based models to identify the disease and conducted post-hoc analyses via explainable models to discover disease-related biomarkers. Most existing frameworks consist of three stages, namely, feature selection, feature extraction for classification, and analysis, where each stage is implemented separately. However, if the results at each stage lack reliability, it can cause misdiagnosis and incorrect analysis in afterward stages. In this study, we propose a novel unified framework that systemically integrates diagnoses (i.e., feature selection and feature extraction) and explanations. Notably, we devised an adaptive attention network as a feature selection approach to identify individual-specific disease-related connections. We also propose a functional network relational encoder that summarizes the global topological properties of FC by learning the inter-network relations without pre-defined edges between functional networks. Last but not least, our framework provides a novel explanatory power for neuroscientific interpretation, also termed counter-condition analysis. We simulated the FC that reverses the diagnostic information (i.e., counter-condition FC): converting a normal brain to be abnormal and vice versa. We validated the effectiveness of our framework by using two large resting-state functional magnetic resonance imaging (fMRI) datasets, Autism Brain Imaging Data Exchange (ABIDE) and REST-meta-MDD, and demonstrated that our framework outperforms other competing methods for disease identification. Furthermore, we analyzed the disease-related neurological patterns based on counter-condition analysis.
+
+
+
+ 60. 标题:Understanding prompt engineering may not require rethinking generalization
+ 编号:[186]
+ 链接:https://arxiv.org/abs/2310.03957
+ 作者:Victor Akinwande, Yiding Jiang, Dylan Sam, J. Zico Kolter
+ 备注:
+ 关键词:explicit training process, achieved impressive performance, prompted vision-language models, learning in prompted, prompted vision-language
+
+ 点击查看摘要
+ Zero-shot learning in prompted vision-language models, the practice of crafting prompts to build classifiers without an explicit training process, has achieved impressive performance in many settings. This success presents a seemingly surprising observation: these methods suffer relatively little from overfitting, i.e., when a prompt is manually engineered to achieve low error on a given training set (thus rendering the method no longer actually zero-shot), the approach still performs well on held-out test data. In this paper, we show that we can explain such performance well via recourse to classical PAC-Bayes bounds. Specifically, we show that the discrete nature of prompts, combined with a PAC-Bayes prior given by a language model, results in generalization bounds that are remarkably tight by the standards of the literature: for instance, the generalization bound of an ImageNet classifier is often within a few percentage points of the true test error. We demonstrate empirically that this holds for existing handcrafted prompts and prompts generated through simple greedy search. Furthermore, the resulting bound is well-suited for model selection: the models with the best bound typically also have the best test performance. This work thus provides a possible justification for the widespread practice of prompt engineering, even if it seems that such methods could potentially overfit the training data.
+
+
+
+ 61. 标题:Improved prediction of ligand-protein binding affinities by meta-modeling
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2310.03946
+ 作者:Ho-Joon Lee, Prashant S. Emani, Mark B. Gerstein
+ 备注:61 pages, 3 main tables, 6 main figures, 6 supplementary figures, and supporting information. For 8 supplementary tables and code, see this https URL
+ 关键词:drug development efforts, filtering potential candidates, candidate drug ligands, development efforts, candidate drug
+
+ 点击查看摘要
+ The accurate screening of candidate drug ligands against target proteins through computational approaches is of prime interest to drug development efforts, as filtering potential candidates would save time and expenses for finding drugs. Such virtual screening depends in part on methods to predict the binding affinity between ligands and proteins. Given many computational models for binding affinity prediction with varying results across targets, we herein develop a meta-modeling framework by integrating published empirical structure-based docking and sequence-based deep learning models. In building this framework, we evaluate many combinations of individual models, training databases, and linear and nonlinear meta-modeling approaches. We show that many of our meta-models significantly improve affinity predictions over individual base models. Our best meta-models achieve comparable performance to state-of-the-art exclusively structure-based deep learning tools. Overall, we demonstrate that diverse modeling approaches can be ensembled together to gain substantial improvement in binding affinity prediction while allowing control over input features such as physicochemical properties or molecular descriptors.
+
+
+
+ 62. 标题:LaTeX: Language Pattern-aware Triggering Event Detection for Adverse Experience during Pandemics
+ 编号:[192]
+ 链接:https://arxiv.org/abs/2310.03941
+ 作者:Kaiqun Fu, Yangxiao Bai, Weiwei Zhang, Deepthi Kolady
+ 备注:arXiv admin note: text overlap with arXiv:1911.08684
+ 关键词:United States, accentuated socioeconomic disparities, Household Pulse Survey, pandemic has accentuated, accentuated socioeconomic
+
+ 点击查看摘要
+ The COVID-19 pandemic has accentuated socioeconomic disparities across various racial and ethnic groups in the United States. While previous studies have utilized traditional survey methods like the Household Pulse Survey (HPS) to elucidate these disparities, this paper explores the role of social media platforms in both highlighting and addressing these challenges. Drawing from real-time data sourced from Twitter, we analyzed language patterns related to four major types of adverse experiences: loss of employment income (LI), food scarcity (FS), housing insecurity (HI), and unmet needs for mental health services (UM). We first formulate a sparsity optimization problem that extracts low-level language features from social media data sources. Second, we propose novel constraints on feature similarity exploiting prior knowledge about the similarity of the language patterns among the adverse experiences. The proposed problem is challenging to solve due to the non-convexity objective and non-smoothness penalties. We develop an algorithm based on the alternating direction method of multipliers (ADMM) framework to solve the proposed formulation. Extensive experiments and comparisons to other models on real-world social media and the detection of adverse experiences justify the efficacy of our model.
+
+
+
+ 63. 标题:Improving classifier decision boundaries using nearest neighbors
+ 编号:[199]
+ 链接:https://arxiv.org/abs/2310.03927
+ 作者:Johannes Schneider
+ 备注:
+ 关键词:learning optimal decision, optimal decision boundaries, decision boundaries, learning optimal, optimal decision
+
+ 点击查看摘要
+ Neural networks are not learning optimal decision boundaries. We show that decision boundaries are situated in areas of low training data density. They are impacted by few training samples which can easily lead to overfitting. We provide a simple algorithm performing a weighted average of the prediction of a sample and its nearest neighbors' (computed in latent space) leading to a minor favorable outcomes for a variety of important measures for neural networks. In our evaluation, we employ various self-trained and pre-trained convolutional neural networks to show that our approach improves (i) resistance to label noise, (ii) robustness against adversarial attacks, (iii) classification accuracy, and to some degree even (iv) interpretability. While improvements are not necessarily large in all four areas, our approach is conceptually simple, i.e., improvements come without any modification to network architecture, training procedure or dataset. Furthermore, they are in stark contrast to prior works that often require trade-offs among the four objectives or provide valuable, but non-actionable insights.
+
+
+
+ 64. 标题:Multitask Learning for Time Series Data\\with 2D Convolution
+ 编号:[200]
+ 链接:https://arxiv.org/abs/2310.03925
+ 作者:Chin-Chia Michael Yeh, Xin Dai, Yan Zheng, Junpeng Wang, Huiyuan Chen, Yujie Fan, Audrey Der, Zhongfang Zhuang, Liang Wang, Wei Zhang
+ 备注:
+ 关键词:related tasks simultaneously, closely related tasks, Multitask learning, aims to develop, develop a unified
+
+ 点击查看摘要
+ Multitask learning (MTL) aims to develop a unified model that can handle a set of closely related tasks simultaneously. By optimizing the model across multiple tasks, MTL generally surpasses its non-MTL counterparts in terms of generalizability. Although MTL has been extensively researched in various domains such as computer vision, natural language processing, and recommendation systems, its application to time series data has received limited attention. In this paper, we investigate the application of MTL to the time series classification (TSC) problem. However, when we integrate the state-of-the-art 1D convolution-based TSC model with MTL, the performance of the TSC model actually deteriorates. By comparing the 1D convolution-based models with the Dynamic Time Warping (DTW) distance function, it appears that the underwhelming results stem from the limited expressive power of the 1D convolutional layers. To overcome this challenge, we propose a novel design for a 2D convolution-based model that enhances the model's expressiveness. Leveraging this advantage, our proposed method outperforms competing approaches on both the UCR Archive and an industrial transaction TSC dataset.
+
+
+
+ 65. 标题:An Efficient Content-based Time Series Retrieval System
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2310.03919
+ 作者:Chin-Chia Michael Yeh, Huiyuan Chen, Xin Dai, Yan Zheng, Junpeng Wang, Vivian Lai, Yujie Fan, Audrey Der, Zhongfang Zhuang, Liang Wang, Wei Zhang, Jeff M. Phillips
+ 备注:
+ 关键词:Content-based Time Series, Time Series Retrieval, Time Series, time series emerged, information retrieval system
+
+ 点击查看摘要
+ A Content-based Time Series Retrieval (CTSR) system is an information retrieval system for users to interact with time series emerged from multiple domains, such as finance, healthcare, and manufacturing. For example, users seeking to learn more about the source of a time series can submit the time series as a query to the CTSR system and retrieve a list of relevant time series with associated metadata. By analyzing the retrieved metadata, users can gather more information about the source of the time series. Because the CTSR system is required to work with time series data from diverse domains, it needs a high-capacity model to effectively measure the similarity between different time series. On top of that, the model within the CTSR system has to compute the similarity scores in an efficient manner as the users interact with the system in real-time. In this paper, we propose an effective and efficient CTSR model that outperforms alternative models, while still providing reasonable inference runtimes. To demonstrate the capability of the proposed method in solving business problems, we compare it against alternative models using our in-house transaction data. Our findings reveal that the proposed model is the most suitable solution compared to others for our transaction data problem.
+
+
+
+ 66. 标题:Toward a Foundation Model for Time Series Data
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2310.03916
+ 作者:Chin-Chia Michael Yeh, Xin Dai, Huiyuan Chen, Yan Zheng, Yujie Fan, Audrey Der, Vivian Lai, Zhongfang Zhuang, Junpeng Wang, Liang Wang, Wei Zhang
+ 备注:
+ 关键词:time series, machine learning model, machine learning, large and diverse, diverse set
+
+ 点击查看摘要
+ A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.
+
+
+
+ 67. 标题:Leveraging Low-Rank and Sparse Recurrent Connectivity for Robust Closed-Loop Control
+ 编号:[205]
+ 链接:https://arxiv.org/abs/2310.03915
+ 作者:Neehal Tumma, Mathias Lechner, Noel Loo, Ramin Hasani, Daniela Rus
+ 备注:
+ 关键词:Developing autonomous agents, Developing autonomous, machine learning, interact with changing, open challenge
+
+ 点击查看摘要
+ Developing autonomous agents that can interact with changing environments is an open challenge in machine learning. Robustness is particularly important in these settings as agents are often fit offline on expert demonstrations but deployed online where they must generalize to the closed feedback loop within the environment. In this work, we explore the application of recurrent neural networks to tasks of this nature and understand how a parameterization of their recurrent connectivity influences robustness in closed-loop settings. Specifically, we represent the recurrent connectivity as a function of rank and sparsity and show both theoretically and empirically that modulating these two variables has desirable effects on network dynamics. The proposed low-rank, sparse connectivity induces an interpretable prior on the network that proves to be most amenable for a class of models known as closed-form continuous-time neural networks (CfCs). We find that CfCs with fewer parameters can outperform their full-rank, fully-connected counterparts in the online setting under distribution shift. This yields memory-efficient and robust agents while opening a new perspective on how we can modulate network dynamics through connectivity.
+
+
+
+ 68. 标题:RTDK-BO: High Dimensional Bayesian Optimization with Reinforced Transformer Deep kernels
+ 编号:[208]
+ 链接:https://arxiv.org/abs/2310.03912
+ 作者:Alexander Shmakov, Avisek Naug, Vineet Gundecha, Sahand Ghorbanpour, Ricardo Luna Gutierrez, Ashwin Ramesh Babu, Antonio Guillen, Soumyendu Sarkar
+ 备注:2023 IEEE 19th International Conference on Automation Science and Engineering (CASE)
+ 关键词:guided by Gaussian, Transformer Deep Kernel, critical problem inherent, Deep Kernel, Gaussian process
+
+ 点击查看摘要
+ Bayesian Optimization (BO), guided by Gaussian process (GP) surrogates, has proven to be an invaluable technique for efficient, high-dimensional, black-box optimization, a critical problem inherent to many applications such as industrial design and scientific computing. Recent contributions have introduced reinforcement learning (RL) to improve the optimization performance on both single function optimization and \textit{few-shot} multi-objective optimization. However, even few-shot techniques fail to exploit similarities shared between closely related objectives. In this paper, we combine recent developments in Deep Kernel Learning (DKL) and attention-based Transformer models to improve the modeling powers of GP surrogates with meta-learning. We propose a novel method for improving meta-learning BO surrogates by incorporating attention mechanisms into DKL, empowering the surrogates to adapt to contextual information gathered during the BO process. We combine this Transformer Deep Kernel with a learned acquisition function trained with continuous Soft Actor-Critic Reinforcement Learning to aid in exploration. This Reinforced Transformer Deep Kernel (RTDK-BO) approach yields state-of-the-art results in continuous high-dimensional optimization problems.
+
+
+
+ 69. 标题:PyDCM: Custom Data Center Models with Reinforcement Learning for Sustainability
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2310.03906
+ 作者:Avisek Naug, Antonio Guillen, Ricardo Luna Gutiérrez, Vineet Gundecha, Dejan Markovikj, Lekhapriya Dheeraj Kashyap, Lorenz Krause, Sahand Ghorbanpour, Sajad Mousavi, Ashwin Ramesh Babu, Soumyendu Sarkar
+ 备注:The 10th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation (BuildSys '23), November 15--16, 2023, Istanbul, Turkey
+ 关键词:increasing global emphasis, reducing carbon emissions, data center model, data center, data center design
+
+ 点击查看摘要
+ The increasing global emphasis on sustainability and reducing carbon emissions is pushing governments and corporations to rethink their approach to data center design and operation. Given their high energy consumption and exponentially large computational workloads, data centers are prime candidates for optimizing power consumption, especially in areas such as cooling and IT energy usage. A significant challenge in this pursuit is the lack of a configurable and scalable thermal data center model that offers an end-to-end pipeline. Data centers consist of multiple IT components whose geometric configuration and heat dissipation make thermal modeling difficult. This paper presents PyDCM, a customizable Data Center Model implemented in Python, that allows users to create unique configurations of IT equipment with custom server specifications and geometric arrangements of IT cabinets. The use of vectorized thermal calculations makes PyDCM orders of magnitude faster (30 times) than current Energy Plus modeling implementations and scales sublinearly with the number of CPUs. Also, PyDCM enables the use of Deep Reinforcement Learning via the Gymnasium wrapper to optimize data center cooling and offers a user-friendly platform for testing various data center design prototypes.
+
+
+
+ 70. 标题:CrysFormer: Protein Structure Prediction via 3d Patterson Maps and Partial Structure Attention
+ 编号:[214]
+ 链接:https://arxiv.org/abs/2310.03899
+ 作者:Chen Dun, Qiutai Pan, Shikai Jin, Ria Stevens, Mitchell D. Miller, George N. Phillips, Jr., Anastasios Kyrillidis
+ 备注:
+ 关键词:decades-long open question, open question, decades-long open, protein, structure
+
+ 点击查看摘要
+ Determining the structure of a protein has been a decades-long open question. A protein's three-dimensional structure often poses nontrivial computation costs, when classical simulation algorithms are utilized. Advances in the transformer neural network architecture -- such as AlphaFold2 -- achieve significant improvements for this problem, by learning from a large dataset of sequence information and corresponding protein structures. Yet, such methods only focus on sequence information; other available prior knowledge, such as protein crystallography and partial structure of amino acids, could be potentially utilized. To the best of our knowledge, we propose the first transformer-based model that directly utilizes protein crystallography and partial structure information to predict the electron density maps of proteins. Via two new datasets of peptide fragments (2-residue and 15-residue) , we demonstrate our method, dubbed \texttt{CrysFormer}, can achieve accurate predictions, based on a much smaller dataset size and with reduced computation costs.
+
+
+
+ 71. 标题:Class-Incremental Learning Using Generative Experience Replay Based on Time-aware Regularization
+ 编号:[215]
+ 链接:https://arxiv.org/abs/2310.03898
+ 作者:Zizhao Hu, Mohammad Rostami
+ 备注:
+ 关键词:accumulatively without forgetting, forgetting remains, remains a critical, critical challenge, tasks accumulatively
+
+ 点击查看摘要
+ Learning new tasks accumulatively without forgetting remains a critical challenge in continual learning. Generative experience replay addresses this challenge by synthesizing pseudo-data points for past learned tasks and later replaying them for concurrent training along with the new tasks' data. Generative replay is the best strategy for continual learning under a strict class-incremental setting when certain constraints need to be met: (i) constant model size, (ii) no pre-training dataset, and (iii) no memory buffer for storing past tasks' data. Inspired by the biological nervous system mechanisms, we introduce a time-aware regularization method to dynamically fine-tune the three training objective terms used for generative replay: supervised learning, latent regularization, and data reconstruction. Experimental results on major benchmarks indicate that our method pushes the limit of brain-inspired continual learners under such strict settings, improves memory retention, and increases the average performance over continually arriving tasks.
+
+
+
+ 72. 标题:Accelerated Neural Network Training with Rooted Logistic Objectives
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2310.03890
+ 作者:Zhu Wang, Praveen Raj Veluswami, Harsh Mishra, Sathya N. Ravi
+ 备注:
+ 关键词:real world scenarios, cross entropy based, real world, world scenarios, scenarios are trained
+
+ 点击查看摘要
+ Many neural networks deployed in the real world scenarios are trained using cross entropy based loss functions. From the optimization perspective, it is known that the behavior of first order methods such as gradient descent crucially depend on the separability of datasets. In fact, even in the most simplest case of binary classification, the rate of convergence depends on two factors: (1) condition number of data matrix, and (2) separability of the dataset. With no further pre-processing techniques such as over-parametrization, data augmentation etc., separability is an intrinsic quantity of the data distribution under consideration. We focus on the landscape design of the logistic function and derive a novel sequence of {\em strictly} convex functions that are at least as strict as logistic loss. The minimizers of these functions coincide with those of the minimum norm solution wherever possible. The strict convexity of the derived function can be extended to finetune state-of-the-art models and applications. In empirical experimental analysis, we apply our proposed rooted logistic objective to multiple deep models, e.g., fully-connected neural networks and transformers, on various of classification benchmarks. Our results illustrate that training with rooted loss function is converged faster and gains performance improvements. Furthermore, we illustrate applications of our novel rooted loss function in generative modeling based downstream applications, such as finetuning StyleGAN model with the rooted loss. The code implementing our losses and models can be found here for open source software development purposes: https://anonymous.4open.science/r/rooted_loss.
+
+
+
+ 73. 标题:Information Geometry for the Working Information Theorist
+ 编号:[223]
+ 链接:https://arxiv.org/abs/2310.03884
+ 作者:Kumar Vijay Mishra, M. Ashok Kumar, Ting-Kam Leonard Wong
+ 备注:12 pages, 3 figures, 1 table
+ 关键词:spaces of probability, geometric perspective, probability distributions, statistical manifolds, Information geometry
+
+ 点击查看摘要
+ Information geometry is a study of statistical manifolds, that is, spaces of probability distributions from a geometric perspective. Its classical information-theoretic applications relate to statistical concepts such as Fisher information, sufficient statistics, and efficient estimators. Today, information geometry has emerged as an interdisciplinary field that finds applications in diverse areas such as radar sensing, array signal processing, quantum physics, deep learning, and optimal transport. This article presents an overview of essential information geometry to initiate an information theorist, who may be unfamiliar with this exciting area of research. We explain the concepts of divergences on statistical manifolds, generalized notions of distances, orthogonality, and geodesics, thereby paving the way for concrete applications and novel theoretical investigations. We also highlight some recent information-geometric developments, which are of interest to the broader information theory community.
+
+
+
+ 74. 标题:Small batch deep reinforcement learning
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2310.03882
+ 作者:Johan Obando-Ceron, Marc G. Bellemare, Pablo Samuel Castro
+ 备注:Published at NeurIPS 2023
+ 关键词:value-based deep reinforcement, deep reinforcement learning, size parameter specifies, batch size parameter, replay memories
+
+ 点击查看摘要
+ In value-based deep reinforcement learning with replay memories, the batch size parameter specifies how many transitions to sample for each gradient update. Although critical to the learning process, this value is typically not adjusted when proposing new algorithms. In this work we present a broad empirical study that suggests {\em reducing} the batch size can result in a number of significant performance gains; this is surprising, as the general tendency when training neural networks is towards larger batch sizes for improved performance. We complement our experimental findings with a set of empirical analyses towards better understanding this phenomenon.
+
+
+
+ 75. 标题:Non Commutative Convolutional Signal Models in Neural Networks: Stability to Small Deformations
+ 编号:[226]
+ 链接:https://arxiv.org/abs/2310.03879
+ 作者:Alejandro Parada-Mayorga, Landon Butler, Alejandro Ribeiro
+ 备注:
+ 关键词:results recently published, paper we discuss, recently published, algebraic signal, neural networks
+
+ 点击查看摘要
+ In this paper we discuss the results recently published in~[1] about algebraic signal models (ASMs) based on non commutative algebras and their use in convolutional neural networks. Relying on the general tools from algebraic signal processing (ASP), we study the filtering and stability properties of non commutative convolutional filters. We show how non commutative filters can be stable to small perturbations on the space of operators. We also show that although the spectral components of the Fourier representation in a non commutative signal model are associated to spaces of dimension larger than one, there is a trade-off between stability and selectivity similar to that observed for commutative models. Our results have direct implications for group neural networks, multigraph neural networks and quaternion neural networks, among other non commutative architectures. We conclude by corroborating these results through numerical experiments.
+
+
+
+ 76. 标题:Model Complexity of Program Phases
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2310.03865
+ 作者:Arjun Karuvally, J. Eliot B. Moss
+ 备注:
+ 关键词:limited computing systems, resource limited computing, sequence prediction models, computing systems, tight constraints
+
+ 点击查看摘要
+ In resource limited computing systems, sequence prediction models must operate under tight constraints. Various models are available that cater to prediction under these conditions that in some way focus on reducing the cost of implementation. These resource constrained sequence prediction models, in practice, exhibit a fundamental tradeoff between the cost of implementation and the quality of its predictions. This fundamental tradeoff seems to be largely unexplored for models for different tasks. Here we formulate the necessary theory and an associated empirical procedure to explore this tradeoff space for a particular family of machine learning models such as deep neural networks. We anticipate that the knowledge of the behavior of this tradeoff may be beneficial in understanding the theoretical and practical limits of creation and deployment of models for resource constrained tasks.
+
+
+
+ 77. 标题:Variational Barycentric Coordinates
+ 编号:[232]
+ 链接:https://arxiv.org/abs/2310.03861
+ 作者:Ana Dodik, Oded Stein, Vincent Sitzmann, Justin Solomon
+ 备注:this https URL
+ 关键词:additional control compared, offers additional control, generalized barycentric coordinates, barycentric coordinates, propose a variational
+
+ 点击查看摘要
+ We propose a variational technique to optimize for generalized barycentric coordinates that offers additional control compared to existing models. Prior work represents barycentric coordinates using meshes or closed-form formulae, in practice limiting the choice of objective function. In contrast, we directly parameterize the continuous function that maps any coordinate in a polytope's interior to its barycentric coordinates using a neural field. This formulation is enabled by our theoretical characterization of barycentric coordinates, which allows us to construct neural fields that parameterize the entire function class of valid coordinates. We demonstrate the flexibility of our model using a variety of objective functions, including multiple smoothness and deformation-aware energies; as a side contribution, we also present mathematically-justified means of measuring and minimizing objectives like total variation on discontinuous neural fields. We offer a practical acceleration strategy, present a thorough validation of our algorithm, and demonstrate several applications.
+
+
+
+ 78. 标题:OpenIncrement: A Unified Framework for Open Set Recognition and Deep Class-Incremental Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2310.03848
+ 作者:Jiawen Xu, Claas Grohnfeldt, Odej Kao
+ 备注:
+ 关键词:neural network retraining, network retraining, pre-identified for neural, neural network, open set
+
+ 点击查看摘要
+ In most works on deep incremental learning research, it is assumed that novel samples are pre-identified for neural network retraining. However, practical deep classifiers often misidentify these samples, leading to erroneous predictions. Such misclassifications can degrade model performance. Techniques like open set recognition offer a means to detect these novel samples, representing a significant area in the machine learning domain.
+In this paper, we introduce a deep class-incremental learning framework integrated with open set recognition. Our approach refines class-incrementally learned features to adapt them for distance-based open set recognition. Experimental results validate that our method outperforms state-of-the-art incremental learning techniques and exhibits superior performance in open set recognition compared to baseline methods.
+
+
+
+ 79. 标题:Less is More: On the Feature Redundancy of Pretrained Models When Transferring to Few-shot Tasks
+ 编号:[237]
+ 链接:https://arxiv.org/abs/2310.03843
+ 作者:Xu Luo, Difan Zou, Lianli Gao, Zenglin Xu, Jingkuan Song
+ 备注:
+ 关键词:frozen features extracted, conducting linear probing, easy as conducting, classifier upon frozen, pretrained
+
+ 点击查看摘要
+ Transferring a pretrained model to a downstream task can be as easy as conducting linear probing with target data, that is, training a linear classifier upon frozen features extracted from the pretrained model. As there may exist significant gaps between pretraining and downstream datasets, one may ask whether all dimensions of the pretrained features are useful for a given downstream task. We show that, for linear probing, the pretrained features can be extremely redundant when the downstream data is scarce, or few-shot. For some cases such as 5-way 1-shot tasks, using only 1\% of the most important feature dimensions is able to recover the performance achieved by using the full representation. Interestingly, most dimensions are redundant only under few-shot settings and gradually become useful when the number of shots increases, suggesting that feature redundancy may be the key to characterizing the "few-shot" nature of few-shot transfer problems. We give a theoretical understanding of this phenomenon and show how dimensions with high variance and small distance between class centroids can serve as confounding factors that severely disturb classification results under few-shot settings. As an attempt at solving this problem, we find that the redundant features are difficult to identify accurately with a small number of training samples, but we can instead adjust feature magnitude with a soft mask based on estimated feature importance. We show that this method can generally improve few-shot transfer performance across various pretrained models and downstream datasets.
+
+
+
+ 80. 标题:Contextualized Structural Self-supervised Learning for Ontology Matching
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2310.03840
+ 作者:Zhu Wang
+ 备注:
+ 关键词:Ontology matching, entails the identification, identification of semantic, semantic relationships, critical step
+
+ 点击查看摘要
+ Ontology matching (OM) entails the identification of semantic relationships between concepts within two or more knowledge graphs (KGs) and serves as a critical step in integrating KGs from various sources. Recent advancements in deep OM models have harnessed the power of transformer-based language models and the advantages of knowledge graph embedding. Nevertheless, these OM models still face persistent challenges, such as a lack of reference alignments, runtime latency, and unexplored different graph structures within an end-to-end framework. In this study, we introduce a novel self-supervised learning OM framework with input ontologies, called LaKERMap. This framework capitalizes on the contextual and structural information of concepts by integrating implicit knowledge into transformers. Specifically, we aim to capture multiple structural contexts, encompassing both local and global interactions, by employing distinct training objectives. To assess our methods, we utilize the Bio-ML datasets and tasks. The findings from our innovative approach reveal that LaKERMap surpasses state-of-the-art systems in terms of alignment quality and inference time. Our models and codes are available here: this https URL.
+
+
+
+ 81. 标题:Chameleon: Increasing Label-Only Membership Leakage with Adaptive Poisoning
+ 编号:[240]
+ 链接:https://arxiv.org/abs/2310.03838
+ 作者:Harsh Chaudhari, Giorgio Severi, Alina Oprea, Jonathan Ullman
+ 备注:
+ 关键词:numerous critical applications, critical applications introduces, machine learning, integration of machine, numerous critical
+
+ 点击查看摘要
+ The integration of machine learning (ML) in numerous critical applications introduces a range of privacy concerns for individuals who provide their datasets for model training. One such privacy risk is Membership Inference (MI), in which an attacker seeks to determine whether a particular data sample was included in the training dataset of a model. Current state-of-the-art MI attacks capitalize on access to the model's predicted confidence scores to successfully perform membership inference, and employ data poisoning to further enhance their effectiveness. In this work, we focus on the less explored and more realistic label-only setting, where the model provides only the predicted label on a queried sample. We show that existing label-only MI attacks are ineffective at inferring membership in the low False Positive Rate (FPR) regime. To address this challenge, we propose a new attack Chameleon that leverages a novel adaptive data poisoning strategy and an efficient query selection method to achieve significantly more accurate membership inference than existing label-only attacks, especially at low FPRs.
+
+
+
+ 82. 标题:Learning A Disentangling Representation For PU Learning
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2310.03833
+ 作者:Omar Zamzam, Haleh Akrami, Mahdi Soltanolkotabi, Richard Leahy
+ 备注:
+ 关键词:data commonly referred, Unlabeled data commonly, commonly referred, Unlabeled data, address the problem
+
+ 点击查看摘要
+ In this paper, we address the problem of learning a binary (positive vs. negative) classifier given Positive and Unlabeled data commonly referred to as PU learning. Although rudimentary techniques like clustering, out-of-distribution detection, or positive density estimation can be used to solve the problem in low-dimensional settings, their efficacy progressively deteriorates with higher dimensions due to the increasing complexities in the data distribution. In this paper we propose to learn a neural network-based data representation using a loss function that can be used to project the unlabeled data into two (positive and negative) clusters that can be easily identified using simple clustering techniques, effectively emulating the phenomenon observed in low-dimensional settings. We adopt a vector quantization technique for the learned representations to amplify the separation between the learned unlabeled data clusters. We conduct experiments on simulated PU data that demonstrate the improved performance of our proposed method compared to the current state-of-the-art approaches. We also provide some theoretical justification for our two cluster-based approach and our algorithmic choices.
+
+
+
+ 83. 标题:ECAvg: An Edge-Cloud Collaborative Learning Approach using Averaged Weights
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2310.03823
+ 作者:Atah Nuh Mih, Hung Cao, Asfia Kawnine, Monica Wachowicz
+ 备注:Key words: edge-cloud collaboration, averaging weights, Edge AI, edge computing, cloud computing, transfer learning
+ 关键词:edge devices, edge, computationally intensive tasks, devices, complements the shortcomings
+
+ 点击查看摘要
+ The use of edge devices together with cloud provides a collaborative relationship between both classes of devices where one complements the shortcomings of the other. Resource-constraint edge devices can benefit from the abundant computing power provided by servers by offloading computationally intensive tasks to the server. Meanwhile, edge devices can leverage their close proximity to the data source to perform less computationally intensive tasks on the data. In this paper, we propose a collaborative edge-cloud paradigm called ECAvg in which edge devices pre-train local models on their respective datasets and transfer the models to the server for fine-tuning. The server averages the pre-trained weights into a global model, which is fine-tuned on the combined data from the various edge devices. The local (edge) models are then updated with the weights of the global (server) model. We implement a CIFAR-10 classification task using MobileNetV2, a CIFAR-100 classification task using ResNet50, and an MNIST classification using a neural network with a single hidden layer. We observed performance improvement in the CIFAR-10 and CIFAR-100 classification tasks using our approach, where performance improved on the server model with averaged weights and the edge models had a better performance after model update. On the MNIST classification, averaging weights resulted in a drop in performance on both the server and edge models due to negative transfer learning. From the experiment results, we conclude that our approach is successful when implemented on deep neural networks such as MobileNetV2 and ResNet50 instead of simple neural networks.
+
+
+
+ 84. 标题:Logical Languages Accepted by Transformer Encoders with Hard Attention
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2310.03817
+ 作者:Pablo Barcelo, Alexander Kozachinskiy, Anthony Widjaja Lin, Vladimir Podolskii
+ 备注:
+ 关键词:Hard Attention Transformers, Unique Hard Attention, Average Hard Attention, Attention Transformers, Hard Attention
+
+ 点击查看摘要
+ We contribute to the study of formal languages that can be recognized by transformer encoders. We focus on two self-attention mechanisms: (1) UHAT (Unique Hard Attention Transformers) and (2) AHAT (Average Hard Attention Transformers). UHAT encoders are known to recognize only languages inside the circuit complexity class ${\sf AC}^0$, i.e., accepted by a family of poly-sized and depth-bounded boolean circuits with unbounded fan-ins. On the other hand, AHAT encoders can recognize languages outside ${\sf AC}^0$), but their expressive power still lies within the bigger circuit complexity class ${\sf TC}^0$, i.e., ${\sf AC}^0$-circuits extended by majority gates. We first show a negative result that there is an ${\sf AC}^0$-language that cannot be recognized by an UHAT encoder. On the positive side, we show that UHAT encoders can recognize a rich fragment of ${\sf AC}^0$-languages, namely, all languages definable in first-order logic with arbitrary unary numerical predicates. This logic, includes, for example, all regular languages from ${\sf AC}^0$. We then show that AHAT encoders can recognize all languages of our logic even when we enrich it with counting terms. We apply these results to derive new results on the expressive power of UHAT and AHAT up to permutation of letters (a.k.a. Parikh images).
+
+
+
+ 85. 标题:Fishnets: Information-Optimal, Scalable Aggregation for Sets and Graphs
+ 编号:[252]
+ 链接:https://arxiv.org/abs/2310.03812
+ 作者:T. Lucas Makinen, Justin Alsing, Benjamin D. Wandelt
+ 备注:13 pages, 9 figures, 2 tables. Submitted to ICLR 2024
+ 关键词:modern deep learning, network science, essential component, component of modern, modern deep
+
+ 点击查看摘要
+ Set-based learning is an essential component of modern deep learning and network science. Graph Neural Networks (GNNs) and their edge-free counterparts Deepsets have proven remarkably useful on ragged and topologically challenging datasets. The key to learning informative embeddings for set members is a specified aggregation function, usually a sum, max, or mean. We propose Fishnets, an aggregation strategy for learning information-optimal embeddings for sets of data for both Bayesian inference and graph aggregation. We demonstrate that i) Fishnets neural summaries can be scaled optimally to an arbitrary number of data objects, ii) Fishnets aggregations are robust to changes in data distribution, unlike standard deepsets, iii) Fishnets saturate Bayesian information content and extend to regimes where MCMC techniques fail and iv) Fishnets can be used as a drop-in aggregation scheme within GNNs. We show that by adopting a Fishnets aggregation scheme for message passing, GNNs can achieve state-of-the-art performance versus architecture size on ogbn-protein data over existing benchmarks with a fraction of learnable parameters and faster training time.
+
+
+
+ 86. 标题:HandMeThat: Human-Robot Communication in Physical and Social Environments
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2310.03779
+ 作者:Yanming Wan, Jiayuan Mao, Joshua B. Tenenbaum
+ 备注:NeurIPS 2022 (Dataset and Benchmark Track). First two authors contributed equally. Project page: this http URL
+ 关键词:holistic evaluation, instruction understanding, introduce HandMeThat, physical and social, HandMeThat
+
+ 点击查看摘要
+ We introduce HandMeThat, a benchmark for a holistic evaluation of instruction understanding and following in physical and social environments. While previous datasets primarily focused on language grounding and planning, HandMeThat considers the resolution of human instructions with ambiguities based on the physical (object states and relations) and social (human actions and goals) information. HandMeThat contains 10,000 episodes of human-robot interactions. In each episode, the robot first observes a trajectory of human actions towards her internal goal. Next, the robot receives a human instruction and should take actions to accomplish the subgoal set through the instruction. In this paper, we present a textual interface for our benchmark, where the robot interacts with a virtual environment through textual commands. We evaluate several baseline models on HandMeThat, and show that both offline and online reinforcement learning algorithms perform poorly on HandMeThat, suggesting significant room for future work on physical and social human-robot communications and interactions.
+
+
+
+ 87. 标题:Lightweight Boosting Models for User Response Prediction Using Adversarial Validation
+ 编号:[255]
+ 链接:https://arxiv.org/abs/2310.03778
+ 作者:Hyeonwoo Kim, Wonsung Lee
+ 备注:7 pages, 4 figures, ACM RecSys 2023 Challenge Workshop accepted paper
+ 关键词:ACM RecSys Challenge, ACM RecSys, organized by ShareChat, aims to predict, app being installed
+
+ 点击查看摘要
+ The ACM RecSys Challenge 2023, organized by ShareChat, aims to predict the probability of the app being installed. This paper describes the lightweight solution to this challenge. We formulate the task as a user response prediction task. For rapid prototyping for the task, we propose a lightweight solution including the following steps: 1) using adversarial validation, we effectively eliminate uninformative features from a dataset; 2) to address noisy continuous features and categorical features with a large number of unique values, we employ feature engineering techniques.; 3) we leverage Gradient Boosted Decision Trees (GBDT) for their exceptional performance and scalability. The experiments show that a single LightGBM model, without additional ensembling, performs quite well. Our team achieved ninth place in the challenge with the final leaderboard score of 6.059065. Code for our approach can be found here: this https URL.
+
+
+
+ 88. 标题:Functional data learning using convolutional neural networks
+ 编号:[259]
+ 链接:https://arxiv.org/abs/2310.03773
+ 作者:Jose Galarza, Tamer Oraby
+ 备注:38 pages, 23 figures
+ 关键词:convolutional neural networks, functional data, convolutional neural, functional, neural networks
+
+ 点击查看摘要
+ In this paper, we show how convolutional neural networks (CNN) can be used in regression and classification learning problems of noisy and non-noisy functional data. The main idea is to transform the functional data into a 28 by 28 image. We use a specific but typical architecture of a convolutional neural network to perform all the regression exercises of parameter estimation and functional form classification. First, we use some functional case studies of functional data with and without random noise to showcase the strength of the new method. In particular, we use it to estimate exponential growth and decay rates, the bandwidths of sine and cosine functions, and the magnitudes and widths of curve peaks. We also use it to classify the monotonicity and curvatures of functional data, algebraic versus exponential growth, and the number of peaks of functional data. Second, we apply the same convolutional neural networks to Lyapunov exponent estimation in noisy and non-noisy chaotic data, in estimating rates of disease transmission from epidemic curves, and in detecting the similarity of drug dissolution profiles. Finally, we apply the method to real-life data to detect Parkinson's disease patients in a classification problem. The method, although simple, shows high accuracy and is promising for future use in engineering and medical applications.
+
+
+
+ 89. 标题:Investigating Alternative Feature Extraction Pipelines For Clinical Note Phenotyping
+ 编号:[260]
+ 链接:https://arxiv.org/abs/2310.03772
+ 作者:Neil Daniel
+ 备注:11 pages, 0 figures, 1 table
+ 关键词:detailed patient observations, clinical notes, consist of detailed, clinical, medical
+
+ 点击查看摘要
+ A common practice in the medical industry is the use of clinical notes, which consist of detailed patient observations. However, electronic health record systems frequently do not contain these observations in a structured format, rendering patient information challenging to assess and evaluate automatically. Using computational systems for the extraction of medical attributes offers many applications, including longitudinal analysis of patients, risk assessment, and hospital evaluation. Recent work has constructed successful methods for phenotyping: extracting medical attributes from clinical notes. BERT-based models can be used to transform clinical notes into a series of representations, which are then condensed into a single document representation based on their CLS embeddings and passed into an LSTM (Mulyar et al., 2020). Though this pipeline yields a considerable performance improvement over previous results, it requires extensive convergence time. This method also does not allow for predicting attributes not yet identified in clinical notes.
+Considering the wide variety of medical attributes that may be present in a clinical note, we propose an alternative pipeline utilizing ScispaCy (Neumann et al., 2019) for the extraction of common diseases. We then train various supervised learning models to associate the presence of these conditions with patient attributes. Finally, we replicate a ClinicalBERT (Alsentzer et al., 2019) and LSTM-based approach for purposes of comparison. We find that alternative methods moderately underperform the replicated LSTM approach. Yet, considering a complex tradeoff between accuracy and runtime, in addition to the fact that the alternative approach also allows for the detection of medical conditions that are not already present in a clinical note, its usage may be considered as a supplement to established methods.
+
+
+
+ 90. 标题:Progressive reduced order modeling: empowering data-driven modeling with selective knowledge transfer
+ 编号:[261]
+ 链接:https://arxiv.org/abs/2310.03770
+ 作者:Teeratorn Kadeethum, Daniel O'Malley, Youngsoo Choi, Hari S. Viswanathan, Hongkyu Yoon
+ 备注:
+ 关键词:constant demand, Data-driven modeling, modeling, information, Data-driven
+
+ 点击查看摘要
+ Data-driven modeling can suffer from a constant demand for data, leading to reduced accuracy and impractical for engineering applications due to the high cost and scarcity of information. To address this challenge, we propose a progressive reduced order modeling framework that minimizes data cravings and enhances data-driven modeling's practicality. Our approach selectively transfers knowledge from previously trained models through gates, similar to how humans selectively use valuable knowledge while ignoring unuseful information. By filtering relevant information from previous models, we can create a surrogate model with minimal turnaround time and a smaller training set that can still achieve high accuracy. We have tested our framework in several cases, including transport in porous media, gravity-driven flow, and finite deformation in hyperelastic materials. Our results illustrate that retaining information from previous models and utilizing a valuable portion of that knowledge can significantly improve the accuracy of the current model. We have demonstrated the importance of progressive knowledge transfer and its impact on model accuracy with reduced training samples. For instance, our framework with four parent models outperforms the no-parent counterpart trained on data nine times larger. Our research unlocks data-driven modeling's potential for practical engineering applications by mitigating the data scarcity issue. Our proposed framework is a significant step toward more efficient and cost-effective data-driven modeling, fostering advancements across various fields.
+
+
+
+ 91. 标题:Deep Reinforcement Learning Algorithms for Hybrid V2X Communication: A Benchmarking Study
+ 编号:[262]
+ 链接:https://arxiv.org/abs/2310.03767
+ 作者:Fouzi Boukhalfa, Reda Alami, Mastane Achab, Eric Moulines, Mehdi Bennis
+ 备注:
+ 关键词:autonomous vehicles demand, today era, par with aircraft, demand a safety, Radio Access Technologies
+
+ 点击查看摘要
+ In today's era, autonomous vehicles demand a safety level on par with aircraft. Taking a cue from the aerospace industry, which relies on redundancy to achieve high reliability, the automotive sector can also leverage this concept by building redundancy in V2X (Vehicle-to-Everything) technologies. Given the current lack of reliable V2X technologies, this idea is particularly promising. By deploying multiple RATs (Radio Access Technologies) in parallel, the ongoing debate over the standard technology for future vehicles can be put to rest. However, coordinating multiple communication technologies is a complex task due to dynamic, time-varying channels and varying traffic conditions. This paper addresses the vertical handover problem in V2X using Deep Reinforcement Learning (DRL) algorithms. The goal is to assist vehicles in selecting the most appropriate V2X technology (DSRC/V-VLC) in a serpentine environment. The results show that the benchmarked algorithms outperform the current state-of-the-art approaches in terms of redundancy and usage rate of V-VLC headlights. This result is a significant reduction in communication costs while maintaining a high level of reliability. These results provide strong evidence for integrating advanced DRL decision mechanisms into the architecture as a promising approach to solving the vertical handover problem in V2X.
+
+
+
+ 92. 标题:Physics Informed Neural Network Code for 2D Transient Problems (PINN-2DT) Compatible with Google Colab
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2310.03755
+ 作者:Paweł Maczuga, Maciej Skoczeń, Przemysław Rożnawski, Filip Tłuszcz, Marcin Szubert, Marcin Łoś, Witold Dzwinel, Keshav Pingali, Maciej Paszyński
+ 备注:21 pages, 13 figures
+ 关键词:Physics Informed Neural, Informed Neural Network, open-source Physics Informed, Neural Network environment, Dirichlet boundary conditions
+
+ 点击查看摘要
+ We present an open-source Physics Informed Neural Network environment for simulations of transient phenomena on two-dimensional rectangular domains, with the following features: (1) it is compatible with Google Colab which allows automatic execution on cloud environment; (2) it supports two dimensional time-dependent PDEs; (3) it provides simple interface for definition of the residual loss, boundary condition and initial loss, together with their weights; (4) it support Neumann and Dirichlet boundary conditions; (5) it allows for customizing the number of layers and neurons per layer, as well as for arbitrary activation function; (6) the learning rate and number of epochs are available as parameters; (7) it automatically differentiates PINN with respect to spatial and temporal variables; (8) it provides routines for plotting the convergence (with running average), initial conditions learnt, 2D and 3D snapshots from the simulation and movies (9) it includes a library of problems: (a) non-stationary heat transfer; (b) wave equation modeling a tsunami; (c) atmospheric simulations including thermal inversion; (d) tumor growth simulations.
+
+
+
+ 93. 标题:Generative Hyperelasticity with Physics-Informed Probabilistic Diffusion Fields
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2310.03745
+ 作者:Vahidullah Tac, Manuel K Rausch, Ilias Bilionis, Francisco Sahli Costabal, Adrian Buganza Tepole
+ 备注:22 pages, 11 figures
+ 关键词:exhibit highly complex, natural materials exhibit, materials exhibit highly, strain energy functions, strain energy
+
+ 点击查看摘要
+ Many natural materials exhibit highly complex, nonlinear, anisotropic, and heterogeneous mechanical properties. Recently, it has been demonstrated that data-driven strain energy functions possess the flexibility to capture the behavior of these complex materials with high accuracy while satisfying physics-based constraints. However, most of these approaches disregard the uncertainty in the estimates and the spatial heterogeneity of these materials. In this work, we leverage recent advances in generative models to address these issues. We use as building block neural ordinary equations (NODE) that -- by construction -- create polyconvex strain energy functions, a key property of realistic hyperelastic material models. We combine this approach with probabilistic diffusion models to generate new samples of strain energy functions. This technique allows us to sample a vector of Gaussian white noise and translate it to NODE parameters thereby representing plausible strain energy functions. We extend our approach to spatially correlated diffusion resulting in heterogeneous material properties for arbitrary geometries. We extensively test our method with synthetic and experimental data on biological tissues and run finite element simulations with various degrees of spatial heterogeneity. We believe this approach is a major step forward including uncertainty in predictive, data-driven models of hyperelasticity
+
+
+
+ 94. 标题:Diffusion Random Feature Model
+ 编号:[267]
+ 链接:https://arxiv.org/abs/2310.04417
+ 作者:Esha Saha, Giang Tran
+ 备注:7 Figures, 18 pages
+ 关键词:Diffusion probabilistic models, Diffusion probabilistic, probabilistic models, Random feature, generate data
+
+ 点击查看摘要
+ Diffusion probabilistic models have been successfully used to generate data from noise. However, most diffusion models are computationally expensive and difficult to interpret with a lack of theoretical justification. Random feature models on the other hand have gained popularity due to their interpretability but their application to complex machine learning tasks remains limited. In this work, we present a diffusion model-inspired deep random feature model that is interpretable and gives comparable numerical results to a fully connected neural network having the same number of trainable parameters. Specifically, we extend existing results for random features and derive generalization bounds between the distribution of sampled data and the true distribution using properties of score matching. We validate our findings by generating samples on the fashion MNIST dataset and instrumental audio data.
+
+
+
+ 95. 标题:A Marketplace Price Anomaly Detection System at Scale
+ 编号:[269]
+ 链接:https://arxiv.org/abs/2310.04367
+ 作者:Akshit Sarpal, Qiwen Kang, Fangping Huang, Yang Song, Lijie Wan
+ 备注:10 pages, 4 figures, 7 tables
+ 关键词:execute large volume, marketplaces execute large, individual marketplace sellers, execute large, large volume
+
+ 点击查看摘要
+ Online marketplaces execute large volume of price updates that are initiated by individual marketplace sellers each day on the platform. This price democratization comes with increasing challenges with data quality. Lack of centralized guardrails that are available for a traditional online retailer causes a higher likelihood for inaccurate prices to get published on the website, leading to poor customer experience and potential for revenue loss. We present MoatPlus (Masked Optimal Anchors using Trees, Proximity-based Labeling and Unsupervised Statistical-features), a scalable price anomaly detection framework for a growing marketplace platform. The goal is to leverage proximity and historical price trends from unsupervised statistical features to generate an upper price bound. We build an ensemble of models to detect irregularities in price-based features, exclude irregular features and use optimized weighting scheme to build a reliable price bound in real-time pricing pipeline. We observed that our approach improves precise anchor coverage by up to 46.6% in high-vulnerability item subsets
+
+
+
+ 96. 标题:Integrating Transformations in Probabilistic Circuits
+ 编号:[271]
+ 链接:https://arxiv.org/abs/2310.04354
+ 作者:Tom Schierenbeck, Vladimir Vutov, Thorsten Dickhaus, Michael Beetz
+ 备注:
+ 关键词:study addresses, addresses the predictive, remedy to overcome, predictive limitation, probabilistic circuits
+
+ 点击查看摘要
+ This study addresses the predictive limitation of probabilistic circuits and introduces transformations as a remedy to overcome it. We demonstrate this limitation in robotic scenarios. We motivate that independent component analysis is a sound tool to preserve the independence properties of probabilistic circuits. Our approach is an extension of joint probability trees, which are model-free deterministic circuits. By doing so, it is demonstrated that the proposed approach is able to achieve higher likelihoods while using fewer parameters compared to the joint probability trees on seven benchmark data sets as well as on real robot data. Furthermore, we discuss how to integrate transformations into tree-based learning routines. Finally, we argue that exact inference with transformed quantile parameterized distributions is not tractable. However, our approach allows for efficient sampling and approximate inference.
+
+
+
+ 97. 标题:Fair Feature Importance Scores for Interpreting Tree-Based Methods and Surrogates
+ 编号:[272]
+ 链接:https://arxiv.org/abs/2310.04352
+ 作者:Camille Olivia Little, Debolina Halder Lina, Genevera I. Allen
+ 备注:
+ 关键词:large-scale machine learning, fair feature importance, feature importance score, feature importance, criminal justice
+
+ 点击查看摘要
+ Across various sectors such as healthcare, criminal justice, national security, finance, and technology, large-scale machine learning (ML) and artificial intelligence (AI) systems are being deployed to make critical data-driven decisions. Many have asked if we can and should trust these ML systems to be making these decisions. Two critical components are prerequisites for trust in ML systems: interpretability, or the ability to understand why the ML system makes the decisions it does, and fairness, which ensures that ML systems do not exhibit bias against certain individuals or groups. Both interpretability and fairness are important and have separately received abundant attention in the ML literature, but so far, there have been very few methods developed to directly interpret models with regard to their fairness. In this paper, we focus on arguably the most popular type of ML interpretation: feature importance scores. Inspired by the use of decision trees in knowledge distillation, we propose to leverage trees as interpretable surrogates for complex black-box ML models. Specifically, we develop a novel fair feature importance score for trees that can be used to interpret how each feature contributes to fairness or bias in trees, tree-based ensembles, or tree-based surrogates of any complex ML system. Like the popular mean decrease in impurity for trees, our Fair Feature Importance Score is defined based on the mean decrease (or increase) in group bias. Through simulations as well as real examples on benchmark fairness datasets, we demonstrate that our Fair Feature Importance Score offers valid interpretations for both tree-based ensembles and tree-based surrogates of other ML systems.
+
+
+
+ 98. 标题:Neur2RO: Neural Two-Stage Robust Optimization
+ 编号:[274]
+ 链接:https://arxiv.org/abs/2310.04345
+ 作者:Justin Dumouchelle, Esther Julien, Jannis Kurtz, Elias B. Khalil
+ 备注:
+ 关键词:solving decision-making problems, Robust optimization, mathematical framework, framework for modeling, modeling and solving
+
+ 点击查看摘要
+ Robust optimization provides a mathematical framework for modeling and solving decision-making problems under worst-case uncertainty. This work addresses two-stage robust optimization (2RO) problems (also called adjustable robust optimization), wherein first-stage and second-stage decisions are made before and after uncertainty is realized, respectively. This results in a nested min-max-min optimization problem which is extremely challenging computationally, especially when the decisions are discrete. We propose Neur2RO, an efficient machine learning-driven instantiation of column-and-constraint generation (CCG), a classical iterative algorithm for 2RO. Specifically, we learn to estimate the value function of the second-stage problem via a novel neural network architecture that is easy to optimize over by design. Embedding our neural network into CCG yields high-quality solutions quickly as evidenced by experiments on two 2RO benchmarks, knapsack and capital budgeting. For knapsack, Neur2RO finds solutions that are within roughly $2\%$ of the best-known values in a few seconds compared to the three hours of the state-of-the-art exact branch-and-price algorithm; for larger and more complex instances, Neur2RO finds even better solutions. For capital budgeting, Neur2RO outperforms three variants of the $k$-adaptability algorithm, particularly on the largest instances, with a 5 to 10-fold reduction in solution time. Our code and data are available at this https URL.
+
+
+
+ 99. 标题:Applying Reinforcement Learning to Option Pricing and Hedging
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2310.04336
+ 作者:Zoran Stoiljkovic
+ 备注:57 pages, 14 figures, 8 tables, 3 appendices
+ 关键词:Q-Learning Black Scholes, Black Scholes approach, hedging financial instruments, introduced by Halperin, reinforcement learning approach
+
+ 点击查看摘要
+ This thesis provides an overview of the recent advances in reinforcement learning in pricing and hedging financial instruments, with a primary focus on a detailed explanation of the Q-Learning Black Scholes approach, introduced by Halperin (2017). This reinforcement learning approach bridges the traditional Black and Scholes (1973) model with novel artificial intelligence algorithms, enabling option pricing and hedging in a completely model-free and data-driven way. This paper also explores the algorithm's performance under different state variables and scenarios for a European put option. The results reveal that the model is an accurate estimator under different levels of volatility and hedging frequency. Moreover, this method exhibits robust performance across various levels of option's moneyness. Lastly, the algorithm incorporates proportional transaction costs, indicating diverse impacts on profit and loss, affected by different statistical properties of the state variables.
+
+
+
+ 100. 标题:Convergent ADMM Plug and Play PET Image Reconstruction
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2310.04299
+ 作者:Florent Sureau, Mahdi Latreche, Marion Savanier, Claude Comtat
+ 备注:
+ 关键词:learnt Deep Neural, Deep Neural Network, Neural Network operator, hybrid PET reconstruction, investigate hybrid PET
+
+ 点击查看摘要
+ In this work, we investigate hybrid PET reconstruction algorithms based on coupling a model-based variational reconstruction and the application of a separately learnt Deep Neural Network operator (DNN) in an ADMM Plug and Play framework. Following recent results in optimization, fixed point convergence of the scheme can be achieved by enforcing an additional constraint on network parameters during learning. We propose such an ADMM algorithm and show in a realistic [18F]-FDG synthetic brain exam that the proposed scheme indeed lead experimentally to convergence to a meaningful fixed point. When the proposed constraint is not enforced during learning of the DNN, the proposed ADMM algorithm was observed experimentally not to converge.
+
+
+
+ 101. 标题:Accelerating optimization over the space of probability measures
+ 编号:[287]
+ 链接:https://arxiv.org/abs/2310.04006
+ 作者:Shi Chen, Qin Li, Oliver Tse, Stephen J. Wright
+ 备注:
+ 关键词:machine learning applications, gradient-based optimization methods, Acceleration of gradient-based, machine learning problems, issue of significant
+
+ 点击查看摘要
+ Acceleration of gradient-based optimization methods is an issue of significant practical and theoretical interest, particularly in machine learning applications. Most research has focused on optimization over Euclidean spaces, but given the need to optimize over spaces of probability measures in many machine learning problems, it is of interest to investigate accelerated gradient methods in this context too. To this end, we introduce a Hamiltonian-flow approach that is analogous to moment-based approaches in Euclidean space. We demonstrate that algorithms based on this approach can achieve convergence rates of arbitrarily high order. Numerical examples illustrate our claim.
+
+
+
+ 102. 标题:On Wasserstein distances for affine transformations of random vectors
+ 编号:[290]
+ 链接:https://arxiv.org/abs/2310.03945
+ 作者:Keaton Hamm, Andrzej Korzeniowski
+ 备注:
+ 关键词:quadratic Wasserstein distance, Wasserstein space, quadratic Wasserstein, Wasserstein distance, random vectors
+
+ 点击查看摘要
+ We expound on some known lower bounds of the quadratic Wasserstein distance between random vectors in $\mathbb{R}^n$ with an emphasis on affine transformations that have been used in manifold learning of data in Wasserstein space. In particular, we give concrete lower bounds for rotated copies of random vectors in $\mathbb{R}^2$ with uncorrelated components by computing the Bures metric between the covariance matrices. We also derive upper bounds for compositions of affine maps which yield a fruitful variety of diffeomorphisms applied to an initial data measure. We apply these bounds to various distributions including those lying on a 1-dimensional manifold in $\mathbb{R}^2$ and illustrate the quality of the bounds. Finally, we give a framework for mimicking handwritten digit or alphabet datasets that can be applied in a manifold learning framework.
+
+
+
+ 103. 标题:Provable benefits of annealing for estimating normalizing constants: Importance Sampling, Noise-Contrastive Estimation, and beyond
+ 编号:[292]
+ 链接:https://arxiv.org/abs/2310.03902
+ 作者:Omar Chehab, Aapo Hyvarinen, Andrej Risteski
+ 备注:
+ 关键词:Monte Carlo methods, Monte Carlo, developed several Monte, Carlo methods, Recent research
+
+ 点击查看摘要
+ Recent research has developed several Monte Carlo methods for estimating the normalization constant (partition function) based on the idea of annealing. This means sampling successively from a path of distributions that interpolate between a tractable "proposal" distribution and the unnormalized "target" distribution. Prominent estimators in this family include annealed importance sampling and annealed noise-contrastive estimation (NCE). Such methods hinge on a number of design choices: which estimator to use, which path of distributions to use and whether to use a path at all; so far, there is no definitive theory on which choices are efficient. Here, we evaluate each design choice by the asymptotic estimation error it produces. First, we show that using NCE is more efficient than the importance sampling estimator, but in the limit of infinitesimal path steps, the difference vanishes. Second, we find that using the geometric path brings down the estimation error from an exponential to a polynomial function of the parameter distance between the target and proposal distributions. Third, we find that the arithmetic path, while rarely used, can offer optimality properties over the universally-used geometric path. In fact, in a particular limit, the optimal path is arithmetic. Based on this theory, we finally propose a two-step estimator to approximate the optimal path in an efficient way.
+
+
+
+ 104. 标题:Euclid: Identification of asteroid streaks in simulated images using deep learning
+ 编号:[298]
+ 链接:https://arxiv.org/abs/2310.03845
+ 作者:M. Pöntinen (1), M. Granvik (1 and 2), A. A. Nucita (3 and 4 and 5), L. Conversi (6 and 7), B. Altieri (7), B. Carry (8), C. M. O'Riordan (9), D. Scott (10), N. Aghanim (11), A. Amara (12), L. Amendola (13), N. Auricchio (14), M. Baldi (15 and 14 and 16), D. Bonino (17), E. Branchini (18 and 19), M. Brescia (20 and 21), S. Camera (22 and 23 and 17), V. Capobianco (17), C. Carbone (24), J. Carretero (25 and 26), M. Castellano (27), S. Cavuoti (21 and 28), A. Cimatti (29), R. Cledassou (30 and 31), G. Congedo (32), Y. Copin (33), L. Corcione (17), F. Courbin (34), M. Cropper (35), A. Da Silva (36 and 37), H. Degaudenzi (38), J. Dinis (37 and 36), F. Dubath (38), X. Dupac (7), S. Dusini (39), S. Farrens (40), S. Ferriol (33), M. Frailis (41), E. Franceschi (14), M. Fumana (24), S. Galeotta (41), et al. (76 additional authors not shown)
+ 备注:18 pages, 11 figures
+ 关键词:ESA Euclid space, offer multiband visual, Euclid space telescope, Euclid offer multiband, ESA Euclid
+
+ 点击查看摘要
+ Up to 150000 asteroids will be visible in the images of the ESA Euclid space telescope, and the instruments of Euclid offer multiband visual to near-infrared photometry and slitless spectra of these objects. Most asteroids will appear as streaks in the images. Due to the large number of images and asteroids, automated detection methods are needed. A non-machine-learning approach based on the StreakDet software was previously tested, but the results were not optimal for short and/or faint streaks. We set out to improve the capability to detect asteroid streaks in Euclid images by using deep learning.
+We built, trained, and tested a three-step machine-learning pipeline with simulated Euclid images. First, a convolutional neural network (CNN) detected streaks and their coordinates in full images, aiming to maximize the completeness (recall) of detections. Then, a recurrent neural network (RNN) merged snippets of long streaks detected in several parts by the CNN. Lastly, gradient-boosted trees (XGBoost) linked detected streaks between different Euclid exposures to reduce the number of false positives and improve the purity (precision) of the sample.
+The deep-learning pipeline surpasses the completeness and reaches a similar level of purity of a non-machine-learning pipeline based on the StreakDet software. Additionally, the deep-learning pipeline can detect asteroids 0.25-0.5 magnitudes fainter than StreakDet. The deep-learning pipeline could result in a 50% increase in the number of detected asteroids compared to the StreakDet software. There is still scope for further refinement, particularly in improving the accuracy of streak coordinates and enhancing the completeness of the final stage of the pipeline, which involves linking detections across multiple exposures.
+
+
+
+ 105. 标题:Droplets of Good Representations: Grokking as a First Order Phase Transition in Two Layer Networks
+ 编号:[300]
+ 链接:https://arxiv.org/abs/2310.03789
+ 作者:Noa Rubin, Inbar Seroussi, Zohar Ringel
+ 备注:
+ 关键词:deep neural networks, neural networks, key property, ability to learn, property of deep
+
+ 点击查看摘要
+ A key property of deep neural networks (DNNs) is their ability to learn new features during training. This intriguing aspect of deep learning stands out most clearly in recently reported Grokking phenomena. While mainly reflected as a sudden increase in test accuracy, Grokking is also believed to be a beyond lazy-learning/Gaussian Process (GP) phenomenon involving feature learning. Here we apply a recent development in the theory of feature learning, the adaptive kernel approach, to two teacher-student models with cubic-polynomial and modular addition teachers. We provide analytical predictions on feature learning and Grokking properties of these models and demonstrate a mapping between Grokking and the theory of phase transitions. We show that after Grokking, the state of the DNN is analogous to the mixed phase following a first-order phase transition. In this mixed phase, the DNN generates useful internal representations of the teacher that are sharply distinct from those before the transition.
+
+
+
+ 106. 标题:Investigating Deep Neural Network Architecture and Feature Extraction Designs for Sensor-based Human Activity Recognition
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2310.03760
+ 作者:Danial Ahangarani, Mohammad Shirazi, Navid Ashraf
+ 备注:Seventh International Conference on Internet of Things and Applications (IoT 2023)
+ 关键词:Internet of Things, implementing sensor-based activity, sensor-based activity recognition, extensive ubiquitous availability, activity recognition
+
+ 点击查看摘要
+ The extensive ubiquitous availability of sensors in smart devices and the Internet of Things (IoT) has opened up the possibilities for implementing sensor-based activity recognition. As opposed to traditional sensor time-series processing and hand-engineered feature extraction, in light of deep learning's proven effectiveness across various domains, numerous deep methods have been explored to tackle the challenges in activity recognition, outperforming the traditional signal processing and traditional machine learning approaches. In this work, by performing extensive experimental studies on two human activity recognition datasets, we investigate the performance of common deep learning and machine learning approaches as well as different training mechanisms (such as contrastive learning), and various feature representations extracted from the sensor time-series data and measure their effectiveness for the human activity recognition task.
+
+
+
+ 107. 标题:A Novel Deep Learning Technique for Morphology Preserved Fetal ECG Extraction from Mother ECG using 1D-CycleGAN
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2310.03759
+ 作者:Promit Basak, A.H.M Nazmus Sakib, Muhammad E. H. Chowdhury, Nasser Al-Emadi, Huseyin Cagatay Yalcin, Shona Pedersen, Sakib Mahmud, Serkan Kiranyaz, Somaya Al-Maadeed
+ 备注:24 pages, 11 figures
+ 关键词:infant mortality rate, easily detect abnormalities, non-invasive fetal electrocardiogram, Fetal ECG Database, fetal heart rate
+
+ 点击查看摘要
+ Monitoring the electrical pulse of fetal heart through a non-invasive fetal electrocardiogram (fECG) can easily detect abnormalities in the developing heart to significantly reduce the infant mortality rate and post-natal complications. Due to the overlapping of maternal and fetal R-peaks, the low amplitude of the fECG, systematic and ambient noises, typical signal extraction methods, such as adaptive filters, independent component analysis, empirical mode decomposition, etc., are unable to produce satisfactory fECG. While some techniques can produce accurate QRS waves, they often ignore other important aspects of the ECG. Our approach, which is based on 1D CycleGAN, can reconstruct the fECG signal from the mECG signal while maintaining the morphology due to extensive preprocessing and appropriate framework. The performance of our solution was evaluated by combining two available datasets from Physionet, "Abdominal and Direct Fetal ECG Database" and "Fetal electrocardiograms, direct and abdominal with reference heartbeat annotations", where it achieved an average PCC and Spectral-Correlation score of 88.4% and 89.4%, respectively. It detects the fQRS of the signal with accuracy, precision, recall and F1 score of 92.6%, 97.6%, 94.8% and 96.4%, respectively. It can also accurately produce the estimation of fetal heart rate and R-R interval with an error of 0.25% and 0.27%, respectively. The main contribution of our work is that, unlike similar studies, it can retain the morphology of the ECG signal with high fidelity. The accuracy of our solution for fetal heart rate and R-R interval length is comparable to existing state-of-the-art techniques. This makes it a highly effective tool for early diagnosis of fetal heart diseases and regular health checkups of the fetus.
+
+
+
+ 108. 标题:A Unified Framework for Uniform Signal Recovery in Nonlinear Generative Compressed Sensing
+ 编号:[304]
+ 链接:https://arxiv.org/abs/2310.03758
+ 作者:Junren Chen, Jonathan Scarlett, Michael K. Ng, Zhaoqiang Liu
+ 备注:Accepted to NeurIPS 2023
+ 关键词:Lipschitz continuous generative, mathbf, continuous generative model, mathbb, generative compressed sensing
+
+ 点击查看摘要
+ In generative compressed sensing (GCS), we want to recover a signal $\mathbf{x}^* \in \mathbb{R}^n$ from $m$ measurements ($m\ll n$) using a generative prior $\mathbf{x}^*\in G(\mathbb{B}_2^k(r))$, where $G$ is typically an $L$-Lipschitz continuous generative model and $\mathbb{B}_2^k(r)$ represents the radius-$r$ $\ell_2$-ball in $\mathbb{R}^k$. Under nonlinear measurements, most prior results are non-uniform, i.e., they hold with high probability for a fixed $\mathbf{x}^*$ rather than for all $\mathbf{x}^*$ simultaneously. In this paper, we build a unified framework to derive uniform recovery guarantees for nonlinear GCS where the observation model is nonlinear and possibly discontinuous or unknown. Our framework accommodates GCS with 1-bit/uniformly quantized observations and single index models as canonical examples. Specifically, using a single realization of the sensing ensemble and generalized Lasso, {\em all} $\mathbf{x}^*\in G(\mathbb{B}_2^k(r))$ can be recovered up to an $\ell_2$-error at most $\epsilon$ using roughly $\tilde{O}({k}/{\epsilon^2})$ samples, with omitted logarithmic factors typically being dominated by $\log L$. Notably, this almost coincides with existing non-uniform guarantees up to logarithmic factors, hence the uniformity costs very little. As part of our technical contributions, we introduce the Lipschitz approximation to handle discontinuous observation models. We also develop a concentration inequality that produces tighter bounds for product processes whose index sets have low metric entropy. Experimental results are presented to corroborate our theory.
+
+
+
+ 109. 标题:Enhancing Healthcare with EOG: A Novel Approach to Sleep Stage Classification
+ 编号:[305]
+ 链接:https://arxiv.org/abs/2310.03757
+ 作者:Suvadeep Maiti, Shivam Kumar Sharma, Raju S. Bapi
+ 备注:
+ 关键词:EEG data acquisition, addressing the discomfort, data acquisition, raw EOG signal, introduce an innovative
+
+ 点击查看摘要
+ We introduce an innovative approach to automated sleep stage classification using EOG signals, addressing the discomfort and impracticality associated with EEG data acquisition. In addition, it is important to note that this approach is untapped in the field, highlighting its potential for novel insights and contributions. Our proposed SE-Resnet-Transformer model provides an accurate classification of five distinct sleep stages from raw EOG signal. Extensive validation on publically available databases (SleepEDF-20, SleepEDF-78, and SHHS) reveals noteworthy performance, with macro-F1 scores of 74.72, 70.63, and 69.26, respectively. Our model excels in identifying REM sleep, a crucial aspect of sleep disorder investigations. We also provide insight into the internal mechanisms of our model using techniques such as 1D-GradCAM and t-SNE plots. Our method improves the accessibility of sleep stage classification while decreasing the need for EEG modalities. This development will have promising implications for healthcare and the incorporation of wearable technology into sleep studies, thereby advancing the field's potential for enhanced diagnostics and patient comfort.
+
+
+
+ 110. 标题:A Multi-channel EEG Data Analysis for Poor Neuro-prognostication in Comatose Patients with Self and Cross-channel Attention Mechanism
+ 编号:[306]
+ 链接:https://arxiv.org/abs/2310.03756
+ 作者:Hemin Ali Qadir, Naimahmed Nesaragi, Per Steiner Halvorsen, Ilangko Balasingham
+ 备注:4 pages, 3 figures, 50th Computing in Cardiology conference in Atlanta, Georgia, USA on 1st - 4th October 2023
+ 关键词:poor neurological outcomes, recordings towards efficient, work investigates, investigates the predictive, predictive potential
+
+ 点击查看摘要
+ This work investigates the predictive potential of bipolar electroencephalogram (EEG) recordings towards efficient prediction of poor neurological outcomes. A retrospective design using a hybrid deep learning approach is utilized to optimize an objective function aiming for high specificity, i.e., true positive rate (TPR) with reduced false positives (< 0.05). A multi-channel EEG array of 18 bipolar channel pairs from a randomly selected 5-minute segment in an hour is kept. In order to determine the outcome prediction, a combination of a feature encoder with 1-D convolutional layers, learnable position encoding, a context network with attention mechanisms, and finally, a regressor and classifier blocks are used. The feature encoder extricates local temporal and spatial features, while the following position encoding and attention mechanisms attempt to capture global temporal dependencies. Results: The proposed framework by our team, OUS IVS, when validated on the challenge hidden validation data, exhibited a score of 0.57.
+
+
+
+ 111. 标题:EMGTFNet: Fuzzy Vision Transformer to decode Upperlimb sEMG signals for Hand Gestures Recognition
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2310.03754
+ 作者:Joseph Cherre Córdova, Christian Flores, Javier Andreu-Perez
+ 备注:
+ 关键词:increasing interest nowadays, Hand Gesture Recognition, Gesture Recognition, Deep Learning methods, interest nowadays
+
+ 点击查看摘要
+ Myoelectric control is an area of electromyography of increasing interest nowadays, particularly in applications such as Hand Gesture Recognition (HGR) for bionic prostheses. Today's focus is on pattern recognition using Machine Learning and, more recently, Deep Learning methods. Despite achieving good results on sparse sEMG signals, the latter models typically require large datasets and training times. Furthermore, due to the nature of stochastic sEMG signals, traditional models fail to generalize samples for atypical or noisy values. In this paper, we propose the design of a Vision Transformer (ViT) based architecture with a Fuzzy Neural Block (FNB) called EMGTFNet to perform Hand Gesture Recognition from surface electromyography (sEMG) signals. The proposed EMGTFNet architecture can accurately classify a variety of hand gestures without any need for data augmentation techniques, transfer learning or a significant increase in the number of parameters in the network. The accuracy of the proposed model is tested using the publicly available NinaPro database consisting of 49 different hand gestures. Experiments yield an average test accuracy of 83.57\% \& 3.5\% using a 200 ms window size and only 56,793 trainable parameters. Our results outperform the ViT without FNB, thus demonstrating that including FNB improves its performance. Our proposal framework EMGTFNet reported the significant potential for its practical application for prosthetic control.
+
+
+
+ 112. 标题:ECGNet: A generative adversarial network (GAN) approach to the synthesis of 12-lead ECG signals from single lead inputs
+ 编号:[308]
+ 链接:https://arxiv.org/abs/2310.03753
+ 作者:Max Bagga, Hyunbae Jeon, Alex Issokson
+ 备注:
+ 关键词:generative adversarial networks, ECG signals, GAN, GAN model, reproducing ECG signals
+
+ 点击查看摘要
+ Electrocardiography (ECG) signal generation has been heavily explored using generative adversarial networks (GAN) because the implementation of 12-lead ECGs is not always feasible. The GAN models have achieved remarkable results in reproducing ECG signals but are only designed for multiple lead inputs and the features the GAN model preserves have not been identified-limiting the generated signals use in cardiovascular disease (CVD)-predictive models. This paper presents ECGNet which is a procedure that generates a complete set of 12-lead ECG signals from any single lead input using a GAN framework with a bidirectional long short-term memory (LSTM) generator and a convolutional neural network (CNN) discriminator. Cross and auto-correlation analysis performed on the generated signals identifies features conserved during the signal generation-i.e., features that can characterize the unique-nature of each signal and thus likely indicators of CVD. Finally, by using ECG signals annotated with the CVD-indicative features detailed by the correlation analysis as inputs for a CVD-onset-predictive CNN model, we overcome challenges preventing the prediction of multiple-CVD targets. Our models are experimented on 15s 12-lead ECG dataset recorded using MyoVista's wavECG. Functional outcome data for each patient is recorded and used in the CVD-predictive model. Our best GAN model achieves state-of-the-art accuracy with Frechet Distance (FD) scores of 4.73, 4.89, 5.18, 4.77, 4.71, and 5.55 on the V1-V6 pre-cordial leads respectively and shows strength in preserving the P-Q segments and R-peaks in the generated signals. To the best of our knowledge, ECGNet is the first to predict all of the remaining eleven leads from the input of any single lead.
+
+
+
+ 113. 标题:A Deep Learning Sequential Decoder for Transient High-Density Electromyography in Hand Gesture Recognition Using Subject-Embedded Transfer Learning
+ 编号:[309]
+ 链接:https://arxiv.org/abs/2310.03752
+ 作者:Golara Ahmadi Azar, Qin Hu, Melika Emami, Alyson Fletcher, Sundeep Rangan, S. Farokh Atashzar
+ 备注:
+ 关键词:AI-powered human-computer interfaces, Hand gesture recognition, deep spatiotemporal dynamics, peripheral nervous system, gained significant attention
+
+ 点击查看摘要
+ Hand gesture recognition (HGR) has gained significant attention due to the increasing use of AI-powered human-computer interfaces that can interpret the deep spatiotemporal dynamics of biosignals from the peripheral nervous system, such as surface electromyography (sEMG). These interfaces have a range of applications, including the control of extended reality, agile prosthetics, and exoskeletons. However, the natural variability of sEMG among individuals has led researchers to focus on subject-specific solutions. Deep learning methods, which often have complex structures, are particularly data-hungry and can be time-consuming to train, making them less practical for subject-specific applications. In this paper, we propose and develop a generalizable, sequential decoder of transient high-density sEMG (HD-sEMG) that achieves 73% average accuracy on 65 gestures for partially-observed subjects through subject-embedded transfer learning, leveraging pre-knowledge of HGR acquired during pre-training. The use of transient HD-sEMG before gesture stabilization allows us to predict gestures with the ultimate goal of counterbalancing system control delays. The results show that the proposed generalized models significantly outperform subject-specific approaches, especially when the training data is limited, and there is a significant number of gesture classes. By building on pre-knowledge and incorporating a multiplicative subject-embedded structure, our method comparatively achieves more than 13% average accuracy across partially observed subjects with minimal data availability. This work highlights the potential of HD-sEMG and demonstrates the benefits of modeling common patterns across users to reduce the need for large amounts of data for new users, enhancing practicality.
+
+
+
+ 114. 标题:A Simple Illustration of Interleaved Learning using Kalman Filter for Linear Least Squares
+ 编号:[310]
+ 链接:https://arxiv.org/abs/2310.03751
+ 作者:Majnu John, Yihren Wu
+ 备注:8 pages, 1 figure
+ 关键词:biologically inspired training, inspired training method, machine learning algorithms, promising results, Interleaved learning
+
+ 点击查看摘要
+ Interleaved learning in machine learning algorithms is a biologically inspired training method with promising results. In this short note, we illustrate the interleaving mechanism via a simple statistical and optimization framework based on Kalman Filter for Linear Least Squares.
+
+
+
+ 115. 标题:Health diagnosis and recuperation of aged Li-ion batteries with data analytics and equivalent circuit modeling
+ 编号:[311]
+ 链接:https://arxiv.org/abs/2310.03750
+ 作者:Riko I Made, Jing Lin, Jintao Zhang, Yu Zhang, Lionel C. H. Moh, Zhaolin Liu, Ning Ding, Sing Yang Chiam, Edwin Khoo, Xuesong Yin, Guangyuan Wesley Zheng
+ 备注:20 pages, 5 figures, 1 table
+ 关键词:second-life Li-ion batteries, Li-ion batteries, second-life Li-ion, Battery health assessment, assessment and recuperation
+
+ 点击查看摘要
+ Battery health assessment and recuperation play a crucial role in the utilization of second-life Li-ion batteries. However, due to ambiguous aging mechanisms and lack of correlations between the recovery effects and operational states, it is challenging to accurately estimate battery health and devise a clear strategy for cell rejuvenation. This paper presents aging and reconditioning experiments of 62 commercial high-energy type lithium iron phosphate (LFP) cells, which supplement existing datasets of high-power LFP cells. The relatively large-scale data allow us to use machine learning models to predict cycle life and identify important indicators of recoverable capacity. Considering cell-to-cell inconsistencies, an average test error of $16.84\% \pm 1.87\%$ (mean absolute percentage error) for cycle life prediction is achieved by gradient boosting regressor given information from the first 80 cycles. In addition, it is found that some of the recoverable lost capacity is attributed to the lateral lithium non-uniformity within the electrodes. An equivalent circuit model is built and experimentally validated to demonstrate how such non-uniformity can be accumulated, and how it can give rise to recoverable capacity loss. SHapley Additive exPlanations (SHAP) analysis also reveals that battery operation history significantly affects the capacity recovery.
+
+
+
+ 116. 标题:SCVCNet: Sliding cross-vector convolution network for cross-task and inter-individual-set EEG-based cognitive workload recognition
+ 编号:[312]
+ 链接:https://arxiv.org/abs/2310.03749
+ 作者:Qi Wang, Li Chen, Zhiyuan Zhan, Jianhua Zhang, Zhong Yin
+ 备注:12 pages
+ 关键词:exploiting common electroencephalogram, cognitive workload recognizer, common electroencephalogram, individual sets, paper presents
+
+ 点击查看摘要
+ This paper presents a generic approach for applying the cognitive workload recognizer by exploiting common electroencephalogram (EEG) patterns across different human-machine tasks and individual sets. We propose a neural network called SCVCNet, which eliminates task- and individual-set-related interferences in EEGs by analyzing finer-grained frequency structures in the power spectral densities. The SCVCNet utilizes a sliding cross-vector convolution (SCVC) operation, where paired input layers representing the theta and alpha power are employed. By extracting the weights from a kernel matrix's central row and column, we compute the weighted sum of the two vectors around a specified scalp location. Next, we introduce an inter-frequency-point feature integration module to fuse the SCVC feature maps. Finally, we combined the two modules with the output-channel pooling and classification layers to construct the model. To train the SCVCNet, we employ the regularized least-square method with ridge regression and the extreme learning machine theory. We validate its performance using three databases, each consisting of distinct tasks performed by independent participant groups. The average accuracy (0.6813 and 0.6229) and F1 score (0.6743 and 0.6076) achieved in two different validation paradigms show partially higher performance than the previous works. All features and algorithms are available on website:this https URL.
+
+
+
+ 117. 标题:Phase Synchrony Component Self-Organization in Brain Computer Interface
+ 编号:[313]
+ 链接:https://arxiv.org/abs/2310.03748
+ 作者:Xu Niu, Na Lu, Huan Luo, Ruofan Yan
+ 备注:
+ 关键词:identifying brain activities, analyzing functional brain, functional brain connectivity, synchrony information plays, brain activities
+
+ 点击查看摘要
+ Phase synchrony information plays a crucial role in analyzing functional brain connectivity and identifying brain activities. A widely adopted feature extraction pipeline, composed of preprocessing, selection of EEG acquisition channels, and phase locking value (PLV) calculation, has achieved success in motor imagery classification (MI). However, this pipeline is manual and reliant on expert knowledge, limiting its convenience and adaptability to different application scenarios. Moreover, most studies have employed mediocre data-independent spatial filters to suppress noise, impeding the exploration of more significant phase synchronization phenomena. To address the issues, we propose the concept of phase synchrony component self-organization, which enables the adaptive learning of data-dependent spatial filters for automating both the preprocessing and channel selection procedures. Based on this concept, the first deep learning end-to-end network is developed, which directly extracts phase synchrony-based features from raw EEG signals and perform classification. The network learns optimal filters during training, which are obtained when the network achieves peak classification results. Extensive experiments have demonstrated that our network outperforms state-of-the-art methods. Remarkably, through the learned optimal filters, significant phase synchronization phenomena can be observed. Specifically, by calculating the PLV between a pair of signals extracted from each sample using two of the learned spatial filters, we have obtained an average PLV exceeding 0.87 across all tongue MI samples. This high PLV indicates a groundbreaking discovery in the synchrony pattern of tongue MI.
+
+
+
+ 118. 标题:A Knowledge-Driven Cross-view Contrastive Learning for EEG Representation
+ 编号:[314]
+ 链接:https://arxiv.org/abs/2310.03747
+ 作者:Weining Weng, Yang Gu, Qihui Zhang, Yingying Huang, Chunyan Miao, Yiqiang Chen
+ 备注:14pages,7 figures
+ 关键词:gained substantial traction, EEG signals integrated, numerous real-world tasks, EEG signals, abundant neurophysiological information
+
+ 点击查看摘要
+ Due to the abundant neurophysiological information in the electroencephalogram (EEG) signal, EEG signals integrated with deep learning methods have gained substantial traction across numerous real-world tasks. However, the development of supervised learning methods based on EEG signals has been hindered by the high cost and significant label discrepancies to manually label large-scale EEG datasets. Self-supervised frameworks are adopted in vision and language fields to solve this issue, but the lack of EEG-specific theoretical foundations hampers their applicability across various tasks. To solve these challenges, this paper proposes a knowledge-driven cross-view contrastive learning framework (KDC2), which integrates neurological theory to extract effective representations from EEG with limited labels. The KDC2 method creates scalp and neural views of EEG signals, simulating the internal and external representation of brain activity. Sequentially, inter-view and cross-view contrastive learning pipelines in combination with various augmentation methods are applied to capture neural features from different views. By modeling prior neural knowledge based on homologous neural information consistency theory, the proposed method extracts invariant and complementary neural knowledge to generate combined representations. Experimental results on different downstream tasks demonstrate that our method outperforms state-of-the-art methods, highlighting the superior generalization of neural knowledge-supported EEG representations across various brain tasks.
+
+
+人工智能
+
+ 1. 标题:Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2310.04413
+ 作者:Zhang-Wei Hong, Aviral Kumar, Sathwik Karnik, Abhishek Bhandwaldar, Akash Srivastava, Joni Pajarinen, Romain Laroche, Abhishek Gupta, Pulkit Agrawal
+ 备注:Accepted NeurIPS 2023
+ 关键词:learning decision-making policies, collecting additional data, decision-making policies, policies using existing, collecting additional
+
+ 点击查看摘要
+ Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at this https URL.
+
+
+
+ 2. 标题:Policy-Gradient Training of Language Models for Ranking
+ 编号:[10]
+ 链接:https://arxiv.org/abs/2310.04407
+ 作者:Ge Gao, Jonathan D. Chang, Claire Cardie, Kianté Brantley, Thorsten Joachim
+ 备注:
+ 关键词:incorporating factual knowledge, chat-based web search, Text retrieval plays, language processing pipelines, ranging from chat-based
+
+ 点击查看摘要
+ Text retrieval plays a crucial role in incorporating factual knowledge for decision making into language processing pipelines, ranging from chat-based web search to question answering systems. Current state-of-the-art text retrieval models leverage pre-trained large language models (LLMs) to achieve competitive performance, but training LLM-based retrievers via typical contrastive losses requires intricate heuristics, including selecting hard negatives and using additional supervision as learning signals. This reliance on heuristics stems from the fact that the contrastive loss itself is heuristic and does not directly optimize the downstream metrics of decision quality at the end of the processing pipeline. To address this issue, we introduce Neural PG-RANK, a novel training algorithm that learns to rank by instantiating a LLM as a Plackett-Luce ranking policy. Neural PG-RANK provides a principled method for end-to-end training of retrieval models as part of larger decision systems via policy gradient, with little reliance on complex heuristics, and it effectively unifies the training objective with downstream decision-making quality. We conduct extensive experiments on various text retrieval benchmarks. The results demonstrate that when the training objective aligns with the evaluation setup, Neural PG-RANK yields remarkable in-domain performance improvement, with substantial out-of-domain generalization to some critical datasets employed in downstream question answering tasks.
+
+
+
+ 3. 标题:Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2310.04406
+ 作者:Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, Yu-Xiong Wang
+ 备注:Website and code can be found at this https URL
+ 关键词:large language models, demonstrated impressive performance, simple acting processes, Language Agent Tree, Agent Tree Search
+
+ 点击查看摘要
+ While large language models (LLMs) have demonstrated impressive performance on a range of decision-making tasks, they rely on simple acting processes and fall short of broad deployment as autonomous agents. We introduce LATS (Language Agent Tree Search), a general framework that synergizes the capabilities of LLMs in planning, acting, and reasoning. Drawing inspiration from Monte Carlo tree search in model-based reinforcement learning, LATS employs LLMs as agents, value functions, and optimizers, repurposing their latent strengths for enhanced decision-making. What is crucial in this method is the use of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that moves beyond the limitations of existing techniques. Our experimental evaluation across diverse domains, such as programming, HotPotQA, and WebShop, illustrates the applicability of LATS for both reasoning and acting. In particular, LATS achieves 94.4\% for programming on HumanEval with GPT-4 and an average score of 75.9 for web browsing on WebShop with GPT-3.5, demonstrating the effectiveness and generality of our method.
+
+
+
+ 4. 标题:Leveraging Self-Consistency for Data-Efficient Amortized Bayesian Inference
+ 编号:[14]
+ 链接:https://arxiv.org/abs/2310.04395
+ 作者:Marvin Schmitt, Daniel Habermann, Paul-Christian Bürkner, Ullrich Köthe, Stefan T. Radev
+ 备注:
+ 关键词:amortized Bayesian inference, leveraging universal symmetries, Bayesian inference, amortized Bayesian, probabilistic joint model
+
+ 点击查看摘要
+ We propose a method to improve the efficiency and accuracy of amortized Bayesian inference (ABI) by leveraging universal symmetries in the probabilistic joint model $p(\theta, y)$ of parameters $\theta$ and data $y$. In a nutshell, we invert Bayes' theorem and estimate the marginal likelihood based on approximate representations of the joint model. Upon perfect approximation, the marginal likelihood is constant across all parameter values by definition. However, approximation error leads to undesirable variance in the marginal likelihood estimates across different parameter values. We formulate violations of this symmetry as a loss function to accelerate the learning dynamics of conditional neural density estimators. We apply our method to a bimodal toy problem with an explicit likelihood (likelihood-based) and a realistic model with an implicit likelihood (simulation-based).
+
+
+
+ 5. 标题:Hermes: Unlocking Security Analysis of Cellular Network Protocols by Synthesizing Finite State Machines from Natural Language Specifications
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2310.04381
+ 作者:Abdullah Al Ishtiaq, Sarkar Snigdha Sarathi Das, Syed Md Mukit Rashid, Ali Ranjbar, Kai Tu, Tianwei Wu, Zhezheng Song, Weixuan Wang, Mujtahid Akon, Rui Zhang, Syed Rafiul Hussain
+ 备注:Accepted at USENIX Security 24
+ 关键词:natural language cellular, framework to automatically, representations from natural, automatically generate formal, generate formal representations
+
+ 点击查看摘要
+ In this paper, we present Hermes, an end-to-end framework to automatically generate formal representations from natural language cellular specifications. We first develop a neural constituency parser, NEUTREX, to process transition-relevant texts and extract transition components (i.e., states, conditions, and actions). We also design a domain-specific language to translate these transition components to logical formulas by leveraging dependency parse trees. Finally, we compile these logical formulas to generate transitions and create the formal model as finite state machines. To demonstrate the effectiveness of Hermes, we evaluate it on 4G NAS, 5G NAS, and 5G RRC specifications and obtain an overall accuracy of 81-87%, which is a substantial improvement over the state-of-the-art. Our security analysis of the extracted models uncovers 3 new vulnerabilities and identifies 19 previous attacks in 4G and 5G specifications, and 7 deviations in commercial 4G basebands.
+
+
+
+ 6. 标题:Confronting Reward Model Overoptimization with Constrained RLHF
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2310.04373
+ 作者:Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, Stephen McAleer
+ 备注:
+ 关键词:Large language models, typically aligned, reward models, human preferences, simpler reward models
+
+ 点击查看摘要
+ Large language models are typically aligned with human preferences by optimizing $\textit{reward models}$ (RMs) fitted to human feedback. However, human preferences are multi-faceted, and it is increasingly common to derive reward from a composition of simpler reward models which each capture a different aspect of language quality. This itself presents a challenge, as it is difficult to appropriately weight these component RMs when combining them. Compounding this difficulty, because any RM is only a proxy for human evaluation, this process is vulnerable to $\textit{overoptimization}$, wherein past a certain point, accumulating higher reward is associated with worse human ratings. In this paper, we perform, to our knowledge, the first study on overoptimization in composite RMs, showing that correlation between component RMs has a significant effect on the locations of these points. We then introduce an approach to solve this issue using constrained reinforcement learning as a means of preventing the agent from exceeding each RM's threshold of usefulness. Our method addresses the problem of weighting component RMs by learning dynamic weights, naturally given by the Lagrange multipliers. As a result, each RM stays within the range at which it is an effective proxy, improving evaluation performance. Finally, we introduce an adaptive method using gradient-free optimization to identify and optimize towards these points during a single run.
+
+
+
+ 7. 标题:A Language-Agent Approach to Formal Theorem-Proving
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2310.04353
+ 作者:Amitayush Thakur, Yeming Wen, Swarat Chaudhuri
+ 备注:
+ 关键词:large language model, Language agents, large language, capable of in-context, in-context learning
+
+ 点击查看摘要
+ Language agents, which use a large language model (LLM) capable of in-context learning to interact with an external environment, have recently emerged as a promising approach to control tasks. We present the first language-agent approach to formal theorem-proving. Our method, COPRA, uses a high-capacity, black-box LLM (GPT-4) as part of a policy for a stateful backtracking search. During the search, the policy can select proof tactics and retrieve lemmas and definitions from an external database. Each selected tactic is executed in the underlying proof framework, and the execution feedback is used to build the prompt for the next policy invocation. The search also tracks selected information from its history and uses it to reduce hallucinations and unnecessary LLM queries.
+We evaluate COPRA on the miniF2F benchmark for Lean and a set of Coq tasks from the Compcert project. On these benchmarks, COPRA is significantly better than one-shot invocations of GPT-4, as well as state-of-the-art models fine-tuned on proof data, at finding correct proofs quickly.
+
+
+
+ 8. 标题:Adjustable Robust Reinforcement Learning for Online 3D Bin Packing
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2310.04323
+ 作者:Yuxin Pan, Yize Chen, Fangzhen Lin
+ 备注:Accepted to NeurIPS2023
+ 关键词:Designing effective policies, stringent physical constraints, incoming box sequences, bin packing problem, box sequence distribution
+
+ 点击查看摘要
+ Designing effective policies for the online 3D bin packing problem (3D-BPP) has been a long-standing challenge, primarily due to the unpredictable nature of incoming box sequences and stringent physical constraints. While current deep reinforcement learning (DRL) methods for online 3D-BPP have shown promising results in optimizing average performance over an underlying box sequence distribution, they often fail in real-world settings where some worst-case scenarios can materialize. Standard robust DRL algorithms tend to overly prioritize optimizing the worst-case performance at the expense of performance under normal problem instance distribution. To address these issues, we first introduce a permutation-based attacker to investigate the practical robustness of both DRL-based and heuristic methods proposed for solving online 3D-BPP. Then, we propose an adjustable robust reinforcement learning (AR2L) framework that allows efficient adjustment of robustness weights to achieve the desired balance of the policy's performance in average and worst-case environments. Specifically, we formulate the objective function as a weighted sum of expected and worst-case returns, and derive the lower performance bound by relating to the return under a mixture dynamics. To realize this lower bound, we adopt an iterative procedure that searches for the associated mixture dynamics and improves the corresponding policy. We integrate this procedure into two popular robust adversarial algorithms to develop the exact and approximate AR2L algorithms. Experiments demonstrate that AR2L is versatile in the sense that it improves policy robustness while maintaining an acceptable level of performance for the nominal case.
+
+
+
+ 9. 标题:Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2310.04306
+ 作者:Qing Zhu, Qirong Mao, Jialin Zhang, Xiaohua Huang, Wenming Zheng
+ 备注:11 pages,3 figures
+ 关键词:human behavior analysis, Group-level emotion recognition, behavior analysis, aiming to recognize, inseparable part
+
+ 点击查看摘要
+ Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
+
+
+
+ 10. 标题:Coding by Design: GPT-4 empowers Agile Model Driven Development
+ 编号:[47]
+ 链接:https://arxiv.org/abs/2310.04304
+ 作者:Ahmed R. Sadik, Sebastian Brulin, Markus Olhofer
+ 备注:
+ 关键词:Large Language Models, Large Language, language, code, natural language
+
+ 点击查看摘要
+ Generating code from a natural language using Large Language Models (LLMs) such as ChatGPT, seems groundbreaking. Yet, with more extensive use, it's evident that this approach has its own limitations. The inherent ambiguity of natural language presents challenges for complex software designs. Accordingly, our research offers an Agile Model-Driven Development (MDD) approach that enhances code auto-generation using OpenAI's GPT-4. Our work emphasizes "Agility" as a significant contribution to the current MDD method, particularly when the model undergoes changes or needs deployment in a different programming language. Thus, we present a case-study showcasing a multi-agent simulation system of an Unmanned Vehicle Fleet. In the first and second layer of our approach, we constructed a textual representation of the case-study using Unified Model Language (UML) diagrams. In the next layer, we introduced two sets of constraints that minimize model ambiguity. Object Constraints Language (OCL) is applied to fine-tune the code constructions details, while FIPA ontology is used to shape communication semantics and protocols. Ultimately, leveraging GPT-4, our last layer auto-generates code in both Java and Python. The Java code is deployed within the JADE framework, while the Python code is deployed in PADE framework. Concluding our research, we engaged in a comprehensive evaluation of the generated code. From a behavioural standpoint, the auto-generated code aligned perfectly with the expected UML sequence diagram. Structurally, we compared the complexity of code derived from UML diagrams constrained solely by OCL to that influenced by both OCL and FIPA-ontology. Results indicate that ontology-constrained model produce inherently more intricate code, but it remains manageable and low-risk for further testing and maintenance.
+
+
+
+ 11. 标题:Identifying Representations for Intervention Extrapolation
+ 编号:[49]
+ 链接:https://arxiv.org/abs/2310.04295
+ 作者:Sorawit Saengkyongam, Elan Rosenfeld, Pradeep Ravikumar, Niklas Pfister, Jonas Peters
+ 备注:
+ 关键词:generalizability or robustness, intervention extrapolation, improve the current, paradigm in terms, terms of generalizability
+
+ 点击查看摘要
+ The premise of identifiable and causal representation learning is to improve the current representation learning paradigm in terms of generalizability or robustness. Despite recent progress in questions of identifiability, more theoretical results demonstrating concrete advantages of these methods for downstream tasks are needed. In this paper, we consider the task of intervention extrapolation: predicting how interventions affect an outcome, even when those interventions are not observed at training time, and show that identifiable representations can provide an effective solution to this task even if the interventions affect the outcome non-linearly. Our setup includes an outcome Y, observed features X, which are generated as a non-linear transformation of latent features Z, and exogenous action variables A, which influence Z. The objective of intervention extrapolation is to predict how interventions on A that lie outside the training support of A affect Y. Here, extrapolation becomes possible if the effect of A on Z is linear and the residual when regressing Z on A has full support. As Z is latent, we combine the task of intervention extrapolation with identifiable representation learning, which we call Rep4Ex: we aim to map the observed features X into a subspace that allows for non-linear extrapolation in A. We show using Wiener's Tauberian theorem that the hidden representation is identifiable up to an affine transformation in Z-space, which is sufficient for intervention extrapolation. The identifiability is characterized by a novel constraint describing the linearity assumption of A on Z. Based on this insight, we propose a method that enforces the linear invariance constraint and can be combined with any type of autoencoder. We validate our theoretical findings through synthetic experiments and show that our approach succeeds in predicting the effects of unseen interventions.
+
+
+
+ 12. 标题:Searching for Optimal Runtime Assurance via Reachability and Reinforcement Learning
+ 编号:[54]
+ 链接:https://arxiv.org/abs/2310.04288
+ 作者:Kristina Miller, Christopher K. Zeitler, William Shen, Kerianne Hobbs, Sayan Mitra, John Schierman, Mahesh Viswanathan
+ 备注:
+ 关键词:runtime assurance system, assurance system, runtime assurance, plant enables, enables the exercise
+
+ 点击查看摘要
+ A runtime assurance system (RTA) for a given plant enables the exercise of an untrusted or experimental controller while assuring safety with a backup (or safety) controller. The relevant computational design problem is to create a logic that assures safety by switching to the safety controller as needed, while maximizing some performance criteria, such as the utilization of the untrusted controller. Existing RTA design strategies are well-known to be overly conservative and, in principle, can lead to safety violations. In this paper, we formulate the optimal RTA design problem and present a new approach for solving it. Our approach relies on reward shaping and reinforcement learning. It can guarantee safety and leverage machine learning technologies for scalability. We have implemented this algorithm and present experimental results comparing our approach with state-of-the-art reachability and simulation-based RTA approaches in a number of scenarios using aircraft models in 3D space with complex safety requirements. Our approach can guarantee safety while increasing utilization of the experimental controller over existing approaches.
+
+
+
+ 13. 标题:Assessing Robustness via Score-Based Adversarial Image Generation
+ 编号:[56]
+ 链接:https://arxiv.org/abs/2310.04285
+ 作者:Marcel Kollovieh, Lukas Gosch, Yan Scholten, Marten Lienen, Stephan Günnemann
+ 备注:
+ 关键词:norm constraints, ell, adversarial, norm, constraints
+
+ 点击查看摘要
+ Most adversarial attacks and defenses focus on perturbations within small $\ell_p$-norm constraints. However, $\ell_p$ threat models cannot capture all relevant semantic-preserving perturbations, and hence, the scope of robustness evaluations is limited. In this work, we introduce Score-Based Adversarial Generation (ScoreAG), a novel framework that leverages the advancements in score-based generative models to generate adversarial examples beyond $\ell_p$-norm constraints, so-called unrestricted adversarial examples, overcoming their limitations. Unlike traditional methods, ScoreAG maintains the core semantics of images while generating realistic adversarial examples, either by transforming existing images or synthesizing new ones entirely from scratch. We further exploit the generative capability of ScoreAG to purify images, empirically enhancing the robustness of classifiers. Our extensive empirical evaluation demonstrates that ScoreAG matches the performance of state-of-the-art attacks and defenses across multiple benchmarks. This work highlights the importance of investigating adversarial examples bounded by semantics rather than $\ell_p$-norm constraints. ScoreAG represents an important step towards more encompassing robustness assessments.
+
+
+
+ 14. 标题:From task structures to world models: What do LLMs know?
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2310.04276
+ 作者:Ilker Yildirim, L.A. Paul
+ 备注:
+ 关键词:large language model, large language, knowledge, language model, instrumental knowledge
+
+ 点击查看摘要
+ In what sense does a large language model have knowledge? The answer to this question extends beyond the capabilities of a particular AI system, and challenges our assumptions about the nature of knowledge and intelligence. We answer by granting LLMs "instrumental knowledge"; knowledge defined by a certain set of abilities. We then ask how such knowledge is related to the more ordinary, "worldly" knowledge exhibited by human agents, and explore this in terms of the degree to which instrumental knowledge can be said to incorporate the structured world models of cognitive science. We discuss ways LLMs could recover degrees of worldly knowledge, and suggest such recovery will be governed by an implicit, resource-rational tradeoff between world models and task demands.
+
+
+
+ 15. 标题:A Comprehensive Evaluation of Large Language Models on Benchmark Biomedical Text Processing Tasks
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2310.04270
+ 作者:Israt Jahan, Md Tahmid Rahman Laskar, Chun Peng, Jimmy Huang
+ 备注:arXiv admin note: substantial text overlap with arXiv:2306.04504
+ 关键词:Large Language Models, demonstrated impressive capability, Language Models, Large Language, biomedical
+
+ 点击查看摘要
+ Recently, Large Language Models (LLM) have demonstrated impressive capability to solve a wide range of tasks. However, despite their success across various tasks, no prior work has investigated their capability in the biomedical domain yet. To this end, this paper aims to evaluate the performance of LLMs on benchmark biomedical tasks. For this purpose, we conduct a comprehensive evaluation of 4 popular LLMs in 6 diverse biomedical tasks across 26 datasets. To the best of our knowledge, this is the first work that conducts an extensive evaluation and comparison of various LLMs in the biomedical domain. Interestingly, we find based on our evaluation that in biomedical datasets that have smaller training sets, zero-shot LLMs even outperform the current state-of-the-art fine-tuned biomedical models. This suggests that pretraining on large text corpora makes LLMs quite specialized even in the biomedical domain. We also find that not a single LLM can outperform other LLMs in all tasks, with the performance of different LLMs may vary depending on the task. While their performance is still quite poor in comparison to the biomedical models that were fine-tuned on large training sets, our findings demonstrate that LLMs have the potential to be a valuable tool for various biomedical tasks that lack large annotated data.
+
+
+
+ 16. 标题:DRIFT: Deep Reinforcement Learning for Intelligent Floating Platforms Trajectories
+ 编号:[64]
+ 链接:https://arxiv.org/abs/2310.04266
+ 作者:Matteo El-Hariry, Antoine Richard, Vivek Muralidharan, Baris Can Yalcin, Matthieu Geist, Miguel Olivares-Mendez
+ 备注:
+ 关键词:control floating platforms, deep reinforcement learning-based, deep reinforcement learning, investigation introduces, reinforcement learning-based suite
+
+ 点击查看摘要
+ This investigation introduces a novel deep reinforcement learning-based suite to control floating platforms in both simulated and real-world environments. Floating platforms serve as versatile test-beds to emulate microgravity environments on Earth. Our approach addresses the system and environmental uncertainties in controlling such platforms by training policies capable of precise maneuvers amid dynamic and unpredictable conditions. Leveraging state-of-the-art deep reinforcement learning techniques, our suite achieves robustness, adaptability, and good transferability from simulation to reality. Our Deep Reinforcement Learning (DRL) framework provides advantages such as fast training times, large-scale testing capabilities, rich visualization options, and ROS bindings for integration with real-world robotic systems. Beyond policy development, our suite provides a comprehensive platform for researchers, offering open-access at this https URL.
+
+
+
+ 17. 标题:Comparing Auxiliary Tasks for Learning Representations for Reinforcement Learning
+ 编号:[73]
+ 链接:https://arxiv.org/abs/2310.04241
+ 作者:Moritz Lange, Noah Krystiniak, Raphael C. Engelhardt, Wolfgang Konen, Laurenz Wiskott
+ 备注:
+ 关键词:gained steady popularity, gained steady, steady popularity, popularity in reinforcement, potential to improve
+
+ 点击查看摘要
+ Learning state representations has gained steady popularity in reinforcement learning (RL) due to its potential to improve both sample efficiency and returns on many environments. A straightforward and efficient method is to generate representations with a distinct neural network trained on an auxiliary task, i.e. a task that differs from the actual RL task. While a whole range of such auxiliary tasks has been proposed in the literature, a comparison on typical continuous control benchmark environments is computationally expensive and has, to the best of our knowledge, not been performed before. This paper presents such a comparison of common auxiliary tasks, based on hundreds of agents trained with state-of-the-art off-policy RL algorithms. We compare possible improvements in both sample efficiency and returns for environments ranging from simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks is beneficial for environments of higher dimension and complexity, and that learning environment dynamics is preferable to predicting rewards. We believe these insights will enable other researchers to make more informed decisions on how to utilize representation learning for their specific problem.
+
+
+
+ 18. 标题:The WayHome: Long-term Motion Prediction on Dynamically Scaled
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2310.04232
+ 作者:Kay Scheerer, Thomas Michalke, Juergen Mathes
+ 备注:
+ 关键词:autonomous vehicles, surrounding environment, ability to accurately, accurately predict, vehicles
+
+ 点击查看摘要
+ One of the key challenges for autonomous vehicles is the ability to accurately predict the motion of other objects in the surrounding environment, such as pedestrians or other vehicles. In this contribution, a novel motion forecasting approach for autonomous vehicles is developed, inspired by the work of Gilles et al. [1]. We predict multiple heatmaps with a neuralnetwork-based model for every traffic participant in the vicinity of the autonomous vehicle; with one heatmap per timestep. The heatmaps are used as input to a novel sampling algorithm that extracts coordinates corresponding to the most likely future positions. We experiment with different encoders and decoders, as well as a comparison of two loss functions. Additionally, a new grid-scaling technique is introduced, showing further improved performance. Overall, our approach improves stateof-the-art miss rate performance for the function-relevant prediction interval of 3 seconds while being competitive in longer prediction intervals (up to eight seconds). The evaluation is done on the public 2022 Waymo motion challenge.
+
+
+
+ 19. 标题:A Fixed-Parameter Tractable Algorithm for Counting Markov Equivalence Classes with the same Skeleton
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2310.04218
+ 作者:Vidya Sagar Sharma
+ 备注:75 pages, 2 Figures
+ 关键词:Bayesian networks, random variables, Markov equivalent DAGs, Causal DAGs, encoding conditional dependencies
+
+ 点击查看摘要
+ Causal DAGs (also known as Bayesian networks) are a popular tool for encoding conditional dependencies between random variables. In a causal DAG, the random variables are modeled as vertices in the DAG, and it is stipulated that every random variable is independent of its ancestors conditioned on its parents. It is possible, however, for two different causal DAGs on the same set of random variables to encode exactly the same set of conditional dependencies. Such causal DAGs are said to be Markov equivalent, and equivalence classes of Markov equivalent DAGs are known as Markov Equivalent Classes (MECs). Beautiful combinatorial characterizations of MECs have been developed in the past few decades, and it is known, in particular that all DAGs in the same MEC must have the same ''skeleton'' (underlying undirected graph) and v-structures (induced subgraph of the form $a\rightarrow b \leftarrow c$).
+These combinatorial characterizations also suggest several natural algorithmic questions. One of these is: given an undirected graph $G$ as input, how many distinct Markov equivalence classes have the skeleton $G$? Much work has been devoted in the last few years to this and other closely related problems. However, to the best of our knowledge, a polynomial time algorithm for the problem remains unknown.
+In this paper, we make progress towards this goal by giving a fixed parameter tractable algorithm for the above problem, with the parameters being the treewidth and the maximum degree of the input graph $G$. The main technical ingredient in our work is a construction we refer to as shadow, which lets us create a "local description'' of long-range constraints imposed by the combinatorial characterizations of MECs.
+
+
+
+ 20. 标题:Keyword Augmented Retrieval: Novel framework for Information Retrieval integrated with speech interface
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2310.04205
+ 作者:Anupam Purwar, Rahul Sundar
+ 备注:
+ 关键词:low cost manner, knowledge retrieval automation, Language models, quick and low, manner without hallucinations
+
+ 点击查看摘要
+ Retrieving answers in a quick and low cost manner without hallucinations from a combination of structured and unstructured data using Language models is a major hurdle which prevents employment of Language models in knowledge retrieval automation. This becomes accentuated when one wants to integrate a speech interface. Besides, for commercial search and chatbot applications, complete reliance on commercial large language models (LLMs) like GPT 3.5 etc. can be very costly. In this work, authors have addressed this problem by first developing a keyword based search framework which augments discovery of the context to be provided to the large language model. The keywords in turn are generated by LLM and cached for comparison with keywords generated by LLM against the query raised. This significantly reduces time and cost to find the context within documents. Once the context is set, LLM uses that to provide answers based on a prompt tailored for Q&A. This research work demonstrates that use of keywords in context identification reduces the overall inference time and cost of information retrieval. Given this reduction in inference time and cost with the keyword augmented retrieval framework, a speech based interface for user input and response readout was integrated. This allowed a seamless interaction with the language model.
+
+
+
+ 21. 标题:Introducing the Attribution Stability Indicator: a Measure for Time Series XAI Attributions
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2310.04178
+ 作者:Udo Schlegel, Daniel A. Keim
+ 备注:16 pages, 6 figures, ECML-PKDD Workshop XAI-TS: Explainable AI for Time Series: Advances and Applications
+ 关键词:provide interpretable insights, time series data, time series, Attribution Stability Indicator, weather forecasting
+
+ 点击查看摘要
+ Given the increasing amount and general complexity of time series data in domains such as finance, weather forecasting, and healthcare, there is a growing need for state-of-the-art performance models that can provide interpretable insights into underlying patterns and relationships. Attribution techniques enable the extraction of explanations from time series models to gain insights but are hard to evaluate for their robustness and trustworthiness. We propose the Attribution Stability Indicator (ASI), a measure to incorporate robustness and trustworthiness as properties of attribution techniques for time series into account. We extend a perturbation analysis with correlations of the original time series to the perturbed instance and the attributions to include wanted properties in the measure. We demonstrate the wanted properties based on an analysis of the attributions in a dimension-reduced space and the ASI scores distribution over three whole time series classification datasets.
+
+
+
+ 22. 标题:Dynamic Relation-Attentive Graph Neural Networks for Fraud Detection
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2310.04171
+ 作者:Heehyeon Kim, Jinhyeok Choi, Joyce Jiyoung Whang
+ 备注:5 pages, 3 figures, 3 tables. 23rd IEEE International Conference on Data Mining Workshops (ICDMW)
+ 关键词:leaving fake reviews, making abnormal transactions, discover fraudsters deceiving, leaving fake, abnormal transactions
+
+ 点击查看摘要
+ Fraud detection aims to discover fraudsters deceiving other users by, for example, leaving fake reviews or making abnormal transactions. Graph-based fraud detection methods consider this task as a classification problem with two classes: frauds or normal. We address this problem using Graph Neural Networks (GNNs) by proposing a dynamic relation-attentive aggregation mechanism. Based on the observation that many real-world graphs include different types of relations, we propose to learn a node representation per relation and aggregate the node representations using a learnable attention function that assigns a different attention coefficient to each relation. Furthermore, we combine the node representations from different layers to consider both the local and global structures of a target node, which is beneficial to improving the performance of fraud detection on graphs with heterophily. By employing dynamic graph attention in all the aggregation processes, our method adaptively computes the attention coefficients for each node. Experimental results show that our method, DRAG, outperforms state-of-the-art fraud detection methods on real-world benchmark datasets.
+
+
+
+ 23. 标题:Self-Supervised Neuron Segmentation with Multi-Agent Reinforcement Learning
+ 编号:[107]
+ 链接:https://arxiv.org/abs/2310.04148
+ 作者:Yinda Chen, Wei Huang, Shenglong Zhou, Qi Chen, Zhiwei Xiong
+ 备注:IJCAI 23 main track paper
+ 关键词:scale electron microscopy, large scale electron, existing supervised neuron, supervised neuron segmentation, accurate annotations
+
+ 点击查看摘要
+ The performance of existing supervised neuron segmentation methods is highly dependent on the number of accurate annotations, especially when applied to large scale electron microscopy (EM) data. By extracting semantic information from unlabeled data, self-supervised methods can improve the performance of downstream tasks, among which the mask image model (MIM) has been widely used due to its simplicity and effectiveness in recovering original information from masked images. However, due to the high degree of structural locality in EM images, as well as the existence of considerable noise, many voxels contain little discriminative information, making MIM pretraining inefficient on the neuron segmentation task. To overcome this challenge, we propose a decision-based MIM that utilizes reinforcement learning (RL) to automatically search for optimal image masking ratio and masking strategy. Due to the vast exploration space, using single-agent RL for voxel prediction is impractical. Therefore, we treat each input patch as an agent with a shared behavior policy, allowing for multi-agent collaboration. Furthermore, this multi-agent model can capture dependencies between voxels, which is beneficial for the downstream segmentation task. Experiments conducted on representative EM datasets demonstrate that our approach has a significant advantage over alternative self-supervised methods on the task of neuron segmentation. Code is available at \url{this https URL}.
+
+
+
+ 24. 标题:Reinforcement Learning with Fast and Forgetful Memory
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2310.04128
+ 作者:Steven Morad, Ryan Kortvelesy, Stephan Liwicki, Amanda Prorok
+ 备注:
+ 关键词:inherently partially observable, Reinforcement Learning, real world tasks, Supervised Learning, partially observable
+
+ 点击查看摘要
+ Nearly all real world tasks are inherently partially observable, necessitating the use of memory in Reinforcement Learning (RL). Most model-free approaches summarize the trajectory into a latent Markov state using memory models borrowed from Supervised Learning (SL), even though RL tends to exhibit different training and efficiency characteristics. Addressing this discrepancy, we introduce Fast and Forgetful Memory, an algorithm-agnostic memory model designed specifically for RL. Our approach constrains the model search space via strong structural priors inspired by computational psychology. It is a drop-in replacement for recurrent neural networks (RNNs) in recurrent RL algorithms, achieving greater reward than RNNs across various recurrent benchmarks and algorithms without changing any hyperparameters. Moreover, Fast and Forgetful Memory exhibits training speeds two orders of magnitude faster than RNNs, attributed to its logarithmic time and linear space complexity. Our implementation is available at this https URL.
+
+
+
+ 25. 标题:Nash Welfare and Facility Location
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2310.04102
+ 作者:Alexander Lam, Haris Aziz, Toby Walsh
+ 备注:
+ 关键词:Nash welfare, serve a set, set of agents, agents located, Nash welfare objective
+
+ 点击查看摘要
+ We consider the problem of locating a facility to serve a set of agents located along a line. The Nash welfare objective function, defined as the product of the agents' utilities, is known to provide a compromise between fairness and efficiency in resource allocation problems. We apply this welfare notion to the facility location problem, converting individual costs to utilities and analyzing the facility placement that maximizes the Nash welfare. We give a polynomial-time approximation algorithm to compute this facility location, and prove results suggesting that it achieves a good balance of fairness and efficiency. Finally, we take a mechanism design perspective and propose a strategy-proof mechanism with a bounded approximation ratio for Nash welfare.
+
+
+
+ 26. 标题:A Deeply Supervised Semantic Segmentation Method Based on GAN
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2310.04081
+ 作者:Wei Zhao, Qiyu Wei, Zeng Zeng
+ 备注:6 pages, 2 figures, ITSC conference
+ 关键词:witnessed rapid advancements, Semantic segmentation, recent years, rapid advancements, semantic segmentation model
+
+ 点击查看摘要
+ In recent years, the field of intelligent transportation has witnessed rapid advancements, driven by the increasing demand for automation and efficiency in transportation systems. Traffic safety, one of the tasks integral to intelligent transport systems, requires accurately identifying and locating various road elements, such as road cracks, lanes, and traffic signs. Semantic segmentation plays a pivotal role in achieving this task, as it enables the partition of images into meaningful regions with accurate boundaries. In this study, we propose an improved semantic segmentation model that combines the strengths of adversarial learning with state-of-the-art semantic segmentation techniques. The proposed model integrates a generative adversarial network (GAN) framework into the traditional semantic segmentation model, enhancing the model's performance in capturing complex and subtle features in transportation images. The effectiveness of our approach is demonstrated by a significant boost in performance on the road crack dataset compared to the existing methods, \textit{i.e.,} SEGAN. This improvement can be attributed to the synergistic effect of adversarial learning and semantic segmentation, which leads to a more refined and accurate representation of road structures and conditions. The enhanced model not only contributes to better detection of road cracks but also to a wide range of applications in intelligent transportation, such as traffic sign recognition, vehicle detection, and lane segmentation.
+
+
+
+ 27. 标题:Automatic Aspect Extraction from Scientific Texts
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2310.04074
+ 作者:Anna Marshalova, Elena Bruches, Tatiana Batura
+ 备注:
+ 关键词:scientific literature review, key insights, main points, important information, literature review
+
+ 点击查看摘要
+ Being able to extract from scientific papers their main points, key insights, and other important information, referred to here as aspects, might facilitate the process of conducting a scientific literature review. Therefore, the aim of our research is to create a tool for automatic aspect extraction from Russian-language scientific texts of any domain. In this paper, we present a cross-domain dataset of scientific texts in Russian, annotated with such aspects as Task, Contribution, Method, and Conclusion, as well as a baseline algorithm for aspect extraction, based on the multilingual BERT model fine-tuned on our data. We show that there are some differences in aspect representation in different domains, but even though our model was trained on a limited number of scientific domains, it is still able to generalize to new domains, as was proved by cross-domain experiments. The code and the dataset are available at \url{this https URL}.
+
+
+
+ 28. 标题:AI Regulation in Europe: From the AI Act to Future Regulatory Challenges
+ 编号:[136]
+ 链接:https://arxiv.org/abs/2310.04072
+ 作者:Philipp Hacker
+ 备注:Final version forthcoming in: Ifeoma Ajunwa & Jeremias Adams-Prassl (eds), Oxford Handbook of Algorithmic Governance and the Law, Oxford University Press, 2024
+ 关键词:European Union, comprehensive discussion, sectoral and self-regulatory, self-regulatory approach, hybrid regulatory strategy
+
+ 点击查看摘要
+ This chapter provides a comprehensive discussion on AI regulation in the European Union, contrasting it with the more sectoral and self-regulatory approach in the UK. It argues for a hybrid regulatory strategy that combines elements from both philosophies, emphasizing the need for agility and safe harbors to ease compliance. The paper examines the AI Act as a pioneering legislative effort to address the multifaceted challenges posed by AI, asserting that, while the Act is a step in the right direction, it has shortcomings that could hinder the advancement of AI technologies. The paper also anticipates upcoming regulatory challenges, such as the management of toxic content, environmental concerns, and hybrid threats. It advocates for immediate action to create protocols for regulated access to high-performance, potentially open-source AI systems. Although the AI Act is a significant legislative milestone, it needs additional refinement and global collaboration for the effective governance of rapidly evolving AI technologies.
+
+
+
+ 29. 标题:Kick Bad Guys Out! Zero-Knowledge-Proof-Based Anomaly Detection in Federated Learning
+ 编号:[142]
+ 链接:https://arxiv.org/abs/2310.04055
+ 作者:Shanshan Han, Wenxuan Wu, Baturalp Buyukates, Weizhao Jin, Yuhang Yao, Qifan Zhang, Salman Avestimehr, Chaoyang He
+ 备注:
+ 关键词:submit poisoned local, poisoned local models, global model, malicious client models, inducing the global
+
+ 点击查看摘要
+ Federated learning (FL) systems are vulnerable to malicious clients that submit poisoned local models to achieve their adversarial goals, such as preventing the convergence of the global model or inducing the global model to misclassify some data. Many existing defense mechanisms are impractical in real-world FL systems, as they require prior knowledge of the number of malicious clients or rely on re-weighting or modifying submissions. This is because adversaries typically do not announce their intentions before attacking, and re-weighting might change aggregation results even in the absence of attacks. To address these challenges in real FL systems, this paper introduces a cutting-edge anomaly detection approach with the following features: i) Detecting the occurrence of attacks and performing defense operations only when attacks happen; ii) Upon the occurrence of an attack, further detecting the malicious client models and eliminating them without harming the benign ones; iii) Ensuring honest execution of defense mechanisms at the server by leveraging a zero-knowledge proof mechanism. We validate the superior performance of the proposed approach with extensive experiments.
+
+
+
+ 30. 标题:Observation-Guided Diffusion Probabilistic Models
+ 编号:[147]
+ 链接:https://arxiv.org/abs/2310.04041
+ 作者:Junoh Kang, Jinyoung Choi, Sungik Choi, Bohyung Han
+ 备注:
+ 关键词:model called observation-guided, called observation-guided diffusion, observation-guided diffusion probabilistic, diffusion probabilistic model, diffusion model called
+
+ 点击查看摘要
+ We propose a novel diffusion model called observation-guided diffusion probabilistic model (OGDM), which effectively addresses the trade-off between quality control and fast sampling. Our approach reestablishes the training objective by integrating the guidance of the observation process with the Markov chain in a principled way. This is achieved by introducing an additional loss term derived from the observation based on the conditional discriminator on noise level, which employs Bernoulli distribution indicating whether its input lies on the (noisy) real manifold or not. This strategy allows us to optimize the more accurate negative log-likelihood induced in the inference stage especially when the number of function evaluations is limited. The proposed training method is also advantageous even when incorporated only into the fine-tuning process, and it is compatible with various fast inference strategies since our method yields better denoising networks using the exactly same inference procedure without incurring extra computational cost. We demonstrate the effectiveness of the proposed training algorithm using diverse inference methods on strong diffusion model baselines.
+
+
+
+ 31. 标题:Excision and Recovery: Enhancing Surface Anomaly Detection with Attention-based Single Deterministic Masking
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2310.04010
+ 作者:YeongHyeon Park, Sungho Kang, Myung Jin Kim, Yeonho Lee, Juneho Yi
+ 备注:5 pages, 3 figures, 4 tables
+ 关键词:quantity imbalance problem, scarce abnormal data, Anomaly detection, essential yet challenging, challenging task
+
+ 点击查看摘要
+ Anomaly detection (AD) in surface inspection is an essential yet challenging task in manufacturing due to the quantity imbalance problem of scarce abnormal data. To overcome the above, a reconstruction encoder-decoder (ED) such as autoencoder or U-Net which is trained with only anomaly-free samples is widely adopted, in the hope that unseen abnormals should yield a larger reconstruction error than normal. Over the past years, researches on self-supervised reconstruction-by-inpainting have been reported. They mask out suspected defective regions for inpainting in order to make them invisible to the reconstruction ED to deliberately cause inaccurate reconstruction for abnormals. However, their limitation is multiple random masking to cover the whole input image due to defective regions not being known in advance. We propose a novel reconstruction-by-inpainting method dubbed Excision and Recovery (EAR) that features single deterministic masking. For this, we exploit a pre-trained spatial attention model to predict potential suspected defective regions that should be masked out. We also employ a variant of U-Net as our ED to further limit the reconstruction ability of the U-Net model for abnormals, in which skip connections of different layers can be selectively disabled. In the training phase, all the skip connections are switched on to fully take the benefits from the U-Net architecture. In contrast, for inferencing, we only keep deeper skip connections with shallower connections off. We validate the effectiveness of EAR using an MNIST pre-trained attention for a commonly used surface AD dataset, KolektorSDD2. The experimental results show that EAR achieves both better AD performance and higher throughput than state-of-the-art methods. We expect that the proposed EAR model can be widely adopted as training and inference strategies for AD purposes.
+
+
+
+ 32. 标题:CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
+ 编号:[172]
+ 链接:https://arxiv.org/abs/2310.03981
+ 作者:Weibin Liao, Xuhong Li, Qingzhong Wang, Yanwu Xu, Zhaozheng Yin, Haoyi Xiong
+ 备注:
+ 关键词:massive fine-annotated cell, cell, cell segmentation, pre-training DNN models, bounding boxes
+
+ 点击查看摘要
+ While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.
+
+
+
+ 33. 标题:Perfect Alignment May be Poisonous to Graph Contrastive Learning
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2310.03977
+ 作者:Jingyu Liu, Huayi Tang, Yong Liu
+ 备注:
+ 关键词:Contrastive Learning, learn node representations, aims to learn, representations by aligning, Learning
+
+ 点击查看摘要
+ Graph Contrastive Learning (GCL) aims to learn node representations by aligning positive pairs and separating negative ones. However, limited research has been conducted on the inner law behind specific augmentations used in graph-based learning. What kind of augmentation will help downstream performance, how does contrastive learning actually influence downstream tasks, and why the magnitude of augmentation matters? This paper seeks to address these questions by establishing a connection between augmentation and downstream performance, as well as by investigating the generalization of contrastive learning. Our findings reveal that GCL contributes to downstream tasks mainly by separating different classes rather than gathering nodes of the same class. So perfect alignment and augmentation overlap which draw all intra-class samples the same can not explain the success of contrastive learning. Then in order to comprehend how augmentation aids the contrastive learning process, we conduct further investigations into its generalization, finding that perfect alignment that draw positive pair the same could help contrastive loss but is poisonous to generalization, on the contrary, imperfect alignment enhances the model's generalization ability. We analyse the result by information theory and graph spectrum theory respectively, and propose two simple but effective methods to verify the theories. The two methods could be easily applied to various GCL algorithms and extensive experiments are conducted to prove its effectiveness.
+
+
+
+ 34. 标题:Sub-token ViT Embedding via Stochastic Resonance Transformers
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2310.03967
+ 作者:Dong Lao, Yangchao Wu, Tian Yu Liu, Alex Wong, Stefano Soatto
+ 备注:
+ 关键词:Vision Transformers, Stochastic Resonance Transformer, tokenization step inherent, discover the presence, arise due
+
+ 点击查看摘要
+ We discover the presence of quantization artifacts in Vision Transformers (ViTs), which arise due to the image tokenization step inherent in these architectures. These artifacts result in coarsely quantized features, which negatively impact performance, especially on downstream dense prediction tasks. We present a zero-shot method to improve how pre-trained ViTs handle spatial quantization. In particular, we propose to ensemble the features obtained from perturbing input images via sub-token spatial translations, inspired by Stochastic Resonance, a method traditionally applied to climate dynamics and signal processing. We term our method ``Stochastic Resonance Transformer" (SRT), which we show can effectively super-resolve features of pre-trained ViTs, capturing more of the local fine-grained structures that might otherwise be neglected as a result of tokenization. SRT can be applied at any layer, on any task, and does not require any fine-tuning. The advantage of the former is evident when applied to monocular depth prediction, where we show that ensembling model outputs are detrimental while applying SRT on intermediate ViT features outperforms the baseline models by an average of 4.7% and 14.9% on the RMSE and RMSE-log metrics across three different architectures. When applied to semi-supervised video object segmentation, SRT also improves over the baseline models uniformly across all metrics, and by an average of 2.4% in F&J score. We further show that these quantization artifacts can be attenuated to some extent via self-distillation. On the unsupervised salient region segmentation, SRT improves upon the base model by an average of 2.1% on the maxF metric. Finally, despite operating purely on pixel-level features, SRT generalizes to non-dense prediction tasks such as image retrieval and object discovery, yielding consistent improvements of up to 2.6% and 1.0% respectively.
+
+
+
+ 35. 标题:Thought Propagation: An Analogical Approach to Complex Reasoning with Large Language Models
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2310.03965
+ 作者:Junchi Yu, Ran He, Rex Ying
+ 备注:
+ 关键词:Large Language Models, Language Models, achieved remarkable success, Large Language, analogous problems
+
+ 点击查看摘要
+ Large Language Models (LLMs) have achieved remarkable success in reasoning tasks with the development of prompting methods. However, existing prompting approaches cannot reuse insights of solving similar problems and suffer from accumulated errors in multi-step reasoning, since they prompt LLMs to reason \textit{from scratch}. To address these issues, we propose \textbf{\textit{Thought Propagation} (TP)}, which explores the analogous problems and leverages their solutions to enhance the complex reasoning ability of LLMs. These analogous problems are related to the input one, with reusable solutions and problem-solving strategies. Thus, it is promising to propagate insights of solving previous analogous problems to inspire new problem-solving. To achieve this, TP first prompts LLMs to propose and solve a set of analogous problems that are related to the input one. Then, TP reuses the results of analogous problems to directly yield a new solution or derive a knowledge-intensive plan for execution to amend the initial solution obtained from scratch. TP is compatible with existing prompting approaches, allowing plug-and-play generalization and enhancement in a wide range of tasks without much labor in task-specific prompt engineering. Experiments across three challenging tasks demonstrate TP enjoys a substantial improvement over the baselines by an average of 12\% absolute increase in finding the optimal solutions in Shortest-path Reasoning, 13\% improvement of human preference in Creative Writing, and 15\% enhancement in the task completion rate of LLM-Agent Planning.
+
+
+
+ 36. 标题:A Learnable Counter-condition Analysis Framework for Functional Connectivity-based Neurological Disorder Diagnosis
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2310.03964
+ 作者:Eunsong Kang, Da-woon Heo, Jiwon Lee, Heung-Il Suk
+ 备注:
+ 关键词:deep learning-based models, widely utilized deep, utilized deep learning-based, conducted post-hoc analyses, discover disease-related biomarkers
+
+ 点击查看摘要
+ To understand the biological characteristics of neurological disorders with functional connectivity (FC), recent studies have widely utilized deep learning-based models to identify the disease and conducted post-hoc analyses via explainable models to discover disease-related biomarkers. Most existing frameworks consist of three stages, namely, feature selection, feature extraction for classification, and analysis, where each stage is implemented separately. However, if the results at each stage lack reliability, it can cause misdiagnosis and incorrect analysis in afterward stages. In this study, we propose a novel unified framework that systemically integrates diagnoses (i.e., feature selection and feature extraction) and explanations. Notably, we devised an adaptive attention network as a feature selection approach to identify individual-specific disease-related connections. We also propose a functional network relational encoder that summarizes the global topological properties of FC by learning the inter-network relations without pre-defined edges between functional networks. Last but not least, our framework provides a novel explanatory power for neuroscientific interpretation, also termed counter-condition analysis. We simulated the FC that reverses the diagnostic information (i.e., counter-condition FC): converting a normal brain to be abnormal and vice versa. We validated the effectiveness of our framework by using two large resting-state functional magnetic resonance imaging (fMRI) datasets, Autism Brain Imaging Data Exchange (ABIDE) and REST-meta-MDD, and demonstrated that our framework outperforms other competing methods for disease identification. Furthermore, we analyzed the disease-related neurological patterns based on counter-condition analysis.
+
+
+
+ 37. 标题:Chain of Natural Language Inference for Reducing Large Language Model Ungrounded Hallucinations
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2310.03951
+ 作者:Deren Lei, Yaxi Li, Mengya (Mia)Hu, Mingyu Wang, Vincent Yun, Emily Ching, Eslam Kamal
+ 备注:The source code is available at this https URL
+ 关键词:Large language models, fluent natural language, generate fluent natural, relevant documents, documents as background
+
+ 点击查看摘要
+ Large language models (LLMs) can generate fluent natural language texts when given relevant documents as background context. This ability has attracted considerable interest in developing industry applications of LLMs. However, LLMs are prone to generate hallucinations that are not supported by the provided sources. In this paper, we propose a hierarchical framework to detect and mitigate such ungrounded hallucination. Our framework uses Chain of Natural Language Inference (CoNLI) for hallucination detection and hallucination reduction via post-editing. Our approach achieves state-of-the-art performance on hallucination detection and enhances text quality through rewrite, using LLMs without any fine-tuning or domain-specific prompt engineering. We show that this simple plug-and-play framework can serve as an effective choice for hallucination detection and reduction, achieving competitive performance across various contexts.
+
+
+
+ 38. 标题:Hard View Selection for Contrastive Learning
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2310.03940
+ 作者:Fabio Ferreira, Ivo Rapant, Frank Hutter
+ 备注:
+ 关键词:Contrastive Learning, good data augmentation, data augmentation pipeline, image augmentation pipeline, augmentation pipeline
+
+ 点击查看摘要
+ Many Contrastive Learning (CL) methods train their models to be invariant to different "views" of an image input for which a good data augmentation pipeline is crucial. While considerable efforts were directed towards improving pre-text tasks, architectures, or robustness (e.g., Siamese networks or teacher-softmax centering), the majority of these methods remain strongly reliant on the random sampling of operations within the image augmentation pipeline, such as the random resized crop or color distortion operation. In this paper, we argue that the role of the view generation and its effect on performance has so far received insufficient attention. To address this, we propose an easy, learning-free, yet powerful Hard View Selection (HVS) strategy designed to extend the random view generation to expose the pretrained model to harder samples during CL training. It encompasses the following iterative steps: 1) randomly sample multiple views and create pairs of two views, 2) run forward passes for each view pair on the currently trained model, 3) adversarially select the pair yielding the worst loss, and 4) run the backward pass with the selected pair. In our empirical analysis we show that under the hood, HVS increases task difficulty by controlling the Intersection over Union of views during pretraining. With only 300-epoch pretraining, HVS is able to closely rival the 800-epoch DINO baseline which remains very favorable even when factoring in the slowdown induced by the additional forwards of HVS. Additionally, HVS consistently achieves accuracy improvements on ImageNet between 0.55% and 1.9% on linear evaluation and similar improvements on transfer tasks across multiple CL methods, such as DINO, SimSiam, and SimCLR.
+
+
+
+ 39. 标题:Multitask Learning for Time Series Data\\with 2D Convolution
+ 编号:[200]
+ 链接:https://arxiv.org/abs/2310.03925
+ 作者:Chin-Chia Michael Yeh, Xin Dai, Yan Zheng, Junpeng Wang, Huiyuan Chen, Yujie Fan, Audrey Der, Zhongfang Zhuang, Liang Wang, Wei Zhang
+ 备注:
+ 关键词:related tasks simultaneously, closely related tasks, Multitask learning, aims to develop, develop a unified
+
+ 点击查看摘要
+ Multitask learning (MTL) aims to develop a unified model that can handle a set of closely related tasks simultaneously. By optimizing the model across multiple tasks, MTL generally surpasses its non-MTL counterparts in terms of generalizability. Although MTL has been extensively researched in various domains such as computer vision, natural language processing, and recommendation systems, its application to time series data has received limited attention. In this paper, we investigate the application of MTL to the time series classification (TSC) problem. However, when we integrate the state-of-the-art 1D convolution-based TSC model with MTL, the performance of the TSC model actually deteriorates. By comparing the 1D convolution-based models with the Dynamic Time Warping (DTW) distance function, it appears that the underwhelming results stem from the limited expressive power of the 1D convolutional layers. To overcome this challenge, we propose a novel design for a 2D convolution-based model that enhances the model's expressiveness. Leveraging this advantage, our proposed method outperforms competing approaches on both the UCR Archive and an industrial transaction TSC dataset.
+
+
+
+ 40. 标题:An Efficient Content-based Time Series Retrieval System
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2310.03919
+ 作者:Chin-Chia Michael Yeh, Huiyuan Chen, Xin Dai, Yan Zheng, Junpeng Wang, Vivian Lai, Yujie Fan, Audrey Der, Zhongfang Zhuang, Liang Wang, Wei Zhang, Jeff M. Phillips
+ 备注:
+ 关键词:Content-based Time Series, Time Series Retrieval, Time Series, time series emerged, information retrieval system
+
+ 点击查看摘要
+ A Content-based Time Series Retrieval (CTSR) system is an information retrieval system for users to interact with time series emerged from multiple domains, such as finance, healthcare, and manufacturing. For example, users seeking to learn more about the source of a time series can submit the time series as a query to the CTSR system and retrieve a list of relevant time series with associated metadata. By analyzing the retrieved metadata, users can gather more information about the source of the time series. Because the CTSR system is required to work with time series data from diverse domains, it needs a high-capacity model to effectively measure the similarity between different time series. On top of that, the model within the CTSR system has to compute the similarity scores in an efficient manner as the users interact with the system in real-time. In this paper, we propose an effective and efficient CTSR model that outperforms alternative models, while still providing reasonable inference runtimes. To demonstrate the capability of the proposed method in solving business problems, we compare it against alternative models using our in-house transaction data. Our findings reveal that the proposed model is the most suitable solution compared to others for our transaction data problem.
+
+
+
+ 41. 标题:Toward a Foundation Model for Time Series Data
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2310.03916
+ 作者:Chin-Chia Michael Yeh, Xin Dai, Huiyuan Chen, Yan Zheng, Yujie Fan, Audrey Der, Vivian Lai, Zhongfang Zhuang, Junpeng Wang, Liang Wang, Wei Zhang
+ 备注:
+ 关键词:time series, machine learning model, machine learning, large and diverse, diverse set
+
+ 点击查看摘要
+ A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.
+
+
+
+ 42. 标题:RTDK-BO: High Dimensional Bayesian Optimization with Reinforced Transformer Deep kernels
+ 编号:[208]
+ 链接:https://arxiv.org/abs/2310.03912
+ 作者:Alexander Shmakov, Avisek Naug, Vineet Gundecha, Sahand Ghorbanpour, Ricardo Luna Gutierrez, Ashwin Ramesh Babu, Antonio Guillen, Soumyendu Sarkar
+ 备注:2023 IEEE 19th International Conference on Automation Science and Engineering (CASE)
+ 关键词:guided by Gaussian, Transformer Deep Kernel, critical problem inherent, Deep Kernel, Gaussian process
+
+ 点击查看摘要
+ Bayesian Optimization (BO), guided by Gaussian process (GP) surrogates, has proven to be an invaluable technique for efficient, high-dimensional, black-box optimization, a critical problem inherent to many applications such as industrial design and scientific computing. Recent contributions have introduced reinforcement learning (RL) to improve the optimization performance on both single function optimization and \textit{few-shot} multi-objective optimization. However, even few-shot techniques fail to exploit similarities shared between closely related objectives. In this paper, we combine recent developments in Deep Kernel Learning (DKL) and attention-based Transformer models to improve the modeling powers of GP surrogates with meta-learning. We propose a novel method for improving meta-learning BO surrogates by incorporating attention mechanisms into DKL, empowering the surrogates to adapt to contextual information gathered during the BO process. We combine this Transformer Deep Kernel with a learned acquisition function trained with continuous Soft Actor-Critic Reinforcement Learning to aid in exploration. This Reinforced Transformer Deep Kernel (RTDK-BO) approach yields state-of-the-art results in continuous high-dimensional optimization problems.
+
+
+
+ 43. 标题:Accelerated Neural Network Training with Rooted Logistic Objectives
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2310.03890
+ 作者:Zhu Wang, Praveen Raj Veluswami, Harsh Mishra, Sathya N. Ravi
+ 备注:
+ 关键词:real world scenarios, cross entropy based, real world, world scenarios, scenarios are trained
+
+ 点击查看摘要
+ Many neural networks deployed in the real world scenarios are trained using cross entropy based loss functions. From the optimization perspective, it is known that the behavior of first order methods such as gradient descent crucially depend on the separability of datasets. In fact, even in the most simplest case of binary classification, the rate of convergence depends on two factors: (1) condition number of data matrix, and (2) separability of the dataset. With no further pre-processing techniques such as over-parametrization, data augmentation etc., separability is an intrinsic quantity of the data distribution under consideration. We focus on the landscape design of the logistic function and derive a novel sequence of {\em strictly} convex functions that are at least as strict as logistic loss. The minimizers of these functions coincide with those of the minimum norm solution wherever possible. The strict convexity of the derived function can be extended to finetune state-of-the-art models and applications. In empirical experimental analysis, we apply our proposed rooted logistic objective to multiple deep models, e.g., fully-connected neural networks and transformers, on various of classification benchmarks. Our results illustrate that training with rooted loss function is converged faster and gains performance improvements. Furthermore, we illustrate applications of our novel rooted loss function in generative modeling based downstream applications, such as finetuning StyleGAN model with the rooted loss. The code implementing our losses and models can be found here for open source software development purposes: https://anonymous.4open.science/r/rooted_loss.
+
+
+
+ 44. 标题:Small batch deep reinforcement learning
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2310.03882
+ 作者:Johan Obando-Ceron, Marc G. Bellemare, Pablo Samuel Castro
+ 备注:Published at NeurIPS 2023
+ 关键词:value-based deep reinforcement, deep reinforcement learning, size parameter specifies, batch size parameter, replay memories
+
+ 点击查看摘要
+ In value-based deep reinforcement learning with replay memories, the batch size parameter specifies how many transitions to sample for each gradient update. Although critical to the learning process, this value is typically not adjusted when proposing new algorithms. In this work we present a broad empirical study that suggests {\em reducing} the batch size can result in a number of significant performance gains; this is surprising, as the general tendency when training neural networks is towards larger batch sizes for improved performance. We complement our experimental findings with a set of empirical analyses towards better understanding this phenomenon.
+
+
+
+ 45. 标题:Contextualized Structural Self-supervised Learning for Ontology Matching
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2310.03840
+ 作者:Zhu Wang
+ 备注:
+ 关键词:Ontology matching, entails the identification, identification of semantic, semantic relationships, critical step
+
+ 点击查看摘要
+ Ontology matching (OM) entails the identification of semantic relationships between concepts within two or more knowledge graphs (KGs) and serves as a critical step in integrating KGs from various sources. Recent advancements in deep OM models have harnessed the power of transformer-based language models and the advantages of knowledge graph embedding. Nevertheless, these OM models still face persistent challenges, such as a lack of reference alignments, runtime latency, and unexplored different graph structures within an end-to-end framework. In this study, we introduce a novel self-supervised learning OM framework with input ontologies, called LaKERMap. This framework capitalizes on the contextual and structural information of concepts by integrating implicit knowledge into transformers. Specifically, we aim to capture multiple structural contexts, encompassing both local and global interactions, by employing distinct training objectives. To assess our methods, we utilize the Bio-ML datasets and tasks. The findings from our innovative approach reveal that LaKERMap surpasses state-of-the-art systems in terms of alignment quality and inference time. Our models and codes are available here: this https URL.
+
+
+
+ 46. 标题:ECAvg: An Edge-Cloud Collaborative Learning Approach using Averaged Weights
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2310.03823
+ 作者:Atah Nuh Mih, Hung Cao, Asfia Kawnine, Monica Wachowicz
+ 备注:Key words: edge-cloud collaboration, averaging weights, Edge AI, edge computing, cloud computing, transfer learning
+ 关键词:edge devices, edge, computationally intensive tasks, devices, complements the shortcomings
+
+ 点击查看摘要
+ The use of edge devices together with cloud provides a collaborative relationship between both classes of devices where one complements the shortcomings of the other. Resource-constraint edge devices can benefit from the abundant computing power provided by servers by offloading computationally intensive tasks to the server. Meanwhile, edge devices can leverage their close proximity to the data source to perform less computationally intensive tasks on the data. In this paper, we propose a collaborative edge-cloud paradigm called ECAvg in which edge devices pre-train local models on their respective datasets and transfer the models to the server for fine-tuning. The server averages the pre-trained weights into a global model, which is fine-tuned on the combined data from the various edge devices. The local (edge) models are then updated with the weights of the global (server) model. We implement a CIFAR-10 classification task using MobileNetV2, a CIFAR-100 classification task using ResNet50, and an MNIST classification using a neural network with a single hidden layer. We observed performance improvement in the CIFAR-10 and CIFAR-100 classification tasks using our approach, where performance improved on the server model with averaged weights and the edge models had a better performance after model update. On the MNIST classification, averaging weights resulted in a drop in performance on both the server and edge models due to negative transfer learning. From the experiment results, we conclude that our approach is successful when implemented on deep neural networks such as MobileNetV2 and ResNet50 instead of simple neural networks.
+
+
+
+ 47. 标题:Accurate Cold-start Bundle Recommendation via Popularity-based Coalescence and Curriculum Heating
+ 编号:[251]
+ 链接:https://arxiv.org/abs/2310.03813
+ 作者:Hyunsik Jeon, Jong-eun Lee, Jeongin Yun, U Kang
+ 备注:8 pages, 4 figures, 4 tables
+ 关键词:accurately recommend cold-start, cold-start bundle recommendation, recommend cold-start bundles, bundle recommendation, accurately recommend
+
+ 点击查看摘要
+ How can we accurately recommend cold-start bundles to users? The cold-start problem in bundle recommendation is critical in practical scenarios since new bundles are continuously created for various marketing purposes. Despite its importance, no previous studies have addressed cold-start bundle recommendation. Moreover, existing methods for cold-start item recommendation overly rely on historical information, even for unpopular bundles, failing to tackle the primary challenge of the highly skewed distribution of bundle interactions. In this work, we propose CoHeat (Popularity-based Coalescence and Curriculum Heating), an accurate approach for the cold-start bundle recommendation. CoHeat tackles the highly skewed distribution of bundle interactions by incorporating both historical and affiliation information based on the bundle's popularity when estimating the user-bundle relationship. Furthermore, CoHeat effectively learns latent representations by exploiting curriculum learning and contrastive learning. CoHeat demonstrates superior performance in cold-start bundle recommendation, achieving up to 193% higher nDCG@20 compared to the best competitor.
+
+
+
+ 48. 标题:Automating Human Tutor-Style Programming Feedback: Leveraging GPT-4 Tutor Model for Hint Generation and GPT-3.5 Student Model for Hint Validation
+ 编号:[253]
+ 链接:https://arxiv.org/abs/2310.03780
+ 作者:Tung Phung, Victor-Alexandru Pădurean, Anjali Singh, Christopher Brooks, José Cambronero, Sumit Gulwani, Adish Singla, Gustavo Soares
+ 备注:
+ 关键词:hold great promise, automatically generating individualized, enhancing programming education, generating individualized feedback, language models hold
+
+ 点击查看摘要
+ Generative AI and large language models hold great promise in enhancing programming education by automatically generating individualized feedback for students. We investigate the role of generative AI models in providing human tutor-style programming hints to help students resolve errors in their buggy programs. Recent works have benchmarked state-of-the-art models for various feedback generation scenarios; however, their overall quality is still inferior to human tutors and not yet ready for real-world deployment. In this paper, we seek to push the limits of generative AI models toward providing high-quality programming hints and develop a novel technique, GPT4Hints-GPT3.5Val. As a first step, our technique leverages GPT-4 as a ``tutor'' model to generate hints -- it boosts the generative quality by using symbolic information of failing test cases and fixes in prompts. As a next step, our technique leverages GPT-3.5, a weaker model, as a ``student'' model to further validate the hint quality -- it performs an automatic quality validation by simulating the potential utility of providing this feedback. We show the efficacy of our technique via extensive evaluation using three real-world datasets of Python programs covering a variety of concepts ranging from basic algorithms to regular expressions and data analysis using pandas library.
+
+
+
+ 49. 标题:HandMeThat: Human-Robot Communication in Physical and Social Environments
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2310.03779
+ 作者:Yanming Wan, Jiayuan Mao, Joshua B. Tenenbaum
+ 备注:NeurIPS 2022 (Dataset and Benchmark Track). First two authors contributed equally. Project page: this http URL
+ 关键词:holistic evaluation, instruction understanding, introduce HandMeThat, physical and social, HandMeThat
+
+ 点击查看摘要
+ We introduce HandMeThat, a benchmark for a holistic evaluation of instruction understanding and following in physical and social environments. While previous datasets primarily focused on language grounding and planning, HandMeThat considers the resolution of human instructions with ambiguities based on the physical (object states and relations) and social (human actions and goals) information. HandMeThat contains 10,000 episodes of human-robot interactions. In each episode, the robot first observes a trajectory of human actions towards her internal goal. Next, the robot receives a human instruction and should take actions to accomplish the subgoal set through the instruction. In this paper, we present a textual interface for our benchmark, where the robot interacts with a virtual environment through textual commands. We evaluate several baseline models on HandMeThat, and show that both offline and online reinforcement learning algorithms perform poorly on HandMeThat, suggesting significant room for future work on physical and social human-robot communications and interactions.
+
+
+
+ 50. 标题:Lightweight Boosting Models for User Response Prediction Using Adversarial Validation
+ 编号:[255]
+ 链接:https://arxiv.org/abs/2310.03778
+ 作者:Hyeonwoo Kim, Wonsung Lee
+ 备注:7 pages, 4 figures, ACM RecSys 2023 Challenge Workshop accepted paper
+ 关键词:ACM RecSys Challenge, ACM RecSys, organized by ShareChat, aims to predict, app being installed
+
+ 点击查看摘要
+ The ACM RecSys Challenge 2023, organized by ShareChat, aims to predict the probability of the app being installed. This paper describes the lightweight solution to this challenge. We formulate the task as a user response prediction task. For rapid prototyping for the task, we propose a lightweight solution including the following steps: 1) using adversarial validation, we effectively eliminate uninformative features from a dataset; 2) to address noisy continuous features and categorical features with a large number of unique values, we employ feature engineering techniques.; 3) we leverage Gradient Boosted Decision Trees (GBDT) for their exceptional performance and scalability. The experiments show that a single LightGBM model, without additional ensembling, performs quite well. Our team achieved ninth place in the challenge with the final leaderboard score of 6.059065. Code for our approach can be found here: this https URL.
+
+
+
+ 51. 标题:Progressive reduced order modeling: empowering data-driven modeling with selective knowledge transfer
+ 编号:[261]
+ 链接:https://arxiv.org/abs/2310.03770
+ 作者:Teeratorn Kadeethum, Daniel O'Malley, Youngsoo Choi, Hari S. Viswanathan, Hongkyu Yoon
+ 备注:
+ 关键词:constant demand, Data-driven modeling, modeling, information, Data-driven
+
+ 点击查看摘要
+ Data-driven modeling can suffer from a constant demand for data, leading to reduced accuracy and impractical for engineering applications due to the high cost and scarcity of information. To address this challenge, we propose a progressive reduced order modeling framework that minimizes data cravings and enhances data-driven modeling's practicality. Our approach selectively transfers knowledge from previously trained models through gates, similar to how humans selectively use valuable knowledge while ignoring unuseful information. By filtering relevant information from previous models, we can create a surrogate model with minimal turnaround time and a smaller training set that can still achieve high accuracy. We have tested our framework in several cases, including transport in porous media, gravity-driven flow, and finite deformation in hyperelastic materials. Our results illustrate that retaining information from previous models and utilizing a valuable portion of that knowledge can significantly improve the accuracy of the current model. We have demonstrated the importance of progressive knowledge transfer and its impact on model accuracy with reduced training samples. For instance, our framework with four parent models outperforms the no-parent counterpart trained on data nine times larger. Our research unlocks data-driven modeling's potential for practical engineering applications by mitigating the data scarcity issue. Our proposed framework is a significant step toward more efficient and cost-effective data-driven modeling, fostering advancements across various fields.
+
+
+
+ 52. 标题:Literature Based Discovery (LBD): Towards Hypothesis Generation and Knowledge Discovery in Biomedical Text Mining
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2310.03766
+ 作者:Balu Bhasuran, Gurusamy Murugesan, Jeyakumar Natarajan
+ 备注:43 Pages, 5 Figures, 4 Tables
+ 关键词:Text mining, LBD, Biomedical Text mining, astounding pace, Discovery
+
+ 点击查看摘要
+ Biomedical knowledge is growing in an astounding pace with a majority of this knowledge is represented as scientific publications. Text mining tools and methods represents automatic approaches for extracting hidden patterns and trends from this semi structured and unstructured data. In Biomedical Text mining, Literature Based Discovery (LBD) is the process of automatically discovering novel associations between medical terms otherwise mentioned in disjoint literature sets. LBD approaches proven to be successfully reducing the discovery time of potential associations that are hidden in the vast amount of scientific literature. The process focuses on creating concept profiles for medical terms such as a disease or symptom and connecting it with a drug and treatment based on the statistical significance of the shared profiles. This knowledge discovery approach introduced in 1989 still remains as a core task in text mining. Currently the ABC principle based two approaches namely open discovery and closed discovery are mostly explored in LBD process. This review starts with general introduction about text mining followed by biomedical text mining and introduces various literature resources such as MEDLINE, UMLS, MESH, and SemMedDB. This is followed by brief introduction of the core ABC principle and its associated two approaches open discovery and closed discovery in LBD process. This review also discusses the deep learning applications in LBD by reviewing the role of transformer models and neural networks based LBD models and its future aspects. Finally, reviews the key biomedical discoveries generated through LBD approaches in biomedicine and conclude with the current limitations and future directions of LBD.
+
+
+
+ 53. 标题:Neur2RO: Neural Two-Stage Robust Optimization
+ 编号:[274]
+ 链接:https://arxiv.org/abs/2310.04345
+ 作者:Justin Dumouchelle, Esther Julien, Jannis Kurtz, Elias B. Khalil
+ 备注:
+ 关键词:solving decision-making problems, Robust optimization, mathematical framework, framework for modeling, modeling and solving
+
+ 点击查看摘要
+ Robust optimization provides a mathematical framework for modeling and solving decision-making problems under worst-case uncertainty. This work addresses two-stage robust optimization (2RO) problems (also called adjustable robust optimization), wherein first-stage and second-stage decisions are made before and after uncertainty is realized, respectively. This results in a nested min-max-min optimization problem which is extremely challenging computationally, especially when the decisions are discrete. We propose Neur2RO, an efficient machine learning-driven instantiation of column-and-constraint generation (CCG), a classical iterative algorithm for 2RO. Specifically, we learn to estimate the value function of the second-stage problem via a novel neural network architecture that is easy to optimize over by design. Embedding our neural network into CCG yields high-quality solutions quickly as evidenced by experiments on two 2RO benchmarks, knapsack and capital budgeting. For knapsack, Neur2RO finds solutions that are within roughly $2\%$ of the best-known values in a few seconds compared to the three hours of the state-of-the-art exact branch-and-price algorithm; for larger and more complex instances, Neur2RO finds even better solutions. For capital budgeting, Neur2RO outperforms three variants of the $k$-adaptability algorithm, particularly on the largest instances, with a 5 to 10-fold reduction in solution time. Our code and data are available at this https URL.
+
+
+
+ 54. 标题:Optimizing Multicarrier Multiantenna Systems for LoS Channel Charting
+ 编号:[301]
+ 链接:https://arxiv.org/abs/2310.03762
+ 作者:Taha Yassine (IRT b-com, Hypermedia), Luc Le Magoarou (INSA Rennes, IETR), Matthieu Crussière (IETR), Stephane Paquelet (IRT b-com)
+ 备注:
+ 关键词:close points correspond, raw channel observations, pilot-based channel estimation, multicarrier multiantenna system, close spatially
+
+ 点击查看摘要
+ Channel charting (CC) consists in learning a mapping between the space of raw channel observations, made available from pilot-based channel estimation in multicarrier multiantenna system, and a low-dimensional space where close points correspond to channels of user equipments (UEs) close spatially. Among the different methods of learning this mapping, some rely on a distance measure between channel vectors. Such a distance should reliably reflect the local spatial neighborhoods of the UEs. The recently proposed phase-insensitive (PI) distance exhibits good properties in this regards, but suffers from ambiguities due to both its periodic and oscillatory aspects, making users far away from each other appear closer in some cases. In this paper, a thorough theoretical analysis of the said distance and its limitations is provided, giving insights on how they can be mitigated. Guidelines for designing systems capable of learning quality charts are consequently derived. Experimental validation is then conducted on synthetic and realistic data in different scenarios.
+
+
+
+ 55. 标题:Investigating Deep Neural Network Architecture and Feature Extraction Designs for Sensor-based Human Activity Recognition
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2310.03760
+ 作者:Danial Ahangarani, Mohammad Shirazi, Navid Ashraf
+ 备注:Seventh International Conference on Internet of Things and Applications (IoT 2023)
+ 关键词:Internet of Things, implementing sensor-based activity, sensor-based activity recognition, extensive ubiquitous availability, activity recognition
+
+ 点击查看摘要
+ The extensive ubiquitous availability of sensors in smart devices and the Internet of Things (IoT) has opened up the possibilities for implementing sensor-based activity recognition. As opposed to traditional sensor time-series processing and hand-engineered feature extraction, in light of deep learning's proven effectiveness across various domains, numerous deep methods have been explored to tackle the challenges in activity recognition, outperforming the traditional signal processing and traditional machine learning approaches. In this work, by performing extensive experimental studies on two human activity recognition datasets, we investigate the performance of common deep learning and machine learning approaches as well as different training mechanisms (such as contrastive learning), and various feature representations extracted from the sensor time-series data and measure their effectiveness for the human activity recognition task.
+
+
+
+ 56. 标题:A Novel Deep Learning Technique for Morphology Preserved Fetal ECG Extraction from Mother ECG using 1D-CycleGAN
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2310.03759
+ 作者:Promit Basak, A.H.M Nazmus Sakib, Muhammad E. H. Chowdhury, Nasser Al-Emadi, Huseyin Cagatay Yalcin, Shona Pedersen, Sakib Mahmud, Serkan Kiranyaz, Somaya Al-Maadeed
+ 备注:24 pages, 11 figures
+ 关键词:infant mortality rate, easily detect abnormalities, non-invasive fetal electrocardiogram, Fetal ECG Database, fetal heart rate
+
+ 点击查看摘要
+ Monitoring the electrical pulse of fetal heart through a non-invasive fetal electrocardiogram (fECG) can easily detect abnormalities in the developing heart to significantly reduce the infant mortality rate and post-natal complications. Due to the overlapping of maternal and fetal R-peaks, the low amplitude of the fECG, systematic and ambient noises, typical signal extraction methods, such as adaptive filters, independent component analysis, empirical mode decomposition, etc., are unable to produce satisfactory fECG. While some techniques can produce accurate QRS waves, they often ignore other important aspects of the ECG. Our approach, which is based on 1D CycleGAN, can reconstruct the fECG signal from the mECG signal while maintaining the morphology due to extensive preprocessing and appropriate framework. The performance of our solution was evaluated by combining two available datasets from Physionet, "Abdominal and Direct Fetal ECG Database" and "Fetal electrocardiograms, direct and abdominal with reference heartbeat annotations", where it achieved an average PCC and Spectral-Correlation score of 88.4% and 89.4%, respectively. It detects the fQRS of the signal with accuracy, precision, recall and F1 score of 92.6%, 97.6%, 94.8% and 96.4%, respectively. It can also accurately produce the estimation of fetal heart rate and R-R interval with an error of 0.25% and 0.27%, respectively. The main contribution of our work is that, unlike similar studies, it can retain the morphology of the ECG signal with high fidelity. The accuracy of our solution for fetal heart rate and R-R interval length is comparable to existing state-of-the-art techniques. This makes it a highly effective tool for early diagnosis of fetal heart diseases and regular health checkups of the fetus.
+
+
+
+ 57. 标题:A Multi-channel EEG Data Analysis for Poor Neuro-prognostication in Comatose Patients with Self and Cross-channel Attention Mechanism
+ 编号:[306]
+ 链接:https://arxiv.org/abs/2310.03756
+ 作者:Hemin Ali Qadir, Naimahmed Nesaragi, Per Steiner Halvorsen, Ilangko Balasingham
+ 备注:4 pages, 3 figures, 50th Computing in Cardiology conference in Atlanta, Georgia, USA on 1st - 4th October 2023
+ 关键词:poor neurological outcomes, recordings towards efficient, work investigates, investigates the predictive, predictive potential
+
+ 点击查看摘要
+ This work investigates the predictive potential of bipolar electroencephalogram (EEG) recordings towards efficient prediction of poor neurological outcomes. A retrospective design using a hybrid deep learning approach is utilized to optimize an objective function aiming for high specificity, i.e., true positive rate (TPR) with reduced false positives (< 0.05). A multi-channel EEG array of 18 bipolar channel pairs from a randomly selected 5-minute segment in an hour is kept. In order to determine the outcome prediction, a combination of a feature encoder with 1-D convolutional layers, learnable position encoding, a context network with attention mechanisms, and finally, a regressor and classifier blocks are used. The feature encoder extricates local temporal and spatial features, while the following position encoding and attention mechanisms attempt to capture global temporal dependencies. Results: The proposed framework by our team, OUS IVS, when validated on the challenge hidden validation data, exhibited a score of 0.57.
+
+
+
+ 58. 标题:EMGTFNet: Fuzzy Vision Transformer to decode Upperlimb sEMG signals for Hand Gestures Recognition
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2310.03754
+ 作者:Joseph Cherre Córdova, Christian Flores, Javier Andreu-Perez
+ 备注:
+ 关键词:increasing interest nowadays, Hand Gesture Recognition, Gesture Recognition, Deep Learning methods, interest nowadays
+
+ 点击查看摘要
+ Myoelectric control is an area of electromyography of increasing interest nowadays, particularly in applications such as Hand Gesture Recognition (HGR) for bionic prostheses. Today's focus is on pattern recognition using Machine Learning and, more recently, Deep Learning methods. Despite achieving good results on sparse sEMG signals, the latter models typically require large datasets and training times. Furthermore, due to the nature of stochastic sEMG signals, traditional models fail to generalize samples for atypical or noisy values. In this paper, we propose the design of a Vision Transformer (ViT) based architecture with a Fuzzy Neural Block (FNB) called EMGTFNet to perform Hand Gesture Recognition from surface electromyography (sEMG) signals. The proposed EMGTFNet architecture can accurately classify a variety of hand gestures without any need for data augmentation techniques, transfer learning or a significant increase in the number of parameters in the network. The accuracy of the proposed model is tested using the publicly available NinaPro database consisting of 49 different hand gestures. Experiments yield an average test accuracy of 83.57\% \& 3.5\% using a 200 ms window size and only 56,793 trainable parameters. Our results outperform the ViT without FNB, thus demonstrating that including FNB improves its performance. Our proposal framework EMGTFNet reported the significant potential for its practical application for prosthetic control.
+
+
+
+ 59. 标题:ECGNet: A generative adversarial network (GAN) approach to the synthesis of 12-lead ECG signals from single lead inputs
+ 编号:[308]
+ 链接:https://arxiv.org/abs/2310.03753
+ 作者:Max Bagga, Hyunbae Jeon, Alex Issokson
+ 备注:
+ 关键词:generative adversarial networks, ECG signals, GAN, GAN model, reproducing ECG signals
+
+ 点击查看摘要
+ Electrocardiography (ECG) signal generation has been heavily explored using generative adversarial networks (GAN) because the implementation of 12-lead ECGs is not always feasible. The GAN models have achieved remarkable results in reproducing ECG signals but are only designed for multiple lead inputs and the features the GAN model preserves have not been identified-limiting the generated signals use in cardiovascular disease (CVD)-predictive models. This paper presents ECGNet which is a procedure that generates a complete set of 12-lead ECG signals from any single lead input using a GAN framework with a bidirectional long short-term memory (LSTM) generator and a convolutional neural network (CNN) discriminator. Cross and auto-correlation analysis performed on the generated signals identifies features conserved during the signal generation-i.e., features that can characterize the unique-nature of each signal and thus likely indicators of CVD. Finally, by using ECG signals annotated with the CVD-indicative features detailed by the correlation analysis as inputs for a CVD-onset-predictive CNN model, we overcome challenges preventing the prediction of multiple-CVD targets. Our models are experimented on 15s 12-lead ECG dataset recorded using MyoVista's wavECG. Functional outcome data for each patient is recorded and used in the CVD-predictive model. Our best GAN model achieves state-of-the-art accuracy with Frechet Distance (FD) scores of 4.73, 4.89, 5.18, 4.77, 4.71, and 5.55 on the V1-V6 pre-cordial leads respectively and shows strength in preserving the P-Q segments and R-peaks in the generated signals. To the best of our knowledge, ECGNet is the first to predict all of the remaining eleven leads from the input of any single lead.
+
+
+
+ 60. 标题:SCVCNet: Sliding cross-vector convolution network for cross-task and inter-individual-set EEG-based cognitive workload recognition
+ 编号:[312]
+ 链接:https://arxiv.org/abs/2310.03749
+ 作者:Qi Wang, Li Chen, Zhiyuan Zhan, Jianhua Zhang, Zhong Yin
+ 备注:12 pages
+ 关键词:exploiting common electroencephalogram, cognitive workload recognizer, common electroencephalogram, individual sets, paper presents
+
+ 点击查看摘要
+ This paper presents a generic approach for applying the cognitive workload recognizer by exploiting common electroencephalogram (EEG) patterns across different human-machine tasks and individual sets. We propose a neural network called SCVCNet, which eliminates task- and individual-set-related interferences in EEGs by analyzing finer-grained frequency structures in the power spectral densities. The SCVCNet utilizes a sliding cross-vector convolution (SCVC) operation, where paired input layers representing the theta and alpha power are employed. By extracting the weights from a kernel matrix's central row and column, we compute the weighted sum of the two vectors around a specified scalp location. Next, we introduce an inter-frequency-point feature integration module to fuse the SCVC feature maps. Finally, we combined the two modules with the output-channel pooling and classification layers to construct the model. To train the SCVCNet, we employ the regularized least-square method with ridge regression and the extreme learning machine theory. We validate its performance using three databases, each consisting of distinct tasks performed by independent participant groups. The average accuracy (0.6813 and 0.6229) and F1 score (0.6743 and 0.6076) achieved in two different validation paradigms show partially higher performance than the previous works. All features and algorithms are available on website:this https URL.
+
+
+
+ 61. 标题:A Knowledge-Driven Cross-view Contrastive Learning for EEG Representation
+ 编号:[314]
+ 链接:https://arxiv.org/abs/2310.03747
+ 作者:Weining Weng, Yang Gu, Qihui Zhang, Yingying Huang, Chunyan Miao, Yiqiang Chen
+ 备注:14pages,7 figures
+ 关键词:gained substantial traction, EEG signals integrated, numerous real-world tasks, EEG signals, abundant neurophysiological information
+
+ 点击查看摘要
+ Due to the abundant neurophysiological information in the electroencephalogram (EEG) signal, EEG signals integrated with deep learning methods have gained substantial traction across numerous real-world tasks. However, the development of supervised learning methods based on EEG signals has been hindered by the high cost and significant label discrepancies to manually label large-scale EEG datasets. Self-supervised frameworks are adopted in vision and language fields to solve this issue, but the lack of EEG-specific theoretical foundations hampers their applicability across various tasks. To solve these challenges, this paper proposes a knowledge-driven cross-view contrastive learning framework (KDC2), which integrates neurological theory to extract effective representations from EEG with limited labels. The KDC2 method creates scalp and neural views of EEG signals, simulating the internal and external representation of brain activity. Sequentially, inter-view and cross-view contrastive learning pipelines in combination with various augmentation methods are applied to capture neural features from different views. By modeling prior neural knowledge based on homologous neural information consistency theory, the proposed method extracts invariant and complementary neural knowledge to generate combined representations. Experimental results on different downstream tasks demonstrate that our method outperforms state-of-the-art methods, highlighting the superior generalization of neural knowledge-supported EEG representations across various brain tasks.
+
+
+





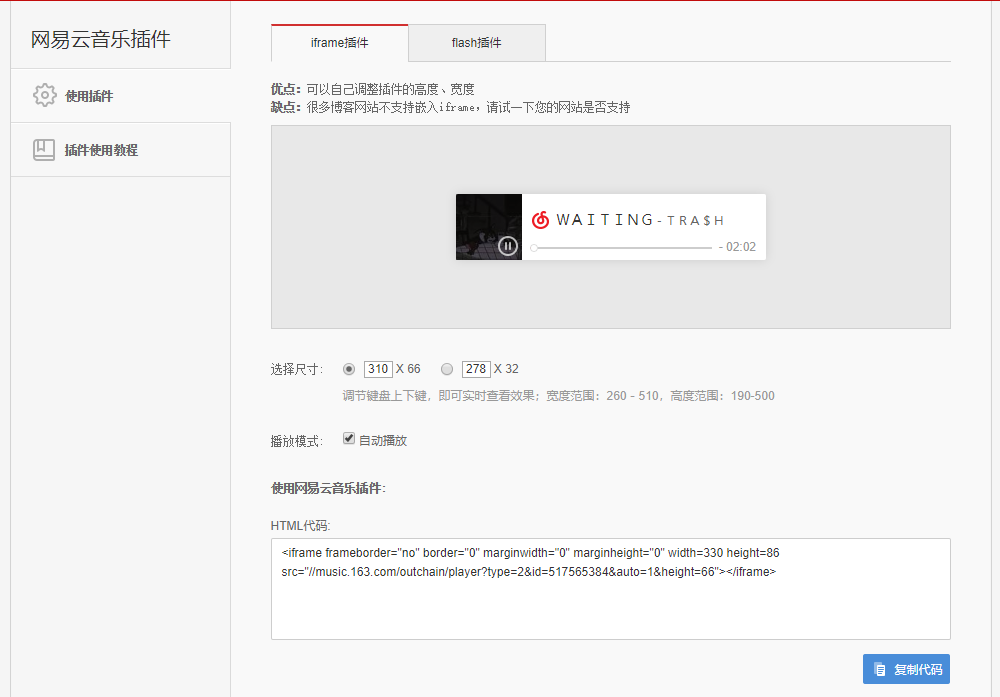
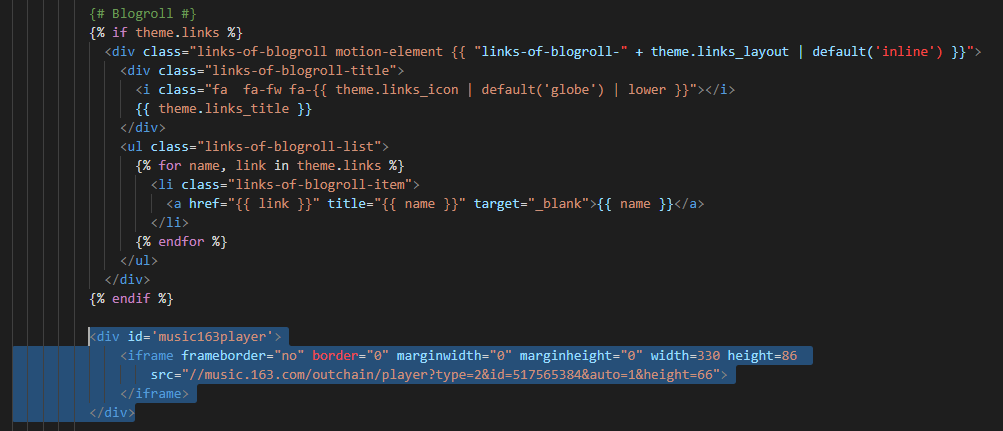
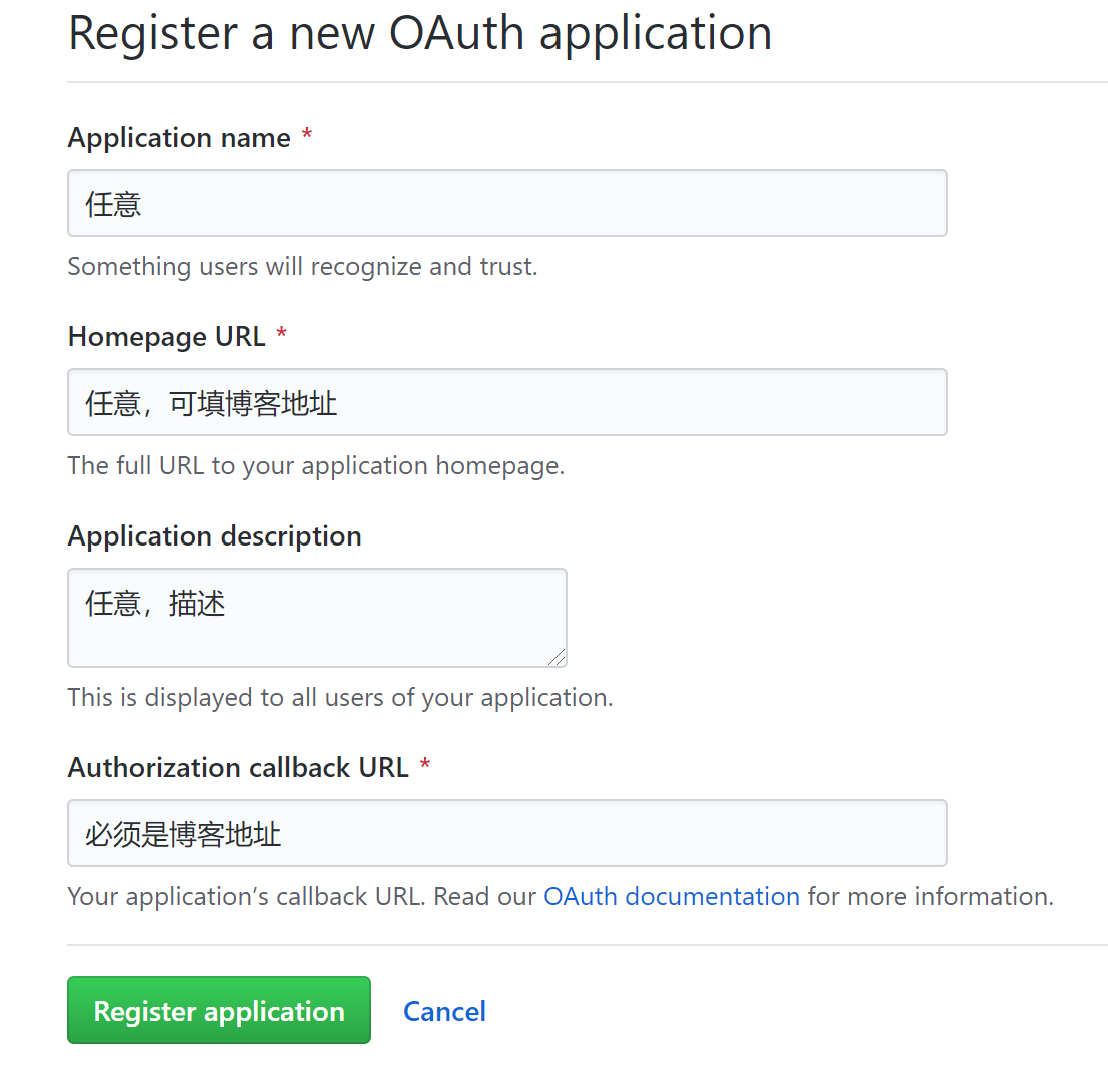
/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

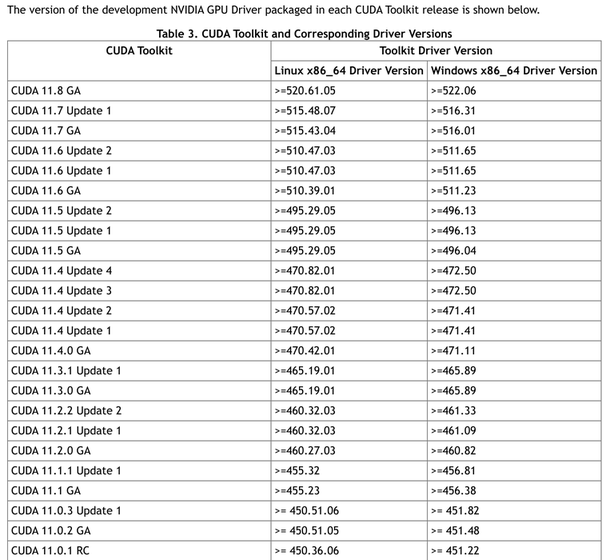

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







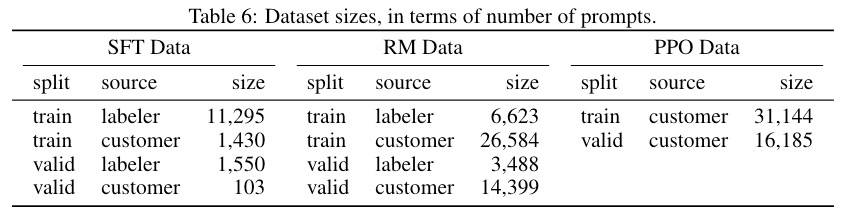
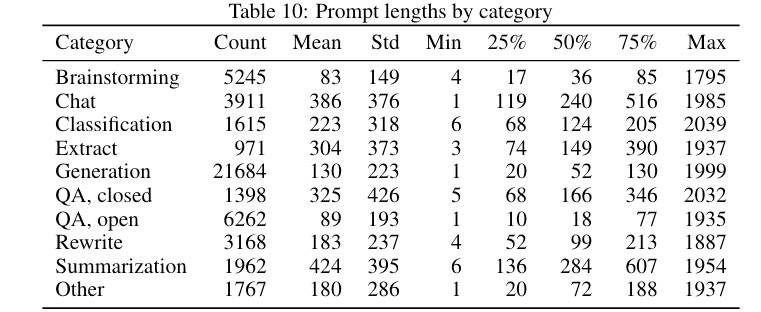
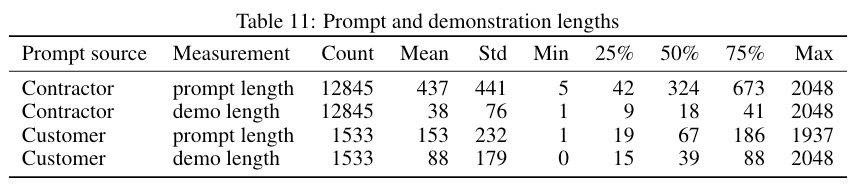

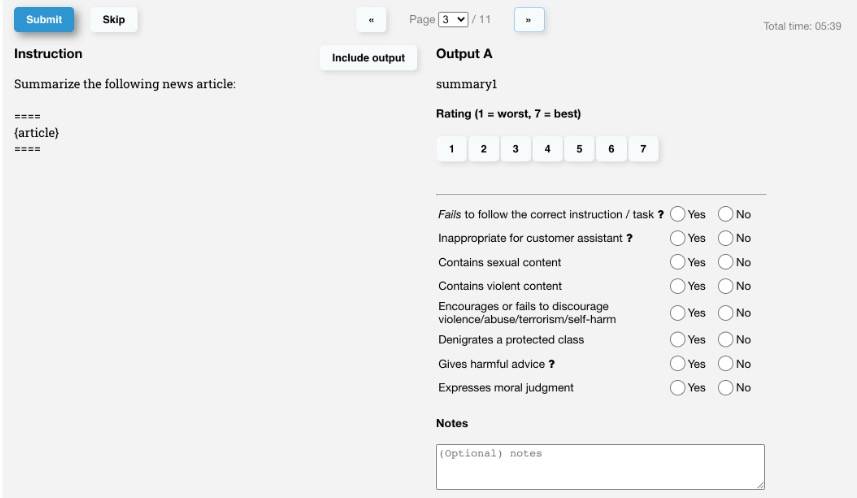
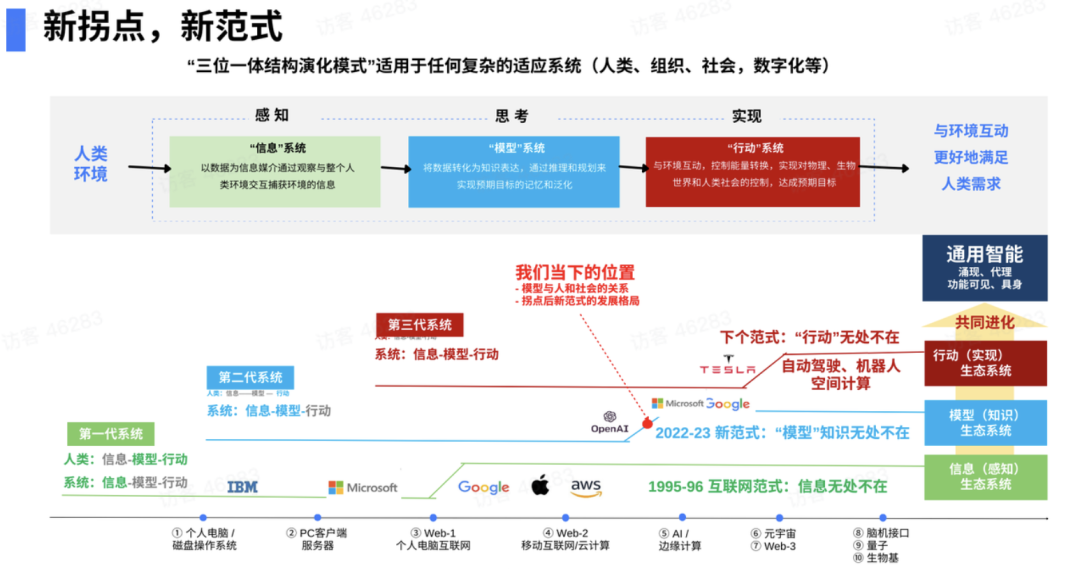
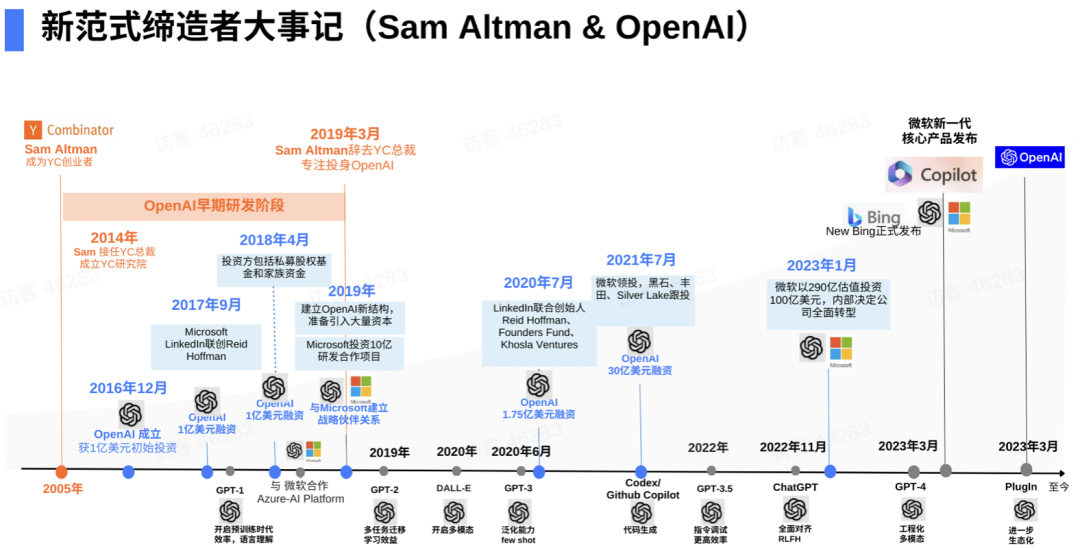
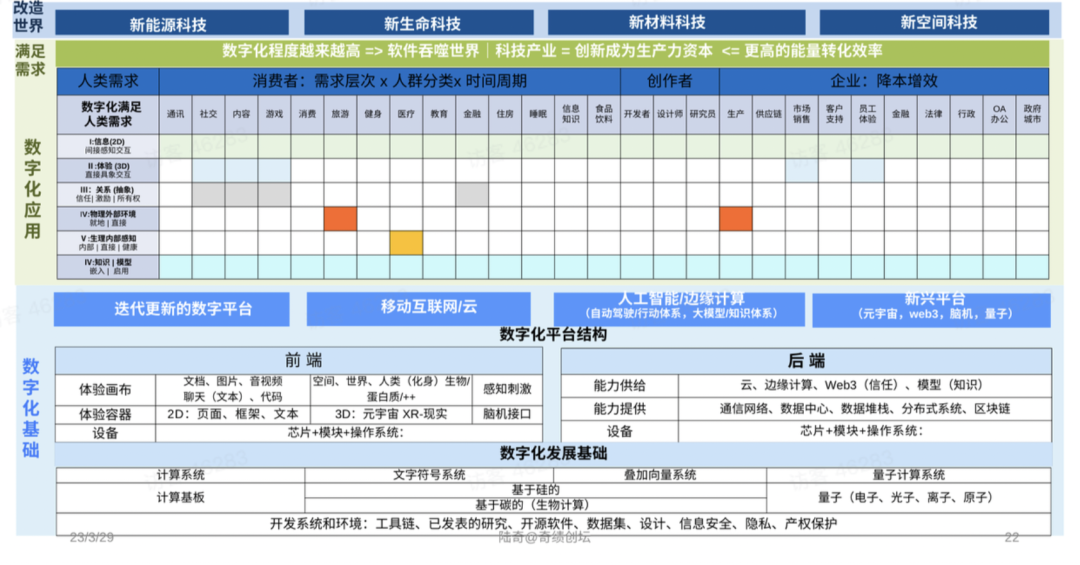
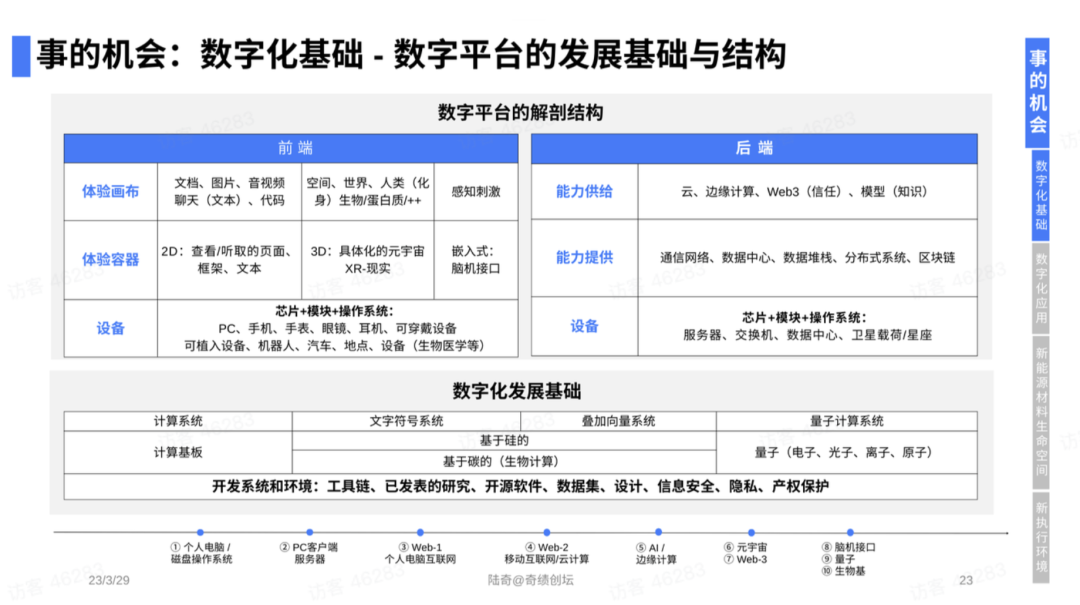



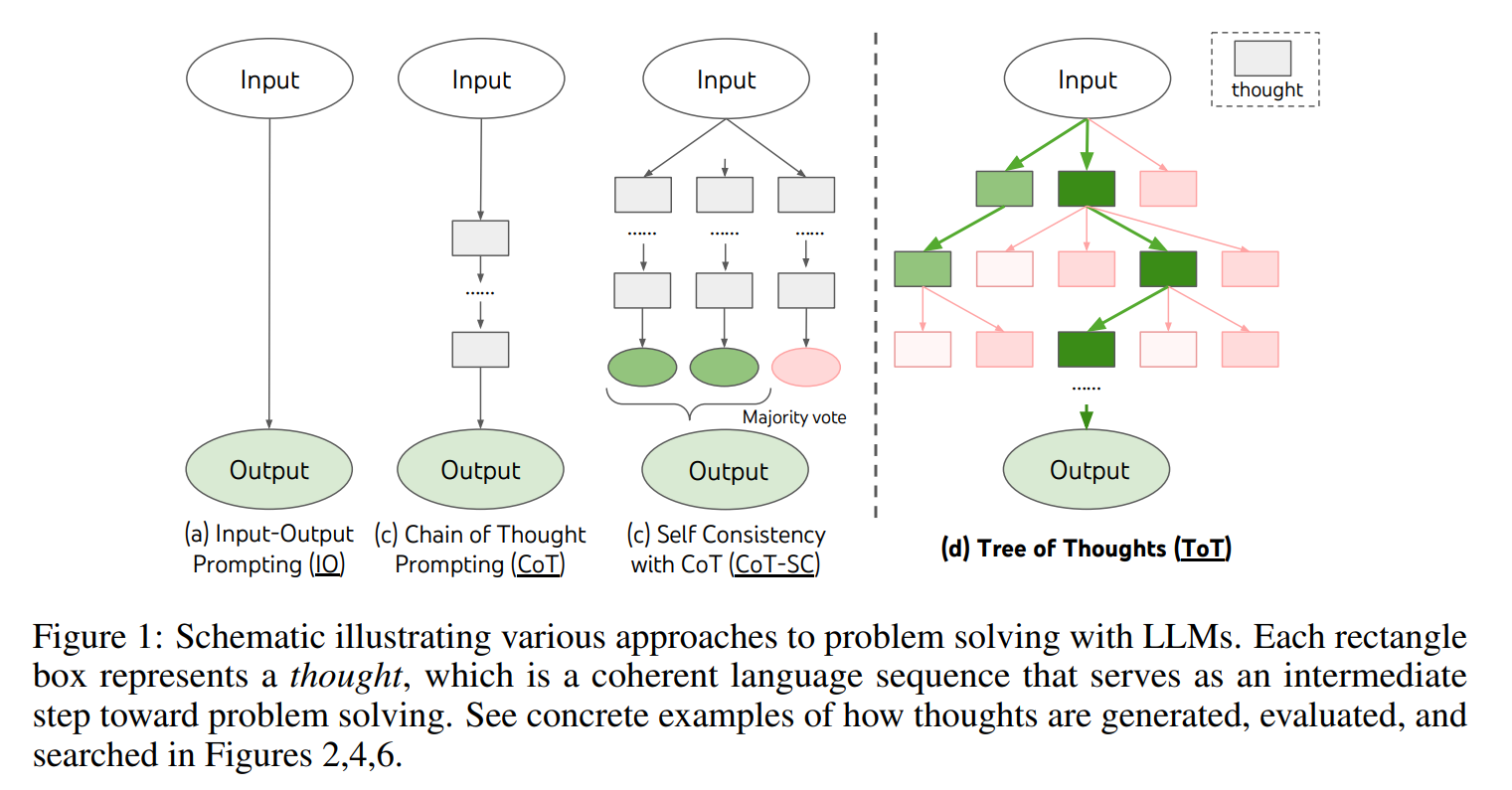


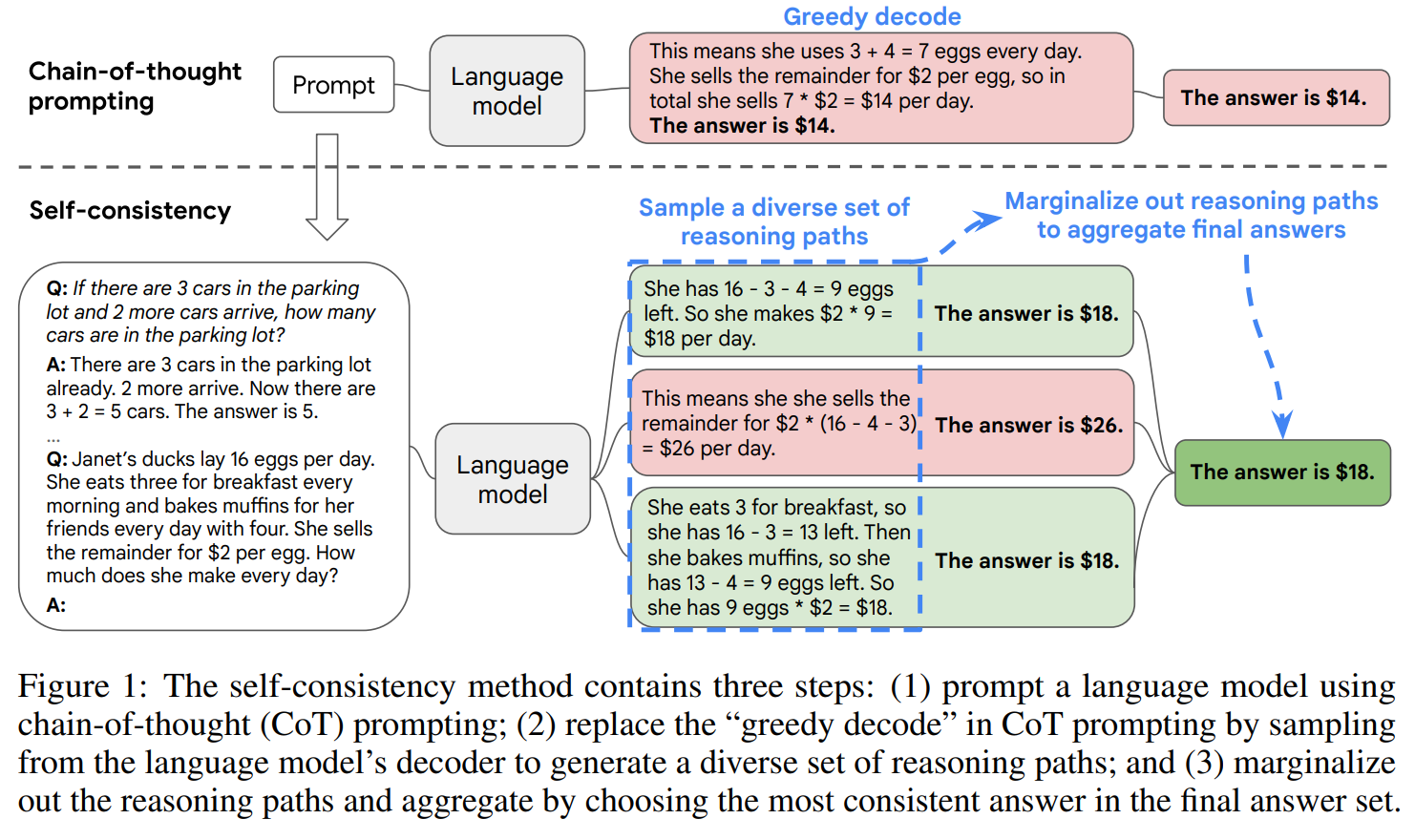
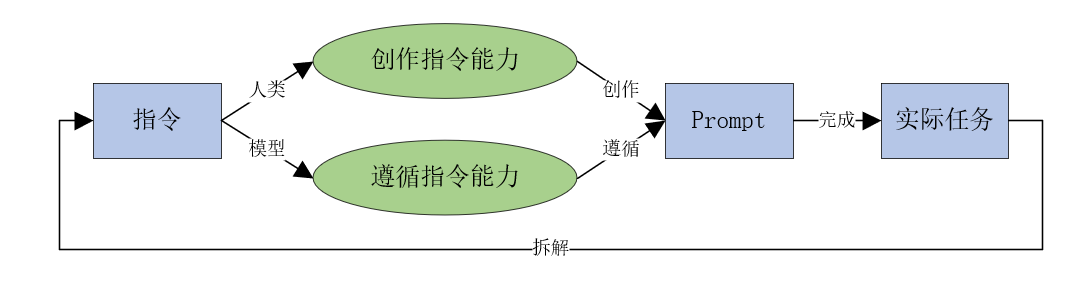



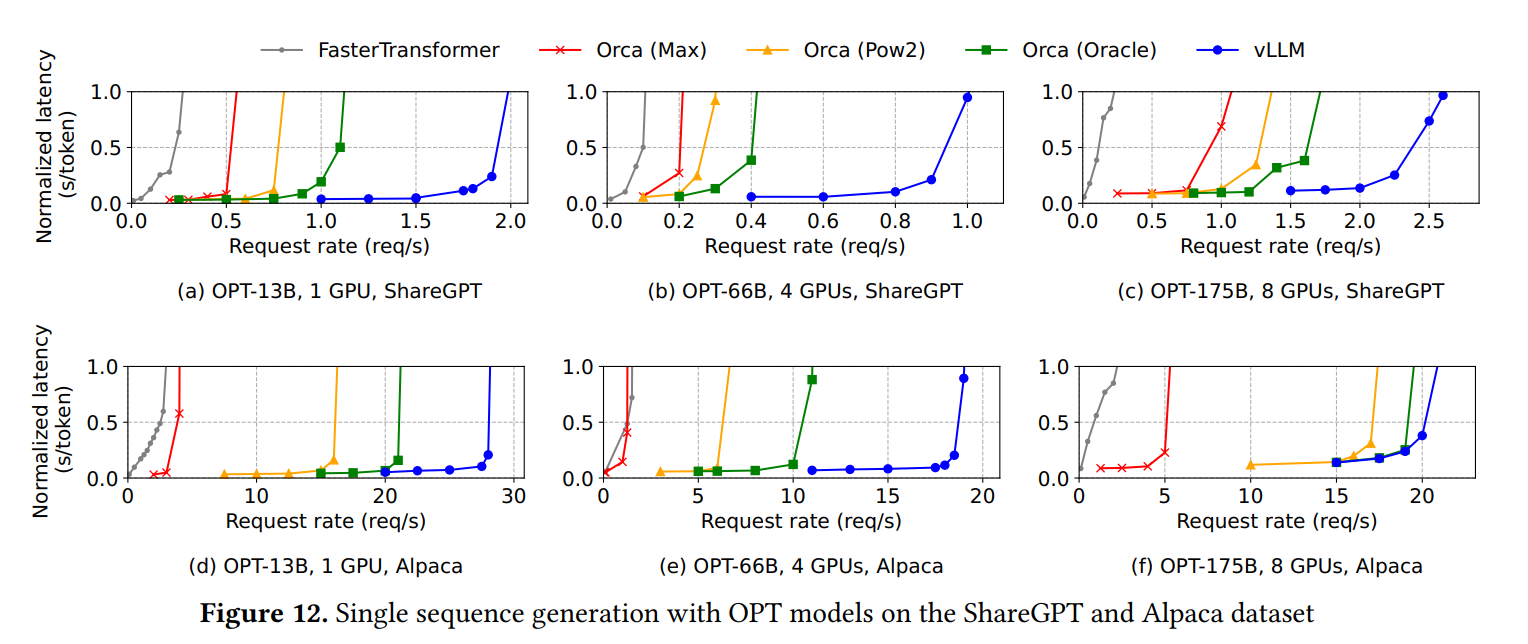
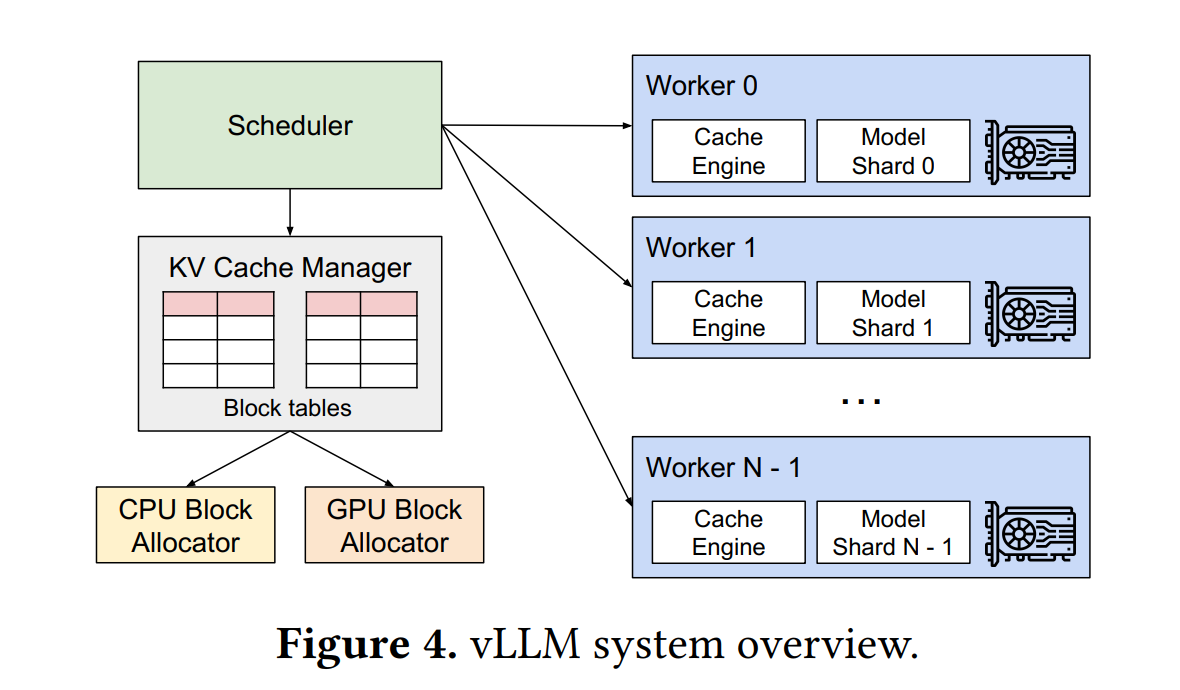
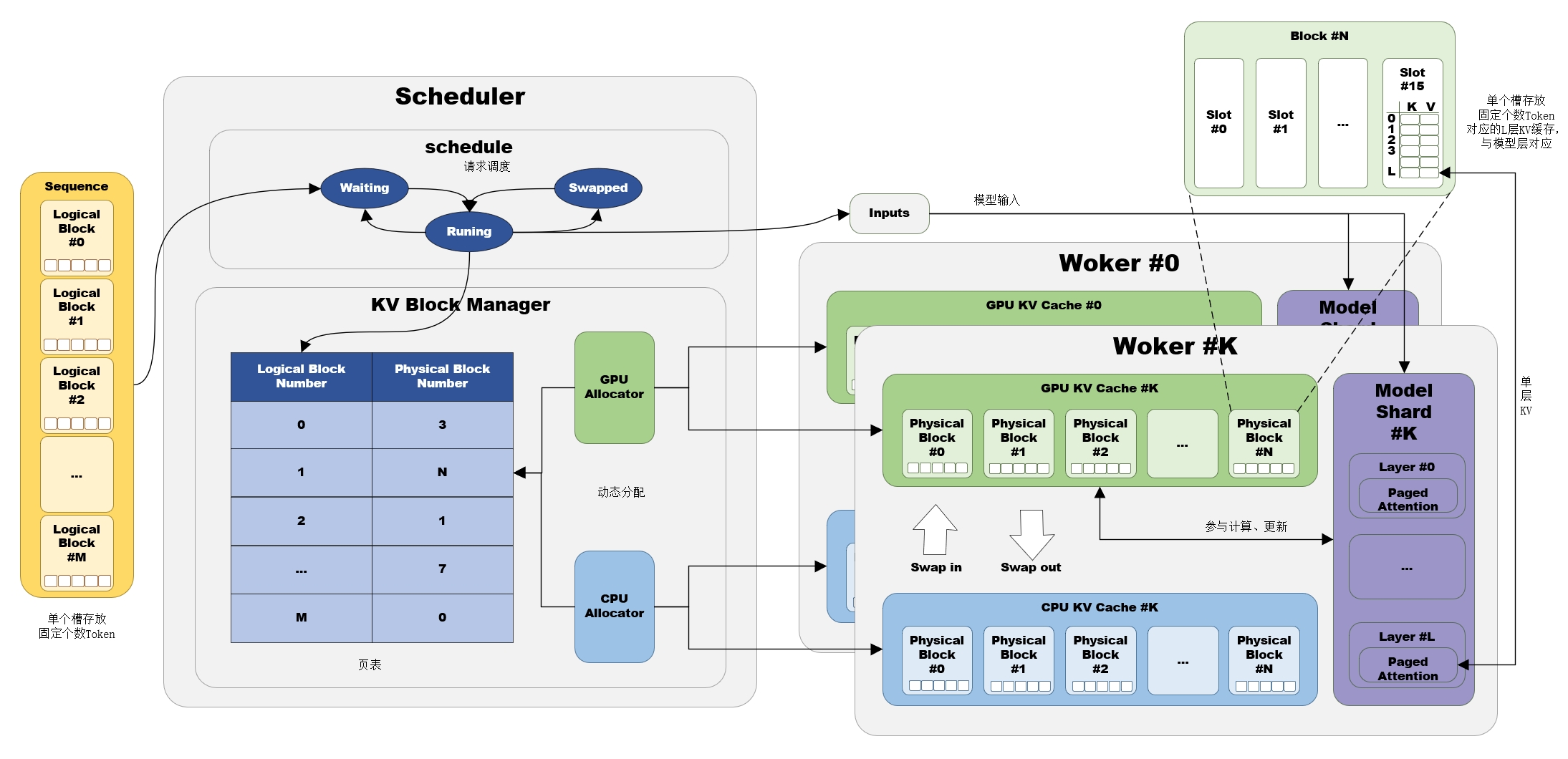
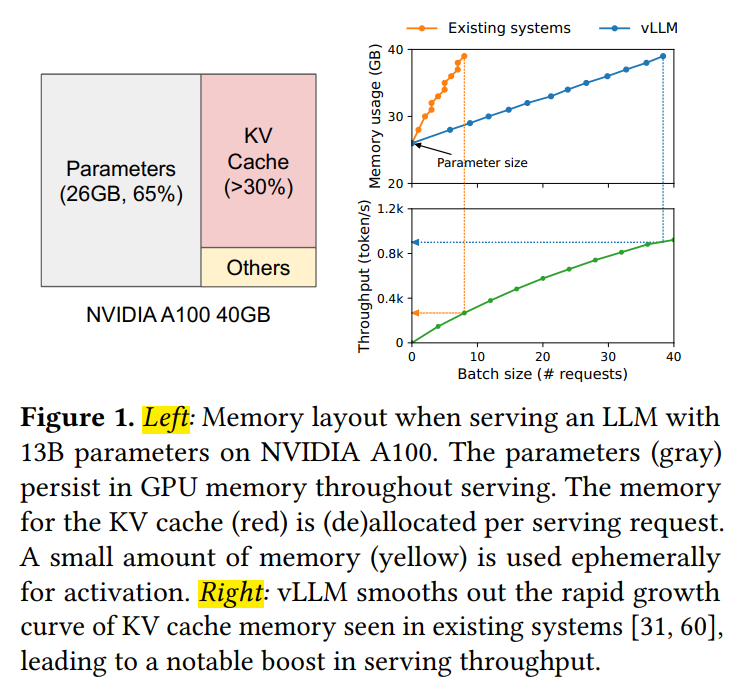
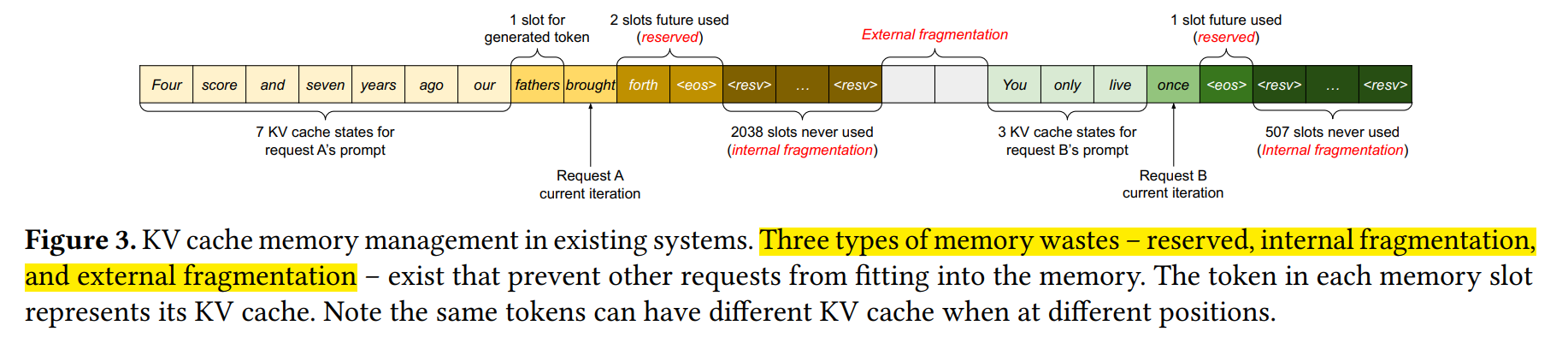
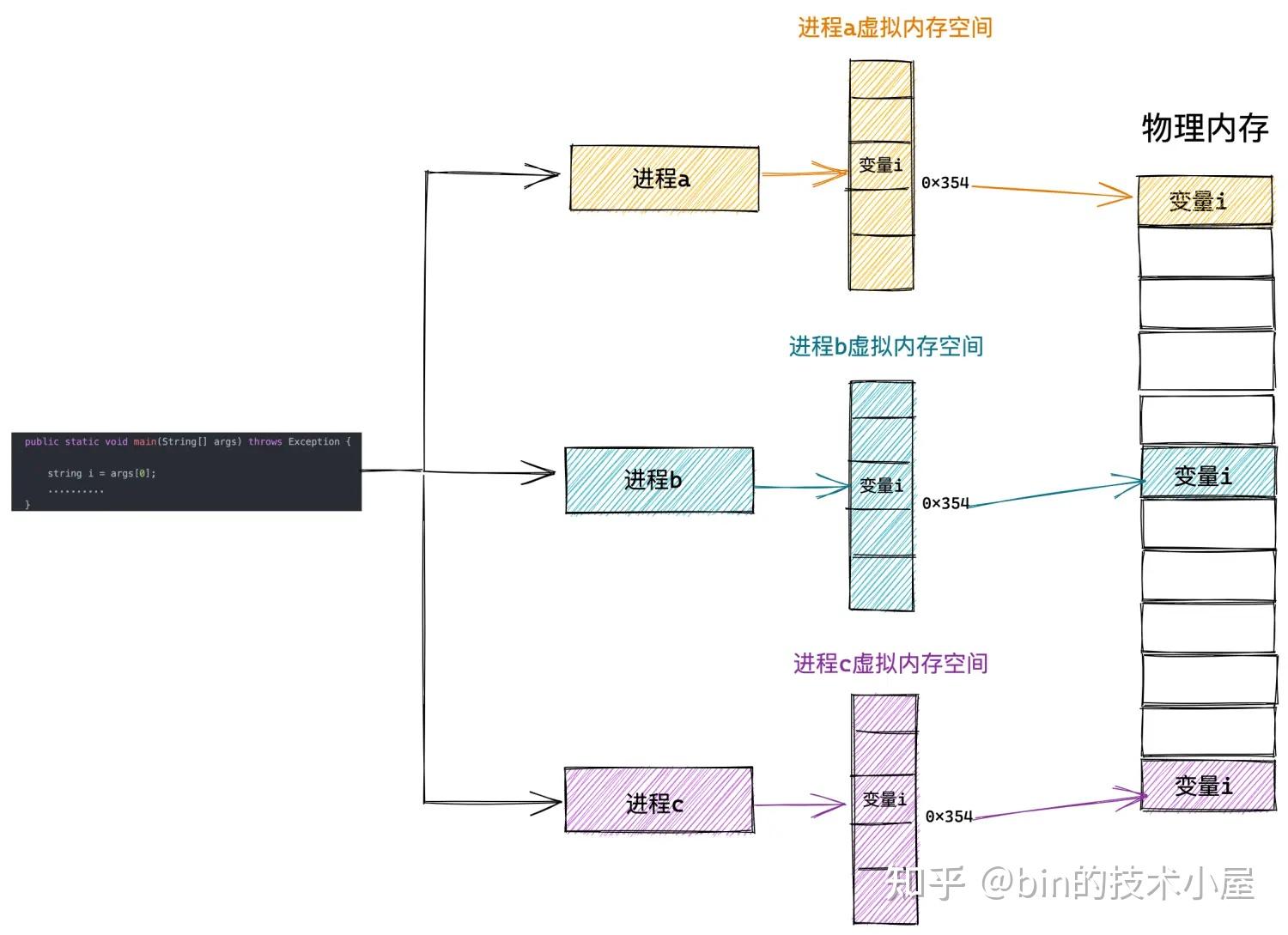
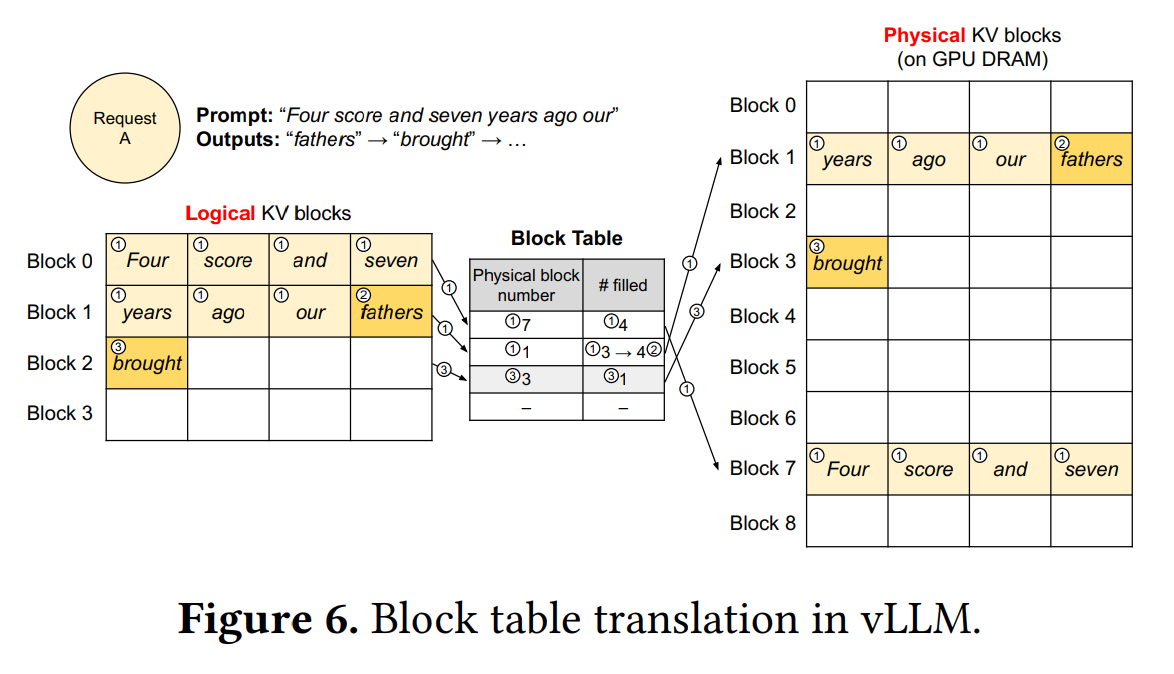
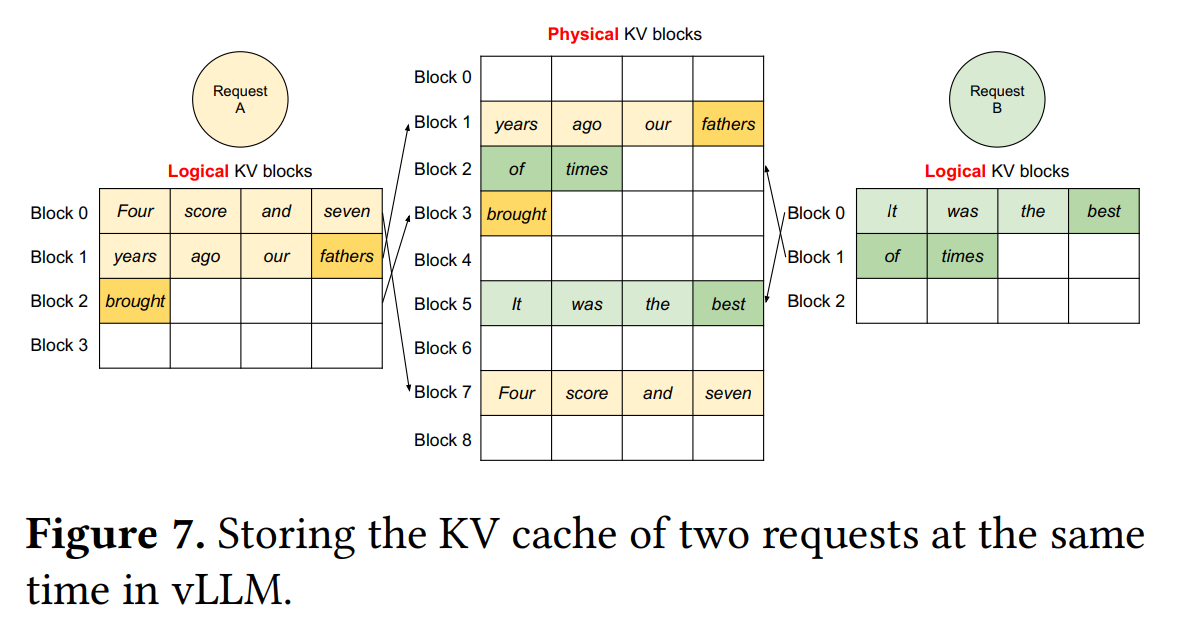
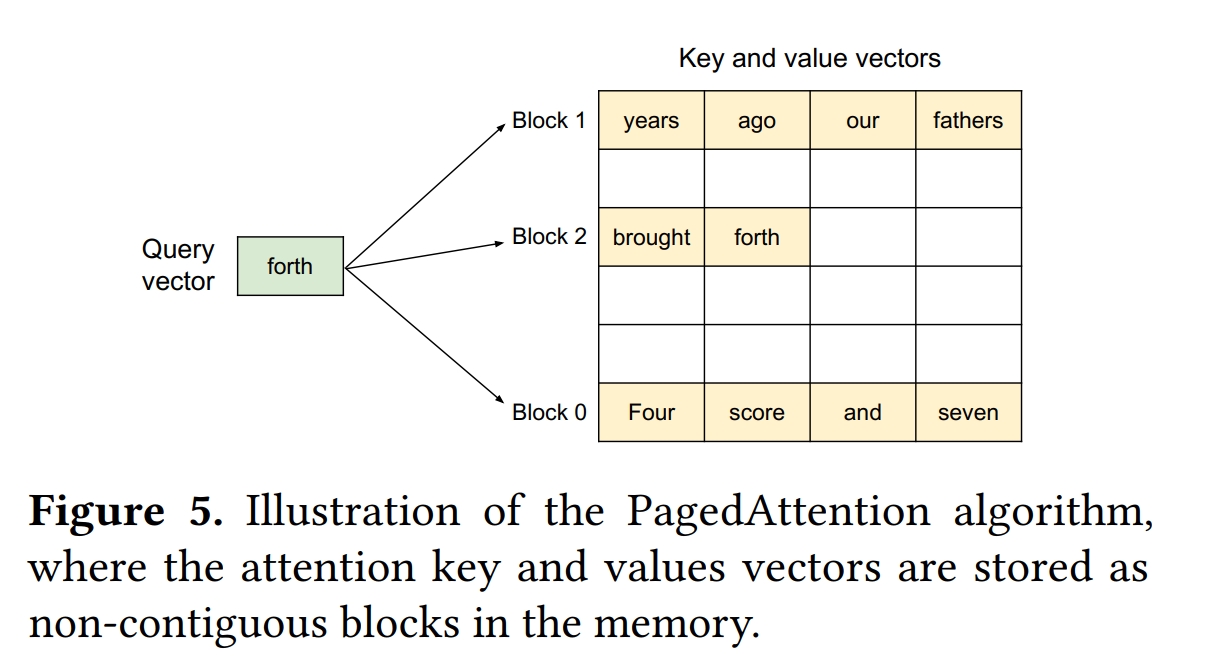
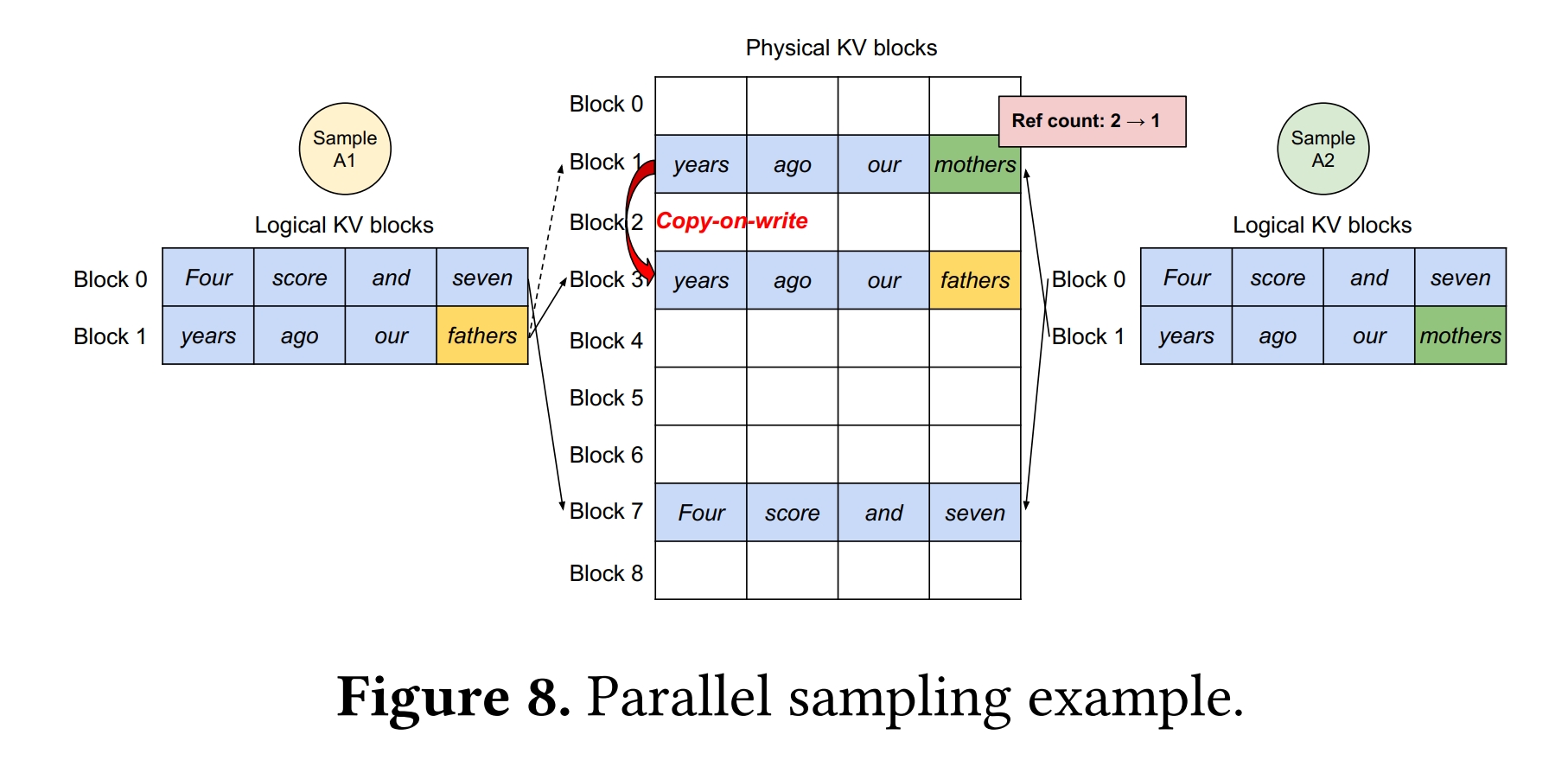
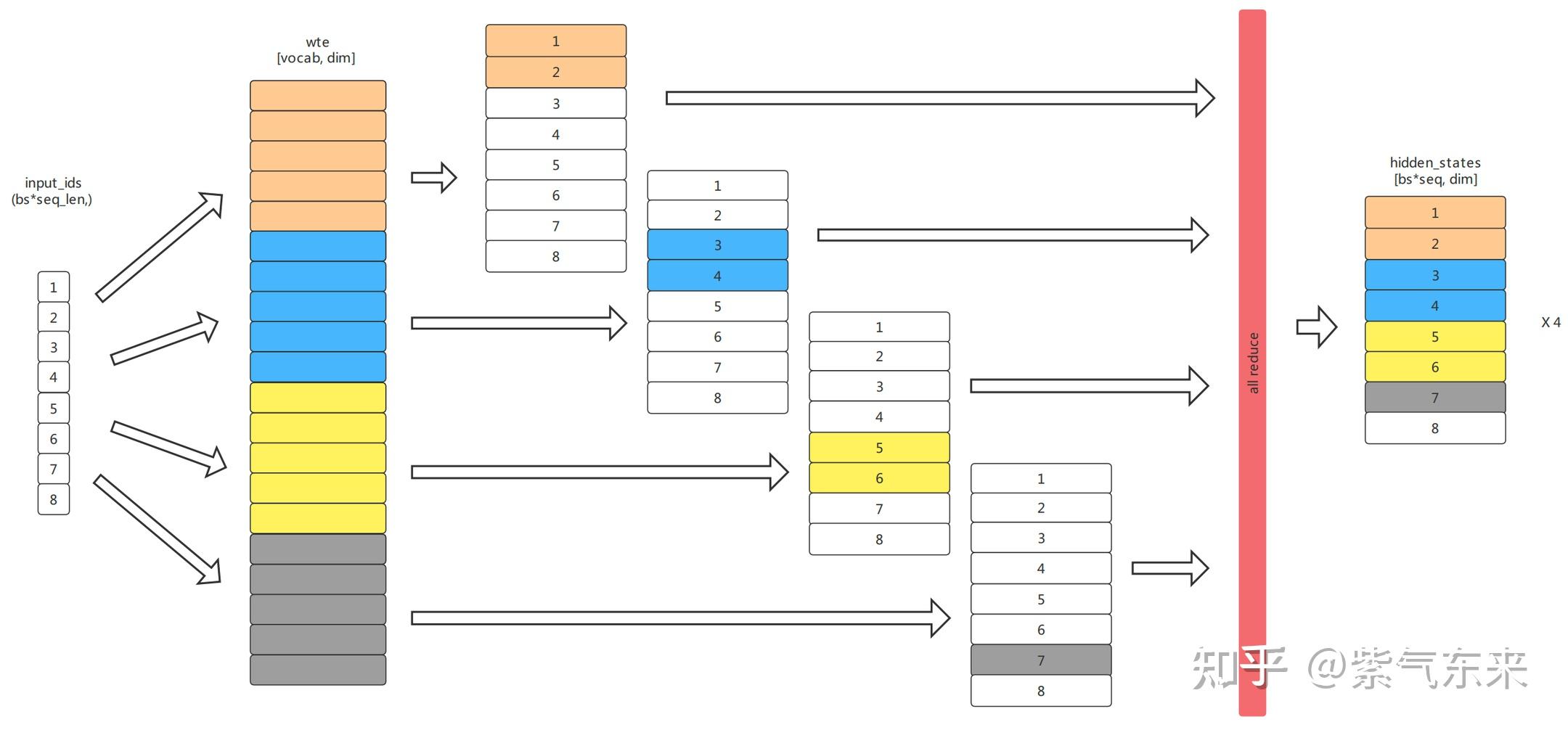
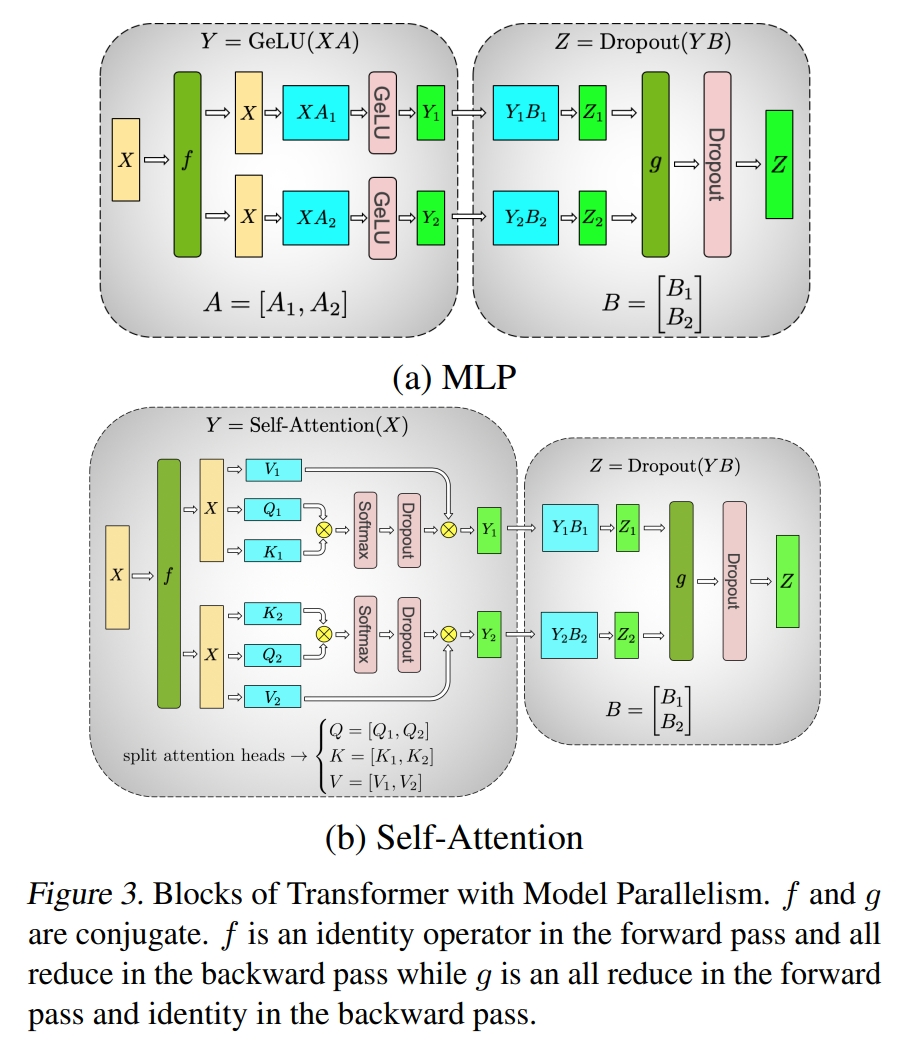








 ' +
+ '
' +
+ '